- 投稿日:2019-01-27T23:19:21+09:00
Javaでシステム情報を取得するライブラリ「OSHI」
概要
Javaでシステム情報を取得できるOSHIというライブラリについてのメモです。
Sigarとの違い
システム情報を取得するライブラリとして他にSigarがありますが、下記の点でOSHIの方がいい感じです。
- SigarはDLLなどのネイティブなバイナリが必要だが、OSHIの場合は不要
- SigarはWindows版の場合、Java9以降では使用できない(JVMがクラッシュする!)が、OSHIは問題なく使用可能
インストール
build.gradledependencies { compile group: 'com.github.oshi', name: 'oshi-core', version: '3.13.0' }使ってみる
OSHIで取得できる情報を適当に抜粋して紹介します。右のコメントは私の環境での出力結果です。
OS情報
var si = new SystemInfo(); var os = si.getOperatingSystem(); // OSの種類 System.out.println(os.getFamily()); // macOS // バージョン System.out.println(os.getVersion().getVersion()); // 10.14.2 // メーカー System.out.println(os.getManufacturer()); // Apple // 何ビットか System.out.println(os.getBitness()); // 64 // コードネーム System.out.println(os.getVersion().getCodeName()); // MojaveCPU情報
var si = new SystemInfo(); var hard = si.getHardware(); var cpu = hard.getProcessor(); // 物理プロセス数 System.out.println(cpu.getPhysicalProcessorCount()); // 4 // 論理プロセス数 System.out.println(cpu.getLogicalProcessorCount()); // 8 // 名前 System.out.println(cpu.getName()); // Intel(R) Core(TM) i7-4870HQ CPU @ 2.50GHz // 識別子 System.out.println(cpu.getIdentifier()); // Intel64 Family 6 Model 70 Stepping 1 // ベンダID System.out.println(cpu.getVendor()); // GenuineIntel // コンテキストスイッチ数 System.out.println(cpu.getContextSwitches()); // 130336 // ロードアベレージ System.out.println(cpu.getSystemLoadAverage()); // 2.65576171875メモリ情報
var si = new SystemInfo(); var hard = si.getHardware(); var memory = hard.getMemory(); // トータルメモリ容量 System.out.println(memory.getTotal()); // 17179869184 // トータルスワップ容量 System.out.println(memory.getSwapTotal()); // 1073741824 // ページサイズ System.out.println(memory.getPageSize()); // 4096 // 使用可能容量 System.out.println(memory.getAvailable()); // 5858844672USBデバイス
var si = new SystemInfo(); var hard = si.getHardware(); var usbs = hard.getUsbDevices(false); for(var usb : usbs) { // 色々あるのでとりあえずマウスに絞ってみる if(usb.getName().contains("Mouse")) { // 名前 System.out.println(usb.getName()); // USB Laser Mouse // メーカー System.out.println(usb.getVendor()); // Logitech } }センサー
var si = new SystemInfo(); var hard = si.getHardware(); var sensor = hard.getSensors(); // CPU温度 System.out.println(sensor.getCpuTemperature()); // 48.75 // CPU電圧 System.out.println(sensor.getCpuVoltage()); // 3.63 // CPUファンスピード System.out.println(Arrays.toString(sensor.getFanSpeeds())); // [2159, 2000]その他
多いので全部は紹介できないですが、上記以外にもファイルシステム情報、ディスク情報、プロセス情報、サウンドカード情報、電源情報などなど、様々な情報を取得することができます。
参考リンク
- 投稿日:2019-01-27T20:40:05+09:00
Spring Boot2で環境毎にInjection対象を変える
はじめに
Spring Bootで
@Autowiredでinjectionしますが、環境毎に読み込む対象を変えたいというケースがあった場合の対応について書きます。ここでいう環境とはSpring Boogの起動引数
spring.profiles.activeのことで、この起動引数を変えた場合に読み込むクラスを変えるという話です。環境
Java10
Spring Boot2.0.4.RELEASEちょっと前に作ったものなので、環境が古いですがJava11とBoot2.1系でもこれで動くはずです。
interfaceを用意する
まずはinterface(abstract classでも可)を用意します。
public interface TestInterface { void print(); }interfaceの実体を用意する
環境毎に読み込む対象を変えたいということで先ほどのinterfaceをimplementsしたクラスを2つ生成します。
この2つのクラスを起動引数によって変更します。
引数にはtestとtest2`を与えるとします。@Service @Profile("test") public class TestServiceA implements TestInterface { public void print() { System.out.println("test"); } }@Service @Profile("test2") public class TestServiceB implements TestInterface { public void move() { System.out.println("test2"); } }
@Profileを付けるだけです。
これを付けておくと起動引数が合わない場合はBean化対象とされません。使う側の実装
今回はControllerからこのクラスを使用します。
@Controller public class TestController { @Autowired private TestInterface testInterface; // Controllerの処理 }対象のクラスをinterfaceにするだけです。
ProfileにてBeanとなっている対象が1つのみとなっているため、起動引数によって対象が変わります。
- 投稿日:2019-01-27T17:41:12+09:00
JavaDo #14 Kotlinハンズオン
- 投稿日:2019-01-27T17:40:47+09:00
Java開発者に送るKotlinのClass part.2
可視性
JavaとKotlinの可視性はやや異なります。
- Kotlinのデフォルト可視性は
public- Kotlinに
package privateは無い- Kotlin独自の可視性
internalがある (同一モジュール内で参照可)- Kotlinはデフォルトで継承不可 (Javaのfinal扱い)
継承
KotlinでAnimalクラスを継承したDogクラスを定義してみます。
open class Animal { // 継承可なクラスにするためopenをつける open fun greet() { // オーバーライド可能な関数にするためopenをつける } } class Dog: Animal() { // コロンに続けて親クラス名を override fun greet() { // override修飾子をつける println("Bow wow") } }クラスを継承するときは、
classサブクラス名:スーパークラスのコンストラクタと記述します。コンストラクタに引数が必要な場合を見てみましょう。
open class Animal(val name: String) { open fun greet() { } } // Dogのコンストラクタ引数 `name` をAnimalクラスのコンストラクタに渡す class Dog(name: String): Animal(name) { override fun greet() { println("Bow wow") } }コンパニオンオブジェクト
Kotlinにはstatic修飾子はありません。
(あれ?無いですよね?)Kotlinのクラスでstaticメンバやstatic関数を扱いたい場合は、
コンパニオンオブジェクトを使います。コンパニオンオブジェクトとは、
特別なシングルトンインスタンスです。class Dog { companion object { val ancestorName: String = "wolf" } fun greet() { println("Bow wow") } } val ancestor = Dog.ancestorName
companion objectの中でancestorNameというプロパティを定義しました。
このプロパティにアクセスするにはDog.ancestorNameと、staticメンバのようにアクセスします。※ただし、Javaとの互換性のため、staticとしてコンパイルするためのアノテーションは存在します。
object宣言
Kotlinにはシングルトンを簡単に実装する仕組みがあります。
object Application { fun exit() { // ... } } Application.exit()
objectキーワードに続けてシングルトンなクラスを定義できます。
通常のクラスと同様にプロパティや関数を定義できますが、
object宣言ではコンストラクタだけ定義できません。
シングルトンなインスタンスにアクセスするにはクラス名を用います。
Javaのstaticメンバへのアクセスに似ています。dataクラス
データを保持するためのシンプルなクラスは、頻繁に実装しますよね?
data class ApplicationState(val isForeground : Boolean, val applicationName: String) { }
dataキーワードに続けてクラスを定義します。
data classはプライマリコンストラクタで宣言されたプロパティを全て、以下の関数で考慮します。
- equals関数...一致チェックにプロパティの値を考慮
- hashCode関数...ハッシュ値生成にプロパティの値を考慮
- toString関数...プロパティの値を出力
また、copy関数が自動生成されます。
これは、任意のプロパティを変更しながらコピーすることができます。fun updateState(state: ApplicationState): ApplicationState { return state.copy(isForeground = true) }プロパティは全てvalで宣言し、クラスはImmutableとしながら、
値を書き換えたコピーは簡単に生成できます。sealedクラス
sealedクラスは同一ファイル内でしか継承できないクラスです。
sealed class Animal { } class Dog: Animal() { } class Cat: Animal() { }fun greet(animal: Animal) = when(animal) { is Dog -> "bow wow" is Cat -> "meow meow" // else -> elseケースは不要! }上記のgreet関数の中のwhenにご注目ください。
elseケースがありません。
これはsealedクラスの効果です。innerクラス
Javaではクラスの中にクラスを定義する場合、static修飾子をつけるか否かで意味合いが変わります。Kotlinの記述方法と比較してみます。
※あるクラスの中に定義されたAというクラス
Java Kotlin static class A class A class A inner class A Kotlinのデフォルトは
Javaのstatic付きネストクラスと同義となります。プロパティとバッキングフィールド
Kotlinのプロパティは1行で宣言できますが、
ゲッター、セッターをそれぞれカスタマイズすることが可能です。class Dog(name: String) { var name: String = name get() { // カスタムゲッター // ゲッターの中ではfield変数が利用できる // このゲッターはnameに"ちゃん"をつけて返す return field + "ちゃん" } set(value) { // カスタムセッター // セッターは引数名を指定する // このセッターは名前の前から空白を除去してフィールドにセットする field = value.trimMargin() } }デリゲート
Kotlinのクラスはデフォルトで継承不可です。
継承をせずに機能を拡張していく仕組みがあります。Movableというインターフェースと、
Movableを実装したMovableImplクラスを定義しました。interface Movable { fun walk() fun run() fun currentCount(): Int } class MovableImpl: Movable { private var count: Int = 0 override fun walk() { this.count += 1 } override fun run() { this.count += 3 } override fun currentCount(): Int = this.count }このMovableの機能を拡張したDogクラスを定義します。
class Dog(movable: MovableImpl): Movable by movable { }
byキーワードに続けて、Movableの機能を委譲するインスタンスを指定します。
このDogクラスはMovableインターフェースに関する実装が何もありませんが、
自動的にMovableImplに委譲されます。val dog = Dog(MovableImpl()) dog.walk() dog.walk() dog.run() println(dog.currentCount()) // 5プロパティデリゲート
プロパティのゲッター、セッターの振る舞いを委譲することができます。
このようなクラスを定義します。class Dog { var name: String by NameFormatter() } class Cat { var name: String by NameFormatter() }DogクラスもCatクラスもnameというプロパティを持ちます。
どちらもbyに続いてNameFormatterを指定しています。
下のコードを実行してみます。val dog = Dog() dog.name = " ぽち" println(dog.name) //ぽちちゃん val cat = Cat() cat.name = " たま" println(cat.name) //たまちゃんいずれも、nameに代入した文字列から空白を除去し、
ゲッターではサフィックスとして"ちゃん"が付加されています。それでは、NameFormatterの実装を見てみましょう。
class NameFormatter { private var name: String = "" operator fun getValue(thisRef: Any?, property: KProperty<*>): String { return this.name + "ちゃん" } operator fun setValue(thisRef: Any?, property: KProperty<*>, value: String) { this.name = value.trimStart() } }
operatorキーワードに続けて、getValueメソッドとsetValueメソッドを実装します。このように、プロパティの挙動を外部に委譲することができます。
- 投稿日:2019-01-27T17:40:04+09:00
Java開発者に送るKotlinのNull安全
null許容型とnull非許容型
Kotlinの型システムはnullになり得る型と、
なり得ない型を区別します。
nullになり得る型は型名の後に?をつけます。val num: Int = null // コンパイルエラー nullになり得ない val num: Int? = null // null許容型であればOKnull許容型の関数やプロパティに直接アクセスすることは出来ません。
コンパイルエラーとなります。val num: Int? = null // null許容型として宣言 val floatNum = num.toFloat() // コンパイルエラーNullPointerExceptionのリスクが大きく軽減されます。
安全呼び出し
Javaでこのようなnullチェックは良く見かけるかと思います。
// Java Dog dog = //nullかも知れない dog.run(); // NullPointerExceptionの可能性アリ if (dog != null) { dog.run(); // Nullチェック済み }同じことをKotlinでも実装してみます。
val dog: Dog? = //nullかも知れない dog.run() // コンパイルエラー if (dog != null) { dog.run() // nullチェック済みのブロックではOK }null許容型オブジェクトの関数は直接呼び出すことが出来ません。
nullチェック済みのifブロックの中ではnull非許容型に自動的にキャストされ、
関数を呼び出すことが出来ます。
これをスマートキャストと言います。また、Kotlinにはもっと便利な糖衣構文があります。
val dog: Dog? = // nullかも知れない dog?.run()
?.に続けて関数の呼び出しやプロパティにアクセスできます。
上の例だとdogがnullだった場合は、ただnullが返されるだけです。
これを安全呼び出しと言います。安全キャスト
Javaでこのようなダウンキャストのコードを見かけるかと思います。
/* * DogクラスはAnimalクラスのサブクラスです */ Animal animal = // ... ((Dog)animal).run(); // ClassCastExceptionの可能性アリ if (animal instanceof Dog) { Dog dog = (Dog)animal; dog.run(); }同じことをKotlinで実装してみます。
/* * DogクラスはAnimalクラスのサブクラスです */ val animal: Animal = // ... (animal as Dog).run() // // ClassCastExceptionの可能性アリ if (animal is Dog) { animal.run() }Kotlinのキャストは
as演算子を使います。
キャストに失敗るすとClassCastExceptionがスローされます。Javaの
instanceof相当するのはis演算子です。
こちらもスマートキャストによって、
ifブロックの中で変数animalはDog型に自動的にキャストされ、
Dogクラスのメソッドがそのまま呼び出せます。また、Kotlinにはもっと便利な糖衣構文があります。
val animal: Animal = // ... (animal as? Dog)?.run()
as?演算子によって、上の例ですとDog?型にキャストされます。
キャストできない場合はnullが返るため安全です。非null表明
安全呼び出し(
.?をつける) 以外にnull許容型を扱う方法があります。val num: Int? = // nullかも知れない val floatNum = num.toFloat() // コンパイルエラー val floatNum = num!!.toFloat() // コンパイルOK しかしNullPointerExceptionの可能性アリ
.!!を付けます。
必要な場面もありますが、極力使うべきではないでしょう。エルビス演算子
Javaでこのような分岐処理をよく見かけるかと思います。
// Java Dog dog = getDog(); // getDogの戻り値はnullかも知れない if (dog == null) { dog = new Dog(); } dog.run();kotlinには「もしnullだったら」の時に便利な演算子があります。
val dog = getDog() ?: Dog() dog.run()
?:エルビス演算子の
左側にはnull許容型の変数
右側にはnullだった場合に実行される処理を記述します。
代替オブジェクトの生成やExceptionをthrowするのが一般的でしょう。非null許容型のクラスプロパティ
クラスのプロパティを宣言する際に、null許容型にせざるを得ない場合があるかと思います。
コンストラクタをオーバーライド出来ないフレームワークのクラス、
あるコールバックの後でなければ初期化出来ないプロパティなど...しかしそれらは通常、null許容型で扱うのは面倒で、実質的に非null許容型で扱いたい場合があります。 (実際にKotlinで開発しているとよくあります)
そんな時は
lateinit修飾子が便利です。// ログイン用のViewクラス class LoginView { // TextViewやButtonなどの子要素を持つが、 // これらはリソースから生成される...という仮想UIシステム lateinit var emailTextView: TextView lateinit var passwordTextView: TextView lateinit var loginButton: Button // Viewがリソースからロードされると子要素が取得可能となる fun onLoadViewFromResource(viewResource: View) { this.emailTextView = viewResource.children[0] this.passwordTextView = viewResource.children[1] this.loginButton = viewResource.children[2] } }
lateinit修飾子は、初期化を遅らせることが出来ますが、
初期化前にプロパティにアクセスするとExceptionとなるので注意が必要です。この他に、
lazyというプロパティデリゲートがあります。
初期化にコストのかかるプロパティなどを遅延初期化させる時に便利です。class LoginView { val loginConnection: LoginConnection by lazy { LoginConnection() // LoginConnectionは生成にコストがかかる } }
- 投稿日:2019-01-27T17:38:50+09:00
Java開発者に送るKotlinの関数とラムダ
関数の定義
関数は以下のように定義します。
// Int型の引数をインクリメントして返す関数 fun increment(i: Int): Int { return i + 1 }fun
関数名(引数リスト):戻り値の型
これが基本形です。名前付き引数
引数の多い関数の呼び出しでは、どの値がどの引数に対応しているのか
分かりづらくなることがあります。Kotlinはこの問題を解消する機能があります。
/* * たこ焼きを注文します * * @param isKarashiMayo からしマヨネーズを選択するか否か * @param isPutAonori 青のりののせるか否か * * @return たこ焼きのインスタンスが返ります */ fun oderTakoyaki(isKarashiMayo: Boolean, isPutAonori: Boolean): Takoyaki { // ... } val takoyaki = oderTakoyaki(true, false) // どっちフラグが青のりだっけ? val takoyaki = oderTakoyaki(isKarashiMayo = true, isPutAonori = false) // 呼び出し側に仮引数名をつけることができます // コードの意図が読み取り易い val takoyaki = oderTakoyaki(isPutAonori = false, isKarashiMayo = true) // 名前を付けると、関数に定義されている順番でなくてもOKデフォルト引数
引数の数が違うだけのオーバーロードが多数存在するクラスが、よくあると思います。
例えば...Kotlinではデフォルト引数を用いることで、このようにバリエーションが増えてしまう状況を回避できます。
/* * たこ焼きを注文します * * @param isKarashiMayo からしマヨネーズを選択するか否か * @param isPutAonori 青のりののせるか否か * * @return たこ焼きのインスタンスが返ります */ fun oderTakoyaki(isKarashiMayo: Boolean = false, isPutAonori: Boolean = true): Takoyaki { // ... } // 呼び出し時に引数を省略可能。省略した場合は、デフォルト値が使用される。 val takoyaki = oderTakoyaki()拡張関数
既存のクラスに、後から勝手に関数を追加できます。
独自の日付フォーマットでパースする関数をString型に追加してみましょう。fun String.toDate(): Date { val format = SimpleDateFormat("yyyy年MM月dd日") return format.parse(this) } val str = "2019年03月09日" val date = str.toDate()fun
拡張対象の型.関数名(引数リスト):戻り値
↑のように定義します。
ちなみに、通常の関数は...
fun関数名(引数リスト):戻り値の型
↑こうでした。
関数名の前に拡張対象の型をつけると拡張関数になります。ちなみに、この拡張対象のオブジェクトをKotlinではレジーバーオブジェクトと呼びます。
単一式関数
関数が1つの式からなる場合は、
{ }を省略することが可能です。
単一式関数は戻り値の型が推論可能な場合、戻り値の型を省略することもできます。// 通常の関数 fun double(x: Int): Int { return x * 2 } // 単一式関数で記述 fun double(x: Int): Int = x * 2 // 単一式関数で戻り値の型を推論 fun double(x: Int) = x * 2ラムダ式
ラムダ式は↓のように書きます。
val sum = { x: Int, y: Int -> x + y }{
引数リスト->本体}
または引数がなければ
{本体}
となります。ラムダ式のパラメータが1つの場合は暗黙の変数
itが使用できます。val double: (Int)->Int = { it * 2 }尚、関数型は次のように記述します。
(引数の型) ->戻り値の型inline関数
ラムダ式は実行コストの高い仕組みです。
Kotlinのラムダ式は無名クラスとして実現されています。変数をキャプチャしたラムダ式は実行されるたびに無名クラスのインスタンスが生成されます。
(Kotlin1.1 Java8バイトコード生成は直接Javaのラムダ式にコンパイルされるらしい)そこで、inline関数です。
inline関数は呼び出される箇所に関数本体を置き換えてコンパイルされます。inline fun edit(context: DataBaseContext, block: (DataBaseContext.Transaction)->Unit) { val transaction = context.beginTransaction() block(transaction) transaction.commit() }inline関数が効力を発揮するのは
引数にラムダ式を受け、それを内部で実行する関数です。
inline関数では、引数のラムダ式も一緒に呼び出し元に展開します。上のinline関数
editを呼び出すサンプルです。val dataBaseContext = DataBaseContext() edit(dataBaseContext) { transaction -> val newObject = Any() transaction.add(newObject) }
edit関数はコンパイル時に展開され、次のようなコードになります(イメージです)val dataBaseContext = DataBaseContext() // ここからedit関数が展開 val transaction = dataBaseContext.beginTransaction() val newObject = Any() transaction.add(newObject) transaction.commit() // ここまでedit関数が展開もう一つのinlineの出番
Kotlinのジェネリックは実行時に型情報は失われます。
例えば、次の関数はコンパイルエラーとなります。
fun <T> mapFilter(list: List<Any>): List<T> { return list.filter { it is T } .map { it as T } }
mapFilter関数の型パラメータTは実行時に失われるためです。
そこで、inline関数にreified修飾子を付加します。// ↓ここ! inline fun <reified T> mapFilter(list: List<Any>): List<T> { return list.filter { it is T } .map { it as T } }このようにすることで、実行時に型情報を保持したまま展開されるため
mapFilter関数がコンパイルできるようになります。
- 投稿日:2019-01-27T17:37:43+09:00
Java開発者に送るKotlinのClass
Java開発者の方に向けて、Kotlinのクラスについて書きます。
クラスの定義
classキーワードに続いて、クラス名を記述します。
Dogクラスを定義してみます。class Dog { }クラスの継承やインターフェースの実装はコロンに続けて記述します。
先ほどのDogクラス、Animalクラスを継承させてみます。class Dog: Animal() { }さらに、Walkableインターフェースを実装してみましょう。
class Dog: Animal(), Walkable { }プロパティ
Kotlinのクラスはプロパティを持つことができます。
これはJavaのフィールド、ゲッター、セッターを合わせたものです。
DogクラスにnameというString型のプロパティを宣言してみましょう。
varキーワードを使います。class Dog { var name: String = "pochi" } val dog = Dog() val aName = dog.name // ゲッターとして動作 dog.name = "taro" // セッターとして動作読み取り専用にしたければ、
valキーワードを使いましょう。class Dog { val name: String = "pochi" } val dog = Dog() val aName = dog.name // ゲッターとして動作 dog.name = "taro" // コンパイルエラー!
valキーワードは再代入不可のため、クラス内部からも値を変更できません。
クラス内で変更可能とする場合はprivate setキーワードを使います。class Dog { var name: String = "pochi" private set fun updateName(newName: String) { this.name = newName } } val dog = Dog() dog.updateName("taro")ここで、「いやいや、JavaでフィールドをPublicにしたのと一緒でしょ?」と思った方は鋭いです。
Kotlinのプロパティはゲッター、セッターそしてフィールドが明確に分かれています。
詳しくはこちらプライマリコンストラクタ
Kotlinのコンストラクタは少し変わった位置に書きます。
class Dog constructor(/* ここがコンストラクタ */) { }
constructorキーワードは省略できます。アノテーションを付加する場合などは省略できません。
この位置に書くコンストラクタをプライマリコンストラクタと呼びます。
コンストラクタと言っても、記述できるのはプロパティとコンストラクタの引数リストです。コンストラクタでプロパティ定義する
コンストラクタ引数に
varやvalキーワードをつけると、そのままプロパティになります。class Dog(var name: String) { }↑は↓と同義です。
class Dog(name: String) { var name: String = name }JavaとKotlinを見比べてみる
JavaでDogクラスを定義します。
nameとageというフィールドがあり、それぞれゲッターとセッターが定義されています。public class Dog { private String name; private int age; public Dog(String name, int age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } }これをKotlinで書くと?
class Dog(var name: String, var age: Int)これだけで済んでしまいます。
- 投稿日:2019-01-27T16:24:29+09:00
Spring なぜMyBatisの実行したSQLがSpringの管理しているトランザクションで実行できるのか?
なぜMyBatisの実行したSQLがSpringの管理しているトランザクションで実行できるのか、を調べる。そのために、 mybatis-spring の実装を追っていく。
対象バージョン
- java version "11.0.1" 2018-10-16 LTS
- Spring Boot 2.1.2.RELEASE
- mybatis-spring-boot-starter 2.0.0
はじめに
トランザクション管理は複雑で難しそうな印象があるが、結局は Spring、MyBatis ともに JDBC Driver API を利用する。そのため、以下のような処理をライブラリの中で実行しているんだ、ということを理解しておくと、読み進めやすい。
public static void main(String[] args) throws SQLException { HikariDataSource ds = new HikariDataSource(); ds.setUsername("dev"); ds.setDriverClassName("org.postgresql.Driver"); ds.setJdbcUrl("jdbc:postgresql://192.168.11.116:5432/dev"); ds.setPassword("secret"); // トランザクションの設定 Connection conn = ds.getConnection(); conn.setAutoCommit(false); conn.setTransactionIsolation(Connection.TRANSACTION_READ_COMMITTED); // 同一コネクションを利用し、様々なSQLを実行する // これで同一トランザクションで処理が実行される PreparedStatement pstmt1 = conn.prepareStatement("INSERT INTO sample VALUES ('apple')"); pstmt1.executeUpdate(); PreparedStatement pstmt2 = conn.prepareStatement("INSERT INTO sample VALUES ('banana')"); pstmt2.executeUpdate(); conn.commit(); }処理の流れを追おう
MyBatis に詳しくない人は、あらかじめ MyBatis の概要を理解しておくと良いかもしれません。
参考 Deep Dive into MyBatis 概要編ソースコード
以下を実行しながら、処理の流れを追っていく。
複雑な箇所は適宜、シーケンス図を作成する。(メインの流れではないと判断したところは適宜省略して記載するので、正確さにはやや欠けます)Main.java@RequiredArgsConstructor @SpringBootApplication public class Main { public static void main(String[] args) { new SpringApplicationBuilder(Main.class) .web(WebApplicationType.NONE) .run(); } private final SampleService service; @Bean public CommandLineRunner run() { return i -> service.insert(); } }SampleServiceImpl.java@Service @RequiredArgsConstructor public class SampleServiceImpl implements SampleService { private final SampleRepository sampleRepository; @Override @Transactional public void insert() { sampleRepository.save("apple"); sampleRepository.save("banana"); } }SampleRepository.java@Mapper public interface SampleRepository { @Insert("INSERT INTO sample VALUES (#{name})") int save(@Param("name") String name); }application.propertiesspring.datasource.driver-class-name=org.postgresql.Driver spring.datasource.url=jdbc:postgresql://192.168.11.116:5432/dev spring.datasource.username=dev spring.datasource.password=secret処理の概要
- Spring は、コネクションをスレッドローカルな値として管理する
- MyBatis は、スレッドローカルに管理されたコネクションを取得し、同一のコネクションを利用してSQLを発行する
- 上記2点により、 MyBatis で実行した SQL が Spring のトランザクションで実行できるようになる
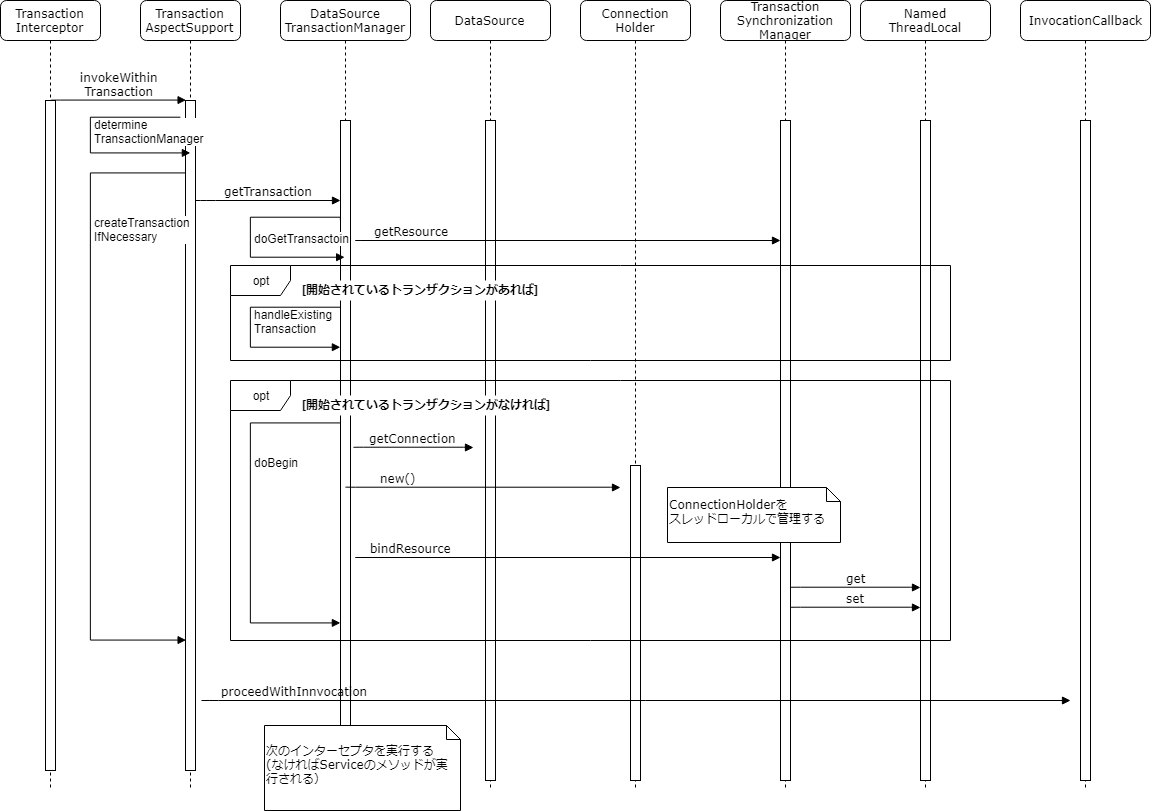
Spring のトランザクション処理
Spring は、
@Transactionalがついたメソッドの実行前に、 TransactionInterceptor#invoke を実行する。
この処理は、 DataSource から Connection を取得し、@Transactionalアノテーションに設定された Isolation や propagation に基づいて Connection の設定を行う。また、TransactionSynchronizationManager にスレッドローカルな値として Connection を格納する。
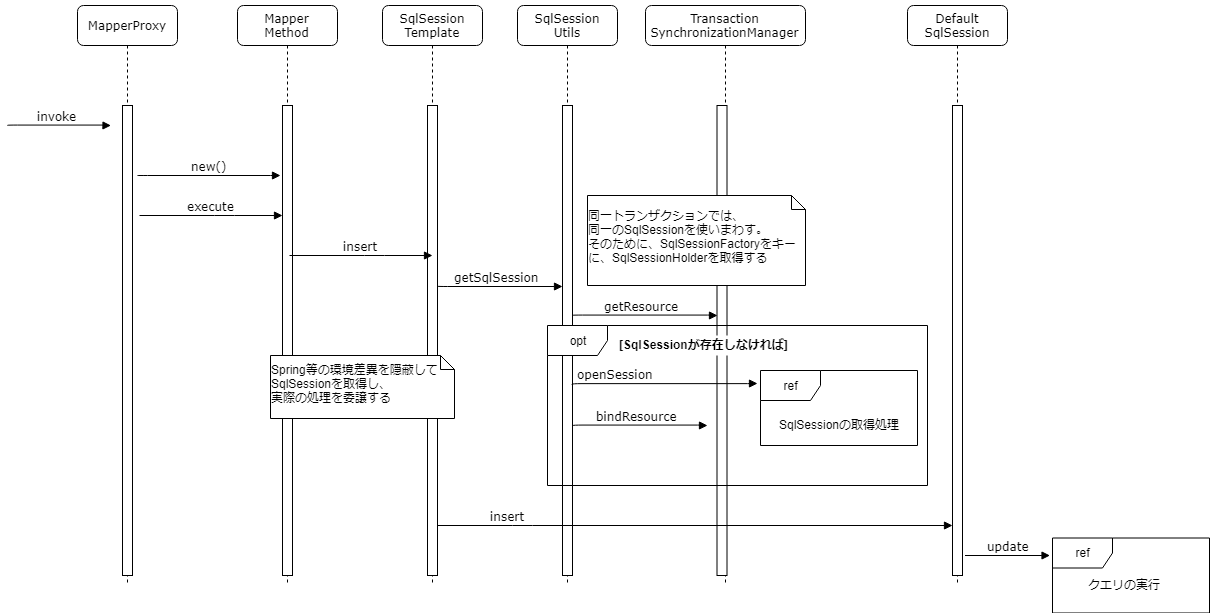
MyBatis のメソッド実行の処理
MyBatis のMapperインタフェースを実行すると、以下の処理を実行する。
SqlSession を継承した SqlSessionTemplate というクラスは spring-mybatis が提供しており、このクラスが MyBatis の SqlSession を管理している。これによって、同一トランザクションでは同一の SqlSession インスタンスが取得できる。
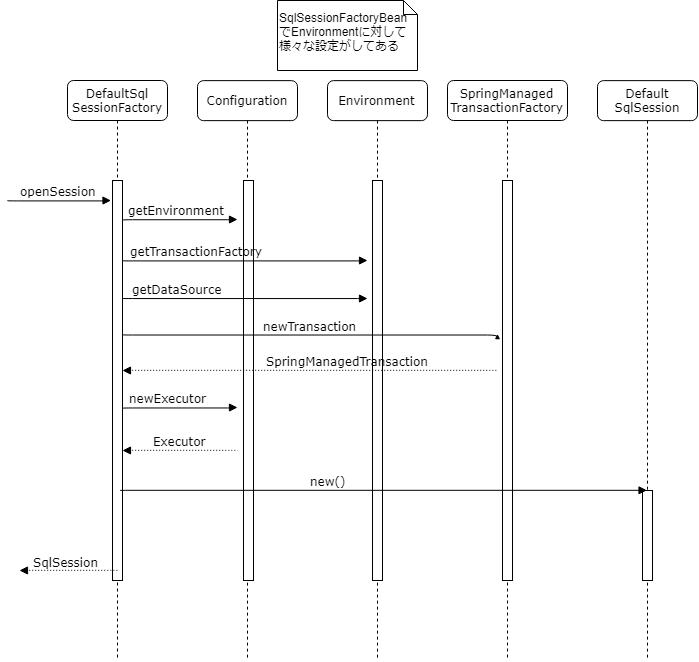
SqlSession の取得処理
SqlSession を取得する処理。Transaction クラスを継承した SpringManagedTransaction を返す点がポイント。
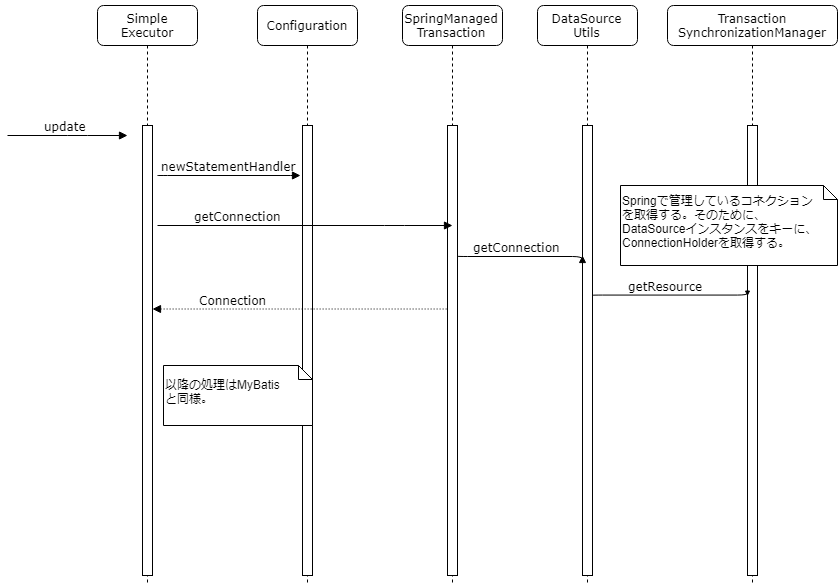
クエリの実行
Executor がクエリを実行する処理。TransactionSynchronizationManager から Connection を取得する。Spring のコネクションと同様の Connection を利用して SQL を実行することで、 Spring のトランザクション上で MyBatis の処理が実行される。
最後に
なるほどー。
- 投稿日:2019-01-27T16:23:43+09:00
2019年2月以降はどこを見ればJavaリリース内容がわかるのか?問題について
※ @yamadamn さんからのコメントを元に加筆・修正してます。
※ @yamadamn さんからのコメントのきっかけとなったツイート : https://twitter.com/msakamoto_sf/status/1089117012977041408
2019年1月になり、いよいよOracleビルドとしてのJava8 SEの最後のDLとなった(と理解してるが、これが間違ってると以降の本記事の前提がいろいろ崩れる)。2019年1月までで終わるのは商用ユーザ向けのJava SE 8で、個人ユーザ向けには2020年12月末まで提供される。Oracle Java SE サポート・ロードマップ 参照のこと。
→商用ユーザ向けのJava SE8、つまりビジネスで開発するためのJDK8 および開発したソフトウェアを動かすためのJava8のJRE環境については「Java Is Still Free / Javaは今も無償です」 の冒頭にも記載があるとおり、"JDKバイナリ" が必要であればRedHat, AdoptOpenJDK, Azul, IBM などからそれぞれの無償LTSとして提供されるJava8 OpenJDK を使うことになる、と思われる。以下、日本語訳から引用:2019年1月以降にJava SE 8をアップデートが必要なら、OpenJDKプロバイダから配布されるOpenJDKバイナリを使ってください。OpenJDKプロバイダは、たとえばLinuxディストリビュータやAdoptOpenJDK、Azul、 IBM、レッドハットなどです。
完全に個人の趣味で動かすだけのJDK8であれば、個人ユーザ向けとして2020年12月末まで提供される。これについては「Java Is Still Free / Javaは今も無償です」の「Q. 商用ソフトウェアの実行にOracle JDK 8を使っている場合、2019年1月移行はライセンスを購入する必要がありますか?」に回答があり、日本語訳より引用:
また、Oracle JDK 8は、少なくとも2020年まで個人のデスクトップでの利用に対して無償でアップデートが提供されることにも注意してください。
というわけで、今後もJava8 SE(OpenJDKベース、さらに正確には public JREだけでなくJDKの方も含めて)を商用の開発案件で使おうとしたら、AdoptOpenJDK や Azul Systems の Zulu, IBM, RedHatLinux, AWS Correto などが提供するLTSを使うことになる。
またJava11もいよいよLTSになる。予定どおりなら、2019年3月には OpenJDK 12 がリリースされる。そうなったときに、Javaのリリース情報はどこを見れば良いのか?というのがわからなくなった。
- Oracle公式バイナリは2種類。
- フィーチャー・リリース: 3月/9月にリリースされる、Java11, 12, 13, ... と進んでく。
- アップデート・リリース: 四半期ごとの1月, 4月, 7月, 10月にリリースされる。その時点でのフィーチャー・リリースに対する脆弱性やバグ修正などが含まれる。
- その他のベンダによるリリース
- OpenJDKベース(HotSpot)はどうなるのだろうか。OpenJDKに合わせるなら、Oracle公式バイナリに揃えてリリースされる?
フィーチャー・リリースの内容
新しいリリースサイクルにおける「フィーチャー・リリース」とはJava9, 10, 11, 12, ... と進んでく、以前の「メジャーリリース」に代わるもの。
- フィーチャー・リリースのリリース内容については https://jdk.java.net/ を見れば良さそう。
- Oracle公式バイナリについては https://www.oracle.com/technetwork/java/javase/downloads/index.html からアップデート・リリース含めて辿れる。
- ここから、各フィーチャー・リリースに対応するアップデート・リリースも含めたリリース・ノートを辿れる。
- https://www.oracle.com/technetwork/java/javase/jdk-relnotes-index-2162236.html
フィーチャー・リリースでの機能追加は jdk.java.net と Oracle サイトの両方から辿れそうなので、いわゆるメジャーアップデートの内容は上記から辿れると思われる。
アップデート・リリースの内容
各フィーチャー・リリースごとに、バグや脆弱性の修正が行われたアップデート・リリースが提供される。Oracleのビルドバイナリの場合は、四半期ごとの Critical Patch Update (CPU) で提供される。
- これも https://jdk.java.net/ から辿れるは辿れるのだけど、2019-01時点では、例えば https://jdk.java.net/11/ では最新のアップデート・リリースの内容(11.0.2) については辿れるが、一つ前の 11.0.1 については見つけることができなかった。
- https://jdk.java.net/10/ に至ると、release noteのリンクが Oracle 側の JDK 10.0.2 リリース・ノートになっている。
- (それくらいなら、最初からもう release note のリンクを全部 Oracle 側にしておけよ・・・とか思ってしまう・・・)
- 「アップデート・リリース」というのはOpenJDKに対するOracle公式ビルドのOracle側の呼び名なので、結局、最も正確で読みやすいのがOracleのサイトになってしまう。
- セキュリティ修正について
- https://www.oracle.com/technetwork/topics/security/alerts-086861.html
- Java以外のOracle製品も含んだ一覧が提供されている。
- セキュリティ以外のバグ修正も含んだ、Javaの各リリースノート全体
LTSリリースの内容
これ(LTSリリースそのものではなく、「リリースノート」としてのLTSリリースの変更点サマリ)がどうなるか、2019-01時点では見当がつかない。
- Oracleの場合、2019-02からはLTSが2バージョン(8 と 11, このうち8は有償, 11は無償・・・であってるのかな・・・??) とフィーチャー・リリースで合計3バージョンをリリースする。
- この場合、四半期ごとのアップデート・リリース内容はCPU側に、フィーチャー・リリースはそちらでのリリースになるのか?
- その他のLTSベンダとしては、Java8 LTSはどうなるのだろうか・・・。
- 例えば AdoptOpenJDK の場合、GitHub上でリリースを出しているが特にリリースノートなどは用意していない。
- https://github.com/AdoptOpenJDK/openjdk8-binaries/releases
有償LTSとなった後のJava8
良く理解できていないのが、Oracle側が有償LTS化した後のOpenJDK側のJava8のソースコードの扱い。
- https://openjdk.java.net/projects/jdk8u/ としてjdk8のupdateプロジェクト自体は継続しているのだが、ここで、Oracleの有償LTSのJava8アップデート・リリースの内容がバックポートされるのだろうか?
- Oracleとしては有償化した以上、それをOpenJDKにわざわざバックポートするのだろうか?
- 他のLTSベンダとしても、特に有償LTSを提供しているところなどは、独自の修正を行う可能性がある。とはいえ、OpenJDKベースであればGPLということもあり、有償LTS向けのパッチがOpenJDK側にバックポートされることを期待できる(が、確実にそうなるという確証も無い)。
つまりJava8については、今後は Oracle版有償LTS化されたJava8 と、OpenJDKベースで各LTSベンダからのパッチが取り込まれていくJava8に分裂するのではないか?という疑問が拭えない。(誰か知ってる人いたらおしえてください)→ @yamadamn さんからのコメントにあるIntroduction to Java 11: Support and JVM Features #jjug を見てみると、方向性としてはコミュニティによる管理に移行する流れらしい。開発リードとしては「Java Is Still Free / Javaは今も無償です」の「OpenJDKのアップデートプラン」に書かれているが、RedHatが主導する可能性が高い。以下日本語訳より引用:
2019年1月に、オラクルがOpenJDK 8のアップデートを停止したあと、レッドハットがOpenJDK 8のリーダに志願する意向です。重要なことですが、レッドハットはOpenJDK 6と7のプロジェクトを主導していますが、彼らが唯一のコントリビュータではないということに注意してください。他のベンダも時々パッチや修正を提供しています。OpenJDK 8では、レッドハット関連企業ではないところ、たとえばアマゾンやAzul、IBMなどからかつてないほどのコントリビュートがあるでしょう。
よって分裂に対する不安感は大分低減される。実際、OpenJDKベースであればライセンスがGPLv2である以上、各ベンダそれぞれで修正したパッチについては公開(厳密にはそのバイナリを入手できる人に対してだが、無償LTS版の公開DLを提供するのであれば事実上全世界に公開)することになるので、OpenJDK側にバックポートされる期待値は高い。
Javaに対する安心と新しい不安
Javaが有償化する、という不安は大分収まったと感じる。やはり各LTSベンダが積極的にJava無償化と、一部ベンダではJava8の無償LTS化を宣伝した効果ではないだろうか。
一方で、LTSがベンダごとに分裂してしまうのではないか?という新しい不安を感じる。
いくらOpenJDKという同じコードからビルドしているとはいえ、Oracleが有償サポートで四半期ごとにアップデート・リリースをするJava8と、RedHatLinux/Azul Systems/AdoptOpenJDK/IBM/AWS Correto のJava8は「同じ」と言えるのだろうか?
もちろんTCKで互換テストはパスしているのだろうが、JVM起動の "-XX" オプションまで本当に同一なのか?
Oracle側のドキュメントに記載されている機能は、本当に全てが他のJava8 LTSリリースでも使えるのだろうか?
Oracle側の有償LTSで修正されたJava8のバグは、OpenJDKに反映されて、他のベンダのLTSにも取り込まれるのだろうか?
そもそもOracle側の有償LTSで修正された内容は、今までどおりOracle CPUやOracleのJava SEのページに書かれるのだろうか?
(このあたり、自分の資料調査不足もあると思うので、良いポインタ資料知ってる人いたら教えてほしい・・・。)
そのあたりが全く見通しがつかない。TCKパスしてればまず大丈夫だろうとは思うけど、油断できないと考えてる。
あるベンダのJava8 LTSで使えた "-XX" オプションが、別のベンダのJava8 LTSでは使えないとか無いよね・・・?
(そもそも "-XX" オプション使うときにそれが特定ベンダの特定LTS固有のものかどうかちゃんと調べておけよ、という話ではあるけど)→ @yamadamn さんコメント中の資料などから、確かに微妙に異なる可能性はあるが、 それは以前からもそうだった 。「Java Is Still Free / Javaは今も無償です」の「新しい6ヶ月リリースサイクルとLTS」にある「Java / OpenJDKでのLTSは何を意味するのか?」の中でさらっと触れられており、日本語訳より引用:
注記: このことは、OracleのJDKが、他プロバイダが作成するOpenJDKベースのバイナリと異なる可能性があるということを意味します (これは今までもつねにそうでした)。これは、バイナリがTCKをパスする限り、そうしたバイナリもTCKをパスしているのであれば、Java SE標準との互換性がありますので、安心してお使いください。
つまりTCKをパスしたものであれば「標準」には互換性がある、ただし独自のオプションなど「標準ではないもの」については互換性が無いよ、それは今までもそうだった、ということで、確かにその通りで、そのための「標準」でありTCKがあるのだろう。
例えばJava7 については無償サポート終了後もOracle CPU でアップデートが続けられている。
- 無償サポート範囲のOracle側リリースノートは 1.7.0_80 までで終わっている。
- 有償サポート範囲のOracle側リリースノートがその後も続いていて、最新は2019-01-15 CPUリリースの 1.7.0_211-b07 となっている。
では上記リリースが OpenJDK7 側にも反映されているのか?については調べきれていない。
openjdk.net 側のJava7 updateプロジェクトのML(jdk7u-dev : https://mail.openjdk.java.net/pipermail/jdk7u-dev/ ) も軽く直近半年ほどあたってみたが、主にMLで動いているのはRedHatの人たちらしい。
Oracle側のCPUリリースの少しあとでOpenJDKのMLにも同じバージョンでのリリースアナウンスが流れてるので、多少動きは連動してると思われる。
ただ、もしかしたら一見連動しているように見えるだけで、RedHat側の都合が反映されているのかもしれず、このあたり、Oracle側とOpenJDK側の手綱のバランスがどうなっているか正直外からはすぐにわからない。
また、Java8がどうなるかについてもやはり見通しがつかない。→ @yamadamn さんコメント中の資料「Java Is Still Free / Javaは今も無償です」の「OpenJDKのアップデートプラン」にあるとおり、OpenJDK8側のコードベースについては2019年1月から先はRedHatがリードする方向となっている。Java7についても、MLでの動きの通り、RedHatがメンテナンスを引き継いでいる。
また「Introduction to Java 11: Support and JVM Features #jjug」にもあるが、Oracle側のリリース後、他のベンダー側では1-2週間ほど遅れてリリースされる場合もあるとのこと。
つまり大枠としては以下のようになると思われる。
- 2019年1月以降は、OpenJDK8のメンテナンスはコミュニティに引き継がれ、おそらくRedHatがリードする。
- OpenJDK8自体はGPLv2なので、各LTSベンダごとの修正パッチは最終的にOpenJDK8にバックポートされる可能性が高い。よって、OpenJDK8のLTS版が「分裂」する危険性は低い。
- ただし分裂の危険性というのはあくまでも「標準」部分に関するものであり、それ以外の独自 "-XX" オプションなどについては、(今までもそうだったが)「非標準」な領域についてはベンダごとの差異はある。(「標準」が分裂することは無いが、それ以外の「非標準」な領域については分裂・・・というよりは単純に「差異」として存在するだろう、ということ。)
今の所、Javaリリースサイクルの変更の説明と有償化に対する誤解を解くためのLTSベンダによる宣伝が入り乱れており、「じゃぁ、実際にLTSになった後どうなるの?」という話が見えない。
Oracleからの資料はあくまでもOracleとOpenJDKの話しか書かれておらず、他のLTSベンダとの関連についてはわからない。→ @yamadamn さんコメント中の資料「Java Is Still Free / Javaは今も無償です」が総合的に、LTS後の動向や、他のLTSベンダとの関わりについても解説されているので、これを参照するのがおすすめ。
肝心の「リリースノート」についてだが、おそらく厳密にリリース内容を調査するのであれば、当然ながらOracle含めた各LTSベンダの有償サポートを契約するのが確実なのだろう。
無償の範囲でどこまで情報が取れるのか、そこはまだ不明。(必要なのは読める文章・サマリとしてのリリースノートなので、単にバイナリがDLだけでは不満。で、そうしたリリースノートとしてはどこを見ればよいのか?)2019年は、そのあたりの動向を見定める一年となりそう。
最後にぶっちゃけるなら、非標準の "-XX" オプションやアップデート・リリースで増えたり減ったりする セキュリティ or システムプロパティやトラブル時の解析技法についてLTSベンダ間の互換性がどうのこうのとそこまで気にする用途だったら素直に有償LTS契約しろよという話で、それが無理なら、そうした細かい変更に影響受けないように自動テスト整備してリグレッションテスト回せるようにした上でそうしたJVMの細かい修正に影響されないように全体設計しろよ、という話でそれ自体は全くの正論なんですが現実(予算)を前にすると無償LTSベンダにひれ伏すしかないので無力。
あと、セキュリティ系にうるさいところでJava使っていると、やっぱりJavaアップデートが公開されたら自分たちのシステムに影響出ないか調べるじゃないですか、そうしたときに何かしらリリースノートが出てるとやっぱり違うなって。OpenJDK のMLを見てても、細かいマージやバグ修正の動きは見えるのですが、最終的にリリースされたときに変更点一覧としてわかりやすいサマリが流れてくるわけでもないので、そうした点からもやっぱりどこかで修正サマリとして見れるリリースノートが無いとつらたん。
参考
- Java Is Still Free
- Javaは今も無償です
Oracle側:
- JDK 新しいリリースモデル解説 (ver. 2.2)
- JDKの新しいリリース・モデル、および提供ライセンスについて
- Oracle Java SE サポート・ロードマップ
- Critical Patch Updates and Security Alerts
- Java SE - Downloads | Oracle Technology Network | Oracle
OpenJDK:
- https://openjdk.java.net/
- ここはOpenJDKの開発プロジェクト全般がまとめられている。OpenJDKのダウンロードやリリースノートについては、↓を参照したほうが良い。
- https://jdk.java.net/
ただ、なんとなく java.net のサイト全体が見づらい。歴史的な事情もあるし、Oracle側にある内容など重複するしいろいろ事情はあるのだろうけど・・・。
主なOpenJDKバイナリベンダ:
- AdoptOpenJDK
- Azul Systems (Zulu Enterprise)
- IBM Knowledge Center - IBM SDK Java Technology Edition
- RedHat
- OpenJDK ライフサイクルおよびサポートポリシー
- Windowsバイナリ
その他:
- Java 10以降のJava: リリースサイクルの変更とOpenJDKへの統合- JfokusでのMark Reinhold氏のセッションから - Fight the Future
- Javaのリリースは6ヶ月ごととなる
- Introduction to Java 11: Support and JVM Features #jjug
- 投稿日:2019-01-27T14:02:09+09:00
AWS LambdaでApache PDFBox®を使う際の注意点
Apache PDFBox®とはPDFをゴニョゴニョするためのJavaのオープンソースライブラリです。
AWS LambdaではJava8のランタイムを使えるので、これをAWS Lambda上で動かすこと自体は特に難しいことではないのですがちょっとだけ注意点があったので記事に残します。
注意点
Lambda実行時の仕様として
/tmp以外のフォルダは書き込みなどのアクセス権が制限されていますが、PDFBoxのデフォルトの動作としてfont cacheを更新しようとするのでその際にアクセス権の関係でエラーになります。これを回避するには
pdfbox.fontcacheというシステムプロパティを/tmpにする必要があります。たとえばLambdaのハンドラー関数実行後、PDFBoxを使う前に
ハンドラー関数System.setProperty("pdfbox.fontcache", "/tmp");とすることなどで回避できます。
参考
- 投稿日:2019-01-27T11:21:01+09:00
BeanUtils.copyPropertiesを利用することは思考停止していないか?
Javaの「BeanUtils.copyProperties」は非常に便利な機能ですが
適切な利用が本当にされているでしょうか?今回はEntityとDTOおよびFormのパターンについて語りたいと思います。
※DTOだけデザインパターンなのにこの名称で語られるのに違和感がありますが・・・EntityとDTOおよびFormはBeanとして実装されるケースを見ます。
しかし、その理由が「BeanUtils.copyProperties」を利用したいだけになっていませんか?例えばこんな実装
class EntityBean { private int value; public int getValue(){ return value; } public void setValue(int value){ this.value = value; } } class DtoBean { private int value; public int getValue(){ return value; } public void setValue(int value){ this.value = value; } } class FormBean { private int value; public int getValue(){ return value; } public void setValue(int value){ this.value = value; } }Entity、DTO、Formに同じフィールドを持てば「BeanUtils.copyProperties」を
利用することは確かにでき、便利だと思います。しかし、よく考えてみてください。
Entity、DTO、Formは異なる実装を吸収するためにあるものではないでしょうか?「BeanUtils.copyProperties」を利用したいがゆえに同じフィールドを持つことを
強制していないでしょうか? そうなってしまうと変化に強くもなく、データベースの仕様を
Entity、DTO、Formの3箇所を人力で運用し続けなければならなくなります。DBの仕様変更でフィールド名を変更した場合
Entityのvalue -> hogeに変更しました。
class EntityBean { private int hoge; public int getHoge(){ return hoge; } public void setHoge(int hoge){ this.hoge = hoge; } } class DtoBean { private int value; public int getValue(){ return value; } public void setValue(int value){ this.value = value; } } class FormBean { private int value; public int getValue(){ return value; } public void setValue(int value){ this.value = value; } }これって「BeanUtils.copyProperties」を使う限りビルドは通るし
それなりに動いてしまう可能性があります。DTOとForm作っている人に(もしかしたら自分)に
伝達して、修正してもらわなければなりません。動作を維持するならテストコードも必要になります。ここまでのコストを支払う価値ってどこにありますか?
実装ミスってませんか?Entity、DTO、Formの3箇所に同じフィールドを持つことを強制する(できる)のであれば
実装としては継承が適切です。class EntityBean { private int hoge; public int getHoge(){ return hoge; } public void setHoge(int hoge){ this.hoge = hoge; } } class DtoBean extends EntityBean { } class FormBean extends DtoBean { }同じフィールドを持つことを担保できますし、変更があればコードレベルで
変わってくるので、ビルド時のエラーに気づけます。継承しているので、プロパティを削りたければアップキャストすれば実現可能になり
「BeanUtils.copyProperties」を使う必要は全くありません。でもEntity、DTO、Formの3箇所に同じフィールドを持つというのは、そもそもの目的を潰していませんか?
本当にやりたいことはこういうことのはず。
class EntityBean { // Entityでは日付を日付型で持つ private DateTime date; public DateTime getDate(){ return date; } public void setDate(DateTime date){ this.date = date; } } class DtoBean { // DTOでは日付を文字列型で持つ private String date; public String getDate(){ return date; } public void String(String date){ this.date = date; } } class FormBean { // Formでは日付を年月日別で持つ private String year; private String month; private String day; }「Entity、DTO、Form」がそれぞれ異なる実装を持つ可能性があるからこそ
分けるのであって、同じ実装が前提になっていたら何の意味もないのです。
「BeanUtils.copyProperties」を使う限り、抽象度は低く何の備えにもなっていません。そもそもですが、「Entity」と「Form」の変換は誰が担うべきなんでしょうか?
「BeanUtils.copyProperties」を使うことで責任をうやむやにしていませんか?ちなみに上記の例に限って場合「DTO」って誰得の何の役割を持つのでしょうか?
私は不要だと考えます。DTOは複数のEntityと絡みがない限りは必要ないのです。本当は「Entity」と「Form」の変換の役割に担う別の人が必要になります。
class EntityBean { // Entityでは日付を日付型で持つ private DateTime date; public DateTime getDate(){ return date; } public void setDate(DateTime date){ this.date = date; } } class Converter { // 相互に変換するメソッドを用意してこいつが責任を負う public static EntityBean convert(FormBean form) ... 実装は割愛 public static FormBean convert(EntityBean form) ... 実装は割愛 } class FormBean { // Formでは日付を年月日別で持つ private String year; private String month; private String day; }「Converter」の中で、「BeanUtils.copyProperties」を使うのであれば
抽象度は保たれていると思います。Entity、DTO、Formの3箇所に同じフィールドを手動で作成してかつ
それを設計上の前提条件として「BeanUtils.copyProperties」を利用している
ケースはみなさんの周りにはないでしょうか?本当にそれって正しいのか? 私は疑問に思います。
ご意見ご感想お待ちしております。
- 投稿日:2019-01-27T02:23:29+09:00
SpringBoot+インメモリデータグリッド入門
インメモリデータグリッドについて勉強してみたついでに、実際にアプリに組み込むとどうなるのか気になったので入門してみた。
インメモリデータグリッドとは
- データを複数サーバで分散管理する仕組み。
- 全サーバが重複してデータを持つこと(レプリケーション方式)もできれば、あるグループのサーバにとってのみ必要なデータを、そのグループ内で重複して管理する(パーティション方式)といった柔軟なデータの信頼性確保が可能。
- DBのようにディスクI/Oが発生しないため、高速にデータのCRUD操作、P2Pのデータ同期が行える。
- 信頼性、高速性を備えたアーキテクチャ。らしい。
下記の記事を参考に学習
- 概要を掴むのにおすすめ
- 具体的なアーキテクチャの種類SpringBoot + Apach GEODEでアプリを作ってみよう
- 色々と記事をザッピングしたところで実際に作ってみたくなったので
SpringDataGeodeというプロジェクトがSpringのgitリポジトリにあるので、それを使ってSpringBootでインメモリデータグリッドを体感してみようと思います。ユーザ登録・検索を行うサーバアプリケーションを想定して作成します。
Apache GEODEのclient/serverモデルでアプリを作る
- Spring Initializerでclient,serverのアプリの雛形を作成する。
- Web,lombokのみ選択。
- 今回は
gradleでプロジェクトを作成。client側アプリを作成
- build.gradleの依存関係に
spring-data-geodeを追加。build.gradledependencies { implementation('org.springframework.boot:spring-boot-starter-web'){ // log4jのライブラリがspring-data-geodeの依存するlog4jのライブラリと競合するため、除外 exclude group: 'org.springframework.boot', module:'spring-boot-starter-logging' } // ドメインモデルを扱うプロジェクトを依存に追加 compile project(':geodeCommon') compileOnly('org.projectlombok:lombok') compile(group: 'org.springframework.data', name: 'spring-data-geode', version: '2.1.3.RELEASE') }
- 起動クラスのコード
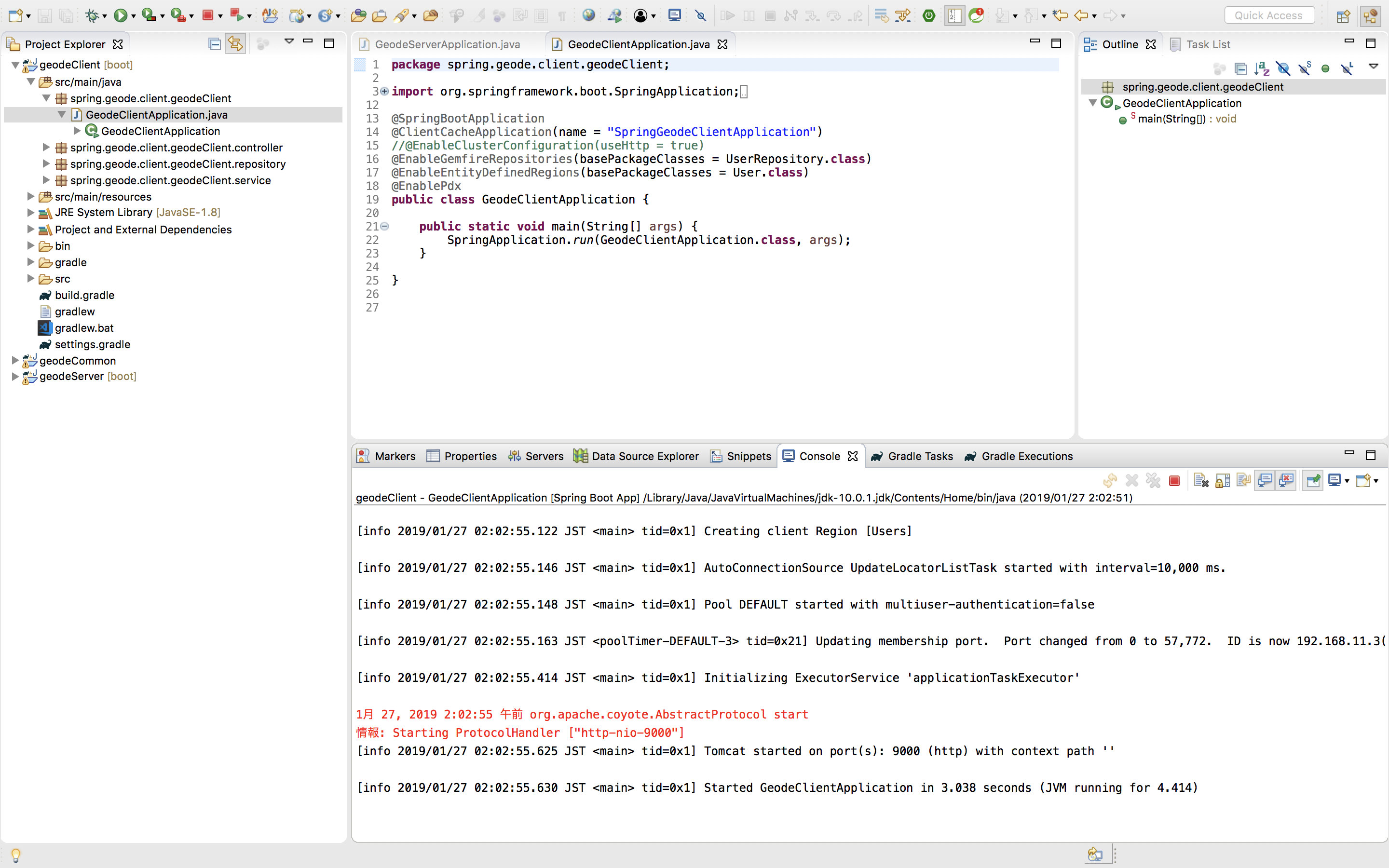
GeodeClientApplication.javapackage spring.geode.client.geodeClient; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.data.gemfire.config.annotation.ClientCacheApplication; import org.springframework.data.gemfire.config.annotation.EnableEntityDefinedRegions; import org.springframework.data.gemfire.config.annotation.EnablePdx; import org.springframework.data.gemfire.repository.config.EnableGemfireRepositories; import spring.geode.client.geodeClient.repository.UserRepository; import spring.geode.geodeCommon.model.User; @SpringBootApplication @ClientCacheApplication(name = "SpringGeodeClientApplication") //① @EnableGemfireRepositories(basePackageClasses = UserRepository.class) //② @EnableEntityDefinedRegions(basePackageClasses = User.class) //③ @EnablePdx //④ public class GeodeClientApplication { public static void main(String[] args) { SpringApplication.run(GeodeClientApplication.class, args); } }
アノテーションの説明
- ①:
Apache GEODEにおけるclientのアプリケーションとして起動する設定- ②: 指定したクラスを
Apache GEODEのデータアクセサとして機能させる設定- ③: 指定したRegion(RDBで言うところのテーブル)を自動的に作成する設定
- ④:
Apache GEODEの扱うデータのシリアライズ/デシリアライズに関する設定(必須ではなさそう)Controllerクラス
UserController.javapackage spring.geode.client.geodeClient.controller; import org.springframework.web.bind.annotation.PathVariable; import org.springframework.web.bind.annotation.RequestBody; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RequestMethod; import org.springframework.web.bind.annotation.RestController; import lombok.RequiredArgsConstructor; import spring.geode.client.geodeClient.service.UserService; import spring.geode.geodeCommon.model.User; import spring.geode.geodeCommon.model.UserRequest; @RestController @RequiredArgsConstructor public class UserController { private final UserService userService; //nameでのユーザ検索API @RequestMapping(path = "/find/user/{name}", method = RequestMethod.GET) public User findById(@PathVariable String name) { return userService.findByName(name); } //ユーザ全件検索API @RequestMapping("/findAll") public List<User> findAll() { return userService.findAll(); } //新規ユーザ登録API @RequestMapping(path = "/register/user", method = RequestMethod.POST) public String register(@RequestBody UserRequest request) { return userService.register(request).getName(); } }
- serviceクラス
UserService.javapackage spring.geode.server.geodeServer.service; import java.util.ArrayList; import java.util.List; import org.springframework.stereotype.Service; import lombok.RequiredArgsConstructor; import spring.geode.geodeCommon.model.User; import spring.geode.geodeCommon.model.UserRequest; import spring.geode.server.geodeServer.repository.UserRepository; @RequiredArgsConstructor @Service public class UserService { private final UserRepository rep; public User findByName(String name) { User user=rep.findByName(name).get(0); return user; } public User register(UserRequest request) { User commited = rep.save(new User(request)); return commited; } public List<User> findAll(){ List<User> users=new ArrayList<>(); rep.findAll().forEach(user -> users.add(user));; return users; } }Repositoryクラス
UserRepository.javapackage spring.geode.server.geodeServer.repository; import java.util.List; import org.springframework.data.gemfire.repository.GemfireRepository; import spring.geode.geodeCommon.model.User; public interface UserRepository extends GemfireRepository<User, Integer> { List<User> findByName(String name); }
- 設定ファイル
application.propertiesspring.data.gemfire.pool.locators=localhost[40404] server.port=9000clientアプリケーションが接続する先のlocatorのIP,portを設定。
今回はserverアプリケーションの設定でlocatorを起動するため、localhostを指定。
Apache GEODEにおけるclient,server,locatorの関係は以下の記事に記載。
Apache GEODE の概要ここまででclientアプリケーションは実装完了。
扱うデータオブジェクト(Userクラス)はclient,serverプロジェクトで共通のクラスを使う必要があるため、Commonプロジェクトに集約して後ほど作成する。server側アプリを作成
起動クラス以外は、clientアプリケーションのコードをそのままserverアプリケーションのプロジェクトに持ち込めば良い。
- 起動クラス
GeodeServerApplication.javapackage spring.geode.server.geodeServer; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.context.annotation.Configuration; import org.springframework.data.gemfire.config.annotation.CacheServerApplication; import org.springframework.data.gemfire.config.annotation.EnableEntityDefinedRegions; import org.springframework.data.gemfire.config.annotation.EnableLocator; import org.springframework.data.gemfire.config.annotation.EnableManager; import org.springframework.data.gemfire.config.annotation.EnablePdx; import org.springframework.data.gemfire.repository.config.EnableGemfireRepositories; import spring.geode.geodeCommon.model.User; import spring.geode.server.geodeServer.repository.UserRepository; @SpringBootApplication @CacheServerApplication(locators = "localhost[40404]") //① @EnableGemfireRepositories(basePackageClasses = UserRepository.class) @EnableEntityDefinedRegions(basePackageClasses = User.class) @EnablePdx public class GeodeServerApplication { public static void main(String[] args) { SpringApplication.run(GeodeServerApplication.class, args); } @Configuration @EnableLocator(port = 40404) //② @EnableManager(start = true) //③ static class LocatorManagerConfiguration { } }
- アノテーションの説明
- ①:
Apache GEODEにおけるserverのアプリケーションとして起動する設定。接続してくるlocatorはlocalhostの40404ポートであることを設定。- ②: locatorを40404ポートで起動する設定
- ③: client/serverのアプリケーションの監視を行うサービスを起動する設定
ここまででserverアプリケーションは実装完了。
データモデルの作成
- Webアプリにおけるclientからのリクエストモデル(
Apache GEODEにおけるclientとは異なる)UserRequest.javapackage spring.geode.geodeCommon.model; import java.io.Serializable; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; @Data @AllArgsConstructor @NoArgsConstructor public class UserRequest implements Serializable{ private static final long serialVersionUID = 1L; private String name; private int age; }
Apache GEODEに永続化するドメインモデルUser.javapackage spring.geode.geodeCommon.model; import java.io.Serializable; import java.util.UUID; import org.springframework.data.gemfire.mapping.annotation.Region; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; @Data @AllArgsConstructor @NoArgsConstructor @Region("Users") //① public class User implements Serializable { private static final long serialVersionUID = 1L; private Integer id; private String name; private int age; public User(UserRequest request) { this.name=request.getName(); this.age=request.getAge(); this.id=UUID.randomUUID().hashCode(); } }
アノテーションの説明
- ①: このモデルが紐付くRegionを設定する。
データモデルを実装したプロジェクトはclient,serverアプリケーションのプロジェクトに依存されるため、client,serverアプリケーションの
settings.gradleに以下の内容を記載settings.gradle// geodeCommonは自分の作成したプロジェクト名に読み換える include ':geodeCommon' project(':geodeCommon').projectDir = new File('../geodeCommon')ここまでで、データモデルの実装は完了
起動してみる
clientアプリケーションは起動時にlocatorへ接続するため、先にserverアプリケーションを起動する必要がある。
serverアプリケーション起動(組み込みTomacatはポート番号
9090で起動)
clientアプリケーション起動(組み込みTomcatはポート番号
9000で起動)
正常に両方のアプリケーションが起動できれば、client,locator,serverの接続はできているはずです。
ユーザをclientアプリケーションに登録してみる
curl -H "Content-Type: application/json" -X POST -d '{"name":"John","age":23}' http://localhost:9000/register/user/; curl -H "Content-Type: application/json" -X POST -d '{"name":"Bob","age":10}' http://localhost:9000/register/user/;serverアプリケーションからユーザを検索してみる
curl -i http://localhost:9090/findAll検索結果で、clientアプリケーションに登録したユーザが検索できればOK
HTTP/1.1 200 Content-Type: application/json;charset=UTF-8 Transfer-Encoding: chunked Date: Sat, 26 Jan 2019 17:10:37 GMT [{"id":-1174841827,"name":"Bob","age":10},{"id":-516984913,"name":"John","age":23}]念のため、name指定での検索も行う
curl -i http://localhost:9090/find/user/John; HTTP/1.1 200 Content-Type: application/json;charset=UTF-8 Transfer-Encoding: chunked Date: Sat, 26 Jan 2019 17:12:33 GMT {"id":-516984913,"name":"John","age":23}client,serverでデータが同期されていることを確認できました。
以下の公式ドキュメントを参考に実装してみました。
https://geode.apache.org/docs/今後はpeerモデルでのアプリケーション作成や、AWSでのアプリ構成、非同期永続化など作り込んでいってみようと思います。

- 投稿日:2019-01-27T01:45:52+09:00
JavaでZabbix API
今回はなるべく自力でZabbixサーバーとやり取りするためのプログラムを作成.
用意するものを少なくするために, httpclientのコーディングは標準ライブラリで何とかする.用意するもの
ここのDownloadのthe latest JARからjarファイルをダウンロード
HttpClient
ここを参考にした.
ZabbixサーバーにJsonRPCの規則に従ってJSONオブジェクトを投げると, jsonrpc, result, idで構成されたJSONオブジェクトが返ってくる.public class Api { public String Post(JSONObject json) { try { URL url = new URL("http://127.0.0.1/zabbix/api_jsonrpc.php"); HttpURLConnection connection = null; try { connection = (HttpURLConnection) url.openConnection(); connection.setDoOutput(true); connection.setRequestMethod("POST"); connection.setRequestProperty("Content-Type", "application/json; charset=utf-8"); BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(connection.getOutputStream(), StandardCharsets.UTF_8)); writer.write(json.toString()); //ここでJSONデータを投げる writer.flush(); if (connection.getResponseCode() == HttpURLConnection.HTTP_OK) { try (InputStreamReader isr = new InputStreamReader(connection.getInputStream(), StandardCharsets.UTF_8); BufferedReader reader = new BufferedReader(isr)) { String line; while ((line = reader.readLine()) != null) { return line; //ここでJSONデータを受け取る } } } } finally { if (connection != null) { connection.disconnect(); } } } catch (IOException e) { e.printStackTrace(); } return ""; } }JSONオブジェクトの作成
クライアントは, jsonrpc, method, params, id, authで構成されるJSONオブジェクトをサーバーに投げる.今回は, バージョンの取得とログインをする.
public class Main { public static void main(String[] args) { String result; Api api = new Api(); JSONObject json = new JSONObject(); JSONObject param = new JSONObject(); json.put("jsonrpc", "2.0"); json.put("method", "apiinfo.version"); json.put("params", param); json.put("id", 1); json.put("auth", null);//バージョンの取得の際は必要ない result = api.Post(json); System.out.println(result); param.put("user", "name");//ユーザー名 param.put("password", "pass");//パスワード json.put("jsonrpc", "2.0"); json.put("method", "user.login"); json.put("params", param); json.put("id", 1); json.put("auth", null); result = api.Post(json); System.out.println(JSON.parseObject(result).get("result")); } }実行結果
バージョンの取得は生のJSONデータが返ってくるようにした.authはresultから抽出した.
{"jsonrpc":"2.0","result":"4.0.3","id":1} 012225192b38d347ddf6098d291f30df次はきれいにまとめます.