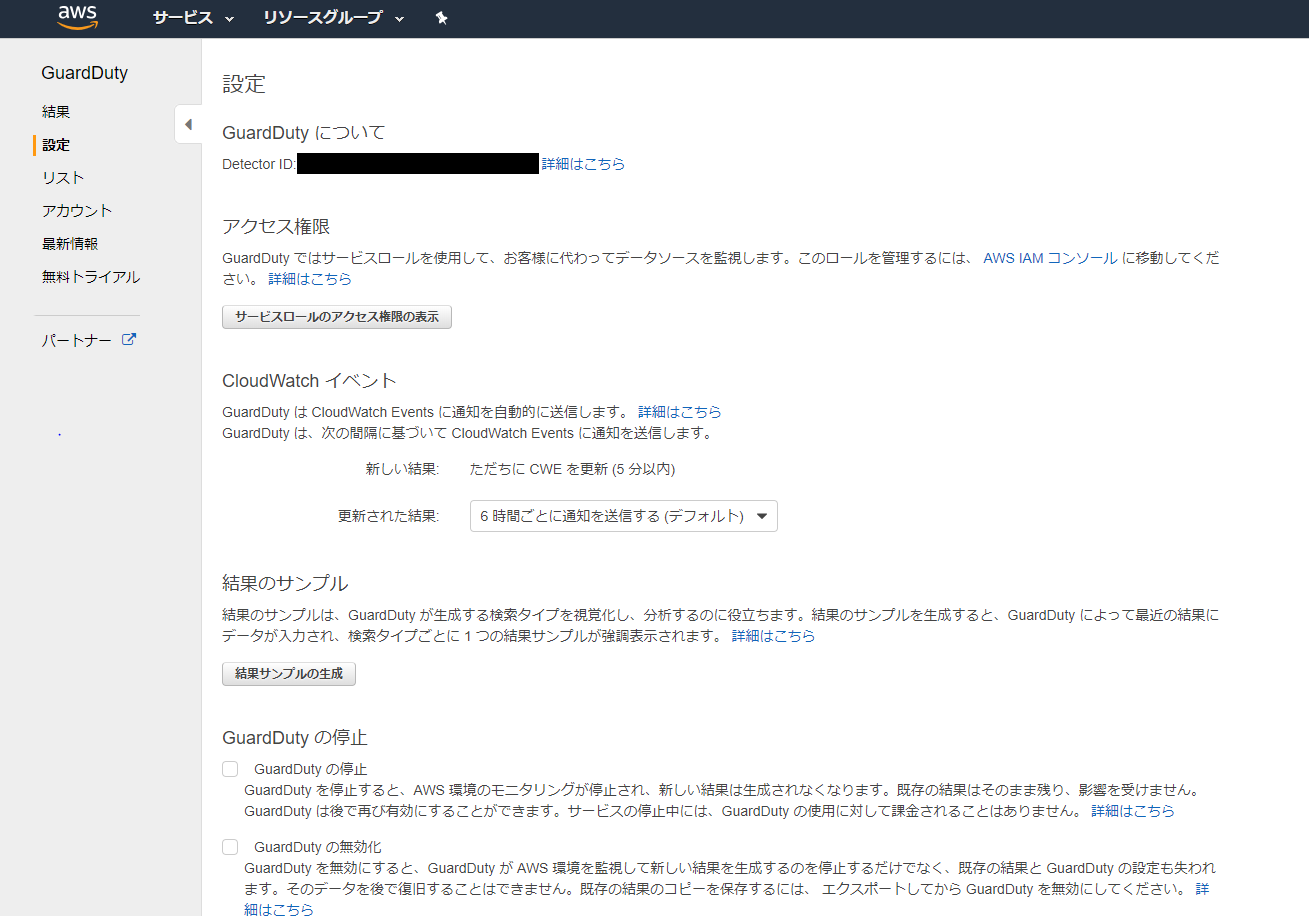
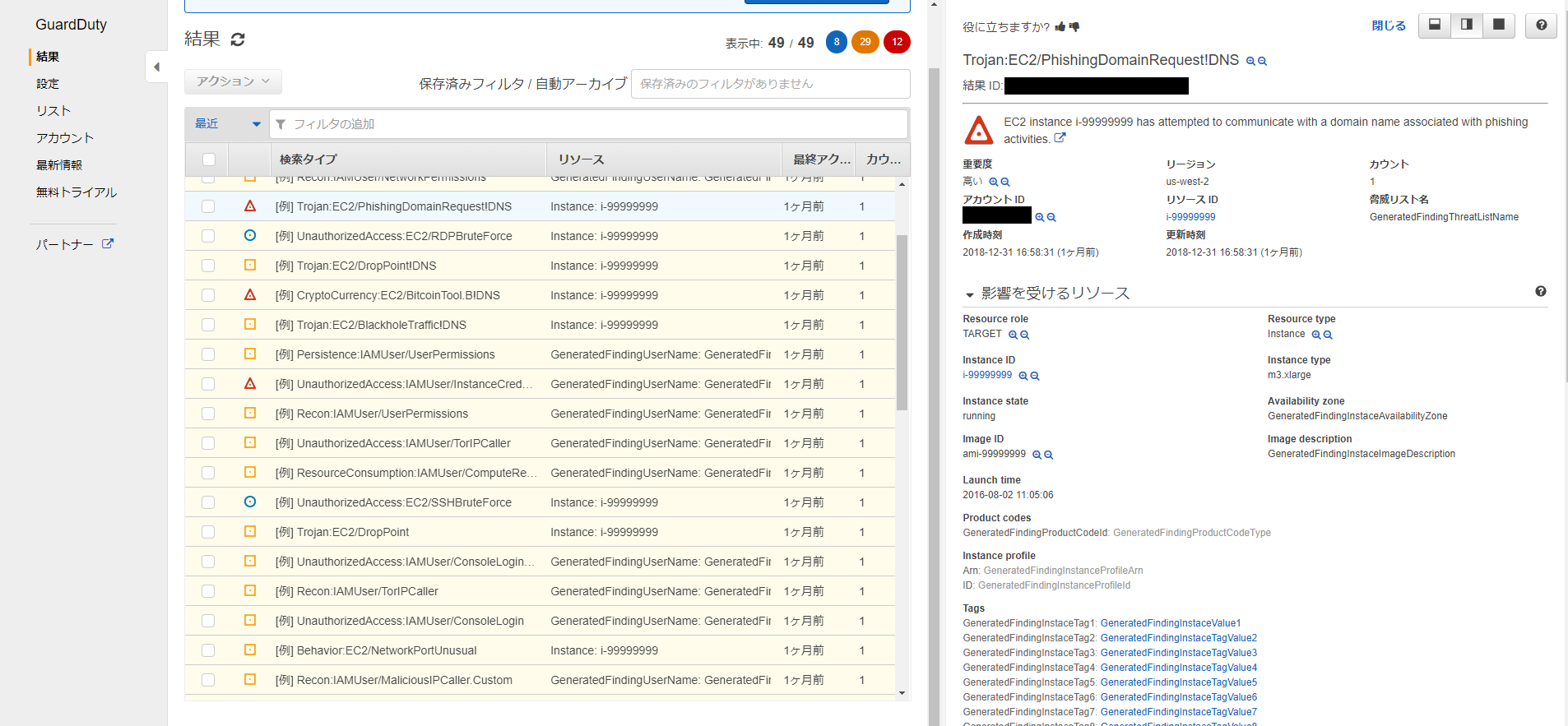
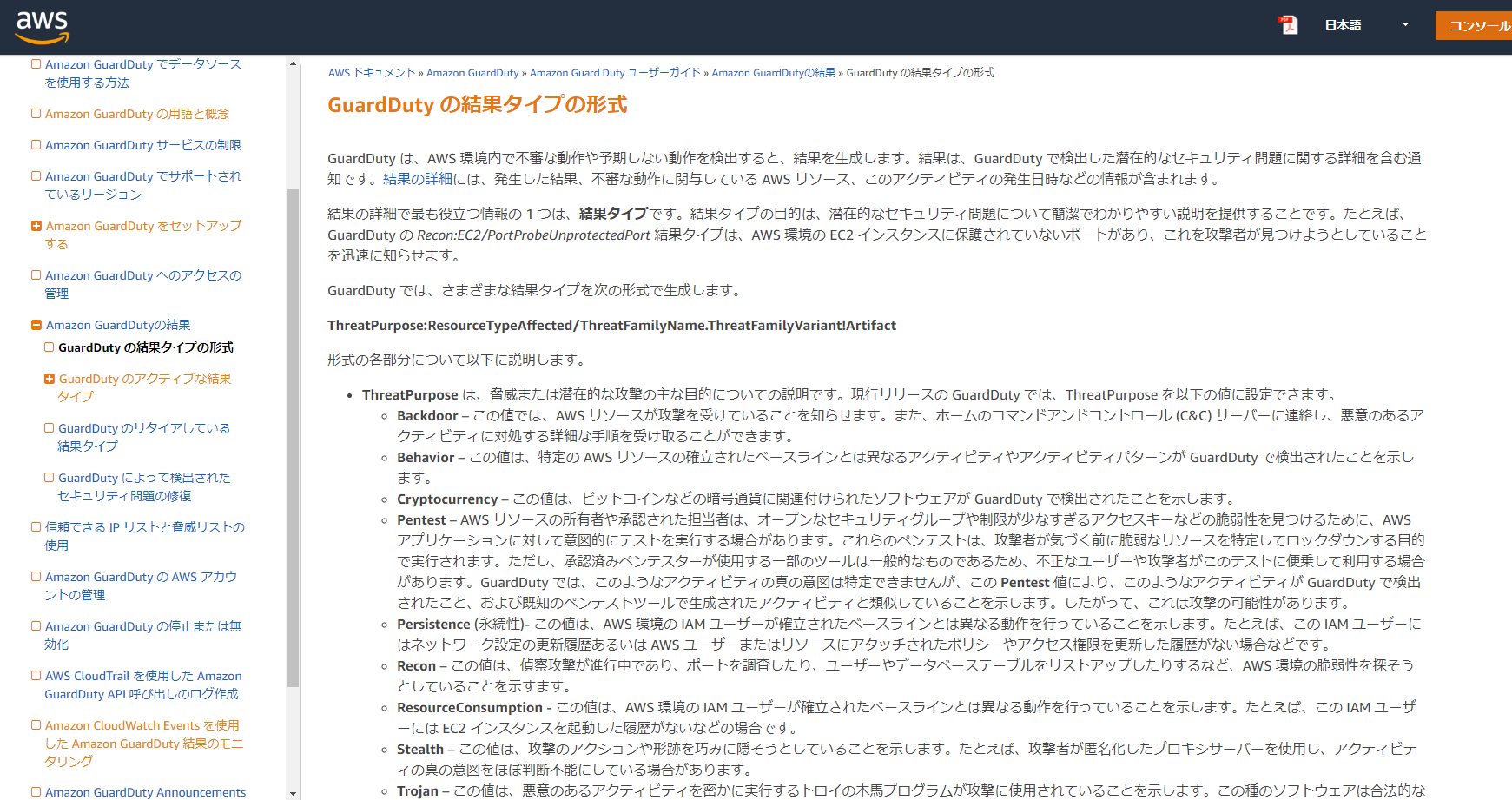
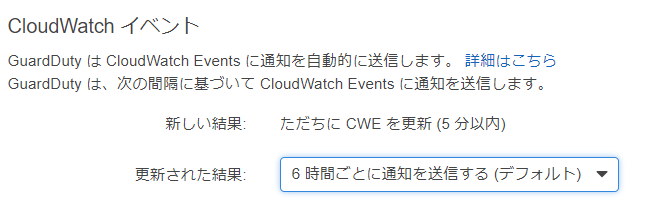
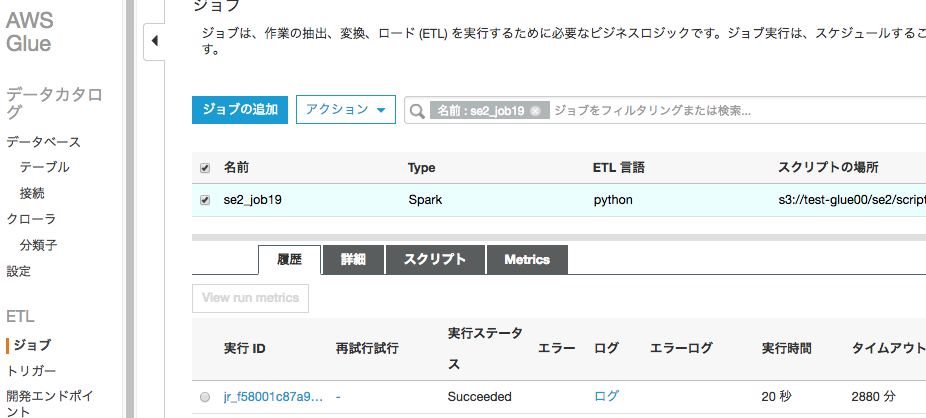
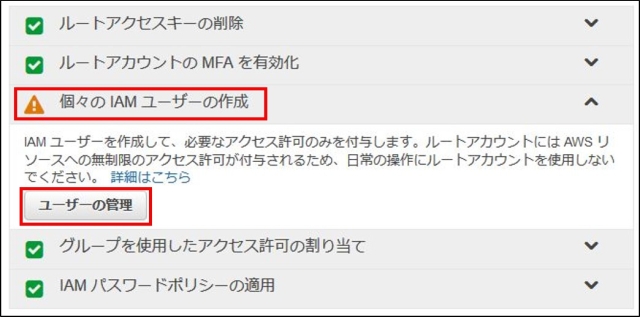
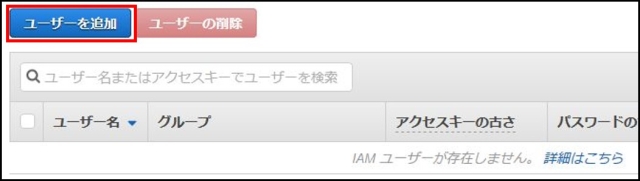
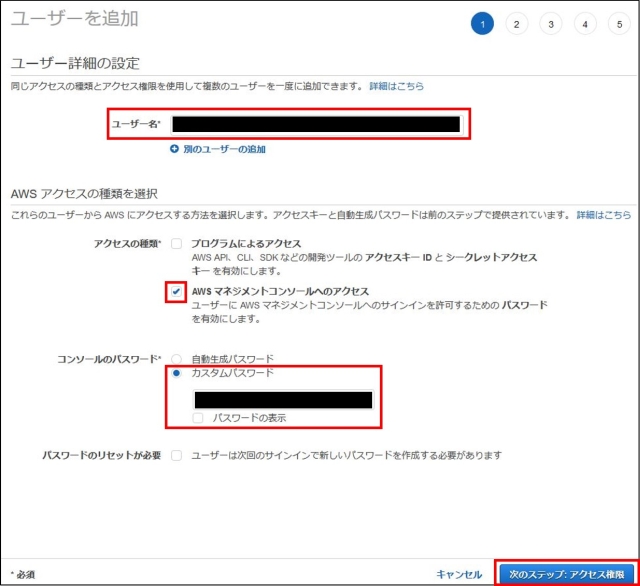
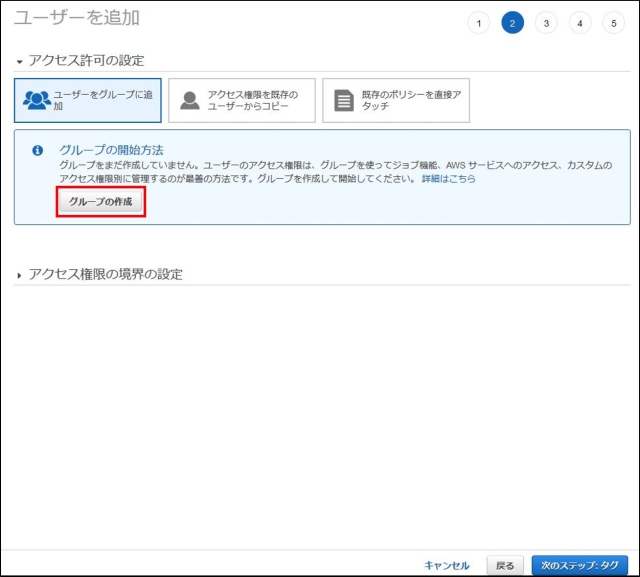
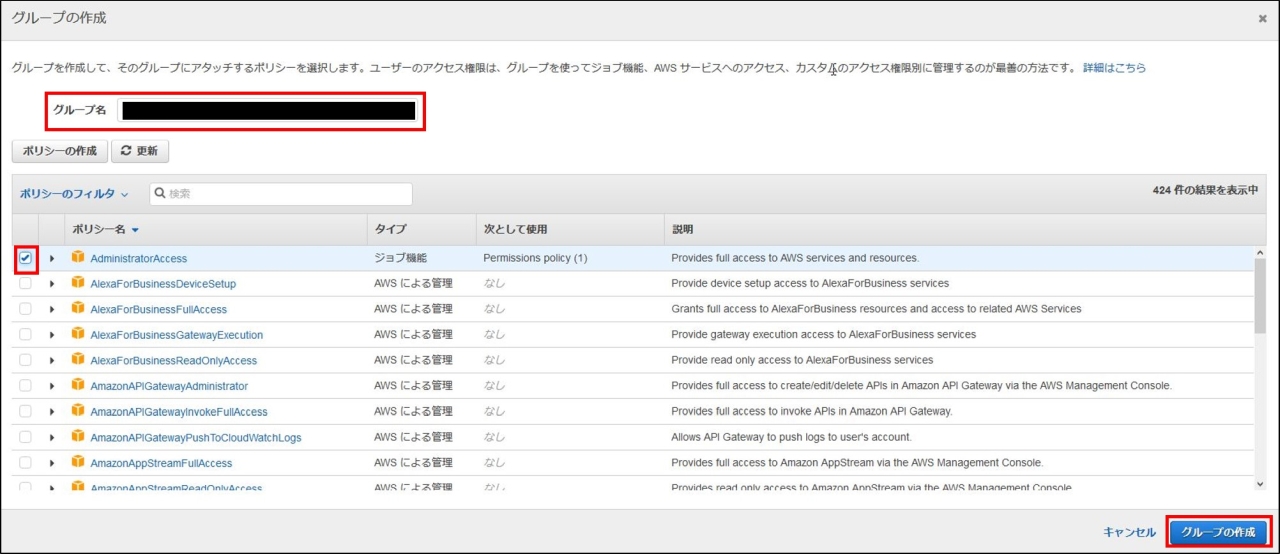
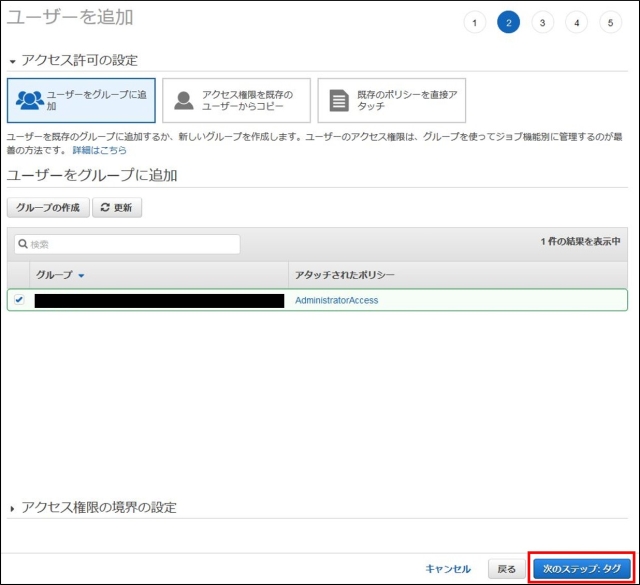
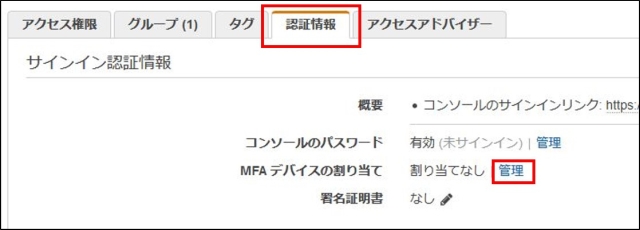
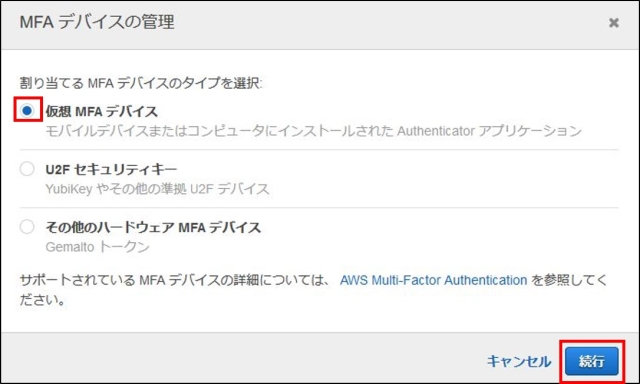
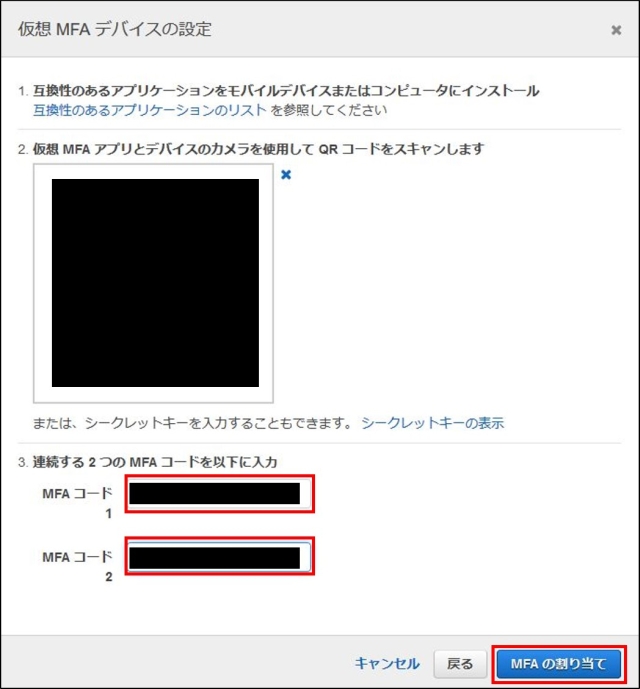
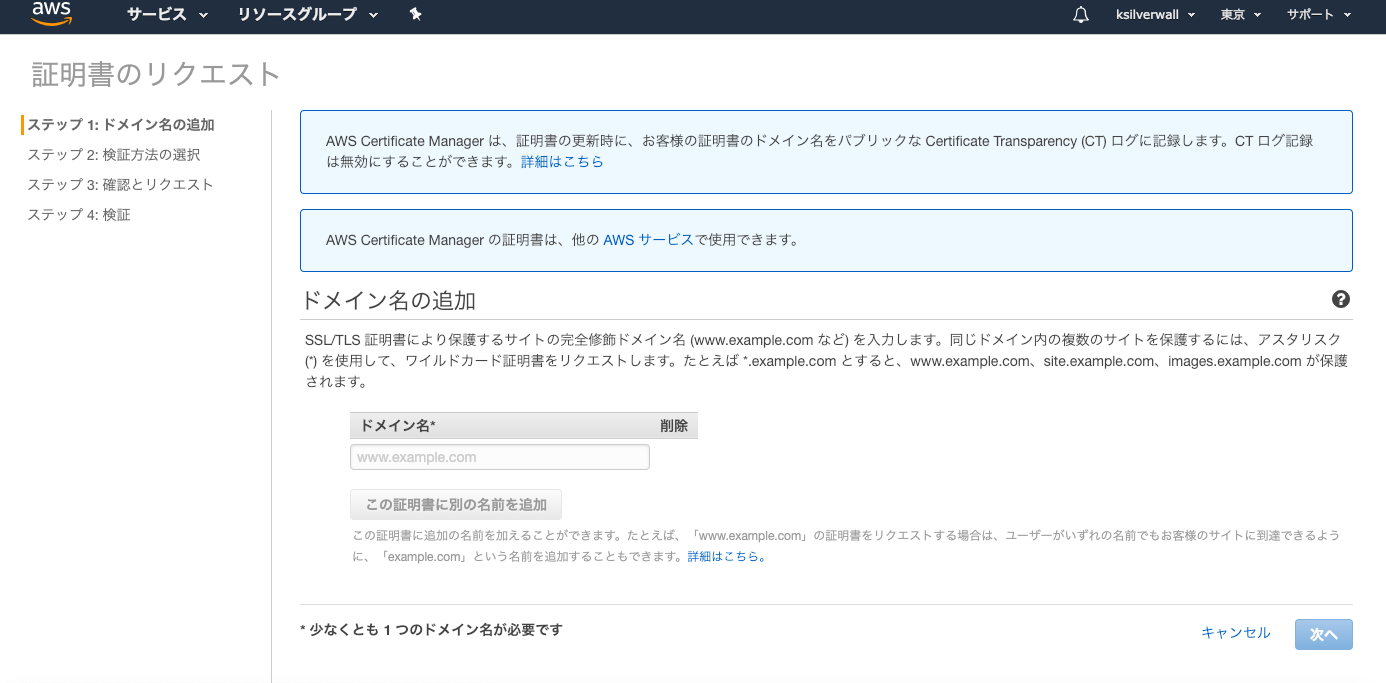
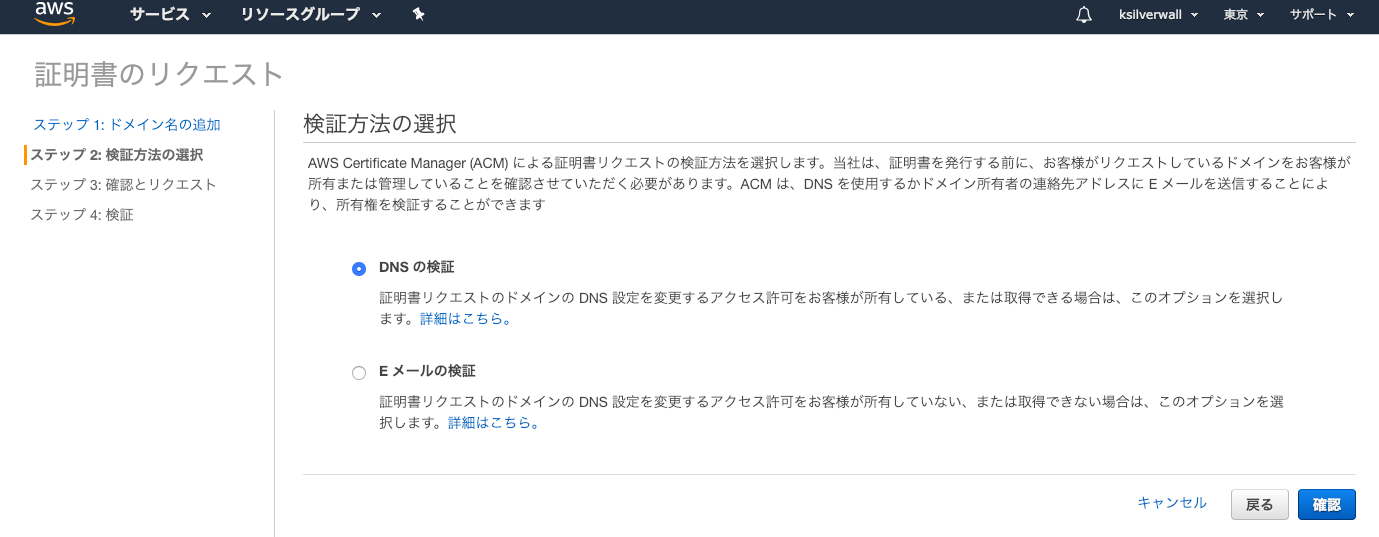
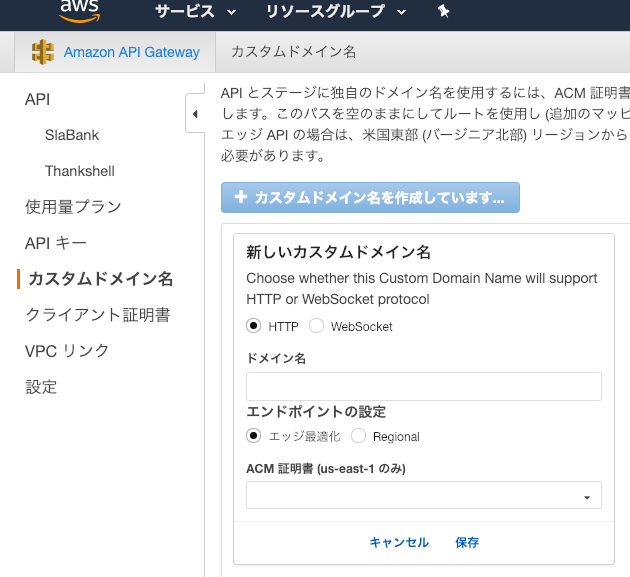
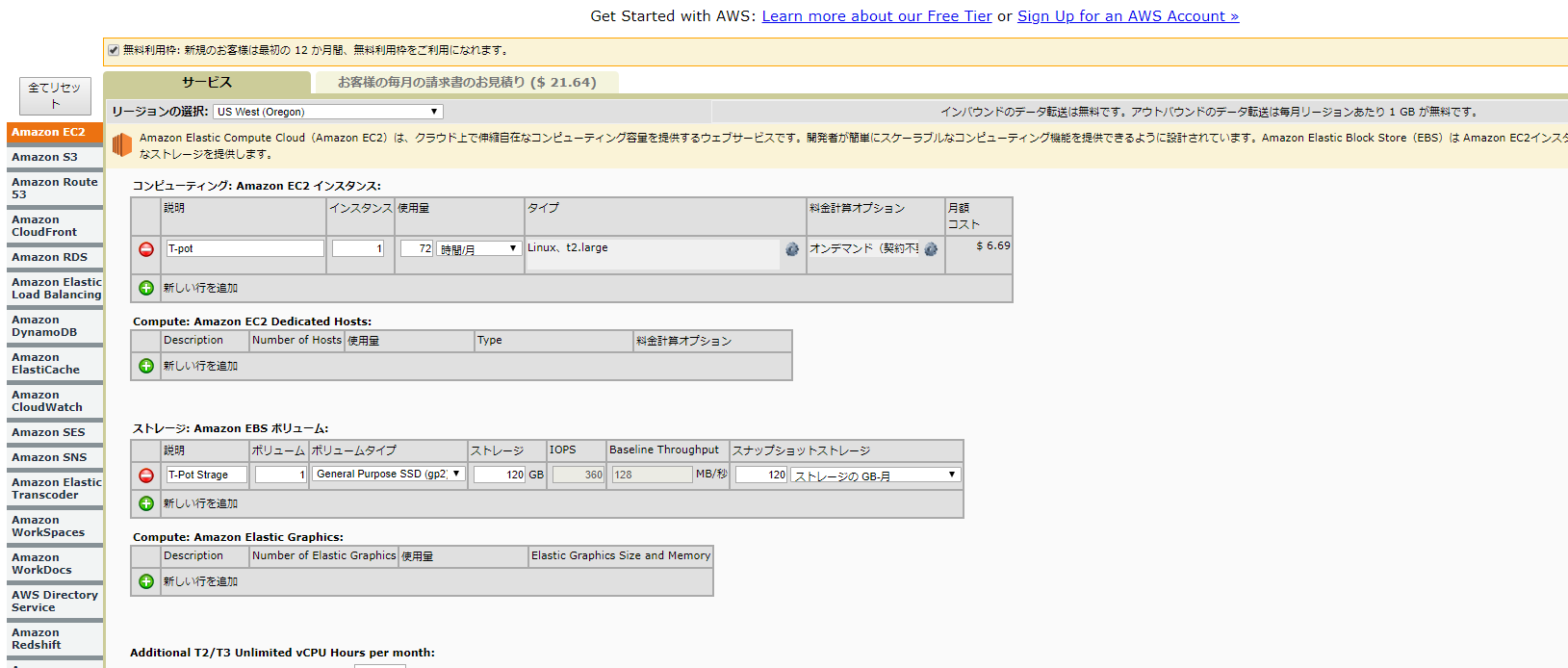
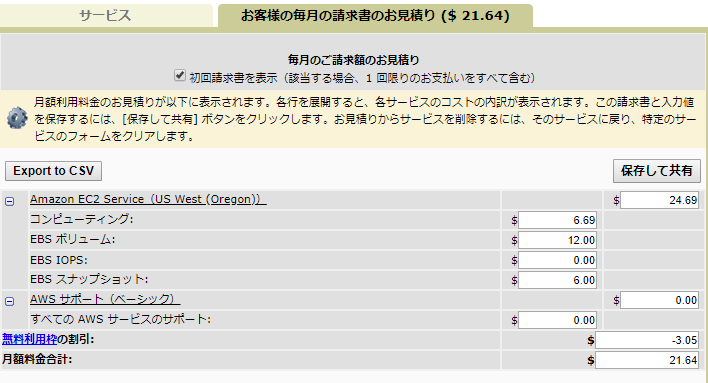
IAMはIdentity and Access Managementの略。AWSへのアクセス権限を人やAWS以外のサーバに付与するためのもの。ただ、自分一人しか使わない場合でも、常にAWSアカウントを作った時のルートユーザで作業し続けるのは危険なので、最低限の権限を与えたIAMユーザで作業するのがベストプラクティスらしい。
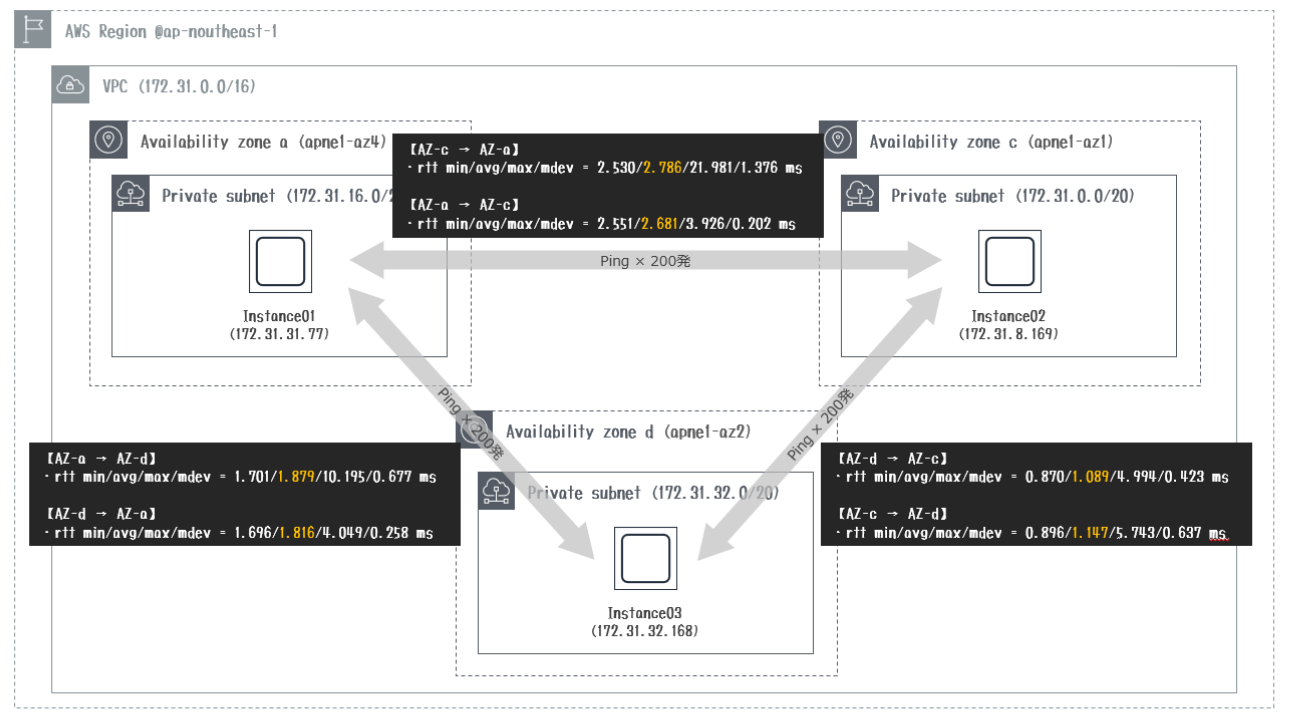
[ec2-user@ip-172-31-31-77 ~]$ ping 172.31.8.169
PING 172.31.8.169 (172.31.8.169) 56(84) bytes of data.
64 bytes from 172.31.8.169: icmp_seq=1 ttl=255 time=2.89 ms
64 bytes from 172.31.8.169: icmp_seq=2 ttl=255 time=2.58 ms
64 bytes from 172.31.8.169: icmp_seq=3 ttl=255 time=2.70 ms
64 bytes from 172.31.8.169: icmp_seq=4 ttl=255 time=2.62 ms
64 bytes from 172.31.8.169: icmp_seq=5 ttl=255 time=2.55 ms
<以下省略>
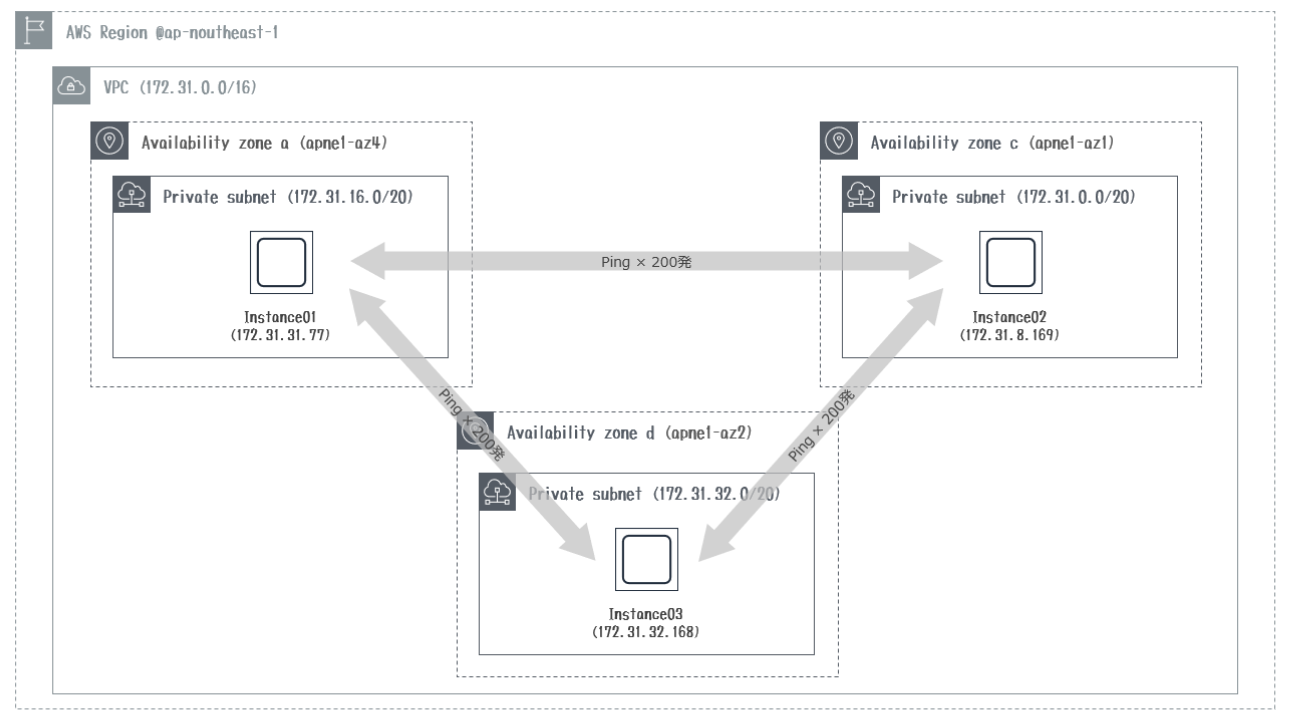
②AZ-a(az4)→AZ-d(az2)
[ec2-user@ip-172-31-31-77 ~]$ ping 172.31.32.168
PING 172.31.32.168 (172.31.32.168) 56(84) bytes of data.
64 bytes from 172.31.32.168: icmp_seq=1 ttl=255 time=1.73 ms
64 bytes from 172.31.32.168: icmp_seq=2 ttl=255 time=1.74 ms
64 bytes from 172.31.32.168: icmp_seq=3 ttl=255 time=1.73 ms
64 bytes from 172.31.32.168: icmp_seq=4 ttl=255 time=1.76 ms
64 bytes from 172.31.32.168: icmp_seq=5 ttl=255 time=1.81 ms
<以下省略>
③AZ-d(az2)→AZ-c(az1)
[ec2-user@ip-172-31-32-168 ~]$ ping 172.31.8.169
PING 172.31.8.169 (172.31.8.169) 56(84) bytes of data.
64 bytes from 172.31.8.169: icmp_seq=1 ttl=255 time=1.07 ms
64 bytes from 172.31.8.169: icmp_seq=2 ttl=255 time=1.07 ms
64 bytes from 172.31.8.169: icmp_seq=3 ttl=255 time=0.930 ms
64 bytes from 172.31.8.169: icmp_seq=4 ttl=255 time=0.943 ms
64 bytes from 172.31.8.169: icmp_seq=5 ttl=255 time=1.03 ms
<以下省略>
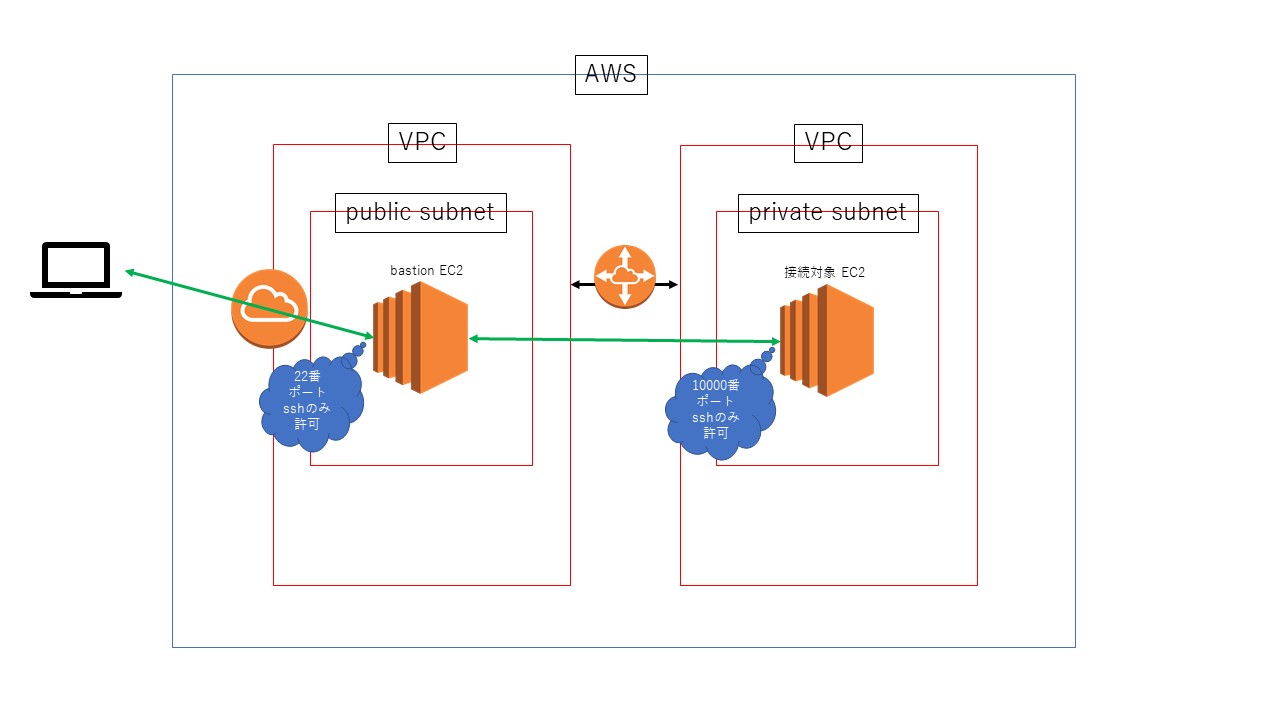
[ec2-user@ip-10-1-0-184 ~]$ ssh -p 22 -i .ssh/bastion_cli_key.pem ec2-user@10.2.0.78
ssh: connect to host 10.2.0.78 port 22: Connection refused
[ec2-user@ip-10-1-0-184 ~]$ ssh -i .ssh/bastion_cli_key.pem -p 10000 ec2-user@10.2.0.78
Last login: Sun Jan 27 03:35:37 2019 from 10.1.0.184
__| __|_ )
_| ( / Amazon Linux 2 AMI
___|\___|___|
https://aws.amazon.com/amazon-linux-2/
AWSのVDIサービスであるWorkSpacesですが、OSはWindowsではなく、Windows Server OSです。ですので、手持ちのソフトウェアがサーバOSをサポートしておらず、使いたいソフトウェアが利用できないという場合がありますので注意が必要です。また、デフォルトでは英語版が起動するため、日本語パックをインストールしたりOSの言語設定を日本語に変えるなどある程度の作業が発生してしまいます。
Solaris は公開されていない
AWSのセミナーでは x86/amd64 用のOSは自作のOSも含めてすべてAWSで利用できると説明を受けましたが、2019年現在、Oracle Solaris (x86/amd64版)のAMIはラインナップされていません。昔はOpenSolarisが公開されていましたが、今は公開中止となったようです。現状、AWSでSolarisは使えないか、使えたとしても簡単には利用できなさそうです(ライセンス周りやAMIのベース構築など)。