- 投稿日:2020-11-15T23:35:53+09:00
AtCoder Beginner Contest 183のメモ
前置き
Atcoderをやってみたので、自分用のメモです。
あとから加筆・修正する予定です。問題
https://atcoder.jp/contests/abc183
A
Q_A.gopackage main import ( "fmt" ) func main() { var x int fmt.Scanf("%d", &x) var ans int if x > 0{ ans = x } else{ ans = 0 } fmt.Printf("%d\n", ans) }B
Q_B.gopackage main import ( "fmt" ) func main() { var S_x, S_y, G_x, G_y int fmt.Scanf("%d %d %d %d", &S_x, &S_y, &G_x, &G_y) var a float64 a = float64(G_y + S_y) / float64(G_x - S_x) var ans float64 ans = float64(S_y) / a + float64(S_x) fmt.Printf("%f\n", ans) }C
Q_C.gopackage main import ( "fmt" ) func remove(t []int, i int) []int { s := make([]int, len(t)) copy(s, t) s[i] = s[len(s)-1] return s[:len(s)-1] } func greedy(n int, k int64, list []int, T [][]int64, now int) int{ var num int = 0 if n == 1{ if T[now-1][0] == k{ return 1 } else { return 0 } } else if k<0{ return 0 } for i:=1; i<n; i++{ next := list[i] var list_2 = remove(list, i) w := T[now-1][next-1] num += greedy(n-1, k-w, list_2, T, next) } return num } func main() { var N int var K int64 fmt.Scanf("%d %d", &N, &K) T := make([][]int64, N) for i := 0; i < N; i++ { T[i] = make([]int64, N) for j:=0; j<N; j++{ fmt.Scanf("%d", &T[i][j]) } } List := make([]int, N) for i := 0; i < N; i++ { List[i] = i+1 } ans := greedy(N, K, List, T, 1) fmt.Printf("%d\n", ans) }D
覚えてたら後で書きます。
E
覚えてたら後で書きます。
F
覚えてたら後で書きます。
- 投稿日:2020-11-15T21:32:35+09:00
Goのスライスについて学ぼう
この記事は、 Arrays, slices (and strings): The mechanics of 'append' を翻訳、加筆したものです。
Introduction
手続き型プログラミング言語の最も一般的な機能の1つは、配列の概念です。
配列は単純なもののように見えますが、言語に配列を追加するときのメカニズムには多くの疑問が残ります。
- 固定長 or 可変長?
- 要素の型は?
- 多次元配列はどうなっているか?
- 空の配列の意味は?
これらの疑問への回答は、配列が言語の単なる機能であるか、その設計のコア部分であるかにまで影響してきます。
Goの初期の開発ではこれらの疑問に対する答えを持った正しい設計を考えるのに約1年かかりました。
一番苦労したのは、スライスの導入でした。
スライスは、固定サイズの配列に基づいて構築され、柔軟で拡張可能なデータ構造を提供します。
しかし、Goを初めて使用するプログラマーは、スライスの動作に関してつまずくことがよくあります。 これは、おそらく他の言語での経験が影響しています。
この投稿では、混乱を解消しようとします。
これを行うには、組み込み関数
appendがどのように機能するのか、そしてなぜそれがそのように機能するのかを説明するために必要なコンポーネントを一つ一つ解説していきます。配列(Arrays)
配列はGoの重要な構成要素ですが、スライスの背後に隠れた重要なコンポーネントです。
スライスが持つ、興味深く、強力で、目立つアイデアに移る前に、配列についての簡単な説明が必要になってきます。
配列は固定長なのであまりGoのプログラム中で見かけることはありません。
宣言する際には
var buffer [256]byteこの宣言では 256バイトを保持する
bufferという変数を宣言しています。
bufferは型が[256]byteとサイズを含んだ型になっています。 512バイトを保持する場合は[512]byteになります。配列と結び付けられているデータは、文字通り要素の配列です。 概略的には、
bufferはメモリ内で次のようになります。buffer: byte byte byte ... 256 times ... byte byte byteつまりこの変数は256バイトのデータ以外は何も持っていません。
各要素にはよく見慣れたインデックスを使ってアクセスできます。(buffer[0], buffer[1], ..., buffer[255])
配列外にインデックスアクセスしようとしたときにはプログラムはクラッシュします。
配列、スライスや他のいくつかのデータ型は、要素数を返す
lenと呼ばれる組み込み関数があります。配列の場合、lenが何を返すかは明らかです。 この例では、
len(buffer)は固定値256を返します。配列の使い所としては変換行列を適切に表現する場合などが挙げられますが、Goでの最も一般的な目的はスライスのストレージを保持することです。
Slices: スライスヘッダについて
スライスはよく使用されるデータ構造ですが、うまく使用するには、スライスが何であり何をするのかを正確に理解する必要があります。
スライスはその内部で、配列のある連続な区間を記述しているデータ構造で、スライス自体は配列ではありません。スライスは配列の一部を表しています。
前のセクションの配列を表す変数
bufferを前提としてこの配列をスライスすることにより、要素100から150(正確には、100から149を含む)を記述するスライスを作成できます。var slice []byte = buffer[100:150]上の例では、明示的な変数宣言を使用しました。
変数
sliceは[]byte型で、「byte型のスライス」と発音され、要素100から150をスライスすることで、配列bufferから初期化しています。より慣用的な構文では、設定される型の記述が省略できます。
var slice = buffer[100:150]関数内部では次のような短い宣言も可能です。
slice := buffer[100:150]このスライス変数は正確にはどういう構造をしているのでしょうか?
全てをここでは話しませんが、今のところスライスは長さと配列の要素へのポインタという2つの要素を持つ小さなデータ構造と考えてください。
つまりスライスは裏でこのように構築されていると考えることができます:
type sliceHeader struct { Length int ZerothElement *byte } slice := sliceHeader{ Length: 50, ZerothElement: &buffer[100], }もちろん、これは単なる例で実際の構造ではありません。
このコード例では、sliceHeader構造体はプログラマには表示されず、配列へのポインタの型は配列の要素の型によって異なりますが、これにより、メカニズムの一般的な考え方がわかります。
これまで、配列に対してスライス操作を使用してきましたが、次のようにスライスをスライスすることもできます。
slice2 := slice[5:10]前と同じように、この操作は新しいスライスを作成します。
この場合、元のスライスの要素5から9([5,9])を使用します。
これは、元の配列の要素105から109を表しています。
変数
slice2の基になるsliceHeader構造体は次のようになります。slice2 := sliceHeader{ Length: 5, ZerothElement: &buffer[105], }このヘッダは配列の参照先として、もとになった
sliceと同じbufferを参照していることに注意してください。再度スライスすることもできます。つまり、スライスを切り取って、次のように結果を元のスライス構造に保存します。
slice = slice[5:10]変数
sliceのsliceHeader構造は、変数slice2の場合と同じように見えます。スライスの一部を切り捨てる場合にこのような方法がよく取られます。次の例はスライスの最初と最後の要素を切り捨てています。
slice = slice[1:len(slice)-1]経験豊富なGoプログラマーが「スライスヘッダ」について話すのをよく耳にします。
なぜならスライスヘッダこそが、実際にはスライス変数に格納されているものだからです。
たとえば、
bytes.IndexRuneなど、引数としてスライスを受け取る関数を呼び出すと、そのスライスヘッダが関数に渡されます。slashPos := bytes.IndexRune(slice, '/')例えば、この関数呼び出しでは実際に関数に渡されているのはスライスヘッダです。
スライスヘッダにはもう1つのデータ項目があります。これについては以降で説明しますが、最初にスライスを使用したプログラムを書く場合にスライスヘッダの存在がどのような意味を持ってくるのかを見てみましょう。
スライスを引数としたとき
スライスにポインタが含まれていても、スライス自体は値であるという事実を理解することが重要です。
スライスの構造は、ポインタと長さを保持する構造体の値です。 構造体へのポインタではありません。
これは重要です。前の例で
IndexRuneを呼び出したとき、スライスヘッダのコピーが渡されました。 その動作には重要な影響があります。この単純な関数を考えてみましょう。
func AddOneToEachElement(slice []byte) { for i := range slice { slice[i]++ } }名前通り、スライスをループして各イテレーションでスライスの要素をインクリメントする関数です。
次のプログラムを試してみましょう。
func main() { slice := buffer[10:20] for i := 0; i < len(slice); i++ { slice[i] = byte(i) } fmt.Println("before", slice) AddOneToEachElement(slice) fmt.Println("after", slice) }before [0 1 2 3 4 5 6 7 8 9] after [1 2 3 4 5 6 7 8 9 10] Program exited.スライスヘッダ自体は値として渡されました(つまりコピーして渡された)が、ヘッダには配列の要素へのポインタが含まれているため、元のスライスヘッダーと関数に渡されるヘッダのコピーの両方が同じ配列を参照します。
したがって関数が戻ると、変更された要素は元のスライス変数を通して見ることができます。
この例が示すように、関数の引数は実際にはコピーです。
func SubtractOneFromLength(slice []byte) []byte { slice = slice[0 : len(slice)-1] return slice } func main() { fmt.Println("Before: len(slice) =", len(slice)) newSlice := SubtractOneFromLength(slice) fmt.Println("After: len(slice) =", len(slice)) fmt.Println("After: len(newSlice) =", len(newSlice)) }Before: len(slice) = 50 After: len(slice) = 50 After: len(newSlice) = 49 Program exited.この例では、スライス引数の内容は関数で変更できますが、ヘッダそのものは変更できないことがわかります。
関数には元のヘッダではなくスライスヘッダのコピーが渡されるため、スライス変数に格納されている長さ(元のヘッダのLengthプロパティ)は関数の呼び出しによって変更されません。
したがって、ヘッダを変更する関数を作成する場合は、この例で行ったように、変更したスライスを戻り値として返す必要があります。
元のスライス変数は変更されていませんが、戻り値で返されるスライスは新しい長さになり、newSliceに格納されます。
メソッドレシーバとしてのスライスのポインタ
関数がスライスヘッダに干渉するもう一つの方法は、スライスのポインタを渡すことだ
func PtrSubtractOneFromLength(slicePtr *[]byte) { slice := *slicePtr *slicePtr = slice[0 : len(slice)-1] } func main() { fmt.Println("Before: len(slice) =", len(slice)) PtrSubtractOneFromLength(&slice) fmt.Println("After: len(slice) =", len(slice)) }Before: len(slice) = 50 After: len(slice) = 49 Program exited.上の例は、あまりスマートな例には見えません。
スライスへのポインタが表示される一般的なケースが1つあります。
例えば、スライスの変更を行うメソッドにレシーバとしてポインタを使用するのはよくある手法です。
ファイルのパスから最後の
/でスライスを切り捨てるメソッドが必要だったとしましょう。例えば
dir1/dir2/dir3ならdir1/dir2となる必要があります。これを満たすメソッドは以下のように書くことができます:
type path []byte func (p *path) TruncateAtFinalSlash() { i := bytes.LastIndex(*p, []byte("/")) if i >= 0 { *p = (*p)[0:i] } } func main() { pathName := path("/usr/bin/tso") // Conversion from string to path. pathName.TruncateAtFinalSlash() fmt.Printf("%s\n", pathName) }実行してみれば適切に動作することがわかるはずです。今回は呼び出し側のメソッドでスライスが変更されています。
一方、パス内のASCII文字を大文字にする(英語以外は無視する)メソッドを記述したい場合、配列の参照先は同じまま、その中身だけを変更するのでメソッドのレシーバは値でも大丈夫です。
type path []byte func (p path) ToUpper() { for i, b := range p { if 'a' <= b && b <= 'z' { p[i] = b + 'A' - 'a' } } } func main() { pathName := path("/usr/bin/tso") pathName.ToUpper() fmt.Printf("%s\n", pathName) }ここでは
ToUpperメソッドは配列のインデックスとそのインデックスに対応する要素を持った2つの変数をfor range構文の中で使っています。こうすることで
p[i]といちいち記述する回数を減らすことができます。Capacity: スライスの容量
引数で渡したint型のスライス
sliceにelementを付け足して拡張する以下の関数をみてみよう。func Extend(slice []int, element int) []int { n := len(slice) slice = slice[0 : n+1] slice[n] = element return slice }実行してみましょう
func main() { var iBuffer [10]int slice := iBuffer[0:0] for i := 0; i < 20; i++ { slice = Extend(slice, i) fmt.Println(slice) } }[0] [0 1] [0 1 2] [0 1 2 3] [0 1 2 3 4] [0 1 2 3 4 5] [0 1 2 3 4 5 6] [0 1 2 3 4 5 6 7] [0 1 2 3 4 5 6 7 8] [0 1 2 3 4 5 6 7 8 9] panic: runtime error: slice bounds out of range [:11] with capacity 10 goroutine 1 [running]: main.Extend(...) /tmp/sandbox021597325/prog.go:16 main.main() /tmp/sandbox021597325/prog.go:25 +0x105 Program exited: status 2.スライスはどんどん拡張されていきますが、途中で止まってしまいました。
スライスヘッダの3番目のコンポーネントである
capacityについて説明します。配列ポインタと長さに加えて、スライスヘッダにはその容量(
capacity)も格納されます。type sliceHeader struct { Length int Capacity int ZerothElement *byte }
capacityフィールドには、基になる配列が実際持っているスペースの量が入ります。これは、
Lengthが到達できる最大値です。 スライスをその容量を超えて拡大しようとすると、配列の制限を超える、つまり配列外アクセスをすることになりパニックが発生します。
slice := iBuffer[0:0]で作成されたスライスのヘッダはslice := sliceHeader{ Length: 0, Capacity: 10, ZerothElement: &iBuffer[0], }
capacityフィールドは、基になる配列の長さから、スライスの最初の要素が対応する配列のインデックス(この場合は0)を引いたものに等しくなります。スライスの容量を確認する場合は、組み込み関数
capを使用します。if cap(slice) == len(slice) { fmt.Println("slice is full!") }Make
スライスをその容量を超えて拡張したい場合はどうすればいいでしょうか?
できません! 定義上、
capacityは拡張の限界です。ただし、新しい配列を割り当て、データをコピーし、スライスの内容を変更して新しい配列を参照することで、同等の結果を得ることができます。
割り当てから始めましょう。 新しい組み込み関数を使用して、より大きな配列を割り当て、結果をスライスすることもできますが、代わりに組み込み関数
makeを使用する方が簡単です。新しい配列を割り当て、それに参照するスライスヘッダを一発で作成します。
make関数は、スライスの型、その初期の長さ、およびそのcapacity(makeがスライスデータを保持するために割り当てる配列の長さ)の3つの引数を取ります。以下の例を実行するとわかるように、この呼び出しは長さ10のスライスを作成し、さらに裏の配列にはサイズ5つ分(15-10)の余裕があります。
slice := make([]int, 10, 15) fmt.Printf("len: %d, cap: %d\n", len(slice), cap(slice))len: 10, cap: 15 Program exited.slice := make([]int, 10, 15) fmt.Printf("len: %d, cap: %d\n", len(slice), cap(slice)) newSlice := make([]int, len(slice), 2*cap(slice)) for i := range slice { newSlice[i] = slice[i] } slice = newSlice fmt.Printf("len: %d, cap: %d\n", len(slice), cap(slice))len: 10, cap: 15 len: 10, cap: 30 Program exited.このコードを実行した後のスライスは、拡張するためのスペースが遥かに増えています (5 -> 20)
スライスを作成するとき、長さと容量が同じになることはよくあることです。 組み込み関数
makeには、この一般的なケースの省略形があります。gophers := make([]Gopher, 10) // = make([]Gopher, 10, 10)容量を指定しなかった場合、そのデフォルト値は長さと同じになるため、上のように省略して両方を同じ値に設定できます。
Copy
前のセクションでスライスの容量を2倍にしたとき、古いデータを新しいスライスにコピーするループを作成しました。
Goには、これを簡単にするための組み込み関数
copyがあります。 その引数は2つのスライスであり、データを右側の引数から左側の引数にコピーします。
copyを使用するように書き直した例を次に示します。newSlice := make([]int, len(slice), 2*cap(slice)) copy(newSlice, slice)関数
copyは賢くコピーを行ってくれます。 両方の引数の長さに注意を払いながら、可能な分だけをコピーします。つまり、コピーする要素の数は、2つのスライスの長さの最小値です。
これにより、記述量を少し節約できます。 また、copyは、コピーした要素の数である整数値を返しますが、常にチェックする価値があるとは限りません。
関数
copyは、コピー元とコピー先が重複している場合にも適切に処理されます。つまり、単一のスライスで中身を移動するために使用できます。 コピーを使用してスライスの中央に値を挿入する方法は次のとおりです。
// Insert inserts the value into the slice at the specified index, // which must be in range. // The slice must have room for the new element. func Insert(slice []int, index, value int) []int { // Grow the slice by one element. slice = slice[0 : len(slice)+1] // Use copy to move the upper part of the slice out of the way and open a hole. copy(slice[index+1:], slice[index:]) // Store the new value. slice[index] = value // Return the result. return slice }上の例ではいくつか気を付けるべき点としては、長さが変更されているので変更したスライスを必ず返り値として返す必要があるところでしょう。
また要素を追加するので capacity > length である必要もあります。
Append
数セクション前に、スライスを1つの要素だけ拡張する関数
Extendを作成しました。ただし、スライスの容量が小さすぎると関数がクラッシュするため、バグがありました。 (
Insertの例にも同じ問題があります。)これを修正するための要素が揃ったので、整数スライスを拡張する
Extendのしっかりした実装を作成しましょう。func Extend(slice []int, element int) []int { n := len(slice) if n == cap(slice) { // スライスが満タンなので拡張の必要あり // 新しい容量は 2x+1 とする (+1しているのはx=0のときのため) newSlice := make([]int, len(slice), 2*len(slice)+1) copy(newSlice, slice) slice = newSlice } slice = slice[0 : n+1] slice[n] = element return slice }この場合も、参照先の配列がまるっきり変わるので、スライスを返り値として返す必要があります。
Extend関数を使って拡張を行ってスライスが満タンになったときの挙動を確認してみましょう。slice := make([]int, 0, 5) for i := 0; i < 10; i++ { slice = Extend(slice, i) fmt.Printf("len=%d cap=%d slice=%v\n", len(slice), cap(slice), slice) fmt.Println("address of 0th element:", &slice[0]) }len=1 cap=5 slice=[0] address of 0th element: 0xc000078030 len=2 cap=5 slice=[0 1] address of 0th element: 0xc000078030 len=3 cap=5 slice=[0 1 2] address of 0th element: 0xc000078030 len=4 cap=5 slice=[0 1 2 3] address of 0th element: 0xc000078030 len=5 cap=5 slice=[0 1 2 3 4] address of 0th element: 0xc000078030 len=6 cap=11 slice=[0 1 2 3 4 5] address of 0th element: 0xc00005e060 len=7 cap=11 slice=[0 1 2 3 4 5 6] address of 0th element: 0xc00005e060 len=8 cap=11 slice=[0 1 2 3 4 5 6 7] address of 0th element: 0xc00005e060 len=9 cap=11 slice=[0 1 2 3 4 5 6 7 8] address of 0th element: 0xc00005e060 len=10 cap=11 slice=[0 1 2 3 4 5 6 7 8 9] address of 0th element: 0xc00005e060 Program exited.サイズ5の初期配列がいっぱいになったときの再割り当てに注意してください。
新しい配列が割り当てられると、
capacityと0番目の要素のアドレスの両方が変更されます。堅牢な
Extend関数をガイドとして使用すると、スライスを複数の要素で拡張できる、さらに優れた関数を作成できます。 これを行うには、関数が呼び出されたときに関数の引数のリストをスライスに変換として扱うGoの機能、つまり、Goの可変個引数関数を利用します。関数
Appendを呼び出しましょう。 最初のバージョンでは、Extendを繰り返し呼び出すことができるため、可変個引数関数のメカニズムが明確になります。Append関数のシグネチャは次のとおりです。func Append(slice []int, items ...int) []intこのシグネチャは、一つのスライスと、それに続く0個以上のint型の値を引数としてとることを示しています。
// Append appends the items to the slice. // First version: just loop calling Extend. func Append(slice []int, items ...int) []int { for _, item := range items { slice = Extend(slice, item) } return slice }注意すべきこととしては、
for rangeループは[]intとして扱われている引数itemsの要素を各ループで扱っています。 また_という識別子で、今回のケースでは不要なスライスのインデックスを捨てていることにも注意が必要です。slice := []int{0, 1, 2, 3, 4} fmt.Println(slice) slice = Append(slice, 5, 6, 7, 8) fmt.Println(slice)この例で登場する新しい手法として、スライスの型とそれに続く中括弧内の要素で構成される複合リテラルを書き込むことによってスライスを初期化することが挙げられます。
slice := []int{0, 1, 2, 3, 4}
Append関数のさらに面白い点は、要素を追加できるだけでなく、呼び出し側で...表記を使用してスライスを引数に"分解"することにより、2番目のスライスそのものを引数として追加できる点です。slice1 := []int{0, 1, 2, 3, 4} slice2 := []int{55, 66, 77} fmt.Println(slice1) slice1 = Append(slice1, slice2...) // The '...' is essential! fmt.Println(slice1)前回の
Appendでは元のスライスの2倍の長さにしていたので、追加するelementsの数では配列の再割り当てが複数回行われる可能性がありましたが、下の例のAppendでは1回の割り当てだけで住むように効率化されています。// Append appends the elements to the slice. // Efficient version. func Append(slice []int, elements ...int) []int { n := len(slice) total := len(slice) + len(elements) if total > cap(slice) { // Reallocate. Grow to 1.5 times the new size, so we can still grow. newSize := total*3/2 + 1 newSlice := make([]int, total, newSize) copy(newSlice, slice) slice = newSlice } slice = slice[:total] copy(slice[n:], elements) return slice }新しく割り当てたメモリへスライスのデータをコピーする際と、追加するアイテムを配列の末尾にコピーする際と、2回
copyが呼び出されていることに注意してください。組み込み関数としてのAppend
やっと組み込み関数
appendの設計の理由を説明するためのピースが整いました。組み込み関数
appendは、上記のAppendの例とまったく同じように、同等の効率で実行されますが、どのスライス型でも機能します。Goの弱点は、ジェネリック型の操作をランタイムで提供する必要があることです。
いつか変わるかもしれませんが、今のところ、スライスの操作を簡単にするためにGoにはジェネリックな
append関数が組み込みで用意されています。これは、
[]intのスライスと同じように機能しますが、どのスライス型でも機能します。スライスヘッダは
appendの呼び出しによって常に更新されるため、呼び出し後に返されたスライスを保存する必要があることに注意してください。実際、コンパイラでは、結果を保存せずにappendを呼び出すことはできません。
以下に、
appendの使用例を掲載します。実際に実行してみたり、編集したりしてみると面白いかもしれません。// Create a couple of starter slices. slice := []int{1, 2, 3} slice2 := []int{55, 66, 77} fmt.Println("Start slice: ", slice) fmt.Println("Start slice2:", slice2) // Add an item to a slice. slice = append(slice, 4) fmt.Println("Add one item:", slice) // Add one slice to another. slice = append(slice, slice2...) fmt.Println("Add one slice:", slice) // Make a copy of a slice (of int). slice3 := append([]int(nil), slice...) fmt.Println("Copy a slice:", slice3) // Copy a slice to the end of itself. fmt.Println("Before append to self:", slice) slice = append(slice, slice...) fmt.Println("After append to self:", slice)Start slice: [1 2 3] Start slice2: [55 66 77] Add one item: [1 2 3 4] Add one slice: [1 2 3 4 55 66 77] Copy a slice: [1 2 3 4 55 66 77] Before append to self: [1 2 3 4 55 66 77] After append to self: [1 2 3 4 55 66 77 1 2 3 4 55 66 77] Program exited.特に、上の例の最後の
appendは、スライスの設計がなぜシンプルなのかを考えるのにいい例になるでしょう有志のコミュニティによって作られた"Slice Tricks" Wiki pageには
append,'copy',その他のスライスに関する様々な関数や処理の例が紹介されています。Nil
余談ですが、今回学んだ新たな知識により、
nilスライスが実際にどう表現されているかを知ることができます。当然、これはスライスヘッダのゼロ値です。
sliceHeader{ Length: 0, Capacity: 0, ZerothElement: nil, }または
sliceHeader{}鍵となるのは、要素のポインタが
nilである点です。array[0:0]このように作られた配列は長さも容量も0ですが、ポインタは
nilではなく、nilスライスとして扱われません。自明ですが、(容量がゼロ以外であると仮定すれば)空のスライスは大きくなる可能性があります
しかし
nilスライスには値を入れる配列がなく、要素を保持できるように拡張することはできません。とはいえ、
nilスライスは、何も指していなくても、機能的には長さ0のスライスと同等ですので、appendを使えば、配列の割り当てが行われて要素を追加できます。Strings
ここでは、スライスの視点からGoの文字列について簡単な説明をしましょう。
実際には文字列のメカニズムは非常に単純です。文字列は読み取り専用のバイト型のスライスであり、言語からの構文サポートが少し追加されています。
それらは読み取り専用であるため、容量は必要ありません(つまり拡張できない)が、それを除けばほとんどの場合、読み取り専用のバイト型のスライスのように扱うことができます。
手始めに、個々のバイトにアクセスするためにそれらにインデックスを付けることができます。
slash := "/usr/ken"[0] // yields the byte value '/'.文字列をスライスして部分文字列を抽出することも可能です。
usr := "/usr/ken"[0:4] // yields the string "/usr"文字列のスライス時に何が裏で起こっているかはここまで読んだみなさんには自明のことでしょう。
またバイト型のスライスを次のように変換して文字列を生成することも可能です。
str := string(slice)その逆も可能です。
slice := []byte(usr)文字列の基になるbyteの配列は表には現れません。つまり、文字列を介する以外にその内容にアクセスする方法はありません。
これらの変換のいずれかを実行するときは、byte配列のコピーを作成する必要があります。
もちろん、Goがこれを処理するので、ユーザーが自身でそうする必要はありません。これらの変換のいずれかの後、バイトスライスの基になる配列への変更は、対応する文字列に影響を与えません。(例えば、
str := string(slice)のあとでsliceを変更してもstrには影響がない)文字列をスライスのように設計したことの結果として重要な点は、部分文字列の作成が非常に効率的であることです。
必要なのは、2ワードの文字列ヘッダを作成することだけです。文字列は読み取り専用であるため、元の文字列とスライス操作の結果の部分文字列は、同じ配列を安全に共有できます。
歴史的なメモ:文字列の最も初期の実装では、部分文字列の作成の際に、新しいbyte配列が常に割り当てられていましたが、スライスが言語に追加されたとき、それらは効率的な文字列処理のモデルを提供しました。その結果、一部のベンチマークでは大幅なスピードアップが見られました。
もちろん、文字列にはさらに多くのものがあり、別のブログ投稿で文字列についてさらに詳しく説明しています。
まとめ
スライスがどのように機能するかを理解するには、スライスがどのように実装されているかを理解することが役立ちます。
スライス変数に関連付けられたアイテムであるスライスヘッダという小さなデータ構造があり、そのヘッダは個別に割り当てられた配列の一部分を参照します。
スライス値を渡すと、ヘッダはコピーされますが、それが指す配列は常に共有されます。
それらがどのように機能するかを理解すると、スライスは使いやすいだけでなく、特に
copyとappendの組み込み関数の助けを借りて、強力で表現力豊かなデータ構造になります。また他のGoに関しての記事も書いていますよかったらどうぞ!
参考
- 投稿日:2020-11-15T21:23:27+09:00
多言語からみるマルチコアの活かし方
多言語からみるマルチコアの活かし方
はじめに
近年では1つのCPUに複数のコアが搭載されたマルチコアが一般的になっています。
しかし、現状のプログラミング言語ではエンジニアが意識せずにマルチコアをしたプログラムを作ることは難しいです。
そこで、様々な言語から見たマルチコアの活かし方について説明していきます。プロセスとスレッド
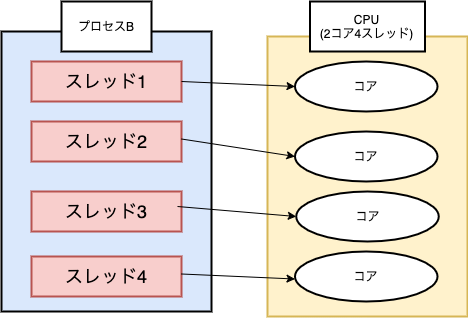
プロセスとは1つ1つのアプリケーションといった実行中のプログラムのことで、スレッドは CPU利用の単位です。プロセスは次のように1つ以上のスレッドを持っており、CPUのコア数分だけスレッドを処理することができます。(また、近年ではSMTという技術によって1つの物理コアで2スレッドといった複数のスレッドを処理することができます。2コア4スレッドみたいなやつです)
マルチコアを有効活用してプログラムを実行するためにはCPUが処理できるコア数に対して適切な数のスレッドをプログラム側で生成する必要があります。コア数以上のスレッドを生成する事も可能ですが、CPUはコア数分のスレッドしか処理を行うことができず、実行するスレッドの切り替えにより処理が遅くなってしまう問題が発生します。並列と並行
並列(parallel)と並行(concurrent)という似たような言葉が存在しますが、違うものを示します。
並列(parallel)とは複数の処理を同時に行うことで、複数のコアで複数のスレッドを処理するような場合を示します。(シングルコアでは複数処理を同時に実行できないため並列を実現することはできません。)
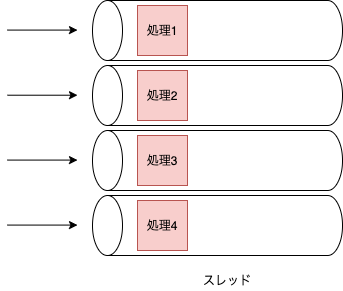
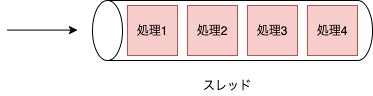
並行(concurrent)とは複数の処理を切り替えながら同時に実行しているようにすることで、1つのスレッドで複数の処理を切り替えながら実行するような場合を示します。
複数のスレッドで処理を切り替えながら実行することも可能なため、並列かつ並行を実現することも可能です。C10K問題
WebサーバーのApacheではユーザのリクエスト毎にプロセスを生成する方式を取っており、クライアントが約1万台に達すると、Webサーバーのハードウェア性能に余裕があるにも関わらず、レスポンス性能が大きく下がるというC10K問題というものが存在していました。(C10K問題の具体的な原因はこちらの記事が分かりやすかったです。)
そこで、nginxやNode.jsではシングルスレッドで非同期I/Oに処理をすることにより、並行に処理を行を行うことでC10K問題を解決しようとしました。Node.js
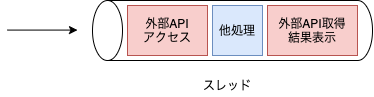
前述したように、Node.jsはシングルスレッドで動作をし、async/awaitといった非同期処理で並行に処理を行うというアプローチがされています。イメージとしては下図のように、外部APIアクセスをする際に結果が返ってくるまでの時間に他の処理を行い、結果が取得できたらその処理の続きを行うようなイメージです。(詳細はこちらの記事が分かりやすかったです。)
従って標準の非同期処理を行う場合は、マルチコアの性能を引き出すことができません。そこでNode.jsではClusterを用いてプロセスを複数作成するか、worker_threadsを用いてスレッドを複数作成する必要があります。このようにマルチコアコアを活かすためには、プログラム側からプロセスかスレッドを複数作成してあげる必要があり、マルチスレッドでは変数の値の共有を行うことができますが、マルチプロセスではメモリ空間が分離され、変数の値の共有ができないというそれぞれのメリット・デメリットが存在します。RubyやPythonで起こるGIL
Node.jsでは、プロセスかスレッドを複数作成してあげることでマルチコアを活かすことができました。しかし、RubyやPythonではグローバルインタプリタロック(GIL)というものが存在し、複数のスレッドを作成しても並列に実行することができません。(正確にはC言語で実装されたCPythonとCRubyの場合ですが、ここでは省略します。)
従って、これらの言語でマルチコアを活かそうとした場合、マルチスレッドでは実現できず、プロセスを複数作成してあげる必要があります。Go言語でのgoroutine
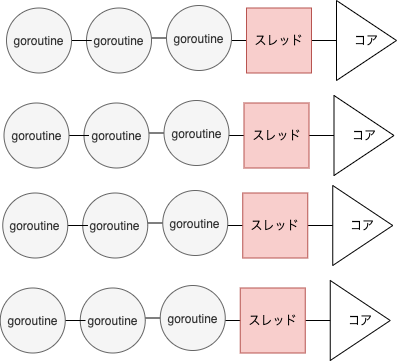
Go言語では、goroutineというものを用いて非同期処理を並列・並行に実現しており、デフォルトでCPUのコア数が設定された
GOMAXPROCSというものが設定されています。この値の数だけスレッドが用意され、そのスレッドの中で軽量スレッドであるgoroutineを実行します。
CPUのコア数が4のGOMAXPROCS=4の場合のイメージとしては下図です。
このようにgoroutineを用いることによりマルチコアを活かして並列・並行にプログラムの実行を行えます。
(goroutineが軽量な理由についてはこちらの記事が分かりやすかったです。)Rustでのasync/await
Rustでは、async/awaitを用いて非同期処理を行えます。この際、どのランタイムを用いるかによって非同期処理のスレッドの実行割当方法を選択できます。
人気があるランタイムとしては、tokioが挙げられます。tokioではコア数に対してスレッドが生成され、そのスレッドに非同期処理が渡されるというgoroutineと同様のマルチコアの活かし方が実現できます。(他の割当方法や、Rustでの非同期処理についてはこちらの記事が分かりやすかったです。特にここの実行モデルについてが分かりやすいです。)さいごに
RubyやPythonでは仕組み上マルチスレッドにすることが難しく、Node.jsの非同期処理は、そのままではマルチコアを活かすことができませんでした。
しかし、近年人気のあるGo言語やRustでは非同期処理を呼ぶ事により、エンジニアが意識せずに並列・並行処理を行え、マルチコアを活かすことができます。
マルチコアのCPUが一般的になってきた現代に、Go言語やRustが人気がある事も納得です。参考
【図解】CPUのコアとスレッドとプロセスの違い,コンテキストスイッチ,マルチスレッディングについて
プロセスとスレッドとタスクの違いを知ってUnity非同期完全理解に近付く
Node.jsの非同期I/Oについて調べてみた
いまさら聞けないNode.js
Pythonで並列処理をするなら知っておくべきGILをできる限り詳しく調べてみた
goroutineはなぜ軽量なのか
Rustの非同期プログラミングをマスターする

- 投稿日:2020-11-15T21:08:20+09:00
log.Fatalはメッセージ出力後に終了ステータス1としてプログラムを終了しようとする
結論: APIを利用する場合はきちんとドキュメントを読みましょう(´・ω・`)
go言語の
log.Fatal、log.Fatalfおよびlog.Fatallnはメッセージ出力後にos.Exit(1)を発行し、プロセスを終了しようとします。たとえば以下のようなプログラムがあったとします。main.gopackage main import ( "fmt" "log" ) func main() { fmt.Println("BEFORE") log.Fatalln("FATAL") fmt.Println("AFTER") }これをビルドして実行すると、
FATALを出力した後に終了ステータス1でプログラムが終了してしまっていることがわかります (AFTERが出力されていない)$ go build . $ $ ./fataltest BEFORE 2020/11/15 21:02:55 FATAL $ $ echo $? 1ほかのプログラミング言語やライブラリによってはログレベルとしてFATALを有しているものがあります。要するに
log.Fatal系の関数を「FATALレベルのログを出力してくれるものなのか!」と思って使うと、思わぬバグを生む可能性があります--というかわたしは生みました (反省)参考
- GoDoc: Package log
- 稼働確認環境: go version go1.15.1 linux/amd64
- 投稿日:2020-11-15T15:45:24+09:00
僕がGolangで参考にした記事
- 公式ドキュメント
- A Tour of Go
- 【Go】基本文法
A tour of Go よりわかりやすい- Go言語:文法基礎まとめ
- インタフェースの実装パターン #golang
- Goで学ぶポインタとアドレス
- 未読