- 投稿日:2019-07-19T22:04:47+09:00
【備忘録】rails newやbundle installでmysql2がインストールできないエラーの解消方法
(2019/07/21 修正)
開発環境
- macOS Mojave 10.14.5
エラー内容
長らく悩まされていたエラーがようやく解決できたので,備忘録として。
$ rails new アプリ名 -d mysqlを実行すると,毎回このエラーが発生していた。
Fetching mysql2 0.5.2 Installing mysql2 0.5.2 with native extensions Gem::Ext::BuildError: ERROR: Failed to build gem native extension. (中略) An error occurred while installing mysql2 (0.5.2), and Bundler cannot continue. Make sure that `gem install mysql2 -v '0.5.2' --source 'https://rubygems.org/'` succeeds before bundling. In Gemfile: mysql2 run bundle exec spring binstub --all Could not find gem 'mysql2 (>= 0.4.4, < 0.6.0)' in any of the gem sources listed in your Gemfile. Run `bundle install` to install missing gems.色々調べて試してみるも効果無し。
(最初の)解決方法
解決できたコマンドは次のコマンドだった。
※2019/07/21追記 根本的な解決方法はこれではない可能性大,下記参照【参考】 mysql2 gemインストール時のトラブルシュート
$ cd アプリ名 $ gem install mysql2 -v '0.5.2' --source 'https://rubygems.org/' -- --with-cppflags=-I/usr/local/opt/openssl/include --with-ldflags=-L/usr/local/opt/openssl/lib $ bundle installこの後,「rails new」でアプリを作成してもエラーが出なくなった。長かった……
2019/07/21追記 正しい解決法?
次のコマンドを実行した時,また上記エラーが発生した。
$ bundle install --path vendor/bundle再度調査したところ,次の記事を発見。
このコマンドを実行し,「macOS_SDK_headers_for_macOS_10.14」をインストールすることで解決。macOS Mojaveに原因があるらしいとのこと。道理で解決方法がすぐに見つからなかったわけだ……
$ sudo open /Library/Developer/CommandLineTools/Packages/macOS_SDK_headers_for_macOS_10.14.pkg
- 投稿日:2019-07-19T22:04:47+09:00
【備忘録】rails newでmysql2がインストールできないエラーの解消方法
(2019/07/21 修正)
開発環境
- macOS Mojave 10.14.5
エラー内容・(最初の)解決方法
長らく悩まされていたエラーがようやく解決できたので,備忘録として。
$ rails new アプリ名 -d mysqlを実行すると,毎回このエラーが発生していた。
Fetching mysql2 0.5.2 Installing mysql2 0.5.2 with native extensions Gem::Ext::BuildError: ERROR: Failed to build gem native extension. (中略) An error occurred while installing mysql2 (0.5.2), and Bundler cannot continue. Make sure that `gem install mysql2 -v '0.5.2' --source 'https://rubygems.org/'` succeeds before bundling. In Gemfile: mysql2 run bundle exec spring binstub --all Could not find gem 'mysql2 (>= 0.4.4, < 0.6.0)' in any of the gem sources listed in your Gemfile. Run `bundle install` to install missing gems.色々調べて試してみるも効果無し。
解決できたコマンドは次のコマンドだった。
※2019/07/21追記 根本的な解決方法はこれではない可能性大,下記参照【参考】 mysql2 gemインストール時のトラブルシュート
$ cd アプリ名 $ gem install mysql2 -v '0.5.2' --source 'https://rubygems.org/' -- --with-cppflags=-I/usr/local/opt/openssl/include --with-ldflags=-L/usr/local/opt/openssl/lib $ bundle installこの後,「rails new」でアプリを作成してもエラーが出なくなった。長かった……
2019/07/21追記 正しい解決法?
次のコマンドを実行した時,また上記エラーが発生した。
$ bundle install --path vendor/bundle再度調査したところ,次の記事を発見。
このコマンドを実行し,「macOS_SDK_headers_for_macOS_10.14」をインストールすることで解決。macOS Mojaveに原因があるらしいとのこと。道理で解決方法がすぐに見つからなかったわけだ……
$ sudo open /Library/Developer/CommandLineTools/Packages/macOS_SDK_headers_for_macOS_10.14.pkg
- 投稿日:2019-07-19T19:17:17+09:00
【読みながら更新】『データベース技術[実践]入門』を読んだまとめ
- データベース技術の歴史は長い
- それでもDB由来の問題が発生する
- データベースの理解が十分でないから
データベースがないと何が困るのか
- 技術的に高度かどうかは売れるかどうかに直結しない
- いい商品コンセプトカどうかが大事
- 変更があることが前提のソフトウェア工学
- データベースに詳しいという若い人は少ない
- そもそも何のために必要か理解できていない
- 現実ではデータベースを使わないアプリは皆無
- 実務で一度失敗してから理解する
- 本質部分がわかっていないと対処療法的になる
- わかっていると一過性のブームか見分けられる
データベースがないと困ること
- 大量データから高速に返せない
- 「サーチ(探索)」という技術領域
- Excelではできない
- 大量データはメモリだけでは無理!
- 障害時の迅速な復旧ができない
- トランザクションなど
- 並列性の制御が難しい
- 複数で同時に書き込み
- 銀行口座の取引
- 排他制御と速度のバランス
- データ整合性の保証が難しい
- 同時アクセス
- 履歴管理
- 参照整合性制約
データベースはレガシーなテーマではない。「複数人」で「大量のデータ」を扱い「壊れたら大変なことになる」アプリでは必須。これは業務でしか経験しない。
インデックスで高速アクセス
キーと値のペア管理
- 全件検索はデータが大量だとムリ!
- 線形探索
- データがN倍になれば時間もN倍
- 一瞬でたどり着く方法は?
- 単純に固定長で管理
- 必ずおさまる保証はない
- 拡張性がない
- インデックスを導入
- 索引
- 「キーと値が何バイト目から始まるか」が書いてある
- これがインデックスファイル
- キーとバイト位置の2つだけ
- データ量を気にしなくていい
- 高速検索
- ハッシュインデックス
- キー値はいろんな種類が入る
- ハッシュ値を使えば同じサイズになる
- 固定長にできる
- ハッシュインデックスが苦手なもの
- 10,000円以下のお中元
- 「Final」で始まるゲーム名
- 投稿を新しい順に
B+Treeインデックス
上からルートブロック、ブランチブロック、リーフブロック。ルート→ブランチ→リーフと辿っていく。
- 多分木と二分木
- B+Treeは多分木
- 二分木は階層が深くなる
- B+TReeとB-Tree
- B-Treeはリーフ以外も値をもつ
- B+TreeがRDBMSのデファクト
RDBMSでの最適化
- 一意性
- ハッシュインデックスは一意性の保証もできる
- 値が同じになるから
- マルチカラムインデックス
- ユーザーIDと最終更新日のAND検索
- インデックスだけを読む検索
- インデックスマージ
- インデックスで拾ってきてからANDやORで検索
- ランダムアクセスはHDDでは半回転
更新コスト削減
- ディスクへのまとめ書き
- 更新順だとランダムアクセス発生
- メモリやファイルに一時保存
- まとめてリーフを更新
- MySQL
- 並列更新性能を高める
- インデックス組み替え終了までブロック
- 並列性上がらない
- マルチコアCPUでの要求増す
- パーティション表を使う
- 内部的に複数に分割管理
インデックスはデータサイズを増やしてしまう。余計な処理を増える。何にインデックスをつけるのか判断が大事。
テーブル設計とリレーション
データモデリング技術の重要性
- 「どのようなデータ項目が必要か」が大事
- 「そのデータを何に使うのか」という業務要件
- あとで追加しやすい設計
従業員、組織、部門
- ヒアリングの結果
- 社員番号は一意
- 同姓同名の社員もいる
- フリガナが同じの社員もいる
- メールアドレスは一意
- メールアドレスがない社員もいる
- どこかの部署には所属している
- 部門名は一意
- 部門の電話番号がまちまち
- データ項目と関連性
- Excelでいいのか?
- 万単位では不可能
- 数百でも整合性確認は目視
- 何をしたら整合性が崩れるのか
- オーソドックスなテーブル
- 社員番号(emp_id)、これが主キーとなる
- 社員名(emp_name)
- 社員ローマ字(emp_roman)
- メールアドレス(emp_email)
- 部門名(dept_name)
- 部門別電話番号(dept_tel)
- これだと同じ部門名、電話番号があちこちに出てくる
ポイント1. テーブルを分割する
重複した情報を持たせるということは、コピペを多用したプログラムと同じ。変更が変更を呼んでいつのまにかぐちゃぐちゃになる。
従業員、部門、別々のテーブルにしてはどうか。部門にidを持たせて主キーとする。部門名や部門番号の打ち間違いがなくなる。やった。
- 外部キー制約
- 部門コードの打ち間違いをどうするか。「100」を「1000」
- 存在するか自動チェック
- 整合性を管理してくれる
- 万能ではない
- 存在するものだと通ってしまう
- リモートサーバーだとチェックできない
- アプリ側でチェックする
- インデックス検索で素早く存在確認
ポイント2. テーブル設計の妥当性を検証
1人の社員は1つの部門しか登録できない。部門ごとに違う社員IDを使うようにする。アカウントを2つ覚えておかないといけない。めんどくさい。ではどうするのか?
- 連番の列を導入
- 部門を3つまで登録できるようにする
- 3つ以上になったときに破綻する
- 列がどんどん増えるときはイマイチ
- 1:Nを導入
- マッピングテーブル(中間テーブル)を作る
- 主キーの値がよく変わる
- 兼務の開始日終了日を追加して常に追記にもできる
- レコード数が増える
- 数千万ユーザーのマッチングだとツライ
正規化理論の基本
- 第1正規形でない
- コピペだらけのテーブル
- 重複値がたくさん
- カンマなどで値が2つ入っている
- 第2正規形でない
- 主キーが複数列ある
- dept_idとdept_nameがempのテーブルにある
- 部分的に決まる値がある
- 第3正規形でない
- 主キーでないキーで決まる値がある
第3正規形まで条件を満たしても部署の兼務ができないという問題は克服できていない。どうやったら問題に気付けるか。これはテーブル設計に慣れるしかない。
SQL文の特徴と使いこなし
テーブル操作
- テーブル作成
- CREATE TABLE
- DB相互の互換性はあまりない
- RDBMS間の差異
- 特にデータ型
- 過度に標準化しないほうがいい
- 一度作ると変更は難しい
- 設計が大事
- データ操作
- INSERT
- SELECT
- UPDATE
- DELETE
- TRUNCATE TABLEはテーブル定義残る
- DROP TABLE
- ジョイン
- 社員の所属する部署は?
- 中間テーブルがあると3回のアクセス
- DBへのアクセスはリモートアクセス
- 重たい処理
- 分散データベース環境とジョイン
- テーブル単位で複数のサーバーにする
- Shardingと呼ぶ
- ジョインができない
ジョインが遅いのではなくSQL文の書き方が悪いから遅くなる。ジョインで一回のところSELECT100回のときもある。
SQL文の実行効率を意識
- 適切なインデックスが使われているか
- インデックスされていない列をWHEREで使わない
- EXPLAINでDBが判断してくれる
- rowsの積がざっくりDBアクセス数
- 各テーブル1だともっとも効率がいい
- EXPLAINをかける前にクエリ分析ツールで見つける
- 管理系コマンド
- 秒間何回実行しているか確認
- DBの安定性や性能がわかる
SQLの長所と短所
- 習得がカンタン
- チューニングの奥は深い
- 機能面
- ロジックはプログラミング言語、データ操作はSQL
可用性とデータの複製
- 典型的な障害
- ソフトウェアの障害
- OSの障害
- デバイスドライバの不具合
- 高負荷処理が一定時間発生後など
- 最新ドライバへアップデートを心がける
- ある程度枯れた技術を使う
- ハードウェアの障害
- 操作ミス
- ディスクの冗長化によって防ぐ
- 障害を前提に設計
- RAID
- ホットスワップ
- サーバの冗長化
レプリケーション
- 片方向レプリケーション
- 片方向/非同期
- マスタを更新したらスレーブに非同期に伝播する
- 「反映されていない」ときがある
- スレーブで最後まで受信されていない
- OSが生きていればSSH接続
- バイナリログの実行が終わっていない
- スレーブのバイナリログで遅延解消
- 最後まで実行されたか確認してから更新する
- 片方向/準同期
- バイナリログの受信を同期にする
- 更新情報受信が保証される
- レスポンスは遅くなる
- 片方向/同期
- すぐスレーブでサービス再開できる
- 投稿日:2019-07-19T13:49:26+09:00
Docker+Redash+MySQLでデータ可視化環境セットアップ手順
何を作るか
OSSのBIツールを試してみるために,有名どころのRedashを使ってみようと思いました。
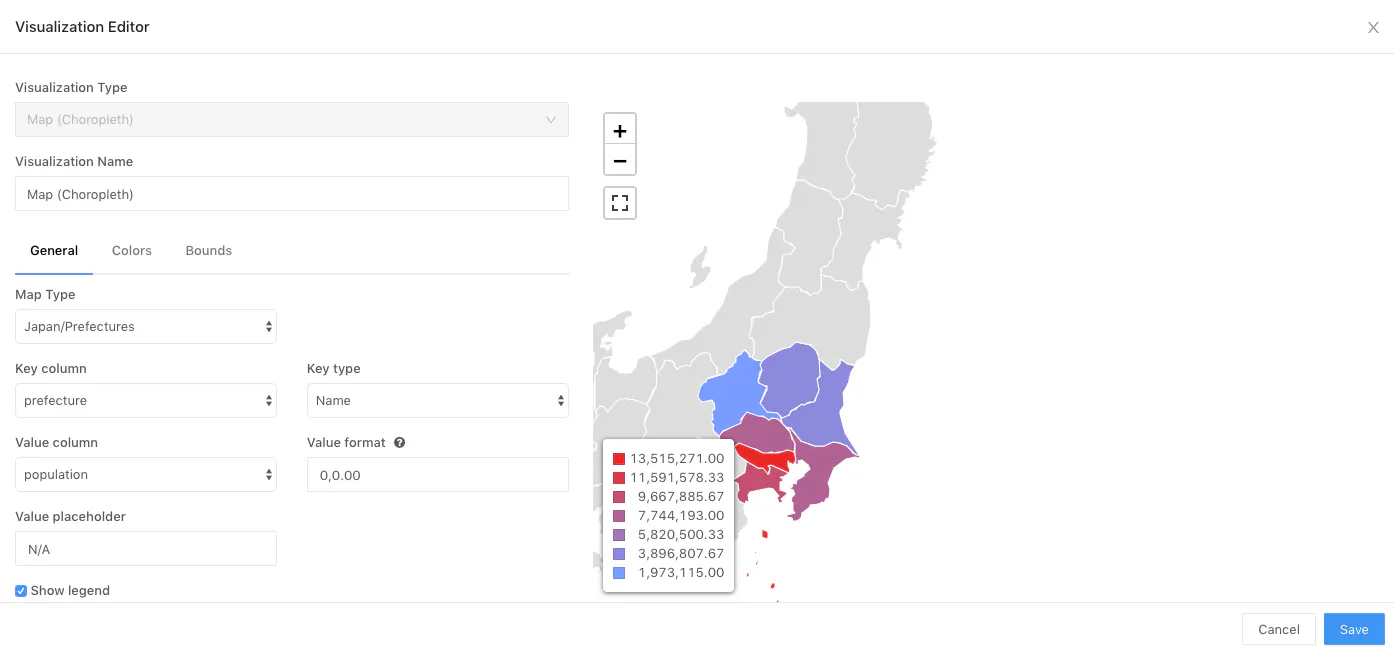
今回は関東の人口のヒートマップを作ることを目的とします。
関東の人口を記述した表形式のデータをMySQLに保存します。
データソースとなるMySQLはDocker外に出します。環境
macOS High Sierra
バージョン 10.13.6インストールするもの
- Docker for Mac(https://qiita.com/kurkuru/items/127fa99ef5b2f0288b81)
- Docker compose(https://qiita.com/zembutsu/items/dd2209a663cae37dfa81)
- MySQL
- Node.js(https://qiita.com/kyosuke5_20/items/c5f68fc9d89b84c0df09)
手順概要
Redashの公式サイト(https://redash.io/help/open-source/dev-guide/docker)
を参考に、進めていく。1.Gitレポジトリのクローン
2.Dockerイメージのビルド
3.npmパッケージのインストール
4.RedashのPostgresデータベースの作成
5.Devサーバーの実行
6.MySQLデータベースへの接続
7.クエリーを取得して、地図に可視化1.Gitレポジトリのクローン
git clone https://github.com/getredash/redash.git cd redash/2.Dockerイメージのビルド
docker-compose up -dredashディレクトリにdocker-compose.ymlがインストールされている。
ビルド済みイメージ(Redash web server, worker, PostgreSQL and Redis)をフェッチし、Dockerイメージをビルドする。
今回は、特にdocker-compose.ymlファイルを編集はしなかった。3.npmパッケージのインストール
package.jsonを用いることで、インストールパッケージの種類やバージョンを指定できる。
npm install4.データベースの作成
テーブルの作成
docker-compose run --rm server create_dbテスト用のデータベースの作成(https://qiita-image-store.s3.ap-northeast-1.amazonaws.com/0/121324/284bfc6e-d03e-dff0-2f76-1ecbb04cd91f.png)
docker-compose run --rm postgres psql -h postgres -U postgres -c "create database tests"5.Devサーバーの実行
npm run buildnpm run starthttp://localhost:8080でアクセスできる
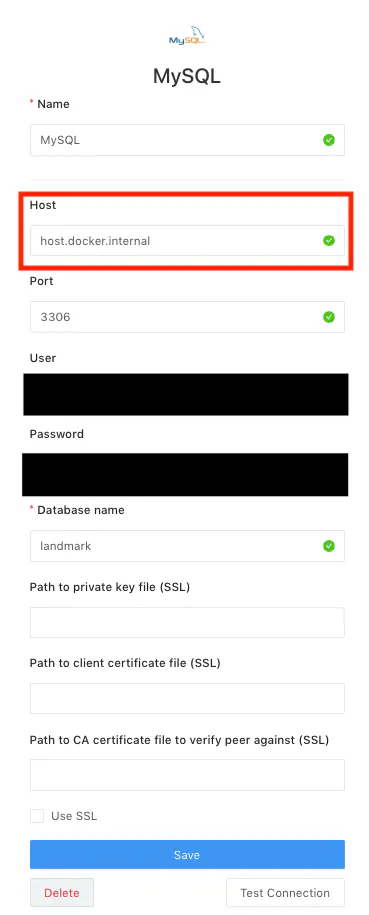
6.データベースの接続
MySQLを用いたデータベース接続は、別の資料を参考。
Docker for macで作成されたコンテナはLocalhostでは接続できないことを知らなかったため、一番苦労しました。
Docker for macでコンテナの中からホストに接続する方法はこちらのサイトを参照して解決。(https://cockscomb.hatenablog.com/entry/docker-for-mac-localhost)以下のようにデータベースを設定
7.クエリーを取得して、地図に可視化
適当なテーブルからSELECT文で、クエリーを取得。
クエリーから以下を用いて、可視化の設定を行う。
※おまけ
東京のマクドナルドのデータを緯度、経度を指定し、表示
今後の展望
・県区切りではなく、県の市区町村区切りで、人口を可視化したい
→shapeファイルの設定の変更ができれば実現が可能・データソースを今回は,MySQLを使ったが、他のデータソースも使ってみたい
・メッシュコードに応じたコロプレス図、マーカー図を使ってみたい
・綺麗なダッシュボードの作成(https://github.com/kakakakakku/redash-hands-on/blob/master/README.md)

- 投稿日:2019-07-19T12:48:48+09:00
Rails で MySQL インデックスヒントを使う (USE INDEX, IGNORE INDEX, FORCE INDEX)
MySQL を使った Rails で
Model.where(created_at: 1.yea.ago..1.day.ago).order(:id).lastなどとすると、MySQL の仕様で
created_atの INDEX ではなく、PRIMARYを使ってしまってものすごく遅くなることがあった。調べてみたところ、どうやら自分で拡張するしかないようなので書いたという話です。
Concern
ググると類似コードが出てきますが、違いは下記の通り
- カラム名で指定可能
- 複合インデックスも
[カラム名, カラム名]で指定可能- 普通にインデックス名もok
app/models/concerns/index_hint.rbmodule IndexHint extend ActiveSupport::Concern class_methods do def convert_to_index_name_in_case_of_column_name(*names) names.map { |idx| find_index_name_by_colomun_names(idx) || idx } end private def find_index_name_by_colomun_names(column_names) column_names = Array.wrap(column_names).map(&:to_s) name = connection.indexes(self.table_name).find { |index| index.columns == column_names }&.name connection.quote_column_name(name) if name end end included do scope :use_index, lambda { |*indexes| index_names = convert_to_index_name_in_case_of_column_name(*indexes) from("#{self.quoted_table_name} USE INDEX(#{index_names.join(', ')})") } scope :ignore_index, lambda { |*indexes| index_names = convert_to_index_name_in_case_of_column_name(*indexes) from("#{self.quoted_table_name} IGNORE INDEX(#{index_names.join(', ')})") } scope :force_index, lambda { |*indexes| index_names = convert_to_index_name_in_case_of_column_name(*indexes) from("#{self.quoted_table_name} FORCE INDEX(#{index_names.join(', ')})") } end endUse
ApplicationRecordレベルでincludeしてあげれば全てのモデルで使えますね。
モデル単体でincludeしてもokです。app/models/application_record.rbclass ApplicationRecord < ActiveRecord::Base include IndexHint ...実際に使うとこんな感じ
Model.use_index(:created_at).to_sql #=> "SELECT `models`.* FROM `models` USE INDEX(`index_models_on_created_at`)" Model.force_index([:section, :name]).to_sql #=> "SELECT `models`.* FROM `models` FORCE INDEX(`index_models_on_section_and_name`)" Model.ignore_index([:section, :name], :created_at).to_sql #=> "SELECT `models`.* FROM `models` IGNORE INDEX(`index_models_on_section_and_name`, `index_models_on_created_at`)"注意点
from,use_index,force_index,ignore_indexを組み合わせられない参考
- 投稿日:2019-07-19T12:02:12+09:00
Laravel で updateOrCreate を使う際に Unknown column 'id' in 'where clause' でハマった
概要
Laravel の Eloquent が持っている updateOrCreate という関数を使った。
https://readouble.com/laravel/5.7/ja/eloquent.htmlMySQL でも気軽に Upsert 処理ができて便利だと思った。
実装例
App\VeryGoodSystem::updateOrCreate(
['user_id' => 12345],
['is_registered' => true]
);いざ利用してみたところ、下記のようなエラーが出た。
Unknown column 'id' in 'where clause' ...エラーを追うと、 updateOrCreate で実行されている SQL 文に
where `id` is nullという条件が付いていることがわかった。コードを見ても、
idという変数を使っている所は無く、途方に暮れながら調べていたら、良い Q&A を見つけた。(最下部、参考サイト)つまり、 model に primaryKey が設定されていないと default で id という文字列を使って updateOrCreate 用の SQL を作成してしまうようだった。
利用している Model に
$primaryKey = 'user_id'の一行を追加することで解決した。参考サイト
https://laracasts.com/discuss/channels/eloquent/understanding-of-updateorcreate
- 投稿日:2019-07-19T11:41:57+09:00
MySQLのRangeパーティションの指定とpartitionの削除方法
partitionの追加方法
CREATE TABLE quarterly_report_status ( report_id INT NOT NULL, report_status VARCHAR(20) NOT NULL, report_updated TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP ) PARTITION BY RANGE ( UNIX_TIMESTAMP(report_updated) ) ( PARTITION p0 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-01-01 00:00:00') ), PARTITION p1 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-04-01 00:00:00') ), PARTITION p2 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-07-01 00:00:00') ), PARTITION p3 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-10-01 00:00:00') ), PARTITION p4 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-01-01 00:00:00') ), PARTITION p5 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-04-01 00:00:00') ), PARTITION p6 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-07-01 00:00:00') ), PARTITION p7 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-10-01 00:00:00') ), PARTITION p8 VALUES LESS THAN ( UNIX_TIMESTAMP('2010-01-01 00:00:00') ), PARTITION p9 VALUES LESS THAN (MAXVALUE) );上記例でいうと、
2008-01-01未満のreport_updated日付のデータはp0に格納され、
2008-01-01〜2008-04-01未満の日付のデータはp1に格納される。
なので、トランザクション系のデータは不要になったらパーティションごと削除するということが簡単に行える。テーブル作成時に未来何年分か作成しておくとサービス稼働後に追加しなくて済むので楽。
RANGE COLUMNSはMySQL5.5から
partitionの削除方法
テーブルのパーティション指定でそのパーティションに格納されているデータを削除できる。
ALTER TABLE quarterly_report_status DROP PARTITION p2;余談
ちなみに公式にこういう記述もあった。
従業員ジョブコードに基づいてテーブルをパーティション化できます。たとえば、正規従業員に 2 桁のジョブコード、オフィスおよびサポート従業員に 3 桁のコード、および管理職に 4 桁のコードが使用されると想定すると、次のステートメントを使用してパーティション化されたテーブルを作成できます。
従業員コードの採番ルールの定義帯を分別することによりこういうパーティション分割も可能というのはtimestampで設定できるのだから確かに、なるほどなと思った。
従業員コードを削除するのか?というのは置いておくとしてこういう定義の方法はどこかしらで使えそうだと思う。CREATE TABLE employees ( id INT NOT NULL, fname VARCHAR(30), lname VARCHAR(30), hired DATE NOT NULL DEFAULT '1970-01-01', separated DATE NOT NULL DEFAULT '9999-12-31', job_code INT NOT NULL, store_id INT NOT NULL ) PARTITION BY RANGE (job_code) ( PARTITION p0 VALUES LESS THAN (100), PARTITION p1 VALUES LESS THAN (1000), PARTITION p2 VALUES LESS THAN (10000) );参照:https://dev.mysql.com/doc/refman/5.6/ja/partitioning-range.html
- 投稿日:2019-07-19T02:42:30+09:00
0からAWSでLAMPとLaravel環境構築(Windows)
手順
1.AWSアカウントを作成。
参照:AWS アカウント作成の流れ2.EC2というAmazonのクラウド上の仮想サーバーを構築。
参照:AWS EC2でWebサーバーを構築してみる3.LAMP環境を構築。
参照:チュートリアル: Amazon Linux 2 に LAMP ウェブサーバーをインストールする4.Laravelをインストール。
参照:AWSのEC2を立ち上げてLaravelのログイン機能を動かすまで
AWSでLaravelを立ち上げた1.AWSアカウントを作成
AWS は Amazon Web Services の略で、Amazon のクラウドサーバーを使用できるサービスです。
一年間無料でいろんな機能を試せます。
アカウントの登録は参照(AWS アカウント作成の流れ)に沿って行えばすぐできます。2.EC2構築
AWSにログインすると最初はこの画面が表示されると思います。
右上の地域はリージョンといい、自分の所在地に合わせて選択します。これは利用するデータセンターの場所を意味します。理論上近いほどレスポンスタイムが短いので、近いところを選びましょう。自分の場合は「東京」です。そしたら、左上のサービスからEC2を選択。
左のメニューの「インスタンス」 → 「インスタンス作成」を選択
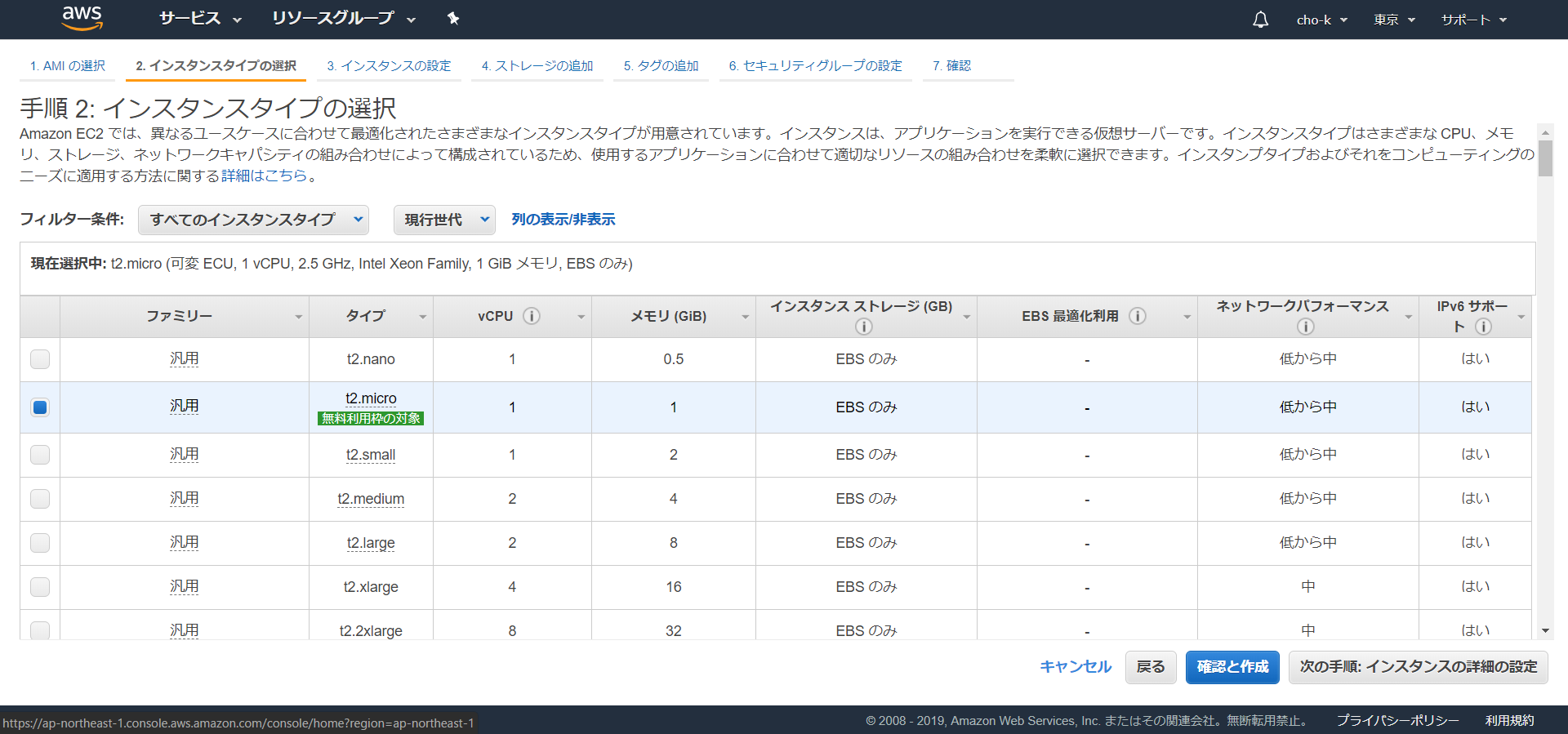
一番目のAmazon Linux2 AMIを選択。
無料利用枠のt2.microにチェックを入れ、
他の設定は特にいじらずセキュリティグループの設定まで飛ばします。「新しいセキュリティグループを作成する」を選択し、「セキュリティグループ名と「説明」を好きなように入力し、画像のように五つのタイプを追加します。「ソース」のところでIP指定ができます。「任意の場所」を選択するとどこでもアクセスすることができ、「マイIP」を選択すると自分が現在使用しているネットワーク環境のIPでしかアクセスできなくなります。趣味程度の個人利用でしたら任意の場所で問題ありません。
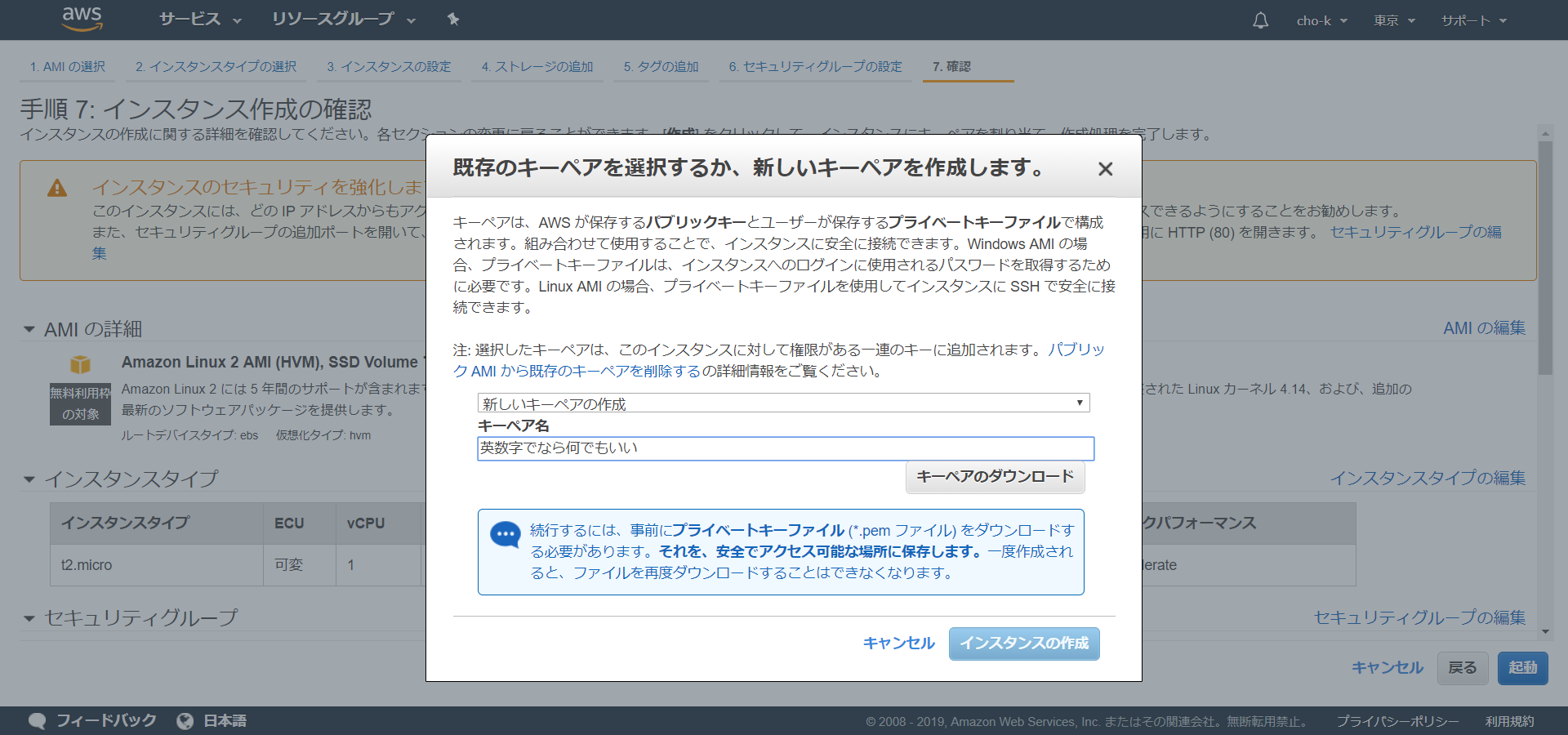
右下の「確認と作成」 → 「起動」を押してから、このように表示されます。「新しいキーペアの作成」でキーペア名を入力。重要ですが、キーペアのダウンロードは必ずしてください。サーバーにアクセスするために必要となります。
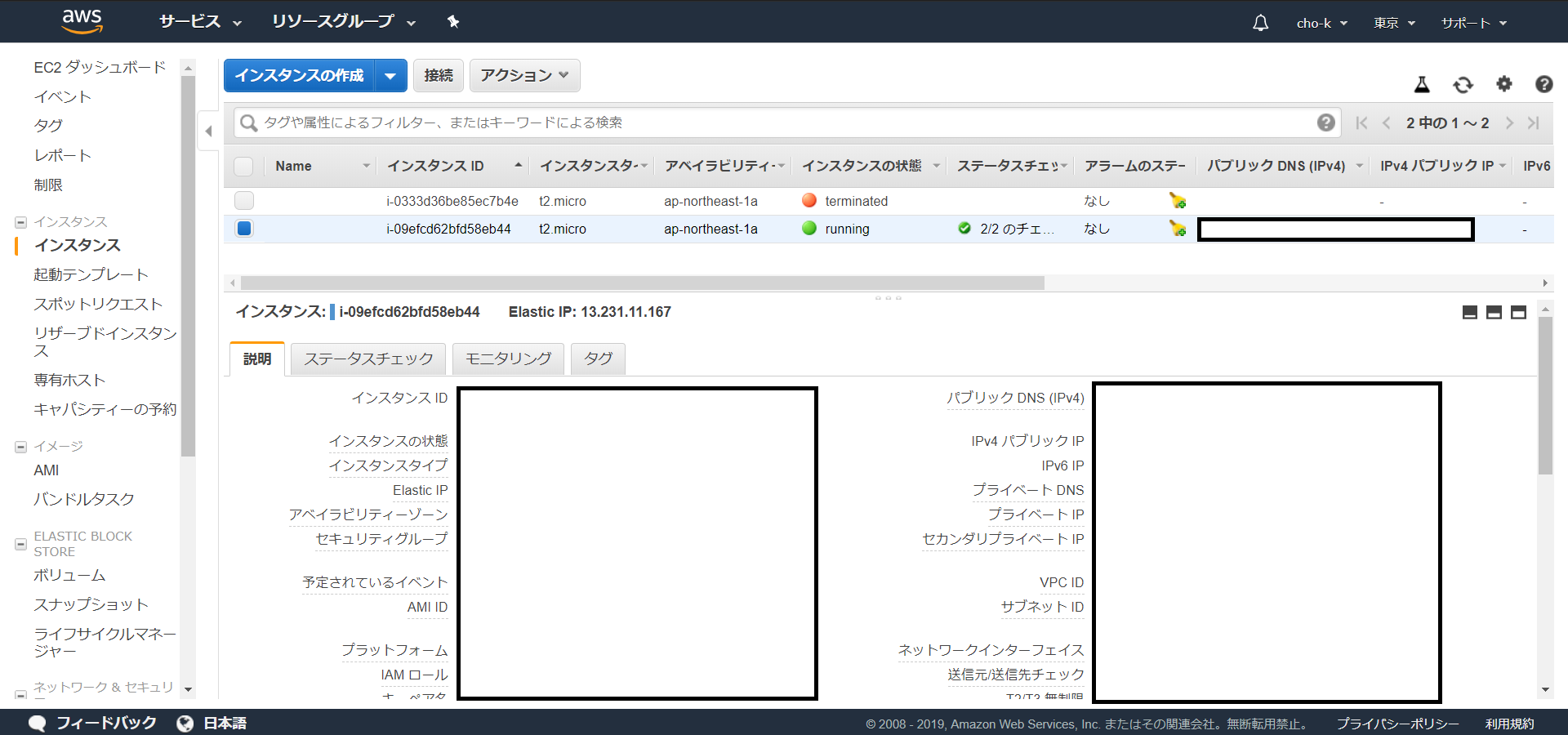
「インスタンスの作成」 → 「インスタンスの表示」を順番に進めると、インスタントの画面に戻ります。
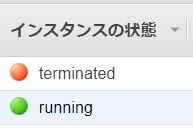
インスタンスの状態が running になっていれば作成成功です。
プラスα(オプション)
今作ったインスタンスに固定IPを割り当てることができます。左のメニューから「Elastic IP
」 → 「新しいアドレスの割り当て」 → 「割り当て」 → 「閉じる」で固定IPを一つゲットします。リストからIPを右クリック → 「アドレスの関連付け」で作成したインスタンスを選択し結びつけれます。3.LAMP環境の構築
①インスタンスに接続
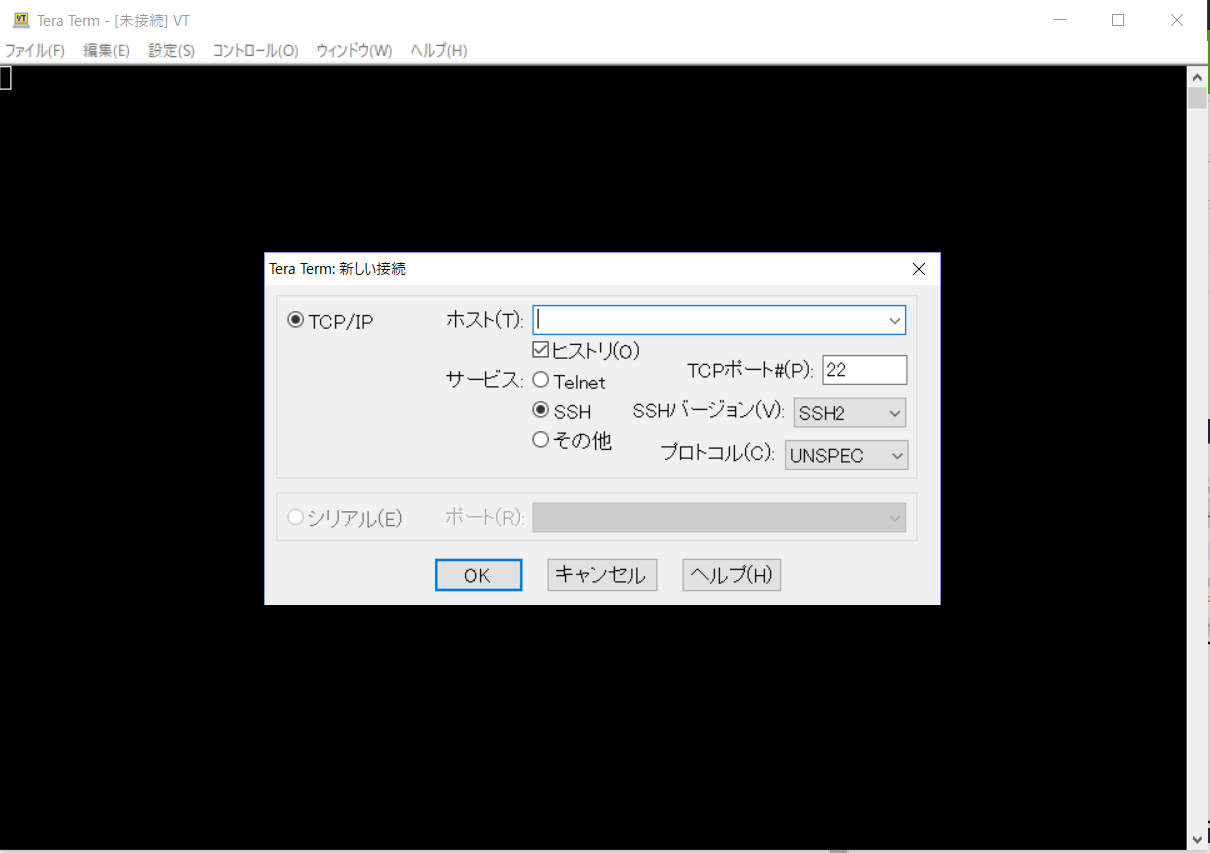
サーバーに接続するため、ssh接続できるターミナルTeraTermをダウンロードします。インスタンス画面下の説明から固定IPとっていれば「IPv4 パブリック IP」、とっていなければ「パブリック DNS (IPv4)」をTeraTermのホストに入力して「OK」します。
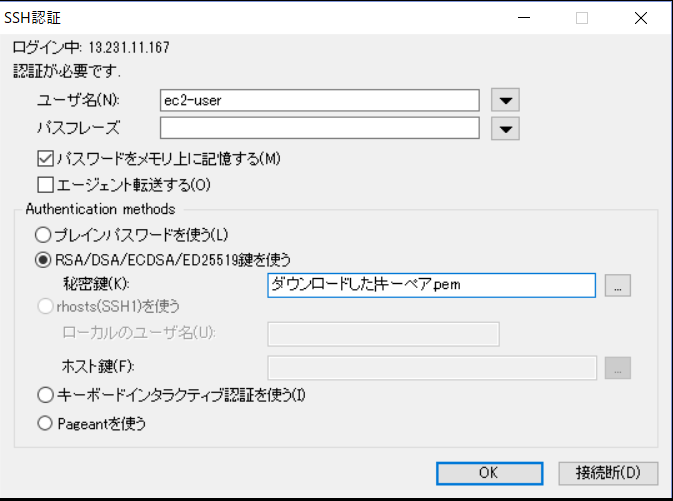
次にユーザー名に「ec2-user」、秘密鍵に先ほどインスタンスを作るときにダウンロードしたキーペアファイルをセットして「OK」。
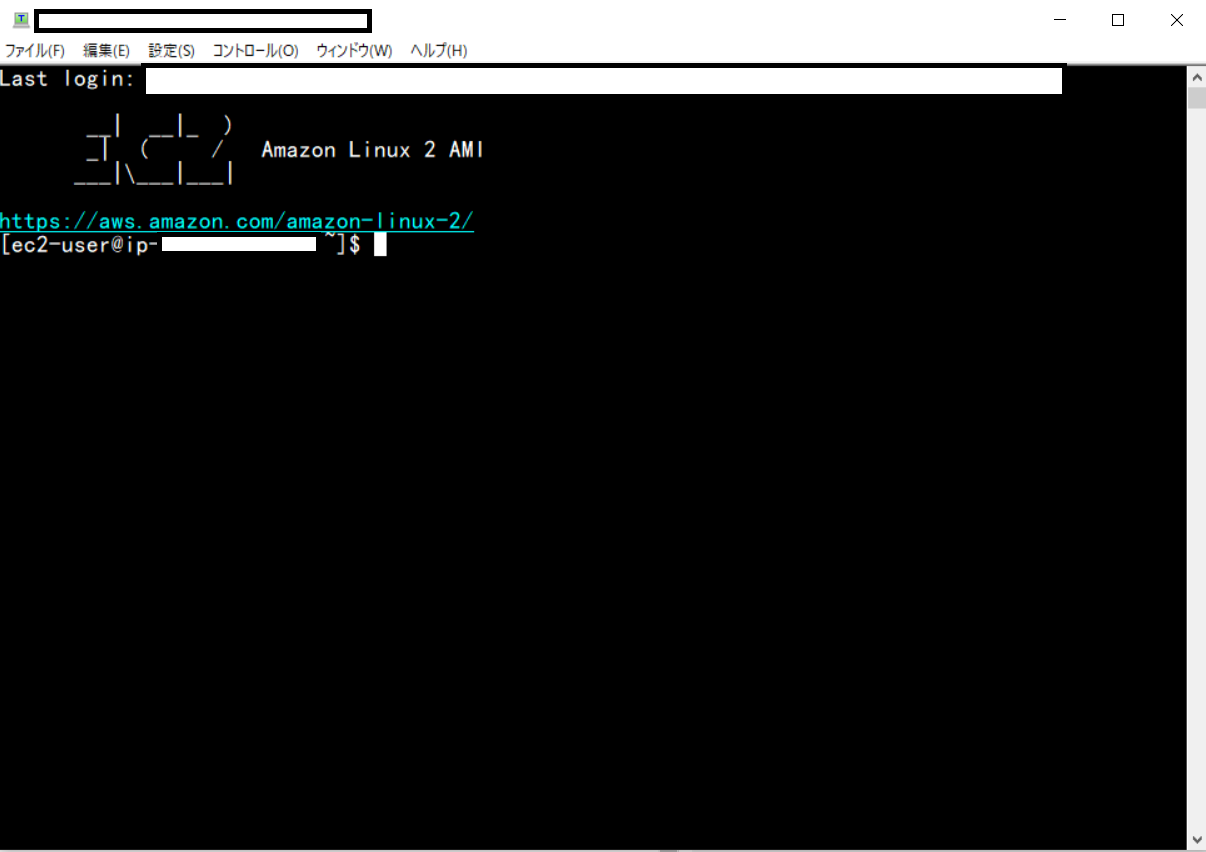
サーバーに接続できました。
直接とは関係ないですがコマンドでsudoを打つかどうかについて「root権限で`sudo`を付けた場合と付けない場合の違いに`su`は何の略?」を読めばわかると思います。②EC2のタイムゾーン設定
「Amazon EC2のタイムゾーンを日本時間に変更する方法」でわかりやすく書かれていますが、いくつか補足があります。
/etc/sysconfig/clockにはこのように変更すると書いてありますが、# ZONE="UTC" ZONE="Japan" UTC=true
trueのところをfalseにしないと再起動するときにタイムゾーンがUTCに戻ることがあります。# ZONE="UTC" ZONE="Japan" UTC=flaseここでルート権限を持たないため、
vimで保存するときにきっとこのようなエラーが出ると思います。E45: 'readonly' option is set (add ! to override)この解決法として自分がrootになるか、「[vim]read only のファイルをsudoで強制的に保存する」を参照してください。
オプションとして、「AWSの初期設定でrootパスワードを設定する」。一行目の
sshなんちゃらはすでにTeraTermログイン時にできてますので無視。
lnのオプションの意味は【 ln 】コマンド――ファイルのハードリンクとシンボリックリンクを作るに書いてあります。③LAMP環境構築
AWSの公式チュートリアル「チュートリアル: Amazon Linux 2 に LAMP ウェブサーバーをインストールする」の順序を追えばできます。自分はSQLに慣れているため、オプションの phpMyAdmin のインストールはしていません。phpMyAdmin はデータベースをGUIで管理できるツールです。
4.Laravelのインストール
①Composerをダウンロード
Composerについては「PHP開発でComposerを使わないなんてありえない!基礎編」。
以下ダウンロードコマンドです。$ curl -sS https://getcomposer.org/installer | sudo php $ sudo mv composer.phar /usr/local/bin/composerこれで
composer.pharというファイルが/usr/local/bin/composer/の下に置かれます。
このcomposer.pharファイルをcomposerというコマンドで実行できたら便利なので、composerというコマンドを作ります。alias composer='php /usr/local/bin/composer/composer.phar'ただし、これだけだと再起動するとリセットされて
composerが効かなくなりますので、常に成立するようにルートに存在する.bashrcというファイルに書き込みます。$ cd ~ # ルートに移動 $ ls -la # .bashrcがあるかどうかを確認 $ vi .bashrc # 「alias composer='php /usr/local/bin/composer/composer.phar'」を書き込むそしたらターミナルが起動すると読み込まれる
.bash_profileに.bashrcを参照するようにします。$ vi .bash_profile # 「source ~/.bashrc」を一番下に書き込む②拡張ライブラリをダウンロード
Laravelをダウンロードするのに必要なライブラリーは3つあります。
mbstring、mysqlndとxmlです。$ sudo yum install -y php-mbstring php-mysqlnd php-xml③Laravelをインストール
Laravel をインストールするディレクトリに移動します。自分の場合は
/var/www/の下にしました。$ cd /var/www $ composer create-project --prefer-dist laravel/laravel自分の場合ここで「proc_open(): fork failed errors」というエラーが出ました。「[PHP]Composer使用時に「proc_open(): fork failed errors」エラーが出た時の対処法」を見て解決できたので共有します。
-prefer-distって何ぞやと知りたい方には「composer の–prefer-distってよく使うけど何してる?」へ。④Apacheのドキュメントルートの設定と.htaccessの有効化
$ sudo vi /etc/httpd/conf.d/custom.confに
custom.conf# ドキュメントルート DocumentRoot "/var/www/laravel/public" # .htaccess 有効化 <Directory /var/www/laravel/public> AllowOverride All </Directory>を加えます。
そしたらApacheを再起動してください。$ sudo service httpd restart⑤パーミッションを変更
自分はパーミッションについてまだちんぷんかんぷんで、どの権限をどうすればいいか自分ではわかっていないので、他の方のブログを見たほうがいいかもしれません。基本的にパーミッションが合ってないとシステムにこのファイルに書き込めないよと怒られます。どうやらLaravelの場合は
storageとbootstrapの権限を変更する必要があるらしい。$ cd ~ $ sudo groupadd www $ sudo usermod -a -G www ec2-user $ exit一度ログアウトして再度入り直して、
$ cd /var/www $ sudo chmod -R 777 laravel/storage $ sudo chmod -R 775 laravel/bootstrap/cache $ sudo chown -R root:www /var/wwwこれでLaravelが使えるようになったはず。