- 投稿日:2019-05-07T20:36:12+09:00
Go による機械学習推論フレームワークの最新動向 2019
Golang で推論
昨今では「機械学習と言えば Python」「Python と言えば機械学習」と思われがちなのですが、推論用途であれば学習済みモデルを利用して色々なプログラミング言語から扱えます。Go から扱える機械学習ライブラリの内、学習済みモデルが利用できる物としてはおおよそ以下の3つに絞られます。
Golang で TensorFlow
Golang で TensorFlow を利用する場合はオフィシャルから Go の binding が提供されているので Go の import 文で GitHub リポジトリを指して利用します。Jetson や Raspberry Pi での動作実績もあります。TensorFlow 自体が色々な CPU 命令の最適化まで行っているので Python とそん色ないパフォーマンスで動作します。もちろん GPU を有効にしても扱えます。さらに Go であれば推論処理を並行処理させる事で他の言語よりも省メモリで高速に処理する事も可能です。簡単な使い方は以前ブログに書きました。
Big Sky :: golang で tensorflow のススメ
ただし TensorFlow は Python から利用する場合と同様にフットプリントが大きく、また実行中のメモリ使用量も巨大になります。Raspberry Pi の様なリソースの乏しい環境から利用すると無視できない程の負荷が掛かります。
Golang で TensorFlow Lite
TensorFlow Lite はモバイル用途で利用される推論用ライブラリです。こちらは筆者が開発中の go-tflite を使えば toco で変換したモデルファイルを利用して推論を実行する事が出来ます。
Big Sky :: TensorFlow Lite の Go binding を書いた。
TensorFlow に比べ Lite の API の方が推論に対して直観的なので、わりかし覚えやすいと思います。Windows からも利用できるようになっています。ビルドには libtensorflow_c というライブラリが必要です。README を見ながら導入して下さい。なお現在送っている pull-request がマージされればいずれ皆さんも簡単に Windows から TensorFlow Lite を利用できる様になる予定です。以下は Google が提供している SSD MobileNet v1 のモデルファイルを利用して OpenCV から取り込んだ動画にリアルタイムでラベル付けするサンプルの実行画面です。
TensorFlow Lite の Windows 版で SSD。現状の TfLite には Android/iOS 以外での GPU delegate 等の最適化がないので遅いけどコア1個100%でこの程度動くならまぁ使い道がなくもないかな。 pic.twitter.com/PvfQLMcZE1
— mattn (@mattn_jp) May 6, 2019https://github.com/mattn/go-tflite/tree/master/_example
この他にも go-tflite の _examples には TesnorFlow が提供しているサンプルとほぼ同じ物が Go でポーティングされています。Go で TensorFlow Lite をやってみたい方は参考にして下さい。
TensorFlow Lite は CPU 最適化や GPU による高速化が一部のターゲットだけにしか提供されていない為、それらの環境外では若干遅くはなりますが、メモリ使用量がとてもも小さく、Raspberry Pi で動作させてもそれほど負荷を感じません。
Golang で ONNX
さて Go から扱える学習済みモデルのもう1つの候補 ONNX ですが現在 Go から ONNX を利用する手段としては2つあります。
1つは Prefered Network 社が提供している menoh の Go binding を利用する物。もう1つは Olivier Wulveryck 氏が開発している onnx-go を使う物です。
Menoh は ONNX を扱う事ができる推論専用ライブラリで、go-menoh からも同様に扱う事が出来る様になっています。以前、go-menoh を使ったリアルタイム物体認識を書きました。
Big Sky :: リアルタイム物体認識を2本作ってみた。
筆者の体感では TensorFlow ほどメモリは消費しないけれど、Raspberry Pi で動作させるのは少し辛いくらいのリソース消費になります。(もちろんサーバ等で動作させれば良い性能は出せます)
onnx-go
もう1つの候補 onnx-go は筆者が知る限りまだあまり広まっていません。onnx-go は Pure Go で書かれています。Pure Go で書かれているので Go をサポートする OS/CPU アーキテクチャであればどこでも動作するというメリットがあります。onnx-go は内部で gonum という行列演算ライブラリを利用しており、環境によっては blas による高速化が行われます。
onnx-go は以前 gorgonia とう gonum ベースの機械学習フレームワークから ONNX を利用する為に作られ、gorgonnx というリポジトリで開発されていましたが、そこから onnx 関連のみ抜き出しシェイプアップした物が現在の onnx-go になっています。以前から onnx-go を追っかけていたのですが、最近ようやく色々な物が動作する様になってきたのでそろそろ Qiita で紹介しようと思い立ちました。
emotions のサンプルを試してみた。
— mattn (@mattn_jp) May 7, 2019
Computation time: 1.1050632s
happiness / 67.85%
neutral / 30.88%
happiness なんですか? pic.twitter.com/O9DJFistTYリポジトリに同梱されている emotions というサンプルコードを動かすと画像から感情を推論するデモを見る事ができます。
サンプルコードも短いので直ぐに API を覚えられると思います。ONNX Zoo というモデルファイルの一次配布場所とその README を参照すれば、簡単にアプリケーションを書く事も出来ます。
https://github.com/onnx/models
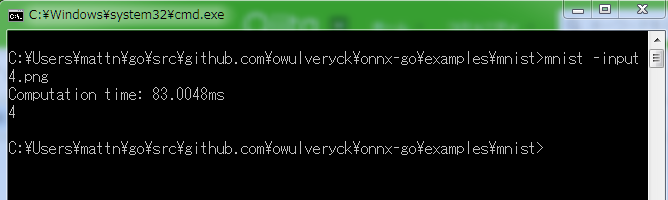
例えば mnist 手書き数字のモデルであれば以下に説明が書かれています。
https://github.com/onnx/models/tree/master/mnist
README に書かれている通り入力画像を 28x28 のグレー画像(2値)に変換して設定し Run を呼び出すと推論できます。出力は GetOutputTensors から得られます。この辺は TensorFlow も TensorFlow Lite も onnx-go もそれほど扱い方は変わりません。
package main import ( "flag" "fmt" "image" "image/color" _ "image/jpeg" _ "image/png" "io/ioutil" "log" "os" "github.com/nfnt/resize" "github.com/owulveryck/onnx-go" "github.com/owulveryck/onnx-go/backend/x/gorgonnx" "github.com/owulveryck/onnx-go/internal/x/images" "gorgonia.org/tensor" ) const ( height = 28 width = 28 ) func convertToGray(img image.Image) *image.Gray { img = resize.Resize(width, height, img, resize.Bilinear) gray := image.NewGray(img.Bounds()) bounds := img.Bounds() for y := 0; y < bounds.Dy(); y++ { for x := 0; x < bounds.Dx(); x++ { gray.Set(x, y, color.GrayModel.Convert(img.At(x, y))) } } return gray } func main() { model := flag.String("model", "model.onnx", "path to the model file") filename := flag.String("input", "file.png", "path to the input file") flag.Parse() backend := gorgonnx.NewGraph() m := onnx.NewModel(backend) // Read model binary b, err := ioutil.ReadFile(*model) if err != nil { log.Fatal(err) } // Decode it into the model err = m.UnmarshalBinary(b) if err != nil { log.Fatal(err) } // Read input image f, err := os.Open(*filename) if err != nil { log.Fatal(err) } defer f.Close() img, _, err := image.Decode(f) if err != nil { log.Fatal(err) } // Convert to gray image imgGray := convertToGray(img) // Create tensor dimensioned by 1x1x28x28 input := tensor.New(tensor.WithShape(1, 1, height, width), tensor.Of(tensor.Float32)) err = images.GrayToBCHW(imgGray, input) if err != nil { log.Fatal(err) } m.SetInput(0, input) err = backend.Run() if err != nil { log.Fatal(err) } output, err := m.GetOutputTensors() if err != nil { log.Fatal(err) } // Find maximum value of prediction results max := float32(-9999) maxi := -1 for i, v := range output[0].Data().([]float32) { if v > max { max = v maxi = i } } fmt.Println(maxi) }
Pure Go なので Windows からも特に苦労する事なく利用出来ます。
まとめ
Go から利用できる機械学習の推論フレームワークを紹介しました。TensorFlow が今すぐ新しいブレイクスルーを起こす事は無いと思いますが、TensorFlow Lite はもしかすると今後 Android/iOS 以外の環境で GPU による高速化が行われる様になるかもしれません。(ならないかもしれません、いやなって欲しい)
onnx-go はこれから利用できるオペレータがどんどん増え、パフォーマンスに関しても cuda や clBLAS 等を利用した高速化が行われる様になるかもしれません。(ならないかもしれません、いやなって欲しい)
色々と期待の多い Go の推論フレームワーク界隈なので、いずれまた新しいニュースと共にご紹介したいと思います。



- 投稿日:2019-05-07T20:36:12+09:00
Go による機械学習 推論フレームワークの最新動向 2019
Golang で推論
昨今では「機械学習と言えば Python」「Python と言えば機械学習」と思われがちなのですが、推論用途であれば学習済みモデルを利用して色々なプログラミング言語から扱えます。Go から扱える機械学習ライブラリの内、学習済みモデルが利用できる物としてはおおよそ以下の3つに絞られます。
Golang で TensorFlow
Golang で TensorFlow を利用する場合はオフィシャルから Go の binding が提供されているので Go の import 文で GitHub リポジトリを指して利用します。Jetson や Raspberry Pi での動作実績もあります。TensorFlow 自体が色々な CPU 命令の最適化まで行っているので Python とそん色ないパフォーマンスで動作します。もちろん GPU を有効にしても扱えます。さらに Go であれば推論処理を並行処理させる事で他の言語よりも省メモリで高速に処理する事も可能です。簡単な使い方は以前ブログに書きました。
Big Sky :: golang で tensorflow のススメ
ただし TensorFlow は Python から利用する場合と同様にフットプリントが大きく、また実行中のメモリ使用量も巨大になります。Raspberry Pi の様なリソースの乏しい環境から利用すると無視できない程の負荷が掛かります。
Golang で TensorFlow Lite
TensorFlow Lite はモバイル用途で利用される推論用ライブラリです。こちらは筆者が開発中の go-tflite を使えば toco で変換したモデルファイルを利用して推論を実行する事が出来ます。
Big Sky :: TensorFlow Lite の Go binding を書いた。
TensorFlow に比べ Lite の API の方が推論に対して直観的なので、わりかし覚えやすいと思います。Windows からも利用できるようになっています。ビルドには libtensorflow_c というライブラリが必要です。README を見ながら導入して下さい。なお現在送っている pull-request がマージされればいずれ皆さんも簡単に Windows から TensorFlow Lite を利用できる様になる予定です。以下は Google が提供している SSD MobileNet v1 のモデルファイルを利用して OpenCV から取り込んだ動画にリアルタイムでラベル付けするサンプルの実行画面です。
TensorFlow Lite の Windows 版で SSD。現状の TfLite には Android/iOS 以外での GPU delegate 等の最適化がないので遅いけどコア1個100%でこの程度動くならまぁ使い道がなくもないかな。 pic.twitter.com/PvfQLMcZE1
— mattn (@mattn_jp) May 6, 2019https://github.com/mattn/go-tflite/tree/master/_example
この他にも go-tflite の _examples には TesnorFlow が提供しているサンプルとほぼ同じ物が Go でポーティングされています。Go で TensorFlow Lite をやってみたい方は参考にして下さい。
TensorFlow Lite は CPU 最適化や GPU による高速化が一部のターゲットだけにしか提供されていない為、それらの環境外では若干遅くはなりますが、メモリ使用量がとてもも小さく、Raspberry Pi で動作させてもそれほど負荷を感じません。
Golang で ONNX
さて Go から扱える学習済みモデルのもう1つの候補 ONNX ですが現在 Go から ONNX を利用する手段としては2つあります。
1つは Prefered Network 社が提供している menoh の Go binding を利用する物。もう1つは Olivier Wulveryck 氏が開発している onnx-go を使う物です。
Menoh は ONNX を扱う事ができる推論専用ライブラリで、go-menoh からも同様に扱う事が出来る様になっています。以前、go-menoh を使ったリアルタイム物体認識を書きました。
Big Sky :: リアルタイム物体認識を2本作ってみた。
筆者の体感では TensorFlow ほどメモリは消費しないけれど、Raspberry Pi で動作させるのは少し辛いくらいのリソース消費になります。(もちろんサーバ等で動作させれば良い性能は出せます)
onnx-go
もう1つの候補 onnx-go は筆者が知る限りまだあまり広まっていません。onnx-go は Pure Go で書かれています。Pure Go で書かれているので Go をサポートする OS/CPU アーキテクチャであればどこでも動作するというメリットがあります。onnx-go は内部で gonum という行列演算ライブラリを利用しており、環境によっては blas による高速化が行われます。
onnx-go は以前 gorgonia とう gonum ベースの機械学習フレームワークから ONNX を利用する為に作られ、gorgonnx というリポジトリで開発されていましたが、そこから onnx 関連のみ抜き出しシェイプアップした物が現在の onnx-go になっています。以前から onnx-go を追っかけていたのですが、最近ようやく色々な物が動作する様になってきたのでそろそろ Qiita で紹介しようと思い立ちました。
emotions のサンプルを試してみた。
— mattn (@mattn_jp) May 7, 2019
Computation time: 1.1050632s
happiness / 67.85%
neutral / 30.88%
happiness なんですか? pic.twitter.com/O9DJFistTYリポジトリに同梱されている emotions というサンプルコードを動かすと画像から感情を推論するデモを見る事ができます。
サンプルコードも短いので直ぐに API を覚えられると思います。ONNX Zoo というモデルファイルの一次配布場所とその README を参照すれば、簡単にアプリケーションを書く事も出来ます。
https://github.com/onnx/models
例えば mnist 手書き数字のモデルであれば以下に説明が書かれています。
https://github.com/onnx/models/tree/master/mnist
README に書かれている通り入力画像を 28x28 のグレー画像(2値)に変換して設定し Run を呼び出すと推論できます。出力は GetOutputTensors から得られます。この辺は TensorFlow も TensorFlow Lite も onnx-go もそれほど扱い方は変わりません。
package main import ( "flag" "fmt" "image" "image/color" _ "image/jpeg" _ "image/png" "io/ioutil" "log" "os" "github.com/nfnt/resize" "github.com/owulveryck/onnx-go" "github.com/owulveryck/onnx-go/backend/x/gorgonnx" "github.com/owulveryck/onnx-go/internal/x/images" "gorgonia.org/tensor" ) const ( height = 28 width = 28 ) func convertToGray(img image.Image) *image.Gray { img = resize.Resize(width, height, img, resize.Bilinear) gray := image.NewGray(img.Bounds()) bounds := img.Bounds() for y := 0; y < bounds.Dy(); y++ { for x := 0; x < bounds.Dx(); x++ { gray.Set(x, y, color.GrayModel.Convert(img.At(x, y))) } } return gray } func main() { model := flag.String("model", "model.onnx", "path to the model file") filename := flag.String("input", "file.png", "path to the input file") flag.Parse() backend := gorgonnx.NewGraph() m := onnx.NewModel(backend) // Read model binary b, err := ioutil.ReadFile(*model) if err != nil { log.Fatal(err) } // Decode it into the model err = m.UnmarshalBinary(b) if err != nil { log.Fatal(err) } // Read input image f, err := os.Open(*filename) if err != nil { log.Fatal(err) } defer f.Close() img, _, err := image.Decode(f) if err != nil { log.Fatal(err) } // Convert to gray image imgGray := convertToGray(img) // Create tensor dimensioned by 1x1x28x28 input := tensor.New(tensor.WithShape(1, 1, height, width), tensor.Of(tensor.Float32)) err = images.GrayToBCHW(imgGray, input) if err != nil { log.Fatal(err) } m.SetInput(0, input) err = backend.Run() if err != nil { log.Fatal(err) } output, err := m.GetOutputTensors() if err != nil { log.Fatal(err) } // Find maximum value of prediction results max := float32(-9999) maxi := -1 for i, v := range output[0].Data().([]float32) { if v > max { max = v maxi = i } } fmt.Println(maxi) }
Pure Go なので Windows からも特に苦労する事なく利用出来ます。
まとめ
Go から利用できる機械学習の推論フレームワークを紹介しました。TensorFlow が今すぐ新しいブレイクスルーを起こす事は無いと思いますが、TensorFlow Lite はもしかすると今後 Android/iOS 以外の環境で GPU による高速化が行われる様になるかもしれません。(ならないかもしれません、いやなって欲しい)
onnx-go はこれから利用できるオペレータがどんどん増え、パフォーマンスに関しても cuda や clBLAS 等を利用した高速化が行われる様になるかもしれません。(ならないかもしれません、いやなって欲しい)
色々と期待の多い Go の推論フレームワーク界隈なので、いずれまた新しいニュースと共にご紹介したいと思います。
- 投稿日:2019-05-07T19:14:25+09:00
go modulsを使った開発を始めよう
概要
この記事は以下のページを参考にして、go modulesの開発に移行できる準備を行うためのものです。
https://github.com/golang/go/wiki/Modulesgo modulesとは
モジュール間の依存関係を解決するシステムです
メリット
GOPATH配下以外、各個人の自由な環境でプロジェクトの開発を始めることができます。
プロジェクトパスを意識する必要がなくなります。依存moduleが一箇所に集中するので管理が容易になります。
ファイルの説明
go.mod
依存関係が定義されたファイルです。
以下は一例です。module github.com/sample-account/sample-go-module.git go 1.12 require rsc.io/quote v1.5.2module の値がこのプロジェクト内でimportされるときの接頭辞として使用されます。
go.sum
moduleバージョン毎の暗号チェックsumが記録されています。
.lockファイルではありません。go Modulesの利用開始方法
利用する環境を確認する
- goのVersionが
1.11以上である
- YES => 特にすることはありません
- NO => 1.11以上をインストールしてください
- GOPATHの外にディレクトリを作成して、git cloneなどをした
- YES => 特にすることはありません
- NO =>
export GO111MODULE=onを実行してください
- 新規で作成したプロジェクトである
- YES =>
go mod initを実行してください。go.modファイルが作成され、moduleの定義が行われます。- NO => 特にすることはありません
依存解決を行う
go modulesではビルド時に、自動的に依存解決が行われます。
下記の方法で実行してください。
- ビルドする
go build ./{{ main.goが存在するディレクトリ }}
- 依存解決が正しく行われているか検証する
go test ./{{ test対象が存在するディレクトリ }}依存モジュールの更新、および追加
依存関係の更新は以下のコマンドによって行われます
go buildgo testgo get依存関係の整理を行う
以下のコマンドで使用されていない依存関係を取り除くことができます。
また、依存関係を整理しますので困った時は実行すると解決することがあります。
go mod tidy便利そうなTool
https://github.com/marwan-at-work/mod
go.modのmoduleを変更した場合は、自力でプロジェクト内のソースコードを駆け回り置換していく必要があります。
このモジュールはその行為を1コマンドで実行します。
- 投稿日:2019-05-07T07:54:39+09:00
【GORM公式ドキュメントの焼き回し】GORMについて分かりやすくまとめてみた
はじめに
GORMは公式ドキュメントがすごく良いのですが、途中から分かりづらかったり日本語訳が途切れたりしていたので、自分の理解向上のついでに構成を分かりやすくし全て日本語でまとめました。
よって、本記事は公式ドキュメントの焼き回しになります。前提知識
- ORMとは何かくらいは知っている
- SQLの基本知識
- Goの基本知識
インストール
$ go get -u github.com/jinzhu/gormDB接続
各種DBMSの接続方法
Open関数でDB接続します。DBMSの種類によって、引数の与え方が若干異なります。
また、DBドライバをラップしたパッケージをimportする必要があります。MySQL
import _ "github.com/jinzhu/gorm/dialects/mysql"db, err := gorm.Open("mysql", "user:password@/dbname?charset=utf8&parseTime=True&loc=Local")PostgreSQL
import _ "github.com/jinzhu/gorm/dialects/postgres"db, err := gorm.Open("postgres", "host=myhost port=myport user=gorm dbname=gorm password=mypassword")Sqlite3
import _ "github.com/jinzhu/gorm/dialects/sqlite"db, err := gorm.Open("sqlite3", "/tmp/gorm.db")SQL Server
import _ "github.com/jinzhu/gorm/dialects/mssql"db, err := gorm.Open("mssql", "sqlserver://username:password@localhost:1433?database=dbname")その他接続設定
// SetMaxIdleConnsはアイドル状態のコネクションプール内の最大数を設定します db.DB().SetMaxIdleConns(10) // SetMaxOpenConnsは接続済みのデータベースコネクションの最大数を設定します db.DB().SetMaxOpenConns(100) // SetConnMaxLifetimeは再利用され得る最長時間を設定します db.DB().SetConnMaxLifetime(time.Hour)モデル
モデルの基本
モデルはテーブルを構造体で表現したものです。
データ操作では、モデルに取得した情報を詰め込めんだり、更新したい情報をモデルに詰め込んで使用したりします。GORMの核となる部品です。
本記事では以下のUserモデルがたびたび具体例で扱われます。type User struct { gorm.Model Name string Age sql.NullInt64 Birthday *time.Time Email string `gorm:"type:varchar(100);unique_index"` Role string `gorm:"size:255"` // フィールドサイズを255にセットします MemberNumber *string `gorm:"unique;not null"` // MemberNumberをuniqueかつnot nullにセットします Num int `gorm:"AUTO_INCREMENT"` // Numを自動インクリメントにセットします Address string `gorm:"index:addr"` // `addr`という名前のインデックスを作ります IgnoreMe int `gorm:"-"` // このフィールドは無視します }gorm.Model
gorm.ModelはID,CreatedAt,UpdatedAt,DeletedAtをフィールドに持つ構造体です。// gorm.Modelの定義 type Model struct { ID uint `gorm:"primary_key"` CreatedAt time.Time UpdatedAt time.Time DeletedAt *time.Time }
IDフィールドはGORMにおいて特別な意味を持ちます。全てのIDは自動で主キーとして扱われます。
CreatedAtフィールドはレコードが初めて作成された時に自動で設定されます。db.Create(&user) // `CreatedAt`には現在時刻が設定されます
UpdatedAtフィールドはレコードが更新された時に自動で設定されます。db.Save(&user) // `UpdatedAt`に現在時刻が設定されます
DeletedAtフィールドはレコードが削除された時に自動で設定されます。db.Delete(&user) // `DeletedAt`に現在時刻が設定されますGoでは構造体を入れ子で定義できるので、
gorm.Modelを独自のモデルに組み込めば、これらのフィールドを自前で定義する必要はありません。type User struct { gorm.Model Name string }もちろん、自前で定義してもよいです。
type User struct { ID int Name string }タグ
GORM用のタグ(
gorm:)を使って主キーやら制約やらを色々設定できます。
タグの一覧はこちらを参照ください。また、複数のフィールドに
primary_keyを指定すると複合主キーになります。type Product struct { ID string `gorm:"primary_key"` LanguageCode string `gorm:"primary_key"` Code string Name string }タグ自体はアプリケーションの動作に直接影響しませんが、主に後述するマイグレーションで効果を発揮します。
マイグレーション
自動マイグレーション
モデル定義に合わせた自動マイグレーション機能が用意されています。
db.AutoMigrate(&User{})しかし、プロダクションでしっかり使うには不十分です。
理由としては、不足しているカラムやインデックスの生成はするが、カラムの削除まではやってくれないからです。
Goには他にマイグレーションライブラリが豊富に用意されていますので、そちらを利用しましょう。スキーマ操作
テーブル系
テーブルの存在確認
// `User`モデルのテーブルが存在するかどうか確認します db.HasTable(&User{}) // `usersテーブルが存在するかどうか確認します db.HasTable("users")テーブルの作成
// `User`モデルのテーブルを作成します db.CreateTable(&User{}) // `users`テーブル作成時に、SQL文に`ENGINE=InnoDB`を付与します db.Set("gorm:table_options", "ENGINE=InnoDB").CreateTable(&User{})テーブルの削除
// `User`モデルのテーブルを削除します db.DropTable(&User{}) // `users`テーブルを削除します db.DropTable("users") // `User`モデルのテーブルと`products`テーブルを削除します db.DropTableIfExists(&User{}, "products")カラム系
カラムの型変更
// `User`モデルのdescriptionカラムのデータ型を`text`に変更します db.Model(&User{}).ModifyColumn("description", "text")カラムの削除
// `User`モデルのdescriptionカラムを削除します db.Model(&User{}).DropColumn("description")インデックス系
インデックスの追加
// `name`カラムのインデックスを`idx_user_name`という名前で追加します db.Model(&User{}).AddIndex("idx_user_name", "name") // `name`,`age`のインデックスを`idx_user_name_age`という名前で追加します db.Model(&User{}).AddIndex("idx_user_name_age", "name", "age") // ユニークインデックスを追加します db.Model(&User{}).AddUniqueIndex("idx_user_name", "name") // 複数カラムのユニークインデックスを追加します db.Model(&User{}).AddUniqueIndex("idx_user_name_age", "name", "age")インデックスの削除
// インデックスを削除します db.Model(&User{}).RemoveIndex("idx_user_name")外部キー系
外部キーの追加
// 外部キーを追加します // パラメータ1 : 外部キー // パラメータ2 : 対象のテーブル(id) // パラメータ3 : ONDELETE // パラメータ4 : ONUPDATE db.Model(&User{}).AddForeignKey("city_id", "cities(id)", "RESTRICT", "RESTRICT")外部キーの削除
db.Model(&User{}).RemoveForeignKey("city_id", "cities(id)")テーブル名のルール
モデル名の複数形
モデルからマイグレーションする場合は、デフォルトでモデル名の複数形がテーブル名になります。
type User struct {} // `デフォルトのテーブル名は`users`です複数形の設定をやめたい場合は以下で無効化できます。
// テーブル名の複数形化を無効化します。trueにすると`User`のテーブル名は`user`になります db.SingularTable(true)テーブル名を明示的に指定
CreateTable関数使用時にTable関数で明示的にテーブル名を指定することができます。
// User構造体の定義を使って`deleted_users`テーブルを作成します db.Table("deleted_users").CreateTable(&User{})テーブル名命名規則を指定
DefaultTableNameHandler関数でデフォルトのテーブル名を設定できます。
以下は、テーブル名の先頭にprefix_という文字列を付与する例です。gorm.DefaultTableNameHandler = func (db *gorm.DB, defaultTableName string) string { return "prefix_" + defaultTableName; }カラム名のルール
モデルからマイグレーションする場合は、デフォルトでカラム名はモデルのフィールド名のスネーク形式になります。
type User struct { ID uint // カラム名は`id` Name string // カラム名は`name` Birthday time.Time // カラム名は`birthday` CreatedAt time.Time // カラム名は`created_at` }明示的にカラム名を設定する場合はタグで指定できます。
// カラム名の上書き type Animal struct { AnimalId int64 `gorm:"column:beast_id"` // カラム名を`beast_id`に設定します Birthday time.Time `gorm:"column:day_of_the_beast"` // カラム名を`day_of_the_beast`に設定します Age int64 `gorm:"column:age_of_the_beast"` // カラム名を`age_of_the_beast`に設定します }データ操作(CRUD)
INSERT
Create関数でデータを挿入します。
var animal = Animal{Age: 99, Name: ""} db.Create(&animal) // INSERT INTO animals("age") values('99');SELECT
様々な取得方法
取得方法が複数用意されています。
取得した情報は引数で与えたモデルに格納されます。(取得方法①)全てのレコードを取得
Find関数で全レコードを取得します。
db.Find(&users) //// SELECT * FROM users;(取得方法②)カラムを指定した取得
Select関数でカラムを指定します。
Table関数でテーブルを指定することもできます。db.Select("name, age").Find(&user) //// SELECT name, age FROM users; db.Select([]string{"name", "age"}).Find(&user) //// SELECT name, age FROM users; db.Table("users").Select("COALESCE(age,?)", 42).Rows() //// SELECT COALESCE(age,'42') FROM users;(取得方法③)最初のレコードを取得(ソート)
First関数で主キーでソートされた最初のレコードを一行取得します。
db.First(&user) //// SELECT * FROM users ORDER BY id LIMIT 1;(取得方法④)最後のレコードを取得(ソート)
Last関数で主キーでソートされた最後のレコードを一行取得します。
db.Last(&user) //// SELECT * FROM users ORDER BY id DESC LIMIT 1;(取得方法⑤)最初のレコードを取得(ソートなし)
Take関数でソートなしで最初のレコードを一行取得します。
db.Take(&user) //// SELECT * FROM users LIMIT 1;WHERE
Where関数で条件を指定します。
プレースホルダを使えます。// 条件に一致した最初のレコードを取得します db.Where("name = ?", "jinzhu").First(&user) //// SELECT * FROM users WHERE name = 'jinzhu' limit 1; // 条件に一致したすべてのレコードを取得します db.Where("name = ?", "jinzhu").Find(&user) //// SELECT * FROM users WHERE name = 'jinzhu'; // <> db.Where("name <> ?", "jinzhu").Find(&user) // IN db.Where("name in (?)", []string{"jinzhu", "jinzhu 2"}).Find(&user) db.Where([]int64{20, 21, 22}).Find(&users) //// SELECT * FROM users WHERE id IN (20, 21, 22); // LIKE db.Where("name LIKE ?", "%jin%").Find(&user) // AND db.Where("name = ? AND age >= ?", "jinzhu", "22").Find(&user) // BETWEEN db.Where("created_at BETWEEN ? AND ?", lastWeek, today).Find(&user)構造体やマップをWhereに指定すると、そのまま条件として扱われます。
// Struct db.Where(&User{Name: "jinzhu", Age: 20}).First(&user) //// SELECT * FROM users WHERE name = "jinzhu" AND age = 20 LIMIT 1; // Map db.Where(map[string]interface{}{"name": "jinzhu", "age": 20}).Find(&user) //// SELECT * FROM users WHERE name = "jinzhu" AND age = 20;Not
db.Not("name", "jinzhu").First(&user) //// SELECT * FROM users WHERE name <> "jinzhu" LIMIT 1;Or
db.Where("role = ?", "admin").Or("role = ?", "super_admin").Find(&users) //// SELECT * FROM users WHERE role = 'admin' OR role = 'super_admin';ソート
Order関数でソートします。
db.Order("age desc, name").Find(&users) //// SELECT * FROM users ORDER BY age desc, name; // Multiple orders db.Order("age desc").Order("name").Find(&users) //// SELECT * FROM users ORDER BY age desc, name; // ReOrder db.Order("age desc").Find(&users1).Order("age", true).Find(&users2) //// SELECT * FROM users ORDER BY age desc; (users1) //// SELECT * FROM users ORDER BY age; (users2)Limit
Limit関数で取得件数を指定します。
db.Limit(3).Find(&users) //// SELECT * FROM users LIMIT 3; // Cancel limit condition with -1 db.Limit(10).Find(&users1).Limit(-1).Find(&users2) //// SELECT * FROM users LIMIT 10; (users1) //// SELECT * FROM users; (users2)Offset
Offset関数で取得レコードの先頭いくつをスキップするかを指定します。」
db.Offset(3).Find(&users) //// SELECT * FROM users OFFSET 3; // Cancel offset condition with -1 db.Offset(10).Find(&users1).Offset(-1).Find(&users2) //// SELECT * FROM users OFFSET 10; (users1) //// SELECT * FROM users; (users2)Count
Count関数で取得レコード数を取得します。
db.Where("name = ?", "jinzhu").Or("name = ?", "jinzhu 2").Find(&users).Count(&count) //// SELECT * from USERS WHERE name = 'jinzhu' OR name = 'jinzhu 2'; (users) //// SELECT count(*) FROM users WHERE name = 'jinzhu' OR name = 'jinzhu 2'; (count) db.Model(&User{}).Where("name = ?", "jinzhu").Count(&count) //// SELECT count(*) FROM users WHERE name = 'jinzhu'; (count) db.Table("deleted_users").Count(&count) //// SELECT count(*) FROM deleted_users;Group
Group関数で指定カラムでのグループ化します。
rows, err := db.Table("orders").Select("date(created_at) as date, sum(amount) as total").Group("date(created_at)").Rows() for rows.Next() { ... }Having
Having関数でグループ化したものを条件判定します。
rows, err := db.Table("orders").Select("date(created_at) as date, sum(amount) as total").Group("date(created_at)").Having("sum(amount) > ?", 100).Rows() for rows.Next() { ... } type Result struct { Date time.Time Total int64 } db.Table("orders").Select("date(created_at) as date, sum(amount) as total").Group("date(created_at)").Having("sum(amount) > ?", 100).Scan(&results)FirstOrInit
FirstOrInit関数で、指定した条件でレコードが存在していた場合は最初のレコードを取得しモデルを初期化します。存在しなければその条件でモデルを初期化します。
// Found db.Where(User{Name: "Jinzhu"}).FirstOrInit(&users) //// user -> User{Id: 111, Name: "Jinzhu", Age: 20} db.FirstOrInit(&user, map[string]interface{}{"name": "jinzhu"}) //// user -> User{Id: 111, Name: "Jinzhu", Age: 20} // Unfound db.FirstOrInit(&user, User{Name: "non_existing"}) //// user -> User{Name: "non_existing"}存在しなかった場合に、追加する情報を増やす場合はAttrs関数を併用します。
// Unfound db.Where(User{Name: "non_existing"}).Attrs(User{Age: 20}).FirstOrInit(&users) //// SELECT * FROM USERS WHERE name = 'non_existing'; //// user -> User{Name: "non_existing", Age: 20} db.Where(User{Name: "non_existing"}).Attrs("age", 20).FirstOrInit(&users) //// SELECT * FROM USERS WHERE name = 'non_existing'; //// user -> User{Name: "non_existing", Age: 20} // Found db.Where(User{Name: "Jinzhu"}).Attrs(User{Age: 30}).FirstOrInit(&users) //// SELECT * FROM USERS WHERE name = jinzhu'; //// user -> User{Id: 111, Name: "Jinzhu", Age: 20}また、存在するしないに関わらずモデルを設定する場合はAssign関数を使用します。
// Unfound db.Where(User{Name: "non_existing"}).Assign(User{Age: 20}).FirstOrInit(&users) //// user -> User{Name: "non_existing", Age: 20} // Found db.Where(User{Name: "Jinzhu"}).Assign(User{Age: 30}).FirstOrInit(&users) //// SELECT * FROM USERS WHERE name = jinzhu'; //// user -> User{Id: 111, Name: "Jinzhu", Age: 30}FirstOrCreate
FirstOrCreate関数で、指定した条件でレコードが存在していた場合は最初のレコードを取得しモデルを初期化します。存在しなければその条件でレコードを保存します。
// Found db.Where(User{Name: "Jinzhu"}).FirstOrCreate(&users) //// user -> User{Id: 111, Name: "Jinzhu"} // Unfound db.FirstOrCreate(&users, User{Name: "non_existing"}) //// INSERT INTO "users" (name) VALUES ("non_existing"); //// user -> User{Id: 112, Name: "non_existing"}存在しなかった場合に、追加する情報を増やす場合はAttrs関数を併用します。
// Unfound db.Where(User{Name: "non_existing"}).Attrs(User{Age: 20}).FirstOrCreate(&users) //// SELECT * FROM users WHERE name = 'non_existing'; //// INSERT INTO "users" (name, age) VALUES ("non_existing", 20); //// user -> User{Id: 112, Name: "non_existing", Age: 20} // Found db.Where(User{Name: "jinzhu"}).Attrs(User{Age: 30}).FirstOrCreate(&users) //// SELECT * FROM users WHERE name = 'jinzhu'; //// user -> User{Id: 111, Name: "jinzhu", Age: 20}また、存在するしないに関わらずレコードを挿入あるいは更新する場合はAssign関数を使用します。
// Unfound db.Where(User{Name: "non_existing"}).Assign(User{Age: 20}).FirstOrCreate(&users) //// SELECT * FROM users WHERE name = 'non_existing'; //// INSERT INTO "users" (name, age) VALUES ("non_existing", 20); //// user -> User{Id: 112, Name: "non_existing", Age: 20} // Found db.Where(User{Name: "jinzhu"}).Assign(User{Age: 30}).FirstOrCreate(&users) //// SELECT * FROM users WHERE name = 'jinzhu'; //// UPDATE users SET age=30 WHERE id = 111; //// user -> User{Id: 111, Name: "jinzhu", Age: 30}取得結果に対しての処理
RowとRows
取得結果は
*sql.Rowや*sql.Rowsとして取得できます。row := db.Table("users").Where("name = ?", "jinzhu").Select("name, age").Row() // (*sql.Row) row.Scan(&name, &age) rows, err := db.Model(&User{}).Where("name = ?", "jinzhu").Select("name, age, email").Rows() // (*sql.Rows, error) defer rows.Close() for rows.Next() { ... rows.Scan(&name, &age, &email) ... }また、
sql.Rowsをモデルに変換することもできます。rows, err := db.Model(&User{}).Where("name = ?", "jinzhu").Select("name, age, email").Rows() // (*sql.Rows, error) defer rows.Close() for rows.Next() { var user User // ScanRowsは1行をuserに変換します db.ScanRows(rows, &user) // 何らかの処理を行います }別のモデルに格納
例えば、Resultという適当なモデルを用意して、それに格納することも可能です。
type Result struct { Name string Age int } var result Result db.Table("users").Select("name, age").Where("name = ?", 3).Scan(&result) // Raw SQL db.Raw("SELECT name, age FROM users WHERE name = ?", 3).Scan(&result)特定カラムのみ抽出
値が格納されているモデルから特定カラムを抽出するにはPluck関数を使用します。
var ages []int64 db.Find(&users).Pluck("age", &ages) var names []string db.Model(&User{}).Pluck("name", &names) db.Table("deleted_users").Pluck("name", &names)UPDATE
全フィールドの更新
Save関数で全フィールドを更新します。
db.First(&user) user.Name = "jinzhu 2" user.Age = 100 db.Save(&user) //// UPDATE users SET name='jinzhu 2', age=100, birthday='2016-01-01', updated_at = '2013-11-17 21:34:10' WHERE id=111;特定のカラムのみを更新
UpdateあるいはUpdates関数で特定のカラムのみを更新します。
// nameカラムの値を"hello"に更新します db.Model(&user).Update("name", "hello") //// UPDATE users SET name='hello', updated_at='2013-11-17 21:34:10' WHERE id=111; // 条件付き(active==trueならば)でnameカラムの値を"hello"に更新します db.Model(&user).Where("active = ?", true).Update("name", "hello") //// UPDATE users SET name='hello', updated_at='2013-11-17 21:34:10' WHERE id=111 AND active=true; // `map` で複数のフィールドを更新します(対象のフィールドのみ) db.Model(&user).Updates(map[string]interface{}{"name": "hello", "age": 18, "actived": false}) //// UPDATE users SET name='hello', age=18, actived=false, updated_at='2013-11-17 21:34:10' WHERE id=111; // `struct` で複数のフィールドを更新します(空ではないフィールドのみ) db.Model(&user).Updates(User{Name: "hello", Age: 18}) //// UPDATE users SET name='hello', age=18, updated_at = '2013-11-17 21:34:10' WHERE id = 111;DELETE
論理削除
テーブルに
DeletedAtフィールドが存在する場合に、Delete関数を実行すると自動で論理削除になります。db.Delete(&user) //// UPDATE users SET deleted_at="2013-10-29 10:23" WHERE id = 111;物理削除
テーブルに
DeletedAtフィールドが存在する場合に物理削除したい場合は、Unscoped().Delete関数を利用します。db.Unscoped().Delete(&order) //// DELETE FROM orders WHERE id=10;また、テーブルに
DeletedAtフィールドが存在しない場合に、Delete関数を実行すると物理削除になります。db.Delete(&email) //// DELETE from emails where id=10;素のSQLを実行する
SELECTはRaw関数、その他はExec関数で素のSQLを引数に渡して実行します。
type Result struct { Name string Age int } var result Result db.Raw("SELECT name, age FROM users WHERE name = ?", 3).Scan(&result) db.Exec("DROP TABLE users;") db.Exec("UPDATE orders SET shipped_at=? WHERE id IN (?)", time.Now(), []int64{11,22,33})素のSQLも実行結果は
*sql.Rowや*sql.Rowsとして取得できます。rows, err := db.Raw("select name, age, email from users where name = ?", "jinzhu").Rows() // (*sql.Rows, error) defer rows.Close() for rows.Next() { ... rows.Scan(&name, &age, &email) ... }副問い合わせ
db.Where("amount > ?", DB.Table("orders").Select("AVG(amount)").Where("state = ?", "paid").QueryExpr()).Find(&orders) // SELECT * FROM "orders" WHERE "orders"."deleted_at" IS NULL AND (amount > (SELECT AVG(amount) FROM "orders" WHERE (state = 'paid')))テーブルの結合
Joins関数で結合するテーブルと条件を指定します。
結合結果はRowsでもモデルでもどちらにでも格納可能です。rows, err := db.Table("users").Select("users.name, emails.email").Joins("left join emails on emails.user_id = users.id").Rows() for rows.Next() { ... } db.Table("users").Select("users.name, emails.email").Joins("left join emails on emails.user_id = users.id").Scan(&results)以下は3テーブル結合する例です。
// multiple joins with parameter db.Joins("JOIN emails ON emails.user_id = users.id AND emails.email = ?", "jinzhu@example.org").Joins("JOIN credit_cards ON credit_cards.user_id = users.id").Where("credit_cards.number = ?", "411111111111").Find(&user)トランザクション
トランザクション中の即時メソッド
デフォルトではデータの整合性を保つために、即時メソッドとトランザクションの関係は1:1になっています。
1つのトランザクション内で複数の即時メソッドを実行するための操作は以下です。// トランザクションを開始します tx := db.Begin() // データベース操作をトランザクション内で行います(ここからは'db'でなく'tx'を使います) tx.Create(...) // ... // エラーが起きた場合はトランザクションをロールバックします tx.Rollback() // もしくはトランザクションをコミットします tx.Commit()具体例:
func CreateAnimals(db *gorm.DB) error { // Note the use of tx as the database handle once you are within a transaction tx := db.Begin() defer func() { if r := recover(); r != nil { tx.Rollback() } }() if err := tx.Error; err != nil { return err } if err := tx.Create(&Animal{Name: "Giraffe"}).Error; err != nil { tx.Rollback() return err } if err := tx.Create(&Animal{Name: "Lion"}).Error; err != nil { tx.Rollback() return err } return tx.Commit().Error }フック
フックとは、各トランザクション中で自動で実行されるメソッドです。
モデルごとにフックを定義できます。INSERT
トランザクション内の流れ
- トランザクションの開始
- BeforeSave
- BeforeCreate
- 関連の保存前
CreatedAtとUpdatedAtのタイムスタンプ更新- データの保存処理
- デフォルト値か空値のフィールドの再ロード
- 関連の保存後
- AfterCreate
- AfterSave
- トランザクションのコミットもしくはロールバック
フック例
func (u *User) BeforeSave() (err error) { if u.IsValid() { err = errors.New("不正な値を保存できません") } return } func (user *User) BeforeCreate(scope *gorm.Scope) error { scope.SetColumn("ID", uuid.New()) return nil } func (u *User) AfterCreate(scope *gorm.Scope) (err error) { if u.ID == 1 { scope.DB().Model(u).Update("role", "admin") } return }SELECT
トランザクション内の流れ
- データベースからのデータロード
- プリロード(eager loading)
- AfterFind
フック例
unc (u *User) AfterFind() (err error) { if u.MemberShip == "" { u.MemberShip = "user" } return }UPDATE
トランザクション内の流れ
- トランザクションの開始
- BeforeSave
- BeforeUpdate
- データの更新処理
UpdatedAtのタイムスタンプ更新- モデルの持つ情報を保存
- 関連の保存後
- AfterUpdate
- AfterSave
- トランザクションのコミットもしくはロールバック
フック例
func (user *User) BeforeSave(scope *gorm.Scope) (err error) { if pw, err := bcrypt.GenerateFromPassword(user.Password, 0); err == nil { scope.SetColumn("EncryptedPassword", pw) } } func (u *User) BeforeUpdate() (err error) { if u.readonly() { err = errors.New("読み出し専用ユーザーです") } return } // Updating data in same transaction func (u *User) AfterUpdate(tx *gorm.DB) (err error) { if u.Confirmed { tx.Model(&Address{}).Where("user_id = ?", u.ID).Update("verfied", true) } return }DELETE
トランザクション内の流れ
- トランザクションの開始
- BeforeDelete
- データの削除処理
- AfterDelete
- トランザクションのコミットもしくはロールバック
フック例
// 同一トランザクション内でデータを更新します func (u *User) AfterDelete(tx *gorm.DB) (err error) { if u.Confirmed { tx.Model(&Address{}).Where("user_id = ?", u.ID).Update("invalid", false) } return }メソッドチェーン
メソッドチェーンは条件を鎖つなぎで指定する方法です。
条件だけなので、即時メソッド(Create, First, Find, Take, Save, UpdateXXX, Delete, Scan, Row, Rows… 等のCRUD操作をするメソッド)が実行されるまで実行されません。db, err := gorm.Open("postgres", "user=gorm dbname=gorm sslmode=disable") // 新規リレーションを作成します tx := db.Where("name = ?", "jinzhu") // さらにフィルタを追加します if someCondition { tx = tx.Where("age = ?", 20) } else { tx = tx.Where("age = ?", 30) } if yetAnotherCondition { tx = tx.Where("active = ?", 1) }また、条件を関数化し、Scopes関数でメソッドチェーンにすることも可能です。
func AmountGreaterThan1000(db *gorm.DB) *gorm.DB { return db.Where("amount > ?", 1000) } func PaidWithCreditCard(db *gorm.DB) *gorm.DB { return db.Where("pay_mode_sign = ?", "C") } func PaidWithCod(db *gorm.DB) *gorm.DB { return db.Where("pay_mode_sign = ?", "C") } func OrderStatus(status []string) func (db *gorm.DB) *gorm.DB { return func (db *gorm.DB) *gorm.DB { return db.Scopes(AmountGreaterThan1000).Where("status in (?)", status) } } db.Scopes(AmountGreaterThan1000, PaidWithCreditCard).Find(&orders) // クレジットカードの注文かつ1000件以上の注文を取得します db.Scopes(AmountGreaterThan1000, PaidWithCod).Find(&orders) // CODによる注文かつ1000件以上の注文を取得します db.Scopes(AmountGreaterThan1000, OrderStatus([]string{"paid", "shipped"})).Find(&orders) // 支払い済みで発送済みの注文かつ1000件以上の注文を取得しますエラーハンドリング
即時メソッドを使う際はエラーハンドリングをすべきです。
if err := db.Where("name = ?", "jinzhu").First(&user).Error; err != nil { // エラーハンドリング... }GORMはレコードが見つからなかった時だけRecordNotFoundという特別なエラーを返します。
より親切なエラーハンドリングができます。if err := db.Where("name = ?", "jinzhu").First(&user).Error; gorm.IsRecordNotFoundError(err) { // レコードが見つかりません }ログ
デフォルトモードではエラーが起きた場合のみ出力します。
// ロガーを有効にすると、詳細なログを表示します db.LogMode(true) // ロガーを無効化すると、エラーさえも出力しなくなります db.LogMode(false) // 1回だけ操作をデバッグしてこの操作中の詳細なログのみ出力します db.Debug().Where("name = ?", "jinzhu").First(&User{})まとめ
- GORMはMySQL/PostgreSQL/sqlite/SQLServerに対応している
- モデル(構造体)を中心にデータ操作を行う
- gorm用のタグでフィールドに制約を付けられる
- GORMのマイグレーションは基本的に使わない
- データ操作時のGORMの関数の呼び出し順が実際の解析と同じ順で分かりやすい
- 投稿日:2019-05-07T07:54:21+09:00
OpenAPI3を使ってみよう!Go言語を例にクライアントとスタブの自動生成までをまとめます
はじめに
本記事はZOZOテクノロジーズのTECH BLOGにも同じ内容で投稿しています。
よろしければ他の記事もご覧ください。
こんにちは!
@gold_kouと申します。いきなりですが、皆さんはAPI仕様書をどのように管理されていらっしゃいますか?
Confluence、Wiki、Markdown、Spreadsheet、Excelなど色々手段やツールはあると思います。私が担当しているプロジェクトではOpenAPIを導入しています。
この記事ではOpenAPIの基本と実際に導入して得られたノウハウをご紹介いたします。
OpneAPIの恩恵はただの管理の仕方にとどまらないので、ぜひこの記事を読んで開発効率化のお役に立てばと思います。また、弊社のテックブログで以前、OpenAPI(Swagger)のバージョン2系に関する開発効率を上げる!Swaggerの記法まとめ や 開発効率を上げる!Swaggerで作るWEB APIモック が投稿されておりますが、今回は対象バージョンが3系となります。
OpenAPI概要
OpenAPI Specification(OAS)
OASはREST-APIの標準仕様です。OASのことを単にOpenAPIと呼ぶこともあります。
YAMLかJSON形式で記述します。
現在はバージョン3系が最新ですので、特別な事情がない限り3系を使いましょう。
2系から3系への変更点は様々あるのですが、一番大きな変更はComponentsオブジェクト(後述)が追加されたことです。
DRYにかけるため、OpenAPIが目指している "human readable" へ近づきました。
Swagger Toolsを活用することで効率的に記述できます。OpenAPIを使うメリットとデメリット
メリット
- 効率的に記述できる
- Swagger Editorのおかげ
- 3系からより効率的に
- human readable & machine readable
- APIクライアントとサーバースタブを自動生成できる
- OpenAPI Generatorのおかげ
- スキーマ駆動開発できる
- 開発工数を削減できる
- かっこいいビジュアルのAPI仕様書を作れる
- Swagger UIのおかげ
- バージョン管理しやすい
- 書き方に統一性を持たせられる
我々がOpenAPIを導入した理由は上記メリットのうち、特に「APIクライアントとサーバースタブを自動生成できる」点に魅力を感じたためです。
スキーマ駆動開発を実践しているわけではないのですが、APIを定義すればある程度のソースコードを自動生成できる一石二鳥感は充分な選定理由だと思います。デメリット
- 学習コスト
- YAML/JSONの記法
- 自動生成のやり方
Swagger
OpenAPIを勉強するうえで避けては通れないSwaggerについて説明します。
まず歴史的な話なのですが、もともとOpenAPIの前段としてSwagger Specificationというものがありました。
それがOpenAPI Initiativeという団体に管理が移ったことで、名称がOpenAPI Specificationに変更されました。
しかし、ツールセットの開発は現在もSwaggerで行われているものもあり、ツール名には「Swagger」が名残で残っています。Swagger Tools
OpenAPIを効率的に記載するためのOSSのツールセットです。
Swagger Editor
ブラウザ上で記述するタイプのエディタです。インストール不要なので手軽に試せます。
リンクはこちらインターネット上でAPI情報を記載することに抵抗がある場合は、以下のようにローカルでDockerイメージをpullして、起動することもできます。
$ docker pull swaggerapi/swagger-editor $ docker run -d -p 80:8080 swaggerapi/swagger-editorブラウザで
localhost:80にアクセスすれば、以下が表示されます。
また、Visual Studio CodeにはSwagger Viewer(プラグイン)が用意されています。
プログラミングと同じエディタで編集できるので便利です。Swagger UI
OpenAPIに則って記述されたスキーマをAPI仕様書化するツールです。
YAMLファイルやJSONのままでは人間には見るのが辛い部分もありますが、これを使えば統一されたカッコいいUIを提供します。
Swagger EditorやSwagger Viewerの右側はこれを利用しています。
APIクライアントツールとして利用することも可能です。認証まわりも対応していますので、トークンを埋め込んで実行することもできます。Swagger Codegen
OpenAPIに則って記述されたスキーマからAPIクライアントとスタブサーバーを自動生成するツールです。
自動生成により開発コストを削減するだけでなく、スタブサーバーがあることでフロントエンドの開発もバックエンドの開発を待たずに進めることができます。いわゆるスキーマ駆動開発というやつですね。
3系対応を進めるためSwagger CodegenをフォークしたOpenAPI Generatorの開発がコミュニティドリブンで進んでいるそうです。
後述ですが、私の担当プロジェクトではOpenAPI GeneratorのDockerコンテナを使用しています。OpenAPIの基本記法(YAML)
公式サンプルを中心にYAMLでの基本記法をまとめます。
読めばなんとなくわかるのですが、一応1つずつ説明していきます。
また、サンプルには無くてもよく使う記法もいくつかピックアップします。
その他の記法や詳細は公式ドキュメントをご参照ください。ファイル名
ルートのファイル名は
openapi.ymlが推奨されていますが、それ以外に特に決まりはありません。
<システム名>.ymlとかもよく見ます。OpenAPIオブジェクト
openapiフィールドでOpenAPIのバージョンを設定します。openapi: "3.0.0"Infoオブジェクト
メタ情報を設定します。
versionフィールドでAPIドキュメントのバージョンを設定します。titleフィールドでAPIドキュメントのタイトルを設定します。descriptionフィールドで説明を設定します。termsOfServiceフィールドでサービス規約を設定します。例では、内容が長くなるのでURLになっていますね。contactフィールドで連絡先情報(name/url)を設定します。licenseフィールドでライセンス情報(name/url)を設定します。info: version: 1.0.0 title: Swagger Petstore description: A sample API that uses a petstore as an example to demonstrate features in the OpenAPI 3.0 specification termsOfService: http://swagger.io/terms/ contact: name: Swagger API Team email: apiteam@swagger.io url: http://swagger.io license: name: Apache 2.0 url: https://www.apache.org/licenses/LICENSE-2.0.htmlServerオブジェクト
APIサーバー情報を設定します。
urlフィールドでURLを設定します。今回の具体例は1つだけですが、リスト形式で設定できるため例えば、「ローカル環境用」「ステージング環境用」「プロダクション環境用」などをそれぞれ設定することも可能です。servers: - url: http://petstore.swagger.io/apiPathsオブジェクト
各エンドポイント仕様を設定します。
Path Itemオブジェクト(/petsなど)で1つ以上のパスを設定します。
Operationオブジェクト(postなど)で1つのパスの1つのメソッドの単位を設定します。
operationIdフィールドでOpenrationオブジェクトを一意にする識別IDを設定します。APIクライアントを自動生成する際に使用されます。requestBodyフィールドでリクエストボディを設定します。
required: trueとすることでリクエスト時にこのボディがあることを必須とします。contentでボディの中身を設定します。
schemaフィールドでは$refでcomponents配下に定義したスキーマを読み込み、DRYな記述ができます。もちろんここに直接記述することもできます。また、$refは外部ファイルも読み込めるため、ファイルを分割することも可能です。responsesフィールドでレスポンスを設定します。ステータスコードをキーにして、その他はdefaultとします。こちらもschemaを$refできます。- こちらの例には無いですが、
TagsオブジェクトでOperationオブジェクトをグループ化するためのタグを設定します。
nameフィールドでtag名を設定します。paths: /pets: post: description: Creates a new pet in the store. Duplicates are allowed operationId: addPet requestBody: description: Pet to add to the store required: true content: application/json: schema: $ref: '#/components/schemas/NewPet' responses: '200': description: pet response content: application/json: schema: $ref: '#/components/schemas/Pet' default: description: unexpected error content: application/json: schema: $ref: '#/components/schemas/Error'
Parameterオブジェクトでパラメータを設定します。
nameフィールドでパラメータ名を設定します。inフィールドでパラメータの場所を設定します。query/header/path/cookieのいずれかを選択します。
- query:
/items?id=###のようにURL末尾に?でパラメータを設定する場合です。- path:
/items/{itemId}のようにパス内にパラメータを埋め込む場合です。requiredフィールドでパラメータが必須かどうかを設定します。inフィールドの値がpathの場合は必然的にtrueになります。paths: /pets: get: parameters: - name: tags in: query description: tags to filter by required: false style: form schema: type: array items: type: stringpaths: /pets/{id}: get: parameters: - name: id in: path description: ID of pet to fetch required: true schema: type: integer format: int64Componentsオブジェクト
再利用する部品を定義します。
また、再利用しないとしてもリクエストボディやレスポンスは極力Componentsオブジェクトに記載することで、記載方法に統一性を持たせ可読性を向上できます。
Schemaオブジェクトでスキーマを設定します。スキーマ名(Petなど)は$refで参照する際に使用されます。スキーマ内でさらに$refして入れ子構造にすることも可能です。propertiesフィールドでプロパティ(パラメータ)を設定します。typeフィールドではinteger(整数)/number(少数)/string/boolean/array/objectのいずれかを設定します。formatフィールドではint32/int64/float/double/byte/binary/date/date-time/passwordのいずれかを設定します。typeフィールドと組み合わせます。requiredフィールドでプロパティ単位に必須パラメータを設定します。- こちらの例には無いですが、
minimumとmaximumフィールドで数値の下限上限を設定します。- こちらの例には無いですが、
exampleフィールドでそのプロパティが取りうる値を具体例として設定します。components: schemas: Pet: allOf: - $ref: '#/components/schemas/NewPet' - required: - id properties: id: type: integer format: int64 NewPet: required: - name properties: name: type: string tag: type: string Error: required: - code - message properties: code: type: integer format: int32 message: type: stringAPIクライアントとスタブサーバーを自動生成する
OpenAPIを利用するメリットの1つである自動生成についてです。
いくつか手段はありますが、今回はDockerを使用する方法です。APIクライアント
上記の具体例でも使用していた
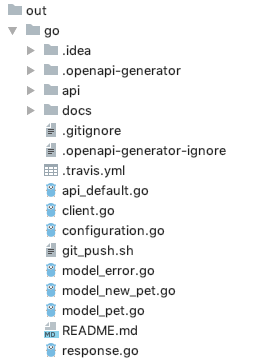
petstore-expanded.yamlからAPIクライアント(Go言語)を自動生成します。$ docker run -v ${PWD}:/local openapitools/openapi-generator-cli:v3.3.4 generate -i /local/petstore-expanded.yaml -g go -o /local/out/go [main] WARN o.o.c.ignore.CodegenIgnoreProcessor - Output directory does not exist, or is inaccessible. No file (.openapi-generator-ignore) will be evaluated. [main] INFO o.o.c.languages.AbstractGoCodegen - Environment variable GO_POST_PROCESS_FILE not defined so Go code may not be properly formatted. To define it, try `export GO_POST_PROCESS_FILE="/usr/local/bin/gofmt -w"` (Linux/Mac) [main] INFO o.o.c.languages.AbstractGoCodegen - NOTE: To enable file post-processing, 'enablePostProcessFile' must be set to `true` (--enable-post-process-file for CLI). [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/model_error.go [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/docs/Error.md [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/model_new_pet.go [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/docs/NewPet.md [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/model_pet.go [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/docs/Pet.md [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/api_default.go [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/docs/DefaultApi.md [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/api/openapi.yaml [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/README.md [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/git_push.sh [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/.gitignore [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/configuration.go [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/client.go [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/response.go [main] INFO o.o.codegen.DefaultGenerator - writing file /local/out/go/.travis.yml [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/.openapi-generator-ignore [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/.openapi-generator/VERSIONすると、カレントディレクトリ以下に下記のようなディレクトリやファイルが生成されます。
これらをもとに開発を進めていけば定型部分がだいぶ自動生成されているので、開発工数を削減できるはずです。
上記で実行したopenapitools/openapi-generator-cliイメージのgenerateコマンドのオプションは以下です。
- g: 生成コードの種類の指定(言語やFWなど)
- i: yamlファイルの指定
- o: 出力パスの指定
また、gオプションで指定できるクライアントとサーバーのgeneratorの種類は以下です。
$ docker run --rm openapitools/openapi-generator-cli:v3.3.4 list The following generators are available: CLIENT generators: - ada - android - apex - bash - c - clojure - cpp-qt5 - cpp-restsdk - cpp-tizen - csharp - csharp-dotnet2 - csharp-refactor - dart - dart-jaguar - eiffel - elixir - elm - erlang-client - erlang-proper - flash - go - groovy - haskell-http-client - java - javascript - javascript-closure-angular - javascript-flowtyped - jaxrs-cxf-client - jmeter - kotlin - lua - objc - perl - php - powershell - python - r - ruby - rust - scala-akka - scala-gatling - scala-httpclient - scalaz - swift2-deprecated - swift3 - swift4 - typescript-angular - typescript-angularjs - typescript-aurelia - typescript-axios - typescript-fetch - typescript-inversify - typescript-jquery - typescript-node SERVER generators: - ada-server - aspnetcore - cpp-pistache-server - cpp-qt5-qhttpengine-server - cpp-restbed-server - csharp-nancyfx - erlang-server - go-gin-server - go-server - haskell - java-inflector - java-msf4j - java-pkmst - java-play-framework - java-undertow-server - java-vertx - jaxrs-cxf - jaxrs-cxf-cdi - jaxrs-jersey - jaxrs-resteasy - jaxrs-resteasy-eap - jaxrs-spec - kotlin-server - kotlin-spring - nodejs-server - php-laravel - php-lumen - php-silex - php-slim - php-symfony - php-ze-ph - python-flask - ruby-on-rails - ruby-sinatra - rust-server - scala-finch - scala-lagom-server - scalatra - spring (以下省略)スタブサーバー
APIクライアント同様に、スタブサーバー(Go言語)を生成します。
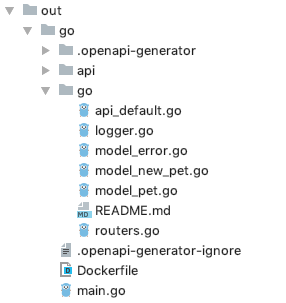
gオプションで指定するものが違うだけですね。$ docker run -v ${PWD}:/local openapitools/openapi-generator-cli:v3.3.4 generate -i /local/petstore-expanded.yaml -g go-server -o /local/out/go [main] WARN o.o.c.ignore.CodegenIgnoreProcessor - Output directory does not exist, or is inaccessible. No file (.openapi-generator-ignore) will be evaluated. [main] INFO o.o.c.languages.AbstractGoCodegen - Environment variable GO_POST_PROCESS_FILE not defined so Go code may not be properly formatted. To define it, try `export GO_POST_PROCESS_FILE="/usr/local/bin/gofmt -w"` (Linux/Mac) [main] INFO o.o.c.languages.AbstractGoCodegen - NOTE: To enable file post-processing, 'enablePostProcessFile' must be set to `true` (--enable-post-process-file for CLI). [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/go/model_error.go [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/go/model_new_pet.go [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/go/model_pet.go [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/go/api_default.go [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/api/openapi.yaml [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/main.go [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/Dockerfile [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/go/routers.go [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/go/logger.go [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/go/README.md [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/.openapi-generator-ignore [main] INFO o.o.codegen.AbstractGenerator - writing file /local/out/go/.openapi-generator/VERSIONカレントディレクトリ以下に下記のようなディレクトリやファイルが生成されます。
特にスタブとして重要なのは下記ファイルです。
リクエストが来たらStatus.OKを返すようになっています。
当然ながらビジネスロジックは記述されていません。api_default.go/* * Swagger Petstore * * A sample API that uses a petstore as an example to demonstrate features in the OpenAPI 3.0 specification * * API version: 1.0.0 * Contact: apiteam@swagger.io * Generated by: OpenAPI Generator (https://openapi-generator.tech) */ package openapi import ( "net/http" ) // AddPet - func AddPet(w http.ResponseWriter, r *http.Request) { w.Header().Set("Content-Type", "application/json; charset=UTF-8") w.WriteHeader(http.StatusOK) } // DeletePet - func DeletePet(w http.ResponseWriter, r *http.Request) { w.Header().Set("Content-Type", "application/json; charset=UTF-8") w.WriteHeader(http.StatusOK) } // FindPetById - func FindPetById(w http.ResponseWriter, r *http.Request) { w.Header().Set("Content-Type", "application/json; charset=UTF-8") w.WriteHeader(http.StatusOK) } // FindPets - func FindPets(w http.ResponseWriter, r *http.Request) { w.Header().Set("Content-Type", "application/json; charset=UTF-8") w.WriteHeader(http.StatusOK) }サーバー起動します。
$ go run main.go 2019/03/20 21:28:21 Server startedcurlリクエストすると200が返ってきました。
$ curl -s http://localhost:8080/api/pets -o /dev/null -w '%{http_code}\n' 200クライアント開発チーム用にこのスタブを残してスキーマ駆動開発にしたり、サーバーサイド側の開発工数をさげたりできます。
なお、私が所属するプロジェクトでは、一連のコマンドをmakeコマンドで実行できるようにしています。現場からのTips
ここからは実際の開発で得られたノウハウやつまずいたこと、もう少し良くしたいと考えていることをご紹介したいと思います。
定義したobjcet型のプロパティが自動生成されなかった
以下は実例を簡略化し、一部抜粋したものです。SampleBに関する記述であることに着目してください。
SampleB: type: object properties: status: type: integer example: 200 message: type: string example: successfully resource: type: object properties: count: type: integer example: 1 results: type: array items: type: string example: "1234567890ABCDEFGHIJKLMNOPQRSTUVWXYZ"以下が自動生成されたモデルです。
Resourceの型に着目してください。なぜか、定義したSampleBでなく別のSampleAのポインタ型のフィールドが宣言されています。package httpmodel type SampleB struct { Status int32 `json:"status"` Message string `json:"message"` Resource * SampleAResource `json:"resource,omitempty"` //あれ、なんでAなの? }原因は、既にプロパティ名とexample値が同一のobject型のプロパティがあることでした。
どうやら、OpenAPI Generatorはモデル自動生成時に同一のものがある場合は、YAMLファイル上でより上に定義されたものをDRYに生成してくれるようです。
ちなみに、あえてDRYにしたくない場合は、$refを使ったり、exmaple値を異なるものにすることでも回避できます。array型プロパティを持つモデルが期待通りに生成されなかった
以下のように
type: arrayを持つスキーマを定義し、モデルを自動生成したところ、期待通りにスライスをプロパティとしてもつモデルを生成できませんでした。
(以下は実例を簡略化し、一部抜粋したものです)components: schemas: RequestA: description: こちらはサンプルです type: array items: properties: sku30: description: こちらはサンプルです example: 123abc type: string required: - sku30// RequestA - こちらはサンプルです type RequestA struct { Inner []map[string]interface{} `json:"inner,omitempty"` }原因はこちらのPRでしょうか。
トップレベルにarrayかmapのプロパティがあるとgenerateしてくれないようです。解決策は2通りあります。
1つ目は、.openapi-generator-ignoreファイルに自動生成を無視するファイルを指定し、手動で実装する方法です。これを多用しすぎると自動生成の恩恵を受けられないため、OpenAPIを利用するメリットがかなり薄れてしまいます。
2つ目は、下記のように、type: arrayをtype: objectで包む方法です。モデルが1つ増え、独自型のスライスのプロパティを持つことになります。components: schemas: RequestA: description: こちらはサンプルです type: object properties: inner: type: array items: properties: sku30: description: こちらはサンプルです example: 1234567890ABCDEFGHIJKLMNOPQRSTUVWXYZ type: string required: - sku30 type: object// RequestA - こちらはサンプルです type RequestA struct { Inner [] RequestAInner `json:"inner,omitempty"` }type RequestAInner struct { // こちらはサンプルです Sku30 string `json:"sku30"` }命名に気を使う必要がある
スキーマ名や
operationIdフィールド名などは自動生成コードでのstruct名やフィールド名、ファイル名などに反映されるものです。したがって、一意に認識しやすい名前をつける必要があります。
これを怠るとソースコードの可読性低下につながってしまいます。
こちらはOpenAPIならではの悩みです。バリデーションを手動で実装している
これは、今後改善したいと考えていることです。
現在、ozzo-validaitonというバリデーションのライブラリを使用して、API仕様書の情報を見ながらバリデーションを手動で実装しています。
これは二度手間感がある上、人が実装しているので、バリデーション漏れなどのミスが発生する可能性もあります。
例えば、Rubyであればoas_parserとjson_schemaというgemを組み合わせる方法があります。OpenAPIで定義したファイルのrequiredやtype、example値などの情報を使って自動でバリデーションを自動生成できます。Go言語でも同様のことができるライブラリを探そうと考えていますリクエストパラメータのバリデーションライブラリの選定
go-playground/validatorは、最もポピュラーなGo言語のバリデーションライブラリです。しかし、今回は別のライブラリ(上述)を採用しました。
理由としては、OpenAPIとの相性が悪いと判断したためです。
go-playground/validatorはstructにバリデーション用のタグを記述するスマートな方法です。しかしながら、モデルを自動生成した際に上書きされてタグの記述内容が消失するケースもあります。
自動生成した後にタグを記述し、.openapi-generator-ignoreにファイル名を追記すれば解決するのですが、開発時の運用が複雑になってしまうと判断し、採用を見送りました。ここでの連携ができれば利便性がすごく高いと思います。API仕様書とソースコードの乖離
開発時にAPIの仕様変更にドキュメントが追従できず、API仕様とソースコードで乖離が発生する経験はありますでしょうか。これは実装者とレビュアが普段の開発で注意し、定期的に乖離の発生状況を確認するべきでしょう。
OpenAPIを有効活用すれば乖離の発生を抑えることができます。
なぜならば、リクエストとレスポンス用のモデルは定義ファイルにしたがって自動生成されるため、レスポンスでの乖離は発生しません。
リクエストに関しては、リクエストパラメータのバリデーションに関して自動生成を導入していないケースでは、乖離が発生し得ます。例えばGo言語などの静的言語で実装しているのであれば、型の確認は可能ですが、ビジネスロジック面でのチェック(値の範囲など)まではできません。まとめ
今回はOpenAPIの基本記法と、実際の開発現場で得られたつまずきやTipsをいくつかご紹介しました。
OpenAPIは単にAPI定義をスマートに記述できるだけでなく、そこからある程度まで自動生成してくれます。
良さそうだなと感じたら、OpenAPIを使ってみてください。


- 投稿日:2019-05-07T07:54:04+09:00
いまさらだけどGoの並行処理と排他制御を分かりやすくまとめてみた
はじめに
この記事ではgoroutineおよび関連性の高いsyncパッケージの基本知識や使い方をまとめます。
Goの基本的な文法はざっと触れたが、「goroutine」、「WaitGroup」、「channel」、「Mutex」などの言葉を聞いて全く心配ないとは言い切れない人向けの記事です。
残念ながら、メモリやCPU、プロセスなどのOSに近いところまでは踏み入れません。goroutineは簡単だとよく聞きますが、そもそも並行処理そのものが難しいので1つずつ理解してきましょう!
本記事での動作確認環境は以下です。
$ go version go version go1.11.4 darwin/amd64Goでの並行処理
ネットワーク通信などで待ち時間の大きい処理を非同期に行いたい、直列で動作させる必要がない処理群を高速に終わらせたいなどを理由に並行処理を使うことが多いと思います。
Goではgoroutineと呼ばれる軽量スレッドを簡単に動かせます。なぜ「軽量」か
- メモリ消費量が少ない
- goroutineの生成と破棄コストが低い
- コンテキストスイッチのコストが低い
詳細はgoroutineはなぜ軽量なのかをご参照ください。
並行処理と並列処理の違い
たくさんの記事で説明されているので省略します。Goは並行処理です。
並行処理、並列処理のあれこれ
「なんとなく」で終わらせてませんか?"いらすと"で覚える並列と並行の違いgoroutineを動かしてみる
Goではgo文に関数を指定することで、簡単に並行処理を実装できます。
言語名まんまの構文が用意されているあたり、よほど並行処理に力を入れている雰囲気を感じます。下記では、main関数内でhoge関数を並行処理させています。
time.Sleepしているのは、hoge関数が並行処理開始される前に、main関数が終了してしまうためです。func main() { fmt.Println("main") go hoge() //goroutine time.Sleep(time.Second) } func hoge() { fmt.Println("hoge") }実行結果main hogeまた、go文には無名関数を指定することも可能です。
関数呼び出しなので、末尾に()を付け忘れないようにしましょう。func main() { fmt.Println("main") go func() { fmt.Println("hoge") }() // ()を忘れずに time.Sleep(time.Second) }実行結果main hogechannel
channelは複数goroutine間で「簡単に安全にデータのやりとりを行うための特別なデータ構造」です。
データ(channel)の送受信をスレッド間で行うため、明示的な排他制御をプログラマが実装する必要がありません。
channelの仕組みが無い他言語では、複数スレッド間でデータのやりとりを行うために排他制御を明示的に行う必要がありました。(後述しますが、GoにもMutexでその仕組みを実現することもできます。)
Goの並行処理に関するスローガンDo not communicate by sharing memory; instead, share memory by communicating.をchannelが実現する格好になっています。基本文法
宣言
下記はint型のchannelを作る例です。
var ch chan intmakeコマンドで生成することも可能です。
ch := make(chan int)読み書き
channelへの書き込みは下記のようにします。
ch <- 1channelからの読み込みは変数を用意して、そこに代入します。
tmp := <-ch最初は記法に慣れないかもしれませんが、
<-を矢印と思えばイメージが湧きやすいと思います。channelとgoroutineの組み合わせ
channelとgoroutineを組み合わせた簡単な例を示します。
他ルーチンで宣言したchannelは共有できます。func main() { ch := make(chan int) go func() { ch <- 1 }() a := <-ch fmt.Println(a) }実行結果1バッファ付きchannel
バッファ付きchannelとは、指定した数の書き込み用バッファを持つchannelです。
キューのような性質を持ち、FIFO(先入れ先出し)となります。
バッファの上限まで書き込んだら、読み込まれるまでは書き込みがブロックされ、読み込まれて空きができたら、再びその空きの分だけ書き込めます。下記の例では、サブルーチンで
chに1〜5までしか書き込めないので、それ以降の書き込み処理は読み込まれるまでいったんブロックになります。
次に、メインルーチンの1つ目のforループで1〜5がchから読み込まれて空きができたので、残りの6〜10がサブルーチンで再び書き込まれます。
次に、メインルーチンの2つ目のforループで6〜10がchから読み込まれます。func main() { ch := make(chan int, 5) // バッファ付きchannel宣言 go func() { for i := 1; i <= 10; i++ { ch <- i } }() // 念のためchにデータが書き込まれるのを待つ time.Sleep(time.Second) // 1〜5を読み込んで出力 for i := 1; i <= 5; i++ { tmp := <-ch fmt.Println(tmp) } // 6〜10がchに書き込まれるのを待つ fmt.Println("waiting") time.Sleep(time.Second) // 6〜10を読み込んで出力 for i := 1; i <= 5; i++ { tmp := <-ch fmt.Println(tmp) } }実行結果1 2 3 4 5 waiting 6 7 8 9 10バッファに空きがないchannelに書き込もうとするとランタイムパニックになります。
func main() { ch := make(chan int, 2) ch <- 1 ch <- 2 ch <- 3 }実行結果fatal error: all goroutines are asleep - deadlock!channelに格納されているデータの個数を調べる
len関数でデータの個数を調べられます。(バッファサイズではありません。)
func main() { ch := make(chan int, 5) ch <- 1 ch <- 2 fmt.Println(len(ch)) }実行結果2channelを閉じる
close関数でchannelを閉じます。
channelを閉じると、すべてのgoroutineへ通知が飛びます。
channelは一度しか閉じることができません。閉じたchannelへの書き込み
閉じたchannelへデータを書き込もうとするとランタイムパニックになります。
func main() { ch := make(chan int, 5) ch <- 1 close(ch) ch <- 2 }実行結果panic: send on closed channel閉じたchannelからの読み込み
バッファが無いchannelの場合、closeしたchannelからデータを読み込もうとすると、ランタイムパニックを起こします。
また、<-chの2番目の戻り値でchannelが空いているかどうか(空いていればtrue、閉じているばfalse)を知ることができます。func main() { ch := make(chan int) go func() { ch <- 1 ch <- 2 ch <- 3 }() time.Sleep(time.Second) close(ch) for { a, ok := <-ch if !ok { fmt.Println("error") break } fmt.Println(a) } }実行結果error panic: send on closed channelバッファ付きchannelの場合、閉じてもchannelに値が残っている場合は、全てを読みだしてからcloseが実施されます。
最後にerrorが出力されているのは、closeされているからです。
つまり、okがtrueかfalseかの厳密の定義は「channelのバッファが空きでかつcloseであるかどうか」となります。func main() { ch := make(chan int, 3) go func() { ch <- 1 ch <- 2 ch <- 3 }() time.Sleep(time.Second) close(ch) for { a, ok := <-ch if !ok { fmt.Println("error") break } fmt.Println(a) } }実行結果1 2 3 errorselect構文
select構文を使えば、読み書き可能なchannelがある場合のみ処理を実行することができます。
case節の条件を満たせばそのcase節の処理になります。いずれのcase節にも処理が入らなかった場合は、default節の処理になります。下記の例では、1週目のforループでは
chに値が入っているためそれを読み込んで処理をしていますが、2周目のforループではchに値が入っていないため、defaultの処理に入っています。func main() { ch := make(chan string) go func() { ch <- "cat" }() time.Sleep(time.Second) for i := 0; i < 2; i++ { select { case a := <-ch: fmt.Println(a) default: fmt.Println("nothing in ch") } } }実行結果cat nothing in ch複数のcase節が実行可能な場合、どのcase節が実行されるかはランダムです。(上が優先ではないので要注意)
func main() { ch1 := make(chan string) ch2 := make(chan string) go func() { ch1 <- "cat" }() go func() { ch2 <- "dog" }() time.Sleep(time.Second) select { case a1 := <-ch1: fmt.Println(a1) case a2 := <-ch2: fmt.Println(a2) default: fmt.Println("nothing in ch") } }goroutineのキャンセル
キャンセルが必要な理由
- 後続の処理を続けるため
- 例えば外部APIを実行する際にレスポンスが異常に遅い場合はネットワーク障害などの可能性もあるためタイムアウトする必要があります。
- リソース解放のため
- goroutineをキャンセルせずに放置するとそのままリソースを消費し続ける可能性があります。
Context
goroutineのキャンセルには
context.Contextを使用します。
context.Contextは他に、リクエストスコープの変数を扱う用途でも使用されますが、Goの並行処理から外れた話になりますので、そちらは割愛させていただきます。下記はWithCancel関数を使い外部から任意のタイミングでgoroutineを停止させる例です。
func main() { // 空のcontextを生成 ctx := context.Background() // 子のcontextを作成。第二返り値を使って子のコンテキストをキャンセルできる。 ctxChild, cancel := context.WithCancel(ctx) // キャンセルされるまで無限ループするgoroutineを生成 go func() { for { select { // キャンセルされると入る処理 case <-ctxChild.Done(): fmt.Println("context done") return // キャンセルされない間の処理 default: fmt.Println("hello") } } }() // goroutineの処理が始まる前にキャンセルされるのを防ぐためスリープ time.Sleep(1 * time.Second) // キャンセル実行 cancel() time.Sleep(1 * time.Second) fmt.Println("main end") }実行結果hello hello (省略) hello context done main end外部からcancel()を呼び出してキャンセルしたからといって、goroutine自体の処理が止まるわけではありません。returnしてあげる必要があります。
他に、WithDeadline関数で指定時刻にgorouitenをキャンセルする方法やWithTimeout関数で指定時間後にgoroutineをキャンセルする方法もあります。
syncパッケージ
sync.Mutexとsync.RWMutex
Goではchannelのおかげで明示的な排他制御を記述する必要がありません。
しかし、Mutexで明示的な排他制御を記述することもできます。
これは他言語でも存在する(Javaのsynchronizedなど)伝統的なロックの仕方です。排他制御をしなかった場合
当然ですが、複数goroutineで何の排他制御もせずにchannelでない変数を共有して更新処理をしてしまうと、更新処理前のデータを読み取ってしまい、不整合が発生してしまいます。
下記の例では、1000個のgoroutineを作成し、channelでないデータ(int型変数)を排他ロックを行わずにカウントアップさせます。
実行結果は、1000を満たしません。これは、あるgoroutineでのカウントアップ前の値を別のgoroutineが読み取ってカウントアップしてしまうからです。func main() { c := 0 for i := 0; i < 1000; i++ { go func() { c++ }() } time.Sleep(time.Second) fmt.Println(c) }実行結果959排他ロック
sync.MutexのLock関数とUnlock関数で排他ロックの取得と解除ができます。
排他ロックなので、排他ロックを得たgoroutineが存在する場合は、ロックを得ようとする他のgoroutineは処理を待ちます。下記のように、排他ロックをかけると期待通り最終結果が1000になります。
deferでUnlockするのはお決まりのパターンです。func main() { var mu sync.Mutex c := 0 for i := 0; i < 1000; i++ { go func() { mu.Lock() // 排他ロック取得 defer mu.Unlock() // 関数終了時に排他ロック解除 c++ }() } time.Sleep(time.Second) fmt.Println(c) }実行結果1000共有ロック
sync.RWMutexのRlock関数とRunlock関数で共有ロックの取得と解除ができます。(sync.RWMutexはLock関数とUnLock関数も持っています。)
共有ロック同士であれば処理を進めることができます。共有ロックを得たgoroutineが存在する場合は、排他ロックを取得しようとするgoroutineは待ちます。
基本的な使い方は排他ロックと同じです。Mutexとchannelの使い分け
Mutexとchannelはどのように使い分けるべきなのでしょうか。
各ドキュメントを読んでみました。GitHubのwikiによると
GoのGitHubのwikiによると、「どちらも似たようなことはできるよ。よりシンプルに書ける方法をケースバイケースで選択してね。Go初心者はchannelばかり使いがちだけど
sync.Mutexも恐れず使っていこうぜ。」(意訳)とのことです。
一応、下の使い分けがプラクティスとして紹介されていますが、あまり今の自分にはピンと来ませんでした。channelを使うケース
- データの所有権を受け渡ししたい場合
- 処理を分散したい場合
- 非同期で結果を受け渡ししたい場合
Mutexを使うケース
- キャッシュを扱う場合
- 状態を扱う場合
A Tour of Goによると
A Tour of Goによると、「情報のやりとりが必要ない時、あるいはコンフリクトを避けるために1つのgoroutineで1つの変数のみにアクセスするときは
sync.Mutex使おう」(意訳)とのことです。こちらもピンと来ませんでした。The Go blogによると
The Go blogによると、mapはスレッドセーフでないため、mapを扱う処理で排他制御をかけたいときに
sync.RWMutexを使うのが一般的とのことです。これはピンと来ました。
例えば、下記のように複数goroutineで共通のmapを更新しようとするとエラーになります。func main() { tmpMap := make(map[string]int) for i := 0; i < 1000; i++ { go func() { tmpMap["something"] = i }() } fmt.Println(tmpMap) }実行結果fatal error: concurrent map writes下記のようにロックをかければ処理を継続できます。
// mapとmutexをstructのプロパティに持たせる type SafeCounter struct { v map[string]int mux sync.RWMutex } // Inc 指定したkeyのvalueをインクリメントする func (c *SafeCounter) Inc(key string) { // 排他ロックをかけて値更新 c.mux.Lock() defer c.mux.Unlock() c.v[key]++ } // GetValue ゲッター func (c *SafeCounter) GetValue(key string) int { // 共有ロックをかけて値取得 c.mux.RLock() defer c.mux.RUnlock() return c.v[key] } func main() { c := SafeCounter{v: make(map[string]int)} for i := 0; i < 1000; i++ { go c.Inc("somekey") } time.Sleep(time.Second) fmt.Println(c.GetValue("somekey")) }実行結果1000しかしながら、Go1.9以降では
sync.Mapが標準パッケージに含まれるようになったため、自身でRWMutexとmapの併用を記述する必要がなくなりました。func main() { // mapの宣言。keyとvalueはinterface型。 sMap := sync.Map{} for i := 0; i < 1000; i++ { go func() { // 更新 sMap.Store("something", i) }() } time.Sleep(time.Second) // 取得 if val, ok := sMap.Load("something"); ok { fmt.Println(val) } }実行結果1000その他
上記に加えて、他言語での実装をできるだけそのままリプレイスしたいときに、伝統的な排他処理であるMutexを使うのかなと思いました。
sync.WaitGroup
sync.WaitGroupを利用して、動作中の全てのgoroutineの処理が完了してから次の処理を実行するようにできます。
time.Sleepでは必ずしもgoroutineの全ての処理が完了するとは限らないですし、無駄に時間を待つ場合もあります。
基本的にはsync.WaitGroupを使いましょう。例えば、上記の例でSleepで待っていた例は下のように書き換えられます。
func main() { var wg sync.WaitGroup fmt.Println("main") wg.Add(1) // 待っておいて欲しいジョブ数を与える go func() { defer wg.Done() // ジョブが完了したら完了通知する。残りジョブ数がデクリメントされる。 fmt.Println("hoge") }() wg.Wait() // 全てのジョブが完了するまで待つ }実行結果main hoge複数goroutineでも、もちろん全て待ちます。
func main() { var wg sync.WaitGroup for i := 1; i <= 10; i++ { wg.Add(1) // 待っておいて欲しいジョブ数を与える go func() { defer wg.Done() // ジョブが完了したら完了通知する。残りジョブ数がデクリメントされる。 fmt.Println("hello") }() } wg.Wait() // 全てのジョブが完了するまで待つ fmt.Println("done") }実行結果hello hello hello hello hello hello hello hello hello hello donesync.Once
sync.Onceで一度だけ関数を実行するようにできます。
一般的に初期化処理用に使用されます。
init関数と異なり、実行タイミングを任意に指定できます。var once sync.Once func something() { fmt.Println("Hello") } func main() { // something関数を2回呼び出そうとするが、実際には1回しか呼び出されない。 once.Do(something) once.Do(something) }実行結果Hellosync.Cond
sync.Condは他言語であるような状態が変わったことを通知するコンディション変数として使えます。
Broadcast関数でファンアウトを実現する方法が一般的です。
channelでもクローズすれば全てのgoroutineに完了通知することが可能ですが、クローズは一度だけしかできないですし、channelへの書き込み処理はできなくなります。func main() { var wg sync.WaitGroup var mu sync.Mutex cond := sync.NewCond(&mu) for _, sport := range []string{"Basketball", "Baseball", "Football"} { wg.Add(1) go func(sport string) { defer wg.Done() mu.Lock() defer mu.Unlock() cond.Wait() // 完了通知されるまで待つ fmt.Println(sport) }(sport) } // 事前にやっておきたい処理 fmt.Println("My favorite sports: ") // 事前処理完了通知。待っていた他の処理を開始させる。 cond.Broadcast() wg.Wait() }実行結果My favorite sports: Football Basketball BaseballGoでの並行処理の実装パターン
並行処理の実装パターン化をまとめている記事がありましたので、掲載させていただきます。
- Goにおける並行・並列処理のパターン集
- WEB+DB PRESS Vol.95
- バッファ付きchannelを使って同時に実行されるgoroutineの数を制限しよう(セマフォ)
- channelを利用して指定した数のワーカにデータの排他制御無しでファンアウトする
- channelを利用して排他制御無しで連番を扱う
- etc
まとめ
- go文で簡単にgoroutineを実装できる
- time.SleepでなくWaitGroupを使う
- channelかMutexかはケースバイケースだが初心者はとりあえずchannelに走る
- select構文でchannelの場合分け
- 並行処理はやはり複雑。用法用量を守らないと変に複雑なコードになりがち。
- 投稿日:2019-05-07T00:29:47+09:00
kubernetesのホットリロード開発環境をvolumeMountsでシンプルに実現
経緯
kubernetesのローカル開発環境といえば、skaffoldを使うのがポピュラーなのかと思います。まあ、あんまり他所の事情は知りませんが・・・
しかし、個人的にskaffold devを使うのってあんまり好きじゃないんですよね・・・例えば以下のような理由です。
- 毎回build・Pod再起動するの時間がかかる
- GoとかのImageならマシだが、Railsとかだと遅さが目立つ
- DockerImageがどんどん増える
- 自分はDocker for Mac使ってるので、ローカルのDocker環境が汚染されるのもイヤ
- 当然容量も圧迫する。特にRailsとかだと顕著。
DockerImage増える問題に関しては、kanikoを利用すれば問題にならないかもしれませんが、build・再起動に時間かかる問題に関してはどうしようもありません。それに落ち着いて考えると、コード変更が入るたびにdocker buildするのってどうなのって感じですし・・・
代替法の検討
TelepresenceとかのOSSを利用することも考えましたが、今回はよりシンプルな方法を自作しました。
方法として、特に捻りも何もないですが単にローカルマシンのディレクトリをPodに
VolumeMountするだけです。前提環境
- Goが使える環境
- k8sに対応したDocker for Mac
今回使用するサンプル
今回は例として、Goの簡単なサーバーをサンプルとして用意しました。
main.gopackage main import ( "fmt" "log" "net/http" ) func main() { http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) { fmt.Fprintf(w, "Hello k8s") }) log.Fatal(http.ListenAndServe(":8080", nil)) }これをGoが動く適当なディレクトリに
main.goというファイル名で置きます。
以降は、main.goを配置したディレクトリのパスを、PATHと表記します。Docker for Macの設定
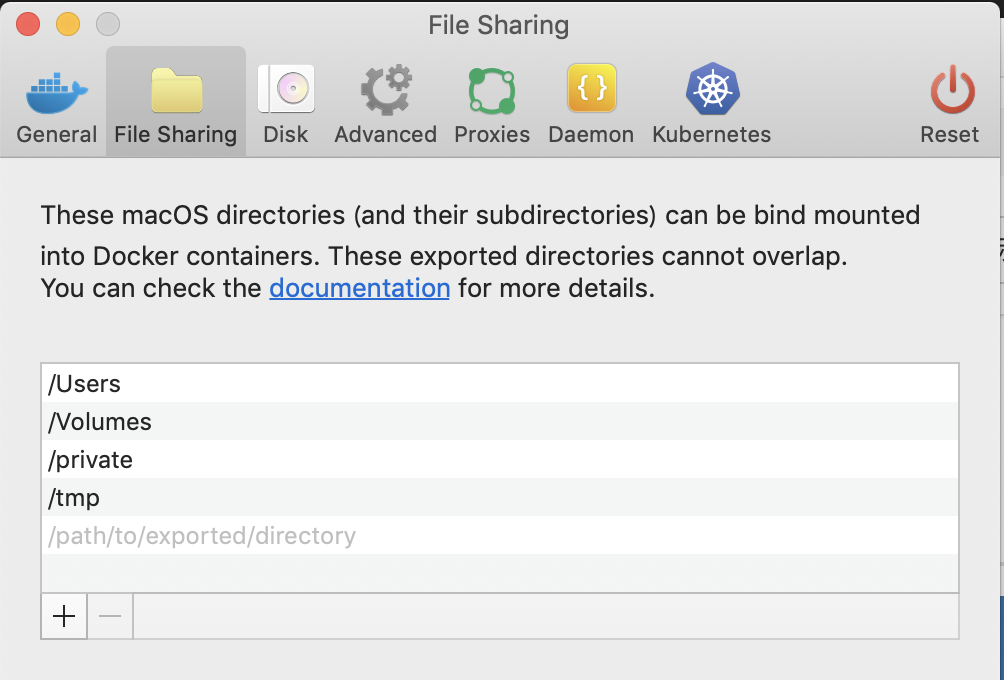
Docker for Macのkubernetesで、先ほどのディレクトリを共有できるように設定します。
Preferences -> File Sharingから、先ほど配置したPATHを入力します。
Dockerfileの作成
以下のDockerfileを作成し、
PATHに配置します。FROM golang:1.11-alpine as goapp ENV APP_ROOT /go/src/app WORKDIR $APP_ROOT ADD main.go $APP_ROOT CMD ["go", "run", "main.go"]golangのDockerImageを作成する際は、マルチステージビルドを使って最終的に出来上がったバイナリだけを軽量なBaseImageに載せるみたいな工夫をすると思いますが、今回はあえて
go runを使います。とりあえずbuildも済ませておきます。
docker build -t echo:v0.1 .マニフェストファイルの作成
先ほどのDockerfileで作成したイメージを、deploymentリソースとしてデプロイします。
以下がdeploymentのマニフェストファイルになります。deployment.yamlapiVersion: apps/v1beta1 kind: Deployment metadata: name: echo spec: replicas: 1 selector: matchLabels: app: echo template: spec: containers: - name: echo image: echo:v0.1 ports: - containerPort: 8080 volumeMounts: - name: echo-volume mountPath: /go/src/app volumes: - name: echo-volume hostPath: path: PATH先ほどDocker for MacでFile Sharingに登録した
PATHをvolumsのhostPathに記述します。これでPATHのディレクトリと、Pod内の/go/src/appディレクトリが共有されます。deploymentの定義はこれでOKなので、k8sクラスタにデプロイします。
kubectl apply -f deployment.yamlついでに、動作検証用のloadbalancerリソースも作成しておきます。
service.yamlapiVersion: v1 kind: Service metadata: name: echo-svc spec: type: LoadBalancer selector: app: echo ports: - port: 8080 targetPort: 8080 protocol: TCPデプロイします
kubectl apply -f service.yamlこれで
localhost:8080にアクセスすると、以下のように表示されます。
ファイルを更新してみる
それでは、ファイルを更新してみます。
main.goの11行目で"Hello k8s"としている部分を、"Updated hello k8s"に書き換えます。fmt.Fprintf(w, "Updated hello k8s")これで、Pod内のファイルも書き換わります。Rails等のアプリケーションならこれだけでもOKなのですが、今回はGoなのでコンパイルし直す必要があります。Dockerfileのentrypointを
go run main.goにしてあるので、Podを再起動すればOKです。再起動させるにはkubectlでPodを削除するのが手っ取り早いですが、毎回するのはしんどいので、このページの方法を参考にしてmakefileを作りました。reload: @kubectl patch deployment echo -p "{\"spec\":{\"template\":{\"metadata\":{\"annotations\":{\"reloaded-at\":\"`date +'%Y%m%d%H%M%S'`\"}}}}}"
echodeploymentのannotationsを書き換えて無理やりRollingUpdateさせる感じですね。以下のコマンドで再起動できるようになりました。make reload変更を監視して自動でリロードする
せっかくなのでファイル変更が入ったら自動でリロードできるようにしてみます。
今回、変更の監視にはCompileDaemonを利用しました。
go get github.com/githubnemo/CompileDaemon go install github.com/githubnemo/CompileDaemon先ほどのmakefileを書き換えます。
hot_reload: CompileDaemon -command="$(MAKE) reload" reload: kubectl patch deployment echo -p "{\"spec\":{\"template\":{\"metadata\":{\"annotations\":{\"reloaded-at\":\"`date +'%Y%m%d%H%M%S'`\"}}}}}"以下のコマンドで、ファイル変更があった際には自動で
reloadが実行されるようになりました。make hot_reloadまとめ
今回はGoをアプリケーションを扱ったのでリロードの仕組みも作りましたが、Rails等のアプリケーションなら頻繁なリロードも必要ないのでもっと簡単ですね。
skaffoldを使う場合と比較して、良い点・悪い点いずれもあるかと思います。良い点
- 反映が早い。特にImageが大きいほど有利。
- Docker Imageが毎回増えない
悪い点
- 開発環境用のマニフェストファイルが本番用と乖離しやすい
- 管理したいリソースが増えると、makefile等の自作設定ファイルの管理が必要
次はTelepresenceも試してみたいと思います。

- 投稿日:2019-05-07T00:02:16+09:00
GCF-goチュートリアルズ
お題
Google Cloud Functions(Go1.11)のクイックスタートとチュートリアルを通して各機能を確認していく。
今回は、ひとまずクイックスタート。
あと、Goモジュールを使ったプロジェクトのデプロイに関するチュートリアルだけ。基本的に以下を参考に進めていく。
https://cloud.google.com/functions/docs/前提
- GCPは知っている。
以下は済んだ上での作業。
- GCPプロジェクトの作成
- Cloud SDKのインストールと初期化・認証
開発環境
# OS
$ cat /etc/os-release NAME="Ubuntu" VERSION="18.04.2 LTS (Bionic Beaver)"# Cloud SDK
$ gcloud version Google Cloud SDK 244.0.0# Golang
$ go version go version go1.11.4 linux/amd64実践
Quickstart
参考
https://cloud.google.com/functions/docs/quickstart
ソース
[QuickStart/helloworld.go]package Quickstart import ( "fmt" "net/http" ) func HelloWorld(w http.ResponseWriter, r *http.Request) { if _, err := fmt.Fprint(w, "Hello, World! (go111)"); err != nil { fmt.Println(err) } }デプロイと動作確認
$ pwd /home/sky0621/work/src/go111/src/github.com/sky0621/tips-go/try/gcp/gcfgo/Quickstart $ $ gcloud functions deploy HelloWorld --runtime=go111 --trigger-http Deploying function (may take a while - up to 2 minutes)...done. 〜〜 省略 〜〜
$ curl https://us-central1-【GCPプロジェクトID】.cloudfunctions.net/HelloWorld Hello, World! (go111)Structured
参考
https://cloud.google.com/functions/docs/writing/
留意点
Goランタイムの場合、関数はプロジェクトのルートにあるGoパッケージに含まれている必要がある。
関数をmainパッケージにするのは不可。
サブパッケージは、Goモジュールを使用している場合にのみサポート。ソース
$ tree . ├── function.go ├── go.mod ├── go.sum └── subpkg └── jsonform.go[Structured/function.go]package Structured import ( "Structured/subpkg" "encoding/json" "fmt" "net/http" "go.uber.org/zap" ) var lgr *zap.Logger func init() { var err error lgr, err = zap.NewProduction() if err != nil { panic(err) } } func StructuredHello(w http.ResponseWriter, r *http.Request) { var jf subpkg.JsonForm if err := json.NewDecoder(r.Body).Decode(&jf); err != nil { lgr.Error(err.Error()) } if _, err := fmt.Fprintf(w, "Hello, %s(%s)", jf.Name, jf.ID); err != nil { lgr.Error(err.Error()) } }[Structured/subpkg/jsonform.go]package subpkg type JsonForm struct { ID string `json:"id"` Name string `json:"name"` }デプロイと動作確認
$ pwd /home/sky0621/work/src/go111/src/github.com/sky0621/tips-go/try/gcp/gcfgo/Structured $ $ gcloud functions deploy StructuredHello --runtime=go111 --trigger-http Deploying function (may take a while - up to 2 minutes)...done. 〜〜 省略 〜〜
$ curl -X POST \ > https://us-central1-【GCPプロジェクトID】.cloudfunctions.net/StructuredHello \ > -H 'Content-Type: application/json' \ > -H 'cache-control: no-cache' \ > -d '{ > "id": "001", > "name": "Sato" > }' Hello, Sato(001)
- 投稿日:2019-05-07T00:02:16+09:00
Google Cloud Functions (Go1.11) チュートリアル
お題
Google Cloud Functions(Go1.11)のクイックスタートとチュートリアルを通して各機能を確認していく。
今回は、ひとまずクイックスタート。
あと、Goモジュールを使ったプロジェクトのデプロイに関するチュートリアルだけ。基本的に以下を参考に進めていく。
https://cloud.google.com/functions/docs/前提
- GCPは知っている。
以下は済んだ上での作業。
- GCPプロジェクトの作成
- Cloud SDKのインストールと初期化・認証
開発環境
# OS
$ cat /etc/os-release NAME="Ubuntu" VERSION="18.04.2 LTS (Bionic Beaver)"# Cloud SDK
$ gcloud version Google Cloud SDK 244.0.0# Golang
$ go version go version go1.11.4 linux/amd64実践
Quickstart
参考
https://cloud.google.com/functions/docs/quickstart
ソース
[QuickStart/helloworld.go]package Quickstart import ( "fmt" "net/http" ) func HelloWorld(w http.ResponseWriter, r *http.Request) { if _, err := fmt.Fprint(w, "Hello, World! (go111)"); err != nil { fmt.Println(err) } }デプロイと動作確認
$ pwd /home/sky0621/work/src/go111/src/github.com/sky0621/tips-go/try/gcp/gcfgo/Quickstart $ $ gcloud functions deploy HelloWorld --runtime=go111 --trigger-http Deploying function (may take a while - up to 2 minutes)...done. 〜〜 省略 〜〜
$ curl https://us-central1-【GCPプロジェクトID】.cloudfunctions.net/HelloWorld Hello, World! (go111)Structured
参考
https://cloud.google.com/functions/docs/writing/
留意点
Goランタイムの場合、関数はプロジェクトのルートにあるGoパッケージに含まれている必要がある。
関数をmainパッケージにするのは不可。
サブパッケージは、Goモジュールを使用している場合にのみサポート。ソース
$ tree . ├── function.go ├── go.mod ├── go.sum └── subpkg └── jsonform.go[Structured/function.go]package Structured import ( "Structured/subpkg" "encoding/json" "fmt" "net/http" "go.uber.org/zap" ) var lgr *zap.Logger func init() { var err error lgr, err = zap.NewProduction() if err != nil { panic(err) } } func StructuredHello(w http.ResponseWriter, r *http.Request) { var jf subpkg.JsonForm if err := json.NewDecoder(r.Body).Decode(&jf); err != nil { lgr.Error(err.Error()) } if _, err := fmt.Fprintf(w, "Hello, %s(%s)", jf.Name, jf.ID); err != nil { lgr.Error(err.Error()) } }[Structured/subpkg/jsonform.go]package subpkg type JsonForm struct { ID string `json:"id"` Name string `json:"name"` }デプロイと動作確認
$ pwd /home/sky0621/work/src/go111/src/github.com/sky0621/tips-go/try/gcp/gcfgo/Structured $ $ gcloud functions deploy StructuredHello --runtime=go111 --trigger-http Deploying function (may take a while - up to 2 minutes)...done. 〜〜 省略 〜〜
$ curl -X POST \ > https://us-central1-【GCPプロジェクトID】.cloudfunctions.net/StructuredHello \ > -H 'Content-Type: application/json' \ > -H 'cache-control: no-cache' \ > -d '{ > "id": "001", > "name": "Sato" > }' Hello, Sato(001)