- 投稿日:2019-05-07T22:01:58+09:00
ディープラーニングガジェット品評会のネタ
ディープラーニングガジェット品評会で発表するネタをまとめておきます。
私は、handtracking↓を使った複数のネタを発表する予定です。
ネタ1 夢を叶えるインターフェイス
詳しくはこちら
続報は作成中...ネタ2 作業時間の自動計測装置
作成中...


- 投稿日:2019-05-07T22:01:22+09:00
夢を叶えるインターフェイス
無駄に未来感があるインターフェイスを作ってみました。
※こちらはディープラーニングガジェット品評会のネタです。
やりたかったこと
- 映画「マイノリティリポート」に出てくる格好いいやつを作りたかった
- タッチパネルが使えない状況(手が汚れている等)でも使用可能なインターフェイスを作りたかった
結果
まずは、結果をご覧ください。
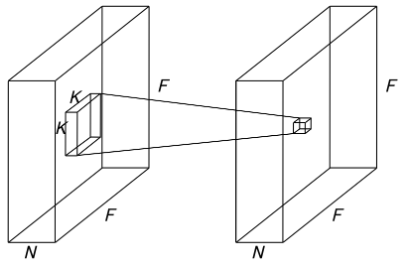
キャプチャ範囲の設定(両手を使います。)
キャプチャ画像の移動・拡大
環境
- Raspberry Pi 3
- USB camera
- NCS2
実はクソアプリ
このアプリ、全く使い物に立ちません。その理由は以下のとおりです。
- もっと便利な商品がある
- ハード代が高価(3万円弱)
- 使うと腕が疲れる
アルゴリズム
アルゴリズムは簡単です。
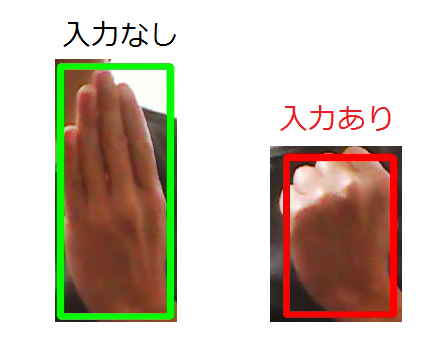
まず、handtracking-OpenVINOを使って、手を検出します。
そして、検出した手が閉じていると、「入力あり」と見なしています。
手の開閉は、手の検出枠(バウンディングボックス)の「縦横比」で判定しています。
縦長(手が開いている)であれば「入力なし」、それ以外であれば「入力あり」と判定しています。ただ、縦横比をはっきりさせるために、親指を曲げて手を開いています。
お釈迦様のような手にしないといけません。また、手のひらをカメラに向けると、手が二つあるように認識してしまい、
うまく判定ができません。
従って、手の甲をカメラに向けています。
改善に向けて
今のところ、完成度が低いため、コードは公開しませんが、改善できたら
公開しようと思います。少しでもクソアプリから脱却すべく、以下の項目を改善したいです。
手の認識
前述したように、手の動作に制約があります。
制約を無くすためには、DOCやTripletLossを使うと、高速にかつ正確に
手の開閉を認識できるようになります。親指を曲げて手を開く必要もないですし、手の甲を見せる必要もなくなるでしょう。
価格について
現状はハード代が高価です。
ハードをJetson Nanoに代えると、価格を一万円強に抑えることができます。
スピードは未知数ですが、10FPSくらいにはなると思います。最後に
handtrackingは、元々普通のPCで動くように開発されたものです。(CPUで10FPS)
従って、元のリポジトリを改造すれば、普通のPCでもこのアプリを動かすことができます。
やってみたいという方がいましたら、チャレンジしてみてください!

- 投稿日:2019-05-07T21:33:37+09:00
SENet論文読み
はじめに
論文名:’Squeeze-and-Excitation Networks’(https://arxiv.org/pdf/1709.01507v3.pdf)
著者:Jie Hu,Li Shen,Samuel Albanie,Gang Sun,Enhua Wu
公開日:25 Oct 2018参考:
1.https://towardsdatascience.com/squeeze-and-excitation-networks-9ef5e71eacd7
2.https://qiita.com/daisukelab/items/0ec936744d1b0fd8d523そもそもSENetとは
SEブロックと他のネットワークを組み合わせたもの
モチベーション
畳み込み層に手を加え、パラメータ数と計算量の削減・表現力の向上を目指す
(軽量化によってさらに層を重ねることが可能になり、精度向上にも繋がる)論旨
何をするのか?
CNNは空間情報とチャンネル情報の2つを合わせて特徴を捉えている
そのうちのチャンネル情報に焦点をあて、CNNの特徴マップのチャンネルを重みづけする
通常の畳み込み層では各チャンネルが均等に出力されるが、それを重み付けすることで情報価値の高いものを強調して比較的価値の低いものを抑える(=表現の質を上げる!)※空間・チャンネル情報の畳み込みについては「補足:depthwise/pointwise convolution」を参照
従来の手法との違い
従来の手法は空間情報に着目したものが多く、計算も複雑で計算量が大きいものが多い(らしい)
SEブロックは非常に単純で、既存のモデルに追加するだけで性能を大幅に改善できるうえ、
追加計算も非常に少ない(計算量の増加は1%以下!)提案手法
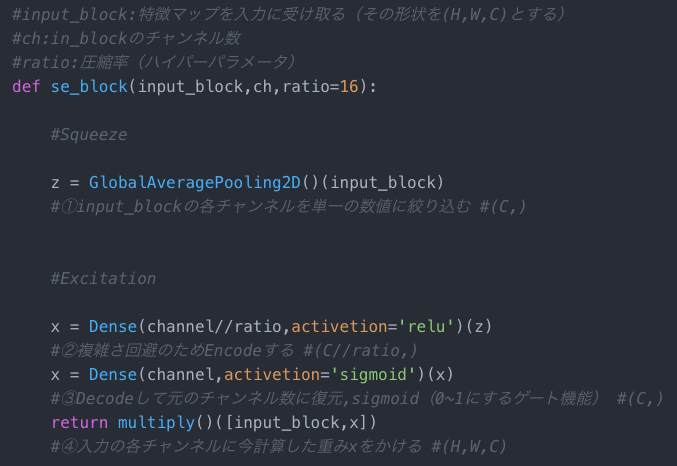
SEブロックの実装からその働きを見てみます
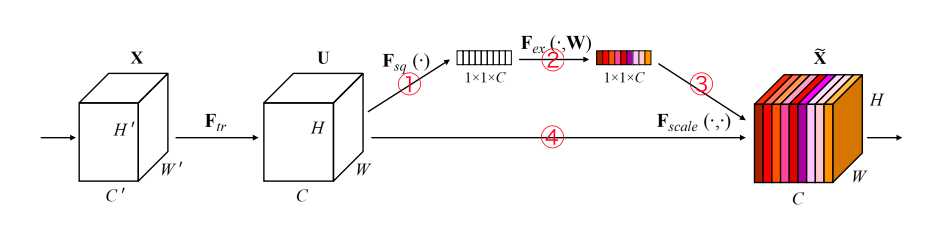
①input_blockの各チャンネルを単一の数値に絞り込む
(空間方向に)画像全体の画素値の平均をとり、各チャンネルを単一の数値に変換
チャンネル方向について、局所的な情報だけでなくグローバルな情報を捉えるため②複雑さ回避のためEncodeする
Encodeすることで複雑化を制限(=一般化)
③Decodeして元のチャンネル数に復元,sigmoid(0~1にするゲート機能)
チャンネル間の相関を捉えるための基準として
1.非線形な相互作用を表現できる
2.one-hotのような排他的な重み付けではなく、複数のチャンネルを重み付けできる
この2つを満たすsigmoidをゲートに利用④入力の各チャンネルに今計算した重みxをかける
①~③で計算した重みとinput_blockをかける(=input_blockのチャンネルを重み付けする)
SENetの例
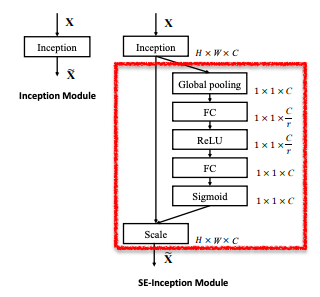
Inceptionとの組み合わせ
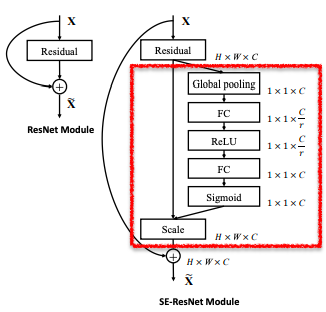
左図(Inceptionモジュール)を元としてSEブロック(赤枠部分)を加えたものが右図ResNetとの組み合わせ
残差接続があってもSEブロックを付け加えるだけで実装可能実験結果
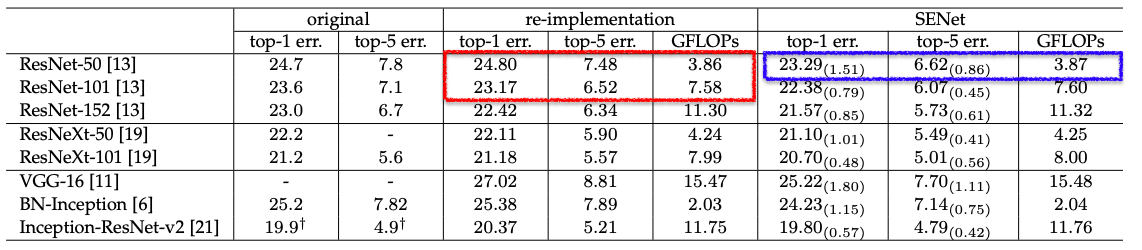
ImageNetのデータセットを利用した実験結果
original:元の論文で報告された結果
re-implementation:originalを再訓練したもの(比較で公平性を保つため)
SENet:SEブロックを追加したモデルここでは代表例としてSEブロックを追加したResNet-50(青枠部分)を見てみます
計算量(GFLOPsは計算コストの単位)はResNet-50とほぼ変わりませんが(0.26%の増加)
性能はResNet-101を超える精度を持っていることが分かります補足:depthwise/pointwise convolution
参考:
3.http://deeplearning.hatenablog.com/entry/slicenet
4.https://qiita.com/yu4u/items/34cd33b944d8bdca142dSENetのチャンネル情報の抽出やそれによる計算量の削減について、特にpointwise畳み込みの考え方が似ていて分かりやすかったので補足として挙げます
depthwise畳み込み
チャンネルに対して独立で、空間情報のみを抽出
入力:(F,F,N)
フィルタ:(K,K,1)
出力:(F,F,N)pointwise畳み込み
空間に対して独立で、チャンネル情報のみを抽出
入力:(F,F,N)
フィルタ:(1,1,N)
出力:(F,F,M)計算量の違い
(計算量ついては参考4がとても分かりやすいです)
通常の畳み込みをpw・dw畳み込みの2つで置き換えるとどのくらい計算量を削減できるのか
左から通常の畳み込み・dw畳み込み・pw畳み込み(dwとpwは再掲)通常の畳み込み
→フィルタ1つにつき、コスト$NK^2$の計算を$F^2$箇所で計算
→計算量:$F^2NK^2M$ パラメータ:$NK^2M$dw畳み込み
→フィルタ1つにつき、コスト$1*(K^2)$の計算を$F^2$箇所で計算
→計算量:$F^2NK^2$ パラメータ:$NK^2$pw畳み込み
→フィルタ1つにつき、コスト $N*(1^2)$ の計算を $F^2$ 箇所で計算
→計算量:$F^2NM$ パラメータ:$NM$通常の畳み込みをdwとpwに置き換えることで
計算量:$F^2NK^2M$ → $F^2N(K^2+M)$
パラメータ:$NK^2M$ → $N(K^2+M)$
に削減することが出来る計算比率は $F^2N(K^2+M)/$$F^2NK^2M$ = $1/M + 1/K^2$
Kはフィルタのサイズなので通常$K=3$または$K=5$
Mはフィルタの数(出力のチャンネル数)なので通常$M>=32$以上から多くの場合$M>>K^2$ → $1/K^2>>1/M$となるので、
計算量を$1/K^2$と近似して考えると概ね$1/9$から$1/25$程度に削減できるとわかるちなみに
SE = Squeeze(圧搾)& Excitation(励起)
圧搾→各チャンネルを単一の数値に変換〔ぎゅっと絞る〕
励起→各チャンネル〔基底状態〕を
相関関係に基づく重み付け〔外場〕によって
重要度を高める〔励起状態にする〕
の意かなと
- 投稿日:2019-05-07T18:51:36+09:00
論文まとめ:Monocular Total Capture: Posing Face, Body, and Hands in the Wild
はじめに
CVPR2019 に poster で accept された以下の論文
[1]D. Xiang, et. al, "Monocular Total Capture: Posing Face, Body, and Hands in the Wild"
のまとめarXivのリンク
https://arxiv.org/abs/1812.01598コードは近日中に公開されるらしいが、現在(19/5/4)のところ見当たらず
以下、個人的に興味があるbody推定のロジック部分のみまとめ(手と顔の部分は省略)。
概要
- 単眼RGBカメラのみから体、手、顔の3次元モデルを復元した
- モデルの途中でPOFs(part orientation fields)を推定し、これと関節のヒートマップから3次元モデルを復元させる
- 複数フレームの情報を処理してtrackingも行う
位置付けとしては、去年CVPR2018で発表された Adam model[2] を単眼カメラでやった感じ。total captureと研究室も同じ。
以下が3D total body motion を生成した例。それぞれ左側が入力画像、右側が3D total body motion。
モデルの全体像
全体像は以下の図。
1)左から $i$ フレームの input image $I_i$ をCNNに入れて関節信頼度マップ(joint confidence map)$S$ とPOFs(part orientation fields) $L$ を出力する。
2)これらの情報を元に3次元メッシュモデル $\Psi_i$ を構築する。
3)これに前フレームの画像 $I_{i-1}$ や3Dモデル $\Psi_{i-1}$ を加えて時間方向に安定させ、3Dモデルの精度を上げる
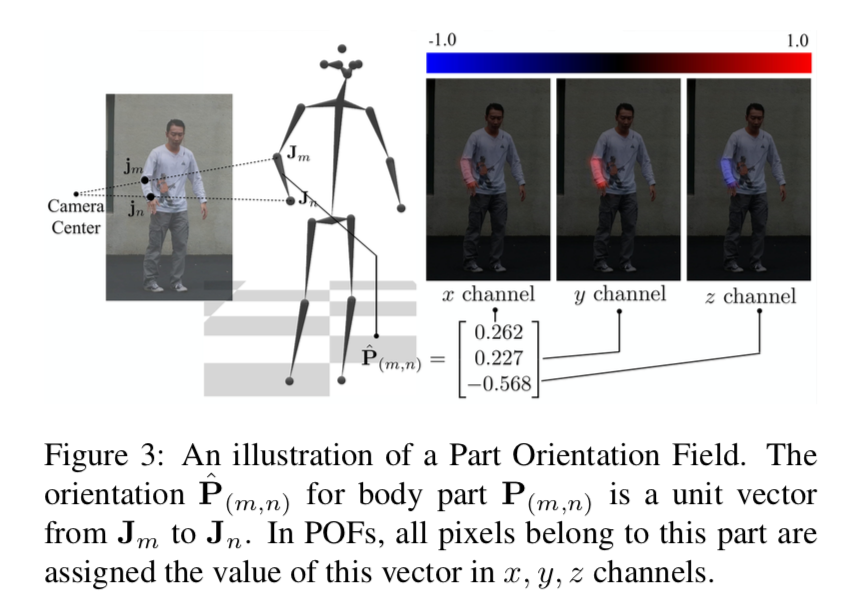
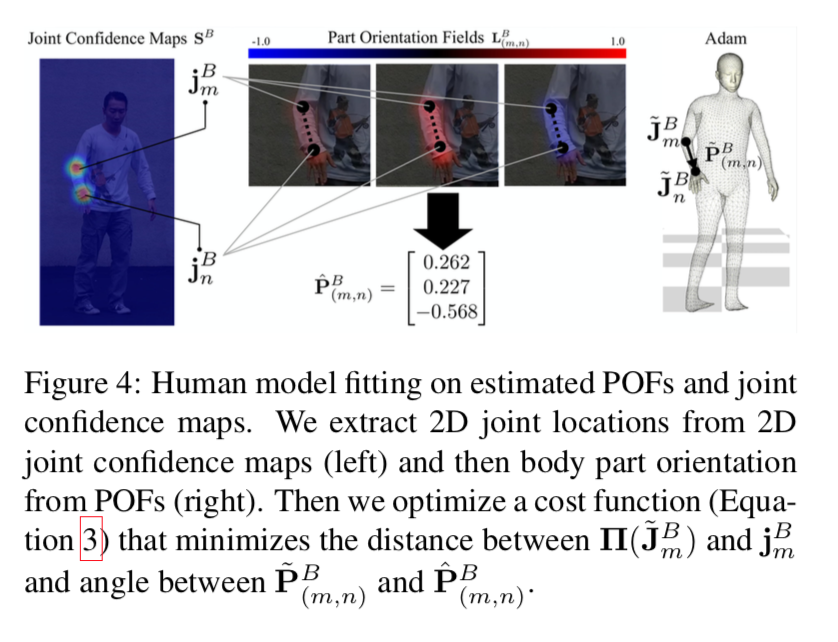
POFs(part orientation fields)による3D骨格の推定
本手法の最大の特徴であるPOFs部分。
先にざっくり仕組みを概観すると、以下の図のように
各limbの親関節から子関節(図中の例では右肘から右手首)の3次元ベクトルをそれぞれ $x, y, z$ に分け、それぞれを1チャンネル内の値で表す。
細かく定義すると、まず
$\mathbb{S}$ :骨格のヒエラルキーで、親関節ー子関節のセットからなる
$J_m \in \mathbb{R}^3$ :親関節の3次元表示
$J_n \in \mathbb{R}^3$ :子関節の3次元表示
$P_{(m,n)}$ :カメラ座標における親関節から子関節へのベクトル
$\hat{P}_{(m,n)}$ :3次元座標における親関節から子関節への単位ベクトル・・・つまり\hat{P}_{(m,n)} = \frac{J_n - J_m}{\| J_n - J_m \|}これらを用いて POFs $L_{(m,n)} \in \mathbb{R}^{3 \times h \times w}$ を3チャンネルで表す。
L_{(m,n)}(x) = \begin{cases} \hat{P}_{(m,n)} & if \ x \in P_{(m,n)} \\ 0 & otherwise. \end{cases}この POFs は OpenPoseの PAFs によく似ている。実際、著者らはここまでのモデルをOpenPoseのPAFsの2チャンネルを3チャンネルに変更して使用している。
3D modelの構築
関節の信頼度マップと POFs から3D model を求める手順の概要は以下の図。
左端が関節の信頼度マップで、中央がPOFsで、この2つから3次元上の骨格の推定値が求まる。
これに対して予め用意した Adam モデルという人の3次元メッシュモデルとを近づけるように最適化する。
具体的には以下。
まず関節の信頼度マップは、body(B)だと $J$ 個ある。
\{ J_m^B \}^J_{m=1}$S^B$ の各チャンネルの中で最大値となるピクセルをその関節の位置と推定する。
この関節のうち、親関節側から子関節側へPOFsの足跡を辿ることで対応する子関節を求める。(手法はOpenPoseのPAFsと同じ)
この3次元メッシュモデル $\Psi$ を規定する body motion parameters $\theta$ 、global translation parameter $t$ 、shape coefficients $\phi$ を以下の最適化問題を解くことで求める。
\mathcal{F}^B (\theta, \phi, t) = \mathcal{F}^B_{2D}(\theta, \phi, t) + \mathcal{F}^B_{POF}(\theta, \phi) + \mathcal{F}^B_p(\theta)このうちまず $\mathcal{F}^B_{2D}$ は以下。
\mathcal{F}^B_{2D}( \theta, \phi, t) = \sum_m \| j^B_m - \prod(\tilde{J}^B_m ( \theta, \phi, t)) \|^2ここで $\tilde{J}^B_m$ はAdam のモデル、$\prod$ は3次元から2次元へのprojection。
また $\mathcal{F}^B_{POF}$ は以下。
\mathcal{F}^B_{POF} (\theta, \phi) = w^B_{POF} \sum_{(m,n) \in \mathbb{S}} 1 - \hat{P}^B_{(m,n)} \cdot \tilde{P}^B_{(m,n)} (\theta, \phi)ここで $\tilde{P}^B_{(m,n)}$ は Adam モデルにおける $P^B_{(m,n)}$ の単位ベクトル。
よって単位ベクトル同士の内積が1・・・・単位ベクトル同士が同じになるようにする。
また $\mathcal{F}^B_p(\theta)$ は以下。
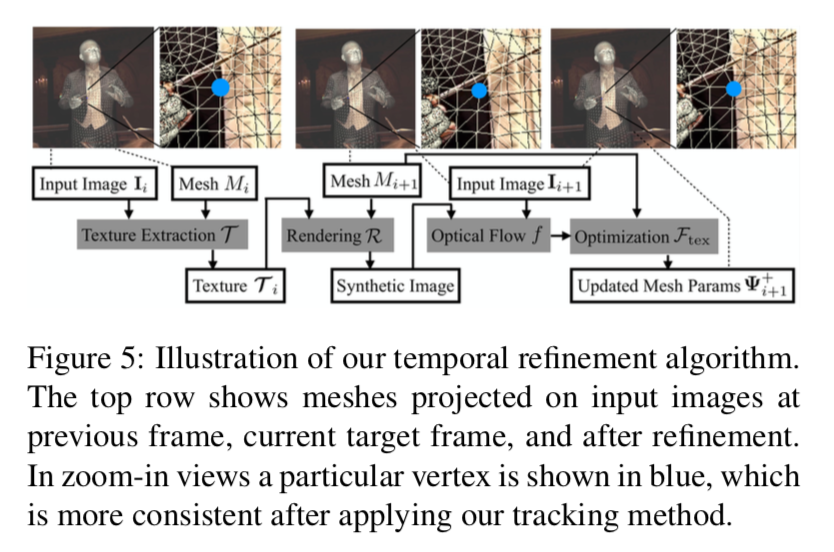
\mathcal{F}^B_p(\theta) = w^B_p \| A^B_{\theta} ( \theta - \mu^B_{\theta} )\|^2時系列処理による精度向上
以下が概要の図。
1)まず前の時刻 $i$ のメッシュ $M(\Psi_i)$ にはるテクスチャー $\mathcal{T}_i$ を入力画像 $I_i$ から求める。
\bf \mathcal{T} \rm _i = \mathcal{T} (I_i, M(\Psi_i))このテクスチャー $\mathcal{T}_i$ は現時刻 $t+1$ でも変わらないと考える。
そうすると、 このテクスチャーを現時刻のメッシュ $M_{i+1}$ にはりつけたものを画像へ投影したもの $\mathcal{R} ( M_{i+1}, \mathcal{T}_i)$ (以下synthetic imageという)との差分が存在する。よってこれらからオプティカルフローを求める。
f_{i+1} = f(\mathcal{R} (M_{i+1}, \mathcal{T}_i), I_{i+1})このオプティカルフロー関数に現時刻のメッシュ各頂点を投影したもの $v_n (i+1)$ を入力^し、求まった各頂点の投影座標と、現時刻のパラメータ $\Psi^{+}_{i+1}$ から求めた各頂点の投影座標との差を縮めるよう、パラメータを最適化する。
\mathcal{F}_{tex} (\Psi^{+}_{i+1}) = \sum_n \| v^{+}_n (i+1) - v^{'}_n (i+1) \|^2これはメッシュを画像 $(x,y)$ へ投影した上での頂点同士のロス。z軸方向が加味されてない。よって以下のロスも加える。
\mathcal{F}_{\Delta z} (\theta^{+}_{i+1}, \phi^{+}_{i+1}, t^{+}_{i+1}) = \sum_m (J_m^{+z} (i+1) - J_m^z (i))^2最終的に、トータルのロスは以下。
\mathcal{F}^{+} (\Psi^+_{i+1} ) = \mathcal{F}_{tex} + \mathcal{F}_{\Delta z} +\mathcal{F}_{POF} +\mathcal{F}^Freference
[2] H. Joo, T. Simon, and Y. Sheikh. Total capture: A 3d de- formation model for tracking faces, hands, and bodies. In CVPR, 2018.


- 投稿日:2019-05-07T13:53:59+09:00
KerasでAlexNetを構築しCifar-10を学習させてみた
タイトル通りKerasを用いてAlexNetを構築し,Cifar-10を用いて学習させてみます.やりつくされている感はありますが,私自身の勉強を兼ねてということで.
AlexNetとは
2012年のImageNetを用いた画像認識コンペILSVRCでチャンピオンに輝き,Deep Learningの火付け役となったモデルです.5つの畳み込み層,3つの全結合層などから構成されています.具体的な構成は以下の通りです.
Layer Kernel_size Filters Strides Padding Output_size Conv_1 (11, 11) 96 (4, 4) 0 (None, 55, 55, 96) Max_pool_1 (3, 3) - (2, 2) - (None, 27, 27, 96) Conv_2 (5, 5) 256 (1, 1) 2 (None, 27, 27, 256) Max_pool_2 (3, 3) - (2, 2) - (None, 13, 13, 256) Conv_3 (3, 3) 384 (1, 1) 1 (None, 13, 13, 384) Conv_4 (3, 3) 384 (1, 1) 1 (None, 13, 13, 384) Conv_5 (3, 3) 256 (1, 1) 1 (None, 13, 13, 256) Max_pool_5 (3, 3) - (2, 2) - (None, 6, 6, 256) FC_6 - - - - (None, 4096) FC_7 - - - - (None, 4096) FC_8 - - - - (None, 1000) AlexNetの構築
構築にあたりこちらの記事を参考にさせていただきました.ありがとうございました.
論文における入力は(224, 224, 3)となっていますが,1層目の畳み込み層の出力が合わないため,(227, 227, 3)としています.
また,LRNの代わりにBatchNormalizationを用いています.alexnet.pyimport keras from keras.models import Sequential from keras.layers import Dense, Dropout, Activation, Flatten from keras.layers import Conv2D, MaxPooling2D, BatchNormalization from keras.optimizers import SGD from keras.initializers import TruncatedNormal, Constant num_classes = 1000 image_size = 227 channel = 3 def conv2d(filters, kernel_size, strides=(1, 1), padding='same', bias_init=1, **kwargs): trunc = TruncatedNormal(mean=0.0, stddev=0.01) cnst = Constant(value=bias_init) return Conv2D( filters, kernel_size, strides=strides, padding=padding, activation='relu', kernel_initializer=trunc, bias_initializer=cnst, **kwargs ) def dense(units, activation='tanh'): trunc = TruncatedNormal(mean=0.0, stddev=0.01) cnst = Constant(value=1) return Dense( units, activation=activation, kernel_initializer=trunc, bias_initializer=cnst, ) def AlexNet(): model = Sequential() #conv1 model.add(conv2d(96, 11, strides=(4, 4), padding='valid', bias_init=0, input_shape=(image_size, image_size, channel))) #pool1 model.add(MaxPooling2D(pool_size=(3, 3), strides=(2,2))) model.add(BatchNormalization()) #conv2 model.add(conv2d(256, 5)) #pool2 model.add(MaxPooling2D(pool_size=(3, 3), strides=(2,2))) model.add(BatchNormalization()) #conv3 model.add(conv2d(384, 3, bias_init=0)) #conv4 model.add(conv2d(384, 3)) #conv5 model.add(conv2d(256, 3)) #pool5 model.add(MaxPooling2D(pool_size=(3, 3), strides=(2,2))) model.add(BatchNormalization()) #fc6 model.add(Flatten()) model.add(dense(4096)) model.add(Dropout(0.5)) #fc7 model.add(dense(4096)) model.add(Dropout(0.5)) #fc8 model.add(dense(num_classes, activation='softmax')) model.compile(optimizer=SGD(lr=0.01), loss='categorical_crossentropy', metrics=['accuracy']) return model model = AlexNet() model.summary()重みは平均0, 標準偏差0.01としたガウス分布で初期化,バイアスは2,4,5番目の畳み込み層及び全結合層は1で,それ以外の層は0で初期化したと論文に書かれており,上のコードにおけるtrunc, cnstがそれにあたります.その他に関しては,上の表と見比べていただければある程度理解できると思います.
出力は以下の通りです.
output_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_1 (Conv2D) (None, 55, 55, 96) 34944 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 27, 27, 96) 0 _________________________________________________________________ batch_normalization_1 (Batch (None, 27, 27, 96) 384 _________________________________________________________________ conv2d_2 (Conv2D) (None, 27, 27, 256) 614656 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 13, 13, 256) 0 _________________________________________________________________ batch_normalization_2 (Batch (None, 13, 13, 256) 1024 _________________________________________________________________ conv2d_3 (Conv2D) (None, 13, 13, 384) 885120 _________________________________________________________________ conv2d_4 (Conv2D) (None, 13, 13, 384) 1327488 _________________________________________________________________ conv2d_5 (Conv2D) (None, 13, 13, 256) 884992 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 6, 6, 256) 0 _________________________________________________________________ batch_normalization_3 (Batch (None, 6, 6, 256) 1024 _________________________________________________________________ flatten_1 (Flatten) (None, 9216) 0 _________________________________________________________________ dense_1 (Dense) (None, 4096) 37752832 _________________________________________________________________ dropout_1 (Dropout) (None, 4096) 0 _________________________________________________________________ dense_2 (Dense) (None, 4096) 16781312 _________________________________________________________________ dropout_2 (Dropout) (None, 4096) 0 _________________________________________________________________ dense_3 (Dense) (None, 1000) 4097000 ================================================================= Total params: 62,380,776 Trainable params: 62,379,560 Non-trainable params: 1,216 _________________________________________________________________Cifar-10の学習
画像の入力サイズが違う(Cifar-10は32x32)ため,モデルを少々変更します.変更に際してはこちらの記事を参考にさせていただきました.ありがとうございました.
構成は以下の通りです.赤字が変更箇所になります.
Layer Kernel_size Filters Strides Padding Output_size Conv_1 (3, 3) 96 (1, 1) 1 (None, 32, 32, 96) Max_pool_1 (2, 2) - (2, 2) - (None, 16, 16, 96) Conv_2 (5, 5) 256 (1, 1) 2 (None, 16, 16, 256) Max_pool_2 (2, 2) - (2, 2) - (None, 8, 8, 256) Conv_3 (3, 3) 384 (1, 1) 1 (None, 8, 8, 384) Conv_4 (3, 3) 384 (1, 1) 1 (None, 8, 8, 384) Conv_5 (3, 3) 256 (1, 1) 1 (None, 8, 8, 256) Max_pool_5 (2, 2) - (2, 2) - (None, 4, 4, 256) FC_6 - - - - (None, 4096) FC_7 - - - - (None, 4096) FC_8 - - - - (None, 10) 作成したものはこちらに置いておきます.
結果は以下のようになりました.val_accは最高で86%です.
おわりに
AlexNetにおけるCifar-10の精度は89%だそうです(参考).LRNやPCA Color Augmentationを使用することで精度向上できるのかな?気が向いたらやってみたいと思います.
参考論文
A. Krizhevsky, I. Sutskever, and G. E. Hinton : ImageNet Classification with Deep Convolutional Neural Networks, In Advances in Neural Information Processing Systems. [PDF]
- 投稿日:2019-05-07T11:01:07+09:00
Kerasでとりあえず動かしてみるTPUでのディープラーニング
はじめに
GPUが載ってないPCでディープラーニングをやってみたい、という人向けです。
今回は前回作成した数字の判定をTPUを使ってやってみます。
https://qiita.com/norikawamura/items/a5c3844e7555202c35a4#_reference-64514a0a96dfd9b1648e事前準備
ColaboratoryでハードウェアアクセラレータにTPUを選択します。
ColaboratoryでTPUを使用するには
結論としては以下の変更が必要なようです。(2019/5/7時点)
①「keras.~」でimportしていたパッケージを「tensorflow.keras.~」とtensorflowの物に変更する。(optimizerの指定等も含む)
②CPU/GPU向けで作成したモデルをTPU向けのモデルに変換する。
・環境情報を取得後、keras_to_tpu_model()で変換する。
③TPUモデルではpredict_classes()が使えないので、分類を行う場合は代わりにpredict()の結果の最大値をとる。
④TPUモデルではpredict()に渡すデータの件数が、TPUコア数(8)の倍数である必要がある。データの準備
前回と同様です。
import sklearn as skl from sklearn import datasets import pandas as pd dgt = skl.datasets.load_digits() digits_df = pd.DataFrame(dgt.data) target_df = pd.DataFrame(dgt.target) # 特徴量のセットを変数Xに、ターゲットを変数yに格納 X = digits_df.values y = target_df.values学習データと検証用データに分けます。
kerasの代わりにtensorflow.kerasに変更しています。
また、検証用データの数を8の倍数にしておきます。
※学習用データの数は8の倍数になっている必要はないようです。import numpy as np import tensorflow.keras as keras # データの順番を入れ替えるためのランダムなNumPy配列 np.random.seed(42) indices = np.random.permutation(len(X)) val_len = int(len(X) * -0.1) // 8 * 8 #TPUを使った場合のために8の倍数にする # 学習用のデータ。全体から100データを省いたもの X_train = X[indices[:val_len]] y_train = y[indices[:val_len]] # テスト用のデータ。全体から100データ取り出したもの X_test = X[indices[val_len:]] y_test = y[indices[val_len:]] # サンプル数、特徴量の次元、クラス数の取り出し (n_samples, n_features) = X_train.shape n_classes = len(np.unique(y)) # ターゲットyをkeras用の形式に変換 y_keras = keras.utils.to_categorical(y_train, n_classes)損失関数のグラフ表示
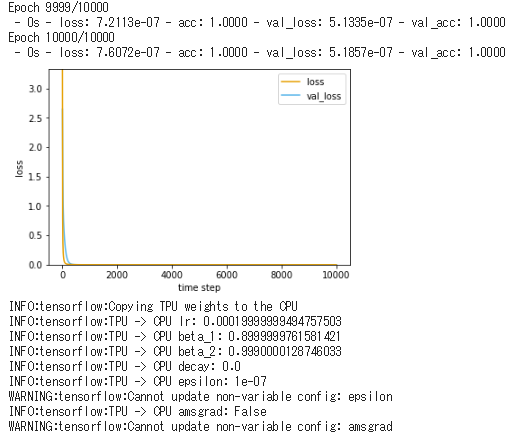
前回のものと同じです。
import matplotlib.pyplot as plt #損失関数グラフ def plotHistory(history): # 損失関数のグラフの軸ラベルを設定 plt.xlabel('time step') plt.ylabel('loss') # グラフ縦軸の範囲を0以上と定める plt.ylim(0, max(np.r_[history.history['val_loss'], history.history['loss']])) # 損失関数の時間変化を描画 val_loss, = plt.plot(history.history['val_loss'], c='#56B4E9') loss, = plt.plot(history.history['loss'], c='#E69F00') # グラフの凡例(はんれい)を追加 plt.legend([loss, val_loss], ['loss', 'val_loss']) # 描画したグラフを表示 plt.show()モデルの定義・学習
「#TPU」のコメントの下のkeras_to_tpu_model()を呼ぶまでの部分が、今回追加したTPU用にモデルを変換する部分です。
import os import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import BatchNormalization from tensorflow.keras.layers import Conv2D, MaxPooling2D from tensorflow.keras.layers import Flatten from tensorflow.keras.layers import Dense, Dropout from tensorflow.keras.optimizers import Adam from tensorflow.keras.callbacks import EarlyStopping X_train = X_train.reshape(-1, 8, 8, 1) X_test = X_test.reshape(-1, 8, 8, 1) savefile = 'keras_clf_skldigit_tpu.h5' useSavedModel = False if useSavedModel == False: # ニューラルネットワークを定義 model = Sequential() # ニューラルネットワークを定義 model = Sequential() # 中間層と入力層を定義 model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(8,8,1,))) model.add(Conv2D(64, (3, 3), activation='relu')) #model.add(MaxPooling2D(pool_size=(2, 2))) #model.add(BatchNormalization()) model.add(Conv2D(128, (3, 3), activation='relu')) model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(BatchNormalization()) # 出力層を定義 model.add(Dense(units=n_classes, activation='softmax')) # モデルのコンパイル model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.0002), metrics=['accuracy']) # TPU tpu_grpc_url = "grpc://"+os.environ["COLAB_TPU_ADDR"] tpu_cluster_resolver = tf.contrib.cluster_resolver.TPUClusterResolver(tpu_grpc_url) #strategy = keras_support.TPUDistributionStrategy(tpu_cluster_resolver) strategy = tf.contrib.tpu.TPUDistributionStrategy(tpu_cluster_resolver) model = tf.contrib.tpu.keras_to_tpu_model(model, strategy=strategy) # モデルの学習 early_stopping = EarlyStopping(monitor='val_loss', mode='min', patience=1000) plotHistory( model.fit( X_train ,y_keras ,epochs=10000 ,validation_split=0.1 ,batch_size=n_samples ,verbose=2 ,callbacks=[early_stopping] ) ) # 学習結果を保存 model.save(savefile) else: # 学習済ファイルを読み込んでmodelを作成 model = keras.models.load_model(savefile)
判定処理
TPUだとmodel.predict_classes()が使えないので、predict()の結果の最大値をnumpy.argmax()で取得して代用します。
y_test2 = y_test.reshape(-1) # 結果の表示 #result = model.predict_classes(X_test, verbose=0) y_result = model.predict(X_test, verbose=0) import numpy as np result = np.zeros(y_test2.shape, int) for idx, data in enumerate(y_result): result[idx] = int(np.argmax(data)) print('ターゲット') print(y_test2) print('ディープラーニングによる予測') print(result) # データ数をtotalに格納 total = len(result) # ターゲット(正解)と予測が一致した数をsuccessに格納 success = sum(result==y_test2) # 正解率をパーセント表示 print('正解率') print(100.0*success/total)
次回予定
未定です。