- 投稿日:2019-07-19T23:23:17+09:00
pythonのprintで%dや%sを使う方法やformat文についてもメモ書き
はじめに
未来電子テクノロジーでインターンをしています、Sotaです。
プログラミング初心者のため、内容に誤りがあるかもしれません。
もし、誤りがあれば修正するので、どんどん指摘してください。自分はc言語からプログラミングを勉強したので、%dや%fの表現に慣れています。
そのため、桁数指定などで、ストレスを感じたので、pythonでも%dや%fを使える表現をメモします。pythonで%dや%sを使う
pythonでprintf文のような表現を使うには、
'文字列' % 変数とすれば記述できます。
(例)y = 10000 d = 100 print('100$は%d円' % y) #100$は10000万円 print('%d円は%d$' % (y, d)) #10000万円は100$このような感じです。
もちろん文字列やfloat、桁数指定%.2fなども可能です。format文
文字列メソッド
format()をでも似たような書き方ができます。
文字列中に置換フィールド{}が指定した引数と対応して置換されます。
文字列.format(変数)と書きます。
(例)y = 10000 d = 100 print('100$は{}万円'.format(y)) #100$は10000万円 print('{}万円は{}$'.format(y, d)) #10000万円は100$
- 投稿日:2019-07-19T23:23:17+09:00
Pythonのprintで%dや%sを使う方法やformatメソッドについてもメモ書き
はじめに
未来電子テクノロジーでインターンをしています、Sotaです。
プログラミング初心者のため、内容に誤りがあるかもしれません。
もし、誤りがあれば修正するので、どんどん指摘してください。自分はC言語からプログラミングを勉強したので、%dや%fの表現に慣れています。
そのため、桁数指定などで、ストレスを感じたので、Pythonでも%dや%fを使える表現をメモします。Pythonで%dや%sを使う
Pythonでprintf関数のような表現を使うには、
'文字列' % 変数とすれば記述できます。
(例)y = 10000 d = 100 print('100$は%d円' % y) #100$は10000万円 print('%d円は%d$' % (y, d)) #10000万円は100$このような感じです。
もちろん文字列やfloat、桁数指定%.2fなども可能です。formatメソッド
文字列メソッド
format()でも似たような書き方ができます。
文字列中に置換フィールド{}が指定した引数と対応して置換されます。
文字列.format(変数)と書きます。
(例)y = 10000 d = 100 print('100$は{}万円'.format(y)) #100$は10000万円 print('{}万円は{}$'.format(y, d)) #10000万円は100$
- 投稿日:2019-07-19T23:08:21+09:00
LeetCode / Length of Last Word
(ブログ記事からの転載)
[https://leetcode.com/problems/length-of-last-word/]
Given a string s consists of upper/lower-case alphabets and empty space characters ' ', return the length of last word in the string.
If the last word does not exist, return 0.
Note: A word is defined as a character sequence consists of non-space characters only.
Example:
Input: "Hello World"
Output: 5Discussionで'This problem is not fun at all'とか言われちゃってましたが、、、LeetCodeは個人的にはなかなか難易度高い問題も多いので、こういう箸休め的問題は欲しいなと思います。
英単語で構成された文の中で、末尾の単語の長さを返す問題です。解答・解説
解法1
リストlsに対して、2つのポインタとなる変数slow, fastを用意し、slowは末尾の単語の末尾を、fastは末尾の単語の先頭のインデックスを返すように計算します。
末尾の単語の長さを判定するので、リストを逆向きにループさせていきます。
まず、slowは初期値を-1とします。list[-1]とするとlistの末尾の要素を示すのは自明ですね。そこから逆向きにループさせて、ブランクでない位置まで辿ります。
通常、'Hellow World'のように末尾の単語の後ろにブランクはなく、slowは初期値の-1のまま(ループは進まない)になることが多いと思います。ls = len(ls) slow = -1 while slow >= -ls and s[slow] == ' ': slow -= 1次に、fastは初期値をslowと同値とします。そこから逆向きにループさせて、ブランクの位置まで辿ります。
fast = slow while fast >= -ls and s[fast] != ' ': fast -= 1最後に、slow - fastとすれば、末尾の単語の長さを計算できます。
まとめると以下のようになります。class Solution: def lengthOfLastWord(self, s: str) -> int: ls = len(s) slow = -1 while slow >= -ls and s[slow] == ' ': slow -= 1 fast = slow while fast >= -ls and s[fast] != ' ': fast -= 1 return slow - fast解法2
1 line solutionを示して、今日は終わります。rstripで文末の余計なブランクを剥ぎ取ってしまうという力技。
class Solution: def lengthOfLastWord(self, s): return len(s.rstrip(' ').split(' ')[-1])
- 投稿日:2019-07-19T21:39:09+09:00
水汲み問題(water jug problem)をPython、Javascriptで実装してみた
動機
研究室内の課題で水汲み問題を解く問題が出たので始めにPyhtonで書き、Javascriptの勉強中だったのでJavascriptでも書いてWebサイト風にアレンジしてみました。これをサーバーで公開するのもなぁと思ったのでコピペしてブラウザで開いてみてください。
Pythonのコード
warer_jug.pyimport queue class Bottle: def __init__(self,one,two): self.one = 0 #一個目のボトル self.two = 0 #二個目のボトル self.one_max = one self.two_max = two def put(self,now_one,now_two,num,past_list): #oneのボトルを水で満たす copy = past_list.copy() if num ==1: now_one = self.one_max elif num ==2: now_two = self.two_max for i in range(len(copy)): if copy[i] != [now_one,now_two]: if (i== len(copy)-1): copy.append([now_one,now_two]) queue.put(copy) break else: break def pour(self,now_one,now_two,num,past_list): #numから一方のボトルに水を移す copy = past_list.copy() if num==1: #oneからtwo now_two += now_one if now_two >= self.two_max: #あふれる場合,全部は入れない場合 now_one = now_two - self.two_max now_two = self.two_max else: now_one = 0 elif num ==2: #twoからone now_one += now_two if now_one >= self.one_max: #あふれる場合,全部は入れない場合 now_two = now_one - self.one_max now_one = self.one_max else: now_two = 0 for i in range(len(copy)): if copy[i] != [now_one,now_two]: if (i== len(copy)-1): copy.append([now_one,now_two]) queue.put(copy) break else: break def away(self,now_one,now_two,num,past_list): #水を捨てる copy = past_list.copy() if num==1: now_one = 0 elif num==2: now_two = 0 for i in range(len(copy)): if copy[i] != [now_one,now_two]: if (i== len(copy)-1): copy.append([now_one,now_two]) queue.put(copy) break else: break past_op = [] queue = queue.Queue() num_one = int(input("Bottle1? ")) num_two = int(input("Bottle2? ")) num_Want = int(input("How much do you want? ")) bottle = Bottle(num_one,num_two) bottle.one = bottle.one_max past_op.append([bottle.one,bottle.two]) queue.put(past_op) while (True): get_queue = queue.get() now = get_queue[-1] bottle.one,bottle.two = now[0],now[1] if (bottle.one == num_Want or bottle.two == num_Want): for i in get_queue: print(i) break if bottle.one > 0 and num_one > bottle.one: bottle.put(bottle.one,bottle.two,1,get_queue) bottle.pour(bottle.one,bottle.two,1,get_queue) #oneからtwo bottle.away(bottle.one,bottle.two,1,get_queue) #oneを捨てる if bottle.one == 0: bottle.put(bottle.one,bottle.two,1,get_queue) if bottle.one == num_one: bottle.pour(bottle.one,bottle.two,1,get_queue) #oneからtwo bottle.away(bottle.one,bottle.two,1,get_queue) if bottle.two > 0 and num_two > bottle.two: bottle.put(bottle.one,bottle.two,2,get_queue) bottle.pour(bottle.one,bottle.two,2,get_queue) #oneからtwo bottle.away(bottle.one,bottle.two,2,get_queue) #oneを捨てる if bottle.two == 0: bottle.put(bottle.one,bottle.two,2,get_queue) if bottle.two == num_two: bottle.pour(bottle.one,bottle.two,2,get_queue) #oneからtwo bottle.away(bottle.one,bottle.two,2,get_queue) if(queue.empty()): print("無理です") breakはい、めちゃくちゃ長いです。頑張ればもうちょい短くなると思います。
やってることはBottleクラスでボトル1と2の入っている水量とサイズを定義し、水を入れる関数と水を移す関数、水を捨てる関数を定義します。
あとはキューに今までの水の推移を表したリストを入れていき、ボトル1か2が目的の水量になったらその推移を表したリストを表示して終了です。
もし不可能な組み合わせ(例:6Lと3Lの容器で4Lを測るなど)をしたらいずれキューが空になるのでそうなったら無理と表示して終わりです。Javascript(+HTML+CSS)のコード
water_jug.html<!DOCTYPE html> <html lang="ja"> <head> <meta charset="utf-8"> <title>水量を測る</title> <h1>水を測ってみよう!</h1> <style type="text/css"> body{ text-align: center; } #table{ position: relative; } #table table{ position:absolute; left: 50%; } </style> <script> var queue = []; var past_op = []; function Bottle(one,two){ this.one = 0; this.two = 0; this.one_max = one; this.two_max = two; } function show(list_water){ var table = document.getElementById("table"); var string = "<table><tr><th>ボトル1</th><th>ボトル2</th></tr><br>"; for(var i = 0; i<= list_water.length-1; i++){ string += "<tr><td>"+list_water[i][0]+"</td><td>"+list_water[i][1]+"</td></tr><br>"; } string +="</table><br>"; table.innertHTML = string; } function calc_water(myForm) { var bottle = new Bottle(Number(myform.Bottle1.value),Number(myform.Bottle2.value)); bottle.one = bottle.one_max; past_op.push([bottle.one,bottle.two]) queue.push(past_op) while (1){ var get_queue = queue.shift() var now = get_queue[get_queue.length -1] bottle.one = now[0]; bottle.two = now[1]; if (bottle.one == Number(myform.Want_Water.value) || bottle.two == Number(myform.Want_Water.value)){ for (var i=0; i < get_queue.length; i++){ console.log(get_queue[i]); } show(get_queue); break; } if (bottle.one > 0 && bottle.one_max > bottle.one){ bottle.put(bottle.one,bottle.two,1,get_queue); bottle.pour(bottle.one,bottle.two,1,get_queue); //oneからtwo bottle.away(bottle.one,bottle.two,1,get_queue); //oneを捨てる } if (bottle.one == 0){ bottle.put(bottle.one,bottle.two,1,get_queue); } if (bottle.one == bottle.one_max){ bottle.pour(bottle.one,bottle.two,1,get_queue); //oneからtwo bottle.away(bottle.one,bottle.two,1,get_queue); } if (bottle.two > 0 && bottle.two_max > bottle.two){ bottle.put(bottle.one,bottle.two,2,get_queue); bottle.pour(bottle.one,bottle.two,2,get_queue); //oneからtwo bottle.away(bottle.one,bottle.two,2,get_queue); //oneを捨てる } if (bottle.two == 0){ bottle.put(bottle.one,bottle.two,2,get_queue); } if (bottle.two == bottle.two_max){ bottle.pour(bottle.one,bottle.two,2,get_queue); //oneからtwo bottle.away(bottle.one,bottle.two,2,get_queue); } if (queue.length == 0){ cant(); break; } } } Bottle.prototype.put = function(now_one,now_two,num,past_list){ var copy = Array.from(past_list); if (num ==1){ now_one = this.one_max; } else if (num ==2){ now_two = this.two_max; } for (var i=0;i< copy.length;i++){ if (past_list[i].toString() != [now_one,now_two].toString()){ if (i==copy.length-1){ copy.push([now_one,now_two]); queue.push(copy); break; } } else{ break; } } } Bottle.prototype.pour = function(now_one,now_two,num,past_list){ var copy = Array.from(past_list) if (num==1) { now_two += now_one; if (now_two >= this.two_max){ //あふれる場合,全部は入れない場合 now_one = now_two - this.two_max; now_two = this.two_max; } else { now_one = 0; } } else if (num ==2){ //twoからone now_one += now_two; if (now_one >= this.one_max){//あふれる場合,全部は入れない場合 now_two = now_one - this.one_max; now_one = this.one_max; } else{ now_two = 0; } } for (var i=0;i< copy.length;i++){ if (past_list[i].toString() != [now_one,now_two].toString()){ if (i==copy.length-1){ copy.push([now_one,now_two]); queue.push(copy); break; } } else{ break; } } } Bottle.prototype.away = function(now_one,now_two,num,past_list){ //水を捨てる var copy = Array.from(past_list) if (num==1){ now_one = 0; } else if (num==2){ now_two = 0; } for (var i=0;i< copy.length;i++){ if (past_list[i].toString() != [now_one,now_two].toString()){ if (i==copy.length-1){ copy.push([now_one,now_two]); queue.push(copy); break; } } else{ break; } } } </script> </head> <body> <form id="myform" name="myform"><p> Bottle1の大きさ:<input type="text" name="Bottle1"><br> Bottle2の大きさ:<input type="text" name="Bottle2"><br> 欲しい水の量:<input type="text" name="Want_Water"><br> <input type="button" value="計算" name="calc" onclick="calc_water(this.form)"><br> </p></form> <div id = "table"> </div> </body> </html>javascriptは勉強して1週間でクソザコナメクジなのでもっといいコードが書けるかもしれません
やってることはpythonとほとんど同じです。解が見つかったら表を作成するHTMLコードを作成し表示するって感じです。
質問またはこうした方がいいってのがあったら気軽にコメントしてください
- 投稿日:2019-07-19T21:17:26+09:00
PythonでGoogleスプレッドシートに結合cellを作成する方法
Motive
単にスプレッドシートにデータを入力したい場合は
gspreadライブラリを使えばsheet.update_acell('A1', "AAA")でよいし、 cellに線や色を付ける、文字のタイプ、文字フォント、または文字寄せなどを設定する場合はgspread-formattingを使ってimport gspread_formatting as gsformat fmt = gsformat.cellFormat( backgroundColor=gsformat.color(0.0, 0.5, 0.0), textFormat=gsformat.textFormat(foregroundColor=gsformat.color(0, 0, 0)), horizontalAlignment='LEFT', ) gsformat.format_cell_range(sheet, 'A1:A10', fmt)とすると反映は可能です。
ですが、
A1:A5までcellを結合したい!
思った場合、gspread、gspread-formattingにそれっぽいメソッドはないです。レイアウトを整えるのは重要事項なのでもっとコードでなんとかしたい!
と思った時は、下記の例はresponseで送るjson形式に似たものを用いる方法をまとめたので記述します。
Method
対処法としてですが
gspreadのbatch_update(dict)メソッドを用います。code
value.json{ "requests" : [ { "mergeCells": { "range": { "startRowIndex": 0, "endRowIndex": 1, "startColumnIndex": 0, "endColumnIndex": 5 }, "mergeType": "MERGE_ALL" } } ] }import configparser import json import os import json from oauth2client.service_account import ServiceAccountCredentials import gspread def main(): config = configparser.ConfigParser() ini_file = os.path.join("./", 'setting.ini') config.read(ini_file) scope = ["https://spreadsheets.google.com/feeds", "https://www.googleapis.com/auth/drive"] book_id = config.get("googleSpreadSheet", "book_id") path = os.path.join("./", config.get("googleSpreadSheet", "keyfile_name")) credentials = ServiceAccountCredentials.from_json_keyfile_name(path, scope) client = gspread.authorize(credentials) gfile = client.open_by_key(book_id) dst = {} with open("value.json", encoding='utf-8') as fin: dst = json.load(fin) gfile.batch_update(dst) if __name__ == "__main__": main()これで
A1:A5のセルが結合されました。
Future
batch_updateメソッドはcell結合以外にもcopy&pasteやsortもできるみたいで、内部ではPOST https://sheets.googleapis.com/v4/spreadsheets/{spreadsheetId}:batchUpdateにリクエストをかけています。ヒントは(https://developers.google.com/sheets/api/reference/rest/v4/spreadsheets/request)
にあります。Reference
gspread
gspread-formatting
PythonでGoogleSpreadSheetのセルにコメントを付加したり色や枠線をつける
Basic Formatting
Method: spreadsheets.batchUpdate
- 投稿日:2019-07-19T21:03:29+09:00
Goかpythonでブロックチェーンを理解する
最近ビットコインがまた上昇しているという話ですね。五月あたりに一気に上昇したとかで私のTwitterのTLにいるビットコインの取引している人はめちゃめちゃ喜んでました。そんなわけで今回はブロックチェーンがどのような仕組みになっているかGoとpython(Goとpythonで同じ内容を実装します。所属学部の関係上、pythonが読める人が友達に多いので)で実装しながら説明していきます。最後にまあ最低限ブロックチェーンのシミュレーションといっても差し支えないだろうというもの(主観です)をGoで実装します。
ブロックチェーンとは何か
ブロックチェーンとは、分散型台帳技術、または、分散型ネットワークである。ビットコインの中核技術(サトシ・ナカモトが開発)を原型とするデータベースである。
とあるように新しい種類のデータベースです。(これは私の考えです。でもたぶんあってます。)よく知られている応用例としてbitcoinやethereumなんかがあります。基本的にbitcoinはお金の記録を保存するもの、ethereumはそれに加えてプログラムの保存をするもののように考えています。ただ、近年はbitcoinにもethereumと同じような機能が実装されてきているらしいです。ブロックチェーンと聞くと「インターネット上にあるお金」を想像する方もいらっしゃると思うんですけど、ブロックチェーンの技術自体はお金とは無関係です。しかしその防御力の高さからかお金の保存や取引などに利用されます。(嘘です。みんながお金をかけても掘りたくなるような実装が組み込まれてるんですけど、それは今回はやりません。)
ブロックチェーンの構造
ハッシュ
ブロックチェーンを理解するのに欠かせない知識の一つにハッシュというものがあります。
ハッシュ、ハッシュ値 - データから算出した小さな値。各データを区別・表現する目的に用いる。
>>certutil -hashfile hogehoge.txt SHA256windowsのコマンドプロンプトでこのように入力するとファイルのハッシュ値を計算することができます。ハッシュ値を算出するための関数をハッシュ関数といいます。ハッシュ関数は出力された値から入力された値を逆算することができないという特徴を持ちます。二つの異なるデータのハッシュ値は互に異なるように設計されているため(必ずしも違う値が出力されるわけではない)、データのハッシュ値が違う場合、互いのデータが違う値であるということが言えます。パスワードの保管などセキュリティが重視される場合、ハッシュ関数にはハッシュの衝突(別のデータのハッシュ値を計算したときに同じ値が出力される現象)ができるだけ少ないSHA(secure hash algorithmの略)と呼ばれる種類のハッシュ関数が使われます。
*ハッシュ値は5次関数に値を代入したらすぐに答えが求まるのに対して5次方程式は解けないというのとイメージは同じです。(たぶん)
基本構造
ブロックチェーンの基本構造は上の図のように(わかりにくかったらごめんなさい)あるブロックはその前のブロックのハッシュ値をもっているというリンクリストのような構造になっています。先頭は左のブロックです。ブロックチェーンの名前の由来はここです。これで何がうれしいかを説明します。まず、攻撃者が先頭のブロックのデータを書き換えたとします。そうすると次のブロックの中にある先頭のブロックのハッシュ値と、書き換えられた先頭のブロックのハッシュ値が一致しなくなります。そこで攻撃者は矛盾点を消すため二番目のブロックのハッシュ値を書き換えます。すると今度は二番目と三番目のブロックの間に矛盾が生じます。矛盾を消すために攻撃者が三番目のブロックを書き換えます。このように情報を書き換えようと攻撃した場合、書き換えたブロックから一番最後のブロックまですべてのブロックの情報を書き換えなければならないことになります。とりあえずここまでで攻撃するのはいっぱい書き換えなきゃいけないしなんか大変そうだなあってことがわかっていただければよいです。
Goでプログラムを書いてみる
ここまでの説明をプログラムにしてみます。
まずはブロックの構造体とブロックを格納する配列(ブロックチェーン)を定義します。
//後で使うパッケージをimportしとく package main import ( "fmt" "bytes" "crypto/sha256" "encoding/hex" "encoding/json" ) //ブロックの構造体 type block struct { Prevhash [32]byte } //都合がいいのでハッシュ値を入れるとブロックを作ってくれる関数も作っとく //ブロックを作成 func makeBlock(hash [32]byte) block{ var a block a.Prevhash = hash return a } //ブロックチェーン //最初のブロックのハッシュ値は0にしとく var chain = []block{makeBlock([32]byte{})}次にブロックをjson文字列にする関数と[]byteを渡すとSHA256のハッシュ値を計算してくれる関数を定義
//ブロックをjson文字列に変換する func convjson(b block) string{ var buf bytes.Buffer byt, _ := json.Marshal(b) buf.Write(byt) return buf.String() } //ハッシュ値を計算する関数 func hash(str []byte) [32]byte { return [32]byte(sha256.Sum256(str)) }最後にブロックをつなげてく関数をつくって終了!
//マイニング func mine() string{ lastBlock := chain[len(chain) - 1] lastBlock_json := convjson(lastBlock) n := makeBlock(hash([]byte(lastBlock_json))) chain = append(chain,n) return convjson(n) } //ハッシュ値はbyteの配列で保存されています。つまり1byteごとの数字の羅列 //かっちょよく16進数に変換したい場合はこの関数も定義しときましょう。 //[32]byteを[]byteに変換して16進数文字列に変換する func convhex(b [32]byte) string{ by := make([]byte,32) for i:=0;i<32;i++{ by[i] = b[i] } return hex.EncodeToString(by) }ホリホリ
func main(){ //マイニングの回数 n := 5 for i:=0;i<n;i++{ mine() } fmt.Println(chain) /* さっきのconvhex関数を定義してたらこっちの方がカッコイイ for i:=0;i<len(chain);i++{ fmt.Println(convhex(chain[i].Prevhash)) } */ }pythonでプログラムを書いてみる
pythonはGoよりもいくらか簡単にプログラムを書くことができます。すごく短いので説明はコメントアウトしてちょちょっと書きます。さっきと違うこととしては、ブロックを構造体ではなくdictionary(辞書)で作りました。
from hashlib import sha256 # ハッシュ関数 import json #dictionaryをjsonの文字列に変換するため class blockChain(): def __init__(self): self.chain = [{"prevhash":'0'*64}] # 初期値は0に #ディクショナリ、辞書、連想配列(いろんな呼び方があります。) #それでブロックを作る関数 def makeBlock(self,hash): b = {} #新しいブロックをdictionaryで b["prevhash"] = hash return b #ブロックののjsonを取得しハッシュ値を計算する def hash(self,map): data = json.dumps(map) #dictionaryをjsonに変換 #文字列をエンコードしてハッシュ値を計算して十六進数の文字列に変換 hash = sha256(data.encode()).hexdigest() return hash #ブロックをつなげていく def mine(self): lastBlock = self.chain[-1] # 一番最後のブロックを取得 hash = self.hash(lastBlock) # ハッシュ値を計算 nextBlock = self.makeBlock(hash) # 新しいブロックを作る self.chain.append(nextBlock) # ブロックをつなげる c = blockChain() for i in range(5): c.mine() print(c.chain)こんな感じで書けます。
ブロックチェーンをより安全にする
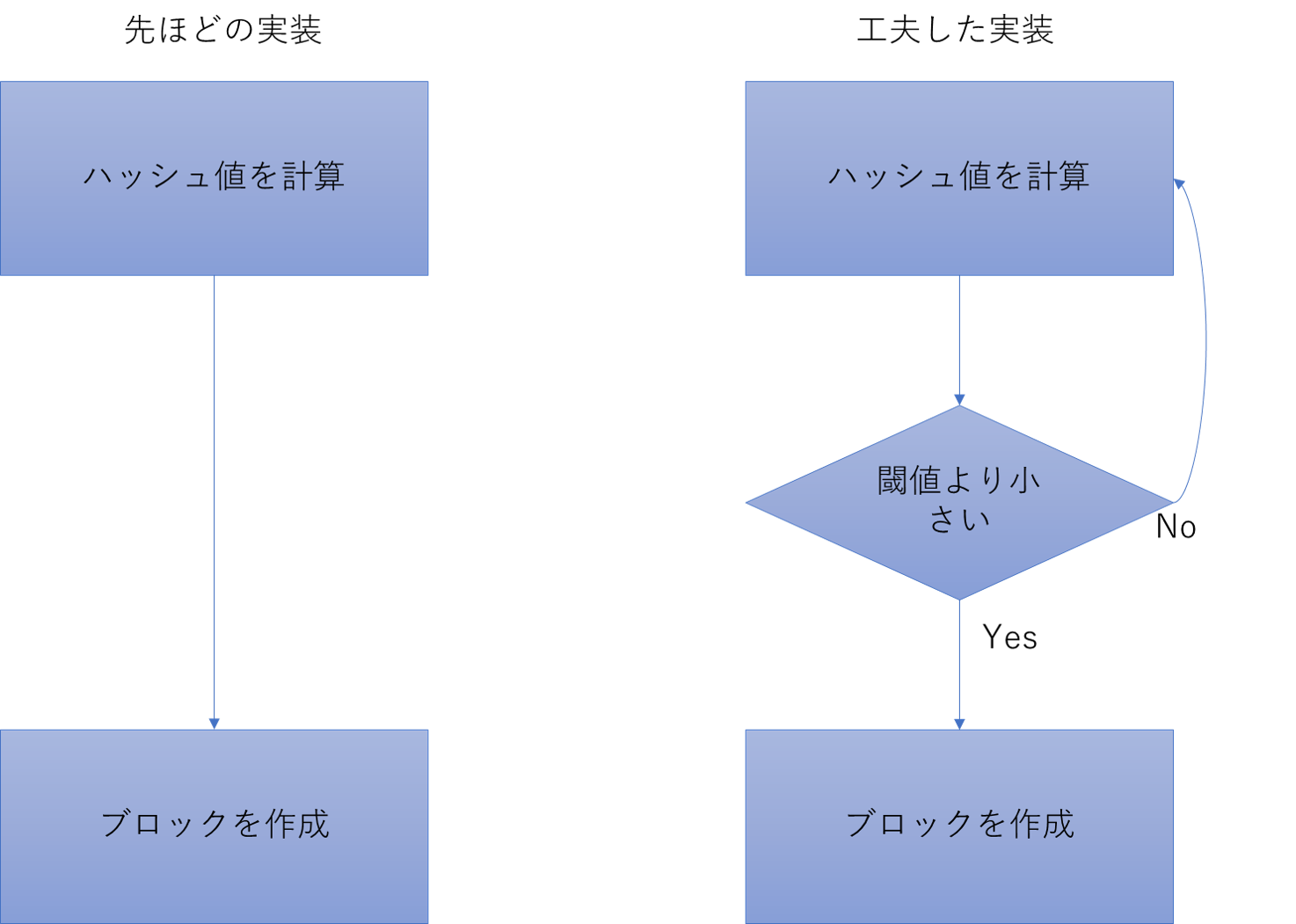
上では、ただただ前のブロックのハッシュ値を計算するだけでブロックをつなげていきました。しかし、ハッシュ値を計算するのは一瞬です。これだけの速度でチェーンを伸ばしていけると全て書き換えるのはかんたんです。なので、実際のブロックチェーンは一工夫されています。
上の部分はハッシュ値の計算からブロックの生成までのフローチャートです。前回の実装ではハッシュ値を計算したらそのままブロックを作成しています。しかし、工夫した実装ではハッシュ値に制限をもうけています。性能の良いハッシュ関数は出現する値の確率が一様です。ですので、制限を設けてあげるとそのハッシュ値が出るまで何回も何回も計算しなければいけません。ただし、同じデータについてハッシュ値を計算しても同じ値が出力されるだけです。ですので、ブロックに自由に変更できる要素を追加してその要素をごちゃごちゃ変えて条件を満たすハッシュ値を探していきます。
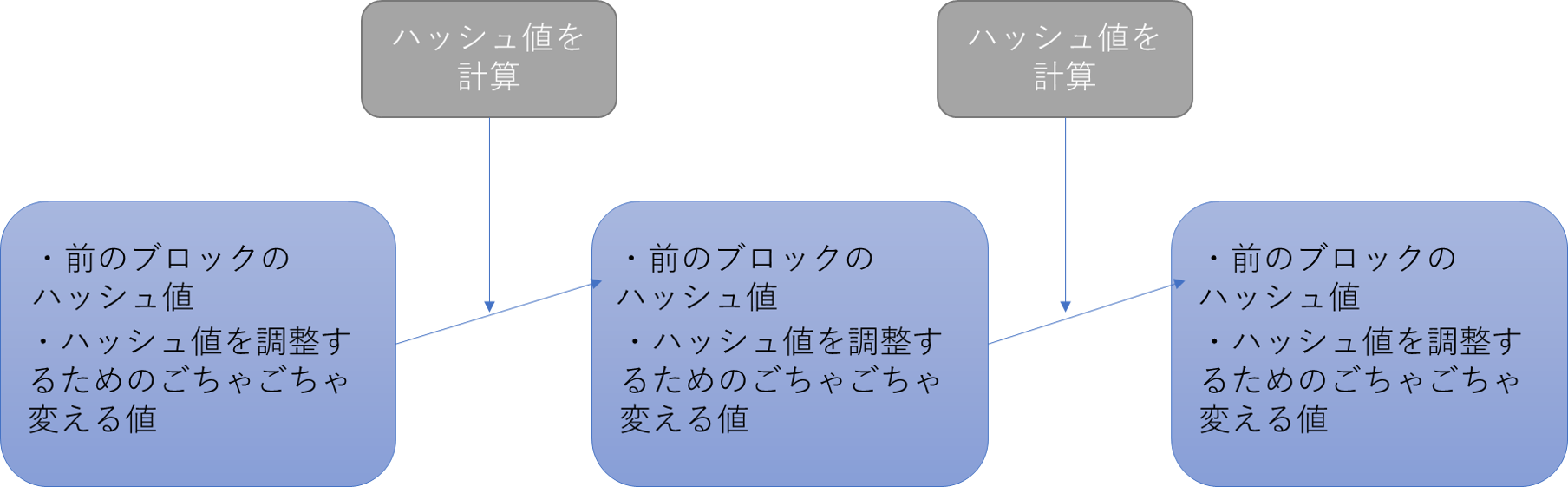
チェーンは上の図のようになります。これも先頭は左のブロックです。ハッシュ値は入力される値が少し変わるだけで大きく変動するのでごちゃごちゃ値をこねくり回して条件にあうものをさがします。ハッシュ値の制限を厳しくすればするほど合う値を探すのに時間がかかります。こうすることでブロックを改変するのに非常に大きなコストがかかって攻撃が受けにくくなります。*ビットコインでは1ブロックつなげるのに平均10分程度かかるようにハッシュ値の制限がかかっています。また、時期によって多くの人が掘る場合やあまり掘られない場合があるので制限がちょうどいいくらいになるように2週間程度に一回制限が修正されます。
Goでプログラムを書いてみる
【変更】まず、構造体にごちゃごちゃ値を変えてハッシュ値を探す値を追加します。この値は一般的にNonceと呼ばれるので変数名にそれを使います。ブロックチェーンの初期値にnonceを追加しときます。
//ブロックチェーン var chain = []block{makeBlock([32]byte{},0)} //ブロックチェーンの中身の構造体 type block struct { Prevhash [32]byte Nonce int //ごちゃごちゃ変える値 } //ブロックを作成 func makeBlock(hash [32]byte,nonce int) block{ var a block a.Prevhash = hash a.Nonce = nonce return a }【追加】閾値のバイト配列と二つのバイト配列を比較する関数を設定します。aに算出したハッシュ値、bに閾値を入れるとa<bのとき1が返されます。
//256bitのバイト列の比較 a < bのとき1 func comper(a [32]byte,b []byte) int{ check := make([]byte,32) for i:=0;i<32;i++{ check[i] = a[i] } return bytes.Compare(b,check) }閾値のバイト配列を生成します。指数の計算を今回は32bitで収まる範囲の整数の計算しかしないのでこんな感じで書いてますが、たぶんmathとかのパッケージにあると思うので使うといいと思います。
//指数 func pow(n int,m int) int{ if m == 1{ return n }else if m == 0 { return 1 }else if m % 2 == 0{ k := pow(n,m/2) return k*k }else { return n*pow(n,m-1) } } //2^nの256bitのバイト列を生成 func makebyte(n int) []byte{ ans := make([]byte,32) //256以上の値が引数に渡されたら制限がないといってよいので //とりあえず一番大きい桁に255入れときます。 //(凝る人はすべてに255入れるループ書いても良いよ) if n >= 256{ ans[0] = byte(255) return ans } amari := n % 8 syo := n / 8 check := pow(2,amari) ans[31-syo] = byte(check) return ans }【変更】mine関数のなかで、望んだ範囲のハッシュ値が算出されるまで何度もnonceを変更しながら計算するようにコードを変更します。
//マイニング diffが小さいほど制約が大きい func mine(diff int) string{ lastBlock := chain[len(chain) - 1] lastBlock_json := convjson(lastBlock) lastBlock_hash := hash([]byte(lastBlock_json)) counter := 0 limit := makebyte(diff) var n block for { n = makeBlock(lastBlock_hash,counter) nowBlock_json := convjson(n) nowBlock_hash := hash([]byte(nowBlock_json)) if comper(nowBlock_hash,limit) == 1{ break } counter ++ } chain = append(chain,n) return convjson(n) }動かしてみます。
func main(){ //マイニングの回数 n := 5 for i:=0;i<n;i++{ block := mine(240) //難易度を240にしてホリホリ fmt.Println(string(block)) } }出力
{"Prevhash":[205,238,133,119,21,139,235,115,177,165,36,115,169,188,168,141,124,99,113,3,149,95,2,232,207,114,60,12,88,69,28,28],"Nonce":280}
{"Prevhash":[0,0,6,23,177,48,240,93,239,0,196,205,228,167,78,52,50,128,27,144,125,8,172,233,27,33,169,127,40,252,55,220],"Nonce":18792}
{"Prevhash":[0,0,93,198,62,162,247,57,110,183,62,209,236,28,195,179,116,88,163,84,1,80,249,49,38,43,253,165,176,14,1,124],"Nonce":7932}
{"Prevhash":[0,0,232,216,132,117,74,174,19,142,116,9,172,50,160,160,64,209,74,47,215,0,182,22,132,178,3,178,166,254,253,70],"Nonce":62563}
{"Prevhash":[0,0,57,142,21,48,208,108,153,110,201,129,204,153,207,154,101,222,46,77,167,82,189,90,50,115,19,20,226,196,53,90],"Nonce":95247}難易度をかえて掘るのに時間がかかることを確認してみてください。
pythonでプログラムを書いてみる
【変更】さっきのmakeBlock関数にnonce値を加えます。nonce値はごちゃごちゃ変えて欲しいハッシュ値を探す値です。
def makeBlock(self,hash,nonce): b = {} b["prevhash"] = hash b["nonce"] = nonce return b【変更】mine関数の引数にdiffという引数を追加します。これは、ハッシュ値の閾値です。ハッシュ値が2^diffよりも小さい値だった場合はブロックをつなげます。違う場合はnonceを変えてハッシュ値を計算しなおします。
def mine(self,diff): lastBlock = self.chain[-1] hash = self.hash(lastBlock) counter = 0 while True: nextBlock = self.makeBlock(hash,counter) if int(self.hash(nextBlock),16) < 2**diff:break counter += 1 self.chain.append(nextBlock) return nextBlock実行!
c = blockChain() n = 5 for i in range(n): block = c.mine(240) print(block)出力
{'prevhash': 'fb197130829d450616b62e431f55fb639aa7ba5989dc82282aeb7b3435856677', 'nonce': 76517}
{'prevhash': '0000c25cb0503255c52ad386cde40b418ec7e0b876dde7cb40039195621c584d', 'nonce': 60994}
{'prevhash': '0000c4180e4cdc8bfaf24ec8738af39800bd08ef9926ab47a56a203194408276', 'nonce': 60232}
{'prevhash': '000030a575effc930f2c4d8529b39ad0e3052853e01b9d3e277dce3cd560877f', 'nonce': 240649}
{'prevhash': '000018c5d3e7bab0564d1b8dce874ed1efd0722c79427709a7ea304537b6cae0', 'nonce': 102298}ブロックチェーンが安全である理由
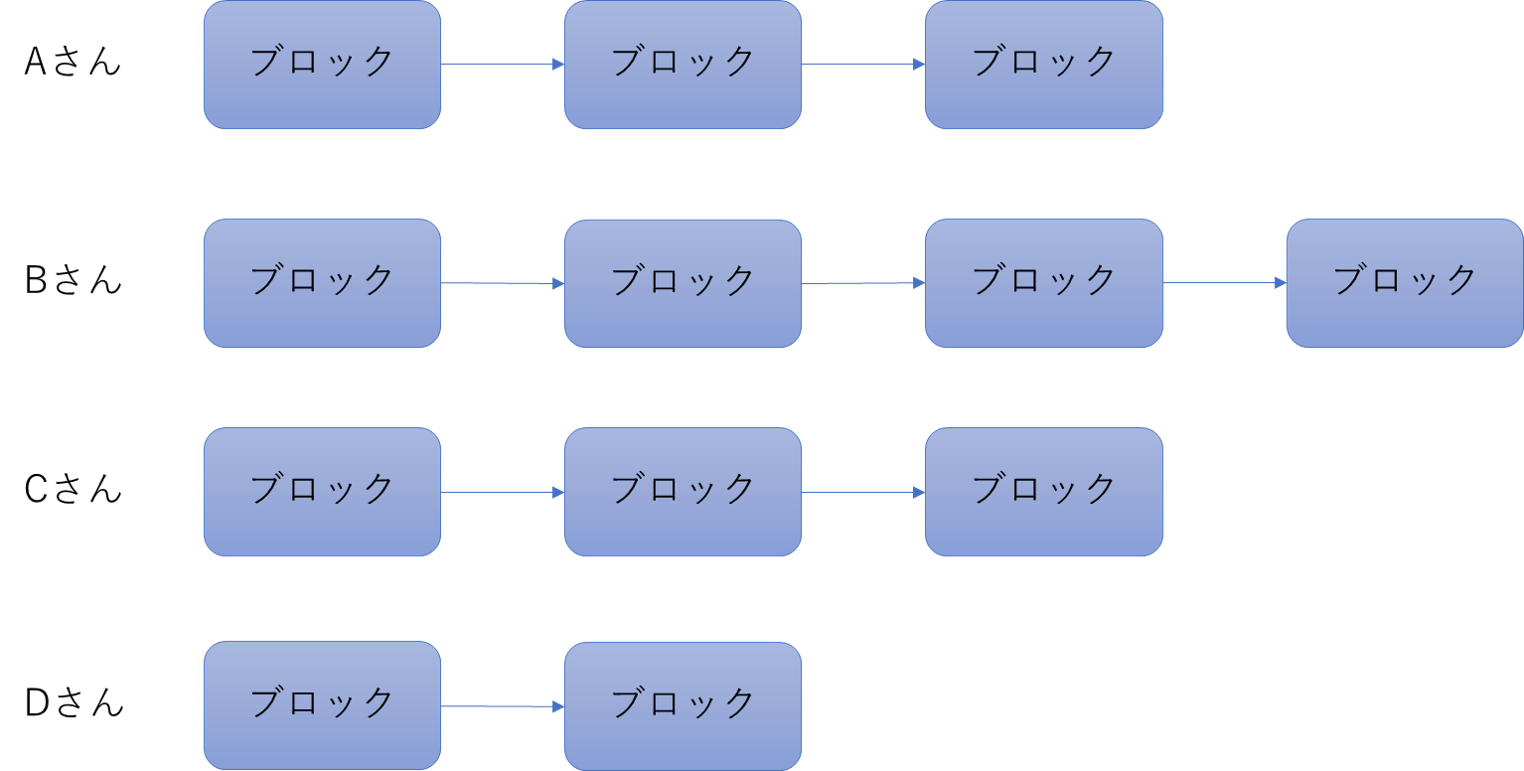
ここまでで、新しいブロックを生成するには非常に大きなコストがかかることがわかりました。しかし、これだけでは時間をかけて計算すればすべてのブロックを改変してしまうことができてしまうと思うと思います。ここで、Aさん、Bさん、Cさん、Dさんの四人がSumiSumicoinという暗号通貨をマイニングするときを考えます。四人が掘り始めていくらか時間が経ちました。その時に四人それぞれが掘り進めたブロックのチェーンが下のようになっているとします。
このとき、全員のブロックが違ってはいけないので全員のブロックを統一します。結論から言いますと、統一するために一番長くチェーンをつなげた人のブロックを採用します。今回の場合でいくとBさんのブロックが採用されて、Aさん、Cさん、DさんはBさんのつなげたブロックをコピーします。また、ブロックのつながりに矛盾が生じるもの(ハッシュ値が一致しないもの)は採用しないようにします。このようにすることで、攻撃者がブロックの改ざんをする場合にはほかのまじめにマイニングしている人全員よりも速い速度でブロックをつなげる必要が出てきます。つまり、攻撃者はすべてのマイニングをする人の総和よりも多くの計算リソースを用意する必要が出てくるためそれはほぼ不可能です。私はそれだけ多くのコンピューターを用意して攻撃して採算が取れるとは思いません。まともな人間ならまずやらないでしょう。(個人的な意見です)この後は複数人でマイニングをした場合を一つのパソコンでシミレーションをするということを行います。ですが、なかなかに長いコードになってしまい、型のないpythonで書くのは辛くなってしまったのでGoのみの実装となります。ご了承ください。
Goで実装してみる
上にも書いたように複数人でマイニングをする場合を実装します。並列処理を実装することであたかも複数人でマイニングをしているように見せかけることができます。
とりあえずこんだけのパッケージをimportしとくと良いです。
import ( "math/rand" "fmt" "reflect" "bytes" "crypto/sha256" "encoding/hex" "encoding/json" "time" "os" )まずはブロックの構造を変更します。複数人で掘るということで、マイナーの名前をブロックに記録することにします。また、他人のチェーンが整合性が取れているかどうか判別するためにハッシュ値の制限の閾値を入れてあげます。その変更に合わせてブロックを作成する関数も変更します。
//ブロックチェーンの中身の構造体 type block struct { Prevhash [32]byte Nonce int Difficulty int //難易度 Name string //マイナーの名前 } //ブロックを作成 func makeBlock(hash [32]byte,nonce int,difficulty int,name string) block{ var a block a.Prevhash = hash a.Nonce = nonce a.Difficulty = difficulty a.Name = name return a }今回はブロックチェーンを複数人で掘ります。ですので、人数分のチェーンが必要になります。これに合わせてチェーンを初期化する関数も用意します。
//ブロックチェーン //var chain = []block{makeBlock([32]byte{},0)} //チェーンのリスト var list = make([][]block,4) //初期化 func initList(){ for i:=0;i<4;i++{ list[i] = []block{makeBlock([32]byte{},0,256,"")} } }チェーンの整合性が取れているかどうかを判別します。これは、他人が悪意のあるチェーンを作った時に自分のチェーンと間違えて置き換えないようにするためです。
//チェーンの整合性をチェック func check(ls []block) bool{ //前後のブロックとハッシュ値の関係に矛盾がないかどうか for i:=0;i<len(ls) - 1;i++{ //前のブロックのハッシュ値 before := hash([]byte(convjson(ls[i]))) //次のブロックに書いてある前のブロックのハッシュ値 after := ls[i+1].Prevhash if ! reflect.DeepEqual(after,before){ return false } } //ハッシュ値が2^difficultyよりも小さいかどうか for i:=0;i<len(ls);i++{ //制限のバイト配列 limit := makebyte(ls[i].Difficulty) //現在のブロックのハッシュ値 nowBlock_hash := hash([]byte(convjson(ls[i]))) if comper(nowBlock_hash,limit) != 1{ fmt.Println("yei") return false } } return true }一番長くて整合性のあるチェーンを返す関数です。ポインタだけ渡されるみたいなことがあると怖いので、最後にコピー走らせてます。
//全てのチェーンを調べて一番長くて整合性のあるチェーンを返す func consensys() []block{ //チェーンの長さを入れる。整合性のないチェーンの場合は-1 chainLength := make([]int,len(list)) for i:=0;i<len(list);i++{ if check(list[i]){ chainLength[i] = len(list[i]) } else { chainLength[i] = -1 } } maxLength := 0 maxIndex := 0 for i:=0;i<len(chainLength);i++{ if chainLength[i] > maxLength{ maxLength = chainLength[i] maxIndex = i } } ansChain := make([]block,maxLength) for i:=0;i<maxLength;i++{ ansChain[i] = list[maxIndex][i] } return ansChain }mine関数も変えます。まず、1から順に探していたnonce値を乱数にします。これは、複数の人間が全く同じようにnonce値を探していたらちょっと早く掘り始めた人の一人勝ちになってしまうからです。(たぶん)実験はしてません。たぶんそうです。たぶん...
また、ひとブロック掘るごとに一番長いチェーンを自分のチェーンに置き換えます。この実装だと長いチェーンが自分だとしても自分のチェーンをコピーして置き換えるという操作をしているので凝る人は高速化できると思います。引数のindexはさっき作ったチェーンのリストのインデックスを指定してください。//マイニング diffが小さいほど制約が大きい indexはチェーンのリストの何番目か func mine(diff int,index int,name string) string{ lastBlock := list[index][len(list[index]) - 1] lastBlock_json := convjson(lastBlock) lastBlock_hash := hash([]byte(lastBlock_json)) limit := makebyte(diff) var n block for { // 乱数にする↓ n = makeBlock(lastBlock_hash,rand.Int(),diff,name) nowBlock_json := convjson(n) nowBlock_hash := hash([]byte(nowBlock_json)) if comper(nowBlock_hash,limit) == 1{ break } } //一番長いチェーンを自分の所に置き換える list[index] = append(list[index],n) list[index] = consensys() return convjson(n) }最後にホリホリするためのmain関数を書きます。A、B、C、Dの四人でマイニングをします。それぞれmine関数に名前とインデックスを指定します。また、もう一つ5秒おきに最長のチェーンの状態を出力してくれるものも並列で実行しときます。
func main(){ initList() //Aさん go func() { for { mine(235,0,"A") } }() //Bさん go func() { for { mine(235,1,"B") } }() //Cさん go func() { for { mine(235,2,"C") } }() //Dさん go func() { for { mine(235,3,"D") } }() //五秒おきに最長チェーンの状態を出力 go func() { for { time.Sleep(5*time.Second) ls := consensys() for i:=0;i<len(ls);i++{ fmt.Println(ls[i]) } } }() //四人で5分マイニングした後最長チェーンの状態をファイルに書き込む time.Sleep(300*time.Second) // ファイル名を指定↓ file, err := os.Create(`directory\\hogehoge.txt`) if err != nil { // Openエラー処理 } defer file.Close() ls := consensys() for i:=0;i<len(ls);i++{ output := convjson(ls[i]) + "\r\n" file.Write(([]byte)(output)) } }ここまで出来たら実行してあげましょう。五分後には自作ブロックチェーンの結果がファイルに出力されているはずです。私のPC(2コア4スレッド2.50GHz - 2.71GHz)では235がちょうどよい難易度だったのでそれになってまずが、もっといいプロセッサが積んであるコンピューターではもう少し数字を下げてあげてもいいかもしれません。
最後に
ここまで作ってきましたが、やはりブロックチェーンの構造は面白いですね。これでとりあえず変更されにくいチェーンを組めたので、あとはブロックの中にどんな機能を入れるかによってさまざまな性質のブロックチェーンを作ることができます。世の中にたくさんの暗号通貨が存在しているのはそのためです。(ほかにさして知識のない人が自分の通貨を作りたいと言って作る人もいますが...)なんにせよ、ブロックチェーンは未来ある技術なので今後の展開が楽しみです。あと、私はこれからテスト期間に入るので勉強頑張ります。

- 投稿日:2019-07-19T20:24:30+09:00
pythonで定時実行するAWS Lambda処理を作った
はじめに
相変わらず競馬関係のプログラムを書いています。
これまではHeroku上で開発していたのですが、仕事でAWSを使っていることもあり、個人開発でもAWSを使い始めました。Herokuだと毎日決まった時間に動作する処理を書く場合、Heroku Schedulerを使う形になりますが、AWSだとLambdaをCloudWatchイベントでキックする形…とはいうもののひとまとめになっている情報が見当たらなかったので、やってみたことを残しておきたいと思います。
※2019年7月時点の情報です。AWSはサービス改善のスピードが速すぎてWebにまとめた情報があっという間に陳腐化するので、そこはご注意を…
AWS SAMのテンプレート
AWS SAMを使ってみたのですが、元になるテンプレートを作成するためにsam initコマンドを使うとAPIゲートウェイからキックされる処理のテンプレートになります。
定時実行する処理用のテンプレートは…ということで調べたところ、以下にありました。
CloudWatch イベント アプリケーションの AWS SAM テンプレートだけど、これは定時実行ではなくて定期実行、かつ今回必要ないようなリソースも使っていたりだったので、定期実行する最低限のテンプレートを作りました。
template.yamlAWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: > notify_hitokuchi Sample SAM Template for notify_hitokuchi Globals: Function: Timeout: 10 Resources: NotifyHitokuchiFunction: Type: AWS::Serverless::Function Properties: CodeUri: notify_hitokuchi/ Handler: app.lambda_handler Runtime: python3.7 Events: NotifyHitokuchi: Type: Schedule Properties: Schedule: cron(30 12 * * ? *)一番下の行のScheduleの行が定時実行する時刻の指定。式の記述方法は以下を参照。
ルールのスケジュール式ハンドラでもらえるイベント情報の時刻
先程のテンプレートだと、notify_hitokuchi/app.py内のlambda_handler関数が実行時に呼び出される関数になります。
app.pydef lambda_handler(event, context):eventには辞書形式でイベント情報が入ってきます。
今回はCloudWatchイベントでキックされた時刻が欲しかったのですが、実行時刻はevent['time']にISO 8601形式で入ってきます。
それをそのまま「datetime.fromisoformat()」関数に渡せばdatetimeが入手できる…と思いきや、「2019-07-10T12:30:00Z」という形だと「datetime.fromisoformat()」は処理できないようでして…
以下のようなコードでdatetimeを入手しました。# event['time']に'2019-07-10T12:30:00Z'形式の文字列が入ってくる datetime_str = event['time'].replace('Z', '+00:00') # '2019-07-10T12:30:00+00:00'形式だとfromisoformatで処理できる datetime_utc = datetime.fromisoformat(date_str)pip等でインストールしたライブラリ
pip等でインストールしたライブラリをAWS Lambdaで使う場合、ライブラリを1箇所にまとめてZIPで固めて…という話をよく見かけますが、samを使っている分にはsam buildで済むようです。
$ sam build 2019-07-19 07:42:34 Building resource 'NotifyHitokuchiFunction' 2019-07-19 07:42:34 Running PythonPipBuilder:ResolveDependencies 2019-07-19 07:42:44 Running PythonPipBuilder:CopySource Build Succeeded Built Artifacts : .aws-sam/build Built Template : .aws-sam/build/template.yaml Commands you can use next ========================= [*] Invoke Function: sam local invoke [*] Package: sam package --s3-bucket <yourbucket>↓↓↓2019-07-20追記↓↓↓
sam buildの前にrequirements.txtをCodeUriで指定したパスに設置が必要です。
自分はpipenvを使っているので、以下でrequirements.txtを生成しました。$ $ pipenv lock -r > notify_hitokuchi/requirements.txt $ cat notify_hitokuchi/requirements.txt -i https://pypi.org/simple beautifulsoup4==4.7.1 bs4==0.0.1 certifi==2019.6.16 chardet==3.0.4 decorator==4.4.0 html5lib==1.0.1 idna==2.8 mojimoji==0.0.9.post0 py==1.8.0 python-dotenv==0.10.3 requests==2.22.0 retry==0.9.2 six==1.12.0 soupsieve==1.9.2 urllib3==1.25.3 webencodings==0.5.1また、上記requirements.txtに記載のあるmojimojiのようにC/C++で作られているライブラリは動作環境でコンパイルする必要がありますが、sam buildに--use-containerオプションを付けることでdockerコンテナ上でビルドが行われ、Lambda上で動くライブラリを作ることができます。素晴らしい!
$ sam build --use-container 2019-07-20 09:43:51 Starting Build inside a container 2019-07-20 09:43:51 Building resource 'NotifyHitokuchiFunction' Fetching lambci/lambda:build-python3.7 Docker container image...... 2019-07-20 09:43:55 Mounting /Users/masaminh/develop/notify_hitokuchi_aws/notify_hitokuchi as /tmp/samcli/source:ro,delegated inside runtime container Build Succeeded Built Artifacts : .aws-sam/build Built Template : .aws-sam/build/template.yaml Commands you can use next ========================= [*] Invoke Function: sam local invoke [*] Package: sam package --s3-bucket <yourbucket> Running PythonPipBuilder:ResolveDependencies Running PythonPipBuilder:CopySource↑↑↑2019-07-20追記↑↑↑
ローカルでの動作確認
まずハンドラに渡されるイベント情報を作っておく必要がありますが、その元はsam local generate-eventを使って取得できます。
今回はCloudWatchのイベントですが、以下で作成しました。$ sam local generate-event cloudwatch scheduled-event > event.json $ cat event.json { "id": "cdc73f9d-aea9-11e3-9d5a-835b769c0d9c", "detail-type": "Scheduled Event", "source": "aws.events", "account": "", "time": "1970-01-01T00:00:00Z", "region": "us-east-1", "resources": [ "arn:aws:events:us-east-1:123456789012:rule/ExampleRule" ], "detail": {} }実際にローカルで動作確認を行う際には、
$ sam local invoke -e event.json NotifyHitokuchiFunction 2019-07-19 08:03:10 Invoking app.lambda_handler (python3.7) 2019-07-19 08:03:10 Found credentials in shared credentials file: ~/.aws/credentials Fetching lambci/lambda:python3.7 Docker container image......という感じで呼び出すことができます。Dockerコンテナ上で動くので起動するのに少し時間がかかります。
デプロイ
まずパッケージを作成。
$ sam package --s3-bucket バケット名 --output-template-file package.yaml Successfully packaged artifacts and wrote output template to file package.yaml. Execute the following command to deploy the packaged template aws cloudformation deploy --template-file /Users/masaminh/develop/notify_hitokuchi_aws/package.yaml --stack-name <YOUR STACK NAME>引き続き、メッセージに従ってデプロイ...
$ aws cloudformation deploy --template-file package.yaml --stack-name notify-hitokuchi Waiting for changeset to be created.. Failed to create the changeset: Waiter ChangeSetCreateComplete failed: Waiter encountered a terminal failure state Status: FAILED. Reason: Requires capabilities : [CAPABILITY_IAM]メッセージのままだと上記のように怒られるので、capabilitiesにCAPABILITY_IAMを設定します。
$ aws cloudformation deploy --template-file package.yaml --stack-name notify-hitokuchi --capabilities CAPABILITY_IAM Waiting for changeset to be created.. Waiting for stack create/update to complete Successfully created/updated stack - notify-hitokuchiデプロイできました。
ログ出しに関して
app.pyimport logging logger = logging.getLogger() logger.setLevel(logging.INFO) def lambda_handler(event, context): logger.info('start: event.time=%s', event['time'])こんな感じで普通にloggerから出力すれば、CloudWatchで見られます。
[INFO] 2019-07-18T12:30:28.336Z 51865e95-cacd-4f9d-80e9-6e1f148357b9 start: event.time=2019-07-18T12:30:00Zおわりに
今回は競馬的なことは書かずにノウハウ的なところのみでした。(Lambda関数名からして競馬系の処理だなぁという感じではありますが・笑)
引き続き競馬系の個人開発はやってますので、またそのうち競馬開発系の記事を書きたいな〜と思います(笑)
- 投稿日:2019-07-19T18:07:49+09:00
データ数が入力次元より少ない場合の重回帰分析
はじめに
この記事は古川研究室 Workout_calendar 4日目の記事です。
本記事は古川研究室の学生が学習の一環として書いたものです。本記事では重回帰分析について述べます。
重回帰分析を扱った時にプログラムは回ったのに予測値がめちゃくちゃ!ってことはよくありますよね。その原因の一つに学習データの型(サイズ)があるかもしれません。重回帰では入力の次元数よりもデータ数が少ないと、出力値に大きな差が出ることがあります。
本記事では重回帰分析のアルゴリズムについて詳しく述べた後、入力が高次元かつデータ数が少ない場合に何が起こっているのか、またその解決法について述べます。重回帰分析とは
問題設定
観測データとしてD次元のベクトルの入力$\mathbf x\in \mathbb R^D$と出力$y\in \mathbb R$のペア$\left\{(\mathbf{x}_n,y_n)\right\} _{n=1}^N $から$y=f(\bf{x})$となるような関数$f$を推定すること
重回帰分析を解く
$\begin{equation}
f(\mathbf{x})=w^{(1)}x^{(1)}+w^{(2)}x^{(2)}+...+w^{(D)}x^{(D)} \tag{1}
\end{equation}$
とモデルを定義します。
$\begin{equation}
f(\mathbf{x})=\sum_{d=1}^{D}{w^{(d)}}{x^{(d)}} \tag{2}
\end{equation}$
$\mathbf{w}=({w^{(1)}},{w^{(2)}},...,{w^{(D)}})^T,\mathbf{x}=(x^{(1)},x^{(2)},...x^{(D)})^T$とおくと
$\begin{equation}
f(\mathbf{x})=\mathbf{w}^T\mathbf{x} \tag{3}
\end{equation}$観測データの出力とモデルの出力の二乗誤差の総和$J_\mathrm{LS}(\mathbf{w})$が最小となる$\mathbf{w}$を求めていきます。
\begin{align} J_\mathrm{LS}(\mathbf{w})&=\sum_{n=1}^{N}(y_n-f(\mathbf{w}))\\ &=\sum_{n=1}^{N}(y_n-\mathbf{w}^T\mathbf{x}_n)\\ &=\sum_{n=1}^{N}(y_n-\mathbf{x}_n^T\mathbf{w}) \end{align}\mathbf{y}=(y_1,y_2,...,y_N)^T,\mathbf{X}=\begin{pmatrix}x_1^{(1)} & x_1^{(2)} & \cdots & x_1^{(D)} \\ x_2^{(1)} & x_2^{(2)} & \cdots & x_2^{(D)} \\ \vdots & \vdots & \ddots & \vdots \\ x_N^{(1)} & x_N^{(2)} & \cdots & x_N^{(D)}&\end{pmatrix}とおくと
\begin{eqnarray} J_\mathrm{LS}(\mathbf{w})&=&(\mathbf{y}-\mathbf{X}\mathbf{w})^T(\mathbf{y}-\mathbf{X}\mathbf{w})\\ &=&(\mathbf{y}^T-\mathbf{w}^T\mathbf{X}^T)(\mathbf{y}-\mathbf{X}\mathbf{w})\\ &=&\mathbf{y}^T\mathbf{y}-\mathbf{y}^T\mathbf{X}\mathbf{w}-\mathbf{w}^T\mathbf{X}^T\mathbf{y}+\mathbf{w}^T\mathbf{X}^T\mathbf{X}\mathbf{w}\\ &=&\mathbf{y}^T\mathbf{y}-2\mathbf{w}^T\mathbf{X}^T\mathbf{y}+\mathbf{w}^T\mathbf{X}^T\mathbf{X}\mathbf{w}\\ \end{eqnarray}上式を$\mathbf{w}$について偏微分し0とおくと
\begin{eqnarray} \frac{\partial}{\partial \mathbf{w}}J_\mathrm{LS}&=&\frac{\partial}{\partial \mathbf{w}}(\mathbf{y}^T\mathbf{y}-2\mathbf{w}^T\mathbf{X}^T\mathbf{y}+\mathbf{w}^T\mathbf{X}^T\mathbf{X}\mathbf{w})\\ 0&=&0-2\mathbf{X}^T\mathbf{y}+\{\mathbf{X}^T\mathbf{X}+(\mathbf{X}^T\mathbf{X})^T\}\mathbf{w}\\ 2\mathbf{X}^T\mathbf{X}\mathbf{w}&=&2\mathbf{X}^T\mathbf{y}\\ \mathbf{X}^T\mathbf{X}\mathbf{w}&=&\mathbf{X}^T\mathbf{y}\\ \mathbf{w}&=&(\mathbf{X}^T\mathbf{X})^{-1}\mathbf{X}^T\mathbf{y} \end{eqnarray}となりパラメータ$\mathbf{w}$を求めることができました!
具体的な例を当てはめてみる
アイスクリーム屋の一日の売上をその日の気温と湿度より予測する重回帰問題を考えてみます。
# 必要なライブラリのimport import numpy as np import random import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D # 入力データセット N = 20 a1 = 1 a2 = 15 temp = np.random.uniform(22,35,N) humi = np.random.uniform(0.0,0.9,N) sales = a1*temp + a2*humi + np.random.rand(N)*2 - 1 # キャンバス作成 fig = plt.figure(figsize=(9, 9)) ax = fig.add_subplot(1, 1, 1, projection='3d') ax.set_title("example data: sales of ice") ax.set_xlabel("humidity") ax.set_ylabel("temperature") ax.set_zlabel("sales of ice") ax.scatter(temp, humi, sales,s=30, c='red')
# データセットを行列に x_1 =temp [:,None] x_2 =humi [:,None] y = sales X = np.concatenate([x_1,x_2],axis=1) # 重回帰の解 w = np.linalg.inv(X.T@X)@X.T@ynew_samples_num = 30 new_temp,new_humi=np.meshgrid(np.linspace(22,35,new_samples_num),np.linspace(0.0,0.9)) new_temp=new_temp[:,:,None] new_humi=new_humi[:,:,None] new_X=np.concatenate([new_temp, new_humi], axis=2) new_y=new_X[:,:,0]*w[0]+new_X[:,:,1]*w[1] fig=plt.figure(1) ax=Axes3D(fig) ax.set_xlabel('temperature') ax.set_ylabel('humidity') ax.set_zlabel('sales') ax.set_title('regression by linear model') ax.scatter(X[:,0],X[:,1],y,c='red',label='trainig data $(x_{n1},x_{n2},y_n)$') ax.plot_wireframe(new_X[:,:,0], new_X[:,:,1], new_y, color='b',label='estimated function $f_w(x)$') plt.legend(fontsize=12) plt.show()
気温と湿度からその日のアイスの売上を予測することができるようになりました!
入力の次元数がデータ数よりも多い場合
以下の重回帰モデルの解を見てみると、重回帰では$\mathbf{X}^T\mathbf{X}$が逆行列を持つ、すなわち正則であることが前提としてあることが分かります。
\begin{eqnarray} \mathbf{w}&=&(\mathbf{X}^T\mathbf{X})^{-1}\mathbf{X}^T\mathbf{y} \end{eqnarray}ここで入力の次元数$D$がデータ数$N$より多い場合を考えてみましょう。$(D>N)$
$\mathbf{X}$を特異値分解します。\begin{eqnarray} \mathbf{X}=U\Sigma V^T \end{eqnarray}ただし$\Sigma$は$N \times D$の行列で以下に示す性質を持っています。
\begin{eqnarray} \Sigma &=& [\Delta,\mathbf{0}] \\ \Delta &=& {\rm diag}(\sigma_1, \dots, \sigma_N) \end{eqnarray}このとき
\begin{eqnarray} \mathbf{X}^T\mathbf{X}&=&(U\Sigma V^T)^TU\Sigma V^T\\ &=&V \Sigma^T U^T U \Sigma V^T\\ &=&V \Sigma^T \Sigma V^T\\ &=&V\begin{pmatrix} \Delta ^2 & \mathbf{0} \\ \mathbf{0} & \mathbf{0} \end{pmatrix}V^T \end{eqnarray}となり$\mathbf{X}^T\mathbf{X}$は非正則となります。数学的には、「逆行列は求められない」で終わりなのですが、数値計算上では$\Sigma^T \Sigma$の要素が常識のように完全に$0$になるのではなく、$0$に近い非常に小さな値が入ります。それに対して無理やり逆行列を計算することになるので$\mathbf{w}$の要素にはとても大きな値が入ることになり、そのモデルから導かれた出力間には大きな差がでてしまいます。
解決法
$\mathbf{X}^T\mathbf{X}$が非正則である時にリッジ回帰という手法が使えます。(他にも過学習を防ぐ場合などにも使われます)
リッジ回帰では重みベクトル$\mathbf{w}$の大きさにペナルティを加えます。($\alpha>0$)\begin{eqnarray} J_\mathrm{LS}(\mathbf{w})&=&\|\mathbf{y}-\mathbf{Xw}\|^2+\alpha\|\mathbf{w}\|^2 \end{eqnarray}同様に$\mathbf{w}$で微分して0とおくと
\begin{eqnarray} \mathbf{w}=(\mathbf{X}^T\mathbf{X}+\alpha I)^{-1}\mathbf{X}^T\mathbf{y} \end{eqnarray}となりますね。
$\mathbf{X}$の特異値分解を考えると\begin{eqnarray} \mathbf{X}&=&U\Sigma V^T\\ \mathbf{X}^T\mathbf{X}+\alpha I &=& (U\Sigma V^T)^T U\Sigma V^T+\alpha I\\ &=&V\Sigma^2V^T+\alpha VIV^T\\ &=&V(\Sigma^2+\alpha I)V^T \end{eqnarray}となります。
$\mathbf{X}^T\mathbf{X}+\alpha I$の特異値は$\mathbf{X}$の特異値の2乗に正の値を足したものとなるため全て正となるので…\begin{eqnarray} \rm{det}(\mathbf{X}^T\mathbf{X}+\alpha I)>0 \end{eqnarray}となり、$\mathbf{X}^T\mathbf{X}+\alpha I$は正則となって逆行列を持ちます!
まとめ
重回帰分析において入力の次元数に対してデータ数が足りない場合の解決法とそれで解決される理由を示しました。
皆さんも問題が発生した際は自分が扱っている手法が何を前提としているかを考えるのもいいかもしれません。参考文献:パターン認識と機械学習(上・下)


- 投稿日:2019-07-19T17:20:50+09:00
PythonでベクトルをL2正規化(normalization)する方法一覧
Pythonを使ってベクトルをL2正規化(normalization)する方法が色々あるのでまとめます。
※L2正則化(regularization)= Ridgeではありません。L2正規化とは
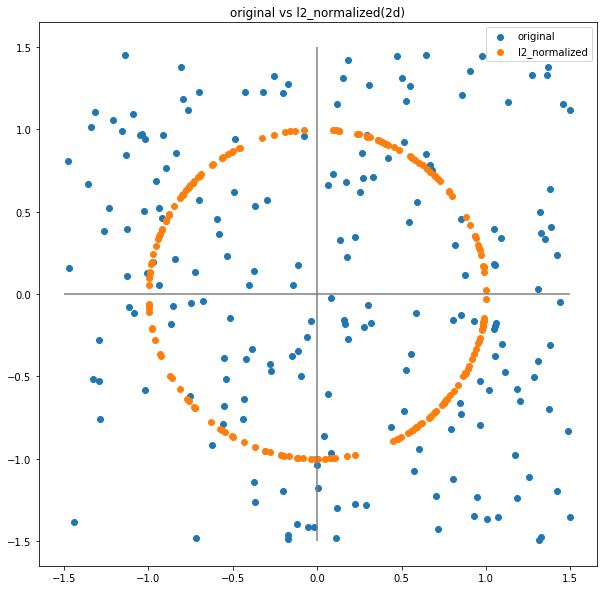
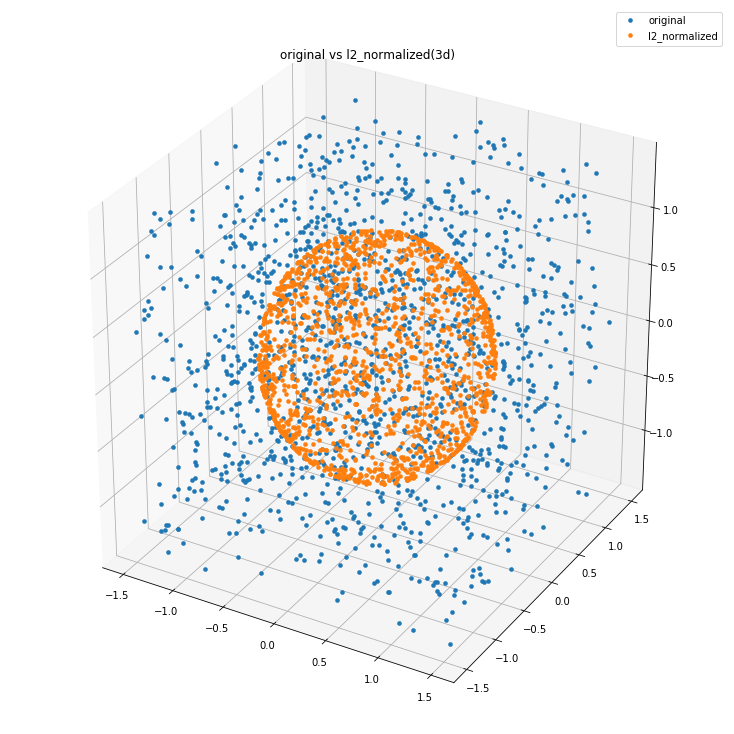
ベクトル$x = (x_1,x_2,...,x_n)$に対応するL2正規化は以下のように定式化されます。
x_{L2\,norm} = \frac{x}{||x||_2}ここで、$||x||_2$は、以下の式で求まる$x$のL2ノルムです。
||x||_2 = \sqrt{(\sum_i x_i^2)} = \sqrt{x_1^2 + x_2^2 + ... + x_n^2}ベクトル$x$をL2正規化すると、長さが1のベクトルになります。
2次元空間で考えた場合、この操作は任意の2次元ベクトルを原点を中心とした半径1の円上へのベクトルに変換していると考えることができます。
3次元の場合は原点を中心とした半径1の球面上へのベクトルに変換します。
4次元以上はイメージが難しいですが、同じように原点を中心とする半径1の超球面上へのベクトルに変換すると考えれば良いと思います。
pythonでの計算方法
上記のようなL2正規化ですが、pythonでは色々と計算方法があるようなので以下にまとめます。
他にもあると思うので、見つけたら追記します。直接計算する
定義に従って計算すれば良いです。
# 定義に従って計算 x = np.array([1,2,3,4,5]) x_l2_norm = sum(x**2)**0.5 x_l2_normalized = x / x_l2_norm # 検算 np.linalg.norm(x_l2_normalized,ord=2) # 1.0
numpy.linalg.norm
numpy.linalg.normを使って計算することも可能です。
こいつはベクトルxのL2ノルムを返すので、L2ノルムを求めた後にxを割ってあげる必要があります。# numpy.linalg.normを使う x = np.array([1,2,3,4,5]) x_l2_norm = np.linalg.norm(x,ord=2) x_l2_normalized = x / x_l2_norm # 検算 np.linalg.norm(x_l2_normalized,ord=2) # 1.0
sklearn.preprocessing.normalizeみんな大好きscikit-learnでも計算可能です。
2次元の場合はaxisで軸の指定します。axis=0で列方向、axis=1(デフォルト)で行方向に正規化を行います。# sklearn.preprocessing.normalizeを使う from sklearn.preprocessing import normalize x = [[1,2,3,4,5],] x_l2_normalized = normalize(x,norm='l2') x_2d = [[1,2,3,4,5],[6,7,8,9,10]] x_2d_l2_normalized = normalize(x_2d,norm='l2') x_2d_l2_normalized2 = normalize(x_2d,norm='l2',axis=0) # 検算 print(np.linalg.norm(x_l2_normalized,ord=2)) print(np.linalg.norm(x_2d_l2_normalized[0,:],ord=2)) print(np.linalg.norm(x_2d_l2_normalized[1,:],ord=2)) print(np.linalg.norm(x_2d_l2_normalized2[:,0],ord=2)) print(np.linalg.norm(x_2d_l2_normalized2[:,1],ord=2)) print(np.linalg.norm(x_2d_l2_normalized2[:,2],ord=2)) print(np.linalg.norm(x_2d_l2_normalized2[:,3],ord=2)) print(np.linalg.norm(x_2d_l2_normalized2[:,4],ord=2)) # 1.0 # 1.0 # 1.0 # 1.0 # 1.0 # 1.0 # 1.0 # 0.9999999999999999
keras.backend.l2_normalizekerasにもあります。backendはtensorflowです。
(tf.keras.backend.l2_normalizeというものもありました)# keras.backend.l2_normalizeを使う from keras import backend as K x = [1.,2.,3.,4.,5.] x_2d = [[1.,2.,3.,4.,5.],[6.,7.,8.,9.,10.]] x_l2_normalized = K.l2_normalize(x,axis=0) x_2d_l2_normalized = K.l2_normalize(x_2d,axis=0) x_2d_l2_normalized2 = K.l2_normalize(x_2d,axis=1) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) x_l2_normalized = sess.run(x_l2_normalized) x_2d_l2_normalized = sess.run(x_2d_l2_normalized) x_2d_l2_normalized2 = sess.run(x_2d_l2_normalized2) # 検算 print(np.linalg.norm(x_l2_normalized,ord=2)) print(np.linalg.norm(x_2d_l2_normalized[:,0],ord=2)) print(np.linalg.norm(x_2d_l2_normalized[:,1],ord=2)) print(np.linalg.norm(x_2d_l2_normalized[:,2],ord=2)) print(np.linalg.norm(x_2d_l2_normalized[:,3],ord=2)) print(np.linalg.norm(x_2d_l2_normalized[:,4],ord=2)) print(np.linalg.norm(x_2d_l2_normalized2[0,:],ord=2)) print(np.linalg.norm(x_2d_l2_normalized2[1,:],ord=2)) #1.0000001 #1.0 #0.99999994 #1.0 #0.99999994 #1.0 #1.0000001 #1.0
tf.math.l2_normalize※tensorflow 1.11までは
tf.nn.l2_normalizeとして提供されていたようです。import tensorflow as tf x = tf.Variable([1,2,3,4,5], dtype=tf.float32) x_2d = tf.Variable([[1,2,3,4,5],[6,7,8,9,10]], dtype=tf.float32) x_l2_normalized = tf.math.l2_normalize(x,axis=0) x_2d_l2_normalized = tf.math.l2_normalize(x_2d,axis=0) x_2d_l2_normalized2 = tf.math.l2_normalize(x_2d,axis=1) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) x_l2_normalized = sess.run(x_l2_normalized) x_2d_l2_normalized = sess.run(x_2d_l2_normalized) x_2d_l2_normalized2 = sess.run(x_2d_l2_normalized2) # 検算 print(np.linalg.norm(x_l2_normalized,ord=2)) print(np.linalg.norm(x_2d_l2_normalized[:,0],ord=2)) print(np.linalg.norm(x_2d_l2_normalized[:,1],ord=2)) print(np.linalg.norm(x_2d_l2_normalized[:,2],ord=2)) print(np.linalg.norm(x_2d_l2_normalized[:,3],ord=2)) print(np.linalg.norm(x_2d_l2_normalized[:,4],ord=2)) print(np.linalg.norm(x_2d_l2_normalized2[0,:],ord=2)) print(np.linalg.norm(x_2d_l2_normalized2[1,:],ord=2)) #1.0000001 #1.0 #0.99999994 #1.0 #0.99999994 #1.0 #1.0000001 #1.0おわりに
いろいろありますねー。用途に合わせて使い分けていきましょー(?)
(pythonは変数のスコープどうなってんすか。。。)
- 投稿日:2019-07-19T16:42:32+09:00
畳み込み演算とim2col
CNNの畳み込みの計算をpythonで実装してみたらim2colになっていた話。
im2colって?
かの有名な「ゼロから作るdeep learning」の畳み込み演算に出てくる関数。(自分はこの本持ってませんが…)検索するとこんなのが出てきます。
def im2col(input_data, filter_h, filter_w, stride=1, pad=0): N, C, H, W = input_data.shape out_h = (H + 2*pad - filter_h)//stride + 1 out_w = (W + 2*pad - filter_w)//stride + 1 img = np.pad(input_data, [(0,0), (0,0), (pad, pad), (pad, pad)], 'constant') col = np.zeros((N, C, filter_h, filter_w, out_h, out_w)) for y in range(filter_h): y_max = y + stride*out_h for x in range(filter_w): x_max = x + stride*out_w col[:, :, y, x, :, :] = img[:, :, y:y_max:stride, x:x_max:stride] col = col.transpose(0, 4, 5, 1, 2, 3).reshape(N*out_h*out_w, -1) return colimg2colでも引っ掛かりますが、多分同じ内容です。
単純な畳み込み計算
単純にfor文で畳み込みを計算してみます。
入力$(224,224,8)$を出力$(224,224,16)$に変換するサイズ$(3,3)$の二次元畳み込みを考えるとします。
畳み込みをforループの力業で無理に計算しようとすれば以下のような計算をすればよいことになります。import numpy as np import itertools np.random.seed(100) #(224,224,8)=>(224,224,16) input = np.ones((224,224,8)) output = np.zeros((224,224,16)) weight = np.random.random_sample((3,3,8,16)) input = np.pad(input, [(1,1),(1,1),(0,0)], 'constant') # (224,224,8)=>(226,226,8) x = np.zeros((224,224,8,16)) # case simple conv cal for ch1, ch2, i, j, k, l in itertools.product(range(8), range(16), range(224), range(224), range(3), range(3)): x[i,j,ch1,ch2] += input[i+k,j+l,ch1] * weight[k,l,ch1,ch2] output = np.sum(x, axis=(2))output1= [[[17.6167424 16.46092477 16.71833326 ... 15.7476869 16.24364858 15.14112872]... time= 74.62933945655823[s]単純な式で記述出来ますが、この多重for文では計算に非常に時間がかかります。
この単純な畳み込み計算は現実的ではありません。一次元畳み込みの場合
最初は簡単な一次元畳み込みを代わりに考えてみます。
ここで$*$は畳み込み演算子です。するとこの式は以下のように記述できます。
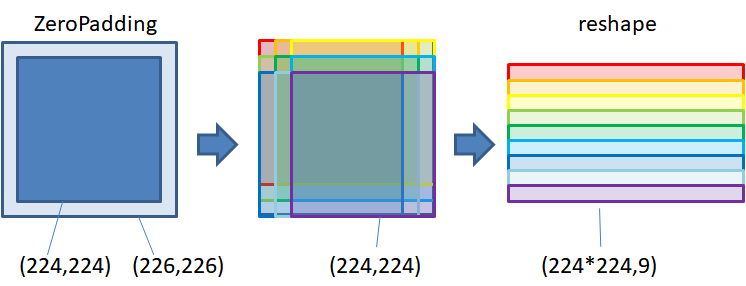
この整理した$z_i$の要素はZeroPaddingした$(0,x_1,x_2,...,x_{n},0)$からひとつずつずらしながら取り出す長さ$n$の配列になります。
このようにZeroPaddingした配列をずらして得た配列をあらかじめ用意してやり、これに畳み込みfilter要素を行列計算してやると多重for文よりも高速になります。\begin{align} y &= A*x \\ y &= (A_1,A_2,A_3) * (x_1, x_2, x_3, ... x_m, ... ,x_n)\\ &=(A_2x_1+A_3x_2, A_1x_1+A_2x_2+A_3x_3, ... \\ &\qquad A_1x_{m-1}+A_2x_{m}+A_3x_{m+1},...\\ &\qquad A_1x_{n-1}+A_2x_{n} )\\ &=A_1(0,x_1,x_2,...,x_{n-2},x_{n-1})\\ &+A_2(x_1,x_2,x_3...,x_{n-1},x_{n})\\ &+A_3(x_2,x_3,x_4...x_{n},0)\\ &=(A_1,A_2,A_3)\cdot(z_1,z_2,z_3) \end{align}二次元の畳み込みの場合もこれと同様に考える事ができます。
実装
以下はZeroPaddingしたinputをずらしてxの配列を取り、それを変形して重みとの行列積計算を行います。ここでfilter要素数9×入力チャンネル数8=内積計算の長さ$72$になってます。
念のため範囲を全部書けば$(224,224)$をZeroPaddingした$(226,226)$の配列の内$(0:224,0:224),$$(1:225,0:224),$$(2:226,0:224),$$(0:224,1:225),$$(1:225,1:225),$$(2:226,1:225),$$(0:224,2:226),$$(1:225,2:226)$$,(2:226,2:226)$の9通りの範囲になります。input = np.pad(input, [(1,1),(1,1),(0,0)], 'constant') # (224,224,8)=>(226,226,8) # case im2col x = np.zeros((224,224,8,3,3)) weight = weight.transpose((2,0,1,3)) # (3,3,8,16) => (8,3,3,16) weight = np.reshape(weight,(72,16)) # (8,3,3,16) => (72,16) for i, j in itertools.product(range(3), range(3)): x[:,:,:,i,j] = input[i:224+i,j:224+j] x = np.reshape(x,(224*224,72)) # (224,224,8,3,3) => (224*224,72) x = np.dot(x,weight) # (224*224,72)*(72,16) => (224*224,16) output = np.reshape(x,(224,224,16)) # (224*224,16) => (224,224,16)output2= [[[17.6167424 16.46092477 16.71833326 ... 15.7476869 16.24364858 15.14112872]... time= 0.0625007152557373[s]この場合、計算時間はかなり短くなりました。また、計算結果も単純な畳み込み計算結果と合ってます。
ここでこの内容を探してみると前述のim2col関数が引っ掛かりました。
比較してみるとim2col関数にはSample数の次元がありますが、やってることはほとんど同じです。
結局、畳み込み演算も単なる行列積演算なんですね。
備考:
1. 畳み込みフィルターの大きさが(5,5)の場合
input = np.pad(input, [(2,2),(2,2),(0,0)], 'constant') # (224,224,8)=>(228,228,8) x = np.zeros((224,224,8,5,5)) for i, j in itertools.product(range(5), range(5)): x[:,:,:,i,j] = input[i:224+i,j:224+j]2. stridesの大きさが(1,2)の場合
strides = (1,2) input = np.pad(input, [(1,1),(1,1),(0,0)], 'constant') # (224,224,8)=>(226,226,8) for i, j in itertools.product(range(3), range(3)): x[:,:,:,i,j] = input[i:224+i:strides[0],j:224+j:strides[1]]3. dilated convolutionの場合
input = np.pad(input, [(2,2),(2,2),(0,0)], 'constant') # (224,224,8)=>(228,228,8) for i, j in itertools.product(range(3), range(3)): x[:,:,:,i,j] = input[i*2:224+i*2,j*2:224+j*2]
- 投稿日:2019-07-19T16:22:43+09:00
タブローで地図情報を扱う時
目的
BigQueryにある緯度経度情報をTableauで可視化したい
問題
緯度経度情報(GEO系)をBigqueryでPOINTとかに変換してもTableauで文字列としてしか認識してくれない
解決方法
・python でshapeファイルに変換(geojsonとかでもなんでもいいと思う)
サンプルコード
import csv import shapefile w = shapefile.Writer("../data/point", shapeType=shapefile.POINT) w.field("id", "C", "40") w.field("date", "C", "40") w.field("price", "C", "40") w.field("flg", "C", "40") with open("../data/___.csv") as text: reader = csv.DictReader(text) for row in reader: w.record(str(row['id']), str(row['date']), str(row['price']), str(row['flg'])) w.point(float(row['longitude']), float(row['latitude'])) w.close()
- 投稿日:2019-07-19T16:14:50+09:00
Toioで遊んでみる (2)
前回はToioのキューブに対する基本的な操作まで触れたので、今回はそれらを組み合わせて「キューブを好きな座標に移動する」といったナビゲーション処理について書いてみる。
ナビゲーション処理
このへん: https://github.com/tomoto/tomotoio/blob/master/tomotoio/navigator.py
キューブの底面にはカメラが付いており、マットやシールに印刷された特殊パターンを読み取って、「今マット上のどの座標にどの角度でいる」とか「今どのシールの上に乗っている」といった情報(仕様書の用語だとToio ID)がわかる仕組みになっている。こういった位置情報に基づき、キューブが目的の位置なり姿勢なりに到達するようモーターにフィードバック制御をかけるのがこのナビゲーション処理である。
このナビゲーション処理は、位置情報のNotificationストリームに駆動される形で実装されている。つまり、Notificationのコールバックの中で次のモーターの状態を決定して指示を出す。そのため、Notificationストリームがスムーズに流れない環境であれば意図しない動作をする可能性がある。また、タイミングの変化を相殺する仕組みもあまり入れていないため、ストリームの流れる速度が変われば(例えば20イベント/秒で流れる環境と5イベント/秒で流れる環境とでは)加減速カーブなどが変わってしまう可能性がある。結局のところ、自分のRaspberry Pi 4に合わせてロジックやパラメタを調整しているので、環境が変わればそれなりの対応が必要かもしれないことに注意して欲しい。
指定された方向への回転(rotate)
このへん: https://github.com/tomoto/tomotoio/blob/master/tomotoio/navigator.py#L57
rotate.py でデモしている動きである。ナビゲーションの中では最も簡単。なるべく迅速に方向が決まるよう、現在の角速度、目標角度までの残り角度などを用いて、スムーズにモーターの速度を上げ下げする工夫をしているくらい。目標精度±3度くらいシャキッと余裕で決まる。
指定された座標への移動(move)
このへん: https://github.com/tomoto/tomotoio/blob/master/tomotoio/navigator.py#L95
symmetric.py でデモしている動きである。一見簡単そうだが見た目ほど自明ではなく、様々なアプローチが考えられる類のもの。変にカクカクした動きや無駄な大回りを避けるため、まず目標座標が自分のおよそ前方(デフォルトで±30度以内)になければ前節のrotateナビゲーションを行い、およそ前方にあればそこに至る円弧の曲率を計算して左右のモーターの速度を設定する、という方式にした。目標地点でちゃんと止まれるようにスムーズな速度の上げ下げを行うのは前節と同じ。将来的には経由点を指定しできるようにして、それらを滑らかに踏んでいくような処理にしたい。
指定された円上の周回運動(circle)
このへん: https://github.com/tomoto/tomotoio/blob/master/tomotoio/navigator.py#L149
circle.py でデモしている動きである。円の中心座標と半径を指定すると、その円上をキューブが周回運動する。実装的には、目標円上の自分に一番近い点から接線方向ちょっと先の座標を目標として、前節のmoveナビゲーションをかけるというふうになっている(したがい実際の移動軌跡は目標円より若干外側になると考えられる)。目標座標は常に接線方向ちょっと先に更新されるので、「人参をぶらさげた馬」のように決して止まることはない。回転方向はデフォルトで時計回りで、マットからはみ出しそうになると回転方向を反転する。
目標パラメタの動的な変更
上記3種類のナビゲーションすべて、目標角度・目標座標・目標円のパラメタを動的に変えることができ(
updateTarget())、キューブはそれに追随して動く。モーターの時限制御
モーターを回すときには1秒ちょっとの時間制限をかけておくのがよい。理論的には無限時間でもいいのだが、マットから落ちたりしてNotificationストリームが止まった時にモーターが延々と回り続けるのは具合が悪い。
マット情報
位置情報から得られる座標は仕様書のここに書かれているようにマットによって値の範囲が異なる。(ちなみに工作生物ゲズンロイドのマットは認識してくれない。何らかの隠しオプションを設定する必要があるのだろう。)
Navigatorには自分がどのマット上にいるかの情報が乗っており、マット上の相対位置取得やはみ出し防止処理を書けるようになっているが、現時点ではトイオ・コレクションマットの表側に決め打ちしてある。(See https://github.com/tomoto/tomotoio/blob/master/tomotoio/navigator.py#L180)一人サッカー
最初に紹介した一人サッカーについて軽く紹介してみよう。
コードはこれ: https://github.com/tomoto/tomotoio/blob/master/examples/soccer.pyボールの動き
このへん: https://github.com/tomoto/tomotoio/blob/master/examples/soccer.py#L20
ボールは独立・自律的である。つまり、プレイヤーなど周囲の環境に依存することなく、ちょんと押されたらその方向にしばらく動いて止まるだけである。これはカスタムナビゲーションロジックとして実装し、
Navigator.setCommand()でボールのNavigatorに設定してしまうのが楽である。こうすればNotificationスレッドの側で勝手に処理されるので、あとは忘れておいてよい。「ちょんと押された」の判定はなかなか難しい。感度は高い方がよく、しかしノイズを拾って勝手に動き出さない程度にしたいのだが、結局ぎこちない反応になってしまった。
プレイヤーの動き
このへん: https://github.com/tomoto/tomotoio/blob/master/examples/soccer.py#L84
ボールとは異なり、メインループの方で実装している。ナビゲーションとして実装することもできるが、まあ好みである。
- 基本的にはボールに向かってmoveナビゲーションで突っ込む。
- ボールを蹴ったらちょっと後ろに下がってボールが止まるのを待つ。
- そればかりやっているとボールをマット外に蹴り出してしまうので、ボールがマットの端に近い場合はcircleナビゲーションを使って外側に回り込む。
- moveしているはずなのに同じ位置にとどまっていることが検出されたら、何かにstuckしていると判断し、ちょっと後ろに下がって仕切り直す。
- 状態に応じていろいろ音を鳴らす(
setMusic())。もう一台キューブがあれば、互いに相手のゴールにボールを蹴り込む自律ゲームが作れるんだけどなー。
- 投稿日:2019-07-19T16:09:25+09:00
Pythonではじめる機械学習 KNeighborsによる回帰など
はじめに
教師あり機械学習を掘り下げていく
機械学習の種類
機械学習はクラス分類と回帰の2つに分類することができる。
クラス分類
クラス分類は前回行ったアイリスの品種判別であり,あらかじめ与えられた選択肢の中からクラスラベルを予測するものである。このクラス分類もまた2つに分けられており,2クラス分類と多クラス分類である。多クラス分類はアイリスのような例である。2クラス分類は特殊なケースで,答えがYes or Noとなるものである。例としては,メールがスパムであるかどうかなどが挙げられる。回帰
回帰は連続値の予測を目的としたものである。例えば,ある人の年収を学歴,年齢,住所などから予測する問題などが考えられる。forgeデータセット
クラス分類
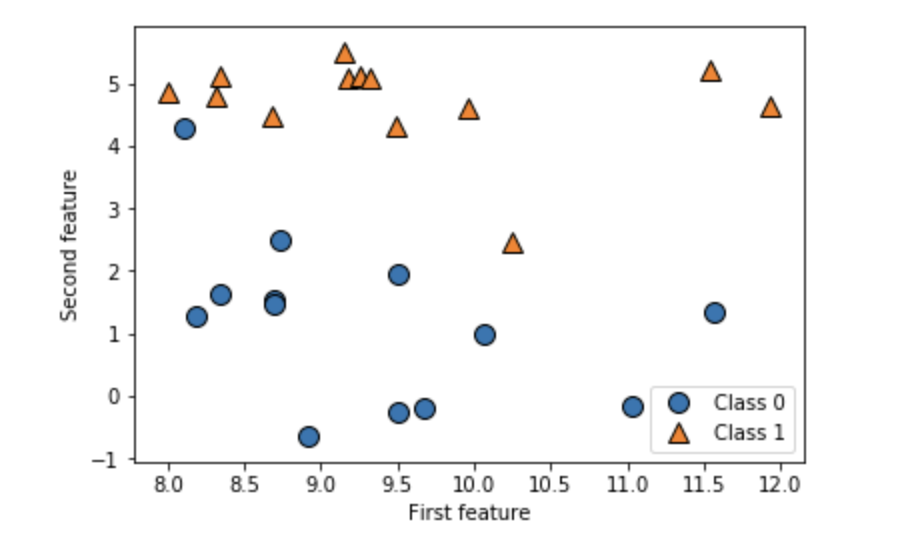
教師あり機械学習の例としてforgeデータセットを見てみる。forgeセットは2つの特徴量を持っており,2クラス分類の例である。
下記のコードでは第1の特徴量をx軸に,第2の特徴量をy軸に取っており,Jupyter notebookに散布図を表示する。In[1]: %matplotlib inline import matplotlib.pyplot as plt import mglearn import warnings # Jupyter notebookの警告文を非表示にする warnings.filterwarnings('ignore') X, y = mglearn.datasets.make_forge() # データセットの作成 mglearn.discrete_scatter(X[:, 0], X[:, 1], y) # データセットをプロット plt.legend(["Class 0", "Class 1"], loc=4) # 凡例(図の右下)の位置や内容を設定する plt.xlabel("First feature") plt.ylabel("Second feature") print("X.shape: {}".format(X.shape)) Out[1]: X.shape: (26, 2) # 2つの特徴量を持つ26つのデータポイントを意味する↓
回帰
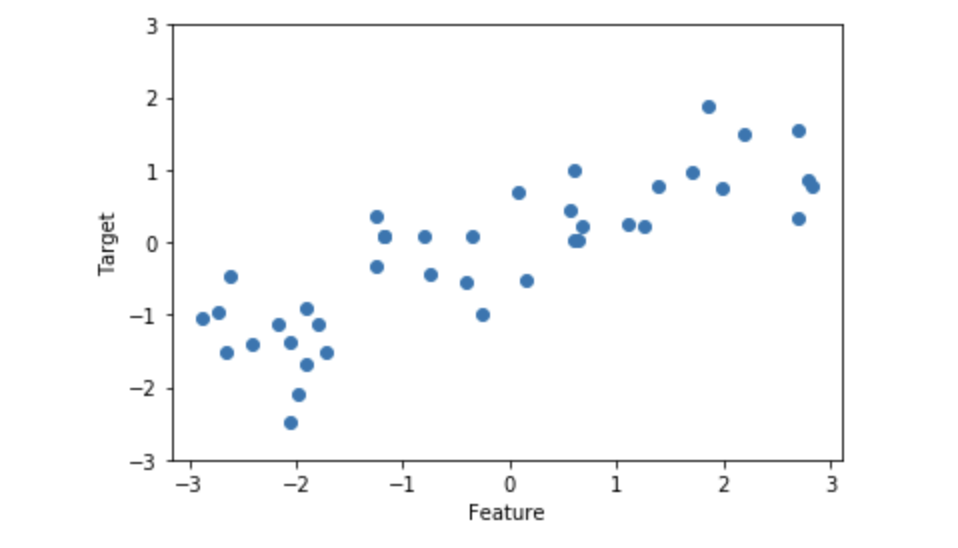
回帰アルゴリズムの例として,ここではwaveデータセットを用いる。waveデータセットは1つの特徴量(入力)とモデルの対象となる連続値のターゲット変数を持つ。下記のコードでは特徴量をx軸に,回帰のターゲット(出力)をy軸に取っており,Jupyter notebookに散布図を表示するIn[2]: X, y = mglearn.datasets.make_wave(n_samples=40) # 40のサンプル数 plt.plot(X, y, 'o') plt.ylim(-3, 3) # 座標の範囲を設定 plt.xlabel("Feature") plt.ylabel("Target") Out[2]: Text(0, 0.5, 'Target')↓
cancerデータセット
次はウィスコンシン乳癌データセット(cancer)を見ていく。これは癌の腫瘍を計測したもので,それぞれの癌に良性(benign)・悪性(malignant)のラベルが付けられている。ここでは新たな腫瘍が良性か悪性かを判別するモデルの実装を行う。
このデータセットはscikit-learnのload_breast_cancer関数でロードすることができる。In[3]: from sklearn.datasets import load_breast_cancer cancer = load_breast_cancer() print("cancer.keys(): \n{}".format(cancer.keys())) Out[3]: dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'file name']) In[4]: print("Shape of cancer data: {}".format(cancer.data.shape)) # cancerデータセットの特徴量とサンプル数を取得 Out[4]: Shape of cancer data: (569, 30) # 569のサンプル数と30の特徴量 In[5]: import numpy as np print("Sample counts per class:\n{}".format({n: v for n, v in zip(cancer.target_names, np.bincount(cancer.target))})) # # 辞書内包表記でzip関数を用いている bincountではcancer.target内の0と1(benign,malignant)の個数を数えている Out[5]: Sample counts per class: {'malignant': 212, 'benign': 357} In[6]: print("Feature names:\n{}".format(cancer.feature_names)) # 特徴量を取得 Out[6]: Feature names: ['mean radius' 'mean texture' 'mean perimeter' 'mean area' 'mean smoothness' 'mean compactness' 'mean concavity' 'mean concave points' 'mean symmetry' 'mean fractal dimension' 'radius error' 'texture error' 'perimeter error' 'area error' 'smoothness error' 'compactness error' 'concavity error' 'concave points error' 'symmetry error' 'fractal dimension error' 'worst radius' 'worst texture' 'worst perimeter' 'worst area' 'worst smoothness' 'worst compactness' 'worst concavity' 'worst concave points' 'worst symmetry' 'worst fractal dimension']boston_housingデータセット
In[7]: from sklearn.datasets import load_boston boston = load_boston() print("Data shape: {}".format(boston.data.shape)) # bostonの特徴量とサンプル数を取得する Out[7]: Data shape: (506, 13) # 506のサンプル数と13の特徴量 In[8]: X, y = mglearn.datasets.load_extended_boston() # 特徴量が104つに拡張されたデータセットを読み込む print("X.shape: {}".format(X.shape)) Out[8]: X.shape: (506, 104) # 504のサンプル数と104の特徴量上記のデータセットを用いて機械学習のアルゴリズムを見ていく。
K-最近傍法
In[9]: mglearn.plots.plot_knn_classification(n_neighbors=1) # 訓練データのうちで予測したいデータポイントに最も近い1点を示す In[10]: mglearn.plots.plot_knn_classification(n_neighbors=3) # 訓練データのうちで予測したいデータポイントに最も近い3点を示す↓
Out[9]:
Out[10]:
上記の例では2クラス分類の問題であるが,2クラス分類だけでなく任意のクラス数の場合でも予測が可能である。
scikit-learnを用いたK-最近傍点の予測
In[11]: from sklearn.model_selection import train_test_split X, y = mglearn.datasets.make_forge() X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) In[12]: from sklearn.neighbors import KNeighborsClassifier clf = KNeighborsClassifier(n_neighbors=3) # 近傍点の数を3としている In[13]: clf.fit(X_train, y_train) In[14]: print("Test set predictions: {}".format(clf.predict(X_test))) # テストセットへ対して,訓練セット内の近傍点を計算し最も多いクラスを予測したものを取得する Out[14]: Test set predictions: [1 0 1 0 1 0 0] In[15]: print("Test set accuracy: {:.2f}".format(clf.score(X_test, y_test))) Out[15]: Test set accuracy: 0.86 # テストサンプルのうち86%に対して正しいクラスを予測したKNeighborsClassifierの解析
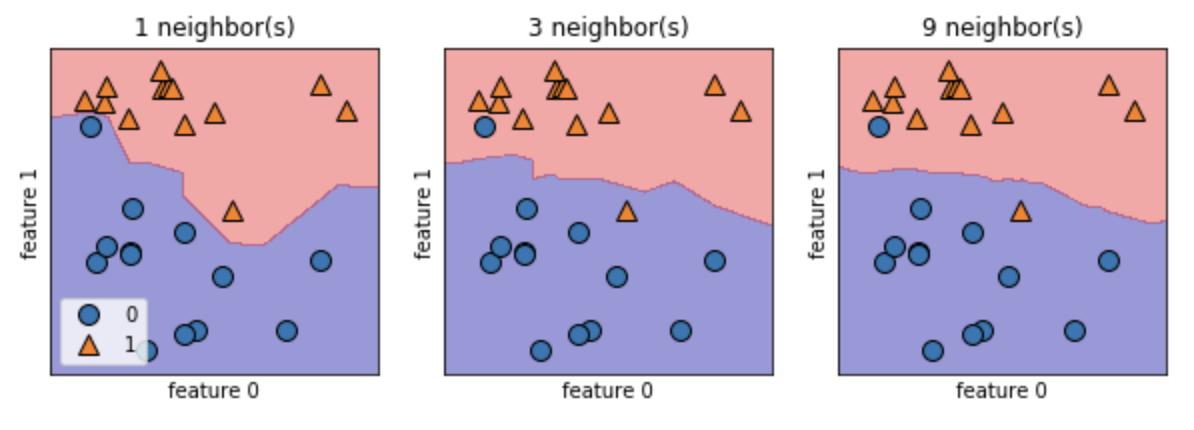
平面を,そこに点があったら分類されていたであろうクラスにしたがって色をつける。こうすることでクラス0とクラス1に割り当てた場合の決定境界が見える。
In[16]: fig, axes = plt.subplots(1, 3, figsize=(10, 3)) # plt.subplotsでは図を1x3の3つに分割して,figsizeで図のサイズを決めている for n_neighbors, ax in zip([1, 3, 9], axes): #近傍点の数を指定する clf = KNeighborsClassifier(n_neighbors=n_neighbors).fit(X, y) # インスタンスを生成する mglearn.plots.plot_2d_separator(clf, X, fill=True, eps=0.5, ax=ax, alpha=.4) # 境界線を2に分割する mglearn.discrete_scatter(X[:, 0], X[:, 1], y, ax=ax) # Xの値,yの値,各データのラベルを指定 ax.set_title("{} neighbor(s)".format(n_neighbors)) # 散布図のタイトルを設定する ax.set_xlabel("feature 0") # Xのラベルを設定する ax.set_ylabel("feature 1") # yのラベルを設定する axes[0].legend(loc=3) # 凡例の位置を設定するOut[16]:
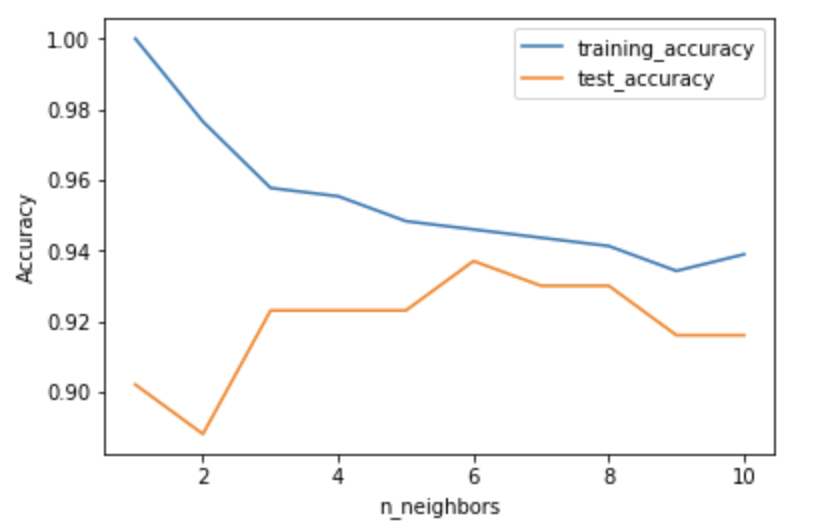
次に近傍点を増やすことによるモデルの複雑さと汎化性能の関係を調べる。ここではcancerデータセットを用いる。
In[17]: from sklearn.datasets import load_breast_cancer cancer = load_breast_cancer() X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, stratify=cancer.target, random_state=66) training_accuracy = [] test_accuracy = [] neighbors_settings = range(1, 11) # n_neighborsを1から11まで試す for n_neighbors in neighbors_settings: clf = KNeighborsClassifier(n_neighbors=n_neighbors) # モデルを構築 clf.fit(X_train, y_train) training_accuracy.append(clf.score(X_train, y_train)) # 訓練セット精度を記録 test_accuracy.append(clf.score(X_test, y_test)) # 汎化精度を記録 plt.plot(neighbors_settings, training_accuracy, label="training_accuracy") plt.plot(neighbors_settings, test_accuracy, label="test_accuracy") plt.ylabel("Accuracy") plt.xlabel("n_neighbors") plt.legend()Out[17]:
上記のグラフではy軸は精度を,x軸では近傍点の数を示している。グラフの1番左の近傍点が1つの時(過剰適合の時)には訓練セットに対する予測は完璧である。逆にグラフの1番左の近傍点が10つの時(適合不足の時)ではモデルがシンプルになりすぎて訓練セットに対する予測の精度は低くなっている。一方,テストセットに対する位予測で,近傍点が1つの場合と10つの場合では,近傍点が1つの場合の方が予測精度が低くなっている。これはモデルが複雑化されているためである。予測精度が1番低い場合でも 88%程度の精度はあるため,モデルとしてはこれで十分である。K-近傍回帰
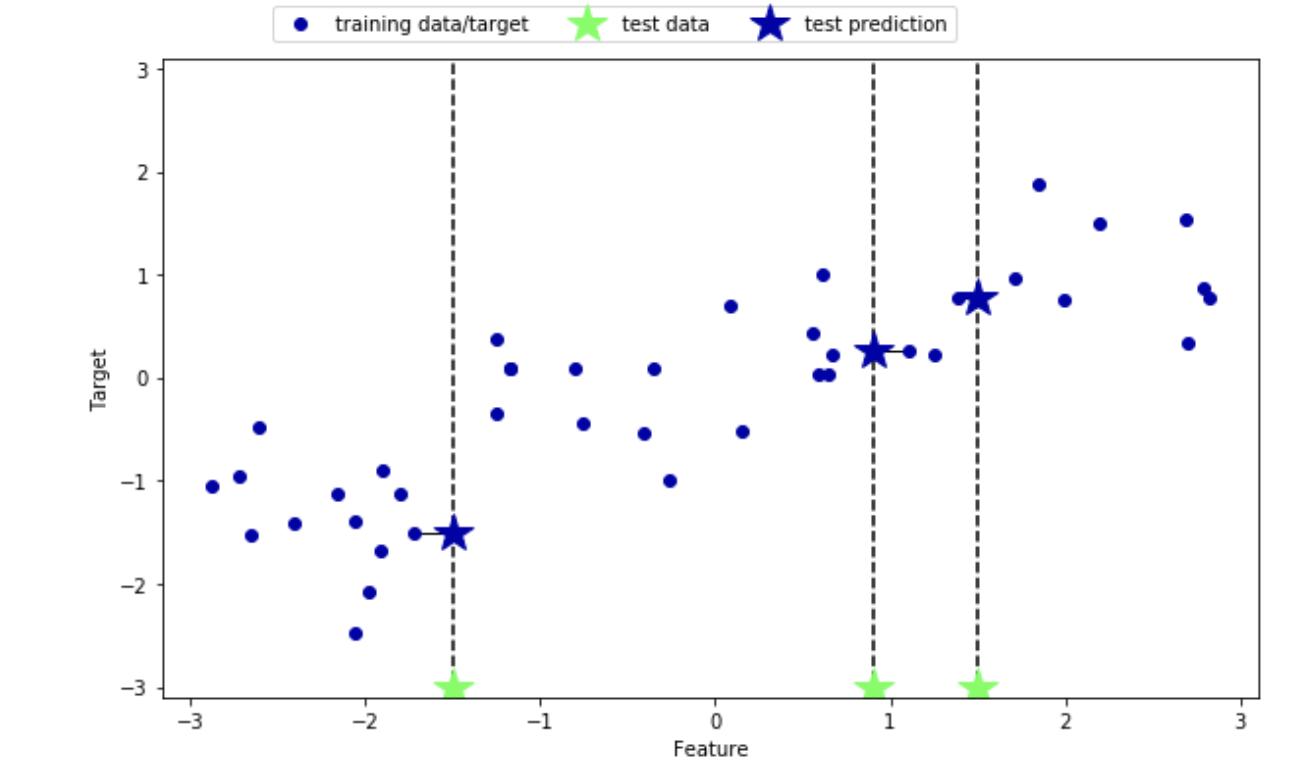
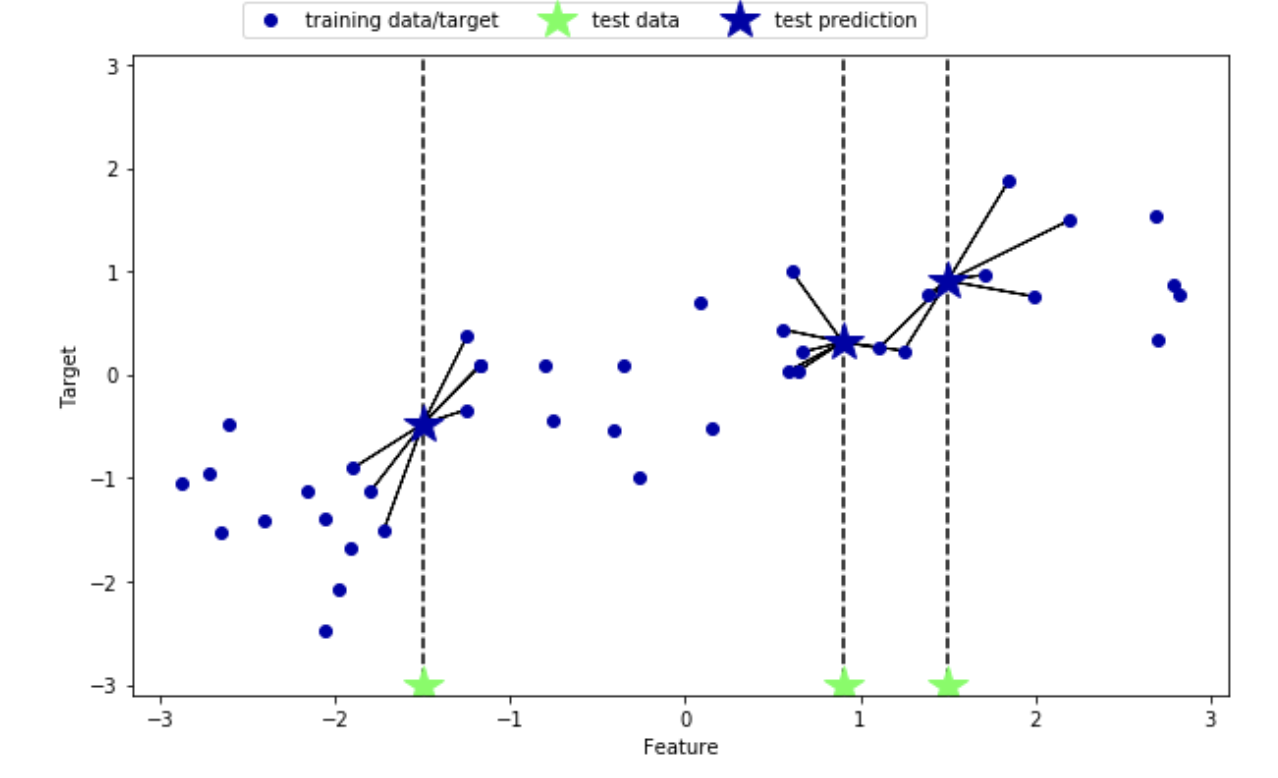
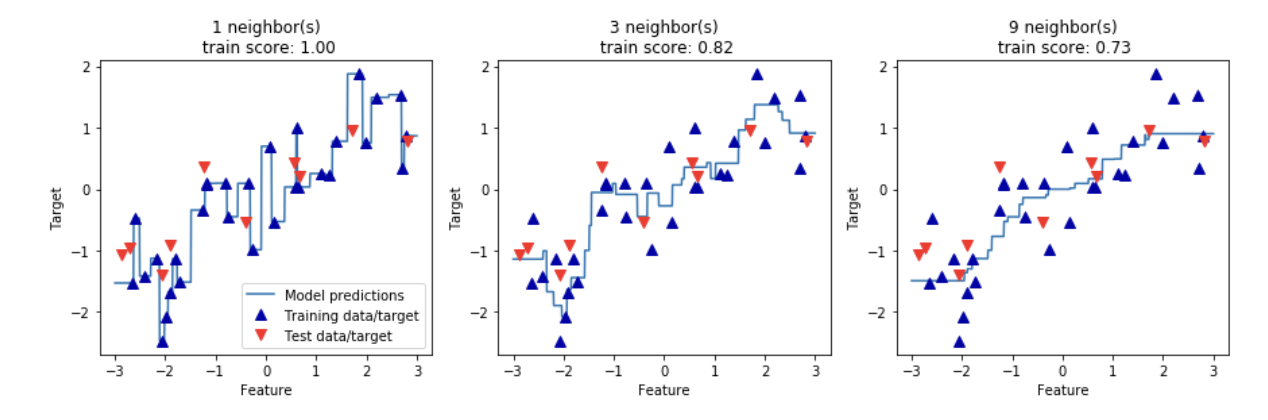
K-最近傍法では,回帰を行うことも可能である。この例を近傍点数が1つのものから見ていく。ここではwaveデータセットを用いる。
In[18]: mglearn.plots.plot_knn_regression(n_neighbors=1)Out[18]:
緑の点がテストデータポイントであり,青い点が予測されたデータポイントである。次に近傍点が3つの場合を見ていく。In[19]: mglearn.plots.plot_knn_regression(n_neighbors=3)Out[19]:
このように複数の近傍点を用いた予測を行うことも可能である。K-近傍回帰はscikit-learnのKNeighborsRegressorクラスに実装されており,KNeighborsClassifierと同様に利用できる。
In[20]: from sklearn.neighbors import KNeighborsRegressor X, y = mglearn.datasets.make_wave(n_samples=40) X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) # waveデータセットを訓練セットとテストセットに分類 reg = KNeighborsRegressor(n_neighbors=3) # 3つの近傍点を考慮したモデルのインスタンスを作成 reg.fit(X_train, y_train) # 訓練データと訓練ターゲットを用いてモデルを学習させる # ↑これでテストセットに対して予測を行うことができる。 In[21]: print("Test set predictions:\n{}".format(reg.predict(X_test))) Out[21]: Test set predictions: [-0.05396539 0.35686046 1.13671923 -1.89415682 -1.13881398 -1.63113382 0.35686046 0.91241374 -0.44680446 -1.13881398]scoreメソッドを用いてモデル評価を行うことも可能である。scoreメソッドに対して回帰予測器はR^2スコア(決定係数)を返す。R^2スコアは回帰モデルの予測の精度を測る指数であり,0から1までの値をとる。1は完全な予測であり,0は訓練セットのレスポンス値(y_train)の平均値を返すだけのものである。
それではR^2を用いたモデルの評価を見ていく。In[22]: print("Test set R^2: {:.2f}".format(reg.score(X_test, y_test))) Out[22]: Test set R^2: 0.83ここでのスコアは0.83となっているため比較的よいモデルであるということがわかる。
KNeighborsRegressorの解析
1次元のデータセットに対して,全てのデータポイントに対する予測を見ていく。
In[23]: for n_neighbors, ax in zip([1, 3, 9], axes): # 近傍点の数を指定する 1, 3, 9の近傍点で予測 reg = KNeighborsRegressor(n_neighbors=n_neighbors) # インスタンスを生成する reg.fit(X_train, y_train) # 訓練データと訓練ターゲットを用いてモデルを学習させる ax.plot(line, reg.predict(line)) ax.plot(X_train, y_train, '^', c=mglearn.cm2(0), markersize=8) # マーカーの形,色,大きさを指定 ax.plot(X_test, y_test, 'v', c=mglearn.cm2(1), markersize=8) # マーカーの形,色,大きさを指定 ax.set_title("{} neighbor(s)\n train score: {:.2f}".format( n_neighbors, reg.score(X_train, y_train), # 訓練セットの評価を行う reg.score(X_test, y_test))) # テストセットの評価を行う ax.set_xlabel("Feature") # ラベル名の指定 ax.set_ylabel("Target") # ラベル名の指定 axes[0].legend(["Model predictions", "Training data/target", "Test data/target"], loc="best") # 凡例の指定Out[23]:
上記のグラフでは近傍点の個数が1つの時,予測は全て訓練データポイントを通っている。そのため予測は不安定なものとなっている。考慮する近傍点の個数を増やしていくと予測はスムーズになっていくが,訓練データに対する適合度は下がる。おわりに
長くなるのでここで一旦区切る。
次は線形モデルの回帰から行う。
- 投稿日:2019-07-19T14:41:45+09:00
anacondaにpolyglotをインストールする
背景
- pipだとビルド周りで失敗したのでanacondaを使用
- コンフリクトを避けるためpipは使わずcondaだけでパッケージ管理
- polyglotをインストールしたい
- pip使うインストール方法しかヒットしなかったので書いた
実行環境
- CentOS 6.7
- (pyenv)anaconda3-5.3.1
- conda createで仮想環境を作ってその中でインストール
インストール作業
polyglotが使うライブラリをインストール $ conda install numpy -y $ conda install -c conda-forge icu -y $ conda install -c conda-forge pyicu -y pyicuはpython3.6をピンポイントで要求する ここからはPyPIのパッケージからcondaパッケージを作ってインストールする $ conda skeleton pypi morfessor $ conda build morfessor $ conda install --use-local morfessor -y $ conda skeleton pypi --python-version 3.6 pycld2 pyicuがpython3.6を要求するので明示的にpython3.6でビルドしておく $ conda build --python 3.6 pycld2 なんかすごい警告出るけど動く $ conda install --use-local pycld2 最後にpolyglotを入れる $ conda skeleton pypi --python-version 3.6 polyglot これは失敗するので自分でレシピファイルを作る $ mkdir polyglot $ vim polyglot/meta.yamlpolyglotのレシピファイル
- polyglot/meta.yaml を以下のように編集する
{% set name = "polyglot" %} {% set version = "16.7.4" %} package: name: "{{ name|lower }}" version: "{{ version }}" source: url: https://files.pythonhosted.org/packages/e7/98/e24e2489114c5112b083714277204d92d372f5bbe00d5507acf40370edb9/polyglot-16.7.4.tar.gz sha256: f7d9cca9a212622548e9416fb89f1238b994b8860ef49e03b7c82c67f9b6269b build: number: 0 script: "{{ PYTHON }} -m pip install . --no-deps --ignore-installed -vvv " requirements: host: - pip - python run: - python - six test: imports: - polyglot
- source.url にはPyPIのtar.gzファイルのパスを記述
- source.sha256 にはtar.gzファイルのSHA256チェックサムを記述
レシピファイルが完成したらビルドしてインストール
$ conda build --python 3.6 polyglot ビルドできたら掃除する $ conda build purge インストールする $ conda install --use-local polyglot参考
- 投稿日:2019-07-19T14:34:16+09:00
Pythonの基本的な書き方について
はじめに
pythonを初めにやる方が必要になりそうなことをまとめてみました。
・変数の宣言
・キーボード入力
・表示こういったことを解説します。
変数の宣言
pythonでは、変数を宣言する際に型名は必要ありません。
型宣言をしない分、型が勝手に変わることもあるので、そこは注意が必要です。
例を以下に示します。declear.pya = 12 b = 13.5 s = 'Hello World!'キーボード入力
pythonのキーボード入力は
input関数を使用するだけです。
ここで1つ注意したいのは、input関数で取得した変数の型はString型であるということです。
例を以下に示します。input.pynum = input() #これで 変数s に入力した文字が代入されます。 #例えば、numを数値として扱いたい場合は、キャストしましょう。 num2 = int(num) #これでキャスト終了です。表示
pythonの表示方法も簡単で、
print関数を使用するだけです。
以下に例を示します。output.pyprint(num) print(a + b) #(こうするとa + bの値が表示されます。)終わりに
今回は、初めてpythonを学ぶ時に最低限必要になる機能をご紹介しました。
何かに役立てば幸いです。
- 投稿日:2019-07-19T13:46:22+09:00
Toioで遊んでみる (1)
Toioがやってきた!
発表時から気になっていたToio (https://toio.io/ )を入手した。アメリカでは売っておらず、Amazon Japanのglobal shippingにも対応しておらず、結局国際転送サービスのお世話になった。これは絶対に楽しいに決まってるやつや!

こいつ、動くぞ!
めだま生物 https://t.co/q8XXH1bQ9d
— Tomoto S. Washio (@tomoto335) 2019年7月19日
遊んでみよう!
製品としての遊び方も丁寧に作られていて非常にハイクオリティなのだが、ここではもちろんハッカー流の遊び方の話である。
Toioのキューブは仕様書 (https://toio.github.io/toio-spec/ )が公開されていて、これに従ってBLEでキューブを制御できる。このキューブの特筆すべき点は、マット上に印刷された特殊なパターンとキューブに仕込まれたカメラにより、キューブの座標と姿勢を正確に把握できるということである。普通この手のロボットを正確な座標に向けて動かそうと思ったら、天井にカメラを付けて画像処理と組み合わせたり、かなりハードル高いのである。Toioならわりと簡単にこんな「一人サッカーロボット」とかできてしまう。
Toio project: Self-soccer Robot https://t.co/6gtgWZiquy
— Tomoto S. Washio (@tomoto335) 2019年7月19日なお、キューブ操作用のライブラリは誰かが既に作っているかもしれないが、それに乗るだけでは「一番おいしいところを持ってかれる」ようなものなので自分で書く。車輪の再発明ドントコーイ(゚∀゚)!!
ソースコード
ここにどんどん放り込んでいくのでよろしく: https://github.com/tomoto/tomotoio
- 言語: Python 3
- OS: Linux (BLE通信にbluepyを使用しているので)
- ハード: Raspberry Pi 4 + Raspbian Stretchを使用。Windows 10上のVMwareではBLEが不安定で意図通り動かず。
- Python 3の仮想環境作って
pip install -e .すれば使えるはず。キューブのスキャン
このへん: https://github.com/tomoto/tomotoio/blob/master/tomotoio/scanner.py
接続先キューブのMACアドレスはあらかじめスキャンしてファイルに書いておく。どうせ持ってるキューブは固定なので、root権限が必要なスキャン操作を毎回走らせるのはnonsenseという考え。スキャン処理自体はbluepyの基本機能だけででき、何の変哲もない。
サンプルたち
この中にある: https://github.com/tomoto/tomotoio/tree/master/examples
簡単な順に紹介:
*simple.py接続と切断だけの最小のサンプル。
*soundeffects.pyプリセットの効果音を順番に再生する。
*rotate.pyキューブ#2の方向にキューブ#1を向ける。(めだま生物のキビキビ版)
*symmetric.pyキューブ#2の点対称の位置にキューブ#1を移動する。
*circle.pyキューブ#2を中心にキューブ#1を周回させる。
*soccer.py上で紹介した一人サッカー。なお
utils.pyにあるのはお決まりの初期化処理。接続時にキューブに光と音で「番号、いち!に!」と言わせるのはここ。基盤機能
キューブ操作
このへん: https://github.com/tomoto/tomotoio/blob/master/tomotoio/cube.py
インスタンスの入手は、このへん https://github.com/tomoto/tomotoio/blob/master/tomotoio/factory.py の関数にMACアドレスを指定して行う。以下のような操作ができる。
cube.xxx.get()属性値(toioID, motion, button, battery)の取得cube.xxx.enableNotification()Notificationの有効化(属性値が変化するとcube.xxx.addListener()で登録した関数が呼ばれる)cube.setXxx()モーター、音、光などの設定cube.release()接続切断「指定座標に移動」のような処理はこれだけではまだ難しいので、次回以降扱う。
BLE通信
このへん: https://github.com/tomoto/tomotoio/blob/master/tomotoio/blepeer.py
見ての通り、bluepyの薄いラッパ。Notificationの処理は下記のようにちょっとめんどうなのでここに隠蔽する。
1. subscribeスレッドを上げてwaitForNotifications呼び出しを回す
2.writeCharacteristicsがwaitForNotificationsと被らないよう、write要求はスレッド間キューをかましてsubscribeスレッドの側で処理するBLEメッセージのエンコードとデコード
このへん: https://github.com/tomoto/tomotoio/blob/master/tomotoio/messages.py
仕様書をひたすら写経しただけ。エンコード前・デコード後のデータの入れ物は https://github.com/tomoto/tomotoio/blob/master/tomotoio/data.py で定義。
次回

- 投稿日:2019-07-19T13:37:49+09:00
Python3 > datetime > カレンダの特定日に印を付ける (C++ BuilderのTCalendarのARow, ACol計算用)
動作環境ideone (Python 3 (python 3.5)概要
- C++ Builderで設計中の機能をPython実装でさっと確認
- 年を通した366の要素にあらかじめマークを付け、それをもとにカレンダの該当箇所をマーク付けする
- C++ BuilderのTCalenderのACol, ARowの計算に使う
備考
曜日の定義は
- 0(Monday): python
- https://docs.python.org/3.7/library/calendar.html#calendar.weekday
Returns the day of the week (0 is Monday) for year (1970–…), month (1–12), day (1–31).- 1(Sunday): Delphi
実装
# [x] PEP8 check from datetime import datetime aymd = datetime(2019, 7, 18, 12, 30, 45) def getWeekDay(adate): return (adate.weekday() + 1) % 7 # for 0:Sunday[Delphi] def getYearDay(adate): return (adate.timetuple().tm_yday) def dispCal(alist): for idx in range(len(alist)): print(alist[idx], end='') if idx % 7 == 6: print() # CRLF # 1. preparation ------------------------- NUM_YEAR = 366 # maximum number of days in a year (including leap-year) yrs = [[]]*NUM_YEAR for idx in range(NUM_YEAR): yrs[idx] = 0 yrs[getYearDay(datetime(2019, 1, 1, 0, 0, 0))] = 1 # Jan yrs[getYearDay(datetime(2019, 2, 1, 0, 0, 0))] = 1 # Feb. yrs[getYearDay(datetime(2019, 3, 1, 0, 0, 0))] = 1 # Mar. NUM_MONTH = 37 # 6 lines in calendar ( 7 * 5 lines + 2 [30, 31 days]) mts = [[]]*NUM_MONTH for idx in range(NUM_MONTH): mts[idx] = 0 # 2. main part ------------------------- adt = datetime(2019, 2, 1, 0, 0, 0) # ymdhns awday = getWeekDay(adt) ayday = getYearDay(adt) for idx in range(31): # 31: maximum for one month mts[awday + idx] = yrs[ayday + idx] print('Feb') dispCal(mts)結果
Feb 0000010 0000000 0000000 0000000 0000010 00備考
確認は済んだので、このコードはここまで。
さらに良いコードにする時間は今回は取らない。
関連
- Python
- Delphi (C++ Builder)
- C++ Builder
- SysUtils.DayOfWeek 関数
- > 日曜が週の先頭で,土曜が 7 番めの曜日です。
- DateUtils.DayOfTheYear 関数
- DateUtils.DayOfTheWeek 関数
- > 1 は月曜,7 は日曜を示します。
C++ Builderに関してはDateUtilsを使う。
- 投稿日:2019-07-19T13:04:04+09:00
anacondaにsentencepieceをwheelファイル経由でインストールする
背景
- 機械学習関連のライブラリをインストールするためにanacondaを使用
- コンフリクトを避けるためpipは使わずcondaでパッケージ管理
- sentencepieceのPythonバインディングをインストールしたい
実行環境
- CentOS 6.7
- (pyenv)anaconda3-5.3.1
- conda createで仮想環境を作ってその中でインストール
リポジトリにあるか確認
$ conda search sentencepieceヒットせず。
conda skeleteonを使ってみる(失敗)
- anacondaのリポジトリになくてPyPIにある(pip installできる)パッケージは、conda skeletonを使うことでcondaにインストールするためのレシピファイルを作成できる
$ conda skeleton pypi sentencepieceError: No source urls found for sentencepiece
というエラーが出て失敗。sentencepieceのPyPIにはwhlファイルはあるが
tar.gzファイルがなかったのでインストールできず失敗した模様。自分でcondaレシピを作る
- conda skeletonで作られるレシピを参考に作る
- meta.yaml, build.shが必要って書いてあったけどmeta.yamlだけでインストールできた
- sentencepiece/meta.yaml を編集する
$ mkdir sentencepiece $ vim sentencepiece/meta.yaml
- meta.yaml はこんな感じ
{% set name = "sentencepiece" %} {% set version = "0.1.82" %} package: name: "{{ name|lower }}" version: "{{ version }}" source: url: https://github.com/google/sentencepiece/releases/download/v0.1.82/sentencepiece-0.1.82-cp37-cp37m-manylinux1_x86_64.whl sha256: 3fc02ba62f2d5c624f3f107cc256c1c5f877fb7fa80754e2e7cd7f0aa5e0c86f build: number: 0 script: "{{ PYTHON }} -m pip install sentencepiece-0.1.82-cp37-cp37m-manylinux1_x86_64.whl --no-deps --ignore-installed -vvv " requirements: host: - pip - python run: - python test: imports: - sentencepiece
- ポイント
- 先頭にインストール対象のライブラリ名(sentencepiece)とバージョン(0.1.82)を記述する
- source.urlにGitHub上のwhlファイルのURLを記述する
- sha256チェックサムはなくても動くらしいが、一応事前にダウンロードしてチェックサムを調べてから書いておく
- build.scriptにwhlファイルをpip installするコマンドを書く(build.shの代わり)
- --no-deps --ignore-installedを付けているのは他の依存ライブラリをインストールさせないため
- もしかしたら必要ない行があるかも
- できたらビルドする
$ conda build sentencepiece 最後にファイルが残ってると言われるので掃除する $ conda build purge
- ビルドが無事完了したらインストールする
$ conda install --use-local sentencepiece
- インストールが完了したら作成したレシピディレクトリを削除する
$ rm -r sentencepieceまとめ
- conda skeleton pypiで上手くレシピが作れなくても自分でmeta.yaml書けばインストールできる
- wheelファイルがあるライブラリなら大体condaでもインストールできそう
参考
- 投稿日:2019-07-19T10:24:21+09:00
xgboost で Feature Importance を算出する。
TL;DR
xgboost を用いて Feature Importanceを出力します。
object のメソッドから出すだけなので、よくご存知の方はブラウザバックしていただくことを推奨します。この記事の内容
前回の記事
- xgboost でトレーニングデータに CSVファイルを指定したらなんか相当つまづいた。
Feature Importance とは、(私の理解で言えば) 説明変数ごとに出力結果に与える影響の度合いを数値化したもの。
- 例えば、カレーを作るをときに、このカレーの味を決めているのはどの調味料の影響が大きいのか
(ターメリックなのか?, コリアンダーなのか? みたいなこと)
をスコアとして出力してくれるみたいな感じです。(たぶん)今回の内容
- 前回、学習をさせるには至ったので、いよいよ Feature Importance の算出をする。
そして、もはや毎度のことなのですが、
あまり説明などが正確ではありませんことをご承知おきください。大変遅くなりました。
記事自体はほとんどできていたのですが、
最近は研究周りの作業が忙しく、なかなか投稿する時間が取れませんでした。
すみません。まずは、出力の仕方を知る。
例によって例のごとく、既に確立されている方法において、Feature Importance はどのように出力されているのかを確認します。
プログラム
前回も参考にさせていただいた下記のサイトにまたお世話になります。
Python: XGBoost を使ってみる のうち、「特徴量の重要度を可視化する」xgb_fi.pyimport xgboost as xgb from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from matplotlib import pyplot as plt """XGBoost で特徴量の重要度を可視化するサンプルコード""" # sklearn にある Iris datasetを読み込む。 dataset = datasets.load_iris() x, y = dataset.data, dataset.target x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, shuffle=True, stratify=y) # 可視化のために特徴量の名前を渡しておく dtrain = xgb.DMatrix(x_train, label=y_train, feature_names=dataset.feature_names) dtest = xgb.DMatrix(x_test, label=y_test, feature_names=dataset.feature_names) xgb_params = { 'objective': 'multi:softmax', 'num_class': 3, 'eval_metric': 'mlogloss', } evals = [(dtrain, 'train'), (dtest, 'eval')] evals_result = {} bst = xgb.train(xgb_params, dtrain, num_boost_round=100, early_stopping_rounds=10, evals=evals, evals_result=evals_result ) y_pred = bst.predict(dtest) acc = accuracy_score(y_test, y_pred) print("Accuracy : ", acc) # 性能向上に寄与する度合いで重要度をプロットする _, ax = plt.subplots(figsize=(12, 4)) xgb.plot_importance(bst, ax=ax, importance_type='gain', show_values=False) plt.show()出力された表について
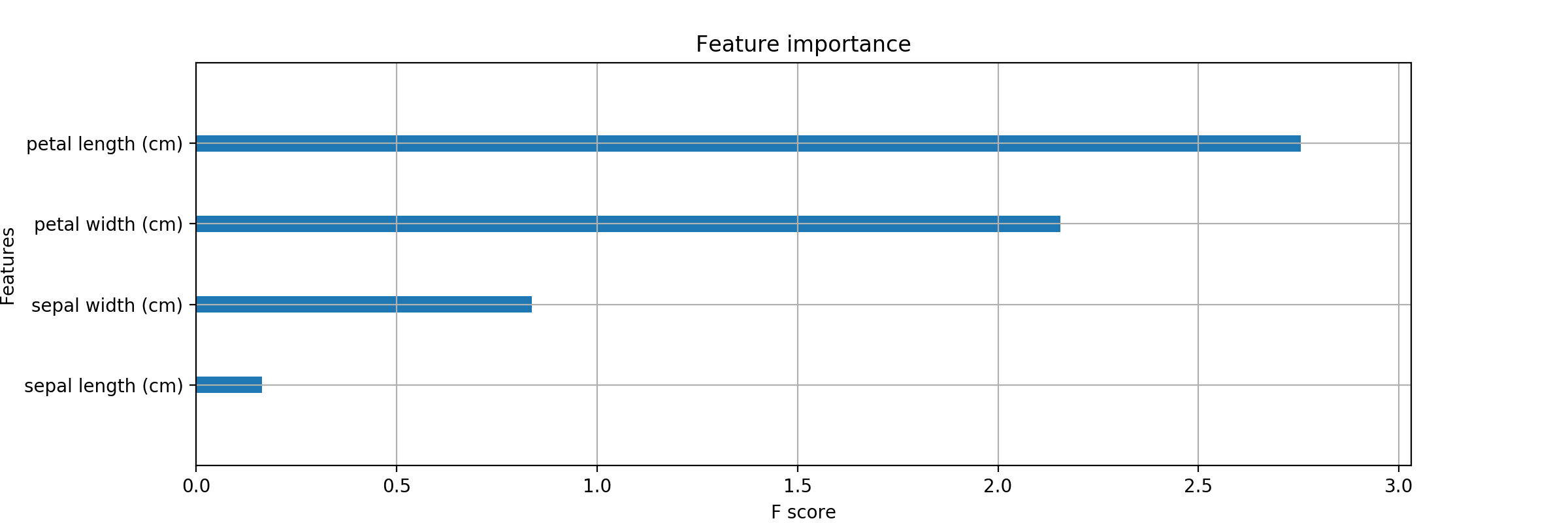
そうして出力されたものがこちらになります。
(n分クッキング感)
悪くない..が。棒グラフだけしかねえ。
数値でも欲しいなあ。# よく見ると、最後の引数に show_values って書いてある。 xgb.plot_importance(bst, ax=ax, importance_type='gain' #show_values=False )と、雑にコメントアウトして、実行。
(もちろんshow_values=Trueと指定しても良いです。)
おおん? なんだこのきちゃない値..
この記事を参考にさせていただくと
どうやら、Feature Importance には
3種類の指標が用意されているらしいことがわかりました。ちなみに、公式(?)ドキュメントにも同じようなことが書いてありました。
xgboost.plot_importance(booster, ax=None, ..., importance_type='weight', ...)
Plot importance based on fitted trees.
Parameters
...
importance_type (str, default "weight") –
How the importance is calculated: either “weight”, “gain”, or “cover”
”weight” is the number of times a feature appears in a tree
”gain” is the average gain of splits which use the feature
”cover” is the average coverage of splits which use the feature where coverage is defined as the number of samples affected by the splitということで、ですね。
# この第3引数の importance_type を xgb.plot_importance(bst, ax=ax, importance_type='gain' #show_values=False )# このようにコメントアウトするか、 xgb.plot_importance(bst, ax=ax #importance_type='gain' #show_values=False )# weight の指定にすると xgb.plot_importance(bst, ax=ax, importance_type='weight' #show_values=False )
こんな風に、いい感じで表示できます。
余談ですが、
参考サイトでは「default の指定が gain になった」とのことでしたが
コメントアウトしたときと、weightで指定したときで同様の結果がでるということは、
さっきの公式っぽいDocument にあるようにimportance_type (str, default "weight") –
デフォは weight なのですかね。
辞書もほしい。
それはさておき。
もう1つ欲しいものがあります。Feature Importanceの情報を持っている辞書です。
どうしたものか.. と思い、色々雑に print してみたり、検索かけていたら
ここでいいものを見つけました。bst.get_fscore()
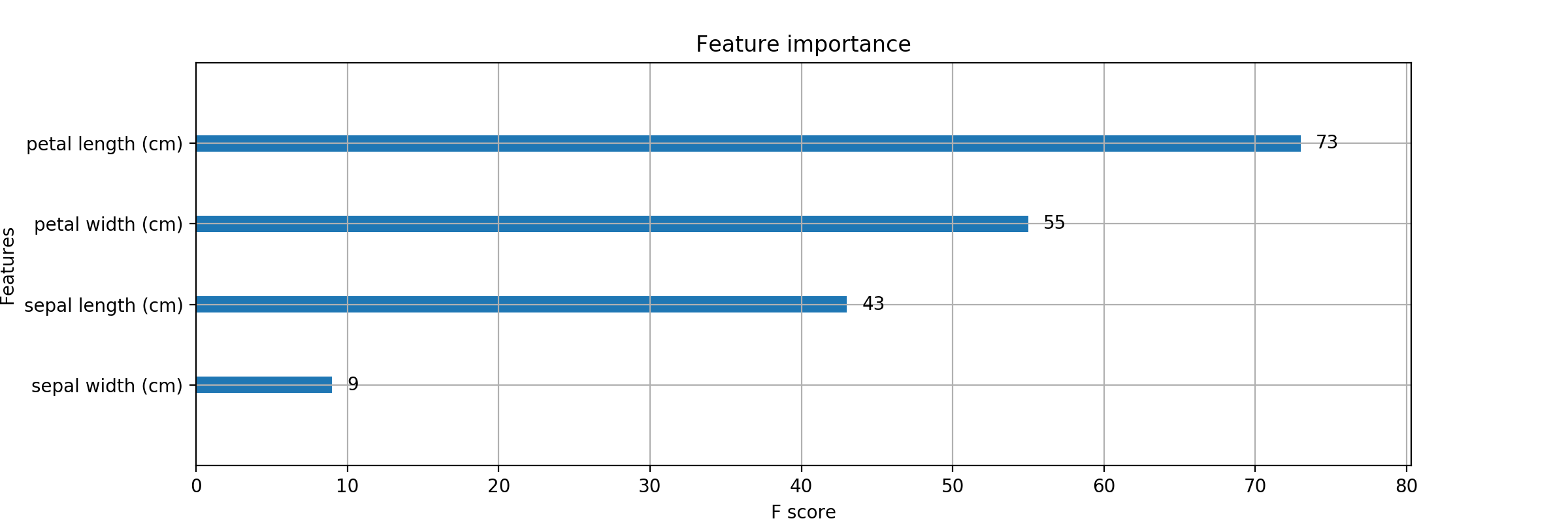
{'f0': 17, 'f1': 16, 'f2': 95, 'f3': 59}これじゃね? 早速 print します。
(入れる場所はprint(Accuracy..)の下あたりに..)print(bst.get_fscore()){'petal length (cm)': 84, 'petal width (cm)': 42, 'sepal length (cm)': 22, 'sepal width (cm)': 19}いい感じ! これが知りたかったのよ。
一旦まとめます。
ここまででできたプログラム
xgb_fi.pyimport xgboost as xgb from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from matplotlib import pyplot as plt """XGBoost で特徴量の重要度を可視化するサンプルコード""" # sklearn にある Iris datasetを読み込む。 dataset = datasets.load_iris() x, y = dataset.data, dataset.target x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, shuffle=True, stratify=y) # 可視化のために特徴量の名前を渡しておく dtrain = xgb.DMatrix(x_train, label=y_train, feature_names=dataset.feature_names) dtest = xgb.DMatrix(x_test, label=y_test, feature_names=dataset.feature_names) xgb_params = { 'objective': 'multi:softmax', 'num_class': 3, 'eval_metric': 'mlogloss', } evals = [(dtrain, 'train'), (dtest, 'eval')] evals_result = {} bst = xgb.train(xgb_params, dtrain, num_boost_round=100, early_stopping_rounds=10, evals=evals, evals_result=evals_result ) y_pred = bst.predict(dtest) acc = accuracy_score(y_test, y_pred) print("Accuracy : ", acc) # Feature Importance の情報を持つ辞書を出力 print(bst.get_fscore()) # 性能向上に寄与する度合いで重要度をプロットする _, ax = plt.subplots(figsize=(12, 4)) xgb.plot_importance(bst, ax=ax) plt.show()これで、Feature Importance に関しては
棒グラフとそれに対応する辞書の形で取得することができるようになりました。任意のファイル(特にCSVファイル)に対して出力できるようにしたい。
さて、欲しいものの出力の仕方はわかったのですが、前回同様、データには sklearn の datasets から読んだものを使用しています。
今後、自分で勝手なデータを持ってきて、出力したいときのために、
sklearn の datasets でなくともできるようにしたいのです。お気付きの方も多いと思いますが
こんなコードが出てきていました。
# 可視化のために特徴量の名前を渡しておく dtrain = xgb.DMatrix(x_train, label=y_train, feature_names=dataset.feature_names) dtest = xgb.DMatrix(x_test, label=y_test, feature_names=dataset.feature_names)=>
feature_names=dataset.feature_names
ここで datasets のメソッドを用いているのですよね。
(ちなみに、dataset とはdataset = datasets.load_iris()でした。)この中身をみてみます。
print(dataset.feature_names)['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']あ、ヘッダのリストか。いけそう(罠)
Pandas で columnを得る
失敗例
長くなってもあれなので、一気に行きます。
概ね実行スクリプトの後ろにある #の後が出力結果という見た目になります。
お急ぎの方は次の見出しまで飛ばしてください。使用したCSVファイルは Iris dataset の
1行欠けたものをCSV形式にしてあるものになります。
(ファイル名 : Fishers_Irises_train.csv)# read_csv import pandas as pd file_pass = '(pardir)/Fishers_Irises_train.csv' iris_csv = pd.read_csv(data) #print(iris_csv) # この辺りは前回の記事から持ってきています.. ## iloc[1:]指定しているのはヘッダを読まないため。 x = iris_csv.iloc[1:, :3] x = x.values.astype(float) #print('Feature data :', x) y = iris_csv.iloc[1:, 3] y = y.values.astype(int) y = y -1 #print('answer :', y_pd)# カラム名をリスト型で取得する # --- 失敗例 --- print(iris_csv.columns) # >> Index(['PetalLength', 'SepalLength', 'SepalWidth', 'Species'], dtype='object')また objectかいな..
print(iris_csv.iloc[0]) """ 出力結果 >> PetalLength 1.4 SepalLength 5.1 SepalWidth 3.5 Species 1.0 Name: 0, dtype: float64 # 違うそうじゃない.. """ print(iris_csv.iloc[0].dtype) # >> float64 (そうでもない)# 考えてみた。 # # astype で型変換できるんじゃ..? (アホ) feature_cloumns = iris_csv.columns.astype(list) # >> Index(['PetalLength', 'SepalLength', 'SepalWidth', 'Species'], dtype='object') (できへんで。)# 調べたら values で 変換できるとか.. feature_cloumns = iris_csv.columns.values print(feature_cloumns) # ['PetalLength' 'SepalLength' 'SepalWidth' 'Species'] お。 print(type(feature_cloumns)) # <class 'numpy.ndarray'> え。 print(type(feature_cloumns) == list) # False おうふ。やっとできた。
# pandas で読み込んだ csv data から column 情報を取得 columns = iris_csv.columns # columns を values で (npdarrayの)リストに変換 cloumns_ndarray = columns.values # numpy の型変換を用いて、 ndarray を python 標準の list に変換 feature_cloumns = cloumns_ndarray.tolist() # 結果観察 print(feature_cloumns) # >> ['PetalLength' 'SepalLength' 'SepalWidth' 'Species'] お。 print(type(feature_cloumns)) # >> <class 'list'> お。 print(type(feature_cloumns) == list) # >> True っしゃあ。 (めんどくさくね??)やっていること
結局、pandasで読み込んだ CSVのカラム名を
dataframe.columnsで取得し
これが objectなので、dataframe.valuesを用いて ndarray に変換し
ndarray.tolist()を用いて NumPy配列を Python標準のリスト型に直しています。愚かですね。
そうして Feature Importance の出力へ。
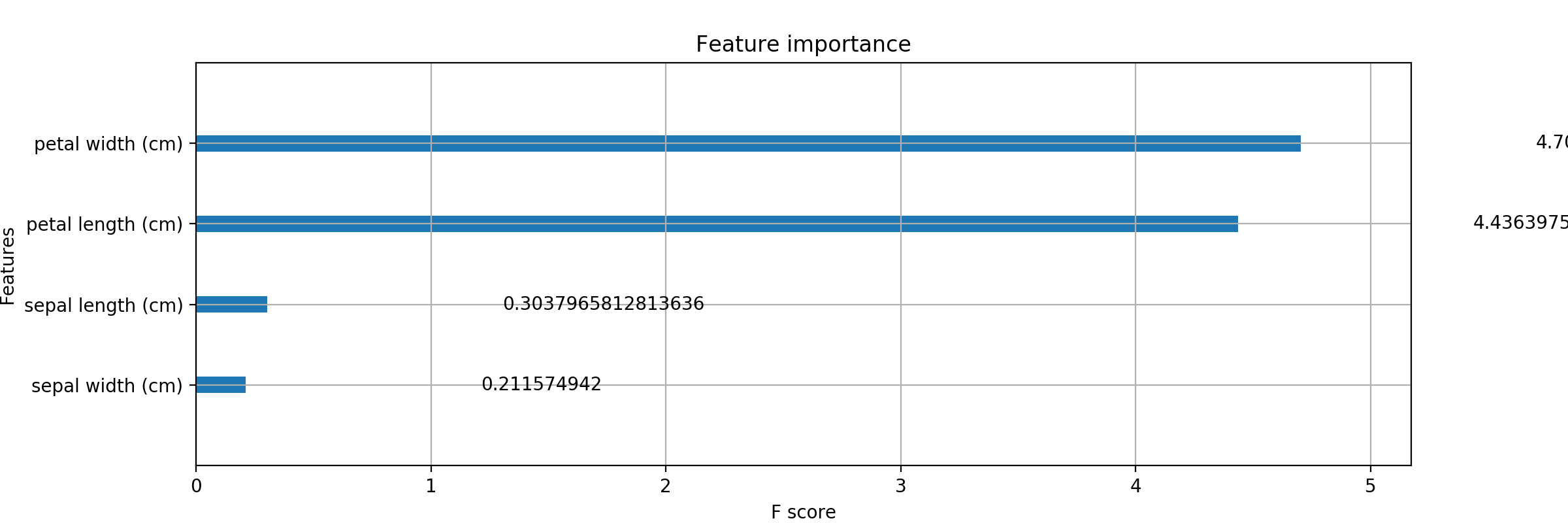
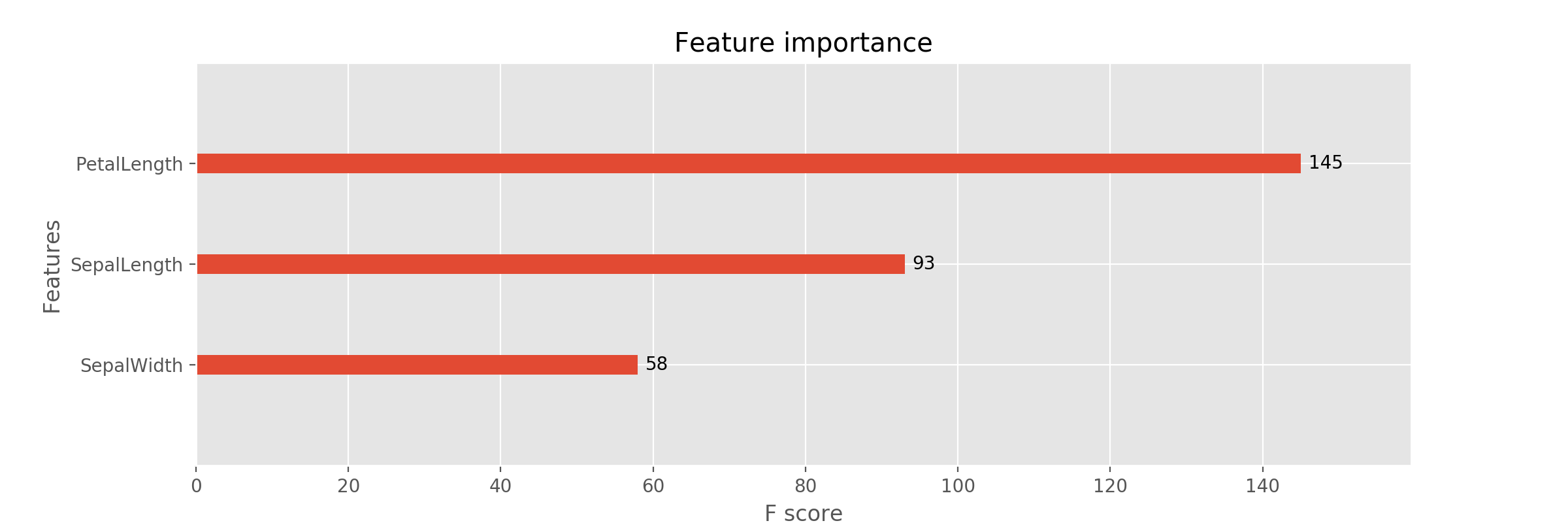
xgb_fi.pyimport numpy as np import xgboost as xgb import pandas as pd from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score import matplotlib.pyplot as plt plt.style.use('ggplot') file_pass = '(pardir)/Fishers_Irises_train.csv' iris_csv = pd.read_csv(file_pass) #print(iris_csv) ## iloc[1:]指定しているのはヘッダを読まないため。 x = iris_csv.iloc[1:, :3] x = x.values.astype(float) #print('Feature data :', X_pd) y = iris_csv.iloc[1:, 3] y = y.values.astype(int) y = y -1 #print('answer :', y) # --- fearure columns の取得 --- # pandas で読み込んだ csv data から column 情報を取得 columns = iris_csv.columns # columns を values で (npdarrayの)リストに変換 cloumns_ndarray = columns.values # numpy の型変換を用いて、 ndarray を python 標準の list に変換 feature_cloumns = cloumns_ndarray.tolist() #print(feature_cloumns) # ['PetalLength' 'SepalLength' 'SepalWidth' 'Species'] #print(type(feature_cloumns)) #print(type(feature_cloumns) == list) x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, shuffle=True, stratify=y) # 可視化のためにこの時点で特徴量の名前を渡しておく dtrain = xgb.DMatrix(x_train, label=y_train, feature_names=feature_cloumns[0:3]) dtest = xgb.DMatrix(x_test, label=y_test, feature_names=feature_cloumns[0:3]) # feature_columns = ['PetalLength' 'SepalLength' 'SepalWidth' 'Species'] # 'Species' を指定しないように [0:3] ([0] ~ [2])で指定。 """ # これでもよい。('Species' を先に削っておくスタイル。) # 正解ラベルのカラム名 'Species' を含んでしまっているので、これを popする。 feature_cloumns.pop() dtrain = xgb.DMatrix(x_train, label=y_train, feature_names=feature_cloumns) dtest = xgb.DMatrix(x_test, label=y_test, feature_names=feature_cloumns) """ xgb_params = { 'objective': 'multi:softmax', 'num_class': 3, 'eval_metric': 'mlogloss' } evals = [(dtrain, 'train'), (dtest, 'eval')] evals_result = {} bst = xgb.train(xgb_params, dtrain, num_boost_round=100, early_stopping_rounds=10, evals=evals, evals_result=evals_result ) y_pred = bst.predict(dtest) acc = accuracy_score(y_test, y_pred) print("Accuracy : ", acc) print(bst.get_fscore()) # 性能向上に寄与する度合いで重要度をプロットする _, ax = plt.subplots(figsize=(12, 4)) xgb.plot_importance(bst, ax=ax) plt.show()これを実行しますと
$ python xgb_fi.py{'PetalLength': 145, 'SepalLength': 93, 'SepalWidth': 58}このような Feature Importance の情報を持つ辞書と
それに対応した棒グラフ (スコア入り)が出力されます。
まとめ
こんな感じでややつまづきながらも、
Feature Importanceを所望のファイルに対して出力する方法を
知ることができたかなと思います。それにしても xgboost は結構完成された(機能もりもりの、という意味の)
ライブラリであることがわかってびっくりしています。いろんなメソッドを持たせることって、予知能力というか、先見の明というか、
ニーズを察する力が必要だなあと感じるので、すごいなあという感じですね。今回は使い方の勉強と、「出力をすること」に重きをおいていたので、
パラメータだとか正しさだとかいう点で保証ができないのですが
そのうち、何か目的を持って使うときにここで学んだことが活きればいいなと思います。ここまで読んでいただきありがとうございました。
それでは。
- 投稿日:2019-07-19T07:11:01+09:00
【Programming News】Qiitaまとめ記事 July 18, 2019 Vol.4
筆者が昨日2019/7/18(木)に気になったQiitaの記事をまとめました。昨日のまとめ記事はこちら。
Java
Python
- Beginner
- Tips
- K近傍法
Node.js
Nuxt.js
Swift
Laravel
MySQL
- Beginner
Git
- Beginner
Visual Studio
AWS
- Beginner
- Tips
- Cognito
- S3
- EC2
- Elasticsearch
Docker
Google Apps Script
- Tips
Develop
Raspberry
- Tips
- Apps
UML
- PlantUML
Go言語
- Beginner
- Tips
R言語
awk
LaTex
Redmine
- Tips
更新情報
- 投稿日:2019-07-19T04:49:03+09:00
Pythonインタプリタをショボーンインタプリタにする
この記事は Pythonインタプリタをショボーンインタプリタにする - narupoのブログ からの転載になります。
Pythonインタプリタをショボーンインタプリタにする
こんにちは、narupoです。
Pythonインタプリタも長いあいだ使ってると飽きるものです。
そこでインタプリタを改造して気分を変えることにしました。インタプリタに
(´・ω・`)ショボーンを表示させればインタプリタが可愛くなるかも?!
果たして本当にそうなるのでしょうか。やってみたいと思います。
CPythonをゲットする
Pythonには色々な実装がありますが、今回改造するのは最も一般的と思われる
CPythonの実装です。
Gitを使ってCPythonのプロジェクトをクローンします。$ git clone https://github.com/python/cpython.gitあとは
configureとやってmakeしてPythonをビルドします。
環境はWindows10のWSLを使っています。Ubuntu16.04ですね。なので生成されるPythonがpython.exeになってますね。$ cd cpython $ ./configure $ make $ python.exeCPythonを改造する
Programs/python.cにPythonプログラムのエントリーポイントがありました。#ifdef MS_WINDOWS int wmain(int argc, wchar_t **argv) { return Py_Main(argc, argv); } #else int main(int argc, char **argv) { return Py_BytesMain(argc, argv); } #endifWindows10のWSL(Ubuntu16.04)の環境では後者のmainが呼ばれます。
Py_BytesMainはModules/main.cで定義されています。int Py_BytesMain(int argc, char **argv) { _PyArgv args = { .argc = argc, .use_bytes_argv = 1, .bytes_argv = argv, .wchar_argv = NULL}; return pymain_main(&args); }
pymain_mainも同ファイル内に定義されています。static int pymain_main(_PyArgv *args) { PyStatus status = pymain_init(args); if (_PyStatus_IS_EXIT(status)) { pymain_free(); return status.exitcode; } if (_PyStatus_EXCEPTION(status)) { pymain_exit_error(status); } return Py_RunMain(); }
Py_RunMainも同様です。int Py_RunMain(void) { int exitcode = 0; pymain_run_python(&exitcode); if (Py_FinalizeEx() < 0) { /* Value unlikely to be confused with a non-error exit status or other special meaning */ exitcode = 120; } pymain_free(); if (_Py_UnhandledKeyboardInterrupt) { exitcode = exit_sigint(); } return exitcode; }
pymain_run_pythonの中身はなんじゃらほい?static void pymain_run_python(int *exitcode) { ... pymain_header(config); ... else { *exitcode = pymain_run_stdin(config, &cf); } }
pymain_headerが対話モードのバージョンとかを表示している関数です。
対話モードではpymain_run_stdinが呼ばれるようです。先に
pymain_headerを見てみます。static void pymain_header(const PyConfig *config) { if (config->quiet) { return; } if (!config->verbose && (config_run_code(config) || !stdin_is_interactive(config))) { return; } fprintf(stderr, "Python %s on %s\n", Py_GetVersion(), Py_GetPlatform()); if (config->site_import) { fprintf(stderr, "%s\n", COPYRIGHT); } }バージョンとかコピーライトを表示していますね。
stderrに出力しているようです。
ここのPythonをショボーンに変えておきましょう。fprintf(stderr, "(´・ω・`)ショボーン %s on %s\n", Py_GetVersion(), Py_GetPlatform());
pymain_run_stdinに戻ります。static int pymain_run_stdin(PyConfig *config, PyCompilerFlags *cf) { ... int run = PyRun_AnyFileExFlags(stdin, "<stdin>", 0, cf); ... }
PyRun_AnyFileExFlagsを見てみましょう。
Python/pythonrun.cで定義されています。int PyRun_AnyFileExFlags(FILE *fp, const char *filename, int closeit, PyCompilerFlags *flags) { ... int err = PyRun_InteractiveLoopFlags(fp, filename, flags); ... }
PyRun_InteractiveLoopFlagsが呼ばれています。この関数を見てみましょう。int PyRun_InteractiveLoopFlags(FILE *fp, const char *filename_str, PyCompilerFlags *flags) { ... do { ret = PyRun_InteractiveOneObjectEx(fp, filename, flags); } while (ret != E_EOF); ... }
do while文の中でstdinを監視してループしているようです。
ここがPythonの対話モードでループされている所ですね。ループの所にショボーンを追加しときましょう。
... do { fprintf(stderr, ">>> (´・ω・`)ショボーン\n"); ret = PyRun_InteractiveOneObjectEx(fp, filename, flags); ... } while (ret != E_EOF); ...これでショボーンインタプリタができました。
エラー時のカワイソスも追加します。... do { fprintf(stderr, ">>> (´・ω・`)ショボーン\n"); ret = PyRun_InteractiveOneObjectEx(fp, filename, flags); if (ret == -1 && PyErr_Occurred()) { /* Prevent an endless loop after multiple consecutive MemoryErrors * while still allowing an interactive command to fail with a * MemoryError. */ if (PyErr_ExceptionMatches(PyExc_MemoryError)) { if (++nomem_count > 16) { PyErr_Clear(); err = -1; break; } } else { nomem_count = 0; } PyErr_Print(); // エラー出力のあとにカワイソスを表示 fprintf(stderr, ">>> (´・ω・`)カワイソス\n"); flush_io(); } else { nomem_count = 0; } #ifdef Py_REF_DEBUG if (show_ref_count) { _PyDebug_PrintTotalRefs(); } #endif } while (ret != E_EOF); ...動作風景
↓がショボーンインタプリタの動作風景です。
おわりに
しばらくこのインタプリタを使ってみた感想ですが、ショボーンがうざかったです。
みなさんもインタプリタを改造して気分を変えてみましょう。以上、narupoでした。

- 投稿日:2019-07-19T04:49:03+09:00
Pythonインタプリタをショボーンインタプリタに改造する
この記事は Pythonインタプリタをショボーンインタプリタに改造する - narupoのブログ からの転載になります。
Pythonインタプリタをショボーンインタプリタにする
こんにちは、narupoです。
Pythonインタプリタも長いあいだ使ってると飽きるものです。
そこでインタプリタを改造して気分を変えることにしました。インタプリタに
(´・ω・`)ショボーンを表示させればインタプリタが可愛くなるかも?!
果たして本当にそうなるのでしょうか。やってみたいと思います。
CPythonをゲットする
Pythonには色々な実装がありますが、今回改造するのは最も一般的と思われる
CPythonの実装です。
Gitを使ってCPythonのプロジェクトをクローンします。$ git clone https://github.com/python/cpython.gitあとは
configureとやってmakeしてPythonをビルドします。
環境はWindows10のWSLを使っています。Ubuntu16.04ですね。なので生成されるPythonがpython.exeになってますね。$ cd cpython $ ./configure $ make $ python.exeCPythonを改造する
Programs/python.cにPythonプログラムのエントリーポイントがありました。#ifdef MS_WINDOWS int wmain(int argc, wchar_t **argv) { return Py_Main(argc, argv); } #else int main(int argc, char **argv) { return Py_BytesMain(argc, argv); } #endifWindows10のWSL(Ubuntu16.04)の環境では後者のmainが呼ばれます。
Py_BytesMainはModules/main.cで定義されています。int Py_BytesMain(int argc, char **argv) { _PyArgv args = { .argc = argc, .use_bytes_argv = 1, .bytes_argv = argv, .wchar_argv = NULL}; return pymain_main(&args); }
pymain_mainも同ファイル内に定義されています。static int pymain_main(_PyArgv *args) { PyStatus status = pymain_init(args); if (_PyStatus_IS_EXIT(status)) { pymain_free(); return status.exitcode; } if (_PyStatus_EXCEPTION(status)) { pymain_exit_error(status); } return Py_RunMain(); }
Py_RunMainも同様です。int Py_RunMain(void) { int exitcode = 0; pymain_run_python(&exitcode); if (Py_FinalizeEx() < 0) { /* Value unlikely to be confused with a non-error exit status or other special meaning */ exitcode = 120; } pymain_free(); if (_Py_UnhandledKeyboardInterrupt) { exitcode = exit_sigint(); } return exitcode; }
pymain_run_pythonの中身はなんじゃらほい?static void pymain_run_python(int *exitcode) { ... pymain_header(config); ... else { *exitcode = pymain_run_stdin(config, &cf); } }
pymain_headerが対話モードのバージョンとかを表示している関数です。
対話モードではpymain_run_stdinが呼ばれるようです。先に
pymain_headerを見てみます。static void pymain_header(const PyConfig *config) { if (config->quiet) { return; } if (!config->verbose && (config_run_code(config) || !stdin_is_interactive(config))) { return; } fprintf(stderr, "Python %s on %s\n", Py_GetVersion(), Py_GetPlatform()); if (config->site_import) { fprintf(stderr, "%s\n", COPYRIGHT); } }バージョンとかコピーライトを表示していますね。
stderrに出力しているようです。
ここのPythonをショボーンに変えておきましょう。fprintf(stderr, "(´・ω・`)ショボーン %s on %s\n", Py_GetVersion(), Py_GetPlatform());
pymain_run_stdinに戻ります。static int pymain_run_stdin(PyConfig *config, PyCompilerFlags *cf) { ... int run = PyRun_AnyFileExFlags(stdin, "<stdin>", 0, cf); ... }
PyRun_AnyFileExFlagsを見てみましょう。
Python/pythonrun.cで定義されています。int PyRun_AnyFileExFlags(FILE *fp, const char *filename, int closeit, PyCompilerFlags *flags) { ... int err = PyRun_InteractiveLoopFlags(fp, filename, flags); ... }
PyRun_InteractiveLoopFlagsが呼ばれています。この関数を見てみましょう。int PyRun_InteractiveLoopFlags(FILE *fp, const char *filename_str, PyCompilerFlags *flags) { ... do { ret = PyRun_InteractiveOneObjectEx(fp, filename, flags); } while (ret != E_EOF); ... }
do while文の中でstdinを監視してループしているようです。
ここがPythonの対話モードでループされている所ですね。ループの所にショボーンを追加しときましょう。
... do { fprintf(stderr, ">>> (´・ω・`)ショボーン\n"); ret = PyRun_InteractiveOneObjectEx(fp, filename, flags); ... } while (ret != E_EOF); ...これでショボーンインタプリタができました。
エラー時のカワイソスも追加します。... do { fprintf(stderr, ">>> (´・ω・`)ショボーン\n"); ret = PyRun_InteractiveOneObjectEx(fp, filename, flags); if (ret == -1 && PyErr_Occurred()) { /* Prevent an endless loop after multiple consecutive MemoryErrors * while still allowing an interactive command to fail with a * MemoryError. */ if (PyErr_ExceptionMatches(PyExc_MemoryError)) { if (++nomem_count > 16) { PyErr_Clear(); err = -1; break; } } else { nomem_count = 0; } PyErr_Print(); // エラー出力のあとにカワイソスを表示 fprintf(stderr, ">>> (´・ω・`)カワイソス\n"); flush_io(); } else { nomem_count = 0; } #ifdef Py_REF_DEBUG if (show_ref_count) { _PyDebug_PrintTotalRefs(); } #endif } while (ret != E_EOF); ...動作風景
↓がショボーンインタプリタの動作風景です。
おわりに
しばらくこのインタプリタを使ってみた感想ですが、ショボーンがうざかったです。
みなさんもインタプリタを改造して気分を変えてみましょう。以上、narupoでした。
- 投稿日:2019-07-19T01:14:06+09:00
pythonのdatetime
pythonのdatetimeについて何回も同じことを調べるため、備忘録としてまとめました。
※IDLE等の対話モードで検証しました。
必要なモジュール
import datetime from pytz import timezone取得
現在日時
TODAY = datetime.datetime.now() #datetime.datetime.today() も同様の結果 TODAY #print(TODAY) → datetime.datetime(2019, 7, 19, 15, 55, 42, 566682)単体要素
TODAY.year → 2019 TODAY.month → 7 TODAY.day → 19 TODAY.hour → 15 TODAY.minute → 55 TODAY.second → 42 TODAY.microsecond → 566682日付のみ
datetime.date.today() #TODAY.date() も同様の結果 → datetime.datetime(2019, 7, 19)変更
時刻を「0時0分0秒」に変更したい
TODAY.replace(hour=0, minute=0, second=0, microsecond=0) → datetime.datetime(2019, 7, 19, 0, 0)変換
日付型→文字列
TODAY.strftime("%Y年%m月%d日-%H時%M分%S秒") → '2019年07月19日-15時55分42秒'文字列→日付型
DATE_STR = "2019-07-19T15:55:42Z" datetime.datetime.strptime(DATE_STR, "%Y-%m-%dT%H:%M:%SZ") → datetime.datetime(2019, 7, 19, 15, 55, 42)TimeZone
UTC
# UTCの現在時 datetime.datetime.utcnow() → datetime.datetime(2019, 7, 19, 7, 56, 45, 543211) # 取得済みJSTをUTCへ変換 NOW = datetime.datetime.now() # JST NOW → datetime.datetime(2019, 7, 19, 7, 57, 02, 227882) NOW.astimezone(timezone('UTC')) → datetime.datetime(2019, 7, 19, 7, 57, 02, 227882, tzinfo=<UTC>)計算
# 今日の日時から昨日を計算 YESTERDAY = TODAY - datetime.timedelta(days=1) YESTERDAY → datetime.datetime(2019, 7, 18, 15, 55, 42, 566682) # 30分後の計算 TODAY + datetime.timedelta(minutes=30) → datetime.datetime(2019, 7, 19, 16, 25, 42, 566682) # timedeltaの使える引数 [days, seconds, microseconds, milliseconds, minutes, hours, weeks]比較
比較記号
> >= < <= ==
TODAY > YESTERDAY → True TODAY < YESTERDAY → Falseaware VS naive
aware
datetimeオブジェクトがTimeZone情報を持つオブジェクト
naive
datetimeオブジェクトがTimeZone情報を持たないオブジェクト
→ aware同士、naive同士しか比較できない
以下はエラーとなる
AWARE_TIME = datetime.datetime.now().astimezone(timezone('Asia/Tokyo')) AWARE_TIME → datetime.datetime(2019, 7, 19, 17, 57, 36, 45409, tzinfo=<DstTzInfo 'Asia/Tokyo' JST+9:00:00 STD>) NAIVE_TIME = datetime.datetime.now() NAIVE_TIME → datetime.datetime(2019, 7, 19, 17, 57, 58, 622168) # 比較 AWARE_TIME > NAIVE_TIME ---------------------------------------------------------------- Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: can't compare offset-naive and offset-aware datetimes解決法
#1 naiveに統一 AWARE_TIME.replace(tzinfo=None) > NAIVE_TIME → False #エラーがなく、ちゃんと比較結果が表示されている #2 awareに統一 AWARE_TIME > NAIVE_TIME.astimezone(timezone('Asia/Tokyo')) → False #エラーがなく、ちゃんと比較結果が表示されている
- 投稿日:2019-07-19T00:40:07+09:00
公営競技を題材にGCPを勉強する
直接的にお金が絡まないと中々やる気が出ないため、公営競技を題材にしてGCPをざっくり勉強する。
なるべくサーバレスな感じで、なるべく開発もWebベースで。
GCPの色々なサービスを使ってみることを目的にしてるので、無駄の多い構成になってしまっているかも。。やったこと(ざっくり)
- GKE上のAirflowでバッチ処理作成
- GKE関連のファイル類はSourceRepositoriesで管理し、PushしたらCloudBuildでデプロイ
- Functionsでとある公営競技の過去レースのデータをダウンロードしGCSに格納する
- GCSからBigQueryに格納
- BigQueryに格納したデータを元にAI Platformでモデル作成
- Functionsでスクレイピングしたデータと上記モデルからオンライン予測し、結果をFireStoreに投入
- Functionsで予測した結果を購入
開発環境
多分これだけしか使ってない
マシン:Chromebook(ASUS Chromebook Flip C101PA)
ツール:GCP、Cloud Shell、Google Colaboratory最初に構築した構成イメージ
①バッチ処理基盤
このあたりは一番しんどかったので、以下記事にて少し整理
https://qiita.com/yakamazu/items/0dbf643c5e8e0b65e520
https://qiita.com/yakamazu/items/aff066b0ae811dd61f02②バッチ処理
PubSub
バッチ日付をパブリッシュする
Cloud Functions
バッチ日付のパブリッシュをトリガーに、該当日付の結果ファイルをダウンロード、解凍、整形
ファイルをダウンロードするときは/tmpディレクトリにダウンロードするのが注意点
https://cloud.google.com/functions/docs/concepts/execStackdriver Monitoring
CloudFunctionsのエラーをFunction名を指定してアラート出すことができる
参考URLCloud Storage
ダウンロードファイルと整形後のファイルをひたすら蓄積
BigQuery
GCSのファイルをロードし、サマリテーブルの作成
③予測モデル作成とWebスクレイピング
AI Platform
XGBoostがAI Platformで使えるようだったので、cloudshellからモデル作成ジョブをキック
モデルはGCSに保存する
その後オンライン予測用にモデルをデプロイする
やり方は公式ドキュメント見たら何とかなったちなみに機械学習素人の個人的感覚だと、XGBoostはパラメータチューニングなしでもそれなりの精度になってる雰囲気がある。
少しハマったのは、BigQueryからPandasにデータ投入するときに、
google-cloudパッケージを使用すると「'QueryJob' object has no attribute 'to_dataframe'」が発生
⇒setup.py 作ってpandas-gbqインストール、使用する方法で解決
参考Cloud Scheduler
cronのサービス
決まった時間にPubSubメッセージのパブリッシュができる(HTTPリクエストも送れる)Cloud Functions(Python)
当日の情報をスクレイピング(Beautiful Soup)で取得
取得した情報を元にAI Platformのオンライン予測を使って順位を予測
一定の期待値を超えてたらPubSubに購入情報をパブリッシュCloud Functions(Node.js)
購入情報のパブリッシュをトリガーに起動
Puppeteerというライブラリを使用してヘッドレスブラウザ操作で対象を購入するFirestore
当日のスクレイピングした情報や、購入情報を格納する
NoSQL(ドキュメント指向データベース)と呼ばれるもので、RDBと違って格納するデータのレイアウトが途中で変わったりしても問題なし
BigQueryへのImportもすんなりできるこの構成はお金がかかる。。
個人でやる際に、この構成で大きくお金がかかる部分は主に以下
- GKE
- Airflow動かそうと思ったらそれなりスペックのインスタンスを立ち上げる必要あり
- プリエンプティブにしても月2000円くらいはかかってしまった
- AI Platformのオンライン予測
- 一日に150回くらいオンライン予測すると、一日50円くらいかかる
なるべくお金がかからない感じで再構築したイメージ
①バッチ処理基盤
GKEでのAirflowをやめて、Cloud Scheduler⇒Cloud Functionsでまとめて実行に切替
個人でやる規模ならこれで十分な気がする
GKEをやめることでさらにサーバレスな感じになった
この部分の料金は今のところかかってない②オンライン予測
AI Platformのオンライン予測機能を使わずに、
GCSからモデルをダウンロードして、それをImportして予測を実施
個人でやる規模ならこれで十分な気がする
この部分の料金は今のところかかってない感想
ChromebookとGoogleのサービスだけで結構色んなことできそう。
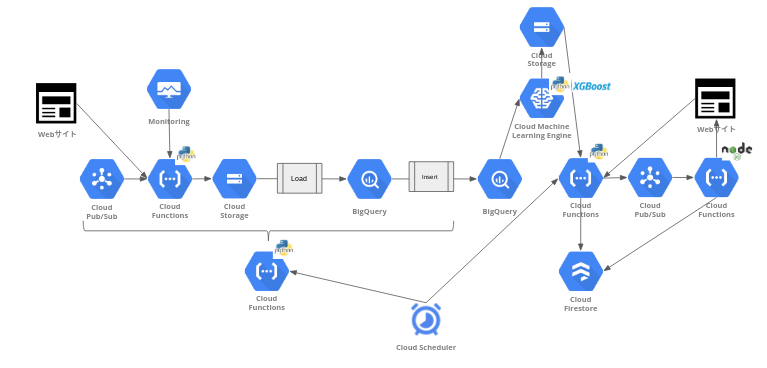
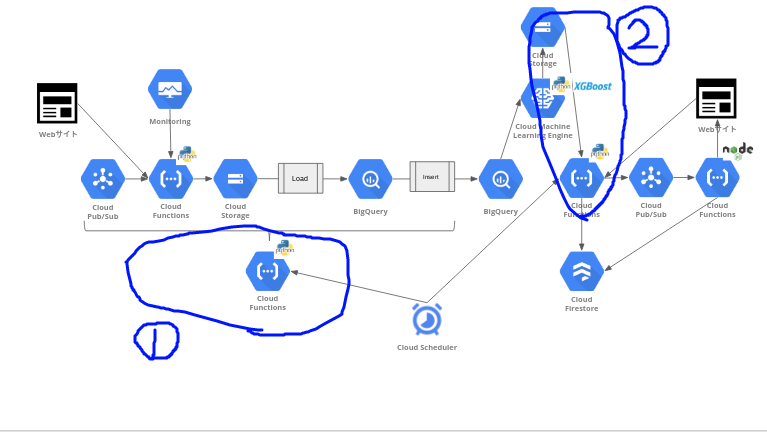
- 投稿日:2019-07-19T00:12:26+09:00
Pythonで凸包走査実装(2D版)
Pythonで凸包走査実装
はじめに
今回は2Dの凸包走査を実装です。
凸包走査とは与えられた点群のうち一番外側の点を取り出すアルゴリズム。。。です(という認識です)
取り出された点を結ぶと鈍角ができない多角形(凸多角形)になります。
この性質がDepthセンサーで取得したポイントクラウド処理や建築設計において使えそうだなと思い実装してみました。
その忘備録として。グラハム走査(Graham scan)
今回使用した凸包走査アルゴリズムは実装が簡単だとされるグラハム走査というものを使用しています。
ちなみに、よく目にするもので以下のような凸包走査アルゴリズムがあります。・Gift Wrapping
・Graham scan
・Quickhull
・Divide and conquerなどなど。参考
結構奥が深そうなアルゴリズムですが、いつもながら難しいこと抜きに実装していきます。笑
アルゴリズムの流れ
- x座標が最小の点pを求める。
- p周りの点を反時計周りで角度順に並べる。
- 凸部の頂点を削除。
がざっくりとした流れになります。
この中でテクニックが必要なのが3の凸部頂点削除です。
ここでは符号付き面積を求めることによって、凸部となる頂点を判断します。符号付き面積に関しては別の機会に図示しながらまとめようと思います。
簡単に説明しますと、3点の座標値を使用して三角形の面積を計算します。
この際に絶対値を考慮しない面積がマイナスになる場合が存在してしまいます。その面積のプラス、マイナスを見ることによって、3点の並びを知ることができるというモノです。実装
ここでは座標点をp = [x, y, z]のようなリスト構造を使用し表しています。
p_listは座標点を格納するリストです。convex_hull関数を実行すれば、凸包を構成する座標値が返されます。
その点と点を順番につないでいけば凸包図形を描画することが可能です。詳細は省きますが僕自身はRhinocerosという3DCADを使用して描画しました。
Convexhull.py# coding: utf-8 def signed_area(p1, p2, p3): '''符号付き面積を計算 ''' area = (((p2[0] - p1[0]) * (p3[1] - p1[1])) - ((p3[0] - p1[0]) * (p2[1] - p1[1]))) / 2 return area def convex_hull(p_list): '''グラハムの凸包走査 ''' p_sort = [] for i in p_list: p_sort.append(i[0]) # x座標が最小のものをリストの先頭に配置。 min_index = p_sort.index(min(p_sort)) min_p = p_list.pop(min_index) p_list.insert(0, min_p) # 座標最小の点と他の点との角度順にソート ソートアルゴリズムに選択の余地が有る。 p_length = len(p_list) count = 0 index = 0 while True: count += 1 index += 1 area_sign = signed_area(p_list[0], p_list[index], p_list[index + 1]) # 符号付き面積が負ならば点を入れ替え if area_sign < 0: p_list[index], p_list[index + 1] = p_list[index + 1], p_list[index] count = 0 if count == p_length - 1: break if index == p_length - 2: index = 0 # 凹部の点を削除する。 index = -1 count = 0 while True: index += 1 count += 1 area_sign = signed_area(p_list[index], p_list[index + 1], p_list[index + 2]) if area_sign < 0: del p_list[index + 1] count = 0 if count == len(p_list): break if index >= len(p_list) - 3: index = -1 return p_listおわりに
最後までお読みいただきありがとうございました。
次の機会にQuickhullで実装した3D対応の凸包走査を記事にまとめようと考えていますのでよろしくお願いいたします。