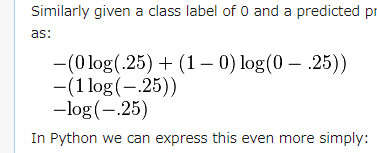はじめに 本来、論文や数式を全く読めない私が、論文内の図示だけを見て、 「これは凄そうだ!」 と直感的に感じてワクワクしたため、メモとしてココに残す。 あまりのワクワク感から論文の全文を日本語に翻訳したが、著者に無断で翻訳後の論文を公の場で公開することや図示を引用することは著作権に抵触するらしいので、この場では公開しない。 あくまで個人の趣味利用でPrivate Gitなどを利用してワキワキ楽しむだけのレベルとする。 読み込んだ論文 AMCL 2018で発表された論文。 http://www.acml-conf.org/2018/ACML%202018%20Main_Home.html RDEC: Integrating Regularization into Deep Embedded Clustering for Imbalanced Datasets http://proceedings.mlr.press/v95/tao18a/tao18a.pdf Yaling Tao yaling1.tao@toshiba.co.jp Kentaro Takagi kentaro1.takagi@toshiba.co.jp Kouta Nakata kouta.nakata@toshiba.co.jp Corporate R&D Center, Toshiba Corporation, Kawasaki, Japan Editors: Jun Zhu and Ichiro Takeuchi ポイント 不均衡データのための正則化ディープエンベデッドクラスタリング (RDEC) 不均衡なデータのごく少数派のクラスに適切な重心を置いて、物凄くうまく分類できる クラスタリング手法 ディープラーニングとの組み合わせ 正則化項あり 2018.11 時点で最高のパフォーマンス (state-of-the-art) 異常検知分野で猛威を振るうに違いない 私に機械学習の実装スキルがあれば即座に再現実装してみたいのですが。。。数式読めない時点でかなりダメね。。。 MNISTデータセットによる分類精度は 98.41%、 MNISTから派生した非常に不均衡なデータセットによる分類精度は 85.45% で、現在の最善の結果よりも 8% 近く高い 日本語訳を公開してもいいか? なんて、TOSHIBAさん相手に聞く勇気なんて全く無いです。。。 おわりに せめて私に力があれば。。。
本来、論文や数式を全く読めない私が、論文内の図示だけを見て、 「これは凄そうだ!」 と直感的に感じてワクワクしたため、メモとしてココに残す。 あまりのワクワク感から論文の全文を日本語に翻訳したが、著者に無断で翻訳後の論文を公の場で公開することや図示を引用することは著作権に抵触するらしいので、この場では公開しない。 あくまで個人の趣味利用でPrivate Gitなどを利用してワキワキ楽しむだけのレベルとする。
AMCL 2018で発表された論文。 http://www.acml-conf.org/2018/ACML%202018%20Main_Home.html
RDEC: Integrating Regularization into Deep Embedded Clustering for Imbalanced Datasets http://proceedings.mlr.press/v95/tao18a/tao18a.pdf
Yaling Tao yaling1.tao@toshiba.co.jp Kentaro Takagi kentaro1.takagi@toshiba.co.jp Kouta Nakata kouta.nakata@toshiba.co.jp Corporate R&D Center, Toshiba Corporation, Kawasaki, Japan Editors: Jun Zhu and Ichiro Takeuchi
98.41%
85.45%
8%
せめて私に力があれば。。。
今回は、コーヒーブレイクネタと、ネクストアクションを書き留めます。 コーヒーブレイク そもそも作りたいシステムはFXのデータを使ったAIで自動売買できるシステム。 世の中にはその手のシステムが増えてきている、、、。 少しでも自分の環境を構築する上で参考になるものを調べていたら、こんなものを発見した。 https://qiita.com/jiji_platform/items/268377c542706e6f44b1 これはとても素晴らしい!! FXのデータだけではなく、他の経済情報も考慮に入れたAIシステム。 しかも、オープンソース!! 今回はここから少し学びました。 経済情報ってどこから入手するものなの? 一般的にはあらゆる経済情報が提供されているところから、スクレイピングして取得するの主流のようですが、なんと素晴らしいことに、そういう情報をAPIで提供してくれるサービスがあった。 Quandl(https://www.quandl.com/) このサイトでは無料で参照できる情報と、有料となる情報がある。 有料の場合は、各情報に応じて、1ヶ月~1年ぐらいで参照ライセンスが付与されるようです。 にしても、無料だけでも十分な量を提供されているようなので、必要な部分はコスト見合いで購入するのもありですね。 Alphavantage(https://www.alphavantage.co/) こちらは無料で為替情報へのAPIが提供されているようです。 ここは、主に下記の情報に特化しているようです。FXや仮想通貨、テクニカルインジケータをリアルタイムで提供してくれます。 - Free APIs in JSON and CSV formats - Realtime and historical stock data - FX and cryptocurrency feeds - 50+ technical indicators その他 https://blog.rapidapi.com/best-finance-apis/ こちらのサイトにも色々掲載されていた。 気になったのでφ(..)メモメモ 学習データの保存 FXのデータを使うのであれば、一度、モデルを作って終わり、、、とは行きません。 そんな中で、どうやって新しいデータを学習していくんだ? と言う疑問がよぎりました。あまりその辺を明示的に書いている記事が見つからず、、、。 先程のJijiの中でヒントがありました。 Jijiの先にMongoDBと、TensorFlowへ接続し、そのTensorflowの先には、、、「.ckpt」の文字が、、、。 これをGoogle先生に聞いてみた。 .ckpt Tensorflow用の学習モデルをCheckpoint(.ckpt)ファイルに保存するようです。 後述の学習モデルの保存では、Kerasのものですが、Tensorflowの場合は、「Save and Restore」で保存するようですね。 学習モデルと、結果を保存するのは https://m0t0k1ch1st0ry.com/blog/2016/07/17/keras/ では、実際に学習モデルと結果を保存するにはどうするのか? model_json_str = model.to_json() open('mnist_mlp_model.json', 'w').write(model_json_str) model.save_weights('mnist_mlp_weights.h5'); これで保存 # モデルを読み込む model = model_from_json(open('mnist_mlp_model.json').read()) # 学習結果を読み込む model.load_weights('mnist_mlp_weights.h5') 利用するときには読み込む必要があるようようだ。 以前、 https://qiita.com/yanaitti/items/f28951b8231bd8596900 の記事で取り上げた例では参考にしたページの記載では下記の通りだった。 # モデルを保存 model.save('model.h5') # 追加部分 # モデルを読み込む model = load_model(os.path.abspath(os.path.dirname(__file__)) + '/model.h5') model.save() これはモデルの重みと構成を両方保存する場合に利用し、load()により両方が読み出されます。 model.save_weights() これはモデルの重みだけを保存する場合に利用し、JSONファイルからモデルを再構築する為の追加コードが必要になるとのこと。 なんか、着実に進んでいるのを実感している、、、が、ゴールはどこなのかww
今回は、コーヒーブレイクネタと、ネクストアクションを書き留めます。
そもそも作りたいシステムはFXのデータを使ったAIで自動売買できるシステム。 世の中にはその手のシステムが増えてきている、、、。
少しでも自分の環境を構築する上で参考になるものを調べていたら、こんなものを発見した。
https://qiita.com/jiji_platform/items/268377c542706e6f44b1 これはとても素晴らしい!! FXのデータだけではなく、他の経済情報も考慮に入れたAIシステム。 しかも、オープンソース!!
今回はここから少し学びました。
一般的にはあらゆる経済情報が提供されているところから、スクレイピングして取得するの主流のようですが、なんと素晴らしいことに、そういう情報をAPIで提供してくれるサービスがあった。
このサイトでは無料で参照できる情報と、有料となる情報がある。 有料の場合は、各情報に応じて、1ヶ月~1年ぐらいで参照ライセンスが付与されるようです。
にしても、無料だけでも十分な量を提供されているようなので、必要な部分はコスト見合いで購入するのもありですね。
こちらは無料で為替情報へのAPIが提供されているようです。 ここは、主に下記の情報に特化しているようです。FXや仮想通貨、テクニカルインジケータをリアルタイムで提供してくれます。 - Free APIs in JSON and CSV formats - Realtime and historical stock data - FX and cryptocurrency feeds - 50+ technical indicators
https://blog.rapidapi.com/best-finance-apis/ こちらのサイトにも色々掲載されていた。 気になったのでφ(..)メモメモ
FXのデータを使うのであれば、一度、モデルを作って終わり、、、とは行きません。 そんな中で、どうやって新しいデータを学習していくんだ? と言う疑問がよぎりました。あまりその辺を明示的に書いている記事が見つからず、、、。
先程のJijiの中でヒントがありました。
Jijiの先にMongoDBと、TensorFlowへ接続し、そのTensorflowの先には、、、「.ckpt」の文字が、、、。 これをGoogle先生に聞いてみた。
Tensorflow用の学習モデルをCheckpoint(.ckpt)ファイルに保存するようです。 後述の学習モデルの保存では、Kerasのものですが、Tensorflowの場合は、「Save and Restore」で保存するようですね。
https://m0t0k1ch1st0ry.com/blog/2016/07/17/keras/ では、実際に学習モデルと結果を保存するにはどうするのか?
model_json_str = model.to_json() open('mnist_mlp_model.json', 'w').write(model_json_str) model.save_weights('mnist_mlp_weights.h5');
これで保存
# モデルを読み込む model = model_from_json(open('mnist_mlp_model.json').read()) # 学習結果を読み込む model.load_weights('mnist_mlp_weights.h5')
利用するときには読み込む必要があるようようだ。
以前、 https://qiita.com/yanaitti/items/f28951b8231bd8596900 の記事で取り上げた例では参考にしたページの記載では下記の通りだった。
# モデルを保存 model.save('model.h5') # 追加部分
# モデルを読み込む model = load_model(os.path.abspath(os.path.dirname(__file__)) + '/model.h5')
これはモデルの重みと構成を両方保存する場合に利用し、load()により両方が読み出されます。
これはモデルの重みだけを保存する場合に利用し、JSONファイルからモデルを再構築する為の追加コードが必要になるとのこと。
なんか、着実に進んでいるのを実感している、、、が、ゴールはどこなのかww
こんにちは。今日は自分が新しくDeepLearning用のマシンを購入したので、それの環境構築が意外とすんなりいったので、メモとして記録していきます。 昔のCUDAといえばおぞましく入れるのが面倒な必須ライブラリでしたが、今となっては結構簡単に入るようです。 WindowsでDeep Learningしたい!! Windows上で動く快適なDeepLearningを楽しむ基本的な手順としては Visual Studio C++環境をインストールし、CUDAを迎える準備を整える CUDA10を迎え入れる 必要なpythonパッケージを迎え入れる Visual Studio Codeを迎え入れる Visual Studio CodeをJupyter化 といった形を行うことで、コード生成や実験の早いDeepLearningの研究用の環境が整います。 今回使用した環境 今回、自宅で仕事を処理するために使おうと思い、新しくPCを新調しました!大体のスペックは以下の通りです。 Intel i9-9900K 8core 16thread. RTX 2080 Ti 11GB GDDR6. 32GB DDR4 RAM 500GB NVMe SSD(正直1TBにすればよかった) 新調するために2013年に自作PCした時の知識を更新したのは 最新高性能GPUはRTX 2080Tiになって価格は18万円近くする RAMは規格がDDR4になってる。価格はサイズあたりそんなに下がってない。これから下がるらしい。速度も早くなってるらしい。 SSDがPCIeで接続するようになって超高速化。10倍近い進化。 更にM.2規格でGPUを挿すPCIeの場所とは別の場所ができてる。 SSDにSATA使うのはもはや時代遅れ。 価格がめちゃくちゃ安くなってる。1TB 2万円とか。早いのに大容量で安い。 一方でNVMeのSSDはめちゃ発熱するのでヒートシンクが必要 ご参考までにどうぞ。 1. Visual Studioを迎える Visual Studioを迎える準備をします。CUDAを迎える前に、まずC++ビルドできる環境にする必要があります。 詳しくはこちらの記事も有用なので参考にしてください。 Visual Studio をダウンロード ここから、Community版をダウンロードし、インストール。 Visual Studioをインストール ここ、画像が用意できなくて申し訳ないんですが、重要な点を記載しておきます。 そのままインストールするとVisual Studio*だけ*をインストールされてしまうので意味ない。 必ずC++の開発オプションをつける 必ずPython開発オプションをつける C++は大枠をCheckすれば大丈夫。Python開発のオプションではAnaconda3 64bit版などの必要なオプションをインストールするのも忘れないようにしよう。 しっかりと設定を行ったら、インストールを行いましょう。 2.CUDAを迎え入れる ここからCUDA10をダウンロードしてインストールを行いましょう。 手順を進めていけばOKですが しっかり出てくる文章を読むこと。 Visual Studioがインストールされていないけど大丈夫か?という英語メッセージが出たらC++系が入っていないので1番をもう一度確認しましょう。 3.必要なパッケージを入れる このAnaconda Promptをどうにかして管理者権限で開きます。 このAnacondaはVisual Studioのオプションで入ったものですが、Python Versionは3.6.5になります。 Chainerを入れる とりあえずChainerを入れてみましょう。 C:\Windows\system32> pip install msgpack C:\Windows\system32> pip install cupy C:\Windows\system32> pip install chainer をそれぞれ入力しましょう。 msgpackはcupyに必要なパッケージです。 PyTorchを入れる PyTorchは公式サイトを参考にやるとすんなり行きます。(行かなかったらコメントください) C:\Windows\system32> pip install https://download.pytorch.org/whl/cu100/torch-1.0.0-cp36-cp36m-win_amd64.whl C:\Windows\system32> pip install torchvision 4.Visual Studio Codeを迎え入れる。 Visual Studio Codeを迎え入れましょう。 日本語化 拡張機能でJapaneseと検索すると、日本語化パッケージがあるのでこれを選択。 Python対応 拡張機能でPythonと検索すると、Python対応パッケージが出るのでそれをインストール Jupyter対応 詳しくはこちらが非常に参考になります。 Visual studio CodeのJupyterについてはこちらが参考になります。 5.Enjoy! Let's 研究ライフ! そのうちベンチマーク的なコードを載せれたら載せたいと思います。
こんにちは。今日は自分が新しくDeepLearning用のマシンを購入したので、それの環境構築が意外とすんなりいったので、メモとして記録していきます。 昔のCUDAといえばおぞましく入れるのが面倒な必須ライブラリでしたが、今となっては結構簡単に入るようです。
Windows上で動く快適なDeepLearningを楽しむ基本的な手順としては
といった形を行うことで、コード生成や実験の早いDeepLearningの研究用の環境が整います。
今回、自宅で仕事を処理するために使おうと思い、新しくPCを新調しました!大体のスペックは以下の通りです。
新調するために2013年に自作PCした時の知識を更新したのは
ご参考までにどうぞ。
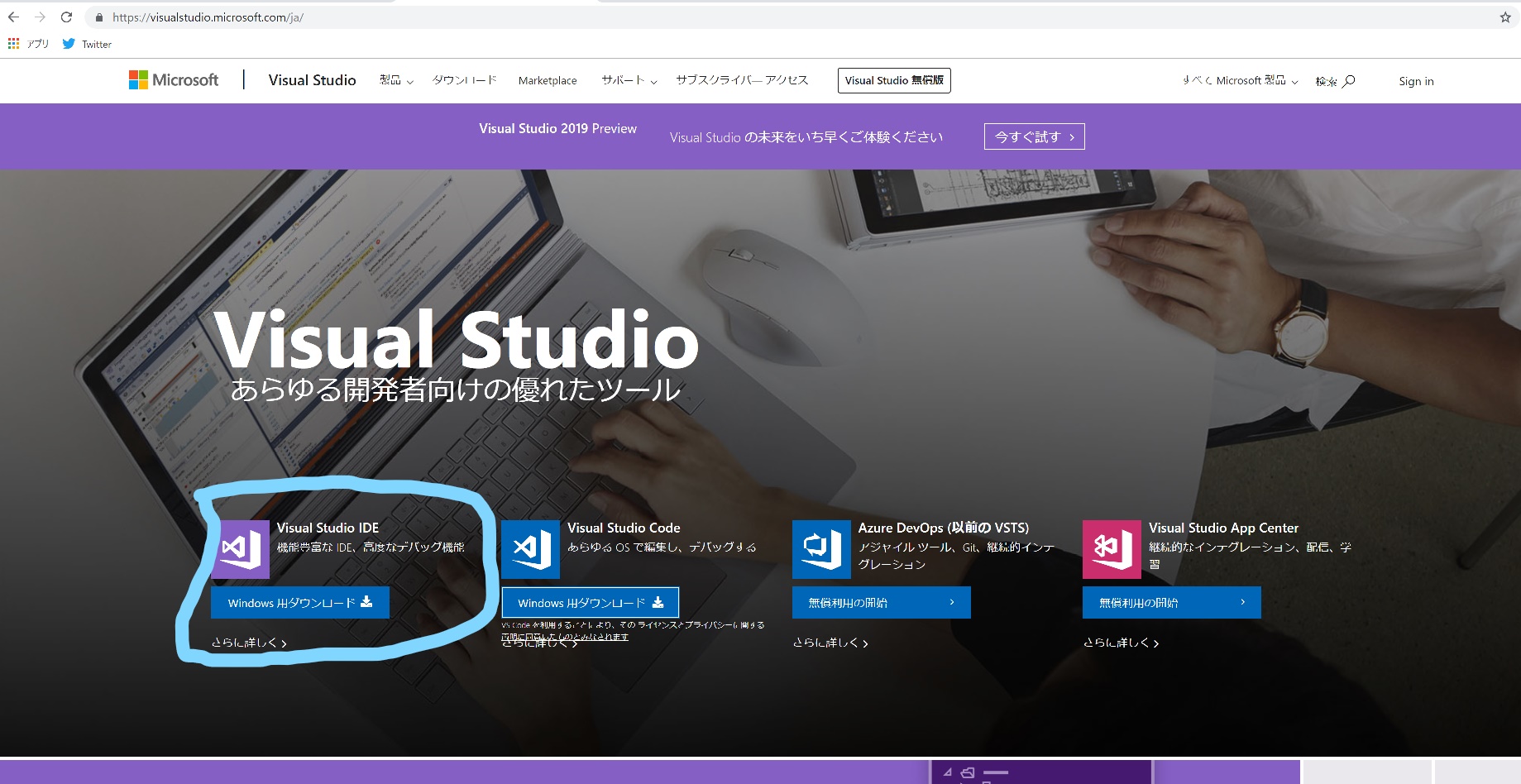
Visual Studioを迎える準備をします。CUDAを迎える前に、まずC++ビルドできる環境にする必要があります。
詳しくはこちらの記事も有用なので参考にしてください。
ここから、Community版をダウンロードし、インストール。
ここ、画像が用意できなくて申し訳ないんですが、重要な点を記載しておきます。
しっかりと設定を行ったら、インストールを行いましょう。
ここからCUDA10をダウンロードしてインストールを行いましょう。 手順を進めていけばOKですが
このAnaconda Promptをどうにかして管理者権限で開きます。 このAnacondaはVisual Studioのオプションで入ったものですが、Python Versionは3.6.5になります。
とりあえずChainerを入れてみましょう。
C:\Windows\system32> pip install msgpack C:\Windows\system32> pip install cupy C:\Windows\system32> pip install chainer
をそれぞれ入力しましょう。 msgpackはcupyに必要なパッケージです。
PyTorchは公式サイトを参考にやるとすんなり行きます。(行かなかったらコメントください)
C:\Windows\system32> pip install https://download.pytorch.org/whl/cu100/torch-1.0.0-cp36-cp36m-win_amd64.whl C:\Windows\system32> pip install torchvision
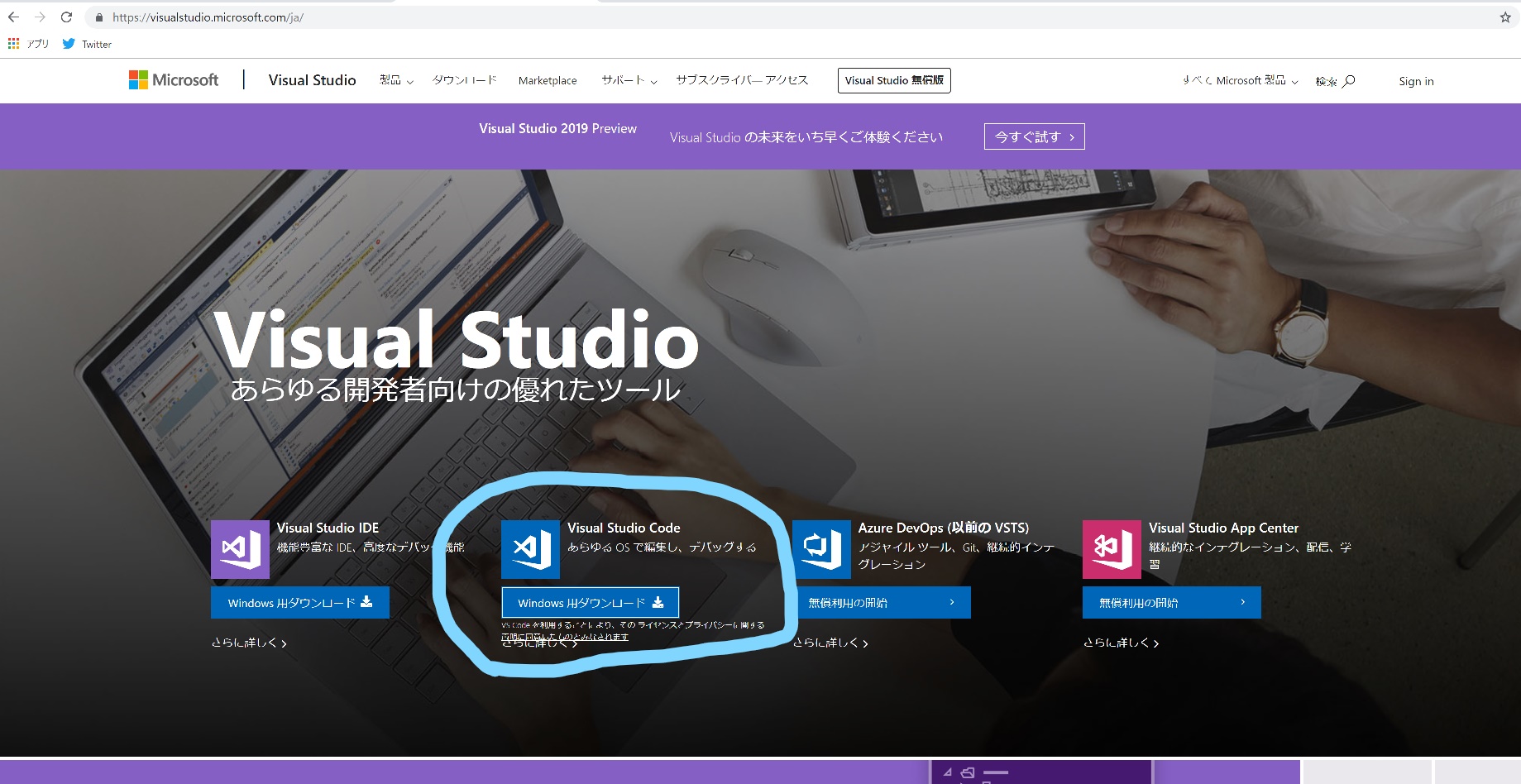
Visual Studio Codeを迎え入れましょう。
拡張機能でJapaneseと検索すると、日本語化パッケージがあるのでこれを選択。
拡張機能でPythonと検索すると、Python対応パッケージが出るのでそれをインストール
詳しくはこちらが非常に参考になります。 Visual studio CodeのJupyterについてはこちらが参考になります。
Let's 研究ライフ! そのうちベンチマーク的なコードを載せれたら載せたいと思います。
本記事はfast.aiのwikiのLog Lossページの要約となります。 筆者の理解した内容で記載します。 一言でいうと、クロスエントロピー。0~1の予測値を入力してモデルの性能を測る指標を出力する。 概要 Logarithmic Lossのこと 分類モデルの性能を測る指標。(このLog lossへの)入力は0~1の確率の値をとる。 この値を最小化したい。完璧なモデルではLog lossが0になる。 予測値が正解ラベルから離れるほどLog lossは増加する。 Accuracyとの違い Accuracyは予測した値と正解が一致していた数のカウント。正解/不正解しかないのでいつも良い指標とは限らない(惜しかった、などが測れない) Log Lossは実際のラベルからどのくらい違っていたのかを考慮できる 可視化 下記のグラフは正解ラベルが例えば犬=1の場合にLog lossが取りうる値を示す 予測値が1に近づくとLog lossはゆっくり減少する 予測値が0に近づくと急増する Log lossはモデルが間違ったラベルを、高い確信度で出力したときに、特に高くなる コード pythonの場合。 関数の入力が0~1に収まるようにnp.clip()を通す logloss.py import numpy as np import math def logloss(true_label, predicted, eps=1e-15): p = np.clip(predicted, eps, 1 - eps) if true_label == 1: return -math.log(p) else: return -math.log(1 - p) 数学的なこと 1つの出力値に対するlog lossの計算式を示す。データセットに対してモデルを評価するときは単にすべての出力でlog lossを計算して平均する。 以降で使用する変数の定義 $N$ : データ数 $M$ : 全クラスラベル数 $\log$ : 対数関数(底は$e$) $y$ : クラスラベル。0または1をとる。(観測$o$がクラス$c$に属している場合は1を設定している) $p$ : モデルによって出力された、観測$o$がクラス$c$に属する確率 2値分類の場合 2値分類(M=2)の場合の式は、 -(y\log p +(1-y)\log(1-p) ) \tag{1} 例1: クラスラベルが1で予測値0.25が出力されたとき、$(1)$式よりlog lossは \begin{align} &-(1\log 0.25 +(1-1)\log(1-0.25) ) \\ &=-(\log 0.25 +0\log(0.75) ) \\ &=-\log0.25 \end{align} 例2: 同様にクラスラベルが0で予測値0.25が出力されたときは \begin{align} &-(0\log 0.25 +(1-0)\log(1-0.25) ) \\ &=-(1\log (0.75)) \\ &=-\log(0.75) \end{align} * ちなみに2番目の例は元記事では となっており、第二項目のlogの中が$0-.25$と表記されているが、 $(1)$式で第2項目のlogの中身は$1-p$であるのでこれは誤りで、$1-.25$が正しい。 (2019/1/27現在) 多クラスの場合 クラス数M>2の場合、各クラスの予測に関するlog lossの和になる。 -\sum_{c=1}^M y_{o,c} \log(p_{o,c}) log lossに負号がついているのは、 $\log n (0<n<1)$が負の値を返すから。 負号をつけないといつも戻り値が負になって、2つのモデルの性能を比較するときとかによくわからない。 MinMaxルール 上記式$(1)$では、予測値が0または1の時に未定義となるので、予測値の調整をすることがある。 max(min(p, 1−10^−15), 10^-15) 予測値p=0の場合 min関数を適用。max(0,10^-15)になる max関数を適用。10^-15になる 予測値0は10^-15(~0.0000000000000001) に変換された。 予測値p=1の場合 min関数を適用。max(1-10^-15,10^-15)になる max関数を適用。1-10^-15になる 予測値1は1-10^-15(~0.9999999999999999)に変換された。 Log LossとCross-Entropyは ほぼ同じものである。 特に機械学習で0~1の範囲で誤り率を計算するときは同じものを解いている。 p \in \bigl\{y, 1-y \bigr\}, q \in \bigl\{ \hat{y}, 1-\hat{y}\bigr\} とすれば、 H(p,q)=-\sum p_i \log q_i = -y log \hat{y} - (1-y)log(1-\hat{y}) と書くことができ、一致している。 ここで $p$: 正解ラベルの集合 $q$: 予測の集合 $y$: 真のラベル $\hat{y}$: 予測値 である。
本記事はfast.aiのwikiのLog Lossページの要約となります。 筆者の理解した内容で記載します。
一言でいうと、クロスエントロピー。0~1の予測値を入力してモデルの性能を測る指標を出力する。
Logarithmic Lossのこと 分類モデルの性能を測る指標。(このLog lossへの)入力は0~1の確率の値をとる。 この値を最小化したい。完璧なモデルではLog lossが0になる。 予測値が正解ラベルから離れるほどLog lossは増加する。
下記のグラフは正解ラベルが例えば犬=1の場合にLog lossが取りうる値を示す
Log lossはモデルが間違ったラベルを、高い確信度で出力したときに、特に高くなる
pythonの場合。 関数の入力が0~1に収まるようにnp.clip()を通す
np.clip()
import numpy as np import math def logloss(true_label, predicted, eps=1e-15): p = np.clip(predicted, eps, 1 - eps) if true_label == 1: return -math.log(p) else: return -math.log(1 - p)
1つの出力値に対するlog lossの計算式を示す。データセットに対してモデルを評価するときは単にすべての出力でlog lossを計算して平均する。
2値分類(M=2)の場合の式は、
-(y\log p +(1-y)\log(1-p) ) \tag{1}
クラスラベルが1で予測値0.25が出力されたとき、$(1)$式よりlog lossは
\begin{align} &-(1\log 0.25 +(1-1)\log(1-0.25) ) \\ &=-(\log 0.25 +0\log(0.75) ) \\ &=-\log0.25 \end{align}
同様にクラスラベルが0で予測値0.25が出力されたときは
\begin{align} &-(0\log 0.25 +(1-0)\log(1-0.25) ) \\ &=-(1\log (0.75)) \\ &=-\log(0.75) \end{align}
ちなみに2番目の例は元記事では となっており、第二項目のlogの中が$0-.25$と表記されているが、 $(1)$式で第2項目のlogの中身は$1-p$であるのでこれは誤りで、$1-.25$が正しい。 (2019/1/27現在)
クラス数M>2の場合、各クラスの予測に関するlog lossの和になる。
-\sum_{c=1}^M y_{o,c} \log(p_{o,c})
$\log n (0<n<1)$が負の値を返すから。 負号をつけないといつも戻り値が負になって、2つのモデルの性能を比較するときとかによくわからない。
上記式$(1)$では、予測値が0または1の時に未定義となるので、予測値の調整をすることがある。
max(min(p, 1−10^−15), 10^-15)
max(0,10^-15)
10^-15
max(1-10^-15,10^-15)
1-10^-15
ほぼ同じものである。 特に機械学習で0~1の範囲で誤り率を計算するときは同じものを解いている。
p \in \bigl\{y, 1-y \bigr\}, q \in \bigl\{ \hat{y}, 1-\hat{y}\bigr\}
とすれば、
H(p,q)=-\sum p_i \log q_i = -y log \hat{y} - (1-y)log(1-\hat{y})
と書くことができ、一致している。 ここで
である。
こ、これは、、いったい何よ? ひと振りするだけで、コインがザックザク出てくる 、というサービス(デモ版)を作ってみた、というお話です。 http://35.237.23.189/jcoin_generator.html → まずは、[ Shake it ! ] ボタンを押してみてください。 (URLは変更または廃止することがあります) 以前、コインをバラまいた画像から合計金額を推定するAI という記事を投稿しましたが、それに用いた学習データ生成エンジンを切り出し、 サービス化したものです。 そ、それで、、何をしたいのよ? いまどきのAI(人工知能)といえば、機械学習とその応用を指すことが多いように思います。 機械学習は一般に、たっくさんのデータが必要となります。 機械学習の中ではポピュラーな「教師あり学習」については、個々の学習用データに「教師データ」(=正解ラベル)を付与する必要があります。 たとえば、画像につけるタイトルが教師データとなります。 (下記では、ねこ、いぬ、さる) = ねこ = いぬ = さる ところが、これ(教師データを付与すること=ラべリンク)は、死ぬほど手間がかかります。 きょうびの機械学習では、何千個、何万個、・・のラべリングが必要になることがありますが、これらは通常、人間が作業せざるを得ません。 そんなわけで、フリー?なデータがネット上で用意していただいていたりするわけですが、 http://www.cs.toronto.edu/~kriz/cifar.html http://yann.lecun.com/exdb/mnist/ おっと! まとめてくれてる人がいました。。すばらしい! https://www.codexa.net/ml-dataset-list/ しかし当然ながら、独自のデータを用意したいときは大変! もっとも、ある程度のデータがたまれば、元データを機械的に加工する「水増し」とよばるデータ拡張が可能な場合はあるにはありますが・・。 =ねこ =ねこ =ねこ もちろん、水増しだけではやっていけません。 ところが、逆に教師データから学習用データを自動生成が可能な機械学習の分野があるのではないか、と考えました。 本件のコインバラまきネタ、などがそういう例です。 =16円 =28円 =12円 =9円 =21円・・・・・ (他にも自動生成ネタがあるのですが、それは別の機会に紹介しようかと・・) 実際には、金額そのものが教師データではなく、各種類それぞれのコインの枚数を教師データとしました。データ生成手順は次の通りです。 乱数で各コインの枚数を決める。(この時点で金額が確定) その後、各コインの枚数に応じたバラまき画像を生成。 これで学習したモデルが、現時点で実用に使えるわけではありません。 しかし、「多くのデータで学習する機械学習のモデルの振る舞い」を研究する材料となり得る、と考えました。 打ち出の小槌サービスの画面を、もう一度参照して下さい。生成するデータの属性や数をパラメータで制御できる、のは自動生成ならでは、です。 こ、このサービスって、今どう使えるのよ? と言われると、これは「こんなことができるよー」という単なるデモでして、 しいて言えば、生成されたページを右クリックとかして「名前を付けて保存」(ウェブページ、完全、=chromeブラウザの場合)とかすると、教師データがHTMLに記載された画像データのセットが得られます。 しかし、このサービスそのものは、ショボくて安い IAAS の仮想マシンを使っており、大量のデータ生成を想定していません。(酷使するとたぶん死にます。) 本当に大量のデータを作りたい場合は、コインバラまきネタのソースコード をとってきて、各自の環境に移植してください。 億万長者になれるかも。先は長いですが。 もし、今年中にこの記事に「いいね!」を100個もらえたら、本件のデータを使って「金額推定コンテスト」を開催しようと企んでいます。(ムリかーー) 【まとめ】本件に限らず、機械学習用のデータを最初から自動生成する仕組みを「打ち出の小槌(うちでのこづち)」と呼ぶことにします。
そんなわけで、フリー?なデータがネット上で用意していただいていたりするわけですが、 http://www.cs.toronto.edu/~kriz/cifar.html http://yann.lecun.com/exdb/mnist/
おっと! まとめてくれてる人がいました。。すばらしい! https://www.codexa.net/ml-dataset-list/
しかし当然ながら、独自のデータを用意したいときは大変!
もっとも、ある程度のデータがたまれば、元データを機械的に加工する「水増し」とよばるデータ拡張が可能な場合はあるにはありますが・・。 =ねこ =ねこ =ねこ
もちろん、水増しだけではやっていけません。
ところが、逆に教師データから学習用データを自動生成が可能な機械学習の分野があるのではないか、と考えました。
本件のコインバラまきネタ、などがそういう例です。 =16円 =28円 =12円 =9円 =21円・・・・・ (他にも自動生成ネタがあるのですが、それは別の機会に紹介しようかと・・)
実際には、金額そのものが教師データではなく、各種類それぞれのコインの枚数を教師データとしました。データ生成手順は次の通りです。
これで学習したモデルが、現時点で実用に使えるわけではありません。
しかし、「多くのデータで学習する機械学習のモデルの振る舞い」を研究する材料となり得る、と考えました。
打ち出の小槌サービスの画面を、もう一度参照して下さい。生成するデータの属性や数をパラメータで制御できる、のは自動生成ならでは、です。