- 投稿日:2019-08-21T23:49:09+09:00
くずし字 (kuzushiji) でまっちゃん
はじめに
現在、人文学データセンターがホストとなりkaggleにて、くずし字の認識コンペが開催されています。今回は、センターから公開されているくずし字のデータセットを使って、まっちゃんを描画します。
まっちゃん
本記事は、同じくkaggleに公開されている下記カーネルを参考にさせていただきました。
・Kuzushiji-MNIST Catデータセット
データは、こちらからダウンロードできます。
『KMNISTデータセット』(CODH作成) 『日本古典籍くずし字データセット』(国文研ほか所蔵)を翻案 doi:10.20676/00000341
今回は、Kuzushiji-49内のk49-train-imgs.npzを使用します。
環境
ローカルにデータをダウンロードして、jupyter notebook にて実行します。
カレントフォルダに、上記の "k49-train-img.npz" および、まっちゃん画像 "matchan.jpg" を用意します。macOS Mojave
・python 3.6.5
・numpy 1.16.3
・pandas 0.24.2
・mlcrate 0.2.0
・skimage 0.15.0
・matplotlib 3.0.3実装
ライブラリのインポート
import numpy as np import pandas as pd import mlcrate as mlc from skimage.io import imread, imsave from skimage.transform import resize import matplotlib.pyplot as plt %matplotlib inline元画像の読み込み
次に、元画像を読み込み、白黒画像(グレースケール化)します。
image = imread('matchan.jpg') # => image.shape = (252, 200, 3) # グレースケール化 image = image[:,:,0] plt.imshow(img, cmap='gray')
データセット読み込み
くずし字データセットを読み込み、各文字の画像におけるグレーレベル(白黒の比率)を見てみる。また、各文字とそのグレーレベルを辞書化。
imgs_train = np.load('k49-train-img.npz')['arr_0'] means = (255 - imgs_train).mean(axis=1).mean(axis=1) plt.hist(means, bins=50, log=True) # 辞書化 from collections import defaultdict character_bins = defaultdict(list) for char, mean in zip(imgs_train, means): character_bins[int(mean)].append(char)
このグラフから、このデータセットには、グレーレベルが低い(約90以下)画像は無いことがわかる。元画像をリスケール
# 各ピクセルが文字に置き換えられるので、これに28x28が乗算される。 OUTPUT_RESOLUTION = (96, 75) # データセットには、グレーレベルが低い画像が無いため、各ピクセルを(120, 245)にリスケールする。 img_small = (resize(img, OUTPUT_RESOLUTION, preserve_range=True) / 2) + 120 plt.hist(img_small.flatten(), bins=50, log=True) plt.title('Gray level') plt.show() plt.imshow(img_small, cmap='gray')
新しい画像を作成
上記、まっちゃん画像の全てのピクセルをループして、くずし字画像から同じグレーレベルのものをランダムに選択し、新しい画像の同じ位置に配置していく。
# 新しい空の画像 new_img = np.zeros((img_small.shape[0]*28, img_small.shape[1]*28), dtype=np.unit8) # ループ ix = 0 iy = 0 for iy in range(img_small.shape[0]): for ix in range(img_small.shape[1]): level = int(img_small[iy, ix]) charbin = character_bins[level] if len(charbin) == 0: charbin = character_bins[level + 1] if len(charbin) == 0: charbin = character_bins[level - 1] char = 255 - charbin[np.random.choice(np.arange(len(charbin)))] new_img[iy*28:(iy+1)*28, ix*28:(ix+1)*28] = char # カレントディレクトリに画像の保存 imsave('kuzushiji_matchan.jpg', new_img)くずし字まっちゃん
上記、設定だと解像度も高いので、拡大するとくずし字がはっきりわかる。







- 投稿日:2019-08-21T23:49:09+09:00
[python] くずし字 (kuzushiji) でまっちゃん
はじめに
現在、人文学データセンターがホストとなりkaggleにて、くずし字の認識コンペが開催されています。今回は、センターから公開されているくずし字のデータセットを使って、まっちゃんを描画します。
本記事は、同じくkaggleに公開されている下記カーネルを参考にさせていただきました。
・Kuzushiji-MNIST Catデータセット
データは、こちらからダウンロードできます。
『KMNISTデータセット』(CODH作成) 『日本古典籍くずし字データセット』(国文研ほか所蔵)を翻案 doi:10.20676/00000341
今回は、Kuzushiji-49内のk49-train-imgs.npzを使用します。
環境
ローカルにデータをダウンロードして、jupyter notebook にて実行します。
カレントフォルダに、上記の "k49-train-img.npz" および、まっちゃん画像 "matchan.jpg" を用意します。macOS Mojave
・python 3.6.5
・numpy 1.16.3
・pandas 0.24.2
・mlcrate 0.2.0
・skimage 0.15.0
・matplotlib 3.0.3実装
ライブラリのインポート
import numpy as np import pandas as pd import mlcrate as mlc from skimage.io import imread, imsave from skimage.transform import resize import matplotlib.pyplot as plt %matplotlib inline元画像の読み込み
次に、元画像を読み込み、白黒画像(グレースケール化)します。
image = imread('matchan.jpg') # => image.shape = (252, 200, 3) # グレースケール化 image = image[:,:,0] plt.imshow(img, cmap='gray')
データセット読み込み
くずし字データセットを読み込み、各文字の画像におけるグレーレベル(白黒の比率)を見てみる。また、各文字とそのグレーレベルを辞書化。
imgs_train = np.load('k49-train-img.npz')['arr_0'] means = (255 - imgs_train).mean(axis=1).mean(axis=1) plt.hist(means, bins=50, log=True) # 辞書化 from collections import defaultdict character_bins = defaultdict(list) for char, mean in zip(imgs_train, means): character_bins[int(mean)].append(char)
このグラフから、このデータセットには、グレーレベルが低い(約90以下)画像は無いことがわかる。元画像をリスケール
# 各ピクセルが文字に置き換えられるので、これに28x28が乗算される。 OUTPUT_RESOLUTION = (96, 75) # データセットには、グレーレベルが低い画像が無いため、各ピクセルを(120, 245)にリスケールする。 img_small = (resize(img, OUTPUT_RESOLUTION, preserve_range=True) / 2) + 120 plt.hist(img_small.flatten(), bins=50, log=True) plt.title('Gray level') plt.show() plt.imshow(img_small, cmap='gray')
新しい画像を作成
上記、まっちゃん画像の全てのピクセルをループして、くずし字画像から同じグレーレベルのものをランダムに選択し、新しい画像の同じ位置に配置していく。
# 新しい空の画像 new_img = np.zeros((img_small.shape[0]*28, img_small.shape[1]*28), dtype=np.unit8) # ループ ix = 0 iy = 0 for iy in range(img_small.shape[0]): for ix in range(img_small.shape[1]): level = int(img_small[iy, ix]) charbin = character_bins[level] if len(charbin) == 0: charbin = character_bins[level + 1] if len(charbin) == 0: charbin = character_bins[level - 1] char = 255 - charbin[np.random.choice(np.arange(len(charbin)))] new_img[iy*28:(iy+1)*28, ix*28:(ix+1)*28] = char # カレントディレクトリに画像の保存 imsave('kuzushiji_matchan.jpg', new_img)くずし字まっちゃん
上記、設定だと解像度も高いので、拡大するとくずし字がはっきりわかる。
- 投稿日:2019-08-21T23:28:27+09:00
RaspberryPiで監視カメラ(カメラモジュール+USB Audioのデータをブラウザで表示+再生)
はじめに
前回、WebSocketで受信した画像をブラウザで表示する仕組みを調べたので、RaspberryPiのカメラモジュールと繋げてみました。
あと、USB Audioデバイスを買ったのでWebSocketでデータを流して、ブラウザで再生する処理も入れてみました。
簡易的な監視カメラができたので、記事としてまとめておきます。
ハードウェア
Raspberry Pi 3 Model B+
カメラモジュール
USB audio
秋月で400円くらい。lsusbで認識された情報だとIntel製。ボリュームが小さくでちょっと不満。もっと高いのにすればよかった。
クライアント
chromeで動作確認
仕様
- Imageサーバーは、ソケット接続されたらカメラの画像を送信し続ける
- Audioサーバーは、ソケット接続されたらAudio INから取得したデータを送信し続ける
- ブラウザで画像データを受信して、canvasに描画する
- ブラウザで音声データを受信して、db値をcanvasに描画する
- ボタンをクリックすると、WebAudioで音声を再生する
音声再生中はタブにスピーカーのアイコンが表示されます。
クライアント側
ブラウザで表示するためのhtmlとjsを用意します。
HTML
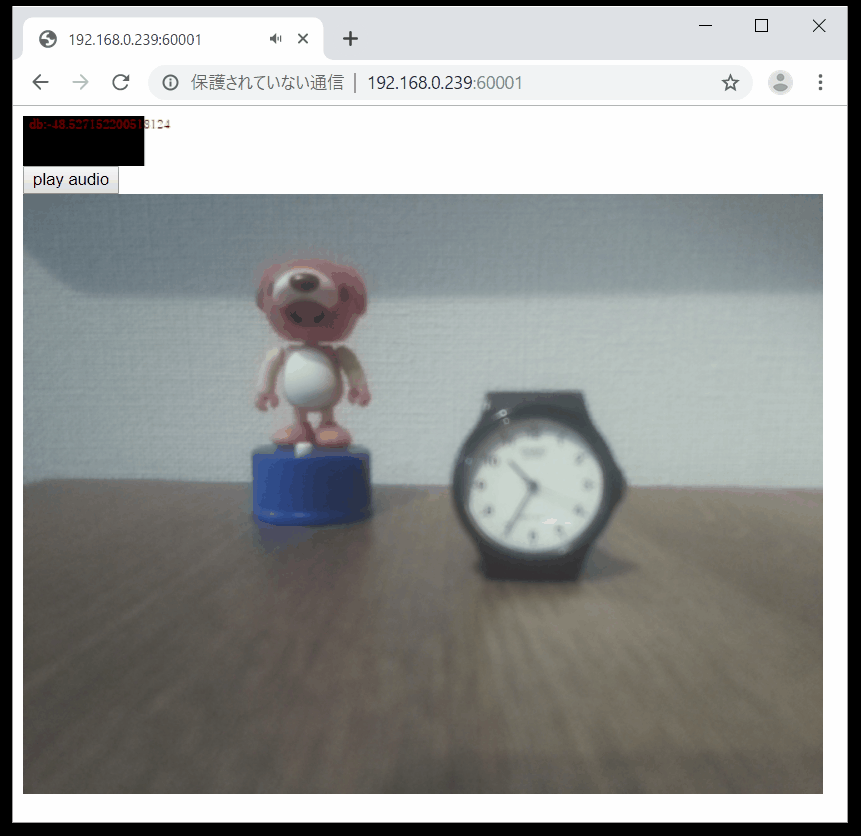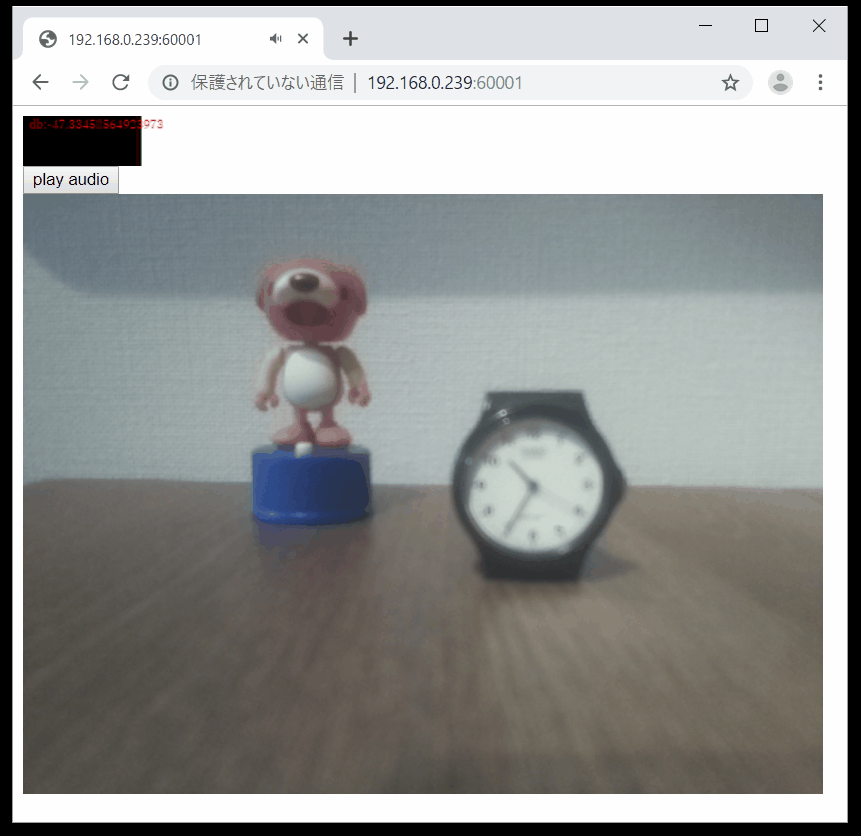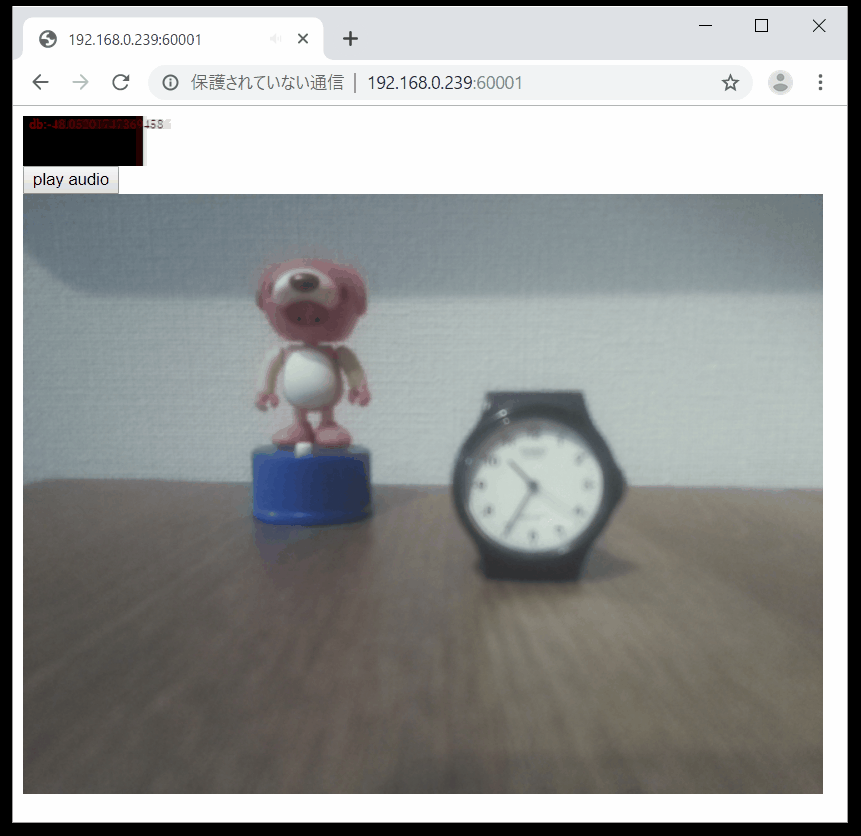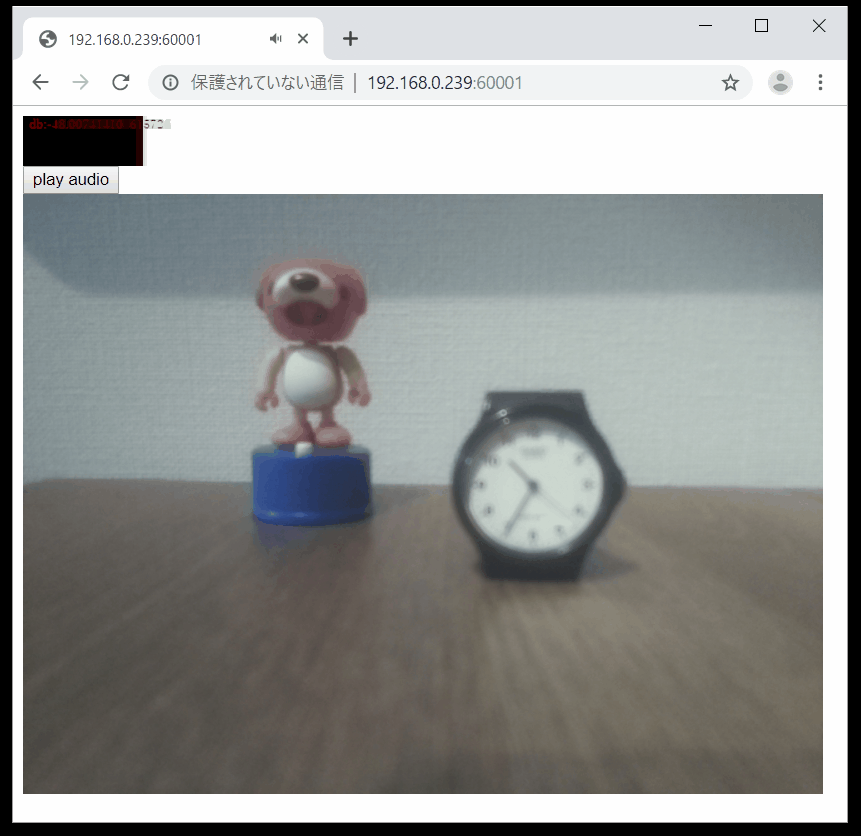
音声データ表示用のcanvasと再生ボタン、画像用のcanvasを用意します。
WebAudioはユーザー操作のイベントで開始する必要があるので、ボタンを用意する必要があります。
index.html<html> <head> <script src="./client.js"></script> </head> <body onload="on_load();"> <div> <canvas id="canvas_audio" width="500" height="40"></canvas> </div> <input type="button" value="play audio" onclick="on_button_play_audio();"> <div> <canvas id="canvas_image" width="640" height="480"></canvas> </div> </body> </html>javascript
画像データ受信ハンドラでcanvasに描画、音声データ受信ハンドラでcanvasにグラフを表示する&音声再生します。
- 画像データ
前回のサンプルのままだと大きい画像のbase64文字列の生成でエラーになりました。調査時はシンプルなPNGにしたので圧縮率が高かったけど、写真のjpegになったらサイズが小さくならなかったと推測。かっこ悪いですがループで文字列を結合してbase64変換しています。
- 音声データ
WebAudioを使用して音声を再生します。受信データがfloat32なのでそのまま流せば再生できます。
ユーザー操作しないと音声再生できないので、クリックのイベントを用意します。
データが受信できているかを確認できるようにdb値をcanvasに表示します。db値の計算はネットで調べてて適当に実装したから合ってるか自信ないです。
client.jsvar image_socket = null; var audio_socket = null; var audio_ctx = null; var scheduled_time = 0; var delay_sec = 1; function on_load(){ // ここではaudioの再生に関する処理は許可されないのでWebSock処理のみ行う // 画像通信用WebSocket接続 img_url = "ws://" + location.hostname + ":60002" image_socket = new WebSocket(img_url); image_socket.binaryType = 'arraybuffer'; image_socket.onmessage = on_image_message; // 音声通信用WebSocket接続 audio_url = "ws://" + location.hostname + ":60003" audio_socket = new WebSocket(audio_url); audio_socket.binaryType = 'arraybuffer'; audio_socket.onmessage = on_audio_message; } function on_button_play_audio(){ // ユーザー操作イベントでAudioの再生操作を行う if(audio_ctx == null){ audio_ctx = new (window.AudioContext||window.webkitAudioContext) } } function on_image_message(recv_data){ // 受信したデータをbase64文字列に変換 var recv_image_data = new Uint8Array(recv_data.data); var base64_data = "" for (var i=0; i < recv_image_data.length; i++) { base64_data += String.fromCharCode(recv_image_data[i]); } // 画像をcanvasに描画 var canvas_image = document.getElementById('canvas_image'); var ctx = canvas_image.getContext('2d'); var image = new Image(); image.onload = function() { ctx.drawImage(image, 0, 0); } image.src = 'data:image/jpeg;base64,' + window.btoa(base64_data); } function on_audio_message(recv_data){ audio_f32 = new Float32Array(recv_data.data); if(audio_ctx != null){ play_audio(audio_f32); } draw_audio_graph(audio_f32); } function play_audio(data){ var audio_buffer = audio_ctx.createBuffer(1, data.length, 44100); var buffer_source = audio_ctx.createBufferSource(); var current_time = audio_ctx.currentTime; audio_buffer.getChannelData(0).set(data); buffer_source.buffer = audio_buffer; buffer_source.connect(audio_ctx.destination); if (current_time < scheduled_time) { buffer_source.start(scheduled_time); scheduled_time += audio_buffer.duration; } else { buffer_source.start(current_time); scheduled_time = current_time + audio_buffer.duration + delay_sec; } } function draw_audio_graph(data){ var canvas_image = document.getElementById('canvas_audio'); var ctx_2d = canvas_image.getContext('2d'); // db値計算(自信ない) sum_data = data.reduce((a,b)=>Math.abs(a)+Math.abs(b)); mean_data = sum_data / data.length; dB = 20 * Math.log10(mean_data); // 前回描画をクリア ctx_2d.fillStyle = '#ffffff'; ctx_2d.fillRect(0,0,500,40); var rate = 2; var graph_x = Math.abs(dB) * rate; ctx_2d.fillStyle = '#000000'; ctx_2d.fillRect(0,0,graph_x,40); // 値表示 ctx_2d.fillStyle = '#ff0000'; ctx_2d.font = "10px serif"; ctx_2d.fillText("db:" + dB , 5 , 10 ); }サーバー側
画像用と音声用で2つのWebSoket通信を行うので、2つWebSoketのサーバーを用意します。
httpのサーバーも必要になるので、まとめて起動する処理も用意します。
Imageサーバー
PiCameraで取得した画像をブラウザに送信します。
imageServer.pyimport asyncio import websockets import io from picamera import PiCamera class ImageServer: def __init__(self, loop, address , port): self.loop = loop self.address = address self.port = port self.camera = PiCamera() async def _handler(self, websocket, path): with io.BytesIO() as stream: for _ in self.camera.capture_continuous(stream, format='jpeg', use_video_port=True, resize=(640,480)): stream.seek(0) try: await websocket.send(stream.read()) except: print('image send Error.') break stream.seek(0) stream.truncate() def run(self): self._server = websockets.serve(self._handler, self.address, self.port) self.loop.run_until_complete(self._server) self.loop.run_forever() if __name__ == '__main__': loop = asyncio.get_event_loop() ws_is = ImageServer(loop, '0.0.0.0', 60002) ws_is.run()Audioサーバー
pyaudioで取得した音声データをブラウザに送信します。クライアントであるWebAudioにfloat32で渡すのでpaFloat32を指定します。
同一スレッドで読み込みと送信を行ったらバッファ不足のエラーが出たので読み込みと送信は別スレッドで行うようにしています。
複数接続は考慮していない実装です。
AudioServer()クラスに、デバイス名を指定するので環境に合わせた文字列を設定してください。
AudioServer.pyimport asyncio import websockets import pyaudio import threading import queue class AudioServer: def __init__(self, loop, address, port, device_name): self.loop = loop self.address = address self.port = port self.chunk = 1024 * 4 self.device_index = self._find_device_index(device_name) self.rec_loop = False self.q = queue.Queue() def _rec_thread(self): audio = pyaudio.PyAudio() stream = audio.open( format = pyaudio.paFloat32, channels = 1, rate = 44100, input = True, frames_per_buffer = self.chunk, input_device_index=self.device_index) while self.rec_loop: audio_data = stream.read(self.chunk) self.q.put(audio_data) stream.close() audio.terminate() async def _handler(self, websocket, path): if self.rec_loop: print("_rec_thread is exists.") return # Audio INから読み出すスレッドを起動 self.rec_loop = True send_thread = threading.Thread(target=self._rec_thread) send_thread.start() # スレッドで読み込んだデータを送信する send_loop = True while send_loop: try: send_data = self.q.get(timeout=1) await websocket.send(send_data) except: print('audio send Error.') send_loop = False break self.rec_loop = False send_thread.join() def run(self): self._server = websockets.serve(self._handler, self.address, self.port) self.loop.run_until_complete(self._server) self.loop.run_forever() @staticmethod def get_devices(): '''使用可能なデバイスを列挙''' device_name_list = [] audio = pyaudio.PyAudio() for i in range(audio.get_device_count()): device = audio.get_device_info_by_index(i) device_name_list.append(device['name']) return device_name_list @staticmethod def _find_device_index(find_name): '''引数のデバイス名に対応するindexを返す''' device_index = -1 audio = pyaudio.PyAudio() for i in range(audio.get_device_count()): device = audio.get_device_info_by_index(i) if device['name'] == find_name: device_index = i break return device_index if __name__ == '__main__': device_name = None devices = AudioServer.get_devices() print("devices len = {}".format(len(devices))) if len(devices) > 0: device_name = devices[0] print("device_name = {}".format(device_name)) loop = asyncio.get_event_loop() ws_as = AudioServer(loop, '0.0.0.0', 60003, device_name) ws_as.run()httpサーバー
まとめて起動する仕組みも用意しましたが終了時のことは考慮していないので、ちゃんと実装する人は他の方法がいいと思います。
以下のスクリプトを実行して http://localhost:60001/ にアクセスすれば動作確認できます。
monitor_run.pyimport threading import http.server import socketserver import asyncio from ImageServer import ImageServer from AudioServer import AudioServer def _http_thread(): _handler = http.server.SimpleHTTPRequestHandler httpd = socketserver.TCPServer(("", 60001), _handler) httpd.serve_forever() def _image_thread(): loop = asyncio.new_event_loop() asyncio.set_event_loop(loop) ws_is = ImageServer(loop, '0.0.0.0', 60002) ws_is.run() def _audio_thread(): loop = asyncio.new_event_loop() asyncio.set_event_loop(loop) device_name = None devices = AudioServer.get_devices() print("devices len = {}".format(len(devices))) if len(devices) > 0: device_name = devices[0] print("device_name = {}".format(device_name)) loop = asyncio.get_event_loop() ws_as = AudioServer(loop, '0.0.0.0', 60003, device_name) ws_as.run() if __name__ == '__main__': imageThread = threading.Thread(target=_image_thread) imageThread.start() audioThread = threading.Thread(target=_audio_thread) audioThread.start() httpThread = threading.Thread(target=_http_thread) httpThread.start() imageThread.join() audioThread.join() httpThread.join()おわりに
WebAudio+pyaudioの組み合わせをやってる人がいなくて試行錯誤でした。
dB値の計算は昔やったことあるけど細かいこと忘れた。正しいdB値が欲しいわけじゃないから適当で。
激しく寝返りするようになった娘のベビーモニターとして利用するつもりですが、暗い部屋だと映らないので赤外線カメラに変更するか、USBライトの点灯制御するか悩むところ。
100均のUSBライトの点灯制御ができたら更新記事をアップしようと思います。
参考


- 投稿日:2019-08-21T23:01:02+09:00
JSONアンエスケープ by Python
ニッチな内容だけど、JSONのvalueの中の入れ子なJSON形式を、「"」をアンエスケープさせつつ文字列として格納する方法のメモ。
jsonパッケージを使う。
import jsonまず、入れ子構造になったJSON形式を、jsonパッケージで文字列にdumpすると下記の通り。
dict1 = { "key1" : { "key2" : { "key3" : "value" } } } s = json.dumps(dict1) s #出力結果 #'{"key1": {"key2": {"key3": "value"}}}'という感じで、入れ子要素もすべて「"キー" : "値"」というフラットな構造の文字列となる。
これに対し、入れ子要素を文字列として保存し、さらにその入れ子も文字列として、、と保存する。
やり方は、単純に、段階的にjson.dumpsを呼べば良い。dict1["key1"]["key2"] = json.dumps(dict1["key1"]["key2"]) #文字列 '{"key3": "value"}' dict1['key1'] = json.dumps(dict1["key1"]) #文字列 '{"key2": "{\\"key3\\": \\"value\\"}"}' s = json.dumps(dict1) s #出力結果 '{"key1": "{\\"key2\\": \\"{\\\\\\"key3\\\\\\": \\\\\\"value\\\\\\"}\\"}"}'という感じでJSON文字列の入れ子を作れる。
なお、json.dumpsは「"」をアンエスケープしてくれる仕様のため、入れ子の深さの数だけ「"」がアンエスケープした形で保持される。復号には、同じ回数のjson.loadsを呼べば良い。
key1_d = json.loads(s) key1_d #出力結果 {'key1': '{"key2": "{\\"key3\\": \\"value\\"}"}'} key2_d = json.loads(key1_d["key1"]) key2_d #出力結果 {'key2': '{"key3": "value"}'} key3_d = json.loads(key2_d["key2"]) key3_d #出力結果 {'key3': 'value'}呼び出しのたびにエスケープされつつ、文字列が復元されるのがわかる。
ちなみに、文字列に日本語(UTF8)が含まれる場合、json.dumpsは、バイト列に変換するためアンエスケープがさらに激しいことになるが、驚かないようにされたい。
dict1 = { "key1" : { "key2" : { "key3" : "こんにちは" } } } dict1["key1"]["key2"] = json.dumps(dict1["key1"]["key2"]) dict1['key1'] = json.dumps(dict1["key1"]) s = json.dumps(dict1) s #出力結果 '{"key1": "{\\"key2\\": \\"{\\\\\\"key3\\\\\\": \\\\\\"\\\\\\\\u3053\\\\\\\\u3093\\\\\\\\u306b\\\\\\\\u3061\\\\\\\\u306f\\\\\\"}\\"}"}'と、なかなか読み難いものになる。
同様に復号も可能。
key1_d = json.loads(s) key1_d #出力結果 {'key1': '{"key2": "{\\"key3\\": \\"\\\\u3053\\\\u3093\\\\u306b\\\\u3061\\\\u306f\\"}"}'} key2_d = json.loads(key1_d["key1"]) key2_d #出力結果 {'key2': '{"key3": "\\u3053\\u3093\\u306b\\u3061\\u306f"}'} key3_d = json.loads(key2_d["key2"]) key3_d #出力結果 {'key3': 'こんにちは'}以上。
- 投稿日:2019-08-21T21:49:08+09:00
運用管理ツール(Webアプリ)のjsonDL機能を気軽にローカルに保存したかった話
前置き
- 商品管理をしているサーバに対する運用管理ツールにおいて、全商品のDL(.json)みたいな機能が存在
- いちいち要ログインの管理ツールにアクセスして、DLボタン押して保存して、作業ディレクトリに移動とか面倒
- 一連の流れを自動化する想定で、コマンドベースでローカルのディレクトリにjsonを保存したい
- 管理ツール的には
https://xxxx.yyyy.zz/aaa/bbb/downloadのリンクでアクセスさえできればDL可能結論
- wgetじゃ無理(ファイルの実体が指定できない)
- curlじゃ無理(ログインが必要な管理ツールなので、何か無理だった)
- スクレイピングで頑張る
詰まった点
- ログイン画面を突破しないと叩きたいURL
https://xxxx.yyyy.zz/aaa/bbb/downloadにたどり着けない(404になる)
- → ログインして、該当のURLを叩くようにする
- ログイン画面でid/passをpostする際のURLが分からん
- → 調べ方があるのでそれで対応
- 詰まったではないが、逐次処理にしたらゲロ遅かった(約730[sec])
- → 並列処理にした
- 並列処理時に、パラメータを2つ以上渡すのがシンプルにできなかった
- → 文字列の配列をルール決めて渡すようにした
対応方法
1. ログイン画面のpostするURLを調べる
- chromeでデベロパーツール開く
- デベロパーツール上で、Networkタブを選択
- ログイン画面開く
- いつも通りログインしてみる
- ログイン時の内容が結果のとこに出るので、Nameらへんでpost時のURLがわかる
2. スクレイピングするスクリプトを頑張って書く
dl_json.pyimport sys import yaml import json from bs4 import BeautifulSoup import requests from concurrent import futures # yamlにid/pass定義して、それをロードする形にした with open('config.yaml') as file : config_yml = yaml.load(file, Loader=yaml.SafeLoader) # 実際ログイン画面のid/passで定義されているhtmlタグの属性idの値にブッコムhashを作成 payload = { 'login_id': config_yml['login']['id'], 'password': config_yml['login']['pass'], } # 並列処理するために、1セッション1jsonDLできるように関数定義する def dl_process(args) : """ プロセス単位の各種DL処理 Args: args : 以下の2データをstrのlistで id : 100 | 200 category : normal | special """ id = args[0] category = args[1] # authenticity_tokenの取得 session = requests.Session() res = session.get('https://xxxx.yyyy.zz/') # 管理ツールのtop画面URL soup = BeautifulSoup(res.text, 'html.parser') auth_token = soup.find(attrs={'name': 'authenticity_token'}).get('value') payload['authenticity_token'] = auth_token # login res = session.post('https://xxxx.yyyy.zz/login', data=payload) # 対応手順1で調べたpost時のURL res.raise_for_status() # DL 'https://xxxx.yyyy.zz/aaa/bbb/' + id +'/' + category + '/download' res = session.get(url) # パスをテキトーに指定して保存 path_w = category + '_' + id + '.json' file = open(path_w, 'w') file.write(res.text) # 各種必要なjsonをDL&saveを並列実行 with futures.ProcessPoolExecutor() as executor: f1 = executor.submit(dl_process, ['100', 'normal']) f2 = executor.submit(dl_process, ['100', 'special']) f3 = executor.submit(dl_process, ['200', 'normal']) f4 = executor.submit(dl_process, ['200', 'special']) f1.result() f2.result() f3.result() f4.result()感想
- 並列処理にしたら約730[sec]から、約210[sec]まで縮んだ。(3倍以上)
- スクレイピングしないでもっと楽にできる方法が欲しい……
- ちょっと書き方が雑感n
参考
- 投稿日:2019-08-21T21:46:02+09:00
RaspberryPi 人感センサーを使って検知したことをプログラムで出力する
-
毎日試しては更新するように心がけます
この記事について
今回はRaspberryPのスターターキットを購入したので色々と遊んでみる
OSOYOO(オソヨー) Raspberry Pi... https://www.amazon.jp/dp/B01M6ZFNSS?ref=ppx_pop_mob_ap_shareまずは人感センサー
ラズパイに人感センサーを繋いで赤外線で人、物を検知する。
それをプログラム上に出力する。ネットの記事を何個か見て試してみたが上手くいかず少しつまずいた
動作環境
- Raspberry Pi Model B+
- Python3.7.4
用意するもの
- Raspberry Pi Model B+
- 電源アダプター(5V/3000mA)
- 人感センサー(HC-SR501 PIR motion sensor)
- ジャンパワイヤ 3本
センサー
動作電圧 DC5V - 12V 出力 LOW - 0V , HIGH - 3.3V 遅延時間 調整可能 (0.3-18秒) 遮断時間 0.2秒 検出範囲 7m未満 120度未満 動作温度 -15 ~ 70度 トリガーモード LOWは繰り返し× トリガーモードがよく理解できなかった
自分なりの解釈は遅延時間が5秒の場合
LOWは、検知し遅延時間中にさらに検知してもその検知はトリガーされないHIGHの場合は検知し遅延時間中にさらに検知したら
直前に検知した遅延時間がトリガーされるうまく説明できないので
要するにLOWは延長してくれないけどHIGHは延長してくれるっていう理解でいいのかな
はい、次
プログラムを書く
human_sensor.pyimport RPi.GPIO as GPIO import time PIN = 14 GPIO.setmode(GPIO.BCM) GPIO.setup(PIN, GPIO.IN) try: print ('-----Start-----') n = 1 while True: if GPIO.input(PIN) == GPIO.HIGH: print("{}".format(n) + "回目検知") n += 1 time.sleep(2) else: print(GPIO.input(PIN)) time.sleep(2) except KeyboardInterrupt: print("Cancel") finally: GPIO.cleanup() print("-----end-----")感度、遅延時間の調節
少しいじってみた感じ感度調節の方はあまり差がわからなかった
けど手をかざせばほとんど反応するから精度は悪くないと思う。問題は遅延時間
遅延時間の範囲は0.3秒-18秒。
試しに写真の位置に合わせて測ってみようと思い計測(だいたい5-7秒くらいかなーと予測)
結果…
56秒あまり意味がわからなかったのでとりあえず左に回してもう一度計測(数値で言えば0の状態)
結果は遅延無し
これは思ったように動いた。…
…計測する
1回目 56秒 2回目 52秒 3回目 56秒 4回目 55秒 5回目 52秒 6回目 56秒 7回目 55秒 8回目 52秒 9回目 51秒 10回目 56秒 計測してもよくわかんないけど大体50秒-56秒遅延されてた。
ちなみに途中で計測は終了したが右にいっぱい(数値で言えば100の状態)回して止めた時点では2500秒(41分)だった。
もしかしたら途中で誤検知してしまったかもしれないがさっきの写真くらいの位置で平均して50秒だったら右いっぱい回したら永遠に検知状態かも。*なぜこうなるのかわかる方がいれば是非教えてください
動かしてみる
追加
ジャンパワイヤ +2本
ブレッドボード
抵抗 220Ω
LED 2V 10mAわかりやすいように指を検知したらLED光らせてみる
*LEDの光らせ方は前回の記事に書いてます。
human_led_sensor.pyimport RPi.GPIO as GPIO import time PIN = 14 LED = 15 # 追加 GPIO.setmode(GPIO.BCM) GPIO.setup(PIN, GPIO.IN) GPIO.setup(LED, GPIO.OUT) # 追加 try: print ('-----Start-----') n = 1 while True: if GPIO.input(PIN) == GPIO.HIGH: print("{}".format(n) + "回目検知") GPIO.output(LED, GPIO.HIGH) # 追加 n += 1 time.sleep(2) GPIO.output(LED, GPIO.LOW) # 追加 else: print(GPIO.input(PIN)) time.sleep(2) except KeyboardInterrupt: print("Cancel") finally: GPIO.cleanup() print("-----end-----")検知してから2秒後にLEDを消すようにした。
こんな感じ
まとめ
- 多少反応は悪いがある程度検知する
- 遅延時間が上手く動かなかったがそれ以外はある程度動いた
- 調べてる段階では難しくてできるかなーと思ってたけど実際に動かしてみたらつまずきはしたがやり切れた。
今度は監視カメラのように物体を検知した時にカメラを起動して写真をとるようにしたい。
参考記事
OSOYOO-HC-SR501 PIRモーションセンサー
OSOYOO-Raspberry Piで人体感知センサーモジュールを作動し、LEDを点灯する




- 投稿日:2019-08-21T21:46:02+09:00
【RaspberryPi】 人感センサーを使って検知したことをプログラムで出力する
-
毎日試しては更新するように心がけます
この記事について
今回はRaspberryPのスターターキットを購入したので色々と遊んでみる
OSOYOO(オソヨー) Raspberry Pi... https://www.amazon.jp/dp/B01M6ZFNSS?ref=ppx_pop_mob_ap_shareまずは人感センサー
ラズパイに人感センサーを繋いで赤外線で人、物を検知する。
それをプログラム上に出力する。ネットの記事を何個か見て試してみたが上手くいかず少しつまずいた
動作環境
- Raspberry Pi Model B+
- Python3.7.4
用意するもの
- Raspberry Pi Model B+
- 電源アダプター(5V/3000mA)
- 人感センサー(HC-SR501 PIR motion sensor)
- ジャンパワイヤ 3本
センサー
動作電圧 DC5V - 12V 出力 LOW - 0V , HIGH - 3.3V 遅延時間 調整可能 (0.3-18秒) 遮断時間 0.2秒 検出範囲 7m未満 120度未満 動作温度 -15 ~ 70度 トリガーモード LOWは繰り返し× トリガーモードがよく理解できなかった
自分なりの解釈は遅延時間が5秒の場合
LOWは、検知し遅延時間中にさらに検知してもその検知はトリガーされないHIGHの場合は検知し遅延時間中にさらに検知したら
直前に検知した遅延時間がトリガーされるうまく説明できないので
要するにLOWは延長してくれないけどHIGHは延長してくれるっていう理解でいいのかな
はい、次
プログラムを書く
human_sensor.pyimport RPi.GPIO as GPIO import time PIN = 14 GPIO.setmode(GPIO.BCM) GPIO.setup(PIN, GPIO.IN) try: print ('-----Start-----') n = 1 while True: if GPIO.input(PIN) == GPIO.HIGH: print("{}".format(n) + "回目検知") n += 1 time.sleep(2) else: print(GPIO.input(PIN)) time.sleep(2) except KeyboardInterrupt: print("Cancel") finally: GPIO.cleanup() print("-----end-----")感度、遅延時間の調節
少しいじってみた感じ感度調節の方はあまり差がわからなかった
けど手をかざせばほとんど反応するから精度は悪くないと思う。問題は遅延時間
遅延時間の範囲は0.3秒-18秒。
試しに写真の位置に合わせて測ってみようと思い計測(だいたい5-7秒くらいかなーと予測)
結果…
56秒あまり意味がわからなかったのでとりあえず左に回してもう一度計測(数値で言えば0の状態)
結果は遅延無し
これは思ったように動いた。…
…計測する
1回目 56秒 2回目 52秒 3回目 56秒 4回目 55秒 5回目 52秒 6回目 56秒 7回目 55秒 8回目 52秒 9回目 51秒 10回目 56秒 計測してもよくわかんないけど大体50秒-56秒遅延されてた。
ちなみに途中で計測は終了したが右にいっぱい(数値で言えば100の状態)回して止めた時点では2500秒(41分)だった。
もしかしたら途中で誤検知してしまったかもしれないがさっきの写真くらいの位置で平均して50秒だったら右いっぱい回したら永遠に検知状態かも。*なぜこうなるのかわかる方がいれば是非教えてください
動かしてみる
追加
ジャンパワイヤ +2本
ブレッドボード
抵抗 220Ω
LED 2V 10mA
ピン ポート 2 5V 5V(OUT) 6 GND GND 8 14 制御(UCC) 10 15 制御(UCC) 14 GND GND わかりやすいように指を検知したらLED光らせてみる
*LEDの光らせ方は前回の記事に書いてます。
human_led_sensor.pyimport RPi.GPIO as GPIO import time PIN = 14 LED = 15 # 追加 GPIO.setmode(GPIO.BCM) GPIO.setup(PIN, GPIO.IN) GPIO.setup(LED, GPIO.OUT) # 追加 try: print ('-----Start-----') n = 1 while True: if GPIO.input(PIN) == GPIO.HIGH: print("{}".format(n) + "回目検知") GPIO.output(LED, GPIO.HIGH) # 追加 n += 1 time.sleep(2) GPIO.output(LED, GPIO.LOW) # 追加 else: print(GPIO.input(PIN)) time.sleep(2) except KeyboardInterrupt: print("Cancel") finally: GPIO.cleanup() print("-----end-----")検知してから2秒後にLEDを消すようにした。
こんな感じ
まとめ
- 多少反応は悪いがある程度検知する
- 遅延時間が上手く動かなかったがそれ以外はある程度動いた
- 調べてる段階では難しくてできるかなーと思ってたけど実際に動かしてみたらつまずきはしたがやり切れた。
今度は監視カメラのように物体を検知した時にカメラを起動して写真をとるようにしたい。
参考記事
OSOYOO-HC-SR501 PIRモーションセンサー
OSOYOO-Raspberry Piで人体感知センサーモジュールを作動し、LEDを点灯する

- 投稿日:2019-08-21T21:11:19+09:00
sqlalchemyを使用してpythonでDBアクセスをする
はじめに
pythonでDBアクセスをする際によく使われるORマッパーとして、SQLAlchemyがあります。
基本的なselectやinsertといったDBの操作はいろいろなサイトに乗っていて簡単に使えるのですが
DB操作以外でちょっと調べたのでまとめます。環境
- python3:3.6.5
- SQLAlchemy:1.3.7
- psycopg2:2.8.3
インストール
インストールは普通にpipでインストールします。
>pip install sqlalchemy >pip install psycopg2使用するクラスは次のクラスを使います。
from sqlalchemy import Column, Integer, String, DateTime from sqlalchemy.ext.declarative import declarative_base Base = declarative_base() class Pets(Base): __tablename__ = 'pets' id = Column(Integer, primary_key=True) name = Column(String) age = Column(Integer) birthday = Column(DateTime) def __init__(self, name, age, birthday): self.name = name self.age = age self.birthday = birthday def __str__(self): return 'id:{}, name:{}, age:{}, birthday:{}'.format(self.id, self.name, self.age, self.birthday)セッションの生成
大抵のプログラムでDBの操作をするときは、効率化のためにセッションを生成して、そのセッションを使いまわします。
SQLAlchemyも同様にグローバル変数にセッションを生成して、それを関数内で呼び出して使用すると使いまわしてくれます。
sql発行後にlocal_session.close()をしていますが、これはグローバル変数にセッションを戻しているだけなので生成したセッションは消えていません。
セッションを切断するためにはengine.dispose()をする必要がありますが基本セッションを使いまわすのであまり必要ないです。ポイント
ENGINE = create_engine(接続文字列) SESSION = sessionmaker(ENGINE) local_session = SESSION() 取得結果 = local_session.query(ORマップ用クラス).all() local_session.close()実験
pyMod.pyfrom sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker DATABASE = 'postgresql' USER = 'postgres' PASSWORD = 'postgres' HOST = 'localhost' PORT = '5431' DB_NAME = 'animal_db' CONNECT_STR = '{}://{}:{}@{}:{}/{}'.format(DATABASE, USER, PASSWORD, HOST, PORT, DB_NAME) ENGINE = None SESSION = None def read_data(name): local_session = SESSION() try: pets = local_session.query(Pets).filter(Pets.name=="pochi").all() for pet in pets: print(pet) finally: local_session.close() if __name__ == "__main__": ENGINE = create_engine(CONNECT_STR) SESSION = sessionmaker(ENGINE) print('--------------- before select 1 ------------------------') print(' session:{}'.format(ENGINE.pool.status())) read_data('pochi') print('--------------- after select 1 ------------------------') print(' session:{}'.format(ENGINE.pool.status())) print('--------------- before select 2 ------------------------') print(' session:{}'.format(ENGINE.pool.status())) read_data('tama')結果
# python3 pyMod.py --------------- before select 1 ------------------------ session:Pool size: 5 Connections in pool: 0 Current Overflow: -5 Current Checked out connections: 0 id:1, name:pochi, age:4, birthday:1990-02-12 00:00:00 --------------- after select 1 ------------------------ session:Pool size: 5 Connections in pool: 1 Current Overflow: -4 Current Checked out connections: 0 --------------- before select 2 ------------------------ session:Pool size: 5 Connections in pool: 1 Current Overflow: -4 Current Checked out connections: 0 id:2, name:tama, age:3, birthday:1992-08-06 20:02:21 --------------- after select 2 ------------------------ session:Pool size: 5 Connections in pool: 1 Current Overflow: -4 Current Checked out connections: 0結果を見るとbefore select1の時にはConnections in poolが0でselect実行後には、1になっています。
また、Current Overflowも-5から1つ生成して-4になっています。
select 2を見るとselect 1で使ったセッションを使いまわしているため、コネクションの数が変わっていません。セッションの制限
DBの設定によってはセッション数を制限しておりセッションの生成を管理したい場合があります。
その際はengine作成時にパラメータを入れてあげるだけで制限できました。ポイント
ENGINE = create_engine(CONNECT_STR, pool_size=コネクション数, max_overflow=制限を超えて生成できるコネクション数)pool_sizeの実験
上のソースから変更部分のみ
pyMod.pyENGINE = create_engine(CONNECT_STR, pool_size=2, max_overflow=1)結果
# python3 pyMod.py --------------- before select 1 ------------------------ session:Pool size: 2 Connections in pool: 0 Current Overflow: -2 Current Checked out connections: 0 id:1, name:pochi, age:4, birthday:1990-02-12 00:00:00 --------------- after select 1 ------------------------ session:Pool size: 2 Connections in pool: 1 Current Overflow: -1 Current Checked out connections: 0 --------------- before select 2 ------------------------ session:Pool size: 2 Connections in pool: 1 Current Overflow: -1 Current Checked out connections: 0 id:2, name:tama, age:3, birthday:1992-08-06 20:02:21 --------------- after select 2 ------------------------ session:Pool size: 2 Connections in pool: 1 Current Overflow: -1 Current Checked out connections: 0 PS C:\Users\minkl\OneDrive\ドキュメント\program\python\sql_alchemy>結果を見るとPool sizeが指定した2になっています。
max_overflowの実験
上のソースから変更部分のみ
pyMod.pyENGINE = create_engine(CONNECT_STR, pool_size=0, max_overflow=1)結果
# python3 pyMod.py --------------- before select 1 ------------------------ session:Pool size: 0 Connections in pool: 0 Current Overflow: 0 Current Checked out connections: 0 id:1, name:pochi, age:4, birthday:1990-02-12 00:00:00 --------------- after select 1 ------------------------ session:Pool size: 0 Connections in pool: 1 Current Overflow: 1 Current Checked out connections: 0 --------------- before select 2 ------------------------ session:Pool size: 0 Connections in pool: 1 Current Overflow: 1 Current Checked out connections: 0 id:2, name:tama, age:3, birthday:1992-08-06 20:02:21 --------------- after select 2 ------------------------ session:Pool size: 0 Connections in pool: 1 Current Overflow: 1 Current Checked out connections: 0結果を見るとCurrent Overflowが1になっています。
オーバーしたときの実験
上のソースから変更部分のみ
pyMod.pyENGINE = create_engine(CONNECT_STR, pool_size=0, max_overflow=0)結果
# python3 pyMod.py --------------- before select 1 ------------------------ session:Pool size: 0 Connections in pool: 0 Current Overflow: 0 Current Checked out connections: 0結果のところから進まなくなりタイムアウトしました。設定値的にセッションを生成できないけど、機能的にはセッションの解放待ちになっています。
取得型の指定
基本はDBの値をクラスで取得しますが、queryに指定することでコレクション型で取得することができます。
pyMod.pypets = local_session.query(Pets.name, Pets.age).all() print(type(pets)) for pet in pets: print(type(pet)) print(pet)結果
# python3 pyMod.py --------------- before select 1 ------------------------ session:Pool size: 2 Connections in pool: 0 Current Overflow: -2 Current Checked out connections: 0 <class 'list'> <class 'sqlalchemy.util._collections.result'> ('pochi', 4) <class 'sqlalchemy.util._collections.result'> ('tama', 3)オートインクリメントのタイミング
postgresqlにはserialという数字を自動的にインクリメント(+1)してくれる機能があります。
そのインクリメントのタイミングを調べました。pyMod.pydef insert_date(name): local_session = SESSION() try: pet = Pets(name, 4, datetime(year=1990, month=2, day=12)) print(pet.id) local_session.add(pet) print(pet.id) local_session.commit() print(pet.id) except: local_session.rollback() finally: local_session.close()結果
None None 4結果を見るとコミットしたタイミングでインクリメントされました。
一括アップデート
アップデートはselectで取得したクラスの変数を書き換えてaddをしますが、性能的な問題で一括で更新したいことがあります。
その際は、直接更新できるようです。pyMod.pydef update_data(): local_session = SESSION() local_session.query(Pets).filter(Pets.age==4).update({Pets.name:'mink'}) local_session.commit() local_session.close()結果
id:4, name:mink, age:4, birthday:1990-02-12 00:00:00 ---- update ----- id:4, name:mink, age:4, birthday:1990-02-12 00:00:00 id:1, name:mink, age:4, birthday:1990-02-12 00:00:00 id:3, name:mink, age:4, birthday:1990-02-12 00:00:00おわりに
SQLAlchemyでDBに接続してみました。カーソル等を使わなくて済むのでとても使いやすいですが、セッションあたりが混乱しやすいです。
未だにセッションを返却する関数がcloseなのか納得がいっていないので人に説明するときにすごく苦労しています。
- 投稿日:2019-08-21T20:49:18+09:00
pythonでべたに使うもの(python3)
目的
pythonをちょこちょこ調べらながら書いていて、今後も使用するであろうものをまとめる。
※初心者向けdict(辞書)からキーがなくても落ちない方法
下記のようにdictから取得すると実行時にエラーが発生してしまう。
dict = {} print(dict['test'])実行結果Traceback (most recent call last): File "sample.py", line 2, in <module> print(dict['test']) KeyError: 'test'dictのgetメソッドを使用することで、キーがなくてもエラーにならずにNoneが返却される。
dict = {} print(dict.get('test'))実行結果None数値のチェック
# 数値であるかチェックします。 # 半角数値、少数の場合Trueを返します。 def isNum(num): return re.compile('^([1-9]\\d*|0)(\\.\\d+)?$').match(num) is not None正の整数のチェック
# 正の整数(0を除く)であるかチェックします。 # 正の整数(0を除く)である場合Trueを返します。 def isPlusInteger(num): return re.compile('^[1-9]\\d*$').match(num) is not None少数第1位で切り捨て
from decimal import Decimal,ROUND_DOWN def roundDown(val): return Decimal(val).quantize(Decimal('0.1'), rounding=ROUND_DOWN)少数を整数に切り捨て
from decimal import Decimal # 整数に切り捨てます。 def truncateNum(val): return str(math.floor(Decimal(val)))日付のフォーマット
from datetime import datetime # YYYYMMDDをYYYY/MM/DDの形式にフォーマットします。 def dayFormat(day): return datetime.strptime(day, '%Y%m%d').strftime('%Y/%m/%d')AWSで日本時間で現在日時を取得します。
def getNowTime(): # AWSの時刻は、UTCなのでJSTに変換 return datetime.now(timezone(timedelta(hours=+9), 'JST'))最後に
メソッド名のセンスのなさが悩み。
- 投稿日:2019-08-21T20:18:57+09:00
PythonのIDLEにIVS付きの文字を入力すると落ちる件のメモ
落ちる
IDLEのシェルまたはエディタで IVS付きの文字を入力すると、何も言わずに実行を終了する。
※ Windows10 の Python 3.7.3 (64bit) で確認。Windows 以外はわかりません。キーボードからIVSを入力するのは少々面倒なので、大抵はコピペした文字列にそういう文字が混じっていたというケースになります。そういったデータを扱う機会の多い人が IDLEで何かしようと企んだ時だけ起こりうる事故で、とてもびっくりします。
※ たとえば次項「IVSとは」の本文を貼り付けると、落ちます。IVSとは
IVSは「異体字セレクタ」の一種で、フォントが内蔵する別字体をUnicodeで指定するための仕組み。
例として、「進(U+9032)」を表示するとき。
「進」の左側は、戦後日本では一点のしんにょう(辶)とされているが、もし二点(辶)で表示したい場合には、文字コードの後にセレクタを付与して「進?(U+9032, U+E0101)」あるいは「進?(U+9032, U+E0103)」とすれば選択できる。
……と、UnicodeコンソーシアムのIVD(漢字異体字データベース)には登録されている。※ U+E0101 の方は「Adobe-Japan1」コレクション、U+E0103 の方は「Hanyo-Denshi(汎用電子情報交換環境整備プログラム)」コレクション、または「Moji_Joho(文字情報基盤整備事業)」のコレクション
実際に表示されるかどうかはフォントの実装次第。なので、どれも「進」にしか見えない可能性もあるが、使用フォントが例えば Adobe-Japan1 に対応する「游ゴシック」か「游明朝」ならば、「進?(U+9032, U+E0101)」は二点(辶)になるだろう。
参考
- Wikipedia 『異体字セレクタ』 https://ja.wikipedia.org/wiki/%E7%95%B0%E4%BD%93%E5%AD%97%E3%82%BB%E3%83%AC%E3%82%AF%E3%82%BF
- Unicode Ideographic Variation Database https://unicode.org/ivd/
- 投稿日:2019-08-21T20:06:53+09:00
pythonのログ出力(python3)
目的
python3でのログ出力をまとめる。
ソース
ログレベルERRORの例
logTest.pyimport logging # ログオブジェクト作成 def get_logger(workername, logLvel): # ログの出力名を設定 logger = logging.getLogger(workername) # ログレベルの設定 logger.setLevel(logLvel) return logger def main(): # ロガー logger = get_logger(__name__, logging.ERROR) logger.debug('デバッグログです') logger.info('インフォログです') logger.warning('ワーニングです') logger.error('エラーです') logger.critical('クリティカルです') if __name__ == "__main__": main()上記例のログレベルであるlogging.ERRORは、int型。
実際の値は下記。
ログレベル 値 DEBUG 10 INFO 20 WARNING 30 ERROR 40 CRITICAL 50 参考
python3のloggingのAPI
https://docs.python.org/ja/3/library/logging.html#levels最後に
ログレベルは、外部ファイルや環境変数を読み込んで設定するのが普通なのかと思います。
- 投稿日:2019-08-21T20:01:21+09:00
Python基礎7 pandas 応用メモ
pythonの基礎を備忘録として残しておく
summary
df = pd.read_csv('./data/stock_8308.tsv', sep='\t') # タブ区切りは'\t'で * macは、'option'+'¥' zenba = df[df['session'] == 0] # ' session'=0のデータフレーム del zenba['session'] # 'session'項目を削除 dic = {} # 辞書の箱作成 for i in zenba.columns[1:]: dic[i] = i + '_zenba' # 辞書の追加 zenba = zenba.rename(columns=dic) # 辞書を使って項目変更 # 辞書を利用した項目のrename dic = {i:i+'_goba' for i in goba.columns[1:]} # 辞書を利用したrename(内包表記) df = zenba.merge(goba, on='date') # 'zenba'と'goba'を'date'でマージ df[df.isnull().any(axis=1)] # 欠損値をデータフレームで確認 df = df.dropna() # 欠損値を削除して表示 df['open'] = df['open_zenba'] # 対応 df['high'] = df[['high_zenba', 'high_goba']].max(axis=1) # 大きい方 df['low'] = df[['low_zenba', 'low_goba']].min(axis=1) # 小さい方 df['volume'] = df[['volume_zenba','volume_goba']].sum(axis=1) # 合計1 df['value'] = df['value_zenba'] + df['value_goba'] # 合計2 # 項目の各種置換 col = [i for i in df.columns if 'zenba' not in i and 'goba' not in i] df = df[col] # 'zenba','goba'を含まない項目のみにする plt.plot(df['close']) # 'close'の折れ線グラフ df = df[df["close"] < 50000] df = df.reset_index(drop=True) # グラフの最大値を50000以下に制限する (df['close'] - df['open'] > 0).astype(int) # 大きければ1、そうでなければ0 x = df[['open', 'high', 'low', 'close', 'volume', 'value']] y = df[['y']] print(np.array(x.iloc[:threshold, :])) # train_x print(np.array(y.iloc[:threshold, :]).flatten()) # train_y # x, yのデータフレームを作り、np.arrayでデータ作成ライブラリーのインポート
import numpy as np import pandas as pd import matplotlib.pyplot as pltCSVファイルの読み込み
* タブ区切りの場合はsep='\t'で読み込む。なお、Macで'\'の入力は、option+'¥'df = pd.read_csv('./data/stock_8308.tsv', sep='\t') print(df.head()) # 出力 date session open ... close volume value 0 2007-01-04 0 323000.0 ... 325000.0 28930 9331985000 1 2007-01-04 1 NaN ... NaN 0 0 2 2007-01-05 0 324000.0 ... 321000.0 33418 10823882000 3 2007-01-05 1 321000.0 ... 321000.0 22827 7342975000 4 2007-01-09 0 320000.0 ... 329000.0 29230 9509112000``前場(session = 0)のデータのみ表示
zenba = df[df['session'] == 0] print(zenba.head()) # 出力 date session open ... close volume value 0 2007-01-04 0 323000.0 ... 325000.0 28930 9331985000 2 2007-01-05 0 324000.0 ... 321000.0 33418 10823882000 4 2007-01-09 0 320000.0 ... 329000.0 29230 9509112000 6 2007-01-10 0 332000.0 ... 329000.0 32163 10618725000 8 2007-01-11 0 328000.0 ... 329000.0 18594 6115344000後場(session = 1)のデータのみ表示
goba = df[df['session'] == 1] print(goba.head()) # 出力 date session open ... close volume value 1 2007-01-04 1 NaN ... NaN 0 0 3 2007-01-05 1 321000.0 ... 321000.0 22827 7342975000 5 2007-01-09 1 329000.0 ... 330000.0 31357 10375287000 7 2007-01-10 1 328000.0 ... 328000.0 20511 6729752000 9 2007-01-11 1 329000.0 ... 326000.0 16628 5437101000前場、後場の項目が被らないようにリネームする。但し、'session'は削除、'date'はそのまま。
まず、前場をfor文でdel zenba['session'] print(zenba.columns) dic = {} for i in zenba.columns[1:]: dic[i] = i + '_zenba' print(dic) zenba = zenba.rename(columns=dic) print(zenba.head()) # 出力 Index(['date', 'open', 'high', 'low', 'close', 'volume', 'value'], dtype='object') {'open': 'open_zenba', 'high': 'high_zenba', 'low': 'low_zenba', 'close': 'close_zenba', 'volume': 'volume_zenba', 'value': 'value_zenba'} date open_zenba ... volume_zenba value_zenba 0 2007-01-04 323000.0 ... 28930 9331985000 2 2007-01-05 324000.0 ... 33418 10823882000 4 2007-01-09 320000.0 ... 29230 9509112000 6 2007-01-10 332000.0 ... 32163 10618725000 8 2007-01-11 328000.0 ... 18594 6115344000後場を内包表記で
del goba['session'] print(goba.columns) dic = {i:i+'_goba' for i in goba.columns[1:]} print(dic) print() goba = goba.rename(columns=dic) print(goba.head()) # 出力 Index(['date', 'open', 'high', 'low', 'close', 'volume', 'value'], dtype='object') {'open': 'open_goba', 'high': 'high_goba', 'low': 'low_goba', 'close': 'close_goba', 'volume': 'volume_goba', 'value': 'value_goba'} date open_goba ... volume_goba value_goba 1 2007-01-04 NaN ... 0 0 3 2007-01-05 321000.0 ... 22827 7342975000 5 2007-01-09 329000.0 ... 31357 10375287000 7 2007-01-10 328000.0 ... 20511 6729752000 9 2007-01-11 329000.0 ... 16628 5437101000zenba と goba を'date'でマージする
df = zenba.merge(goba, on='date') print(df.head()) # 出力 date open_zenba ... volume_goba value_goba 0 2007-01-04 323000.0 ... 0 0 1 2007-01-05 324000.0 ... 22827 7342975000 2 2007-01-09 320000.0 ... 31357 10375287000 3 2007-01-10 332000.0 ... 20511 6729752000 4 2007-01-11 328000.0 ... 16628 5437101000欠損値を確認する
tmp = df[df.isnull().any(axis=1)] print(tmp) # 出力 date open_zenba ... volume_goba value_goba 0 2007-01-04 323000.0 ... 0 0 244 2007-12-28 200000.0 ... 0 0 245 2008-01-04 191000.0 ... 0 0 414 2008-09-08 NaN ... 13819 1433030300 486 2008-12-25 NaN ... 0 0 487 2008-12-26 NaN ... 0 0 488 2008-12-29 NaN ... 0 0 489 2008-12-30 NaN ... 0 0 490 2009-01-05 1450.0 ... 0 0欠損値を除いて表示
df = df.dropna() print(df.head()) # 出力 date open_zenba ... volume_goba value_goba 1 2007-01-05 324000.0 ... 22827 7342975000 2 2007-01-09 320000.0 ... 31357 10375287000 3 2007-01-10 332000.0 ... 20511 6729752000 4 2007-01-11 328000.0 ... 16628 5437101000 5 2007-01-12 329000.0 ... 49509 16530550000以下の列を追加
open : session=0のopen
high : session=0とsession=1のhighの大きい方
low : session=0とsession=1のlowの小さい方
close : session=1のclose
volume: session=0とsession=1のvolumeの合計
value: session=0とsession=1のvalueの合計df['open'] = df['open_zenba'] df['high'] = df[['high_zenba', 'high_goba']].max(axis=1) df['low'] = df[['low_zenba', 'low_goba']].min(axis=1) df['close'] = df['close_goba'] df['volume'] = df[['volume_zenba','volume_goba']].sum(axis=1) df['value'] = df['value_zenba'] + df['value_goba'] # こちらの方が直感的かも print(df.head()) # 出力 date open_zenba ... volume value 1 2007-01-05 324000.0 ... 56245 18166857000 2 2007-01-09 320000.0 ... 60587 19884399000 3 2007-01-10 332000.0 ... 52674 17348477000 4 2007-01-11 328000.0 ... 35222 11552445000 5 2007-01-12 329000.0 ... 77776 25854436000zenba、goba が含まれていない項目のみ除いて表示
col = [i for i in df.columns if 'zenba' not in i and 'goba' not in i] print(col) df = df[col] print(df.head()) # 出力 date open high ... close volume value 1 2007-01-05 324000.0 326000.0 ... 321000.0 56245 18166857000 2 2007-01-09 320000.0 333000.0 ... 330000.0 60587 19884399000 3 2007-01-10 332000.0 333000.0 ... 328000.0 52674 17348477000 4 2007-01-11 328000.0 331000.0 ... 326000.0 35222 11552445000 5 2007-01-12 329000.0 336000.0 ... 334000.0 77776 25854436000'close'項目のグラフを作成する
plt.plot(df['close']) plt.show()
closeの値が50000未満の範囲でグラフを表示print(df.shape) df = df[df["close"] < 50000] df = df.reset_index(drop=True) print(df.shape) plt.plot(df["close"]) plt.show()
y項目を追加し、翌日の'open'が当日の'close'より高い場合は'1'低い場合は'0'とする
print((df['close'] - df['open']).head()) print() print((df['close'] - df['open'] > 0).astype(int).head()) y = list((df['close'] - df['open'] > 0).astype(int)) y = y[1:] + [np.nan] df['y'] = y print(df.tail()) # 出力 0 -6.0 1 21.0 2 12.0 3 -10.0 4 -21.0 dtype: float64 0 0 1 1 2 1 3 0 4 0 dtype: int64 date open high low close volume value y 2100 2017-07-31 568.0 574.6 566.5 568.4 15107800 8613256740 1.0 2101 2017-08-01 571.3 577.5 568.4 574.3 14936500 8552405910 0.0 2102 2017-08-02 578.4 579.6 569.1 573.8 10136000 5812332060 1.0 2103 2017-08-03 574.0 574.8 567.2 574.3 9567600 5468152880 0.0 2104 2017-08-04 573.0 574.8 570.4 572.8 8018300 4591509180 NaN欠損値を除いて表示
print(df.shape) df = df.dropna() print(df.shape) print(df.head()) # 出力 (2105, 8) (2104, 8) date open high low close volume value y 0 2009-01-06 1450.0 1454.0 1436.0 1444.0 3377400 4888187300 1.0 1 2009-01-07 1454.0 1482.0 1451.0 1475.0 3653000 5359326000 1.0 2 2009-01-08 1459.0 1482.0 1455.0 1471.0 3269100 4805717900 0.0 3 2009-01-09 1471.0 1486.0 1460.0 1461.0 4637100 6825123700 0.0 4 2009-01-13 1441.0 1442.0 1417.0 1420.0 3908100 5573985800 1.0先頭9割の行と残り1割の行に分割し、さらに、y列とそれ以外の列(x列)に分割する
その際、4つデータフレームはnumpyのarray型に変換し、y列のarrayは1次元配列に変換するprint(len(df)) threshold = int(len(df) * 0.9) print(threshold) x = df[['open', 'high', 'low', 'close', 'volume', 'value']] y = df[['y']] print(np.array(x.iloc[:threshold, :])) # train_x print() print(np.array(y.iloc[:threshold, :]).flatten()) # train_y print() print(np.array(x.iloc[threshold:, :])) # test_x print() print(np.array(y.iloc[threshold:, :]).flatten()) # test_y # 出力 2104 1893 [[1.45000000e+03 1.45400000e+03 1.43600000e+03 1.44400000e+03 3.37740000e+06 4.88818730e+09] [1.45400000e+03 1.48200000e+03 1.45100000e+03 1.47500000e+03 3.65300000e+06 5.35932600e+09] [1.45900000e+03 1.48200000e+03 1.45500000e+03 1.47100000e+03 3.26910000e+06 4.80571790e+09] ... [4.35300000e+02 4.70000000e+02 4.24800000e+02 4.69100000e+02 3.00463000e+07 1.36255238e+10] [4.65700000e+02 4.72500000e+02 4.59600000e+02 4.68100000e+02 2.77592000e+07 1.29561912e+10] [4.67900000e+02 4.69800000e+02 4.60200000e+02 4.62000000e+02 1.43791000e+07 6.67774531e+09]] [1. 1. 0. ... 1. 0. 1.] [[4.38100000e+02 4.53000000e+02 4.36700000e+02 4.49300000e+02 2.40786000e+07 1.07343711e+10] [4.39500000e+02 4.42000000e+02 4.29400000e+02 4.32200000e+02 1.48967000e+07 6.45213641e+09] [4.33000000e+02 4.35800000e+02 4.28600000e+02 4.30600000e+02 1.74649000e+07 7.54749060e+09] ... [5.71300000e+02 5.77500000e+02 5.68400000e+02 5.74300000e+02 1.49365000e+07 8.55240591e+09] [5.78400000e+02 5.79600000e+02 5.69100000e+02 5.73800000e+02 1.01360000e+07 5.81233206e+09] [5.74000000e+02 5.74800000e+02 5.67200000e+02 5.74300000e+02 9.56760000e+06 5.46815288e+09]] [0. 0. 1. 0. 1. 1. 0. 0. 0. 0. 0. 1. 0. 1. 0. 1. 1. 0. 1. 1. 1. 1. 1. 0. 0. 1. 0. 1. 0. 1. 1. 1. 1. 1. 1. 0. 1. 1. 0. 0. 1. 1. 0. 1. 1. 1. 1. 1. 0. 1. 0. 1. 1. 1. 1. 0. 1. 0. 1. 1. 1. 1. 0. 1. 1. 1. 0. 0. 1. 0. 1. 0. 0. 1. 0. 1. 1. 0. 0. 1. 1. 1. 1. 0. 0. 1. 0. 1. 1. 1. 1. 0. 0. 1. 1. 0. 1. 0. 0. 0. 0. 0. 1. 1. 0. 1. 1. 0. 0. 1. 1. 1. 0. 1. 1. 0. 1. 0. 1. 1. 0. 1. 0. 1. 0. 0. 0. 0. 0. 0. 1. 1. 0. 1. 1. 1. 0. 1. 1. 1. 0. 1. 1. 1. 0. 1. 0. 1. 0. 0. 1. 0. 1. 0. 0. 1. 1. 0. 0. 0. 1. 0. 0. 0. 1. 1. 1. 0. 1. 1. 1. 1. 0. 1. 1. 0. 0. 1. 0. 0. 0. 1. 0. 1. 1. 0. 1. 1. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 1. 1. 1. 0. 1. 0.]


- 投稿日:2019-08-21T20:01:02+09:00
Python基礎6 matplotlibメモ
pythonの基礎を備忘録として残しておく
summary
plt.plot(X, Y, marker='o', color='red', linestyle='--') # 折れ線グラフ plt.xlabel('time') # xラベル plt.ylabel('count') # yラベル plt.title('Shop A') # タイトル plt.grid() # グリッド線 x= np.arange(-5, 5, 0.01) # xデータの連続生成 plt.plot(x, food, label='food') # 凡例'food' plt.legend(loc='upper left') # 凡例表示 plt.bar(x, y) # 棒グラフ plt.scatter(sugar_x, sugar_y, label='sugar') # 散布図 plt.scatter(x, y, marker="o", color="green", alpha=0.5) # 透明度 x = np.random.rand(1000) # 0-1のランダムな数字1000個生成 plt.hist(x, bins=20, rwidth=0.7) # ヒストグラム fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2) # 複数グラフ(subplots) ax1.plot(x, food) # 1つ目のグラフ ax1.set_title('food') # 1つ目のタイトル fig = plt.figure() # 複数グラフ(add_subplot) ax1 = fig.add_subplot(1, 2, 1) # 1つ目のグラフ設定 ax1.plot(x, food) # 1つ目のグラフ ax1.set_title('food') # 1つ目のタイトル ax1.set_ylabel("food") # 1つ目のグラフのyラベル ymin, ymax = ax1.get_ylim() # y軸の最小・最大の取得 ax2.set_ylim(ymin, ymax) # y軸の最小・最大の設定 fig = plt.figure() ax1 = fig.add_subplot(1, 1, 1) ax1.bar(tick_label, sales, label="sales", color="b", alpha=0.5) ax2 = ax1.twinx() # ax1の2軸目にax2を ax2.plot(temperature, label="temperature", color="r", marker="x") # 棒と折れ線グラフの混在 handler1, label1 = ax1.get_legend_handles_labels() # ax1のハンドルとラベルを取得 handler2, label2 = ax2.get_legend_handles_labels() # ax2のハンドルとラベルを取得 plt.legend(handler1+handler2, label1+label2) # ハンドルとラベルを合成して表示 # 棒と折れ線グラフの混在の場合の凡例表示matplotlib のインポート
import matplotlib.pyplot as pltyデータのみのグラフ
data = [1.0, 2.1, 2.8, 4.2, 6.1, 3.5] plt.plot(data) plt.show()
マーカー指定 marker='' 'o', 'x', 'v' ...
カラー指定 color='' 'red', 'green', 'blue' ...
x軸'time'、y軸'count'、タイトル'Shop A'、グリッド付きでグラフを描くX = [1, 2, 3, 4 ,5, 6] Y = [13, 23, 20, 19, 10, 11] plt.plot(X, Y, marker='o', color='red', linestyle='--') plt.xlabel('time') plt.ylabel('count') plt.title('Shop A') plt.grid() plt.show()
y = -x**2 + 1 y = 0.5*x - 5
の2つのグラフをxが-5から+5の範囲で描くimport numpy as np x= np.arange(-5, 5, 0.01) y1 = - x ** 2 + 1 y2 = 0.5 * x - 5 plt.plot(x, y1) plt.plot(x, y2) plt.show()
凡例labelの表示位置指定 plt.legend(loc = '')
* upper right(デフォルト)、upper left、lower right、lower leftx = [1, 2, 3, 4, 5] food = [23, 21, 42, 32, 23] drink = [33, 25, 41, 36, 16] plt.plot(x, food, label='food') plt.plot(x, drink, label='drink') plt.legend(loc='upper left') plt.show()
棒グラフ
x = ['A', 'B', 'C', 'D', 'E'] y = [10, 13, 9, 6, 10] plt.bar(x, y) plt.show()
散布図
sugar_x = [1, 3, 2, 4, 6] sugar_y = [29, 31, 22, 43, 26] salt_x = [4, 1, 1, 3, 2] salt_y = [22, 32, 12, 33, 36] plt.scatter(sugar_x, sugar_y, label='sugar') plt.scatter(salt_x, salt_y, label='salt') plt.legend() plt.show()
x, yともに0-1までの値をとるランダムな小数を100個散布図を作成
*色は緑、マーカーは'o'、アルファ(透明度)=0.5import numpy as np x, y = np.random.rand(100), np.random.rand(100) plt.scatter(x, y, marker="o", color="green", alpha=0.5) plt.show()
0-1までの値をとるランダムな小数を1000個ヒストグラムで表示
*バーの数は20本、線の太さは0.7、y軸のラベルに「count」と表示import numpy as np x = np.random.rand(1000) # 0-1のランダムな数字1000個生成 plt.hist(x, bins=20, rwidth=0.7) plt.ylabel("count") plt.show()
subplots による複数グラフ表示
x = [1, 2, 3, 4, 5] food = [23, 21, 42, 32, 23] drink = [33, 25, 41, 36, 16] fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2) ax1.plot(x, food) ax1.set_title('food') ax2.plot(x, drink) ax2.set_title('drink') plt.show()
add_subplot による折れ線グラフの複数表示
x = [1, 2, 3, 4, 5] food = [23, 21, 42, 32, 23] drink = [33, 25, 41, 36, 16] fig = plt.figure() ax1 = fig.add_subplot(1, 2, 1) ax1.plot(x, food) ax1.set_title('food') ax2 = fig.add_subplot(1, 2, 2) ax2.plot(x, drink) ax2.set_title('drink') plt.show()
add_subplot による棒グラフの複数表示
x = ['A', 'B', 'C', 'D', 'E'] food = [23, 21, 42, 32, 23] drink = [33, 25, 41, 36, 16] fig = plt.figure() ax1 = fig.add_subplot(2, 1, 1) ax1.bar(x, food) ax1.set_ylabel('food') ax2 = fig.add_subplot(2, 1, 2) ax2.bar(x, drink) ax2.set_ylabel('drink') plt.tight_layout() plt.show()
add_subplot による折れ線グラフの複数表示
1行2列で、変数名をタイトルとし、y軸のレンジを統一して表示x = [1, 2, 3, 4, 5] food = [23, 21, 42, 32, 23] drink = [33, 25, 41, 36, 16] fig = plt.figure() ax1 = fig.add_subplot(1, 2, 1) ax1.plot(x, food) ax1.set_title('food') ymin, ymax = ax1.get_ylim() # y軸の最小、最大を取得 ax2 = fig.add_subplot(1, 2, 2) ax2.plot(x, drink) ax2.set_title('drink') ax2.set_ylim(ymin, ymax) # y軸の最小、最大を設定 plt.show()
2軸でグラフ表示し、変数名を凡例として表示する
x = ['week1', 'week2', 'week3', 'week4', 'week5'] sales = [293, 221, 240, 145, 223] temperature = [33, 28, 30, 24, 28] fig = plt.figure() ax1 = fig.add_subplot(1, 1, 1) ax1.bar(x, sales, label="sales", color="b", alpha=0.5) ax2 = ax1.twinx() # 2軸目のグラフを設定 ax2.plot(temperature, label="temperature", color="r", marker="x") handler1, label1 = ax1.get_legend_handles_labels() # ハンドルとラベルを取得 handler2, label2 = ax2.get_legend_handles_labels() # ハンドルとラベルを取得 plt.legend(handler1+handler2, label1+label2) # 2つのハンドルとラベルを表示 plt.show()













- 投稿日:2019-08-21T20:00:42+09:00
Python基礎5 pandas メモ
pythonの基礎を備忘録として残しておく
summary
pd.read_csv('./data/test.csv', sep=',') # CSVデータ読み込み df[['job','age']] # 'job','age'列 df['job'] # 'job'列のシリーズデータ df[df['age']>=40] # 'age'が40以上 df[(df['age'] <=30) & (df['marital'] == 'married')] # 'age'が30以下かつ'marital'が'married' df['over_35'] = 'yes' # 'over_35'列を作成し値は全て'yes' df.loc[df['age'] <=35, 'over_35'] ='no' # 'age'が35以下の'over_35'は全て'no' df.drop(columns = 'age') # 'age'列を削除 df.loc[len(df), :] = df.loc[len(df) -1 , :] # 最終行を最後に追加 df[df == "yes"] = np.nan # 'yes'のセルを欠損値に df.isnull().any() # 各列の欠損値の有無 df[df.isnull().any(axis = 1)] # 欠損値のある行表示 df.dropna() # 欠損値のある行の削除 df.dropna(axis = 1) # 欠損値のある列を削除 df.fillna("unknown") # 欠損値を'unknown'に置き換え df.drop_duplicates("job") # 'job'列の重複行を削除 (df == "unknown").sum() # 列毎の'unknown'の個数 (df == "unknown").sum().sum() # 'unknown'の総個数 ((df["age"] >= 30) & (df["age"] < 35)).sum() # 'age'が30以上35未満の個数 df.rename(columns={"job":"work"}) # 'job'を'work'にリネーム df.index = ["No." + str(i) for i in range(len(df))] # indexを'No.'に df = df.reset_index(drop=True) # indexをリセット df[["job", "age"]].groupby("job").max() # 'job'毎の'age'の最大 df[["job", "age", "marital"]].groupby(["job","marital"]).mean() # 'job','marital'毎の'age'の平均 * groupbyの項目が複数の場合はリストで df.pivot_table(values='age', index=['marital', 'job'], aggfunc=np.mean) # 'marital','job'をインデックスに'age'をピボットテーブル df['age'] = df['age'].astype(int) # 'age'列をint型に df.sort_values("age", ascending=False) # 'age'列を降順に new_df = pd.DataFrame(data=[[1,2],[3,4],[5,6]], columns=['A','B']) # データフレーム作成 df.merge(new_df, on='marital') # dfにnew_dfを'marital'でマージ df.append(new_df, ignore_index=True) # new_dfを追加し、indexリセット pd.get_dummies(df['marital']) # 'marital'をワンホットエンコーディングpandsのインポート
import pandas as pdcsvファイルの内容
age,job,marital,housing,loan 30,blue-collar,married,yes,no 39,services,single,no,no 25,services,married,yes,no 38,services,married,unknown,unknown 47,admin.,married,yes,no 32,services,single,no,no 32,admin.,single,yes,no 41,entrepreneur,married,yes,no 31,services,divorced,no,no 35,blue-collar,married,no,nocsvファイルの読み込み (セパレータは sep=''で指定。デフォルトは',')
df = pd.read_csv('./data/test.csv', sep=',') # sep=','は省略化 print(df) # 出力 age job marital housing loan 0 30 blue-collar married yes no 1 39 services single no no 2 25 services married yes no 3 38 services married unknown unknown 4 47 admin. married yes no 5 32 services single no no 6 32 admin. single yes no 7 41 entrepreneur married yes no 8 31 services divorced no no 9 35 blue-collar married no no'job','age'の列をデータフレーム形式で表示
tmp = df[['job','age']] print(tmp.head()) # 出力 job age 0 blue-collar 30 1 services 39 2 services 25 3 services 38 4 admin. 47'job'の列をシリーズ形式で表示
tmp = df['job'] print(tmp.head()) # 出力 0 blue-collar 1 services 2 services 3 services 4 admin. Name: job, dtype: object'age'の列が40以上の行を表示
tmp = df[df['age']>=40] print(tmp) # 出力 age job marital housing loan 4 47 admin. married yes no 7 41 entrepreneur married yes no'age'列が30以下かつ、'marital'列が'married'の行を表示する
tmp = df[(df['age'] <=30) & (df['marital'] == 'married')] print(tmp) # 出力 age job marital housing loan 0 30 blue-collar married yes no 2 25 services married yes no'over_35'列を追加し、値は全て'yes'にする
df['over_35'] = 'yes' print(df.head()) # 出力 age job marital housing loan over_35 0 30 blue-collar married yes no yes 1 39 services single no no yes 2 25 services married yes no yes 3 38 services married unknown unknown yes 4 47 admin. married yes no yesover_35が、'age'が35以下の場合は値を'no'、それ以外は'yes'にする
df['over_35'] = 'yes' df.loc[df['age'] <=35, 'over_35'] ='no' print(df.head()) # 出力 age job marital housing loan over_35 0 30 blue-collar married yes no no 1 39 services single no no yes 2 25 services married yes no no 3 38 services married unknown unknown yes 4 47 admin. married yes no yes'age'列を削除して表示する
tmp = df.drop(columns = 'age') print(tmp.head()) # 出力 job marital housing loan over_35 0 blue-collar married yes no no 1 services single no no yes 2 services married yes no no 3 services married unknown unknown yes 4 admin. married yes no yes最終行と同じ行を最終行の後に追加する
df.loc[len(df), :] = df.loc[len(df) -1 , :] print(df.tail()) # 出力 age job marital housing loan over_35 6 32.0 admin. single yes no no 7 41.0 entrepreneur married yes no yes 8 31.0 services divorced no no no 9 35.0 blue-collar married no no no 10 35.0 blue-collar married no no noセルの値が'yes'の場合は全て'NaN'(欠損値)に置き換える
import numpy as np df[df == "yes"] = np.nan print(df.head()) # 出力 age job marital housing loan over_35 0 30.0 blue-collar married NaN no no 1 39.0 services single no no NaN 2 25.0 services married NaN no no 3 38.0 services married unknown unknown NaN 4 47.0 admin. married NaN no NaN各列に欠損値があるかどうかを表示する
tmp = df.isnull().any() print(tmp) # 出力 age False job False marital False housing True loan False over_35 True dtype: bool欠損値がある行を全て表示する
tmp = df[df.isnull().any(axis = 1)] print(tmp) # 出力 age job marital housing loan over_35 0 30.0 blue-collar married NaN no no 1 39.0 services single no no NaN 2 25.0 services married NaN no no 3 38.0 services married unknown unknown NaN 4 47.0 admin. married NaN no NaN 6 32.0 admin. single NaN no no 7 41.0 entrepreneur married NaN no NaN欠損値がある行を削除して表示
tmp = df.dropna() print(tmp) # 出力 age job marital housing loan over_35 5 32.0 services single no no no 8 31.0 services divorced no no no 9 35.0 blue-collar married no no no 10 35.0 blue-collar married no no no欠損値がある列を削除して表示
tmp = df.dropna(axis = 1) print(tmp.head()) # 出力 age job marital loan 0 30.0 blue-collar married no 1 39.0 services single no 2 25.0 services married no 3 38.0 services married unknown 4 47.0 admin. married no欠損値('NaN')を'unknown'に置き換える
df = df.fillna("unknown") print(df.head()) # 出力 age job marital housing loan over_35 0 30.0 blue-collar married unknown no no 1 39.0 services single no no unknown 2 25.0 services married unknown no no 3 38.0 services married unknown unknown unknown 4 47.0 admin. married unknown no unknown'job'列の重複行を削除して表示する
tmp = df.drop_duplicates("job") print(tmp) # 出力 age job marital housing loan over_35 0 30.0 blue-collar married unknown no no 1 39.0 services single no no unknown 4 47.0 admin. married unknown no unknown 7 41.0 entrepreneur married unknown no unknown'age'列の最大、最小、平均値
print(df['age'].max()) print(df['age'].min()) print(df['age'].mean()) # 出力 47.0 25.0 35.0列毎に'unknown'の個数を表示する
tmp = (df == "unknown").sum() print(tmp) # 出力 age 0 job 0 marital 0 housing 6 loan 1 over_35 4 dtype: int64'unknown'の総個数を表示する
tmp = (df == "unknown").sum().sum() print(tmp) # 出力 11'age' が30以上かつ、35未満を表示する
tmp = ((df["age"] >= 30) & (df["age"] < 35)).sum() print(tmp) # 出力 4列名'job'を'work'に変更する
tmp = df.rename(columns={"job":"work"}) print(tmp) # 出力 age work marital housing loan over_35 0 30.0 blue-collar married unknown no no 1 39.0 services single no no unknown 2 25.0 services married unknown no no 3 38.0 services married unknown unknown unknown 4 47.0 admin. married unknown no unknownindexを「No.{数字}」に変更
df.index = ["No." + str(i) for i in range(len(df))] print(df.head()) # 出力 age job marital housing loan over_35 No.0 30.0 blue-collar married unknown no no No.1 39.0 services single no no unknown No.2 25.0 services married unknown no no No.3 38.0 services married unknown unknown unknown No.4 47.0 admin. married unknown no unknownindex をリセット
df = df.reset_index(drop=True) print(df.head()) # 出力 age job marital housing loan over_35 0 30.0 blue-collar married unknown no no 1 39.0 services single no no unknown 2 25.0 services married unknown no no 3 38.0 services married unknown unknown unknown 4 47.0 admin. married unknown no unknown'job'毎の最大値を表示
tmp = df[["job", "age"]].groupby("job").max() print(tmp) # 出力 job admin. 47.0 blue-collar 35.0 entrepreneur 41.0 services 39.0'job'毎、'marital'毎の'ageの平均
tmp = df[["job", "age", "marital"]].groupby(["job","marital"]).mean() print(tmp) # 出力 age job marital admin. married 47.000000 single 32.000000 blue-collar married 33.333333 entrepreneur married 41.000000 services divorced 31.000000 married 31.500000 single 35.500000'marital'、'job'をインデックス、'age'を値としてピボットテーブルを表示する
tmp = df.pivot_table(values='age', index=['marital', 'job'], aggfunc=np.mean) print(tmp) # 出力 divorced services 31.000000 married admin. 47.000000 blue-collar 33.333333 entrepreneur 41.000000 services 31.500000 single admin. 32.000000 services 35.500000'age'列をint型に変更する
df['age'] = df['age'].astype(int) print(df.head()) # 出力 age job marital housing loan over_35 0 30 blue-collar married unknown no no 1 39 services single no no unknown 2 25 services married unknown no no 3 38 services married unknown unknown unknown 4 47 admin. married unknown no unknown'age'列を降順に
tmp = df.sort_values("age", ascending=False) print(tmp.head()) # 出力 age job marital housing loan over_35 4 47 admin. married unknown no unknown 7 41 entrepreneur married unknown no unknown 1 39 services single no no unknown 3 38 services married unknown unknown unknown 9 35 blue-collar married no no no以下のデータフレームを作る
A, B
1, 2
3, 4
5, 6new_df = pd.DataFrame(data=[[1,2],[3,4],[5,6]], columns=['A','B']) print(new_df) # 出力 A B 0 1 2 1 3 4 2 5 6以下のデータフレームを作成し、'marital'列でmergeする
marital, m_index
single, 1
married, 2
divorce, 3new_df = pd.DataFrame(data=[['single',1], ['married',2], ['divorced',3]], columns=['marital','m_index']) tmp =df.merge(new_df, on='marital') print(tmp) # 出力 age job marital housing loan over_35 m_index 0 30 blue-collar married unknown no no 2 1 25 services married unknown no no 2 2 38 services married unknown unknown unknown 2 3 47 admin. married unknown no unknown 2 4 41 entrepreneur married unknown no unknown 2 5 35 blue-collar married no no no 2 6 35 blue-collar married no no no 2 7 39 services single no no unknown 1 8 32 services single no no no 1 9 32 admin. single unknown no no 1 10 31 services divorced no no no 31-3 行をコピー、最終行に追加し、インデックスは初期化する
new_df = df.iloc[:3, :] tmp = df.append(new_df, ignore_index=True) print(tmp) # 出力 age job marital housing loan over_35 0 30 blue-collar married unknown no no 1 39 services single no no unknown 2 25 services married unknown no no 3 38 services married unknown unknown unknown 4 47 admin. married unknown no unknown 5 32 services single no no no 6 32 admin. single unknown no no 7 41 entrepreneur married unknown no unknown 8 31 services divorced no no no 9 35 blue-collar married no no no 10 35 blue-collar married no no no 11 30 blue-collar married unknown no no 12 39 services single no no unknown 13 25 services married unknown no no'marital'をone-hotエンコーディングしたデータフレームを表示する
tmp = pd.get_dummies(df['marital']) print(tmp.head()) # 出力 divorced married single 0 0 1 0 1 0 0 1 2 0 1 0 3 0 1 0 4 0 1 0
- 投稿日:2019-08-21T20:00:17+09:00
Python基礎4 numpy メモ
pythonの基礎を備忘録として残しておく
summary
array = np.array([[1, 2, 3],[4, 5, 6]]) # 配列作成 print(array) print(array.shape) # 行列数 print(array.ndim) # 次元数 print(array.size) # 要素数 print(array.reshape(3, 2)) # 3行2列に print(array.reshape(-1, 3)) # 3列のみ指定し、行は自動(-1)で print(array.flatten()) # 1次元に print(np.arange(10)) print(np.arange(1, 10)) print(np.arange(1, 10, 2)) print(np.zeros(6)) print(np.zeros((2, 3))) # 二重括弧に注意 print(array_1 + array_2) # 各要素の足し算 print(np.append(array_1, array_2)) # 追加 print(array[0]) # 0行目 print(array[0][1]) # 0行1列目 print(array[0, 1]) # 0行1列目 print(array[:, 1]) # 全行1列目 print(array[-1, :]) # 最後の行全列 array = np.arange(9).reshape(3, 3) print(array) for i in array: # 行の抽出 print(i) for i in array.flatten(): # 要素1つづつの抽出 print(i) print(array+10) # ブロードキャスト print(array*2) print(array/2) array_1 = np.arange(9).reshape(3, 3) array_2 = np.arange(3).reshape(3, 1) print(array_1 + array_2) # ブロードキャスト print(np.dot(array_1, array_2)) # 内積 print(np.sum(array, axis = 0)) # 行方向の足し算 print(np.sum(array, axis = 1)) # 列方向の足し算numpyのインポート
import numpy as np1. 配列
配列の基本操作
array = np.array([[1, 2, 3],[4, 5, 6]]) # 配列作成 print(array) print(array.shape) # 行列数 print(array.ndim) # 次元数 print(array.size) # 要素数 print(array.reshape(3, 2)) # 3行2列に print(array.reshape(-1, 3)) # 3列のみ指定し、行は自動(-1)で print(array.flatten()) # 1次元に # 出力 [[1 2 3] [4 5 6]] (2, 3) 2 6 [[1 2] [3 4] [5 6]] [[1 2 3] [4 5 6]] [1 2 3 4 5 6]np.arange関数による配列作成
print(np.arange(10)) print(np.arange(1, 10)) print(np.arange(1, 10, 2)) # 出力 [0 1 2 3 4 5 6 7 8 9] [1 2 3 4 5 6 7 8 9] [1 3 5 7 9]np.zeros関数による配列作成
print(np.zeros(6)) print(np.zeros((2, 3))) # 出力 [0. 0. 0. 0. 0. 0.] [[0. 0. 0.] [0. 0. 0.]]np.random.rand関数による配列作成。直前に、np.random.seed = *** 指定で再現性のある乱数を得る。
print(np.random.rand(3)) print(np.random.rand(2, 2)) # 出力 [0.17272856 0.47712631 0.51327601] [[0.89263947 0.86838467] [0.33546726 0.56882862]]要素の追加
array_1 = np.array([1, 2, 3]) array_2 = np.array([4, 5, 6]) print(array_1 + array_2) # 足し算では各要素が足されるだけ print(np.append(array_1, array_2)) # 追加はnp.append関数を使う # 出力 [5 7 9] [1 2 3 4 5 6]要素の参照
array = np.arange(9).reshape(3, 3) print(array) print(array[0]) # 0行目 print(array[0][1]) # 0行1列目 print(array[0, 1]) # 0行1列目 print(array[:, 1]) # 全行1列目 print(array[-1, :]) # 最後の行全列 # 出力 [[0 1 2] [3 4 5] [6 7 8]] [0 1 2] 1 1 [1 4 7] [6 7 8]for 文での要素参照
array = np.arange(9).reshape(3, 3) print(array) for i in array: # 行の抽出 print(i) for i in array.flatten(): # 要素1つづつの抽出 print(i) # 出力 [[0 1 2] [3 4 5] [6 7 8]] [0 1 2] [3 4 5] [6 7 8] 0 1 2 3 4 5 6 7 8ブロードキャスト(配列、スカラー)
array = np.arange(9).reshape(3, 3) print(array) print(array+10) print(array*2) print(array/2) # 出力 [[0 1 2] [3 4 5] [6 7 8]] [[10 11 12] [13 14 15] [16 17 18]] [[ 0 2 4] [ 6 8 10] [12 14 16]] [[0. 0.5 1. ] # 割り算を行うとFloat型になる [1.5 2. 2.5] [3. 3.5 4. ]]ブロードキャスト(配列、配列)
array_1 = np.arange(9).reshape(3, 3) array_2 = np.arange(3).reshape(3, 1) print(array_1) print(array_2) print(array_1 + array_2) # 出力 [[0 1 2] [3 4 5] [6 7 8]] [[0] [1] [2]] [[ 0 1 2] [ 4 5 6] [ 8 9 10]]行列間の加減算
array_1 = np.arange(9).reshape(3, 3) array_2 = np.arange(0, 90, 10).reshape(3, 3) print(array_1) print(array_2) print(array_1 + array_2) # 出力 [[0 1 2] [3 4 5] [6 7 8]] [[ 0 10 20] [30 40 50] [60 70 80]] [[ 0 11 22] [33 44 55] [66 77 88]]行列の内積
array_1 = np.array([[0, 1],[2, 3]]) array_2 = np.array([[4, 5],[6, 7]]) print(array_1) print(array_2) print(np.dot(array_1, array_2)) # 出力 [[0 1] [2 3]] [[4 5] [6 7]] [[ 6 7] # 0*4+1*6 0*5+1*7 [26 31]] # 2*4+3*6 2*5+3*7
行方向・列方向の処理
array = np.array([[0, 1, 2], [3, 4, 5]]) print(array) print(np.sum(array)) print(np.sum(array, axis = 0)) print(np.sum(array, axis = 1)) # 出力 [[0 1 2] [3 4 5]] 15 [3 5 7] [ 3 12]

- 投稿日:2019-08-21T19:59:18+09:00
Python基礎2 for文、内包表記、lambda式のメモ
pythonの基礎を備忘録として残しておく
summary
x = ['a', 'b', 'c'] for i in x: # 配列を読み出す for i in range(3): # 0〜2を読み出す for i, j in enumerate(x): #インデックスと配列を読み出す for i, j, k in zip(x, y, z) # 複数の配列を読み出す # x = {'a':1, 'b':2, 'c':3} for k in x: # キーを読み出す for v in x.values(): # バリューを読み出す for k, v in x.items(): # キーとバリューを読み出す x = [1, 2, 3] l = [] for i in x: l.append(i*3) # 全ての要素を3倍(ノーマル) [i*3 for i in x] # 全ての要素を3倍(内包表記) x = [1, '2', 3] l = [] for i in x: if isinstance(i, str): continue l.append(i) # strを除く [i for i in x if not isinstance(i, str)] # strを除く(内包表記) func = lambda x:print('引数は'+ x) func = lambda x="未入力": print('引数は' + x) (lambda x="未入力": print('引数は' + x))('整数') (lambda x="未入力": print('引数は' + x))()1. for 文
for 文は配列から要素を順次読み出して処理を行います。配列には、文字列、リスト、辞書、タプル、セットが該当します。
for 変数 in 配列: 処理具体的な例を見て行きましょう。リストを読み込み、処理をする。
x = ['a', 'b', 'c'] for i in x: print(i) # 出力結果 a b crange関数を使ってインデックスを読み込み、処理をする。range(初期値, 回数, 増分)で、初期値と増分は記載しなければ、初期値=0、増分=1です。
for i in range(3): print(i) # 出力結果 0 1 2enumerate関数を使って、インデックスとリストを両方読み込み、処理をする。
x = ['a', 'b', 'c'] for i, j in enumerate(x): print(i, j) # 出力結果 0 a 1 b 2 czip関数を使って、2種類以上のリストを読み込み、処理をする。
x = ['a', 'b', 'c'] y = ['L', 'M', 'S'] z = ['X', 'Y', 'Z'] for i, j, k in zip(x, y, z) print(i, j, k) # 出力結果 a L X b M Y c S Z辞書 {キー1:バリュー1, キー2:バリュー2, ...} からキーを読み出す。普通に書くとキーを読み出します。
# x = {'a':1, 'b':2, 'c':3} for k in x: print(k) # 出力結果 a b cvalues関数を使って、辞書からバリューを読み出す。
x = ['a':1, 'b':2, 'c':3] for v in x.values(): print(v) # 出力結果 1 2 3items関数を使って、辞書からキーとバリューを読み出す。
x = ['a':1, 'b':2, 'c':3] for k, v in x.items(): print(k, v) # 出力結果 a 1 b 2 c 32. 内包表記
for 文には内包表記という便利なものがあります。
[iの処理 for i in 配列]具体的な例を通常表記と内包表記の2つの場合で、みて行きましょう。
リストを与えると全ての要素を3倍にして返す関数(例:[1, 2, 3] → [3, 6, 9])def func(x): l = [] for i in x: l.append(i*3) return l def func(x): return[i*3 for i in x]整数と整数の文字列の混じる要素のリストを与えると、全ての要素を整数にして返す関数(例:[1, '2', 3] → [1, 2, 3])
def func(x): l = [] for i in x: l.append(int(i)) return l def func(x): return [ int(i) for i in x]整数と整数の文字列の混じる要素のリストを与えると、文字列を取り除いたリストを返す関数(例:[1, '2', 3] → [1, 3]
def func(x): l = [] for i in x: if isinstance(i, str): continue l.append(i) return l def func(x): return[i for i in x if not isinstance(i, str)]3. 無名関数(lambda式)
lambda式を使うと、def文を使わずに関数を定義できます。基本構文は、以下の様です。
lambda 引数:処理具体的な例を記します。
func = lambda x:print('引数は'+ x) func('整数') # 出力 引数は整数lambda式で引数xが設定されている場合は、引数がないとその設定が有効になる。
func = lambda x="未入力": print('引数は' + x) func('整数') func() # 出力 引数は整数 引数は未入力lambda式を( )で囲って、引数を( )で後ろにくっ付けるやり方もある。
(lambda x="未入力": print('引数は' + x))('整数') (lambda x="未入力": print('引数は' + x))() # 出力 引数は整数 引数は未入力
- 投稿日:2019-08-21T19:58:37+09:00
Python基礎1 リスト型、ディクト型、セット型の操作メモ
pythonの基礎を備忘録として残しておく
summary
x = [0, 1, 2, 3, 4] print(x[0]) # 1番目の要素切り出し print(x[1:4]) # 2番目から4番目の要素の切り出し print(x[-1]) # 最後の要素の切り出し print(x[-2:]) # 後ろから2つの要素の切り出し x[2] = 6 # 3番目の要素を6に変更 x.append(5) # 最後に5を追加 print(len(x)) # リストの長さ print(sum(x)) # 要素の合計 print(max(x)) # 最大値 print(min(x)) # 最小値 print(2 in x) # 2がリストに存在するか print(tuple(x)) # リストをタプルへ変換 x = list(range(1, 11)) # 1〜10のリスト x.sort() # 昇順 x.sort(reverse = True) # 降順 * print(x.sort()) はダメ。Noneが返って来る x = {'A': 10, 'B': 20, 'C': 30} x['A'] = 15 # 'A'のバリューを15に変更 x['D'] = 60 # 'D':60 を追加 print(x.keys()) # キーの取り出し print(list(x.keys())) # キーを取り出し、リストに print(x.values()) # バリューの取り出し print(list(x.values())) # バリューを取り出し、リストに print(x.items()) # キーとバリューを取り出す print(list(x.items())) # キーとバリューを取り出し、リストに print(x['B']) # キー'B'のバリュー print(x.get('B')) # キー'B'のバリュー print(x.get('D')) # キー'D'のバリュー(存在しないと'None') x['C'] = x['C']*10 # 'C'のバリューを10倍 x = [3, 2, 1, 6, 6, 5, 5, 4] print( set(x) ) # セット(出力は{}) print( list(set(x)) ) # セットをリストに * 重複は削除され昇順になる print( set(x1) | set(x2) ) # 和集合 print( set(x1) & set(x2) ) # 積集合 print( set(x1) - set(x2) ) # 差集合1.リスト型
リストからの要素の切り出し
x = [0, 1, 2, 3, 4] print(x[0]) # 1番目の要素切り出し print(x[1:4]) # 2番目から4番目の要素の切り出し print(x[-1]) # 最後の要素の切り出し print(x[-2:]) # 後ろから2つの要素の切り出し # 出力 0 [1, 2, 3] 4 [3, 4]リストの要素変更
x = [0, 1, 2, 3, 4] x[2] = 6 # 3番目の要素を6に変更 print(x) # 出力 [0, 1, 6, 3, 4]リストへの要素追加
x = [0, 1, 2, 3, 4] x.append(5) # 最後に5を追加 print(x) # 出力 [0, 1, 2, 3, 4, 5]リスト操作
x = [0, 1, 2, 3, 4] print(len(x)) # リストの長さ print(sum(x)) # 要素の合計 print(max(x)) # 最大値 print(min(x)) # 最小値 print(2 in x) # 2がリストに存在するか print(tuple(x)) # リストをタプルへ変換 # 出力 5 10 4 0 True (0, 1, 2, 3, 4)リストの結合
x1 = [0, 1, 2] x2 = [3, 4, 5] print(x1 + x2) # 出力 [0, 1, 2, 3, 4, 5]range関数を使って、1〜10までのリストを作る
x = list(range(1, 11)) print(x) # 出力結果 [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]リストの並べ変え。print(x.sort())とかやると None が返って来るので注意。
x = [ 1, 3, 2, 4, 5] x.sort() # 昇順(数字の低いものから) print(x) x.sort(reverse = True) # 降順(数字の高いものから) print(x) # 出力 [1, 2, 3, 4, 5] [5, 4, 3, 2, 1]2. ディクト型
ディクショナリーは、dict()のキーワード引数を利用して作成できる。
x = dict(A = 10, B = 20, C = 30) print(x) # 出力 {'A': 10, 'B': 20, 'C': 30}ディクショナリーの要素を変更する
x = {'A': 10, 'B': 20, 'C': 30} x['A'] = 15 # 'A'のバリューを15に変更 print(x) # 出力 {'A': 15, 'B': 20, 'C': 30}ディクショナリーに要素を追加する
x = {'A': 10, 'B': 20, 'C': 30} x['D'] = 60 # 'D':60 を追加 print(x) # 出力 {'A': 10, 'B': 20, 'C': 30, 'D': 60}key を取り出し、リストに変換
x = {'A': 10, 'B': 20, 'C': 30} print(x.keys()) # キーの取り出し print(list(x.keys())) # リストに変換 # 出力 dict_keys(['A', 'B', 'C']) ['A', 'B', 'C']バリューを取り出し、リストに変換
x = {'A': 10, 'B': 20, 'C': 30} print(x.values()) # バリューの取り出し print(list(x.values())) # リストに変換 # 出力 dict_values([10, 20, 30]) [10, 20, 30]キーとバリューの両方を取り出す
x = {'A': 10, 'B': 20, 'C': 30} print(x.items()) # キーとバリューを取り出す print(list(x.items())) # リストに変換 # 出力 dict_items([('A', 10), ('B', 20), ('C', 30)]) [('A', 10), ('B', 20), ('C', 30)]ディクト型 { キー1:バリュー1, キー2:バリュー2, .... } から、キーに該当するバリューを取り出す。
x['B'] と x.get('B') は同じ結果になる。しかし、リストに存在しないキーの場合、x['D']はエラーになるが、x.get['D']はNoneが返る。x = {'A':10, 'B':20, 'C':30} print(x['B']) # キーが'B'のバリュー取得 print(x.get('B')) # get関数によるバリュー取得 print(x.get('D')) # リストに存在しない場合、Noneが返る # 出力結果 20 20 Noneget関数を使って、キーがあればそのバリューを、キーがなければ'存在しません'と出力する。
def func(key): x = {'A':10, 'B':20, 'C':30} v = x.get(key) if v == None: print('存在しません') else: print(v) func('D') func('C') # 出力 存在しません 30'C' のバリューを10倍にする
x = { 'A':10, 'B':20, 'C':30 } x['C'] = x['C']*10 # 'C'のバリューに、'C'のバリューを10倍したものを代入 print( x ) # 出力 {'A': 10, 'B': 20, 'C': 300}3. セット型
リストからセット{ }を作ると、要素の重複が省かれ、昇順に並ぶ。list関数でリストに変換。
x = [3, 2, 1, 6, 6, 5, 5, 4] print( set(x) ) print( list(set(x)) ) # 出力 {1, 2, 3, 4, 5, 6} # セット型 [1, 2, 3, 4, 5, 6] # リスト型セット(集合)の演算
x1 = [1, 2, 3] x2 = [3, 4, 5] print( set(x1) | set(x2) ) # 和集合 print( set(x1) & set(x2) ) # 積集合 print( set(x1) - set(x2) ) # 差集合 # 出力結果 {1, 2, 3, 4, 5} # セット型 {3} # セット型 {1, 2} #セット型
- 投稿日:2019-08-21T18:56:34+09:00
【Airflow on Kubernetes】トラブルシューティング - AttributeError: '_jpype.PyJPField' object has no attribute 'getStaticAttribute'
概要
JPype1==0.7.0を利用してJdbcOperator()を実行すると表題のエラーが出力される。目次
バージョン
DAG
一部抜粋
from airflow.operators.jdbc_operator import JdbcOperator sql_task = JdbcOperator( task_id='sql_cmd', jdbc_conn_id='my_connection_id', #template_searchpath='/etc/dev/airflow/templates', #sql=['sample.sql'], sql=['select id,name from sample_table'], params={"db":'MY_DBNAME'}, dag=dag )エラー詳細
ログの見方:DAGの実行結果ログを確認する
[2019-08-21 09:30:48,913] {taskinstance.py:1047} ERROR - '_jpype.PyJPField' object has no attribute 'getStaticAttribute' Traceback (most recent call last): File "/usr/local/lib/python2.7/dist-packages/airflow/models/taskinstance.py", line 922, in _run_raw_task result = task_copy.execute(context=context) File "/usr/local/lib/python2.7/dist-packages/airflow/operators/jdbc_operator.py", line 63, in execute self.hook.run(self.sql, self.autocommit, parameters=self.parameters) File "/usr/local/lib/python2.7/dist-packages/airflow/hooks/dbapi_hook.py", line 159, in run with closing(self.get_conn()) as conn: File "/usr/local/lib/python2.7/dist-packages/airflow/hooks/jdbc_hook.py", line 51, in get_conn jars=jdbc_driver_loc.split(",")) File "/usr/local/lib/python2.7/dist-packages/jaydebeapi/__init__.py", line 381, in connect jconn = _jdbc_connect(jclassname, url, driver_args, jars, libs) File "/usr/local/lib/python2.7/dist-packages/jaydebeapi/__init__.py", line 183, in _jdbc_connect_jpype types_map[i.getName()] = i.getStaticAttribute() AttributeError: '_jpype.PyJPField' object has no attribute 'getStaticAttribute'対策
JPype1==0.6.3ではエラーにならないのでダウングレードをする。参考
- 投稿日:2019-08-21T18:05:53+09:00
DjangoのCRUDで体重を記録する!!
どうもjackです。
8月からPythonをメインにエンジニア業務に従事することになりまして。
諸事情により12月までに7キロの減量を目標に生きてる駆け出しエンジニアです。
今回は表題の通りDjangoのCRUDで体重を記録したいと思います。私の開発環境は以下となっています。
- Python 3.6.7
- Django 2.2.3
- macOS
では、早速。
前回、既にqiitaディレクトリを作成しているのでその中に体重計管理アプリを作成していきます。python3 manage.py startapp weight作成したweightアプリの存在をsettings.pyに編集。
settings.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'weight',今回の入力値は「体重」と「日付」です。
従ってweightディレクトリにあるmodels.pyにこれらを入力していきます。models.pyfrom django.db import models from django.utils import timezone # Create your models here. class Weight(models.Model): weight = models.FloatField(default=0) date = models.DateField(default=timezone.now)入力が終わったらデータベースの作成を行います。
python3 manage.py makemigrations python3 manage.py migrateこの作成したモデルをもとに入力フォームを作成していきます。
その為にweightアプリのディレクトリにforms.pyファイルを作成します。qiitaディレクトリ├── qiita │ ├── __pycache__ │ ├── _init_.py │ ├── setting.py │ ├── urls.py │ └── wsgi.py ├── weight │ ├── migrations │ ├── _init_.py │ ├── admin.py │ ├── apps.py │ ├── forms.py ←これ │ ├── models.py │ ├── tests.py │ └── views.py └── manage.py編集内容は以下の通りです。
forms.pyfrom django import forms from .models import Weight class WeightForm(forms.ModelForm): class Meta: model = Weight fields = ['weight', 'date']次にviews.pyの編集を行います。
views.pyfrom django.shortcuts import render, redirect from .models import Weight from .forms import WeightForm # Create your views here. def index(request): data = Weight.objects.all() params = { 'title' : 'my weight memory', 'data' : data } return render(request, 'weight/index.html', params) def create(request): params = { 'title': 'score', 'form': WeightForm() } if (request.method=='POST'): obj = Weight() weight = WeightForm(request.POST, instance=obj) weight.bmi = 4 weight.save() return redirect(to='/weight') return render(request, 'weight/create.html', params) def edit(request, num): obj = Weight.objects.get(id=num) if (request.method=='POST'): weight = WeightForm(request.POST, instance=obj) weight.save() return redirect(to='/weight') params = { 'title' : 'edit', 'id':num, 'msg': '改ざんすなよ', 'form': WeightForm(instance=obj) } return render(request, 'weight/edit.html', params) def delete(request, num): weight = Weight.objects.get(id=num) if (request.method=='POST'): weight.delete() return redirect(to='/weight') params = { 'title': 'delete', 'msg': 'ほんまに消してええの?', 'id':num, 'obj':weight } return render(request, 'weight/delete.html', params)そしてqiitaディレクトリにあるurls.pyの編集を行います。
urls.pyfrom django.contrib import admin from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path('weight/', include('weight.urls')), ]次にweightアプリのディレクトリにurls.pyファイルを作成して、編集します。
qiitaディレクトリ├── qiita │ ├── __pycache__ │ ├── _init_.py │ ├── setting.py │ ├── urls.py │ └── wsgi.py ├── weight │ ├── migrations │ ├── _init_.py │ ├── admin.py │ ├── apps.py │ ├── forms.py │ ├── models.py │ ├── tests.py │ ├── urls.py ←これ │ └── views.py └── manage.py編集内容は以下の通りです。
urls.pyfrom django.urls import path from . import views urlpatterns = [ path('', views.index, name='index'), path('create', views.create, name='create'), path('edit/<int:num>', views.edit, name='edit'), path('delete/<int:num>', views.delete, name='delete'), ]次にテンプレートディレクトリを作成してその中にアプリ名と同じディレクトリを作成し、
htmlを格納していきます。qiitaディレクトリ├── qiita │ ├── __pycache__ │ ├── _init_.py │ ├── setting.py │ ├── urls.py │ └── wsgi.py ├── weight │ ├── migrations │ ├── templates │ │ └── weight │ │ ├── index.html ←こいつら │ │ ├── create.html←こいつら │ │ ├── delete.html←こいつら │ │ └── edit.html ←こいつら │ ├── _init_.py │ ├── admin.py │ ├── apps.py │ ├── forms.py │ ├── models.py │ ├── tests.py │ ├── urls.py │ └── views.py └── manage.py作成したhtmlを編集していきます。
index.html{% load static %} <!DOCTYPE html> <html lang="ja" dir="ltr"> <head> <meta charset="utf-8"> <link rel="stylesheet" type="text/css" href="{% static 'weight/css/style.css'%}"> <title>{{title}}</title> </head> <body> <table> <tr> <th>ID</th> <th>Weight</th> <th>date</th> <th>編集</th> <th>削除</th> </tr> {% for item in data %} <tr> <td>{{item.id}}</td> <td>{{item.weight}}</td> <td>{{item.date}}</td> <td><a href="{% url 'edit' item.id %}">edit</a></td> <td><a href="{% url 'delete' item.id %}">delete</a></td> </tr> {% endfor %} </table> <a href="{% url 'create'%}">体重を記録する</a> </body> </html>create.html{% load static %} <!DOCTYPE html> <html lang="ja" dir="ltr"> <head> <meta charset="utf-8"> <link rel="stylesheet" type="text/css" href="{% static 'weigth/css/style.css'%}"> <title>{{title}}</title> </head> <body> <h1>{{title}}</h1> <form action="{% url 'create' %}" method="post"> {% csrf_token%} {{ form.as_table}} <tr> <td></td><td><input type="submit" name="" value="send"></td> </tr> </form> <a href="{% url 'index'%}">indexへ戻る</a> </body> </html>delete.html{% load static%} <!DOCTYPE html> <html lang="ja" dir="ltr"> <head> <meta charset="utf-8"> <link rel="stylesheet" type="text/css" href="{% static 'weight/css/style.css'%}"> <title>{{title}}</title> </head> <body> <h1>{{title}}</h1> <h2>{{msg}}</h2> <table> <tr> <th>ID</th><td>{{obj.id}}</td> </tr> <tr> <th>Weight</th><td>{{obj.weight}}</td> </tr> <tr> <th>Date</th><td>{{obj.date}}</td> </tr> <form action="{% url 'delete' id%}" method="post"> {% csrf_token %} <tr> <td><input type="submit" name="" value="削除"></td> </tr> </form> </table> </body> </html>edit.html{% load static%} <!DOCTYPE html> <html lang="ja" dir="ltr"> <head> <meta charset="utf-8"> <link rel="stylesheet" type="text/css" href="{% static 'weight/css/style.css'%}"> <title>{{title}}</title> </head> <body> <h1>{{title}}</h1> <h2>{{msg}}</h2> <table> <form action="{% url 'edit' id %}" method="post"> {% csrf_token%} {{ form.as_table}} <tr> <td></td><td><input type="submit" name="" value="send"></td> </tr> </form> </table> </body> </html>最後にcssを格納する為のディレクトリを作成してstyle.cssを編集します。
qiitaディレクトリ├── qiita │ ├── __pycache__ │ ├── _init_.py │ ├── setting.py │ ├── urls.py │ └── wsgi.py ├── weight │ ├── migrations │ ├── static │ │ └── weight │ │ └──css │ │ └── style.css ← こいつ │ ├── templates │ │ └── weight │ │ ├── index.html │ │ ├── create.html │ │ ├── delete.html │ │ └── edit.html │ ├── _init_.py │ ├── admin.py │ ├── apps.py │ ├── forms.py │ ├── models.py │ ├── tests.py │ ├── urls.py │ └── views.py └── manage.pystyle.csstable { margin: 10px; font-size: 14px; text-align: center; } table tr th { background-color: #009; color: white; padding: 2px 10px; border-width: 2px; text-align: center; } table tr rd { background-color: #eee; color: #666; padding: 2px 10px; border-width: 2px; text-align: center; }ではローカルに立ち上げて見てみましょう!
早速、体重を記録してみます。
編集は?
削除は?
よしよし
ただ、日付が日本語じゃない、、、settings.pyLANGUAGE_CODE = 'ja' TIME_ZONE = 'Asia/Tokyo' USE_I18N = True USE_L10N = True USE_TZ = Trueこれでよし。
しっかり日本語表示できました!!
これで体重管理して痩せるぞーーーー!!





- 投稿日:2019-08-21T17:30:45+09:00
Pythonのスクレイピング
Pythonを使用したスクレイピング
Pythonのスクレイピングのメモです。
動作環境
- Mac OS Mojave
- Python 3.6.5
HTML要素にclass、idセレクタが付いていない場合
name属性が付いていると仮定しますが、以下のようなタグだった場合
<input type="text" name="hoge" value="fuga" autocomplete="off">上記を取得するには以下のようなPythonコードであれば取得可能
HTTPS対応とかは別途必要。# アクセス先のURL url = 'http://hoge.com' # レスポンス取得 res = requests.get(url) # BeautifulSoupで形成 soup = BeautifulSoup(res.text, "html.parser") # inputタグのname属性"hoge"のvalueを取得する name_hoge_val = soup.find('input', {'name':'hoge'})['value']適宜追加予定...
- 投稿日:2019-08-21T17:29:49+09:00
Pythonのmedian_grouped()
初歩的なことかもしれませんがハマったのでメモ。
statistics.median_grouped([1, 2.4])の値はなーんだ?
答えは1.9。
通常のメジアンmedian()は偶数個のデータがあるとき真ん中2つの中間値になります。
import statistics print(statistics.median([1, 2.4]))結果
1.7しかし、median_grouped()は補間メジアンなのでこうなります。
import statistics print(statistics.median_grouped([1, 2.4]))結果
1.9なぜ?
まず、次のように実際のデータから仮に「中央の値」をとってきて、
Python37/Lib/statistics.py# Find the value at the midpoint. Remember this corresponds to the # centre of the class interval. x = data[n//2]これを中点とする区間(メジアン区間と仮に呼ぶ)を考えます。幅はmedian_grouped(data, interval=1)の
intervalです。そして線形補間で算出です。median_grouped([1, 2.4])の場合は、2.4を中央とする半開区間 [1.9, 2.9) をとり、
1.9と求まります((n+1)/2番目の値を考えるmedian()と違って、n/2個になる点を考えるところに注意)。別の例
import statistics print(statistics.median_grouped([1,2,2]))結果
1.75位置1を中点として区間[1.5, 2.5)を考えると、そこで累計データ数が1個から3個に増えているので、
1.5個になる点は、線形補間で、1+{1*(1.5-1)/(3-1)}=1.75です。通常のメジアン(2)よりも"中央っぽい"です。注意点
ここでメジアン区間内には他の値が含まれないほどintervalが小さいことが想定されているようです。
Pythonドキュメントの例もそうですし、Wikipediaの計算式もそうなっています。
Pythonでも、もし他の値が含まれても存在しないかのように計算されます。statistics.py# Uses bisection search to search for x in data with log(n) time complexity # Find the position of leftmost occurrence of x in data l1 = _find_lteq(data, x) # Find the position of rightmost occurrence of x in data[l1...len(data)] # Assuming always l1 <= l2 l2 = _find_rteq(data, l1, x) cf = l1 f = l2 - l1 + 1 return L + interval*(n/2 - cf)/fしかしこの計算方式は唯一のものではなく、区間内の他の値も加味する定義もあるようです。
(何しろ、分位数には10種類もの定義があるそうで、Wolfram言語のQuantile[ ]にはどの計算法を用いるかを
指定する4つのパラメーターがあるそうですし、pandasのquantile()にもパラメーターがあるようです)組み込みのmedian_grouped()という名前は、データをいくつかの階級(class)にグループ分けした連続分布とみなす
というニュアンスを込め、あとはこういう関数を使う人には説明不要という判断での命名な気がしますが、
定義が混在していて計算が食い違ったりして初心者にはややこしいですね。
- 投稿日:2019-08-21T17:02:58+09:00
ある条件で行列の要素の値を変更する。
ある条件をもとに行列内の値を変更する。
A = np.array([[1,2,3,4],[-1,2,-9,10],[7,6,10,-8]]) print(A) #[[ 1 2 3 4] #[-1 2 -9 10] #[ 7 6 10 -8]] #行列の要素が0以下の場合0にする A[A <= 0] = 0 print(A) #[[ 1 2 3 4] #[ 0 2 0 10] #[ 7 6 10 0]]
- 投稿日:2019-08-21T15:35:29+09:00
【python】簡単クローリング&スクレイピング
開発案件でPythonでクローリング&スクレイピングをする機会があったので、そこで新たに学んだことを使い、簡単にクローリング&スクレイピングをやってみます。
目標
日経電子版を対象にカテゴリー名を引数に指定カテゴリーページ1ページ分の全タイトルを返すだけの簡単なものをつくっていきます。
上図の青枠で囲った記事タイトルを取得します。
また今回新たに学んだこととしてエラー処理についても簡単に実装します。
コード
from typing import List import requests from bs4 import BeautifulSoup def get_nikkei_news(category: str) -> List[str]: """ 記事カテゴリーを指定して日経電子版のホームページをクローリング @param category: 記事カテゴリー @return:記事タイトルのリスト """ titles = list() base_url = 'https://www.nikkei.com/' base_url_2 = '/archive/' try: response = requests.get(base_url + category + base_url_2) response.raise_for_status() response.encoding = response.apparent_encoding soup = BeautifulSoup(response.text, "html.parser") # スクレイピング title_list = soup.find_all('span', class_='m-miM09_titleL') for title in title_list: title_text = title.text titles.append(title_text) except requests.exceptions.HTTPError: print("{}カテゴリーページへのアクセス失敗".format(category)) except Exception as e: print(e) return titlestitle_name_list = get_nikkei_news("technology") for title_name in title_name_list: print(title_name)実行結果
オプト、AIで広告分類する仕組み開発 ディーカレット、仮想通貨を電子マネーにチャージ トレードオフ破る非常識の無線通信、軍艦島で実証中 五輪の感染症対策 ワクチン接種と防蚊準備を 自動運転バス、既に実用化 福島第1原発を走っている 日本マイクロソフト、独SAPと連携してクラウド拡販 「総合証券サービス目指す」 LINE証券の一問一答 アルトア、「自撮り」の本人確認で融資可能に [FT]逆転の発想が生んだ世界最大のAI用チップ LINE、証券サービス開始 1株単位で取引可能コード解説
try~except構文:発生した例外に応じたエラー処理ができる。try節の中でエラーが発生すると、そのエラーに対応したexcept節の処理へと移行する。requests.get('url'):指定したURLに対してHTTPリクエストを送信し、サーバから返却されるHTTPレスポンスを戻り値として返す。response.raise_for_status():ステータスコードが200番台以外だった場合エラーを起こす
HTTPステータスコード 意味 100番台 処理中 200番台 成功 300番台 リダイレクト 400番台 クライアントエラー 500番台 サーバーエラー
response.encoding = response.apparent_encoding:極力文字化けが起こらないようにコンテンツを取得できるBeautifulSoup(response.text, "html.parser"):第一引数にHTML、第二引数にHTMLパーサーを指定できる。最初から使えるhtml.parserを指定している。HTMLの字句解析をして、タグなどを判断してデータ構造として取得するプログラムをHTMLパーサーという。soup.find_all('span', class_='m-miM09_titleL'):グの子孫要素を調べてフィルタにマッチする全ての子孫要素をリスト型で返すexcept requests.exceptions.HTTPError::ステータスコードが200番台以外だった場合のエラー時の処理except Exception as e::例外の内容を知る

- 投稿日:2019-08-21T15:12:17+09:00
ABC138参戦記(A問題~C問題)
先日行われたABC137に参加したのでコンテスト中のあれこれをメモしておこうかと思います。使用言語はpython3、結果はABC3完で2403位(順位表情報)でした。コンテストへのリンクはこちら→https://atcoder.jp/contests/abc138
A - Red or Not
$a$が3200以上か未満かで場合分けして"red"を出力するか$s$を出力するか決めれば良さそうです。提出コードはこちら。
ABC138_A.pya = int(input()) s = str(input()) if a < 3200: print("red") else: print(s)B - Resistors in Parallel
$A_1, A_2, ..., A_N$の逆数を順に足していき、最後にその逆数を出力すれば良さそうです。提出コードはこちら。
ABC138_B.pyN = int(input()) A = list(map(int, input().split())) ans = 0 for i in range(N): ans += 1/A[i] print(1/ans)C - Alchemist
サンプルなどを見てみると、小さい方から順に合成していくとあまり小さくならなそうな感じがするので、そのような実装をしました。ちゃんと証明した方がいいのかなとは思いましたがサンプルが全て通ったので提出してみたらACしました
ABC138_C.pyN = int(input()) v = list(map(int, input().split())) v.sort() tmp = (v[0] + v[1]) / 2 for i in range(2,N): tmp = (tmp + v[i]) / 2 print(tmp)D - Ki
本番中通すことができませんでした...
keyが根、valueがkeyを根とする頂点であるような辞書を作ってそこに含まれる全ての頂点のカウンターにいっぺんに$x$を足していくみたいなことをやったのですが当然のようにTLEしました...ABC138_D.pyfrom collections import defaultdict from collections import deque import sys sys.setrecursionlimit(700000) def setD(d, N): for i in range(N): d[i] = setsub(d, i) def setsub(d, i): tmp = deque() for x in d[i]: tmp.append(x) if d[x] != 0: tmp += setsub(d, x) return tmp N, Q = map(int, input().split()) d = defaultdict(deque) for i in range(N-1): a, b = map(int, input().split()) a -= 1 b -= 1 d[a].append(b) setD(d, N) ans = [0 for i in range(N)] for i in range(Q): p, x = map(int, input().split()) p -= 1 ans[p] += x for i in d[p]: ans[i] += x for i in range(N): ans[i] = str(ans[i]) print(" ".join(ans))コンテスト後に解説動画やACされてるコードなどをみて累積和のようなことをすればいいということを理解し、一応通せたのですがコンテスト後にテストケースが追加されてるのでもう一度復習してみたいところです。
反省
今回はC問題まで通すことができました。時間配分は大体A-2分、B-3分、C-6分半という感じでした。とにかくDが通せなかったのは痛いですね...要復習です...
- 投稿日:2019-08-21T15:02:20+09:00
M5StickVをとりあえず使ってみる (おまけ:起動音の低減)
【内容】
いきなり手渡されたM5Stack社のM5StickV。
なんか深センで直接売り込まれたとかなんとか。
本当は別のEdgeデバイスを取り扱う予定でしたが、予定通りに届かなかったので、とりあえず予備知識無しでM5StickVを使ってみます。なお、作業にはWindows 10 Pro (1809)を利用しています。
【Quick Start】
基本的には公式の手順を踏襲しますが、何箇所かハマりました。
【M5StickV Quick Start - M5Stack】【ファームウェアの更新】
まずはファームウェアの更新を行います
EasyLoaderを使ったファームウェアの更新 (失敗)
QuickStartのトップに書かれているEasyLoaderを使ってファームウェアの更新を試みます。
EasyLoaderはWindowsのみに提供されています。
手順自体はソフトウェアをダウンロードしたら、アプリを起動して、COMポートの設定をしたら「Burn」ボタンを押すだけで、非常に簡単です。
この画面で止まってしまいました。
一時間ほど放置してみましたが改善する様子がないため諦めました。Kflash_GUIを使ったファームウェアの更新
次に、Kflash_GUI使ったFirmwareの更新を試みます。
事前に「click to download firmware」ボタンから最新のファームウェアをダウンロードしておきます。
その下に「Kflash_GUI」と書かれている部分に各プラットフォーム用のFlashツール用のダウンロードリンクがありますので、ダウンロードして適当なフォルダに解凍します。
本手順では「Windows」版をダウンロードしました。
解凍したフォルダ内に含まれている「Kflash_GUI.exe」というファイルを実行します。
実行すると、下記の画面が表示されるとともに、Githubのリポジトリが表示されます。
Gitリポジトリによると、本記事を書いている2019年8月21日現在、Release版が「v1.3.2」、Pre-release版が「v1.5.3」となっています。
起動したアプリの表示は「v1.2」となっているので古いようです。とりあえず人柱として「v1.5.3」をダウンロードして使ってみました。
なお、Gitリポジトリ上のWindows版のアーカイブファイルは7z形式で圧縮されているため、解凍には7-zipなどのアプリが必要になります。改めて最新バージョンを起動します。
タイトルバーのバージョン番号が「V1.5」になっています。
この状態で事前にダウンロードしたファームウェアファイルおよびシリアルポートなどの設定を行い、「Download」ボタンを押します。
なお、上記設定では「Board」を「M5StickV」に「Baudrate」を「115200」に変更しています。
進捗状況が進み、「Download Success」の表示がされたら、更新完了です。
【シリアルデバッグツール】
次にシリアルデバッグツールに接続してみます。
M5StickVに付属していたType-Cのケーブルをコネクタをつないで、PCのUSBに接続するとCOMポートで接続できるようになります。公式手順ではPuttyを使っていますが、今回はTeraTermを使いました。
以下の設定で接続できました。
重要なのは「Baud rate」の設定で、「115200」で設定しないと文字化けしてしまいました。
正常に接続できると以下のような画面が表示されます。
ちなみにデフォルトではカメラ映像に対して顔検知を行うようプログラムが実行されているため、顔を認識すると認識した結果がログとして流れます。
BoundingBoxとスコア、認識した数やインデックス値が返ってきているようです。なお、
Ctrl+Cを押すとプログラムが終了して、Pythonのコンソール状態になります。
(上記画像はCtrl+Cを押した直後の状態)
この状態ではPythonのコードが打てる状態になっています。【Hello World】
上記のコンソール状態で、「Hello World」を実行します。
コンソールに以下のコードを入力すると、画面下部に赤字で「hello world」が表示されます。hello.pyimport lcd lcd.init() lcd.draw_string(100, 100, "hello world", lcd.RED, lcd.BLACK)
【ファイルの追加、編集】
ファイルを新規に作成し、そのファイルに上記のスクリプトを保存してみようと思います。
まず、現在保存中のファイルを確認するためにコンソールでos.listdir()を実行します。
以下の4つのファイルが保存されています。ファイル一覧_1['ding.wav', 'startup.jpg', 'boot.py', 'freq.conf']新たにファイルを作成して、編集を行います。
pye("hello.py")を実行して編集モードに入ります。
pye命令は指定したファイルが存在しない場合は新規で作成し、存在する場合は既存ファイルを開いて編集状態になります。上記の 「Hello World」で実行した内容を入力して、
Ctrl+Sを押すと保存ファイル名を聞いてきますので、そのままEnterを押すと保存されます。
その後Ctrl+Qを押すと編集状態から抜け出します。細かい操作方法は、下記のURLで確認できます。
【Pyboard Editor.pdf - Github】なお、私の環境では前の文字を削除しようと
Backspaceを押すと置換モードになってしまいました。
代わりにDelキーで前の文字を削除することが出来ました。確認のために再度 `os.listdir()` を実行します。
ファイル一覧_2['ding.wav', 'startup.jpg', 'freq.conf', 'hello.py', 'boot.py']
hello.pyが追加されていることが確認できます。【ファイルの実行】
上記で保存した
hello.pyを実行します。
コードの実行に関して公式手順では二通りの方法が書いてありますが、本記事では繰り返し実行可能な方法を採用します。
具体的には以下のコードを実行します。exec_hello.pywith open("hello.py") as f: exec(f.read())二行目の
exec(f.read())を入力してEnterキーを押すとインデントが保持され入力待ち状態になりますが、Backspaceキーでインデントを戻して空欄状態でEnterキーを押すとコードが実行されます。
うまく動けばディスプレイ上に赤い文字で「hello world」と表示されるはずです。【最後に】
とりあえず、基本的な操作方法はわかりました。
次の記事ではファイルアップロードツールとIDEツールを使ってみようと思います。【おまけ:起動音の低減】
M5StickVの電源投入時にはかなり大きな音で起動音がなります。
静かなオフィスなどではかなり注目を集めてしまいます。
そこで、pye命令を使って起動スクリプトを編集して、起動音を低減させます。
具体的にはシリアルデバッグツールに接続し、デフォルトで保存されているboot.pyの32行目にある音量設定部分を調整します。boot.pyの編集pye('boot.py')boot.py:32行目の変更点player.volume(100) # 変更前 ↓↓↓ player.volume(10) # 変更後変更後
Ctrl+S>Enterで保存後、Ctrl+Qで編集状態から抜けてください。
その後、Ctrl+Dで再起動がかかります。
上記変更がうまく行えていれば、起動時の音量が10分の1(?)になります。
なお、player.volume(0)にすると起動音がしなくなります。また、変更部分の一行前にはWAVファイルを指定している部分がありますので、好みの起動音に変更することも可能そうです。















- 投稿日:2019-08-21T14:57:31+09:00
MySQL(MariaDB)の表データからElasticsearchのインデックスにデータをインポートする
MariaDBの表データからPythonスクリプトでElasticsearchにインポートする方法を記載します。
RDBのデータをインデックス化する時の参考になればと思います。MariaDBのインストールとサンプルデータの準備は下記を参照しました。
Ubuntu 18.04 LTS に MariaDB 10.3 をインストール
https://qiita.com/cherubim1111/items/61cbc72673712431d06e
【SQL】MySQL公式サンプルデータベースを使う
https://qiita.com/yukibe/items/fc6016348ecf4f3b10bf
MySQL Serverに外部から接続する
https://qiita.com/tocomi/items/0c009d7299584df49378上記のサンプルデータベースのcityテーブルを丸ごとインポートすることを目指したいと思います。
0. 事前準備
事前にPython3とpython3-pipが導入されているものとします。
スクリプトで使用するMySQL(MariaDB)とElasticsearchのPythonライブラリをインストールします。
なお、MySQLのPythonライブラリはいくつかありますが、個人的にはpymysqlが最も安定しているように感じました。pip3 install pymysql pip3 install elasticsearch1. cityインデックスのmapping定義
cityテーブルの構造は下記の通りです。
MariaDB [world]> desc city; +-------------+----------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------------+----------+------+-----+---------+----------------+ | ID | int(11) | NO | PRI | NULL | auto_increment | | Name | char(35) | NO | | | | | CountryCode | char(3) | NO | MUL | | | | District | char(20) | NO | | | | | Population | int(11) | NO | | 0 | | +-------------+----------+------+-----+---------+----------------+ 5 rows in set (0.005 sec)mapping定義するにあたり、Name、CountryCode、Districtはのtypeはkeywordに、Populationのtypeはintegerとします。
keywordではなくtextと定義することも考えられますが、国名などは文章ではないのでkeywordで十分だと考えます。
なお、IDはドキュメントIDとして使用する想定で、mappingの定義内容には含みません。cityインデックスのmappingを定義するPythonスクリプトは下記のとおりとなります。
putCityMapping.py#!/usr/bin/python3 from elasticsearch import Elasticsearch from pprint import pprint # Elasticsearch接続設定 es = Elasticsearch(['XX.XX.XX.XX:9200']) #ElasticsearchサーバーのIPアドレス # mappingの定義クエリ city = {} city["settings"] = {} city["settings"]["number_of_shards"] = 3 city["settings"]["number_of_replicas"] = 1 city["mappings"] = {} city["mappings"]["properties"] = {} city["mappings"]["properties"]["Name"] = {} city["mappings"]["properties"]["Name"]["type"] = "keyword" city["mappings"]["properties"]["CountryCode"] = {} city["mappings"]["properties"]["CountryCode"]["type"] = "keyword" city["mappings"]["properties"]["District"] = {} city["mappings"]["properties"]["District"]["type"] = "keyword" city["mappings"]["properties"]["Population"] = {} city["mappings"]["properties"]["Population"]["type"] = "integer" # クエリの内容を表示 pprint("クエリの内容を表示") pprint(city) print() # クエリの実行 response = es.indices.create(index='city',body=city) # クエリのレスポンスの表示 pprint("レスポンスの内容を表示") pprint(response)このスクリプトを実行すると下記のような結果が得られます。
$ ./putCityMapping.py 'クエリの内容を表示' {'mappings': {'properties': {'CountryCode': {'type': 'keyword'}, 'District': {'type': 'keyword'}, 'Name': {'type': 'keyword'}, 'Population': {'type': 'integer'}}}, 'settings': {'number_of_replicas': 1, 'number_of_shards': 3}} 'レスポンスの内容を表示' {'acknowledged': True, 'index': 'city', 'shards_acknowledged': True}2. cityインデックスのmappingの定義内容の取得
続いて、作成したmappingの定義内容を表示するスクリプトを作成します。
内容は下記の通りです。getCityMapping.py#!/usr/bin/python3 from elasticsearch import Elasticsearch from pprint import pprint # Elasticsearch接続設定 es = Elasticsearch(['XX.XX.XX.XX:9200']) #ElasticsearchサーバーのIPアドレス response = es.indices.get_mapping(index='city') pprint(response)このスクリプトを実行すると下記のような結果が得られます。
$ ./getCityMapping.py {'city': {'mappings': {'properties': {'CountryCode': {'type': 'keyword'}, 'District': {'type': 'keyword'}, 'Name': {'type': 'keyword'}, 'Population': {'type': 'integer'}}}}}3. cityドキュメントの作成(1つだけ)
作成したcityインデックスにドキュメントを1つだけ作成します。
いきなりCityテーブルから全データをインポートするのではなく、SQLで表示したデータを使用することにします。ドキュメント化するデータは下記の通りです。
MariaDB [world]> select * from city where id=1; +----+-------+-------------+----------+------------+ | ID | Name | CountryCode | District | Population | +----+-------+-------------+----------+------------+ | 1 | Kabul | AFG | Kabol | 1780000 | +----+-------+-------------+----------+------------+ 1 row in set (0.004 sec)このデータのドキュメントを作成するスクリプトは下記の通りです。
putKabulDoc.py#!/usr/bin/python3 from elasticsearch import Elasticsearch from pprint import pprint # Elasticsearch接続設定 es = Elasticsearch(['XX.XX.XX.XX:9200']) #ElasticsearchサーバーのIPアドレス index_id = "1" kabul_doc = {} kabul_doc["Name"] = "Kabul" kabul_doc["CountryCode"] = "AFG" kabul_doc["District"] = "Kabol" kabul_doc["Population"] = 1780000 pprint(kabul_doc) print() response = es.index(index="city", doc_type="_doc", id=index_id,body=kabul_doc) pprint(response)このスクリプトを実行すると下記のような結果が得られます。
$ ./putKabulDoc.py {'CountryCode': 'AFG', 'District': 'Kabol', 'Name': 'Kabul', 'Population': 1780000} {'_id': '1', '_index': 'city', '_primary_term': 1, '_seq_no': 0, '_shards': {'failed': 0, 'successful': 1, 'total': 2}, '_type': '_doc', '_version': 1, 'result': 'created'}4. ドキュメントの表示
KabulドキュメントをElasticsearchから取得するスクリプトを作成します。
ここでは検索クエリではなく、id=1のドキュメントを取得するクエリとします。getId1Doc.py#!/usr/bin/python3 from elasticsearch import Elasticsearch from pprint import pprint # Elasticsearch接続設定 es = Elasticsearch(['XX.XX.XX.XX:9200']) #ElasticsearchサーバーのIPアドレス response = es.get(index='city',id='1') pprint(response)このスクリプトを実行すると下記のような結果が得られます。
$ ./getId1Doc.py {'_id': '1', '_index': 'city', '_primary_term': 1, '_seq_no': 0, '_source': {'CountryCode': 'AFG', 'District': 'Kabol', 'Name': 'Kabul', 'Population': 1780000}, '_type': '_doc', '_version': 1, 'found': True}5.cityテーブルからPythonでデータを取得する
cityテーブルから全データをインポートする前に、テーブルからデータを取得する方法を確認したいと思います。
getCityTable.py#!/usr/bin/python3 import pymysql.cursors from pprint import pprint # MySQL(MariaDB)接続設定 db = pymysql.connect(host="XX.XX.XX.XX", user="ユーザー名", password="パスワード") cursor=db.cursor(pymysql.cursors.DictCursor) cursor.execute("USE world") db.commit() sql = 'SELECT * FROM city' cursor.execute(sql) city = cursor.fetchall() pprint(city)このスクリプトを実行すると下記のような結果が得られます。
$ ./getCityTable.py [{'CountryCode': 'AFG', 'District': 'Kabol', 'ID': 1, 'Name': 'Kabul', 'Population': 1780000}, {'CountryCode': 'AFG', 'District': 'Qandahar', 'ID': 2, 'Name': 'Qandahar', 'Population': 237500}, {'CountryCode': 'AFG', 'District': 'Herat', 'ID': 3, 'Name': 'Herat', 'Population': 186800}, (省略) {'CountryCode': 'PSE', 'District': 'Rafah', 'ID': 4079, 'Name': 'Rafah', 'Population': 92020}]6.全データのインポート
ようやくですが、cityテーブルの全データをスクリプトでインポートしたいと思います。
スクリプトの内容は下記の通りです。importFromCityTable.py#!/usr/bin/python3 import pymysql.cursors from elasticsearch import Elasticsearch from pprint import pprint # MySQL接続設定 db = pymysql.connect(host="XX.XX.XX.XX", user="ユーザーID", password="パスワード") cursor=db.cursor(pymysql.cursors.DictCursor) cursor.execute("USE world") db.commit() # Elasticsearch接続設定 es = Elasticsearch(['XX.XX.XX.XX:9200']) # MySQLからcityデータをまるごと取得 sql = 'SELECT * FROM city' cursor.execute(sql) city_table = cursor.fetchall() # cityデータをレコード単位でループ for city_record in city_table: index_id = str(city_record["ID"]) city_doc = {} city_doc["Name"] = city_record["Name"] city_doc["CountryCode"] = city_record["CountryCode"] city_doc["District"] = city_record["District"] city_doc["Population"] = city_record["Population"] response = es.index(index="city", doc_type="_doc", id=index_id, body=city_doc) print(response)このスクリプトを実行すると下記のような結果が得られます。
# ./importFromCityTable.py {'_index': 'city', '_type': '_doc', '_id': '1', '_version': 2, 'result': 'updated', '_shards': {'total': 2, 'successful': 1, 'failed': 0}, '_seq_no': 1, '_primary_term': 1} {'_index': 'city', '_type': '_doc', '_id': '2', '_version': 1, 'result': 'created', '_shards': {'total': 2, 'successful': 1, 'failed': 0}, '_seq_no': 0, '_primary_term': 1} {'_index': 'city', '_type': '_doc', '_id': '3', '_version': 1, 'result': 'created', '_shards': {'total': 2, 'successful': 1, 'failed': 0}, '_seq_no': 1, '_primary_term': 1} (省略) {'_index': 'city', '_type': '_doc', '_id': '4078', '_version': 1, 'result': 'created', '_shards': {'total': 2, 'successful': 1, 'failed': 0}, '_seq_no': 1350, '_primary_term': 1} {'_index': 'city', '_type': '_doc', '_id': '4079', '_version': 1, 'result': 'created', '_shards': {'total': 2, 'successful': 1, 'failed': 0}, '_seq_no': 1379, '_primary_term': 1}インポートしたデータの確認はここでは省略したいと思います。
getId1Doc.pyを編集するか、Kibanaコンソールから確認して下さい。7. Bulk APIを使ったインポート
cityテーブル程度のサイズでしたらimportFromCityTable.pyのように1つのドキュメントごとにPUTしてもそこまで時間はかかりませんが、都度通信が発生するためレコード数や1レコードのサイズが大きくなると時間がかかってしまいます。
そのような時は、Bulk APIを使用してドキュメントを配列形式でまとめてPUTした方がインポートの時間が短くて済みます。
Bulk APIを使用したスクリプトは下記のようになります。bulkImportFromCityTable.py#!/usr/bin/python3 import pymysql.cursors from elasticsearch import Elasticsearch from elasticsearch import helpers from pprint import pprint # MySQL接続設定 db = pymysql.connect(host="XX.XX.XX.XX", user="ユーザーID", password="パスワード") cursor=db.cursor(pymysql.cursors.DictCursor) cursor.execute("USE world") db.commit() # Elasticsearch接続設定 es = Elasticsearch(['XX.XX.XX.XX:9200']) # MySQLからcityデータをまるごと取得 sql = 'SELECT * FROM city' cursor.execute(sql) city_table = cursor.fetchall() # Bulk送信用のドキュメントの配列 bulk_doc = [] # bulkで送信するドキュメント数とカウンター bulk_number = 1000 n = 1 # cityデータをレコード単位でループ for city_record in city_table: index_id = str(city_record["ID"]) city_doc = {} city_doc["Name"] = city_record["Name"] city_doc["CountryCode"] = city_record["CountryCode"] city_doc["District"] = city_record["District"] city_doc["Population"] = city_record["Population"] # bulk配列に追加 bulk_doc.append({"_index":"city", "_type":"_doc", "_id":index_id, "_source":city_doc}) # 格納数がbulk_numberに達したら送信、未達なら次のcity_doc生成とbulk配列へのappendに進む if n < bulk_number: n = n + 1 else : response = helpers.bulk(es, bulk_doc) pprint(response) n = 1 bulk_index = [] # bulk_numberに達しなうでループが終わってしまった分を送信 response = helpers.bulk(es, bulk_doc) pprint(response)このスクリプトを実行すると下記のような結果が得られます。
$ ./bulkImportFromCityTable.py (1000, []) (2000, []) (3000, []) (4000, []) (4079, [])実行環境にもよりますが、こちらの方が速くインポートが完了すると思います。
- 投稿日:2019-08-21T13:17:37+09:00
【書籍まとめ】データサイエンス初心者が1年間で読んだ本
プログラミング経験ゼロから、1年間で読んできたPython、数学、統計学、資格、機械学習、深層学習などの書籍をまとめています。Qiitaには別の諸先輩方が記載している書籍まとめ記事がいっぱいありますが、そもそもプログラミング自体も知らない本当の素人が試行錯誤して読んできた本をここに備忘録的にもまとめておきます。
バックグラウンド
- 大学院では脳神経科学の研究室にいた生物系
- 物理、微分積分、線形代数、統計学などは大学生のときに基礎科目として学んだ程度
- プログラミングはそれすらない本当のゼロ
- 新卒で臨床試験の開発部署に(プログラミング、データ解析等とは無縁)
- 医療画像診断や臨床統計学に興味を持ち始めたのがデータサイエンス学習へのきっかけ
------Python------
独学プログラマー
プログラミング学習への第一歩。Pythonというより、Pythonを通じて、まずはプログラミングとは何か、何ができるか、そのためには何が必要かを学ぶことができ、プログラマーとしての仕事の仕方・方法に至るまでが網羅的に記述されていました。もちろんこれ1冊だけでプログラマーになれるはずもありませんが、全くの素人でも今後何をやるべきかの方針が漠然とでも掴めたのはとても有意義でした。筆者の経験談も交えて記述されているためとても読みやすく、本当の最初の1冊としておすすめ。退屈なことはPythonにやらせよう
上記「独学プログラマー」で紹介されている書籍のうちトップに記載されている本。プログラミングの便利さ、計算の速さなどを具体的な事例を通じて体感でき、その後のモチベーションアップに繋がりました。本書のタイトルの通り、特に仕事をする上で必要だが単純で退屈な作業を自動化してしまう方法がたくさん載っています。ファイル管理、Excelシート操作、PDF操作、メール送信など、今でもたまに読み返して利用しているものもあります。詳細! Python3 入門ノート
「Pythonプログラミングを全力で学ぶならこの1冊!」の触れ込み通り、変数、ライブラリ、条件分岐、リスト、タプル、辞書、関数定義、イテレータ・ジェネレータ、クラス定義などの一連の「使い方」が手を動かしながら身につく本です。最後の応用編では、numpy配列や機械学習入門のチャプターまで用意されています。Pythonに触れたこともない段階から、機械学習でとりあえずどんなことができるのかが理解できるまでを、非常に丁寧に解説しています。わかりやすいの一言。Pythonによるデータ分析入門
Pythonではじめる機械学習を先に読んでいた際にコードが分からず、どうやらデータ分析に必要なライブラリがいくつかあるらしい、ということで購入。9章までしか読んでいませんが、Numpy, Pandas, matplotlib, seabornなどのデータ分析ツールの基本的な使い方はマスター。特にseabornによるデータ可視化の便利さと綺麗さに感動。カラー図がふんだんに掲載されており、読みやすい。と同時に、データ分析ツールのメソッドのあまりの多さに目が点になり、この頃からプログラミングスクールへの入校を考え始める。------線形代数------
大学では丸暗記しただけの科目だったのでどうしよ、今後一番必要でかつ自分が一番弱い分野。ということで以下3冊で線形代数の凄さを体感。
マンガでわかる線形代数
この手のマンガ本は、キャラクターやマンガとしてのストーリーなどが混在して解説が進んで行くので苦手だったが、背に腹は変えられないのでまずは雰囲気を味わうためにも購入。基底、写像、線型独立、固有値・固有ベクトルなど、懐かしい文字をマンガを通して「鑑賞」。特にCGの分野で活躍しているらしい。学問というより道具として役立つ分野であることを理解し、肩肘張らずにほんわりと読了。まずはこの一冊から 意味がわかる線形代数
線形代数の本を書店で見て回ってもなんか分かるような分からんようなでしたが、この本は分かりやすかったです。行列表記で式の簡素化、固有ベクトルと主成分分析など、線形代数はやっぱり道具として便利なんだなということを理解できる。対象読者は文理問わない内容だったのでありがたかったです。あらゆる箇所で手計算しながら地道に読み進めて行く構成になっているので、辛いけど理解も深まります。プログラミングのための線形代数
数学という学問で初めて感動した本。固有値、固有ベクトル、対角化、ランクなどが、Rubyによるアニメーション動画で幾何的に対応づけられ、行列の意味を本書冒頭で視覚的に理解することができる。なので本の中身の読解もスムーズ。変わり種、プログラミング自体とは関係ない、数学的厳密性に欠ける、などのコメントもネットで見かけますが、直感的にも行列を理解できるのはありがたかったです。Jordan標準形あたりから難解。内容も濃いので、1ヶ月ほどかけてじっくり読む必要あり。------統計学------
- 臨床統計(特に治験のアウトカム評価、欠損データの取り扱い、症例数設計等)の道も考えていたので、プログラミングより統計に本腰を入れていた時期も。
- 統計検定準1級を目指していたが、2級の時点でデータサイエンスが面白くなってきたので、準1級はペンディング状態。本当はいけないんですけどね...。
- 統計検定対策には別途、公式解説書と公式問題集によるテスト慣れが必要でした。
完全独習 統計学入門
統計学の入門書を読むための入門書。「統計学の本質は数学記号とは別」との筆者の言葉通り、図と文章だけで文字通り統計学を「説明」している。式展開はほぼなし。確率も使わない。統計学の最初のイメージ作りにもってこい。標本数が少ない際にt分布を使い、正規母集団で母分散未知の場合の母平均の区間推定をとりあえずやってみるのが本書のゴール。仕事帰りに本気で読んで3日、のんびりでも1週間あれば読めます。はじめての統計学
上記「統計学入門」で1番目に紹介されていた入門書。ハードカバーの重厚な見た目とは裏腹に、文理関係なく理解できるように書かれていてわかりやすい。「統計学入門」の流れを体系的におさらいして読み進めることができる。これならわかる! ベイズ統計学
巷で流行りのベイズとはなんじゃい、ということで購入。事後確率のベイズ推定に関する色々なお話が解説されていますが、根本的にはベイズの定理の大元の式1つをベースに考えていくので、スーッと読み進めました。病気の検査、迷惑メール、産地推定、経済予測など、幅広い分野で応用されている事例の解説は面白かったです。基礎統計学Ⅰ 統計学入門
王道中の王道。通称「赤本」。上記までで統計学のイメージを散々作っていたので、話の流れはスムーズについていけました。が、紙面の都合上、式展開が省略されているため数式の理解が初見では難しく、高校の数Ⅲの公式に至るまで、あらゆる箇所に書き込みをして何度も読み返しました。難しい確率分布(ベータ、ガンマ、コーシー、ワイブルなど)となると、未だにその式の意味や応用はよく分かりません...。統計学演習
理論が分かっても問題が解けない、参考書の章末問題は難解だし解説も不足、統計検定公式本はあくまで検定本という感じ。ということで演習本を購入。統計用語の解説も申し分程度に、あとは例題と問題をストイックに解いていく本。これには助かりました。問題を解くことで理解も深まります。データ解析のための統計モデリング入門
評価が分かれるであろう分かりやすい本。通称「緑本」。統計モデリングという難解な分野を、私のように分かった気にさせてくれる入門書としては最高な良書なのかもしれません。植物データに対する単純なポアソン分布の当てはめから、現実の世界の多様なパラメータを考慮した一般化線形モデルに向かっていき、MCMCのメトロポリス法による定常分布のサンプリングにより、確率分布を統計モデルのパラメータと考えるベイズモデルと組み合わせることで、最後は一般化線形混合モデルのベイズモデル化に帰着させる、というのが私が理解している本書の流れです。難解ですね。統計学は深い。今後は一般化線形モデル入門と自然科学の統計学をじっくり読んでいきたいですね。
------機械学習------
Pythonではじめる機械学習
機械学習の分野へ突入してみたものの、途中からデータ分析用のライブラリを使ったコードが分からず、Pythonによるデータ分析入門を挟んで読んだ本。代表的な機械学習モデルを網羅し、数学的な理論背景はひとまず置いておいてとりあえずデータを使ってscikit-learnを動かしてみようという趣旨の内容が前半部分。後半は特徴量エンジニアリング、交差検証、グリッドサーチ、評価指標などのKaggleでも利用されるような基本的な内容を扱い、自然言語処理のさわりで終わる。scikit-learnの使い方を自然とマスターでき、読了後もしばらくは使い方を忘れた際のバイブルとして有用。数学的背景やコードを追うようないわゆる「理論」に関する内容はほぼなく、初心者は全てのアルゴリズムを理解する必要はないと断言する趣旨で書かれているので、どうやって動いているかの理解は別途対応が必要。機械学習のエッセンス
どのような機械学習アルゴリズムで動いているのか気になったので購入。本書後半で数値計算(桁落ち、勾配降下法、ラグランジュ未定乗数法等)、機械学習モデル(リッジ・ラッソ回帰、SVM、k-Means、PCA等)がほぼNumpyのみを用いてスクラッチ実装されたコードがまとまっている。Numpyの次元変換・ブロードキャスト計算を利用したコードや数式を実現する条件分岐の実際の実装方法など、コーディング力を上げるためのヒントが詰まっており、素晴らしい本でした。アルゴリズムの背景理論の式展開まで丁寧に記載されており、じっくり読むと理解が容易。内容が濃いので私の本は書き込みだらけです。はじめてのパターン認識
データサイエンス畑を目指すなら最低限理解していなければならない基準となる(らしい)本。通称「はじパタ」。パターン認識の理論が200ページにコンパクトにまとまっていて読みやすい...と油断していて火傷した本。「まとまっている」=「理解しやすい」ではないので、PRMLを時間かけて読むのが一番いいのだろうけど、その余裕がなかったので調べて考えてひたすら書き込むスタイルでなんとか乗り切る。------深層学習------
ゼロから作るDeepLearning
ニューラルネットワークをNumpyのみを用いてスクラッチ実装していく本。通称「ゼロつく」。人工ニューラルネットワークの原理、畳み込み・活性化関数・プーリング層の構成、順伝播、ソフトマックス、損失関数、誤差逆伝播、ミニバッチ処理の各機構をゼロから作り上げていく。各層のインプット・アウトプットの次元の数・順番・大きさと常に格闘しながら実装していくshapeマンになれる本です。特徴量がどのように伝播し、誤差から逆伝播してどのように学習パラメータが調整されていくのかが自然とわかります。CNN1層目でエッジ検出、その後の出力テクスチャで抽象度を上げていって最後はクラス分類の全結合層に帰着する構造が、人間の神経ネットワークを人工的に模倣したものだということがよく理解できます。機械学習以上に、深層学習はライブラリを動かしただけでは何をやっているかさっぱりわからなかったので、非常に有益でした。Python機械学習プログラミング
機械学習・深層学習が盛り沢山のモンスター本。理論とコードをバランスよく掲載しており、じっくり読めば理解は難しくないがとにかく分量が多い。最初はアヤメから始まり、最後はTensorFlowを使ったCNN、RNNの実装まで突っ走るとんでもない本。読了まで丸1ヶ月かかりましたが、相当な力がつきます。ネット情報、Kaggle、論文等で断片的に理解するより、時間がかかってもまずは基本を体系的に学べる本としてとてもよかったと思います。つくりながら学ぶ! PyTorchによる発展ディープラーニング
現在鋭意読解中。発展的な内容で四苦八苦してますが、今後仕事をする上でも役立つ画像認識アルゴリズムを解説、という趣旨で書かれているので非常に勉強になる。複雑なコードを懇切丁寧に解説してくれているので分かりやすい。自由度の高いPyTorchで物体検出できるRaspberry pi 戦車に改良できないかなと思案中。------画像処理------
スバラシク実力がつくと評判のフーリエ解析キャンパス・ゼミ
生物系ながら、研究室時代に漠然と理解していたフーリエ変換の知識を洗い直すために、わかりやすいと評判の本書を購入。式展開が完全にトレースされながら進んで行くので、行き詰まる点がない。複素関数の正則条件、コーシーの積分定理など、複素数や微積で勉強不足な箇所(物理系の人には常識なのでしょうが)があるものの、パルス波、熱伝導などの方程式・グラフが三角関数の無限級数で表現できることが素人でも分かる。画像の各領域の周波数特徴量の数値化やフィルタによるスペクトル操作など、画像処理で大活躍しているのでフーリエ解析の基本的な理解は必須。画像処理エンジニア検定
ディープラーニングによる画像解析が熱を帯びる前から画像処理の分野で開発されてきた技術が網羅されている。機械学習・深層学習を学んでも、それを応用する際に応用先のドメイン知識も必要になってくることが分かり始めた際に、画像処理の基礎も知らないのではまずいだろうということで購入。エッジ検出、ノイズ除去、幾何変換、画像復元、パターン認識、物体追跡に至るまで、画像処理全般の知識を効率的に学べる。深層学習に加えて画像処理の色々な選択肢が頭の中で増える。「そんなもの」と考えても何も始まらないし、資格は勉強の目標にもなるのでおすすめ。今後は、今までネットでつまみ食いしてきた画像認識をプロフェッショナルシリーズで体系的に学んでいきたいですね。ただ、時間が...。























- 投稿日:2019-08-21T13:13:04+09:00
Windows環境にてSpark+Pythonを試してみる
きっかけ
米国のBigDataの担当者にBigDataを扱うならSparkでSQLとかを分散させるとええでと言われたので、ちょっと試してみようかなという気になったので試してみる。
検証環境
・Windows10 Home (Ver.1803)
環境構築
・JDK
・Spark
・PythonJDK
入っている気がしたので、確認
java -version
もう入ってた。入っていない場合は要インストール。
Python
Anacondaで入れているけど、念のため確認。
python --version
モジュールとしてfindsparkが必要らしいのでインストールしておく
python -m pip install findsparkSpark
これが今回の本筋。
ダウンロード
https://spark.apache.org/downloads.html
winutilsも必要になるので、ダウンロードしておく
https://github.com/steveloughran/winutils/blob/master/hadoop-2.7.1/bin/winutils.exe配置
解凍して適当なところに置き、そこに対して環境変数を設定
今回は以下に配置
C:\tools\spark-2.4.3-bin-hadoop2.7
※winutils.exeはbinの中に格納環境変数は
SPARK_HOME,HADOOP_HOME:配置したフォルダ(今回だと[C:\tools\spark-2.4.3-bin-hadoop2.7])
PATH:[%SPARK_HOME%\bin]を追加確認
spark-shell
使える状態になっている (と思われる)
pyspark
使える状態になっている (と思われる)
試してみる
Anaconda promptでpysparkを実行し以下を流してみる。
import pyspark # only run after findspark.init() from pyspark.sql import SparkSession spark = SparkSession.builder.getOrCreate() df = spark.sql('''select 'spark' as hello ''') df.show()
動いているような気がする。
が、これで大量データをさばけるのか?という大事な部分がよくわからない。。。で、もう一つサンプルを実行してみたところ、例外発生。
import json, os, datetime, collections from pyspark.sql import SQLContext, Row from pyspark.sql.types import * csv_file = r"C:\work\20190821\click_data_sample.csv" print(csv_file) if not os.path.exists(csv_file): print("csv file not found at master node, will download and copy to HDFS") whole_raw_log = sc.textFile("/user/hadoop/click_data_sample.csv") header = whole_raw_log.first() whole_log = whole_raw_log.filter(lambda x:x !=header).map(lambda line: line.split(","))\ .map(lambda line: [datetime.datetime.strptime(line[0].replace('"', ''), '%Y-%m-%d %H:%M:%S'), int(line[1]), line[2].replace('"', '')]) whole_log.take(3)上記の
header = whole_raw_log.first()
のところで例外。
File "C:\tools\spark-2.4.3-bin-hadoop2.7\python\lib\py4j-0.10.7-src.zip\py4j\protocol.py", line 328, in get_return_value py4j.protocol.Py4JJavaError: An error occurred while calling o31.partitions. : org.apache.hadoop.mapred.InvalidInputException: Input path does not exist: file:/user/hadoop/click_data_sample.csv??
file:/user/hadoop/click_data_sample.csv
はどこを指しているんだろう??
Sparkの環境はできたとしても、もちっと仕組みを知らないと「使う」ことはできなさそうな感じがする。参考
https://www.guru99.com/pyspark-tutorial.html
https://goodbyegangster.hatenablog.com/entry/2018/06/27/022915
https://knaka20blue.hatenablog.com/entry/20180812/1534035813
https://qiita.com/tomotagwork/items/1431f692387242f4a636
https://qiita.com/taka4sato/items/4ab2cf9e941599f1c0ca
https://qiita.com/miyamotok0105/items/bf3638607ef6cb95f01b







- 投稿日:2019-08-21T13:02:08+09:00
LeetCode / Min Stack
(ブログ記事からの転載)
[https://leetcode.com/problems/min-stack/]
Design a stack that supports push, pop, top, and retrieving the minimum element in constant time.
push(x) -- Push element x onto stack.
pop() -- Removes the element on top of the stack.
top() -- Get the top element.
getMin() -- Retrieve the minimum element in the stack.Example:
MinStack minStack = new MinStack();
minStack.push(-2);
minStack.push(0);
minStack.push(-3);
minStack.getMin(); --> Returns -3.
minStack.pop();
minStack.top(); --> Returns 0.
minStack.getMin(); --> Returns -2.変わり種の問題ですが、push, pop, top, getMinのメソッドを持つクラスを定義する問題です。
クラス・メソッドの定義の仕方が分かっていれば造作もない問題ですが、ちょっとした落とし穴はあります。解答・解説
解法1
何も考えずに書けば、このようになると思います。
class MinStack(object): def __init__(self): self.stack = [] def push(self, x): self.stack.append(x) def pop(self): if len(self.stack) > 0: self.stack.pop() def top(self): if len(self.stack) == 0: return None return self.stack[-1] def getMin(self): return min(self.stack)これでもsubmitは通るんですが、getMinメソッドの実行時に$O(n)$の空間計算量が必要になります。しかし実際にはその必要はありません。
解法2
今回は、push, pop, topメソッドで各要素を追加・削除・取得すること以外には、getMinで最小値を取得することだけがやりたい処理です。
そこでpushメソッドでlistの変数stackにappendする値を、(追加した要素, これまでの最小値と追加した要素のうち小さい方の値)のタプルにします。
これにより、getMinではstack[-1][1]で最小値を取得できるので、$O(1)$で処理できることになります。class MinStack(object): def __init__(self): self.stack = [] def push(self, x): if len(self.stack) == 0: self.stack.append([x,x]) else: self.stack.append([x, min(x, self.stack[-1][1])]) def pop(self): if len(self.stack) > 0: self.stack.pop() def top(self): if len(self.stack) == 0: return None return self.stack[-1][0] def getMin(self): return self.stack[-1][1]
- 投稿日:2019-08-21T12:43:14+09:00
TensorflowでRuntimeError: Missing implementation that supportsが出た場合の対処方法
あまり起こりえないことのようですが、発生した場合の対処方法です。
■環境
Python3.7(Anacondaでインストール)
■エラー内容
retrain.pyを実行時に、以下のエラーが発生する。
RuntimeError: Missing implementation that supports: loader(*(‘C:\\Users\\Alber\\AppData\\Local\\Temp\\tfhub_modules\\xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx’,), **{})
■原因
以下のディレクトリ内が空っぽになっていることで起こっているようです。
‘C:\\Users\\Alber\\AppData\\Local\\Temp\\tfhub_modules\\xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx’
■対処方法
tfhub_modulesフォルダを削除し、再度retrain.pyを実行します。
(tfhub_modulesフォルダは再作成されます)■参考文献
https://stackoverflow.com/questions/54029556/how-to-fix-runtimeerror-missing-implementation-that-supports-loader-when-cal
https://github.com/tensorflow/hub/issues/212