- 投稿日:2020-11-15T22:23:39+09:00
【個人メモ】RailsアプリをAWSへデプロイする際につまづいたことまとめ
index
下記の記事の通りにRailsアプリをAWSへデプロイする際につまづいたことを個人的な備忘としてまとめました。
(下準備編)世界一丁寧なAWS解説。EC2を利用して、RailsアプリをAWSにあげるまで
https://qiita.com/naoki_mochizuki/items/f795fe3e661a3349a7ce
https://qiita.com/naoki_mochizuki/items/22cfbf4bf7ec95f6ac1c
https://qiita.com/naoki_mochizuki/items/814e0979217b1a25aa3e
https://qiita.com/naoki_mochizuki/items/5a1757d222806cbe0cd1RDSインスタンスが生成できない
RDSの設定をして、「データベースの作成」をクリックすると、こんなエラーが発生。
DB Subnet Group doesn't meet availability zone coverage requirement. Please add subnets to cover at least 2 availability zones. Current coverage: 1 (Service: AmazonRDS; Status Code: 400; Error Code: DBSubnetGroupDoesNotCoverEnoughAZs; Request ID: 3e87202c-e6b3-46dc-8396-47c64a2f0dd6)こちらの記事を参考にしました。
https://www.wantanblog.com/entry/2019/09/24/225020
どうやらサブネットグループを1つしか作っていなかったことが問題のようなので、「VPC」→「サブネット」→「サブネットの作成」から、下記設定でサブネットをもう一つ作成したところ、RDSインスタンスが作成できるようになった。
・VPC ・・・作成したVPCを選ぶ
・アベイラビリティーゾーン ・・・既に作成したサブネットと違う場所を指定する
・IPv4 CIDR ブロック ・・・10.0.1.0/24EC2へSSHでログインできない
*[ .ssh ] $: ssh -i mumu.pem ec2-user@54.92.121.123でEC2へログインしようとすると、しばらく待ってから接続エラーになりました。
こちらの記事を参考にしました。
https://xn--o9j8h1c9hb5756dt0ua226amc1a.com/?p=3583
EC2が配置されているサブネットのルートテーブルを確認したところ、外部への経路(送信先0.0.0.0/0、ターゲットigw-...)が設定されていませんでした(うっかり)
「VPC」→「ルートテーブル」→「該当のルートテーブルにチェック」→「ルートテーブル」→「ルートテーブルの編集」→「ルートを追加」で下記を追加したところ、EC2へSSH接続できるようになりました。
・送信先 ・・・ 0.0.0.0/0
・ターゲット ・・・igw-...(作成したインターネットゲートウェイ)公開鍵作成するときにssh-keygem not foundのエラー
タイポでした。
ssh-keygemではなくssh-keygenでした。rake secretでシークレットキーが作れない
下記のエラーが発生
$ rake secret You must use Bundler 2 or greater with this lockfile.こちらの記事を参考にしました。
https://programming-beginner-zeroichi.jp/articles/169$ gem install bundler $ bundle install $ bundle exec rake secretで解決しました。(※ちなみに筆者はアプリのデータベースをsqliteに設定していたため、「bundle install」でエラーが発生し、次の記事の手順を踏んでから、「bundle install」をしました。
bundle installしたとき、sqlite3をインストールしてくださいのエラー
MySQLをデータベースに使う予定なので、railsアプリのデータベースをsqliteからMySQLへ変更します。
こちらの記事を参考にしました。
https://note.com/itoa06/n/n31fe4f9cd6b9差分はこちら
/Gemfile-gem 'sqlite3', '~> 1.4' +gem 'mysql2', '>= 0.4.4'/config/database.yml
default: &default - adapter: sqlite3 + adapter: mysql2 + encoding: utf8mb4 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> - timeout: 5000 + username: root + password: + host: localhost development: <<: *default - database: db/development.sqlite3 + database: hello_rails_development test: <<: *default - database: db/test.sqlite3 + database: hello_rails_test production: <<: *default - database: db/production.sqlite3 + database: hello_rails_production + username: hello_rails + password: <%= ENV['HELLO_RAILS_DATABASE_PASSWORD'] %>Failed to start mysqld.service: Unit not found.
MySQLを立ち上げようとしたところエラーが発生しました
sudo service mysqld start Redirecting to /bin/systemctl start mysqld.service Failed to start mysqld.service: Unit not found.こちらの記事を参考にしました。
https://qiita.com/hamham/items/fd77bb0bb167a150dc8e#mysql57%E3%81%AE%E5%B0%8E%E5%85%A5@MurakamiKazutaka さんがコメントで書かれていましたが、Amazon Linux2ではyumでmysqlをインストールしようとするとmariaDBをインストールしようとするらしいです。
$ yum -y install http://dev.mysql.com/get/mysql57-community-release-el7-11.noarch.rpm $ yum -y install mysql mysql-community-server $ mysqld --version mysqld Ver 5.7.23 for Linux on x86_64 (MySQL Community Server (GPL)) $ cd /var/www/rails/アプリ名 $ sudo service mysqld startで無事解決しました。
と思ったら、無事ではありませんでした。この場合、MySQLが勝手にrootユーザーのパスワードを作成してしまうので、@hat_log さんがおっしゃっているように、パスワードをdatabase.ymlに記載する必要があります。
https://qiita.com/Dough/items/7493ad374a51b24abb58$ sudo cat /var/log/mysqld.log | grep 'temporary password' [Note] A temporary password is generated for root@localhost: XXXXXX $ mysql -u root -p Enter password: XXXXXX mysql> set password for root@localhost=password('passwordPASSWORD@999');次にdatabase.ymlにパスワードを記載
production: <<: *default database: mumu_production username: root password: passwordPASSWORD@999NoMethodError (undefined method `deep_symbolize_keys' forのエラー
データベース作成時にエラーが発生しました。
$ rake db:create RAILS_ENV=production ... NoMethodError (undefined method `deep_symbolize_keys' for....ymlファイルの書式が間違っているということで、おそらくインデントのスペースが2個になっていないのだろうと思い探しました。
そしたら、config/secrets.ymlでキー名secret_key_base:を書いていませんでした(うっかり)。誤り↓
production: (生成したシークレットキー)正しい方↓
production: secret_key_base: (生成したシークレットキー)Job for nginx.service failed because the control process exited with error codeのエラー
Nginxを起動しようとしたときにエラーが発生
$ sudo service nginx start Redirecting to /bin/systemctl start nginx.service Job for nginx.service failed because the control process exited with error code. See "systemctl status nginx.service" and "journalctl -xe" for details.こちらの記事を参考にしました。
https://qiita.com/shota0701nemoto/items/a6929ef6f396cf3bede4$ sudo nginx -t nginx: the configuration file /etc/nginx/nginx.conf syntax is ok nginx: [emerg] open() "/var/www/rails/[誤ったアプリ名]/log/nginx.error.log" failed (2: No such file or directory) nginx: configuration file /etc/nginx/nginx.conf test failedエラーの内容は人によって違うと思います。自分は"/var/www/rails/[誤ったアプリ名]/log/nginx.error.log"が無いということだったので、ファイルへ移動したところ、
$ cd /var/www/rails/[誤ったアプリ名]/log -bash: cd: /var/www/rails/[誤ったアプリ名]/log: No such file or directoryと言われ、よく見るとアプリ名のハイフン(-)とアンダーバー(_)を書き間違えていることに気付きました。
$ vim config/unicorn.conf.rb $ cd /etc/nginx/conf.d/ $ sudo vim mumu.confで誤った箇所を修正しました。
$ cd /var/www/rails/[アプリ名]/ $ sudo service nginx startで無事に起動しました。
We're sorry, but something went wrong. パート1
Nginxを起動した後に、EC2のIPアドレスへChromeでアクセスしてみると、
We're sorry, but something went wrong.となった。
RDSを一旦停止したせいかと思い、$ sudo service mysqld startMySQLを起動しましたが、変化無し。
$ less log/production.logでRailsのログを確認したところ(一番下の方が最新の情報)、
ActionView::Template::Error (The asset "application.css" is not present in the asset pipeline.のエラーが出ていたので、こちらの記事を参考にconfig/envitonments/production.rbを書き換え。
https://kanoe.studio/archives/791# Do not fallback to assets pipeline if a precompiled asset is missed. config.assets.compile = trueアプリケーションサーバーを再起動して、
(こちらの記事を参考にしました
https://qiita.com/takuyanagai0213/items/259ca105e35f6eb066d6
)$ ps -ef | grep unicorn | grep -v grep takuya 2460 1 0 3月11 ? 00:00:04 unicorn_rails master -c /var/www/rails/myapp/config/unicorn.conf.rb -D -E production takuya 2465 2460 0 3月11 ? 00:00:05 unicorn_rails worker[0] -c /var/www/rails/myapp/config/unicorn.conf.rb -D -E production takuya 2467 2460 0 3月11 ? 00:00:04 unicorn_rails worker[1] -c /var/www/rails/myapp/config/unicorn.conf.rb -D -E production $ kill 2460 $ unicorn_rails -c /var/www/rails/myapp(自分のアプリ名)/config/unicorn.conf.rb -D -E production再びEC2のIPアドレスにアクセスしましたが、相変わらず「We're sorry, but something went wrong.」
次に続く(まだエラーあんのかよ。。。)We're sorry, but something went wrong. パート2
引き続き、再度、ログを確認したところ、
$ less log/production.log ActionView::Template::Error (Webpacker can't find application in /var/www/rails/hello-rails/public/packs/manifest.json. Possible causes: 1. You want to set webpacker.yml value of compile to true for your environment unless you are using the `webpack -w` or the webpack-dev-server. 2. webpack has not yet re-run to reflect updates. 3. You have misconfigured Webpacker's config/webpacker.yml file. 4. Your webpack configuration is not creating a manifest.のエラーが発生していました。
ちょっと何言ってるかわからないです
こちらの記事を参考にしました。
https://qiita.com/natecotus/items/a2bd9f3ebd5b1866d48e$ rm -rf bin/webpack* $ rails webpacker:install Webpacker requires Node.js >= 8.16.0 and you are using 6.17.1 Please upgrade Node.js https://nodejs.org/en/download/またしてもエラーが発生。Node.jsのversionが古いみたいです。
こちらの記事を参考にしました。
https://qiita.com/paranishian/items/bddaed7c3aacedb11967$ git clone git://github.com/creationix/nvm.git .nvm $ . ~/.nvm/nvm.sh $ nvm install $ curl -o- -L https://yarnpkg.com/install.sh | bash $ source ~/.bashrc $ yarn -vそれでは、改めまして〜
$ rails webpacker:install [Ynaqdhm] Y [Ynaqdhm] Y $ RAILS_ENV=production bundle exec rails webpacker:compileコンパイルができたようなので、UnicornとNginxを再起動します。
$ ps -ef | grep unicorn | grep -v grep $ kill [プロセスID] $ unicorn_rails -c /var/www/rails/[アプリ名]/config/unicorn.conf.rb -D -E production $ sudo nginx -s reloadこれで、IPアドレスでつないでみたら。。。
やった表示された!
- 投稿日:2020-11-15T22:13:35+09:00
railsのサーバーが起動できない時の対処法
はじめに
初めまして。
私は未経験エンジニアとして転職するべく、1週間前にMacBookProを購入し、Progateで学習をしている者です。
早速ですが、Ruby on Railsの環境構築をする時に詰みました。rails s が起動しない
Progateに言われるがままAtom, Homebrew, rbenv, Railsをインストールし、後はローカルでサーバーを建てるだけ。
しかし、rails sと入力すると
Could not find gem 'rails (~> 6.0.3, >= 6.0.3.4)' in any of the gem sources listed in your Gemfile. Run `bundle install` to install missing gems.何のことやら。
とりあえずbundle installと入力しろと書いてあるので実行してみます。
An error occurred while installing bindex (0.8.1), and Bundler cannot continue. Make sure that `gem install bindex -v '0.8.1' --source 'https://rubygems.org/'` succeeds before bundling.初学者の心を折りに来ています。
Google先生に聞くこと数時間、sudo gem install bindex -v '0.8.1'これでパスワードを入力してインストールすれば良いみたいです。
さて、再度bundle installを実行すると、An error occurred while installing msgpack (1.3.3), and Bundler cannot continue. Make sure that `gem install msgpack -v '1.3.3' --source 'https://rubygems.org/'` succeeds before bundling.またですか。
しかし、同じようにsudo gem install msgpack -v '1.3.3'でインストールしていきます。
このあともbundle installを実行しては足りないものをインストールする作業を繰り返していき、最終的にはrails sが実行できるようになりました。おわりに
私のように出鼻をくじかれている方の助けになれば幸いです。
- 投稿日:2020-11-15T22:13:35+09:00
Railsのサーバーが起動できない時の対処法
はじめに
初めまして。
私は未経験エンジニアとして転職するべく、1週間前にMacBookProを購入し、Progateで学習をしている者です。
早速ですが、Ruby on Railsの環境構築をする時に詰みました。rails s が起動しない
Progateに言われるがままAtom, Homebrew, rbenv, Railsをインストールし、後はローカルでサーバーを建てるだけ。
しかし、rails sと入力すると
Could not find gem 'rails (~> 6.0.3, >= 6.0.3.4)' in any of the gem sources listed in your Gemfile. Run `bundle install` to install missing gems.何のことやら。
とりあえずbundle installと入力しろと書いてあるので実行してみます。
An error occurred while installing bindex (0.8.1), and Bundler cannot continue. Make sure that `gem install bindex -v '0.8.1' --source 'https://rubygems.org/'` succeeds before bundling.初学者の心を折りに来ています。
Google先生に聞くこと数時間、sudo gem install bindex -v '0.8.1'これでパスワードを入力してインストールすれば良いみたいです。
さて、再度bundle installを実行すると、An error occurred while installing msgpack (1.3.3), and Bundler cannot continue. Make sure that `gem install msgpack -v '1.3.3' --source 'https://rubygems.org/'` succeeds before bundling.またですか。
しかし、同じようにsudo gem install msgpack -v '1.3.3'でインストールしていきます。
このあともbundle installを実行しては足りないものをインストールする作業を繰り返していき、最終的にはrails sが実行できるようになりました。おわりに
私のように出鼻をくじかれている方の助けになれば幸いです。
- 投稿日:2020-11-15T21:49:36+09:00
Ruby on Railsの開発環境をDockerで構築する方法(Rails 6.x)
Docker公式手順を参考に、Rails 6系で Dockerの開発環境を構築する手順を詳解します。
各コマンドの詳しい解説は私が以前に書いた Rails5系での手順 で解説しているので、本記事では割愛します。
Rails プロジェクトを作成
$ docker-compose run web rails new . --force --no-deps --database=mysqlコンテナをビルド
$ docker-compose buildデータベースファイルの修正
上記実行後、config/database.yml ファイルを下記の通りにまるっと修正します。
config/database.ymldefault: &default adapter: mysql2 encoding: utf8mb4 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: root password: host: localhost development: <<: *default database: myapp_development host: db username: root password: password test: <<: *default database: myapp_test host: db username: root password: passwordデータベースを作成
$ docker-compose run web rails db:createWebpackerをインストール
Rails 6系から Webpacker が必要となっているため、webサーバのコンテナにwebpackerをインストールします。
$ docker-compose run web rails webpacker:installdocker-compose でコンテナを起動
$ docker-compose up -dアクセスして起動を確認
ブラウザから localhost:3000 にアクセスし、Rails の初期画面が表示されることを確認しましょう。
コンテナを停止
検証を終え、コンテナを停止させるときも docker-compose を使います。
$ docker-compose down

- 投稿日:2020-11-15T21:24:17+09:00
TECH CAMP (エンジニア転職)6週目の学習内容の振り返り
火曜日から本格的に最終課題の学習にはいったのですが、火曜日から日曜日までで6割ぐらいは進めた(?)と思います。この調子ですすめて22日までは必要な作業すべてを終わらせたいですね。それが終われば自分のポートフォリオを進めれる、、、ぐへへへ(変人感)
復習に入っていきたいところですがその前に、最終課題とはなんなのか、どんなことをやるのか少し話していきたいと思います。最終課題ではメルカリのようなフリマアプリの作成を通してサーバーサイドの実装を行っていきます。フロントサイドに関してはすでに用意されているのでやらなくても大丈夫です。この最終課題と今までの学習内容の違いはなにかというと、目標を達成(機能実装)するための手順を自分で考えないといけないところです。今までのカリキュラムだと、テキストに沿って決められたことをこなしていけばよかったのですが、最終課題においては機能実装を行うためにどのような工程が必要か自分で道筋を立てながら学習していくことになります。
例えば、ユーザー登録機能を作るならカラムの洗い出しとDB作成、必要なアクションの定義などなどがあります。最終課題以前だとカリキュラムに書かれたそれらの項目をこなしていくことで実装できるのですが、今回だと実装のための過程が明示されていないのでプロセスを考えないといけないという難しさがあります。私は今の所は大丈夫ですが、終盤にどうなるかが心配です。(笑)
ではでは、今週の学習内容をざざっと振り返ろうかなと思います。11/10~11/15までの進捗状況
・herokuへのデプロイ
・Basic認証の導入
・テーブル read.meの作成
・ユーザー管理(登録 ログイン ログアウト)機能の実装
・商品を出品機能の実装
・トップページに商品を表示する機能の実装herokuへのデプロイについて
これと認証に関してはやることがそう多くないですね
heroku内にアプリケーション作成をして、mysqlを作成、アプリケーションの情報をgitからプッシュしてマイグレーションを実行することでデプロイが可能となります!Basic認証について
Basic認証はauthenticate_or_request_with_http_basicメソッドを用いることでidとpasswordを要求することができます。ここで注意すべき点は、環境変数にidとpasswordを入れることです。コントローラーにそのまま設定してたらどちらもgithubで漏洩してしまうので。テーブル設計 Read.meの作成
それぞれのテーブルに必要なカラムを洗い出します。難しいことはないですが、read.meのバー(|や-)を揃えるのがかなり面倒ですユーザー管理機能の実装
deviseの導入と正規表現の導入がかなり苦戦しました。
passwordだと半角英数字混合6文字以上というのがあったり、半角カタカナ限定だったりと、、、あとちゃんと機能しているか確認のためテストコードを書くのですが、100行以上かくはめになりました。がんばったなぁ()商品を出品機能の実装
ここでは商品の状態や発送元、送料の負担などをプルダウン機能を用いて実装していくのですが、結構調べるのに時間がかかってしまいました。商品の値段に下限と上限があり、そのバリデーションをどうかけるのか全くわからなかったですね。自分のググり力が上がる食べ物があったらそれを主食にしたいです。トップページに商品を表示する機能の実装
トップページに登録された商品が新しいものから上に表示されるように実装を行いました。
横並びにするのに試行錯誤して2時間ほどかかってしまいました。
- 投稿日:2020-11-15T21:23:27+09:00
多言語からみるマルチコアの活かし方
多言語からみるマルチコアの活かし方
はじめに
近年では1つのCPUに複数のコアが搭載されたマルチコアが一般的になっています。
しかし、現状のプログラミング言語ではエンジニアが意識せずにマルチコアをしたプログラムを作ることは難しいです。
そこで、様々な言語から見たマルチコアの活かし方について説明していきます。プロセスとスレッド
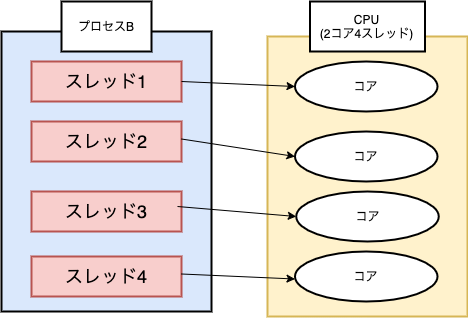
プロセスとは1つ1つのアプリケーションといった実行中のプログラムのことで、スレッドは CPU利用の単位です。プロセスは次のように1つ以上のスレッドを持っており、CPUのコア数分だけスレッドを処理することができます。(また、近年ではSMTという技術によって1つの物理コアで2スレッドといった複数のスレッドを処理することができます。2コア4スレッドみたいなやつです)
マルチコアを有効活用してプログラムを実行するためにはCPUが処理できるコア数に対して適切な数のスレッドをプログラム側で生成する必要があります。コア数以上のスレッドを生成する事も可能ですが、CPUはコア数分のスレッドしか処理を行うことができず、実行するスレッドの切り替えにより処理が遅くなってしまう問題が発生します。並列と並行
並列(parallel)と並行(concurrent)という似たような言葉が存在しますが、違うものを示します。
並列(parallel)とは複数の処理を同時に行うことで、複数のコアで複数のスレッドを処理するような場合を示します。(シングルコアでは複数処理を同時に実行できないため並列を実現することはできません。)
並行(concurrent)とは複数の処理を切り替えながら同時に実行しているようにすることで、1つのスレッドで複数の処理を切り替えながら実行するような場合を示します。
複数のスレッドで処理を切り替えながら実行することも可能なため、並列かつ並行を実現することも可能です。C10K問題
WebサーバーのApacheではユーザのリクエスト毎にプロセスを生成する方式を取っており、クライアントが約1万台に達すると、Webサーバーのハードウェア性能に余裕があるにも関わらず、レスポンス性能が大きく下がるというC10K問題というものが存在していました。(C10K問題の具体的な原因はこちらの記事が分かりやすかったです。)
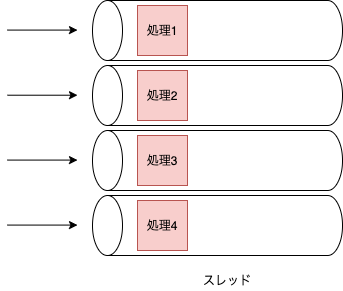
そこで、nginxやNode.jsではシングルスレッドで非同期I/Oに処理をすることにより、並行に処理を行を行うことでC10K問題を解決しようとしました。Node.js
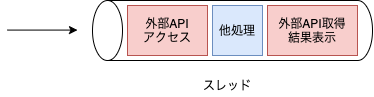
前述したように、Node.jsはシングルスレッドで動作をし、async/awaitといった非同期処理で並行に処理を行うというアプローチがされています。イメージとしては下図のように、外部APIアクセスをする際に結果が返ってくるまでの時間に他の処理を行い、結果が取得できたらその処理の続きを行うようなイメージです。(詳細はこちらの記事が分かりやすかったです。)
従って標準の非同期処理を行う場合は、マルチコアの性能を引き出すことができません。そこでNode.jsではClusterを用いてプロセスを複数作成するか、worker_threadsを用いてスレッドを複数作成する必要があります。このようにマルチコアコアを活かすためには、プログラム側からプロセスかスレッドを複数作成してあげる必要があり、マルチスレッドでは変数の値の共有を行うことができますが、マルチプロセスではメモリ空間が分離され、変数の値の共有ができないというそれぞれのメリット・デメリットが存在します。RubyやPythonで起こるGIL
Node.jsでは、プロセスかスレッドを複数作成してあげることでマルチコアを活かすことができました。しかし、RubyやPythonではグローバルインタプリタロック(GIL)というものが存在し、複数のスレッドを作成しても並列に実行することができません。(正確にはC言語で実装されたCPythonとCRubyの場合ですが、ここでは省略します。)
従って、これらの言語でマルチコアを活かそうとした場合、マルチスレッドでは実現できず、プロセスを複数作成してあげる必要があります。Go言語でのgoroutine
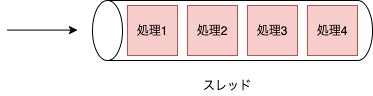
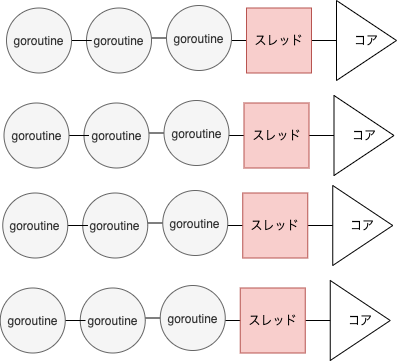
Go言語では、goroutineというものを用いて非同期処理を並列・並行に実現しており、デフォルトでCPUのコア数が設定された
GOMAXPROCSというものが設定されています。この値の数だけスレッドが用意され、そのスレッドの中で軽量スレッドであるgoroutineを実行します。
CPUのコア数が4のGOMAXPROCS=4の場合のイメージとしては下図です。
このようにgoroutineを用いることによりマルチコアを活かして並列・並行にプログラムの実行を行えます。
(goroutineが軽量な理由についてはこちらの記事が分かりやすかったです。)Rustでのasync/await
Rustでは、async/awaitを用いて非同期処理を行えます。この際、どのランタイムを用いるかによって非同期処理のスレッドの実行割当方法を選択できます。
人気があるランタイムとしては、tokioが挙げられます。tokioではコア数に対してスレッドが生成され、そのスレッドに非同期処理が渡されるというgoroutineと同様のマルチコアの活かし方が実現できます。(他の割当方法や、Rustでの非同期処理についてはこちらの記事が分かりやすかったです。特にここの実行モデルについてが分かりやすいです。)さいごに
RubyやPythonでは仕組み上マルチスレッドにすることが難しく、Node.jsの非同期処理は、そのままではマルチコアを活かすことができませんでした。
しかし、近年人気のあるGo言語やRustでは非同期処理を呼ぶ事により、エンジニアが意識せずに並列・並行処理を行え、マルチコアを活かすことができます。
マルチコアのCPUが一般的になってきた現代に、Go言語やRustが人気がある事も納得です。参考
【図解】CPUのコアとスレッドとプロセスの違い,コンテキストスイッチ,マルチスレッディングについて
プロセスとスレッドとタスクの違いを知ってUnity非同期完全理解に近付く
Node.jsの非同期I/Oについて調べてみた
いまさら聞けないNode.js
Pythonで並列処理をするなら知っておくべきGILをできる限り詳しく調べてみた
goroutineはなぜ軽量なのか
Rustの非同期プログラミングをマスターする

- 投稿日:2020-11-15T21:05:17+09:00
現役保育士+駆け出しエンジニア
初めまして。現在保育士をしていて、WEB系エンジニアに転職を考えているNOZOMIです。
学習を始めて1ヶ月が経とうとしています。
現在の私の学習状況と取り組みについてまとめておこうと思います。ドットインストール
完了済み
- 実践!アプリ紹介ページを作ろう (全16回)
- 詳解HTML 基礎文法編 (全22回)
- はじめてのRuby (全9回)
- JavaScriptでモーダルウィンドウを作ろう (全8回)
- JavaScriptでタブメニューを作ろう (全10回)
- はじめてのPython (全9回)
- はじめてのJavaScript (全11回)
- 【試験運用中】はじめてのPHP [macOS版] (全12回)
- 【試験運用中】Dockerを導入しよう [macOS版] (全2回)
- はじめてのCSS (全15回)
- はじめてのHTML (全14回)
進行中
- 詳解CSS 基礎文法編 (全33回)
- CSSでチャット風のUIを作ってみよう (全7回)
- 詳解HTML フォーム部品編 (全8回)
- Ruby入門 (全26回)
- 詳解JavaScript 基礎文法編 (全26回)
- 詳解PHP 基礎文法編 (全34回)
かなりのスロースターターと自負しております・・・。徐々にエンジン全開にして行けるように頑張ります!!
雑食系サロン入会
YOUTUBEがきっかけで勝又さんの雑食系サロンに入会しました。かなりレベルの高い方がたくさんいらっしゃって、ポートフォリオも参考にさせていただいています。オフ会やもくもく会等参加したいと考えています。
MENTA
雑食系サロンでのYOUTUBEライブで、未経験者はメンターをつけてコードレビューをしてもらうべきとのお話を伺い、MENTAに登録し、chilldrainさんに5000円でポートフォリオ作りのロードマップを作成していただいています。
企業探し
保育士の経験を活かして働いて行けるような、保育系システムの自社開発系企業に絞りました。
- エクシオジャパン
- 日本ソフト開発株式会社
- キッズコネクト株式会社
来年の4月入社を目指して、頑張ります!!
- 投稿日:2020-11-15T20:43:01+09:00
【Rails】テーブルのカラム名の変更方法
テーブルのカラム名の変更方法について
Railsでテーブルのカラム名の変更方法についてまとめました。
ステップとしては下記の通りです。① migrationファイル作成
② migrationファイルの編集
③ データベースへ反映今回は下記のようにカラム名を変更します。
変更前
wheather変更後
weather
モデル名 カラム名(変更前) カラム名(変更後) users wheather weather ① migrationファイル作成
まずはカラム名を変更するためのmigrationファイルを作成します。
$rails generate migration rename_【変更前のカラム名】_column_to_【モデル名(複数形)】今回は
$rails generate migration rename_wheather_column_to_users
と記述する。② migrationファイルの編集
/db/migrateに新しいファイルが作成されるので、changeメソッドを追加し、そこに変更したいカラム名を記述する。今回作成されたファイル:
20201115004326_rename_wheather_column_to_users.rb
*作成日によって数字の部分は変わります。下記のように記述する。
/db/migrate/20201115004326_rename_wheather_column_to_users.rbclass RenameWheatherColumnToUsers < ActiveRecord::Migration[6.0] def change rename_column :モデル名, :カラム名(変更前), :カラム名(変更後) end end今回の場合は下記の通り記述。
/db/migrate/20201115004326_rename_wheather_column_to_users.rbclass RenameWheatherColumnToUsers < ActiveRecord::Migration[6.0] def change rename_column :users, :wheather, :weather end end③ データベースへ反映
最後に、データベースへ反映し、カラム名の変更は完了。
$rails db:migrate以上です。
weatherをwheatherと書き間違えたばかりに、このような作業が発生してしまいました(笑)
皆様はくれぐれもスペルミスの無いようにお気をつけください☆
- 投稿日:2020-11-15T20:12:29+09:00
[初心者]一気に複数行のインデント修正ができるワザ「矩形選択(ブロック選択)」について
はじめに
Railsなどで、コードを打ち終わった後に、全体のバランスを整えたいと思う時ってありますよね。
コードを考えるのに夢中になってしまい、見返してみたら、インデントがバラバラで、めちゃくちゃ見にくいバランスになってしまっていたり。
また、複数の要素をまたぐ形で、親要素を後から追加しようと思って、子要素の全ての行に対して、1スペース分のインデントを空けなければならない時もあると思います。
プログラミング駆け出しの私は、インデントを空ける為に、ひたすらTABキーを打ち続けていました。そんな中、「矩形選択」なるワザを知ってから、世界が変わりました。
知っている方も多いと思いますが、もし使っていないor知らない方がいたら、非常にもったいないと思いますので、この便利な技を共有させてもらいます。こんな時ってどうしてますか?
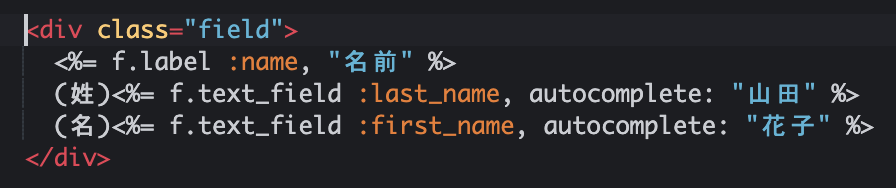
次のコードをご覧ください。
deviseを利用して、ユーザーの新規登録画面を作成したコードです。
これだけで、機能としては利用できるのですが、見た目が美しくありません。Bootstrapを利用して、バランスを整えたいと思い、全体を
<div class="container">
<div class="row">
で囲もうと思います。qiita.rb<div class="container" > <div class="row" > ------------- ←ここに上のコードを入れ込みたい!!! </div > </div >そうですね。
間に入れるだけならそれで良いのですが、リーダブルコードを意識するなら、全ての行にインデントを空ける方が美しくなりそうです。でも、面倒ですよね。
分かります。
そんな時に、利用できるのがこの「矩形選択」です!矩形選択(ブロック選択)とは?
非常に便利な機能の使い方は簡単です。
macOSの場合、キーボードによる矩形選択のコマンド開始する箇所をクリックしておく [Shift]+[Option]+[Command]+矢印キー そのままドラッグこれだけです。
もっと分かりやすく説明すると、
このように、開始する箇所をクリックしておきます。
そして、↑のコマンドを打ち込むと、
何と便利なことに、<div class="field">全体を囲むように、ポインタが拡大されました。
ここまで出来ると、もう簡単です。
見やすいように、↑の部分だけインデントを空けると、こんな感じになります。
はい、メチャクチャ便利です。矩形選択の他の使い方
もちろん、スペースを空けるだけじゃなく、文字を打つことも出来ます。
一度文字を打ち込むだけで、矩形選択した他の行にも同じ文字を打つことができました。
他にも色々と応用した使い方があるので、興味がある方は調べてみてください!おわりに
プログラミングの世界には、このように作業時間を縮小できるような小ワザがたくさんあると思います。
全てを一気に覚えるのは難しいですが、一つ一つ体に馴染ませていけば、非常にスマートなプログラマーになれる日が近づくかもしれません!



- 投稿日:2020-11-15T19:38:52+09:00
[Rails][ jQuery]フォームの入力ならびに選択が完了するまで送信ボタンを押せないようにする。
はじめに
今回は、jQueryを使って、フォームの入力ならびに選択が完了するまで送信ボタンが押せないように設定していきます。
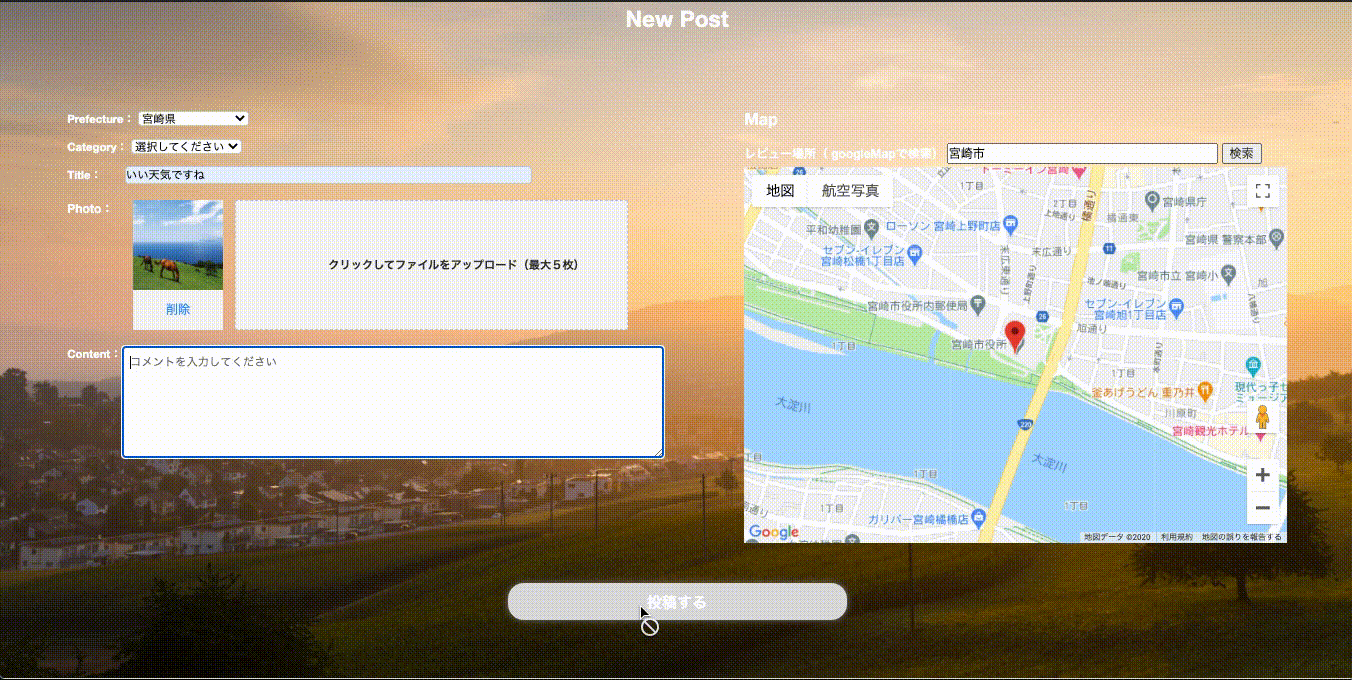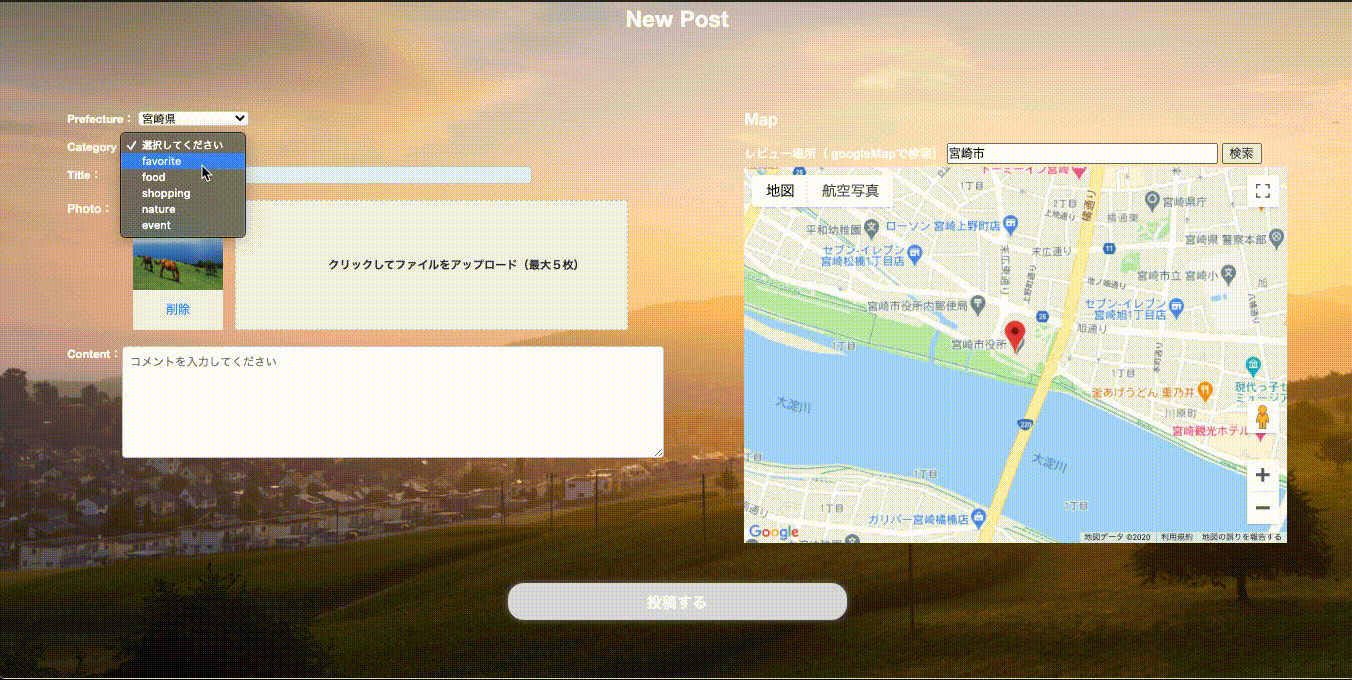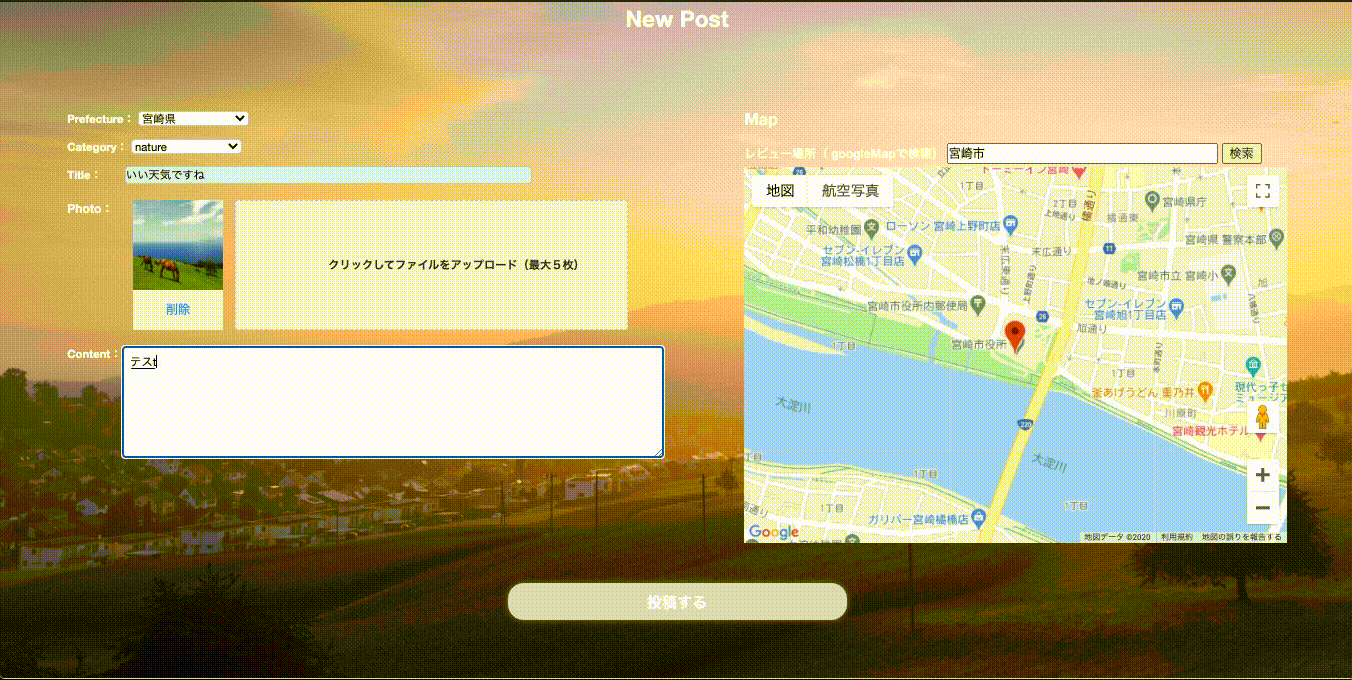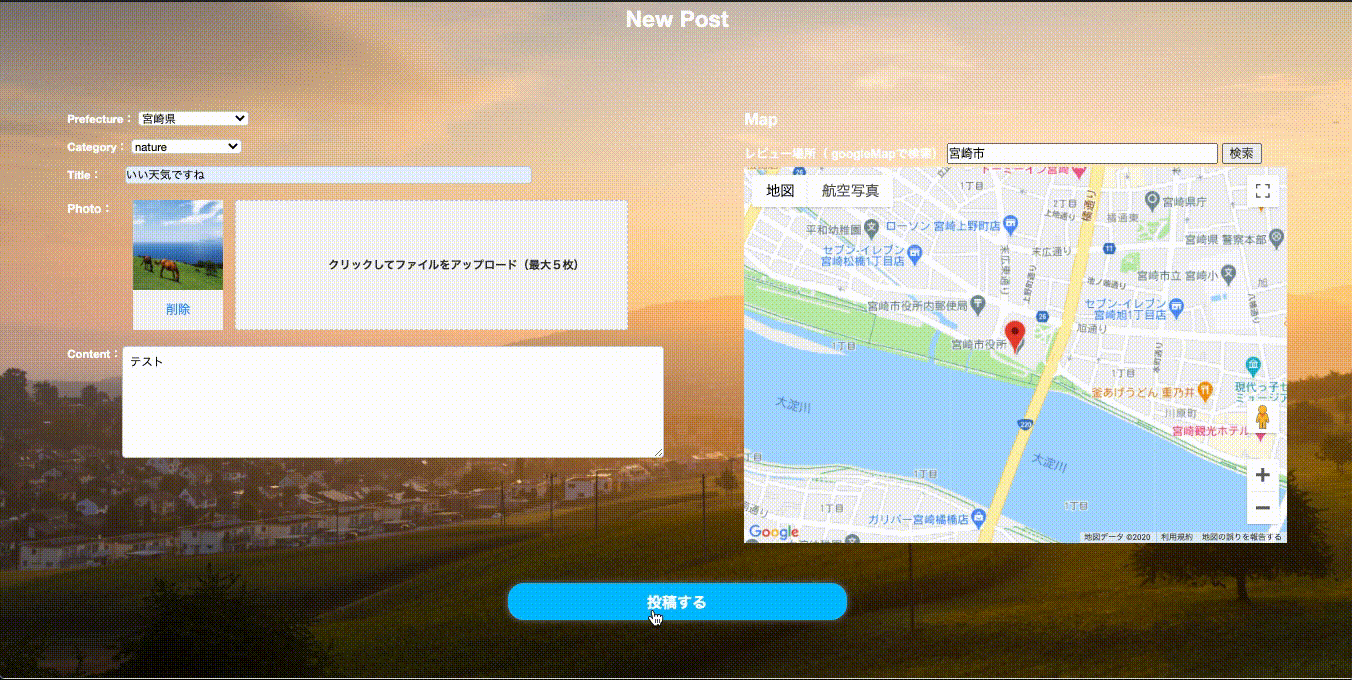
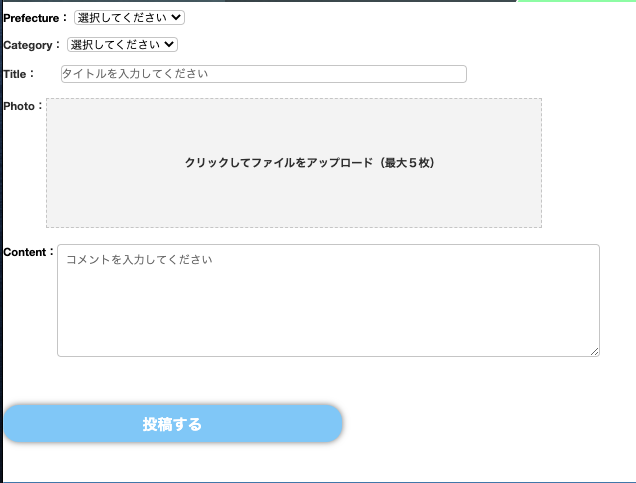
完成イメージ
記事を書いた目的
情報の共有ならびに、自身の備忘録として執筆する。
導入した目的
誤送信を防ぎ、ユーザビリティを向上させるため。
環境
MacOS 10.15.7
ruby 2.6.5
Ruby on Rails 6.0.0前提条件
- jQueryが導入済みであること。
- 画像の複数枚投稿機能を実装している。
記事執筆者の状況
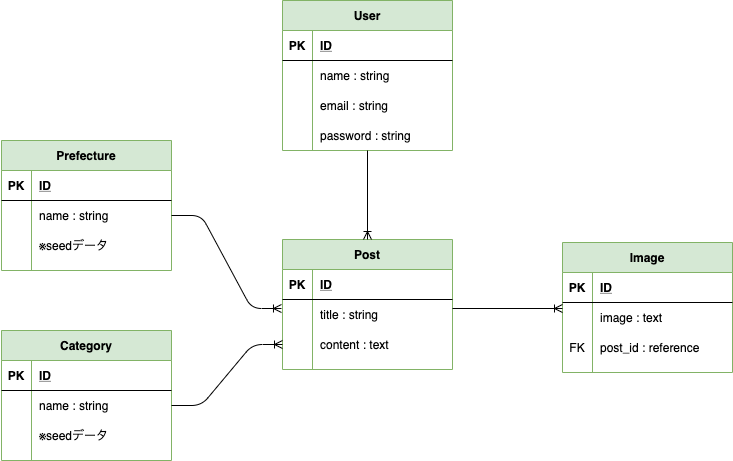
テーブル
Userテーブルが「投稿者」、Postテーブルが「投稿」、Imageテーブルが「投稿画像」、Prefectureテーブルが「都道府県データ」、Categoryテーブルが「投稿カテゴリー」となります。
PrefectureテーブルとCategoryテーブルはseedデータを活用しております。
コントローラー
新規投稿機能はposts_controller.rbが担当しております。
posts_controller.rbclass PostsController < ApplicationController def new @post = Post.new @post.build_spot @post.images.build() end def create @post = Post.new(post_params) if @post.save redirect_to root_path, notice: "投稿が完了しました" else flash.now[:alert] = "必須項目を入力してください" @post.images.build() render :new end end ...下記一部記述を省略 . . . private def post_params params.require(:post).permit(:title, :content, :prefecture_id, :category_id, images_attributes: [:id, :image, :_destroy]).merge(user_id: current_user.id) endそれでは作業していきましょう。
①-1 new.html.erbを作成する
まずはフォームをhtmlで作成していきます。
new.html.erb<%= form_with(model: @post, local: true, multipart: true) do |form| %> <ul class='formSpace'> <li class="prefecture"> <label class="labelName" for="Prefecture">Prefecture:</label> <%= form.collection_select :prefecture_id, Prefecture.all, :id, :name, {include_blank: '選択してください'}, {class: "prefecture__input", id: 'input01'} %> </li> <li class="category"> <label class="labelname" for="category">Category:</label> <%= form.collection_select :category_id, Category.all, :id, :name, {include_blank: '選択してください'}, {class: "category__input", id: 'input02'} %> </li> <li class="title"> <label class="labelName" for="titleSpace">Title:</label> <%= form.text_field :title, class: 'title__input', id: "input03", placeholder: "タイトルを入力してください" %> </lil <li class='newImage'> <label class="labelName" for="imageSpace">Photo:</label> <div class="prevContent"> </div> <div class="labelContent"> <label class="labelBox" for="post_images_attributes_0_image"> <div class="labelBox__text-visible"> クリックしてファイルをアップロード(最大5枚) </div> </label> </div> <div class="hiddenContent"> <%= form.fields_for :images do |i| %> <%= i.file_field :image, class: "hiddenField", id: "post_images_attributes_0_image", name: "post[images_attributes][0][image]", type: "file" %> <%= i.file_field :image, class: "hiddenField", id: "post_images_attributes_1_image", name: "post[images_attributes][1][image]", type: "file" %> <%= i.file_field :image, class: "hiddenField", id: "post_images_attributes_2_image", name: "post[images_attributes][2][image]", type: "file" %> <%= i.file_field :image, class: "hiddenField", id: "post_images_attributes_3_image", name: "post[images_attributes][3][image]", type: "file" %> <%= i.file_field :image, class: "hiddenField", id: "post_images_attributes_4_image", name: "post[images_attributes][4][image]", type: "file" %> <% end %> </div> </li> <li class='content'> <label class="labelName" for="contentSpace">Content:</label> <%= form.text_area :content, class: 'content__input', id: "input05", placeholder: "コメントを入力してください" %> </li> </ul> <div class='send'> <%# <%= form.submit "送信中", class: 'send__btn', id: 'sending', value: "投稿する" %> <input type='submit' id='sending' class='send__btn' value='投稿する'> </div> <% end %>続いてscssを記述します。
new.scss.formSpace { height: auto; } .labelName { color: #000000; } // 都道府県================================================================ .prefecture { height: auto; width: auto; margin-top: 1vh; font-size: 1.5vh; line-height: 1.5; color: #fff; &__input { width: auto; border: 1px solid #ccc; background-color: #fff; border-radius: 5px; text-align: center; color: #000000; } } // カテゴリー============================================== .category { height: auto; width: auto; margin-top: 1vh; font-size: 1.5vh; line-height: 1.5; color: #fff; &__input { width: auto; border: 1px solid #ccc; background-color: #fff; border-radius: 5px; color: #000000; } } //Title=================================================================== .title { height: auto; width: auto; margin-top: 1vh; font-size: 1.5vh; line-height: 1.5; color: #fff; &__input { width: 30vw; border-radius: 5px; border: 1px solid #ccc; background-color: #fff; color: #000000; margin-left: 25px; } } //Image====================================================================== .newImage { display: block; margin: 16px auto 0; display: flex; flex-wrap: wrap; cursor: pointer; } .imageLabelName { color: #fff; margin-right: 25px; } .prevContent { display: flex; } .previewBox { height: 162px; width: 112px; margin: 0 15px 10px 0; } .upperBox { height: 112px; width: 100%; img { width: 112px; height: 112px; } } .lowerBox { display: flex; text-align: center; } .deleteBox { color: #1e90ff; width: 100%; height: 50px; line-height: 50px; background: #f5f5f5; display: flex; justify-content: center; align-items: center; cursor: pointer; } .imageDeleteBtn { background-color: #f5f5f5; line-height: 4vh; height: 4vh; width: 60px; } .imageDeleteBtn:hover { color: rgba($color: #1e90ff, $alpha: 0.7); } //投稿クリックエリアのCSS .labelContent { margin-bottom: 10px; width: 620px; .labelBox { display: block; border: 1px dashed #ccc; position: relative; background: #f5f5f5; width: 100%; height: 162px; cursor: pointer; &__text-visible { position: absolute; top: 50%; left: 16px; right: 16px; text-align: center; font-size: 14px; line-height: 1.5; font-weight: bold; -webkit-transform: translate(0, -50%); transform: translate(0, -50%); pointer-events: none; white-space: pre-wrap; word-wrap: break-word; } } } //file_fieldのcss .hiddenContent { .hiddenField { display: none; } .hidden-checkbox { display: none; } } //コメント==================================================================== .content { display: flex; height: auto; width: auto; margin-top: 5px; line-height: 1.5; font-size: 1.5vh; &__input { height: 15vh; width: 40vw; border-radius: 5px; color: #000000; border: 1px solid #ccc; background-color: #fff; margin-left: 0px; padding: 1vh; } } //SENDボタン========================================================================= .send { display: flex; justify-content: center; &__btn { height: 5vh; width: 25vw; margin: 50px 0; border-radius: 20px; background-color: #87cefa; border: none; box-shadow: 0 0 8px gray; color: #ffffff; line-height: 1.5; font-size: 2vh; font-weight: bold; -webkit-transition: all 0.3s ease; -moz-transition: all 0.3s ease; -o-transition: all 0.3s ease; transition: all 0.3s ease; } :hover { background-color: #00bfff; } .send__btn[disabled] { background-color: #ddd; cursor: not-allowed; } }ここまで行うと次のような形になると思います。
ポイント
今回、JavaScriptにてフォームが入力または選択されているかどうかを状態管理するために
<%= form.collection_select :prefecture_id, Prefecture.all, :id, :name, {include_blank: '選択してください'}, {class: "prefecture__input", id: 'input01'} %>という風に、
id: 'input01'という形でidを指定しています。このように、各フォームにidを指定していくのですが、idは同名のものを使い回しすることが不可のため、今回は
id='input02'、id='input03'・・・という形でidを順番に振っています。
(クラス名を統一して、使い回すのもありですが、今回は省略します。)SCSSについては、ボタン(class:send__btn)が有効・無効の状態別でボタンの色を変更する記述をしております。ボタンの状態管理は後述するdistabledという値を使って管理します。
無効の場合にはdistabledという値が要素に付与されることになるので、scssの方で.send__btn[disabled] { background-color: #ddd; cursor: not-allowed; }という記述をして、ボタンが無効状態の場合は色を灰色にして、カーソルを無効にしています。
①-2 submit.jsに処理を記述
あとはjsファイルにフォームの入力・選択がされているかどうかを判定し、送信ボタンの有効・無効を切り替える処理を記述していきます。
今回はsubmit.jsというファイルに記述していきます。
submit.js// フォームを入力・選択するまで送信ボタンが押せないようにする============================================= $(function() { //最初に送信ボタンを無効にする $('#sending').prop("disabled", true); //idに「input」と設定している入力欄の操作時 $("[id^= input],#post_images_attributes_0_image").change(function () { //入力欄が空かどうか判定を定義するために、sendという変数を使ってフォームの中身の状態管理を行う。 let send = true; //id=input~と指定している入力欄をひとつずつチェック&画像(インデックス番号が0番の画像)をチェックする $("[id^= input],#post_images_attributes_0_image").each(function(index) { //フォームの中身(値)を順番に確認し、もしフォームの値が空の時はsend = false とする if ($("[id^= input],#post_images_attributes_0_image").eq(index).val() === "") { send = false; } }); //フォームが全て埋まっていたら(send = trueの場合) if (send) { //送信ボタンを有効にする $('#sending').prop("disabled", false); } // フォームが一つでも空だったら(send = falseの場合) else { //送信ボタンを無効にする $('#sending').prop("disabled", true); } }); });ポイント
最初に送信ボタン
<input type='submit' id='sending' class='send__btn' value='投稿する'>に対して、
prop(disabled, false)として、ボタンを無効化しています。propメソッドは指定した属性に値を設定する役割を持っています。
distabledとは指定したHTML要素を無効化できる属性のことです。
propメソッドと組み合わせて使うことで
prop( ‘disabled’, true)」・・・要素を無効化
prop( ‘disabled’, false)」・・・要素を有効化
というふうに使用することができます。参照:
propメソッド・・・http://js.studio-kingdom.com/jquery/attributes/prop
distabled・・・https://persol-tech-s.co.jp/hatalabo/it_engineer/463.html#disabled次に、
$("[id^= input],#post_images_attributes_0_image").change(function ()と記述しています。
「
[id^= input]と#post_images_attributes_0_imageの値が変化した時に、イベントが発火する」という記述になります。注目いただきたいのは
javascript
[id^= input]
の部分です。
こちらはjQueryの属性を使った指定方法を採用しています。
指定方法には大まかに分けて4つあります。
- 前方一致
- 後方一致
- 部分一致
- 否定
「前方一致」は「属性 ^= 属性名」のように「^」を追加するだけで、属性名の先頭部分の文字列が一致するすべての要素を取得することができます。
今回の場合、
[id^= input]とすることで、id="input01", id="input02,・・・ id="input05の要素、つまりid名にinputと命名されている要素を全て取得することができます。なお、jQueryの属性を使った指定方法についてはこちらの記事を参考にさせていただきました。前方一致指定意外にも知りたい方はご覧いただければと思います。
続いて、
let send = true;については、入力欄が空かどうか判定するために、sendという変数を用いてフォームの状態管理を行うために記述しています。trueの場合は、フォームが全て埋まっている状態を表します。
$("[id^= input],#post_images_attributes_0_image").each(function(index) { //フォームの中身(値)を順番に確認し、もしフォームの値が空の時はsend = false とする if ($("[id^= input],#post_images_attributes_0_image").eq(index).val() === "") { send = false; } });については、eachメソッドを使って、idにinputと命名している要素を、要素の個数分に応じて取り出します。
取り出す際、eachメソッドの引数にコールバック関数を定義する必要があるので、「function(index)」と指定します。こうすることでindex番号を取得することができ、取り出した要素にそれぞれindex番号を振り分けます。今回の場合、イメージとしては
0 : id="input01"の要素 1 : id="input02"の要素 2 : id="input03"の要素 3 : id="input04"の要素 4 : id="input05"の要素このような形になるかと思います。
加えて、
#post_images_attributes_0_imageも対象のオブジェクトに加えております。正直なところ、
複数枚画像投稿する際、上手いidの設定、指定ができなくて、ここに加えております。
(他に上手い方法があれば教えていただけると助かります!)eachメソッドでインデックス番号と一緒に取り出したあと、
if ($("[id^= input],#post_images_attributes_0_image").eq(index).val() === "") { send = false; }の処理に移ります。
ここでは、取り出した要素1つ1つのフォームの中身が空なのかを検証しています。
1つ1つ検証するにあたり、eqメソッドを使用しています。
eqメソッドとは現在マッチしている要素をインデックス番号でフィルタリングします。(eqメソッド参照サイト)idにinputと命名されている要素は、eachメソッドでインデックス番号が0〜4が振られているので、順番にeqメソッドの引数にインデックス番号が入るイメージです。(例: eq(0),eq(1)...eq(4) )
フォームの値を取得するのはvalメソッドを使用します(valメソッド参照サイト)
〜〜 === ""とは、「〜〜は空である」という意味を表します。1つ1つ取り出した要素を検証して、1つでもフォームの値が空の要素があれば、
send = falseを返します。最後の
//フォームが全て埋まっていたら(send = trueの場合) if (send) { //送信ボタンを有効にする $('#sending').prop("disabled", false); } // フォームが一つでも空だったら(send = falseの場合) else { //送信ボタンを無効にする $('#sending').prop("disabled", true); }の部分については、
if (send)(if send ==trueという意味)の場合つまりフォームが全て埋まっている場合は、$('#sending').prop("disabled", false);というふうに、送信ボタンを有効にして、押せる状態にしています。
else(send == false)の場合つまりフォームが1つでも空だった場合は、$('#sending').prop("disabled", true);という形で、送信ボタンを無効にして、押せない状態にします。①-3 完成
以上で完成です。
最後に
初学者のためまだまだ理解不足な部分も多く、今回の実装については正直、改善の予知が多くあると思いますので、もっと良い実装の方法等がありましたらご教示いただけますと幸いです。
また、この記事をご覧いただきましたら、LGTMもいただけるとすごく嬉しいです。何卒よろしくお願い致します。

- 投稿日:2020-11-15T19:26:27+09:00
`Array#index` は途中から探索できない、 `String#index` はできる
環境 : Ruby 2.7.1
リファレンスマニュアル:
例えば、「各要素が0と1のみから成る配列から、1であるインデックスを探して何か処理する」ことを考える。探すだけなら
each_with_indexなどで可能だが、元の配列を書き換える(続きの探索に影響しうる)など複雑な処理である場合はループ文で地道に頑張る必要がある。Rubyの場合はインデックスをループで回さなくても
Array#indexで位置を特定できる。しかしこれには欠点があり、前回の続きから探索するということができない。seq = [1, 0, 1, 0, 1, 1, 1, 1, 0, 0, 0, 1, 0, 0, 1] i = -1 while (i = seq.index(1, i + 1)) # i が必要な複雑な処理 p i end #=> ArgumentError (wrong number of arguments (given 2, expected 0..1))でも文字列の場合はできる。
seq = [1, 0, 1, 0, 1, 1, 1, 1, 0, 0, 0, 1, 0, 0, 1].map(&:chr).join i = -1 while (i = seq.index(1.chr, i + 1)) # i が必要な複雑な処理 p i end #=> 0 2 4 5 6 7 11 14逆順に探索する
#rindexも同じ。
配列を文字列に変えて
#indexで探索する場合は以下の特徴がある。
- 利点
- (上で述べた通り)途中から探索できる
- 要素をまたぐ条件指定が簡単にできる:固定文字列または正規表現
- 欠点
- 要素の種類が非常に限られる
- 文字そのもの、または文字コードの範囲内の整数
- 数値の場合は文字と変換する手間も発生
- ブロックを渡せないので複雑な条件を指定できない(数値が偶数である、など)
- 投稿日:2020-11-15T19:21:09+09:00
【Rails】link_to で formatの指定
タイトルのとおり、
link_toメソッドでフォーマットを指定する方法についてですかなり簡単ですが、意外と記事がヒットしなかったので備忘録的として残しておきます
そもそもformatって?
出力形式のことです
通常はhtml形式で、htmlファイルがレンダリングされてますよね
他にもjson形式やpdf、csvなどがあります今回はPDFの出力を想定してやってみます
linkの書き方
pathの引数にformatを指定するだけです!
slimファイル= link_to '表示名', xxx_path(format: :pdf)他にidを指定したり、parameterを設定する場合にも同じ様に引数に突っ込んじゃってOKです
slimファイル= link_to '表示名', xxx_path(format: :pdf, id: @post, parameter_name: parameter_content)コントローラでの処理
コントローラではformatを指定して処理を記述すればOK
pdfの場合はsend_fileを使ってファイルを表示させたりダウンロードさせたりすることが多いと思います。
次のように記述すると、ファイル名を指定してブラウザ上でPDFファイルを開いてくれますコントローラclass HogesController < ApplicationController def show respond_to do |format| format.pdf do send_file(pdf_path, filename: filename, disposition: 'inline') end end end private def pdf_path # pdfの保存場所を指定 @post.pdf.path # ← carrierwave使ってればこんな感じかな end def filename # pdfのファイル名を指定 "#{@post.id}.pdf" end end余談
rails routesをするとURIパターンの中に(.:format)ってありますよね
これがformat指定したときのURIになります
たとえば今回のようにformatをpdfにした場合は、URLが
https://xxxxxx/xxx.pdfみたいになります
フォーマットに応じて末尾に.フォーマット形式の形で追加されるってことなんですね〜

- 投稿日:2020-11-15T19:05:12+09:00
【Ruby On Rails】ネストした状態で、link_toメソッド内Prefixの後に書く括弧内の記述
すみません。完全なる備忘録です。。笑
前提
show.html.erb<% @fuga_events.each do |event| %> ---------------------------------------- <ul> <div> <%= "名前:#{event.hoge.name}" %> </div> <div> <%= "アプリ:#{event.hoge.app_name}" %> </div> <div> <%= "開始日:#{event.started_at}"%> </div> <div> <%= "終了日:#{event.finished_at}" %> </div> <div> <%= "todo:#{event.todo}" %> </div> <div> <%= "場所:#{event.place}" %> </div> <div> <%= "見込:#{event.expected_reward}" %> </div> <div> <%= "報酬:#{event.reward}" %> </div> </ul> <div> <%= link_to "編集する", edit_hoge_fuga_event_path(), method: :get %> <%= link_to "削除する", hoge_fuga_event_path(), method: :delete %> </div> <% end %>今回は、()内に渡したいparameterのid(キー)に相当するものを記述したい。
上記では、次の様にhogeが親でfuga_eventsが子のネスト状態となっている。routes.rb(前略) resources :hoges, except: [:index] do resources :fuga_events, except: [:index] end (後略)実際に、link_toメソッド内に記述されているPrefix(パス)、今回で言うとedit_hoge_fuga_event_pathとhoge_fuga_event_pathの後の括弧内にはどの様な記述が必要となるでしょうか。
書き方
show.html.erb<%= link_to "編集する", edit_hoge_fuga_event_path(event.papa_id, event.id), method: :get %> <%= link_to "削除する", hoge_fuga_event_path(event.papa_id, event.id), method: :delete %>編集(editアクション)と削除(destroyアクション)機能には、それぞれ(event.papa_id, event.id)を記述しました。
考え方
私は赤色がネストの親、青色がネストの子を表していて、それぞれに対応するキーを記述する と考えました。
<%= link_to "編集する", edit_ hoge _ fuga_event _path ( event.papa_id , event.id ), method: :get %>
<%= link_to "削除する", hoge _ fuga_event _path ( event.papa_id , event.id ), method: :delete %>
気付き
決してこの様な書き方が必ずではありません。結局、考え方としては、パスの後に書く括弧内ではどの様なidが渡されるかを指定して書いてあげることが重要であると気がつきました。
- 投稿日:2020-11-15T17:03:29+09:00
Ruby on Railsの開発環境をDockerで構築する方法
この記事では、Dockerを用いてRuby on Rails(以下、rails)の開発環境を構築する方法を紹介します。
通常、rails の初学者の方はマシンに直接インストールして開発環境を構築する人がほとんどだと思います。
しかし、環境の微妙な際(Rubyのバージョンや環境変数など)によってつまづいた場合、
そのトラブルシューティングには多くの時間を要してしまうかと思います。そこで、Dockerで仮想環境上にrailsの環境を構築してあげることで
どのマシン上の開発環境でも等しい動作を行うことができるため、環境の差異によるエラーを避けることができます。
環境をいじりすぎた時には最悪一度リセットを出来るというのもメリットですね。また、作成したアプリケーションを本番環境として外部へ公開しようとするときにも
開発環境と本番環境での違いを最小限に抑え、安定したアプリケーションとして稼働させることができます.
Dockerで仮想環境を作って公開するなんて難しそうと思うかもしれませんが、
最近ではAWSといったクラウドサービスでもDockerコンテナをそのまま実行できるECS等のサービスが整っているので
Dockerで作った環境を公開するのも楽になってきています。前提条件
マシンに Docker がインストールされていること
Docker をインストールしていない人は、公式サイトから Docker のインストーラをダウンロードしてインストールしておきましょう。
→Docker公式また、任意の作業フォルダを作成しておきます。
ここでは "rails-docker" というフォルダを作成し、その中で作業していくことにします。$ mkdir rails-docker $ cd rails-dockerDocker関連ファイルの準備
rails-docker 内に以下4つの空ファイルを準備しておきます。
VScode を利用しているなら新規ファイルの作成で作ったり、
Mac のターミナルから touch コマンドを使ってもよいです。. ├── Dockerfile # 新規作成 ├── Gemfile # 新規作成 ├── Gemfile.lock # 新規作成 └── docker-compose.yml # 新規作成Dockerファイルの解説
Dockerでは、Dockerfileというファイルに基づいてコンテナのビルドが行われ、
Docker Image(コンテナの雛形)が作成されることになります。まず Dockerfile の全文を記載します。
使用する Ruby のバージョンは 2.7.0 としています。FROM ruby:2.7.0 RUN apt-get update -qq && apt-get install -y build-essential nodejs RUN mkdir /app WORKDIR /app COPY Gemfile /app/Gemfile COPY Gemfile.lock /app/Gemfile.lock RUN bundle install COPY . /app箇条書きとはなりますが、それぞれの意味を解説します。
- FROM ruby:2.7.0
- 公開されている ruby インストール済みコンテナのうち、Rubyのバージョンが 2.7.0 であるものを引っ張ってきます。
- RUN apt-get update -qq && apt-get install -y build-essential nodejs
- Rails の実行に必要なパッケージをインストールしています
- RUN mkdir /app
- Rails のプロジェクトファイルを作成するアプリディレクトリを作成
- WORKDIR /app
- 作業用のディレクトリを指定
- COPY Gemfile /app/Gemfile
- 自分のマシン(PC)上にある Gemfile をコンテナの作業用ディレクトリに移動させ、コンテナから利用できるようにします
- Gemfile.lock も同様
- RUN bundle install
- Gemfileに記載されているgemを一括インストール
- COPY . /app
- Dockerファイルが置いてあるフォルダのファイルすべてをコンテナ内の app ディレクトリにコピー
- Rails の実行に必要なファイルをコンテナに含めるためにコピーしています
Gemfile の解説
Ruby では Gemfile というファイルで環境で使いたい gem を定義することができます。
gemとはRubyのライブラリのことをいいます。
gemはRubyGemsと呼ばれるRuby用のパッケージ管理システムで管理されており、RubyGemsが提供するgemコマンドを通じてインストール等ができます。source 'https://rubygems.org' gem 'rails', '5.2.1'また少し解説します。
- source 'https://rubygems.org'
- gem のダウンロード元を指定
- gem 'rails', '5.2.1'
- インストールする gem である rails というパッケージ名と、バージョンを指定
- 今回は rails のバージョンは 5.2.1 を指定しています
- どのバージョンを指定してもよいのですが rails 6 以降は webpacker, yarn が必要になるので注意してください
- ここでは簡単に検証するため rails 5 系を使用
Gemfile があるディレクトリで "bundle install" コマンドを実行すると、
Gemfile の定義に従って、定義した gem をインストールすることができます。先ほど解説した Docker ファイルでも、Gemfile をコンテナの作業用ディレクトリにコピーして
そのフォルダ内で bundle install を実行するように指定していましたね。Gemfile.lock の解説
実は Gemfile.lock は最初の時点では何も書き込む必要がありません。
これは直接編集するようなファイルではなく、
Gemfile に基づいて bundle install を実行した後に
インストールされた gem が Gemfile.lock に一覧として記述されるようになります。使い方としては、Gemfile.lock を参照すればインストールされている gem とバージョンが分かり、
Gemfile.lock から bundle install を実行することもできるので
完全に同じ環境をもう一度作りたいときや、多人数で開発をするときに Gemfile.lock が使われます。Gemfile だけでも良いのでは?と思った鋭い方に補足しますと、Gemfile では実はこういう書き方もできることが理由の一つになっています。
gem 'rails', '~> 5.2.1'この場合、bundle install でインストールされる rails のバージョンは 5.2.1 以上であるものの
実際にインストールできる(公開されている)バージョンはその時点によって変わってきます。しかし Gemfile.lock では Gemfile に従ってインストールしようとした時に実際にインストールされた gem 本体と具体的なバージョン、
付随して必要となるためにインストールされたパッケージまで記録されます。少し整理すると Gemfile は「アプリで必要な gem の一覧」であり、
一方の Gemfile.lock は「Gemfile に従った結果、実際にインストールした gem の情報」が記述されることになります。docker-compose.yml の解説
この yml ファイルは Docker Compose で使用されます。
Docker Composeは、複数のコンテナで構成されるアプリケーションについて
Dockerイメージのビルドや各コンテナの起動・停止といった管理を行うためのツールです。Docker Composeでは、Dockerビルドやコンテナ起動のオプションも含め、複数のコンテナのための定義を docker-compose.yml というファイルに記述し、
それを利用して Docker イメージのビルドやコンテナ起動をすることができます。開発環境のように、Rails をそれ単体で動かすならば Dockerfile だけでもよいのですが
Rails を動かすためのアプリケーションサーバに加え、
実際に公開するときにはインターネットからのアクセスを受け付けるための Web サーバや、
またデータを保存・処理するためのデータベースサーバも用意することがあります。docker-compose.ymlversion: '3' services: web: build: . command: bundle exec rails s -p 3000 -b '0.0.0.0' volumes: - .:/app ports: - 3000:3000 depends_on: - db tty: true stdin_open: true db: image: mysql:5.7 volumes: - db-volume:/var/lib/mysql environment: MYSQL_ROOT_PASSWORD: password volumes: db-volume:rails ではデータベースも必要になるため、WebサーバだけではなくMySQLを用いたデータベースサーバのコンテナも構築します。
ここでは詳解しませんが、web という欄の中の「depends_on」で rails が連携するデータベースサーバ(コンテナ)を名前で指定しています。rails の立ち上げ
rails プロジェクトの作成 (rails new)
docker-compose.yml が置いてあるフォルダ(rails-dockerフォルダ)で以下の docker-compose コマンドを実行します。
$ docker-compose run web rails new . --force --database=mysqlコマンドについて、オプション含め少し読み方を解説します↓
- docker-compose: docker-compose というツールをつかって
- run: 以下のコマンドを実行します
- web: web コンテナで
- rails new: rails で新しいプロジェクトを作成する
- . : 現在のディレクトリに対して
- --force: 既存の file (ここでは Gemfile, Gemfile.lock) は上書きする形で
- --database=mysql: ただし rails のデータベースには MySQL を使用します
という意味を持っているのです。
この一行のコマンドを実行すると数分単位で処理に時間がかかるので、チョコレートでも食べながら気長に待ちましょう。
build の実行
Gemfile に追記された gem のインストール、
および作成されたファイルをコンテナ内に取り込むため build を実行します。$ docker-compose buildデータベース設定ファイルの編集
build が完了したら、rails で使用するデータベースファイルの設定を編集します。
config ディレクトリ内の database.yml というファイルが対象です。config/database.ymldefault: &default adapter: mysql2 encoding: utf8 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: root password: password # 追加 host: db # 変更password は docker-compose.yml で指定したパスワードと合わせる必要があります。
docker-compose.yml... environment: MYSQL_ROOT_PASSWORD: password # ここと合わせる ...また、host の欄は MySQL コンテナ名を設定しています。
コンテナの起動
コンテナを起動するため、次のコマンドを実行します。
$ docker-compose up -ddocker-compose up がコンテナをdocker-compose.yml に基づいて起動するコマンドであり、
オプションの「-d」によりバックグラウンドで起動させることができます。データベースの作成
いまはまだコンテナが起動しただけであり、データベースは作成されていないので
次のコマンドを実行してデータベースを作成します。$ docker-compose run web bundle exec rails db:createrails を実行している web コンテナで、rails db:create (=データベースの新規作成)を実行する処理となっています。
rails 開発用サーバの起動確認
これで無事に rails の開発用サーバが起動したことになります。
ブラウザのアドレスバーに localhost:3000 と入力し、起動を確認してみましょう。
rails ではお馴染みの画面が表示されれば完了です。
コンテナの停止
開発用サーバを止めるため、コンテナを一括で停止するには以下のコマンドを実行します。
$ docker-compose downまた立ち上げたいときには docker-comopose up -d を実行しましょう。
最後に
これによって作られるファイルの一式は Github にあげています。
フォルダ構成が分からなくなったり、自分の環境でうまくいっているか比較して確かめたい方はご参照ください。
- 投稿日:2020-11-15T17:03:29+09:00
Ruby on Railsの開発環境をDockerで構築する方法(Rails 5.x)
この記事では、Dockerを用いてRuby on Rails(以下、rails)の 5.x 系における開発環境を構築する方法を紹介します。
※Rails 6.x 系で Docker 環境を作りたい場合は こちら をご覧ください。Docker で環境構築をするメリットとは?
通常、rails の初学者の方はマシンに直接インストールして開発環境を構築する人がほとんどだと思います。
しかし、環境の微妙な際(Rubyのバージョンや環境変数など)によってつまづいた場合、
そのトラブルシューティングには多くの時間を要してしまうかと思います。そこで、Dockerで仮想環境上にrailsの環境を構築してあげることで
どのマシン上の開発環境でも等しい動作を行うことができるため、環境の差異によるエラーを避けることができます。
環境をいじりすぎた時には最悪一度リセットを出来るというのもメリットですね。また、作成したアプリケーションを本番環境として外部へ公開しようとするときにも
開発環境と本番環境での違いを最小限に抑え、安定したアプリケーションとして稼働させることができます.
Dockerで仮想環境を作って公開するなんて難しそうと思うかもしれませんが、
最近ではAWSといったクラウドサービスでもDockerコンテナをそのまま実行できるECS等のサービスが整っているので
Dockerで作った環境を公開するのも楽になってきています。前提条件
マシンに Docker がインストールされていること
Docker をインストールしていない人は、公式サイトから Docker のインストーラをダウンロードしてインストールしておきましょう。
→Docker公式また、任意の作業フォルダを作成しておきます。
ここでは "rails-docker" というフォルダを作成し、その中で作業していくことにします。$ mkdir rails-docker $ cd rails-dockerDocker関連ファイルの準備
rails-docker 内に以下4つの空ファイルを準備しておきます。
VScode を利用しているなら新規ファイルの作成で作ったり、
Mac のターミナルから touch コマンドを使ってもよいです。. ├── Dockerfile # 新規作成 ├── Gemfile # 新規作成 ├── Gemfile.lock # 新規作成 └── docker-compose.yml # 新規作成Dockerファイルの解説
Dockerでは、Dockerfileというファイルに基づいてコンテナのビルドが行われ、
Docker Image(コンテナの雛形)が作成されることになります。まず Dockerfile の全文を記載します。
使用する Ruby のバージョンは 2.7.0 としています。FROM ruby:2.7.0 RUN apt-get update -qq && apt-get install -y build-essential nodejs RUN mkdir /app WORKDIR /app COPY Gemfile /app/Gemfile COPY Gemfile.lock /app/Gemfile.lock RUN bundle install COPY . /app箇条書きとはなりますが、それぞれの意味を解説します。
- FROM ruby:2.7.0
- 公開されている ruby インストール済みコンテナのうち、Rubyのバージョンが 2.7.0 であるものを引っ張ってきます。
- RUN apt-get update -qq && apt-get install -y build-essential nodejs
- Rails の実行に必要なパッケージをインストールしています
- RUN mkdir /app
- Rails のプロジェクトファイルを作成するアプリディレクトリを作成
- WORKDIR /app
- 作業用のディレクトリを指定
- COPY Gemfile /app/Gemfile
- 自分のマシン(PC)上にある Gemfile をコンテナの作業用ディレクトリに移動させ、コンテナから利用できるようにします
- Gemfile.lock も同様
- RUN bundle install
- Gemfileに記載されているgemを一括インストール
- COPY . /app
- Dockerファイルが置いてあるフォルダのファイルすべてをコンテナ内の app ディレクトリにコピー
- Rails の実行に必要なファイルをコンテナに含めるためにコピーしています
Gemfile の解説
Ruby では Gemfile というファイルで環境で使いたい gem を定義することができます。
gemとはRubyのライブラリのことをいいます。
gemはRubyGemsと呼ばれるRuby用のパッケージ管理システムで管理されており、RubyGemsが提供するgemコマンドを通じてインストール等ができます。source 'https://rubygems.org' gem 'rails', '5.2.1'また少し解説します。
- source 'https://rubygems.org'
- gem のダウンロード元を指定
- gem 'rails', '5.2.1'
- インストールする gem である rails というパッケージ名と、バージョンを指定
- 今回は rails のバージョンは 5.2.1 を指定しています
- どのバージョンを指定してもよいのですが rails 6 以降は webpacker, yarn が必要になるので注意してください
- ここでは簡単に検証するため rails 5 系を使用
Gemfile があるディレクトリで "bundle install" コマンドを実行すると、
Gemfile の定義に従って、定義した gem をインストールすることができます。先ほど解説した Docker ファイルでも、Gemfile をコンテナの作業用ディレクトリにコピーして
そのフォルダ内で bundle install を実行するように指定していましたね。Gemfile.lock の解説
実は Gemfile.lock は最初の時点では何も書き込む必要がありません。
これは直接編集するようなファイルではなく、
Gemfile に基づいて bundle install を実行した後に
インストールされた gem が Gemfile.lock に一覧として記述されるようになります。使い方としては、Gemfile.lock を参照すればインストールされている gem とバージョンが分かり、
Gemfile.lock から bundle install を実行することもできるので
完全に同じ環境をもう一度作りたいときや、多人数で開発をするときに Gemfile.lock が使われます。Gemfile だけでも良いのでは?と思った鋭い方に補足しますと、Gemfile では実はこういう書き方もできることが理由の一つになっています。
gem 'rails', '~> 5.2.1'この場合、bundle install でインストールされる rails のバージョンは 5.2.1 以上であるものの
実際にインストールできる(公開されている)バージョンはその時点によって変わってきます。しかし Gemfile.lock では Gemfile に従ってインストールしようとした時に実際にインストールされた gem 本体と具体的なバージョン、
付随して必要となるためにインストールされたパッケージまで記録されます。少し整理すると Gemfile は「アプリで必要な gem の一覧」であり、
一方の Gemfile.lock は「Gemfile に従った結果、実際にインストールした gem の情報」が記述されることになります。docker-compose.yml の解説
この yml ファイルは Docker Compose で使用されます。
Docker Composeは、複数のコンテナで構成されるアプリケーションについて
Dockerイメージのビルドや各コンテナの起動・停止といった管理を行うためのツールです。Docker Composeでは、Dockerビルドやコンテナ起動のオプションも含め、複数のコンテナのための定義を docker-compose.yml というファイルに記述し、
それを利用して Docker イメージのビルドやコンテナ起動をすることができます。開発環境のように、Rails をそれ単体で動かすならば Dockerfile だけでもよいのですが
Rails を動かすためのアプリケーションサーバに加え、
実際に公開するときにはインターネットからのアクセスを受け付けるための Web サーバや、
またデータを保存・処理するためのデータベースサーバも用意することがあります。docker-compose.ymlversion: '3' services: web: build: . command: bundle exec rails s -p 3000 -b '0.0.0.0' volumes: - .:/app ports: - 3000:3000 depends_on: - db tty: true stdin_open: true db: image: mysql:5.7 volumes: - db-volume:/var/lib/mysql environment: MYSQL_ROOT_PASSWORD: password volumes: db-volume:rails ではデータベースも必要になるため、WebサーバだけではなくMySQLを用いたデータベースサーバのコンテナも構築します。
ここでは詳解しませんが、web という欄の中の「depends_on」で rails が連携するデータベースサーバ(コンテナ)を名前で指定しています。rails の立ち上げ
rails プロジェクトの作成 (rails new)
docker-compose.yml が置いてあるフォルダ(rails-dockerフォルダ)で以下の docker-compose コマンドを実行します。
$ docker-compose run web rails new . --force --database=mysqlコマンドについて、オプション含め少し読み方を解説します↓
- docker-compose: docker-compose というツールをつかって
- run: 以下のコマンドを実行します
- web: web コンテナで
- rails new: rails で新しいプロジェクトを作成する
- . : 現在のディレクトリに対して
- --force: 既存の file (ここでは Gemfile, Gemfile.lock) は上書きする形で
- --database=mysql: ただし rails のデータベースには MySQL を使用します
という意味を持っているのです。
この一行のコマンドを実行すると数分単位で処理に時間がかかるので、チョコレートでも食べながら気長に待ちましょう。
build の実行
Gemfile に追記された gem のインストール、
および作成されたファイルをコンテナ内に取り込むため build を実行します。$ docker-compose buildデータベース設定ファイルの編集
build が完了したら、rails で使用するデータベースファイルの設定を編集します。
config ディレクトリ内の database.yml というファイルが対象です。config/database.ymldefault: &default adapter: mysql2 encoding: utf8 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: root password: password # 追加 host: db # 変更password は docker-compose.yml で指定したパスワードと合わせる必要があります。
docker-compose.yml... environment: MYSQL_ROOT_PASSWORD: password # ここと合わせる ...また、host の欄は MySQL コンテナ名を設定しています。
コンテナの起動
コンテナを起動するため、次のコマンドを実行します。
$ docker-compose up -ddocker-compose up がコンテナをdocker-compose.yml に基づいて起動するコマンドであり、
オプションの「-d」によりバックグラウンドで起動させることができます。データベースの作成
いまはまだコンテナが起動しただけであり、データベースは作成されていないので
次のコマンドを実行してデータベースを作成します。$ docker-compose run web bundle exec rails db:createrails を実行している web コンテナで、rails db:create (=データベースの新規作成)を実行する処理となっています。
rails 開発用サーバの起動確認
これで無事に rails の開発用サーバが起動したことになります。
ブラウザのアドレスバーに localhost:3000 と入力し、起動を確認してみましょう。
rails ではお馴染みの画面が表示されれば完了です。
コンテナの停止
開発用サーバを止めるため、コンテナを一括で停止するには以下のコマンドを実行します。
$ docker-compose downまた立ち上げたいときには docker-comopose up -d を実行しましょう。
最後に
これによって作られるファイルの一式は Github にあげています。
フォルダ構成が分からなくなったり、自分の環境でうまくいっているか比較して確かめたい方はご参照ください。
- 投稿日:2020-11-15T17:01:09+09:00
Amazon S3に画像を保存する(Local/Heroku)
はじめに
自分用の備忘録
手順(Local)
Gemインストール
Gemfilegem "aws-sdk-s3", require: false保存先を変更
config/environments/development.rbconfig.active_storage.service = :local #下記に変更 config.active_storage.service = :amazonstorage.ymlに追記
config/storage.ymlamazon: service: S3 access_key_id: <%= ENV['AWS_ACCESS_KEY_ID'] %> secret_access_key: <%= ENV['AWS_SECRET_ACCESS_KEY'] %> region: ap-northeast-1 bucket: バケット名環境変数を設定
ターミナル# Catalina以降 % vim ~/.zshrc [insert mode] export AWS_ACCESS_KEY_ID="Access key ID" export AWS_SECRET_ACCESS_KEY="Secret access key" [:wqで保存] # 反映させるコマンド % source ~/.zshrc手順(Heroku)
※Gemインストール済
保存先を変更
config/environments/production.rbconfig.active_storage.service = :local #下記に変更 config.active_storage.service = :amazon環境変数を設定
ターミナルheroku config:set AWS_ACCESS_KEY_ID="Access key ID" heroku config:set AWS_SECRET_ACCESS_KEY="Secret access key"確認コマンド
ターミナル% heroku configpushして反映
おわりに
バケットは使いまわせるのでいちいち作らなくてよろしい。
✔︎
- 投稿日:2020-11-15T16:27:45+09:00
[ Ruby ] 継承ツリーをメソッドが探索される流れを見ながら調べてみる
はじめに
メソッドを呼ぶ際に、そのメソッドは自身のクラス内に定義されている場合の他にも
スーパークラス内や、module、又はクラスから作成されたインスタンスに特異メソッドとして定義されているなど
様々なケースがあるかと思います。
今回は、それらのケースの、メソッドの探索の流れについて
まとめていきたいと思います。自身のメソッド
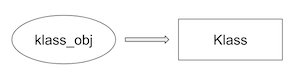
class Klass def hello puts "Hello_from_Klass" end end klass_obj = Klass.new klass_obj.hello # => Hello_from_Klass最も単純なケースかと思われます。
objオブジェクトに対してhelloメソッドが呼ばれた際、
直接のクラスであるKlassクラスを参照し、そこにhelloメソッドがないかを探します。
今回の場合は、そこで見つけることが出来たので、そこで探索は終了しそのメソッドを実行します。
スーパークラスのメソッド
class Klass def hello puts "Hello from Klass" end end class SubKlass < Klass end sub_klass_obj = SubKlass.new sub_klass_obj.hello # => Hello_from_Klass探索方向は、まず直接のクラスを参照し、そこになければ
その親クラス、なければ更にその親クラス・・・
のようにクラスの継承順序と等しくなります。
今回のケースでは、SubKlassを参照しhelloメソッドが無かったため
その親クラスであるKlassを参照し、helloメソッドが定義されていたため
探索は終了し、メソッドを実行します。
特異メソッド
class Klass def hello puts "Hello from Klass" end end obj = Klass.new def obj.hello puts "Hello from singleton" end obj.hello # => Hello from singletonこのケースでは、直接のクラスに定義した
helloメソッドではなく
特異メソッドとして定義したhelloメソッドが呼ばれました。
つまり、特異クラスはオブジェクトのクラスより先にメソッドが探索されていることが
わかります。
クラスにmixinされたメソッド
スーパークラスとmoduleに同名メソッドを定義して
サブクラスのインスタンスからそのメソッドを呼んでみます。module HelloModule def hello puts "Hello from HelloModule" end end class Klass def hello puts "Hello from Klass" end end class SubKlass < Klass include HelloModule end sub_klass_obj = SubKlass.new sub_klass_obj.hello # => Hello from HelloModuleincludeしたmoduleの
helloメソッドが呼ばれました。
includeされたmodulueは、includeしたクラスの親クラスとの間に
存在することになります。
この時、moduleをラップしたかのような無名クラスが作られ継承ツリーの中に埋め込まれています。
ちなみに、この無名クラスはRubyのプログラムからは触れることが出来ません。
このように無名クラスが作成され、継承ツリーに埋め込まれるため、
メソッドの探索も通常の継承が行われている時と同じルールで参照することができています。
複数のmoduleをinclude
先ほどは、1つのmoduleのみをincludeさせましたが、
moduleのincludeはクラスの継承と異なり
1つのクラスに対して複数のmoduleをincludeすることが出来ます。実際に複数のmoduleをincludeさせてメソッドを呼んでみます。
module FirstModule def hello puts "Hello from FirstModule" end end module SecondModule def hello puts "Hello from SecondModule" end end class Klass def hello puts "Hello from Klass" end end class SubKlass < Klass include FirstModule include SecondModule end sub_klass_obj = SubKlass.new sub_klass_obj.hello # => Hello from SecondModule複数のmoduleをincludeさせた場合、
最後にincludeさせたmoduleのメソッドが呼ばれました。
このように複数のmoduleを同一のクラスにincludeさせた場合、
includeさせた順にmoduleはそのクラスの継承ツリーに埋め込まれていきます。まず、FirstModuleがincludeされ以下の継承ツリーになります。
その後、下に記述してあるSecondModuleがincludeされると、以下のようになります。
moduleをincludeした後に、再度include
今度は、先ほどのように
FirstModuleSecondModuleの順に読み込んだ後に
再度FirstModuleを読み込んでみます。module FirstModule def hello puts "Hello from FirstModule" end end module SecondModule def hello puts "Hello from SecondModule" end end class Klass def hello puts "Hello from Klass" end end class SubKlass < Klass include FirstModule include SecondModule include FirstModule end sub_klass_obj = SubKlass.new sub_klass_obj.hello # => Hello from SecondModule最後にincludeの記述があるのは
FirstModuleですが
呼ばれたのはSecondModuleのメソッドでした。実は継承ツリーにmoduleをラップしたクラスを差し込む際に、
継承ツリーに同じmoduleがないかを確認しています。
そのため、2回目のinclude FirstModuleが呼ばれた際に、
既にFirstModuleがincludeされているため
差し込まれずにincludeメソッドが終了します。オブジェクトに存在しないメソッドを呼び出す
module HelloModule def hello puts "Hello from FirstModule" end end class Klass def hello puts "Hello from Klass" end end class SubKlass < Klass include HelloModule end obj = SubKlass.new obj.bye # => undefined method `bye' for #<SubKlass:0x00007fb5fb80c628> (NoMethodError)オブジェクトのどこにも存在しない
byeメソッドを呼んでみたところ
NoMethodErrorを吐きました。byeメソッドが呼ばれると継承ツリーを順に辿ってそのメソッドを探していきます。
しかし、今回はどこにも定義していないため継承ツリーの最上位であるBasicObjectまで探した後
直接のクラスであるSubKlassまで戻り、今度はmethod_missingメソッドを継承ツリーの順番に探していきます。
今回は自分でmethod_missingメソッドを定義していないため最上位である
BasicObjectのmethod_missingメソッドが呼ばれNoMethodErrorを例外として発生させます。そのため、
BasicObjectまでの継承ツリーの途中でmethod_middingメソッドがあれば
それを呼び出します。module HelloModule def hello puts "Hello from FirstModule" end end class Klass def hello puts "Hello from Klass" end def method_missing(method_name, *args) puts "#{method_name}?そんなメソッドないよ" end end class SubKlass < Klass include HelloModule end obj = SubKlass.new obj.bye # => bye?そんなメソッドないよまとめ
探索の流れとして
1 , レシーバの特異クラス
2 , 直接のクラス
2', moduleがincludeされていればmodule
3 , 2の親クラス
3', moduleがincludeされていればmodule
4 ,3をメソッドが見つかるまで繰り返す
5 , 継承ツリーの最上位(BasicObject)まで探索しなければ、そのメソッドでの探索を終了
6 , メソッド名を引数にして、method_missingメソッドを1から探していく
7 , なければBasicObjectのmethod_missingが呼ばれNoMethodErrorの例外が発生おわり





- 投稿日:2020-11-15T16:27:45+09:00
[ Ruby ] 継承ツリーについてメソッドが探索される流れを見ながら調べてみる
はじめに
メソッドを呼ぶ際に、そのメソッドは自身のクラス内に定義されている場合の他にも
スーパークラス内や、module、又はクラスから作成されたインスタンスに特異メソッドとして定義されているなど
様々なケースがあるかと思います。
今回は、それらのケースの、メソッドの探索の流れについて
まとめていきたいと思います。自身のメソッド
class Klass def hello puts "Hello_from_Klass" end end klass_obj = Klass.new klass_obj.hello # => Hello_from_Klass最も単純なケースかと思われます。
objオブジェクトに対してhelloメソッドが呼ばれた際、
直接のクラスであるKlassクラスを参照し、そこにhelloメソッドがないかを探します。
今回の場合は、そこで見つけることが出来たので、そこで探索は終了しそのメソッドを実行します。
スーパークラスのメソッド
class Klass def hello puts "Hello from Klass" end end class SubKlass < Klass end sub_klass_obj = SubKlass.new sub_klass_obj.hello # => Hello_from_Klass探索方向は、まず直接のクラスを参照し、そこになければ
その親クラス、なければ更にその親クラス・・・
のようにクラスの継承順序と等しくなります。
今回のケースでは、SubKlassを参照しhelloメソッドが無かったため
その親クラスであるKlassを参照し、helloメソッドが定義されていたため
探索は終了し、メソッドを実行します。
特異メソッド
class Klass def hello puts "Hello from Klass" end end obj = Klass.new def obj.hello puts "Hello from singleton" end obj.hello # => Hello from singletonこのケースでは、直接のクラスに定義した
helloメソッドではなく
特異メソッドとして定義したhelloメソッドが呼ばれました。
つまり、特異クラスはオブジェクトのクラスより先にメソッドが探索されていることが
わかります。
クラスにmixinされたメソッド
スーパークラスとmoduleに同名メソッドを定義して
サブクラスのインスタンスからそのメソッドを呼んでみます。module HelloModule def hello puts "Hello from HelloModule" end end class Klass def hello puts "Hello from Klass" end end class SubKlass < Klass include HelloModule end sub_klass_obj = SubKlass.new sub_klass_obj.hello # => Hello from HelloModuleincludeしたmoduleの
helloメソッドが呼ばれました。
includeされたmodulueは、includeしたクラスの親クラスとの間に
存在することになります。
この時、moduleをラップしたかのような無名クラスが作られ継承ツリーの中に埋め込まれています。
ちなみに、この無名クラスはRubyのプログラムからは触れることが出来ません。
このように無名クラスが作成され、継承ツリーに埋め込まれるため、
メソッドの探索も通常の継承が行われている時と同じルールで参照することができています。
複数のmoduleをinclude
先ほどは、1つのmoduleのみをincludeさせましたが、
moduleのincludeはクラスの継承と異なり
1つのクラスに対して複数のmoduleをincludeすることが出来ます。実際に複数のmoduleをincludeさせてメソッドを呼んでみます。
module FirstModule def hello puts "Hello from FirstModule" end end module SecondModule def hello puts "Hello from SecondModule" end end class Klass def hello puts "Hello from Klass" end end class SubKlass < Klass include FirstModule include SecondModule end sub_klass_obj = SubKlass.new sub_klass_obj.hello # => Hello from SecondModule複数のmoduleをincludeさせた場合、
最後にincludeさせたmoduleのメソッドが呼ばれました。
このように複数のmoduleを同一のクラスにincludeさせた場合、
includeさせた順にmoduleはそのクラスの継承ツリーに埋め込まれていきます。まず、FirstModuleがincludeされ以下の継承ツリーになります。
その後、下に記述してあるSecondModuleがincludeされると、以下のようになります。
moduleをincludeした後に、再度include
今度は、先ほどのように
FirstModuleSecondModuleの順に読み込んだ後に
再度FirstModuleを読み込んでみます。module FirstModule def hello puts "Hello from FirstModule" end end module SecondModule def hello puts "Hello from SecondModule" end end class Klass def hello puts "Hello from Klass" end end class SubKlass < Klass include FirstModule include SecondModule include FirstModule end sub_klass_obj = SubKlass.new sub_klass_obj.hello # => Hello from SecondModule最後にincludeの記述があるのは
FirstModuleですが
呼ばれたのはSecondModuleのメソッドでした。実は継承ツリーにmoduleをラップしたクラスを差し込む際に、
継承ツリーに同じmoduleがないかを確認しています。
そのため、2回目のinclude FirstModuleが呼ばれた際に、
既にFirstModuleがincludeされているため
差し込まれずにincludeメソッドが終了します。moduleをprepend
module PrependModule def hello puts "Hello from PrependModule" end end module IncludeModule def hello puts "Hello from IncludeModule" end end class Klass prepend PrependModule include IncludeModule def hello puts "Hello from Klass" end end klass_obj = Klass.new klass_obj.hello # => Hello from PrependModuleincludeはmoduleをラップした無名クラスを
includeしたクラスより上位に埋め込むのに対して
prependはそのクラスより下位に埋め込まれます。(prependしたクラスより優先的にメソッドが呼ばれる)
そのため、prependするmodule内でsuperの呼び出しを行うと、
prependしたクラスの同名メソッドが呼ばれます。
オブジェクトに存在しないメソッドを呼び出す
module HelloModule def hello puts "Hello from FirstModule" end end class Klass def hello puts "Hello from Klass" end end class SubKlass < Klass include HelloModule end obj = SubKlass.new obj.bye # => undefined method `bye' for #<SubKlass:0x00007fb5fb80c628> (NoMethodError)オブジェクトのどこにも存在しない
byeメソッドを呼んでみたところ
NoMethodErrorを吐きました。byeメソッドが呼ばれると継承ツリーを順に辿ってそのメソッドを探していきます。
しかし、今回はどこにも定義していないため継承ツリーの最上位であるBasicObjectまで探した後
直接のクラスであるSubKlassまで戻り、今度はmethod_missingメソッドを継承ツリーの順番に探していきます。
今回は自分でmethod_missingメソッドを定義していないため最上位である
BasicObjectのmethod_missingメソッドが呼ばれNoMethodErrorを例外として発生させます。そのため、
BasicObjectまでの継承ツリーの途中でmethod_middingメソッドがあれば
それを呼び出します。module HelloModule def hello puts "Hello from FirstModule" end end class Klass def hello puts "Hello from Klass" end def method_missing(method_name, *args) puts "#{method_name}?そんなメソッドないよ" end end class SubKlass < Klass include HelloModule end obj = SubKlass.new obj.bye # => bye?そんなメソッドないよまとめ
探索の流れとして
1 , レシーバの特異クラス
2 , 直接のクラス
2', moduleがincludeされていればmodule
3 , 2の親クラス
3', moduleがincludeされていればmodule
4 ,3をメソッドが見つかるまで繰り返す
5 , 継承ツリーの最上位(BasicObject)まで探索しなければ、そのメソッドでの探索を終了
6 , メソッド名を引数にして、method_missingメソッドを1から探していく
7 , なければBasicObjectのmethod_missingが呼ばれNoMethodErrorの例外が発生おわり

- 投稿日:2020-11-15T16:11:30+09:00
初心者がWebアプリを公開してから1か月間でやったことまとめ[個人開発]
初めに
僕はちょうど一か月前にWebアプリを公開しました。そこで公開してから1か月間やったこと、立ちはだかった問題などを振り返ってみようと思います。
作ったWebアプリ
URL
https://www.code-sell.net/プログラムコードを販売できるサービスです。公開した直後にqiitaでも宣伝させていただきました。
コードを販売できるサービス「Code-sell」をリリースした!(個人開発)やったこと
ここからが本題です。どのようなことを、いつ、どうして、やったかを振り返っていきます
1 動作確認
いつ...公開した直後
どうして...開発環境ではうごいても本番環境では動かないということがあるからまあこれは皆さん普通にやると思います。ただ筆者の場合これが甘すぎました。
アカウント登録と有効化
コード販売
購入機能このくらいしかしませんでした。おかげで細かいところでエラーの目撃が相次ぎました。
送金機能、検索機能、アカウント編集機能、ページが開けないなど...
こういうのはサービスの信頼にかかわるのでしっかりやることをお勧めします。焦らずに、すべてのページを開いてすべての機能を試したほうがいいです。しかもこれをしっかりしなかったせいで、後で紹介する致命的バグに3,4週間くらい気づけないことになります。2 初期データ投稿
いつ...動作確認が終わってから
どうして...初期データがないと使ってもらえないからこれはいろんなサイトで言われていますが、だれも投稿していないあやしいサイトを使おうと思いますか?使わないでしょう。
だから初期データを作るか、トップページでは投稿されてるかどうかわからなくしたほうがいいです。3 めっちゃ宣伝
qiita
dev.to
service safari
つくろぐ
startapp
eggineer
ロケットリリース
note
zenn
crieitくらいですかね。宣伝できる場所があれば徹底的にやりました。特にqiitaとservice safariとnoteが効果が大きかったと思います。
4 バグ・エラー修正
いつ...qiitaなどで宣伝した直後(本当は動作確認で気づくべき)
がばがば動作確認によって発生したバグ・エラーたちを修正します。
5 機能追加
いつ...バグ・エラー修正が一通り終わったころ
公開してから追加した機能は
技術メモ...廃止済み
運営からのおしらせ...最初から実装しとくべきでした。
フォロー...なくてもいいかも
pv機能...なくてもいいかもくらいですかね。技術メモは「このままだとオワコンになるかも!」とか言って深夜テンションで作ってしまった黒歴史です。qiitaには投稿できないようなしょっぼいメモを残すというものです。全く使われませんでした。しかもサービスの機能の統一性がなくなるのでSEOも弱くなるかもしれません。
皆さんがwebアプリを作るときは一つのサービスだけをやりましょう。6 公式ツイッターをつくる
いつ...機能追加してる合間
これは、もっとユーザーが増えてからでもいいかもしれません。宣伝効果もないし、アップデートはお知らせでできるし。
7 致命的バグに気づく
いつ...公開してから3,4週間たってから
どうのようなバグかというと送金先がみんな同じになるというものです。
幸い、お金の取引はまだされていなかったので大丈夫でしたが本当に取り返しのつかなくなるところでした。なぜここまで発見が遅れたか
基本的な機能過ぎて逆に見直してなかった
管理画面を見てもアカウント数がある程度がないとわかならい
testコードを書いていなかった
一つや二つのアカウントだけで動作させているとわかならい(お問い合わせが来なかった理由)
みなさんも動作確認するとき1つや2つのユーザーではなくseedで5~10くらいのテストユーザーを作ってやりましょう。
8 SEO対策や速度改善(現在)
今は機能を追加するというよりSEO対策や速度改善などを中心にしています。トップページのデザインを細かく変えたり、サイトマップを作りGoogle Search Consoleに送ったり、余計なcssを消したりしています。
まとめ
ここ一か月いろいろありました。急にアカウント数が増えたり、バグに気づき冷や汗をかいたりすごい良い体験をして一か月だったなと思います。よかったら開発したアプリ使ってみてください。

- 投稿日:2020-11-15T16:11:30+09:00
個人開発でWebアプリを公開してからやった8つのこと
初めに
僕はちょうど一か月前にWebアプリを公開しました。そこで公開してから1か月間やったこと、立ちはだかった問題などを振り返ってみようと思います。
作ったWebアプリ
URL
https://www.code-sell.net/プログラムコードを販売できるサービスです。公開した直後にqiitaでも宣伝させていただきました。
コードを販売できるサービス「Code-sell」をリリースした!(個人開発)やったこと
ここからが本題です。どのようなことを、いつ、どうして、やったかを振り返っていきます
1 動作確認
いつ...公開した直後
どうして...開発環境ではうごいても本番環境では動かないということがあるからまあこれは皆さん普通にやると思います。ただ筆者の場合これが甘すぎました。
アカウント登録と有効化
コード販売
購入機能このくらいしかしませんでした。おかげで細かいところでエラーの目撃が相次ぎました。
送金機能、検索機能、アカウント編集機能、ページが開けないなど...
こういうのはサービスの信頼にかかわるのでしっかりやることをお勧めします。焦らずに、すべてのページを開いてすべての機能を試したほうがいいです。しかもこれをしっかりしなかったせいで、後で紹介する致命的バグに3,4週間くらい気づけないことになります。2 初期データ投稿
いつ...動作確認が終わってから
どうして...初期データがないと使ってもらえないからこれはいろんなサイトで言われていますが、だれも投稿していないあやしいサイトを使おうと思いますか?使わないでしょう。
だから初期データを作るか、トップページでは投稿されてるかどうかわからなくしたほうがいいです。3 めっちゃ宣伝
qiita
dev.to
service safari
つくろぐ
startapp
eggineer
ロケットリリース
note
zenn
crieitくらいですかね。宣伝できる場所があれば徹底的にやりました。特にqiitaとservice safariとnoteが効果が大きかったと思います。
4 バグ・エラー修正
いつ...qiitaなどで宣伝した直後(本当は動作確認で気づくべき)
がばがば動作確認によって発生したバグ・エラーたちを修正します。
5 機能追加
いつ...バグ・エラー修正が一通り終わったころ
公開してから追加した機能は
技術メモ...廃止済み
運営からのおしらせ...最初から実装しとくべきでした。
フォロー...なくてもいいかも
pv機能...なくてもいいかもくらいですかね。技術メモは「このままだとオワコンになるかも!」とか言って深夜テンションで作ってしまった黒歴史です。qiitaには投稿できないようなしょっぼいメモを残すというものです。全く使われませんでした。しかもサービスの機能の統一性がなくなるのでSEOも弱くなるかもしれません。
皆さんがwebアプリを作るときは一つのサービスだけをやりましょう。6 公式ツイッターをつくる
いつ...機能追加してる合間
これは、もっとユーザーが増えてからでもいいかもしれません。宣伝効果もないし、アップデートはお知らせでできるし。
7 致命的バグに気づく
いつ...公開してから3,4週間たってから
どうのようなバグかというと送金先がみんな同じになるというものです。
幸い、お金の取引はまだされていなかったので大丈夫でしたが本当に取り返しのつかなくなるところでした。なぜここまで発見が遅れたか
基本的な機能過ぎて逆に見直してなかった
管理画面を見てもアカウント数がある程度がないとわかならい
testコードを書いていなかった
一つや二つのアカウントだけで動作させているとわかならい(お問い合わせが来なかった理由)
みなさんも動作確認するとき1つや2つのユーザーではなくseedで5~10くらいのテストユーザーを作ってやりましょう。
8 SEO対策や速度改善(現在)
今は機能を追加するというよりSEO対策や速度改善などを中心にしています。トップページのデザインを細かく変えたり、サイトマップを作りGoogle Search Consoleに送ったり、余計なcssを消したりしています。
まとめ
今回学んだこと
動作確認は慎重に、seedを利用しテストユーザーを作ってからやる
宣伝、完璧な状態になってからやる
変なノリでいらない機能は作らない。
ここ一か月いろいろありました。急にアカウント数が増えたり、バグに気づき冷や汗をかいたりすごい良い体験をして一か月だったなと思います。よかったら開発したアプリ使ってみてください。
- 投稿日:2020-11-15T16:11:30+09:00
[個人開発]Webアプリを公開してからやった8つのこと
初めに
僕はちょうど一か月前にWebアプリを公開しました。そこで公開してから1か月間やったこと、立ちはだかった問題などを振り返ってみようと思います。
作ったWebアプリ
URL
https://www.code-sell.net/プログラムコードを販売できるサービスです。公開した直後にqiitaでも宣伝させていただきました。
コードを販売できるサービス「Code-sell」をリリースした!(個人開発)やったこと
ここからが本題です。どのようなことを、いつ、どうして、やったかを振り返っていきます
1 動作確認
いつ...公開した直後
どうして...開発環境ではうごいても本番環境では動かないということがあるからまあこれは皆さん普通にやると思います。ただ筆者の場合これが甘すぎました。
アカウント登録と有効化
コード販売
購入機能このくらいしかしませんでした。おかげで細かいところでエラーの目撃が相次ぎました。
送金機能、検索機能、アカウント編集機能、ページが開けないなど...
こういうのはサービスの信頼にかかわるのでしっかりやることをお勧めします。焦らずに、すべてのページを開いてすべての機能を試したほうがいいです。しかもこれをしっかりしなかったせいで、後で紹介する致命的バグに3,4週間くらい気づけないことになります。2 初期データ投稿
いつ...動作確認が終わってから
どうして...初期データがないと使ってもらえないからこれはいろんなサイトで言われていますが、だれも投稿していないあやしいサイトを使おうと思いますか?使わないでしょう。
だから初期データを作るか、トップページでは投稿されてるかどうかわからなくしたほうがいいです。3 めっちゃ宣伝
qiita
dev.to
service safari
つくろぐ
startapp
eggineer
ロケットリリース
note
zenn
crieitくらいですかね。宣伝できる場所があれば徹底的にやりました。特にqiitaとservice safariとnoteが効果が大きかったと思います。
4 バグ・エラー修正
いつ...qiitaなどで宣伝した直後(本当は動作確認で気づくべき)
がばがば動作確認によって発生したバグ・エラーたちを修正します。
5 機能追加
いつ...バグ・エラー修正が一通り終わったころ
公開してから追加した機能は
技術メモ...廃止済み
運営からのおしらせ...最初から実装しとくべきでした。
フォロー...なくてもいいかも
pv機能...なくてもいいかもくらいですかね。技術メモは「このままだとオワコンになるかも!」とか言って深夜テンションで作ってしまった黒歴史です。qiitaには投稿できないようなしょっぼいメモを残すというものです。全く使われませんでした。しかもサービスの機能の統一性がなくなるのでSEOも弱くなるかもしれません。
皆さんがwebアプリを作るときは一つのサービスだけをやりましょう。6 公式ツイッターをつくる
いつ...機能追加してる合間
これは、もっとユーザーが増えてからでもいいかもしれません。宣伝効果もないし、アップデートはお知らせでできるし。
7 致命的バグに気づく
いつ...公開してから3,4週間たってから
どうのようなバグかというと送金先がみんな同じになるというものです。
幸い、お金の取引はまだされていなかったので大丈夫でしたが本当に取り返しのつかなくなるところでした。なぜここまで発見が遅れたか
基本的な機能過ぎて逆に見直してなかった
管理画面を見てもアカウント数がある程度がないとわかならい
testコードを書いていなかった
一つや二つのアカウントだけで動作させているとわかならい(お問い合わせが来なかった理由)
みなさんも動作確認するとき1つや2つのユーザーではなくseedで5~10くらいのテストユーザーを作ってやりましょう。
8 SEO対策や速度改善(現在)
今は機能を追加するというよりSEO対策や速度改善などを中心にしています。トップページのデザインを細かく変えたり、サイトマップを作りGoogle Search Consoleに送ったり、余計なcssを消したりしています。
まとめ
今回学んだこと
動作確認は慎重に、seedを利用しテストユーザーを作ってからやる
宣伝、完璧な状態になってからやる
変なノリでいらない機能は作らない。
ここ一か月いろいろありました。急にアカウント数が増えたり、バグに気づき冷や汗をかいたりすごい良い体験をして一か月だったなと思います。よかったら開発したアプリ使ってみてください。
- 投稿日:2020-11-15T15:31:33+09:00
include?メソッドを使った名前入力確認
以下備忘録
def check_name(str) if str.include?(".") puts "!エラー!記号は登録できません" elsif str.include?(" ") puts "!エラー!空白は登録できません" else puts "登録が完了しました" end end puts "登録したい名前を入力してください(例)YamadaTaro" str = gets check_name(str)check_nameメソッドでは、「ピリオドや空白がない場合は登録を行い、ピリオドや空白がある場合はエラーを出す」という条件分岐を行うためにif文を使用しています。
引数strで受け取った文字列に対してinclude?メソッドを使用し、”.”(ピリオド)と
” ”(空白)がないか判断を行います。
- 投稿日:2020-11-15T14:16:04+09:00
『CAPTCHA』を突破するサービス『2Captcha』とRuby+Chrome_Remoteで自動スクレイピング
はじめに
スクレイピングしていると、CAPTCHAが出てプログラムが止まった経験、あると思います。
(そういう方しかこの記事は見ませんよね。)
なんとかCAPTHCAを回避するために、BOTっぽくない動きをさせたり、IP分散という手もありますが、今回は素直にCAPTCHAを解いてやろうと思います。
もちろん、エンジニアなので自分の手で解くより、プログラム上で自動的に解かせたいですよね。
機械学習は学習コストや導入コストが高く、もっと楽したいです。
2Cpathcaというサービスがそれを叶えてくれます。
他にも色々サービスがあるので、自分にあったものを見つけてください。
Pythonの記事はあったのですが、Rubyの記事は見つからなかったので書きました。2Capthcaとは
CAPTHCA機能を突破するためのサービスで、APIを利用することで認証を自動化することができます。
有料サービスですが、reCAPTCHA v2なら1,000リクエストで$2.99と安いです。
念の為お断りを入れておきますが、私と2Captchaとの間に販促等での金銭のやりとりはございません。Chrome_Remoteとは
ChromeのインスタンスをRubyから操作できるライブラリです。
詳しい使い方は解説ページやリポジトリをご参照ください。
スクレイピングする前提として、そもそもCAPTHCAが出にくいようにしてやる必要があります。
Selenium等と違ってChromeをそのまま動かすChrome_RemoteのほうがBOT判定されにくいと思います。(そのうち違いを検証したい。)やりたいこと
reCAPTCHAのデモページを突破します。
2Capthcaのアカウントの作成やapiキーの取得については先人の記事をご参照ください。『2Captcha』とRuby+Chrome_RemoteでreCAPTHCAを突破
2Captchaのapiキーを取得して、ファイル保存しておきます。
key.yaml--- :2Capthca: 2CaptchaのapiキーChromeをdebugging-portつきで起動します。
Macの場合/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome --remote-debugging-port=9222 &必要なGemをインストールします.
Gemfilesource "https://rubygems.org" gem 'nokogiri' gem 'chrome_remote'bundle installrubyプログラム本体です。
crawler.rbrequire 'nokogiri' require 'chrome_remote' require 'yaml' class CaptchaDetectedException < StandardError; end class ChromeController def initialize @chrome = ChromeRemote.client # Enable events @chrome.send_cmd "Network.enable" @chrome.send_cmd "Page.enable" end def open(url) # ページアクセス move_to url captcha_detect end def reload_page sleep 1 @chrome.send_cmd "Page.reload", ignoreCache: false wait_event_fired end def execute_js(js) @chrome.send_cmd "Runtime.evaluate", expression: js end def wait_event_fired @chrome.wait_for "Page.loadEventFired" end # ページ移動 def move_to(url) sleep 1 @chrome.send_cmd "Page.navigate", url: url wait_event_fired end # HTMLを取得 def get_html response = execute_js 'document.getElementsByTagName("html")[0].innerHTML' html = '<html>' + response['result']['value'] + '</html>' end def captcha_detect bot_detect_cnt = 0 begin html = get_html raise CaptchaDetectedException, 'captchaが確認されました' if html.include?("captcha") rescue CaptchaDetectedException => e p e bot_detect_cnt += 1 p "captcha突破試行: #{bot_detect_cnt}回目" doc = Nokogiri::HTML.parse(html, nil, 'UTF-8') return if captcha_solve(doc) == '解除成功' reload_page retry if bot_detect_cnt < 3 p 'captcha突破エラー。Rubyを終了します' exit end p 'captchaはありませんでした' end def captcha_solve(doc) id = request_id(doc).match(/(\d.*)/)[1] solution = request_solution(id) return false unless solution submit_solution(solution) p captcha_result end def request_id(doc) # APIキーの読み込み @key = YAML.load_file("key.yaml")[:"2Capthca"] # data-sitekey属性の値を取得 googlekey = doc.at_css('#recaptcha-demo')["data-sitekey"] method = "userrecaptcha" pageurl = execute_js("location.href")['result']['value'] request_url="https://2captcha.com/in.php?key=#{@key}&method=#{method}&googlekey=#{googlekey}&pageurl=#{pageurl}" # captcha解除を依頼 fetch_url(request_url) end def request_solution(id) action = "get" response_url = "https://2captcha.com/res.php?key=#{@key}&action=#{action}&id=#{id}" sleep 15 retry_cnt = 0 begin sleep 5 # captcha解除コードを取得 response_str = fetch_url(response_url) raise 'captcha解除前' if response_str.include?('CAPCHA_NOT_READY') rescue => e p e retry_cnt += 1 p "リトライ:#{retry_cnt}回目" retry if retry_cnt < 10 return false end response_str.slice(/OK\|(.*)/,1) end def submit_solution(solution) # 解除コードを所定のtextareaに入力 execute_js("document.getElementById('g-recaptcha-response').innerHTML=\"#{solution}\";") sleep 1 # 送信ボタンクリック execute_js("document.getElementById('recaptcha-demo-submit').click();") end def captcha_result sleep 1 html = get_html doc = Nokogiri::HTML.parse(html, nil, 'UTF-8') doc.at_css('.recaptcha-success') ? '解除成功' : '解除失敗' end def fetch_url(url) sleep 1 `curl "#{url}"` end end crawler = ChromeController.new url = 'https://www.google.com/recaptcha/api2/demo' crawler.open(url)プログラムを実行すると、reCAPTCHAのデモページにアクセスして、CAPTCHAの突破を試みます。
bundle exec ruby crawler.rb最後に
スクレイピングを行う目的や態様、スクレイピングで得たデータの取り扱い方によっては、著作権法、個人情報保護法に抵触してしまう恐れがあります。
皆さんに楽しいスクレイピングライフがあることを祈ります。

- 投稿日:2020-11-15T14:15:01+09:00
ArgumentError(wrong number of arguments (given 0, expected 1))のエラーメッセージ
はじめに
「rails s」をしたときにdestroyメソッドに関するエラーが出て、どこを直せば良いのかよくわからずに苦労したので、記録として書きます。
エラーメッセージ
persistence.rb:325:in `destroy': wrong number of arguments (given 0, expected 1) (ArgumentError)原因
モデルの中の記述の仕方に問題がありました。
user.rbclass User < ApplicationRecord devise :database_authenticatable, :registerable, :recoverable, :rememberable, :validatable attachment :profile_image has_many :tasks, dependent: destroy end解決策
すごく単純ですが、モデルの中のファイルの記述を治してあげれば解決しました。
user.rbclass User < ApplicationRecord devise :database_authenticatable, :registerable, :recoverable, :rememberable, :validatable attachment :profile_image has_many :tasks, dependent: :destroy end
- 投稿日:2020-11-15T07:56:00+09:00
【Ruby on Rails】NoMethodError: undefined method `t' for #<ActiveRecord::Migration:〇〇〇〇>エラーの対処
エラー画面
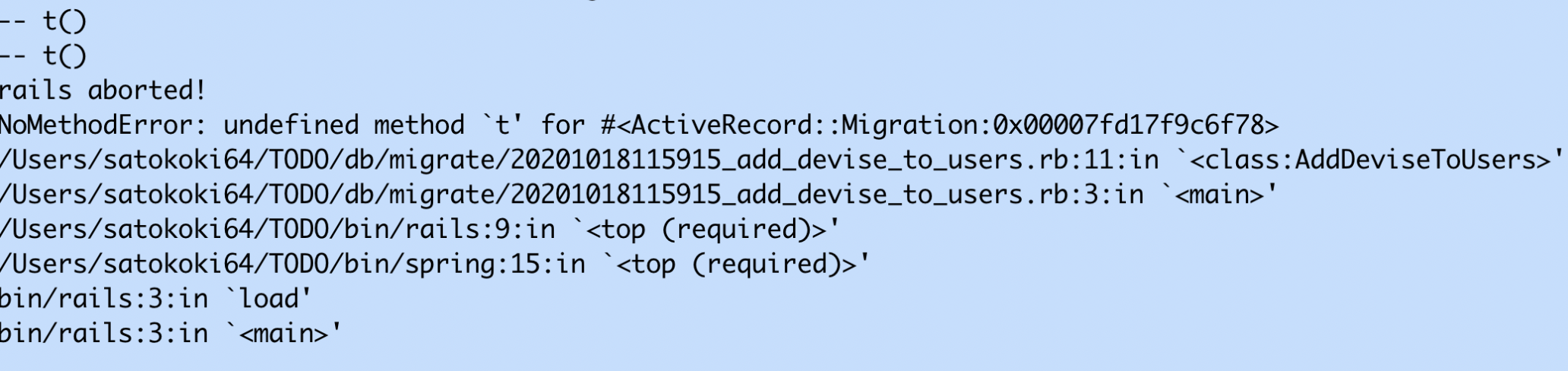
該当のソースコード
class AddDeviseToUsers < ActiveRecord::Migration[6.0] def change create_table :users do |t| t.string :name, null: false t.text :profile end end t.string :email, null: false, default: '' t.string :encrypted_password, null: false, default: '' end原因
メソッドtの定義はそのcreate_tableのdoに対するendまでの範囲でしか使えない
解決
class AddDeviseToUsers < ActiveRecord::Migration[6.0] def change create_table :users do |t| t.string :name, null: false t.text :profile #下の二行をdoの中に入れた t.string :email, null: false, default: '' t.string :encrypted_password, null: false, default: '' end end end補足
rake db:migrateしてもSchema.rbに反映されない方はrake db:migrate:rollbackで一度マイグレーションを落としてからrake db:migrateしてください。【参考資料】https://qiita.com/s_tatsuki/items/3e1f119c91e21b8f0c33
- 投稿日:2020-11-15T06:30:54+09:00
ボーボボで学ぶスレッド
趣旨
ボーボボを秋葉原のブックオフでまとめ買いしたんだけどレシートの印字から面白すぎて泣いちゃった pic.twitter.com/0WmibrI9vL
— 公太郎(アペリス教信者) (@ObenNKT) November 14, 2020
ツイッターで見かけたボーボボのレシートがマルチスレッドの勉強になるかなー、と思ったので投稿します。なぜ Ruby か?
いま Python を勉強しているので、Python でスレッドの勉強しようかなー、って思ったけど、書きなれている Ruby をチョイスしました。GIL とかあるので、Java か C++ を使うべきなのでしょうけど、めんどいのでやりません。
コード
(1..28).map{|i| Thread.new{ puts "ボボボーボ・ボーボボ(#{i})" } }.map(&:join)ボボボーボ・ボーボボ(1) ボボボーボ・ボーボボ(16) ボボボーボ・ボーボボ(28) ボボボーボ・ボーボボ(4) ボボボーボ・ボーボボ(5) ボボボーボ・ボーボボ(7) ボボボーボ・ボーボボ(8) ボボボーボ・ボーボボ(9) ボボボーボ・ボーボボ(10) ボボボーボ・ボーボボ(18) ボボボーボ・ボーボボ(6) ボボボーボ・ボーボボ(21) ボボボーボ・ボーボボ(11) ボボボーボ・ボーボボ(12) ボボボーボ・ボーボボ(20) ボボボーボ・ボーボボ(22) ボボボーボ・ボーボボ(26) ボボボーボ・ボーボボ(23) ボボボーボ・ボーボボ(13) ボボボーボ・ボーボボ(14) ボボボーボ・ボーボボ(15) ボボボーボ・ボーボボ(17) ボボボーボ・ボーボボ(19) ボボボーボ・ボーボボ(25) ボボボーボ・ボーボボ(27) ボボボーボ・ボーボボ(2) ボボボーボ・ボーボボ(24) ボボボーボ・ボーボボ(3)おわりに
これはスレッドの勉強じゃないだろ、って?俺もそう思う。
- 投稿日:2020-11-15T02:31:57+09:00
Railsにて検索機能を追加する。
概要
アプリケーション内でデータを検索できる機能があると、ユーザーがデータを探す際便利である。検索機能はSNS等でもよくある機能なので、実際に検索機能を実装してみる。
userというテーブルがあるとした場合、userを検索する機能を実装する。1.ルーティングの設定
userを扱うUserModel、UsersControllerは作成されていることを前提とします。
/config/routes.rb# 省略 resources :users do get "search", on: :collection endsearchアクションはリソースの集合を表すためon: :collectionを追加します。
2.モデルにクラスメソッドsearchを追加
/app/model/user.rbclass User < ApplicationRecord class << self def search(query) rel = order("id") if query.present? rel = rel.where("カラム名 LIKE ?, "%#{query}%") end rel end end endclass << self〜endでクラスメソッドを定義できます。
ローカル変数relを定義し、検索ワードが空でなければSQLのLIKEを使用し、該当カラムから対象のレコードを絞り込みます。3.コントローラにsearchアクションを追加
app/controllers/users_controller.rb# 省略 def search @users = User.search(params[:q]) render "index" endUserモデルで定義したクラスメソッドsearchをここで使用します。
4.viewにフォームを記載
app/views/users/index.html.erb# 省略 <%= form_tag :search_users, method: :get, class: "search" do %> <%= text_field_tag "q", params[:q] %> <%= submit_tag "検索" %> <% end %>form_tagは引数にパスを指定したフォームを作成します。デフォルトのmethodがPOSTであるため、getメソッドを指定しています。
text_field_tagでフォームを作り、検索ワード"q"は検索後もフォーム内に残しておくために第2引数にparams[:q]を指定しています。まとめ
以上で、検索機能を実装できます。
SQLを扱う箇所もありましたので、これを機会に勉強していきたいです。
- 投稿日:2020-11-15T02:31:36+09:00
Hashのvalue側がarrayで全部取り出したいときの速度比較
TL;DR
value側が
深さ1
スピードはeach_valueが最速
メソッドチェーン続けたい感じだったらflat_mapも考えられる深さ2以上で全部flatにしたいとき
values.flattenが早いけどeach_value + flattenとあまり速さ変わらないので好み。実行環境 Ruby 2.7.1
パターン
sample = { a: [1, 2, 3], b: [2, 3, 4], c: [3, 4, 5] }1. each
ary = [] sample.each { |_k, v| ary.concat(v) } ary # => [1, 2, 3, 2, 3, 4, 3, 4, 5]2. each_value
ary = [] sample.each_value { |v| ary.push(*v) } # 上の例もconcatじゃなくてpushでも大丈夫 ary # => [1, 2, 3, 2, 3, 4, 3, 4, 5]3. values + flatten
sample.values.flatten # => [1, 2, 3, 2, 3, 4, 3, 4, 5]4. flat_map
# ruby 2.7だったら sample.flat_map { _2 } # => [1, 2, 3, 2, 3, 4, 3, 4, 5] # _2が使えないなら sample.flat_map { |_, v| v } # => [1, 2, 3, 2, 3, 4, 3, 4, 5] # flat_mapのレシーバーのvalueが何なのかココで示したいときはあえて書くのもありかなと思う sample.flat_map { |_, number_ary| number_ary } # => [1, 2, 3, 2, 3, 4, 3, 4, 5]テスト
テスト1
深さ1のvalueをflatなArrayで取り出したいとき
結果は以下のとおりです。(1秒間に何回ループを回せるかという数字なので、デカイほうが早いです)
Comparison: each_value: 2859228.9 i/s each concat: 2745728.9 i/s - same-ish: difference falls within error flat_map(_,v): 1986117.7 i/s - 1.44x (± 0.00) slower flat_map(_2): 1971975.8 i/s - 1.45x (± 0.00) slower values flatten: 918971.6 i/s - 3.11x (± 0.00) slower
テストコード
require 'benchmark/ips' sample = { a: [1, 2, 3], b: [2, 3, 4], c: [3, 4, 5] } def method_1(h) ary = [] h.each { |_k, v| ary.concat(v) } ary end def method_2(h) ary = [] h.each_value { |v| ary.push(*v) } ary end def method_3(h) h.values.flatten end def method_4(h) h.flat_map { _2 } end def method_5(h) h.flat_map { |_, v| v } end Benchmark.ips do |x| x.config(:time => 20, :warmup => 2) x.report("each concat") { method_1(sample) } x.report("each_value ") { method_2(sample) } x.report("values flatten") { method_3(sample) } x.report("flat_map(_2)") { method_4(sample) } x.report("flat_map(_,v)") { method_5(sample) } x.compare! endテスト2
深さ2の値で全部flatにして取り出したいとき
Comparison: values flatten: 800647.1 i/s each_value.flatten: 759526.1 i/s - 1.05x (± 0.00) slower flat_map flatten: 676500.5 i/s - 1.18x (± 0.00) slower each_value in flatten: 468859.1 i/s - 1.71x (± 0.00) slower
テストコード
require 'benchmark/ips' sample = { a: [1, 2, [3]], b: [2, 3, [4]], c: [3, 4, [5]] } def method_1(h) ary = [] h.each_value { |v| ary.push(*v.flatten) } ary end def method_2(h) ary = [] h.each_value { |v| ary.push(*v) } ary.flatten end def method_3(h) h.values.flatten end def method_4(h) h.flat_map { _2 }.flatten end Benchmark.ips do |x| x.config(:time => 20, :warmup => 2) x.report("each_value in flatten") { method_1(sample) } x.report("each_value.flatten") { method_2(sample) } x.report("values flatten") { method_3(sample) } x.report("flat_map flatten") { method_4(sample) } x.compare! end結論
深さ1のとき
each_valueでやるとのが一番早い。(eachを使うのとあまり変わらないが、可読性考えても普通にeach_valueか)
flat_mapだと返り値が欲しい値になっててメソッドチェーン続けやすいが遅め
values.flattenはかなり遅くなる深さ2以上で全部flatにしたいとき
values.flattenが早いけどeach_value + flattenと同じようなもん。実行環境 Ruby 2.7.1
- 投稿日:2020-11-15T00:22:57+09:00
【業務未経験・独学】自社開発企業様から内定をもらうまでのお話
筆者のプロフィール
プログラミング歴三年弱
独学どのくらい応募したか
エージェントの経由での応募も含めるとだいたい70−80社ほど。そのうち書類通過は15社くらい。
内定は3社いただきました。(1社は自社開発ではないです。)
選考途中のものは全てお断りしたのでもしかしたらもう1−2社くらい内定いただけかもしれないです。
就活期間 2020年10月初旬〜2020年11月中旬の1ヶ月ちょい概要
社内で管理しているエクセルファイルとかを勝手にVBAで自動化するうちにプログラミングが楽しくなり、WEB系エンジニアにジョブチェンジ
具体的な学習方法
基本ほぼ全てアウトプットをベースに学習しました(最近はインプットもするように心がけています。)
なので最初に必ずやりたいことがあってそれを実現する方法を調べるという手順になります。※途中から学習方法というよりは私がプログラミングができるようになるまでの過程になってます。なんか初学者の方のヒントになればとは思います。
★具体例
エクセルで毎回毎回同じフィルターかけるのめんどくさいからボタンを何個か設置してよく使うフィルターはボタン押したら発動するようにしたいわ
と思ったとします。
学習の初期の初期段階を想定すると分からないことというのは以下の通りだと思います。(基本的なエクセルの使い方はわかっている想定です。)1.ボタンってどうやって設置すんの? 2.プログラムってどこに書くの? 3.そもそもプログラミング分からんこんな感じかと思います。
ということでそもそもプログラムする前に解決すべき問題がプログラムをどこに書くのか、そしてボタンの設置方法ということが分かります。
なのでまずそれを調べます。実際私がこのあとにとった行動はとりあえずマクロの記録をしてそれをボタンを押したら呼べるようにするということをしました。(マクロの記録とは記録中にマウスやキーボードで操作した手順を記憶して実行させることができる機能です。もちろんマクロの記録の仕方も最初は分からないので調べます。)
ここまででとりあえずボタンを設置してプログラムを走らせるところまでは分かりました。
次は記録したマクロを編集する方法を調べます。そうすれば自ずとどこにプログラミングを書けばいいかも分かります。
編集の仕方を調べたらちょっといじってみます。
例えば"田中"という名前でフィルターをするマクロを記録したとしたらこんな感じのコードが出力されていたとします。Selection.AutoFilter ActiveSheet.Range("$A$1:$B$5").AutoFilter Field:=1, Criteria1:="田中"そうするとあーこれ"田中"の部分を自分の好きな文字に変えたらいいんじゃね?
となると思います。
かなりざっくりですが最初はそんな感じのことをひたすら繰り返してました。
とりあえず近い動きのマクロの記録して実際やりたい動きにするにはどこの数字や文字をいじれば良さそうかなーと考えて適当に触りまくります。
この時点ではもう細かいことは全て無視です。デバックの仕方もしらないのでひたすらコードを編集したら保存してボタンを押して実行、エラーがでたらまた編集そんな感じです。一見効率が悪いように思えるかもしれませんが自分がやりたいことを最短で実現できるため、自分の書いたプログラムが動くことの楽しさを最短で味わうことができ挫折の確率は下がるのではないかと思います。
そんなこんなで動いたソースコードをひたすらコピペしまくるだけで一通り自分のやりたいことが実現できるスーパーコピペプログラマーになりましたとさ
ただそんなことばかり繰り返しているものだから半年以上は関数を一切使わずにVBAをぶん回していました記憶があります。(関数の存在は知っていたのですがイマイチ必要な理由が分からない+戻り値と返り値が理解できないので使えない)
そんな感じで半年以上続けているとコードを改修する機会も多くなり、スーパーコピペプログラマーとして名を馳せていた私はある日同じ処理が10箇所くらい存在していることに気がつきました。(もっと早く気付け)その瞬間、関数の必要性が分かったんです。そして同時に今まで戻り値、返り値が理解出来なかったのが不思議なくらい分かったんです。
それに衝撃を受け私はしばらくリファクタリングにハマりました。どんどんコードが短くなり、保守性が高くなっていく感覚、リファクタリングが最高に楽しくなりました。そうして一年くらいの時を経て私はついに【関数】を会得しました。
それからWEBアプリケーションの世界に進んでいくのでした。WEBアプリケーションになってもやることは同じです。作りたいものを決めそれを作るために分からないことを調べる。少しずつそれをやってみる。最初は意味も分からずコピペしまくる。気にしない。動くことを最優先。それを繰り返していくとふと、今までコピペしていた内容が分かる瞬間がきます。
それが成長の時ではないでしょうか。現在のスキル
そんなこんなでプログラミングを始めてから3年弱が過ぎもっとつよつよなプラグラマーになりたいと強く思い転職活動を始めました。
活動期間は冒頭に書いてます。開発に使用した言語、技術
HTML/CSS(scss,bootstrap)/PHP/Python/Ruby(Ruby on Rails)/JavaScript(Vue.js,JQuery)/VBA/DB(MS SQL,PostgreSQL,MySQL)/AWS(EC2,S3,Route53)/さくらVPS/centOS7/Nginx/Apache/Ajax/docker/gitもちろんひとつひとつのスキルは大したことはないですが上記のような技術を組み合わせて一応WEBアプリケーションはイチから作りたいものは作れるようなレベルにはなりました。
作ったもの
・売上、在庫、経費管理アプリ
・ホームページ(PHPでフルスクラッチ)ポートフォリオは?
残念ながら現在も社内で稼働していて色々パスワード等ベタ書きしてるところもあり、ソースは公開しておらず、書類選考時にはYoutubeのURLを貼ってなんとなくWEBアプリケーション全体の動きが分かるようにはしてあります。
就活の感想
面接官がエンジニアじゃなくて技術の知識がない人事だといまいち今まで身につけたスキルが評価されずいわゆる面接中のコミュニケーションが上手いかどうかで判断されがちで辛いことがありました。
面接する方が技術者だと話が弾むこともあって楽しい傾向にあります。これからプログラミング始める方へ
小さなものでいいのでまず自分の作りたいものから作ってみてください。
特にExcelのVBAとスプレッドシートのGASは環境構築もいらないですし現在の業務で使ってる可能性が非常に高いのでおすすめです。
自分の作りたいものができた時初めてプログラミングって楽しい。そう感じると思います。
給料が良さそうだからとかフリーランスで自由に働きたいとかリモートワークがいいとかおそらくそういった動機でプログラミングで始められる方はほとんど挫折すると思います。
プログラミングは目的ではなく金を稼ぐ為の手段という人もいますがもちろんそういった側面があることも否めませんがもっと単純に、楽しいからやる。
そういった人がもっと社会全体で増えて来るともっと面白い未来が見えてくると思います。
- 投稿日:2020-11-15T00:20:10+09:00
【rails 初心者向け】複数Deviseモデルのログイン後の遷移先指定
管理者(admin)、顧客側(customer/user等)などを作成した際に、それぞれのログイン後のリダイレクト先を指定したい
前提
・devise使用モデルとしてadminモデルとcustomerモデルがある(モデル名は置き換えて考えてください)
実装
application_controller.erbclass ApplicationController < ActionController::Base def after_sign_in_path_for(resource) case resource when Admin admin_top_path #pathは設定したい遷移先へのpathを指定してください when Customer root_path #ここもpathはご自由に変更してください end end end記述してみると簡単で、すぐ覚えられそうですね。
記述内容について、少し解説してみます!
・after_sign_in_path_for(resource)の引数(resource)の情報で条件分岐します。
・resouseインスタンスの中身が、AdminなのかCustomerなのかでcase文で処理をわけています。
ここまで調べるとresourceってどこから来てて、なんでこんな命名なんだ?@userとかでもいいんじゃないか、、とか考えてしまったので調べました。(以下は興味ある方のみ見てみてください)おまけ
registrations/new.html.erb<h2>Sign up</h2> <%= form_for(resource, as: resource_name, url: new_customer_registration_path(resource_name)) do |f| %> #以下省略上記のコードはDevise使用時に自動生成してくれるViewページの1つですね。
少し調べてみました。↓・Deviseは、複数のModelに対する認証を同時に扱えるフレームワークなので、どのようなModelのインスタンスが来ても大丈夫なように定義されているらしいです。
Deviseの内部では、それをresourceという名前で参照できるように統一しているようですね。
同様に、どのModelを認証しようとしているかの情報は、resource_nameという名前で参照できるようです。
・urlに(resource_name)が入っていますが、new_customer_registration_pathだけでは、どのModelの登録か分からないため(resource_name)が必要になるようです。少し物足りない説明になってしまったかもしれませんが、、普段便利すぎて何も考えずに実装してしまっていた部分についてある程度深堀り出来るいい機会になりました。
プログラミング経験数か月の新米ですので、おかしな部分等はご指摘お願いします、、!