- 投稿日:2020-08-03T21:56:51+09:00
AWS HoneyCodeに詳しい人に聞いてみた
いつも忘れないように、コンセプトから。
コンセプト
・お金かけてまでやりたくないのでほぼ無料でAWSを勉強する
→ちょっとしたサービスを起動すると結構高額になりやすい。
・高いレベルのセキュリティ確保を目指す
→アカウントを不正に使われるととんでもない額を請求されるので防ぐどこの誰から聞いたとは書けないんですが、まとまって聞いたので参考までにメモってみました。
そんなに深い内容ではありませんのであしからず。。。HoneyCodeのコンセプト
4つの概念で構成されています。4つの概念を簡単に表現してもらいました。
・Tables:包含されたデータベースの活用
・App builder:GUIによるアプリ開発
・Automations:ワークフローの自動化、Cronの設定、通知
・Teams:ACLの設定環境
開発環境と動作環境は異なっているようです。
開発環境:Chrome
動作環境:Chrome、Edge、Firefox、SafariHoneycodeコミュニティでオススメは?
Honeycode coursesで学ぶのが一番近道
価格に関すること
Basic(無料)はworkbook(プロジェクト毎のTableの行数が2500まで)
ユーザーは20人まで。上限を緩和すると有料になる。
→2500行までだとやれることは限られるなぁと思います。。。現状の作成手順
・Honeycodeアカウントを登録
・テンプレートからワークブック作成
・テーブル変更と確認
・アプリのカスタマイズとテストチームメンバーの共有と追加ちょっとしたTips
・デフォルトではWebとモバイルの画面が同期された形で生成される。同期を切ることもできる
・ビジネスロジックはAppsの確認オブジェクトのData部分に記載するイメージ
・Automationsでメール送信できるメールアドレスは、現状では任意のメールではなく、Teamsに登録されているメンバー限定
・ワークブックをシェアすると、ワークブックの変更もシェアされる。シェアAppだと、アプリケーションの利用だけがシェアされる
・現状アカウントが別だが、AWSアカウントと統合されていくか?
→現状では未定
・Honeycodeアカウントが無いとアプリは使えないのか?
→β版ではできない
・AWSのサービスとどのように連携してできるか?
→有料のアカウントを作成すれば、Lambda連携可能とまぁこの程度の内容でした。コミュニティかどこかで実装してほしいこととかをリクエストしたいと思います。それにしても今年はAWSサミットがオンラインになってしまい残念ですね。。。
- 投稿日:2020-08-03T21:48:42+09:00
aws の練習
AWSでサーバーを立ち上げ、Apache をインストールするまで。もしくはmysqlの設定まで。udemy の aws 講座の内容です。
VPC(Virtual Private Could)の作成
ログインしてVPC dashboardへ。
Create VPC
Name tag に名前。
IPv4 CIDR に10.0.0.0/16Subntets から Create subnet
Name tag を入力
VPCを選択
Availability Zone を選択
IPv4 CIDR block に 10.0.10.0/24create internet gateway
Action からVPCにアタッチ。
vpc を選択
ルートテーブルの作成
name を入れて
vpc を選ぶ。
subnet 関連付けcreate ec2 instance
AMIの選択。ex. Amazon Linux
Instance Type の選択 General purpose t2.micro(無料なので)
Step 3 Coufigure Instance Details
Network 作ったやつ
Subnet 作ったやつ
Capacity Reservation None今回は
next
Step4 Add Strage 8g next
Step5 Add Tags
key Name
Value yamaki今回はStep6 Configure Security Group
check Create a new security group
name yamaki-sg
description yamaki-sg
nextLaunch
Key pair file を作って保存Security Group設定
- 投稿日:2020-08-03T19:47:37+09:00
AWS Lambda+API Gateway+DynamoDBでCRUD APIを作るのをGolangでやってみた
この記事について
Developers.IO 2020のサーバーレスセッションに触発されました。
[動画公開] 初めてのサーバーレスアプリケーション開発 #devio2020というわけで、Golangを用いてAWSで基本的なサーバーレスをやってみたその手順をまとめました。
具体的には以下の手順を紹介します。
- GolangでLambdaを動かしAPI Gatewayと連携させる
- LambdaとDynamoDBと連携してAPIを作る
使用する環境・バージョン
- OS : macOS Mojave 10.14.5
- Golang : version go1.14 darwin/amd64
読者に求める前提知識
Golangの基本的な文法がわかること。
Lambda関数の作成
コンソールで関数を作成
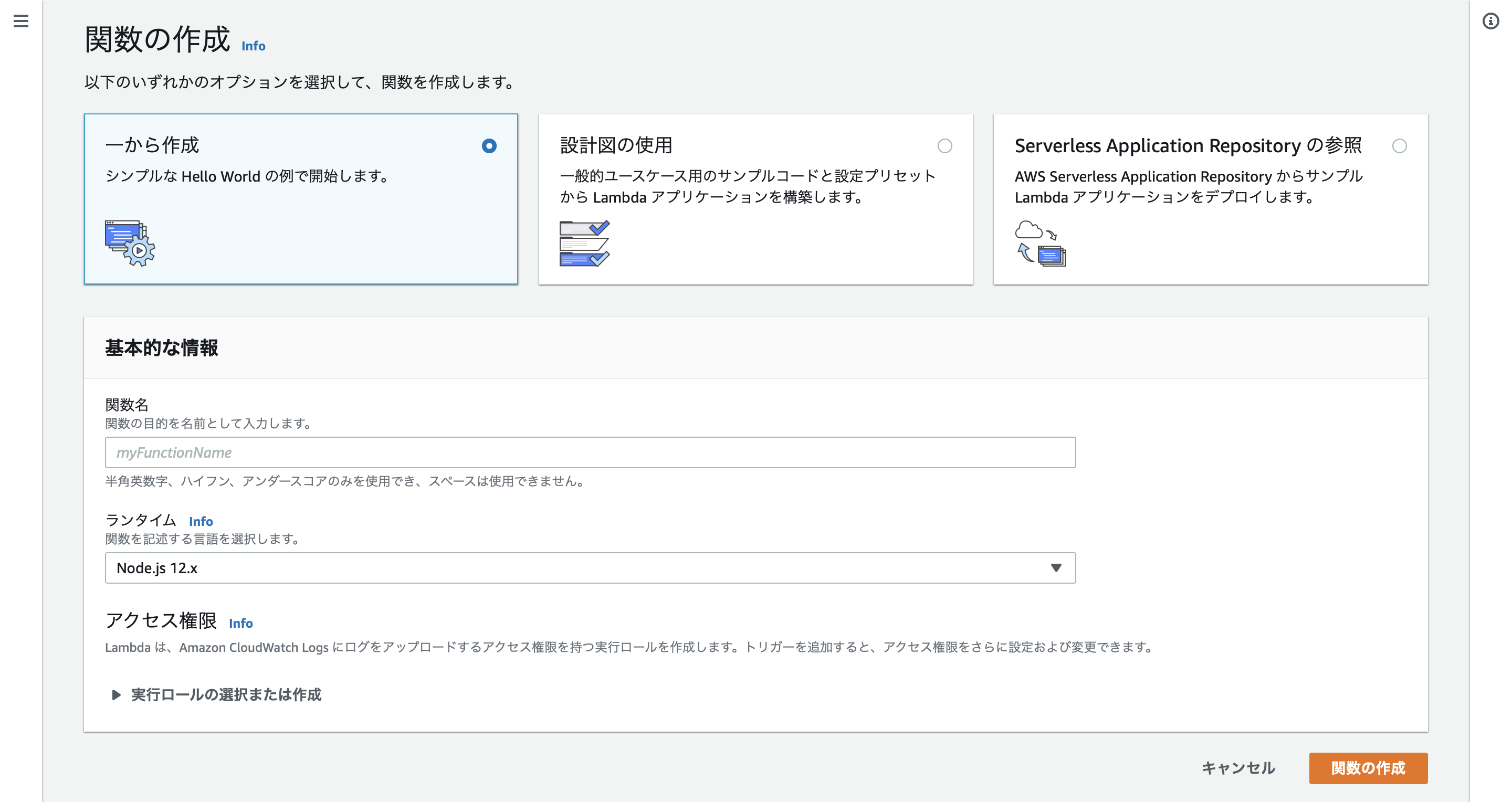
AWS Lambdaのコンソールを開くと、以下のような画面になります。
右上にある「関数の作成」ボタンをクリックします。
すると、以下のような関数作成画面に遷移します。
「一から作成」を選択し、関数名・ランタイムを記入します。今回は以下のように設定しました。
- 関数名: 好きな名前を入力(今回はmyTestFunction)
- ランタイム: Go1.x
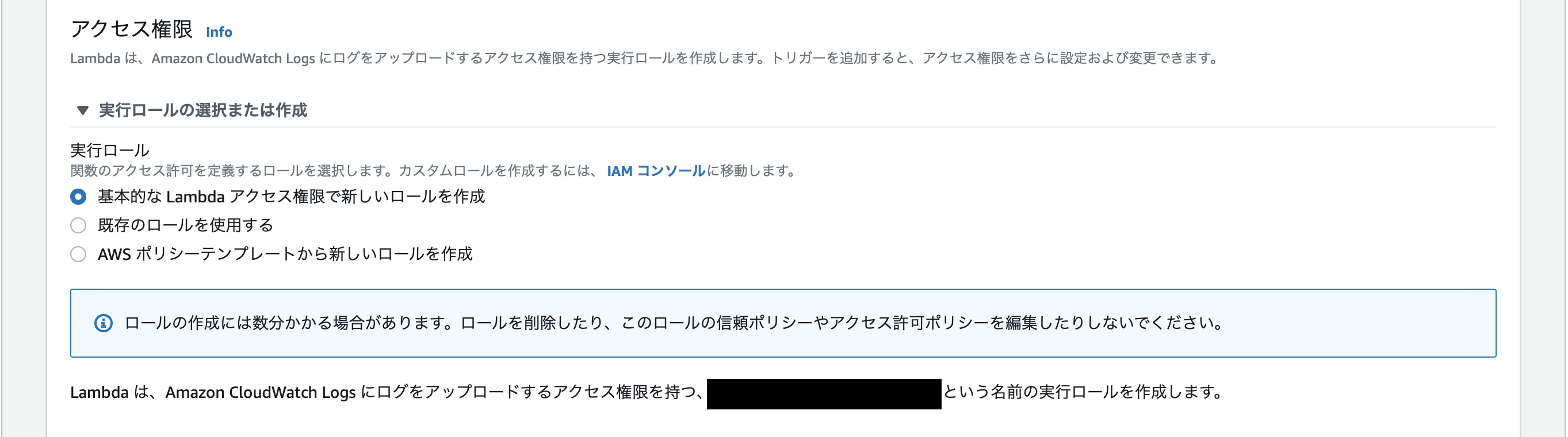
次にLambda関数のアクセス権限の設定をします。
「実行ロールの選択または作成」のプルダウンを開くと、以下のようなフォームが表れます。
今回Lambdaを動かすのは初めてなので、「基本的なLambdaアクセス権限で新しいロールを作成」を選択します。
これで、Lambda関数作成時に、関数のログをCloudWatchに出力するためのロールが作られます。ここまでの入力が終わったら、関数を作成します。
正常に作成されたら、以下のような画面になります。
補足: このとき関数と同時に作られたロールとCloudWatchのロググループは、このLambda関数を削除しても消されず残ったままになります。つまり、ロール・ロググループの削除は、Lambda関数の削除とは別に手動で行う必要があるということです。関数のコードを作成
作ったばかりの関数の中身は「hello,world」を返すだけのデフォルト状態なので、これからLambda上で動かしたいプログラムを別に書いてやる必要があります。
今は手始めに「httpリクエストを受けたら、httpメソッド・リクエストボディ・パスパラメータ・クエリパラメータをjsonにして返す」という関数を作成してみます。
まずは、ローカルに必要なライブラリをインストールします。
go get -u github.com/aws/aws-lambda-go/lambda go get -u github.com/aws/aws-lambda-go/eventsインストールしたら、コードを書いていきます。
hello.gopackage main import ( "encoding/json" "github.com/aws/aws-lambda-go/events" "github.com/aws/aws-lambda-go/lambda" ) type Response struct { RequestMethod string `json:RequestMethod` RequestBody string `json:"RequestBody` PathParameter string `json:"PathParameter"` QueryParameter string `json:"QueryParameter"` } func handler(request events.APIGatewayProxyRequest) (events.APIGatewayProxyResponse, error) { // httpリクエストの情報を取得 method := request.HTTPMethod body := request.Body pathParam := request.PathParameters["pathparam"] queryParam := request.QueryStringParameters["queryparam"] // レスポンスとして返すjson文字列を作る res := Response{ RequestMethod: method, RequestBody: body, PathParameter: pathParam, QueryParameter: queryParam, } jsonBytes, _ := json.Marshal(res) // 返り値としてレスポンスを返す return events.APIGatewayProxyResponse{ Body: string(jsonBytes), StatusCode: 200, }, nil } func main() { lambda.Start(handler) }参考:AWS公式ドキュメント Go の AWS Lambda 関数ハンドラー
参考:Go+Lambdaで最速サーバレスチュートリアルここで、コードについていくつか解説します。
main関数について
Lambdaで実行されるのはmain関数です。そのため、Lambdaにアップロードするコードには必ずmain関数を用意してやる必要があります。
今回は、handlerというAPIハンドラ(関数)を起動する操作をmain関数に書きました。API Gatewayからhttpリクエストの情報を取得する方法
ハンドラは
events.APIGatewayProxyRequest型の変数requestを引数にとっています。この変数requestの中に、どのようなhttpリクエストを受け取ったかの情報が格納されています。
例えば、今回の場合は以下のように情報を取得しています。
- リクエストメソッド:
request.HTTPMethodで取得- リクエストボディ:
request.Bodyで取得- パスパラメータ(
/{pathparam}とAPI Gatewayで設定した部分):equest.PathParameters["pathparam"]で取得- クエリパラメータ(
/?queryparam=の部分):request.QueryStringParameters["queryparam"]で取得
events.APIGatewayProxyRequest型の定義をGo Docで確認すると、他にもどのようなフィールドがあるのかがわかります。やりたい処理に合わせて活用すればよいでしょう。type APIGatewayProxyRequest struct { Resource string `json:"resource"` // The resource path defined in API Gateway Path string `json:"path"` // The url path for the caller HTTPMethod string `json:"httpMethod"` Headers map[string]string `json:"headers"` MultiValueHeaders map[string][]string `json:"multiValueHeaders"` QueryStringParameters map[string]string `json:"queryStringParameters"` MultiValueQueryStringParameters map[string][]string `json:"multiValueQueryStringParameters"` PathParameters map[string]string `json:"pathParameters"` StageVariables map[string]string `json:"stageVariables"` RequestContext APIGatewayProxyRequestContext `json:"requestContext"` Body string `json:"body"` IsBase64Encoded bool `json:"isBase64Encoded,omitempty"` }参考:GoDoc package aws/aws-lambda-go/events
API Gatewayにレスポンスを返す方法
ハンドラは返り値に
events.APIGatewayProxyResponse型をとります。なので、所望のレスポンス内容に沿ったこの型の変数を作成するのが、ハンドラ内で行う処理内容です。
events.APIGatewayProxyResponse型の定義は以下のようになっています。type APIGatewayProxyResponse struct { StatusCode int `json:"statusCode"` Headers map[string]string `json:"headers"` MultiValueHeaders map[string][]string `json:"multiValueHeaders"` Body string `json:"body"` IsBase64Encoded bool `json:"isBase64Encoded,omitempty"` }参考:GoDoc package aws/aws-lambda-go/events
今回の場合は、以下のようにレスポンスを作っています。
- StatusCode: httpレスポンスコード200を指定
- Body: 自作の構造体(
Response)からjson.Marshal→stringと変換コードをLambdaにアップロード
Lambdaにアップロードするのはコンパイル済みの実行ファイルである必要があるので、上で書いた
hello.goをビルドしてバイナリファイルhelloを作ります。
また、アップロードの形式がzipファイルなので、ビルド後にhelloをzip圧縮します。$ GOOS=linux GOARCH=amd64 go build -o hello hello.go $ zip hello.zip hello先ほど作った
myTestFunction関数をLambdaコンソールで開き、以下の設定画面からhello.zipをアップロードします。
注意:アップロードする実行ファイルの名前
「一から作成」のオプションから作成したLambda関数に渡す実行ファイルの名前は、必ず
helloである必要があります。
これは一から作成のLambda関数がデフォルトで「helloという名前のバイナリファイルを実行する」という設定になっているため、他の名前だと以下のようなPathErrorが起きます。{ “errorMessage”: “fork/exec /var/task/binaryname: permission denied”, “errorType”: “PathError” }Lambdaのテスト
Lambda関数は、Webコンソール上でテストを実行することができます。
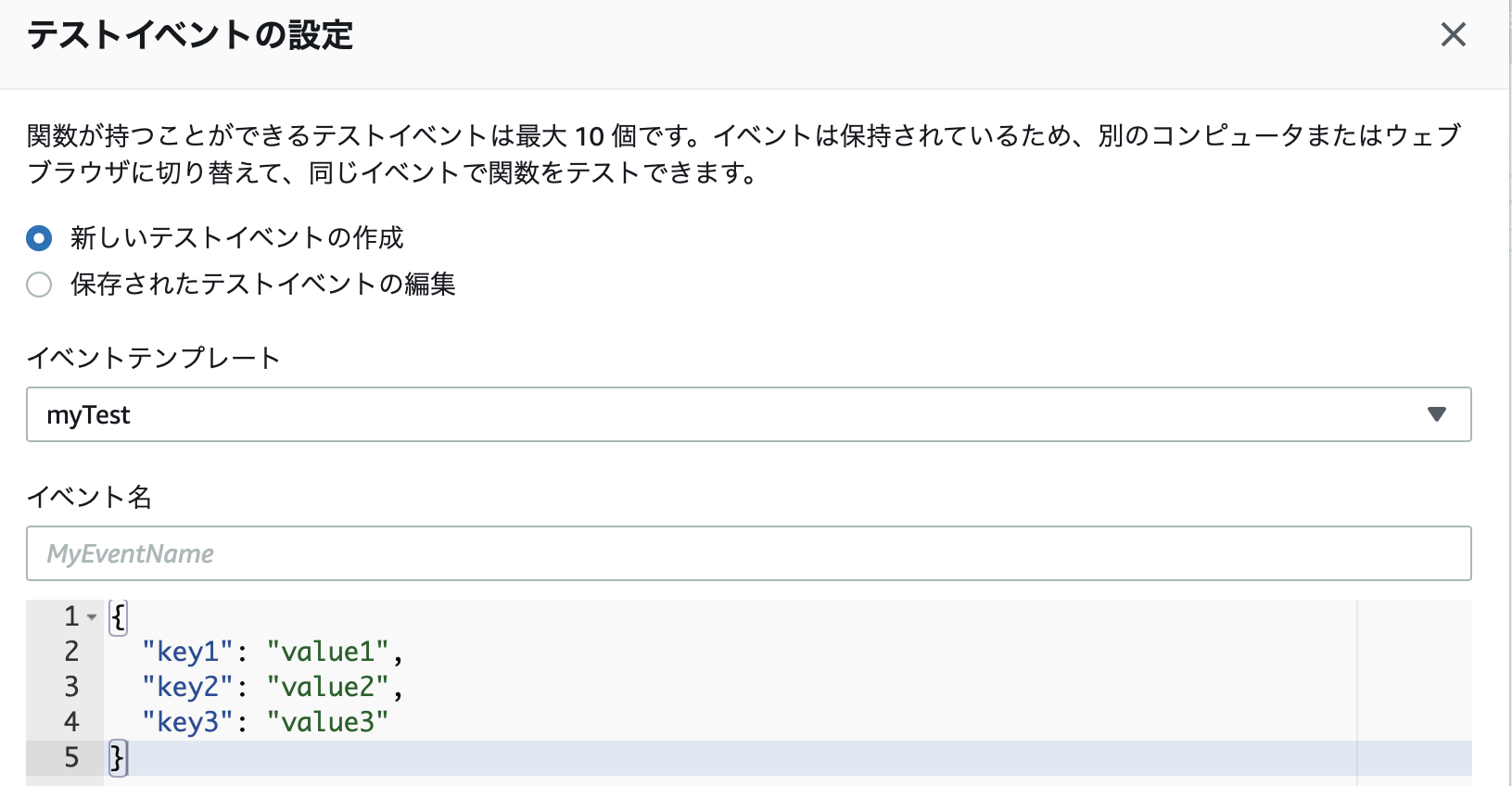
コンソール上で、右上の「テスト」のボタンをクリックします。
すると、テストリクエストを編集する画面が表れます。
デフォルトだとこのような状態です。このまま名前をつけて保存します。
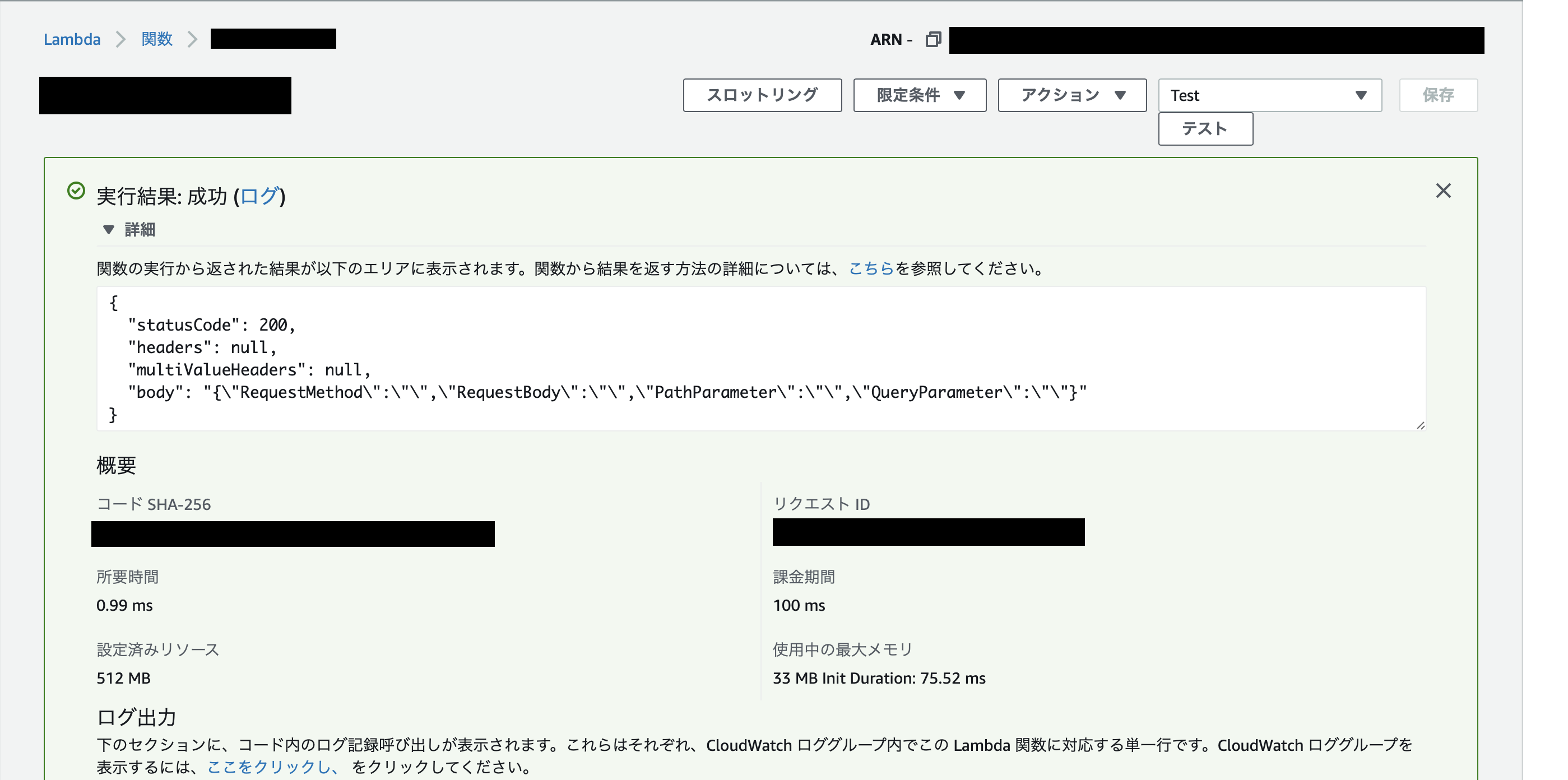
この状態で「テスト」ボタンをクリックすると、テストが実行・結果が表示されます。
きちんとステータスコード200が返ってくることが確認できました。補足: このテストはAPI Gateway経由のリクエストを送っているわけではないので、httpメソッドやボディなどのリクエスト情報が空のときの結果が表示されています。
API Gatewayと連携
APIの作成
開始画面から、「今すぐはじめる」ボタンをクリックします。
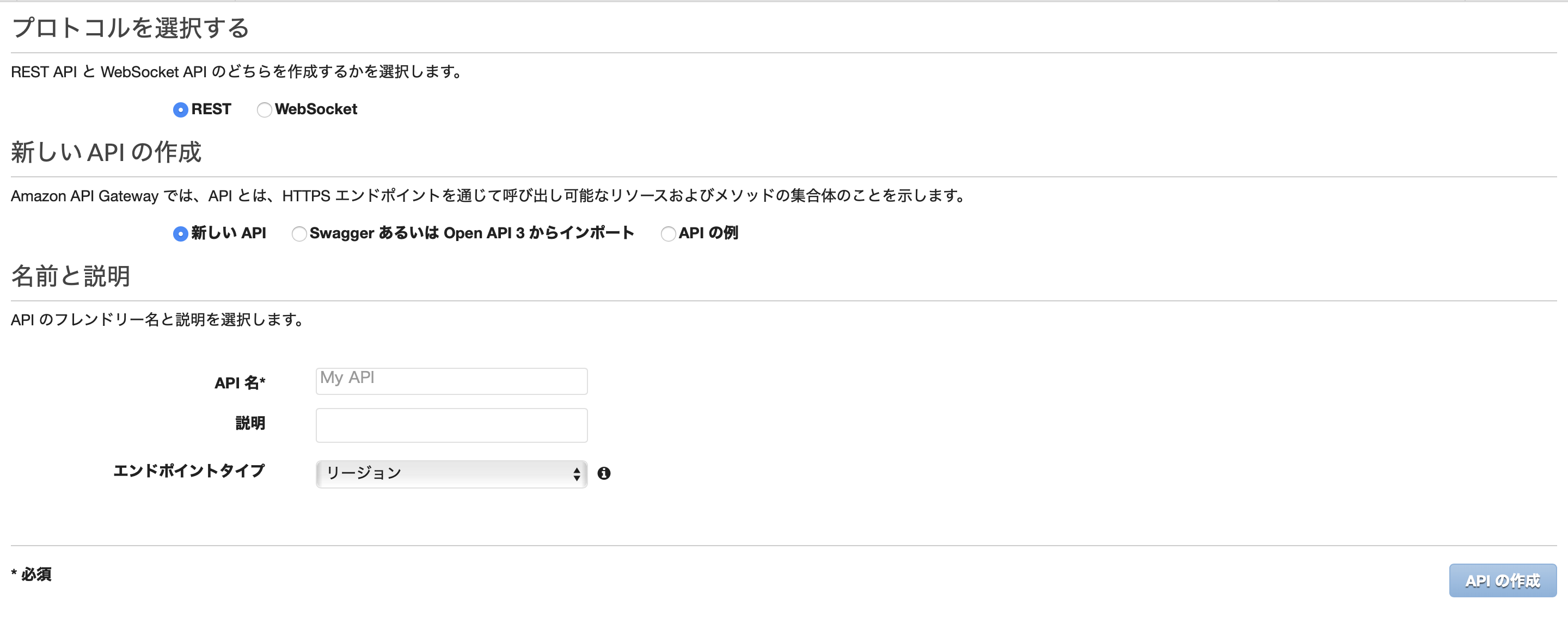
すると、以下のようなAPI作成画面になります。
以下のような設定を入力して作成します。
- プロトコル: REST
- 新しいAPIの作成: 新しいAPI
- API名: 好きな名前をつける
- 説明: 好きな説明文を書く
- エンドポイントタイプ: リージョン
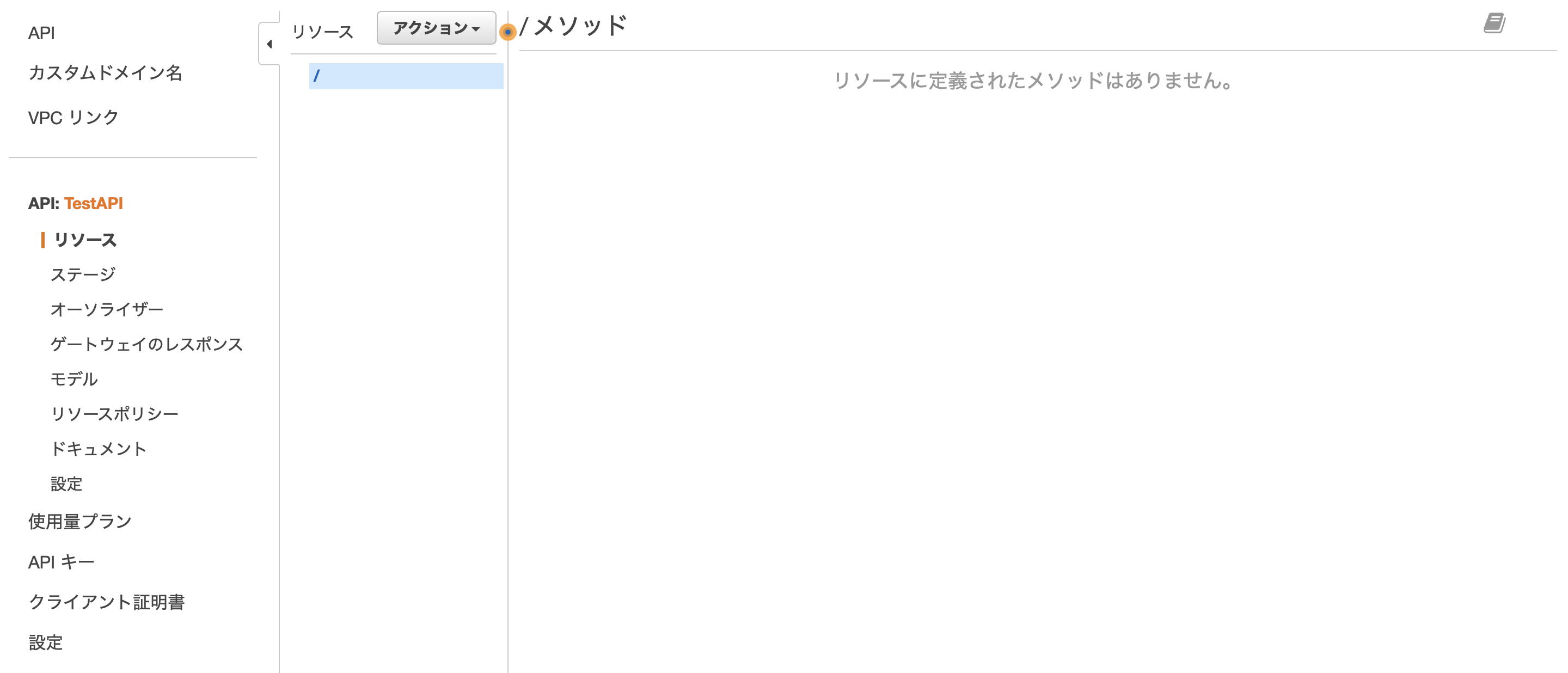
APIを作成したら、「どのパス・どのメソッドにどの処理を結びつけるか」の設定を行う画面が表示されます。URLリソースの作成
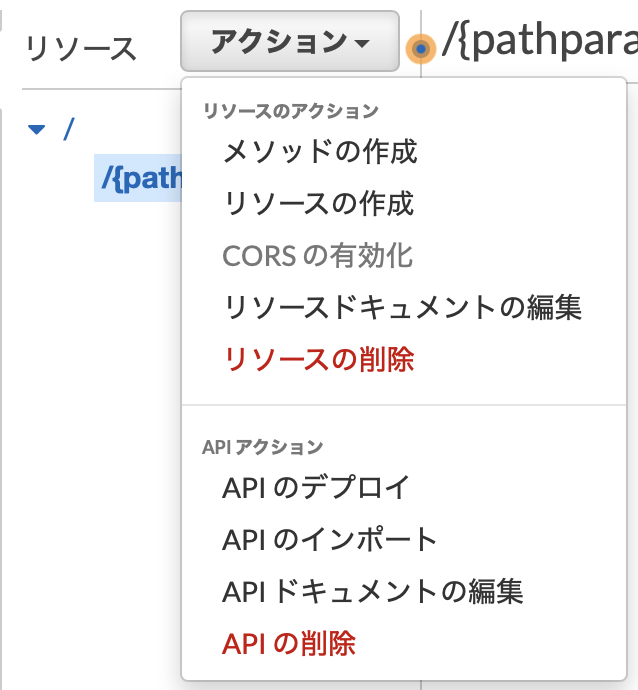
まずは、URLリソースの作成を行います。「アクション」→「リソースの作成」を選択します。
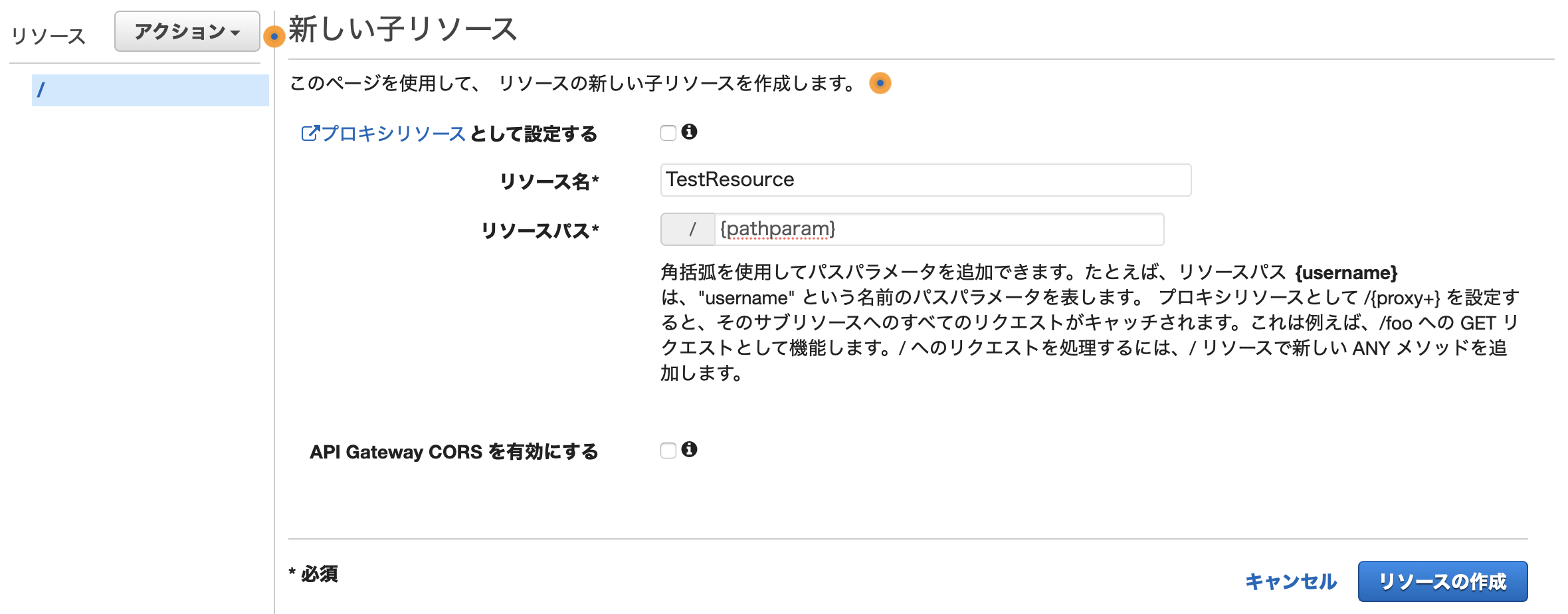
以下のような、パスパラメータの名前等を設定する画面になります。
- プロキシリソース: なし
- リソース名: 好きな名前をつける
- リソースパス: {pathparam}
- API Gateway CORS : なし
以上の設定でリソースを作成します。
メソッドの作成
次に、httpリクエストメソッドーLambda関数の紐付けを行います。
/{pathparam}を選択した状態で、「アクション」→「メソッドの作成」を選択します。
プルダウンから、設定を行いたいリクエストメソッドを選択します。GETやPOSTなどの特定メソッドの選択はもちろん、全てのメソッドに対しての設定を行いたい場合はANYという選択肢もあります。今回はANYを選択します。
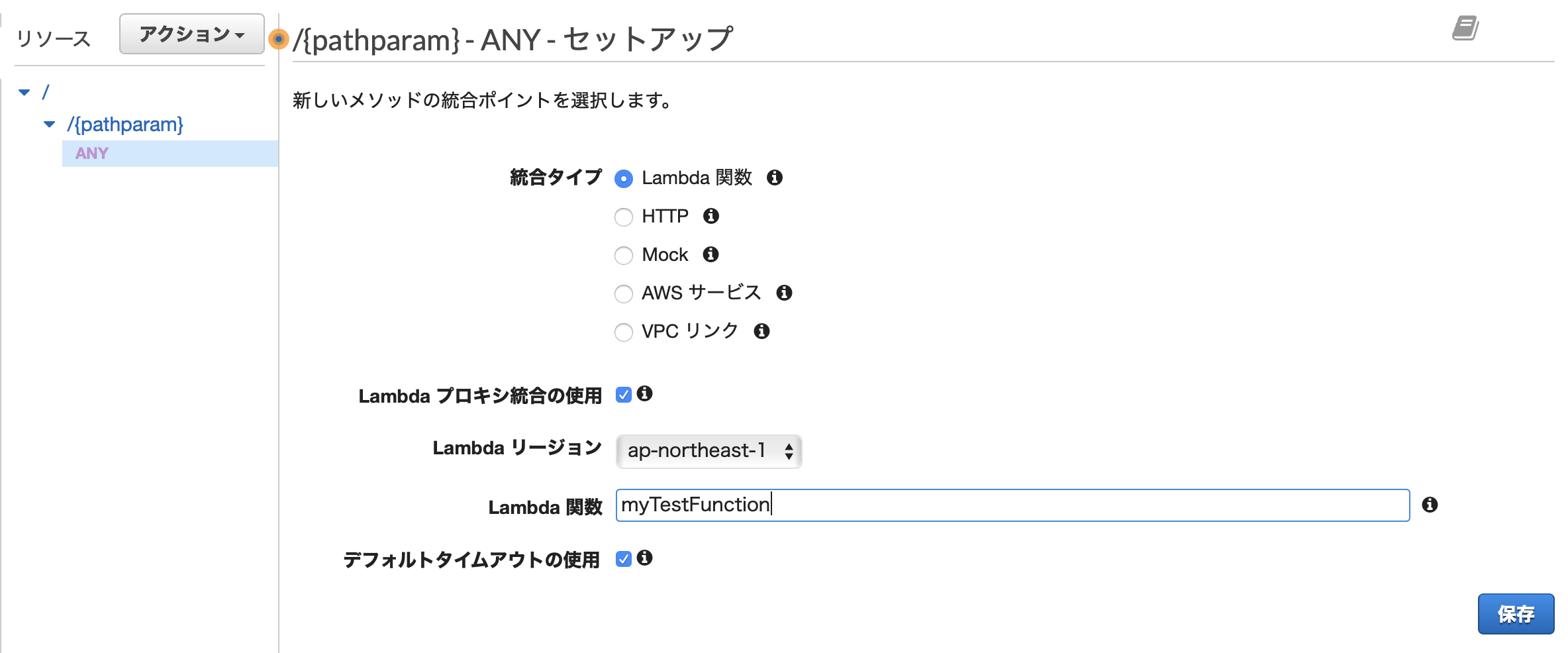
メソッドを選択したら、その選択メソッドにどんな処理(Lambda関数)を紐づけるのかの設定画面が表示されます。
- 統合タイプ: Lambda関数
- Lambdaプロキシ統合の使用: あり
- Lambdaリージョン: ap-northeast-1
- Lambda関数: myTestFunction
- デフォルトタイムアウトの使用: あり
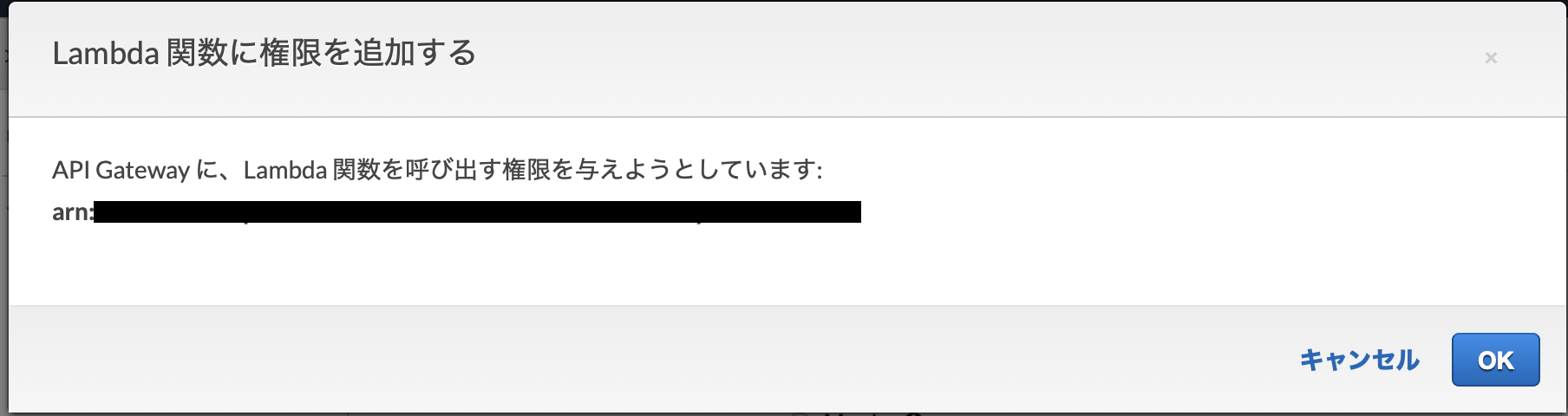
以上の設定で保存をクリックすると、以下のような確認画面が出ます。
問題ないので、OKを選択します。結果は以下の通り。
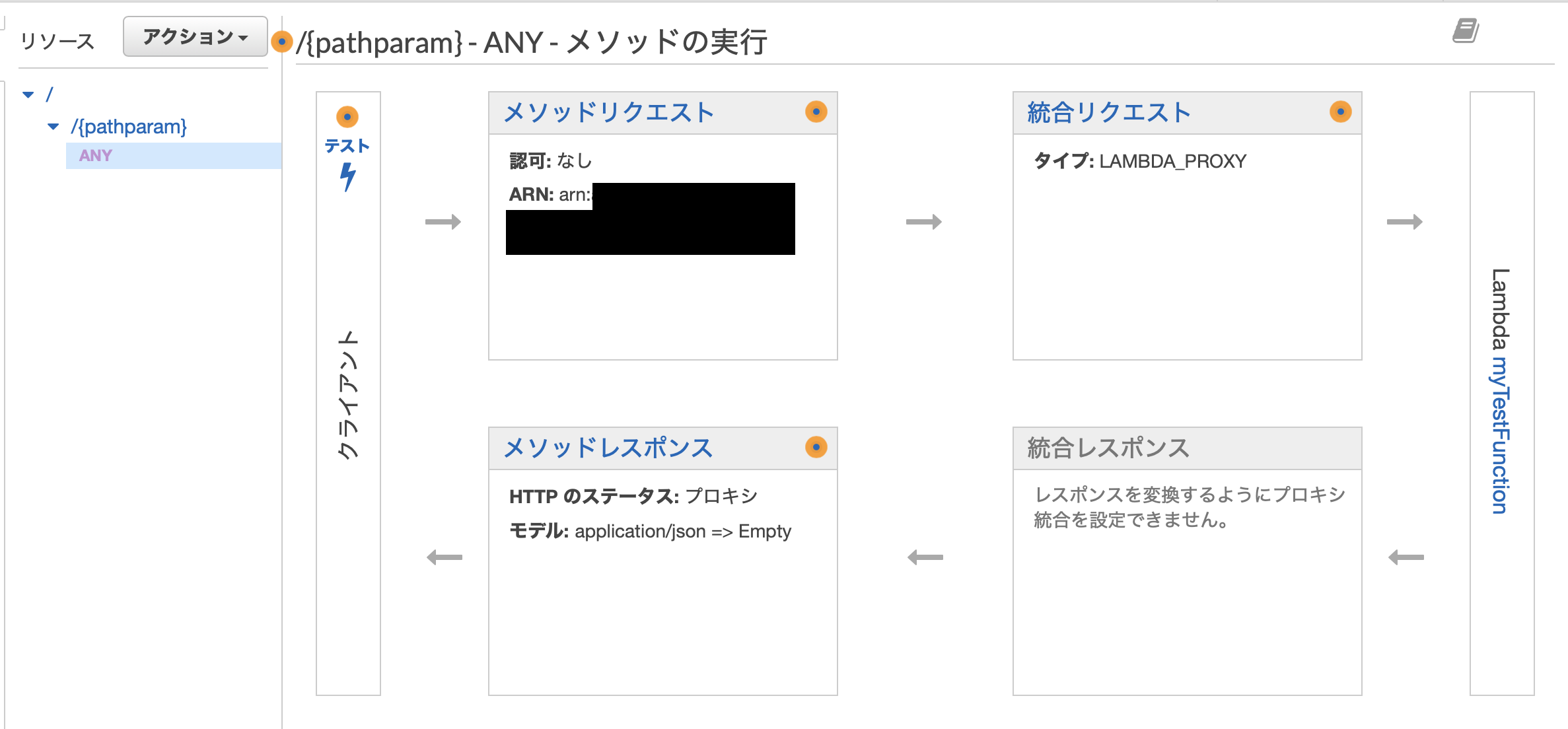
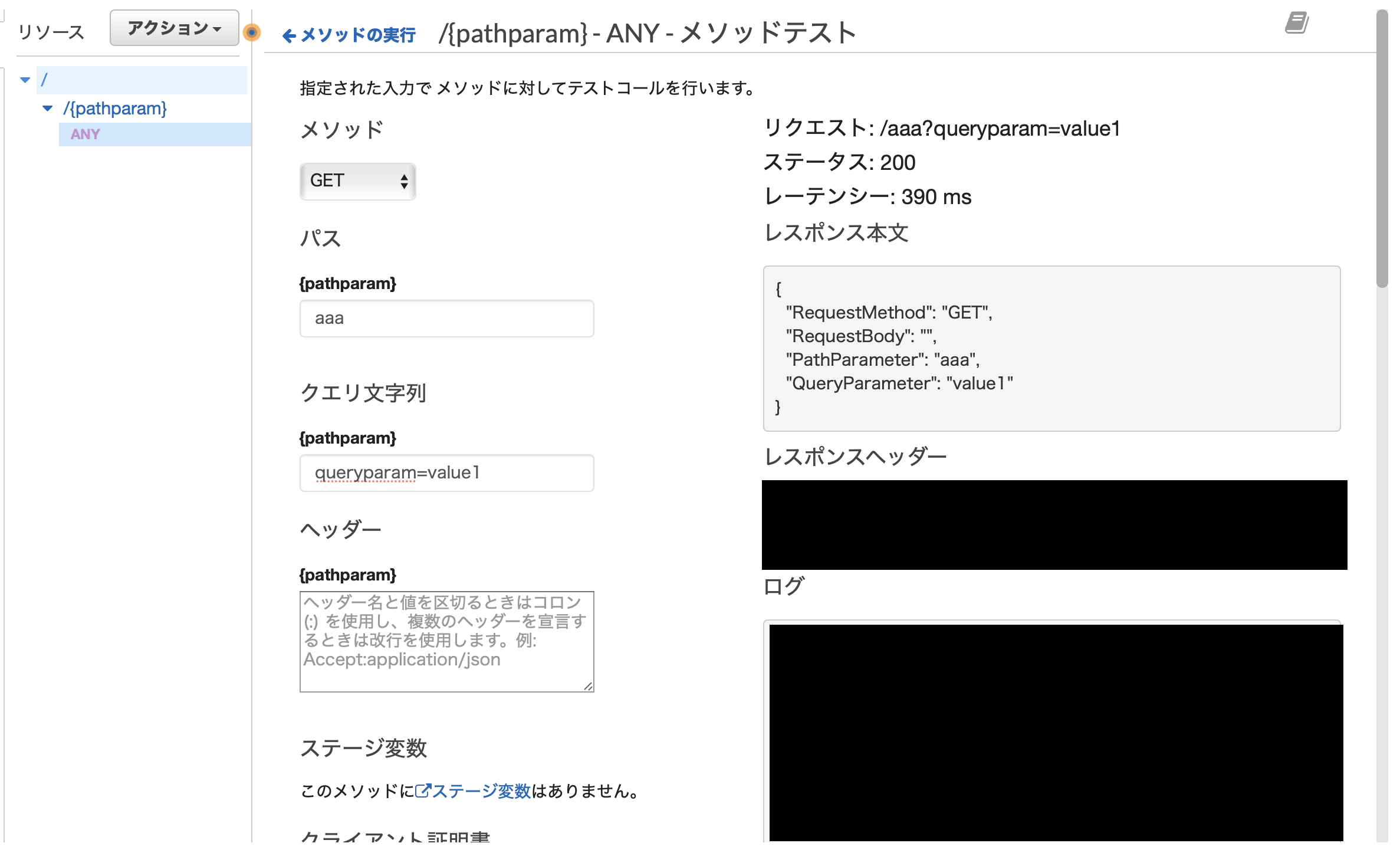
テストの実行
上の画面で「テスト⚡️」をクリックすることで、API Gatewayからリクエストを送ったときにきちんと動くかどうかのテストを実行することができます。
このように、パスパラメータ・クエリパラメータ・リクエストメソッド・ボディなどを自由にコンソール上で設定して、それに対してどのような応答が返ってくるのかを確認することができます。APIのデプロイ
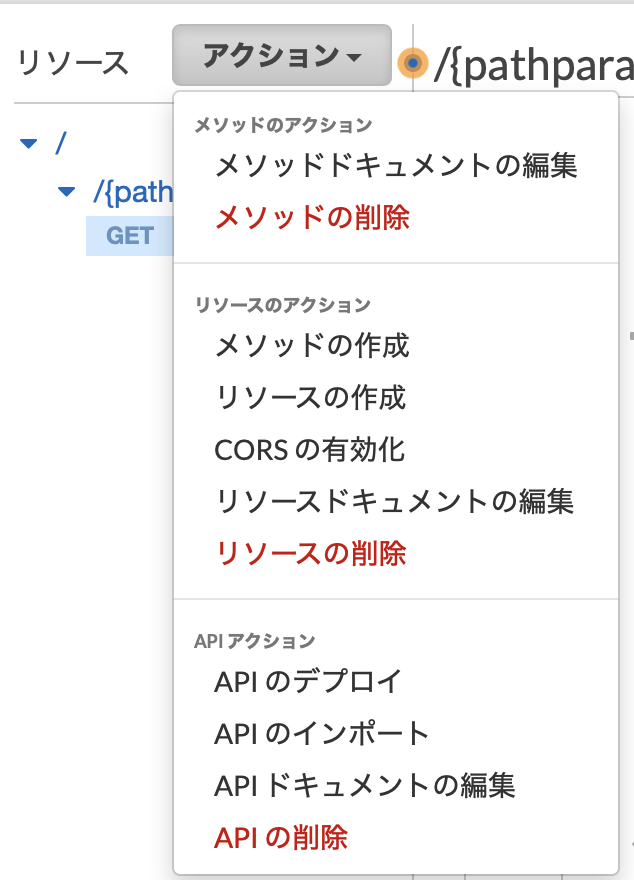
実際にAPIをデプロイするには、「アクション」→「APIのデプロイ」を選択します。
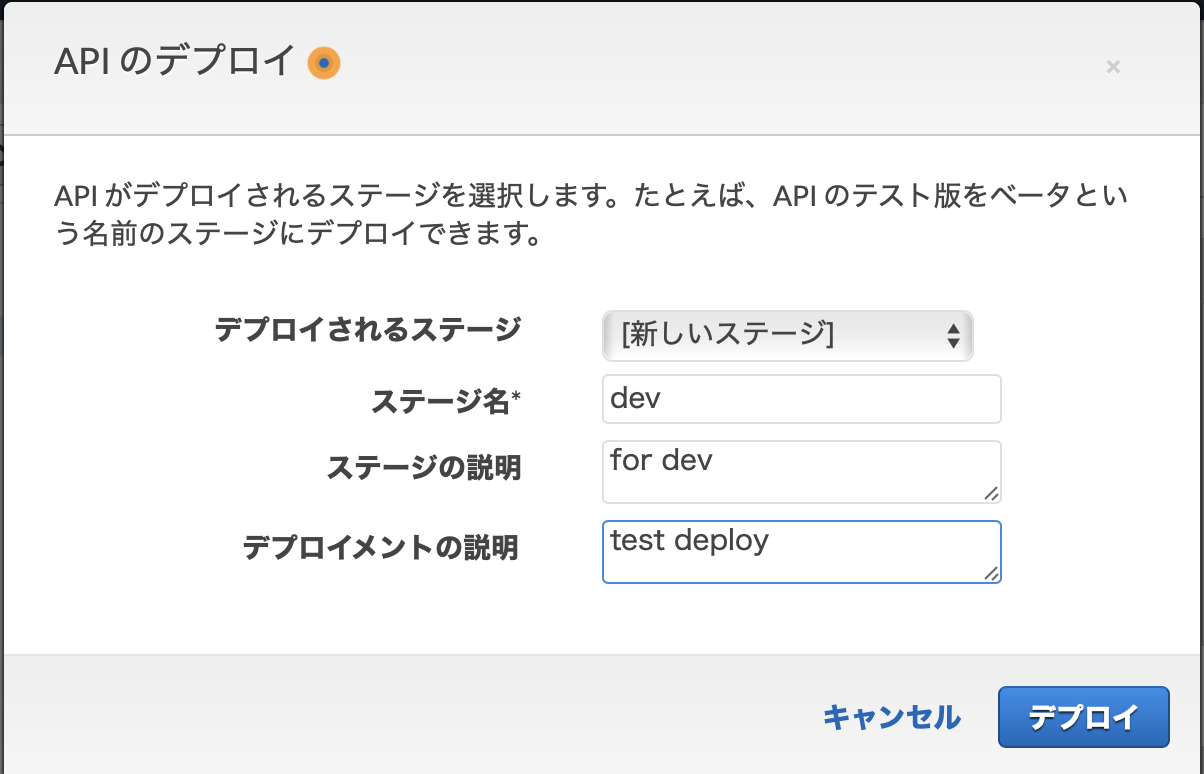
すると、デプロイステージを指定する画面になります。
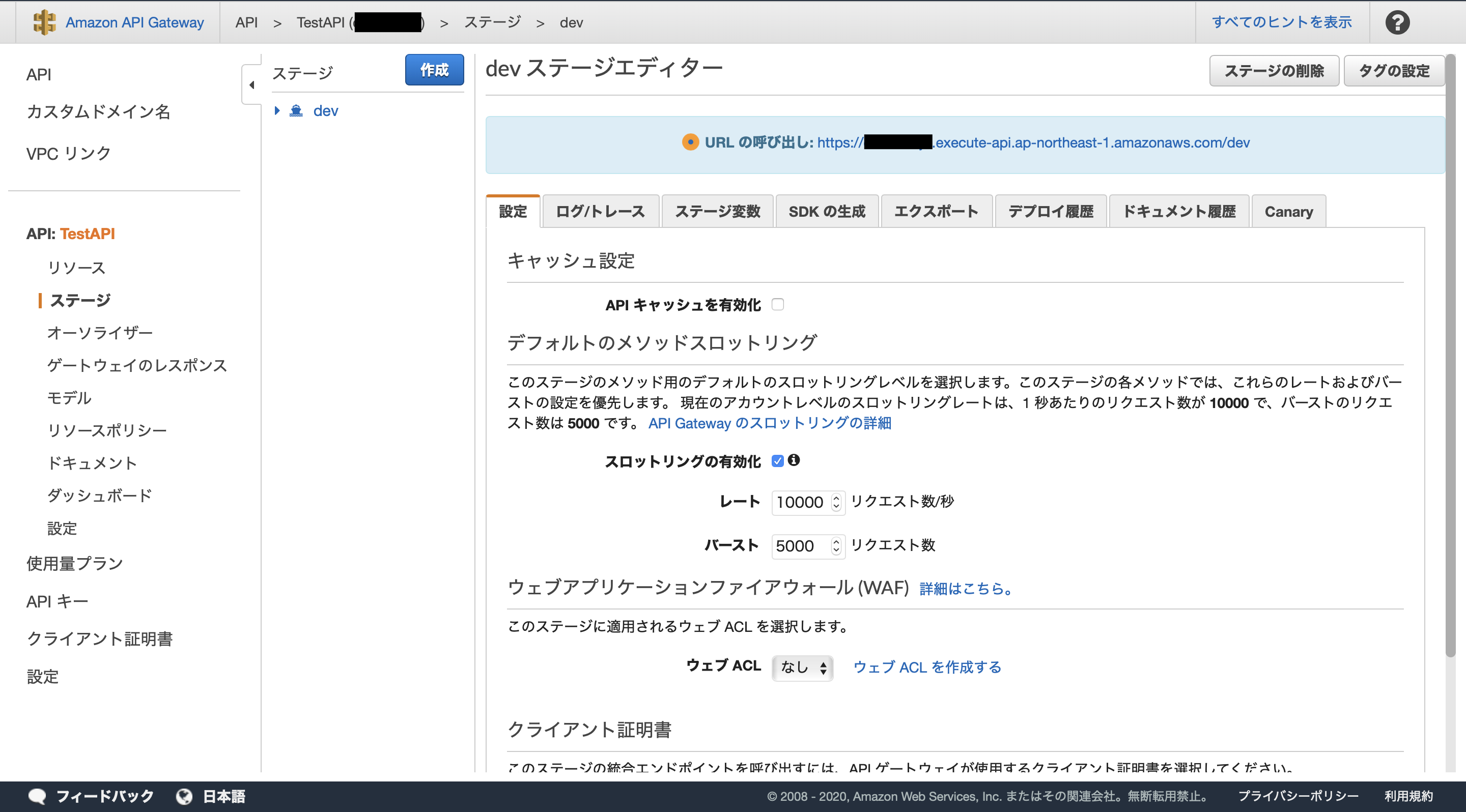
ステージを指定して「デプロイ」ボタンを押すと、以下のような画面に遷移します。
ここで、APIが公開されているURLを確認することができます。
参考:【AWS】API Gateway + LambdaでAPIをつくる
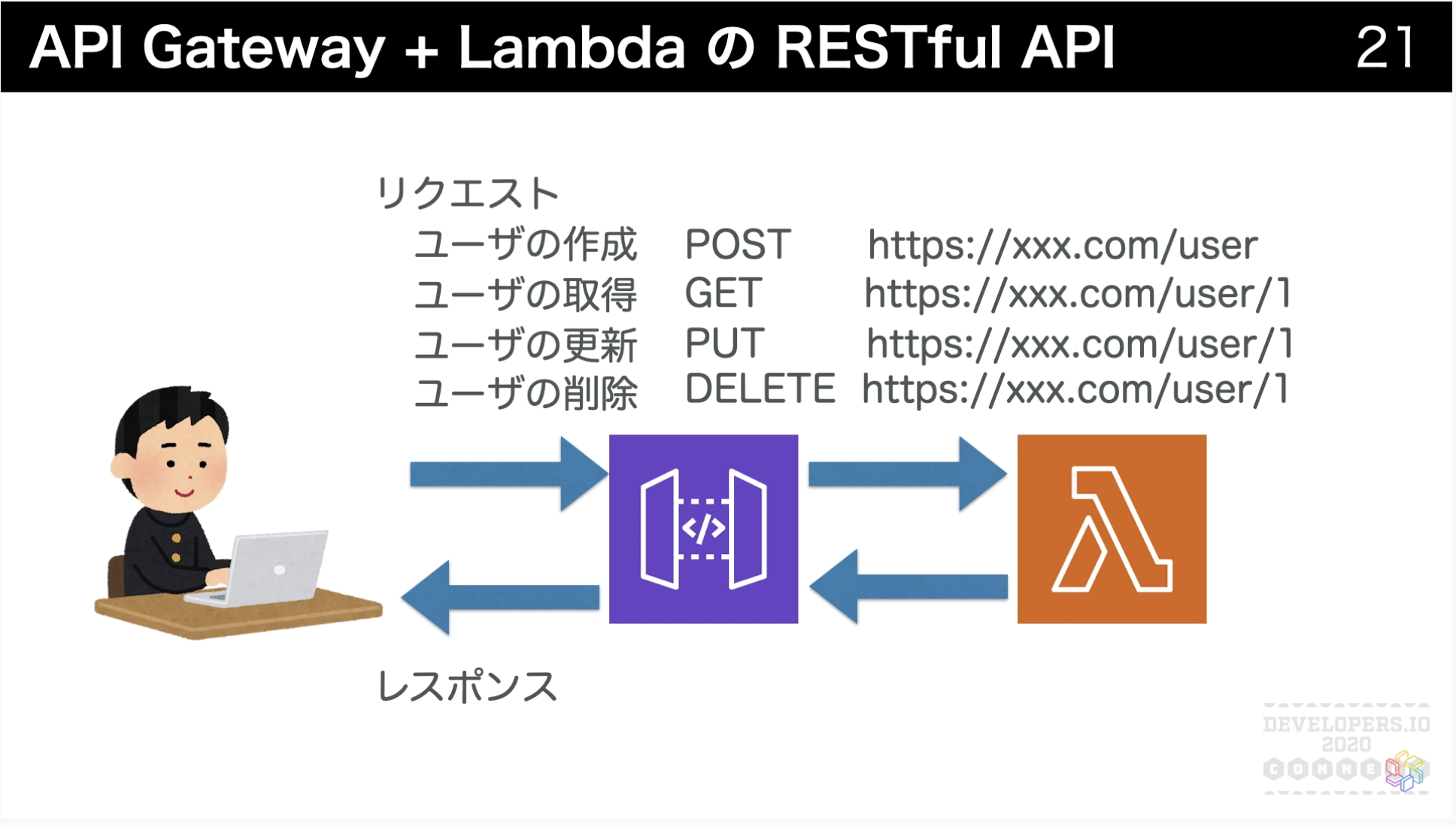
DynamoDBと連携
ここからは、[動画公開] 初めてのサーバーレスアプリケーション開発 #devio2020で紹介された、以下のようなCRUDを行うDB連携APIを新しく作っていきます。
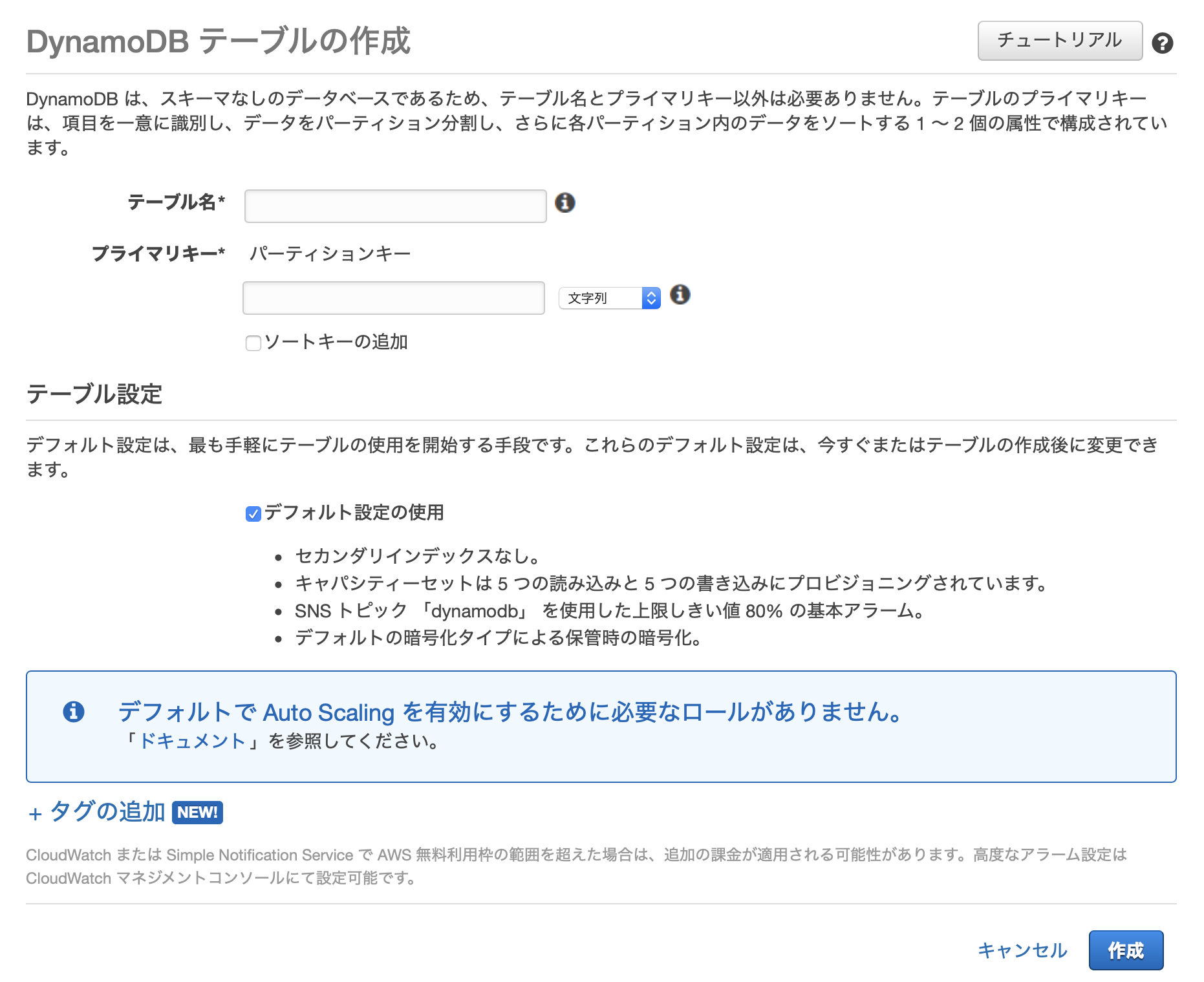
テーブル作成
テーブル作成画面で、以下のような設定を入力して作成します。
- テーブル名: 好きな名前(ここではuser)
- プライマリーキー: userid(数値)
- ソートキー: 追加しない
- テーブル設定: デフォルト設定の使用
補足: プライマリーキーに設定できるデータ型は文字列orバイナリor数値です。
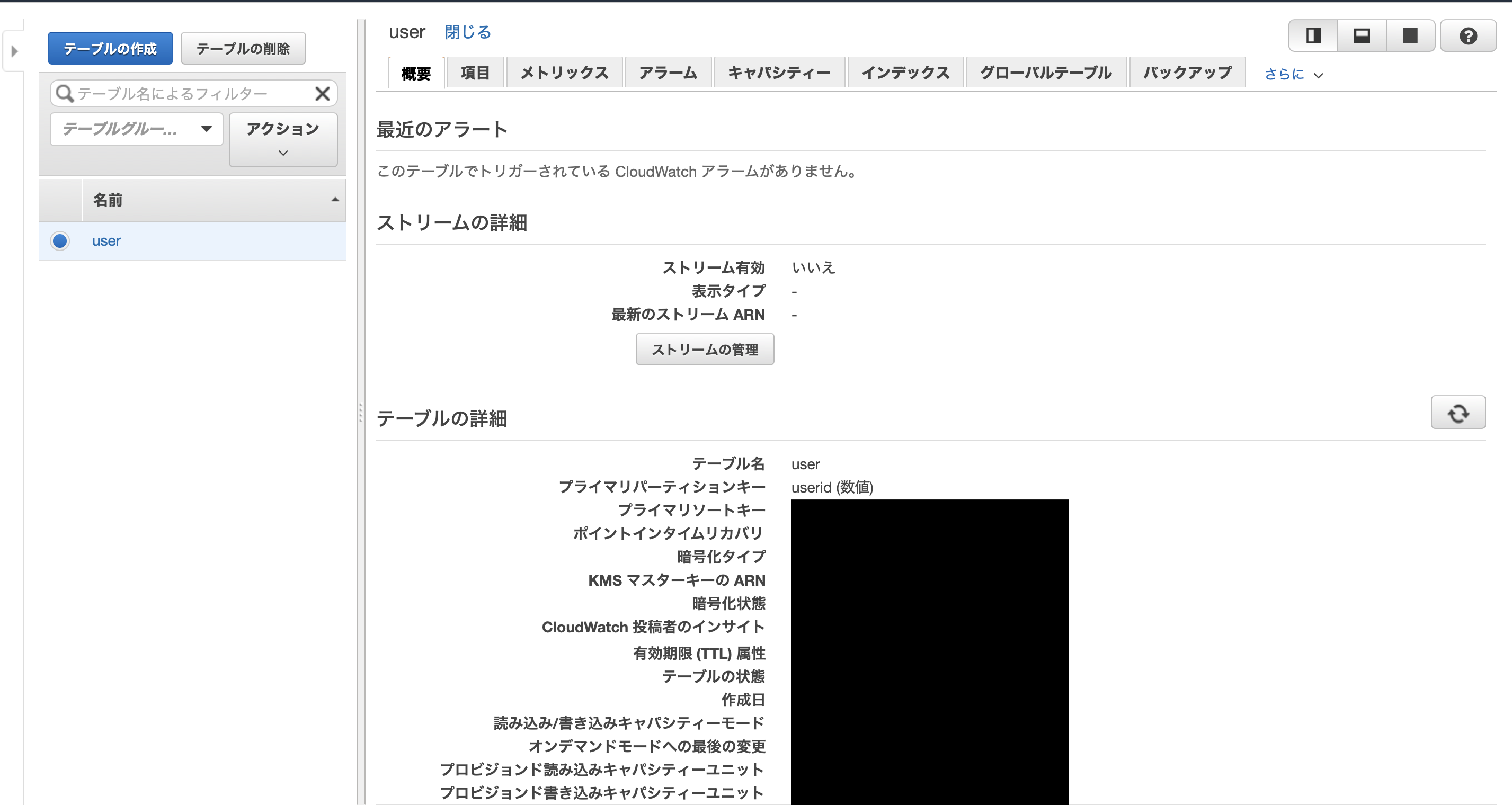
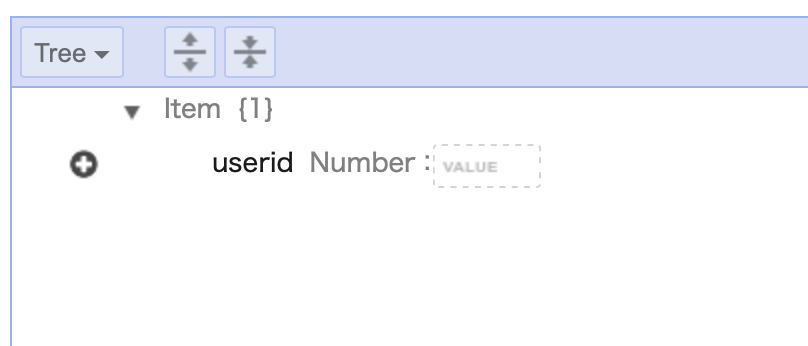
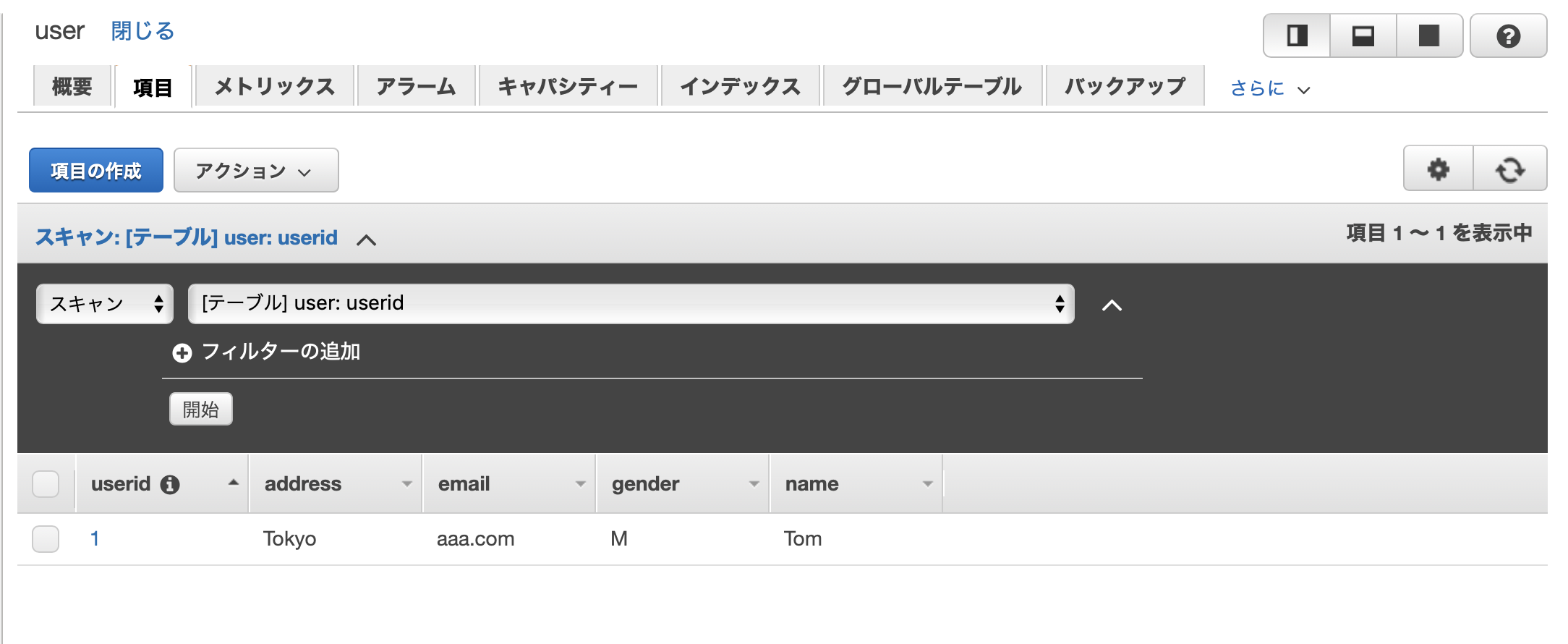
作成に成功すると、以下のような画面に遷移します。データ項目の追加
作成直後は、プライマリーキー以外の属性が存在しないので、他のキーが欲しいのならば手動で追加する必要があります。
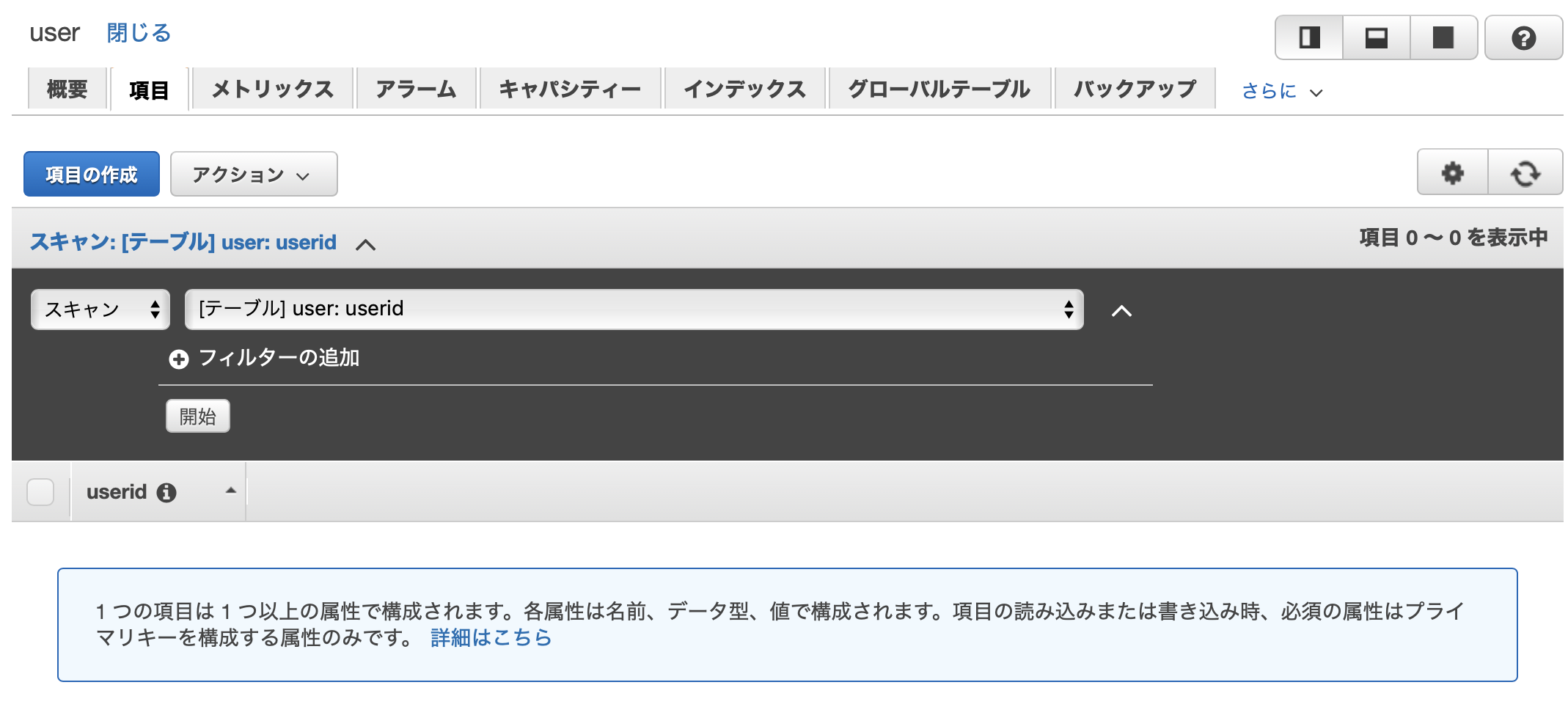
テーブルの項目タブを開きます。
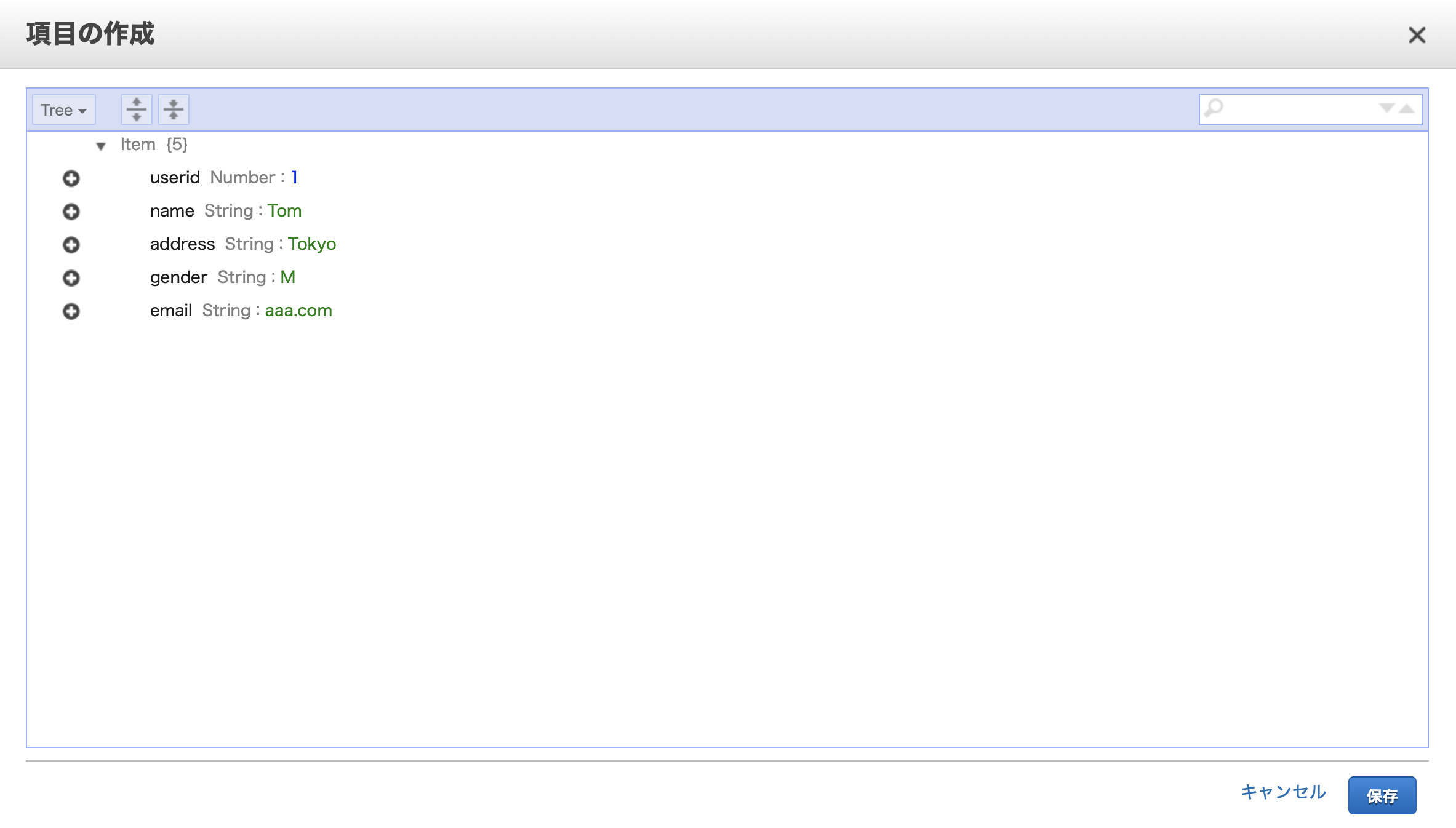
「項目の作成」ボタンをクリックすると、以下のような項目編集画面が表示されます。
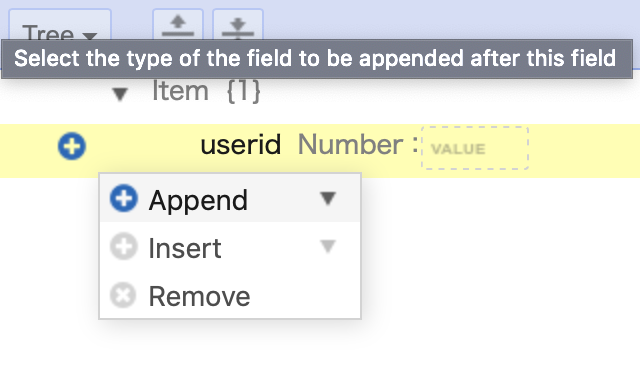
+をクリックします。
Appendを選択します。
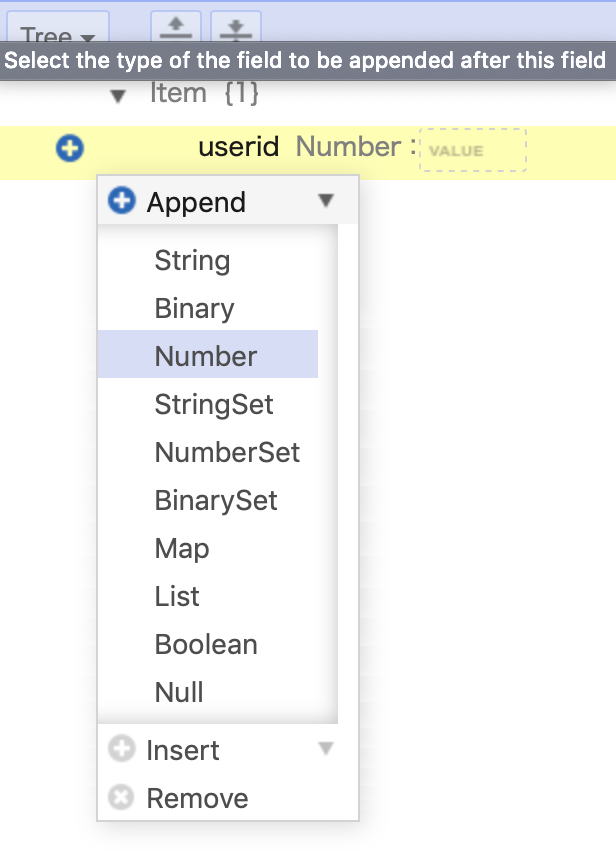
すると、どういう型のフィールドを追加するかを選択できます。
今回はStringを選択しました。
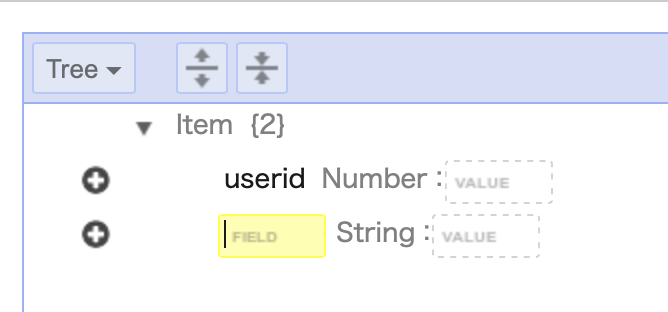
すると、String型のフィールドが追加されました。好きにフィールド名をつけたり、値も設定を行ったりします。
項目の追加を複数回行い、最終的にこうなりました。これで保存します。
無事にプライマリーキー以外の項目が作成されたことが確認できます。参考:初めてのサーバーレスアプリケーション開発 ~DynamoDBにテーブルを作成する~
Lambda用のロールを作成
Lambda関数がDynamoDBにアクセスできるように、Lambda関数に付与するロールを作成します。
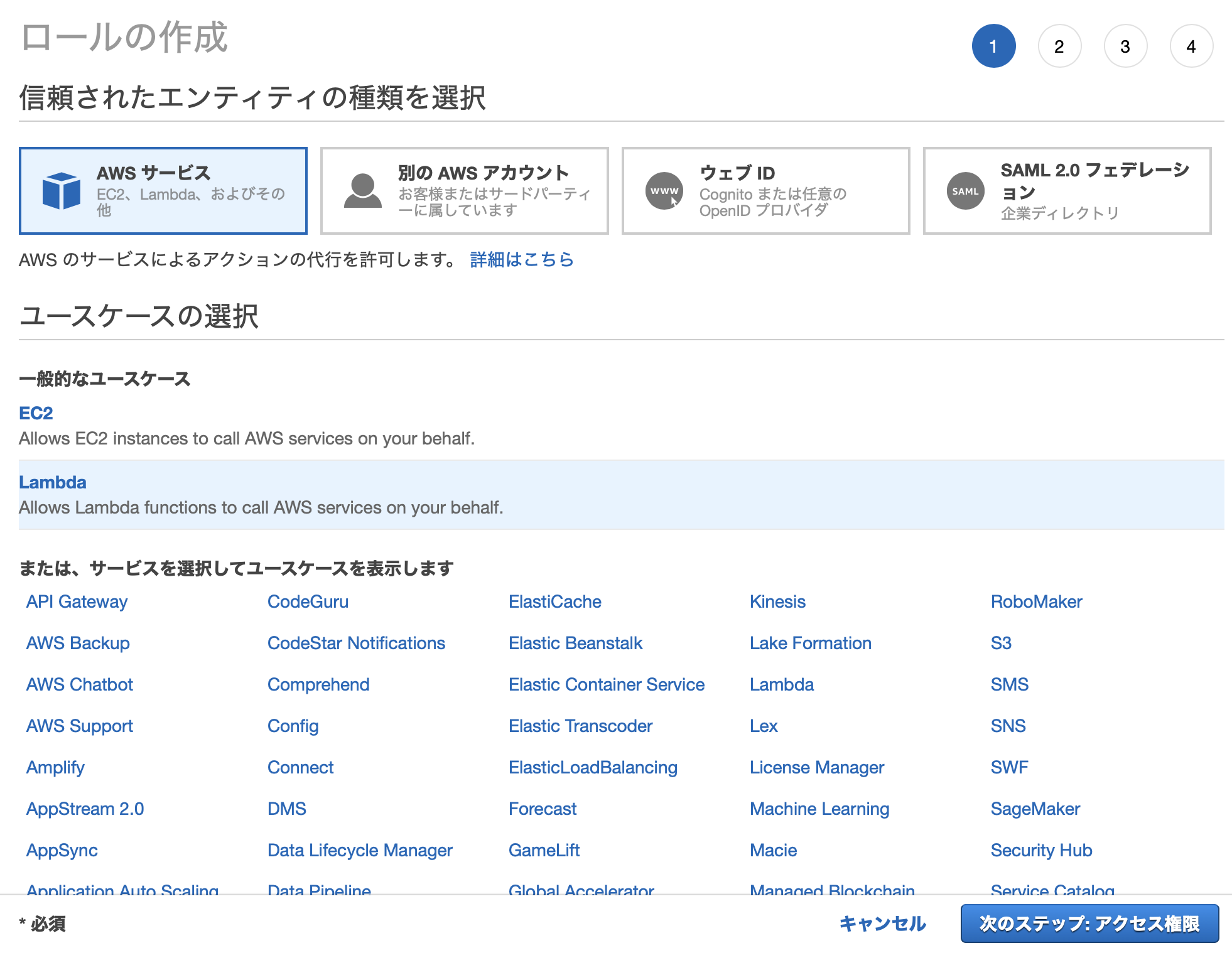
IAMコンソール→ロールから作成画面を開きます。
AWSサービス、Lambdaを選択します。
そして、以下のアクセス権限を追加して、ロールを作成します。
- AmazonDynamoDBFullAccess
- AWSLambdaDynamoDBExecutionRole
DynamoDBとの接続を必要とするLambda関数には、今作ったロールを付加します。
参考:初めての、LambdaとDynamoDBを使ったAPI開発
Lambda関数のコードを作成
いよいよDBにアクセスしてCRUD操作を行う関数コードを書いていきます。
まず、必要なパッケージをダウンロードします。
$ go get -u github.com/aws/aws-sdk-go/aws $ go get -u github.com/aws/aws-sdk-go/aws/session $ go get -u github.com/aws/aws-sdk-go/service/dynamodbCreate(POST)の作成
package main import ( "encoding/json" "github.com/aws/aws-lambda-go/events" "github.com/aws/aws-lambda-go/lambda" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/dynamodb" "github.com/aws/aws-sdk-go/service/dynamodb/dynamodbattribute" ) // Item DBに入れるデータ type Item struct { UserID int `dynamodbav:"userid" json:userid` Address string `dynamodbav:"address" json:address` Email string `dynamodbav:"email" json:email` Gender string `dynamodbav:"gender" json:gender` Name string `dynamodbav:"name" json:name` } // Response Lambdaが返答するデータ type Response struct { RequestMethod string `json:RequestMethod` Result Item `json:Result` } func handler(request events.APIGatewayProxyRequest) (events.APIGatewayProxyResponse, error) { method := request.HTTPMethod // DBと接続するセッションを作る→DB接続 sess, err := session.NewSession() if err != nil { return events.APIGatewayProxyResponse{ Body: err.Error(), StatusCode: 500, }, err } db := dynamodb.New(sess) // リクエストボディのjsonから、Item構造体(DB用データの構造体)を作成 reqBody := request.Body resBodyJSONBytes := ([]byte)(reqBody) item := Item{} if err := json.Unmarshal(resBodyJSONBytes, &item); err != nil { return events.APIGatewayProxyResponse{ Body: err.Error(), StatusCode: 500, }, err } // Item構造体から、inputするデータを用意 inputAV, err := dynamodbattribute.MarshalMap(item) if err != nil { return events.APIGatewayProxyResponse{ Body: err.Error(), StatusCode: 500, }, err } input := &dynamodb.PutItemInput{ TableName: aws.String("user"), Item: inputAV, } // insert実行 _, err = db.PutItem(input) if err != nil { return events.APIGatewayProxyResponse{ Body: err.Error(), StatusCode: 500, }, err } // httpレスポンス作成 res := Response{ RequestMethod: method, } jsonBytes, _ := json.Marshal(res) return events.APIGatewayProxyResponse{ Body: string(jsonBytes), StatusCode: 200, }, nil } func main() { lambda.Start(handler) }ここでやっていることは以下の操作です。
- DBに接続
- リクエストボディからItem構造体を作る
- Item構造体から、DBにinsertするためのデータを作る
- insertを実行する
- レスポンスを作成
1. DBに接続
以下のコードが該当します。
sess, err := session.NewSession() if err != nil { return events.APIGatewayProxyResponse{ Body: err.Error(), StatusCode: 500, }, err } db := dynamodb.New(sess)これは、DynamoDBに接続する処理を行うときには必ず必要な定型句といってもいいでしょう。
2. リクエストボディからItem構造体を作る
httpリクエストボディに、DBに挿入したいデータがjson形式で格納されています。
example-requestbody.json{ "userid": 2, "address": "Osaka", "email": "bbb.jp", "gender": "F", "name": "Nancy" }
request.Bodyで得られるリクエストボディはstring型なので、これをjson.Unmarshalでパースして構造体形式(上だとItem構造体)に変換することで、ボディに格納されているデータを扱えるようにします。3. Item構造体から、DBにinsertするためのデータを作る
DynamoDBにデータを挿入する関数は、
db.PutItem()です。func (c *DynamoDB) PutItem(input *PutItemInput) (*PutItemOutput, error)参考:GoDoc github.com/aws/aws-sdk-go/service/dynamodb#DynamoDB.PutItem
しかし、見ての通りこの関数の引数はdynamodb.PutItemInput型なので、Item型をそのままDBに渡すことはできません。そのため、Item型をdynamodb.PutItemInput型に変換する必要があります。
dynamodb.PutItemInput型の定義を見てみましょう。type PutItemInput struct { // 今回関係ないフィールドを省略 Item map[string]*AttributeValue `type:"map" required:"true"` TableName *string `min:"3" type:"string" required:"true"` }参考:GoDoc github.com/aws/aws-sdk-go/service/dynamodb#PutItemInput
TableNameは、データを追加したDynamoDBのテーブル名を指定するフィールドです。
追加するデータの内容を入れるフィールドは、map[string]*AttributeValue型のItemです。つまり、2でリクエストボディから作ったItem型構造体を、このmap[string]*AttributeValue型に変換してやる必要があるわけです。まさに、この変換を行う関数が公式から提供されています。
dynamodbattribute.MarshalMapという関数です。// Item型のitem変数を、map[string]*AttributeValue型のimputAVに変換 inputAV, err := dynamodbattribute.MarshalMap(item)この変換を正しく行うためには、Item型構造体に指定のメタタグをつける必要があります。
(json.Unmarshalでjsonを構造体にパースするために、構造体にjsonタグをつけたのと同じ論理です)
ここで、Item型を以下のように定義していました。type Item struct { UserID int `dynamodbav:"userid" json:userid` Address string `dynamodbav:"address" json:address` Email string `dynamodbav:"email" json:email` Gender string `dynamodbav:"gender" json:gender` Name string `dynamodbav:"name" json:name` }この構造体の各フィールドにつけている
dynamodbavタグは、「各フィールドがDynamoDBのどのキーに対応しているか」ということを示しています。例えば、UserIDフィールドは、DynamoDBではuseridキーに紐づいています。
dynamodbattribute.MarshalMapを実行するためには、各フィールドにこのdynamodbavタグを確実につけましょう。4. insertを実行する
db.PutItem()を実行します。5. レスポンスを作成
APIを作成したときと要領は同じなので割愛します。
Read(GET)の作成
package main import ( "encoding/json" "github.com/aws/aws-lambda-go/events" "github.com/aws/aws-lambda-go/lambda" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/dynamodb" "github.com/aws/aws-sdk-go/service/dynamodb/dynamodbattribute" ) // Item構造体とResponse構造体は、Createのときと同じなので割愛 func handler(request events.APIGatewayProxyRequest) (events.APIGatewayProxyResponse, error) { method := request.HTTPMethod pathparam := request.PathParameters["userid"] // DB接続 sess, err := session.NewSession() if err != nil { return events.APIGatewayProxyResponse{ Body: err.Error(), StatusCode: 500, }, err } db := dynamodb.New(sess) // 検索条件を用意 getParam := &dynamodb.GetItemInput{ TableName: aws.String("user"), Key: map[string]*dynamodb.AttributeValue{ "userid": { N: aws.String(pathparam), }, }, } // 検索 result, err := db.GetItem(getParam) if err != nil { return events.APIGatewayProxyResponse{ Body: err.Error(), StatusCode: 404, }, err } // 結果を構造体にパース item := Item{} err = dynamodbattribute.UnmarshalMap(result.Item, &item) if err != nil { return events.APIGatewayProxyResponse{ Body: err.Error(), StatusCode: 500, }, err } // httpレスポンス作成 res := Response{ RequestMethod: method, Result: item, } jsonBytes, _ := json.Marshal(res) return events.APIGatewayProxyResponse{ Body: string(jsonBytes), StatusCode: 200, }, nil } // main関数はCreateのときと同じなので割愛ここでやっていることは以下の操作です。
- DBに接続(説明割愛)
- DBに問い合わせる検索条件を作る
- DBに問い合わせてデータを取得する
- レスポンスを作成(説明割愛)
2. DBに問い合わせる検索条件を作る
DBに問い合わせてデータを取得する関数は
db.GetItem()です。func (c *DynamoDB) GetItem(input *GetItemInput) (*GetItemOutput, error)参考:GoDoc github.com/aws/aws-sdk-go/service/dynamodb#DynamoDB.GetItem
この引数としてとるのはdynamodb.GetItemInput型なので、この型の変数を作成します。
dynamodb.GetItemInput型の定義を確認します。type GetItemInput struct { // 今回関係ないフィールドを省略 Key map[string]*AttributeValue `type:"map" required:"true"` TableName *string `min:"3" type:"string" required:"true"` }
TableNameはCreateのときと同様に、対象テーブルの名前を指定するフィールド、Keyは、取得したいレコードのプライマリーキーを指定するフィールドです。
そのため、db.GetItem()に渡すdynamodb.GetItemInput型引数を以下のように作成します。getParam := &dynamodb.GetItemInput{ TableName: aws.String("user"), Key: map[string]*dynamodb.AttributeValue{ "userid": { N: aws.String(pathparam), }, }, }このコードの意味は以下の通りです。
- TableName: userテーブルを検索
- Key: ここでは、Number型(N)のキーであるuseridの値が、
aws.String(pathparam)であるデータを検索するという意味
Keyフィールドで、useridキーが数値型であることを、Nという風に指定しています。各データ型がどの表現に対応するのかは以下の表をご覧ください。
データ型 アルファベット バイナリ B ブール型 BOOL バイナリセット BS リスト L マップ M 数値 N 数値セット NS null NULL 文字列 S 文字列セット SS また、
Keyフィールドは、dynamodb.PutItemInput型のItemフィールドと同じくmap[string]*AttributeValue型なのです。しかし、Createのときと同様にKeyフィールドをdynamodbattribute.MarshalMap関数から作ろうとしてもうまくいきません。// ダメな例 searchItem := Item{UserID: userid} searchAV, _ := dynamodbattribute.MarshalMap(searchItem) getParam := &dynamodb.GetItemInput{ TableName: aws.String("user"), Key: searchAV, }これはおそらく
dynamodb.PutItemInput.Itemフィールドとは異なり、Keyフィールドには「プライマリーキーの情報だけを含めなければいけない」という仕様が関係していると推測されます。
dynamodbattribute.MarshalMap(Item{UserID: userid})には、主キーであるUserID以外にも、ゼロ値に設定された他フィールドが含まれてしまっているのでうまくいかないんだと思います。3. DBに問い合わせてデータを取得する
db.GetItem()を実行すればOKです。Update(PUT)の作成
package main import ( "encoding/json" "github.com/aws/aws-lambda-go/events" "github.com/aws/aws-lambda-go/lambda" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/dynamodb" "github.com/aws/aws-sdk-go/service/dynamodb/expression" ) // Item構造体とResponse構造体は、Createのときと同じなので割愛 func handler(request events.APIGatewayProxyRequest) (events.APIGatewayProxyResponse, error) { method := request.HTTPMethod pathparam := request.PathParameters["userid"] // まずはDBと接続するセッションを作る sess, err := session.NewSession() if err != nil { return events.APIGatewayProxyResponse{ Body: err.Error(), StatusCode: 500, }, err } db := dynamodb.New(sess) // リクエストボディのjsonから、Item構造体を作成 reqBody := request.Body resBodyJSONBytes := ([]byte)(reqBody) item := Item{} if err := json.Unmarshal(resBodyJSONBytes, &item); err != nil { return events.APIGatewayProxyResponse{ Body: err.Error(), StatusCode: 500, }, err } // updateするデータを作る update := expression.UpdateBuilder{} if address := item.Address; address != "" { update = update.Set(expression.Name("address"), expression.Value(address)) } if email := item.Email; email != "" { update = update.Set(expression.Name("email"), expression.Value(email)) } if gender := item.Gender; gender != "" { update = update.Set(expression.Name("gender"), expression.Value(gender)) } if name := item.Name; name != "" { update = update.Set(expression.Name("name"), expression.Value(name)) } expr, err := expression.NewBuilder().WithUpdate(update).Build() if err != nil { return events.APIGatewayProxyResponse{ Body: err.Error(), StatusCode: 500, }, err } input := &dynamodb.UpdateItemInput{ TableName: aws.String("user"), Key: map[string]*dynamodb.AttributeValue{ "userid": { N: aws.String(pathparam), }, }, ExpressionAttributeNames: expr.Names(), ExpressionAttributeValues: expr.Values(), UpdateExpression: expr.Update(), } // update実行 _, err = db.UpdateItem(input) if err != nil { return events.APIGatewayProxyResponse{ Body: err.Error(), StatusCode: 500, }, err } // httpレスポンス作成 res := Response{ RequestMethod: method, } jsonBytes, _ := json.Marshal(res) return events.APIGatewayProxyResponse{ Body: string(jsonBytes), StatusCode: 200, }, nil } // main関数はCreateのときと同じなので割愛ここでやっていることは以下の操作です。
- DBに接続(説明割愛)
- リクエストボディからItem構造体を作る
- DBのデータをどう更新するかを指定する
- update実行
- レスポンスを作成(説明割愛)
2. リクエストボディからItem構造体を作る
Createのときとやり方は全く同じです。
今回は、パスパラメータで指定されたuseridレコードの、emailとnameを更新したくて以下のようなリクエストボディがきたと仮定します。
example-requestbody.json{ "email": "ccc.com", "name": "Emily" }3. DBのデータをどう更新するかを指定する
更新を行う
db.UpdateItemの引数となるdynamodb.UpdateItemInput型の変数を作成します。
dynamodb.UpdateItemInput型の定義は以下の通りです。type UpdateItemInput struct { // 今回関係ないフィールドを省略 ExpressionAttributeNames map[string]*string `type:"map"` ExpressionAttributeValues map[string]*AttributeValue `type:"map"` Key map[string]*AttributeValue `type:"map" required:"true"` TableName *string `min:"3" type:"string" required:"true"` UpdateExpression *string `type:"string"` }参考:GoDoc github.com/aws/aws-sdk-go/service/dynamodb#UpdateItemInput
KeyとTableNameについてはReadのときと意味は同様です。残り3つのフィールドについては、データの更新の種類・やり方について記述する場所です。「データの更新」といっても、ただ今ある値を捨てて新しい値に書き換えるだけではなく、データ型によって様々な操作が考えられます。主たる例を以下に挙げます。
- 数値型を収める属性Aを、Bという値に上書き保存したい
- 属性Aが保持しているリストに、Bという値を追加したい
- 指定したレコードから属性Aを消したい
- 属性Aが保持しているセット型から、Bというセットを消したい
参考:DynamoDBでデータを更新する際に使うUpdateExpressionについて一通りまとめてみた
そのため、「その属性を操作したいか」を
ExpressionAttributeNamesに、「上書きしたり追加したりしたい値」をExpressionAttributeValuesに、「上書きなのか追加なのかという更新の種類」をUpdateExpressionに記述するのです。例えば、今回の「"name"という属性を、変数
nameの値に上書きしたい」という操作をドキュメントどおりに記述するのならば以下のようになります。input := &dynamodb.UpdateItemInput{ TableName: aws.String("user"), Key: map[string]*dynamodb.AttributeValue{ "userid": { N: aws.String(pathparam), }, }, ExpressionAttributeNames: map[string]*string{ // "name"という属性名を以下#nameと扱う "#name": aws.String("name"), }, ExpressionAttributeValues: map[string]*dynamodb.AttributeValue{ // 上書きしたい値nameを以下:name_valueとして扱う ":name_value": { S: aws.String(name), }, }, // #name属性を、:name_valueという値に上書き(set)する UpdateExpression: aws.String("set #name = :name_value"), }参考:あえて aws-sdk-go で dynamoDB を使うときの基本操作
しかし、属性名を
#で指定したり、更新したい値を:で指定したりするドキュメントどおりの書き方は少々面倒です。
そのため、これらの構造表現をコードベースで生成するパッケージが公式から提供されています(github.com/aws/aws-sdk-go/service/dynamodb/expression)。せっかくなのでその方法に書き換えていきましょう。まずは、
expression.UpdateBuilder{}という型の構造体を用意して、その型のメソッドを用いて「どう更新したいのか」を記述します。update := expression.UpdateBuilder{} if name := item.Name; name != "" { update = update.Set(expression.Name("name"), expression.Value(name)) }上の部分は、「DBの"name"という属性を、
nameという変数の中身に上書きする」という操作を、expression.UpdateBuilder{}型のupdateに記録しています。このupdateの内容を指定し終わったら、updateの内容を
ExpressionAttributeNames等のフィールドに入れられる形に変換します。expr, err := expression.NewBuilder().WithUpdate(update).Build()このexprを使って、
db.UpdateItemを作ると以下のようになります。input := &dynamodb.UpdateItemInput{ TableName: aws.String("user"), Key: map[string]*dynamodb.AttributeValue{ "userid": { // Nはnumber型の意味 N: aws.String(pathparam), }, }, ExpressionAttributeNames: expr.Names(), ExpressionAttributeValues: expr.Values(), UpdateExpression: expr.Update(), }4. update実行
db.UpdateItemを実行すればOKです。Delete(DELETE)の作成
package main import ( "encoding/json" "github.com/aws/aws-lambda-go/events" "github.com/aws/aws-lambda-go/lambda" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/dynamodb" ) // Item構造体とResponse構造体は、Createのときと同じなので割愛 func handler(request events.APIGatewayProxyRequest) (events.APIGatewayProxyResponse, error) { method := request.HTTPMethod pathparam := request.PathParameters["userid"] // まずはDBと接続するセッションを作る sess, err := session.NewSession() if err != nil { return events.APIGatewayProxyResponse{ Body: err.Error(), StatusCode: 500, }, err } db := dynamodb.New(sess) // deleteするデータを指定 deleteParam := &dynamodb.DeleteItemInput{ TableName: aws.String("user"), Key: map[string]*dynamodb.AttributeValue{ "userid": { // Nはnumber型の意味 N: aws.String(pathparam), }, }, } // delete実行 _, err = db.DeleteItem(deleteParam) if err != nil { return events.APIGatewayProxyResponse{ Body: err.Error(), StatusCode: 500, }, err } // httpレスポンス作成 res := Response{ RequestMethod: method, } jsonBytes, _ := json.Marshal(res) return events.APIGatewayProxyResponse{ Body: string(jsonBytes), StatusCode: 200, }, nil } // main関数はCreateのときと同じなので割愛ここでやっていることは以下の操作です。
- DBに接続(説明割愛)
- deleteするデータを指定する
- delete実行
- レスポンスを作成(説明割愛)
2. deleteするデータを指定する
Read(GET)のときと同じ方法で
dynamodb.DeleteItemInput型の変数を作り、消去したいデータを指定します。3. delete実行
db.DeleteItem()を実行すればOKです。Lambda関数コードの参考文献
参考:AWS Lambda, API Gateway, DynamoDB, Golang でREST APIを作る
参考:DynamoDB×Go連載#2 AWS SDKによるDynamoDBの基本操作Lambda関数のコードをアップロード→API Gatewayと連携
ここは既にやった手順と同じなので割愛します。
上述した通り、Lambda関数にDynamoDB用のロールを付与するのを忘れないでください。まとめ
これでAPI Gateway-Lambda-Dynamo DBの3つを連携させたサーバーレスAPIの構築が完了です。お疲れ様でした。







- 投稿日:2020-08-03T19:20:40+09:00
Amazon Cognitoの認証情報をAmazon API Gateway+AWS Lambdaで取得
Goで取得してみます。
APIGatewayの統合リクエストで Lambdaプロキシ統合の使用 にチェックを入れてください。
Go側では、
github.com/aws/aws-lambda-go/eventsのevents.APIGatewayProxyRequestで受け取ります。
下記のように取れます。func handler(ctx context.Context, req events.APIGatewayProxyRequest) (*events.APIGatewayProxyResponse, error) { claims := req.RequestContext.Authorizer["claims"].(map[string]interface{}) res := &events.APIGatewayProxyResponse{ StatusCode: 200, Body: claims["cognito:username"].(string), } return res, nil } func main() { lambda.Start(handler) }
- 投稿日:2020-08-03T17:11:51+09:00
AWS開発中 sudo yum install nodejs npm --enablerepo=epelが通らなかった話
環境
EC2(Amazon Linux 2)
詰まったこと
現在AWSにて環境構築中の初学者です。アプリケーション用のEC2を作成中。
各種パッケージをインストールしていたのですがnodejs npmがインストール出来ず苦戦したことを記事にします。@naoki_mochizuki さんの
https://qiita.com/naoki_mochizuki/items/814e0979217b1a25aa3e
という記事を参考に環境構築を行っていました。__| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/ [shimo0108@~]$ sudo yum install \ > git make gcc-c++ patch \ > openssl-devel \ > libyaml-devel libffi-devel libicu-devel \ > libxml2 libxslt libxml2-devel libxslt-devel \ > zlib-devel readline-devel \ > ImageMagick ImageMagick-devel \ > epel-release 読み込んだプラグイン:extras_suggestions, langpacks, priorities, update-motd amzn2core | 3.7 kB 00:00:00 パッケージ 1:make-3.82-24.amzn2.x86_64 はインストール済みか最新バージョンです パッケージ libxml2-2.9.1-6.amzn2.4.1.x86_64 はインストール済みか最新バージョンです パッケージ epel-release は利用できません。 . . . 完了しました! epel-release is available in Amazon Linux Extra topic "epel" To use, run # sudo amazon-linux-extras install epel Learn more at https://aws.amazon.com/amazon-linux-2/faqs/#Amazon_Linux_ExtrasWEBアプリ用のEC2にログイン。パッケージをインストールしました。
epel-release以外は正常にinstallできた事が確認できます。
ここでなぜかepel-releaseがインストール出来なかったんですよね。ちなみにepel-release(EPEL)とは、、、
EPEL リポジトリとは、CentOS 標準のリポジトリでは提供されていないパッケージを、yum コマンドでインストールすることを可能にするリポジトリのことです。
EPEL は、エンタープライズ向けのリポジトリなので、サードパーティー製リポジトリの中では信頼性の高いものになっています。
EPEL 以外のサードパーティ製リポジトリには、Remi、RPMForge があります。特徴としては、Remi は最新バージョンのパッケージを入手可能、RPMForge は大量のパッケージを入手可能と言われているようです。
実際には、用途やパッケージの依存関係を考慮して各リポジトリを活用することになります。標準のリポジトリでは提供されないパッケージを使うことができますが、利用に関してはCentOSのサードパーティ製のリポジトリに関する記述を考えると、自己責任、ということになります。
[shimo0108@ ~]$ sudo yum install nodejs npm --enablerepo=epel 読み込んだプラグイン:extras_suggestions, langpacks, priorities, update-motd Error getting repository data for epel, repository not foundその後上記コマンド実行するもインストールできず。。
しかしエラーログ文の中にTo use, run # sudo amazon-linux-extras install epelを発見。これインストールすればいいのかなと。思ったわけです。
[shimo0108@ ~]$ sudo amazon-linux-extras install epel Installing epel-release リポジトリーを清掃しています: amzn2-core amzn2extra-docker amzn2extra-epel 12 個の metadata ファイルを削除しました 4 個の sqlite ファイルを削除しました 0 個の metadata ファイルを削除しました 読み込んだプラグイン:extras_suggestions, langpacks, priorities, update-motd . . . 依存性の解決をしています --> トランザクションの確認を実行しています。 ---> パッケージ epel-release.noarch 0:7-11 を インストール --> 依存性解決を終了しました。 依存性を解決しました ======================================================================================================= Package アーキテクチャー バージョン リポジトリー 容量 ======================================================================================================= インストール中: epel-release noarch 7-11 amzn2extra-epel 15 k トランザクションの要約 ======================================================================================================= インストール 1 パッケージ 総ダウンロード容量: 15 k インストール容量: 24 k Is this ok [y/d/N]: y Downloading packages: epel-release-7-11.noarch.rpm | 15 kB 00:00:00 Running transaction check Running transaction test Transaction test succeeded Running transaction インストール中 : epel-release-7-11.noarch 1/1 検証中 : epel-release-7-11.noarch 1/1 インストール: epel-release.noarch 0:7-11 完了しました! 0 ansible2 available \ [ =2.4.2 =2.4.6 =2.8 =stable ] 2 httpd_modules available [ =1.0 =stable ] 3 memcached1.5 available \ [ =1.5.1 =1.5.16 =1.5.17 ] 5 postgresql9.6 available \ [ =9.6.6 =9.6.8 =stable ] 6 postgresql10 available [ =10 =stable ] 8 redis4.0 available \ [ =4.0.5 =4.0.10 =stable ] 9 R3.4 available [ =3.4.3 =stable ] 10 rust1 available \ [ =1.22.1 =1.26.0 =1.26.1 =1.27.2 =1.31.0 =1.38.0 =stable ] 11 vim available [ =8.0 =stable ] 13 ruby2.4 available \ [ =2.4.2 =2.4.4 =2.4.7 =stable ] 15 php7.2 available \ [ =7.2.0 =7.2.4 =7.2.5 =7.2.8 =7.2.11 =7.2.13 =7.2.14 =7.2.16 =7.2.17 =7.2.19 =7.2.21 =7.2.22 =7.2.23 =7.2.24 =7.2.26 =stable ] 17 lamp-mariadb10.2-php7.2 available \ [ =10.2.10_7.2.0 =10.2.10_7.2.4 =10.2.10_7.2.5 =10.2.10_7.2.8 =10.2.10_7.2.11 =10.2.10_7.2.13 =10.2.10_7.2.14 =10.2.10_7.2.16 =10.2.10_7.2.17 =10.2.10_7.2.19 =10.2.10_7.2.22 =10.2.10_7.2.23 =10.2.10_7.2.24 =stable ] 18 libreoffice available \ [ =5.0.6.2_15 =5.3.6.1 =stable ] 19 gimp available [ =2.8.22 ] 20 docker=latest enabled \ [ =17.12.1 =18.03.1 =18.06.1 =18.09.9 =stable ] 21 mate-desktop1.x available \ [ =1.19.0 =1.20.0 =stable ] 22 GraphicsMagick1.3 available \ [ =1.3.29 =1.3.32 =1.3.34 =stable ] 23 tomcat8.5 available \ [ =8.5.31 =8.5.32 =8.5.38 =8.5.40 =8.5.42 =8.5.50 =stable ] 24 epel=latest enabled [ =7.11 =stable ] 25 testing available [ =1.0 =stable ] 26 ecs available [ =stable ] 27 corretto8 available \ [ =1.8.0_192 =1.8.0_202 =1.8.0_212 =1.8.0_222 =1.8.0_232 =1.8.0_242 =stable ] 28 firecracker available [ =0.11 =stable ] 29 golang1.11 available \ [ =1.11.3 =1.11.11 =1.11.13 =stable ] 30 squid4 available [ =4 =stable ] 31 php7.3 available \ [ =7.3.2 =7.3.3 =7.3.4 =7.3.6 =7.3.8 =7.3.9 =7.3.10 =7.3.11 =7.3.13 =stable ] 32 lustre2.10 available \ [ =2.10.5 =2.10.8 =stable ] 33 java-openjdk11 available [ =11 =stable ] 34 lynis available [ =stable ] 35 kernel-ng available [ =stable ] 36 BCC available [ =0.x =stable ] 37 mono available [ =5.x =stable ] 38 nginx1 available [ =stable ] 39 ruby2.6 available [ =2.6 =stable ] 40 mock available [ =stable ] 41 postgresql11 available [ =11 =stable ] 42 php7.4 available [ =stable ] 43 livepatch available [ =stable ] 44 python3.8 available [ =stable ] 45 haproxy2 available [ =stable ]よし!できた!これでインストールだ!と思ったのですが
[shimo0108 ~]$ sudo yum install nodejs npm --enablerepo=epel 読み込んだプラグイン:extras_suggestions, langpacks, priorities, update-motd amzn2-core | 3.7 kB 00:00:00 amzn2extra-docker | 3.0 kB 00:00:00 amzn2extra-epel | 1.7 kB 00:00:00 One of the configured repositories failed (不明), and yum doesn't have enough cached data to continue. At this point the only safe thing yum can do is fail. There are a few ways to work "fix" this: 1. Contact the upstream for the repository and get them to fix the problem. 2. Reconfigure the baseurl/etc. for the repository, to point to a working upstream. This is most often useful if you are using a newer distribution release than is supported by the repository (and the packages for the previous distribution release still work). 3. Run the command with the repository temporarily disabled yum --disablerepo=<repoid> ... 4. Disable the repository permanently, so yum won't use it by default. Yum will then just ignore the repository until you permanently enable it again or use --enablerepo for temporary usage: yum-config-manager --disable <repoid> or subscription-manager repos --disable=<repoid> 5. Configure the failing repository to be skipped, if it is unavailable. Note that yum will try to contact the repo. when it runs most commands, so will have to try and fail each time (and thus. yum will be be much slower). If it is a very temporary problem though, this is often a nice compromise: yum-config-manager --save --setopt=<repoid>.skip_if_unavailable=true Cannot retrieve metalink for repository: epel/x86_64. Please verify its path and try againとまたまたエラー。
yumで行うコマンドがすべて止まってしまう。。(泣)[shimo0108@ ~]$ sudo yum install nodejs npm --enablerepo=epel 読み込んだプラグイン:extras_suggestions, langpacks, priorities, update-motd amzn2-core | 3.7 kB 00:00:00 amzn2extra-docker | 3.0 kB 00:00:00 amzn2extra-epel | 1.7 kB 00:00:00 . .ここまで読み込んで必ず止まります。1日位格闘してエラーログに
Cannot retrieve metalink for repository: epel/x86_64. Please verify its path and try againを発見。リポジトリのメタリンクを取得できませんと。言うことです。
調べた結果
CentOS6.xでEPELリポジトリ入れたときのエラー対処
https://qiita.com/maruware/items/eb659266a45021cf486c
という記事を発見。どうやらEPELリポジトリがSSL3.0を使っているのが原因とのことで、記事の通り以下を実行してhttps→httpに変更することで解決するらしい。[shimo0108@ ~]$ sudo vi /etc/yum.repos.d/epel.repoここの/epel.repoをvimにて確認。
[epel] name=Extra Packages for Enterprise Linux 7 - $basearch #baseurl=https://download.fedoraproject.org/pub/epel/7/$basearch metalink=https://mirrors.fedoraproject.org/metalink?repo=epel-7&arch=$basearch failovermethod=priority enabled=1 gpgcheck=1 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7たしかに
metalink=https://mirrors.fedoraproject.org/metalink?repo=epel-7&arch=$basearch #httpsになってる。。。 ↓ [epel] name=Extra Packages for Enterprise Linux 7 - $basearch #baseurl=http://download.fedoraproject.org/pub/epel/7/$basearch metalink=http://mirrors.fedoraproject.org/metalink?repo=epel-7&arch=$basearch failovermethod=priority enabled=1 gpgcheck=1 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7 # https//→http//へ変更しました。再び
sudo yum install nodejs npm --enablerepo=epel
を実行。
今度は成功しました!!!
- 投稿日:2020-08-03T16:39:41+09:00
CLIでS3のファイルをアップロードしよう
はじめに
S3をマネジメントコンソール画面で作ることはできるが、CLIで操作して作成したことがないため、今回挑戦してみた。
手順
AWS CLIの確認
AWS CLIがインストールされているか下記のコマンドで確認。
aws --versionS3の権限設定
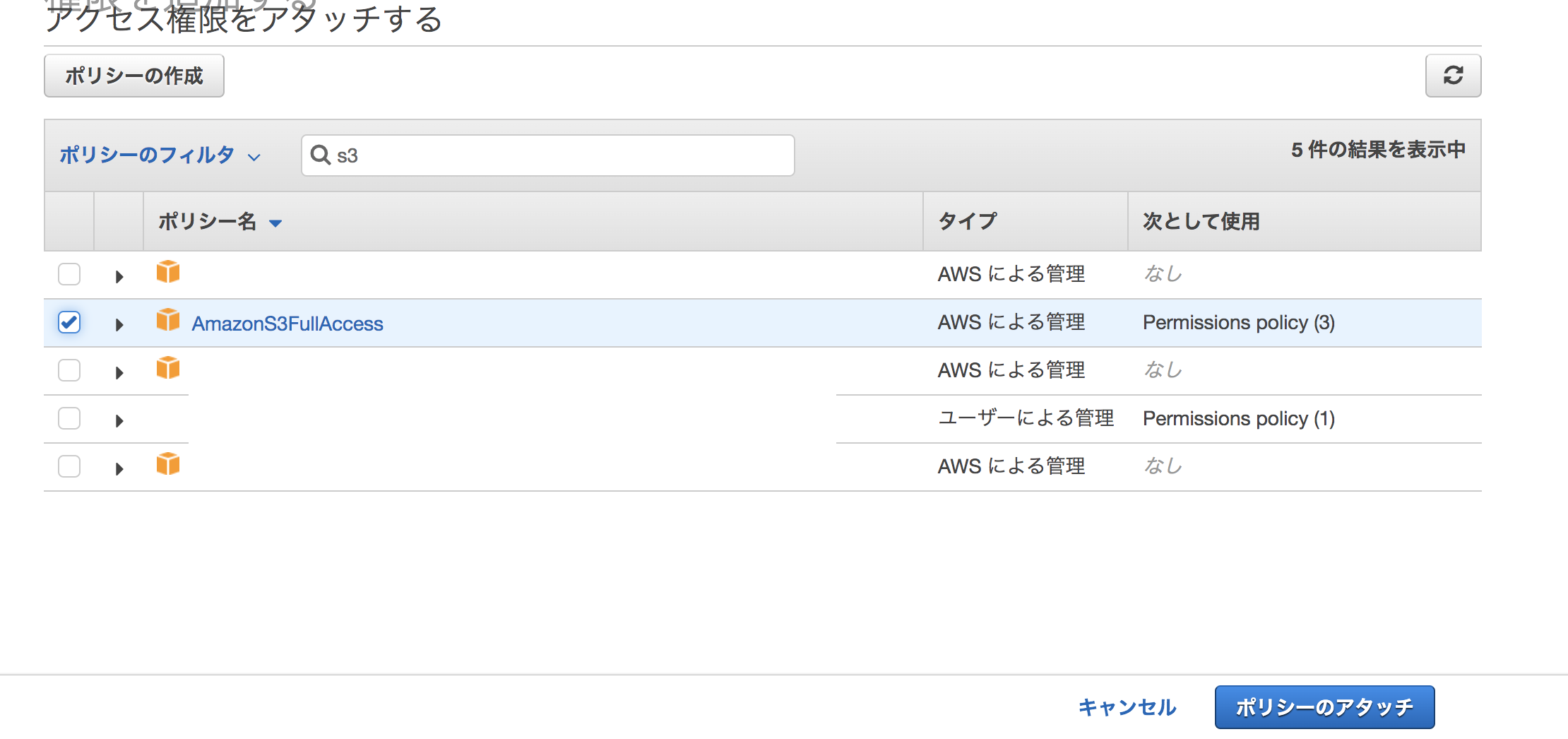
IAM>ロール>権限を設定したいロールをクリック。
「ポリシーをアタッチします」ボタンを押す。
ポリシーのフィルタでs3と入力し、「AmazonFullAccess」を選択。ポリシーのアタッチを押す。
アタッチされました、と表示される。
デフォルトリージョンを設定
$ aws configure AWS Access Key ID [None]: AWS Secret Access Key [None]: Default region name [None]: ap-northeast-1 Default output format [None]: json「AWS Access Key ID [None]:」と「AWS Secret Access Key [None]:」には何も指定しない。
S3バケットを作成
$ aws mb s3://hoge ※hogeの部分は重複負荷なので、一意になるようにする。 $aws s3 ls ※バゲットが作成できたか確認。マネジメントコンソールでも確認できる。
S3バケットにファイルをアップロード
インターネット上で任意の画像をアップロードする。
Chromeブラウザの場合は画像を右クリックして、「画像アドレスをコピー」を選択。
作業をするためのworkディレクトリをホームディレクトリに作成。
workディレクトリにwgetコマンドで画像アドレスを引数に指定して、ダウンロード。$ mkdir ~/work $ cd ~/work $ wget https://hogehoge/hogehoge.pngs3 lsコマンドをバケットを指定して、実行。画像があるか確認する。
$ aws s3 ls s3://hogeマネジメントコンソールでも画像があるか確認可能。
下記コマンドでCLIからパブリックなアクセス権限を設定。
$ aws s3api put-object-acl --acl public-read --bucket ファイル名 --key 画像名(hoge.png)アクセスコントロールリストで許可設定があるか確認する。
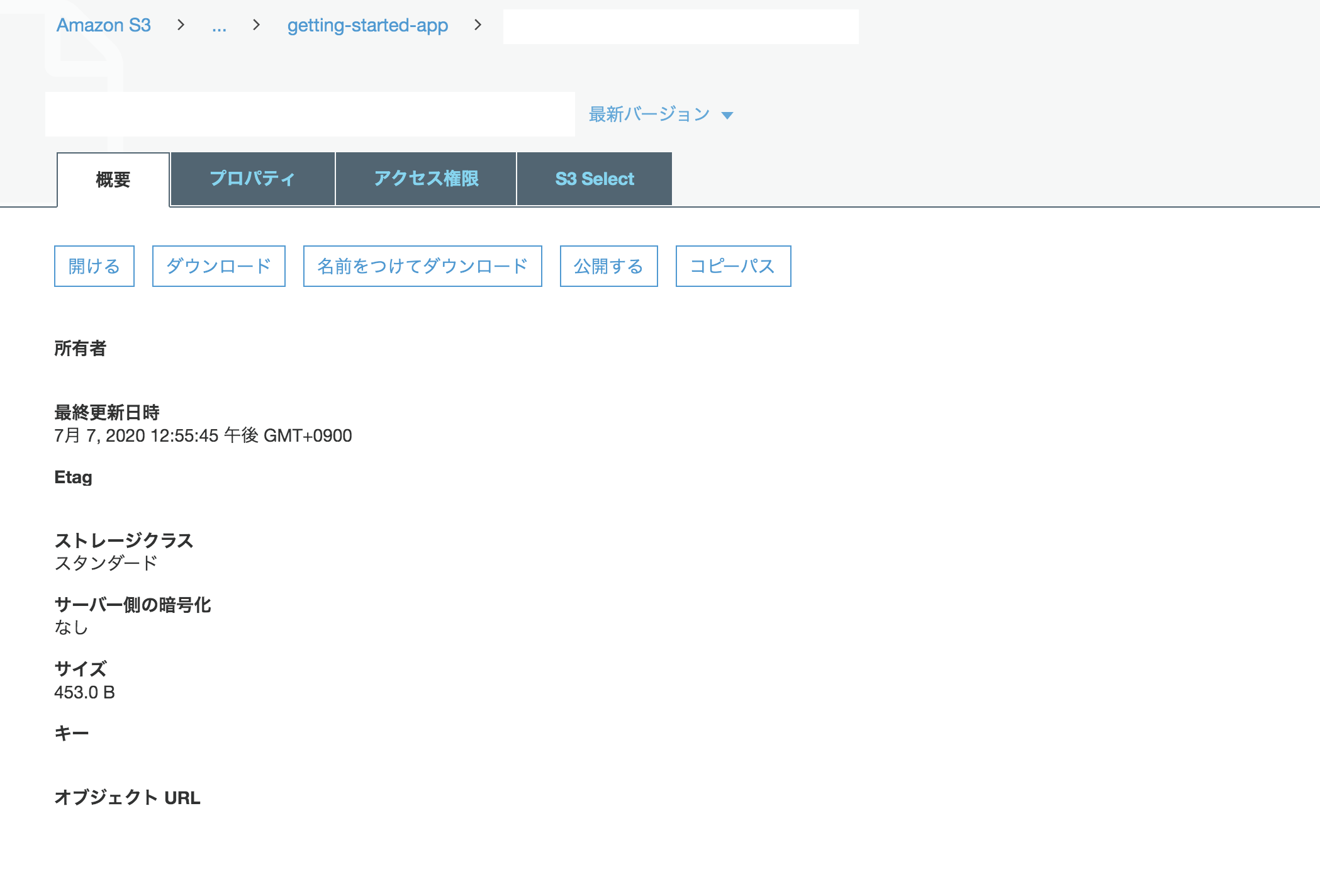
$ aws s3api get-object-acl --bucket ファイル名 --key 画像名(hoge.png)マネジメントコンソールでオブジェクトURLをクリックして、画像が開けるか確認。
上記のような手順を踏むと、画像が表示される。もしオブジェクトURLを押しても「AccessDenied」となって画像が表示されなかったら、該当オブジェクトの概要の「公開する」ボタンをおせば、表示される。
参考
AWSではじめるLinux入門ガイド


- 投稿日:2020-08-03T12:26:09+09:00
Snowflakeにおける安全な共有(Direct Share・Data Exchange)によるマルチクラウド・マルチリージョンでのデータ共有について
概要
Snowflakeにおけるデータシェア機能(Direct Share・Data Exchange)を用いたマルチクラウド・マルチリージョンでのデータ共有の実施に関する調査内容を共有します。内容としてまとまりがなく、情報の羅列になってしまっていますが、下書きに保存されたままになっていたので、共有しちゃいます。
前提として、下記の項目があります。
- 自社内の利用を想定していること
- 外部へのデータ販売を実施しないこと
- 分析システム(BIツール、解析ツール)を特定のクラウドサービスにて実施すること
背景
マルチクラウドを考慮したデータ連携を実施した際には、いわゆるP2P(ピア・ツー・ピア)型のデータ連携を実施することが多く、開発・運用が煩雑化するという問題があります。
上記の問題を解決するために、各クラウドベンダー・各リージョン間でData LakeとDWHのデータ連携を簡単に行うために、下記のような構成が実施できないかを検討しました。
現時点での結論
Snowflakeを直接連携するのではなく、各クラウドベンダーのおけるストレージに差分連携用データを配置して、そのストレージをSnowflakeに連携する方針がよさそうです。
Snowflakeは、単一アカウントにて力を発揮するツールであるため、マルチクラウド・マルチリージョンで同期する目的で利用するのは最適ではないようです。当初の目的である管理煩雑さの回避は難しそうです。
Snowflakeのおける安全な共有とは
Snowflakeにおける下記機能群であり、Snowflakeアカウント間でデータを同期する方法の総称です。
今回は、Direct Share、および、Data Exchangeを検討しました。
- Direct Share
- Snowflake Data Marketplace
- Data Exchange
引用元:Secure Data Sharingのための製品の概要
Direct Shareとは
下記のように説明されております。
Direct Shareは、SnowflakeのSecure Data Sharingを利用して、アカウント間のデータ共有を可能にする最も簡単な形式のデータ共有です。
データプロバイダーは他の会社と簡単にデータを共有できるため、データをコピーしたり移動したりせずに、Snowflakeアカウントに表示できます。
引用元:Secure Data Sharingのための製品の概要
Data Exchangeとは
下記のように説明されております。
Data Exchangeは、招待したメンバーの選択したグループ間でデータを安全にコラボレーションするための独自のデータハブです。これにより、プロバイダーはデータを 公開 できるようになり、コンシューマーはデータを 探索 できるようになります。
サプライヤー、パートナー、ベンダー、顧客などのビジネスエコシステム全体や、自社の他のビジネスユニットと大規模にデータを共有できます。誰がデータに参加、公開、利用、アクセスできるかを制御できます。
引用元:Secure Data Sharingのための製品の概要
Direct ShareとData Exchangeを、マルチクラウド・マルチリージョンで実施する際の注意事項
Direct Shareの説明分にて、”データをコピーしたり移動したりせずに”と記載がありますが、マルチクラウド・マルチリージョン間で同期する際にはデータベースの複製を実施する必要があるようです。
グローバルSnowflakeでは、データベースの複製を利用して、データプロバイダーが異なる 地域 およびクラウドプラットフォーム間でデータコンシューマーとデータを安全に共有できます。
引用元:地域とクラウドプラットフォーム間で安全にデータを共有する
Data Exchangeにおいても下記の記載があり、データベースの複製を実施する必要があります。
地域間でのデータ共有には、Snowflakeデータ複製機能を利用します。。
引用元:データリストの管理 - リモート地域でのリストの作成とデータの複製に関する考慮事項
データベースの複製とは
下記のように説明されております。
(同じ組織内の)Snowflakeアカウント間でデータベースを複製し、データベースオブジェクトと保存データの同期を維持できます。
データベースの複製の考慮事項として、ドキュメントに記載があるので事前に確認が必要です。
このトピックの内容:
- 複製と自動クラスタリング
- 複製とマテリアライズドビュー
- 複製およびマスキングポリシー
- Time Travel
- 複製と大規模でチャーン率の高いテーブル
- 複製とクローニング
- 別のデータベース内のオブジェクトへの参照
- 複製とアクセス制御
- 履歴使用データ
引用元:データベースの複製の考慮事項
データ連携時には更新・削除の処理を実施しないように
今回のシナリオとしては、"複製と大規模でチャーン率の高いテーブル"という観点で主な考慮が必要となり、簡単に言うと更新と削除の処理がなるべく実施されないようにする必要があります。
テーブルの1つ以上の行が更新または削除されると、このデータをプライマリデータベースに保存する、影響を受けるすべてのマイクロパーティションが再作成され、セカンダリデータベースと同期する必要があります。大規模でチャーン率の高いディメンションテーブルの場合、複製コストがかなり高くなる可能性があります。
引用元:データベースの複製の考慮事項 - 複製と大規模でチャーン率の高いテーブル
データベースの複製のコストについて
下記のコストがかかるようです。大量データとなった場合には、データ転送量と複製先のストレージのコストがけっこう高くなる可能性があります。
- データのメンテナンス(マテリアライズドビューの更新等)の仮想ウェアハウス
- データ転送量
- 複製先のストレージ
結論
データベースの複製を実施する場合には、データ転送量のコスト、および、複製先のストレージのコストが高額となる可能性があることから、各クラウド・各リージョンで処理したファイルによる連携シナリオがよさそうという結論に至りました。
Snowflakeというツールは、マルチクラウドなSaaS型データウェアハウスと言われておりますが、マルチクラウドに展開することは可能だが、マルチクラウドで連携するためには従来のサービス同様の制約があることに注意が必要です。



- 投稿日:2020-08-03T10:30:33+09:00
AWS EC2 AmazonLinux2 Node.jsをインストールしてnpmコマンドを使用できる様にする
目的
- AWS EC2のAmazonLinux2インスタンスにNode.jsを入れてnpmコマンドを使用できる様にする方法をまとめる
前提条件
- 実施環境のリンク先の方法またはそれに準ずる方法で、AmazonLinux2インスタンスが作成され、ssh接続できること。
前提情報
- 下記で実行するコマンドはAmazonLinux2インスタンスにsshでログインしてから実行する物とする。
- 下記と同じ方法で構築したインスタンスでnpmコマンドを実行できる様にする。
読後感
- インスタンス内でnpmコマンドを実行することができる。
概要
- リポジトリの追加
- インストール
- 確認
詳細
リポジトリの追加
下記コマンドを実行してリポジトリを登録する。
$ curl -sL https://rpm.nodesource.com/setup_8.x | sudo bash -インストール
下記コマンドを実行してNode.jsをインストールする。
$ sudo yum install --enablerepo=nodesource nodejsリポジトリが「nodesource」になっていることを確認して
yを入力してEnterを押下する。
確認
下記を実行してエラーメッセージが出ないことを確認する。
$ npm

- 投稿日:2020-08-03T10:10:48+09:00
[AWS CloudWatch]グラフの時間をUTC(協定世界時)からJST(日本標準時)に変更する




- 投稿日:2020-08-03T10:10:43+09:00
オンプレミスからパブリッククラウドへの 移行ツールの最適解 ~Veritas Resiliency Platform(VRP)~
はじめに
クラウドへのDR/移行ソリューションである「Veritas Resiliency Platform(VRP)」をご紹介します。
【お知らせ】
2020/7/29にGAになったNetBackup8.3から、NetBackupキャパシティライセンスで、VRPの全機能が使用可能なりました!!前回の記事では、「VRP管理サーバの構築・設定・操作手順」について、解説しています。
今回は、VRPの「移行ツールとしてのメリット」「できること」「動作の仕組み」について解説します。ぜひ、合わせてご参照ください。Veritas Resiliency Platform(VRP)とは
↑ VRPで実現できる構成は多岐にわたります。①と②はVRPのレプリケーション機能(データムーバー)を使用する構成です。③と④はNetBackupと連携する構成になります。今回は、②の中の「VMware→AWS」にフォーカスした内容です。サポート構成の詳細は、サポートマトリックスとマニュアルを参照ください。
VRP の 移行ツールとしてのメリット
↑ VRPであれば、従来の移行ツールの課題を解決できます。
↑ VRPは、S3を経由せず、直接EBSにレプリケーションし、高速にインスタンスを起動できます。
導入事例 | 京セラドキュメントソリューションズ株式会社 - Veritas
↑ DR用途ですが、事例を公開しておりますのでご参照ください。YouTube動画はこちら!!本記事では、「VRP概要」「移行ツールとしてのメリット」「事例」について、ご紹介しました。
SlideShareにはフルバージョンの紹介資料を掲載しておりますので、下記より参照ください。
「VRPの移行が早い4つの理由」「動作詳細(マイグレーション、リハーサル、テイクオーバ、再同期)」「デモ画面キャプチャ」を確認することができます。
オンプレミスからパブリッククラウドへの移行ツールの最適解
~ Veritas Resiliency Platform ご紹介 ~
↑↑↑ SlideShareにリンクしています
- 従来の移行ツールの課題を解決するVRPの特長
- VRPの動作
- 移行後もお任せ。Veritasデータ管理ソリューション
- 【付録】VRPの動作詳細(リハーサル、テイクオーバー、再同期)
- 【付録】VRPクラウド移行 デモ画面キャプチャ
商談のご相談はこちら
本稿からのお問合せをご記入の際には「コメント/通信欄」に#GWCのタグを必ずご記入ください。
ご記入いただきました内容はベリタスのプライバシーポリシーに従って管理されます。その他のリンク
【まとめ記事】ベリタステクノロジーズ 全記事へのリンク集もよろしくお願いいたします。








- 投稿日:2020-08-03T09:21:29+09:00
Python(boto3)でクレデンシャルを切り替える8つの方法
はじめに
AWSの各種リソースをPythonでコントロールする際に使うboto3ですが、クレデンシャルを切り替える方法はいくつかの種類があり、優先順序が混乱しがちな為復習を兼ねて調べてみました。これでAWS環境の切り替えも楽々です。
boto3のクレデンシャル検索順序
boto3は以下の順序でクレデンシャルを検索し使用します。
- boto.client()メソッドのパラメータとして渡されたクレデンシャル
- セッションオブジェクトを作成する際のパラメータとして渡されたクレデンシャル
- 環境変数
- 共有クレデンシャルファイル (~/.aws/credentials)
- AWS config ファイル(~/.aws/config)
- Assume Role provider
- Boto2 config ファイル (/etc/boto.cfg , ~/.boto)
- IAMロールが設定されているAmazon EC2インスタンス上のインスタンスメタデータサービス
以下、YOUR_ACCESS_KEY、YOUR_SECRET_KEYは適宜自身の環境の値で読み替えてください。
1. boto.client()メソッドのパラメータとして渡されたクレデンシャル
import boto3 client = boto3.client( 's3', aws_access_key_id=YOUR_ACCESS_KEY, aws_secret_access_key=YOUR_SECRET_KEY, )boto3.clientを呼び出すときに明示的に使用したい環境のクレデンシャル情報を渡す方法です。
実際の値は環境変数経由で取得するなどとし、コード内に生の値を書き込むことは回避する方が良いです。2. Sessionオブジェクトを作成する際のパラメータとして渡されたクレデンシャル
import boto3 session = boto3.Session( aws_access_key_id=YOUR_ACCESS_KEY, aws_secret_access_key=YOUR_SECRET_KEY, )1と同様、boto3.Sessionを作成する際に明示的に使用したい環境のクレデンシャル情報を渡す方法です。
3. 環境変数
export AWS_ACCESS_KEY_ID=YOUR_AWS_ACCESS_KEY_ID export AWS_SECRET_ACCESS_KEY=YOUR_AWS_SECRET_ACCESS_KEYPythonを実行する環境の環境変数にクレデンシャル情報をセットしておくと、boto3が参照してくれます。
クレデンシャルの切り替えが発生しない場合には簡単な方法であり、使用することも多いです。4. 共有クレデンシャルファイル (~/.aws/credentials)
~/.aws/credentials[your_profile_name] aws_access_key_id = YOUR_ACCESS_KEY aws_secret_access_key = YOUR_SECRET_KEYimport boto3 session = boto3.Session(profile_name='your_profile_name') client = session.client('s3')
~/.aws/credencialsにプロファイルごとのaws_access_key_id、aws_secret_access_keyを設定した後、boto3では設定したプロファイル名を指定します。
awscliでおなじみの方法で設定したプロファイル情報を利用できるので視認性に優れており、ローカル開発環境でもよく利用します。5. AWS config ファイル(~/.aws/config)
~/.aws/config[profile YOUR_PROFILE_NAME] region = YOUR_REGION output = TOUR_OUTPUT aws_access_key_id = YOUR_AWS_ACCESS_KEY_ID aws_secret_access_key = YOUR_SECRET_KEY
aws configureコマンドでクレデンシャルを設定した場合、access_key_id及びsecret_access_keyはcredentialsファイルに記載されます。この内容はconfigファイルに記載することも可能な為、regionやoutput情報に加えて、上記のようにクレデンシャル情報を記載することができます。6. Assume Role provider
~/.aws/config[profile YOUR_TARGET_PROFILE_NAME] role_arn = YOUR_TARGRT_ROLE_ARN source_profile = YOUR_PROFILE_NAME対象となるAWSアカウントのアクセスキー、シークレットキーを直接利用せず、IAMロールを通じて操作をする場合は対象のAWS環境へAssumeRoleをリクエストし、返されたクレデンシャルを用いることで操作することができます。
~/.aws/configへ利用するロールのARNと元となるプロファイル名を設定することで利用可能です。7. Boto2 設定ファイル (/etc/boto.cfg, ~/.boto)
boto2との下位互換性がある為、
Boto_CONFIGが設定されていればBOTO_CONFIGが指定するファイルをチェックし、そうでなければ/etc/boto.cfgと~/.botoをチェックします。8. IAMロールが設定されているAmazon EC2インスタンス上のインスタンスメタデータサービス
Amazon EC2にはIAMロールを割り当てることができる為、EC2上で動作しており、上記のいずれも設定されていない場合はインスタンスのメタデータサービスから資格情報を読み込みます。
この機能を利用するには、EC2インスタンスの作成時に使用するIAMロールを指定しておく必要があります。参考文献
この記事は以下の情報を参考にして執筆しました。

- 投稿日:2020-08-03T09:11:12+09:00
AWS Lambda(Node.js)においてmiddyを使ってAmazon RDSに接続する方法
AWS Lambda(Node.js)において、middyを使ってAmazon RDSに接続する方法を紹介します。
はじめに
データベースエンジン
この記事ではデータベースエンジンとしてAurora MySQLを使用している場合の例を示しますが、他のデータベースエンジンの場合も基本的な実装は変わりません。
プログラミング言語
この記事ではソースコードをTypeScriptで書いているので型定義をインストールしたり型アノテーションを記述したりしていますが、JavaScriptで書く場合は不要です。
ミドルウェア
middyでRDSに接続するために、@middy/db-managerを使います。
@middy/db-managerでは、データベースクライアントとしてKnex.jsが使われます。接続情報をAWS Secrets Managerで管理していない場合
接続情報をAWS Secrets Managerで管理していない場合、ミドルウェアとして@middy/db-managerのみを使います。
パッケージをインストール
middyを使うために、@middy/coreパッケージをインストールします。
$ npm i -d @middy/coremiddyでRDSに接続するために、@middy/db-managerパッケージをインストールします。
$ npm i -d @middy/db-managerまた、データベースエンジンに応じたパッケージをインストールします。
今回はAurora MySQLなので、mysqlパッケージをインストールします。$ npm i -d mysqlLambdaの型定義として、@types/aws-lambdaパッケージをインストールします。
$ npm i -D @types/aws-lambdaハンドラーを作成
middyを用いて、ハンドラーをつくります。
src/index.tsimport middy from '@middy/core' import dbManager from '@middy/db-manager' import lambda from 'aws-lambda' import Knex from 'knex' interface Context extends lambda.Context { db: Knex } const handler = middy(async ( event: any, context: Context, callback: lambda.Callback<any> ): Promise<void> => { const users = await context.db.select('*').from('users') console.log(users) }) handler.use(dbManager({ config: { client: 'mysql', connection: { host: '127.0.0.1', port: 3306, user: 'your_database_user', password: 'your_database_password', database: 'myapp_test' } } })) export { handler }詳しく解説していきます。
interface Context extends lambda.Context { db: Knex }@middy/db-managerを使うとコンテキストの
dbプロパティにKnexインスタンスが割り当てられるので、dbプロパティを持つContextを定義しています。const handler = middy(async ( event: any, context: Context, callback: lambda.Callback<any> ): Promise<void> => { const users = await context.db.select('*').from('users') console.log(users) })ハンドラーを
middy関数でラップすることで、middyfy(middy化)しています。
ハンドラー内では、context.dbからKnex.jsのAPIを用いてデータベース操作が行なえます。handler.use(dbManager({ config: { client: 'mysql', connection: { host: '127.0.0.1', port: 3306, user: 'your_database_user', password: 'your_database_password', database: 'myapp_test' } } }))ハンドラーで、ミドルウェアとして
dbManagerを使っています。
configには、Knex.jsの設定オブジェクトを渡します。
ここでは例示のために接続情報をべた書きしていますが、実際には環境変数やAWS Secrets Managerで管理すべきでしょう。接続情報をAWS Secrets Managerで管理している場合
接続情報をAWS Secrets Managerで管理している場合、ミドルウェアとして@middy/db-managerと@middy/secrets-managerを使います。
パッケージをインストール
middyを使うために、@middy/coreパッケージをインストールします。
$ npm i -d @middy/coremiddyでRDSに接続するために、@middy/db-managerパッケージをインストールします。
$ npm i -d @middy/db-managerまた、データベースエンジンに応じたパッケージをインストールします。
今回はAurora MySQLなので、mysqlパッケージをインストールします。$ npm i -d mysqlmiddyでSecrets Managerに接続するために、@middy/secrets-managerパッケージをインストールします。
$ npm i -d @middy/secrets-managerLambdaの型定義として、@types/aws-lambdaパッケージをインストールします。
$ npm i -D @types/aws-lambdaハンドラーを作成
middyを用いて、ハンドラーをつくります。
src/index.tsimport middy from '@middy/core' import dbManager from '@middy/db-manager' import secretsManager from '@middy/secrets-manager' import lambda from 'aws-lambda' import Knex from 'knex' interface Context extends lambda.Context { db: Knex } const MIDDY_RDS_SECRET_KEY = 'MIDDY_RDS_SECRET' const handler = middy(async ( event: any, context: Context, callback: lambda.Callback<any> ): Promise<void> => { const users = await context.db.select('*').from('users') console.log(users) }) handler.use(secretsManager({ secrets: { [MIDDY_RDS_SECRET_KEY]: 'secret_name' }, cache: true, throwOnFailedCall: true })) handler.use({ before: (handler, next) => { interface Secret { host: string port: number username: string password: string dbname: string } interface Connection { host: string port: number user: string password: string database: string } interface Context extends lambda.Context { [MIDDY_RDS_SECRET_KEY]: Secret | Connection } const context = handler.context as Context const secret = context[MIDDY_RDS_SECRET_KEY] as Secret context[MIDDY_RDS_SECRET_KEY] = { host: secret.host, port: secret.port, user: secret.username, password: secret.password, database: secret.dbname } return next() } }) handler.use(dbManager({ config: { client: 'mysql' }, secretsPath: MIDDY_RDS_SECRET_KEY, removeSecrets: true })) export { handler }詳しく解説していきます。
interface Context extends lambda.Context { db: Knex }@middy/db-managerを使うとコンテキストの
dbプロパティにKnexインスタンスが割り当てられるので、dbプロパティを持つContextを定義しています。const handler = middy(async ( event: any, context: Context, callback: lambda.Callback<any> ): Promise<void> => { const users = await context.db.select('*').from('users') console.log(users) })ハンドラーを
middy関数でラップすることで、middyfy(middy化)しています。
ハンドラー内では、context.dbからKnex.jsのAPIを用いてデータベース操作が行なえます。handler.use(secretsManager({ secrets: { [MIDDY_RDS_SECRET_KEY]: 'secret_name' }, cache: true, throwOnFailedCall: true }))ハンドラーで、ミドルウェアとして
secretsManagerを使っています。
secretsでは、コンテキストのどのプロパティに対してSecrets Managerのどのシークレットを割り当てるかを指定します。
cacheをtrueにすることで、キャッシュを有効化しています。
throwOnFailedCallをtrueにすることで、シークレットの取得に失敗した場合にエラーをスローするようにしています。handler.use({ before: (handler, next) => { interface Secret { host: string port: number username: string password: string dbname: string } interface Connection { host: string port: number user: string password: string database: string } interface Context extends lambda.Context { [MIDDY_RDS_SECRET_KEY]: Secret | Connection } const context = handler.context as Context const secret = context[MIDDY_RDS_SECRET_KEY] as Secret context[MIDDY_RDS_SECRET_KEY] = { host: secret.host, port: secret.port, user: secret.username, password: secret.password, database: secret.dbname } return next() } })Secrets Managerに保存されているシークレットを、Knex.jsに渡す形式に変換しています。
シークレットの形式は、データベースエンジンによって異なります。1handler.use(dbManager({ config: { client: 'mysql' }, secretsPath: MIDDY_RDS_SECRET_KEY, removeSecrets: true }))ハンドラーで、ミドルウェアとして
dbManagerを使っています。
secretsPathには、Secrets Managerのシークレットが割り当てられているコンテキストのプロパティを指定します。
removeSecretsをtrueにすることで、データベースに接続後にコンテキストからシークレットを削除しています。
- 投稿日:2020-08-03T01:49:50+09:00
AWS Systems Manager パラメータストアを使った、AWS Lambda関数を登録して動かしてみる
What's?
前にこんな記事を書いたのですが、環境変数がふつうに見えてしまうことに困っていました。
Terraformで、AWS Lambda関数を登録して動かしてみる
「転送時の暗号化に使用するヘルパー」という話もあるのですが、そういえばと思い、設定をAWS Systems Managerのパラメータストアから取得する方法も試してみようかなと。
AWS Systems Manager パラメータストアを使う場合は、AWS Lambdaの環境変数とは別に設定することになります。
Lambda 関数のグループに共通の環境変数を設定できますか?
というわけで、こんなことをやってみます。
- AWS Lambda関数は、Terraformでzip圧縮してアップロードする
- AWS Lambda関数からログを出力する
- Amazon CloudWatch Logsへ出力するようにロググループを作成する
- AWS Lambda関数から、AWS Systems Manager パラメータストアを使って設定を読み込む
- AWS Systems Manager パラメーターストアに格納する値は、AWS KMSのCMKで暗号化する
- 動作確認はAWS CLIで行う
前に書いた記事の内容から、AWS Systems Manager パラメータストアを使用するように変更しただけですね。
AWS Lambda関数から、AWS Systems Manager パラメータストアを使う時の注意点
通常は、AWS Lambda関数からAWS Systems Manager パラメータストアにアクセスするには、権限を追加する以外の作業は不要です。
これが、VPC内で動作するAWS Lambda関数の場合は、話が変わってきます。
VPC の Lambda 関数で Systems Manager パラメータストアにアクセスするにはどうしたらよいですか?
この場合は、AWS Lambda関数にインターネットアクセスが可能なように設定、またはVPCエンドポイントを使用する必要があります。
環境
今回の環境は、こちらです。
$ terraform version Terraform v0.12.29 + provider.archive v1.3.0 + provider.aws v2.70.0AWSのクレデンシャルは、環境変数で設定します。
$ export AWS_ACCESS_KEY_ID=... $ export AWS_SECRET_ACCESS_KEY=... $ export AWS_DEFAULT_REGION=ap-northeast-1AWS Lambda関数を作成する
作成するAWS Lambda関数も、前回とほぼ同じ。リクエストで受け取った内容から、メッセージを作って返すものにします。
ここで、メッセージの一部を前回は環境変数から受け取っていたのですが、ここをAWS Systems Manager パラメータストア経由にします。
ソースコードは、こちら。
app/lambda.pyimport boto3 import logging logger = logging.getLogger('lambda_logger') logger.setLevel(logging.INFO) client = boto3.client('ssm') base_message_parameter = client.get_parameter( Name = '/App/Lambda/Config/BASE_MESSAGE', WithDecryption = True ) base_message = base_message_parameter['Parameter']['Value'] def handler(event, context): logger.info('function = %s, version = %s, request_id = %s', context.function_name, context.function_version, context.aws_request_id) logger.info('event = %s', event) last_name = event['last_name'] first_name = event['first_name'] return { 'message': f'{base_message}, {first_name} {last_name}!!' }AWS LambdaのPythonランタイムには、Boto3が含まれているため、そのまま使えます。
import boto3今回は、起動時に値を取得してしまうことにしました。
client = boto3.client('ssm') base_message_parameter = client.get_parameter( Name = '/App/Lambda/Config/BASE_MESSAGE', WithDecryption = True ) base_message = base_message_parameter['Parameter']['Value']今回はAWS Systems Manager パラメータストアから単一の値を取得していますが、ある程度一括で取得することも可能です。
Terraformの構成ファイルを書く
基本的には、前の記事と同じです。先に、ポイントだけ絞って書いていきます。
ソースコード全体は、最後に載せることにします。
AWS Lambda関数のリソース定義は、こんな感じに。環境変数(
environment)の定義はありません。resource "aws_lambda_function" "function" { function_name = local.function_name handler = "lambda.handler" role = aws_iam_role.lambda_role.arn runtime = "python3.8" filename = data.archive_file.function_source.output_path source_code_hash = data.archive_file.function_source.output_base64sha256 depends_on = [aws_iam_role_policy_attachment.lambda_policy, aws_cloudwatch_log_group.lambda_log_group] }AWS KMSキーおよびエイリアスを作成すると共に、AWS Systems Manager パラメータストアに設定を追加します。
resource "aws_kms_key" "lambda_key" { description = "My Lambda Function Customer Master Key" enable_key_rotation = true deletion_window_in_days = 7 } resource "aws_kms_alias" "lambda_key_alias" { name = "alias/my-lambda-key" target_key_id = aws_kms_key.lambda_key.id } resource "aws_ssm_parameter" "lambda_variable_message_base" { name = "/App/Lambda/Config/BASE_MESSAGE" type = "SecureString" value = "Hello" key_id = aws_kms_key.lambda_key.id }前の記事では、AWS Lambda関数のリソース定義に、こんな感じで入っていました。
kms_key_arn = aws_kms_key.lambda_key.arn ... environment { variables = { BASE_MESSAGE = "Hello" } }あと、AWS Lambdaに付与するIAMロールに、AWS Systems Manager パラメータストアにアクセスできるように権限設定も必要ですね。
ssm:GetParameterを追加します。data "aws_iam_policy_document" "lambda_policy" { source_json = data.aws_iam_policy.lambda_basic_execution.policy statement { effect = "Allow" actions = [ "kms:Decrypt", "ssm:GetParameter" ] resources = ["*"] } }確認
これで、
applyして$ terraform applyログを
tailしつつ$ aws logs tail /aws/lambda/my_lambda_function --follow確認。
$ aws lambda invoke --function-name my_lambda_function \ --payload '{"first_name": "Taro", "last_name": "Tanaka"}' \ --cli-binary-format raw-in-base64-out \ --log-type Tail output.txt $ cat output.txt {"message": "Hello, Taro Tanaka!!"}OKですね。
これで、AWS Lambda関数からAWS Systems Manager パラメータストアから、値を取得できるようにTerraformで構成できました、と。
オマケ
以下、Terraformの構成ファイル全体です。
main.tfterraform { required_version = "0.12.29" } provider "aws" { version = "2.70.0" } provider "archive" { version = "1.3.0" } locals { function_name = "my_lambda_function" } data "archive_file" "function_source" { type = "zip" source_dir = "app" output_path = "archive/my_lambda_function.zip" } resource "aws_lambda_function" "function" { function_name = local.function_name handler = "lambda.handler" role = aws_iam_role.lambda_role.arn runtime = "python3.8" filename = data.archive_file.function_source.output_path source_code_hash = data.archive_file.function_source.output_base64sha256 depends_on = [aws_iam_role_policy_attachment.lambda_policy, aws_cloudwatch_log_group.lambda_log_group] } data "aws_iam_policy_document" "assume_role" { statement { actions = ["sts:AssumeRole"] effect = "Allow" principals { type = "Service" identifiers = ["lambda.amazonaws.com"] } } } data "aws_iam_policy" "lambda_basic_execution" { arn = "arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole" } data "aws_iam_policy_document" "lambda_policy" { source_json = data.aws_iam_policy.lambda_basic_execution.policy statement { effect = "Allow" actions = [ "kms:Decrypt", "ssm:GetParameter" ] resources = ["*"] } } resource "aws_iam_policy" "lambda_policy" { name = "MyLambdaPolicy" policy = data.aws_iam_policy_document.lambda_policy.json } resource "aws_iam_role_policy_attachment" "lambda_policy" { role = aws_iam_role.lambda_role.name policy_arn = aws_iam_policy.lambda_policy.arn } resource "aws_iam_role" "lambda_role" { name = "MyLambdaRole" assume_role_policy = data.aws_iam_policy_document.assume_role.json } resource "aws_cloudwatch_log_group" "lambda_log_group" { name = "/aws/lambda/${local.function_name}" } resource "aws_kms_key" "lambda_key" { description = "My Lambda Function Customer Master Key" enable_key_rotation = true deletion_window_in_days = 7 } resource "aws_kms_alias" "lambda_key_alias" { name = "alias/my-lambda-key" target_key_id = aws_kms_key.lambda_key.id } resource "aws_ssm_parameter" "lambda_variable_message_base" { name = "/App/Lambda/Config/BASE_MESSAGE" type = "SecureString" value = "Hello" key_id = aws_kms_key.lambda_key.id }
- 投稿日:2020-08-03T01:16:41+09:00
AWS Lambdaからコンテナを呼び出してみた。
はじめに
Web APIを提供する際に、Amazon API GatewayとAWS Lambdaを組み合わせて実装するケースがあるかと思います。API Gateway + Lambda 関数で処理を完結するケースもあれば、既に実装されている他のサービスを呼び出して処理を完結させるケースもあるでしょう。今回は、後者、つまり、ALambda関数が他のサービスを呼び出して処理を完結するケース、具体的には、AWS Lambdaが AWS Fargateのタスクで実装されたサービスを呼び出す場合の方法と応答結果について書きたいと思います。
ちなみに、2020年8月2日に東京リージョンのAWS Lambdaを使って試した結果であり、仕様について、挙動について解説するものではありません。
要約
- Lambda関数から NLB/ALBを経由で呼び出す場合とPriateHostedzoneに登録されたサービス名で呼び出す場合のレイテンシーは大差ない結果となった
- CloudMap経由で呼び出す場合、それだけでCloudMapの応答時間が上乗せされてレイテンシーが大きくなる結果となった。
1.想定ケース
まず、想定ケースについて説明する前に、1点お伝えすることとして、冒頭ではAPI Gatewayのバックエンドという形で例に挙げましたが、Lambda関数のイベントソースは、この解説では重要ではありません。Amazon API Gatewayだろうと、Amazon SQSだろうと、AWS Step Functionsだろうと何でもよいです。今回の記事のポイントはAWS LambdaがAWS Fargateのタスクを呼び出す部分がポイントです。
今回の記事では、Lambda関数からAWS Fargateのタスク、つまり、コンテナをLambda関数からHTTPで呼び出す前提とます。
AWS FargateはVPCで動くAWSサービスです。VPCで動くということは、つまり、VPC のいずれかの Subnet の中に配置され、Private IP アドレス(設定によってはPublicIPアドレスも)をAWS Faragetのタスク単位に保持する形になります。今回は以下の想定でLambda関数から AWS Fargateのタスクにアクセスすることとします。
- Lambda 関数からはFargateに対して今回は、HTTPで通信を行い、アクセスすることを想定します。
- Fargateのタスクは、インターネットから直接アクセスができない、いわゆる、プライベートなSubnetに今回は配置されている前提 とします。
- 上記前提により、プライベートなSubnetに配置されたFargateのタスクにAWS Lambdaがアクセスするために、Lambda関数は、VPC内リソースにアクセスするためのLambda関数の設定を有効化にします。
なお、Fargateを構成された方はFargateを直接Lambdaから呼び出すケースなの?と疑問に思われるかもしれませんが、それについては、2.2で説明します。
2 Lambda関数からAWS FaragetのタスクにHTTPでアクセスするために
2.1 サービスディスカバリ
AWS Fargateのタスクに対してHTTP経由でアクセスする方法としては、幾つかあります。
AWS Fargateのタスク、つまり、コンテナはスケールイン・スケールアウトの設定次第ではありますが、随時、起動・停止が行われたり、不具合が発生すると新規のタスクが起動されます。つまり、IPアドレスが都度かわっていくため、HTTPでアクセスするには、その時動いているタスクのIPを正しくみつけ、アクセスする必要があります。では、刻々と変わっていくIPアドレスを取得するには、何が必要かというと、IPアドレスを登録する「レジストリ」とそのレジストリにアクセスしてIPアドレスを取得する仕組みが必要となります。このように動的に変わっていくサービスの実行インスタンスを発見することをサービスディスカバリといいます。サービスディスカバリをするためには、レジストリとそのレジストリにアクセスして位置情報(今回はIP)を取得するアプリが必要です。
2.2 IPアドレスの登録(レジストリ)
AWS Fargate のタスクが起動するとそのタスクのIPアドレスの登録先として以下があります。
1. ALBのターゲットグループ
2. NLBのターゲットグループ
3. AWS CloudMap
4. Route53 のPrivate Hostedzone上記は、AWS Fargateのサービス構成時に設定が可能で、3,4のケースではサービス名を独自に決定して登録することで、そのサービス名で名前解決、つまり、IPアドレス(設定方法によっては、ポート番号も)を取得することができます(つまり、Lambda内から、独自に定義した名前でアクセスすることが可能)
なお、「1. 想定ケース」で説明した通り、今回のLambda関数は、プライベートなSubnetでアクセスするするFargateにアクセスしますが、前述の2.1.1で登場した方法としてALBやNLBを利用してアクセスする場合は、ALBやNLBがどこに配置されているかによって、経路が変わります。今回は、Fargateが配置されたSubnetと同じSubnetにALB/NLBを配置する前提とします。
2.3 AWS LambdaがFargateにアクセスする場合のサービスディスカバリ
まず、ALB/NLB経由でアクセスする場合には、NLB/ALBの名前解決ができればALB/NLBがFargateに接続をするため、Fargateのタスクのサービスディスカバリについて気にする必要はありません。
また、Route53のPrivate Hostedzoneを利用する場合も、「名前解決」という意味では、ALB/NLBのケースと同じでDNSによる名前解決でサービスのIPアドレスを取得できるため、特別なことはありません。
一方、AWS CloudMapを利用する場合はアプリケーション、つまり、ここではLambda関数側でCloudMapのAPIでサービスの情報を取得し、そこからサービスにアクセスする形となります。
3.動作確認
ということで、今回は上記の4つのパターンについて実際にアクセスをしその結果を計測したいと思います。
いずれのパターンも名前解決が必要(具体的には、ALBやNLB,CloudMapの名前解決が必要)で、HTTPでアクセスるとリゾルバが Amazon DNS サーバーに問い合わせて解決をしアクセスします。CloudMapの場合は、CloudMapのエンドポイントの名前解決は Amazon DNS サーバーで実施し、アクセスしたいサービス(Farageのタスクとして動いているサービス)の解決をCloudMapが行います。また、Route 53のPrivate Hostedzoneを利用するケースは2.3で書いた通りALB/NLBと同じでHTTPアクセスすれば自動的に名前解決がされて考慮が不要となります。。
No. 登録先レジストリ IP登録方法 名前解決 経路 1 ALBターゲットグループ ECSタスク起動時にIPを登録 ALBの名前解決をDNSで実施 Lambda関数->ALB->Fargate 2 NLBターゲットグループ ECSタスク起動時にIPを登録 NLBの名前解決をDNSで実施 Lambda関数->NLB->Fargate 3 CloudMap ECSタスク起動時にIPを登録 CloudMapで名前解決 Lambda関数->CloudMap(IPを応答)->Lambda関数->Fargate 4 Route53 Private Hostedzone ECSタスク起動時にCloudMap経由でIPを登録 Route53 で名前解決 Lambda関数->Fargate さて、1点重要なこととして、PrivateなSubnetにAWS Lambdaをもし配置した場合、注意する点として、NAT Gateway等を経由してCloudMapにアクセスする必要があるという点です。今回はケース3については、NAT Gateway経由でCloudMap APIを呼び出している。
app.pyimport boto3 import os import requests from aws_xray_sdk.core import xray_recorder from aws_xray_sdk.core import patch_all patch_all() servicediscovery = boto3.client('servicediscovery') appId=os.environ['AppId'] envId=os.environ['EnvId'] serviceName=os.environ['ServiceName'] def lambda_handler(event, context): for num in range(2): httpRequestByRoute53() httpRequestByCloudMap() httpRequestByALB() httpRequestByNLB() return def httpRequestByALB(): response= requests.get("http://internal-FargatXXXXX.ap-northeast-1.elb.amazonaws.com/") def httpRequestByNLB(): response= requests.get("http://InternalNLB-8f6bXXXXXXXX.elb.ap-northeast-1.amazonaws.com/") def httpRequestByCloudMap(): instances = servicediscovery.discover_instances( NamespaceName='fargatetest', ServiceName='hogehoge2', ) ipaddress= instances['Instances'][0]['Attributes']['AWS_INSTANCE_IPV4'] response= requests.get("http://"+ipaddress+"/") def httpRequestByRoute53(): response= requests.get("http://hogehoge2.fargatetest/")3.処理結果
各ケースについて、以下、X-Rayによる測定結果は以下の通り。なお、上記ソースコードにあるとおり、Lambda関数からサービスを呼ぶ際にはループで二回呼び出している。
No. アクセス先 関数処理時間 呼び出し先処理時間 1 ALB経由 90ms 40ms 2 NLB経由 82ms 37ms 3 CloudMap利用・直接アクセス 205ms 53ms 4 Route53 Private Hostedzone利用、直接アクセス 106ms 46ms ALB/NLB間は僅かな差であり、何回か試したが時にはALBのほうが速い場合もあったため、誤差の範囲といえる。また、Route 53経由の場合も今回計測した結果からは誤差の範囲内といえる。
ただ、CloudMap経由の場合は、CloudMapを呼び出すのに数十msかかっており、これがオーバーヘッドとなって遅延が発生する。
実際のX-Rayの画面は以下の通り。3.1 ALB経由
ALB経由でFargateにアクセス
3.2 NLB経由
NLB経由でFargateにアクセス
3.3 CloudMap経由
Lambda関数から二つのサービスを呼び出しており、servicediscoveryとなっているのが、CloudMapのAPIである。そして、CloudMapの戻り値を利用して10.0.10.85(Fargate)にアクセスしている。
3.4 Route53 Private Hostedzone 利用時
ECSのサービスで定義した名前(hogehoge2.fargatetest)で直接アクセスしている。
4.サマリ
CloudMapを利用してアクセスすると他の方法に比べてAPI呼び出しのオーバーヘッドが発生するため処理時間としてはマイナスな結果となった。コンテナのIPアドレスは動的に変わっていくことを考えると、キャッシュをしておくのが良いか、接続してみて404が応答されたらCloudMapを問い合わせる形にするのか・・・・何か良い方法をご存じの方がいればお教えください。




- 投稿日:2020-08-03T00:13:04+09:00
[AWS]機種変更後のMFA認証端末移行設定
概要
本書ではMFA認証に使用しているスマートフォンを機種変更する際に、旧端末から新規端末をMFA認証端末に切り替えるように設定します。新規端末にMFA認証を切り替えずに旧端末を売却やキャリアに返還すると、MFA認証が通らずAWSにログインできない可能性がありますので、旧端末を手放す前に必ず新規端末にMFA認証を切り替えます。
0.前提条件
- 旧端末にMFA認証を設定していること。
- 本書ではPCはMacBookAir2019,MFA認証端末はiPhoneSE2を使用します。
1. 新規端末にMFA認証アプリをインストール
新規購入したiPhoneやAndroid端末にMFA認証アプリをAppStoreやGooglePlayからインストールします。主にMicrosoft AuthenticatorやGoogle Authenticatorなどがあります。
2. ルートアカウントのMFA認証切り替え設定
AWSマネジメントコンソールにログインします。MFA認証画面が表示されたら、旧端末にインストールされているMFA認証アプリを立ち上げ、「MFAコード」を入力し「送信」をクリックします。
上部メニューから「サービス」→「IAM」をクリックします。
「ルートアカウントのMFAを有効化」を開き、「MFAの管理」をクリックします。
「多要素認証(MFA)」を開き、「管理」をクリックします。
「削除」を選択し、「削除」をクリックします。
旧端末情報を削除後、「MFAの有効化」をクリックします。
「仮想MFAデバイス」を選択し、「続行」をクリックします。
下記の手順にて新規端末にMFA認証を設定します。
- 新規端末端末にインストールしたMFA認証アプリ(Microsoft AuthenticatorやGoogle Authenticatorなど)を起動します。
- 「QRコードの表示をクリック」をクリックし、QRコードが表示されたことを確認します。
- MFA認証アプリを使用してQRコードを撮影し、MFA認証アプリにAWSアカウントが追加されたことを確認します。(アプリによって動作が異なる場合があります)
- アプリに表示されているAWSアカウントのMFAコードを確認します。番号が切り替わる前に表示されているMFAコードを「MFAコード1」に入力します。
- アプリに表示されているMFAコードが新しい番号に切り替わったら、番号が切り替わる前に表示されているMFAコードを 「MFAコード2」に入力します。
- 「MFAの割り当て」をクリックします。

「仮想MFAが正常に割り当てられました」と表示されたことを確認します。その後、「閉じる」をクリックします。
AWSマネジメントコンソールからログアウトし、再度ログインします。その際、新規端末にインストールしたMFA認証アプリでMFA認証が通ることを確認します。
2. IAMユーザーのMFA認証切り替え設定
ルートアカウントまたはIAM設定権限があるユーザーにてログインし、IAMメニューから「ユーザー」をクリックします。
MFA認証を切り替えるユーザーをクリックします。
「認証情報」タブをクリックし、「MFAデバイスの割り当て」の「管理」をクリックします。
「削除」を選択し、「削除」をクリックします。
「MFAデバイスの割り当て」の「管理」をクリックします。
「仮想MFAデバイス」を選択し、「続行」をクリックします。
下記の手順にて新規端末にMFA認証を設定します。
- 新規端末端末にインストールしたMFA認証アプリ(Microsoft AuthenticatorやGoogle Authenticatorなど)を起動します。
- 「QRコードの表示をクリック」をクリックし、QRコードが表示されたことを確認します。
- MFA認証アプリを使用してQRコードを撮影し、MFA認証アプリにAWSアカウントが追加されたことを確認します。(アプリによって動作が異なる場合があります)
- アプリに表示されているAWSアカウントのMFAコードを確認します。番号が切り替わる前に表示されているMFAコードを「MFAコード1」に入力します。
- アプリに表示されているMFAコードが新しい番号に切り替わったら、番号が切り替わる前に表示されているMFAコードを 「MFAコード2」に入力します。
- 「MFAの割り当て」をクリックします。
「仮想MFAが正常に割り当てられました」と表示されたことを確認します。その後、「閉じる」をクリックします。
MFA認証を設定したIMAユーザーを使用してAWSマネジメントコンソールにログインします。その際、新規端末にインストールしたMFA認証アプリでMFA認証が通ることを確認します。
最後に
旧端末を手放してMFA認証が通らないようなトラブルが発生しないように、機種変更したら忘れずに新規端末にMFA認証アプリをインストールし、MFA認証端末を切り替えましょう。












