- 投稿日:2019-05-07T23:46:42+09:00
[AWS]DeepArchiveに放り込んだら料金を見とけ!
ざっくりいうと
awsのDeep Archiveを見つけて「もうHDDなんて卒業だ!」と大量に大きいファイルのアップロードを仕掛けたら謎の料金請求が止まらず焦って調べたら、マルチパートアップロードが途中で止まった場合、アップロード途中のデータ分がS3料金で請求されるとわかった話。
対策もあるので、以下をご覧ください。ことのはじめ
2019年のGWは10連休でした。
普通の連休ではできないようなことができましたね!
私は…バックアップ体制の見直しをしました。
…って個人のファイルなんですけど。でも重要でしょ?これまでは500GBの外付けハードディスクに保存してました。
でも…もう7年以上(!)使ってましたし、なんともセキュリティ確保のために毎度暗号化するのも面倒だなぁと思ってました。
もう少しGlacierの料金が下がらないかなぁ…と思っていたら!!https://aws.amazon.com/jp/blogs/news/new-amazon-s3-storage-class-glacier-deep-archive/
これいいじゃない!
$0.00099 per GB-Monthって、1TB使っても$0.99って月100円!
バックアップのためにHDD買うなんてもうやめた!っていう料金に喜んで手を出しました。大量にデータをアップロード
HDDに入っていた200GBぐらいのデータを昼夜問わず複数のセッションで一気に上げました。
途中で失敗しても、再度やり直せばいいんでしょ?ぐらいの気持ちで。
で、実際に何回か失敗したんですけど、まぁ平成の内にやり切ったわけですわ。
でもここに落とし穴が…安いはずなのに…
令和になって、毎日のように請求料金を見ていたわけです。
すると…
Amazon Simple Storage Service USW2-TimedStorage-GDA-Staging $0.06
はぁ?
$0.021 per GB-Month of storage used in GlacierStagingStorage 2.955 GB-Mo
開始5日で3GB弱ってことは実際のところ18GBぐらいがどこかにあるってか?
GlacierStagingStorage?ステージングストレージって何?
何これ!レートこれ高いだろ!高すぎ!ネットでこれ!ということがググってもなかなか出てこない。
で、いろいろ詮索しているうちに…ここにたどり着きました。
マルチパートアップロードを開始すると、 アップロードを完了または中止するまで すべてのパートが AmazonS3 によって保持されます。はぁ
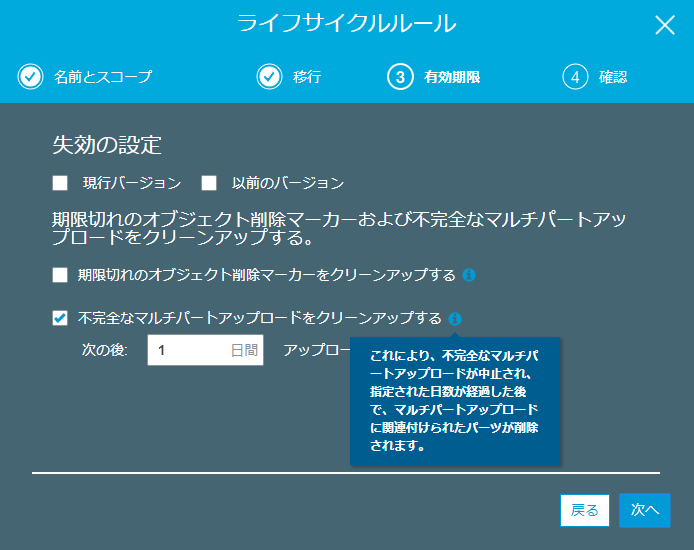
マルチパートアップロードを開始したら、パートをアップロードし始めます。 (中略) マルチパートアップロードの完了リクエストが正常に送信されなかった場合、 Amazon S3 はパートを組み立てず、オブジェクトを作成しません。 したがって、パートは Amazon S3 に残るため、 Amazon S3 に保存されたパートに対して支払いが発生します。 ベストプラクティスとして、ストレージコストを最小限に抑えるため、 ライフサイクルルールを設定することをお勧めしますつまり…
- アップロードに失敗したらS3に残骸が残りっぱなしになるからね
- それがいやならライフサイクルに設定しなさいよ
そういうこと??
残骸を確認するすべは請求を見て「-Staging」というキーワードが含まれているか確認するしかないという…(S3の実態ファイルとして見えない)
ここをみてもわかるけどたどり着けるかどうか…そういうわけでライフサイクルに設定した。
終わりに
やっぱり新サービスを使ったら料金を確認しないと何が起きているかわからない。
私はこれに3日使いました。
救われた方はイイネ!してね。ではでは。
- 投稿日:2019-05-07T20:03:18+09:00
AWSome Day受講メモ
AWS Innovate(2019年4月8日 ~ 5月7日開催)でAWSome Dayをオンライン受講できたので、受講した内容を簡単にまとめる。
AWSome Dayは4セッションが公開されており、各30分の2時間程度で受講完了できる。
セッション1: AWSのグローバルインフラストラクチャとネットワークおよびコンピューティング
- 1リージョンごとに2つ以上のAZで構成されている。
- 1つのAZは1-6個のDCで構成されている。<-これはAWS InnovateのLiveセッション開発者視点でのウェブサイトホスティング入門 on AWSで話してた)
- ELBがいつのまにかALB(Application Load Balancer)とNLB(Network Load Balancer)に別れてた、L7スイッチとか確かに高かったし嬉しい機能。
そういえばMultiAZを簡単に設定することができるようになったけど、オンプレで複数拠点で相互に通信できるネットワークを組むとかあまり想像したくない。
セッション2: ストレージとデータベース
- S3は複数AZにまたがって冗長化している
- RDSでレプリケーションを張った場合、レプリカ側にもコピーされるところまでトランザクションを保持するのでマスターとレプリカでデータにずれは発生しない
ElastiCacheなんてのもいつ間にか出てた。まぁredisがあれだけ流行ってたらAWSでも提供始めるよね。
セッション3: AWSのセキュリティの基本
- インスタンスのファイアウォール -> セキュリティグループ
- サブネットのファイアウォール -> ネットワークACL
- ユーザの権限(AWSサービスのアクセス権限) -> IAM
- AWSアカウントのルートユーザーのアクセスキーは作成しない(もしあるなら削除)
- 基本的に操作はIAMで作成した管理者アクセス権を持ったユーザーで行う
セッション4: Well-Architected Frameworkと料金の話
- Well-Architected Framework -> ベストプラクティス集
- ベストプラクティスの質問を活用することで改善点、リスクを把握できる
- 投稿日:2019-05-07T19:41:48+09:00
AWS rds-backup-to-s3
問題
RDSのバックアップをスナップショットだけではなく手元に置かないと安心できないとの意見があったら
ソース
- RDSスナップショットからインスタンスを作成し、それをdumpしてS3へアップする
#!/bin/bash -l export JAVA_HOME=/usr/lib/jvm/jre export AWS_BIN=/opt/aws/bin export PATH=$PATH:$EC2_HOME/bin:$AWS_BIN export EC2_REGION=ap-northeast-1 Account="aws13" keypair="/usr/lib/zabbix/externalscripts/key_pair.csv" #複数アカウントをまとめ管理する場合 while IFS=',' read -r f1 f2 f3 do if [[ $Account == "$f1" ]]; then export AWS_ACCESS_KEY_ID="$f2" export AWS_SECRET_ACCESS_KEY="$f3" break fi done < "$keypair" INSTANCE=mysql-190501 RDS_SUBDOMAIN=cwtt780wxxxx VPC_SECURITY_GROUP_IDS=sg-xxxxcd6 DATABASE_NAME=hogedb DATABASE_USER=mysqladmin DATABASE_PASS=mysqlpass BACKUP_DATE=`date '+%Y%m%d'` YESTERDAY_DATE=`date --date '1 day ago' '+%Y-%m-%d'` YESTERDAY_DATE_2=`date --date '3 day ago' '+%Y%m%d'` BK_SNAPSHOT=`aws rds describe-db-snapshots --region=$EC2_REGION |jq '.DBSnapshots[].DBSnapshotIdentifier' --raw-output | grep $INSTANCE-$YESTERDAY_DATE` _STAT="status.log" _WORK="/tmp" _DATE="date +%Y/%m/%d-%H:%M:%S" #インスタンス起動 echo $BK_SNAPSHOT aws rds restore-db-instance-from-db-snapshot --db-instance-identifier dumpdb-$INSTANCE-bak --db-instance-class db.t2.micro --db-subnet-group-name 'hogedb-grp' --region=$EC2_REGION --db-snapshot-identifier $BK_SNAPSHOT #ステータスがavailableになるまで待つ _SLEEP_TIME=180 sleep 600 for (( i = 0; i < 3; i++ )); do sleep ${_SLEEP_TIME} status=`aws rds describe-db-instances --region=ap-northeast-1 --db-instance-identifier dumpdb-$INSTANCE-bak --query "DBInstances[*].DBInstanceStatus" --output text` echo $status is_break=false is_exit=false case ${status} in available) is_break=true echo ok;; backing-up) ;; creating) ;; deleted) is_break=false is_exit=true ;; deleting) is_break=false is_exit=true ;; failed) is_break=false is_exit=true ;; incompatible-restore) is_break=false is_exit=true ;; incompatible-paraameters) is_break=false is_exit=true ;; modifying) ;; rebooting) ;; resetting-master-credentials) is_break=false is_exit=true ;; storage-full) is_break=false is_exit=true ;; *) is_break=false is_exit=true ;; esac if ${is_break}; then echo -e "\033[0;35m`${_DATE}` break (${status})\033[0;39m" >> $_WORK/$_STAT aws rds modify-db-instance --db-instance-identifier dumpdb-$INSTANCE-bak --vpc-security-group-ids $VPC_SECURITY_GROUP_IDS --apply-immediately --region=$EC2_REGION sleep 180 #もしローカルIPが引けない場合 #DB_HOST=`nslookup dumpdb-$INSTANCE-bak.$RDS_SUBDOMAIN.ap-northeast-1.rds.amazonaws.com 10.0.0.2 |grep "Address: " |cut -f2 -d " " |cut -f 1` echo "Creating backup of database....." mysqldump -u$DATABASE_USER -p$DATABASE_PASS -h dumpdb-$INSTANCE-bak.$RDS_SUBDOMAIN.ap-northeast-1.rds.amazonaws.com --opt --single-transaction $DATABASE_NAME --compress --compact |gzip --fast -c > /tmp/dump-$INSTANCE-rds-$BACKUP_DATE.bak.gz echo "Uploading backup to Amazon S3 bucket....." aws s3 cp /tmp/dump-$INSTANCE-rds-$BACKUP_DATE.bak.gz s3://rds-backup-aws13 sleep 180 echo "Successfully uploaded backup to S3" aws rds delete-db-instance --db-instance-identifier dumpdb-$INSTANCE-bak --skip-final-snapshot --region=$EC2_REGION echo "Deleting backup file(3日以上経過したtempファイルを削除)…" rm -rf /tmp/dump-$INSTANCE-rds-$YESTERDAY_DATE_2.bak.gz echo "Deleting backup file(3日以上経過したS3ファイルを削除)…" aws s3 rm s3://rds-backup-aws13/dump-$INSTANCE-rds-$YESTERDAY_DATE_2.bak.gz break fi if ${is_exit}; then echo -e "\033[0;31m`${_DATE}` exit 1 (${status})\033[0;39m" >> $_WORK/$_STAT exit 1 fi echo -e "\033[0;32m`${_DATE}` sleep ${_SLEEP_TIME} (${status})\033[0;39m" >> $_WORK/$_STAT doneメモ
さすが今はスナップショットを信用しています。
ソースを捨てるにはもったいなかったので記録とします。ご参考まで。
- 投稿日:2019-05-07T15:19:58+09:00
goでs3をいじるまで
このページについて
golangを使ってs3のapiを叩くためにセットアップを行った際のメモです。
環境: Mac OS
手順
awscliのインストール
$ brew install awsclicliが使う環境変数のセットアップ
$ aws configure AWS Access Key ID [None]: your-key AWS Secret Access Key [None]: your-token Default region name [None]: ap-northeast-1 Default output format [None]:golang clientのインストール
こちらを使う
$ go get github.com/aws/aws-sdk-gosdk はデフォルトで
~/.aws/credentialsの設定情報を読みに行くので
aws configureでファイルを作りました。(ここに書いてあります)あとはサンプルコードを動かすだけです
package main import ( "context" "fmt" "os" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/s3" ) func main() { sess := session.Must(session.NewSession(aws.NewConfig().WithRegion("ap-northeast-1"))) svc := s3.New(sess) ctx := context.Background() objects := []string{} myBucket := "your-backet" err := svc.ListObjectsPagesWithContext(ctx, &s3.ListObjectsInput{ Bucket: aws.String(myBucket), }, func(p *s3.ListObjectsOutput, lastPage bool) bool { for _, o := range p.Contents { objects = append(objects, aws.StringValue(o.Key)) } return true // continue paging }) if err != nil { panic(fmt.Sprintf("failed to list objects for bucket, %s, %v", myBucket, err)) } fmt.Println("Objects in bucket:", objects) }とりあえず、指定したbucket内のファイル名をとるスクリプトを公式からもってきました
そのため、動かす前にbucketの作成と中に適当なファイルを突っ込んでみてください参考
自身の環境に入れるcredentialのユーザは権限しぼったもの入れましょう
作り方はこちらを見ました
- 投稿日:2019-05-07T14:27:20+09:00
[AWS Glue]クエリベースでCloudfrontログを parquet & JSTにETL(+パーティション分割)する手順
リマインドとして、下記のユースケースへの対応手順を記載します。
(awsコンソールの使い方等の、細かい部分は割愛)ユースケース
・CloudfrontログをAthenaで分析したい
・Cloudfrontログ内の時間はUTCなので、あらかじめJSTに変更しておきたい
・Athenaでフルスキャンが起きないよう、データを日付でパーティション分割したい(分割できるフォーマットに変換したい)
・過去に集計した分も、再度ETLしてパーティションごとに上書きできるようにしたい手順例
手順例の前提
・Cloudfrontログのテーブル定義の データベース & テーブル名: cloudfront_access_logs.app_log
・ETL後のparquetの出力先: s3://some-bucket/ETL_cloudfront_logs
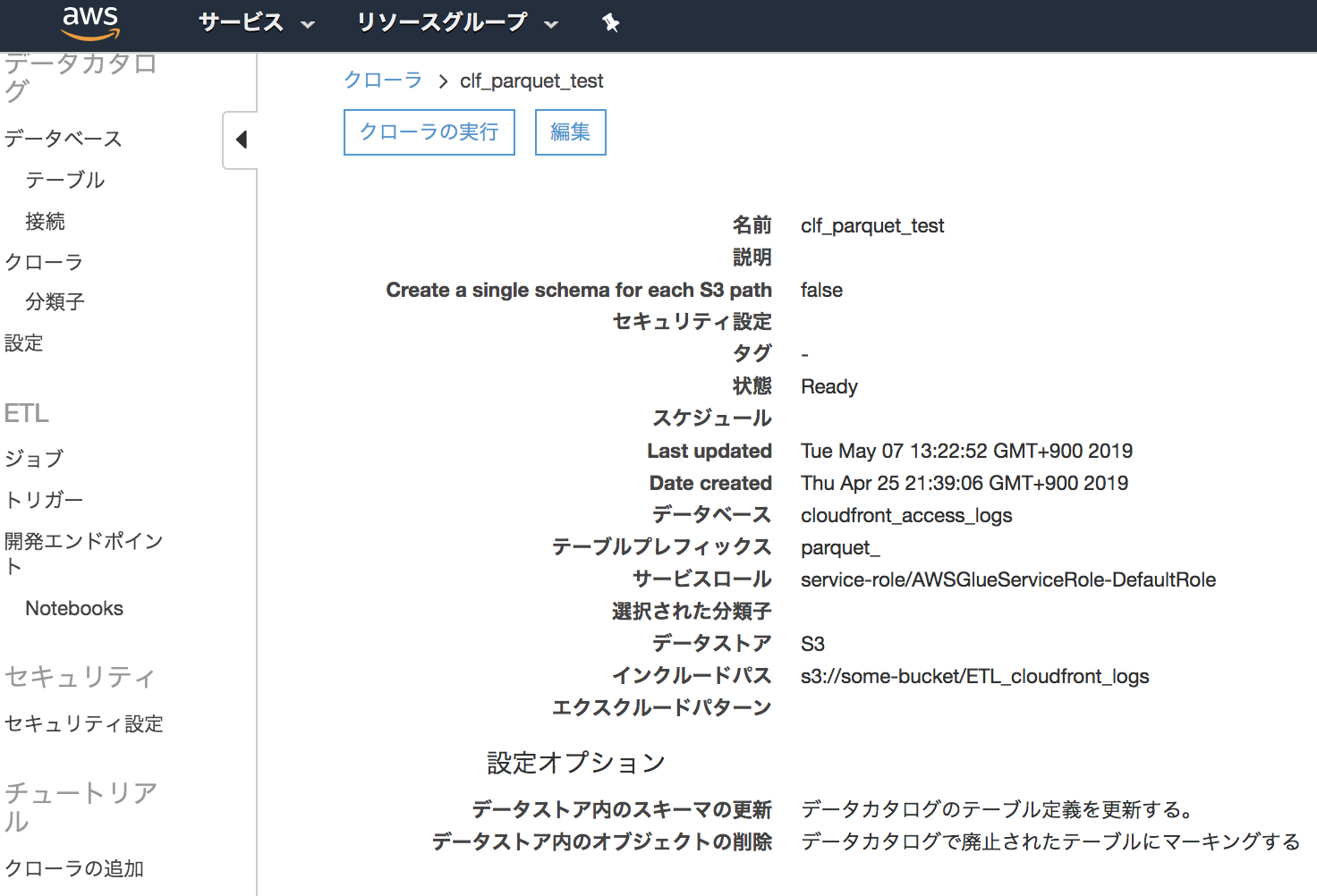
・Glue Crawler名: clf_parquet_test
・保存方法: overwrite
・ETLの指針: 極力Spark SQLで済ます(ローカルなどでETLの検証がしやすい)1. Cloudfrontのログ機能を有効にする
2. Cloudfrontログのテーブル定義を作成
下記あたりを参考に
https://qiita.com/ytanaka3/items/ad5e7d96bc425ff4c8433. ETL出力後のparquetデータ のテーブル定義を更新するGlue Crawlerを追加
4. 2.をparquet & JST にETL + 最後に3. のCrawlerを呼び出すGlue Jobを作成
[スクリプト]
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job from awsglue.dynamicframe import DynamicFrame import boto3 ## @params: [JOB_NAME] args = getResolvedOptions(sys.argv, ['JOB_NAME']) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args['JOB_NAME'], args) datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "cloudfront_access_logs", table_name = "app_log", transformation_ctx = "datasource0") ## Transform df = datasource0.toDF() df.createOrReplaceTempView('tmp') # クエリベースでETL (ログ内の時間のUTCをJSTに変換 + パーティション分割用にyyyy-MM-ddのカラムを追加) df_sql = spark.sql( ''' SELECT date_format( from_utc_timestamp(concat( request_date, " ", request_time ), 'JST'), 'yyyy-MM-dd') AS `dt`, unix_timestamp( from_utc_timestamp(concat( request_date, " ", request_time ), 'JST')) AS `timestamp_JST`, from_utc_timestamp(concat( request_date, " ", request_time ), 'JST') AS `date_JST`, `x_edge_location`, `sc_bytes`, `client_ip`, `cs_method`, `cs_host`, `cs_uri_stem`, `sc_status`, `cs_referer`, `user_agent`, `uri_query`, `cookie`, `x_edge_result_type`, `x_edge_request_id`, `x_host_header`, `cs_protocol`, `cs_bytes`, `time_taken`, `x_forwarded_for`, `ssl_protocol`, `ssl_cipher`, `x_edge_response_result_type`, `cs_protocol_version` FROM tmp WHERE cs_method != '' or cs_method is NOT NULL ''') #df_sql.show() #確認用 # 追加したカラムでpartition分割し、overwrite df_sql.repartition(*["dt"]).write.partitionBy(["dt"]).mode("overwrite").parquet("s3://some-bucket/ETL_cloudfront_logs", compression="gzip") # Crawlerの開始 aws_glue_client = boto3.client('glue', region_name='us-east-1') aws_glue_client.start_crawler(Name='clf_parquet_test') job.commit()あとは用途に応じて、S3のログ保存期間の設定・クエリによる取り込み期間の指定などを行う。
- 投稿日:2019-05-07T13:38:33+09:00
SystemManager Automationを使って、ノンコーディングでEC2インスタンスをタグで自動起動・停止する
はじめに
EC2インスタンスの自動起動停止は、2016年頃はLambdaFunctionを使って実現してました。
LambdaFunctionが出たばかりで楽しくて書いてみたんですけど、まじめに実現しようとすると仕組みが複雑化したり、バグがでたりすることなどが少し悩みでした。
https://github.com/uzresk/aws-auto-operations-using-lambda
その後SystemManagerのオートメーションが発表され、CloudWatchEventsからSSM Automationの組み込みのドキュメントを使って実現していました。
バグで動かないなんてことも無くなったのでよかったのですが、対象とするEC2インスタンスが増えてくると自動停止・起動対象のEC2インスタンスIDをCloudWatchEventsのパラメータに設定するのが厳しくなってきました。
さてどうしたか
ゴリゴリ書かずにAWSの機能だけでタグベースで自動起動・停止を実現できないかを考えていたのですが、AutomationActionにexecuteAwsApiが指定できるようになって実現できるようになりました。
AWS Systems Manager の新しい Automation アクションの使い方を紹介
https://aws.amazon.com/jp/blogs/news/onica-demonstrates-uses-for-new-aws-systems-manager-automation-actions/つまり、CloudWatch EventsからSSM Automation Document(AWS-StopEC2Instance、AWS-StartEC2Instance)を呼び出すときにはインスタンスIDが必須になるのですが、ドキュメントを自分で作ることでタグやリソースグループを指定して起動停止できるようになります。
早速やってみます。
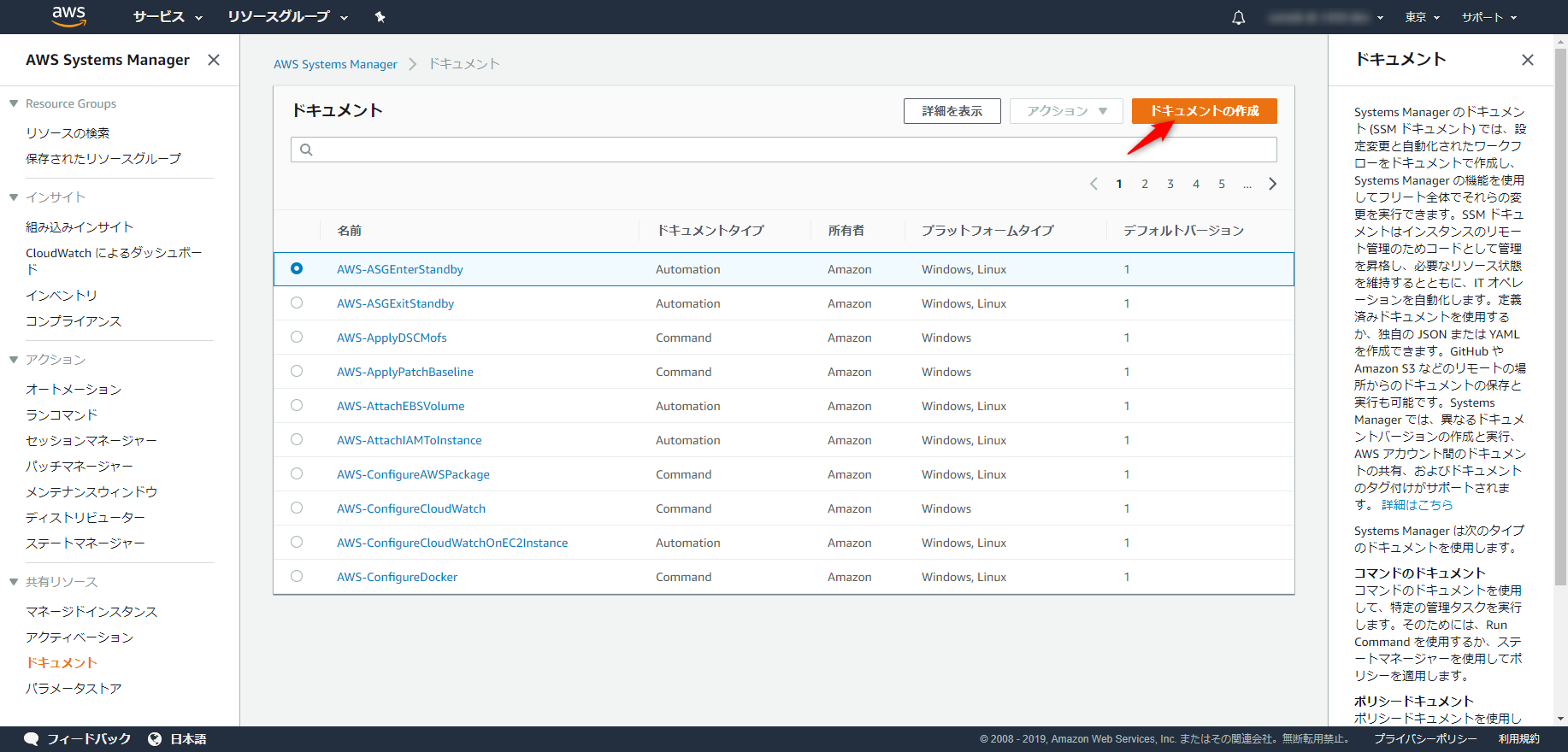
ドキュメントの作成
SystemManagerの画面を開き、左メニューのドキュメント→「ドキュメントの作成」を選びます。
名前を適当に決め、ドキュメントタイプ・オプションに「オートメーションドキュメント」を選択します。
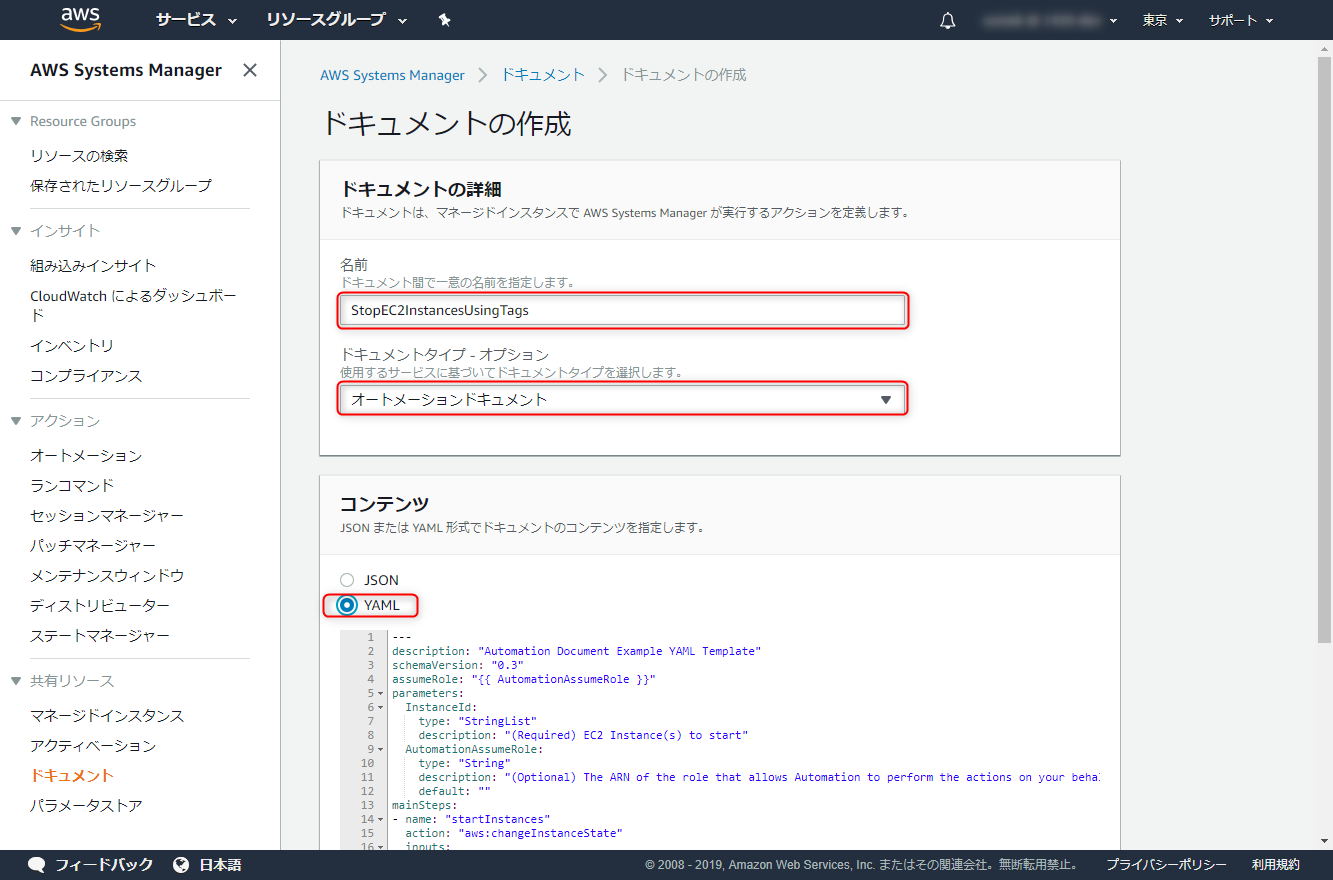
コンテンツはyamlを選択し、以下のyamlを貼り付けます。
タグ Key:AutoStopTime, Value:8pm or 11pmをAWS-StopEC2Instanceドキュメントに引数として渡してあげるように記載されています。
--- description: Exec AWS-StopEC2Instances schemaVersion: "0.3" assumeRole: "{{ AutomationAssumeRole }}" parameters: AutoStopTime: type: String default: 11pm description: (Required) 8pm or 11pm allowedValues: - 8pm - 11pm AutomationAssumeRole: type: String description: (Optional) The ARN of the role that allows Automation to perform the actions on your behalf. default: "" mainSteps: - name: StopEC2Instances action: aws:executeAwsApi inputs: Service: ssm Api: StartAutomationExecution DocumentName: AWS-StopEC2Instance TargetParameterName: "InstanceId" Targets: - Key: tag:AutoStopTime Values: - "{{ AutoStopTime }}"これでドキュメントの作成は完成です。
動作確認してみる
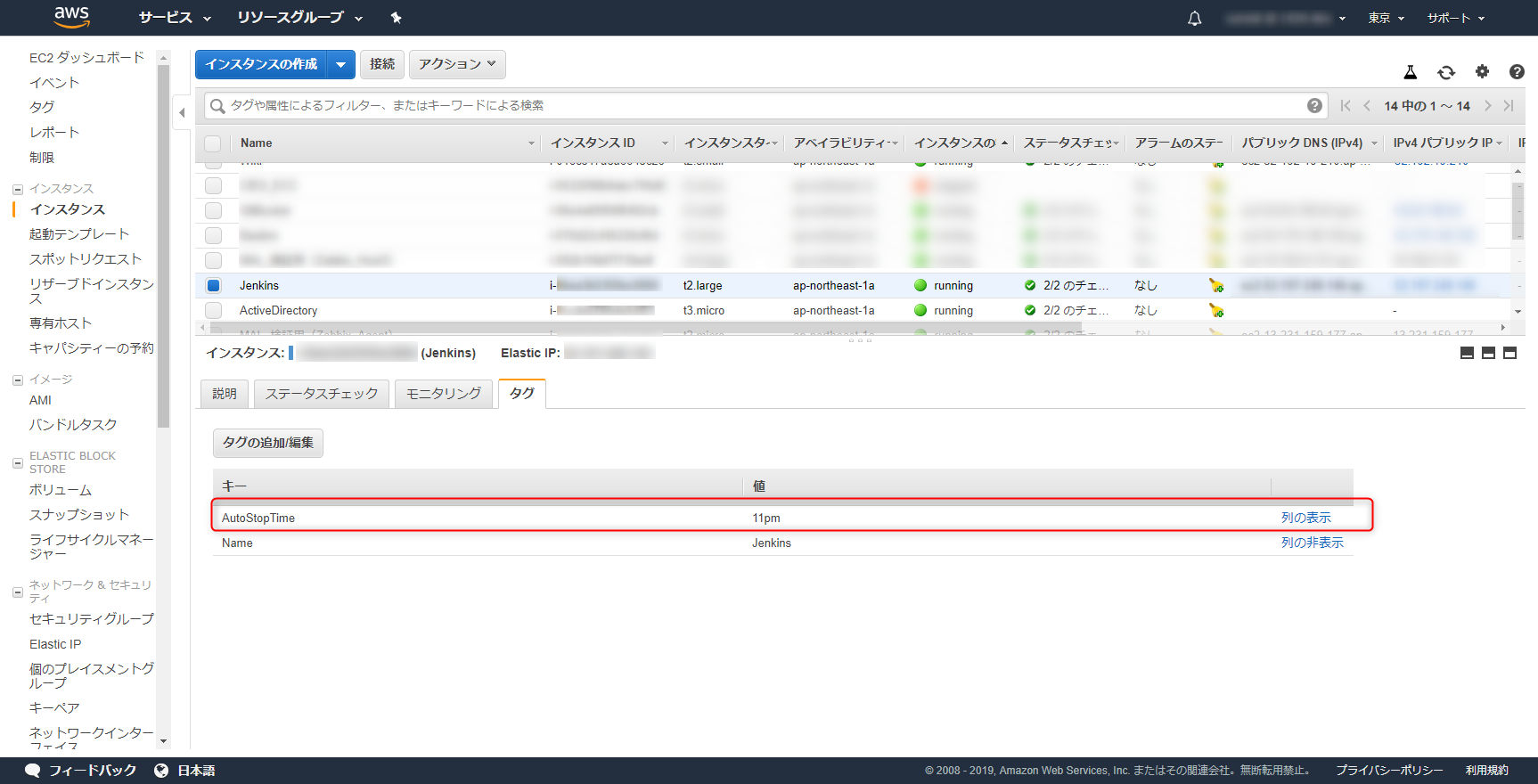
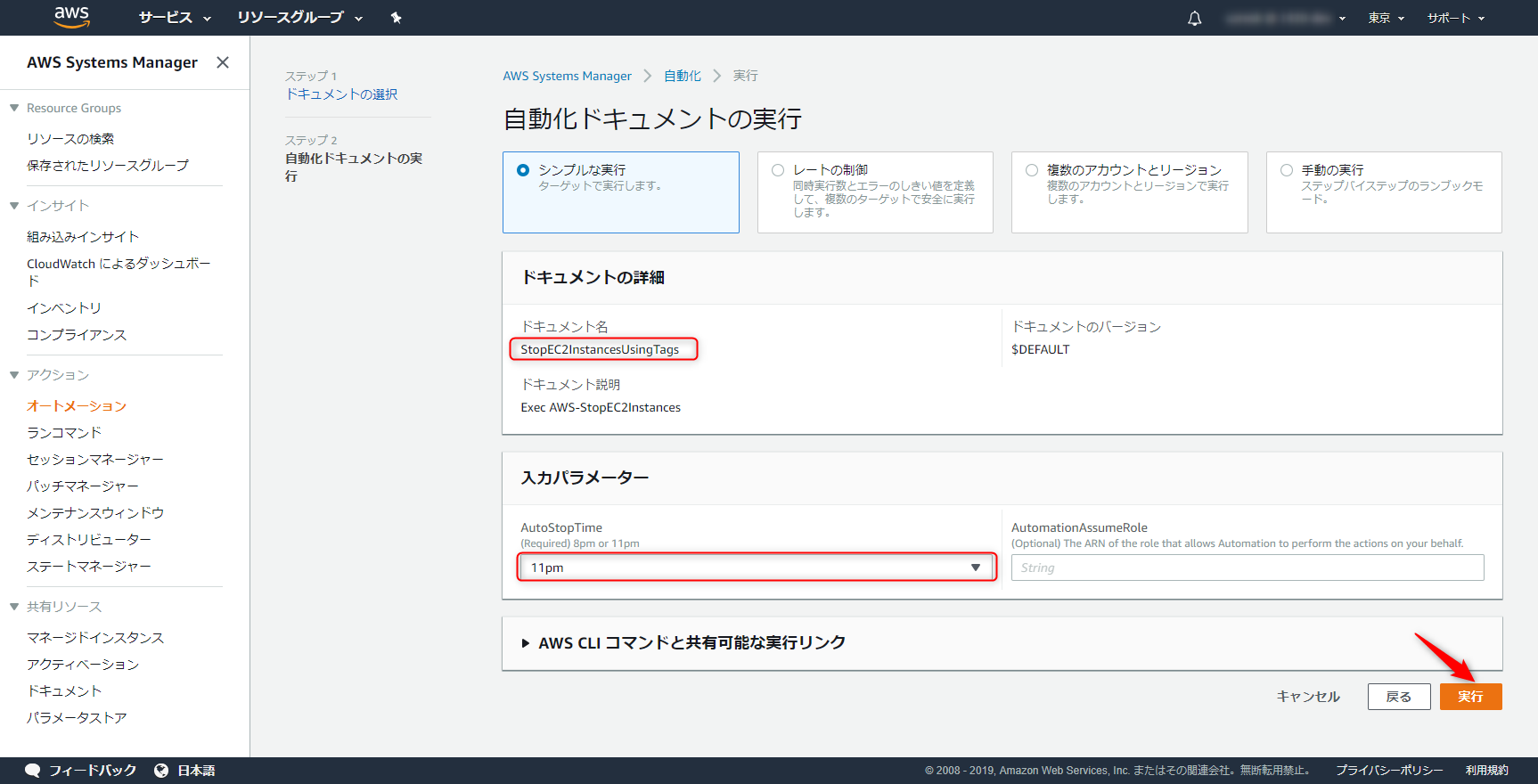
対象のEC2インスタンスのタグにAutoStopTime:11pmというタグを付与します。
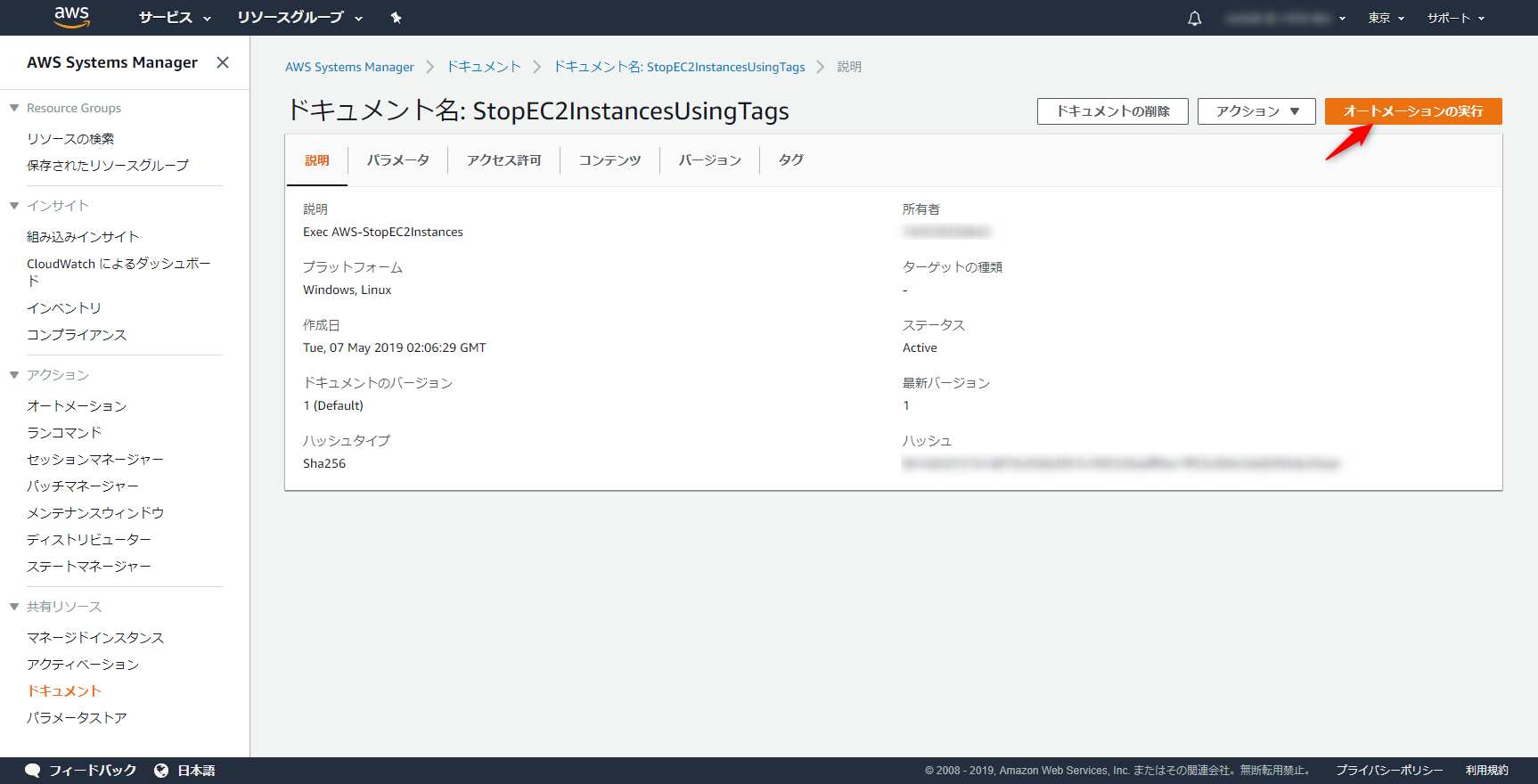
先ほど作ったドキュメントStopEC2InstancesUsingTagsを開き、オートメーションの実行をクリックします。
入力パラメータに11pmを指定して、実行します。
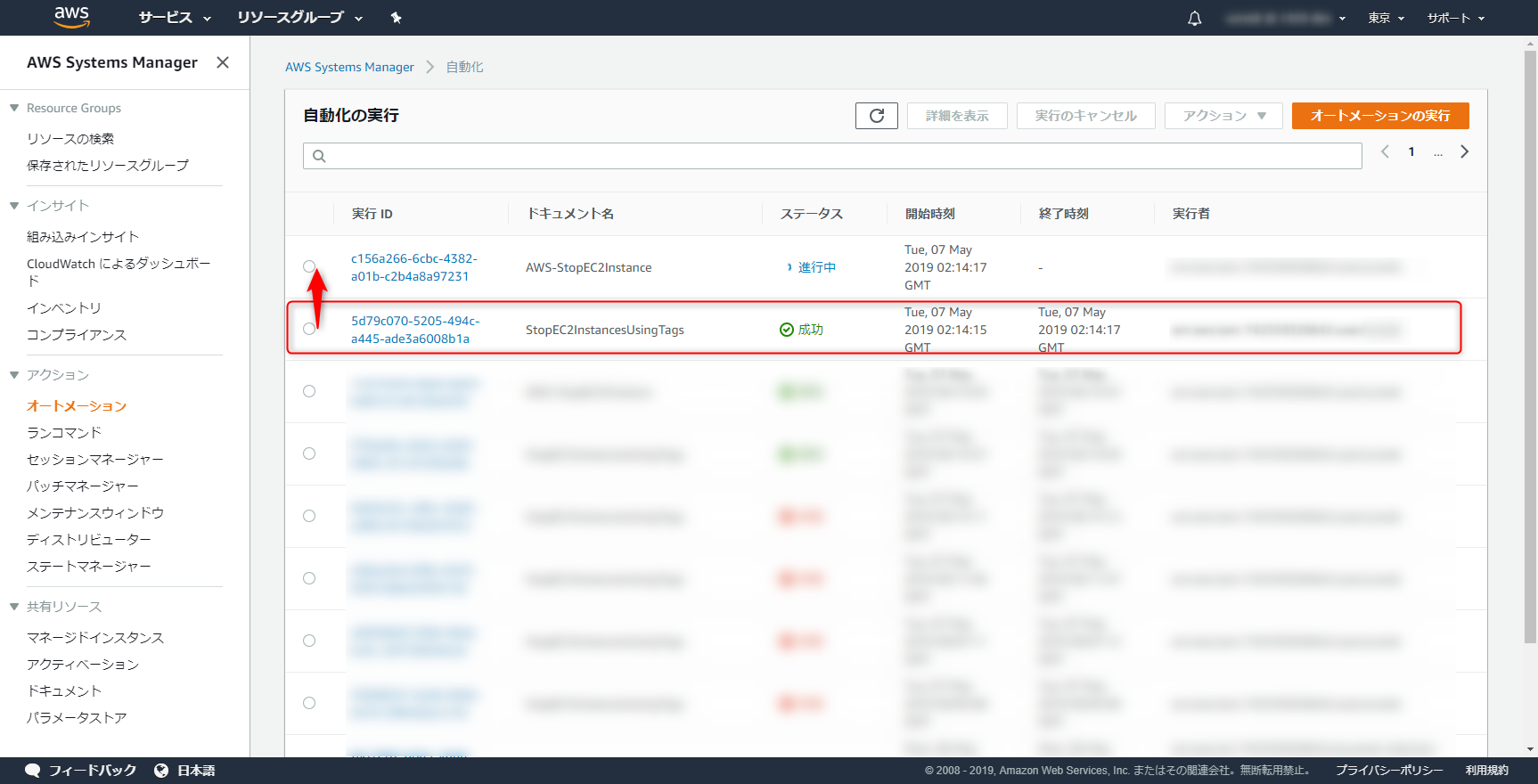
実行の状況はこのように見えます。
StopEC2InstancesUsingTagsが成功すると、組み込みドキュメントであるAWS-StopEC2Instanceが起動しているのが確認できます。
EC2インスタンスが停止したことをマネジメントコンソールで確認しましょう。
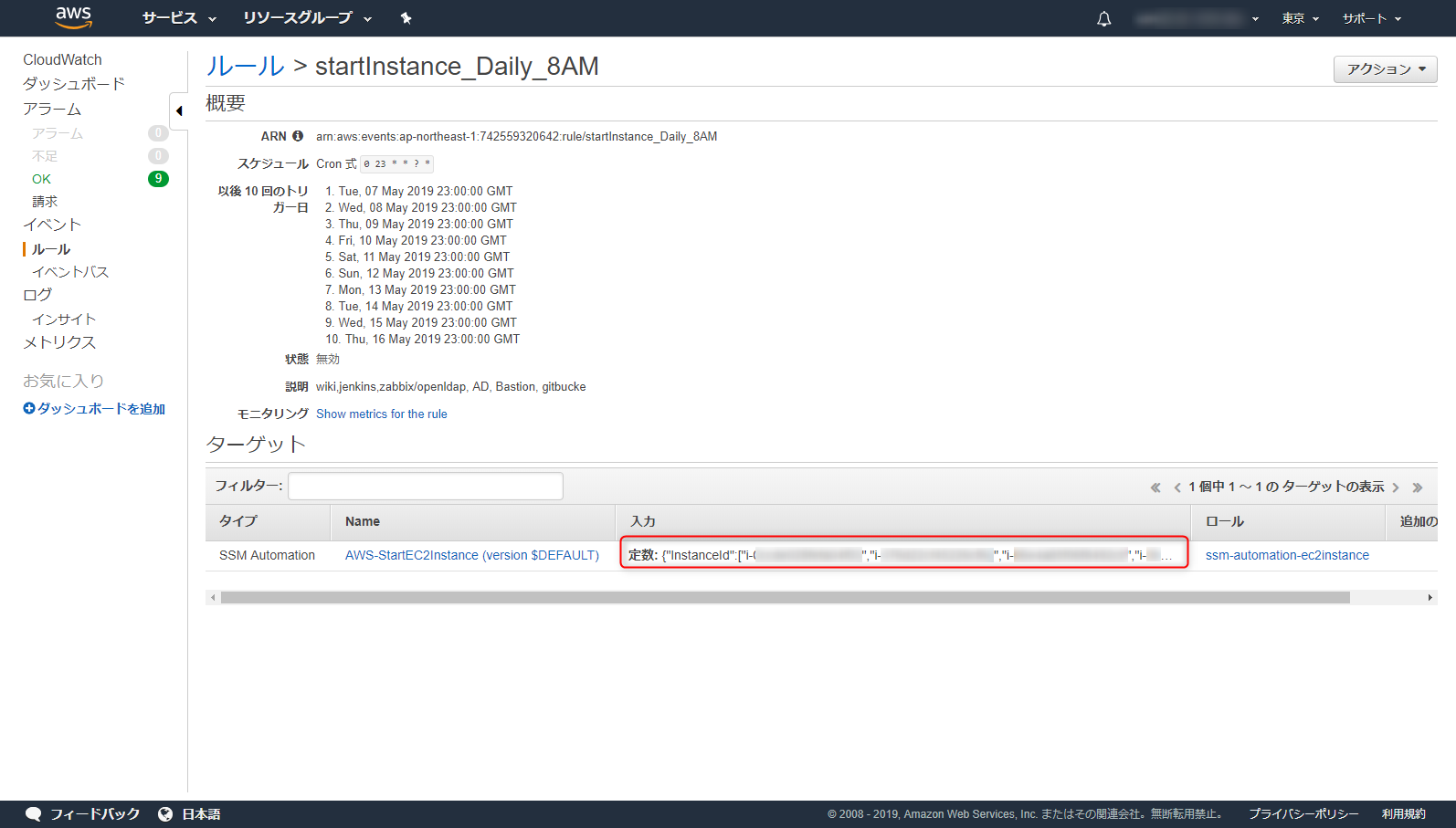
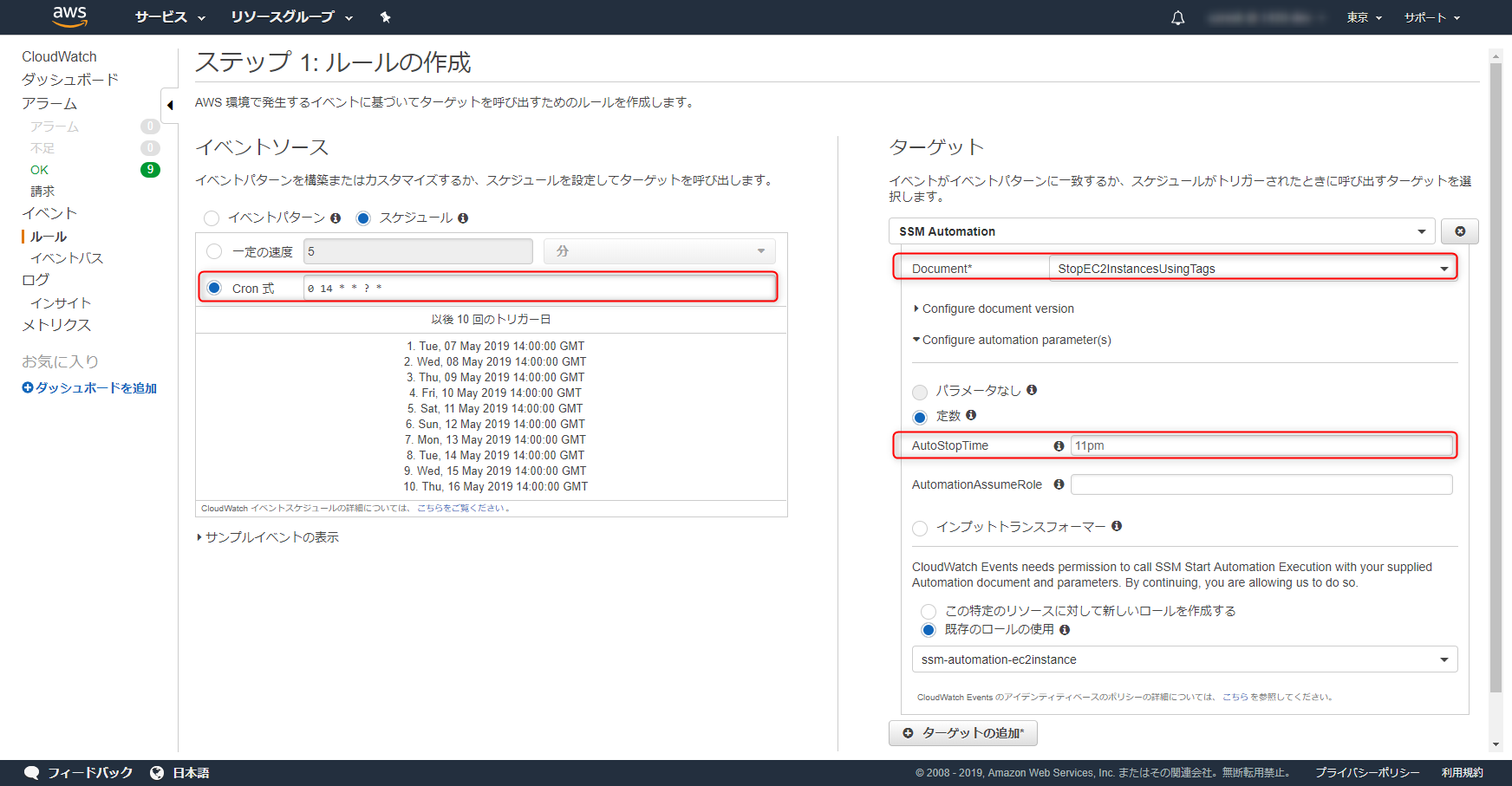
CloudWatchEventでスケジューリングする
午後11時に11pmタグが指定されたEC2インスタンスを停止するようにCloudWatchEventsに設定してみます。
ポイントは「SSM Automation」に先ほど指定したドキュメントを指定してください。
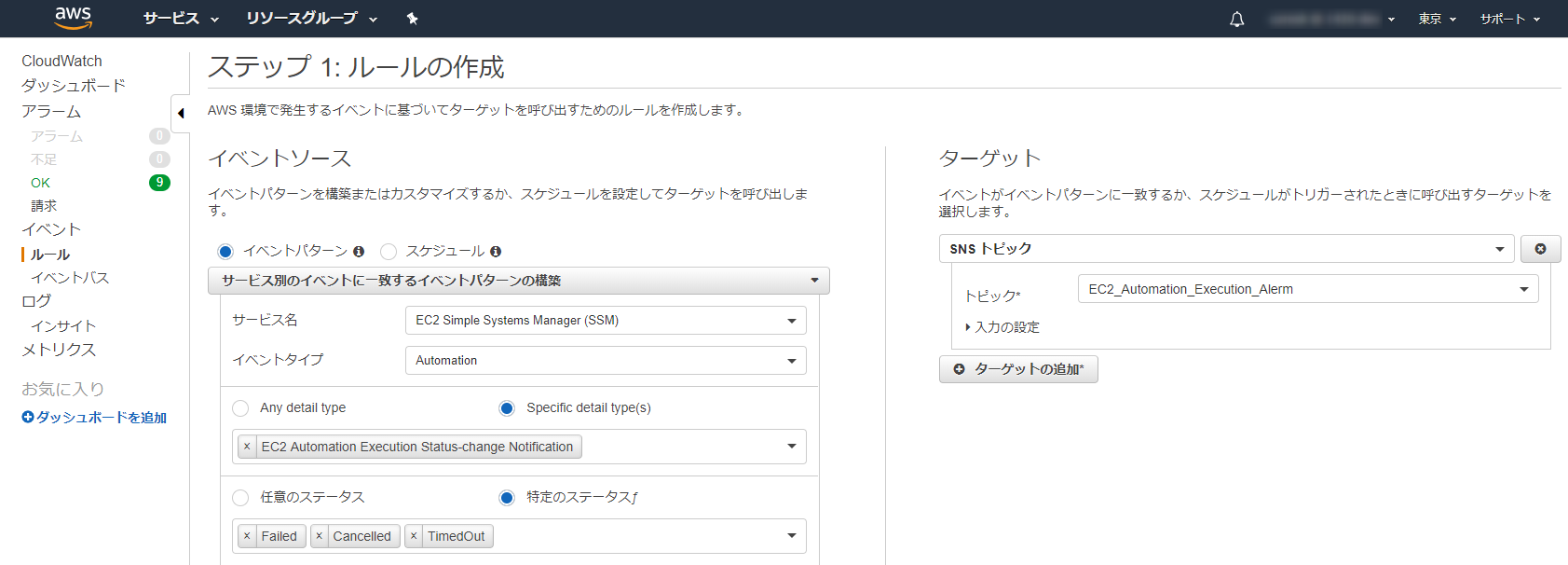
Automationの失敗を通知する
これもCloudWatchEventsで設定します。
Automationのイベントが変更されたタイミングでFailed,Timeout,CancelledになったときにSNSを使って通知します。
CloudWatchEventsは複数設定した場合でもこの通知設定は一つで問題ありません。
さいごに
AWS Systems Manager の新しい Automation アクションexecuteAwsApiがサポートされたことでより柔軟にアクションが指定できるようになりました。同じようにEC2の起動や、RDSの停止というアクションも実現可能ですしリソースグループを指定した停止も実現できるようになります。
参考までにリソースグループを指定する場合のドキュメントを張っておきます。
SystemManagerの画面でリソースグループを作成後、リソースグループ名を指定することでリソースグループまとめて停止が可能になります。--- description: Exec AWS-StopEC2Instances schemaVersion: "0.3" assumeRole: "{{ AutomationAssumeRole }}" parameters: ResourceGroupName: type: String description: (Required) ResourceGroup Name to stop AutomationAssumeRole: type: String description: (Optional) The ARN of the role that allows Automation to perform the actions on your behalf. default: "" mainSteps: - name: StopEC2Instances action: aws:executeAwsApi inputs: Service: ssm Api: StartAutomationExecution DocumentName: AWS-StopEC2Instance TargetParameterName: "InstanceId" Targets: - Key: ResourceGroup Values: - "{{ ResourceGroupName }}"参考
- 投稿日:2019-05-07T11:14:14+09:00
AWSの資格期限が2年から3年に変更されていた
AWSの資格期限が2年から3年に変更されていた
自分の資格の更新期限が近づいたので、重い腰を上げて勉強しようかなーと
思っていた時に、令和始めのショッキングな事があったのでカキカキしておきます。上記サイトより
AWS 認定は 3 年間有効です。AWS 認定を維持するため、定期的な再認定プロセスにより、引き続き専門性を有しておられることを実証していただきます。再認定によって、お持ちの AWS 認定の全体的な価値が高まり、認定において最新の AWS についての知識、スキル、およびベストプラクティスがカバーされていることを個人や雇用主に対して実証できます。
以前は2年間が有効で、1年過ぎたら再試験(初回よりは出題数が少ないやつ)を
受けられる感じだったと記憶しています。
しっかり3年と明記されていますね。そして、よくよくみたらメールがきていました。
※件名に重要と書いてあったのに、しっかり見逃していました m(_ _)m2019年2月末までに、現在および将来のAWS認定はすべて、2年間ではなく3年間有効となります。つまり、AWS認定アカウントにおいて、「有効期限」と「再認定のための最終日」が同じになります。
また、2月末までに、個別の再認定試験の実施を廃止します。認定を更新するために、50%割引で完全な試験を受験するか、または同じく50%割引でソリューションアーキテクト - プロフェッショナル試験にアップグレードすることができます。ソリューションアーキテクト - アソシエイトまたはプロフェッショナルベータ試験(利用可能な場合)への参加結果が合格の場合も、再認定要件が満たされます。
再認定方法
再認定ポリシーの変更により、次のオプションが提供されます。
再認定のためにもう1年待機する:2月末まで、有効期限を「再認定のための最終日」に一致させるために、有効期限が1年間延長されたことを確認できるようになります。今から1年後、有効期限が近付いていることについて再度リマインダー通知を受け取ります。その時点で、50%割引でソリューションアーキテクト - アソシエイト試験を受験するか、または、50%割引でソリューションアーキテクト – プロフェッショナルへアップグレードする準備を整えることができます。
試しに自分のを証明書をみてみた
たしかに伸びている !
しかも、期限内であれば半額でプロが受験できるぞい!
ということで、直近で再認定試験を受ける必要がなくなりホッとしていますw
それまでにプロとるぞー!!!ということで、良い AWS ライフを!

- 投稿日:2019-05-07T09:11:20+09:00
Amazon AthenaのワークグループとIAMによるデータベース単位のアクセス管理をやってみた
背景
Athenaが良い感じに女神様なので、他チームに展開したいと考えました。
しかし、そのまま使うとデータベースやら何やらすべて見えてしまうようで、おおっと...と思っていたら最近ワークグループという機能で実装されたらしいのでこれを使って見ました。まとめ
ワークグループ単位でAthenaを分けられ、データベースやテーブル単位まで(今回はやってませんが)、アクセス管理が出来るようになり、安心してチームごとにAthenaが使えるようになって熱いです。
またチームごとに容量制限が行えるので、心理的なハードルが低い状態で試行錯誤がしやすいのが熱いです。流れ
ワークグループを作成し、IAMで適用します。
ワークグループの作成
Athenaの画面上部のタブというかメニューの「ワークグループ:」をクリックするとワークグループの画面に移動できます。「ワークグループを作成する」から作成できます。
主な設定項目
◆ワークグループ名
変更出来ないので少し注意。いやかなり注意。
◆説明
日本語で書けるのが地味に嬉しいです。
◆クエリの結果の場所、暗号化
クエリを保存する場所や暗号化を指定できます。
OutputLocationなどを指定しない場合に指定した場所にクエリ結果が出力されます。◆クライアント側の設定を上書きする
こちらにチェックをすることで、上述の「クエリの結果の場所、暗号化」が強制的に適用されます。
試したところ、ようは以下のような挙動になりました。↓設定ONの挙動
OutputLocationを指定してもスルーされ(エラーにはならない)、ワークグループで指定した場所にクエリ結果が出力される
↓設定OFFの挙動
OutputLocationを指定すると、ワークグループの設定を無視してOutputLocationで指定した場所にクエリ結果が出力される。
今回やろうとしていることを考えると、設定ON一択ですね。
データの制限
一度ワークグループを作成後、「詳細を表示する」から「データ使用状況の制御」というタブに行くことで、そのワークグループで実行(スキャン)出来る最大データサイズを指定することができます。
この機能により、他チームに展開するうえで「えっ、ミスるとお金掛かるんでしょ・・・?」みたいなハードルを下げることが出来るのは相当熱いです。
実際、SQL自体をすらすら書ける人は多くとも「データのスキャン量まで事前に正確に考えてSQLを書ける人」となるとデータ構造やデータ設計側のスキルを要する事となり、相応にハードルが上がると思います。IAMまわり
IAMでワークグループ用ポリシーを作成する
こちらを参考にポリシーを作成します。
リソースを「指定」とし、上記で作成したワークグループを指定します。
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/workgroups-iam-policy.html
基本的にこの通りで問題ありません。
記載の通り、arnにはリージョンとアカウントも必要です。arn:aws:athena:<region>:<user-account>:workgroup/<workgroup-name>
IAMでワークグループ用ポリシーに、データベースへのアクセス制御を入れる
上記の手順の他に実際にデータベースやテーブルへのアクセスを制御するためには AWS Glue側のポリシーが必要となります。
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/fine-grained-access-to-glue-resources.htmlそんな感じで、以下のような「特定のワークグループの特定のデータベースのみ操作が行える」ポリシーを作成しました。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "glue:UpdateDatabase", "glue:CreateTable", "glue:GetTables", "glue:DeleteTable", "glue:DeletePartition", "glue:GetTable" ], "Resource": [ "arn:aws:glue:<region>:<accountid>:table/<データベース名>/*", "arn:aws:glue:<region>:<accountid>:database/<データベース名>", "arn:aws:glue:<region>:<accountid>:catalog" ] }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": "athena:*", "Resource": "arn:aws:athena:<region>:<accountid>:workgroup/<ワークグループ名>" } ] }これで、やろうとしていたことが出来るようになりました。
その他、絶妙にハマったこと
IAMの反映ラグ
IAMのポリシーの反映には絶妙に(~数分?)のラグがあるようで、これだ!と思った反映をしたあとは一旦コーヒー休憩などをして確認すると良いです。比較的即時反映の時もあるような気がするのでハマります。また、キャッシュを持っているようで、連続で実行すると成功→失敗→成功みたいな感じにもなるようです。
Athenaの画面へのIAMの反映
Athenaの画面に対しては、時間を置いてもIAMの設定が反映されない現象が起きました。
これはサインアウト→再度サインインによって見えるようになりました。
- 投稿日:2019-05-07T04:54:37+09:00
AWS実務未経験者がAWSソリューションアーキテクトアソシエイトに勉強時間40時間ぐらいで合格した話
はじめに
2019年2月にAWSソリューションアーキテクトアソシエイト(以下、SAA)合格しました(1000点中726点)。
そのときの話を友人にしたところ、なかなか好評でしたので、使った教材や勉強方法などをまとめたいと思います。筆者のバックグラウンド(勉強開始時点)
- SIer新卒入社4年目
- アプリケーション開発からインフラ設計まで広く浅く経験
- AWSは実務経験ほぼ無し(EC2インスタンスの起動と停止をした程度)
- 取得済資格
- 基本情報技術者試験取得済
- 応用情報技術者試験取得済
- TOEIC R&L 650点〜800点(ここ数年で上がったり下がったり)
前提
本エントリは、以下を前提としています。
- 基本・応用情報レベルに出てくるインフラ、ミドルウェアの用語(サブネットやWEBサーバなど)をある程度知っている
- 英語に対して苦手意識が無い
使った教材
教本
各種サービスの概要等、AWSの基本を押さえる用として、以下の2冊を使いました。どちらの本も平易に書かれており、AWS初学者向けには良い教材かと思います。
補助資料
サービスの組み合わせ方(パターン)、各サービスの深い知識、AWSでの設計の考え方については、以下の補助資料を使いました。
- サービスの組み合わせ方(パターン)
- 各サービスの深い知識
- AWSでの設計の考え方
問題集
勉強方法
(1)試験ガイドを読む(勉強時間:10分程度)
まずはざっと試験ガイドを読み、受験者に何が求められているのかを押さえました。
AWS 認定ソリューションアーキテクト – アソシエイト 試験ガイド
(2)教本で基本を押さえる (勉強時間:5時間程度)
自分は教本2冊を2周しました。
1周目は、概要を掴む程度の感覚でざっと流し読みし、2周目で精読しました。
上記の各教本には、各章のおわりに確認問題が何題かありますが、完璧に解けるまで繰り返し、本を読み込みました。(3)補助資料で足りない知識を補う(勉強時間:15時間程度)
教本で基本を押さえた後は以下のように補助資料を使って勉強しました。
- 「Amazon Web Services パターン別構築・運用ガイド 改訂第2版」、「Amazon Web Services 定番業務システム14パターン 設計ガイド」、「クラウドデザインパターン」を読み、各サービスがどのように組み合わされて使われるかを勉強。
- 「ブラックベルトシリーズ」で各サービスの深い部分を勉強。
- 「AWSによる優れた設計のフレームワーク」でAWSを使った設計の大原則を勉強。
補助資料を全部読むのは時間の都合上難しかったので、私は、苦手意識があるところや興味を持ったところだけをピックアップして勉強しました。ただ、「AWSによる優れた設計のフレームワーク」については熟読するようにしました。
(4)Udemyの問題集をひたすら解き、復習する(勉強時間:10時間程度)
Udemyの問題集は内容は英語ですが、解説が充実しているので、解けた解けなかったに限らず、解説を読み込みました。
(5)模擬試験を受ける
- (1)〜(4)を一通り終えた後、模擬試験を受験しました(受験料2000円)。試験本番の予行演習になるので受験することをおすすめします。
- 模擬試験の結果は正答率しか分からず、各問題の正否を見たり、問題を見返したりすることはできません。 後で復習したい場合は、問題文をメモしておくと良いと思います。
(6)ひたすら苦手な部分を潰していく(勉強時間:10時間程度)
後は試験本番まで余力ある限り、補助資料を読んだり、何回も間違えた問題を解き直したり、苦手な部分をひたすら潰していきました。
最後に
結果として、上記の教材・勉強方法で合格できました。
私の場合、時間の都合上できませんでしたが、実際にAWS上で環境構築してみると知識の定着がグッとよくなるかと思います。以上です。最後まで読んでいただきありがとうございました。
P.S.
2019年4月にAWSデベロッパーアソシエイトに合格しましたので、近いうちにエントリを書く予定です。
- 投稿日:2019-05-07T03:30:07+09:00
AWSの機械学習エンジニア認定試験を受けてきた
AWS Certified Machine Learning - Specialtyを受けてきた。830点くらいで合格できた。その攻略方法を後学のためにメモ書き。
試験の流れ
制限時間は180分。出題数は65問だった。
試験のあとに10問程度のアンケートがある。
時間に関してはかなり余裕があるので心配無用。試験を受けるために本人確認書類が必要である。運転免許証とクレジットカードでなんとかなった。運転免許証と保険証ではNGみたい。
出題されたサービス
- 超重要
- SageMaker
- S3
- Glue
- Kinesis[Stream/Firehose/Analytics]
- Athena
- Spark
- 知っておくべき
- Redshift
- EMR
- Polly,Comprehendなどの自然言語処理系のサービス
- Cloudwatch
- QuickSight
- Elastic Search
- ECR
- Storage Gateway
- 名前だけ出てきた
- Lambda
- Dynamo/Auroraなどのデータベース
試験のサンプルではAmazon Machine Learningという古めかしいサービスがやたらと参照されていたが、実際のところあまり重要ではなかった。
本当に重要なのはSageMakerなので、ドキュメントは読み込んだほうが良い。これをどこまで熟知しているかで合否が決まる。
特に重要なポイントを挙げる。
- S3との連携
- Pipeモード、RecordIO protobuf 形式
- 「S3に巨大なデータがあって、リアルタイムにトレーニングしたいんだけど〜」みたいな設定が多かった
- ステップ 2.2.3: トレーニングデータセットを変換し、Amazon S3 にアップロードする - Amazon SageMaker
- エンドポイントの負荷テスト
- ハイパーパラメータの調整
- 組み込みアルゴリズム
- ランダムカットフォレストがよく出た
Tips
機械学習の知識は基本的なところまででOK
- DeepLearningの問題が出てくるが、AlexNetやVGGなどの固有名詞は出なかった。
- seq2seqやCNNなどがわかればOK。
- 学習曲線のグラフからモデルの評価が出来るようにしておく。
- 本格的なGPUの使い方などは出なかった。インスタンスタイプ(P3とG3の違い)くらいまで。
- TP/TN/FP/FN、AUC、F1、Recall/Precision...などは簡単なので落とさない。
- DBSCAN/T-SNEくらいの用語は選択肢に出てくるので「あーあのクラスタリングのアルゴリズムね」くらいは把握しておく必要あり。
- 欠損値の埋め方(多重代入、ペアワイズ)とかカテゴリ変数の処理(One-hot/ラベル/ターゲット)なども出てくる。
試験サンプルでは不均衡データの扱いが多かったが、本番でも多少出てきた。アンダーサンプリング/オーバーサンプリング/重み付けなどでどれが適切かをきちんと選べるようにしておく。
学習/検証のerrorが乖離していく → 過学習/未学習に対する打ち手を選ばせる問題も多かった。
教師あり/教師なしがわかれば一発などの設問もあるので、ある程度詳しい人は特に対策しなくていいと思う。
性能面、セキュリティ、作業量(コード量)を考慮して回答する設問が多い
「ぱっと見では全部の選択肢で実現可能なんだけど、一番効率がいいのはどれ?」みたいな設問が多かった。これがこの認定試験の難しい&参考になるポイントなんだと思う。基本的にはAWSのベストプラクティスに書いてあるが、選択肢からなんとなく感じたコツを書いておく。
作業量が最も少ないものを選べ→ Glueなどのマネージドサービスを選ぶ大量のデータを処理したい→ SageMakerやAthenaなどの分散処理が効きそうなものを選ぶ。(結局マネージドサービスを選ぶ)データをインターネットに出せない→ VPCエンドポイントでS3とノートブックインスタンスを接続迷ったら新しいサービスを選ぶ。OSSは選ばない?
選択肢の中に「EC2にOSSの〜を突っ込んで〜する」みたいなものが出てきた。これが正答になることはほぼないと思われる。
AWSも「自社のサービスを知って欲しい、使って欲しい」という目的でこの試験を作っているのだから、AWSのサービスを差し置いて「単純にOSSを使おう!」を選ばせるとは思えない。おそらくAWSのサービスが正答になるような問題を作ってくるはずである。
その他所感
- 日本語は機械的に翻訳されたなーという感じの文章。意図が汲み取れない場合は英語に切り替えることも可能なので、応募するときは日本語でいいと思う。
- 試験のサンプルと比べて、出てくるサービスが新しい。
- PollyやTranslateなどのマネージドサービスも出てくる
- セキュリティ重視
- 問題の想定シーンが割とリアル
- 新サービスを出すときに経営陣から「絶対にミスるなよ?」と言われています(どうデプロイするか?)
- 大量のデータがS3に格納されていて前処理をする必要があります。もっとも効率良い方法は?
- ヒストグラムが出てスケールを変更できるボタン?があったが押しても何も機能しなかった。1
おすすめ勉強法
AWSのこのレベルの試験は対策本や問題集がないので、ドキュメントやベストプラクティスを読み込むしかない。とはいえ、「これは効果的だったな」というものがいくつかあるので紹介する。
ブログを読め
AWSのブログは非常に参考になったのでおすすめ。
この試験は性能面やセキュリティを考慮した実戦的な設問が多いため、ドキュメントを読むだけだと「問い」と「答え」が結びつかないように思う。ブログでは「各サービスをどう連携するか?」「メリットはどこにあるか?」などを関連づけて学ぶことができるし、おそらくそれが試験の答えになるはず。具体的なリンク先をいくつかピックアップしておく。あまりにも新しい記事は出題されないので去年くらいの記事を見ておくといいかも。
- SageMaker | Amazon Web Services ブログ
- Amazon SageMaker 推論パイプラインと Scikit-learn を使用して予測を行う前に入力データを前処理する | Amazon Web Services ブログ
- Amazon SageMaker ランダムカットフォレストアルゴリズムを使用した Amazon DynamoDB ストリームでの異常検出 | Amazon Web Services ブログ
- Amazon SageMaker Object2Vec の概要 | Amazon Web Services ブログ
SageMakerは触って覚える
SageMakerはこの試験で一番よく出てくるサービスなので実際に触っておくと問題文からイメージが湧きやすい。実際にJupyter Notebookのサンプルを動かしてみたり、推論エンドポイントを立ててみたりすると勉強が捗ると思う。
お金かけたくない!クラウド破産こわい!という人はYoutubeでもいい。
Live Coding with AWS | Training and Deploying AI with Amazon SageMaker - YouTube
機械学習の基礎知識
広く浅い知識が求められる。適当な入門書を一冊読んでおけば十分2だと思う。scikit-learnのチートシートを見て、すんなりわかるようなら基本事項に関しては心配無用。XGBoostやDeepLearning系のアルゴリズム、SageMakerのビルトインアルゴリズムも覚えておく。

- 投稿日:2019-05-07T00:11:55+09:00
Amazon Alexa+AWS Lambda(Node.js)でスクレイピングして詰まったところ。
まとまった休みが取れたので、以前から興味のあったAmazon Alexaにチャレンジしましたが、思いのほか躓いてしまったので記録しておきます。
やったことは公式のサンプルをなぞっただけですので、詳しい手順はそちらを参照して頂けたらと思います。やったこと
スマートスピーカーのEcho dotに問い合わせを行うと、Alexaスキルがその回答をWEBスクレイピングをして答えてくれる。
私のスペック
今回のチャレンジにあたっての私のスペックです。
プログラミング歴は19年くらいありますが、どれもこれも初めて。
- Amazon Alexa:はじめて
- AWS Lambda:はじめて
- Node.js:はじめて
- Java Script:はじめて
Amazon Alexa について
Alexa公式 動画シリーズ「Alexa道場」が親切丁寧なので、アカウントの作成〜スキル作成までを一通り悩まずにできました。
動画の本数が多いので「うお」と思いますが、1本の動画が5分程なので自分のテンポで進められます。AWS Lambda について
当初、上記で作成する「alexa developer console」内でスクレイピングまでやろうと試行錯誤していましたが、どうもブラウザのJavaScriptでできるようなDom操作が、Node.jsの標準ライブラリではできないようなので、スクレイピングを簡単にするために、やむなくAWS Lambdaを使う事にしました。
これにあたり、「alexa developer console」のカスタムスキルのリクエスト先をAWS Lambdaに変更する必要ができたので、公式のカスタムスキルをAWS Lambda関数としてホスティングするを参考に実施しました。
ハマり① 移植
「alexa developer console」で実装したものを、「AWS Lambda関数」に移植しないといけませんが、サンプルコードがまあまあ違うので、移植先のサンプルコードを理解しないといけません。
インテント名を手掛かりにすると、移植しやすいかと思います。ハマり② AlexaスキルとAWS Lambdaの関連付け
「AlexaスキルのスキルID」と「AWS Lambda関数のARN」を交換しないといけません。
確かに一緒のページには書いてあるのですが、一方がサンプルの記事の中にさらっと書いてあったので見落としていました。
- AlexaスキルのスキルIDの交換については、Alexa Skills Kitトリガーを追加するの3でやってます。
- AWS Lambda関数のARNの交換については、 カラーエキスパート設計図のサンプル対話モデルの4でやってます。
ハマり③ タイムアウト
AWS Lambda関数のデフォルトのタイムアウト値は3秒です。
最初は3秒以内で動いていたのですが、HTTPSでWEBページを取得する処理を追加したり、スクレイピングの処理を追加したりするうちに、いつの間にか処理時間が延びていた事に気づかず、ロジックを見て困っていました。
処理を追加してエラーが発生したらタイムアウトも疑ってみてください。
AWS Lambdaのマネジメントコンソールにて、タイムアウト値の変更が可能です。
https://aws.amazon.com/jp/blogs/news/aws-lambda-timeout-15min/Node.js について
JavaScriptならなんとかなるかな。と思ってNode.jsについてロクに調べもせずに取り掛かってしまいました。
ハマり① ノンブロッキングIO
HTMLの取得を待たずにパース処理が動いてしまいます。
標準ライブラリに含まれるhttpを使って通信を行うと、結果を待たずに先に進んでしまいました。(で、解析失敗)
これは、「ノンブロッキングIO」と言うNode.jsの仕様であり、メインスレッド1本で複数のリクエストを裁くタイプのサーバーの特徴だそうです。とはいえ、HTMLの取得を待ってパースを行う必要があるので調べた結果、Promiseという非同期処理を制御(直列実行・並列実行)できるものがある事がわかった為、下記記事を参考に実装を一部やり直しました。
お気楽 Node.js 超入門
いまさら聞けないNode.jsの基礎知識とnpm、Gulpのインストール
Node.jsのhttpsモジュールを用いた通信処理をPromiseで書き直して解読してみたハマり② スクレイピング
「Node.jsでスクレイピングするならこれが本命(たぶん)」を参考に(と言うかコピペ)させていただいて、HTMLの取得とパースが簡単にできました。
が、HTMLのパースで使うcheerioというライブラリは、パース結果をjQueryオブジェクトで返すとのこと。
jQueryについても知らない為、ハマったと言うか、JavaScriptを舐めてた為に理解するものが増えてしまい、時間がかかってしまいました。
HTMLと下記記事を何回も交互に見ながら、なんとか取りたい情報を取得する事に成功しました。
- 投稿日:2019-05-07T00:09:19+09:00
いますぐ使うCodeBuild
CodeBuildとは
AWSのなかでCI/CDを担うCode三兄弟のひとつ、という説明では一切何もわからなかったので、軽く触った理解をメモとして残します。
AWS CodeBuildは、Jenkinsジョブ相当のものを「Build project」と呼び、任意のDockerイメージを起動して、コンテナ内で任意のコマンドを起動できるサービスと理解しました。
私自身はCircleCIあるし時間の無駄でしょと思って敬遠してましたが、CI/CDという色眼鏡を外すと、活用の幅が非常に広い面白い製品です。使わないのはもったいない!
こんなことに使えそう
- CircleCIやTravisCIなどの CI as a Service を利用されてるなら、料金面や速度など強い不満なければ、わざわざ移設するほどのものではありません
- EC2サーバーにJenkinsを立ててCI/CDに供しているなら、一部のJenkinsジョブをCodeBuildのBuild Projectに移設すると、Dockerコンテナで動かせるフルマネージドサービスなど利点を享受できる可能性があります
- EC2サーバーにSSHして定型作業をしているなら、CodeBuildのBuildProjectとして定型化できる可能性があります
- EC2サーバー1台でcronジョブを動かして、SPOFや性能面のスケールに課題を感じているなら、CodeBuildのBuildProjectに移設し利点を享受できる可能性があります
- ウェブアプリのリリース時のRDBマイグレーションの実行場所に悩んでるなら、CodeBuildのBuildProjectに移設できる可能性があります
- DockerコンテナをLambdaで動かしたいよなあ、という妄想は、CodeBuildで実現できそう
CodeBuildの制限
私が思いついた使い道の範囲でも、色々と制限が絡んできます。
- CodeBuild の制限 - AWS CodeBuild
- 初期値での並列実行数はそんなに多くない
- Amazon VPC の制限 - Amazon Virtual Private Cloud
- VPCでも動かすなら、起動中はENIとIPを使うことを念頭に。実行が終わったら、CodeBuildがENIは削除、IPは開放してくれる。
- IAM エンティティおよびオブジェクトの制限 - AWS Identity and Access Management
- BuildProjectごとにIAM管理ポリシーを勝手に作らせると、気がついたら上限到達してそう。
- AWS サービスの制限 - アマゾン ウェブ サービス
- 環境変数の値をSSMパラメータストアから取ってくるなら念頭に。最近緩和されましたが同時接続数なども。
サンプル: CodeBuildでGithubリポジトリを取ってきてRDS MySQLに接続する
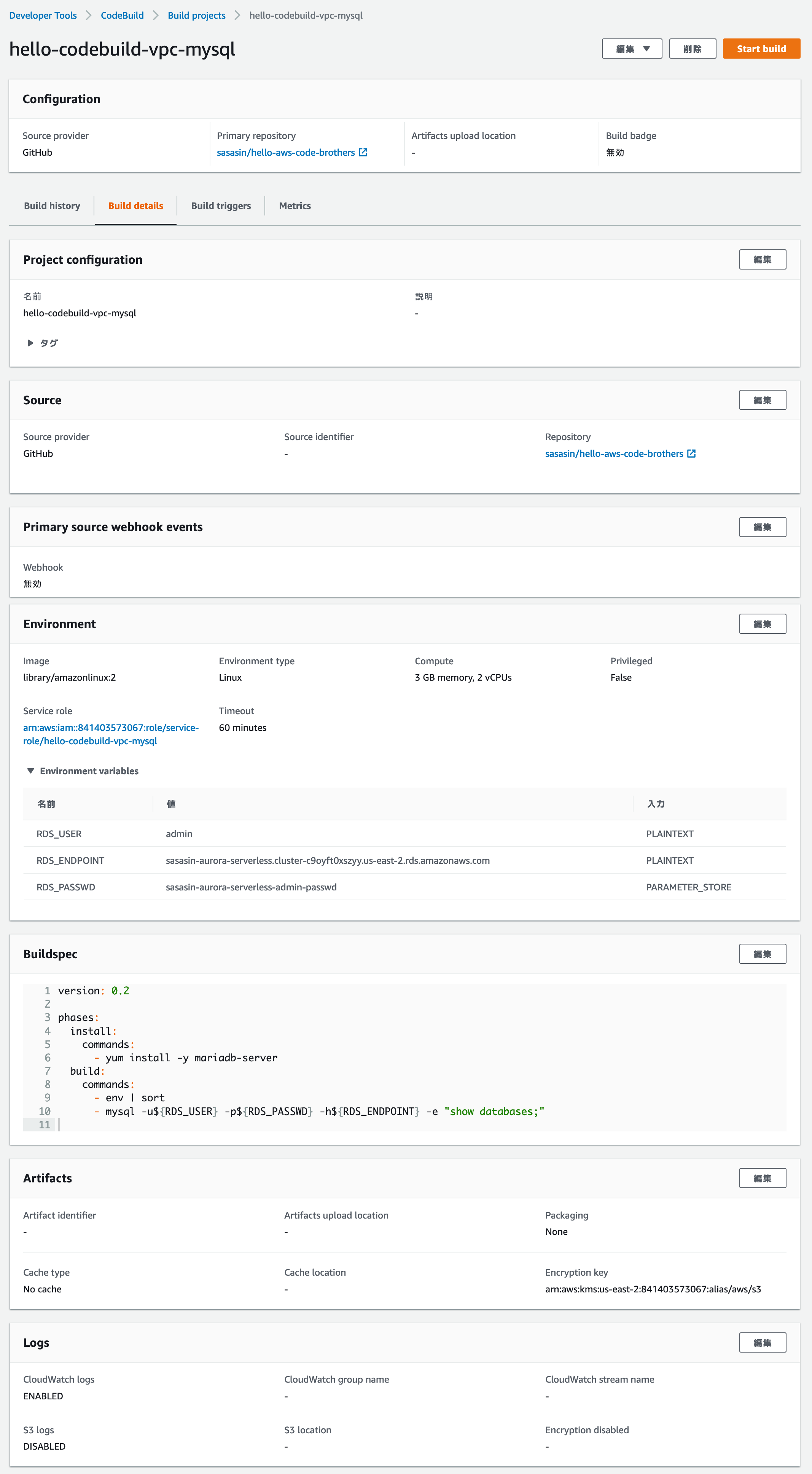
妄想を並べるのもどうかと思うので、動きそうなサンプルを組んでみました。
- GitHubリポジトリを持ってくる
- CodeBuild提供ではないDockerイメージで動かす
- VPCで動かす
- MySQLに接続する
- MySQLの接続情報はSSMパラメータストア(暗号化)から取ってくる
- 定期実行させる
これだけ要素を押さえれば、cronジョブ実行に使えそうだとか、RDBマイグレにも使えそうだとかわかりそうなので。
作業するあなたは IAMFullAccess 権限を有している必要があります
CodeBuildのBuildProjectを作成する過程で、IAM権限を構成させるためです。
VPCを準備する
VPCで動作させるなら、以下の準備が必要です。
- Publicサブネットを用意する
- PublicサブネットにNATゲートウェイを立てる
- Privateサブネットを用意する
- Privateサブネットのルートテーブルに、0.0.0.0/0がNATゲートウェイを経由するよう記載
RDSを立てる
VPC Privateサブネットに立てておきます。VPCで動くCodeBuildから接続できるよう、RDS側セキュリティグループに穴を開けておきます。
SSMパラメータストアに、RDS接続パスワードをテキトーな名前で入れておく
- 名前は「sasasin-aurora-serverless-admin-passwd」
- 利用枠は標準
- タイプは「安全な文字列」
- KMS主要なソースは「現在のアカウント」
- KMSキーIDは「alias/aws/ssm」
GitHubリポジトリを準備する
とりあえず作るだけなので、README.mdだけ転がってるリポジトリでよいです。
CodeBuild に Build Project を作る
CodeBuild管理画面を開く。Create Build Project。
- 名前は hello-codebuild-vpc-mysql
- SourceProviderは GitHub
- Repository in my GitHub Account で準備したGitHubリポジトリを指定
- 初回はOAuth認証を要求されるので、Authしてあげて
- webhook
- 設定組むと「特定のブランチでpushされたら」などが実現できる。今回は割愛
- Envirionment
- Environment Image: Custom image
- Environment Type: Linux
- External Image URL: library/amazonlinux:2
- Service Role: New
- Role Name: hello-codebuild-vpc-mysql
- 追加設定
- VPC, Subnet, Security Group: 用意したPrivateサブネットを選択。セキュリティグープは、RDSに接続可能なものを選択。
- Environment variables:
- RDS_USER: (RDSに接続す るユーザーを)、Plaintext
- RDS_ENDPOINT: (RDSのエンドポイントURLを)、Plaintext
- RDS_PASSWD: (SSMパラメータストアの名前を)、Parameter
- こいつだけ Parameterなことに注意
- 私は「sasasin-aurora-serverless-admin-passwd」としていました
- BuildSpec
- insert
- switch to editor 押して、内容は以下
version: 0.2 phases: install: commands: - yum install -y mariadb-server build: commands: - env | sort - mysql -u${RDS_USER} -p${RDS_PASSWD} -h${RDS_ENDPOINT} -e "show databases;"amazonlinux:2では、mysqlコマンドはmariadb-serverに含まれている。mysqlではなくmariadbなのでこのように。
envを見ているのは、まあ、環境変数で指定した値や、SSMパラメータストアから取ることにした環境変数は、このように取れますよというご確認で。
できあがり
こんな。
Build Projectを実行してみる
Start Buildボタン押したら、しばらくして実行されます。
今回の作例ではyum installが時間食って2分くらいかかってますね。実行頻度や料金が気になってきたら、予めyum installしたコンテナイメージをECRかDockerhubに入れて使うと良いでしょう。
定期実行させる
なんも悩む要素ないです。build projectを選んで、Build triggers、create triggerで実行周期を設定するだけです。書いた時刻はGMTで解釈されるようです。
他の方法で実行させる
- webhookで実行する
- 設定組むと「特定のブランチでpushされたら」などが実現できる。今回は割愛
- 任意のタイミングで、AWS SDKのCodeBuild.Client.start_build()で実行する
- AWSイベントをLambdaで受けて、CodeBuildのBuild Projectを実行する
- 任意のイベントをZapier経由でLambdaで受けて、CodeBuildのBuild Projectを実行する
などなど
ここまでをコード化する
TerraformかCloudFormationでしょう。
- https://www.terraform.io/docs/providers/aws/r/codebuild_project.html
- https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/aws-resource-codebuild-project.html
buildspec.ymlをどこで管理するのが正解か。私は今のところ、TerraformかCloudFormationと一緒に置いておくのが良いのではないかなあという気がしています。正直、buildspec.ymlだけ見たところで何もわからない。ジョブ定義の全体を見なければわからない。
自前のDockerfileがあるなら、同じくTerraformかCloudFormationと一緒に置いておくと、見通しが良いように感じてます。
ハマりどころ
- VPCで実行さすと10~20秒、余分にかかる。VPCで実行する確かな理由がないなら、VPC指定無しで実行するのが総合的に正しい
- ca-certificateが入ってないDockerイメージを使い、かつ、SSMパラメータストアの暗号化した値を取り出そうとするとハマる。buildspec.ymlで入れようとしても、それより前の段階でSSMパラメータストアから復号化してるため間に合わない。具体的にはalpineでDOWNLOAD_SOURCEという段階で、こんなエラーログが出ます。今回はAmazonLinux2のイメージを利用し回避しました。
[Container] 2019/05/06 07:53:44 Phase complete: DOWNLOAD_SOURCE State: FAILED [Container] 2019/05/06 07:53:44 Phase context status code: Decrypted Variables Error Message: RequestError: send request failed caused by: Post https://ssm.us-east-2.amazonaws.com/: x509: certificate signed by unknown authority