- 投稿日:2019-07-19T22:57:18+09:00
Raspberry Pi をサーバとしてRailsのアプリケーションをデプロイするまで
概要
開発中のRailsアプリケーションを実際に自分でも使いたいので、できるだけ金をかけずにデプロイする方法を考えた。URLとかドメインとかの個人的なこだわりとアプリケーションの使用環境を考えるとHerokuはやなので、Apache&Passengerのコンボで以前購入したRaspberry Piをサーバーとして、アプリケーションをデプロイしてみる。作業が色々回りくどかったことと、あまり包括的にラズパイでのサーバー構築に関してカバーしてる記事がなかったので備忘として残しておくことに。
自分も初めてやったし独学なので、今後のために極力わかりやすく丁寧に書く。
*セキュリティは現段階では(おそらく)貧弱なので自己責任でお願いします。ご指摘いただけると幸いです。
*各ステップにおける説明の加減は自分の理解度が低いところに優先的に比重をかけています。前提
使用するのは主に、
- Raspberry Pi
- Filezilla (Piへのファイル転送用)
- Apache
- Passenger
- Ruby&Rails (Ruby 2.6.0, Rails 5.2.3)
- ドメインと転送設定他Raspberry Piは、以前トライしてみたHeadlessインストール(ディスプレイなしでのインストール)で要素が増えすぎて大変だったので、Noob経由でRaspbian Liteをインストール。sshを有効にした状態からスタート。操作はMacbookからsshで行う。
ApacheとPassengerはこれから導入していく。
RubyとRailsもこれからインストール。すでに作成したアプリケーションがあるのでそれをデプロイする。
ドメインは、フリードメインを入手してある(.tk)。Piが繋がってるルーターで転送設定して、かつドメインからDNSでルータに繋がるように設定済み。ドメインのところは、それはそれで初心者にはややこしい。また機会があれば書くけれど、今回は面倒なので割愛。特にドメインとかいらないよって場合は、この記事ではドメインをpublic IPで置き換えて入れればだいたいうまくいくはず。というかそちらの方が要素が少ないので確実。
目標
最終的に、ブラウザーで専用のドメインのURLを入力して、アプリケーションのトップページが表示されれば成功。
流れ
全体的な流れは以下のように進めます。
0. スタート地点の確認
1. RubyとRailsをインストール
2. Apacheをインストール
3. Passengerをインストール
4. Testアプリで動作確認
5. アプリケーションの転送と設定
6. 最終確認長くなりそう。
それでは早速。0. スタート地点の確認
前提でも書きましたが、目標に照らしてさらっと現状を確認します。
現段階でブラウザにURL入れるとこんな感じ。
当たり前。
当たり前すぎてある意味安心。1. RubyとRailsをインストール
下準備として、まずRubyをPiに入れていきます。今回は2.6.0でいきます。
sshでpiにログイン
MacbookのTerminalからsshでPiにログインします。
ssh pi@YOUR_DOMAIN
piはRaspberry Piのユーザ名(デフォルトはpiです)、YOUR_DOMAINのところに自分のドメインか、転送設定をしたpublic IPを入れます。バージョン管理のための下準備
アプリケーションによって使用するrubyのバージョンが異なる場合があるので、バージョン管理をするために使うrbenvを入れます。
まずはパッケージの更新。
pi$ sudo apt-get update $ sudo apt-get upgradegitを入れる。rbenv入れるのとかupdateに使います。
pisudo apt install gitnodejs (念のため)
pi$ sudo apt-get install nodejsrbenvインストール (バージョン管理用)
rbenv
pi$ sudo git clone https://github.com/rbenv/rbenv.git ~/.rbenvこれでrbenvは入ったんですが、これを
rbenv init ほにゃららで実行できるようにするため、俗にいう「pathを通す」ということをします。pi$ echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bashrc $ echo 'eval "$(rbenv init -)"' >> ~/.bashrc.bashrcはbashが起動されるたびに実行される。
>>は追記という意味なので、.bashrcにrbenv init -を追記することになる。.bassh_profileはログイン時のみなのでsshだとめんどくさそうということで、ここでは.bashrcにしておく。(sshでrapberry pi再起動した時は嫌な思い出しかない)次。ruby-buildを入れておきます。rbenvでrubyをインストールするために必要です。~/.rbenv/plugingsに作成されます。
pi$ git clone https://github.com/sstephenson/ruby-build.git ~/.rbenv/plugins/ruby-build最後にrehashする。
pi$ sudo rbenv rehashrbenvでは、バージョンごとに実行するファイルを分けるためにerb, gem, irb等ごとにフォルダを用意し、以下にバージョンごとのファイルを振り分けてくれます。shimと呼ばれるやつです。こうしておくことで、rbenv関連のコマンドが入ると、~/.rbenv/shimsを通して、バージョンに適切なファイルを実行できるようにしてあります。このshimsは、新しいgemなどを入れるたびに更新する必要があるため、それを行なっているのが上記のコマンド。
ここで念のため、一度MacbookのTerminalも閉じて、もう一度sshを接続し直します。
Rubyをインストール
まずはインストールできるバージョンを確認。上記でgitからrbenv/ruby-buildを入れているなら最新なはずです。
2.6.0があるか確認。
pi$ rbenv install --list
あった。よし。今回は2.6.0を入れます。
2.4, 2.5あたり以前を入れる場合は注意。CPUとの相性がどうたらでPassengerでBus ErrorやSegmentation Fault Errorが出たりします。解決法はありますが、めんどいので2.6.0。解決法はここ(HatenaBlog)
時間かかるので注意。僕の場合は30分弱かかった。pi$ rbenv install 2.6.0 $ rbenv global 2.6.0 # 以降使用するバージョンを設定 $ rbenv rehash # 恒例のrehashインストールできたか確認する。
pi$ ruby --version => ruby 2.6.0p0 (2018-12-25 revision 66547) [armv7l-linux-eabihf]バージョン情報が表示されたということは、入ってる。
よし。Railsのインストール
導入
Railsを入れていきます。
まずパッケージ管理用のbundlerを入れます。pi$ gem install bundlerRailsを入れます。
これは僕の場合は15分くらいかかりました。pi$ gem install rails動作確認。
pi$ rails --version => Rails 5.2.3おっけい。
2. Apacheをインストール
こちらは、Raspberry Pi公式でドキュメンテーションがあるのでそれに従います。(この記事では利用しませんが、index.htmlを変更して自分の簡単なwebサイトをApacheに表示させる方法も書いてあります。)
pi$ sudo apt-get update $ sudo apt-get install apache2 -y-yは、
--assume-yesの略で、promptに対して自動でyで回答するというもの。Apache動作確認
ここまでうまくいって入れば、ブラウザでURLを入力すればApacheの初期画面が表示されるはず。
やってみる。
やった...! (涙目3. Passengerをインストール
次。ApacheでRailsアプリケーションを動かすために、ApacheのモジュールであるPhusion Passengerを入れます。インストールと初期設定(configuration)で少し量があるので見出し分けます。
インストール
まずはPassengerをgemでインストール。
5分ほどかかります。sudoは使わない。pi$ gem install passenger次に、ApacheとPassengerを連帯させます。コマンドを入力するとインストラクションが表示されるので、従っていけば大丈夫です。しっかり読みながら進めます。
pi$ passenger-install-apache2-moduleいくつかEnterを押すと、自動でチェックを始める。
チェックが終わると、必要なもののインストール方法を教えてくれる。
従順に従って、すべてインストールします。
文頭にはsudoをつけて実行します。
僕の場合は、
-sudo apt-get install libcurl4-openssl-dev
-sudo apt-get install ruby-dev
-sudo apt-get install apache2-threaded-dev
-sudo apt-get install libapr1-dev
-sudo apt-get install libaprutil1-devやってみると、エラーが出た。
pi$ sudo apt-get install apache2-threaded-dev => Reading package lists... Done Building dependency tree Reading state information... Done E: Unable to locate package apache2-threaded-dev対処法は、こう書き換えて実行すること。原因は不明。
sudo apt-get install apache2-dev全部終わったら、再度
pi$ passenger-install-apache2-moduleここは20分以上かかりました。
備考:
仮にインストールしたはずなのにまた同じインストール要求をされる場合は、
sudo apt autoremove
を行なって、apache2-devのみ入れて、もう一度
passenger-install-apache2-module
を行なってみるとうまくいくかも。終了すると以下のような表示が出ます。
Apache configurationファイルを編集し、以下を追記してくださいという表示です。僕の場合はこのように出ています。
piLoadModule passenger_module /home/pi/.rbenv/versions/2.6.0/lib/ruby/gems/2.6.0/gems/passenger-6.0.2/buildout/apache2/mod_passenger.so <IfModule mod_passenger.c> PassengerRoot /home/pi/.rbenv/versions/2.6.0/lib/ruby/gems/2.6.0/gems/passenger-6.0.2 PassengerDefaultRuby /home/pi/.rbenv/versions/2.6.0/bin/ruby </IfModule>これは環境によって変わる可能性があるので、ご自分のコンソールに表示されたものをコピーしておいてください。
初期設定 (configuration)
上記でコピーを取ったものをApacheのconfigurationファイルに追加します。
"Press ENTER when you are done editing."
とあるので、念のため別のsshセッションを開始してそこから編集します。
基本的にApacheのconfigurationファイルは、
/etc/apache2/
内にある、apache2.confです。編集権限を持たせるためsudoでテキストエディタ(nano)を起動します。
pi$ sudo nano /etc/apache2/apache2.confコピペ。
ctr+xのちにY、そしてEnterを押すと保存してnanoを終了します。1つめのsshに戻って、
Enterを押すと、インストールが正しく行われたかチェックしてくれます。
Everything looks good. :-)
を表示されればOk.最後に念のため、PassengerとApache双方がうまく動いているか確認。
pi$ sudo passenger-config validate-installすると
おっと、
pi* Checking whether the Passenger module is correctly configured in Apache... ✗ Incorrect Passenger module path detected Phusion Passenger for Apache requires a 'LoadModule passenger_module' directive inside an Apache configuration file. This directive has been detected in the following config file: /etc/apache2/apache2.conf However, the directive refers to the following Apache module, which is wrong: /home/pi/.rbenv/versions/2.6.0/lib/ruby/gems/2.6.0/gems/passenger-6.0.2/buildout/apache2/mod_passenger.so Please edit the config file and change the directive to this instead: LoadModule passenger_module /var/lib/gems/2.5.0/gems/passenger-6.0.2/buildout/apache2/mod_passenger.soconfigファイルは存在するけど、Apacheへのパスの設定が間違っている、と言っています。
ただ僕はrubyをrbenvで管理しており、rubyも2.6.0を入れたので、パスはあっていると判断。
続行します。4. Testアプリで動作確認
Railsでテスト用のアプリを作成し、Passengerにそのファイルを参照させることで、URLにアクセスするとRuby on Railsの初期画面が表示されるところまで持っていきます。これで、Apache, Passenger, Railsが正しく動作することを確認。
TestアプリをRailsで作成
ただプロジェクトを作るだけです。
プロジェクトを作成するパスまでナビゲートし、rails用のフォルダを作成。pi$ cd /var/www/ $ sudo mkdir rails # rails用のフォルダ作成 $ sudo chmod -R 777 rails # permissionを設定 (注意!) $ cd rails # 作ったフォルダに移動3行目の
sudo chmod -R 777 railsは、危険な方法です。
今回はRailsが必要なフォルダを作成するためにrailsフォルダの全ての権限を解放しています。しかし、これは今回の目的が実験的にRailsを動かすためであるからで、セキュリティ的には危険です。ウェブサイトとして公開した際、訪問者がrailsフォルダ内のデータをどうとでもできる状態です。本来はApacheのみに権限を与えることでRailsが必要な挙動を許可されるようにします。 参考1, 参考2今回は個人的なテストなのでよしとして、ここで、Railsプロジェクトを作成。
pi$ rails new TestApp --skip-bundle
--skip-bundleは、初期に自動でbundle installするのを飛ばします。古いバージョンのRailsでは、初期のbundle installが問題を起こすことがあったので念のため。PassengerをTestAppに向ける
まず、使うrubyのパスを調べます。
pi$ passenger-config about ruby-command => passenger-config was invoked through the following Ruby interpreter: Command: /home/pi/.rbenv/versions/2.6.0/bin/ruby # これがrubyのパス。 Version: ruby 2.6.0p0 (2018-12-25 revision 66547) [armv7l-linux-eabihf]ということで、
/home/pi/.rbenv/versions/2.6.0/bin/rubyがrubyのパス。次に、
/etc/apache2/apache2.configを再度nanoで編集し、以下を追記します。pi<VirtualHost *:80> ServerName yourserver.com # 自分のドメイン # Tell Apache and Passenger where your app's 'public' directory is DocumentRoot /var/www/rails/TestApp/public # 先ほど作ったTestApp内の'public'というフォルダ PassengerRuby /home/pi/.rbenv/versions/2.6.0/bin/ruby # 今見つけたrubyへのパス。 # Relax Apache security settings <Directory /var/www/rails/TestApp/public> # ここのパスも、先ほどと同じくTestAppのpublicフォルダ Allow from all Options -MultiViews # Uncomment this if you're on Apache > 2.4: #Require all granted </Directory> </VirtualHost>先ほどと同じように、
ctr+x→Y→Enterで保存してnanoを終了します。できたら、Apacheを再起動します。
pi$ sudo apachectl restartここまできたら、早速ブラウザからドメインにアクセスして見ましょう。
なんでやねん。まずは、ブラウザ上からエラーメッセージの詳細を確認できるように設定しましょう。
/etc/apache2/apache2.confに、piPassengerFriendlyErrorPages onと追記します。
VirtualHostタグの中に。
Apacheを再起動。
pi$ sudo apachectl restartブラウザを更新すると、
よし、進歩。わかった、bundleだ。
pi$ cd /var/www/rails/TestApp $ bundle install更新。
なんでやねん。あ、わかった、RailsアプリがDevelopmentになってると、Passengerはアプリを起動してくれません。それを、Developmentモードでも大丈夫だよとPassengerに伝えるために、Apacheのコンフィギュレーションをいじります。
なので、
/etc/apache2/apache2.confを再度編集し、RailsEnv developmentの記述を追加します。pi$ sudo nano /etc/apache2/apache2.conf
できたら、
sudo apachectl restartでApacheを再起動。ブラウザを更新すると...
これが見えた時の喜びのすごさよ。5. アプリケーションの転送と設定
ただのRailsの画面では面白くないので、あらかじめ作成しておいたアプリをPiに転送して、それが動くか確かめて見る。
FileZillaで転送します。
Quick ConnectionでPiに接続後、アプリのフォルダを
/var/www/rails内にドラッグドロップします。転送が完了したら、
apache2.confを編集。僕の場合アプリ名(つまりフォルダ名)は
Daruma
なので、
/etc/apache2/apache2.confをnanoで編集し、VirtualHostの部分を以下のように編集します。pi<VirtualHost *:80> ServerName YOUR DOMAIN # ドメイン名またはIP # Tell Apache and Passenger where your app's 'public' directory is DocumentRoot /var/www/rails/Daruma/public # ← ここを変更。 RailsEnv development PassengerRuby /home/pi/.rbenv/versions/2.6.0/bin/ruby PassengerFriendlyErrorPages on # Relax Apache security settings <Directory /var/www/rails/TestApp/public> Allow from all Options -MultiViews # Uncomment this if you're on Apache > 2.4: #Require all granted </Directory> </VirtualHost>できたら保存。
忘れずに、
pi$ bundle install6. 最終確認
ブラウザーを更新して、アプリのトップページが表示されるか確かめます。
よっしゃ。
目標達成!!!/















- 投稿日:2019-07-19T22:04:47+09:00
【備忘録】rails newでmysql2がインストールできないエラーの解消方法
【参考】mysql2 gemインストール時のトラブルシュート
長らく悩まされていたエラーがようやく解決できたので,備忘録として。
$ rails new アプリ名 -d mysqlを実行すると,毎回このエラーが発生していた。
Fetching mysql2 0.5.2 Installing mysql2 0.5.2 with native extensions Gem::Ext::BuildError: ERROR: Failed to build gem native extension. (中略) An error occurred while installing mysql2 (0.5.2), and Bundler cannot continue. Make sure that `gem install mysql2 -v '0.5.2' --source 'https://rubygems.org/'` succeeds before bundling. In Gemfile: mysql2 run bundle exec spring binstub --all Could not find gem 'mysql2 (>= 0.4.4, < 0.6.0)' in any of the gem sources listed in your Gemfile. Run `bundle install` to install missing gems.色々調べて試してみるも効果無し。
解決できたコマンドは【参考】に書かれていた次のコマンドだった。$ cd アプリ名 $ gem install mysql2 -v '0.5.2' --source 'https://rubygems.org/' -- --with-cppflags=-I/usr/local/opt/openssl/include --with-ldflags=-L/usr/local/opt/openssl/lib $ bundle installこの後,「rails new」でアプリを作成してもエラーが出なくなった。長かった……
- 投稿日:2019-07-19T21:18:52+09:00
【Rials】フォロー機能1~多対多のモデルの構造
Rialsでのフォロー機能についてのメモです。
ツイッタークローンのフォロー機能のモデルの説明です。こちらの続きです。
フォロー機能の概要
投稿機能は1対多で、
フォロー機能は、モデルの多対多の関係で成り立ちます。投稿機能では、ユーザ(1)に対して、投稿(多)という関係が成り立ちました。
フォロー機能では、ユーザ(多)に対して、ユーザ(多)という構造を取ります。
「ユーザって言っても、自分は一人やし、1対多なんじゃないの?」と疑問に思われる方もいらっしゃるかと思いますが、半分合ってます!前回も使わせてもらいましたが、こちらの記事を参考にしてみてください。めっちゃ分かりやすいです。
https://qiita.com/kazukimatsumoto/items/14bdff681ec5ddac26d1多対多のモデルの構造の場合、中間にテーブルを新しく作成し、相互のやり取りをするのが一般的です。
全体像
モデル
User(ユーザ)
name:string amail:string password_digest:stringRelationship (中間テーブル)
user:references follow:referencesユーザ同士のフォロー機能なので、中間テーブルをはさむことによって、
モデルの構造はUser-Relationship-Userのようになります。
User(フォローする側)-Relationship-User(フォローされる側)と分けることが出来ます。
もう一つ細かく分けると、
User(フォローする側)-(フォローするための中間テーブル)Relationship(フォローされるための中間テーブル)-User(フォローされる側)
となります。モデルの構成で表してみると、
User(フォローする側)-(user)Relationship(follow)-User(フォローされる側)
こうなります。User(フォローする側)-(user)Relationship
User(フォローされる側)-(follow)Relationship
とも捉えることができます。(捉え方多すぎ!笑)こうすると1対多+1対多となっているように見えてきませんか?
実は、多対多は、中間テーブル(多)を挟んだ1対多+1対多なのです!モデルの作成
上記の構成を参考に、モデルの作成をしましょう。
マイグレーションファイルでの設定
中間テーブルのモデルの下記のコードのマイグレーションファイルが出来上がっているかと思います。
db/migrate/年月日時_create_relationships.rbclass CreateRelationships < ActiveRecord::Migration[5.0] def change create_table :relationships do |t| t.references :user, foreign_key: true t.references :follow, foreign_key: true t.timestamps end end enduserもfollowもUserテーブルに紐づけたいです。
railsでは、別のテーブル名をモデルのカラム名に設定すると、自動で参照してくれます。なので、t.references :user は、Userテーブルを参照することが出来ます。t.references :followをUserテーブルに紐づけたい。。
そんなときは、
t.references :follow, foreign_key: { to_table: :users }
こう記述すればfollowをUserテーブルに紐づけることが出来ます!
下記のコードに書き換えます。db/migrate/年月日時_create_relationships.rbclass CreateRelationships < ActiveRecord::Migration[5.0] def change create_table :relationships do |t| t.references :user, foreign_key: true t.references :follow, foreign_key: { to_table: :users } t.timestamps t.index [:user_id, :follow_id], unique: true end end endここで、
t.index [:user_id, :follow_id], unique: true
というコードを追記しています。unique: trueを記述することで、フォローとフォロワーがごっちゃにならないよにしています。モデル
モデルのコードを見てみましょう。
まず、中間テーブルから。
app/models/relationship.rbclass Relationship < ApplicationRecord belongs_to :user belongs_to :follow, class_name: 'User' end多対多の構造は、細かく見ていくと
1対多+1対多
だと説明しました。なので、relationshipテーブル(中間テーブル)では、haa_manyではなく、belongs_to でUserテーブルと紐づけてます。Userテーブルで、has_manyでrelationshipテーブルと紐づけることで多対他になります。
また、Userテーブルと各カラムを紐づけたいのですが、このままの状態ではuserカラムしか紐づいていないです。(railsの機能でカラムと同じ名前のテーブルを探しにいくため)
belongs_to :follow, class_name: 'User'ですが、class_name: 'User'と追加で指定することで、followカラムもUserテーブルを参照することが出来るようになります。Userテーブルを見てみましょう!
app/models/user.rbclass User < ApplicationRecord has_many :microposts has_many :relationships has_many :followings, through: :relationships, source: :follow has_many :reverses_of_relationship, class_name: 'Relationship', foreign_key: 'follow_id' has_many :followers, through: :reverses_of_relationship, source: :user end
has_many :micropostsは、投稿機能を追加したときに作成したコードです。下の4つについて見ていきましょう。
has_many :relationshipsで、relationshipsテーブルから、データを取得してくることが出来ます。1対多の関係です。
自分がフォローしているユーザを取得します。
railsでは、同じ名前のテーブル・カラムがあると自動で取得してくれるので、RelationテーブルにUserカラムの情報を取得していることになります。一行飛ばして、
has_many :reverses_of_relationship, class_name: 'Relationship', foreign_key: 'follow_id'を見てみましょう。
reverses_of_relationshipというのは自由に決められる名前です。
class_name: 'Relationship'では、Relationshipテーブルからデータを取ってきてるということを表しています。
そして、foreign_key: 'follow_id'でfollow_idのデータですよ!というようになります。
has_many :reverses_of_relationship, class_name: 'Relationship', foreign_key: 'follow_id'
では、reverses_of_relationshipという名前の箱に、Relationshipテーブルを通して、follow_idのデータが入ると言えます。
では、
has_many :followings, through: :relationships, source: :follow has_many :followers, through: :reverses_of_relationship, source: :user endについて見ていきます。
throughとsourceがミソになってきます。
through: :中間テーブル, source: :カラム名
で、中間テーブルに設定されているカラムのデータを引っ張てくることが出来ます。今回のように、ユーザがフォローしているユーザを取得したければ、中間テーブルを通過することで、
has_many :followings, through: :relationships, source: :follow
は、ユーザ(user)がフォローしているユーザ(followings)を取得
has_many :followers, through: :reverses_of_relationship, source: :user
end
で、ユーザ(User)のことをフォローしているユーザ(followers)を取得することが出来ます。例えば、ユーザ(user)がフォローしているユーザ(followings)を取得したい場合、
@user = User.find(params[:id]) @followings = @user.followings.page(params[:page])というような記述の仕方も可能になります。
- 投稿日:2019-07-19T19:35:50+09:00
マルチテナンシー(Multitenancy)を簡単に実現できるgem 「acts_as_tenant」を実装
背景
仕訳記録用の会計ソフトを開発しています。ユーザのサインアップ、検証、ログイン、ログアウト機能は既にできています。
ただし、例えばユーザAが登録した仕訳が、新しくサインアップしてログインしたユーザBに漏れなく見られてしまいます。つまり、全てのデータは全員共有という状態です。
望ましいのは、ユーザAが登録した仕訳がユーザAのみに見られ、ユーザBがサインアップしてログインすると、またきれいな環境になり、ユーザBがユーザBのみ見られる仕訳を登録できるようになるということです。
ただし、一部の汎用勘定科目はAもBも見れます。
また、アプリのURLは変わらないです。AもBも同じURLで同じシステムをログインします。いろいろ調べた結果
希望な機能は「マルチテナンシー」(Multitenancy)と呼ばれます。
幸いなのは、Railsの中に既にいくつかのGemがありました。苦労せず実現できそうな感じです。
一番流行っているらしいのが「Apartment」というGemです。違うテナントは違うsubdomainを通じてデータの隔離することを実現します。
Apartment+PostgreSQLの場合、微妙な問題がありそうです。未だに完璧に解決できていないようです。
二番目有名なGemは「acts_as_tenant」というGemです。今回使ってみたのはこれです。
いよいよ始めよう
gem 'acts_as_tenant'をGemfileに入れます
Bundle Installを実行します。完了です。
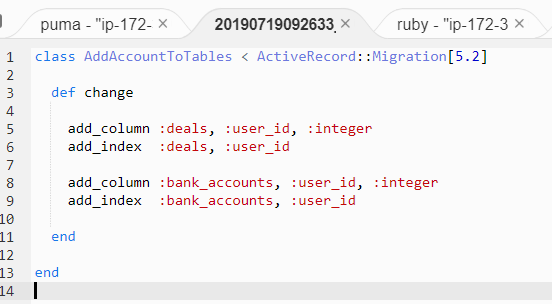
rails g migration addAccountToTablesでMigration Fileを生成させ、下記のように書きます。
説明:
① dealsは仕訳を保存するテーブル、bank_accounts は銀行口座を保存するテーブルです。そしてユーザごとにデータを隔離したいテーブルです。両方とも既にあったテーブルです。② usersは既にあったユーザを保存するテーブルです。今回はuserごとにデータを隔離したいので、ここでは:user_idを入れてOKです。もし一つのAccount(Tenant)に複数のuserが含まれ、同じTenantのuserたちはデータを共有するという形がほしかったら、別途Accountテーブルを作る必要があります。
③ 勘定科目を共有したいため、勘定科目テーブルgl_accountsはそのまま変わらないです。
p.s.Migration Fileの名前は「AddAccountToTables」じゃなくても何でもいいです。
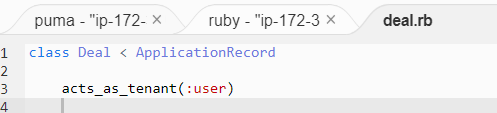
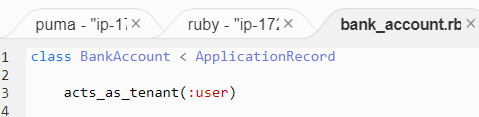
acts_as_tenant(:user)を追加
隔離したいModelだけが必要です。勘定科目のmodel-GlAccountはそのまま何も変わらないです。
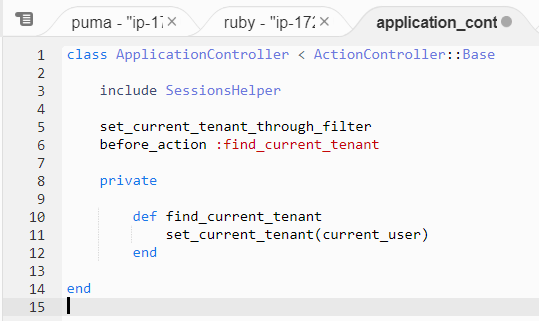
説明:
① ここのset_current_tanant_through_filterはgemが提供してくれる関数です。名前は変えられないです。
②find_current_tenantは自分で作ったprivate関数です。好きな名前にしてもOKです。
③set_current_tenantはgemが提供してくれる関数です。名前は変えられないです。
④ パラメータのcurrent_userは自分がその前に書いた関数です。目的はログインしているユーザをゲットすることです。
以上だけ設定すると、ユーザAもBも自分しか見れない/作れないデータをできるようになりました。
非常にシンプルで分かりやすいGemだと思います。
- 投稿日:2019-07-19T19:20:44+09:00
doker docsにあるサンプルのRails+Postglesを使って環境構築をしてみた
知り合いと飲んだ勢いで、簡単なwebアプリを作成することになったので、
開発環境として、docker docsのRails+Postglesのサンプルを元に、
開発環境を作成してみたら、簡単にできたので、投稿してみました。プロジェクトのディレクトリを作成する
/hoge_project
Dockerfileを作成する/hoge_project |_ DockerfileDockerfileFROM ruby:2.6.3 RUN apt-get update -qq && apt-get install -y nodejs postgresql-client RUN mkdir /myapp WORKDIR /myapp COPY Gemfile /myapp/Gemfile COPY Gemfile.lock /myapp/Gemfile.lock RUN bundle install COPY . /myapp # Add a script to be executed every time the container starts. COPY entrypoint.sh /usr/bin/ RUN chmod +x /usr/bin/entrypoint.sh ENTRYPOINT ["entrypoint.sh"] EXPOSE 3000 # Start the main process. CMD ["rails", "server", "-b", "0.0.0.0"]
Gemfileを作成する/hoge_project |_ Dockerfile |_ GemfileGemfilesource 'https://rubygems.org' gem 'rails', '5.2.3'
Gemfile.lockを作成する/hoge_project |_ Dockerfile |_ Gemfile |_ Gemfile.lock
entrypoint.shを作成する/hoge_project |_ Dockerfile |_ Gemfile |_ Gemfile.lock |_ entrypoint.shentrypoint.sh#!/bin/bash set -e # Remove a potentially pre-existing server.pid for Rails. rm -f /myapp/tmp/pids/server.pid # Then exec the container's main process (what's set as CMD in the Dockerfile). exec "$@"
server.pidがあるかないかでサーバーを再起動させないようにするらしい
docker-compose.ymlを作成する/hoge_project |_ Dockerfile |_ Gemfile |_ Gemfile.lock |_ entrypoint.sh |_ docker-compose.ymldocker-compose.ymlversion: '3' services: db: image: postgres volumes: - ./tmp/db:/var/lib/postgresql/data ports: - "8000:5432" web: build: . command: bash -c "rm -f tmp/pids/server.pid && bundle exec rails s -p 3000 -b '0.0.0.0'" volumes: - .:/myapp ports: - "3000:3000" depends_on: - db
doker docsでのサンプルではpostgresのポートが明示的に設定されていないので、
下記のように設定しました。ports: - "8000:5432"
docker-compose runでプロジエクトを作成する下記のコマンドを実行すると...
docker-compose run web rails new . --force --no-deps --database=postgresqlプロジェクトができる!!!
/hoge_project |_ app |_ bin |_ config |_ db |_ lib |_ log |_ public |_ storage |_ test |_ tmp |_ vendor |_ .gitignore |_ .ruby-version |_ config.ru |_ docker-compose.yml |_ Dockerfile |_ entrypoint.sh |_ Gemfile |_ Gemfile.lock |_ package.json |_ Rakefile |_ README.md
Gemfileが更新されたので、再度、イメージを作成するdocker-compose build作成するデータベースと向き先を変更する
config/database.ymldefault: &default adapter: postgresql encoding: unicode host: db username: postgres password: pool: 5 development: <<: *default database: myapp_development test: <<: *default database: myapp_test
docker-compose upでコンテナを起動するdocker-compose upデータベースを作成する
docker-compose run web rake db:createアクセスできるか、確認する
Railshttp://localhost:3000PostgreSQLhost:localhost port:8000 Database:myapp_development user:postgres password:完成〜
まだまだ設定しないといけない部分はありますが、
簡単に動くものなら、意外と簡単にできるので、
みなさんもやってみてください〜
- 投稿日:2019-07-19T19:20:44+09:00
doker docsにあるサンプルのRails+Postglesを使って開発環境を構築してみた
知り合いと飲んだ勢いで、簡単なwebアプリを作成することになったので、
開発環境として、docker docsのRails+Postglesのサンプルを元に、
開発環境を作成してみたら、簡単にできたので、投稿してみました。プロジェクトのディレクトリを作成する
/hoge_project
Dockerfileを作成する/hoge_project |_ DockerfileDockerfileFROM ruby:2.6.3 RUN apt-get update -qq && apt-get install -y nodejs postgresql-client RUN mkdir /myapp WORKDIR /myapp COPY Gemfile /myapp/Gemfile COPY Gemfile.lock /myapp/Gemfile.lock RUN bundle install COPY . /myapp # Add a script to be executed every time the container starts. COPY entrypoint.sh /usr/bin/ RUN chmod +x /usr/bin/entrypoint.sh ENTRYPOINT ["entrypoint.sh"] EXPOSE 3000 # Start the main process. CMD ["rails", "server", "-b", "0.0.0.0"]
Gemfileを作成する/hoge_project |_ Dockerfile |_ GemfileGemfilesource 'https://rubygems.org' gem 'rails', '5.2.3'
Gemfile.lockを作成する/hoge_project |_ Dockerfile |_ Gemfile |_ Gemfile.lock
entrypoint.shを作成する/hoge_project |_ Dockerfile |_ Gemfile |_ Gemfile.lock |_ entrypoint.shentrypoint.sh#!/bin/bash set -e # Remove a potentially pre-existing server.pid for Rails. rm -f /myapp/tmp/pids/server.pid # Then exec the container's main process (what's set as CMD in the Dockerfile). exec "$@"
server.pidがあるかないかでサーバーを再起動させないようにするらしい
docker-compose.ymlを作成する/hoge_project |_ Dockerfile |_ Gemfile |_ Gemfile.lock |_ entrypoint.sh |_ docker-compose.ymldocker-compose.ymlversion: '3' services: db: image: postgres volumes: - ./tmp/db:/var/lib/postgresql/data ports: - "8000:5432" web: build: . command: bash -c "rm -f tmp/pids/server.pid && bundle exec rails s -p 3000 -b '0.0.0.0'" volumes: - .:/myapp ports: - "3000:3000" depends_on: - db
doker docsでのサンプルではpostgresのポートが明示的に設定されていないので、
下記のように設定しました。ports: - "8000:5432"
docker-compose runでプロジエクトを作成する下記のコマンドを実行すると...
docker-compose run web rails new . --force --no-deps --database=postgresqlプロジェクトができる!!!
/hoge_project |_ app |_ bin |_ config |_ db |_ lib |_ log |_ public |_ storage |_ test |_ tmp |_ vendor |_ .gitignore |_ .ruby-version |_ config.ru |_ docker-compose.yml |_ Dockerfile |_ entrypoint.sh |_ Gemfile |_ Gemfile.lock |_ package.json |_ Rakefile |_ README.md
Gemfileが更新されたので、再度、イメージを作成するdocker-compose build作成するデータベースと向き先を変更する
config/database.ymldefault: &default adapter: postgresql encoding: unicode host: db username: postgres password: pool: 5 development: <<: *default database: myapp_development test: <<: *default database: myapp_test
docker-compose upでコンテナを起動するdocker-compose upデータベースを作成する
docker-compose run web rake db:createアクセスできるか、確認する
Railshttp://localhost:3000PostgreSQLhost:localhost port:8000 Database:myapp_development user:postgres password:完成〜
まだまだ設定しないといけない部分はありますが、
簡単に動くものなら、意外と簡単にできるので、
みなさんもやってみてください〜
- 投稿日:2019-07-19T19:06:35+09:00
rails ActionMailerでファイル名が日本語のファイルを添付する
- 投稿日:2019-07-19T16:47:34+09:00
【Rails on Rails】.envの環境変数をjsファイル内で利用する方法
はじめに
Rails内で環境変数を.envファイル内に書いておくと、ENV["環境変数名"]で利用することが出来ます。
しかし、erbファイル内では利用することが出来ますが、jsファイルで利用することが出来ません。
そこで、jsファイル内で環境変数を利用する方法を解説します。
gemのインストール
以下の2つのgemをインストールします。
Gemfileに以下の2つのgemを記入し、
Gemfilegem 'gon' gem 'dotenv-rails'bundle installします。
bundle install.envファイルの作成作成
jsファイル内で利用したい、環境変数を.envファイルに記入します。
.envKEY = "xxx".gitignoreファイルを編集
念の為、GithubなどにAPI KEYなどの環境変数が公開されていように設定します。
.envに以下の1行を追加します。.gitignore/.envapplication.html.erbの編集
application.html.erbのhead内に以下の1行を追加します。
application.html.erb<%= include_gon %>
【注意】javascriptより上に書くこと
コントローラーの編集
環境変数を利用したいコントローラーのメソッドに追記。
xxx_controller.erbdef xxx gon.xxx_key = ENV['KEY'] end
jsファイルの編集
xxx.jsconst KEY = gon.xxx_key;// 環境変数これでjsファイル内で環境変数を利用することが出来ます。
参考リンク
- 投稿日:2019-07-19T16:06:36+09:00
[Rails]C3.js × gonでチャートを表示する
できるだけ簡単に、かつクオリティの高いチャートを表示したい・・・。
そんなあなたにはC3.jsがオススメです。
また、データベースやコントローラーにあるデータを表示したい場合はgemgonを使うと便利です。今回は、C3.jsとgonを使った以下のような棒グラフの描画方法を紹介します。
環境
バージョン
$ ruby -v ruby 2.5.1p57 (2018-03-29 revision 63029) [x86_64-darwin18] $ rails -v Rails 5.2.3導入gem
gonを導入します。gem 'gon' gem 'haml-rails'ビューにはhamlを採用しています。
ライブラリとgonの読み込み
C3.jsはD3.jsのラッパーライブラリーなのでC3.jsと一緒にD3.jsを読み込みます。
今回はCDNを使って読み込むことにしました。(もちろん、gemとして読み込むこともできます。RailsでC3.jsを使う)
また、gonを適用するためにheadタグの中で以下のように追記します。application.html.haml# jsファイルよりも前に読み込む = Gon::Base.render_data %link{ href: "https://cdnjs.cloudflare.com/ajax/libs/c3/0.6.7/c3.css", rel: "stylesheet"} %script{src: "https://d3js.org/d3.v4.min.js", type: "text/javascript"} %script{src: "https://cdnjs.cloudflare.com/ajax/libs/c3/0.6.7/c3.js", type: "text/javascript"}ビュー
チャートを挿入したい要素にIDを指定しておきます。
html.haml.container #bar / ここにチャートを挿入コントローラー
gon.◯◯という変数に値を代入することでjsファイルで呼び出すことができます。controller.rbgon.x = ["x","07/13","07/14","07/15","07/16","07/17","07/18","07/19"] gon.cash = ["現金",2000000,1000000,1000000,1000000,1000000,1000000,1000000] gon.crypto = ["仮想通貨",8000000,9000000,10000000,8000000,6000000,4000000,2000000]わかりやすくするため値を直接代入していますが、
コントローラーでDBの情報を取得してjsに変数を渡したいときに利用すると便利です。jsファイル
同様に
gon.◯◯とすることでコントローラで定義した変数を取り出すことができます。window.onload = function() { // 棒グラフを挿入 var barGraph = c3.generate({ bindto: '#bar', // 挿入する要素のIDを指定(デフォルトは#chart) data: { x : 'x', columns: [ // コントローラーで定義した変数の呼び出し gon.x, //x軸のメモリに表示する文字列 gon.cash, // 値1 gon.crypto, // 値2 ], groups: [ // 値1と値2を連結させた棒グラフを表示 ['現金', '仮想通貨'] ], type: 'bar' // チャートタイプを指定(今回は棒グラフ) }, axis: { x: { type: 'category' // x軸のメモリ(今回は日付)を読み込むために必要 }, y: { label: { // y軸のラベルを追加 text: '価格 / 円', position: 'outer-middle' }, tick: { // 3桁ずつ「,」を挿入 format: d3.format(",") } } }, // チャートの余白を指定できる padding: { top: 10, bottom: 0 } }); }指定できるチャートタイプやその他設定は公式リファレンスがわかりやすいです。C3.js
gonの仕組み
application.html.hamlのheadタグの中で
Gon::Base.render_dataを記述した場所がどう表示されているかを確認してみます。html<script> //<![CDATA[ window.gon={}; gon.x=["x","07/13","07/14","07/15","07/16","07/17","07/18","07/19"]; gon.cash=["現金",2000000,1000000,1000000,1000000,1000000,1000000,1000000]; gon.crypto=["仮想通貨",8000000,9000000,10000000,8000000,6000000,4000000,2000000]; //]]> </script>
window.gon={}とすることでgonというグローバル変数を定義し、空のオブジェクトを代入して初期化しています。(グローバル変数はwindowオブジェクトのプロパティです)
そして、コントローラーで指定した値をgonのプロパティとして代入しています(windowは省略可能)。
これにより、jsファイルで変数を読み込むことが可能になります。参考

- 投稿日:2019-07-19T14:23:04+09:00
Rails+Rspec+Headless Chromeの設定
試した環境:
- rails 5.1.6.2
- rspec-rails 3.8.2
- capybara 3.26.0
- selenium-webdriver 3.142.3
- webdrivers 4.1.1
- Google Chrome 75
Gemfilegroup :test do gem 'rspec-rails' gem 'capybara' gem 'webdrivers' endspec_helper.rbCapybara.register_driver :headless_chrome do |app| chrome_options = Selenium::WebDriver::Chrome::Options.new chrome_options.args << '--headless' driver = Capybara::Selenium::Driver.new(app, browser: :chrome, options: chrome_options) driver.browser.manage.window.size = Selenium::WebDriver::Dimension.new(2000, 3000) driver end Capybara.javascript_driver = :headless_chrome Capybara.default_max_wait_time = 5 Capybara.server = :puma, { Silent: true }2019年5月以降、Rspecのfeature specがまともに動かないことで悩まされてきました。Chrome 74では謎のネットワークエラーが発生し、Chrome 75ではブラウザーがヘッドレスにならない、というものです。上記の設定により無事動くようになりました。
参考にしたのは、Rails 5.2のsystem testのソースコードです。
- https://github.com/rails/rails/blob/5-2-stable/actionpack/lib/action_dispatch/system_testing/driver.rb
- https://github.com/rails/rails/blob/5-2-stable/actionpack/lib/action_dispatch/system_testing/browser.rb
Rails 5.1.7と5.2以降 1 では、feature specではなく system spec を使うほうがよいと思いますが、なかなかRailsをバージョンアップできない環境もありますので。
これより前では、system testでCapybara 3が使えない。 ↩
- 投稿日:2019-07-19T12:48:48+09:00
Rails で MySQL インデックスヒントを使う (USE INDEX, IGNORE INDEX, FORCE INDEX)
MySQL を使った Rails で
Model.where(created_at: 1.yea.ago..1.day.ago).order(:id).lastなどとすると、MySQL の仕様で
created_atの INDEX ではなく、PRIMARYを使ってしまってものすごく遅くなることがあった。調べてみたところ、どうやら自分で拡張するしかないようなので書いたという話です。
Concern
ググると類似コードが出てきますが、違いは下記の通り
- カラム名で指定可能
- 複合インデックスも
[カラム名, カラム名]で指定可能- 普通にインデックス名もok
app/models/concerns/index_hint.rbmodule IndexHint extend ActiveSupport::Concern class_methods do def convert_to_index_name_in_case_of_column_name(*names) names.map { |idx| find_index_name_by_colomun_names(idx) || idx } end private def find_index_name_by_colomun_names(column_names) column_names = Array.wrap(column_names).map(&:to_s) name = connection.indexes(self.table_name).find { |index| index.columns == column_names }&.name connection.quote_column_name(name) if name end end included do scope :use_index, lambda { |*indexes| index_names = convert_to_index_name_in_case_of_column_name(*indexes) from("#{self.quoted_table_name} USE INDEX(#{index_names.join(', ')})") } scope :ignore_index, lambda { |*indexes| index_names = convert_to_index_name_in_case_of_column_name(*indexes) from("#{self.quoted_table_name} IGNORE INDEX(#{index_names.join(', ')})") } scope :force_index, lambda { |*indexes| index_names = convert_to_index_name_in_case_of_column_name(*indexes) from("#{self.quoted_table_name} FORCE INDEX(#{index_names.join(', ')})") } end endUse
ApplicationRecordレベルでincludeしてあげれば全てのモデルで使えますね。
モデル単体でincludeしてもokです。app/models/application_record.rbclass ApplicationRecord < ActiveRecord::Base include IndexHint ...実際に使うとこんな感じ
Model.use_index(:created_at).to_sql #=> "SELECT `models`.* FROM `models` USE INDEX(`index_models_on_created_at`)" Model.force_index([:section, :name]).to_sql #=> "SELECT `models`.* FROM `models` FORCE INDEX(`index_models_on_section_and_name`)" Model.ignore_index([:section, :name], :created_at).to_sql #=> "SELECT `models`.* FROM `models` IGNORE INDEX(`index_models_on_section_and_name`, `index_models_on_created_at`)"注意点
from,use_index,force_index,ignore_indexを組み合わせられない参考
- 投稿日:2019-07-19T12:38:44+09:00
Rails6 のちょい足しな新機能を試す56(create_table if_not_exists編)
はじめに
Rails 6 に追加されそうな新機能を試す第56段。 今回は、
create_table if_not_exists編です。
Rails 6 では、create_tableに:if_not_existsオプションが追加されました。Ruby 2.6.3, Rails 6.0.0.rc1 で確認しました。Rails 6.0.0.rc1 は
gem install rails --prereleaseでインストールできます。$ rails --version Rails 6.0.0.rc1マイグレーションファイルを作る
$ bin/rails g migration CreateUser nameマイグレーションファイルを修正する
:if_not_existsオプションを指定します。db/migrate/20190713221959_create_user.rbclass CreateUser < ActiveRecord::Migration[6.0] def change create_table :users, if_not_exists: true do |t| t.string :name end end endデータベースを作成する
データベースを作成します。
$ bin/rails db:createpsql でテーブルを作ります
先に users テーブルを psql で作成します。
ちょっと手抜きで id カラムは省略します。app_development=# create table users ( name varchar(256) ) CREATE TABLEテーブルができたことを確認しておきます。カラムの情報も確認します。
app_development=# \dt List of relations Schema | Name | Type | Owner --------+----------------------+-------+---------- public | ar_internal_metadata | table | postgres public | schema_migrations | table | postgres public | users | table | postgres (3 rows) app_development=# \d users; Table "public.users" Column | Type | Collation | Nullable | Default --------+------------------------+-----------+----------+--------- name | character varying(256) | | |マイグレーションを実行する
マイグレーションを実行します。エラーは発生しません。
$ bin/rails db:migrate == 20190713221959 CreateUser: migrating ======================================= -- create_table(:users, {:if_not_exists=>true}) -> 0.0019s == 20190713221959 CreateUser: migrated (0.0019s) ==============================psql で users テーブルを確認すると id カラムが無いので、マイグレーションによってテーブルはできなかったことがわかります。
app_development=# \d users; Table "public.users" Column | Type | Collation | Nullable | Default --------+------------------------+-----------+----------+--------- name | character varying(256) | | |ロールバックする
ロールバックしてみます。
$ bin/rails db:rollback == 20190713221959 CreateUser: reverting ======================================= -- drop_table(:users, {:if_not_exists=>true}) -> 0.0031s == 20190713221959 CreateUser: reverted (0.0043s) ==============================psql で確認すると users テーブルが削除されていることがわかります。
app_development=# \dt List of relations Schema | Name | Type | Owner --------+----------------------+-------+---------- public | ar_internal_metadata | table | postgres public | schema_migrations | table | postgres (2 rows)マイグレーションを実行する
users テーブルが無い状態でマイグレーションしてみます。
$ bin/rails db:migratepsql で確認するとテーブルが作られていることがわかります。
app_development=# \dt List of relations Schema | Name | Type | Owner --------+----------------------+-------+---------- public | ar_internal_metadata | table | postgres public | schema_migrations | table | postgres public | users | table | postgres (3 rows)カラムの情報を確認すると id カラムも存在しており、 migration によって作られたことがわかります。
app_development=# \d users; Table "public.users" Column | Type | Collation | Nullable | Default --------+-------------------+-----------+----------+----------------------------------- id | bigint | | not null | nextval('users_id_seq'::regclass) name | character varying | | | Indexes: "users_pkey" PRIMARY KEY, btree (id)テーブルを削除してからロールバックする
psql で users テーブルを削除します。
app_development=# drop table usersロールバックするとエラーが発生します。
$ bin/rails db:rollback == 20190713221959 CreateUser: reverting ======================================= -- drop_table(:users, {:if_not_exists=>true}) rails aborted! StandardError: An error has occurred, this and all later migrations canceled: PG::UndefinedTable: ERROR: table "users" does not existエラーを回避するには
エラーを回避するには、
db/migrate/20190713221959_create_user.rbclass CreateUser < ActiveRecord::Migration[6.0] def change create_table :users, if_not_exists: true, if_exists: true do |t| t.string :name end end endとするか
db/migrate/20190713221959_create_user.rbclass CreateUser < ActiveRecord::Migration[6.0] def up create_table :users, if_not_exists: true do |t| t.string :name end end def down drop_table :users, if_exists: true end endとすれば良いようです。後者の方が直感的でわかりやすいので、個人的にはオススメです。
(というか前者は訳わからんし、将来、 ActiveRecord の動作が変わったりすると痛い目に合いそうです。)試したソース
試したソースは以下にあります。
https://github.com/suketa/rails6_0_0rc1/tree/try056_create_table_if_not_exists参考情報
- 投稿日:2019-07-19T11:56:18+09:00
An error occurred while installing mysql2 (0.5.2), and Bundler cannot continue. Make sure that `gem install mysql2 -v '0.5.2' --source 'https://rubygems.org/'` succeeds before bundling.と出てきたときの対処法
最近の勉強で学んだ事を、ノート代わりにまとめていきます。
主に自分の学習の流れを振り返りで残す形なので色々、省いてます。
Webエンジニアの諸先輩方からアドバイスやご指摘を頂けたらありがたいです!どういうエラーなのか
railsのリポジトリをクローンしてきてちゃんと動くか確かめようとした時に発生しました!
やったことはbundle installをしたら最後に以下のような感じのものが出てきました//省略 An error occurred while installing mysql2 (0.5.2), and Bundler cannot continue. Make sure that `gem install mysql2 -v '0.5.2' --source 'https://rubygems.org/'` succeeds before bundling.エラーに対応策が書いていたので
gem install mysql2 -v '0.5.2' --source'https://rubygems.org/'そのまま入力したのですが解決されず
なんなんやこれはって思っていたら以下の記事を見つけました。恐らくほとんど一緒のエラー?
なのかと思うのですが記事に書いてあるとの解決策を試したところ問題解決しました。
mysql2 gemインストール時のトラブルシュート$ gem install mysql2 -v '0.5.2' --source 'https://rubygems.org/' -- --with-cppflags=-I/usr/local/opt/openssl/include --with-ldflags=-L/usr/local/opt/openssl/lib Building native extensions with: '--with-cppflags=-I/usr/local/opt/openssl/include --with-ldflags=-L/usr/local/opt/openssl/lib'このように入力したらやっと問題なくbundle installできました。
Railsではこのようなエラーに遭遇することが多いのですがなぜ、そもそもこのようなエラーが起きているのかの原因究明を参考にした記事のようにできていなかったので全てできるかは分からないですが徐々にしていきたいと思います。
- 投稿日:2019-07-19T10:32:58+09:00
Pay.jpを使用してクレジットカード登録削除機能の実装をしてみた
はじめに
軽く自己紹介から
TECH::EXPRETというプログラミングスクールに通っております。
53期で活動して、そろそろ終わりに近づいてきましたので、実装した部分くらいは
アウトプットするかーってことで、やります。
テストはやってないので、それ目的の方はごめんなさい。今回この記事を書く目的は3つほどあります。
1.チームメンバーに学んだ技術の共有の為
なんか作ったらわかりやすいかなーと思ってます
2.就活で学んだことをしっかりアウトプットできますよとアピールする為
話すよりも論理的に組み立てているか、全体像をみて考えているかをこういうところでみてもらう為
3.アウトプットを通して、今回学んだ内容をしっかり定着させる為
ぶっちゃけ忘れているところが多々あります笑 思い出すためにもしっかり書きます笑
開発環境
ruby 2.5.1
rails 5.2.1
mysqlゴール
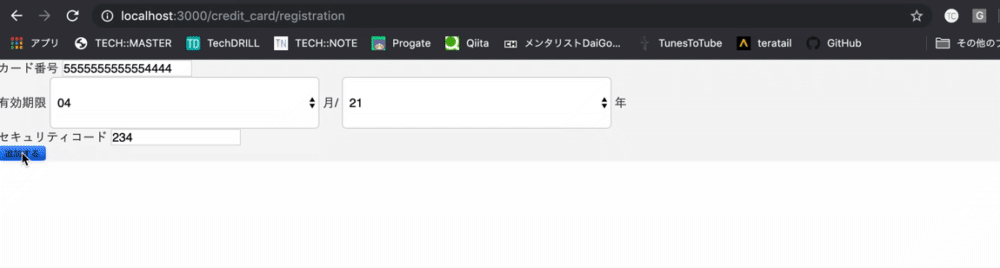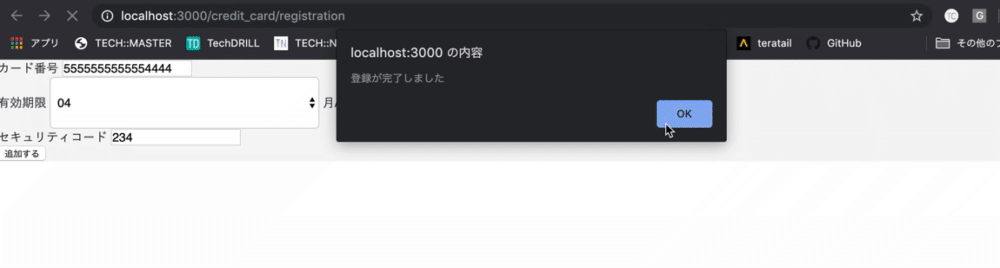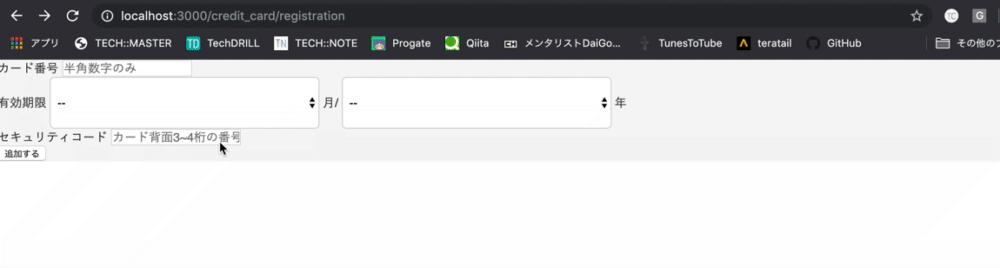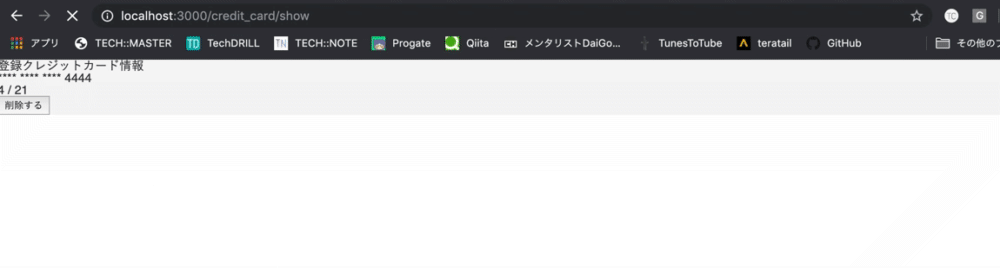
以下のように登録をrails5でできるようにしましょう
- 実際のビュー

- Sequel Pro の CreditCardの画面

- payjpの画面

前提準備
deviseでのユーザログイン機能の実装
処理の概要
1) pay.jpのgemをインストール
作業目的:Pay.jpを使用できるようにする為
Gemfilegem 'payjp'2) Pay.jpの公式のjavascriptを読み込ませられるようする
作業目的:Pay.jpの公式のjavascriptを読み込ませられるようする為
app/views/layouts/application.html.haml%script{src: "https://js.pay.jp/", type: "text/javascript"}3) クレジットカードテーブルを作成する
作業目的: クレジットカード情報を保存するテーブルを作成
Colun Type Options 意味 user_id references null: false, foreign_key: true ログインユーザ costomer_id integer null: false 顧客ID情報(pay.jpから返ってくるデータ) card_id integer null: false カードID情報(pay.jpから返ってくるデータ) costomer_id, card_idは、カード情報(16桁のやつ),有効期限年月,セキュリティーコードを渡すとpay.jpから返ってくるデータのこと
db/migrate/***************_create_credit_cards.rbclass CreateCreditCards < ActiveRecord::Migration[5.2] def change create_table :credit_cards do |t| t.references :user ,foreign_key: true, null: false t.string :customer_id, null: false t.string :card_id, null: false t.timestamps end end endなんで、DBにカード情報とか保存しないの?っと疑問に持たれる人もいると思いますので、ここで解説
以下のURLを参照していただければわかるのですが、
Pay.jp側の方で、
セキュリティーの観点から
クレジット情報は、勝手にDBに保存するな。俺が管理する。お前らにはIDやるから我慢しろ。っと言われているからなんですよねー
めんどいですが、クレジット情報や購入情報は毎回Pay.jpに問い合わせる必要があります。http://payjp-announce.hatenablog.com/entry/2017/11/10/182738
4) クレジットカード情報の追加と削除のコントローラを作っていきます
1つのget、3つのpostの実装
get
- edit
post
- create
payjpとCardのデータベース作成を実施します。- delete
payjpとCardのデータベースを削除する。- show
DBのCreditCard情報を、payjpに送りcustomer情報を取り出すために実装感想
まだ途中です。。。。。

- 投稿日:2019-07-19T04:00:24+09:00
Railsでメタプログラミング(黒魔術)と呼ばれるsendメソッドを活用してみた
はじめに
この記事を書こうと思ったのはsendメソッドを活用するイメージが湧かない方に、僕はRailsでこんな感じで使う場面がありましたよー的な意味で紹介するために書きました。
sendメソッドを使うのが最善かどうかは置いといて...笑メタプログラミングとは?
まずメタプログラミングの意味を軽く紹介します。
Railsチュートリアルではこのように説明されてます。メタプログラミングを一言で言うと「プログラムでプログラムを作成する」ことです。メタプログラミングはRubyが有するきわめて強力な機能であり、Railsの一見魔法のような機能 (「黒魔術」とも呼ばれます) の多くは、Rubyのメタプログラミングによって実現されています。
プログラムでプログラムを作成する?ちょっとこの説明だけ読んでもよくわからないですね笑
Railsチュートリアルでは実際にsendメソッドというものを利用してメタプログラムを作成していますのでそちらを見るとよりイメージが湧くかも。
※この後実際に例を用いて説明しますsendメソッドとは?
Rubyにはsendというメソッドがあります。
どのように使うか簡単な例で説明します。例えば、upcaseという文字列を大文字に変換して出力するメソッドを例に使います。
string = "ruby" #=> "ruby" string.upcase #=> "RUBY" string.send(:upcase) #=> "RUBY" string.send("upcase") #=> "RUBY"このようにsendメソッドの引数に呼び出したいメソッド名のシンボルか文字列を渡すと通常通りメソッドの呼び出しが起こります。
では次に引数を持つメソッドを呼び出したい時にどのようにするか、splitメソッド例を出しましょう。
Railsチュートリアルではここまでは説明されていませんが意外と簡単です。splitメソッドは文字列などを引数に渡した区切りで分割して配列にしてくれます。
string = "aaaaaxbbbbbxccccc" #=> "aaaaaxbbbbbxccccc" string.split("x") #=> ["aaaaa", "bbbbb", "ccccc"] string.send(:split, "x") #=> ["aaaaa", "bbbbb", "ccccc"] string.send("split", "x") #=> ["aaaaa", "bbbbb", "ccccc"]引数をメソッドに渡したい場合sendメソッドの第二引数以降に渡します。
Railsでsendメソッド活用
では本題に入ります。
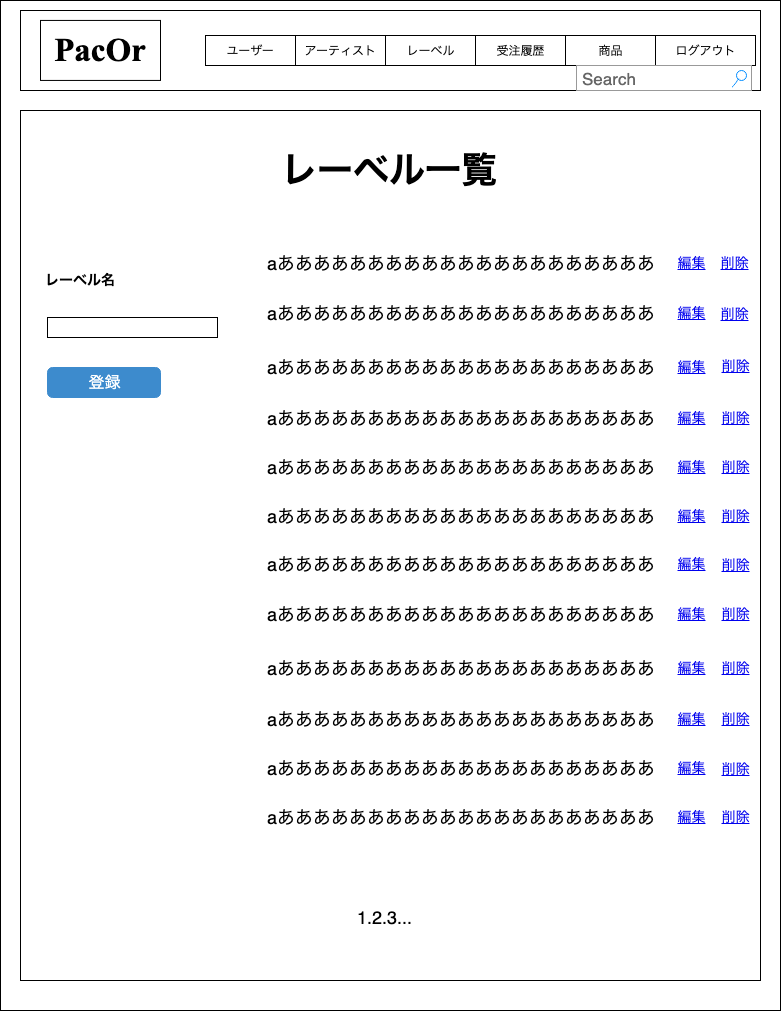
RailsでECサイトを作っていたのですが、3つのモデル(Artist, Label, Genre)のデータを一覧表示するviewがほぼ同じだったのでこれをパーシャル化してしまおうという場面で使いました。
どのようなレイアウトか一応簡単なモックアップを載せておきます。(かなり雑なのは気にしないでください笑)モックアップ
うん、これはもう表示するデータしかほぼ変わらないですね。これをパーシャル化せずに何をする?ということでパーシャル化しました。
コントローラ
app/controllers/artists_controller.rb# 中略 def index @artists = Artist.page(params[:page]) @artist = Artist.new end # 中略app/controllers/genres_controller.rb# 中略 def index @genres = Genre.page(params[:page]) @genre = Genre.new end # 中略app/controllers/labels_controller.rb# 中略 def index @labels = Label.page(params[:page]) @label = Label.new end # 中略ビュー
app/views/artists/index.html.erb<h2>アーティスト一覧</h2> <%= render 'layouts/object_list', objects: @artists, object: @artist %>app/views/genres/index.html.erb<h2>ジャンル一覧</h2> <%= render 'layouts/object_list', objects: @genres, object: @genre %>app/views/labels/index.html.erb<h2>レーベル一覧</h2> <%= render 'layouts/object_list', objects: @labels, object: @label %>app/views/layouts/_object_list.html.erb<div class="row"> <div class="col-sm-5"> <%= render 'layouts/error', object: object %> <%= form_with model: object, local: true do |f| %> <%= f.label :name %> <%= f.text_field :name %> <%= f.submit "登録" %> <% end %> </div> <div class="col-sm-7"> <div class="index-wrapper"> <% object_name = object.class.to_s.downcase # それぞれのオブジェクトのクラス名を変数に代入 %> <% objects.each do |data| %> <% edit_path = self.send("edit_#{object_name}_path", data) ### ここで使用!!### %> <% destroy_path = self.send("#{object_name}_path", data) ### ここで使用!!### %> <%= data.name %> <%= link_to "編集", edit_path %> <%= link_to "削除", destroy_path, method: :delete, data: { "confirm" => "本当に削除しますか?" } %> <% end %> </div> <%= paginate objects, class: "pagination" %> </div> </div>それぞれの
index.html.erbで書かれているパーシャルテンプレートの呼び出しは大丈夫だと思います。(わからない方はググってください)
_object_list.html.erbのコードで今回テーマのsendメソッドに関係するコードだけ説明していきます。解説
まずそれぞれ渡されたオブジェクトのクラス名(全部小文字)を変数に代入します。
何故かは後々わかります。<% object_name = object.class.to_s.downcase # それぞれのオブジェクトのクラス名を変数に代入 %>一つずつ説明すると、
.class→ 呼び出したオブジェクトのクラスを取得
.to_s→ 文字列に変換
.downcase→ 文字列を小文字に変換なのでまとめると
# 渡ってきた元のインスタンス変数 → object_nameに入る文字列 @artist → "artist" @genre → "genre" @label → "label"となります。
次に本題のsendメソッドのコード
<% edit_path = self.send("edit_#{object_name}_path", data) ### ここで使用!!### %> <% destroy_path = self.send("#{object_name}_path", data) ### ここで使用!!### %>ここでしたいことは、
edit_path,destroy_pathそれぞれにeachメソッドで取り出されるオブジェクト+パーシャルの呼び出しで渡ってきたオブジェクトの種類(artistかgenreかlabel)によって動的にパスを生成し、代入するということです。
つまり、呼び出すメソッドを動的に決めるということ。これがRubyのメタプログラムです。sendメソッドの実行結果は以下のようになります。
# artist edit_path = edit_artist_path(data) destroy_path = artist_path(data) # genre edit_path = edit_genre_path(data) destroy_path = genre_path(data) # label edit_path = edit_label_path(data) destroy_path = label_path(data)ここで、ん?
self.ってなに?てか、railsの~_pathってメソッドなの?メソッドって***.メソッドって感じで何かオブジェクトに対して呼び出すものじゃないの?
って思うかもしれません。特に他の言語(JavaScriptやPHPなど)をやったことがありrubyやrailsを始めたばかりの方なら~_pathは関数じゃないの?って思うかもしれませんが、メソッドです!!
というかRubyには関数がありません。この話をすると長くなってしまうので少し省略しますが、Rubyは全てがオブジェクトであり
~_pathもなんらかのオブジェクトのメソッドになるのです。そして自身のメソッド呼び出す際には
self.メソッドという感じで書きます。しかしこれはself.を省略できてメソッド名だけで呼び出すことが可能です。つまり、
~_pathは普段はself.が省略されていて、実際にはself.~_pathでも呼び出せます。じゃあsendメソッドを呼び出すときも
self.を省略できるのかと。
その通りです。上で紹介したコードはさらに短くこのようにできます。<% edit_path = send("edit_#{object_name}_path", data) ### ここで使用!!### %> <% destroy_path = send("#{object_name}_path", data) ### ここで使用!!### %>今回説明しやすいようにはじめは
self.をつけた状態にしておきましたが、これが短く書くとしたら完成系になります。まとめ
実際sendメソッドなんて使わなくてももっと簡単にできます。
prefix(~_path)を使わずに直接相対パスを書き、その相対パスに変数を入れ込めばそこまで難しいことではないでしょう。
しかし、ただただこの黒魔術と呼ばれるメソッドを使いたかったのです。笑
皆さんも遊び感覚であえて難しい実装方法を選んでみても面白いかもしれませんよ〜。
- 投稿日:2019-07-19T00:33:11+09:00
Rails radioボタンの選択肢を記憶させる
やりたいこと
Railsアプリで、何かしらのモデルの一覧ページに下記のような検索フォームを実装しました
ラジオボタンを選択後に検索を行いリダイレクトしたとき、ラジオボタンの選択肢がリセットされて困ったので、対処してみました。formのradioボタン
formのradio_buttonはこんな感じです。
index.html.erb<%= radio_button_tag(:state, "a") %> <%= label_tag(:state_a, "A") %> <%= radio_button_tag(:state, "b") %> <%= label_tag(:state_b, "B") %> <%= radio_button_tag(:state, "c") %> <%= label_tag(:state_c, "C") %> <%= radio_button_tag(:state, "d") %> <%= label_tag(:state_d, "D") %>controller
お次はコントローラ
何も選択されていないとき(params[:state]がnilのとき)は"全て"を選択するようにし、何かが選択されているときはその選択肢をクラスメソッドに代入しています。posts_controller.rbdef index @state = params[:state] # この書き方チョット気になる @posts = Post.where(state: @state) end一覧ページ下部に追記
最後、index.html.erbに「リダイレクト前にチェックされていたラジオボタンをチェックする」処理を書けばOKです。
下記はindex.html.erbの一番下に追記します。index.html.erb<script type="text/javascript"> state = "<%= @state %>"; $(`#${state}`).prop('checked', true); </script>これでバッチリ実装!
selectの場合
ちなみに、selectタグの場合はもっと実装が簡単なので、チラッと書いておきます。
index.html.erb<%= select_tag :state, options_for_select([["A"], ["B"], ["C"], ["C"]], :selected => @selected) %>posts_controller.rbdef index @posts = Post.where(state: params[:state]) params[:state].blank? ? @selected = "A" : @selected = params[:state] end
