- 投稿日:2020-08-03T23:13:02+09:00
AtCoder Beginner Contest 174 C問題(Python)
最初に考えた方法
素直に7をいっぱい並べた数を作って、ひたすらKで割って0になるかを判定する。
Kが$10^6$以下なのでその範囲まで7を並べる。
7が$10^6$並んだものなんて考えたら当然TLEK = int(input()) flg = False for i in range(10 ** 6): n = int('7' * (i + 1)) if n % K == 0: flg = True break if flg: print(len(str(n))) else: print(-1)競プロの神(@tanakh)の解法と公式解説読んで作成
筆算的なものを実装すればよいらしい。
普通の筆算は割り切れるまで(気が済むまで)あまりに0を足して計算を続けるが、代わりに7を足すというもの。
例えば、 $ 10 \div 8 $は普通以下のようになる10 \div 8 = 1 \, あまり \, 2 \\ 20 \div 8 = 2 \, あまり \, 4 \\ 40 \div 8 = 5 \, あまり \, 0 \\ 答え: \,1.25これを以下のようにする。
10 \div 8 = 1 \, あまり \, 2 \\ (20 + 7) \div 8 = 3 \, あまり \, 3 \\ (30 + 7) \div 8 = 4 \, あまり \, 5 \\ ...Pythonで実装してみるとこんな。(数値例のK=101の場合)
一回一回の計算もあまりに対してなので高速。それを$10^6$回なら許容範囲。
(追記: コメントより、余りはK以下のK通りしかありえないのでK回で十分だそうです。ありがとうございます! )K = 101 cur = 7 for i in range(100): mod = cur % K print(f'{cur} % {K} = {mod}') if mod == 0: ans = i + 1 print(f'Answer: {ans}') break else: cur = mod * 10 + 7 """ (output) 7 % 101 = 7 77 % 101 = 77 777 % 101 = 70 707 % 101 = 0 Answer: 4 """最終的に以下でAC
K = int(input()) cur = 7 flg = False for i in range(10 ** 6): mod = cur % K if mod == 0: ans = i + 1 flg = True break else: cur = mod * 10 + 7 if flg: print(ans) else: print(-1)
- 投稿日:2020-08-03T22:56:29+09:00
PythonのSliceにモヤっとした話
モヤッとした
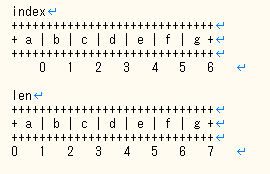
Python初心者がざっくり以下のようなコードを書いてるときに想定したのと違った結果が返ってきてモヤっとした話です。
コード
p=0 q=1 l=['a','b','c','d','e','f','g'] print(l[p:q]) #['a']ちなみに初心者の私が想定した出力結果のは以下の通りでした。
#['a','b']何故結果が異なる?
以下の記事で解決いたしました。
【Python】スライス操作についてまとめ
仕様ということのようです。でも納得行かない
参考のリンクを拝見させて頂いたりした結果、開発の意図としては
[a:b]という記述は between a to b であるという事のようです、日本語で言うならa以上b未満。しかし初見でこの記述をbetween a to b であるとを理解しろと言うのは中々ハードルが高い気がします。
[恵比寿:六本木]と記載されてる記述を見たら私は from 恵比寿 to 六本木だと解釈してしまうでしょう、まさか降りる駅が広尾だとは思いませんでした。
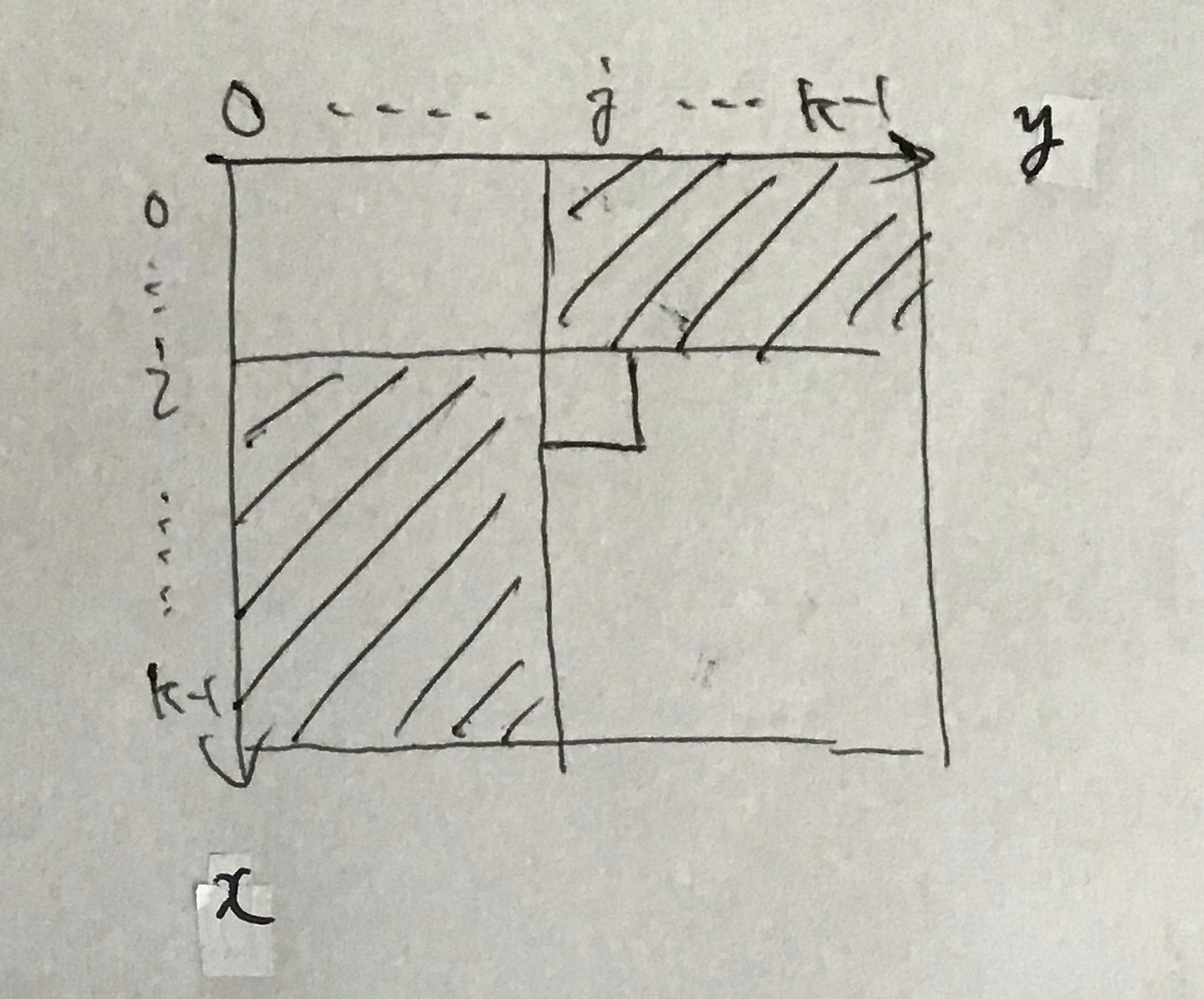
そもそも slice の a to b がそれぞれ上記画像の from index to len の意味になるわけで、感覚的もプログラマ的にも解釈するのは辛いと感じてしまいました。
そんな感じで[なんかの変数のindex,len(なんかの変数)]と指定して単一要素を取り出す事に意味が見いだせず調べ物に時間を費やしてしまう結果に。明確なメリットが有るんだよという回答をお持ちの方がいらっしゃったなら、是非ご教示いただければ幸いです。
気になりすぎて
ラブライブのMV自動再生してる暇がなかった
- 投稿日:2020-08-03T22:46:53+09:00
アルゴリズム 体操19 No-repeat Substring
No-repeat Substring
文字列を指定して、繰り返し文字がない最長の部分文字列の長さを見つけます。
例
Input: String="aabccbb"
Output: 3(abc)Input: String="abbbb"
Output: 2(ab)Input: String="abccde"
Output: 3 (abc" または cde)説明
この問題はスライディングウィンドウパターンで、動的スライディングウィンドウ戦略を使用できます。 HashMap(dict)を使用して、処理した各文字の最後のインデックスを記憶できます。 繰り返し文字を取得するたびに、スライディングウィンドウを縮小して、スライディングウィンドウに常に異なる文字があることを確認します。
実装
from collections import defaultdict def non_repeat_substring(str1): window_start = 0 max_length = 0 substring_frequency = defaultdict(int) for window_end in range(len(str1)): right_char = str1[window_end] substring_frequency[right_char] += 1 while substring_frequency[right_char] > 1: left_char = str1[window_start] substring_frequency[left_char] -= 1 if substring_frequency[left_char] == 0: del substring_frequency[left_char] window_start += 1 max_length = max(max_length, window_end - window_start + 1) return max_length
- 投稿日:2020-08-03T21:56:38+09:00
relation of the Fibonacci number series and the Golden ratio
relation of the Fibonacci number series and the Golden ratio
Fibonacci number series:
$$
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946, ...]
$$Fibonacci number series displayed by a recurrence relation:
$$
\displaystyle
\begin{eqnarray}
a_{n} &=& a_{n-2} + a_{n-1} \nonumber\\
n&\geq&2 \nonumber\\
a_0 = 0&,& a_1 = 1 \nonumber\\
\end{eqnarray}
$$Galden Ratio:
$$
\displaystyle
\begin{eqnarray}
1 &:& \frac{1+\sqrt{5}}{2} \nonumber\\
\frac{-1+\sqrt{5}}{2} &:& 1 \nonumber\\
\end{eqnarray}
$$https://en.wikipedia.org/wiki/Fibonacci_number
Fibonacci numbers are strongly related to the golden ratio: Binet's formula expresses the nth Fibonacci number in terms of n and the golden ratio, and implies that the ratio of two consecutive Fibonacci numbers tends to the golden ratio as n increases.
Fibonacci number series by Python
f = [0,1] for _ in range(50): f+=[f[-1]+f[-2]] print(f)[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946, 17711, 28657, 46368, 75025, 121393, 196418, 317811, 514229, 832040, 1346269, 2178309, 3524578, 5702887, 9227465, 14930352, 24157817, 39088169, 63245986, 102334155, 165580141, 267914296, 433494437, 701408733, 1134903170, 1836311903, 2971215073, 4807526976, 7778742049, 12586269025, 20365011074]Find the Golen ratio from Fibonacci number series
$$
\displaystyle
\begin{eqnarray}
A &=& \lim_{n \to \infty} \frac{a_{n-1}}{a_n} = \lim_{n \to \infty} \frac{a_{n-2}}{a_{n-1}} \nonumber\\
\frac{a_{n-1}}{a_n} = \frac{a_{n-1}}{a_{n-2}+a_{n-1}} &=& \left( \frac{a_{n-2}+a_{n-1}}{a_{n-1}}\right)^{-1} = \left(\frac{a_{n-2}}{a_{n-1}}+1\right)^{-1} \nonumber\\
A &=& \left(A+1\right)^{-1} \nonumber\\
A \cdot (A + 1) &=& 1 \nonumber\\
A^2 + A -1 &=& 0 \nonumber\\
\end{eqnarray}
$$Solve by SymPy
from sympy import Symbol,solve,factor a = Symbol('A') func = a*a + a - 1 a = factor(solve([func, a>0])) A = float(a.rhs.n()) display(func,a,a.n()) A$\displaystyle A^{2} + A - 1$
$\displaystyle A = \frac{-1 + \sqrt{5}}{2}$
$\displaystyle A = 0.618033988749895$0.6180339887498949Numerical iteration
Get the golden ratio from the fibonacci
table = [(i,a/b) for i,(a,b) in enumerate(zip(f,f[1:]))] table[(0, 0.0), (1, 1.0), (2, 0.5), (3, 0.6666666666666666), (4, 0.6), (5, 0.625), (6, 0.6153846153846154), (7, 0.6190476190476191), (8, 0.6176470588235294), (9, 0.6181818181818182), (10, 0.6179775280898876), (11, 0.6180555555555556), (12, 0.6180257510729614), (13, 0.6180371352785146), (14, 0.6180327868852459), (15, 0.6180344478216818), (16, 0.6180338134001252), (17, 0.6180340557275542), (18, 0.6180339631667066), (19, 0.6180339985218034), (20, 0.618033985017358), (21, 0.6180339901755971), (22, 0.6180339882053251), (23, 0.618033988957902), (24, 0.6180339886704432), (25, 0.6180339887802427), (26, 0.618033988738303), (27, 0.6180339887543226), (28, 0.6180339887482036), (29, 0.6180339887505408), (30, 0.6180339887496481), (31, 0.618033988749989), (32, 0.6180339887498588), (33, 0.6180339887499086), (34, 0.6180339887498896), (35, 0.6180339887498969), (36, 0.6180339887498941), (37, 0.6180339887498951), (38, 0.6180339887498948), (39, 0.6180339887498949), (40, 0.6180339887498948), (41, 0.6180339887498949), (42, 0.6180339887498948), (43, 0.6180339887498949), (44, 0.6180339887498949), (45, 0.6180339887498949), (46, 0.6180339887498949), (47, 0.6180339887498949), (48, 0.6180339887498949), (49, 0.6180339887498949), (50, 0.6180339887498949)]Good. Then, give a bias by -A to see the errors
import math error = [(i,a/b - A) for i,(a,b) in enumerate(zip(f,f[1:]))] error[(0, -0.6180339887498949), (1, 0.3819660112501051), (2, -0.1180339887498949), (3, 0.04863267791677173), (4, -0.018033988749894925), (5, 0.0069660112501050975), (6, -0.0026493733652794837), (7, 0.0010136302977241662), (8, -0.00038692992636546464), (9, 0.00014782943192326314), (10, -5.6460660007306984e-05), (11, 2.15668056606777e-05), (12, -8.237676933475768e-06), (13, 3.1465286196574738e-06), (14, -1.201864649025275e-06), (15, 4.590717869179528e-07), (16, -1.7534976970434712e-07), (17, 6.697765930763211e-08), (18, -2.5583188345557062e-08), (19, 9.771908504596638e-09), (20, -3.732536946188247e-09), (21, 1.4257022229458016e-09), (22, -5.445698336714599e-10), (23, 2.080070560239733e-10), (24, -7.945166746736732e-11), (25, 3.034783535582619e-11), (26, -1.1591949622413722e-11), (27, 4.427680444507587e-12), (28, -1.6913137557139635e-12), (29, 6.459277557269161e-13), (30, -2.468025783741723e-13), (31, 9.414691248821327e-14), (32, -3.608224830031759e-14), (33, 1.3655743202889425e-14), (34, -5.329070518200751e-15), (35, 1.9984014443252818e-15), (36, -7.771561172376096e-16), (37, 2.220446049250313e-16), (38, -1.1102230246251565e-16), (39, 0.0), (40, -1.1102230246251565e-16), (41, 0.0), (42, -1.1102230246251565e-16), (43, 0.0), (44, 0.0), (45, 0.0), (46, 0.0), (47, 0.0), (48, 0.0), (49, 0.0), (50, 0.0)]In the above, it indicates that the 39th iteration meets the golden ratio in $10^{-16}$ order (but the underflow issue occurred).
To avoid the underflow, use
decimalmodule.import decimal F = [0,1] for _ in range(500): F+=[F[-1]+F[-2]] decimal.getcontext().prec = 220 error2 = [(i,decimal.Decimal(a)/decimal.Decimal(b) - (-decimal.Decimal(1) + decimal.Decimal(5).sqrt())/decimal.Decimal(2)) for i,(a,b) in enumerate(zip(F,F[1:]))] error2[-50:][(451, Decimal('2.6586319293364935194863016834099E-189')), (452, Decimal('-1.0155070334308318486203693038262E-189')), (453, Decimal('3.878891709560020263748062280696E-190')), (454, Decimal('-1.481604794371742305040493803816E-190')), (455, Decimal('5.65922673555206651373419130762E-191')), (456, Decimal('-2.16163226293877649079763588460E-191')), (457, Decimal('8.2567005326426295865871634629E-192')), (458, Decimal('-3.1537789685401238517851315416E-192')), (459, Decimal('1.2046363729777419687682311629E-192')), (460, Decimal('-4.601301503931020545195619462E-193')), (461, Decimal('1.757540782015641947904546765E-193')), (462, Decimal('-6.71320842115905298518020825E-194')), (463, Decimal('2.56421744332073947649515719E-194')), (464, Decimal('-9.7944390880316544430526323E-195')), (465, Decimal('3.7411428308875685642063259E-195')), (466, Decimal('-1.4289894046310512495663445E-195')), (467, Decimal('5.458253830055851844927085E-196')), (468, Decimal('-2.084867443857043039117801E-196')), (469, Decimal('7.96348501515277272426327E-197')), (470, Decimal('-3.04178060688788778161170E-197')), (471, Decimal('1.16185680551089062057193E-197')), (472, Decimal('-4.4378980964478408010398E-198')), (473, Decimal('1.6951262342346161974012E-198')), (474, Decimal('-6.474806062560077911627E-199')), (475, Decimal('2.473155845334071760878E-199')), (476, Decimal('-9.44661473442137370999E-200')), (477, Decimal('3.60828574992340352128E-200')), (478, Decimal('-1.37824251534883685374E-200')), (479, Decimal('5.2644179612310704005E-201')), (480, Decimal('-2.0108287302048426632E-201')), (481, Decimal('7.680682293834575900E-202')), (482, Decimal('-2.933759579455301059E-202')), (483, Decimal('1.120596444531327286E-202')), (484, Decimal('-4.28029754138680789E-203')), (485, Decimal('1.63492817884715091E-203')), (486, Decimal('-6.2448699515464475E-204')), (487, Decimal('2.3853280661678342E-204')), (488, Decimal('-9.111142469570543E-205')), (489, Decimal('3.480146747033295E-205')), (490, Decimal('-1.329297771529334E-205')), (491, Decimal('5.07746567554716E-206')), (492, Decimal('-1.93941931134804E-206')), (493, Decimal('7.4079225849706E-207')), (494, Decimal('-2.8295746414305E-207')), (495, Decimal('1.0808013393219E-207')), (496, Decimal('-4.128293765343E-208')), (497, Decimal('1.576867902819E-208')), (498, Decimal('-6.02309943106E-209')), (499, Decimal('2.30061926507E-209')), (500, Decimal('-8.7875836406E-210'))]Plot iteration
The red dashed line indicates the golden ratio (
A = 0.6180339887498949).The curve indicates the convergence to A in the oscillation condition
from matplotlib import pyplot as plt import math plt.figure(figsize=(15,4),dpi=80,facecolor='white') plt.plot([a/b for a,b in zip(f,f[1:])]) plt.axhline(y=A,color='r',linestyle='dashed',alpha=0.4) plt.title(r'$\frac{a_n}{a_{n+1}}$') plt.yticks(ticks=[0,0.5,A,1],labels=['0.0','0.5','A','1.0']) plt.grid() plt.show()
See the errors
plt.figure(figsize=(16,15),dpi=60,facecolor='white') for i,(start,end) in enumerate([(0,51),(0,7),(6,13),(20,27),(36,43),(42,49)],start=1): plt.subplot(3,2,i) plt.plot(*list(zip(*error[start:end]))) plt.axhline(y=0,color='r',linestyle='dashed',alpha=0.4) plt.title(r'$\frac{a_n}{a_{n+1}}-A$, (Error['+str(start)+':'+str(end)+'])') plt.grid() plt.tight_layout() plt.show()
- $0 \leq n \leq 6$: The curve indicates the cnvergence to 0 in a simple oscillation
- $6 \leq n \leq 12$: The curve also indicates the cnvergence to 0 in more smaller oscillation
- $20 \leq n \leq 26$: The curve indicates an oscillation in $10^{-9}$ order's interval
- $39 \leq n$: The curve is incorrect shape by underflow issue
- $43 \leq n$: There are meaningless data. It indicates a horizontal line likes y=0, but this is just failing to calculate the values
Spread significant figures
list
errorissues underflow state, but listerror2works fine by thedecimal.Decimalmethod.plt.figure(figsize=(16,20),dpi=60,facecolor='white') for i,(start,end) in enumerate([(0,501),(0,7),(6,13),(20,27),(36,43),(42,49),(194,201),(494,501)],start=1): plt.subplot(4,2,i) plt.plot(*list(zip(*error2[start:end]))) plt.axhline(y=0,color='r',linestyle='dashed',alpha=0.4) plt.title(r'$\frac{a_n}{a_{n+1}}-A$, (Error2['+str(start)+':'+str(end)+'])') plt.grid() plt.tight_layout() plt.show()
- $194 \leq n \leq 200$: The curve also has a similar shape and more smaller oscillation in $10^{-82}$ order's interval
- $494 \leq n \leq 500$: The curve is still a similar and very micro oscillation in $10^{-207}$ order's interval



- 投稿日:2020-08-03T21:47:04+09:00
色々な確率分布の起こる現象を理解した上でpythonで実装
はじめに
確率論や統計学を勉強したら色々な確率分布が出られて、どんな分布がどんな状況で使うか迷ってしまうくらいいっぱいあるのですね。
自然に発生する現象における確率変数の値はどの確率分布で説明できるかは現象によって色々違うのです。
この記事では各種の確率分布が発生する現象をpythonでシミュレーションして分布を描いてみます。
実は分布の由来がわからなくても、scipyのscipy.statsモジュールを使ったら色んな確率分布を簡単に実装できますが、まずはどんな事情でどうやってこんな分布ができるかわかることに意味があると思います。
なのでここでpythonのrandomモジュールとnumpyだけで実装します。
一つずつランダムする時はrandomモジュールを、一気にたくさんランダムする時はnumpyを使います。(グラフはmatplotlibで)
その後scipy.statsでも使って結果を比較してみます。その分布の意味の理解が間違いなければ結果は一致するはずです。
scipy.statsの使い方についてはこの記事など https://qiita.com/supersaiakujin/items/71540d1ecd60ced65add 色んな記事に書いてあるのでは詳しく説明しません。
基本的に確率分布は離散型確率分布と連続型確率分布に二種類に分けられ、実装方法はちょっと違います。
主な違いとして例えば、離散型確率分布は確率質量関数(PMF)で確率分布を示するのに対し、連続型確率分布は確率密度関数(PDF)で確率分布を示します。
ここで説明する確率分布は
離散型確率分布
- 二項分布
- ベルヌーイ分布
- 幾何分布
- 負の二項分布
- ポアソン分布連続型確率分布
- 連続一様分布
- 指数分布
- 正規分布
- カイ二乗分布
- ベータ分布離散型確率分布
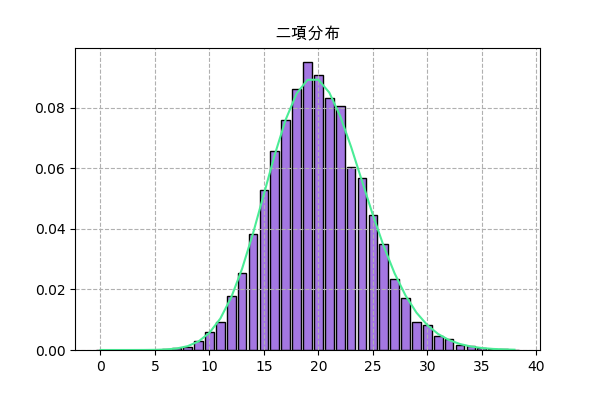
二項分布
成功か失敗のいずれかという結果になる実験をする時、成功する回数の確率分布は二項分布になるのです。
確率質量関数は
P(x) = C(n,x)p^x(1-p)^{n-x}p=成功する確率
n=行なった回数
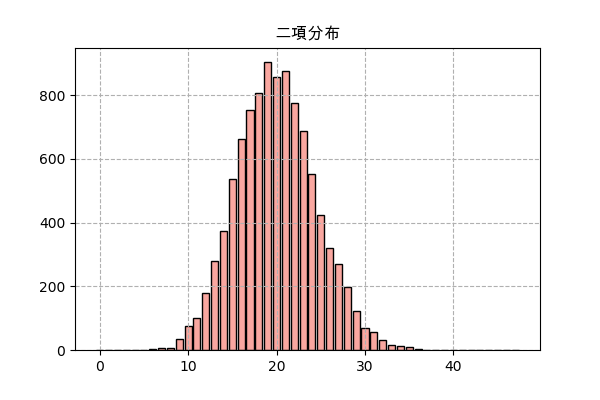
$C(n,x)$はn個からx個を選ぶ組合せ関数例えば、あるゲームではあるモンスターを倒すと確率pでアイテムをドロップし、もしn匹倒したらどれくらいアイテムがドロップするか、という話でドロップの数は二項分布になるはずです。
実際にランダムして結果を見てみます。ここでn=2000、p=0.01で、サンプリング回数は10000にします。
import random import numpy as np import matplotlib.pyplot as plt import scipy.stats # ここでまず全部使うモジュールをimportしておきます。 n_sampl = 10000 # サンプリング回数 n = 2000 # 倒すモンスターの数 p = 0.01 # アイテムがドロップする確率 n_drop = [] # 各ドロップ数の回数 for _ in range(n_sampl): # n個ランダムをしてp以下かどうか判断 drop = np.random.random(n)<=p n_drop.append(drop.sum()) # ドロップ数を格納 y = np.bincount(n_drop) # 各ドロップ数の回数を数える x = np.arange(len(y)) # 棒グラフを描く plt.title('二項分布',family='Arial Unicode MS') plt.bar(x,y,color='#f9a7a0',ec='k') plt.grid(ls='--') plt.savefig('binom.png',dpi=100) plt.close()
次はscipy.statsでの実装。ここで.rvs()を使ってランダムして、.pmf()を使ってグラフを書きます。
f = scipy.stats.binom(n,p) plt.title('二項分布',family='Arial Unicode MS') h = np.bincount(f.rvs(10000)) x = np.arange(len(h)) plt.bar(x,h/n_sampl,color='#a477e2',ec='k') plt.plot(x,f.pmf(x),'#4aec96') plt.grid(ls='--') plt.savefig('binom2.png',dpi=100) plt.close()
.rvs()で描いた分布は.pmf()のグラフと大体一致しますし、上の図とも一致します。だだし、ここでは全部合わせて1になるようにnサンプリング回数で割ります。
ベルヌーイ分布
二項分布でn=1の場合、ベルヌーイ分布と呼ばれます。
二項分布の確率質量関数にn=1にすると
P(x) = p^x(1-p)^{1-x}となります。1回の実行なので、結果は0(成功)と1(失敗)しかない。
コードは二項分布より簡単になります。
n_sampl = 10000 p = 0.2 # アイテムがドロップする確率 n_drop = [] # 各ドロップ数の回数(0か1) for _ in range(n_sampl): n_drop.append(random.random()<=p) # ランダム値がp以下かどうか y = np.bincount(n_drop) x = np.arange(len(y)) plt.title('ベルヌーイ分布',family='Arial Unicode MS') plt.bar(x,y,color='#f9a7a0',ec='k') plt.grid(ls='--') plt.savefig('bernulli.png',dpi=100) plt.close()
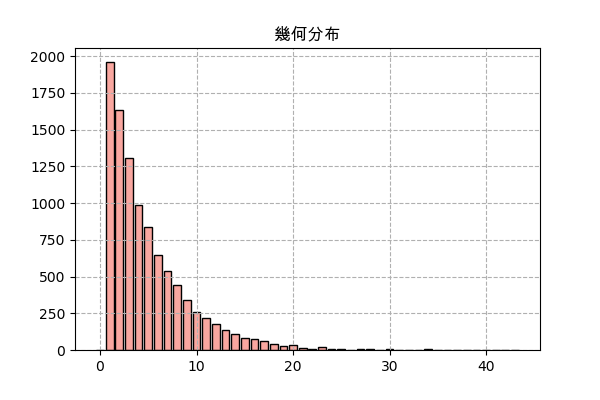
幾何分布
二項分布と同じように、幾何分布も成功と失敗のある実験を行なう時に発生する分布ですが、幾何分布で考慮するのは成功するまでの回数の分布です。
ある成功か失敗のいずれかになる実行を、成功するまでの回数の分布は幾何分布になるということです。
成功する確率はpだとしたら、成功するまでの回数の確率質量関数は
P(x) = p(1-p)^{x-1}例えば、ゲームで確率pでアイテムがドロップするモンスターが、何匹倒したらドロップするか、その回数の確率分布は幾何分布。
ランダムするものは二項分布の場合と同じですが、今回は倒すモンスターの数が固定ではなく、一回成功するまで繰り返すということになります。
n_sampl = 10000 # サンプリング回数 p = 0.2 # ドロップする確率 kaime_drop = [] # 何回目でドロップするかという結果を格納するリスト for _ in range(n_sampl): n_kai = 1 # 倒したモンスターの数 # 成功するまで繰り返す while(random.random()>p): n_kai += 1 # 成功した後で倒したモンスターの数を格納 kaime_drop.append(n_kai) y = np.bincount(kaime_drop) # 倒したモンスターの数を数える x = np.arange(len(y)) # 棒グラフを描く plt.title('幾何分布',family='Arial Unicode MS') plt.bar(x,y,color='#f9a7a0',ec='k') plt.grid(ls='--') plt.savefig('geom.png',dpi=100) plt.close()
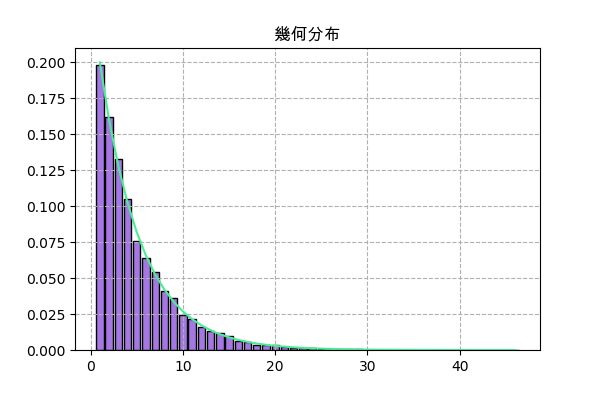
scipyで実装
f = scipy.stats.geom(p) plt.title('幾何分布',family='Arial Unicode MS') h = np.bincount(f.rvs(10000)) x = np.arange(1,len(h)) h = h[1:] plt.bar(x,h/n_sampl,color='#a477e2',ec='k') plt.plot(x,f.pmf(x),'#4aec96') plt.grid(ls='--') plt.savefig('geom2.png',dpi=100) plt.close()
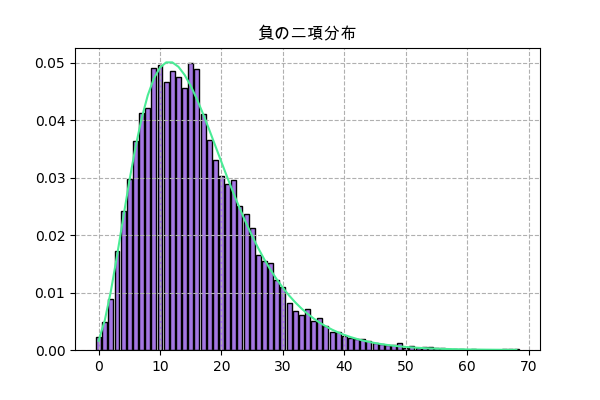
負の二項分布
幾何分布と似て、負の二項分布も実行する回数の分布ですが、一回成功するだけで満足するのではなく、ある特定の成功回数まで実行する回数を考えることになります。
確率質量関数は
P(x) = C(k+r-1,k)(1-p)^rp^kp=成功する確率
r=達成したい回数rが1だったら幾何分布になります。
例えば、確率pでアイテムをドロップするモンスターから、アイテムをr個欲しい場合、どれくらい倒す必要があるか、という例題。
やり方のは幾何分布よりちょっと複雑になりますが、ほぼ同じ。
n_sampl = 10000 p = 0.2 # ドロップする確率 r = 4 # 欲しい成功回数 kaime_drop = [] for _ in range(n_sampl): n_kai = 0 # 倒したモンスターの回数 n_drop = 0 # ドロップ回数 # 何回も繰り返しモンスターを倒す while(n_drop<r): # ドロップかどうか if(random.random()<=p): n_drop += 1 n_kai += 1 # r回ドロップした後、倒したモンスターの回数を格納 kaime_drop.append(n_kai) y = np.bincount(kaime_drop) x = np.arange(len(y)) plt.title('負の二項分布',family='Arial Unicode MS') plt.bar(x,y,color='#f9a7a0',ec='k') plt.grid(ls='--') plt.savefig('nbinom.png',dpi=100) plt.close()
scipyで実装
f = scipy.stats.nbinom(r,p) plt.title('負の二項分布',family='Arial Unicode MS') h = np.bincount(f.rvs(10000)) x = np.arange(len(h)) plt.bar(x,h/n_sampl,color='#a477e2',ec='k') plt.plot(x,f.pmf(x),'#4aec96') plt.grid(ls='--') plt.savefig('nbinom2.png',dpi=100) plt.close()
ポアソン分布
ある出来事がどんな時でも同じ確率で起きる場合、ある特定の区間の中に起きる回数はポアソン分布となります。
確率質量関数は
P(x) = \frac{λ^x e^{-λ}}{x!}λ=ある特定の区間の中で起きる平均回数
例えば、あるゲームでモンスターが大体一時間にλ回現れるとしたら、実際に各一時間の間に現れる回数。
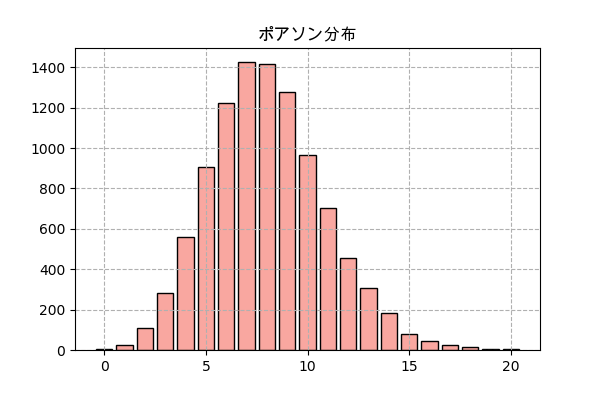
n = 10000 # 分ける時間の区間の数 λ = 8 # ある時間にある平均回数 # 起きる時間をランダム jikan = np.random.uniform(0,n,n*λ) # 1時間単位に分けて、各区間の中の回数を数える kaisuu = np.bincount(jikan.astype(int)) # 回数の分布を見るために、どれくらいの回数が何個あるか数える y = np.bincount(kaisuu) x = np.arange(len(y)) plt.title('ポアソン分布',family='Arial Unicode MS') plt.bar(x,y,color='#f9a7a0',ec='k') plt.grid(ls='--') plt.savefig('poisson.png',dpi=100) plt.close()やや複雑ですが、要するにまずは起こる時間をランダムします。ある区間でλくらい回起きるというのだから、ランダムの範囲は分ける区間の数(n)と同じにして、ランダム回数はnλにします。
その後、np.bincount()で各区間に起きる回数を数えます。
そして全部の区間の起きる回数の分布を数えるために又np.bincount()を使います。
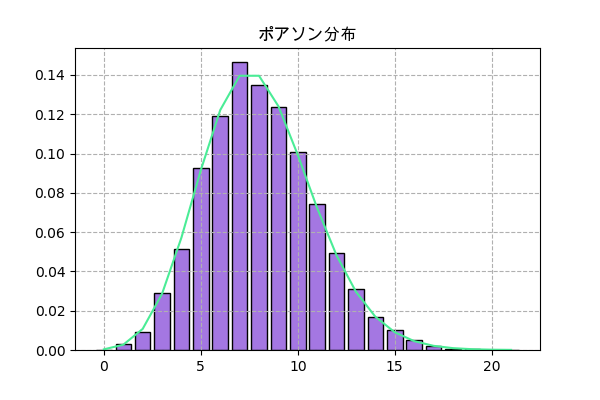
scipyでの実装
f = scipy.stats.poisson(λ) plt.title('ポアソン分布',family='Arial Unicode MS') h = np.bincount(f.rvs(10000)) x = np.arange(len(h)) plt.bar(x,h/n,color='#a477e2',ec='k') plt.plot(x,f.pmf(x),'#4aec96') plt.grid(ls='--') plt.savefig('poisson2.png',dpi=100) plt.close()
連続型確率分布
ある特定の数字だけの確率を持つ離散型確率分布とは違って、連続値型確率分布の場合ある特定の数字になる確率が0になり、代わりに求まるのは値が各範囲にあるという確率なので、確率密度関数で確率分布を表示することになります。
連続一様分布
連続一様分布は、ある範囲の中だけで同じような確率分布を持つという簡単な分布です。
確率密度関数は
f(x) = \frac{1}{b-a}a=分布範囲の最小
b=分布範囲の最大簡単にnp.random.uniformやrandom.uniformで実装できます。
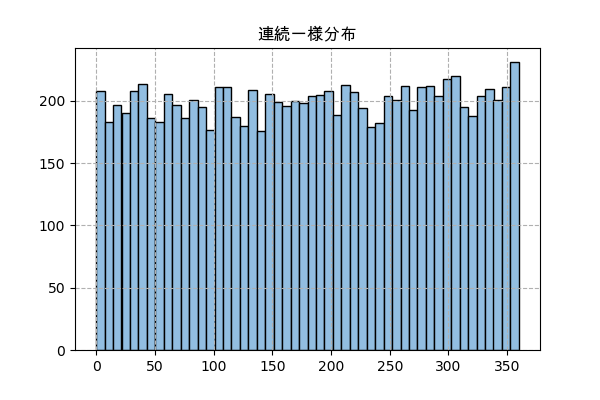
例えば、ある区間のないルーレットの話です。そのルーレットにボールを投げたら普通に考えると、0度から360度まで同じ確率に止まるはずです。
n_sampl = 10000 a = 0 # 最小限 b = 360 # 最大限 x = np.random.uniform(a,b,n_sampl) # ランダム # ヒストグラムを書く plt.title('連続一様分布',family='Arial Unicode MS') plt.hist(x,50,color='#92bee1',ec='k') plt.grid(ls='--') plt.savefig('uniform.png',dpi=100) plt.close()
連続一様分布は場合、np.bincount()で数を数えて棒グラフを描くのではなく、plt.hist()で密度を示すヒストグラムにします。
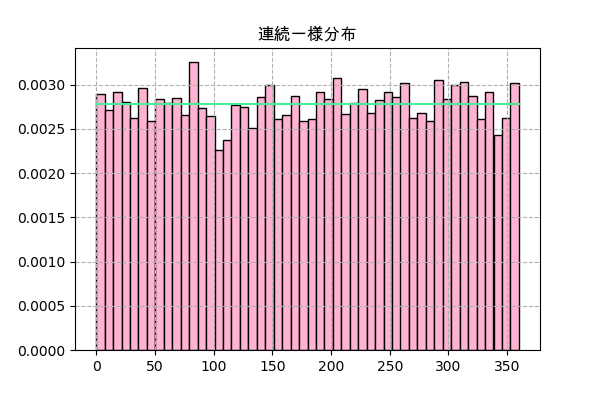
scipyにはscipy.stats.uniformがありますが、.rvs()を使う場合はあまりnp.random.uniformと変わらないようです。
scipy.statsで分布関数のメソッドは離散型とは違って、連続型は.pmf()ではなく、.pdf()になります。
plt.hist()で.rvs()の分布を描く時density=Trueにしたら全部のサンプル数で割られて.pdf()の値と一致することになります。
f = scipy.stats.uniform(a,b) plt.title('連続一様分布',family='Arial Unicode MS') _,h,_ = plt.hist(f.rvs(10000),50,color='#ffb3d3',ec='k',density=True) x = np.linspace(h.min(),h.max(),101) plt.plot(x,f.pdf(x),'#4aec96') plt.grid(ls='--') plt.savefig('uniform2.png',dpi=100) plt.close()
指数分布
指数分布はポアソン分布が発生する同時に発生する分布です。
ある出来事がある時間の中でいつでも起これるとしたら、毎回起きる間の時間の分布は指数分布になります。
確率密度関数は
f(x) = λe^{-λx}ポアソン分布の場合と同じく、λはある特定の区間の中に起きる平均回数
例えば、モンスターが一時間でλ回現れるとしたら、一匹が現れた後、どれくらい待ったら次は現れるか、という話。
やり方はポアソン分布と似ていますが、指数分布の方が簡単に見えます。
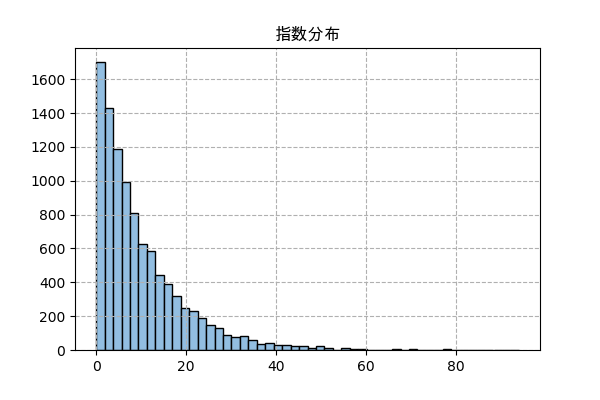
n = 10000 # 時間の長さ λ = 10 # 一時間で起きる平均回数 t = np.random.uniform(0,n*λ,n) # 起きる時間をランダム t = np.sort(t) # 並べ替え x = t[1:]-t[:-1] # 時間の差 # ヒストグラムを描く plt.title('指数分布',family='Arial Unicode MS') plt.hist(x,50,color='#92bee1',ec='k') plt.grid(ls='--') plt.savefig('expon.png',dpi=100) plt.close()
scipyで実装
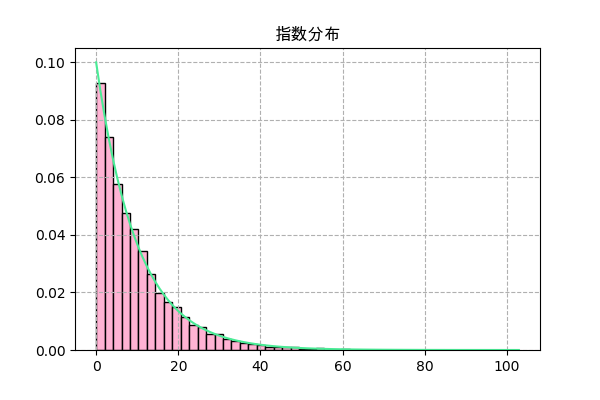
f = scipy.stats.expon(0,λ) plt.title('指数分布',family='Arial Unicode MS') _,h,_ = plt.hist(f.rvs(10000),50,color='#ffb3d3',ec='k',density=True) x = np.linspace(h.min(),h.max(),101) plt.plot(x,f.pdf(x),'#4aec96') plt.grid(ls='--') plt.savefig('expon2.png',dpi=100) plt.close()
正規分布
正規分布、またはガウス分布は一番起こりやすい分布なので、ありふれた分布で世界最強。
正規分布は色んな状況で発生できますが、今回は中心極限定理によって発生する正規分布を試します。
中心極限定理によると、あるたくさんの確率変数の平均値を取ったら、(元々の分布はどうであれ)その平均値の確率分布は正規分布になるということです。
正規分布の確率密度関数は
f(x) = \frac{1}{\sqrt{2πσ^2}}e^{\left(-\frac{(x-μ)^2}{2σ^2}\right)}連続一様分布の例題と同じように無限ルーレットで試しますがね今回は100回の結果の平均値の分布を見ます。
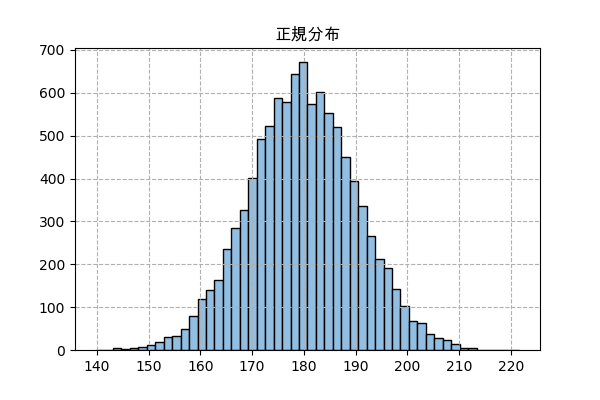
n_sampl = 10000 n = 100 a,b = 0,360 x = np.random.uniform(a,b,[n_sampl,n]).mean(1) plt.title('正規分布',family='Arial Unicode MS') plt.hist(x,50,color='#92bee1',ec='k') plt.grid(ls='--') plt.savefig('norm.png',dpi=100) plt.close()
次はscipy.statsで正規分布を実装しますが、まずは平均値と標準偏差を合わせるために計算が必要です。
連続一様分布の平均値は$\frac{b+a}{2}$で、標準偏差は$\frac{(b-a)^2}{12}$ですが、大数の法則$n$によると、回試した結果の標準偏差は$\frac{1}{\sqrt{n}}$となります。
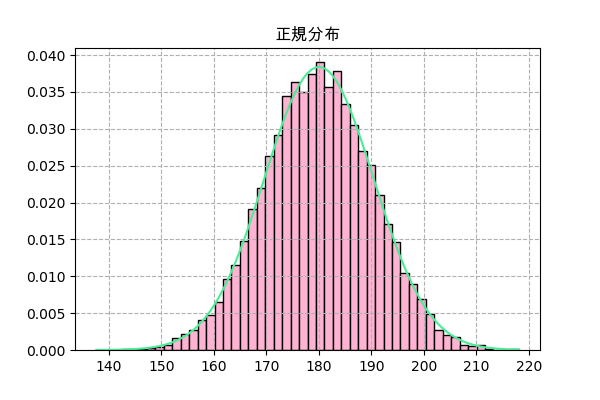
μ = (a+b)/2 # 平均値μを計算 σ = np.sqrt((b-a)**2/12/n) # 標準偏差σを計算 f = scipy.stats.norm(μ,σ) plt.title('正規分布',family='Arial Unicode MS') _,h,_ = plt.hist(f.rvs(10000),50,color='#ffb3d3',ec='k',density=True) x = np.linspace(h.min(),h.max(),101) plt.plot(x,f.pdf(x),'#4aec96') plt.grid(ls='--') plt.savefig('norm2.png',dpi=100) plt.close()
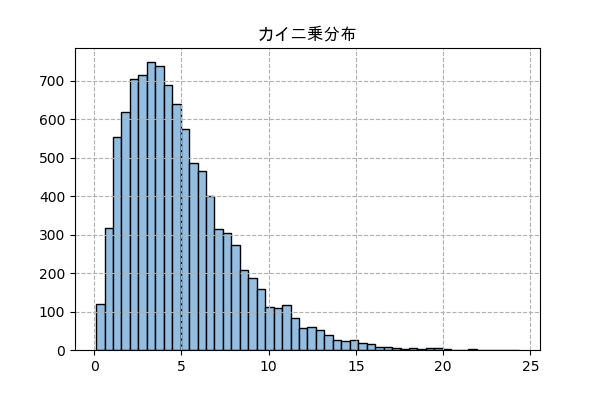
カイ二乗分布
正規分布に従う確率変数をk回試したら、$\sum_{i=1}^{k}x_i^2$の分布はカイ二乗分布になります。
改二とは関係ない確率密度関数は
f(x) = \frac{x^{k/2-1}e^{-x/2}}{\,2^{k/2} \Gamma(k/2)}正規分布のランダムから始める実装
n_sampl = 10000 k = 5 randn = np.random.randn(n_sampl,k) x = (randn**2).sum(1) plt.title('カイ二乗分布',family='Arial Unicode MS') plt.hist(x,50,color='#92bee1',ec='k') plt.grid(ls='--') plt.savefig('chi2.png',dpi=100) plt.close()
scipyで実装
f = scipy.stats.chi2(k) plt.title('カイ二乗分布',family='Arial Unicode MS') _,h,_ = plt.hist(f.rvs(10000),50,color='#ffb3d3',ec='k',density=True) x = np.linspace(h.min(),h.max(),101) plt.plot(x,f.pdf(x),'#4aec96') plt.grid(ls='--') plt.savefig('chi22.png',dpi=100) plt.close()
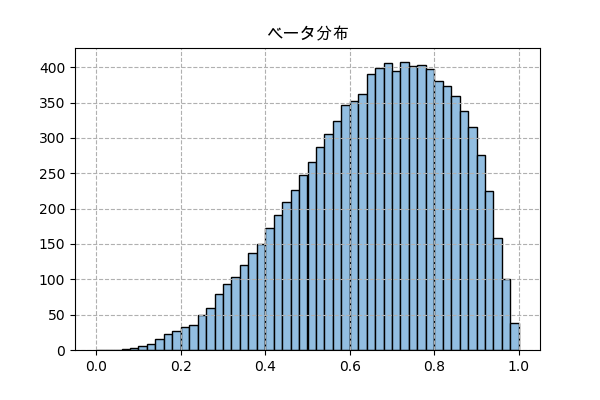
ベータ分布
ベータ分布はベイズ確率を考える時に発生する確率分布で、かなり他の分布より複雑です。
ある出来事が発生する確率が不明で、成功する回数からその確率を推測する場合、その確率の確率分布はベータ分布になります。
確率密度関数は
f(x) = \frac{x^{α-1}(1-x)^{β-1}}{B(α,β)}α-1=成功の回数
β-1=失敗の回数
Bはベータ関数詳しくはこの完全独習 ベイズ統計学入門という本で書いてあります。
この分布を表現する方法は色々あるはずですが、ここでは0から1の確率の区間を50に分けて考慮します。
4回の中で3回成功するという場合を考えます。
n_sampl = 10000 # サンプリング回数 n_bin = 50 # 分ける区間の数 n = 4 # 全部の回数 k = 3 # 成功の回数 p = [] # 区間の番号を格納するリスト x = (np.arange(n_bin)+0.5)/n_bin # 各区間の確率の中心 (0.01, 0.03, 0.05, ..., 0.99) i_shikou = 0 # 試行した回数 while(i_shikou<n_sampl): rand = np.random.random(n) # 成功か失敗かを決める数字をランダム for i in range(n_bin): # その区間の確率での場合で成功する回数 if((rand<=x[i]).sum()==k): # 特定の数と同じなら区間の番号を格納 p.append(i) i_shikou += 1 y = np.bincount(p) plt.title('ベータ分布',family='Arial Unicode MS') plt.bar(x,y,width=1/n_bin,color='#92bee1',ec='k') plt.grid(ls='--') plt.savefig('beta.png',dpi=100) plt.close()
plt.histではなくnp.bincountとplt.barを使っているが、ベータ分布も連続型分布だから実際に描いたのはヒストグラム。
scipy.statsで実装
α = k+1 # 4 β = n-k+1 # 2 f = scipy.stats.beta(α,β) plt.title('ベータ分布',family='Arial Unicode MS') plt.hist(f.rvs(10000),50,color='#ffb3d3',ec='k',density=True) x = np.linspace(0,1,101) plt.plot(x,f.pdf(x),'#4aec96') plt.grid(ls='--') plt.savefig('beta2.png',dpi=100) plt.close()
纏め
実際にランダムして結果を見ると、やはりこういう分布がこうやって起こるんだな、と実感できて理解を深めて納得できますね。
以上説明した分布をここで纏めています。
名 関数 xの範囲 scipy.stats パラメータ 二項分布 $C(n,x)p^x(1-p)^{n-x}$ 0,1,2,...,n scipy.stats.binom(n,p) $n\in${$1,2,3,...$}, $p\in[0,1]$ ベルヌーイ分布 $p^x(1-p)^{1-x}$ 0,1 scipy.stats.bernoulli(p) $p\in[0,1]$ 幾何分布 $p(1-p)^{x-1}$ 1,2,... scipy.stats.geom(p) $p\in[0,1]$ 負の二項分布 $C(x+r-1,x)(1-p)^rp^x$ 0,1,2,... scipy.stats.nbinom(r,p) $r\in${$1,2,3,...$}, $p\in[0,1]$ ポアソン分布 $\frac{λ^x e^{-λ}}{x!}$ 0,1,2,... scipy.stats.poisson(λ) $\lambda\in(0,\infty)$ 連続一様分布 $\frac{1}{b-a}$ [a,b] scipy.stats.uniform(a,b) $a\in(-\infty,\infty)$, $b\in(-\infty,\infty)$ 指数分布 $λe^{-λx}$ [0,∞) scipy.stats.expon(0,λ) $\lambda\in(0,\infty)$ 正規分布 $\frac{1}{\sqrt{2πσ^2}}e^{\left(-\frac{(x-μ)^2}{2σ^2}\right)}$ (-∞,∞) scipy.stats.norm(μ,σ) $\mu\in(-\infty,\infty)$,$\sigma\in(0,\infty)$ カイ二乗分布 $\frac{x^{k/2-1}e^{-x/2}}{\,2^{k/2} \Gamma(k/2)}$ [0,∞) scipy.stats.chi2(k) $k\in${$1,2,3,...$} ベータ分布 $\frac{x^{α-1}(1-x)^{β-1}}{B(α,β)}$ [0,1] scipy.stats.beta(α,β) $\alpha\in(0,\infty)$,$\beta\in(0,\infty)$ この記事にも参考
https://qiita.com/qiita_kuru/items/d9782185652351c78aac
https://qiita.com/hamage/items/738b65668b1093dd9660




- 投稿日:2020-08-03T21:14:08+09:00
ABC174
AtCorder Beginner Contest 174 に参加しました。
ABDの3問ACでした。
Python3を使用しています。A問題
ifで条件分岐させます。
import sys def input(): return sys.stdin.readline()[:-1] def main(): s=int(input()) if s >= 30: print("Yes") else: print("No") if __name__ == "__main__": main()B問題
i番目の点と中心からの距離の2乗の値を、リストL[i]に入れます。
これがDの2乗より大きいかifで判定します。import sys def input(): return sys.stdin.readline()[:-1] def main(): N, D = map(int,input().split()) X = [0] * N Y = [0] * N L = [0] * N ans = 0 for i in range(N): X[i], Y[i] = map(int, input().split()) L[i] = X[i] ** 2 + Y[i] ** 2 if L[i] <= D ** 2: ans += 1 print(ans) if __name__ == "__main__": main()C問題
$7、77、777、…$となる数列に$K$で割った余りが$0$となる数を求めます。
数列は$70、700、7000…$と増えるため、$K$と$10$が互いに素である場合のみしか成り立たない。
(この数列が$7$の倍数のため、$70$でなく$10$としている)
まずKが$2$の倍数または$5$の倍数のとき、数列にKの倍数は現れないので場合分けをします。
次に$7、77、777、…$となる数列を作り、それがKで割った余りが$0$となるまでwhile文で繰り返します。
$ x = (x * 10 + 7) % K $ではなく$ x = (x + 7 * 10 ** i) % K $
とすると$ 7 $ * $ 10 $ ** $ i $を計算するのに時間がかかるため、TLEとなりました。(2020/08/04編集しました)
下記は時間が終わってからACになった回答です。import sys def input(): return sys.stdin.readline()[:-1] def main(): K = int(input()) x = 0 i = 0 if K % 2 == 0 or K % 5 == 0: print(-1) exit() while True: x = (x * 10 + 7) % K i += 1 if x == 0: print(i) break if __name__ == "__main__": main()D問題
左から右に並べられたN個の石を、左側にR右側にWとなるように並べます。
問題文を読むと、2つの石を入れ替える操作と1つの石の色を変える操作があります。
しかし、最小回数の操作で並べることを考えると、2つの石を入れ替える操作のみ行えば良いことが分かります。
まず石の並び順を文字列として読み込み、白い石の数wを求めます。
左から0~w番目は白い石であるべきなので、この範囲にある赤い石の数を求めます。
これが操作を行うべき数となり、答えです。import sys def input(): return sys.stdin.readline()[:-1] def main(): N = int(input()) c = list(input()) w = c.count("R") hidari = c[:w] ans = 0 for i in hidari: if i == "W": ans += 1 print(ans) if __name__ == "__main__": main()
- 投稿日:2020-08-03T20:21:39+09:00
PDFファイルにページ番号を追加する方法(Pythonで)
Table of Contents
はじめに
小学生の娘が算数で間違った問題を、スキャンしてまとめてPDF化しています。しかし、必要なページだけ印刷したつもりが、結構ページ番号がずれていて、何度もやりなおしたりしています。電子化したつもりが意外とアナログです。そこで、自動でPDFファイルにページ番号を付けたいと思いました。ヒューマンエラーによるページ番号のずれが防げる、またはずれてもすぐに気がつくので。
しかし、PDFにページ番号を付けたいという単純なことなのに、意外にも良い実現方法が見つかりません。検索した結果、いくつかWebサービスを見つけて試してみましたが、あるものはページを入れる位置が気に入らない、またあるものは、たくさんページ番号を付けていると有料になる(しかも月極subscription)などでした。
そこで、最近使えるようになって気を良くしているPythonで、PDFにページ番号が付けられないか調べてみたのですが、このユースケースに対応するPDFライブラリは無さそう(少なくとも単体では)、ということがわかりました。
この記事は https://achiwa912.github.io/ にも載せました。
ReportLab PDFライブラリ
PythonでのPDFライブラリで有名なものは、PyPDF2, pdfrwあたりのようです。これらは、複数のPDFファイルをマージしたり、逆に分割したり、ページを入れ替えたりといったことが得意ですが、「既存PDFファイルにページ番号を付加する」というユースケースには対応していないようです。
更に調べてみると、どうやらReportLabライブラリでページ番号を付けられそうだ、ということがわかりました。
https://www.blog.pythonlibrary.org/2013/08/12/reportlab-how-to-add-page-numbers/このWebページはとても期待させるタイトルなのですが、サンプルコードを見てみると疑問がわいてきます。そもそも、既存PDFファイルを読み込んでおらず、新規に作成したPDFのページにページ番号を付与しているようです。駄目じゃん。。。
マニュアルにも一通り目を通してみます。
https://www.reportlab.com/docs/reportlab-userguide.pdfここでも、既存PDFファイルを読み込む説明はありませんでした。
ReportLab + pdfrwを組み合わせる
それでも諦めずに検索を続けたところ、見つけました。
https://stackoverflow.com/questions/28281108/reportlab-how-to-add-a-footer-to-a-pdf-fileさすがstackoverflow! 日本のqiitaと並んで大好きです。
どうやら、ReportLabとpdfrwを組み合わせるとできそうなことが書いてあります。
気になる記述もありますが。。。DISCLAIMER: Tested on Linux using as input file a pdf file generated by Reportlab. It would probably not work in an arbitrary pdf file.
「ReportLabで作成したPDFファイルでテストしたけど、任意のPDFファイルだと動かないんじゃないかな」
・・・えー!! でもこれしか頼れる物がありません。試してみましょう。
stakoverflowのページに載っているサンプルコードを改変してみます。
from reportlab.pdfgen.canvas import Canvas from pdfrw import PdfReader from pdfrw.toreportlab import makerl from pdfrw.buildxobj import pagexobj import sys import os if len(sys.argv) != 2 or ".pdf" not in sys.argv[1].lower(): print(f"Usage: python {sys.argv[0]} <pdf filename>") sys.exit() input_file = sys.argv[1] output_file = os.path.splitext(sys.argv[1])[0] + "_pgn.pdf" reader = PdfReader(input_file) pages = [pagexobj(p) for p in reader.pages] canvas = Canvas(output_file) for page_num, page in enumerate(pages, start=1): canvas.doForm(makerl(canvas, page)) footer_text = f"{page_num}/{len(pages)}" canvas.saveState() canvas.setStrokeColorRGB(0, 0, 0) canvas.setFont('Times-Roman', 14) canvas.drawString(290, 10, footer_text) canvas.restoreState() canvas.showPage() canvas.save()そして実行すると、、、、
あれ、さくっと動いてしまいました。念のため、ページの下に書いてある7/88というところが、今回入れたページ番号です。あのdisclaimerは何だったのか。。。使用方法
f-stringを使っているので、python 3.6以降で使ってください。
PDFライブラリインストール
pip install reportlab pip install pdfrw上記コードをaddpagenum.pyとしてセーブ。(ファイル名は好きに変えてください)
実行
python addpagenum.py <pdf_filename>ページ番号はA4でページ中央下に表示します。
カスタマイズ方法
このあたりを適当に変えてください。
footer_text = f"{page_num}/{len(pages)}" canvas.setFont('Times-Roman', 14) canvas.drawString(290, 10, footer_text)
- 表示内容を変える場合はfooter_textを変える
- ページ番号表示位置を変えたい場合は、x=290, y=10を変える
なお、ReportLabのcanvasにおいて、座標の(x=0, y=0)はページ左下になっています。
A4以外のLetter等にしたい場合は、canvasオブジェクトを作成する際に指定します。
詳しくはReportLabマニュアルを参照してください。
- 投稿日:2020-08-03T18:41:03+09:00
Windows 10 on ARM 用 Python3 を Windows 10 on ARM 上の Visual Studio 2019 (x86) でビルドする
はじめに
前回投稿の「Windows 10 on ARM 用 7-zip (19.00) を Windows 10 on ARM 上の Visual Studio 2019 (x86) でビルドする」に続きまして、今回は Python3 をビルドしてみました。
自分自身はあまり Python の経験はないのですが、OSS のビルド補助スクリプトとしてちょこちょこ使用されているのは見かけているので、ネイティブにしておくとそれなりに便利かなぁと思って調べていましたら こちら の方で何やらいけそうな感じのやり取りを見かけましたのでチャレンジしてみた次第です。
Python3 のビルド
とりあえず今回は現時点の Stable である 3.8 系でいきます。
少しばかし制約(後述)はありますが、以下のコマンド群でサクッとビルドできました。git clone https://github.com/python/cpython -b 3.8 cd .\cpython\PCbuild build.bat -p ARM64 -c Release
制約
Python ビルド時に NuGet で各種外部モジュールが
.\cpython\externals以下にインストールされるようですが、いくつかの外部モジュールは ARM64 用が未対応で入ってなく、ビルドがスキップされています。そのなかでも Python 標準の GUI モジュールである tkinter (TclTk) が使用できないのは少し寂しいかなぁと思いまして TclTk のビルドにもチャレンジしてみました。
tkinter (TclTk) のビルド
今回の Python ビルド時に NuGet でインストールされた TclTk はバージョン 8.6.9 でしたが、ビルドが少しでも通りやすくなっていると信じて こちら のサイトから tcl8610-src.zip および tk8610-src.zip をダウンロードして作業場所に展開します。
ファイル内容修正
スクリプトが対応できていないようなので、今回は強引に ARM64 を指定しました。
.\tcl8.6.10\winのrules.vc
473行目の MACHINE パラメーターに ARM64 をセット
MACHINE=$(ARCH)→MACHINE=ARM64また、cpuid関数はアセンブラっぽいので、今回は強引にオミットしました。
.\tcl8.6.10\winのtclWin32Dll.c
820行目をコメントアウト
__cpuid(regsPtr, index);→/*__cpuid(regsPtr, index);*/※ Tk のビルド時にも Tcl 側の上記ファイルを参照するようで、Tk 側は修正しなくてもいいみたいです。
TclTk のビルド
普通に展開したならば、それぞれ
.\tcl8.6.10\winと.\tk8.6.10\winのフォルダ位置でコマンド ウィンドウを立ち上げます。いつものように ARM64 用のツールセット環境を準備して
"C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Auxiliary\Build\vcvarsall.bat" x86_arm64いざ、ビルド開始!
なのですが、何故か Windows 10 on ARM 上でビルドする場合は 「TCLSH_NATIVE が設定されていません」と怒られるので、とりあえず python のビルド時に NuGet でインストールされた TclTk の x86 版を指定しておきました。
nmake -f makefile.vc release OPTS=threads TCLSH_NATIVE="work\cpython\externals\tcltk-8.6.9.0\win32\bin\tclsh86t.exe"基本的には上記のコマンドでビルドは通りましたが、Tcl 側ビルドの sqlite モジュールのコンパイル時に下記のようにリソースコンパイラ絡みのエラーでスキップがありました。
.\tcl8.6.10\pkgs\sqlite3.30.1.2\win\Release_ARM64_VC1926\sqlite_ThreadedDynamic\sqlite.rc(4) : error RC2167 : unrecognized VERSIONINFO field; BEGIN or comma expected NMAKE : fatal error U1077: '"C:\Program Files (x86)\Windows Kits\10\bin\10.0.19041.0\x86\rc.EXE"' : リターン コード '0x2' Stop.多分 tkinter には影響ないであろうと思い今回はスルーしました。 ^^;
今後、気が向いた時にでも ARM64 用ビルド時のリソースコンパイラの扱いも調べてみようとは思います。TclTk のインストール
とりあえずバージョン番号の違いは気にせず、Python のビルド時に NuGet でインストールされた TclTk のところの arm64 フォルダに突っ込んでいます。
nmake -f makefile.vc install INSTALLDIR="work\cpython\externals\tcltk-8.6.9.0\arm64" TCLSH_NATIVE="work\cpython\externals\tcltk-8.6.9.0\win32\bin\tclsh86t.exe"tkinter のビルド(Python のリビルド)
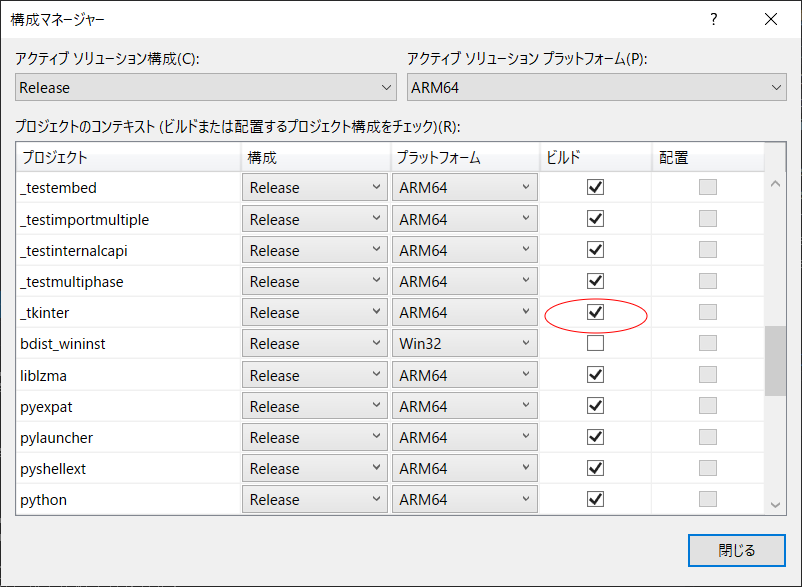
以上、TclTk の準備が整ったので tkinter のビルド(Python のリビルド)をするのですが、うまい具合にリコンフィグしてくれるのかよくわからなかったので今回は
.\cpython\PCbuild内にあるpcbuild.slnから Visual Studio の IDE を立ち上げて、こちらの「ビルドの構成」で tkinter を追加してリビルドしました。
詳細な動作検証まではしていませんが、とりあえず tkinter による GUI ウィンドウが立ち上がるところまでどうにか漕ぎ着けることができました。
おわりに
この、悪戦苦闘しつつも少しづつ環境が充実していく感じがマイナー機ならではの味わいですかね?
とはいえ、普及に弾みをつけるためにも、早く公式から ARM64 版が配布されるようになるよう願っています。

- 投稿日:2020-08-03T18:32:56+09:00
Pythonで地理院地図タイルを敷き詰める
背景
「地図を背景に路線図を作りたい」という場合、これまで自分の手作業で地理院地図タイル画像Excel方眼紙にコピペして敷き詰めていましたが、たいへん面倒な作業ですのでPythonにやらせることにしました。
地理院地図タイルとは
詳しいことはこちらに記載されていますが、要するに国土地理院が作成した地形図をタイル画像で利用できますよということです。
タイル画像には座標値があって、今回はそれを指定することで、欲しい領域の地図を取得することにしています。
その座標値は国土地理院のタイル座標確認ページでご確認ください。タイル画像を取得する
まず必要なライブラリをimportしておきます。
必要に応じてinstallしておいてください。
(pip install requestsなど)chiriinMap.pyimport cv2 import numpy as np import os import requestsタイル画像を取得し、保存する関数を次のように定義します。
下記ではカレントディレクトリにtileというフォルダを用意して保存しています。
ちなみに1枚分だけなので、
こんな感じです。chiriinMap.pydef get_tile(z, x, y): """ 今回は標準地図を取得するとしてURLを指定する。 与えられた座標に対応する地理院地図タイル画像を保存する。 """ url = "https://cyberjapandata.gsi.go.jp/xyz/std/{}/{}/{}.png".format(z, x, y) file_name = "tile/{}_{}_{}.jpg".format(z, x, y) response = requests.get(url) image = response.content with open(file_name, "wb") as aaa: aaa.write(image)領域を指定してタイル画像を取得する
先の
get_tile関数では地図タイル1枚分しか取得できませんので、領域まるごと取得するようにします。
将来に備えて、欲しい画像がすでに存在している場合はスキップさせています。
ただし、前回の取得からあまりにも時間が経過している場合、地図が更新されている場合もあるので、そういった場合は画像を削除するといいと思います。
次節で複数のタイル画像を1枚にまとめるので、個別の画像はその都度消してしまってもいいかもしれません。
そのあたりは皆さんにおまかせします。chiriinMap.pydef get_tile_area(north_west, south_east): """ 北西端・南東端のタイル座標を指定した上で、タイル画像を取得する。 """ assert north_west[0] == south_east[0], "ズームレベルzを確認してください。" zoom = north_west[0] im_v_lst = [] for i in range(south_east[1]-north_west[1]+1): for j in range(south_east[2]-north_west[2]+1): filepath = path = "tile/{}_{}_{}.jpg".format(zoom, i+north_west[1], j+north_west[2]) if os.path.exists(filepath) == True: continue get_tile(zoom, i+north_west[1], j+north_west[2])領域内のタイル画像を1枚の画像にまとめる
膨大な時間を費やしていた敷き詰め作業は次のようにして克服します。
最後の画像の名前は自由に変更してください。chiriinMap.pydef cat_tile(north_west, south_east): zoom = north_west[0] im_v_lst = [] for i in range(south_east[2]-north_west[2]+1): im_h_lst = [] for j in range(south_east[1]-north_west[1]+1): path = "tile/{}_{}_{}.jpg".format(zoom, j+north_west[1], i+north_west[2]) im1 = cv2.imread(path,-1) im_h_lst.append(im1) im_h = cv2.hconcat(im_h_lst) im_v_lst.append(im_h) im_v = cv2.vconcat(im_v_lst) cv2.imwrite("tile/tile.png", im_v)やってみる
やってみます。
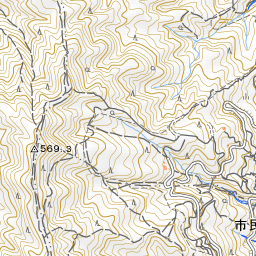
chiriinMap.pynorth_west = (15, 28223, 13124) south_east = (15, 28244, 13144) get_tile_area(north_west, south_east) cat_tile(north_west, south_east)
こんな感じです。福岡県の糸島半島です。
手作業だと何時間かかることか…
これで楽できますね。ちなみに、この画像そのままだと30MBくらいあります。
画質を落としてもいい場合は、サイズダウンしたほうがいいかもしれません。出典
地図画像:国土地理院
- 投稿日:2020-08-03T17:56:49+09:00
Google Ads APIでキーワードプランナーの検索ボリューム・CPC・競合性を取得する
はじめに
以前、AdWords APIを使ってキーワードプランナーのデータを取得する、というシステムを作ったのですが、
最近AdWords APIが終了する(?)という噂を耳にし、慌てて新しいGoogle Ads APIを試してみることになりました。Google Ads APIの公式サイトはこちら
Google Ads API Beta
※ 執筆時点(2020年8月3日時点)でまだBetaは取れていないようです。前回記事はこちら
AdWords APIでキーワードプランナーの検索ボリューム・CPC・競合性を取得するキーワードプランナーのデータを取得するまで
前回と同様、以下の流れで説明します。
- Google Ads APIを利用するための準備
- Google Ads API Client Library for Python のインストール
- OAuth2 認証の設定
- APIで検索ボリューム・CPC・競合性の取得
1. Google Ads APIを利用するための準備
Google Ads APIは無料で利用できますが、利用にあたってはMCCアカウントと開発者トークンの申請/承認手続きが必要です。
前回記事で取得しているため、ここでは省略します。
・Google Ads API 公式(クイックスタート)
・前回記事はこちら2. Google Ads API Client Library for Python のインストール
※ 既にインストール済みであればこの項は不要です。
今回はGoogleが提供しているAPIクライアントライブラリ(Python)を使って取得してみます。
こちらを参考にインストールしておきます。
Google Ads API Beta > クライアントライブラリを取得する
具体的には下記コマンドで入ります(pip)$ pip install google-ads※ 本記事で検証している
google-adsのバージョンは6.0.0です。
※ Pythonのバージョンは3.7以上3. OAuth2 認証の設定
前回記事で設定しているため、ここでは省略します。
・Google Ads API(クイックスタート)
・前回記事はこちら
※ 前回のAdWords APIとは変わって、今回の設定ファイルはgoogle-ads.yamlです。
※google-ads.yamlはこちらを参考にしました。
https://github.com/googleads/google-ads-python/blob/master/google-ads.yaml
※ Google Ads APIを有効にする必要があります。
Google Ads APIは、Google APIコンソールでAPIライブラリを広告に絞ると表示されます。
4. APIで検索ボリューム・CPC・競合性の取得
処理の流れをざっくり説明します。
公式の説明はここにあります。
https://developers.google.com/google-ads/api/docs/keyword-planning/generate-historical-metrics
キーワードプランナーのデータを取得するためにはKeywordPlanService.GenerateHistoricalMetricsを使う必要があります。
このAPIでは、流れとして
1. キーワードプラン(KeywordPlan,KeywordPlanCampaigns,KeywordPlanAdGroups,KeywordPlanKeywords, andKeywordPlanNegativeKeywords.)の作成
2. 過去の指標データ(KeywordPlanService.GenerateHistoricalMetrics)を取得
となるので、
まずは公式を参考にキーワードプランの作成部を起こし、
※ ここは公式のサンプルを参考にしました。KeywordPlanNegativeKeywordsについては今回は不要だと考えて省いてます。
その後過去の指標データを取得する部分を作ります。
※ 過去の指標データ(Historical Metrics)を取得するサンプルがないため、予測データ(Forecast Metrics)を取得するサンプルを参考にして過去の指標データ取得に書き換えます。以下が完成したサンプルコードです(Python3.7)
get_historical_metrics.py#!/usr/bin/env python3 # -*- coding: utf-8 -*- import argparse import sys import uuid from google.ads.google_ads.client import GoogleAdsClient from google.ads.google_ads.errors import GoogleAdsException ONE_MILLION = 1.0e6 def main(client, customer_id, target_keywords): # キーワードプランの作成 try: resource_name = add_keyword_plan(client, customer_id, target_keywords) except GoogleAdsException as ex: print(f'Request with ID "{ex.request_id}" failed with status ' f'"{ex.error.code().name}" and includes the following errors:') for error in ex.failure.errors: print(f'\tError with message "{error.message}".') if error.location: for field_path_element in error.location.field_path_elements: print(f'\t\tOn field: {field_path_element.field_name}') sys.exit(1) # 過去の指標データを取得 keyword_plan_service = client.get_service('KeywordPlanService') keyword_competition_level_enum = client.get_type('KeywordPlanCompetitionLevelEnum', version='v4').KeywordPlanCompetitionLevel try: response = keyword_plan_service.generate_historical_metrics(resource_name) except GoogleAdsException as ex: print('Request with ID "{}" failed with status "%s" and includes the ' 'following errors:'.format(ex.request_id, ex.error.code().name)) for error in ex.failure.errors: print('\tError with message "{}".'.format(error.message)) if error.location: for field_path_element in error.location.field_path_elements: print('\t\tOn field: {}'.format(field_path_element.field_name)) sys.exit(1) results = [] for i, historical in enumerate(response.metrics): metrics = historical.keyword_metrics results.append({ 'keyword': historical.search_query.value, 'avg_monthly_searches': metrics.avg_monthly_searches.value, 'competition': keyword_competition_level_enum.Name(metrics.competition), 'competition_index': metrics.competition_index.value, 'low_top_of_page_bid': metrics.low_top_of_page_bid_micros.value / ONE_MILLION, 'high_top_of_page_bid': metrics.high_top_of_page_bid_micros.value / ONE_MILLION }) print(results) def add_keyword_plan(client, customer_id, target_keywords): keyword_plan = create_keyword_plan(client, customer_id) keyword_plan_campaign = create_keyword_plan_campaign(client, customer_id, keyword_plan) keyword_plan_ad_group = create_keyword_plan_ad_group(client, customer_id, keyword_plan_campaign) create_keyword_plan_ad_group_keywords(client, customer_id, keyword_plan_ad_group, target_keywords) return keyword_plan def create_keyword_plan(client, customer_id): operation = client.get_type('KeywordPlanOperation', version='v4') keyword_plan = operation.create keyword_plan.name.value = (f'Keyword plan for traffic estimate {uuid.uuid4()}') forecast_interval = client.get_type('KeywordPlanForecastIntervalEnum', version='v4').NEXT_MONTH keyword_plan.forecast_period.date_interval = forecast_interval keyword_plan_service = client.get_service('KeywordPlanService', version='v4') response = keyword_plan_service.mutate_keyword_plans(customer_id, [operation]) resource_name = response.results[0].resource_name print(f'Created keyword plan with resource name: {resource_name}') return resource_name def create_keyword_plan_campaign(client, customer_id, keyword_plan): operation = client.get_type('KeywordPlanCampaignOperation', version='v4') keyword_plan_campaign = operation.create keyword_plan_campaign.name.value = f'Keyword plan campaign {uuid.uuid4()}' # 上限クリック単価は画面で作成した時のデフォルト値(260円)で設定してみる # この設定はキャンペーンではなくて広告グループや個々のキーワード毎でも設定できる keyword_plan_campaign.cpc_bid_micros.value = 260000000 keyword_plan_campaign.keyword_plan.value = keyword_plan keyword_plan_network = client.get_type('KeywordPlanNetworkEnum', version='v4') network = keyword_plan_network.GOOGLE_SEARCH keyword_plan_campaign.keyword_plan_network = network geo_target = client.get_type('KeywordPlanGeoTarget', version='v4') # 2392:日本 geo_target.geo_target_constant.value = 'geoTargetConstants/2392' keyword_plan_campaign.geo_targets.extend([geo_target]) language = client.get_type('StringValue', version='v4') # 1005:日本語 language.value = 'languageConstants/1005' keyword_plan_campaign.language_constants.extend([language]) keyword_plan_campaign_service = client.get_service('KeywordPlanCampaignService', version='v4') response = keyword_plan_campaign_service.mutate_keyword_plan_campaigns(customer_id, [operation]) resource_name = response.results[0].resource_name print(f'Created keyword plan campaign with resource name: {resource_name}') return resource_name def create_keyword_plan_ad_group(client, customer_id, keyword_plan_campaign): operation = client.get_type('KeywordPlanAdGroupOperation', version='v4') keyword_plan_ad_group = operation.create keyword_plan_ad_group.name.value = f'Keyword plan ad group {uuid.uuid4()}' #keyword_plan_ad_group.cpc_bid_micros.value = 2500000 keyword_plan_ad_group.keyword_plan_campaign.value = keyword_plan_campaign keyword_plan_ad_group_service = client.get_service('KeywordPlanAdGroupService', version='v4') response = keyword_plan_ad_group_service.mutate_keyword_plan_ad_groups(customer_id, [operation]) resource_name = response.results[0].resource_name print(f'Created keyword plan ad group with resource name: {resource_name}') return resource_name def create_keyword_plan_ad_group_keywords(client, customer_id, plan_ad_group, target_keywords): match_types = client.get_type('KeywordMatchTypeEnum', version='v4') keywords = [] for target_keyword in target_keywords: keyword_plan_ad_group_keyword = client.get_type('KeywordPlanAdGroupKeyword', version='v4') keyword_plan_ad_group_keyword.text.value = target_keyword #keyword_plan_ad_group_keyword.cpc_bid_micros.value = 2000000 keyword_plan_ad_group_keyword.match_type = match_types.BROAD keyword_plan_ad_group_keyword.keyword_plan_ad_group.value = plan_ad_group keywords.append(keyword_plan_ad_group_keyword) operations = [] for keyword in keywords: operation = client.get_type('KeywordPlanAdGroupKeywordOperation', version='v4') operation.create.CopyFrom(keyword) operations.append(operation) keyword_plan_ad_group_keyword_service = client.get_service('KeywordPlanAdGroupKeywordService', version='v4') response = (keyword_plan_ad_group_keyword_service.mutate_keyword_plan_ad_group_keywords(customer_id, operations)) for result in response.results: print('Created keyword plan ad group keyword with resource name: ' f'{result.resource_name}') if __name__ == '__main__': # GoogleAdsClient will read the google-ads.yaml configuration file in the # home directory if none is specified. google_ads_client = GoogleAdsClient.load_from_storage() parser = argparse.ArgumentParser(description='Creates a keyword plan for specified customer.') # The following argument(s) should be provided to run the example. parser.add_argument('-c', '--customer_id', type=str, required=True, help='The Google Ads customer ID.') args = parser.parse_args() target_keywords = ['ダイエット', '筋トレ', 'グルテンフリー'] main(google_ads_client, args.customer_id, target_keywords)※ ここでは「ダイエット」「筋トレ」「グルテンフリー」というキーワードでキーワードプランナーのデータを取得しています。
※google-ads.yamlはホームディレクトリに配置している想定です。場所を指定する場合はGoogleAdsClient.load_from_storage()の引数にパスを指定します。
※ 上限クリック単価は画面で作成した時のデフォルト値(260円)で設定
※ APIでは、low_top_of_page_bid(低額帯CPC)とhigh_top_of_page_bid(高額帯CPC)は単位がmicroのため、1000000で割っています。おわりに
Google広告に関するAPIは刷新され、今後はGoogle Ads APIに統一される流れのようです。
今回 AdWords API で行っていたキーワードプランナーのデータ取得を Google Ads API 移行してみましたが、APIだけでなくデータ項目等も変わっていて少し戸惑いました。
特にCPCが今回から低額帯と高額帯の2つに分かれており(キーワードプランナーの画面もそうなっている)今まで AdWords API で取得していた平均CPCとの整合性はどうすべきか。
低額帯と高額帯を単純に2つの平均で計算するか、もしくは今回使った過去の指標データ(Historical Metrics)ではなく予測データ(Forecast Metrics)のCPCを使うか。
時間ができればそのあたりも調べてみようと思っています。
- 投稿日:2020-08-03T17:45:45+09:00
pandas 1.1.0 および1.0.0の主な追加機能
この記事について
pandasは2020年7月28にバージョン1.0から1.1.0にアップデートされました。この記事で1.1.0の主な追加機能と、N番煎じではありますが、2020年1月の0.25.3から1.0.0へアップデートにおける主な追加機能についてまとめています。
公式の情報は
https://pandas.pydata.org/pandas-docs/dev/whatsnew/v1.0.0.html
https://pandas.pydata.org/pandas-docs/dev/whatsnew/v1.1.0.html
を参照ください。
検証環境
バージョン1.0は1.0.5、1.1は1.0.0で検証しています。0.25は0.25.1で検証しています。
1.0
pd.NA
0.25まではmissing valueを表すのに、floatなら
np.nan、object(文字列)ならばnp.nanorNone、時刻データならばpd.NaT、と様々な値が使われていた。1.0でmissing valuesを表すのに
pd.NAが導入された。例えば、
pd.Series([1, 2, None], dtype="Int64")の3要素目はバージョン0.25では
np.nanだったのが、1.0ではpd.NAとなる。0.25まではmissing(np.nan)が存在する数値カラムは強制的にfloat64になってしまっていたが、1.0ではpd.NAが存在するInt8型のカラムというのも可能。
string(StringDtype)型
stringデータのSeries(DataFrameのカラム)を表す型 string(StringDtype)型が追加された。文字列のSeries(or カラム)を扱うときはstring型の使用を推奨とのこと。
0.25まではstringデータを含むSeries(or カラム)を表すのはobject型だったため、
pd.Series(['abc', True, 'def'], dtype="object")(文字とbooleanの混合)が許されてしまう表現しかできなかったが、
1.0からは
pd.Series(['abc', 'def'], dtype="string")とすれば、そのSeries(or カラム)は文字列だけ許されることになる。
pd.Series(['abc', True, 'def'], dtype="string")はエラー。
pd.Series(['abc', 'def', None], dtype="string")の3要素目は
pd.NA。ただし
pd.Series(['abc', True, 'def'])(dtypeの指定なし)は従来通りobject型で、この表現も許容される。
boolean(booleanDtype)型
booleanデータを表す型 boolean(booleanDtype)型が追加された。boolean(TrueまたはFalse)のSeries(or カラム)を扱うときはboolean型の使用を推奨。
pd.Series([True, False, 0], dtype="booleal")はエラー。(dtypeの指定が無しならば、エラーなく許容。`dtype="bool" ならば0はFalseに変換される)
missing valueの取扱については、
pd.Series([True, False, np.nan]) pd.Series([True, False, None])の3要素目はそれぞれnp.nan、Noneだが
pd.Series([True, False, np.nan], dtype="boolean") pd.Series([True, False, None], dtype="boolean")とすると、3要素目はいずれもpd.NAとなる。
pd.Series([True, False, np.nan], dtype="bool") pd.Series([True, False, None], dtype="bool")の場合は、3要素目はそれぞれTrue、Falseになる。
convert_dtypes関数
df = pd.DataFrame({'x': ['abc', None, 'def'], 'y': [1, 2, np.nan], 'z': [True, False, True]})はx列:object、y列:float64、z列:bool となる。せっかくstring型、boolean型ができたのに...
そこで、
df.convert_dtypes()で、x列:string、y列:Int64、z列:boolean と変換される。Noneやnp.nanもこれでpd.NAとなる。
以上NAと型についての機能ははexperimentalな機能なため、変更の可能性があります。
ignore_index 引数
DataFrame.sort_values()とDataFrame.drop_duplicates()にignore_index引数が追加された。ignore_index=Trueでソート後などのindexが0から順に振り直される。pandasのindexうざい派には朗報。1.1
dtype="string", astype("string")
pd.Series([1, "abc", np.nan], dtype="string") pd.Series([1, 2, np.nan], dtype="Int64").astype("string")ですべての要素が文字列に。1.0までは要素がすべて文字列かnanじゃないとエラー。
groupby
df = pd.DataFrame([[1, 2, 3], [1, None, 4], [2, 1, 3], [1, 2, 2]], columns=["a", "b", "c"]) df.groupby(by=["b"], dropna=False).sum()の結果が
a c b 1.0 2 3 2.0 2 5 NaN 1 4のようになり、byで指定したカラムの値がNAの行ついても集計される。Rのdplyrのgroup_byと同じような挙動。
dropna=True、もしくは指定なしの場合は、byで指定したカラムの値がNAの行は集計されない。
- 投稿日:2020-08-03T17:17:44+09:00
女子プロゴルファーの顔診断AIを作ってみた②
1. はじめに
前回までにデータ前処理の部分である画像の収集、顔部分の取得、データの水増しまでを実施しました。
今回は、実際にモデルを作成して、精度を確かめました。
・自分で構築したモデル
・転移学習(VGG16)
の2つについて書こうと思います。2. 訓練データとテストデータに分けたファイルの作成
preparation.pyfrom PIL import Image import os, glob import numpy as np from PIL import ImageFile import cv2 from keras.utils.np_utils import to_categorical # IOError: image file is truncated回避のため ImageFile.LOAD_TRUNCATED_IMAGES = True # 訓練データの作成 # それぞれ空のリストを作成 img_shibuno = [] img_koiwai = [] img_hara = [] img_lists = [img_shibuno, img_koiwai, img_hara] # face以下のパスを取得 in_dir = './face/*' in_file = glob.glob(in_dir) # 各フォルダ(選手)ごとに処理を行う for num in range(len(in_file)): # 選手のファイルの中の各画像のパスを取得 in_file_name = glob.glob(in_file[num]+'/*') # 各画像について処理を行う for i in range(len(in_file_name)): # イメージを開く img = Image.open(in_file_name[i]) img = img.convert("RGB") # サイズを調整する img = img.resize((64,64)) # ndarrayに変換 data = np.asarray(img) # img_listsに追加する img_lists[num].append(data) # 画像が入ったリストを結合 X_train = np.array(img_shibuno+img_koiwai+img_hara) # それぞれ0~2までの値をいれる y_train = np.array([0]*len(img_shibuno) + [1]*len(img_koiwai) + [2]*len(img_hara)) # テストデータの作成 # それぞれ空のリストを作成 img_shibuno = [] img_koiwai = [] img_hara = [] img_lists = [img_shibuno, img_koiwai, img_hara] in_dir = './valid/*' in_file = glob.glob(in_dir) for num in range(len(in_file)): # 選手のファイルの中の各画像のパスを取得 in_file_name = glob.glob(in_file[num]+'/*') # 各画像について処理を行う for i in range(len(in_file_name)): # イメージを開く img = Image.open(in_file_name[i]) img = img.convert("RGB") # サイズを調整する img = img.resize((64,64)) # ndarrayに変換 data = np.asarray(img) # img_listsに追加する img_lists[num].append(data) # 画像が入ったリストを結合 X_test = np.array(img_shibuno+img_koiwai+img_hara) # それぞれ0~2までの値をいれる y_test = np.array([0]*len(img_shibuno) + [1]*len(img_koiwai) + [2]*len(img_hara)) # one-hot-vectorの処理を行う y_train = to_categorical(y_train) y_test = to_categorical(y_test) # 訓練データとバリデーションデータをファイルに保存する xy = (X_train, X_test, y_train, y_test) np.save('./golfer.npy', xy)これでデータ前処理は完了。次はモデルの評価を行う
3.モデルの作成と評価
自分で作成したモデルと転移学習(vgg16)のモデルそれぞれを作成
※以下のコードは説明のため分けて書いてますが一つにまとめてください。
3-1. モジュールをインポート
from keras.models import Model, Sequential from keras.layers import Conv2D, MaxPooling2D from keras.layers import Activation, Dropout, Flatten, Dense, Input from keras.applications.vgg16 import VGG16 from keras.utils import np_utils import keras from keras import optimizers, models, layers import numpy as np import matplotlib.pyplot as plt classes = ['shibuno', 'koiwai', 'hara'] num_classes = len(classes) image_size = 643-2. データを読み込む関数
def load_data(): X_train, X_test, y_train, y_test = np.load('./golfer.npy', allow_pickle=True) # 入力データの各画素値を0-1の範囲で正規化 X_train = X_train / 255 X_test = X_test / 255 return X_train, y_train, X_test, y_test3-3. モデルを学習する関数
※ 以下の①と②はいずれか一方のみ記述ください。
① 自分で作成したモデル
def train(X_train, y_train, X_test, y_test): model = Sequential() # Xは(296, 64, 64, 3): X.shepe[1:]で(64, 64, 3) model.add(Conv2D(32, (3, 3), padding='same', input_shape=X_train.shape[1:])) model.add(Activation('relu')) model.add(Conv2D(32, (3, 3))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.1)) model.add(Conv2D(64, (3, 3), padding='same')) model.add(Activation('relu')) model.add(Conv2D(64, (3, 3))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(512)) model.add(Activation('relu')) model.add(Dropout(0.45)) model.add(Dense(3)) model.add(Activation('softmax')) model.summary() # 最適化アルゴリズムRMSprop opt = keras.optimizers.rmsprop(lr=0.00005, decay=1e-6) model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy']) return model作成したモデルを可視化
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) (None, 64, 64, 3) 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, 64, 64, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, 64, 64, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, 32, 32, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, 32, 32, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, 32, 32, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, 16, 16, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, 16, 16, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, 16, 16, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, 16, 16, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, 8, 8, 256) 0 _________________________________________________________________ block4_conv1 (Conv2D) (None, 8, 8, 512) 1180160 _________________________________________________________________ block4_conv2 (Conv2D) (None, 8, 8, 512) 2359808 _________________________________________________________________ block4_conv3 (Conv2D) (None, 8, 8, 512) 2359808 _________________________________________________________________ block4_pool (MaxPooling2D) (None, 4, 4, 512) 0 _________________________________________________________________ block5_conv1 (Conv2D) (None, 4, 4, 512) 2359808 _________________________________________________________________ block5_conv2 (Conv2D) (None, 4, 4, 512) 2359808 _________________________________________________________________ block5_conv3 (Conv2D) (None, 4, 4, 512) 2359808 _________________________________________________________________ block5_pool (MaxPooling2D) (None, 2, 2, 512) 0 _________________________________________________________________ flatten_1 (Flatten) (None, 2048) 0 _________________________________________________________________ dense_1 (Dense) (None, 256) 524544 _________________________________________________________________ dropout_1 (Dropout) (None, 256) 0 _________________________________________________________________ dense_2 (Dense) (None, 3) 771 =================================================================② 転移学習
def train(X, y, X_test, y_test): input_tensor = Input(shape=(64, 64, 3)) vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor) # 特徴量抽出部分のモデルを作成しています top_model = vgg16.output top_model = Flatten(input_shape=vgg16.output_shape[1:])(top_model) top_model = Dense(256, activation='sigmoid')(top_model) top_model = Dropout(0.5)(top_model) top_model = Dense(3, activation='softmax')(top_model) # vgg16とtop_modelを連結してください model = Model(inputs=vgg16.input, outputs=top_model) # 以下のfor文を完成させて、15層目までの重みを固定させてください for layer in model.layers[:15]: layer.trainable = False # 学習の前に、モデル構造を確認してください model.summary() model.compile(loss='categorical_crossentropy', optimizer=optimizers.SGD(lr=1e-4, momentum=0.9), metrics=['accuracy']) return model作成したモデルを可視化
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) (None, 64, 64, 3) 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, 64, 64, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, 64, 64, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, 32, 32, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, 32, 32, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, 32, 32, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, 16, 16, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, 16, 16, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, 16, 16, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, 16, 16, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, 8, 8, 256) 0 _________________________________________________________________ block4_conv1 (Conv2D) (None, 8, 8, 512) 1180160 _________________________________________________________________ block4_conv2 (Conv2D) (None, 8, 8, 512) 2359808 _________________________________________________________________ block4_conv3 (Conv2D) (None, 8, 8, 512) 2359808 _________________________________________________________________ block4_pool (MaxPooling2D) (None, 4, 4, 512) 0 _________________________________________________________________ block5_conv1 (Conv2D) (None, 4, 4, 512) 2359808 _________________________________________________________________ block5_conv2 (Conv2D) (None, 4, 4, 512) 2359808 _________________________________________________________________ block5_conv3 (Conv2D) (None, 4, 4, 512) 2359808 _________________________________________________________________ block5_pool (MaxPooling2D) (None, 2, 2, 512) 0 _________________________________________________________________ flatten_1 (Flatten) (None, 2048) 0 _________________________________________________________________ dense_1 (Dense) (None, 256) 524544 _________________________________________________________________ dropout_1 (Dropout) (None, 256) 0 _________________________________________________________________ dense_2 (Dense) (None, 6) 1542 =================================================================3-4. 正答率と損失関数のグラフ作成の関数
def compare_TV(history): # パラメーターを設定する # 学習データに対する分類の正答率 acc = history.history['accuracy'] # バリデーションデータに対する分類の正答率 val_acc = history.history['val_accuracy'] # 学習データに対する損失関数の値 loss = history.history['loss'] val_loss = history.history['val_loss'] # バリデーションデータに対する損失関数の値 epochs = range(len(acc)) # 1) 正答率のグラフ plt.plot(epochs, acc, 'bo' ,label = 'training acc') plt.plot(epochs, val_acc, 'b' , label= 'validation acc') plt.title('Training and Validation acc') plt.legend() plt.figure() # 2) 損失関数のグラフ plt.plot(epochs, loss, 'bo' ,label = 'training loss') plt.plot(epochs, val_loss, 'b' , label= 'validation loss') plt.title('Training and Validation loss') plt.legend() plt.show()3-5. データの読み込みとモデルの学習を行う関数
def main(): # データの読み込み X_train, y_train, X_test, y_test = load_data() # モデルの学習 model = train(X_train, y_train, X_test, y_test) history = model.fit(X_train, y_train, batch_size=32, epochs=70, verbose=1, validation_data=(X_test, y_test)) # 汎化制度の評価・表示 score = model.evaluate(X_test, y_test, batch_size=32, verbose=0) print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score)) compare_TV(history) model.save('./golfer.h5')最後にmain()関数を記述して実行させる。
# これでモデルを学習させ、学習済モデルが生成される main()4. 学習結果
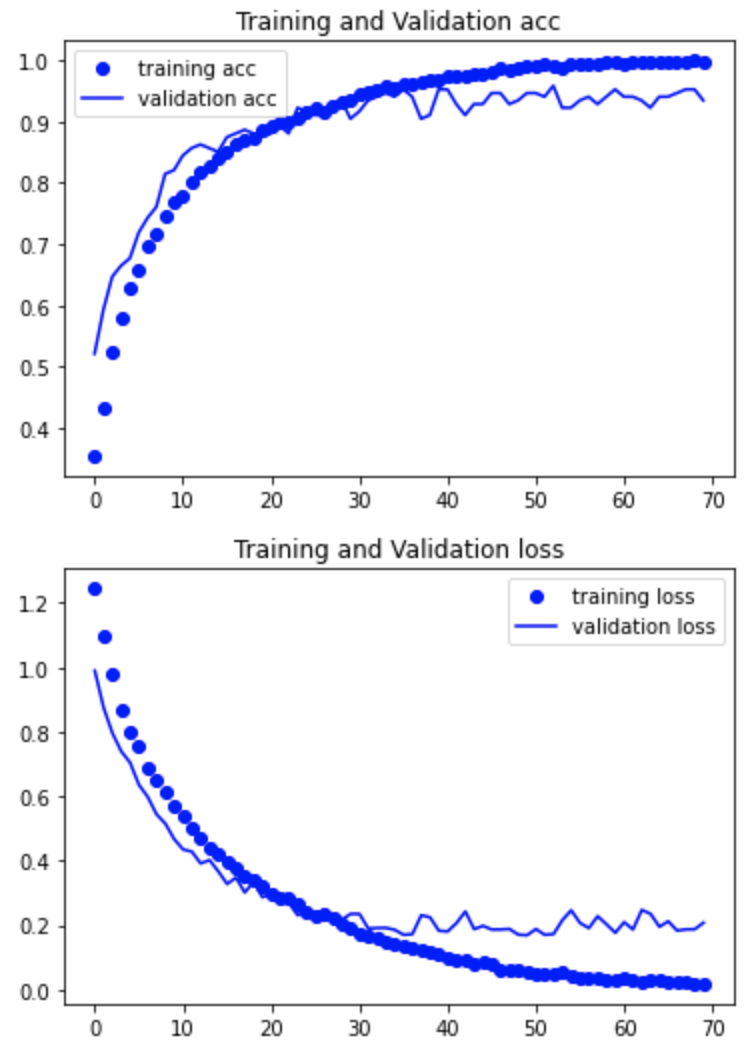
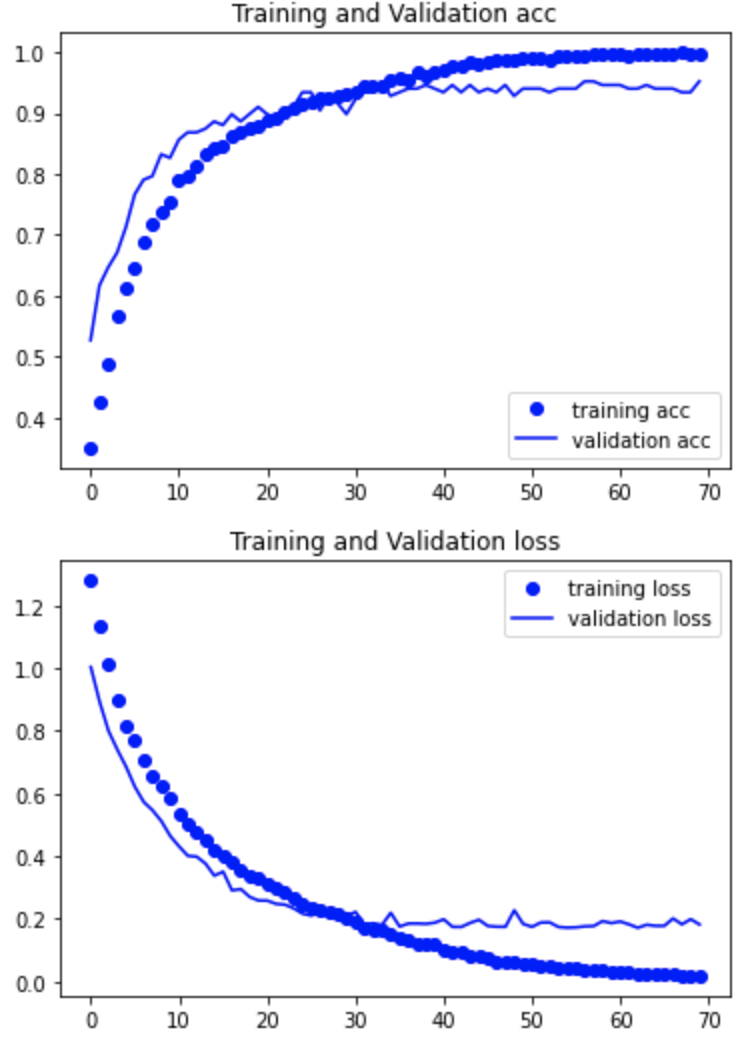
学習結果の正解率と損失関数をグラフにて確認する
① 自分で作成したモデル
正解率:0.93
② 転移学習
正解率:0.95
わずかにですが転移学習の方が上でしたので転移学習のモデルを採用します。
モデルの作成までが完了しました。次回は、アプリケーションを作成して、herokuで公開するところまで書こうと思います。
参考
- 投稿日:2020-08-03T16:39:41+09:00
Pandas で欠損値を含む整数型を扱う
従来、Pandas Series では欠損値を含む整数型は扱うことができなかった。
pd.Series([1, 2, None], dtype=int)TypeError: int() argument must be a string, a bytes-like object or a number, not 'NoneType'型を明示せずに欠損値を含む数値データを読み込んだ際は float64 型にキャストされる。
pd.Series([1, 2, None])0 1.0 1 2.0 2 NaN dtype: float64この振る舞いは「
numpy.nanは float 型の値だから」という理由に起因するが、我々は欠損値が扱いたいのであって別にnumpy.nanである必要はない。これに対して Pandas v0.24.0 から Nullable integer data type が追加された。
numpy.nanの代わりに新たにpandas.NAを導入することでこの問題に対応したようだ。pd.Series([1, 2, None], dtype=pd.Int64Dtype())0 1 1 2 2 <NA> dtype: Int64dtype に指定する値は
pd.Int64Dtype()の代わりに文字列"Int64"でも同様に動く。(Iが大文字である点に注意。)また、ドキュメントに
IntegerArray is currently experimental.
と書かれている通り、この機能はまだ実験段階なので利用する際は注意する必要がある。
- 投稿日:2020-08-03T15:20:19+09:00
パソコンに接続したカメラの映像をGUIに表示する。
1.やりたいこと
カメラから撮れた映像をGUIの画面上に表示します。
カメラのシャッターを押すと、スナップショットを取る機能も追加します。2.プログラムの内容
- OpenCVのVideoCapture()で、カメラのインスタンスを立てます。
- 映像(画像)を表示するスクリーンとしてTkinterのCanvasを使います。
- OpenCVのread()を利用し、カメラの停止画(Frame)を取得します。
- 3.で取得したカメラの停止画(Frame)をTkinterのCanvasに表示します。
- Pythonのupdate()とafter()を利用し、3-4のループを回します。(=Canvasに画像を表示する。これを一秒間数十回行うので、動画に見えます。)
3.設計
3.1. カメラのインスタンス
VideoCapture()を利用し、カメラのインスタンス vcapを立てます。
video_source = 0 内臓カメラ
video_source = 1 USBカメラ当時に、Videoの画像のwidthとheightも取得します。
self.vcap = cv2.VideoCapture( video_source ) self.width = self.vcap.get( cv2.CAP_PROP_FRAME_WIDTH ) self.height = self.vcap.get( cv2.CAP_PROP_FRAME_HEIGHT )3.2. TkinterのCanvas
Tkinterを利用し、Canvasインスタンスを立てます。
self.canvas1 = tk.Canvas(self.frame_cam) self.canvas1.configure( width= self.width, height=self.height) self.canvas1.grid(column= 0, row=0,padx = 10, pady=10)3.3. read()でカメラの停止画を取得
OpenCVのread()を利用して、vcapの画像を取得します。取得したものをframeに格納します。
BGRで取得したものをRGBに変換し、frameに改めて格納します。_, frame = self.vcap.read() frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)3.4.カメラの停止画をTkinterのCanvasに表示します。
一旦、取得したframeをPillowを利用し、photoに変換します。理由は、CanvasにはPillowで処理した画像しか表示できないからです。(多分)
そして、そのphotoをCanvasに表示します。#OpenCV frame -> Pillow Photo self.photo = PIL.ImageTk.PhotoImage(image = PIL.Image.fromarray(frame)) #self.photo -> Canvas self.canvas1.create_image(0,0, image= self.photo, anchor = tk.NW)3.5.Pythonのupdate()とafter()を利用し、3-4のループを回します。
delayでupdate周期を設定します。単位はミリ秒です。今回は15ミリ秒と設定します。
このdelayの値を変更したとき、動画のFPSがどう変わるか確かめてください。
update()をメインの部分に、after()を画像をCanvasに表示する部分に挿入します。self.delay = 15 #[mili seconds] self.update() #............... def update(self): #Get a frame from the video source _, frame = self.vcap.read() frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) self.photo = PIL.ImageTk.PhotoImage(image = PIL.Image.fromarray(frame)) #self.photo -> Canvas self.canvas1.create_image(0,0, image= self.photo, anchor = tk.NW) self.master.after(self.delay, self.update)3.6.スナップショット
スナップショットは、OpenCVのread()で習得したframeをRGBに変換した後、cv2.imwriteに保存することで処理します。
def press_snapshot_button(self): # Get a frame from the video source _, frame = self.vcap.read() frame1 = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) cv2.imwrite( "frame-" + time.strftime( "%Y-%d-%m-%H-%M-%S" ) + ".jpg", cv2.cvtColor( frame1, cv2.COLOR_BGR2RGB ) )4.実行結果
5.まとめ
- カメラから撮れた映像をGUIの画面上に表示できた。
- OpenCVとTkinterを利用します。
- Pythonのupdate(), after()を利用することが肝要です。
6.参考資料
1.Python OpenCV - show a video in a Tkinter window
2.【ラズベリーパイ】カメラモジュールの映像をTkinterに表示する方法
3.Python, OpenCVで動画を読み込み(ファイル・カメラ映像)
4.改造版: Pythonのtkinterでブロック崩しを作ってみた。7.プログラムコード
import tkinter as tk from tkinter import ttk import cv2 import PIL.Image, PIL.ImageTk from tkinter import font import time class Application(tk.Frame): def __init__(self,master, video_source=0): super().__init__(master) self.master.geometry("700x700") self.master.title("Tkinter with Video Streaming and Capture") # --------------------------------------------------------- # Font # --------------------------------------------------------- self.font_frame = font.Font( family="Meiryo UI", size=15, weight="normal" ) self.font_btn_big = font.Font( family="Meiryo UI", size=20, weight="bold" ) self.font_btn_small = font.Font( family="Meiryo UI", size=15, weight="bold" ) self.font_lbl_bigger = font.Font( family="Meiryo UI", size=45, weight="bold" ) self.font_lbl_big = font.Font( family="Meiryo UI", size=30, weight="bold" ) self.font_lbl_middle = font.Font( family="Meiryo UI", size=15, weight="bold" ) self.font_lbl_small = font.Font( family="Meiryo UI", size=12, weight="normal" ) # --------------------------------------------------------- # Open the video source # --------------------------------------------------------- self.vcap = cv2.VideoCapture( video_source ) self.width = self.vcap.get( cv2.CAP_PROP_FRAME_WIDTH ) self.height = self.vcap.get( cv2.CAP_PROP_FRAME_HEIGHT ) # --------------------------------------------------------- # Widget # --------------------------------------------------------- self.create_widgets() # --------------------------------------------------------- # Canvas Update # --------------------------------------------------------- self.delay = 15 #[mili seconds] self.update() def create_widgets(self): #Frame_Camera self.frame_cam = tk.LabelFrame(self.master, text = 'Camera', font=self.font_frame) self.frame_cam.place(x = 10, y = 10) self.frame_cam.configure(width = self.width+30, height = self.height+50) self.frame_cam.grid_propagate(0) #Canvas self.canvas1 = tk.Canvas(self.frame_cam) self.canvas1.configure( width= self.width, height=self.height) self.canvas1.grid(column= 0, row=0,padx = 10, pady=10) # Frame_Button self.frame_btn = tk.LabelFrame( self.master, text='Control', font=self.font_frame ) self.frame_btn.place( x=10, y=550 ) self.frame_btn.configure( width=self.width + 30, height=120 ) self.frame_btn.grid_propagate( 0 ) #Snapshot Button self.btn_snapshot = tk.Button( self.frame_btn, text='Snapshot', font=self.font_btn_big) self.btn_snapshot.configure(width = 15, height = 1, command=self.press_snapshot_button) self.btn_snapshot.grid(column=0, row=0, padx=30, pady= 10) # Close self.btn_close = tk.Button( self.frame_btn, text='Close', font=self.font_btn_big ) self.btn_close.configure( width=15, height=1, command=self.press_close_button ) self.btn_close.grid( column=1, row=0, padx=20, pady=10 ) def update(self): #Get a frame from the video source _, frame = self.vcap.read() frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) self.photo = PIL.ImageTk.PhotoImage(image = PIL.Image.fromarray(frame)) #self.photo -> Canvas self.canvas1.create_image(0,0, image= self.photo, anchor = tk.NW) self.master.after(self.delay, self.update) def press_snapshot_button(self): # Get a frame from the video source _, frame = self.vcap.read() frame1 = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) cv2.imwrite( "frame-" + time.strftime( "%Y-%d-%m-%H-%M-%S" ) + ".jpg", cv2.cvtColor( frame1, cv2.COLOR_BGR2RGB ) ) def press_close_button(self): self.master.destroy() self.vcap.release() def main(): root = tk.Tk() app = Application(master=root)#Inherit app.mainloop() if __name__ == "__main__": main()

- 投稿日:2020-08-03T14:32:14+09:00
[失敗談] ndarray に + 1 したら、意図せず dtype が変わってしまった
前提
拙作の強化学習用ライブラリcpprbの開発の中で遭遇したバグ (issue)
強化学習のExperience Replay用にデータを一時保存しておくためのライブラリであり、そのデータの型はユーザーがコンストラクタで指定し、内部ではNumpyのndarrayとして保存していた。
バグ (失敗)
先日、(厳密には違うが)こんな感じのコードで ndarray に加算を行ったところ、意図せず dtype まで変わってしまい挙動がおかしくなってしまった。
バグimport numpy as np def create_buffer(shape,dtype): return np.zeros(shape=shape,dtype=dtype) + 1 create_buffer(1,np.bool) # array([1]) np.bool ではなくなってる!! np.int64オペレータ
+の代わりに、numpy.add を利用しても出力される型は変わってしまう。
(仮に出力先outに一旦格納した元の変数を指定するとnumpy.core._exceptions.UFuncTypeError: Cannot cast ufunc 'add' output from dtype('int64') to dtype('bool') with casting rule 'same_kind'と怒られる。)解決策
以下のように、計算した結果を要素毎に代入すると(あくまで型が変換可能な場合のみだが)元の型を維持した計算ができる。
修正import numpy as np def create_buffer(shape,dtype): a = np.zeros(shape=shape,dtype=dtype) a[:] = a + 1 return a create_buffer(1,np.bool) # array([True])余談
別の目的があって、たまたま加算を実行しただけであって、加算自体には意味はない。
(boolの加算が...ということは、この記事の本題ではない。)あくまで、ndarray にオブジェクトレベルの演算をしたら、意図せず型を変換されてしまったという失敗談。
- 投稿日:2020-08-03T13:46:27+09:00
AtCoderBeginnerContest174復習&まとめ(前半)
AtCoder ABC174
2020-08-02(日)に行われたAtCoderBeginnerContest174の問題をA問題から順に考察も踏まえてまとめたものとなります.
前半ではABCまでの問題を扱います.
問題は引用して記載していますが,詳しくはコンテストページの方で確認してください.
コンテストページはこちら
公式解説PDFA問題 Air Conditioner
問題文
あなたは、室温が$30$度以上のとき、またそのときに限り、冷房の電源を入れます。
今の室温は$X$度です。冷房の電源を入れますか?
出力
冷房の電源を入れるならば'Yes'、入れないならば'No'を出力せよ。abc174a.pyx = int(input()) if x >= 30: print("Yes") else: print("No")B問題 Distance
問題文
$2$次元平面上に$N$個の点があります。$i$個目の点の座標は$(X_i,Y_i)$です。
これらのうち、原点からの距離が$D$以下であるような点は何個ありますか?
なお、座標$(p,q)$にある点と原点の距離は$\sqrt{p^2+q^2}$で表されます。平方根の計算で誤差が出るのが嫌なので,$\sqrt{p^2+q^2} \leqq D$の両辺を二乗した$p^2+q^2 \leqq D^2$を用いて判定を行った.
abc174b.pyn, d = map(int, input().split()) d = d * d count = 0 for i in range(n): x, y = map(int, input().split()) if x * x + y * y <= d: count+= 1 print(count)C問題 Repsept
問題文
高橋君は$K$の倍数と$7$が好きです。
$7,77,777,…$という数列の中に初めて$K$の倍数が登場するのは何項目ですか?
存在しない場合は代わりに'-1'を出力してください。苦戦しました.
すぐに,$5$の倍数と$2$の倍数は存在しないことはわかったのですが,そこからが個人的には難しく感じました.
かなりの時間をレピュニットの性質を調べるのに使ってしまいました.
個人的な解釈としては,$7,77,777,…$という数列は初項を$a_1=7$とすると,
$a_{n+1}=10a_n+7$
と表すことができる.
これを$mod K$における数列を考えることで解くことができます.
例えば,$K=9$のとき,
$7,77,777,…$の数列を$9$で割った余りの数列は,$7,5,3,1,8,6,4,2,0,7,…$となり$9$項目が$9$の倍数であることがわかる.この数列を$b_n$とする.
例えば$3$項目に着目すると$777$を$9$で割った余りは,$b_3 \equiv 10b_2+7 (mod 9)$で計算することができるため,もし$K$の倍数が存在するならば初項から$K$項目までに少なくとも一回は出現するため($K$で割った余りは,$0 \leqq x \leqq K-1$となるため),その範囲で余りが$0$のものが出現すれば出力し,出現しなければ'-1'を出力する.
実装では,$b_{n+1} \equiv 10b_n+7 (mod K)$から,$K$が$5$の倍数または$2$の倍数の場合,$b_n \equiv 7 (mod K)$となるためそこで場合分けを行い,それ以外の場合は必ず存在するため答えが出るまでループを繰り返すように実装した.abc174c.pyk = int(input()) if k % 2 == 0 or k % 5 == 0: print(-1) else: c = 7 count = 1 while True: if c % k == 0: print(count) break else: c = (10 * c + 7) % k count += 1前半はここまでとなります.
最近は公式の解説がとても丁寧に記述してあったので,詳しい解法はそちらを参考にしてもらえたらと思います.
前半の最後まで読んでいただきありがとうございました.後半はDEF問題の解説となります.
後半に続く.
- 投稿日:2020-08-03T13:46:04+09:00
AtCoderBeginnerContest174復習&まとめ(後半)
AtCoder ABC174
2020-08-02(日)に行われたAtCoderBeginnerContest174の問題をA問題から順に考察も踏まえてまとめたものとなります.
後半ではDEの問題を扱います.前半はこちら
問題は引用して記載していますが,詳しくはコンテストページの方で確認してください.
コンテストページはこちら
公式解説PDFD問題 Alter Altar
問題文
祭壇に、左から右へと一列に並ぶ$N$個の石が祀られています。左から$i$個目$(1 \leqq i \leqq N)$の石の色は文字$c_i$として与えられ、$c_i$が'R'のとき赤、'W'のとき白です。
あなたは、以下の二種の操作を任意の順に何度でも行うことができます。
・石を$2$個選び (隣り合っていなくてもよい)、それらを入れ替える。
・石を$1$個選び、その石の色を変える (赤なら白に、白なら赤に)。
占い師によると、赤い石の左隣に置かれた白い石は災いを招きます。そのような白い石がない状態に至るには、最小で何回の操作が必要でしょうか。問題を読んだときに「・石を$2$個選び (隣り合っていなくてもよい)、それらを入れ替える。」だけで解けそうだと思いました.
「・石を$1$個選び、その石の色を変える (赤なら白に、白なら赤に)。」を使わないことで,最終的な答えのない状態は一通りに定まります.
例えば,$N=9$で
'WRWWWRRWR'
の入力は
'RRRRWWWWW'
となるように操作を最小に行うことを考えれば答えを出すことができる.
これは,入力に含まれる赤い石の個数$N_r$とし,入力の$1$から$N_r$番目までの白い石の個数が必要な操作数であることがわかる.(例の場合,'WRWWWRRWR'の$1$から$4$番目の'WRWW'における白い石の数なので$3$が答えとなる.)abc174d.pyn = int(input()) mozi = input() a_list = [] for i in range(n): if mozi[i] == 'W': a_list.append(0) else: a_list.append(1) r_count = sum(a_list) print(r_count - sum(a_list[0:r_count]))E問題 Logs
問題文
丸太が$N$本あり、それぞれ長さは$A_1,A_2,⋯,A_N$です。
これらの丸太を合計$K$回まで切ることができます。 長さ$L$の丸太を片端から$t(0 < t < L)$の位置で切ると、長さ$t,L−t$の丸太に分かれます。
丸太を合計$K$回まで切った後最も長い丸太の長さが最小でいくつになるか求め、小数点以下を切り上げた値を出力してください。二分探索に気がつけず,$x = 1$から貪欲に探索していたためコンテスト中に解けませんでした.
abc175e.pyn, k = map(int, input().split()) a_list = list(map(int, input().split())) a_list.sort(reverse=True) if k == 0: print(a_list[0]) else: start = 1 end = a_list[0] x = (start + end) // 2 while True: k_count = 0 flag = 1 for a in a_list: temp_k = 0 if a % x == 0: temp_k = a // x - 1 else: temp_k = a // x if temp_k == 0: flag = 1 break k_count += temp_k if k_count > k: flag = 0 break if flag == 1: end = x if flag == 0: start = x next_x = (start + end) // 2 if next_x == x: if flag == 1: print(x) if flag == 0: print(x + 1) break x = next_x後半も最後まで読んでいただきありがとうございました.
- 投稿日:2020-08-03T13:33:52+09:00
【Python】0からWebアプリ!ハンズオン(2)~ハローワールド編~
概要
Pythonで0からWebアプリを作る機会があったので、そのまとめとして!
この記事では環境構築について書いています。こんな方に読んでほしい
- プログラミング未経験だけどアプリ作ってみたい方
- 新人Webプログラマの方
- 経験者だけどPythonでWebアプリ書いたことない方
ゴール
HTML, CSS, JavaScript, Python, SQLを使ってCURD機能を持ったWebアプリを作成するのが目標です。
必要なもの
- PC(Windows OS)
- インターネット回線
- わくわくした気持ち
1. フォルダ構成
今回作成するフォルダ、ファイルは以下の通りです。
todo/
└ api/
└ index.py2. Bottle
Webアプリを作るときに大きな要素となるのがWebフレームワークです。
今回使用するBottleはPythonの軽量Webフレームワークです。
Bottle: Python Web Framework — Bottle 0.13-dev documentation
他にもDjango、Flaskといった有名なフレームワークがありますが、今回は小規模なので軽量で簡単なBottleを使うことにしました。
また、WSGIというインターフェースに対応しています。本来ならWebアプリをサーバーに配置するときに結構いろいろと考慮しなきゃいけないところ、結構簡単にWebアプリが作れるよ!ということです(ざっくり)以下参考までに各フレームワークの特徴です。
- Django: 大規模向け、機能豊富
- Flask: 中小規模向け、そこそこの機能、WSGI準拠
- Bottle: 小規模向け、軽量、WSGI準拠
3. Bottleのインストール
コマンドプロンプトを管理者で開き、以下のコマンドを実行してください。これだけです。
pip install bottle4. ハローワールドしてみる
適当に作業フォルダを作り、そのフォルダをVSCodeで開きます。
そして、以下のフォルダ、ファイルを作成します。(.vscodeはVSCodeが勝手に生成します)
todo/
└ api/
└ index.py
そして、index.pyにコードを書いていきます。
index.py# -*- coding:utf-8 -*- # 外部のパッケージを読み込む from bottle import route, run # @routeに/helloと設定すると、http://localhost:8080/helloでアクセスできる @route('/hello') def hello(): # Hello World!という文字列を返却 return "Hello World!" # Webサーバーの実行構成 # URLの "http://[host]:[port]/[route]" の構成となる run(host='localhost', port=8080, debug=True)F5キーを押して、「Python File」を選択します。
http://localhost:8080/hello
にアクセスしてみると、「Hello World!」と表示されているはずです!まとめ
API実装の第一歩目として、ハローワールドしてみました!
次回は・・・
APIからデータベースに接続します!

- 投稿日:2020-08-03T13:23:24+09:00
【numpy, scipy】半正定値エルミート行列の平方根を計算する方法
- 投稿日:2020-08-03T13:06:13+09:00
Django Girlsのチュートリアルの要約 前半
Django Girlsのチュートリアルでは、djangoを使った簡単なブログを作成する方法が学べます。
本記事は私がその復習のためにノート代わりとして記述したものです。
ここではdjangoプロジェクト作成の手順と最低限の操作をまとめています。環境: Windows 10 + Visual Studio Code
1. 仮想環境の構築とdjangoのインストール
作業フォルダを新規作成して移動します。
terminal> mkdir djangogirls > cd djangogirls仮想環境を構築し、適用します。
terminal> python -m venv myvenv > myvenv/Scripts/activatepipでdjangoをインストールします。(チュートリアルのdjangoのバージョンは2.2.4)
terminal(myvenv)> python -m pip install --upgrade pip (myvenv)> pip install django==2.2.42. プロジェクトの作成
新規プロジェクトmysiteを作成します。
プロジェクト名は任意です。terminal(myvenv)> django-admin startproject mysite .3. 設定ファイル(setting.py)の変更
mysiteにあるsetting.pyにある次の項目の値を変更します。
mysite/setting.py# 1.タイムゾーンを設定 TIME_ZONE = 'Asia/Tokyo' # 2.言語を設定 LANGUAGE_CODE = 'ja' # 3.静的ファイルの場所を設定 STATIC_URL = '/static/' STATIC_ROOT = os.path.join(BASE_DIR, 'static') # 4.ホストのアドレスを設定 ALLOWED_HOSTS = ['127.0.0.1', '.pythonanywhere.com'] # 5.データベースの設定 DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), } }4. アプリの追加
mysiteにblogというアプリを新規作成します。
terminal(myvenv)> python manage.py startapp blogアプリを追加したことをプロジェクトに知らせます。
mysite/setting.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'blog.apps.BlogConfig', # 追加した行 ]5. アプリにモデルを追加
blogアプリにPostモデルを追加します。
blog/models.pyfrom django.conf import settings from django.db import models from django.utils import timezone class Post(models.Model): author = models.ForeignKey(settings.AUTH_USER_MODEL, on_delete=models.CASCADE) title = models.CharField(max_length=200) text = models.TextField() created_date = models.DateTimeField(default=timezone.now) published_date = models.DateTimeField(blank=True, null=True) def publish(self): self.published_date = timezone.now() self.save() def __str__(self): return self.titleモデルを追加したことをDBに知らせます。
この操作はモデル作成時のみで大丈夫です。terminal(myvenv)> python manage.py makemigrations blogモデルをマイグレートします。
今後もモデルの構成に変更がある場合はこの操作を行います。terminal(myvenv)> python manage.py migrate blog6. 管理者を登録する
DjangoにはDjango Adminという機能があり、
管理者権限でログインしなければ見られない管理画面がプロジェクト毎に自動作成されます。まず、管理者権限を持つユーザーを登録します。
terminal(myvenv)> python manage.py createsuperuser指示に従って情報を登録していきます。
terminalUsername: ola Email address: ola@example.com Password: Password (again): Superuser created successfully.以降、登録したユーザーで管理画面にログインできます。
7. 管理画面からモデルを見られるようにする
作成したPostモデルを管理画面で見られるようにします。
blog/admin.pyfrom django.contrib import admin from .models import Post admin.site.register(Post)8. サーバーの起動
terminal(myvenv)> python manage.py runserver起動できたら、例えば管理画面へはhttp://127.0.0.1:8000/admin/からアクセスできます。
9. プロジェクトのデプロイ
デプロイについてはこちらを参照ください。
pythonanywhereを使った小規模なサービスを無料で公開する方法が書かれています。後半
後半ではURLの設定、ビューの設定をしていきます。(作成中)
- 投稿日:2020-08-03T12:49:02+09:00
VSCodeとRemote-Containersとリモートdocker-daemonで最強の環境を手に入れる
はじめに
開発環境構築は開発において最初の関門であり、面倒だし複雑な作業です。
- 従来の環境と衝突して全てが壊れる
- チームのメンバーと微妙に環境が異なってトラブルが発生する
- 環境構築手順が複雑でミスしやすい
- 何かが起きた時に原因究明が難しい
基本編では環境開発の面倒さを解決し、応用編ではさらにセキュリティと開発体験を両立した新しい開発を提案します。
この方法はほとんどの言語に適用可能ですが、今回は開発環境構築が面倒な言語の一つであるpythonを例に説明します。目次
- 基本編: Remote-Containersを使って開発環境レス開発をする
- 応用編: Remote-Containers + Cloud + シンクライアントPCで最強の環境を手に入れる
- 実践編: 実際の開発チームで活用するパターン(後日追記予定)
応用編からが本命です
基本編: Remote-Containersを使って開発環境レス開発をする
VSCodeのRemote-ContainersというExtensionをご存知ですか?
知っていたらこの基本編を飛ばし応用編へどうぞ!公式ページのイメージ図です
簡単にRemote-Containersを説明すると、開発環境をdocker containerで構築し、その中でコードを実行するが、コードの編集やデバッグは手元のVSCodeで行えるという神Extensionです。
開発環境をcontainerに閉じ込めるので
- PCの開発環境を汚さない
- 環境が全てコード化されていて、git管理しやすい
- 開発メンバー間で環境が必ず同じになる
などのメリットがあります。デメリットはほぼありません。
宗教上の理由でVSCodeを使えない人以外は使った方がいいレベルのExtensionです。
こちらに関しては既に様々な記事が書かれているので、導入方法などはそちらを参考にしてください。Remote-Containersの参考リンク
- 公式紹介ページ
安心と信頼の公式ページ。- VS CodeでDocker開発コンテナを便利に使おう
こちらを先に読むと公式ページの内容が頭に入ってきやすくなるかも基本編まとめ
「巨人の肩の上に立つ」ということで基本編の詳しい説明はこの記事ではしませんでしたが、是非参考リンクを見て導入してみてください。
もう開発環境構築で悩むことはなくなります。
(pythonの環境構築ツール戦争にも終止符が打たれるといいなぁ)応用編: Remote-Containers + Cloud + シンクライアントPCで最強の環境を手に入れる
こちらがこの記事の本命です!
Remote-Containersの基本は抑えた前提で話を進めます。概要説明
Remote-Containersはdocker上で開発を行うツールですので、実はローカルPCのdocker-daemonを使う必要はありません。
つまり、以下のような構成が可能です。
ここで重要なのは
- 秘匿性が高く、持ち出したくない「ソースコード」
- マシンパワーが必要な「ビルド & デバッグ」
がリモートマシン上。というところと
- キー入力などレスポンスが気になる「IDE」
- 流出しても大した影響のない「Remote-Contaienrs用設定ファイル」
がローカルマシン上。というところ。
つまり、ローカルマシンは弱々スペックなシンクライアントPCで、VSCodeとその設定だけを保持。ソースコードとデバッグは強いリモートサーバ上という構成が可能。
これは、開発体験とセキュリティを両立しており、新しい開発スタイルになりうるのではと思っています。実際にやってみる on GCP
今回は手元のPCとGCP上のインスタンスを用いて実際に構築してみる。
AWSでも、Azureでもなんでも大丈夫です。GCP以外を使いたい人は適宜読み替えてください。前提
- GCPが使える状態になっている
- gcloudコマンドが使える状態になっている
GCP上にインスタンスを構築し、sshの設定を保存する
GCPにはコンテナを立てることに特化したVMイメージが用意されているので、今回はそちらを使います。
zoneはご自由に設定してください。gcloud compute instances create [instance_name] \ --image-family cos-stable \ --image-project cos-cloud \ --machine-type n1-standard-1インスタンスが立ち上がったら、sshしてみます。
gcloud compute ssh [instance_name]無事にsshができたらsshの設定を手元のPCに書き出します。
gcloud compute config-sshこれで、sshの鍵が手元のPCに保存され、
ssh [instance_name].[zone].[project_name]でsshできるようになります。試してみてください。VM上にプロジェクトを作成する
VMにsshしてください。既に
gitコマンドが入っていると思うので、任意のプロジェクトをgitからcloneしてください。
特に思いつかない場合はapp.pyとrequirements.txtを作成してください。
アクセス権には注意してください。containerの中から触るのでdockerグループにアクセス権が必要です。
面倒であれば今回はchmod 777 -R [プロジェクトディレクトリパス]でとりあえずアクセス権ガバガバにしておいてください。手元のPCの上にRemote-Conteinrs用の設定ファイルを作成する
設定ファイル用のディレクトリを作成して、そこにRemote-Container用の設定ファイルを配置します。pythonプロジェクトを例にして説明します。
まずは設定ファイルが入っているmicrosoftのサンプルプロジェクトをcloneします。git clone https://github.com/microsoft/vscode-remote-try-python.gitpython用のファイルがいろいろ入っているので、
- .devcontainer
- .vscode
以外は全て削除してください。
次に、Remote-ContaienrsプラグインでGCP上のVMのdocker-daemonを使う設定を追加します。
.vscodeの中にsetting.jsonを作成し、以下を書き込みます。{ "docker.host": "ssh://[container_name].[zone].[project_name]" }次にプロジェクトのマウント対象ディレクトリを変更します。
.devcontainer/.devcontainer.jsonに二つのkey-valueを追記します。"workspaceMount": "source=[GCP上のprojectのフルパス],target=/workspace,type=bind,consistency=delegated", "workspaceFolder": "/workspace"この設定で、GCP上でcontainerを立てた時に、先ほど作成したプロジェクトをマウントするようにします。
Remote-Containersで開発する
vscodeのRemote-Containersプラグインのメニューから
Reopen in Containerを選択すると、GCPのVM上のdocker-daemonに接続し、containerを立て、そこでプロジェクトを開きvscodeを接続します。
あとは、自由に開発できます!まとめ
今回は基本編と応用編に分けて説明しました。
基本編やRemote-Containerの詳しい説明は省いてしまいましたが、Remote-Containerを普通に使用するだけでも、開発環境構築が不要になったり、メンバー間で環境が統一できたりとかなりのメリットがあります。
さらに、応用編で紹介したリモートのdocker-daemonを使用する方法を使うことで、手元のPCにコードを置かない、計算リソースを強力なPCに寄せる運用が可能になります。セキュリティと開発体験を両立した開発手法だと考えています。ぜひ試してみてください。
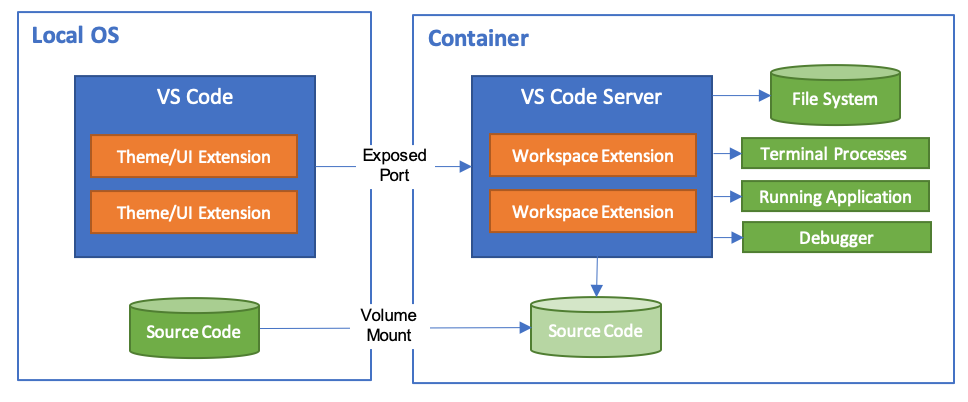
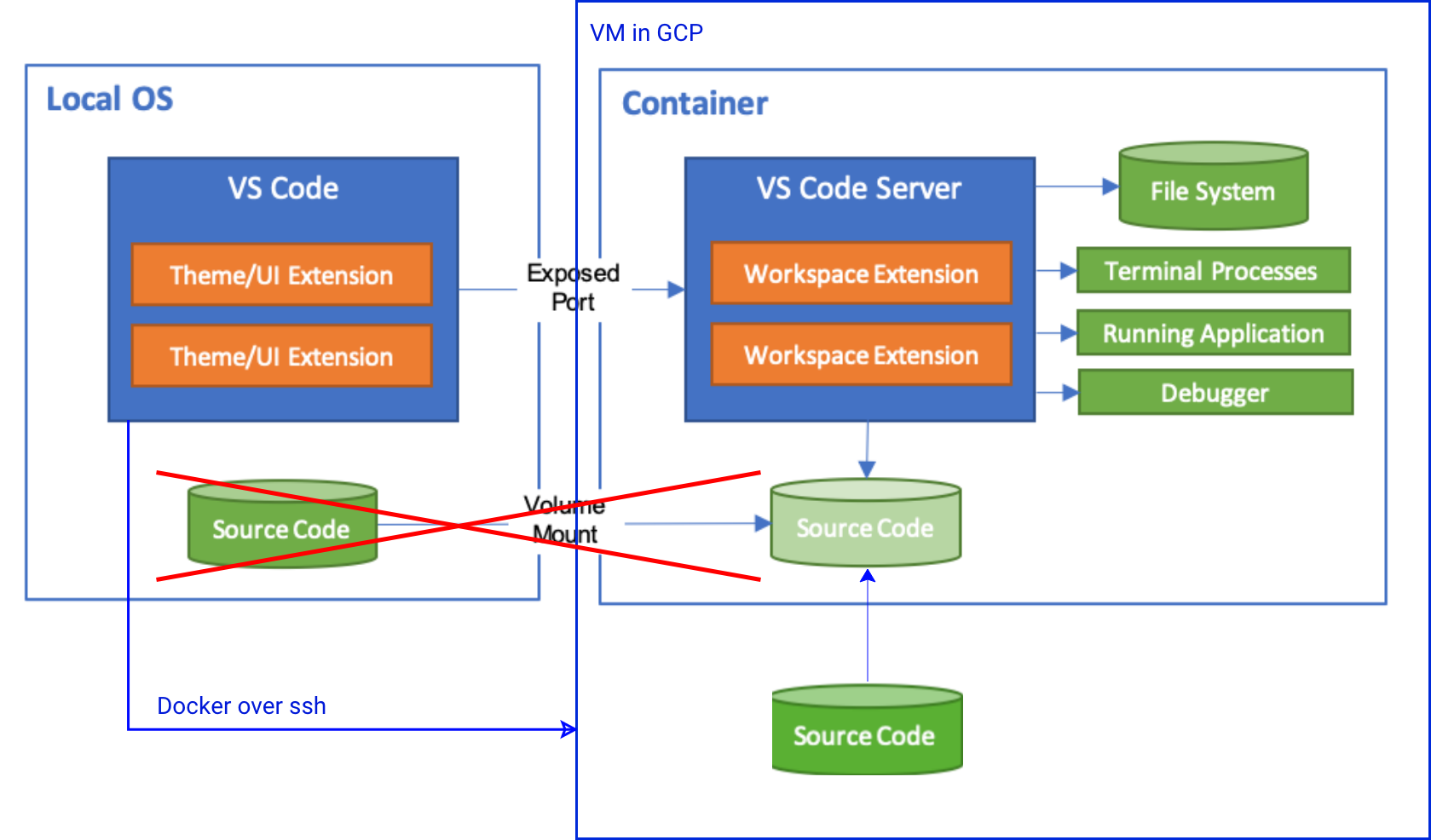
- 投稿日:2020-08-03T12:44:49+09:00
Pythonスクレイピングの基礎の基礎
PythonのrequestsモジュールとBeautiful Soupを使った
スクレイピングの基礎の基礎Webからコンテンツ(主にHTML)を取得する
- URLのHTMLを全て取得して表示するコード:
HTMLを取得import requests url = "https://hogehoge12345.html" response = requests.get(url) response.encoding = response.apparent_encoding print(response.text)・
requests.get()で, 引数のURLに対してHTTPリクエストを送信し, サーバーから返されるHTTPレスポンスを戻り値にする.
・apparent_encodingで, 文字化けが極力起こらないようにする.
・response.textが、取得したコンテンツの中身
・URLでアクセスできるものなら, CSVや画像ファイル、動画ファイルなども取得できる(コードは上と変わらない).1秒の間隔を空けるimport time time.sleep(1)・複数のURLから連続してHTTPを取得する際は, 相手のサイトに迷惑をかけないように最低1秒ずつ間隔を空けること.
・そもそもそのサイトにプログラムからアクセスしてもよいのか, 公開している内容をデータ化してといった利用制限を確認する必要がある.取得したWebコンテンツをファイルに保存するresponse = requests.get(url) response.encoding = response.apparent_encoding exam_html = response.text with open('exam.html', mode='w', encoding='utf-8') as fp: fp.write(exam_html)HTMLの解析
- Beautiful Soup というライブラリを使う.
- HTMLの字句解析をして, タグなどをデータ構造として取得するプログラムをHTMLパーサーという.
import requests from bs4 import BeautifulSoup url = "https://hogehoge12345.html" response = requests.get(url) response.encoding = response.apparent_encoding # HTMLを解析する bs = BeautifulSoup(response.text, 'html.parser') # ulタグで囲まれた部分を抽出する ul_tag = bs.find('ul') # ulタグの中のaタグを抽出する for a_tag in ul_tag.find_all('a'): # aタグのテキストを取得 text = a_tag.text # => "クリックするとリンクに飛びます" # aタグのhref属性を取得 link_url = a_tag['href'] # => "https://hogehoge12345.html/next" print('{}: {}'.format(text, link_url))・
bs.find('ul')で, <ul>から</ul>までのHTMLコードを取得
・findメソッドは先頭から辿って最初の要素だけ取り出すが, find_allメソッドは全ての要素をイテラブルに取り出す(= forループに使える). 詳しくはリンク.CSSセレクター
- 特定のタグ(あるCSSクラスを持つタグなど)の抽出には, CSSセレクターを用いる
- タグとCSSクラスをドットで繋いで表現<div class="exam_exam1"> -> div.exam1selectメソッド# div.exam1で囲まれた部分を抽出する div_exam1 = bs.select('div.exam1')・select()は, 機能はfindやfind_allと同じようにHTML要素の取得してリストで返すことだが, 検索条件にCSSセレクタを指定できる(詳しくはリンク).
- 投稿日:2020-08-03T11:40:47+09:00
暇だったのでカラオケ作ってみた(未完)
はじめに
初投稿です。なにか至らぬ点があるかもしれませんがご容赦ください。
誤字、脱字、質問、改善案等々ありましたら教えていただければ幸いです。全体の内容
予定
- ボーカルをカットする
- 音の高さを表すグラフを表示する(DAMとかでよく見るやつ)
- 得点化
- ガイドボーカル(カットしたボーカルを薄く追加)
可能なら
- 歌詞が流れるやつ(良いAPIが見つからない...)
- 動画が流れる(Youtubeだと利用規約的に難しい... TextAliveの埋め込み?)
- ビブラート、こぶし等の音程以外の採点基準(正直違いが判らない)
今回の内容
とりあえず必要なライブラリのインストール
使用するライブラリ
- pyaudio
音声入力に使用- pyworld
F0(ピッチ)推定に使用- pyreaper
同じくF0(ピッチ)推定に使用- spleeter
ボーカルの分離に使用- pyQt5
グラフの表示に使用Pythonで音声解析入門 [PyWorld, pyreaper]によるとpyworldは音声が長くても高速に動作するみたいです。
ただ短すぎると逆に時間がかかりそうなのでリアルタイムはpyreaperで計算しようと思ってます。
あとで比較する予定です。とりあえずはこのあたりで実現できそうなので、何か必要になればその都度追記していきます。
インストール
conda install -c conda-forge spleeter conda install pyaudio conda install pyQt5 conda install Qt pip install pyworld pip install pyreaperspleeter以外はcondaかpipで入りました。
動作確認
pyaoudio
こちらの記事にあるプログラムを実行して音が出れば成功です。
pyworld
Pythonで音声解析入門 [PyWorld, pyreaper]にあるプログラムに適当に音楽を入れてみてグラフがでればOKです。
pyreaper
import pyreaper import matplotlib.pyplot as plt from scipy.io import wavfile file = "music/spleetertest/test/vocals.wav" fs, data = wavfile.read(file) data = data[:int(1e6),0] #長すぎると時間がかかるので適当にカットする data = data.copy(order='C') #これをしないとエラーが出る pm_times, pm, f0_times, f0, corr = pyreaper.reaper(data, fs) #グラフ表示 plt.subplot(3,1,1) plt.plot(pm_times, pm, linewidth=3, color="red", label="Pitch mark") plt.legend(fontsize=10) plt.subplot(3,1,2) plt.plot(f0_times, f0, linewidth=3, color="green", label="F0 contour") plt.legend(fontsize=10) plt.subplot(3,1,3) plt.plot(f0_times, corr, linewidth=3, color="blue", label="Correlations") plt.legend(fontsize=10) plt.show()
こんなグラフが出ればOKですspleeter
spleeterを試してみたにあるプログラムを実行してエラーが出なければOKです。mp3も大丈夫みたいです。
pyQt5
とりあえずmatplotlibが動いていれば大丈夫そうなので特に検証してません
次回の予定
音楽からvocalのみを抜き出して音程グラフに直すところまでできたらいいなぁ
- 投稿日:2020-08-03T10:53:37+09:00
Pythonで螺旋本!螺旋本でPython!(14章〜)
この記事は随時更新していきます。
螺旋本(14章〜)
螺旋本(〜13章)はこちらをご覧ください。
14章 高度なデータ構造
Union Find Tree
class UnionFindTree(): def __init__(self, n): #木全体の要素数 self.n = n #root[x]<0ならそのノードが根でありその値が木の要素数 self.root = [-1] * (n+1) #ランク self.rank = [1] * (n+1) def find_root(self,x): if self.root[x] < 0: return x else: self.root[x] = self.find_root(self.root[x]) return self.root[x] def unite(self,x,y): x = self.find_root(x) y = self.find_root(y) if x == y: return elif self.rank[x] > self.rank[y]: self.root[x] += self.root[y] self.root[y] = x else: self.root[y] += self.root[x] self.root[x] = y if self.rank[x] == self.rank[y]: self.rank[y] += 1 def is_same(self,x,y): return self.find_root(x) == self.find_root(y) def count_node(self,x): return -1 * self.root[self.find_root(x)]上で作成したUnion find treeをimportして、螺旋本内の問題をときました。
from union_find_tree import UnionFindTree n, q = map(int, input().split()) uft = UnionFindTree(n) ans = [] for i in range(q): com, x, y = map(int, input().split()) if com == 0: uft.unite(x,y) elif com == 1: if uft.is_same(x,y): ans.append(1) else: ans.append(0) for j in ans: print(j) ''' 5 12 0 1 4 0 2 3 1 1 2 1 3 4 1 1 4 1 3 2 0 1 3 1 2 4 1 3 0 0 0 4 1 0 2 1 3 0 '''Union Find Tree実装ついでに、クラスカル法(最小全域木のアルゴリズム)も実装しちゃいます。
from union_find_tree import UnionFindTree v, e = map(int,input().split()) edges = [] for _ in range(e): s, t, w = map(int, input().split()) edges.append((w, s, t)) #edgesは予めsortする edges.sort() def kuruskal(n, edges): uft = UnionFindTree(n) res = 0 for e in edges: w, s, t = e if not uft.is_same(s, t): res += w uft.unite(s, t) return res print(kuruskal(v, edges))
- 投稿日:2020-08-03T10:32:55+09:00
株価データ取得Tips
はじめに
今回は株価データの取得方法についてまとめておく。
身近なサイトでは、Yahoo!ファイナンスの時系列データがお手軽そうではあるがYahoo!ファイナンスはスクレイピング、すなわちWebページから株価データを抽出することは禁止されているようなので、Pandas DataReaderを利用するとよい。
以下の記事を参考にした。
https://ntk-lab.com/import_stock_data/
Pythonで株価データを取得する方法Pandas DataReader
ここにPandas DataReaderで利用する株価データの入手元と、アクセス方法が載っている。
IEX
NY市場上場銘柄ならば、IEXから取ってくるサンプルコードを容易に見つけることができるが、IEXから株価データを取得するには、アカウントを作ってAPIキーを取得する必要がある。
無料のAPIキーを取得可能だが、1日に取得できるデータ量には制限がある。
有料のAPIキーもそんなに高価ではないが、解約方法のページを探しきれなかったのでやめておく。iex
import os import pandas_datareader as pdr from datetime import datetime os.environ['IEX_API_KEY'] = '取得したAPIキーの価' start_date = datetime(2020,1,1) end_date = datetime(2020,7,10) df = pdr.data.DataReader(name='AAPL', data_source="iex", start=start_date, end=end_date) df.to_csv("AAPL.csv")Stooq
使い勝手は良かったのは、Stooq。API キー取得は不要。
取得例は以下。import pandas_datareader.stooq as web from datetime import datetime start_date = datetime(2020,1,1) end_date = datetime(2020,7,10) dr = web.StooqDailyReader('^DJI', start=start_date, end=end_date) df = dr.read() df.to_csv('DOW30.csv')各国インデックスや日本国内銘柄も取得可能。
海外銘柄はティッカーコードで、日本国内銘柄は4桁の証券コードに「.JP」の拡張子を付けたものを指定する。
取得銘柄 指定コード Apple AAPL DOW30 ^DJI NIKKEI225 ^NKX 極洋 1301.JP NF日経ダブルインバース 1357.JP 上場日経2倍 1358.JP まとめ
Pandas DataReaderのstooqは、APIキー取得不要で使い勝手が良い。
日本の上場銘柄が取ってこれるんで、禁断のスクレイピングに手を染める必要がない。
- 投稿日:2020-08-03T10:08:53+09:00
一番シンプルなWindowsによるSpleeter使用方法
前書き
Windows用Spleeterの環境構築にGitをインストールしたりと不要な手順が含まれている記事が多く公開されているので、簡単な手順をまとめてみました。
準備
下記サイトよりMiniconda(Python3.xのWindows installers)をダウンロードします。
https://docs.conda.io/en/latest/miniconda.htmlテキストエディタで「spleeter-cpu.yaml」を作成します。
name: spleeter-cpu channels: - conda-forge - anaconda dependencies: - python=3.7 - tensorflow=1.14.0 - ffmpeg - pandas==0.25.1 - requests - pip - pip: - museval==0.3.0 - musdb==0.3.1 - norbert==0.2.1 - spleeterインストール
- 準備でダウンロードしたMinicondaをデフォルトのままインストールします。
- スタートメニューよりAnaconda Prompt (Miniconda3)を起動します。
- 「conda env create -f "spleeter-cpu.yamlのパス"」を実行します。色々とダウンロードされるので完了するまで待ちます。
- 「conda info --envs」を実行し[spleeter-cpu]が作成されていることを確認します。
使用方法
- スタートメニューよりAnaconda Prompt (Miniconda3)を起動します。
- 「conda activate spleeter-cpu」を実行します。
- 「spleeter separate -i "音源のパス" -o "出力先のパス" -p spleeter:[2/4/5]stems」を実行します。
[2/4/5]の数字は分割したいパート数で使い分けてください。
2: ボーカル/伴奏
4: ボーカル/ドラム/ベース/その他
5: ボーカル/ドラム/ベース/ピアノ/その他
- 投稿日:2020-08-03T10:08:53+09:00
一番簡単なWindowsによるSpleeter使用方法
前書き
Windows用Spleeterの環境構築にGitをインストールしたりと不要な手順が含まれている記事が多く公開されているので、簡単な手順をまとめてみました。
準備
下記サイトよりMiniconda(Python3.xのWindows installers)をダウンロードします。
https://docs.conda.io/en/latest/miniconda.htmlテキストエディタで「spleeter-cpu.yaml」を作成します。
name: spleeter-cpu channels: - conda-forge - anaconda dependencies: - python=3.7 - tensorflow=1.14.0 - ffmpeg - pandas==0.25.1 - requests - pip - pip: - museval==0.3.0 - musdb==0.3.1 - norbert==0.2.1 - spleeterインストール
- 準備でダウンロードしたMinicondaをデフォルトのままインストールします。
- スタートメニューよりAnaconda Prompt (Miniconda3)を起動します。
- 「conda env create -f "spleeter-cpu.yamlのパス"」を実行します。色々とダウンロードされるので完了するまで待ちます。
- 「conda info --envs」を実行し[spleeter-cpu]が作成されていることを確認します。
使用方法
- スタートメニューよりAnaconda Prompt (Miniconda3)を起動します。
- 「conda activate spleeter-cpu」を実行します。
- 「spleeter separate -i "音源のパス" -o "出力先のパス" -p spleeter:[2 or 4 or 5]stems」を実行します。
[2/4/5]の数字は分割したいパート数で使い分けてください。
2: ボーカル/伴奏
4: ボーカル/ドラム/ベース/その他
5: ボーカル/ドラム/ベース/ピアノ/その他おまけ
ドラッグアンドドロップで処理できるバッチも置いておきます。
コマンドプロンプトの仕様上区切り文字として認識される空白、タブ、等号、セミコロン、コンマがファイル名に入っているとエラーになります。@echo off set DESTPATH=%~dp1 set /P ITEM="分割数を入力して下さい(2/4/5):" set FLAG=False if %ITEM%==2 set FLAG=True if %ITEM%==4 set FLAG=True if %ITEM%==5 set FLAG=True if %FLAG%==True ( call C:\Users\<ユーザ名>\miniconda3\Scripts\activate.bat call activate spleeter-cpu for %%f in (%*) do call spleeter separate -i %%f -o %DESTPATH% -p spleeter:%ITEM%stems ) else echo 分割数がおかしいよ。何かキーを押すと終了します。 echo 終わったよ。何かキーを押すと終了します。 pause > nul
- 投稿日:2020-08-03T10:08:53+09:00
一番簡単なWindowsによるSpleeter使用環境構築
はじめに
Spleeterとは?
⇒音楽データを機械学習でパートごとに分離してくれるすごいやつ!!Windows用Spleeterの環境構築にGitをインストールしたりと不要な手順が含まれている記事が多く公開されているので、簡単な手順をまとめてみました。
準備
下記サイトよりMiniconda(Python3.xのWindows installers)をダウンロードします。
https://docs.conda.io/en/latest/miniconda.htmlテキストエディタで「spleeter-cpu.yaml」を作成します。
spleeter-cpu.yamlname: spleeter-cpu channels: - conda-forge - anaconda dependencies: - python=3.7 - tensorflow=1.14.0 - ffmpeg - pandas==0.25.1 - requests - pip - pip: - museval==0.3.0 - musdb==0.3.1 - norbert==0.2.1 - spleeterインストール
- 準備でダウンロードしたMinicondaをデフォルトのままインストールします。
- スタートメニューよりAnaconda Prompt (Miniconda3)を起動します。
- 「conda env create -f [spleeter-cpu.yamlのパス]」を実行します。色々とダウンロードされるので完了するまで待ちます。
- 「conda info --envs」を実行し"spleeter-cpu"が作成されていることを確認します。
使用方法
- スタートメニューよりAnaconda Prompt (Miniconda3)を起動します。
- 「conda activate spleeter-cpu」を実行します。
- 「spleeter separate -i [音楽データのパス] -o [出力先のパス] -p spleeter:[2 or 4 or 5]stems」を実行します。
例: spleeter separate -i hoge.wav -o D:\hoge -p spleeter:2stems
[2 or 4 or 5]の数字は分離したいパート数で使い分けて下さい。
2: ボーカル/伴奏
4: ボーカル/ドラム/ベース/その他
5: ボーカル/ドラム/ベース/ピアノ/その他入力元のフォルダに機械学習データがダウンロードされるので入力元を統一すれば次回以降時間が短縮できます…
おまけ
D&Dで複数ファイル処理できるバッチも置いておきます。
[ユーザ名]は自分の環境に合わせて書きかえて下さい。
コマンドプロンプトの仕様上区切り文字として認識される空白、タブ、等号、セミコロン、コンマが音楽データファイル名に入っていると出力先フォルダが変になります。spleeter.bat@echo off set DESTPATH=%~dp1 set /P ITEM="分離数を入力しEnterを押して下さい(2/4/5):" set FLAG=False if %ITEM%==2 set FLAG=True if %ITEM%==4 set FLAG=True if %ITEM%==5 set FLAG=True if %FLAG%==True ( call C:\Users\[ユーザ名]\miniconda3\Scripts\activate.bat call conda activate spleeter-cpu for %%f in (%*) do call spleeter separate -i %%f -o %DESTPATH% -p spleeter:%ITEM%stems echo 終わったよ。何かキーを押すと終了します。 ) else echo 分離数がおかしいよ。何かキーを押すと終了します。 pause > nul
- 投稿日:2020-08-03T09:59:33+09:00
Pythonアルゴリズム
文字列の操作
1. 逆整数
整数が与えられた場合, 桁を逆にした整数を返します.
注意: 整数は正負のどちらでも構いません.def solution(x): string = str(x) if string[0] == '-': return int('-'+string[:0:-1]) else: return int(string[::-1]) print(solution(-231)) print(solution(345)) Output: -132 543まずはスライスの練習。
負の整数を入れることがポイント2. 平均語数の長さ
与えられた文について、平均的な単語の長さを返します。
注意: 最初に句読点を削除することを忘れないでください.sentence1 = "Hi all, my name is Tom...I am originally from Australia." sentence2 = "I need to work very hard to learn more about algorithms in Python!" def solution(sentence): for p in "!?',;.": sentence = sentence.replace(p, '') words = sentence.split() return round(sum(len(word) for word in words)/len(words),2) print(solution(sentence1)) print(solution(sentence2)) Output: 4.2 4.08一般的な文字列を使った計算アルゴリズムでは
.replace(),.split()といったメソッドがポイントになる。つづく
- 投稿日:2020-08-03T08:47:57+09:00
競プロ精進日記31日目(7/25)
感想
あげるタイミングを逃していました?
現在(8/3)はCodeforcesのバチャやyukicoderを中心に取り組むようにし、一旦AtCoderの過去問埋めから離れています。昨日のコンテストも大失敗しました。実力は伸びてきているはずでメンタルの問題だとは思うのですが、かなりしんどいです…。これまでは特に壁を感じたことはなかったので、今は壁にぶつかっているだけなのかもしれません。
ABC086-D Checker
かかった時間
20分考えて分からず、解説AC
間違えた原因
解いたことのない問題で曖昧な方針しか思い浮かびませんでした。
今後、そのような問題が増えてくるので、対応力をつけたいです。
先日のyukicoderのC問題で類題をコンテスト中に解き切ることができうれしかったです。考察
まず、どの盤面でも必ず同じ色となるマスが存在します。天下りではありますが、$x$座標と$y$座標を$2K$で割った余りがいずれも等しいようなマスです。したがって、全てのマスは$2K \times 2K$のマス目の中で表現することができます。また、そのマスの中で、$x$座標のみが$K$以上離れているマス及び$y$座標のみが$K$以上離れているマスは反対の情報を持ちます。つまり、($x$,$y$)が黒で($x$,$y+K$)が白という情報は同じ意味を持ちます。したがって、$K \times K$のマス内で希望は全て表現することができます。
したがって、この盤面での希望をまとめると以下のようになります。ただし、$l=0$は黒色で$l=1$は白色を表し、$i,j$は$0 \leqq i,j <K$を満たします。
$g[i][j][l]:=$($x$座標が$i$で$y$座標が$j$のマスに帰着できるマスについて$l$に相当する色を希望するマスがいくつあるか)
この盤面においてありうる市松模様のパターンを考えますが、このようなパターンは市松模様の左上のマスがどこであるかとそのマスが白色or黒色で合計$2 \times K \times K$通りあります。左上の座標が$(i,j)$であると仮定すれば下図のようになります
ここで、それぞれの長方形内での希望をまとめる必要がありますが、これは二次元累積和を求めておけば$O(1)$で求めることができます。
また、二次元累積和は以下のように定義して求めました。実装はけんちょんさんの記事を参照しました。
$ac[l][x][y] := [0, x) × [0, y)$ の長方形区間の$l$に相当する色の希望の数
$ac[l][i+1][j+1]=ac[l][i][j+1]+ac[l][i+1][j]-ac[l][i][j]+g[i][j][l]$
ここでは右下の長方形と左上の長方形が白色で右上の長方形と左下の長方形が黒色になるとします(逆の場合も同様に考えられます。)。この時、白色の部分は$①-②-③+2\times ④$であり、黒色の部分は$②+③-2\times ④$となります。
したがって、二次元累積和を半開区間で求めることにのみ気を付ければ、叶えられる希望の数を求められます。よって、ありうる叶えられる希望の数の中で最大の数を出力して答えになります。
Pythonのコード
abc086d.pyn,k=map(int,input().split()) g=[[[0,0] for i in range(k)] for j in range(k)] for i in range(n): x,y,c=input().split() x,y=int(x),int(y) if y%(2*k)<k and x%(2*k)<k: g[y%(2*k)][x%(2*k)][c=="W"]+=1 elif y%(2*k)<k: g[y%(2*k)][x%(2*k)-k][c=="B"]+=1 elif x%(2*k)<k: g[y%(2*k)-k][x%(2*k)][c=="B"]+=1 else: g[y%(2*k)-k][x%(2*k)-k][c=="W"]+=1 ac=[[[0]*(k+1) for i in range(k+1)] for l in range(2)] for l in range(2): for i in range(k): for j in range(k): ac[l][i+1][j+1]=ac[l][i][j+1]+ac[l][i+1][j]-ac[l][i][j]+g[i][j][l] ans=0 for i in range(k): for j in range(k): ans=max(ac[0][k][k]-ac[0][i][k]-ac[0][k][j]+2*ac[0][i][j]+ac[1][i][k]+ac[1][k][j]-2*ac[1][i][j],ans) ans=max(ac[1][k][k]-ac[1][i][k]-ac[1][k][j]+2*ac[1][i][j]+ac[0][i][k]+ac[0][k][j]-2*ac[0][i][j],ans) print(ans)