- 投稿日:2020-11-15T23:44:09+09:00
【Python】初心者でスクレイピングする時に冒頭脳死して書けるコード
スクレイピングをするときに毎回毎回
test.pyfrom bs4 import BeautifulSoupとこのように記述するのが面倒くさいので、とりあえずこれ使っとけば間違いなしのテンプレートを作成します。
test.py!apt-get update !apt install chromium-chromedriver !cp /usr/lib/chromium-browser/chromedriver /usr/bin !pip install selenium !pip install requests-htmlまずはライブラリ関係。
私は普段clbを使っているので、とりあえずこれ入れとく。test.pyimport pandas as pd import datetime from tqdm.notebook import tqdm import requests from bs4 import BeautifulSoup import time import re from urllib.request import urlopen import urllib.request, urllib.error from requests_html import HTMLSession from selenium import webdriver from selenium.webdriver.chrome.options import Options # htmlを取得するところまで options = webdriver.ChromeOptions() options.add_argument('--headless') options.add_argument('--no-sandbox') options.add_argument('--disable-dev-shm-usage') driver = webdriver.Chrome('chromedriver',options=options) driver.implicitly_wait(10) url="https://www.XXX.com" driver.get(url) html = driver.page_source.encode('utf-8') soup = BeautifulSoup(html, "html.parser")はい、ここまで脳死でコピペでOKです。
あとはtest.pysoupこれで、とりあえずhtmlを出力するところまではものの数秒で到達できます。
厳密に言えば、tqdmとか使ってないライブラリもあるんですけど、個人的にスクレイピングするときにほぼ毎回セットで使用しているライブラリをインポートするコードも全部詰め込んでます。
私自身、これでコピペして使いまくってます。
- 投稿日:2020-11-15T23:05:20+09:00
Pythonにおけるdestructorの挙動を確認
サンプルコード class_test.py
class_test.pyclass SampleClass: num = 0 def __init__(self, number=1): SampleClass.num +=1 # インスタンスが生成される度に、クラス変数numを1インクリメントする self.num = number # インスタンス生成時に生成元から受け取った引数numberを、インスタンス変数numに格納する def __del__(self): SampleClass.num -=1 # インスタンスを削除する度に、クラス変数numを1デクリメントする print("このインスタンスを削除しました")上記のスクリプトファイルを格納したディレクトリと同じ階層で、Python3を起動
Terminal$ ls class_test.py $ cat class_test.py class SampleClass: num = 0 def __init__(self, number=1): SampleClass.num +=1 # インスタンスが生成される度に、クラス変数numを1インクリメントする self.num = number # インスタンス生成時に生成元から受け取った引数numberを、インスタンス変数numに格納する def __del__(self): SampleClass.num -=1 # インスタンスを削除する度に、クラス変数numを1デクリメントする print("このインスタンスを削除しました") $ $ python3 >>>class_testモジュールをimportして、SampleClassクラスのインスタンスを、生成し、削除してみます。
Terminal>>> import class_test as ct >>> >>> sample_1 = ct.SampleClass() >>> print(ct.SampleClass.num) 1 >>> >>> print(sample_1.num) 1 >>>( ここでのポイント )
- SampleClassクラスのインスタンスを1つ生成しました。
- インスタンスの個数を管理するクラス変数numの値は、1と表示されました。
- また、生成させたインスタンスsample_1が持つインスタンス変数numの値は、コンストラクタのデフォルト引数で設定された1に設定されています。
Terminal>>> sample_2 = ct.SampleClass(number=4) >>> print(ct.SampleClass.num) 2 >>> print(sample_2.num) 4 >>>( ここでのポイント )
- SampleClassクラスのインスタンスを、もう1つ生成しました。
- インスタンスの個数を管理するクラス変数numの値は、2と表示されました。
- また、生成させたインスタンスsample_2が持つインスタンス変数numの値は、sample_2を生成するときに、コンストラクタに引数として渡した4が、設定されています。
Terminal>>> sample_3 = ct.SampleClass(number=15) >>> print(ct.SampleClass.num) 3 >>> print(sample_3.num) 15 >>>( ここでのポイント )
- SampleClassクラスのインスタンスを、さらにもう1つ、生成しました。これで、合計3個のインスタンスを生成しました。
- インスタンスの個数を管理するクラス変数numの値は、3と表示されました。
- また、生成させたインスタンスsample_3が持つインスタンス変数numの値は、sample_3を生成するときに、コンストラクタに引数として渡した15が、設定されています。
ここからが、destructorの挙動の確認になります
Terminal>>> del sample_2 このインスタンスを削除しました >>>( ここでのポイント )
- SampleClassクラスのdestructor内に記述した*print("このインスタンスを削除しました")が実行されました。
- これで、現在、存在しているインスタンスの数は、2個になりました。
Terminal>>> print(ct.SampleClass.num) 2 >>> print(sample_1.num) 1 >>> print(sample_3.num) 15 >>> print(sample_2.num) Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'sample_2' is not defined >>>( ここでのポイント )
- インスタンスの個数を管理するクラス変数numの値は、2と表示されました。
- sample_2という名前を付けたインスタンスを削除した際に、destructorの中に記述した、クラス変数numを1デクリメントする処理が、きちんと実行されたことがわかります。
- このとき、削除したインスタンスとは別の2つのインスタンス(sample_1およびsample_3)のインスタンス変数は、値が変わることなく、意図せぬ影響を受けていないことも、確認できました。
( 追記 )
import文は、以下にしたほうが、コードが短くなる。
import文(変更後)from class_test import SampleClassTerminal>>> from class_test import SampleClass >>> >>> sample_1 = SampleClass() >>> print(SampleClass.num) 1 >>> print(sample_1.num) 1 >>> >>> sample_2 = SampleClass(number=4) >>> print(SampleClass.num) 2 >>> print(sample_2.num) 4 >>>
( 参考にしたウェブページ )
- 投稿日:2020-11-15T22:41:38+09:00
強化学習2 マルコフ決定過程・ベルマン方程式
Aidemy 2020/11/15
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、強化学習の二つ目の投稿になります。どうぞよろしくお願いします。*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・強化学習の構成要素
・マルコフ決定過程について
・価値、収益、状態
・最適な方策について
・ベルマン方程式について強化学習の構成要素
N腕バンディッド問題と次のステップ
・Chapter1で扱ったN腕バンディッド問題は、「即時報酬である」点と、「エージェントの行動によって状態が変化しない」という点で一般的な問題よりも単純化された問題であった。
・状態とは、環境が今現在どうなっているかを表すものである。ボードゲームを考えるとわかりやすい。エージェントであるプレイヤーが、将棋という環境で、相手にある一手を使われた時、盤面は前の自分の番から変化しているため、次に取るべき行動も変化する。この時「盤面」という状態は変化していると言える。
・また、Chapter1でも軽く触れたが、強化学習では即時報酬ではなく、「ゲームに勝利すること」といった遅延報酬を最大化することが本来の目的である。
・今回は、これらの「状態」「時間」の概念を取り込んだ強化学習を行っていく。強化学習のモデルについて
・強化学習は、「①エージェントが状態$s_{t}$を受け行動$a_{t}$を起こし環境に作用する」「②それを受け環境は状態$s_{t+1}$に遷移する」「③環境はエージェントに報酬$r_{t+1}$を与える」「④エージェントは②③の結果を受けて次の行動$a_{t+1}$を決定する」という流れで進められていく。
・「t」は何回目の動作かを表す「時間ステップ」である。これが強化学習の時間の基本単位となる。状態、行動、報酬の数式化
・環境がとりうる状態を集合化したものを数式化すると以下のようになる。
$S$={$s_{0},s_{1},s_{2},...$}
・同様に、エージェントがとりうる行動の集合は以下のように表す。
$A(s)$={$a_{0},a_{1},a_{2},...$}
・時間ステップ「t+1」の時における報酬「$R_{t+1}$」は次のように表す。
$R_{t+1}$=$r(S_{t},A_{t},S_{t+1})$・上記のような式で報酬を求められる時、$R_{t+1}$を報酬関数と呼ぶ。この報酬関数から分かることでもあるが、未来の状態は現在(t,t+1)の状態・行動のみによって確率的に決定され、過去の挙動とは一切無関係であるという性質のことを「マルコフ性」と呼ぶ。
マルコフ決定過程
マルコフ決定過程とは
・前項で見た通り、未来の状態は現在の状態や行動によってのみ決定するということを「マルコフ性」と呼ぶ。そして、これを満たす強化学習の過程を「マルコフ決定過程(MDP)」という。
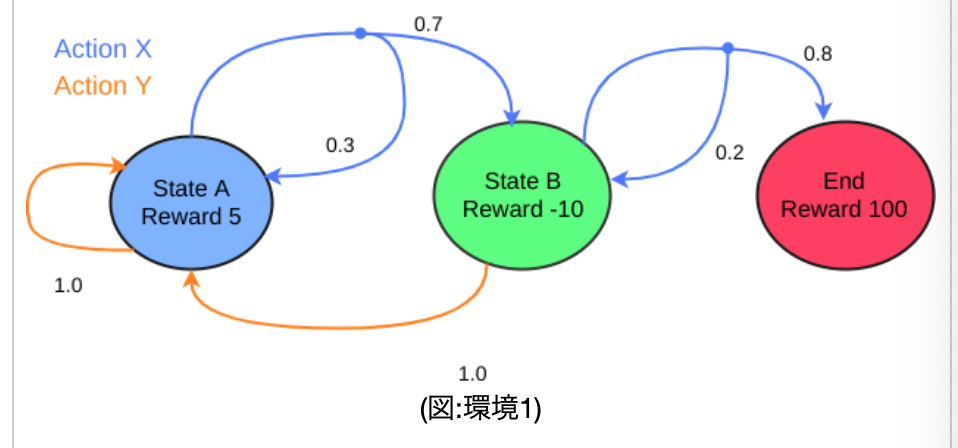
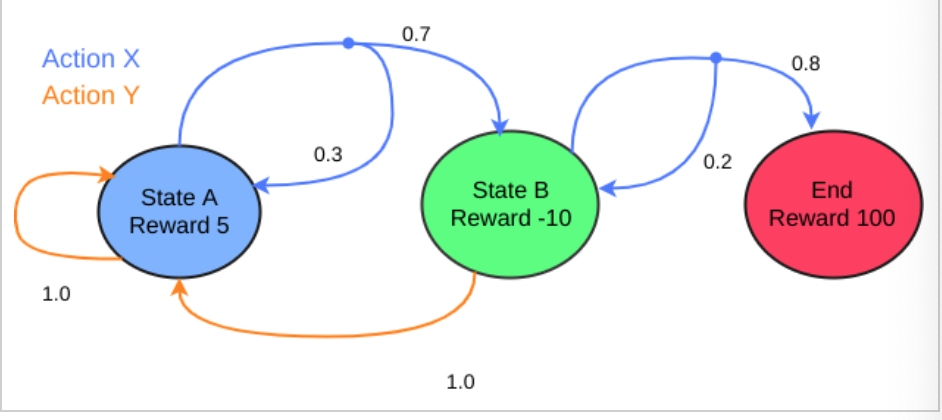
・マルコフ過程は、状態の集合「状態空間$S$」、行動の集合「行動空間$A(s)$」、開始時点の状態を表す確率変数「初期状態分布$P_{0}$」、状態$s$で行動$a$を行った時、状態$s'$になる確率の変遷率を「状態遷移確率$P(s'|s,a)$」、「報酬関数$r(s,a,s')$」の五つの要素を持つ。・以下の図は、今回使っていく環境「環境1」である。StateAからスタートし、actionXを取る場合「0.7」の確率でStateBに移動し、「0.3」の確率でStateAに戻るということが示されている。最終的に、StateBで、actionXの「0.8」を引ければゴール(End)となる。
・この各場合において、上記5要素を[s,s',a,p(s'|a,s),r(s,a,s')]というように表したものを「状態遷移図」という。(sは今どの状態か、s'は次にどの状態にいくか、aはactionXかYか、p(s'|a,s)は、その確率、r(s,a,s')はその報酬である)
・以下のコードは、この環境1のすべての状態遷移図を配列としてまとめたものである。配列にする際は、StateA=0、StateB=1、End=2のように数値で置き換える。
時間の概念を導入-状態と行動
・マルコフ決定過程の構成要素である前項の五つの変数には、まだ時間の概念が導入されていないので、これらの時間の概念を導入し、数式化を行う。
・状態空間Sについて、時間tの概念を入れた「$S_{t}$」と、行動に時間の概念を導入した「$A_{t}$」を定義する。
・定義において使われるのは、前項の「状態遷移図」の配列である。この配列の0列目は「state」つまり「今(t時点)の状態」であるので、これが「$S_{t}$」となり、2列目は「action」つまり「t時点の行動」であるので、これが「$A_{t}$」となる。
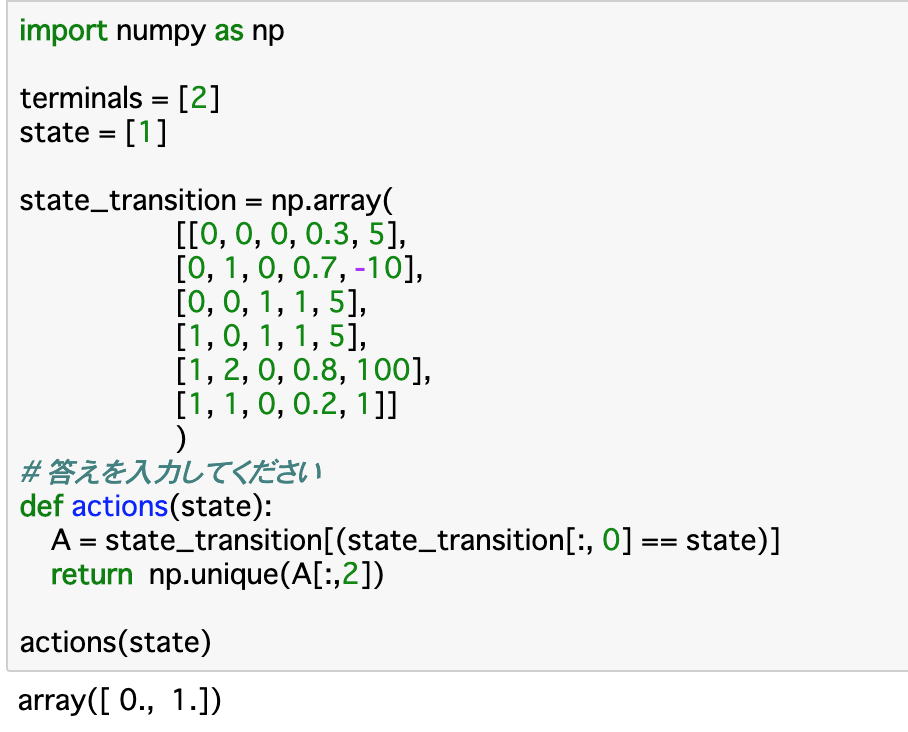
・以下は、$S_{t}$が渡された時、その状態でエージェントがとりうる行動をまとめた$A_{t}$を返す関数である。
・「actions()」関数に渡される「state」が状態「$S_{t}$」であり、Aで参照される「state_transition」が状態遷移図である。この0列目が「$S_{t}$」なので、この部分が渡されたstateと同じ状態のものを参照することを記述し、「A[:,2]」で2列目を参照することでその時にとりうる行動$A_{t}$をリストにして返す。この時、返り値は可能な行動であるので、重複してはいけない、つまり固有の要素でなければならない。これを行うには「np.unique()」を使うと良い。
・実行部分について、今回の状態はStateBにいることを示す「state=[1]」となっている。state_transitionのs部分(現在の状態)、つまり0列目が[1]の行の2列目を見ると、0か1が格納されているので、関数の結果としては、これらが返される。
時間の概念を導入-その他
・ここでは初期状態分布と状態遷移確率、報酬関数を時間の概念を取り入れて再定義する。
・初期状態分布は簡単で、t=0の時の状態$S_{0}$を定義すれば良い。
・状態遷移確率はマルコフ決定過程により、時刻$t+1$における状態$S_{t+1}$は$S_{t}$と$A_{t}$によってのみ決定するものなので、$P(s'|s_{t},a_{t})$というように表せる。
・状態$S_{t+1}$に遷移したときの報酬$R_{t+1}$について、$R_{t+1} = r(s_{t},a_{t},s_{t+1})$で表せる。
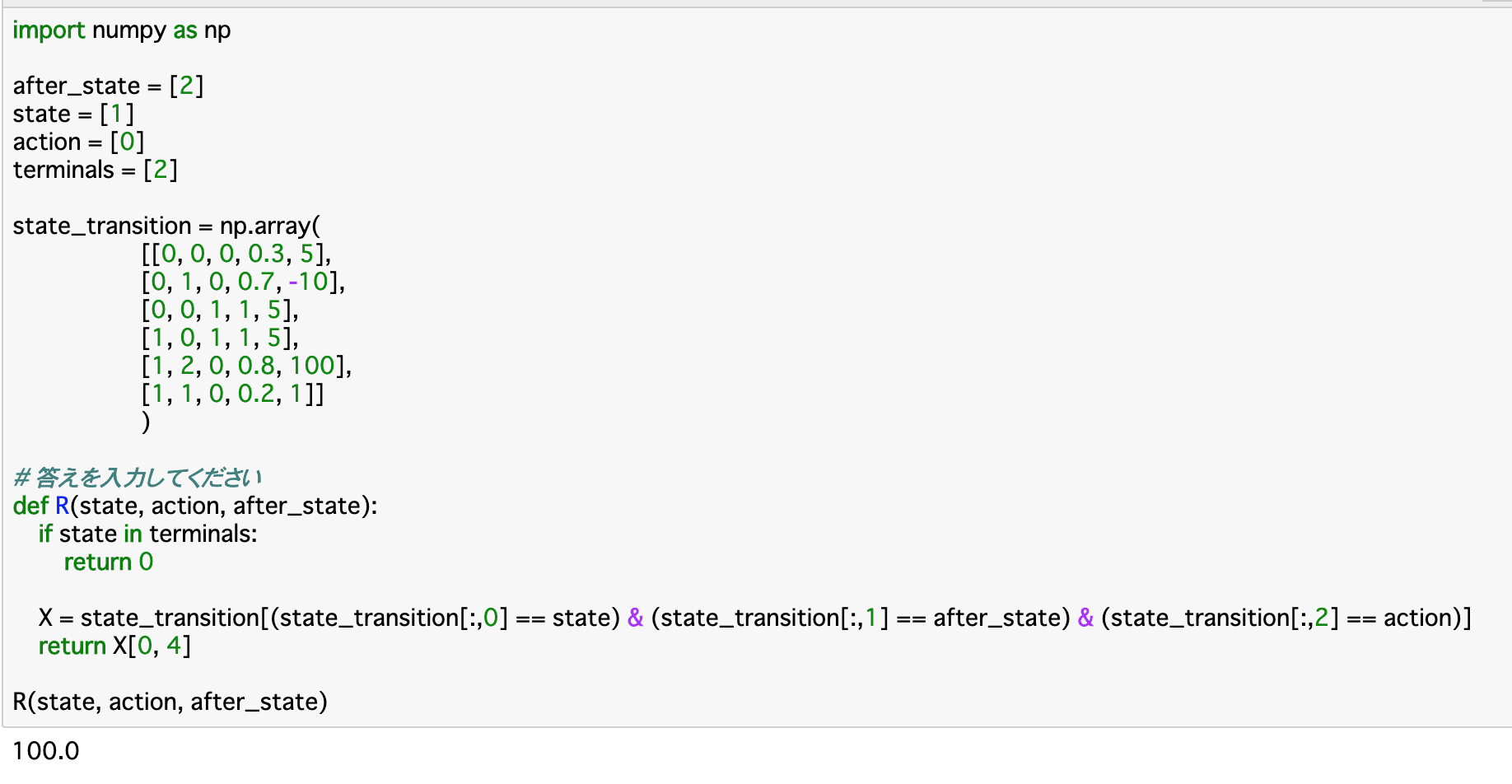
この報酬関数について定義したのが、以下のコードである。
・この関数「R」について、引数では先述した$s_{t},a_{t},s_{t+1}$の三つを渡す。前提として、既に終点(terminal)にいる時は報酬が存在しないので、0を返す。
・今回も「state_transition」を参照して報酬を返すのであるが、報酬はこの配列の4列目にあるので、条件にあった状態(行)を抽出して、その4列目を返すようにすれば良い。
・今回の条件とは、引数で渡された「state,after_state,action」について、それぞれが一致するものをstate_transitionの0,1,2列目から探し出せば良い。・実行部分について、stateが[1]、after_stateが[2]、actionが[0]となっているので、「現在StateBにいて、ActionXを行うことでEndについた」時の状態遷移を参照すれば良い。今回のstate_transitionでいうと、それは4行目の [1, 2, 0, 0.8, 100]であるので、この4列目の報酬が出力されている。
エピソード
・タスク開始から終了までにかかる時間のことを「エピソード」という。「行動→状態変化」というサイクルが何度も続くことによって時間ステップが進んでいき、一つのエピソードが構成されていく。
・強化学習のモデルでは、この一つのエピソードについて「環境を初期化し、エージェントに行動させ、受け取った報酬を元に行動モデルを最適化する」ということを複数回行うことで学習を進めていく。
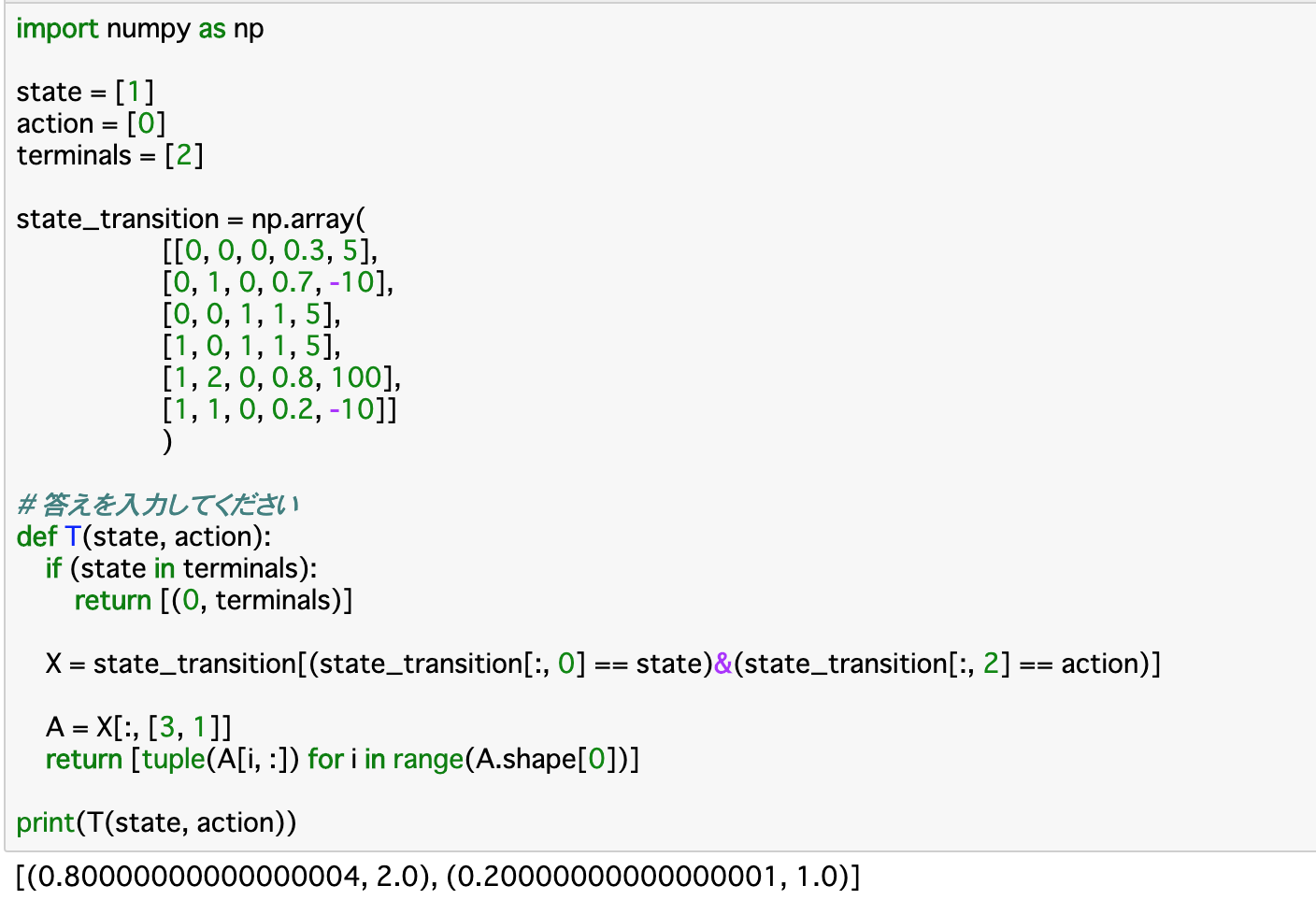
・ターン性のカードゲームなどが例として非常にわかりやすい。ターンごとにプレイヤーの行動によって盤面は変化していき、「勝敗」という形でタスクが終了する。これを一つのエピソードとして、何度も対戦を行うことで、次第に最適な手を学習していくようになる。・以下はエピソードを定義した関数「T()」である。この関数は「現在のstateとactionを渡し、state_transitionから対応するものを抽出し、状態遷移確率と遷移後のstateを返す」というものである。
・Tの定義部分について、既に終点(terminals)にいる時は、状態が遷移することはないので [(0, terminals)]と返すようにする。
・Xについては前項と同様に、渡された引数と一致する行を抽出している。この行の「3列目(状態遷移確率)」と「1列目(遷移後のstate)」をAに格納し、とりうる全ての場合について「tuple(A[i,:])」でタプル化して返す。価値・収益・状態
報酬と収益
・ここまでは強化学習のモデル化、定義を行ってきた。ここからは「何を基準に最適な方策を探っていくか」ということを考える。
・報酬を指標にして考えた場合、これは直前の行動のみによって決まってしまうので、「その時点ではほとんど価値のない行動でも、その後非常に大きな価値を持つ行動」を見落としてしまう。
・これを解決するのが「収益」である。収益はある期間に得られた報酬の合計で算出されるため、その状態より後の報酬も考慮に入れることができる。
・t時点での行動$a_{t}$によって得られる報酬を「$R_{t}$」とすると、ある期間内の報酬の和である収益「$G_{t}$」は次の式で算出できる。
$$
G_{t} =R_{t+1} + \gamma R_{t+2}+ \gamma^2 R_{t+3}+....= \displaystyle\sum_{\tau=0}^{\infty} \gamma^{\tau} R_{t+1+\tau}
$$・$\gamma$は「割引率」と呼ばれ、(0〜1)の値をとる。これは、「将来もらえる報酬をどれぐらい現在の価値とするか」を表すもので、0に近いほど将来の価値を見出さないようになり、1に近いほど将来の価値に重みをつけるようになる。
・また、報酬の合計の算出にはいくつか手法が存在するが、一般的には「割引報酬和」というものが使われる。これは時刻tからある時刻Tまでの収益の平均を算出し、Tの極限を取ることで算出する、というものである。
・割引報酬和は、以下のように二つの関数で定義することができる。
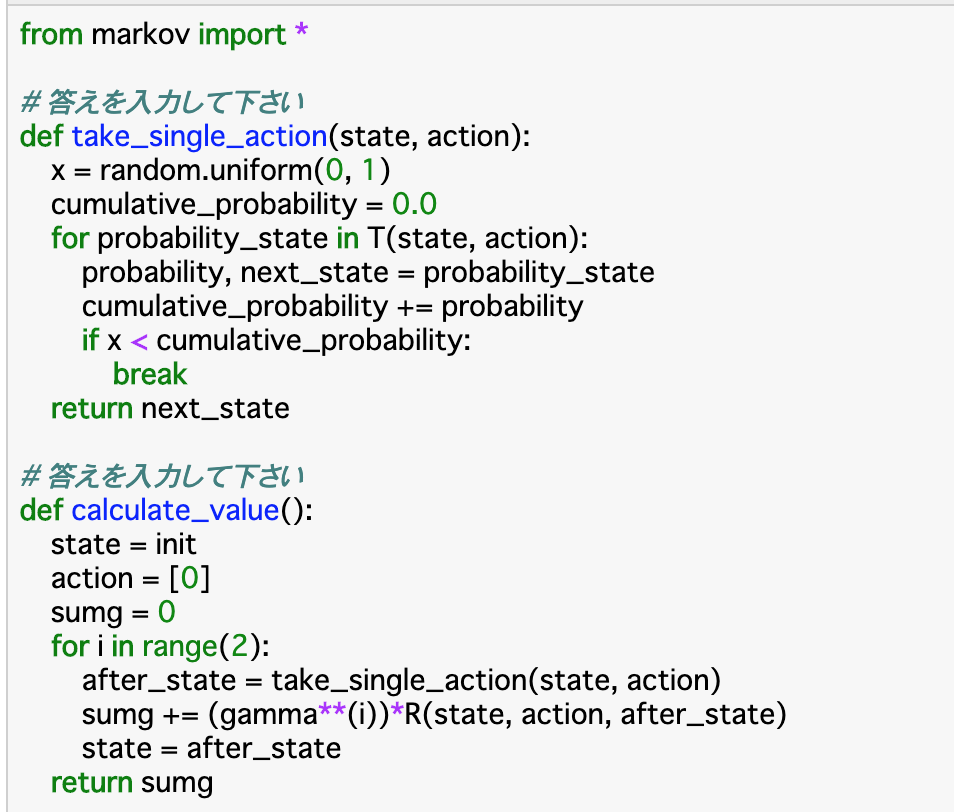
・「take_single_action()」について、これは「遷移確率に基づいて次の状態を決定する」関数である。コードとしては、まず「random.uniform(0,1)」で0〜1の乱数を生成する。また、累積確率「cumlative_probability」を定義する。
・for文では渡されたstate,actionからエピソード「T」ごとに、考えうる確率「probability」と次の状態である「next_state」を抽出し、累積確率「cumlative_probability」にエピソードごとの「probability」を足し、これが「x」より大きくなったらfor文を終了させ、その時点での「next_state」を返す。・もう一つの関数「calculate_value()」について、これが「割引報酬和」を計算する関数になる。はじめに「state」「action」と、割引報酬和「sumg」を定義する。
・for文では、エピソードの回数分の繰り返しを行う。今回は2回としている。この中で、次のstateを「take_single_action」で定義し、これと、その時の「state」「action」を使って$R_{t+1}$を計算し、これと$\gamma^i$をかけたものをsumgに累積していく。そして「state」を更新したら次のエピソードにいき、最終的な割引累積和「sumg」を返す。・実行部分
価値関数・状態価値関数
・前項のやり方のように、報酬を方策の評価基準とするようなやり方では、Rが確率に基づいて決定するため、状態が分岐すればするほど複雑な計算式になってしまうという欠点がある。
・報酬の期待値を取ることで、以上の欠点を解消できる。ある状態をスタートとして、それ以降の行動全てを考慮に入れた報酬の期待値のことを、「価値」または「状態価値」という。方策が良いものであればあるほど状態価値は大きくなる。
・この概念を導入することで、「ある方策において、どの状態が優れているかを比較できる」「ある状態をスタート地点に置いた時の方策ごと良し悪しを比較できる」という二つのことが可能になる。最適な方策の探索
最適方策
・前項の状態価値関数の導入により、方策ごとの良し悪しを比較できるようになった。
・二つの方策$\pi_{1},\pi_{2}$を比較する時
・状態空間Sの全ての状態sにおいて、状態価値$V^{\pi_{1}}(s)$が$V^{\pi_{2}}(s)$以上である
・状態空間Sの少なくとも一つの状態sにおいて、状態価値$V^{\pi_{1}}(s)$が$V^{\pi_{2}}(s)$より大きいの二つが成り立つ時、「$\pi_{1}は\pi_{2}$よりも良い方策である」ということができる。
・また、この時全ての方策の中には最も良い方策が存在するはずであり、これを最適方策と呼び、$\pi^*$と表す。行動価値
・状態価値関数は「ある状態をスタートとした時の報酬の期待値」であるが、実際には「ある状態をスタートとし、ある行動を起こした時の報酬の期待値」というように、行動まで考慮に入れた価値を考えた方が良い場合が多い。この時の価値を「行動価値」といい、ある方策下における行動価値を示す関数を「行動価値関数」という。
・行動価値関数は、各「行動」がどれだけ良いかを判断する関数ということができる。
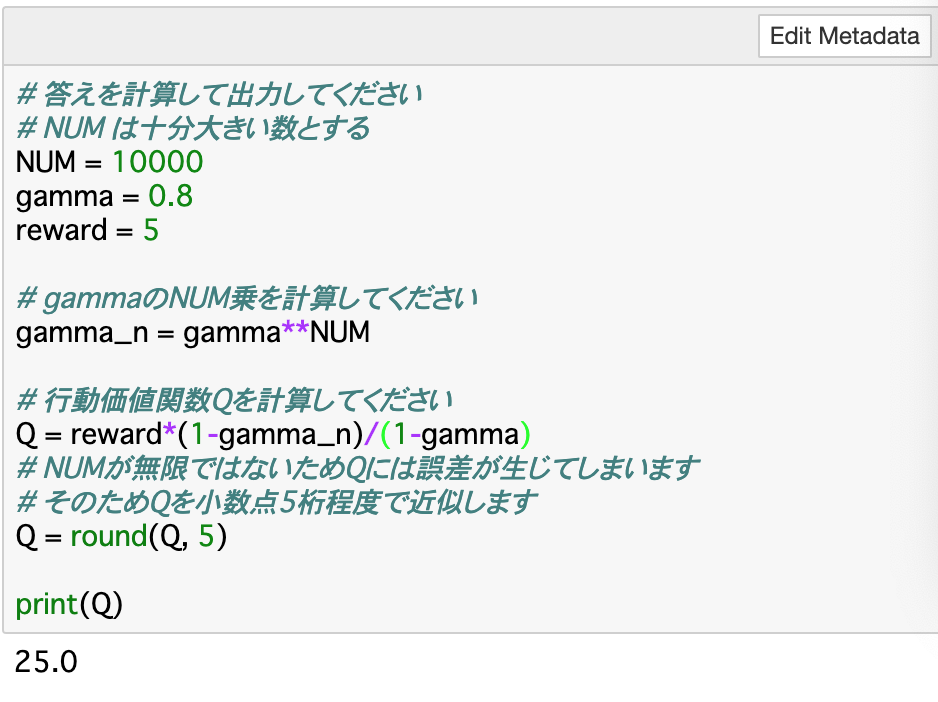
・数式としては、以下の等比級数の公式を使用する。
$$a+ar + ar^2 + \cdots + ar^n = \large\frac{a(1 - r^n)}{1 - r}$$・この公式の「a」をreward(報酬)、「r」をgammaとして、行動価値関数を計算することができる。これについてのコードが以下のようになる。
最適状態価値関数・最適行動価値関数
・ここまでに見てきた「状態価値関数」と「行動価値関数」のうち、最適な方策に従った場合のそれぞれの関数を「最適状態価値関数」「最適行動価値関数」という。それぞれ、「$V^*(s)$」「$Q^*(s)$」と表す。
・一度最適状態価値関数と最適行動価値関数が求められれば、どの行動が最も収益の大きくなる行動かがわかるということなので、常に最適な行動を選び続ける「greedy手法」を選べば良い。ベルマン方程式
最適な状態価値
・最適状態価値関数を求めるには、それぞれの状態価値関数を求め、比較すれば良い。行動価値関数についても同様であるので、ここでは状態価値関数を対象に進めていく。
・それぞれの状態価値関数の求めるには、ベルマン方程式を使う。これは「状態sと行動した結果移行する可能性のある状態s'との間に価値関数の関係式を成り立たせる」という発想から成り立つ。
・ベルマン方程式は以下のようにそれぞれの関数を漸化式のようにすることで使用できる。
$V^{\pi}(s) =\displaystyle\sum_{\alpha \in A(s)}^{} \pi(a|s) \displaystyle\sum_{s' \in S}^{} P(s'|s,a)(r(s,a,s') + \gamma V^{\pi}(s'))$$Q^{\pi}(s,a) =\displaystyle\sum_{s' \in S}^{} (P(s'|s,a)
(r(s,a,s') + \displaystyle\sum_{a' \in A(s')}^{} \gamma \pi(a'|s') Q^{\pi}(s',a')))$・ここでの$\pi(a|s)$ は、行動の選ばれる確率を表している。
・例えば「環境1」において、「s=StateB」、「$\gamma$=0.8」、「ActionXのみを行う」とするとき、ベルマン方程式で価値関数を算出すると
$V^\pi(B)=0.2(-10+\gamma*V^\pi(B))+0.8(100+\gamma*0)$を$V^\pi(B)$についての方程式として解けば良い。
すなわち、より簡単にいうと、「(そのActionを起こす確率) × (行動によるReward + $\gamma$ × 移動後のState)」を全ての場合について算出し、その和を使って方程式を解けば良い。・環境1
ベルマン最適方程式
・先述した最適状態関数、最適行動関数についても、当然にベルマン方程式が適用できる。よって、常に最適な方策をとった時のベルマン方程式を「ベルマン最適方程式」という。
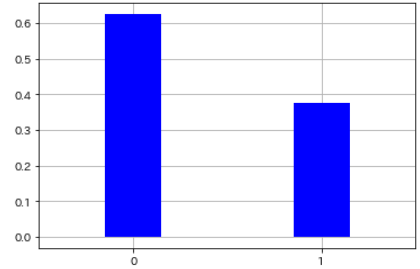
・例えば環境1で「常にActionXをとる方策$\pi_{1}$」「常にActionYをとる方策$\pi_{2}$」のどちらがいい方策であるかを比較するとき、収益(割引報酬和)を算出する関数「caluclate_value()」を使って、以下のように表せる。
・Q_optimumはその時の最大の収益を表し、Q_piはその時の方策を表している。Q_piが[0 0]となっていることから、常にActionXを取る方策$\pi_{1}$を取る方が良いことがわかる。
まとめ
・時間ステップ「t+1」の時における報酬「R_{t+1}」は $r(S_{t},A_{t},S_{t+1})$と表される。この時未来の状態(t+1)は現在の状態や行動(t)によってのみ決定されることを「マルコフ性」といい、これを満たす強化学習の過程をマルコフ決定過程という。
・マルコフ決定過程において、構成要素を[s,s',a,p(s'|a,s),r(s,a,s')]というように配列で表したものを「状態遷移図」という。時間の概念を導入した場合は$[S_{t},S_{t+1},A_{t},S_{0},R_{t+1}]$で表される。
・タスク開始から終了までの時間のことを「エピソード」という。強化学習ではこのエピソードについて「環境を初期化し、エージェントの行動による報酬をもとに最適化する」ことを繰り返して学習を行う。
・実際の強化学習では、即時報酬だけでなく、遅延報酬も含めた「収益」を基準に最適な方策を考える。収益は、各時間ステップにおける報酬に「割引率$\gamma$」をかけたものの和である「割引報酬和」で計算する。
・また、最適な方策を探索するにあたっては、収益についてこのまま計算すると計算量が多くなってしまうので、報酬の期待値である「状態価値関数」「行動価値関数」を計算すると良い。これらを求めるときに使われるのが「ベルマン方程式」である。状態価値関数についてベルマン方程式を使うとすると、「Actionを起こす確率」「報酬」「移動後のState」を使って算出される。今回は以上です。ここまで読んでくださりありがとうございました。



- 投稿日:2020-11-15T22:00:06+09:00
誰かのために
皆様、こんばんは
お久しぶりです。有難いことに、
アルゴリズムの基礎を勉強させてもらい
色々な問題にチャレンジさせてもらっています。問題を解くために自分の中のイメージを言語に落とすアプローチは
自由で大空を飛んでいるようです。目的地に最後まで辿り着く難しさが
何とも言えず、楽しいです。今更ですが、自分はエンジニアではありません。
FAE と言われる、技術営業で、主に半導体(Power IC..DCDC convertor) の
技術サポートと営業活動を生業にしています。実は過去に 8 年 FPGA の FAE もやってたので
プログラム言語も経験しており、評価ボードで検証することも
たまにやっています。そんな FAE 歴は、はや 12,3 年。
あらゆる市場トラブルを体験し、日本のモノづくりの現実を見てきました。そこで痛感した事。
1.何よりも大切なのはコミュニケーション
誰かに奉仕することで給料を貰う以上は、何を満たせば"奉仕"と
認めてもらえるのかはコミュニケーションがないと成り立ちません。2.逃げずに立ち向かった経験は自分のチカラになる
困難はギフトです。毛根がストレスで 10% 壊死したら喜びましょう。
貴方の実力は格段に上がっている(笑)
誰かを救いたい気持ちを折らずに持ち続けられれば不思議と突破できます。私は技術力とは何かを後輩に尋ねられたことがあります。
ふと、こんな風に答えました。
"コミュニケーション力と思いやりじゃない?"すいません、話が逸れてしましました。
今、皆さんは誰のためにプログラムを書いていますか?私は趣味で書いていますが、
色々なアプローチに出会うことで、
様々な需要に合わせた書き方があるのではないか
考えるようになりました。かの有名な映画で描かれているように
人の心には光と闇が混在し、表裏一体です。
この取り扱いの難しいと思われがちな人の心ですが、
自分のためではなく、誰かのために神経を集中できると
とてつもない力を発揮するオーパーツでもあります。私利私欲ではなく、誰かを想いながら書くと
不思議と他のアプローチや考え方が必要じゃないか
考えるようになります。この積み重ねは大きな力になるのではないでしょうか。
ソフトの設計経験があるわけでは無いので見えてない現実は
多分にあると思いますが、人を想い、コミュニケーションを重んじた
設計者が織りなす技術は美しい結晶となって、いつまでも輝き続けると私は信じます。私の拙い人生経験が誰かの役に立てば幸いです。
この記事をちょうど読んでいる貴方が内なる何かに苦しんでいるのであれば、
それは恐らく成長のサインかもしれません。プライドやら欲望やら、全部吐き出して、
何をすべきなのか整理してみましょう。
きっと答えはあると思います。
- 投稿日:2020-11-15T21:54:47+09:00
1. Pythonで学ぶ統計学 2-1. 確率分布[離散型変数]
- 離散型の確率変数は、サイコロの目のように飛び飛びの値をとる変数のことで、例えば「1」の次は「2」、「2」の次は「3」というように、その間に 1.1, 1.2, 1.3, ・・・, 1.8, 1.9 などといった連続的な数値は存在しません。
- 主な離散型の確率分布について、scipy.statsの
pmf(probability mass function : 確率質量関数)やrvs(random variates : 確率変数)を使ってその特徴を見ていきます。# 数値計算ライブラリのインポート import numpy as np import scipy as sp import pandas as pd from pandas import Series, DataFrame # 可視化ライブラリのインポート import matplotlib.pyplot as plt import matplotlib as mpl import seaborn as sns %matplotlib inline # matplotlibの日本語表示モジュール !pip install japanize-matplotlib import japanize_matplotlib⑴ ベルヌーイ分布(Bernoulli distribution)
- 2種類しかない事象のどちらかを発生させることをベルヌーイ試行(Bernoulli trial)といいます。
- ベルヌーイ分布とは1回のベルヌーイ試行において、それぞれの事象が生じる確率分布のことです。
- 例えば、コインを8回投げて表が出たら0、裏が出たら1として結果を次のように仮定します。
x = np.array([0,0,1,1,0,1,0,0]) # 確率分布を計算 p = len(x[x==1]) / len(x) pmf_bernoulli = sp.stats.bernoulli.pmf(x, p) # 可視化 plt.vlines(x, 0, pmf_bernoulli, colors='blue', lw=50) plt.xticks([0,1]) plt.xlim([0 - 0.5, 1 + 0.5]) plt.grid(True)
2種類の事象 確率 0 0.625 1 0.375 ⑵ 二項分布(Binomial distribution)
- 互いに独立したベルヌーイ試行をn回くり返したとき、ある事象が何回起こるかという確率分布のことを二項分布といいます。
- 例えば、表が出る確率pが50%のコインを5回投げて、そのうち2回が表になる確率を
binom.pmfを使って求めます。sp.stats.binom.pmf(n=5, p=0.5, k=2)
- 表が出る確率pが20%のコインを10回投げて表が出た回数を数える、という試行を10000回くり返したと仮定し、
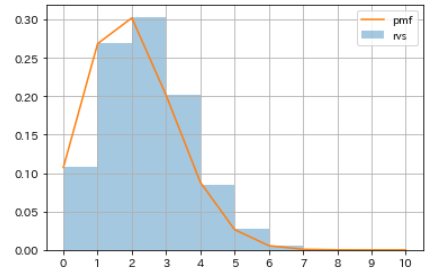
binom.rvsを使って二項分布に従う疑似乱数を生成します。- さらに
binom.pmfを使って、表が出る確率pが20%のコインを10回投げたときに表が出る回数の確率分布を計算し、疑似乱数のヒストグラムと比較してみます。# 疑似乱数を生成 np.random.seed(1) rvs_binom = sp.stats.binom.rvs(n=10, p=0.2, size=10000) # 確率分布を取得 m = np.arange(0, 10+1, 1) pmf_binom = sp.stats.binom.pmf(n=10, p=0.2, k=m) # 可視化 sns.distplot(rvs_binom, bins=m, kde=False, norm_hist=True, label='rvs') plt.plot(m, pmf_binom, label='pmf') plt.xticks(m) plt.legend() plt.grid()
表が出る回数 確率 0 0.107374182 1 0.268435456 2 0.301989888 3 0.201326592 4 0.088080384 5 0.026424115 6 0.005505024 7 0.000786432 8 0.000073728 9 0.000004096 10 0.000000102 ⑶ ポアソン分布(Poisson distribution)
- ごく稀に起こる事象の確率で、例えば単位面積当たりの雨粒の数とか、ある交差点で一年間に発生する事故の回数などがポアソン分布に従います。
- つまり、一定の時間や面積に対して一定の割合で発生する確率分布で、サンプル数nが十分に大きく確率pが非常に小さい場合です。
- 例えば、ある期間に平均5回起こる現象が2回だけ起こる確率を
poisson.pmfを使って求めます。sp.stats.poisson.pmf(k=2, mu=5)
- ポアソン分布のパラメータはある事象の平均発生回数muで、これは強度とかλ(ラムダ)とも呼ばれます。
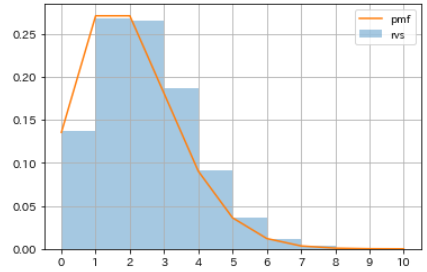
- ある事象が起こる確率pを20%として、起こった回数を数えるという試行を10000回くり返したと仮定し、
poisson.rvsを使ってポアソン分布に従う疑似乱数を生成します。- さらに
poisson.pmfを使って、発生確率pが20%のときの確率分布を計算し、疑似乱数のヒストグラムと比較してみます。# 疑似乱数を生成 np.random.seed(1) rvs_poisson = sp.stats.poisson.rvs(mu=2, size=10000) # 確率分布を取得 m = np.arange(0, 10+1, 1) pmf_poisson = sp.stats.poisson.pmf(mu=2, k=m) # 可視化 sns.distplot(rvs_poisson, bins=m, kde=False, norm_hist=True, label='rvs') plt.plot(m, pmf_poisson, label='pmf') plt.xticks(m) plt.legend() plt.grid()
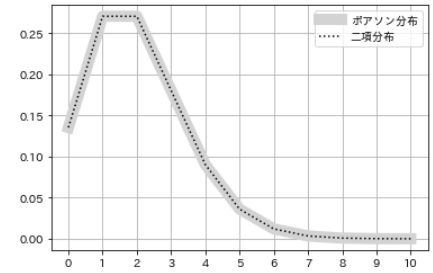
発生回数 確率 0 0.135335283 1 0.270670566 2 0.270670566 3 0.180447044 4 0.090223522 5 0.036089409 6 0.012029803 7 0.003437087 8 0.000859272 9 0.000190949 10 0.000038190
- ここで、ポアソン分布と二項分布の関係を考察します。
- 試行回数nが十分に大きく確率pが非常に小さいときの二項分布の確率分布を計算し、先のポアソン分布の例と比較してみます。
# パラメータを指定 n = 100000000 p = 0.00000002 # 二項分布の確率分布を計算 num = np.arange(0, 10+1, 1) pmf_binom_2 = sp.stats.binom.pmf(n=n, p=p, k=num) # 可視化 plt.plot(m, pmf_poisson, color='lightgray', lw=10, label='poisson') plt.plot(m, pmf_binom_2, color='black', linestyle='dotted', label='binomial') plt.xticks(num) plt.legend() plt.grid()
- この場合、ポアソン分布と二項分布はほぼ一致し、両者が近い関係にあることがわかります。
- ポアソン分布は、二項分布の発生確率pが非常に小さく試行回数nが十分に大きいときの状況を近似的に表します。
⑷ 幾何分布(geometric distribution)
- 成功確率がpの独立したベルヌーイ試行をくり返すとき、初めて成功するまでの試行回数kが従う確率分布を幾何分布といいます。
- 例えば、サイコロを1回だけ投げて「1」が出る確率をscipy.statsの
geom.pmfを使って取得します。%precision 3 sp.stats.geom.pmf(k=1, p=1/6)
- サイコロの目は全部で6つ、すべてが同じ確率とすれば 1/6 で 0.167 になるのは当然ですが、
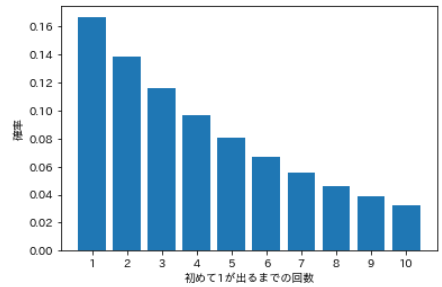
- 次々と投げて、2回目に初めて「1」が出る確率、3回目に初めて「1」が出る確率、・・・・・・、10回目に初めて「1」が出る確率を求めます。
# 試行回数を指定 num = np.arange(1, 11, 1) # 確率分布を計算 prob = [] for i in num: value = sp.stats.geom.pmf(k=i, p=1/6) prob.append(value) # 可視化 plt.bar(num, prob) plt.xticks(num) plt.xlabel('初めて1が出るまでの回数') plt.ylabel('確率') plt.show()
- k回投げて、k-1回目までは失敗し、k回目に初めて成功する確率ということで、この場合の確率分布は次の通りです。
試行回数 確率 計算式 1 0.167 ⅙ 2 0.139 ⅚・⅙ 3 0.116 ⅚・⅚・⅙ 4 0.096 ⅚・⅚・⅚・⅙ 5 0.080 ⅚・⅚・⅚・⅚・⅙ 6 0.067 ⅚・⅚・⅚・⅚・⅚・⅙ 7 0.056 ⅚・⅚・⅚・⅚・⅚・⅚・⅙ 8 0.047 ⅚・⅚・⅚・⅚・⅚・⅚・⅚・⅙ 9 0.039 ⅚・⅚・⅚・⅚・⅚・⅚・⅚・⅚・⅙ 10 0.032 ⅚・⅚・⅚・⅚・⅚・⅚・⅚・⅚・⅚・⅙ ⑸ 離散一様分布(uniform distribution)
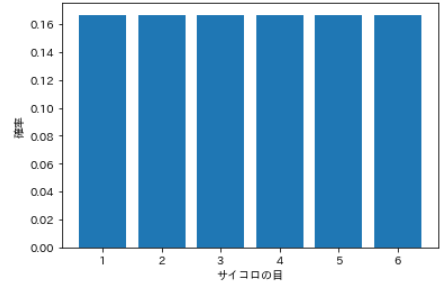
- 一様分布には離散型と連続型があり、確率変数が離散型の一様分布を離散一様分布といいます。
- すべての事象の起こる確率が等しい分布で、例えばサイコロは1から6までの目が出る確率がすべて等しいので離散一様分布に従います。
# 全事象を指定 num = np.arange(1, 7, 1) # 確率分布を計算 prob = [] for i in num: value = 1 / len(num) prob.append(value) # 可視化 plt.bar(num, prob) plt.xticks(num) plt.xlabel('サイコロの目') plt.ylabel('確率') plt.show()
サイコロの目 確率 1 0.167 2 0.167 3 0.167 4 0.167 5 0.167 6 0.167 ⑹ 超幾何分布(hypergeometric distribution)
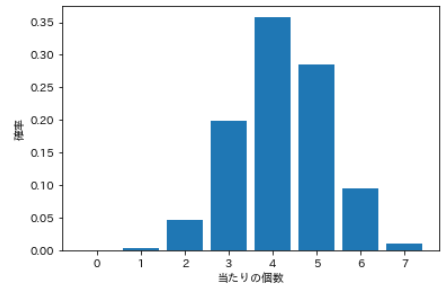
- 例えば、全部で20個のくじがあり、そのうち7個が当たりであるとします。20個からランダムに12個を選んだとき、当たりが何個出るか。
- この「引き当てる個数」を確率変数とする分布を超幾何分布といいます。
- パラメータは3つで、全体の個数M、当たりの個数n、選択する個数Nになります。
# パラメータを指定 M = 20 #全体個数 n = 7 #当たり個数 N = 12 #選択個数 # 確率変数を作成 k = np.arange(0, n+1) # モデルを作成 hgeom = sp.stats.hypergeom(M, n, N) # 確率分布を計算 pmf_hgeom = hgeom.pmf(k) # 可視化 plt.bar(k, pmf_hgeom) plt.xticks(k) plt.xlabel('当たりの個数') plt.ylabel('確率') plt.show()
当たり個数 確率 0 0.00010 1 0.00433 2 0.04768 3 0.19866 4 0.35759 5 0.28607 6 0.09536 7 0.01022 ⑺ 負の二項分布(negative binomial distribution)
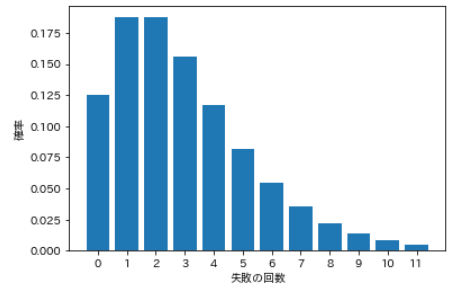
- 負の二項分布では、n回の試行でk回成功する確率を求め、最後の試行が成功であることを条件とします。
- 二項分布では成功回数kが確率変数ですが、負の二項分布では成功回数kは固定です。確率変数には、試行回数nを使う代わりに失敗の数n-kを使います。
- 例えば、コイントスをくり返して3回表が出るまでに何回投げる必要があるか。すなわち3回成功するまでに何回失敗する必要があるか、という失敗回数が確率変数になります。
# パラメータを指定 N = 12 #試行回数 p = 0.5 #成功確率 k = 3 #成功回数 # 確率分布を計算 pmf_nbinom = sp.stats.nbinom.pmf(range(N), k, p) # 可視化 plt.bar(range(N), pmf_nbinom) plt.xlabel('失敗の回数') plt.ylabel('確率') plt.xticks(range(N)) plt.show()
失敗の回数 確率 0 0.125 1 0.188 2 0.188 3 0.156 4 0.117 5 0.082 6 0.055 7 0.035 8 0.022 9 0.013 10 0.008 11 0.005 まとめ
離散型の確率分布を見てきましたが、何が確率変数となるのか、平たく言えばx軸に何を置くかという点を意識して一覧表にまとめます。
確率分布の種類 確率変数 パラメータ ⑴ ベルヌーイ分布 事象0, 1 発生確率p ⑵ 二項分布 試行の回数 発生確率p, 発生回数k, 試行回数n ⑶ ポアソン分布 試行の回数 平均発生回数mu ⑷ 幾何分布 試行の回数 成功確率p, 試行回数k ⑸ 離散一様分布 事象の種類 ※scipy.atatsの一様分布は連続型のみ ⑹ 超幾何分布 成功の個数 全体個数M, 全体中の成功個数n, 選択個数N ⑺ 負の二項分布 失敗の回数 成功確率p, 成功回数k, 試行回数N
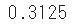
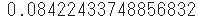
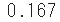
- 投稿日:2020-11-15T21:23:27+09:00
多言語からみるマルチコアの活かし方
多言語からみるマルチコアの活かし方
はじめに
近年では1つのCPUに複数のコアが搭載されたマルチコアが一般的になっています。
しかし、現状のプログラミング言語ではエンジニアが意識せずにマルチコアをしたプログラムを作ることは難しいです。
そこで、様々な言語から見たマルチコアの活かし方について説明していきます。プロセスとスレッド
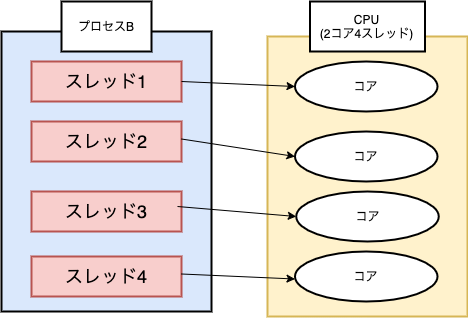
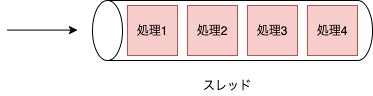
プロセスとは1つ1つのアプリケーションといった実行中のプログラムのことで、スレッドは CPU利用の単位です。プロセスは次のように1つ以上のスレッドを持っており、CPUのコア数分だけスレッドを処理することができます。(また、近年ではSMTという技術によって1つの物理コアで2スレッドといった複数のスレッドを処理することができます。2コア4スレッドみたいなやつです)
マルチコアを有効活用してプログラムを実行するためにはCPUが処理できるコア数に対して適切な数のスレッドをプログラム側で生成する必要があります。コア数以上のスレッドを生成する事も可能ですが、CPUはコア数分のスレッドしか処理を行うことができず、実行するスレッドの切り替えにより処理が遅くなってしまう問題が発生します。並列と並行
並列(parallel)と並行(concurrent)という似たような言葉が存在しますが、違うものを示します。
並列(parallel)とは複数の処理を同時に行うことで、複数のコアで複数のスレッドを処理するような場合を示します。(シングルコアでは複数処理を同時に実行できないため並列を実現することはできません。)
並行(concurrent)とは複数の処理を切り替えながら同時に実行しているようにすることで、1つのスレッドで複数の処理を切り替えながら実行するような場合を示します。
複数のスレッドで処理を切り替えながら実行することも可能なため、並列かつ並行を実現することも可能です。C10K問題
WebサーバーのApacheではユーザのリクエスト毎にプロセスを生成する方式を取っており、クライアントが約1万台に達すると、Webサーバーのハードウェア性能に余裕があるにも関わらず、レスポンス性能が大きく下がるというC10K問題というものが存在していました。(C10K問題の具体的な原因はこちらの記事が分かりやすかったです。)
そこで、nginxやNode.jsではシングルスレッドで非同期I/Oに処理をすることにより、並行に処理を行を行うことでC10K問題を解決しようとしました。Node.js
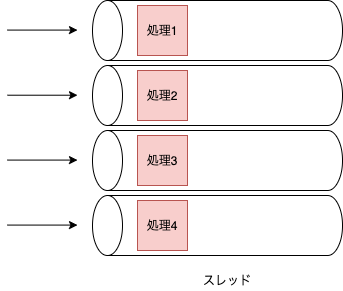
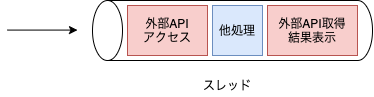
前述したように、Node.jsはシングルスレッドで動作をし、async/awaitといった非同期処理で並行に処理を行うというアプローチがされています。イメージとしては下図のように、外部APIアクセスをする際に結果が返ってくるまでの時間に他の処理を行い、結果が取得できたらその処理の続きを行うようなイメージです。(詳細はこちらの記事が分かりやすかったです。)
従って標準の非同期処理を行う場合は、マルチコアの性能を引き出すことができません。そこでNode.jsではClusterを用いてプロセスを複数作成するか、worker_threadsを用いてスレッドを複数作成する必要があります。このようにマルチコアコアを活かすためには、プログラム側からプロセスかスレッドを複数作成してあげる必要があり、マルチスレッドでは変数の値の共有を行うことができますが、マルチプロセスではメモリ空間が分離され、変数の値の共有ができないというそれぞれのメリット・デメリットが存在します。RubyやPythonで起こるGIL
Node.jsでは、プロセスかスレッドを複数作成してあげることでマルチコアを活かすことができました。しかし、RubyやPythonではグローバルインタプリタロック(GIL)というものが存在し、複数のスレッドを作成しても並列に実行することができません。(正確にはC言語で実装されたCPythonとCRubyの場合ですが、ここでは省略します。)
従って、これらの言語でマルチコアを活かそうとした場合、マルチスレッドでは実現できず、プロセスを複数作成してあげる必要があります。Go言語でのgoroutine
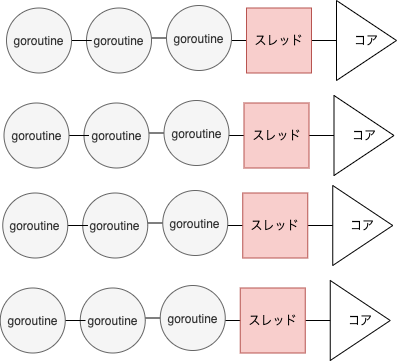
Go言語では、goroutineというものを用いて非同期処理を並列・並行に実現しており、デフォルトでCPUのコア数が設定された
GOMAXPROCSというものが設定されています。この値の数だけスレッドが用意され、そのスレッドの中で軽量スレッドであるgoroutineを実行します。
CPUのコア数が4のGOMAXPROCS=4の場合のイメージとしては下図です。
このようにgoroutineを用いることによりマルチコアを活かして並列・並行にプログラムの実行を行えます。
(goroutineが軽量な理由についてはこちらの記事が分かりやすかったです。)Rustでのasync/await
Rustでは、async/awaitを用いて非同期処理を行えます。この際、どのランタイムを用いるかによって非同期処理のスレッドの実行割当方法を選択できます。
人気があるランタイムとしては、tokioが挙げられます。tokioではコア数に対してスレッドが生成され、そのスレッドに非同期処理が渡されるというgoroutineと同様のマルチコアの活かし方が実現できます。(他の割当方法や、Rustでの非同期処理についてはこちらの記事が分かりやすかったです。特にここの実行モデルについてが分かりやすいです。)さいごに
RubyやPythonでは仕組み上マルチスレッドにすることが難しく、Node.jsの非同期処理は、そのままではマルチコアを活かすことができませんでした。
しかし、近年人気のあるGo言語やRustでは非同期処理を呼ぶ事により、エンジニアが意識せずに並列・並行処理を行え、マルチコアを活かすことができます。
マルチコアのCPUが一般的になってきた現代に、Go言語やRustが人気がある事も納得です。参考
【図解】CPUのコアとスレッドとプロセスの違い,コンテキストスイッチ,マルチスレッディングについて
プロセスとスレッドとタスクの違いを知ってUnity非同期完全理解に近付く
Node.jsの非同期I/Oについて調べてみた
いまさら聞けないNode.js
Pythonで並列処理をするなら知っておくべきGILをできる限り詳しく調べてみた
goroutineはなぜ軽量なのか
Rustの非同期プログラミングをマスターする

- 投稿日:2020-11-15T20:30:11+09:00
iOSで動作する異常検知モデルを作った
背景
農業x深層学習のアプリケーションが作りたい!
という動機のもと、例えば作物の画像を入力してその健康状態を診断するようなアプリが作れるんじゃないかと考えてます。
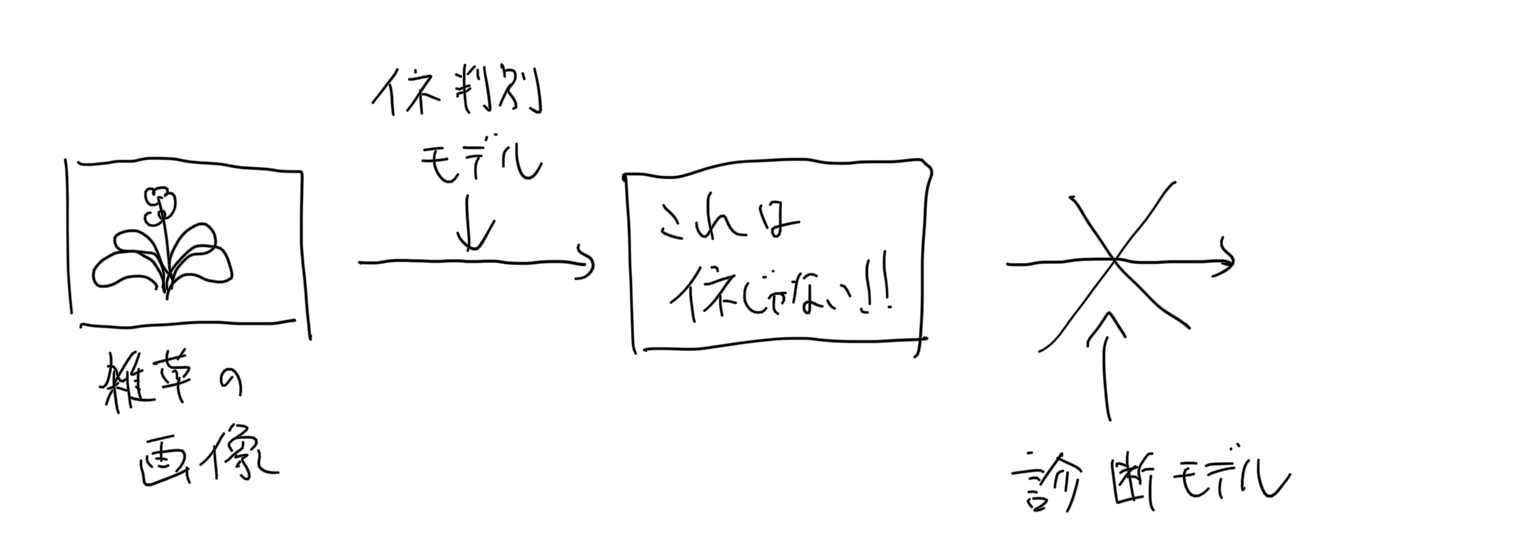
病気を判定できるすごいモデルのせたアプリを作ったとして、ユーザが対象の作物の画像を正しく入力してくれるかどうかは、そのアプリの信頼性を担保する上で重要な問題になります。
例えば、上記の稲の病気を診断してくれるアプリを作ったとして、ユーザが雑草の画像を入力したとしてもそれっぽい結果を出力してしまえば、そのアプリの診断結果自体が疑わしいものになってしまいます。
この問題に対処するため、メインとなるモデルの前段に入力画像の異常画像検知モデルを置いておけばよいのでは、と考えました。
異常検知モデルにおいて正常と判定された画像のみをメインモデルに渡せば、信頼性の高い結果を出力することができそうです。
できたもの
3年前に購入した iPhoneXにアプリをインストールして、稲と雑草の画像を手元のラップトップに表示し、それを撮影してみました。
右上の円型のゲージに注目していただくと、稲と雑草をなんとなく識別している様子がわかると思います。
以下で、どんなことをやったのかをつらつらと書いていきます。
メトリックラーニング
メトリックラーニングは、ある画像のペアが同一かどうかを判別するモデルを作成するために用いられる手法です。今回の要件にあたっては、入力した画像が学習させた正常画像と同じかどうかを判別するためにこの手法を利用しました。
以下の記事を参考にさせていただきました。
https://qiita.com/shinmura0/items/06d81c72601c7578c6d3モデル
モデルの作成にはPytorchを使いました。
スマホに載せることを目標としているので、軽量なMobileNetV2を特徴抽出器として利用します。
MobileNetV2はtorchvisionにデフォルトで用意されています。今回は画像サイズを128x128としました。featuresレイヤーの出力をいい感じに整形して、最終出力を512次元のベクトルにします。
from torchvision.models import MobileNetV2 class MobileNetFeatures(nn.Module): def __init__(self): super(MobileNetFeatures, self).__init__() self.head = MobileNetV2().features self.pool = nn.AvgPool2d(4, 4) self.flat = nn.Flatten() self.fc = nn.Linear(1280, 512) def forward(self, x): x = self.head(x) x = self.pool(x) x = self.flat(x) x = self.fc(x) return x学習
データセット
学習データとして、正常画像と同時にランダムな異常画像を与える必要があります。
そこで、オープンデータセットであるCOCOデータセットから、正常画像と同じ数だけランダムに抽出し、これを異常画像の集合としました。Loss関数
割と新しいLoss関数である Arcface を使いました。
Arcfaceの説明としては下記の記事がめちゃくちゃわかりやすかったです。
https://qiita.com/yu4u/items/078054dfb5592cbb80ccまた、以下のレポジトリではこういったメトリックラーニングの最新の論文実装がライブラリとして提供されているため、こちらを利用させていただきました。
https://github.com/KevinMusgrave/pytorch-metric-learning異常度の測定
学習させたモデルの出力は512次元のベクトル(embedding)です。
入力した画像が異常かどうかを判別するには、正常画像から得られるembeddingとのコサイン類似度をとる必要があります。そのため、学習フェーズではモデルの保存と同時にバリデーションデータのembeddingの平均ベクトルを保存しておくようにします。
そして推論時にはこれを読み込んで、入力した画像とのコサイン類似度をとることで、異常かどうかの判別を行うことができます。
train.pyif save_interval > 0 and epoch_id % save_interval == 0: model.eval() # 正常画像と異常画像のコサイン類似度をそれぞれ測定する. positive_dist = [] negative_dist = [] for batch in valid_loader: images = batch[0].to(device) labels = batch[1].numpy().tolist() labels = [bool(i) for i in labels] with torch.no_grad(): embeddings = model(images).cpu().numpy() positive_embeddings = embeddings[labels] negative_embeddings = embeddings[[not i for i in labels]] mean_embedding = np.mean(positive_embeddings, axis=0) for pe in positive_embeddings: cos_sim = np.dot(mean_embedding, pe) / (np.linalg.norm(mean_embedding, ord=2) * np.linalg.norm(pe, ord=2)) positive_dist.append(cos_sim) for ne in negative_embeddings: cos_sim = np.dot(mean_embedding, ne) / (np.linalg.norm(mean_embedding, ord=2) * np.linalg.norm(ne, ord=2)) negative_dist.append(cos_sim) mean_positive_dist = sum(positive_dist) / len(positive_dist) mean_negative_dist = sum(negative_dist) / len(negative_dist) print(f"epoch{epoch_id}: {mean_positive_dist} {mean_negative_dist}") model.train() # embeddingを保存する features_save_path = f"../saved_features/embedding.txt" np.savetxt(features_save_path, mean_embedding, delimiter=",")スマホモデルへの変換
今回はiOSに載せることを想定し、coreMLを利用しました。
PytorchモデルからcoreMLへの変換のために、一度ONNX形式への変換を経由します。
(coremltoolsの最新版ではONNXを経由せずに変換できるようですが、今回は調査不足のため旧いやり方に従います。)以下のスクリプトを参照ください。
- Pytorch -> ONNX
- ONNX -> CoreML
注意としては、2020/11/14現在 Python3.8.2の環境ではProtocolBuffer関連のエラーが発生し、ONNX -> CoreML への変換が動作しませんでした。
これは3.7.7を利用することで解決できます。あとは生成された
.mlmodelを Swiftへ組み込めばOKです。終わりに
プロジェクト全体は以下のリポジトリに置いてあります。
https://github.com/fltwtn/light_weight_annomaly_detection実際にスマホで動作させてみて、MobileNetV2の速さを改めて実感しました。たぶん30fps以上は出てるんじゃないかな。。。
最近では精度も高く高速なモデルが次々にリリースされているので、今後もいろんなモデルをスマホモデルに変換して試してみようと思います。


- 投稿日:2020-11-15T20:23:33+09:00
[Blender×Python] 関数を自分でつくる&今までの総まとめ
この記事では、より多彩な処理を手軽に行うために関数を自分でつくる方法を紹介します。
目次
0.関数とは
1.関数の種類
2.関数をつくるサンプルコード
3.英単語0.関数とは
関数とは、出力装置のようなものです。
引数の情報を受け取って、処理を実行します。見た目は、
関数名(引数1,引数2,...)のような形をしています。
引数は、パラメーターの役割を果たしています。
つまり、引数をいじると処理の結果が変わってきます。その点、料理と似てます。
塩の量(パラメーター)をいじると、料理の味(出力)も当然変わってきますよね。1.関数の種類
関数には2種類あります。
誰かが用意してくれた関数 と 自分でつくる関数 です。
1-0.誰かが用意してくれた関数
今まで頻繁に使ってきた立方体を追加する関数
primitive_cube_add()などは誰かが用意してくれた関数です。
primitive_cube_add()とか、長い関数名だなと思った方もいるかもしれませんが、きっとどこかのおじさんたちが頑張って話しあって、こんな長い名前の関数ができたんだと思われます。1-1.自分でつくる関数
自分でつくる関数は、おじさんたちが用意してくれた関数をありがたく使ってつくります。
①定義
②使用の順番で進めます。
もう少し具体的にかくと、
def 関数(): 処理のようにして関数を定義したあと、
関数()と書くだけです。
次章で具体的に見てみましょう。
1-2.関数をつくってみる
立方体を1つ出現させる関数を自分でつくってみます。
まず、どこかの誰かが用意してくれた立方体を出現させる関数
primitive_cube_add( )を見てみましょう。import bpy bpy.ops.mesh.primitive_cube_add()これを利用して自分で関数をつくります。
①定義
以下の例では、cube( )という関数を自分で定義しています。
import bpy #オリジナル関数の定義 def cube(): #誰かが用意してくれた関数 bpy.ops.mesh.primitive_cube_add()上のコードでは、自分のオリジナルの関数
cube()をdefを使って定義しています。構造は以下のような形です。def 自分で作る関数の名前(): 関数を呼び出した時にさせたい処理②使用
関数を呼び出してみましょう。cube()これだけです。
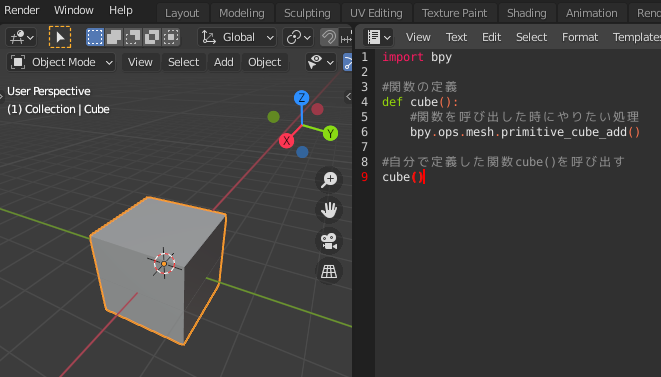
全体像は以下のようになります。import bpy #関数の定義 def cube(): #関数を呼び出した時にやりたい処理 bpy.ops.mesh.primitive_cube_add() #自分で定義した関数cube()を呼び出す cube()
2.関数をつくるサンプルコード
具体例で見て行った方がわかりやすいと思うので、ここからはサンプルコードと簡単な解説を載せていきます。
オブジェクトをワイヤーフレームにする関数をつくる
import bpy def cube(): bpy.ops.mesh.primitive_cube_add() def wireframe(): bpy.ops.object.modifier_add(type='WIREFRAME') cube() wireframe()
wireframe関数を他の関数の中で使う
import bpy #オブジェクトをワイヤーフレームにする関数 def wireframe(): bpy.ops.object.modifier_add(type='WIREFRAME') #サイズを変えながらワイヤーフレームの立方体を出現させる関数 def wireframe_cube(_size = 2,num = 3): for i in range(0,num): bpy.ops.mesh.primitive_cube_add( size = _size * i ) #出現させたオブジェクトを1つずつワイヤーフレームにしていく wireframe() #最初のサイズは、1でそれを倍にしていく。立方体の数は10個。 wireframe_cube(_size = 1,num = 10)
uv_spehreを出現させる関数をつくる
import bpy #sphere()という関数を定義する #滑らかさと出現位置を調整できるようにする def uv_sphere(_segments = 32,_location = (0,0,0)): bpy.ops.mesh.primitive_uv_sphere_add( segments=_segments, location = _location ) #3個出現させる uv_sphere() uv_sphere(_segments = 16,_location = (3,0,0)) uv_sphere(_segments = 3,_location = (6,0,0))
立方体を1列に並べていく関数をつくる
import bpy #好きな場所から好きな個数の立方体を1列に出現させる関数の定義 #引数にデフォルトの値を代入する def cube_line_up(start_position = (0,0,0),num = 2,distance = 2): for i in range(0,num * distance + 1,distance): bpy.ops.mesh.primitive_cube_add( #X軸方向に並べていく location=(start_position[0] + i,start_position[1],start_position[2]) ) #自分で定義した関数cube()を呼び出す cube_line_up() cube_line_up(start_position = (0,-4,0),num = 10,distance = 5) cube_line_up(start_position = (0,-8,0),num = 4,distance = 3)
マテリアル(ガラス)を設定する関数をつくる
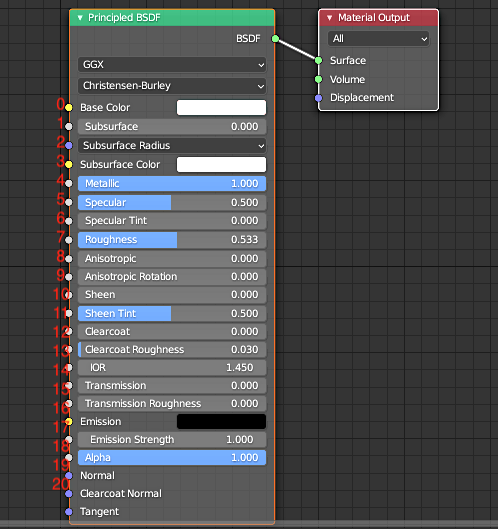
import bpy #立方体を出現させる関数の定義 def cube(): bpy.ops.mesh.primitive_cube_add() #マテリアルの設定をする関数の定義 def material(name = 'material',color = (0, 0, 0, 1)): material_glass = bpy.data.materials.new(name) #ノードを使えるようにする material_glass.use_nodes = True p_BSDF = material_glass.node_tree.nodes["Principled BSDF"] #0→BaseColor/7→roughness(=粗さ)/15→transmission(=伝播) #default_value = (R, G, B, A) p_BSDF.inputs[0].default_value = color p_BSDF.inputs[7].default_value = 0 p_BSDF.inputs[15].default_value = 1 #オブジェクトにマテリアルの要素を追加する bpy.context.object.data.materials.append(material_glass) cube() material(name = 'Red',color = (1, 0, 0, 1))
マテリアル(金属)を設定する関数をつくる
import bpy #立方体を出現させる関数の定義 def cube(): bpy.ops.mesh.primitive_cube_add() #マテリアルの設定をする関数の定義 def material(name = 'material',color = (0, 0, 0, 1)): material_glass = bpy.data.materials.new(name) #ノードを使えるようにする material_glass.use_nodes = True p_BSDF = material_glass.node_tree.nodes["Principled BSDF"] #0→BaseColor/4→Metallic(=金属)/7→Roughness(=粗さ) #default_value = (R, G, B, A) p_BSDF.inputs[0].default_value = color p_BSDF.inputs[4].default_value = 1 p_BSDF.inputs[7].default_value = 0 #オブジェクトにマテリアルの要素を追加する bpy.context.object.data.materials.append(material_glass) cube() material(name = 'Blue',color = (0, 0, 1, 1))
3.英単語
英単語 訳 function 関数 context 文脈/環境 append 追加する default 既定の add 追加する distance 距離 inputs 取得する principled 原理、原則の line up 並べる segments 部分/区切り






- 投稿日:2020-11-15T20:03:40+09:00
強化学習1 入門編
Aidemy 2020/11/15
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、強化学習の一つ目の投稿になります。どうぞよろしくお願いします。*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・強化学習とは
・エージェント、環境、報酬
・強化学習の方策強化学習とは
・機械学習は大別すると「教師あり学習」「教師なし学習」「強化学習」に分けられる。
・そのうち、今回学んでいく強化学習は、「与えられた条件下で最適な行動を発見すること」を目的とした手法である。例えばゲームであれば、強化学習によって勝ち方を発見することができる。強化学習についての詳細
・強化学習は「エージェント(player)」と「環境(stage)」が相互作用するという前提のもとで進められる。
・あるエージェントが状態sにあるとして、環境に対して行動aを取るとすると、これによって環境はその行動の評価として報酬Rを返し、エージェントは次の状態s'に移行するということを繰り返しながらタスクを進めていく。
・例えばスーパーマリオの例で言えば、エージェントである「マリオ」が、「先に進んでゴールを目指すが、敵に当たると終了」という環境で、「敵を(ジャンプで)避ける」という行動を取ると、環境は「その先に進める権利(そこでゲームが終わらない)」という報酬を返す。これを繰り返して、マリオはゴールというタスクに向かって進んでいく。・強化学習においては、その場の報酬「即時報酬」を最大化するだけでなく、その後に得られる報酬「遅延報酬」も含めた「収益」を最大化することが必要になる。
・先のマリオの例では、コインを取ることはその場では価値のない行動であるが、100枚集めて「残機を増やす」ことに価値を見出す場合、報酬を最大化するためにはできる限りコインを取るように行動したほうが良いと言える。N腕バンディット問題
・N腕バンディット問題は強化学習の一例で、「N台のスロットマシーンがあり、あたりなら1外れなら0という報酬が支払われるとする。あたりの確率は台ごとに異なるが、ユーザーからは見えない」とするとき、「ユーザーは1回の試行でどれか一つのスロットを引けるとするとき、試行回数当たりの平均報酬量を最大化するにはどうすれば良いか」を考える問題である。
・考え方としては「最も確率の高い台で引く」ということが理にかなっているが、その台を見つける(推測する)ためにも試行が必要である。というのがこの問題のミソである。
・以降では、この例を使って強化学習について学んでいく。エージェントの作成
・エージェントとは、より詳しくいうと「環境の中で行動を決定し、環境に対して影響を与えるもの」を指す。
・N腕バンディット問題では、どの台を使うかを判断し、報酬を受け取り、次の判断をするユーザーがエージェントである。
・エージェントが取得した報酬から、どのように次の判断を行うかという指標のことを「方策」という。例えば、この問題において方策が「常に1」というようにきまっているとき、エージェントは常に報酬が1となるような台を狙うことになる。
・このエージェントの最適な方策を決定するのが今回の目的である。・以下のコードは、今回の手法「どの台を選ぶか」をランダムで決定する関数「randomselect()」である。これによって、どの台を選ぶのかという「slot_num」が返される。
環境の作成
・環境とは、エージェントが行動を起こす対象である。役割としては、行動を受けて状況を観測し、報酬をエージェントに送信し、時間を一つ進めるというものがある。
・今回の問題における環境は「エージェントがある台を引いた時、その台の確率によって当たりかはずれかを出すプロセス」である。・以下のコードは環境を定義した関数「environment()」である。「coins_p」で各台の当たる確率をNumPy配列で格納し、「results」には「np.random.binomial(n, p)」で試行回数n、確率pの二項分布を求める関数を使用して、スロットを引いた結果を格納する。今回は試行回数1回で確率は「coins_p」であるので、(1, coins_p)と指定すれば良い。environment関数としては、渡された「band_number」の結果を返せば良いので、これを「result」に格納して返す。
報酬の定義
・報酬(reward)とは、エージェントの一連の行動の望ましさを評価する指標のことである。
・今回の問題で言えば、スロットを引いて得られた返り値(0or1)がそのまま報酬である。これは即時報酬に当たる。・以下のコードは報酬を定義した関数「reward()」である。先ほどのenvironment関数で得た結果を「result」に格納し、引数で渡された配列「record」の現在の試行回数を示す「time」番目にこれを格納する。
・また、[[(台の番号),(選択回数),(報酬合計),(報酬合計÷選択回数)],...]となっているリスト「results」に、それぞれの結果を格納していく。
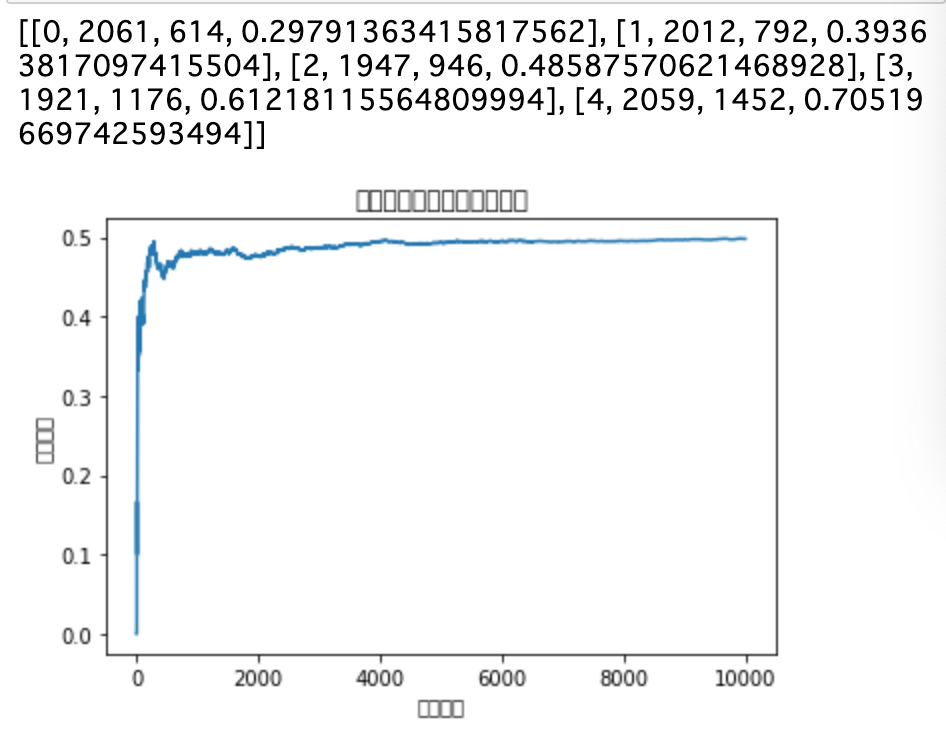
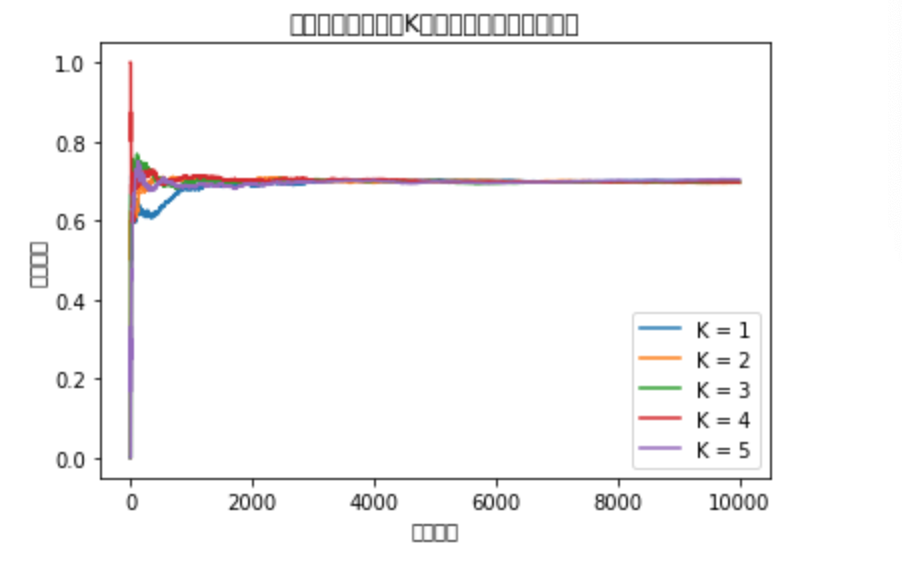
・さらに、これらの関数を使ったり、自分で値を渡したりして「使う台」「あたりかハズレか」「何回試行するか」などを決め、それぞれの台の試行回数と結果を出力し、平均報酬の遷移を図示したものが以下である。
・結果
・この結果を見ると、「どの台を選ぶか」は完全にランダム(1/5)にしているので、台が選ばれる回数は均等で、当たる確率もおよそ設定した値通りになっている。また、グラフから見てわかるように、平均報酬は0.5付近を維持している。
N腕バンディッド問題の方策
greedy手法
・ここまででエージェントや環境、報酬の型は定義できたので、次は実際に「どうやれば平均報酬を上げられるか」という方策を考えていく。
・基本的な方針としては、最初は情報が全くないので、ランダムに台を選ぶしかない。ある程度試行を重ね、台の当たる確率が推測できるようになったら、最も確率の高い台を探し、その台を選び続ける選択を取ることにする。
・この時の、ある程度試行を重ねて情報を収集することを「探索」といい、最終的に最適な台を選び続けることを「利用」という。・この方針を最も単純に行う手法が「greedy手法」である。これは、「これまでの結果から最も期待値の大きいものを選択する」という単純明快なものになっている。
・まずは探索を行う。この時、一台につきn回試行するということをあらかじめ決めておき、それをすべての台について行っていく。これが終了したら、その時点での報酬の期待値$u_{i}$を計算し、一番大きいものを選択する。
・期待値$u_{i}$は「(マシンiの報酬の和)÷(マシンiの試行回数)」で求められる。・以下のコードでは、実際にこの手法を定義して、前項までで作成した環境などを定義した関数も使用して試行した例である。
・greedy手法の定義は、まず「一台の試行回数上限に達するまでslot_numをその台のままにする」というものと、「すべての台が試行回数上限に達したら、slot_numをその時点で最も期待値の高いものにする」というものを定義すれば良い。
・後者について、コードで「np.array()」としているのは、最大値を取得するメソッド「argmax()」を使うためである。
・値を与えてgreedy手法の実践
・結果
・この結果からわかることとして、与えられた探索のための試行回数の上限「n=100」まではすべての台について試行を行なっており、そこからは最も期待値の高い「台4」にすべての試行(残り9500回)を使っている。
ε(イプシロン)-greedy手法
・前項のgreedy手法は、nが小さいほど、つまり探索に使う試行回数が減るほど、間違った台を選ぶ可能性が高くなってしまう。一方、nを大きくすれば最適な台を選ぶ可能性は高くなるが、探索の方に多くの試行回数を使ってしまい、無駄が大きくなってしまう。
・今回の「ε-greedy手法」はこの問題点を解消できる。この手法は探索と利用を織り混ぜることで、探索のコストを減らしつつ間違った台を選び続けるリスクを減らすことができるというものである。
・ε-greedy手法の流れは以下のようになる。
①まだ選択したことのない台があればそれを選ぶ
②確率εで全台からランダムで選択する(探索)
③確率1-εでこれまでの報酬平均(期待値)が最大のマシンを選択する(利用)・つまり、各試行ごとに、確率εで探索を行い、確率1-εで利用を行うというのがこの手法である。
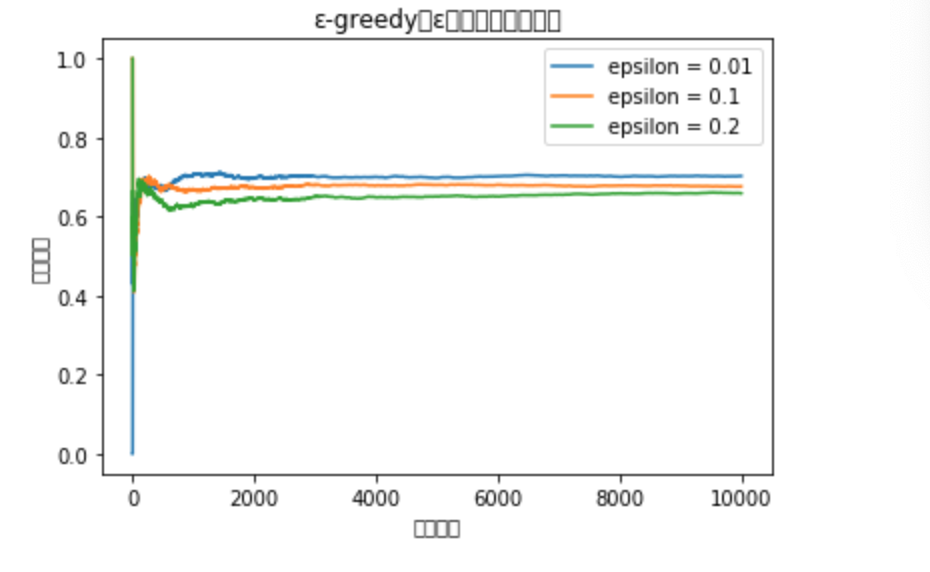
・ε-greedy手法の定義部分
・実行部分
・結果
楽観的初期値法
・greedy手法では、例えば「0.4と0.6の確率で当たる台A,B」があるとして、「Aの台」の期待値を「0.8」のように多めに予測した場合は、初めはAの台を選び続けるが、試行によって実はAの台は期待値が低そうだ(0.4に収束する)ということを認識し、Bの台に移行していくことができる。
・一方で、「Bの台」の期待値を「0.2」のように少なめに予測してしまうと、「Bの台は試行しない」つまり「Aの台しか選ばない」という状況に陥ってしまい、間違いに気づくことができないという問題点がある。
・このようなリスクを減らす手法として、「不確かな時は期待値を高めに(楽観的に)見積もる」という「楽観的初期値法」が使われる。
・具体的な考え方としては、学習の前に、各台から報酬の最大値をK回得ていることにしてから期待値を計算するということを行う。
・よって、この手法を使う際には「報酬の最大値(rsup)」と「最大値を得たと仮定する回数(K)」を指定する必要がある。
・この二つを使った各台の期待値は$\frac{R(N)+Kr_{sup}}{N + K}$で求められる。R(N)は実際に測定した回数(resultsの3列目に格納)、Nは実際に測定した回数(resultsの2列目に格納)である。よって、コードは以下のようになる。
・実行部分
・結果
soft-max法
・ε-greedy法では、探索の際に、明らかに最悪と考えられる台であっても、決められた回数は必ず試行してしまうことが欠点に挙げられる。例えば当たる確率が20%で、あたりだと「1」ハズレだと「-100」となる台があったとすると、この台を引くことは極めて悪い行動になることが予測されるが、ε-greedy法では、これを避けて探索することはできない。
・これを解消できるのが、「soft-max法」である。これは、「価値の高そうな行動を選ばれやすく、低そうな行動を選ばれにくくする」というものである。つまり、「各行動に重み付け」を行う。
・重みは$\frac{\exp{Q_{i}/ \tau}}{\sum^i \exp{Q_{i}/ \tau}}$という式を使って算出する。 $Q_i$は報酬の期待値、$\tau$(タウ)はパラメータであり、$\tau$が小さいほど上記重み付けの傾向が強くなる。
・soft-max法の流れとしては、データがない場合はすべての報酬を「1」と仮定し、各台の選択確率を上記の式で算出し、これに基づいて選択を行い、報酬を得ることで報酬関数を更新する、というように行われる。具体的なコードは以下の通り。
・上記コードについて、まずは報酬の予測期待値「q」を算出する。これはresultsの4列目を参照すれば良い。次に、データがない場合は報酬期待値「q」はすべて「1」とする、すなわちすべての値が1の配列を「np.ones()」で作成する。
・「q」と渡された「tau」を使った上記の式で選択確率「probability」を算出する。そして、確率がprobabilityで、選択される対象は台の番号であるとして、「np.random.choice(配列,p=確率)」で何が選ばれるかを定義する。・実行部分
・上記の結果を見てみると、基本的には台の当たる確率通りに選ばれることが多くなっている。ただし、今回の試行では1番の台が全く当たらず、「確率が0の台」とみなされ、それ以降は選ばれていない。
UCB1アルゴリズム
・UCB1アルゴリズムは、楽観的初期値法を改善した手法である。具体的には、「そのマシンがどれだけ当たってきたか(成功率)」と「そのマシンについてどれだけ知っているか(偶然によるデータのばらつきの大きさ)」を合わせて判断することで、あまり探索されていない台は積極的に探索し、データが集まってきたら最も当選確率の高い台を選択するということを同時に行うことができる。
・流れとしては、まず報酬の最大値と最小値の差「R」を算出する。そして、まだ選んだことのない台があればそれを選択し、得られた結果から各台の報酬の期待値(成功率)「$u_{i}$」を計算する。
・また、これらを使った$R\sqrt{\frac{2logT}{N}}$で、各台の偶然によるデータのばらつきの大きさ「$x_{i}$」を計算する。この時の「T」は総プレイ回数、「N」はマシンiのプレイ回数を表す。
・この「$u_{i}$」と「$x_{i}$」の和が最大となる台が最適であると考えて、それを選択する。
・以上をコードで表すと以下のようになる。(N腕バンディッドではR=1である)
・上記コードについて、「まだ選んだことのないマシン」は、resultsの1列目(試行回数)が0であるものと言い換えることができる。また、「これまでの総試行回数(times)」はこの部分をすべて「sum()」で足し合わせれば良い。
・各台の偶然によるデータのばらつきの大きさ「xi」は上記の公式通りに記述すれば良いが「math.sqrt()」でルート、「math.log()」でlogがそれぞれ表現できる。・実行部分
・この結果について、どの台も最低限の回数は試行されているが、確率の低そうな台はあまり試行されておらず、無駄が少なくなっている。
ここまでの手法について
・ここまでで「greedy手法」「ε-greedy手法」「soft-max手法」「楽観的初期値法」「UCB1アルゴリズム」の五つを見てきたが、明確な優劣はなく、大事なのは問題によって使い分けるということである。
・強化学習の前提として「探索と利用はトレードオフの関係にある」ということが言える。すなわち、探索回数を多くすれば、最適な台以外の試行回数も増えてしまうため無駄が大きくなってしまい、利用回数を多くすれば、最善の台を選ばないリスクが大きくなってしまう。
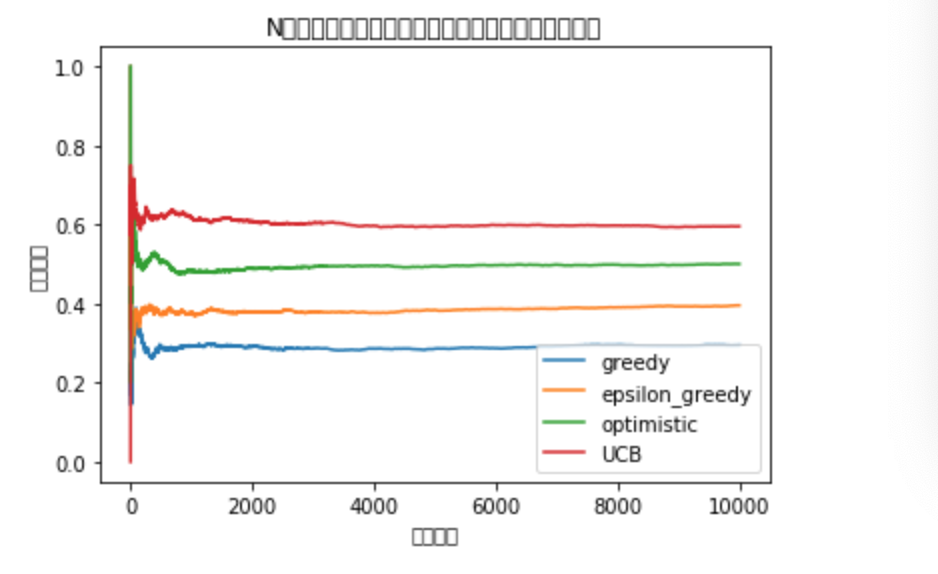
・例えば全体の試行回数が少ない時は、探索の割合が大きい「ε-greedy法」などは最適な台を見つけやすいため、報酬率が高くなりやすい。一方で、試行回数が多い時は探索の無駄が大きくなってしまうこの手法よりもスマートに探索が行え、利用回数が増える「UCB1アルゴリズム」の方が報酬率が高くなりやすい。
・最初からすべての確率が公表されている時は、エージェントはその中から最適なもののみを試行すれば良い、すなわち探索が必要なくなるが、この時の報酬と、上の五つの手法を使った場合の報酬の差分を「リグレット」と呼ぶ。
・五つの手法の中で、最もリグレットを最小化できるのが「UCB1アルゴリズム」である。・各手法の結果を表した図(N腕バンディッド問題の場合)
まとめ
・強化学習とは、与えられた条件下で最適な行動を発見することを目的した手法である。
・強化学習では行動者の「エージェント」が存在する。N腕バンディッド問題では「台を選ぶ」という行動をとる。
・また、エージェントが行動を起こす対象である「環境」も存在する。この場合の環境は「台があたりかハズレかを返すプロセス」である。
・「報酬」は、エージェントの行動の望ましさを評価する指標のことである。この報酬の大きさを最大化することが強化学習の目的である。
・この報酬を最大化するための手法として「greedy手法」「ε-greedy手法」「soft-max手法」「楽観的初期値法」「UCB1アルゴリズム」が挙げられる。どの手法も、はじめにそれぞれの台の確率を推定するために「探索」を行い、その結果から最適な台を選ぶ「利用」を行う。今回は以上です。最後まで読んでいただき、ありがとうございました。














- 投稿日:2020-11-15T19:44:22+09:00
【Alibaba Cloud】OSS / Function Compute でもSSIっぽいことをやる
TL;DR
前回、AWSでSSI(include virtual)が記述されたHTMLを、S3の特定バケットに格納しLambdaでインクルード内のソースを結合した上で別のバケットに格納するような仕組みを作りましたが、それのAlibaba Cloud版です。
やりたかったこと
OSS(Object Storage Service)は静的サイトホスティングサービスのため、サーバーサイド側で動的に処理をするということが原則できません。
もちろんその後キャッシュする先であるCDN側(Alibaba Cloud CDN)もできません。その場合、今であればローカル開発環境を構築しローカル上では別々のファイルにしておき、コンパイルする際に結合する方法がスタンダードだと思いますが、元々SSIが使われていた既存サイトをOSS+CDNへ移管する場合などを含め残念ながらすべての案件でそのフローが導入できるわけでもありません。
なので、元々SSIが使われていた場合、そのまま置換など行わずそのままの形で使用できるようにAlibaba Cloud側で調整を試みました。
やったこと
(前提としてAlibaba Cloud版のIAMであるRAMやKMSの設定が終わった状態です)
基本的に前回の記事を元に、Alibaba Cloud用にカスタマイズしています。
【AWS】S3 / LambdaでSSIっぽいことをやる
Alibaba Cloudの設定についてはSBクラウドさんのこちらの記事が役に立つ思います。
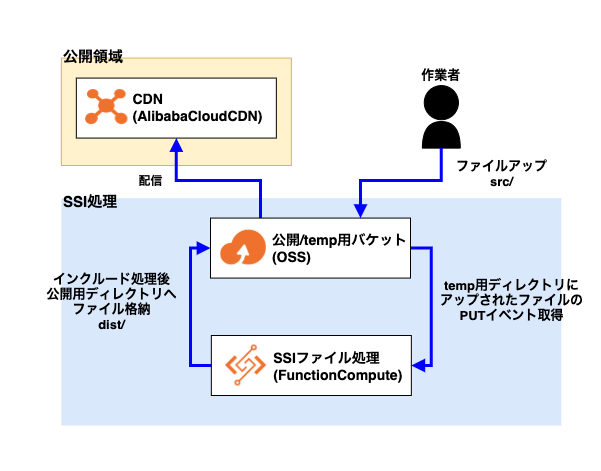
イベント駆動サービス FucntionComputeでオブジェクトストレージを操る構成
前回と構成は同じです。
なので使用するサービスはOSSとFunction ComputeのみでAlibaba Cloud CDNは必要であれば。
設定方法
OSS
Alibaba Cloud版ではファイルアップするバケットは1つにしています。
その中でtemp用のディレクトリと公開用のディレクトリの2つに分けて処理を行います。公開/temp用バケット
名前は何でも良いです。
今回はoss-ssi-includeとしています。各設定
アクセス許可はそれぞれ適宜設定されているものとします。
公開用ディレクトリとtemp用ディレクトリの作成
公開用ディレクトリ
distとtemp用ディレクトリsrcを「ディレクトリの作成」ボタンからそれぞれバケット内に作成してください。Function Compute
Function ComputeではPUTイベントを検知して、
src/ディレクトリ内にアップされたHTMLファイル内にSSI(サーバーサイドインクルード)が記述されていれば、Function Computeでインクルード処理を行い、dist/ディレクトリに格納するような関数を作成します。関数コード
import json import os import logging import oss2 import re import urllib.parse logger = logging.getLogger() logger.setLevel(logging.INFO) OSS_ENDPOINT = "oss-ap-northeast-1.aliyuncs.com" DEST_BUCKET_NAME = "oss-ssi-include" def handler(event, context): logger.info('## ENVIRONMENT VARIABLES') logger.info(os.environ) logger.info('## EVENT') logger.info(event) creds = context.credentials auth = oss2.StsAuth(creds.accessKeyId, creds.accessKeySecret, creds.securityToken) evt = json.loads(event) # 下記書き換える input_bucket = oss2.Bucket(auth, OSS_ENDPOINT, DEST_BUCKET_NAME) logger.info('## INPUT BUKET') logger.info(input_bucket) input_key = urllib.parse.unquote_plus(evt['events'][0]['oss']['object']['key']) logger.info('## INPUT KEY') logger.info(input_key) try: # 入力ファイルの取得 response = input_bucket.get_object(input_key) logger.info(response) # ファイル出力 output_key = re.sub('^src/','dist/',input_key) logger.info('## OUTPUT KEY') logger.info(output_key) if not input_key.endswith('.html'): logger.info(response) input_bucket.put_object(output_key, response) else: input_html = response.read().decode('utf-8') logger.info('## input_html') logger.info(input_html) output_html = input_html # SSI記述を取得 include_path_base = re.findall(r'<!--#include virtual="/(.*?)" -->.*?\n', input_html, flags=re.DOTALL) logger.info('## PATH BASE') logger.info(include_path_base) if len(include_path_base) > 0: for path in include_path_base: include_path = path logger.info('## PATH') logger.info(include_path) # SSIファイルの取得 try: include = input_bucket.get_object('src/' + include_path) include_html = include.read().decode('utf-8') # SSIを実行 output_html = output_html.replace('<!--#include virtual="/' + include_path + '" -->', include_html) except ClientError: pass input_bucket.put_object(output_key, output_html) except Exception as e: logger.info(e) raise eその他の設定
トリガー設定
トリガータイプ:OSS トリガー
トリガー名:put
イベントソース:
acs:oss:ap-northeast-1:xxxxxxxxxxxxxxxxx:ossname
イベント:oss:ObjectCreated:PutObject,oss:ObjectCreated:PostObject
トリガールール:接頭辞src/
ロール操作:既存のロールを選択
既存のロール:
ロールはRAMで設定した以下のポリシーでOKです。{ "Version": "1", "Statement": [ { "Action": [ "fc:InvokeFunction" ], "Resource": "*", "Effect": "Allow" } ] }おわりに
前回、AWSでSSI(include virtual)が記述されたHTMLを、S3の特定バケットに格納しLambdaでインクルード内のソースを結合した上で別のバケットに格納するような仕組みを作りましたが、諸事情でAlibaba Cloudでも作る必要があったため用意してみました。
AWS版と違ってtemp用ディレクトリにファイルアップ→CloudComputeが処理→公開用ディレクトリにファイルが格納されるため、使い良い形にするのであれば公開用ディレクトリに格納されたファイルはCDNへ配信した方が良いと思います。
あと、日本でAlibaba Cloudの情報を得ようとする時はSBクラウドさんのエンジニアブログがおすすめです。
今回のものも大分参考にさせていただきました。ただこれって重要あるのかな。。
現場からは以上です。
- 投稿日:2020-11-15T19:29:25+09:00
[Python] 特定のフォルダに入っている画像ファイルを撮影日時で一括リネーム
はじめに
皆様、携帯(スマホ)のカメラで撮影した写真の管理はどうされていますか?
私の場合は、ある程度撮ったらPCにコピーし、スマホからは消す、ということをして、なるべくスマホに大量のデータを残さないようにしています。
しかし、写真をスマホから消してしまうと、ファイル名の連番が戻ってしまい、PCにコピーしようとしたときに同じ名前のファイルができてしまって面倒なことになります。
ということで、ファイル名被りの問題を解決するため、PCにコピーした画像ファイルを撮影日時を使って一括リネームする方法をご紹介します。
検証環境
- Cygwin (Windows 10 20H2 Home)
- Python 3.6.10
- Pillow 7.2.0
事前準備
$ pip3 install Pillowコード
rename_images.pyfrom PIL import Image from PIL.ExifTags import TAGS from pathlib import Path import datetime # https://www.lifewithpython.com/2014/12/python-extract-exif-data-like-data-from-images.html def get_exif_of_image(file): """Get EXIF of an image if exists. 指定した画像のEXIFデータを取り出す関数 @return exif_table Exif データを格納した辞書 """ im = Image.open(file) # Exif データを取得 # 存在しなければそのまま終了 空の辞書を返す try: exif = im._getexif() except AttributeError: return {} # タグIDそのままでは人が読めないのでデコードして # テーブルに格納する exif_table = {} for tag_id, value in exif.items(): tag = TAGS.get(tag_id, tag_id) exif_table[tag] = value return exif_table # 画像が入っているPC側のフォルダのパスを指定 for filename in Path("/path/to/images").glob("DSC_*.JPG"): exif = get_exif_of_image(filename) if "DateTimeOriginal" in exif: # strftime() で新しい名前のフォーマットを指定 new_name = Path(filename).with_name(datetime.datetime.strptime(exif["DateTimeOriginal"], "%Y:%m:%d %H:%M:%S").strftime("IMG_%Y%m%d_%H%M%S.JPG")) print(f"{filename} \n -> {new_name}") filename.rename(new_name) else: print(f"[WARNING] {filename}: no EXIF header")解説
画像ファイルのEXIFヘッダから撮影日時を取り出し、撮影日時をもとに指定したフォーマットで新しいファイル名を作ってリネームします。
for filename in Path("/path/to/images").glob("DSC_*.JPG"):部分で、特定のフォルダに含まれている画像ファイルを列挙します。DSC_*.JPGの部分はスマホのカメラアプリが生成するファイルフォーマットに合わせてください。このパターンはXperiaの場合の例です。
get_exif_of_image()で、EXIFヘッダの情報を取得します。この関数は以下のページから引用しました。m(_ _)m
Python Tips:画像の Exif データを取得したい - Life with Python
DateTimeOriginalという名前で撮影日時が記録されていますので、日時の文字列をdatetimeモジュールで解析します。この記録フォーマットは統一されているはずなので、strptime()の引数をカメラごとにカスタマイズする必要はありません。
この解析結果をもとに新しいファイル名を作成します。お好みでstrftime()の引数を変更してください。ただし、DSC_%Y%m%d_%H%M%S.JPGのようなオリジナルと同じフォーマットの名前はやめておいたほうが良いと思います。
strptime()やstrftime()のフォーマット文字列の意味についてはこちらをどうぞ。
8.1. datetime --- 基本的な日付型および時間型 — Python 3.6.12 ドキュメント実行例
以下のようにログが表示されます。ファイルが正しくリネームされているか確認してください。
/path/to/images/DSC_0001.JPG -> /path/to/images/IMG_20190928_135805.JPG /path/to/images/DSC_0004.JPG -> /path/to/images/IMG_20191104_172704.JPG /path/to/images/DSC_0005.JPG -> /path/to/images/IMG_20191106_174423.JPG /path/to/images/DSC_0006.JPG -> /path/to/images/IMG_20191106_174752.JPG /path/to/images/DSC_0007.JPG -> /path/to/images/IMG_20191106_174808.JPG /path/to/images/DSC_0009.JPG -> /path/to/images/IMG_20191213_180056.JPG /path/to/images/DSC_0010.JPG -> /path/to/images/IMG_20191213_180103.JPG /path/to/images/DSC_0011.JPG -> /path/to/images/IMG_20191213_180112.JPG補足
もし可能なら、撮影時点でスマホ側でリネームしておくほうが面倒がなくてよいと思います。
Androidならこういうアプリが使えます。私もこれからはアプリを使っていきます。
「DSC Auto Rename」を使って写真撮影時にファイル名を自動的にリネームする | 忘れ荘

- 投稿日:2020-11-15T17:23:26+09:00
Python3エンジニア認定データ分析試験 自作問題集
概要
2020年11月に受験したPython3エンジニア認定データ分析試験で、勉強方法の1つとして作っていた自作問題集です。これから受験される方の一助になれば嬉しいです。
体験記はこちらの記事でまとめています↓
https://qiita.com/pon_maeda/items/a6c008fb3d993278fccb注意点
- この問題集は、隙間時間で手軽に解けるよう、一問一答や穴埋めといった出題形式で作っています。
- 実際の試験は四者択一形式のため(2020/11/15時点)、ご注意下さい。
- 実際の試験よりやや難易度が高くなっています。
- 個人用としてざっくりと作成したものなので、問題文として至らないところもあるかもしれません。ご容赦下さい。
問題集
1. データ分析エンジニアの役割
機械学習は大きく分けて3つ。( ) 学習と、( ) 学習、 ( ) 学習の3である。
答え
- 教師あり学習
- 教師なし学習
- 強化学習
正解ラベルとも呼ばれる、 ( ) 変数は、 ( ) 学習にのみ使用される。
答え
- 目的変数
- 教師あり学習
この正解ラベルが連続値である場合に使われる手法は ( )、その他の値である場合に使われる手法は ( )。
答え
連続値 : 回帰
その他の値 : 分類
教師なし学習の手法で、主な2つは何か。
答え
- クラスタリング
- 次元削減
2. Pythonと環境
venvは、Pythonのバージョンを使い分けることができるツールである。 (Yes / No)
答え
No
venvはPythonの下に組み込むので、Python自体のバージョン管理はできない。
Pythonでファイル名をワイルドカードで指定することができる関数。
答え
glob関数
3. 数学の基礎
sinとcos、tanの日本語読み。
答え
sin : 正弦
con : 余弦
tan : 正接
ネイピア数はいくつか。
答え
2.7182…
1の対数は。
答え
0
1の階乗は。
答え
1
6面体のサイコロを1回振った場合、その出目の数自体は不明なものの、奇数が出ていることを教えられたとする。この場合の確率を ( ) 確率と呼び、これは ( ) の定理の基本となっている。
答え
- 条件付き確率
- ベイズの定理
4. ライブラリによる分析の実践
4.1. NumPy
4.1.1. NumPyの概要
NumPyには配列用の型である ( ) と、行列用の型である ( ) がある。
答え
配列用 : ndarray
行列用 : matrix
※ データ分析試験では、ndarrayが主役
↑の特徴として、型を ( 複数使える or 一種類にしなければならない ) ことが挙げられる。
答え
一種類にしなければならない。
ここが、DataFrameと違うところ。
4.1.2. NumPyでデータを扱う
配列でサイズを確認する関数
答え
shape関数
ravel関数は ( ) を返すのに対して、flatten関数は ( ) を返す。
答え
ravel関数 : 参照 (または浅いコピー) を返す
flatten関数 : (深い) コピーを返す
配列の型を確認する関数
答え
dtype関数
配列の型を変換する関数
答え
astype関数
整数の一様乱数を生成する関数
答え
np.random.randint関数
※ {{第1引数}}以上、{{第2引数}}未満の範囲で生成
※ 第3引数にタプルを渡すと、その行列サイズで生成してくれる
小数の一様乱数を生成する関数
答え
np.random.uniform関数
※ 引数はnp.random.randint関数と同じ
整数の標準正規分布からの乱数を作成する関数
答え
np.random.randn関数
標準正規分布とは、平均 ( ) 、分散 ( )の分布か。
答え
平均0、分散1の分布
正規分布乱数の生成で、平均や標準偏差を指定して生成する関数は何か。
答え
np.random.normal関数
指定した対角要素を持つ単位行列を作る関数
答え
np.eye関数
np.eye(3)とすると、↓こんなのができる
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
要素全てが指定の値の配列を作る関数
答え
np.full関数
例 : np.full((2, 4), np.pi)
指定範囲で均等割りの配列をつくる関数
答え
np.linespace関数
例 : np.linespace(0, 1, 5) // → array([0., 0.25, 0.5, 0.75, 1.0])
配列の要素間の差分を見れる関数
答え
np.diff関数
a = [1, 2, 3] b = [4, 5, 6] np.concatnate([a, b])とすると、以下のどれになるか。
[1, 2, 3, 4, 5, 6][[1, 2, 3],[4, 5, 6]][1, 2, 3, [4, 5, 6]]
答え
1.[1, 2, 3, 4, 5, 6]
np.concatnate関数は、一次元配列同士の連結の場合は、( 行 or 列 )方向連結となる。
答え
列方向に連結される。 (hstack関数と同じ挙動)
np.concatnate関数は、二次元配列同士の連結の場合は、デフォルトで ( 行 or 列 ) 方向に連結される。
答え
行方向に連結される。 (vstack関数と同じ挙動)
この関数に引数axis=1を指定すると ()方向連結となる。
答え
列方向に連結される。 (hstack関数と同じ挙動)
二次元配列を列方向に分割する関数。
答え
np.hsplit関数
例) first, second = np.hsplit(hoge_array, [2]) # → 3列目で分割
二次元配列を行方向に分裂する関数
答え
np.vsplit関数
例) first, second = np.vsplit(hoge_array, [2]) # → 3行目で分割
二次元配列の転置とはどういう意味か。
答え
行と列を入れ替えること
aという二次元配列があった場合に、転置するにはどうするか。
答え
a.T
要素数を指定せずに、一次元配列の次元を増やす関数は何か。
答え
np.newaxis関数
※ 要素数を指定して良ければ、reshape関数を使う方法もある。
a = np.array([1, 5, 4]) # array([[1, 5, 4]])先の関数を使って、上記のように次元を増やすにはどうすればよいか。
答え
a[np.newaxis, :]
a = np.array([1, 5, 4]) # array([[1], [5], [4]])先の関数を使って、上記のように次元を増やすにはどうすればよいか。
答え
a[:, np.newaxis]
グリッドデータを生成する関数は何か。
答え
np.meshgrid関数
np.arange(1, 10, 3)この結果はどうなるか。
答え
array([1, 4, 7])
1以上、10未満(つまり9まで)で、3等分される。
4.1.3. NumPyの各機能
sin()やlog()など、配列要素を一括で変換してくれる、NumPyの便利関数群のことを何というか。
答え
ユニバーサルファンクション
配列要素の絶対値を返す関数
答え
np.abs関数
a = np.array([0, 1, 2]) b = np.array([[-3, -2, -1], [0, 1, 2]]) a + b上記の通り、二次元配列と一次元配列の和はどうなるか。
答え
array([[-3, -1, 1],
[0, 2, 4]])
aが2行になったような形で、bに加算される。
配列にスカラーを演算できることを何というか。
答え
ブロードキャスト
@演算子は何を意味するか。
答え
行列の乗算のための中置演算子
A_matrix @ B_matrixを別の書き方に。
答え
np.dot(A_matrix, B_matrix)
または、A_matrix.dot(B_matrix)
真偽の配列で、Trueの数を求められる関数。
答え
np.count_nonzero関数
または、np.sum関数
- np.count_nonzeroメソット
- 0でない要素数を出力する関数。
- PythonではFalseを0として扱うので、Trueの数を数えてくれる。
- np.sum関数
- 要素内を足し算する関数
- PythonではTrueを1として扱うので、結果的にTrueの数が求められる。
真偽の配列で、Trueが含まれているか求める関数。
答え
np.any関数
真偽の配列で、全ての要素がTrueであるか求める関数。
答え
np.all関数
4.2. pandas
4.2.1. pandasの概要
df.head()とdf.tail()で、でDataFrameの先頭および末尾を、それぞれ ( ) 行のみ出力する。
答え
5行
dfのサイズを知る関数
答え
df.shape
dfから、AカラムとBカラムの2つの情報を取得する方法
答え
df[“A“, “B“]
または、
df.loc[:, [“A“, “B“]]など
4.2.2. データの読み込み・書き込み
4.2.3. データの整形
歩数と摂取カロリーのDataFrameであるdfがあったとして、歩数が10000歩以上のレコードだけを抽出する方法
答え
df[df[“歩数“] >= 10000]または
df[df.loc[:, “歩数“] >= 10000]や
df.query('歩数 >= 10000')など
歩数と摂取カロリーのDataFrameであるdfがあったとして、歩数の降順にソートする方法
答え
df.sort_values(by=”歩数”, ascending=False)
High, Mid, Lowの3つの値が入った運動指数カラムを、接頭語に「運動」と加えてつつ、One-hotエンコーディングする。
答え
df.get_dummies(df.loc[:, “運動指数“], prefix=”運動”)
4.2.4. 時系列データ
2020-01-01〜2020-10-01の日付の配列を作成する方法。
答え
pd.date_range(start=”2020-01-01”, end=”2020-10-01”)
2020-01-01から100日間の日付の配列を作成する。
答え
pd.date_range(start=”2020-01-01”, period=100)
2020-01-01〜2020-10-01の日付のうち、土曜日だけの配列を作成する。
答え
pd.date_range(start=”2020-01-01”, end=”2020-10-01”, freq=”W-SAT”)
時系列データdfに対して、月ごとのデータにグルーピングして、値を平均値にする。
答え
df.groupby(pd.Grouper(freq='M')).mean()または、
df.resample('M'),mean()など
4.2.5. 欠損値処理
fillna関数でNanを前の値で埋めたいときに使う引数。
答え
df.fillna(method='ffill')DataFrameだと、一行上の値で埋める。
bfillだと、逆に一行下の値で埋める。
fillna関数の引数に中央値を与えたい場合どうするか。
答え
df.fillna(df.median())
※method='median'ではないので注意
4.2.6. データ連結
df_1とdf_2を列方向にデータ連結して、df_mergeを作成する。
答え
df_merge = pd.concat([df_1, df_2], axis=1)
4.2.7. 統計データの扱い
最頻値を確認する関数
答え
mode関数
中央値を出す関数
答え
median関数
標準偏差 (標本標準偏差) を出す関数
答え
std関数
標準偏差 (母集団) を出す関数と引数
答え
std関数に、ddof=0引数を渡す
4.3. Matplotlib
円グラフはどこから配置されるか。
答え
上から配置される
円グラフは ( 時計 or 反時計 ) 周りに配置される。
答え
時計回り
円グラフで、時計回りに実装するには ( ) メソッドに ( ) 引数を渡す。
答え
pieメソッドで、counterclock=Falseを渡す。
なんか、世のWebサイトには逆に書いてる。なんで。笑
デフォルトはcounterclock=True
円グラフで、グラフの描画を始める場所を指定するには、 ( ) メソッドに ( ) 引数を渡す。
答え
startangle={{出力を開始したい角度}}
デフォルト値はNoneで、3時の位置から描画される。
90度指定で12時からになる。
4.4. scikit-learn
4.4.1. 前処理
欠損値
欠損値があった場合、データを補完する場合に使うクラスは何か。
答え
Imputerクラス
上記のクラスでstrategy引数に渡す値について。
mean = ①、median = ②、most_frequent = ③
答え
1. 平均
2. 中央値
3. 最頻値
カテゴリ変数のエンコーディング
カテゴリ変数のエンコーディングを行うクラスは何か。
答え
LabelEncoderクラス
エンコーディング後、元の値を確認する属性は何か。
答え
.classes_属性
カテゴリ変数のエンコーディングとともに、メジャーな処理方法と言えば何エンコーディングか。
答え
One-hotエンコーディング
血液型4種類だったら、4カラム追加してフラグにする感じのやつ。
このエンコーディングの別の呼び方は。
答え
ダミー変数化
行列のうち、多くの成分が0である行列と、多くの成分が0でない行列をそれぞれ何というか。
答え
疎行列と密行列
特徴量の正規化
分散正規化とは、特徴量の平均が ( ) 、標準偏差が ( ) になるように、特徴量を変換する処理。
答え
特徴量の平均が0、標準偏差が1
分散正規化を行うクラスは何か。
答え
StanderdScalerクラス
最小最大正規化とは、特徴量の最小値が ( ) 、最大値が ( ) になるように、特徴量を変換する処理。
答え
特徴量の最小値が0、最大値が1
最小最大正規化を行うクラスは何か。
答え
MinMaxScalerクラス
4.4.2. 分類
分類は教師 ( ) 学習の典型的なタスク。
答え
教師あり学習
分類は、既知のデータを教師として利用し、各データをクラスに振り分けるモデルを学習する。
上記は、正解となるラベルを用いるが、そのラベルを ( ) 変数という。
答え
目的変数
分類の代表的なアルゴリズム3つ
答え
- サポートベクタマシン
- 決定木 (けっていぎ)
- ランダムフォレスト
分類モデル構築の流れ
分類モデルの構築には、手元のデータを ( ) する。
答え
学習データセットとテストデータセットに分割する。
分類のおける「学習」とは、( ) データセットを用いて分類モデルを構築することを指す。
答え
学習データセット
構築したモデルのテストデータセットに対する予測から算出した、未知のデータに対する対応能力を何と言うか。
答え
汎化能力
各データセットを分ける関数はなにか。
答え
model_selection.train_test_split関数
scikit-learnでは、学習を ( ) 関数、予測を ( ) 関数を使用する。
答え
学習 : fit関数
予測 : predict関数
サポートベクタマシン
サポートベクタマシンは、分類や回帰だけでなく、( )にも使えるアルゴリズム。
答え
外れ値検出
2つのクラスに属する2次元データを考えたとき、各クラスのデータのうち境界に最も近いデータを何というか。
答え
サポートベクタ
2つのクラスに属する2次元データを考えたとき、サポートベクタ間の距離が最も ( ) くなるように ( ) の直線を引く。
答え
- 大きく (遠く)
- 決定境界
この直線と、サポートベクタの距離を ( ) と呼ぶ。
答え
マージン
ランダムフォレスト
ランダムフォレストで使う、ランダムに選択されたサンプルと特徴量 (説明変数) のデータを何というか。
答え
ブートストラップデータ
ランダムフォレストは決定木の集合であり、このように複数の学習機を用いた学習を何というか。
答え
アンサンブル学習
4.4.3. 回帰
回帰とは、 ( ) 変数を、特徴量で代表される ( ) 変数で説明するタスク。
答え
- 目的変数
- 説明変数
線形回帰は、説明変数が1変数のときを ( ) 、2変数以上のときを ( ) と呼ぶ。
答え
- 単回帰
- 重回帰
4.4.4. 次元削減
データが持っている情報をなるべく損ねずに、データを ( ) するタスク。
答え
圧縮
主成分分析
scikit-learnでは、主成分分析はどのモジュールのどのクラスを使うか。
答え
decompositon.PCSクラス
4.4.5. モデルの評価
カテゴリの分類精度
データのカテゴリをどの程度当てられたかを定量化する指標4つ。
( ) 率、 ( ) 率、 ( ) 率、 ( ) 値
答え
- 適合率
- 再現率
- F値
- 正解率
また、これらの指標は ( ) 行列から計算する。
答え
混同行列
( ) 率と ( ) 率は、トレードオフ関係にある。
答え
- 適合率
- 再現率
予測確率の正確さ
データに対する予測確率の正確さを定量化する指標として、 ( ) 曲線とそこから算出する ( )が用いられる。
答え
- ROC曲線
- AUC
4.4.6. ハイパーパラメータの最適化
ハイパーパラメータは、学習のときに値が ( 決定される or 決定されない )。
答え
決定されない。
学習とは別に、ユーザが値を指定する必要がある。
ハイパーパラメータを最適化する代表的な方法2つ。
答え
- グリッドサーチ
- ランダムサーチ
さいごに
拙い問題ですが、誰かの役に立てば嬉しいです。
誤り等があらば、是非コメントでツッコミ頂けると嬉しいです。
最後までありがとうございました。
- 投稿日:2020-11-15T16:53:02+09:00
大量のRDP接続用のファイル、Pythonで作ってみた
はじめに
複数の端末に対してRDP接続する必要がある場合に、わざわざExcelのリストを見て手入力で接続するのは面倒、と思い、RDPファイルをまとめてPythonで作れるようにしてみました...!!
準備
入力情報、Pythonファイルを以下に示します。
入力情報
以下の2ファイルを作成します。
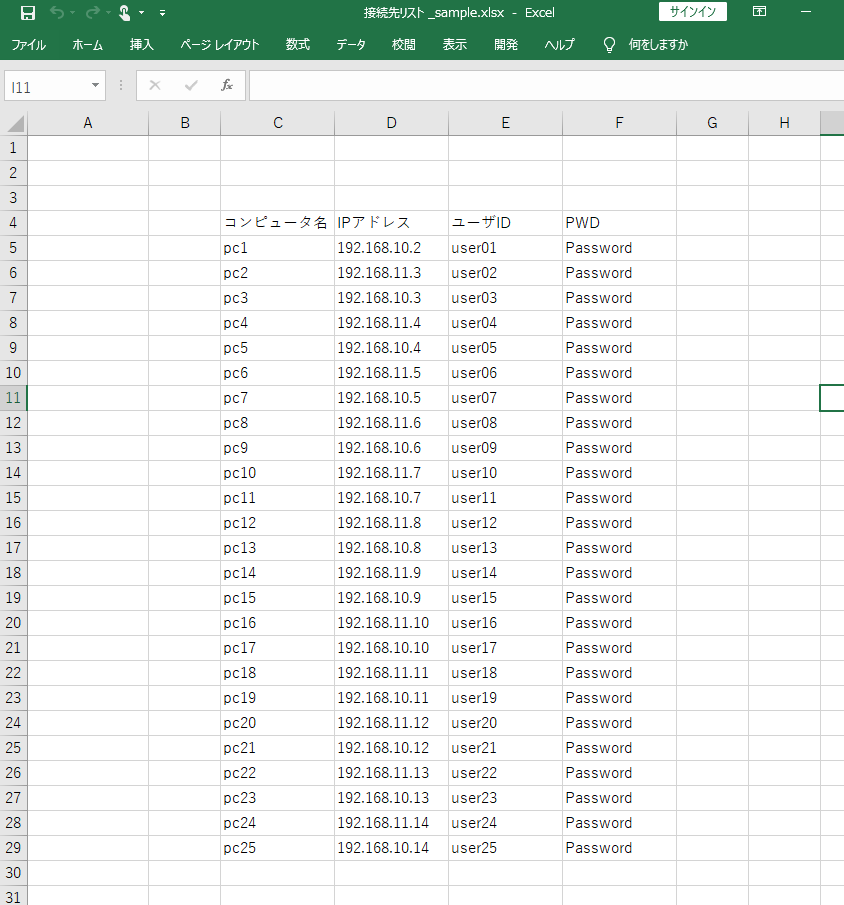
1. RDP接続先リスト(接続先リスト_sample.xlsx)
2. RDPテンプレート(template.rdp)1. RDP接続先リスト(接続先リスト_sample.xlsx)
2. RDPテンプレート(template.rdp)
以下のように「コンピュータ名」を「ComputerAddress」に、「ユーザー名」を「UserName_for_RDP」として、「名前を付けて保存」を使って、template.rdpとして作業用ディレクトリに保存しておきます。
なお、RDP接続ファイル(template.rdp)はテキストエディタで開くと以下のようになっています。パスワードはRDPファイル自体には保存されないことが読み取れます。
template.rdpscreen mode id:i:2 use multimon:i:1 desktopwidth:i:1920 desktopheight:i:1080 session bpp:i:32 winposstr:s:0,1,759,0,980,270 compression:i:1 keyboardhook:i:2 audiocapturemode:i:0 videoplaybackmode:i:1 connection type:i:7 networkautodetect:i:1 bandwidthautodetect:i:1 displayconnectionbar:i:1 enableworkspacereconnect:i:0 disable wallpaper:i:0 allow font smoothing:i:0 allow desktop composition:i:0 disable full window drag:i:1 disable menu anims:i:1 disable themes:i:0 disable cursor setting:i:0 bitmapcachepersistenable:i:1 full address:s:ComputerAddress audiomode:i:0 redirectprinters:i:1 redirectcomports:i:0 redirectsmartcards:i:1 redirectclipboard:i:1 redirectposdevices:i:0 autoreconnection enabled:i:1 authentication level:i:2 prompt for credentials:i:0 negotiate security layer:i:1 remoteapplicationmode:i:0 alternate shell:s: shell working directory:s: gatewayhostname:s: gatewayusagemethod:i:4 gatewaycredentialssource:i:4 gatewayprofileusagemethod:i:0 promptcredentialonce:i:0 gatewaybrokeringtype:i:0 use redirection server name:i:0 rdgiskdcproxy:i:0 kdcproxyname:s: drivestoredirect:s: camerastoredirect:s:* devicestoredirect:s:* username:s:UserName_for_RDPPythonのファイル
RDP_File_Generator.py# -*- coding: utf-8 -*- """ RDPファイル作成PGM """ import tkinter, tkinter.filedialog, sys, os import pandas as pd dir1 = r"C:\Users\XXXXX\Desktop\xxxxxx" # ↑「RDP接続先リスト」や「RDPテンプレート」を格納しているファイルパスを指定 ## tkinterのお決まり。 root = tkinter.Tk() root.withdraw() msg1 = '接続先リストを選択してください' typ1 = [('エクセルファイル','*.xlsx')] inFile1 = tkinter.filedialog.askopenfilename(title=msg1, filetypes = typ1, initialdir = dir1) if (not inFile1): #[キャンセル]クリック時の処理 print('ファイルを選んでください。') sys.exit input_book1 = pd.ExcelFile(inFile1) input_sheet_name1 = input_book1.sheet_names input_sheet_df1 = input_book1.parse(input_sheet_name1[0],header=3) df_s = input_sheet_df1.iloc[:,2:] msg2 = 'RDPファイルを選択してください' typ2 = [('RDPファイル','*.rdp')] inFile2 = tkinter.filedialog.askopenfilename(title=msg2, filetypes = typ2, initialdir = dir1) if (not inFile1): #[キャンセル]クリック時の処理 print('ファイルを選んでください。') sys.exit path_name = os.path.dirname(inFile2) output_folder_path = os.path.join(path_name,"output") ## RDPファイル出力先フォルダ作成(exist_ok:既存の場合はスキップ) os.makedirs(output_folder_path,exist_ok = True) ## RDPテンプレートファイルをテキストファイルとして開く with open(inFile2,encoding='utf_16') as f: s = f.read() ## 接続先リストにある接続先の数だけ、RDPファイルを生成する for i in range(len(df_s)): temp = s temp = temp.replace("UserName_for_RDP", df_s["ユーザID"].iat[i]) temp = temp.replace("ComputerAddress", df_s["IPアドレス"].iat[i]) path_w = os.path.join(output_folder_path,df_s["ユーザID"].iat[i]+".rdp") with open(path_w,mode="w") as f: f.write(temp)実行してみる
以下、実行イメージです。
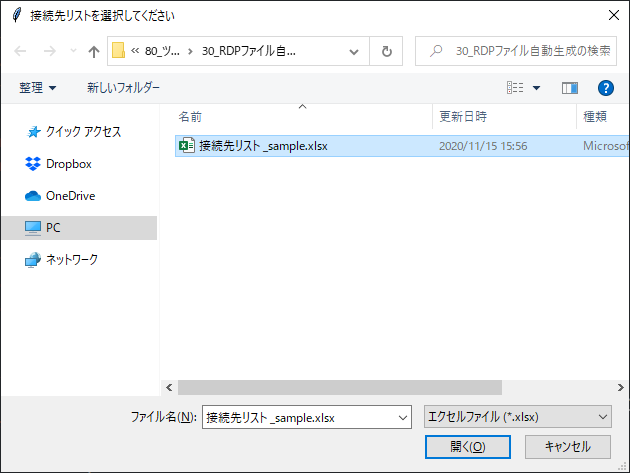
まず、「RDP_File_Generator.py」を実行すると、tkinterによるダイアログが表示されるので、接続先リストを選択します。
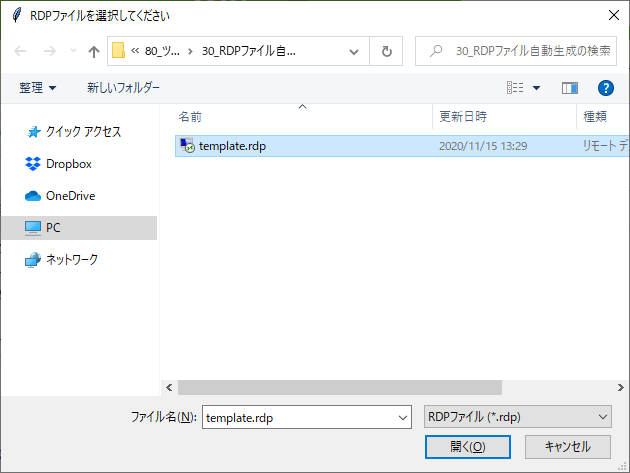
次に、RDPファイルのテンプレートを選択します。
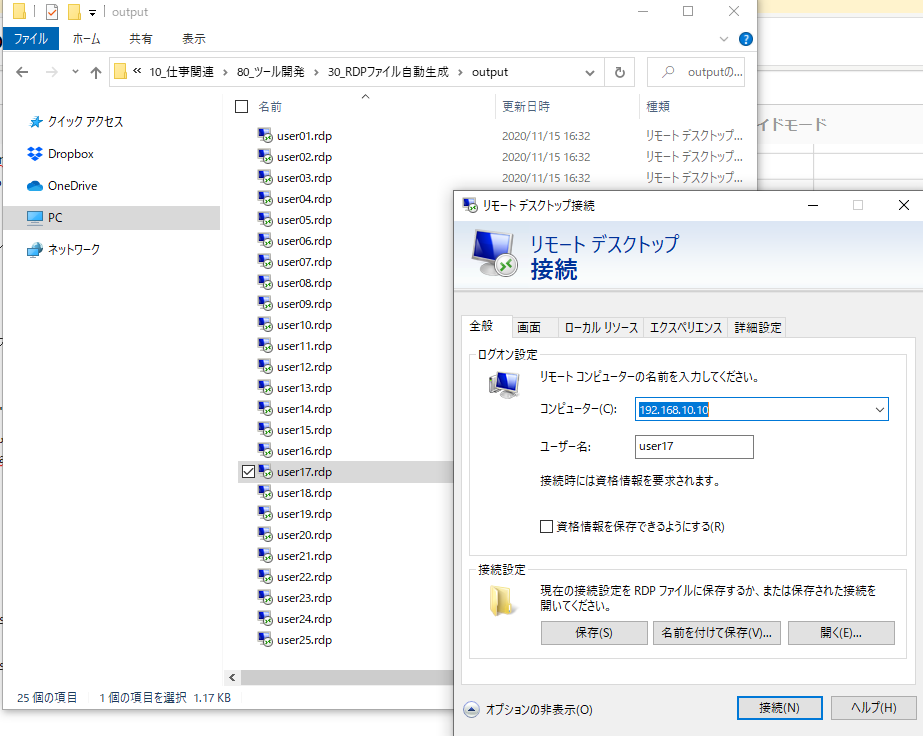
outputフォルダができ、その中にRDPファイルが一括で出力されています!成功です!!
おわりに
パスワードはRDPファイル内に埋め込まれたりすることはないので、初回接続時にパスワード入力して資格情報を接続元PCで保存する、という手間は残りますが、便利だと思うので、良かったら参考にしていただけると嬉しいです!

- 投稿日:2020-11-15T15:01:10+09:00
pythonを使ってLINEで一斉配信をする
はじめに
LINEでシステムから情報を一斉配信したので、その時の手順を残しておきます。
LINEはLINE@とLINE公式アカウントが別々で別れてましたが統合されたようです。
アカウントは無料で作成することができ、登録にはメールアドレスのみで登録できます。
LINEにはAPIがいくつかありますが、一斉配信にはMessaging APIを使用します。
一つのチャンネルで1000通までは無料で配信できるので、十分にテストできると思います。チャネル作成
まずはこちらのURLからビジネスアカウント作成をクリックして、メールアドレスで作成をクリックします。
https://account.line.biz/login次に、作成したビジネスアカウントでログインをしてプロバイダとチャネルを作成してください。
https://developers.line.biz/ja/docs/messaging-api/getting-started/#using-oa-managerチャネルアクセストークン発行
チャネルの個別設定画面の上のタブの「Messaging API設定」を選択します。
その画面の一番下の「チャネルアクセストークン(長期)の発行ボタンをクリックしてトークンを発行してください。
プログラム実行
下のプログラムを実行すると配信できます。
先ほど発行したアクセストークンを変数にセットしてご使用ください。test_delivery.py# -*- coding:utf-8 -*- import requests import urllib.request, urllib.error import json url = 'https://api.line.me/v2/bot/message/broadcast' channel_access_token = '作成したchannel_access_token' # 送信用のデータ # messageの中にtype,textの配列を追加すれば一度に複数のメッセージを送信できます。(最大件数5) data = { 'messages' : [{ 'type':'text', 'text':'配信したいテキスト' }] } jsonstr = json.dumps(data).encode('ascii') request = urllib.request.Request(url, data=jsonstr) request.add_header('Content-Type', 'application/json') request.add_header('Authorization', 'Bearer ' + channel_access_token) request.get_method = lambda: 'POST' # 送信実行(レスポンスが200なら送信成功) response = urllib.request.urlopen(request)詳細な使用方法は公式がわかりやすいです。
https://developers.line.biz/ja/reference/messaging-api/#send-broadcast-message最後に
初めてLINE MessagingAPIを使用しましたが、わかりやすくて非常に使用しやすいものでした。
webhookやOAuthなんかもあるので、そちらも時間ができたら試します。
なにかこちらの記事で間違い等あればご指摘ください。


- 投稿日:2020-11-15T15:00:43+09:00
Anaconda3のpython環境構築手順
この記事について
AnacondaをWindows10に導入し仮想環境を作成するまでの手順を記載します。
仮想環境はプロジェクトごとの固有な設定やライブラリをインストールする際に他のプロジェクトに影響を与えないように開発するための便利な方法です。筆者の環境
OS:Windows10
CPU:AMD Ryzen 5 PRO 350Uw / Radeon Vega Mobile Gfx 2.10Ghz
メモリ:8.00GBインストール
ダウンロード
以下のサイトよりダウンロードし、インストーラーに従ってインストールします。(すべて推奨設定)
https://www.anaconda.com/products/individual仮想環境の作成
プロンプトの起動
インストールするとスタートメニューに作成Anaconda3の起動メニューが作成される。
Anaconda Promptを起動する
仮想環境の作成
#仮想環境の確認 conda info -e #仮想環境の作成 #conda create -n [任意の環境名] conda create -n hogehoge #仮想環境の確認 conda info -e #仮想環境の起動 #activate [作成した環境名] activate hogehogeこれで仮想環境の作成は完了です。
- 投稿日:2020-11-15T14:33:25+09:00
APIサーバーをHTMLからJSONでAjax通信するまでの手順
はじめに
前回の記事で、KaggleのHouse Sales in King County, USAのデータセットを使って、XGboost機械学習で学習モデルを生成して、その学習モデルをFlaskでAPIサーバーにするというのをやりました。今回は、そのAPIサーバー使って、HTMLからJSONでAjax通信するまでの手順を説明しています。機械学習で学習したモデルをAPIサーバーにするまでの手順は以下の記事を参考にしてみてください。
KaggleのHouse Sales in King County, USAのデータセットを使って、機械学習を行い、APIサーバーにするまでの手順
Ajax通信
ここでは、HTMLからjavascriptのAjaxで通信できるようにするために、Flaskで書いた、APIサーバーの起動ファイルを以下のように追記する必要があります。追記するのは、flask_corsというライブラリとそれに関連するコードです。flask_corsは事前にインストールしてある必要があります。
housesails_app.pyimport json from flask import Flask from flask import request from flask import abort from flask_httpauth import HTTPBasicAuth from flask_cors import CORS #追加する import pandas as pd from sklearn.externals import joblib import xgboost as xgb model = joblib.load("house_sales_model.pkl") app = Flask(__name__) # 追加 @app.after_request def after_request(response): response.headers.add('Access-Control-Allow-Origin', '*') response.headers.add('Access-Control-Allow-Headers', 'Content-Type,Authorization') response.headers.add('Access-Control-Allow-Methods', 'GET,PUT,POST,DELETE,OPTIONS') return response # ↑ここまでを追加 # BasicAuth auth = HTTPBasicAuth() users = { "username1": "password1", "username2": "password2" } @auth.get_password def get_pw(username): if username in users: return users.get(username) return None # Get headers for payload headers = ['sqft_living','sqft_above','sqft_basement','lat','long','sqft_living15','grade_3','grade_4','grade_5','grade_6','grade_7','grade_8','grade_9','grade_10','grade_11','grade_12'] @app.route('/house_sails', methods=['POST']) # BasicAuth @auth.login_required def housesails(): if not request.json: abort(400) payload = request.json['data'] values = [float(i) for i in payload.split(',')] data1 = pd.DataFrame([values], columns=headers, dtype=float) predict = model.predict(xgb.DMatrix(data1)) return json.dumps(str(predict[0])) if __name__ == "__main__": app.run(debug=True, port=5000)HTMLからPOSTをしてJSONデータをAPIサーバーに送信する
HTMLファイルは、インターフェイスの部分はタグ内のinputタグなどで、データの入力フォームを作ります。その入力データをjavascriptで受け取って、整形し、JSON形式に変換して、Ajax通信でPOSTしています。通信が成功したら、APIサーバーからの予測値を受け取り、それをtextareaタグのエリア内に表示するという処理をしています。
index.html<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>HTMLファイルからPOSTでJSONデータを送信する</title> <script type="text/javascript" src="http://ajax.googleapis.com/ajax/libs/jquery/2.1.0/jquery.min.js"></script> <link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bootstrap@4.5.3/dist/css/bootstrap.min.css" integrity="sha384-TX8t27EcRE3e/ihU7zmQxVncDAy5uIKz4rEkgIXeMed4M0jlfIDPvg6uqKI2xXr2" crossorigin="anonymous"> </head> <body> <div class="container"> <h1>HTMLファイルからPOSTでJSONデータを送信する</h1> <div class="alert alert-primary" role="alert"> <p>URL: <input type="text" id="url_post" name="url" class="form-control" size="100" value="http://localhost:5000/house_sails"></p> </div> <div class="d-flex bd-highlight"> <div class="flex-fill bd-highlight alert alert-primary mr-3" role="alert"> <p>sqft_living: <input type="number" id="value1" class="form-control" size="30" value=-1.026685></p> </div> <div class="flex-fill bd-highlight alert alert-primary mr-3" role="alert"> <p>sqft_above: <input type="number" id="value2" class="form-control" size="30" value=-0.725963></p> </div> <div class="flex-fill bd-highlight alert alert-primary" role="alert"> <p>sqft_basement: <input type="number" id="value3" class="form-control" size="30" value=-0.652987></p> </div> </div> <div class="d-flex bd-highlight"> <div class="flex-fill bd-highlight alert alert-primary mr-3" role="alert"> <p>lat: <input type="number" id="value4" class="form-control" size="30" value=-0.323607></p> </div> <div class="flex-fill bd-highlight alert alert-primary mr-3" role="alert"> <p>long: <input type="number" id="value5" class="form-control" size="30" value=-0.307144></p> </div> <div class="flex-fill bd-highlight alert alert-primary" role="alert"> <p>sqft_living15: <input type="number" id="value6" class="form-control" size="30" value=-0.946801></p> </div> </div> <div class="alert alert-primary" role="alert"> <p>gradeを選択: <select name="grade" id="grade" class="form-control form-control-lg"> <option value="grade1">grade1</option> <option value="grade2">grade2</option> <option value="grade3">grade3</option> <option value="grade4">grade4</option> <option value="grade5">grade5</option> <option value="grade6">grade6</option> <option value="grade7">grade7</option> <option value="grade8">grade8</option> <option value="grade9">grade9</option> <option value="grade10">grade10</option> <option value="grade11">grade11</option> <option value="grade12">grade12</option> </select> </p> </div> <p>usename: <input type="text" name="username" id="username" class="form-control" value="bitstudio"/></p> <p>password: <input type="password" name="password" id="password" class="form-control" value="hirayama"/></p> <p><button id="button" type="button" class="btn btn-primary">submit</button></p> <textarea id="response" class="form-control" cols=120 rows=4 disabled></textarea> <p><p> </div> </body> <script type="text/javascript"> $(function(){ $("#response").html("Response Values"); $("#button").click( function(){ let value07 = 0; let value08 = 0; let value09 = 0; let value10 = 0; let value11 = 0; let value12 = 0; let value13 = 0; let value14 = 0; let value15 = 0; let value16 = 0; let element = document.getElementById("grade"); let grade01 = element.value; if (grade01 == "grade1") { value07 = 0; }else if (grade01 == "grade2") { value07 = 0; }else if (grade01 == "grade3") { value07 = 1; }else if (grade01 == "grade4") { value08 = 1; }else if (grade01 == "grade5") { value09 = 1; }else if (grade01 == "grade6") { value10 = 1; }else if (grade01 == "grade7") { value11 = 1; }else if (grade01 == "grade8") { value12 = 1; }else if (grade01 == "grade9") { value13 = 1; }else if (grade01 == "grade10") { value14 = 1; }else if (grade01 == "grade11") { value15 = 1; }else{ value16 = 1; } var url = $("#url_post").val(); var feature1 = $("#value1").val() + "," + $("#value2").val() + "," + $("#value3").val() + "," + $("#value4").val() + "," + $("#value5").val() + "," + $("#value6").val() + "," + value07 + "," + value08 + "," + value09 + "," + value10 + "," + value11 + "," + value12 + "," + value13 + "," + value14 + "," + value15 + "," + value16; var JSONdata = { data: feature1 }; alert(JSON.stringify(JSONdata)); var username = $("input#username").val(); var password = $("input#password").val(); $.ajax({ type: 'POST', url: url, //basic認証送信 beforeSend: function(xhr){ xhr.setRequestHeader('Authorization', 'Basic ' + btoa(username+':'+password));}, data: JSON.stringify(JSONdata), contentType: 'application/JSON', dataType: 'JSON', scriptCharset: 'utf-8', success : function(data) { // Success alert("success"); alert(JSON.stringify(JSONdata)); $("#response").html(JSON.stringify(data)); }, error : function(data) { // Error alert("error"); alert(JSON.stringify(JSONdata)); $("#response").html(JSON.stringify(data)); } }); }) }) </script> </html>
- 投稿日:2020-11-15T13:39:49+09:00
【PyTorchチュートリアル⑧】TorchVision Object Detection Finetuning Tutorial
はじめに
前回に引き続き、PyTorch 公式チュートリアル の第8弾です。
今回は TorchVision Object Detection Finetuning Tutorial を進めます。TorchVision Object Detection Finetuning Tutorial
このチュートリアルでは、事前トレーニング済みの Mask R-CNN を利用し、ファインチューニング、転移学習を見ていきます。
学習に利用するデータは歩行者の検出とセグメンテーションのためのPenn-Fudanデータです。このデータは、歩行者(インスタンス)が345人いる、170個の画像が用意されています。まず、pycocotools のライブラリをインストールする必要があります。このライブラリは、「Intersection over Union」 と呼ばれる評価の計算に使用されます。
「Intersection over Union」 は、物体検知における領域の一致具合を評価する手法の1つです。※ 2020.10.18 時点では Colaboratory に pycocotools がすでにインストールされています。以下のコード( pip install )は実行しなくても進めることができました。
%%shell pip install cython # pycocotoolsをインストールします。Colabのデフォルトのバージョンには、https://github.com/cocodataset/cocoapi/pull/354 で修正されたバグがあります。 pip install -U 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'Defining the Dataset(データセットを定義する)
データセットを定義します。
Mask R-CNN で学習されたモデルを利用するため、データセットには特定の属性が必要です。
torchvision のスクリプト (オブジェクト検出、インスタンスセグメンテーション、人物キーポイント検出のライブラリ)を利用することで必要なデータセットを作成することができます。データセットには以下のような属性が必要です。
- image:サイズ(H、W)のPIL画像
- target:次のフィールドを含む辞書(dict)
- boxes(FloatTensor [N, 4]):[x0, y0, x1, y1]形式の N bounding box の座標。範囲は 0〜W および 0〜H
- labels(Int64Tensor [N]):各境界ボックスのラベル
- image_id(Int64Tensor [1]):画像識別子。データセット内のすべての画像間で一意である必要があり、評価中に使用されます。
- area(Tensor [N]):バウンディングボックスの領域。これは、COCOメトリックでの評価中に、小、中、大のボックス間でメトリックスコアを分離するために使用されます。
- iscrowd(UInt8Tensor [N]):iscrowd = Trueのインスタンスは評価中に無視されます。
- masks(オプション)(UInt8Tensor [N, H, W]):各オブジェクトのセグメンテーションマスク(検知する物体の領域を表します)
- keypoints(オプション)(FloatTensor [N, K, 3]):N個のオブジェクトのそれぞれについて、オブジェクトを定義する[x, y, visibility]形式のKキーポイントが含まれます。 visibility = 0は、キーポイントが表示されないことを意味します。データ拡張(Data Augmentation)の場合、キーポイントを反転する概念はデータ表現に依存することに注意してください。
(データセットをざっくり説明すると、boxes で物体を含む四角形を定義し、masks でピクセル単位で物体か否かを定義します。)
モデルが上記のメソッドを返す場合、モデルはトレーニングと評価の両方で機能し、pycocotoolsの評価スクリプトが使用されます。Writing a custom dataset for Penn-Fudan (Penn-Fudanのカスタムデータセットの作成)
Penn-Fudanデータセットのデータセットを出力してみましょう。
まず、
https://www.cis.upenn.edu/~jshi/ped_html/PennFudanPed.zip
のzipファイルをダウンロードして解凍します。%%shell # download the Penn-Fudan dataset wget https://www.cis.upenn.edu/~jshi/ped_html/PennFudanPed.zip . # extract it in the current folder unzip PennFudanPed.zipデータは次のような構成になっています。
PennFudanPed/ PedMasks/ FudanPed00001_mask.png FudanPed00002_mask.png FudanPed00003_mask.png FudanPed00004_mask.png ... PNGImages/ FudanPed00001.png FudanPed00002.png FudanPed00003.png FudanPed00004.png最初の画像を表示してみます。
from PIL import Image Image.open('PennFudanPed/PNGImages/FudanPed00001.png')
(解凍した readme.txt に記載がありますが、マスク画像は 背景が「0」、歩行者ごとに 1 以上のラベルを付けた画像です。)
mask = Image.open('PennFudanPed/PedMasks/FudanPed00001_mask.png') # 各マスクインスタンスは、ゼロからNまでの異なる色を持っています。 # ここで、Nはインスタンス(歩行者)の数です。視覚化を容易にするために、 # マスクにカラーパレットを追加しましょう。 mask.putpalette([ 0, 0, 0, # black background 255, 0, 0, # index 1 is red 255, 255, 0, # index 2 is yellow 255, 153, 0, # index 3 is orange ]) mask
今回のデータは、各画像と歩行者を識別したマスクがあり、マスクの各色は個々の歩行者に対応します。
このデータセットのtorch.utils.data.Datasetクラスを作成しましょう。import os import numpy as np import torch import torch.utils.data from PIL import Image class PennFudanDataset(torch.utils.data.Dataset): def __init__(self, root, transforms=None): self.root = root self.transforms = transforms # すべての画像ファイルをロードし、並べ替えます self.imgs = list(sorted(os.listdir(os.path.join(root, "PNGImages")))) self.masks = list(sorted(os.listdir(os.path.join(root, "PedMasks")))) def __getitem__(self, idx): # 画像とマスクを読み込みます img_path = os.path.join(self.root, "PNGImages", self.imgs[idx]) mask_path = os.path.join(self.root, "PedMasks", self.masks[idx]) img = Image.open(img_path).convert("RGB") # 各色は異なるインスタンスに対応し、0が背景であるため、 # マスクをRGBに変換していないことに注意してください mask = Image.open(mask_path) mask = np.array(mask) # インスタンスは異なる色としてエンコードされます obj_ids = np.unique(mask) # 最初のIDは背景なので、削除します obj_ids = obj_ids[1:] # split the color-encoded mask into a set # of binary masks # 色分けされたマスクをバイナリマスクのセットに分割します masks = mask == obj_ids[:, None, None] # get bounding box coordinates for each mask # 各マスクのバウンディングボックス座標を取得します num_objs = len(obj_ids) boxes = [] for i in range(num_objs): pos = np.where(masks[i]) xmin = np.min(pos[1]) xmax = np.max(pos[1]) ymin = np.min(pos[0]) ymax = np.max(pos[0]) boxes.append([xmin, ymin, xmax, ymax]) boxes = torch.as_tensor(boxes, dtype=torch.float32) # there is only one class # クラスは1つだけです labels = torch.ones((num_objs,), dtype=torch.int64) masks = torch.as_tensor(masks, dtype=torch.uint8) image_id = torch.tensor([idx]) area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0]) # suppose all instances are not crowd # すべてのインスタンスが混雑していないと仮定します iscrowd = torch.zeros((num_objs,), dtype=torch.int64) target = {} target["boxes"] = boxes target["labels"] = labels target["masks"] = masks target["image_id"] = image_id target["area"] = area target["iscrowd"] = iscrowd if self.transforms is not None: img, target = self.transforms(img, target) return img, target def __len__(self): return len(self.imgs)データセットは以上です。このデータセットの出力がどのように構成されているかを見てみましょう
dataset = PennFudanDataset('PennFudanPed/') dataset[0]out(<PIL.Image.Image image mode=RGB size=559x536 at 0x7FC7AC4B62E8>, {'area': tensor([35358., 36225.]), 'boxes': tensor([[159., 181., 301., 430.], [419., 170., 534., 485.]]), 'image_id': tensor([0]), 'iscrowd': tensor([0, 0]), 'labels': tensor([1, 1]), 'masks': tensor([[[0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], ..., [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0]], [[0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], ..., [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0]]], dtype=torch.uint8)})データセットはPIL.Imageと、
boxes、labels、masksなどのいくつかのフィールドを含む辞書を返すことがわかります。チュートリアルにはありませんが、以下のコードで boxes と mask を図示できます。
boxes はインスタンス(人)を含んだ四角形で、masks がインスタンスそのものです。import matplotlib.pyplot as plt import matplotlib.patches as patches fig, ax = plt.subplots() target = dataset[0][1] # 1番目のインスタンスの masks masks_0 = target['masks'][0,:,:] # 1番目のインスタンスの boxes boxes_0 = target['boxes'][0] # mask を出力します ax.imshow(masks_0) # boxes を出力します ax.add_patch( patches.Rectangle( (boxes_0[0], boxes_0[1]),boxes_0[2] - boxes_0[0], boxes_0[3] - boxes_0[1], edgecolor = 'blue', facecolor = 'red', fill=True, alpha=0.5 ) ) plt.show()
Defining your model
このチュートリアルでは、FasterR-CNNをベースにしたMaskR-CNNを使用します。 Faster R-CNNは、物体検出アルゴリズムの1つで、画像内の潜在的なオブジェクトの境界ボックスとクラススコア(物体を含む四角形と、物体が何か)の両方を予測するモデルです。(下の画像は Faster R-CNN の処理イメージです)
Mask R-CNNは、Faster R-CNN の改良版で 物体検知を四角形(box)で判断するだけではなく、ピクセル単位(mask)で判定します。
(下の画像は Mask R-CNN の処理イメージです)
torchvision でモデルをカスタマイズする場合、主な理由は2つあります。
1つ目は、事前にトレーニングされたモデルを利用し、最後のレイヤーを微調整する場合です。
もう1つは、モデルのバックボーンを別のバックボーンに置き換えたい場合です。(例えば、より高速な予測のため)
具体例で説明します。1. Finetuning from a pretrained model(事前トレーニング済みモデルのファインチューニング)
事前にトレーニングされたモデルを利用して、自分が識別したいクラスに合わせてファインチューニングする方法は次のとおりです。
import torchvision from torchvision.models.detection.faster_rcnn import FastRCNNPredictor # COCOで事前トレーニング済みのモデルをロードする model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True) # 分類器を、ユーザー定義の num_classes を持つ新しい分類器に置き換えます num_classes = 2 # 1 class (person) + background : 1クラス(人)+背景 # 分類器の入力特徴数を取得します in_features = model.roi_heads.box_predictor.cls_score.in_features # 事前にトレーニングされた HEAD を新しいものと交換します model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)2. Modifying the model to add a different backbone(モデルを変更して別のバックボーンを追加する)
もう一方のケースは、モデルのバックボーンを別のバックボーンに置き換えたい場合です。例えば、現在のデフォルトのバックボーン(ResNet-50)は、状況によっては大きすぎる可能性があり、より小さなモデルを利用したい場合があります。
以下に、torchvision を活用してバックボーンを変更する方法を記します。import torchvision from torchvision.models.detection import FasterRCNN from torchvision.models.detection.rpn import AnchorGenerator # 分類のために事前にトレーニングされたモデルをロードし、機能のみを返します backbone = torchvision.models.mobilenet_v2(pretrained=True).features # FasterRCNNは、バックボーン内の出力チャネルの数を知る必要があります。 # mobilenet_v2の場合は1280なので、ここに追加する必要があります backbone.out_channels = 1280 # RPNに、5つの異なるサイズと3つの異なるアスペクト比で、 # 空間位置ごとに5 x3のアンカーを生成させましょう。 # 各フィーチャマップのサイズとアスペクト比が異なる可能性があるため、 # Tuple [Tuple [int]]があります。 anchor_generator = AnchorGenerator(sizes=((32, 64, 128, 256, 512),), aspect_ratios=((0.5, 1.0, 2.0),)) # 関心領域のトリミングを実行するために使用するフィーチャマップと、 # 再スケーリング後のトリミングのサイズを定義しましょう。 # バックボーンがTensorを返す場合、featmap_namesは[0]であると予想されます。 # より一般的には、バックボーンはOrderedDict [Tensor]を返す必要があり、 # featmap_namesで使用するフィーチャマップを選択できます。 roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=[0], output_size=7, sampling_ratio=2) # FasterRCNNモデル内にピースをまとめます model = FasterRCNN(backbone, num_classes=2, rpn_anchor_generator=anchor_generator, box_roi_pool=roi_pooler)An Instance segmentation model for PennFudan Dataset(PennFudanデータセットのインスタンスセグメンテーションモデル)
今回のケースでは、データセットが非常に小さいため、事前にトレーニングされたモデルを微調整します。従って、アプローチ番号 1 に従います。
ここでは、インスタンスのセグメンテーションマスクも計算するため(人物の領域をピクセル単位で判定するため)、Mask R-CNNを使用します。※このチュートリアルで利用するモデルは、torchvision の maskrcnn_resnet50_fpn です。
maskrcnn_resnet50_fpnは 公式ドキュメント で説明されていますが、ResNet-50-FPNをカスタマイズしたモデルです。
maskrcnn_resnet50_fpn は COCO train2017 のデータセットで事前学習されています。import torchvision from torchvision.models.detection.faster_rcnn import FastRCNNPredictor from torchvision.models.detection.mask_rcnn import MaskRCNNPredictor def get_instance_segmentation_model(num_classes): # COCOで事前トレーニングされたインスタンスセグメンテーションモデルをロードする model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=True) # 分類器の入力特徴数を取得します in_features = model.roi_heads.box_predictor.cls_score.in_features # 事前にトレーニングされた HEAD を新しいものと交換します model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes) # mask 分類器の入力特徴数を取得します in_features_mask = model.roi_heads.mask_predictor.conv5_mask.in_channels hidden_layer = 256 # and replace the mask predictor with a new one # マスク予測器を新しいものと交換します model.roi_heads.mask_predictor = MaskRCNNPredictor(in_features_mask, hidden_layer, num_classes) return modelこれで、今回のデータセットでモデルをトレーニングおよび評価する準備が整いました。
(今回のモデルと torchvision.models.detection.maskrcnn_resnet50_fpn を比較してみると、以下の箇所 の次元が変わっていることが確認できます。)
(roi_heads): RoIHeads( ・・・ (box_predictor): FastRCNNPredictor( (cls_score): Linear(in_features=1024, out_features=2, bias=True) (bbox_pred): Linear(in_features=1024, out_features=8, bias=True) ) ・・・ (mask_predictor): MaskRCNNPredictor( ・・・ (mask_fcn_logits): Conv2d(256, 2, kernel_size=(1, 1), stride=(1, 1)) ) )Training and evaluation functions (トレーニングおよび評価関数)
torchvision の
vision/references/detection/には、物体検出モデルのトレーニングと評価を簡素化するための多数のヘルパー関数があります。ここでは、references/detection/engine.py,references/detection/utils.py,references/detection/transforms.pyを使用します。これらのファイル(と関連するファイル)をコピーして、使用できるようにします。
%%shell # Download TorchVision repo to use some files from # references/detection git clone https://github.com/pytorch/vision.git cd vision git checkout v0.3.0 cp references/detection/utils.py ../ cp references/detection/transforms.py ../ cp references/detection/coco_eval.py ../ cp references/detection/engine.py ../ cp references/detection/coco_utils.py ../コピーした
refereces/detectionを利用して、データの拡張/変換用のヘルパー関数をいくつか作成しましょう。from engine import train_one_epoch, evaluate import utils import transforms as T def get_transform(train): transforms = [] # 画像を Tensor に変換します transforms.append(T.ToTensor()) if train: # トレーニングの場合、ランダムに画像と教師データを水平方向に反転します。(鏡に映すイメージ) transforms.append(T.RandomHorizontalFlip(0.5)) return T.Compose(transforms)上記のコードは、データの下処理です。
画像を Tensor に変換し、学習データの場合はランダムに反転します。
データの標準化や画像の再スケーリングは不要です。Mask R-CNN モデルが内部でやってくれます。Putting everything together (すべてをまとめる)
これで、データセット、モデル、およびデータ下処理が準備できました。それらをインスタンス化しましょう。
# データセットと定義された変換を使用します dataset = PennFudanDataset('PennFudanPed', get_transform(train=True)) dataset_test = PennFudanDataset('PennFudanPed', get_transform(train=False)) # トレーニングデータとテストデータでデータセットを分割します torch.manual_seed(1) indices = torch.randperm(len(dataset)).tolist() dataset = torch.utils.data.Subset(dataset, indices[:-50]) dataset_test = torch.utils.data.Subset(dataset_test, indices[-50:]) # トレーニングと検証のデータローダーを定義します data_loader = torch.utils.data.DataLoader( dataset, batch_size=2, shuffle=True, num_workers=4, collate_fn=utils.collate_fn) data_loader_test = torch.utils.data.DataLoader( dataset_test, batch_size=1, shuffle=False, num_workers=4, collate_fn=utils.collate_fn)モデルをインスタンス化します。
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu') # 教師データは、背景と人の2クラスのみです num_classes = 2 # ヘルパー関数を使用してモデルを取得します model = get_instance_segmentation_model(num_classes) # モデルを適切なデバイスに移動します model.to(device) # オプティマイザを構築します params = [p for p in model.parameters() if p.requires_grad] optimizer = torch.optim.SGD(params, lr=0.005, momentum=0.9, weight_decay=0.0005) # 学習率を3エポックごとに10分の1に減らす学習率スケジューラ lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=3, gamma=0.1)10エポックでトレーニングします。
各エポックで evaluate 関数で評価します。
(Colaboratory の GPU 環境だと学習に8分程度かかります。None GPU だと実行時エラーが発生します。)# 10エポックでトレーニング num_epochs = 10 for epoch in range(num_epochs): print(epoch) # 1エポックのトレーニング train_one_epoch(model, optimizer, data_loader, device, epoch, print_freq=10) # 学習率を更新する lr_scheduler.step() # テストデータセットで評価する evaluate(model, data_loader_test, device=device)out... Averaged stats: model_time: 0.1179 (0.1174) evaluator_time: 0.0033 (0.0051) Accumulating evaluation results... DONE (t=0.01s). Accumulating evaluation results... DONE (t=0.01s). IoU metric: bbox Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.831 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.990 Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.955 Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000 Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.543 Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.841 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.386 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.881 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.881 Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000 Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.787 Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.887 IoU metric: segm Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.760 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.990 Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.921 Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000 Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.492 Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.771 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.345 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.808 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.808 Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000 Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.725 Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.814※ 評価として上記が出力されます。
evaluate(テストデータの評価)は、以下に解説があるようですので機会があれば調べてみたいと思います。
https://cocodataset.org/#detection-evalトレーニングが終了したので、テストデータセットでどのような結果になるか見てみましょう。
# テストセットから1つの画像を選択します img, _ = dataset_test[4] # モデルを評価モードにします model.eval() with torch.no_grad(): prediction = model([img.to(device)])予測(prediction)を出力すると、辞書のリストになっています。
テストデータを1つ指定したため、下の例ではリストの要素は1つです。
辞書には、画像の予測が含まれています。
この場合、boxes、labels、masks、score が含まれていることが分かります。predictionout[{'boxes': tensor([[173.1167, 27.6446, 240.8375, 313.0114], [325.5737, 64.3967, 453.1539, 352.3020], [222.4494, 24.5255, 306.5306, 291.5595], [296.8205, 21.3736, 379.0592, 263.7513], [137.4137, 38.1588, 216.4886, 276.1431], [167.8121, 19.9211, 332.5648, 314.0146]], device='cuda:0'), 'labels': tensor([1, 1, 1, 1, 1, 1], device='cuda:0'), 'masks': tensor([[[[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]]], [[[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]]], [[[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]]], [[[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]]], [[[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]]], [[[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]]]], device='cuda:0'), 'scores': tensor([0.9965, 0.9964, 0.9942, 0.9696, 0.3053, 0.1552], device='cuda:0')}]画像と予測結果を確認します。
画像(img)は [ 色 , 縦 , 横 ] の Tensor です。
色は 0 - 1 のため 0 - 255 にスケーリングし、 [ 縦 , 横 , 色 ] に入れ替えます。Image.fromarray(img.mul(255).permute(1, 2, 0).byte().numpy())
次に、予測したマスクを可視化します。masksは
[N、1、H、W]として予測されます。ここで、Nは予測したインスタンス(人)の数です。
mask の各値には、ピクセル単位で「人」と判断した度合いの確率が 0-1 で格納されています。Image.fromarray(prediction[0]['masks'][0, 0].mul(255).byte().cpu().numpy())
(以下のように N の値を変えることで他の予測したインスタンス(人)も可視化できます。)
Image.fromarray(prediction[0]['masks'][1, 0].mul(255).byte().cpu().numpy())
Image.fromarray(prediction[0]['masks'][2, 0].mul(255).byte().cpu().numpy())
Image.fromarray(prediction[0]['masks'][3, 0].mul(255).byte().cpu().numpy())
うまく予測できています。
Wrapping up (まとめ)
このチュートリアルでは、自分で定義したデータセットを利用し、物体検知モデルのトレーニングを行う処理を学びました。
データセットは、物体検知特有のデータセットを定義するため、box, maskを保持するtorch.utils.data.Datasetクラスを作成しました。
また、この新しいデータセットで転移学習を実行するために、COCOtrain2017で事前トレーニングされたMaskR-CNNモデルを活用しました。マルチマシン/マルチGPUトレーニングの詳しい例を知りたい方は、torchvision GitHub repoにある references/detection/train.py を確認してください。
終わりに
このチュートリアルでは、事前学習済みのモデルを利用する「転移学習」「ファインチューニング」を学びました。(今回はどうやらファインチューニングと呼ばれるもので、転移学習とファインチューニングの違いは次回で説明されています)
チュートリアルでは、学習データ120、検証データ50で試していましたが、学習データが40ほどでも、まあまあ正しく予測できていました。
これほど少ないテストデータで学習できるとは、転移学習はすごいですね。
次回は「Transfer Learning for Computer Vision Tutorial」を進めてみたいと思います。履歴
2020/11/15 初版公開









- 投稿日:2020-11-15T13:19:39+09:00
Pythonのtkinterで簡易メール送信アプリを作ってみた
はじめに
本記事ではPythonを使ったアプリケーションを開発していきます。
GUIライブラリには標準ライブラリのtkinterを採用しています。
メール送信には標準ライブラリのsmtplibを採用しています。
本記事を読むことである程度pythonを理解しているかであれば、ある程度tkinterの使い方とsmtplibの使い方を覚えることができると思います。tkinterとは
Pythonの標準ライブラリの1つです。
GUIアプリケーションを構築するためのライブラリです。
シンプルな文法と起動の速さが特徴のGUIライブラリです。ウィンドウの作成
まずはとなるウィンドウを作っていきましょう。
import tkinter as tk if __name__ == "__main__": root = tk.Tk() root.mainloop()
画面の作成
オブジェクト指向を意識して書くためにFrameクラスを継承したクラスを作成していきます。
create_widgets()内で必要な部品(ウィジェット)を生成し、配置して画面を作っていきます。import tkinter as tk class Application(tk.Frame): def __init__(self, master): super().__init__(master) self.pack() # 画面サイズとタイトルを設定 master.geometry("300x200") master.title("簡易メール送信アプリ") self.create_widgets() # ウィジェットを生成するメソッド def create_widgets(self): self.label = tk.Label(self,text="簡易メール送信アプリ") self.label.grid(row=0, column=0, columnspan=3) self.to_label = tk.Label(self, text="宛先:") self.to_entry = tk.Entry(self, width=20) self.to_label.grid(row=1, column=0) self.to_entry.grid(row=1, column=1, columnspan=2) self.subject_label = tk.Label(self, text="件名:") self.subject_entry = tk.Entry(self, width=20) self.subject_label.grid(row=2, column=0) self.subject_entry.grid(row=2, column=1, columnspan=2) self.body_label = tk.Label(self, text="本文:") self.body_text = tk.Entry(self, width=20) self.body_label.grid(row=3, column=0) self.body_text.grid(row=3, column=1, columnspan=2) self.button = tk.Button(self, text="送信") self.button.grid(row=4, column=2, sticky=tk.E, pady=10) if __name__ == "__main__": root = tk.Tk() Application(master=root) root.mainloop()
イベント処理の設定
送信ボタンにイベント処理を設定していきます。
イベント処理とはボタンが押されたときに呼び出される処理(メソッド)のことです。
ボタン生成時に引数commandにラムダ式を使ってイベント処理を設定します。
ひとまず入力した値を標準出力(コンソール)に出力する処理を設定します。# ウィジェットを生成するメソッド def create_widgets(self): # ~省略~ self.button = tk.Button(self, text="送信", command=lambda:self.click_event()) self.button.grid(row=4, column=2, sticky=tk.E, pady=10) def click_event(self): to = self.to_entry.get() subject = self.subject_entry.get() body = self.body_text.get() print(f"宛先:{to}") print(f"件名:{subject}") print(f"本文:{body}")
コンソールの表示結果
宛先:takahashi@example.com 件名:先日の打ち合わせについて 本文:先日は打ち合わせありがとうございました。メール送信の準備
メール送信処理を作成する前に少し準備が必要です。
今回はGmailアカウントから送信することを想定して作成します。
まずはGmailアカウントをお持ちでない方は下記リンクから作成してください。
既にお持ちの方も開発用にサブアカウントの取得をオススメします。
(すぐ下にある通り、アカウントのセキュリティの設定を少し下げる必要があります。)
https://accounts.google.com/SignUpアカウントをすでにお持ちの方、もしくは新規作成が終わったらPythonプログラムからメールを送るためにアカウントの設定を少し変更する必要があります。
下記の操作で「アカウント設定画面」を表示します。
次に左側のメニューから「セキュリティ」を選択します。
画面下部の方にスクロールしていき「安全性の低いアプリのアクセス」を「オン」にします。
これでPythonプログラムからGmailにログインしてメールを送信するための準備完了です。
メール送信処理
メール送信処理部分を作っていきます。
まずはメール送信に必要なライブラリをインポートします。from smtplib import SMTP from email.mime.text import MIMEText from email.mime.multipart import MIMEMultipart次にメール送信用のメソッドを作っていきます。
メールを送るたびに動的に変わる部分についてはメソッドの引数で受け取ります。
メールを送るたびに変わらない値についてはメソッド内に定数で定義します。
IDとPASSは送信元のGmailのメールアドレスとパスワードになります。
こちらはご自身の環境に合わせて設定してください。# メール送信処理 def send_mail(self, to, subject, body): # 送信に必要な情報を定数で定義 ID = "mail_address" PASS = "password" HOST = "smtp.gmail.com" PORT = 587 # メール本文を設定 msg = MIMEMultipart() msg.attach(MIMEText(body, "html")) # 件名、送信元アドレス、送信先アドレスを設定 msg["Subject"] = subject msg["From"] = ID msg["To"] = to # SMTPサーバへ接続し、TLS通信開始 server=SMTP(HOST, PORT) server.starttls() server.login(ID, PASS) # ログイン認証処理 server.send_message(msg) # メール送信処理 server.quit() # TLS通信終了イベント処理の紐づけ
最後にイベント処理の部分を先ほど作成したメソッドを呼び出すように変更すると簡易メール送信アプリの完成です。
def click_event(self): to = self.to_entry.get() subject = self.subject_entry.get() body = self.body_text.get() # print(f"宛先:{to}") # print(f"件名:{subject}") # print(f"本文:{body}") self.send_mail(to=to, subject=subject, body=body)完成版ソースコード
完成したソースコードは下記通りです。
import tkinter as tk from smtplib import SMTP from email.mime.text import MIMEText from email.mime.multipart import MIMEMultipart class Application(tk.Frame): def __init__(self, master): super().__init__(master) self.pack() # 画面サイズとタイトルを設定 master.geometry("300x200") master.title("簡易メール送信アプリ") self.create_widgets() # ウィジェットを生成するメソッド def create_widgets(self): self.label = tk.Label(self,text="簡易メール送信アプリ") self.label.grid(row=0, column=0, columnspan=3) self.to_label = tk.Label(self, text="宛先:") self.to_entry = tk.Entry(self, width=20) self.to_label.grid(row=1, column=0) self.to_entry.grid(row=1, column=1, columnspan=2) self.subject_label = tk.Label(self, text="件名:") self.subject_entry = tk.Entry(self, width=20) self.subject_label.grid(row=2, column=0) self.subject_entry.grid(row=2, column=1, columnspan=2) self.body_label = tk.Label(self, text="本文:") self.body_text = tk.Entry(self, width=20) self.body_label.grid(row=3, column=0) self.body_text.grid(row=3, column=1, columnspan=2) self.button = tk.Button(self, text="送信", command=lambda:self.click_event()) self.button.grid(row=4, column=2, sticky=tk.E, pady=10) def click_event(self): to = self.to_entry.get() subject = self.subject_entry.get() body = self.body_text.get() self.send_mail(to=to, subject=subject, body=body) # メール送信処理 def send_mail(self, to, subject, body): # 送信に必要な情報を定数で定義 ID = "mail_address" PASS = "password" HOST = "smtp.gmail.com" PORT = 587 # メール本文を設定 msg = MIMEMultipart() msg.attach(MIMEText(body, "html")) # 件名、送信元アドレス、送信先アドレスを設定 msg["Subject"] = subject msg["From"] = ID msg["To"] = to # SMTPサーバへ接続し、TLS通信開始 server=SMTP(HOST, PORT) server.starttls() # TLS通信開始 server.login(ID, PASS) # ログイン認証処理 server.send_message(msg) # メール送信処理 server.quit() # TLS通信終了 if __name__ == "__main__": root = tk.Tk() Application(master=root) root.mainloop()最後に
一通り試してメール送信アプリが作れたら気になる人はGoogleアカウントのセキュリティの設定を元に戻しておきましょう。
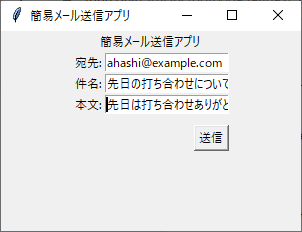
- 投稿日:2020-11-15T12:57:15+09:00
tkinterにファイルをドロップしてそのパスを取得したい【TkinterDnD2】
できそうな気がするんです。
蛇口です。普段はエンジニアでも何でもありません。
特に必要というわけではないんですが巷にあるウィンドウって
たいていファイルをドロップすると、それに対して何かしてくれている気がするんです。Tkinterも見た目からして「私、できますよ」という顔をしていたんですが
まあ普通にファイルをドロップしても何も起きないわけですね。今回、Qiitaには載ってなかったので(見つけらなかっただけかもしれませんが)
今後同じ手間を踏む必要がないようにこちらに投稿しておくことにしました。環境
Windows10 64bit
python3.7TkinterDnD2
どうやら、Tkinterに加えてTkinterDnD2というものを使うことで
ドロップされたファイルを受け取ることができるようになるそうです。じゃあ、いつものように「pip install」すればいいんじゃない?と私は考えました。
pip install tkinterdnd2
ERROR: Could not find a version that satisfies the requirement tkinterdnd2 (from versions: none)
ERROR: No matching distribution found for tkinterdnd2ダメでした。
TkinterDnD2のインストール
インターネットをサーフィンして、ようやくこのサイトにたどり着きました。
こちらから、なんとなく新しいほうをダウンロードしました。ダウンロードしたものを解凍すると、なんと、たくさんファイルがあるではありませんか。
これは混乱です。どうすればいいんでしょうか。これまたインターネットをサーフィンすると
「自分のsite-packagesフォルダにTkinterDnD2フォルダを置く」ということでした。解凍されて出てきたものの中に、確かに「TkinterDnD2」というフォルダがありました。
なるほど、これをsite-packagesに移動させて…。
というところで手が止まりました。
あれsite-packagesって、どこにあるんだっけ?site-packagesの場所が分からない
site-packagesって、なんとなくpip installとかで手に入れる者たちが置かれる場所だと記憶しています。
そして実際に何回か行ったこともあるんですが…、正直どこか思い出せませんでした。これまた私はインターネットをサーフィンしました。
コマンドプロンプトで以下のコマンドを実行することでsite-packagesへのパスを取得することができました。
ありがとう、インターネット。
ありがトンクス!1.Windowsキー+Rで「ファイルを指定して実行」を起動
2.cmdと入力して「OK」
3.python -c "import site; print (site.getsitepackages())"やはり、できない!
苦労してようやくドラッグアンドドロップができるようになったと思いましたが
普通にエラーになってできませんでした。
どうやら、TkinterDnD2のほかにtkDnD2というものが必要のようです。tkって略称っぽいけど、どうやらこの2つは全くの別物のようです。
JavaとJavaScriptは全然別物だよとか、そういうのはもうやめてほしいです。tkDnD2のインストール
ここから64bitに対応しているはずの「tkdnd2.8-win32-x86_64.tar.gz」をダウンロードしました。
gzファイルという見かけないタイプの圧縮でしたが、Lhaplusが簡単に解凍してくれました。
解凍すると、これまたたくさんのファイルが出てきました。今回は以下のフォルダに、すべてをコピーさせるそうです。
(略)\Programs\Python\Python37\tcl\tkdnd
tclまでは既に存在していました。
tkdndはありませんでしたので、自分で作成しました。ドロップされたファイルのパスが獲得できた!
今回は動画のパスを取得して、キャンバスに描写してみました。
今のままだと何の役にも立ちそうにないですが、何かとに組み合わせることには意味がありそうです。
- 投稿日:2020-11-15T12:53:59+09:00
jupyter notebook上でPCのGPUチェック
備忘録
「!」記号を付けることでnotebook上でもcmd上のコマンドを実行できるので、以下のように
!nvidia-smi(base) C:\Users\user>nvidia-smi Sun Nov 15 00:00:00 2020 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 456.71 Driver Version: 456.71 CUDA Version: 11.1 | |-------------------------------+----------------------+----------------------+ | GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 GeForce GTX 1070 WDDM | 00000000:01:00.0 On | N/A | | 0% 50C P8 9W / 151W | 4805MiB / 8192MiB | 6% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 6664 C+G C:\Windows\explorer.exe N/A | +-----------------------------------------------------------------------------+notebookでなくともcmdプロンプト上から行っても同じ。
以上
- 投稿日:2020-11-15T12:53:43+09:00
jupyter notebook上でgithubのリポジトリをclone
- 投稿日:2020-11-15T11:10:30+09:00
Kaggle / Titanic のチュートリアルの RandomForestClassifier のパラメータを調べる
はじめに
Kaggle / Titanic のチュートリアルでは
RandomForestClassifier()で学習している. このパラメータを調整して, 学習精度が向上するか確認する.データの準備
import numpy as np import pandas as pd import seaborn import matplotlib.pyplot as plt train_data = pd.read_csv("../train.csv") from sklearn.model_selection import train_test_split train_data_orig = train_data train_data, cv_data = train_test_split(train_data_orig, test_size=0.3, random_state=1)
train_test_splitを使って, train : cv = 7 : 3 にデータを分割した (cv ; cross validation).train_data.info() <class 'pandas.core.frame.DataFrame'> Int64Index: 623 entries, 114 to 37 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 PassengerId 623 non-null int64 1 Survived 623 non-null int64 2 Pclass 623 non-null int64 3 Name 623 non-null object 4 Sex 623 non-null object 5 Age 496 non-null float64 6 SibSp 623 non-null int64 7 Parch 623 non-null int64 8 Ticket 623 non-null object 9 Fare 623 non-null float64 10 Cabin 135 non-null object 11 Embarked 622 non-null object dtypes: float64(2), int64(5), object(5) memory usage: 63.3+ KBcv_data.info() <class 'pandas.core.frame.DataFrame'> Int64Index: 268 entries, 862 to 92 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 PassengerId 268 non-null int64 1 Survived 268 non-null int64 2 Pclass 268 non-null int64 3 Name 268 non-null object 4 Sex 268 non-null object 5 Age 218 non-null float64 6 SibSp 268 non-null int64 7 Parch 268 non-null int64 8 Ticket 268 non-null object 9 Fare 268 non-null float64 10 Cabin 69 non-null object 11 Embarked 267 non-null object dtypes: float64(2), int64(5), object(5) memory usage: 27.2+ KBtrain が 623 個, cv が 268 個, 合計が 891 個になっている.
チュートリアル通りに学習する
from sklearn.ensemble import RandomForestClassifier features = ["Pclass", "Sex", "SibSp", "Parch"] y = train_data["Survived"] y_cv = cv_data["Survived"] X = pd.get_dummies(train_data[features]) X_cv = pd.get_dummies(cv_data[features]) model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1, max_features="auto") model.fit(X, y) predictions = model.predict(X_cv) print('Train score: {}'.format(model.score(X, y))) print('CV score: {}'.format(model.score(X_cv, y_cv)))Train score: 0.8394863563402889 CV score: 0.753731343283582train は 84% くらいの正解になっているが, CV では 75% の正解に留まる. 過学習? ってことでしょうか?
RandomForestClassifier のパラメータを手動で変更する
n_estimator
n_estimatorの値を変えてみる.rfc_results = pd.DataFrame(columns=["train", "cv"]) for iter in [1, 10, 100]: model = RandomForestClassifier(n_estimators=iter, max_depth=5, random_state=1, max_features="auto") model.fit(X, y) predictions = model.predict(X_cv) rfc_results.loc[iter] = model.score(X, y), model.score(X_cv, y_cv)
train cv 1 0.826645 0.753731 10 0.833066 0.753731 100 0.839486 0.753731 決定木の数が増えるにつれて, train のスコアは微増するが, cv のスコアは変わらない. ムムッ.
max_depth
max_depthの値を変えてみる.max_depth = 2
for iter in [1, 10, 100]: model = RandomForestClassifier(n_estimators=iter, max_depth=2, random_state=1, max_features="auto") model.fit(X, y) predictions = model.predict(X_cv) rfc_results.loc[iter] = model.score(X, y), model.score(X_cv, y_cv)
train cv 1 0.813804 0.731343 10 0.81862 0.753731 100 0.817014 0.761194 cv のスコア 76% が出てきた.
max_depth = 3
for iter in [1, 10, 100]: model = RandomForestClassifier(n_estimators=iter, max_depth=3, random_state=1, max_features="auto") model.fit(X, y) predictions = model.predict(X_cv) rfc_results.loc[iter] = model.score(X, y), model.score(X_cv, y_cv)
train cv 1 0.81862 0.753731 10 0.82504 0.776119 100 0.82504 0.768657 cv のスコア 77.6% が出てきた.
max_depth = 4
for iter in [1, 10, 100]: model = RandomForestClassifier(n_estimators=iter, max_depth=4, random_state=1, max_features="auto") model.fit(X, y) predictions = model.predict(X_cv) rfc_results.loc[iter] = model.score(X, y), model.score(X_cv, y_cv)
train cv 1 0.823435 0.764925 10 0.82825 0.761194 100 0.826645 0.764925 cv のスコアは 76.5% 程度.
以上から,
max_depth=3として,n_estimators=10が一番スコアが高かった.RandomForestClassifier のパラメータを自動で変更する
グリッドサーチ (
GridSearchCV) という方法で, 一番良いパラメータを探す. これは, 列挙したパラメータの組み合わせをしらみつぶしで試してみて, 一番良いものを探すという方法.from sklearn.model_selection import GridSearchCV param_grid = {"max_depth": [2, 3, 4, 5, None], "n_estimators":[1, 3, 10, 30, 100], "max_features":["auto", None]} model_grid = GridSearchCV(estimator=RandomForestClassifier(random_state=1), param_grid = param_grid, scoring="accuracy", # metrics cv = 3, # cross-validation n_jobs = 1) # number of core model_grid.fit(X, y) #fit model_grid_best = model_grid.best_estimator_ # best estimator print("Best Model Parameter: ", model_grid.best_params_)
from行に注意. ネットで調べるとfrom sklearn.grid_search import GridSearchCVという書き方もあったが, 私の場合ではこれでは NG でした.Best Model Parameter: {'max_depth': 3, 'max_features': 'auto', 'n_estimators': 10}手動で試した通り,
max_depth = 3,n_estimators = 10が一番良かった.max_featuresも 2 種類試したが,"auto"が良かった.print('Train score: {}'.format(model.score(X, y))) print('CV score: {}'.format(model.score(X_cv, y_cv))) Train score: 0.826645264847512 CV score: 0.7649253731343284Kaggle / Titanic に submit
今回のパラメタを用いて結果を予測し, Kaggle に submit した. しかし精度は 0.77751 で, チュートリアルそのままのパラメタと変わらなかった. びえん.
おわりに
特徴量で改善を図る前に, 学習のハイパーパラメータを調整することで, ちょっとだけ向上させることができた. 次はいよいよ, 特徴量を検討していきたい.
参考
- 投稿日:2020-11-15T10:39:41+09:00
plotly express が使えるシチュエーションまとめ【matplotlibより使えるときはどんなとき?】
はじめに
グラフの描画といえばmatplotlib + serbornがメジャーですよね。
これらを超えるポテンシャルを秘めたのがインタラクティブなグラフが作成可能なplotly express。
plotly expressを使うとmatplotlib + seabornよりも便利な点に焦点を当てて紹介したいと思います。plotly express、あまり癖がない印象です。plotlyと比較して行数少なくグラフがプロットでき、matplotlibを使ったことがある方はあまり違和感なく導入できると思います。
個人的に考えるplotly expressが役に立つシーンはこんな感じです。
- ヒストグラム書いたけど右に裾が広すぎていまいちよくわからん...かといって右裾だけを拡大したグラフ書くのもなんかかっこ悪い。
- 積み上げ棒グラフ作りたいけど数が少ないやつ潰れてしまう。てかそもそもseabornで積み上げグラフめんどい。
- 散布図で外れているデータを確認したいけど、どのデータが外れているデータなのか探すのが面倒。
- ペアプロットしたけど説明変数が多すぎる...もっと一発でどの説明変数が重要なのか確かめる方法ないのか~
- 時系列データで異常が出ているときの時刻や値が知りたい。この記事でやること
seabornと比較して便利なグラフをプロットしてみます分析データとしてpythonのデータセットのなかからtitanicのデータ、年度ごとの乗客数のデータ、ワインの等級のデータを使います。
titanicデータで
- ヒストグラム
- 積み上げ棒グラフ
- 箱ひげ図
飛行機乗客数データで
- 折れ線グラフ
ワインの等級データで
- 散布図
- 並行座標これらのグラフについて実際のhtmlファイルへのリンクも載せました。htmlリンクからでは実際にぐりぐり動かす感じを味わえます。気持ちいいです。
例えばこちらのグラフとか。
https://nakanakana12.github.io/plotly/hello_world/histgram.html様々なグラフの書き方はこちらの記事がめちゃくちゃ詳しいです。
令和時代のPython作図ライブラリのデファクトスタンダードPlotlyExpressの基本的な描き方まとめ https://qiita.com/hanon/items/d8cbe25aa8f3a9347b0bライブラリのインポート
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import plotly.express as px from sklearn.datasets import load_winetitanicのデータ
df = pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3.csv') #年齢を10歳ごとに丸めた列を追加 df["age10"] = df["age"] // 10 * 10 df["survived_num"] = df["survived"] df["survived"] = df["survived"].replace(1,"alive").replace(0,"dead") df["sex_num"] = df["sex"].replace("female",1).replace("male",0) df = df.reset_index() df.head()
ヒストグラム
右に裾が長い分布に対してはplotlyが便利!
運賃(fare)のヒストグラムを表示します。生存したかどうか(survived)で色分けしました。
運賃は正規分布となっておらず、右側に裾が長い分布となっています。
こういうときって、matplotlibだと数が少ないデータがみづらくなってけっこう困りますよね。plotlyなら少ないところを拡大できるので様子をつかみやすいです。
今回の場合、運賃が高い人は数は少ないけど生存率が高いのが一つのグラフをぐりぐりするだけでわかりました。
fig = px.histogram(df, x="fare", color="survived",nbins=200, opacity=0.4, marginal="box" , title="Survivedごとの運賃のヒストグラム") fig.update_layout(barmode='overlay') fig.show() # htmlで保存 fig.write_html('./histogram.html', auto_open=False)
htmlファイルはこちら。グリグリ動かせます。
https://nakanakana12.github.io/plotly/hello_world/histgram.html積み上げ棒グラフ
plotly expressなら積み上げ棒グラフが簡単で見やすい!
これが一番のおすすめかもしれないです。
積み上げ棒グラフをつくったとき困るのが、分類が多いときですよね。
数の少ないものの数がわからなかったりします。
plotlyなら数が少なくてもカーソルを合わせれば数が確認できるのは便利ですね。ここでは年齢ごとの生存したかどうかを可視化しました。また、性別をまとめて表示した場合とグラフを分けた場合のものをつくってみました。
50代以降は生存率が低くなっていることや、女性の方が生存率が高いのが上手に可視化されていますね。#前処理 df_bar = df.groupby(["survived", "age10","sex"],as_index=False).size().reset_index(drop=True) df_bar.columns = ["survived", "age10","sex","count"] df_bar.head()
fig = px.bar(df_bar, y="age10", x="count", orientation="h",color="survived" , title="年齢ごとのsurvived(まとめて表示)") fig.show()
htmlファイルはこちら。
https://nakanakana12.github.io/plotly/hello_world/bar.htmlfig = px.bar(df_bar, y="age10", x="count", orientation="h",facet_row="sex",color="survived" , title="年齢ごとのsurvived") fig.show()
htmlファイルはこちら。
https://nakanakana12.github.io/plotly/hello_world/bar3.html箱ひげ図
外れ値の確認が簡単!
箱ひげ図の場合、外れ値や信頼区間のデータを簡単に確認できるのが便利です。
また、個人的に便利だと思うのがhover_dataをindexに指定することです。
こうすることで外れ値のindexを簡単に確認でき、その他の列のデータもすぐに確認できます。fig = px.box(df, x="pclass", y="age", color="survived", hover_data=["index"]) fig.show() # htmlで保存 fig.write_html('./box.html', auto_open=False)
htmlファイルはこちら。
https://nakanakana12.github.io/plotly/hello_world/box.html飛行機の乗客データ
折れ線グラフ
異常値の時刻や値が簡単にわかる!
時系列データの場合折れ線グラフが定番ですね。乗客数のデータから各月ごとの推移をプロットしてみます。
表示するグラフを凡例をクリックすることで選択できたり、下のスライダーで表示区間を選択できます。
またマウスで気になる点のx軸、y軸を確認することができます。このデータだと正直恩恵すくないですが、カテゴリが多いときや、異常値をのx軸を確認したいときなどには便利そうです。
df = sns.load_dataset("flights") fig = px.line(df, x="year", y="passengers", color="month", title="乗客数の推移") fig.update_layout(xaxis_range=['1949-01-01', '1961-01-01'], # datetime.datetimeで指定してもよい xaxis_rangeslider_visible=True) fig.show() # htmlで保存 fig.write_html('./time_series.html', auto_open=False)
htmlファイルはこちら。
https://nakanakana12.github.io/plotly/hello_world/time_series.htmlワインの等級データ
データの準備
data_wine = load_wine() df = pd.DataFrame(data_wine["data"], columns=data_wine["feature_names"]) df["target_ID"] = data_wine["target"] df["target"] = df["target_ID"].replace(0,"bad").replace(1,"good").replace(2,"great") df["alcohol_rank"] = np.where(df["alcohol"] < df["alcohol"].mean(),"low", "high") df["flavanoids_rank"] = np.where(df["flavanoids"] < df["flavanoids"].mean(),"low", "high") df = df.reset_index() df.head()
散布図
気になるデータのindexが簡単にわかる!
散布図もマウスをあてることで、どのデータが外れ値なのかを簡単に確認できるのが便利です。
個人的おすすめはhover_dataにindexを指定することですかね。これをすれば、マウスをあてるだけで外れ値のデータのindexがわかり他の値も簡単に確認することができます。
seabornのペアプロットみたいなこともけっこう簡単にできちゃいます。
fig = px.scatter(df, x="alcohol", y="color_intensity", color="target", marginal_x="box", marginal_y="histogram", trendline="ols", hover_data=["index"], title="ワインのアルコール度数と色彩強度の関係") fig.show() # htmlで保存 fig.write_html('./scatter.html', auto_open=False)
htmlファイルはこちら。
https://nakanakana12.github.io/plotly/hello_world/scatter.htmlfig = px.scatter_matrix(df, dimensions=["alcohol", "flavanoids","color_intensity","hue"],color="target", hover_data=["index"], title="ワインの説明変数相関分析") fig.show() # htmlで保存 fig.write_html('./scatter2.html', auto_open=False) 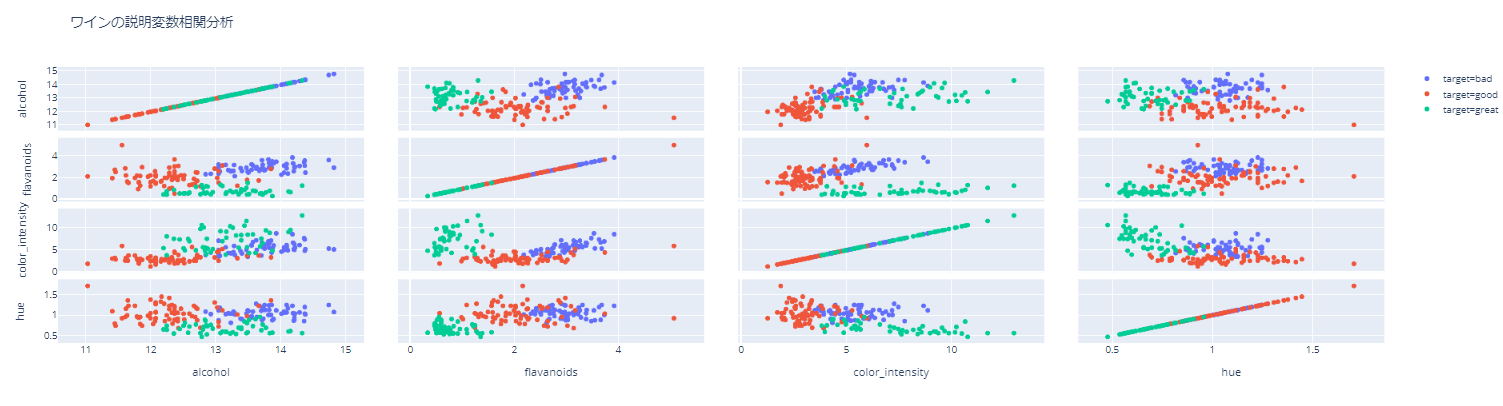htmlファイルはこちら。
https://nakanakana12.github.io/plotly/hello_world/scatter2.html並行座標
変数ごとの相関を確認しやすい!!
説明変数が多いときこれはめちゃくちゃ役に立ちそう。
この図を見るとflavanoidsやhueが小さいとき、color_intensityが大きいときにtarget_IDが大きくなるのが一目瞭然ですね。
他の変数の相関もかなりわかりやすい気がします。カテゴリ化された変数にも使うことができます。
fig = px.parallel_coordinates(df, dimensions=["alcohol","flavanoids", "color_intensity","hue"],color="target_ID") fig.show() # htmlで保存 fig.write_html('./parallel.html', auto_open=False)
htmlファイルはこちら。
https://nakanakana12.github.io/plotly/hello_world/parallel.html#カテゴリカル変数の場合 fig = px.parallel_categories(df, dimensions=["alcohol_rank","flavanoids_rank","target"],color="target_ID") fig.show() # htmlで保存 fig.write_html('./parallel_cat.html', auto_open=False)
htmlファイルはこちら。
https://nakanakana12.github.io/plotly/hello_world/parallel_cat.html終わりに
plotly自体は知っていたのですが、使い方に癖があり学習を断念していました。
それに比べるとplotly expressはけっこう簡単に使い始められる感じです。
外れ値の確認作業などがある場合は本当に便利ですね。3Dの可視化やアニメーションなんかもいつかチャレンジしてみたいです。
最後までお読みいただきありがとうございました。
参考になりましたらLGTMなどしてくれたら励みになります。





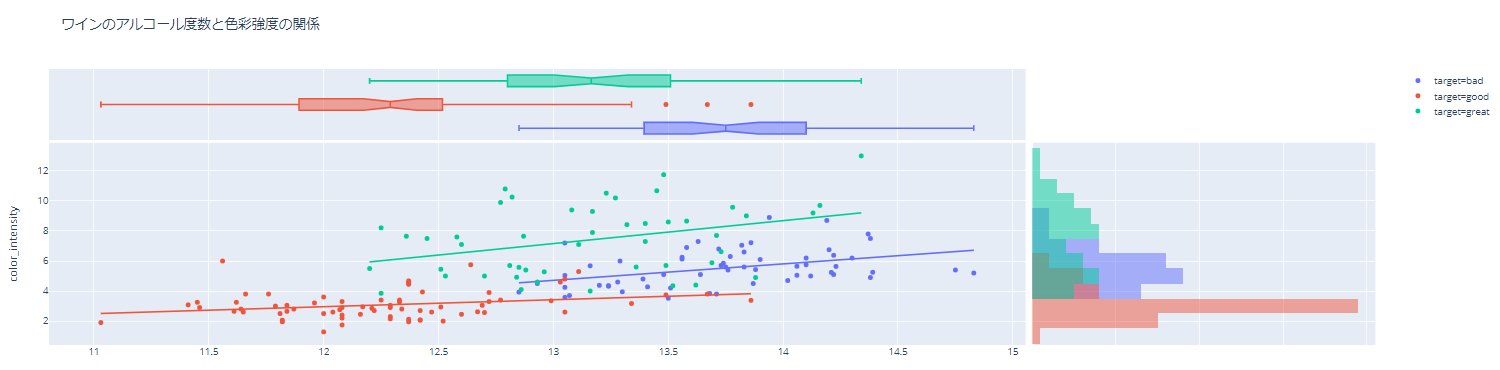
- 投稿日:2020-11-15T09:49:57+09:00
Mask RCNN Object Measurement Package (Mask RCNNで物体径計測)
About this ROS package こういうの作った
RealSenseのようなRGBDセンサを用いて、深層学習により複数の任意のオブジェクトを区別して推測し、その画像上の重心を通る最大・最小の径を算出する。結果はROSトピック(mrcnn/result)として取得可。
https://github.com/moriitkys/mrcnn_measurement
参考になったらLGTMお願いします。こちらはスナップエンドウの大きさを計測する様子。以下で示すボルトや丸太も、自分で学習させた。学習方法についてはこちら( https://github.com/matterport/Mask_RCNN )を参考に。(要望があれば解説の記事書く予定)また、スナップエンドウのrosbagはmrcnn_measurementでダウンロード可。
ボルトの計測の様子。
原木材(丸太)の計測の様子。こちらは非常に数が多いので実行もリアルタイムでは難しい。
最後に、cocoでも実行可能。
実行速度はMask RCNNの推測速度に大きく左右されるので(僕の実行環境で1回推測に約0.2s)、グラボを良くしたりバックボーンをモバイル向け(mobilenetなど)にするとよりリアルタイム性が向上する。
径計測にかかる時間は物体の数が多くなるにつれて増大するので注意。Usage 使用方法
センサがある場合
# 0, Download h5 & rosbag data <= First time only sh download_files.sh # in this package directory cd ~/catkin_ws catkin_make # 1, Turn on RealSnese D435 roslaunch realsense2_camera rs_aligned_depth.launch # 2, Start mrcnn_measurement roslaunch mrcnn_measurement mrcnn_measurement.launchセンサがない場合、rosbagでテスト
# 0, Download h5 & rosbag data <= First time only sh download_files.sh # in this package directory cd ~/catkin_ws catkin_make # 1, Start rosbag & mrcnn_measurement roslaunch mrcnn_measurement mrcnn_measurement_rosbag.launch
- scripts/print_result.pyはmrcnn/resultトピックの中身を読んで表示するサンプルプログラム。物体が一つであればわかりやすく、csvなどにも書き出しやすい(そもそもこのパッケージは物体一つの計測を推奨している)。
- scripts/mrcnn_measurementは実行可能にする必要あるかも。(そのディレクトリでchmod +x mrcnn_measurementなど)
- shファイルを実行するとh5ファイルとrosbagがダウンロードされる。数百GBなので通信環境によってはしばらく待つ必要あり。
- launchファイルののmymodelをcocoにするとmask_rcnn_coco.h5を読み込む。
- Mask RCNNへと入力する画像サイズによっては推測結果が大きく変わるので、注意。例えば、このパッケージではcocoの学習結果を用いる際320*240の画像サイズで入力しているが、640*480で入力すると結構変わる。
- self.array_lines(径計測用の配列)の定義では角度分解能self.angle_stepを6度としているが、より細かく形状の最大最小を見つけたい場合にはself.angle_stepを小さくすること。
- scripts/files/mymodel_classes.csvの"object"を別の名前に変更可。
Rough commentary ざっくり中身の解説
1, RealSenseからのRGB&Depthトピックを受け取る(message_filter)。
2, RGB画像をMask RCNN(ResNet)により物体推測。
3, 推測で生成されたマスク画像のエッジ(mask_i_xy_edges)と、クラス初期化時に作成した径計測用配列(self.array_lines)のアダマール積をマスク重心において実行し、各角度におけるオブジェクト径を計算、diameter_pointsにappendしていく。
4, オブジェクトの重心を通る最大径max(diameter_points)と最小径min(diameter_points)を求め、RealSenseのカメラパラメータfxとマスク部の深度平均(外れ値を除外)から幾何的にオブジェクトの実際の径を計算。
5, 可視化。Error 誤差
現在調査中だけど学習の良し悪しも関係するのでざっくり10%くらい誤差がでると考えたほうがいいかも。丸太のような円形とかなら精度よくなるかも。
Task 課題
計測の誤差を小さくすること。
径計測にかかる時間を小さくすること(特にmaskのROIごとのfor文がネックになっている)。Future work 今後
解説は充実させていくつもり。この記事は更新予定あり。
Requirements
ros kinetic
h5py==2.7.0
Keras==2.1.3
scikit-image==0.13.0
scikit-learn==0.19.1
scipy==0.19.1
tensorflow-gpu==1.4.0
GTX1060, cudnn==6.0, CUDA==8.0
realsense2_camera ( http://wiki.ros.org/realsense2_camera )参考
http://wiki.ros.org/ja/ROS/Tutorials/WritingPublisherSubscriber%28python%29
http://wiki.ros.org/realsense2_camera
https://github.com/matterport/Mask_RCNN
https://qiita.com/_akio/items/5469913fce7fdf0c732a本記事の著者
moriitkys 森井隆禎
ロボットを作ります。
AI・Robotics・3DGraphicsに興味があります。最近はいかにしてお金を稼ぐかを考え、そのお金でハードをそろえようと企んでいます。(E資格挑戦中)
資格・認定:G検定、Pythonエンジニア認定データ分析試験、AI実装検定A級、TOEIC:810(2019/01/13)
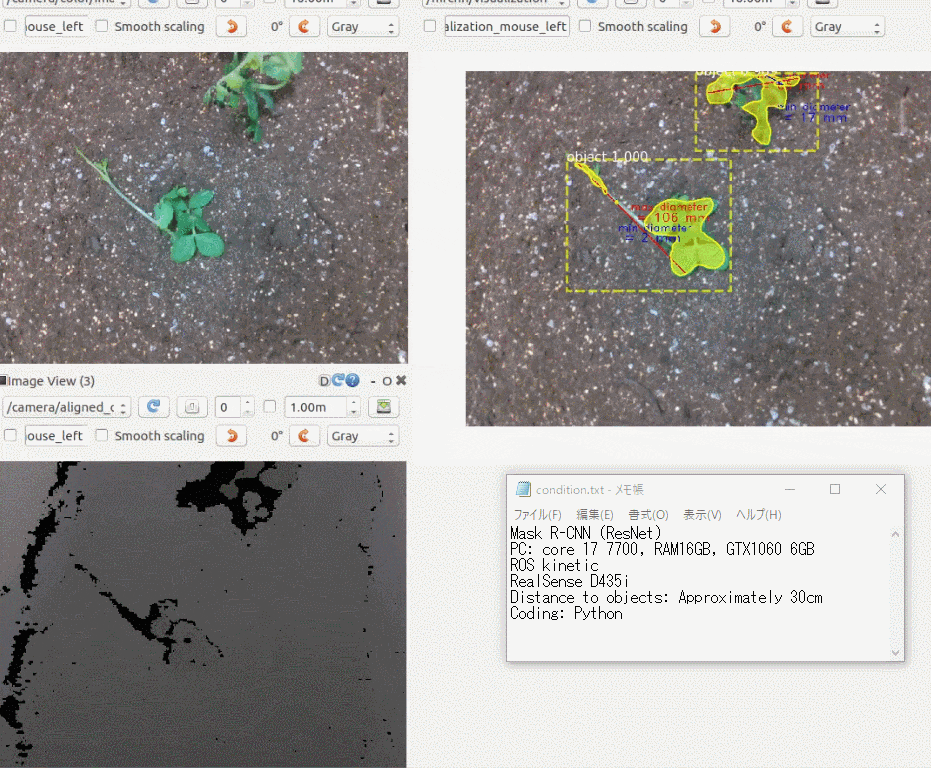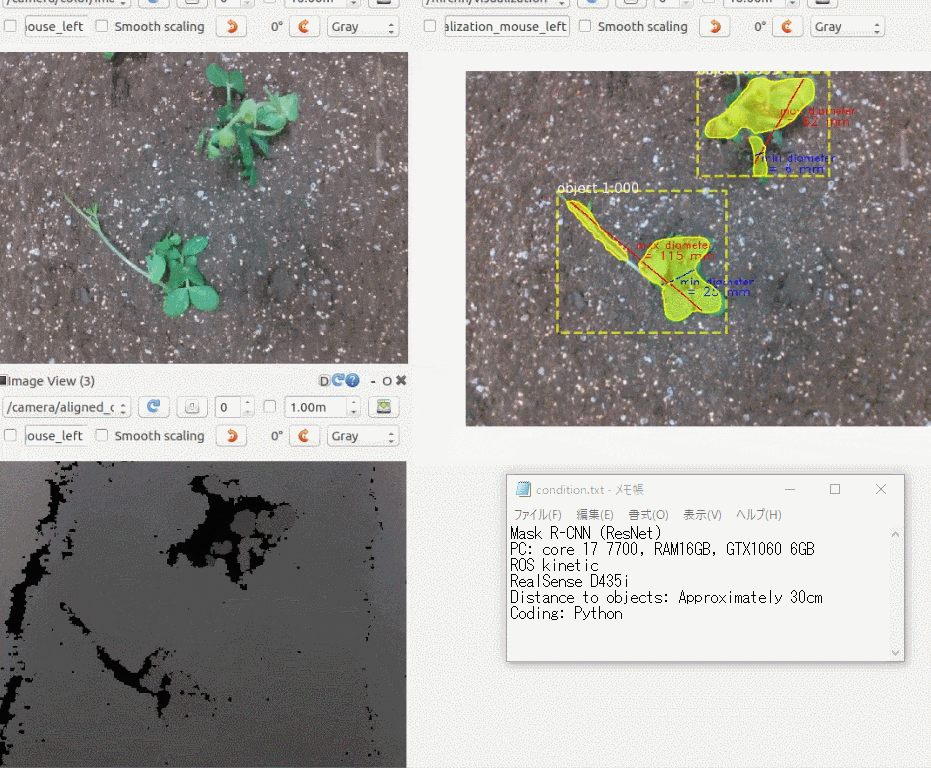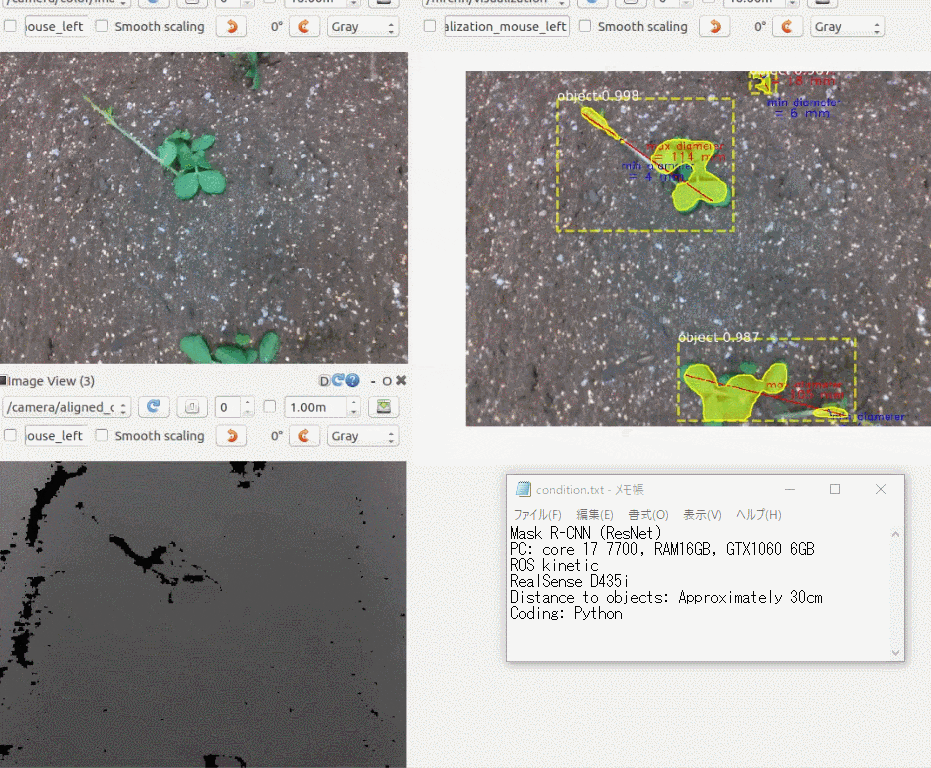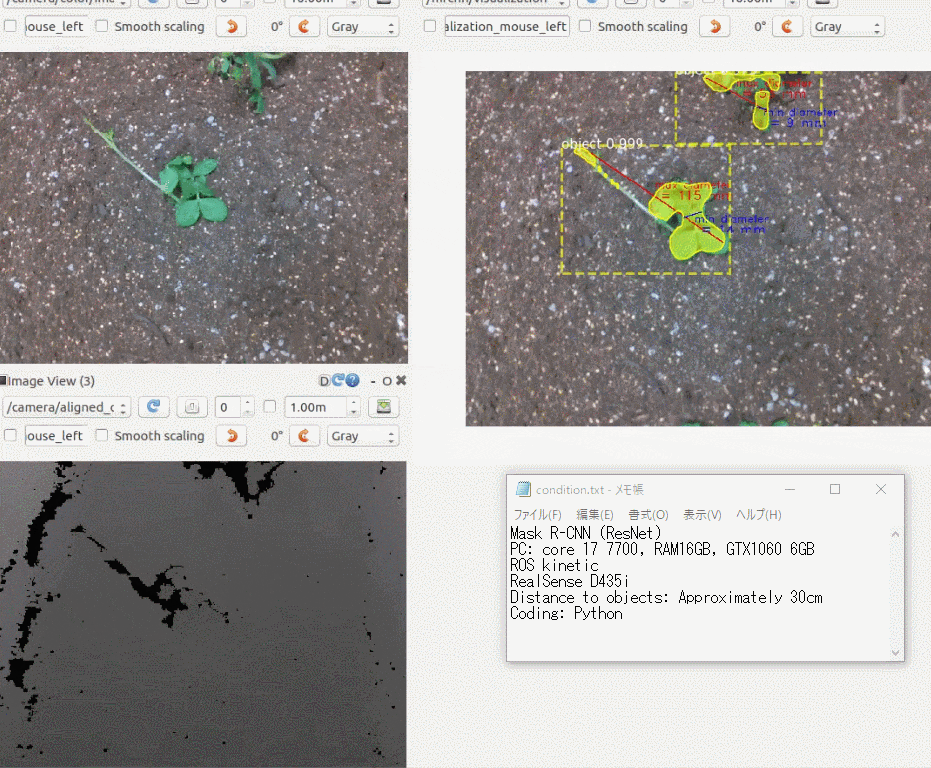

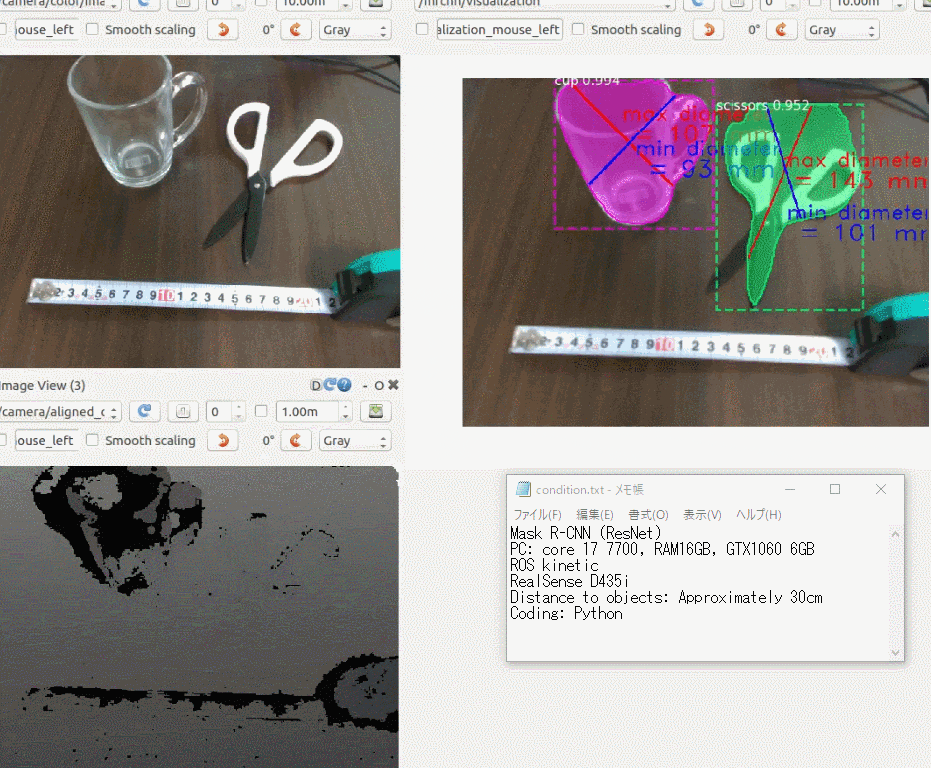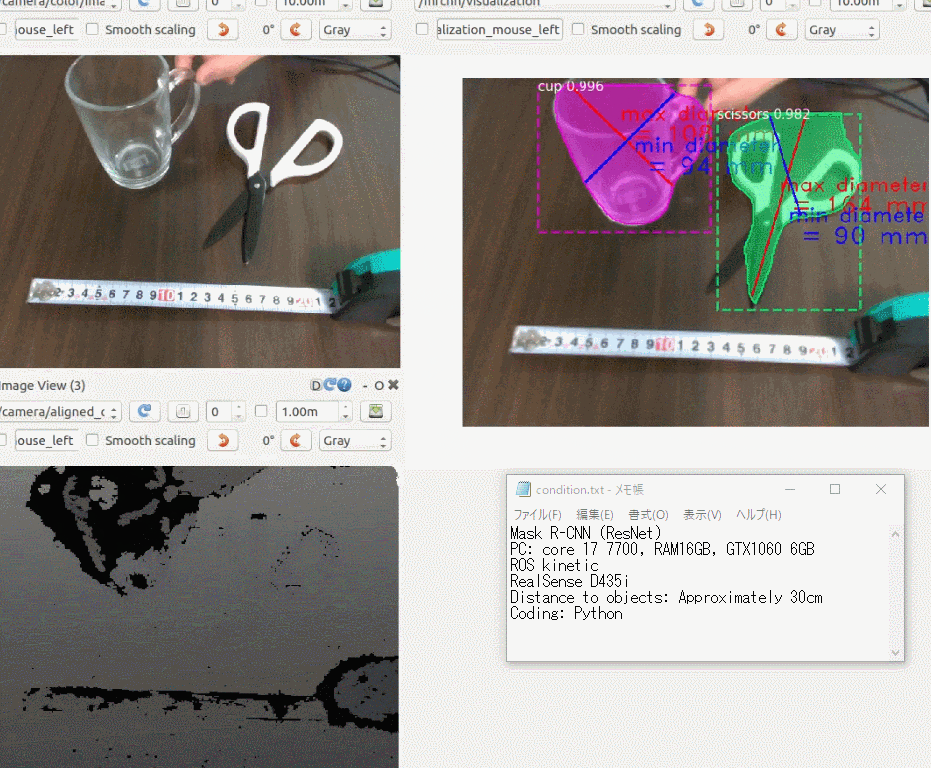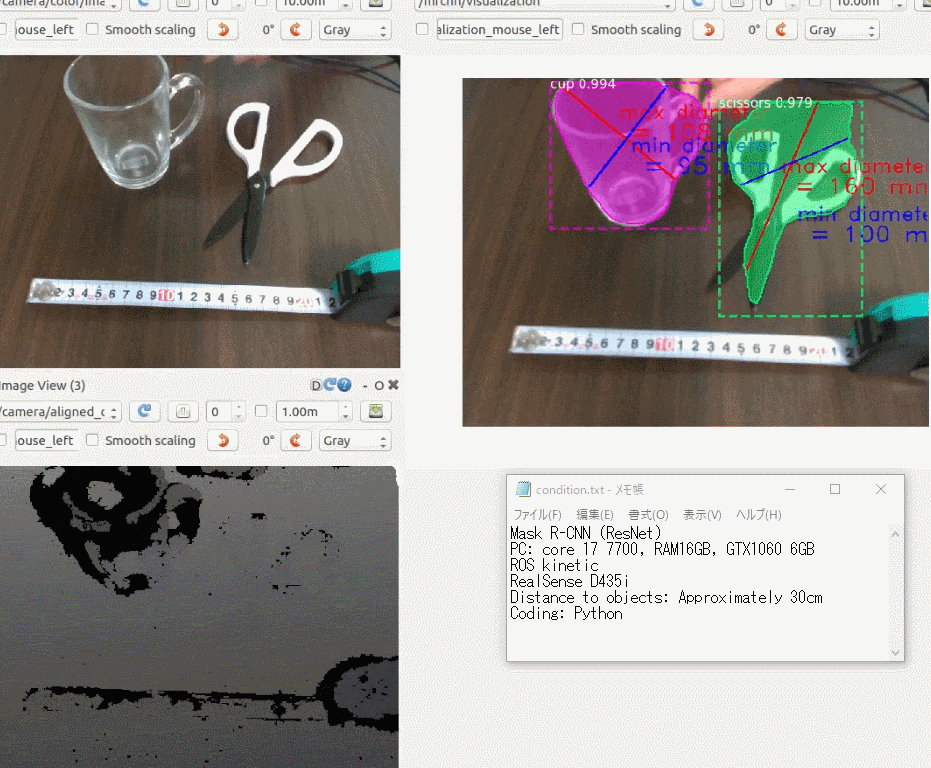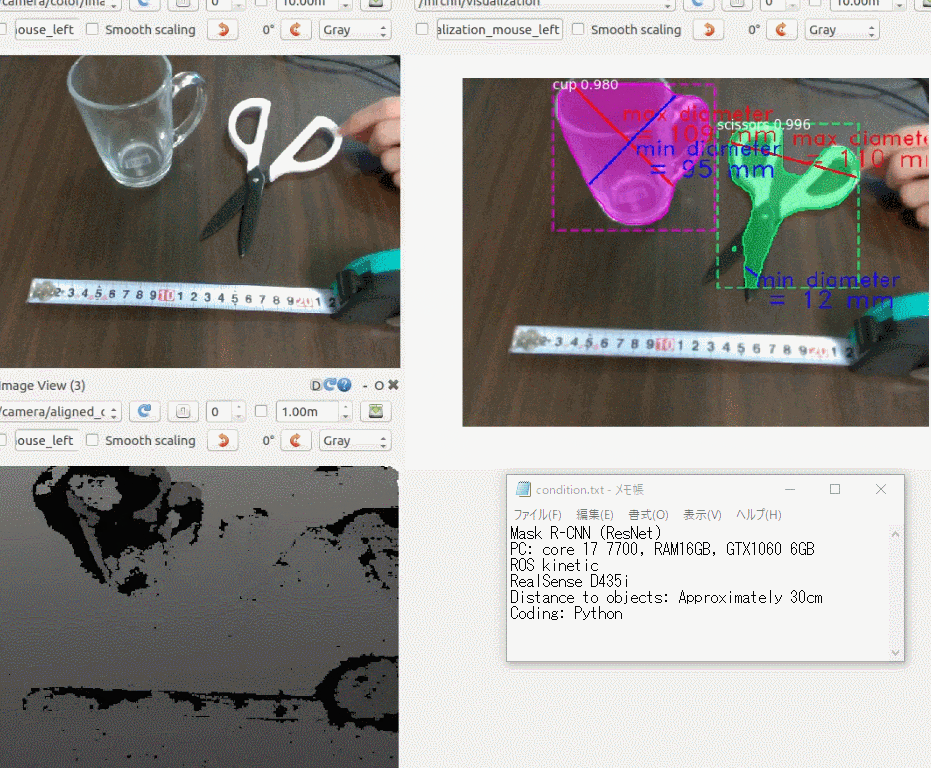
- 投稿日:2020-11-15T09:46:16+09:00
Kaggle / Titanic のチュートリアルをじっくり眺める
はじめに
Kaggle の Titanic の チュートリアル にトライした. コピー & ペーストでランダムフォレストを使った予測ができたのだが, その次のステップに移る前に, チュートリアルで何をしていたのかを確認した.
Kaggle の Titanic の解説文書はネットにたくさん見つけられるが, ここではチュートリアルに沿って私が考えたことなどをまとめておく.データを確認する
head()
チュートリアル では, データを読み込んだ後に
head()を使ってデータを確認している.train_data.head()
test_data.head()
当然ながら,
test_dataにはSurvivedの項がない.describe()
describe()でデータの統計量が分かる.describe(include='O')で, オブジェクトデータの表示ができる.train_data.describe()
train_data.describe(inlude='O')
Ticketを見ると,CA.2343が 7 回出てきているのが分かる. これは家族か何かで, 同じ番号のチケットを持っているということか? 同様にCabinではG6が 4 回出てきている. 同じ部屋に 4 人いるということか? 同じ家族や同じ部屋の人が, 運命を共にしたかどうかには興味がある.test_data.describe()
test_data.describe(include='O')
test_data側では,TicketでPC 17608が 5 回出てきている.CabinではB57 B59 B63 B66が 3 回出てきている.info()
info()でもデータの情報を得られる.train_data.info() <class 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 PassengerId 891 non-null int64 1 Survived 891 non-null int64 2 Pclass 891 non-null int64 3 Name 891 non-null object 4 Sex 891 non-null object 5 Age 714 non-null float64 6 SibSp 891 non-null int64 7 Parch 891 non-null int64 8 Ticket 891 non-null object 9 Fare 891 non-null float64 10 Cabin 204 non-null object 11 Embarked 889 non-null object dtypes: float64(2), int64(5), object(5) memory usage: 83.7+ KBデータの行数は 891 だが,
Ageは 714,Cabinは 204,Embarkedは 889 (惜しい!) しかデータがそろっていない, ということが分かる.test_data.info() <class 'pandas.core.frame.DataFrame'> RangeIndex: 418 entries, 0 to 417 Data columns (total 11 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 PassengerId 418 non-null int64 1 Pclass 418 non-null int64 2 Name 418 non-null object 3 Sex 418 non-null object 4 Age 332 non-null float64 5 SibSp 418 non-null int64 6 Parch 418 non-null int64 7 Ticket 418 non-null object 8 Fare 417 non-null float64 9 Cabin 91 non-null object 10 Embarked 418 non-null object dtypes: float64(2), int64(4), object(5) memory usage: 36.0+ KB
test_dataで, 欠損データがあるのはAge,Fare,Cabinである.train_dataではEmbarkedに欠損データがあったが,test_dataでは揃っている. 逆に,Fareはtrain_dataでは揃っていたが,test_dataでは 1 つ欠損している.corr() ; データの相関性を見る
`corr() で, 各データの相関性を調べることができる.
train_corr = train_data.corr() train_corr
seabornを使って, 可視化する.import seaborn import matplotlib.pyplot as plt seaborn.heatmap(train_data_map_corr, annot=True, vmax=1, vmin=-1, center=0) plt.show()
上記は, オブジェクト型のデータが反映されてない. そこで,
SexとEmbarkedの記号を数字に置き換えて, 同じことをやってみる. データをコピーするときには, 明示的にcopy()を使って, 別のデータを作成する.train_data_map = train_data.copy() train_data_map['Sex'] = train_data_map['Sex'].map({'male' : 0, 'female' : 1}) train_data_map['Embarked'] = train_data_map['Embarked'].map({'S' : 0, 'C' : 1, 'Q' : 2}) train_data_map_corr = train_data_map.corr() train_data_map_corr
seaborn.heatmap(train_data_map_corr, annot=True, vmax=1, vmin=-1, center=0) plt.show()
Survivedの行に着目する. チュートリアルではPclass,Sex,SibSp,Parchで学習しているが,AgeやFare,EmbarkedもSurvivedとの相関が高い.学習
get_dummies()
from sklearn.ensemble import RandomForestClassifier y = train_data["Survived"] features = ["Pclass", "Sex", "SibSp", "Parch"] X = pd.get_dummies(train_data[features]) X_test = pd.get_dummies(test_data[features])scikit-learn を使って学習をする. 使用する特徴量は
featuresで定義してある通り,Pclass,Sex,SibSp,Parchの 4 つ (欠損のない特徴量).学習に使うデータを
pd.get_dummiesで処理している.pd.get_dummiesは, ここでは object 型の変数をダミー変数に変換している.train_data[features].head()
X.head()
Sexという特徴量が,Sex_femaleとSex_maleに変化しているのが分かる.RandomForestClassfier()
ランダムフォレストのアルゴリズム
RandomForestClassifier()を用いて学習する.model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1) model.fit(X, y) predictions = model.predict(X_test)
RandomForestClassifierのパラメータを確認する (説明はアバウトです)
パラメータ 説明 n_estimators 決定木の数. デフォルトは 10 max_depth 決定木の深さの最大値. デフォルトは None (完全に分かれるまで深くなる) max_features 最適な分割をするために, 何個の特徴量を考慮するか. デフォルトは autoで,n_featuresの平方根になる特徴量が 4 つ (ダミー変数化して 5 つ) しかないのに, 決定木を 100 個作るのは, 作り過ぎのような気もする. これの検証は後日.
得られたモデルを確認する
score
print('Train score: {}'.format(model.score(X, y))) Train score: 0.8159371492704826モデル自身で合っているのは 0.8159 となっている (そんなに高くないね).
feature_importances_
特徴量の重要度を確認する (複数形の s の付く場所に注意)
x_importance = pd.Series(data=model.feature_importances_, index=X.columns) x_importance.sort_values(ascending=False).plot.bar()
Sex(Sex_femaleとSex_male) の重要度が高い. 続いてPclass.ParchとSibSpは同じくらいの低さ.決定木の表示 (dtreeviz)
どんな決定木ができたのかを可視化する. いろんな手段があるが, ここでは dtreeviz を使ってみる.
インストール
(参考 ; Python ランダムフォレストの結果を可視化するためのdtreevizとgrahvizのインストール手順)
Windows10 / Anaconda3 を前提に話を進める. まず
pipとcondaを使って, 必要なソフトをインストールする.> pip install dtreeviz > conda install graphviz私の場合,
condaで「書き込めない」というエラーが出た. Anaconda を管理者モードで起動しなおして (Anaconda を右クリックして「管理者モードで起動する」を選択して起動する),condaを実行する.その後,
dot.exeのあるフォルダを, システム環境のPATHに追加する.> dot -V dot - graphviz version 2.38.0 (20140413.2041)上記のように
dot.exeが実行できれば OK.決定木の表示
from dtreeviz.trees import dtreeviz viz = dtreeviz(model.estimators_[0], X, y, target_name='Survived', feature_names=X.columns, class_names=['Not survived', 'Survived']) viz
私がはまったのは,
dtreevizの引数の中で, 以下の項目.
model.estimators_[0];[0]を指定しないとエラーになる. 複数の決定木のうち 1 つだけを表示するので,[0]などで指定するfeature_names; 最初はfeaturesを指定していたが, エラー. 実は学習の際にpd.dummies()でダミー変数化しているので, ダミー変数化した後のX.columnsを指定するきちんと決定木を表示できたときは, ちょっと感動した.
最後に
データの中身や関数のパラメタを注意深く見ることで, 何をしているのかが何となく分かってきた. この次は, パラメータを変更したり, 特徴量を増やすなど, スコアを少しでも上げていきたい.
参考
- データを確認する
- 学習


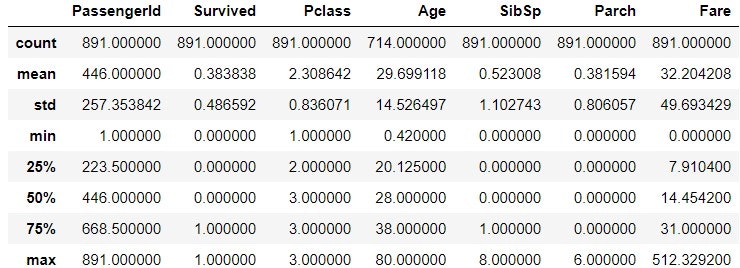
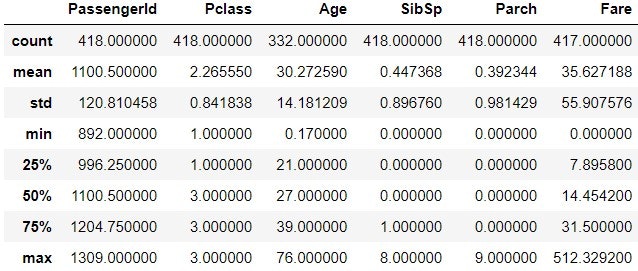
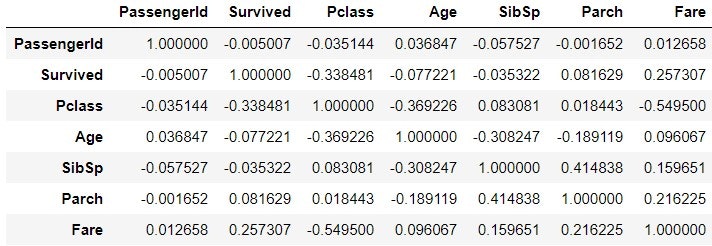

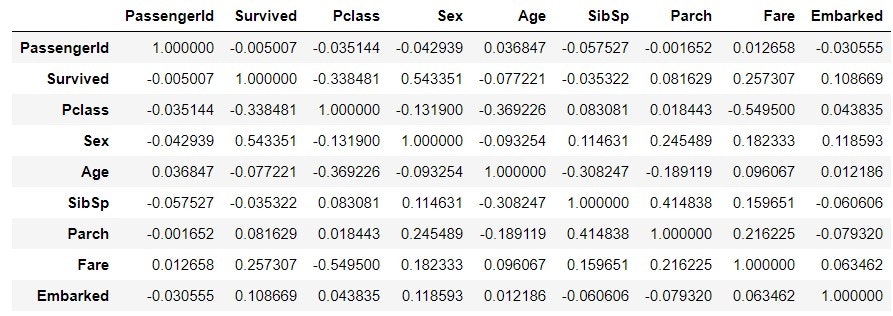
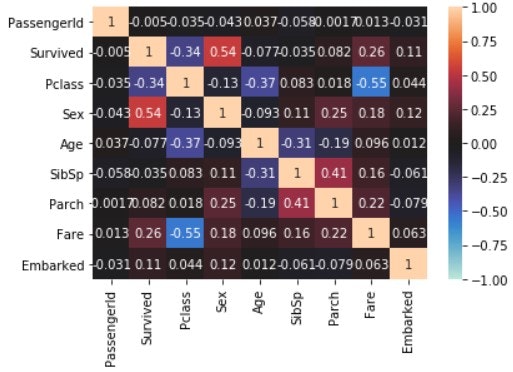
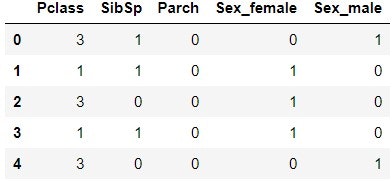
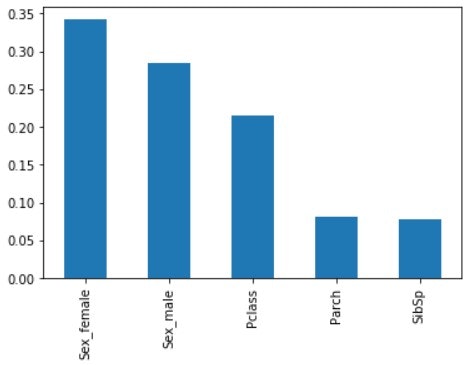

- 投稿日:2020-11-15T08:53:33+09:00
pymysqlのLIKEの%
python3.x
ライブラリpymysqlを使って
connection = pymysql.connect(・・・)
部分一致のLIKE文を動かしたかったのだがwith connection.cursor() as cursor: cursor.execute("SELECT c1 FROM ttt WHERE c2 LIKE 'abc%'", ()) ary = cursor.fetchall()と書くと
TypeError: not enough arguments for format stringとなる。
pymysqlに%を無視してもらうために
%を%でエスケープしないとダメらしい。with connection.cursor() as cursor: cursor.execute("SELECT c1 FROM ttt WHERE c2 LIKE 'abc%%'", ()) ary = cursor.fetchall()で動いた。
- 投稿日:2020-11-15T08:53:33+09:00
pymysqlのLIKEのパーセント
python3.x
ライブラリpymysqlを使って
connection = pymysql.connect(・・・)
部分一致のLIKE文を動かしたかったのだがwith connection.cursor() as cursor: cursor.execute("SELECT c1 FROM ttt WHERE c2 LIKE 'abc%'", ()) ary = cursor.fetchall()と書くと
TypeError: not enough arguments for format stringとなる。
pymysqlに%を無視してもらうために
%を%でエスケープしないとダメらしい。with connection.cursor() as cursor: cursor.execute("SELECT c1 FROM ttt WHERE c2 LIKE 'abc%%'", ()) ary = cursor.fetchall()で動いた。
- 投稿日:2020-11-15T07:50:53+09:00
ロジスティック回帰の理論と実装を徹底解説してみた
はじめに
今回の記事では、tensorflowとsckit-learnを用いてロジスティック回帰を実装していきます。
前回の記事で線形回帰についてまとめたので、よろしければ以下の記事もご覧ください。
Pythonでscikit-learnとtensorflowとkeras用いて重回帰分析をしてみる
今回用いるのはirisデータセットです。
iris(アヤメ)データセットについて
irisデータは、アヤメという花の品種のデータです。
アヤメの品種である
Setosa、Virginica、Virginicaの3品種に関するデータが50個ずつ、全部で150個のデータです。実際に中身を見ていきましょう。
from sklearn.datasets import load_iris import pandas as pd iris = load_iris() iris_df = pd.DataFrame(iris.data, columns=iris.feature_names) print(iris_df.head())sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
3 4.6 3.1 1.5 0.2
4 5.0 3.6 1.4 0.2
iris.feature_namesに各々のカラム名が格納されているので、それをpandasのDataframeの引数に渡すことで上のようなデータを出力できます。
Sepal Lengthはがく弁の長さが、Sepal Widthにはがく弁の幅が、Petal lengthには花びらの長さが、Petal Widthには花びらの幅のデータが格納されています。以下のようにすれ正解ラベルを表示できます。
print(iris.target)[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]このように、アヤメの品種である
setosa、versicolor、virginicaをそれぞれ0, 1, 2としています。今回はロジスティック回帰によるニ値分類を行うため、
virginicaのデータを削除します。そして、目的変数をもとにそれが
setosa、versicolor、のどちらなのかを識別するモデルを作成します。ロジスティック回帰について
ロジスティック回帰について解説します。
ロジスティック回帰とは、回帰という名前がついていますが、やることは二値分類です。
いくつかの説明変数をもとに、確率を計算して、予測を行います。今回の例では花びらの長さや幅のデータなどをもとにそれが
setosa、versicolorのどちらなのかを識別します。ここで、少し話は飛びますが全てのモデルを線形で近似するときの機械学習のモデルを考えていきます。
今、目的変数を「プールの入場者数」とし、説明変数を「気温」であると仮定し、線形回帰を行います。
$$入場者数 = β_0 + β_1 × 気温$$
この場合、左の入場者数を応答変数と呼び、右の式を線形予測子といいます。
しかし、これは明らかに良くないモデルですよね。なぜなら、右側の式は気温によりマイナスになるかもしれませんが、入場者数はマイナスになることはあり得ません。
そこで、応答変数と線形予測子を対応させるために、以下のように変更します。
$$log(入場者数) = β_0 + β_1 × 気温$$
このように左辺に対数関数を適用することで、両辺を正しく対応させることができました。この場合の対数関数のことをリンク関数といいます。
それでは次に、入試の合格を目的変数にしてみましょう。この場合は当然、合格か不合格なので0か1かになりますよね。
説明変数は勉強時間にしましょう。以下のようなモデルが考えられます。
$$合否(1, 0) = β_0 + β_1 × 勉強時間$$
このモデルも良いモデルではありません。左辺は0か1のみですが、明らかに右辺はそれに対応していません。
それでは次のように目的変数を合格率にしたらどうでしょうか。
$$合格率 = β_0 + β_1 × 勉強時間$$
このモデルも良いモデルではありませんね。左辺の合格率は0から1の範囲をとりますが、右辺はそうではありません。
この応答変数と線形予測子を対応させるために、リンク関数としてロジット関数を用います。ロジット関数は以下の式で表します。
f(p) = ln(\frac{p}{1-p}) \quad (0 < p < 1))ロジット関数についてはこちらの記事を参考にしてください。
確率pで起こる事象Aについて、Aが起こる確率と起こらない確率の比$\frac{p}{1-p}$を
オッズといいますロジット関数は以下の形になります。
リンク関数としてロジット関数を用いると、合格率をpとして以下のモデルを作成できます。
ln(\frac{p}{1-p}) = β_0 + β_1 × 勉強時間このモデルは、左辺と右辺が対応しているため良いモデルといえますね。
しかし、今求めたいのは合格率を予測するモデルなので、pについて解いていきましょう。勉強時間を$x_1$とします。
\begin{align} ln(\frac{p}{1-p}) &= β_0 + β_1 × x_1\\ ln(\frac{p}{1-p}) &= z \quad (z = β_0 + β_1 × x_1)\\ \frac{p}{1-p}&=e^z\\ p& = e^z - e^zp\\ p &= \frac{e^z}{1+e^z}\\ p & = \frac{1}{1+e^{-z}} \end{align}このように、シグモイド関数が導出できました。もう少しzを一般化して
z= β_0 + β_1 × x_1 + β_2 × x_2 ... + β_n × x_nとしましょう。これがロジスティック回帰に用いられる式で、βを最適化することが目標になります。
βの最適化について
以下の式を考えれば、重回帰分析と同じように最小二乗法によりβを最適化することができます。
ln(\frac{p}{1-p}) = β_0 + β_1 × x_1 + β_2 × x_2 ... + β_n × x_n最小二乗法についてはこちらの記事を参考にしてください。
もう一つは最尤法を用いる方法です。
最尤法について
最尤法についてはこちらの記事に分かりやすくまとめられているので、参考にしてください。
最尤法について簡単に解説します。
最尤法を考えるためには、尤度や尤度関数について理解する必要があります。
以下はコトバンクからの引用です。
ゆうど【尤度 likelihood】
確率密度関数において確率変数に観測値を代入したものをいう。つまり,確率密度を観測値で評価した値である。また,これを未知母数の関数とみるとき,とくに尤度関数という。尤度関数の自然対数は対数尤度と呼ぶ。観測値とその確率分布が与えられたとき,尤度あるいは対数尤度を最大にする母数の値は,母数の一つの自然な推定量を与える。これは最尤推定量と呼ばれ,標本サイズが大きくなると母数の真値に漸近的に一致するとか,漸近的に正規分布に従うなど,いろいろ好ましい漸近的性質をもつ。以下はwikipediaからの引用です。
尤度関数(ゆうどかんすう、英: likelihood function)とは統計学において、ある前提条件に従って結果が出現する場合に、逆に観察結果からみて前提条件が「何々であった」と推測する尤もらしさ(もっともらしさ)を表す数値を、「何々」を変数とする関数として捉えたものである。また単に尤度ともいう。
なんだかよく分からないので、数式で確認してみましょう。
N個のデータ$x_1,x_2,x_3,...,x_n$を観測したとき、それぞれの値が生じる確率をp(x)とすると、尤度関数は以下の式で表されます。
$$p(x_1)p(x_2)....p(x_3)$$
ここからは自分の理解なのですが、最尤法とは、
データを観測した時にそのデータが生じる確率を考えることで、元々のデータが従う確率分布を推定する方法だと考えてください。例えば、コインを投げる場合を考えてください。当然コインの裏表はイカサマがない限り同じ確率になります。
統計学でいうところの
ベルヌーイ試行ですね。しかし、現実世界ではコインのように確率分布が感覚的に分かっているものを扱うことは少ないです。なので今回は、コインの裏表がでる確率が等しくないということにします。
このコインが従う確率分布はどのように求めたらよいでしょうか?
感覚的には、コインを沢山投げて記録をとればよさそうですよね。今、コインを3回投げたところ、表、表、裏となりました。
表がでる確率を$p$とすると、裏が出る確率は$1-p$となるので、この事象が起きる確率、すなわち尤度関数は
$$p^2(1-p)$$となりますね。今、この事象が
起きたのです。例えばコインの表が出る確率が$\frac{1}{2}$、裏がでる確率が$\frac{1}{2}$だとするとこの事象が起きる確率は$\frac{1}{8}$になります。コインの表が出る確率が$\frac{2}{3}$、裏がでる確率が$\frac{1}{3}$だとするとこの事象が起きる確率は$\frac{4}{27}$となります。このように考えて、「コインを三回投げて表、表、裏となった」という条件のもとで、コインの表がでる確率$p$と裏がでる確率$1-p$を考えるときに、どのような$p$が尤(もっと)もらしいかを考えるときに用いるのが最尤法です。
今、「コインを3回投げたところ、表、表、裏だった」という事象が
起きたので、尤もらしい$p$とはこの「コインを3回投げたところ、表、表、裏だった」という事象が起きる確率が最大になるような$p$ですよね。つまり、「尤もらしい」$p$を求めるため(最尤法)には、「その事象が起きる確率」である尤度関数が最も大きくなるような$p$を選べば良いことが分かります。
つまり、この例においては$p^2(1-p)$が最大になるような$p$を求めればよいので、両辺の対数をとって微分したり、そのまま微分して最大値$p$を求めれば良さそうですよね。
このように、結果から元のデータが従う確率分布を求める方法が最尤推定やベイズ推定と呼ばれるものです。
今回は初めから裏表のベルヌーイ分布に従うことが分かっていたので簡単に尤度関数を求めることができましたが、実際は元のデータが従う確率分布(正規分布,etc)を求めるところから考えなければならないので、もっと大変になります。
こちらのスライドがとても分かりやすかったので、参考にしてください。
改めてβの最適化について
今回のロジスティック回帰について、尤度関数を考えてみましょう。ロジスティック回帰について、目的変数が(0, 1)で与えられ、あるデータについて説明変数$x_1, x_2, x_3, ..., x_n$が与えられた時、そのデータの目的変数が1である確率$p$は
p = \frac{1}{1+e^{-z}} \quad (z= β_0 + β_1 × x_1 + β_2 × x_2 ... + β_n × x_n)となります。 目的変数が1となる確率が$p$であり、目的変数が0となる確率は$1-p$です。
あるデータに対して、目的変数が(0, 1)のどちらなのか分かった時、つまりそのデータがどちらのデータなのか(今回のirisの例ではSetosa、Virginicaのどちらなのか)が分かった時を考えてください。その
あるデータがその目的変数のデータである確率を$L$とすると上記の$p$(目的変数が1である確率)を用いて、$t_n$を目的変数(0, 1)とするとL = p^{t_n}(1-p)^{1-t_n}と表せます。目的変数が1のとき$L$は$p$となり、目的変数が0のとき$L$は$1-p$となっていることが分かります。
つまり、$L$は目的変数が判明したとき、すなわち結果が分かったときにおける「その事象が起きる確率」であることが分かります。「その事象が起きた」という条件の下で、その事象が起きる確率である$L$を最大にする$p$を求めれば、その$p$は尤もらしい$p$であると考えることができます。
この例はある一つのデータに対してだったので、今度は全てのデータに対して考えていきます。
各々のデータに対して独立となるので、全体の尤度関数は以下のように$n$個のデータの尤度関数の積であると考えることができます。
L(β)= \prod_{n = 1}^{N} p_n^{t_n}(1-p_n)^{1-t_n}この$n$個のデータに対しての尤度関数$L(β)$を最大にする$p$を、つまりは$β$を($p$は$β$の関数であるため)見つけることで、パラメータ$β$を最適化することができそうです。
上記の式を計算しやすくするために、両辺の対数をとり、マイナスをつけると以下の式になります。
E(β) = -logL(β) = - \sum^N_{n = 1} \{t_nlogp_n + (1-t_n)log(1-p_n)\}このようにして導出された$E(β)$を交差エントロピー誤差関数といいます。
sckit-learnで実装
それではsckit-learnで実装していきます。まずはデータセットを準備しましょう。
from sklearn.datasets import load_iris import numpy as np import pandas as pd from pandas import Series, DataFrame import seaborn as sns from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn import metrics import matplotlib.pyplot as plt iris = load_iris() iris_data = iris.data[:100] iris_target_data = pd.DataFrame(iris.target[:100], columns=['Species']) iris_df = pd.DataFrame(iris_data, columns=iris.feature_names) print(iris_df)sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
3 4.6 3.1 1.5 0.2
4 5.0 3.6 1.4 0.2
.. ... ... ... ...
95 5.7 3.0 4.2 1.2
96 5.7 2.9 4.2 1.3
97 6.2 2.9 4.3 1.3
98 5.1 2.5 3.0 1.1
99 5.7 2.8 4.1 1.3
setosa、versicolorの二つのデータを分類していきます。そのため、最初の100個のデータのみを取り扱います。最初の50個が
setobaについてのデータであり、後の50個がversicolorについてのデータです。
iris_target_dataの中身をみていきましょう。print(iris_target_data)Species
0 0
1 0
2 0
3 0
4 0
.. ...
95 1
96 1
97 1
98 1
99 1このように0と1のデータが格納されたDataframeになっています。
もともとnumpyのarrayだったものをDataframeに返還したのは、以下のようにDataframeのapplyメソッドを使用するためです。
def species(num): if num == 0: return 'setosa' else: return 'versicolor' iris_target_speacies = iris_target_data['Species'].apply(species) print(iris_target_speacies)0 setosa
1 setosa
2 setosa
3 setosa
4 setosa
...
95 versicolor
96 versicolor
97 versicolor
98 versicolor
99 versicolorこのようにDataframeのapplyメソッドを用いれば、指定したカラムに対して引数で指定した関数を実行し、その戻り値を代入したDataframeを受け取ることができます。
axis=1を指定することで横方向に結合できます。次のコードで
iris_dfとiris_target_speaciesを結合します。iris_all_data = pd.concat([iris_df, iris_target_speacies], axis=1) print(iris_all_data)sepal length (cm) sepal width (cm) ... petal width (cm) Species
0 5.1 3.5 ... 0.2 setosa
1 4.9 3.0 ... 0.2 setosa
2 4.7 3.2 ... 0.2 setosa
3 4.6 3.1 ... 0.2 setosa
4 5.0 3.6 ... 0.2 setosa
.. ... ... ... ... ...
95 5.7 3.0 ... 1.2 versicolor
96 5.7 2.9 ... 1.3 versicolor
97 6.2 2.9 ... 1.3 versicolor
98 5.1 2.5 ... 1.1 versicolor
99 5.7 2.8 ... 1.3 versicolor以下のコードでデータを可視化してみましょう。各々のデータに対しての散布図と存在割合を示します。
sns.pairplot(iris_all_data, hue='Species') plt.show()
このようなデータなら分類できそうですね。
次のコードで
sepal lengthに対しての度数表をみてみましょう。sns.countplot('sepal length (cm)', data=iris_all_data, hue='Species') plt.show()
これでデータについてなんとなく理解できたと思います。
そのまま学習
次のコードでモデルを作成しましょう。トレーニング用とテスト用に分けずにそのまま学習します。
logistic_model = LogisticRegression() logistic_model.fit(iris_df, iris_target_data)これでモデルの作成は完了です。
以下のコードで
β_1,β_2,β_3,β_4の値を出力できます。
print(logistic_model.coef_[0])[-0.40247392 -1.46382925 2.23785648 1.00009294]
このままだと分かりにくいので、以下のコードで分かりやすく出力します。
coeff_df = DataFrame([iris_df.columns, logistic_model.coef_[0]]).T print(coeff_df)0 1
0 sepal length (cm) -0.402474
1 sepal width (cm) -1.46383
2 petal length (cm) 2.23786
3 petal width (cm) 1.00009この結果から、
petal lengthやpetal width大きいとversicolorである確率が高く、sepal widthやsepal lengthが大きいとsetosaである確率が大きいことが分かります。この結果はグラフの図示におおよそ一致していることが分かりますね。
次のコードで予測精度を確かめてみましょう。トレーニングしたモデルでそのままテストを行います。
...py
print(logistic_model.score(iris_df, iris_target_data))
```1.0
100パーセントの精度で分類できています。すごいですね。
次のような方法でも精度を確かめることができます。
class_predict = logistic_model.predict(iris_df) print(class_predict)[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]predictメソッドを用いると、このように与えたデータに対しての予測値をnumpyのarrayの形で得ることができます。
この
class_predictと正解ラベルをmetrics.accuracy_scoreで比較することで予測精度を算出できます。print(metrics.accuracy_score(iris_target_data, class_predict))1.0
こちらの方法でも当然100パーセントです。
テスト用とトレーニング用に分けて学習
次はデータをテスト用とトレー二ング用に分けて学習をしてみましょう。
コードは以下のようになります。
X_train, X_test, Y_train, Y_test = train_test_split(iris_df, iris_target_data) logistic_model2 = LogisticRegression() logistic_model2.fit(X_train, Y_train) coeff_df2 = DataFrame([iris_df.columns, logistic_model2.coef_[0]]).T print(coeff_df2) print(logistic_model2.score(X_test, Y_test))0 1
0 sepal length (cm) -0.381626
1 sepal width (cm) -1.33919
2 petal length (cm) 2.12026
3 petal width (cm) 0.954906
1.0テスト用とトレーニング用にデータを分けても予測精度は100パーセントでした。すごいですね。
tensorflowで実装
tensorflowで実装する場合には、元の数式を理解しておく必要があります。確認しましょう。
p = \frac{1}{1+e^{-z}} \quad (z= β_0 + β_1 × x_1 + β_2 × x_2 ... + β_n × x_n)損失関数には交差エントロピー誤差を使います。尤度関数の対数にマイナスをかけたものです。
E(β) = -logL(β) = - \sum^N_{n = 1} \{t_nlogp_n + (1-t_n)log(1-p_n)\}それでは実装していきます。以下のコードでデータの準備をしましょう。
from sklearn.datasets import load_iris import numpy as np import pandas as pd from pandas import Series, DataFrame import seaborn as sns from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn import metrics import matplotlib.pyplot as plt import tensorflow as tf iris = load_iris() iris_data = iris.data[:100] iris_target_data = pd.DataFrame(iris.target[:100], columns=['Species']) iris_df = pd.DataFrame(iris_data, columns=iris.feature_names) X_train, X_test, Y_train, Y_test = train_test_split(iris_df, iris_target_data) print(X_train.shape) print(X_test.shape) print(Y_train.shape) print(Y_test.shape)(75, 4)
(25, 4)
(75, 1)
(25, 1)次のコードでモデルを作成しましょう。
X = tf.placeholder(dtype=tf.float32, shape=[None, 4]) W = tf.Variable(tf.zeros([4, 1])) b = tf.Variable(tf.zeros([1, 1])) y = tf.nn.sigmoid(tf.matmul(X, W) + b) y = tf.clip_by_value(y, 1e-10, 1.0 - 1e-10) t = tf.placeholder(dtype=tf.float32, shape=[None, 1])Xには説明変数が、tには目的変数が格納されます。 yが上記の数式の$p$にあたります。
yは交差エントロピー誤差関数に代入するときに対数になるため、
y = 0になるとエラーが起きるので、
y = tf.clip_by_value(y, 1e-10, 1.0 - 1e-10)によりyの最小値を1e-10に、yの最大値を
1.0 - 1e-10にしています。以下の式で交差エントロピー誤差関数をAdamで最適化しましょう。
cross_entropy = tf.reduce_sum(t * tf.log(y) + (1 - t) * tf.log(1 - y)) train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)ここまででモデルが完成したので、以下のコードでこのモデルを実行しましょう。
with tf.Session() as sess: sess.run(tf.global_variables_initializer()) for step in range(10000): if step % 10 == 0: loss_val = sess.run(cross_entropy, feed_dict={X: X_train, t: Y_train}) W_val = sess.run(W) b_val = sess.run(b) print('Step: {}, Loss: {} W_val: {} b_val: {}'.format(step, loss_val, W_val, b_val)) sess.run(train_step, feed_dict={X: X_train, t: Y_train}) correct_prediction = sess.run(tf.cast(tf.greater(y, 0.5), tf.int32), feed_dict={X: X_train, t: Y_train}) print('トレーニングデータの評価 : ', metrics.accuracy_score(Y_train, correct_prediction)) test_data = tf.placeholder(dtype=tf.float32, shape=[None, 4]) test_prediction = tf.nn.sigmoid(tf.matmul(test_data, W_val) + b_val) test_correct_prediction = sess.run(tf.cast(tf.greater(test_prediction, 0.5), tf.int32), feed_dict={test_data: X_test}) print('テストデータの評価 : ', metrics.accuracy_score(Y_test, test_correct_prediction))Step: 9990, Loss: 0.10178631544113159 W_val: [[ 0.25520977]
[-3.2158086 ]
[ 3.3751483 ]
[ 3.4625392 ]] b_val: [[-3.2248065]]
トレーニングデータの評価 : 1.0
テストデータの評価 : 1.0
tf.greater(y, 0.5)により、0.5以上のyにはTrueを、0.5より小さいyにはFalseが代入されたブール値が返ってきます。それを
tf.castに代入することで、Trueを1に、Falseを0に変換します。以上でtensorflowによる実装は終了です。
終わりに
ここまでお付き合いいただきありがとうございました。
お疲れさまでした。
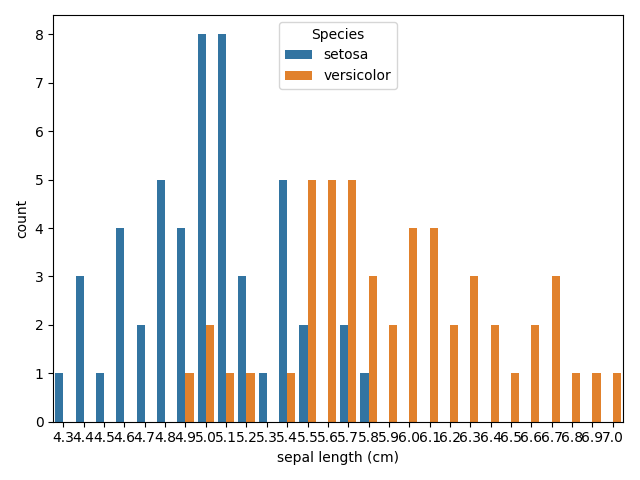
- 投稿日:2020-11-15T07:23:33+09:00
麻雀の和了判定アルゴリズム
麻雀の和了判定アルゴリズム
14枚の手牌の和了が完成しているかを検査します、向聴数を求めるアルゴリズムではありません。
データ形式
牌のデータにはONE-HOTを使用します、ONE-HOT配列を行方向に総和を取ると頭、刻子の判定が楽なのでONE-HOTを選択しました
# ONE-HOT表現の手牌 [ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0] ] # 行方向に総和を取る [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 4, 1, 1, 1, 4, 1, 1, 0, 0, 0, 0, 0, 0, 0] # 3以上の箇所は刻子の判断材料になる # [1, 1, 1] で畳み込みを行い3以上の箇所は順子の判断材料になる # 等の利点がある(ように思う)検査方法
- 「頭」を全パターン検査する(一番外側のループ)
- 「頭」を取り除いた残りで「刻子」を全パターン検査する(内側のループ)
- 検査された「頭」、「刻子」を取り除いた残りで「順子」を検査する
以上の手順で和了完成かどうかを検査します。
ソースコード
import itertools import multiprocessing import numpy as np import os import sys import time # m1-m9, p1-p9, s1-s9, dw, dg, dr, we, ww, ws, wn # 三元牌=Dragon # 風牌=Wind tileKeyIndex = [ "m1", "m2", "m3", "m4", "m5", "m6", "m7", "m8", "m9", "p1", "p2", "p3", "p4", "p5", "p6", "p7", "p8", "p9", "s1", "s2", "s3", "s4", "s5", "s6", "s7", "s8", "s9", "dw", "dg", "dr", "we", "ww", "ws", "wn", ] MTileBits = [ 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 ] PTileBits = [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 ] STileBits = [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0 ] DTileBits = [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0 ] WTileBits = [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1 ] KokusiBits = [ 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1 ] KokusiBits = np.array(KokusiBits) # m1m2m3m4m5m6m7m8m9s1s2s3wnwn def parseTehai(s): if len(s) != 28: print("error in {}, len(s)={}".format(sys._getframe().f_code.co_name, len(s))) sys.exit() tileMatrix = np.zeros((14, len(tileKeyIndex))) for i in range(14): pos = i * 2 idx = tileKeyIndex.index(s[pos:pos + 2]) tileMatrix[i][idx] = 1 return tileMatrix def isShuntsuCompleted(tileMatrix): indexes = [] for tbits in [MTileBits, PTileBits, STileBits]: target = tileMatrix * tbits while True: targetB = (target != 0).astype(int) # [1, 1, 2] みたいな配列を避けるため全て1に変換 b = np.convolve(targetB, [1, 1, 1], mode="valid") if np.max(b) != 3: break idxs = np.where(b == 3)[0] idx = idxs[0] target[idx:idx + 3] -= 1 # 検査済みの牌を取り除く indexes = indexes + list(np.arange(idx, idx + 3, 1)) return indexes def isCompleted(tileMatrix): rowSum = np.sum(tileMatrix, axis=0) headerIdxs = np.where(rowSum >= 2)[0] atama, kotsu, shuntsu = [], [], [] # チートイツ if len(headerIdxs) == 7: return 1, list(headerIdxs) * 2, [], [] # 国士 kokusiCheck = (rowSum != 0).astype(int) if np.sum(kokusiCheck * KokusiBits) == 13 and np.sum(rowSum * KokusiBits) == 14: return 1, np.where(np.array(KokusiBits) == 1)[0], [], [] # 頭を固定する # 刻子を全パターン予め出しておいて各パターン固定で順子を検査する for hidx in headerIdxs: # 元の配列を操作してしまわないようにコピーを作成 calcBuffer = np.array(rowSum) # 頭を取り除く calcBuffer[hidx] -= 2 # 刻子の可能性がある箇所を全て検出しておく kotsuPos = np.where(calcBuffer >= 3)[0] # 検出されたうちの刻子1個だけ有効、検出されたうちの刻子2個だけ有効……検出された刻子全て有効 の全パターンを作成する kotsuPatterns = [] for i in range(len(kotsuPos)): comb = list(itertools.combinations(kotsuPos, i + 1)) kotsuPatterns = kotsuPatterns + comb # 刻子が一つも有効ではないパターンを追加する kotsuPatterns.append(None) for kotsuIndexes in kotsuPatterns: # 元の配列を操作してしまわないようにコピーを作成 calcBuffer2 = np.array(calcBuffer) if isinstance(kotsuIndexes, type(None)): pass else: # 刻子を取り除く for kidx in kotsuIndexes: calcBuffer2[kidx] -= 3 # 順子 shuntsuIndexes = isShuntsuCompleted(calcBuffer2) for idx in shuntsuIndexes: # 順子を取り除く calcBuffer2[idx] -= 1 # 頭、刻子、順子を取り除いた上で残った牌が無ければ完成している #print("np.sum(calcBuffer)", np.sum(calcBuffer2)) if np.sum(calcBuffer2) == 0: atama.append(np.full(2, hidx)) kotsu.append(kotsuIndexes) shuntsu.append(shuntsuIndexes) return len(atama), atama, kotsu, shuntsu def Test1(): #2333345677778 #2333344567888 #2345666777888 #3344455566777 #2223344455677 #1112345556677 #4556677888999 #1425869待ち #14725869待ち #1245678待ち #36258待ち #6257待ち #672583待ち #789436待ち #tileMatrix = parseTehai("m1m2m3m4m5m6m7m8m9s1s2s3wnwn") #tileMatrix = parseTehai("wewewewwwwwwwswswsm9m9m9s1s1") #tileMatrix = parseTehai("s2s3s3s3s3s4s5s6s7s7s7s7s8s9") # s1, s2, s4, s5, s6, s8, s9 #tileMatrix = parseTehai("m2m3m3m3m3m4m4m5m6m7m8m8m8m1") # #tileMatrix = parseTehai("m2m3m4m5m6m6m6m7m7m7m8m8m8?") #tileMatrix = parseTehai("m3m3m4m4m4m5m5m5m6m6m7m7m7?") #tileMatrix = parseTehai("p2p2p2p3p3p4p4p4p5p5p6p7p7?") #tileMatrix = parseTehai("p1p1p1p2p3p4p5p5p5p6p6p7p7?") #tileMatrix = parseTehai("p4p5p5p6p6p7p7p8p8p8p9p9p9?") tileMatrix = parseTehai("m1m9p1p9s1s9wewswwwndwdgdrm1") completeCount, atama, kotsu, shuntsu = isCompleted(tileMatrix) if completeCount > 0: print("OK") print(atama) print(kotsu) print(shuntsu) else: print("NG") def tileMatrixToTehaiString(tileMatrix): s = "" for r in tileMatrix: idx = np.where(r == 1)[0][0] s += tileKeyIndex[idx] return s def appendFile(fileName, data): with open(fileName, mode="a") as f: f.write(data + "\n") def TenhohTestSub(args): seed = time.time() seed = int((seed - int(seed)) * 10000000) np.random.seed(seed) instanceId, tryCount = args size = len(tileKeyIndex) allTile = [] for i in range(size): tmp = [0] * size tmp[i] = 1 for n in range(4): allTile.append(tmp) for i in range(tryCount): np.random.shuffle(allTile) tiles = np.array(allTile[:14]) completeCount, atama, kotsu, shuntsu = isCompleted(tiles) if completeCount > 0: tehaiStr = tileMatrixToTehaiString(tiles) appendFile("tenhoh_{}.txt".format(instanceId), tehaiStr) def TenhohTest(): #TenhohTestSub(1, 400000) tryCount = 1000000 args = [] for i in range(4): args.append([i, tryCount]) with multiprocessing.Pool(4) as p: p.map(TenhohTestSub, args) def main(): #Test1() TenhohTest() if __name__ == "__main__": main() # python main.pyソースコードの使い方
def main(): #Test1() TenhohTest()Test1() ではソースコード内に手入力で準備した牌譜を検査します。
TenhohTest() では4コア使って1コアあたり100万回ランダムに牌譜を作成し和了形だったら記録を取ります、記録は「tenhoh_0.txt」のようにコア毎の番号付きで記録されます。下記に追記する画像変換プログラムを使う事で天和?した牌譜を画像化できます。
牌譜テキストの画像化プログラム
テキストを画像化するプログラムを公開します、使い方は後述。
import PIL.Image import os import sys tileKeyIndex = [ "m1", "m2", "m3", "m4", "m5", "m6", "m7", "m8", "m9", "p1", "p2", "p3", "p4", "p5", "p6", "p7", "p8", "p9", "s1", "s2", "s3", "s4", "s5", "s6", "s7", "s8", "s9", "dw", "dg", "dr", "we", "ww", "ws", "wn", ] haiImageNames = [ "p_ms1_1.gif", "p_ms2_1.gif", "p_ms3_1.gif", "p_ms4_1.gif", "p_ms5_1.gif", "p_ms6_1.gif", "p_ms7_1.gif", "p_ms8_1.gif", "p_ms9_1.gif", "p_ps1_1.gif", "p_ps2_1.gif", "p_ps3_1.gif", "p_ps4_1.gif", "p_ps5_1.gif", "p_ps6_1.gif", "p_ps7_1.gif", "p_ps8_1.gif", "p_ps9_1.gif", "p_ss1_1.gif", "p_ss2_1.gif", "p_ss3_1.gif", "p_ss4_1.gif", "p_ss5_1.gif", "p_ss6_1.gif", "p_ss7_1.gif", "p_ss8_1.gif", "p_ss9_1.gif", "p_no_1.gif", "p_ji_h_1.gif", "p_ji_c_1.gif", "p_ji_e_1.gif", "p_ji_w_1.gif", "p_ji_s_1.gif", "p_ji_n_1.gif", ] def parseTehai(s): if len(s) != 28: print("error in {}, len(s)={}".format(sys._getframe().f_code.co_name, len(s))) sys.exit() indexes, tehai = [], [] for i in range(14): pos = i * 2 idx = tileKeyIndex.index(s[pos:pos + 2]) indexes.append(idx) tehai.append(s[pos:pos + 2]) return indexes, tehai def enumFile(): files = [] for v in os.listdir("./"): if os.path.isfile(v) and v.startswith("tenhoh_"): files.append(v) return files def readFile(fileName): with open(fileName, "r") as f: return f.read() def tileIndexesToImage(indexes): images = [] for idx in indexes: imageFile = os.path.join("./images", haiImageNames[idx]) im = PIL.Image.open(imageFile) images.append(im) imageWidth = 0 maxHeight = 0 for im in images: imageWidth += im.width if im.height > maxHeight: maxHeight = im.height dst = PIL.Image.new('RGB', (imageWidth, maxHeight)) for i, im in enumerate(images): dst.paste(im, (im.width * i, 0)) return dst def main(): files = enumFile() for f in files: lines = readFile(f).split("\n") basename = os.path.basename(f) basename, _ = os.path.splitext(basename) for j, l in enumerate(lines): if len(l) < 28: continue indexes, tehai = parseTehai(l) indexes = sorted(indexes) image = tileIndexesToImage(indexes) destFile = "{}_{:03d}.png".format(basename, j) destFile = os.path.join("./dest", destFile) image.save(destFile) if __name__ == "__main__": main() # https://mj-king.net/sozai/ # python tehai_2_image.py画像化プログラムの使い方
同フォルダの ”tenhoh_???.txt” ファイルを自動的に読み込んで ./images にある画像を元に ./dest へ画像を出力します
m7s5p2p6s7p4m6p7s6p5m5p2p5p6 を
↓
このようにソートして画像変換します。麻雀王国の画像をダウンロードしてきて展開する
./images に「萬子2」「筒子2」「索子2」「字牌2」からダウンロードした画像データを解凍してください
フォルダ構成はこのようになります、 D:\tmp がプログラムフォルダだという体です。
dest フォルダを作成する
出力用のフォルダをあらかじめ作成します
実行する
python tehai_2_image.py正常に実行されれば ./dest に画像化された牌譜が出力されます。
以上です。


- 投稿日:2020-11-15T07:05:37+09:00
【python】【pytchat】でyoutubeLiveのコメントを取得してみる!
ライブのコメントを全部みてみる
橘ひなのさん(vtuber)の全ての動画のライブコメントを取得しました。
./Thinano/data/0IFEp1Bt3qw.jsonをみてください。
データは、https://github.com/1k-ct/Thinano 全部ここにあります。nameがコメントした人の名前、messageがコメントです。
:_naa::_noo: ← これは、メンバーの人だけが使えるスタンプです。
- 他の動画のコメントを見る
- ここをクリックする。
- commentをクリックする。
- 見たいファイルを選ぶ
https://www.youtube.com/watch?v=oQmgxXbT8OE は, oQmgxXbT8OE.jsonこんな感じにしてます- View raw を押してファイルをみてみてください。
スーパーチャットの金額
ここはスパチャの各動画の金額です。
スパチャが一番多い動画は、【祝】収益化きちゃ~~!!6000人もありがとう♡【IBG/橘ひなの】この動画で、約40万円でしょうか?最高合計金額{ "oQmgxXbT8OE": { "¥": 371203.0, "PHP ": 500.0, "₩": 2000.0, "CA$": 55.0, "A$": 10.0 } }
ここからは、調査方法の紹介
今からは、下の2つのURLの一部を紹介です。
https://github.com/taizan-hokuto/pytchat
https://github.com/taizan-hokuto/pytchat/wiki/Home_jp環境
Python 3.8.5
pytchat 0.4.2インストール$ pip install pytchatライブコメントを取得
公式見てください。
https://github.com/taizan-hokuto/pytchat/wiki/PytchatCore_main.pyimport pytchat import time # PytchatCoreオブジェクトの取得 livechat = pytchat.create(video_id = "Zvp1pJpie4I")# video_idはhttps://....watch?v=より後ろの while livechat.is_alive(): # チャットデータの取得 chatdata = livechat.get() for c in chatdata.items: print(f"{c.datetime} {c.author.name} {c.message} {c.amountString}") ''' JSON文字列で取得: print(c.json()) ''' time.sleep(5)スーパーチャット
これも、公式見てください。
https://github.com/taizan-hokuto/pytchat/wiki/SuperchatCalculator_
- 進捗バーをインストール
進捗が分かって結構いい$ pip install tqdmmain.pyfrom tqdm import tqdm from pytchat import Extractor, VideoInfo, SuperchatCalculator import signal ''' 進捗状況を表すプログレスバー ''' class ProgressBar: def __init__(self,total): self.total = total*1000 self.pbar = tqdm(total = self.total, ncols = 80, unit_scale = 1, bar_format='{desc}{percentage:3.1f}%|{bar}|' '[{n_fmt:>7}/{total_fmt}]{elapsed}<{remaining}') def callback(self, actions, fetched): if self.total - fetched < 0: fetched = self.total self.total -= fetched self.pbar.update(fetched) def close(self): self.pbar.update(self.total) self.pbar.close() def cancel(self): self.pbar.close() if __name__ == '__main__': video_id = "GY-LSsYVpJ4" info = VideoInfo(video_id) print('Calculate Superchat: [title] ', info.get_title()) # プログレスバーを用意する。 pbar = ProgressBar(info.get_duration()) # Extractorの生成 ex = Extractor( video_id, callback = pbar.callback, div = 10, processor = SuperchatCalculator() ) #Ctrl+Cでキャンセルする signal.signal(signal.SIGINT, (lambda a, b: ex.cancel())) #抽出の実行 result = ex.extract() #集計結果の表示 pbar.close() print(result)引用
おわりに
説明などは、全て上のURLにあります。
紹介だけで記事にして良いか迷いました。
あと、スーパーチャットのjsonが見づらいです。直そうと思います。
なにかあれば連絡お願いします。ありがとうございます。