- 投稿日:2019-07-19T23:41:02+09:00
RocketChatをCentOS(EC2)にInstallする Install編
前段
・私が所属する会社は無償版でSlackを使用している
・有償版に切り替えたい(個人的な考え・願望)
・但しSlackの利用方法や利用率から考えると有償版に切り替える具体的な説得材料に欠ける
・比較対象としてRocket.Chatが上がった作業前提
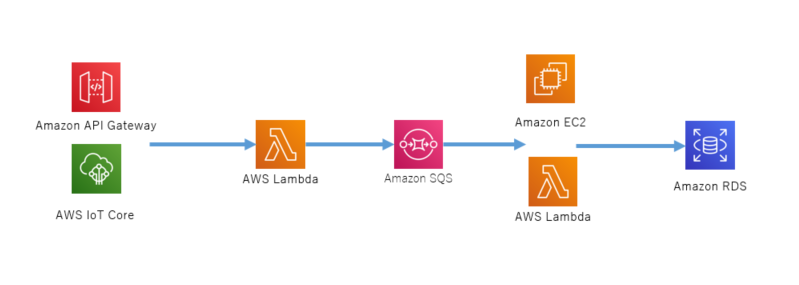
・AWS環境に作ります
・ドメインを保持してRoute53でホストゾーンを管理しています
・ほんとはコンテナでやりたかったんだけどガチャガチャ触れる自信なしなのでOSに直Install記載粒度
・VPCやEC2の作成にはあまりにも触れません
作業開始
インスタンス選定
Single core (2 GHz) 1 GB RAM 30 GB of SSD考えた結果:
・t3.micro(バースト無制限は無効化)
・これで足りなかったらあとでインスタンスタイプ変える
・作業用にEIPはつけておく
・サービスとして待ち受けるのはALB想定事前準備
sudo su - # パッケージ周りは最新に yum update -y # timeZoneは変えておく timedatectl set-timezone Asia/Tokyo # 検証だから一切悩まない sed -i "s/SELINUX=enforcing/SELINUX=disable/g" /etc/sysconfig/selinux rebootここからは基本的にcentosへのinstall手順に従って進めます。
sudo su - # mongoのrepoを追加する cat << EOF | sudo tee -a /etc/yum.repos.d/mongodb-org-4.0.repo [mongodb-org-4.0] name=MongoDB Repository baseurl=https://repo.mongodb.org/yum/redhat/7/mongodb-org/4.0/x86_64/ gpgcheck=1 enabled=1 gpgkey=https://www.mongodb.org/static/pgp/server-4.0.asc EOF # Node.jsのinstall準備ぽい curl -sL https://rpm.nodesource.com/setup_8.x | bash # コンパイラとmongoとNode.jsのinstall yum install -y gcc-c++ mongodb-org nodejs # epelのrepo追加とGraphicsMagickというものをinstallする yum install -y epel-release && sudo yum install -y GraphicsMagick # nodeのパケージマネージャ使ってinheritsとnというものを入れておるが全然わかんないな。 npm install -g inherits n && n 8.11.4RocketChat本体の投入
sudo su - # 多分install用であると思われるtargzの取得 curl -L https://releases.rocket.chat/latest/download -o /tmp/rocket.chat.tgz # /tmpに展開 tar -xzf /tmp/rocket.chat.tgz -C /tmp # ようやくinstall。ぎょうさんWARNIGが出るが見てないふり(ERRORじゃなきゃ焦らないしERRORでも諦めるから大丈夫) cd /tmp/bundle/programs/server && npm install # 多分Buildしたものをopt下に配置してるんだと思う mv /tmp/bundle /opt/Rocket.Chat # 実行ユーザの整理とかプロダクトのディレクトリの権限整理とか useradd -M rocketchat && usermod -L rocketchat chown -R rocketchat:rocketchat /opt/Rocket.Chat # 自動起動スクリプト配置 # ここ自分だと/usr/libの方に置くんだけど、こういうものなのかとか少し悩む cat << EOF | tee -a /lib/systemd/system/rocketchat.service [Unit] Description=The Rocket.Chat server After=network.target remote-fs.target nss-lookup.target nginx.target mongod.target [Service] ExecStart=/usr/local/bin/node /opt/Rocket.Chat/main.js StandardOutput=syslog StandardError=syslog SyslogIdentifier=rocketchat User=rocketchat Environment=MONGO_URL=mongodb://localhost:27017/rocketchat?replicaSet=rs01 MONGO_OPLOG_URL=mongodb://localhost:27017/local?replicaSet=rs01 ROOT_URL=http://localhost:3000/ PORT=3000 [Install] WantedBy=multi-user.target EOF # サービス全般設定 # 何番でmongoがlistenするかは知らないけど、多分DefaultPortなのだろう。 # ROOT_URLは直で受けないから、とりあえずそのままでもいいだろう。 # この辺はサービスあげてから再度見直し。 vi /usr/lib/systemd/system/rocketchat.service ==== MONGO_URL=mongodb://localhost:27017/rocketchat?replicaSet=rs01 MONGO_OPLOG_URL=mongodb://localhost:27017/local?replicaSet=rs01 ROOT_URL=http://your-host-name.com-as-accessed-from-internet:3000 PORT=3000 ==== # mongoの設定ぽいけど何かはわからん。いやなんとなくはわかるよ、なんとなくは。 sed -i "s/^# engine:/ engine: mmapv1/" /etc/mongod.conf sed -i "s/^#replication:/replication:\n replSetName: rs01/" /etc/mongod.confようやく起動
sudo su - # monogの自動起動有効化と起動 systemctl enable mongod && systemctl start mongod # 一応ポート確認 netstat -anp | grep mongo # まじでわからん。調べてもない。だから成長しない。 mongo --eval "printjson(rs.initiate())" # ようやく本体起動 systemctl enable rocketchat && systemctl start rocketchat netstat -anp | grep node繋いでみよう
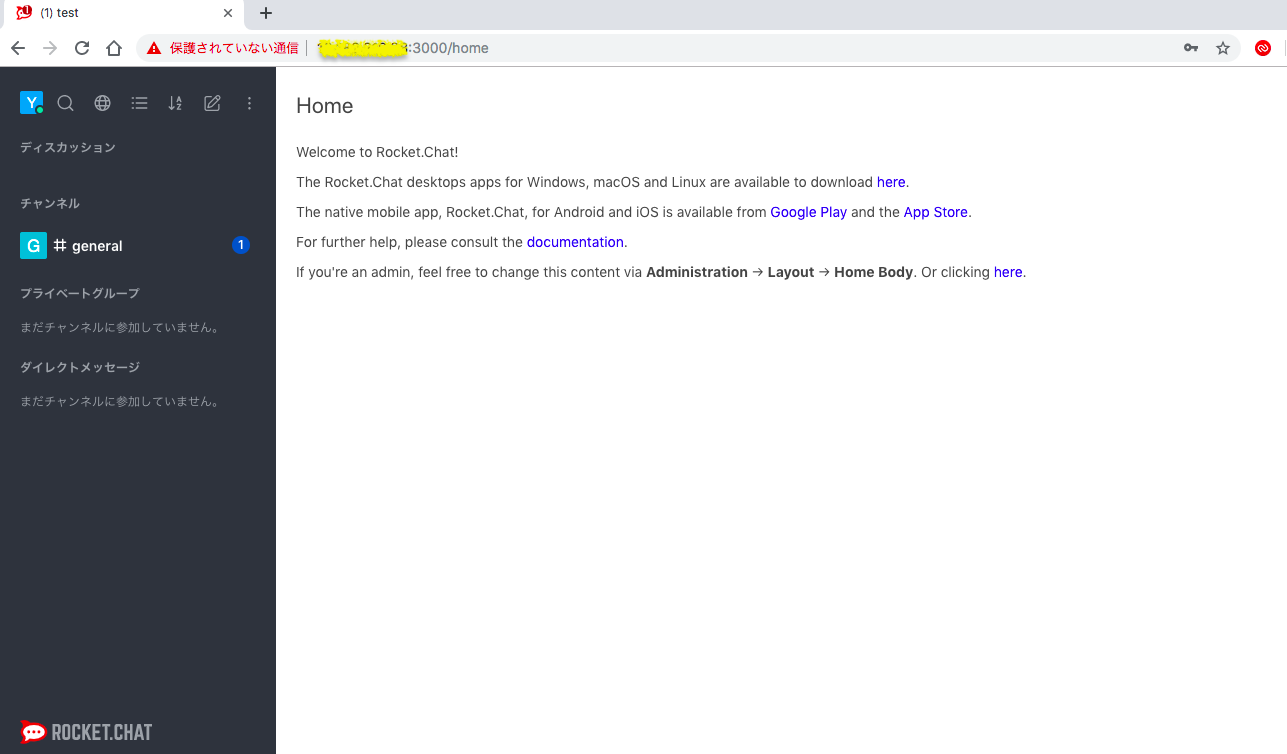
上がっている。
管理者情報をなどなどを入力。
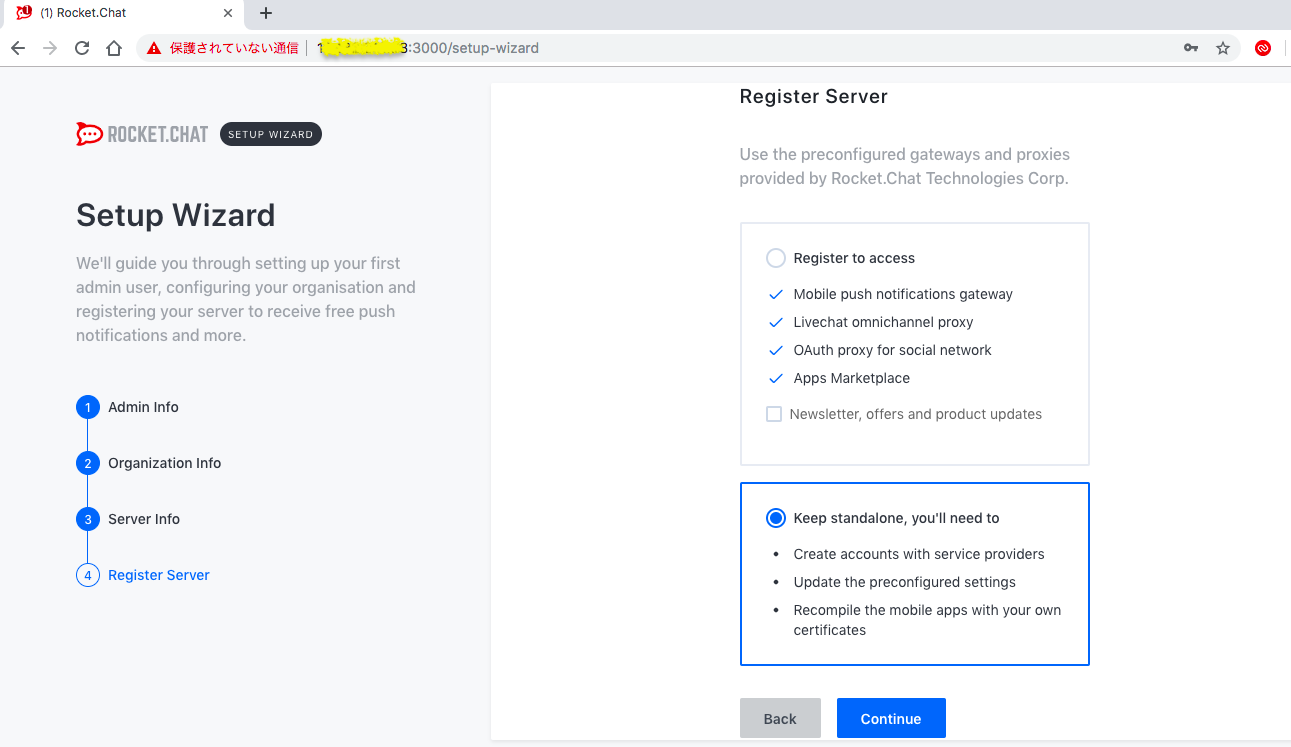
色々入力して、最後は「Keep Satndalone」を選択
表示
ALBへの組み込みとDNS登録とTLS化
・レジストラでNSをRoute53に向けている
・CertificateManagerでサーバ証明書を発行(DNS認証)
・ALBからTCP:3000を受けられうようにEC2のSGに穴あけ
・ALBを作成、ACMから証明書を選択、ターゲットグループのポートは3000
・ALBのDNS名をRoute53に登録(A/エイリアスレコードを選択)
・ちなみにずっとMyIP(自分のPCが外に出る時のIP)をSGで開けてここまで作業してます、今更ですが。TLS化できました!
気になること
サインアップ時のドメイン制限は?
・設定した記憶がない。
・どんなアドレスを使っても登録できてしまう気がする。
そもそもサインアップやパスワード忘れのメールはどこから飛ぶの?
・OutBound25Block外していない
・PostfixからSESへのRelayも何もしてないAnyで開けなきゃだよね、そこの対策は?
・Cognitoを挟む?ユーザビリティ落ちる?
・AWS WAFを手前におく?といった気になるところを次回に解消していこうと思います。
- 投稿日:2019-07-19T21:24:09+09:00
GA記念!AWSCDK for TypeScriptで色んなサービスをデプロイする
はじめに
皆様はAWSのサービスをデプロイするのをどうされていますか?
コンソール画面からGUIで操作して…
AWS-CLIで利用して…
CloudFormationのテンプレートファイルを書いて…
TerraformやServerlessFrameworkなどの構成管理ツールを使って…
などの方法があると思います。
デプロイするサービスが多くなればなるほど、構成管理ツールを用いたほうが管理コストがかからなくなるので良いですよね。
どのサービスをどれだけ、どのサービスと紐づけているのかをソースコードベースで確認することができます。
また不必要なサービスを減らすことができるのも利点の一つかと思います。AWSCDKとは?
AWSCDK(Cloud Development Kit)はCloudForamationのテンプレートファイルを、TypeScriptやJavaScript、Javaなどで書くことができるフレームワークです。
CloudForamationのテンプレートファイルはJSONまたはYAMLで書く必要があり、馴染みのないエンジニアにとっては学習コストが高く感じることがあると思います。
AWS-CDKではtsファイルやjsファイルをビルドするとCloudFormationのYAMLファイルが生成されます。以前、AWS-CDK for TypeScriptで色んなサービスをデプロイするという記事を書いたのですが、先日ついにGAとなりバージョン
1.0.0がリリースされました
だいぶ書き方がスッキリしたので、現在の書き方を紹介していこうと思います。
前提条件
- Node.js >= 8.11.x
- TypeScript => 2.7
- AWSのCredentailの設定(参考)(AWS-CLIの初期設定ができていたらOK)
インストール
$ npm i -g aws-cdk $ cdk --version 0.24.1 (build 67fcf6d)初期設定
$ mkdir hello-cdk $ cd hello-cdk $ cdk init app --language=typescriptコマンド
// デプロイ $ cdk deploy // スタックを指定してデプロイ $ cdk deploy ${StackName} // CloudFormationのテンプレートファイル生成 $ cdk synth // 差分を確認 $ cdk diff基礎知識
CDKの単位は App / Stack / Construct に分かれています。
- App
- 実行可能なプログラム
- CloudFormation(以下CFn)テンプレートに生成とデプロイに利用
- Stack
- デプロイ可能な単位
- リージョンとアカウントを保持
- Construct
- AWSリソースを表現
- 階層的なツリー構造を構成可能
雛形を用意したときに
./bin/cdk-app.tsが用意されています。このcdk-app.ts自体がAppとなります。
cdk-app.tsでインスタンスを生成しているHelloCdkStackというClassがStackにあたります。cdk-app.ts#!/usr/bin/env node import "source-map-support/register" import cdk = require("@aws-cdk/core") import { HelloCdkStack } from "../lib/stacks/hello-cdk-stack" const app: cdk.App = new cdk.App() new HelloCdkStack(app, "HelloCdkStack") // Stack app.synth()
hello-cdk-stack.tsでインスタンスを生成しているs3.BucketがConstructにあたります。
このConstructは各サービスごとにClassが用意されています。hello-cdk-stack.tsimport core = require('@aws-cdk/core'); import s3 = require('@aws-cdk/aws-s3'); export class HelloCdkStack extends core.Stack { constructor(scope: core.App, id: string, props?: core.StackProps) { super(scope, id, props); // Construct new s3.Bucket(this, 'MyFirstBucket', { versioned: true }); } }こういった感じで、Stackの中にConstructを用意していき、その単位でCFnにスタックを作成しデプロイしていくという流れになります。
今回デプロイするパターン
- S3
- APIGateway + Lambda
- IoTCore + DynamoDB
- AppSync + DynamoDB
S3
S3バケットを作成する
Install Package
$ npm i @aws-cdk/aws-s3SourceCode
import cdk = require("@aws-cdk/cdk") import { Bucket } from "@aws-cdk/aws-s3" export class CdkStack extends cdk.Stack { constructor(scope: cdk.App, id: string, props?: cdk.StackProps) { super(scope, id, props); // Create S3 Bucket new Bucket(this, id, { bucketName: "bucketName" }) } }
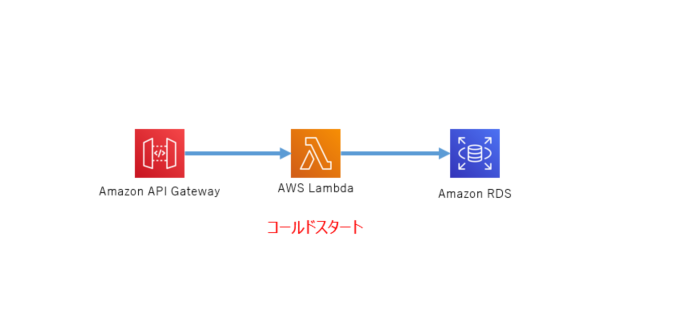
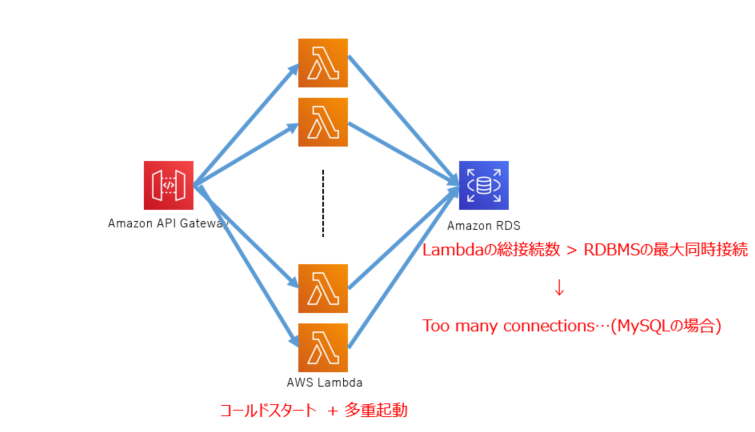
APIGateway + Lambda
APIGatewayとLambdaを作成して、RESTAPIのインターフェースをデプロイする
Install Package
$ npm i @aws-cdk/aws-lambda @aws-cdk/aws-apigatewaySourceCode
import cdk = require("@aws-cdk/core") import { Function, Runtime, Code } from "@aws-cdk/aws-lambda" import { RestApi, Integration, LambdaIntegration, Resource, MockIntegration, PassthroughBehavior, EmptyModel } from "@aws-cdk/aws-apigateway" export class QiitaAPILambda extends cdk.Stack { constructor(scope: cdk.App, id: string, props?: cdk.StackProps) { super(scope, id, props) // Lambda Function 作成 const lambdaFunction: Function = new Function(this, "qiita_demo", { functionName: "qiita_demo", // 関数名 runtime: Runtime.NODEJS_10_X, // ランタイムの指定 code: Code.asset("lambdaSoruces/demo_function"), // ソースコードのディレクトリ handler: "index.handler", // handler の指定 memorySize: 256, // メモリーの指定 timeout: cdk.Duration.seconds(10), // タイムアウト時間 environment: {} // 環境変数 }) // API Gateway 作成 const restApi: RestApi = new RestApi(this, "QiitaDemoAPI", { restApiName: "QiitaDemoAPI", // API名 description: "Deployed by CDK" // 説明 }) // Integration 作成 const integration: Integration = new LambdaIntegration(lambdaFunction) // リソースの作成 const getResouse: Resource = restApi.root.addResource("get") // メソッドの作成 getResouse.addMethod("GET", integration) // CORS対策でOPTIONSメソッドを作成 getResouse.addMethod("OPTIONS", new MockIntegration({ integrationResponses: [{ statusCode: "200", responseParameters: { "method.response.header.Access-Control-Allow-Headers": "'Content-Type,X-Amz-Date,Authorization,X-Api-Key,X-Amz-Security-Token,X-Amz-User-Agent'", "method.response.header.Access-Control-Allow-Origin": "'*'", "method.response.header.Access-Control-Allow-Credentials": "'false'", "method.response.header.Access-Control-Allow-Methods": "'OPTIONS,GET,PUT,POST,DELETE'", } }], passthroughBehavior: PassthroughBehavior.NEVER, requestTemplates: { "application/json": "{\"statusCode\": 200}" } }), { methodResponses: [{ statusCode: "200", responseParameters: { "method.response.header.Access-Control-Allow-Headers": true, "method.response.header.Access-Control-Allow-Origin": true, "method.response.header.Access-Control-Allow-Credentials": true, "method.response.header.Access-Control-Allow-Methods": true, }, responseModels: { "application/json": new EmptyModel() }, }] }) } }
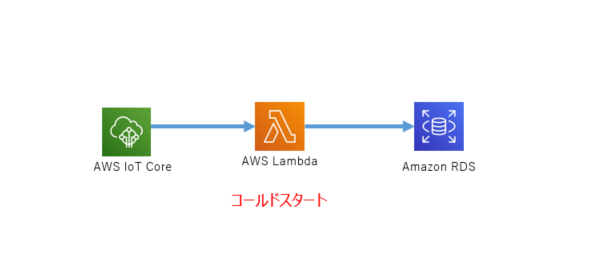
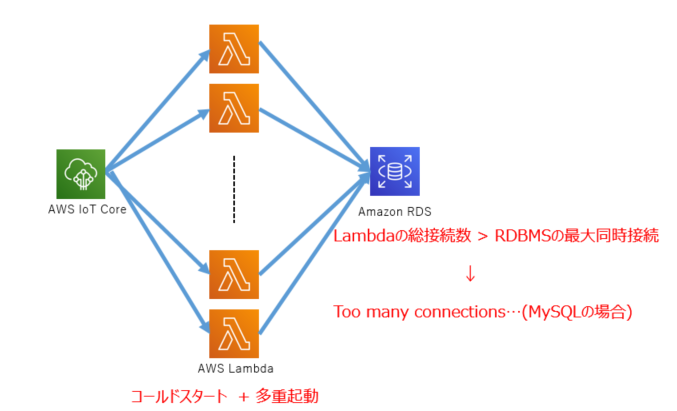
IoTCore + DynamoDB(v2)
IoTCoreのRuleとDynamoDBを作成して、DynamoDBv2の方法でデータをPutするインターフェースをデプロイする
Install Package
$ npm i @aws-cdk/aws-dynamodb @aws-cdk/aws-iot @aws-cdk/aws-iamSourceCode
import cdk = require("@aws-cdk/core") import { Table, TableProps, AttributeType } from "@aws-cdk/aws-dynamodb" import { Role, PolicyStatement, Effect, ServicePrincipal } from "@aws-cdk/aws-iam" import { CfnTopicRule } from "@aws-cdk/aws-iot" export class CdkIoTDynamo extends cdk.Stack { constructor(scope: cdk.App, id: string, props?: cdk.StackProps) { super(scope, id, props) const tableNameValue: string = "CdkIoTDemoTable" const tableParam: TableProps = { tableName: tableNameValue, partitionKey: { name: "id", type: AttributeType.STRING } } // Create DynamoDB Table const table: Table = new Table(this, tableNameValue, tableParam) const roleActions: string[] = ["dynamodb:PutItem"] const roleResorces: string[] = [table.tableArn] // Create RoleStatement const roleStatement: PolicyStatement = new PolicyStatement({ actions: roleActions, resources: roleResorces }) roleStatement.effect = Effect.ALLOW // Create IoTCore ServiceRole const iotServiceRole: Role = new Role(this, "CdkIoTServiceRole", { assumedBy: new ServicePrincipal("iot.amazonaws.com") }) iotServiceRole.addToPolicy(roleStatement) // sql for topic rule const sqlBody: string = "SELECT * FROM 'CdkIoTDemo/#'" // Create TopicRule DynamoDBv2 new CfnTopicRule(this, "CDKIoTDynamoRule", { ruleName: "CDKIoTDynamoRule", topicRulePayload: { actions: [{ dynamoDBv2: { putItem: { tableName: tableNameValue }, roleArn: iotServiceRole.roleArn } }], ruleDisabled: false, sql: sqlBody } }) } }
AppSync + DynamoDB
AppSyncとDynamoDBを作成して、GraphQLでテーブルのデータを取得したり、データを書き込んだりするインターフェースをデプロイする
Install Package
$ npm i @aws-cdk/aws-dynamodb @aws-cdk/aws-iot @aws-cdk/aws-iamSourceCode
import cdk = require("@aws-cdk/core") import { Table, TableProps, AttributeType } from "@aws-cdk/aws-dynamodb" import { Role, ManagedPolicy, ServicePrincipal } from "@aws-cdk/aws-iam" import { CfnGraphQLApi, CfnDataSource, CfnGraphQLSchema, CfnResolver, CfnApiKey } from "@aws-cdk/aws-appsync" export class CdkAppSync extends cdk.Stack { constructor(scope: cdk.App, id: string, props?: cdk.StackProps) { super(scope, id, props) const tableNameValue: string = "CDKAppSyncTable" const tableParam: TableProps = { tableName: tableNameValue, partitionKey: { name: "id", type: AttributeType.STRING }, readCapacity: 2, writeCapacity: 2 } // Create DynamoDB Table new Table(this, tableNameValue, tableParam) const tableRole: Role = new Role(this, "CdkAppSyncServiceRole", { assumedBy: new ServicePrincipal("appsync.amazonaws.com") }) tableRole.addManagedPolicy(ManagedPolicy.fromAwsManagedPolicyName("AmazonDynamoDBFullAccess")) // Create GraphQL API const graphqlAPI: CfnGraphQLApi = new CfnGraphQLApi(this, "CDKAppSyncAPI", { authenticationType: "API_KEY", name: "CDKAppSyncAPI" }) // Create API Key new CfnApiKey(this, "CreateAPIKey", { apiId: graphqlAPI.attrApiId }) const definitionString: string = ` type ${tableNameValue} { id: ID!, name: String } type Paginated${tableNameValue} { items: [${tableNameValue}!]! nextToken: String } type Query { all(limit: Int, nextToken: String): Paginated${tableNameValue}! getOne(id: ID!): ${tableNameValue} } type Mutation { save(name: String!): ${tableNameValue} delete(id: ID!): ${tableNameValue} } type Schema { query: Query mutation: Mutation } ` // Create Schema const apiSchema: CfnGraphQLSchema = new CfnGraphQLSchema(this, "CDKGraphQLSchema", { apiId: graphqlAPI.attrApiId, definition: definitionString }) // Create DataSource const dataSource: CfnDataSource = new CfnDataSource(this, "CDKDataSourse", { apiId: graphqlAPI.attrApiId, name: tableNameValue, type: "AMAZON_DYNAMODB", dynamoDbConfig: { awsRegion: this.region, tableName: tableNameValue }, serviceRoleArn: tableRole.roleArn }) const getOneResolverMappingTemplate: string = ` { "version": "2017-02-28", "operation": "GetItem", "key": { "id": $util.dynamodb.toDynamoDBJson($ctx.args.id) } } ` // Create Get Resolver const getOneResolver: CfnResolver = new CfnResolver(this, "GetOneQueryResolver", { apiId: graphqlAPI.attrApiId, typeName: "Query", fieldName: "getOne", dataSourceName: dataSource.name, requestMappingTemplate: getOneResolverMappingTemplate, responseMappingTemplate: `$util.toJson($ctx.result)` }) getOneResolver.addDependsOn(apiSchema) getOneResolver.addDependsOn(dataSource) const getAllResolverMappingTemplate: string = ` { "version": "2017-02-28", "operation": "Scan", "limit": $util.defaultIfNull($ctx.args.limit, 20), "nextToken": $util.toJson($util.defaultIfNullOrEmpty($ctx.args.nextToken, null)) } ` // Create Scan Resolver const getAllResolver: CfnResolver = new CfnResolver(this, "GetAllQueryResolver", { apiId: graphqlAPI.attrApiId, typeName: "Query", fieldName: "all", dataSourceName: dataSource.name, requestMappingTemplate: getAllResolverMappingTemplate, responseMappingTemplate: `$util.toJson($ctx.result)` }) getAllResolver.addDependsOn(apiSchema) getAllResolver.addDependsOn(dataSource) const saveResolverMappingTemplate: string = ` { "version": "2017-02-28", "operation": "PutItem", "key": { "id": { "S": "$util.autoId()" } }, "attributeValues": { "name": $util.dynamodb.toDynamoDBJson($ctx.args.name) } } ` // Create Put Resolver const saveResolver: CfnResolver = new CfnResolver(this, "SaveMutationResolver", { apiId: graphqlAPI.attrApiId, typeName: "Mutation", fieldName: "save", dataSourceName: dataSource.name, requestMappingTemplate: saveResolverMappingTemplate, responseMappingTemplate: `$util.toJson($ctx.result)` }) saveResolver.addDependsOn(apiSchema) saveResolver.addDependsOn(dataSource) const deleteResolverMappingTemplate: string = ` { "version": "2017-02-28", "operation": "DeleteItem", "key": { "id": $util.dynamodb.toDynamoDBJson($ctx.args.id) } } ` // Create Delete Resolver const deleteResolver: CfnResolver = new CfnResolver(this, "DeleteMutationResolver", { apiId: graphqlAPI.attrApiId, typeName: "Mutation", fieldName: "delete", dataSourceName: dataSource.name, requestMappingTemplate: deleteResolverMappingTemplate, responseMappingTemplate: `$util.toJson($ctx.result)` }) deleteResolver.addDependsOn(apiSchema) deleteResolver.addDependsOn(dataSource) } }
さいごに
GAになる前から注目していたので、実際にCDKを使って色々なサービスをデプロイしています。
やっぱり慣れている言語(ここではTypeScript)でCFnのテンプレートを書くことができるのは最高です!
GAになる前は、かなり激しいアップデートが繰り返されていましたが、GAになったことでそういったことも落ち着くはずです。
この機会にみなさんもCDK使ってみてはいかがでしょうか?
ではまた!!!
- 投稿日:2019-07-19T20:24:30+09:00
pythonで定時実行するAWS Lambda処理を作った
はじめに
相変わらず競馬関係のプログラムを書いています。
これまではHeroku上で開発していたのですが、仕事でAWSを使っていることもあり、個人開発でもAWSを使い始めました。Herokuだと毎日決まった時間に動作する処理を書く場合、Heroku Schedulerを使う形になりますが、AWSだとLambdaをCloudWatchイベントでキックする形…とはいうもののひとまとめになっている情報が見当たらなかったので、やってみたことを残しておきたいと思います。
※2019年7月時点の情報です。AWSはサービス改善のスピードが速すぎてWebにまとめた情報があっという間に陳腐化するので、そこはご注意を…
AWS SAMのテンプレート
AWS SAMを使ってみたのですが、元になるテンプレートを作成するためにsam initコマンドを使うとAPIゲートウェイからキックされる処理のテンプレートになります。
定時実行する処理用のテンプレートは…ということで調べたところ、以下にありました。
CloudWatch イベント アプリケーションの AWS SAM テンプレートだけど、これは定時実行ではなくて定期実行、かつ今回必要ないようなリソースも使っていたりだったので、定期実行する最低限のテンプレートを作りました。
template.yamlAWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: > notify_hitokuchi Sample SAM Template for notify_hitokuchi Globals: Function: Timeout: 10 Resources: NotifyHitokuchiFunction: Type: AWS::Serverless::Function Properties: CodeUri: notify_hitokuchi/ Handler: app.lambda_handler Runtime: python3.7 Events: NotifyHitokuchi: Type: Schedule Properties: Schedule: cron(30 12 * * ? *)一番下の行のScheduleの行が定時実行する時刻の指定。式の記述方法は以下を参照。
ルールのスケジュール式ハンドラでもらえるイベント情報の時刻
先程のテンプレートだと、notify_hitokuchi/app.py内のlambda_handler関数が実行時に呼び出される関数になります。
app.pydef lambda_handler(event, context):eventには辞書形式でイベント情報が入ってきます。
今回はCloudWatchイベントでキックされた時刻が欲しかったのですが、実行時刻はevent['time']にISO 8601形式で入ってきます。
それをそのまま「datetime.fromisoformat()」関数に渡せばdatetimeが入手できる…と思いきや、「2019-07-10T12:30:00Z」という形だと「datetime.fromisoformat()」は処理できないようでして…
以下のようなコードでdatetimeを入手しました。# event['time']に'2019-07-10T12:30:00Z'形式の文字列が入ってくる datetime_str = event['time'].replace('Z', '+00:00') # '2019-07-10T12:30:00+00:00'形式だとfromisoformatで処理できる datetime_utc = datetime.fromisoformat(date_str)pip等でインストールしたライブラリ
pip等でインストールしたライブラリをAWS Lambdaで使う場合、ライブラリを1箇所にまとめてZIPで固めて…という話をよく見かけますが、samを使っている分にはsam buildで済むようです。
$ sam build 2019-07-19 07:42:34 Building resource 'NotifyHitokuchiFunction' 2019-07-19 07:42:34 Running PythonPipBuilder:ResolveDependencies 2019-07-19 07:42:44 Running PythonPipBuilder:CopySource Build Succeeded Built Artifacts : .aws-sam/build Built Template : .aws-sam/build/template.yaml Commands you can use next ========================= [*] Invoke Function: sam local invoke [*] Package: sam package --s3-bucket <yourbucket>↓↓↓2019-07-20追記↓↓↓
sam buildの前にrequirements.txtをCodeUriで指定したパスに設置が必要です。
自分はpipenvを使っているので、以下でrequirements.txtを生成しました。$ $ pipenv lock -r > notify_hitokuchi/requirements.txt $ cat notify_hitokuchi/requirements.txt -i https://pypi.org/simple beautifulsoup4==4.7.1 bs4==0.0.1 certifi==2019.6.16 chardet==3.0.4 decorator==4.4.0 html5lib==1.0.1 idna==2.8 mojimoji==0.0.9.post0 py==1.8.0 python-dotenv==0.10.3 requests==2.22.0 retry==0.9.2 six==1.12.0 soupsieve==1.9.2 urllib3==1.25.3 webencodings==0.5.1また、上記requirements.txtに記載のあるmojimojiのようにC/C++で作られているライブラリは動作環境でコンパイルする必要がありますが、sam buildに--use-containerオプションを付けることでdockerコンテナ上でビルドが行われ、Lambda上で動くライブラリを作ることができます。素晴らしい!
$ sam build --use-container 2019-07-20 09:43:51 Starting Build inside a container 2019-07-20 09:43:51 Building resource 'NotifyHitokuchiFunction' Fetching lambci/lambda:build-python3.7 Docker container image...... 2019-07-20 09:43:55 Mounting /Users/masaminh/develop/notify_hitokuchi_aws/notify_hitokuchi as /tmp/samcli/source:ro,delegated inside runtime container Build Succeeded Built Artifacts : .aws-sam/build Built Template : .aws-sam/build/template.yaml Commands you can use next ========================= [*] Invoke Function: sam local invoke [*] Package: sam package --s3-bucket <yourbucket> Running PythonPipBuilder:ResolveDependencies Running PythonPipBuilder:CopySource↑↑↑2019-07-20追記↑↑↑
ローカルでの動作確認
まずハンドラに渡されるイベント情報を作っておく必要がありますが、その元はsam local generate-eventを使って取得できます。
今回はCloudWatchのイベントですが、以下で作成しました。$ sam local generate-event cloudwatch scheduled-event > event.json $ cat event.json { "id": "cdc73f9d-aea9-11e3-9d5a-835b769c0d9c", "detail-type": "Scheduled Event", "source": "aws.events", "account": "", "time": "1970-01-01T00:00:00Z", "region": "us-east-1", "resources": [ "arn:aws:events:us-east-1:123456789012:rule/ExampleRule" ], "detail": {} }実際にローカルで動作確認を行う際には、
$ sam local invoke -e event.json NotifyHitokuchiFunction 2019-07-19 08:03:10 Invoking app.lambda_handler (python3.7) 2019-07-19 08:03:10 Found credentials in shared credentials file: ~/.aws/credentials Fetching lambci/lambda:python3.7 Docker container image......という感じで呼び出すことができます。Dockerコンテナ上で動くので起動するのに少し時間がかかります。
デプロイ
まずパッケージを作成。
$ sam package --s3-bucket バケット名 --output-template-file package.yaml Successfully packaged artifacts and wrote output template to file package.yaml. Execute the following command to deploy the packaged template aws cloudformation deploy --template-file /Users/masaminh/develop/notify_hitokuchi_aws/package.yaml --stack-name <YOUR STACK NAME>引き続き、メッセージに従ってデプロイ...
$ aws cloudformation deploy --template-file package.yaml --stack-name notify-hitokuchi Waiting for changeset to be created.. Failed to create the changeset: Waiter ChangeSetCreateComplete failed: Waiter encountered a terminal failure state Status: FAILED. Reason: Requires capabilities : [CAPABILITY_IAM]メッセージのままだと上記のように怒られるので、capabilitiesにCAPABILITY_IAMを設定します。
$ aws cloudformation deploy --template-file package.yaml --stack-name notify-hitokuchi --capabilities CAPABILITY_IAM Waiting for changeset to be created.. Waiting for stack create/update to complete Successfully created/updated stack - notify-hitokuchiデプロイできました。
ログ出しに関して
app.pyimport logging logger = logging.getLogger() logger.setLevel(logging.INFO) def lambda_handler(event, context): logger.info('start: event.time=%s', event['time'])こんな感じで普通にloggerから出力すれば、CloudWatchで見られます。
[INFO] 2019-07-18T12:30:28.336Z 51865e95-cacd-4f9d-80e9-6e1f148357b9 start: event.time=2019-07-18T12:30:00Zおわりに
今回は競馬的なことは書かずにノウハウ的なところのみでした。(Lambda関数名からして競馬系の処理だなぁという感じではありますが・笑)
引き続き競馬系の個人開発はやってますので、またそのうち競馬開発系の記事を書きたいな〜と思います(笑)
- 投稿日:2019-07-19T19:57:32+09:00
ユーザー追加したあとSSHで接続できない人へ
ご存知の方が多いかと思いますが、こちらの解決策はすでに公式に解凍がございます。
AWS公式リンクAWSのSSHは癖が強い!単にわたしの技術不足なのだけど。
ユーザ接続しようとすると
Permission denied (publickey,gssapi-keyex,gssapi-with-mic)解決方法
- SSHでec2インスタンスに接続
- cloud-initをインストール
sudo yum install cloud-init3. インスタンスを停止
4. キーベアからパブリックキーを取得ssh-keygen -y -f /path_to_key_pair/my-key-pair.pem5. ユーザデータの表示変更に次のスクリプトを貼り付ける。usernameとssh-rsaはご自分のものを入力してください。
cloud_final_modules: - [users-groups,always] users: - name: username groups: [ wheel ] sudo: [ "ALL=(ALL) NOPASSWD:ALL" ] shell: /bin/bash ssh-authorized-keys: - ssh-rsa AB3nzExample詳しくはAWS公式サイトをご確認ください。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/ec2-user-account-cloud-init-user-data/
- 投稿日:2019-07-19T19:41:33+09:00
EC2をflexibleにrebootされる前に手動で実行してみる
はじめに
タイトル通りの通知がヘルスイベントから来たので対応します。
ただし対象のEC2は本番稼働中でして、そーゆー時(運用の観点)は何するの?でしたので調べました。
いくらぼくでも再起動の手順くらいわかるw
が、サービスインしてるコンテナでもないインスタンスの再起動ってどうやるの?って聞かれると意外と答えられず。。むむむ作業環境
EC2(コンテナとかオーケストレーションとかしてない直立てのインスタンス)
mac作業開始
1.ググる
古来からの伝統に則りググります。よきサイトが見つかりました、めっちゃわかりやすい。
4年前なので情報が現在と結構変わってますので脳内で読み替え。
https://sole-color-blog.com/blog/428/システムリブートとインスタンスリブートで結構変わるんですね。
今回は通知内容からインスタンスリブート(のように読める)なので、基盤レイヤー側で再起動した場合に確認すべきこと・しておきたいことは省く。というかまず公式ドキュメントを読むべきだった。。のでこちらも目を通します。
※先のサイトのリンクから飛びましたhttps://aws.amazon.com/jp/maintenance-help/
スケジューリングされたインスタンスの再起動をどう変更するのかとか、その前に手動でやっちゃってもいいよとかの具体的な手順が書いてますね。
その中でキーワードではないですがポイントになりそうな1文を発見。DNS 名や IP アドレスといったユーザー設定は変わらず、ローカルインスタンスストアのデータにも影響はありません。
ということは再起動前後でユーザー設定が変わってないことを確認できればいい気がします。
02.検証作業
ブログと公式ドキュメントどちらにも書かれていますが、以下の項目をクリアできればOKですね。
1.パブリックDNS名が変更されていないか 2.プライベートIP(ついでにEIP)が変更されていないか 3.インスタンスストアに格納されたすべてのデータが保持されているか。消えていないか。 4.加えてsshできるかもリブート後にテストインスタンスストアだけやり方がわからないので調査。
リブートではデータはすべて保持されるとのこと。
蛇足ですが停止&終了では削除されるらしいので、覚えておこうと思います。http://tmnj.hatenablog.com/entry/2016/11/26/155804
ここでちょっとハマる。インスタンスストアの概要は理解したのですが、具体的な手順は?何をどうするのかがわからない。
頭から煙が出てきてちょっと嫌になりましたがw、以下に記載がありました。
やっぱり公式ドキュメントですよね()!https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/add-instance-store-volumes.html
df -hコマンドとlsblkでマウント状況を確認するようです。
コマンドの意味は以下の通り。$ df -h
ファイルの空き容量を集計する。-hオプションは人間に読みやすくするHumanとのこと。
確かに読みやすいwhttps://www.atmarkit.co.jp/ait/articles/1610/24/news017.html
$ lsblk
現在利用できるブロックデバイスを一覧表示する。今回は特にオプションつけずこのままで。https://www.atmarkit.co.jp/ait/articles/1802/02/news021.html
お、先ほど列挙した条件、これで具体的な手順できそう!
1.パブリックDNS名が変更されていないか →作業前後にRoute53で目視確認 ※ここコマンド化できる? 2.プライベートIP(ついでにEIP)が変更されていないか →作業前後にコンソールで目視確認 ※ここコマンド化できる? 3.インスタンスストアに格納されたすべてのデータが保持されているか。消えていないか。 $ df -h $ lsblk 4.加えてsshできるかもリブート後にテストします $ ssh ホスト名 ※この手順は3.の前に行うOSSでもSaasでもいいんですが、何かしらのサービス入れてるならリブート前後にサービスを止める必要があると思います。
もしくは自動起動にしとくとか。おわりに
めっちゃ作業途中ですが今回は一旦ここでストップ。
ほぼ固まったのでこれベースで作業して、完了したタイミングで結果を追記したいと思います。誰かのお役に立つ記事。。になることを目指してw
- 投稿日:2019-07-19T18:48:33+09:00
【#aws-cli】管理者権限を持たないWindows環境に「AWSコマンドラインインターフェイス(awscli)」をインストールする #AWS #awscli #環境設定 #環境設定
管理者権限を持たないWindows端末に「AWSコマンドラインインターフェイス(awscli)」をインストールした際の内容を自分用のメモとしてまとめました。
環境情報
OS/ソフトウェア バージョン 入手元 Windows 10 pro バージョン1803(OSビルド 17134.858) Microsoft Corporation Python3 3.7.4 https://www.python.org/downloads/windows/ pip 19.1.1 aws-cli 1.16.200 https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/install-windows.html □手順 1: 公式URLからPythonの
executable installerをダウンロードします■URL
https://www.python.org/downloads/windows/■ファイル名
python-3.7.4-amd64.exe□手順 2: ダウンロードした
executable installerを実行します□手順 3:
Customize installationをクリックします□手順 4: 全てのOptional Featuresにチェックを入れて
Nextボタンをクリックします□手順 5: 次のAdvanced Optionsにチェックを入れて
Installボタンをクリックします
Associate files with PythonCreate shortcuts for installed applicationsAdd Python to environment variablesPrecompile standard library□手順 6:
Closeボタンをクリックしexecutable installerを終了します□手順 7: スタートメニューから
Powershellを起動し次ののコマンドを実行します※Pythonがインストールされて、パスが通っていることを確認します
PS C:\> & python --version Ptyhon 3.7.4□手順 8:
pipを最新バージョンにアップグレードしますPS C:\> & easy_install.exe -U pip□手順 9:
pipを使ってawscliを依存モジュールと合わせてインストールしますPS C:\> & pip install --trusted-host pypi.org --trusted-host files.pythonhosted.org awscli私の環境では
--trusted-hostオプションを付与せずに実行すると次のエラーメッセージが出力されてしまいましたPS C:\> & pip install awscli WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1076)'))': /simple/pyyaml/ WARNING: Retrying (Retry(total=3, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1076)'))': /simple/pyyaml/ WARNING: Retrying (Retry(total=2, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1076)'))': /simple/pyyaml/ WARNING: Retrying (Retry(total=1, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1076)'))': /simple/pyyaml/ WARNING: Retrying (Retry(total=0, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1076)'))': /simple/pyyaml/ Could not fetch URL https://pypi.org/simple/pyyaml/: There was a problem confirming the ssl certificate: HTTPSConnectionPool(host='pypi.org', port=443): Max retries exceeded with url: /simple/pyyaml/ (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1076)'))) - skipping ERROR: Could not find a version that satisfies the requirement PyYAML<=5.1,>=3.10 (from awscli) (from versions: none) ERROR: No matching distribution found for PyYAML<=5.1,>=3.10 (from awscli)□手順 10:
aws --versionコマンドを実行してaws-cliが正常にインストールされたことを確認しますPS C:\> & aws --version 拡張子 .py のファイルの関連付けが見つかりません aws-cli/1.16.200 Python/3.7.4 Windows/10 botocore/1.12.190□手順 11:
aws configureコマンドを実行して認証情報などを記録させますPS C:\> & aws configure 拡張子 .py のファイルの関連付けが見つかりません AWS Access Key ID [None]: <My AWS Access Key> AWS Secret Access Key [None]: <AWS Secret Access Key> Default region name [None]: ap-northeast-1 Default output format [None]: json
--profileオプションを付与することでプロファイルの作成も可能ですPS C:\> & aws configure --profile readonly 拡張子 .py のファイルの関連付けが見つかりません AWS Access Key ID [None]: <My AWS Access Key> AWS Secret Access Key [None]: <AWS Secret Access Key> Default region name [None]: ap-northeast-1 Default output format [None]: json手順 11:
aws s3 lsコマンドなどを実行して正常にAWS環境に接できることを確認しますPS C:\> & aws s3 ls --no-verify --profile readonly 拡張子 .py のファイルの関連付けが見つかりません C:%USERPROFILE%\AppData\Local\Programs\Python\Python37\lib\site-packages\urllib3-1.25.3-py3.7.egg\urllib3\connectionpool.py:851: InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings InsecureRequestWarning) 2019-MM-DD hh:mm:ss xxxx :私の環境では
--no-verifyオプションを付与せずに実行すると次のエラーメッセージが出力されてしまいましたPS C:\> & aws s3 ls --profile readonly 拡張子 .py のファイルの関連付けが見つかりません SSL validation failed for https://s3.ap-northeast-1.amazonaws.com/ [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1076)おまけ:
拡張子 .py のファイルの関連付けが見つかりませんという警告メッセージへの対応管理者権限を有しているアカウントで下記コマンドを実行してもらうことができれば解決できるはずです。。。
PS C:\> & assoc .py=Python.File PS C:\> & type Python.File="%USERPROFILE%\AppData\Local\Programs\Python\Python37\python.exe" "%1" %*
以上、管理者権限を持たないWindows端末に「AWSコマンドラインインターフェイス(awscli)」をインストールする手順でした。
- 投稿日:2019-07-19T18:48:33+09:00
【#aws-cli】管理者権限を持たないWindows環境に「AWSコマンドラインインターフェイス(aws-cli)」をインストールする #AWS #awscli #環境構築 #環境設定
管理者権限を持たないWindows端末に「AWSコマンドラインインターフェイス(aws-cli)」をインストールした際の内容を自分用のメモとしてまとめました。
環境情報
OS/ソフトウェア バージョン 入手元 Windows 10 pro バージョン1803(OSビルド 17134.858) Microsoft Corporation Python3 3.7.4 https://www.python.org/downloads/windows/ pip 19.1.1 aws-cli 1.16.200 https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/install-windows.html □手順 1: 公式URLからPythonの
executable installerをダウンロードします■URL
https://www.python.org/downloads/windows/■ファイル名
python-3.7.4-amd64.exe□手順 2: ダウンロードした
executable installerを実行します□手順 3:
Customize installationをクリックします□手順 4: 全てのOptional Featuresにチェックを入れて
Nextボタンをクリックします□手順 5: 次のAdvanced Optionsにチェックを入れて
Installボタンをクリックします
Associate files with PythonCreate shortcuts for installed applicationsAdd Python to environment variablesPrecompile standard library□手順 6:
Closeボタンをクリックしexecutable installerを終了します□手順 7: スタートメニューから
Powershellを起動し次ののコマンドを実行します※Pythonがインストールされて、パスが通っていることを確認します
PS C:\> & python --version Ptyhon 3.7.4□手順 8:
pipを最新バージョンにアップグレードしますPS C:\> & easy_install.exe -U pip□手順 9:
pipを使ってawscliを依存モジュールと合わせてインストールしますPS C:\> & pip install --trusted-host pypi.org --trusted-host files.pythonhosted.org awscli私の環境では
--trusted-hostオプションを付与せずに実行すると次のエラーメッセージが出力されてしまいましたPS C:\> & pip install awscli WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1076)'))': /simple/pyyaml/ WARNING: Retrying (Retry(total=3, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1076)'))': /simple/pyyaml/ WARNING: Retrying (Retry(total=2, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1076)'))': /simple/pyyaml/ WARNING: Retrying (Retry(total=1, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1076)'))': /simple/pyyaml/ WARNING: Retrying (Retry(total=0, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1076)'))': /simple/pyyaml/ Could not fetch URL https://pypi.org/simple/pyyaml/: There was a problem confirming the ssl certificate: HTTPSConnectionPool(host='pypi.org', port=443): Max retries exceeded with url: /simple/pyyaml/ (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1076)'))) - skipping ERROR: Could not find a version that satisfies the requirement PyYAML<=5.1,>=3.10 (from awscli) (from versions: none) ERROR: No matching distribution found for PyYAML<=5.1,>=3.10 (from awscli)□手順 10:
aws --versionコマンドを実行してaws-cliが正常にインストールされたことを確認しますPS C:\> & aws --version 拡張子 .py のファイルの関連付けが見つかりません aws-cli/1.16.200 Python/3.7.4 Windows/10 botocore/1.12.190□手順 11:
aws configureコマンドを実行して認証情報などを記録させますPS C:\> & aws configure 拡張子 .py のファイルの関連付けが見つかりません AWS Access Key ID [None]: <My AWS Access Key> AWS Secret Access Key [None]: <AWS Secret Access Key> Default region name [None]: ap-northeast-1 Default output format [None]: json
--profileオプションを付与することでプロファイルの作成も可能ですPS C:\> & aws configure --profile readonly 拡張子 .py のファイルの関連付けが見つかりません AWS Access Key ID [None]: <My AWS Access Key> AWS Secret Access Key [None]: <AWS Secret Access Key> Default region name [None]: ap-northeast-1 Default output format [None]: json手順 12:
aws s3 lsコマンドなどを実行して正常にAWS環境に接できることを確認しますPS C:\> & aws s3 ls --no-verify --profile readonly 拡張子 .py のファイルの関連付けが見つかりません C:%USERPROFILE%\AppData\Local\Programs\Python\Python37\lib\site-packages\urllib3-1.25.3-py3.7.egg\urllib3\connectionpool.py:851: InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings InsecureRequestWarning) 2019-MM-DD hh:mm:ss xxxx :私の環境では
--no-verifyオプションを付与せずに実行すると次のエラーメッセージが出力されてしまいましたPS C:\> & aws s3 ls --profile readonly 拡張子 .py のファイルの関連付けが見つかりません SSL validation failed for https://s3.ap-northeast-1.amazonaws.com/ [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1076)おまけ:
拡張子 .py のファイルの関連付けが見つかりませんという警告メッセージへの対応管理者権限を有しているアカウントで下記コマンドを実行してもらうことができれば解決できるはずです。。。
PS C:\> & assoc .py=Python.File PS C:\> & type Python.File="%USERPROFILE%\AppData\Local\Programs\Python\Python37\python.exe" "%1" %*
以上、管理者権限を持たないWindows端末に「AWSコマンドラインインターフェイス(awscli)」をインストールする手順でした。
- 投稿日:2019-07-19T18:48:33+09:00
【#awscli】管理者権限を持たないWindows環境に「AWSコマンドラインインターフェイス(aws-cli)」をインストールする #AWS #jawsug #環境構築 #環境設定
管理者権限を持たないWindows端末に「AWSコマンドラインインターフェイス(aws-cli)」をインストールした際の内容を自分用のメモとしてまとめました。
環境情報
OS/ソフトウェア バージョン 入手元 Windows 10 pro バージョン1803(OSビルド 17134.858) Microsoft Corporation Python3 3.7.4 https://www.python.org/downloads/windows/ pip 19.1.1 aws-cli 1.16.200 https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/install-windows.html □手順 1: 公式URLからPythonの
executable installerをダウンロードします■URL
https://www.python.org/downloads/windows/■ファイル名
python-3.7.4-amd64.exe□手順 2: ダウンロードした
executable installerを実行します□手順 3:
Customize installationをクリックします□手順 4: 全ての Optional Features にチェックを入れて
Nextボタンをクリックします□手順 5: 次の Advanced Options にチェックを入れて
Installボタンをクリックします
Create shortcuts for installed applicationsAdd Python to environment variablesPrecompile standard library□手順 6:
Closeボタンをクリックしexecutable installerを終了します□手順 7: スタートメニューから
Powershellを起動し次のコマンドを実行、Pythonがインストールされて、パスが通っていることを確認しますPS C:\> & python --version Ptyhon 3.7.4□手順 8:
pipを最新バージョンにアップグレードしますPS C:\> & easy_install.exe -U pip□手順 9:
pipを使ってawscliを依存モジュールと合わせてインストールしますPS C:\> & pip install --trusted-host pypi.org --trusted-host files.pythonhosted.org awscli私の環境では
--trusted-hostオプションを付与せずに実行すると次のエラーメッセージが出力されてしまいましたPS C:\> & pip install awscli WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1076)'))': /simple/pyyaml/ WARNING: Retrying (Retry(total=3, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1076)'))': /simple/pyyaml/ WARNING: Retrying (Retry(total=2, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1076)'))': /simple/pyyaml/ WARNING: Retrying (Retry(total=1, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1076)'))': /simple/pyyaml/ WARNING: Retrying (Retry(total=0, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1076)'))': /simple/pyyaml/ Could not fetch URL https://pypi.org/simple/pyyaml/: There was a problem confirming the ssl certificate: HTTPSConnectionPool(host='pypi.org', port=443): Max retries exceeded with url: /simple/pyyaml/ (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1076)'))) - skipping ERROR: Could not find a version that satisfies the requirement PyYAML<=5.1,>=3.10 (from awscli) (from versions: none) ERROR: No matching distribution found for PyYAML<=5.1,>=3.10 (from awscli)□手順 10:
aws --versionコマンドを実行してaws-cliが正常にインストールされたことを確認しますPS C:\> & aws --version 拡張子 .py のファイルの関連付けが見つかりません aws-cli/1.16.200 Python/3.7.4 Windows/10 botocore/1.12.190□手順 11:
aws configureコマンドを実行して認証情報などを記録させますPS C:\> & aws configure 拡張子 .py のファイルの関連付けが見つかりません AWS Access Key ID [None]: <My AWS Access Key> AWS Secret Access Key [None]: <AWS Secret Access Key> Default region name [None]: ap-northeast-1 Default output format [None]: json
--profileオプションを付与することでプロファイルの作成も可能ですデフォルトのプロファイルには読み取り権限のみをもったアカウントを登録しておくことで誤った変更などを避けられるので安全です
PS C:\> & aws configure --profile developer 拡張子 .py のファイルの関連付けが見つかりません AWS Access Key ID [None]: <My AWS Access Key> AWS Secret Access Key [None]: <AWS Secret Access Key> Default region name [None]: ap-northeast-1 Default output format [None]: json手順 12:
aws s3 lsコマンドなどを実行して正常にAWS環境に接続できることを確認しますPS C:\> & aws s3 ls --no-verify --profile developer 拡張子 .py のファイルの関連付けが見つかりません %USERPROFILE%\AppData\Local\Programs\Python\Python37\lib\site-packages\urllib3-1.25.3-py3.7.egg\urllib3\connectionpool.py:851: InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings InsecureRequestWarning) 2019-MM-DD hh:mm:ss xxxx :私の環境では
--no-verifyオプションを付与せずに実行すると次のエラーメッセージが出力されてしまいましたPS C:\> & aws s3 ls --profile developer 拡張子 .py のファイルの関連付けが見つかりません SSL validation failed for https://s3.ap-northeast-1.amazonaws.com/ [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1076)おまけ:
拡張子 .py のファイルの関連付けが見つかりませんという警告メッセージへの対応管理者権限を有しているアカウントで下記コマンドを実行してもらうことができれば解決できるはずです。。。
PS C:\> & assoc .py=Python.File PS C:\> & type Python.File="%USERPROFILE%\AppData\Local\Programs\Python\Python37\python.exe" "%1" %*
以上、管理者権限を持たないWindows端末に「AWSコマンドラインインターフェイス(awscli)」をインストールする手順でした。
- 投稿日:2019-07-19T18:40:15+09:00
JavaでLambda関数を書いてSAMでデプロイしてみた
はじめに
これまで、AWS Lambdaを主にPython、時々、Node.jsで作ってきましたが、気分転換にJavaでの開発方法を調べたのでまとめます。
今回は、Javaで書いたLambda関数のソースコードをGradleでビルドしてAWS SAMでデプロイしてみました。
Eclipseでの開発用に AWS Toolkit for Eclipse も提供されていますが、普段はVimで開発してCLIでデプロイしているので、そちらに合わせます。検証環境
- OS: macOS High Sierra 10.13.6
- aws-cli: 1.15.38
- aws-sam: 0.11.0
- Java 1.8.0_221
- JDK: OpenJDK 1.8.0_212 (Amazon Corretto 8.212)
- Gradle 5.5.1
JavaでLambdaを開発する上でのポイント
ランタイムはJava 8のみ
下の公式ドキュメントにあるように、提供されているJavaのランタイムは
Java 8(JDK 8)のみです。
それ以外のバージョンを使用する場合は、サポートされるまで待つかカスタムランタイムを使う必要があります。Java による Lambda 関数のビルド - AWS Lambda
zipファイルかjarファイルにしてでデプロイ
Javaで書かれたアプリケーションを、zipファイルまたはスタンドアロンjarにパッケージしてデプロイします。
公式ドキュメントではMavenを使ってスタンドアロンjarに、Gradleを使ってzipファイルにしてデプロイする方法が紹介されてます。
今回は、Gradleでzipファイルにパッケージングしてデプロイする方法で試しました。Java の AWS Lambda デプロイパッケージ - AWS Lambda
ハンドラー関数のリクエストの受け方・返し方が3種類
ハンドラー関数のリクエストの受け取り方、そして、レスポンスの返し方に、以下のように複数の方式があります。
- Java のシンプルな型
- POJO (Plain Old Java Object) 型
- ストリーム型
それぞれでハンドラー関数の書き方が変わります。つまり、ハンドラー関数の書き方に3種類あるということです。
「このイベントトリガーを使うならこのタイプ」というような決め方というよりも、どういったデータが送られてくるかという視点で使い分けるようです。
この状況にはこれという明確なものはないようなので、実際にJavaでLambda関数を開発する際はどの方式にするか要検討です。今回は、「POJO型」を採用しました。
ハンドラーの入出力タイプ (Java) - AWS Lambda
今回作ったもの
Lambda関数のトリガーとして
API Gatewayを使った、簡単なWebアプリケーションを作成しました。
POSTリクエストを送ると、"Hello"と返してくるだけのシンプルなAPIです。サンプルコード
作成したコードはここに置いてます。
https://github.com/mmclsntr/awslambda-javagradleプロジェクト構成
. ├── build/ │ ├── distributions/ │ │ └── awslambda-javagradle.zip # ビルドで生成されるデプロイパッケージ │ └── ... ├── build.gradle # Gradleビルド設定ファイル ├── src/main/java/awslambda/javagradle │ ├── Greeting.java # アプリの中核となる部分 │ ├── Handler.java # Lambdaのハンドラ関数を格納 │ └── Response.java # Lambdaのレスポンスを整形 └── template.yml # CloudFormationテンプレートファイル └── その他Gradle用ファイルコーディング
ハンドラクラス
Handler.javapackage awslambda.javagradle; import java.util.Collections; import java.util.Map; import java.util.logging.Level; import java.util.logging.Logger; import com.amazonaws.services.lambda.runtime.Context; import com.amazonaws.services.lambda.runtime.RequestHandler; public class Handler implements RequestHandler<Map<String, Object>, Response> { private static final Logger LOG = Logger.getLogger(Handler.class.getName()); @Override public Response handleRequest(Map<String, Object> input, Context context) { LOG.info("received: " + input); LOG.setLevel(Level.INFO); Greeting greetingBody = new Greeting("Hello"); return Response.builder() .setStatusCode(200) .setObjectBody(greetingBody) .build(); } }レスポンスクラス
Response.javapackage awslambda.javagradle; import java.nio.charset.StandardCharsets; import java.util.Base64; import java.util.Collections; import java.util.Map; import org.apache.log4j.Logger; import com.fasterxml.jackson.core.JsonProcessingException; import com.fasterxml.jackson.databind.ObjectMapper; public class Response { private final int statusCode; private final String body; private final Map<String, String> headers; private final boolean isBase64Encoded; public Response(int statusCode, String body, Map<String, String> headers, boolean isBase64Encoded) { this.statusCode = statusCode; this.body = body; this.headers = headers; this.isBase64Encoded = isBase64Encoded; } ... }あいさつクラス
サンプルとしてHelloと返してくれる超シンプルなアプリケーションを作ります。
Greeting.javapackage awslambda.javagradle; public class Greeting { private String greetings; public Greeting(String greetings) { this.greetings = greetings; } public String getGreetings() { return greetings; } public void setGreetings(String greetings) { this.greetings = greetings; } }CloudFormationテンプレート
template.ymlAWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: > AWS Lambda Java with Gradle Globals: Function: Timeout: 20 Resources: PostGreetingFunction: Type: AWS::Serverless::Function Properties: CodeUri: build/distributions/awslambda-javagradle.zip Handler: awslambda.javagradle.Handler::handleRequest Runtime: java8 Events: GetOrder: Type: Api Properties: Path: / Method: post Outputs: ApiEndpoint: Description: "API Gateway endpoint URL for Prod stage" Value: !Sub "https://${ServerlessRestApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/" PostGreetingFunction: Description: "PostGreeting Lambda Function ARN" Value: !GetAtt PostGreetingFunction.Arnデプロイ
ビルド設定ファイル作成
build.gradleapply plugin: 'java' repositories { mavenCentral() } sourceCompatibility = 1.8 targetCompatibility = 1.8 dependencies { compile ( 'com.amazonaws:aws-lambda-java-core:1.1.0', 'com.amazonaws:aws-lambda-java-log4j:1.0.0', 'com.amazonaws:aws-lambda-java-events:1.1.0', 'com.fasterxml.jackson.core:jackson-core:2.8.5', 'com.fasterxml.jackson.core:jackson-databind:2.8.5', 'com.fasterxml.jackson.core:jackson-annotations:2.8.5' ) } // Task for building the zip file for upload task buildZip(type: Zip) { from compileJava from processResources into('lib') { from configurations.runtime } } build.dependsOn buildZipビルド
Gradle コマンドでビルドします。
gradle buildAWS SAMでデプロイ
デプロイ先S3バケット作成
aws s3 mb s3://<デプロイ先S3バケット> --aws-profile=<AWSプロファイル>パッケージ
sam packageで、上で作成したS3バケットへ実行ファイルをアップロード & デプロイ用テンプレートファイルを生成します。sam package \ --s3-bucket <デプロイ先S3バケット名> \ --s3-prefix <デプロイ先S3フォルダ名(プレフィクス) ※任意> \ --output-template-file output.yml \ --profile <AWSプロファイル>アウトプットとして、
output.ymlファイルが作られます。デプロイ
sam deployで、LambdaとAPI Gatewayをデプロイします。sam deploy \ --template-file output.yml \ --stack-name awslambda-javagradle-greeting \ --capabilities CAPABILITY_IAM \ --profile <AWSプロファイル>確認
AWS上にLambda関数とAPI Gatewayが作られたので、エンドポイントにPOSTリクエストを投げて見ます。
リクエストcurl -X POST https://xxxx.execute-api.ap-northeast-1.amazonaws.com/Prod/レスポンス{"greetings":"Hello"}所感
私自身、普段はJavaを使わないのでちょっと時間がかかりましたが、簡単に作れたなという印象です。Pythonなどのスクリプト言語で作るよりも当然ながらコード量は増えますが、厳格なサーバーレス開発ができることは魅力的です。
ハンドラー関数の書き方に複数種類あるといったJavaで書く上での特有の仕様が、今回だけでは把握しきれませんでした。実際に使う際は、その辺りも考慮しながら詳細設計したいと思います。
また、噂通り、初期起動が遅いです (レスポンスされるまで5秒くらい)。
参照: https://cero-t.hatenadiary.jp/entry/20160106/1452090214まとめ
Javaを利用したLambda関数の開発の特徴やコーディング感覚をつかむことができました。
もし、サーブレットから移行するならそこそこ大規模な改修が必要と思いますが、代わりとして使えなくもない印象です。ランタイムがこのままJava8のみなのか、そこのサポートが少し心配です。。
API Gatewayをトリガーとしましたが、他のサービスも試して見たいと思います。参考
https://qiita.com/kamata1729/items/8d88ea10dd3bb61fa6cc
https://qiita.com/riversun/items/7fcc06617b469aed8f27
- 投稿日:2019-07-19T17:34:03+09:00
LaravelからSESでメール送信ができなかったときの確認項目
前回(AmazonSESを使ったメールの受信に苦労した話)に引き続き、SES関連のお話。
エラーメッセージはというと、SignatureDoesNotMatchということで、認証できていないかんじ。
configファイルもenvファイルも何度も何度も見直したけど、正しい値を入れている自信はあった。
(実際には間違っていたから送信できなかった。)Aws/Ses/Exception/SesException with message 'Error executing "SendRawEmail" on "https://email.us-west-2.amazonaws.com"; AWS HTTP error: Client error: `POST https://email.us-west-2.amazonaws.com` resulted in a `403 Forbidden` response: <ErrorResponse xmlns="http://ses.amazonaws.com/doc/2010-12-01/"> <Error> <Type>Sender</Type> <Code>SignatureDo (truncated...) SignatureDoesNotMatch (client): The request signature we calculated does not match the signature you provided. Check your AWS Secret Access Key and signing method. Consult the service documentation for details. - <ErrorResponse xmlns="http://ses.amazonaws.com/doc/2010-12-01/"> <Error> <Type>Sender</Type> <Code>SignatureDoesNotMatch</Code> <Message>The request signature we calculated does not match the signature you provided. Check your AWS Secret Access Key and signing method. Consult the service documentation for details.</Message> </Error> <RequestId>196ba786-9d8c-4d78-bf10-052eff69e893</RequestId> </ErrorResponse>間違っていた箇所と解決策
まず必要な設定は、公式にも記載されているとおり、SESドライバのインストールとconfigファイルの変更。
https://readouble.com/laravel/5.8/ja/mail.html'ses' => [ 'key' => env('SES_KEY'), 'secret' => env('SES_SECRET'), 'region' => env('SES_REGION', 'us-east-1'), ],で、自分が間違っていたのは、SES_KEYとSES_SECRETの値。
AWSコンソールの、SES > SMTP Settings > Using SMTP to Send Email with Amazon SESで作成したユーザーIDとパスワードを入れていた。
実際は、IAM > ユーザー > (SESのwrite権限のあるユーザー) > 認証情報 > アクセスキーの作成 で作ったキーを入力。解決法が間違っていたら教えてくださいm(_ _)m
- 投稿日:2019-07-19T16:57:38+09:00
AWS Summit Tokyo 2019に参加した話
AWS Summitに初参戦
表題のとおり、AWS Summit Tokyo 2019に参加してまいりました!
3日目だけなのですが、色々と勉強になったのでよかったです!
参加したセッションは以下です。
- 基調講演
- メルカリ写真検索における Amazon EKS の活用事例
- Kubernetes on AWS(Amazon EKS実践入門)
- EKSで構築するグリーのエンターテインメントシステム
- めざせ!サーバレスプロフェッショナル
その中でのお話をかいつまんで書き連ねていこうかと思います。
現地到着〜基調講演
入場までのみちのり
今回は開催地は幕張メッセだったので、私の自宅からは30分ほどでした。
着いて早々エスカレーターが2ボトルネックになっており(2基しかない…)、人が溢れていました。笑
改札から出ると人がいっぱいでこの時点で帰りたくなりましたが、暑い中頑張って幕張メッセまで歩きました。
幕張メッセついてからも入口が一番西側だったので結構歩きました。基調講演
入場後はそのまま基調講演の会場へ向かい着席して小休止していると、基調講演が始まりました。
副社長のMarco Argenti氏のお話
まずはお決まりのAmazonの歴史ってこんなのだよ、というところから始まりこんなんやっていきたいね!的な話でした。
次に株式会社メルカリ様のCTOである名村 卓氏がこんなサービス使っています、こんなことやりたいです的な話をしておりました。
が、途中で腹痛に見舞われリタイヤ…体調は整えておかなければなりませんね…。基調講演に関してネガティブな感情を持たれている方はいらっしゃると思いますが、やはりあれだけ大きい企業の経営陣の話を本人の言葉で直接聞けるのは得るものが非常に大きいと思いますので私は参加をおすすめ致します!
メルカリ写真検索における Amazon EKS の活用事例
メルカリ様でSREとしてご活躍されている中河 宏文氏から、メルカリではどのようにしてEKSを活用されているのかを伺えました。
基調講演で名村氏も触れられておりましたが、いわゆる画像検索の機能ですが基調講演で触れるほど温度感高めに取り組まれているのだと思いました。Lykeionというメルカリ様内製のプラットフォーム上に写真検索機能を実装しており、以下のような機能を利用されているようです。
- Training / Service CRD&カスタムコントローラー
- コンテナベース・パイプライン
- Training / Service コンテナイメージ・ビルダー
- モデル・レポジトリ
コンテナベース・パイプライン
AWSとGCPのマルチクラウドで構成されており、その中のTraining KuberunetesクラスターというものをEKSにて運用しているそうです。
細かい部分は理解が誤っている可能性もあるので割愛しますが、Training custom resourceというデータ群を作成するのにコンテナベースのパイプラインを採用しています。理由としては下記です。
- バッチをHourly / Daily / Monthlyで実行しているため
- 工程毎に違うコンテナで利用しているため(ライブラリ依存などがあるため)
- パイプラインをyamlで記述 / 管理できるため
- 各工程の入出力結果も永続ボリューム(EBS)を介して管理しているため
また上記のバッチ実行情報をKuberunetesのCRD上で管理できるため、障害原因の探索や復旧処理の再現性も容易なためKubernetesは維持・運用において非常にパワーを発揮しているとのことでした。
S3上のイメージストア
S3上に画像検索の元となるイメージ群が置かれており、Training custom resourceをインデックスする際にはそれらを持ってこなければいけません。
当然画像数が多く、処理の重いジョブになります。
上述した永続ボリュームであるEBSに一定期間キャッシュさせることで、ダウンロードにかかる負荷を軽減させるアーキテクチャー構成になっています。EKSのメリット / デメリット
メリットとしては以下です
- 柔軟性が高いため細かいカスタムが効く
- 当然ながらAWSサービスとの連動性が高い
デメリットとしては以下です
- マネージド型サービスではあるがKuberunetesの知識が必要
所感
マルチクラウドをうまく使い分けているなぁ、と感じると同時にやはりAWSだけではだめだなと痛感させられました。
エンジニア的な観点からの選択過程や意思決定となるポイントなど非常に勉強になりました。GCP部分の話などまるっと割愛しているので、よろしければご本人の発表資料を見ていただけるとわかりやすいと思います。
メルカリ写真検索における Amazon EKS の活用事例Kubernetes on AWS(Amazon EKS実践入門)
AWSジャパン株式会社様の河野 信吾氏が登壇されておりました。
EKSって何?
Kuberbnetesの運用において、コントロールプレーンが悩みのタネになりがち
- 運用中のバージョンアップはすごく大変
- コントロールプレーンの冗長化は必須
- なにかあっても誰も責任を取ってくれない
これらを解決するのがElastic Container Serice for Kubernetes (EKS)です。
EKSを利用することで以下が実現できます。
- コントロールプレーン運用からの解放
- セキュアなコントロールプレーンを実現(シングルテナントで稼働)
- AWSマネージドサービスとの連携が容易
- 容易なノードの選択
活発なコミュニティ
Kubarnetes自体かなり活発なコミュニティですが、AWSもより便利にするため様々なものをリリースしています。
以下は一例です。
ALB ingress controler
KuberunetesのコンテナへのルーティングをALBで捌く際にプロビジョニングしてくれるツールです。
AWS EKS Cluster Controller
クラスターの実行環境やコントロールプレーンとデータノード間をマネジメントできるツールです。
CloudWatch Container Insights
コンテナだけでなく、ノードやポッド、名前空間からサービスレベルまでCloudwatchに集約してダッシュボード等で利用できるサービスです。まとめ
EKSは怖くない!簡単なのでぜひ試してみてね!
Previewの機能もガンガンつかってレビュー欲しいな!
って感じでした!(EKSはお金が怖い…。)EKSで構築するグリーのエンターテインメントシステム
このセッションはグリー株式会社様のインフラストラクチャ部にてリードエンジニアをされております堀口真司氏から、グリー様がどのようにしてEKSを利用するまでの道のりと現在の活用法を伺うことができました。
EKSまでの道のり
Dockerの利用
Dockerが流行りだした2014ごろから利用開始したものの当時はあまり流行らなかったそうで…理由としては以下になります。
- 手元のPCでは使い勝手が悪い
非Linuxの場合にはdockerの実行自体にVMが必要になり起動があまり早くないため、Dockerのメリットを享受できなかった- サーバー側での設定が困難
上述のことから直接コンテナに入ることや、ネットワークの設定が非常に煩雑だった- 本番ワークロードで利用する場合は何かしらのオーケストレーションツールの導入が必須
Dockerを管理するためのマネージドサービスがなく、Kubernetesなどはまだ学習コストが高い割に実運用している事例が少なかったため手を出すのをためらった。使ってはみたものの、思った以上に手間がかかったというのが主な理由だったようです。
ECSの利用
上述の手間を解消させるマネージド型サービスとして登場したのがECSで、現在においてもグリー様は活用されているとのことです。
ECSを導入し、コンテナ化が促進したことで以下の利益が得られたと発表されておりました。
- インフラ担当の負担を軽減
コンテナ化することで開発チームに環境を管理させることができるため- Optimized AMIがあるためセットアップが容易
あらかじめDockerなどがインストールされたAMIがあるため容易に利用できるため- オーケストレーションツールとしての使い勝手
アップデートが頻繁にあるため日々便利になっていくためDocker単体での利用で感じていた足りない部分を補うようなサービスで、非常に簡単かつ便利にコンテナを利用できるので重宝しているとおっしゃってました。
EKSの導入
ECS運用を通して、もっと細かく管理したいとの思いもありKuberunetesをEC2に導入して管理してみたが運用が非常に大変だったそうです。
以下の理由からKuberunetesを独自で管理するのは断念した経緯があったそうです。
- Kuberunetes自体の構築がすごく大変
- バージョンアップなどのメンテナンス作業も広範に渡り、影響範囲が大きい
- 異常時の対応やデバッグをコードから読み取って対応していく必要がある
- Kuberunetesで動くサービス自体は小規模でもクラスタの維持・運用がそれ以上に手間がかかる
EKSはマネージドサービスなので上述の問題を解消してくれた。
さらにメリットとして以下が挙げられていました。
- kubectlがそのまま利用できるための情報量が多く、使い勝手も良い
- EKSのコントロールプレーンを管理しなくて良いので安心
特にEKSのコントロールプレーンを管理しなくて良いという点に関しては非常にメリットを感じているそうです。
確かにコントロールプレーンに何かあると…というのは必ず挙がる問題だと思うのでそこだけでもEKSの恩恵は大きいのかなと思いました。実運用
実際の運用はどのようにされているのか、という部分もお話しを聞くことができました。
イメージビルド
Jenkisを利用しており master / slave構成でコンテナを実行しているそうです。
ちなみにmasterは公式イメージを引っ張っているだけとおっしゃってました。(シンプルイズベストですね!)
コンテナは所謂Docker in Dockerでしており、ECRにPushするときは最新イメージをlatestラベルを付与してあげる運用をしているそうです。デプロイ
Strategyは現段階で必要性を感じていないため特に調整していないため、一気にコンテナが入れ替わるといったデプロイ戦略を取られているそうです。
ユニークだなぁと思ったのが、Deploymentのannotationsに無作為な時刻を設定してDevelop環境のコンテナを一気に入れ替えるらしいです。samplespec: replicas: 2 selector: matchLabels: run: hogehoge template: metadata: annotations: kubernetes.io/change-cause: "201906151845" #Change hereモニタリング
モニタリングはこんな感じのアーキテクチャー構成(たぶん)
DeamonSetでfluentdを稼働させてログを集約 / フィルタリング / フォワードを実施して、その後CloudWatchLogsに送信している。
フィルタリングをかけることでCloudWatchLogsの料金を削減できるようにしている。
元々EC2にGrafanaを構築して利用していたようで、それをそのまま流用してダッシュボードにて管理している。
Node / Pod / Container毎にメトリクスを取得してモニタリングしているとのこと。運用を通してEKSへの所感
- Kubernetesの知識が必須になるため、マネージドサービスといえど自分自身で管理すべき部分も多く出てくる。
e.g.) NamespaceやRBACの存在、名前解決など- 権限管理が煩雑
IAMユーザーの権限がなくても、Kubernetesクラスタのadmin権限とかも持たせることができちゃう- CLIのみでの操作
現在はまだブラウザで操作できないので、もしものときが心配- AWSリソースは一部標準で対応されていないのでAnnotationでの管理が必要
e.g.) ALB / EFS- コストが高い
コントロールプレーンの管理に対するコストがかかる(HA用に3台EC2が必要とか)まとめ
ECSとEKSを利用していて双方にメリット / デメリットがあり、そこをうまく理解して使い分けすることで十分な恩恵を受けることができる のではないかと思いました。逆にそこを理解していないと余計な運用が増えたり、コストが過剰に掛かったりが今まで以上に遥かに増えると思いました。
ECSの良きところ
- クラスタの管理に費用がかからない
- VPCネイティブなので既存のサービスからすぐに相互アクセスが可能になる
- マネコンからも操作ができて簡単
- Auto Scalingの設定も簡単
- IAMで権限設定するため今までの知識を流用できる
EKSのよきところ
- Kubernetesをインストールするのに比べ、遥かにセットアップが楽
- kubectlをそのまま利用できる
- 標準でAWSリソースに対応していない分、ロギングやモニタリングなどの選択肢が多い
- IAMとRBACが存在することで柔軟な権限管理が可能(煩雑ではあるが…)
- バージョンアップなどは圧倒的に楽
めざせ!サーバレスプロフェッショナル
AWSジャパン株式会社様の清水 崇之氏が登壇されておりました。
自称AWS芸人とのことで、普段は関西で働かれているそうでとてもお話しが上手でした。サーバレスの魅力
- なんと言ってもサーバの管理が不要なこと
- アイドル時の待機費用削減
- スモールスタートが可能
- 使い慣れた開発環境で実施できる
AWS ToolitやAWS SAM CLIなど便利なツールもいっぱいリリースしているから使ってください!
早速SAMをインストールしてみました。$ pip --version pip 18.1 from /usr/local/lib/python3.7/site-packages/pip (python 3.7) $ pip install --user aws-sam-cli Successfully installed Flask-1.0.3 Werkzeug-0.15.4 arrow-0.14.2 aws-lambda-builders-0.3.0 aws-sam-cli-0.17.0 aws-sam-translator-1.10.0 binaryornot-0.4.4 certifi-2019.3.9 chardet-3.0.4 chevron-0.13.1 click-6.7 cookiecutter-1.6.0 dateparser-0.7.1 docker-4.0.1 future-0.17.1 idna-2.8 itsdangerous-1.1.0 jinja2-time-0.2.0 jsonschema-2.6.0 poyo-0.4.2 pytz-2019.1 regex-2019.6.8 requests-2.22.0 serverlessrepo-0.1.8 six-1.11.0 tzlocal-1.5.1 websocket-client-0.56.0 whichcraft-0.5.2 $ sam --version SAM CLI, version 0.17.0今度使って記事を書いてみよー
AWS SAM(Serverless Application Model)
AWS SAMとはAWSサーバレスアプリケーションを作成・管理するための機能です。
- 関数やAPI、イベントソースなどを簡単に記述可能
- 上記を利用してライフサイクルコントロールを実現する
- CloudFormationに対応するための
packageとdeployコマンド特に最後の
packageとdeployコマンドに関しては非常に便利です。
packageはSAMテンプレートをClaudFormationテンプレートに変換してくれます。
deployはCloudFormationが実行されて環境が作成されます。SAMはざっとこんな感じで表記できます。
sample_get_request.yamlAWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 #Specify SAM Version Resources: api_gateway_testFunction: Type: AWS::Serverless::Function #Fixed Properties: CodeUri: s3://sandbox/index.zip #Ran code path Handler: index.handler #Ran function Runtime: nodejs8,10 #Specify runtime Events: GetOrder: Type: Api #API Gateway added by implicit Properties: Path: /sandbox/{request_id} #tail is path parameter Method: get #HTTP method複数のCI/CDにおけるアカウント戦略
上記のサービスやCodeシリーズを利用することでAWSサービスでCI/CDを実現することが可能
しかしリソースの管理やセキュリティの観点から色々と考慮すべき事項が多いうまくアカウントの運用も利用して、理想的な開発を実現することが可能だということでアカウント戦略にもふれられておりました。
同じアカウントでスタックを分ける
同じアカウントを利用するが、環境毎にスタックを分けて運用していくという戦略
小規模な組織や個人に向いているメリット
- リソース管理の容易
- 管理や監視の統合が可能
デメリット
- アカウントへの許可やアクセスの分離が煩雑になりがち
アカウントを分ける
プラットフォームやチーム毎にアカウントを分けて管理するという戦略
大規模な組織や企業に向いているメリット
- アカウント毎のリソース分離が容易
- アクセス管理が楽
デメリット
- 複数アカウント増えると管理が煩雑
インフラ外の部分で運用が煩雑になっている場合には、このような戦略を考えていくことも必要だとお話しされていました。
Tips
- Lambdaの環境変数
SAMと環境変数を利用して同じリソースでも、環境毎にデプロイ可能- Lambdaのバージョニング・エイリアス
バージョン毎にエイリアスを作成できるため、Prd,Stgなどの異なるワークロードにて作業可能- CodeDeployにおける段階的なデプロイ
Gradual Code Deployment を利用して様々なデプロイコントロールが実現できる- AWS CodeStarを利用してCI/CDのテンプレートを作成
AWS Codeシリーズをかき集めたようなサービスでCI/CDのテンプレート化が実現できるsam local start-apiでローカル環境でAPIテストができる
上記コマンドでローカルポート:3000を利用して疎通まとめ
めちゃめちゃ濃い内容のセッションだったので、全然書ききれませんでした…。
7月1日から公開されるようなので、ぜひ見ていただきたいセッションです!企業ブースとその他
様々な企業様がブースを出店しておりました。
その中でいくつか気になったサービスをピックアップします。Sumo Logic
最近ちょくちょく聞くなーと思っていましたが、ブースがあったので中の人に色々と聞いてきました。
ざっくりとこんなかんじです。
- 導入カンタン
- ダッシュボードかっこいい
- 今ならお試し30日間無料
機会があれば使ってみたいな〜と思いました!
CircleCI
言わずと知れたCI/CDツールですね。
こちらも気になっていたので色々と聞いてきました。
- .com版のGithubならぜひ一度使ってみてほしい(1コンテナなら無料だよ)
- Jenkinsとの比較ならサイボウズさんのスライドが秀逸
- 脱Jenkinsおじさん
AWSブース
サービス毎に別れていて、そこにいる方は本当の中の人たちです。
困りごとや要望など色々とコミュニケーションがとれました。
またエキスパートになんでも質問できるコーナーがあったので、困りごとを相談させて貰いました。
色々と聞けて月曜からの業務に早速活かせそうです!ぜひ機会があれば行ってみてください。ちなみに認定者ブースはまずまずの混み具合だったので利用しなかったです。
総評
メリット
- モチベーション爆上がり
- ノベルティいっぱい
- 細かい疑問が解決
- 思いもよらぬひらめき
デメリット
- 人酔いするくらい多い
- セッション予約しても必ずしも座れるとは限らない
結果的に行って大正解でしたー
来年は5月12日〜5月14日にパシフィコ横浜で開催が決定しているので、ぜひタイミングがあえば参加してみてください!
- 投稿日:2019-07-19T10:51:12+09:00
RDS いろいろ
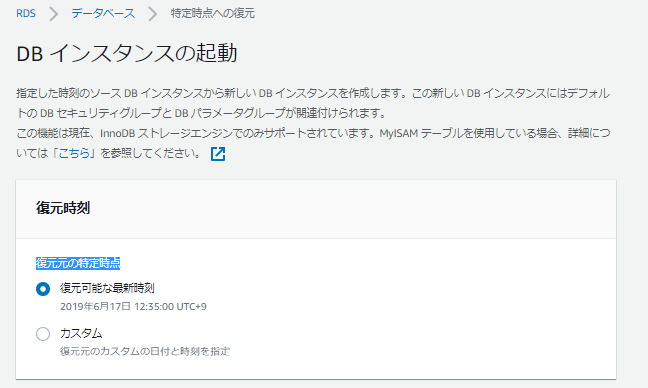
1.「特定時点への復元」をした場合エンドポイントはどうなるか
RDSでは、「特定時点への復元」の機能があり、ポイントタイムリカバリをすることができる。
この特定時点への復元時に、「DB インスタンス識別子」は復元前のものと別の識別子でなければ作成できない。
そのため、エンドポイントも変更になってしまう。
EC2からRDSのエンドポイントを指定している場合、EC2側の設定変更をするのではなく、RDS側で識別子を変更する。
1.元のDBインスタンスの識別子を適当な別名のDBインスタンスの識別子に変える。
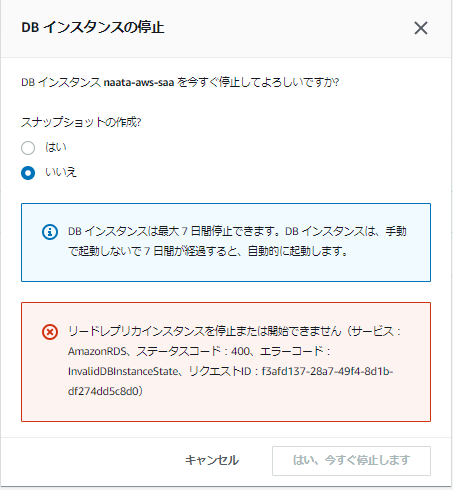
2.新しいDBインスタンスの識別子を元のDBインスタンスの識別子に変える。2.マスター/レプリカ構成での停止の制限
マスター/レプリカで構成されていたとします。
この構成ではマスターは停止できません。レプリカを削除する必要があります。
リードレプリカである DB インスタンスは停止できません。
3.暗号化していないRDS DBインスタンスを暗号化するには
スナップショットから新たにRDS DBインスタンスを作成時に暗号化するのは、EC2と同じだが、
1.「スナップショットのコピー」で暗号化し、スナップショットのコピーを作成する。
2.暗号化したスナップショットから「スナップショットの復元」で、新たにDBインスタンスを作成する必要がある。


- 投稿日:2019-07-19T09:56:16+09:00
社内勉強会:AWS DeepRacer応用編(モデルの分析・可視化)を開催した
はじめに
社内でAWS DeepRacer人口が増えてきており、もっと自分のモデルを分析したい人向けにAWS DeepRacer勉強会応用編を開催したのでその内容を公開します。
本記事ではモデルの分析・可視化について、AWSから提供されているAWS DeepRacerのログ分析ツールを使用しています。
また、関連記事として以下の記事も参考にしてください。
- AWS DeepRacerのログ分析ツールを使ってみた
- AWS DeepRacer Tokyo Summitリーグ表彰台3名のモデルをログ分析ツールにかけてみた
- 社内勉強会:AWS DeepRacer基礎編(モデル作成)を開催した
- 社内勉強会:AWS DeepRacer基礎編(ログ取得)を開催した
- 社内勉強会:AWS DeepRacer基礎編(ハイパーパラメータ)を開催した
注意点
- 準備の項目がない章は、ノートブックを上から実行してください。
- 準備の項目がある章は、準備の内容と照らし合わせながら、ノートブックを実行してください。
- プログラムが長く、補足コメントがあるものに関しては、折りたたみ表示にしています。
導入手順
SageMaker上のノートブック環境の整備、パッケージインストールの手順については、AWS DeepRacerのログ分析ツールを使ってみた>導入手順をご確認ください。
※ パッケージのインストールについて、SageMakerのノートブックインスタンスを停止して起動すると再度インストールする必要があります。
分析対象のモデル
本記事では、以下の条件で学習したモデルを使⽤しています。
- Reward function:Prevent zig-zagベース
- Action space
Action number Steering Speed 0 -25 3 1 -25 6 2 0 3 3 0 6 4 25 3 5 25 6
- Hyperparameter
- Gradient descent batch size:128
- その他:デフォルト
- 学習時間:2時間
用語について
分析する上で以下の用語の定義を理解しておくことが重要になります。
- エピソード:1回の学習の中で⽣成される訓練データ
- イテレーション:1回の学習のことだと考えてよいと思います
詳しくはAWS DeepRacer基本概念と用語をご確認ください。
モデルの分析・可視化
では、AWS DeepRacerのログ分析ツールを使用したモデルの分析・可視化について解説していきます。
Requirements
ライブラリ等の読み込みを行います。
セルを実行してエラーとなる場合は、conda_tensorflow_p36にパッケージがインストールされていないことが原因と考えられます。
AWS DeepRacerのログ分析ツールを使ってみた>導入手順を参考にパッケージをインストールしてください。Download the desired log file given the simulation ID
トレーニング時のシミュレーションIDを使⽤してログファイルをダウンロードします。
準備
stream_nameにトレーニング時のシミュレーションジョブID(AWS DeepRacerコンソールから確認できます)を設定します。
stream_name = 'sim-abcdefg12345' ## ★トレーニング時のシミュレーションジョブIDを設定 fname = 'logs/deepracer-%s.log' %stream_name※ AWS DeepRacerコンソールの以下の場所から、トレーニング時のシミュレーションジョブIDを確認できます。
Load waypoints for the track you want to run analysis on
分析に使用するトラックのwaypointsを読み込みます。
準備
get_track_waypointsの引数を使⽤したいトラック名に変更します。
def get_track_waypoints(track_name): return np.load("tracks/%s.npy" % track_name) waypoints = get_track_waypoints("reinvent_base") # ★引数に使用したいトラックを指定 waypoints.shape※トラックの指定の仕方の例
- 【例1】re:Inventのトラックを使⽤したい場合
waypoints = get_track_waypoints("reinvent_base") # ★引数に使用したいトラックを指定
- 【例2】London Loopのトラックを使⽤したい場合
waypoints = get_track_waypoints("London_Loop_Train") # ★引数に使用したいトラックを指定※ 使⽤可能なトラックは以下のコマンドで確認できます。 現在9種類のトラックが使⽤可能です。(2019年7⽉12⽇時点)
!ls tracks/AWS_track.npy
Bowtie_track.npy
H_track.npy
London_Loop_Train.npy
Oval_track.npy
Straight_track.npy
Tokyo_Training_track.npy
Virtual_May19_Train_track.npy
reinvent_base.npyVisualize the Track and Waypoints
読み込んだwaypointsからトラックを描画します。
実行結果
全てのトラックを描画した結果は以下のようになります。
Helper Functions
以下の関数を読み込みます。
plot_track:トラックをプロットする関数
def plot_track(df, track_size=(500, 800), x_offset=0, y_offset=0): ''' Each track may have a diff track size, For reinvent track, use track_size=(500, 800) Tokyo, track_size=(700, 1000) x_offset, y_offset is used to convert to the 0,0 coordinate system ''' track = np.zeros(track_size) # lets magnify the track by *100 #トラック配列の作成 for index, row in df.iterrows(): #dfの行数文繰り返し x = int(row["x"]) + x_offset #初期座標(0,0)に合わせる修正処理 y = int(row["y"]) + y_offset #初期座標(0,0)に合わせる修正処理 reward = row["reward"] track[y,x] = reward #報酬のセット fig = plt.figure(1, figsize=(12, 16)) #figureの作成(図の作成) ax = fig.add_subplot(111) #axesの作成(軸の作成) print_border(ax, center_line, inner_border, outer_border) #トラックコース描画 return track
plot_top_laps:各エピソードの中で報酬の合計が高いエピソードの軌跡をプロットする関数
def plot_top_laps(sorted_idx, n_laps=5): fig = plt.figure(n_laps, figsize=(12, 30)) #figureの作成(図の作成) for i in range(n_laps): #表示するプロット分繰り返す idx = sorted_idx[i] #各エピソードの中で報酬の合計のトップ順にidxを取得 episode_data = episode_map[idx] #取得したidxのデータを取得 ax = fig.add_subplot(n_laps,1,i+1) #axesの作成(軸の作成) line = LineString(center_line) plot_coords(ax, line) #中央ラインの点を描画 plot_line(ax, line) #中央ラインの直線を描画 line = LineString(inner_border) plot_coords(ax, line) #内側のラインの点を描画 plot_line(ax, line) #内側のラインの直線を描画 line = LineString(outer_border) plot_coords(ax, line) #外側のラインの点を描画 plot_line(ax, line) #外側のラインの直線を描画 for idx in range(1, len(episode_data)-1): #エピソードの数分繰り返し x1,y1,action,reward,angle,speed = episode_data[idx] car_x2, car_y2 = x1 - 0.02, y1 plt.plot([x1*100, car_x2*100], [y1*100, car_y2*100], 'b.') #エピソードの座標を描画(座標の点を大きくするために2点描画) return figLoad the training log
ダウンロードしたログファイルを読み込みます(SIM_TRACE_LOG:を含む行をカンマで分割、項目名を付けてpandasのDataFrameを作成)。
実行結果
補足
データの項目と意味は以下の対応表のようになります。
項目 意味 iteration イテレーション episode エピソード steps ステップ数 x, y 車両の座標 yaw 車両の向いている弧度(heading) steer ステアリング弧度(steering_angle) throttle 車両のスピード(speed) action アクションリストのインデックス番号 reward 報酬 done 終了したか on_track コース上にいるか progress コースの消化状況 closest_waypoint 車両の座標から近いwaypointのインデックス※ track_len トラックの長さ timestamp タイムスタンプ Plot rewards per Iteration
イテレーション毎の報酬の平均・標準偏差を算出しグラフに描画します。
Plot rewards per Iteration
REWARD_THRESHOLD = 100 # ★ 赤で強調させたい閾値を設定 # reward graph per episode # イテレーション毎の報酬のグラフ min_episodes = np.min(df['episode']) max_episodes = np.max(df['episode']) print('Number of episodes = ', max_episodes) # イテレーション毎の合計報酬のリストを作成 total_reward_per_episode = list() for epi in range(min_episodes, max_episodes): df_slice = df[df['episode'] == epi] total_reward_per_episode.append(np.sum(df_slice['reward'])) # イテレーション毎の報酬の平均用の空のリストを作成 average_reward_per_iteration = list() # イテレーション毎の報酬の標準偏差用の空のリストを作成 deviation_reward_per_iteration = list() # イテレーション毎の報酬の平均・標準偏差を算出 buffer_rew = list() for val in total_reward_per_episode: buffer_rew.append(val) if len(buffer_rew) == 20: # ★ 平均・標準偏差で扱いたいエピソード数を設定 average_reward_per_iteration.append(np.mean(buffer_rew)) # 平均を算出 deviation_reward_per_iteration.append(np.std(buffer_rew)) # 標準偏差を算出 # reset buffer_rew = list() # 以下描画用実行結果
グラフの見方
1つ目のグラフ
- 内容:イテレーション毎の報酬の平均をプロットしています。
- 横軸:イテレーション
- 縦軸:報酬の平均
2つ目のグラフ
- 内容:イテレーション毎の報酬の標準偏差をプロットしています。
- 横軸:イテレーション
- 縦軸:報酬の標準偏差
3つ目のグラフ
- 内容:エピソード毎の合計報酬をプロットしています。
- 横軸:エピソード
- 縦軸:合計報酬
補足
平均報酬が閾値以上のプロットを強調するには、REWARD_THRESHOLDの値を指定します。
- 【例1】平均報酬が100以上のプロットを強調させたい場合
REWARD_THRESHOLD = 100 # ★ 赤で強調させたい閾値を設定
- 【例2】平均報酬が50以上のプロットを強調させたい場合
REWARD_THRESHOLD = 50 # ★ 赤で強調させたい閾値を設定
Analyze the reward distribution for your reward function
設定した報酬関数によって報酬の分布がどのようになっているのか視覚的に分かりやすく分析します。
実行結果
グラフの見方
以下の図のようなカラーマップを使用しています。
また、グラフのセンターライン付近を拡大すると以下の図のようになります。
センターラインに近づくに従い、高い報酬が与えられていることがわかります。
補足
以下のプログラムの、plt.imshowのcmapの値を変更することでカラーマップの設定した色に変更可能です。
参考)Choosing Colormaps in Matplotlibtrack = plot_track(df) plt.title("Reward distribution for all actions ") im = plt.imshow(track, cmap='hot', interpolation='bilinear', origin="lower") # ★cmapの中の設定を変更することでカラーマップの設定した色に変更可能Plot a particular iteration
指定したiterationの通過した分布を表示します。
準備
描画したいイテレーションIDをiteration_idに設定します。
iteration_id = 30 # ★描画したいイテレーションIDに変更 track = plot_track(df[df['iteration'] == iteration_id]) plt.title("Reward distribution for all actions ") im = plt.imshow(track, cmap='hot', interpolation='bilinear', origin="lower")実行結果
Path taken for top reward iterations
エピソード毎の報酬合計の上位3位までのエピソードの軌跡を確認できます。
実行結果
Path taken in a particular episode
指定したエピソードの軌跡を確認することが出来ます。
準備
以下のプログラムの、plot_episode_runのEの値を変更することで、描画したいエピソードを指定することができます。
fig=plt.figure(1, figsize=(12, 16)) plot_episode_run(df, E=500, ax=fig.add_subplot(211)) # ★Eの値にエピソードIDを指定実行結果
Path taken in a particular Iteration
指定したイテレーションの中の全てのエピソードの軌跡を確認することができます。
準備
以下のプログラムの、iteration_idの値を変更することで、イテレーションを指定することができます。
iteration_id = 20 # ★イテレーションIDを指定 fig = plt.figure(1, figsize=(12, 16)) ax = fig.add_subplot(211) for i in range((iteration_id-1)*EPISODE_PER_ITER, (iteration_id)*EPISODE_PER_ITER): plot_episode_run(df, E=i, ax=ax)実行結果
Action breakdown per iteration and historgram for action distribution for each of the turns - reinvent track
このプログラムでは、指定したイテレーションについて、どのコースの区間(waypointの区間)でどのアクションが使われているかを分析します。
Action breakdown per iteration and historgram for action distribution for each of the turns - reinvent track
iteration_id = [20] # ★分析したいイテレーションIDを指定 fig = plt.figure(figsize=(16, 24)) iterations_downselect = iteration_id # Track Segment Labels # Trackのセグメントラベルの設定 action_names = ['RIGHT-LOW', 'RIGHT-HIGH', 'STRAIGHT-LOW', 'STRAIGHT-HIGH', 'LEFT-LOW', 'LEFT-HIGH'] # ★アクションスペースに合う名前を指定 vert_lines = [10,25,32,33,40,45,50,53,61,67] # 左図 赤四角の数字描画用 track_segments = [(15, 100, 'hairpin'), # 右図 テキスト表示用 (32, 100, 'right'), (42, 100, 'left'), (51, 100, 'left'), (63, 100, 'left')] # 右図 エラーボックス描画用 segment_x = np.array([15, 32, 42, 51, 63]) segment_y = np.array([0, 0, 0, 0, 0]) segment_xerr = np.array([[5, 1, 2, 1, 2], [10, 1, 3, 2, 4]]) segment_yerr = np.array([[0, 0, 0, 0, 0], [150, 150, 150, 150, 150]]) wpts_array = center_line # イテレーションごとに描画 for iter_num in iterations_downselect: # Slice the data frame to get all episodes in that iteration # 指定したイテレーションのデータのみを抽出する df_iter = df[(iter_num == df['iteration'])] n_steps_in_iter = len(df_iter) print('Number of steps in iteration=', n_steps_in_iter) th = 0.8 # ★ 描画したい報酬の閾値を指定する # アクション数ごとに描画 for idx in range(len(action_names)): ax = fig.add_subplot(6, 2, 2*idx+1) print_border(ax, center_line, inner_border, outer_border) # 閾値以上の報酬で該当するアクションのデータを抽出 df_slice = df_iter[df_iter['reward'] >= th] df_slice = df_slice[df_slice['action'] == idx] ax.plot(df_slice['x'], df_slice['y'], 'b.') # 左図に●をプロット # 左図に赤四角のwaypointを描画 for idWp in vert_lines: ax.text(wpts_array[idWp][0], wpts_array[idWp][1]+20, str(idWp), bbox=dict(facecolor='red', alpha=0.5)) #ax.set_title(str(log_name_id) + '-' + str(iter_num) + ' w rew >= '+str(th)) ax.set_ylabel(action_names[idx]) # 左図のY軸ラベルを描画 # calculate action way point distribution # waypointに含まれるアクションの分布を算出 action_waypoint_distribution = list() for idWp in range(len(wpts_array)): action_waypoint_distribution.append(len(df_slice[df_slice['closest_waypoint'] == idWp])) # 以下描画用準備
イテレーションIDの指定の仕方
iteration_idに分析したいイテレーションを指定します。
iteration_id = [20] # ★分析したいイテレーションIDを指定アクションの指定の仕方
モデルによってアクション数が異なるので、自身のモデルのアクションに対応するように、action_namesを修正する必要があります。
今回はSteering angle granularity:3、Speed arnularity:2の6段階のモデルを対象としているので、サイズ6の配列を使用しています。配列の1番目がAction number 0~6番目がAction number5に対応するように指定します。
- 【例1】Steering angle granularity:3、Speed arnularity:2の6段階のモデルの場合
action_names = ['RIGHT-LOW', 'RIGHT-HIGH', 'STRAIGHT-LOW', 'STRAIGHT-HIGH', 'LEFT-LOW', 'LEFT-HIGH'] # ★アクションスペースに合う名前を指定
- 【例2】Steering angle granularity:3、Speed arnularity:1の3段階のモデルの場合
action_names = ['RIGHT', 'STRAIGHT', 'LEFT'] # ★アクションスペースに合う名前を指定描画したい報酬の閾値の設定の仕方
thに閾値の値を指定します。
- 【例1】閾値を0.8にする場合
th = 0.8 # ★ 描画したい報酬の閾値を指定する
- 【例2】閾値を0.3にする場合
th = 0.3 # ★ 描画したい報酬の閾値を指定する
実行結果
グラフの見方
左のグラフ
- 内容:コース上で該当するアクションが使われた場所をプロットしています。
- 赤四角の数字:その場所に該当するwaypointの番号
右のグラフ
- 内容:waypointの区間で該当するアクションが使われた回数を示しています。
- 横軸:waypoint
- 縦軸:アクション数
縦方向のグラフの違い
- 上からアクションスペースが「'RIGHT-LOW', 'RIGHT-HIGH', 'STRAIGHT-LOW', 'STRAIGHT-HIGH', 'LEFT-LOW', 'LEFT-HIGH'」のグラフを示しています。
- action_names変数に入れた値となります。
Simulation Image Analysis - Probability distribution on decisions (actions)
コース画像に対して、どの程度の信頼度でアクションを選択しているかの分析をしています。
準備
S3 bucketとprefix・ダウンロードするモデルの指定
以下のコマンドを実行するとS3のbucketとprefixが確認できます。
!grep "S3 bucket" $fname !grep "S3 prefix" $fname出力されたS3 bucketとS3 prefixの値を以下s3_bucketとs3_prefixにコピーします。
また、--includeの引数の*model_N*のNにダウンロードしたいイテレーション番号を指定します。※ *model_3*であれば、イテレーションIDが3番と30番台のモデルがダウンロードされます。
s3_bucket = 'aws-deepracer-abcd1234-ab12-cd34-ef56-abcdefg12345' # ★s3 bucketをコピー s3_prefix = 'DeepRacer-SageMaker-RoboMaker-comm-127356273604-20190612111111-12345678-9999-ab12-cd34-abcdefg12345'# ★s3 prefixをコピー !aws s3 sync s3://$s3_bucket/$s3_prefix/model/ intermediate_checkpoint/ --exclude "*" --include "*model_3*" # ★ダウンロードしたいイテレーションの番号を指定する以下のコマンドを実行すると、ダウンロードされたモデルを確認することができます。
!ls $GRAPH_PB_PATH分析するイテレーションの指定の仕方
ダウンロードされたモデルの中から、分析したいイテレーションIDをiterationsに指定します。
Simulation Image Analysis - Probability distribution on decisions
model_inference = [] iterations = [30, 35] # ★GRAPH_PB_PATHフォルダから分析したいモデルを指定する # 各モデルに対して、各コース画像に対する推論結果を算出 for ii in iterations: model, obs, model_out = load_session(GRAPH_PB_PATH + 'model_%s.pb' % ii) arr = [] # 各コース画像に対する推論を実行 for f in all_files[:]: img = Image.open(f) img_arr = np.array(img) img_arr = rgb2gray(img_arr) img_arr = np.expand_dims(img_arr, axis=2) # 画像ファイルを推論用の形式に変換 current_state = {"observation": img_arr} #(1, 120, 160, 1) y_output = model.run(model_out, feed_dict={obs:[img_arr]})[0] # コース画像に対する推論を実行 arr.append (y_output) model_inference.append(arr) # 推論結果をappend model.close() tf.reset_default_graph()model_inference = [] iterations = [30, 35] # ★GRAPH_PB_PATHフォルダから分析したいモデルの番号を指定する実行結果
グラフの見方
横軸、縦軸は以下を示しています。
- 横軸:推論結果が高いアクション上位1位と上位2位の差
- 縦軸:カウント
つまり、0.8~1.0あたりが大きいヒストグラムがよく学習できていると考えることができます。
補足
算出方法について
model_inferenceには以下のようなデータが保存されています。これは左からアクションスペース0~5が推論された確率を示しており、推論結果の確率が917枚分(simulation_episodeのフォルダにある画像の枚数)の含まれるリストが2イテレーション分(今回指定したイテレーション数)含まれるリストになっています。
グラフの比較
以下のグラフはイテレーション0、30、35のグラフを示しています。イテレーションが増えるに従い、0.0付近のヒストグラムが減っているので、よく学習できていることがわかります。
入力値について
推論の入力値として以下のようなコース画像を使用しています。
Model CSV Analysis
モデルのCSVファイルの分析をします。
準備
- AWS DeepRacerのコンソール画面からモデルをダウンロードします。
- ダウンロードしたファイルをintermediate_checkpointフォルダにアップロードします。
- 以下のコマンドを実行しtarファイルを解凍します。
!tar xzf intermediate_checkpoint/model_name.tar.gz -C intermediate_checkpoint/ # ★model_nameを自身のモデル名に変更する実行結果
グラフの見方
1つ目のグラフ
- 内容:トレーニングイテレーション毎の報酬を示しています。
- 横軸:トレーニングイテレーション
- 縦軸:報酬
2つ目のグラフ
- 内容:エピソード毎のエピソードの長さ(ステップ数)示しています。
- 横軸:エピソード
- 縦軸:エピソードの長さ(ステップ数)
Evaluation Run Analyis
評価ログの分析をします。
準備
eval_simにEvaluationに記載されているシミュレーションIDを設定します。
eval_sim = 'sim-abcdefg12345' eval_fname = './logs/deepracer-eval-%s.log' % eval_sim実行結果
Grid World Analysis
スピードをエピソード毎の走行経路と一緒に描画します。
準備
N_EPISODESにEvaluation実行時に指定したラップ数を指定します。
N_EPISODES = 3 # ★Evaluation実行時に指定したラップ数を指定する実行結果
グラフの見方
スピードが速いほど黄色くなっています。
黄色い色が多いほど全体的に高速で走行していると考えられます。補足
Grid Worldについて
処理としては1x1のグリッド内に存在するスピードの平均値をプロットしているようです。
(0, 0)から(max(x), max(y))まで1ずつ増やしていき、データの中で x-1~x、x-1~yまでの間のスピードの平均値をそのマスの値としているようです。Distanceについて
走行距離は2つの座標間の距離を計算したものを足し算した結果のようです。
What is the model looking at?
モデルが画像をどのように見ているのかをGrad-CAMという手法を使って可視化します。
Grad-CAM:Gradient-weighted Class ActivationMapping
Grad-CAM:
Visual Explanations from Deep Networks via Gradient-based Localization
PDFを見ていただくと分かりやすいですが、DogやCatという分類結果に強く影響している領域をヒートマップで表現しています。
AWS DeepRacerに置き換えると、特定のアクションスペース(ステアリング角度とスピードの組み合わせ)を選択する場合に強く影響している領域を可視化しているといえます。
What is the model looking at?
import cv2 import numpy as np import tensorflow as tf # デフォルトは以下の通りです # category_index=0 : アクションスペース0のアクションに対する分析になります # num_of_actions=6 : アクションスペースを6段階で作成したモデルを分析します def visualize_gradcam_discrete_ppo(sess, rgb_img, category_index=0, num_of_actions=6): ''' @inp: model session, RGB Image - np array, action_index, total number of actions @return: overlayed heatmap ''' img_arr = np.array(rgb_img) img_arr = rgb2gray(img_arr) img_arr = np.expand_dims(img_arr, axis=2) # img_arr.shape = (120, 160, 1) # sess.runまでは準備です # 画像データをインプット # x に対して入力のテンソルを紐づけ、そのテンソルに対して画像のデータを設定します # y に対して # get_tensor_by_name で指定する値は下記の中から目的に応じて選択しているようです # sess.graph.get_operations() x = sess.graph.get_tensor_by_name('main_level/agent/main/online/network_0/observation/observation:0') y = sess.graph.get_tensor_by_name('main_level/agent/main/online/network_1/ppo_head_0/policy:0') feed_dict = {x:[img_arr]} # 出力層を取得します #Get he policy head for clipped ppo in coach model_out_layer = sess.graph.get_tensor_by_name('main_level/agent/main/online/network_1/ppo_head_0/policy:0') # 出力層の中で指定したアクションスペースに対応する部分のみを取り出す # multiply: 行列の積 # 引数1: model_out_layerからは、アクションスペース毎の出力が得られる # 引数2: one_hotにより、category_indexで指定したアクションスペースの値以外を0にする loss = tf.multiply(model_out_layer, tf.one_hot([category_index], num_of_actions)) # すべての要素の和を取る loss[0]なのは1次元の配列のため reduced_loss = tf.reduce_sum(loss[0]) conv_output = sess.graph.get_tensor_by_name('main_level/agent/main/online/network_1/observation/Conv2d_4/Conv2D:0') # 勾配を計算する grads = tf.gradients(reduced_loss, conv_output)[0] output, grads_val = sess.run([conv_output, grads], feed_dict=feed_dict) # その領域の平均を重みとして計算します # grads_val.shape (1, 11, 16, 64) weights = np.mean(grads_val, axis=(1, 2)) # (1, 64) # 画素値に重みを加えます cams = np.sum(weights * output, axis=3) # cams :(1, 11, 16) , weights :(1, 64), output :(1, 11, 16, 64) # 11 x 16 の配列要素それぞれに weights * output の要素の合計値が格納される ##im_h, im_w = 120, 160## im_h, im_w = rgb_img.shape[:2] cam = cams[0] #img 0 image = np.uint8(rgb_img[:, :, ::-1] * 255.0) # RGB -> BGR cam = cv2.resize(cam, (im_w, im_h)) # zoom heatmap cam = np.maximum(cam, 0) # relu clip 0以上の値にする #heatmap = cam / np.max(cam) # normalize heatmap = cam / (np.max(cam) + 1E-5) # normalize cam = cv2.applyColorMap(np.uint8(255 * heatmap), cv2.COLORMAP_JET) # grayscale to color カラーマップ JETの256段階でヒートマップを表現する cam = np.float32(cam) + np.float32(image) # overlay heatmap 元画像にヒートマップを重ねる cam = 255 * cam / (np.max(cam) + 1E-5) ## Add expsilon for stability cam = np.uint8(cam)[:, :, ::-1] # to RGB return cam準備
model_pathのmodel_N.pbを分析したいモデルの番号に変更します。
model_path = GRAPH_PB_PATH + 'model_35.pb' # ★分析したいモデルの番号
補足
ヒートマップは画像のどのあたりが行動に影響を与えているかを表現していると思われます。
ただし、色が沢山ついているからといって必ずしも実際にとる行動と一致するわけではないようです。
各アクションスペースに対応するヒートマップを表示してみます。image_idx = 850 num_of_actions = 6 heatmaps = [] model_path = GRAPH_PB_PATH + 'model_35.pb' #Change this to your model 'pb' frozen graph file model, obs, model_out = load_session(model_path) for f in all_files[image_idx:image_idx+1]: img = np.array(Image.open(f)) for idx in range(num_of_actions): heatmap = visualize_gradcam_discrete_ppo(model, img, category_index=idx, num_of_actions=num_of_actions) heatmaps.append(heatmap) tf.reset_default_graph() fig = plt.figure(figsize=(16, 48)) for i in range(len(heatmaps)): ax = fig.add_subplot(1, len(heatmaps), i+1) ax.set_title(action_names[i], fontsize=8) ax.tick_params(labelbottom=False, labelleft=False) plt.xticks([]) plt.yticks([]) ax.imshow(heatmaps[i])
入力画像に対してどのような行動を取る確率が高いかを調べてみます。
# 予測する関数 def predict_for_action_space(sess, rgb_img, num_of_actions=6): img_arr = np.array(rgb_img) img_arr = rgb2gray(img_arr) img_arr = np.expand_dims(img_arr, axis=2) x = sess.graph.get_tensor_by_name('main_level/agent/main/online/network_0/observation/observation:0') y = sess.graph.get_tensor_by_name('main_level/agent/main/online/network_1/ppo_head_0/policy:0') feed_dict = {x:[img_arr]} prediction = sess.run(y, feed_dict=feed_dict) return prediction# グラフ化する関数 # https://www.tensorflow.org/tutorials/keras/basic_classification def plot_value_array(predictions_array, action_labels): plt.grid(False) plt.xticks([]) plt.yticks([]) thisplot = plt.bar(range(len(predictions_array)), predictions_array, color="#777777") plt.xticks(range(len(predictions_array)), action_labels, rotation=90) plt.ylim([0, 1]) predicted_label = np.argmax(predictions_array) thisplot[predicted_label].set_color('red') # What is the model looking at?と同じ画像ファイルを読み込む f = all_files[image_idx] img = np.array(Image.open(f)) prediction = predict_for_action_space(model, img, num_of_actions=6) # 下記で定義したラベルを使います # Action breakdown per iteration and historgram for action distribution for each of the turns - reinvent track action_names = ['RIGHT-LOW', 'RIGHT-HIGH', 'STRAIGHT-LOW', 'STRAIGHT-HIGH', 'LEFT-LOW', 'LEFT-HIGH'] plot_value_array(prediction[0], action_names)入力画像
アクションをとる確率
現実の画像に当てはめてみた結果は以下のようになります。
実機の環境では、コースとあまり関係のない、柱の情報がアクションに影響を及ぼしている場合もあるということがわかります。
まとめ
本記事では、モデルの分析・可視化について解説しました。
効率的にスピードアップを図るためにもモデル分析は有効です。
モデルを分析してAWS DeepRacer世界一を目指しましょう。

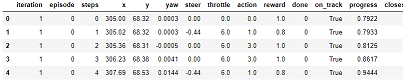
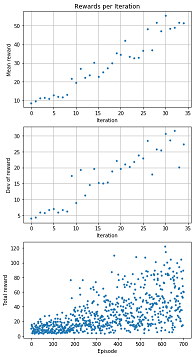
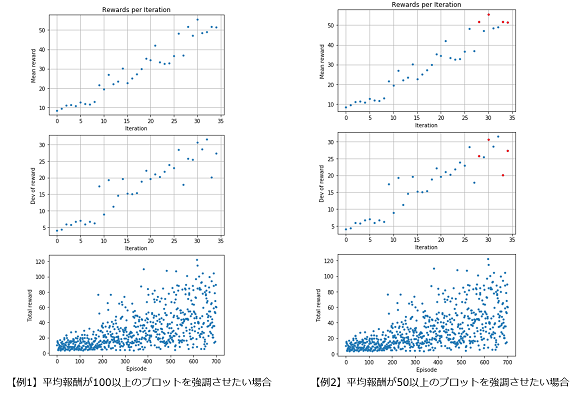
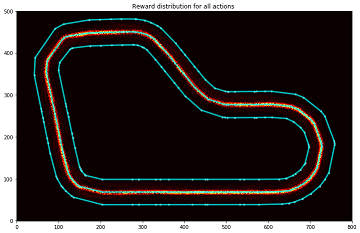


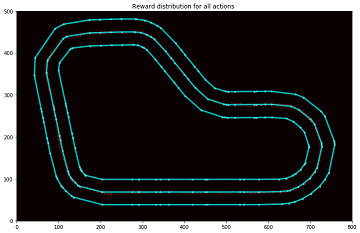
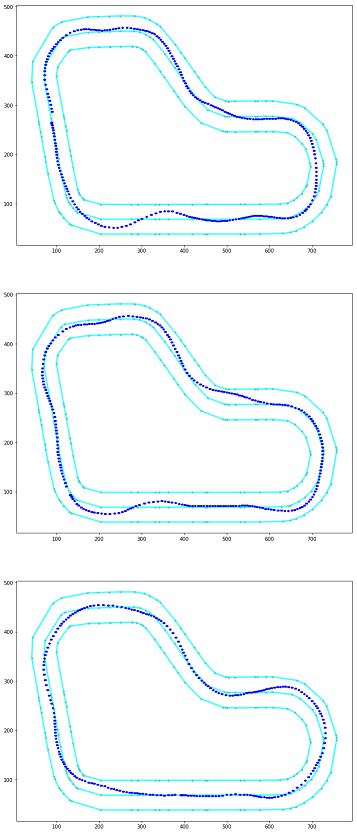
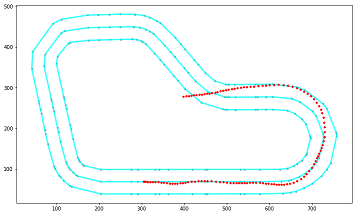
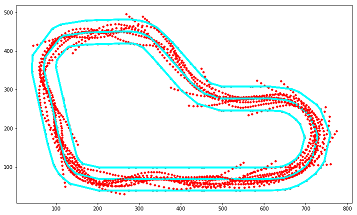
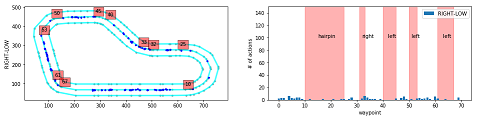
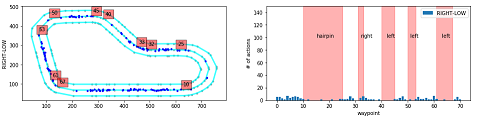
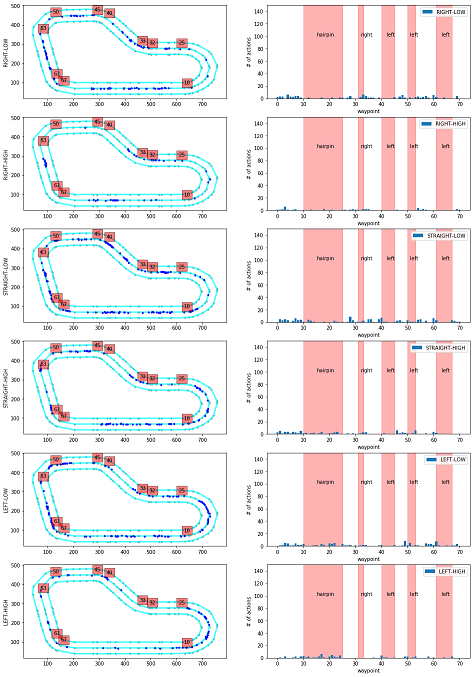
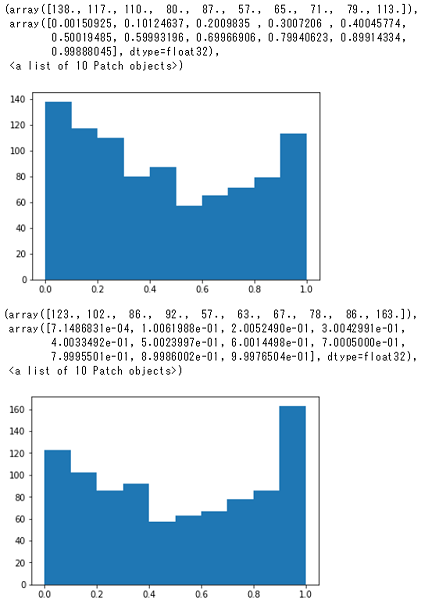
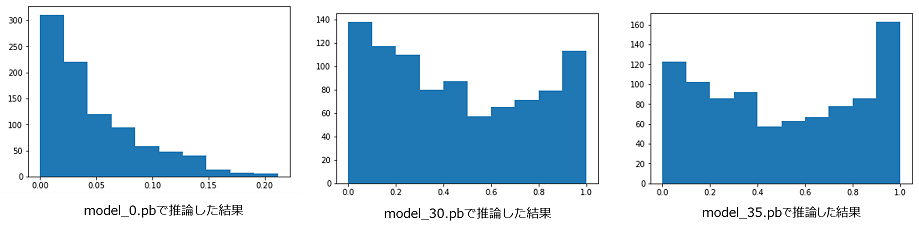


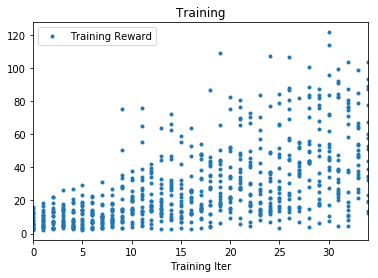
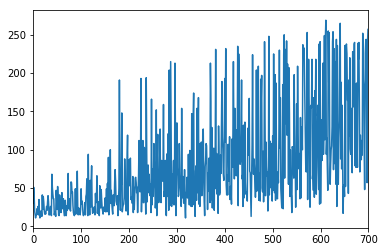

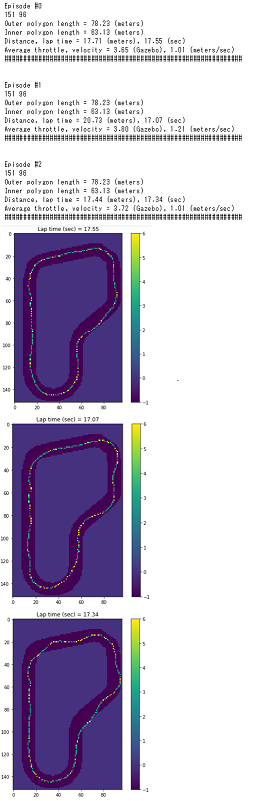
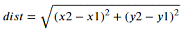
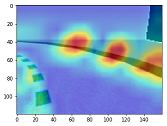


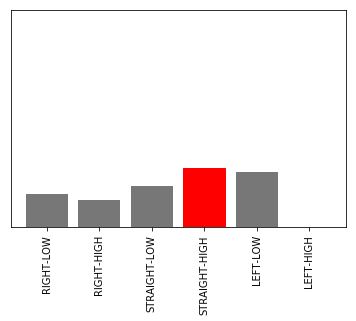


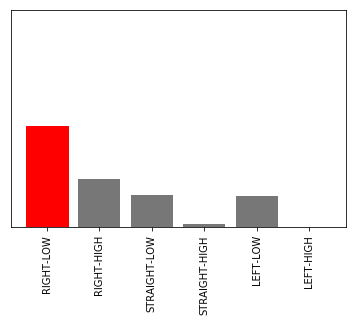
- 投稿日:2019-07-19T09:55:52+09:00
社内勉強会:AWS DeepRacer基礎編(ハイパーパラメータ)を開催した
はじめに
社内でAWS DeepRacer人口が増えてきており、ちょっと乗り遅れてしまった人向けにAWS DeepRacer勉強会基礎編を社内で開催したのでその内容を公開します。
本記事では基礎編のハイパーパラメータについて解説しています。
その他の勉強会の内容については、以下の記事をご確認ください。
- 社内勉強会:AWS DeepRacer基礎編(モデル作成)を開催した
- 社内勉強会:AWS DeepRacer基礎編(ログ取得)を開催した
- 社内勉強会:AWS DeepRacer応用編(ログの分析・可視化)を開催した
ハイパーパラメータ概要
ハイパーパラメータとは、機械学習アルゴリズムの挙動を制御するために人が設定するパラメータのことです。
AWS DeepRacerでは以下のハイパーパラメータが使用されています。
ハイパーパラメータ 有効な値 意味 勾配降下のバッチサイズ 32/64/128/256/512 直近の車両エクスペリエンスの数はエクスペリエンスバッファから無作為に抽出され、基盤となるニューラルネットワークの重みを更新するために使用されます。 エポック数 3-10 勾配降下中にニューラルネットワークの重みを更新するためにトレーニングデータを通過する回数です。 学習率 1e-8 - 1e-3 学習率は、勾配降下の更新がネットワークの重みにどれだけ寄与するかを制御します。 エントロピー 0 - 1 ポリシーに無作為性を追加するタイミングを決定するために使用されます。 割引係数 0 - 1 将来の報酬が期待される報酬にどのくらい寄与するかを指定します。 損失タイプ 平均二乗誤差/Huber損失 ネットワークの重みを更新するために使用される損失(目的)関数のタイプを指定します。 各ポリシー更新反復間のエクスペリエンスエピソードの数 5 - 100 ポリシーネットワークの重み付けを学習する ためのトレーニングデータを取得するために使用されるエクスペリエンスバッファのサイズ。 出典)AWS DeepRacer開発者ガイド > モデルのトレーニングと評価 >
AWS DeepRacerコンソールを使用したモデルのトレーニングと評価 >ハイパーパラメータを体系的に調整する用語の定義
ハイパーパラメータの意味を理解する上で必要な用語の定義を確認します。
- エピソード:車両が任意の出発点から出発し、最終的にトラックを完走するかまたはトラックから外れるまでの期間
- エクスペリエンスバッファ:トレーニング中にさまざまな長さの一定数のエピソードにわたって収集された多数の順序付けられたデータ点
- エピソードの集合体
- エクスペリエンスバッファからランダムに抽出したデータを用いてモデルの学習を行う
ハイパーパラメータのイメージ
各ポリシー更新反復間のエクスペリエンスエピソード数
AWS DeepRacerで使用している強化モデルのトレーニングアルゴリズムはPPO(Proximal Policy Optimization)です。
Experience Replay Buffer及び、ハイパーパラメータの各ポリシー更新反復間のエクスペリエンスエピソード数のイメージは以下になります。
勾配降下のバッチサイズ・エポック数・学習率・損失タイプ
AWS DeepRacer含む機械学習が目指すものは、モデルの予測値と実際値との誤差をなくすことです。
モデルの予測値と損失値の差を損失関数で定義し、損失関数の最小値を求めることが機械学習の目指すものと言い換えることができます。
一般に、機械学習では勾配降下法という手法を用いて最適解(損失関数の最小値)を探索します。勾配降下法のイメージは以下の図のようになります。
損失タイプ
AWS DeepRacerでは、モデルの予測値と絶対値の差に使われる損失関数を、平均二乗誤差とHuber損失から選択することができます。
学習率
学習率(α)は一度でどれだけ学習を進めるかを定義しています。値を大きくするとより早く学習が進みますが、大きくしすぎると発散する危険があります。反対に、小さくするとより細かく学習できますが、局所解に陥るなどの危険があります。
エポック数
エポック数(k)は、1つの学習データを繰り返し学習する回数になります。エポック数は過学習が起きず、学習データでの精度と検証データでの精度がともに高くなるような値に指定する必要があります。
勾配降下のバッチサイズ
学習データセットをサブセットに分けたときのデータ数です。
エントロピー
エントロピーは「わからなさ」「不確実性」「予測できなさ」の意味であり、AWS DeepRacerではエントロピーを大きくするほど、アクションスペースを広く探索することになります。つまり、訓練中のアクションスペースの選択にランダム性を持たせることができます。
割引係数
将来の報酬を算出する式は以下の式で定義されています。
割引係数(γ)は、将来の報酬が期待される報酬にどれだけ影響を及ぼすか、つまり、実行するアクションを決める上でどれだけ将来を考慮するかを示しています。
例)
- γ=0の場合:現在の状態・行動だけを考慮
- γ=0.9の場合:ある程度近い未来を考慮
ハイパーパラメータの考察
数値を上げたときのメリットデメリットの考察は以下になります。
パラメータ メリット デメリット 勾配降下のバッチサイズ 重みの更新が安定化する トレーニングに必要な時間が長くなる エポック数 トレーニングの精度を上げることが可能 トレーニングに必要な時間が長くなる 学習率 早くトレーニングさせることが可能 報酬が収束しづらくなる エントロピー 行動にランダム性を持たせることが可能 トレーニングに必要な時間が長くなる 割引係数 将来のステップを考慮したうえでアクションスペースを選択 トレーニングに必要な時間が長くなる 各ポリシー更新反復間のエクスペリエンスエピソードの数 重みの更新が安定化する トレーニングに必要な時間が長くなる まとめ
本記事では、AWS DeepRacerで使用されるハイパーパラメータについての解説を行いました。
解釈に間違いがあるかもしれませんが、ご容赦いただければと思います。

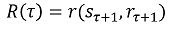
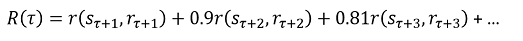
- 投稿日:2019-07-19T09:55:29+09:00
社内勉強会:AWS DeepRacer基礎編(ログ取得)を開催した
はじめに
社内でAWS DeepRacer人口が増えてきており、ちょっと乗り遅れてしまった人向けにAWS DeepRacer勉強会基礎編を社内で開催したのでその内容を公開します。
本記事では基礎編のログ取得について解説しています。
その他の勉強会の内容については、以下の記事をご確認ください。
- 社内勉強会:AWS DeepRacer基礎編(モデル作成)を開催した
- 社内勉強会:AWS DeepRacer基礎編(ハイパーパラメータ)を開催した
- 社内勉強会:AWS DeepRacer応用編(ログの分析・可視化)を開催した
ログについて
ログの取得方法の種類
ログの取得方法はいくつかあります。
- CloudWatchから一部のみ取得する:本記事記載
- CloudWatch APIを使用して全件取得する:社内勉強会:AWS DeepRacer応用編(ログの分析・可視化)を開催した記載
ログの種類とアクセス方法
- Trainingログ:トレーニング中に出力されたログ
Training > Simulation Job > View logsをクリックします。
- Evaluationログ:評価走行中に出力されたログ
Evaluation > Simulation Job > View logsをクリックします。
ログの表示
AWS DeepRacerコンソール画面からTrainingまたはEvaluationのView logsをクリックするとCloudWatchのコンソール画面に遷移します。ログストリームからログをクリックすると該当するログが表示されます。
※ Trainingログのキャプチャ
ログの取得
CloudWatchのコンソール画面の左ペインから、[インサイト]をクリックします。
Logs Insightsのコンソール画面から、以下の項目を入力し、[クエリの実行]ボタンをクリックします。
- ①ロググループ名:/aws/robomaker/SimulationJobs
- ②期間:処理を実行した期間を指定します 例)2019-06-13(00:00:00)-2019-06-13(23:59:59)
- ③クエリ:
- 以下のクエリを使用して、必要な行を取得するとともに、parseを使用して、各項目をCSV形式で取得できるようにします。
- 1行目のシミュレーションIDを適宜書き換えてください。※ 例ではシミュレーションID:sim-abcd12345678
filter @logStream like /sim-abcd12345678/ | filter @message like /SIM_TRACE_LOG:/ | parse @message "SIM_TRACE_LOG:*,*,*,*,*,*,*,*,*,*,*,*,*,*,*" as episodes,tsteps,x,y,yaw,steering_angle,throttle,action_taken,reward,done,on_track,current_progress,closest_waypoint_index,track_length | sort @timestamp ascログのダウンロード
[アクション] > [クエリ結果をダウンロード(CSV)]をクリックするとCSV形式でログをダウンロードすることができます。
ダウンロードしたCSVファイルのデータで、車両が通過した軌跡の視覚化や報酬の確認など、ログの分析をすることが可能です。
例)車両が通過した軌跡を視覚化
ログの出力
報酬関数内でprint文を書くことで、独自のログを出力することができます。
def reward_function(params): ''' Example of penalize steering, which helps mitigate zig-zag behaviors ''' # Read input parameters distance_from_center = params['distance_from_center'] track_width = params['track_width'] steering = abs(params['steering_angle']) # Only need the absolute steering angle waypoints = params['waypoints'] # Calculate 3 markers that are at varying distances away from the center line marker_1 = 0.1 * track_width marker_2 = 0.25 * track_width marker_3 = 0.5 * track_width # Give higher reward if the agent is closer to center line and vice versa if distance_from_center <= marker_1: reward = 1 elif distance_from_center <= marker_2: reward = 0.5 elif distance_from_center <= marker_3: reward = 0.1 else: reward = 1e-3 # likely crashed/ close to off track # Steering penality threshold, change the number based on your action space setting ABS_STEERING_THRESHOLD = 15 # Penalize reward if the agent is steering too much if steering > ABS_STEERING_THRESHOLD: reward *= 0.8 print("CUSTOM_LOG:wp={}".format(waypoints)) return float(reward)なお、Logs Insightsのコンソール画面から、ログを抽出する場合は以下のクエリを実行します。
※ waypointsは何行も表示される必要がないので、limit 1としています。filter @logStream like /sim-abcd12345678/ | filter @message like /CUSTOM_LOG:/ | parse @message "CUSTOM_LOG:wp=*" as waypoints | sort @timestamp asc | limit 1まとめ
本記事では、CloudWatchから一部のログを取得する方法を解説しました。
ログを分析して効率的に精度向上していけたらと思います。

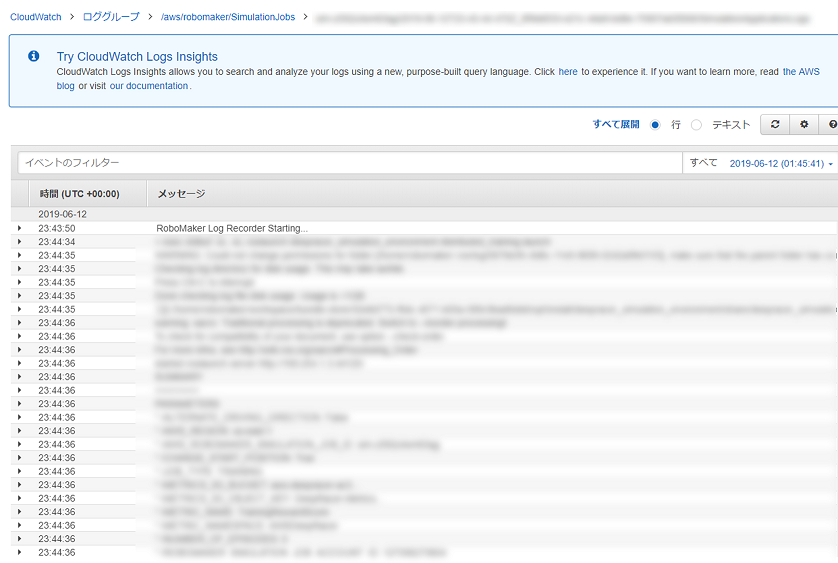
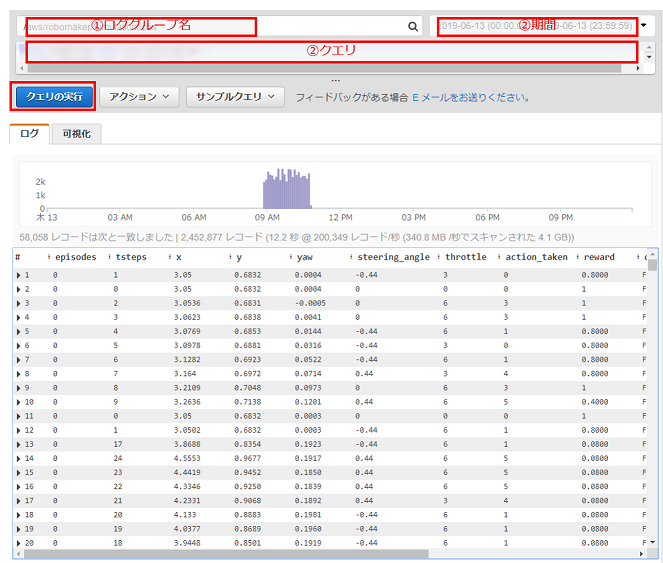
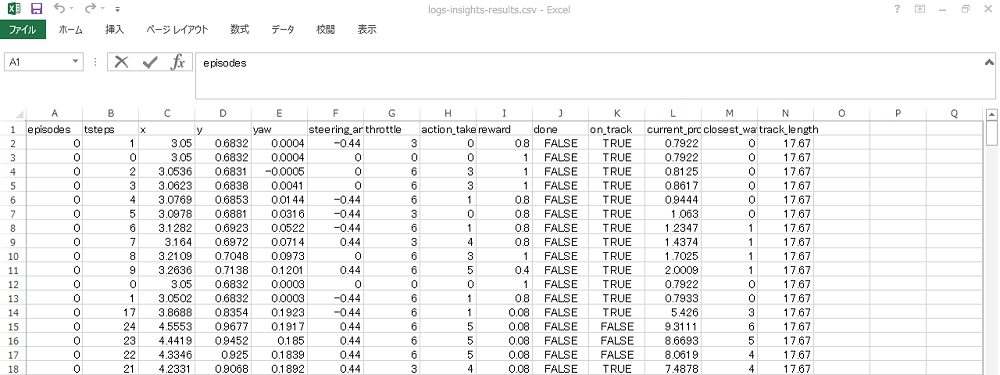
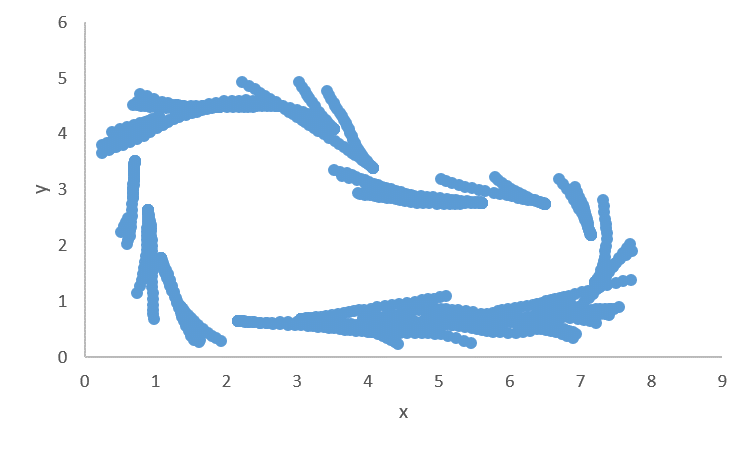
- 投稿日:2019-07-19T09:55:01+09:00
社内勉強会:AWS DeepRacer基礎編(モデル作成)を開催した
はじめに
社内でAWS DeepRacer人口が増えてきており、ちょっと乗り遅れてしまった人向けにAWS DeepRacer勉強会基礎編を開催したのでその内容を公開します。
本記事では基礎編のモデル作成ついて解説しています。
その他の勉強会の内容については、以下の記事をご確認ください。
- 社内勉強会:AWS DeepRacer基礎編(ログ取得)を開催した
- 社内勉強会:AWS DeepRacer基礎編(ハイパーパラメータ)を開催した
- 社内勉強会:AWS DeepRacer応用編(ログの分析・可視化)を開催した
モデル作成準備
AWSマネジメントコンソールにログイン
AWS マネジメントコンソールにログインし、「サービス」の一覧でAWS DeepRacerを検索します。
リージョンの選択
ナビゲーションバー右上からリージョン名を選択し、「米国東部(バージニア北部)/ North Virginia」に変更します。
Rinforcement learningの立ち上げ
AWS DeepRacerコンソールが開いたら、左ペインの[Reinforcement learning]をクリックします。
モデル作成
モデル作成画面の立ち上げ
AWS DeepRacerコンソール画面から[Create model]ボタンをクリックします。
モデル名の設定
モデル名(Model name)とモデルの説明(Model description - optional)を入力します。
※ モデル名はアカウント内で重複しないように設定する必要があります。
Environment simulationの設定
トレーニングに使用するコースを選択します。
※ 7つのコースが利用可能(2019/07/17現在)
Action spaceの設定
以下のAction space(AWS DeepRacerのステアリングの角度とスピード)に関するパラメータを設定します。
- Maximum steering angle:最大のステアリング角度
- Steering angle granularity:ステアリング角度の分割数
- Maximum speed:最大のスピード
- Speed granularity:スピードの分割数
※ 筆者がAWS Summit Tokyo 2019に参加した際は、以下のパラメータに設定しました。
- Maximum steering angle:25 degrees
- Steering angle granularity:3
- Maximum speed:6 m/s
- Speed granularity:2
Reward functionの設定
車両の動作に応じた報酬関数を定義します。[Reward function examples]をクリックすると、報酬関数のサンプルを見ることができます。
※ 3つのサンプルが利用可能(2019/07/17現在)
Follow the center line (Default)
センターラインに沿って走行する報酬関数
def reward_function(params): ''' Example of rewarding the agent to follow center line ''' # Read input parameters track_width = params['track_width'] distance_from_center = params['distance_from_center'] # Calculate 3 markers that are at varying distances away from the center line marker_1 = 0.1 * track_width marker_2 = 0.25 * track_width marker_3 = 0.5 * track_width # Give higher reward if the car is closer to center line and vice versa if distance_from_center <= marker_1: reward = 1.0 elif distance_from_center <= marker_2: reward = 0.5 elif distance_from_center <= marker_3: reward = 0.1 else: reward = 1e-3 # likely crashed/ close to off track return float(reward)
Stay inside the two borders
トラックの境界線内で走行する報酬関数
def reward_function(params): ''' Example of rewarding the agent to stay inside the two borders of the track ''' # Read input parameters all_wheels_on_track = params['all_wheels_on_track'] distance_from_center = params['distance_from_center'] track_width = params['track_width'] # Give a very low reward by default reward = 1e-3 # Give a high reward if no wheels go off the track and # the agent is somewhere in between the track borders if all_wheels_on_track and (0.5*track_width - distance_from_center) >= 0.05: reward = 1.0 # Always return a float value return float(reward)
Prevent zig-zag
ジグザグ走行を抑制する報酬関数
def reward_function(params): ''' Example of penalize steering, which helps mitigate zig-zag behaviors ''' # Read input parameters distance_from_center = params['distance_from_center'] track_width = params['track_width'] steering = abs(params['steering_angle']) # Only need the absolute steering angle # Calculate 3 markers that are at varying distances away from the center line marker_1 = 0.1 * track_width marker_2 = 0.25 * track_width marker_3 = 0.5 * track_width # Give higher reward if the agent is closer to center line and vice versa if distance_from_center <= marker_1: reward = 1 elif distance_from_center <= marker_2: reward = 0.5 elif distance_from_center <= marker_3: reward = 0.1 else: reward = 1e-3 # likely crashed/ close to off track # Steering penality threshold, change the number based on your action space setting ABS_STEERING_THRESHOLD = 15 # Penalize reward if the agent is steering too much if steering > ABS_STEERING_THRESHOLD: reward *= 0.8 return float(reward)※ 筆者がAWS Summit Tokyo 2019に参加した際は、Prevent zig-zagをベースにした報酬関数でトレーニングしました。
Hyperparametersの設定
以下のハイパーパラメータに関する設定をします。
- Gradient descent batch size:勾配降下のバッチサイズ
- Number of epochs:エポック数
- Learning rate:学習率
- Entropy:エントロピー
- Discount factor:割引係数
- Loss type:損失タイプ
- Number of experience episodes between each policy-updating iteration:各ポリシー更新反復間のエクスペリエンスエピソードの数
※ 筆者がAWS Summit Tokyo 2019に参加した際は、Gradient descent batch sizeを128にし、それ以外はデフォルトでトレーニングしました。
※ ハイパーパラメータの詳細については、社内勉強会:AWS DeepRacer基礎編(ハイパーパラメータ)を開催したをご確認ください。Stop conditionsの設定
Maximum timeにトレーニングの時間を設定します。
※ 筆者がAWS Summit Tokyo 2019に参加した際は、re:Invent 2018 2時間、AWS Track 1時間、Bowtie Track 1時間、re:Invent 2018 30分トレーニングしました。
トレーニングの開始
[Start training]をクリックし、トレーニングを開始します。
トレーニング中の画面
左のグラフはトレーニングの進行状況を示しており、横軸はトレーニング時間、縦軸は報酬を示しています。
右上がりのグラフであれば、最適な報酬を探索している状態であると考えられます。右の図(コンソール画面では動画)は走行中の車の視点を示しており、走っている様子を確認することができます。
モデル作成後
トレーニングが終了すると、Trainingの右にCompletedが表示されます。
モデル評価
[Start evaluation]をクリックし、評価したいコースと試行回数を選択しモデルを評価します。
評価が完了すると、AWS DeepRacerコンソール画面から評価結果を確認することができます。
再トレーニング
トレーニングしたモデルを使ってさらにトレーニングをしたい場合、[Clone]ボタンをクリックし、Environment simulation、Reward function、Hyperparameters、Stop conditionsの設定をし、再トレーニングます。
※ Action spaceは変更できません。
モデルのダウンロード
実機で動かしたい場合、[Download model]ボタンをクリックしてモデルをダウンロードします。
Virtual raceの参加
Virtual raceに参加したい場合、[Submit to virtual race]ボタンをクリックし、使用するモデルを選択後、[Submit model]ボタンをクリックします。
Virtual raceの画面から結果を確認することができます。
まとめ
本記事では、モデル作成準備~レースの参加方法まで解説しました。
Action space、Reward function、Hyperparametersについては、精度向上に向けて試行錯誤で色々試してみていただけたらと思います。


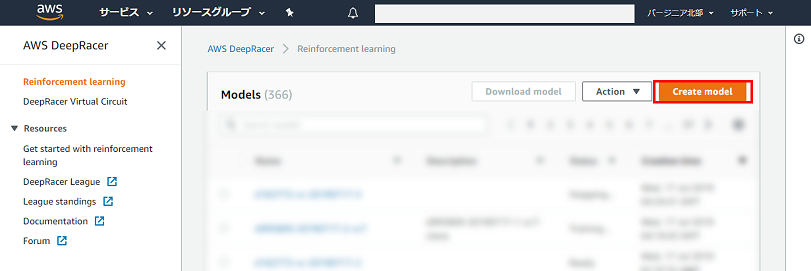
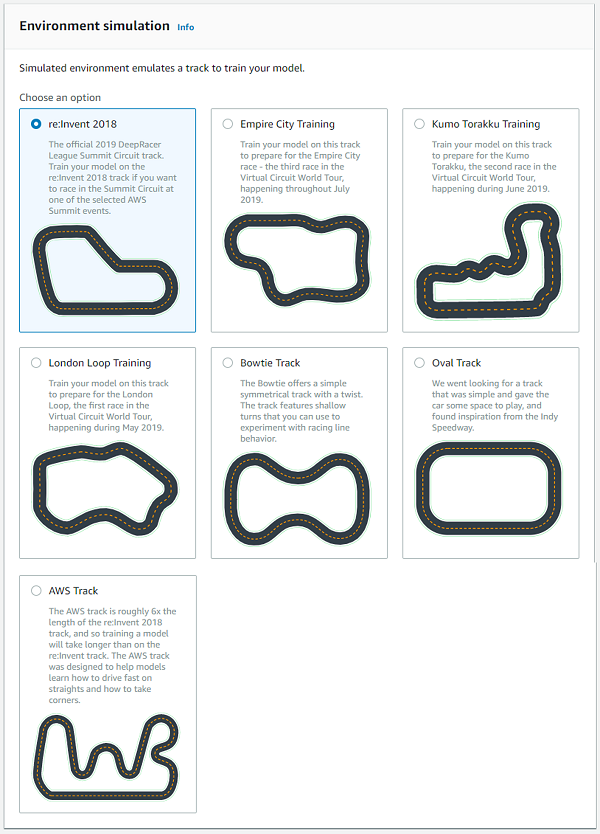
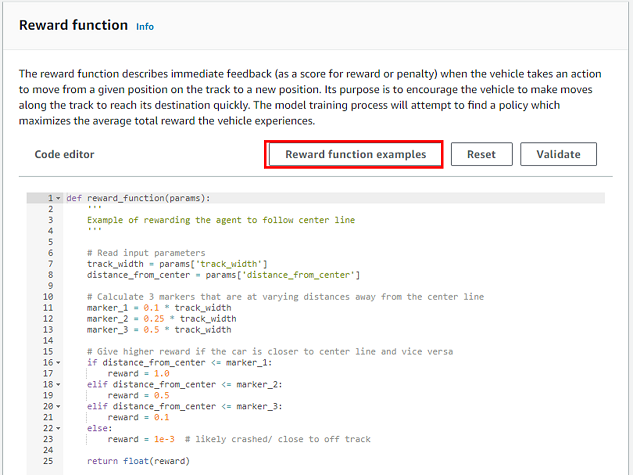
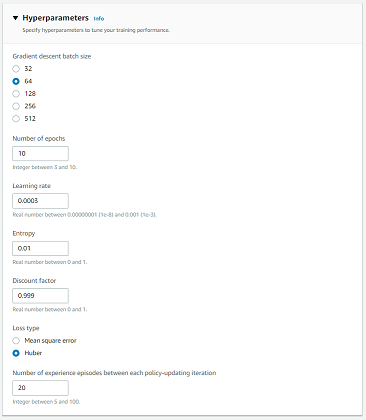
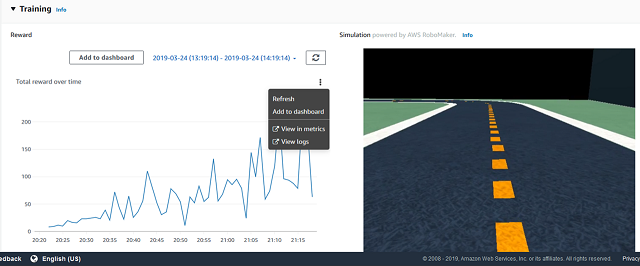
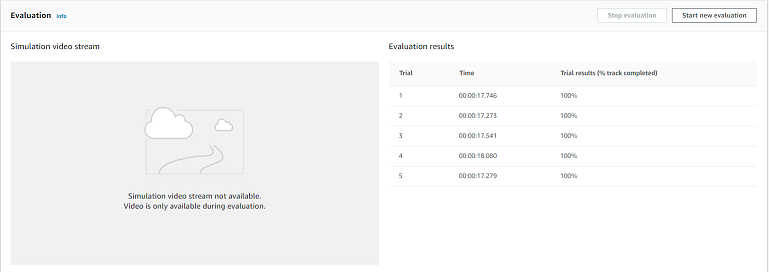
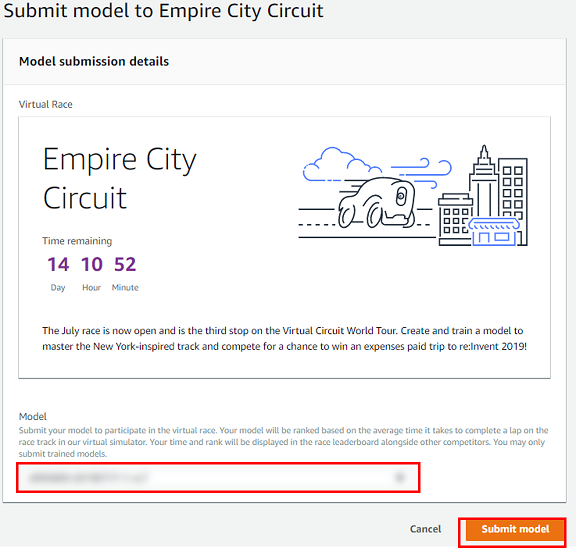
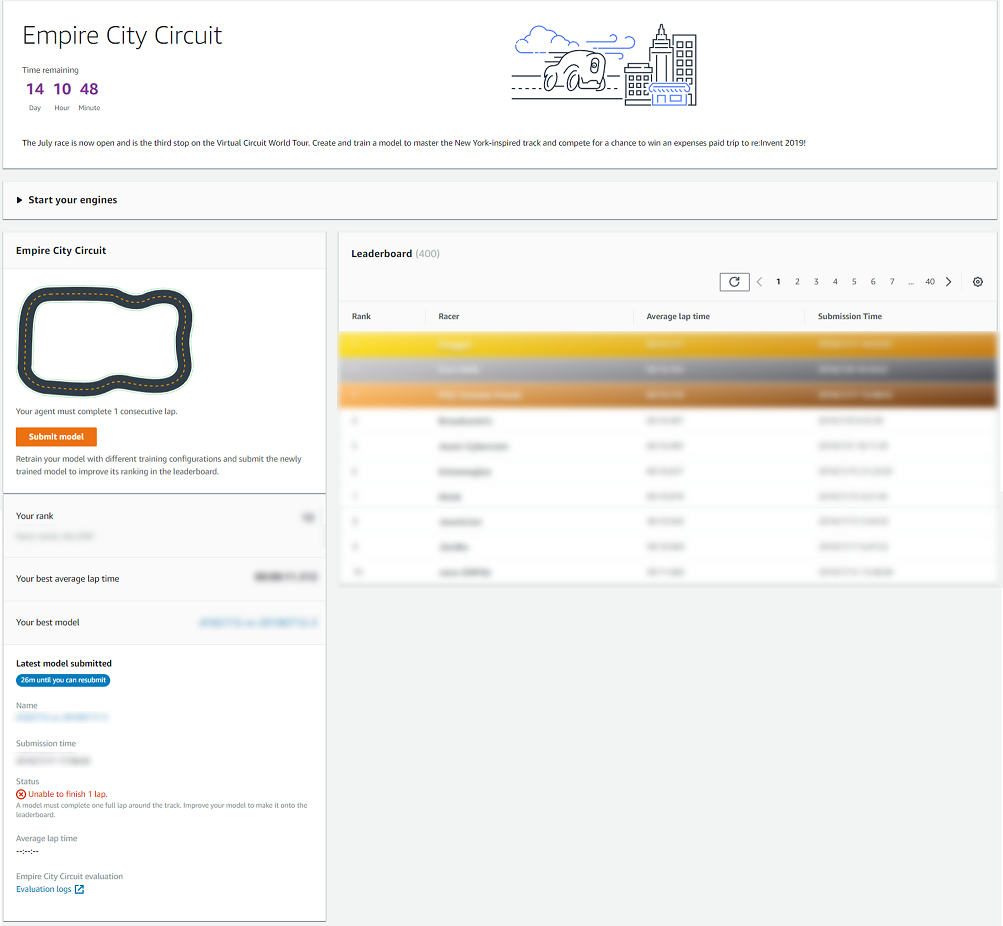
- 投稿日:2019-07-19T09:26:42+09:00
AWSのWebコンソールでスイッチロールを適用した後に名称や色を変更したい
やりたいこと
上の画像のような、AWS Webコンソールでスイッチロールを適用した後に、履歴として保存される各ロールの名称やカラーを変更したいのです。
Webコンソール上ではそれを変更する入り口は見つけられませんでした。
もう1回同じくスイッチロールを適用すれば履歴に追加することができ、
履歴は最大5件までらしいので必要なだけ再適用するのが正攻法でしょうけど、
何か他に方法はないのか?とやってみてうまくいったのでそのメモのようなものです。
結論
AWS Webコンソールでのスイッチロールはブラウザのクッキーに
noflush_awsc-roleInfoのキーで保存されているようで、
それを変更してしまえばWeb画面に反映されます。逆にロール履歴を丸ごと削除したい場合は、クッキーから保存先のキーを削除するしかないようです?
- これから書く方法はクッキーを無理やり変更する方法なので、操作ミスや値ミスなどの人的ミスや、AWSコンソールの仕様変更等で予期せぬ結果を招く可能性がありますし、それによって生じた如何なる問題も私にはどうしようもありません。
- Safariの場合だけを書きます。他のブラウザの場合は手順が異なると思われます。
変更手順
1. 各ブラウザの開発機能からawsが利用しているクッキーを見る。
AWS Webコンソールを開きます。
そしてブラウザ機能の開発者メニューを表示します。* Safariの場合: [開発] -> [Webインスペクタを表示] -> [ストレージ]タブ -> ?Cookie (console.aws.amazon.com)
2.
noflush_awsc-roleInfoのキーを探してコピーする。以下のような、URLエンコードされた値がコピーできます。
%7B%22bn%22%3A%22hogehogetarou%22%2C%22ba%22%3A%22hogehogeaccount%22%2C%22rl%22%3A%5B%7B%22a%22%3A%22fugafuga%22%2C%22r%22%3A%22fugafugarole%22%2C%22d%22%3A%22fugafugarole%2520%2540%25fugafuga%22%2C%22c%22%3A%22B7CA9D%22%7D%5D%7D%0A3.
noflush_awsc-roleInfoの値をデコードしてみる。URLエンコードされているのをデコードしてみると、以下のような設定値のJSONであることがわかりました。
スイッチロール履歴が複数ある場合、rlの配列にその分増えます。{"bn":"hogehogetarou","ba":"hogehogeaccount","rl":[{"a":"fugafuga","r":"fugafugarole","d":"fugafugarole%20%40%fugafuga","c":"B7CA9D"}]}
- 多分
rl配列がスイッチロール履歴で、この各値のdが表示名で、cが表示カラーだと推測できるので、これを変更すればいけそうです。4. 変更したいように値を編集する。
dを表示名、cを表示カラーとして、変更したいように変更します。
cはHEX値です。
スイッチロール画面だと用意された6色しか選べない?と思いますが、有効なHEX値ならどんな色にもできると思います。(事実冒頭のサンプルの画像では、強い赤色に変更しています。)改行など入れて見やすくしたり整形したりすると後で再設定するときにおかしくなると思うので、1行のまま編集していきます。
{"bn":"hogehogetarou","ba":"hogehogeaccount","rl":[{"a":"fugafuga","r":"fugafugarole","d":"fugafugarole%20%40%fugafuga-update","c":"FF0000"}]}5. 変更した値を再びURLエンコードする。
クッキー
noflush_awsc-roleInfoに同じ形式で設定し直すために、[4]で編集した値をURLエンコードします。%7B%22bn%22%3A%22hogehogetarou%22%2C%22ba%22%3A%22hogehogeaccount%22%2C%22rl%22%3A%5B%7B%22a%22%3A%22fugafuga%22%2C%22r%22%3A%22fugafugarole%22%2C%22d%22%3A%22fugafugarole%2520%2540%25fugafuga-update%22%2C%22c%22%3A%22FF0000%22%7D%5D%7D%0A6. URLエンコードした値を
noflush_awsc-roleInfoに設定する。もしかしたらブラウザによっては開発者機能から直接編集できるかもしれませんが、
Safariの場合は、インスペクタからJavaScriptを実行してクッキーを無理やり上書きします。インスペクタ下部の
>の入力欄に、以下のようなクッキーを設定するコードを書いて、エンターキーで実行します。document.cookie='noflush_awsc-roleInfo=『上記でURLエンコードした値』'サンプル
document.cookie='noflush_awsc-roleInfo=%7B%22bn%22%3A%22hogehogetarou%22%2C%22ba%22%3A%22hogehogeaccount%22%2C%22rl%22%3A%5B%7B%22a%22%3A%22fugafuga%22%2C%22r%22%3A%22fugafugarole%22%2C%22d%22%3A%22fugafugarole%2520%2540%25fugafuga-update%22%2C%22c%22%3A%22FF0000%22%7D%5D%7D%0A'
7. AWSコンソール画面をリロードする。
ブラウザで画面をリロードすれば、変更した値の通りにロール履歴の表示名と表示カラーが変わっているはずです。
もしおかしくなったら、同じ手順で何か値ミスがないか探して修正したり、
一旦noflush_awsc-roleInfoを削除して、再度スイッチロールの適用をすれば良いと思います。
おわり
- 投稿日:2019-07-19T08:18:19+09:00
AWS Cloud9 調べてみた
★雑に記載しているため、今後アップデート予定
独断と偏見で、Cloud9のプロジェクト適用について考えてみました。
どこで、Cloud9とは?使い方は?を調べたらいいか。
とりあえず、下記を見たらいい。
・ブラックベルト
https://aws.amazon.com/jp/aws-jp-introduction/aws-jp-webinar-service-cut/
・ユーザーガイド
https://docs.aws.amazon.com/ja_jp/cloud9/latest/user-guide/welcome.html
Cloud9とは
Webブラウザから使える統合開発環境、いわゆるクラウドIDE。
コードを記述、実行、デバッグができる。
Amazonに買収されて、AWSのサービスの一員となったらしい。Cloud9のメリット
・開発環境をローカルにインストールする必要がない
※ローカルマシンのスペックを気にする必要がない。(いわゆるSaaS)
・インターネットにつながれば、どこでも作業が可能
・ソースの共同開発が可能
・サーバレス開発(lambda)が容易らしい。
※ちょっと試してみたいな。。使用パターンを調べる(会社で使用するのか、チームで使用するのか)
https://docs.aws.amazon.com/ja_jp/cloud9/latest/user-guide/get-started.html
会社適用に関して
スモールスタートがいいと思う。
大掛かりにはじめて、結局やりませんでしたってこともよくあるので。。
⇒使用パターン、チームセットアップhttps://docs.aws.amazon.com/ja_jp/cloud9/latest/user-guide/setup.html
チームセットアップに関して
①IAMの設定
https://docs.aws.amazon.com/ja_jp/cloud9/latest/user-guide/setup.html#setup-give-user-access
◎IAMグループの作成
個人的には、いったん2グループで初めてもいいと思う。
1.管理者グループ(ポリシー:AdministratorAccess)
※ポリシーはAWSCloud9Administratでもいいが、その場合は、
別途、AdministratorAccessのグループを作る。
そうでないと、ユーザーの追加ができないから。https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/getting-started_create-admin-group.html
2.Cloud9ユーザーグループ(ポリシー:AWSCloud9User)
https://docs.aws.amazon.com/ja_jp/cloud9/latest/user-guide/auth-and-access-control.html
◎IAMユーザーの作成
ユーザーを作成し、所属グループを設定することで、
そのグループのポリシーがアタッチされた状態になる。②AWS Cloud9 の追加設定オプションの設定
https://docs.aws.amazon.com/ja_jp/cloud9/latest/user-guide/setup-teams.html
ユーザーの環境作成の制限とかできるらしい。
例えば、意図せずユーザーにEC2(サーバ)を複数台作成されてしまったとする。
その場合に、1年間の無料枠を鑑みると、EC21台常時起動だと無料であるが、
2台以上だと確実にお金がかかってくる。
そういうケースに、オプション設定はありかもしれない。③Cloud9の環境作成
https://docs.aws.amazon.com/ja_jp/cloud9/latest/user-guide/create-environment.html
④Cloud9の使用方法を勉強する。
https://docs.aws.amazon.com/ja_jp/cloud9/latest/user-guide/tutorial.html
⑤共有環境を設定する。
https://docs.aws.amazon.com/ja_jp/cloud9/latest/user-guide/share-environment.html
使ってみた
下記のサンプルプログラムを実行してみた。
・python
・phpいままでは下記の感じでやっていた。
・python: anacondaをインストールして付属のspyderで動作確認をしていた。
・php : Zamp PHPをインストールしてブラウザで動作確認していた。Cloud9を使用すると、手軽に環境が作れ、
複数言語のプログラムを横並びで実行して表示できる。
※下のコンソールがpython実行結果、右のブラウザがPHP実行結果
下記の場合に便利かと思いました。
仕事関連で、家で勉強がてらプログラムを動かしてみたい。
環境整備めんどくさい。
あ、CLoud9でちょろっと確認しよ。に最適な気がしました。
自宅PCのスペックを気にする必要もないですし。<参考>
・PHPの準備
https://docs.aws.amazon.com/ja_jp/cloud9/latest/user-guide/sample-python.html・Pythonの準備
https://docs.aws.amazon.com/ja_jp/cloud9/latest/user-guide/sample-python.html
▼python3を使用する場合
https://qiita.com/r-wakatsuki/items/bcaab62850944b1d605a
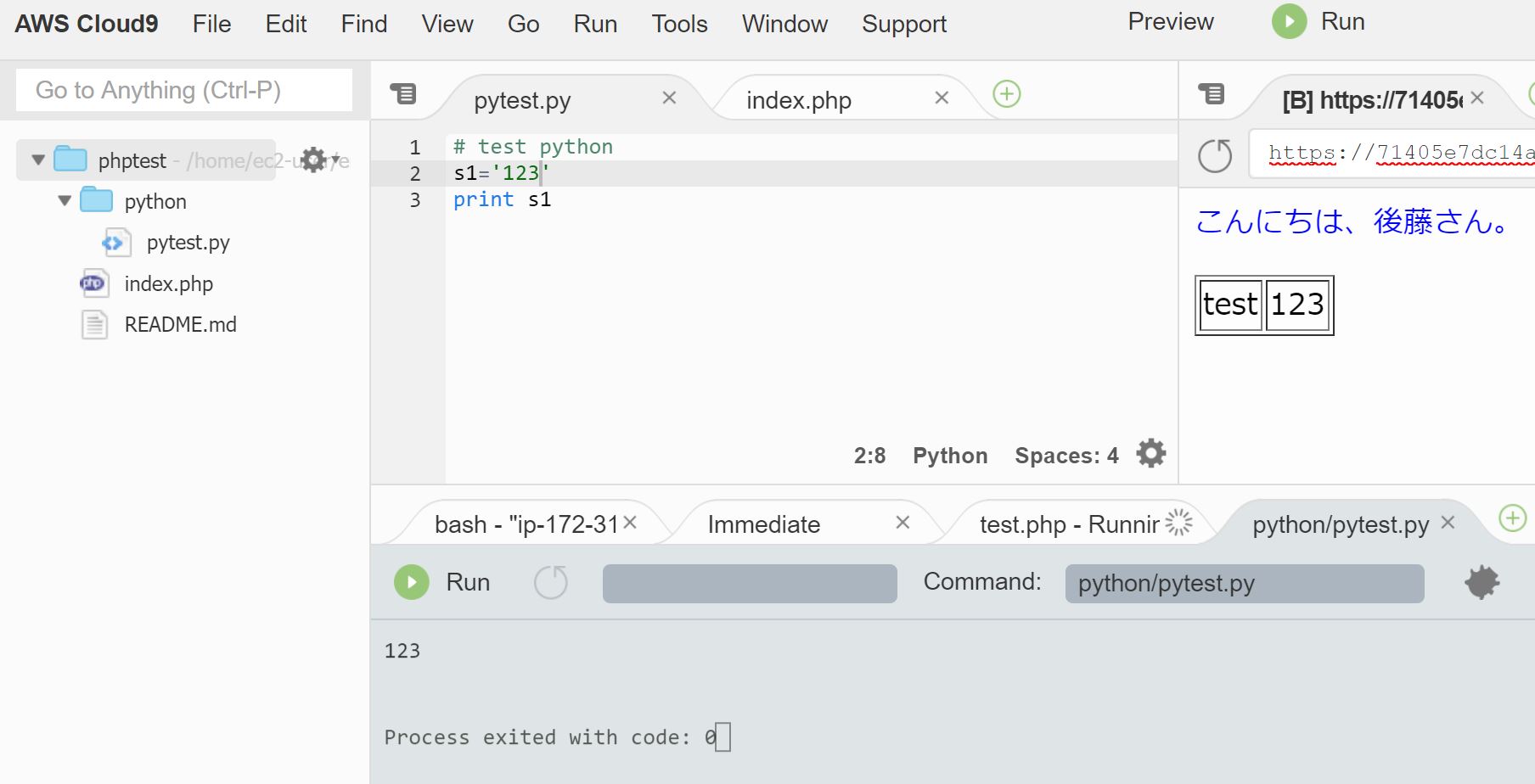
- 投稿日:2019-07-19T02:42:30+09:00
0からAWSでLAMPとLaravel環境構築(Windows)
手順
1.AWSアカウントを作成。
参照:AWS アカウント作成の流れ2.EC2というAmazonのクラウド上の仮想サーバーを構築。
参照:AWS EC2でWebサーバーを構築してみる3.LAMP環境を構築。
参照:チュートリアル: Amazon Linux 2 に LAMP ウェブサーバーをインストールする4.Laravelをインストール。
参照:AWSのEC2を立ち上げてLaravelのログイン機能を動かすまで
AWSでLaravelを立ち上げた1.AWSアカウントを作成
AWS は Amazon Web Services の略で、Amazon のクラウドサーバーを使用できるサービスです。
一年間無料でいろんな機能を試せます。
アカウントの登録は参照(AWS アカウント作成の流れ)に沿って行えばすぐできます。2.EC2構築
AWSにログインすると最初はこの画面が表示されると思います。
右上の地域はリージョンといい、自分の所在地に合わせて選択します。これは利用するデータセンターの場所を意味します。理論上近いほどレスポンスタイムが短いので、近いところを選びましょう。自分の場合は「東京」です。そしたら、左上のサービスからEC2を選択。
左のメニューの「インスタンス」 → 「インスタンス作成」を選択
一番目のAmazon Linux2 AMIを選択。
無料利用枠のt2.microにチェックを入れ、
他の設定は特にいじらずセキュリティグループの設定まで飛ばします。「新しいセキュリティグループを作成する」を選択し、「セキュリティグループ名と「説明」を好きなように入力し、画像のように五つのタイプを追加します。「ソース」のところでIP指定ができます。「任意の場所」を選択するとどこでもアクセスすることができ、「マイIP」を選択すると自分が現在使用しているネットワーク環境のIPでしかアクセスできなくなります。趣味程度の個人利用でしたら任意の場所で問題ありません。
右下の「確認と作成」 → 「起動」を押してから、このように表示されます。「新しいキーペアの作成」でキーペア名を入力。重要ですが、キーペアのダウンロードは必ずしてください。サーバーにアクセスするために必要となります。
「インスタンスの作成」 → 「インスタンスの表示」を順番に進めると、インスタントの画面に戻ります。
インスタンスの状態が running になっていれば作成成功です。
プラスα(オプション)
今作ったインスタンスに固定IPを割り当てることができます。左のメニューから「Elastic IP
」 → 「新しいアドレスの割り当て」 → 「割り当て」 → 「閉じる」で固定IPを一つゲットします。リストからIPを右クリック → 「アドレスの関連付け」で作成したインスタンスを選択し結びつけれます。3.LAMP環境の構築
①インスタンスに接続
サーバーに接続するため、ssh接続できるターミナルTeraTermをダウンロードします。インスタンス画面下の説明から固定IPとっていれば「IPv4 パブリック IP」、とっていなければ「パブリック DNS (IPv4)」をTeraTermのホストに入力して「OK」します。
次にユーザー名に「ec2-user」、秘密鍵に先ほどインスタンスを作るときにダウンロードしたキーペアファイルをセットして「OK」。
サーバーに接続できました。
直接とは関係ないですがコマンドでsudoを打つかどうかについて「root権限で`sudo`を付けた場合と付けない場合の違いに`su`は何の略?」を読めばわかると思います。②EC2のタイムゾーン設定
「Amazon EC2のタイムゾーンを日本時間に変更する方法」でわかりやすく書かれていますが、いくつか補足があります。
/etc/sysconfig/clockにはこのように変更すると書いてありますが、# ZONE="UTC" ZONE="Japan" UTC=true
trueのところをfalseにしないと再起動するときにタイムゾーンがUTCに戻ることがあります。# ZONE="UTC" ZONE="Japan" UTC=flaseここでルート権限を持たないため、
vimで保存するときにきっとこのようなエラーが出ると思います。E45: 'readonly' option is set (add ! to override)この解決法として自分がrootになるか、「[vim]read only のファイルをsudoで強制的に保存する」を参照してください。
オプションとして、「AWSの初期設定でrootパスワードを設定する」。一行目の
sshなんちゃらはすでにTeraTermログイン時にできてますので無視。
lnのオプションの意味は【 ln 】コマンド――ファイルのハードリンクとシンボリックリンクを作るに書いてあります。③LAMP環境構築
AWSの公式チュートリアル「チュートリアル: Amazon Linux 2 に LAMP ウェブサーバーをインストールする」の順序を追えばできます。自分はSQLに慣れているため、オプションの phpMyAdmin のインストールはしていません。phpMyAdmin はデータベースをGUIで管理できるツールです。
4.Laravelのインストール
①Composerをダウンロード
Composerについては「PHP開発でComposerを使わないなんてありえない!基礎編」。
以下ダウンロードコマンドです。$ curl -sS https://getcomposer.org/installer | sudo php $ sudo mv composer.phar /usr/local/bin/composerこれで
composer.pharというファイルが/usr/local/bin/composer/の下に置かれます。
このcomposer.pharファイルをcomposerというコマンドで実行できたら便利なので、composerというコマンドを作ります。alias composer='php /usr/local/bin/composer/composer.phar'ただし、これだけだと再起動するとリセットされて
composerが効かなくなりますので、常に成立するようにルートに存在する.bashrcというファイルに書き込みます。$ cd ~ # ルートに移動 $ ls -la # .bashrcがあるかどうかを確認 $ vi .bashrc # 「alias composer='php /usr/local/bin/composer/composer.phar'」を書き込むそしたらターミナルが起動すると読み込まれる
.bash_profileに.bashrcを参照するようにします。$ vi .bash_profile # 「source ~/.bashrc」を一番下に書き込む②拡張ライブラリをダウンロード
Laravelをダウンロードするのに必要なライブラリーは3つあります。
mbstring、mysqlndとxmlです。$ sudo yum install -y php-mbstring php-mysqlnd php-xml③Laravelをインストール
Laravel をインストールするディレクトリに移動します。自分の場合は
/var/www/の下にしました。$ cd /var/www $ composer create-project --prefer-dist laravel/laravel自分の場合ここで「proc_open(): fork failed errors」というエラーが出ました。「[PHP]Composer使用時に「proc_open(): fork failed errors」エラーが出た時の対処法」を見て解決できたので共有します。
-prefer-distって何ぞやと知りたい方には「composer の–prefer-distってよく使うけど何してる?」へ。④Apacheのドキュメントルートの設定と.htaccessの有効化
$ sudo vi /etc/httpd/conf.d/custom.confに
custom.conf# ドキュメントルート DocumentRoot "/var/www/laravel/public" # .htaccess 有効化 <Directory /var/www/laravel/public> AllowOverride All </Directory>を加えます。
そしたらApacheを再起動してください。$ sudo service httpd restart⑤パーミッションを変更
自分はパーミッションについてまだちんぷんかんぷんで、どの権限をどうすればいいか自分ではわかっていないので、他の方のブログを見たほうがいいかもしれません。基本的にパーミッションが合ってないとシステムにこのファイルに書き込めないよと怒られます。どうやらLaravelの場合は
storageとbootstrapの権限を変更する必要があるらしい。$ cd ~ $ sudo groupadd www $ sudo usermod -a -G www ec2-user $ exit一度ログアウトして再度入り直して、
$ cd /var/www $ sudo chmod -R 777 laravel/storage $ sudo chmod -R 775 laravel/bootstrap/cache $ sudo chown -R root:www /var/wwwこれでLaravelが使えるようになったはず。
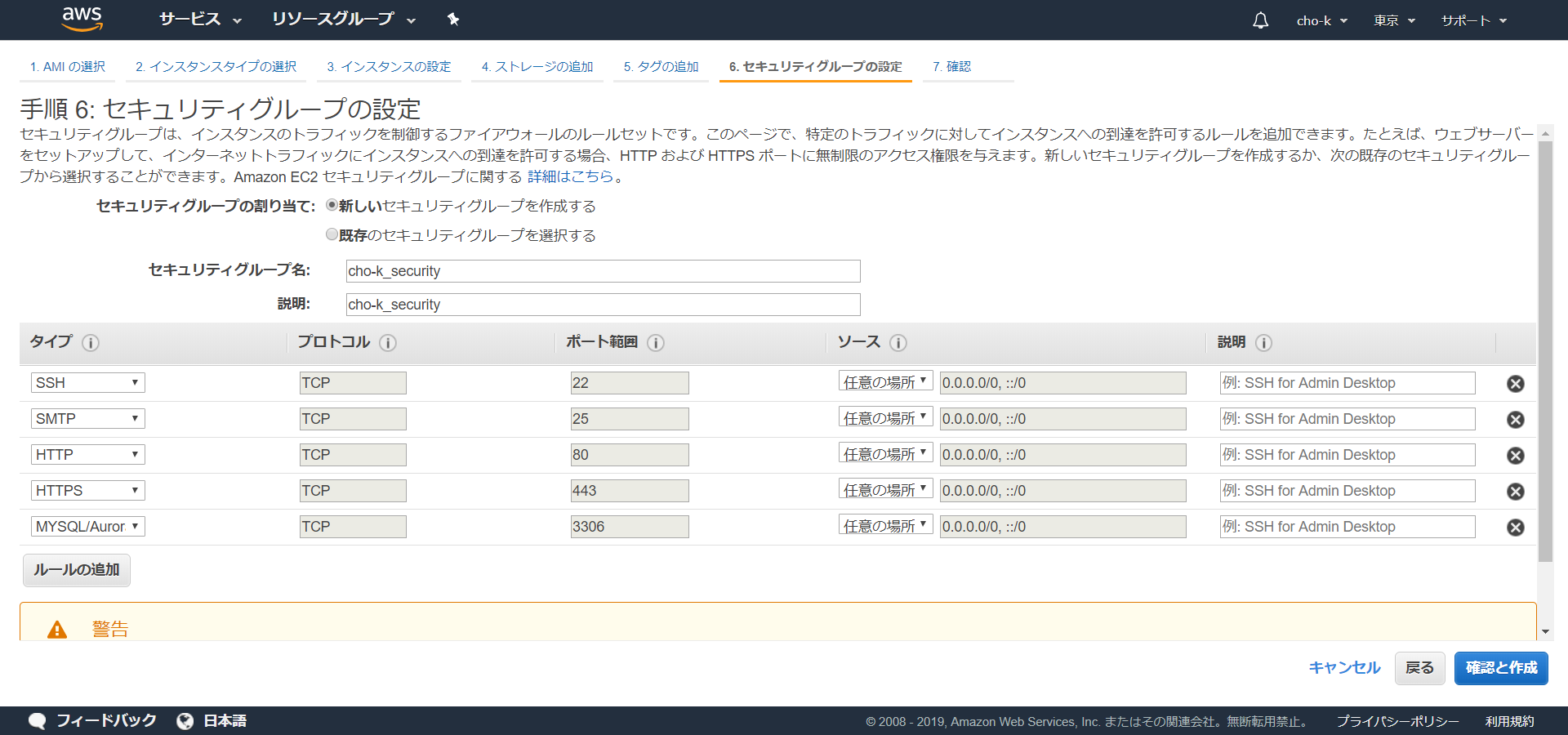
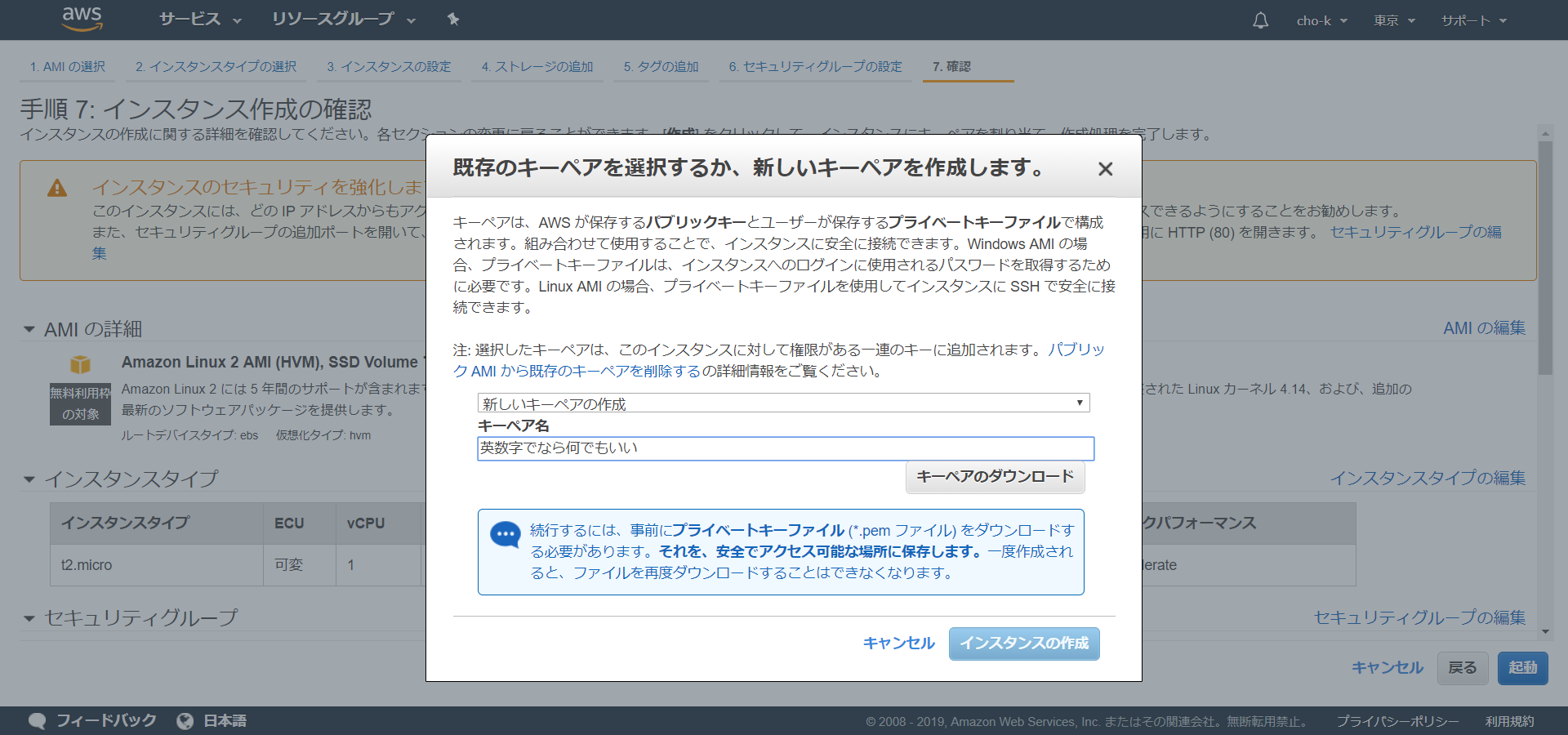
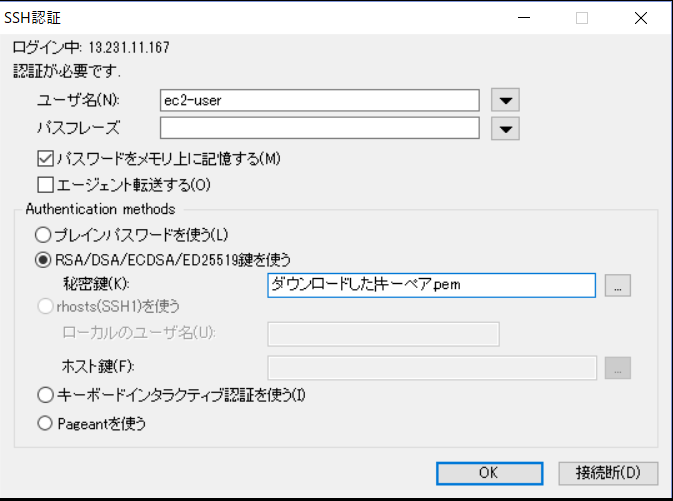
- 投稿日:2019-07-19T01:52:14+09:00
それでも Lambda と RDS を使いたい場合の現実解
LambdaとRDS の理想と現実
こちらの LambdaとRDSで爆死してみる の続編となります。
こちらでは、LambdaとRDSの相性悪い問題を具体例をもって説明するために壮大に爆死してみました。ただ現実問題として、LambdaとRDSを組み合わせて使いたい人は数多くいると思います。
理想はLambdaにこだわるならDynamoDBといったコネクションの上限数などを気にしなくてすむアーキテクチャかと思います。それでも、それでも、現実解としてLambdaとRDSを組み合わせて使う構成をいくつか検討してみました。
ありがちなアンチパターン
まず改めてアンチパターンの紹介です。
API Gatewayとの組み合わせ
クライアントがAPI Gatewayへリクエストを投げて、それがLambdaに渡り、RDSへinsertするパターンですね。
実際よく検討されているパターンかと思います。リクエストの数が少ないと問題ない場合もありますが、
一気にリクエストが来ると以下の状態となり簡単に障害が発生します。
ただこれは負荷テストをやるとすぐに見つかる問題なので、検討はしても実際に本番運用されているのはそれほど多くないと思います。(だってみんな障害嫌いだし)
IoT Core との組み合わせ
これもほとんど同様ですね。
違いは、インターフェイスがAPI Gatewayの場合は HTTP、IoT Coreの場合は MQTT なのと
Lambdaの呼び出しは、API Gatewayの場合は、同期処理、IoT Coareの場合は非同期処理である部分が大きな違いかと思います。
ただ、どちらもリクエスト数が増えると、障害が発生する可能性が高いという点は同じです。
その他のパターン
S3のイベントトリガーでLambdaを呼び出しRDSへinsert などいろいろありますが、ここでは上記の2パターンに絞って記載します。
理想的なパターン
冒頭に述べましたが、RDSの部分をDynamoDBに置き換える パターンです。置き換えるだけなので、図は記載しません。
今回は現実解について書くので、このパターンの詳細は書きません現実解のパターン
まず、ここでの現実解の定義ですが、
Lambdaを使いたいならRDSはやめるべきなのは重々承知してるけど、それでもやはり使いたい。でも、障害は起こしたくない。というざっくりとした要望に対する解とします。その1 : SQSを使うパターン
API Gatewayもしくは IoT Coreで受け取ったリクエストをLambdaが処理する部分まではアンチパターンと変わりませんが、
直接RDSに書き込むのではなく、SQSにキューとして入れます。
そして、SQSからキューを取り出すworkerとして、EC2 もしくは Lambda を利用します。(EC2の部分は、コンテナでもいいと思います。)
そして、EC2(Lambda)内の処理で、RDSへ書き込みを行います。よくある疑問
Q:Lambda使うパターンだと、結局 Lambda が RDS に直接書き込んでるじゃん。コネクション枯渇問題は発生しないの?
A:発生する可能性はありますが、アンチパターンよりは低いです。
具体的な動きとしては、SQSにたまっているキューをLambdaは1度に最大で10個取り出し、処理を行います。
アンチパターンだと、Lambdaは一度の起動で1つのデータしか処理しませんので、ざっくりとした計算で、Lambdaの同時実行数は1/10になり、コネクション数の枯渇がアンチパターンに比べると起こりにくくなっています。
しかし、キューにたまっている数が多すぎると、Lambdaも同時実行数も増えますので、RDSのコネクション数が枯渇することももちろんあるので、その場合はRDSへ書き込むのはLambdaではなくEC2でという選択肢になります。その他の注意点
API Gatewayの場合、データを送るクライアントから見ると、SQSにデータが登録された段階でACKが返ってくるので、RDSへの書き込みは非同期処理となります。
また、SQSの性質上、同じキューが複数回取り出されたりする可能性もあるので、冪等性の確保が必要となります。その他の類似パターン
IoT CoreだとLambdaを仲介せず直接SQSへデータをキューとして登録できるので、このようなパターンもあります。その2:Kinesis Data Streamsを使うパターン
その1のパターンと比較すると、SQSの部分がKinesis Data Streamsに変わったのと、RDSに書き込むのはLambdaだけになっている部分です。仕組みもほぼ同じで、入ってきたデータをLambdaが受け取り、Lambdaの処理でKinesis Data Streamsに保存します。(API Gatewayの場合は、この処理でクライアントにはACKが返ります)
その後、Lambdaが Kinesis Data Streamsをポーリングして、保存されたデータを取得し、RDSに書き込みを行います。よくある疑問
Q:結局 Lambda が RDS に直接書き込んでるじゃん。コネクション枯渇問題は発生しないの?
A:発生する可能性はありますが、極めて低いです。
Kinesis Data Streams と Lambdaの相性は実は抜群によく、LambdaとRDSの相性の悪さを場合によっては帳消しにしてくれることもあります。具体的には、Kinesis Data Streams と Lambdaを組み合わせて利用した場合、Lambdaの同時実行数は必ずKinesis Data Streamsのシャードの数と一致します。1シャードは、1000 TPS or 1MB/s のデータを書き込みできるので、超莫大なリクエストが来ない限りは、シャードが増えすぎることはありません。つまり、Lambdaの同時実行数を抑えることが可能です。
そして、同時実行数を抑えたまま、LambdaがRDSへ書き込みを行うので、コネクションの枯渇が発生することはほとんどありません。Q:その1と同様に LambdaじゃなくてEC2がRDSに書き込むパターンはあるの?
A:あります。が、その場合は、EC2がKinesis Data Streamsをポーリングする処理を自前で実装するかその実装がライブラリ化されたKinesis Client Library を使う必要があります。後者はそれほど難しいことではないですが、Lambdaを使う場合に比べると大変なので、敢えて図には入れていません
(Kinesis Client Libraryの説明はここでは行いません)その他の注意点
API Gatewayの場合、データを送るクライアントから見ると、Kinesis Data Streamsにデータが登録された段階でACKが返ってくるので、RDSへの書き込みは非同期処理となります。
また、RDSに書き込むLambdaでリトライが発生する可能性があるので、冪等性の確保はやはり必要となります。その他の類似パターン
API GatewayでもIoT Coredでも、Lambdaを仲介せず直接Kinesis Data Streamsへデータを保存できるので、上図のようなパターンもあります。
まとめ
ざっくりと、Lambdaを使ってRDSに書き込みを行う現実解について、API Gateway/IoT Coreというインターフェイスを中心に書きました。
理想はDynamoDBなのは分かってるけど、それでも Lambda と RDS を使いたい方の参考になればと思います。個人的には、その2のパターンが一番ラクかなと思います。
Lambdaを中継するかしないかは、Lambdaでデータ整形が必要だったりすれば使って、不要であれば、Lambdaを使わないパターンでいいかなと思います。