$ jekyll new abc
Running bundle install in /Users/***/work/github/new-github-page...
Bundler: Fetching gem metadata from https://rubygems.org/...........
Bundler: Fetching gem metadata from https://rubygems.org/.
Bundler: Resolving dependencies...
Bundler: Using public_suffix 3.0.3
Bundler: Using addressable 2.6.0
Bundler: Using bundler 2.0.1
Bundler: Using colorator 1.1.0
Bundler: Using concurrent-ruby 1.1.4
Bundler: Using eventmachine 1.2.7
Bundler: Using http_parser.rb 0.6.0
Bundler: Using em-websocket 0.5.1
Bundler: Using ffi 1.10.0
Bundler: Using forwardable-extended 2.6.0
Bundler: Using i18n 0.9.5
Bundler: Using rb-fsevent 0.10.3
Bundler: Using rb-inotify 0.10.0
Bundler: Using sass-listen 4.0.0
Bundler: Using sass 3.7.3
Bundler: Using jekyll-sass-converter 1.5.2
Bundler: Using ruby_dep 1.5.0
Bundler: Using listen 3.1.5
Bundler: Using jekyll-watch 2.1.2
Bundler: Using kramdown 1.17.0
Bundler: Using liquid 4.0.1
Bundler: Using mercenary 0.3.6
Bundler: Using pathutil 0.16.2
Bundler: Using rouge 3.3.0
Bundler: Using safe_yaml 1.0.4
Bundler: Using jekyll 3.8.5
Bundler: Using jekyll-feed 0.11.0
Bundler: Using jekyll-seo-tag 2.5.0
Bundler: Using minima 2.5.0
Bundler: Bundle complete! 4 Gemfile dependencies, 29 gems now installed.
Bundler: Use `bundle info [gemname]` to see where a bundled gem is installed.The dependency tzinfo-data (>= 0) will be unused by any of the platforms Bundler is installing for. Bundler is installing for ruby but the dependency is only for x86-mingw32, x86-mswin32, x64-mingw32, java. To add those platforms to the bundle, run `bundle lock --add-platform x86-mingw32 x86-mswin32 x64-mingw32 java`.
Bundler: Following files may not be writable, so sudo is needed:
Bundler: /Library/Ruby/Gems/2.3.0
Bundler: /Library/Ruby/Gems/2.3.0/build_info
Bundler: /Library/Ruby/Gems/2.3.0/cache
Bundler: /Library/Ruby/Gems/2.3.0/doc
Bundler: /Library/Ruby/Gems/2.3.0/extensions
Bundler: /Library/Ruby/Gems/2.3.0/gems
Bundler: /Library/Ruby/Gems/2.3.0/specifications
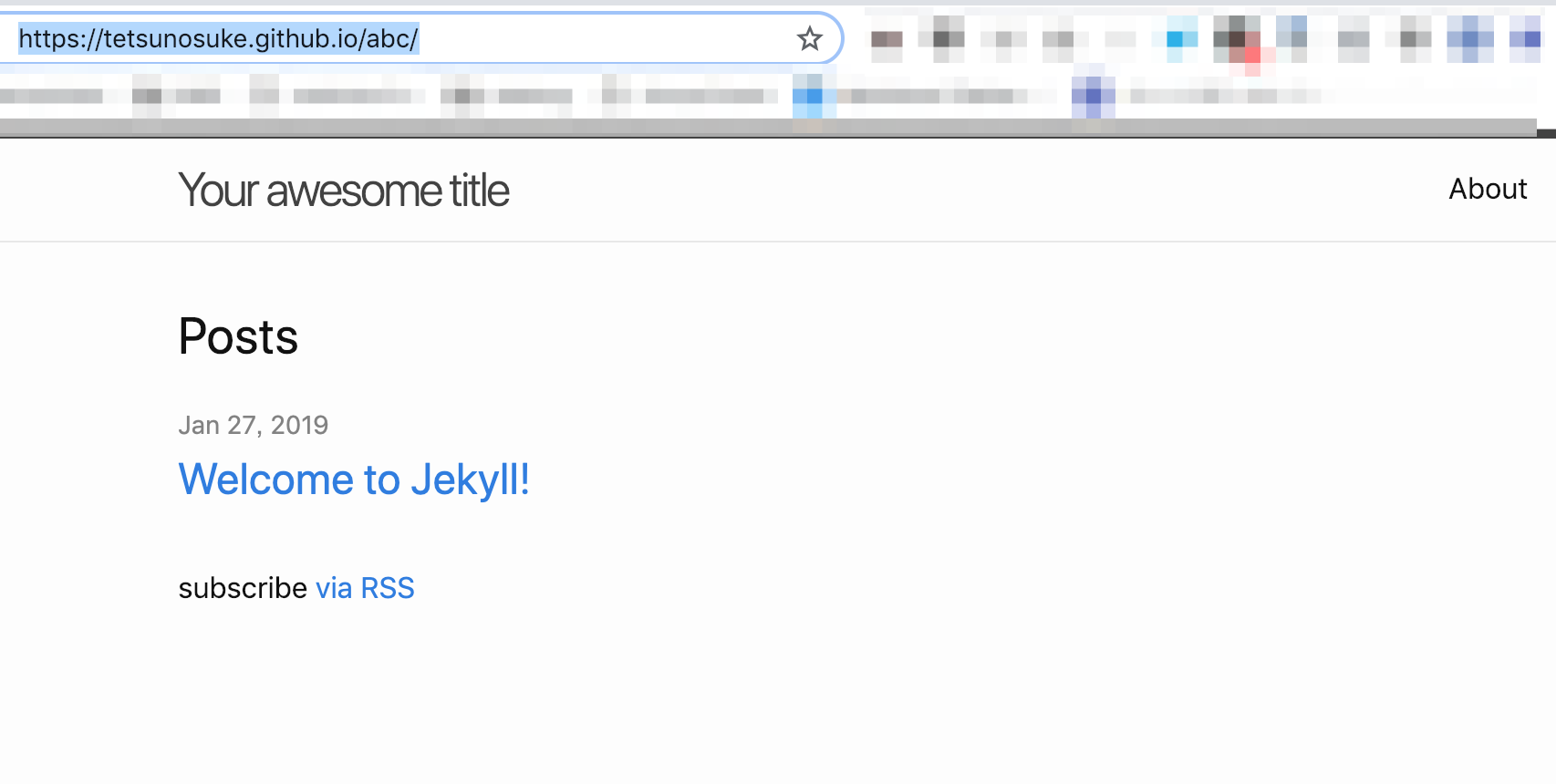
New jekyll site installed in /Users/***/work/github/abc.