- 投稿日:2020-11-15T23:55:59+09:00
IAM Roleがなぜ安全にアクセス権限を委任できるかを理解する
AWSのAPIにアクセスするには、APIへのリクエストに署名する必要があり、署名するための秘密鍵が必要である。IAM Userのアクセス・キーを割り当てることもできるが、AWSのサービス、例えばEC2インスタンスからAPIにアクセスする場合は、IAM Roleを使用すると、秘密情報をホスト内に保存することなく、安全にAPIへのリクエストを行うことができる。
この記事では、AWSの、あるアカウントのEC2インスタンスから、別のアカウントのAWSサービスのAPIをコールする場合を例として、どのようにアクセス権限を委任しているかを順に説明する。
この記事では、以下のリソースを作成するとする。
- アカウントA
- アカウントA内のEC2インスタンスC
- アカウントA内のIAM Role Role_D
- アカウントA内のIAM Policy Policy_E
- アカウントB
- アカウントB内のIAM Role Role_F
EC2インスタンスAにIAM Roleをアタッチする
EC2インスタンスには、一つだけ IAM Roleをアタッチできる。
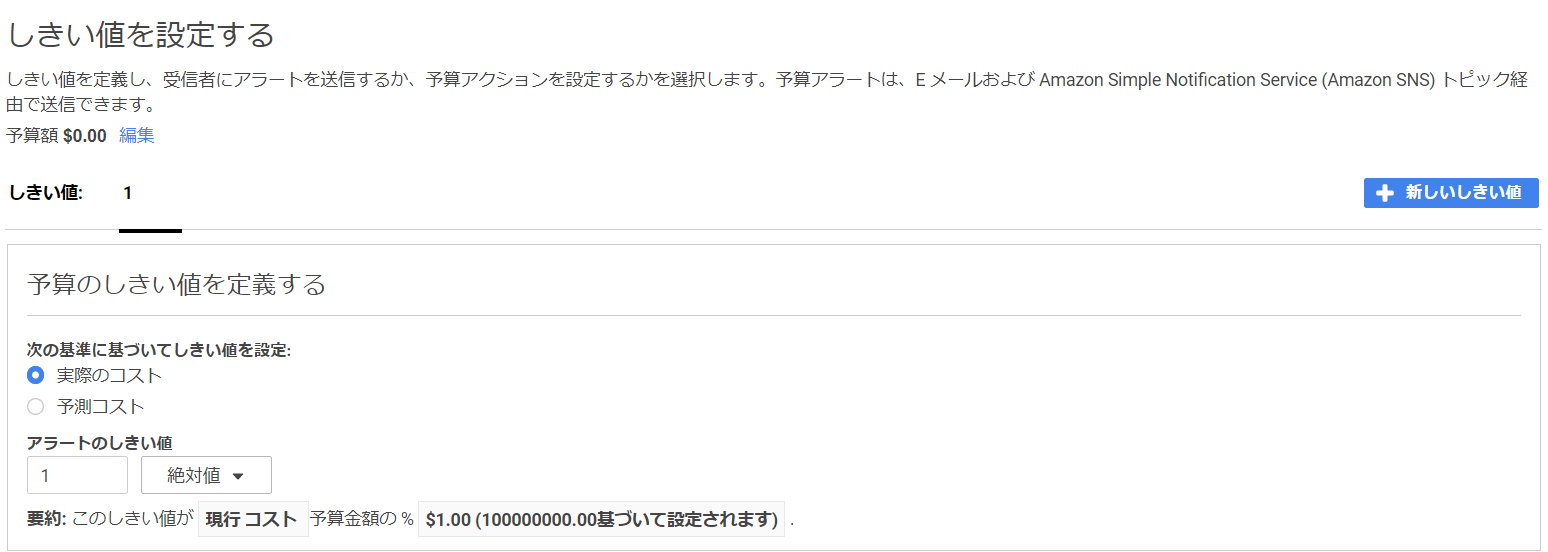
EC2インスタンスにアタッチするIAM Role Role_Dの「信頼関係」のポリシー・ドキュメントは、以下のように PrincipalにEC2サービスを指定し、ActionにSTSサービスのAssumeRoleを指定する。AWSコンソールでIAM Roleを作成する場合は、ウィザードで簡単にポリシー・ドキュメントを作成できる。
Role_D{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "ec2.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }PrincipalがEC2サービスの場合、インスタンス内から以下の仮想的なネットワークのエンドポイントにアクセスすることでActionのサービスを呼び出すことができる。
アクセス先http://169.254.169.254/latest/meta-data/iam/security-credentials/<role-name>レスポンス{ "Code" : "Success", "LastUpdated" : "yyyy-mm-ddThh:mm:ssZ", "Type" : "AWS-HMAC", "AccessKeyId" : "ASIAW7##############", "SecretAccessKey" : "G5sCiFYmltsyiHV#########################", "Token" : "IQoJb3###########################################################################################", "Expiration" : "yyyy-mm-ddThh:mm:ssZ" }IAM Role Role_DのActionに指定した STSサービスのAssumeRole APIが、アクセス・キーを作成する。このアクセス・キーは、IAM Userに割り当てたアクセス・キーと同様に、AWSのサービスのAPIへのリクエストの署名の鍵として使用できる。IAM Userのアクセス・キーとは異なり、STSサービスが生成するアクセス・キーには有効期限が設定されていて、保存することなく、都度生成して使用する。
このIAM Roleのアクセス権限に、例えば、CloudWatchReadOnlyポリシーをアタッチすると、EC2インスタンスからCloud WatchのAPIにアクセスできるようになる。
アカウントBに、アカウントAへ権限を委任するRoleを設置する
アカウントBのIAM Roleのポリシー・ドキュメントに、PrincipalがアカウントAを指すARNを指定し、ActionにSTSサービスのAssumeRoleを指定したRole_Fを作成する。
Role_F{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::<アカウントAのID>:root" }, "Action": "sts:AssumeRole", "Condition": {} } ] }このRoleは、AWSコンソールでは、ウィザードを使用して、アカウントIDを指定するだけで作成できる。
このRoleが存在することで、アカウントAからこのIAM Roleにアタッチしたポリシーの権限の委任を受けることができる。
アカウントAのRole_Dに、アカウントBのRole_Fを要求する権限を与える
Role_Dのアクセス権限に、以下のIAM Policy Policy_Eをアタッチする。Actionに指定した、STSサービスのAssumeRoleにより、Resouceに指定したARNが示すアカウントBのRole_Fにアクセスする権限をこのIAM Roleに与える。
Policy_E{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "sts:AssumeRole", "Resource": "arn:aws:iam::<アカウントBのID>:role/Role_F" } ] }EC2インスタンスAから、アカウントBのIAM Role Role_Fの権限の委任を受ける
EC2インスタンスAから、アカウントBのIAM Role Role_Fを使って、アカウントBのサービスの権限の委任を受けるには、Role_Dの委任により、アカウントAのSTSサービスのAssumeRole APIに、RoleArnパラメータにRole_FのARNを指定してアクセスすることでアクセス・キーを作成し、アカウントBのAWSサービスのAPIへのリクエストの署名の鍵とする。
AWS SDK for Rubyの場合、「AWS STS アクセストークンの作成」のように、Role_FのARNを指定して、アクセスキーを取得する。
rubyによるAPI呼び出しrole_credentials = Aws::AssumeRoleCredentials.new( client: Aws::STS::Client.new, role_arn: "arn:aws:iam::<アカウントBのID>:role/Role_F", role_session_name: "<任意の名前>" ) s3 = Aws::S3::Client.new(credentials: role_credentials)まとめ
EC2インスタンスAは、Role_Dにより、Role_DにアタッチされたIAM Policyによる権限の委任を受け、Policy_Eの権限とアカウントBのRole_FによりRole_FにアタッチされたIAM Policyによる権限の委任を受けることで、アカウントBのサービスにアクセスすることができる。
おつかれさまでした。
- 投稿日:2020-11-15T23:55:59+09:00
IAM Roleがなぜ安全にアクセス許可を委任できるかを理解する
AWSのAPIにアクセスするには、APIへのリクエストに署名する必要があり、署名するための秘密鍵が必要である。IAM Userのアクセス・キーを割り当てることもできるが、AWSのサービス、例えばEC2インスタンスからAPIにアクセスする場合は、IAM Roleを使用すると、秘密情報をホスト内に保存することなく、安全にAPIへのリクエストを行うことができる。
この記事では、AWSの、あるアカウントのEC2インスタンスから、別のアカウントのAWSサービスのAPIをコールする場合を例として、どのようにアクセス許可を委任しているかを順に説明する。
この記事では、以下のリソースを作成するとする。
- アカウントA
- アカウントA内のEC2インスタンスC
- アカウントA内のIAM Role Role_D
- アカウントA内のIAM Policy Policy_E
- アカウントB
- アカウントB内のIAM Role Role_F
EC2インスタンスAにIAM Roleをアタッチする
EC2インスタンスには、一つだけ IAM Roleをアタッチできる。
EC2インスタンスにアタッチするIAM Role Role_Dの「信頼関係」のポリシー・ドキュメントは、以下のように PrincipalにEC2サービスを指定し、ActionにSTSサービスのAssumeRoleを指定する。AWSコンソールでIAM Roleを作成する場合は、ウィザードで簡単にポリシー・ドキュメントを作成できる。
Role_D{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "ec2.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }PrincipalがEC2サービスの場合、インスタンス内から以下の仮想的なネットワークのエンドポイントにアクセスすることでActionのサービスを呼び出すことができる。
アクセス先http://169.254.169.254/latest/meta-data/iam/security-credentials/<role-name>レスポンス{ "Code" : "Success", "LastUpdated" : "yyyy-mm-ddThh:mm:ssZ", "Type" : "AWS-HMAC", "AccessKeyId" : "ASIAW7##############", "SecretAccessKey" : "G5sCiFYmltsyiHV#########################", "Token" : "IQoJb3###########################################################################################", "Expiration" : "yyyy-mm-ddThh:mm:ssZ" }IAM Role Role_DのActionに指定した STSサービスのAssumeRole APIが、アクセス・キーを作成する。このアクセス・キーは、IAM Userに割り当てたアクセス・キーと同様に、AWSのサービスのAPIへのリクエストの署名の鍵として使用できる。IAM Userのアクセス・キーとは異なり、STSサービスが生成するアクセス・キーには有効期限が設定されていて、保存することなく、都度生成して使用する。
このIAM Roleのアクセス権限に、例えば、CloudWatchReadOnlyポリシーをアタッチすると、EC2インスタンスからCloud WatchのAPIにアクセスできるようになる。
アカウントBに、アカウントAへ権限を委任するRoleを設置する
アカウントBのIAM Roleのポリシー・ドキュメントに、PrincipalがアカウントAを指すARNを指定し、ActionにSTSサービスのAssumeRoleを指定したRole_Fを作成する。
Role_F{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::<アカウントAのID>:root" }, "Action": "sts:AssumeRole", "Condition": {} } ] }このRoleは、AWSコンソールでは、ウィザードを使用して、アカウントIDを指定するだけで作成できる。
このRoleが存在することで、アカウントAからこのIAM Roleにアタッチしたポリシーの権限の委任を受けることができる。
アカウントAのRole_Dに、アカウントBのRole_Fを要求する権限を与える
Role_Dのアクセス権限に、以下のIAM Policy Policy_Eをアタッチする。Actionに指定した、STSサービスのAssumeRoleにより、Resouceに指定したARNが示すアカウントBのRole_Fにアクセスする権限をこのIAM Roleに与える。
Policy_E{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "sts:AssumeRole", "Resource": "arn:aws:iam::<アカウントBのID>:role/Role_F" } ] }EC2インスタンスAから、アカウントBのIAM Role Role_Fの権限の委任を受ける
EC2インスタンスAから、アカウントBのIAM Role Role_Fを使って、アカウントBのサービスの権限の委任を受けるには、Role_Dの委任により、アカウントAのSTSサービスのAssumeRole APIに、RoleArnパラメータにRole_FのARNを指定してアクセスすることでアクセス・キーを作成し、アカウントBのAWSサービスのAPIへのリクエストの署名の鍵とする。
AWS SDK for Rubyの場合、「AWS STS アクセストークンの作成」のように、Role_FのARNを指定して、アクセスキーを取得する。
rubyによるAPI呼び出しrole_credentials = Aws::AssumeRoleCredentials.new( client: Aws::STS::Client.new, role_arn: "arn:aws:iam::<アカウントBのID>:role/Role_F", role_session_name: "<任意の名前>" ) s3 = Aws::S3::Client.new(credentials: role_credentials)まとめ
EC2インスタンスAは、Role_Dにより、Role_DにアタッチされたIAM Policyによる権限の委任を受け、Policy_Eの権限とアカウントBのRole_FによりRole_FにアタッチされたIAM Policyによる権限の委任を受けることで、アカウントBのサービスにアクセスすることができる。
おつかれさまでした。
- 投稿日:2020-11-15T23:30:30+09:00
AWSを使ってデプロイ
はじめに
AWSを初めて使ってみたが、難しすぎる…
完全に自分用メモEC2のサーバーにログイン
ssh ~ user@ ~ #ユーザー名とElastic IP アドレスの入ったコード以下、ログイン状態で実行
デプロイ方法
# 開発中のアプリケーションに移動 cd /var/www/アプリケーション名# GitHubの内容をEC2に反映させる git pull origin masterUnicornの再起動方法
- プロセスを確認
ps aux | grep unicorn
- プロセスをkill
kill プロセス番号
- unicorn_railsコマンドを実行
RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -Dエラーログの確認
sudo less /var/log/nginx/error.log
- 投稿日:2020-11-15T22:23:39+09:00
【個人メモ】RailsアプリをAWSへデプロイする際につまづいたことまとめ
index
下記の記事の通りにRailsアプリをAWSへデプロイする際につまづいたことを個人的な備忘としてまとめました。
(下準備編)世界一丁寧なAWS解説。EC2を利用して、RailsアプリをAWSにあげるまで
https://qiita.com/naoki_mochizuki/items/f795fe3e661a3349a7ce
https://qiita.com/naoki_mochizuki/items/22cfbf4bf7ec95f6ac1c
https://qiita.com/naoki_mochizuki/items/814e0979217b1a25aa3e
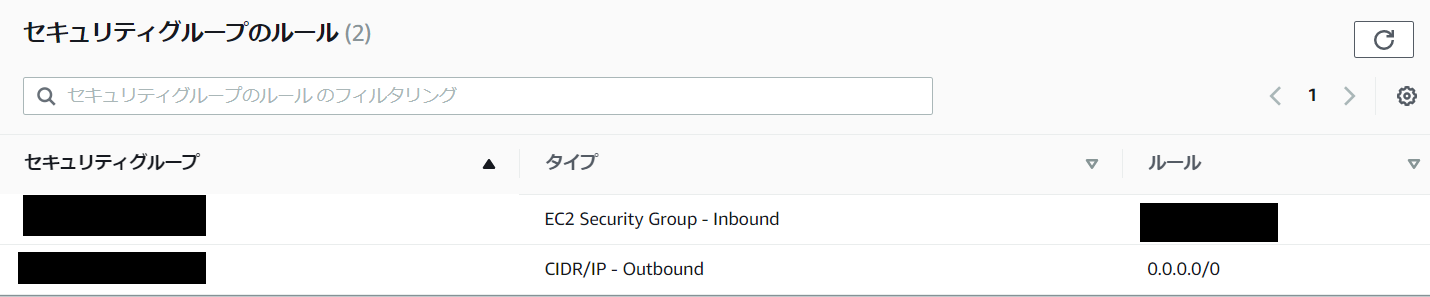
https://qiita.com/naoki_mochizuki/items/5a1757d222806cbe0cd1RDSインスタンスが生成できない
RDSの設定をして、「データベースの作成」をクリックすると、こんなエラーが発生。
DB Subnet Group doesn't meet availability zone coverage requirement. Please add subnets to cover at least 2 availability zones. Current coverage: 1 (Service: AmazonRDS; Status Code: 400; Error Code: DBSubnetGroupDoesNotCoverEnoughAZs; Request ID: 3e87202c-e6b3-46dc-8396-47c64a2f0dd6)こちらの記事を参考にしました。
https://www.wantanblog.com/entry/2019/09/24/225020
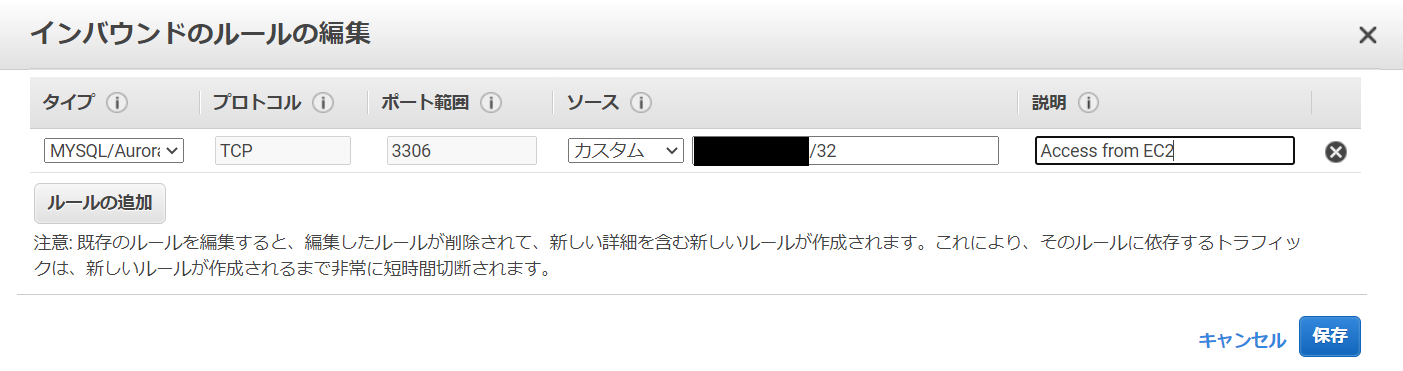
どうやらサブネットグループを1つしか作っていなかったことが問題のようなので、「VPC」→「サブネット」→「サブネットの作成」から、下記設定でサブネットをもう一つ作成したところ、RDSインスタンスが作成できるようになった。
・VPC ・・・作成したVPCを選ぶ
・アベイラビリティーゾーン ・・・既に作成したサブネットと違う場所を指定する
・IPv4 CIDR ブロック ・・・10.0.1.0/24EC2へSSHでログインできない
*[ .ssh ] $: ssh -i mumu.pem ec2-user@54.92.121.123でEC2へログインしようとすると、しばらく待ってから接続エラーになりました。
こちらの記事を参考にしました。
https://xn--o9j8h1c9hb5756dt0ua226amc1a.com/?p=3583
EC2が配置されているサブネットのルートテーブルを確認したところ、外部への経路(送信先0.0.0.0/0、ターゲットigw-...)が設定されていませんでした(うっかり)
「VPC」→「ルートテーブル」→「該当のルートテーブルにチェック」→「ルートテーブル」→「ルートテーブルの編集」→「ルートを追加」で下記を追加したところ、EC2へSSH接続できるようになりました。
・送信先 ・・・ 0.0.0.0/0
・ターゲット ・・・igw-...(作成したインターネットゲートウェイ)公開鍵作成するときにssh-keygem not foundのエラー
タイポでした。
ssh-keygemではなくssh-keygenでした。rake secretでシークレットキーが作れない
下記のエラーが発生
$ rake secret You must use Bundler 2 or greater with this lockfile.こちらの記事を参考にしました。
https://programming-beginner-zeroichi.jp/articles/169$ gem install bundler $ bundle install $ bundle exec rake secretで解決しました。(※ちなみに筆者はアプリのデータベースをsqliteに設定していたため、「bundle install」でエラーが発生し、次の記事の手順を踏んでから、「bundle install」をしました。
bundle installしたとき、sqlite3をインストールしてくださいのエラー
MySQLをデータベースに使う予定なので、railsアプリのデータベースをsqliteからMySQLへ変更します。
こちらの記事を参考にしました。
https://note.com/itoa06/n/n31fe4f9cd6b9差分はこちら
/Gemfile-gem 'sqlite3', '~> 1.4' +gem 'mysql2', '>= 0.4.4'/config/database.yml
default: &default - adapter: sqlite3 + adapter: mysql2 + encoding: utf8mb4 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> - timeout: 5000 + username: root + password: + host: localhost development: <<: *default - database: db/development.sqlite3 + database: hello_rails_development test: <<: *default - database: db/test.sqlite3 + database: hello_rails_test production: <<: *default - database: db/production.sqlite3 + database: hello_rails_production + username: hello_rails + password: <%= ENV['HELLO_RAILS_DATABASE_PASSWORD'] %>Failed to start mysqld.service: Unit not found.
MySQLを立ち上げようとしたところエラーが発生しました
sudo service mysqld start Redirecting to /bin/systemctl start mysqld.service Failed to start mysqld.service: Unit not found.こちらの記事を参考にしました。
https://qiita.com/hamham/items/fd77bb0bb167a150dc8e#mysql57%E3%81%AE%E5%B0%8E%E5%85%A5@MurakamiKazutaka さんがコメントで書かれていましたが、Amazon Linux2ではyumでmysqlをインストールしようとするとmariaDBをインストールしようとするらしいです。
$ yum -y install http://dev.mysql.com/get/mysql57-community-release-el7-11.noarch.rpm $ yum -y install mysql mysql-community-server $ mysqld --version mysqld Ver 5.7.23 for Linux on x86_64 (MySQL Community Server (GPL)) $ cd /var/www/rails/アプリ名 $ sudo service mysqld startで無事解決しました。
と思ったら、無事ではありませんでした。この場合、MySQLが勝手にrootユーザーのパスワードを作成してしまうので、@hat_log さんがおっしゃっているように、パスワードをdatabase.ymlに記載する必要があります。
https://qiita.com/Dough/items/7493ad374a51b24abb58$ sudo cat /var/log/mysqld.log | grep 'temporary password' [Note] A temporary password is generated for root@localhost: XXXXXX $ mysql -u root -p Enter password: XXXXXX mysql> set password for root@localhost=password('passwordPASSWORD@999');次にdatabase.ymlにパスワードを記載
production: <<: *default database: mumu_production username: root password: passwordPASSWORD@999NoMethodError (undefined method `deep_symbolize_keys' forのエラー
データベース作成時にエラーが発生しました。
$ rake db:create RAILS_ENV=production ... NoMethodError (undefined method `deep_symbolize_keys' for....ymlファイルの書式が間違っているということで、おそらくインデントのスペースが2個になっていないのだろうと思い探しました。
そしたら、config/secrets.ymlでキー名secret_key_base:を書いていませんでした(うっかり)。誤り↓
production: (生成したシークレットキー)正しい方↓
production: secret_key_base: (生成したシークレットキー)Job for nginx.service failed because the control process exited with error codeのエラー
Nginxを起動しようとしたときにエラーが発生
$ sudo service nginx start Redirecting to /bin/systemctl start nginx.service Job for nginx.service failed because the control process exited with error code. See "systemctl status nginx.service" and "journalctl -xe" for details.こちらの記事を参考にしました。
https://qiita.com/shota0701nemoto/items/a6929ef6f396cf3bede4$ sudo nginx -t nginx: the configuration file /etc/nginx/nginx.conf syntax is ok nginx: [emerg] open() "/var/www/rails/[誤ったアプリ名]/log/nginx.error.log" failed (2: No such file or directory) nginx: configuration file /etc/nginx/nginx.conf test failedエラーの内容は人によって違うと思います。自分は"/var/www/rails/[誤ったアプリ名]/log/nginx.error.log"が無いということだったので、ファイルへ移動したところ、
$ cd /var/www/rails/[誤ったアプリ名]/log -bash: cd: /var/www/rails/[誤ったアプリ名]/log: No such file or directoryと言われ、よく見るとアプリ名のハイフン(-)とアンダーバー(_)を書き間違えていることに気付きました。
$ vim config/unicorn.conf.rb $ cd /etc/nginx/conf.d/ $ sudo vim mumu.confで誤った箇所を修正しました。
$ cd /var/www/rails/[アプリ名]/ $ sudo service nginx startで無事に起動しました。
We're sorry, but something went wrong. パート1
Nginxを起動した後に、EC2のIPアドレスへChromeでアクセスしてみると、
We're sorry, but something went wrong.となった。
RDSを一旦停止したせいかと思い、$ sudo service mysqld startMySQLを起動しましたが、変化無し。
$ less log/production.logでRailsのログを確認したところ(一番下の方が最新の情報)、
ActionView::Template::Error (The asset "application.css" is not present in the asset pipeline.のエラーが出ていたので、こちらの記事を参考にconfig/envitonments/production.rbを書き換え。
https://kanoe.studio/archives/791# Do not fallback to assets pipeline if a precompiled asset is missed. config.assets.compile = trueアプリケーションサーバーを再起動して、
(こちらの記事を参考にしました
https://qiita.com/takuyanagai0213/items/259ca105e35f6eb066d6
)$ ps -ef | grep unicorn | grep -v grep takuya 2460 1 0 3月11 ? 00:00:04 unicorn_rails master -c /var/www/rails/myapp/config/unicorn.conf.rb -D -E production takuya 2465 2460 0 3月11 ? 00:00:05 unicorn_rails worker[0] -c /var/www/rails/myapp/config/unicorn.conf.rb -D -E production takuya 2467 2460 0 3月11 ? 00:00:04 unicorn_rails worker[1] -c /var/www/rails/myapp/config/unicorn.conf.rb -D -E production $ kill 2460 $ unicorn_rails -c /var/www/rails/myapp(自分のアプリ名)/config/unicorn.conf.rb -D -E production再びEC2のIPアドレスにアクセスしましたが、相変わらず「We're sorry, but something went wrong.」
次に続く(まだエラーあんのかよ。。。)We're sorry, but something went wrong. パート2
引き続き、再度、ログを確認したところ、
$ less log/production.log ActionView::Template::Error (Webpacker can't find application in /var/www/rails/hello-rails/public/packs/manifest.json. Possible causes: 1. You want to set webpacker.yml value of compile to true for your environment unless you are using the `webpack -w` or the webpack-dev-server. 2. webpack has not yet re-run to reflect updates. 3. You have misconfigured Webpacker's config/webpacker.yml file. 4. Your webpack configuration is not creating a manifest.のエラーが発生していました。
ちょっと何言ってるかわからないです
こちらの記事を参考にしました。
https://qiita.com/natecotus/items/a2bd9f3ebd5b1866d48e$ rm -rf bin/webpack* $ rails webpacker:install Webpacker requires Node.js >= 8.16.0 and you are using 6.17.1 Please upgrade Node.js https://nodejs.org/en/download/またしてもエラーが発生。Node.jsのversionが古いみたいです。
こちらの記事を参考にしました。
https://qiita.com/paranishian/items/bddaed7c3aacedb11967$ git clone git://github.com/creationix/nvm.git .nvm $ . ~/.nvm/nvm.sh $ nvm install $ curl -o- -L https://yarnpkg.com/install.sh | bash $ source ~/.bashrc $ yarn -vそれでは、改めまして〜
$ rails webpacker:install [Ynaqdhm] Y [Ynaqdhm] Y $ RAILS_ENV=production bundle exec rails webpacker:compileコンパイルができたようなので、UnicornとNginxを再起動します。
$ ps -ef | grep unicorn | grep -v grep $ kill [プロセスID] $ unicorn_rails -c /var/www/rails/[アプリ名]/config/unicorn.conf.rb -D -E production $ sudo nginx -s reloadこれで、IPアドレスでつないでみたら。。。
やった表示された!
- 投稿日:2020-11-15T22:21:56+09:00
AWS Lambdaを使ってサーバレスアプリを作成(CRUDのR)
記事を閲覧いただき、ありがとうございます。中村です!!
2020年10月にAWSエンジニアとして転職したので、AWSの予習も兼ねてLambdaを使ったアプリ作成について書いきます。AWS Lambdaとは?
ここでつらつら説明するより公式動画の方がわかりやすいという結論に至りました。まずはご覧ください。
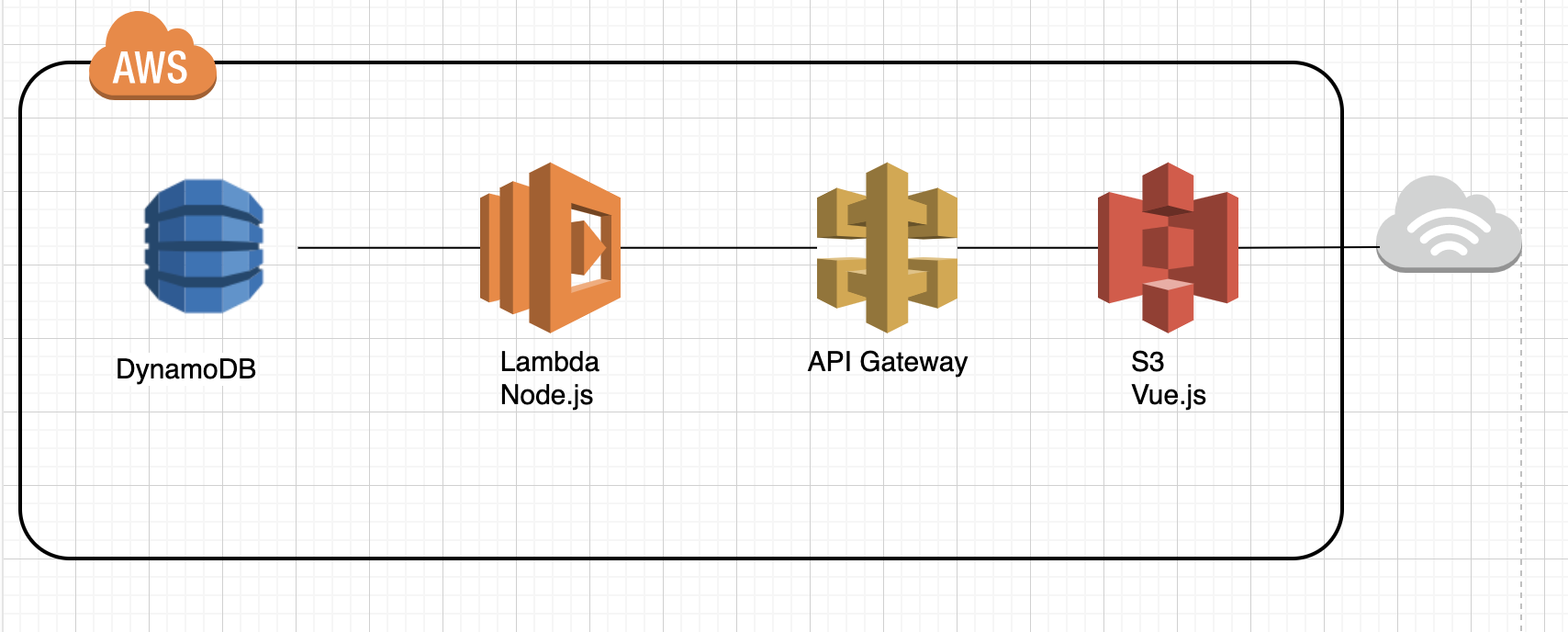
以下を使用して作成ます。
フロントエンド : Vue.js
AWS(インフラ) : S3, API Gateway, Lambda, DynamoDB構成
構成はこんな感じです。
DBはDynamoDB、アプリケーションサーバの代わりにlambdaを使ってサーバレスにする。
lambdaプログラムをAPI Gatewayと連携し、APIとして呼べるようにする。
Webサーバのように使えるS3にフロントエンドのプログラムをデプロイする。
画面
画面こんな感じです。
めちゃシンプルですが、自分の尊敬する人/好きな有名人などの情報を記録するアプリを作ります。
(余談:gifって初めて使ったけど便利ですねぇ。)
手順
以下のような手順で作成します。
が、死ぬほど長くなってしまったので、本記事は①②までとしました!!
③〜⑤は、後ほど作成します!カミングスーン!①DynamoDBテーブルを作成する
1.1 テーブル作成
1.2 カラム作成②GETメソッド作成(CRUDのR)
Lambda関数作成
API Gateway作成
Vue.js作成③POSTメソッド作成(CRUDのC)
Lambda関数作成
API Gateway作成
Vue.js作成④Deleteメソッドの作成(CRUDのD)
Lambda関数作成
API Gateway作成
Vue.js作成⑤PUTメソッドの作成(CRUDのU)
前提条件
AWSアカウント作成ずみであること
(フルアクセス権限のIAMユーザを作ってそこから操作することをお勧めします。)① DynamoDBテーブルを作成する
※ここからAWSマネジメントコンソール画面を操作していきますが、
今後、画面のレイアウト、表示項目などが変わる可能性があります!
本記事と、実際の画面が違った場合は、心で感じ取って、うまく進めてください!!1.1 テーブル作成
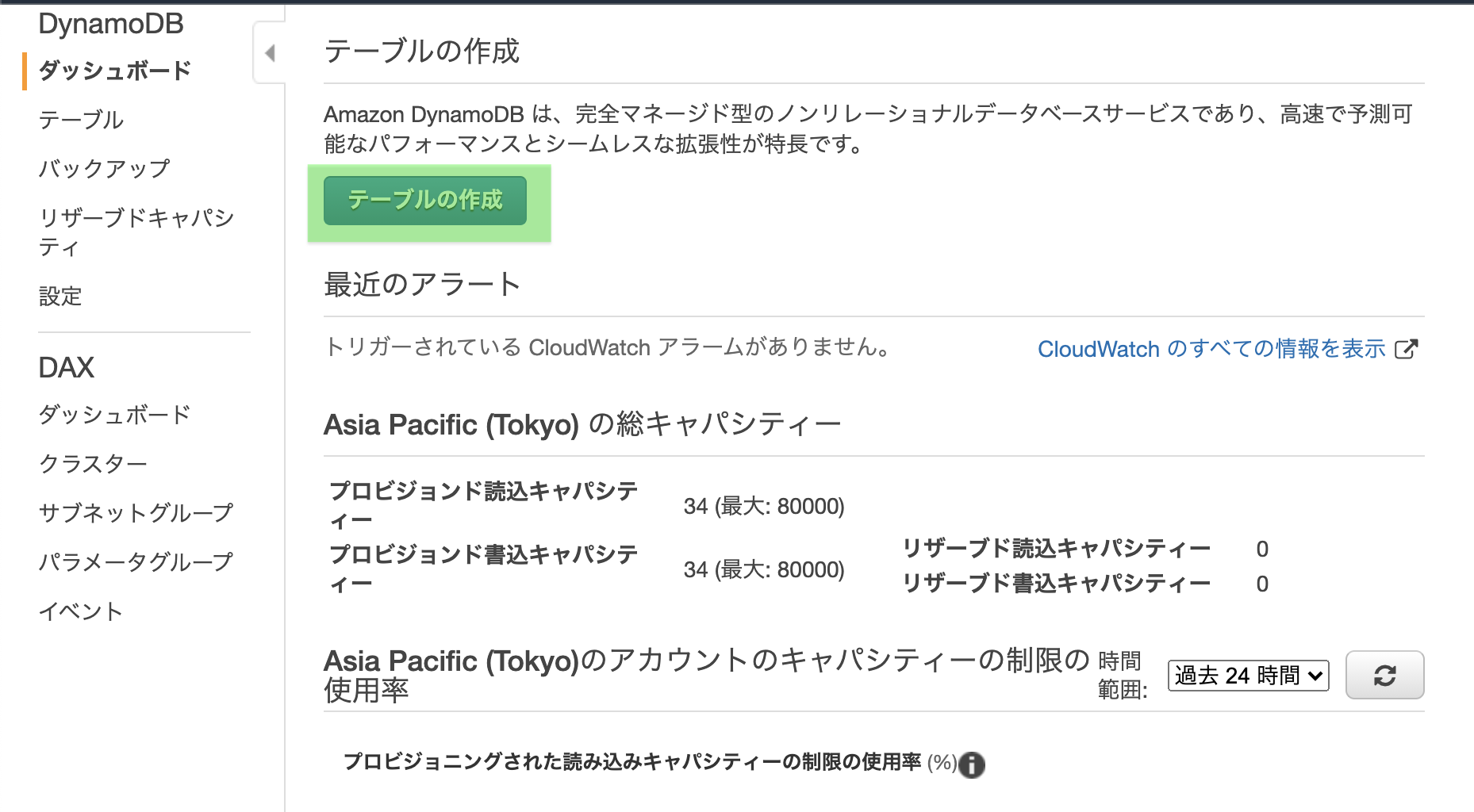
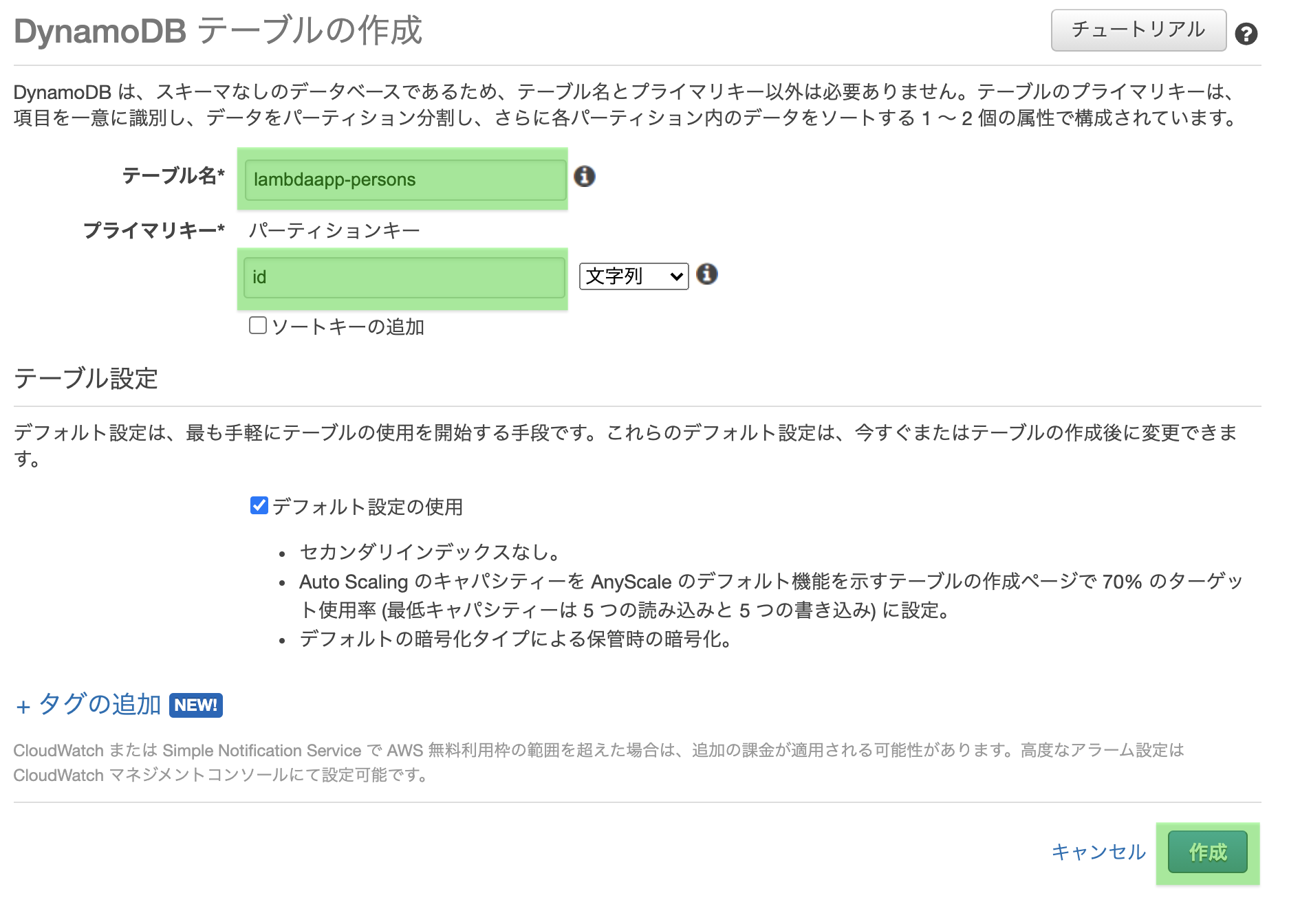
AWSコンソールへログインし、DynamoDBの画面から「テーブル作成」を開く
テーブル名(作ろうとしているアプリ名が良いですかね)とプライマリーキーを入力し、
「作成」を押下する
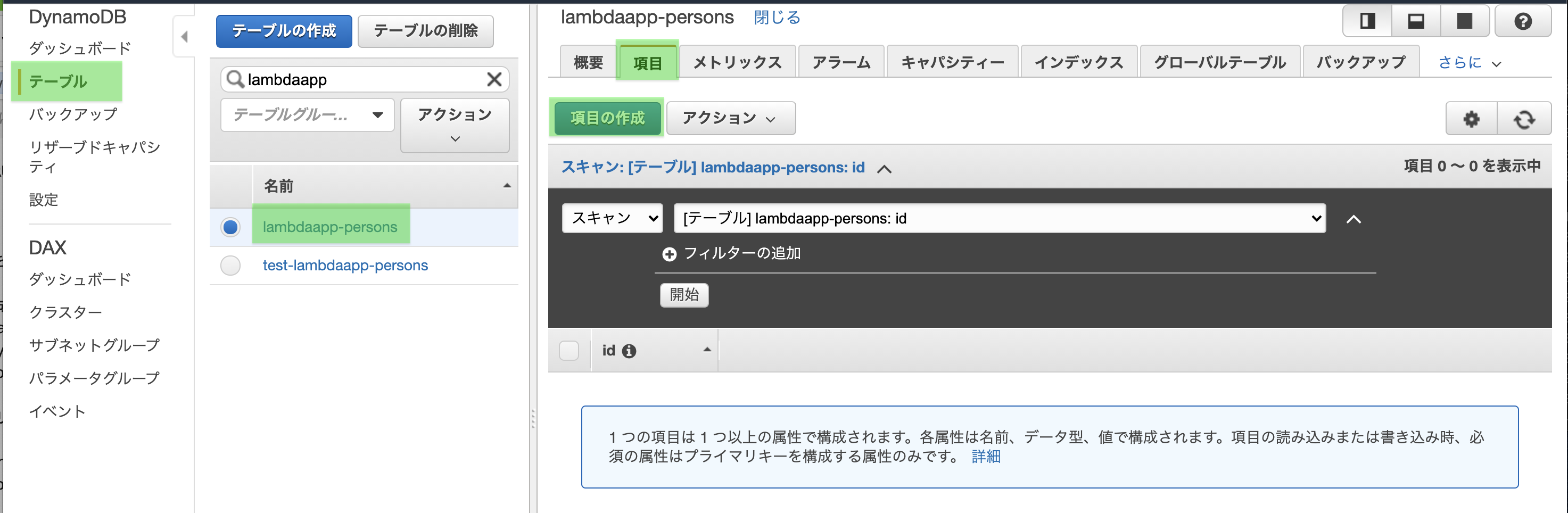
1.2 カラム作成
画面左のメニューから「テーブル」をクリック
作成したテーブル名クリック
「項目」タブを開き
「項目の作成」をクリック
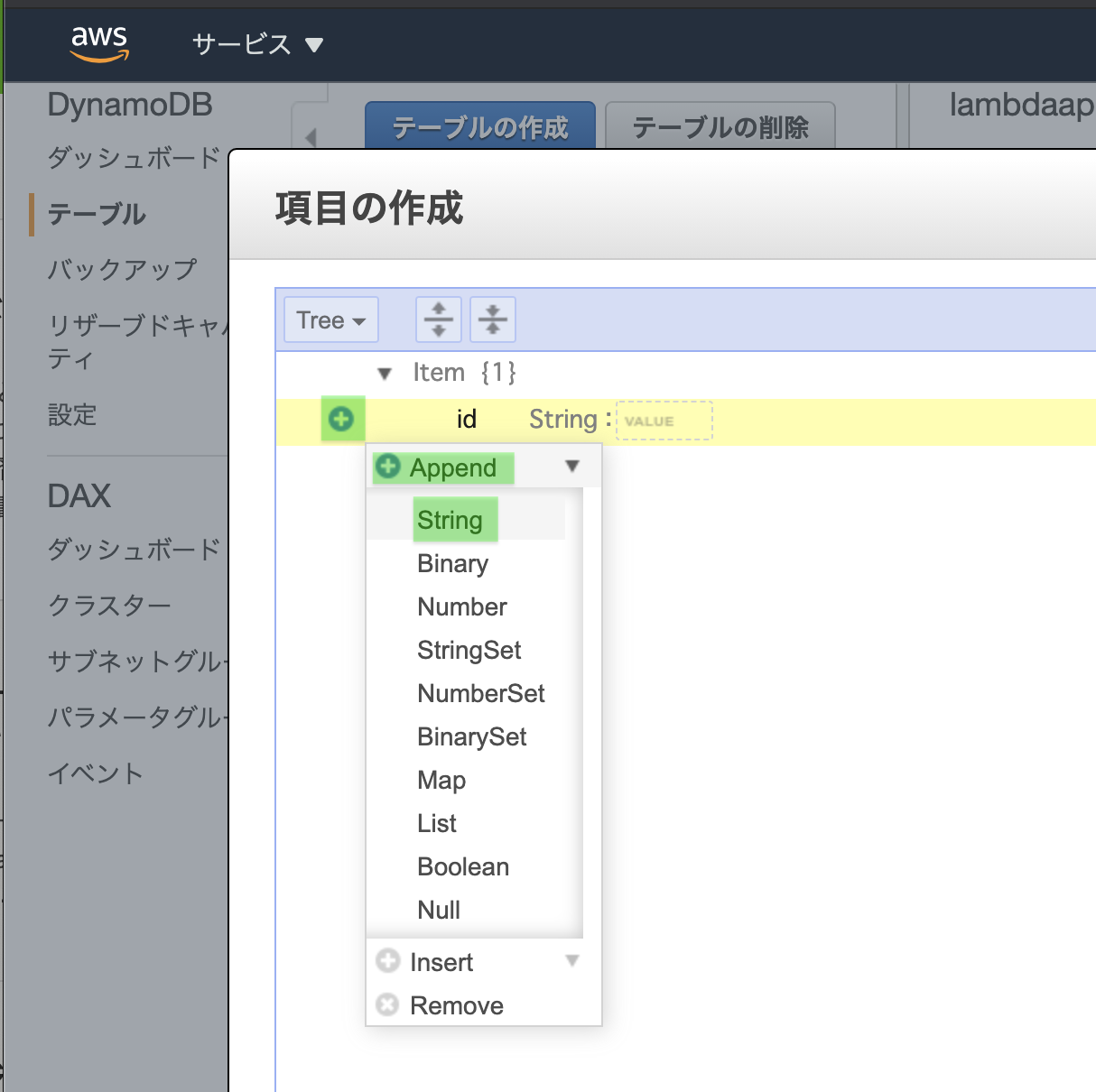
「+」をクリック、「Append」をクリック、「String」を選択
アプリに必要なカラム名を追加する。
同様の操作で必要なカラムを全て作成する。
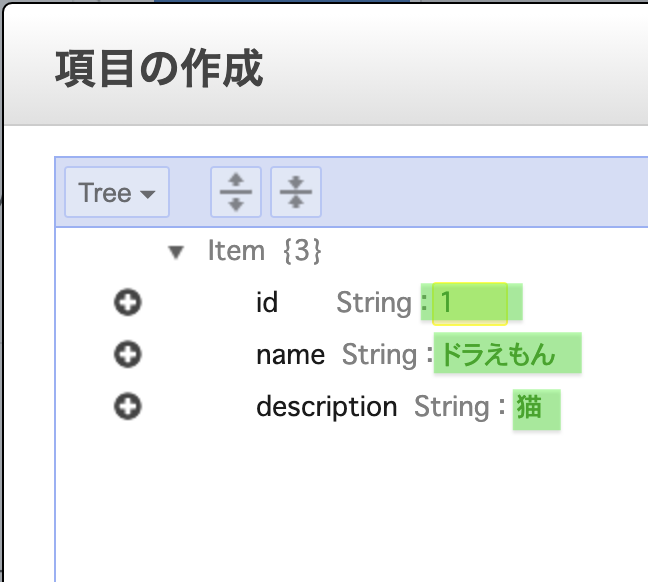
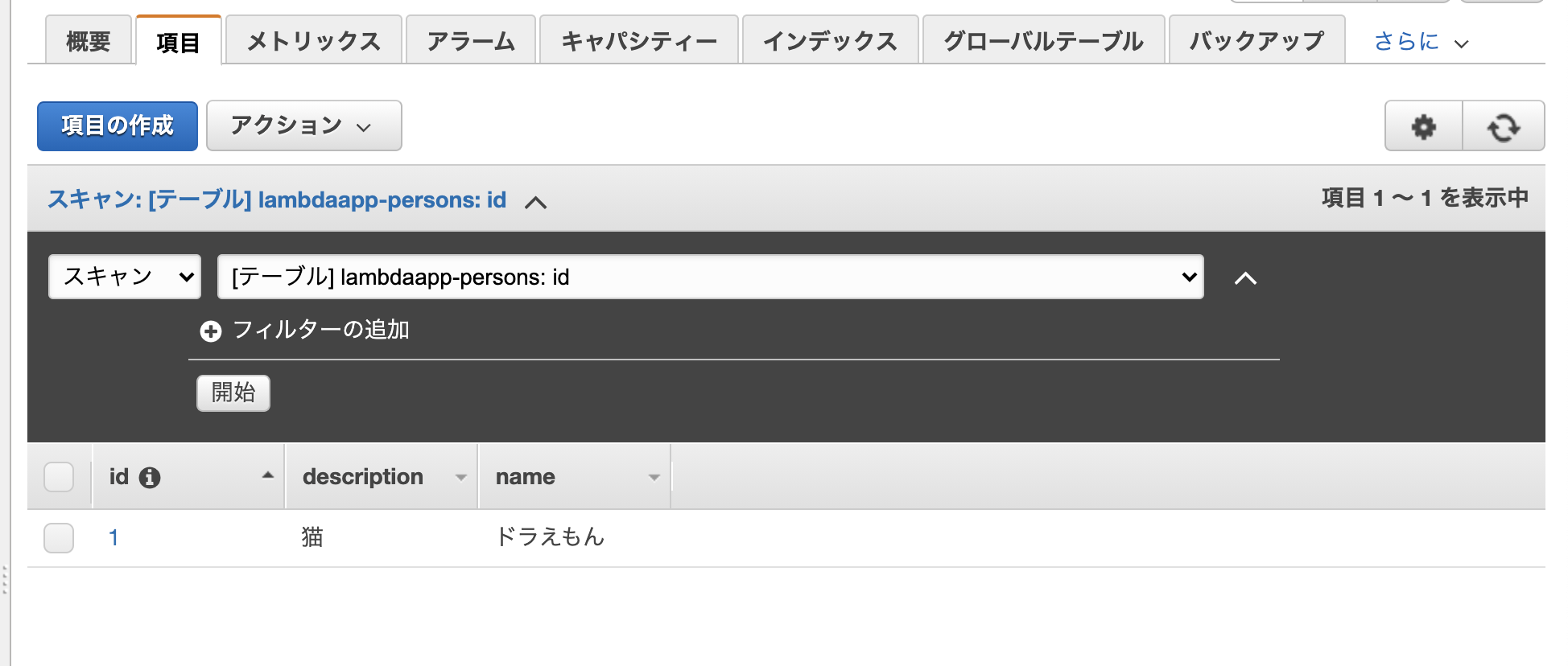
それぞれのカラムに適当なデータを入力します。(ドラえもんはPerson?? まぁいいやw)
「保存」ボタンを押下します。
※データを入れてあげないと下のような赤文字のエラーが出ます。。。?
これでDBは完成です。 ぅえーい!(・∀・)
② GETメソッド作成(CRUDのR)
ここからCRUDごとに処理を作っていきます。
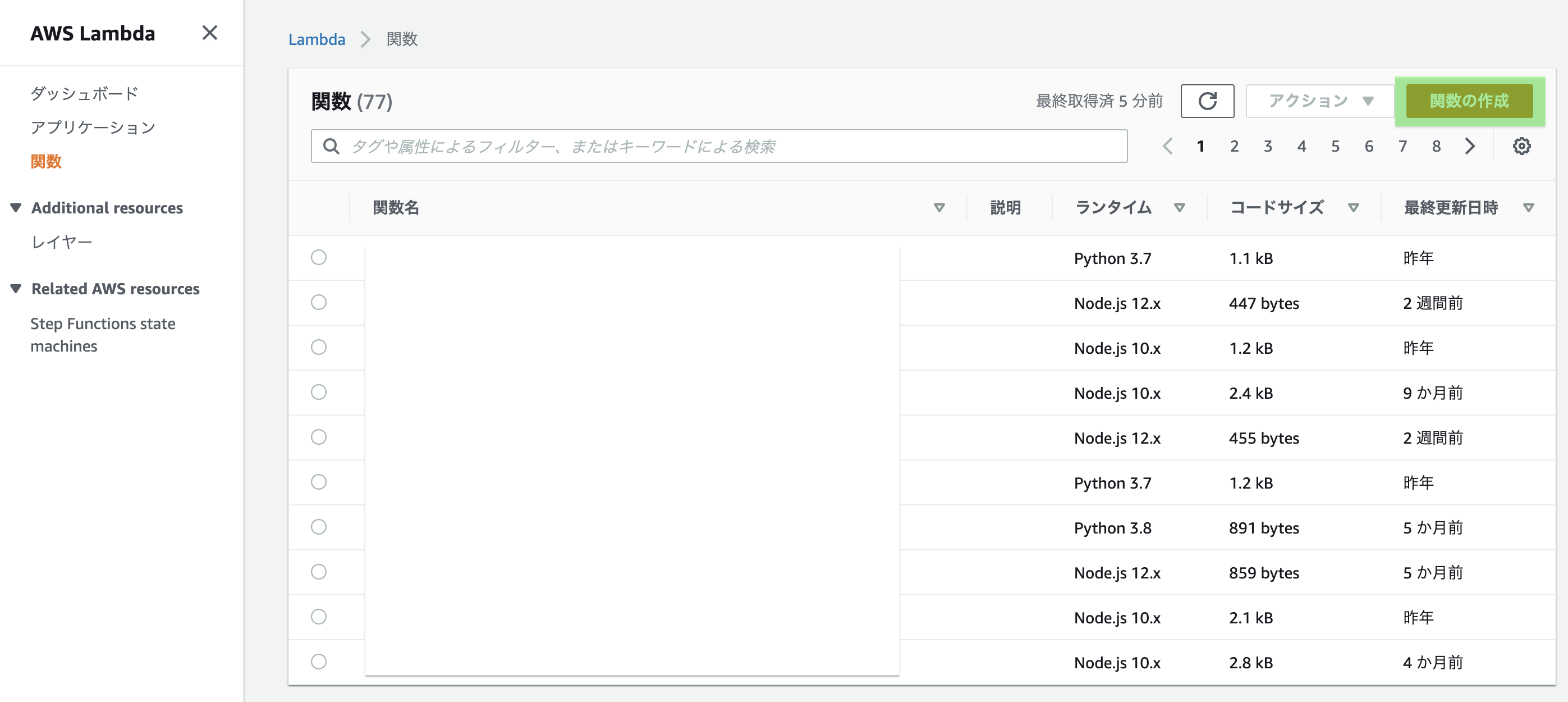
2.1 Lambda関数作成
AWSコンソールからlambda画面へ行き、「関数の作成」をクリックする
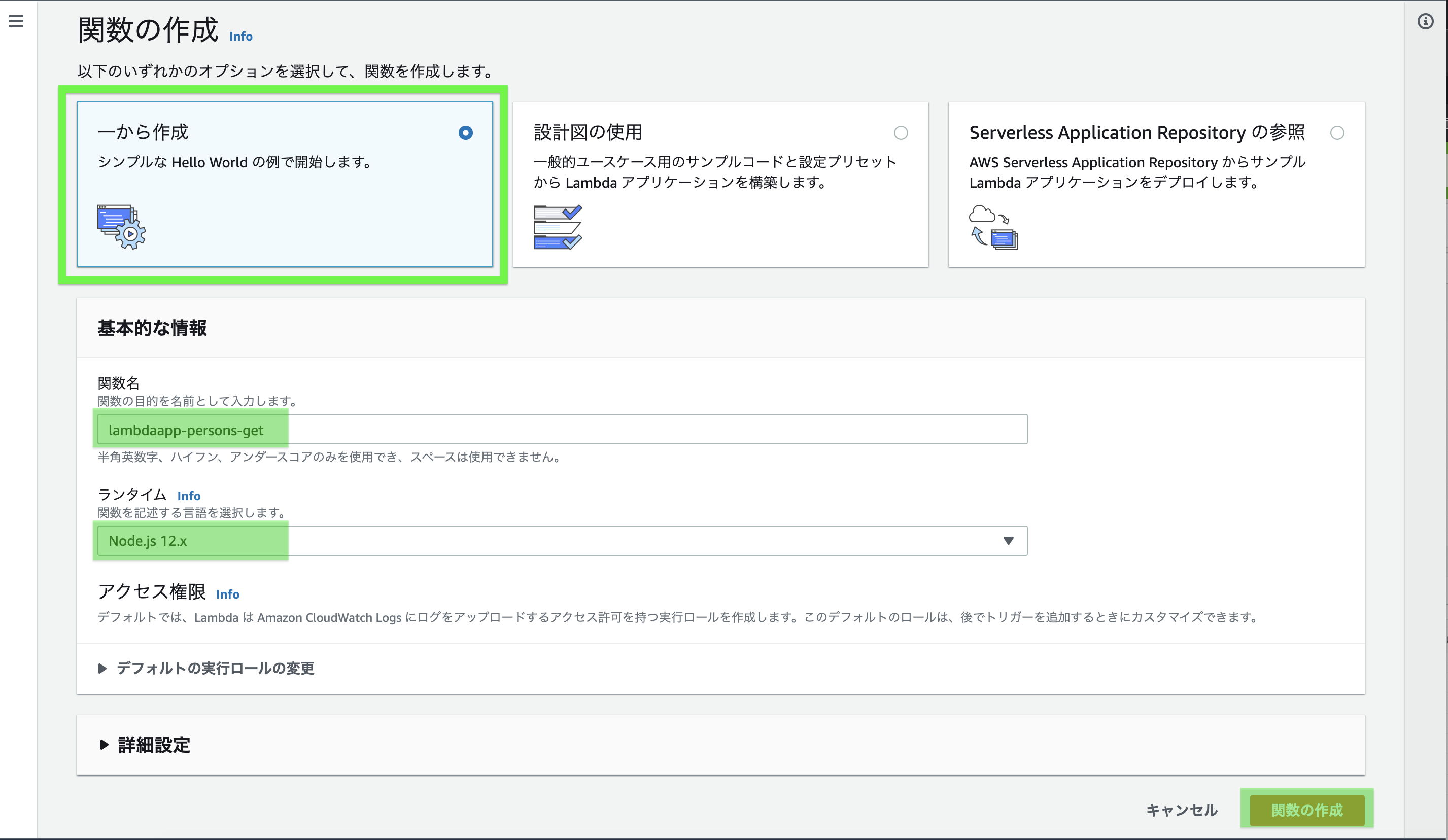
「一から作成」を選択(デフォルト)、
関数名を入力(今回はgetメソッドなので-getとする)
「Node.js」を選択(デフォルト)
「関数の作成」をクリックする
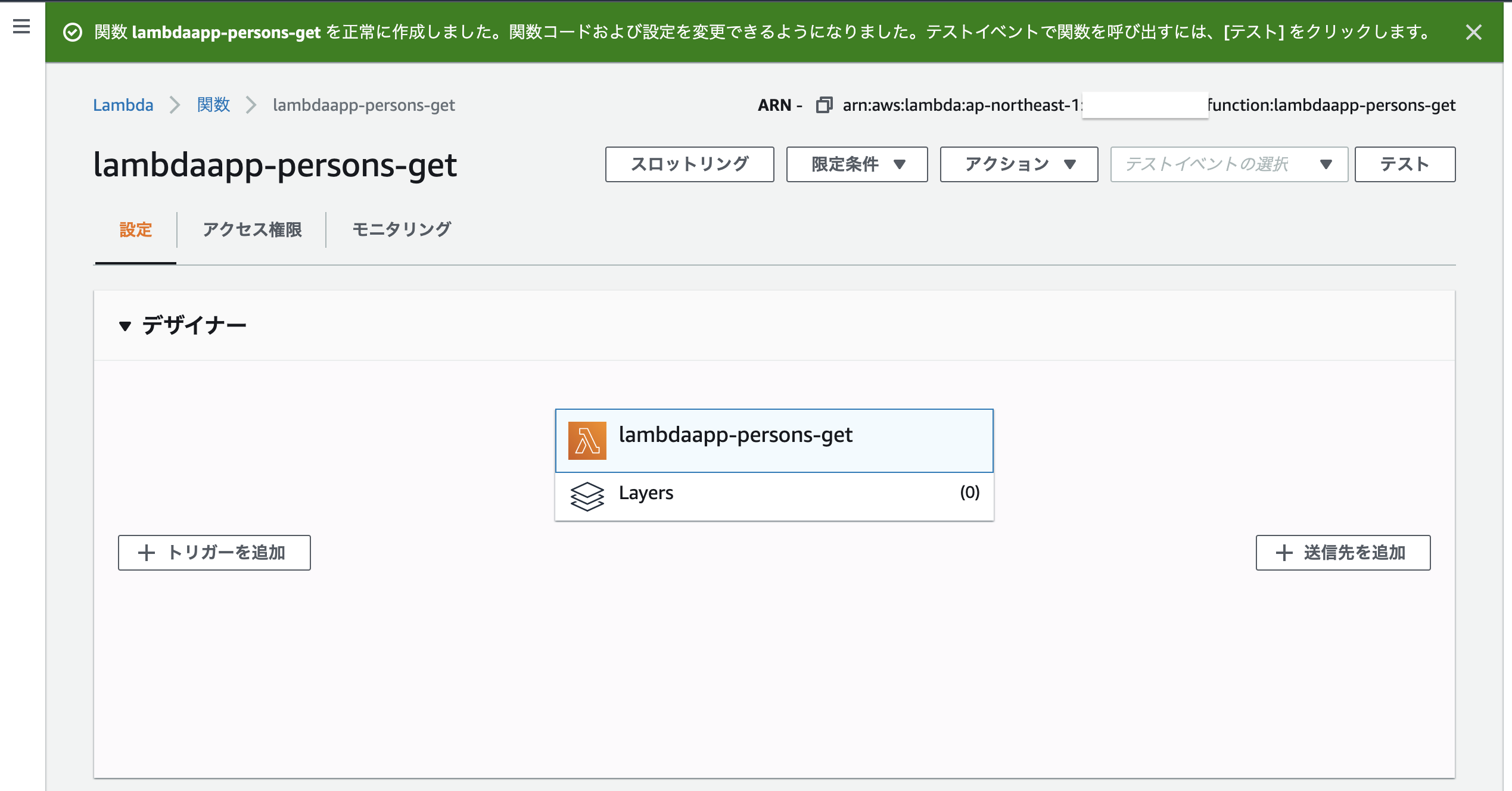
このような画面に遷移すればOKです。
2.1.1 アクセス権限設定(IAMロール)
作成したlambda関数は現時点でDynamoDBにアクセスできません。(上記の作成手順の時に「アクセス権限」がノータッチだった為)
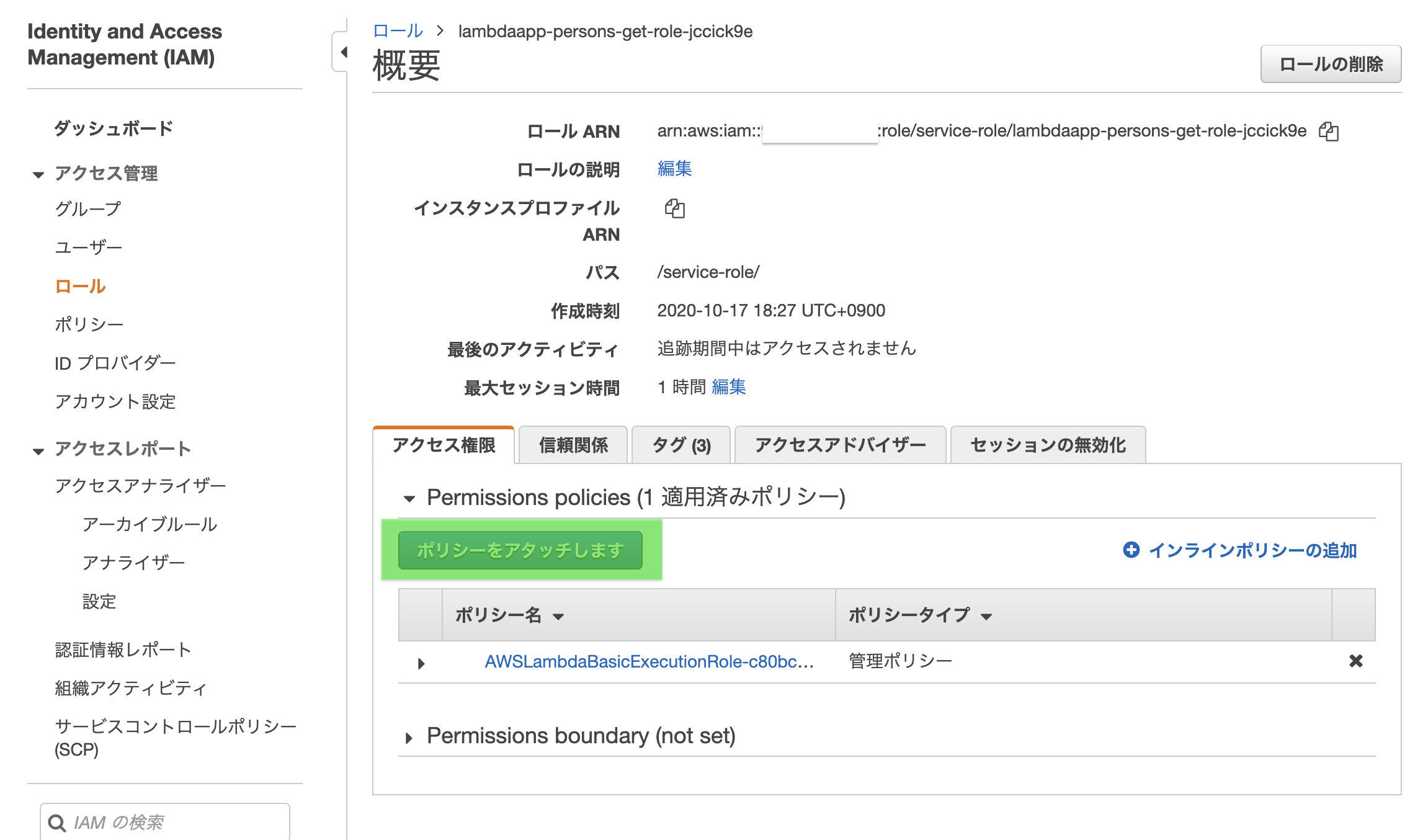
なので、先にそちらの設定をやっちゃいます。作成したlambda関数画面から「アクセス権限」タブを開き、ロール名をクリックします。
このIAMロールはlambda関数作成時に自動で作られています。
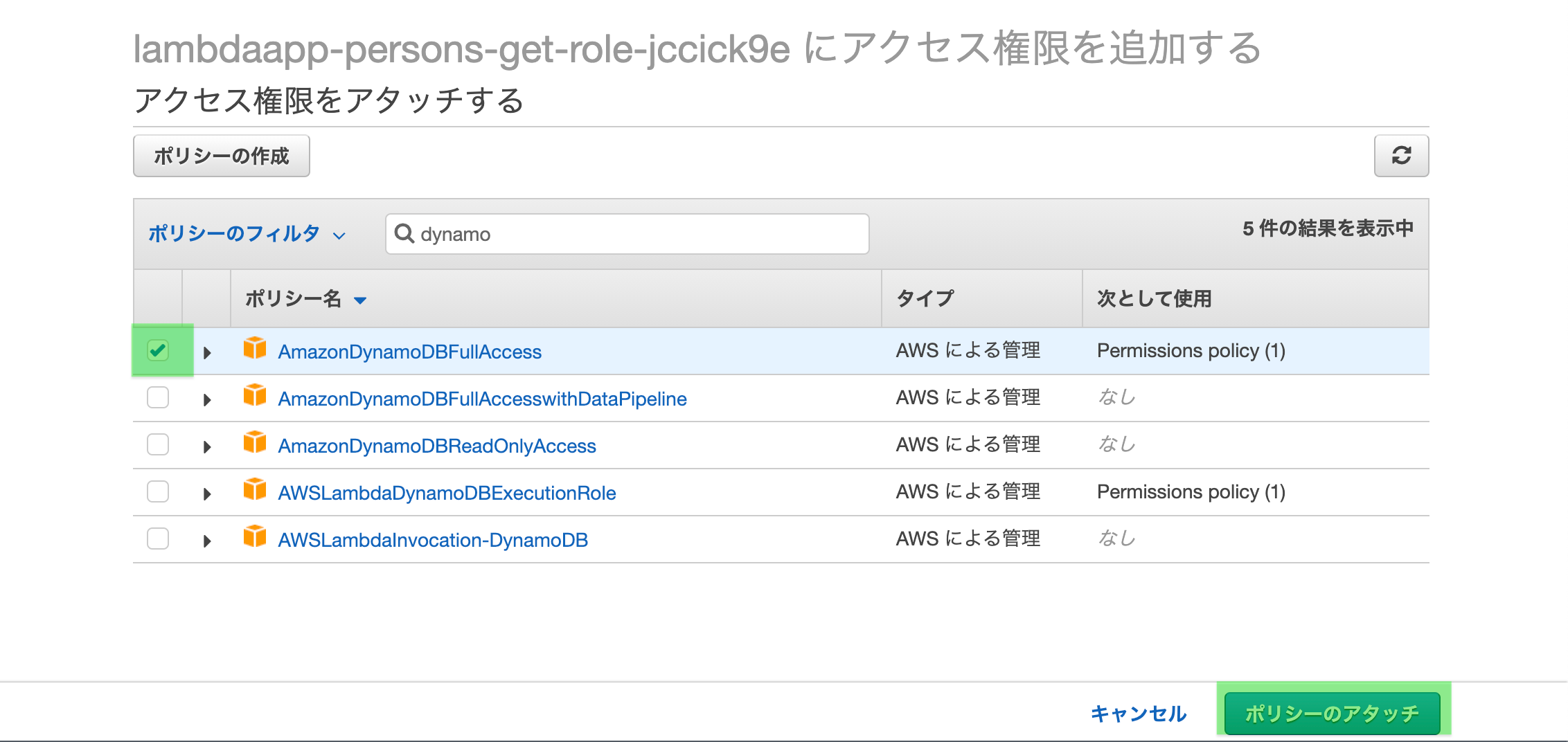
IAMロール画面が開き、「ポリシーをアタッチします」をクリック
検索窓に「dynamo」くらいで検査し、「AmazonDynamoDBFullAccess」を選択する
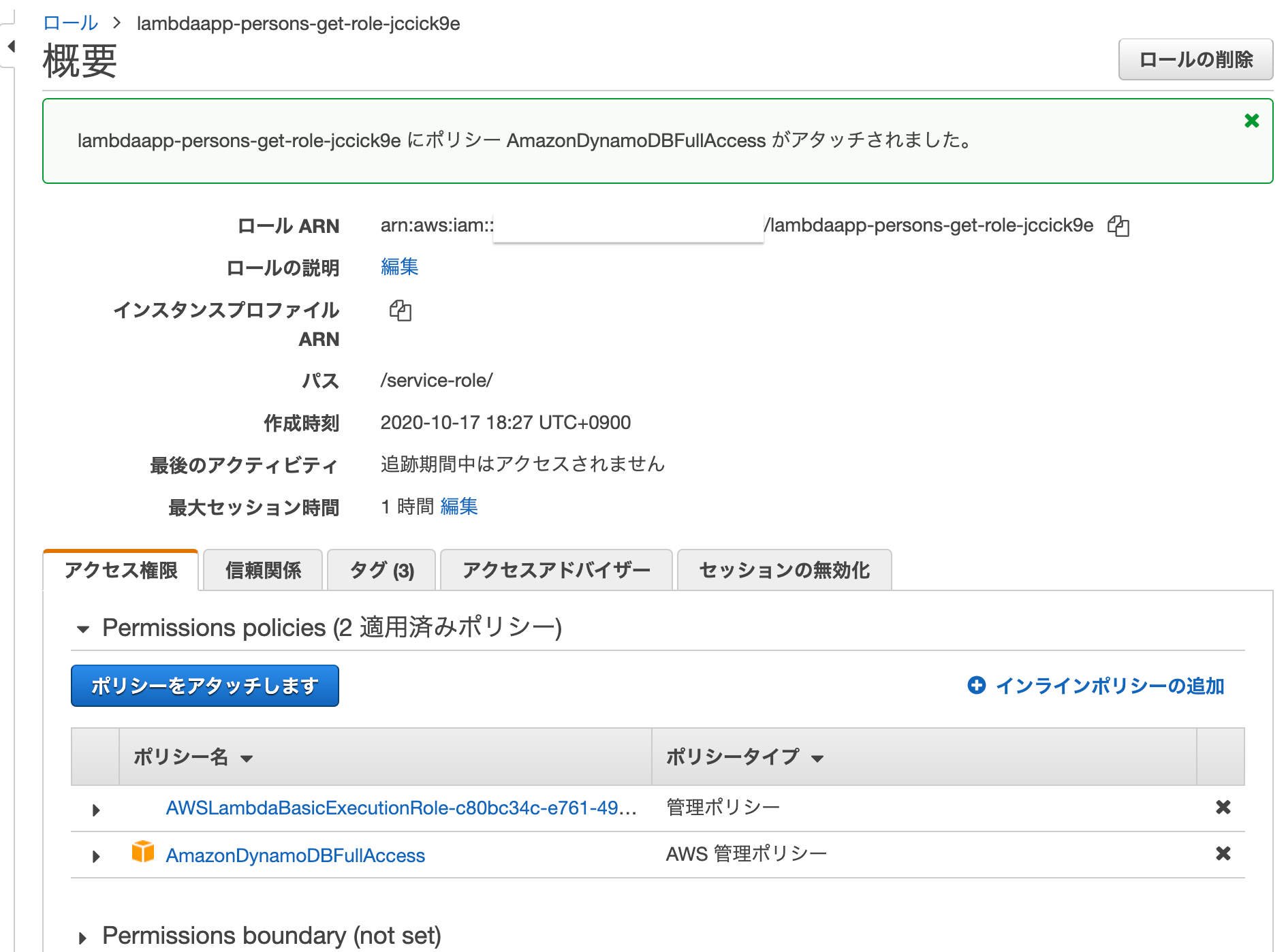
「ポリシーのアタッチ」をクリックする
以下メッセージが出れば、ロール設定完了です。
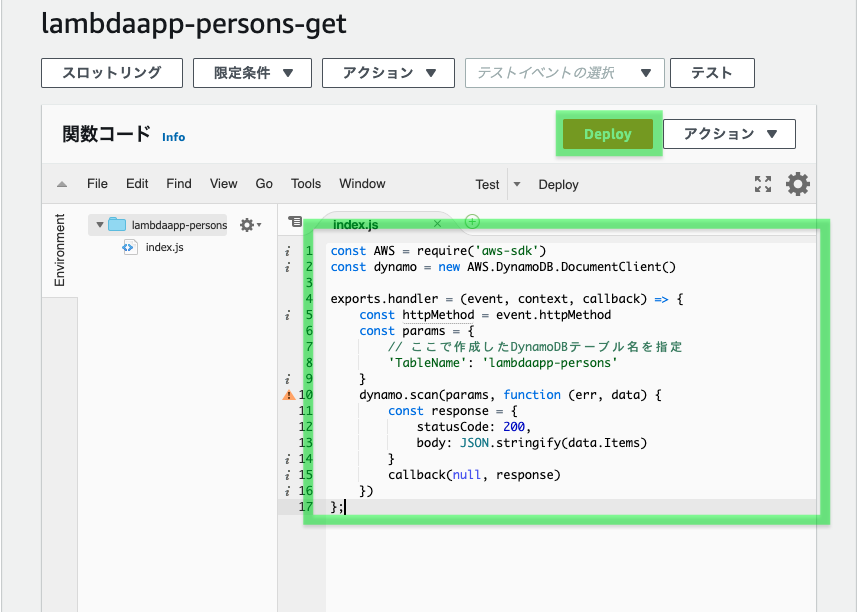
2.1.2 Lambda関数内にGet処理を書く
いよいよlambda関数にgetメソッドを書いていきます。
index.jsconst AWS = require('aws-sdk') const dynamo = new AWS.DynamoDB.DocumentClient() exports.handler = (event, context, callback) => { const httpMethod = event.httpMethod const params = { // ここで作成したDynamoDBテーブル名を指定 'TableName': 'lambdaapp-persons' } dynamo.scan(params, function (err, data) { const response = { statusCode: 200, body: JSON.stringify(data.Items) } callback(null, response) }) };コードエディタの部分にコードを貼り付け、「Deploy」をクリックする
2.1.3 Lambda関数をテストする
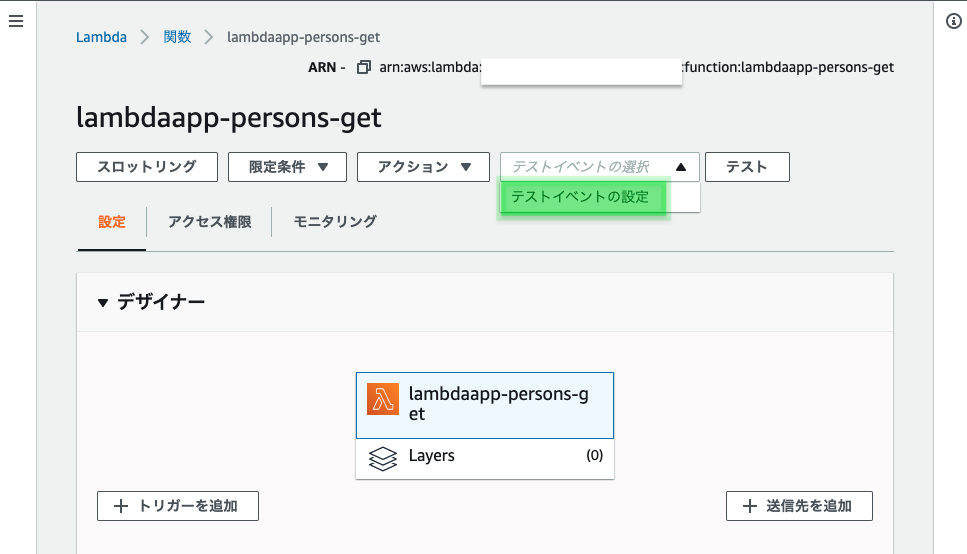
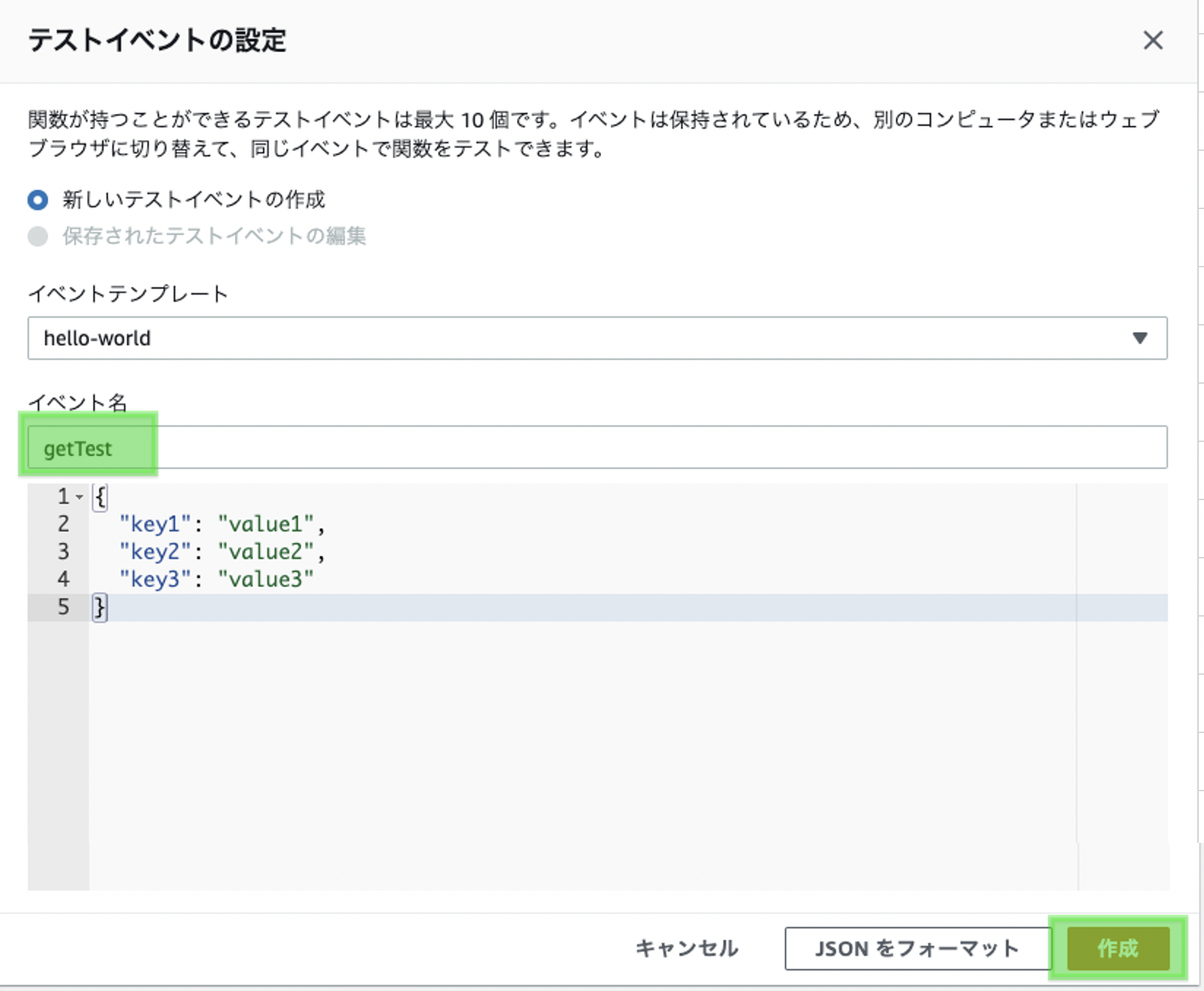
「テストイベントの選択」プルダウンより「テストイベントの設定」を選択
任意のイベント名を入力し、「作成」をクリック
※Getメソッドではパラメータは特にないので、エディタの操作は不要
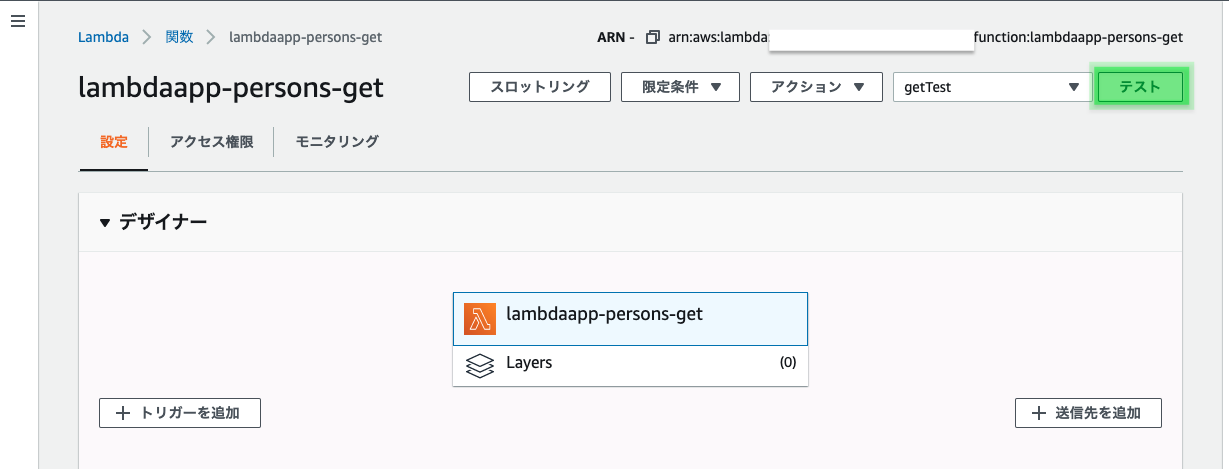
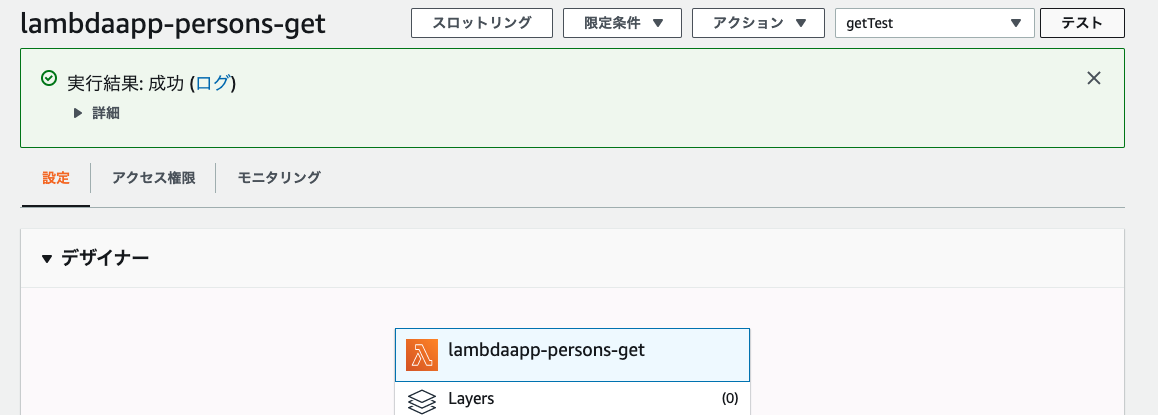
作成したテストイベントが選択された状態で「テスト」をクリック
うまくいくと「実行結果:成功」と表示されます。
結果の詳細を見てみると、DynamoDBに登録したデータが取れているのが分かります。
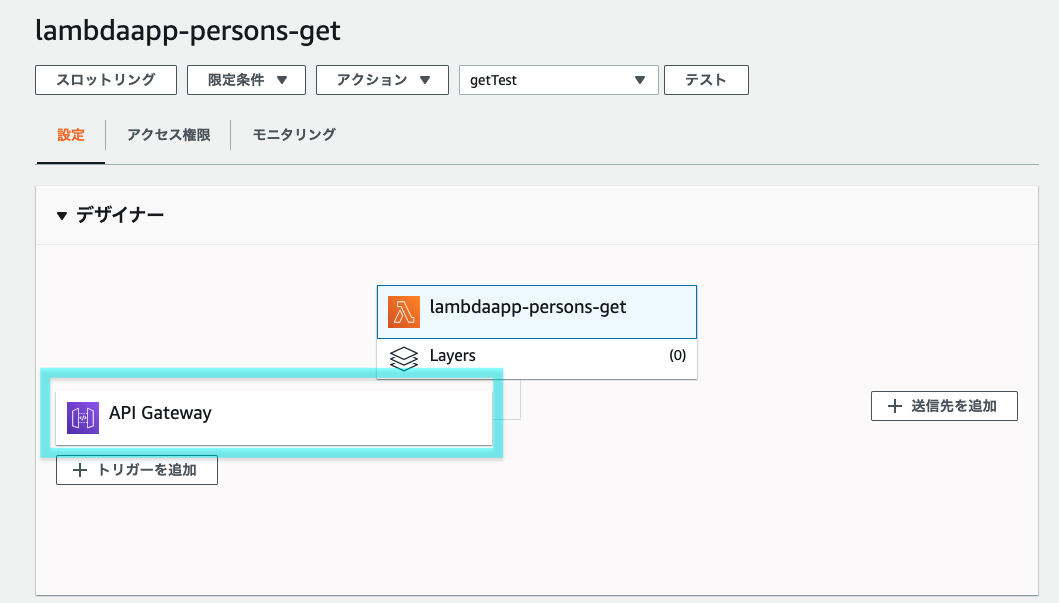
2.2 API Gateway作成
2.2.1 API Gateway作成
先ほど作成したGetメソッドをフロント側から呼び出せるようにAPI Gatewayを作成します。
API Gateway画面から「API 作成」をクリック
API Typeを選択します。「REST API」の「構築」をクリック
「新しいAPI」(デフォルト)を選択、
API名を入力(1つのAPIでCRUD全て追加するので、ここではget、postなどは入れていません)、
「APIの作成」をクリック
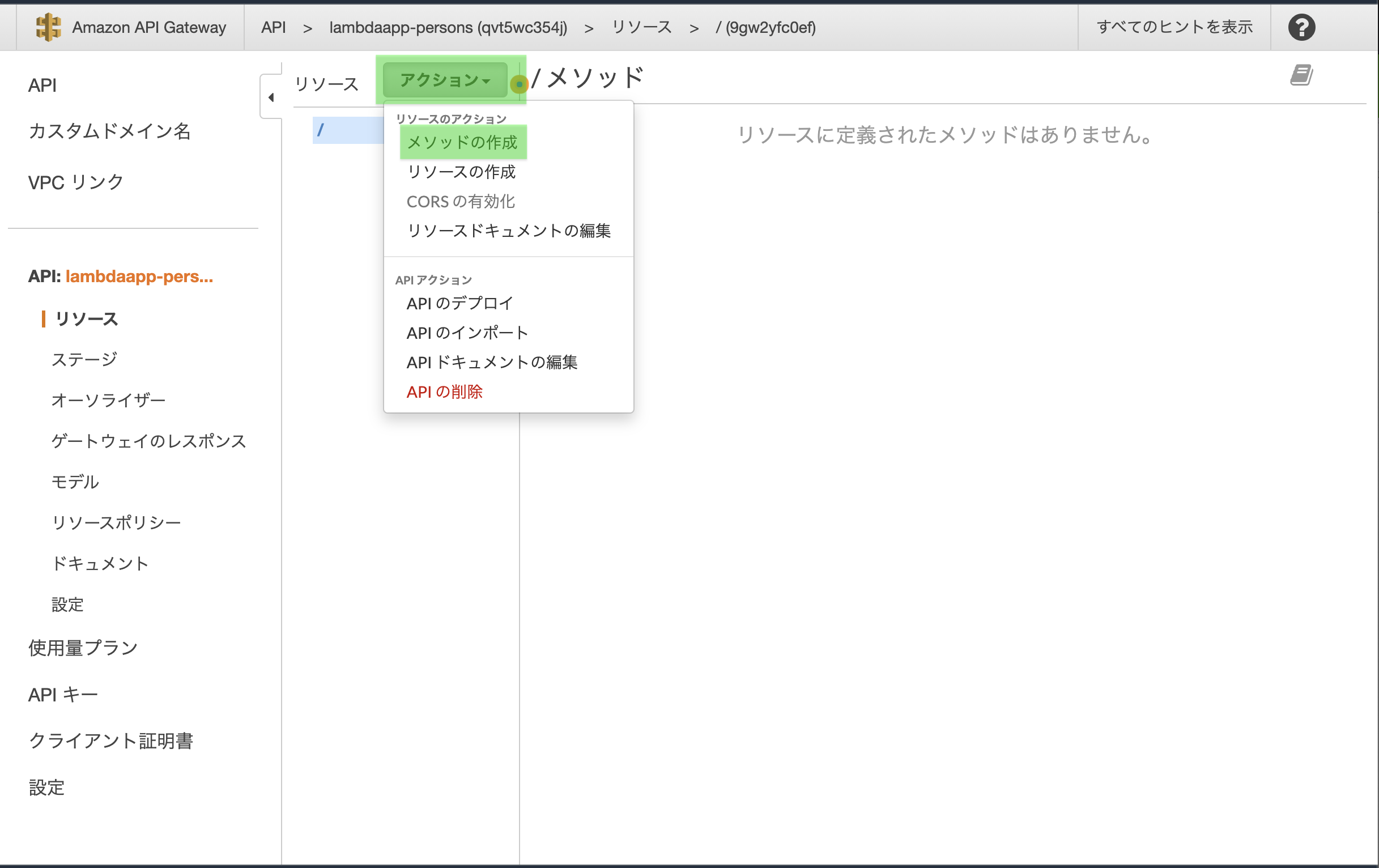
2.2.2 メソッドの作成
作成したAPI Gatewayの画面に遷移します。
「アクション」から「メソッドの作成」をクリック
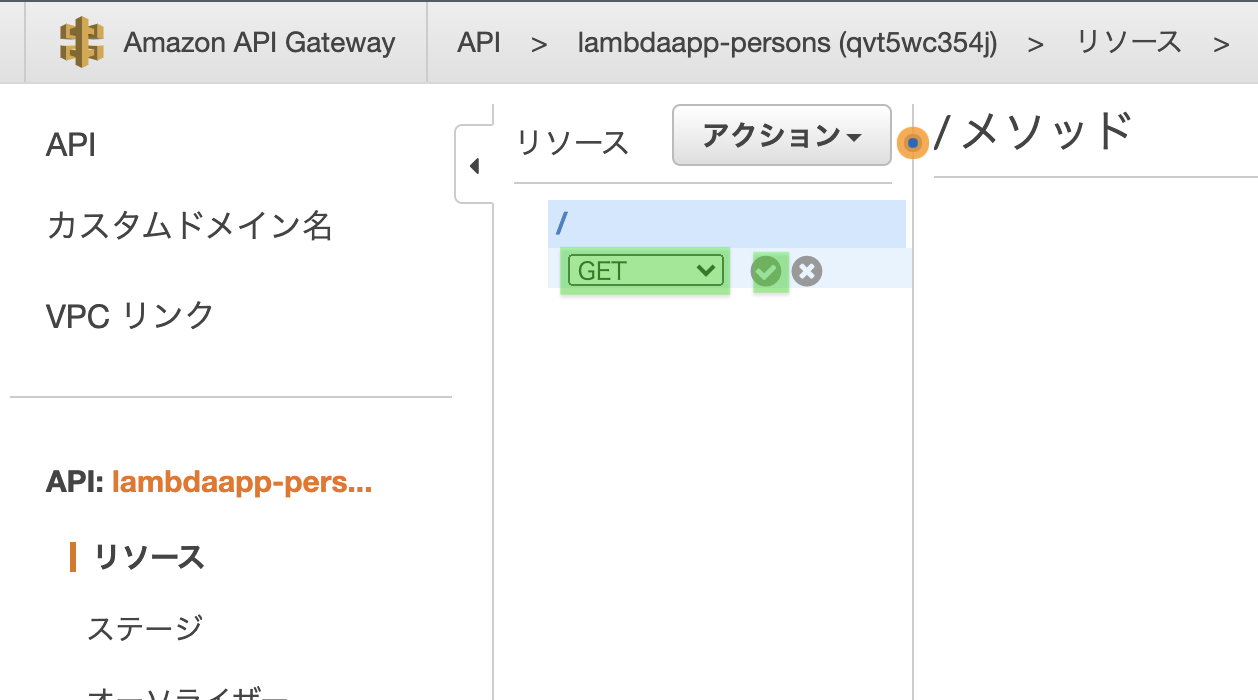
プルダウンから「GET」を選択し、チェックマークをクリック
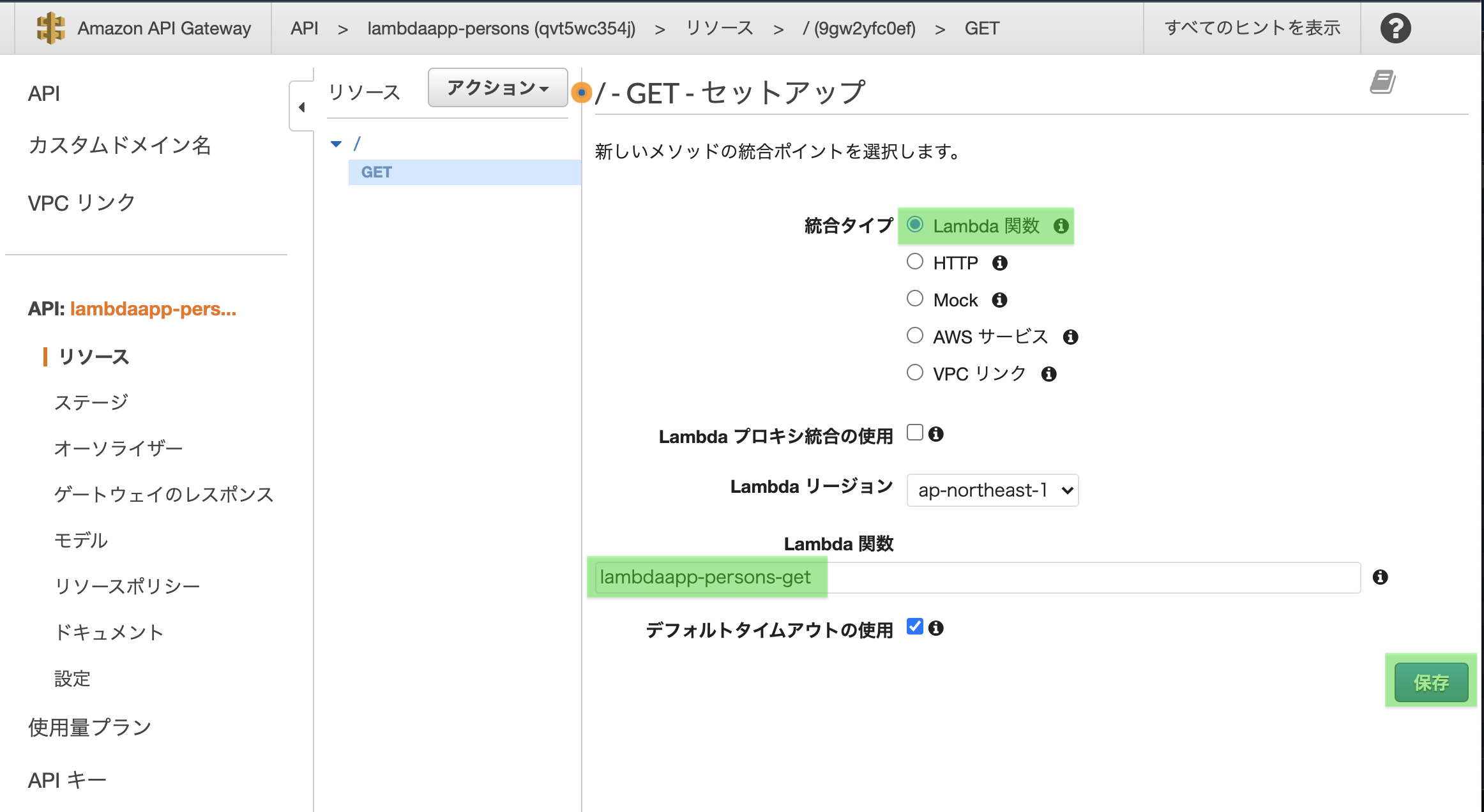
「GET - セットアップ」画面が現れます。
統合タイプ「lambda関数」を選択し、先ほど作成したlambda関数名を入力
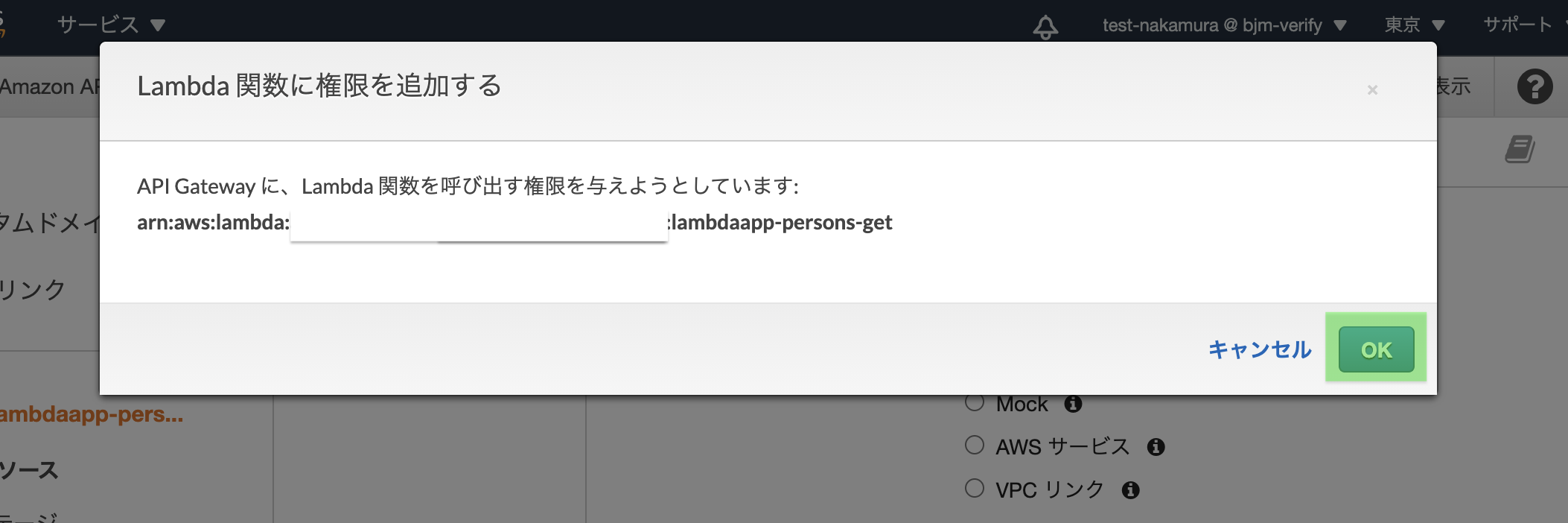
「保存」をクリック
下記メッセージはOKでOK。 ぇ?w
Lambda関数を見てみると、上記「権限を与える」操作によりAPI Gatewayがトリガーとして追加されます。
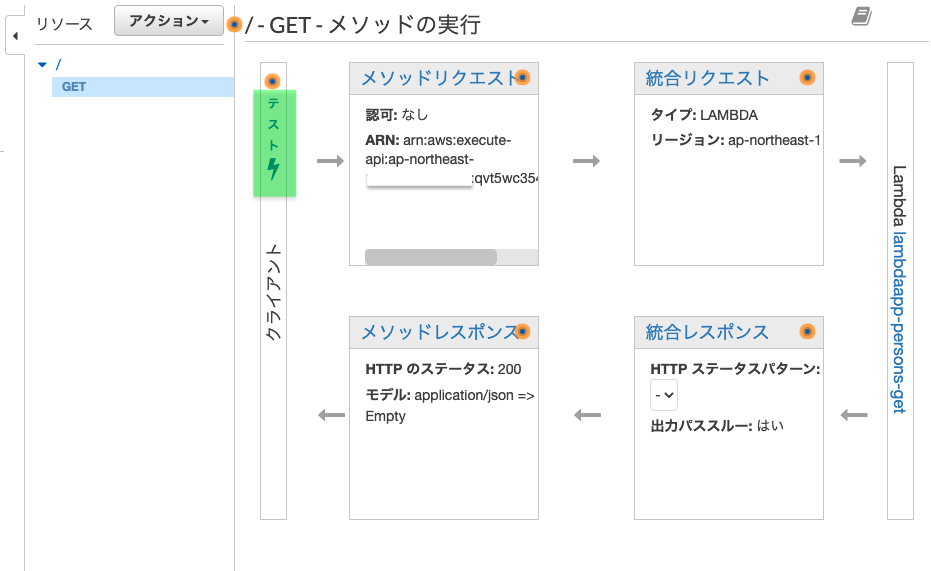
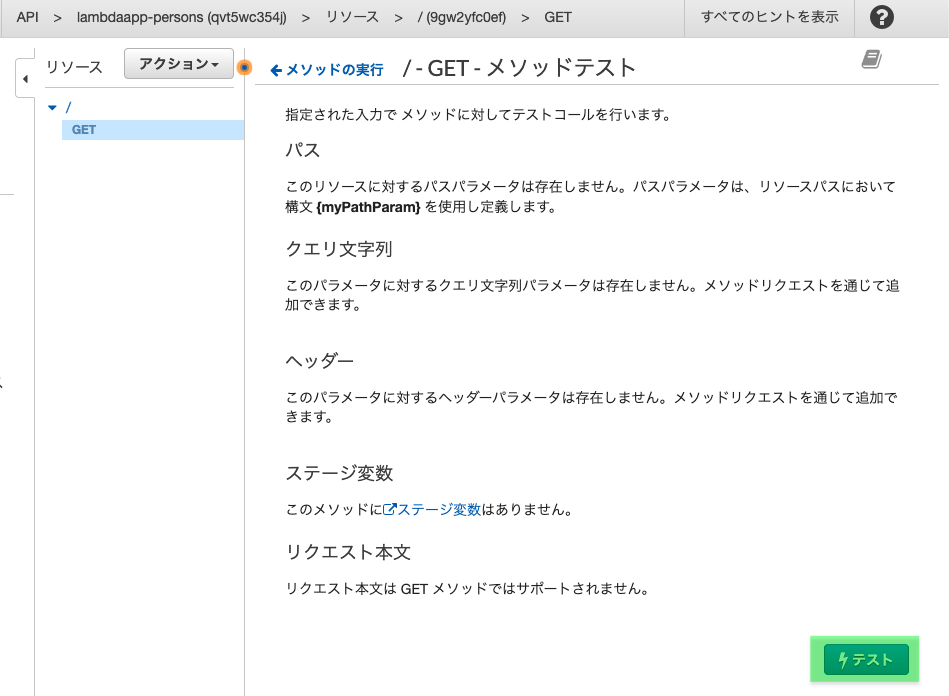
2.2.3 メソッドをテスト
作成したAPI Gatewayメソッドからlambda関数が実行できるかテストします。
「テスト」をクリック
「テスト」をクリック!!
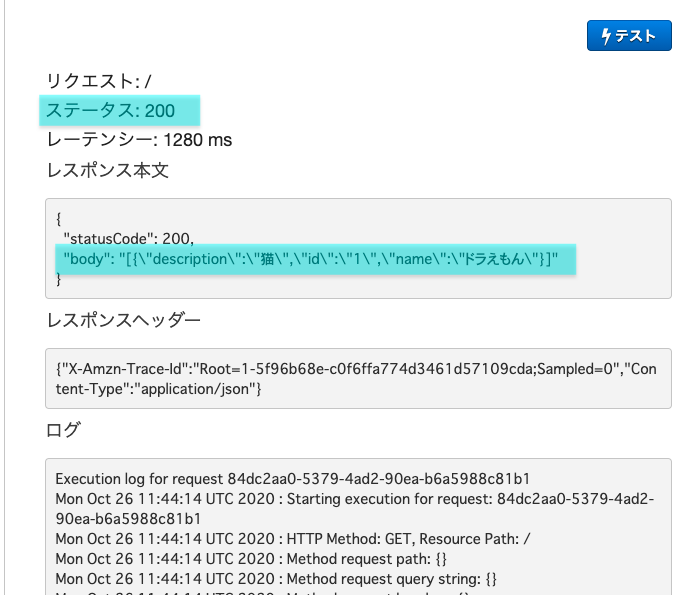
ボタンの下にテスト結果が表示されます。
ステータス:200であればOK。 bodyの所にDynamoDB作成時に作ったデータが入っていますね。
2.2.4 CORSの有効化
説明しよう! CORSとは!
Cross-Origin Resource Sharing(オリジン間リソース共有)の略で
異なるオリジンとの通信ができるようにブラウザへ指示する仕組みだそうです。
今回の例で言うと、HTMLファイルをS3にアップロードして、S3から発行されたURLでブラウザに表示します。
さらにHTMLファイルの中にAPI GatewayのURLを書いて、メソッドを呼び出しています。
①S3のURLと②API GatewayのURLが異なるオリジンということになり、
それらを同時に扱うためにCORSが必要という事ですね。
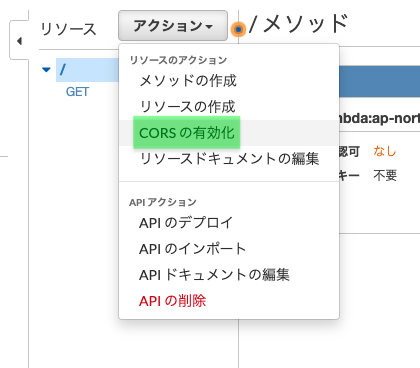
参考「アクション」から「CORSの有効化」をクリック
GETメソッドに✅が入っていることを確認し、「CORSを有効にして既存のCORSヘッダーを置換」をクリック
「はい、既存の値を置き換えます」をクリック
全ての項目に✅が付き、エラーが出なければOK
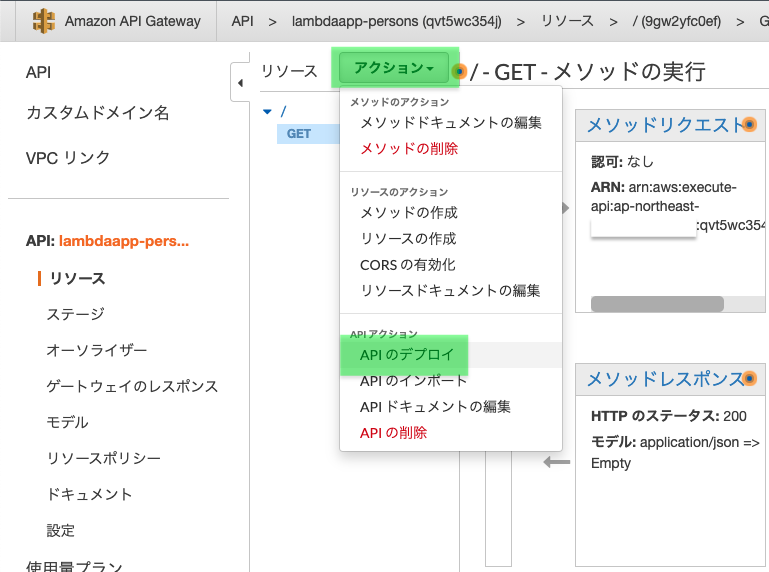
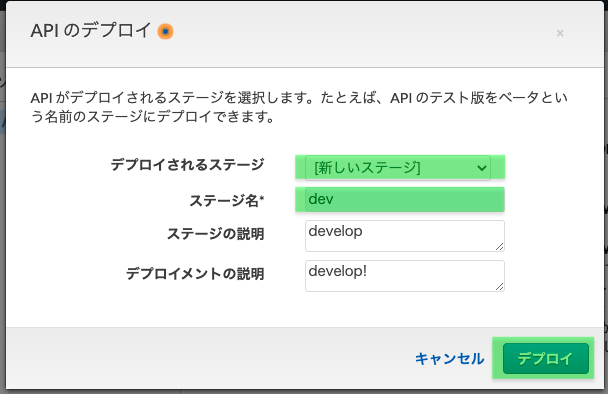
2.2.5 メソッドをデプロイ
「アクション」から「APIのデプロイ」をクリックします。
デプロイされるステージはプルダウンから「新しいステージ」を選択
ステージ名に今回は「dev」と入力。※開発用だったらdev、商用だったらprodといった具合に分けるようですね
ステージの説明、デプロイメントの説明の入力は任意
「デプロイ」をクリック
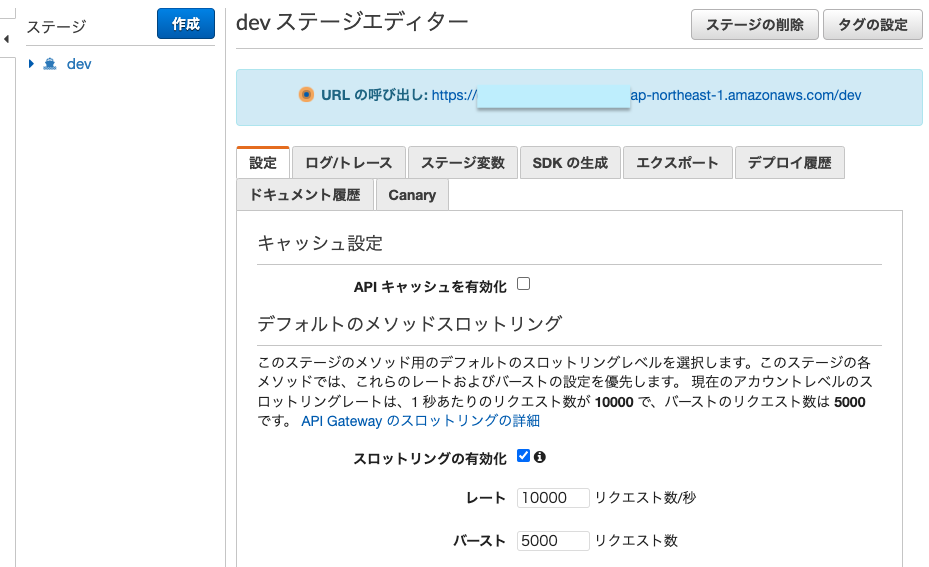
デプロイが成功すると、APIのURLが表示されます。先ほど入力したステージ名が末尾に入っていますね。
2.3 Vue.js作成
2.3.1 ローカルでVue.jsを作成
まずはローカル環境にindex.htmlを作成し、vue.jsで書いていきます。
[作成したAPI GatewayのURL]の箇所をCtrl + Fで探して頂き、作成したAPIのURLを書きます。
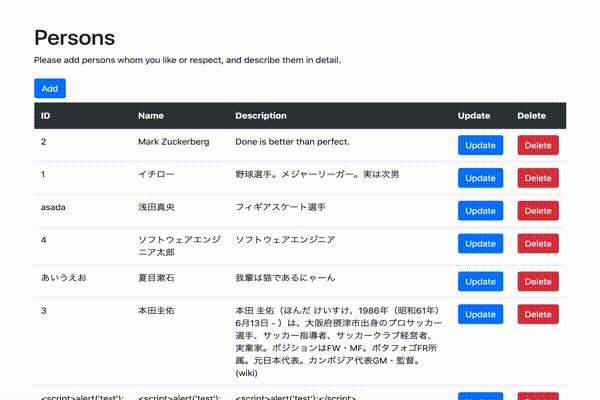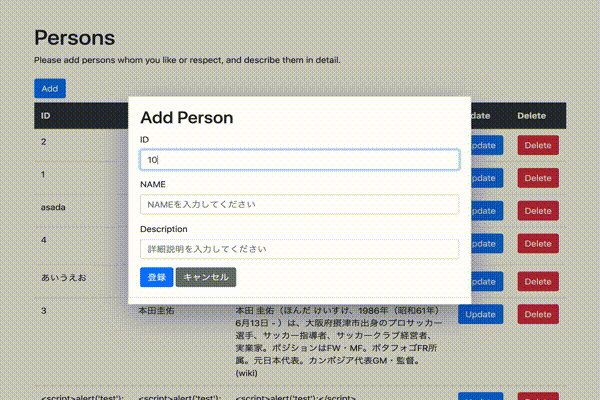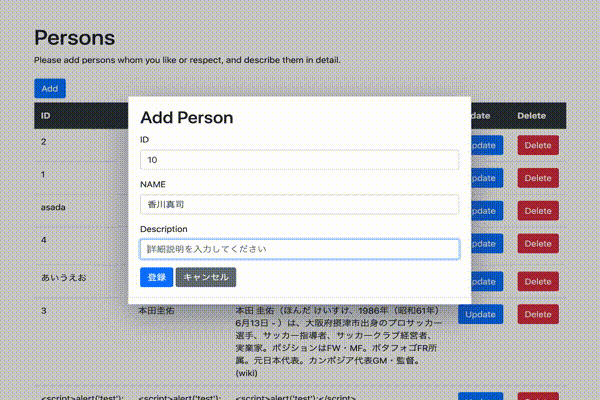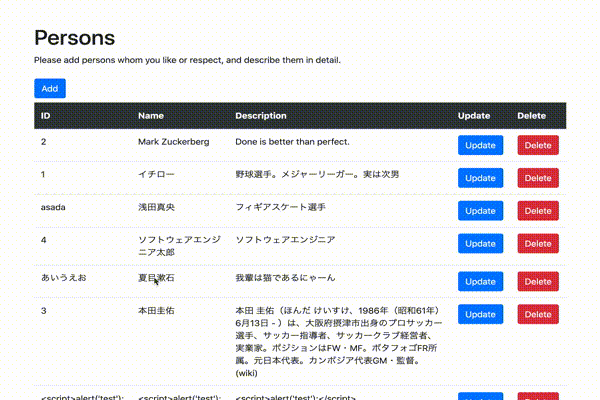
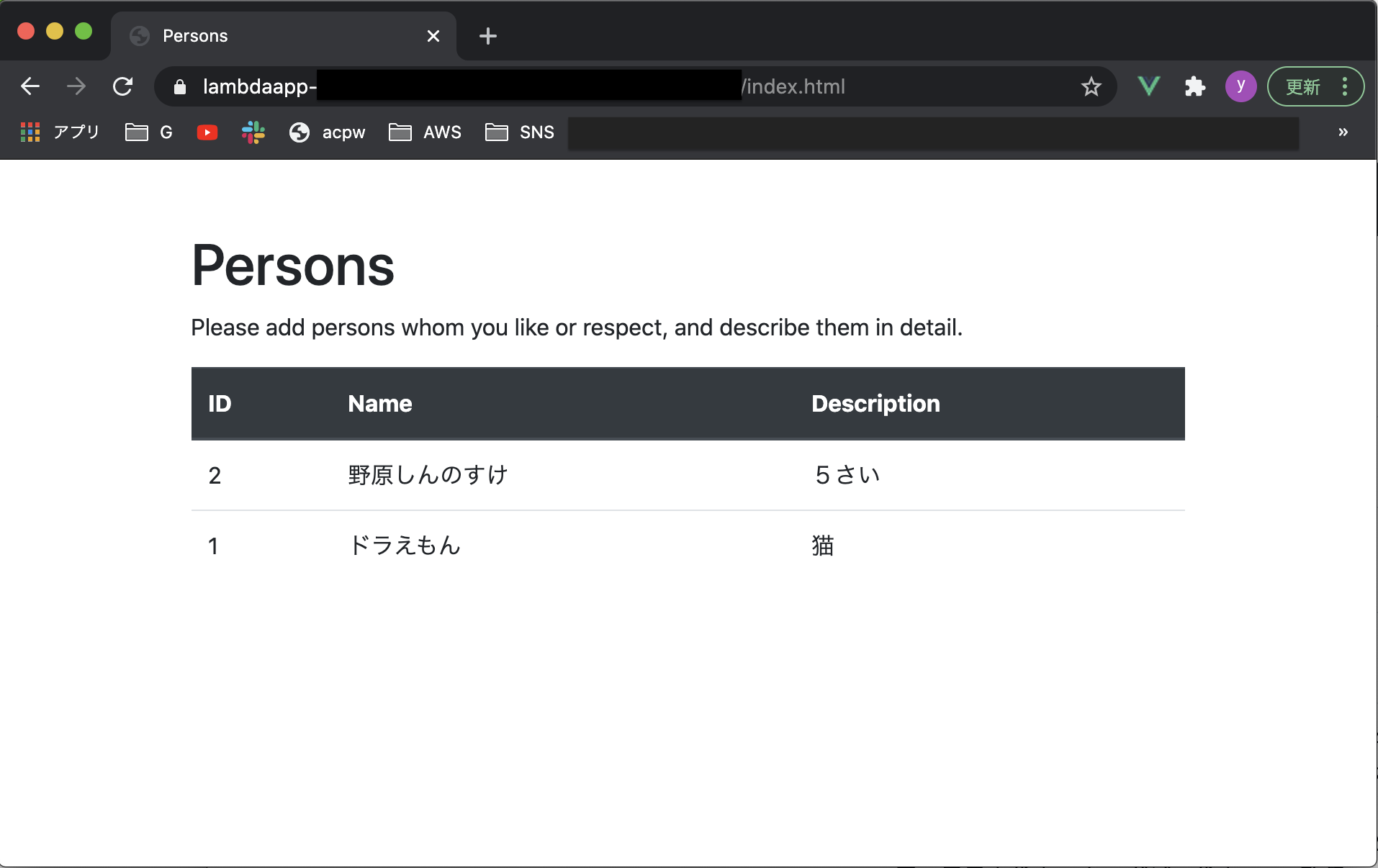
ソースはGithubでも参照いただけます。index.html<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Persons</title> <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/bootstrap.min.css"> </head> <body> <div id="app"> <div class="container mt-5"> <div class="row"> <div class="col-md-12"> <h1>{{ title }}</h1> <h1>{{ psersons }}</h1> <p>Please add persons whom you like or respect, and describe them in detail.</p> <table class="table"> <thead class="thead-dark"> <tr> <th>ID</th> <th>Name</th> <th>Description</th> </tr> </thead> <tbody> <tr v-for="person in persons"> <td>{{ person.id }}</td> <td>{{ person.name }}</td> <td>{{ person.description }}</td> </tr> </tbody> </table> </div> </div> </div> </div> <script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js"></script> <script src="https://cdn.jsdelivr.net/npm/axios/dist/axios.min.js"></script> <script> const vue = new Vue({ el: "#app", data: { title: 'Persons', form: { id:'', name:'', description:'' }, persons: '', editIndex: -1, createFlag: true }, mounted(){ axios .get('[作成したAPI GatewayのURL]') .then(response => (this.persons = JSON.parse(response.data.body))) .catch(function(error){ alert('Personsデータの取得に失敗しましたっ!\n(・Д・)ナンダッテェ!!' ); console.log(error); }); } }); </script> </body> </html>HTMLファイルをブラウザで実行すると以下のような画面が表示されます。
(ドラえもんだけだと寂しいので、もう1レコード追加してみました。てかPersonじゃないっすねwww)
2.3.2 作成したVue.jsをS3へアップロード
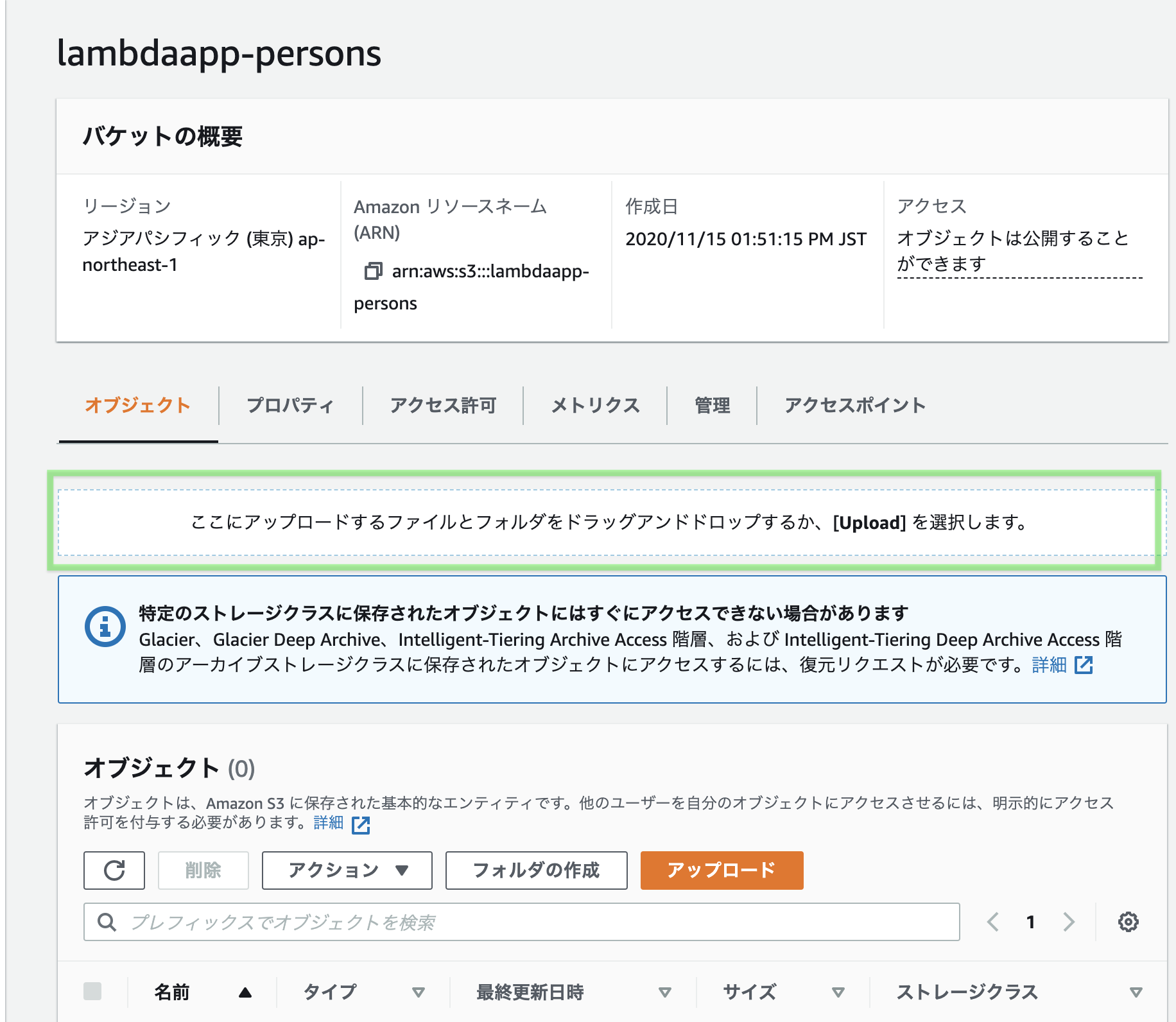
まずS3バケットを作成します。
S3画面へ飛び、「バケットを作成」をクリック
バケット名を入力します。下へスクロール。
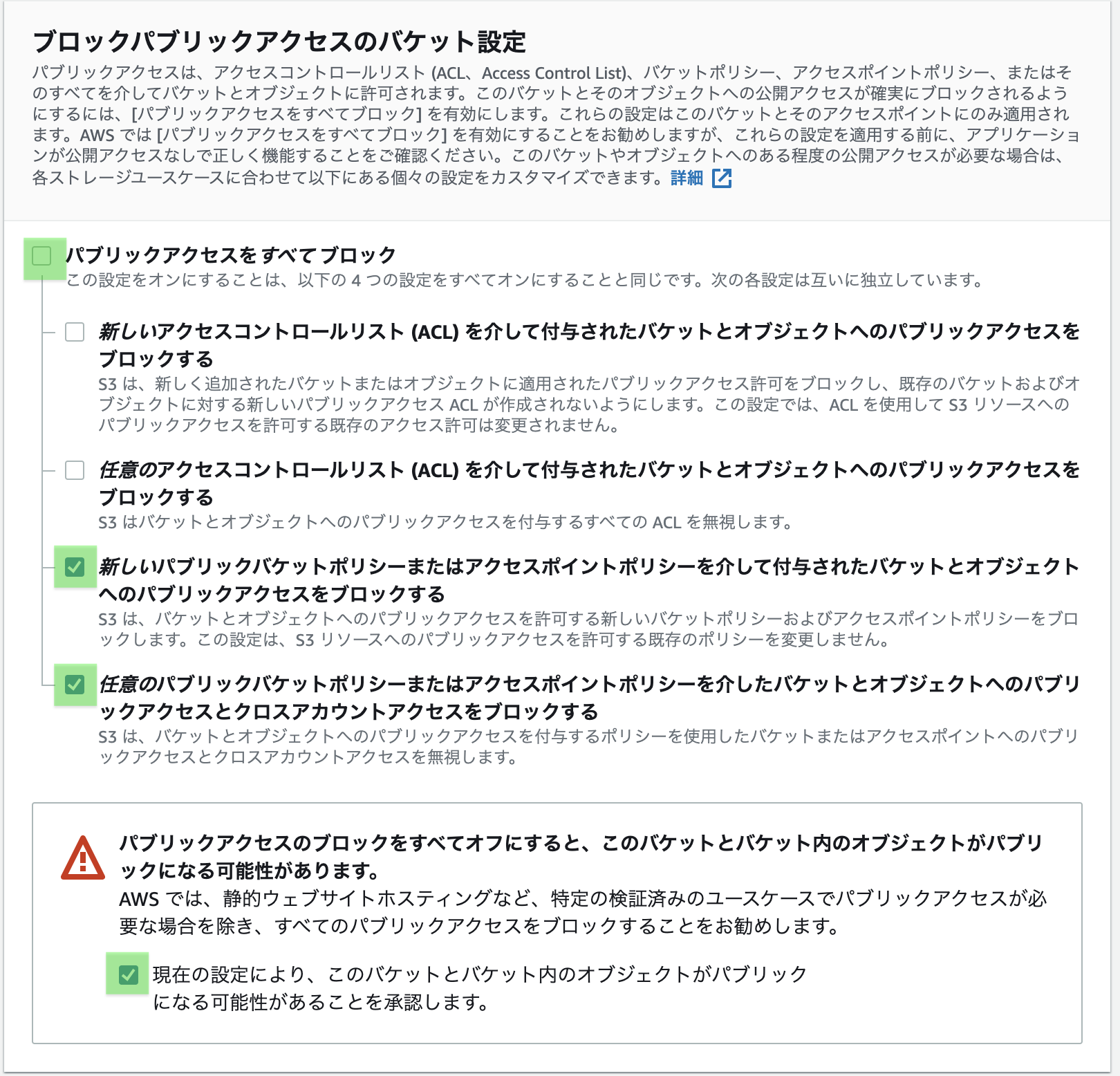
「パブリックアクセスを全てブロック」の✅を外し、下2つに✅をつける。
なかなか分かりづらいですが、要するにS3にあるHTMLファアイルをインターネットから参照できるようにしています。
さらに下へスクロール。
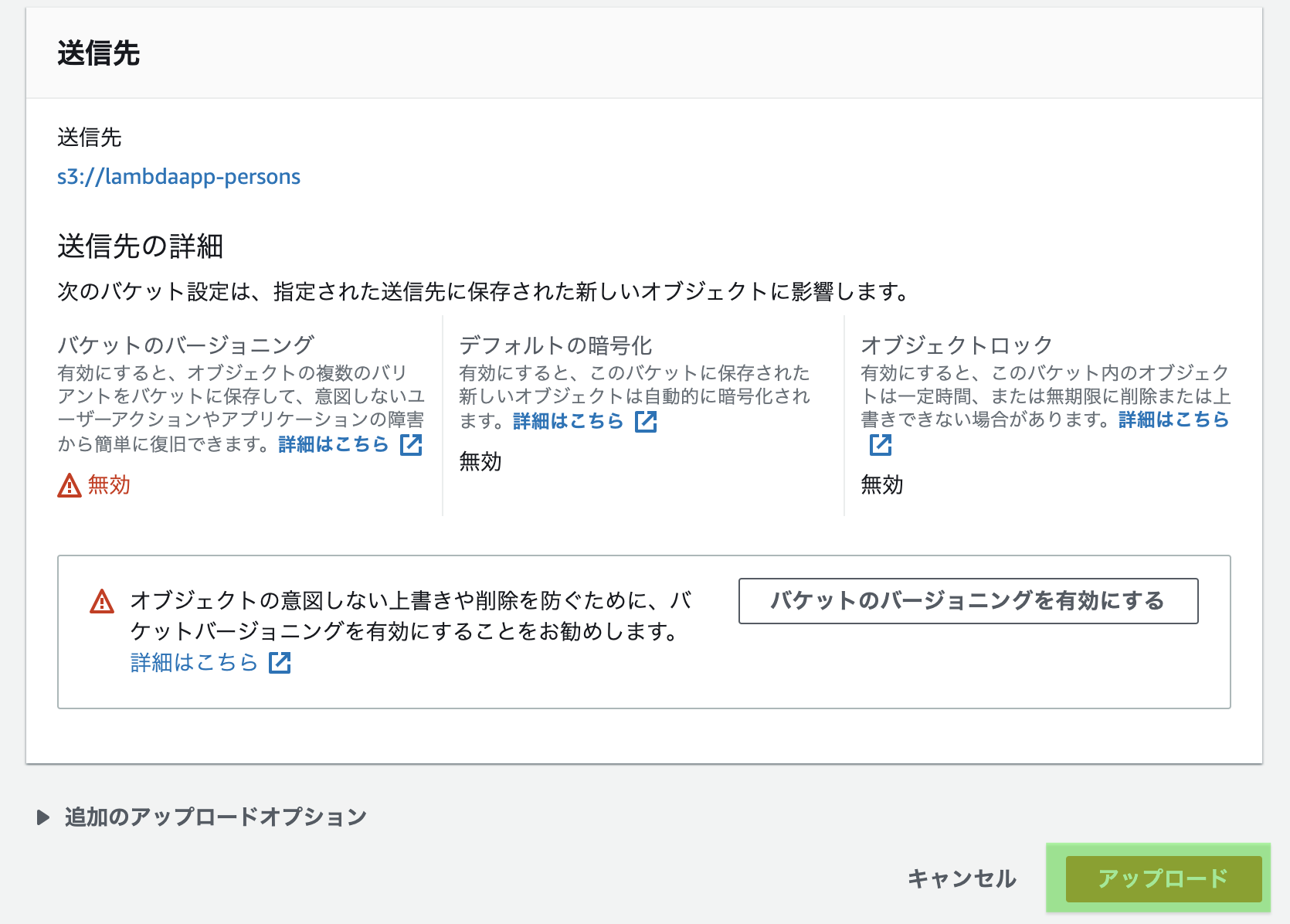
バケットのバージョニングは有効にすると、間違ってアップロードした時なんかに
元に戻せたりするみたいですね。お好みでどうぞ。
筆者はデフォルトの「無効」とします。
さらに下へスクロールし、「バケットを作成」を押下する。
正常に作成されました、と言うメッセージが表示されます。
作成したS3バケットをクリック
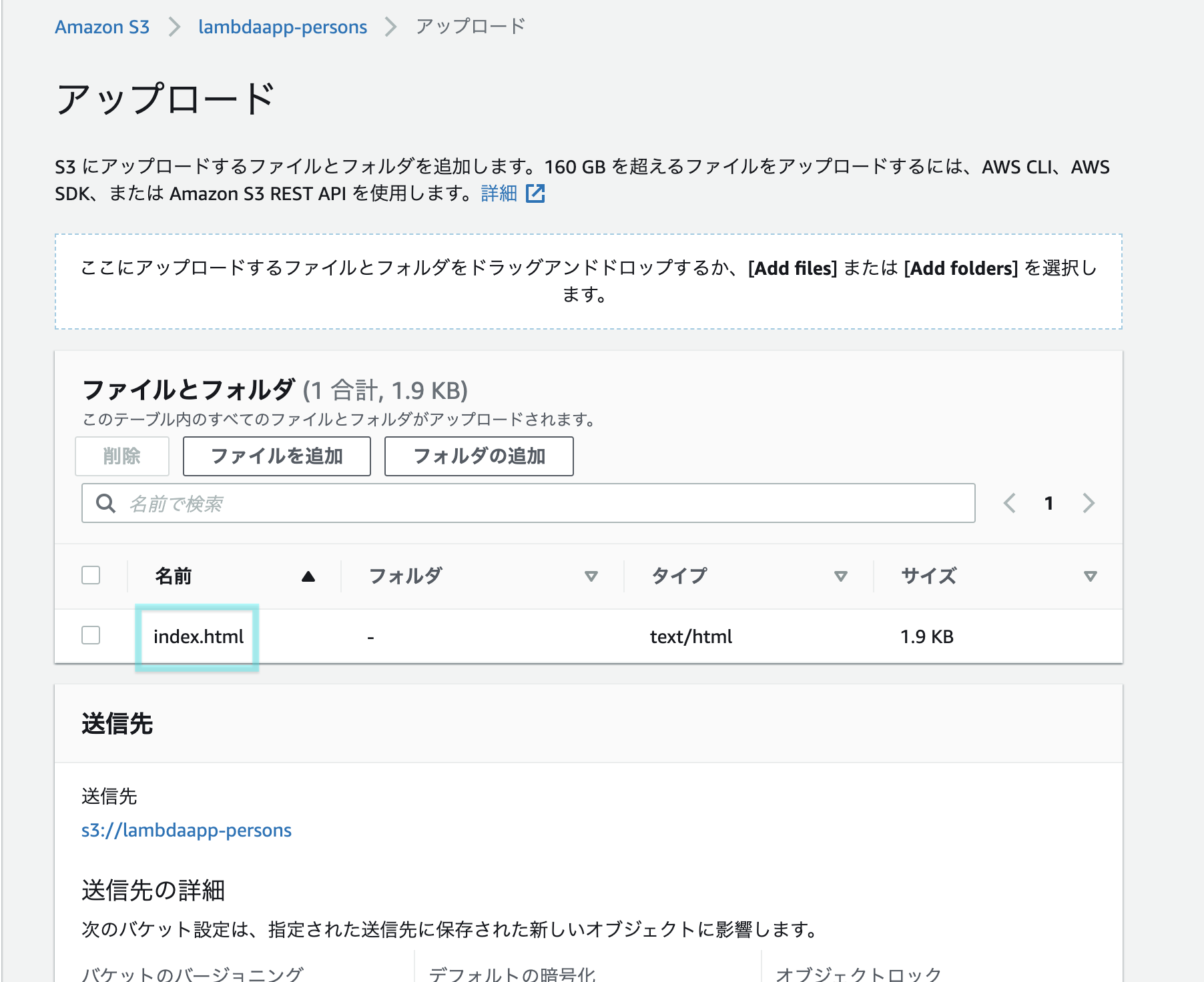
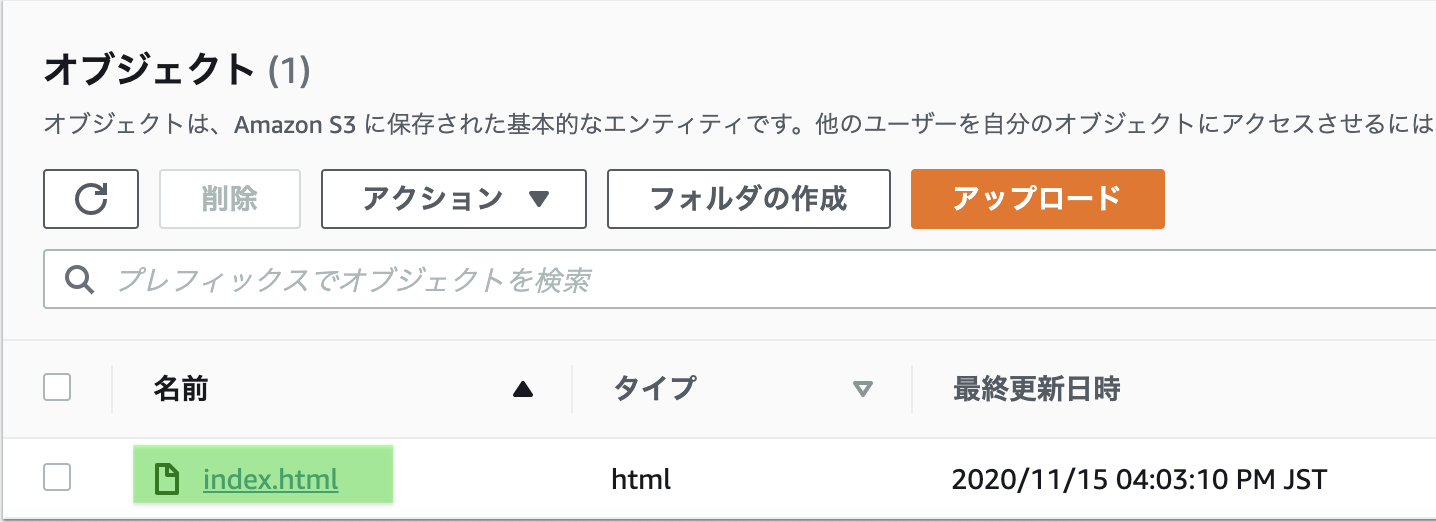
下図のエリアにhtmlファイルをドラッグ&ドロップする
HTMLファイルが表示されます。下へスクロール
「アップロード」をクリック
アップロード成功しました。
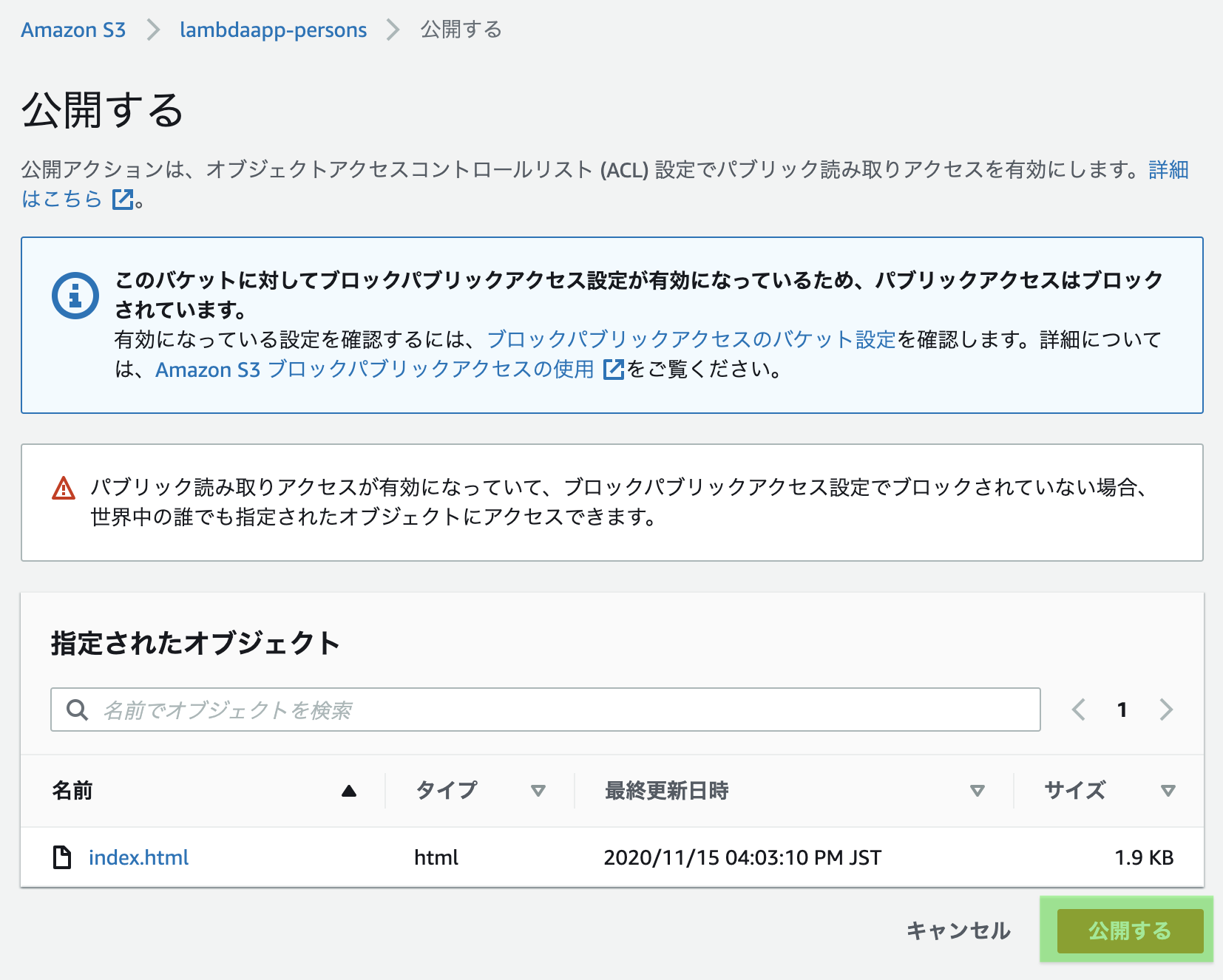
作成したバケットの画面に戻り、
アップロードしたHTMLファイルに✅をつけ、
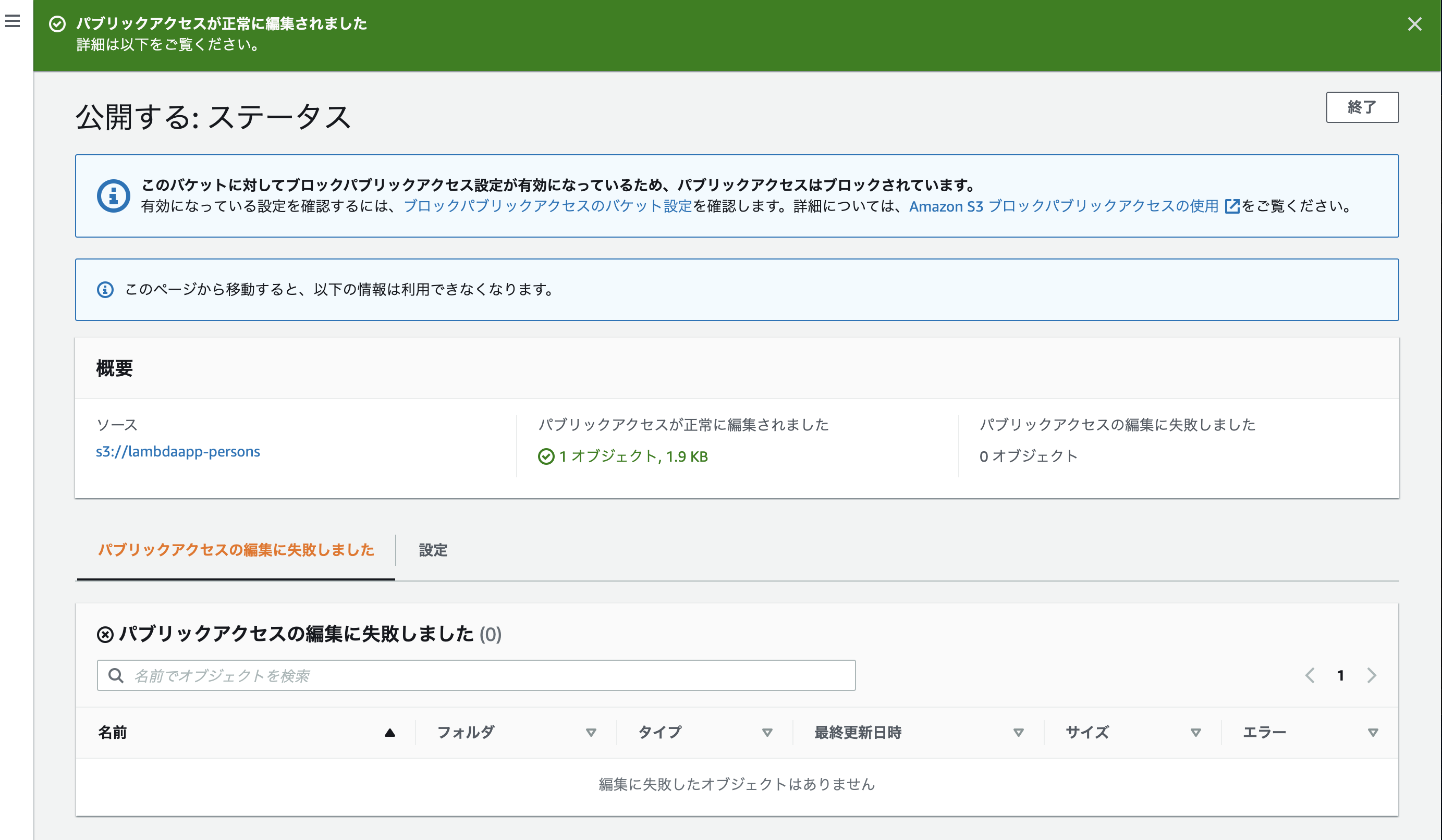
「アクション」から「公開する」をクリック
「公開する」をクリック
正常に公開されました。とメッセージが表示されますね。
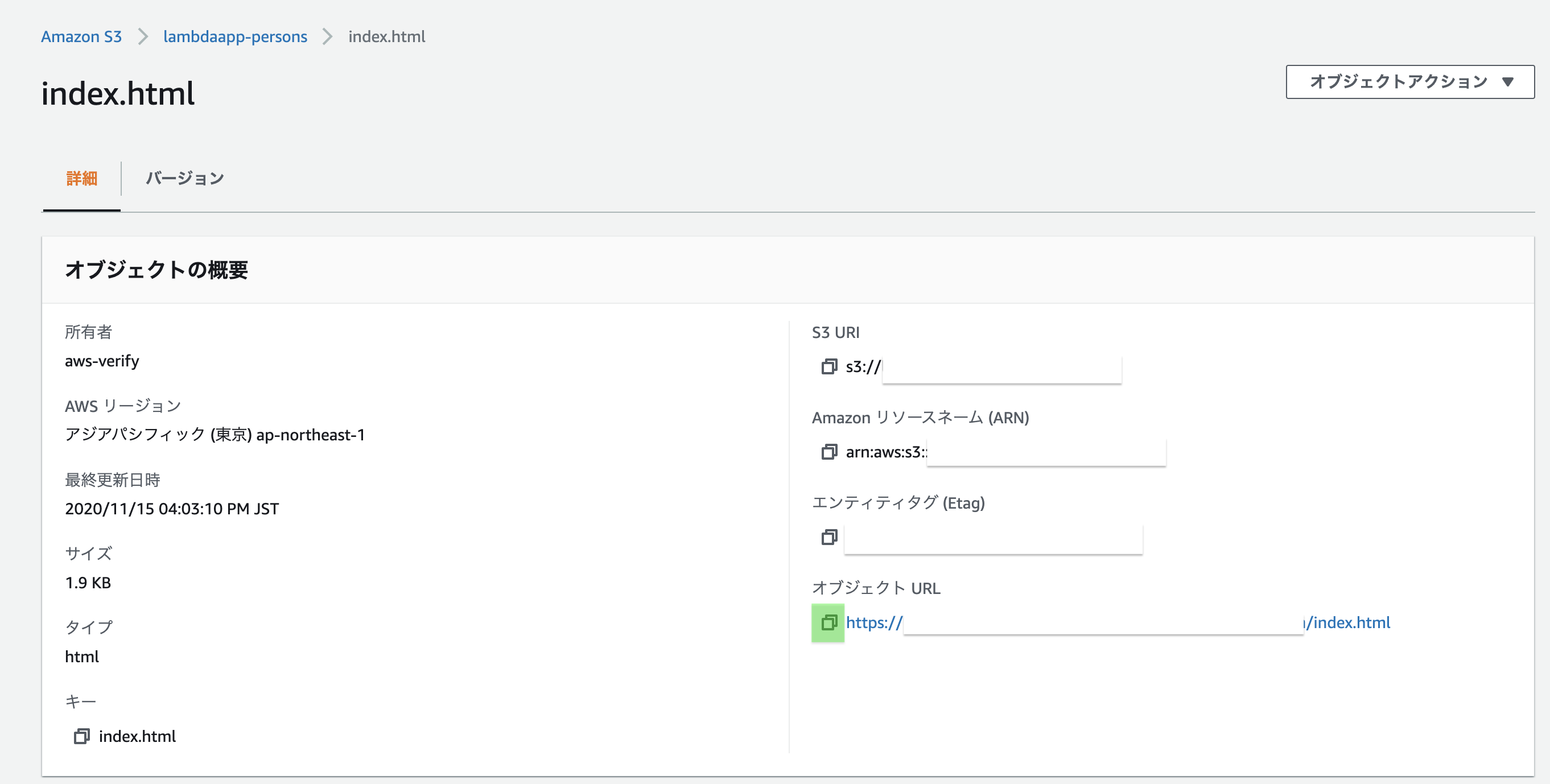
再びバケット画面に戻り、HTMLファイルをクリック
「オブジェクト URL」をコピー
URLをブラウザで実行して、動作確認
(余談ですが、Qiita執筆中にChromeのアプデが来ましたね。右上の「更新」ってやつ)
終わりに
Qiitaを書いてみて
Qiitaを書くこと自体にめちゃめちゃ時間がかかってしまい、
Getメソッドのみになってしまいました!!
画面操作をここまで細かく説明する必要あるのか?という疑問も浮かびましたが、なるべく初学者目線で、をモットーに
そのまま描き続けました。
果たして分かりやすい記事になったのだろうか。。。!!lambdaについて
今回はシンプルなアプリを作成しましたが、
きっともっと色んなことがlambdaを使ってできるはずなので、
(動画や画像など、様々なデータを暑かったりとか)
引き続き、何かを作りながら知見を深めていこうと思います!!
















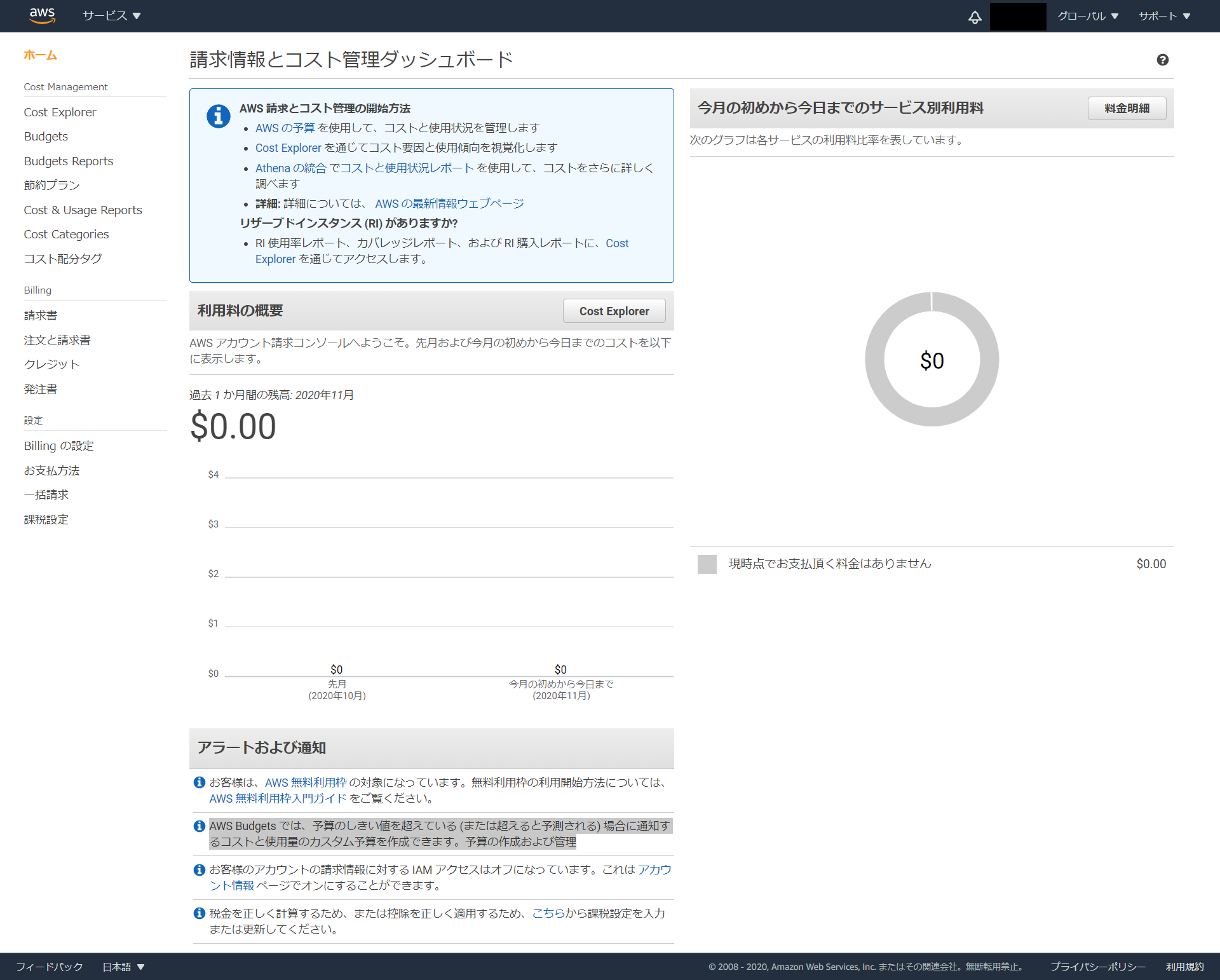
- 投稿日:2020-11-15T20:31:59+09:00
共働き夫婦の月々の精算を自動化してみた
はじめに
我が家は共働きで、家賃や光熱費・食費等の共通の出費はワリカンです。
共通の出費は一つの口座にまとめて紐づけており、その口座の残高のベース残高から減った分(=使った分)だけ割り勘してそれぞれが振り込む、といったルールとしています。
今回は口座残高の取得やワリカン計算を自動化し、Slackのチャンネルに投稿するような仕組みを作りました。やったこと
- AWS Lambda上でHeadless Chrome + Seleniumを動作
- Web家計簿アプリに自動ログインして口座残高を取得
- ワリカンを計算しSlackの家計清算チャンネルにメッセージ送信
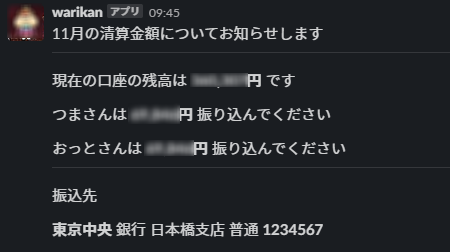
最終的にこんな感じのメッセージが投稿されるようになります。
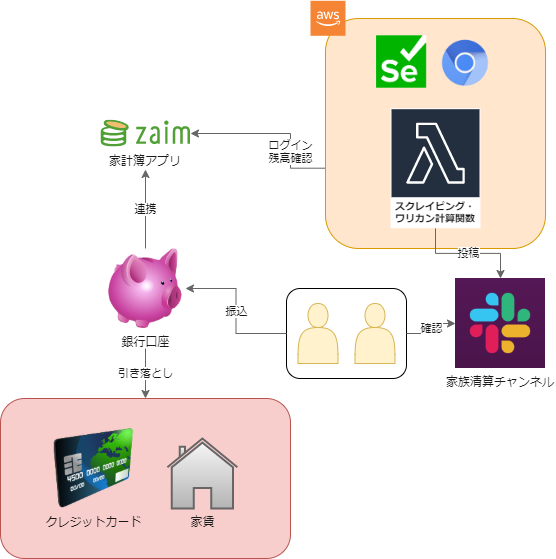
システム概要は以下の図のようになります。
開発環境
- Windows10 Pro 64bit
- VisualStudio Code
- Python3.7
- AWS
- GitLab
1. Slack Incoming Webhookの準備
上記リンク参考にIncoming Webhookを有効にしたSlack appを作成します。
最終的にWebhook投稿用のURLが発行されますので、これを書き留めます。
2. zaimアカウントの作成
本当は銀行から直接API利用で残高など取得できればいいのですが現状個人では利用できないようです。
したがって今回は銀行サービスと連携し、残高を取得できる家計簿アプリを利用させていただきました。
https://auth.zaim.net/users/signup?from=web
zaimという家計簿アプリですがいろいろな銀行と連携可能で残高を取得できます。
このサービスを利用しWebスクレイピングすることで残高を取得します。アカウント作成し、所望の銀行口座の連携登録を実施しておきます。
3. AWS Lambda上でHeadless Chrome + Selenium
参考にした記事は↓
https://qiita.com/nabehide/items/754eb7b7e9fff9a1047d残念ながらPython3.8では動作しなかったので3.7で作成しています。
Headless Chromeのlayer作成
headless-chromiumとchromedriverの両方が必要です。# headless-chromium https://github.com/adieuadieu/serverless-chrome/releases/tag/v1.0.0-37 # chrome-driver https://chromedriver.storage.googleapis.com/2.37/chromedriver_linux64.zip必要なファイルをS3にアップロードしてからCloudformationでlayer作成します。
$ ls chromedriver headless-chromium # このようなディレクトリで $ chmod 755 chromedriver $ chmod 755 headless-chromium $ zip --quiet -r headless-chrome.zip ./ $ aws s3 cp headless-chrome.zip s3://${YOUR_BUCKET_NAME}/headless-chrome.zipパラメータとしてアップロードしたバケット名を与えてください。
AWSTemplateFormatVersion: "2010-09-09" Parameters: BucketName: Type: String Description: name of s3 bucket Resources: LambdaLayer: Type: "AWS::Lambda::LayerVersion" Properties: CompatibleRuntimes: - python3.7 Content: S3Bucket: !Ref BucketName S3Key: headless-chrome.zip Description: something LayerName: headless-chromeSeleniumのlayer作成
GitLabランナーで
amazonlinux:2イメージを利用し作成しました。# .gitlab-ci.ymlのjob定義 Seleniumレイヤー作成job: image: amazonlinux:2 script: # pythonをインストール - yum -y install gcc make tar openssl-devel bzip2-devel libffi-devel wget gzip zip --quiet - mkdir ./python-build - cd ./python-build - wget --quiet https://www.python.org/ftp/python/3.7.5/Python-3.7.5.tgz - tar xzf ./Python-3.7.5.tgz - cd Python-3.7.5 - ./configure --enable-optimizations > /dev/null 2>&1 - make install > /dev/null 2>&1 - cd ${ROOT_DIR} - python3.7 --version # install pip - python3.7 -m pip install --quiet -U pip - pip install --quiet awscli selenium # deploy packageの作成 - mkdir python - pip install --quiet -t ./python -r requirements.txt - zip --quiet -r selenium.zip ./python - aws s3 cp selenium.zip s3://${YOUR_BUCKET_NAME}/selenium.zipこちらもCloudformationでlayer作成します。パラメータとしてアップロードしたバケット名を与えてください。
AWSTemplateFormatVersion: "2010-09-09" Parameters: BucketName: Type: String Description: name of s3 bucket Resources: LambdaLayer: Type: "AWS::Lambda::LayerVersion" Properties: CompatibleRuntimes: - python3.7 Content: S3Bucket: !Ref BucketName S3Key: selenium.zip Description: something LayerName: seleniumLambda Functionの作成
自分は以下の設定でLambdaFunctionを作成しました
- ランタイム: Python3.7
- タイムアウト:60秒(動作は30秒以上かかります)
- 割り当てメモリ: 384MB(メモリが少なすぎるとChromiumの動作に支障があるようです)
そのほか、上記作成したLayerの設定と各種環境変数の設定をしました。
参考ソースコード(長いので折り畳み)
本来はエラー処理など行っていますが処理の正常系の流れだけ追えるように1ファイルにまとめます。
import json import os from datetime import datetime import requests from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.ui import WebDriverWait options = webdriver.ChromeOptions() options.binary_location = "/opt/headless-chromium" options.add_argument("--headless") options.add_argument("--no-sandbox") options.add_argument("--single-process") # Webhook投稿時の本文に利用する要素、環境変数から読み込む WIFE_NAME = os.environ.get("WIFE_NAME") HASBAND_NAME = os.environ.get("HASBAND_NAME") BASE_BALANCE = int(os.environ.get("BASE_BALANCE")) BANK = os.environ.get("BANK") BRANCH = os.environ.get("BRANCH") ACCOUNT = os.environ.get("ACCOUNT") SLACK_WEBHOOK_URL = os.environ.get("SLACK_WEBHOOK_URL") def lambda_handler(event, context): # 1.----残高の確認---- url = "https://auth.zaim.net/" # ログインの情報は環境変数から読み込む user_id = os.environ.get("ZAIM_USER_ID") user_pass = os.environ.get("ZAIM_PASS") driver = webdriver.Chrome("/opt/chromedriver", chrome_options=options) # ログインフォームの読み込み待ち WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, "UserEmail")) ) user_id_input = driver.find_element_by_id("UserEmail") user_id_input.send_keys(user_id) user_pass_input = driver.find_element_by_id("UserPassword") user_pass_input.send_keys(user_pass) login_button = driver.find_element_by_xpath( '//*[@id="UserLoginForm"]/div[4]/input' ) login_button.submit() # 残高の読み込み待ち WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, "total-balance")) ) total_balance = driver.find_element_by_xpath( '//*[@id="total-balance"]/span' ).text total_balance = int(total_balance.strip().replace(",", "").lstrip("¥")) driver.close() driver.quit() # 2.----ワリカンの計算---- # ベース残高からの差を計算 total_charge = BASE_BALANCE - total_balance # total_chargeからそれぞれの補助分を引いて割り勘分を計算 # ここは投稿上1/2のワリカンにしています # 本来はそれぞれの会社からの補助(家賃補助等)を考慮していますが割愛 wife_charge = total_charge/2 hasband_charge = total_charge/2 # 3.----Webhook投稿---- month = datetime.now().month json_payload = { "text": "清算金額のお知らせです", "blocks": [ { "type": "section", "text": { "type": "mrkdwn", "text": "{month}月の清算金額についてお知らせします".format(month=month), }, }, {"type": "divider"}, { "type": "section", "text": { "type": "mrkdwn", "text": "現在の口座の残高は *{:,}円* です".format(total_balance), }, }, { "type": "section", "text": { "type": "mrkdwn", "text": "{}さんは *{:,}円* 振り込んでください".format(WIFE_NAME, wife_charge), }, }, { "type": "section", "text": { "type": "mrkdwn", "text": "{}さんは *{:,}円* 振り込んでください".format( HASBAND_NAME, hasband_charge ), }, }, {"type": "divider"}, {"type": "section", "text": {"type": "mrkdwn", "text": "振込先"}}, { "type": "section", "text": { "type": "mrkdwn", "text": "*{bank}* 銀行 {branch}支店 普通 *{account}*".format( bank=BANK, branch=BRANCH, account=ACCOUNT ), }, }, ], } requests.post(SLACK_WEBHOOK_URL, data=json.dumps(json_payload)) return {"statusCode": 200, "body": json.dumps({"message": "success"})}結果(再掲)
これで夫婦円満!
あとはこの関数を月に1回動作するためにCloudwatch EventsのScheduledRuleを設定していますが、長くなってしまったので紹介は割愛します。
終わりに
初めてのQiita記事投稿でしたが結構な長さになってしまいました。
できるだけ再現性のあるように記載したかったのですがいかがでしたでしょうか?
今回は口座の残高を確認することが目的でしたが、日・週・月毎に一回程度、固定の要素をWebスクレイピングで情報収集したい時などにサーバレスで簡便な構成になったかと思います。
- 投稿日:2020-11-15T19:43:32+09:00
Deploying Spark jobs on Amazon EKSをやってみた
はじめに
EKS上でSparkを動作させる記事を見つけたので、記載されている内容に沿って試してみました。
参照記事:https://aws.amazon.com/jp/blogs/opensource/deploying-spark-jobs-on-amazon-eks/やったこと
- S3バケット作成
- IAMポリシー作成
- EKSクラスター作成
- ECRレポジトリ作成
- DockerイメージBuild/Push
- Spark Job実行
S3バケットの作成
aws s3 mb s3://y-smp-bucket01IAMポリシーの作成
ポリシーをpolicyファイルとして定義
policycat << EOF > policy { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "s3:*", "Resource": "*" } ] } EOFポリシー作成
aws iam create-policy --policy-name eks2s3 --policy-document file://policyEKSクラスター作成
EKSクライアントインストール
curl --silent --location "https://github.com/weaveworks/eksctl/releases/latest/download/eksctl_$(uname -s)_amd64.tar.gz" | tar xz -C /tmp sudo mv /tmp/eksctl /usr/local/bin
eksctl.yamlに作成したポリシーのarnを設定amazon-eks-apache-spark-etl-sample/example/eksctl.yamlapiVersion: eksctl.io/v1alpha5 kind: ClusterConfig metadata: name: spark-cluster region: us-east-1 version: "1.14" availabilityZones: ["us-east-1a", "us-east-1b","us-east-1c"] nodeGroups: - name: spark-nodes instanceType: m5.xlarge volumeSize: 30 desiredCapacity: 4 privateNetworking: true maxPodsPerNode: 10 iam: attachPolicyARNs: - arn:aws:iam::aws:policy/AmazonEKSWorkerNodePolicy - arn:aws:iam::aws:policy/AmazonEKS_CNI_Policy - - <YOUR_AWS_IAM_POLICY_ARN> + - arn:aws:iam::xxxxxxxxxxxx:policy/eks2s3EKSクラスタ作成
eksctl create cluster -f example/eksctl.yaml事前にインストールするのを忘れたので、後からkubectlインストール
curl -LO "https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl" curl -LO https://storage.googleapis.com/kubernetes-release/release/v1.14.0/bin/linux/amd64/kubectl chmod +x ./kubectl sudo mv ./kubectl /usr/local/bin/kubectlkubecltバージョンが
1.14であることを確認kubectl version --client認証設定
aws eks --region us-east-1 update-kubeconfig --name spark-clusterECR作成
レポジトリ作成
aws ecr create-repository --repository-name eks/sparkSpark上で動作するアプリケーションのイメージをBuild
Dependency Resolutionに失敗するので
build.sbtに記載されているTypesafeレポジトリのプロトコルをhttpからhttpsへ変更amazon-eks-apache-spark-etl-sample/build.sbt- resolvers += "Typesafe Repository" at "http://repo.typesafe.com/typesafe/releases/" + resolvers += "Typesafe Repository" at "https://repo.typesafe.com/typesafe/releases/"DockerイメージをBuild
sudo docker build -t xxxxxxxxxxxx.dkr.ecr.us-east-1.amazonaws.com/eks/spark:v1.0 .ECRレジストリ認証設定
aws ecr get-login-password --region us-east-1 | sudo docker login --username AWS --password-stdin xxxxxxxxxxxx.dkr.ecr.us-east-1.amazonaws.comイメージPush
sudo docker push xxxxxxxxxxxx.dkr.ecr.us-east-1.amazonaws.com/eks/spark:v1.0RBAC変更
SparkがJobをサブミットできるようにRBACを変更
kubectl apply -f example/kubernetes/spark-rbac.yamlSpark BaseイメージBuild
spark-submitを実行するイメージをBuild&Pushsudo docker build --target=spark -t xxxxxxxxxxxx.dkr.ecr.us-east-1.amazonaws.com/eks/spark:v2.4.4 . sudo docker push xxxxxxxxxxxx.dkr.ecr.us-east-1.amazonaws.com/eks/spark:v2.4.4spark-job.yaml実行
spark-job.yaml編集amazon-eks-apache-spark-etl-sample/example/kubernetes/spark-job.yamlapiVersion: batch/v1 kind: Job metadata: name: spark-on-eks spec: template: spec: containers: - name: spark - image: <REPO_NAME>/spark:v2.4.4 + image: xxxxxxxxxxxx.dkr.ecr.us-east-1.amazonaws.com/eks/spark:v2.4.4 command: [ "/bin/sh", "-c", "/opt/spark/bin/spark-submit \ --master k8s://https://10.100.0.1:443 \ --deploy-mode cluster \ --name spark-on-eks \ --class ValueZones \ --conf spark.executor.instances=4 \ --conf spark.executor.memory=10G \ --conf spark.executor.cores=2 \ --conf spark.sql.shuffle.partitions=60 \ - --conf spark.kubernetes.container.image=<REPO_NAME>/<IMAGE_NAME>:<TAG> \ + --conf spark.kubernetes.container.image=xxxxxxxxxxxx.dkr.ecr.us-east-1.amazonaws.com/eks/spark:v1.0 \ --conf spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem \ --conf spark.kubernetes.container.image.pullPolicy=Always \ --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \ local:///opt/spark/jars/spark-on-eks-assembly-v1.0.jar \ \"s3a://nyc-tlc/trip data/yellow_tripdata_2018*.csv\" \ \"s3a://nyc-tlc/trip data/green_tripdata_2018*.csv\" \ \"s3a://nyc-tlc/misc/taxi _zone_lookup.csv\" \ - \"s3a://<YOUR_S3_BUCKET>\"" + \"s3a://y-smp-bucket01\"" ] serviceAccountName: spark restartPolicy: Never backoffLimit: 4Job実行前のPodを確認
ubuntu@ip-10-0-1-96:~/amazon-eks-apache-spark-etl-sample$ kubectl get pods No resources found.Job実行
kubectl apply -f example/kubernetes/spark-job.yamlJob実行前のPodを確認
spark-submitにて指定したパラメーターに沿ってPodが作成されていることが確認できるubuntu@ip-10-0-1-96:~/amazon-eks-apache-spark-etl-sample$ kubectl get pods NAME READY STATUS RESTARTS AGE spark-on-eks-1605426627391-driver 1/1 Running 0 45s spark-on-eks-1605426627391-exec-1 1/1 Running 0 30s spark-on-eks-1605426627391-exec-2 1/1 Running 0 30s spark-on-eks-1605426627391-exec-3 1/1 Running 0 30s spark-on-eks-1605426627391-exec-4 1/1 Running 0 30s spark-on-eks-qck66 1/1 Running 0 61sJobの終了に伴いPodが終了していることを確認
ubuntu@ip-10-0-1-96:~/amazon-eks-apache-spark-etl-sample$ kubectl get pods NAME READY STATUS RESTARTS AGE spark-on-eks-1605431350121-driver 0/1 Completed 0 8m35s spark-on-eks-cstdh 0/1 Completed 0 8m52sまとめ
Spark Driverからの要求に応じてKubernetesがリソーススケジューリングを行なっていることが確認できました。
- 投稿日:2020-11-15T17:41:02+09:00
EC2にDockerをインストールして起動してみた
はじめに
EC2 (AmazonLinux2)にDockerをインストールして使ってみた時の備忘録です。
普通はECSやElasticBeanstalkなどのコンテナ基盤を使うと思うので、あまり機会はないかもですが書いてみました。EC2でDockerをインストールしていく
EC2にログインします
$ ssh -i ~/.ssh/****.pem ec2-user@***.***.***.***git をインストール
$ sudo yum install git -yDocker をインストール
$ sudo amazon-linux-extras install docker -yDocker を起動
$ sudo service docker startおわりに
もし
ERROR: Couldn’t connect to Docker daemon at http+docker://localhost – is it running?みたいなエラーが出ればこちら↓の記事を参考にしてみてください。
- 投稿日:2020-11-15T17:33:01+09:00
CDKでAWS 環境の作成 EC2編
概要
CDKを使ってAWS環境を作成するときの方法についてまとめていこうと思います。
今回は前回作成したCDKの定義にEC2の定義を追加してこちらを参照しAdvendCalendarを公開してみました。準備
準備部分は前回等を参照してください。
VPCを作り直す場合はパラメータストアから値を取得しなおすためcdk.context.jsonを一度削除してください。コンパイルの準備
- ライブラリインストール後にプロジェクトを作成したディレクトリに移動して以下のコマンドを実行します。windowsの場合はライブラリのインストール時には停止する必要があるので注意を
npm run watch各モジュールの説明
- モジュールはgithubで公開しています。今回追加した部分のみ追記します。
- /vpc
yum updateを行うためS3へアクセスするためのエンドポイントを追加しています。/rds-s3
- EC2の設定を追加しています。
./bin/rds-s3.tsの方で以下のように設定することで複数のソースの定義を使えるようにしています。今回はEC2の要素を追加しています。import { RdsS3Stack } from '../lib/rds-s3-stack'; import { CdkRdsStack } from '../lib/cdk-rds-stack'; import { CdkS3Stack } from '../lib/cdk-s3-stack'; import { CdkEc2Stack } from '../lib/cdk-ec2-stack'; import { env } from 'process'; const app = new cdk.App(); new RdsS3Stack(app,'RdsS3Stack',{ env: { region: 'ap-northeast-1', account: env.AWS_ACCOUNT, }}); new CdkRdsStack(app,'CdkRdsStack',{ env: { region: 'ap-northeast-1', account: env.AWS_ACCOUNT, }}); new CdkS3Stack(app,'CdkS3Stack',{ env: { region: 'ap-northeast-1', account: env.AWS_ACCOUNT, }}); new CdkEc2Stack(app,'CdkEc2Stack',{ env: { region: 'ap-northeast-1', account: env.AWS_ACCOUNT, }});デプロイするときはStack名を指定して実施します。ワイルドカードの指定も可能です。
cdk deploy *またはcdk deploy CdkRdsStackの用に指定します。- 今回はEC2インスタンスを作成するときにキーペアを登録するためコマンドは次のようになります XXXXXXX の部分はキーペア名を設定します。
cdk deploy CdkEc2Stack -c key_pair=XXXXXXXCDKの定義
VPC
yum updateを行うためS3へアクセスするためのエンドポイントを追加しています。EC2
- 該当部分は以下のようになっています。
let ec2Instance = new ec2.CfnInstance(this, 'ec2-AdventCalendar', { imageId: 'ami-00f58a07aaa3179b8', // 新規でインスタンスを作成する場合は以下を使用 //imageId : new ec2.AmazonLinuxImage().getImage(this).imageId, instanceType: new ec2.InstanceType('t3.micro').toString(), networkInterfaces: [{ associatePublicIpAddress: true, deviceIndex: '0', groupSet: [securityGroup.securityGroupId], subnetId: targetVpc.publicSubnets[0].subnetId }], keyName: this.node.tryGetContext('key_pair'), });
- 事前にdockerのインストールなどを済ませたamiを用意しているためimage-IDを設定しています。
imageId: 'ami-00f58a07aaa3179b8',- amiを使わない場合は次のように設定します。
imageId : new ec2.AmazonLinuxImage().getImage(this).imageId,- インスタンスタイプは無料枠が有効なら
t2.microがよいですが無料枠が終わっている場合はt3.microの方が安いようです。- 今回はキーペアを登録して接続するようにしていますが、セッションマネージャーを利用することも検討してもよさそうです。
- SSHで接続するための設定はコンソールから別途設定しています。
AdventCalendarの作成
dockerのインストール
- 作成したEC2インスタンスにDockerのインストール手順です。
- 事前に以下の状態を確認します。
- アウトバウントの許可 (443,80のポートのみでよいかも)
- S3エンドポイントの追加
- teratermなどでインスタンスにログインし以下を実行します。
sudo yum update -ysudo yum install -y dockersudo usermod -a -G docker ec2-userコンテナの設定
コンテナのダウンロードを行います。
docker run -it --name コンテナ名 -p 8083:3000 mongamaenioh/radvent:latest /bin/bash- ポート番号はCDKの定義でアウトバウンドに指定しているポートを指定します。ポートを変えるときはそちらに合わせてください。
- このコマンドでコンテナを起動するとコンテナ内に入った状態となるので抜けたいときは CTRLキーを押したまま
PとQキーを押します。advent calendar の設定を行います。
cd /home/radventexport SECRET_KEY_BASE=bundle exec rake secret`vi /home/radvent/config/initializers/constants.rb
- こちらのコマンドで公開する日付を修正します。
- AMIいったんコンテナを作って翌年も使用するならこのタイミングでAMIを取得しておきましょう。
AdventCalendarの起動
- 起動させるときは以下のコマンドを実行します。
nohup bundle exec rails server -e production &
- 投稿日:2020-11-15T14:29:58+09:00
AWS Fargateで、タスク定義にAWS FireLensを含めると思わぬ差分が出るという話
What's?
AWS FireLens+Fluent Bitを組み込んだAWS FargateクラスターをTerraformで構成した時に、タスク定義で
terraform plan時に妙に差分が出てきて困ったという話。なお、原因は不明です。
お題
Terraformで、AWS Fargateクラスターを構築します。
タスク定義に含めるコンテナは、nginxとしましょう。
最初はnginxのみのタスク定義とし、あとでFluent Bit(AWS for Fluent Bit)も追加します。
この時の
terraform planの挙動を見てみます。環境
今回の環境は、こちら。
$ terraform version Terraform v0.13.5 + provider registry.terraform.io/hashicorp/aws v3.15.0 $ aws --version aws-cli/2.1.1 Python/3.7.3 Linux/5.4.0-53-generic exe/x86_64.ubuntu.20AWSのクレデンシャルは、環境変数で指定しています。
$ export AWS_ACCESS_KEY_ID=..... $ export AWS_SECRET_ACCESS_KEY=..... $ export AWS_DEFAULT_REGION=.....AWS Fargateのタスク定義を行う(nginxのみ)
ここからは、AWS Fargateクラスターを構築していきますが、タスク定義と補足的なリソースのみを最初に記載します。
リソース定義全体は、最後に載せます。
最初に、nginxのみを含めたタスクを定義します。
resource "aws_ecs_task_definition" "nginx" { family = "nginx-task-definition" cpu = "512" memory = "1024" network_mode = "awsvpc" requires_compatibilities = ["FARGATE"] execution_role_arn = aws_iam_role.ecs_task_execution_role.arn task_role_arn = aws_iam_role.ecs_task_role.arn container_definitions = <<JSON [ { "name": "nginx", "image": "nginx:1.19.4", "essential": true, "portMappings": [ { "protocol": "tcp", "containerPort": 80 } ], "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "/fargate/containers/nginx", "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "nginx" } } } ] JSON }とってもシンプル。
ログは、Amazon CloudWatch Logsに出力するようにしています。あとでAWS FireLensも使うので、ここまでをミニマムとします。
resource "aws_cloudwatch_log_group" "nginx" { name = "/fargate/containers/nginx" }
apply。$ terraform apply動作確認。
$ curl -i [ALBのDNS名] HTTP/1.1 200 OK Date: Sun, 15 Nov 2020 03:32:23 GMT Content-Type: text/html Content-Length: 612 Connection: keep-alive Server: nginx/1.19.4 Last-Modified: Tue, 27 Oct 2020 15:09:20 GMT ETag: "5f983820-264" Accept-Ranges: bytes <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html>ここで、
terraform planを実行してみます。$ terraform planリソースを構築したばかりですし、定義の変更も行っていないので特に差分はありません。
No changes. Infrastructure is up-to-date.
terraform showを実行して$ terraform showタスク定義の部分を見てみます。
# aws_ecs_task_definition.nginx: resource "aws_ecs_task_definition" "nginx" { arn = "arn:aws:ecs:ap-northeast-1:[AWSアカウントID]:task-definition/nginx-task-definition:37" container_definitions = jsonencode( [ { cpu = 0 environment = [] essential = true image = "nginx:1.19.4" logConfiguration = { logDriver = "awslogs" options = { awslogs-group = "/fargate/containers/nginx" awslogs-region = "ap-northeast-1" awslogs-stream-prefix = "nginx" } } mountPoints = [] name = "nginx" portMappings = [ { containerPort = 80 hostPort = 80 protocol = "tcp" }, ] volumesFrom = [] }, ] ) cpu = "512" execution_role_arn = "arn:aws:iam::[AWSアカウントID]:role/MyEcsTaskExecutionRole" family = "nginx-task-definition" id = "nginx-task-definition" memory = "1024" network_mode = "awsvpc" requires_compatibilities = [ "FARGATE", ] revision = 37 task_role_arn = "arn:aws:iam::[AWSアカウントID]:role/MyEcsTaskRole" }JSONに書いていなかった部分も、デフォルト値が入っています。
ここまで確認したら、いったん
terraform destroy。$ terraform destroyAWS Fargateのタスク定義を行う(nginx+AWS for Fluent Bit)
続いて、今度はAWS FireLensを使ったログ出力を行います。
AWSのドキュメントを見ながら、
先ほどのタスク定義にAWS FireLensおよびAWS for Fluent Bitの設定を追加します。
resource "aws_ecs_task_definition" "nginx" { family = "nginx-task-definition" cpu = "512" memory = "1024" network_mode = "awsvpc" requires_compatibilities = ["FARGATE"] execution_role_arn = aws_iam_role.ecs_task_execution_role.arn task_role_arn = aws_iam_role.ecs_task_role.arn container_definitions = <<JSON [ { "name": "log_router", "image": "906394416424.dkr.ecr.ap-northeast-1.amazonaws.com/aws-for-fluent-bit:latest", "essential": true, "firelensConfiguration": { "type": "fluentbit" }, "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "/fargate/containers/fluentbit", "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "fluentbit" } } }, { "name": "nginx", "image": "nginx:1.19.4", "essential": true, "portMappings": [ { "protocol": "tcp", "containerPort": 80 } ], "logConfiguration": { "logDriver": "awsfirelens", "options": { "Name": "cloudwatch", "region": "ap-northeast-1", "log_group_name": "/fargate/containers/nginx", "log_stream_prefix": "nginx", "auto_create_group": "false" } } } ] JSON }nginxのログは、AWS FireLensを介してAmazon CloudWatch Logsに出力するようにします。
Fluent Bit用のロググループも作成。
resource "aws_cloudwatch_log_group" "fluentbit" { name = "/fargate/containers/fluentbit" }タスクロールには、Fluent BitがAmazon CloudWatch Logsにログを出力できるように権限を追加しておきます。
data "aws_iam_policy_document" "ecs_task_role_policy_document" { statement { effect = "Allow" actions = [ "logs:DescribeLogStreams", "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ] resources = ["*"] } }リソース構築。
$ terraform apply動作確認。
$ curl -i [ALBのDNS名] HTTP/1.1 200 OK Date: Sun, 15 Nov 2020 03:41:51 GMT Content-Type: text/html Content-Length: 612 Connection: keep-alive Server: nginx/1.19.4 Last-Modified: Tue, 27 Oct 2020 15:09:20 GMT ETag: "5f983820-264" Accept-Ranges: bytes <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html>ここまではOKです。
で、この状態で
terraform planを実行すると$ terraform planなにも変更していませんが、差分が検出されます。
------------------------------------------------------------------------ An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: ~ update in-place -/+ destroy and then create replacement Terraform will perform the following actions: # aws_ecs_service.nginx will be updated in-place ~ resource "aws_ecs_service" "nginx" { cluster = "arn:aws:ecs:ap-northeast-1:[AWSアカウントID]:cluster/nginx-cluster" deployment_maximum_percent = 200 deployment_minimum_healthy_percent = 50 desired_count = 3 enable_ecs_managed_tags = false health_check_grace_period_seconds = 0 iam_role = "aws-service-role" id = "arn:aws:ecs:ap-northeast-1:[AWSアカウントID]:service/nginx-cluster/nginx-service" launch_type = "FARGATE" name = "nginx-service" platform_version = "1.4.0" propagate_tags = "NONE" scheduling_strategy = "REPLICA" tags = {} ~ task_definition = "arn:aws:ecs:ap-northeast-1:[AWSアカウントID]:task-definition/nginx-task-definition:38" -> (known after apply) wait_for_steady_state = false deployment_controller { type = "ECS" } load_balancer { container_name = "nginx" container_port = 80 target_group_arn = "arn:aws:elasticloadbalancing:ap-northeast-1:[AWSアカウントID]:targetgroup/tf-20201115034033903500000005/31aa063424fafa30" } network_configuration { assign_public_ip = false security_groups = [ "sg-0bdd096a03b3467ab", ] subnets = [ "subnet-07ca48860443af5f7", "subnet-0aa3ac7b0fcf82b5e", ] } } # aws_ecs_task_definition.nginx must be replaced -/+ resource "aws_ecs_task_definition" "nginx" { ~ arn = "arn:aws:ecs:ap-northeast-1:[AWSアカウントID]:task-definition/nginx-task-definition:38" -> (known after apply) ~ container_definitions = jsonencode( ~ [ # forces replacement ~ { - cpu = 0 -> null - environment = [] -> null essential = true firelensConfiguration = { type = "fluentbit" } image = "906394416424.dkr.ecr.ap-northeast-1.amazonaws.com/aws-for-fluent-bit:latest" logConfiguration = { logDriver = "awslogs" options = { awslogs-group = "/fargate/containers/fluentbit" awslogs-region = "ap-northeast-1" awslogs-stream-prefix = "fluentbit" } } - mountPoints = [] -> null name = "log_router" - portMappings = [] -> null - user = "0" -> null - volumesFrom = [] -> null } # forces replacement, ~ { - cpu = 0 -> null - environment = [] -> null essential = true image = "nginx:1.19.4" logConfiguration = { logDriver = "awsfirelens" options = { Name = "cloudwatch" auto_create_group = "false" log_group_name = "/fargate/containers/nginx" log_stream_prefix = "nginx" region = "ap-northeast-1" } } - mountPoints = [] -> null name = "nginx" ~ portMappings = [ ~ { containerPort = 80 - hostPort = 80 -> null protocol = "tcp" }, ] - volumesFrom = [] -> null } # forces replacement, ] ) cpu = "512" execution_role_arn = "arn:aws:iam::[AWSアカウントID]:role/MyEcsTaskExecutionRole" family = "nginx-task-definition" ~ id = "nginx-task-definition" -> (known after apply) memory = "1024" network_mode = "awsvpc" requires_compatibilities = [ "FARGATE", ] ~ revision = 38 -> (known after apply) - tags = {} -> null task_role_arn = "arn:aws:iam::[AWSアカウントID]:role/MyEcsTaskRole" } Plan: 1 to add, 1 to change, 1 to destroy. ------------------------------------------------------------------------コンテナ定義の、デフォルト値まわりが軒並み指摘されているように見えます。
~ container_definitions = jsonencode( ~ [ # forces replacement ~ { - cpu = 0 -> null - environment = [] -> null essential = true firelensConfiguration = { type = "fluentbit" } image = "906394416424.dkr.ecr.ap-northeast-1.amazonaws.com/aws-for-fluent-bit:latest" logConfiguration = { logDriver = "awslogs" options = { awslogs-group = "/fargate/containers/fluentbit" awslogs-region = "ap-northeast-1" awslogs-stream-prefix = "fluentbit" } } - mountPoints = [] -> null name = "log_router" - portMappings = [] -> null - user = "0" -> null - volumesFrom = [] -> null } # forces replacement, ~ { - cpu = 0 -> null - environment = [] -> null essential = true image = "nginx:1.19.4" logConfiguration = { logDriver = "awsfirelens" options = { Name = "cloudwatch" auto_create_group = "false" log_group_name = "/fargate/containers/nginx" log_stream_prefix = "nginx" region = "ap-northeast-1" } } - mountPoints = [] -> null name = "nginx" ~ portMappings = [ ~ { containerPort = 80 - hostPort = 80 -> null protocol = "tcp" }, ] - volumesFrom = [] -> null } # forces replacement, ] )
terraform showで見てみても$ terraform shownginx単体の時とそんなに変わった気はしないんですけどねぇ…。
# aws_ecs_task_definition.nginx: resource "aws_ecs_task_definition" "nginx" { arn = "arn:aws:ecs:ap-northeast-1:[AWSアカウントID]:task-definition/nginx-task-definition:38" container_definitions = jsonencode( [ { cpu = 0 environment = [] essential = true firelensConfiguration = { type = "fluentbit" } image = "906394416424.dkr.ecr.ap-northeast-1.amazonaws.com/aws-for-fluent-bit:latest" logConfiguration = { logDriver = "awslogs" options = { awslogs-group = "/fargate/containers/fluentbit" awslogs-region = "ap-northeast-1" awslogs-stream-prefix = "fluentbit" } } mountPoints = [] name = "log_router" portMappings = [] user = "0" volumesFrom = [] }, { cpu = 0 environment = [] essential = true image = "nginx:1.19.4" logConfiguration = { logDriver = "awsfirelens" options = { Name = "cloudwatch" auto_create_group = "false" log_group_name = "/fargate/containers/nginx" log_stream_prefix = "nginx" region = "ap-northeast-1" } } mountPoints = [] name = "nginx" portMappings = [ { containerPort = 80 hostPort = 80 protocol = "tcp" }, ] volumesFrom = [] }, ] ) cpu = "512" execution_role_arn = "arn:aws:iam::[AWSアカウントID]:role/MyEcsTaskExecutionRole" family = "nginx-task-definition" id = "nginx-task-definition" memory = "1024" network_mode = "awsvpc" requires_compatibilities = [ "FARGATE", ] revision = 38 task_role_arn = "arn:aws:iam::[AWSアカウントID]:role/MyEcsTaskRole" }仕方がないので、指摘されていたデフォルト値を全部埋めてあげると
container_definitions = <<JSON [ { "name": "log_router", "image": "906394416424.dkr.ecr.ap-northeast-1.amazonaws.com/aws-for-fluent-bit:latest", "essential": true, "firelensConfiguration": { "type": "fluentbit" }, "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "/fargate/containers/fluentbit", "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "fluentbit" } }, "cpu": 0, "environment": [], "mountPoints": [], "volumesFrom": [], "portMappings": [], "user": "0" }, { "name": "nginx", "image": "nginx:1.19.4", "essential": true, "portMappings": [ { "protocol": "tcp", "containerPort": 80, "hostPort": 80 } ], "logConfiguration": { "logDriver": "awsfirelens", "options": { "Name": "cloudwatch", "region": "ap-northeast-1", "log_group_name": "/fargate/containers/nginx", "log_stream_prefix": "nginx", "auto_create_group": "false" } }, "cpu": 0, "environment": [], "mountPoints": [], "volumesFrom": [] } ] JSON
planで差分が出なくなります。$ terraform planどうなってるんでしょうね?
No changes. Infrastructure is up-to-date.ちなみに、(まったく意味がないですが)Fluent Bitをタスク定義に入れてもAWS FireLensとして構成していない場合は差分が検出されません。
container_definitions = <<JSON [ { "name": "log_router", "image": "906394416424.dkr.ecr.ap-northeast-1.amazonaws.com/aws-for-fluent-bit:latest", "essential": true, "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "/fargate/containers/fluentbit", "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "fluentbit" } } }, { "name": "nginx", "image": "nginx:1.19.4", "essential": true, "portMappings": [ { "protocol": "tcp", "containerPort": 80 } ], "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "/fargate/containers/nginx", "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "nginx" } } } ] JSON
terraform showで、タスク定義の状態を見てみます。# aws_ecs_task_definition.nginx: resource "aws_ecs_task_definition" "nginx" { arn = "arn:aws:ecs:ap-northeast-1:[AWSアカウントID]:task-definition/nginx-task-definition:39" container_definitions = jsonencode( [ { cpu = 0 environment = [] essential = true image = "906394416424.dkr.ecr.ap-northeast-1.amazonaws.com/aws-for-fluent-bit:latest" logConfiguration = { logDriver = "awslogs" options = { awslogs-group = "/fargate/containers/fluentbit" awslogs-region = "ap-northeast-1" awslogs-stream-prefix = "fluentbit" } } mountPoints = [] name = "log_router" portMappings = [] volumesFrom = [] }, { cpu = 0 environment = [] essential = true image = "nginx:1.19.4" logConfiguration = { logDriver = "awslogs" options = { awslogs-group = "/fargate/containers/nginx" awslogs-region = "ap-northeast-1" awslogs-stream-prefix = "nginx" } } mountPoints = [] name = "nginx" portMappings = [ { containerPort = 80 hostPort = 80 protocol = "tcp" }, ] volumesFrom = [] }, ] ) cpu = "512" execution_role_arn = "arn:aws:iam::[AWSアカウントID]:role/MyEcsTaskExecutionRole" family = "nginx-task-definition" id = "nginx-task-definition" memory = "1024" network_mode = "awsvpc" requires_compatibilities = [ "FARGATE", ] revision = 39 task_role_arn = "arn:aws:iam::[AWSアカウントID]:role/MyEcsTaskRole" }AWS FireLensとして構成した時と比べて、
firelensConfigurationとかログ出力定義とかに差分があるのはもちろんなのですが。AWS FireLensとして構成した場合は、Fluent Bitコンテナに以下の値が追加されています。
"user": "0"なにか、差分になる理由があるんでしょうね…。
userを0に指定しているということは、UIDを指定していることになると思うのですが。AWS FireLensが関係しそうだということはわかったのですが、今回はこれ以上追わないことにします。
リソース定義全体
最後に、ここまでのリソース定義全体を載せておきます。
VPCからALB、AWS Fargateのクラスターやサービス定義などを含め、ここまで登場したタスク定義のJSONについてはコメントで残しています。
有効にして残しているのは、AWS FireLensを使いつつ
planで差分が出ないパターンですね。
main.tfterraform { required_version = "0.13.5" required_providers { aws = { source = "hashicorp/aws" version = "3.15.0" } } } provider "aws" { } module "vpc" { source = "terraform-aws-modules/vpc/aws" version = "2.64.0" name = "my-vpc" cidr = "10.0.0.0/16" enable_dns_hostnames = true enable_dns_support = true azs = ["ap-northeast-1a", "ap-northeast-1c"] public_subnets = ["10.0.10.0/24", "10.0.20.0/24"] private_subnets = ["10.0.30.0/24", "10.0.40.0/24"] map_public_ip_on_launch = true enable_nat_gateway = true single_nat_gateway = false one_nat_gateway_per_az = true } module "load_balancer_sg" { source = "terraform-aws-modules/security-group/aws//modules/http-80" version = "3.16.0" name = "load-balancer-sg" vpc_id = module.vpc.vpc_id ingress_cidr_blocks = ["0.0.0.0/0"] } module "nginx_service_sg" { source = "terraform-aws-modules/security-group/aws" version = "3.16.0" name = "nginx-service-sg" vpc_id = module.vpc.vpc_id ingress_with_cidr_blocks = [ { from_port = 80 to_port = 80 protocol = "tcp" description = "nginx-service inbound ports" cidr_blocks = "10.0.10.0/24" }, { from_port = 80 to_port = 80 protocol = "tcp" description = "nginx-service inbound ports" cidr_blocks = "10.0.20.0/24" } ] egress_with_cidr_blocks = [ { from_port = 0 to_port = 0 protocol = "-1" description = "nginx-service outbound ports" cidr_blocks = "0.0.0.0/0" } ] } module "load_balancer" { source = "terraform-aws-modules/alb/aws" version = "5.9.0" name = "nginx" vpc_id = module.vpc.vpc_id load_balancer_type = "application" internal = false subnets = module.vpc.public_subnets security_groups = [module.load_balancer_sg.this_security_group_id] target_groups = [ { backend_protocol = "HTTP" backend_port = 80 target_type = "ip" health_check = { interval = 20 } } ] http_tcp_listeners = [ { port = 80 protocol = "HTTP" } ] } locals { vpc_id = module.vpc.vpc_id private_subnets = module.vpc.private_subnets nginx_service_security_groups = [module.nginx_service_sg.this_security_group_id] load_balancer_target_group_arn = module.load_balancer.target_group_arns[0] } data "aws_iam_policy_document" "assume_role" { statement { actions = ["sts:AssumeRole"] principals { type = "Service" identifiers = ["ecs-tasks.amazonaws.com"] } } } data "aws_iam_policy" "ecs_task_execution_role_policy" { arn = "arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy" } resource "aws_iam_role" "ecs_task_execution_role" { name = "MyEcsTaskExecutionRole" assume_role_policy = data.aws_iam_policy_document.assume_role.json } resource "aws_iam_role_policy_attachment" "ecs_task_execution_role_policy_attachment" { role = aws_iam_role.ecs_task_execution_role.name policy_arn = data.aws_iam_policy.ecs_task_execution_role_policy.arn } data "aws_iam_policy_document" "ecs_task_role_policy_document" { statement { effect = "Allow" actions = [ "logs:DescribeLogStreams", "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ] resources = ["*"] } } resource "aws_iam_policy" "ecs_task_role_policy" { name = "MyEcsTaskPolicy" policy = data.aws_iam_policy_document.ecs_task_role_policy_document.json } resource "aws_iam_role" "ecs_task_role" { name = "MyEcsTaskRole" assume_role_policy = data.aws_iam_policy_document.assume_role.json } resource "aws_iam_role_policy_attachment" "ecs_task_role_policy_attachment" { role = aws_iam_role.ecs_task_role.name policy_arn = aws_iam_policy.ecs_task_role_policy.arn } resource "aws_cloudwatch_log_group" "nginx" { name = "/fargate/containers/nginx" } resource "aws_cloudwatch_log_group" "fluentbit" { name = "/fargate/containers/fluentbit" } resource "aws_ecs_cluster" "nginx" { name = "nginx-cluster" } resource "aws_ecs_task_definition" "nginx" { family = "nginx-task-definition" cpu = "512" memory = "1024" network_mode = "awsvpc" requires_compatibilities = ["FARGATE"] execution_role_arn = aws_iam_role.ecs_task_execution_role.arn task_role_arn = aws_iam_role.ecs_task_role.arn container_definitions = <<JSON [ { "name": "log_router", "image": "906394416424.dkr.ecr.ap-northeast-1.amazonaws.com/aws-for-fluent-bit:latest", "essential": true, "firelensConfiguration": { "type": "fluentbit" }, "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "/fargate/containers/fluentbit", "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "fluentbit" } }, "cpu": 0, "environment": [], "mountPoints": [], "volumesFrom": [], "portMappings": [], "user": "0" }, { "name": "nginx", "image": "nginx:1.19.4", "essential": true, "portMappings": [ { "protocol": "tcp", "containerPort": 80, "hostPort": 80 } ], "logConfiguration": { "logDriver": "awsfirelens", "options": { "Name": "cloudwatch", "region": "ap-northeast-1", "log_group_name": "/fargate/containers/nginx", "log_stream_prefix": "nginx", "auto_create_group": "false" } }, "cpu": 0, "environment": [], "mountPoints": [], "volumesFrom": [] } ] JSON /* container_definitions = <<JSON [ { "name": "log_router", "image": "906394416424.dkr.ecr.ap-northeast-1.amazonaws.com/aws-for-fluent-bit:latest", "essential": true, "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "/fargate/containers/fluentbit", "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "fluentbit" } } }, { "name": "nginx", "image": "nginx:1.19.4", "essential": true, "portMappings": [ { "protocol": "tcp", "containerPort": 80 } ], "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "/fargate/containers/nginx", "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "nginx" } } } ] JSON */ /* container_definitions = <<JSON [ { "name": "log_router", "image": "906394416424.dkr.ecr.ap-northeast-1.amazonaws.com/aws-for-fluent-bit:latest", "essential": true, "firelensConfiguration": { "type": "fluentbit" }, "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "/fargate/containers/fluentbit", "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "fluentbit" } } }, { "name": "nginx", "image": "nginx:1.19.4", "essential": true, "portMappings": [ { "protocol": "tcp", "containerPort": 80 } ], "logConfiguration": { "logDriver": "awsfirelens", "options": { "Name": "cloudwatch", "region": "ap-northeast-1", "log_group_name": "/fargate/containers/nginx", "log_stream_prefix": "nginx", "auto_create_group": "false" } } } ] JSON */ /* container_definitions = <<JSON [ { "name": "nginx", "image": "nginx:1.19.4", "essential": true, "portMappings": [ { "protocol": "tcp", "containerPort": 80 } ], "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "/fargate/containers/nginx", "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "nginx" } } } ] JSON */ } resource "aws_ecs_service" "nginx" { name = "nginx-service" cluster = aws_ecs_cluster.nginx.arn task_definition = aws_ecs_task_definition.nginx.arn desired_count = 3 launch_type = "FARGATE" platform_version = "1.4.0" deployment_minimum_healthy_percent = 50 network_configuration { assign_public_ip = false security_groups = local.nginx_service_security_groups subnets = local.private_subnets } load_balancer { target_group_arn = local.load_balancer_target_group_arn container_name = "nginx" container_port = 80 } }
- 投稿日:2020-11-15T13:55:57+09:00
【Rails】Capistranoによる自動デプロイで発生したエラー(fatal: not a valid object name: master)
はじめに
現在プログラミングスクール卒業後、ポートフォリオ作成をしており、
Capistranoを使用した自動デプロイで発生したエラーを備忘録として投稿します。■開発環境
- Rails 5.0.7.2
- ruby 2.5.1
- AWS EC2
- Nginx
- Unicorn
- capistrano
Capistrano導入について
下記の記事を参考に、導入しました。
導入方法が分からない方は、私と同様に参考にしてみてください。
自動デプロイツール(Capistrano)導入方法発生したエラーについて
上記の記事を参考にCapistranoを導入し、自動デプロイを実行したところ、途中でエラーが発生しました。
ターミナル(ローカル環境)# アプリケーションのディレクトリで、下記の自動デプロイコマンドを実行する。 $ bundle exec cap production deploy自動デプロイコマンド実行後の、エラー内容はこちら。
ターミナル(ローカル環境)$ bundle exec cap production deploy [Deprecation Notice] Future versions of Capistrano will not load the Git SCM plugin by default. To silence this deprecation warning, add the following to your Capfile after `require "capistrano/deploy"`: require "capistrano/scm/git" install_plugin Capistrano::SCM::Git 00:00 git:wrapper 01 mkdir -p /tmp ✔ 01 ec2-user@52.193.230.41 0.239s Uploading /tmp/git-ssh-smot-production-nakayakouyuu.sh 100.0% 02 chmod 700 /tmp/git-ssh-smot-production-nakayakouyuu.sh ✔ 02 ec2-user@52.193.230.41 0.291s 00:00 git:check 01 git ls-remote git@github.com:nakaya-kousuke/smot.git HEAD 01 5e943870f1583d9775b045f3c40d418324d8ad8a HEAD ✔ 01 ec2-user@52.193.230.41 2.098s 00:02 deploy:check:directories 01 mkdir -p /var/www/smot/shared /var/www/smot/releases ✔ 01 ec2-user@52.193.230.41 0.132s 00:03 deploy:check:linked_dirs 01 mkdir -p /var/www/smot/shared/log /var/www/smot/shared/tmp/pids /var/www/smot/shared/tmp/cache /var/www/smot/shared/tmp/sockets /var/www/smot/sha… ✔ 01 ec2-user@52.193.230.41 0.224s 00:03 git:clone The repository mirror is at /var/www/smot/repo 00:03 git:update 01 git remote set-url origin git@github.com:nakaya-kousuke/smot.git ✔ 01 ec2-user@52.193.230.41 0.237s 02 git remote update --prune 02 Fetching origin ✔ 02 ec2-user@52.193.230.41 2.093s 00:06 git:create_release 01 mkdir -p /var/www/smot/releases/20201103133334 ✔ 01 ec2-user@52.193.230.41 0.226s 02 git archive master | /usr/bin/env tar -x -f - -C /var/www/smot/releases/20201103133334 02 fatal: not a valid object name: master 02 tar: 02 これは tar アーカイブではないようです 02 02 tar: 02 前のエラーにより失敗ステータスで終了します 02 #<Thread:0x00007f9e5507c1f0@/Users/nakaya-kousuke/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/sshkit-1.21.0/lib/sshkit/runners/parallel.rb:10 run> terminated with exception (report_on_exception is true): Traceback (most recent call last): 1: from /Users/nakaya-kousuke/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/sshkit-1.21.0/lib/sshkit/runners/parallel.rb:11:in `block (2 levels) in execute' /Users/nakaya-kousuke/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/sshkit-1.21.0/lib/sshkit/runners/parallel.rb:15:in `rescue in block (2 levels) in execute': Exception while executing as ec2-user@52.193.230.41: git exit status: 2 (SSHKit::Runner::ExecuteError) git stdout: Nothing written git stderr: fatal: not a valid object name: master tar: これは tar アーカイブではないようです tar: 前のエラーにより失敗ステータスで終了します (Backtrace restricted to imported tasks) cap aborted! SSHKit::Runner::ExecuteError: Exception while executing as ec2-user@52.193.230.41: git exit status: 2 git stdout: Nothing written git stderr: fatal: not a valid object name: master tar: これは tar アーカイブではないようです tar: 前のエラーにより失敗ステータスで終了します Caused by: SSHKit::Command::Failed: git exit status: 2 git stdout: Nothing written git stderr: fatal: not a valid object name: master tar: これは tar アーカイブではないようです tar: 前のエラーにより失敗ステータスで終了します Tasks: TOP => git:create_release (See full trace by running task with --trace) The deploy has failed with an error: Exception while executing as ec2-user@52.193.230.41: git exit status: 2 git stdout: Nothing written git stderr: fatal: not a valid object name: master tar: これは tar アーカイブではないようです tar: 前のエラーにより失敗ステータスで終了します上記のエラー内容を確認すると、git:create_releaseの部分でエラーが発生していることが分かります。
ターミナル(ローカル環境)※エラー文のとろこを抜粋00:06 git:create_release 01 mkdir -p /var/www/smot/releases/20201103133334 ✔ 01 ec2-user@52.193.230.41 0.226s 02 git archive master | /usr/bin/env tar -x -f - -C /var/www/smot/releases/20201103133334 02 fatal: not a valid object name: master 02 tar: 02 これは tar アーカイブではないようです 02 02 tar: 02 前のエラーにより失敗ステータスで終了します 02fatal: not a valid object name: master
こちらの内容が、今回のエラーの原因のようですので、
「masterが有効なオブジェクト名ではありません」と言われています。fatal: not a valid object name: master の解決方法を調べてみる!
fatal: not a valid object name: masterを検索して調べると、下記のような記事がたくさん出てきました。
Git エラー「fatal: Not a valid object name: 'master'.」の対処法
【Git】fatal: Not a valid object name: 'master'.の解決方法
fatal: Not a valid object name: 'master'. て言われたときどうした?
【Git】fatal: Not a valid object name: 'master'って怒られた【大体そんなもん】
こちらの記事を読んでみると、fatal: not a valid object name: masterはGitで発生しているエラーのようです。
ほとんどの記事に「マスターブランチにコミット」するように言われているので、下記のように実行。
ターミナル(ローカル環境)# コミットしたいファイルを全て選択する $ git add . # masterブランチへコミット $ git commit -m "fatal: not a valid object name: masterエラー解消のため" # 自動デプロイコマンドを実行 $ bundle exec cap production deployしかし、これでもfatal: not a valid object name: masterエラーは解決できませんでした!
ほかに何が原因か仮説を立ててみる!
Capistranoで、fatal: not a valid object name: master のエラーが出ている記事がひとつも出てこないので、仮説を立ててみました。
「masterが有効なオブジェクト名ではありません」と言われていて、Gitのエラーであることは分かりました。
そもそもGitを使っていて、masterブランチにもpush、commit、pullもできているのになぜ??エラー文の中にあるこれは tar アーカイブではないようですを調べてみると、下記の記事を見つけました。
capistranoエラーtar:これはtarアーカイブのようには見えません
こちらの記事のベストアンサーに、「gitから存在しないブランチを引っ張っている」と書かれていて、もしかしてmasterブランチがgitに存在していないからエラーが発生しているのか?と仮説を立てて調べてみました。
エラー解決!!
さっそく開発中のGitHubを調べてみると、デフォルトブランチが「master」ではなく、「main」になっていました!!!
そのため、Capistranoのgitのブランチを「main」に変更。
config/deploy.rb# config valid only for current version of Capistrano # capistranoのバージョンを記載。固定のバージョンを利用し続け、バージョン変更によるトラブルを防止する lock '3.14.1' # Capistranoのログの表示に利用する set :application, 'smot' # どのリポジトリからアプリをpullするかを指定する set :repo_url, 'git@github.com:nakaya-kousuke/smot.git' ---------- 追記 ---------- # ブランチを指定する set :branch, "main" -------------------------- # バージョンが変わっても共通で参照するディレクトリを指定 set :linked_dirs, fetch(:linked_dirs, []).push('log', 'tmp/pids', 'tmp/cache', 'tmp/sockets', 'vendor/bundle', 'public/system', 'public/uploads') set :rbenv_type, :user set :rbenv_ruby, '2.5.1' #カリキュラム通りに進めた場合、2.5.1か2.3.1です # どの公開鍵を利用してデプロイするか set :ssh_options, auth_methods: ['publickey'], keys: ['~/.ssh/smot.pem'] # プロセス番号を記載したファイルの場所 set :unicorn_pid, -> { "#{shared_path}/tmp/pids/unicorn.pid" } # Unicornの設定ファイルの場所 set :unicorn_config_path, -> { "#{current_path}/config/unicorn.rb" } set :keep_releases, 5 # secrets.yml用のシンボリックリンクを追加 set :linked_files, %w{ config/secrets.yml } # 元々記述されていた after 「'deploy:publishing', 'deploy:restart'」以下を削除して、次のように書き換え after 'deploy:publishing', 'deploy:restart' namespace :deploy do task :restart do invoke 'unicorn:restart' end desc 'upload secrets.yml' task :upload do on roles(:app) do |host| if test "[ ! -d #{shared_path}/config ]" execute "mkdir -p #{shared_path}/config" end upload!('config/secrets.yml', "#{shared_path}/config/secrets.yml") end end before :starting, 'deploy:upload' after :finishing, 'deploy:cleanup' endターミナル(ローカル環境)# 自動デプロイコマンドを実行 $ bundle exec cap production deployこれで自動デプロイに成功することができました!!!
補足情報
なぜGitHubのデフォルトブランチが「main」になっていたのか???を調べてみました。
■参考記事
GitHub、これから作成するリポジトリのデフォルトブランチ名が「main」に。「master」から「main」へ変更なんとGitHubのデフォルトブランチが「master」から「main」へ変更になっていました!
この変更には、2020年5月25日に米国ミネソタ州ミネアポリスでの事件をきっかけとした人権運動を背景にしたものとなっています。
このような事件が、IT業界にも影響されることもあると勉強になりました。
ちなみにGitHubの設定によって新規に作成するリポジトリのデフォルトブランチ名は任意に変更可能のようです。
- 投稿日:2020-11-15T12:24:50+09:00
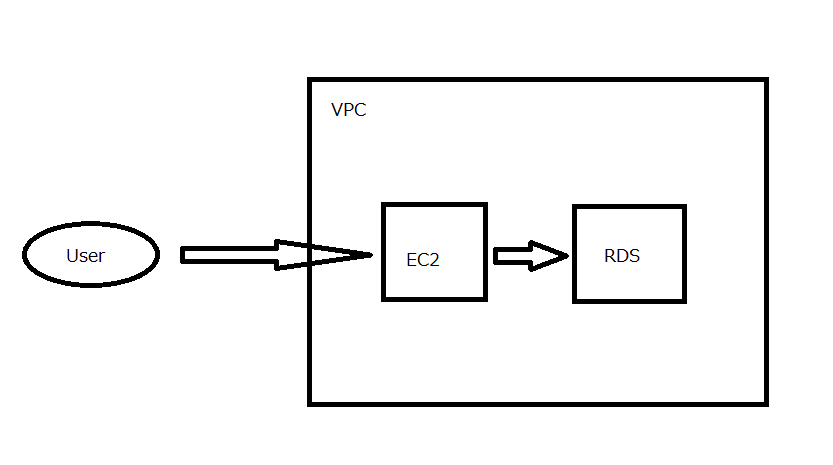
特定のS3の特定のディレクトリ以下だけ読み書き可能なIAMポリシー
ざっくり要件
- 不要なAWSリソースを見たくない・見せたくないIAMユーザを作成したい
- 特定のS3のapp/以下だけ(重要)
- アクションとしては、ディレクトリ作成、アップロード、ダウンロード、閲覧
- 他のS3バケット名も見せない
- IP制限等は別途
- MFA付き等は今回は除外
- バケット名は参考から名前を流用して
AWSDOC-EXAMPLE-BUCKET- S3バケットは東京リージョン
個人的なポイント
- バケットポリシー側をいじる必要はなかった
- S3バケットのアクセス許可も
パブリックアクセスをすべてブロックのままでよい- 特定のURLでアクセスする必要がある
- https://s3.console.aws.amazon.com/s3/buckets/AWSDOC-EXAMPLE-BUCKET?region=ap-northeast-1&prefix=app/
- S3のバケット一覧からは遷移できない(権限がないため。一部だけ閲覧できるやり方を見つけられなかった)
IAMポリシー
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:ListBucketVersions", "s3:ListBucket" ], "Resource": "arn:aws:s3:::AWSDOC-EXAMPLE-BUCKET", "Condition": { "StringLike": { "s3:prefix": "app/*" } } }, { "Effect": "Allow", "Action": "s3:GetBucketVersioning", "Resource": "arn:aws:s3:::AWSDOC-EXAMPLE-BUCKET" }, { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObjectAcl", "s3:GetObject", "s3:DeleteObjectVersion", "s3:GetObjectVersionTagging", "s3:GetObjectVersionAcl", "s3:GetObjectTagging", "s3:DeleteObject", "s3:GetObjectVersion" ], "Resource": "arn:aws:s3:::AWSDOC-EXAMPLE-BUCKET/app/*" } ] }参考
- 投稿日:2020-11-15T12:13:25+09:00
知って得する!? AWSのセキュリティ関連サービスをご紹介!
はじめに
今回はAWSのセキュリティ周りのサービスを紹介します!
YouTube動画
【YouTube動画】 知って得する!? AWSのセキュリティ関連サービスをご紹介!
認証・認可周りのセキュリティ
IAM
IAMはIdentity and Access Managementの略で、AWSサービスやリソースへ安全にアクセスするための管理サービスです。
IAMではグループ、ユーザー、ロール、ポリシー、IDプロバイダーの権限設定ができます。
もし初めてAWSを利用する場合は、最初はルートアカウントになっています。
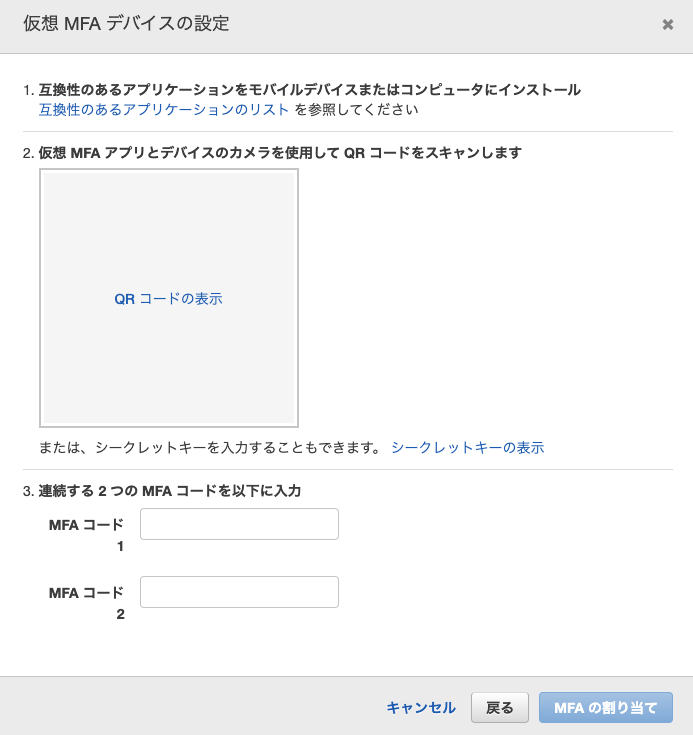
ベストプラクティスとして、別途ユーザーを作成し、ポリシー (権限) をアタッチしておく方が安全です。また、パスワードが流出してもログインされないために、MFAを設定しておくとより安全になります。
MFAデバイスとしては、AuthyやGoogle認証システムなどがあります。
防御方面のセキュリティ
AWSは攻撃を防ぐためのサービスも充実しています。
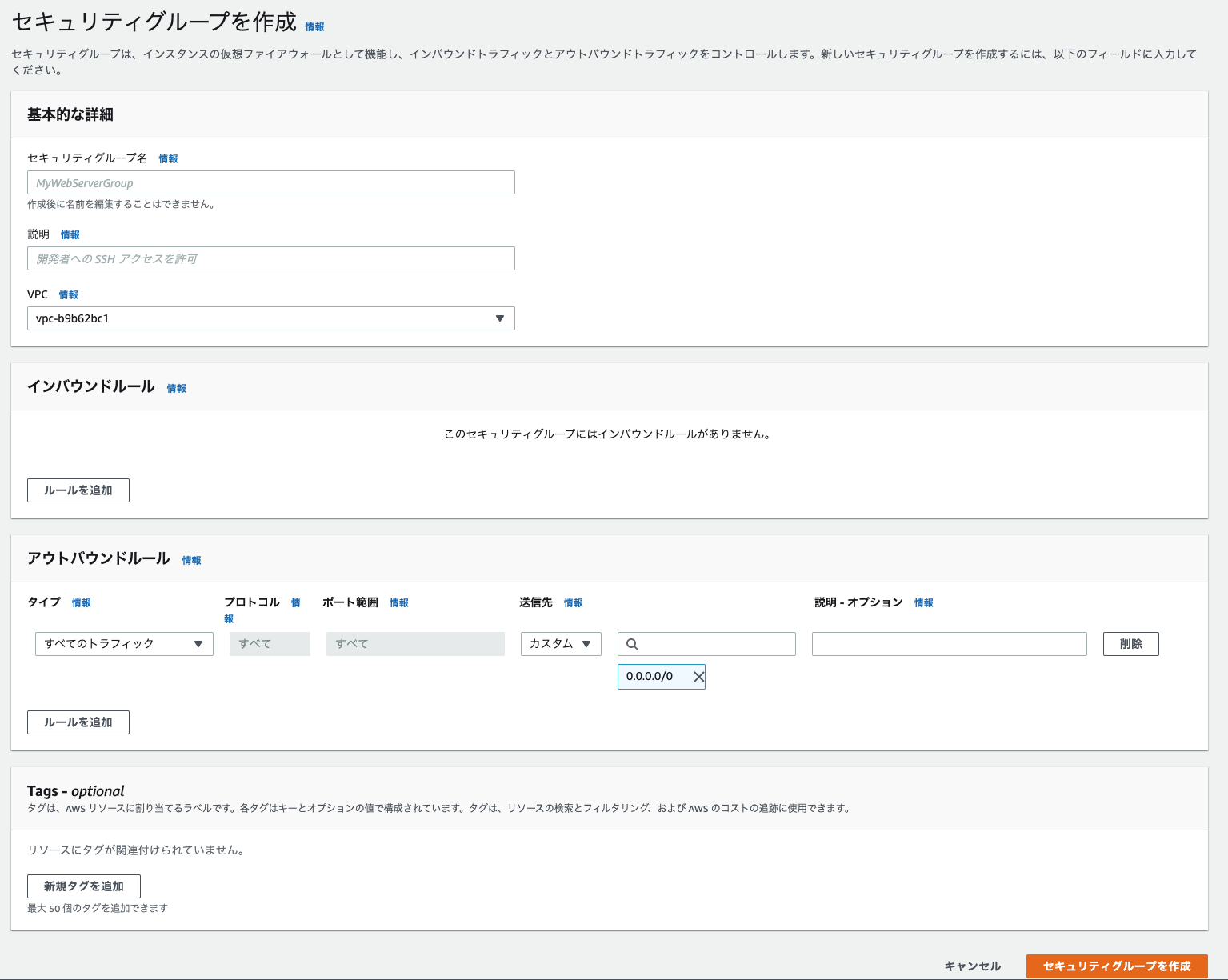
セキュリティグループ
セキュリティグループはインスタンス単位のファイアウォールで、通信の許可のみを設定できます。
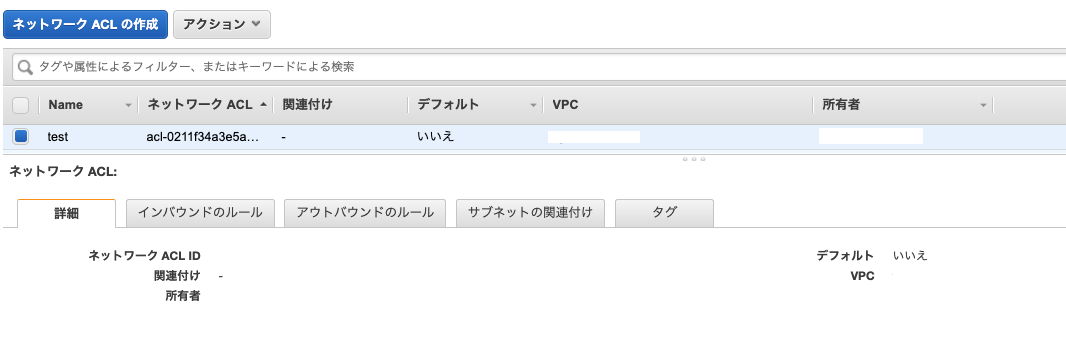
ネットワークACL
ネットワークACLはサブネット単位のファイアウォールで、通信の許可と拒否を設定できます。
AWS WAF
WAFは、Web Application Firewallの略でwebアプリケーションレベルのfirewallです。
AWSやサードパーティが提供しているルールを設定できるため、簡単にセキュリティを高めることができます。
AWS Shield
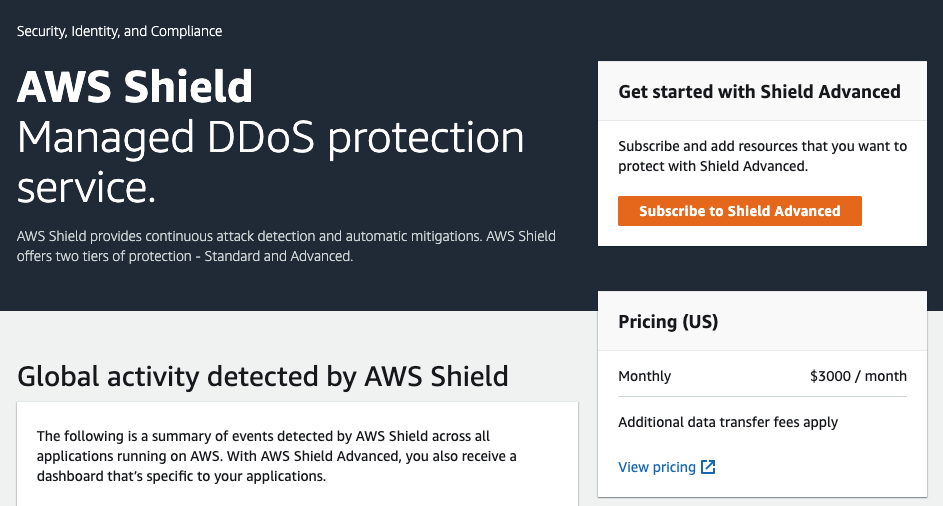
DDoS専用のサービスです。
toC向けなど攻撃されやすいサービスに適用すると良さげです。
検知
ここからは脆弱性や攻撃を検知するためのサービスです。
Amazon Inspector
EC2にエージェントを入れて、セキュリティチェックができるサービスです。
OSやネットワークの脆弱性チェックやPCI-DSSを満たしているか等のチェックもできます。ちなみに、PCI-DSSはクレジットカード会社が規定した情報セキュリティ基準のことです。
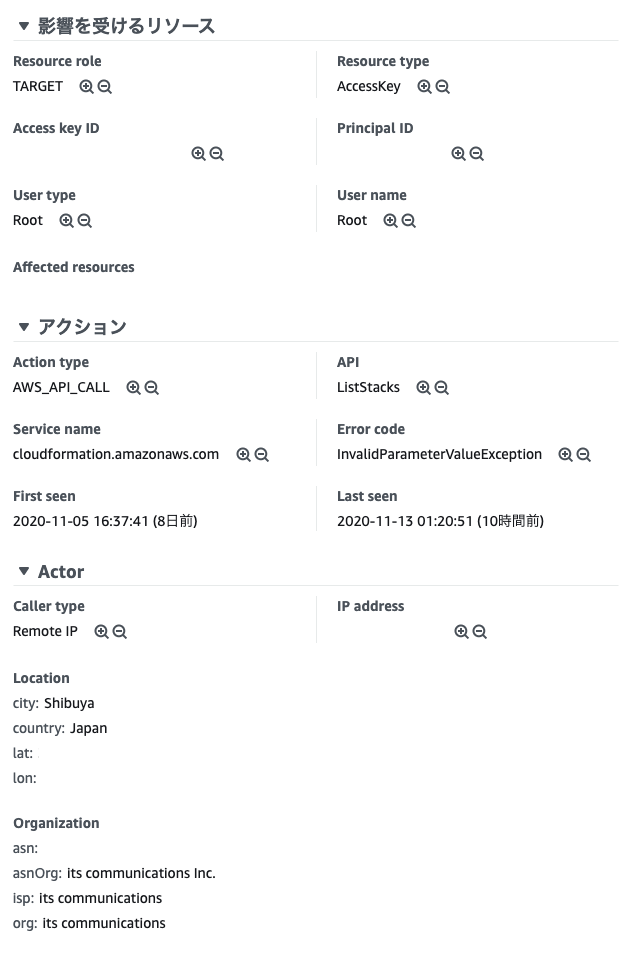
Amazon GuardDuty
AWS環境やAWSアカウントに対する脅威を検知できるサービスです。
例えば、Rootユーザーでログインした場合は以下の通知が表示されます。
これをクリックすると、次のような画面になります。
Actorの部分を確認すると、どこからアクセスされたのかが確認できます。EC2が攻撃された場合もどこから攻撃されたかがわかるようになります。
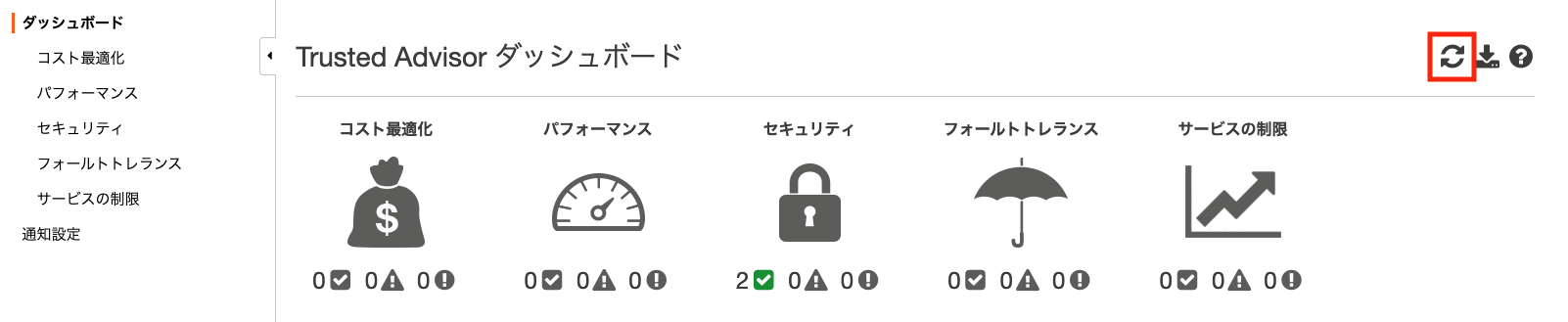
AWS Trusted Advisor
セキュリティだけでなく、コストやパフォーマンスの最適化をしてくれるサービスです。
右上の更新ボタンをクリックすると、開始されます。
セキュリティグループの設定が甘かったり、S3がパブリックだと、以下のような警告が出てきます。
サポートプランを上げると、使用頻度の低いインスタンスを通知したり、使用頻度の高いインスタンスをモニタリングできるようです。
監査 AWS CloudTrail
AWSアカウントの操作ログを保持するサービスです。
誰がインスタンスを立てたのか、消したのかをログに残すことができます。
その他
AWS Artifact
AWSセキュリティの監査レポートが見れるサービスです。
電子署名付きの監査レポートをダウンロードすることができます。
AWS KMS
KMSはKey Management Serviceの略で、機密情報の暗号化と暗号化キーを管理できるサービスです。
AWS内で他のサービスとの連携もできます。
おわり
今回はAWSのセキュリティ周りのサービスを紹介しました。
AWSのサービスを使う際の参考になれば幸いです。以上。






- 投稿日:2020-11-15T11:09:38+09:00
AWSのVPCのよく使われるコンポーネントについて
勉強前イメージ
一応VPCは作って中にインスタンス作れるけど、あんまりちゃんとネットワーク上こう、っては分かってない
特によく使われるやつでもインターネットゲートウェイはあんまり分かってない
今回はちょっだけにしとく。調査
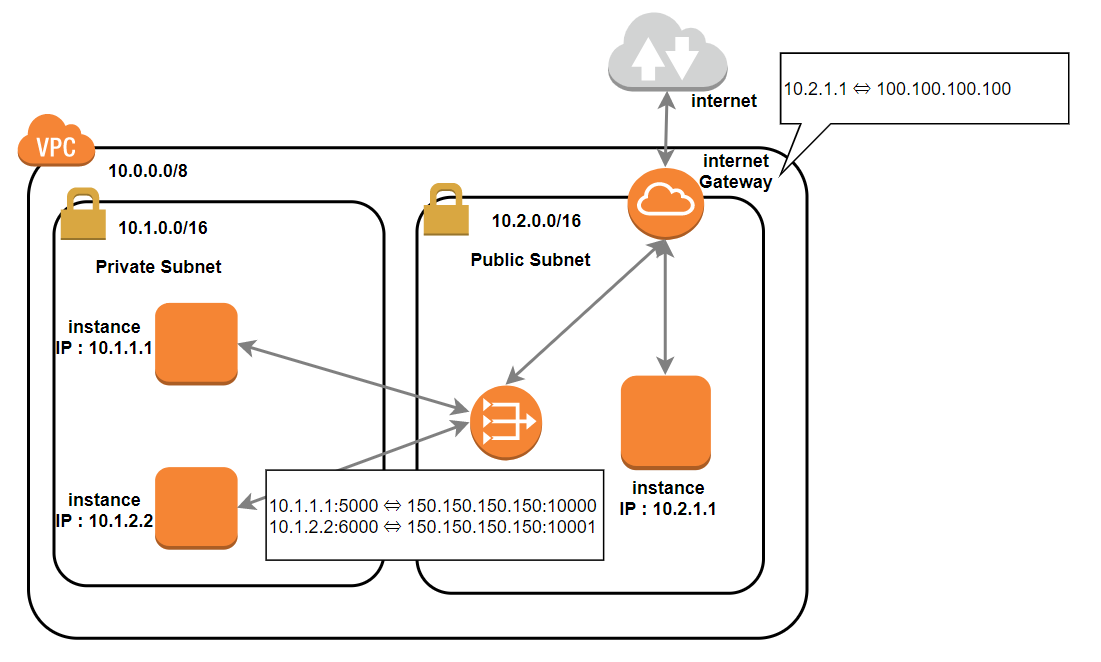
Subnet
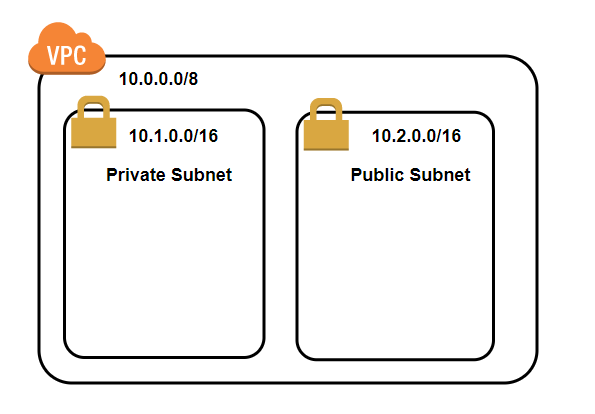
VPCの中に小さなネットワークの集まりを作れるもの。
Subnetでネットワーク空間を区切ります。下記の例であれば
10.0.0.0/8という大きなVPCの中に
ネットワークに接続しない、10.1.0.0/16というPrivate Subnetと
ネットワークに接続する、10.2.0.0/16というPublic Subnetが作成されています。
※subnetはかぶってはだめです。
Internet gateway
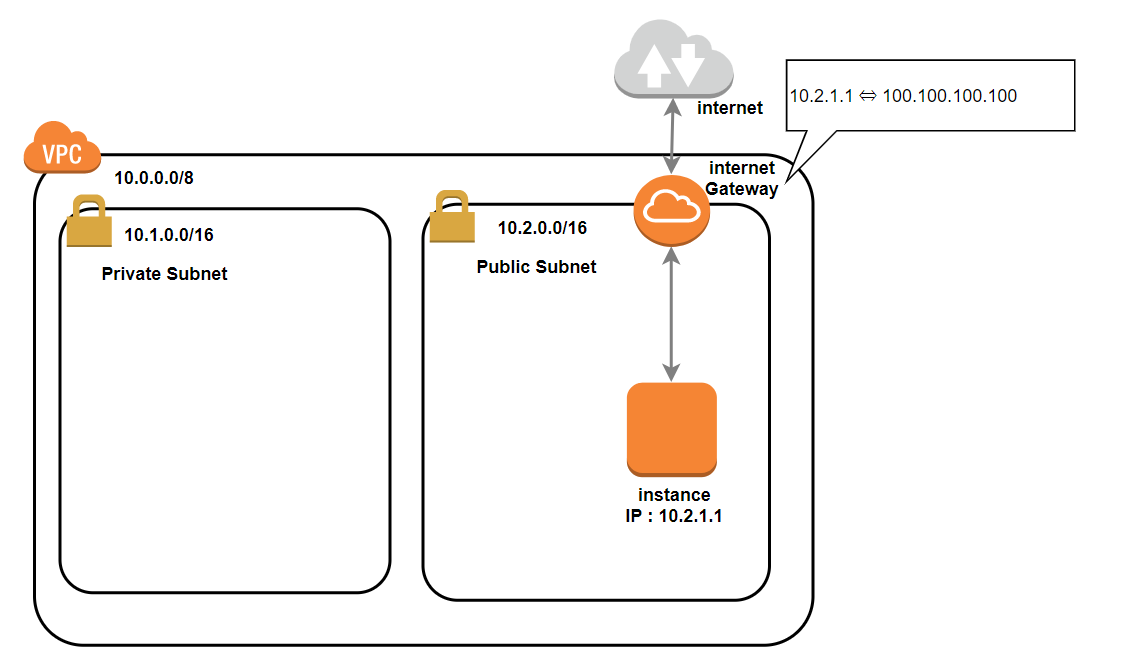
Internet gatewayは
Static NAT、つまりプライベートIPとパブリックIPを1対1で変換します。
以下の図のように、10.2.1.1を100.100.100.100に変換してインターネットから出す役割をします。
インターネットに接続するには必要なコンポーネントです。
NAT gateway
NAT Gatewayは
Dynamic NAPT、 つまりプライベートIPとパブリックIPを多対1で変換します。
複数のインスタンスからの通信が、プライベートIPでNAT gatewayを通過する際、1つのパブリックIPに変換されます。
複数のプライベートIPで1つのパブリックIPに変換してしまうと戻りの通信がわからなくなるので、ポート番号も変換することで正しい通信ができるようになっています。
勉強後イメージ
基本的にデフォルトのVPCしか使ってなかったからあんまり意識したことなかったかも...
ここちゃんと1回自分でも設定してみたい。参考
- 投稿日:2020-11-15T02:58:30+09:00
GitHub ActionでDockerのビルドキャッシュを有効にしてAmazonECSへデプロイする
やること
GitHub Actionを用いてDockerイメージをビルドし、Amazon ECRに保存し、Amazon ECSへデプロイします。
- ポイント
- 本番運用を想定し、ブランチにリリースを作成した場合にGitHub Actionが動作するようにする。
- Dockerのビルドを高速化するために、ビルドキャッシュを有効にする
準備
- 保存先のECRを作成
- デプロイ先のECRを作成
- GitHub Actionで使用するためのAWS IAMユーザーを作成(ECRとECSの権限が必要です)
これらは作成済みとして進めます。
作成するワークフロー
下記のようなワークフローを作成し、レポジトリの
.github/workflows/へdeploy-to-ecs.ymlのような適当な名前で保存します。
mainブランチにtagをpushすることにより、このワークフローが動作し、ECRへDockerイメージがpushされ、ECSへデプロイします。
Githubのリリースを用いることにより運用することを想定しています。
.github/workflows/deploy-to-ecs.ymlname: Deploy to ECS on: push: tags: - v* env: ECR_REPOSITORY: your-repository-name ECS_SERVICE: your-service-name ECS_CLUSTER: your-cluster-name jobs: deploy: name: Deploy to ECS if: github.event.base_ref == 'refs/heads/main' runs-on: ubuntu-latest steps: - name: Checkout code uses: actions/checkout@v2 - name: Configure AWS Credentials # AWSアクセス権限設定 uses: aws-actions/configure-aws-credentials@v1 with: aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }} aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }} aws-region: ap-northeast-1 - name: Login to Amazon ECR # ECRログイン処理 id: login-ecr uses: aws-actions/amazon-ecr-login@v1 - name: Set Docker Tag Env # Docker Imageのバージョンをタグに合わせる run: echo "::IMAGE_TAG=$(echo ${{ github.ref }} | sed -e "s#refs/tags/##g")" >> $GITHUB_ENV - name: Build, tag, and push image to Amazon ECR # Docker イメージ Build&Push env: DOCKER_BUILDKIT: 1 ECR_REGISTRY: ${{ steps.login-ecr.outputs.registry }} run: | docker build --cache-from=$ECR_REGISTRY/$ECR_REPOSITORY:latest --build-arg BUILDKIT_INLINE_CACHE=1 -f Dockerfile -t $ECR_REPOSITORY . docker tag $ECR_REPOSITORY:latest $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG docker tag $ECR_REPOSITORY:latest $ECR_REGISTRY/$ECR_REPOSITORY:latest docker push $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG docker push $ECR_REGISTRY/$ECR_REPOSITORY:latest - name: Render Amazon ECS task definition for app container # appコンテナのECSタスク定義ファイルレンダリング id: render-app-container uses: aws-actions/amazon-ecs-render-task-definition@v1 with: task-definition: .aws/ecs/task-definition.json container-name: app image: ${{ steps.login-ecr.outputs.registry }}/${{ env.ECR_REPOSITORY }}:${{ env.IMAGE_TAG }} - name: Deploy to Amazon ECS service # ECSサービスデプロイ uses: aws-actions/amazon-ecs-deploy-task-definition@v1 with: task-definition: ${{ steps.render-app-container.outputs.task-definition }} service: ${{ env.ECS_SERVICE }} cluster: ${{ env.ECS_CLUSTER }} wait-for-service-stability: false解説
ワークフローの動作について上から順に具体的に説明します。
1. ワークフロー名
name: Deploy to ECSワークフローの名前を決めています。Githubのレポジトリ、Actionタブからワークフローを一覧で確認する際などにこの名前が表示されます。検証環境や本番環境で複数のワークフローを作成する場合は、区別できる分かりやすい名前に変更する事を推奨します。
2. ワークフローの動作条件
on: push: tags: - v*
v1.0.0のようなvで始まるタグがpushされた場合に動作するようにしており、リリースの作成によりこのワークフローが動作することを想定しています。
また、今回は他のブランチにタグがpushされてしまった場合に動作をしないようにjobs内にif: github.event.base_ref == 'refs/heads/main'のようにmainブランチではない場合には動作をしないようにしています。
特定のブランチにpushされた場合に動作するようにするには
ifの記述を無くしon: push: branches: - target-branchのように記述してください。(target-branchはデプロイ対象とするブランチに変更して下さい。)
補足
on: push:の記述方法で、特定のブランチにタグがpushされた場合動作するという事を実現するためにon: push: tags: - v* branches: - target-branchのように記述すると、and条件ではなくor条件(タグかブランチのどちらかがpushされた場合)になってしまう為、
on: push:で対象のタグを指定し、ifで対象のブランチを指定しています。3. 環境変数への代入
env: ECR_REPOSITORY: your-repository-name ECS_SERVICE: your-service-name ECS_CLUSTER: your-cluster-namejobで何度も使う値の記述を減らすために環境変数へ代入しています。
your-〇〇〇-nameは各自の環境のものへ変更して下さい4. Jobsの実行開始
jobs: deploy: name: Deploy to ECS if: github.event.base_ref == 'refs/heads/main' runs-on: ubuntu-latest steps: - name: Checkout code uses: actions/checkout@v2
ubuntu-latestの環境にて対象ブランチにcheckoutし、jobの実行を始めます。
(先程にも記述しましたが、タグがpushされた場合のmainブランチでのみ実行するようにif行を記述しています。動作条件をブランチのpushに変更した場合は不要です。)5. AWSへのログイン
- name: Configure AWS Credentials # AWSアクセス権限設定 uses: aws-actions/configure-aws-credentials@v1 with: aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }} aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }} aws-region: ap-northeast-1pushを行うECR、デプロイ先のECSを作成してあるAWS アカウントへログインをしています。
Githubのシークレットを用いてデプロイを行うIAMのアクセスキーとシークレットキーをAWS_ACCESS_KEY_IDとAWS_SECRET_ACCESS_KEYへ登録してください。6. ECRログイン
- name: Login to Amazon ECR # ECRログイン処理 id: login-ecr uses: aws-actions/amazon-ecr-login@v15.でログインしたAWSアカウントのECRへのログインを行います。
7. Dockerのイメージタグの設定
- name: Set Docker Tag Env # Docker Imageのバージョンをタグに合わせる run: echo "::IMAGE_TAG=$(echo ${{ github.ref }} | sed -e "s#refs/tags/##g")" >> $GITHUB_ENVDockerのイメージタグがgitのtagと同じ値になるようにpushされたtagを
v1.0.0のような形式で取り出し、環境変数へ代入しています。
ワークフローの動作条件にタグを用いない場合は、run: echo "::IMAGE_TAG=${{ github.sha }}" >> $GITHUB_ENVのようにコミットハッシュを用いてイメージタグが一意になるようにすると良いと思います。
8. Dockerイメージのビルド&ECRへのPush
- name: Build, tag, and push image to Amazon ECR # Docker イメージ Build&Push env: DOCKER_BUILDKIT: 1 ECR_REGISTRY: ${{ steps.login-ecr.outputs.registry }} run: | docker build --cache-from=$ECR_REGISTRY/$ECR_REPOSITORY:latest --build-arg BUILDKIT_INLINE_CACHE=1 -f Dockerfile -t $ECR_REPOSITORY . docker tag $ECR_REPOSITORY:latest $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG docker tag $ECR_REPOSITORY:latest $ECR_REGISTRY/$ECR_REPOSITORY:latest docker push $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG docker push $ECR_REGISTRY/$ECR_REPOSITORY:latestローカルでDockerイメージをビルドする場合、前回にビルドしたイメージを用いてビルドが高速化されますが、GitHub Actionでは前回のビルド結果を保持していないため、毎回ビルドに時間が掛かってしまいます。
そこで、ここではDockerのdocker build --cache-fromを用いてビルドの高速化を行っています。
行っている内容としては、dockerイメージをビルドし、環境変数IMAGE_TAGに保存されているタグをpushしつつ、その値はワークフローの動作毎に動的に変化してしまい、前回ビルドした際の値を取得することが難しいためlatestタグもpushし、latestタグをキャシュに用いるようにしています。このようにすることにより、リリースタグと整合性を取りつつ、キャッシュを用いれます。
(DOCKER_BUILDKIT,BUILDKIT_INLINE_CACHEは--cache-fromを用いるために必要なため記述しています。)
注意: Dockerのマルチステージビルドを用いている場合は、Dockerのイメージ中にビルドプロセスが全て含まれていないためこの方法ではキャッシュできません。その場合は、このような記事を参考にすると良いと思います。9. ECSタスク定義の作成
- name: Render Amazon ECS task definition for app container # appコンテナのECSタスク定義ファイルレンダリング id: render-app-container uses: aws-actions/amazon-ecs-render-task-definition@v1 with: task-definition: .aws/ecs/task-definition.json container-name: app image: ${{ steps.login-ecr.outputs.registry }}/${{ env.ECR_REPOSITORY }}:${{ env.IMAGE_TAG }}ECSの実行にはタスク定義が必要になり、そこに使用するDockerイメージのレポジトリやタグの情報を記述する必要があります。
従って、DockerImageを更新した際はタスク定義の更新も必要になり、その処理を行っています。今回はレポジトリへタスク定義ファイル
.aws/ecs/task-definition.jsonを作成してあり、そのファイルを呼び出し、Dockerイメージの情報を更新しています。
task-definition.jsonの参考例){ "containerDefinitions": [ "portMappings": [ { "hostPort": 80, "protocol": "tcp", "containerPort": 80 } ], "image": "your-image-name", "name": "app" } ], "cpu": "256", "executionRoleArn": "your-role-name", "family": "your-family", "memory": "512", "requiresCompatibilities": [ "FARGATE" ], "networkMode": "awsvpc" }s3から読み出す事も可能のようなので各々お好きなタスク定義の管理をして下さい。
10. ECSへデプロイ
- name: Deploy to Amazon ECS service # ECSサービスデプロイ uses: aws-actions/amazon-ecs-deploy-task-definition@v1 with: task-definition: ${{ steps.render-app-container.outputs.task-definition }} service: ${{ env.ECS_SERVICE }} cluster: ${{ env.ECS_CLUSTER }} wait-for-service-stability: false9で作成したタスク定義をもとにECSへデプロイしています。
wait-for-service-stabilityをtrueにすることにより、デプロイが完了するまで実行完了を待機させ、デプロイ完了を通知すること等が可能ですが、Github Actionsの実行時間が増加してしまい、実行枠を越えてしまう等の可能性が存在します。
AWS Lambdaを用いてデプロイの完了をフックし、通知する事も可能なのでデプロイの多い環境ではそうする事を推奨します。11. おわり
上記のフローが正しく動作すればデプロイ完了です。
おまけ. task単体の実行
- name: Run Migrate # Migrationを実行 env: CLUSTER_ARN: your_cluster_arn ECS_SUBNER_FIRST: your_subnet_first ECS_SUBNER_SECOND: your_subner_second ECS_SECURITY_GROUP: your_security_group run: | aws ecs run-task --launch-type FARGATE --cluster $ECS_CLUSTER --task-definition ${{ steps.put-migrate-task.outputs.render-app-container }} --network-configuration "awsvpcConfiguration={subnets=[$ECS_SUBNER_FIRST, $ECS_SUBNER_SECOND],securityGroups=[$ECS_SECURITY_GROUP],assignPublicIp=ENABLED}" > run-task.log TASK_ARN=$(jq -r '.tasks[0].taskArn' run-task.log) aws ecs wait tasks-stopped --cluster $CLUSTER_ARN --tasks $TASK_ARN今回デプロイ前にDBのmigrationを行いたく、このようなjobを手順10のECSへデプロイ前に追加しtaskを単体で実行しました。
このようにすることにより、Github Actions内でtask単体を実行することも可能です。まとめ
ECSへのデプロイですとAWS CodeBuild、AWS CodePipelineを組み合わせるといった選択肢もあると思いますが、GitHub Actionを用いても簡単にデプロイすることが可能です。
参考記事
下記の記事を大変参考にさせて頂きました。
- 投稿日:2020-11-15T02:38:00+09:00
アプリの開発をする(AWSのアカウント作成から環境構築まで)
まえがき
エンジニアは、常に勉強し、技術を磨き続けなければならない。
例えば、外国語を学習するには、その言語を使うことが一番良い方法だという話を聞いたことがある。
実際、自分もそのように考えている。
では、技術を学ぶために一番いい方法は何だろうか?
おそらく、実際にその技術を使うことではないだろうか。
とうことで、今回簡単なWebアプリ的なものを作ることにした。AWSアカウントの作成
これを見ればok
https://aws.amazon.com/jp/register-flow/AWSで構築したいアーキテクチャ
とりあえず、APサーバとDBサーバのみのシンプルな構成から始め、今後必要に応じて変えていくことにする。
(というか、最初から難しいことを色々考えると挫折しそう)
ペイントで作った手抜き図ですまん
環境構築
VPCの作成、EC2インスタンスの作成、RDSインスタンスの作成の順番で説明する。
VPCの作成
まずはVPC(Virtual Private Cloud)を作成する。
EC2インスタンスを家だとすると、VPCは家を建てるための土地みたいなイメージ(合ってるかは分からない)
ネットワークのことはあまり詳しくないので、要勉強さて本題に戻るが、今回は一番上のやつを選んでVPCを作成した。他のやつはお金がかかりそう。
デフォルト設定でVPCを作成
EC2インスタンスの作成
「インスタンスを起動」をクリック
「無料利用枠のみ」にチェックを入れ(ここ重要)、AMIの一覧を見てみる。
今回は、Ubuntuを選択する。
インスタンスタイプは、無料利用枠の対象であるt2.microを選択する。
セキュリティグループを設定する。
EC2インスタンスに対し、自分がアクセスするためのSSHアクセスの設定と、ユーザがアクセスするためのHTTPアクセス設定を追加。
SSHの方のソースには、必要なIPアドレスだけ設定しておきましょう。
例えばある一つのIPだけ指定する場合は、x.x.x.x/32みたいな感じになると思います(多分)
以上の設定でEC2インスタンスを作成します。
新しいキーペアを作成する画面が出てくると思うので、作成してダウンロードしてください。
(スクショし忘れました、すいません)EC2インスタンスにアクセスする
先ほどダウンロードした鍵(.pemファイル)を、~/.ssh直下に移動する。(ここではkey.pemとする)
以下のようなコマンドで先ほど作成したEC2インスタンスにアクセスできるssh -i ~/.ssh/key.pem ubuntu@x.x.x.xここに全て載ってます。
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/AccessingInstancesLinux.htmlRDSインスタンスの作成
この画面からRDSを作成する。
とりあえず簡単作成を選択。
以下のページによると、Amazon AuroraとOracleは無料利用枠の対象外っぽいので注意。今回はMySQLを選択。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/free-tier-rds-launch/
DBインスタンスサイズでは無料利用枠を選択。
あとはマスターユーザー名とマスターパスワードを設定し、RDSインスタンスを作成。
RDSインスタンスにアクセスする
RDSインスタンスのセキュリティグループを編集する。
前者のInboundの方を選択。
EC2のプライベートIPv4アドレスを黒塗りのところに記入する。
ちなみに、EC2のプライベートIPv4アドレスはこんな感じで確認できる。
次に、EC2インスタンスへアクセスする。
アクセスしたら、以下のコマンドでパッケージ一覧を更新する。(これをやらないと、次のコマンドが実行できなかった)sudo apt update続いて、mysqlコマンドを使えるようにするため以下のコマンドを実行する。
sudo apt install mysql-client-core-8.0以下のようになコマンドを打てば、mysqlを良い感じに起動できる。
mysql -h エンドポイント -u root -pちなみにエンドポイントは以下のように確認できる。
ポート番号が3306ではない場合は、以下のようにPオプションを追加する。
mysql -h エンドポイント -P ポート番号 -u root -p予算の設定
これが一番大事だと言っても過言ではない。高額な請求をされて困らないためにも、ちゃんと予算を設定しよう。
この画面から、「予算の作成および管理」を開く。
コスト予算を選択
年単位の予算で$0.000001にすれば、うっかり有料のサービスを使ったとしても、ほぼ無傷で済むでしょう。
とりあえずアラートを設定。実際のコストが1ドルを超えた場合にアラートが飛ぶように設定。
上記設定により、1ドルを超えることはまずないはず。
設定全体を見るとこんな感じ。