- 投稿日:2019-08-21T22:36:47+09:00
How to Boosting Your Jenkins Performance
Minimize the number of builds on the master node
The master node is where the application is actually running, this is the brain of your Jenkins and, unlike a slave, it is not replaceable. So, you want to make your Jenkins master as “free” from work as you can, leaving the CPU and memory to be used for scheduling and triggering builds on slaves only. In order to do so, you can restrict your jobs to a node label.Do not keep too much build history
When you configure a job, you can define how many of its builds, or for how long they, will be left on the filesystem before getting deleted. This feature, called Discard Old Builds, becomes very important when you trigger many builds of that job in a short time. I have encountered cases where the history limit was too high, meaning too many builds were kept on the filesystem. In such cases, Jenkins needed to load many old builds – for example, to display them in the history widget, – and performed very slowly, especially when trying to open those job pages. Therefore, I recommend limiting the number of builds you keep to a reasonable number.Clear old Jenkins data
In continuation of the build date from the previous tip, another important thing to know is the old data management feature. As you probably know, Jenkins keeps the jobs and builds data on the filesystem. When you perform an action, like upgrading your core, installing or updating a plugin, the data format might change. In that case, Jenkins keeps the old data format on the file system and loads the new format to the memory. It is very useful if you need to rollback your upgrade, but there can be cases where there is too much data that gets loaded to the memory. High memory consumption can be expressed in slow UI responsiveness and even OutOfMemory errors. To avoid such cases, it is best to open the old data management page.
Define the right heap size
This tip is relevant to any Java application. A lot of the modern Java applications get started with a maximum heap size configuration. When defining the heap size, there is a very important JVM feature you should know. This feature is called UseCompressedOops, and it works on 64bit platforms, which most of us use. What it does, is to shrink the object’s pointer from 64bit to 32bit, thus saving a lot of memory. By default, this flag is enabled on heaps with sizes up to 32GB (actually a little less) and stops working on larger heaps. In order to compensate for the lost space, the heap should be increased to 48GB(!). So, when defining heap size, it is best to stay below 32GB.
Tune the garbage collector
The garbage collector is an automatic memory management process.
Its main goal is to identify unused objects in the heap and release the memory that they hold. Some of the GC actions cause the Java application to pause (remember the UI freeze?). This will mostly happen when your application has a large heap (> 4GB). In those cases, GC tuning is required to shorten the pause time. After dealing with these issues in several Jenkins environments, my tip contains a few steps:
• Enable G1GC – this is the most modern GC implementation (default on JDK9)
• Enable GC logging – this will help you monitor and tune later
• Monitor GC behavior
• Tune GC with additional flags as needed
• Keep monitoringRelated Blog:
- 投稿日:2019-08-21T20:23:23+09:00
【Gang of Four】デザインパターン学習 - Template Method
Template Method - 鋳型
目次
アルゴリズムの共通部分を抽象化して、振る舞いが異なる部分を具象クラスで実装するパターンです。説明だけ読むとStrategyパターンと同じですがあっちは委譲、こっちは継承で実現します。継承は依存関係が強力になってしまうので個人的にはStrategyパターンのほうが優れているのではないかな?と思っています。
ただ、こちらのほうが実装するクラスが少なくて済みます。
目的
1つのオペレーションにアルゴリズムのスケルトンを定義しておき、その中のいくつかのステップについては、サブクラスでの定義に任せることにする。Template Method パターンでは、アルゴリズムの構造を変えずに、アルゴリズム中のあるステップをサブクラスで再定義する。
構成要素
・AbstractClass 共通部分
・ConcreteClass 共通じゃない部分実装
Strategyパターンと同様、配列をソートするプログラムを実装します。
AbstractClass 共通部分
BubbleSort.ktpackage templatemethod abstract class BubbleSort { private var operations = 0 protected var length = 0 protected fun doSort(): Int { operations = 0 if (length <= 1) return operations for (nextToLast in length - 1 downTo 0) { for (index in 0 until nextToLast) { if (outOfOrder(index)) swap(index) operations++ } } return operations } protected abstract fun swap(index: Int) protected abstract fun outOfOrder(index: Int): Boolean }ConcreteClass 共通じゃない部分
Int型配列用具象クラス
IntBubbleSort.ktpackage templatemethod class IntBubbleSort: BubbleSort() { private lateinit var array: Array<Int> fun sort(theArray: Array<Int>): Int { array = theArray length = theArray.size return doSort() } override fun swap(index: Int) { val temp = array[index] array[index] = array[index + 1] array[index + 1] = temp } override fun outOfOrder(index: Int): Boolean { return array[index] > array[index + 1] } }Double型配列用具象クラス
DoubleBubbleSort.ktpackage templatemethod class DoubleBubbleSort: BubbleSort() { private lateinit var array: Array<Double> fun sort(theArray: Array<Double>): Int { array = theArray length = theArray.size return doSort() } override fun swap(index: Int) { val temp = array[index] array[index] = array[index + 1] array[index + 1] = temp } override fun outOfOrder(index: Int): Boolean { return array[index] > array[index + 1] } }まあこれもジェネリクス使えば一つのクラスで実現できますが…
使う人
Client.ktpackage templatemethod class Client { init { val intArray = arrayOf(332, 1, 13, 3232, 456, 22, 5) println("Int配列ソート前") intArray.forEach { println(it) } // 並べ替え IntBubbleSort().sort(intArray) println("Int配列ソート後") intArray.forEach { println(it) } val doubleArray = arrayOf(10.01, 10.5, 10.4123, 10.12, 10.87) println("Double配列ソート前") doubleArray.forEach { println(it) } // 並べ替え DoubleBubbleSort().sort(doubleArray) println("Double配列ソート後") doubleArray.forEach { println(it) } } }[out-put] Int配列ソート前 332 1 13 3232 456 22 5 Int配列ソート後 1 5 13 22 332 456 3232 Double配列ソート前 10.01 10.5 10.4123 10.12 10.87 Double配列ソート後 10.01 10.12 10.4123 10.5 10.87かなり基本的なパターンですね。あらゆるところで使用するかと思います。
以上
- 投稿日:2019-08-21T16:14:48+09:00
51歳からのプログラミング 備忘 バックグラウンド実行制限 OverView [写経]
https://developer.android.com/about/versions/oreo/background?hl=ja
[写経]:自分用
バックグラウンド制限
システム負荷などで、アプリの予期せぬシャットダウンを回避するため、アプリを直接操作してない時のアプリの実行動作を制限します。制限する方法は次の2つです。
バックグラウンドサービス制限
- アプリがアイドル状態となると、バックグラウンドサービスを制限
- フォアグラウンドサービスには制限は適用しない
ブロードキャスト制限
Android7.0(API24)以降で制限を課し、Android8.0(API26)で制限を強化している
限定的な例外を除き
- アプリはマニフェストを使用して、暗黙的なブロードキャストを登録できない。
- ただしアプリ実行時であれば暗黙的なブロードキャストを登録できる。
- アプリはマニフェストを使用して、明示的なブロードキャストを登録できる。
制限とAPIレベル
Note:
デフォルトでは、これらの制限はAndroid8.0(API26)以降を対象とするアプリにのみ適用。
ただしアプリがAPI26未満を対象としている場合でも、ユーザーは[Settings]画面でアプリに対してこれらの制限の大半を有効にできます。(制約を設けたほうがユーザーエクスペリエンスの質を担保するでしょう)多くの場合、アプリはJobSchedulerで処理することで制限を回避できます。
JobSchedulerは、アプリがアクティブでない時に、処理を実行するように調整させますが、ユーザーエクスペリエンスに影響しないように処理をスケジュールすることもできます。
Android 8.0 では、JobSchedulerにいくつかの改善が追加されており、サービスとブロードキャスト レシーバーをスケジュールされたジョブに簡単に置き替えることができます。詳細については、JobScheduler の改善をご覧ください。
JobScheduler:
いろんな処理を、効率よく実行するように、タスク管理するスケジュールサービス。バックグラウンドサービスの制限
フォアグランドとみなされる場合
- 可視アクティビティがある(一時停止されていたも可)
- フォアグラウンドサービスを利用
- アプリが他のフォアグランドアプリと接続されており、フォアグランドアプリのサービスのどれか一つにバインドしている
- アプリが他のフォアグランドアプリと接続されており、フォアグランドアプリのコンテントプロバイダを使っている
= 他のフォアグランドアプリのバインド例 =
- IME
- Wallpaper service
- Notification listener
- Voice or text service
これら以外の状態なら、アプリはバックグラウンド処理とみなされます。
Note:
上記のルールはバインドされたサービスには適用しません。アプリでバインドされたサービスを定義してる場合、アプリがフォアグランドにあろうとなかろうと、別のコンポーネントをそのサービスにバインドできます。システムによるバックグラウンドアプリの終了
アプリがフォアグランドで実行されている間は、自由にフォアグランドやバックグラウンドサービスを生成したり実行できます。アプリがバックグラウンドに移ると、数分間だけサービスを生成したり実行する余裕が生まれますが、それが過ぎるとシステムはアプリをアイドル状態と判定し、Service.stopSelf()メソッドを使った時のように、アプリのバックグラウンドサービスを停止します。
アプリのホワイトリストへの追加
アプリがホワイトリストに入る条件は、以下のようにユーザーが視認できる処理をしてる時です。
特定の条件のもと、バックグラウンドアプリはテンポラリーなホワイトリストに入り、数分間は自由にサービスを起動できて、実行も許可されます。
- 高い優先度のFirebase Cloud Messageing (FCM)メッセージの処理
- ブロードキャストの受信(SMS/MMSメッセージなど)
- 通知からのPendingIntentの実行
- VPNアプリが、自信をフォアグラウンドにプロモートする前の、VpnServiceの開始
IntentService/JobIntentServiceとAndroid8.0以降
IntentServiceでバックグラウンドサービスを扱っている場合
Note:
IntentServiceはサービスなので、バックグラウンドサービスに対する新しい制限事項の対象になります。ですので、IntentServiceに依存するアプリは、Android8.0以降では正常に動作しません。
こうした理由からAndroid Support Library 26.0.0では、新しくJobIntentServiceクラスを導入しました。このクラスはIntentServiceと同じ機能を提供しますが、Android8.0以降で実行されるとき、サービスの代わりにジョブを使用します。
JobScheduler
多くの場合、アプリはバックグラウンドサービスをJobSchedulerのジョブに置き換えられます(Android8.0:API26以降に移行する場合など)。スケジュールされたジョブは、定期的に起動され、サーバーに対してクエリを実行して終了します。
Android8.0前後でのバックグラウンドサービス生成
Android8.0以前では、バックグラウンドサービスを作成する方法として、バックグラウンドサービスを作成してから、そのサービスをフォアグラウンドにプロモートしてます。
Android8.0以降では、システムはバックグラウンドアプリによるバックグランドサービスの作成を許可しなくなってます。その代わりに、startForegroundService()メソッドが導入されており、このメソッドを使って、フォアグラウンドで新しいサービスを開始います。
startForegroundService()を実行したら、5秒以内にstartForeground()を呼びだし、新しいサービスの通知(notification)をユーザーに表示します。アプリが制限時間内にstartForeground()を呼ばないと、システムによってサービスは停止され、アプリがANR(application not respondeing)となります。
ブロードキャストの制限 省略
移行
API26未満を対象にバックグラウンド制限を適用する方法を紹介します。バックグラウンド制限を設けることは、ユーザーエクスペリエンスの質を保つことに繋がります。
API26未満でも[settings]画面でアプリに対して制限を有効にできます。新しい
制限に準拠するため、アプリをアップデートする必要があるケースがあります。置き換える必要がある場合
- アプリがアイドル状態のときに、バックグランドサービスの処理に依存してる
- マニフェストで暗黙的ブロードキャストに対してレシーバを宣言してる
アプリがアイドル状態のときに、そのアプリがバックグラウンドサービスの処理に依存してる場合、そのアプリは、これらのサービスを置き換える必要があります。
<置き換える方法>
アプリがバックグラウンドにあり、フォアグラウンドサービスを作成する場合
startForegroundServiceメソッドを、startService()の代わりに使用して、フォアグランドサービスを生成ユーザーに表示するサービスはフォアグラウンドサービスにする
startForegroundServiceメソッドを、startService()の代わりに使用して、フォアグランドサービスを生成スケジュールされたジョブを使ってサービス機能を複製
一般的に、ユーザーが認識できる状況で稼働してないサービスの代わりとして、スケジュールされたジョブを使うバックグラウンドでポーリングせず、FCMを使ってネットワークイベントが発生したときにアプリを選択的に起動する
ポーリング:一定間隔で他のシステムに問い合わせするアプリが自然にフォアグランドになるまでバックグランド動作を保留
アプリのマニフェストで定義されているブロードキャストレシーバーを確認。マニフェストで暗黙的なブロードキャストに対してレシーバーを宣言してる場合、それを置き換える必要があります。考えられる解決策は以下です。
<置き換える方法>
マニフェストでレシーバーを宣言するのではなく、Context.registerReceiver()を呼び出し、実行時にレシーバーを作成する
スケジュールされたジョブを使って、暗黙的なブロードキャストのきっかけ条件を確認します
- 投稿日:2019-08-21T14:39:41+09:00
java Scannerループ入力
- 投稿日:2019-08-21T14:06:04+09:00
Azure CosmosDB Java SDK で 集計クエリー (Count) を使う
JavaSDK から CosmosDB で集計クエリーを利用するのにハマった点があったのでメモします。
クエリーにVALUE句を設定しないと以下のエラーになります。
java.lang.IllegalStateException: com.microsoft.azure.documentdb.DocumentClientException: Message: {"Errors":["Cross partition query only supports 'VALUE <AggreateFunc>' for aggregates."]} Caused by: com.microsoft.azure.documentdb.DocumentClientException: Message: {"Errors":["Cross partition query only supports 'VALUE <AggreateFunc>' for aggregates."]}また、setEnableCrossPartitionQuery を true にしないと以下のエラーになります。
java.lang.IllegalStateException: com.microsoft.azure.documentdb.DocumentClientException: Cross partition query is required but disabled. Please set x-ms-documentdb-query-enablecrosspartition to true, specify x-ms-documentdb-partitionkey, or revise your query to avoid this exception. Caused by: com.microsoft.azure.documentdb.DocumentClientException: Cross partition query is required but disabled. Please set x-ms-documentdb-query-enablecrosspartition to true, specify x-ms-documentdb-partitionkey, or revise your query to avoid this exception.以下、Javaのコードです。
// Azure Cosmos DB Libraries for Java // https://docs.microsoft.com/ja-jp/java/api/overview/azure/cosmosdb?view=azure-java-stable String host = "yourhost"; String container_id = "yourcontainer"; String database = "yourdatabase"; // Get key from Azure Web Console // read write key String key = "yourkey"; String endPoint = "https://" + host + ".documents.azure.com:443"; DocumentClient client = new DocumentClient(endPoint, key, // new ConnectionPolicy(), ConsistencyLevel.Session); String collectionLink = String.format("/dbs/%s/colls/%s", database, container_id); String q = String.format("SELECT VALUE count(1) FROM c"); // IF (without 'VALUE' in query) // java.lang.IllegalStateException: com.microsoft.azure.documentdb.DocumentClientException: Message: {"Errors":["Cross partition query only supports 'VALUE <AggreateFunc>' for aggregates."]} // Caused by: com.microsoft.azure.documentdb.DocumentClientException: Message: {"Errors":["Cross partition query only supports 'VALUE <AggreateFunc>' for aggregates."]} FeedOptions feedOptions = new FeedOptions(); feedOptions.setEnableCrossPartitionQuery(true); // IF (EnableCrossPartitionQuery = false) // java.lang.IllegalStateException: com.microsoft.azure.documentdb.DocumentClientException: Cross partition query is required but disabled. Please set x-ms-documentdb-query-enablecrosspartition to true, specify x-ms-documentdb-partitionkey, or revise your query to avoid this exception. // Caused by: com.microsoft.azure.documentdb.DocumentClientException: Cross partition query is required but disabled. Please set x-ms-documentdb-query-enablecrosspartition to true, specify x-ms-documentdb-partitionkey, or revise your query to avoid this exception. try { List<Object> results = client // .queryAggregateValues(collectionLink, q, feedOptions); System.err.println(results.get(0)); } catch (Exception e) { e.printStackTrace(); } finally { client.close(); }以上です。
- 投稿日:2019-08-21T12:47:12+09:00
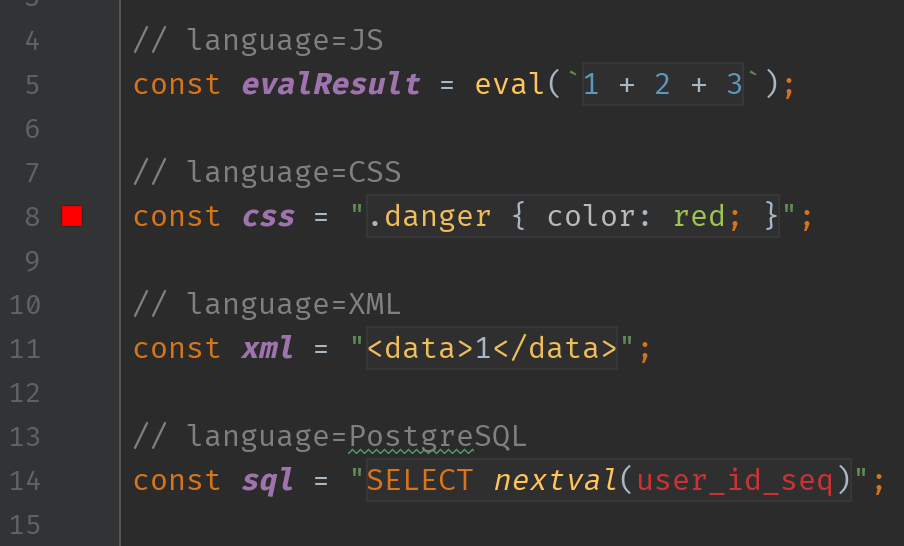
IntelliJ・WebStrom・PhpStorm等のJetBrains製IDEで、文字列の直前に「language=JSON」と書くと、その文字列にJSONのシンタックスハイライトが効いて便利だった。
IntelliJやWebStrom、PhpStormなどのJetBrains製IDEで、文字列の前に
// language=JSONというコメントをつけると、IDEが文字列をJSONとして認識してくれるため、
- JSONとしてのシンタックスハイライト
- JSON構文エラーの警告
- JSONのコード補完
- コード整形
といった、地の文でJSONを書いたときにIDEがやってくれるような恩恵を享受できるようになる。
この機能はLanguage Injectionと呼ばれるもの。コメントが書ける大抵の言語なら、JavaでもPHPでもJavaScriptでもScalaでも使えるようだ。
この機能はJSONに限ったものでなく、
language=SQLやlanguage=HTMLなどのlanguage_IDを指定することで他の言語にも対応可能。// language=<language_ID>
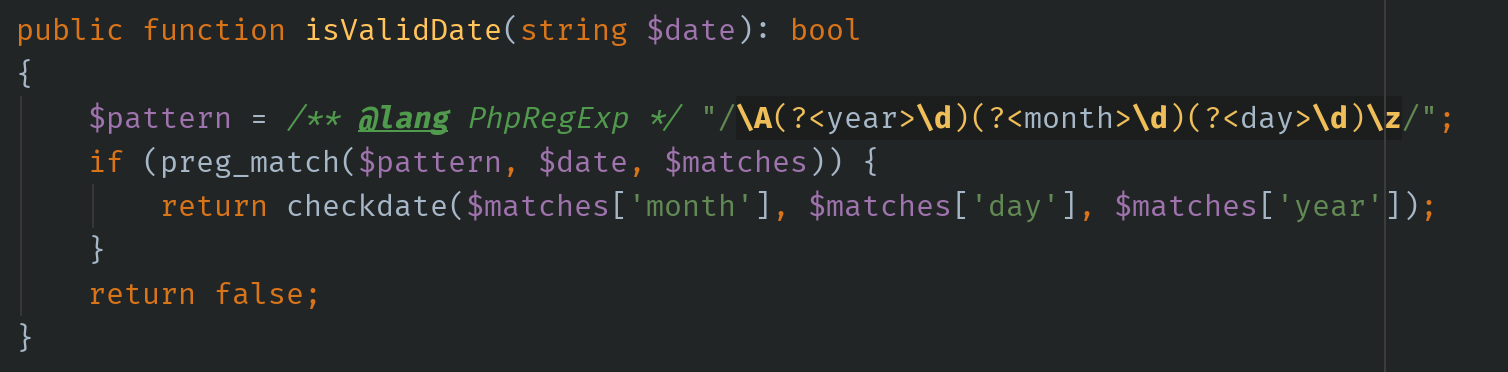
PHPは
@langが使えるPHPではPhpDocの
@langでもLanguage Injectionすることができる。
Javaなどでは
@Languageアノテーションが使えるJavaやGroovy、Kotlinでは
org.jetbrains:annotationsをMavenなどの依存に追加することで、@Languageアノテーションを使うことができる。Scalaには対応していない様子。
参考文献
所感
IntelliJやWebStrom、PhpStormなどのJetBrains製IDEで、
— suin❄️TypeScriptが好き (@suin) August 20, 2019
文字列の前に
// language=JSON
って書くと、
・JSONがシンタックスハイライトされる
・構文エラーが表示される
・補完がされる
・コード整形もできる
って知ってました?
僕は知りませんでした? pic.twitter.com/2UphpOThoM


- 投稿日:2019-08-21T02:00:28+09:00
APIってこんな感じね!
APIとはなんぞや???
初めまして!
JAVAを学びたて、初投稿のぽんぽこです。不備がございましたらご指摘の程よろしくお願い致します。
では本編へ、、、
自学の為に何か作ろうかと考えた。。。
どうせなら人の役に立つための物を作りたい。
ただ、簡単すぎる物を作っても自分のためにならない。
さらに考えた、そこであるワードを思い出した。
『API』
しかし、聞いたことはあるものの何かわからない。
そこで調べに調べた。
APIとは「Application Programming Interface」の頭文字だそうだ。
訳すると「アプリケーション、ソフトウェア」と「プラグラム」をつなぐもの。
ソフトウェアにAPIという外部とやりとりする窓口を作り、外部アプリとコミュニケーションや連携ができる状態にすることで機能性を拡張させ、さらに便利に使えるようにし、欲を言えば両方のアプリにとってウィン・ウィンの状態を生み出すことが目的。
主に利点は以下の3つ
・ソフトウェア開発の効率化
・セキュリティの向上
・最新情報を簡単に取得可能上記の理由から様々な企業がAPIを採用している。
例えば、Amazon、Facebook、Twitter、Google、ぐるなび、楽天などだ。ではデメリットは?
うまい話には裏がある。ということで以下だ。提供されているAPIの仕様が変わったり、提供自体を停止されてしまった場合には、
APIを利用している箇所に不具合が生じてしまう。どういうことかというと、自分の予期しないタイミングで予期していない不具合が発生し、
あたふたしちゃうよ〜ということ。APIはAPIでもよく使われているのはWeb API出そうだ。
上記で述べている企業もWeb APIを使っているのだ。何となくAPIのイメージは掴めた。
じゃあWeb APIってなんだよ!!!続く。。。