- 投稿日:2019-05-07T23:47:21+09:00
ProgateのRuby学習で抑えておきたいポイントまとめ
備忘録として作成
省略形の書き方も覚える
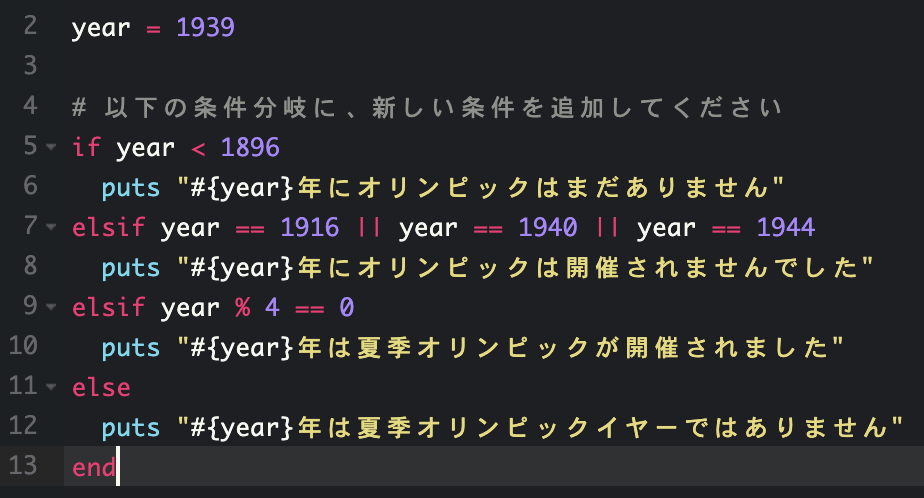
複数の条件を組み合わせるときの書き方
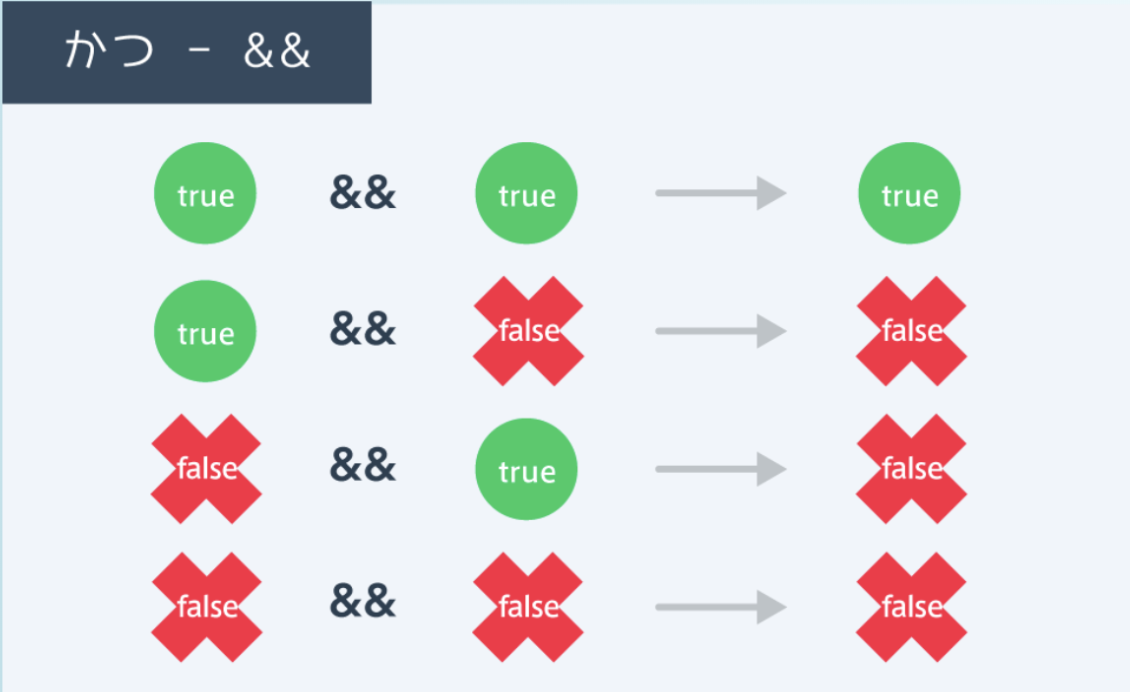
「かつ」は"&&"で表す
条件1 && 条件2 は 条件1かつ条件2という意味で、複数の条件がすべてtrueならtrueになる
↑数学のように10 < x < 30 と表すことはできない
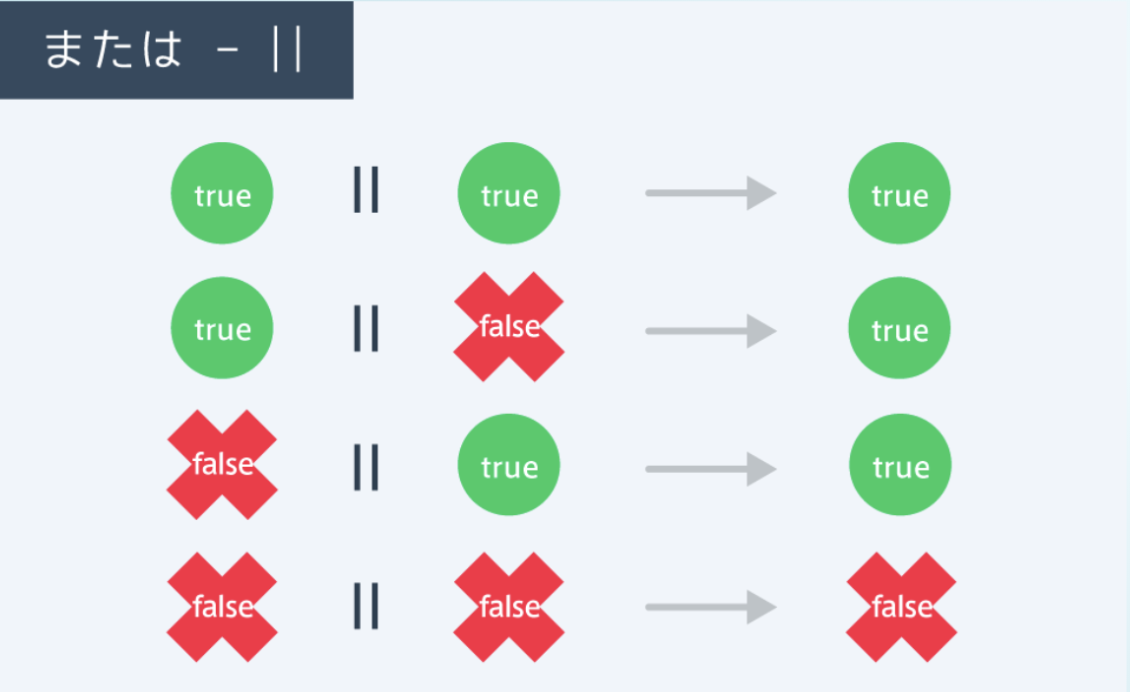
「または」 は ||で表す
使用例
1916年または1940年または1944年はオリンピックが開催されていない年
|条件1| |条件2」は「条件1または条件2」という意味複数の戻り値(return)を使う場合、分岐はelseでなくendを複数用いる
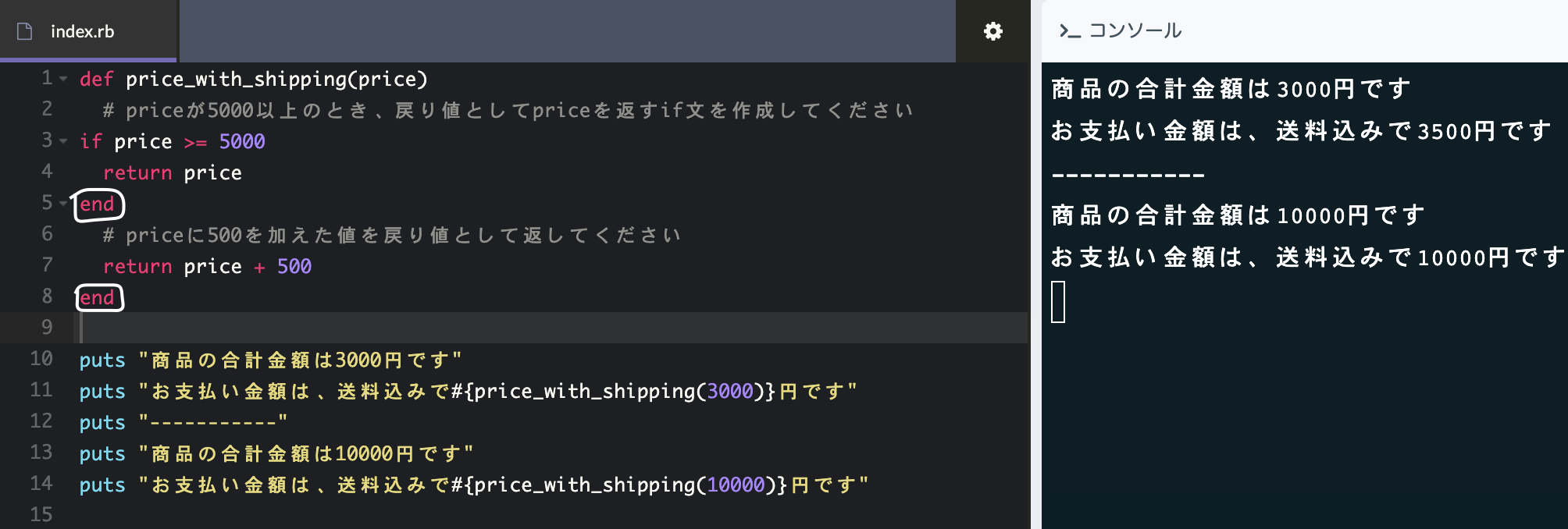
【Ruby 学習コースⅢ 戻り値9. 複数の戻り値】
"分岐するとき=elseやelsifを用いる"ではない
複数の戻り値を使う場合はendを複数使って分岐を表す
returnは、戻り値を返すだけでなく、メソッドの処理を終了させる性質も持っている
returnの後にあるメソッドの処理は実行されないので注意
↑送料込みで価格を表示する際の戻り値(return)使用例↑
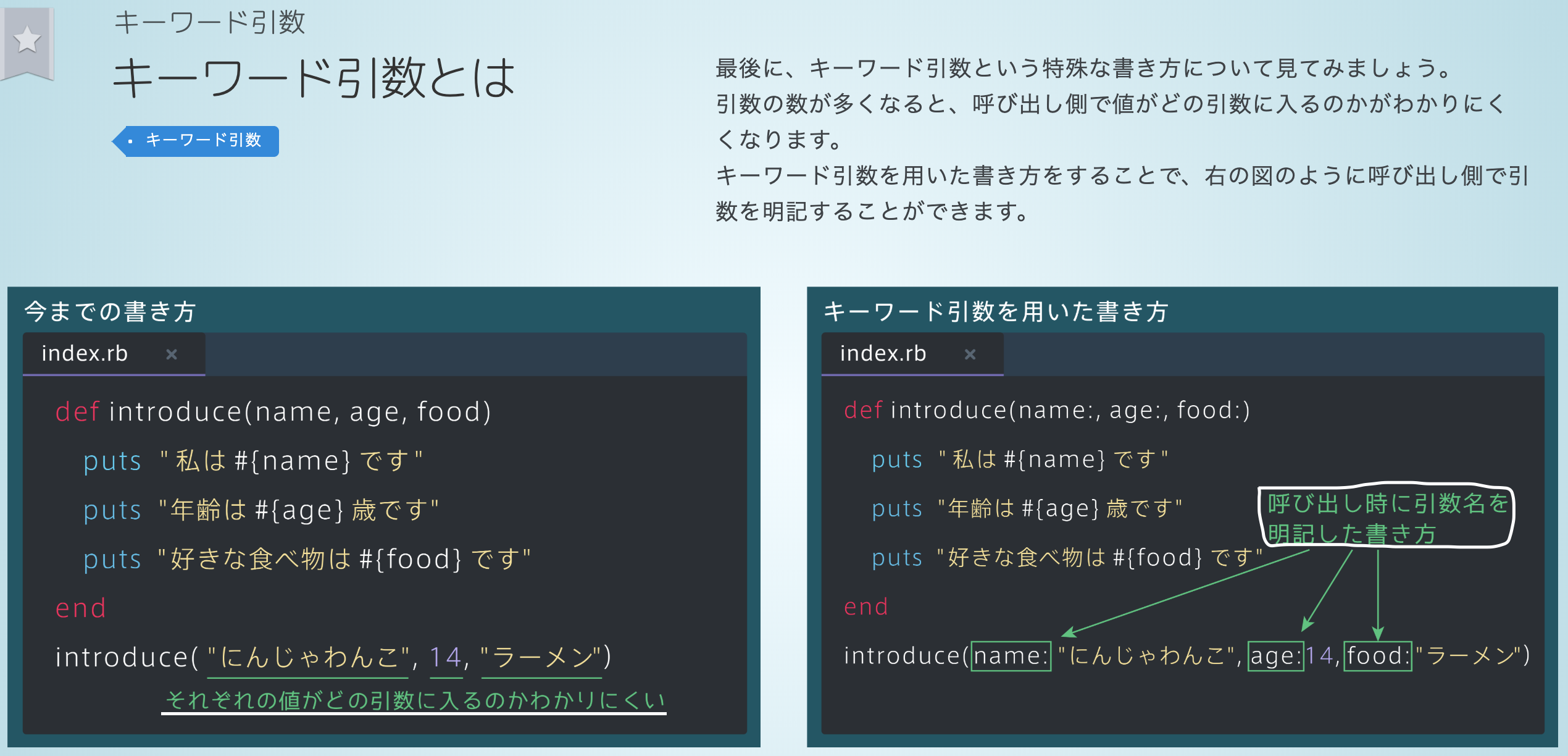
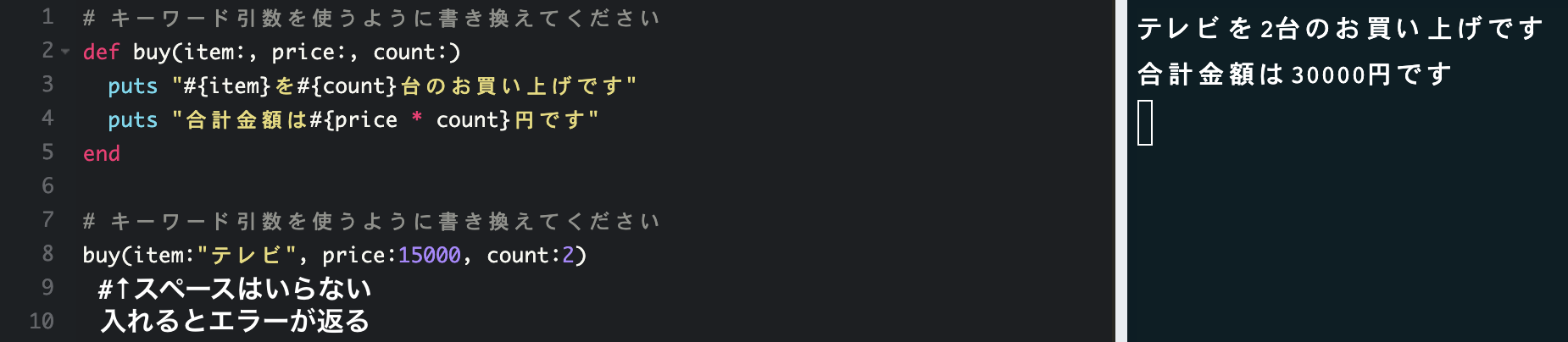
戻り値は値によって表示させたいテキストや画像が異なるときの分岐に役立つ引数の区別を付けるキーワード引数の書き方
引数の種類が多い ≒ 情報の種類が多いときに便利なのがキーワード引数
↑キーワード引数使用例↑
会計システムを作るときに使えそう
商品の種類(item)、価格(price)、個数(count)の組み合わせとか尽大だもんね
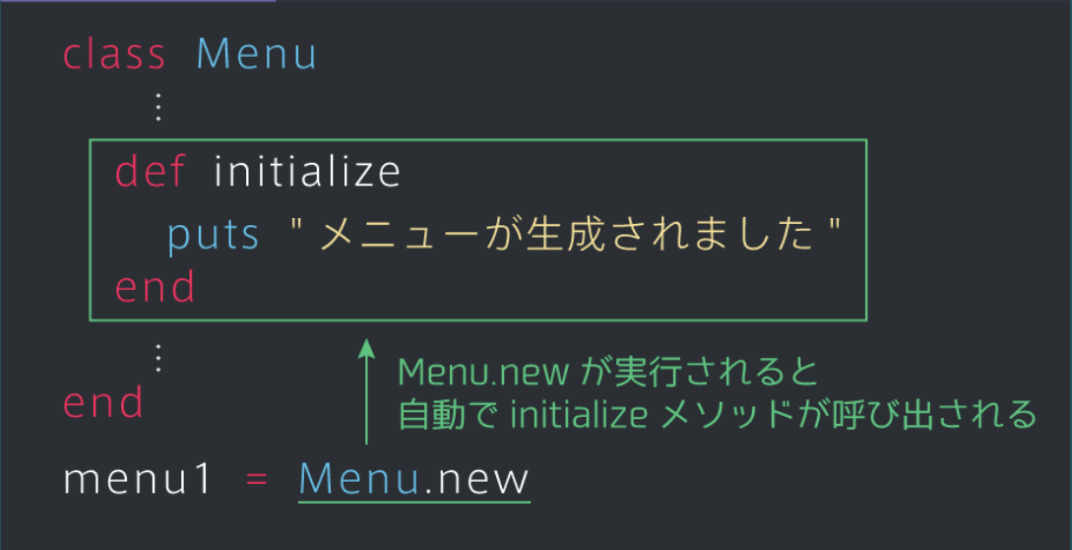
ネテロ会長の百式観音くらい尽大インスタンスを短く書けるinitializeメソッドの使い方
インスタンスを生成するのと同時にインスタンス変数に値を導入できるのがinitializeメソッド
Menu.newを実行するだけでも メニューが生成されました と表示される
インスタンス毎にインスタンス変数の値を変更できる
情報が多いときはキーワード引数を使うと見やすくていい繰り返し処理でメニューを一覧表示し、番号をつける
料理注文システムを作る過程でメニュー表示をする必要があるため作成
0. apple
1. banana
2. orange
と出力される番号をつけるには、番号を保存するための変数(上図では変数index)をeach文の外で用意する
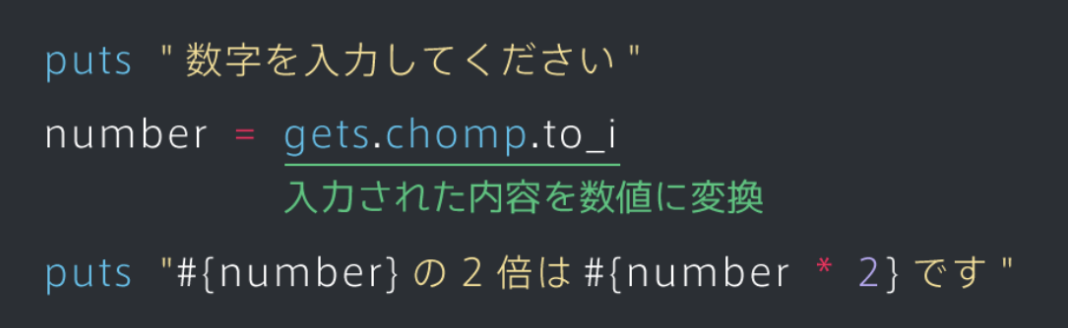
each文の処理の中で値を1だけ増やして更新するようにするユーザーからの入力を受け取る
入力を受け付けるには「gets.chomp」を使う
このコードが実行されると、コンソールが入力待機状態になる
「変数 = gets.chomp」とすると、エンターを押されるまでに入力された値が変数に代入される
↑入力例↑
ユーザーに数字を入力してもらう場合、"gets.chomp.to_i"と書く
すると入力してもらう値が文字列扱いではなく、数値扱いになる








- 投稿日:2019-05-07T22:55:58+09:00
Ruby minitest キーワード引数を叩くMockの定義方法
@koshi_life です。
キーワード付き引数を叩くMockの定義方法でハマったので備忘です。前提
- Ruby 2.6.0
- minitest 5.11.3
検証対象モジュール
比較用に検証対象モジュール内で通常引数、キーワード引数各Mock化する2パターンでテストを書きました。
検証対象モジュールは以下とコード参考。
Hoge#countup_normal_args():
通常引数の@api_client.get,@api_client.updateを叩くHoge#countup_keyword_args():
キーワード引数の@api_client.get(item_id:),@api_client.update(item_id:, value:)を叩くhoge.rbclass Hoge def initialize(api_client) @api_client = api_client end # countupメソッド 通常引数のモジュールを利用する def countup_normal_args(item_id) item = @api_client.get(item_id) new_value = item[:val] + 1 @api_client.update(item_id, new_value) end # countupメソッド キーワード引数のモジュールを利用する def countup_keyword_args(item_id) item = @api_client.get(item_id: item_id) new_value = item[:val] + 1 @api_client.update(item_id: item_id, value: new_value) end endテスト
3つのケースを定義しました。詳細はコード参照。
- 通常引数のメソッドを叩くパターン
- キーワード引数のメソッドを叩くパターン1
- キーワード引数のメソッドを叩くパターン2 Proc 利用
hoge_test.rbrequire 'test_helper' class HogeTest < ActiveSupport::TestCase test '#Mock 通常引数のメソッドを叩くパターン' do item_id = 'id-1' retval_get = { val: 3 } args_get = [item_id] retval_update = true args_update = [item_id, 4] api_mock = MiniTest::Mock.new api_mock.expect(:get, retval_get, args_get) api_mock.expect(:update, retval_update, args_update) # 検証したいモジュールを実行します hoge = Hoge.new(api_mock) result = hoge.countup_normal_args(item_id) assert_equal(true, result) # Mockに送信されたデータを検証します。 api_mock.verify end test 'キーワード引数のメソッドを叩くパターン1' do item_id = 'id-2' retval_get = { val: 3 } args_get = [{ item_id: item_id }] # 配列の中にハッシュで定義 retval_update = true args_update = [{ item_id: item_id, value: 4 }] # 配列の中にハッシュで定義 api_mock = MiniTest::Mock.new api_mock.expect(:get, retval_get, args_get) api_mock.expect(:update, retval_update, args_update) # 検証したいモジュールを実行します hoge = Hoge.new(api_mock) result = hoge.countup_keyword_args(item_id) assert_equal(true, result) # Mockに送信されたデータを検証します。 api_mock.verify end test 'キーワード引数のメソッドを叩くパターン2 Proc利用' do item_id = 'id-3' retval_get = { val: 3 } retval_update = true api_mock = MiniTest::Mock.new api_mock.expect(:get, retval_get) do |item_id:| puts ":get() called args item_id:#{item_id}" item_id == 'id-3' end api_mock.expect(:update, retval_update) do |item_id:, value:| puts ":update() called args (item_id:#{item_id}, value:#{value})" item_id == 'id-3' && value == 4 end # 検証したいモジュールを実行します hoge = Hoge.new(api_mock) result = hoge.countup_keyword_args(item_id) assert_equal(true, result) # Mockに送信されたデータを検証します。 api_mock.verify end end参考
- 投稿日:2019-05-07T22:55:02+09:00
「ビンゴカード作成問題」を解答する
https://blog.jnito.com/entry/2019/05/03/121235
にて紹介されている、ビンゴカード作成問題を解いてみました。
詳しい問題仕様につきましては元リンク先をご参照ください。さてこの記事ですが、単に作成した解答コードを載せるだけですと既に同じような記事がいくつもQiita上にあるのではと思ったので、コード記述のステップを詳しく書いてみることで差別化を図っています。
またRubyの実行はpaiza.ioで行っています。(Ruby 2.5.3)大雑把にまず考えた自分の解答までの道筋は
①「1..15」「16..30」…「61..75」の各配列を作成。
②各配列の中から、重複が出ないように数字を5個ずつ取り出す。
(例:[1,4,7,10,13],[16,19,22,25,28],……,[61,64,67,70,73])
③各配列の1番目の要素、2番めの要素…を順々に組み合わせる。
(例:[1,16,31,46,61],[4,19,34,49,64],……,[13,28,43,58,73])
④以下の条件を加えつつ出力
・パイプ(|)で区切った文字列として出力する
・3行目の3番目の要素は空文字(ビンゴのFreeに当たるため)
・1桁の数字は右詰めという感じでした。
①
連続する数字の配列は、配列([])の中でRangeクラスのオブジェクトを*を付けて展開することで作成できます。
[*1..15] # => [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]今回取得したい5種類の配列は二次元配列の形で取得します。
[[*1..15],[*16..30],[*31..45],[*46..60],[*61..75]]②
①で作成した各配列から、ランダムに5個の要素を取り出します。
配列から指定した個数の要素をランダムに取り出すにはArray#sampleメソッドを使います。[*1..15].sample(5) # => [12, 7, 4, 11, 10] [*1..15].sample(5) # => [6, 9, 10, 4, 3]道筋で想定したように、取り出した要素から新しく二次元配列を作るにはEnumerable#mapを使います(余談ですが、map派です)。
[[*1..15],[*16..30],[*31..45],[*46..60],[*61..75]].map{|s| s.sample(5)} # => [[12, 7, 4, 15, 3], [24, 30, 26, 29, 20], # [32, 39, 33, 43, 34], [50, 56, 55, 46, 53], [68, 67, 63, 70, 65]]③
お次は、上で作成した各配列から1つ目の要素、2つ目の要素…をそれぞれ取得して各要素ごとの新しい配列を作成します。
が、正にその動きをするメソッドの存在自体は知っているのに名前を忘れるという失態。
力技で切り抜けようかとも思いましたが、少し考えても良い感じの書き方を見つけられなかったのでググってしまいました…探していたのはArray#transposeです。
[[*1..15],[*16..30],[*31..45],[*46..60],[*61..75]].map{|s| s.sample(5) }.transpose # => [[13, 18, 35, 49, 75], [11, 19, 42, 53, 61], # [8, 27, 43, 59, 71], [9, 20, 44, 56, 65], [15, 24, 34, 51, 74]]これで出力する番号の元になる数字たちが作れました。
④
後は要件に沿って出力するだけ
なのですがこれがまた厄介。
まず、Bingoクラスのクラスメソッドとして実装する必要があります。Bingo.rbclass Bingo def self.generate_card puts " B| I| N| G| O" # ここにロジックを移植していく end end次に3行目の3番目の要素はビンゴのFreeに当たるので空文字に置換する必要があります。
Bingo.rbclass Bingo def self.generate_card puts " B| I| N| G| O" [[*1..15],[*16..30],[*31..45],[*46..60],[*61..75]].map{|s| s.sample(5) }.transpose.each_with_index{|array, i| array[2] = ' ' if i == 2 # Free部分置換 # ここで1行ずつ出力していく } end end最後に1桁の数字は右詰め&&各数字をパイプで区切って出力するように調整します。
Bingo.rbclass Bingo def self.generate_card puts " B| I| N| G| O" [[*1..15],[*16..30],[*31..45],[*46..60],[*61..75]].map{|s| s.sample(5) }.transpose.each_with_index{|array, i| array[2] = ' ' if i == 2 puts array.map{|s| s.to_s.size < 2 ? " #{s}" : s}.join('|') } end end Bingo.generate_card # => B| I| N| G| O # 9|20|34|46|64 # 13|27|33|47|72 # 5|21| |58|70 # 12|24|38|55|67 # 2|23|44|56|66一旦条件は満たせたように思えます。
うーん、とはいえ最後のFree置換と自力で判定している数字の右詰めがかなり苦しいですね…もう少し調べてみた
自力での解答はここまでにして(
ググってるけど)、より良い書き方がないか調べてみました。
数字の右詰めに関しては、わざわざ自分で判定せずともString#rjustメソッドという素晴らしい解答がありました。Bingo.rbclass Bingo def self.generate_card puts " B| I| N| G| O" [[*1..15],[*16..30],[*31..45],[*46..60],[*61..75]].map{|s| s.sample(5) }.transpose.each_with_index{|array, i| array[2] = ' ' if i == 2 puts array.map{|s| s.to_s.rjust(2)}.join('|') } end end Bingo.generate_cardすこし綺麗になりましたね♪
とはいえまだまだリファクタリング出来ると思いますのでアドバイス、修正すべき点などありましたらコメント頂けると幸いです。
今後も少しずつ別の問題にもチャレンジしていこうと思います。
- 投稿日:2019-05-07T22:53:39+09:00
RPPL
RPPLとは、Read Parse Print Loopの頭字語である。(今考えた。)
次を
~/.pryrcに追記する。1$__is_pry_rubyvm_ast_mode = false def ast! $__is_pry_rubyvm_ast_mode = !$__is_pry_rubyvm_ast_mode end Pry.config.hooks.add_hook(:before_eval, :"RPPL") do |code, _pry| next if code == "ast!\n" next unless $__is_pry_rubyvm_ast_mode x = code.inspect code.clear code << "RubyVM::AbstractSyntaxTree.parse(#{x})" endそしてpryで
ast!を実行する。
するとpryに打ち込んだコードがASTとなって出力されて、便利である。$ pry [1] pry(main)> 1 + 1 => 2 [2] pry(main)> ast! => true [3] pry(main)> 1 + 1 => (SCOPE@1:0-1:5 tbl: [] args: nil body: (OPCALL@1:0-1:5 (LIT@1:0-1:1 1) :+ (ARRAY@1:4-1:5 (LIT@1:4-1:5 1) nil))) [4] pry(main)>https://qiita.com/hanachin_/items/d744e322b4a778574ed7 を参考にしたり、アイディアを得たりしている。
簡単な解説
pryは
before_evalフックでコードを実行する前にフックを実行できる。exec_hook :before_eval, code, self result = current_binding.eval(code, Pry.eval_path, Pry.current_line)フックにはevalする予定の文字列が渡される。
そしてこの文字列はevalにも同じオブジェクトが渡されるため、オブジェクトを破壊的に書き換えればpryが実行するコードを変えることができる。文字列の書き換えは、
String#clearとString#<<を使っている。clearで文字列を空にして、<<でパースを行うコードを書き加えている。
雑に実装しただけだしまだ試しただけなので便利なのかもよくわからないが、ひたすらASTを観察したい時には便利な気がする。
ぱっと思いつく課題を挙げれば、取得したASTに対してメソッドを呼び出したい(RubyVM::AbstractSyntaxTree::Node#childrenなど)という需要は容易に考えられるが、この実装だとその需要を満たすことはできない。
真面目に使うのであれば、その辺を改善していくと良いだろう。より良い実装やアイディアがあったらぜひ教えてほしい。
なおこのコードのライセンスはCC0とする。 https://creativecommons.jp/sciencecommons/aboutcc0/ ↩
- 投稿日:2019-05-07T22:43:07+09:00
多対多 DBに値入らない時
real_shopテーブル----real_shop_expert_collectionテーブル(中間)----expert_collectionテーブル
それぞれテーブルを作る
real_shop.rbhas_many :real_shop_expert_collections has_many :expert_collections, through: :real_shop_expert_collectionsexpert_collection.rbhas_many :real_shop_expert_collections has_many :real_shops, through: :real_shop_expert_collectionsreal_shop_expert_collections.rbbelongs_to :real_shop belongs_to :expert_collectionエキスパートコレクション内でリアルショップに登録してある内容をチェックボックスで全表示させたい!
expert_collections/_form.html.erb<table class="form_area " id="is_shop_area_1"> <tr> <th scope="row">対象店舗</th> <td> <% for shop in current_site.real_shops %> <%= check_box_tag "shop_ids[]", shop.id, @expert_collection.real_shops.ids.include?(shop.id), :id => "shop_id_#{shop.id}" , :class => 'shop'%> <%= label_tag "shop_id_#{shop.id}", shop.name %> <% end %> <% if current_site.real_shops.present? %> <br /> <input type="button" value="全て選択" id="shop-true" class="set_all_button" /> <input type="button" value="全て解除" id="shop-false" class="set_all_button" /> <% end %> </td> </tr> </table>check_box_tagのリファレンス
check_box_tag(要素名 [, 値, checked = false, オプション])
realshopの店舗から選択したエキスパートコレクションがshop_ids[]に格納される
なので
多対多の要素をDBに登録したい
expeert_collections_controller.rbdef new @expert_collection = ExpertCollection.new end def create @expert_collection = ExpertCollection.new(params[:expert_collection]) @expert_collection.site_id = current_site.id @expert_collection.real_shops = RealShop.find(params[:shop_ids]) if params[:shop_ids].present? if @expert_collection.save redirect_to ar_admin_expert_collections_path, :notice => "エキスパートコレクションを作成しました。" else render :new end endcreateの3行目。
params[:shop_ids]があったら@expert_collection.real_shopsに格納
してからsaveすれば中間テーブルに値が入ります。

- 投稿日:2019-05-07T22:39:15+09:00
binding.pryで条件付きでデバッグする
what
Railsで
binding.pryを使って、条件付きで処理を止める方法を知りたい。Android Studioだとこれがデフォルトでできました。
例えば、何回もアクセスされるエンドポイントで、特定の条件のときにだけエラーが起きている場合、関係ないアクセスのときにも処理が止まってしまうとデバッグするのが面倒です。
(ある料理レシピサイトがあったとして、リストの3ページ目にアクセスしたときだけエラーが起きる場合。1ページめを表示したときにも処理が止まると面倒ですよね。)how
まずは、 gemをインストール。
gem install pry-byebugデバッグしたいファイルに以下を追加
require 'pry'処理を止めたい箇所に以下を記述
binding.pryさらに、処理を止めたい条件を以下のように記述
binding.pry if page == 3これで
page == 3のときにだけ処理が止まるようになりました。おまけ
処理を止めた時に使えるコマンド
- next
- 次の行を実行(メソッドは実行される)
- step
- 次の行を実行、メソッドなら中に入る
- continue
- プログラムを実行し、pryを終了
- break
- break
数字=> 数字の行にbreak pointを貼るaliasを貼る
以下を
~/.pryrcに貼り付けるif defined?(PryByebug) Pry.commands.alias_command 'c', 'continue' Pry.commands.alias_command 's', 'step' Pry.commands.alias_command 'n', 'next' Pry.commands.alias_command 'f', 'finish' end直前のコマンドを
Enterキーで繰り返す以下を
~/.pryrcに貼り付けるPry::Commands.command /^$/, "repeat last command" do _pry_.run_command Pry.history.to_a.last end
- 投稿日:2019-05-07T21:08:02+09:00
質問箱をOSS(オープンソースにしてみた)
peing-質問箱-のクローン(OSS)
ソースコードはこちら
https://github.com/seiyatakahashi/peing-questionbox-cloneクローン質問箱の現状はこんな感じです。
質問箱とは
みなさんpeing-質問箱-をご存知ですか?twitterで2017年ごろから流行っている匿名で質問ができるwebサービスのことです。このサービスは個人開発をしているせせり氏が開発したサービスで公開1ヶ月で1億アクセスに達したそうです。
匿名で質問できるという機能はとても面白いと思いました。なのでこれをオープンソース化して、もっといろんな機能をつけていきたいと考えています。
デプロイ deploy
誰でもカンタンにデプロイできるようにしましたので是非みなさんもお使いください。
まずはgitからファイルをダウンロードしてください。
git clone git@github.com:seiyatakahashi/peing-questionbox-clone.gitダウンロードができたらダウンロードしてきたフォルダに移動する
cd peing-questionbox-cloneherokuにログインをする
heroku loginheorku でプロジェクトを作成する
heroku create 作りたいアプリ名heorku にアップロード
git add .
git commit -m "all"
git push heroku masterアップロードしてら、データベースにマイグレード
heroku run rails db:migrate環境変数の設定
heroku config:set APP_NAME="アプリの名前"
heroku config:set APP_NAME_EN="アプリの英語の表記名"
heroku config:set API_KEY="ツイッターのAPI KEY"
heroku config:set API_SECRET="ツイッターのAPI シークレット"
heroku config:set TOKEN="ツイッターのAccess token"
heroku config:set SECRET="ツイッターのaccess token secret"
heroku config:set CURRENT="自分ののツイッターのID"
heroku config:set DESCRIPTION="サイトの情報"
heroku config:set KEYWORDS="サイトのキーワード"
heroku config:set GOOGLE_ANALYTICS="Google アナリティクスのID"
今後つけたい機能
決済機能
質問したい人がお金を払って質問された人がお金をもらえる機能。
複数のSNSログイン
現在twitterでのログインしかできなのでfacebookやlineなどを加えたいです。
ネイティブアプリ化
railsをapi化させて、iosやandroidのようなネイティブなアプリケーションを作りたいです。

- 投稿日:2019-05-07T21:05:48+09:00
Rails+Docker+HerokuでCI/CD
CI/CD初心者が、CI/CDを構築した時のメモ。
初めて触ったので、誤っているところがあるかもしれません。
ご指摘いただければ、幸いです。
以下、参考にした記事等です。
https://qiita.com/kei_f_1996/items/934296e23b0d8d877ff1
https://qiita.com/Kesin11/items/47079bc7f659e71b694c
https://docs.docker.com/compose/rails/環境
OS:mac
Ruby:2.5.0
Rails:5.2.2
CicleCI
Heroku手順
Dockerfileの作成
docker-compose.ymlの作成
database.yml
CicleCI
HerokuDockerfileの作成
基本的にはdocker docsのQuickstartを参考に書きました。
DockerfileFROM ruby:2.5.0 RUN apt-get update -qq && apt-get install -y postgresql-client sudo RUN curl -sL https://deb.nodesource.com/setup_11.x | sudo -E bash - RUN sudo apt-get install -y nodejs RUN mkdir /myapp WORKDIR /myapp ADD Gemfile /myapp/Gemfile ADD Gemfile.lock /myapp/Gemfile.lock RUN bundle install COPY . /myapp CMD ["rails", "server", "-b", "0.0.0.0"]3行目で、nodejsのversionを指定しています。
server.pidファイルが存在する場合に、railsのサーバが再起動しなくなったので、Quickstartに書かれている、
# Add a script to be executed every time the container starts.
の部分を書いておくべきでした。docker-compose.ymlの作成
こちらもQuickstartを基に書いてます。
docker-compose.ymlversion: '3' services: db: image: postgres:9.6 ports: - '5432:5432' volumes: - postgresql-data:/var/lib/postgresql/data web: build: . command: bundle exec rails s -p 3000 -b '0.0.0.0' volumes: - .:/myapp ports: - "3000:3000" depends_on: - db - chrome chrome: image: selenium/standalone-chrome:3.141.59-dubnium ports: - 4444:4444 volumes: postgresql-data: driver: local・自動テスト時に、chromeでのテストがうまくできていなかったみたいなので、chrome部分を追加しました。
(対処として最適かどうかはわかりません)
・コンテナを潰してもDBのデータが消えないようにするために、volumesの部分を追加。database.yml
database.ymlに記述を追加。
これもQuickstartを参考にしました。database.ymldefault: &default adapter: postgresql encoding: unicode #追加 host: db username: postgres password: pool: 5あとはbuildしたりupしたりします。
$ docker-compose build $ docker-compose up $ docker-compose run web bin/rails db:createCicleCI
アプリケーションのルートディレクトリに、.cicleciフォルダを作ります。
.cicleci直下に以下のconfig.ymlを記述します。config.ymlversion: 2 jobs: build: machine: image: circleci/classic:edge steps: - checkout - run: name: docker-compose build command: docker-compose build - run: name: docker-compose up command: docker-compose up -d - run: name: sleep for waiting launch db command: sleep 1 - run: name: "before_test: setup db" command: docker-compose run web rails db:create db:migrate - run: name: test command: docker-compose run web bundle exec rspec - run: name: docker-compose down command: docker-compose down deploy: machine: image: circleci/classic:edge steps: - checkout - run: name: "build docker image" command: docker build --rm=false -t registry.heroku.com/${HEROKU_APP_NAME}/web . - run: name: setup heroku command command: bash .circleci/setup_heroku.sh - run: name: heroku maintenance on command: heroku maintenance:on --app ${HEROKU_APP_NAME} - run: # HEROKU_AUTH_TOKEN is generated by `heroku auth:token` name: "push container to registry.heroku.com" command: | docker login --username=_ --password=$HEROKU_AUTH_TOKEN registry.heroku.com docker push registry.heroku.com/${HEROKU_APP_NAME}/web bash .circleci/heroku-container-release.sh - run: name: heroku db migrate command: heroku run rails db:migrate --app ${HEROKU_APP_NAME} - run: name: heroku maintenance off command: heroku maintenance:off --app ${HEROKU_APP_NAME} workflows: version: 2 build_and_deploy: jobs: - build - deploy: requires: - build filters: branches: only: masterhttps://circleci.com/docs/2.0/configuration-reference/
machine: の部分でdocker-composeをそのまま使えるように設定しています。
CicleCIのEnvironmentValiablesに、
HEROKU_APP_NAME,HEROKU_AUTH_TOKEN,HEROKU_LOGIN
,HEROKU_API_KEYを設定しておきます。デプロイ時に実行するshellは以下の二つです。
setup_heroku.shwget https://cli-assets.heroku.com/branches/stable/heroku-linux-amd64.tar.gz sudo mkdir -p /usr/local/lib /usr/local/bin sudo tar -xvzf heroku-linux-amd64.tar.gz -C /usr/local/lib sudo ln -s /usr/local/lib/heroku/bin/heroku /usr/local/bin/heroku cat > ~/.netrc << EOF machine api.heroku.com login $HEROKU_LOGIN password $HEROKU_API_KEY EOF # machine git.heroku.com # login $HEROKU_LOGIN # password $HEROKU_API_KEY # Add heroku.com to the list of known hosts ssh-keyscan -H heroku.com >> ~/.ssh/known_hostheroku-container-release.sh#!/bin/bash imageId=$(docker inspect registry.heroku.com/${HEROKU_APP_NAME}/web:latest --format={{.Id}}) payload='{"updates":[{"type":"web","docker_image":"'"$imageId"'"}]}' curl -n -X PATCH https://api.heroku.com/apps/${HEROKU_APP_NAME}/formation \ -d "$payload" \ -H "Content-Type: application/json" \ -H "Accept: application/vnd.heroku+json; version=3.docker-releases" \ -H "Authorization: Bearer ${HEROKU_API_KEY}"Heroku
postgresのアドオンを入れ忘れないように気をつけて、herokuの設定も完了すれば、CICDできます。たぶん
- 投稿日:2019-05-07T21:05:39+09:00
Ruby で例外を発生させない方法
例外に悩まされたことはありませんか?
some_exceptional_library.rbmodule SomeExceptionalLibrary class TrivialException < StandardError; end # 雑にランダムで例外を飛ばすように書いているけど、 # 実際は様々な条件が絡み合ってごく稀に例外が発生してしまうような感じ。 def self.some_brilliant_method if rand < 0.01 raise TrivialException.new else 42 end end endmy_app.rbrequire "./some_exceptional_library" puts SomeExceptionalLibrary.some_brilliant_methodこのライブラリはとても素晴らしいライブラリなのですが、時々、例外を発生させてしまいます。
$ ruby my_app.rb 42 $ ruby my_app.rb 42 $ ruby my_app.rb Traceback (most recent call last): 1: from my_app.rb:3:in `<main>' /Users/cedretaber/path/to/sample/some_exceptional_library.rb:7:in `some_brilliant_method': SomeExceptionalLibrary::TrivialException (SomeExceptionalLibrary::TrivialException)例外に対処するのは大変ですよね。
かといって、 例外を握りつぶす のも良くないことと言われています。では、どうすれば良いのでしょうか?
そうですね。 例外を投げられないようにしてやればいい のですね。
例外なんて投げさせない
こんなコード片を挿入してやりましょう。
my_app.rbrequire "./some_exceptional_library" module Kernel def raise *_args1, **_args2 puts "All right. No problem!" end alias fail raise end puts SomeExceptionalLibrary.some_brilliant_methodこれで例外は発生しません。
$ ruby my_app.rb 42 $ ruby my_app.rb 42 $ ruby my_app.rb All right. No problem!お前は何を言っているんだ?
(本気にする人はいないと思いますが)ネタです。プロダクトとかでは絶対にやらないでください。
さて、どうしてこんなことができるのでしょう。
Ruby の予約語一覧を見てみましょう。
nextやreturnといった制御構造、raiseとセットで使うであろうrescueなどは入っていますが、 なんとraiseは予約語ではありません 。じゃあ例外を投げる時に使っている
raiseとは何なのかと言うと、上のコードを見れば一目瞭然で、これはKernelモジュールに定義されたメソッドです。そう、単なるメソッドなのです。そしてご存知の通り、 Ruby はオープンクラスの力を用いることで、組み込みメソッドの挙動すら変更してしまえます。つまり、
raiseの動きは変えることができるのです。なので、引数を全て無視するメソッドに書き換えてやればこの通り、例外の発生自体を封じ込めることができます。
やった! 我々は例外から解放された!これ、役に立つの?
たぶん立ちません。
次のようなコードに変えてみましょう。
my_app.rbrequire "./some_exceptional_library" module Kernel def raise *_args1, **_args2 puts "All right. No problem!" end alias fail raise end puts SomeExceptionalLibrary.some_brilliant_method + 1 # ここ$ ruby my_app.rb 43 $ ruby my_app.rb 43 $ ruby my_app.rb All right. No problem! Traceback (most recent call last): my_app.rb:11:in `<main>': undefined method `+' for nil:NilClass (NoMethodError)はい、封じ込めていたはずの例外が逃げ出していますね。
どういうことかというと、
Kernel#raiseを書き換えて防げるのはあくまで「 Ruby コード中のraiseメソッドで投げている例外」で、 C レベルで発生する例外までは防げないのです。まぁ当然ですね。
ここの NoMethodError はObject#method_missingが発生させている例外ですが、この処理は C で書かれており、rb_exc_raiseという例外を発生させる関数を直接呼び出しています。なので、いくら Kernel のメソッドを上書きしても駄目なのですね。「じゃあ
Object#method_missingを書き換えればいいじゃん」となりそうですが、その他にも例外を発生させる組み込みメソッドはいくらでもありますし(例えば零除算で発生するZeroDivisionError)、それらにいちいち対応するという生産性のない作業に時間を費やすよりは、例外発生の原因を突き止めて問題を解消する方がよほど有意義でしょう。例外から逃げてはいけません。
例外と式と文
上で述べたように 例外を握りつぶす という言葉があります。
次のようなコードを書くことを言います。begin SomeExceptionalLibrary.some_brilliant_method # 例外が飛ぶかも rescue end投げられた例外を捉えて、 特に何もせず処理を終える ことで、例外を呼び出し元にエスカレーションせずに無視するテクニックです。
テクニックと書きましたが、基本的に例外の握りつぶしは禁じ手と言うか、やらない方が良いことと言われています。私もそう思います。
まぁ、「だったら例外自体を発生させなきゃ良いんだろう」というわけではないのですね。
というか、どこで失敗したのか丁寧に教えてくれる例外はとても尊いものです。例外は決して敵ではありません!
なおこの記事は、Ruby の『文』は return, retry, redo, next, break, alias だけというのを読んで、「あれ
raiseは?」と疑問に思い調べてみた結果報告になります。
- 投稿日:2019-05-07T21:03:36+09:00
Ruby2.6.x WSLでbrewを使用し、bundle installのmysqlでコケる際の対処。
tl;dr
WSLのbrewで管理しているのであれば
$ bundle config --local build.mysql2 "--with-ldflags=-L/home/linuxbrew/.linuxbrew/opt/openssl/lib"上記コマンド後に
bundle installで多分解決します。状態
Using kaminari-core 1.1.1 Using kaminari-actionview 1.1.1 Using kaminari-activerecord 1.1.1 Using kaminari 1.1.1 Using launchy 2.4.3 Using ruby_dep 1.5.0 Using listen 3.1.5 Fetching mysql2 0.5.2 Installing mysql2 0.5.2 with native extensions Gem::Ext::BuildError: ERROR: Failed to build gem native extension. current directory: /home/iruk/.rbenv/versions/2.6.0/lib/ruby/gems/2.6.0/gems/mysql2-0.5.2/ext/mysql2 /home/iruk/.rbenv/versions/2.6.0/bin/ruby -I /home/iruk/.rbenv/versions/2.6.0/lib/ruby/2.6.0 -r ./siteconf20190507-7094-1spvp3a.rb extconf.rb --with-ldflags\=-L/usr/local/opt/openssl/lib checking for rb_absint_size()... yes checking for rb_absint_singlebit_p()... yes checking for rb_wait_for_single_fd()... yes ----- Using mysql_config at /home/linuxbrew/.linuxbrew/bin/mysql_config ----- checking for mysql.h... yes checking for errmsg.h... yes checking for SSL_MODE_DISABLED in mysql.h... yes checking for SSL_MODE_PREFERRED in mysql.h... yes checking for SSL_MODE_REQUIRED in mysql.h... yes checking for SSL_MODE_VERIFY_CA in mysql.h... yes checking for SSL_MODE_VERIFY_IDENTITY in mysql.h... yes checking for MYSQL.net.vio in mysql.h... yes checking for MYSQL.net.pvio in mysql.h... no checking for MYSQL_ENABLE_CLEARTEXT_PLUGIN in mysql.h... yes checking for SERVER_QUERY_NO_GOOD_INDEX_USED in mysql.h... yes checking for SERVER_QUERY_NO_INDEX_USED in mysql.h... yes checking for SERVER_QUERY_WAS_SLOW in mysql.h... yes checking for MYSQL_OPTION_MULTI_STATEMENTS_ON in mysql.h... yes checking for MYSQL_OPTION_MULTI_STATEMENTS_OFF in mysql.h... yes checking for my_bool in mysql.h... no ----- Setting libpath to /home/linuxbrew/.linuxbrew/Cellar/mysql/8.0.16/lib ----- creating Makefile current directory: /home/iruk/.rbenv/versions/2.6.0/lib/ruby/gems/2.6.0/gems/mysql2-0.5.2/ext/mysql2 make "DESTDIR=" clean current directory: /home/iruk/.rbenv/versions/2.6.0/lib/ruby/gems/2.6.0/gems/mysql2-0.5.2/ext/mysql2 make "DESTDIR=" compiling client.c In file included from ./mysql2_ext.h:39:0, from client.c:1: client.c: In function ‘rb_set_ssl_mode_option’: ./client.h:22:3: warning: ISO C90 forbids mixed declarations and code [-Wdeclaration-after-statement] mysql_client_wrapper *wrapper; \ ^ client.c:127:3: note: in expansion of macro ‘GET_CLIENT’ GET_CLIENT(self); ^~~~~~~~~~ client.c:128:3: warning: ISO C90 forbids mixed declarations and code [-Wdeclaration-after-statement] int val = NUM2INT( setting ); ^~~ client.c:133:3: warning: ISO C90 forbids mixed declarations and code [-Wdeclaration-after-statement] int result = mysql_options( wrapper->client, MYSQL_OPT_SSL_MODE, &val ); ^~~ client.c: At top level: cc1: warning: unrecognized command line option ‘-Wno-self-assign’ cc1: warning: unrecognized command line option ‘-Wno-parentheses-equality’ cc1: warning: unrecognized command line option ‘-Wno-constant-logical-operand’ cc1: warning: unrecognized command line option ‘-Wno-cast-function-type’ compiling infile.c compiling mysql2_ext.c compiling result.c compiling statement.c statement.c: In function ‘rb_raise_mysql2_stmt_error’: statement.c:47:3: warning: ISO C90 forbids mixed declarations and code [-Wdeclaration-after-statement] VALUE rb_error_msg = rb_str_new2(mysql_stmt_error(stmt_wrapper->stmt)); ^~~~~ statement.c:53:3: warning: ISO C90 forbids mixed declarations and code [-Wdeclaration-after-statement] rb_encoding *default_internal_enc = rb_default_internal_encoding(); ^~~~~~~~~~~ In file included from ./mysql2_ext.h:39:0, from statement.c:1: statement.c: In function ‘rb_mysql_stmt_execute’: ./client.h:22:3: warning: ISO C90 forbids mixed declarations and code [-Wdeclaration-after-statement] mysql_client_wrapper *wrapper; \ ^ statement.c:261:3: note: in expansion of macro ‘GET_CLIENT’ GET_CLIENT(stmt_wrapper->client); ^~~~~~~~~~ statement.c:389:13: warning: ISO C90 forbids mixed declarations and code [-Wdeclaration-after-statement] VALUE rb_val_as_string = rb_funcall(argv[i], intern_to_s, 0); ^~~~~ In file included from ./mysql2_ext.h:39:0, from statement.c:1: statement.c: In function ‘rb_mysql_stmt_fields’: ./client.h:22:3: warning: ISO C90 forbids mixed declarations and code [-Wdeclaration-after-statement] mysql_client_wrapper *wrapper; \ ^ statement.c:491:3: note: in expansion of macro ‘GET_CLIENT’ GET_CLIENT(stmt_wrapper->client); ^~~~~~~~~~ statement.c: At top level: cc1: warning: unrecognized command line option ‘-Wno-self-assign’ cc1: warning: unrecognized command line option ‘-Wno-parentheses-equality’ cc1: warning: unrecognized command line option ‘-Wno-constant-logical-operand’ cc1: warning: unrecognized command line option ‘-Wno-cast-function-type’ linking shared-object mysql2/mysql2.so /usr/bin/ld: cannot find -lssl /usr/bin/ld: cannot find -lcrypto collect2: error: ld returned 1 exit status Makefile:259: recipe for target 'mysql2.so' failed make: *** [mysql2.so] Error 1 make failed, exit code 2 Gem files will remain installed in /home/iruk/.rbenv/versions/2.6.0/lib/ruby/gems/2.6.0/gems/mysql2-0.5.2 for inspection. Results logged to /home/iruk/.rbenv/versions/2.6.0/lib/ruby/gems/2.6.0/extensions/x86_64-linux/2.6.0-static/mysql2-0.5.2/gem_make.out An error occurred while installing mysql2 (0.5.2), and Bundler cannot continue. Make sure that `gem install mysql2 -v '0.5.2' --source 'https://rubygems.org/'` succeeds before bundling. In Gemfile: mysql2MacOS
参考 : mysql2 gemインストール時のトラブルシュート
/usr/bin/ld: cannot find -lsslこの部分が問題となっており、MacOSにおける解決の為のコマンドとしては下記コマンドになります。
$ gem install mysql2 -v '0.5.2' --source 'https://rubygems.org/' -- --with-cppflags=-I/usr/local/opt/openssl/include --with-ldflags=-L/usr/local/opt/openssl/libしかし、WSLのbrewではopensllの存在するディレクトリが違うため上記コマンドでは問題の解決には至りません。
WSL
最初のエラー文を眺めると、
----- Setting libpath to /home/linuxbrew/.linuxbrew/Cellar/mysql/8.0.16/lib -----とあります。
WSLのbrewでは/home/linuxbrew/.linuxbrew/Cellar以下で管理をしているようですね。
では上記のbundle configを上記ディレクトリに合うように書き換えると、最初のコマンドになります。$ bundle config --local build.mysql2 "--with-ldflags=-L/home/linuxbrew/.linuxbrew/opt/openssl/lib"これでopensllを読み取れるようになって
bundle installを正常にパスできるはず。
- 投稿日:2019-05-07T20:54:40+09:00
rubyでジャンケンできるようにしてみた。
今日は皆さんご存知のじゃんけんをrubyで作ってみました。
コードはこちらです!#じゃんけんをプログラミングでできるようにしてみました。 JANKEN = ['rock', 'scissors', 'paper'] $opponent = '' def play_janken # 相手の手はランダムで、自分の手を入力で決めます $opponent = JANKEN.sample puts 'あなたは何を出す?' own = gets.chomp return 'あいこ' if index(own) == index($opponent) if index(own) == 0 compare(1) elsif index(own) == 1 compare(2) elsif index(own) == 2 compare(0) end end # 出した手のインデックスを返します。 def index(a) JANKEN.index(a) end # じゃんけんの勝敗を返します。 def compare(i) return '勝ち' if index($opponent) == i '負け' end今後の改善点
opponent変数はplay_jankenとcompareで使う為グローバル変数にしたが、グローバル変数はあまり使わない方がいいと聞いたので使わないコードを模索中。
インデックスでなく、要素を直接比較できればその分コードが減るのでその実装を構想中。
- 投稿日:2019-05-07T20:47:32+09:00
Ruby で、とある変な if 文を綺麗に書けるか考えた
言語の機能をなるべく使うという条件で、シンプルに書くことを目指す1。
- 人に読みやすいかということはこだわらない
- 文字数にこだわるわけでもない
課題
fetch_aでオブジェクトが取れればそれのx,yで作れるHashを、- 取れなければ
fetch_bを試して取れればそれのx,yで作れるHashを、- どちらもダメなら
nilを返す(空想ではなく、実際に見たコードを一部省略したものです)
if a = fetch_a { x: a.x, y: a.y } elsif b = fetch_b { x: b.x, y: b.y } else nil end
ifの中で代入するのは rubocop style 的に NG だそうなので、なんとかできないかなと思った。この課題については、やりたいこと自体がかなり複雑すぎるなので、書き方を改善すればいいという問題ではない気がしたが、気にしない 2。
思いついた案
instance_eval使う(fetch_a || fetch_b)&.instance_eval { { x: x, y: y } }
instance_evalは長いのが嫌いなので tap にしてみる。instance_evalの代わりにtap(fetch_a || fetch_b)&.tap { |v| break { x: v.x, y: v.y } }
vの名前づけに悩む(3回書くので、丁寧にすれば長くなるし)が、変わらない文字数でできそうRuby 2.7 なら Numbered parameters を使うこともできそう
tap+NumberedParameters(fetch_a || fetch_b)&.tap { break { x: @1.x, y: @1.y } }
- 投稿日:2019-05-07T19:01:53+09:00
Ruby のパターンマッチを利用して任意のメソッドが定義されているかどうかを判定する
ブログ記事からの転載です。
と、いうのが bugs.ruby に来ていたので。
class Runner def run end def stop end end runner = Runner.new case runner in .run & .stop :reachable in .start & .stop :unreachable endほしい気持ちはわかるんだけど流石に上記の提案だと情報が欠落しすぎているのとそもそもパターンマッチでやるべきこと?と思ってしまい個人的にはいまいち。
なんかもっといい感じの構文だといいとは思うんですが…。と、言うことで既存のパターンマッチで出来ないかやってみました。
using Module.new { refine Object do # パターンマッチ内部では #deconstruct_keys を暗黙的に呼び出してそれで判定を行っている # そこで deconstruct_keys を経由してメソッド情報を取得することでパターンマッチで利用できるようにする # { メソッド名: 値... } となるような Hash を返す def deconstruct_keys(keys) keys.select { |name| respond_to?(name) }.to_h { |key| [key, send(key)] } end end } def check(obj) case obj in { run: _, stop: _ } :reachable in { start: _, stop: _ } :unreachable else :none end end class Runner def run end def stop end end runner = Runner.new p check(runner) # => :reachable class Runner2 def start end def stop end end runner2 = Runner2.new p check(runner2) # => :reachableRuby のパターンマッチでは暗黙的に
#deconstruct_keys(や#deconstruct)が呼び出され、その戻り値を参照してパターンマッチを評価します。
上記の実装では{ メソッド名: 値... }というような Hash をパターンマッチで使用できるようにすることでcase obj in { run: _, stop: _ } :reachable in { start: _, stop: _ } :unreachable else :none endというようなパターンマッチをかけるようにしています。
これならメソッドが定義されているかどうかを判定することも出来ますし『任意のメソッドの値』をキャプチャすることも出来ます。# obj.run の値をキャプチャする case obj in { run: status, stop: _ } p "status is #{status}" :reachable in { start: status, stop: _ } p "status is #{status}" :unreachable else :none endこれ、かなり汎用性が高そうなので普通にほしい。ってか、すでに機能としてありそう。
参照
- 投稿日:2019-05-07T17:49:36+09:00
Railsのdeviseで新規登録するとき、belongs_toなものも一緒に作る方法
環境
- Rails 5.2.2
- Ruby 2.5.3
前提
- User belongs_to Organization
- Organization has_many Users
- Userを新規登録するとき、Organizationも一緒に作りたい(というか作れないとエラーで登録できない)
コード
class ApplicationController < ActionController::Base ... before_action :configure_permitted_parameters, if: :devise_controller? protected def configure_permitted_parameters devise_parameter_sanitizer.permit(:sign_up, keys: [organization_attributes: [:name]]) end end# app/views/devise/registrations/new.html.erb ... <% resource.organization ||= Organization.new %> <%= simple_form_for(resource, as: resource_name, url: registration_path(resource_name)) do |f| %> <%= f.error_notification %> <div class="form-inputs"> <%= f.input :email, required: true, autofocus: true , input_html: { autocomplete: "email" }%> <%= f.input :password, required: true, hint: ("#{@minimum_password_length} characters minimum" if @minimum_password_length), input_html: { autocomplete: "new-password" } %> <%= f.input :password_confirmation, required: true, input_html: { autocomplete: "new-password" } %> <%= f.fields_for :organization do |organization_form| %> <%= organization_form.input :name %> <% end %> </div> <div class="form-actions"> <%= f.button :submit, t("devise.sign_up") %> </div> <% end %> ...参考
https://github.com/plataformatec/devise#strong-parameters
https://stackoverflow.com/a/7987480/7824640
- 投稿日:2019-05-07T17:49:36+09:00
Railsのdeviseで新規登録するとき、親のモデル(belongs_toなもの)も一緒に作る方法
環境
- Rails 5.2.2
- Ruby 2.5.3
前提
- User belongs_to Organization
- Organization has_many Users
- Userを新規登録するとき、Organizationも一緒に作りたい(というか作れないとエラーで登録できない)
コード
class ApplicationController < ActionController::Base ... before_action :configure_permitted_parameters, if: :devise_controller? protected def configure_permitted_parameters devise_parameter_sanitizer.permit(:sign_up, keys: [organization_attributes: [:name]]) end end# app/views/devise/registrations/new.html.erb ... <% resource.organization ||= Organization.new %> <%= simple_form_for(resource, as: resource_name, url: registration_path(resource_name)) do |f| %> <%= f.error_notification %> <div class="form-inputs"> <%= f.input :email, required: true, autofocus: true , input_html: { autocomplete: "email" }%> <%= f.input :password, required: true, hint: ("#{@minimum_password_length} characters minimum" if @minimum_password_length), input_html: { autocomplete: "new-password" } %> <%= f.input :password_confirmation, required: true, input_html: { autocomplete: "new-password" } %> <%= f.fields_for :organization do |organization_form| %> <%= organization_form.input :name %> <% end %> </div> <div class="form-actions"> <%= f.button :submit, t("devise.sign_up") %> </div> <% end %> ...参考
https://github.com/plataformatec/devise#strong-parameters
https://stackoverflow.com/a/7987480/7824640
- 投稿日:2019-05-07T16:45:50+09:00
Ruby 配列
配列の生成
a = [1, 2, 3] => [1, 2, 3] a.class => ArrayArray[1, 2, 3] => [1, 2, 3]Array.new(3, "str") => ["str", "str", "str"]Array.new([1, 2, 3]) => [1, 2, 3]Array.new(5) {|i| i * 3} => [0, 3, 6, 9, 12]配列に要素追加
a = [1, 2, 3] => [1, 2, 3]<<メソッド
a << 4 => [1, 2, 3, 4]concatメソッド(破)
a.concat[5, 6] => [1, 2, 3, 4, 5, 6]insertメソッド
a.insert(3, 9) => [1, 2, 3, 9, 4, 5, 6]a.object_id => 47409483356240 b = a + [10] => [1, 2, 3, 9, 4, 5, 6, 10] b.object_id => 47409481926320unshiftメソッド
b.unshift(10) (破) => [10, 1, 2, 3, 9, 4, 5, 6, 10]配列の要素変更
[]=メソッド
a = [1, 2, 3] => [1, 2, 3] a[1] = 10 => 10 a => [1, 10, 3] a[1..2] = [10, 11] => [10, 11] a => [1, 10, 11] a[8] = 5 => 5 a => [1, 10, 11, nil, nil, nil, nil, nil, 5]fillメソッド
a = [1, 2, 3] => [1, 2, 3] a.fill("s") => ["s", "s", "s"] a.fill("t", 1..2) => ["s", "t", "t"] a => ["s", "t", "t"] a.fill(1..2){|index| index} => ["s", 1, 2]replaceメソッド
a = [1, 2, 3] => [1, 2, 3] a.object_id => 47409483213220 a.replace([4, 5, 6]) => [4, 5, 6] a.object_id => 47409483213220配列の要素参照
a = [1, 2, 3] => [1, 2, 3][]メソッド
a[1] => 2 a[1..2] =>[2, 3]atメソッド
a.at(1) => 2 #要素 < indexの場合、nilが返るvalues_atメソッド
a.values_at(1) => [2]fetchメソッド
a.fetch(4) IndexError: index 4 outside of array bounds: -3...3 a.fetch 4, "ERROR" => "ERROR" a.fetch(4){|n| "ERROR #{n}"} => "ERROR 4"firstメソッド
a.first => 1 a.first(2) => [1, 2]lastメソッド
a.last => 3assocメソッド
a.assoc(3) => [3, 4] #配列の配列を検索。最初の要素が指定された値と==で、その配列を返す。rassocメソッド
a.rassoc(4) => [3, 4] #index1の要素を検索。配列の要素調べ
a = [1, 2, 3, 4, 5] => [1, 2, 3, 4, 5]include?メソッド
a.include?(3) => true a.include?(6) => falseindexメソッド
a.index(4) => 3 a.rindex(4) => 3 #該当しない場合、nilを返す。配列の要素削除
a = [1, 2, 3, 4, 5] => [1, 2, 3, 4, 5]delete_atメソッド
a.delete_at(2) => 3 a => [1, 2, 4, 5]delete_ifメソッド
a = [1, 2, 3, 4, 5] => [1, 2, 3, 4, 5] a.delete_if{|n| n % 2 == 0} => [1, 3, 5]deleteメソッド
a = [1, 2, 3, 4, 5] => [1, 2, 3, 4, 5] a.delete(3) => 3 a = [1, 2, 4, 5] a.delete(10) => nil a = [1, 2, 4, 5]clearメソッド
a = [1, 2, 3, 4, 5] => [1, 2, 3, 4, 5] a.clear => []slice!メソッド
a = [1, 2, 3, 4, 5] => [1, 2, 3, 4, 5] a.slice!(2, 2) => [3, 4] a => [1, 2, 5]shiftメソッド
a = [1, 2, 3, 4, 5] => [1, 2, 3, 4, 5] a.shift(2) => [1, 2] a.shift => 3 a => [4, 5] #先頭から指定された数だけ要素を取り除いて返す。指定がなければ1。popメソッド
a = [1, 2, 3, 4, 5] => [1, 2, 3, 4, 5] a.pop(2) => [4, 5] a.pop => 3 a => [1, 2]- メソッド
a = [1, 2, 3, 4, 5] => [1, 2, 3, 4, 5] a - [1, 2] => [3, 4, 5] a - [1, 3, 5, 7] => [2, 4]配列の演算
| メソッド
[1, 2, 3] | [1, 3, 5] => [1, 2, 3, 5] #和集合& メソッド
[1, 2, 3] & [1, 3, 5] => [1, 3] #積集合配列の比較
== メソッド
[1, 2, 3] == [1, 3, 5] => false [1, 2, 3] <=> [1, 3, 5] => -1 #左辺が大きければ、0。右辺が大きければ-1。同じ0。
- 投稿日:2019-05-07T15:13:29+09:00
Ruby IOクラス
IOクラス
- FileクラスのSuperClass
- 入出力機能を備えたクラス
IOからの入力
- IO.read / read
- IO.foreach / each / each_lines
- 指定されたファイルを開き、各行をブロックに渡して実行していく。
- readlines
- 全てのファイルを読み込んで、配列を返す。
- readline / gets
- each_byte
- getbyte / readbyte
- each_char
- getc / readchar
IOへの出力
- wrire
- puts
- printf
- putc
- flush
IOの状態
- stat
- closed?
- eof / eof?
- lineno
- getsメソッドが呼び出された回数
- sync
ファイルポインタの移動・設定
- rewind
- ファイルポインタを先頭に移動し、linenoの値を0に設定。
- pos
- ファイルポインタの位置を取得・設定
- seek
- 投稿日:2019-05-07T14:45:42+09:00
RubyGems,Gemfile,Bundler,Gemfile.lockなどについて
目次
- Rubyのライブラリ
- RubyGemsとは
1.1 Gemfileの-> という記号はどういう意味なのか
- Bundlerとは 2.1 Gemfile/Gemfile.lock/gemspecの違いとは
2.2 bundle install/bundle updateの違いとは
0. Rubyのライブラリ
Rubyのライブラリはgemという形式にまとめてrubygems.orgにて配布されるのが一般的です。
gemには以下のような有用な情報が含まれます。・ メタデータ。名前、バージョン、説明、著者のメアドなど。
・ 含まれるファイルのリスト
・ 実行ファイルとその場所のリスト (binなど)
・ Rubyのload pathに含まれるべきパスのリスト(lib)など。
・ 必要となる他のライブラリ(依存関係)最後の「依存関係」というのがGemfileと重なるところ。
Gemが依存関係を記述するときは、名前とバージョンを範囲をリストアップします。
個々で重要なのは依存先ライブラリのソースについては気にしないということです。1, RubyGemsとは
Rubyに関係するパッケージを総称してRubyGemsといいます。
開発に便利なライブラリやフレームワークをパッケージにし、公開されたそれらはRubylist達は、RubyGems,Gem,Gemsと呼んでいます。
Gemに限らずパッケージの依存関係を管理することが安定のためにも重要です。1.1 Gemfileの -> という記号はどういう意味なのか
RubyGemsの依存関係を管理してくれるBundlerのGemfile内で使われる
~>という記号はどういう意味なのでしょうか。
Bundler のバージョンは 1.16.1 になります。
例えば次のようなGemfileがあった場合はsource 'https://rubygems.org' gem `nokogiri` gem 'rack', '~> 2.0.1` gem 'rspec'次の行には
~>が使われていますgem 'rack', '~> 2.0.1`もしその記号が
~>ではなく>であれば2.0.1より大きいバージョンを,>=であれば2.0.1以上のバージョンを指定することになりますが~>は一体どのようなバージョンを指定することになるのでしょうか.答えは
2.0.1以上2.1.0未満のバージョンを指定することになりますなので次のように書き換えることもできます
gem 'rack', '>= 2.0.1', '< 2.1.0'もう一つの例として, 次のような場合
gem 'nokogiri', '~> 1.4.2'このように書き換えられます
gem 'nokogiri', '>= 1.4.2', '< 1.5.0'Gemfile で ~> という記号をを見かけたときはそう言う意味になります
2, Bundlerとは
Bundler の前にまず、Ruby に関係するパッケージを総称して RubyGems といいます。
開発に便利なライブラリやフレームワークをパッケージして
公開されたそれらを Rubyist 達は RubyGems、Gem、Gems と呼んでいます。
Gem に限らずパッケージの依存関係を管理することが安定の為にも重要です。
そして、Bundlerとは、それら依存関係を管理してくれるツールです。
例えば、ある Gem が依存している別の Gem や、それらのバージョン管理であったり、他にも Test や Dev や Pro といった環境ごとに別のバージョンを使用する等に必要となります。
このBundlerもRubyGemsgem install bundler2.1 Gemfile/Gemfile.lock/gemspecとは
Gemfile
Gemの取得先を記述する
通常はsourceとgemspecの2行、もしくはsourceの1行だけだいい
Gemfile.lockとは
開発環境と運用環境(production)とで同じでgemをインストールするために使います。
bundleなどで自動で生成されます。
installしたgemのversionや取得先が記録される
依存gemのバージョンと取得先が記録されます。gemspecとは
実際の情報を記述するファイル
Gem::Specification.new do |s| s.authors = [] s.homepage = '' ・ ・ ・gemの依存関係をgemの情報を記述するファイル
s.add_dependency '*****' s.add_development_dependency '***'2.2 bundle install/bundle updateの違いとは
bundle install
bundle installを実行すると、railsはgemfile.lockを元にgemのインストールを行います。
このとき、gemfile.lockに記述されてない、且つgemfileに記述されているgemがある場合、そのgemとそのgemに関連するgemをインストール後、gemfile.lockを更新します。
bundle update
bundle updateを実行すると、Bundlerは、gemfileを元にgemのインストールを行います。その後、gemfile.lockを更新します。これら二つのコマンドの使い分けについて
bundle updateは文字通り、gemのバージョンを更新する時に使用します。
これは、bundle installコマンドはgemfile.lockにあるgemについては、更新しないためです。
但し、bundle updateは、本番環境で安易に実行しないでください。
gemのバージョンのズレが起こり、クラッシュする可能性があります。bundle updateは、必ず、ローカル環境で実行してください。
bundle installは、新しい環境や、gemfileに新しくgemを記述した時に使用します。参考記事
Bundlerを使ったRubyGemsの依存関係管理
Bundler, Gemfile, Gemfile.lock について
Bundlerを使ったGem管理について
意外とよくわかっていないbundlerについて
Gemfile の ~> という記号はどういう意味なのか
gemspec と Gemfile と Gemfile.lock との違い.
gemspecとGemfileの役割をはっきりさせておく
Gemfile/Gemfile.lock/gemspec/Rakefileそれぞれの違い・役割
- 投稿日:2019-05-07T14:31:01+09:00
Rubyのprivate修飾子からアクセス修飾子を考える
Rubyの
privateの注意点(特に他の言語とどこが違うのか)については各所の記事で説明がありますが、その背景については断片的にしか情報がないと思ったので、少しまとめてみようと思います。以下の記事の補足のような内容です。
Ruby の private と protected 。歴史と使い分け
https://qiita.com/tbpgr/items/6f1c0c7b77218f74c63e結論だけ先に書くと
次の二点に要約できます。
- アクセス修飾子は、外部から呼べるかどうかを「明示」「記述」するための機能で(も)ある
- 「外部から呼べる」というのは、設計上「呼ばれることを想定している」ということを意味し、「外部から呼べない」というのは、「呼ばれることを想定していない」という意味であり、実際に「呼べる」かどうかの問題ではない
一体何を言っているんだと思われた方は、以下をご覧ください。
きっかけ
いまRubyとRailsを学んでいます。
privateやprotectedのあたりの使い分けに戸惑うのはもはや定番なのだと思いますが、案の定もやもやするものがあったので、調べてみることにしました。まず気になったのが、次の記事での記述です。
Rubyのprivateを考える - sometimes I laugh
https://sil.hatenablog.com/entry/rethinking-ruby-private-access-modifierでも、これとはまた違った話で、そもそもprivateはアクセスコントロールとして設計されたものではないので、そのように使うべきではない。という意見(そもそもprivate不要論)もあって、これはこれで面白い。
Rubyの
privateは「アクセスコントロールとして設計されたものではない」とのことです。そしてそれを示す発言がこちら。「Rubyのpublic/private/protectedはaccess controlとしては壊れている」と言われたが、その答えは「確かに。access controlとして作ってないからな」というものであった。
— Yukihiro Matsumoto (@yukihiro_matz) 2017年11月15日アクセス修飾子は「アクセス制御」のための機能だと思っていたので、この説明が何を意味するのかわかりませんでした。アクセス制御のための機能でないなら、一体なんのためにあるんでしょう。
そもそもprivateを使うと何ができるのか
ひとまず、Rubyにおける
privateがどのような機能なのか振り返ってみます。クラス/メソッドの定義 (Ruby 2.1.0)
https://docs.ruby-lang.org/ja/2.1.0/doc/spec=2fdef.html#limitこの節のタイトルが「呼び出し制限」になっているのがまたややこしいのですが、今回は見なかったことにしましょう。
次のように説明されています。
public に設定されたメソッドは制限なしに呼び出せます。
private に設定されたメソッドは関数形式でしか呼び出せません。ただし、次の二点には注意が必要です。
- 派生クラスからでも呼ぶことができる
- sendを使えば外部からでも呼べる
2番目については、次の例が明快です。
Ruby の private メソッドを外部から呼び出す - Secret Garden(Instrumental)
http://secret-garden.hatenablog.com/entry/2015/07/21/212314class X private def private_method "private_method" end end x = X.new x.send(:private_method) # => "private_method"こういうわけなので、「アクセスコントロール」(外部から使うことが不可能なようにする)には不向きな機能なのではないか、というのが前掲のツイートの背景です。
Rubyのアクセス修飾子の源流
最初に紹介したQiita記事で触れらている以下の記事をよく読んでみると、次のツイートが紹介されています。
JavaやC#の常識が通用しないRubyのprivateメソッド - give IT a try
https://blog.jnito.com/entry/20120315/1331754912@JunichiIto77 privateという名前がJavaやC++に馴染んだ人に誤解を生みやすいのは想定外でした。Rubyを最初に設計した頃にはJavaは一般公開されてませんでしたし、private(など)はC++固有の機能でしたから尊重しませんでした
— Yukihiro Matsumoto (@yukihiro_matz) 2012年3月15日Rubyの
privateが考案された当時は、現在では一般的になっている(と言えるであろう)C++やJava系のprivateの意味合いはまだ浸透していなかったようです。ということは、意図的にややこしくしたわけではなさそうです。
当時はJavaもRubyも黎明期だったので、どちらが正しいという話でもなかったんですね。(Ruby以外の言語の経験が少ない場合、「Rubyのprivate修飾子がなぜわかりにくいと言われるのだろうか」と疑問に思うこともあるようですが、どちらのprivateの用法にもそれぞれ考案当時からの正当性があるわけなので、当然といえば当然かもしれません。)それから、次のツイートが謎を解く鍵になります。
@JunichiIto77 Rubyのprivateの発想の元になったのはSmalltalkの「privateカテゴリ」です。使わないでね、というだけでアクセスできちゃう。Rubyはそれよりは若干強制力があります。Rubyの反C++・親Smalltalkの設計思想が垣間見えますね
— Yukihiro Matsumoto (@yukihiro_matz) 2012年3月15日ここでSmalltalkの話が出ますが、よく知らないので少し調べてみます。次の回答で雰囲気が少しわかりました。
coding style - Smalltalk public methods vs private/protected methods - Stack Overflow
https://stackoverflow.com/questions/7399340/smalltalk-public-methods-vs-private-protected-methodsIndeed, the Smalltalk way is to put private methods in the 'private' category. This indicates that you shouldn't use these methods, but of course doesn't enforce this.
Smalltalkにおいては、
private categoryなので呼ばないでくださいね、と明示することはできても、それに強制力はないという言語仕様になっているようです。そこで、Rubyはそれよりも強制力を強めて、呼ぶことを実際に不可能にした、というのがprivateができた背景ということですね。ここで、これを調べているときに見つけた別のサイトの説明にも注目します。
アクセス修飾子
http://bliki-ja.github.io/AccessModifier/アクセス制御はアクセスを制御するわけではない
privateなフィールドは他のどのクラスもアクセスできないということを意味する……’'’わけない!’'’ほとんどどの言語でも、アクセス制御の仕組みを壊すことは可能なのです。たいていは、リフレクションを使った方法を用います。なぜなら、デバッガやその他システムツールがprivateなデータをみる必要があるためです。そのため、たいていリフレクションインターフェイスによってそれが可能となります。
(中略)
アクセス制御の目的は、アクセスを防ぐことではなく、むしろクラスがあることを秘密にしておきたがっているという合図を送ることなのです。アクセス修飾子を使うということは、プログラミングにおける多くのことがそうであるように、本来はコミュニケーションに関するものなのです。ここにも「アクセスを防ぐことではなく」というくだりがあります。「アクセス制御」と呼んでいるのにも関わらず、「制御」したいわけではないというのはどういうことなんでしょうか。「本来はコミュニケーションに関するものなのです」という説明もなかなか意味深です。
アクセス修飾子の役割
原点に立ち返り、「アクセス修飾子」「アクセス制御」について調べてみます。
次の大学の先生の説明と思しきページの説明がわかりやすいです。オブジェクト指向超入門
http://www.edu.tuis.ac.jp/~mackin/software/2005/objectoriented.htmlこのようにメンバ(フィールドとメソッド)には、外部から使える(見える)、使えない(見えない) という制御が可能であり、定義の頭に"private"や"public"といったアクセス修飾子をつけることで行われる。
オブジェクト指向では、オブジェクトの中身で外に見せるべきでないところを隠し、 見せるべきところだけを公開する方法を取る。 これをカプセル化といい、見せるべきでないところを隠すことを情報隠蔽という。 これらを記述するのがアクセス修飾子である。「外に見せるべきでないところを隠し、 見せるべきところだけを公開する方法を取る」ため、「これらを記述するのがアクセス修飾子」と説明しています。
ここで「制限する」「制御する」とか「制約する」とかではなくて、「記述する」と言っているのがポイントかもしれません。すなわち、Smalltalkの場合と同じく、外部から使っていいのかどうかを明示するために用意された機能である、と読むことができます。もう一つ、辞書的なものも見てみましょう。
What is Access Modifiers? - Definition from Techopedia
https://www.techopedia.com/definition/23/access-modifiersAccess modifiers are keywords used to specify the accessibility of a class (or type) and its members. These modifiers can be used from code inside or outside the current application.
(中略)
The purpose of using access modifiers is to implement encapsulation, which separates the interface of a type from its implementation. With this, the following benefits can be derived:"accessibility"を指定するために使うのがアクセス修飾子ということになります。accessibilityは、英単語としては次のように説明されています。
https://eow.alc.co.jp/search?q=accessibility
《コ》〔ウェブサイト・データベースなどへの〕アクセス可能性、アクセスのしやすさ
さらに、次の文を読むと、"encapsulation"を実現する云々の話があります。ここで、もしやキーワードはこのencapsulationなのでは、ということに気づきます。
オブジェクト指向の基本、「カプセル化」「隠蔽化」
「カプセル化」の一般的な説明をどこで見つけるかという問題もあるのですが、とりあえず辞書を見てみます。
カプセル化(かぷせるか)とは - コトバンク
https://kotobank.jp/word/%E3%82%AB%E3%83%97%E3%82%BB%E3%83%AB%E5%8C%96-2428
(以下孫引用)大辞林 第三版
コンピューターで、ある複合的なデータが存在するときに、データ構造の内部の情報を外部から直接参照できないようにし、代わりにデータ操作のためのインターフェースを外部に提供すること。 → オブジェクト指向プログラミングなぜ直接参照できないようにするのかという部分は、次のように説明されています。
世界大百科事典内のカプセル化の言及
…これによって,外部からの不用意なアクセスによってモデュールが扱うデータの一貫性が損なわれないようにできる。この機能を情報隠蔽やカプセル化などと呼ぶ。ここまでくると、
privateうんぬんの話ではなく、オブジェクト指向ってなんだったっけ?という話になります。オブジェクト指向は、オブジェクトとオブジェクトの間でメッセージをやりとりして、その作用の連鎖によって処理を進めていくという設計手法です。その中で、オブジェクトが別のオブジェクトにメッセージを送るためには、そのための公開されたインタフェースが必要になります。これが
publicなインタフェースということになります。他方で、オブジェクトの内部でどのような値を持っているのかや、どのような処理をしているのかというのは、見えなくてもいい部分になります。じゃあ見えてもいいのではないか、というと、そういうわけではありません。もし内部の値が操作されたり、外部から呼ばれることが想定されていないメソッドが呼ばれたりすると、設計者の意図しない動作を引き起こす可能性があります。また、外部から利用されることが想定されていないメンバは、動作が変更されたり削除されたりする可能性もあり、潜在的なバグの原因になります。そういうわけなので、オブジェクトの内部で起きていることというのは、見えなくていいし、見えないほうがいいと言うことができます。
ということで、オブジェクトの内部だけで扱うべきこと(その系の内側だけの事柄として扱うべきこと)は、そのオブジェクトの内部に閉じ込めておき、外部からは見えないようにしましょう、というのがカプセル化(隠蔽化)です。このカプセル化を実現するために、外部からの利用を想定しているものか、そうでないのかというのを明示する必要があり、そのための機能がアクセス修飾子である、というわけです。
結論
結局オブジェクト指向の復習をしただけじゃないか、という気もします。ここで、先述したポイントを再掲します。
- アクセス修飾子は、外部から呼べるかどうかを「明示」「記述」するための機能で(も)ある
- 「外部から呼べる」というのは、設計上「呼ばれることを想定している」ということを意味し、「外部から呼べない」というのは、「呼ばれることを想定していない」という意味であり、実際に「呼べる」かどうかの問題ではない
アクセス修飾子は、オブジェクト指向の肝でもあるカプセル化を実現するための手段として(それを目的として)用意されたものであって、
privateなものを外部から使おうとするとコンパイルエラーになったり、実行時エラーになったりするというのは(実際に使えなくするという意味での「アクセス制御」は)、あくまでそのおまけ(補助機能)にすぎない、という発想をしたほうがよさそうです。これはもしかしたら、"accessibility"の"-ibility"の部分、「呼べる」の「べる」の部分をどのように捉えるのか、という問題と言えるかもしれません。
「1トンの鉄塊を素手で持ち上げることはできない」というのと、「禁煙車で喫煙をすることはできない」というのでは、「できない」の意味合いが変わってくるわけですが、これと同じです。実際に呼べなくなるという結果中心の見方をとると、「制限できない制限機能」のような印象を受けるのですが、隠蔽化のための記述の一つであるという目的中心の見方をとると、きちんと意味のある機能なんだな、と考えることができると思います。
- 投稿日:2019-05-07T13:52:57+09:00
form_forをもう一度理解する
はじめに
railsの勉強をしていて、避けては通れない
form_forというヘルパーメソッド。今回はこのなんども使うことになるform_forの使い方をもう一度おさらいしていこうと思い、この記事を着手した。form_forとは
form_forは先述した通りrailsのヘルパーメソッドであり、モデルの編集や追加などに使われるメソッドである。つまり、特定のテーブルに対して、レコードの追加やレコードの編集などを行いたい時に、
form_forを用いると簡単にその記述が書けてしまう優れものであるということ。使い方
基本的な使い方は以下の通り。
<%= form_for(モデルクラスのインスタンス) do |f| %> … <% end %>使いたいモデルのインスタンスを引数として渡すことがポイントとなる。
この時に、渡したインスタンスが情報を持っていなければ
createアクションを、インスタンスが情報を持っていたらupdateアクションを行うようになっている。この点が非常に便利となっている一つである。
メソッドの使い方はf.htmlタグ名 :カラム名と指定することで対応するformの作成をすることができる。詳しくはrailsの公式ドキュメントを参照。form_tagとの違い
そして勉強しているときによく似たものとして出てくるのが、
form_tagという存在。この違いを明確にすることで、要所でform_forを扱うことができるようになるだろう。
この二つの大きな違いは、モデルを介する操作かどうかというところによる。
例えば、入力データがモデルを持っていれば、モデルにレコードの追加編集ということでform_forを扱い、入力データがモデルを持っていなければ、単にデータを特定の要件で扱うだけということでform_tagを用いる。form_tagはモデルにレコードとして追加しないため、検索窓、などを作成する時に用いると効果的に扱うことができる。
まとめ
今回は
form_forおよびにform_tagについてまとめてみた。railsを勉強していたら必ずと言っていいほど扱うことになるため、きちんと用途を抑えて扱えるようにしておきたいところだ。
- 投稿日:2019-05-07T12:16:04+09:00
view_contextにしてやられた話
なんだかよく分からないレシーバとの邂逅
不具合がとあるサイトで起きてその改修作業をしていたところ、問題のコードに妙なレシーバを発見した。
view_context
これはなんなんだ?よく分からない。ファイルに対してこの文字列にgrep検索かけても定義された箇所が全く出てこない。おいおい、オメーさんよぉ、一体なんなんだよぉ〜ええ?(ミスタ風)
こいつ、独自にヘルパーメソッド作ったやつ呼ぶのに使われるってよ
独自にヘルパにーメソッドを作るには、
アプリケーション全体で使う場合は、app/helpers/application_helper.rb に書くことができる
app/views/foo/ で使う場合は、app/helpers/foo_helper.rb に書くことができる
ということで、このディレクトリパスに調べに行ったら問題のメソッドを発見することができた。
- 投稿日:2019-05-07T11:51:56+09:00
Ruby2.7の新機能PatternMatchingが最高でした
※ はてなブログで投稿した記事と同じです。
This is 何?
RubyKaigi2019で聞いたRuby2.7から入るPattern Matchの機能に感動したのですが、セッション中は理解しきれない部分があったので、スライドを読み、コードを動かしてみました。
そしたら改めて感動した、という記事です!スライドのはじめに、下記の記載があります。
- PatternMatchingは2.7.0からの新機能ですが、trunkにはもうcommit済
- 仕様はまだ策定中
- 試してフィードバックくださいね!
なお、githubにサンプルコードを置いています。
1. 準備
Ruby2.7.0(dev)はビルドしなきゃかな…と思ってたらrbenvがもう対応してました。
はやい!うれしい!$ brew upgrade rbenv ruby-buildこれで無事
2.7.0-devがリストに出てくるようになります。$ rbenv install --list (略) 2.6.1 2.6.2 2.6.3 2.7.0-dev (略) $ rbenv install 2.7.0-dev (略) Installed ruby-trunk to /Users/makicamel/.rbenv/versions/2.7.0-dev $ rbenv versions * system 2.7.0-dev $ rbenv local 2.7.0-dev $ rbenv version 2.7.0-dev (set by /Users/makicamel/pattern_match/.ruby-version)これで準備完了です!
試しにPatternMatchingを書いてみると動くようになりました!
この時warningが出るのですが、ほんと開発中って感じが、わくわくします…!warning: Pattern matching is experimental, and the behavior may change in future versions of Ruby!2. PatternMatchingとは?
case句に対して複数の値を割り当てられること。従来の
case句ってこんな感じ。完全一致です。case [0, [1, 2, 3]] when [0] :unreachable when [0, [1]] :unreachable when [0, [1, 2, 3]] p 'here' end # => herePatternMatchingが導入されるとこうなります。(
in節になります)case [0, [1, 2, 3]] in [0, [1]] :unreachable in [a, b] p a # => 0 p b # => [1, 2, 3] in [0, [1, 2, 3]] :unreachable endパターンマッチされるだけでなく、マッチした変数名でそのままマッチした値が取り出せます。
*(スプラット演算子)を使ってこんな風にもかけます。case [0, [1, 2, 3]] in [a, [b, *c]] p a # => 0 p b # => 1 p c # => [2, 3] endちゃんと構造もチェックしてくれるので、こうなります。
case [0, [1, 2, 3]] in [a] :unreachable in a p a # => [0, [1, 2, 3]] endハッシュも使えます。
case {a: 0, b: 1} in {a: 0, x: 1} :unreachable in {a: 0, b: var} p var # => 1 endすごい使い所ありそう!
セッションによると、JSONのデータを扱う時に便利ですよ、とのこと。person = '{ "name": "Alice", "children": [ { "name": "Bob", "age": 2 } ] }' case JSON.parse(person, symbolize_names: true) in {name: 'Alice', children: [{name: 'Bob', age: age}]} p age # => 2 endシンプル!!
3. 仕様について
Syntax
- 最初にマッチするまで実行される
- どのパターンもマッチしない場合、
else節が実行される- どのパターンもマッチせず
else節もない場合、NoMatchinPatternErrorが発生する。1と2は現状のcaseと同じですね。
どの条件にも一致しない場合は例外が発生するので、パターンマッチを使う時には網羅性を確認してください、とのことでした。4.
if/unlessで条件づけができるcase [0, 1] in [a, b] unless a == b p a # => 0 p b # => 1 enda, bが先に評価され、マッチした時に
if/unlessが評価されます。
なので、マッチした値を利用した評価が可能。すごい!Pattern
1. ValuePattern
case/whenと同様に、===で評価されます。case 0 in 0 in -1..1 in Integer endどれともマッチします。
whenと同じ挙動。2. VariablePettern
先程までの例のように値をマッチさせ、その変数と値が結び付けられます。
また、_を使うと値を捨てて、ワイルドカード的に使えます。case [0, 1] in [_, _] :reachable end注意点としては、
in節で変数を使うと、case句の外で変数を定義していてもパターンマッチされてしまうこと。
パターンマッチではなく定義された変数として使いたい場合は^を使います。a = 0 case 1 in a p a # => 1 end a = 0 case 1 in ^a :unreachable end # => NoMatchingPatternError3. AlternativePattern
case文を書き始めてしばらくして、こんな感じで書けたら…と思った記憶があります。
現実になった!すごい!case 0 in 0 | 1 | 2 :reachable end4.
AsPatternパターンがマッチした時、
=>で変数名を指定することで変数と値を結び付けられます。
この使い勝手のよさがすごい。
ValuePatternだけじゃなくて、他のパターンでも使えます。case 0 in Integer => a p a # => 0 end case 0 in 0 | 1 | 2 => a p a # => 0 end case [0, [1, 2]] in [0, [1, _] => a] p a # => [1, 2] end5. ArrayPattern
ArrayPatternとはいうけれど、Array以外でも使えます。
以下の3つを満たす時にマッチします。
- Constant === objectの時
- objectがArrayを返すdeconstructメソッドを持つ時
- ネストしたobjectが2の条件を満たす時
また、パターンの書き方は下記のいずれも可能です。
Constant(pattern, pattern, ..., *var, pattern) Constant[pattern, pattern, ..., *var, pattern] [pattern, pattern, ..., *var, pattern]case [0, 1, 2] in Array(0, *a, 2) in Object[0, *a, 2] in [0, *a, 2] in 0, *a, 2 # `[]`は省略できる end p a # => [1]この4つは全て同じ結果。
ふと気になったのが、in [0, *a, 2]って最初の例と同じ。
deconstructメソッド実装しなくていいの?と思って確認してみると、[].methods.include? :deconstruct # => trueでした。
Ruby2.6.2では[].methods.sizeが188、2.7.0-devでは189になっていて、おお…となりました。さて、先述した通り、ArrayPatternはArray以外でも使えます。
objectがArrayを返せばOKなので、実装してあげます。class Struct alias deconstruct to_a end Color = Struct.new(:r, :g, :b) color = Color[0, 10, 20] p color.deconstruct # => [0, 10, 20] case color in Color[0, 0, 0] p 'black' in Color[255, 0, 0] p 'red' in Color[r, g, b] p "#{r}, #{g}, #{b}" endStructがArrayを返すよう、
deconstructをto_aのエイリアスに設定しています。スライドにはASTの例もありましたが、理解が追いつかないのでレベルアップしてから再挑戦します。
6. HashPattern
HashPatternも、Hash以外でも使えます。
以下の3つを満たす時にマッチします。
- Constant === objectの時
- objectがHashを返すdeconstruct_keysメソッドを持つ時
- ネストしたobjectが2の条件を満たす時
また、パターンの書き方もArray同様下記のいずれも可能です。
Constant(id: pattern, id: pattern, ..., **var) Constant[id: pattern, id: pattern, ..., **var] {id: pattern, id: pattern, ..., **var}Arrayに引き続き確認すると、
{}.methods.include? :deconstruct_keys # => true。
ただし今回はRuby2.6.2では{}.methods.sizeが174、2.7.0-devでは176。
ひとつはdeconstruct_keysとして、もうひとつは?と確認してみると、:tallyでした。
tallyは配列の要素数を要素毎に数え上げるEnumerableモジュールのメソッド。
こちらも楽しみです?さて、コードを見てみます。
case {a: 0, b: 1} in Hash(a: a, b: 1) p a # => 0 in Object[a: a] in {a: a} in {a: a, **rest} p rest # => {b: 1} end
{}は省略可。変数名も省略できます(a:==a: a)。case {a: 0, b: 1} in a:, b: p a # => 0 p b # => 1 endまた、
deconstruct_keysの実装で思いがけない値を返すと逆効果になるので、実装に注意してくださいとのことでした。
deconstruct_keysに渡されるkeysはパターンに含まれるkeyの配列keysに含まれていないkeyは無視してOK**restがパターンに含まれる場合はnilが渡る- その場合、全てのkey-valueセットを返さなければならない
コードを見たほうがわかりやすそうです。
class Time VALID_KEYS = %i(year month) def deconstruct_keys(keys) if keys (VALID_KEYS & keys).each_with_object({}) do |k, h| h[k] = send(k) end else {year: year, month: month} end end end now = Time.now # 2019-05-07 ... case now in year: # now.deconstruct_keys([:year])を呼ぶ p year # => {year: 2019} in **rest # now.deconstruct_keys(nil)を呼ぶ p rest # => {year: 2019, month: 5} endArrayとHashの違いで気をつけたいのは、Arrayは完全一致、Hashはサブセットマッチなこと。
ArrayとHashでは使い所が違うから、とのことでした。case [0, 1] in [a] :unreachable in [a, *] :reachable end case {a: 0, b: 1} in {a: a} :reachable endデザイン
Historyは時間がなくてセッション中端折られてしまったのですが、スライドによると2012年にgemを作ったことから端を発して、7年かけて作られた機能。
最初はmatch/patternだったりcase/=>になっていったり、時間をかけて様々考えられ、磨きぬかれていった様にわくわくします!キーワードも、
matchでなくcaseしたのは、matchだと既存のコードを壊してしまう可能性があるから。
新しい予約語を使わないために最初は記号を使ったりしようとしていたのだけど、そうだ、僕らにはfor/inのinがあるじゃないか!と思いついた話がすごく好きです。なるべく自然に書けるように、でも既存のコードを壊さないように。
コードを試し書きしていて何度も気持ちいいなあ、と思ったのですが、Rubyの「開発者が楽しい」ってこうして守られ、作られているんだなあ、と改めて感じ入りました。また、まだもっとよくしたいんだけど、どう思う?というスライドもたくさんあって、わくわくしました。
パターンマッチング、楽しみです!
- 投稿日:2019-05-07T10:42:34+09:00
[OSX] Chrome version 74以降、headlessでページの表示が出来ない(about:blankから移動出来ない)対処法
問題
- OSXだ
- Chromeのバージョンが74以降
- chromedriverもバージョンが74以降
- headlessで動かしている
- capybaraなどで
session.visitしてもsession.current_urlがabout:blankで、session.save_screenshotの内容が空白ページになっている解決方法 ( --use-mock-keychain )
https://bugs.chromium.org/p/chromedriver/issues/detail?id=2870
https://groups.google.com/forum/#!topic/chromedriver-users/ktp-s_0M5NMCapybara.register_driver :chrome do |app| args = [ "--headless" "--disable-gpu" "--use-mock-keychain" # !!! 74からはheadlessでこれが要る ... ] caps = Selenium::WebDriver::Remote::Capabilities.chrome( "goog:chromeOptions" => { args: args, ... } ) Capybara::Selenium::Driver.new( app, browser: :chrome, desired_capabilities: caps, ) end
- 投稿日:2019-05-07T09:18:28+09:00
RubyでWeather Hacksを使って天気を取得してみた
はじめに
前回の記事にて、天気情報取得にAPIキーが必要だったため、APIキーが不要な天気情報取得をやってみました。
RubyでOpenWeatherMapを使って天気を取得してみた環境
macOS Mojave(10.14.4)
Livedoor Weather Web Service
こちらで公開されています。
お天気Webサービス仕様
このサイト内のURLと地域別IDを使用することで、以下情報をJSON形式で取得できます。お天気Webサービス(Livedoor Weather Web Service / LWWS)は、現在全国142カ所の今日・明日・あさっての天気予報・予想気温と都道府県の天気概況情報を提供しています。
取得処理
今回も東京の天気情報取得をやってみます。
地域別IDは以下サイトにまとめられていたので、そこから参照します。
livedoorお天気webサービス地域ID一覧上記サイトを見ると東京のIDは130010のようです。
そのため東京の天気情報取得には以下URLを使用します。
http://weather.livedoor.com/forecast/webservice/json/v1?city=130010RubyでのJSON取得コードは以下になります。
require 'open-uri' require 'json' response = open(url) @parse_text = JSON.parse(response.read) puts JSON.pretty_generate(@parse_text)取得結果
取得できた東京の天気情報がこちらです。
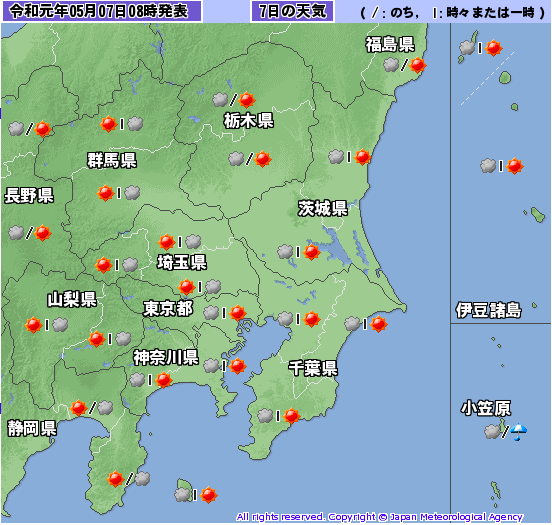
※取得日:2019/5/7{ "pinpointLocations": [ { "link": "http://weather.livedoor.com/area/forecast/1310100", "name": "千代田区" }, ・・・略・・・ ], "link": "http://weather.livedoor.com/area/forecast/130010", "forecasts": [ { "dateLabel": "今日", "telop": "曇時々晴", "date": "2019-05-07", "temperature": { "min": null, "max": { "celsius": "19", "fahrenheit": "66.2" } }, "image": { "width": 50, "url": "http://weather.livedoor.com/img/icon/9.gif", "title": "曇時々晴", "height": 31 } }, ・・・略・・・ } ], "location": { "city": "東京", "area": "関東", "prefecture": "東京都" }, "publicTime": "2019-05-07T05:00:00+0900", "copyright": { "provider": [ { "link": "http://tenki.jp/", "name": "日本気象協会" } ], ・・・略・・・取得ができたので、必要な部分だけ取り出して、今日の天気を出すようにしました。
ついでに関東地方の地域IDがある地点の天気を取得してみました。City: 東京, Weather: 曇時々晴 City: 大島, Weather: 曇時々晴 City: 八丈島, Weather: 曇時々晴 City: 父島, Weather: 曇のち雨 City: 横浜, Weather: 曇時々晴 City: 小田原, Weather: 曇時々晴 City: さいたま, Weather: 晴時々曇 City: 熊谷, Weather: 晴時々曇 City: 秩父, Weather: 晴時々曇 City: 千葉, Weather: 曇時々晴 City: 銚子, Weather: 曇時々晴 City: 館山, Weather: 曇時々晴 City: 水戸, Weather: 曇時々晴 City: 土浦, Weather: 曇時々晴 City: 宇都宮, Weather: 曇のち晴 City: 大田原, Weather: 曇のち晴 City: 前橋, Weather: 晴時々曇 City: みなかみ, Weather: 晴時々曇 City: 甲府, Weather: 晴時々曇 City: 河口湖, Weather: 晴時々曇比較のため、気象庁の天気と比較してみます。
気象庁
※前回はヤフー天気を比較対象に挙げましたが、精度が公表されていないようでした。
そのため精度を公表している気象庁を選択しました。
天気予報の精度検証結果
おおー、あまり外れていないように見えますね。
まとめ
偶然近い結果になったのか分かりませんが、天気予報第2弾はなかなかよい結果でした。
明日、明後日の天気も出して比較すると、さらに面白そうですね。
- 投稿日:2019-05-07T08:35:11+09:00
Rails6 のちょい足しな新機能を試す11(has_secure_password 編)
はじめに
Rails 6 に追加されそうな新機能を試す第11段。 今回のちょい足し機能は、
has_secure_password編です。
has_secure_password にオプションとしてカラムを指定できるようになりました。記載時点では、Rails は 6.0.0.rc1 です。
gem install rails --prereleaseでインストールできます。$ rails --version Rails 6.0.0.rc1プロジェクトを作成する
rails プロジェクトを作成します。
$ rails new sandbox6_0_0rc1 $ cd sandbox6_0_0rc1Gemfile を編集して bcrypt gem を追加する
has_secure_password を使うために bcrypt gem を追加します。
Gemfile の bcrypt の行を有効にします。
Gemfile# Use Active Model has_secure_password gem 'bcrypt', '~> 3.1.7'
bundleを実行します$ bundleUser モデルを作成する
User モデルを作成します。
このとき、password の他に token 用の digest カラムを追加します。$ bin/rails g model User name password_digest token_digest $ bin/rails db:create db:migrateUser モデルを編集する
User model を編集し、
has_secure_passwordを追加します。
:tokenオプションを追加したものとオプションを省略したもの2行を追加します。
オプションを省略した場合は従来と同じですね。app/models/user.rbclass User < ApplicationRecord has_secure_password # これは今までと同じ has_secure_password :token, validations: true # こちらは新機能 end
has_secure_passwordの機能を確認するrails コンソールから確認してみます。
$ bin/rails c Running via Spring preloader in process 393 Loading development environment (Rails 6.0.0.rc1)オプションなしの方は今までと変わりません。
password,password_confirmationなどのメソッドが使えます。irb(main):001:0> u = User.new => #<User id: nil, name: nil, password_digest: nil, token_digest: nil, created_at: nil, updated_at: nil> irb(main):002:0> u.password => nil irb(main):003:0> u.password_confirmation => nilオプションを指定した
:tokenに合わせて、tokentoken_confirmationなどのメソッドが追加されます。irb(main):004:0> u.token => nil irb(main):005:0> u.token_confirmation => nilvalidation を試してみると
passwordだけではなくtokenについてもチェックしていることがわかります。irb(main):006:0> u.valid? => false irb(main):007:0> u.errors.full_messages => ["Password can't be blank", "Token can't be blank"]
tokenとtoken_confirmationが一致しているかどうかのチェックもしてくれます。irb(main):008:0> u.password = 'password' => "password" irb(main):009:0> u.password_confirmation = 'pass' => "pass" irb(main):010:0> u.token = 'token' => "token" irb(main):011:0> u.token_confirmation = 'tok' => "tok" irb(main):012:0> u.valid? => false irb(main):013:0> u.errors.full_messages => ["Password confirmation doesn't match Password", "Token confirmation doesn't match Token"]
password_confirmation,token_confirmationを設定してデータベースに保存してみましょう。irb(main):014:0> u.password_confirmation = 'password' => "password" irb(main):015:0> u.token_confirmation = 'token' => "token" irb(main):016:0> u.name = 'user1' => "user1" irb(main):017:0> u.save (0.3ms) BEGIN User Create (0.5ms) INSERT INTO "users" ("name", "password_digest", "token_digest", "created_at", "updated_at") VALUES ($1, $2, $3, $4, $5) RETURNING "id" [["name", "user1"], ["password_digest", "$2a$10$uvvJuUHV8fNQ/0GRRtyewuboiAEUpD4Q1.0/coyWWhVxOivHnIMia"], ["token_digest", "$2a$10$56jLRgb1n0WjLOa/9NqIoOm3Il8nfyXCCisk5oieTxe27/EE56UpC"], ["created_at", "2019-05-03 23:04:03.971339"], ["updated_at", "2019-05-03 23:04:03.971339"]] (7.3ms) COMMIT => true今保存したデータを読み直します。
irb(main):022:0> u = User.last User Load (0.6ms) SELECT "users".* FROM "users" ORDER BY "users"."id" DESC LIMIT $1 [["LIMIT", 1]] => #<User id: 2, name: "user1", password_digest: [FILTERED], token_digest: "$2a$10$56jLRgb1n0WjLOa/9NqIoOm3Il8nfyXCCisk5oieTxe...", created_at: "2019-05-03 23:04:03", updated_at: "2019-05-03 23:04:03">password は今まで通り
authenticateで認証できます。irb(main):023:0> u.authenticate('pass') => false irb(main):024:0> u.authenticate('password') => #<User id: 2, name: "user1", password_digest: [FILTERED], token_digest: "$2a$10$56jLRgb1n0WjLOa/9NqIoOm3Il8nfyXCCisk5oieTxe...", created_at: "2019-05-03 23:04:03", updated_at: "2019-05-03 23:04:03">
tokenはauthenticate_tokenで認証できます。irb(main):025:0> u.authenticate_token('password') => false irb(main):026:0> u.authenticate_token('token') => #<User id: 2, name: "user1", password_digest: [FILTERED], token_digest: "$2a$10$56jLRgb1n0WjLOa/9NqIoOm3Il8nfyXCCisk5oieTxe...", created_at: "2019-05-03 23:04:03", updated_at: "2019-05-03 23:04:03">
validations: falseにしたときは?
validations: falseのときは、validation のチェックをしません。 authenticate_token (authenticate_xxx) は使えます。app/models/user.rbclass User < ApplicationRecord has_secure_password has_secure_password :token, validations: false endirb(main):007:0> u = User.new => #<User id: nil, name: nil, password_digest: nil, token_digest: nil, created_at: nil, updated_at: nil> irb(main):008:0> u.valid? => false irb(main):009:0> u.errors.full_messages => ["Password can't be blank"] irb(main):010:0> u.password = u.password_confirmation = 'password' => "password" irb(main):011:0> u.token = 'token' => "token" irb(main):012:0> u.save (0.3ms) BEGIN User Create (0.7ms) INSERT INTO "users" ("password_digest", "token_digest", "created_at", "updated_at") VALUES ($1, $2, $3, $4) RETURNING "id" [["password_digest", "$2a$10$NC1IH2S8G/RKX7myjNfeeepMknnQUuKIqD60S70iom3ZOQl92j/Cq"], ["token_digest", "$2a$10$xFYYXX7Bxk6qAOaqd3M7COlkZBCYodZK4HYQoBxLTNjr2dibMU/MK"], ["created_at", "2019-05-03 23:42:47.628292"], ["updated_at", "2019-05-03 23:42:47.628292"]] (7.2ms) COMMIT => true irb(main):013:0> u = User.last User Load (0.6ms) SELECT "users".* FROM "users" ORDER BY "users"."id" DESC LIMIT $1 [["LIMIT", 1]] => #<User id: 3, name: nil, password_digest: [FILTERED], token_digest: "$2a$10$xFYYXX7Bxk6qAOaqd3M7COlkZBCYodZK4HYQoBxLTNj...", created_at: "2019-05-03 23:42:47", updated_at: "2019-05-03 23:42:47"> irb(main):014:0> u.authenticate_token('pass') => false irb(main):015:0> u.authenticate_token('token') => #<User id: 3, name: nil, password_digest [FILTERED], token_digest: "$2a$10$xFYYXX7Bxk6qAOaqd3M7COlkZBCYodZK4HYrQoBxLTNj...", created_at: "2019-05-03 23:42:47", updated_at: "2019-05-03 23:42:47">"'"]
:validationsオプションを省略したときは?
validations: trueを指定したときと同じ動作になります。おまけ
irb の出力で
password_digestが[FILTERED]となっているのにtoken_digestが[FILTERED]にならないのは、
config/initializers/filter_parameter_logging.rbで設定されていないからです。
tokenも追加してあげれば[FILTERED]になります。config/initializers/filter_parameter_logging.rb# Configure sensitive parameters which will be filtered from the log file. Rails.application.config.filter_parameters += [:password, :token]参考情報
- 投稿日:2019-05-07T07:26:16+09:00
GTFSデータをSQLに変換してみる
GTFS Advent Calendar 3日目の記事です。
今日はGTFSデータをSQL文に変換する方法を紹介しようと思います。2日目の記事では、GTFSデータをRDBMSに格納する手順を紹介しました。その際、あらかじめGTFSデータをSQLに変換しておき、それをMySQLに流し込むという方法でデータを用意していました。
具体的なSQLファイルは以下になります。用意したRDBMS環境では、GTFSのファイル(CSVファイル)名をDBのテーブル名にし、CSVのフィールドをテーブルのフィールド名に対応付けているので、比較的簡単にGTFSデータをSQLに変換できています。
変換用のスクリプトは以下の場所に用意してあります。GTFSデータを展開したディレクトリで
gtfs_csv2sql.rbを実行するとSQLが生成されます。$ git clone https://github.com/ValLaboratory/advcal.git $ cd advcal/2019/gw/docker_env/script $ $ # 北恵那交通株式会社(http://www.kitaena.co.jp)のGTFSデータ。 $ curl -s -o kitaena.zip 'http://www.kitaena.co.jp/info/GTFS%282019-03-13_1606%29.zip' $ unzip kitaena.zip Archive: kitaena.zip extracting: agency.txt extracting: agency_jp.txt extracting: calendar.txt extracting: calendar_dates.txt extracting: fare_attributes.txt extracting: fare_rules.txt extracting: feed_info.txt extracting: routes.txt extracting: shapes.txt extracting: stops.txt extracting: stop_times.txt extracting: translations.txt extracting: trips.txt $ $ # SQLを生成します。 $ ruby gtfs_csv2sql.rb INSERT INTO routes(route_id,agency_id,route_short_name,route_long_name,route_desc,route_type,route_color,route_text_color) VALUES ('4033','3200001023316','','馬籠線[上り・中切経由]','','3','FF0080','FFFFFF') ; INSERT INTO routes(route_id,agency_id,route_short_name,route_long_name,route_desc,route_type,route_color,route_text_color) VALUES ('2006','3200001023316','','加子母線[下り]','','3','FF0080','FFFFFF') ;適当なファイルに出力して...。
$ ruby gtfs_csv2sql.rb > kitaena.sqlMySQLからSQLを読み込ませれば完了です。
$ docker cp kitaena.sql mysql01:/tmp $ docker exec -ti mysql01 mysql -uroot -p mysql> mysql> -- SQLファイルを読み込ませる。 mysql> source /tmp/kitaena.sql ...中略... mysql> -- 投入されたデータを確認する。 mysql> SELECT * FROM fare_attributes LIMIT 10 ; +---------+-------+---------------+----------------+-----------+-------------------+ | fare_id | price | currency_type | payment_method | transfers | transfer_duration | +---------+-------+---------------+----------------+-----------+-------------------+ | 170_00 | 170 | JPY | 0 | 0 | NULL | | 180_00 | 180 | JPY | 0 | 0 | NULL | | 190_00 | 190 | JPY | 0 | 0 | NULL | | 200_00 | 200 | JPY | 0 | 0 | NULL | | 210_00 | 210 | JPY | 0 | 0 | NULL | | 220_00 | 220 | JPY | 0 | 0 | NULL | | 230_00 | 230 | JPY | 0 | 0 | NULL | | 240_00 | 240 | JPY | 0 | 0 | NULL | | 250_00 | 250 | JPY | 0 | 0 | NULL | | 260_00 | 260 | JPY | 0 | 0 | NULL | +---------+-------+---------------+----------------+-----------+-------------------+ 10 rows in set (0.00 sec) mysql>これでGTFSとして提供されているデータをRDBMSに格納することができました。
まとめ
GTFSデータをSQLに変換するスクリプトを紹介しました。
RDBMSにデータを格納することで、CSVの形ではちょっと煩雑になりがちなデータの結合や抽出等も、SQLクエリの実行という形で楽に処理できそうです。
- 投稿日:2019-05-07T05:04:26+09:00
【10日間でポートフォリオ作成に挑戦】10日目:AWSでのデプロイ
概要
今回は、2019年のGW期間(10日間)を全て費やして取り組む
ポートフォリオの製作過程を取りまとめた内容を投稿させて頂きます。(投稿は毎日行う予定)全体通した取り組みの詳細については、前回までの記事をご参照ください。
【10日間でポートフォリオ作成に挑戦】1日目:要件定義〜記事投稿のCRUD
【10日間でポートフォリオ作成に挑戦】2日目:アクセス制限〜コメントのCRUD機能
【10日間でポートフォリオ作成に挑戦】3日目:ページネーション~CKEditorの導入
【10日間でポートフォリオ作成に挑戦】4日目:テーブル分割〜CKEditorのフォームへの反映
【10日間でポートフォリオ作成に挑戦】5日目:CKEditorへ画像アップロード機能を追加
【10日間でポートフォリオ作成に挑戦】6日目:テストコードの実装
【10日間でポートフォリオ作成に挑戦】7日目:検索機能〜いいね機能の実装
【10日間でポートフォリオ作成に挑戦】8日目:記事ストック機能〜ユーザーフォロー機能の実装
【10日間でポートフォリオ作成に挑戦】9日目:フロントエンドの実装〜各種機能の修正今日一日の作業内容
ここからは、今日1日で取り組んだ作業内容をご説明します。
本番環境へのデプロイ
一通りの機能の実装が完了したので、本番環境へのデプロイを行います。
デプロイにあたっては、AWSを利用しています。下記の様な構成です
- 仮想サーバー:EC2(AWS)
- ストレージ:S3(AWS)
- アプリケーションサーバー:Unicorn
- WEBサーバー:Nginx
- データベース:MySQL
- 自動デプロイ:Capistrano
これでデプロイ出来たものが、下記のURLです。
http://3.112.115.114/今日の失敗
ここから、今日の失敗をまとめます。
画像アップロードが本番環境で動作しない
開発環境では正常に動作していた画像アップロードですが、本番環境ではエラーが発生してしまい、正常に動作しませんでした。
アクセスキーの設定ミス
エラーログを確認して見ると、下記の様な内容でした。
rake stderr: rake aborted! NoMethodError: undefined method `match' for nil:NilClass色々調べて見ると、どうやらAWSのアクセスキーの読み込みが上手く行っていなかった様でした。
これまで、
secrets.ymlで読み込ませる方法しか実践した事が無かったのですが、今回Rails5.2を利用する事にした為、secrets.ymlがcredentials.ymlに置き換わっていた事を失念していました。なので、
credentials.ymlからアクセスキーを読み込ませる様に設定を変更しました。
なお、credentials.ymlは直接エディタで編集を行えない為、ターミナルから下記コマンドを実行して、編集を行う必要があります。$ EDITOR="vi" bin/rails credentials:editまた、復号化に必要な
master.keyは、デフォルトで.gitignoreに追加されているため、Capistranoの自動デプロイに関する設定ファイルに読み込ませる為の記述を追加する必要があります。config/deploy.rbset :linked_files, %w{ config/master.key } (中略) desc 'upload master.key' task :upload do on roles(:app) do |host| if test "[ ! -d #{shared_path}/config ]" execute "mkdir -p #{shared_path}/config" end upload!('config/master.key', "#{shared_path}/config/master.key") end end before :starting, 'deploy:upload' after :finishing, 'deploy:cleanup' end私は、前に実装したコードをそのまま引用した為に、
master.keyと指定すべき箇所を、secrets.ymlと指定してエラーになってしまいました。Shrineの設定
上記のアクセスキーの設定を行った後も、別のエラーが発生しました。
Shrine::Error (storage :cache isn't registered on ImageUploader):公式のリファレンスも確認して、コードを書き換えたりしたのですが、これが一向に解消されません。
uploaders/image_uploader.rbrequire 'image_processing/mini_magick' class ImageUploader < Shrine plugin :remove_attachment plugin :pretty_location plugin :processing plugin :versions plugin :delete_raw plugin :store_dimensions, analyzer: :mini_magick process(:store) do |io, _| versions = { original: io } io.download do |original| pipeline = ImageProcessing::MiniMagick.source(original) versions[:standard] = pipeline.resize_to_limit!(400, 400) end versions end endconfig/initializers/shrine.rbrequire 'shrine/storage/s3' if Rails.env.production? s3_options = { access_key_id: Rails.application.credentials.dig(:aws, :access_key_id), secret_access_key: Rails.application.credentials.dig(:aws, :secret_access_key), region: 'ap-northeast-1', bucket: 'gooderorrs', } Shrine.storages = { cache: Shrine::Storage::S3.new(prefix: "cache", **s3_options), store: Shrine::Storage::S3.new(**s3_options), } else require 'shrine/storage/file_system' Shrine.storages = { cache: Shrine::Storage::FileSystem.new('public', prefix: 'uploads/cache'), store: Shrine::Storage::FileSystem.new('public', prefix: 'uploads') } end Shrine.plugin :activerecord Shrine.plugin :backgrounding Shrine.plugin :logging Shrine.plugin :determine_mime_type Shrine.plugin :cached_attachment_data Shrine.plugin :restore_cached_dataこれについては、今日中の解決が困難だった為、一旦持ち越しにしています。
今後の予定
結局、当初予定していた機能を期間内で全て実装する事が出来ませんでした・・・
その辺りの改善点などは、また時間が取れた時にまとめて投稿しようと思います。また、これで終了ではなく、機能拡張は続けて行くので、それもある程度まとまった内容が書ける段階で記事に出来ればと考えています。
おまけ
最後になりますが、現在、私は下記の目標を立てて学習に取り組んでいます。
- 3年間で「10,000時間」をプログラミングに費やす
- その間、毎日ブログの投稿を行う
Twitterでは、その過程で学んだ事などを発信しています。
もし宜しければフォローしてみてください。
