- 投稿日:2020-08-03T21:28:37+09:00
[GitHub初心者] 他人のGithubをcloneして、自分のレポジトリにpushする
他の方がGithubに公開されているプロジェクトを、自分のローカルPCにプロジェクト毎DL?して、自分のGithubアカウントにpushするやり方です。
参考記事
・【git】他人のからclone して自分のにpushする
・CloneしてからローカルPCで開発&変更を加えるまずローカルPCにプロジェクトをclone(ダウンロードするイメージ)
$ git clone [クローン元のリポジトリURL]ローカルで開発する
$bundle install #まずはgemをインストール $ rails db:create #DBを作成 $ rails db:migrate $ rails s #サーバー起動自分のGithubアカウントにpushする
$ git add . $ git commit -m "my-first-clone" $ git remote add origin <push先のURL> $ git push origin master
- 投稿日:2020-08-03T19:58:19+09:00
git rebase --rebase-margeについて
対象
gitでrebaseをよくするし、mergeはマージコミットを残す人。
rebaseするとmergeのマージコミットの記録が失われるのが困る人。概要
付け替えたいブランチの先端を作業コピーにして以下を実施
git rebase --rebase-merge <付け替え先> -igit rebase --rebase-merge <付け替えたいブランチの根本> --onto <付け替え先> -igit rebase --rebase-merge=rebase-cousin <付け替え先> -iなるべく
-iをつけてTODOリストを表示し、作業内容を確認する。
--rebase-mergeとはBy default, a rebase will simply drop merge commits from the todo list, and put the rebased commits into a single, linear branch. With --rebase-merges, the rebase will instead try to preserve the branching structure within the commits that are to be rebased, by recreating the merge commits. Any resolved merge conflicts or manual amendments in these merge commits will have to be resolved/re-applied manually.1
デフォルトでは、リベースは単にマージコミットを TODO リストから削除し、リベースされたコミットを単一の直線的なブランチにまとめます。rebase-merges を指定すると、リベースはマージコミットを再作成することで、リベースされるコミット内の分岐構造を維持しようとします。マージの競合が解決された場合や、マージコミットの修正が手動で行われた場合は、手動で修正を適用しなければなりません。2すごい!
使い方
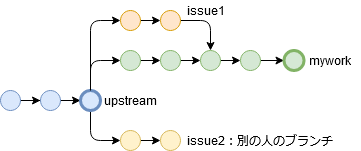
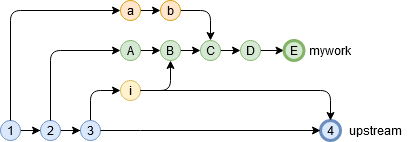
今自分のブランチがmyworkという状態でissue1をマージした状態で作り込みを行っています。本流はupstreamで、自分とは別に誰かほかの人がつくったブランチissue2があるとします。
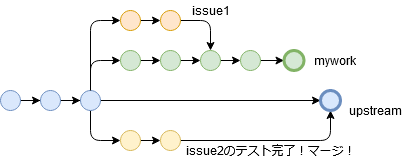
別の人のブランチがテスト完了してマージされ、upstreamが更新されました。
さて、myworkが新しいupstreamでどうなるのか検証するため、rebaseで追従させたいと思います。
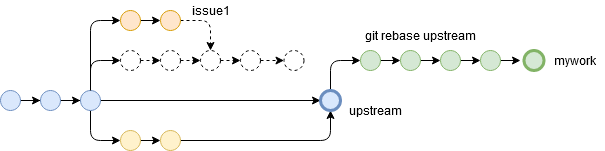
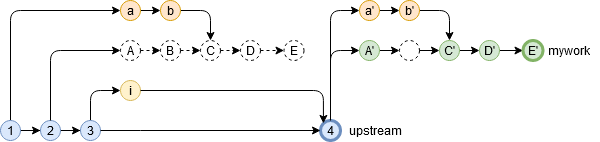
普通のrebaseの場合
普通のrebaseだとこうなります。
git checkout mywork git rebase upstream
ひとつ質問いいかな。マージコミット、どこいった?
……君のような勘のいい(ry
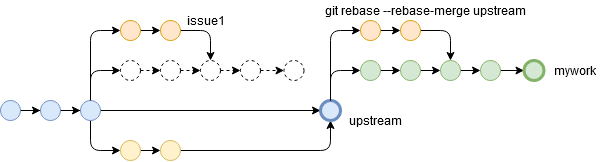
--rebase-mergeの場合マージコミットも含めてリベースしたい………そんな時に役に立つのが
git rebase --rebase-mergeです。git checkout mywork git rebase --rebase-merge upstream
すごい!!
ただ、図中のissue1のように、ほかのブランチは別のコミットとして扱われてしまうので、ラベルを張りなおす必要があります。
-i付きでTODOリストを表示&編集ちなみに、
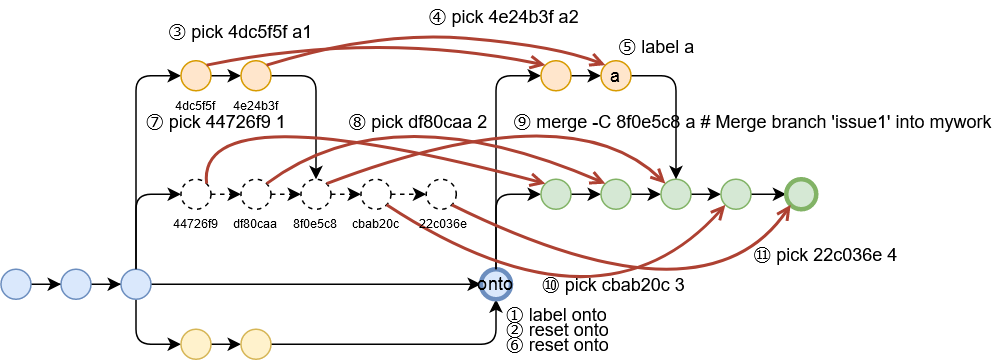
git rebase --rebase-merge -i upstreamとすると、以下のようなTODOリストが出てきて、rebaseで何をやっているのかがわかります。txtlabel onto # Branch a reset onto pick 4dc5f5f a1 pick 4e24b3f a2 label a reset onto pick 44726f9 1 pick df80caa 2 merge -C 8f0e5c8 a # Merge branch 'issue1' into mywork pick cbab20c 3 pick 22c036e 4
マージコミットを形成するための⑨は、もともと8f0e5c8のコミットでマージした時のコミットメッセージを使って➄でaとラベル付けしたコミットをマージする、という意味です。
ブランチの作成も一緒に行う
これが理解できるようになったら、以下のようにしてブランチ作成もやってしまうといいでしょう。
label onto # Branch a reset onto pick 4dc5f5f a1 pick 4e24b3f a2 label a exec git branch -f -c issue1 issue1-old exec git branch issue1-new reset onto pick 44726f9 1 pick df80caa 2 merge -C 8f0e5c8 a # Merge branch 'issue1' into mywork pick cbab20c 3 pick 22c036e 4 exec git branch -f -m issue1-new issue1ブランチのpickが終わったらもともとのブランチに
-oldと付けたブランチを複製で作っておき、pick済みの新しいブランチには、-newを付けたブランチを新しく作ります。
すべてが終わったら、-newを取り去って新しいブランチにします。こうすれば途中で失敗して--abortしても安心です。
一応念のため-oldはつけたままにしておき、検証がすんだら破棄しましょう。--ontoと一緒に使う
git rebase --rebase-merge <付け替えたいブランチの根本> --onto <付け替え先>ということもできます付け替えたいブランチの根本というのは、
--ontoがない場合は付け替え先と現在のブランチの分岐点になるのですが、以下のようなケースですと、やりたいことがうまくできません。
この状況で、
git rebase --rebase-merge upstreamをしてみると、以下のようになります。
最も新しい分岐点の➂からの付け替えを行った結果、このようになったようです。
このようにマージコミットのトポロジが複雑で、うまくリベースできなさそうな場合、 --onto で付け替えたいブランチの根本と、付け替え先を明示してやるとうまくいくことがあります。
上図の一番古い分岐点は➀なので、➀のコミットから生えているmyworkを、➃のupstreamのところに付け替えたいとしましょう。ここで、➀のハッシュは"df41069"だとしましょう。git rebase --rebase-merge df41069 --onto upstream
-i付きでTODOリストの表示&編集これで正しいものが得られます。
ただ、この方法ですと、A'を作る際に、コンフリクトが発生します。
理由は以下のTODOリストを見るとわかります。
git rebase --rebase-merge df41069 --onto upstream -ilabel onto # Branch foo reset onto pick b8514a7 2 label branch-point pick 1bcbd43 3 pick c459ffb i label foo # Branch hoge reset onto pick 4937acb a pick 303b05e b label hoge reset branch-point # 2 pick a7e5334 A merge -C 018c043 foo # Merge branch 'foo' into mywork merge -C 02a6784 hoge # Merge branch 'hoge' into mywork pick 55fefc3 D pick a2c1508 Eすでにupstreamには、➁のコミットが含まれていますが、さらに
pick b8514a7 2としています。➂もⓘもpickし、
➀からⒺに至るまでの道筋を愚直に再現しているようです。
-iで最初に編集できるTODOリストを編集して消してしまってもいいのですが、もう少し頭のいい方法を紹介します。
--rebase-merge=rebase-cousinモードでリベースする場合cousinというのはいとこという意味ですね。親の違うコミットも含めてrebase対象にしましょう、というモードです。
git rebase --rebase-merge=rebase-cousin upstream -i以下のようなTODOリストが得られます。
--rebase-merge=rebase-cousinslabel onto # Branch hoge reset onto pick 4937acb a pick 303b05e b label hoge reset onto pick a7e5334 A merge -C 018c043 onto # Merge branch 'foo' into mywork merge -C 02a6784 hoge # Merge branch 'hoge' into mywork pick 55fefc3 D pick a2c1508 E必要なものだけをピックアップしていますね。
まとめ
git rebase --rebase-mergeは複雑になればなるほど難しい上にコンフリクトも発生しますので、失敗するとものすごく時間の無駄遣いになってしまいます。
できればq-iでTODOリストを表示し、何を行うか理解したうえで行いたいところですね。
git rebase --rebase-merge <付け替え先> -i: 比較的単純な場合はこれ。git rebase --rebase-merge <付け替えたいブランチの根本> --onto <付け替え先> -i: 根本を指定したい場合はこれ。git rebase --rebase-merge=rebase-cousin <付け替え先> -i: 付け替え先と同じ祖先をもっているものの違うコミットから生えていて、自身にマージされたブランチ(いとこ関係のブランチ)もピックアップして取り込みたい場合はこれ。ちなみに、ここまで
--rebase-mergeと長いオプション名で説明していましたが、-rの短いオプション名でもOKです。
例)git rebase -r upstream

- 投稿日:2020-08-03T13:58:41+09:00
Computing average life expectancy of a line of code
Motivation
Some time ago when I asked one of my colleagues, what whas his main motivation for becoming a programmer. He then replied in a sense that he wants his code be part of a software which can be useful for many years.
Since my colleague worked as a Web Developer at that time, I was pretty skeptical of this answer. In my previous experience, the front-end part of an average project tends to be rewritten every three months or so, so this is not a very good place to look for "stable" and "unchanging" code.
Later, however, I became more curious and decided to check, how long on average the line of code lives in our company's repository. The additional benefit was that I got myself a great excuse to play around with GitPython package during my work time!
If you have not heard this name before, GitPython provides a Python-interface to git. Since we will use it heavily below, the basic familiarity is assumed and welcomed. I will also use pandas below pretty much as well.
Finally, one last word before we embark on a journey. While working on this, I made myself an explicit goal to NOT to use anything except GitPython and pandas (remember, one of my goals was to learn the former). However, if you look for something more user-friendly, there are other packages built on top of GitPython, which provide much more rich and friendly interface. In particular, PyDriller popped out during my searches. But perhaps, plenty of others exist too.
Main work
Ok, so here we go. First, we initialize
Repoobject which will represent our repository. Make sure you have downloaded the repository and checked out the newest version. ReplacePATH_TO_REPObelow with path to your git repository on your disk.from git import Repo PATH_TO_REPO = "/Users/nailbiter/Documents/datawise/dtws-rdemo" repo = Repo("/Users/nailbiter/Documents/datawise/dtws-rdemo") assert not repo.bareNext, we check out the branch we want to investigate (see the variable
BRANCHbelow). In your case it probably will bemaster, but our main branch is calleddevelopmentfor some reasons.import pandas as pd BRANCH = "development" head = repo.commit(f"origin/{BRANCH}") from IPython.display import HTML def head_to_record(head): return {"sha":head.hexsha[:7], "parent(s)":[sha.hexsha[:7] for sha in head.parents], "name":head.message.strip(), "commit_obj":head } records = [] while head.parents: # print(f"parent(s) of {head.hexsha} is/are {[h.hexsha for h in head.parents]}") records.append(head_to_record(head)) head = head.parents[0] records.append(head_to_record(head)) pd.DataFrame(records)
sha parent(s) name commit_obj 0 31ad850 [c77bfb0] docs 31ad850b08014bbf299e534e28cdfee32be90654 1 c77bfb0 [d4935dc] stash c77bfb02b6aa0992be7d51ddc09c295a9b25d4d1 2 d4935dc [f294f04] rename owner d4935dc2157c6f968db8bae7d68868955c06f6ea 3 f294f04 [c51257b] stash f294f049161ac9c8c2215f33b8d0bc25f49f88b3 4 c51257b [b684146] stash c51257b1b89ea10bd213ed5ba575033fd0514e89 ... ... ... ... ... 298 e636c9f [0f9ad8d] [Task] Ran Prettier e636c9ff7f9125064c2f3d367680107baebae250 299 0f9ad8d [ec1c72f] [Task] Setup Prettier 0f9ad8d85d18010098228cabae36e674b4402686 300 ec1c72f [e4da3e5] [Feat.] Can Set Initial State ec1c72fe382a5b9dfa42a8810a740f96eb72c05c 301 e4da3e5 [b17eb26] Initial DTWS commit e4da3e5ae67322feae1b93e2180b219054339182 302 b17eb26 [] Initial commit from Create React App b17eb263f8cf0adc7eb8cda7e0a0ae4aee8aff82 303 rows × 4 columns
Now, variables
recordsin the code above represents all the commits ondevelopmentbranch since the beginning till the current moment.Next we need to go along these commits and collect info regarding every line which appeared/disappeared in that commit. This information later will help us to determine lifetime of each line which ever appeared in our repository.
To do so, we create the variable
reswhich is a dictionary. It's keys are tuples of the form(<line_content>,<commit>,<filename>)and its values are sets containing hashes of all the commits in which this line appeared. It is a rather big structure and computing it takes some time.Therefore, be ready that the code below will take some time to finish (around 100 seconds on my reasonably new MacBook Pro with our repository having only ~300 commits).
I guess, there should be much more effective and elegant way to collect this data, but I have not came up with it yet. Suggestions are welcomed.
import pandas as pd from tqdm import tqdm def collect_filestates(end,start=None): """this procedure collects names of all files which changed from commit `start` till commit `end` (these assumed to be adjacent)""" if start is not None: diffs = start.diff(other=end) fns = [diff.b_path for diff in diffs] change_types = [diff.change_type for diff in diffs] res = [{"filename":t[0],"status":t[1]} for t in zip(fns,change_types)] return res else: fns = end.stats.files.keys() return [{"filename":f,"status":"C"} for f in fns] def collect_lines(end,start=None): """collects information about all lines that changed from `start` to `end`""" filestates = [r for r in collect_filestates(end,start) if r["status"] != "D"] res = {} for fs in filestates: fn = fs["filename"] blame = repo.blame(end,file=fn) for k,v in blame: for vv in v: res[(vv,k.hexsha,fn)] = end.hexsha return res res = {} for i in tqdm(range(len(records))): _res = collect_lines(end=records[i]["commit_obj"],start=None if (i+1)==len(records) else records[i+1]["commit_obj"]) for k,v in _res.items(): if k in res: res[k].add(v) else: res[k] = {v} {k:v for k,v in list(res.items())[:5]}100%|██████████| 303/303 [01:41<00:00, 2.99it/s] {('*.swo', 'a73ec421cfc05cc3816cb3b2b2505d228e60c386', 'pipeline/.gitignore'): {'31ad850b08014bbf299e534e28cdfee32be90654', 'a73ec421cfc05cc3816cb3b2b2505d228e60c386'}, ('*.swp', 'a73ec421cfc05cc3816cb3b2b2505d228e60c386', 'pipeline/.gitignore'): {'31ad850b08014bbf299e534e28cdfee32be90654', 'a73ec421cfc05cc3816cb3b2b2505d228e60c386'}, ('.pulled_data.json', 'a73ec421cfc05cc3816cb3b2b2505d228e60c386', 'pipeline/.gitignore'): {'31ad850b08014bbf299e534e28cdfee32be90654', 'a73ec421cfc05cc3816cb3b2b2505d228e60c386'}, ('.config.custom.json', 'a73ec421cfc05cc3816cb3b2b2505d228e60c386', 'pipeline/.gitignore'): {'31ad850b08014bbf299e534e28cdfee32be90654', 'a73ec421cfc05cc3816cb3b2b2505d228e60c386'}, ('.stderr.txt', 'a73ec421cfc05cc3816cb3b2b2505d228e60c386', 'pipeline/.gitignore'): {'31ad850b08014bbf299e534e28cdfee32be90654', 'a73ec421cfc05cc3816cb3b2b2505d228e60c386'}}Now, as we have our marvelous
resstructure, we can easily compute the lifetime of every line which ever appeared in our repository: for every key inreswe simply compute the duration between oldest and newest commit in its value set.But again, this may take some time (around 6 minutes on my machine).
from datetime import datetime import pandas as pd from tqdm import tqdm _records = [] for k in tqdm(res): dates = [datetime.fromtimestamp(repo.commit(sha).committed_date) for sha in res[k]] _records.append(dict(line=k[0],commit=k[1],file=k[2],lifetime=max(dates)-min(dates))) lines_df = pd.DataFrame(_records) lines_df100%|██████████| 1806272/1806272 [05:52<00:00, 5123.11it/s]
line commit file lifetime 0 *.swo a73ec421cfc05cc3816cb3b2b2505d228e60c386 pipeline/.gitignore 144 days 19:07:29 1 *.swp a73ec421cfc05cc3816cb3b2b2505d228e60c386 pipeline/.gitignore 144 days 19:07:29 2 .pulled_data.json a73ec421cfc05cc3816cb3b2b2505d228e60c386 pipeline/.gitignore 144 days 19:07:29 3 .config.custom.json a73ec421cfc05cc3816cb3b2b2505d228e60c386 pipeline/.gitignore 144 days 19:07:29 4 .stderr.txt a73ec421cfc05cc3816cb3b2b2505d228e60c386 pipeline/.gitignore 144 days 19:07:29 ... ... ... ... ... 1806267 supports-color@^5.3.0: b17eb263f8cf0adc7eb8cda7e0a0ae4aee8aff82 yarn.lock 0 days 00:00:00 1806268 through@^2.3.6: b17eb263f8cf0adc7eb8cda7e0a0ae4aee8aff82 yarn.lock 0 days 00:00:00 1806269 typedarray@^0.0.6: b17eb263f8cf0adc7eb8cda7e0a0ae4aee8aff82 yarn.lock 0 days 00:00:00 1806270 whatwg-fetch@3.0.0: b17eb263f8cf0adc7eb8cda7e0a0ae4aee8aff82 yarn.lock 0 days 00:00:00 1806271 xtend@^4.0.0, xtend@~4.0.1: b17eb263f8cf0adc7eb8cda7e0a0ae4aee8aff82 yarn.lock 0 days 00:00:00 1806272 rows × 4 columns
The table
lines_dfwe assembled above contains the following columns:
line-- that's line's contentcommit-- that's the first commit in which this line appeared.file-- filename in which this line appearslifetime-- lifetime of a lineIn the code below we add two more columns to this table:
*author-- author of the line (to protect their privacy, I do not list real names, but rather one-letter nicknames)
*ext-- file extension offilenamefrom os.path import splitext, isfile import json if not isfile("author_masks.json"): to_author = lambda s:s else: with open("author_masks.json") as f: d = json.load(f) to_author = lambda s:d[s] lines_df.sort_values(by="lifetime",ascending=False) lines_df["author"] = [to_author(str(repo.commit(sha).author)) for sha in lines_df["commit"]] lines_df["ext"] = [splitext(fn)[1] for fn in lines_df["file"]] lines_df
line commit file lifetime author ext 0 *.swo a73ec421cfc05cc3816cb3b2b2505d228e60c386 pipeline/.gitignore 144 days 19:07:29 L 1 *.swp a73ec421cfc05cc3816cb3b2b2505d228e60c386 pipeline/.gitignore 144 days 19:07:29 L 2 .pulled_data.json a73ec421cfc05cc3816cb3b2b2505d228e60c386 pipeline/.gitignore 144 days 19:07:29 L 3 .config.custom.json a73ec421cfc05cc3816cb3b2b2505d228e60c386 pipeline/.gitignore 144 days 19:07:29 L 4 .stderr.txt a73ec421cfc05cc3816cb3b2b2505d228e60c386 pipeline/.gitignore 144 days 19:07:29 L ... ... ... ... ... ... ... 1806267 supports-color@^5.3.0: b17eb263f8cf0adc7eb8cda7e0a0ae4aee8aff82 yarn.lock 0 days 00:00:00 J .lock 1806268 through@^2.3.6: b17eb263f8cf0adc7eb8cda7e0a0ae4aee8aff82 yarn.lock 0 days 00:00:00 J .lock 1806269 typedarray@^0.0.6: b17eb263f8cf0adc7eb8cda7e0a0ae4aee8aff82 yarn.lock 0 days 00:00:00 J .lock 1806270 whatwg-fetch@3.0.0: b17eb263f8cf0adc7eb8cda7e0a0ae4aee8aff82 yarn.lock 0 days 00:00:00 J .lock 1806271 xtend@^4.0.0, xtend@~4.0.1: b17eb263f8cf0adc7eb8cda7e0a0ae4aee8aff82 yarn.lock 0 days 00:00:00 J .lock 1806272 rows × 6 columns
Analysis
Finally, having this info, we can then group, and average
lifetimeon various parameters.For example, below, we see the average lifetime of every line conditional on file extension:
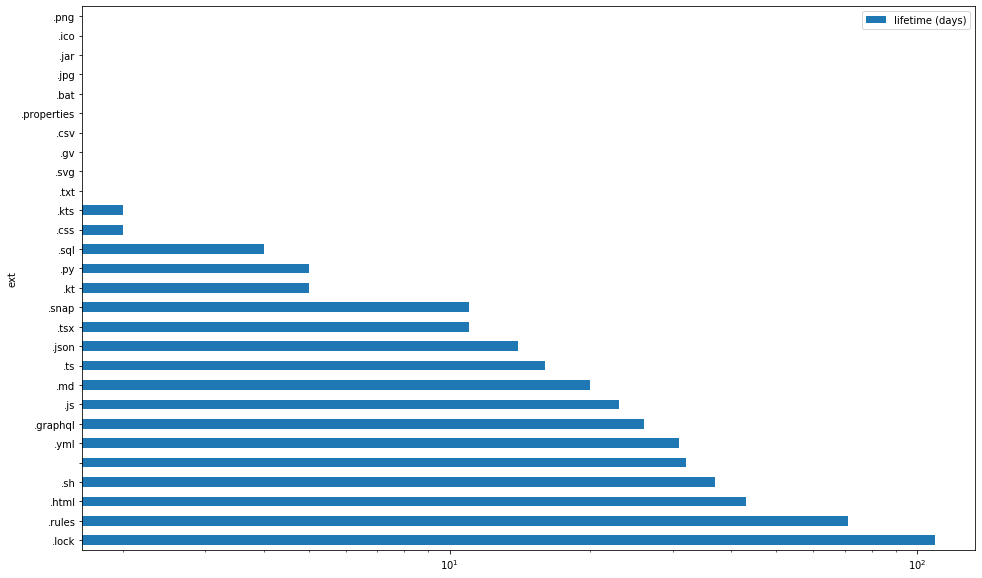
from datetime import timedelta from functools import reduce def averager(key, df=lines_df): ltk = "lifetime (days)" return pd.DataFrame([ {key:ext, ltk:(reduce(lambda t1,t2:t1+t2.to_pytimedelta(),slc["lifetime"],timedelta())/len(slc)).days } for ext,slc in df.groupby(key) ]).set_index(key).sort_values(by=ltk,ascending=False) averager("ext").plot.barh(figsize=(16,10),logx=True)
You can see that ironically, the lines that stay unchanged the longest, belong to "insignificant" files like
.lock(that's variousyarn.lock's),.rules(that's Firabase rules),.html(that'sindex.htmland since our project uses React, the mainindex.htmlalso receives almost no changes) and others. In particular, files with empty extension refer to.gitignore's.And finally, we can see the average lifetime of a line of code, conditional on author.
averager("author").plot.barh(figsize=(16,10))
We can see that the colleague I mentioned in the beginning (he goes by the nickname "J" here) indeed authored the longest-surviving lines in the whole repository. Good for him.
However, let's look more closely at the secret of his success:
_df = lines_df[[ext=="J" for ext in lines_df["author"]]].loc[:,["line","file","lifetime","ext"]] _df = averager(df=_df,key="ext") _df[[x>0 for x in _df["lifetime (days)"]]]
lifetime (days) ext .html 181 .lock 165 154 .rules 91 .yml 54 .md 39 .ts 38 .js 26 .json 18 .snap 11 .css 5 .tsx 4 Being the founder of the repository under consideration, he in particular mostly authored the aforementioned
index.html,yarn.lockand*.rulesfiles. As I explained before, these received almost no changes during the subsequent development.Further work
Since we store the info on filenames as well, we can compute the averages conditional on folders, thus seeing, which parts of project are more "stable" than the others.

- 投稿日:2020-08-03T08:34:07+09:00
Androidアプリ開発探求記(その4)
概要
今回は git の .ignore に関して、探求してみたいと思います。
やること
Android Studio で作成したデフォルトの .ignore ファイルに対して、以下のことをしてみようと思います。
- 現在の実験コード1上にフィルタリング対象が存在する項目に対してコメントを追加
- 現在の実験コード上にフィルタリング対象が存在しない項目を削除
※ 自明と思われるものについては例外的に .ignore に含めていこうと思います。2
背景
.ignore に関してはネット上に様々な情報が存在し、.ignore.io のような便利な自動生成ツールも存在します。
しかし、状況によっては必要となるグレーゾーンのファイルまでバッサリ切り捨ててしまっているため、弊害もあります。
例えば、開発プロジェクトでスペルチェック用辞書を共有する方法では辞書ファイルは idea/dictionaries フォルダ以下に配置されますが、.gitignore.io [AndroidStudio] ではバッサリ切り捨てられてしまっています。
実際問題としては、Android Studio 上での辞書共有にはいろいろと欠点もあるため、デフォルトでバッサリ切り捨ててしまったほうが安全だと思います。しかし、最初から切り捨ててしまうと、存在自体を気づけないという弊害があり、これは探求記的には許容できません。
ということで、今後 .ignore に関しては、全項目を把握していこうと思います。
Android Project
Android Studio で作成したデフォルトの .ignore ファイルは2つあります。
◆ Root Project
/build◆ Sub Project
*.iml .gradle /local.properties /.idea/caches /.idea/libraries /.idea/modules.xml /.idea/workspace.xml /.idea/navEditor.xml /.idea/assetWizardSettings.xml .DS_Store /build /captures .externalNativeBuild .cxx.gitignore を削除してみる
.gitignore を削除し、Reimport gradle project, Rebuild Project を行い、差分を確認してみます。
$ git status On branch comment_on_dot_ignore_files Changes to be committed: (use "git restore --staged <file>..." to unstage) deleted: .gitignore deleted: app/.gitignore Untracked files: (use "git add <file>..." to include in what will be committed) .gradle/ .idea/caches/ .idea/libraries/ .idea/modules.xml .idea/modules/ .idea/workspace.xml app/build/ local.properties必須の項目だけ復活させる
現状でフィルタが必要、もしくは自明の項目だけを復活させてみます。
### Android Studio ### # IDEAのモジュール定義ファイル。自動生成されるものなので、commit されるべきではない。 *.iml # IDEローカルのキャッシュ情報だと思われる。commit されるべきではない。 /.idea/caches # IDE上で利用されるライブラリの情報だと思われる。自動制裁される情報であり、共有の必要もないので、commit されるべきではない。 /.idea/libraries # IDE上のモジュール構成情報だと思われる。IDEの利用状況により異なる情報であり、共有の必要もないので、commit されるべきではない。 /.idea/modules.xml # IDEローカルの情報なので commit されるべきではない。 /.idea/workspace.xml # This file is automatically generated by Android Studio. This file should *NOT* be checked into Version Control Systems, as it contains information specific to your local configuration. /local.properties ### Gradle ### # gradle の work 領域。gradle により自動生成されるものなので commit されるべきではない。 .gradle # gradle の build 成果物用フォルダ。build により自動生成されるものなので commit されるべきではない。 /build ### MAC ### # MAC OS上の不可視ファイル。commit されるべきではない。 .DS_Store削除された項目
/.idea/navEditor.xml /.idea/assetWizardSettings.xml /captures .externalNativeBuild .cxxまとめ
今回は、Android Studio で作成したデフォルトの .ignore ファイルに対して、現時点で必須なものだけに対してコメントを付与し、そうでないものは削除してみました。
今後も同様の対応をしていこうと思います。
.DS_Storeなど ↩
- 投稿日:2020-08-03T01:24:46+09:00
年齢の commit graph 作成スクリプト(git merge --no-ff の説明用)
先日投稿した記事( Gitで急いで戻したいならmerge --no-ffを使う )でご紹介した、年齢のcommit graphを作成するスクリプトです
スクリプト
c.sh#!/bin/sh git init echo '0歳' > a.txt git add a.txt git commit -a -m '0歳' git tag -a age0 -m '0歳' # 0歳に戻ります git checkout master git reset --hard age0 #git log --oneline --graph # non fast-forward のcommit graphを作ります git checkout -b youjiki master echo '1歳' > a.txt; git commit -a -m '1歳' echo '2歳' > a.txt; git commit -a -m '2歳' echo '3歳' > a.txt; git commit -a -m '3歳' git checkout master git merge --no-ff youjiki -m '幼児期のおわり' #git log --oneline --graph git checkout -b youchien master echo '4歳' > a.txt; git commit -a -m '4歳' echo '5歳' > a.txt; git commit -a -m '5歳' echo '6歳' > a.txt; git commit -a -m '6歳' git checkout master git merge --no-ff youchien -m '幼稚園卒園' git log --oneline --graph # 0歳に戻ります git checkout master git reset --hard age0 git branch -D youjiki git branch -D youchien #git log --oneline --graph # fast-forward のcommit graphを作ります git checkout -b youjiki2 master echo '1歳' > a.txt; git commit -a -m '1歳' echo '2歳' > a.txt; git commit -a -m '2歳' echo '3歳' > a.txt; git commit -a -m '3歳' git checkout master git merge --ff youjiki2 -m '幼児期のおわり' #git log --oneline --graph git checkout -b youchien2 master echo '4歳' > a.txt; git commit -a -m '4歳' echo '5歳' > a.txt; git commit -a -m '5歳' echo '6歳' > a.txt; git commit -a -m '6歳' git checkout master git merge --ff youchien2 -m '幼稚園卒園' git log --oneline --graph git branch -D youjiki2 git branch -D youchien2実行結果
git merge --no-ff のグラフ
* fa6cf7c (HEAD -> master) 幼稚園卒園 |\ | * 0b9ffb0 (youchien) 6歳 | * 74a3283 5歳 | * 9dfb758 4歳 |/ * aace58b 幼児期のおわり |\ | * 6e848f8 (youjiki) 3歳 | * 0edd54f 2歳 | * d979b3a 1歳 |/ * 798a893 (tag: age0) 0歳git merge --ff のグラフ
* d35dd2e (HEAD -> master, youchien2) 6歳 * f758c86 5歳 * ceddede 4歳 * 88e1396 (youjiki2) 3歳 * be9c037 2歳 * 6b0691a 1歳 * 798a893 (tag: age0) 0歳使い方
- 適当なディレクトリに設置して
- 下記スクリプトをコピペして
- 保存し
- 実行してください
% mkdir agegraph % cd agegraph % vim c.sh % sh c.sh毎回手動で作るとけっこう大変だったので、もしよかったらご利用くださいませ。
元の記事は( Gitで急いで戻したいならmerge --no-ffを使う )です。