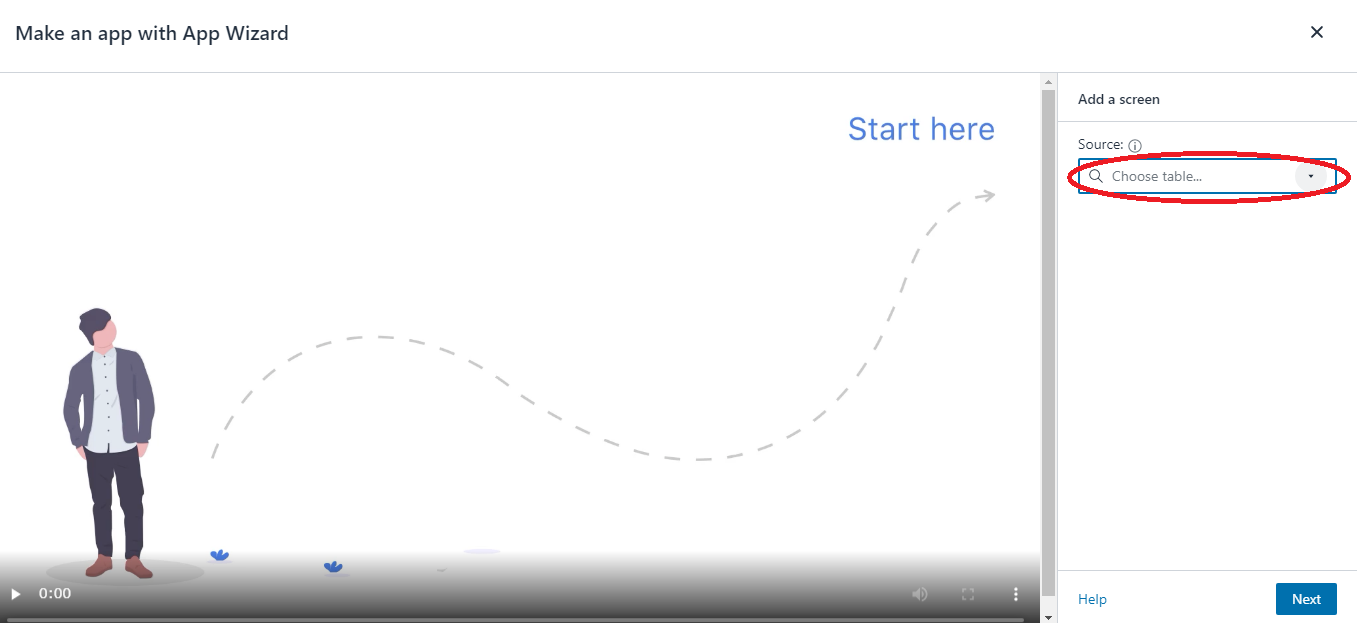
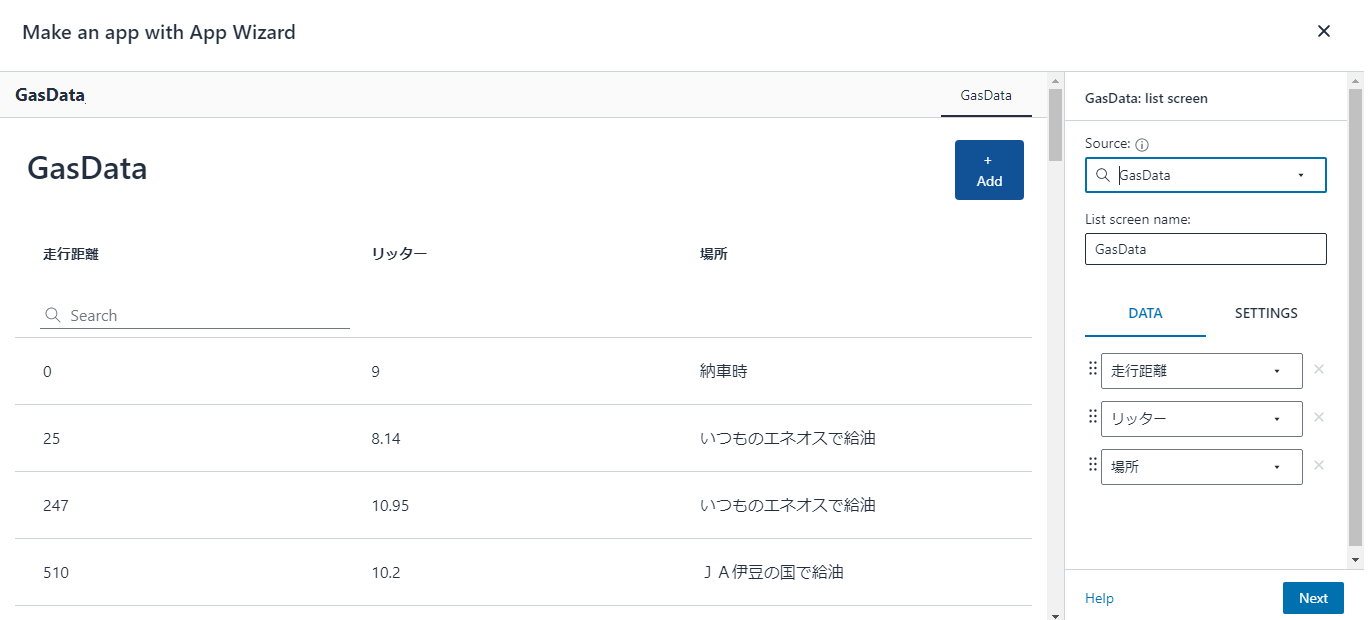
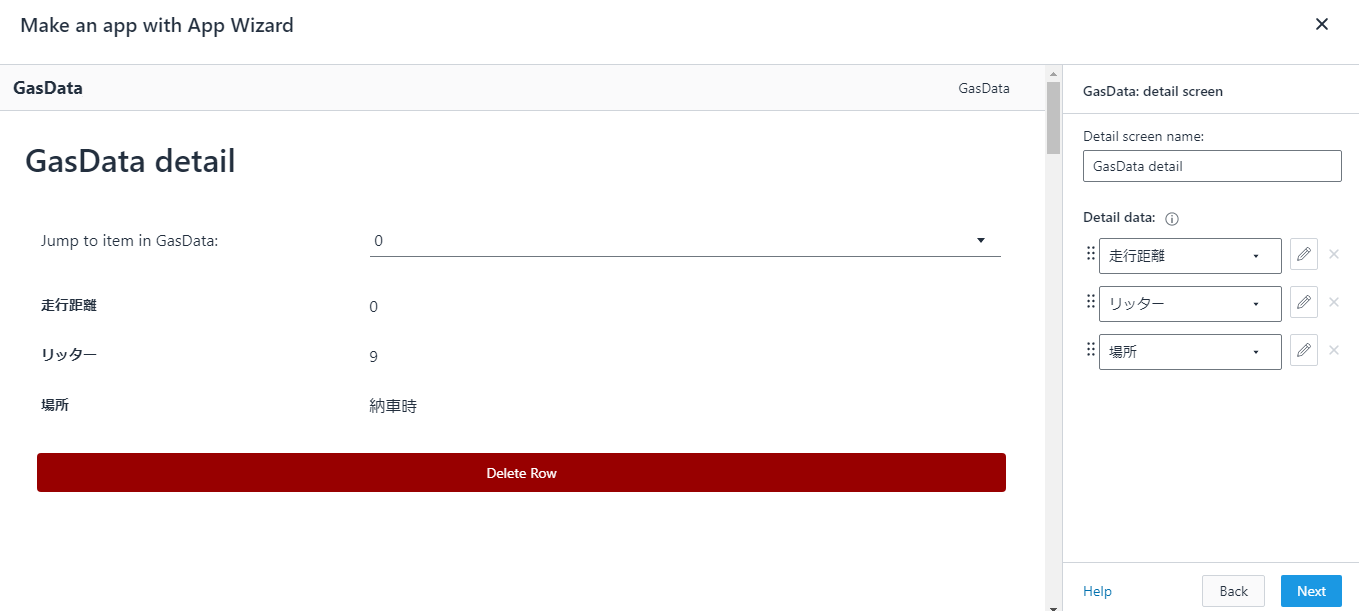
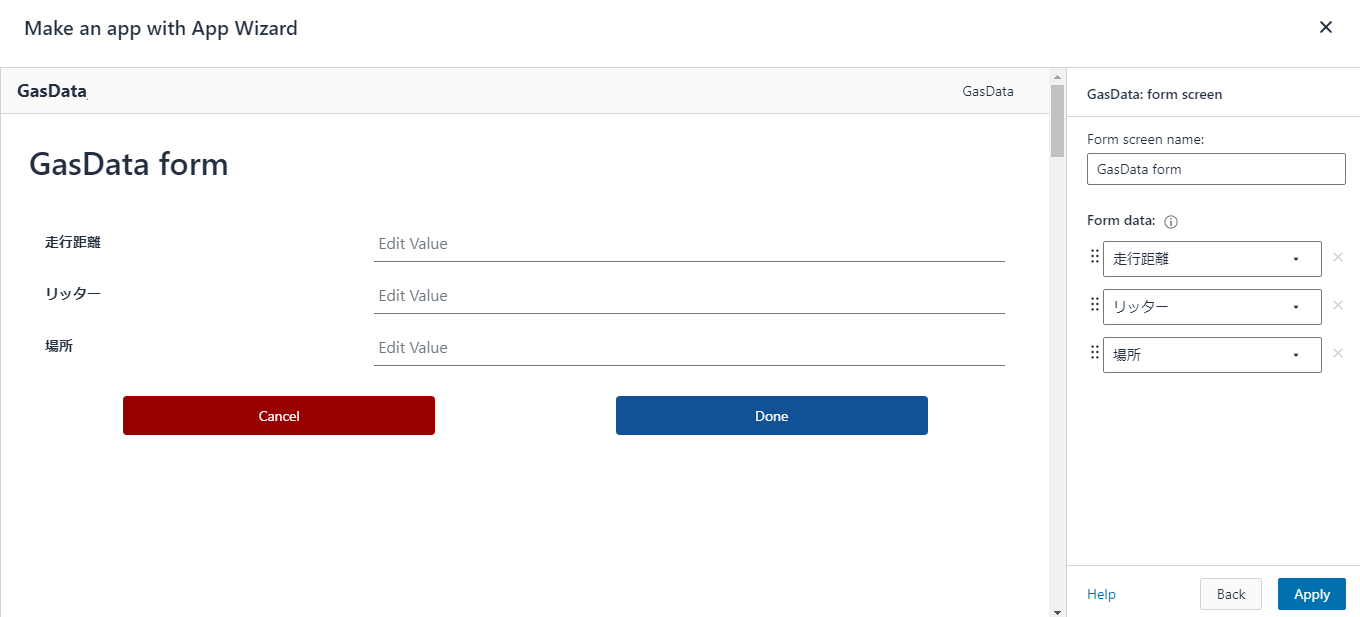
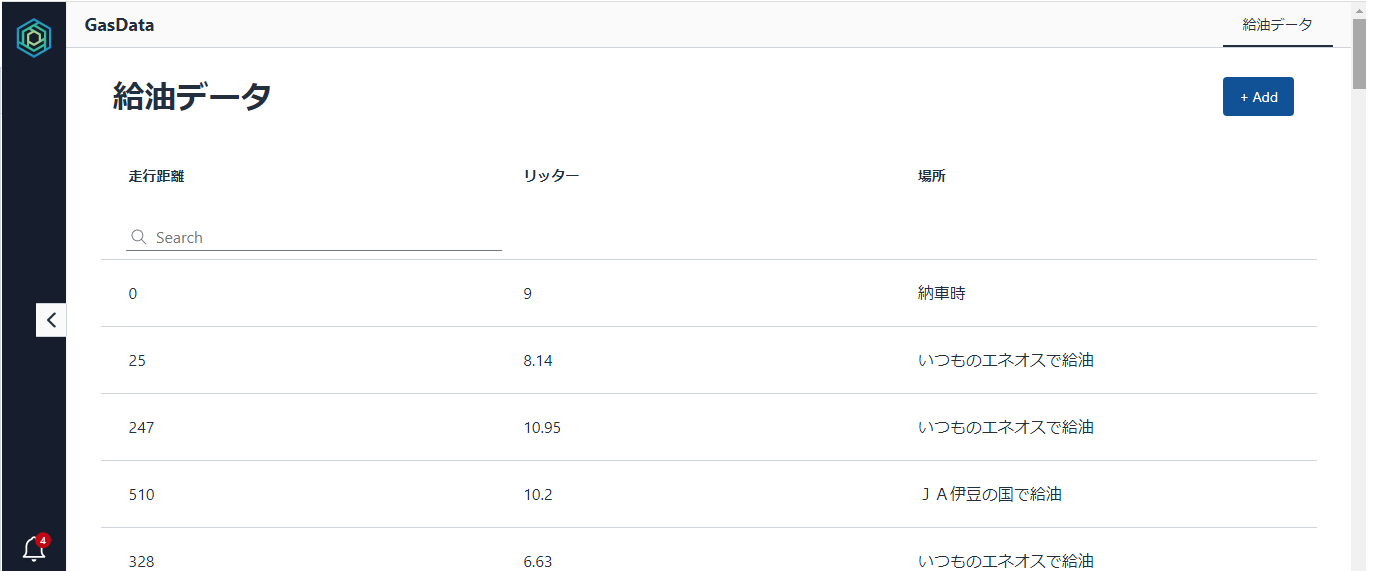
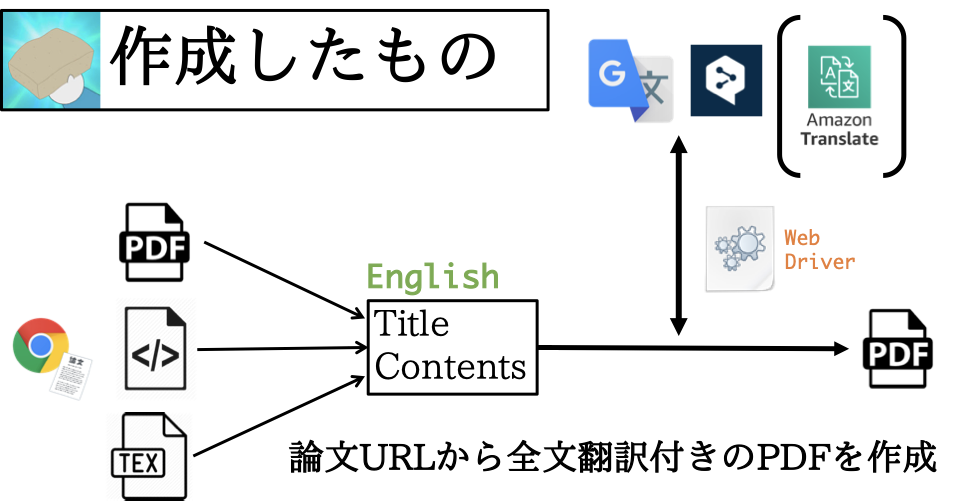
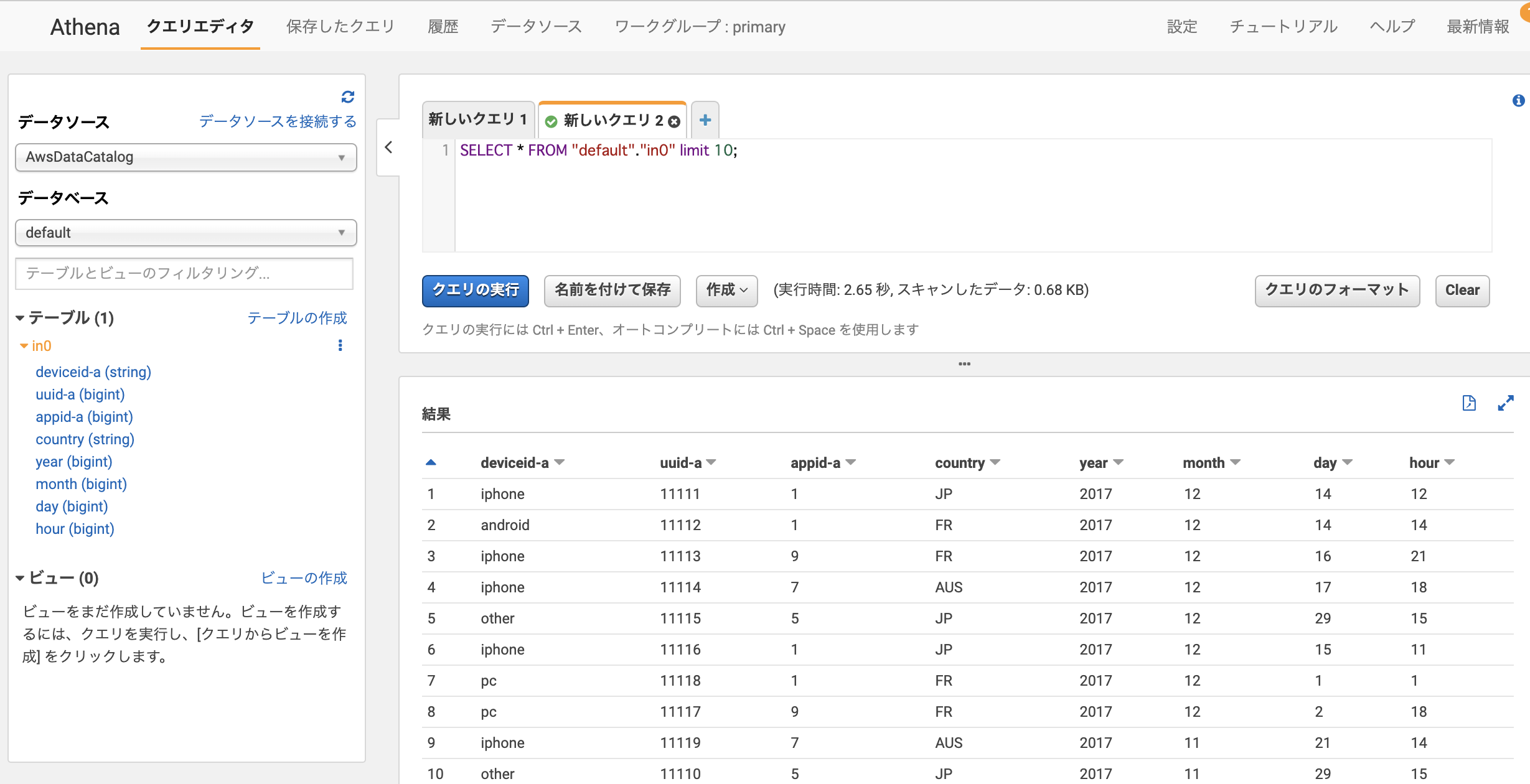
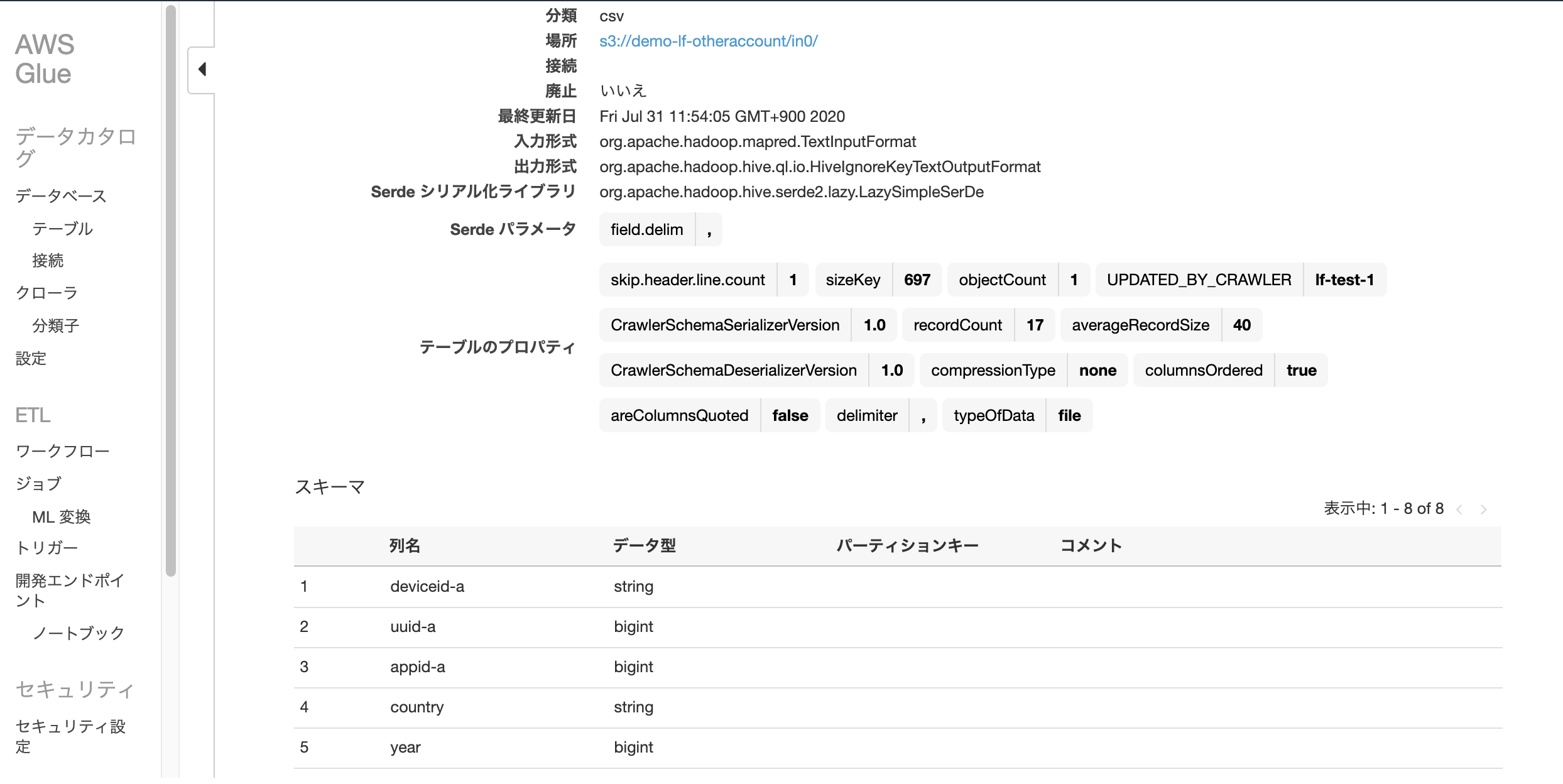
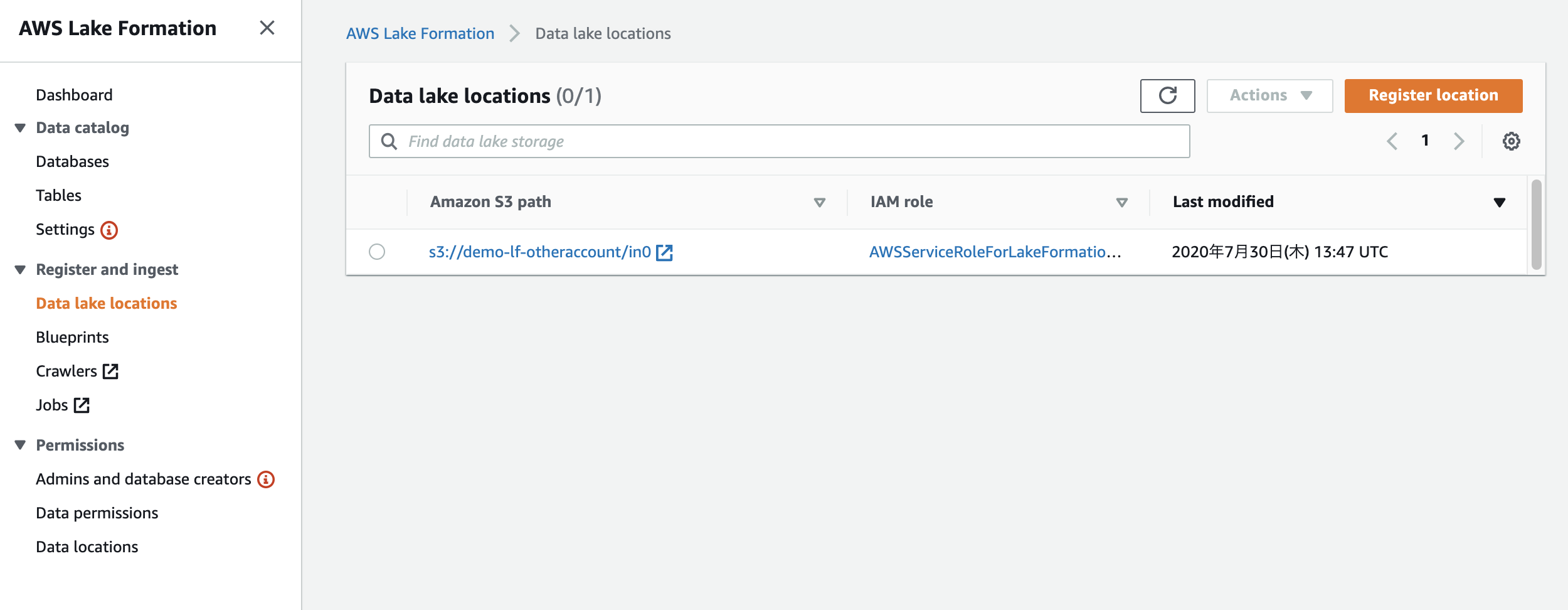
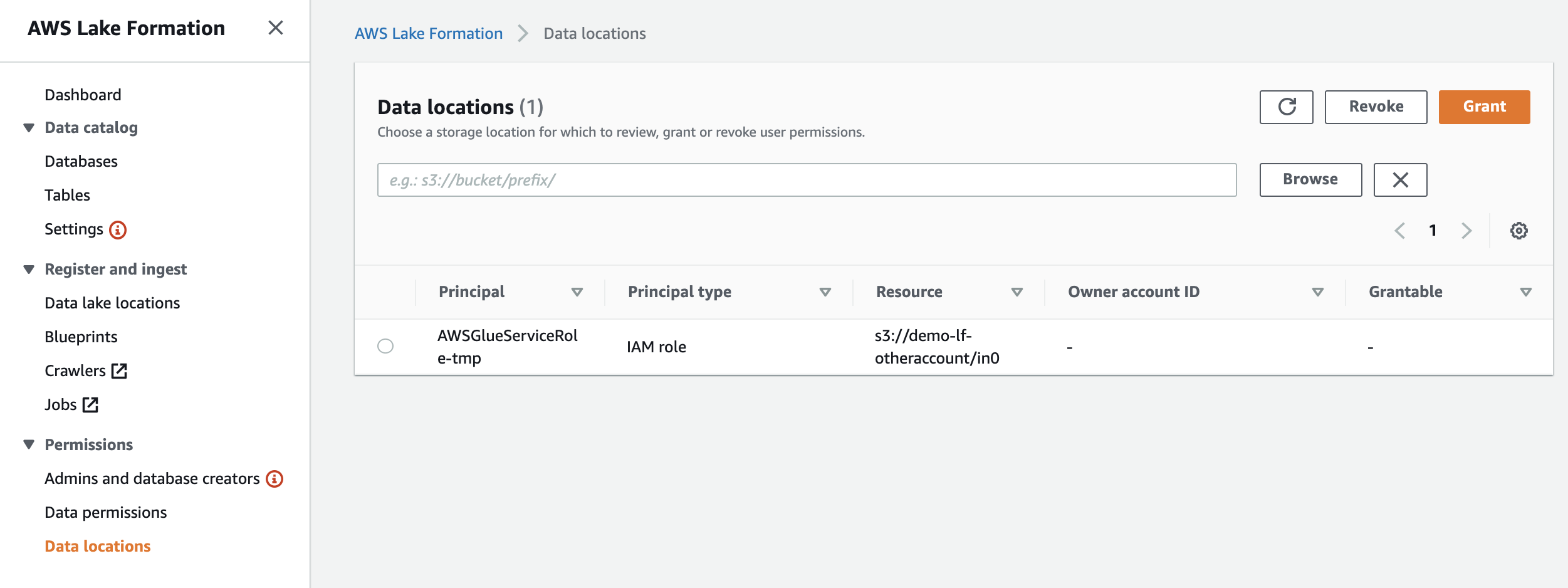
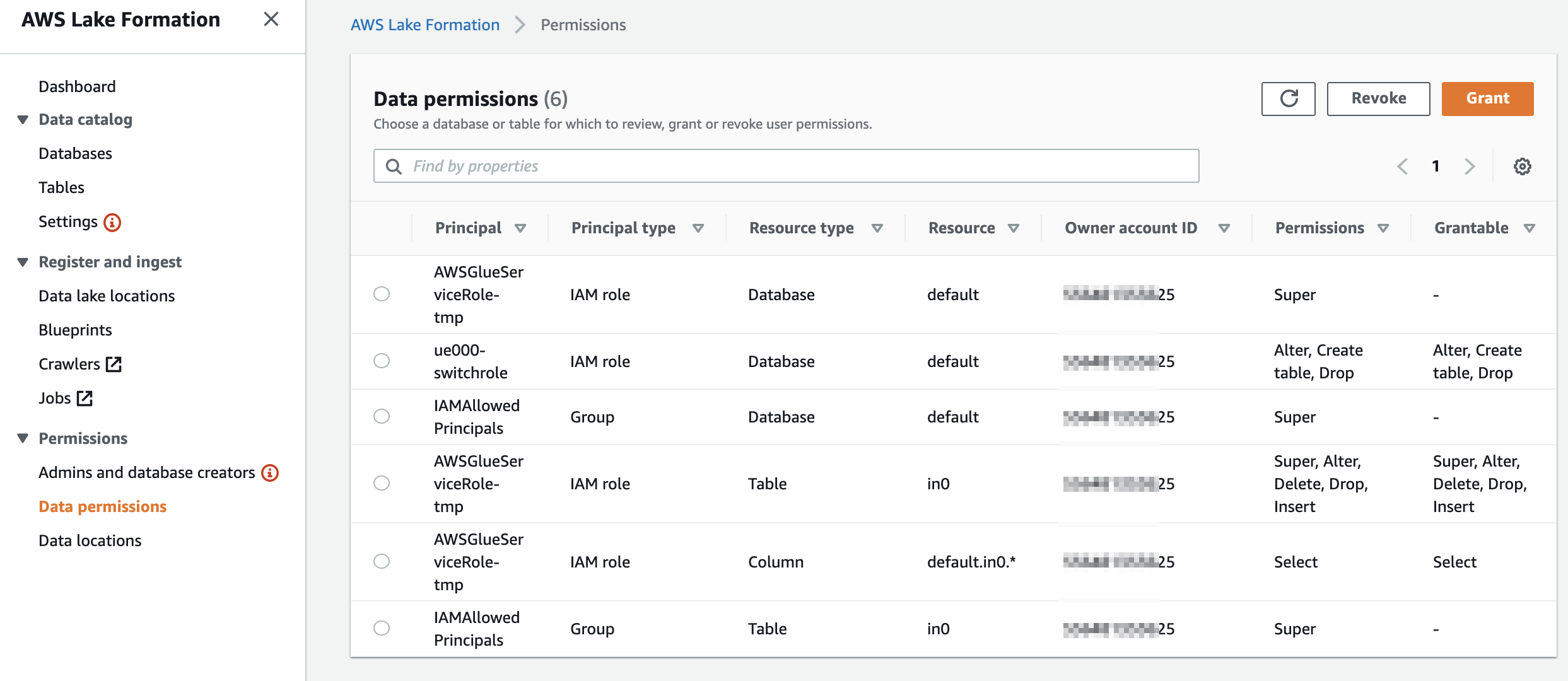
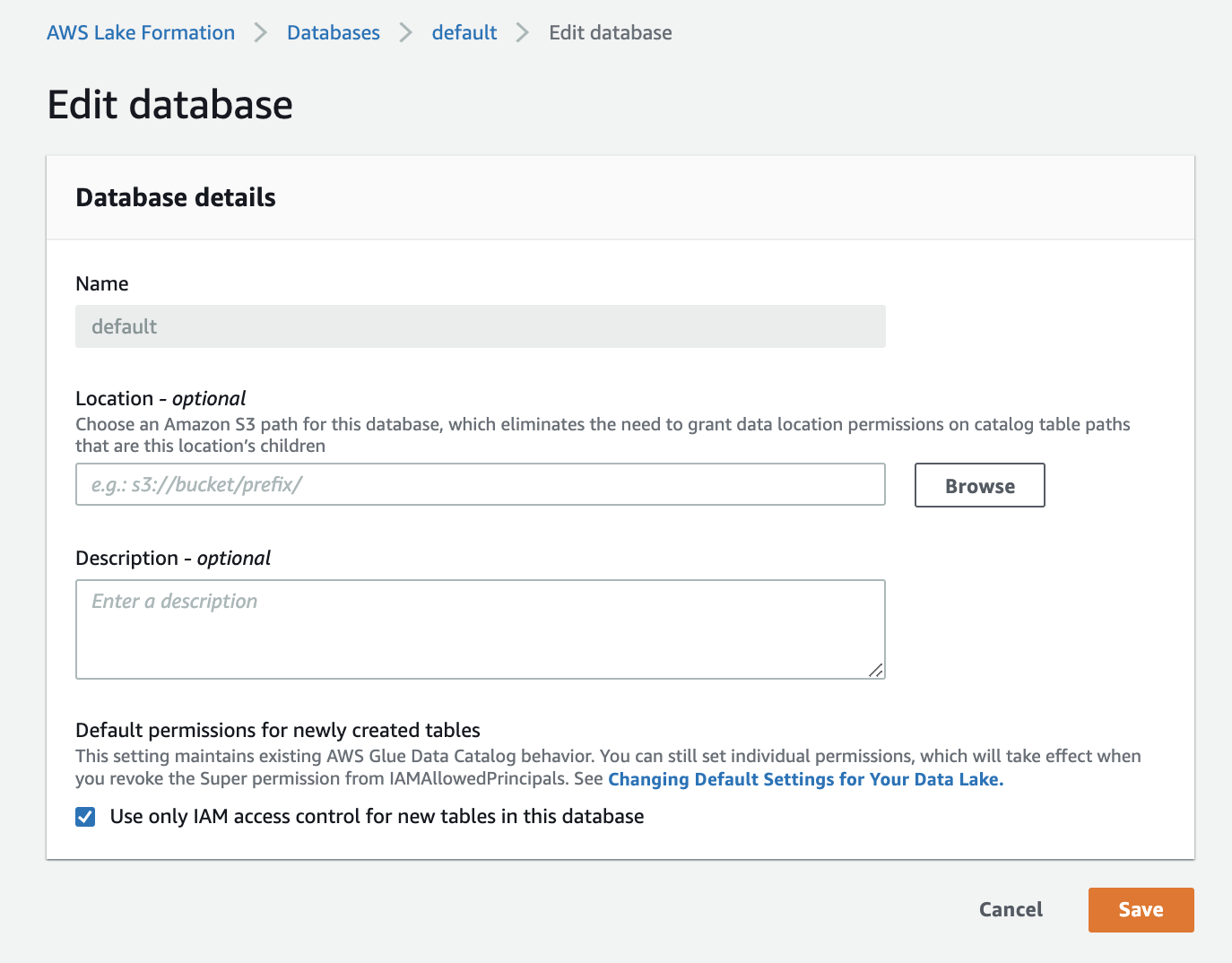
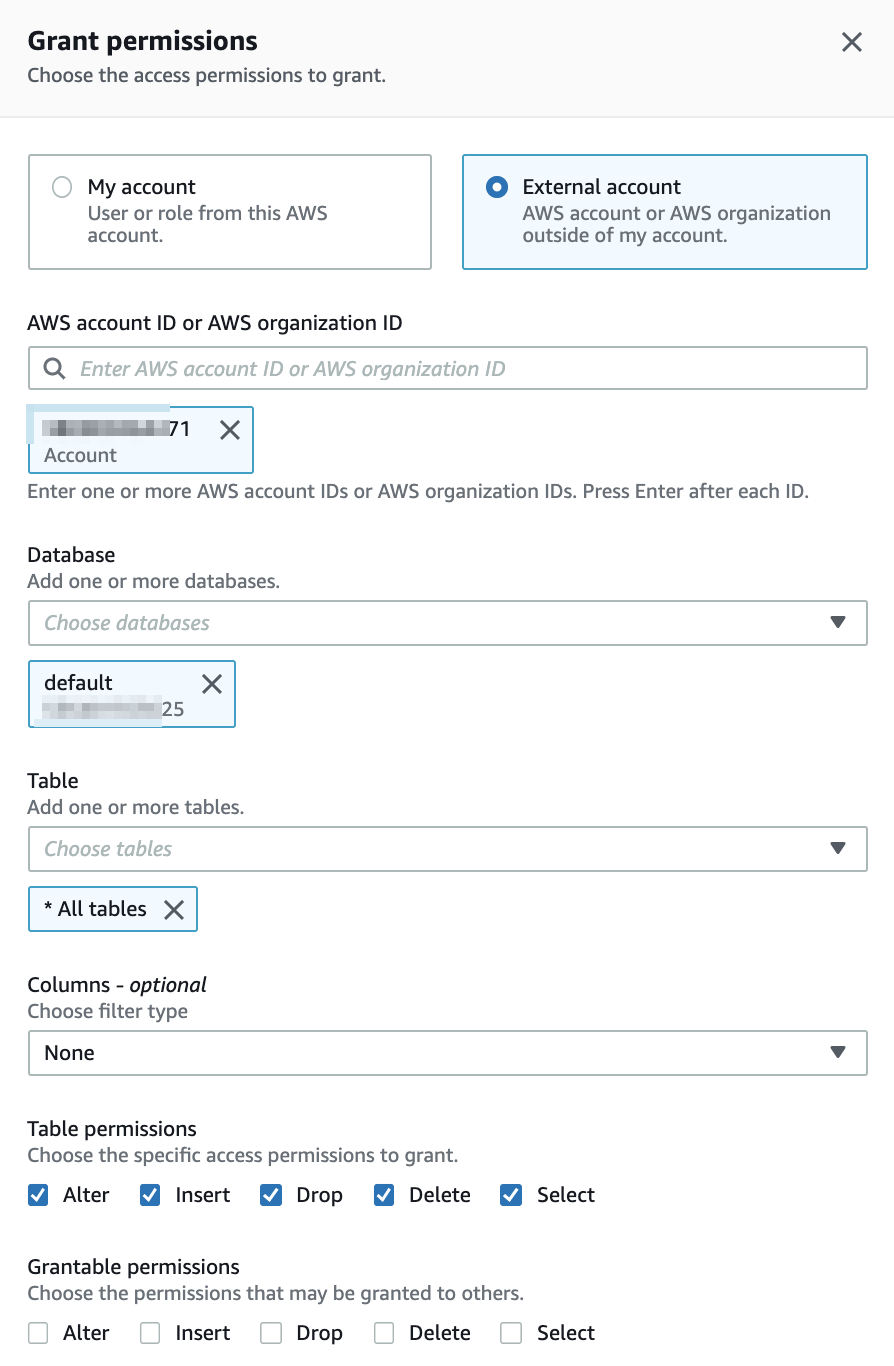
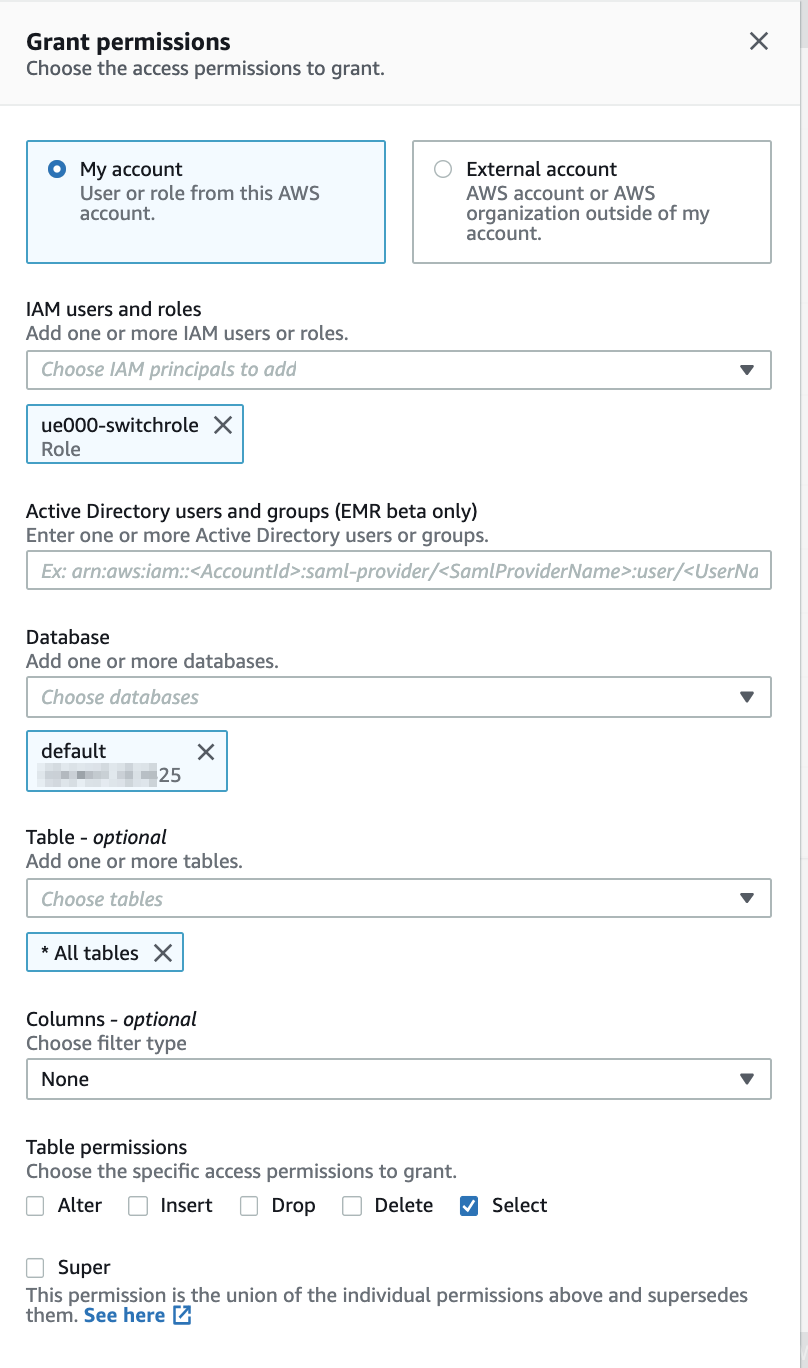
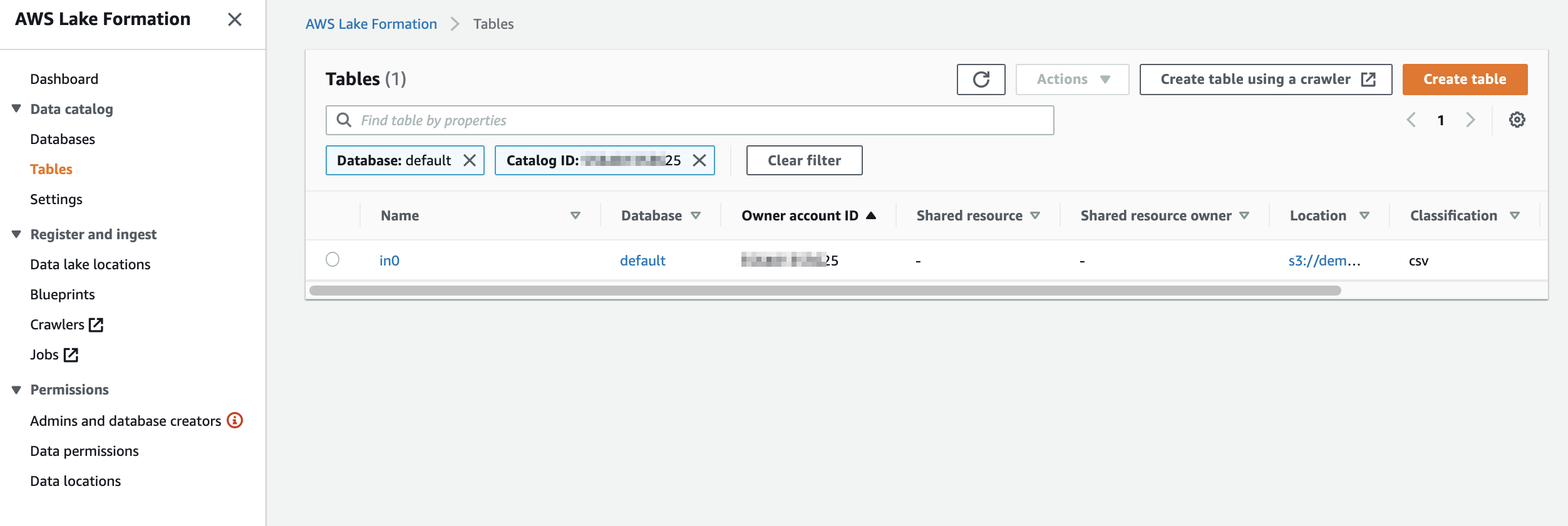
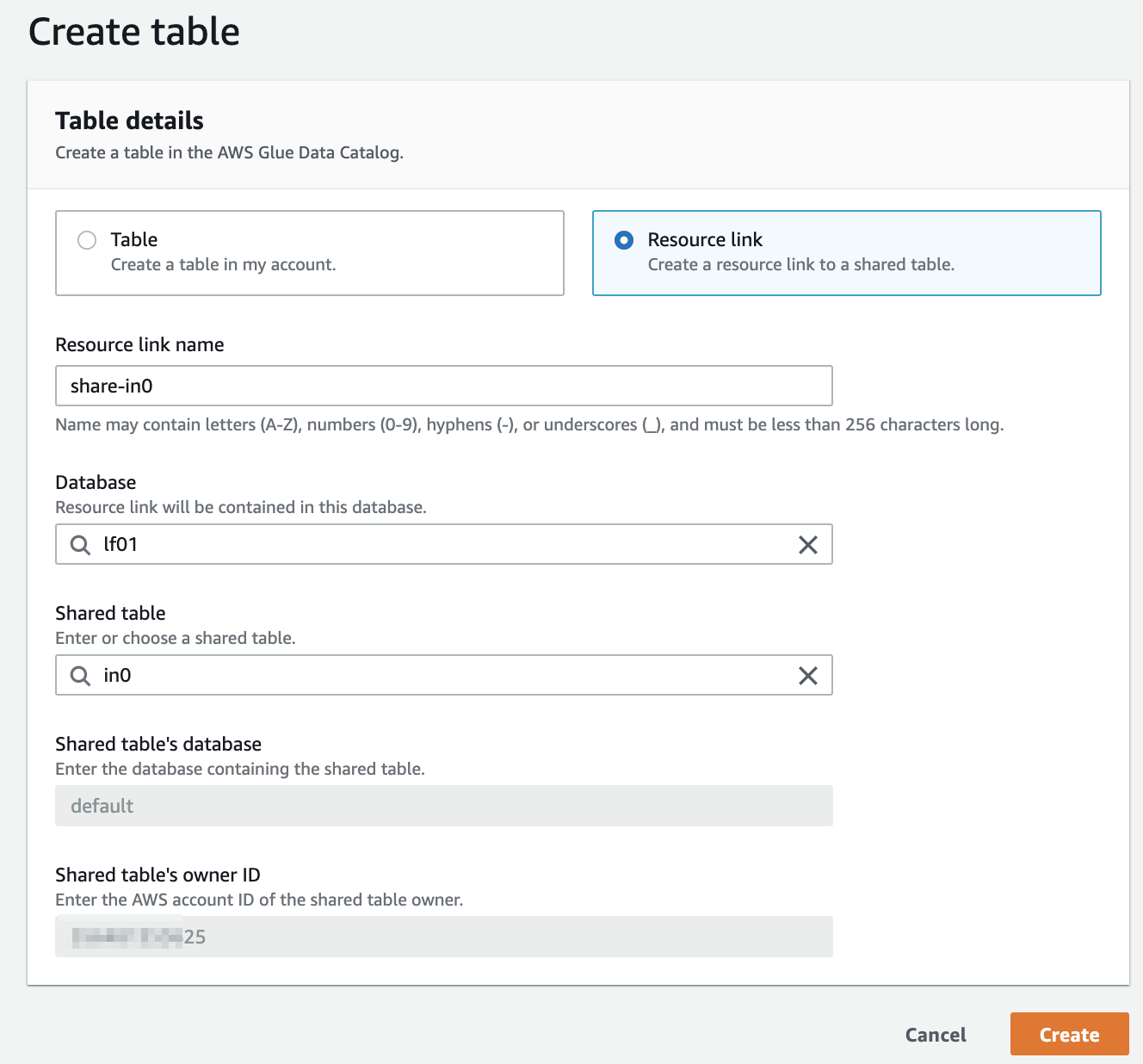
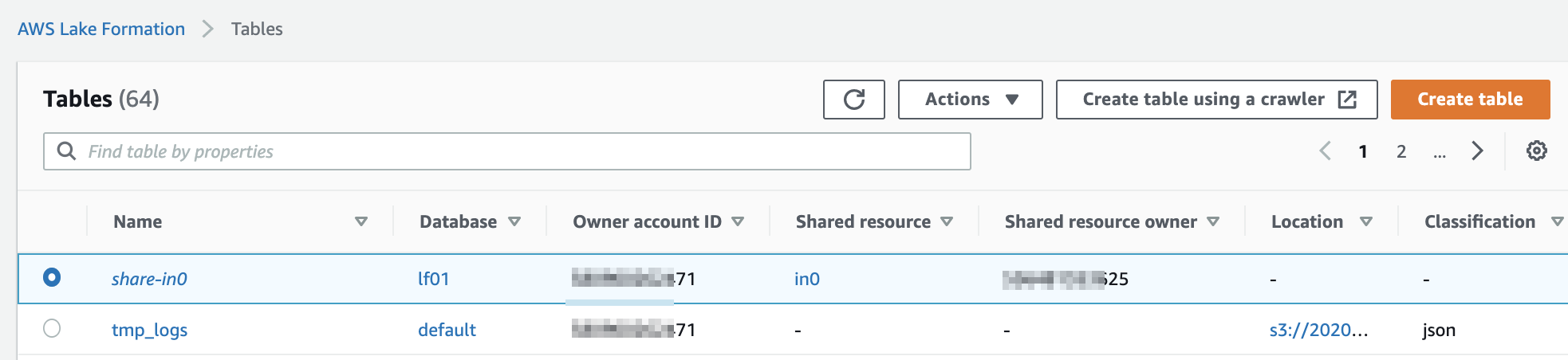
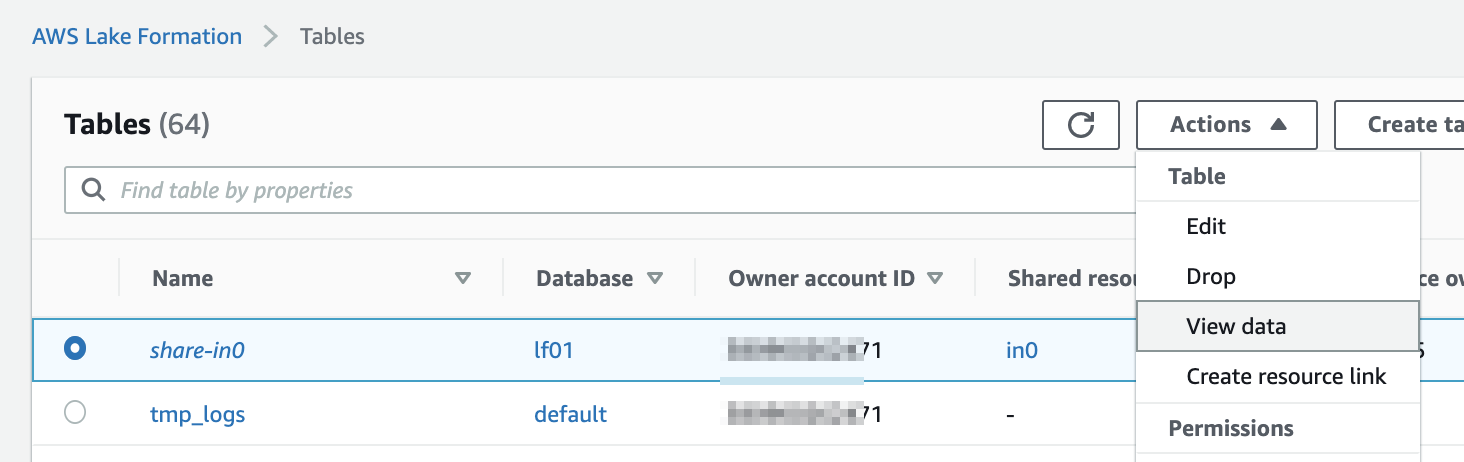
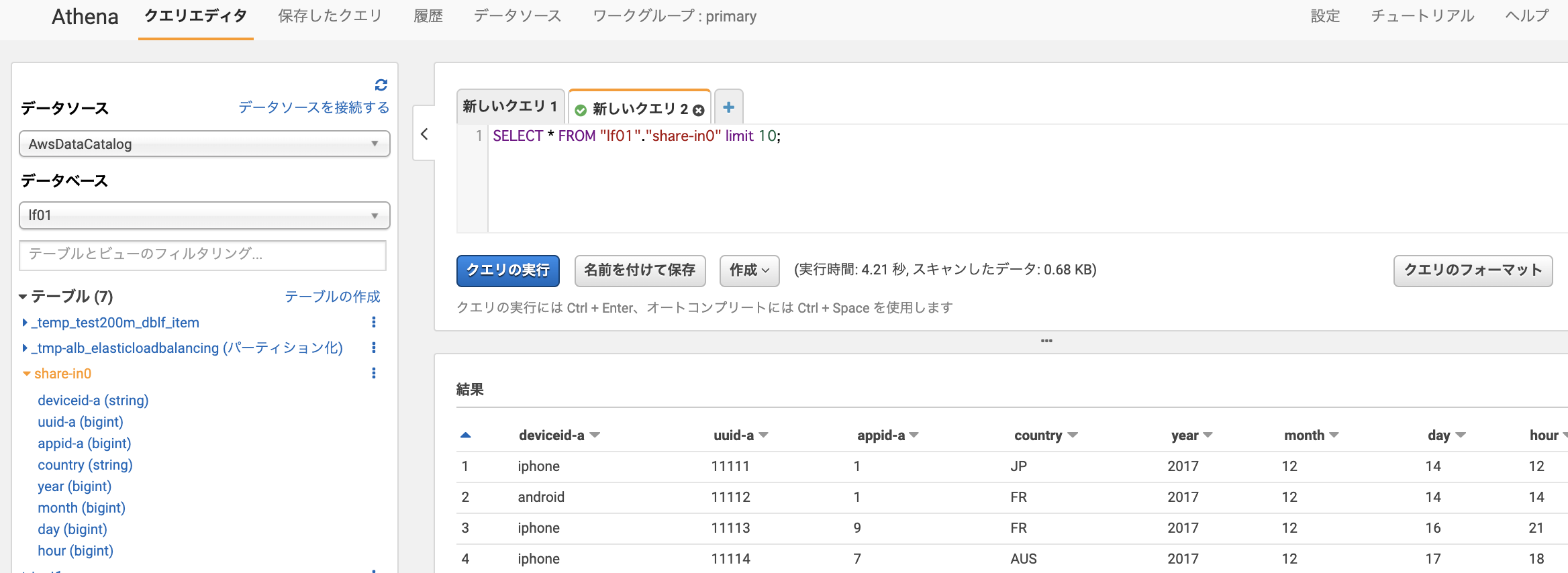
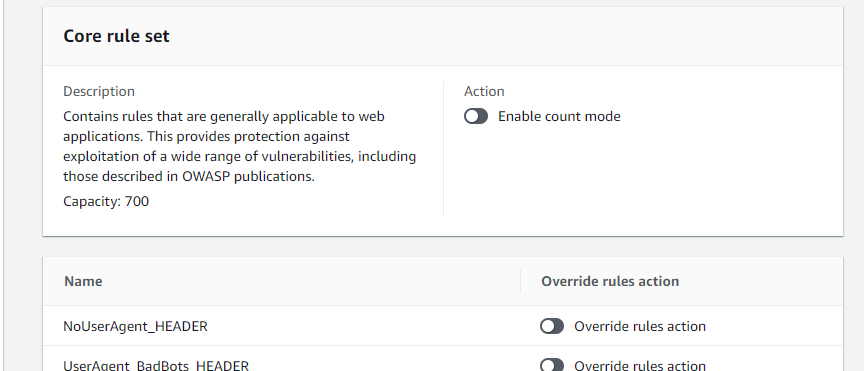
データベース側に「Use only IAM access control for new tables in this database」(このデータベースの新しいテーブルにIAMAllowPrincipalsを付ける)の設定があるか確認します。あればチェックを外しておきます
今回はdefaultという名前のデータベース
せっかく RAML で API ドキュメントを作ってもローカルでしか閲覧できないのは悲しいよねって話
はじめに
API ドキュメントの管理を Excel や Word などから Raml のような API ドキュメンテーションツールに切り替えるチームも増えていると思います。しかし作成した API ドキュメントはプロジェクトを git clone してローカルで閲覧する、というようなちょっと残念な方法をとっているチームもあるような気がします。
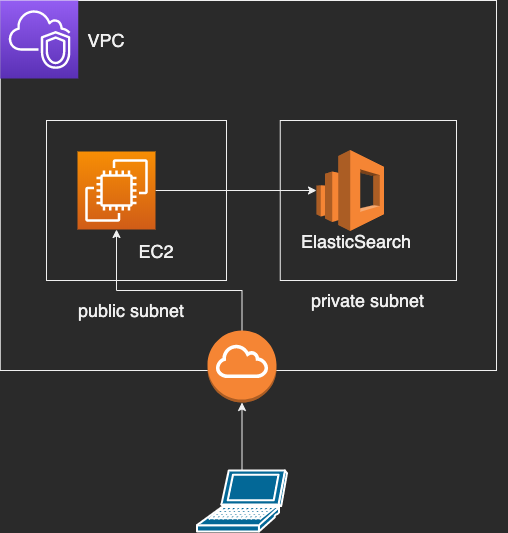
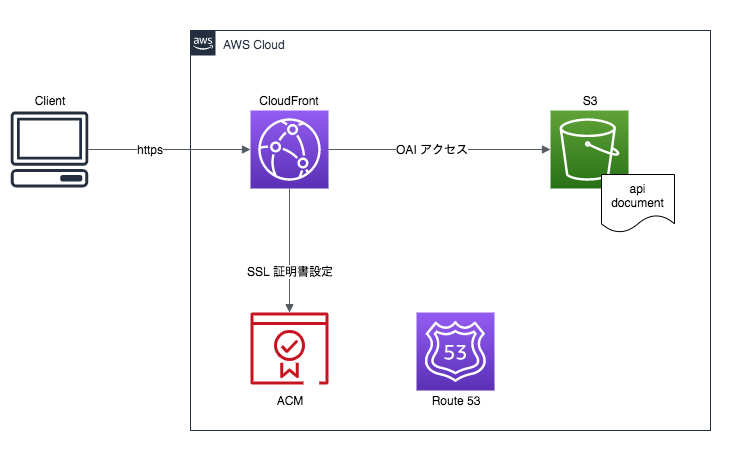
そこで本記事では、作成した API ドキュメントを AWS にサクッと数分でホスティングする方法をまとめました。本記事では API ドキュメントを対象としますが、ホスティング対象は静的コンテンツであれば何でも構いません。
yuta@DESKTOP-PT34LID:~$ curl https://test.vamdemic.black -H "User-Agent:a"
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<title>302 Found</title>
</head><body>
<h1>Found</h1>
<p>The document has moved <a href="https://test.vamdemic.black/dist/">here</a>.</p>
</body></html>
yuta@DESKTOP-PT34LID:~$