- 投稿日:2020-08-03T17:17:44+09:00
女子プロゴルファーの顔診断AIを作ってみた②
1. はじめに
前回までにデータ前処理の部分である画像の収集、顔部分の取得、データの水増しまでを実施しました。
今回は、実際にモデルを作成して、精度を確かめました。
・自分で構築したモデル
・転移学習(VGG16)
の2つについて書こうと思います。2. 訓練データとテストデータに分けたファイルの作成
preparation.pyfrom PIL import Image import os, glob import numpy as np from PIL import ImageFile import cv2 from keras.utils.np_utils import to_categorical # IOError: image file is truncated回避のため ImageFile.LOAD_TRUNCATED_IMAGES = True # 訓練データの作成 # それぞれ空のリストを作成 img_shibuno = [] img_koiwai = [] img_hara = [] img_lists = [img_shibuno, img_koiwai, img_hara] # face以下のパスを取得 in_dir = './face/*' in_file = glob.glob(in_dir) # 各フォルダ(選手)ごとに処理を行う for num in range(len(in_file)): # 選手のファイルの中の各画像のパスを取得 in_file_name = glob.glob(in_file[num]+'/*') # 各画像について処理を行う for i in range(len(in_file_name)): # イメージを開く img = Image.open(in_file_name[i]) img = img.convert("RGB") # サイズを調整する img = img.resize((64,64)) # ndarrayに変換 data = np.asarray(img) # img_listsに追加する img_lists[num].append(data) # 画像が入ったリストを結合 X_train = np.array(img_shibuno+img_koiwai+img_hara) # それぞれ0~2までの値をいれる y_train = np.array([0]*len(img_shibuno) + [1]*len(img_koiwai) + [2]*len(img_hara)) # テストデータの作成 # それぞれ空のリストを作成 img_shibuno = [] img_koiwai = [] img_hara = [] img_lists = [img_shibuno, img_koiwai, img_hara] in_dir = './valid/*' in_file = glob.glob(in_dir) for num in range(len(in_file)): # 選手のファイルの中の各画像のパスを取得 in_file_name = glob.glob(in_file[num]+'/*') # 各画像について処理を行う for i in range(len(in_file_name)): # イメージを開く img = Image.open(in_file_name[i]) img = img.convert("RGB") # サイズを調整する img = img.resize((64,64)) # ndarrayに変換 data = np.asarray(img) # img_listsに追加する img_lists[num].append(data) # 画像が入ったリストを結合 X_test = np.array(img_shibuno+img_koiwai+img_hara) # それぞれ0~2までの値をいれる y_test = np.array([0]*len(img_shibuno) + [1]*len(img_koiwai) + [2]*len(img_hara)) # one-hot-vectorの処理を行う y_train = to_categorical(y_train) y_test = to_categorical(y_test) # 訓練データとバリデーションデータをファイルに保存する xy = (X_train, X_test, y_train, y_test) np.save('./golfer.npy', xy)これでデータ前処理は完了。次はモデルの評価を行う
3.モデルの作成と評価
自分で作成したモデルと転移学習(vgg16)のモデルそれぞれを作成
※以下のコードは説明のため分けて書いてますが一つにまとめてください。
3-1. モジュールをインポート
from keras.models import Model, Sequential from keras.layers import Conv2D, MaxPooling2D from keras.layers import Activation, Dropout, Flatten, Dense, Input from keras.applications.vgg16 import VGG16 from keras.utils import np_utils import keras from keras import optimizers, models, layers import numpy as np import matplotlib.pyplot as plt classes = ['shibuno', 'koiwai', 'hara'] num_classes = len(classes) image_size = 643-2. データを読み込む関数
def load_data(): X_train, X_test, y_train, y_test = np.load('./golfer.npy', allow_pickle=True) # 入力データの各画素値を0-1の範囲で正規化 X_train = X_train / 255 X_test = X_test / 255 return X_train, y_train, X_test, y_test3-3. モデルを学習する関数
※ 以下の①と②はいずれか一方のみ記述ください。
① 自分で作成したモデル
def train(X_train, y_train, X_test, y_test): model = Sequential() # Xは(296, 64, 64, 3): X.shepe[1:]で(64, 64, 3) model.add(Conv2D(32, (3, 3), padding='same', input_shape=X_train.shape[1:])) model.add(Activation('relu')) model.add(Conv2D(32, (3, 3))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.1)) model.add(Conv2D(64, (3, 3), padding='same')) model.add(Activation('relu')) model.add(Conv2D(64, (3, 3))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(512)) model.add(Activation('relu')) model.add(Dropout(0.45)) model.add(Dense(3)) model.add(Activation('softmax')) model.summary() # 最適化アルゴリズムRMSprop opt = keras.optimizers.rmsprop(lr=0.00005, decay=1e-6) model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy']) return model作成したモデルを可視化
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) (None, 64, 64, 3) 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, 64, 64, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, 64, 64, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, 32, 32, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, 32, 32, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, 32, 32, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, 16, 16, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, 16, 16, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, 16, 16, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, 16, 16, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, 8, 8, 256) 0 _________________________________________________________________ block4_conv1 (Conv2D) (None, 8, 8, 512) 1180160 _________________________________________________________________ block4_conv2 (Conv2D) (None, 8, 8, 512) 2359808 _________________________________________________________________ block4_conv3 (Conv2D) (None, 8, 8, 512) 2359808 _________________________________________________________________ block4_pool (MaxPooling2D) (None, 4, 4, 512) 0 _________________________________________________________________ block5_conv1 (Conv2D) (None, 4, 4, 512) 2359808 _________________________________________________________________ block5_conv2 (Conv2D) (None, 4, 4, 512) 2359808 _________________________________________________________________ block5_conv3 (Conv2D) (None, 4, 4, 512) 2359808 _________________________________________________________________ block5_pool (MaxPooling2D) (None, 2, 2, 512) 0 _________________________________________________________________ flatten_1 (Flatten) (None, 2048) 0 _________________________________________________________________ dense_1 (Dense) (None, 256) 524544 _________________________________________________________________ dropout_1 (Dropout) (None, 256) 0 _________________________________________________________________ dense_2 (Dense) (None, 3) 771 =================================================================② 転移学習
def train(X, y, X_test, y_test): input_tensor = Input(shape=(64, 64, 3)) vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor) # 特徴量抽出部分のモデルを作成しています top_model = vgg16.output top_model = Flatten(input_shape=vgg16.output_shape[1:])(top_model) top_model = Dense(256, activation='sigmoid')(top_model) top_model = Dropout(0.5)(top_model) top_model = Dense(3, activation='softmax')(top_model) # vgg16とtop_modelを連結してください model = Model(inputs=vgg16.input, outputs=top_model) # 以下のfor文を完成させて、15層目までの重みを固定させてください for layer in model.layers[:15]: layer.trainable = False # 学習の前に、モデル構造を確認してください model.summary() model.compile(loss='categorical_crossentropy', optimizer=optimizers.SGD(lr=1e-4, momentum=0.9), metrics=['accuracy']) return model作成したモデルを可視化
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) (None, 64, 64, 3) 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, 64, 64, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, 64, 64, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, 32, 32, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, 32, 32, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, 32, 32, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, 16, 16, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, 16, 16, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, 16, 16, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, 16, 16, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, 8, 8, 256) 0 _________________________________________________________________ block4_conv1 (Conv2D) (None, 8, 8, 512) 1180160 _________________________________________________________________ block4_conv2 (Conv2D) (None, 8, 8, 512) 2359808 _________________________________________________________________ block4_conv3 (Conv2D) (None, 8, 8, 512) 2359808 _________________________________________________________________ block4_pool (MaxPooling2D) (None, 4, 4, 512) 0 _________________________________________________________________ block5_conv1 (Conv2D) (None, 4, 4, 512) 2359808 _________________________________________________________________ block5_conv2 (Conv2D) (None, 4, 4, 512) 2359808 _________________________________________________________________ block5_conv3 (Conv2D) (None, 4, 4, 512) 2359808 _________________________________________________________________ block5_pool (MaxPooling2D) (None, 2, 2, 512) 0 _________________________________________________________________ flatten_1 (Flatten) (None, 2048) 0 _________________________________________________________________ dense_1 (Dense) (None, 256) 524544 _________________________________________________________________ dropout_1 (Dropout) (None, 256) 0 _________________________________________________________________ dense_2 (Dense) (None, 6) 1542 =================================================================3-4. 正答率と損失関数のグラフ作成の関数
def compare_TV(history): # パラメーターを設定する # 学習データに対する分類の正答率 acc = history.history['accuracy'] # バリデーションデータに対する分類の正答率 val_acc = history.history['val_accuracy'] # 学習データに対する損失関数の値 loss = history.history['loss'] val_loss = history.history['val_loss'] # バリデーションデータに対する損失関数の値 epochs = range(len(acc)) # 1) 正答率のグラフ plt.plot(epochs, acc, 'bo' ,label = 'training acc') plt.plot(epochs, val_acc, 'b' , label= 'validation acc') plt.title('Training and Validation acc') plt.legend() plt.figure() # 2) 損失関数のグラフ plt.plot(epochs, loss, 'bo' ,label = 'training loss') plt.plot(epochs, val_loss, 'b' , label= 'validation loss') plt.title('Training and Validation loss') plt.legend() plt.show()3-5. データの読み込みとモデルの学習を行う関数
def main(): # データの読み込み X_train, y_train, X_test, y_test = load_data() # モデルの学習 model = train(X_train, y_train, X_test, y_test) history = model.fit(X_train, y_train, batch_size=32, epochs=70, verbose=1, validation_data=(X_test, y_test)) # 汎化制度の評価・表示 score = model.evaluate(X_test, y_test, batch_size=32, verbose=0) print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score)) compare_TV(history) model.save('./golfer.h5')最後にmain()関数を記述して実行させる。
# これでモデルを学習させ、学習済モデルが生成される main()4. 学習結果
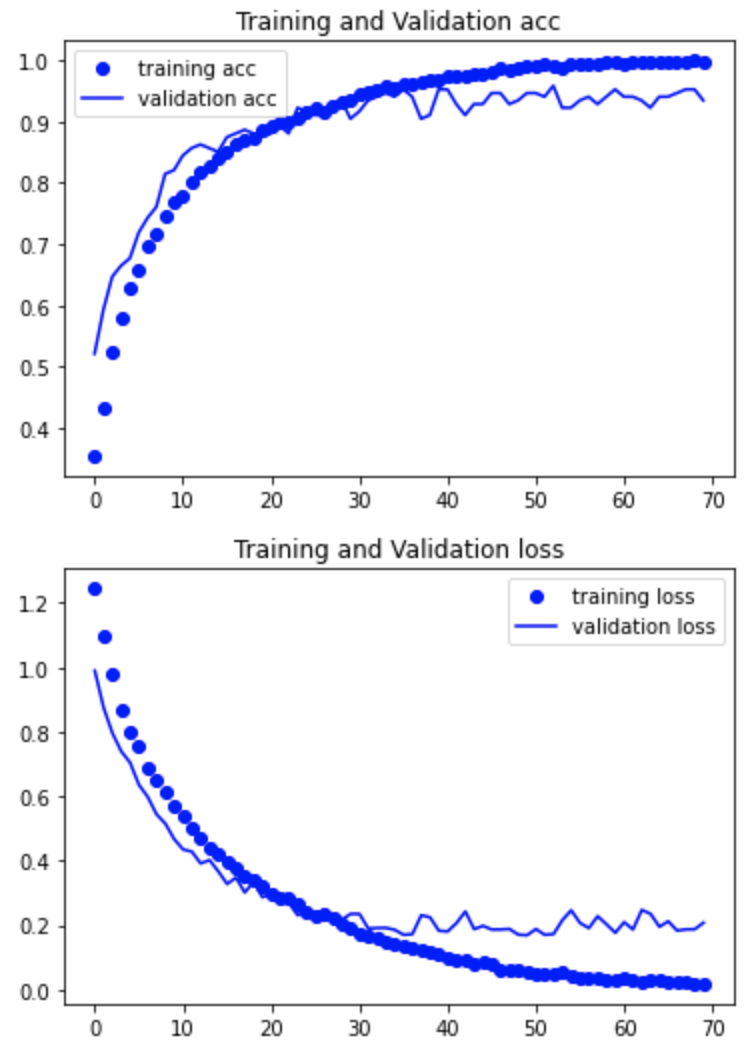
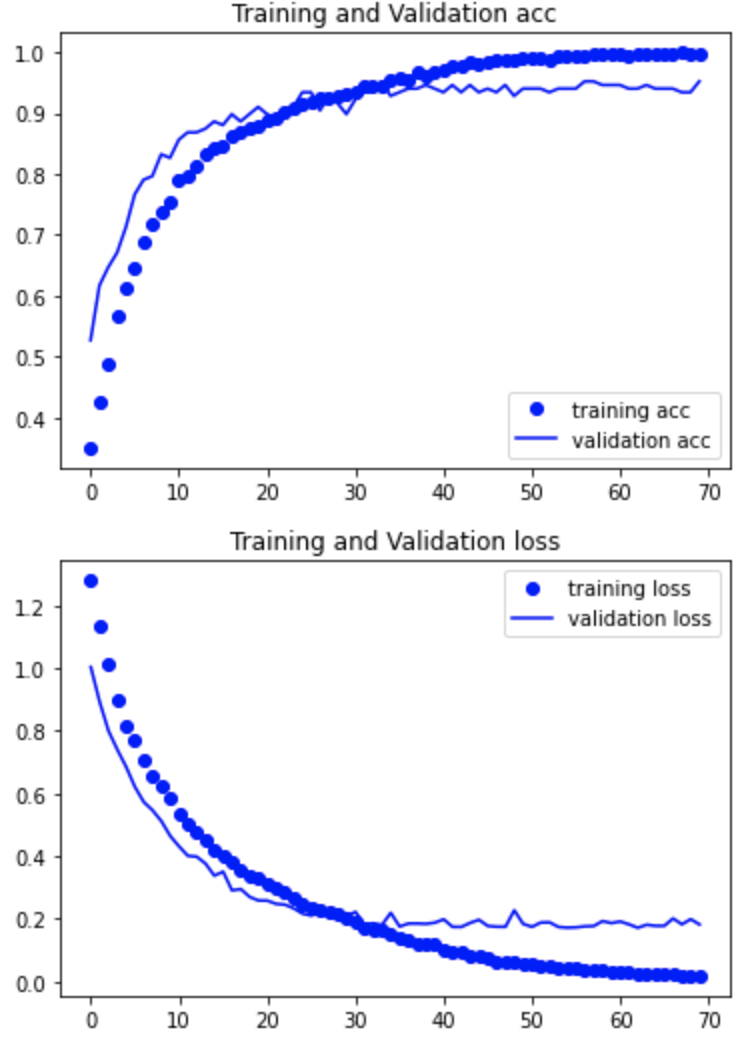
学習結果の正解率と損失関数をグラフにて確認する
① 自分で作成したモデル
正解率:0.93
② 転移学習
正解率:0.95
わずかにですが転移学習の方が上でしたので転移学習のモデルを採用します。
モデルの作成までが完了しました。次回は、アプリケーションを作成して、herokuで公開するところまで書こうと思います。
参考