- 投稿日:2020-08-03T23:53:48+09:00
【ROS】Ubuntu(18.04)にROS(melodic)をインストールした時のメモ
1. ROSのインストールコマンド
Ubuntu(18.04)にROS(melodic)を入れるためのコマンド. 本当はkineticを入れたかったけどUbuntuのバージョンが18.04だとkineticは入れられないらしい.
sudo sh -c 'echo "deb http://packages.ros.org/ros/ubuntu $(lsb_release -sc) main" > /etc/apt/sources.list.d/ros-latest.list' sudo apt-key adv --keyserver 'hkp://keyserver.ubuntu.com:80' --recv-key C1CF6E31E6BADE8868B172B4F42ED6FBAB17C654 sudo apt-get -y update sudo apt-get -y upgrade sudo apt-get -y install ros-melodic-desktop-full apt-cache search ros-melodic sudo apt-get install python-rosdep sudo rosdep init rosdep update echo "source /opt/ros/kinetic/setup.bash" >> ~/.bashrc source ~/.bashrc source /opt/ros/kinetic/setup.bash sudo apt-get -y install python-rosinstall2. ROSが入ったことの確認
ワークスペースを作ってroscoreを実行することでROSのバージョンを確認できる. これが実行できたらROSのインストール成功.
mkdir -p ~/catkin_ws/src cd ~/catkin_ws/src catkin_init_workspace cd ~/catkin_ws catkin_make roscore
- 投稿日:2020-08-03T23:53:48+09:00
【ROS】Ubuntu(18.04)にROS(melodic)をインストール
1. ROSのインストールコマンド
Ubuntu(18.04)にROS(melodic)を入れるためのコマンド. 本当はkineticを入れたかったけどUbuntuのバージョンが18.04だとkineticは入れられないらしい.
sudo sh -c 'echo "deb http://packages.ros.org/ros/ubuntu $(lsb_release -sc) main" > /etc/apt/sources.list.d/ros-latest.list' sudo apt-key adv --keyserver 'hkp://keyserver.ubuntu.com:80' --recv-key C1CF6E31E6BADE8868B172B4F42ED6FBAB17C654 sudo apt-get -y update sudo apt-get -y upgrade sudo apt-get -y install ros-melodic-desktop-full apt-cache search ros-melodic sudo apt-get install python-rosdep sudo rosdep init rosdep update echo "source /opt/ros/kinetic/setup.bash" >> ~/.bashrc source ~/.bashrc source /opt/ros/kinetic/setup.bash sudo apt-get -y install python-rosinstall2. ROSが入ったことの確認
ワークスペースを作ってroscoreを実行することでROSのバージョンを確認できる. これが実行できたらROSのインストール成功.
mkdir -p ~/catkin_ws/src cd ~/catkin_ws/src catkin_init_workspace cd ~/catkin_ws catkin_make roscore
- 投稿日:2020-08-03T22:31:57+09:00
Dockerコンテナを持ち歩こう
概要
USBメモリを使い、管理者権限一切不要でWindowsPCがあればどこでもDockerコンテナを動かせる環境を構築します。
USBメモリについて
USB3.0対応の速度の速いものを選ばないと書き込み速度に引っ張られて動作が遅くなります。
CrystalDiskMarkのランダム書き込み(右下2つ)の値が1.0を超えていないと辛いと思います(※体感には個人差があります)
ちなみに自分はI-O DATAのU3-MAX2/32Kを使っています。
多少嵩張ってもいいのならポータブルSSDにすれば不良品でもない限り速度面で問題は出ないはず。
32GBまでのUSBメモリの場合、初期状態では概ねFAT32でフォーマットされていますが、FAT32は1ファイル最大4Gまでという制限があり、1ファイルで構成されている仮想ストレージがすぐに足りなくなり書き込みエラーが発生するのでNTFSやexFATでフォーマットしなおす必要があります。
また性質上書き込みを大量に行うので最悪いつ壊れてもいいように対応はしておきましょう。
仮想化ソフトのインストール
Qemu
Dockerは(64bitの)Linux上でしか動きませんので、仮想化ソフトでLinuxを動作させる必要があります、仮想化ソフトにはQemuを使います。
Qemuはエミュレート速度はいまいちですが、管理者権限が必須な各種アクセラレーターを有効にしない状態で起動することができます。つまり、遅くてもいいなら管理者権限なしで起動することが可能です。
WSL2や他の仮想化ソフトは管理者権限が必須な上ポータブル運用はできませんし、ポータブル運用を想定したPortable-VirtualBoxは管理者権限が必須です。
アクセラレーターなしではGnome等のデスクトップ環境を動かすのは困難ですが、CUI(コマンドライン)環境ならそれなりに動きます。(※体感には個人差があります)
Docker界隈では基本的にUIはWebブラウザが担うのがほとんどなのでさほど問題ではないです。32bitPC・OS上でも64bitPCをエミュレートできる点もポイント高いです。
ダウンロード・インストール
公式サイトからQemuのWindows版(32bit版または64bit版)をダウンロードします。
Windows版のQemuは管理者権限が必要なインストーラー形式でしか配布をしていないようなので、インストーラーの解凍に対応したUniversal Extractor2(直リンク)でUSBメモリに解凍します。
ちなみに管理者権限を使ってインストールをし、インストールされたファイルをUSBメモリにコピーしても使えます。
Linuxのインストール
Alpine Linux
QemuをUSBメモリにインストール(コピー)したら、仮想PCにLinuxをインストールします。
インストールするLinuxデストリビューションは64bit対応でDockerをインストールできるものなら何でもいいのですが、
個人的にはAlpine Linuxがオススメです。インストールが爆速です。Debian等のよく使われるLinuxデストリビューションをイチからインストールしようとすると、ただでさえ遅いQemu上では最小構成でも数時間は覚悟しないといけませんが、数分でインストールが終わります。
Alpine Linuxは誤解を恐れずざっくりいうと互換性を犠牲にして軽量化にこだわったデストリビューションで、サイズが小さいためDockerの公式イメージのベースとしてよく採用されており、Docker界隈ではよく目にします。
一部他のLinuxデストリビューションで使わているソフトウェアが使えないなど互換性に難がありますが、Alpine Linux本体はDockerホストに徹し、ソフトウェアは基本的にDockerコンテナ上で動かすという運用をすれば問題になりません。
isoダウンロード
公式サイトにisoのダウンロードページがあるのでx86_64版をダウンロードします。
Standard(124M)でもいいのですが、仮想PC用のさらにサイズの小さいVirtual(40M)をお勧めします。
ダウンロードするとalpine-virt-3.12.0-x86_64.isoといった長いファイル名になるので、alpine.isoとかに変えておくと後が楽です。
インストール
Qemuは他の仮想化ソフトとは異なりすべてコマンドラインで設定・起動する仕組みになっています(GUIで動かすためのフロントエンドはいろいろありますが)
仮想ストレージファイルの作成
> qemu-img create -f qcow2 linux.qcow2 20G最後の20Gは仮想ストレージファイルの最大容量になるので環境に合わせて変更しましょう。
いきなり20G全容量を確保するのではなく、最大容量に達するまで必要に応じてサイズが大きくなっていく仕組みになっています。isoファイルをブートディスクにして起動
Qemuのオプションはドキュメントを見てください、自分は以下のように設定しています。
> qemu-system-x86_64.exe -display sdl -smp 2 -boot d -m 2048 -net nic,model=virtio -hda linux.qcow2 -cdrom alpine.iso問題がなければウインドウが出てLinuxのブートを開始するはずです。ブートには1分から数分かかります。
インストール
ブートが終了するとコンソールのログイン画面が出てきますが、rootと入力してエンターを押すとパスワードなしでログインできます。
localhost login: rootログインしたら、
# setup-alpineでインストールを開始します。コマンドライン上でいくつか質問されるので、答えていくとインストールを始めます。
具体的にどんな内容なのかはここらへんを参考にどうぞ。長いので省略します。
インストールが終わったら
# poweroffでシャットダウンします。
Linux起動・設定
起動
> qemu-system-x86_64.exe -display sdl -smp 2 -m 2048 -net nic,model=virtio -net user,hostfwd=tcp::22-:22,hostfwd=tcp::9000-:9000 -hda linux.qcow2自分はこのようにして起動しています(一部を除く)。
「-net user,hostfwd=tcp::22-:22,hostfwd=tcp::9000-:9000」の部分で指定したポートを通じてQemu内Linux上のサーバーに接続できるようになります。ポートフォワーディングというらしい。
(※同一PCのローカル接続の話であって外部PCからの接続はWindowsファイアウォールやルータ等の関係でそのままでは出来ませんし管理者権限が必要です)例えばこの場合だとlocalhost:22でWindowsホストではなく、Qemu内のLinuxで22番ポートを待ち受けしているサーバーに接続できるようになります。
ここではSSH用の22番とPortainer用の9000番を割り当てています。上記のように,でつないでいけば複数のポートを開くことができますが、すでに別のサーバーで待っているポートを指定するとQemu自体エラーで起動しないので注意してください。
ちなみに、Dockerコンテナ上のサーバーの接続にも有効です。つまり、Qemuの起動時に9000番ポートへの待ち受けを有効にしていれば、Linuxホストの9000番ポートを待ち受ける設定で起動したDockerコンテナにWindowsホストから9000番ポートで接続できるということです。
SSHの設定
インストール時同様にログイン画面が出たら、IDはroot、パスワードはインストール時に設定したパスワードでログインします。
Qemuのウインドウではコマンドのコピペが出来ず何かと不便なのでSSHを使えるようにします。
Alpine Linuxは最初からSSHサーバーが入っていますが(インストール時のSSHの質問でnoneと答えなかった場合)、SSHサーバーの仕様でそのままではrootユーザーでログイン出来ないようになっているので、ここでは手っ取り早く設定ファイルを追記してrootでログインできるようにします。
# echo "PermitRootLogin yes" >> /etc/ssh/sshd_configさらにパスワードなしで運用する場合は次も入力します
# echo "PermitEmptyPasswords yes" >> /etc/ssh/sshd_config設定ファイルを変更したらQemuを一度シャットダウンして再起動するかまたはSSHサーバーを再起動します
# service sshd restart接続
最近のWindows10は標準でOpehSSHクライアントが入っていますが、そのまま使うとユーザーフォルダに.sshフォルダを作ってしまいポータブルではなくなってしまうので、以下のように設定ファイルを読み込まず、鍵のチェックをせず、KnownHostsファイルを残さないオプションをつけて起動します。
> ssh -F /dev/null -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null root@localhostDockerインストール
Alpine Linuxはapkという独自のパッケージマネージャーを持っていますが、初期状態ではdockerをインストールできないので、インストールできるようにviで/etc/apk/repositoriesを編集します。
# vi /etc/apk/repositories初期状態では2行目のcommunityリポジトリが#でコメントアウトされていますが、#を消して有効にします。
#/media/cdrom/apks http://dl-cdn.alpinelinux.org/alpine/v3.12/main http://dl-cdn.alpinelinux.org/alpine/v3.12/community #http://dl-cdn.alpinelinux.org/alpine/edge/main #http://dl-cdn.alpinelinux.org/alpine/edge/community #http://dl-cdn.alpinelinux.org/alpine/edge/testing保存したら、apkでdockerとdocker-composeパッケージをインストールします
# apk update # apk add docker docker-composeインストールが終わったらdockerを起動します。
# service docker start起動時に自動で開始するように設定しておきます。
# rc-update add docker bootちゃんと動作しているかを確認する場合は(多分)そのために用意されているhello-worldイメージをダウンロードしてコンテナとして動作させてみます。
# docker run --rm hello-world上手く行けば以下のような表示が出るはずです。
Unable to find image 'hello-world:latest' locally latest: Pulling from library/hello-world 0e03bdcc26d7: Pull complete Digest: sha256:49a1c8800c94df04e9658809b006fd8a686cab8028d33cfba2cc049724254202 Status: Downloaded newer image for hello-world:latest Hello from Docker! This message shows that your installation appears to be working correctly. To generate this message, Docker took the following steps: 1. The Docker client contacted the Docker daemon. 2. The Docker daemon pulled the "hello-world" image from the Docker Hub. (amd64) 3. The Docker daemon created a new container from that image which runs the executable that produces the output you are currently reading. 4. The Docker daemon streamed that output to the Docker client, which sent it to your terminal. To try something more ambitious, you can run an Ubuntu container with: $ docker run -it ubuntu bash Share images, automate workflows, and more with a free Docker ID: https://hub.docker.com/ For more examples and ideas, visit: https://docs.docker.com/get-started/Portainerのインストール
Dockerコンテナをすべてコマンドラインで管理するのが辛い場合は、Webブラウザ上でDockerコンテナを管理できるPortainerをお勧めします。
Dockerをインストール出来ていれば以下のコマンド1行でインストール完了です。
# docker run -d -p 9000:9000 --name=portainer --restart=always -v /var/run/docker.sock:/var/run/docker.sock -v portainer_data:/data portainer/portainerインストール完了後、Webブラウザで http://localhost:9000 にアクセスすればPortainerのログイン画面が出てくるはずです。
セキュリティ
rootでの運用はこの場合はUSBメモリをPCに接続しQemuが動作している間しか機能せず、かつ通常ローカル接続しかできないのであまり問題にはなりませんが、基本的にはやってはいけない運用であることは覚えておきましょう。またUSBメモリの紛失盗難には気を付けましょう。
さいごに
これでDockerコンテナをUSBメモリで持ち歩く環境が完成しました。
自分が自由に管理できるPCがない人におすすめです。
- 投稿日:2020-08-03T20:09:18+09:00
CORS問題の対応の仕方をミスってた話
フロントエンドとサーバサイドプログラムの連携をRestっぽい感じでやるようになって久しいが
ここに来て結構なポカミスをやったので備忘録として。フロントには固定値のjsonを返すだけのダミーAPIを作って実装を進めてもらい
バックエンドはprod用としてそのダミーが動的なものになるように実装、最終的にダミーと差し替え
みたいな流れで制作をしている。で、バックエンドはphpを使うが色々ごちゃごちゃやった後に
test.php色々やる〜 header('Content-Type: application/json'); echo $json; exit;としてjsonを出力するのがセオリーである。
フロントはtest.phpをエンドポイントとしてjsとかで実行するわけだが
大体いつも問題になるのがCORSである。セキュリティリスクを追々考えなければと思いつつApache側で
Header set Access-Control-Allow-Origin *レスポンスヘッダに全てのドメインからアクセスOK!!を付けている。
で、それをすっかり忘れてphpの方にも記載したのがまずかった。header('Content-Type: application/json'); header('Access-Control-Allow-Origin *'); echo $json; exit;Access to XMLHttpRequest at 'https://xxxxx.jp/api/test' from origin 'null' has been blocked by CORS policy: The 'Access-Control-Allow-Origin' header contains multiple values '*, *', but only one is allowed.エラーメッセージの冒頭だけ見てOriginの設定してるはずなのにな〜って思ってたが
よく見るとAccess-Control-Allow-Originヘッダが複数設定されてるよってエラーだった。どっちか消して解消、というかまぁこの場合はphpの方で良いと思うが。
分かってるんだけど気付かないパターンのミスが一番怖い。おわり。
- 投稿日:2020-08-03T18:16:08+09:00
シンボリックリンクの生成で相対パスを指定すると危険だった話
08/04追記
コメントにて補足や訂正を頂いたので、適宜修正をしていきます。はじめに
シェルコマンドを学習しているとき、シンボリックリンクに関して沼にハマってしまったので、備忘録を残します。
これがベストプラクティスかどうかは知らないが、シンボリックリンクの生成はなるべく絶対パスを使おう。これは時と場合によるので、ベストプラクティスとは言えません。
リンク元のファイル・リンクをまとめて管理したい場合、設置場所変更に弱くなるためです。
※Webページのリンク ( ハイパーリファレンス ) を絶対URLで書くか、相対URLで書くかと同じ問題
@angel_p_57シンボリックリンクとは
シンボリックリンクとは、オペレーティングシステム(OS)のファイルシステムの機能の一つで、特定のファイルやディレクトリを指し示す別のファイルを作成し、それを通じて本体を参照できるようにする仕組み。
IT用語辞典 e-WordsLinuxにおけるシンボリックリンクは、Windowsでいうところのショートカットのようなものだと認識しています。
目的は似ていますが、実態は大分違います。加えて、Windowsにも ( リパース・ポイントという機能を利用した ) シンボリックリンクが存在します。
ショートカットは、指定のファイルをアプリで開くための情報を持ったランチャーに過ぎませんが、シンボリックリンクは指定のファイルの代替として使えるファイルです。
@angel_p_57シンボリックリンクの作成
シンボリックリンクの作成に用いるコマンドは以下です。
hoge.jpgは任意のファイル名、fugaは任意のディレクトリ名です。
ここではhoge.jpgというファイルのシンボリックリンクを、fugaディレクトリに生成します。$ ln -s hoge.jpg fuga補足:このケースでは『既にfugaディレクトリが存在していれば』意図どおりに正常に実行されます。
fugaディレクトリがなければ、同一ディレクトリにfugaという名前のシンボリックリンクが生成されてしまいます。
$ ln -s hoge.jpg fuga/とすれば、ディレクトリが存在していれば実行するコマンドになります。
(頂いたコメントを参考にしました)やりたいこと
~/Picture/konosuba.jpg のシンボリックリンクを、
~/Picture/foobar に生成したい。やってみたこと
相対パスで指定した場合(failed)
カレントディレクトリが ~/Pictureだとする。
~/Picture $ ln -s konosuba.jpg foobarfoobarディレクトリに konosuba.jpgは いちおう生成されるが、
先にいっておくと、これは間違い。カレントディレクトリ内に存在する konosuba.jpgのシンボリックリンクが、相対パスとして指定したfoobarフォルダ内に生成される・・・というわけではない。
foobarディレクトリに生成されたシンボリックリンク konosuba.jpgは、
自身から見た相対パス konosuba.jpg つまり同ディレクトリ内のkonosuba.jpgを参照しにいく、と考えよう。つまり、自身を参照するシンボリックリンクという謎のファイルを生成してしまう。
(これは、シェルコマンドの第一引数である"konosuba.jpg"を、シンボリックリンク自身の位置を基準とした相対パスとして読み取ってしまうため)
相対パスで指定した場合(successed)
カレントディレクトリが ~/Pictureだとする。
~/Picture $ ln -s ../konosuba1.jpg foobarfoobarディレクトリに konosuba.jpgが生成される。
こいつは正解。
foobar ディレクトリに生成されたシンボリックリンクkonosuba.jpg は、
自身の位置から見て "../konosuba1.jpg"を参照するリンクとして生成される。慣れると問題ないのかもしれないが、正直僕にはややこしく感じました。
その場合は、-r ( --relative ) というオプションを使います。相対位置はコマンドが自動的に判断してくれますから。
ln -s hoge.jpg fuga/ だと、作成されるシンボリックリンク fuga/hoge.jpg は循環参照を起こして役に立ちませんが、ln -s -r hoge.jpg fuga/ とすれば、fuga/hoge.jpg -> ../hoge.jpg という適切なリンクを作成してくれます。
@angel_p_57絶対パスで書く
$ ln -s ~/Picture/konosuba.jpg ~/Picture/foobar絶対パスなら参照元が意図と異なるリスクをぐっと減らせる。
ディレクトリ構造がややこしくなると、とんでもないことになりそうな気もするが、とりあえず間違えることはなくなるはずだ・・おわりに
なんだかうまく書けた気がしないので、適宜変更を加えていこうと思う・・
参考文献
Linuxコマンドライン入門
Ubuntu Manuals
- 投稿日:2020-08-03T17:11:51+09:00
AWS開発中 sudo yum install nodejs npm --enablerepo=epelが通らなかった話
環境
EC2(Amazon Linux 2)
詰まったこと
現在AWSにて環境構築中の初学者です。アプリケーション用のEC2を作成中。
各種パッケージをインストールしていたのですがnodejs npmがインストール出来ず苦戦したことを記事にします。@naoki_mochizuki さんの
https://qiita.com/naoki_mochizuki/items/814e0979217b1a25aa3e
という記事を参考に環境構築を行っていました。__| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/ [shimo0108@~]$ sudo yum install \ > git make gcc-c++ patch \ > openssl-devel \ > libyaml-devel libffi-devel libicu-devel \ > libxml2 libxslt libxml2-devel libxslt-devel \ > zlib-devel readline-devel \ > ImageMagick ImageMagick-devel \ > epel-release 読み込んだプラグイン:extras_suggestions, langpacks, priorities, update-motd amzn2core | 3.7 kB 00:00:00 パッケージ 1:make-3.82-24.amzn2.x86_64 はインストール済みか最新バージョンです パッケージ libxml2-2.9.1-6.amzn2.4.1.x86_64 はインストール済みか最新バージョンです パッケージ epel-release は利用できません。 . . . 完了しました! epel-release is available in Amazon Linux Extra topic "epel" To use, run # sudo amazon-linux-extras install epel Learn more at https://aws.amazon.com/amazon-linux-2/faqs/#Amazon_Linux_ExtrasWEBアプリ用のEC2にログイン。パッケージをインストールしました。
epel-release以外は正常にinstallできた事が確認できます。
ここでなぜかepel-releaseがインストール出来なかったんですよね。ちなみにepel-release(EPEL)とは、、、
EPEL リポジトリとは、CentOS 標準のリポジトリでは提供されていないパッケージを、yum コマンドでインストールすることを可能にするリポジトリのことです。
EPEL は、エンタープライズ向けのリポジトリなので、サードパーティー製リポジトリの中では信頼性の高いものになっています。
EPEL 以外のサードパーティ製リポジトリには、Remi、RPMForge があります。特徴としては、Remi は最新バージョンのパッケージを入手可能、RPMForge は大量のパッケージを入手可能と言われているようです。
実際には、用途やパッケージの依存関係を考慮して各リポジトリを活用することになります。標準のリポジトリでは提供されないパッケージを使うことができますが、利用に関してはCentOSのサードパーティ製のリポジトリに関する記述を考えると、自己責任、ということになります。
[shimo0108@ ~]$ sudo yum install nodejs npm --enablerepo=epel 読み込んだプラグイン:extras_suggestions, langpacks, priorities, update-motd Error getting repository data for epel, repository not foundその後上記コマンド実行するもインストールできず。。
しかしエラーログ文の中にTo use, run # sudo amazon-linux-extras install epelを発見。これインストールすればいいのかなと。思ったわけです。
[shimo0108@ ~]$ sudo amazon-linux-extras install epel Installing epel-release リポジトリーを清掃しています: amzn2-core amzn2extra-docker amzn2extra-epel 12 個の metadata ファイルを削除しました 4 個の sqlite ファイルを削除しました 0 個の metadata ファイルを削除しました 読み込んだプラグイン:extras_suggestions, langpacks, priorities, update-motd . . . 依存性の解決をしています --> トランザクションの確認を実行しています。 ---> パッケージ epel-release.noarch 0:7-11 を インストール --> 依存性解決を終了しました。 依存性を解決しました ======================================================================================================= Package アーキテクチャー バージョン リポジトリー 容量 ======================================================================================================= インストール中: epel-release noarch 7-11 amzn2extra-epel 15 k トランザクションの要約 ======================================================================================================= インストール 1 パッケージ 総ダウンロード容量: 15 k インストール容量: 24 k Is this ok [y/d/N]: y Downloading packages: epel-release-7-11.noarch.rpm | 15 kB 00:00:00 Running transaction check Running transaction test Transaction test succeeded Running transaction インストール中 : epel-release-7-11.noarch 1/1 検証中 : epel-release-7-11.noarch 1/1 インストール: epel-release.noarch 0:7-11 完了しました! 0 ansible2 available \ [ =2.4.2 =2.4.6 =2.8 =stable ] 2 httpd_modules available [ =1.0 =stable ] 3 memcached1.5 available \ [ =1.5.1 =1.5.16 =1.5.17 ] 5 postgresql9.6 available \ [ =9.6.6 =9.6.8 =stable ] 6 postgresql10 available [ =10 =stable ] 8 redis4.0 available \ [ =4.0.5 =4.0.10 =stable ] 9 R3.4 available [ =3.4.3 =stable ] 10 rust1 available \ [ =1.22.1 =1.26.0 =1.26.1 =1.27.2 =1.31.0 =1.38.0 =stable ] 11 vim available [ =8.0 =stable ] 13 ruby2.4 available \ [ =2.4.2 =2.4.4 =2.4.7 =stable ] 15 php7.2 available \ [ =7.2.0 =7.2.4 =7.2.5 =7.2.8 =7.2.11 =7.2.13 =7.2.14 =7.2.16 =7.2.17 =7.2.19 =7.2.21 =7.2.22 =7.2.23 =7.2.24 =7.2.26 =stable ] 17 lamp-mariadb10.2-php7.2 available \ [ =10.2.10_7.2.0 =10.2.10_7.2.4 =10.2.10_7.2.5 =10.2.10_7.2.8 =10.2.10_7.2.11 =10.2.10_7.2.13 =10.2.10_7.2.14 =10.2.10_7.2.16 =10.2.10_7.2.17 =10.2.10_7.2.19 =10.2.10_7.2.22 =10.2.10_7.2.23 =10.2.10_7.2.24 =stable ] 18 libreoffice available \ [ =5.0.6.2_15 =5.3.6.1 =stable ] 19 gimp available [ =2.8.22 ] 20 docker=latest enabled \ [ =17.12.1 =18.03.1 =18.06.1 =18.09.9 =stable ] 21 mate-desktop1.x available \ [ =1.19.0 =1.20.0 =stable ] 22 GraphicsMagick1.3 available \ [ =1.3.29 =1.3.32 =1.3.34 =stable ] 23 tomcat8.5 available \ [ =8.5.31 =8.5.32 =8.5.38 =8.5.40 =8.5.42 =8.5.50 =stable ] 24 epel=latest enabled [ =7.11 =stable ] 25 testing available [ =1.0 =stable ] 26 ecs available [ =stable ] 27 corretto8 available \ [ =1.8.0_192 =1.8.0_202 =1.8.0_212 =1.8.0_222 =1.8.0_232 =1.8.0_242 =stable ] 28 firecracker available [ =0.11 =stable ] 29 golang1.11 available \ [ =1.11.3 =1.11.11 =1.11.13 =stable ] 30 squid4 available [ =4 =stable ] 31 php7.3 available \ [ =7.3.2 =7.3.3 =7.3.4 =7.3.6 =7.3.8 =7.3.9 =7.3.10 =7.3.11 =7.3.13 =stable ] 32 lustre2.10 available \ [ =2.10.5 =2.10.8 =stable ] 33 java-openjdk11 available [ =11 =stable ] 34 lynis available [ =stable ] 35 kernel-ng available [ =stable ] 36 BCC available [ =0.x =stable ] 37 mono available [ =5.x =stable ] 38 nginx1 available [ =stable ] 39 ruby2.6 available [ =2.6 =stable ] 40 mock available [ =stable ] 41 postgresql11 available [ =11 =stable ] 42 php7.4 available [ =stable ] 43 livepatch available [ =stable ] 44 python3.8 available [ =stable ] 45 haproxy2 available [ =stable ]よし!できた!これでインストールだ!と思ったのですが
[shimo0108 ~]$ sudo yum install nodejs npm --enablerepo=epel 読み込んだプラグイン:extras_suggestions, langpacks, priorities, update-motd amzn2-core | 3.7 kB 00:00:00 amzn2extra-docker | 3.0 kB 00:00:00 amzn2extra-epel | 1.7 kB 00:00:00 One of the configured repositories failed (不明), and yum doesn't have enough cached data to continue. At this point the only safe thing yum can do is fail. There are a few ways to work "fix" this: 1. Contact the upstream for the repository and get them to fix the problem. 2. Reconfigure the baseurl/etc. for the repository, to point to a working upstream. This is most often useful if you are using a newer distribution release than is supported by the repository (and the packages for the previous distribution release still work). 3. Run the command with the repository temporarily disabled yum --disablerepo=<repoid> ... 4. Disable the repository permanently, so yum won't use it by default. Yum will then just ignore the repository until you permanently enable it again or use --enablerepo for temporary usage: yum-config-manager --disable <repoid> or subscription-manager repos --disable=<repoid> 5. Configure the failing repository to be skipped, if it is unavailable. Note that yum will try to contact the repo. when it runs most commands, so will have to try and fail each time (and thus. yum will be be much slower). If it is a very temporary problem though, this is often a nice compromise: yum-config-manager --save --setopt=<repoid>.skip_if_unavailable=true Cannot retrieve metalink for repository: epel/x86_64. Please verify its path and try againとまたまたエラー。
yumで行うコマンドがすべて止まってしまう。。(泣)[shimo0108@ ~]$ sudo yum install nodejs npm --enablerepo=epel 読み込んだプラグイン:extras_suggestions, langpacks, priorities, update-motd amzn2-core | 3.7 kB 00:00:00 amzn2extra-docker | 3.0 kB 00:00:00 amzn2extra-epel | 1.7 kB 00:00:00 . .ここまで読み込んで必ず止まります。1日位格闘してエラーログに
Cannot retrieve metalink for repository: epel/x86_64. Please verify its path and try againを発見。リポジトリのメタリンクを取得できませんと。言うことです。
調べた結果
CentOS6.xでEPELリポジトリ入れたときのエラー対処
https://qiita.com/maruware/items/eb659266a45021cf486c
という記事を発見。どうやらEPELリポジトリがSSL3.0を使っているのが原因とのことで、記事の通り以下を実行してhttps→httpに変更することで解決するらしい。[shimo0108@ ~]$ sudo vi /etc/yum.repos.d/epel.repoここの/epel.repoをvimにて確認。
[epel] name=Extra Packages for Enterprise Linux 7 - $basearch #baseurl=https://download.fedoraproject.org/pub/epel/7/$basearch metalink=https://mirrors.fedoraproject.org/metalink?repo=epel-7&arch=$basearch failovermethod=priority enabled=1 gpgcheck=1 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7たしかに
metalink=https://mirrors.fedoraproject.org/metalink?repo=epel-7&arch=$basearch #httpsになってる。。。 ↓ [epel] name=Extra Packages for Enterprise Linux 7 - $basearch #baseurl=http://download.fedoraproject.org/pub/epel/7/$basearch metalink=http://mirrors.fedoraproject.org/metalink?repo=epel-7&arch=$basearch failovermethod=priority enabled=1 gpgcheck=1 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7 # https//→http//へ変更しました。再び
sudo yum install nodejs npm --enablerepo=epel
を実行。
今度は成功しました!!!
- 投稿日:2020-08-03T16:39:41+09:00
CLIでS3のファイルをアップロードしよう
はじめに
S3をマネジメントコンソール画面で作ることはできるが、CLIで操作して作成したことがないため、今回挑戦してみた。
手順
AWS CLIの確認
AWS CLIがインストールされているか下記のコマンドで確認。
aws --versionS3の権限設定
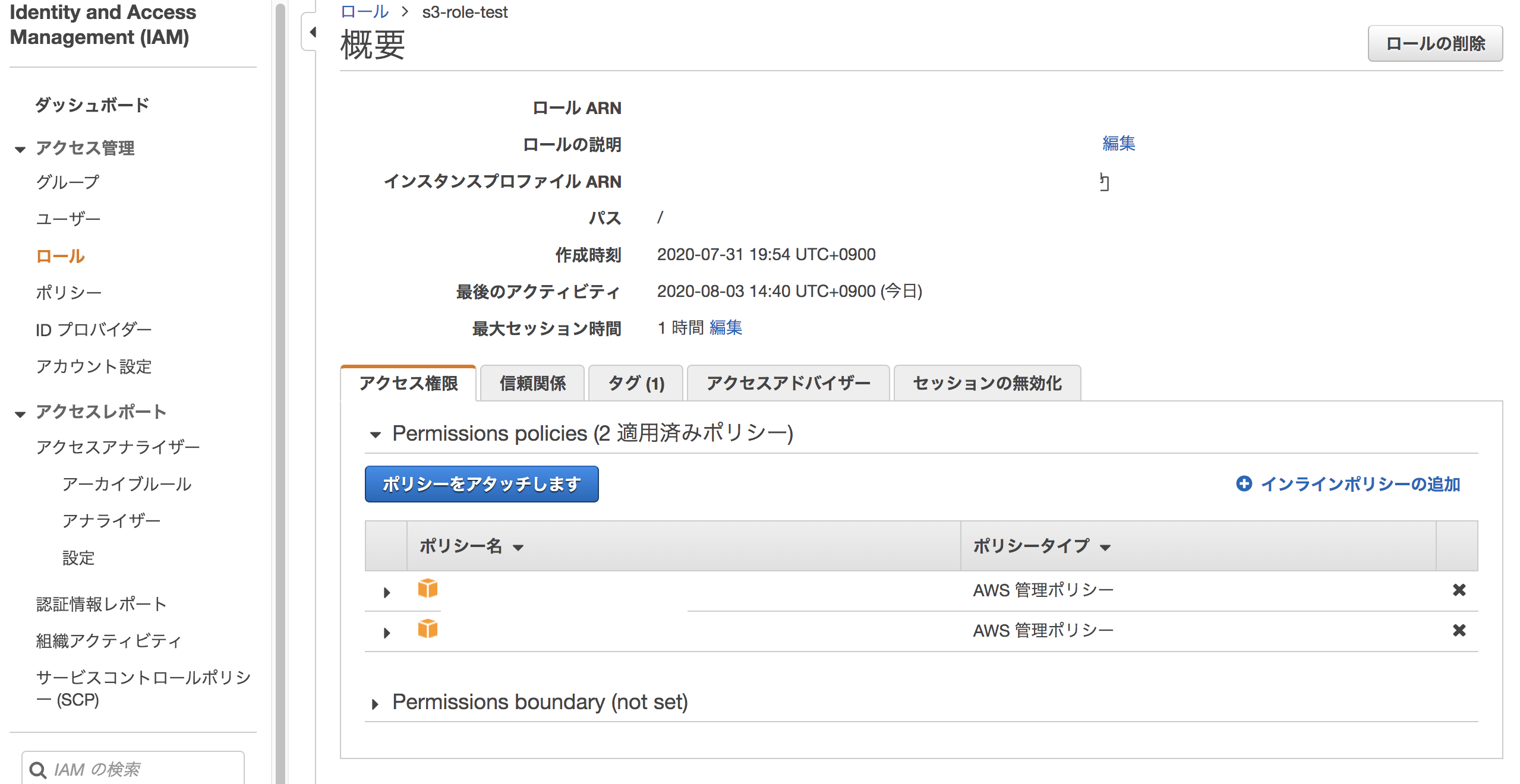
IAM>ロール>権限を設定したいロールをクリック。
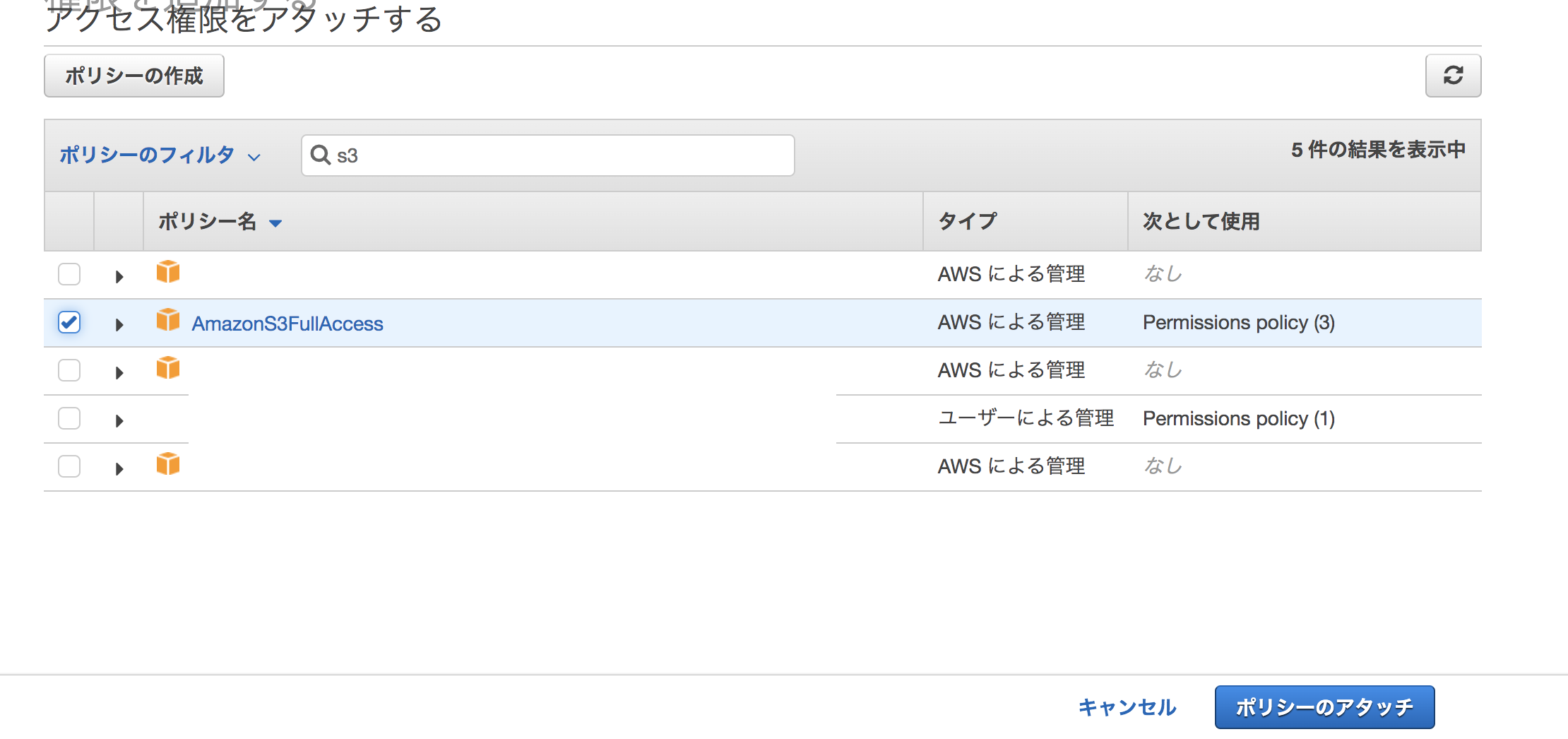
「ポリシーをアタッチします」ボタンを押す。
ポリシーのフィルタでs3と入力し、「AmazonFullAccess」を選択。ポリシーのアタッチを押す。
アタッチされました、と表示される。
デフォルトリージョンを設定
$ aws configure AWS Access Key ID [None]: AWS Secret Access Key [None]: Default region name [None]: ap-northeast-1 Default output format [None]: json「AWS Access Key ID [None]:」と「AWS Secret Access Key [None]:」には何も指定しない。
S3バケットを作成
$ aws mb s3://hoge ※hogeの部分は重複負荷なので、一意になるようにする。 $aws s3 ls ※バゲットが作成できたか確認。マネジメントコンソールでも確認できる。
S3バケットにファイルをアップロード
インターネット上で任意の画像をアップロードする。
Chromeブラウザの場合は画像を右クリックして、「画像アドレスをコピー」を選択。
作業をするためのworkディレクトリをホームディレクトリに作成。
workディレクトリにwgetコマンドで画像アドレスを引数に指定して、ダウンロード。$ mkdir ~/work $ cd ~/work $ wget https://hogehoge/hogehoge.pngs3 lsコマンドをバケットを指定して、実行。画像があるか確認する。
$ aws s3 ls s3://hogeマネジメントコンソールでも画像があるか確認可能。
下記コマンドでCLIからパブリックなアクセス権限を設定。
$ aws s3api put-object-acl --acl public-read --bucket ファイル名 --key 画像名(hoge.png)アクセスコントロールリストで許可設定があるか確認する。
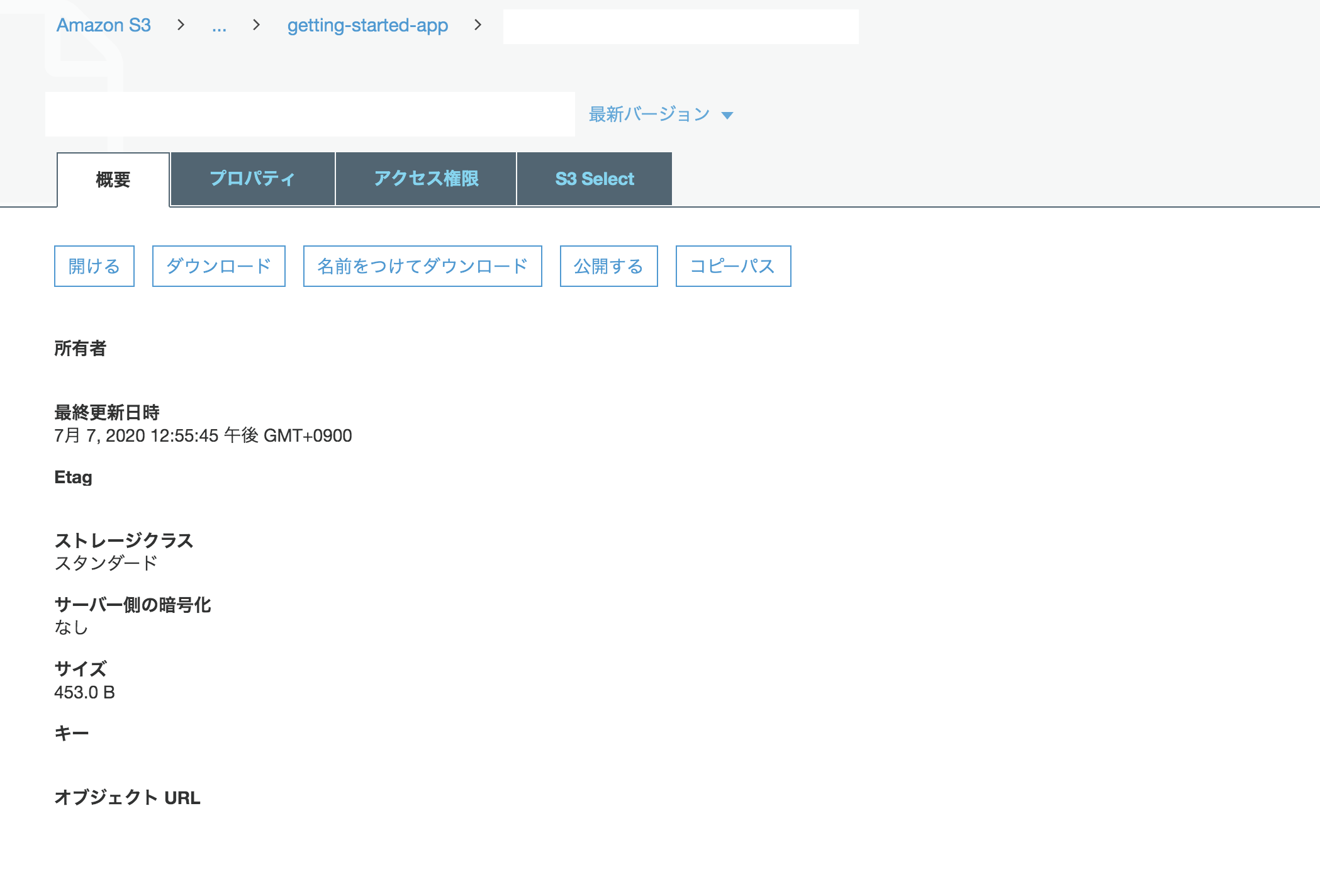
$ aws s3api get-object-acl --bucket ファイル名 --key 画像名(hoge.png)マネジメントコンソールでオブジェクトURLをクリックして、画像が開けるか確認。
上記のような手順を踏むと、画像が表示される。もしオブジェクトURLを押しても「AccessDenied」となって画像が表示されなかったら、該当オブジェクトの概要の「公開する」ボタンをおせば、表示される。
参考
AWSではじめるLinux入門ガイド


- 投稿日:2020-08-03T12:09:36+09:00
Linux基本コマンド
ls -la | grep 文字列・・指定された文字列が含まれる全てのファイルやディレクトリを詳細に表示する※dから始まる→ディレクトリ
-から始まる→ファイル
※.はフォルダー自身
..は一個上のフォルダー
- 投稿日:2020-08-03T12:09:36+09:00
ls -la | grep 文字列
ls -la | grep 文字列・・指定された文字列が含まれる全てのファイルやディレクトリを詳細に表示する結果(例)
drwx------@ 3 ・・・ drwx------@ 7 ・・・ drwx------+ 4 ・・・ -rwx------@ 17・・・ drwxr-xr-x 3 ・・・※dから始まる→ディレクトリ
-から始まる→ファイル
- 投稿日:2020-08-03T04:41:16+09:00
【初心者向け】Linuxでのfor文の使い方(変数とか)
はじめに
この記事では私自身、for文を使おうとしてよくわからなかった部分(とくに変数の使い方あたり)について書いていこうと思います。
そもそも for文の使い方
for文の基本的な形for 変数 in 値のリスト do 処理 doneLinuxでfor文を使うには、以下のような方法があります。
1. シェルスクリプトとして読み込む
適当なエディタ(メモ帳とか)でファイルを作り(拡張子は .shにする)、上の形でfor文を書いて、Linux上で読み込みます。
ファイルの先頭行に#!/bin/bashという文字を書いておきます。メモ帳などで作る(hoge.sh)#!/bin/bash for i in 1 2 3 do echo $i ## 1 2 3 を画面に出力する done作ったファイル(シェルスクリプト)を読み込むには、Linuxの画面上でファイル名を打ち込めばOKです。ただしファイルのパスを指定しなければいけないので「./ファイル名」( . は現在のディレクトリを指す)とします。(※作ったファイルは事前に現在のディレクトリ内に配置しておきます)
出力結果$ ./hoge.sh 1 2 32. コマンドライン上で書く(複数行)
上のようにメモ帳に書いた内容をLinuxの画面上にコピペしてもOKです。
その場合、行替えごとに>マークが自動でつきます。コマンド&出力結果$ for i in 1 2 3 > do > echo $i > done 1 2 33. コマンドライン上で書く(1行)
行替えする代わりに、forの行とdoneの手前に
;を付けることで、1行で書くこともできます。コマンド&出力結果$ for i in 1 2 3; do echo $i; done 1 2 3以下の説明では、2の方法でfor文を使っていきます。
for文内での変数の使い方
基本的にはシェルスクリプトでの変数の使い方と同じです。
「シェルスクリプト 変数」とかで調べるとたくさんサイトがあるので、ぜひ調べてみてください!・初心者向けシェルスクリプトの基本コマンドの紹介
・シェルスクリプトの基礎知識まとめ
・変数の利用 - Linux Mintのメモ簡単にいくつかのケースを説明したいと思います。
1. 「$変数名」で値を使用する
変数
iの値は、$iで使用することができます。(上の例参照)2. 変数に文字列が隣接する場合は「${変数名}」とする
$iと文字列が連続している場合には、${i}とする必要があります。$ for i in 1 2 3 > do > echo $ixxx > echo ${i}xxx > done ## "ixxx" という変数は存在しないので、何も出力されない。 1xxx ## "変数iの値(=1)" + "xxx" が出力される。 2xxx 3xxx3. 変数は
''ではなく""で囲むダブルクォート "" ... 変数の中身を読み込む(ex. "$i" -> 1) シングルクォート '' ... 文字列をそのまま表示(ex. '$i' -> $i という文字列) バッククォート `` ... コマンドとして読み込む(ex. `cat test.txt` -> test.txtの中身を出力)Linuxでは
''""に上記のような差があるので、変数をクォーテーションで囲むときは必ず""を使用します。$ cat test01.txt 1xxxxxxxxxx xxx2xxxxxxx xxxxx3xxxxx xxxxxxxx4xx xxxxxxxxxx5 ## 1 4 5 を含む行だけ抽出 $ for i in 1 4 5 > do > cat test01.txt | grep "$i" > done 1xxxxxxxxxx xxxxxxxx4xx xxxxxxxxxx5 ## $i という文字列を含む行を抽出(何も出力されない) $ for i in 1 4 5 > do > cat test01.txt | grep '$i' > done値のリストの書き方
ざっくりリストアップするとこんな感じです(他にもいろいろあると思います)。
## i を 1 2 3 4 5 で動かす for i in 1 2 3 4 5 for i in {1..5} for i in `seq 1 5` for i in `seq 5` for ((i=1; i<=5; i++)) ## i を 2 ずつ動かす ( 1 3 5 7 9 ) for ((i=1; i<=10; i=i+2)) ## (最初の値; iの条件; iの増え方(or減り方)) for ((i=1; i<=10; i+=2)) ## i に文字を代入 for i in aa bb cc ## ファイル内の各行を読み込む (空白でもループが区切られるので注意; 後述) for i in `cat test.txt` ## ディレクトリ内のファイルを指定 for i in *.txt for i in `ls`参考:
【 for 】コマンド(応用編その2)――コマンドの実行結果と組み合わせて、繰り返し処理を行う
【 for 】コマンド(応用編その3)――回数を指定して繰り返し処理を行うおまけ:ファイル内の各行を読み込む(while read line)
for文より
while文で読み込むやり方の方がメジャーなようです(→追記参照)。
方法は何パターンかありますが、読み込むファイルの最終行で改行されていない場合には、方法によっては最終行だけ読み込まれない場合があるので、注意が必要です。参考:
コピペ可|bash/while read lineで行単位で処理:5パターン
BASHのwhile readで最終行が処理されない問題の解決方法調べた限り、ヒアドキュメントで渡す方法(下の方法)ではその問題を回避できるので、個人的にはこの方法が良いのではないかと思います。
$ cat test02.txt 1 2 3 4 5 ## 改行されていない ## 最終行が読み込まれない $ cat test02.txt | while read line > do > echo line : $line > done line : 1 line : 2 line : 3 line : 4 ## 最終行まで読み込まれる $ while read line > do > echo line : $line > done << Hear > `cat test02.txt` > Hear line : 1 line : 2 line : 3 line : 4 line : 5追記
上のリンクの説明にもある通り、for文の場合、改行だけでなく空白でもループが区切られてしまうので、各行ごとに処理を行いたい場合には
while read lineを使った方が汎用性は高いです。$ cat test02.txt 1 x 2xx 3 4 5 ## forは空白でも区切られる $ for i in `cat test02.txt` > do > echo line : $i > done line : 1 line : x line : 2xx line : 3 line : 4 line : 5 ## whileは空白で区切られない $ while read line > do > echo line : $line > done << Hear > `cat test02.txt` > Hear line : 1 x line : 2xx line : 3 line : 4 line : 5
- 投稿日:2020-08-03T02:17:52+09:00
Linuxカーネルに入門したいのだけどlist head構造体って何するもの?
Table of Contents
はじめに
Linuxユーザーのエンジニアであれば、Linuxがどのように動くのかに興味ありますよね。いつかはLinuxカーネルについて勉強してみたいと思っている方も少なくないのではないでしょうか。
この記事では、Linuxカーネルに入門しようとしている初心者が、割と早いうちに途方に暮れると思われる壁「list_head構造体」について見ていきたいと思います。
この記事は私のブログ https://achiwa912.github.io/ にも載せました。
ソースコードの入手
まずはLinuxカーネルのソースコードを入手しましょう。
Linuxカーネルの開発はずっと続いているので、書籍などで引用されているコードはすでに古くなっています。折角なので、最新版を入手したいですよね。
Linuxカーネルのソースコードをgit cloneして持ってきましょう。git clone http://git.kernel.org/pub/scm/linux/kernel/git/stable/linux-stable.git20−30分くらいかかります。放置して待ちましょう。
~/git % git clone http://git.kernel.org/pub/scm/linux/kernel/git/stable/linux-stable.git Cloning into 'linux-stable'... warning: redirecting to https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux-stable.git/ remote: Enumerating objects: 1189260, done. remote: Counting objects: 100% (1189260/1189260), done. remote: Compressing objects: 100% (165947/165947), done. remote: Total 8680156 (delta 1022459), reused 1186934 (delta 1020762), pack-reused 7490896 Receiving objects: 100% (8680156/8680156), 1.57 GiB | 3.01 MiB/s, done. Resolving deltas: 100% (7328421/7328421), done. Updating files: 100% (69365/69365), done. warning: the following paths have collided (e.g. case-sensitive paths on a case-insensitive filesystem) and only one from the same colliding group is in the working tree: 'include/uapi/linux/netfilter/xt_CONNMARK.h' 'include/uapi/linux/netfilter/xt_connmark.h' 'include/uapi/linux/netfilter/xt_DSCP.h' 'include/uapi/linux/netfilter/xt_dscp.h' 'include/uapi/linux/netfilter/xt_MARK.h' 'include/uapi/linux/netfilter/xt_mark.h' 'include/uapi/linux/netfilter/xt_RATEEST.h' 'include/uapi/linux/netfilter/xt_rateest.h' 'include/uapi/linux/netfilter/xt_TCPMSS.h' 'include/uapi/linux/netfilter/xt_tcpmss.h' 'include/uapi/linux/netfilter_ipv4/ipt_ECN.h' 'include/uapi/linux/netfilter_ipv4/ipt_ecn.h' 'include/uapi/linux/netfilter_ipv4/ipt_TTL.h' 'include/uapi/linux/netfilter_ipv4/ipt_ttl.h' 'include/uapi/linux/netfilter_ipv6/ip6t_HL.h' 'include/uapi/linux/netfilter_ipv6/ip6t_hl.h' 'net/netfilter/xt_DSCP.c' 'net/netfilter/xt_dscp.c' 'net/netfilter/xt_HL.c' 'net/netfilter/xt_hl.c' 'net/netfilter/xt_RATEEST.c' 'net/netfilter/xt_rateest.c' 'net/netfilter/xt_TCPMSS.c' 'net/netfilter/xt_tcpmss.c' 'tools/memory-model/litmus-tests/Z6.0+pooncelock+poonceLock+pombonce.litmus' 'tools/memory-model/litmus-tests/Z6.0+pooncelock+pooncelock+pombonce.litmus'おめでとうございます。これで、Linuxカーネルのソースコードを一式入手することができました。意外と簡単ですね。
最初の一歩?
Linuxのカーネルは巨大です。一体、どこから見始めればよいのか検討もつきません。普通は参考文献にあるようなLinuxカーネル本をガイドにするのがよいと思います。ところで、私の場合はVFSに興味があります。inodeとかsuperblockとかのあれです。若干いきなりすぎる感もありますが、superblockのデータ構造を見てみましょう。
linux-stable/include/linux/fs.hにありました。struct super_block { struct list_head s_list; /* Keep this first */ dev_t s_dev; /* search index; _not_ kdev_t */ unsigned char s_blocksize_bits; unsigned long s_blocksize; loff_t s_maxbytes; /* Max file size */ struct file_system_type *s_type; const struct super_operations *s_op; const struct dquot_operations *dq_op; const struct quotactl_ops *s_qcop; const struct export_operations *s_export_op; unsigned long s_flags; unsigned long s_iflags; /* internal SB_I_* flags */ unsigned long s_magic; struct dentry *s_root; struct rw_semaphore s_umount; int s_count; atomic_t s_active; <snip>これが、superblockのデータ構造です。中身はさっぱりわかりませんが。。。
構造体の中の1行目に着目します。struct list_head s_list; /* Keep this first */これです。list head構造体。こいつが、カーネルのソースコードを少しでも読もうとする私のような初心者を突き放す、手強いやつなのです。しかも、やたらとたくさん出てきます。今回の記事では、これが何を意味するのかについて見ていきたいと思います。
list head構造体
背景
LinuxカーネルはC言語で書かれています。C言語には、よりモダンなプログラミング言語と違って、サポートするデータ構造は貧弱で、オブジェクト指向の仕組みも入っていません。例えば、Python等にあるリスト構造(['abc', 'def']みたいなやつ)はとても便利で、無くてはかったるくてプログラムなど書いていられないほどですが、C言語にリストはありません。同様にC言語にはクラスもありません。あるのは構造体のみ。
Linuxカーネル開発者達はこれらのモダンなデータ構造を、ユニークなやり方で実現しています。その一つが、リスト構造を実現するlist head構造体です。
list head構造体の定義
では、list head構造体の定義を見てみましょう。
linux-stable/include/linux/types.hにあります。struct list_head { struct list_head *next, *prev; };拍子抜けするほど単純ですね。前方、後方の、自身と同じlist head構造体へのポインタが入っているだけでした。なるほど、双方向リンクトリストなのですね。こういったやつです。(厳密には、循環双方向リンクトリストです)
+------+ +------+------+------+ +------+-----+------+ +------+ | null | <-> | prev | ... | next | <-> | prev | ... | next | <-> | null | +------+ +------+------+------+ +------+-----+------+ +------+Linuxカーネルでの使われ方
いや、ちょっと待ってください。リストって、前後のポインタだけ入っていても意味が無いです。リストを構成する各ノードのデータが入っていないと。例えばinodeをリンクトリストで持つ場合、inodeはinode自身のデータをたくさん持っているはずです。ファイル名とか、オーナーとか、パーミッションとか。上の図で言うと・・・の部分です。
実は、list head構造体は、それを他の構造体に埋め込むことで、埋め込まれたペアレント構造体をリンクトリスト化できる便利なやつなのです。すごい!発想の転換です。
そう言えば、superblockの構造体は、list head構造体をメンバーとして持っていました。
struct super_block { struct list_head s_list; /* Keep this first */ dev_t s_dev; /* search index; _not_ kdev_t */ unsigned char s_blocksize_bits; <snip>こうすることで、superblockがリンクトリストのノードになっているのです。
更に、いくつものlist_head構造体を埋め込むことで、複数のリンクトリストに同時に登録することも可能です。構造体の定義を見ただけで、これは何と何と何のリンクトリストに含まれるかもわかります(コメントが書いてあるので)。これはPythonのリンクには真似ができませんね。
ペアレント構造体へのポインタを得る
リストを持たないC言語でリンクトリストを実現するため、という目的はわかりましたが、一つ問題が残っています。リストヘッド構造体は、同じリストヘッド構造体同士を結びつけるだけなのですが、本当に欲しいのはそれを埋め込んだペアレント構造体へのポインタです。ペアレント構造体をリンクトリスト化したいのですから。
それをするための関数が定義されています。
/** * list_entry - get the struct for this entry * @ptr: the &struct list_head pointer. * @type: the type of the struct this is embedded in. * @member: the name of the list_head within the struct. */ #define list_entry(ptr, type, member) \ container_of(ptr, type, member)list_entry()関数です。この3つの引数は、
- ptr: このlist_head構造体へのポインタ
- type: list_headを埋め込んであるペアレント構造体のタイプ(上の例ではsuper_block)
- member: このlist_head構造体の、ペアレント構造体内のメンバー名(上の例ではs_list)
であり、ペアレント構造体へのポインタを返します。
よかった、よかった。ですが、list_entry()関数の定義内容が気になります。
container_of()って何でしょうか。
grepで探したところ、linux-stable/include/linux/kernel.hに定義がありました。/** * container_of - cast a member of a structure out to the containing structure * @ptr: the pointer to the member. * @type: the type of the container struct this is embedded in. * @member: the name of the member within the struct. * */ #define container_of(ptr, type, member) ({ \ void *__mptr = (void *)(ptr); \ BUILD_BUG_ON_MSG(!__same_type(*(ptr), ((type *)0)->member) && \ !__same_type(*(ptr), void), \ "pointer type mismatch in container_of()"); \ ((type *)(__mptr - offsetof(type, member))); })ポイントだけ抜き出します。
#define container_of(ptr, type, member) ({ \ void *__mptr = (void *)(ptr); \ ((type *)(__mptr - offsetof(type, member))); })まずは、voidへのポインタ__mptrに、list_head構造体へのポインタptrをvoidへのポインタにキャストして代入しています。list_head構造体へのポインタのままだと使えないですからね。
次の行で、__mptrを、offsetof(type, member)分前にずらしているようです。offsetof(type, member)は上の例の場合、super_block構造体の中でのメンバーstruct list_head s_listのオフセットです。つまり、ペアレントであるsuper_block構造体へのポインタに変換しているのでした。そしてこれを、super_block構造体へのポインタにキャストしています。
まとめると、
- list_head構造体をvoidへのポインタにキャストして扱いやすくする
- 作ったポインタを手前にずらして、ペアレント構造体の先頭を指すようにする
- 最後に、ペアレント構造体へのポインタにキャストする
ということでした。
なお、container_ofについては、参考文献のLinux Kernel Developmentの中では次のように定義されていました。
#define container_of(ptr, type, member) ({ \ const typeof( ((type *)0)->member ) *__mptr = (ptr); \ (type *)( (char *)__mptr - offsetof(type,member) );})これを見て、「((type *)0)->memberって何だ? これは一体何をしているんだ???」と相当悩んだことがこの記事を書く動機だったのですが、最新のソースでは、若干わかりやすくなっていました。
まとめ
Linuxカーネルで定義するデータ構造においt、list_head構造体が埋め込まれた構造体があったら、それは何かのリンクトリストに含まれるということがわかりましたね。ソースのコメントを読めば、大抵は何のリンクトリストかが書いてあります。
list_entry()関数を使って、list_head構造体のポインタから、それが埋め込まれたペアレント構造体へのポインタに変換できます。そして、Linuxカーネルでのlist_entry() - contaier_of()の実装を少し見てみました。
参考文献
- Linux Kernel Development 3rd Edition, Robert Love