- 投稿日:2020-07-31T23:59:40+09:00
Docker上のMySQLのデータをvolumeでホストのディレクトリにマウントすると権限周りで面倒なことになる
Dockerの
volumesについてあまり知らなかったゆえにハマったのだが……次のようにdocker-composeでホスト上の任意のディレクトリにマウントさせるようなVolumeを設定すると、環境によってはコンテナ内のユーザーが持っている権限とマウントされたディレクトリの権限が一致せずコンテナが立ち上がらないことがあります。
docker-compose.ymlversion: "3" services: db: image: mysql:8.0 volumes: - ./data:/var/lib/mysql - ./logs:/var/log/mysql ...特にDocker for Macで作った
docker-compose.ymlをLinuxホストのDockerで実行しようとしたときに発生します。解決法1: データの永続化は名前付きボリュームにする
ホストのディレクトリにマウントするのを諦めて、名前付きボリュームを用いる方法です。
MySQLのデータのバックアップなど「データの移動」は別の方法を考えましょう。docker-compose.ymlversion: "3" services: db: image: mysql:8.0 volumes: - db-store:/var/lib/mysql - ./logs:/var/log/mysql environment: ... volumes: db-store:ちなみに名前付きボリュームはどこかというと
ホストのディレクトリにVolumeをマウントする理由の一つとして「コンテナで使ったデータは自分が把握しやすい場所で管理したい」というのがあると思います。
先程の名前付きボリュームにデータを永続化させるとデータはDockerによる管理になり、一見するとどこに行ったかわからなくなります。そこで、
docker volume lsでボリュームの名前を調べて、docker volume inspectのMountpointに記載されているpathで名前付きボリュームの保存先を調べることができます。$ docker volume ls DRIVER VOLUME NAME local 1fff58055cdf5d6d088b79ca40970b7cc7b74103647cd2d5cd47292ebc51037b local 09d44f5c50e868ee1420322768a4bf5de5c6573d48eb9e534c6b2be464542f83 local sample-docker-compose-api-flask_db-store $ docker volume inspect sample-docker-compose-api-flask_db-store [ { "CreatedAt": "2020-02-20T16:00:20Z", "Driver": "local", "Labels": { "com.docker.compose.project": "sample-docker-compose-api-flask", "com.docker.compose.version": "1.25.4", "com.docker.compose.volume": "db-store" }, "Mountpoint": "/var/lib/docker/volumes/sample-docker-compose-api-flask_db-store/_data", "Name": "sample-docker-compose-api-flask_db-store", "Options": null, "Scope": "local" } ]Docker for Macで名前付きボリュームにアクセスできない
Docker for Macの場合、
Mountpointにそのままアクセスしようとしても「存在しない」とエラーになります。
macOS上でDockerを動作させてvolumeを作成しているのではなく、LinuxKitと呼ばれるVMを立ち上げてその中にvolumesを作成しているからです。volumes内のファイルを確認するにはVMの中に入る必要があります。
$ ls /var/lib/docker/volumes/sample-docker-compose-api-flask_db-store/_data ls: /var/lib/docker/volumes/sample-docker-compose-api-flask_db-store/_data: No such file or directory次のコマンドでVMの中に入り、
Ctrl + Dを入力します。Ctrl + Dを入力するまでの間画面には何も表示されません。$ screen ~/Library/Containers/com.docker.docker/Data/vms/0/tty ... __ __ Welcome to LinuxKit ## . ## ## ## == ## ## ## ## ## === /"""""""""""""""""__/ === { / ===- _____ O __/ __/ _________/ docker-desktop login: root (automatic login) Welcome to LinuxKit! NOTE: This system is namespaced. The namespace you are currently in may not be the root. System services are namespaced; to access, use `ctr -n services.linuxkit ...` login[5397]: root login on 'ttyS0' esktop:~# ls /var/lib/docker/volumes/sample-docker-compose-api-flask_db-store/_data/ #innodb_temp binlog.index mysql auto.cnf ca-key.pem mysql.ibd binlog.000001 ca.pem performance_schema binlog.000002 client-cert.pem private_key.pem binlog.000003 client-key.pem public_key.pem binlog.000004 homestead server-cert.pem binlog.000005 ib_buffer_pool server-key.pem binlog.000006 ib_logfile0 sys binlog.000007 ib_logfile1 undo_001 binlog.000008 ibdata1 undo_002 docker-desktop:~#
Ctrl + ACtrl + Kと入力し、Really kill this window [y/n]の質問にyと入力すると脱出できます。最新のDocker for Macでは
screenでDockerのVMに入れない2020/07/31現在のDocker for Macでは、次のように操作が許可されていない旨のエラーが出てVMに入れなくなってます。
sudoで昇格してもダメです。Cannot exec '~/Library/Containers/com.docker.docker/Data/vms/0/tty': Permission denied
そこで、VMに入るためのコンテナであるnsenter1を使います、
docker run -it --privileged --pid=host debian nsenter -t 1 -m -u -n -i sh脱出方法も
exitと入力するだけで簡単です。Docker for Windowsでも使えるか試してみます?
解決策2: コンテナ内のユーザーID(uid, gid)を
docker-compose実行ユーザーのものに揃えておくちょっと脱線しましたが、この解決策は ホスト上の任意のディレクトリを指定して コンテナのデータを保存することができます。
docker-composeを実行してコンテナを立ち上げるユーザーで次のコマンドを実行してuid, gidを調べます、id -u $USER id -g $USER次に、
docker-compose.ymlでVolumeを使うサービスのcommandに次を追加します。docker-compose.ymlcommand: bash -c 'usermod -o -u <UID> mysql; groupmod -o -g <GID> mysql; chown -R mysql:root /var/run/mysqld/ /var/log/mysql/ /var/lib/mysql/; /entrypoint.sh mysqld --user=mysql --console'
docker-compose.ymlに環境固有の値を入れるとGitで管理する際に支障が出るため、.envに追記する形に変更します。docker-compose.ymlversion: "3" services: db: image: mysql:8.0 volumes: - ./data:/var/lib/mysql - ./logs:/var/log/mysql ... command: bash -c 'usermod -o -u $LINUX_MYSQL_UID mysql; groupmod -o -g $LINUX_MYSQL_GID mysql; chown -R mysql:root /var/run/mysqld/ /var/log/mysql/ /var/lib/mysql/; /entrypoint.sh mysqld --user=mysql --console'.envLINUX_MYSQL_UID=501 LINUX_MYSQL_GID=501実行環境のuid, gidを取得して
.envに追記するシェルスクリプトを同梱することで立ち上げも簡単になります(その代わり実行するのを忘れると設定すべきuid, gidが空っぽになります)set-environ-uid.sh#!/bin/sh echo "LINUX_MYSQL_UID=$(id -u $USER)" >> .env echo "LINUX_MYSQL_GID=$(id -g $USER)" >> .env参考
docker composeでMySQLのデータ領域をローカルにマウントする | WEB EGG
https://blog.leko.jp/post/how-to-mount-data-volume-to-local-with-docker-compose/Docker for MacのDisk Imageの場所が変わった - Qiita
https://qiita.com/amuyikam/items/938781ff5898e654fd7cDockerのまとめ - コンテナとボリューム編 - Qiita
https://qiita.com/kompiro/items/7474b2ca6efeeb0df80fGetting a Shell in the Docker for Mac Moby VM · GitHub
https://gist.github.com/BretFisher/5e1a0c7bcca4c735e716abf62afad389
- 投稿日:2020-07-31T23:59:40+09:00
Docker上のMySQLのデータをVolumeでホストのディレクトリにマウントすると権限周りで面倒なことになる
Dockerの
volumesについてあまり知らなかったゆえにハマったのだが……次のようにdocker-composeでホスト上の任意のディレクトリにマウントさせるようなVolumeを設定すると、環境によっては コンテナ内のユーザーが持っている権限とマウントされたディレクトリの権限が一致せずコンテナが立ち上がらないことがあります。
docker-compose.ymlversion: "3" services: db: image: mysql:8.0 volumes: - ./data:/var/lib/mysql - ./logs:/var/log/mysql ...特にDocker for Macで作った
docker-compose.ymlをLinuxホストのDockerで実行しようとしたときに「コンテナ内の/var/lib/mysqlにアクセスできない」旨のエラーが発生します。解決法1: データの永続化は名前付きボリュームにする
ホストのディレクトリにマウントするのを諦めて、名前付きボリュームを用いる方法です。次の例では
/var/lib/mysqlの部分を名前付きボリュームにしました。
MySQLのデータのバックアップなど「データの移動」は別の方法を考えましょう。docker-compose.ymlversion: "3" services: db: image: mysql:8.0 volumes: - db-store:/var/lib/mysql - ./logs:/var/log/mysql environment: ... volumes: db-store:ちなみに名前付きボリュームはどこかというと
ホストのディレクトリにコンテナのVolumeをマウントする理由の一つとして「コンテナで使ったデータは自分が把握しやすい場所で管理したい」というのがあると思います。
先程の名前付きボリュームにデータを永続化させるとデータはDockerによる管理になり、一見するとどこに行ったかわからなくなります。そこで、
docker volume lsでボリュームの名前を調べて、docker volume inspectのMountpointに記載されているpathで名前付きボリュームの保存先を調べることができます。$ docker volume ls DRIVER VOLUME NAME local 1fff58055cdf5d6d088b79ca40970b7cc7b74103647cd2d5cd47292ebc51037b local 09d44f5c50e868ee1420322768a4bf5de5c6573d48eb9e534c6b2be464542f83 local sample-docker-compose-api-flask_db-store $ docker volume inspect sample-docker-compose-api-flask_db-store [ { "CreatedAt": "2020-02-20T16:00:20Z", "Driver": "local", "Labels": { "com.docker.compose.project": "sample-docker-compose-api-flask", "com.docker.compose.version": "1.25.4", "com.docker.compose.volume": "db-store" }, "Mountpoint": "/var/lib/docker/volumes/sample-docker-compose-api-flask_db-store/_data", "Name": "sample-docker-compose-api-flask_db-store", "Options": null, "Scope": "local" } ]Docker for Macで名前付きボリュームにアクセスできない
LinuxホストでDockerを動作させている場合では
Mountpointにそのままアクセスできますが、Docker for Macの場合は「存在しない」とエラーになります。
これはmacOS上でDockerを動作させてvolumeを作成しているのではなく、Dockerが自動的にLinuxKitと呼ばれるVMを立ち上げてその中にVolumeを作成しているからです。Docker for MacでVolume内のファイルを確認するにはVMの中に入る必要があります。
$ ls /var/lib/docker/volumes/sample-docker-compose-api-flask_db-store/_data ls: /var/lib/docker/volumes/sample-docker-compose-api-flask_db-store/_data: No such file or directory次のコマンドでVMの中に入り、
Ctrl + Dを入力します。Ctrl + Dを入力するまでの間画面には何も表示されません。"Welcome to LinuxKit"と表示され、操作可能になると
Mountpointで示されたpathにアクセスできます。$ screen ~/Library/Containers/com.docker.docker/Data/vms/0/tty ... __ __ Welcome to LinuxKit ## . ## ## ## == ## ## ## ## ## === /"""""""""""""""""__/ === { / ===- _____ O __/ __/ _________/ docker-desktop login: root (automatic login) Welcome to LinuxKit! NOTE: This system is namespaced. The namespace you are currently in may not be the root. System services are namespaced; to access, use `ctr -n services.linuxkit ...` login[5397]: root login on 'ttyS0' docker-desktop:~# ls /var/lib/docker/volumes/sample-docker-compose-api-flask_db-store/_data/ #innodb_temp binlog.index mysql auto.cnf ca-key.pem mysql.ibd binlog.000001 ca.pem performance_schema binlog.000002 client-cert.pem private_key.pem binlog.000003 client-key.pem public_key.pem binlog.000004 homestead server-cert.pem binlog.000005 ib_buffer_pool server-key.pem binlog.000006 ib_logfile0 sys binlog.000007 ib_logfile1 undo_001 binlog.000008 ibdata1 undo_002 docker-desktop:~#
Ctrl + ACtrl + Kと入力し、Really kill this window [y/n]の質問にyと入力すると脱出できます。最新のDocker for Macでは
screenでDockerのVMに入れない2020/07/31現在のDocker for Macでは、次のように操作が許可されていない旨のエラーが出てVMに入れなくなってます。
sudoで昇格してもダメです。Cannot exec '~/Library/Containers/com.docker.docker/Data/vms/0/tty': Permission denied
そこで、VMに入るためのコンテナであるnsenter1を使います、
docker run -it --privileged --pid=host debian nsenter -t 1 -m -u -n -i sh脱出方法も
exitと入力するだけで簡単です。Docker for Windowsでも使えるか試してみます?
解決策2: コンテナ内のユーザーID(uid, gid)を
docker-compose実行ユーザーのものに揃えておくちょっと脱線しましたが、この解決策は ホスト上の任意のディレクトリを指定して コンテナのデータを保存することができます。
docker-composeを実行してコンテナを立ち上げるユーザーで次のコマンドを実行してuid, gidを調べます、id -u $USER id -g $USER次に、
docker-compose.ymlでVolumeを使うサービスのcommandに次の順番でコマンドを追加します。
- コンテナ内のuid, gidを変更するコマンド
- ホスト上のディレクトリに紐付けたコンテナ内のディレクトリの所有権を変更するコマンド
- 通常のコンテナ立ち上げ時に実行されるコマンド
MySQLのコンテナを使う場合は次のとおりです
docker-compose.ymlcommand: bash -c 'usermod -o -u <調べたuid> mysql; groupmod -o -g <調べたgid> mysql; chown -R mysql:root /var/run/mysqld/ /var/log/mysql/ /var/lib/mysql/; /entrypoint.sh mysqld --user=mysql --console'
docker-compose.ymlに環境固有の値を入れるとGitで管理する際に支障が出るため、.envに追記する形に変更します。docker-compose.ymlversion: "3" services: db: image: mysql:8.0 volumes: - ./data:/var/lib/mysql - ./logs:/var/log/mysql ... command: bash -c 'usermod -o -u $LINUX_MYSQL_UID mysql; groupmod -o -g $LINUX_MYSQL_GID mysql; chown -R mysql:root /var/run/mysqld/ /var/log/mysql/ /var/lib/mysql/; /entrypoint.sh mysqld --user=mysql --console'.env(例)LINUX_MYSQL_UID=501 LINUX_MYSQL_GID=501実行環境のuid, gidを取得して
.envに追記するシェルスクリプトを同梱することで立ち上げも簡単になります(その代わり実行するのを忘れると設定すべきuid, gidが空っぽになります)set-environ-uid.sh#!/bin/sh echo "LINUX_MYSQL_UID=$(id -u $USER)" >> .env echo "LINUX_MYSQL_GID=$(id -g $USER)" >> .envこの環境で初めてプロジェクトのdocker-composeを使う場合は./set-environ-uid.sh docker-compose up -d db参考
docker composeでMySQLのデータ領域をローカルにマウントする | WEB EGG
https://blog.leko.jp/post/how-to-mount-data-volume-to-local-with-docker-compose/Docker for MacのDisk Imageの場所が変わった - Qiita
https://qiita.com/amuyikam/items/938781ff5898e654fd7cDockerのまとめ - コンテナとボリューム編 - Qiita
https://qiita.com/kompiro/items/7474b2ca6efeeb0df80fGetting a Shell in the Docker for Mac Moby VM · GitHub
https://gist.github.com/BretFisher/5e1a0c7bcca4c735e716abf62afad389
- 投稿日:2020-07-31T23:16:58+09:00
Docker for MacのLaravelが遅いから速くしたい
要約
- Docker for Macのファイルマウントが遅すぎるので、ファイルマウント量を減らす
- ファイルマウントに:delegatedや:cachedを使う
- php.iniの設定でOPcacheを有効化する
- composerも遅いのでリポジトリの変更し、プライグイン導入
ファイルマウント量を減らす、かつマウントする時は:delegatedや:cachedを使う
- .gitはマウントする意味がないので、除外する
- マウントがどうしても必要な時は:delegatedや:cachedを使う
例
docker-compose.ymlversion: '3' services: web: image: nginx:${Version} ports: - "8000:80" depends_on: # 追加 - app volumes: - ./docker/web/default.conf:/etc/nginx/conf.d/default.conf - .:/var/www/html:delegated #:delegatedを追加 - exclude:/var/www/html/laravel-dir/.git #追加 container_name: web app: build: ./docker/php volumes: - .:/var/www/html:delegated #:delegatedを追加 - exclude:/var/www/html/laravel-dir/.git #追加 depends_on: - mysql mysql: image: mysql:5.7 environment: MYSQL_DATABASE: hoge MYSQL_USER: hoge MYSQL_PASSWORD: hoge MYSQL_ROOT_PASSWORD: hoge ports: - "3306:3306" volumes: - mysql-data:/var/lib/mysql:cached #:cachedを追加php.iniの設定でOPcacheを有効化する
php.ini~~省略~~ opcache.memory_consumption=128 opcache.interned_strings_buffer=8 opcache.max_accelerated_files=4000 opcache.revalidate_freq=60 opcache.fast_shutdown=1 opcache.enable_cli=1composerも遅いのでリポジトリの変更し、プライグイン導入
FROM php:7.4-fpm ~~省略~~ # composerの高速化 RUN composer config -g repos.packagist composer https://packagist.jp && composer global require hirak/prestissimo WORKDIR /var/www/html参考
光遅い問題に対応して Composer を100倍速くする
Macのdockerが遅いストレスから解放されよう
Laravel で 最適化 高速化 手法一覧
- 投稿日:2020-07-31T20:51:00+09:00
環境構築: VS Code Remote Container で Azure + Terraform + GitHub Actions
Intro
Fork して clone したらすぐに Azure を Terraform できる devcontainer を作りました。 VS Code の Remote Development (Remote - Containers) 機能を使っているので、ローカルに VS Code と Docker Desktop の環境があれば、以下のようなことがほんの少しの準備で実行できます。
- Terraform で Azure を管理する
terraformや Azure CLIazコマンドがすでに Docker コンテナ上のインストールされています。- GitHub Actions で Push された内容を自動で反映する
GitHub レポジトリは以下です。
https://github.com/hoisjp/terraform-azure-ghactions-devcontainer手順
事前に必要なもの
以下を準備してください。たったこれだけです!
- Visual Studio Code : https://code.visualstudio.com/download
- VS Code Extension : VS Code Remote Development (Remote - Containers)
- Docker Desktop : https://www.docker.com/get-started
Windows/Mac/Linux、いずれの OS でも大丈夫なはずです。いざ!Remote Development!
- ローカル環境で、Docker Desktop が実行中であることを確認してください。
- 以下の GitHub リポジトリを Fork してください。あやまって秘密キーなどをプッシュしてしまわないよう、まずはプライベートレポジトリにしておくことをおすすめします。
https://github.com/hoisjp/terraform-azure-ghactions-devcontainer
※ fork せずに直接 git clone も可能ですが、後続の GitHub Actions を利用するためにはご自身のリポジトリに fork していただく必要があります。fork したリポジトリを clone します。リポジトリ名は置き換えてください。
git clone <your repository>VS Code を clone したディレクトリで開いて、左下にある、Remote Development アイコンをクリックします。(コマンドパレットから実行しても構いません。)
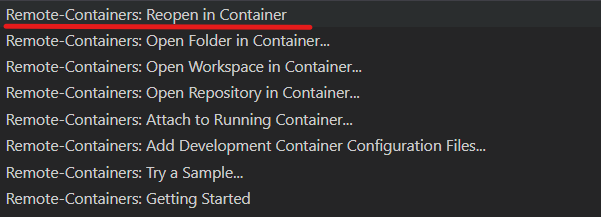
メニューから、
Remote-Containers: Reopen in Containers...を選択します。
ウィンドウが開き直りました。これは、ローカルの Docker コンテナ上で VS Code を開いている形になります。
VS Code のターミナルで以下を実行してみましょう。$ terraform -v Terraform v0.12.29 $ az --version azure-cli 2.9.1 ...できました!準備OKです!
FYI: ちなみに、
tflintやterragruntコマンドもすでにインストールされています。くわしくは、Dockerfile を見てください。Azure を Terraform で操作
Terraform backends 用の Azure Storage
まず、Terraform backends 用の Azure Storage を作ってみます。この Storage は Terraform のステートを管理するために必要なものです。
VS Code のターミナルを開きます。レポジトリのホームディレクトリにいるはずです。
$ pwd /workspace/<your repository name>Azure にログインします。ログイン用のページを開いて、指定されたコードを入力するよう求められます。以下、
************の部分は置き換えてください。$ az login To sign in, use a web browser to open the page https://microsoft.com/devicelogin and enter the code ************ to authenticate.ログイン成功したら、所有している Azure サブスクリプションの一覧が JSON フォーマットでずらっと返されます。
適切なサブスクリプションを選んで、以下のコマンドを実行します。ご自身のサブスクリプションの GUID で置き換えてください。先ほどの JSON 結果の
idプロパティのものです。$ az account set --subscription <your subscription GUID>では、以下のディレクトリに移動します。
sh
$ cd 00-create-azurerm-backend
Terraform を実行するために状態を初期化する必要があります。
以下のようにterraform initを実行します。$ terraform init Initializing the backend... Initializing provider plugins... Terraform has been successfully initialized! You may now begin working with Terraform. Try running "terraform plan" to see any changes that are required for your infrastructure. All Terraform commands should now work. If you ever set or change modules or backend configuration for Terraform, rerun this command to reinitialize your working directory. If you forget, other commands will detect it and remind you to do so if necessary.初期化が成功しました。次に、
terraform planを実行します。
ストレージアカウント名の入力を求められます。これはグローバルでユニークである必要があります。他と重複しないよう入力します。$ terraform plan var.backend_storage_account_name Storage account name for terraform backend Enter a value: ****以下のような terraform plan 結果が出力されればOKです。
... ... Plan: 3 to add, 0 to change, 0 to destroy.注意: もし Azure にログインしていないと、以下のようなエラーメッセージが出ます。戻って
az loginから進めてください。Error: Error building AzureRM Client: Authenticating using the Azure CLI is only supported as a User (not a Service Principal).では
terraform applyを実行してリソースを作成します。ストレージアカウント名をもう一度求められますので、先ほど terraform plan で確認した名前を入力します。$ terraform apply var.backend_storage_account_name Storage account name for terraform backend Enter a value: ****確認メッセージを求められますので、確認OKであれば
yesを入力します。... ... Plan: 3 to add, 0 to change, 0 to destroy. Do you want to perform these actions? Terraform will perform the actions described above. Only 'yes' will be accepted to approve. Enter a value: yes作成されていますね。少し待ちましょう。
azurerm_resource_group.rg: Creating... azurerm_resource_group.rg: Creation complete after 0s [id=/subscriptions/****GUID****/resourceGroups/terraform-rg] azurerm_storage_account.strg: Creating... azurerm_storage_account.strg: Still creating... [10s elapsed] azurerm_storage_account.strg: Still creating... [20s elapsed] azurerm_storage_account.strg: Creation complete after 20s [id=/subscriptions/****GUID****/resourceGroups/terraform-rg/providers/Microsoft.Storage/storageAccounts/****your storage account name****] azurerm_storage_container.strg-container: Creating... azurerm_storage_container.strg-container: Creation complete after 0s [id=https://********.blob.core.windows.net/tfstate]以下のメッセージが表示されたら完了です!
Apply complete! Resources: 3 added, 0 changed, 0 destroyed.念のため、ストレージアカウントが作成されているか確認してみましょう。
$ az group show --name terraform-rg --out table (result) $ az storage account show --name '<replace by yours>' --out table (result)Go for GitHub Actions
(ここは後ほど更新します。仕組みをご存じのかたは以下のファイルを見ていただければと)
https://github.com/hoisjp/terraform-azure-ghactions-devcontainer/blob/master/.github/workflows/01-hello-azure.ymlカスタマイズ
一度動いたらばいろいろと環境をカスタマイズしたくなってきますね。以下のファイルたちを変更するとカスタマイズできます。
詳しくは、VS Code のドキュメント も参考にしてください。
- .devcontainer/devcontainer.json
- .devcontainer/Dockerfile
- Azure CLI のイメージ
mcr.microsoft.com/azure-cli:latestをベースに、Terraform 各種をインストールしています。dotfiles で各自のお好み味付け
このリポジトリをチームで利用すると便利ですが、シェルの設定などお好みのものがあるかもしれません。そんなときは利用者それぞれがご自身の dotfiles でコンテナ上の設定をパーソナライズできます。以下のファイルの該当箇所を見てみましょう。
.devcontainer/devcontainer.json
"settings": { // ... // dotfiles "dotfiles.repository": "hoisjp/terraform-azure-ghactions-devcontainer", // change here to your repository. "dotfiles.targetPath": "~/.devcontainer/dotfiles", "dotfiles.installCommand": "~/.devcontainer/dotfiles/install.sh" },ここで dotfiles リポジトリの参照先を変更するとコンテナ作成時に適用してくれます。
仕組みはこのドキュメントを参考にしてください。 Personalizing with dotfile repositoriesまとめ
VS Code の Remote Development 機能は非常に強力です。このように、チームメンバーで全く同じコンテナ環境を、特別な手間なく自然に(ここが大事)共有することができます。
従来、Azure CLI をインストールして、Terraform をインストールして、、、といった準備を、チームの全員が各自それぞれで行う必要がありましたが、devcontainer の仕組みを使うことで、もう「環境準備手順書」のようなものは必要ありません。環境設定はすべて git 上で管理されています。誰かが環境を改善すれば、たたちにチーム全員に反映されます。
これで Azure と Terraform に集中できますね!参考
VS Code ドキュメント
- Developing inside a Container : https://code.visualstudio.com/docs/remote/containers
- VS Code 本を書きましたのでよかったら!
: https://www.amazon.co.jp/dp/4839970920/
Terraform for Azure ドキュメント
- https://docs.microsoft.com/en-us/azure/developer/terraform/
- Terraform - Azure Provider : https://www.terraform.io/docs/providers/azurerm/index.html
- Terraform - Azure Provider - GitHub Repos
- Terraform - Azure Provider - GitHub Repos - Examples
GitHub Actions for Azure ドキュメント

- 投稿日:2020-07-31T20:24:02+09:00
Dockerコンテナのリソース制限機能を使った実践的な体験談 その3
このチュートリアルでは、Alibaba Cloud ECS上でDockerコンテナのリソース制限機能を利用した実践的な体験ができます。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
--cpuset-cpus Sysbenchを使う
構文:
実行を許可する CPU 数 (0-3, 0, 1)
両方のCPUを使ってベンチテストを行います。
docker run -it --rm --name mybench --cpuset-cpus 0,1 centos:bench /bin/sh -c 'time sysbench --threads=2 --events=4 --cpu-max-prime=800500 --verbosity=0 cpu run' real 0m1.957s user 0m3.813s sys 0m0.025sCPU 0を使用してベンチテストを行います。
docker run -it --rm --name mybench --cpuset-cpus 0 centos:bench /bin/sh -c 'time sysbench --threads=2 --events=4 --cpu-max-prime=800500 --verbosity=0 cpu run' real 0m3.789s user 0m3.740s sys 0m0.029sCPU 1 を使用してベンチテストを行います。
docker run -it --rm --name mybench --cpuset-cpus 1 centos:bench /bin/sh -c 'time sysbench --threads=2 --events=4 --cpu-max-prime=800500 --verbosity=0 cpu run' real 0m3.809s user 0m3.761s sys 0m0.025s結果: 2 つの CPU の方が 1 つよりも高速です。
サーバーに 2 つ以上の CPU がある場合は、cpuset-CPUs の組み合わせを使って、より多くのテストを実行することができます。
ただ、 --threads= の設定はテストする CPU の数と同じでなければならないことに注意してください: 各 CPU は個別のスレッドワークロードを持つ必要があります。
もし本当に高速にしたいのであれば、max-prime の数を 100 倍に減らすことを検討してください。しかし、以下に示すように、このような短いランタイムでは、起動時の CPU 処理のオーバーヘッドが非常に多く、実際のウォールクロックの経過時間は、2 つの CPU が 1 つの 2 倍の速さであることを明確には示していません。したがって、テストの実行時間を短くしすぎないようにしてください。
docker run -it --rm --name mybench --cpuset-cpus 0,1 centos:bench /bin/sh -c 'time sysbench --threads=2 --events=4 --cpu-max-prime=8005 --verbosity=0 cpu run' real 0m0.053s user 0m0.023s sys 0m0.017s上のCPU2個対下のCPU1個。
docker run -it --rm --name mybench --cpuset-cpus 0 centos:bench /bin/sh -c 'time sysbench --threads=2 --events=4 --cpu-max-prime=8005 --verbosity=0 cpu run' real 0m0.066s user 0m0.025s sys 0m0.023sDocker --cpuset-cpusのトレーニングが完了しました。
sysbenchのトレーニングを開始しました: centos:benchコンテナに実行し、sysbench --helpを実行してトレーニングを継続します。
--cpu-shares Sysbenchを使う
先ほど、2つのスレッドを使用して0.277秒で動作することを確認しました。
docker run -it --rm --name mybench --cpus 1 centos:bench /bin/sh -c 'time sysbench --threads=2 --events=4 --cpu-max-prime=100500 --verbosity=0 cpu run'
相対的なCPU時間の共有比率だけをテストしたいので、1スレッドで十分です。
相対的な CPU 時間の共有率をテストしたいだけなので、1 CPU で十分です。
実行1:別のシェルを起動して実行します。
for var in `seq 1 20`; do docker stats --no-stream ; doneオリジナルのシェル:
docker run -d --name mybench100 --cpus 1 --cpu-shares=100 centos:bench /bin/sh -c 'for var in `seq 1 10`; do time sysbench --threads=1 --events=4 --cpu-max-prime=50500 --verbosity=0 cpu run ; done' docker run -d --name mybench500 --cpus 1 --cpu-shares=500 centos:bench /bin/sh -c 'for var in `seq 1 10`; do time sysbench --threads=1 --events=4 --cpu-max-prime=50500 --verbosity=0 cpu run ; done' docker run -d --name mybench1024 --cpus 1 --cpu-shares=1024 centos:bench /bin/sh -c 'for var in `seq 1 10`; do time sysbench --threads=1 --events=4 --cpu-max-prime=50500 --verbosity=0 cpu run ; done'docker stats は 1 つのコンテナの実行をキャッチしていません。
さらに重要なのは、share=500 が起動する前に shares=100 が終了してしまったことです。3つのコンテナを同時に実行させることを考えています。-cpu-shares - 各コンテナの設定に基づいて、比例して CPU を共有するようにしたいのです。
新しいアプローチ: 各コンテナを同じ時間までスリープさせ、その後、すべてのコンテナが同時にベンチマークを実行します。以下の sleep コマンドに注意してください。
実行 2: 別のシェルを起動して実行します。
for var in `seq 1 20`; do docker stats --no-stream ; done直後のオリジナルシェル:
docker run -d --name mybench100 --cpu-shares=100 centos:bench /bin/sh -c 'sleep 4; for var in `seq 1 3`; do time sysbench --threads=1 --events=4 --cpu-max-prime=500500 --verbosity=0 cpu run ; done' docker run -d --name mybench200 --cpu-shares=200 centos:bench /bin/sh -c 'sleep 3; for var in `seq 1 3`; do time sysbench --threads=1 --events=4 --cpu-max-prime=500500 --verbosity=0 cpu run ; done' docker run -d --name mybench300 --cpu-shares=300 centos:bench /bin/sh -c 'sleep 2; for var in `seq 1 3`; do time sysbench --threads=1 --events=4 --cpu-max-prime=500500 --verbosity=0 cpu run ; done' docker run -d --name mybench600 --cpu-shares=600 centos:bench /bin/sh -c 'for var in `seq 1 4`; do time sysbench --threads=1 --events=4 --cpu-max-prime=500500 --verbosity=0 cpu run ; done'これは2秒だけの有用な出力を提供しています。
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS d3744f5a52ee mybench600 94.14% 1.23MiB / 985.2MiB 0.12% 508B / 0B 13.1MB / 0B 0 5c694381ef2f mybench300 50.96% 1.34MiB / 985.2MiB 0.14% 508B / 0B 12.4MB / 0B 0 8894176a9b72 mybench200 34.10% 1.215MiB / 985.2MiB 0.12% 508B / 0B 12.4MB / 0B 0 8b783befba46 mybench100 15.71% 1.223MiB / 985.2MiB 0.12% 578B / 0B 12.4MB / 0B 0 CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS d3744f5a52ee mybench600 93.73% 1.348MiB / 985.2MiB 0.14% 578B / 0B 13.1MB / 0B 0 5c694381ef2f mybench300 55.25% 1.219MiB / 985.2MiB 0.12% 578B / 0B 13.1MB / 0B 0 8894176a9b72 mybench200 33.25% 1.223MiB / 985.2MiB 0.12% 578B / 0B 12.4MB / 0B 0 8b783befba46 mybench100 16.21% 1.227MiB / 985.2MiB 0.12%CPU % は指定した --cpu-shares と一致します。
--cpu-shares はコンテナの CPU リソースを利用可能なすべての CPU サイクルに対して優先的に使用します。上記のテストでは、テスト実行中に200% = ALL CPUリソースを使用しています。8コアや16コアのサーバーを使用している場合は、このようなことはしたくないでしょう。
実行3の目的: テスト実行を1つのCPUに限定する。サーバー構成に基づいて、任意のCPU番号を選択してください。
run 3: 別のシェルを起動して実行します。
for var in `seq 1 20`; do docker stats --no-stream ; done直後のオリジナルシェル:
docker run -d --name mybench100 --cpuset-cpus 0 --cpu-shares=100 centos:bench /bin/sh -c 'sleep 4; for var in `seq 1 3`; do time sysbench --threads=1 --events=4 --cpu-max-prime=500500 --verbosity=0 cpu run ; done' docker run -d --name mybench200 --cpuset-cpus 0 --cpu-shares=200 centos:bench /bin/sh -c 'sleep 3; for var in `seq 1 3`; do time sysbench --threads=1 --events=4 --cpu-max-prime=500500 --verbosity=0 cpu run ; done' docker run -d --name mybench300 --cpuset-cpus 0 --cpu-shares=300 centos:bench /bin/sh -c 'sleep 2; for var in `seq 1 3`; do time sysbench --threads=1 --events=4 --cpu-max-prime=500500 --verbosity=0 cpu run ; done' docker run -d --name mybench600 --cpuset-cpus 0 --cpu-shares=600 centos:bench /bin/sh -c 'for var in `seq 1 4`; do time sysbench --threads=1 --events=4 --cpu-max-prime=500500 --verbosity=0 cpu run ; done'期待される出力:
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS 61a4f3d31614 mybench600 49.88% 1.215MiB / 985.2MiB 0.12% 648B / 0B 13.1MB / 0B 0 199ee60e6e1d mybench300 24.92% 1.348MiB / 985.2MiB 0.14% 648B / 0B 13.1MB / 0B 0 ee9b719a6d88 mybench200 16.77% 1.23MiB / 985.2MiB 0.12% 648B / 0B 12.4MB / 0B 0 016fc5d86d68 mybench100 8.26% 1.227MiB / 985.2MiB 0.12% 648B / 0B 12.4MB / 0B 0成功しました。全体的に100%のCPUパワーを使用しました(2つのCPUのうち1つは200%)。
実行4:
別のアプローチ:コンテナのCPUパワーを10%に制限し、その中でCPUシェアを指定通りに分配させたいと思います。以下の出力を参照してください。残念ながら、これはうまくいきません。
docker run -d --name mybench100 --cpus .1 --cpu-shares=100 centos:bench /bin/sh -c 'sleep 2; for var in `seq 1 4`; do time sysbench --threads=1 --events=4 --cpu-max-prime=500500 --verbosity=0 cpu run ; done' docker run -d --name mybench200 --cpus .1 --cpu-shares=200 centos:bench /bin/sh -c 'sleep 2; for var in `seq 1 3`; do time sysbench --threads=1 --events=4 --cpu-max-prime=500500 --verbosity=0 cpu run ; done' docker run -d --name mybench300 --cpus .1 --cpu-shares=300 centos:bench /bin/sh -c 'sleep 1; for var in `seq 1 3`; do time sysbench --threads=1 --events=4 --cpu-max-prime=500500 --verbosity=0 cpu run ; done' docker run -d --name mybench600 --cpus .1 --cpu-shares=600 centos:bench /bin/sh -c 'for var in `seq 1 3`; do time sysbench --threads=1 --events=4 --cpu-max-prime=500500 --verbosity=0 cpu run ; done'--cpus .1 は --CPU-shares の設定を上書きします。各コンテナは10%のCPUを使用します。
docker stats --no-stream outputCONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS d1efffa6b398 mybench600 9.98% 1.223MiB / 985.2MiB 0.12% 648B / 0B 13.1MB / 0B 0 e5761b1fd9ae mybench300 9.94% 1.227MiB / 985.2MiB 0.12% 648B / 0B 13.1MB / 0B 0 d25746948b3d mybench200 9.95% 1.348MiB / 985.2MiB 0.14% 648B / 0B 13.1MB / 0B 0 9003482281bd mybench100 9.94% 1.227MiB / 985.2MiB 0.12%––cpuset-mems
Opterons や Nelahem Xeons などの NUMA アーキテクチャを持つサーバーでのみ動作します。
実行を許可するメモリノード (MEM) を指定します (0-3, 0, 1)
私はハイエンドサーバを持っていないので、これらのオプションは使えませんでした。基本的にcpusetは以下のように使えます。
- --cpuset-cpusは非NUMAサーバで使用します。
- NUMAサーバでは --cpuset-mems を使用します。
ストレスベンチツールを使用した––memory と--memory-swap (スワップ不可)
コンテナを実行し、RAMを制限: --memory=20m --memory-swap=20m
dockerコンテナの実行 -ti --rm --memory=20m --memory-swap=20m --name memtest centos:bench /bin/sh
sh-4.2# シェルプロンプトに示すようにコマンドを入力します。
構文は以下の通りです。
stress --vm 1 --vm-bytes 18M
- 1人のvmワーカーを割り当てます。
- 18 MB の RAM を割り当てます。
sh-4.2# stress --vm 1 --vm-bytes 18M stress: info: [50] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hddこれは、指定された --memory=20m の制限内にあるので動作します。
CTRL-cを押してストレステストを終了します。
sh-4.2# stress --vm 1 --vm-bytes 19M stress: info: [53] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd stress: FAIL: [53](415) <-- worker 54 got signal 9 stress: WARN: [53](417) now reaping child worker processes stress: FAIL: [53](451) failed run completed in 0sコンテナがRAM切れのため、19MB RAMの割り当てに失敗しました。( コンテナ自体がいくつかの起動時のオーバーヘッド RAM を使用しています)
ストレスヘルプを読む。
sh-4.2# stress
--vm-hang N sleep N secs before free (default none, 0 is inf)現在、RAMを割り当てると、高速ループで割り当てられ、CPU時間を100%消費します。この vm-hang オプションを使用して、stress が xxx 秒ごとに RAM を割り当てるようにすることができます。
残念ながら、以前のクラッシュでは一部のRAMを使用していたため、18Mのテストでも同様にクラッシュしてしまいました。
そのため、17 MB の RAM 割り当てを使用してください。
sh-4.2# stress --vm 1 --vm-bytes 17M stress: info: [64] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd別のシェルを開いて、RESまたはSHRでソートを実行すると、100% CPUを使用してリストの一番上の近くにストレスを見つけることができるはずです。
ここで実行します。
sh-4.2# stress --vm 1 --vm-bytes 17M --vm-hang 3 stress: info: [70] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hddトップでは、CPU使用量が大幅に減少しています。
最終テスト:
sh-4.2# stress --vm 1 --vm-bytes 30M --vm-hang 3 stress: info: [72] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd stress: FAIL: [72](415) <-- worker 73 got signal 9 stress: WARN: [72](417) now reaping child worker processes stress: FAIL: [72](451) failed run completed in 0s sh-4.2# exitこのコンテナには20MBのRAMしかないので、ストレスで失敗します。
--memoryと--memory-swapは同じ意味でスワップは許可されていないので、ストレスは失敗します。
まとめ : コンテナを制限するために --memory = --memory-swap を設定 : スワップは許可されない
ベンチツールを使ってDockerイメージを作成してしまえば、これらのテストをいかに簡単に素早く行うことができるかに注目してください。
ストレスベンチツールを使用した --memory と --memory-swap (スワップ可能)
コンテナを実行し、RAMを制限: --memory=20m --memory-swap=30m
上記のオプションでは、コンテナのスワップを10MBに制限しています。
docker container run -ti --rm --memory=20m --memory-swap=30m --name memtest centos:bench /bin/sh
sh-4.2# シェルプロンプトに表示されているようにコマンドを入力します。
sh-4.2# stress --vm 1 --vm-bytes 25M --vm-hang 3 stress: info: [9] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd25 MB の割り当てがうまくいく - 5 MB 以上のスワップを使用しています。
別のシェルで top を使用します。swap列を表示します。スワップを使ったストレスに注意。
Tasks: 125 total, 2 running, 123 sleeping, 0 stopped, 0 zombie %Cpu(s): 0.3 us, 4.9 sy, 0.0 ni, 83.5 id, 11.1 wa, 0.0 hi, 0.2 si, 0.0 st MiB Mem : 985.219 total, 460.227 free, 166.090 used, 358.902 buff/cache MiB Swap: 1499.996 total, 1492.684 free, 7.312 used. 636.930 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND SWAP 2565 root 20 0 32.3m 18.0m S 9.0 1.8 0:24.97 stress 7.1mCTRL-cでストレスランを終了します。
sh-4.2# stress --vm 1 --vm-bytes 35M --vm-hang 3 stress: info: [11] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd stress: FAIL: [11](415) <-- worker 12 got signal 9 stress: WARN: [11](417) now reaping child worker processes stress: FAIL: [11](451) failed run completed in 0s sh-4.2# exitRAMを全体的に確保しようとすると、予想通りに失敗します。
--memory=20m --memory-swap=30m
予想通り、10MBのスワップ制限内でRAMを割り当てても問題ありません。
––memory-swap 未設定
memory-swap が未設定で --memory が設定されている場合、ホストコンテナにスワップメモリが設定されている場合、コンテナは --memory 設定の 2 倍のスワップを使用することができます。例えば、--memory="300m" で --memory-swap が設定されていない場合、コンテナは 300m のメモリと 600m のスワップを使用することができます。
実際に見てみましょう。
コンテナを実行し、RAMを制限: --memory=20m --memory-swap UNSET
ドキュメントに基づいて、私たちのコンテナは、tpにアクセスできるようにする必要があります。
docker container run -ti --rm --memory=20m --memory-swap=30m --name memtest centos:bench /bin/shsh-4.2# シェルプロンプトに表示されているようにコマンドを入力します。
sh-4.2# stress --vm 1 --vm-bytes 35M --vm-hang 3 stress: info: [9] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd ^C上記:メモリ設定の2倍以下の割り当てが動作します。
sh-4.2# stress --vm 1 --vm-bytes 38M --vm-hang 3 stress: info: [11] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd stress: FAIL: [11](415) <-- worker 12 got signal 9 stress: WARN: [11](417) now reaping child worker processes stress: FAIL: [11](451) failed run completed in 1s上記: メモリ設定の2倍以上の割り当ては失敗します。重要: コンテナの他のRAMオーバーヘッドを考慮してください。
sh-4.2# stress --vm 1 --vm-bytes 37M --vm-hang 3 stress: info: [13] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd ^C上記: メモリを2回に分けて確保する設定が動作しますが、既に確保されている他のRAM(この場合は3MB)を考慮すると、2回に分けて確保した方が良いでしょう。
sh-4.2# exit読み出し/書き込み : IOレート制限
これらの設定により、コンテナのIOレートを制限することができます。
- --デバイスからの読み取り速度(毎秒バイト)を制限します。
- --device-read-iops デバイスからの読み取り速度を制限する (IO per second)
- --device-writebps デバイスへの書き込み速度を制限する (bytes per second)
- --device-write-iops デバイスへの書き込み速度を制限する (IO per second)
- --io-maxbandwidth システムドライブの最大IO帯域幅制限 (Windowsのみ)
- --io-maxiops システムドライブの最大IOps制限 (Windowsのみ) 見ての通り、最後の2つはWindows専用です。ここでは、デバイス書き込みbpsに適用されているのと同じ原理を使って簡単にテストできるので、ここでは取り上げません。
構文:
--dev-write-bps /dev/your-device:IO-rate-limit (例: 1mb)
このチュートリアルでは、名前付きボリュームは使用しません。事前に固定された割り当て済みのデバイス名を用意しておけば、もう少し簡単になるでしょう。
残念ながら、レート制限を設定する前に、コンテナのデバイスマッパー論理デバイス番号を決定する必要があります。しかし、この番号を取得できるのはコンテナが起動してからです。
Dockerはデバイスマッパー論理デバイス番号をアノンボリュームに順次割り当てます。
そのため、コンテナを起動し、その番号を覗いてからコンテナを終了しなければなりません。
そして、再度コンテナを起動することができます - 今度は --device-write-bps の設定でこの番号を使用します。
このようにするとわかりやすくなります。
実行:
df -hリストの一番下を観察してください。
実行:
docker run -it --rm alpine:3.8 /bin/shこれで、新しい dm 番号が割り当てられたコンテナが稼働しています。
別のシェルで実行します。
df -h割り当てられた新しいdm番号をリストの一番下に見つけられますか?それはあなたが必要とする番号です。
前のシェルに戻って、コンテナを終了するには exit を入力します。rm はコンテナが自動的に自爆することを意味します。
9999を自分の番号に置き換えてください。
私はCentOS 7をイメージとして使用しています。おそらく、すでにダウンロードしたDebian / Ubuntuのイメージを使うことができます。
Alpineは使えません - ddコマンドはoflagオプションをサポートしていません。
docker run -it --rm --dev-write-bps /dev/dm-9999:1mb centos:7 /bin/sh
表示されているようにddコマンドを入力します。
sh-4.2# time dd if=/dev/zero of=test.out bs=1M count=10 oflag=direct 10+0 records in 10+0 records out 10485760 bytes (10 MB) copied, 10.0027 s, 1.0 MB/s real 0m10.009s user 0m0.001s sys 0m0.015s sh-4.2# exit exitdd コマンドは、10 MB のゼロを test.out ( if = 入力ファイル、of = 出力ファイル ) にコピーします。
実数は壁時計の時間で、1MB/s×10秒=10MBをコピーしています。
--device-write-bpsは動作します。データ書き込み速度は指定した通りに制限されます。
コンポーズファイルのリソース制限
このチュートリアルでは、簡単なRUNコマンドの設定を使ってCPUとRAMのリソース制限を体験していただいただけです。
コンポーズファイルのリソース制限については、ドキュメントを参照してください。
https://docs.docker.com/compose/compose-file/#resources
https://docs.docker.com/compose/compose-file/compose-file-v2/#cpu-and-other-resources
--cap-add=sys_nice
構文:
renice [-n] priority process-pid
reniceは、1つ以上の実行中のプロセスのスケジューリングの優先度を変更します。
最初の引数は使用する優先度の値です。
他の引数はプロセスIDとして解釈されます。コンテナ内のプロセスは、デフォルトでは優先度を変更することができません。というエラーメッセージが表示されます。
sh-4.2# renice -n -10 1 renice: failed to set priority for 1 (process ID): Permission deniedコンテナを --cap-add=sys_nice で実行すると、スケジューリングの優先度を変更できるようになります。
docker run -it --rm --name mybench --cap-add=sys_nice centos:bench /bin/sh sh-4.2# renice -n -10 1 1 (process ID) old priority 0, new priority -10 sh-4.2# renice -n -19 1 1 (process ID) old priority -10, new priority -19 sh-4.2# renice -n 19 1 1 (process ID) old priority -19, new priority 19 sh-4.2# exit exit上記の構文に基づいて、pid = 1でプロセスのスケジューリング優先度を変更しています。
reniceの後に別のシェルでtopを使用します。優先度の列でソートします。変更された優先度のshプロセスを簡単に見つけることができるはずです。
幸いなことに、私たちのコンテナはCPU集約的な作業をしていないので、優先度を弄っても開発サーバを使っている他の人には何の影響もありません。
結論
このチュートリアルシリーズでは、様々なDockerのリソース制限コマンドを探索し、実験してきました。これらのツールは再現性のある結果が得られるように特別に設計されているので、sysbenchや stressなどの実際のLinuxベンチマークツールを使うべきです。
あとは、コンテナ化された本番アプリケーションのために定義したい正しいCPU、RAM、IO制限を決定するのはあなた次第です。良好に動作するアプリケーションに制限をかける必要はありません。実績のあるリソース・ホグスを制限することに努力を集中してください。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ
- 投稿日:2020-07-31T20:23:39+09:00
Terraformを使って3ノードDocker Enterprise 2.1クラスタを構築する方法
この記事では、Terraformを使って3ノードのDocker Enterprise 2.1クラスタのビルドを完全に自動化する方法を紹介します。
Dockerエンタープライズ版
Docker Enterprise 2.1は、セキュアなソフトウェアサプライチェーンを実現し、多様なアプリケーションをオンプレミスとクラウドの両方の異種インフラストラクチャ上で高可用性を実現するコンテナ・アズ・ア・サービス(CaaS)プラットフォームです。マルチテナントのLinux、Windows Server 2016、IBM Z環境にまたがるアプリケーションの構築とオーケストレーションを行うための、セキュアでスケーラブルでサポートされたコンテナ・プラットフォームです。
私がDockerについていつも気に入っていることの1つは、彼らのシンプルさと顧客中心主義です。今回のEnterprise 2.1のリリースでも、まさにそれが実現されました。Docker EE 2.1では、選択の自由が得られるようになりました。
- WindowsとLinuxの両方のコンテナを確実にサポートします。
- クラウドプラットフォームやオンプレミスのデータセンターでホストされている。
- Docker SwarmとKubernetesオーケストレーションの両方を互換的に使用できます。
レガシーアプリケーションをコンテナに移行するプロジェクトに着手しようとしている企業のお客様や、新しいアプリケーションの開発にDevOpsを積極的に取り入れたいと考えているお客様には、CaaSプラットフォームとしてDocker EE 2.1を強くお勧めします。
小規模から始めて、コンテナベースの成長に合わせてクラスタを拡張することができます。初期のオーケストレーションにはシンプルなDocker Swarmを利用し、必要に応じて後からKubernetesに切り替えることもできます。
Docker EE 2.1クラスタには、以下のようなコンポーネントも含まれています。
- Docker UCP - クラスタ全体に単一のガラス窓を提供します。
- Docker Trusted Registry - コンテナイメージを安全にホストします。 また、暗号化通信、アプリケーション分離、イメージの脆弱性スキャンなどのエンタープライズセキュリティ機能も備えています。
Terraform
Terraformは私のお気に入りのオーケストレーション/IaCツールの一つだ。あらゆるパブリッククラウドプラットフォームに新しいサービスをデプロイするために、Terraformが提供するパワーと柔軟性が気に入っています。必要なものを定義して、Terraformに頼んで構築してもらうだけ。とてもシンプルです。
私はこの自動化のためにTerraformを選びました。どのクラウド・サービス・プロバイダーにも同じテンプレートを使うことはできませんが、特定のクラウド・プラットフォーム用に開発されたテンプレートは、別のプロバイダーにカスタマイズすることも簡単にできます。
Terraformの詳細については、HashiCorpのウェブサイトを参照するか、MVPであるAlberto Roura氏のTech Shareの記事を参照してほしい。
Dockerエンタープライズクラスターの構築
今回のデモでは、小さな3ノードのDocker Enterprise 2.1クラスタを構築することにしました。
- Docker UCPとDocker Trusted Registry (DTR)の両方をホストするAlibaba Cloud ECS Linuxサーバー1台。同じノードをDocker Swarm ManagerとKubernetes Masterとしても構成します。
- UCPホストが作成したDocker Swarmにワーカーノードとして自動的に参加する1台のLinuxホスト。
- 3. UCPホストが作成したDocker Swarmにワーカーノードとして自動的に参加するWindowsホスト1台。
クラスタ構築をすぐに始めたい場合は、私のGitHubリポジトリにアクセスして指示に従ってください。
前提条件の準備ができれば、30分もかからずにクラスタを構築することができます。
Terraformファイルの説明
行動に移す前にまずテンプレートを理解したいという方のために、以下のセクションではTerraformファイルの詳細を説明します。
私のGitHubリポジトリにある
Terraformの設定ファイルや、bash&powershellスクリプトには十分なコメントがついているので、より理解しやすくなっています。この記事では、それらのテンプレートやスクリプトのそれぞれの目的を中心に説明したいと思います。ご存知のように、Terraformは、ユーザーが必要なものを定義することで、HCL(High-level Configuration Language)を使用してインフラストラクチャのデプロイを支援します。Terraformは、この定義に基づいて詳細な実行計画を構築し、指定されたプラットフォーム上にインフラストラクチャをデプロイします。
Terraformは幅広いクラウドサービスプロバイダをサポートしており、主要なクラウドプロバイダやVMWare vSphereをオンプレミス・データセンター向けにサポートしています。
定義ファイルで指定することができますが、メンテナンスと読みやすさを考慮して、複数の.tfファイルに分割することをお勧めします。メインフォルダ内のすべての.tfファイルは、root`(メイン)モジュールの一部を形成します。Terraformは、フォルダ内のすべての設定ファイル(
.tfファイル)をアルファベット順にロードします。設定ファイル内で定義されている変数、リソースなどの順番は関係ありません。Terraformの設定は宣言的なものなので、他のリソースや変数への参照は、定義された順番には関係ありません。変数
入力変数はTerraformモジュールのパラメータとして機能します。すべての変数は
.tfファイル(例:variables.tf)で宣言され、その値は実行中にコマンドラインで渡されるか、別の.tfvarsファイル(例:terraform.tfvars)で渡されなければなりません。入力変数名には、ローカル変数や terraform リソース名を使って定義された terraform ローカル変数と区別できるように、大文字小文字を使用することをお勧めします。また、変数の値を別の
terraform.tfvarsファイルに格納しておくと、アカウントの秘密鍵やパスワードなどが含まれている可能性があるため、他の人と共有する際にこのファイルを送信しないようにすることもできます。実行中に terraform が .tfvars ファイルを見つけられず、変数のデフォルト値が定義されていない場合は、ユーザーにプロンプトを表示します。プロバイダ
provider.tf
このファイルは、Alicloudに接続するためのキーと作成するリソースのリージョンを定義します。ネットワークとセキュリティ
network-security.tf
このファイルは、VPC、vSwitch、Security Group、セキュリティ/ファイアウォールルールを定義し、dockerホストへのアクセスを制限します。このファイルで定義されたvSwitchとSecurityグループはECS (Elastic Compute Service)の定義でホストにマッピングされます。
いくつかの注意点があります。
- セキュリティロールの優先度は1~100の範囲です。値が小さいほど優先度が高くなります。
- RDP、WinRM、SSHアクセスは特定のIP、つまり自分のパブリックIPからのみ許可されます。
- Kubernetes、Docker、アプリケーションへのアクセスはどこからでも許可される
Docker UCP Managerのための計算
docker-host.tfこのファイルはDocker UCPとDTRをインストールするメインホストを定義します。Docker UCPのインストールの一環として、他のホストがワーカーノードとして参加するDocker Swarmの作成を開始します。
いくつかの注意点があります。
-
internet_max_bandwidth_out属性は、VM作成の一部としてPublic IPを確実に割り当てます。
- このPublic IPは、ファイルプロビジョナーがインストールスクリプトをコピーしたり、リモートexecプロビジョナーがDocker EE、UCP、DTRのセットアップを自動的に実行したりするための接続定義で使用されます。
- UCP ホストと linux ワーカーノードのssh key pairは、key-pair.tfで定義されています。Docker Workerノードの計算
linux-worker.TF
このファイルはlinuxのワーカーノードを定義しています。docker-host.tfファイルとよく似ていますが、Docker EEをインストールしてワーカーノードとして参加するためのスクリプトのみが含まれています。
windows-worker.tf
このファイルはwindowsワーカーノードを定義しています。Linuxノードの定義との主な違いは以下の通りです。
- Linuxイメージの代わりにWindowsイメージを使用しています。
- ssh-keyペアにLinuxで使用されるkey_name属性の代わりにpassword属性を使用しています。
- ユーザーデータ属性は、WinRM の設定を含む VM のブートストラップに使用され、WinRM を使用してスクリプトを実行できるようにします。
- 接続タイプはLinuxホストで使用しているsshではなくwinRMです。
出力
output.tf
このファイルは、モジュールが返す値を定義します。これらの値は、Terraformが正常に実行を完了すると出力されます。
output.tfに定義された値は、実行に成功した後、terraform outputコマンドを使用していつでも出力することができます。Terraformの実行の詳細を取得するには、terraform showを使用します。
Dockerコンポーネントのビルドを自動化するスクリプト
Linux ホストのブートストラップに使用されるスクリプトは lin-files フォルダにあります。これらはECS VM定義のremote-execプロビジョナーを使って呼び出されます。
これらのスクリプトは、DockerのWebサイトのドキュメントに従って、Docker Enterprise、Docker UCP、Docker Trusted Registryを設定するために使用します。
Windowsホストをブートストラップするために使用されるスクリプトは、win-filesフォルダにあります。これらはECS VM定義のremote-execプロビジョナーを使って呼び出されます。
これらのスクリプトはDocker Enterpriseのセットアップや、ワーカーノードとして参加する際に使用します。Docker UCPとDocker Trusted RegistryはWindowsホストにはインストールできません。ワーカーノードにしかなれません。
Windowsスクリプトの注意点
Docker APIへのアクセス時にInvoke-RestMethodが正常に動作するようにするために、Docker APIを呼び出す前にスクリプト内で以下の変更を行う必要がありました。
1、powershellのデフォルトTLSバージョンを1.0から1.2に変更する。
2、Docker APIへの接続時に証明書エラーを無視するようにした。結論
この記事は、Docker Enterpriseの基本的な概念と、Terraformを使ってAlibaba Cloudでのデプロイを自動化する方法を紹介することのみを目的としています。GitHubリポジトリにある定義ファイルとスクリプトは、基本的なDocker Enterpriseクラスタのセットアップに役立つだけでなく、他のインストールにも使えるヒントを提供してくれます。
以降の記事では、ロードバランサや追加ノードを使ってクラスタをスケールする方法や、Docker SwarmやKubernetesオーケストレーションを使ってコンテナをデプロイする方法の詳細を見ていきます。
主な参考文献
このセクションでは、Docker、Terraform、Automationについて詳しく知りたい場合に役立つ参考文献をいくつか挙げています。
Dockerエンタープライズ
https://docs.docker.com/ee/
https://www.docker.com/products/docker-enterpriseテラフォーム
https://www.terraform.io
https://www.terraform.io/docs/providers/alicloud/index.html私のGitHubリポジトリ
https://github.com/sajiv3m/docker-terraform-alicloudアリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ
- 投稿日:2020-07-31T18:31:08+09:00
WSL2を有効化してからカスペルスキーのファイルスキャンが度々停止する
先日からKaspersky Internet Security 20 でファイルスキャン(カスタム,簡易関わらず)を行おうとすると,スキャン中に勝手にスキャン停止してしまうようになった
TL;DR
カスペルスキーのハードウェア仮想化を使用した保護とHyper-Vが干渉していた模様
Hyper-VやVMWareなどの仮想化技術を使用する場合には,カスペルスキーのハードウェア仮想化を使用した保護を無効化しましょうカスペルスキーのハードウェア仮想化を使用した保護の無効化方法
可能な場合はハードウェアを仮想化するのチェックを外す
参考:
エラー「 ハードウェアを仮想化できません。互換性のないハードウェアまたはソフトウェアが検出されました。」まとめ
Windows10でDockerを使うためにWSL2を有効化した為,仮想化技術の競合が発生してしまった?
スキャンプロセスが瞬時にKillされるのでウイルスに感染でもしたのかと焦りましたが仕様?で良かったです

- 投稿日:2020-07-31T16:51:41+09:00
Docker 環境での Jest が遅すぎる問題
Docker の問題
タイトルには Jest がと書いたが、Jest 自体はあまり関係なく、Docker のパフォーマンスに依存する問題のように思う。
環境
Mac
$ system_profiler SPHardwareDataTypeHardware: Hardware Overview: Model Name: MacBook Pro Model Identifier: MacBookPro14,1 Processor Name: Dual-Core Intel Core i7 Processor Speed: 2.5 GHz Number of Processors: 1 Total Number of Cores: 2 L2 Cache (per Core): 256 KB L3 Cache: 4 MB Hyper-Threading Technology: Enabled Memory: 16 GB Boot ROM Version: 207.0.0.0.0 SMC Version (system): 2.43f10Docker
Docker Desktop for Mac
- Version: 2.3.0.4(46911)
docker version
$ docker versionClient: Docker Engine - Community Version: 19.03.12 API version: 1.40 Go version: go1.13.10 Git commit: 48a66213fe Built: Mon Jun 22 15:41:33 2020 OS/Arch: darwin/amd64 Experimental: false Server: Docker Engine - Community Engine: Version: 19.03.12 API version: 1.40 (minimum version 1.12) Go version: go1.13.10 Git commit: 48a66213fe Built: Mon Jun 22 15:49:27 2020 OS/Arch: linux/amd64 Experimental: false containerd: Version: v1.2.13 GitCommit: 7ad184331fa3e55e52b890ea95e65ba581ae3429 runc: Version: 1.0.0-rc10 GitCommit: dc9208a3303feef5b3839f4323d9beb36df0a9dd docker-init: Version: 0.18.0 GitCommit: fec3683改善前
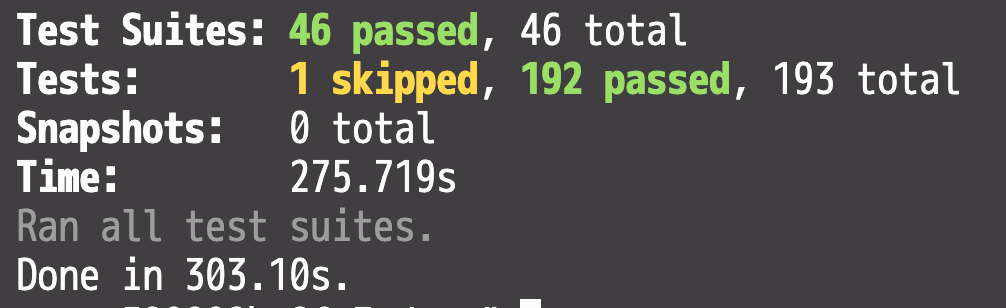
ストレスの塊。
改善後
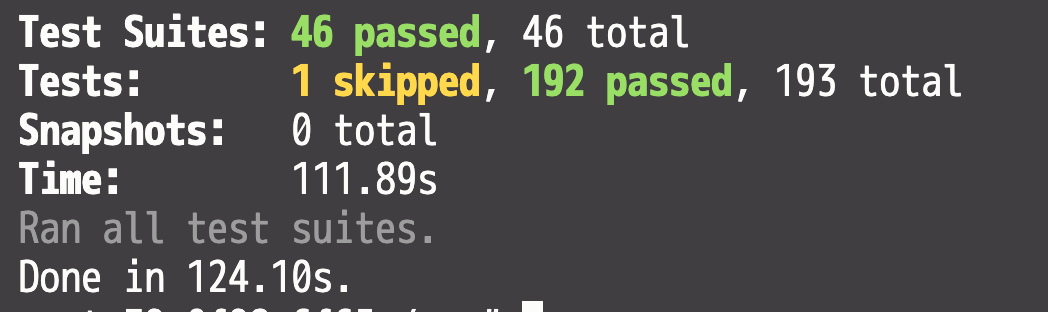
まだ遅いが、改善前と比べれば…
やったこと
volumes に delegated のオプションを追加した
詳しくは: https://qiita.com/ysKey2/items/346c429ac8dfa0aed892
Docker を使用しない場合
なんとかここに近づけたい。
さいごに
DXを大幅に低下させるDocker for Macを捨ててMac最速のDocker環境を手に入れる
こっちも試してみたい
- 投稿日:2020-07-31T16:06:31+09:00
Docker コンテナ内でmatplotlibなどを使った画像表示されない場合の対処法
Docker コンテナ内でmatplotlib等で画像表示しようと思ったらこけたので記します
Ubuntu 16.04.6 LTS環境でやってます。[問題点]
Docker run した後にコンテナに入り、matplotlibでplot.show()すると画像が何も表示されず、コマンドが終わる。
もしくはdocker _tkinter.TclError: couldn't connect to display
_tkinter.TclError: no display name and no $DISPLAY environment variable
_tkinter.TclError: couldn't connect to display :0.0
みたいなエラーが出てくる。[対処法]
①まずターミナルに以下のコマンドをうつ$sudo apt-get install x11-xserver-utils $xhost +②docker run する時には以下をオプションにつける
-v /tmp/.X11-unix:/tmp/.X11-unix
-e DISPLAY=unix$DISPLAY③もしmatplotlibがコンテナに入ってなかったらコンテナ起動後のインテラクティブモードで
pip install matplotlib
④ もしtkinterがコンテナに入っていなかったらコンテナ起動後のインテラクティブモードで
apt-get update
apt-get python3-tk
なおpython3-tkをインストールする際、居住地域を答えるくだりがありました。これでうまくコンテナ内でも画像表示されるようになりました。

- 投稿日:2020-07-31T14:06:32+09:00
Mutagenチートシート
SSH経由、Dockerホスト/コンテナ間など様々な環境同士でファイルを同期できるツール「Mutagen」の(主に自分用の)チートシートです。
Mutagenの使い方を学びながら、少しずつ足していきます。1. インストール/デーモン
コマンド 意味 brew install mutagen-io/mutagen/mutagenHomebrew(macOS)でのインストール mutagen daemon startデーモンの起動 mutagen daemon stopデーモンの停止 $ mutagen daemon help Control the lifecycle of the Mutagen daemon Usage: mutagen daemon [flags] mutagen daemon [command] Available Commands: start Start the Mutagen daemon if it's not already running stop Stop the Mutagen daemon if it's running register Register the Mutagen daemon to start automatically on login [Experimental] unregister Unregister automatic Mutagen daemon start-up [Experimental] Flags: -h, --help Show help information Use "mutagen daemon [command] --help" for more information about a command.2. ファイル同期
コマンド 意味 mutagen sync help同期セッションについてのヘルプの表示 mutagen sync create <同期元> <同期先>同期セッションの作成 mutagen sync create ~/foo user@host:bar同期セッションの作成(SSH接続の例) mutagen sync create --name <セッション名> ...同期セッションのセッション名の指定 mutagen sync list同期セッションの一覧表示 mutagen sync monitor <セッション名>同期セッションのモニタリング(状況確認) mutagen sync pause <セッション名>同期セッションの一時停止 mutagen sync resume <セッション名>同期セッションの再開 mutagen sync terminate <セッション名>同期セッションの停止と削除 $ mutagen sync help Create and manage synchronization sessions Usage: mutagen sync [flags] mutagen sync [command] Available Commands: create Create and start a new synchronization session list List existing synchronization sessions and their statuses monitor Show a dynamic status display for a single session flush Force a synchronization cycle pause Pause a synchronization session resume Resume a paused or disconnected synchronization session reset Reset synchronization session history terminate Permanently terminate a synchronization session Flags: -h, --help Show help information Use "mutagen sync [command] --help" for more information about a command.3. その他
コマンド 意味 mutagen helpヘルプの表示 mutagen versionバージョン番号の表示 $ mutagen version 0.11.5 $ mutagen help Mutagen is a remote development tool built on high-performance synchronization Usage: mutagen [flags] mutagen [command] Available Commands: sync Create and manage synchronization sessions forward Create and manage forwarding sessions [Experimental] project Orchestrate sessions for a project [Experimental] tunnel Create and manage tunnels [Experimental] login Log in to mutagen.io logout Log out from mutagen.io daemon Control the lifecycle of the Mutagen daemon version Show version information legal Show legal information help Help about any command Flags: -h, --help Show help information Use "mutagen [command] --help" for more information about a command.
- 投稿日:2020-07-31T12:11:20+09:00
Dockerコンテナのリソース制限機能を使った実践的な体験談 その2
このチュートリアルでは、Alibaba Cloud ECS上でDockerコンテナのリソース制限機能を利用した実践的な体験ができます。
他のコンテナに比例するcpu-shares
このテストでは、CPUシェアは他のコンテナに比例します。デフォルト値の1024は本質的な意味を持ちません。
すべてのコンテナのCPU占有率が4の場合、すべてのコンテナでCPU時間を均等に共有します。
これは、すべてのコンテナがCPUシェア=1024の場合、すべてのコンテナがCPU時間を均等に共有しているのと同じです。
実行します。
docker container run -d --cpu-shares=4 --name mycpu1024a alpine:3.8 /bin/sh -c 'time dd if=/dev/urandom bs=1M count=100 | md5sum' docker container run -d --cpu-shares=4 --name mycpu1024b alpine:3.8 /bin/sh -c 'time dd if=/dev/urandom bs=1M count=100 | md5sum' docker container run -d --cpu-shares=4 --name mycpu1024c alpine:3.8 /bin/sh -c 'time dd if=/dev/urandom bs=1M count=100 | md5sum'ログを調査します。
docker logs mycpu1024a docker logs mycpu1024b docker logs mycpu1024cコンテナをpruneして終了です。
docker container prune -f彼らはまだすべて同じ時間を実行したことに注意してください。4/1024が遅くなることはありませんでした。
cpu-share:CPU サイクルが制限されている場合のみ有効
cpu-shareは CPU サイクルが制限されている場合にのみ適用されます。
他のコンテナが稼働していない状態で、1つのコンテナのcpu-shareを定義することは無意味です。
docker container run -d --cpu-shares=4 --name mycpu1024a alpine:3.8 /bin/sh -c 'time dd if=/dev/urandom bs=1M count=100 | md5sum' docker logs mycpu1024areal 0m 12.67s user 0m 0.00s sys 0m 12.27s今すぐ共有を4000に増やして再実行してください - 参照 - ランタイムの違いはありません。
1つのコンテナが利用可能なすべてのCPU時間を使用しています。
docker container run -d --cpu-shares=4000 --name mycpu1024a alpine:3.8 /bin/sh -c 'time dd if=/dev/urandom bs=1M count=100 | md5sum'この1つのコンテナをプルーニングして、これで終わりです。
docker container prune -f--cpus= コンテナが使用できるCPUリソースの量を定義する
コンテナが利用可能なすべてのCPUリソースのうち、どれだけのCPUリソースを使用できるかを指定します。例えば、ホストマシンに2つのCPUがあり、--cpus="1.5 "と設定した場合、コンテナは最大でもCPUの1/2が保証されます。
以下のコマンドで使用している --CPUs の値の範囲に注意してください。実行してみてください。
docker container run -d --cpus=2 --name mycpu2 alpine:3.8 /bin/sh -c 'time dd if=/dev/urandom bs=1M count=50 | md5sum' docker container run -d --cpus=1 --name mycpu1 alpine:3.8 /bin/sh -c 'time dd if=/dev/urandom bs=1M count=50 | md5sum' docker container run -d --cpus=.5 --name mycpu.5 alpine:3.8 /bin/sh -c 'time dd if=/dev/urandom bs=1M count=50 | md5sum' docker container run -d --cpus=.25 --name mycpu.25 alpine:3.8 /bin/sh -c 'time dd if=/dev/urandom bs=1M count=20 | md5sum' docker container run -d --cpus=.1 --name mycpu.1 alpine:3.8 /bin/sh -c 'time dd if=/dev/urandom bs=1M count=10 | md5sum'dockerの統計を調査します。
docker stats期待される出力
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS 843bea7263fb mycpu2 57.69% 1.258MiB / 985.2MiB 0.13% 578B / 0B 1.33MB / 0B 0 186ba15b8258 mycpu1 55.85% 1.25MiB / 985.2MiB 0.13% 578B / 0B 1.33MB / 0B 0 3bcc26eab1ac mycpu.5 46.60% 1.262MiB / 985.2MiB 0.13% 578B / 0B 1.33MB / 0B 0 79d7d7e3c38c mycpu.25 25.43% 1.262MiB / 985.2MiB 0.13% 508B / 0B 1.33MB / 0B 0 b4ba5503a048 mycpu.1 9.76% 1.328MiB / 985.2MiB 0.13% 508B / 0B 1.33MB / 0B 0mycpu.1, mycpu.25, mycpu.5は完全に制限が適用されていることを示しています。
しかし、mycpu1とmycpu2は100 + 200 %の追加CPUを持っていません。したがって、これらの設定は無視され、残りのCPU時間を均等に共有します。
--cpus CPUの数
cpus設定はコンテナが使用するCPUの数を定義します。
DockerやLinuxディストロではCPUは次のように定義されます。
CPUs = Threads per core X cores per socket X sockets
CPUは物理的なCPUではありません。
私のサーバーのCPU数を調べてみましょう。
lscpu | head -n 10Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 2 On-line CPU(s) list: 0,1 Thread(s) per core: 1 Core(s) per socket: 2 Socket(s): 1 NUMA node(s): 1 Vendor ID: GenuineIntel不要な情報を削除しました。
lscpu | head -n 10 CPU(s): 2 On-line CPU(s) list: 0,1 Thread(s) per core: 1 Core(s) per socket: 2 Socket(s): 1CPUs = Threads per core X cores per socket X sockets
CPU=1×2×1=2CPU
で確認してください。
grep -E 'processor|core id' /proc/cpuinfo2 core id = 2 cores per socket
2 processors = 2 cpusprocessor : 0 core id : 0 processor : 1 core id : 1OK このサーバーは2つのCPUを持っています。あなたのサーバは異なるでしょうから、以下のテストを行う際にはその点を考慮してください。
cpus設定はコンテナが使用するCPUの数を定義します。
ここでは両方のCPUを使用し、1つだけ、1/2、1/4のCPUを使用し、CPU負荷の高いワークロードのためのランタイムを記録してみましょう。
注意: --cpus=2
docker container run --cpus=2 --name mycpu alpine:3.8 /bin/sh -c 'time dd if=/dev/urandom bs=1M count=30 | md5sum'期待される出力
real 0m 3.61s user 0m 0.00s sys 0m 3.50s比較するものが何もありません。他のテストを実行してみましょう
docker container prune -f注意:--cpus=1
docker container run --cpus=1 --name mycpu alpine:3.8 /bin/sh -c 'time dd if=/dev/urandom bs=1M count=30 | md5sum' real 0m 3.54s user 0m 0.00s sys 0m 3.37sdocker container prune -f注意: --cpus=.5
docker container run --cpus=.5 --name mycpu alpine:3.8 /bin/sh -c 'time dd if=/dev/urandom bs=1M count=30 | md5sum' real 0m 9.97s user 0m 0.00s sys 0m 4.78sdocker container prune -f注意: --cpus=.25
docker container run --rm --cpus=.25 --name mycpu alpine:3.8 /bin/sh -c 'time dd if=/dev/urandom bs=1M count=30 | md5sum' real 0m 19.55s user 0m 0.00s sys 0m 4.69s--cpus=2 realtime. 3.6秒
--cpus=1 realtime. 3.5秒
--cpus=.5 realtime: 9.9秒
--cpus=.25 realtime: 19.5秒私たちの単純なベンチマークでは、2つのCPUを同時に使用することは効果的ではありません。
半分のCPUは2倍遅く、4分の1のCPUは4倍遅く動作します。
CPUsの設定は有効です。コンテナ内のアプリケーションがマルチスレッド化できない場合や、1つ以上のCPUを効果的に使用できない場合は、1つのCPUだけを割り当ててください。
--CPU-period と --CPU-quota
廃止されたオプションです。Docker 1.13以降を使用している場合は、代わりに--cpusを使用してください。
--cpu-period CPU CFS(Completely Fair Scheduler)の期間を制限する
--cpu-quota CPU CFS (Completely Fair Scheduler) のクォータを制限します。上記の演習では、--CPUの設定がいかに簡単にできるかを明確に示しています。
--cpuset-cpus 実行を許可するCPU (0-3, 0,1)
--cpuset-cpus - 実行を許可するCPU (0-3, 0, 1)
残念ながら私のサーバーには2つのCPUしかなく、1つ以上のCPUを使っても効果がないことは先ほど見ました。
サーバーに複数のCPUが搭載されている場合、-cpuset設定のより興味深い組み合わせを実行できますが、これは役に立たないでしょう:この特定のベンチマークは1つのスレッドしか使用しません。
このチュートリアルの後半では、スレッド数を指定できる sysbench (実際のベンチマークツール) を使ったテストがあります。
私の結果は以下の通りです: 2つのCPUを使っても違いはありません。
docker container run --rm --cpuset-cpus=0,1 --name mycpu alpine:3.8 /bin/sh -c 'time dd if=/dev/urandom bs=1M count=30 | md5sum' Expected output : real 0m 3.44s user 0m 0.00s sys 0m 3.35sdocker container run --rm --cpuset-cpus=0 --name mycpu alpine:3.8 /bin/sh -c 'time dd if=/dev/urandom bs=1M count=30 | md5sum' Expected output : real 0m 4.15s user 0m 0.00s sys 0m 4.00sdocker container run --rm --cpuset-cpus=1 --name mycpu alpine:3.8 /bin/sh -c 'time dd if=/dev/urandom bs=1M count=30 | md5sum' Expected output : real 0m 3.40s user 0m 0.00s sys 0m 3.28s実際のベンチマークアプリケーションを使用したテストコンテナの限界
上記のテストはすべてクイックハックを使用しています。
コンテナのリソース制限を適切にテストするには、実際の Linux ベンチアプリケーションが必要です。
私はCentOSを使い慣れているので、ベンチコンテナのベースとして使用します。どちらのベンチアプリケーションもDebian / Ubuntuでも利用可能です。yumのインストールをapt-getのインストールに変換すれば、簡単に同じ結果が得られます。
2つのベンチアプリケーションをコンテナにインストールする必要があります。最良の方法は、これらのアプリケーションを含むイメージを構築することです。
そのため、dockerbenchディレクトリを作成します。
mkdir dockerbench cd dockerbench nn DockerfileFROM centos:7 RUN set -x \ && yum -y install https://www.percona.com/redir/downloads/percona-release/redhat/0.0-1/percona-release-0.0-1.x86_64.rpm \ && yum -y install sysbench \ && curl http://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm -o epel-release-latest-7.noarch.rpm \ && rpm -ivh epel-release-latest-7.noarch.rpm \ && yum -y install stress最初のインストールでは、sysbench のホームである percona yum repo を追加します。
その後、Yum は sysbench をインストールします。
curlはEPELのyumレポを追加します。
そして、Yum は stress をインストールします。
私たちのベンチのイメージを構築します。インターネットでの yum ダウンロード + yum 依存関係の解決と他の通常の活動に基づいて、約1分かかります。
もしCentOS 7のイメージをダウンロードしていない場合は、さらに1分かかるかもしれません。
docker build --tag centos:bench --file Dockerfile .これでCentOSのベンチイメージができたので、繰り返し使えるようになりました。
docker run -it --rm centos:bench /bin/sh
--cpus Sysbenchツールでテスト
構文:
sysbench --threads=2 --events=4 --cpu-max-prime=800500 —>verbosity=0 cpu run
- --threads=2 ... 2つのスレッドを実行することで、2つのCPUと1つのCPUを比較することができます。
- --events=4 ... 4回実行
- --cpu-max-prime=800500 ... 800500までの素数を計算します。
- --verbosity=0 ... 詳細な出力を表示しません。
- cpu run ... CPUという名前のテストを実行します。 実験を経て、私は10年前のコンピュータで800500がテストを素早く実行するための良い値であると判断しました。CPUマーク700。0桁が多いと読みにくいので、そこに5を入れてみました。
2つのCPU:
docker run -it --rm --name mybench --cpus 2 centos:bench /bin/sh sh-4.2# time sysbench --threads=2 --events=4 --cpu-max-prime=800500 --verbosity=0 cpu run real 0m1.952s user 0m3.803s sys 0m0.029s sh-4.2# sh-4.2# exit exitRealはウォールクロック時間-sysbenchの開始から終了までの時間:1.9秒。
Userはsysbench内のユーザモードコード(カーネル外)で使用したCPU時間です。2台のCPUを使用しています:それぞれ1.9秒のCPU時間を使用していますので、合計のユーザ時間はそれぞれのCPUの時間を足したものです。
経過したウォールクロック時間は1.9秒です。2つのCPUが同時に/同時に作業していたので、それらの合計時間がユーザー時間として表示されます。
Sysはカーネルがシステムコールを行っているCPUの時間です。
1つのCPU:
docker run -it --rm --name mybench --cpus 1 centos:bench /bin/sh sh-4.2# time sysbench --threads=2 --events=4 --cpu-max-prime=800500 --verbosity=0 cpu run real 0m4.686s user 0m4.678s sys 0m0.026s sh-4.2# sh-4.2# exit exitこれらの比較を実行するより便利な方法は、docker の run line で bench コマンドを実行することです。
この方法で1つのCPUを再実行してみましょう。
docker run -it --rm --name mybench --cpus 1 centos:bench /bin/sh -c 'time sysbench --threads=2 --events=4 --cpu-max-prime=800500 --verbosity=0 cpu run' real 0m4.659s user 0m4.649s sys 0m0.028sこの方法で半分のCPUを実行してみましょう。
docker run -it --rm --name mybench --cpus .5 centos:bench /bin/sh -c 'time sysbench --threads=2 --events=4 --cpu-max-prime=800500 --verbosity=0 cpu run' real 0m10.506s user 0m5.221s sys 0m0.035s結果は完璧に筋が通っています。
- 2 CPUs : real 0m1.952s
- 1 CPU : real 0m4.659s
- 5 CPUs : real 0m10.506s 私たちのイメージにあるsysbenchを使えば、このようなテストを非常に簡単かつ迅速に行うことができます。ほんの数秒でDockerコンテナのCPU使用量を制限することができます。
率直に言って、.5CPUテストのために10.506秒も待つのは長すぎます。
職場の開発サーバでこれを行った場合、CPU負荷は1分以上の経過で劇的に変化します。開発者は 2 秒間の 2CPU 実行中にコンパイルを行い、サーバは 5 秒間の 1CPU 実行中に CPU が静かになる可能性があり、数値は完全に歪んでしまいます。
このような状況の変化に対して、ある程度ロバストなアプローチが必要です。すべてのテストは、可能な限り迅速に、そして直接次から次へと実行しなければなりません。
それを試してみましょう。最大素数を100倍に減らします。
これら3つの命令をすべてカットアンドペーストして、一度に行って、結果を観察します。
docker run -it --rm --name mybench --cpus 2 centos:bench /bin/sh -c 'time sysbench --threads=2 --events=4 --cpu-max-prime=8005 --verbosity=0 cpu run' docker run -it --rm --name mybench --cpus .5 centos:bench /bin/sh -c 'time sysbench --threads=2 --events=4 --cpu-max-prime=8005 --verbosity=0 cpu run' docker run -it --rm --name mybench --cpus 1 centos:bench /bin/sh -c 'time sysbench --threads=2 --events=4 --cpu-max-prime=8005 --verbosity=0 cpu run'期待される出力
2 CPUs real 0m0.049s user 0m0.016s sys 0m0.021s 1 CPUs real 0m0.049s user 0m0.019s sys 0m0.020s .5 CPU real 0m0.051s user 0m0.020s sys 0m0.019sベンチマーク起動時のオーバーヘッドがウォールクロックの実時間を圧倒しています。テストは絶望的に短すぎます。
3回の個人的な実験の後、元のワークロードを10倍に減らせば完璧だと思います。
docker run -it --rm --name mybench --cpus 2 centos:bench /bin/sh -c 'time sysbench --threads=2 --events=4 --cpu-max-prime=100500 --verbosity=0 cpu run' docker run -it --rm --name mybench --cpus 1 centos:bench /bin/sh -c 'time sysbench --threads=2 --events=4 --cpu-max-prime=100500 --verbosity=0 cpu run' docker run -it --rm --name mybench --cpus .5 centos:bench /bin/sh -c 'time sysbench --threads=2 --events=4 --cpu-max-prime=100500 --verbosity=0 cpu run'(中の5は000000の長い文字列を読みやすくするためのものです)
2 CPUs real 0m0.152s user 0m0.225s sys 0m0.015s 1 CPU real 0m0.277s user 0m0.279s sys 0m0.019s .5 CPU real 0m0.615s user 0m0.290s sys 0m0.024s比率は完璧です。全体的な実行時間は 1 秒未満で、開発サーバーの CPU 負荷の変化による影響を最小限に抑えています。
ここで説明されていることを理解するために、お使いのサーバーで数分遊んでみてください。
run コマンドで --rm を使用したことに注意してください。これは /bin/sh でコンテナに渡されたコマンドを終了した後、コンテナを自動的に削除します。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ
- 投稿日:2020-07-31T09:48:14+09:00
今さら言えないことを書く会:コンテナ技術①
はじめに
仕事でよく「コンテナ」という話をよく聞くが、実は良く分っていない。
みんな本当にわかっているんだろうか??って思う。
正直自分は良く分っていない。
きっとわかっているようでわかっていない人も多いだろう。
それなら、これを機にいろいろ勉強しなおし、分かりやすく纏められないかと思い、記事を書くに至った。コンテナ技術の最初の壁
コンテナの何が分かりにくいか、振り返って考えてみると、
最初にぶつかる壁としては
- コンテナと通常の仮想化の違いが分からない
- 用語・製品が多くて良く分らない
という2点があがった。
なので、今回はこの2点について分かる範囲でまとめていきたい。※本稿に記載した内容は個人の感想なので、間違っていても怒らないでください。
1.コンテナ技術と普通の仮想化の違い
コンテナ技術でできることを学んでいくと、VMwareなどで仮想マシンを作るのと何が違うの?
という疑問にぶつかってしまった。
ここが上手く説明できないと理解が進まないし、お客さんにも提案できないので、いろいろ調べてみた。1.1.コンテナ技術でできること
コンテナ技術でできることを調べていくと、最終的にできることは
- 1つのOS/カーネルで複数の環境が用意できる
- 同じ環境をどんどん増やすことができる
といった情報が多い。確かに便利かもしれないが、単純にそれなら仮想マシンで良くない?と思ってしまう。
「同じような環境・OSを展開・用意する」という目的としては、普通の仮想化技術でも達せられからである。
ではコンテナ技術の凄いところはどこなのか?というと、その方法や展開した後の運用に差があるのだと思う。1.2.コンテナ技術の良いところ
コンテナ技術の良いところの1つとして、軽いというところが挙げられる。
何故軽いのか?
それはアプリケーションを動かすために必要な物が少ないから。例えば仮想マシンであるプリケーションの環境を複数用意する場合、
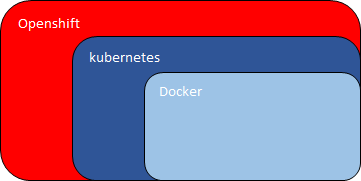
1.ハードウェア > 2.ホストOS/HyperVisor > 3.仮想マシン > 4.OS/カーネル > 5.アプリケーション
と言うような形になります。
対してコンテナの場合、たとえHyperVisor上で動かしている環境の場合、
1.ハードウェア > 2.ホストOS > 3.仮想マシン > 4.OS/カーネル > 5.コンテナ > 6.アプリケーション
となる。
あれ?コンテナのほうが階層が多い?ってなるかもしれないが、
これが複数環境を用意していく場合、話が変わってくる。<普通の仮想マシンで複数環境を用意する場合>
1.ハードウェア > 2.ホストOS/HyperVisor > 3.仮想マシン > 4.OS/カーネル > 5.アプリケーション
> 3.仮想マシン > 4.OS/カーネル > 5.アプリケーション
> 3.仮想マシン > 4.OS/カーネル > 5.アプリケーション
> 3.仮想マシン > 4.OS/カーネル > 5.アプリケーション
:
:<コンテナで複数環境を用意する場合>
1.ハードウェア > 2.ホストOS > 3.仮想マシン > 4.OS/カーネル > 5.コンテナ > 6.アプリケーション
> 5.コンテナ > 6.アプリケーション
> 5.コンテナ > 6.アプリケーション
> 5.コンテナ > 6.アプリケーション
:
:おわかりいただけただろうか。
複数環境を用意する場合、普通の仮想マシンであればOSから複数用意する必要がある。
OSは本来アプリケーションを動かすために必要な物以外のサービスも動いており、
その分リソースを多く消費する。対してコンテナの場合、コンテナを増やすだけで済む。
もちろんコンテナを増やすことで多少のリソース消費はあるが、OSを増やすに比べると非常に少なくて済む。ここが普通の仮想化に比べてて、コンテナ技術の優れている点の1つのようだ。
もちろん他にも
・環境を簡単に増やせる
⇒仮想マシンだとテンプレートの展開やクローンが必要
・同じ環境を用意できる
⇒仮想マシンでは様々な理由で環境の差異ができやすい
など利点はあると思うが、おいおい詳しく調べて記事にしていきたい。2.用語・製品について
コンテナ関連の用語として
Docker
kubernetes
OpenShift
などを聞くが、それぞれ何が違うのか、そもそも同じレベルの用語なのかが分からなかった。2.1.Docker
Dockerというのは何か
Dockerとはコンテナーを生成することができる機能を持つサービス。
コンテナエンジンという。これと同じレイヤーの製品として
LXC(Linux Containers)
というものがある。
普通の仮想基盤のイメージとしてはESXサーバに位置づけか?
2.2.kubernetes
kubernetesとはDockerによってつくられるコンテナ環境を管理するツール。
Googleが開発したオープンソースで、
- オーケストレーションツール
- オーケストレータ
というような名称で呼ばれている。
イメージとしては仮想基盤を管理する、vCenterのような位置づけ。このオーケストレーションツールにはkubernetes以外にも
- Dockerの「Swarm」
- CoreOSの「fleet」
- Rancher Labsの「Rancher」
- Mesosの「Marathon」
という製品がある。
Docker自身も管理ツールを出していたが、kubernetesが標準になっている。(なりつつある?)2.3.Openshift
kubernetesをベースとして、Redhatが作った製品。
アプリケーションを開発したり、動かしたりするために便利な機能を追加したもの。大まかなイメージとしてはこういう枠組み。
まとめ
結局うまくまとめられたかどうかわからないが、
コンテナ技術について自分が調べたことを纏めてみた。所感としては小規模であればコンテナ技術と通常の仮想化技術ではそれほど差が無く、
大きな環境になればなるほど良い面が出てくるのだなという感想。
引き続き、勉強していきたいと思う。参考文献
https://speakerdeck.com/moriwaka/kontenatosabajia-xiang-hua-falsewei-ito-docker-kubernetes-openshift
https://www.osscons.jp/cloud/%E3%83%80%E3%82%A6%E3%83%B3%E3%83%AD%E3%83%BC%E3%83%89/?action=common_download_main&upload_id=698
https://www.ossnews.jp/compare/Docker/LXC
- 投稿日:2020-07-31T09:48:14+09:00
今さら聞けないことを書く会:コンテナ技術①
はじめに
仕事でよく「コンテナ」という話をよく聞くが、実は良く分っていない。
みんな本当にわかっているんだろうか??って思う。
正直自分は良く分っていない。
きっとわかっているようでわかっていない人も多いだろう。
それなら、これを機にいろいろ勉強しなおし、分かりやすく纏められないかと思い、記事を書くに至った。コンテナ技術の最初の壁
コンテナの何が分かりにくいか、振り返って考えてみると、
最初にぶつかる壁としては
- コンテナと通常の仮想化の違いが分からない
- 用語・製品が多くて良く分らない
という2点があがった。
なので、今回はこの2点について分かる範囲でまとめていきたい。※本稿に記載した内容は個人の感想なので、間違っていても怒らないでください。
1.コンテナ技術と普通の仮想化の違い
コンテナ技術でできることを学んでいくと、VMwareなどで仮想マシンを作るのと何が違うの?
という疑問にぶつかってしまった。
ここが上手く説明できないと理解が進まないし、お客さんにも提案できないので、いろいろ調べてみた。1.1.コンテナ技術でできること
コンテナ技術でできることを調べていくと、最終的にできることは
- 1つのOS/カーネルで複数の環境が用意できる
- 同じ環境をどんどん増やすことができる
といった情報が多い。確かに便利かもしれないが、単純にそれなら仮想マシンで良くない?と思ってしまう。
「同じような環境・OSを展開・用意する」という目的としては、普通の仮想化技術でも達せられからである。
ではコンテナ技術の凄いところはどこなのか?というと、その方法や展開した後の運用に差があるのだと思う。1.2.コンテナ技術の良いところ
コンテナ技術の良いところの1つとして、軽いというところが挙げられる。
何故軽いのか?
それはアプリケーションを動かすために必要な物が少ないから。例えば仮想マシンであるプリケーションの環境を複数用意する場合、
1.ハードウェア > 2.ホストOS/HyperVisor > 3.仮想マシン > 4.OS/カーネル > 5.アプリケーション
と言うような形になります。
対してコンテナの場合、たとえHyperVisor上で動かしている環境の場合、
1.ハードウェア > 2.ホストOS > 3.仮想マシン > 4.OS/カーネル > 5.コンテナ > 6.アプリケーション
となる。
あれ?コンテナのほうが階層が多い?ってなるかもしれないが、
これが複数環境を用意していく場合、話が変わってくる。<普通の仮想マシンで複数環境を用意する場合>
1.ハードウェア > 2.ホストOS/HyperVisor > 3.仮想マシン > 4.OS/カーネル > 5.アプリケーション
> 3.仮想マシン > 4.OS/カーネル > 5.アプリケーション
> 3.仮想マシン > 4.OS/カーネル > 5.アプリケーション
> 3.仮想マシン > 4.OS/カーネル > 5.アプリケーション
:
:<コンテナで複数環境を用意する場合>
1.ハードウェア > 2.ホストOS > 3.仮想マシン > 4.OS/カーネル > 5.コンテナ > 6.アプリケーション
> 5.コンテナ > 6.アプリケーション
> 5.コンテナ > 6.アプリケーション
> 5.コンテナ > 6.アプリケーション
:
:おわかりいただけただろうか。
複数環境を用意する場合、普通の仮想マシンであればOSから複数用意する必要がある。
OSは本来アプリケーションを動かすために必要な物以外のサービスも動いており、
その分リソースを多く消費する。対してコンテナの場合、コンテナを増やすだけで済む。
もちろんコンテナを増やすことで多少のリソース消費はあるが、OSを増やすに比べると非常に少なくて済む。ここが普通の仮想化に比べてて、コンテナ技術の優れている点の1つのようだ。
もちろん他にも
・環境を簡単に増やせる
⇒仮想マシンだとテンプレートの展開やクローンが必要
・同じ環境を用意できる
⇒仮想マシンでは様々な理由で環境の差異ができやすい
など利点はあると思うが、おいおい詳しく調べて記事にしていきたい。2.用語・製品について
コンテナ関連の用語として
Docker
kubernetes
OpenShift
などを聞くが、それぞれ何が違うのか、そもそも同じレベルの用語なのかが分からなかった。2.1.Docker
Dockerというのは何か
Dockerとはコンテナーを生成することができる機能を持つサービス。
コンテナエンジンという。これと同じレイヤーの製品として
LXC(Linux Containers)
というものがある。
普通の仮想基盤のイメージとしてはESXサーバに位置づけか?
2.2.kubernetes
kubernetesとはDockerによってつくられるコンテナ環境を管理するツール。
Googleが開発したオープンソースで、
- オーケストレーションツール
- オーケストレータ
というような名称で呼ばれている。
イメージとしては仮想基盤を管理する、vCenterのような位置づけ。このオーケストレーションツールにはkubernetes以外にも
- Dockerの「Swarm」
- CoreOSの「fleet」
- Rancher Labsの「Rancher」
- Mesosの「Marathon」
という製品がある。
Docker自身も管理ツールを出していたが、kubernetesが標準になっている。(なりつつある?)2.3.Openshift
kubernetesをベースとして、Redhatが作った製品。
アプリケーションを開発したり、動かしたりするために便利な機能を追加したもの。大まかなイメージとしてはこういう枠組み。
まとめ
結局うまくまとめられたかどうかわからないが、
コンテナ技術について自分が調べたことを纏めてみた。所感としては小規模であればコンテナ技術と通常の仮想化技術ではそれほど差が無く、
大きな環境になればなるほど良い面が出てくるのだなという感想。
引き続き、勉強していきたいと思う。参考文献
https://speakerdeck.com/moriwaka/kontenatosabajia-xiang-hua-falsewei-ito-docker-kubernetes-openshift
https://www.osscons.jp/cloud/%E3%83%80%E3%82%A6%E3%83%B3%E3%83%AD%E3%83%BC%E3%83%89/?action=common_download_main&upload_id=698
https://www.ossnews.jp/compare/Docker/LXC
- 投稿日:2020-07-31T01:27:24+09:00
Flutter in Docker - Dockerコンテナ内にFlutter開発環境を構築して利用する方法
1. はじめに
Flutterの開発環境をDockerコンテナ (今回はUbuntu 20.04 LTS) に構築し、macOSやLinux OSのHost PCからあたかもHost PC上で開発しているのと同じような環境を構築する方法を紹介します。この仕組みを利用すれば、リモート (サーバー) に開発環境を構築し、それにローカルPCからアクセスしてFlutterアプリの開発が可能です。
Flutter in Docker全体像
(補足) 今回はトライしていませんが、Dockerコンテナ内にAndroid版 (Aundroid Studioを利用したエミュレータ上での動作) も原理上は動作可能なはずです。
Dockerコンテナ化するメリット (例)
- 開発環境を複製・削除し易く、同じ環境を第三者に配ることが可能
- 環境をDockerコンテナ化しておくとCI/CD時に便利
- OSに依存せず (Linux or macOS) 、Android/iOS以外の環境での動作確認が可能
ターゲット (Host PC) 環境
- macOS
- Linux OS (Flutter, Dockerが動作する64bit Linux環境であれば基本的にどのディストリービューションでもOK)
2. Dockerインストール
Docker自体のインストール方法については割愛しますが、基本的に公式サイトの手順通りに進めれば大丈夫です。
- macOS: Install Docker Desktop on Mac
- Linux (Ubuntu): Install Docker Engine on Ubuntu
3. Dockerコンテナイメージの作成
Dockerコンテナイメージを作成する手順について説明します。Dockerコンテナ内のOS (rootfs) はUbuntu 20.04にしました。今回はDockerfileは利用せず、全て手動による手順での説明です。
Ubuntu 20.04 イメージ (rootfs) の取得
$ docker pull ubuntu:20.04Dockerコンテナの起動
以下のコマンドでDockerコンテナを起動してそのコンテナ中に入ります。基本的にセキュリティなし (
--privileged) で、Host PCのOSと同じ権限でアクセス出来るようにします。なお、ここで指定したパラメータを後述のDocker-composeの設定ファイルでも利用するため、まずはこの設定のまま実行して下さい。
$ docker run -it --name flutter-docker ¥ --privileged -h flutter -u root -w /root ¥ --add-host=flutter:127.0.1.1 --net=host ubuntu:20.04問題がなければプロンプトが
#に変わり、Dockerコンテナ内の操作に切り替わっています。例えば、unameコマンドを打つとLinux OSになっていることが分かります。# root@flutter:~# uname -a Linux flutter 4.19.76-linuxkit #1 SMP Tue May 26 11:42:35 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux必要なツールのインストール
Dockerコンテナ内のUbuntu OSに必要なパッケージをインストールします。
xserver-xorgのインストール時にはロケールやキーボードの情報を求められますが、適当で良いです (無難ならUS) 。# apt update # apt install git unzip clang xserver-xorg pkg-config libgtk-3-dev curl cmake ninja-buildChromeブラウザのインストール (必要があれば)
# apt install wget gnupg # sh -c 'echo "deb http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google.list' # wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | apt-key add - # apt update # apt-get install google-chrome-stable参考: https://qiita.com/pyon_kiti_jp/items/e6032eb6061a4774aece
Flutter SDKのインストール
Flutter SDKをgit cloneして、/opt以下に配置します。
# https://github.com/flutter/flutter.git # mv flutter /opt/コンテナイメージの保存
ここまででコンテナ内での作業は全て終了です。なので、コンテナから抜けます。
# exit作成したコンテナをDockerイメージファイルとして保存します。ここで指定したパラメータを後述のDocker-composeの設定ファイルでも利用するため、まずはこの設定のまま実行して下さい。
$ docker commit flutter-docker flutter-docker/ubuntu:latest4. Host PC側の設定 (macOSの場合のみ)
Dockerコンテナ内のGUIアプリケーションはX11プロトコルで動作するため、そのGUIアプリの画面をHost PC側のX11サーバーに転送する必要があります。macOSの場合、Host側のX11サーバーとしてXQuartzがありますので、それをインストールして利用します。
XQuartzのインストール
$ brew cask install xquartzHost PCを再起動します。再起動後、
DISPLAY環境変数が以下のように設定されていることを確認します。$ echo $DISPLAY /private/tmp/com.apple.launchd.NagCeWDLYl/org.macosforge.xquartz:0DockerコンテナのX11クライアントからのアクセスを許可します。
$ xhost +$(hostname) $ xhost + local:rootコマンドラインもしくは、LaunchPadから
XQuartzを立ち上げておきます。
5. Host PC側の設定 (Linux OSの場合のみ)
Linux OSの場合は大抵がX11デフォルトだと思いますので、以下の対応だけを行います。
$ xhost + local:root6. VSCode環境構築
VSCodeのインストールとVSCodeからDockerコンテナを利用するためのExtensions等をインストールします。
VSCodeのインストール
以下を参考にしてインストールしてください。
- Linux (Ubuntu): https://qiita.com/yoshiyasu1111/items/e21a77ed68b52cb5f7c8
- macOS: https://qiita.com/watamura/items/51c70fbb848e5f956fd6
VSCode Extensionsインストール
以下の3つのExtensionsをインストールします。
7. Docker Composeファイルの作成
VSCodeからDockerコンテナ内のFlutter SDKを利用するために、Docker Composeと先ほどインストールしたVSCode Extensionsの
Remote Developmentの設定ファイルを作成します。作成したファイルは https://github.com/Kurun-pan/flutter-docker に置いているため、Host OS (Linux or macOS) に合わせて利用して下さい。$ mkdir flutter_docker $ cd flutter_dockerカレントディレクトリ (flutter_docker) 以下に
docker-compose.ymlファイルと.devcontainer/devcontainer.jsonファイルの2つを作成します。
Host OSがmacOSの場合
DISPLAY環境変数にhost.docker.internal:0を設定するのがポイントのはずでしたが、上手く行かなかったため、{write your host name!!}の部分はmacOSのhostnameを指定してください。。誰か正しい方法を知っていれば教えて下さい。https://github.com/Kurun-pan/flutter-docker/tree/master/macos
docker-compose.ymlversion: "3" services: flutter: image: flutter-docker/ubuntu:latest working_dir: /root/workspace command: sleep infinity environment: - HOME=/root - no_proxy=127.0.0.1,localhost #- DISPLAY="host.docker.internal:0" - DISPLAY={write your host name!!}:0 volumes: - ~/.gitconfig:/home/root/.gitconfig - ./:/root/workspace - ~/.Xauthority:/root/.Xauthority network_mode: "host" extra_hosts: - flutter:127.0.1.1.devcontainer/devcontainer.json{ "name": "Flutter docker", "dockerComposeFile": [ "../docker-compose.yml", ], "service": "flutter", "remoteUser": "root", "remoteEnv": { "QT_X11_NO_MITSHM": "1", "PATH": "/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/opt/flutter/bin", }, "settings": { "terminal.integrated.shell.linux": null }, "runArgs": [ "--privileged", "-P", ], "extensions": ["dart-code.flutter"], "workspaceMount": "source=${localWorkspaceFolder}/workspace,target=/root/workspace,type=bind,consistency=delegated", "workspaceFolder": "/root/workspace" }Host OSがLinuxの場合
Linux OSの場合、OpenGLでDRM (DRI) をDockerコンテナ内のFlutterアプリが利用できるように、
/dev/driをbind-mountします。https://github.com/Kurun-pan/flutter-docker/tree/master/linux
docker-compose.ymlversion: "3" services: flutter: image: flutter-docker/ubuntu:latest working_dir: /root/workspace command: sleep infinity environment: - HOME=/root - no_proxy=127.0.0.1,localhost volumes: - ~/.gitconfig:/home/root/.gitconfig - ./:/root/workspace - /tmp/.X11-unix:/tmp/.X11-unix devices: - /dev/dri:/dev/dri network_mode: "host" extra_hosts: - flutter:127.0.1.1Host OSの
DISPLAY環境変数を引継ぎます。.devcontainer/devcontainer.json{ "name": "Flutter docker", "dockerComposeFile": [ "../docker-compose.yml", ], "service": "flutter", "remoteUser": "root", "remoteEnv": { "QT_X11_NO_MITSHM": "1", "DISPLAY": "${localEnv:DISPLAY}", "XAUTHORITY": "/tmp/.X11-unix", "PATH": "/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/opt/flutter/bin", }, "settings": { "terminal.integrated.shell.linux": null }, "runArgs": [ "--privileged", "-P", ], "extensions": ["dart-code.flutter"], "workspaceMount": "source=${localWorkspaceFolder}/workspace,target=/root/workspace,type=bind,consistency=delegated", "workspaceFolder": "/root/workspace" }8. Flutter in Dockerの実行
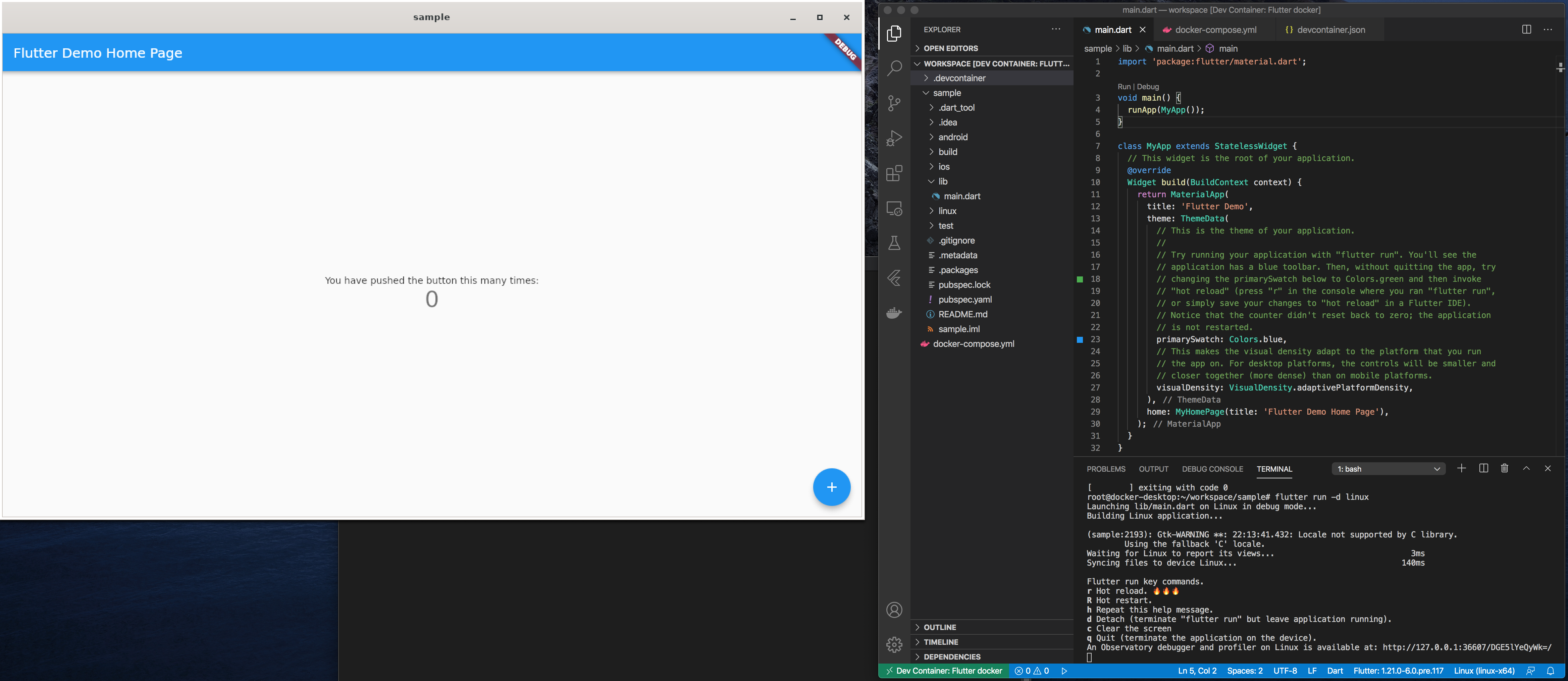
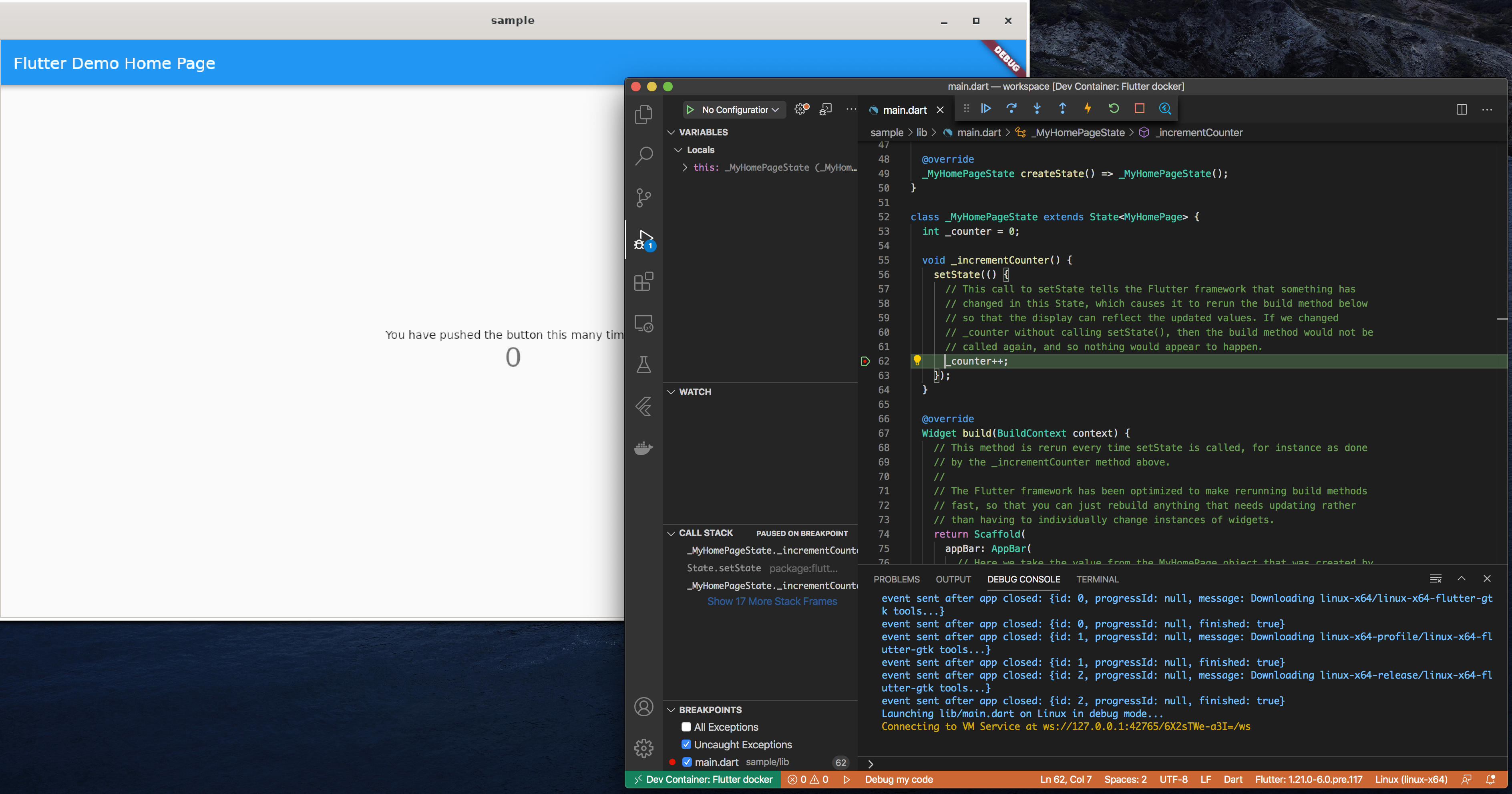
VSCode立ち上げ
docker-compose.ymlが存在するディレクトリでVSCodeを立ち上げます。$ code .VSCode Remote Containerのオープン
ウインドウ左下の
><の部分をクリックもしくは、shift+alt+pでコマンドパレットを開き、Remote-containers: Open Folder in Container...を選択します。
Openをクリックします。
VSCodeウインドウ下部にターミナルが開きます。このターミナル操作対象は作成したDockerコンテナイメージ (flutter-docker/ubuntu:latest) です。
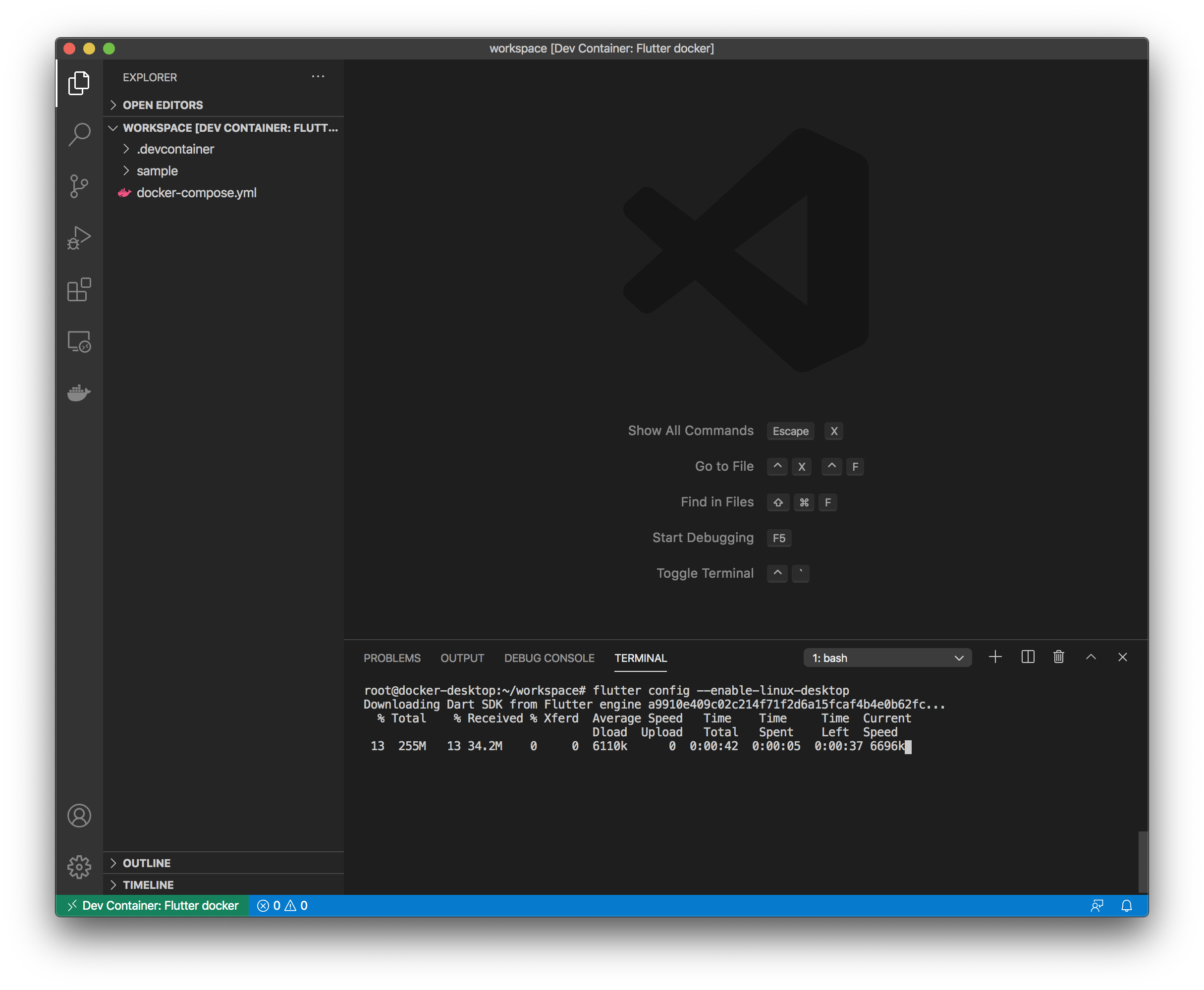
Flutterサンプルアプリのプロジェクト作成
ここからVSCodeのターミナル (Dockerコンテナ) で以下のコマンドを実行し、Flutterサンプルアプリを実行します。
# flutter config --enable-linux-desktop # flutter config --enable-web # mkdir sample # cd sample # flutter create .
Flutterサンプルアプリの実行
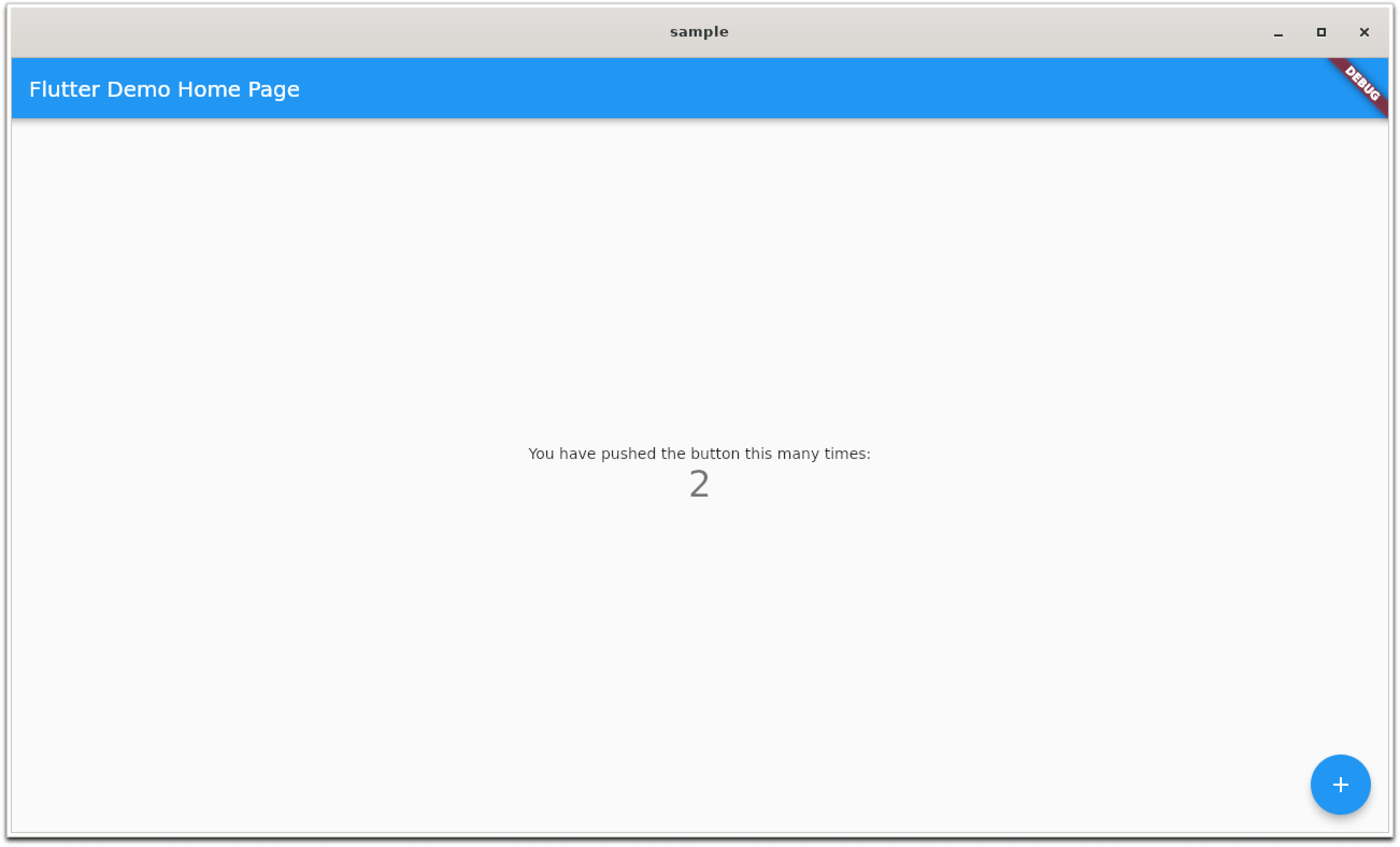
サンプルアプリ for Linux Desktop
# flutter run -d linux
コマンドを実行する以外には、VSCodeでdartソースコードを開いて、GUI操作でもアプリ実行やブレークポイントを利用したデバッグ等が可能です。
サンプルアプリ for Web
対応中なので少々お待ちを。。
# flutter run -d chrome






- 投稿日:2020-07-31T00:37:06+09:00
WSL2に切り替えたらhomeディレクトリで難儀した
どうでも良い背景
WSLの登場でWindowsでもWeb開発がしやすくなったがいつからかdockerが動かなくなってしまったらしい.まぁdockerの思想や性質を考えるとWindowsでLinuxのコンテナが使えること自体が異常な気もするんだけども.ともあれ,WSL2とは相性が良くなったらしい.
僕は自宅でサーバーを動かしていて,MinecraftサーバーやらDiscordのミュージックボットやらを提供している.仕事でやっているわけではなく趣味の範囲なので,全部同居しているのだが,そうするとだんだん環境がカオスになってきて手に負えなくなりそうだったので,半年ぐらい前にdockerを導入してサービスを切り分けた.
そこまでは良かったんだが,サービスを立ち上げるまでの試行錯誤をサーバー上のviでガシガシ書くのは流石に骨が折れる.変数を少し変えるだけならいざ知らず,1から建てるとなるとなかなかのコストになるので,vscode使いとしては普段使いのPCで作業して,アップをしたいわけ.そこでいろいろ方法を考えた
- SFTPで接続してリモートとローカルを同期する
- セキュリティのためにrootでのSSHログインを許可していない
- rootしかアクセス許可してないディレクトリだとroot以外のユーザーはパーミションエラー
- 上記2点をクリアするためにはセキュリティを下げるしか無いため断念.
- GitHubでpush&pull
- とにかくめんどくさい
- そもそも動くかわかってないものを上げてるとなんでコミットしてるんだっけ?ってなる
- 今まではとりあえずなんとかやってきたんだが,限界を感じてしまった
- Windows desktop向けのdockerを導入してWSLから使えるようにする
- 色々設定が面倒くさそう
- そもそも設定したところで推奨されているわけではないので使えなくなる可能性がある
まぁこんなところで思案していて,dockerが普通に動かせるようになったと噂のWSL2を試してみることにした.
WSLとWSL2の違いについて簡単に解説
自分の情報整理のために,WSLとWSL2の違いが何なのか,dockerを使うという観点から解説する.厳密には間違っている可能性は多々あるので,正確な情報が知りたい人は公式ドキュメントを読むと良いだろう.
ざっくりと説明すると,WSLはLinuxのカーネルをエミュレートしていて,WSL2では仮想マシンを裏で立ち上げ,そのカーネルを使うという方式に切り替わったらしい.WSLからWSL2に変えるとファイルの読み込みが遅くなるというのはこのあたりに起因する.LinuxとWindowsはそれぞれ違うファイルシステムを使っていて,WSLの時代では全てWindowsのファイルシステムで動いていたからファイルの読み込みに時間がかからなかったわけ.その代わりLinuxのファイルシステムをエミュレートするわけだから,コマンドの実効速度が遅いってわけ.
対してWSL2ではゲスト側のLinuxが仮想マシンとして動いていて(つまりファイルシステムがそもそもLinux),ホストマシンのディレクトリは/mnt/以下にマウントされているという状況になっている.だからコマンドの実効速度自体は速い.ただし,ホストマシンのファイルとのやりとりはどうやらTCPかなにかの通信をしてネットワーク越しの通信のようなことをしているらしい.だからホストゲスト間のディレクトリをまたいだやり方は問題が起きやすい(某白笛並感)
ちなみに,コマンド実行は速いとは言ったものの,そのコマンド自体がファイルアクセスを伴うコマンドだった場合にはとにかく実行が遅い.lsコマンドにしても数秒遅れるみたいな状況で,ともすれば画面をたたき割りかねないような環境になる.今回やったこと(できたこと)
- WSLの環境をそのままWSL2にお引っ越しできた
- WSL時代にWindows側の%Users/(user name)/wslというディレクトリにおいてあったホームディレクトリをLinux側の/home/(user name)に移動した
- dockerを動かしてローカルで実験できる環境が整った
個人的に心配だったWSLの開発環境をそのままWSL2に持って行けるのか?という問題については,コンバートすればそのまま使えるという知見を得たので,心配な人は安心して欲しい.
WSL to WSL2
まず大前提としてWSL2を使いたかったら今ならWindowsのバージョンを2004に上げる必要がある.(プレビュー機能として使えなくは無いが,2004に上げてデフォルトで使えるようにする方が無難だろう.何を言ってるかわからない人はこのページを見ないとは思うが,万が一わからない場合はWinボタンを押してwinverと入力してEnterすれば幸せになれると思う)
WSL2の使用前にHyper-Vを有効にする必要があるが,WSLを使っていた人ならこの辺はONになっているはずで,特に操作は必要無いと思う.(ちなみに,Hyper-Vを有効にすると,サードパーティ製の仮想マシンはもれなく死ぬ)次に,WSL2を有効にするにはWSL2向けのLinuxカーネルコンポーネントの更新がいるらしい.Microsoftのページから「最新のWSL2 Linuxカーネル更新プログラムパッケージをダウンロード」とあるので,そちらをインストールする.詳しくはリンク先に書いてある.
前準備が終わったら管理者権限でPowerShellを立ち上げて,以下のコマンドを入力する.必須ではないが,Web開発をするためにWSL使ってるならWSLを使いたい理由は特にないと思うし,やっちゃっても特に問題は無いんじゃないだろうか.言うまでも無いが,デフォルトのWSLのバージョンを2にするだけ.
wsl --set-default-version 2既存のWSL環境をWSL2にコンバートするには以下のコマンドを実行する.コマンドを見る限りWSL2からWSLへもコンバートできるみたい(未検証).
wsl --set-version <distribution name> <version>versionはWSL2にしたいなら2とする.distribution nameはWSLを入れるときにMicrosoft StoreからインストールしたLinuxの名前だが,わからない場合は以下のコマンドで確認できる.NAMEの欄がdistribution nameに対応している.
wsl --list --verboseWSLがWSL2に切り替わったか確認したいときも同じコマンドでVERSIONの項目を見ればOKだ.
homeディレクトリを使いやすくしたい
さて,homeディレクトリの位置を弄ってない人は特に気にならないかも知れないが,僕はWSLを使っていたときにアクセスしやすいようhomeディレクトリの位置をWindowsのユーザーディレクトリの下に置いていた.そのせいで,WSLからWSL2にコンバートした直後は笑えるぐらいコマンド一つ一つに時間がかかった.
これでは使い物にならないと/home/(user name)にホームディレクトリの位置を戻した.ちなみにやった操作としては,/etc/passwdを直接viエディタで弄っただけだ.しかしこれでめでたしめでたしと言うわけにはいかない(個人的こだわり).そもそもアクセスしにくいからホームディレクトリを移していたのに,元の位置に戻したらまたアクセスしづらくなる.ゲストtoホストのファイル操作はめったに無いが,ホストtoゲストのファイル操作はチョコチョコ必要になったりする.
上の方でも少し触れたが,ホストtoゲストはネットワーク越しのようにアクセスすることが出来る.
\\wsl$\<distribution name>\home\<user name>というアドレスをエクスプローラに入れる事で,アクセスが出来る.つまり,ネットワークドライブとして認識が出来るので,エクスプローラにネットワークドライブとして登録できる(というか登録した.毎回探すのは面倒だから)余談だが,調べてみたらどうやらWSLにはあらかじめ特別なコマンドが用意されていて,
explorer.exe .と入力すればカレントディレクトリがホスト側のエクスプローラで開けるらしい.(今まで知らなかったが結構便利だなぁ・・・)docker(は特に語ること無いけど少しだけ)
WSL2を入れた状態でdockerをインストールすると,WSL2にインテグレートするかどうかをインストール時に聞いてくれる.これにチェックを入れておくと,次回のWSL2起動からdockerkコマンドがLinux環境よろしく使えるようになっている.
ちなみに,この記事を書いている最中にdockerがアップデートに失敗してアンインストールだけ綺麗にしちゃってくれたのだが,その状態だとzshでdockerコマンドの予測は出るが,実行するとコマンドがないっていうギャグみたいな状況が発生した.まとめその他
やはりdockerをローカルから使えると開発が捗る.業務ではMacを使っているのだが,わざわざ使う必要性もないのかなと感じている.Winのデフォルト文字コードがUTF8になったしね.
WSL2はWSLの単純な上位互換とはいかず,今のところ一長一短といった感じだ.が,Linux環境で閉じた作業しかしない人ならWSL2への以降をした方が絶対に良いと思う.WSL側からWinのファイルシステムを使うのがメインの人はWSLを維持した方が良い.どちらもやるというひとなら,WSLとWSL2の環境をそれぞれ用意するという方法が良さそうだ.ちゃんと調べてはいないが,コマンドの使い方などから察するに,そもそも複数環境セットアップできるような設計になっているような気がする.
- 投稿日:2020-07-31T00:23:26+09:00
docker buildがどんなコマンドなのかメモ
一文で説明すると
docker fileがあるディレクトリに対して
docker buildすることでdocker imageが作り出される。※補足
docker build
docker fileがあるディレクトリに対してdocker buildすると、ディレクトリごとdocker deamon(ドッカーデーモン)に渡されて、docker deamonからdocker imageが作り出される。docker fileとは
docker imageを作るための設計図が書かれているファイル。docker imageとは
コンテナを作るための道具。
docker run <コンテナID> コマンドを実行することでコンテナが作られる。