- 投稿日:2019-05-07T22:46:25+09:00
DashをGoogle App Engine(GAE)にデブロイする
この記事は、Deploying Dash to Google App Engine (© Jamie Phillips クリエイティブ・コモンズ・ライセンス(表示4.0 国際))を翻訳、一部改変して書いています。
Deploying Dash to Google App Engine
Flaskのデブロイする記事はちょこちょこ見るのですが、Dashの日本語記事がなかったため、自分の備忘用も兼ねて訳したものを残します。
開発環境は、Ubuntu 18.04.LTSです。
Step 1: 仮想環境の構築
$ cd ~ $ python3 -m venv .venvs/dash構築後、仮想環境に入ります。
$ source .venvs/dash/bin/activateStep 2: project folderのsetup
以下の様にフォルダ・ファイル構成にします。
フォルダ構成. ┗ dash-gcp ┣ app.yaml ┣ main.py ┗ requirements.txt※※ 次のStepで作成します。
コマンド$ mkdir dash-gcp $ cd dash-gcp $ touch app.yaml $ touch main.pyStep 3: Dashをインストール&requirements.txtの作成
公式に従ってDashをインストールします。('19/5/7)
$ pip install dash==0.42.0 $ pip install dash-daq==0.1.0Version 0.37.0以降は、dash-html-components等のインストール別途不要とのこと。
$ pip freeze > requirements.txt元記事では、「requirements.txtに "pkg-resources==0.0.0"が含まれてて、エラーになるから削除してね!」とあったが私の環境では含まれていなかった。
Step 4:Dash appのビルド
今回は、公式の以下サンプルと同じものをmain.pyに編集します。
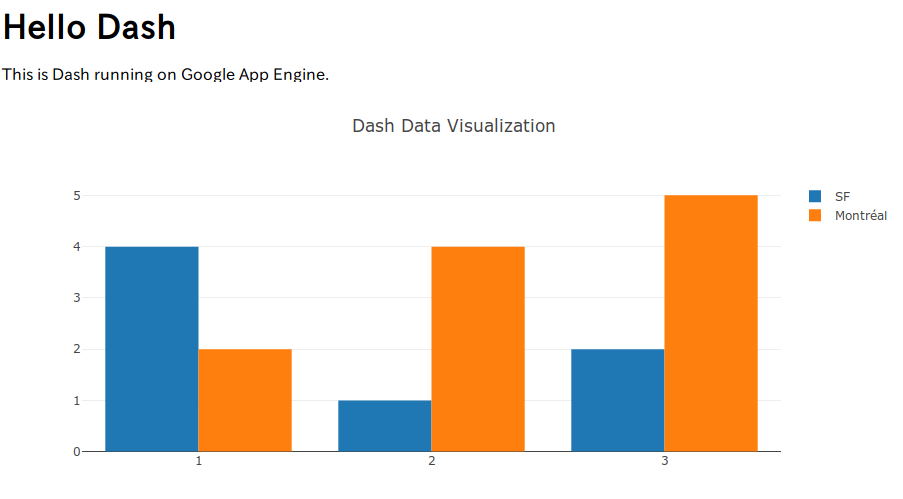
import dash import dash_core_components as dcc import dash_html_components as html dash_app = dash.Dash() app = dash_app.server dash_app.layout = html.Div(children=[ html.H1(children='Hello Dash'), html.Div(children=''' This is Dash running on Google App Engine. '''), dcc.Graph( id='example-graph', figure={ 'data': [ {'x': [1, 2, 3], 'y': [4, 1, 2], 'type': 'bar', 'name': 'SF'}, {'x': [1, 2, 3], 'y': [2, 4, 5], 'type': 'bar', 'name': u'Montreal'}, ], 'layout': { 'title': 'Dash Data Visualization' } } ) ]) if __name__ == '__main__': dash_app.run_server(debug=True)※ éはeに置き換えました。
保存したら、動作確認のためローカルで実行します。
$ python main.pyブラウザから、http://localhost:8050/にアクセスし正しく動作しているか確認します。
Step 5:app.yamlの編集
app.yamlを開いて、以下の様に編集します。
runtime: python37以上で準備が整ったので、次はいよいよデブロイです。
Step 6: Publishing to Google App Engine
デブロイにはGoogle Cloud SDKが必要なので、インストールしてない場合は、インストールします。
Let's deploy!
ロケーションとかは適当に好きなところを選んでください。$ gcloud app deploy You are creating an app for project [dash-gcp]. WARNING: Creating an App Engine application for a project is irreversible and the region cannot be changed. More information about regions is at <https://cloud.google.com/appengine/docs/locations>. Please choose the region where you want your App Engine application located: [1] asia-east2 (supports standard and flexible) [2] asia-northeast1 (supports standard and flexible) [3] asia-south1 (supports standard and flexible) [4] australia-southeast1 (supports standard and flexible) [5] europe-west (supports standard and flexible) [6] europe-west2 (supports standard and flexible) [7] europe-west3 (supports standard and flexible) [8] northamerica-northeast1 (supports standard and flexible) [9] southamerica-east1 (supports standard and flexible) [10] us-central (supports standard and flexible) [11] us-east1 (supports standard and flexible) [12] us-east4 (supports standard and flexible) [13] us-west2 (supports standard and flexible) [14] cancel Please enter your numeric choice: 11 Creating App Engine application in project [dash-gcp] and region [us-east1]....done. Services to deploy: descriptor: [~/code/dash-gcp/app.yaml] source: [~/code/dash-gcp] target project: [dash-gcp] target service: [default] target version: [20190223t141951] target url: [https://dash-gcp.appspot.com] Do you want to continue (Y/n)? Beginning deployment of service [default]... Created .gcloudignore file. See `gcloud topic gcloudignore` for details. ╔════════════════════════════════════════════════════════════╗ ╠═ Uploading 3 files to Google Cloud Storage ═╣ ╚════════════════════════════════════════════════════════════╝ File upload done. Updating service [default]...failed. ERROR: (gcloud.app.deploy) Error Response: [7] Access Not Configured. Cloud Build has not been used in project dash-gcp before or it is disabled. Enable it by visiting https://console.developers.google.com/apis/api/cloudbuild.googleapis.com/overview?project=dash-gcp then retry. If you enabled this API recently, wait a few minutes for the action to propagate to our systems and retry.元記事だと、上記の様に「おや?」っとErrorが出たそうです。ただ、私の環境では、以下の様なエラーが出ました。
Updating service [default]...failed. ERROR: (gcloud.app.deploy) Error Response: [7] Access Not Configured. Cloud Build has not been used in project denoleagc before or it is disabled. Enable it by visiting https://console.developers.google.com/apis/api/cloudbuild.googleapis.com/overview?project=denoleagc then retry. If you enabled this API recently, wait a few minutes for the action to propagate to our systems and retry.APIが有効になってないとのことですので、記載してあるURLにアクセスして有効化しました。
その後、再度実行すると、以下の様な感じで無事実行できました。
$ gcloud app deploy Services to deploy: descriptor: [~/code/dash-gcp/app.yaml] source: [~/code/dash-gcp] target project: [dash-gcp] target service: [default] target version: [20190223t142211] target url: [https://dash-gcp.appspot.com] Do you want to continue (Y/n)? Y Beginning deployment of service [default]... ╔════════════════════════════════════════════════════════════╗ ╠═ Uploading 0 files to Google Cloud Storage ═╣ ╚════════════════════════════════════════════════════════════╝ File upload done. Updating service [default]...done. Setting traffic split for service [default]...done. Deployed service [default] to [https://dash-gcp.appspot.com] You can stream logs from the command line by running: $ gcloud app logs tail -s default To view your application in the web browser run: $ gcloud app browseうまく動作していると以下のような画面が表示されます。
以上
最後まで読んでいただきありがとうございました。
- 投稿日:2019-05-07T22:40:52+09:00
Google ColaboratoryをGoogle DriveにマウントしてPythonを実行する。
Googleが無料提供している、オンラインJupyter Notebook環境、Google Colaboratory。
Colaboratory は、完全にクラウドで実行される Jupyter ノートブック環境です。設定不要で、無料でご利用になれます。
Colaboratory を使用すると、コードの記述と実行、解析の保存や共有、強力なコンピューティング リソースへのアクセスなどをブラウザからすべて無料で行えますGoogle Driveにマウントして、まるでGoogle DriveにUbuntuのシェルがついたように扱えるので便利です。
(´-`).。oO(表示が崩れていますが…)Pythonを実行して、実行結果のファイルなどをGoogle Driveに保存する使い方をよくしているので、知見をまとめました。(Python以外の言語も実行できます。)
1. ルールと使い方
完全無料で使えるGoogle Colaboratoryですが、俗に12時間ルールと90分ルールと呼ばれる使用上の制限があります。これはBitcoin採掘やBotなど、一般的なモラルに反した利用を制限するためのものです。下の、秒速Colabの記事がわかりやすいので参照してください。また、基本的な使い方も書いてあります。
【秒速で無料GPUを使う】TensorFow(Keras)/PyTorch/Chainer環境構築 on Colaboratory
2. Pythonのスクリプトを実行する方法
上記事を参照した上で
Google Driveのマウント
- Google Driveをマウントする
from google.colab import drive drive.mount('/content/drive')出力されるリンク先でGoogleアカウントにログインして、トークンをColabの入力を受け付けている部分にコピペしてください。Google Driveがマウントされます。
2. Google Drive上のフォルダに移動する%cd "drive/My Drive/(任意のフォルダ)"cdは
%を付けるあるいは付けません。lsなどは!でも%でも付けなくても動きます。これはJupyterのバックエンドであるIpython側の仕様が%lsmagicAvailable line magics:
%alias %alias_magic %autocall %automagic %autosave %bookmark %cat %cd %clear %colors %config %connect_info %cp %debug %dhist %dirs %doctest_mode %ed %edit %env %gui %hist %history %killbgscripts %ldir %less %lf %lk %ll %load %load_ext %loadpy %logoff %logon %logstart %logstate %logstop %ls %lsmagic %lx %macro %magic %man %matplotlib %mkdir %more %mv %notebook %page %pastebin %pdb %pdef %pdoc %pfile %pinfo %pinfo2 %pip %popd %pprint %precision %profile %prun %psearch %psource %pushd %pwd %pycat %pylab %qtconsole %quickref %recall %rehashx %reload_ext %rep %rerun %reset %reset_selective %rm %rmdir %run %save %sc %set_env %shell %store %sx %system %tb %time %timeit %unalias %unload_ext %who %who_ls %whos %xdel %xmodeAvailable cell magics:
%%! %%HTML %%SVG %%bash %%bigquery %%capture %%debug %%file %%html %%javascript %%js %%latex %%perl %%prun %%pypy %%python %%python2 %%python3 %%ruby %%script %%sh %%shell %%svg %%sx %%system %%time %%timeit %%writefileJupyter Notebookでマジックコマンド一覧を確認する%lsmagic | note.nkmk.me
Automagic is ON, % prefix IS NOT needed for line magics.なるmagicコマンドを用意しているのと、Colab特有の
!でBashシェルコマンドがあるためのようです。
cdが!で動かないのは!cdはサブプロセスでcdした結果が返り値になってるだけで今のプロセスには適用されてないためと考えられます。同じチームの、@2-propanolさんが記事を書いてくれました。
!lsは「結果の表示」が目的のコマンドなので、結果的にどちらでも動くと考えています。ですので、Bashシェルコマンドを使いたい場合は
!、cdを使う場合は%または何も付けないで実行という使い分けになると思います。Besides %cd, other available shell-like magic functions are %cat, %cp, %env, %ls, %man, %mkdir, %more, %mv, %pwd, %rm, and %rmdir, any of which can be used without the % sign if automagic is on.
Ubuntuのシェルが動いているため、
!apt-get install screenfetch!screenfetch
!apt-get install neofetch!neofetch
などできます。なお、12時間でランタイムがリセットされるため、次回にマウントしたときは、デフォルトでinstallされているパッケージ以外はinstallする必要があります。
Colabで.pyファイルを実行する
コードセルで
%run hogehoge.pyあるいは
!python hogehoge.pyをshift+Enterで実行できます。
3. 地味に使いにくい仕様
Google ColaboratoryとGoogle Driveが同期されるのに時間がかかるところ
例えば、Colaboratory側からフォルダをリムーブしても、Google Driveに反映されるのに約2分かかります。プログラムで連続してファイル/フォルダ操作する場合は注意が必要です。重複ファイルと見なされて、名前を勝手に変更される場合があります。
I/Oが弱いところ
画像ファイルなどデータセットが数千から数万ファイルになることはよくあることだと思うのですが、
drive.mount() が失敗して「タイムアウト」と表示されることがあるのはどうしてですか。また、drive.mount() でマウントしたフォルダでの I/O オペレーションが失敗することがあるのはどうしてですか。
Google ドライブのオペレーションは、フォルダ内のファイル数やサブフォルダ数が増えすぎるとタイムアウトすることがあります。数千件ものアイテムが最上位の「マイドライブ」フォルダの直下にあると、ドライブのマウント処理がタイムアウトする可能性が高くなります。マウントを繰り返し試みると最終的に成功することがあります。これは、タイムアウトするまで、失敗するたびに部分的な状態がローカルのキャッシュに保存されるためです。この問題が発生した場合は、「マイドライブ」の直下にあるファイルやフォルダをサブフォルダに移動してみてください。drive.mount() が正常終了した後で他のフォルダから読み取りを行うと、同様の問題が発生することがあります。多くのアイテムが含まれているフォルダ内のアイテムにアクセスすると、OSError: [Errno 5] Input/output error(python 3)または IOError: [Errno 5] Input/output error(python 2)のようなエラーが発生することがあります。この問題も同様に、直下にあるアイテムをサブフォルダに移動することで解決できます。
注: ファイルやサブフォルダをゴミ箱に移動して「削除」するだけでは、この問題を解決できないことがあります。この方法で解決できない場合は、ゴミ箱を空にしてください。といったI/Oのエラーがマウント時や、プログラム実行時に発生することがあります。数回実行すると成功するので、I/Oが弱いということを知っておく必要があります。
このリンクに定期的にゴミ箱を空にするGASがあるので参照してください。
マウント時のエラー
Enter your authorization code: ·········· --------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-2-3b8a479202a4> in <module>() ----> 1 drive.mount('/content/drive') /usr/local/lib/python3.6/dist-packages/google/colab/drive.py in mount(mountpoint, force_remount, timeout_ms) 178 ': timeout during initial read of root folder; for more info: ' 179 'https://research.google.com/colaboratory/faq.html#drive-timeout%27) --> 180 raise ValueError('mount failed' + extra_reason) 181 elif case == 2: 182 # Not already authorized, so do the authorization dance. ValueError: mount failed: timeout during initial read of root folder; for more info: https://research.google.com/colaboratory/faq.html#drive-timeoutファイルを読み取るプログラムを実行したときのエラー
OSError: [Errno 5] Input/output error:どちらのエラーも数回実行すると通ります。
長時間連続利用時のペナルティ
私は経験がないのですが、kaggler-jaの19/5/5のスレッドによると連続で毎日12時間ランタイムを利用すると、リソース不足による利用制限があるそうです。
(おまけ)19/04/29時点でのスペック
!nvidia-smiGPUが新しくなった(Tesla K80→Tesla T4)ので、秒速Colabの記事から変わった部分だけ書いておきます。(19/4/29)
```Mon Apr 29 01:01:43 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 418.56 Driver Version: 410.79 CUDA Version: 10.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 73C P0 32W / 70W | 0MiB / 15079MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
```このような出力があり、Tesla T4 というGPUが現在利用できることがわかります。
!cat /etc/issueUbuntu 18.04.2 LTS \n \l
!df -hFilesystem Size Used Avail Use% Mounted on overlay 359G 25G 316G 8% / tmpfs 6.4G 0 6.4G 0% /dev tmpfs 6.4G 0 6.4G 0% /sys/fs/cgroup tmpfs 6.4G 12K 6.4G 1% /var/colab /dev/sda1 365G 29G 337G 8% /opt/bin shm 6.0G 4.0K 6.0G 1% /dev/shm tmpfs 6.4G 0 6.4G 0% /sys/firmware drive 15G 13G 2.6G 83% /content/drive!free -htotal used free shared buff/cache available Mem: 12G 520M 9.3G 916K 3.0G 11G Swap: 0B 0B 0B!cat /proc/cpuinfoprocessor : 0 vendor_id : GenuineIntel cpu family : 6 model : 79 model name : Intel(R) Xeon(R) CPU @ 2.20GHz stepping : 0 microcode : 0x1 cpu MHz : 2200.000 cache size : 56320 KB physical id : 0 siblings : 2 core id : 0 cpu cores : 1 apicid : 0 initial apicid : 0 fpu : yes fpu_exception : yes cpuid level : 13 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc cpuid tsc_known_freq pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single pti ssbd ibrs ibpb stibp fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm rdseed adx smap xsaveopt arat arch_capabilities bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf bogomips : 4400.00 clflush size : 64 cache_alignment : 64 address sizes : 46 bits physical, 48 bits virtual power management:processor : 1 vendor_id : GenuineIntel cpu family : 6 model : 79 model name : Intel(R) Xeon(R) CPU @ 2.20GHz stepping : 0 microcode : 0x1 cpu MHz : 2200.000 cache size : 56320 KB physical id : 0 siblings : 2 core id : 0 cpu cores : 1 apicid : 1 initial apicid : 1 fpu : yes fpu_exception : yes cpuid level : 13 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc cpuid tsc_known_freq pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single pti ssbd ibrs ibpb stibp fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm rdseed adx smap xsaveopt arat arch_capabilities bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf bogomips : 4400.00 clflush size : 64 cache_alignment : 64 address sizes : 46 bits physical, 48 bits virtual power management:!cat /proc/driver/nvidia/gpus/0000:00:04.0/informationModel: Tesla T4 IRQ: 11 GPU UUID: GPU-d674dfb0-17a0-1298-4f54-da7ee0624fb3 Video BIOS: 90.04.21.00.01 Bus Type: PCI DMA Size: 47 bits DMA Mask: 0x7fffffffffff Bus Location: 0000:00:04.0 Device Minor: 0 Blacklisted: No



- 投稿日:2019-05-07T22:36:46+09:00
線形代数を学ぶ理由
はじめに
少し前(2019年4月頃)に、「AI人材」という言葉がニュースを賑わせていました。「現在流行っているディープラーニングその他を使いこなせる人材」くらいの意味だと思いますが、こういうバズワードの例の漏れず、人によって意味が異なるようです。併せて「AI人材のために線形代数の教育をどうするか」ということも話題になっています。
線形代数という学問は、本来は極めて広く、かつ強力な分野ですが、とりあえずは「行列とベクトルの性質を調べる学問」と思っておけば良いです。理工系の大学生は、まず基礎解析とともに線形代数を学ぶと思います。そして、何に使うのかわからないまま「固有値」や「行列式」などの概念が出てきて、例えば試験で3行3列の行列の固有値、固有ベクトルを求め、4行4列の行列の行列式を求めたりしてイヤになって、そのまま身につかずに卒業してしまい、後で必要になって後悔する人が出てきたりします(例えば私)。
線形代数は重要な学問ですから、それを学ぶこと、強化すること自体は喜ぶべきことです。しかし、若い人がニュースなどを見て「線形代数はAIに必要だから重要」とか思ってしまうのは困ります。それでは「僕はAIをやらつもりないから線形代数いらない」という人が出てきてしまいます。
言うまでもありませんが、線形代数はAIに必要だから重要なのではありません。そもそも重要とか必要とかいうレベルではなく、誤解を恐れずにいえば「理工系の学問のほぼ全ての領域にわたってほぼ必須」と言ってよい学問です。線形代数が関わる分野は膨大で、その全てをサーベイすることは私には不可能です。とりあえず本稿では、主に数値計算において「なぜ線形代数が重要であるか」を紹介したいと思います。
本稿は、大学の一年生ないし二年生で、線形代数を学んでいる or 学んだけど、何に使うかわからないので学ぶモチベーションがぼんやりしている、という学生さんを対象に書きます。以下、(特に用語の使い方において)かなりいい加減な書き方をするので、「線形代数が重要なのは当然だろ」と思っている人とか、数学ガチ勢な皆さんとかはブラウザの「戻る」ボタンを押してください。
用語の整理
まず、ざっと線形代数の用語の定義をしておきましょう。以下のような2行2列の行列を考えます。
A = \begin{pmatrix} 5/4 & 3/4 \\ 3/4 & 5/4 \end{pmatrix}固有値と固有ベクトル
$$
A v = \lambda v
$$のように、ある行列$A$にベクトル$v$をかけた結果$A v$が、入力ベクトルの定数倍$\lambda v$になった時、$v$を$A$の固有ベクトル、$\lambda$を固有値と呼ぶのでした。
先程の行列の固有ベクトルはそれぞれこんな感じになります。
v_1 = \frac{1}{\sqrt{2}} \begin{pmatrix} 1 \\ 1 \end{pmatrix}v_2 = \frac{1}{\sqrt{2}} \begin{pmatrix} 1 \\ -1 \end{pmatrix}固有値はそれぞれ2と1/2です。
\begin{align} A v_1 &= 2 v_1 \\ A v_2 &= \frac{1}{2} v_2 \end{align}二つのベクトル$x,y$から一つのスカラー値を作る写像$(x,y)$を内積と呼びます1。内積は、「あるベクトル$x$からあるベクトル$y$へ射影したときの長さ」、すなわち「あるベクトル$x$に、あるベクトル$y$の成分がどれくらい含まれるか」を表現するものです。内積が0の場合は、「このベクトル$x$はベクトル$y$の成分を全く含まない」ことを意味します。これを直交しているといいます。先程の二つの固有ベクトルはお互いに直交しています。直交しているからには平行ではありえません。お互いに平行ではないベクトルは線形独立であるといいます(直交性は必ずしも線形独立性の条件ではありません)。空間次元と同じ数だけ線形独立なベクトルの集合を持ってくれば、空間の任意のベクトルをそのベクトルの線形和で表現できるのでした。このようなベクトルを空間の基底と呼びます。
基底が、「自分自身との内積は1、それ以外の基底との内積が0」を満たす場合、その基底の集合を正規直交基底と呼びます。
基底の線形和で任意のベクトルを表現できるのでした。例えば、あるベクトル$a$を先程の基底で表現してみましょう。
a = c_1 v_1 + c_2 v_2基底$v_1, v_2$が正規直交基底である場合、両辺$v_1$や$v_2$との内積を取るだけで、係数$c_1$や$c_2$が求まるのでした。
\begin{align} (v_1,a) &= c_1 (v_1,v_1) + c_2 (v_1 , v_2)\\ &= c_1 \end{align}ここで、$(v_1 , v_1 )= 1$、$(v_1 , v_2) = 0$を使っています。
この行列や固有値の意味を考えてみましょう。この行列$A$は、$v_1$の方向に2倍に引き伸ばし、$v_2$の方向に半分に縮めるような変換になっています。
この図を見ると、「時計回りに45度傾けたような座標で考えた方が楽そうだな」と気づくと思います。従って、例えば何kのベクトルに$A$を何度もかける必要がある場合、一度世界を回して固有ベクトルの張る空間にして、そのあと演算してから、また元に戻した方が計算が楽です。
行列式
行列$A$は、「ある方向に2倍に引き伸ばし、その方向と直交する方向に半分に縮める」という変換を引き起こすことから「$A$をかけるという変換が図形の形を変えても、面積は変えないだろう」という予想がつきます。実際に計算してみましょう。
ベクトル${}^t(1,0)$と${}^t(0,1)$とで表現された単位正方形が、行列$A$でどのような図形に移されるか見てみましょう。それぞれ$A$をかけると、${}^t(5/4,3/4)$と${}^t(3/4,5/4)$になります。二つのベクトル${}^t(a_1,a_2)$と${}^t(b_1,b_2)$で張られる四角形の面積は$|a_1 b_2 - b_1 a_2|$で計算されるのでした。これは行列$A$の行列式$|A|$にほかなりません。実際に計算してみると、$A$の行列式は1になります。
$$
|A| = \frac{5}{4} \times \frac{5}{4}
- \frac{3}{4} \times \frac{3}{4} = 1
$$これは、$A$による変換により、図形の面積が変化しないことを意味しています。
フーリエ・ラプラス解析
物理とは世の中を記述する学問ですが、世の中は「支配方程式」と呼ばれる微分方程式で記述されています。したがって、何か世の中を記述、理解したいと思えば、微分方程式を解く必要が出てきます。しかし、微分方程式は、一般に線形でなければ解くことができません。この線形(偏)微分方程式をフーリエ変換、もしくはラプラス変換で解けるようになる、というのが理工系の大学における数学の一つのハイライトとなります。「微分・積分」は「解析学」に属す概念でありながら、フーリエ変換やラプラス変換は線形代数における基底の変換になっている、と理解することがポイントです。
先程、二つのベクトルからスカラーを作る写像として内積を定義しました。同様に二つの関数$f, g$の間にも、以下のようにして内積が定義できます。
$$
(f,g) \equiv \int_{-\infty}^{\infty} f^* g dx
$$ここで$f^*$は$f$の複素共役ですが、とりあえずは気にしなくて大丈夫です。フーリエ変換では、$\exp{(ikx)}$という「基底」で関数を展開するのでした。ある関数$f(x)$のフーリエ変換$\hat{f}(k)$を求めるのに、関数$f$と$\exp{(ikx)}$との内積、
\begin{align} \hat{f}(k) &= (f, \exp{(ikx)}) \\ &= \int_{-\infty}^{\infty} f^* g dx \end{align}を計算しているのを思い出しましょう。これは、$f(x)$という関数を様々な波数$k$を持つ基底関数で展開した時の、ある特定の$k$を持つ基底関数$\exp{(ikx)}$の係数を計算したことになります。つまりこれは、ある空間から$\exp{(ikx)}$という形の基底関数が張る空間への変換になっています。
ではなぜ$\exp{(ikx)}$という基底で展開するのでしょうか。それは指数関数が微分演算子の固有関数だからです。$\exp{(ikx)}$を$x$で微分しても$ik$が出てくるだけで、またもとの関数に戻ります。微分演算子を$A$、関数$\exp{(ikx)}$を$v_{ik}$と表現すると、
$$
A v_{ik} = ik v_{ik}
$$となり、先程の2行2列の行列の場合と全く同様に扱えることがわかるでしょう。ラプラス変換も同様です。
このように、線形(偏)微分方程式がフーリエ・ラプラス変換で簡単に解けるのは、「指数関数が微分演算子の固有関数である」「固有関数で展開してしまえば計算が楽になる」という事実を利用しています。さらにいえば、これが「平面波展開」になっていることを授業で学ぶはずです。
ここで、演算子がもっとややこしい形をしていても、固有関数で展開してしまえば計算が楽になるだろう、と予想がつくでしょう。極座標の計算はかなり面倒ですが、球面調和関数を使えば計算が楽になります。これは球面調和関数が極座標のラプラシアンの固有関数になっているからです。エルミート多項式やルジャンドル多項式もまったく同様に理解できます。
数値計算
線形代数は様々な分野に顔を出しますが、数値計算でも極めて重要な役割を果たします。既に述べたように、この世界は微分方程式で記述されており、ほとんどの場合において厳密に解くことができません。そこで、数値的に近似解を求めることになりますが、その際に方程式を離散化することで数値的に扱えるようにします。すると、微分方程式という連続な世界から、自然に行列やベクトルが出てきます。スパコンのランキングで有名なTop500では、非常に大きな連立一次方程式を解きます。これは、ベンチマークとしてよい性質を持っている、ということもありますが、そもそも数値計算において馬鹿でかい連立一次方程式を解くというニーズがあるからベンチマークとして選ばれているという側面もあります。以下では、微分方程式を離散化すると、線形代数が顔を出す様子を見てみましょう。
熱伝導方程式
まず、簡単な例として熱伝導方程式を考えましょう。一次元ならこんな方程式です。
$$
\frac{\partial T}{\partial t} = \frac{\partial^2 T}{\partial x^2}
$$ここで、$T(x;t)$は、時刻$t$における位置$x$の温度です。周期境界条件をとるので、輪になっている針金の温度を表現していると思ってください。簡単のため、熱伝導率を1としています。さて、この方程式はフーリエ変換で厳密に解けますが、差分化して数値的に解くことにします。空間方向は刻み幅1で、時間方向は時間刻み$h$で離散化しましょう。$t=0$を$0$ステップ目とすると、$n$ステップ目、$i$番目の位置の温度を$v_n^i$で表現します。先ほどの微分方程式を、空間方向は中央差分、時間方向は一次のオイラー法で差分化すると、
$$
v^i_{n+1} = v^i_n + h (v_n^{i-1} - 2 v_n^i + v_n^{i+1})
$$と書き換えられます。初期条件として$v_i^0$が与えられれば、上記の式に従って$v_i^1, v_i^2, \cdots ,v_i^n$と、任意の時刻、場所の温度が求められることになります。これを素直にコードに実装してみましょう。空間を$N$分割し、周期境界条件を課して、初期条件として山型の温度分布を与えます。適当な時間刻みで時間発展させ、途中の温度を重ねてプロットするPythonコードはこんな感じになるでしょう2。
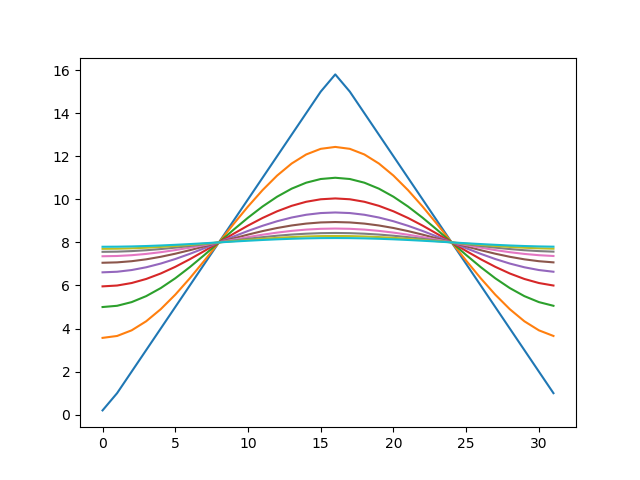
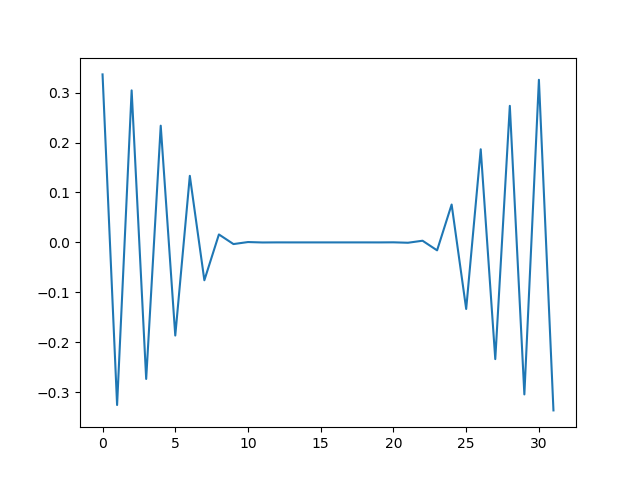
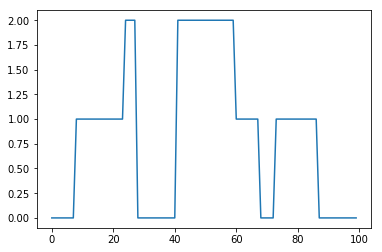
import copy import matplotlib import matplotlib.pyplot as plt import numpy as np def calc(v, h): v2 = copy.copy(v) N = len(v) for i in range(N): i1 = (i+1) % N i2 = (i - 1 + N) % N v[i] = v2[i] + (v2[i1] - 2.0*v2[i] + v2[i2])*h N = 32 v = np.array([min(x, N-x) for x in range(N)], dtype='float64') h = 0.1 r = [] for i in range(1000): calc(v, h) if (i % 100) == 0: r.append(copy.copy(v)) for s in r: plt.plot(s)上記をJupyter NotebookかGoogle Colabで実行すれば、以下のような出力が得られます。
初期条件として山型の温度分布を与えたのが、だんだんとなまっていき、最終的に直線、すなわち一様な温度分布になったことがわかります。
さて、先ほどの離散化した式ですが、以下のような行列とベクトルの積の成分を表示したものと思うことができます。
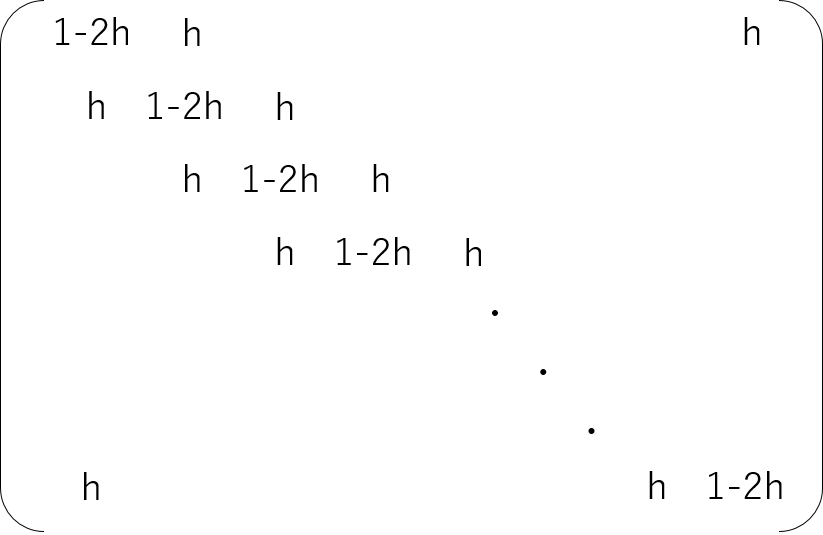
\vec{v}_{n+1} = A \vec{v}_nただし、$A$は以下のような形をした$N$行$N$列の行列です。
対角成分が$1-2h$、その両隣が$h$となる三重対角行列になっていますが、周期境界条件の影響で、上端と下端だけ$h$の場所がずれています。
もともと時間発展は微分方程式で記述されていましたが、離散化により状態がベクトルで表現され、そのベクトルに行列をかけると次のステップの状態が得られる、という行列とベクトルの問題に帰着されました。離散化により自然に線形代数が出てきたのがわかるかと思います。
この、「現在の温度分布を表すベクトルに行列をかけると次のステップの温度分布が出てくる」という計算を素直にコードに落とすとこんな感じになるでしょう。後で使うので
scipyからlinalgをインポートしてあります。import copy import matplotlib import matplotlib.pyplot as plt from scipy import linalg import numpy as np N = 32 h = 0.1 v = np.array([min(x, N-x) for x in range(N)], dtype='float64') A = np.zeros((N, N)) # 行列Aを作る for i in range(N): i1 = (i + 1) % N i2 = (i - 1 + N) % N A[i][i] = 1.0 - 2.0*h A[i][i1] = h A[i][i2] = h r = [] for i in range(1000): v = A.dot(v) # Aをかけると次のステップの状態が得られる if (i % 100) == 0: r.append(copy.copy(v)) for s in r: plt.plot(s)実行すると先ほどと同じ結果が得られます。
さて、せっかく時間発展を表現する行列が得られたので、その行列の性質と時間発展の関係を見てみましょう。
この行列$A$の$i$番目の固有値と、対応する固有ベクトルをそれぞれ$\lambda_i$と$\vec{e}_i$で表現しましょう。
ここで、固有値は絶対値の大きい順に並んでいるものとします。すなわち$\lambda_1 \geq \lambda_2 \geq \cdots \geq \lambda_N$です。
まず、初期条件を表すベクトルを$\vec{v}_0$としましょう。これを行列$A$の固有ベクトルの線形結合で以下のように表現できたとします。
\vec{v}_0 = c_1 \vec{e}_1 + c_2 \vec{e}_2 + \cdots c_N \vec{e}_NこれにAをかけてみましょう。
A \vec{e}_i = \lambda_i \vec{e}_iですから、
\vec{v}_1 = A \vec{v}_0 = c_1 \lambda_1 \vec{e}_1 + c_2 \lambda_2 \vec{e}_2 + \cdots c_N \lambda_N \vec{e}_Nとなります。
$A$を$n$回かけるとこんな感じです。
\vec{v}_n = c_1 \lambda_1^n \vec{e}_1 + c_2 \lambda_2^n \vec{e}_2 + \cdots c_N \lambda_N^n \vec{e}_Nここで、行列$A$の最大固有値を求めてみましょう。PythonならSciPyを使えばあっという間です。
w, v = linalg.eigh(A, eigvals=(N-1,N-1)) print(w) #=> [1.]1.0が出てきました。すなわち、この行列の最大固有値は1です。
linalg.eigh(A, eigvals=(N-2,N-2))とすると、二番目に大きな固有値を得ることができますが、その値は$0.99615706$です。つまり、最大固有値が$\lambda_1 = 1$で、それ以外はすべて真に1より小さい、つまり$\lambda_i < 1 \quad (i\neq 1)$が成り立ちます。従って、何度も$A$をかけると、最大固有値に対応するベクトル以外の成分は消えます。\lim_{n \rightarrow \infty} A^n \vec{v}_0 = c_1 \vec{e}_1先ほど得られた固有ベクトルも見てみましょう。
w, v = linalg.eigh(A, eigvals=(N-1,N-1)) print(v)[[-0.1767767] [-0.1767767] [-0.1767767] [-0.1767767] [-0.1767767] (snip) [-0.1767767] [-0.1767767]]全て同じ値($-1/\sqrt{32}$)になっています。つまり、一様な温度ということです。このベクトルと、初期条件ベクトルの内積をとれば、係数$c_1$が求まり、すぐに定常状態$c_1 \vec{e}_1$が求まることになります。
熱伝導方程式を離散化すると、状態がベクトルに、時間発展は行列をかけることに対応し、時間発展行列の最大固有状態が定常状態に対応することがわかったかと思います。
シュレーディンガー方程式
カリキュラムによりますが、理工系の大学ならどこかで量子力学を学ぶことになるでしょう。時間非依存・一体・一次元のシュレーディンガー方程式は以下のように書けます。
$$
\left(
\frac{-\hbar^2}{2m} \frac{d^2 }{d x^2} + V(x)
\right) \psi(x) = E \psi(x)
$$ここで、$\hbar$はプランク定数、$m$は質量、$V(x)$はポテンシャル、$\psi(x)$が波動関数です。例えば$V$として井戸型ポテンシャルを取ると、閉じ込めによりエネルギーが少し上がること、井戸の外に波動関数が少ししみ出すことなど、量子力学特有の不思議な現象が起きます。量子力学において重要なのは、一番エネルギーの低い基底状態と呼ばれる状態です。この方程式を離散化し、数値的に解くことで基底状態を求めてみましょう。面倒なので$\hbar^2/2m$を$1$とする単位系を取りましょう。系を離散化し、波動関数$\psi(x)$をベクトル$\vec{v}$で表現します。先程のシュレーディンガー方程式を、熱伝導方程式と同様に離散化すると
$$
-v_{i+1} + 2 v_i - v_{i-1} + V_i v_i = E v_i
$$となります。ただし、$V_i$は、$V(x)$を離散化した時の$i$番目の要素です。これは、行列とベクトルで書くこともできます。
$$
H \vec{v} = E \vec{v}
$$ただし、$H$は以下のような要素を持つ行列です。
こうして、シュレーディンガー方程式を離散化することで、行列の固有値問題に落ちました。これを解くと波動関数が求まります。早速基底状態を求めてみましょう。Pythonを使えば楽勝です。世の中を32分割し、井戸型ポテンシャルの深さ$d$は$5$くらいにして、8から16まで$-d$、それ以外は0という形にしましょう。たとえばこんなスクリプトになるでしょう。
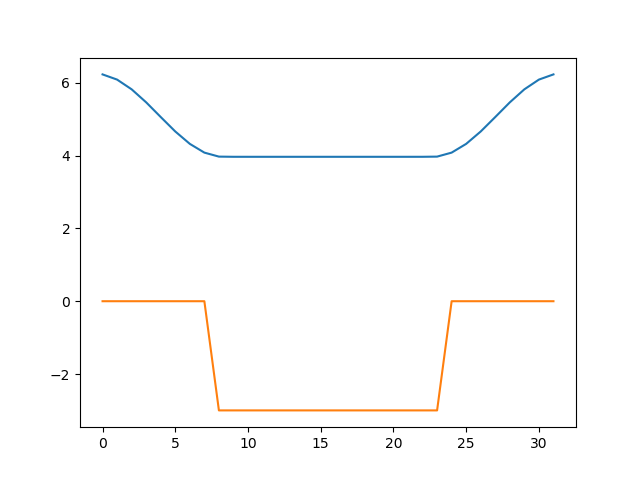
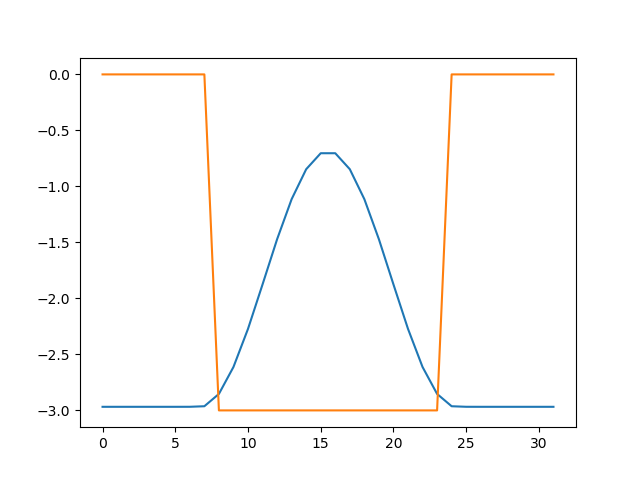
import matplotlib.pyplot as plt from scipy import linalg import numpy as np N = 32 A = np.zeros((N, N)) d = 5.0 V = np.array([-d if i in range(N//4, 3*N//4) else 0 for i in range(N)]) for i in range(N): i1 = (i + 1) % N i2 = (i - 1 + N) % N A[i][i] = 2.0 + V[i] A[i][i1] = -1 A[i][i2] = -1 w, v = linalg.eigh(A) v = v.transpose() i0 = np.argmax(abs(w)) v0 = np.power(v, 2)[i0] plt.plot(v0*20+w[i0]) print(w[i0]) plt.plot(V)これは、先程の行列の絶対値最大固有値と対応する固有ベクトルを求め、絶対値最大固有値を表示し、固有ベクトル(波動関数)をポテンシャル関数とともにプロットするスクリプトになっています。
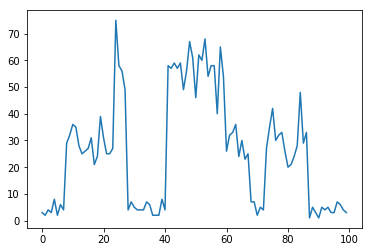
実行すると、固有値
-4.9672674197348705の他に、以下のような図が出力されると思います。
ポテンシャルの形がオレンジで、波動関数の二乗が青で描いてあります。波動関数は20倍に誇張してあります。井戸の中に電子が閉じ込められており、少し井戸の外側に染み出していること、固有エネルギーが、ポテンシャルの底(-5.0)よりも、若干高い(-4.97)ことがわかります。このように、ポテンシャルに閉じ込められた状態を束縛状態といいます。
さて、ここまでは楽勝でした。では、ポテンシャルの底を少し浅くしてみましょう。どうなるでしょうか?先程のスクリプトを$d=3$にして再度実行してみます。
何かおかしなことになりました。固有値も負ではなく、正の値(3.967956931783471)になっています。波動関数の二乗ではなく、生の波動関数を表示してみましょう。
基底状態では節が無いはずの波動関数がばたついています。実はこれは、束縛されていない、自由な電子の状態を拾っています。もともとのシュレーディンガー方程式において、井戸の中の状態は離散化され、エネルギーは飛び飛びの値をとります。しかし、ある程度以上のエネルギーを持つ電子は井戸に束縛されておらず、自由に飛び回ることができます。この時のエネルギー準位は連続値を取りますが、離散化によりこちらも飛び飛びの値になります。井戸の中に束縛された電子のエネルギー準位が離散的なのはもともとの方程式の特性ですが、井戸に束縛されていない電子のエネルギー準位が離散的になるのは、方程式を離散化した影響、いわばフェイクです3。
これを解決するには、絶対値最大ではなく、最小の固有値を拾ってくればOKです。
# i0 = np.argmax(abs(w)) ↓以下に修正 i0 = np.argmin(w)
正しい基底状態を拾うことができました。
ここではすべての固有状態を求めているため、「最初から最小の固有値と対応する固有状態を求めれば良いじゃないか」と思うかもしれません。しかし、一般の問題では全部の固有値を求めるのは計算が重すぎるため、一部の固有値だけを求めるということがよく行われます4。その際、もっとも簡単な方法が、絶対値最大の固有値と固有状態を求める累乗法(Power Method)と呼ばれる方法です。この方法は簡単ですが、ナイーブな方法では絶対値最大の固有値と固有状態しか求められないため、上記のような状態で「最小の固有値と対応する固有状態」を求めたい時には工夫が必要になります。
一般に、何か方程式を離散化して解く時、多くの場合においてそのままライブラリに放り込めば解けます。しかし、状況によっては変なことが起きることがあります。その時に「何が起きたか」「何が原因か」「正しい解を得るにはどうすればよいか」を考えるためには、量子力学だけでなく、線形代数の知識も必要となります。ここでは固有値問題の題材として量子力学を取り上げましたが、応用面において固有値問題が頻出するのは有限要素法でしょう。建物の構造解析や、材料の強度のチェックなど、産業応用で有限要素法は欠かせません。有限要素法を扱うためのライブラリやアプリケーションは多数存在します。しかし、有限要素法における前処理や、反復解法の性質を知らないと収束が遅くなったり、おかしなことが起きても気づかない、なんてことがおきます。そのためにも線形代数の知識は必須です。
運動方程式
先の二つの例では空間を離散化することで行列やベクトルが出てきましたが、今回は時間の離散化を見るために運動方程式を考えてみます。
以下のようなハミルトニアンを考えます。
$$
H = p^2/2 + q^2/2
$$$p$が一般化運動量、$q$が一般化座標で、これは調和振動子を記述するハミルトニアンです。ハミルトンの運動方程式は以下のように書けます。
\begin{align} \dot{p} &= -q \\ \dot{q} &= p \end{align}これは、以下のように行列の形でも書けます。
\frac{d}{dt} \begin{pmatrix} p \\ q \end{pmatrix} = \begin{pmatrix} 0 & -1 \\ 1 & 0 \end{pmatrix} \begin{pmatrix} p \\ q \end{pmatrix} = L \begin{pmatrix} p \\ q \end{pmatrix}ただし、$L$は
L= \begin{pmatrix} 0 & -1 \\ 1 & 0 \end{pmatrix}です。この方程式を形式的に解くと
\begin{pmatrix} p(t) \\ q(t) \end{pmatrix} = \exp{(tL)} \begin{pmatrix} p(0) \\ q(0) \end{pmatrix}ここで、
\exp{(tL)} = I + tL + \frac{t^2 L^2}{2!} + \cdots + \frac{t^n L^n}{n!} + \cdotsです。一般には指数関数の肩に行列が乗ったものは厳密に計算できませんが、今回は計算できます。
\exp{(tL)} = \begin{pmatrix} \cos t & \sin t \\ -\sin t & \cos t \end{pmatrix}つまり、これは原点を中心として時計回りの回転になります。さて、この厳密解を知らないものとして、時間発展を離散化してみましょう。以下、時間刻みを$h$とし、時刻$t$から$t+h$の状態を求めることを繰り返すことで時間発展させることにします。
最も簡単なのは一次のオイラー法です。それはこんな式で書けます。
\begin{align} p(t+h) &= p(t) - h q(t) \\ q(t+h) &= q(t) + h p(t) \\ \end{align}行列表示するとこうなります。
\begin{pmatrix} p(t+h) \\ q(t+h) \end{pmatrix} = \begin{pmatrix} 1 & -h \\ h & 1 \end{pmatrix} \begin{pmatrix} p \\ q \end{pmatrix} \equiv \tilde{U}_E \begin{pmatrix} p \\ q \end{pmatrix}これは、厳密解を$t$に関して一次までテイラー展開していることに対応していることがわかります。しかし、この方法で計算すると、どんどんエネルギーが増えて行きます。
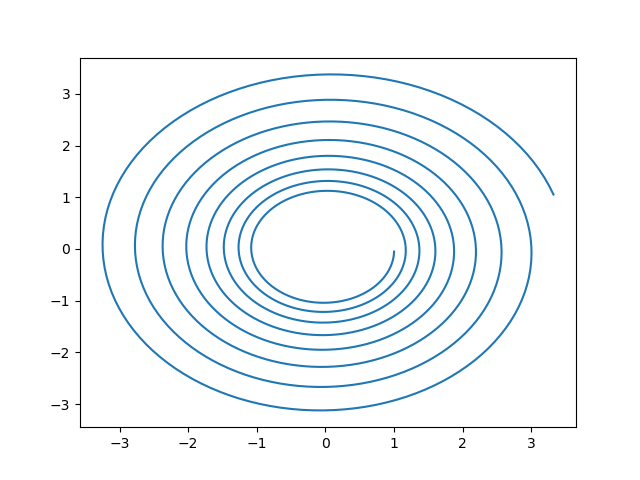
import matplotlib.pyplot as plt vq = [] vp = [] h = 0.05 q = 1.0 p = 0.0 for i in range(1000): (tp, tq) = (p, q) (p, q) = (tp - h * tq, tq + h * tp) vp.append(p) vq.append(q) plt.plot(vq, vp)
本来、円を描くはずの軌道が螺旋を描きながらエネルギー(半径)が大きくなっています。
なぜエネルギーが大きくなるかというと、時間発展を記述する行列$\tilde{U}_E$の行列式が$1$より大きいからです。実際に行列式を計算してみると、
$$
|\tilde{U}_E| = 1 + h^2 > 1
$$と1より大きいため、この行列が引き起こす写像が、面積を増加させていることがわかります。面積が増える、すなわち空間を引き伸ばしているので、エネルギーも単調に増えていきます。
次に、運動方程式を離散化する際によく行われるシンプレクティック積分を試してみましょう。一次のシンプレクティック積分は以下のようにかけます。
\begin{align} p(t+h) &= p(t) - h q(t) \\ q(t+h) &= q(t) + h p(t+h) \\ \end{align}次のステップの$q$を計算する際、すでに更新した$p$を使うのがポイントです。計算してみましょう。
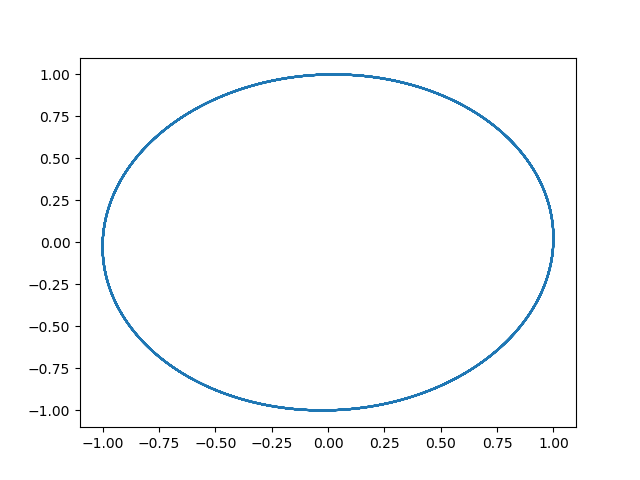
import matplotlib.pyplot as plt vq = [] vp = [] h = 0.05 q = 1.0 p = 0.0 for i in range(1000): p = p - h * q q = q + h * p vp.append(p) vq.append(q) plt.plot(vq, vp)
軌道が閉じて円になり、エネルギーが発散しなくなりました。先程の方程式を行列表示してみましょう。
\begin{pmatrix} p(t+h) \\ q(t+h) \end{pmatrix} = \begin{pmatrix} 1 & -h \\ h & 1 - h^2 \end{pmatrix} \begin{pmatrix} p \\ q \end{pmatrix} \equiv \tilde{U}_S \begin{pmatrix} p \\ q \end{pmatrix}全体としてのテイラー展開の精度は1次ですが、一つだけ二次まで展開されています。時間発展を記述する行列$\tilde{U}_S$の行列式は
$$
|\tilde{U}_S| = 1 - h^2 + h^2 = 1
$$と、厳密に1になっています。軌道は厳密解からずれているものの、近似された時間発展演算子(を記述する行列)は、変換の前後で面積要素を厳密に保存します。これがシンプレクティック積分の特徴です。この性質により、エネルギーが厳密な値から揺らぐものの、一方的に増加もしくは減少しないため、安定に長時間積分できます。
今回は調和振動子を扱ったので、時間発展演算子が行列で表現できましたが、一般には非線形になるために行列では表現できません。しかし、時間発展演算子が空間の面積(体積)を保存するかどうかは、時間発展のヤコビ行列式が1になるかどうかで判断できます。このように、運動方程式の数値積分という分野にも線形代数が顔を出すことがわかります。
シンプレクティック積分に興味がある方は解析力学の幾何学的側面シリーズを参照してください。
線形安定性解析
線形偏微分方程式は解くことができますが、非線形の微分方程式は一般には解くことができません。でも、その微分方程式で記述された系の性質を調べたい場合があります。そのような時に使うのが線形安定性解析です。
車が渋滞する状況を記述する、最適速度模型(Optimal Velocity Model)という模型があります。サーキットの中を$N$台の車が同じ方向に進んでいる状況を考えます。$n$番目の車の位置と速度を$x_n$、$v_n$とすると、最適速度模型は以下のような微分方程式で記述されます。
\begin{align} \dot{v_n} &= a \left(V(x_{n+1}-x_n) - v_n \right) \\ \dot{x_n} &= v_n \end{align}ただし$V(x)$は、最適速度関数と呼ばれる関数で、以下のように定義されます。
$$
V(x) = \tanh(x-2) - \tanh(2)
$$この模型は、「自分の前の車を見て、車間距離から決まる最適速度に合わせてアクセルやブレーキを踏む」というドライバーの振る舞いをモデル化したもので、パラメータによってスムーズに流れたり、渋滞ができたりします。詳しくは紹介記事を書いたのでそちらを参照してください。
さて、この方程式は非線形であり、厳密解を得ることは困難です。しかし、「全員が等間隔に並び、その車間距離で決まる最適速度で走っている状況」が、この方程式の解であることがわかります。
いま、サーキットの全長を$L$としましょう。$N$台の車が等間隔に並ぶと、車間距離は$b \equiv L/N$です。この車間距離での最適速度は$\bar{v} = V(b)$です。各車が車間距離$b$だけあけて、それぞれ最適速度$\bar{v}$ぴったりで走っている時は、$\dot{v}_n = 0$、すなわち速度変化がなく、一定速度で走っている状態になります。全員が同じ速度で走っているので車間距離も変化せず、同じ車間距離を保ったまま回り続けます。この解を一様流解といいます。一様流解は以下のような式で表現できます。
\begin{align} v_n &= \bar{v} \\ x_n &= \bar{v}t + bn \end{align}さて、一様流解の状態で、誰かがブレーキもしくはアクセルを踏んだとしましょう。その「乱れ」は増幅されるでしょうか?それとも時間とともに消えていくでしょうか?それを調べるのが線形安定性解析です。
一様流解の状態から、それぞれ速度が$\delta v_n$、位置が$\delta x_n$だけずれた状態を考えましょう。ずれが小さいと思うと、
$$
U(x_{n+1} - x_n) \sim U(b) + U'(b) (\delta x_{n+1} - \delta x_{n})
$$と展開できます。すると、運動方程式が、$\delta v_n$と$\delta x_n$に関する連立微分方程式、
\begin{align} \dot{\delta v_n} &= a U'(b) (\delta x_{n+1} - \delta x_{n}) - \delta v_n\\ \dot{\delta x_n} &= \delta v_n \end{align}と書けます。$\delta v_n$と$\delta x_n$の時間微分が$\delta v_n$と$\delta x_n$の線形結合でかけていますから、これは方程式が線形化されたことを意味します。
したがって、$\delta v_n$と$\delta x_n$を並べたベクトル$\vec{z}$に関する時間発展だと思うと、適当な行列$L$を用いて
$$
\frac{d \vec{z}}{dt} = L \vec{z}
$$と書くことができます。この方程式の安定性は、$L$の最大固有値の実部で決まります。これはフーリエ級数により求めることができて、$N$が十分大きい時の線形安定条件
$$
a > 2 V'(b)
$$が得られます。
まとめ
本稿では、主に数値計算における線形代数の有用性を紹介するため、熱伝導方程式、シュレーディンガー方程式、ハミルトンの運動方程式、そして最適速度模型を取り上げました。線形代数の有用性というか、要するに微分方程式をなんかしようと思うと、ほぼ間違いなく線形代数が顔を出すということがなんとなくわかっていただけたかと思います。
私はAIの専門家ではないので確かなことは言えませんし、「AI人材」というのが何を意味するのか私にはわかりません。線形代数があやふやでも、TensorFlowやChainerといったフレームワークを使って成果を出すことはできるでしょう。ただ、「AI人材」というのを「とりあえずフレームワークを使える人材」もしくは「必要に応じて計算の定義に立ち返って検証したり、新たなフレームワークを構築できる人材」と定義するならば、個人的には学生さんは後者を目指して欲しいな、という気がしています。
しつこいですが線形代数は広範な範囲にまたがって活躍する重要な学問です。ここで挙げた例以外にも様々な分野で出てきます(例えばCGとか)。線形代数には、ここで紹介した用語(主に固有値や固有ベクトル)の他にも「行列のランク」「対角和(トレース)」「正則性」など、初学者にとっては「計算方法や定義はわかったけど、それってなんの役に立つのさ?」という用語が多数出てきます。もちろん重要だからそういう用語が定義されるのですが、それらの紹介をする前に執筆者が力尽きました。他の方による記事の投稿を待つことにします。
後で関数の内積を使いたいのでカッコを使っていますが、内積とベクトルの表記がごっちゃになっていますね。まぁ文脈でわかると思うのでこのままにします。 ↩
シンプルに書くために非効率的に書いています。 ↩
実際には空間を有限に限定していることにより自由電子の準位も離散化されますが、今回のケースでは離散化による影響の方が大きいです。 ↩
そもそも波動関数のベクトルを数本メモリに格納するのがやっとで、ハミルトニアンをまるごと保持するのは不可能であるような大きい問題を解くことも多いです。その場合はハミルトニアンの全対角化はかなり厳しくなります。 ↩
すみません、この記事でちゃんと線形安定性解析をやろうと思ったのですが、ここで力尽きました。 ↩




- 投稿日:2019-05-07T22:36:28+09:00
QuantXでボリンジャーバンドのアルゴリズムを改良してみる
QuantXに初挑戦!
自己紹介
理系大学で、統計を専攻しています。
pythonは初心者で、金融に関してはファイナンスを少しかじってました。
SmartTradeでインターンをすることになりました、よろしくお願いします!!開発に慣れるためにも、QuantXを使ってアルゴリズムを一つ作ってみました。qiita初投稿としてまとめてみました。
目標
QuantXに慣れる、一つアルゴリズムを作ってみる。
作りたいアルゴリズム
ボリンジャーバンドの特徴を活かしてトレードします。
スクイーズではσバンドで逆張りのシグナル
エクスパンションのときは順張りのシグナル
この2点を踏まえて、順張りと逆張りを切り替えるアルゴリズムを作っていきます。完成コード
完成したコードはこちら
解説
重要な部分だけ少し解説してみます。
1.使用する関数の作成
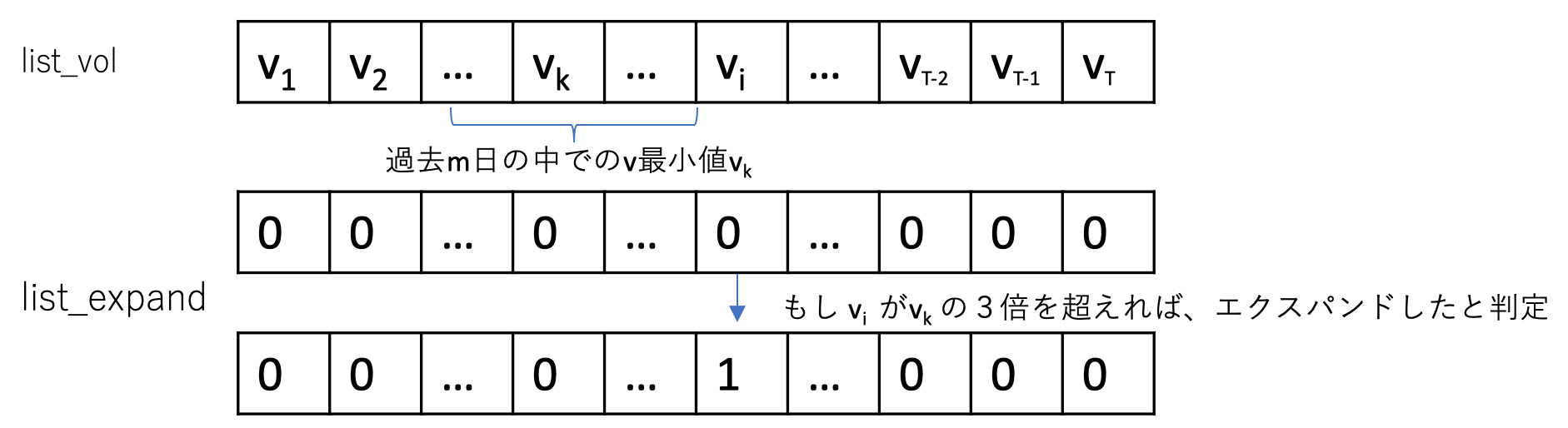
エクスパンドを判定してフラグを立てる関数 #6~#16
def judge_expand(ar_upperband,ar_lowerband,m): ar_volatility = ar_upperband - ar_lowerband list_vol = ar_volatility.tolist() list_expand = [0]*len(list_vol) for i in range(m,len(list_vol)): if list_vol[i] > 3*min(list_vol[i-m:i]): list_expand[i]=1 return np.array(list_expand)引数に配列
ar_upperband、ar_lowerband、整数mをとります。
ar_upperband、ar_lowerbandにはボリンジャーバンドの上と下の値が格納されています。ボリンジャーバンドの幅はその差であり、ar_volatilityに格納し、.tolist()でリストlist_volに直します。
また、エクスパンドしているかどうかの状態を0/1で格納するリストlist_expandをlist_volと同じ長さで値は全て0で用意しておきます。今回はエクスパンドしている状態を、「過去m日のボリンジャーバンドの幅の最小値の3倍をその日のボリンジャーバンドの幅が越えればエキスパンド している」、と定義します。
list_expandへの数字の格納の仕方は下図のようになります。
最後に
list_expandを配列に直して返します。バンドをはみ出したかを判定してフラグを立てる関数 #18~#26
#バンドの上をはみ出したかどうか判定する関数 def judge_plus_sigma(sr_upperband,sr_price): ar_a = np.greater(sr_price,sr_upperband) return ar_a.astype(int) #バンドの下をはみ出したかどうか判定する関数 def judge_minus_sigma(sr_lowerband,sr_price): ar_a = np.less(sr_price,sr_lowerband) return ar_a.astype(int)引数はpandasのseriesである
sr_upperband(sr_lowerband)、sr_priceをとります。sr_upperband(sr_lowerband)はボリンジャーバンドの上(下)の値、sr_priceは終値が格納されています。
ボリンジャーバンドの上(下)の値を、終値が超えたら(下回ったら)、trueをar_aに格納します。最後にtrueを1に直して返します。2.フラグをシグナルに変換する部分 #85~#88
df_ag_buy_sig[sym] = df_minus_sigma[sym] - df_minus_sigma[sym]*df_expand[sym] df_ag_sell_sig[sym] = df_plus_sigma[sym] - df_plus_sigma[sym]*df_expand[sym] df_fol_buy_sig[sym] = df_plus_sigma[sym]*df_expand[sym] df_fol_sell_sig[sym] = df_minus_sigma[sym]*df_expand[sym]ここでは株価が立てたフラグを、シグナルに変換していきます。
df_が付いているのは、全てindexが日付、columnsが銘柄のpandas.Dataframeです。
df_minus_sigma: 終値がボリンジャーバンドの下を下回っていたら1、そうでなければ0、が入っているdf_plus_sigma: 終値がボリンジャーバンドの上を超えていたら1、そうでなければ0、が入っているdf_expand: エクスパンドしたら1、そうでなければ0、が入っているこの3つは上で用意した関数を使って格納しています。
また、以下のデータフレームに
df_ag_buy_sig: 逆張りで買いのシグナルdf_ag_sell_sig:逆張りで売りのシグナルdf_fol_buy_sig:順張りで買いのシグナルdf_fol_sell_sig:順張りで売りのシグナルを格納していきます。
上3つのフラグのデータフレームから下4つのシグナルのデータフレームへの変換は、コードの式を使えば変換できます。
真偽値表のようなものを見るとわかりやすいでしょうか...
左3つを、右4つに変換します。
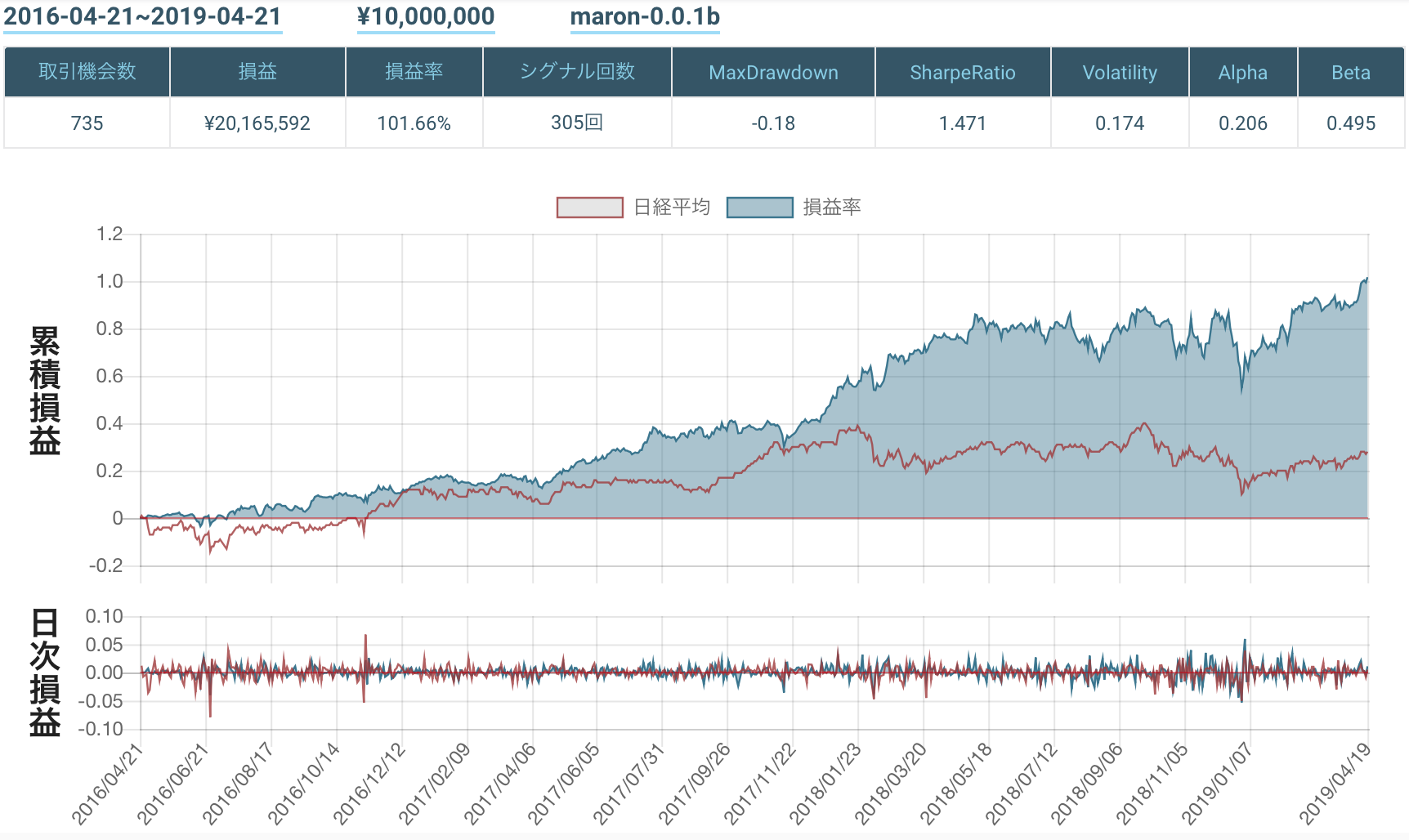
超える 下回る エクスパンド 逆張り買い 逆張り売り 順張り買い 順張り売り 1 0 0 0 1 0 0 1 0 0 0 0 1 0 0 1 0 1 0 0 0 0 1 1 0 0 0 1 結果
markdownは大きく、αも小さい...
初アルゴということで許してください笑個別
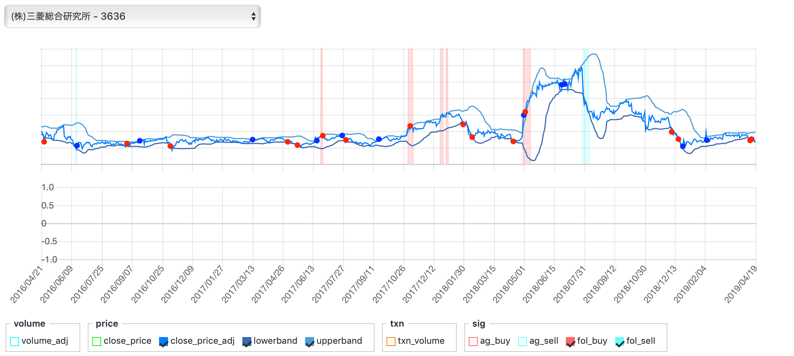
一つの銘柄に注目してみると...
三菱総研
順張りのシグナルを表示してみましたが、思い通りに動いていそうですね!
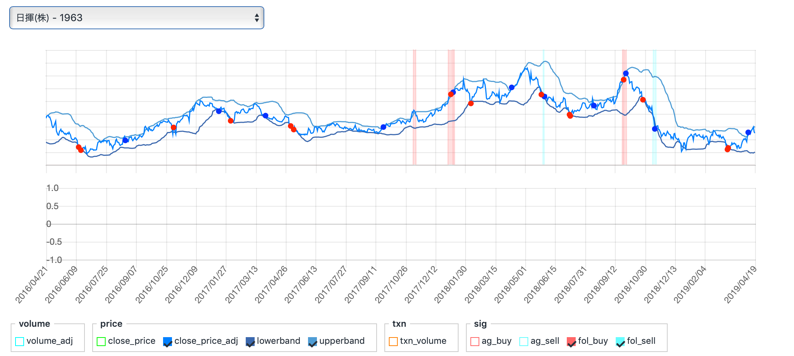
日揮
これは、シグナルがエクスパンド後に出てしまっています、判定の関数のパラメータを変える必要がありそうです。
最後に
とりあえず初アルゴリズムはこれくらいで...
このアルゴリズムのブラッシュアップや、他のアルゴリズムの作成など、どんどん行っていきたいと思います!勉強会の宣伝
SmartTrade社では毎週水曜日18:00から勉強会を行っています。(https://python-algo.connpass.com/)
免責注意事項
このコードや知識を使った実際の取引で生じた損益に関しては一切の責任を負いかねますので御了承下さい
- 投稿日:2019-05-07T22:32:25+09:00
Jupyter Notebook における「%run hoge.py」と「!python hoge.py」の違い
TL;DR:
%runだと.pyでやったことを覚えてるけど、!pythonだと覚えてない検証
runOrPython.ipynb - Colaboratory
hoge.pyhoge = 256piyo.pypiyo = 512test.ipynbprint(hoge) # -> NameError %run hoge.py print(hoge) # -> 256 print(piyo) # -> NameError !python piyo.py print(piyo) # -> NameError参考
- 投稿日:2019-05-07T22:32:25+09:00
IPython における「%run hoge.py」と「!python hoge.py」の違い
TL;DR:
%runでは.py中の名前空間が取り込まれる。!pythonはそうならない。経緯
Google Calaboratory (クラウド型 Jupyter Notebook環境)で.pyファイルの実行方法に
%run hoge.py!python hoge.pyの2種類があり、どちらでも実行できてしまう。
両者に違いがあるのかないのかハッキリさせたい。検証
hoge.pyhoge = 256piyo.pypiyo = 512test.ipynbprint(hoge) # -> NameError %run hoge.py print(hoge) # -> 256 print(piyo) # -> NameError !python piyo.py print(piyo) # -> NameError結果:
%runでは名前空間が取り込まれたが、!pythonはそうならない。Google Colaboratoryで実験する
→ runPyFile.ipynb - Colaboratoryなぜ?
IPython公式ドキュメントの IPython as a system shell の節には
Since each command passed by IPython to the underlying system is executed in a subshell which exits immediately, you can NOT use !cd to navigate the filesystem.
と書かれている。
(
!で始める)シェルコマンドはサブシェルで実行されてすぐに破棄される、よって!cdではカレントディレクトリは変更されない。(意訳)つまり、
!pythonではpythonがサブシェルで実行されるため名前空間が共有されることはない。対して、Built-in magic commands の節には
%runについてThis is similar to running at a system prompt
python file args, but with the advantage of giving you IPython’s tracebacks, and of loading all variables into your interactive namespace for further use (unless -p is used, see below).と書かれている。
シェルで
python [.pyファイル] -引数...とやるのに似てるけど、トレースバックと名前空間のロードが付いてきてお得。(意訳)つまり、
%runでは.pyファイルで用意した変数が次のセル以降でも維持される。
逆に%run実行以前に定義していた変数は%runの実行で上書きされる。
(-pオプションの挙動と変数の上書きは runPyFile.ipynb - Colaboratory でも実験できる)結局
%run: .pyの中身をセルに展開して実行したみたいな挙動
!python: .pyの中身をセルに展開せず実行したみたいな挙動
- 投稿日:2019-05-07T22:19:37+09:00
Pythonで文字列操作(分割と連結)
はじめに
テーブル作成支援ツールのPython移植 #9へのコメントにていろいろテクニックをご教示頂いた。
が、自身のPython知識レベルが低くて思考についていけない部分があった。
まだまだ「Python的」な感覚に疎いので、基本的なところを確認する。実装
text = "index number\titem name\tdata" print( text ) splitText = text.split('\t') print( splitText ) joinText = '/'.join( splitText ) print( joinText )結果
index number item name data ['index number', 'item name', 'data'] index number/item name/data
text.split('\t')はイメージ通りだが、'/'.join( splitText )は.前と引数が逆な感じがして気持ち悪い。。。
検索したらこの話題で議論している人たちがいたので、仲間が居てホッとした(笑とは言っても正しくは
'/'.join( splitText )である以上は慣れるしかないので
違和感が消えるて自然に使えるように頑張ろう
- 投稿日:2019-05-07T22:03:50+09:00
pythonのマングリングについて
pythonにはprivate変数はありません。
しかしprivate変数に近いことは
実現できます。「_」1つのprefix
PEP8上のコーディング規約としては
「_」1つのprefixをclass内のみで利用する変数とされています。この変数は
from M import *とした場合、
importされません。しかし、この変数は
インスタンス化したオブジェクトからのアクセス時には
物理的な機構はなくカプセル化としての役目は果たせません。「__」2つのprefix
「__」2つのprefixをつけた場合、
ネームマングリング機構が働きます。Name Manglingとは名前修飾という意味で、
該当のprefixが付いている変数にはpythonコード上で意味が与えられます。該当の変数名は「_class名」のprefixがついた変数名へと
置換されます。ただし、これもあくまで変数名が置換されるために
通常のような、インスタンスからの変数名へのアクセスが
できなくなるだけです。
通常よりは硬い実装にはなりますね。あくまで変数名が変わっているだけなので
置換後の変数名へのアクセスは許します。本来、ネームマングリング機構は
親クラスと子クラス間での名前衝突を避ける目的の為のもののようです。
(__init__や、__main__などのメソッドの所属元クラスをはっきりさせる)class HogeHoge: _dummy_prv = "hoge" __almost_prv = "hoge" class Main: hogehoge = HogeHoge() # 丸見え a = hogehoge._dummy_prv # エラー b = hogehoge.__almost_prv # こうすると見えちゃう c = hogehoge._HogeHoge__almost_prv参考
- 投稿日:2019-05-07T22:03:50+09:00
pythonのカプセル化とマングリングについて
pythonにはprivate変数はありません。
しかしprivate変数に近いことは実現できます。
「_」1つのprefix
PEP8上のコーディング規約としては
「_」1つのprefixをclass内のみで利用する変数とされています。この変数は
from M import *とした場合、
importされません。しかし、この変数は
インスタンス化したオブジェクトからのアクセス時には
物理的な機構はなくカプセル化としての役目は果たせません。「__」2つのprefix
「__」2つのprefixをつけた場合、
ネームマングリング機構が働きます。Name Manglingとは名前修飾という意味で、
該当のprefixが付いている変数にはpythonコード上で意味が与えられます。該当の変数名は「_class名」のprefixがついた変数名へと
置換されます。ただし、これもあくまで変数名が置換されるために
通常のような、インスタンスからの変数名へのアクセスが
できなくなるだけです。
通常よりは硬い実装にはなりますね。あくまで変数名が変わっているだけなので
置換後の変数名へのアクセスは許します。本来、ネームマングリング機構は
親クラスと子クラス間での名前衝突を避ける目的の為のもののようです。
(__init__や、__main__などのメソッドの所属元クラスをはっきりさせる)class HogeHoge: _dummy_prv = "hoge" __almost_prv = "hoge" class Main: hogehoge = HogeHoge() # 丸見え a = hogehoge._dummy_prv # エラー b = hogehoge.__almost_prv # こうすると見えちゃう c = hogehoge._HogeHoge__almost_prv参考
- 投稿日:2019-05-07T22:01:58+09:00
ディープラーニングガジェット品評会のネタ
ディープラーニングガジェット品評会で発表するネタをまとめておきます。
私は、handtracking↓を使った複数のネタを発表する予定です。
ネタ1 夢を叶えるインターフェイス
詳しくはこちら
続報は作成中...ネタ2 作業時間の自動計測装置
作成中...


- 投稿日:2019-05-07T22:01:22+09:00
夢を叶えるインターフェイス
無駄に未来感があるインターフェイスを作ってみました。
※こちらはディープラーニングガジェット品評会のネタです。
やりたかったこと
- 映画「マイノリティリポート」に出てくる格好いいやつを作りたかった
- タッチパネルが使えない状況(手が汚れている等)でも使用可能なインターフェイスを作りたかった
結果
まずは、結果をご覧ください。
キャプチャ範囲の設定(両手を使います。)
キャプチャ画像の移動・拡大
環境
- Raspberry Pi 3
- USB camera
- NCS2
実はクソアプリ
このアプリ、実は全く使い物に立ちません。その理由は以下のとおりです。
- もっと便利な商品がある
- ハード代が高価(3万円弱)
- 使うと腕が疲れる
アルゴリズム
アルゴリズムは簡単です。
まず、handtracking-OpenVINOを使って、手を検出します。
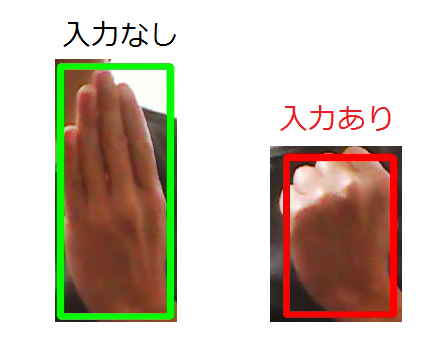
そして、検出した手が閉じていると、「入力あり」と見なしています。
手の開閉は、手の検出枠(バウンディングボックス)の「縦横比」で判定しています。
縦長(手が開いている)であれば「入力なし」、それ以外であれば「入力あり」と判定しています。ただ、縦横比をはっきりさせるために、親指を曲げて手を開いています。
お釈迦様のような手にしないといけません。また、手のひらをカメラに向けると、手が二つあるように認識してしまい、
うまく判定ができません。
従って、手の甲をカメラに向けています。
改善に向けて
今のところ、完成度が低いため、コードは公開しませんが、改善できたら
公開しようと思います。少しでもクソアプリから脱却すべく、以下の項目を改善したいです。
手の認識
前述したように、手の動作に制約があります。
制約を無くすためには、DOCやTripletLossを使うと、高速にかつ正確に
手の開閉を認識できるようになります。親指を曲げて手を開く必要もないですし、手の甲を見せる必要もなくなるでしょう。
価格について
現状はハード代が高価です。
ハードをJetson Nanoに代えると、価格を一万円強に抑えることができます。
スピードは未知数ですが、10FPSくらいにはなると思います。最後に
handtrackingは、元々普通のPCで動くように開発されたものです。(CPUで10FPS)
従って、元のリポジトリを改造すれば、普通のPCでもこのアプリを動かすことができます。
やってみたいという方がいましたら、チャレンジしてみてください!

- 投稿日:2019-05-07T21:51:00+09:00
Python3 初心者 反復処理その他
zip()を使った複数のシーケンスの処理
シーケンスとは
シーケンスはリストやタプルなどの並んでいる順番で処理をするもののこと
では実際にzip()を使ったものを使ってみます。これから示す例は班行動で何をするのか、何を昼ごはんに食べるのかというものです。
moths=['number 1', 'number 2', 'number 3'] doings=['play baseball', 'go shopping', 'buy cakes'] lunchs=['sushi', 'ramen', 'udon'] for moth, doing, lunch in zip(moths, doings, lunchs): print('Your moth is', moth, 'You do', doing, 'You eat', lunch) Your moth is number 1 You do play baseball You eat sushi Your moth is number 2 You do go shopping You eat ramen Your moth is number 3 You do buy cakes You eat udonまあfor文はシーケンスに入っている要素の''をなくすようなものだと思ってください!!
range()による数値シーケンスの作成
range()を使うことによって値をコンパクトな形でストリームを返すことができる。rangeはrange(最初の数、 指定した数の一つ低い値)まあ説明したほうが早いですね!笑笑
for x in range(0, 5): print(x) 0 1 2 3 4って感じになります!!
内包表記
リスト内包表記
リストといえば
list=[1, 2, 3, 4]とかが普通ですが、内包表記ではリストの中に反復処理などを入れるような感じですね!!
number=[num for num in range(0, 6)] number [0, 1, 2, 3, 4, 5]のようにリストの中に条件を書いたりすることが可能になります。これだとコードが短く済んで処理が早くなりますしみやすくもなります!!
[表示したい結果 for 結果 in どのようなものか]だいたいこんな感じです笑笑。まあやってみるのが一番わかりやすいと思います!!これから使うコードは「オライリージャパンさんの入門python3」をみてやっていきます。下の方にリンクを貼っておきますのでわかりやすい参考書なのでぜひ読んでみてください!!
rows=range(1, 4) cols=range(1, 3) cells=[(row, col) for row in rows for col in cols] for cell in cells: print(cell) (1, 1) (1, 2) (2, 1) (2, 2) (3, 1) (3, 2)このコードは考えてみると簡単でrowsには(1, 2, 3),colsには(1, 2)が入っている。そしてrowとcolをタプル化しています。このようにしてタプルのアンパックを使えばタプルからrow、colを引き抜くことが可能になる。
for row, col in cells: print(row, col) 1 1 1 2 2 1 2 2 3 1 3 2辞書包括表記
文字列を辞書化していく。今からやるものは文字列の文字を数えるものである
word='letters' letters_counts={letter: word.count(letter) for letter in word) letters_counts {'l': 1, 'e': 2, 't': 2, 'r': 1, 's': 1}これは確かに間違っていないことはないが、もっと早く処理する方法がある。この場合だと全てのwordが出てきてその数を数える形になっているが、in wordのところをin set(word)にすることによって一つ一つの値を確認して行なっている一つ目のコードよりも楽になる。
集合内包表記
これはif文とかも使えることができる。
numbers={number for number in range(1, 6) if number%2==0} numbers {2, 4}オライリージャパン入門python3
https://www.oreilly.co.jp/books/9784873117386/
- 投稿日:2019-05-07T20:52:28+09:00
Djangoのページネーション実装でページあたりのコンテンツ数を変更できるように
はじめに
Djangoでページネーションの実装を行う必要があった。
その際、ページあたりのコンテンツの表示数を変更できるような実装を行いたかった。
今回は記事の一覧表示を行うアプリケーションを参考に実装方法を示す。環境
- Python 3.7.3
- Django 2.1.6
- bootstrap4
Model
app/models.pyfrom django.db import models class Article(models.Model): title = models.CharField('title', max_length=255) content = models.CharField('content', max_length=255)Form
コンテンツの表示数を10〜50で変更できるようにしている。
また、今回はセレクトボックスで値を選択した時点で、submitも行いたいため、
widget=forms.Select(attrs={'onchange': 'submit(this.form);})
のようにしている。app/forms.pyfrom django import forms PAGINATE_BY_CHOICES = ( ('', '-'*10), (10, '10'), (20, '20'), (30, '30'), (40, '40'), (50, '50') ) class Paginate(forms.Form): paginate_by = forms.ChoiceField( label='記事表示数', widget=forms.Select(attrs={'onchange': 'submit(this.form);'}), choices=PAGENATE_BY_CHOICES )View
Viewは
django.view.Viewを利用している。現在Djangoを勉強中のため、むやみに汎用ビューを使いたくないという理由からです。
デフォルトではページあたり10個の記事を表示します。
また、セッションに選択したページあたりのコンテンツ数を保存することで、ページ遷移しても大丈夫なようにしています。app/views.pyfrom django.views import View from .models import Article from . import forms from django.core.paginator import Paginator, PageNotAnInteger, EmptyPage class ArticleList(View): paginate_by = 10 def get(self, request, **kwargs): form = forms.Paginate(request.GET or None) if 'paginate_by' in request.GET: request.session['paginate_by'] = request.GET['paginate_by'] if 'paginate_by' in request.session: self.paginate_by = request.session['paginate_by'] queryset = Article.objects.all() paginator = Paginator(queryset, self.paginate_by) try: contents = paginator.page(kwargs['page']) except PageNotAnInteger: contents = paginator.page(1) except EmptyPage: contents = paginator.page(paginator.num_pages) context = {} context['contents'] = contents context['form'] = form return render(request, 'app/article_list.html', context)URLs
app/urls.pyfrom django.urls import path from . import views app_name = 'app' urlpatterns = [ path('article_list/<int:page>', views.ArticleList.as_view(), name='article_list'), ]Template
app/aritcle_list.html<form name="paginate_form" action="{% url 'main:user_list' 1 %}" method="get"> {{ form.paginate_by.label }} {{ form.paginate_by }} </form> <table class="table twitter-user-list"> <thead> <tr> <th scope="col">タイトル</th> <th scope="col">内容</th> </tr> </thead> <tbody> {% for article in contents %} <tr> <td class="align-middle">{{ article.title }}</td> <td class="align-middle">{{ article.content }}</td> </tr> {% endfor %} </tbody> </table> <nav aria-label="Page navigation"> <ul class="pagination justify-content-center"> {% if contents.has_previous %} <li class="page-item"> <a href="{% url 'app:article_list' 1 %}" class="page-link">1</a> </li> <li class="page-item"> <a href="{% url 'app:article_list' contents.previous_page_number %}" class="page-link"><</a> </li> {% else %} <li class="page-item disabled"> <a href="#" class="page-link">1</a> </li> <li class="page-item disabled"> <a href="#" class="page-link"><</a> </li> {% endif %} <li class="page-item active"> <a class="page-link" href="#">{{ contents.number }}</a> </li> {% if contents.has_next %} <li class="page-item"> <a href="{% url 'app:article_list' contents.next_page_number %}" class="page-link">></a> </li> <li class="page-item"> <a href="{% url 'app:article_list' contents.paginator.num_pages %}" class="page-link">{{ contents.paginator.num_pages }}</a> </li> {% else %} <li class="page-item disabled"> <a href="#" class="page-link">></a> </li> <li class="page-item disabled"> <a href="#" class="page-link">{{ contents.paginator.num_pages }}</a> </li> {% endif %} </ul> </nav>
- 投稿日:2019-05-07T20:32:56+09:00
Python3 初心者 forによる反復処理
pythonはイテレータ(イテレーションごとにリストや辞書から要素を一つずつ取り出して返すこと)がよく使われているが、そのようにしているのはデータがどれくらいのサイズなのかなどを知らなくてもデータを操作できる。そのようなものはforを使ってやれば楽にデータを取り出して処理することができる。
animals=['dog', 'cat', 'elephant', 'snake'] for animal in animals: print(animal) dog cat elephant snakeこれはまずanimalsが何かを定義した後それに名前をつけていると考えてくれるといい。だからanimalは全ての値を読み込むことが可能になる。もしここでforを使わないとどうなるのか
animals=['dog', 'cat', 'elephant', 'snake'] print(animals) ['dog', 'cat', 'elephant', 'snake']これだとリスト自体を読み込んでしまっていることになっているので要素を一つ一つ読み込んで取り出すことができない。このようなリストはイテラブルなためforを使った時にこのような処理ができる。辞書などの時はkeysとvaluesのどちらかが読み取られるの?と考えることもあるかもしれない。それは普段の辞書と同じで両方好きな時に返すことが可能になる。
animals={'Hello': 'dog', 'Bob': 'cat', 'hat': 'elephant', 'King': 'snake'} #ここではkeysを読み取りたい時後ろにkeys()と書いているがかかなくてもよし for name in animals.keys(): print(name) #valuesを読み取りたい時 for animal in animals.values(): print(animal) #items()を読み取りたい時 for item in animals.items(): print(animal)で可能になります。またforもwhileとにtリルこともありwhileと同じようにbreakやcontinueなどを使うことができます。
- 投稿日:2019-05-07T19:29:35+09:00
[Python]LineMessageAPIのemoticon送信方法
デコードデコードエンコードデコード
やりたいこと
LineMessageAPIをつかった通知で絵文字を送信したい。(Python版)
結果
import codecs code = "1000A5" bin = '0' * (8 - len(code)) + code bin = codecs.decode(bin,'hex_codec').decode('utf-32BE').encode('utf-8').decode('utf-8')参考
https://github.com/line/line-bot-sdk-php/issues/54
https://qiita.com/hisaharu/items/613baad81a4161c3c6c2
- 投稿日:2019-05-07T19:26:40+09:00
Chainerで可変長の入力を正しく扱う
はじめに
ディープラーニングでは、各入力データの長さが一致していないと色々と不都合があり、入力に文(単語列)などを扱う場合は度々この問題が発生します。
この記事では、Chainerで可変長入力を正しく扱うためのテクニックを紹介します。(主に著者の忘記録用ですが)
前提:なぜ入力データの長さが一致していないと問題なのか?
そもそもなぜ入力データの長さが一致していないと問題なのでしょうか?
その理由は、「計算を高速に実施するために、numpy・cupy上の行列演算を使いたいから」です。ディープラーニングではよくミニバッチ学習が採用されますが、このミニバッチ単位で効率よく損失の計算ををしたいわけです。この時にミニバッチ内の各入力を1つずつ読んでいてはあまりにも非効率です。
for x in x_lst: h = self.encoder(x) (以下略)この計算を高速化するために、numpyやcupyを使用します(なぜ高速になるのかはここでは解説しません)。
import numpy x = numpy.array(x_lst) h = self.encoder(x)ただし、入力の長さがそろっていないと行列化できません。上記の例の x_lst に含まれる各要素の長さが一定でないと、numpy.arrayで落ちてしまうわけですね。
可変長入力の扱い方
可変長入力を扱うときは、以下の3つのテクニックを用いるのが直感的で簡単です。
- padding
- embedding
- masking
ほかにもreshapeを駆使することでmaskingの代わりにすることもできますが、本記事での解説は省きます。
paddingとembeddingは単純かつ簡単で、本記事以外にも多数の解説があります。maskingも単純なのですが、よくミスをしてしまいがちです。maskingを適当にやってしまうと、正しい計算が行われなくなる危険性があります。
1:padding
まず長さが足りていない入力に適当な値を埋めることで、無理やりnumpy.arrayを通します。
[ [4, 2, 5] [9] [6, 3, 7, 1] ] ↓padding [ [4, 2, 5, -1] [9, -1, -1, -1] [6, 3, 7, 1] ]paddingについては、ディープラーニングフレームワークで可変長の入力を扱うときのTipsでわかりやすく紹介されています。
Chainerでは、
functions.pad_sequenceモジュールを利用するのが良いでしょう。2:embedding
embeddingする際にpaddingで適当に埋めた値に対しては、基本的にゼロベクトルを与えてやりましょう。
Chainerの
link.EmbedIDでは、ゼロベクトルを返す値をignore_labelオプションで指定することができます。
paddingする値を-1、ignore_label=-1 としてやるのが一般的なようです。3:masking
計算を進めていく中で、要所要所に
function.whereによるmaskingを入れて、paddingに相当する部分をゼロにしましょう。たとえば、ゼロが入るとNaNが発生する割り算やlogを含んだ計算後で、ネットワーク内の学習対象である重み行列との演算前に、maskingの処理を入れるのが妥当です。import numpy import chainer.functions as F x = F.log(x + 0.0001) # NaaN回避のため、微小値を加算 x = F.where(mask, x, numpy.full(x.shape, 0., numpy.float32))※変数maskはxと同じshapeを持つnumpy.boolの行列です。
Chainer の whereに関しては公式ドキュメントを参照してください。ここで問題となるのは、maskをどのように作るかです。
まず最初に思いつくのは
x.data != 0ですが、これまでの計算の結果、偶然ゼロが発生していたりすると危険です。またDropout関数を噛ませていると、paddingした箇所とDropoutした場所を判別することは困難です。解決策の1つは、embeddingした時点でmaskを作成し、通常の入力に対するforwardの計算に合わせてmaskも更新していくことです。
x = self.embed(inputs) mask = numpy.absolute(x.data) > 0. x = F.dropout(x, 0.1) x = F.reshape(x, shape) mask = F.reshape(mask, shape) (中略) x = F.log(x + 0.0001) x = F.where(mask, x, numpy.full(x.shape, 0., numpy.float32))更新中は、maskがbool型である点に気を付けましょう。和や積などに対してbool型に対応したnumpyライブラリを使いましょう。
たとえば、以下のような形になります。# x1, x2: 入力側の値 # x: 出力側の値 # m1, m2: x1, x2のmask # x の maskを計算したい x = F.sum(x1 * x2, axis=-1) mask = numpy.all(numpy.logical_and(m1, m2), axis=-1)まとめ
- Chainerで可変長入力を扱うときは、padding, embedding, masking
- maskingでミスが発生しやすい
- embeddingした時点でmaskを作り、forwardの計算に合わせてmaskを更新していく
- 投稿日:2019-05-07T19:20:03+09:00
【Python】R指定のかっこいいパンチラインをスクレイピングし、結果をランダムで返してくれるLINE BOTを作った話
結論(何を作ったか)
LINE BOTに"R指定"と入力してメッセージを送ると、R指定のかっこいいパンチラインをランダムで3つ返してくれる
背景
フリースタイルダンジョンというテレビ番組が好きでよく見ている。その中で一番好きなモンスターがR指定だ。(今はモンスターとして出ていない。)R指定のラップは即興性があって、心地のいい韻を踏んでいる。素人の私が聞いていても、気持ちがいい。そこで、R指定が今までに繰り出してきたかっこいいパンチラインを見れたらいいなと思い、Pythonの学習を兼ねて今回のLINE BOTを作ることにした。以前にもLINE BOTを作っているが、今回はスクレイピングする部分を関数にしているところがポイント。
以前作ったLINE BOT↓
【Python】平成最後だから流行語で振り返る LINE BOTを作った話全体の流れ
① LINE BOTにR指定と入力してメッセージを送る
② R指定のかっこいいパンチラインをスクレイピングする
③ スクレイピングした中からランダムで3つ抽出する
④ 結果がLINE BOTから返ってくる
⑤ 返ってきたパンチラインを眺めて感心するこんな感じ↓
実際のコード
スクレイピング処理のファイル。関数にしている。R指定というメッセージを受けると処理が始まる。
scrape.py# モジュールの読み込み import requests from bs4 import BeautifulSoup import urllib.request import random # スクレイピング処理 def getIn(): r = requests.get("https://in-note.com/rappers/1") soup = BeautifulSoup(r.content, "html.parser") # 韻一覧取得 word = soup.find_all("div", class_ = "word") wordlist = [x.text.replace("\n"," ") for x in word] # タグを取り除き、余分な改行を削除 wordlist = random.sample(wordlist, 3) # ランダムで3つ抽出 wordlist = "【R指定】" + "\n" + "> " + wordlist[0] + "\n\n" + "> " + wordlist[1] + "\n\n" + "> " + wordlist[2] return wordlistLINE BOT側の処理。スクレイピングの処理が一緒になっていないのでコードがスッキリ。
main.py# モジュールの読み込み from flask import Flask,request,abort from linebot import LineBotApi,WebhookHandler from linebot.exceptions import InvalidSignatureError from linebot.models import MessageEvent,TextMessage,TextSendMessage import os import requests import scrape as sc # scrape.py読み込み app=Flask(__name__) # トークン等の情報を格納 YOUR_CHANNEL_ACCESS_TOKEN="**************************" YOUR_CHANNEL_SECRET="**************************" line_bot_api=LineBotApi(YOUR_CHANNEL_ACCESS_TOKEN) handler=WebhookHandler(YOUR_CHANNEL_SECRET) # herokuへの指示 @app.route("/callback",methods=["POST"]) def callback(): signature=request.headers["X-Line-Signature"] body=request.get_data(as_text=True) app.logger.info("Request body"+body) try: handler.handle(body,signature) except InvalidSignatureError: abort(400) return "OK" # LINE BOTの処理 @handler.add(MessageEvent,message=TextMessage) def handle_message(event): # 入力された文字列を格納 push_text = event.message.text # 返信する文字列の条件 if push_text == "R指定": reply_text = sc.getIn() # scrape.pyからの結果 else: # R指定以外の文字が入力された場合の返答 reply_text = "R指定と入力してください!" # 返答する内容を格納 line_bot_api.reply_message(event.reply_token,TextSendMessage(text=reply_text)) if __name__=="__main__": port=int(os.getenv("PORT",5000)) app.run(host="0.0.0.0",port=port)まとめ
自分の興味のあるものをPython学習に使うと、楽しいし、学習もはかどる。今回は関数を使ったり、スクレイピング処理について学習することができた。LINE BOTは工夫すればもっと面白いことができそう。他にもアイデアはあるのでどんどんさわって作っていこうと思う。
参考にした情報
韻ノート
PythonとLINE APIとHerokuで自動返信BOTを作る【Python編】
LINE+Python+天気API を活用してチャットボットを作成してみた
BeautifulSoupで抽出したタグリストからテキストのみをリスト形式で抽出したい
- 投稿日:2019-05-07T19:04:58+09:00
pythonでMQTT送受信
はじめに
このページは,
の1ページです.
全体を見たい場合は上記ページへお戻りください.概要
前回はmosquittoのコマンドラインツールを使って,PublishとSubscribeを行いました.
今回はPythonプログラムでPublishとSubscribeを行います.いい加減,Publish/Subscribeと書くのが大変になってきたので,
今後はPub/Subと省略して書こうと思います(^^;)準備するもの
今回もdronekit-sitlのために準備したUbuntu Linuxの入ったPCを利用します.
参考サイト
このサイトのプログラムを改変しました.
Raspberry PiでMQTTの動作環境を作る(RabbitMQ + Paho + Python)
https://make-muda.net/2015/06/2898/当該サイトは,ブローカーにRabbitMQを使っているのですが,
Pythonプログラムは,どんなブローカーにも繋がるので,
一番シンプルで読みやすかったここのプログラムを利用させてもらいました.Pythonライブラリのインストール
PythonでMQTTを取り扱うためには,paho-mqttというライブラリを使用します.
そのため,pipコマンドを使ってインストールする必要があります.$pip install paho-mqtt※pipの利用状況によっては
sudoを付けてルート権限でインストールしないといけないかもしれません.Subscribeプログラム
Sub側のプログラムです.
コメントを細かく書いておきました.sample_sub.py# -*- coding: utf-8 -*- import paho.mqtt.client as mqtt # MQTTのライブラリをインポート # ブローカーに接続できたときの処理 def on_connect(client, userdata, flag, rc): print("Connected with result code " + str(rc)) # 接続できた旨表示 client.subscribe("drone/001") # subするトピックを設定 # ブローカーが切断したときの処理 def on_disconnect(client, userdata, flag, rc): if rc != 0: print("Unexpected disconnection.") # メッセージが届いたときの処理 def on_message(client, userdata, msg): # msg.topicにトピック名が,msg.payloadに届いたデータ本体が入っている print("Received message '" + str(msg.payload) + "' on topic '" + msg.topic + "' with QoS " + str(msg.qos)) # MQTTの接続設定 client = mqtt.Client() # クラスのインスタンス(実体)の作成 client.on_connect = on_connect # 接続時のコールバック関数を登録 client.on_disconnect = on_disconnect # 切断時のコールバックを登録 client.on_message = on_message # メッセージ到着時のコールバック client.connect("localhost", 1883, 60) # 接続先は自分自身 client.loop_forever() # 永久ループして待ち続けるPublishプログラム
Pub側のプログラムです.
こちらもコメントを多めに書いておきました.sample_pub.py# -*- coding: utf-8 -*- import paho.mqtt.client as mqtt # MQTTのライブラリをインポート from time import sleep # 3秒間のウェイトのために使う # ブローカーに接続できたときの処理 def on_connect(client, userdata, flag, rc): print("Connected with result code " + str(rc)) # ブローカーが切断したときの処理 def on_disconnect(client, userdata, flag, rc): if rc != 0: print("Unexpected disconnection.") # publishが完了したときの処理 def on_publish(client, userdata, mid): print("publish: {0}".format(mid)) # メイン関数 この関数は末尾のif文から呼び出される def main(): client = mqtt.Client() # クラスのインスタンス(実体)の作成 client.on_connect = on_connect # 接続時のコールバック関数を登録 client.on_disconnect = on_disconnect # 切断時のコールバックを登録 client.on_publish = on_publish # メッセージ送信時のコールバック client.connect("localhost", 1883, 60) # 接続先は自分自身 # 通信処理スタート client.loop_start() # subはloop_forever()だが,pubはloop_start()で起動だけさせる # 永久に繰り返す while True: client.publish("drone/001","Hello, Drone!") # トピック名とメッセージを決めて送信 sleep(3) # 3秒待つ if __name__ == '__main__': # importされないときだけmain()を呼ぶ main() # メイン関数を呼び出す※末尾のif文について
__name__に'__main__'が入っているとき,というのは,
python sample_pub.pyのようにファイル自身が実行された事を意味しています.
__name__に'__main__'が入っていない場合は,
import sample_pubのように別のプログラムからサブルーチンとして呼び出された事を意味します.すなわち,
if __name__ == '__main__':の中に書かれた命令は,
自分自身が実行されたときにだけ動作させたい,という意志で書かれています.
Pythonプログラムでよく使われる記述です.実行と実行結果
sub側,pub側をそれぞれ別の端末(ターミナル)で実行してください.
sample_sub.pyの実行画面$python sample_sub.py Receive message 'Hello, Drone!' on topic 'drone/001' with QoS 0 Receive message 'Hello, Drone!' on topic 'drone/001' with QoS 0 Receive message 'Hello, Drone!' on topic 'drone/001' with QoS 0 ...sample_pub.pyの実行画面$python sample_pub.py publish: 1 publish: 2 publish: 3 ...sample_pub.pyが3秒おきに送ってくるメッセージを,
sample_sub.pyが受信している様子がわかると思います.おわりに
pythonプログラムからメッセージの送受信ができました.
次回はdronekit-sitlの情報をPub/Subしてみたいと思います.
- 投稿日:2019-05-07T17:57:47+09:00
隠れマルコフモデル(HMM hidden markov model)による推定その1:事前準備編
はじめに
実務でベイズ推論をやる必要があるので、事前知識として「ベイズ推論による機械学習入門」を読んで実装しています。
https://www.amazon.co.jp/dp/4061538322/ref=cm_sw_r_tw_dp_U_x_mxt0CbTB5QCRP
この本の5.3隠れマルコフモデルの実装を、自分の備忘録を兼ねてやってみます。今回は、隠れマルコフモデルによりサンプルを生成してプロットしてみるところをやります。次回以降で、そのデータを(パラメータは知らないものとして)推論してみることにします。余裕があれば、何か実データ(株価など?)もやってみることにします。
モデルの詳細の説明は本と被ってしまうので、興味のある方は本を読んでみてください。この記事は実装中心です。隠れマルコフモデル概要
確率モデルの1つで、時系列の相関を含むモデルです。音声認識、バイオインフォマティクス、形態素解析(自然言語処理)、楽譜追跡、部分放電など、時系列パターンの認識に応用されている(wikipediaより)とのことです。株価などにも応用できそうですね。
隠れマルコフモデル
時系列で状態 $s$ (潜在変数)が変化し、その状態 $s$に基づいて $x$ が生成されます。潜在変数sは、初期値のみカテゴリ分布に従って生成されます。
$$
p(s_1|\pi) = Cat(s_1|\pi)
$$
$\pi$ には事前分布としてディリクレ分布を導入
$$
p(\pi) = Dir(\pi|\alpha)
$$
時系列の次のデータからは、直前の潜在変数 $s_{n-1}$ の値により潜在変数 $s_{n}$ が生成されます。
$$
p(\boldsymbol{S}|\pi, \boldsymbol{A}) = p(s_1|\pi)\prod_{n=2}^N{p(s_n|s_{n-1, \boldsymbol{A}})}
$$
$\boldsymbol{A}$はK×Kのサイズの状態遷移確率。
$x$はこのカテゴリsに基づいて生成されるが、生成モデルはポアソン分布でもガウス分布でも選べます。例えばポアソン分布を仮定すると、
$$
p(x_n|s_n, \lambda) = \prod_{k=1}^N{Poi(x_n|\lambda_k)^{s_{n,k}}}
$$
また、パラメータ $\lambda_k$ の事前分布として、ガンマ分布を導入することにします。
$$
p(\lambda_k)=Gam(\lambda_k|a,b)
$$事前準備
このモデルに従って、サンプルを生成してプロットしてみることにします。隠れマルコフモデルは混合モデルなので、事前準備として、必要な基本の確率モデルを実装してみます。
ディリクレ分布
カテゴリ分布のパラメータπの事前分布であるディリクレ分布を実装します。ディリクレ分布は以下のような分布です。
$$
Dir(\pi|\alpha) = C_D(\alpha)\prod_{k=1}^{K}\pi_k^{\alpha_k-1}
$$
ただし
$$
C_D(\alpha)=\frac{\Gamma(\sum_{k=1}^{K}\alpha_k)}{\prod_{k=1}^{K}\Gamma(\alpha_k)}
$$
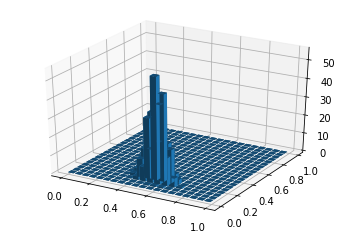
αの値に応じて、πの確率をプロットするコードを書いてみます。今回は、カテゴリ数は3にしてみました。def plot_dir_ln(alpha): pi0 = np.arange(0,1, 0.05) pi1 = np.arange(0,1, 0.05) #指数や階乗が出てきて途中でオーバーフローしやすいので、対数をとって計算します。 lncd_c=1 for i in range(1, np.sum(alpha)): lncd_c+=math.log(i) lncd_p = 1 for i in range(len(alpha)): for j in range(1, alpha[i]): lncd_p+=math.log(j) lncd = lncd_c-lncd_p p=np.zeros((len(pi0),len(pi1))) x=np.zeros((len(pi0)*len(pi1))) y=np.zeros((len(pi0)*len(pi1))) z=np.zeros((len(pi0)*len(pi1))) k=0 for i in range(len(pi0)): for j in range(len(pi1)): if pi0[i]>0 and pi1[j] and 1-pi0[i]-pi1[j] >0: lnp = lncd + (alpha[0]-1)*math.log(pi0[i]) + (alpha[1]-1)*math.log(pi1[j]) + (alpha[2]-1)*math.log(1-pi0[i]-pi1[j]) p[i][j]=math.exp(lnp) x[k]=pi0[i] y[k]=pi1[j] k+=1 k=0 for j in range(len(p)): for i in range(len(p)): z[k]=p[i][j] k+=1 fig = plt.figure() ax = fig.add_subplot(111, projection='3d') ax.bar3d(x, y, 0, 0.04, 0.04, z) plot_dir_ln([10,10,10]) plot_dir_ln([10,30,20])以下のように出力されました!
例えば、パラメータα=[10,10,10]のときは、確率が最大となるπはπ=[0.33, 0.33, 0.33]位、α=[10,30,20]のときは、π=[0.15, 0.5, 0.35]位になるようです。ちなみにπ=[0.33, 0.33, 0.33]のカテゴリ分布というのは、3つのカテゴリが同じ確率で出現するということです。ガンマ分布
次はポアソン分布のパラメータλの事前分布であるガンマ分布を実装します。ガンマ分布は以下のような分布です。
$$
Gam(\lambda|a,b) = C_G(a,b)\lambda^{a-1}e^{-b\lambda}
$$
ただし
$$
C_G(a,b)=\frac{b^a}{\Gamma(a)}
$$
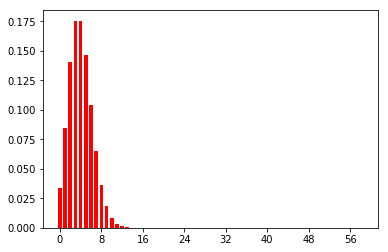
パラメータa, bの値に応じて、λの確率をプロットするコードを書いてみます。def plot_gam(a, b): lam = np.arange(1,100, 0.1) #こちらもオーバーフローしやすいので対数をとって計算 lna = 0 #本当はガンマ関数ですが、aを整数に限ることにして階乗で計算 for i in range(1, a): lna+=math.log(i) lncg = a*math.log(b)-lna p = [] for item in lam: lnp = lncg+(a-1)*math.log(item)-b*item p.append(math.exp(lnp)) plt.plot(lam,p) plt.show plot_gam(1200,20) plot_gam(450,15) plot_gam(20, 4)このようにプロットされました!
[a,b] = [1200,20]のが青、[450,15]のがオレンジ、[20, 4]のが緑です。ガンマ分布の期待値はa/bになるので、合っていそうです。サンプルデータの生成
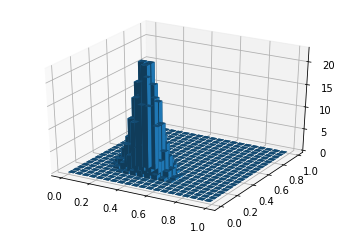
これらの事前分布を使って、サンプルを生成してみます。
カテゴリ分布のパラメータπの生成
まずは、最初のサンプルのカテゴリをカテゴリ分布により生成するため、カテゴリ分布のパラメータπを、事前分布であるディリクレ分布により生成します。本当は、確率なので、ディリクレ分布に従って確率的に生成しますが、今回はそこは端折って、確率が最大に近いπに決めてしまうことにします。
alpha = [50,30,10] #事前分布のパラメータはとりあえず決め打ちする lncd_c=1 for i in range(1, np.sum(alpha)): lncd_c+=math.log(i) lncd_p = 1 for i in range(len(alpha)): for j in range(1, alpha[i]): lncd_p+=math.log(j) lncd = lncd_c-lncd_p p_max = 0 for i in range(1, 100): ii = i/100 for j in range(1, 100): jj = j/100 if 1-ii-jj >0: lnp = lncd + (alpha[0]-1)*math.log(ii) + (alpha[1]-1)*math.log(jj) + (alpha[2]-1)*math.log(1-ii-jj) p=math.exp(lnp) if p>p_max: p_max=p pi0 = ii pi1 = jj pi = [pi0, pi1, 1-pi0-pi1] print("pi:", pi)あまりコードがきれいじゃなくてすみません。上記のコードを実行すると、πの値は
π = [0.57, 0.33, 0.10]
のように生成されました。カテゴリが3つなので、1つ目のカテゴリになる確率が57%位、2番目が33%位、3番目が10%位ということになります。最初のカテゴリの生成
先ほど生成したπにより最初のカテゴリを生成します。ここはちゃんと確率的に、乱数を使ってカテゴリを生成しました。
s=[] r = random.random() if r<=pi[0]: s.append(0) elif r<=pi[0]+pi[1]: s.append(1) else: s.append(2) print("最初のカテゴリ:", s[0])もちろん、確率的にカテゴリ0, 1, 2の中から選ばれますが、今回の私の実行では一番確率の高い「0」が生成されました。
2番目以降のカテゴリの生成
2番目以降のカテゴリは、状態遷移確率Aによって生成されます。このコードを書いて2番目から100番目のカテゴリを生成してみます。
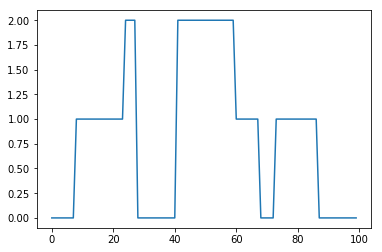
※追記:後から分かったのですが、本の推論の方では、AもK次元のディリクレ分布から生成していました。とりあえずサンプルデータ生成はこのままで進めます。A=[[0.95, 0.045, 0.005],[0.025, 0.95, 0.025],[0.005, 0.045, 0.95]] for i in range(1, 100): r = random.random() if r<A[s[i-1]][0]: s.append(0) elif r<A[s[i-1]][0]+A[s[i-1]][1]: s.append(1) else: s.append(2) t = range(0, len(s)) plt.plot(t,s) plt.show()Aの値により、状態の遷移の仕方が色々変わります。今回は、いちどその状態になったら、あまり変化しないようにしてみました。このようにしてできたsをプロットしてみると以下のようになりました。
ポアソン分布のパラメータλを生成
次に、各カテゴリのポアソン分布のパラメータλを、事前分布のガンマ分布より生成します。こちらも、本当は確率的に生成する必要がありますが、端折って確率が最大になるλ(整数)を選択してしまうことにします。
#事前分布のパラメータa,bを、カテゴリーごとに決め打ち a = [20, 450, 1200] b = [4, 15, 20] lam=[0]*3 for i in range(len(a)): lna = 0 #本当はガンマ関数ですが、aを整数に限ることにして階乗で計算 for j in range(1, a[i]): lna+=math.log(j) lncg = a[i]*math.log(b[i])-lna pmax=0 for j in range(1, 100): lnp = lncg+(a[i]-1)*math.log(j)-b[i]*j p=math.exp(lnp) if p>pmax: pmax=p lam[i] = j print(lam)λ=[5, 30, 60]
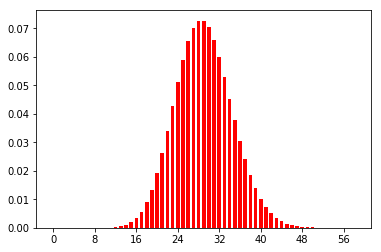
のように生成されました。ポアソン分布の期待値はλなので、λ=5、30のときのポアソン分布は以下のようになります。(ここはコードには書いてありません)
サンプルxの生成
最後に、各時系列のカテゴリ(潜在変数)と、各カテゴリのパラメータλにより、ポアソン分布でサンプルxを生成してプロットしてみます。(先ほど生成したカテゴリと並べてみます)
x = [] for i in range(len(s)): while True: x_tmp = random.randint(0,100) p=lam[s[i]]**x_tmp/math.factorial(x_tmp)*np.exp(-lam[s[i]]) r = random.random() if r<=p: x.append(x_tmp) break plt.plot(t,s) plt.show() plt.plot(t,x) plt.show()カテゴリ
生成されたx
このような感じで、カテゴリとポアソン分布に基づいて、データが生成できました。※カテゴリのプロットとの対応が分かりやすいように、恣意的にλの値を生成しましたので(カテゴリが小さい=λが小さい)λの値によってはもちろんこのようにはなりません。
次はこのサンプルデータを、パラメータは未知として推論してみることにします。


- 投稿日:2019-05-07T16:26:55+09:00
【2019年5月】Scrapy の自作パイプラインで Firestore に結果を叩き込む
Scrapy の結果を Firestore に出力したい。
Scrapy のドキュメントにはオリジナルのパイプラインで MongoDB にデータ投入する、というサンプルが掲載されておりました。
これにインスパイアされて直接、Firestore にデータを投入してみよう、という試みです。
いくつかハマりポイントがあったのでメモしておきます。
対象環境
- Python: Anaconda + 3.7
Jupyter notebook から動かしてみてます。
準備
1. パッケージのインストール
以下のコマンドで scrapy と google-cloud-apiをインストールします。
jupyter_notebook!conda install scrapy -y !pip install google-cloud-firestore2. サービスアカウントの作成
Google Cloud Platform の管理画面から Cloud Firestore 編集者、Firebase 管理者 のロールを持ったサービスアカウントを作成し、json形式で秘密鍵をダウンロードしてください。
ダウンロードしたファイルは "cred/service_account.json" など適当な名前でnotebookから参照できる場所に置いておきます。
サービスアカウントからAPIで firestore を叩く場合、セキュリティルールは無視されます。
というか、サービスアカウントのパーミッションが効きます。書き込む場合は Firestore 編集者とFirebase 管理者 のロールが必要です。※ ただし今回使用した Firestore は Firebaseから有効にした Firestoreでした。Firebase 管理者が本当に必要なのかどうか、環境に応じて検証が必要ですね。。。
3. クローラー、Spider の作成
ここでは Scrapy の Spider 実装には触れません。よろしく実装して下さい。
Cloud Firestore も Mongo 同様にドキュメント型のデータベースでありますので scrapy.Item を base とする item なら dict(item) でデータ投入できます。
安心して Spider 作って下さい。自前パイプラインの実装
scrapyコマンドでgenerateした場合、プロジェクトの直下に pipelines.py が生成されていると思います。これを以下のように置き換えます。
pipelines.py# -*- coding: utf-8 -*- from google.cloud import firestore class CloudFireStorePipeline(object): def __init__(self, collection_name): self.collection_name = collection_name @classmethod def from_crawler(cls, crawler): return cls( collection_name = crawler.spider.name ) def open_spider(self, spider): self.client = firestore.Client.from_service_account_json('./cred/credential.json') self.db = self.client.collection(self.collection_name) def process_item(self, item, spider): self.db.add(dict(item)) return itemここではspiderの名前がそのままコレクション名としてデータを保存しています。
コレクション名が決め打ちであればコンストラクタやfrom_crawlerの実装は不要です。
./cred/credential.jsonの箇所は上記のサービスアカウント作成の際にダウンロードしたjsonファイルの保存場所に差し替えてください。パイプラインの有効化
settings.pyにて上記のパイプラインを有効にする必要があります。
ただし、settings.pyでコメントアウトされている箇所をコメント外してクラス名を修正するだけでOKです。settings.py... ITEM_PIPELINES = { 'myProject.pipelines.CloudFireStorePipeline': 300, } ...上記の
myProjectは Scrapy のプロジェクト名に差し替えてください。実行
以下のコマンドでクローラーを実行します。例によって jupyter notebook から実行です。
jupyter_notebook!scrapy crawl mySpider
mySpiderは実行する Spider の名前です。参考サイト
- 投稿日:2019-05-07T16:20:20+09:00
[面倒なことはPythonで!]ネットから画像の自動収集
はじめに
こんにちは。
今回の記事ではネットから必要な画像を自動で収集する方法を紹介しようと思います。今までの記事で書いたような画像分類をする場合、必要になってくるのが画像収集です。しかも、画像分類となるとAIに学習させるためにできるだけたくさんの画像が必要になってきます。場合によっては1000枚、2000枚になることもあるので、それをいちいち自分の手で検索して保存していくのはめちゃくちゃしんどいです。。。今回紹介するやり方を知るまでの僕はいちいち手動でやっていたのでその作業だけで疲れて勉強どころではなくなっていました(涙)
みなさんにはそんな苦労を味わって欲しくないので、楽してできるだけたくさんの画像を集めちゃいましょう!筆者の開発環境
・macOS Mojave バージョン10.14.3
・MacBook Air(11-inch, Early 2015)
・プロセッサ 1.6 GHz Intel Core i5
・Python 3.7.1これで問題なく動きました!
手順
①今回使うサイトはFlickrというサイトで、たくさんの画像を共有するサイトになっています。
まずYahooアカウントを取得しましょう。既に持っている人はお持ちのアカウントで構いません。
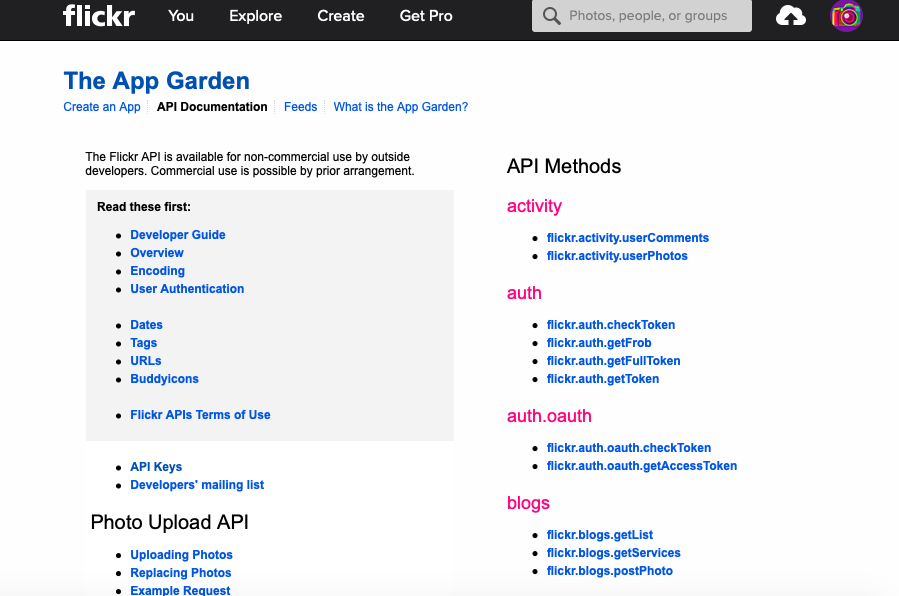
次に https://www.flickr.com/services/api/ を検索して以下のような画面に飛びます。
この画面の灰色の枠のすぐ下にある API Keys をクリックするとYahooアカウントでのログインを求められるのでそのままログインします。
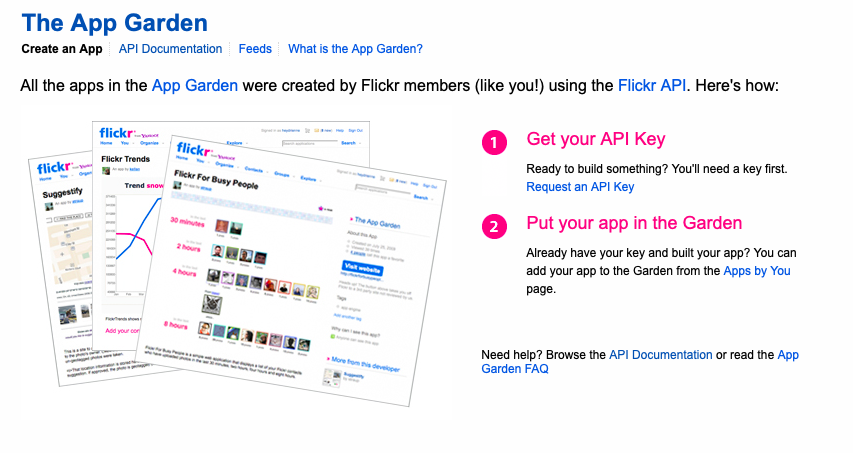
無事ログインできたら先ほどの画面の「The App Garden」という文字の下にある「Create an App」をクリックします。
するとこのような画面になるので
Get Your API Keyのすぐ下のRequest an API Keyをクリックしましょう。
そして次の画面で 「APPLY FOR A NON-COMMERCIAL KEY」をクリックすると
こんな画面に移動するので、What's the name of your app?のところに作りたいアプリの名前、What are you building?のところに目的を書きましょう。私は画像分類アプリを作りたかったので「Image Classifier」、「To Classify Some Images」と入力しました。内容はなんでも大丈夫なので各自で自由に入力しましょう。
入力してSUBMITをクリックし、このような画面になったら成功です。おめでとうございます!
この画面にあるKeyとSecretを写真に撮るなりなんなりして忘れないようにしてください!後で使います!②次になんでもいいのでテキストエディタを使って以下のようなコードを書きます。
from flickrapi import FlickrAPI from urllib.request import urlretrieve from pprint import pprint import os, time, sys #この辺りのモジュールは各自インストールしておいてください。 pip install 〜でインストールするのが一番簡単です。 # APIキーの情報 key = "先ほどの画面で表示されたKey" secret = "先ほどの画面で表示されたSecret" wait_time = 1 #保存フォルダの指定 imagename = sys.argv[1] savedir = "./" + imagename flickr = FlickrAPI(key, secret, format='parsed-json') result = flickr.photos.search( text = imagename, per_page = 400,#400枚保存するという意味 media = 'photos', sort = 'relevance', safe_search = 1, extras = 'url_q, licence' ) photos = result['photos'] # 返り値を表示する # pprint(photos) for i, photo in enumerate(photos['photo']): url_q = photo['url_q'] filepath = savedir + '/' + photo['id'] + '.jpg' if os.path.exists(filepath): continue urlretrieve(url_q,filepath) time.sleep(wait_time)このコードをdownload.pyという名前で保存します。
そしてこのdownload.pyが含まれているフォルダに自分が検索したいキーワードを名前として設定したフォルダを新規作成します。ライオンの画像を検索したければ「lion」というフォルダ名で良いです。例えばAnimal
|
|--download.py
|--lionのような感じで大丈夫です。このlionというフォルダに今から画像が格納されていきます。
このAnimalフォルダをデスクトップに置きましょう。そしてterminal.appを開いて、
「cd Desktop」→「cd Animal」の順に入力したら、次に「python download.py lion」と入力すると、もう自動でFlickrからライオンの画像が保存されていきます!確認してちゃんと保存されていたら成功です!終わりに
いかがだったでしょうか?
こんな感じで面倒な作業が簡単にできちゃうので、画像がどうしてもたくさん必要な場合はぜひ使ってみてください。無駄な労力を使わなくて良くなりますよ!
- 投稿日:2019-05-07T16:09:54+09:00
#python の str と repr の違いって何なの? ( str は非公式のオブジェクト表現 / repr は公式の表現 )
ref
str vs. repr
According to the official Python documentation, repr is a built-in function used to compute the "official" string reputation of an object, while str is a built-in function that computes the "informal" string representations of an object. So both repr and str are used to represent objects, but in different ways. The best way to understand the difference between these two functions is to see them in action:Google日本語訳
str vs. repr
公式のPythonドキュメントによると、reprはオブジェクトの「公式の」文字列レピュテーションを計算するために使用される組み込み関数ですが、strはオブジェクトの「非公式の」文字列表現を計算する組み込み関数です。そのため、reprとstrはどちらもオブジェクトを表すために使用されますが、その使用方法は異なります。これら2つの機能の違いを理解するための最良の方法は、それらが実際に動作していることを確認することです。str は非公式で repr は公式らしいです。
まだよくわかりませんが。
文字列を書くときってクォーテーションで囲いますよね
>>> "some" 'some'そのまま書いたら未定義ですよって怒られます
Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'some' is not defined文字列はevalできないけど
>>> eval("some") Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<string>", line 1, in <module> NameError: name 'some' is not defined文字列の repr は eval できるわけですよ
>>> eval(repr("some")) 'some'文字列は文字列で
>>> "some" 'some' >>> str("some") 'some'repr はオブジェクトの「フォーマルな表現」みたいですね?
>>> repr("some") "'some'"つまり repr で得られる文字列は eval できるわけです
>>> eval("'some'") 'some'こんな理解で合ってますでしょうか?
それではごきげんよう。
Original by Github issue
- 投稿日:2019-05-07T15:16:46+09:00
音声認識デバイスを使って声に反応するラジコンを作ってみた
概要
特定の声に反応するモジュールであり、Raspberry Piに接続できるモジュールであるCodamaで、声のする方向に移動するラジコンを作ってみた。
Codamaとは?
特徴はざっくり言うと2つ
- 特定のワードに反応する
- 声の角度を計測する
セットアップの方法はCodamaのマニュアルに記載してあるので、その通りに行えばセットアップは完了である。
完成品
方向を転換して移動していることが分かる。(トリガーワードを声に出しています)
上に乗っかっているのはぬいぐるみである。
なので、AIB〇が無くてもペットを飼っているような気分になる!かもしれない・・・材料
その辺にあるものを寄せ集めて作ったので、ラズパイとCodama以外は割と適当である。しかし、材料は市販のものを使用したため、各々が手に入るもので作成できるとはずである。
- Raspberry Pi3 BodelB+
- Codama
- 無限回転サーボ2つ
- 小型キャスター2つ
- プラスチック段ボール
- ジャンパワイヤ
- 結束バンド
ラジコンの形
形は以下の写真の通りである。
>
2つのサーボ以外にキャスターを付けている理由は安定させるためである。
また、写真にはないが本来はRaspberry Pi等のマイコンボードは
下部に固定する設計にしている。
もしマイコンボードが床に接してしまうなら、車輪とボードの間に板などをかまして高さを調節してほしい。ラジコンを動作させる
サーボの制御のプログラムはこのサイトを参考に行った。
プログラムは以下のとおりである。# -*- coding: utf-8 -*- import RPi.GPIO as GPIO import time import signal import sys import subprocess import math def res_cmd(cmd): return subprocess.Popen(cmd, stdout=subprocess.PIPE,shell=True).communicate()[0] def main(): GPIO.setmode(GPIO.BCM) #GPIO4を制御パルスの出力に設定 gp_outR = 4 gp_outL = 6 GPIO.setup(gp_outR, GPIO.OUT) GPIO.setup(gp_outL, GPIO.OUT) #「GPIO4出力」でPWMインスタンスを作成する。 #GPIO.PWM( [ピン番号] , [周波数Hz] ) #SG92RはPWMサイクル:20ms(=50Hz), 制御パルス:0.5ms~2.4ms, (=2.5%~12%)。 servoR = GPIO.PWM(gp_outR, 50) servoL = GPIO.PWM(gp_outL, 50) #パルス出力開始。 servo.start( [デューティサイクル 0~100%] ) #とりあえずゼロ指定だとサイクルが生まれないので特に動かないっぽい? servoR.start(0) servoL.start(0) time.sleep(1) cmd = ("/home/pi/codama/codama-doc/utils/./codama_i2c DOAANGLEKWD") value = res_cmd(cmd) target_angle = int(value.strip("DOAANGLEKWD:")) print 'Target angle:' + str(target_angle) time.sleep(0.5) if target_angle < 90: #sleep.timeで角度を調整 servoR.ChangeDutyCycle(0.5) servoL.ChangeDutyCycle(0.5) turnTime = round(math.cos(math.radians(target_angle)) ,3) time.sleep(turnTime) elif target_angle > 90: servoR.ChangeDutyCycle(12.5) servoL.ChangeDutyCycle(12.5) turnTime = round(-1*math.cos(math.radians(target_angle)) ,3) time.sleep(turnTime) else: time.sleep(0.2) servoR.ChangeDutyCycle(0.5) servoL.ChangeDutyCycle(12.5) time.sleep(1) servoR.stop() servoL.stop() GPIO.cleanup() if __name__ == '__main__': main()ラジコンを動かすのは大きく分けてこの順番で行った。
1. トリガーワードが発せられた角度に向ける
2. 直進へ移動する項目1については、Codamaの機能の1つであるトリガーワード検出時の角度を検出する機能を使う。
方法は簡単で、cmd = ("/home/pi/codama/codama-doc/utils/./codama_i2c DOAANGLEKWD")
のDOAANGLEKWDのコマンドをたたけばやってくれる。
また、サーボの動かし方であるが、Raspberry Piに接続してあるCodamaにはこのように接続している。
Codamaは公式サイトの図に示されている通り、Raspberry Piと同様にGPIOを使うことができる。
今回は、gp_outR,gp_out_LでGPIOピンを指定して2つのサーボを制御した。
マイコンボードにはこのようにぶっ刺している。
>
これは、公式サイトのGPIOの配置を参考にGPIOの番号を指定し、接続した。
次に角度の調整であるが、これはサーボを動かし左右に角度を向ける時間を制御することで行っている。
サーボが動作する時間は、time.sleepで制御している。servoR.ChangeDutyCycle(0.5) servoL.ChangeDutyCycle(0.5)で、サーボを制御をすれば右に向き、
servoR.ChangeDutyCycle(12.5) servoL.ChangeDutyCycle(12.5)で、左に向いてくれる。
また、移動する時間はturnTime = round(math.cos(math.radians(target_angle)) ,3)の通りcos関数で算出しているが、これは1秒動作すれば90°傾くことが分かったが、
角度をいい感じに向いてくれる動作時間の算出の式を色々試したところcos関数であったためである。項目2は、
servoR.ChangeDutyCycle(0.5) servoL.ChangeDutyCycle(12.5)でサーボを制御すれば直進してくれることが分かった。
1秒動かすことで、ちょっとずつ前進するようにしている。まとめ
期間は2日ちょっとだが、突貫工事気味でも動くものが作れた。



- 投稿日:2019-05-07T13:09:34+09:00
#python の文字列埋め込み・連結を進歩させよう ( .format を利用 ) ( #初心者 向け )
連結するやつ
first_name = 'Alice' last_name = 'Liddel' first_name + ' is ' + last_name 'Alice is Liddel'なんかちょっとスマートそうな埋め込み
"{} is {}".format(first_name, last_name) 'Alice is Liddel'辞書で渡して名前付きで埋め込むやつ
可読性が高いよね!たぶん。
"{first_name} is {last_name}".format(**{"first_name":"Alice", "last_name":"Liddell"}) 'Alice is Liddell'Original by Github issue
- 投稿日:2019-05-07T12:03:56+09:00
適時開示情報の取得
JPXの適時開示情報のページを参照閲覧する
tekiji_kaiji.pyfrom urllib.request import urlopen from bs4 import BeautifulSoup import pandas as pd def fn_test(url): #変数設定 a,b,c,d,e,f = [],[],[],[],[],[] #リストを6つ用意 df = pd.DataFrame() #取得結果格納用のデータフレーム #ページの閲覧 html = urlopen(url) bsObj = BeautifulSoup(html, "html.parser") tbl3 = bsObj.findAll("table")[3] trs = tbl3.findAll("tr") for tr in trs: lst=[] tds = tr.findAll('td') for td in tds: #各tdの値を各リストに各々格納 if td.get("class")[1] =="kjTime":a += [td.text ] #開示時刻 if td.get("class")[1] =="kjCode":b += [td.text ] #コード if td.get("class")[1] =="kjName":c += [td.text ] #社名 if td.get("class")[1] =="kjTitle":d += [td.text ] #表題 if td.get("class")[1] =="kjTitle": #pdfのリンクURL e += [td.a.get("href") ] if td.a is not None else [td.a ] if td.get("class")[1] =="kjXbrl" : #XBRLのDLリンク f += [td.a.get("href") ] if td.a is not None else [td.a ] #取得結果格納リスト群からデータフレーム生成 df = pd.DataFrame( data={'A': a, 'B': b, 'C': c, 'D': d, 'E': e, 'F': f}, columns=['A', 'B', 'C', 'D', 'E', 'F']) return df # 日付 date = '20190426' #900件超 #date = '20190502' #0件 #date = '20190506' #1件 # URL文字列の生成 url0 = 'https://www.release.tdnet.info/inbs/' url1 = url0 + 'I_list_{}_{}.html'.format('001',date) # 該当URLを閲覧 html = urlopen(url1) bsObj = BeautifulSoup(html, "html.parser") tbl1 = bsObj.findAll("table")[1] dv1 = tbl1.findAll("div",{"class":"kaijiSum"}) dv2 = tbl1.findAll("div",{"class":"pager-O"}) dv3 = tbl1.findAll("div",{"class":"pager-M"}) if dv1 ==[]: print('開示0件') else: print(str(dv1).split('全')[1].split('</')[0]) lst =[ int(i.string) for i in dv3] if lst ==[]: df = fn_test(url1) print(df) else: # ページ数の取得 mxpg= max(lst) print( mxpg ) # 再度URL文字列の生成 for i in range(mxpg): s = str(i + 1) url1= url0 + 'I_list_{}_{}.html'.format(s.zfill(3) ,date) print(s , url1) # ページを逐次閲覧して開示情報を取得 df = fn_test(url1) print(df)・まざりもの氏のブログを参考に、JPXの適時開示情報ページを閲覧して、開示情報を取得するスクリプトを書いてみた。
・JPXの適時開示情報のWebページはiframeタグ(インラインフレーム)で構成されているので、埋め込まれている方のURL(ページ番号+日付yyyymmdd)を直接参照してbeautifulsoupでWebスクレイピングするようなイメージで逐次適時開示情報を取得。・最初に001ページの先頭にある上部のテーブルからページ数を取得して、そのページ数の分だけループ処理で逐次ページを閲覧して開示情報を取得格納するイメージ。また日によっては開示が0件であったり、あるいは開示件数が少なくて次ページがない001ページのみの場合があるので、上記スクリプトでは分岐させている。
・このページによると、各列の値を格納するリスト群を用意して、例えば6つの列のあるHTMLテーブルの情報をpandasのデータフレームオブジェクトを生成しようとする場合、各列に対応するlistを6つ(A列用のリスト、B列用のリスト、C列用のリスト、D列用のリスト、E列用のリスト、F列用のリスト)用意して上記のようにオブジェクト生成した方が処理が早いとのことなので参考にしました。(自分今までは1行ずつレコードのデータをリストで生成して、1件ずつappendか何かでデータフレームオブジェクトに行追加していくイメージで、pandasのデータフレームオブジェクトを生成していたような気が汗...)
・適時開示のページは閲覧可能な日付が1ヶ月分であり、過去のデータは閲覧できない。なので毎日逐次閲覧して取得格納するイメージの運用になるのかなと思われ。(過去分の適時開示情報を参照したい場合は、日経電子版or株探or四季報オンラインなどを参照する必要があるかと。)
・生成したpandasデータフレームはto_sql()などでご本尊のRDBなどに接続して、最寄りのデータベースの最寄りのテーブルに格納しておく的な後続処理が必要になってくるかと。(今回は割愛)・決算短信にはXBRLファイルのDLリンクが付いているので、忘れずに取得しておくべし。想定される後続処理としては、これら決算短信のXBRLファイルをダウンロードして、XBRLファイルをパースして数値等を取得してデータベースに格納するといった処理が考えられる。
・ただし決算短信以外の情報にはXBRLファイルが付いていない。例えば業績予想の修正の会社リリースや長期経営計画の会社リリースにはXBRLファイルが付いていない。投資家的には、XBRLの付いていないこれら業績予想の修正や長期経営計画の会社リリースの方が欲しいのかもしれないですね。(その場合はXBRLが付いていないので、pdfをダウンロードして、pdftotextなどでテキスト情報に変換処理が必要になってくるかと)
・欧米ではアルゴリズム取引が盛んらしく、提出書類をテキストマイニングで瞬時に読み込んで、売りか買いかを瞬時にジャッジメントして取引を大量に実行するようなので。上記スクリプトもそういうアルゴ取引の方向に活用改良すればいいんじゃなくね?と思うものの。さはさりながらも日本の現在の適時開示の状況を鑑みると、大多数の発表が後場が閉まった午後3時以降の発表が多いことを考えると、秒殺処理をする必要性は低いのかも(なので翌日のマーケットが開く朝9時までに処理が完了できればOKよ的なイメージ?いや知らんけど)
おまけ:有報キャッチャーのAPIを利用する
ufo_catcher_api.pyimport requests from bs4 import BeautifulSoup sic=9658 url='http://resource.ufocatch.com/atom/tdnetx/query/'+str(sic) r = requests.get(url) soup = BeautifulSoup( r.text,'html.parser') enty = soup.find_all("entry") print(enty)・自分は今まで「有報キャッチャー」は、有価証券報告書や四半期報告書といったEDINETの提出書類が利用できるAPIだと思っていましたが、どうやらTDNETの開示書類も閲覧可能との事。atomの種類は「tdnet」もしくは「tdnetx」(XBRLが付いた書類限定)と指定してあげれば、TDNETつまり適時開示の書類も参照可能。
・何件か観察してみたが。12時に発表があった決算短信が1分後に有報キャッチャーAPIでも検索できたので、こちらを利用してもいいかもしれませんね!(ただし決算発表が集中する日に同等の速度が出ているかは不明、ていうか未確認)
- 投稿日:2019-05-07T08:32:53+09:00
「'environment_kernels.EnvironmentKernelSpecManager' could not be imported」でJupyter notebookが起動しない
Anacondaを再インストールして、Pythonのバージョンが3.7にアップデートした辺りからか、Jupyter notebookが起動しなくなった。
環境
Windows7 64bit
Anaconda
Python3.7エラー表示っぽいもの
[C 08:16:21.905 NotebookApp] Bad config encountered during initialization:
[C 08:16:21.905 NotebookApp] The 'kernel_spec_manager_class' trait of notebookapp.NotebookApp object at 0x00000000023B54A8> instance must be a type, b
ut 'environment_kernels.EnvironmentKernelSpecManager' could not be imported解決方法
以下のサイトを参考。
http://d.hatena.ne.jp/mopper27/20181102/15411712881.管理者権限で「Anaconda Prompt」を起動する(base環境で起動する)
2.pipをupdate
python -m pip install --upgrade pipこの次の「jupyter_environment_kernels」をやるためには、pip ver 10.0.1が必要だったようだ
3.jupyter_environment_kernelsをインストール
以下コマンドを入力する。
pip install environment_kernelsあとがき
Udemyで講師に聞いても、「それだけじゃ分からないッス」と言われ、自力で解決しようと決意。
エンジニアは口を揃えて、「エラー表示くらい見ろよ笑」と言うので、上記のエラー?のワードをググる。
「'environment_kernels.EnvironmentKernelSpecManager'」でググり、趣旨が違うサイトに辿り着くが解決方法は同じだったので、結果オーライ。
単に、jupyter_enbironment_karnelsをインストールすればいいだけだった。
それにしてもなぜ突然起動しなくなったのか。
他パッケージかPython3.7のせいか不明。
- 投稿日:2019-05-07T02:12:37+09:00
CNNを利用して判別(Udemyコースの応用)
1.はじめに
1.1 お断り
自身がUdemyを利用して学んだことをアウトプットするものです。
必ずしもUdemyがすべての人に有用だと主張するつもりはありません。
Udemyのご利用はご自身の判断でお願いします。
いいコースと思って利用していますが、それはあくまで私個人の主観でありすべての人に適用されるものではありません。
また、私は一利用者であり、Udemyやコースの関係者ではありません。1.2 目的
Udemyのコースを利用して学習をしていましたがアウトプットとして利用するものです。
1.3 対象コース
ディープラーニング : Pythonでゼロから構築し学ぶ人工知能(AI)と深層学習の原理
(途中ですが投稿します。)
※下書きにしないのは更新するモチベーション維持のためです。
下書きだと更新が見えないことから、頓挫しそうと考えるためです。
- 投稿日:2019-05-07T01:43:08+09:00
pythonで学歴と賃金の関係を簡単にプロットする
こんにちは、entershareの大森です。
大学の時に本当に少しだけPythonを触ったりしていましたが、最近ではRubyとPHPしか触っていない気がします。
今回は少しだけmatplotlibを使ってグラフを描画してみたいと思います。
単にデータをプロットしているだけなので入門と考えてください。また今回Jupyter Notebookを使用しています。
下記のInstallを見るとAnacondaとpipでのインストールが可能なようですが、Anacondaを使うのが簡単で公式サイトもおすすめしているようです。
https://jupyter.org/それではやっていきましょう。
必要なモジュールをインストール
まずは必要なモジュールをインポートしていきます。
今回はグラフを描画するために必要なmatplotlibと数値計算を簡単にしてくれるnumpyをインポートしています。# こう書くことでjupyter notebookの中でmatplotlibをいい感じに描画してくれる %matplotlib inline # matplotlibはグラフなどの描画モジュール import matplotlib.pyplot as plt # numpyは数値計算を効率的に行うためのモジュール import numpy as npひたすら数値を入れる
後はプロットする前にひたすら数値をいれていきます。
numpyの配列を使うことでmatplotlibで簡単に描画ができます。世代(generations)をX軸、全世代(average_data)、中学卒業後就職(junior_high)、高校卒業後就職(high_school)、短大・高専卒業後就職(short_university)、大学卒業後就職(univercity)のそれぞれの平均収入をY軸に描画する予定です。
なお使用したデータは厚生労働省の平成30年賃金構造基本統計調査になります。
generations = np.array([ '20-24', '25-29', '30-34', '35-39', '40-44', '45-49', '50-54', '55-59', '60-64', '65-69', '70-' ]) average_data = np.array([ 209.7, 240.3, 273.5, 301.7, 327.4, 352.4, 373.8, 370.3, 278.4, 245.3, 243.3 ]) junior_high = np.array([ 197.1, 217.4, 237.0, 256.9, 271.4, 285.7, 288.8, 292.1, 227.2, 206.6, 199.8 ]) high_school = np.array([ 195.5, 217.9, 240.0, 260.2, 281.3, 296.4, 309.2, 310.8, 237.1, 214.4, 209.3 ]) short_university = np.array([ 207.0, 229.5, 252.8, 273.5, 296.0, 320.4, 330.5, 325.8, 267.8, 250.0, 261.0 ]) university = np.array([ 226.9, 257.2, 306.8, 355.1, 405.3, 462.2, 513.2, 505.0, 375.2, 372.0, 443.0 ])グラフをプロット
最後にグラフをプロットします。
最初の3行はタイトル、X軸のラベル、Y軸のラベルを設定しています。次に
plt.plot()を使ってグラフを描画しています。
第1引数はX軸のデータ、第2引数はY軸のデータ、第3引数はグラフのラベルです。
plt.grid()を使うことで、グリットを表示させることもできます。また
plt.legend()で凡例(グラフのラベル)を表示させるともできます。
引数にloc = 'upper left'のように渡すことで位置の指定も可能です。plt.title('education and income') plt.xlabel('age') plt.ylabel('income') plt.plot(generations, average_data, label='all') plt.plot(generations, university, label='univercity') plt.plot(generations, junior_high, label='junior_highschool') plt.plot(generations, short_university, label='short_university') plt.plot(generations, high_school, label='high_school') plt.grid() plt.legend(loc = 'upper left')以上のコードを実行すると以下のようにプロットされます。
予想通りの結果ではあると思いますが、簡単に傾向を読み解いてみましょう。
やはり大学卒業後就職の場合の収入は、平均で飛び抜けて高いようです。
全体的な傾向としては50-54歳までは賃金は上昇傾向にあり、55を過ぎると横ばいに近づきます。
そして定年後はガクッと落ちるパターンがどの場合にも見受けられます。また目立つのが大学卒業後就職した人の収入が60~69で落ち込み、その後70歳をすぎると跳ね上がることです。
短大・高専卒業後就職の場合でもこのような傾向は多少ありますが、この2つ以外ではそのような傾向は見られません。こちらは賃金の調査なので年金などは含まれていないはずです。
それでもこのような結果が出るのは70歳を超えても、現役時に働いていた知識や経験を生かして価値を生み出せている可能性が1つ。
もしくはそもそも働いている人が少ないので、高い役職についていた人が引き続き働き、平均賃金を押し上げているというのが1つ。どちらなのか、もしくは他の答えがあるのかはこの表からだけではわかりません。
ただ雇用されて働く場合には、平均的にこのグラフのように賃金が変化することを頭にいれて人生設計をする必要はあるでしょう。それではまた!
全体のコード
最後に全体のコードを載せておきます。
# こう書くことでjupyter notebookの中でmatplotlibをいい感じに描画してくれる %matplotlib inline # matplotlibはグラフなどの描画モジュール import matplotlib.pyplot as plt # numpyは数値計算を効率的に行うためのモジュール import numpy as np generations = np.array([ '20-24', '25-29', '30-34', '35-39', '40-44', '45-49', '50-54', '55-59', '60-64', '65-69', '70-' ]) average_data = np.array([ 209.7, 240.3, 273.5, 301.7, 327.4, 352.4, 373.8, 370.3, 278.4, 245.3, 243.3 ]) university = np.array([ 226.9, 257.2, 306.8, 355.1, 405.3, 462.2, 513.2, 505.0, 375.2, 372.0, 443.0 ]) junior_high = np.array([ 197.1, 217.4, 237.0, 256.9, 271.4, 285.7, 288.8, 292.1, 227.2, 206.6, 199.8 ]) short_university = np.array([ 207.0, 229.5, 252.8, 273.5, 296.0, 320.4, 330.5, 325.8, 267.8, 250.0, 261.0 ]) high_school = np.array([ 195.5, 217.9, 240.0, 260.2, 281.3, 296.4, 309.2, 310.8, 237.1, 214.4, 209.3 ]) plt.title('education and income') plt.xlabel('age') plt.ylabel('income') plt.plot(generations, average_data, label='all') plt.plot(generations, university, label='univercity') plt.plot(generations, junior_high, label='junior_highschool') plt.plot(generations, short_university, label='short_university') plt.plot(generations, high_school, label='high_school') plt.grid() plt.legend(loc = 'upper left')
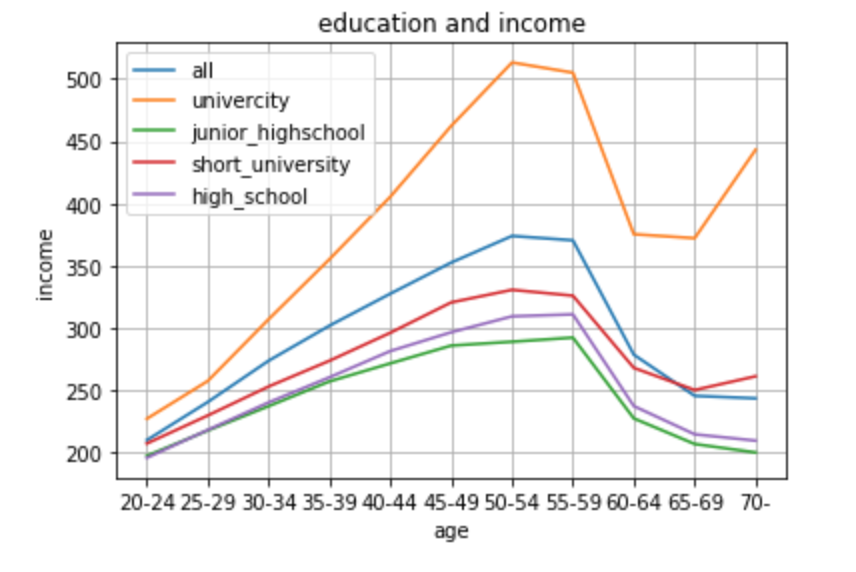
- 投稿日:2019-05-07T00:28:07+09:00
Twitter APIを使って自動でTweetする
AWSのLambdaなどサーバレス環境とTwitter APIを使って自動でTweetする仕組みの構築を目指す。
Twitterのドキュメントから、まず以下のステップで認証を行いTweetを行う必要がある。OAuth1.0に従ったフローのようだ。
- Request Tokenの取得
- Twitterの認証
- Access Tokenの取得
- Tweetを実行
Request Tokenの取得
- Resource URL
https://api.twitter.com/oauth/request_token- Method
Post- Authorization Header Parameters
以下のパラメータをAuthorizationヘッダーにセットする
Authorization: OAuth oauth_callback="http%3A%2F%2F127.0.0.1", oauth_nonce="...
- oauth_callback(必須)
APIに登録済みのコールバックURL
ユーザがTwitterの認証後にリダイレクトされる- x_auth_access_type(オプション)
アクセス権の設定
readもしくはwriteを設定可能- oauth_consumer_key(必須)
Twitter APIのAPI Key- oauth_signature_method(必須)
このリクエストの署名のアルゴリズム(HMAC-SHA1など)- oauth_signature(必須)
署名- oauth_timestamp(必須)
リクエスト発行時のUNIXTIME- oauth_nonce(必須)
リクエスト毎に一意なランダムな値- oauth_version(オプション)
1.0- Request Body
なし- サンプルコード
requests_oauthlibを使えば簡単だが、勉強がてら使わずに実装してみたget_request_token.pyimport time import base64 import os import uuid import hashlib import hmac import urllib.parse import requests REQUEST_URL = 'https://api.twitter.com/oauth/request_token' REQUEST_METHOD = 'POST' API_KEY = os.environ.get('API_KEY') API_SECRET = os.environ.get('API_SECRET') TOKEN_SECRET = '' CALLBACK_URL = os.environ.get('CALLBACK_URL') SIGNATURE_METHOD = 'HMAC-SHA1' def _create_timestamp(): return str(int(time.time())) def _create_nonce(): return str(uuid.uuid4()) def _create_base_string(params: dict): string = '' for key, val in sorted(params.items()): string += key + '=' + val + '&' return string.rstrip('&') def _convert_dict(dict_: dict): string = '' for key, val in dict_.items(): string += key + '="' + val + '", ' return string.rstrip(', ') def _create_signature(base_string: str): base_string = REQUEST_METHOD + '&' + urllib.parse.quote(REQUEST_URL, safe='') + '&' + urllib.parse.quote(base_string, safe='') key = API_SECRET + '&' + TOKEN_SECRET hashed_string = hmac.new(key.encode(), base_string.encode(), hashlib.sha1) return urllib.parse.quote(base64.standard_b64encode(hashed_string.digest()), safe='') def _create_authorization_params(): authorization_params = {} authorization_params['oauth_timestamp'] = _create_timestamp() authorization_params['oauth_consumer_key'] = urllib.parse.quote(API_KEY, safe='') authorization_params['oauth_nonce'] = _create_nonce() authorization_params['oauth_callback'] = urllib.parse.quote(CALLBACK_URL, safe='') authorization_params['oauth_signature_method'] = SIGNATURE_METHOD authorization_params['oauth_version'] = '1.0' authorization_params['oauth_signature'] = _create_signature(_create_base_string(authorization_params)) return authorization_params def _create_authorization_header(): authorization_header_val = 'OAuth ' params = _create_authorization_params() authorization_header_val += _convert_dict(params) return {'Authorization': authorization_header_val} def execute(): headers = _create_authorization_header() return requests.post(REQUEST_URL, headers=headers) result = _execute() print(result.text) # -> oauth_token=xxxxxxxxxxxxxxxx&oauth_token_secret=yyyyyyyyyyyyyyyyyyyyyyyyyyyyy&oauth_callback_confirmed=truerequests_oauthlibを使った場合は以下のように簡単に書ける
get_request_token_w_authlib.pyimport os import requests from requests_oauthlib import OAuth1Session from urllib.parse import parse_qsl REQUEST_URL = 'https://api.twitter.com/oauth/request_token' REQUEST_METHOD = 'POST' API_KEY = os.environ.get('API_KEY') API_SECRET = os.environ.get('API_SECRET') TOKEN_SECRET = '' CALLBACK_URL = os.environ.get('CALLBACK_URL') SIGNATURE_METHOD = 'HMAC-SHA1' twitter_api = OAuth1Session(API_KEY, API_SECRET) response = twitter_api.post(REQUEST_URL, params={'oauth_callback': CALLBACK_URL}) print(response.text) # -> oauth_token=xxxxxxxxxxxxxxxx&oauth_token_secret=yyyyyyyyyyyyyyyyyyyyyyyyyyyyy&oauth_callback_confirmed=trueここで取得したトークンを用いた以降の手続きは、次回以降でアップする予定です。
- 投稿日:2019-05-07T00:15:31+09:00
WEBアプリの勉強を兼ねてDjangoで備忘録登録アプリを作ってみる
◇この記事について
今回、初めての投稿となります(ホントは平成の間に初投稿といきたかったのですが、よくある日程遅延で令和までもつれ込みました・・)。
私自身プログラミング経験はあったんですが、WEBアプリ関係の知識がほとんどなかったため、知識・スキルを広げることを目的にこのアプリを作成してみました。
まずは、このアプリをベースにWEBアプリケーションに関する知識を少しずつ深めていければと思います。◇開発環境
- OS : Ubuntu 18.04.2 LTS(Windows Subsystem for Linux)
- 言語 : Python 3.6.7
- Webアプリフレームワーク : Django (2.2)
- DB : SQLite3
◇事前知識
- Python : 勉強始めて1年程度
- HTML/CSS/JavaScript : 勉強始めて2~3か月程度( 主にpaizaラーニング、ドットインストールを使って学習 )
- Django : Djangoドキュメントのはじめての Django アプリ作成をさらっと試した程度
◇実装内容
◆初期設定関係
Djangoのインストール手順は、はじめての Django アプリ作成に沿って進めていきました。細かい部分は省略しますが、以下のコマンドで、プロジェクトおよび備忘録用アプリを新規作成します。
Terminal$ django-admin startproject mysite $ python manage.py startapp memorandum次に、自動作成されたファイルの中にある
settings.pyを修正します。具体的には、
INSTALLED_APPS内へのmemorandum.apps.MemorandumConfigの追加LANGUAGE_CODEをjaに修正TIME_ZONEをAsia/Tokyoに修正を行っています。
mysite/mysite/settings.py---略--- # Application definition INSTALLED_APPS = [ 'memorandum.apps.MemorandumConfig', 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', ] ---略--- # Internationalization # https://docs.djangoproject.com/en/2.1/topics/i18n/ # LANGUAGE_CODE = 'en-us' LANGUAGE_CODE = 'ja' # TIME_ZONE = 'UTC' TIME_ZONE = 'Asia/Tokyo' USE_I18N = True USE_L10N = True USE_TZ = True ---略---
INSTALLED_APPS内へのmemorandum.apps.MemorandumConfigの追加ここでは、
mysite/memorandum/apps.py内にあるclass MemorandumConfigをプロジェクトに登録しています。
コード中にもあるように、name = 'memorandum'としているため、この名前(memorandum)で登録しても問題なさそう(実際、そうやっている説明サイトもある)でしたが、今回は参考にしたドキュメントに倣ってクラス名自体を記述しています。mysite/memorandum/apps.pyfrom django.apps import AppConfig class MemorandumConfig(AppConfig): name = 'memorandum'
TIME_ZONEをAsia/Tokyoに修正については、最初は修正をしてなかったんですが、一通りアプリができた後の検証作業でデータの追加日時がずれるという問題が発生したため、原因を調査して追加で修正しました。
この修正を行うことによって、日時が日本時刻で表示されるようになります。
※USE_TZ = Trueをしておくと、内部的に保存されるデータはUTCで保存される仕様のようです。USE_TZ = True TIME_ZONE = 'Asia/Tokyo'この設定の組み合わせで、
- 内部で保存されるデータはUTC
- 表示される日時データは日本時刻に自動変換される
という形になります。
参考URL:Djangoで、タイムゾーンの変換
◆ファイル構成
treeコマンド実行時のターミナル出力結果(__pycache__下のファイルなどは削ってます)を下に載せます。自分で明示的に追加・修正した部分については、<-でコメントを追記してます。Terminal$ tree mysite/ mysite/ ├── db.sqlite3 ├── manage.py ├── memorandum │ ├── __init__.py │ ├── __pycache__ │ ├── admin.py │ ├── apps.py │ ├── migrations │ │ ├── 0001_initial.py │ │ ├── __init__.py │ │ └── __pycache__ │ ├── models.py <-データベース内容定義等 │ ├── static │ │ └── memorandum │ │ └── css │ │ └── memorandum.css <-スタイルシート用ファイル │ ├── templates │ │ └── memorandum │ │ ├── base-layout.html <-レイアウト用ファイル │ │ ├── create-tag.html <-新規タグ作成ページ │ │ ├── create.html <-新規記事作成ページ │ │ ├── delete.html <-記事削除ページ │ │ ├── detail.html <-記事詳細表示ページ │ │ ├── index.html <-トップページ(記事一覧表示) │ │ └── update.html <-記事内容修正ページ │ ├── tests.py │ ├── urls.py <-memorandum内のルーティング定義等 │ └── views.py <-各関数のメイン処理定義等 └── mysite ├── __init__.py ├── __pycache__ ├── settings.py <-言語設定、タイムゾーン設定等の定義(前述のとおり) ├── urls.py <-mysiteプロジェクト全体のルーティング定義等 └── wsgi.py◆データベースのモデル定義(models.py)
モデルの定義として、
ArticleクラスとTagクラスの2つに分けて作成しました。
Tagクラスを分けたのは、一つの記事に複数のタグが登録できるようにしたいという考えからです。
Tagクラスでは、タグ名(name)のみを保存し、
メインのデータベースとなるArticleクラスでは、
- タイトル(
title)- タグ名(
tag)- 本文(
body)- 作成日(
published_date)- 更新日(
modified_date)を定義し、タグ名(
tag)については、TagクラスをManyToManyFieldを付けて参照しています。
ManyToManyField を付けることによって、多対多の関係で紐づけが可能になります。参考URL:Django2.0 ManyToMany(多対多)リレーションを使う
また、作成日(
published_date)はauto_now_add=True、更新日(modified_date)はauto_now=Trueのオプションを付けています。
auto_now_add=True:データが新規作成される際に、その時の日付が自動で設定されます。auto_now=True:データが新規作成または更新される際に、その時の日付が自動で設定されます。これらのオプションを付けておくと、新規記事作成ページなどで作成日(
published_date)と更新日(modified_date)のフォームを追加せずに自動で値が設定されます。参考URL:モデルフィールドリファレンス
models.pyfrom django.db import models # Create your models here. class Tag(models.Model): name = models.CharField(max_length=128, unique=True) def __str__(self): return self.name class Article(models.Model): title = models.CharField(max_length=255) tag = models.ManyToManyField(Tag) body = models.TextField() published_date = models.DateField(auto_now_add=True) modified_date = models.DateField(auto_now=True) #これ入れないと、リスト一覧でタイトル名が表示されない def __str__(self): return self.title
models.pyの修正が終わったら、以下コマンドを実行し、修正したモデル定義をプロジェクトに反映させます。Terminal$ python manage.py makemigrations $ python manage.py migrate◆URLルーティングの定義(urls.py)
まず、
mysite下のurls.pyで、全体のURLルーティングを設定します。mysite/urls.py"""mysite URL Configuration The `urlpatterns` list routes URLs to views. For more information please see: https://docs.djangoproject.com/en/2.1/topics/http/urls/ Examples: Function views 1. Add an import: from my_app import views 2. Add a URL to urlpatterns: path('', views.home, name='home') Class-based views 1. Add an import: from other_app.views import Home 2. Add a URL to urlpatterns: path('', Home.as_view(), name='home') Including another URLconf 1. Import the include() function: from django.urls import include, path 2. Add a URL to urlpatterns: path('blog/', include('blog.urls')) """ from django.contrib import admin from django.urls import include, path urlpatterns = [ path('memorandum/', include('memorandum.urls')), path('admin/', admin.site.urls), ]
urlpatternsにpath('memorandum/', include('memorandum.urls')),を追加することにより、WEBアプリのmemorandum/下にアクセスが来た場合、memorandum下のurls.pyのルールが適用されるようになります。次に、
memorandum/のURLルーティングを設定します。memorandum/urls.pyfrom django.urls import path from . import views app_name = "memorandum" urlpatterns = [ # path("", views.index, name="index"), path("", views.ArticleListView.as_view(), name="index"), path("create/", views.ArticleCreateView.as_view(), name="create"), path("<int:pk>/detail/", views.ArticleDetailView.as_view(), name="detail"), path("<int:pk>/update/", views.ArticleUpdateView.as_view(), name="update"), path("<int:pk>/delete/", views.ArticleDeleteView.as_view(), name="delete"), path("tag/create/", views.TagCreateView.as_view(), name="create_tag"), ]この記載をすることにより、例えば、
memorandum/create/にアクセスがあった場合、views.py内のArticleCreateView.as_view()関数が呼び出されるといった動作になります。
name="create"で名前を付けておくことによって、HTML内のhrefなどでその名前を使ってリンクさせることが可能になります。◆ビュー関数の定義(views.py)
views.pyで、それぞれのページアクセス時にどのデータを表示するか記述していきます。
ちなみに、今回はDjangoでサポートしているクラスベースビューというものを使用しています。
※このクラスベースビュー機能は、ListViewやCreateViewなど汎用的なビュークラスについてあらかじめDjnagoで定義されており、これらのクラスを使うことにより、実装作業を効率化できるというものです。参考URL:Djangoにおけるクラスベース汎用ビューの入門と使い方サンプル
views.pyfrom django.shortcuts import render,redirect from django.urls import reverse_lazy from django.http import HttpResponse from django.views import generic from .models import Tag, Article class ArticleListView(generic.ListView): model = Article #参照するhtmlファイルを指定 template_name = "memorandum/index.html" class ArticleDetailView(generic.DetailView): model = Article #参照するhtmlファイルを指定 template_name = "memorandum/detail.html" class ArticleCreateView(generic.edit.CreateView): model = Article fields = ["title","tag","body"] #参照するhtmlファイルを指定 template_name = "memorandum/create.html" success_url = reverse_lazy('memorandum:index') #POSTが正しく行われた際に飛ばすURL class ArticleUpdateView(generic.edit.UpdateView): model = Article fields = ["title","tag","body"] #参照するhtmlファイルを指定 template_name = "memorandum/update.html" success_url = reverse_lazy('memorandum:index') #POSTが正しく行われた際に飛ばすURL class ArticleDeleteView(generic.edit.DeleteView): model = Article #参照するhtmlファイルを指定 template_name = "memorandum/delete.html" success_url = reverse_lazy('memorandum:index') #POSTが正しく行われた際に飛ばすURL class TagCreateView(generic.edit.CreateView): model = Tag fields = ["name"] #参照するhtmlファイルを指定 template_name = "memorandum/create-tag.html" success_url = reverse_lazy('memorandum:index') #POSTが正しく行われた際に飛ばすURLそれぞれのクラスの最初の
model = Articleormodel = Tagで使用するモデル定義を選択しており、最低限、これだけでリスト等の表示が行えますが、必要に応じてデフォルト設定から書き換えたい部分については、書き換えていく形になります。
template_nameはページアクセス時に返すhtmlファイルのローカル側のパスになります(デフォルトではクラス名_list.htmlのような名前のhtmlファイルを探してしまうようなので、基本的に明示的に設定してあげた方がいいかと思います)。success_urlはUpdateViewやCreateViewの際に使用されるもので、保存実行時に正常に終了した場合に遷移させるページのURLになるようです。reverse_lazyは、'memorandum:index'などで定義したルーティング情報をURLに変換する関数のようです(完全に理解できてない・・)。
参考サイトを読んだ限りでは、success_urlで設定する場合、reverse関数ではなく、reverse_lazy関数を使う必要があるとのことだったので、それに倣っています。参考URL:[Django] success_urlとget_success_urlおよびreverseとreverse_lazyの使い分け
◆テンプレート(HTMLファイル)の作成
最後に、HTMLファイルとCSSファイルの作成を行います。全てのHTMLページを載せると記事が冗長になるため、いくつかかいつまんで載せていきます。
□
base-layout.htmlの作成ページタイトル、ロゴ画面については、共通テンプレートを使用して記述しています。
base-layout.html{% load static %} <!DOCTYPE html> <html lang="ja"> <head> <link rel="stylesheet" href="{% static 'memorandum/css/memorandum.css' %}"> <title>{% block title %}Memo Site{% endblock title %}</title> {% block head %}{% endblock head %} </head> <body> <header> <div class="top-title"> <a class="home-link-text" href="{% url 'memorandum:index' %}">備忘録登録サイト</a> </div> {% block header %} {% endblock header %} </header> <div class="main-content"> {% block content %} {% endblock content %} </div> </body> </html>□トップページ(記事一覧表示)
index.htmlの作成
object_list内にモデル定義したデータが入っているため、forループで中のアイテムを一つづつ取り出し、そのデータを表示しています。
それぞれの要素については、models.pyで定義した変数名(titleなど)を{{ item.title }}という形で指定すればそのデータが表示されます。index.html{% extends 'memorandum/base-layout.html' %} {% block content %} <div class="local-nav"> <ul class="local-nav-list"> <li class="local-nav-item"><a class="local-nav-link-text item-normal" href="{% url 'memorandum:create' %}">新規記事</a></li> <li class="local-nav-item"><a class="local-nav-link-text item-normal" href="{% url 'memorandum:create_tag' %}">新規TAG</a></li> </ul> </div> <ul class="article-list"> {% for item in object_list %} <li class="article-list-item"> <a class="link-text" href="{% url 'memorandum:detail' item.pk %}">{{ item.title }}</a> <div class="article-date">作成日: {{ item.published_date|date:"Y年m月d日(D)" }}<br>更新日: {{ item.modified_date|date:"Y年m月d日(D)" }}</div> </li> {% endfor %} </ul> {% endblock content %}
□記事詳細表示ページ
detail.htmlの作成基本的には、
index.html同様、{{ object.title }}といった形で表示したいデータを指定します。
今回は、一つの記事の詳細を表示する形なのでforループは不要です。
また、{{ object.body | linebreaks }}のように、linebreaksを入れることにより、フォームで入力した改行コードがHTML表示に反映されます。参考URL:Django: 組み込みタグとフィルタの一覧
detail.html{% extends 'memorandum/base-layout.html' %} {% block content %} <div class="local-nav"> <ul class="local-nav-list"> <li class="local-nav-item"><a class="local-nav-link-text item-normal" href="{% url 'memorandum:update' object.pk %}">編集</a></li> <li class="local-nav-item"><a class="local-nav-link-text item-caution" href="{% url 'memorandum:delete' object.pk %}">削除</a></li> </ul> </div> <div class="main-article"> <h1 class="article-title">{{ object.title }}</h3> <ul class="article-tag-group"> タグ: {% for tag in object.tag.all %} <li> <div class="article-tag">{{ tag }}</div> </li> {% endfor %} </ul> <div class="article-date"> <span class="">作成日: {{ object.published_date|date:"Y年m月d日(D)" }}</span> <span class="">更新日: {{ object.modified_date|date:"Y年m月d日(D)" }}</span> </div> <p class="article-body">{{ object.body | linebreaks }}</p> </div> {% endblock content %}
□新規記事作成ページ
create.htmlの作成
create.htmlでは、フォームを使用してデータの追加をしていきます。
{{ form.title }}という形でタイトル用の入力フォームを表示できます。
また、{{ form.title.label_tag }}というようにlabel_tag を付けると、その要素の名前が表示されます。create.html{% extends 'memorandum/base-layout.html' %} {% block content %} <div class="main-article"> <form method="post">{% csrf_token %} <div class="input-form"> <div class="input-form-position partition-bottom-line"> <span class="input-label-text">{{ form.title.label_tag }}</span> <div class="input-form-title">{{ form.title }}</div> </div> <div class="input-form-tag-group partition-bottom-line"> <div class="input-form-position"> <span class="input-label-text">{{ form.tag.label_tag }}</span> <div class="input-form-tag">{{ form.tag }}</div> </div> <a class="update-inner-link-text item-normal" href="{% url 'memorandum:create_tag' %}">Add New TAG</a> </div> <div class="input-form-position partition-bottom-line"> <span class="input-label-text">{{ form.body.label_tag }}</span> <div class="input-form-body">{{ form.body }}</div> </div> </div> <!-- {{ form.as_p }} --> <input class="button-common" type="submit" value="Save"> </form> </div> {% endblock content %}
update、deleteについては今回は割愛します。
ここまでの作業で備忘録の新規追加、一覧表示、詳細表示、記事修正、削除の機能をもつWEBアプリを作成することができました。
※TAGについては、現状createしかできず、TAGを削除する場合はadminサイトから行う必要があるため、今後直していければと思います◇その他、参考にした記事
- Djangoの 汎用クラスビューをまとめて、実装について言及する
- [Django]NoReverseMatch ‘hoge’ is not a valid view function or pattern name.とエラーが出た時の確認事項
◇今後追加したい機能
- タイトル検索、タグ検索機能の実装(現状、タグが役に立っていない・・)。
- タグの管理メニュー(現状追加しかできない・・)。
- 新規タグ追加画面からタグを追加した場合にtopページに飛んでしまうため、その点の修正。
- フォームの改善(forms.pyの作成)。
- CSSフレームワーク(Bootstrapなど)の導入(今回のアプリレベルでcssファイルが雑多になってきたため・・)
⇒フレームワークどーせ入れるならSass(SCSS or SASS)も試してみたい。◇最後に
- 今回、初めての投稿となったわけですが、記事作成に想定よりも時間がかかるというのを改めて痛感しました(結局、GW最終日の夜中まで掛かった)。。
- 私よりわかりやすい記事を書いている方々の凄さを実感するとともに、そんな記事を載せてくれる人達のありがたみがを再認識できるGWとなりました。
- Djangoについては、Qiita内でも多くの記事が既に出ていますので、そちらの方が参考になるかとは思いますが、少しでも参考になる方がいれば幸いです。