- 投稿日:2019-05-07T20:36:12+09:00
Go による機械学習推論フレームワークの最新動向 2019
Golang で推論
昨今では「機械学習と言えば Python」「Python と言えば機械学習」と思われがちなのですが、推論用途であれば学習済みモデルを利用して色々なプログラミング言語から扱えます。Go から扱える機械学習ライブラリの内、学習済みモデルが利用できる物としてはおおよそ以下の3つに絞られます。
Golang で TensorFlow
Golang で TensorFlow を利用する場合はオフィシャルから Go の binding が提供されているので Go の import 文で GitHub リポジトリを指して利用します。Jetson や Raspberry Pi での動作実績もあります。TensorFlow 自体が色々な CPU 命令の最適化まで行っているので Python とそん色ないパフォーマンスで動作します。もちろん GPU を有効にしても扱えます。さらに Go であれば推論処理を並行処理させる事で他の言語よりも省メモリで高速に処理する事も可能です。簡単な使い方は以前ブログに書きました。
Big Sky :: golang で tensorflow のススメ
ただし TensorFlow は Python から利用する場合と同様にフットプリントが大きく、また実行中のメモリ使用量も巨大になります。Raspberry Pi の様なリソースの乏しい環境から利用すると無視できない程の負荷が掛かります。
Golang で TensorFlow Lite
TensorFlow Lite はモバイル用途で利用される推論用ライブラリです。こちらは筆者が開発中の go-tflite を使えば toco で変換したモデルファイルを利用して推論を実行する事が出来ます。
Big Sky :: TensorFlow Lite の Go binding を書いた。
TensorFlow に比べ Lite の API の方が推論に対して直観的なので、わりかし覚えやすいと思います。Windows からも利用できるようになっています。ビルドには libtensorflow_c というライブラリが必要です。README を見ながら導入して下さい。なお現在送っている pull-request がマージされればいずれ皆さんも簡単に Windows から TensorFlow Lite を利用できる様になる予定です。以下は Google が提供している SSD MobileNet v1 のモデルファイルを利用して OpenCV から取り込んだ動画にリアルタイムでラベル付けするサンプルの実行画面です。
TensorFlow Lite の Windows 版で SSD。現状の TfLite には Android/iOS 以外での GPU delegate 等の最適化がないので遅いけどコア1個100%でこの程度動くならまぁ使い道がなくもないかな。 pic.twitter.com/PvfQLMcZE1
— mattn (@mattn_jp) May 6, 2019https://github.com/mattn/go-tflite/tree/master/_example
この他にも go-tflite の _examples には TesnorFlow が提供しているサンプルとほぼ同じ物が Go でポーティングされています。Go で TensorFlow Lite をやってみたい方は参考にして下さい。
TensorFlow Lite は CPU 最適化や GPU による高速化が一部のターゲットだけにしか提供されていない為、それらの環境外では若干遅くはなりますが、メモリ使用量がとてもも小さく、Raspberry Pi で動作させてもそれほど負荷を感じません。
Golang で ONNX
さて Go から扱える学習済みモデルのもう1つの候補 ONNX ですが現在 Go から ONNX を利用する手段としては2つあります。
1つは Prefered Network 社が提供している menoh の Go binding を利用する物。もう1つは Olivier Wulveryck 氏が開発している onnx-go を使う物です。
Menoh は ONNX を扱う事ができる推論専用ライブラリで、go-menoh からも同様に扱う事が出来る様になっています。以前、go-menoh を使ったリアルタイム物体認識を書きました。
Big Sky :: リアルタイム物体認識を2本作ってみた。
筆者の体感では TensorFlow ほどメモリは消費しないけれど、Raspberry Pi で動作させるのは少し辛いくらいのリソース消費になります。(もちろんサーバ等で動作させれば良い性能は出せます)
onnx-go
もう1つの候補 onnx-go は筆者が知る限りまだあまり広まっていません。onnx-go は Pure Go で書かれています。Pure Go で書かれているので Go をサポートする OS/CPU アーキテクチャであればどこでも動作するというメリットがあります。onnx-go は内部で gonum という行列演算ライブラリを利用しており、環境によっては blas による高速化が行われます。
onnx-go は以前 gorgonia とう gonum ベースの機械学習フレームワークから ONNX を利用する為に作られ、gorgonnx というリポジトリで開発されていましたが、そこから onnx 関連のみ抜き出しシェイプアップした物が現在の onnx-go になっています。以前から onnx-go を追っかけていたのですが、最近ようやく色々な物が動作する様になってきたのでそろそろ Qiita で紹介しようと思い立ちました。
emotions のサンプルを試してみた。
— mattn (@mattn_jp) May 7, 2019
Computation time: 1.1050632s
happiness / 67.85%
neutral / 30.88%
happiness なんですか? pic.twitter.com/O9DJFistTYリポジトリに同梱されている emotions というサンプルコードを動かすと画像から感情を推論するデモを見る事ができます。
サンプルコードも短いので直ぐに API を覚えられると思います。ONNX Zoo というモデルファイルの一次配布場所とその README を参照すれば、簡単にアプリケーションを書く事も出来ます。
https://github.com/onnx/models
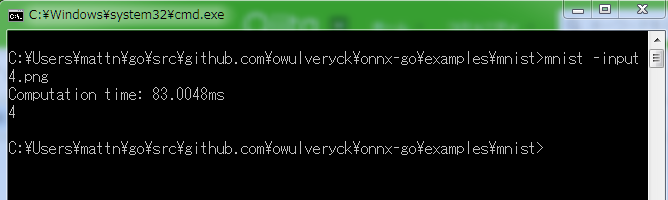
例えば mnist 手書き数字のモデルであれば以下に説明が書かれています。
https://github.com/onnx/models/tree/master/mnist
README に書かれている通り入力画像を 28x28 のグレー画像(2値)に変換して設定し Run を呼び出すと推論できます。出力は GetOutputTensors から得られます。この辺は TensorFlow も TensorFlow Lite も onnx-go もそれほど扱い方は変わりません。
package main import ( "flag" "fmt" "image" "image/color" _ "image/jpeg" _ "image/png" "io/ioutil" "log" "os" "github.com/nfnt/resize" "github.com/owulveryck/onnx-go" "github.com/owulveryck/onnx-go/backend/x/gorgonnx" "github.com/owulveryck/onnx-go/internal/x/images" "gorgonia.org/tensor" ) const ( height = 28 width = 28 ) func convertToGray(img image.Image) *image.Gray { img = resize.Resize(width, height, img, resize.Bilinear) gray := image.NewGray(img.Bounds()) bounds := img.Bounds() for y := 0; y < bounds.Dy(); y++ { for x := 0; x < bounds.Dx(); x++ { gray.Set(x, y, color.GrayModel.Convert(img.At(x, y))) } } return gray } func main() { model := flag.String("model", "model.onnx", "path to the model file") filename := flag.String("input", "file.png", "path to the input file") flag.Parse() backend := gorgonnx.NewGraph() m := onnx.NewModel(backend) // Read model binary b, err := ioutil.ReadFile(*model) if err != nil { log.Fatal(err) } // Decode it into the model err = m.UnmarshalBinary(b) if err != nil { log.Fatal(err) } // Read input image f, err := os.Open(*filename) if err != nil { log.Fatal(err) } defer f.Close() img, _, err := image.Decode(f) if err != nil { log.Fatal(err) } // Convert to gray image imgGray := convertToGray(img) // Create tensor dimensioned by 1x1x28x28 input := tensor.New(tensor.WithShape(1, 1, height, width), tensor.Of(tensor.Float32)) err = images.GrayToBCHW(imgGray, input) if err != nil { log.Fatal(err) } m.SetInput(0, input) err = backend.Run() if err != nil { log.Fatal(err) } output, err := m.GetOutputTensors() if err != nil { log.Fatal(err) } // Find maximum value of prediction results max := float32(-9999) maxi := -1 for i, v := range output[0].Data().([]float32) { if v > max { max = v maxi = i } } fmt.Println(maxi) }
Pure Go なので Windows からも特に苦労する事なく利用出来ます。
まとめ
Go から利用できる機械学習の推論フレームワークを紹介しました。TensorFlow が今すぐ新しいブレイクスルーを起こす事は無いと思いますが、TensorFlow Lite はもしかすると今後 Android/iOS 以外の環境で GPU による高速化が行われる様になるかもしれません。(ならないかもしれません、いやなって欲しい)
onnx-go はこれから利用できるオペレータがどんどん増え、パフォーマンスに関しても cuda や clBLAS 等を利用した高速化が行われる様になるかもしれません。(ならないかもしれません、いやなって欲しい)
色々と期待の多い Go の推論フレームワーク界隈なので、いずれまた新しいニュースと共にご紹介したいと思います。



- 投稿日:2019-05-07T20:36:12+09:00
Go による機械学習 推論フレームワークの最新動向 2019
Golang で推論
昨今では「機械学習と言えば Python」「Python と言えば機械学習」と思われがちなのですが、推論用途であれば学習済みモデルを利用して色々なプログラミング言語から扱えます。Go から扱える機械学習ライブラリの内、学習済みモデルが利用できる物としてはおおよそ以下の3つに絞られます。
Golang で TensorFlow
Golang で TensorFlow を利用する場合はオフィシャルから Go の binding が提供されているので Go の import 文で GitHub リポジトリを指して利用します。Jetson や Raspberry Pi での動作実績もあります。TensorFlow 自体が色々な CPU 命令の最適化まで行っているので Python とそん色ないパフォーマンスで動作します。もちろん GPU を有効にしても扱えます。さらに Go であれば推論処理を並行処理させる事で他の言語よりも省メモリで高速に処理する事も可能です。簡単な使い方は以前ブログに書きました。
Big Sky :: golang で tensorflow のススメ
ただし TensorFlow は Python から利用する場合と同様にフットプリントが大きく、また実行中のメモリ使用量も巨大になります。Raspberry Pi の様なリソースの乏しい環境から利用すると無視できない程の負荷が掛かります。
Golang で TensorFlow Lite
TensorFlow Lite はモバイル用途で利用される推論用ライブラリです。こちらは筆者が開発中の go-tflite を使えば toco で変換したモデルファイルを利用して推論を実行する事が出来ます。
Big Sky :: TensorFlow Lite の Go binding を書いた。
TensorFlow に比べ Lite の API の方が推論に対して直観的なので、わりかし覚えやすいと思います。Windows からも利用できるようになっています。ビルドには libtensorflow_c というライブラリが必要です。README を見ながら導入して下さい。なお現在送っている pull-request がマージされればいずれ皆さんも簡単に Windows から TensorFlow Lite を利用できる様になる予定です。以下は Google が提供している SSD MobileNet v1 のモデルファイルを利用して OpenCV から取り込んだ動画にリアルタイムでラベル付けするサンプルの実行画面です。
TensorFlow Lite の Windows 版で SSD。現状の TfLite には Android/iOS 以外での GPU delegate 等の最適化がないので遅いけどコア1個100%でこの程度動くならまぁ使い道がなくもないかな。 pic.twitter.com/PvfQLMcZE1
— mattn (@mattn_jp) May 6, 2019https://github.com/mattn/go-tflite/tree/master/_example
この他にも go-tflite の _examples には TesnorFlow が提供しているサンプルとほぼ同じ物が Go でポーティングされています。Go で TensorFlow Lite をやってみたい方は参考にして下さい。
TensorFlow Lite は CPU 最適化や GPU による高速化が一部のターゲットだけにしか提供されていない為、それらの環境外では若干遅くはなりますが、メモリ使用量がとてもも小さく、Raspberry Pi で動作させてもそれほど負荷を感じません。
Golang で ONNX
さて Go から扱える学習済みモデルのもう1つの候補 ONNX ですが現在 Go から ONNX を利用する手段としては2つあります。
1つは Prefered Network 社が提供している menoh の Go binding を利用する物。もう1つは Olivier Wulveryck 氏が開発している onnx-go を使う物です。
Menoh は ONNX を扱う事ができる推論専用ライブラリで、go-menoh からも同様に扱う事が出来る様になっています。以前、go-menoh を使ったリアルタイム物体認識を書きました。
Big Sky :: リアルタイム物体認識を2本作ってみた。
筆者の体感では TensorFlow ほどメモリは消費しないけれど、Raspberry Pi で動作させるのは少し辛いくらいのリソース消費になります。(もちろんサーバ等で動作させれば良い性能は出せます)
onnx-go
もう1つの候補 onnx-go は筆者が知る限りまだあまり広まっていません。onnx-go は Pure Go で書かれています。Pure Go で書かれているので Go をサポートする OS/CPU アーキテクチャであればどこでも動作するというメリットがあります。onnx-go は内部で gonum という行列演算ライブラリを利用しており、環境によっては blas による高速化が行われます。
onnx-go は以前 gorgonia とう gonum ベースの機械学習フレームワークから ONNX を利用する為に作られ、gorgonnx というリポジトリで開発されていましたが、そこから onnx 関連のみ抜き出しシェイプアップした物が現在の onnx-go になっています。以前から onnx-go を追っかけていたのですが、最近ようやく色々な物が動作する様になってきたのでそろそろ Qiita で紹介しようと思い立ちました。
emotions のサンプルを試してみた。
— mattn (@mattn_jp) May 7, 2019
Computation time: 1.1050632s
happiness / 67.85%
neutral / 30.88%
happiness なんですか? pic.twitter.com/O9DJFistTYリポジトリに同梱されている emotions というサンプルコードを動かすと画像から感情を推論するデモを見る事ができます。
サンプルコードも短いので直ぐに API を覚えられると思います。ONNX Zoo というモデルファイルの一次配布場所とその README を参照すれば、簡単にアプリケーションを書く事も出来ます。
https://github.com/onnx/models
例えば mnist 手書き数字のモデルであれば以下に説明が書かれています。
https://github.com/onnx/models/tree/master/mnist
README に書かれている通り入力画像を 28x28 のグレー画像(2値)に変換して設定し Run を呼び出すと推論できます。出力は GetOutputTensors から得られます。この辺は TensorFlow も TensorFlow Lite も onnx-go もそれほど扱い方は変わりません。
package main import ( "flag" "fmt" "image" "image/color" _ "image/jpeg" _ "image/png" "io/ioutil" "log" "os" "github.com/nfnt/resize" "github.com/owulveryck/onnx-go" "github.com/owulveryck/onnx-go/backend/x/gorgonnx" "github.com/owulveryck/onnx-go/internal/x/images" "gorgonia.org/tensor" ) const ( height = 28 width = 28 ) func convertToGray(img image.Image) *image.Gray { img = resize.Resize(width, height, img, resize.Bilinear) gray := image.NewGray(img.Bounds()) bounds := img.Bounds() for y := 0; y < bounds.Dy(); y++ { for x := 0; x < bounds.Dx(); x++ { gray.Set(x, y, color.GrayModel.Convert(img.At(x, y))) } } return gray } func main() { model := flag.String("model", "model.onnx", "path to the model file") filename := flag.String("input", "file.png", "path to the input file") flag.Parse() backend := gorgonnx.NewGraph() m := onnx.NewModel(backend) // Read model binary b, err := ioutil.ReadFile(*model) if err != nil { log.Fatal(err) } // Decode it into the model err = m.UnmarshalBinary(b) if err != nil { log.Fatal(err) } // Read input image f, err := os.Open(*filename) if err != nil { log.Fatal(err) } defer f.Close() img, _, err := image.Decode(f) if err != nil { log.Fatal(err) } // Convert to gray image imgGray := convertToGray(img) // Create tensor dimensioned by 1x1x28x28 input := tensor.New(tensor.WithShape(1, 1, height, width), tensor.Of(tensor.Float32)) err = images.GrayToBCHW(imgGray, input) if err != nil { log.Fatal(err) } m.SetInput(0, input) err = backend.Run() if err != nil { log.Fatal(err) } output, err := m.GetOutputTensors() if err != nil { log.Fatal(err) } // Find maximum value of prediction results max := float32(-9999) maxi := -1 for i, v := range output[0].Data().([]float32) { if v > max { max = v maxi = i } } fmt.Println(maxi) }
Pure Go なので Windows からも特に苦労する事なく利用出来ます。
まとめ
Go から利用できる機械学習の推論フレームワークを紹介しました。TensorFlow が今すぐ新しいブレイクスルーを起こす事は無いと思いますが、TensorFlow Lite はもしかすると今後 Android/iOS 以外の環境で GPU による高速化が行われる様になるかもしれません。(ならないかもしれません、いやなって欲しい)
onnx-go はこれから利用できるオペレータがどんどん増え、パフォーマンスに関しても cuda や clBLAS 等を利用した高速化が行われる様になるかもしれません。(ならないかもしれません、いやなって欲しい)
色々と期待の多い Go の推論フレームワーク界隈なので、いずれまた新しいニュースと共にご紹介したいと思います。
- 投稿日:2019-05-07T13:06:16+09:00
日本一詳しくGrad-CAMとGuided Grad-CAMのソースコードを解説してみる(Keras実装)
背景
今更ながらGrad-CAMとGuided Grad-CAMを使う機会があったので、Keras実装のメジャーっぽいリポジトリを改造して利用したのですが、結構詰まりポイントが多かったので(私だけ?)復習もかねてソースコードを解説しようと思います。
そもそもGrad-CAM, Guided Grad-CAMとは?
簡単に言ってしまうと、CNNの判断根拠の可視化技術になります。
私は可視化については完全にビギナーなのですが、そんな私でも知ってるぐらい可視化の中ではメジャーどころなのではないでしょうか。論文は2017に出されているので、おそらく発展手法(Grad-CAM++とか?)も沢山出ているとは思いますが、ビギナーなので情報の充実しているGrad-CAMを今回は使ってみました。
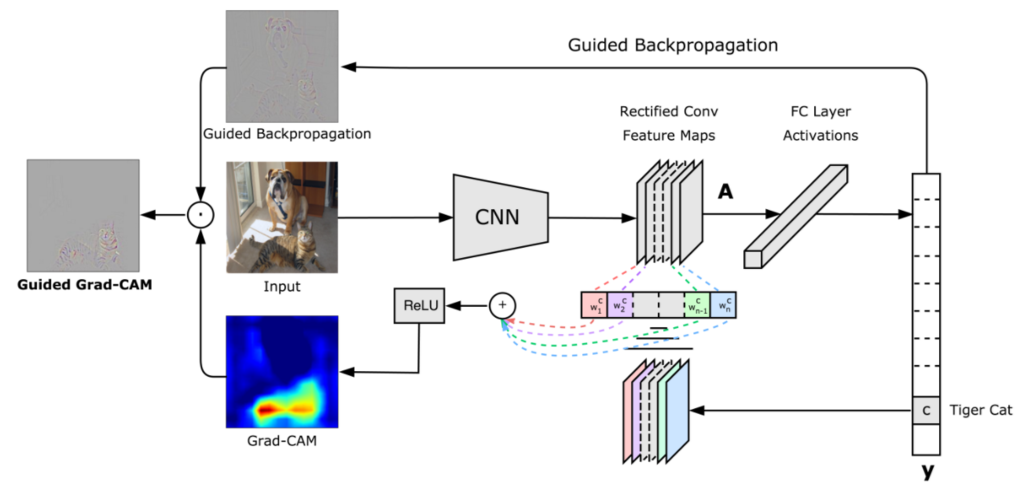
Grad-CAMの論文見たことがあるかも知れませんがこちらがGrad-CAMとGuided Grad-CAMをかけた結果になります。
以下の場合、評価したモデルは入力画像を"犬"として分類しています。
入力画像 Grad-CAM Guided Grad-CAM Grad-CAMではCNNが分類のために注視している範囲をカラーマップで表示してくれます。
Grad-CAMの発想は、予測クラスのloss値に寄与の大きいところ(勾配の大きいところ)が分類予測を行う上で、重要な箇所なのではないか。といったものです。
勾配に関しては最後の畳み込み層(以下最後のconv層)の予測クラスのloss値に対する勾配が用いられます。
Guided Grad-CAMではより詳細にどういう特徴を拾って分類しているのかを可視化してくれます。
Guided Grad-CAMはGrad-CAMとGuidedBackPropagationを組み合わせて可視化する手法になります。
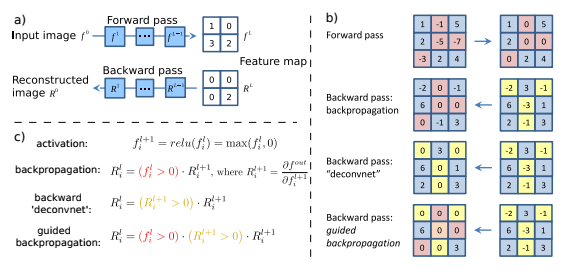
GuidedBackPropagationは以下の論文で提案されています。
基本的な発想は、最後のconv層に対する入力の勾配の大きいところを表示すれば、クラス分類に有意な情報を可視化できるのではないか。といったものです。
勾配を際立たせるために、順伝搬/逆伝搬で値がマイナスの部分は0に置き換えて、勾配計算を行います。
Striving for Simplicity: The All Convolutional NetGuidedBackPropagationの結果とGrad-CAMのヒートマップの結果を足し合わせたものがGaided Grad-CAMとなります。
今回解説するリポジトリ
Grad-CAMのソースの解説
1. Grad-Camのmainの処理
mainの処理は
- 入力画像の読み込み
- モデルの読み込み
- 入力画像の予測確率(predictions)と予測クラス(predicted_class)の計算
- Grad-Camの計算
- 画像の保存
となっています。
「4. Grad-Camの計算」以外は特別な処理もないため、処理4のみ解説します。Grad-CAMのmain処理# ① 入力画像の読み込み # 入力画像を変換する場合はこちらを変更 preprocessed_input = load_image(sys.argv[1]) #preprocessed_input = load_image("./examples/boat.jpg") # ② モデルの読み込み # 自作モデルを使用する場合はこちらを変更 model = VGG16(weights='imagenet') # ③ 入力画像の予測確率(predictions)と予測クラス(predicted_class)の計算 # VGG16以外のモデルを使用する際はtop_1=~から3行はコメントアウト predictions = model.predict(preprocessed_input) top_1 = decode_predictions(predictions)[0][0] print('Predicted class:') print('%s (%s) with probability %.2f' % (top_1[1], top_1[0], top_1[2])) predicted_class = np.argmax(predictions) # ④ Grad-Camの計算 # 自作モデルの場合、引数の"block5_conv3"を自作モデルの最終conv層のレイヤー名に変更. cam, heatmap = grad_cam(model, preprocessed_input, predicted_class, "block5_conv3") # ⑤ 画像の保存 cv2.imwrite("gradcam.jpg", cam)2. grad_cam関数の処理
Grad-Camの計算は以下の手順で行われます。
- 入力画像の予測クラスを計算
- 予測クラスのLossを計算
- 予測クラスのLossから最後のconv層への逆伝搬(勾配)を計算
- 最後のconv層のチャンネル毎に勾配を平均(Global Average Pooling)を計算して、各チャンネルの重要度(重み)とする
- 最後のconv層の順伝搬の出力にチャンネル毎の重みをかけて、足し合わせて、ReLUを通す → heatmapの計算が出来た!!
- 入力画像とheatmapをかける → Grad-Camの計算が出来た!!!
詳細の説明についてはソースコードにコメントを入れる形で解説していきます。
grad_camdef grad_cam(input_model, image, category_index, layer_name): ''' Parameters ---------- input_model : model 評価するKerasモデル image : tuple等 入力画像(枚数, 縦, 横, チャンネル) category_index : int 入力画像の分類クラス layer_name : str 最後のconv層の後のactivation層のレイヤー名. 最後のconv層でactivationを指定していればconv層のレイヤー名. batch_normalizationを使う際などのようなconv層でactivationを指定していない場合は、 そのあとのactivation層のレイヤー名. Returns ---------- cam : tuple Grad-Camの画像 heatmap : tuple ヒートマップ画像 ''' # 分類クラス数 nb_classes = 1000 # ----- 1. 入力画像の予測クラスを計算 ----- # 入力のcategory_indexが予想クラス # ----- 2. 予測クラスのLossを計算 ----- # 入力データxのcategory_indexで指定したインデックス以外を0にする処理の定義 target_layer = lambda x: target_category_loss(x, category_index, nb_classes) # 引数のinput_modelの出力層の後にtarget_layerレイヤーを追加 # modelのpredictをすると予測クラス以外の値は0になる x = input_model.layers[-1].output x = Lambda(target_layer, output_shape=target_category_loss_output_shape)(x) model = keras.models.Model(input_model.layers[0].input, x) # 予測クラス以外の値は0なのでsumをとって予測クラスの値のみ抽出 loss = K.sum(model.layers[-1].output) # 引数のlayer_nameのレイヤー(最後のconv層)のoutputを取得する conv_output = [l for l in model.layers if l.name is layer_name][0].output # ----- 3. 予測クラスのLossから最後のconv層への逆伝搬(勾配)を計算 ----- # 予想クラスの値から最後のconv層までの勾配を計算する関数を定義 # 定義した関数の # 入力 : [判定したい画像.shape=(1, 224, 224, 3)]、 # 出力 : [最後のconv層の出力値.shape=(1, 14, 14, 512), 予想クラスの値から最後のconv層までの勾配.shape=(1, 14, 14, 512)] grads = normalize(K.gradients(loss, conv_output)[0]) gradient_function = K.function([model.layers[0].input], [conv_output, grads]) # 定義した勾配計算用の関数で計算し、データの次元を整形 # 整形後 # output.shape=(14, 14, 512), grad_val.shape=(14, 14, 512) output, grads_val = gradient_function([image]) output, grads_val = output[0, :], grads_val[0, :, :, :] # ----- 4. 最後のconv層のチャンネル毎に勾配を平均を計算して、各チャンネルの重要度(重み)とする ----- # weights.shape=(512, ) # cam.shape=(14, 14) # ※疑問点1:camの初期化はzerosでなくて良いのか? weights = np.mean(grads_val, axis = (0, 1)) cam = np.ones(output.shape[0 : 2], dtype = np.float32) #cam = np.zeros(output.shape[0 : 2], dtype = np.float32) # 私の自作モデルではこちらを使用 # ----- 5. 最後のconv層の順伝搬の出力にチャンネル毎の重みをかけて、足し合わせて、ReLUを通す ----- # 最後のconv層の順伝搬の出力にチャンネル毎の重みをかけて、足し合わせ for i, w in enumerate(weights): cam += w * output[:, :, i] # 入力画像のサイズにリサイズ(14, 14) → (224, 224) cam = cv2.resize(cam, (224, 224)) # 負の値を0に置換。処理としてはReLUと同じ。 cam = np.maximum(cam, 0) # 値を0~1に正規化。 # ※疑問2 : (cam - np.min(cam))/(np.max(cam) - np.min(cam))でなくて良いのか? heatmap = cam / np.max(cam) #heatmap = (cam - np.min(cam))/(np.max(cam) - np.min(cam)) # 私の自作モデルではこちらを使用 # ----- 6. 入力画像とheatmapをかける ----- # 入力画像imageの値を0~255に正規化. image.shape=(1, 224, 224, 3) → (224, 224, 3) #Return to BGR [0..255] from the preprocessed image image = image[0, :] image -= np.min(image) # ※疑問3 : np.uint8(image / np.max(image))でなくても良いのか? image = np.minimum(image, 255) # heatmapの値を0~255にしてカラーマップ化(3チャンネル化) cam = cv2.applyColorMap(np.uint8(255*heatmap), cv2.COLORMAP_JET) # 入力画像とheatmapの足し合わせ cam = np.float32(cam) + np.float32(image) # 値を0~255に正規化 cam = 255 * cam / np.max(cam) return np.uint8(cam), heatmapこちらのソースのなかで疑問点が3つあります。
分かる方いましたら是非教えてください。
- 疑問1 : camの初期化はzerosでなくて良いのか?
- KerasのVGG16でcat_dog.pngを読み込んだ際は、加重平均後のcamの値が-400~1065と1に対して大きいため問題になりませんが、私の自作モデルではcamの値が1に近かったためzerosで初期化しないとぼやけたヒートマップになってしまいました。
- 疑問2 : (cam - np.min(cam))/(np.max(cam) - np.min(cam))でなくて良いのか?
- 私の自作モデルでcamをzerosで初期化した際は問題にはならなくなりましたが、onesで初期化した際はcamの値が正規化前から0以上だったため、最大値を1に正規化するだけではヒートマップがぼけてしまいました。
- 疑問3 : np.uint8(image / np.max(image))でなくても良いのか?
私が自作モデルで使用する際は疑問1, 2の部分を変更して使っています。
Guided Grad-Camのソース解説
3. Guided Grad-Camのmain処理
mainの処理は
- GuidedBackPropagation用勾配の実装
- ReLUの勾配計算をGuidedBackPropagationの勾配計算に変更
- GaidedBackPropagation計算用の関数の定義
- GaidedBackPropagationの計算
- Guided Grad-CAMの計算
- 画像の保存
となっています。
ここでは本筋の処理である1~3の処理の関数について解説を行います。GuidedGrad-CAMのmain処理# ① GuidedBackPropagation用勾配の実装 register_gradient() # ② ReLUの勾配計算をGuidedBackPropagationの勾配計算に変更 guided_model = modify_backprop(model, 'GuidedBackProp') # ③ GaidedBackPropagation計算用の関数の定義 # 自作クラスを使う場合は、こちらの引数に最後のconv層のレイヤー名を追加で指定 saliency_fn = compile_saliency_function(guided_model) # ④ GaidedBackPropagationの計算 saliency = saliency_fn([preprocessed_input, 0]) # ⑤ Guided Grad-CAMの計算 gradcam = saliency[0] * heatmap[..., np.newaxis] # ⑥ 画像の保存 cv2.imwrite("guided_gradcam.jpg", deprocess_image(gradcam))4. register_gradient関数の処理
こちらの関数ではGuidedBackPropagationの処理を登録しています。
今回作成する勾配関数「_GuidedBackProp」の処理としては、
逆伝搬してきた勾配のうち、順伝搬/逆伝搬の値がマイナスのセルのみ0にして逆伝搬する
になります。register_gradientdef register_gradient(): # GuidedBackPropが登録されていなければ登録 if "GuidedBackProp" not in ops._gradient_registry._registry: # 自作勾配を登録するデコレーター # 今回は_GuidedBackProp関数を"GuidedBackProp"として登録 @ops.RegisterGradient("GuidedBackProp") def _GuidedBackProp(op, grad): '''逆伝搬してきた勾配のうち、順伝搬/逆伝搬の値がマイナスのセルのみ0にして逆伝搬する''' dtype = op.inputs[0].dtype # grad : 逆伝搬してきた勾配 # tf.cast(grad > 0., dtype) : gradが0以上のセルは1, 0以下のセルは0の行列 # tf.cast(op.inputs[0] > 0., dtype) : 入力のが0以上のセルは1, 0以下のセルは0の行列 return grad * tf.cast(grad > 0., dtype) * \ tf.cast(op.inputs[0] > 0., dtype)5. modify_backprop関数の処理
こちらの関数では、モデルのReLUの勾配を、定義した"GuidedBackoProp"に置き換えています。
modify_backpropdef modify_backprop(model, name): ''' ReLU関数の勾配を"name"勾配に置き換える''' # with内のReLUは"name"に置き換えられる g = tf.get_default_graph() with g.gradient_override_map({'Relu': name}): # ▽▽▽▽▽ 疑問4 : 新規モデルをreturnしているのに、引数のモデルのreluの置き換えが必要なのか? ▽▽▽▽▽ # activationを持っているレイヤーのみ抜き出して配列化 # get layers that have an activation layer_dict = [layer for layer in model.layers[1:] if hasattr(layer, 'activation')] # kerasのRelUをtensorflowのReLUに置き換え # replace relu activation for layer in layer_dict: if layer.activation == keras.activations.relu: layer.activation = tf.nn.relu # △△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△ # 新しくモデルをインスタンス化 # 自作モデルを使用する場合はこちらを修正 # re-instanciate a new model new_model = VGG16(weights='imagenet') return new_modelこちらの処理での疑問点としては疑問4の引数のモデルのKeras ReLUをtensorflow ReLUに置き換えているところです。
戻り値として新規作成したインスタンスを返しているのに、引数のモデルを変更して意味があるのかがわかりませんでした。
私の環境で試したところ 「# ▽▽~」と「#△△~」の間をすべてコメントアウトしても、動作が変わらないように思えました。6. compile_saliency_function関数の処理
こちらの処理では指定レイヤーに対する入力の勾配を計算する関数を作成しています。
compile_saliency_functiondef compile_saliency_function(model, activation_layer='block5_conv3'): '''指定レイヤーのチャンネル方向最大値に対する入力の勾配を計算する関数の作成''' # モデルのインプット input_img = model.input # 入力層の次の層以降をレイヤー名とインスタンスの辞書として保持 layer_dict = dict([(layer.name, layer) for layer in model.layers[1:]]) # 引数で指定したレイヤー名のインスタンスの出力を取得 shape=(?, 14, 14, 512) layer_output = layer_dict[activation_layer].output # チャンネル方向に最大値を取る shape=(?, 14, 14) max_output = K.max(layer_output, axis=3) # 指定レイヤーのチャンネル方向最大値に対する入力の勾配を計算する関数 saliency = K.gradients(K.sum(max_output), input_img)[0] return K.function([input_img, K.learning_phase()], [saliency])まとめ
今回はGrad-CAMとGuided Grad-CAMのソースコードの処理について詳細に解説してみました。
疑問点がいくつかあるのでタイトルは誇大広告気味ですが、わかる方がいらしたら是非教えてください。Gitリポジトリ
今回解説したコメント入りのソースになります。
kinziro/keras-grad-cam参考にさせて頂いたサイト
Grad-Cam関係
ディープラーニングの判断根拠を理解する手法
Grad-CAM: Why did you say that? Visual Explanations from Deep Networks via Gradient-based Localizationtensorflow, Keras関係



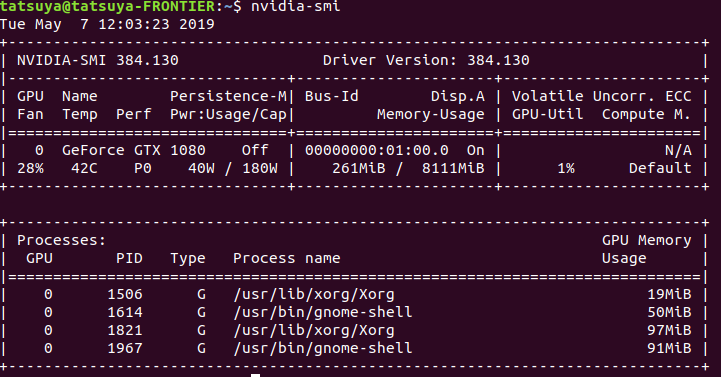
- 投稿日:2019-05-07T12:59:11+09:00
tensorflow-gpuを動かすまで
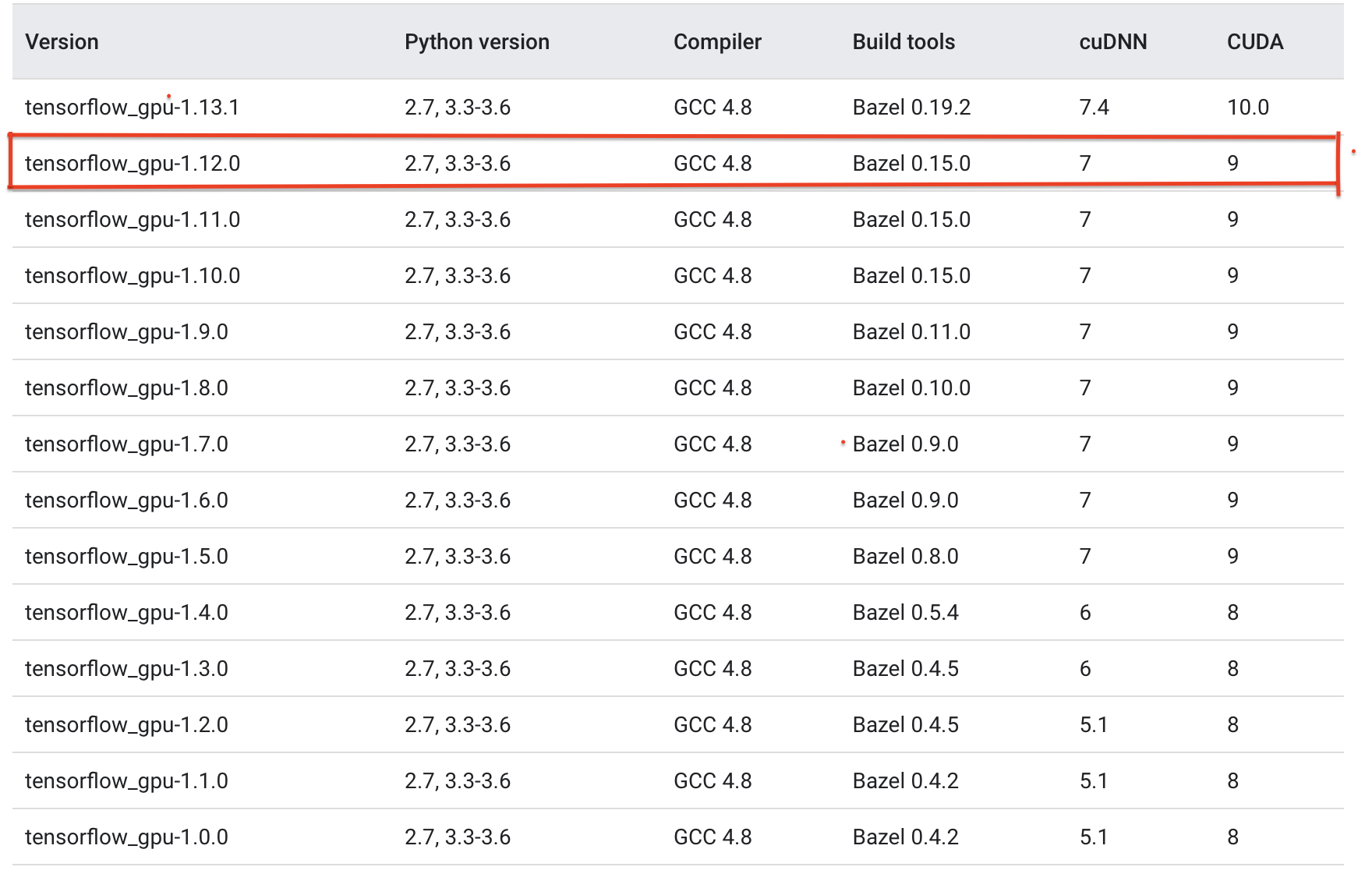
環境構築概要
ubuntu : 17.10
GPU : GTX 1080
nvidia : 384
CUDA : 9.0
cudnn : 7.1.4
tensorflow-gpu : 1.12.0今までMATLABでGPUを使用していましたが、tensorflowの方でGPUを動かしたので今回はバージョンをtensorflow-gpuに合わせました。
以下参照
これを見る限り、cudnnのversionは 7 ですが、上手く動かなかったので 7.1.4 を使用しました
nvidia-driver のインストール
Ubuntu17.10にNVIDIAドライバをインストールしてみた。
*以前に書いた記事があるので参照してください。cudnn のインストール
UbuntuにcuDNNをインストール
*以前に書いた記事があるので参照してください。CUDA のインストール
UbuntuにCUDAをインストールする方法
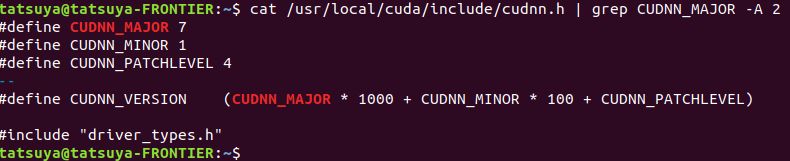
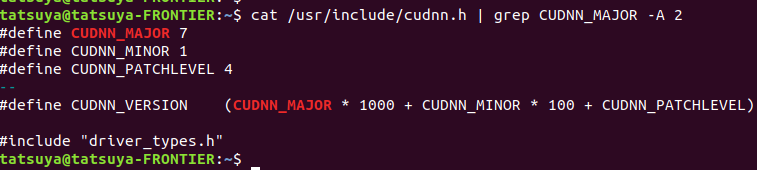
*以前に書いた記事があるので参照してください。cudnn の version確認コマンド
$ cat /use/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
$ cat /usr/include/cudnn.h | grep CUDNN_MAJOR -A 2
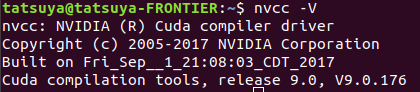
CUDA の version確認
$ nvcc -V
Nvidia driver の情報
$ nvidia-smi
tensorflow-gpu のインストール
$ sudo pip3 install tensorflow-gpuでインストールすると最新版がインストールされます。
バージョンを指定する場合には$ sudo pip3 install tensorflow-gpu==1.12.0のように ==X.X.Xでバージョンを指定してください。
+α
nvidia と cuda の削除
$ sudo apt-get --purge remove nvidia-* $ sudo apt-get --purge remove cuda-*削除できているかの確認
$ dpkg -l | grep nvidia $ dpkg -l | grep cuda何も出てこなければ削除できています。
nvidia install
$ sudo apt-get install nvidia-384インストール可能なnvidia driver 一覧
$ sudo add-apt-repository ppa:xorg-edgers/ppa -y $ sudo apt-get update $ apt-cache search "^nvidia-[0-9]{3}$"最後に
この作業にかなりの時間を費やしてしましました、、
cudaのバージョン違うものをたくさん入れていたので
一旦全て削除してやり直しました。
少しでも、参考になればと思います!参照
- 投稿日:2019-05-07T11:01:07+09:00
Kerasでとりあえず動かしてみるTPUでのディープラーニング
はじめに
GPUが載ってないPCでディープラーニングをやってみたい、という人向けです。
今回は前回作成した数字の判定をTPUを使ってやってみます。
https://qiita.com/norikawamura/items/a5c3844e7555202c35a4#_reference-64514a0a96dfd9b1648e事前準備
ColaboratoryでハードウェアアクセラレータにTPUを選択します。
ColaboratoryでTPUを使用するには
結論としては以下の変更が必要なようです。(2019/5/7時点)
①「keras.~」でimportしていたパッケージを「tensorflow.keras.~」とtensorflowの物に変更する。(optimizerの指定等も含む)
②CPU/GPU向けで作成したモデルをTPU向けのモデルに変換する。
・環境情報を取得後、keras_to_tpu_model()で変換する。
③TPUモデルではpredict_classes()が使えないので、分類を行う場合は代わりにpredict()の結果の最大値をとる。
④TPUモデルではpredict()に渡すデータの件数が、TPUコア数(8)の倍数である必要がある。データの準備
前回と同様です。
import sklearn as skl from sklearn import datasets import pandas as pd dgt = skl.datasets.load_digits() digits_df = pd.DataFrame(dgt.data) target_df = pd.DataFrame(dgt.target) # 特徴量のセットを変数Xに、ターゲットを変数yに格納 X = digits_df.values y = target_df.values学習データと検証用データに分けます。
kerasの代わりにtensorflow.kerasに変更しています。
また、検証用データの数を8の倍数にしておきます。
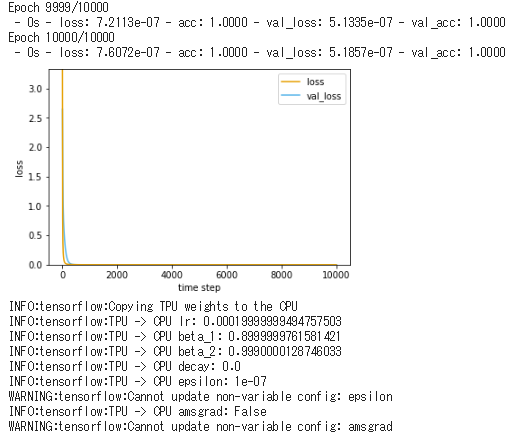
※学習用データの数は8の倍数になっている必要はないようです。import numpy as np import tensorflow.keras as keras # データの順番を入れ替えるためのランダムなNumPy配列 np.random.seed(42) indices = np.random.permutation(len(X)) val_len = int(len(X) * -0.1) // 8 * 8 #TPUを使った場合のために8の倍数にする # 学習用のデータ。全体から100データを省いたもの X_train = X[indices[:val_len]] y_train = y[indices[:val_len]] # テスト用のデータ。全体から100データ取り出したもの X_test = X[indices[val_len:]] y_test = y[indices[val_len:]] # サンプル数、特徴量の次元、クラス数の取り出し (n_samples, n_features) = X_train.shape n_classes = len(np.unique(y)) # ターゲットyをkeras用の形式に変換 y_keras = keras.utils.to_categorical(y_train, n_classes)損失関数のグラフ表示
前回のものと同じです。
import matplotlib.pyplot as plt #損失関数グラフ def plotHistory(history): # 損失関数のグラフの軸ラベルを設定 plt.xlabel('time step') plt.ylabel('loss') # グラフ縦軸の範囲を0以上と定める plt.ylim(0, max(np.r_[history.history['val_loss'], history.history['loss']])) # 損失関数の時間変化を描画 val_loss, = plt.plot(history.history['val_loss'], c='#56B4E9') loss, = plt.plot(history.history['loss'], c='#E69F00') # グラフの凡例(はんれい)を追加 plt.legend([loss, val_loss], ['loss', 'val_loss']) # 描画したグラフを表示 plt.show()モデルの定義・学習
「#TPU」のコメントの下のkeras_to_tpu_model()を呼ぶまでの部分が、今回追加したTPU用にモデルを変換する部分です。
import os import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import BatchNormalization from tensorflow.keras.layers import Conv2D, MaxPooling2D from tensorflow.keras.layers import Flatten from tensorflow.keras.layers import Dense, Dropout from tensorflow.keras.optimizers import Adam from tensorflow.keras.callbacks import EarlyStopping X_train = X_train.reshape(-1, 8, 8, 1) X_test = X_test.reshape(-1, 8, 8, 1) savefile = 'keras_clf_skldigit_tpu.h5' useSavedModel = False if useSavedModel == False: # ニューラルネットワークを定義 model = Sequential() # ニューラルネットワークを定義 model = Sequential() # 中間層と入力層を定義 model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(8,8,1,))) model.add(Conv2D(64, (3, 3), activation='relu')) #model.add(MaxPooling2D(pool_size=(2, 2))) #model.add(BatchNormalization()) model.add(Conv2D(128, (3, 3), activation='relu')) model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(BatchNormalization()) # 出力層を定義 model.add(Dense(units=n_classes, activation='softmax')) # モデルのコンパイル model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.0002), metrics=['accuracy']) # TPU tpu_grpc_url = "grpc://"+os.environ["COLAB_TPU_ADDR"] tpu_cluster_resolver = tf.contrib.cluster_resolver.TPUClusterResolver(tpu_grpc_url) #strategy = keras_support.TPUDistributionStrategy(tpu_cluster_resolver) strategy = tf.contrib.tpu.TPUDistributionStrategy(tpu_cluster_resolver) model = tf.contrib.tpu.keras_to_tpu_model(model, strategy=strategy) # モデルの学習 early_stopping = EarlyStopping(monitor='val_loss', mode='min', patience=1000) plotHistory( model.fit( X_train ,y_keras ,epochs=10000 ,validation_split=0.1 ,batch_size=n_samples ,verbose=2 ,callbacks=[early_stopping] ) ) # 学習結果を保存 model.save(savefile) else: # 学習済ファイルを読み込んでmodelを作成 model = keras.models.load_model(savefile)
判定処理
TPUだとmodel.predict_classes()が使えないので、predict()の結果の最大値をnumpy.argmax()で取得して代用します。
y_test2 = y_test.reshape(-1) # 結果の表示 #result = model.predict_classes(X_test, verbose=0) y_result = model.predict(X_test, verbose=0) import numpy as np result = np.zeros(y_test2.shape, int) for idx, data in enumerate(y_result): result[idx] = int(np.argmax(data)) print('ターゲット') print(y_test2) print('ディープラーニングによる予測') print(result) # データ数をtotalに格納 total = len(result) # ターゲット(正解)と予測が一致した数をsuccessに格納 success = sum(result==y_test2) # 正解率をパーセント表示 print('正解率') print(100.0*success/total)
次回予定
未定です。