- 投稿日:2020-07-31T23:50:35+09:00
yukicoder contest 259 参戦記
yukicoder contest 259 参戦記
A 1139 Slime Race
「衝突時間を順番に割り出して処理していかないといけない、すごい難しい!」と思わせておいて、速度が引き継がれるので、衝突がないとしても同じだった. 引っ掛けられた、やられた.
速度の合計でDを割って切り上げたのが答え.
N, D = map(int, input().split()) x = list(map(int, input().split())) v = list(map(int, input().split())) t = sum(v) print((D + t - 1) // t)B 1140 EXPotentiaLLL!
解けず. フェルマーの小定理が絡んでいるのかなあと悩んだけど、数式変換思いつかず.
C 1141 田グリッド
累積積で簡単に解けるやーと書いた後に、Ai,j が0の時に何が起こるかを考えて無くてハマった.
0を除いた累積積を、全部と各行と各列に対して計算する. 上からri行目、または左からci列目を塗りつぶしてもまだ0が残っていたら、そのクエリの答えは0. 0が残っていなかったら、事前に計算した累積積を使って O(1) でクエリの答えを計算すればいい.
H, W = map(int, input().split()) A = [list(map(int, input().split())) for _ in range(H)] Q = int(input()) m = 1000000007 total = 1 rows = [1] * H cols = [1] * W totalm = 0 rowsm = [0] * H colsm = [0] * W for i in range(H): for j in range(W): x = A[i][j] if x == 0: totalm += 1 rowsm[i] += 1 colsm[j] += 1 else: total *= x total %= m rows[i] *= x rows[i] %= m cols[j] *= x cols[j] %= m result = [] for _ in range(Q): r, c = map(lambda x: int(x) - 1, input().split()) x = A[r][c] t = 0 if x == 0: t = 1 if totalm - rowsm[r] - colsm[c] + t > 0: result.append(0) else: if x == 0: result.append(total * pow(rows[r], -1, m) % m * pow(cols[c], -1, m) % m) else: result.append(total * pow(rows[r], -1, m) % m * pow(cols[c], -1, m) % m * x % m) print(*result, sep='\n')
- 投稿日:2020-07-31T23:43:43+09:00
【機械学習】カーネル密度推定を使った教師あり学習
カーネル密度推定を使った教師あり学習
この記事は機械学習の初心者が書いています。
予めご了承ください。What's カーネル密度推定
ぶっちゃけWIkipediaを見たほうが早い。
横軸が年齢、縦軸が自動車事故の死亡数であるヒストグラムを想像してください。
10代と高齢者が高く、それ以外は低いグラフになります。
ここから「10代・高齢者なら自動車事故で死亡する確率が高い」「そうでなければ相対的に確率が低い」と言えます。
グラフが高い部分では生じる確率が高く、グラフが低い部分では生じる確率が低い……。
どこかで聞いたことがないでしょうか?これは確率密度関数の考えと同じです。
このヒストグラムは、
自動車事故で死亡する確率の真の確率密度関数を実際の死亡者数をもとに推定したものになります。
カーネル関数を使ってもっと連続的に、もっとなめらかに推定する方法がカーネル密度推定です。What's 教師あり学習
Wikipedia先生を見るか、他の方のQiitaを読もう。
カーネル密度推定と教師あり学習
教師あり学習の「教師」は、「データ」と「正解ラベル」のセットです。
正解ラベルが「0, 1, 2」のデータセットを考えましょう。
これをラベル0のデータ、ラベル1のデータ、ラベル2のデータに分けます。ここで正解ラベルが0の教師データを使ってカーネル密度推定をすると、ラベルが0になるデータの確率密度関数が推定できるはずです!
つまり「ここらへんのデータはラベルが0になる確率が高い」「ここらへんのデータはラベルが0になる確率が低い」ということが計算できます。教師データを用いて、0~2すべてのラベルについてカーネル密度推定を行います。これが学習に相当します。
3つの確率密度関数を推定できれば、すべての点について「ラベル0になる確率」「ラベル1になる確率」「ラベル2になる確率」が求まります。
この確率密度関数にテストデータを代入し、一番確率が高いラベルを「テストデータの予測ラベル」として出力しましょう。
という仮説です。とりあえず実装してみよう
この世界は素晴らしい。
なぜなら、ガウシアンカーネルを用いたカーネル密度推定がSciPyで既に実装されているのだから。Gaussian KDEの使い方
SciPyのgaussian_kdeの使い方を簡単にまとめます。
カーネル密度推定を行う
kernel = gaussian_kde(X, bw_method="scotts_factor", weights="None")
- X : カーネル密度推定を行うデータセット。
- bw_method : カーネルのバンド幅。指定しない場合はscotts_factor。
- weights : カーネル密度推定を行う際のウェイト。指定しない場合はすべて均等なウェイト。
確率を計算する
推定された確率密度関数に新たなデータを入力して、確率を計算します。
probabilities = kernel.evaluate(Z)
- Z : 確率を計算したいデータ点(複数可)。
Zの確率が格納されたリスト配列として返されます。
教師あり学習を行ってみる
Scikit-learnのirisデータセットで試してみましょう!
流れはこんな感じ
irisデータセット読み込み
→train_test_splitで訓練データとテストデータを分割
→訓練データとテストデータの標準化
→訓練データを使ってラベルごとにカーネル密度推定を実行
→テストデータのラベル別確率を計算
→一番確率が高いラベルを出力↓スクリプト↓
from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from scipy.stats import gaussian_kde # irisデータセットの読み込み iris = datasets.load_iris() X = iris.data y = iris.target # 訓練データ、テストデータの分割 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1, stratify=y) # 標準化 sc = StandardScaler() sc = sc.fit(X_train) X_train_std = sc.transform(X_train) X_test_std = sc.transform(X_test) # カーネル密度推定 kernel0 = gaussian_kde(X_train_std[y_train==0].T) kernel1 = gaussian_kde(X_train_std[y_train==1].T) kernel2 = gaussian_kde(X_train_std[y_train==2].T) # テストデータの確率を計算 p0s = kernel0.evaluate(X_test_std.T) p1s = kernel1.evaluate(X_test_std.T) p2s = kernel2.evaluate(X_test_std.T) # 予測ラベルの出力 y_pred = [] for p0, p1, p2 in zip(p0s, p1s, p2s): if max(p0, p1, p2) == p0: y_pred.append(0) elif max(p0, p1, p2) == p1: y_pred.append(1) else: y_pred.append(2)標準化の注意事項
訓練データの平均と標準偏差を用いてテストデータの標準化を行います。
別々に標準化を行うと、データに偏り・ズレが生じてしまうことがあるからです。カーネル密度推定の注意事項
gaussian_kdeにそのままデータセットを読み込ませると、列ベクトルが1つのデータとして処理されるようです。
しかしirisデータセットは行ベクトルが1つのデータなので、データを転置します。
テストデータの確率を計算する際も同様です。予測ラベルの出力
y_pred = [] for p0, p1, p2 in zip(p0s, p1s, p2s): if max(p0, p1, p2) == p0: y_pred.append(0) elif max(p0, p1, p2) == p1: y_pred.append(1) else: y_pred.append(2)テストデータの確率は、ラベルごとにp0s、p1s、p2sに格納されます。
それぞれ1つずつ取り出し、
- ラベル0の確率が最大なら0
- ラベル1の確率が最大なら1
- そうでなければ2
結果をテストデータの順にリストy_predに格納します。
結果発表
scikit-learnのaccuracy_scoreで予測ラベルの正解率を確かめよう。
ドキドキ。from sklearn.metrics import accuracy_score print(accuracy_score(y_test, y_pred)) # 1.0わーい。
最後に
カーネル密度推定の結果を教師あり学習の分類器にしてみました。
現実には、このような手法はあまり使われていません。
計算量が多くなったり、データによって精度が著しく落ちたりする欠点があるのだと思います。しかし今回の試行から、データによっては割と速く、いい感じに分類できることがわかりました。
また「確率密度関数を推定して最も確率が高いラベルを出力する」という過程は、直感的に理解しやすいです。wineデータセットと円型データセットで試した結果もありますので、機会があったらまとめます。
- 投稿日:2020-07-31T21:16:51+09:00
YOLP Yahoo!スタティックマップAPI で地図情報 XML ファイルを取得する
概要
- Python で YOLP Yahoo!スタティックマップAPI をコールして地図画像と地図情報XMLを取得する
- YOLP Yahoo!スタティックマップAPI の output パラメータに xml を指定すると、output=xml ではないときに取得する地図画像についての情報を XML で取得できる
- 動作確認環境: macOS Catalina + Python 3.8.5
Python によるプログラム
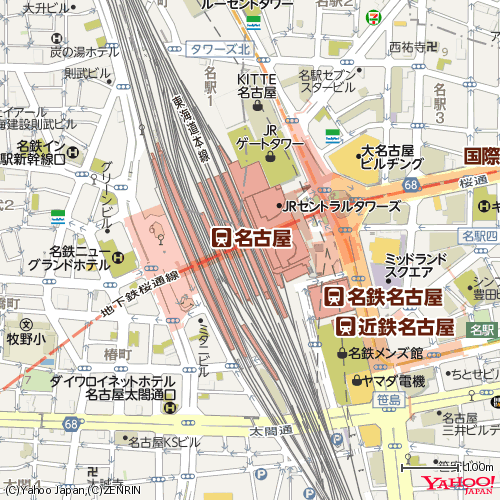
from urllib.request import Request, urlopen import xml.dom.minidom as MD appid = 'YOUR APPLICATION ID' # アプリケーションIDを指定 headers = {'User-Agent': 'Yahoo AppID: {0}'.format(appid)} # lat=中心の緯度, lon=中心の経度, z=縮尺レベル, output=出力形式 # 今回は名古屋駅の緯度・経度を指定 png_url = 'https://map.yahooapis.jp/map/V1/static?lat=35.170476&lon=136.882250&z=17' xml_url = 'https://map.yahooapis.jp/map/V1/static?lat=35.170476&lon=136.882250&z=17&output=xml' # 地図の画像をダウンロードして保存 req = Request(png_url, headers=headers) with urlopen(req) as res: with open ('map.png', mode='wb') as file: file.write(res.read()) # 地図情報のXMLを出力 req = Request(xml_url, headers=headers) with urlopen(req) as res: body = res.read().decode('utf-8') with open ('map.xml', mode='w') as file: # XML を整形して出力 dom = MD.parseString(body) dom.writexml(file, addindent=' ', newl='\n', encoding='utf-8')出力結果
地図画像
取得した地図画像。
地図情報XML
主な要素と属性の意味。
- Coordinates: 地図の中心座標
- Coordinate-UL: 地図左上の座標
- Coordinate-UR: 地図右上の座標
- Coordinate-DL: 地図左下の座標
- Coordinate-DR: 地図右下の座標
- Image: 地図のサイズ (単位: pixel)
- Scales: 地図の中心座標にて地図が表示可能な縮尺値のリスト
- mode: 地図の種類
- Scale: 縮尺値
- zlevel: 縮尺レベル
- sc: 縮尺ID
取得した XML ファイル。
map.xml<?xml version="1.0" encoding="utf-8"?> <ResultSet xmlns="urn:yahoo:jp:olp:static" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="urn:yahoo:jp:olp:static http://olp.yahooapis.jp/OpenLocalPlatform/V1/staticResponse.xsd"> <Result> <Coordinates datum="WGS84" format="lon,lat">136.88225,35.170476</Coordinates> <Coordinate-UL> <Coordinates datum="WGS84" format="lon,lat">136.8768855819702,35.1748609813922</Coordinates> </Coordinate-UL> <Coordinate-UR> <Coordinates datum="WGS84" format="lon,lat">136.8876144180298,35.1748609813922</Coordinates> </Coordinate-UR> <Coordinate-DL> <Coordinates datum="WGS84" format="lon,lat">136.8768855819702,35.1660907821191</Coordinates> </Coordinate-DL> <Coordinate-DR> <Coordinates datum="WGS84" format="lon,lat">136.8876144180298,35.1660907821191</Coordinates> </Coordinate-DR> <Scale zlevel="17" sc="4">23842</Scale> <Image> <Width>500</Width> <Height>500</Height> </Image> <Scales mode="map"> <Scale zlevel="1" sc="20">1562498438</Scale> <Scale zlevel="2" sc="19">781249219</Scale> <Scale zlevel="3" sc="18">390624609</Scale> <Scale zlevel="4" sc="17">195312305</Scale> <Scale zlevel="5" sc="16">97656152</Scale> <Scale zlevel="6" sc="15">48828076</Scale> <Scale zlevel="7" sc="14">24414038</Scale> <Scale zlevel="8" sc="13">12207019</Scale> <Scale zlevel="9" sc="12">6103510</Scale> <Scale zlevel="10" sc="11">3051755</Scale> <Scale zlevel="11" sc="10">1525877</Scale> <Scale zlevel="12" sc="9">762939</Scale> <Scale zlevel="13" sc="8">381469</Scale> <Scale zlevel="14" sc="7">190735</Scale> <Scale zlevel="15" sc="6">95367</Scale> <Scale zlevel="16" sc="5">47684</Scale> <Scale zlevel="17" sc="4">23842</Scale> <Scale zlevel="18" sc="3">11921</Scale> <Scale zlevel="19" sc="2">5960</Scale> <Scale zlevel="20" sc="1">2980</Scale> </Scales> <Scales mode="map-mobile"> <Scale zlevel="1" sc="20">1562498438</Scale> <Scale zlevel="2" sc="19">781249219</Scale> <Scale zlevel="3" sc="18">390624609</Scale> <Scale zlevel="4" sc="17">195312305</Scale> <Scale zlevel="5" sc="16">97656152</Scale> <Scale zlevel="6" sc="15">48828076</Scale> <Scale zlevel="7" sc="14">24414038</Scale> <Scale zlevel="8" sc="13">12207019</Scale> <Scale zlevel="9" sc="12">6103510</Scale> <Scale zlevel="10" sc="11">3051755</Scale> <Scale zlevel="11" sc="10">1525877</Scale> <Scale zlevel="12" sc="9">762939</Scale> <Scale zlevel="13" sc="8">381469</Scale> <Scale zlevel="14" sc="7">190735</Scale> <Scale zlevel="15" sc="6">95367</Scale> <Scale zlevel="16" sc="5">47684</Scale> <Scale zlevel="17" sc="4">23842</Scale> <Scale zlevel="18" sc="3">11921</Scale> <Scale zlevel="19" sc="2">5960</Scale> <Scale zlevel="20" sc="1">2980</Scale> </Scales> <Scales mode="photo"> <Scale zlevel="1" sc="20">1562498438</Scale> <Scale zlevel="2" sc="19">781249219</Scale> <Scale zlevel="3" sc="18">390624609</Scale> <Scale zlevel="4" sc="17">195312305</Scale> <Scale zlevel="5" sc="16">97656152</Scale> <Scale zlevel="6" sc="15">48828076</Scale> <Scale zlevel="7" sc="14">24414038</Scale> <Scale zlevel="8" sc="13">12207019</Scale> <Scale zlevel="9" sc="12">6103510</Scale> <Scale zlevel="10" sc="11">3051755</Scale> <Scale zlevel="11" sc="10">1525877</Scale> <Scale zlevel="12" sc="9">762939</Scale> <Scale zlevel="13" sc="8">381469</Scale> <Scale zlevel="14" sc="7">190735</Scale> <Scale zlevel="15" sc="6">95367</Scale> <Scale zlevel="16" sc="5">47684</Scale> <Scale zlevel="17" sc="4">23842</Scale> <Scale zlevel="18" sc="3">11921</Scale> <Scale zlevel="19" sc="2">5960</Scale> <Scale zlevel="20" sc="1">2980</Scale> <Scale zlevel="21" sc="1">1490</Scale> </Scales> <Scales mode="hybrid"> <Scale zlevel="1" sc="20">1562498438</Scale> <Scale zlevel="2" sc="19">781249219</Scale> <Scale zlevel="3" sc="18">390624609</Scale> <Scale zlevel="4" sc="17">195312305</Scale> <Scale zlevel="5" sc="16">97656152</Scale> <Scale zlevel="6" sc="15">48828076</Scale> <Scale zlevel="7" sc="14">24414038</Scale> <Scale zlevel="8" sc="13">12207019</Scale> <Scale zlevel="9" sc="12">6103510</Scale> <Scale zlevel="10" sc="11">3051755</Scale> <Scale zlevel="11" sc="10">1525877</Scale> <Scale zlevel="12" sc="9">762939</Scale> <Scale zlevel="13" sc="8">381469</Scale> <Scale zlevel="14" sc="7">190735</Scale> <Scale zlevel="15" sc="6">95367</Scale> <Scale zlevel="16" sc="5">47684</Scale> <Scale zlevel="17" sc="4">23842</Scale> <Scale zlevel="18" sc="3">11921</Scale> <Scale zlevel="19" sc="2">5960</Scale> <Scale zlevel="20" sc="1">2980</Scale> <Scale zlevel="21" sc="1">1490</Scale> </Scales> <Scales mode="map-b1"> <Scale zlevel="19" sc="3">5960</Scale> <Scale zlevel="20" sc="2">2980</Scale> <Scale zlevel="21" sc="1">1490</Scale> </Scales> <Scales mode="hd"> <Scale zlevel="1" sc="20">1562498438</Scale> <Scale zlevel="2" sc="19">781249219</Scale> <Scale zlevel="3" sc="18">390624609</Scale> <Scale zlevel="4" sc="17">195312305</Scale> <Scale zlevel="5" sc="16">97656152</Scale> <Scale zlevel="6" sc="15">48828076</Scale> <Scale zlevel="7" sc="14">24414038</Scale> <Scale zlevel="8" sc="13">12207019</Scale> <Scale zlevel="9" sc="12">6103510</Scale> <Scale zlevel="10" sc="11">3051755</Scale> <Scale zlevel="11" sc="10">1525877</Scale> <Scale zlevel="12" sc="9">762939</Scale> <Scale zlevel="13" sc="8">381469</Scale> <Scale zlevel="14" sc="7">190735</Scale> <Scale zlevel="15" sc="6">95367</Scale> <Scale zlevel="16" sc="5">47684</Scale> <Scale zlevel="17" sc="4">23842</Scale> <Scale zlevel="18" sc="3">11921</Scale> <Scale zlevel="19" sc="2">5960</Scale> <Scale zlevel="20" sc="1">2980</Scale> </Scales> <Scales mode="hd-mobile"> <Scale zlevel="1" sc="20">1562498438</Scale> <Scale zlevel="2" sc="19">781249219</Scale> <Scale zlevel="3" sc="18">390624609</Scale> <Scale zlevel="4" sc="17">195312305</Scale> <Scale zlevel="5" sc="16">97656152</Scale> <Scale zlevel="6" sc="15">48828076</Scale> <Scale zlevel="7" sc="14">24414038</Scale> <Scale zlevel="8" sc="13">12207019</Scale> <Scale zlevel="9" sc="12">6103510</Scale> <Scale zlevel="10" sc="11">3051755</Scale> <Scale zlevel="11" sc="10">1525877</Scale> <Scale zlevel="12" sc="9">762939</Scale> <Scale zlevel="13" sc="8">381469</Scale> <Scale zlevel="14" sc="7">190735</Scale> <Scale zlevel="15" sc="6">95367</Scale> <Scale zlevel="16" sc="5">47684</Scale> <Scale zlevel="17" sc="4">23842</Scale> <Scale zlevel="18" sc="3">11921</Scale> <Scale zlevel="19" sc="2">5960</Scale> <Scale zlevel="20" sc="1">2980</Scale> </Scales> <Scales mode="loco"> <Scale zlevel="1" sc="20">1562498438</Scale> <Scale zlevel="2" sc="19">781249219</Scale> <Scale zlevel="3" sc="18">390624609</Scale> <Scale zlevel="4" sc="17">195312305</Scale> <Scale zlevel="5" sc="16">97656152</Scale> <Scale zlevel="6" sc="15">48828076</Scale> <Scale zlevel="7" sc="14">24414038</Scale> <Scale zlevel="8" sc="13">12207019</Scale> <Scale zlevel="9" sc="12">6103510</Scale> <Scale zlevel="10" sc="11">3051755</Scale> <Scale zlevel="11" sc="10">1525877</Scale> <Scale zlevel="12" sc="9">762939</Scale> <Scale zlevel="13" sc="8">381469</Scale> <Scale zlevel="14" sc="7">190735</Scale> <Scale zlevel="15" sc="6">95367</Scale> <Scale zlevel="16" sc="5">47684</Scale> <Scale zlevel="17" sc="4">23842</Scale> <Scale zlevel="18" sc="3">11921</Scale> <Scale zlevel="19" sc="2">5960</Scale> <Scale zlevel="20" sc="1">2980</Scale> </Scales> <Positions/> <Copyright>(C)Yahoo Japan,(C)ZENRIN</Copyright> </Result> </ResultSet>参考資料
- 投稿日:2020-07-31T20:58:08+09:00
【Python】numpyでの計算方法
numpyでの計算
numpyを使用して0~10の配列を作ります。
import numpy as np arr = np.arange(11) arr実行結果.array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])sqrtメソッドを使用することで各数字の平方根の計算できます。
np.sqrt(arr)実行結果.array([ 0.48273727, -1.28739284, 1.52422575, -1.73666091, -0.25126809, -0.41952278, -0.75042054, -0.64585434, -0.86014472, -0.44542315])random.randn()で正規分布(平均=0,分散=1)の乱数を計算することができます。
A = np.random.randn(10)実行結果.array([-0.94897439, -0.43075947, 0.088691 , 0.37859721, -0.2141078 , 1.30327378, 0.41654781, -0.42907224, -1.61139916, -0.651694 ])addメソッドを使用することで足し算をすることができます。
B = np.random.randn(10) B array([ 0.05623043, 1.97843447, -0.02581691, 0.70663108, 0.51213852, -0.70386143, 1.50729471, -0.00577632, -1.08456477, -0.38103167]) np.add(A,B)実行結果.array([ 0.5389677 , 0.69104164, 1.49840884, -1.03002983, 0.26087043, -1.1233842 , 0.75687417, -0.65163066, -1.94470949, -0.82645482])subtractメソッドで引き算ができます。
np.subtract(A,B)実行結果.array([ 0.42650684, -3.26582731, 1.55004266, -2.44329199, -0.76340661, 0.28433865, -2.25771524, -0.64007803, 0.22442006, -0.06439147])multiplyメソッドで掛け算ができます。
np.multiply(A,B)実行結果.array([ 0.02714452, -2.54702237, -0.0393508 , -1.22717858, -0.12868407, 0.2952859 , -1.1311049 , 0.00373066, 0.93288266, 0.16972033])divideメソッドで割り算ができます。
np.divide(A,A)実行結果.array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
- 投稿日:2020-07-31T19:37:17+09:00
「ほん訳コンニャク」 を食べて 論文を読もう
TL;DR;
以下の「ほん訳こんにゃく」を作った。
作りたかったもの
研究室配属で、かねてから取り組みたかった 「シナプス可塑性におけるmiRNA機能とそれらが記憶や学習などの高次認知機能に与える影響の解明」 を自分の研究テーマ(※暫定)にすることができ、生物系の論文を読む機会が圧倒的に増えたのですが、元々深層学習系統の論文しか読んでいなかったため、常識や背景知識不足に悩まされ、DeepLやGoogle Translateなしには論文が読めないという日々が続いていました。
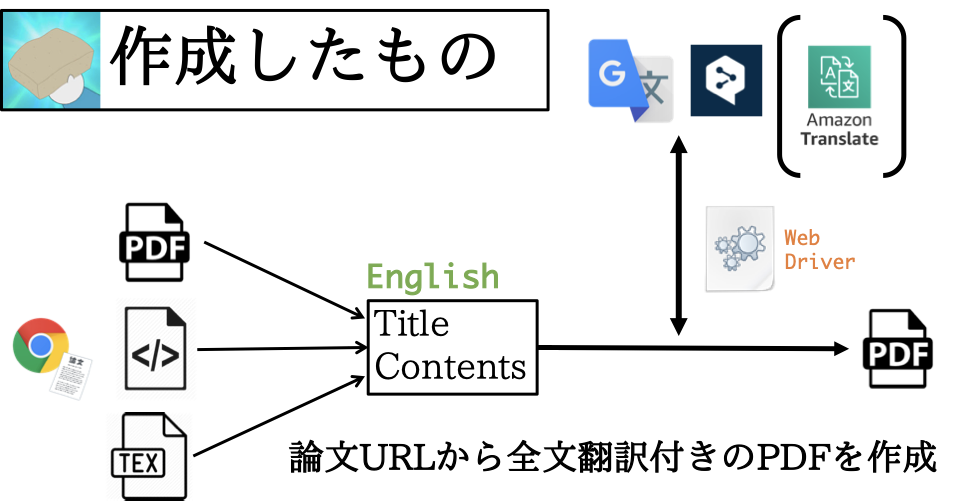
論文を読みながら適宜翻訳するのは非効率ですし、iPadにPDFを保存して電車内で読むなんてこともできず、かといって全部一度翻訳するのは非常に面倒で、「これ、自動化したいな〜」と思ったので、「論文のURLを投げれば、全文翻訳付きのPDFを生成するプログラム」を作りました。
論文たくさん読みたいけど英語の勉強もしたいので、url投げたら全文翻訳付きのPDFに変換してもらうことにした。 pic.twitter.com/dMvqU2PBa4
— しゅーと (@cabernet_rock) June 29, 2020Python Package
まず、Pythonでライブラリ(Translation-Gummy)を作成しました。先に述べたことを実現するために必要な機能は
- URLから論文の内容をスクレイピング →
requests,Beautiful Soup,pdfminer,pylatexenc- スクレイピングした内容(英語)を日本語に翻訳 →
selenium, DeepL, Google Translate- 両者を並べたPDFを作成 →
jinja2,pdfkitですが、それぞれ右に記した各種ライブラリ/サービスを使えば、実現可能です。
なお、翻訳の際に
seleniumの WebDriver を使っていますが、これは以下のようにrequests.getでサイト(https://translate.google.co.jp/#ja/en/これはペンです)の内容を取得しても、動的なサイトであるため翻訳結果を取得することができないためです。# coding:utf-8 import requests from bs4 import BeautifulSoup html = requests.get("https://translate.google.co.jp/#ja/en/これはペンです").content soup = BeautifulSoup(markup=html, features="html.parser") :※ より詳しいプログラムコードが見たい方は、Githubからどうぞ。
PDF converter
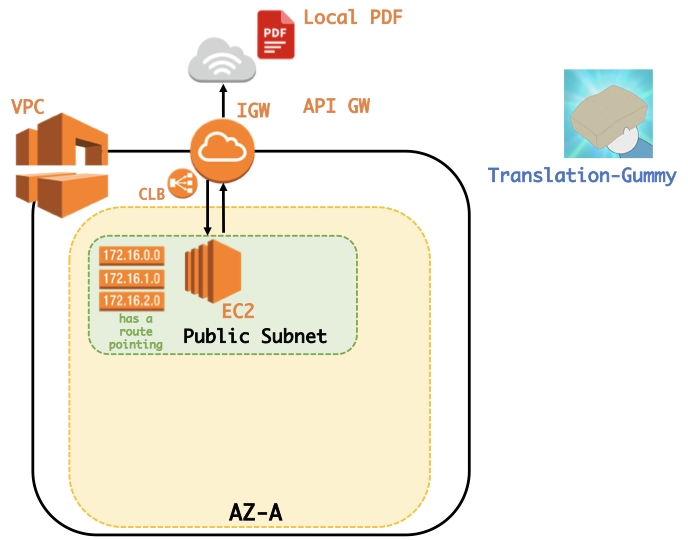
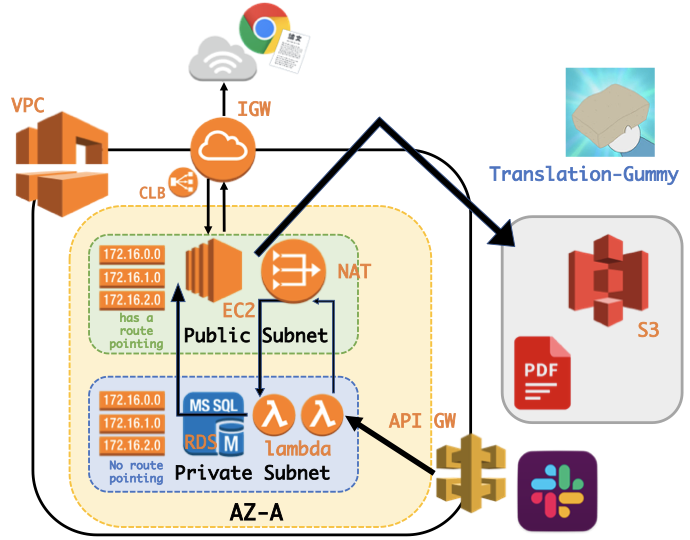
ローカルにあるPDFファイルを翻訳してくれるWebサイトがあれば良いなと思い、作成しました。ここではpdfminerを用いて翻訳を行っていますが、かなり雑な実装になってしまっているので、Pull requests をお待ちしています。(gummy.journals.LocalPDFCrawlerというクラスを用いています。)なお、WebサイトはAWSのEC2を使って公開しております。
PythonしかかけないけどWebサイトを公開したい、という方はこの記事:『PythonかければWebアプリぐらい作れる。』が参考になるかと思います。(自分の記事を紹介してしまい、すみません。)
Slack App
Slack App として、コマンドで呼び出せれば楽だと思い、作成し公開しました。
この時、
- OAuth認証を用いてワークスペースに基づいた
SLACK ACCESS TOKENを取得し、BOT投稿するためにPrivate Subnet内のRDSにSLACK ACCESS TOKENを保存する。- lambdaからデータベースへの多すぎるコネクションにより過負荷になることを避けるため、RDS PRoxyを使用し、コネクションプールを確立および管理をする。
- Slack Botに3秒以内にレスポンスを返さないといけないためlambdaからlambdaを非同期で呼ぶ。
- Private Subnet内のlambdaから直接lambdaを呼べないため、Public subnetに配置したNAT Gatewayを利用する。
- 負荷を分散するためにLoad Balancerを設置する。
などの機能を実現するため、以下のような少し複雑な構成となってしまいました。(改良点等あればコメントでご指摘ください?♂️)
終わりに
自分の欲しい機能を全て実現したサービスができたと思います。対応ジャーナルの数を増やしたり、PDFの解析をより正確に行ったり、PDFをより綺麗に整えたりとまだまだ足りない機能は多々ありますが、使っていただけると幸いです。

- 投稿日:2020-07-31T19:33:51+09:00
Pythonの無限スクロールスクレイピングの終わらせ方
Pythonで無限スクロールがあるWebページのスクレイピングを実装中、終わらせ方がわからなくてつまづいたのでメモ
サンプル
>>> t = 0 >>> start_at = time.time() >>> t = time.time() - start_at >>> t == 5 >>> break解説
start_atは、実行してから経過している時間
tは、その差
tが5(5秒経過)になると、処理を終了する参考
https://note.nkmk.me/python-datetime-timedelta-measure-time/
https://ai-inter1.com/python-selenium/#st-toc-h-14
- 投稿日:2020-07-31T19:32:56+09:00
PythonとFlaskで類似画像を検索できるアプリを作ってみようPart1
PythonとFlaskで類似画像を検索できるアプリを作ってみようPart1
概要
タイトルの通りです。今回は簡単にデータが手に入ってかつデータサイズも小さいご存知MNISTに対してMNISTの画像を入れると似たMNISTの画像を見つけてくれる、そんなアプリを作ることで近似近傍探索についての話とFlaskを使ったアプリ作りについての話を自分のメモもかねて書いていきます。
手順
作業ディレクトリをつくろう!
- 作業ディレクトリ
適当に名前を決めていいですが、私は調子に乗って SSAM-SimilaritySearchAppwithMNIST なんて洒落た名前をつけてみました。
- MNIST用ディレクトリ
次にMNISTのデータを保存しておくフォルダを作成しましょう。そうしないと毎回ダウンロードしてくる必要があって面倒です。
static/mnist_dataみたいな名前でフォルダを作っておきましょう。
- 現在のディレクトリ構成はこんな感じです
SSAM-SimilaritySearchAppwithMNIST └── static └── mnist_dataMNISTデータをダウンロードしてこよう!
MNISTって何?
有名なので、今更説明もいらないと思いますが知らない人のために説明すると、28x28サイズの手書きの数字の画像です。
手軽に使えるデータなので、よく機械学習のモデルの精度の評価に使われたりしますが、まぁそれはそれは綺麗なデータなので大体精度は高く出ます。
(この記事みたいに)MNISTで高い精度の出るモデルを作れました!みたいな記事はそこんところ注意した方がいいです。おーおー、またMNISTごときでイキってる記事が上がってるぞくらいのスタンスで見た方が安全です。(これはただの自虐ネタのつもりなので他のMNISTを扱う記事を煽ってるわけではないです、本当です。)使用するライブラリ
コードって細かく分割して逐一解説入れながら書いてくのが分かりやすいのか、一気に書いてしまって後から補足説明入れる方が分かりやすいのか少し悩みますね。今後ちょっと考えたいので参考意見があると嬉しいです。(Qiitaにコメント機能があるのかすら知りませんが。)
とりあえず少なくとも、今回使うライブラリはまとめて書いておいた方が親切だと思うのでそうします。pipインストールは適宜各自しておいてください。
import os import gzip import pickle import numpy as np import urllib.request from mnist import MNIST from annoy import AnnoyIndex from sklearn.metrics import accuracy_scoreMNISTをダウンロードする
早速コードを書いていきます。
上でも書きましたがコードって細かく分割して逐一解説入れながら書いてくのが親切なのか、一気に書いてしまって後から補足説明入れる方が親切なのか少し悩みます。そこそこコメント丁寧に書いているので、今回は一気に書いてみますが、ここら辺意見欲しいです。まずMNISTをダウンロードしてくるコードです。
def load_mnist(): # MNISTのデータをダウンロードしてくる url_base = 'http://yann.lecun.com/exdb/mnist/' key_file = { 'train_img':'train-images-idx3-ubyte.gz', 'train_label':'train-labels-idx1-ubyte.gz', 'test_img':'t10k-images-idx3-ubyte.gz', 'test_label':'t10k-labels-idx1-ubyte.gz' } # ファイルをダウンロード(.gz形式) for filename in key_file.values(): file_path = f'./static/mnist_data/{filename}' # 読み込んでくる.gzファイルのパス if os.path.isfile(file_path.replace('.gz', '')): continue # すでにファイルがあるときは飛ばす urllib.request.urlretrieve(url_base + filename, file_path) # .gzの解凍と.gzファイルの削除 with gzip.open(file_path, mode='rb') as f: mnist = f.read() # 解凍して保存 with open(file_path.replace('.gz', ''), 'wb') as w: w.write(mnist) os.remove(file_path) # .gzファイルの削除 # mnistのデータをnp.arrayの形に読み込んで返す mndata = MNIST('./static/mnist_data/') # train images, labels = mndata.load_training() train_images, train_labels = np.reshape(np.array(images), (-1,28,28)), np.array(labels) # np.arrayに変換する mnistの画像は28x28 # test images, labels = mndata.load_testing() test_images, test_labels = np.reshape(np.array(images), (-1,28,28)), np.array(labels) # np.arrayに変換する mnistの画像は28x28 return train_images, train_labels, test_images, test_labels上記コードを実行すると、まずMNISTのデータが置いてある場所から.gzファイルという圧縮されたファイルをダウンロードしてstatic/mnist_data/の下におきます。(./static/mnist_data/は事前にフォルダを作っておかないとフォルダがないよとエラーが出るかもしれません。すみません。)
そしたら.gzを解凍して.gzファイルはいらないので削除しておきます。実はこの解凍してきたファイルはバイナリ形式なので扱いが面倒なのですが、from mnist import MNISTというなんとも間抜けな名前のライブラリを使うとtrain用のデータとtest用のデータで分けてarray型にしてくれる様です。実はここでだいぶ悩んで数時間かけてたりするのはここだけの秘密です。
そんな感じでいつの間にかMNISTデータをダウンロードしてくる関数が完成しました。近似最近傍探索
最近傍探索とは
wikipediaから定義を引用してみると、下の様に書いています。
最近傍探索(英: Nearest neighbor search, NNS)は、距離空間における最も近い点を探す最適化問題の一種、あるいはその解法。近接探索(英: proximity search)、類似探索(英: similarity search)、最近点探索(英: closest point search)などとも呼ぶ。問題はすなわち、距離空間 M における点の集合 S があり、クエリ点 q ∈ M があるとき、S の中で q に最も近い点を探す、という問題である。多くの場合、M には d次元のユークリッド空間が採用され、距離はユークリッド距離かマンハッタン距離で測定される。低次元の場合と高次元の場合で異なるアルゴリズムがとられる。 ~wikipediaより
これを日本語に訳すと、なんらかの類似度を測る関数を決めて、それに基づいて類似度の高い点を見つけてくるアルゴリズムということが書いてあります。つまりそういうことです。
近似?
今回使うアルゴリズムはannoyというものを使うのですが、これには"近似"最近傍探索とついています。この"近似"とはなんなのでしょうか?
実はこの近傍探索アルゴリズム、きちんと計算しようとするとかなり計算資源を食います。例えば最も単純に全画素値の差を計算してみるかwなどと思ってしまった日には大変なことになります。特に画像の場合は縦x横xチャンネル数あるので爆発的に計算時間が伸びます。
今回のMNISTは所詮28x28でしかもグレイスケール(白黒画像)なので大したことはないのですが、よっしゃーお父さん今日は張り切ってフルHD1920×1080の類似画像を愚直に探索するぞーなんてした日にはお父さんは絶望して寝れなくなります。
指数的爆発の怖さについては、計算量おねえさんが体を張って教えてくれます。面白い上に勉強になる最強のコンテンツなので是非知らない人は一度見ておいて、お姉さんの執念に涙しましょう。
『フカシギの数え方』 おねえさんといっしょ! みんなで数えてみよう!今回使うアルゴリズム
似た画像を見つけてくるのに近似最近傍探索ライブラリのannoyと言うものを使います。
これを使う理由は自分が慣れているからというのと、比較的コードが読みやすいと思うからです。アルゴリズムの詳しい内容についてはannoy作者のこのブログNearest neighbors and vector models – part 2 – algorithms and data structuresの解説と、日本語では近似最近傍探索の最前線このスライドシェアの解説がわかりやすいです。この記事を見る前にこっちを見た方がためになります。
面倒くさいやという人のためにここで簡単に説明すると、データポイントが存在する空間を再帰的に区切っていって2分木をいくつか作っておくことで高速にO(logn)近傍を探索できる様にしたアルゴリズムとのことです。とはいえ決定木をビルドする必要はあるのですが。
実はannoyの作者がいくつかの近似最近傍探索ライブラリの比較をして他のライブラリの方がいいぞと勧めてくれてたりします。New approximate nearest neighbor benchmarks
本当に速度を追い求めるならおそらくFacebook謹製のfaissを使うのがいいっぽいのですが、こいつはcondaからしかインストールできないらしくそれだけで使う気をなくします。annoyの使用
少し説明が長くなりました。さっそくannoyを使った近傍探索を試してみましょう。
def make_annoy_db(train_imgs): # 近似近傍探索のライブラリannoyを使う # 入力するデータのshapeとmetricを決めて、データを突っ込んでいく annoy_db = AnnoyIndex((28*28), metric='euclidean') # 入力されるデータと類似度の計算方法を与える、MNISTは28x28のサイズなのでそのまま28*28と書いちゃう for i, train_img in enumerate(train_imgs): annoy_db.add_item(i, train_img.flatten()) # インデックスとそれと対応するデータを入れていく annoy_db.build(n_trees=10) # ビルド annoy_db.save('./static/mnist_db.ann') # static配下に作成したデータベースを保存するこんな感じになるでしょうか。データベースと言う言葉を使っていますが、これは僕が他にいい適切な言葉を知らないだけで厳密にはデータベースとは違います、多分。
ちなみにAnnoyIndexには一次元の配列しか与えられないので画像データを入れたいときはflatten()を使ったり、reshapeしたり、今回の様にハードコーディングしたりしてください。精度をみてみる
近似最近傍探索と言うだけあって厳密な類似度を計算しているわけではないので、もちろん多少の誤差が生じます。(annoyではこれを複数の木を使ったりなんだりして解決してます。詳しくは上記URLで)
本当に精度があるのか、少し確かめてみましょうか。幸いMNISTには各画像とそれに対応する正解ラベルがすでに用意されています。テストデータに対して類似した画像を一つ引っ張って来てもらって、正解と同じかどうか確認してみましょう。
train_imgs, train_lbls, test_imgs, test_lbls = load_mnist() if not os.path.isfile('./static/mnist_db.ann'): make_annoy_db(train_imgs) # .annファイルがまだないなら、annoydbのビルド annoy_db = AnnoyIndex((28*28), metric='euclidean') annoy_db.load('./static/mnist_db.ann') # annoyのデータベースをロードする # テストデータを入力して近い近傍を取ってきて実際と比較することで試しに精度をみてみる y_pred = [train_lbls[annoy_db.get_nns_by_vector(test_img.flatten(), 1)[0]] for test_img in test_imgs] score = accuracy_score(test_lbls, y_pred) print('acc:', score) # 出力 acc: 0.9595なんとも高い精度が出ました。せっかくなら0.2525と出た方がニコ厨かよwとネタにできるのですが現実はそう甘くありません。(いったい僕は何をいってるのでしょうか?)
実際の画像の場合、正解のラベルが同じだからといってそれが本当に似た画像かどうかはなんともいえないのですが(例えばどっちも猫画像だとしても背景が違ったり、黒猫と白猫だったりした場合、人の脳は似た画像だとは判断しない)、このMNISTに限っていえばきれいなデータセットなので多分似た画像が出てきているのでしょう。
全体のコード
ここまでの全体を通してのコードが以下の様になります。
import os import gzip import pickle import numpy as np import urllib.request from mnist import MNIST from annoy import AnnoyIndex from sklearn.metrics import accuracy_score def load_mnist(): # MNISTのデータをダウンロードしてくる url_base = 'http://yann.lecun.com/exdb/mnist/' key_file = { 'train_img':'train-images-idx3-ubyte.gz', 'train_label':'train-labels-idx1-ubyte.gz', 'test_img':'t10k-images-idx3-ubyte.gz', 'test_label':'t10k-labels-idx1-ubyte.gz' } # ファイルをダウンロード(.gz形式) for filename in key_file.values(): file_path = f'./static/mnist_data/{filename}' # 読み込んでくる.gzファイルのパス if os.path.isfile(file_path.replace('.gz', '')): continue # すでにファイルがあるときは飛ばす urllib.request.urlretrieve(url_base + filename, file_path) # .gzの解凍と.gzファイルの削除 with gzip.open(file_path, mode='rb') as f: mnist = f.read() # 解凍して保存 with open(file_path.replace('.gz', ''), 'wb') as w: w.write(mnist) os.remove(file_path) # .gzファイルの削除 # mnistのデータをnp.arrayの形に読み込んで返す mndata = MNIST('./static/mnist_data/') # train images, labels = mndata.load_training() train_images, train_labels = np.reshape(np.array(images), (-1,28,28)), np.array(labels) # np.arrayに変換する mnistの画像は28x28 # test images, labels = mndata.load_testing() test_images, test_labels = np.reshape(np.array(images), (-1,28,28)), np.array(labels) # np.arrayに変換する mnistの画像は28x28 return train_images, train_labels, test_images, test_labels def make_annoy_db(train_imgs): # 近似近傍探索のライブラリannoyを使う # 入力するデータのshapeとmetricを決めて、データを突っ込んでいく annoy_db = AnnoyIndex((28*28), metric='euclidean') for i, train_img in enumerate(train_imgs): annoy_db.add_item(i, train_img.flatten()) annoy_db.build(n_trees=10) # ビルド annoy_db.save('./static/mnist_db.ann') def main(): # mnist画像の読み込み処理 train_imgs, train_lbls, test_imgs, test_lbls = load_mnist() print(train_imgs.shape, train_lbls.shape, test_imgs.shape, test_lbls.shape) # MNISTがどのくらいの枚数データがあるのか確認したかった if not os.path.isfile('./static/mnist_db.ann'): make_annoy_db(train_imgs) # .annファイルがまだないなら、annoydbのビルド annoy_db = AnnoyIndex((28*28), metric='euclidean') annoy_db.load('./static/mnist_db.ann') # annoyのデータベースをロードする # テストデータを入力して近い近傍を取ってきて実際と比較することで試しに精度をみてみる y_pred = [train_lbls[annoy_db.get_nns_by_vector(test_img.flatten(), 1)[0]] for test_img in test_imgs] score = accuracy_score(test_lbls, y_pred) print('acc:', score) if __name__ == "__main__": main()次の目標
なんだかんだここまでで、既に分量が多くなったので続きは次回に回します。
今回はannoyを使って類似画像を探索できそうだと言うところまでやりました。
次回は、Flaskを使って画像を選んだら似た画像が出てくるアプリを作っていきましょう。
(僕が飽きたり忙しくなかったら)続く:-> (次のURL)おまけ:本当にどうでもいい愚痴なのですが、僕はEmacsのorgmodeが大好きで今回の記事もorgmodeで書くぞーと勇んで書き始めたのですが、悲しいかな互換性の弱さには対応しきれず結局Markdownで書いてしまっていました。
単体でいえばorgmodeが文書作成ソフトでは最強だと思ってるのですが(というかMarkdownって使いにくくないですか?どこの馬鹿が考えたら半角スペース二回で改行にしようとか思いつくのか)、どうしても他との連携を考えるとそうもいっていられないのが悲しいところです。
orgmodeにもexport as markdownみたいなものがあり、それでなんとかしようと思っていたのですが、それをさらにQiitaに載せるぞとなると思ったよりきれいにならなかったりしてねぇ...何とも悲しいものです。
Emacsもキーバインドが独特でVScodeの楽さになれちゃうとどうも使いづらくてねー、一応VScodeにもorgmode extension的なのはありますが、一番重要なtabキーで目だしを折り畳んだする表示状態を切換える機能と、htmlとかへのexport機能がないじゃないかとかねえ、VHS対ベータマックスみたいなものを連想してしまいました、世知辛いものです。そういえば、Software Design 2020年8月号の表紙を見て悲しくなりました。Vimと戦うのはEmacs、昔からそうだったじゃねえかよ。もう無理なのかEmacs?そんな感じで記事を閉めたいと思います。

- 投稿日:2020-07-31T19:19:49+09:00
[Tkinter] Eventオブジェクトでスレッドを制御する
はじめに
前回の記事で、Tkinter GUIでスレッドを利用して、応答性をよくする方法を紹介しました。
今回は、このスレッドの動作を制御する方法をご紹介します。
やりたいこと
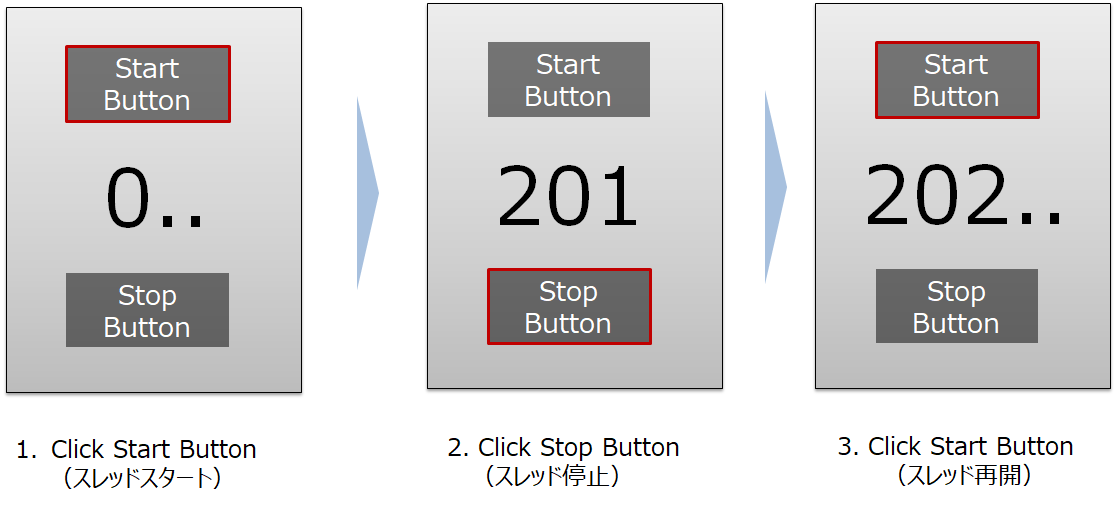
下記の図を見てみてください。
スタートボタンを押すと、数字がカウントされるGUIプログラムを作りたいと思います。途中で下部のストップボタンを押すと、数字のカウントを一旦止めてもらいます。
また、上部のスタートボタンを押すことで、数字のカウントが再開されるイメージです。
スレッドにはStartがあってもStopがない。
最初は、数字をカウントする関数をWhile文を用いて作り、スタートボタンを押すとスレッドを立ち上げ、ストップボタンを押すとスレッドを中止することを考えました。
最初に考えたコードがこちらです。スレッドをよく使うユーザがこのコードを見ると怒るかもしれません。
def _start_func(self): self.thread_main=threading.Thread(target=self._main_func) self.thread_main.start() def _stop_func(self): self.thread_main=threading.Thread(target=self._main_func) self.thread_main.stop()1番目の_start_func()は間違ってないです。しかし、2番目の_stop_func()は大間違いがあります。そうです。スレッドには.start()メソッドがあっても、.stop()メソッドはありません。 スレッドは途中で強制的に立ち下げるように設計されていません。
それではどうすればいいでしょうか?
その時は、スレッドを立ち上げて、それを臨時停止したり、再開したりすることになります。ここで登場するヒーローがEventオブジェクトです。
Eventオブジェクトの利用
Eventオブジェクトは、スレッドの動作を内部フラグの値で管理します。
内部フラグの値がTrueなら、スレッドを動かす。Falseなら、スレッドを停止する。それだけです。
その内部フラグの制御に関する重要なメソッドを下記の表に整理します。
Event関連メソッド 説明 備考 wait() スレッドを待機させる(=臨時停止する。) 内部フラグがTrueになるまで、スレッドを待機させる。 set() スレッドを動かす 内部フラグの値をTrueにする。 clear() スレッドを止める。 内部フラグの値をFalseにする。 is_set() 内部フラグの値を返す スレッドの運転状態を判断するときに利用。 メソッドの名前がbegin()ではなく、set()などになって、最初は理解が難しいかもしれませんが、内部フラグをTrue、Falseにsetし、その動作を制御すると考えれば、理解しやすいと思います。
プログラムの構造
Eventオブジェクトを利用し、やりたいことのプログラムの構造を書くと次のようになります。
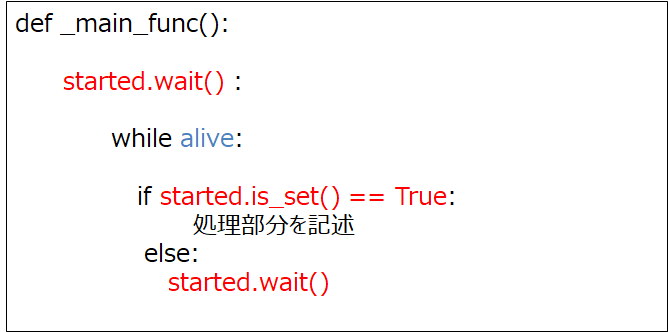
まず、プログラムが立ち上がる際に、スレッドも同時にstartメソッドで立ち上げておきます。
次にイベントのインスタンスとして、startedを用意しておきます。このstartedの内部フラグでスレッドの動作を制御することになります。スレッドのtargetになる関数_main_func()の冒頭にstarted.wait()を入れておきます。_main_func()は、while文でできており、while文はaliveで制御します。(aliveは最後にプログラムを立ち下げるときに使いますが、ここではコードだけに掲載し、説明は割愛します。)
GUIのスタートボタンに、内部フラグをTrueにする.set()メソッドをバインドし、GUIのストップボタンに、内部フラグをFalseにするclear()メソッドをバインドします。
_main_func()のWhile文の内部の構造は、まず.is_set()メソッドにより、内部フラグの状態を確認します。内部フラグの値がTrueの場合、スレッドで実行したい処理を行います。内部フラグがFalseと分かった場合、.wait()メソッドでスレッドを待機させます。
プログラムのコード
全体のプログラムコードを掲載します。
GUI_Contol_Thread_with_Event_Object.pyimport tkinter as tk from tkinter import ttk from tkinter import font import threading class Application(tk.Frame): def __init__(self,master): super().__init__(master) self.pack() self.master.geometry("300x300") self.master.title("Tkinter GUI with Event") self.font_lbl_big = font.Font( family="Meiryo UI", size=30, weight="bold" ) self.font_lbl_middle = font.Font( family="Meiryo UI", size=15, weight="bold" ) self.font_lbl_small = font.Font( family="Meiryo UI", size=12, weight="normal" ) self.create_widgets() #-------------------------------------------- # Setup Threading Start #-------------------------------------------- self.started = threading.Event() # Event Object self.alive = True # Loopの条件 self._start_thread_main() def create_widgets(self): # Frame self.main_frame = tk.LabelFrame( self.master, text='', font=self.font_lbl_small ) self.main_frame.place( x=25, y=25 ) self.main_frame.configure( height=250, width=250 ) self.main_frame.grid_propagate( 0 ) self.main_frame.grid_columnconfigure( 0, weight=1 ) #Start Button self.btn_Start = ttk.Button(self.main_frame) self.btn_Start.configure(text ='Start') self.btn_Start.configure(command = self._start_func) self.btn_Start.grid(column = 0, row = 0, padx=10, pady = 10,sticky='NESW' ) # Stop Button self.btn_Stop = ttk.Button(self.main_frame) self.btn_Stop.configure(text = 'Stop') self.btn_Stop.configure(command = self._stop_func) self.btn_Stop.grid(column = 0, row = 1, padx=10, pady = 10,sticky='NESW') # Label self.lbl_result = ttk.Label(self.main_frame) self.lbl_result.configure(text = 'Threading Result Shown Here') self.lbl_result.grid(column = 0, row = 2, padx= 30, pady=10,sticky='NESW') # Kill Button self.btn_Kill = ttk.Button(self.main_frame) self.btn_Kill.configure(text = 'Kill Thread') self.btn_Kill.configure(command = self._kill_thread) self.btn_Kill.grid(column=0, row=3, padx = 10, pady=20,sticky='NESW') #-------------------------------------------------- # Callback Function #-------------------------------------------------- def _start_func(self): self.started.set() print("Threading Begin") print( 'Thread status', self.thread_main ) def _stop_func(self): self.started.clear() print("\n Threading Stopped") print( 'Thread status', self.thread_main ) def _start_thread_main(self): self.thread_main = threading.Thread(target=self._main_func) self.thread_main.start() print('main function Threading Started') print('Thread status', self.thread_main) def _kill_thread(self): if self.started.is_set() == False: self.started.set() self.alive = False self.thread_main.join() else: self._stop_func() self.started.set() self.alive = False #self.thread_main.join() print("Thread was killed.") print( 'Thread status', self.thread_main ) def _main_func(self): i = 0 self.started.wait() while self.alive: if self.started.is_set() == True: i = i + 1 print( "{}\r".format( i ), end="" ) self.lbl_result.configure( text=i ,font = self.font_lbl_big ) else: self.lbl_result.configure( text= 'Stopped' ,font = self.font_lbl_big) self.started.wait() pass def main(): root = tk.Tk() app = Application(master=root)#Inherit app.mainloop() if __name__ == "__main__": main()実行結果
実行結果です。設計通りGUIプログラムの制御されることを確認が可能となりました。
まとめ
- Tkinter GUIの応答性をよくするために、スレッドを利用します。
- スレッドの動作を制御するとき、Eventオブジェクトを使います。
- Eventの内部フラグを制御する四つのメソッドを利用し、スレッドの制御が可能となります。
参考文献
1.Python公式文書 Event オブジェクト
2.[Tkinter] GUIの応答性をよくする
3.おまいらのthreading.Eventの使い方は間違っている
4.Python スレッドの停止と再開の簡易サンプル


- 投稿日:2020-07-31T18:27:34+09:00
【Python】0からWebアプリ!ハンズオン(1)~設計、DB構築編~
概要
Pythonで0からWebアプリを作る機会があったので、そのまとめとして!
この記事ではアプリの設計、データベースの設計、構築について書いています。前回の記事
【Python】0からWebアプリ!ハンズオン(0)~環境構築編~ - Qiitaこんな方に読んでほしい
- プログラミング未経験だけどアプリ作ってみたい方
- 新人Webプログラマの方
- 経験者だけどPythonでWebアプリ書いたことない方
ゴール
HTML, CSS, JavaScript, Python, SQLを使ってCURD機能を持ったWebアプリを作成するのが目標です。
必要なもの
- PC(Windows OS)
- インターネット回線
- わくわくした気持ち
1. アプリのイメージ
今回は題材として簡単なTodoアプリを作りたいと思います。
必要となる機能は
- Todo一覧(Read)
- Todo追加(Create)
- Todo更新(Update)
- Todo削除(Delete)
の4つとします。これらの頭文字をとってCRUDと表現することがあり、業務系アプリのほとんどはこれらの機能がベースとなっています。
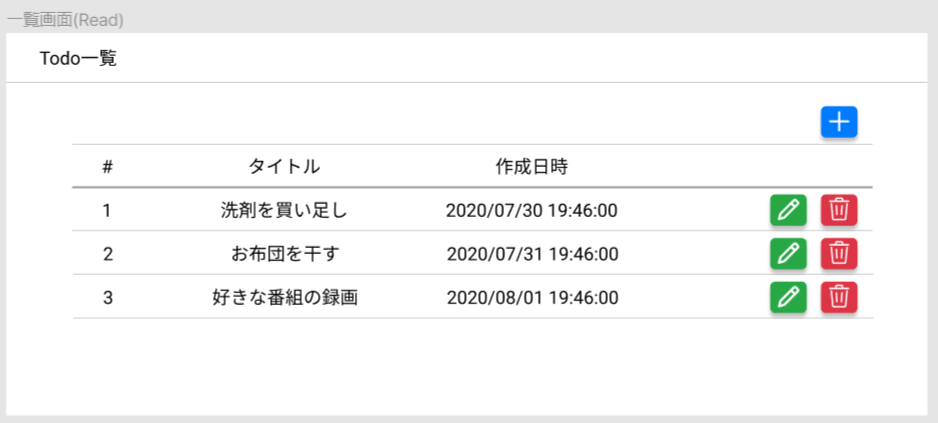
それぞれの画面イメージを作成してみました。Todo一覧
登録されたTodoを一覧形式で表示します。
新規追加ボタンがあり、そこから新規登録フォームが開きます。
各行に編集、削除は各行に配置されたボタンから行えます。
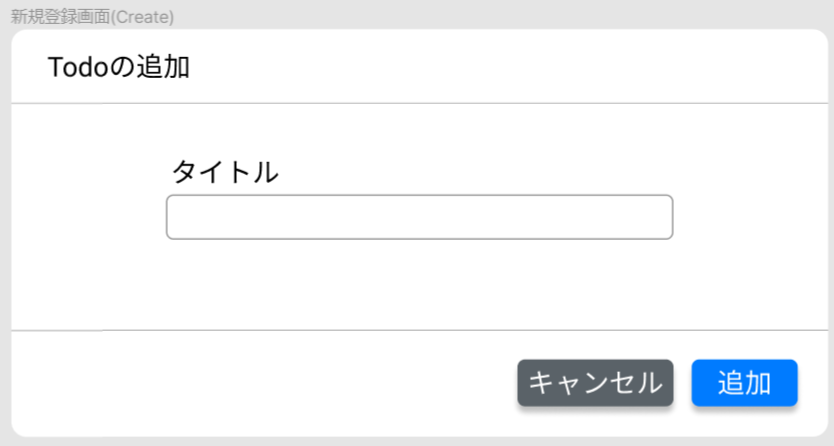
Todo追加
Todoの新規登録フォームです。タイトルを入力し、「追加」ボタンを押すことで一覧に追加されます。
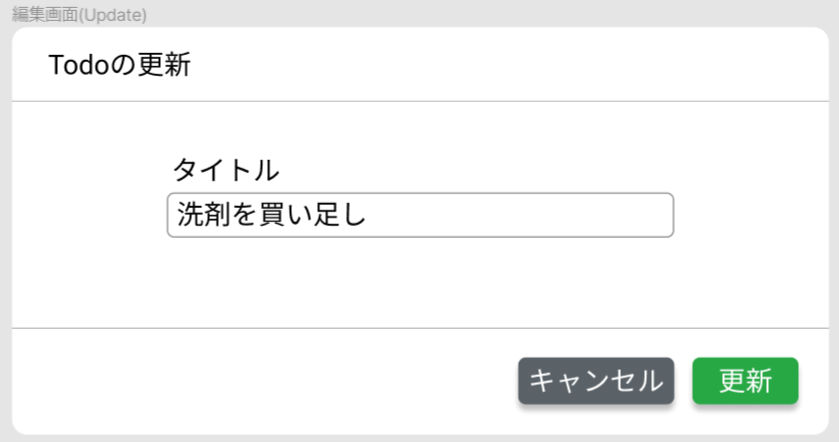
Todo更新
Todoの編集フォームです。タイトルを更新し、「更新」ボタンを押すことでTodoが更新されます。
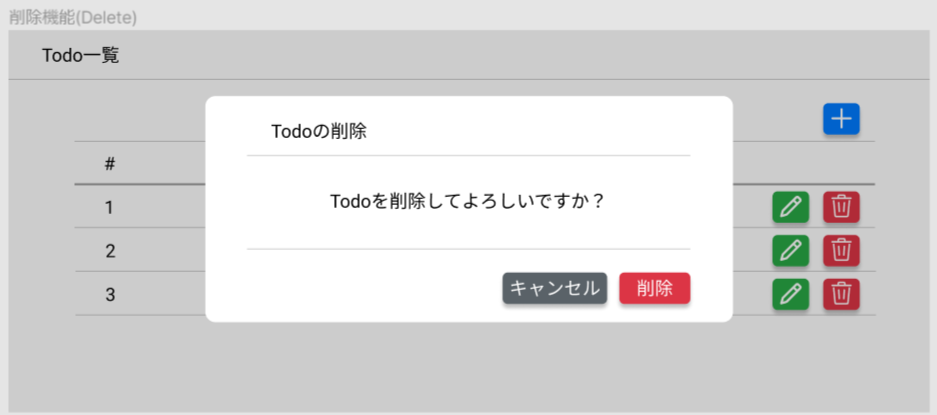
Todo削除
一覧の削除ボタンを押すと、該当行のデータが削除されます。そのとき、削除してよいかどうかのメッセージが表示され、「削除」ボタンを押すとTodoが削除されます。
2. データベースの設計
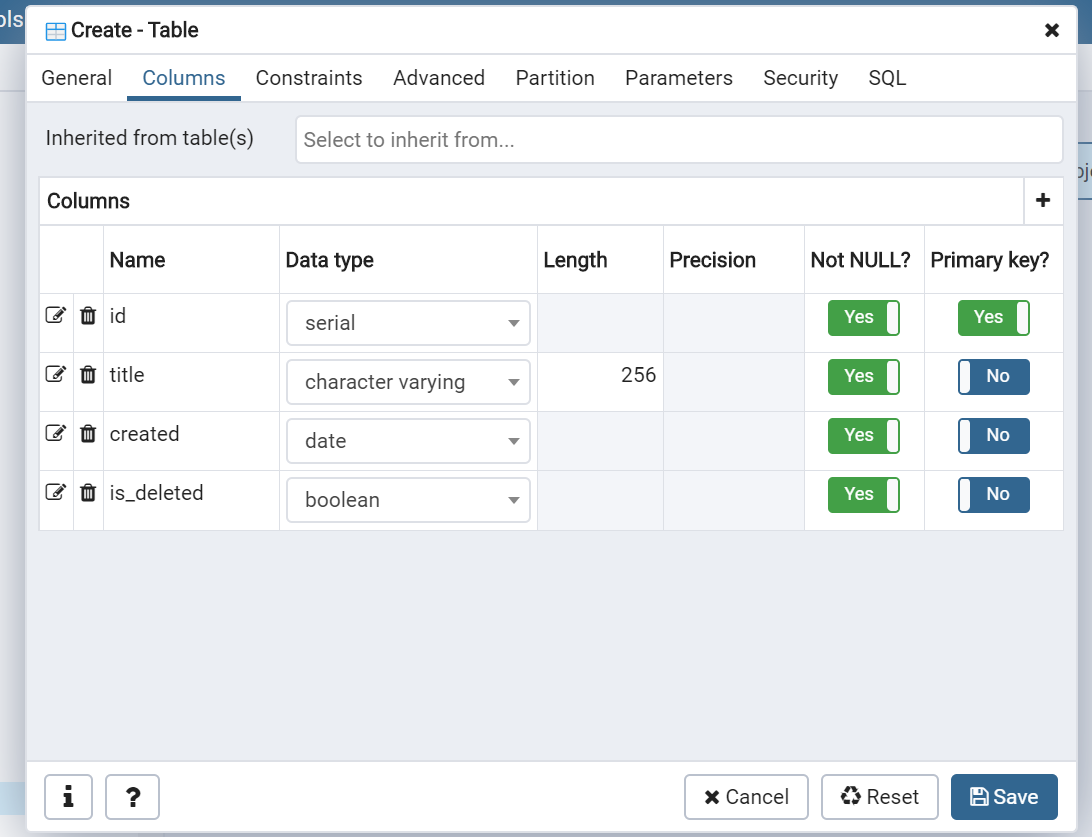
データベースの設計はこれだけです(笑)
ポイントとしてはis_deletedという列を設けることで、Todoの論理削除を可能とするところです。
論理削除というのは、データは残っているが「消えた or 消えていない」のフラグを持たせることでユーザーからは削除されたように見える
方法のことです。消すときにはis_deleted= trueとして、一覧ではis_deletedがtrueのデータは表示しないこととします。反対に、SQLのDELETE文でデータベースから完全にデータを削除することを「物理削除」といいます。
id: TodoのIDです(一意)
title: Todoの題名です
created: Todoを作成した日時です
isDeleted: Todoが削除されたかどうかです3. データベースの構築
では、実際にデータベースから作っていきましょう!
pgAdmin4はブラウザで動作するツールです。Windowsの場合、メニューバーの検索ボックスに「pgadmin」と入力すると出てくるはずです。
ここから以下の順番で生成していきます。
サーバーグループ -> サーバー -> データベース -> スキーマ -> テーブルサーバーグループの作成
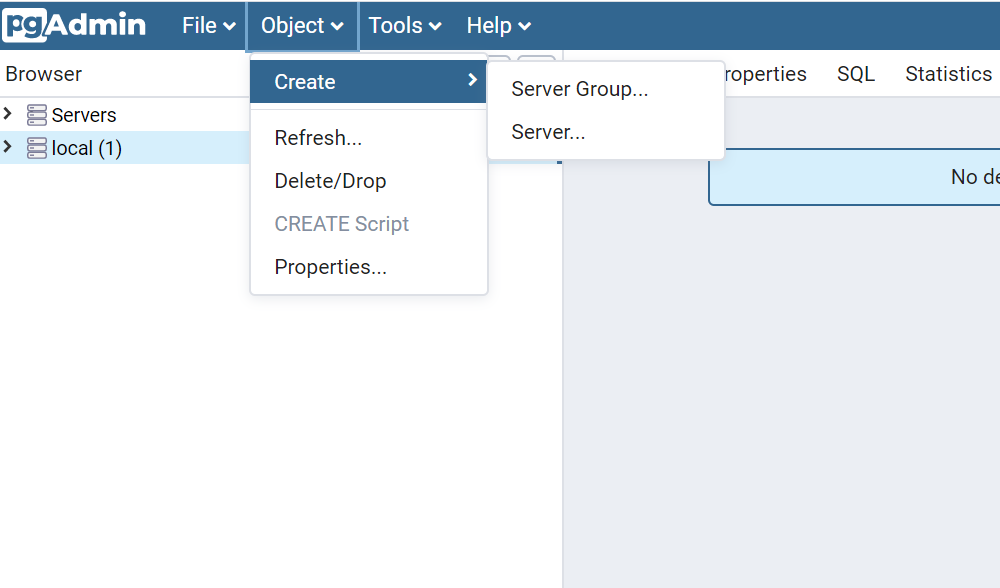
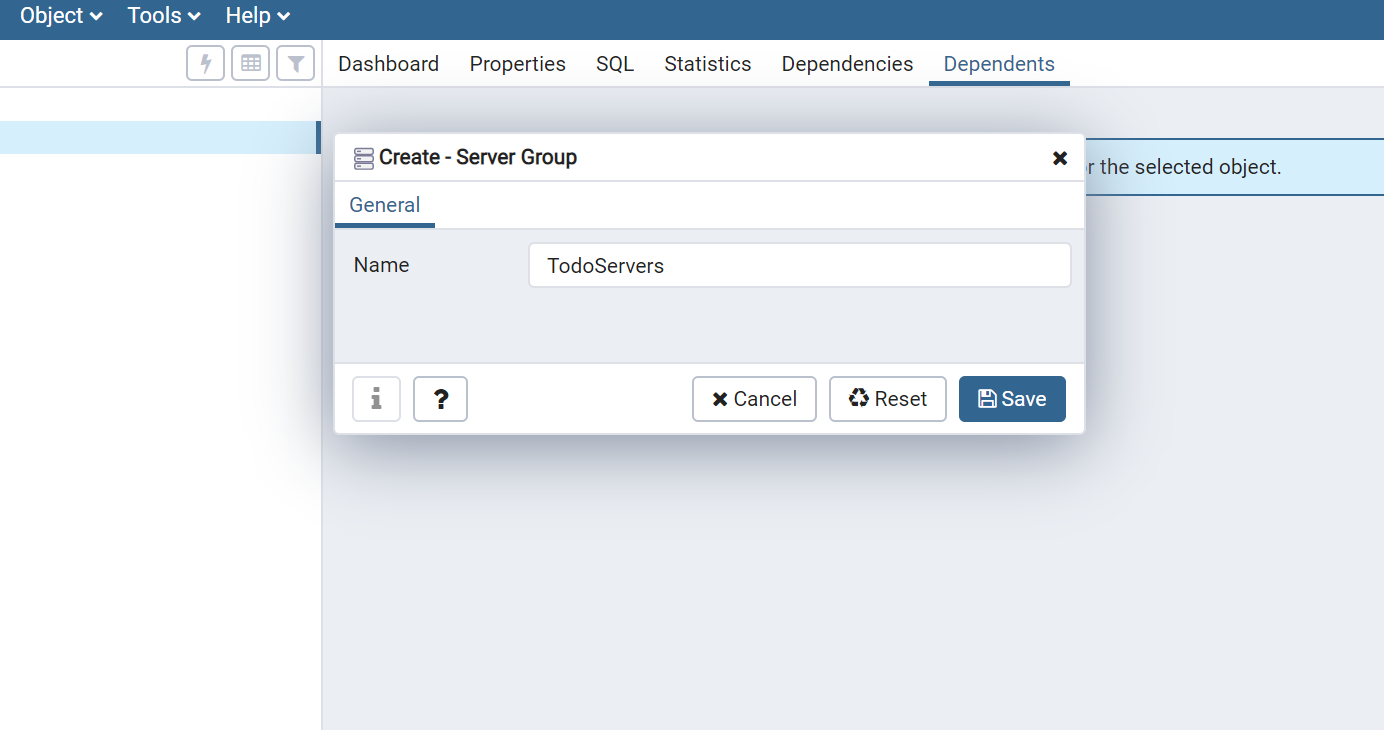
まずはデータベースのサーバーグループを作成する必要があります。
Object > Create > Server Groupを選択します。
名前は「TodoServers」としました。
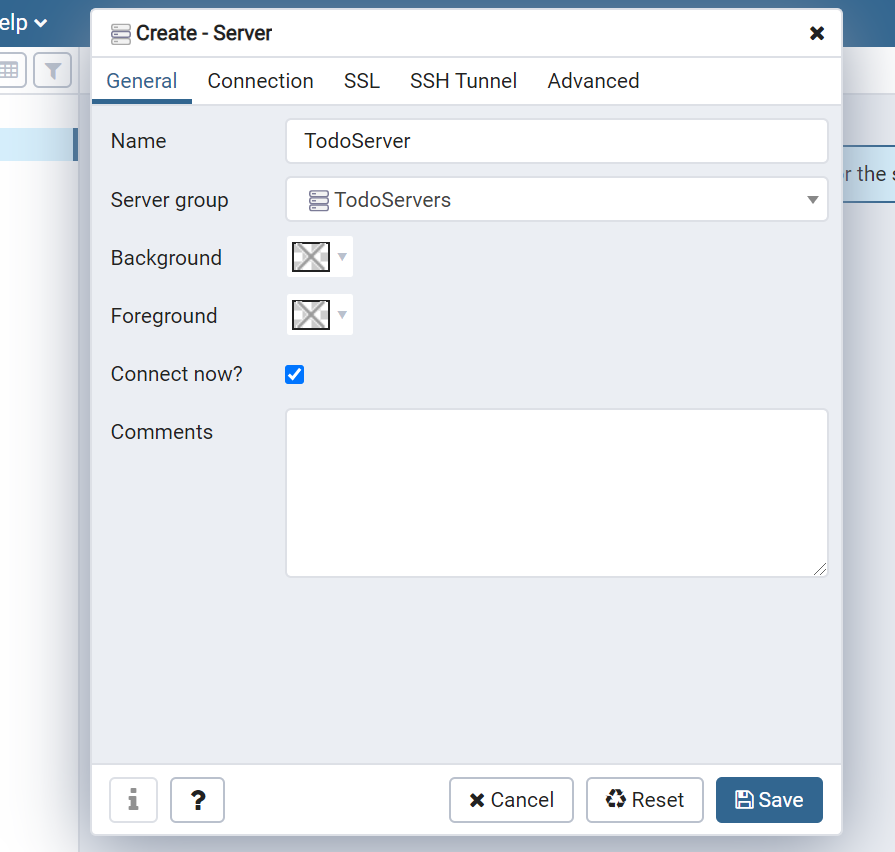
サーバーの作成
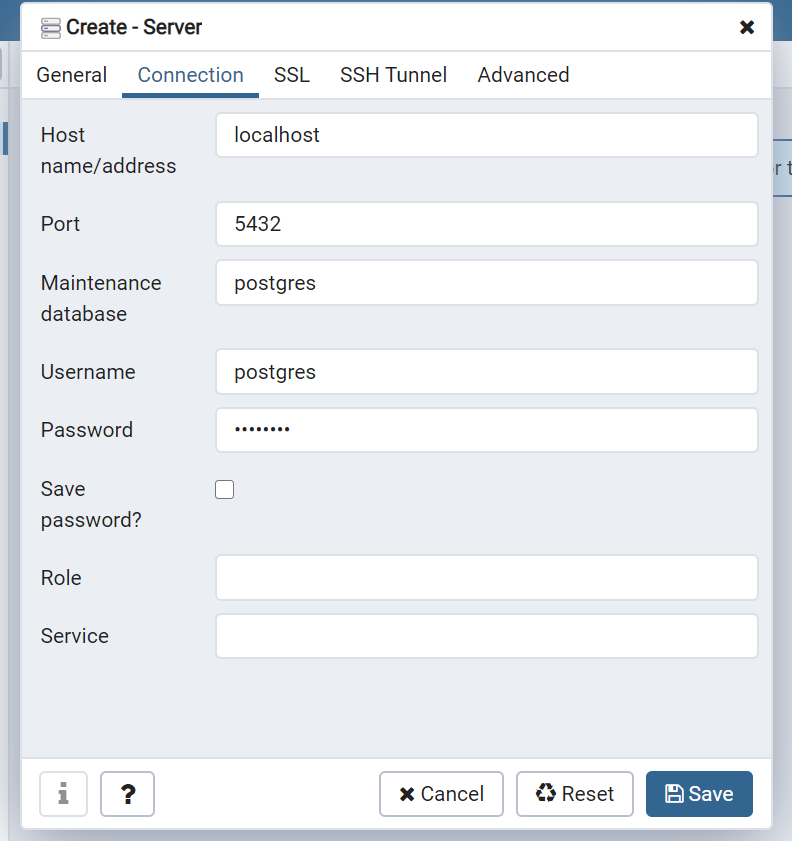
続いて、サーバーを作成します。
TodoServersを右クリック > Create > Serverを選択します。
Nameは「TodoServer」としました。
Connectionタブにて、
Host name/address: localhost
Password: postgres
を入力し、Saveしてください。
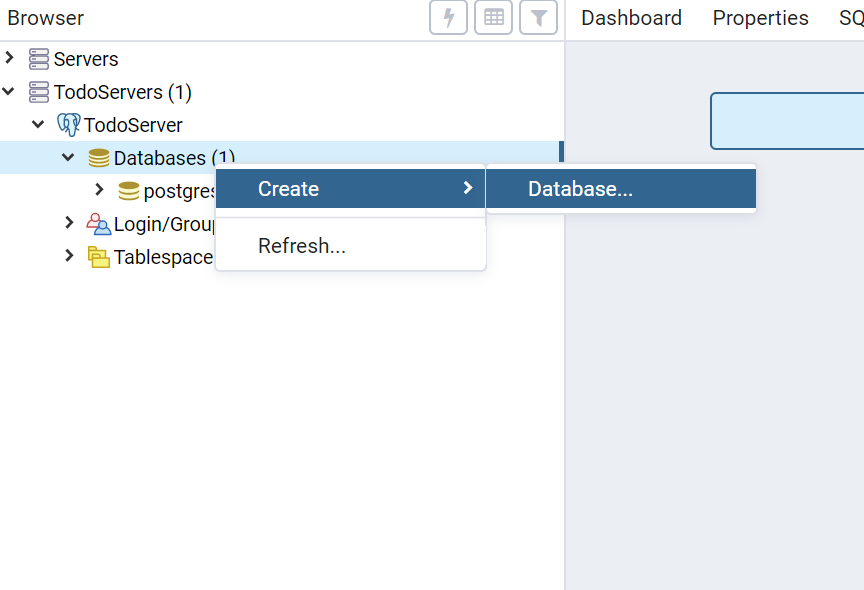
データベースの作成
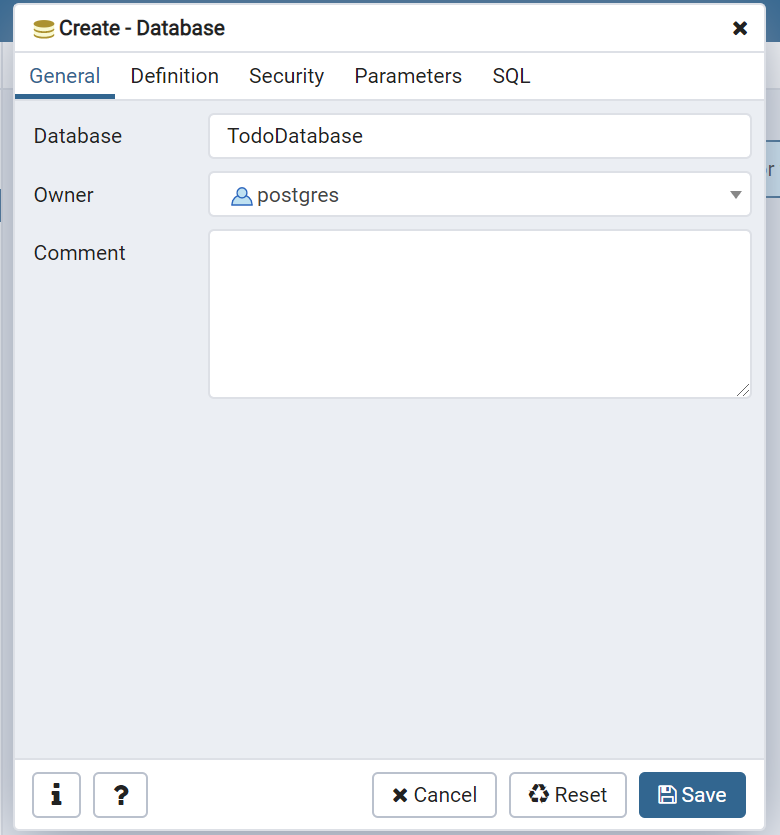
続いてデータベースを作成します。
TodoServerのDatabasesを右クリックして、Create > Databaseを選択します。
名前を「TodoDatabase」としてSaveしてください。
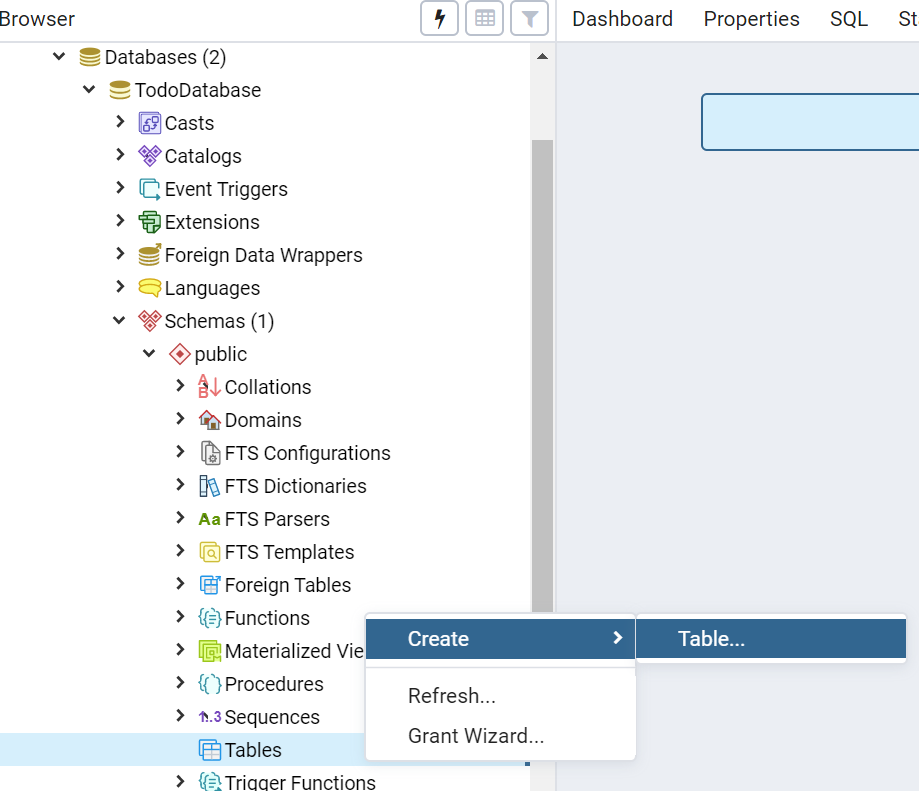
テーブルの作成
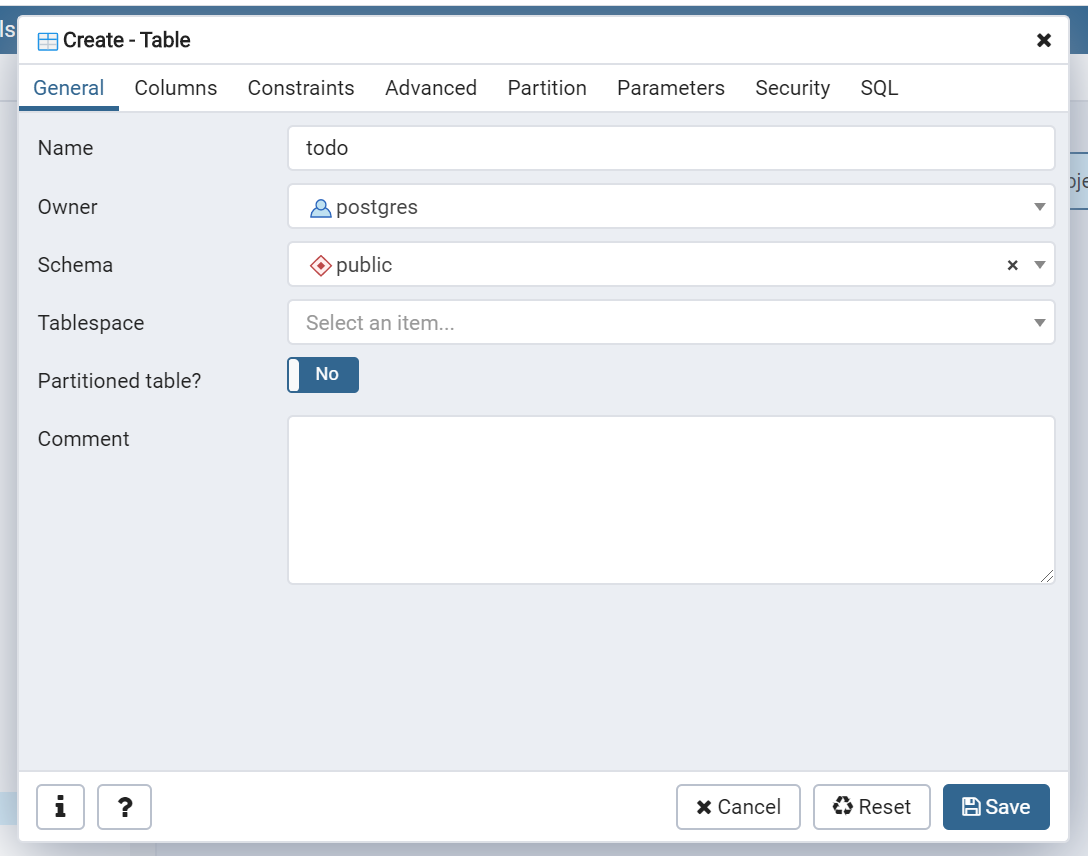
TodoDatabaseのSchemas > public > Tablesを右クリックし、Create > Tableを選択します。
Nameは「todo」とします。
Columnsタブで画像の通り列を設定していき、Saveしてください。(右上の+ボタンから追加できます)
まとめ
今回はここまで!
アプリの簡単な画面設計、データベース設計、データベース構築を行いました!次回は・・・
サーバーサイド(Rest API)の構築を行います!


- 投稿日:2020-07-31T18:25:39+09:00
【Python】0からWebアプリ!ハンズオン(0)~環境構築編~
概要
Pythonで0からWebアプリを作る機会があったので、そのまとめとして!
この記事では環境構築について書いています。こんな方に読んでほしい
- プログラミング未経験だけどアプリ作ってみたい方
- 新人Webプログラマの方
- 経験者だけどPythonでWebアプリ書いたことない方
ゴール
HTML, CSS, JavaScript, Python, SQLを使ってCURD機能を持ったWebアプリを作成するのが目標です。
必要なもの
- PC(Windows OS)
- インターネット回線
- わくわくした気持ち
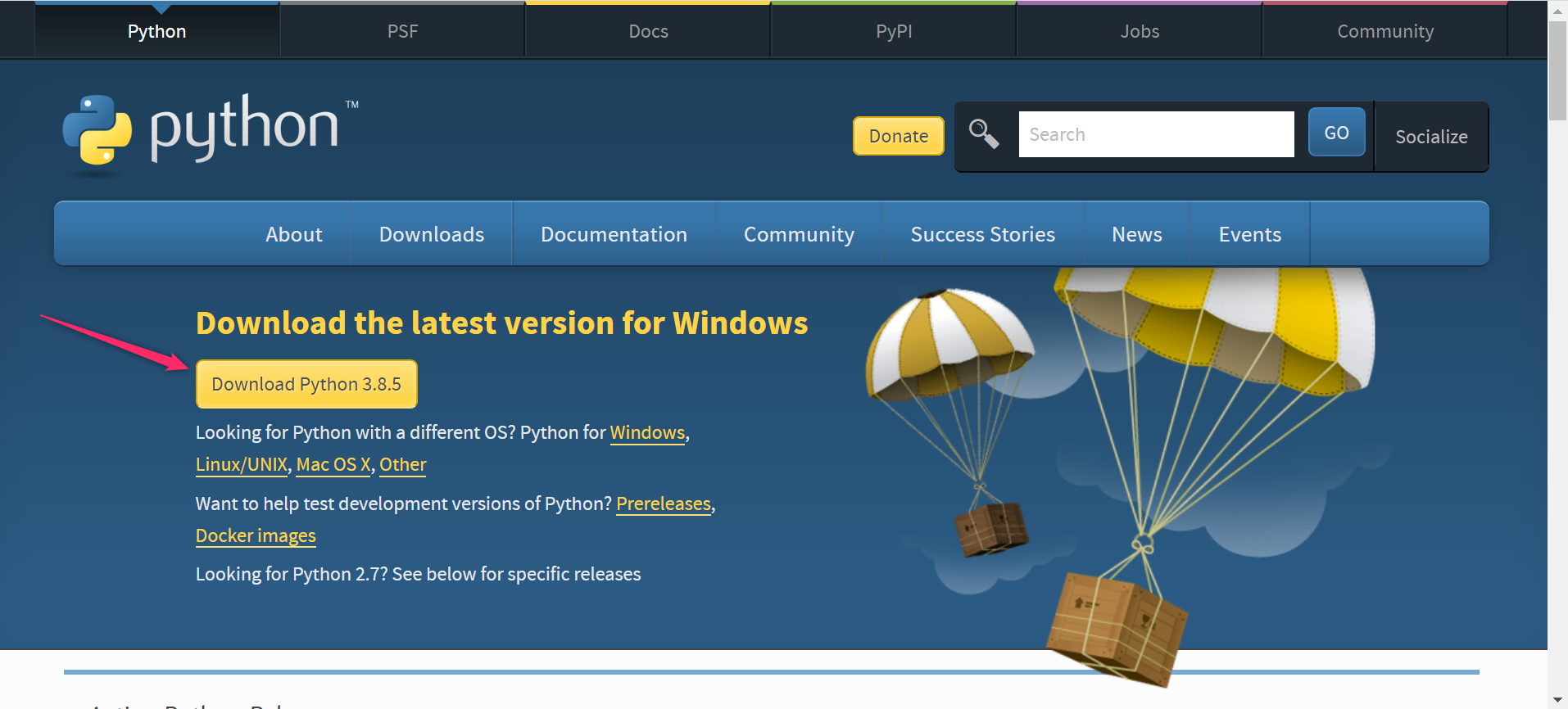
1. Pythonのインストール
公式サイトからダウンロードできます。
Download Python | Python.org
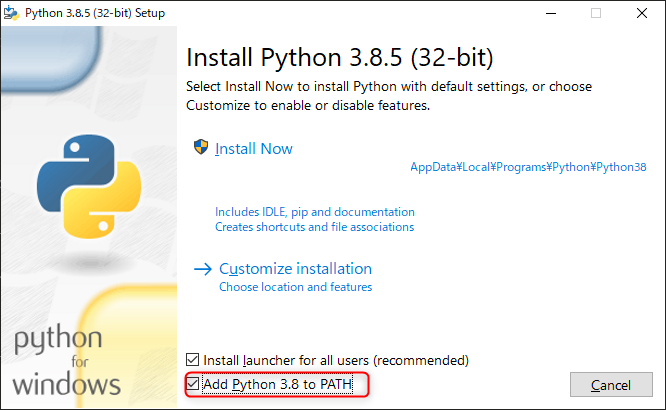
インストーラを起動したら、「Add Python 3.8 to PATH」にチェックを付けて「Install Now」してください。
コマンドプロンプトを起動し、
pythonと入力して画像のようになったらインストール成功です。
2. Visual Studio Codeのインストール
公式サイトからダウンロードできます。
Visual Studio Code - Code Editing. Redefined
インストーラを起動し、基本的には次へ次へ進めてOKです。
「エクスプローラーのファイルコンテキストメニューに[Codeで開く]アクションを追加する」と「エクスプローラーのディレクトリコンテキストメニューに[Codeで開く]アクションを追加する」の2つにチェックを入れると、エクスプローラー上でフォルダ右クリックしてVSCodeで開けたりするので便利です。
3. Visual Studio Codeプラグインのインストール
VSCodeでは便利な拡張機能が多数配布されています。サイドバーから確認できます。
とりあえずぼくが入れている & 今回使いそうな最低限のものをご紹介します。Japanese Language Pack for Visual Studio Code
デフォルト英語のVSCodeを日本語化してくれます。
Python
Pythonの実行をVSCode上でできます。
Prettier - Code formatter
コードフォーマッターです。(コードのインデントやスペースを自動で整えてくれるやつ)
VSCode標準のフォーマッターもあるんですが、Prettierは幅広く、カスタマイズ容易なので使っています。
4. PostgreSQLのインストール
EDBのサイトからダウンロードできます。
Download PostgreSQL Database for Windows, Linux and MacOS & 32-bit or 64-bit Versions | EDB
インストーラを起動し、基本的には次へ次へ進めてOKです。
pgAdmin4はPostgreSQLを簡単に扱うためのGUIツールです。これがないとCLIからの操作(コマンドライン)になるので、慣れていない方はpgAdmin4にチェックしたままインストールしてください。まとめ
今回はここまで!
サーバーサイド言語、データベース、コードエディターの環境を整備しました!次回は・・・
アプリの設計、データベースの構築を行います!
【Python】0からWebアプリ!ハンズオン(1)~設計、DB構築編~ - Qiita

- 投稿日:2020-07-31T18:22:58+09:00
Pandasの基本的な操作
こんにちは、Mottyです。
最近kaggleを初めましたので、必須であるPandasを使ったデータ加工の簡単な操作を記事にまとめていきたいと思います('`)。
・Kaggle公式HP
https://www.kaggle.com/
・Pandas UserGuide
https://pandas.pydata.org/docs/user_guide/index.html概要
PandasはPythonのデータ加工ライブラリです。テーブルの操作や集計、欠損値の補完などが簡単に行えます。他にも列を結合したり相関行列を表示したり、クロス集計できたり・・・と様々です。
使用するデータ
kaggle定番ですが、タイタニックの生存状況に関するデータを使用します。
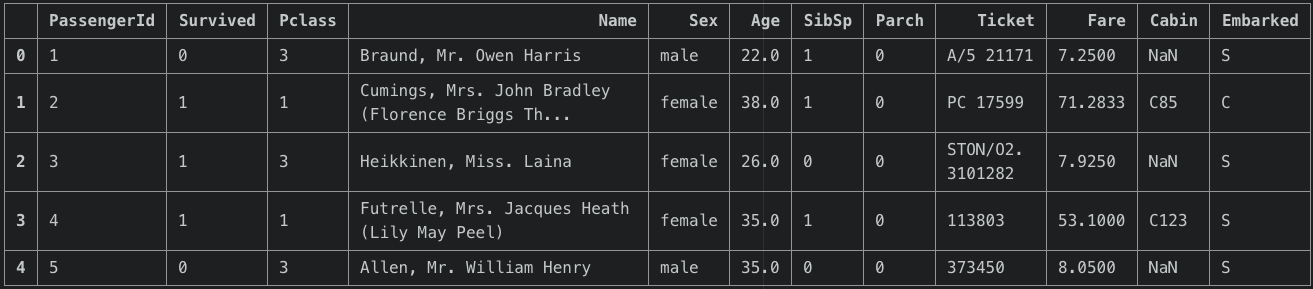
import numpy as np import matplotlib.pyplot as plt %matplotlib.inline import pandas as pd df_train = pd.read_csv("train.csv")データの確認
df_train.columns #項目リストIndex(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object')df_train.shape #サイズ(891,12) 行列のサイズですね。
先頭の5行だけ覗いてみましょう。df_train.head()
量的データと質的データが混在していますね。(PClassも互いに量的な関係ではないので質的データと見なせますね!。)列/行の抽出
df_train["Name"] #1列抽出 df_train.loc[:,["Name","Sex"]] #複数列抽出 df_train[10:15] #行抽出 df_train[10:20:2] #1行飛ばし df_train[df_train["Age"] < 20] #値指定 df_train[1:300].query('Age < 20 and Sex == "male"') #queryで複数条件指定集計
df_train["Pclass"].value_counts()3 491
1 216
2 184
Name: Pclass, dtype: int64
各項目についての集計結果を返してくれます。欠損値の確認
df_train.isnull() #True→欠損値 df_train.isnull().sum()PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64各列項目のNaNの合計数が一覧で得られます。これを基に欠損値補完の方針を立てていきます。
相関行列の表示
相関行列は各変数間の相関係数です。
Python
df_train.corr() #相関係数の表示
PassengerId Survived Pclass Age SibSp Parch Fare
PassengerId 1.000000 -0.005007 -0.035144 0.036847 -0.057527 -0.001652 0.012658
Survived -0.005007 1.000000 -0.338481 -0.077221 -0.035322 0.081629 0.257307
Pclass -0.035144 -0.338481 1.000000 -0.369226 0.083081 0.018443 -0.549500
Age 0.036847 -0.077221 -0.369226 1.000000 -0.308247 -0.189119 0.096067
SibSp -0.057527 -0.035322 0.083081 -0.308247 1.000000 0.414838 0.159651
Parch -0.001652 0.081629 0.018443 -0.189119 0.414838 1.000000 0.216225
Fare 0.012658 0.257307 -0.549500 0.096067 0.159651 0.216225 1.000000対角成分は自分自身との相関となるので必ず1となります。しかし量的データだけでなく、文字列(Sex,Embark)や数字を使った質的データ(Pclass)などがありこれらをone-hot表現に変換してあげなければなりません。
dummy_df = pd.get_dummies(df_train, columns = ["Sex","Embarked","Pclass"]) #ダミー変数の取得 dummy_df.columnsIndex(['PassengerId', 'Survived', 'Name', 'Age', 'SibSp', 'Parch', 'Ticket',
'Fare', 'Cabin', 'Sex_female', 'Sex_male', 'Embarked_C', 'Embarked_Q',
'Embarked_S', 'Pclass_1', 'Pclass_2', 'Pclass_3'],
dtype='object')dummy_df.corr()巨大なので書きませんが、先ほどの相関行列は文字列データについては省かれていました。今回は質的変数をダミー(0,1)に置き換えたものとの相関行列が返ってきます。
可視化
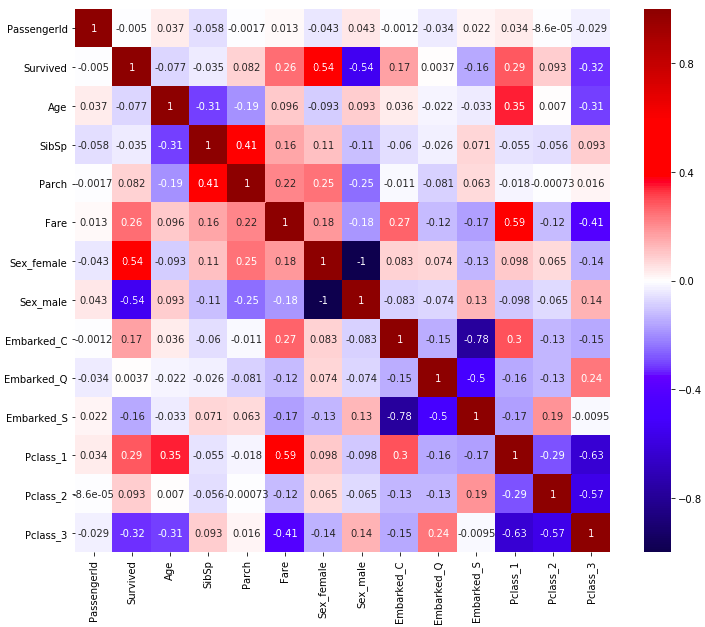
seabornのHeatMapを使って相関行列をみてみましょう。カラーパレットは、0を中心として色の濃さが対照的なを選びました。
import seaborn as sns plt.figure(figsize = (12,10)) sns.heatmap(dummy_df.corr(), cmap = "seismic",vmin = -1 ,vmax = 1, annot = True)
Servivedと高い相関関係にあるものが、Servivedに影響を及ぼしていると考えることができます。Sex_femaleとPclass_1との相関が高いですね。これは女性であったり部屋の階級が1である人の生存率が高いということになります。
うまく使ってあげれば機械学習の前段階で方針の目星はつけることもできるということですね!参考文献
以下の記事を参考にさせていただきました。
参考URL
・データ分析で頻出のPandas基本操作
https://qiita.com/ysdyt/items/9ccca82fc5b504e7913a
・追伸。そろそろおまえもseabornヒートマップを使うように。 母より
https://qiita.com/hiroyuki_kageyama/items/00d0f52724f16ad7cf77
参考書籍
前処理大全[データ分析のためのSQL/R/Python実践テクニック]
現場で使える!pandasデータ前処理入門 機械学習・データサイエンスで役立つ前処理手法終わりに
単にデータ処理だけならNumpy配列に入れるだけでもできるんじゃないの?と思っていましたが、データ加工が簡単にできるのが魅力ですね。逆にDataFrameに対して高度な計算を行うのであれば1度配列に移したほうがいいのかも・・・?

- 投稿日:2020-07-31T17:57:22+09:00
どんなニュース見出しでも緩やかに景気回復させてくれるプログラム
プログラム
import feedparser
RSS_URL = 'https://news.yahoo.co.jp/pickup/rss.xml'
d = feedparser.parse(RSS_URL)
for entry in d.entries:
print(entry.title,'だから緩やかに景気回復しています。')引用元 h1
https://techacademy.jp/magazine/19148
メモ h1
↑にprintをくっつけただけ。楽しみながらプログラムを作りたい。
https://youtu.be/DsSNpegZLoA
5分40秒〜
- 投稿日:2020-07-31T17:26:41+09:00
FastAPI 利用方法 ③OpenAPI
書いてあること
- FastAPIを利用した際のメモ(個人用メモのため間違っている可能性あり・・・)
- 公式サイトのドキュメントからOpenAPIの挙動に関係するものを抜粋
参考
環境
Docker環境を構築して動作確認
起動
bash# main.pyがルートディレクトリにある場合 $ uvicorn main:app --reload --host 0.0.0.0 --port 8000 # main.pyがルートディレクトリにない場合 $ uvicorn app.main:app --reload --host 0.0.0.0 --port 8000Source
main.pyimport uvicorn from fastapi import FastAPI, Query, Path, Body from typing import Optional from pydantic import BaseModel, Field # 各タグの説明 tags_metadata = [ { "name": "users", "description": "Operations with users. The **login** logic is also here.", }, { "name": "items", "description": "Manage items. So _fancy_ they have their own docs.", "externalDocs": { "description": "Items external docs", "url": "https://fastapi.tiangolo.com/", }, }, ] items = { 1: {"item_no": 1, "item_name": "name1", "price": 100}, 2: {"item_no": 2, "item_name": "name2", "price": 200}, 3: {"item_no": 3, "item_name": "name3", "price": 300}, } users = { 1: {"user_no": 1, "user_name": "name1", "email": "name1@example.com"}, 2: {"user_no": 2, "user_name": "name2", "email": "name2@example.com"}, 3: {"user_no": 3, "user_name": "name3", "email": "name3@example.com"}, } # スキーマの説明、データ例 class Item(BaseModel): name: str description: Optional[str] = Field( None, title="The description of the item", max_length=300 ) price: float = Field( ..., gt=0, description="The price must be greater than zero" ) tax: Optional[float] = None class Config: schema_extra = { "example": { "name": "example_name", "description": "example_description", "price": 100, "tax": 10, } } # OpenAPI自体の設定 app = FastAPI( title="FastAPI Sample Project", description="This is a very fancy project, with auto docs for the API and everything", version="1.0.1", openapi_tags=tags_metadata, docs_url="/api/v1/docs", redoc_url="/api/v1/redoc", openapi_url="/api/v1/openapi.json", ) # 各urlの設定 @app.get( "/items", tags=["items"], summary="read items summary", ) async def read_items( option: Optional[str] = Query( None, title="Query Parameter Title", description="Query Parameter Description", ), ): return {"items": items} @app.get( "/items/{item_no}", tags=["items"], summary="read item summary", ) async def read_item( item_no: str = Path( None, title="Path Parameter Title", description="Path Parameter Description", deprecated=True, ), ): return {"item": items[item_no]} @app.post( "/items/{item_no}", tags=["items"], summary="create item summary", ) async def create_item( item_id: int, item: Item = Body(..., embed=True), ): results = {"item_id": item_id, "item": item} return results @app.get( "/users", tags=["users"], ) async def read_users(): """ Create an item with all the information: - **name**: each item must have a name - **description**: a long description - **price**: required - **tax**: if the item doesn't have tax, you can omit this - **tags**: a set of unique tag strings for this item - FastAPIドキュメント反映テスト """ return {"users": users} @app.get( "/user/{user_no}", tags=["users"], ) async def read_user(user_no: str): return {"user": users[user_no]} if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=8000)生成されたドキュメント

- 投稿日:2020-07-31T17:23:25+09:00
PythonでラズパイのCPU温度を測定する
Raspberry PiのCPU温度は
vcgencmd measure_tempで取得できます。
モニタリング用に1秒ごと60回測定し、最後にその平均を表示するようにしました。コード
使用言語はPython3.7です。
ラズパイではPythonと打つと標準ではPython2が出てきますが、3.7とは互換性がないのでエラーとにらめっこしないようお気を付けください。
え?そんなことするのは私だけですね。ハイ。
sudo chmod a+x temp.pyで実行権限を付与して./temp.pyとすれば動きます。temp.py#!/usr/bin/python3.7 import subprocess import time import sys import re num = 60 ave = 0 print(subprocess.run('lsb_release -a', shell=True, encoding='utf-8', stdout=subprocess.PIPE).stdout) try: while num > 0: temp = subprocess.run('vcgencmd measure_temp', shell=True, encoding='utf-8', stdout=subprocess.PIPE).stdout.split('=') freq = subprocess.run('vcgencmd measure_clock arm', shell=True, encoding='utf-8', stdout=subprocess.PIPE).stdout.split('=') volt = subprocess.run('vcgencmd measure_volts', shell=True, encoding='utf-8', stdout=subprocess.PIPE).stdout.split('=') temp = temp[1].replace('\n', '') freq = int(freq[1].replace('\n', '')) / 1000000000 volt = volt[1].replace('\n', '') print('Temp: ' + temp + ', Freq: ' + f'{freq:.2f}' + 'GHz, Volt: ' + str(volt) + ' (' + str(num) + ')') ave += int(re.sub('\\D', '', temp)) num -= 1 time.sleep(1) print('Average: ' + f'{ave / 600:.1f}' + "'C (60s)") except KeyboardInterrupt: sec = 60 - num print(' Aborted.\nAverage: ' + f'{ave / sec / 10:.1f}' + "'C (" + str(sec) + 's)') sys.exit()工夫したところ
夏休みの自由研究かよっていう見出しですがご容赦ください。
初心者なりに色々調べて書きました。バージョン情報
めっちゃ要らないですが、最初にLinuxのバージョン情報を表示させてます。
ループ前のlsb_release -aを書き換えれば好きなコマンドの実行結果を表示できます。
完全に自己満足です。Subprocess
調べたところpythonからコマンドを実行するには
subprocessが良いようです。
理由はよくわかりませんが長い物には巻かれろということでsubprocessを使いました。温度以外の値
温度だけではつまらないので(何が)、クロック周波数と動作電圧も表示するようにしました。
これが余計と思いきや見ていて結構面白いです。
私の環境では、意外と1.5GHzまでは使っていないですね。KeyboardInterrupt
Ctrl + Cでループを抜けられますがエラーが吐き出されてしまいます。
精神衛生上よろしくないということでループ処理をtryで囲ってCtrl + Cをexcept KeyboardInterruptでキャッチしています。
こうすることでエラーも吐き出されませんし、抜けるときの処理も書き込むことができます。その他
- 変数
numの60を変えれば測定する秒数を変えられます。- 本ファイルを
/{hogehoge}に置いて、ln -s /{hogehoge}/temp.py /usr/bin/tempとすれば任意のディレクトリでtempと打つだけで本プログラムを実行できます。- 趣味グラマーの初投稿故にお見苦しい点が多々あるかと思いますが、ご容赦ください。
- 「プロ」グラマーの方、何かコメントがありましたら是非ビシバシとご指摘ください。
- 投稿日:2020-07-31T17:14:17+09:00
GCP App Engine StorageのExcelファイル読込、内容変更、書込
やりたいこと
- GCP StorageからExcelファイル読込
- Excel内容変更
- GCP StorageにExcelファイル書込
- ファイルダウンロード
Example
# -*- coding: utf-8 -*- import logging from flask import render_template, Flask, Response from google.cloud import storage import openpyxl from openpyxl.writer.excel import save_virtual_workbook import io app = Flask(__name__) logging.getLogger().setLevel(logging.INFO) @app.route('/applicationform/a0026', methods=['GET', 'POST']) def a0026(): client = storage.Client() bucket = client.get_bucket('★プロジェクト名★.appspot.com') blob = bucket.blob('a0025.xlsx') blob_io = io.BytesIO(blob.download_as_string()) wb = openpyxl.load_workbook(blob_io, keep_vba=False) sheet = wb.get_sheet_by_name('★シート名★') sheet['K5'] = 'Test Test' save_data = save_virtual_workbook(wb) new_blob = bucket.blob('a0025_new.xlsx') new_blob.upload_from_string(save_data, content_type='application/vnd.openxmlformats-officedocument.spreadsheetml.sheet') res = Response(save_data, content_type='application/vnd.openxmlformats-officedocument.spreadsheetml.sheet') res.headers['Content-Disposition'] = 'attachment; filename="a0025_new.xlsx"' return res if __name__ == '__main__': app.run(host='127.0.0.1', port=8080, debug=True)マクロ有のファイルの場合
keep_vbaをTrueにする。
wb = openpyxl.load_workbook(blob_io, keep_vba=True)Content-Type「application/vnd.ms-excel.sheet.macroEnabled.12」に変更
new_blob.upload_from_string(save_data, content_type='application/vnd.ms-excel.sheet.macroEnabled.12') res = Response(save_data, content_type='application/vnd.ms-excel.sheet.macroEnabled.12')拡張子変更
new_blob = bucket.blob('a0025_new.xlsm') res.headers['Content-Disposition'] = 'attachment; filename="a0025_new.xlsm"'memo
- Excel処理はOpenPyXL使用
- 投稿日:2020-07-31T17:07:06+09:00
メモ
c = [list(input()) for _ in range(h)]..#
.#.
↓
[['.', '.', '#'], ['.', '#', '.']]
- 投稿日:2020-07-31T16:53:37+09:00
[Tkinter] GUIの応答性をよくする
1.はじめに
今日はGUIアプリケーションを作るとき、Threadingを利用して、その応答性をよくする方法について説明します。
2.やりたいこと
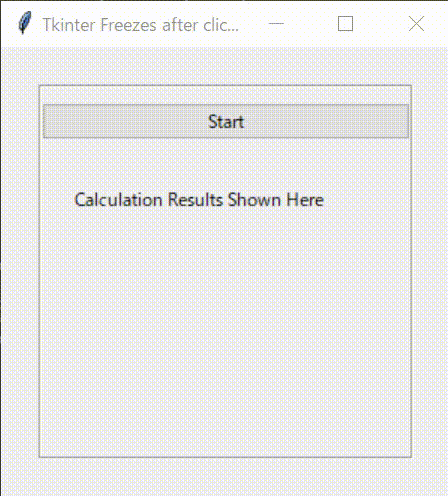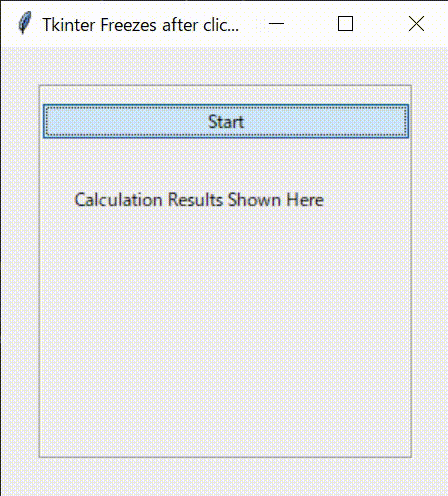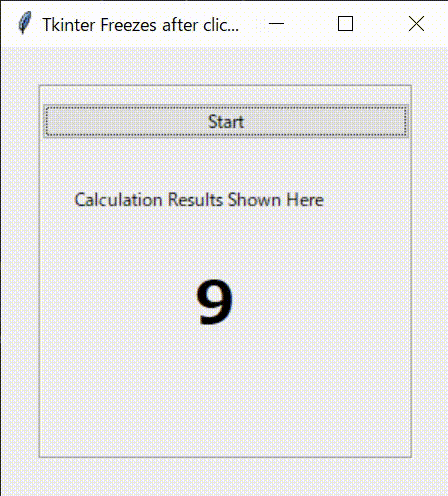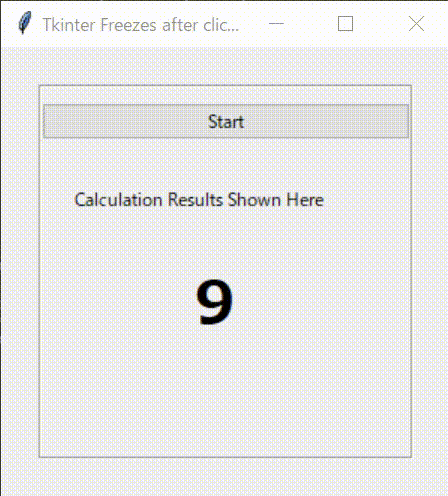
下記の図のようなシンプルなGUI画面を設計します。上部のボタン(Button)がクリックされると、下部に0から9まで順番に表示されるものです。
早速、Tkinterでコードを書いてみましょう。3.応答性が悪いコード
まず、下記のようなコードを書いてみました。
ボタンを押すと、_main_func()を実行する構造となっています。_main_func()は、For文を利用して0から9まで表示する関数です。結果の表示には、Tkinterのラベルと、print文の2種類を用いました。
3.1.プログラミングコード(1)
tkinter_wo_threading.pyimport tkinter as tk from tkinter import ttk from tkinter import font import time class Application(tk.Frame): def __init__(self,master): super().__init__(master) self.pack() self.master.geometry("300x300") self.master.title("Tkinter Freezes after clicking Buttons") self.font_lbl_big = font.Font( family="Meiryo UI", size=30, weight="bold" ) self.font_lbl_middle = font.Font( family="Meiryo UI", size=15, weight="bold" ) self.font_lbl_small = font.Font( family="Meiryo UI", size=12, weight="normal" ) self.create_widgets() def create_widgets(self): # Frame self.main_frame = tk.LabelFrame(self.master, text ='', font = self.font_lbl_small) self.main_frame.place(x=25,y=25) self.main_frame.configure(height = 250, width=250) self.main_frame.grid_propagate(0) self.main_frame.grid_columnconfigure(0, weight = 1) # Start Button self.btn_Start = ttk.Button( self.main_frame) self.btn_Start.configure( text='Start' ) self.btn_Start.configure( command=self._main_func) self.btn_Start.grid( column=0, row=0, pady=10 , sticky='NESW') # Label Title self.lbl_title = ttk.Label( self.main_frame) self.lbl_title.configure( text='Calculation Results Shown Here' ) self.lbl_title.grid( column=0, row=1, padx = 20, pady=20 ,sticky='EW') # Label Result self.lbl_result = ttk.Label( self.main_frame ) self.lbl_result.configure( text='' ) self.lbl_result.grid( column=0, row=2, padx = 100, pady=10 ,sticky='EW') def _main_func(self): for i in range(10): print(i) self.lbl_result.configure(text = i, font = self.font_lbl_big) time.sleep(0.1) def main(): root = tk.Tk() app = Application(master=root)#Inherit app.mainloop() if __name__ == "__main__": main()3.2.実行結果
このコードを実行してみます。
ボータンを押すと、for文のループが終わるまで、プログラムが応答しなくなります。print文で結果を連続に表示してくれますが、GUIは止まったままです。そして、for文のループが終わると最後の数字だけ表示してくれます。最初に期待したものと違いますね。これはPythonがコードを1行ずつ逐次実行することが原因です。このままだと、GUIプログラムでの一つのイベント処理が終わるまで、ほかのイベントがスタートすらできなくなる応答性が悪くなります。
4.Threadingを利用し、応答性をよくしたコード
この時、Threadingを利用します。Threadingに関する内容は、参考資料を参照にしました。
4.1.応答性を改善したプログラミングコード(1)
まず、threadingを導入します。
import threading順番として、ボタン(Button)のコールバック関数を_start_thread()に変更します。
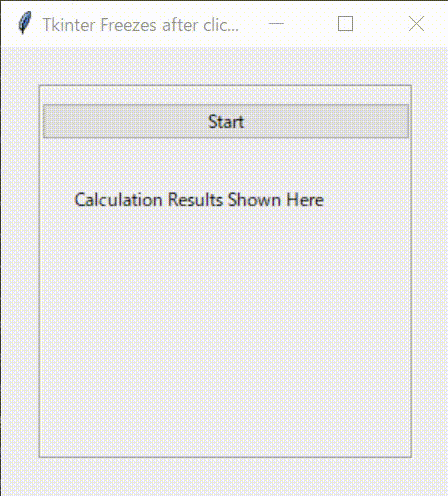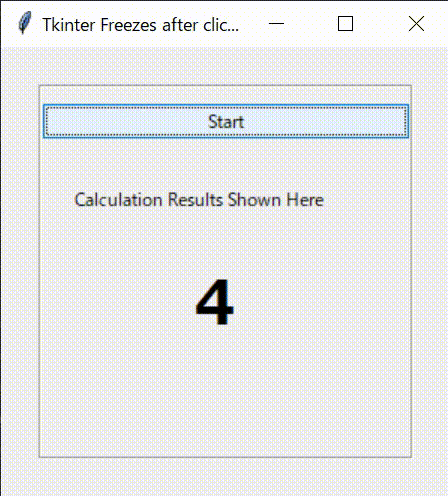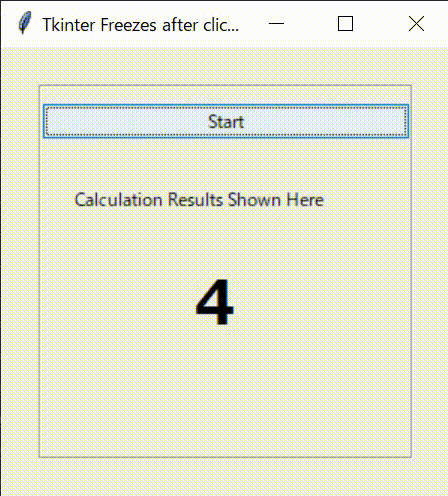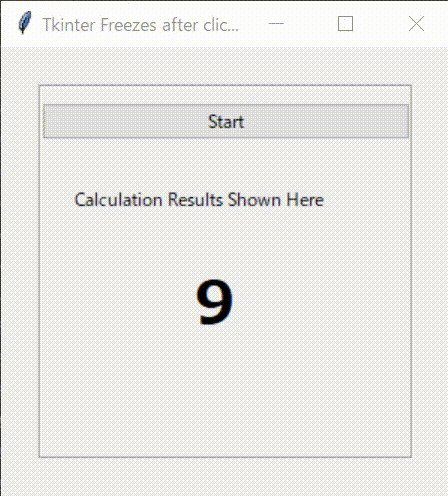
その_start_thread()に、_main_func()をスレッドとしてstartする機能を入れておきます。ターゲットとして指定し、スタートを書けるイメージです。def _start_thread(self): self.thread_main = threading.Thread(target = self._main_func) self.thread_main.start()全体のコードです。
tkinter_with_threading.pyimport tkinter as tk from tkinter import ttk from tkinter import font import time import threading class Application(tk.Frame): def __init__(self,master): super().__init__(master) self.pack() self.master.geometry("300x300") self.master.title("Tkinter Freezes after clicking Buttons") self.font_lbl_big = font.Font( family="Meiryo UI", size=30, weight="bold" ) self.font_lbl_middle = font.Font( family="Meiryo UI", size=15, weight="bold" ) self.font_lbl_small = font.Font( family="Meiryo UI", size=12, weight="normal" ) self.create_widgets() def create_widgets(self): # Frame self.main_frame = tk.LabelFrame(self.master, text ='', font = self.font_lbl_small) self.main_frame.place(x=25,y=25) self.main_frame.configure(height = 250, width=250) self.main_frame.grid_propagate(0) self.main_frame.grid_columnconfigure(0, weight = 1) # Start Button self.btn_Start = ttk.Button( self.main_frame) self.btn_Start.configure( text='Start' ) self.btn_Start.configure( command=self._start_thread) self.btn_Start.grid( column=0, row=0, pady=10 , sticky='NESW') # Label Title self.lbl_title = ttk.Label( self.main_frame) self.lbl_title.configure( text='Calculation Results Shown Here' ) self.lbl_title.grid( column=0, row=1, padx = 20, pady=20 ,sticky='EW') # Label Result self.lbl_result = ttk.Label( self.main_frame ) self.lbl_result.configure( text='' ) self.lbl_result.grid( column=0, row=2, padx = 100, pady=10 ,sticky='EW') #----------------------------------------------------------- # Start Thread # ----------------------------------------------------------- def _start_thread(self): self.thread_main = threading.Thread(target = self._main_func) self.thread_main.start() def _main_func(self): for i in range(10): print(i) self.lbl_result.configure(text = i, font = self.font_lbl_big) time.sleep(0.1) def main(): root = tk.Tk() app = Application(master=root)#Inherit app.mainloop() if __name__ == "__main__": main()4.2.実行結果
Threadingを利用したコードの実行結果です。
最初に意図した通りにプログラムが動くことが確認できました。プログラムの反応性もよくなり、ほかのイベント処理も可能となりました。
まとめ
スレッドを利用し、GUIプログラムの応答性をよくすることができました。
参考資料
1.python#Threading
2.Pythonのthreadingとmultiprocessingを完全理解
3.[Python] スレッドで実装する

- 投稿日:2020-07-31T16:47:24+09:00
女子プロゴルファーの顔診断AIを作ってみた①
1. はじめに
今学んでるディープラーニングを使って制作物を作ろうと考えました。
画像を使ったAIアプリを作れたらいいなと思い、取り組みました。題材を何にしようか悩んでいたら父親が女子プロゴルファーにハマっていたので女子プロの診断アプリを作成しようと思った。
渋野日向子プロ、小祝さくらプロ、原英莉花プロの画像診断アプリを作ることにした。※本当はここにも顔写真載せたかったけど著作権の関係からだめそうなので諦めました。
2. 進め方
①画像収集
②顔部分のみを取得
③不要データを削除(例えば違う顔だったり、サングラスかけてたり、なぜかおじさんの画像)
④テストデータとバリデーションデータとに分ける
⑤画像の水増し
⑥モデルの構築(今回はvgg16の転移学習)
⑦公開用のアプリケーション作成
⑧デプロイ
なかなかハードでした・・・試したこといろいろ書こうと思います。
3. 画像収集
やり方はいろいろあると思いますがicrawlerを用いました。
icrawlerとは?
Webクローラーのミニフレームワークです。画像や動画などのメディアデータをサポートしており、テキストやその他の種類のファイルにも適用可能です。Scrapyは重くて強力ですが、icrawlerは軽いみたいです。
公式リファレンス
インストール方法も載っていますのでご参考ください。search.pyfrom icrawler.builtin import BingImageCrawler import os import shutil # 検出する画像 golfer_lists = {'渋野日向子': 'shibuno', '小祝さくら': 'koiwai', '原英莉花': 'hara'} # フォルダの作成 os.makedirs('./origin_image', exist_ok=True) # keyに検索用の名前、valueはフォルダ名 for key, value in golfer_lists.items(): # 取得した画像の保存先を指定 crawler = BingImageCrawler(storage={'root_dir': value}) # キーワードと取得枚数を指定 crawler.crawl(keyword=key, max_num=1000) # フォルダを移動 path = os.path.join('./', value) shutil.move(path, './origin_image/')これでそれぞれ画像の取得ができました。1000枚としたけど実際は700枚くらいでした。
4. 顔部分の取得
顔部分の取得はface_recognitionを使いました。
face_recognition.pyimport cv2 from PIL import Image import os, glob import numpy as np import random from PIL import ImageFile import face_recognition # 元画像が入っている大元のフォルダ in_dir = './origin_image/*' # 顔部分のみ取り出した画像が入る out_dir = './face' # 各選手のフォルダ in_file = glob.glob(in_dir) # 各選手のフォルダ名を取得 fileName_lists = os.listdir('./origin_image') # テストファイルの保存先 test_image_path = './test_image/' # 各フォルダごとに処理を行う for golfer, fileName in zip(in_file, fileName_lists): # 各選手の画像リストを取得 in_jpg = glob.glob(golfer + '/*') # 各選手の画像名 in_fileName=os.listdir(golfer) # 各選手のフォルダーパス folder_path = out_dir + '/' + fileName # 各選手の出力フォルダを作成 os.makedirs(folder_path, exist_ok=True) # 各画像について処理を行う for i in range(len(in_jpg)): # 画像を読み込む # image(縦, 横, 3色) image = face_recognition.load_image_file(str(in_jpg[i])) faces = face_recognition.face_locations(image) # 画像が存在したら([(911, 2452, 1466, 1897)])のような出力がされる if len(faces) > 0: # 取得した顔画像の中で最大の物を選ぶ((top - bottom)*(right - left)を計算) face_max = [(abs(faces[i][0]-faces[i][2])) * (abs(faces[i][1]-faces[i][3])) for i in range(len(faces))] top, right, bottom, left = faces[face_max.index(max(face_max))] # 顔部分の画像を抜き出す faceImage = image[top:bottom, left:right] # Image.fromarray()にndarrayを渡すとPIL.Imageが得られ、そのsave()メソッドで画像ファイルとして保存できる。 final = Image.fromarray(faceImage) final = np.asarray(final.resize((64, 64))) final = Image.fromarray(final) file_path = folder_path + '/' + str(i) + '.jpg' final.save(file_path) else: print('No Face')ちょっと長いですがこのようになっています。
現在のフォルダ体系の確認
これで顔部分を取得できました。
あとはひたすら1枚ずつ確認する作業・・・・
大変だけどこれが大事なんです。5. 訓練データとバリデーションデータに分ける
訓練データ80%、バリデーションデータ20%に分ける。
split.py# 訓練データとバリデーションデータとに分ける import os, glob import shutil # 顔部分のみ取り出した画像が入る in_dir = './face/*' # 各選手のフォルダ ['./face/shibuno' './face/koiwai', './face/hara'] in_file = glob.glob(in_dir) # 各選手のフォルダ名を取得 ['shibuno', 'koiwai', 'hara'] fileName_lists = os.listdir('./face') # テストファイルの保存先 test_image_path = './valid/' # 各フォルダごとに処理を行う for golfer, fileName in zip(in_file, fileName_lists): # 各選手の画像リストを取得 in_jpg = glob.glob(golfer + '/*') # 各選手の画像名 in_fileName=os.listdir(golfer) # validation用のデータを保存する test_path = test_image_path + fileName os.makedirs(test_path, exist_ok=True) # バリデーション用のフォルダへ移動する for i in range(len(in_jpg)//5): shutil.move(str(in_jpg[i]), test_path+'/')
こんな感じになっていればOK。
次に訓練データの画像の水増しを行う。6. データのかさ増し(水増し)
画像データを集めて、取捨選択することは非常に手間がかかり大変です。(ほんとに大変でした)
そこで画像データを反転したり、ずらしたりすることで新たなデータを作り出します。pic_addimport PIL from keras.preprocessing.image import load_img, img_to_array, ImageDataGenerator, array_to_img import numpy as np import os, glob import matplotlib.pyplot as plt import cv2 # 元画像が入っている大元のフォルダ in_dir = './face/*' # 顔部分のみ取り出した画像が入る out_dir = './face' # 各選手のフォルダパス in_files = glob.glob(in_dir) # 各フォルダ名 folder_names = os.listdir('./face') # 各選手のパスとフォルダ名 for file, name in zip(in_files, folder_names): # 各画像 image_files = glob.glob(file + '/*') # 各ファイル名 in_fileName = os.listdir(file) SAVE_DIR = './face/' + name # 保存先ディレクトリが存在しない場合、作成する。 if not os.path.exists(SAVE_DIR): os.makedirs(SAVE_DIR) # 各画像それぞれに水増しを行う for num in range(len(image_files)): datagen = ImageDataGenerator( rotation_range=40, # ランダムに回転する回転範囲(単位degree) width_shift_range=0.2, # ランダムに水平方向に平行移動する、画像の横幅に対する割合 height_shift_range=0.2, # ランダムに垂直方向に平行移動する、画像の縦幅に対する割合 shear_range=0.2, # せん断の度合い。大きくするとより斜め方向に押しつぶされたり伸びたりしたような画像になる(単位degree) zoom_range=0.2, # ランダムに画像を圧縮、拡大させる割合。最小で 1-zoomrange まで圧縮され、最大で 1+zoom_rangeまで拡大される。 horizontal_flip=True, # Trueを指定すると、ランダムに水平方向に反転します。 fill_mode='nearest') img_array = cv2.imread(image_files[num]) # 画像読み込み img_array = img_array.reshape((1,) + img_array.shape) # 4次元データに変換(flow()に渡すため) # flow()により、ランダム変換したイメージのバッチを作成。 # 指定したディレクトリに生成画像を保存する。 i = 0 for batch in datagen.flow(img_array, batch_size=1, save_to_dir=SAVE_DIR, save_prefix='add', save_format='jpg'): i += 1 if i == 5: break # 停止しないと無限ループこれで訓練データの画像は1000枚を超えた。
かなり長くなったのでモデルの作成は次回に持ち越す。
番外編としてカスケード分類器を用いた場合のコードも記載する。
※カスケード分類器について
当初カスケード分類器を用いて顔部分を取得しようとしたが文字部分や顔を取得できずにデータ量が六分の1くらいになってしまった。
一応カスケード分類器についても載せておきます
下記位リンク先より「haarcascade_frontalface_default.xml」をダウンロードしておく。(https://github.com/opencv/opencv/tree/master/data/haarcascades)
cascade.pyimport cv2 from PIL import Image import os, glob import numpy as np import random from PIL import ImageFile # 元画像が入っている大元のフォルダ in_dir = './origin_image/*' # 顔部分のみ取り出した画像が入る out_dir = './face_image' # 各選手のフォルダ in_file = glob.glob(in_dir) # 各選手のフォルダ名を取得 fileName_lists = os.listdir('./origin_image') # テストファイルの保存先 test_image_path = './face_image/test_image/' cascade_path = './haarcascade_frontalface_alt.xml' face_cascade = cv2.CascadeClassifier(cascade_path) # 各フォルダごとに処理を行う for golfer, fileName in zip(in_file, fileName_lists): # 各選手の画像リストを取得 in_jpg = glob.glob(golfer + '/*') # 各選手の画像名 in_fileName=os.listdir(golfer) # 各選手のフォルダーパス folder_path = out_dir + '/' + fileName # 各選手の出力フォルダを作成 os.makedirs(folder_path, exist_ok=True) # 各画像について処理を行う for i in range(len(in_jpg)): # 画像を読み込む image=cv2.imread(str(in_jpg[i])) # グレースケールにする image_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) faces = face_cascade.detectMultiScale(image_gray, scaleFactor=1.1, minNeighbors=2, minSize=(64, 64)) if len(faces) > 0: for j, face in enumerate(faces,1): x, y ,w, h =face save_img_path = folder_path + '/' + str(i) +'_' + str(j) + '.jpg' cv2.imwrite(save_img_path , image[y:y+h, x:x+w]) else: print ('image' + str(i) + ':NoFace')


- 投稿日:2020-07-31T16:30:10+09:00
Google 検索から Search results page の保存までを一気に行う Python スクリプト
目的
思いつくままにキーワードを打ち込んで Google検索を行っても、何をどう検索したのかを記録しておかないと重複して検索を行ってしまうなど非効率なことになりがちです。
とはいえ、いちいちメモを取るのも面倒なので、Google の検索結果ページを Page Source や Web archive の形で保存して改めてゆっくり検討される方も多いかと思います。
しかし、それも少し面倒臭い。
そこで、検索キーワードの入力から HTML 保存までをワンステップにまとめました。
機能
- ①検索キーワード及び②1ページあたりの結果表示件数を与えると、検索結果ページが作業ディレクトリ(CWD)にHTMLファイルとして保存されます。
- ページ下部に表示される、2ページ目以降へのリンク及び「次へ」のリンクは無効です(相対パスなので)。
- この点については、②1ページあたりの結果表示件数(最大 100 results/page)を増やして対応 してください。
使い方
プロンプトが2回出るので、
- 最初のプロンプトでクエリ(検索キーワード)を入力、
- 検索オプション(site:go.jp や filetype:pdf など)を加える場合は、この段階で一緒に入力します。c.f. ウェブ検索の精度を高める
- 次のプロンプトで検索結果ページ1ページあたりの結果表示件数を入力します。
スクリプトについて
- 諸般の事情により無駄に class になっていますが、お察しください…。
- 今回は、html_text を得た段階ですぐに HTML ファイルに落としていますが、もちろんファイルに落とさないでそのまま活用することも可能です。
- my_headers の設定は必須ではありませんが、その有無によって返ってくるHTMLが微妙に違ってきます。これは上記の「活用」場面で意味を持ってきます。
検索結果ページの構造
- HTML を見ると、結果のリンク先は一件あたり4回、姿を変え形を変えて出てきます。
- 構造化の総本山(?)だけあって、さすがに良くできていますね…。
google_fetcher.pyimport os from urllib.parse import quote_plus, urlunsplit import requests import re PROJECT_ROOT_PATH = '.' class GoogleResultsPage: '''Query text, Results number per page -> search results response''' def __init__(self, query, rslts_num): self.__qry = query self.__num = rslts_num query_string = 'q='+quote_plus(self.__qry)+'&num='+str(self.__num) search_string = urlunsplit( ('https', 'www.google.com', '/search', query_string, '')) self.__sstr = search_string def page_fetcher(self): '''Fetch the result page and return as a text response''' my_headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6)\ AppleWebKit/537.36 (KHTML, like Gecko)\ Chrome/84.0.4147.105 Safari/537.36'} response = requests.get(self.__sstr, headers=my_headers, timeout=(3.05, 27)) return response.text ################################ # Output to a file. def html_to_file(html_text): '''Text response content to a HTML file.''' output_file_name = re.sub(r'[\/.:;*?"<>| ]', r'_', query)+'.html' output_file_path = os.path.join(PROJECT_ROOT_PATH, output_file_name) with open(output_file_path, 'w') as f: f.write(html_text) print('Done! ', end='') print('File path:', output_file_path) if __name__ == '__main__': query = input('Query? >> ') rslts_num = input('Results per page (upto 100)? >> ') html_text = GoogleResultsPage(query, rslts_num).page_fetcher() html_to_file(html_text)
- 投稿日:2020-07-31T15:58:17+09:00
Pythonのf文字(format済み文字列)
- 投稿日:2020-07-31T15:56:36+09:00
機械学習による株価予測で食っていくことは可能か[機械学習編その1]
はじめに
前回の投稿で、日経225の値幅を60%の精度で予測できたら、年率48%の利益が得られるという戯言を吐いた。
そこで、Qiitaで情報収集。
まずは、以下の記事に注目。
https://qiita.com/akiraak/items/b27a5616a94cd64a8653Accuracy =72%ってあるやん。
これを追試する。使っている技術はTensorFlow。くだんの記事はTensorFlowを使ったコードを詳細に解説していて、ソースコードも公開されている。当方の理解はちんぷんかんぷんだが、さわって試してみることはできる。ただ、2017年の記事なので、いろいろ変わっていて動かすには苦労した。
元記事のスキーム
前日まで過去3日分の各市場(FTSE, GDAXI, HSI, N225, SSEC等)の値動きを説明変数、当日のSP500の引値を教師データとしてTensorflowで機械学習を行い、当日のSP500の前日比の符号を予測する予測器を構築し、その性能を評価している。ただし、詳細な原理とかは頭悪いんで理解できていない。
その結果が、Accuracy=70%台。
これは期待が持てる。
今回のスキーム
予測対象は1358日経レバ2倍とし、説明変数も微修正。
説明変数には、前日までのNIKKEI225、各国のインデックスだけでなく円ドルも含める。
教師ラベル:当日の1358日経レバ2倍の値幅(引け値-寄値)が上昇または下落
説明変数:
DOW30, NASDAQ_COMP, S&P500, FTSE_MIB, DAX, CAC40, HANG_SENG, usdjpy, NIKKEI225 各指標の過去3日分の終値(9×3=27次元)モデルは元ソースのまま
入力層:[27, 50], stddev=0.0001 隠れ層1:[50, 25], stddev=0.0001 隠れ層2:[25, 2], stddev=0.0001 出力層:[2]実験結果
学習期間 = 2014-10-30 〜 2017-10-31
評価期間 = 2017-11-22 〜 2020-07-09
学習回数:12000回
学習データによる精度の推移
1000 0.5241935 2000 0.55241936 3000 0.5510753 4000 0.5591398 5000 0.5645161 6000 0.56989247 7000 0.57123655 8000 0.56989247 9000 0.56182796 10000 0.5577957 11000 0.5591398 12000 0.56182796評価期間での精度
評価数 = 673 上昇, 正解 = 127 下落, 正解 = 216 上昇, 不正解 = 130 下落, 不正解 = 200 Accuracy = 0.5096582466567607損益シミュレーション(バックテスト)
上昇予想の場合:1358上場日経2倍
下落予想の場合:1357日経ダブルインバース
10,000,000円分を寄り付きで購入し、引けで売却する
2017-11-22 〜 2020-07-09まで、この方法を繰り返した場合の損益
-1,551,671円
月別損益
2017年11月: -83249円 2017年12月: -83258円 2018年1月: 341621円 2018年2月: -595994円 2018年3月: 626082円 2018年4月: -222331円 2018年5月: -332350円 2018年6月: -384622円 2018年7月: -375612円 2018年8月: 355649円 2018年9月: 472170円 2018年10月: -262912円 2018年11月: -251190円 2018年12月: 1321959円 2019年1月: 1181772円 2019年2月: -545563円 2019年3月: -427964円 2019年4月: 82859円 2019年5月: -465943円 2019年6月: -265452円 2019年7月: 96485円 2019年8月: 936343円 2019年9月: -723723円 2019年10月: -432153円 2019年11月: 396537円 2019年12月: 181781円 2020年1月: -303620円 2020年2月: -109976円 2020年3月: -3523718円 2020年4月: -35221円 2020年5月: 630419円 2020年6月: 1731269円結果の考察
学習はできているようだけど、取り置きした評価データでの精度は、サイコロを振ったのと同レベル。当然ながら、バックテストの結果も全くダメ。
予測と全く逆の売買をすると損益は若干プラスになるようだが。。。
前日までの各国市場のインデックスから当日のNIKKEI225の寄り値を予測することは、先人たちの結果はAccuracy=0.7以上いけそうということだったが、寄り値を予測したところであまりご利益は無い。
単に寄る前に板を見たらわかることで、予測する必要すらない。今回のスキームのように値幅を予測するということは、寄り値とその先の引値を予測しなければならない訳で、このAccuracyが0.5096ということは、そんな予測はできないということになる。当然といえば当然。寄った先は所詮ランダムウォーク。
2017/12から2020/2までは、まさにサイコロ振って売買したが如く収支トントン。
2020/2から2020/3で損失を大きくしているが、これは新型コロナ蔓延以前の平穏な状態を学習させた予測器を使用したため、コロナ渦で大きく予測を外したということが言えるのではないだろうか。累積損益のグラフを眺めると、全期間が全くランダムではなく、いいとき(予測が当たるとき)と悪いときがまとまって存在するように見える。
同じ収支トントンでも累積損益グラフがAのような場合と、今回のようなBのような場合とでは、予測器の質が異なるように思う。BよりもAのほうが質がいい。今回の予測器は質が悪い!
今回の予測器で、たまたま2018/12から運用を開始したとすると、最初の数か月は大儲け状態となり、「俺って天才!」と浮かれてしまい、その後の判断を誤り大やけどを負うことになってしまう。
損益に大きな周期が出るような予測器Bはダメな予測器であり、小刻みにプラスを積み重ねるような予測器Cを作ることを新たな目標にするということで、今回は締めくくる。
まとめ
- 代表市場のインデックスの過去3日の引値を、翌日の日経平均の 値幅の符号を教師ラベルとして機械学習させてみたが、Accuracyが0.5096しかなく、 うまくいかなかった。
- 質の良い予測器はどんなものかの考察ができ、目標ができた。
つづく


- 投稿日:2020-07-31T15:55:46+09:00
PythonでPower BI Desktopを自動更新する
PowerBI便利ですよね。
一回作っておけば毎月の分析が自動でされる気持ちよさ。
自由にグラフ配置できて、求めるデータが一目で理解できる明確さ。
マウス操作だけで自分なりに分析を深めていけるフィルタやヒント機能。
直感的につなげられるテーブル間のリレーション。
様々なデータソースとの連携。
何しろこれで無料というんだからびっくりです。自分も、数億件規模のデータを分析するのに使っています。
ヒント機能使って、その時間に何が起きていたか表示するの楽しいですよね。
ただ、一つ問題が。更新がめんどくさい!!
データの前処理しているとはいえ、データ読み込んでくるの数十分はかかります。
ぱっと出したいときなんかはストレスです。PC重くなるし。
それに、スペック低いPCで更新しようものなら、メモリ不足で落ちます。
Power BI Desktopじゃなくて、無印のPower BIなら自動更新もできるそうですけど、有料になっちゃうし、アカウント管理とか大変。ということで、今回PowerBI DeskTopを自動化するプログラムをPythonでつくりました。
環境・構成
Windows 10 Proのタスクスケジューラを使って、Pythonのプログラムを定期実行しています。
Pywinautoを使ってGUIでpbixファイルを開いて、「更新」ボタンをクリックしてから保存しています。
ちなみに、データソースはサーバー上のMySQLとつないで取得してきています。コード
auto_pbi.pyimport os import sys import time from pywinauto import Desktop, Application, keyboard def main(workbook): exe = 'PBIDesktop.exe' # ファイルを開く os.system('start "" "{0}"'.format(workbook)) app = Application(backend='uia').connect(path=exe) time.sleep(60) try: # Windowを指定 win = app.window(title_re = '.*Power BI Desktop') win.set_focus() # ホーム>更新をクリック win.ホーム.wait("visible") win.ホーム.click_input() win.更新.wait("visible") win.更新.click_input() win.キャンセル.wait_not("visible",timeout=6000) # 保存 keyboard.send_keys("^s") time.sleep(120) except Exception as e: print(e) finally: app.kill() if __name__ == '__main__': try: file_path = sys.argv[1] except (IndexError): print('ファイルを指定してください。') sys.exit() main(file_path)上記のコードをauto_pbi.batで指定してタスクスケジューラで走らせています。
auto_pbi.batcd 指定フォルダ python.exe auto_pbi.py レポート.pbix exitPythonや.pyファイル、pbixファイルについては、絶対パスで書いておくことをお勧めします。
自分はフォルダ内にレポートとpyファイル入れてしまっているので、最初の行でフォルダ移動しています。注意点
タスクスケジューラの実行
自分はリモートPCでこのプログラムを実行しようとしましたが、うまくいきませんでした。
タスクスケジューラを自分で「実行」するとうまくいきますが、リモート接続を切ってトリガーで実行させようとするとうまくいかなくなります。
これは、リモートPCの場合、リモートデスクトップの接続が切れたときに、デスクトップ画面がロックされてしまうからです。
以下のようなエラーが出ます。there is no active desktop required for moving mouse cursor!この対策をするためには、リモートデスクトップを切った時にデスクトップ画面がロックアウトしないように設定する必要があります。
https://pywinauto.readthedocs.io/en/latest/remote_execution.html自分は、リモートデスクトップを切るときに以下のコマンドを使うという方法をとりました。
#80となっているところは環境に合わせて変えてください。
リモート先のPCでタスクマネージャー>ユーザーと開き、各カラムの見出し部分を右クリックして「セッション」にチェックをつけると、リモートセッションIDが表示されます。
リモートデスクトップのセッションを切るときに以下のコマンドをコマンドプロンプトから入力してください。TSCON RDP-Tcp#80 /dest:consoleスリープ処理
pbiを立ち上げてから少し待たないと、Windowが立ち上がってこないためエラーが出ました。
あと、意外と注意しないとなと思ったのは、Ctrl+Sで保存したあとのスリープ処理。
30秒くらいで保存処理完了できるかと思いましたが、できませんでした。
思っているより長めにとっておいたほうがよいかと思います。その他
更新したらファイルコピーして送るとか、エラー出たらメールはいるようにしておくとか、これをベースにしていただければ、毎日のビッグデータ更新みたいな面倒な処理が省けて、快適なPowerBIライフを送っていただけるんじゃないかと思います!
- 投稿日:2020-07-31T15:52:01+09:00
PythonのSQLiteで外部キー(Foreign Key)[備忘録]
PythonのSQLiteで外部キーを使っていきます
まずPersonテーブルを作ります。
db = "./exsample.db" con = sqlite3.connect(db) cur = con.cursor() table = "Person" # テーブル名 sql = f"""create table {table}( id integer primary key autoincrement, name text, age integer, )""" cur.execute(sql) # SQL実行 self.con.commit() # 保存
idはprimary keyで主キーにし、autoincrementで自動で振り分けるようにしています。外部テーブルを作ります。
table = "Memo" # テーブル名 sql = f"""create table {table}( id integer primary key autoincrement, title text, content text, writer_id integer, foreign key(writer_id) references Person(id) )""" cur.execute(sql) # SQL実行 self.con.commit() # 保存
foreign key(writer_id) references Person(id)に注目です。
ここで、writer_id integerでいったんintegerの項目をつくり、その下で
foreign key(<項目名>) references <繋ぐテーブル名>(<繋ぐテーブルの項目名>)、とします。
- 投稿日:2020-07-31T15:48:28+09:00
Pandas DataFrame に期待する列が存在するかどうかをチェックする
例えば以下のような「DataFrame を加工する関数」があったとする。
import pandas as pd def preprocess(df: pd.DataFrame) -> pd.DataFrame: df["full_name"] = df["first_name"] + " " + df["last_name"] return dfこの関数の引数の DataFrame には
first_nameとlast_nameという列が含まれることが期待されるが、これを関数のはじめでチェックしたいことがある。これは set 型 1 の演算を使うと簡単に書ける。
import pandas as pd def preprocess(df: pd.DataFrame) -> pd.DataFrame: required_columns = {"first_name", "last_name"} if not required_columns <= set(df.columns): raise ValueError(f"missing columns: {required_columns - set(df.columns)}") df["full_name"] = df["first_name"] + " " + df["last_name"] return dfこのように書いておくと、必要な列が抜けていた場合に ValueError を投げてくれる。
df = pd.DataFrame([{"first_name": "John", "age": 30}]) # 'last_name' 列が抜けている DataFrame preprocess(df) #=> ValueError: missing columns: {'last_name'}
- 投稿日:2020-07-31T15:45:15+09:00
numpy2次元配列を3次元Onehot表現
やりたかったこと
- numpy2次元配列を3次元Onehot表現
- (Qiitaに初投稿?)
- より良い書き方を知りたいです!詳しい方教えて下さい。
想定する場面
- 画像セグメンテーションであれば
- 2次元配列は「正解ラベルの元画像」に相当
- 3次元配列は「加工済の正解ラベル」に相当
コード
import numpy as np # クラス数 class_num = 4 # 各要素がクラスに該当する2次元の配列 arr_2d = np.array([[0, 1] ,[2, 1]]) # 各層がクラスに対応する3次元の配列 np.identity(class_num)[arr_2d].transpose(2,0,1)まだやってないこと
- numpyだけでなくpytorchのTensor配列でも同様のことができそう
- 複数枚の処理
- 投稿日:2020-07-31T15:38:44+09:00
PDFにパスワードをかける
個人情報満載のPDFが見つかり、パスワードをかけておいた方がいいかなと思いたつ。Adobeのアクロバットを買えばいいのだろうけれど、そしてフリーのソフトもあるのだろうけれど、せっかくだからPyPDF2を使ってかけてみる。
PDF_pw.pyimport PyPDF2 src_pdf = PyPDF2.PdfFileReader('./**パスワードをかけたいPDF**.pdf') pass_pdf = './**パスワードをかけた後の出力先**.pdf' password = '**任意のPassword**' dst_pdf = PyPDF2.PdfFileWriter() dst_pdf.cloneReaderDocumentRoot(src_pdf) d = {key: src_pdf.documentInfo[key] for key in src_pdf.documentInfo.keys()} dst_pdf.addMetadata(d) dst_pdf.encrypt(password) with open(pass_pdf, 'wb') as f: dst_pdf.write(f)生成までちょっと間がある印象。パスワードをかけたいPDFとパスワードをかけた後の出力先を同一にすると、上書きされる。でも、なんか失敗してPasswordもわかんないみたいな最悪の事態になるのは嫌だから、別にした方がいいと思う。
- 投稿日:2020-07-31T14:30:41+09:00
Jupyter notebookの使い方[超基礎]
Jupyter notebookの超基礎
Jupyter notebookの基本的な説明になっています。
非常にざっくりとした使い方になっているので、内容は初めて使う方向けです。
したがって、特に高度なことは書いていません。
ご注意ください。Jupyter notebook起動直後の画面
概観
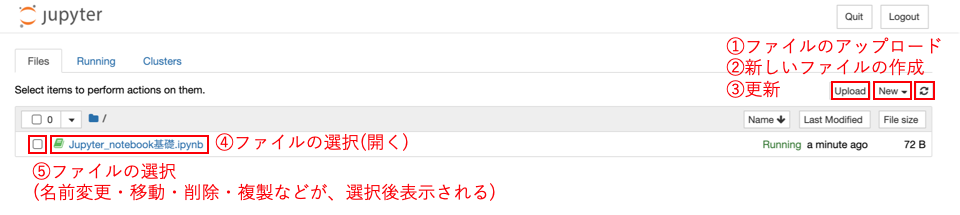
- Upload : 新しいファイルをここに、アップロードできる。
- New : ファイル(jupyter notebook形式など)やフォルダを作成する。
- 更新 : このディレクトリ(フォルダ)中を更新する
- ファイル名 : このファイル名をクリックするとjupyter notebook形式で開ける
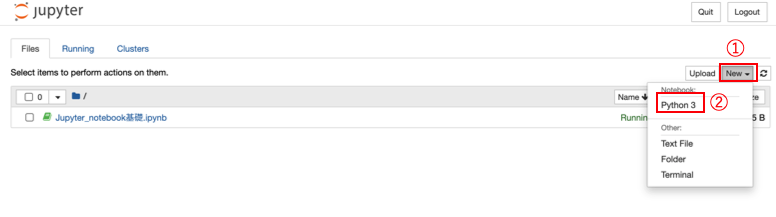
- □ : ☑︎を入れるとファイルを選択できる。削除・複製・編集などが、その後選択できる。 ##ファイルの作成 Newを押すと以下のような表示が出るので、Python3をクリックするとJupyter Notebook形式のファイルを作成できる。
ファイルの編集・削除など
☑︎を入れるとファイルを選択できる。その後以下のような表示がされて、複製・削除・編集などが出来る
Jupyter notebookでのプログラム実行
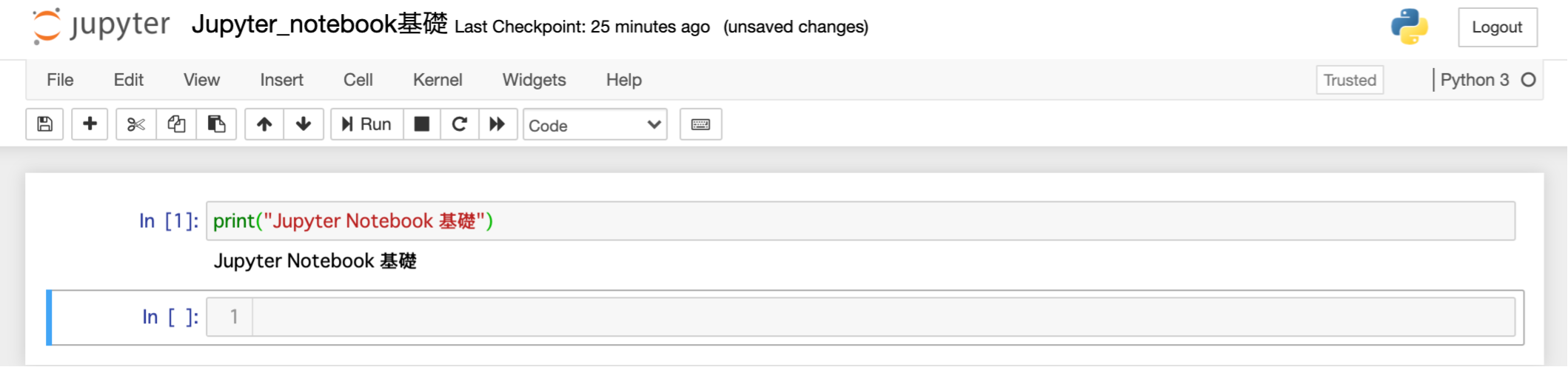
起動直後
起動直後は、上のような状態になっている。セルに入力する
In []:
となっている横の部分(セル)にプログラムを入力することができる。プログラムの実行
実行は、上の "Run"をクリックするか、Shift + Enterで実行ができる。
そして、新たなセルが作られる(次のセルがすでにある時は、新たにセルは作られません)Jupyter Notebookのツールバー
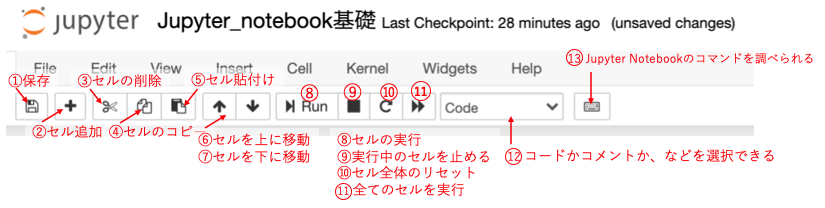
- 保存:保存を行う。Ctrl + sでも保存可能
- 新たにセルを追加できる。選択しているセルの下に追加される
- 選択しているセルを削除する。
- 選択しているセルをコピーできる
- コピーしたセルを貼り付ける
- 選択しているセルを一つ下に移動させる
- 選択しているセルを一つ上に移動させる
- セルを実行する。Shift + Enterでも可能。
- 実行しているセルコードを停止させる
- セルをリセットさせる。保存されていた変数など全てリセットされる
- 全てのセルを初めから実行し直す
- 選択しているセルに対して、コードか、コメントか、などを選択する事が出来る。
- Jupyter notebookのコマンドを調べられる。便利なものがいくつもあります。
最後に
このページでは、初歩的な使い方しか説明していないので、もっと便利に使いたい方・インストール方法から知りたい方がいれば、以下のサイトなどを参考にしてください。
おすすめの参考サイト
Jupyter notebook ショートカット解説:
https://qiita.com/forusufia/items/bea3f6fd6160cd2f5843Python初心者向けぜひ覚えておきたいJupyter Notebookのショートカットキーまとめ:
https://tonari-it.com/python-jupyter-notebook-shortcut-key/Jupyter Notebookのインストールから解説:
https://techacademy.jp/magazine/17430



- 投稿日:2020-07-31T12:59:25+09:00
全自分に捧ぐショートカットキー一覧
pyAutoGUIはキーボード入力で動かさないと意味がない
こう見えて最初に会社の講習で最初にSikuliを習った派閥に属している(not SikuliX)。
ちょっと端末の状況変わると動かない…だとかを講習中に見せられ…
結局、自分で組んだ時は画像認識を一切使わなかったのを思い出す。アプリケーションを利用せずにPythonを触る時だってそう。
画像認識やマウスの座標を拾って作業している人を見ると(´・ω・)oO(え…動かないかもしれんとか、不安じゃないんかな…)
と内心ハラハラしっぱなしだ。
もしかしたら、昔「デスクトップはカスタマイズするもの」という世界線で生きていたからかもしれない。そういえば、ついさっき新入社員に
「pyAutoGUI使えばいいんじゃね?」
と答えはしたけど
あー、きっと彼らはpyAutoGUIのマウス操作とかが心に響いちゃうんだろうなぁぁぁ…
と気が気ではない。
キーボード操作でやれば基本的に環境変わっても同じに動くんやで…いつものことながら、聞かれるまでは黙ってるスタイル。
…まぁ、彼らも[win] + [数字]でタスクバーから起動してる人には言われたくないだろうってことで。ショートカットキーをド忘れした時に見るサイト
さて、前置きが長くなったが本題。
ショートカットキーをド忘れした時にいつもお世話になっているサイトを自分用に一覧にしておいた。普段はwin32com.clientを利用しているが、ちょっとした問題からpyAutoGUIを利用することも増えてきた。
MicroSoft製品(Excel,Word,PowerPoint,Outlook)に関するショートカットキー
137個のWindowsショートカットキー一覧表(PDF有)MicroSoftTeamsに関するショートカットキー
Microsoft Teams で使用するショートカット キーブラウザに関するショートカットキー
Chrome のキーボード ショートカット
Internet Explorer 11 のキーボード ショートカット
Firefox のキーボードショートカット
- 投稿日:2020-07-31T12:13:53+09:00
【Python】BeautifulSoupでタグを指定して削除
最近、Pythonでスクレイピングをしていて、いらないタグを指定して削除したいな〜〜〜〜と思ったらあったのでメモ
BeautifulSoupインストール
BeautifulSoupを使用するのでBeautifulSoup4をインストールします。
$ pip install beautifulsoup4サンプル
from bs4 import BeautifulSoup >>> marks = '<p><span class="category">Information</span><span class="bdy"><a href="https://www.sample.com/">Now <br>available!</a></span></p>' >>> soup = BeautifulSoup(marks, 'html.parser') >>> a_tag = soup.find("a") >>> print(a_tag) >>> br_tag = soup.find("a") >>> br_tag.decompose() >>> print(a_tag) # 出力結果 # <a href="https://www.sample.com/">Now <br/>available!</a> # <None></None>参考
https://www.whyit.work/entry/2019/04/04/101538
https://qiita.com/mtskhs/items/edf7dbba9b0b0246ef8f
- 投稿日:2020-07-31T09:18:12+09:00
PythonでSQLite3を扱ってみる[備忘録]
初めに
sqliteはPythonに標準で入っているモジュール。インストールせずにimportできる。コネクト
import sqlite3 db = "./exsample.db" # データベースまでのパス con = sqlite3.connect(db) # コネクトテーブルを作る
cur = con.cursor() table = "Friend" # テーブル名 sql = f"""create table {table}( id integer primary key autoincrement, name text, age integer, )""" cur.execute(sql) # SQL実行 self.con.commit() # 保存
idはprimary keyで主キーにし、autoincrementで自動で振り分けるようにしている。テーブルがなかったら作る。
table = "Friend" # テーブル名 sql = f"""create table if not exists {table}( id integer primary key autoincrement, name text, age integer, )""" cur.execute(sql) # SQL実行 self.con.commit() # 保存
if not existsを入れる。テーブル編集
old_table = "Friend" # 古いテーブル名 new_table = "NewFriend" # 新しいテーブル名 sql = f"alter table {old_table} rename to {new_table}" cur.execute(sql) # SQL実行 self.con.commit() # 保存テーブル削除
table = "NewFriend" # 削除したいテーブル sql = f"drop table {table}" cur.execute(sql) # SQL実行 self.con.commit() # 保存型一覧
型名 情報 NULL NULL値 INTEGER 符号付整数。1, 2, 3, 4, 6, or 8 バイトで格納 REAL 浮動小数点数。8バイトで格納 TEXT テキスト。UTF-8, UTF-16BE or UTF-16-LEのいずれかで格納 BLOB 入力データをそのまま格納 レコード挿入
table = "Friend" # テーブル名 sql = f"insert into {table} (name, age) values ('次郎', 20)" cur.execute(sql) # SQL実行 self.con.commit() # 保存又は、
table = "Friend" # テーブル名 sql = f"insert into {table} (name, age) values (?, ?)" data = ("次郎", 20) cur.execute(sql, data) # SQL実行 self.con.commit() # 保存
?にして、第2引数にタプルを入れることで挿入できる。レコード編集
次郎を太郎に変換してみる
table = "Friend" # テーブル名 id = 1 # 編集したいレコードのid sql = f"update {table} set name='太郎' where id={id}" cur.execute(sql) # SQL実行 self.con.commit() # 保存レコード削除
table = "Friend" # テーブル名 id = 1 # 削除するレコードのid sql = f"delete from {table} where id={id}" cur.execute(sql) # SQL実行 self.con.commit() # 保存