- 投稿日:2020-07-31T20:55:42+09:00
[MyBatis] 1対多の関係にあるテーブルに対する照会クエリをネストされたBeanにマッピングしたい
問題
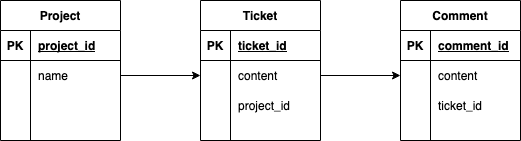
JIRAやRedmineのようなバグトラッキングシステムを例とします。このシステムでは、トピックごとにプロジェクトを作成します。チケットはプロジェクトごとに作成され、利用者はチケットにコメントを付与することができるとします。ER図は以下の通りです。
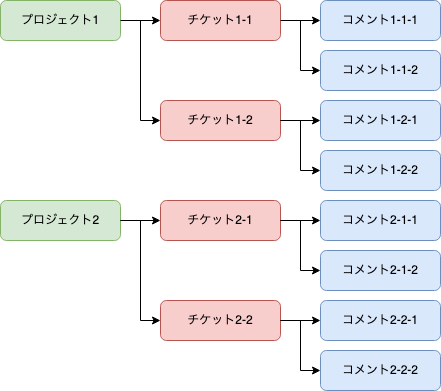
データについては、次のようになっているとします。
ここで、プロジェクトとそれにひもづくチケット・コメントをすべて取得することを考えます。クエリを書くことは簡単ですが、
Project.javaというネストされたJava Beanに結果をマッピングした場合、どのようにすればよいでしょうか? 言い換えれば、1対多の関係にあるテーブルに対する照会クエリをネストされたBeanにマッピングしたい場合、どのようにすればよいでしょうか?Project.java@Data @ToString(exclude = {"tickets"}) public class Project { private int projectId; private String name; private List<Ticket> tickets; }Ticket.java@Data @ToString(exclude = {"comments"}) public class Ticket { private int ticketId; private String content; private List<Comment> comments; }Comment.java@Data public class Comment { private int commentId; private String content; }回答
resultMapとcollectionという機能を利用します。 上記の例であれば、以下のようなxmlを作成します。ProjectMapper.xml<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.example.demo.mapper.ProjectMapper"> <select id="findAllProject" resultMap="findAllProjectResultMap"> SELECT project.project_id, project.name as project_name, ticket.ticket_id, ticket.content as ticket_content, comment.comment_id, comment.content as comment_content FROM project JOIN ticket ON project.project_id = ticket.project_id JOIN comment ON ticket.ticket_id = comment.ticket_id </select> <resultMap id="findAllProjectResultMap" type="com.example.demo.dto.Project"> <id property="projectId" column="project_id" /> <result property="name" column="project_name"/> <collection property="tickets" ofType="com.example.demo.dto.Ticket"> <id property="ticketId" column="ticket_id" /> <result property="content" column="ticket_content"/> <collection property="comments" ofType="com.example.demo.dto.Comment"> <id property="commentId" column="comment_id" /> <result property="content" column="comment_content"/> </collection> </collection> </resultMap> </mapper>以下のコードではSQLを実行結果がどのような形でJava BeanにマッピングされたのかをPretty Printすることで、確認することができます
CommandlineappliApplication.java@Component public class CommandlineappliApplication implements CommandLineRunner{ @Autowired private ProjectMapper projectMapper; @Override public void run(String... args) throws Exception { for (Project project : projectMapper.findAllProject()) { System.out.printf("%s%n", project); for (Ticket ticket : project.getTickets()) { System.out.printf(" └ %s%n", ticket); for (Comment comment : ticket.getComments()) { System.out.printf(" └ %s%n", comment); } } } } }実際に動かした結果は次の通り。ネストされたBeanに対して、SQLの実行結果が想定通りマッピングされていることがわかります。
Project(projectId=1, name=プロジェクト1) └ Ticket(ticketId=1, content=チケット1-1) └ Comment(commentId=1, content=コメント1-1-1) └ Comment(commentId=2, content=コメント1-1-2) └ Ticket(ticketId=2, content=チケット1-2) └ Comment(commentId=3, content=コメント1-2-1) └ Comment(commentId=4, content=コメント1-2-2) Project(projectId=2, name=プロジェクト2) └ Ticket(ticketId=3, content=チケット2-1) └ Comment(commentId=5, content=コメント2-1-1) └ Comment(commentId=6, content=コメント2-1-2) └ Ticket(ticketId=4, content=チケット2-2) └ Comment(commentId=7, content=コメント2-2-1) └ Comment(commentId=8, content=コメント2-2-2)環境情報
pom.xml<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.3.2.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.example</groupId> <artifactId>mybatis-sample</artifactId> <version>0.0.1-SNAPSHOT</version> <name>mybatis-sample</name> <description>Demo project for Spring Boot</description> <properties> <java.version>11</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-batch</artifactId> </dependency> <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>2.1.3</version> </dependency> <dependency> <groupId>com.h2database</groupId> <artifactId>h2</artifactId> <scope>runtime</scope> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> <exclusions> <exclusion> <groupId>org.junit.vintage</groupId> <artifactId>junit-vintage-engine</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.springframework.batch</groupId> <artifactId>spring-batch-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> </project>
- 投稿日:2020-07-31T20:38:52+09:00
【Effective Javaを読む】 第3章 項目12 『Comparableの実装を検討する』
Comparableの実装を検討する
他のメソッドとは異なりcompareToメソッドはObjectでは宣言されていません。
正確に言えば、compareToメソッドはComparableインターフェースの唯一のメソッドです。
アルファベット順、数値順、年代順などの明らかに自然な順序を持つ値クラスを書くのであれば、ちょっとの努力で恩恵が受けられるのでComparableを実装しましょう。サンプルコード
public int compareTo(PhoneNumber pn) { //市外局番を比較する if (areaCode < pn.areaCode) return -1; if (areaCode > pn.areaCode) return 1; //市外局番は等しく、市内局番の前半を比較する if (prefix < pn.prefix) return -1; if (prefix > pn.prefix) return 1; //市外局番と市内局番の前半は等しく、市内局番の後半を比較する if (lineNumber < pn.lineNumber) return -1; if (lineNumber > pn.lineNumber) return 1; return 0; //全てのフィールドが等しい }
- 投稿日:2020-07-31T20:21:55+09:00
【Effective Javaを読む】 第3章 項目10 『toStringを常にオーバーライドする』
toStringを常にオーバーライドする
新しいクラスを作ってtoStringしてみても
"PhoneNumber@163b91"のような別にもらっても嬉しくない文字列がかえってきます。
toStringに関する一般契約は「簡潔だが、人が読みやすくなっている有益な表現」です。サンプルコード
/** * この電話番号の文字列表現を返します * 文字列は14文字で構成されていて、その形式は、"(XXX) YYY-ZZZZ"です。 * XXXは市外局番で、 YYY-ZZZZは市内局番です。 * (各大文字は、1桁の数字を表しています。) * * この電話番号の3つの部分のどれかが、そのフィールドを埋めるには * 桁が少ない場合には、そのフィールドの先頭が0で埋められます。 * たとえば、最後の4桁部分の番号が"123"だとしたら、文字列表現の最後の * 4文字は"0123"となります。 * * 市外局番のカッコの後に、市内局番と区切るための空白が一つあることに注意してください。 */ @Override public String toString(){ return String.format("(%03d) %03d-%04d", areaCode, prefix, lineNumber); }これで
"{Jenny=(707) 867-5309}"が返ってきますね!
toStringをきっちりオーバーライドすることは、このクラスを使う別な人のプログラムの解析をする時間を省略してあげることにつながります。続く
【Effective Javaを読む】 第3章 項目12 『Comparableの実装を検討する』
https://qiita.com/Natsukii/items/1942f7f41ac39b914591
- 投稿日:2020-07-31T19:57:42+09:00
【Effective Javaを読む】 第3章 項目9 『equalsをオーバーライドする時は、常にhashCodeをオーバーライドする』
equalsをオーバーライドする時は、常にhashCodeをオーバーライドする
equalsをオーバーライドしているすべてのクラスは、一緒にhashCodeもオーバーライドしなければObject.hashCodeの一般契約を破ってしまうよ、というお話
サンプルコード
以下のコードはequalsはオーバーライドしていますが
hashCodeはオーバーライドしていません例1public final class PhoneNumber { private final short areaCode; private final short prefix; private final short lineNumber; public PhoneNumber(int areaCode, int prefix, int lineNumber){ rangeCheck(areaCode, 999, "area code"); rangeCheck(prefix, 999, "prefix"); rangeCheck(lineNumber, 9999, "line number"); this.areaCode = (short)areaCode; this.prefix = (short)prefix; this.lineNumber = (short)lineNumber; } private static void rangeCheck(int arg, int max, String name){ if (arg < 0 || arg > max) throw new IllegalArgumentException(name +": " + arg); } @Override public boolean equals(Object o){ if (o == this) return true; if (!(o instanceof PhoneNumber)) return false; PhoneNumber pn = (PhoneNumber)o; return pn.lineNumber == lineNumber && pn.prefix == prefix && pn.areaCode == areaCode; } // 不完全 - hashCodeメソッドがない! ... // 残りは省略 }例1をHashMapで使用することを想定してみる。
例2でm.get(new PhoneNumber(707, 867, 5309))は"Jenny"を返すと期待されるけれども、帰ってくるのはnullです。
hashCodeをオーバーライドしていないので、putしたPhoneNumberとgetしているPhoneNumberはハッシュ値が別物だからです。例2Map<PhoneNumber, String> m = new HashMap<PhoneNumber, String>(); m.put(new PhoneNumber(707, 867, 5309), "Jenny");以下はあくまで例ですがhashCodeをオーバーライドしてあげましょう。
例3@Override public int hashCode(){ int result = hashCode; if (result == 0){ result = 17; result = 31 * result + areaCode; result = 31 * result + prefix; result = 31 * result + lineNumber; hashCode = result; } return result; }続く
【Effective Javaを読む】 第3章 項目10 『toStringを常にオーバーライドする』
https://qiita.com/Natsukii/items/6e2cd2e77e144048819d
- 投稿日:2020-07-31T17:59:35+09:00
【Java】文字列の登場回数を調べる
目次
- はじめに
- 前提
- 実現したいこと
- やってみたこと
- 問題
- 解決方法
- 実装内容
- 終わりに
はじめに
ふと、MapとかListとか勉強したい!!と思ったので課題考えて作ってみましたが
MapとListの役割とか変換とかでかなり躓きました。
オンラインで検索してもあんましいいの出てこなかったので、自分なりにまとめたので記事にします。前提
- 実現したいこと
- n個の任意の文字列型入力(n_1 n_2 n_3... ...n)に対し、最も多く登場した文字列の特定。
やってみたこと
- Map map = Map();として、[key:入力文字列, value:登場回数]を実装。
- mapを[value]でソートして一番最初の[key]を取り出せばいいじゃん!
問題
- Map系[HashMap, LinkedHashMap, TreeMap]は、基本的には要素に順番を持たない。
- map[0]のように、インデックスでは値を取り出せない。
解決方法
- Map.Entryクラスを利用して、マップのkeyとvalueの組み合わせを取得できる。
- List内にEntryオブジェクトを格納して、List[i]のEntryのvalueでソートができる。
実装内容
解決方法をもとに実装した内容が以下です。
CountMain.javaimport java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.Map.Entry; import java.util.Scanner; public class CountMain { public static void main(String[] args) { // 入力検知 Scanner sc = new Scanner(System.in); String count = sc.nextLine(); String[] line = sc.nextLine().split(" "); // マップ作製 Map<String, Integer> map = new HashMap<String, Integer>(); for(int i=0; i<line.length; i++){ if(!map.containsKey(line[i])){ map.put(line[i], 1); } else { int tmp = map.get(line[i]); map.remove(line[i]); map.put(line[i], tmp+1); } } // mapのエントリを取得→listへ格納 List<Entry<String, Integer>> list = new ArrayList<Entry<String, Integer>>(); for (Map.Entry<String, Integer> entry : map.entrySet()){ list.add(entry); } // list内entryのバリューを比較→ソート for (int i = 0; i < list.size(); i++){ for (int j = list.size()-1; j > i; j--){ if (list.get(j).getValue() > list.get(j-1).getValue()){ Map.Entry<String, Integer> tmpEntry = list.get(j-1); list.set(j-1, list.get(j)); list.set(j, tmpEntry); } } } System.out.print(list.get(0).getKey()); try { int i = 1; while( list.get(i).getValue() == list.get(i-1).getValue() ){ System.out.print(" " + list.get(i).getKey()); i++; } } catch (IndexOutOfBoundsException e){ return; } finally { System.out.println(""); sc.close(); } } }終わりに
- まとめ
- 各クラスごとの役割を意識するのが大事
- Mapは連想配列、順序付けの配列が必要な時は機能をListに投げる
- これができてないから最初にMapをソートしようとしてわからなくなってた
- 今後の課題
- list内のソートは人力バブルソートでやってるけど、Collection.sort()とか使えそう。
- Comparator<>みたいなのとかが役に立ちそう。
- 以下参考リンク
- 投稿日:2020-07-31T17:59:35+09:00
【Java】文字の出現回数を調べる
目次
- はじめに
- 前提
- 実現したいこと
- やってみたこと
- 問題
- 解決方法
- 実装内容
- 終わりに
はじめに
ふと、MapとかListとか勉強したい!!と思ったので課題考えて作ってみましたが
MapとListの役割とか変換とかでかなり躓きました。
オンラインで検索してもあんましいいの出てこなかったので、自分なりにまとめたので記事にします。前提
- 実現したいこと
- n個の任意の文字列型入力(n_1 n_2 n_3... ...n)に対し、最も多く登場した文字列の特定。
やってみたこと
- Map map = Map();として、[key:入力文字列, value:登場回数]を実装。
- mapを[value]でソートして一番最初の[key]を取り出せばいいじゃん!
問題
- Map系[HashMap, LinkedHashMap, TreeMap]は、基本的には要素に順番を持たない。
- map[0]のように、インデックスでは値を取り出せない。
解決方法
- Map.Entryクラスを利用して、マップのkeyとvalueの組み合わせを取得できる。
- List内にEntryオブジェクトを格納して、List[i]のEntryのvalueでソートができる。
実装内容
解決方法をもとに実装した内容が以下です。
CountMain.javaimport java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.Map.Entry; import java.util.Scanner; public class CountMain { public static void main(String[] args) { // 入力検知 Scanner sc = new Scanner(System.in); String count = sc.nextLine(); String[] line = sc.nextLine().split(" "); // マップ作製 Map<String, Integer> map = new HashMap<String, Integer>(); for(int i=0; i<line.length; i++){ if(!map.containsKey(line[i])){ map.put(line[i], 1); } else { int tmp = map.get(line[i]); map.remove(line[i]); map.put(line[i], tmp+1); } } // mapのエントリを取得→listへ格納 List<Entry<String, Integer>> list = new ArrayList<Entry<String, Integer>>(); for (Map.Entry<String, Integer> entry : map.entrySet()){ list.add(entry); } // list内entryのバリューを比較→ソート for (int i = 0; i < list.size(); i++){ for (int j = list.size()-1; j > i; j--){ if (list.get(j).getValue() > list.get(j-1).getValue()){ Map.Entry<String, Integer> tmpEntry = list.get(j-1); list.set(j-1, list.get(j)); list.set(j, tmpEntry); } } } System.out.print(list.get(0).getKey()); try { int i = 1; while( list.get(i).getValue() == list.get(i-1).getValue() ){ System.out.print(" " + list.get(i).getKey()); i++; } } catch (IndexOutOfBoundsException e){ return; } finally { System.out.println(""); sc.close(); } } }終わりに
- まとめ
- 各クラスごとの役割を意識するのが大事
- Mapは連想配列、順序付けの配列が必要な時は機能をListに投げる
- これができてないから最初にMapをソートしようとしてわからなくなってた
- 今後の課題
- list内のソートは人力バブルソートでやってるけど、Collection.sort()とか使えそう。
- Comparator<>みたいなのとかが役に立ちそう。
- 以下参考リンク
- 投稿日:2020-07-31T17:52:07+09:00
eclipseにspring bootとgradleを追加する【初心者がTODOアプリを作るまで#2】
前回の記事はこちら
Javaの環境構築をしてhelloworldを出力する今回はspring bootとgradleを追加してみましょう。
spring bootってなに?
JavaによるWebアプリケーションの開発を迅速かつ効率的に行う仕組みを備えたフレームワークです。
フレームワークとはプログラミングを効率化するために用意された、プログラムのひな形のようなものです。
要はプログラムを簡単に書くためのヤツです。Gradleってなに?
wikiより
GradleはApache AntやApache Mavenのコンセプトに基づくオープンソースビルド自動化システムであり、プロジェクト設定の宣言にはApache Mavenが利用するXML形式ではなくGroovyベース、もしくはKotlin Scriptベースのドメイン固有言語 (DSL) を採用している
うん。よくわからん。調べたところこちらの記事がとてもわかりやすかったです(Gradle入門)
開発するうえで便利なものはいろいろあります。それを使うためのものを毎回1つづつ取ってくるのは面倒なのでGradleさんにこれよろしく~といえばGradleさんがやってくれる。みたいな感じだと思っています。
追加する
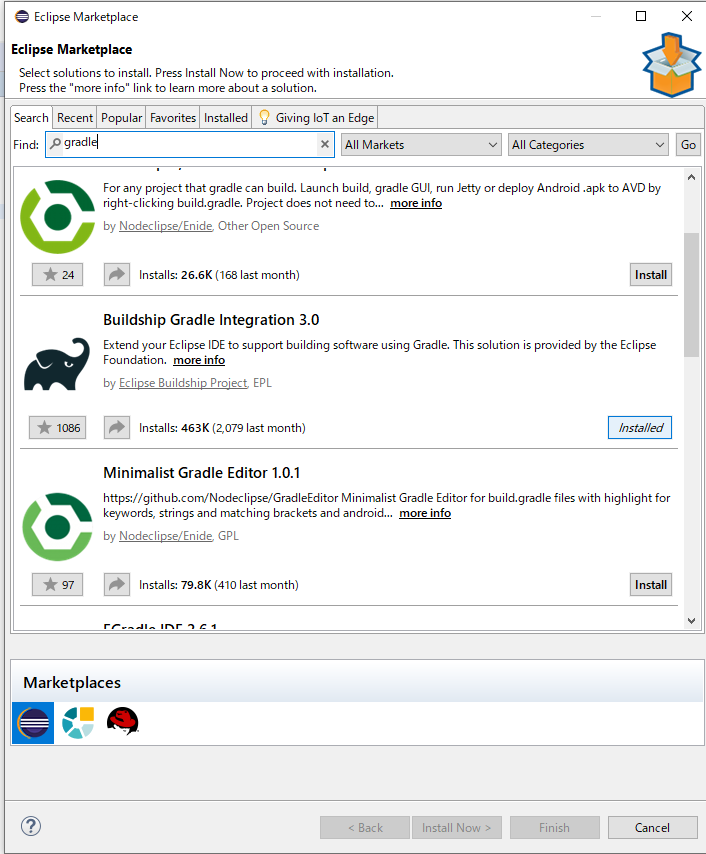
Eclipse Marketplaceから追加します。
1.[Help] => [Eclipse Marketplace]を開く
2.serchにgradleと入力して検索し、インストールを押下
3.ライセンスのレビューがでるのでI acceptを選択してfinish
4.インストールが完了すると再起動してねと言われるので再起動して完了です。1~4と同じ要領でプラグインの追加ができますのでspringも追加しましょう。
次回は開発に便利なプラグインを追加します。
次 => Eclipseにプラグインをインストールする
- 投稿日:2020-07-31T17:52:07+09:00
eclipseにspring bootとgradleを追加する
前回の記事はこちら
Javaの環境構築をしてhelloworldを出力する今回はspring bootとgradleを追加してみましょう。
spring bootってなに?
JavaによるWebアプリケーションの開発を迅速かつ効率的に行う仕組みを備えたフレームワークです。
フレームワークとはプログラミングを効率化するために用意された、プログラムのひな形のようなものです。
要はプログラムを簡単に書くためのヤツです。Gradleってなに?
wikiより
GradleはApache AntやApache Mavenのコンセプトに基づくオープンソースビルド自動化システムであり、プロジェクト設定の宣言にはApache Mavenが利用するXML形式ではなくGroovyベース、もしくはKotlin Scriptベースのドメイン固有言語 (DSL) を採用している
うん。よくわからん。調べたところこちらの記事がとてもわかりやすかったです(Gradle入門)
開発するうえで便利なものはいろいろあります。それを使うためのものを毎回1つづつ取ってくるのは面倒なのでGradleさんにこれよろしく~といえばGradleさんがやってくれる。みたいな感じだと思っています。
追加する
Eclipse Marketplaceから追加します。
1.[Help] => [Eclipse Marketplace]を開く
2.serchにgradleと入力して検索し、インストールを押下
3.ライセンスのレビューがでるのでI acceptを選択してfinish
4.インストールが完了すると再起動してねと言われるので再起動して完了です。1~4と同じ要領でプラグインの追加ができますのでspringも追加しましょう。
springのプロジェクトをつくってみる
追加ができたのでspringを使ったプロジェクトを作ってみましょう。
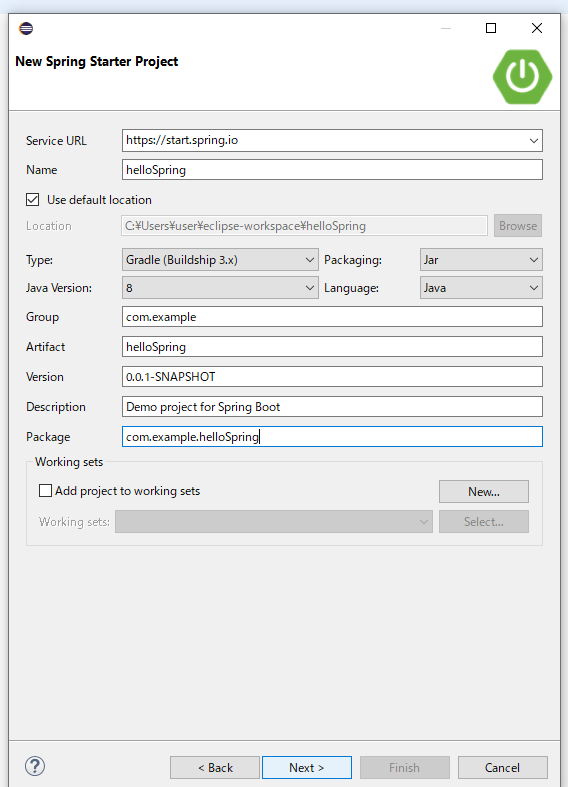
1.[file] => [new] => [Other] => [Spring Starter Project] を選択
2.プロジェクトやパッケージの名前を決めます。今回はhelloSpringとしました。
3.プロジェクト依存関係の選択。今回はサンプルなのでwebを選びました
4.finishを押下して完了。こんな感じでできました。
依存関係ってなに?
4で記述した依存関係についてです。正直よくわかってませんが、使いたいSpringフレームワークをここで選ぶということみたいです。Gradleさんにこれよろしく~と頼むものを選ぶイメージですかね。Gradleの設定ファイルをいじることで後から追加もできます。
(認識が違ったら教えていただけますと幸いです)作成したプロジェクトの中を見てみます。
Gradleの設定ファイルはbuild.gradleになってますのでこれを開いてみます。buid.gradleplugins { id 'org.springframework.boot' version '2.3.2.RELEASE' id 'io.spring.dependency-management' version '1.0.9.RELEASE' id 'java' } group = 'com.example' version = '0.0.1-SNAPSHOT' sourceCompatibility = '1.8' repositories { mavenCentral() } dependencies { /*追加されている↓*/ implementation 'org.springframework.boot:spring-boot-starter-web' implementation 'org.springframework.boot:spring-boot-starter-web-services' /*追加されている↑*/ testImplementation('org.springframework.boot:spring-boot-starter-test') { exclude group: 'org.junit.vintage', module: 'junit-vintage-engine' } } test { useJUnitPlatform() }依存関係の選択時に選んだ
webとweb serviceが追加されていますね。このあたりは私もまだまだ知識が足りないのでいつかまとめたいと思います。

- 投稿日:2020-07-31T17:35:39+09:00
igvメモリー設定
起こったこと
メモリー積み積みマシーンでメモリー不足エラーでファイルが開けないだと????
はじめに
DNAやRNAなどの核酸配列を読むマスィーンをシークエンサーを呼ぶ。
この内、10年以上前に実用化された、これまでのサンガーシークエンスなどでは
実現できなかった大量の配列を一気に読めるようになったシークエンサーを次世代シークエンさー、NGSと呼ぶ。
いつまで次世代やってんのというのはあるが、とりあえずNGSと呼ぶのさ。で、NGSで吐き出された各種の配列情報は、アレヤコレヤの処理を経て、
例えば変異のリストや、例えば遺伝子産物の多寡のリストになっていく。この中でよく出てくる中間ファイルにbamがある。
これは各種の配列情報に、然るべきアルゴリズムで位置情報を付与した後、
読み込み側道向上のためにバイナリ化したものである。
詳しくはこの辺を読もう。
http://array.cell-innovator.com/?p=3014で、特定の遺伝子の、この領域について、アライメント、つまりそれぞれのリードに付与された位置情報を
視覚的に確認したいときには、それ用のビューワーが必要で、
その代表がigvである。
開発はおなじみの神様仏様Broad様である。https://bi.biopapyrus.jp/rnaseq/mapping/igv/
で、ゲノム上の遺伝子の位置情報なんかを見るだけなら大したメモリー消費はしないんだけど、
例えば数十Gを超える巨大なBam(全エクソンや全ゲノムとかになるとこのレベル)を開こうとすると、メモリー不足で突然落ちたりする。
せめてエラーメッセージを吐けと思うんだけど、突然落ちる。
で、igvはjavaでうごいているので、物理メモリに余裕があるようであれば起動オプションの指定でなんとかなる。解決策
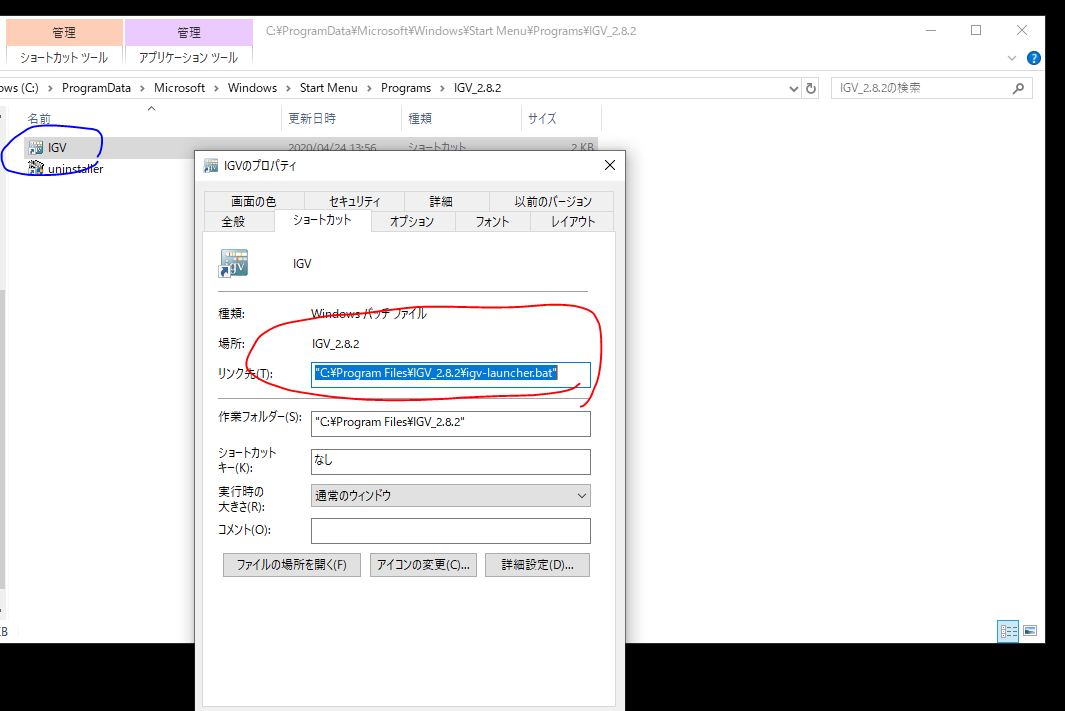
igvの起動アイコンは、batファイルへのショートカットなのでここからbatファイルに至り、
javaの起動オプションを変更することで、一応メモリー不足問題に対応可能である。起動アイコン
右クリック→その他→ファイルの場所を開く
起動アイコンのフォルダが開かれる。
アイコンを右クリック→プロパティ
本命batファイルの場所が記載されている。
ワイの場合はC:\Program Files\IGV_2.8.2\igv-launcher.batだった。バージョンが多少違うかもだが、他は大体同じじゃないかな?
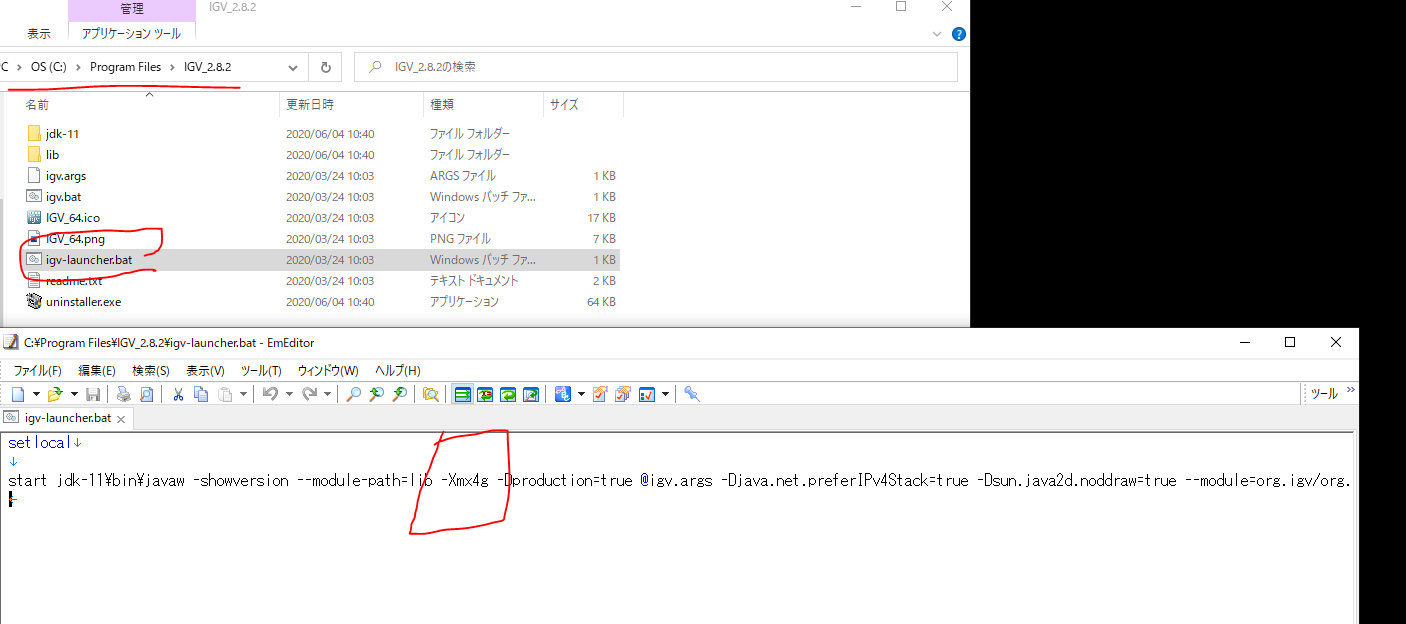
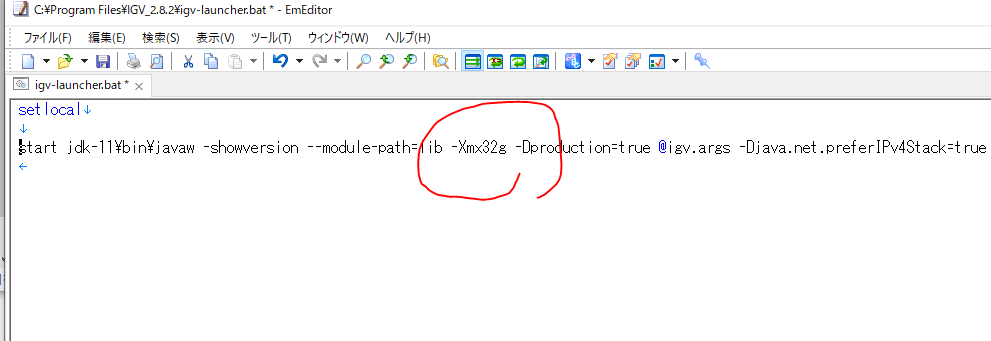
適当なテキストエディタでそのファイルを開くと以下のような記載が。
このうち、下の赤四角が最大メモリーのオプションである。
下は32Gまで使って良い、という設定にしたもの。
あくまで設定の問題の場合。本格的にメモリー足りない場合はこれでは解決しない。
メモリーを足すか、たくさん積んだマシーンを使うかしよう。

- 投稿日:2020-07-31T15:59:14+09:00
Javaの環境構築をしてhelloworldを出力する【初心者がTODOアプリを作るまで#1】
java未経験で入社して勉強したことを少しずつ残していきます。アウトプットは大事ですね。
1からTODOアプリを作るところまでをメモしていこうと思いますが、超初心者が作ったので用語解説など多めです。また、なにかおかしな点などありましたらご指摘いただけますと幸いです。1.JDKのインストール
こちらからダウンロードできます。
ダウンロード手順や動作確認などは書かれている記事がたくさんあるのでここでは省略します。JDKってなに?
Java Development Kit(ジャヴァ・デベロップメント・キット)の略で、Javaの開発環境。
Javaを作ったり動かしたりするときに必要なあれやこれやが必要になりますが、それらがセットになった開発キットです。2.Eclipseのインストール
こちらからダウンロードできます。
こちらも手順等は割愛します。eclipseってなに?
開発を効率的に行うための統合開発環境で、IDEとも呼ばれます。
ここで実際にコードを書いたりする作業スペースみたいなものです。3.helloworldをとにかく出してみる
せっかくJavaが使えるようになったのでとにかく書いてみましょう。
eclipseを開いて左上にファイルというのがあるのでそこから新しいプロジェクトを作成します。
file -> new -> Java Project の順でクリックし、名前を決めたらfinishで完了です。今回はhelloworldプロジェクトとします。
srcにカーソルを合わせて右クリックしnew -> classよりHelloWordクラスを作ります。ここにコードを書いてみます。
(クラスなので1文字目は大文字でHelloWordとしてください。画像はミスです)
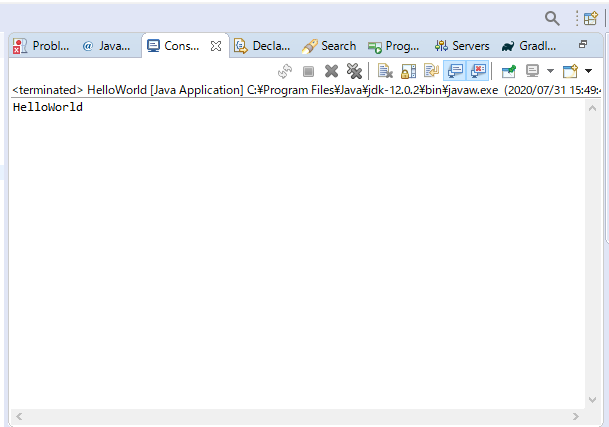
コンソールに出力するコードを書きます。
HelloWorld.javapackage helloworld; public class HelloWorld { public static void main(String args[]){ System.out.println("HelloWorld"); } }runで実行
無事に出力できました。
割愛した環境構築ですが参考サイトを載せておきます。
https://techacademy.jp/magazine/9039次はgradleとspringを入れてみましょう
次 => eclipseにspring bootとgradleを追加する
- 投稿日:2020-07-31T15:59:14+09:00
Javaの環境構築をしてhelloworldを出力する
java未経験で入社して勉強したことを少しずつ残していきます。アウトプットは大事ですね。
なにかおかしな点などありましたらご指摘いただけますと幸いです。1.JDKのインストール
こちらからダウンロードできます。
ダウンロード手順や動作確認などは書かれている記事がたくさんあるのでここでは省略します。JDKってなに?
Java Development Kit(ジャヴァ・デベロップメント・キット)の略で、Javaの開発環境。
Javaを作ったり動かしたりするときに必要なあれやこれやが必要になりますが、それらがセットになった開発キットです。2.Eclipseのインストール
こちらからダウンロードできます。
こちらも手順等は割愛します。eclipseってなに?
開発を効率的に行うための統合開発環境で、IDEとも呼ばれます。
ここで実際にコードを書いたりする作業スペースみたいなものです。3.helloworldをとにかく出してみる
せっかくJavaが使えるようになったのでとにかく書いてみましょう。
eclipseを開いて左上にファイルというのがあるのでそこから新しいプロジェクトを作成します。
file -> new -> Java Project の順でクリックし、名前を決めたらfinishで完了です。今回はhelloworldプロジェクトとします。
srcにカーソルを合わせて右クリックしnew -> classよりHelloWordクラスを作ります。ここにコードを書いてみます。
(クラスなので1文字目は大文字でHelloWordとしてください。画像はミスです)
コンソールに出力するコードを書きます。
HelloWorld.javapackage helloworld; public class HelloWorld { public static void main(String args[]){ System.out.println("HelloWorld"); } }runで実行
無事に出力できました。
割愛した環境構築ですが参考サイトを載せておきます。
https://techacademy.jp/magazine/9039
- 投稿日:2020-07-31T15:32:05+09:00
【Effective Javaを読む】 第3章 項目8 『equalsをオーバーライドする時は一般契約に従う』
第3章について
第2章はオブジェクトの生成と消滅についてのエッセンスでした。
第3章は「Object」クラスについてのお話です。Objectクラスと一般契約
・Objectは具象クラスであるにもかかわらず主に拡張されるために設計されている
・finalでないメソッド(equals, hashCode, toString, clone, finalize)はすべてオーバーライドされるように設計されているので、明示的な一般契約(general contract)を持っている
・オーバーライドするクラスは一般契約に従わないと適切に動作しなくなるequalsをオーバーライドする時は一般契約に従う
equalsメソッドをオーバーライドしてはならない場合
equalsメソッドをオーバーライドするのは簡単ですが、間違った方法でオーバーライドしてしまう場合が多々あるので、次の条件のどれかに当てはまる場合はオーバーライドしないほうがいい。
・クラスの個々のインスタンスが、本質的に一意である場合
・「論理的等価性(logical equality)」検査を、クラスが提供するかどうか関心がない場合
・スーパークラスが既にequalsをオーバーライドしており、スーパークラスの振る舞いがこのクラスに対して適切である場合
・クラスがprivateあるいはパッケージプライベートであり、そのequalsメソッドが決して呼び出されないことが確かである場合
一般契約
以下がequalsメソッドの一般契約です。
これを守らないとプログラムが不規則に振る舞ったりクラッシュしたりする。equalsメソッドの実装は同値関係(equivalence relation)を実装します。すなわち
・反射的(reflexive):nullでない任意の参照値xに対して、x.equals(x)はtrueを返さなければならない
・対照的(symmetric):nullでない任意の参照値xとyに対して、y.equals(x)がtrueを返す場合にのみ、x.equals(y)はtrueを返さなければならない
・推移的(transitive):nullでない任意の参照値x,y,zに対して、もしx.equals(y)とy.equals(z)がtrueを返すならば、x.equals(z)はtrueを返さなければならない
・整合的(consistent):nullでない任意の参照値xとyに対して、オブジェクトに対するequals比較に使用される情報が変更されなければ、x.equals(y)の複数回呼び出しは、終始一貫してtrueを返すか、終始一貫してfalseを返さなけらばならない続く
【Effective Javaを読む】 第3章 項目9 『equalsをオーバーライドする時は、常にhashCodeをオーバーライドする』
https://qiita.com/Natsukii/items/ac195b5542ba3348ed29
- 投稿日:2020-07-31T14:51:30+09:00
【Effective Javaを読む】 第2章 項目7 『ファイナライザを避ける』
ファイナライザを避ける
ファイナライザ(finalizer)は、予測不可能で、たいていは危険であり、一般には必要ない。有効な使用方法は多少あるけれども基本的に使わないほうがいい、というお話。
用語集
ファイナライザ
finalize()メソッドのこと。
finalize()メソッドは、Java言語におけるすべてのクラスの継承元であるjava.lang.Object クラスに定義されている。
すなわち、すべてのクラスは finalize()メソッドを持つ。
ガベージコレクタが走ったタイミングで呼ばれるメソッド。ネイティブピア(native peer)
通常のオブジェクトがネイティブメソッドを通して委譲を行うネイティブオブジェクト。
通常のオブジェクトではないので、ガベージコレクタは感知せず通常のオブジェクトが回収される時にネイティブピアを回収できない。ファイナライザ連鎖(finalizer chaining)
クラスがファイナライザを持ちサブクラスがそれをオーバーライドしているならば、そのサブクラスのファイナライザはスーパークラスのファイナライザを手作業で呼び出さなければならない(例2)
ファイナライザガーディアン(finalizer guardian)
サブクラスの実装者がスーパークラスのファイナライザをオーバーライドして、スーパークラスのファイナライザを呼び出すのを忘れたとしたら、スーパークラスのファイナライザは決して呼ばれることがない。このような不注意あるいは悪意のあるサブクラスから防御するためにファイナライザガーディアンが有効である(例3)
サンプルコード
例1//終了メソッドの実行を保証するtry-finallyブロック Foo foo = new Foo(...); try { //fooで行わなければならない処理を行う ... } finally { foo.terminate(); //明示的終了メソッド }例2//手作業によるファイナライザ連鎖 @Override protected void finalize() throws Throwable { try { ... //サブクラスのファイナライザ処理 } finally { super.finalize(); } }例3//ファイナライザガーディアンのイデオム public class Foo { //このオブジェクトの唯一の目的は、外側のFooオブジェクトのファイナライズを行うこと private final Object finalizerGuardian = new Object() { @Override protected void finalize() throws Throwable { ... //外側のFooオブジェクトをファイナライズする } }; ... // 残りは省略 }ファイナライザの2つの欠点
1つ目 即座にファイナライザが実行される保証がない
・ファイナライザが実行されるまでの時間はどれだけの長さにもなりえるので、時間的に制約のあることをファイナライザで行うべきではない
・重要な永続性のある状態を更新するのにファイナライザに決して頼るべきではない2つ目 ファイナライザの使用には深刻なパフォーマンスのペナルティがある
・ファイナライザを持つオブジェクトの生成と解放は、そうでないオブジェクトと比べて約430倍遅い
ファイナライザを書く代わりにどのような実装をすべきか?
・明示的終了メソッド(explicit termination method)を提供する(例1)
・終了を保証するために明示的終了メソッドはたいていtry-finally構文と一緒に使用されるファイナライザが有効な場合
1つ目 明示的終了メソッドの呼び出しをオブジェクトの所有者が忘れた場合の「安全ネット」として振舞う場合
2つ目 ネイティブピア(native peer)を回収する場合
続く
【Effective Javaを読む】 第3章 項目8 『equalsをオーバーライドする時は一般契約に従う』
https://qiita.com/Natsukii/items/bcc5846dbfa69bfda9b0
- 投稿日:2020-07-31T13:57:37+09:00
【Effective Javaを読む】 第2章 項目6 『廃れたオブジェクト参照を取り除く』
廃れたオブジェクト参照を取り除く
C言語のようにメモリ管理を手動でする言語からすると、ガベージコレクタは魔法のようなものに見えるかもしれない。
しかしそれでもメモリリークを引き起こす原因は存在するから注意しようねって話。サンプルコード
例1//"メモリリーク"を発見できますか? public class Stack { private Object[] elements; private int size = 0; private static final int DEFAULT_INITIAL_CAPACITY = 16; public Stack() { this.elements = new Object[DEFAULT_INITIAL_CAPACITY]; } public void push(Object e) { ensureCapacity(); elements[size++] = e } public Object pop() { if (size == 0) throw new EmptyStackException(); return elements[--size]; } /** * 配列を大きくする必要があるごとに要領をだいたい倍にして、 * 最低もう一つの要素分の要領を確保する。 */ private void ensureCapacity() { if (elements.length == size) elements = Array.copyOf(elements, 2 * size + 1); } }例2public Object pop() { if (size==0) throw new EmptyStackException(); Object result = elements[--size]; elements[size] = null; //廃れた参照を取り除く return result; }メモリリークを引き起こす3つの原因
1つ目 廃れた参照
例1は一見問題ないように見えますが廃れた参照を保持しています。
例2のようにいらなくなった参照にはnullを設定してあげることでメモリリークを防ぐことができます。ですが、全ての使い終わったプログラムに対して過度にnullを設定する必要はありません。
Stackクラスは独自のメモリ管理をしています。
そのようなクラスのどの参照が不要なのか、ガベージコレクタは知ることができません。
nullを手作業で設定することによってガベージコレクタに無効な部分を効果的に教えてあげることができます。2つ目 キャッシュ
オブジェクト参照をいったんキャッシュへ入れてしまうと、オブジェクト参照がそこにあることを忘れがちですし、そのオブジェクト参照の意味がなくなったかなり後でもキャッシュに残したままにしがちです。キャッシュの外にあるエントリーのキーへの参照が存在するかぎりそのエントリーに意味があるキャッシュを実装するのであれば、そのキャッシュをWeakHashMapで表現するのが良い。
WeakHashMap:エントリーが廃れてしまうと自動的に取り除かれる3つ目 リスナーやコールバック
明示的に登録を解除しないAPIを実装すると、何らかの処理を行わなければコールバックが蓄積されてしまいます。迅速にコールバックがガベージコレクトされることを保証する最善の方法は、それらに対する弱い参照(weak reference)だけを保存することです。
続く
【Effective Javaを読む】 第2章 項目7 『ファイナライザを避ける』
https://qiita.com/Natsukii/items/785ae41361cb7324e45b
- 投稿日:2020-07-31T13:07:44+09:00
深層学習クイックスタートのための胸部・腹部X線画像の自動分類器の作成
なぜ記事にしたか
2年前に勉強会を開催させていただいたのですが、もう古くなってしまったので、備忘録の意味で公開します。
やってみたこと
胸部レントゲン画像と腹部レントゲン画像とを自動で判別できるアプリケーションを開発する。
モチベーション
何かを二値に分類することは重要なことです。
どんなに複雑な課題も、体系的にまとめることができれば課題を部分ごとに分解できます。分解した課題をさらに細かく分解していくと、最終的にはYes or Noの選択になります。部分を細分化して答えを出していけば、Yes or Noの選択の繰り返しのみで難しい課題も解ける(のではないか)ということです。
テーマは何でも良かったのですが、メディカルで画像の二値分類の体験をするためのトレーニング題材を探していたら、ちょうど良いのがこのテーマでした。
元はこの論文です。Hello World Deep Learning in Medical Imaging使ったもの
- ノートパソコン(一般のもの)
- Optional: NVIDIA-GPU(今回は1050Ti)
環境
- ubuntu 18.04 (javaなのでOSは細かく問わない)
- maven + dl4j関連
- eclipse (2018)
- JDK8 or higher
- (もう、こういうテーマに興味ある人はpythonでやってますよね)
データ
以下のGitHubリンクで公開されています。
https://github.com/paras42/Hello_World_Deep_Learning/tree/9921a12c905c00a88898121d5dc538e3b524e520
画像は「Open_I_abd_vs_CXRs.zip」です。
abdはAbdomen、CXRsはChest-X-raysの略です。たぶん。
ダウンロード後、解凍して使います。
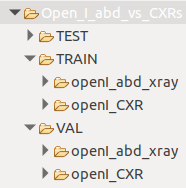
全75枚の画像になっており、38枚のchest X-rays、37枚のabdominal X-raysになっています。
フォルダ階層はこのようになっています。TEST、TRAIN、VAL(Validationの略)のフォルダに分かれており、TRAINとVALフォルダにはそれぞれで胸部と腹部の画像フォルダが作られています。
TESTフォルダには胸部と腹部の画像が一枚ずつ入っており、これらはフォルダに振り分けられていません。作業
データは解凍したら適当な場所に保存します。
私の場合は、Mavenプロジェクトの直下に置きました。
コードと解説
POM.xmlはこのページの末尾に記載しています。(future work)
importステートメントも末尾に記載しています。(future work)
最終的なコードは、この節の最後にまとめています。
バージョンによっては、見ているパッケージが違うことがあるので注意して下さい。
(頻繁に変わる印象、、)セットアップ
まず、学習の基本的なパラメータや設定を準備します。
学習時には重みの計算や、トレーニングデータの自動割り振りなど、いろんなところでランダム変数が利用されます。
これはとても便利ですが、毎回結果がかわってしまうと厄介です。
毎回同じランダム変数を設定するために、シードを定義しておきます。long seed = 42; final Random RAND_NUM_GEN = new Random(seed);今回は画像を対象にしていますので、画像の入力が必要になります。
どのような画像でも入力する!としていると、たまたまフォルダ内に紛れていた変なデータが吸い込まれてしまうことがあります。
これを防ぐために、入力可能な画像フォーマットを設定します。ここではデフォルトで汎用の画像フォーマットを入力できるようにしています。final String[] ALLOWED_FORMATS = BaseImageLoader.ALLOWED_FORMATS;機械学習(教師あり)では、教師ラベルデータを自作することが多いのですが、以下のように設定すると、フォルダ名をクラス名として自動で認識して、自動でラベルを振り分けてくれます。
(今回の場合は、例えば、胸部画像1.png : [0,1](左側が腹部、右側が胸部)のように、ラベルの並び順に沿って、インデックスを着けていきます。インデックスは何でも良いのですが、一般的には「1」が使われます。)ParentPathLabelGenerator LABEL_GENERATOR_MAKER = new ParentPathLabelGenerator();次に、学習にデータを流す際に、データをランダムに選択しながら、同じ数だけ入力するようにする設定をします。
BalancedPathFilter PATH_FILTER = new BalancedPathFilter(RAND_NUM_GEN, ALLOWED_FORMATS, LABEL_GENERATOR_MAKER);モデルの学習に必要な基本的な設定を行います。
コメントにあるとおりですが、
numLabelsは、ラベルの数です。今回は胸部と腹部の分類ですので、ラベルは2つ、ということになります。
height、width、channelsは、モデルに入力する画像(予測したい画像)の縦横のマトリックスと、カラーチャンネルを設定します。
inputShapeは、これらを組み合わた配列で、モデルの入力層の設定値になります。
batchSizeは一回の学習で利用するデータの量で、これらのデータが処理されてからネットワークの重みが更新されます。
epochsは学習回数です。一回の学習でbatchSize分のデータを学習し、ネットワークの重みを更新します。int numLabels = 2;// chest or abd int height = 64;// image size for train int width = 64;// image size for train int channels = 3;// image channels(in this case, image type is RGB, so 3 channels) int[] inputShape = new int[] {channels, height, width}; int batchSize = 32;// train data size in 1 epoch int epochs = 50;画像データ入力のパイプライン
基本的な設定が完了したので、画像を入力する方法を設定します。
入力したい学習データフォルダまでのパスを指定して、FileSplitとInputSplitのオブジェクトを構築します。
本来、これらは自動でトレーニング用/検証用/テスト用の画像を振り分けたりするために使うのですが、今回はフォルダで振り分けが完了しているので、データをコードで分けることはせず、トレーニング、バリデーション(検証)、テストのそれぞれで入力のパイプラインを構築しています。System.out.println("Preparing data...."); // Prepare train File trainDir = new File("./Open_I_abd_vs_CXRs/TRAIN/"); FileSplit trainSplit = new FileSplit(trainDir, NativeImageLoader.ALLOWED_FORMATS, RAND_NUM_GEN); InputSplit train = trainSplit.sample(PATH_FILTER, 1.0)[0];//すべてを訓練へ // Prepare val File valDir = new File("./Open_I_abd_vs_CXRs/VAL/"); FileSplit valSplit = new FileSplit(valDir, NativeImageLoader.ALLOWED_FORMATS, RAND_NUM_GEN); InputSplit val = valSplit.sample(PATH_FILTER, 1.0)[0];//すべてを検証へ // Prepare test File testDir = new File("./Open_I_abd_vs_CXRs/TEST/"); FileSplit testSplit = new FileSplit(testDir, NativeImageLoader.ALLOWED_FORMATS, RAND_NUM_GEN); InputSplit test = testSplit.sample(PATH_FILTER, 1.0)[0];//すべてをテストへ System.out.println("train data total sample size " + train.length()); System.out.println("validation total data sample size " + val.length()); System.out.println("test data total sample size " + test.length());オーグメンテーション(疑似データの増幅処理)
今回のデータセットではデータ量がとても少ない(深層学習では各クラスで数百単位のデータが必要)ので、擬似的にデータを増やしてモデルの精度を検討します。
これでうまく行けば、データを増やしても結構いい線いくモデルが開発できそうだ!とわかるためです。
画像の増幅の方法には、フリップ、回転、クロップ、位置のスライド、アフィン変換による変形など、いろいろなことが出来ます。注意点は、ありえない画像を増幅させないようにすることです。例えば、超音波画像で、後方エコーがあるにも関わらず、180°回転させて疑似画像を作るなどが失敗例です。
ここでは、そこまで厳密には考えず、ImageTransformを使って、ランダムなフリップと位置の並行移動を設定しました。
いくつかのImageTransformを作り、最終的にこれらをListにまとめて、PipelineImageTransformとして構築してパイプラインが出来上がります。
PipelineImageTransformのshuffleがTrueの場合、パイプラインの順序がランダムに選ばれます。Falseの場合はシーケンシャルにList順に処理されます。System.out.println("Prepare augumentation...."); ImageTransform flipTransform1 = new FlipImageTransform(new Random(seed)); ImageTransform flipTransform2 = new FlipImageTransform(new Random(seed)); ImageTransform warpTransform = new WarpImageTransform(new Random(seed), inputShape[1]/10); boolean shuffle = false; List<Pair<ImageTransform, Double>> pipeline = Arrays.asList(new Pair<>(flipTransform1, 0.9), new Pair<>(flipTransform2, 0.8), new Pair<>(warpTransform, 0.9)); ImageTransform transform = new PipelineImageTransform(pipeline, shuffle);画像の入力とデータ増幅の紐付け
ここまでで画像の入力部分と、データの増強処理の設定が出来ました。
あとはこれらを紐付けます。
一般的に、トレーニングデータに対してのみデータの増強を行います。
以下のコードのように、その画像の入力に対して増強するかを指定します。
この画像入力と増強処理の管理はImageRecordReaderが担ってくれます。// data reader setup ImageRecordReader recordReaderTrain = new ImageRecordReader(height, width, channels, LABEL_GENERATOR_MAKER); ImageRecordReader recordReaderVal = new ImageRecordReader(height, width, channels, LABEL_GENERATOR_MAKER); /* * 今回は配布元のデータ構造に合わせるので、 * テストデータは階層のラベルを自動計算させない。 * (利用する際は、データのフォルダ階層を他と同じにして利用する。) */ // ImageRecordReader recordReaderTest = new ImageRecordReader(height, width, channels, LABEL_GENERATOR_MAKER); ImageRecordReader recordReaderTest = new ImageRecordReader(height, width, channels); try { // recordReaderTrain.initialize(train);// Train without transformations recordReaderTrain.initialize(train,transform);// Train with transformations recordReaderVal.initialize(val);//検証データにはオーグメンテーションをしない recordReaderTest.initialize(test); } catch (IOException e) { e.printStackTrace(); }モデルの構築
ちょっと簡単にしたいと思ったのですが、せっかくなので、SimpleCNNというModelZooシリーズのネットワークを借りてやってみます。
ここに示す例は、完全なSimpleCNNではなく、最後の出力層をこの検討のために調整して追加しています。
難しいことはやっておらず、SimpleCNN.javaコードからコピペして、出力層をマルチクラス分類用にしたのみです(2クラスなので、バイナリ分類も出来ますが、ここではSoftMaxを使う例でいきます)。
ここは説明を省略しますが、DL4Jは、ここで使っているMultiLayerNetworkが基本的かつシンプルなCNNの概念になります。
深層学習に興味のある人がよく知っているモデルは、もっと複雑で巨大なものもありますが、このような複雑・巨大なモデルはこのMultiLayerNetworkを組み合わせて構成されます。System.out.println("Start construct SimpleCNN model..."); MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder().trainingWorkspaceMode(WorkspaceMode.ENABLED) .inferenceWorkspaceMode(WorkspaceMode.ENABLED).seed(seed).activation(Activation.IDENTITY) .weightInit(WeightInit.RELU).optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT) .updater(new AdaDelta()).convolutionMode(ConvolutionMode.Same).list() // block 1 .layer(0, new ConvolutionLayer.Builder(new int[] { 7, 7 }).name("image_array").nIn(inputShape[0]).nOut(16) .build()) .layer(1, new BatchNormalization.Builder().build()) .layer(2, new ConvolutionLayer.Builder(new int[] { 7, 7 }).nIn(16).nOut(16).build()) .layer(3, new BatchNormalization.Builder().build()) .layer(4, new ActivationLayer.Builder().activation(Activation.RELU).build()) .layer(5, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.AVG, new int[] { 2, 2 }).build()) .layer(6, new DropoutLayer.Builder(0.5).build()) // block 2 .layer(7, new ConvolutionLayer.Builder(new int[] { 5, 5 }).nOut(32).build()) .layer(8, new BatchNormalization.Builder().build()) .layer(9, new ConvolutionLayer.Builder(new int[] { 5, 5 }).nOut(32).build()) .layer(10, new BatchNormalization.Builder().build()) .layer(11, new ActivationLayer.Builder().activation(Activation.RELU).build()) .layer(12, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.AVG, new int[] { 2, 2 }).build()) .layer(13, new DropoutLayer.Builder(0.5).build()) // block 3 .layer(14, new ConvolutionLayer.Builder(new int[] { 3, 3 }).nOut(64).build()) .layer(15, new BatchNormalization.Builder().build()) .layer(16, new ConvolutionLayer.Builder(new int[] { 3, 3 }).nOut(64).build()) .layer(17, new BatchNormalization.Builder().build()) .layer(18, new ActivationLayer.Builder().activation(Activation.RELU).build()) .layer(19, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.AVG, new int[] { 2, 2 }).build()) .layer(20, new DropoutLayer.Builder(0.5).build()) // block 4 .layer(21, new ConvolutionLayer.Builder(new int[] { 3, 3 }).nOut(128).build()) .layer(22, new BatchNormalization.Builder().build()) .layer(23, new ConvolutionLayer.Builder(new int[] { 3, 3 }).nOut(128).build()) .layer(24, new BatchNormalization.Builder().build()) .layer(25, new ActivationLayer.Builder().activation(Activation.RELU).build()) .layer(26, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.AVG, new int[] { 2, 2 }).build()) .layer(27, new DropoutLayer.Builder(0.5).build()) // block 5 .layer(28, new ConvolutionLayer.Builder(new int[] { 3, 3 }).nOut(256).build()) .layer(29, new BatchNormalization.Builder().build()) .layer(30, new ConvolutionLayer.Builder(new int[] { 3, 3 }).nOut(256).build()) .layer(31, new GlobalPoolingLayer.Builder(PoolingType.AVG).build()) //output .layer(32, new OutputLayer.Builder().nIn(256).nOut(2) .lossFunction(LossFunctions.LossFunction.MCXENT) .weightInit(WeightInit.XAVIER) .activation(Activation.SOFTMAX) .build()) .setInputType(InputType.convolutional(inputShape[2], inputShape[1], inputShape[0])) .backpropType(BackpropType.Standard) .build(); MultiLayerNetwork network = new MultiLayerNetwork(conf); network.init(); System.out.println(network.summary());学習の過程を可視化する
学習がどのように各エポックで進むのかを確認するために、DL4Jに組み込まれている機能を使います。
この記事のコードを最後まで繋ぎ合わせ、実行した後、学習が進んでいきますが、このときに、自分のウェブブラウザを立ち上げて、http://localhost:9000をURLに入力してページに移動してみて下さい。
自分のPCで学習の進捗をグラフィカルに確認できます。// visualize train process // URL:http://localhost:9000/train/overview UIServer uiServer = UIServer.getInstance(); StatsStorage statsStorage = new InMemoryStatsStorage(); uiServer.attach(statsStorage);学習の過程をどのようにモニタリングするかも設定することが出来ます。
モデルの汎用情報を集めてくれるStatsListenerと、指定した間隔でモデル精度(ロスが主です)を計算してくれるScoreIterationListenerがよく利用されます。// set Stats Listener, to check confusion matrix for each epoch network.setListeners(new StatsListener(statsStorage), new ScoreIterationListener(1));画像の入力をモデルの入力へ
学習までもう一息です。
ここまでですでに画像データ入力のパイプラインは作成しましたが、これをモデルの入力用に変換してくれる設定を追加します。
DataSetIteratorです。
DataSetIteratorは、繰り返し学習を行う度に、必要なデータを学習用に準備してくれる役割を担っています。
今回は、TRAIN、VAL(検証)、TESTの3つのDataSetIteratorを作ります。
このうち、TESTの画像データに関しては、元のデータフォルダを見て分かるように、他のデータと違って、クラスフォルダごとに画像データが割り振られておらず、TESTフォルダの中に直接画像が入っています。
他のデータと同じようにフォルダを作って、コピーしてもよいのですが、よい機会なので、フォルダ分けせずに入力する方法も併せて示します。DataSetIterator traindataIter = new RecordReaderDataSetIterator(recordReaderTrain, batchSize, 1, numLabels); DataSetIterator valdataIter = new RecordReaderDataSetIterator(recordReaderVal, batchSize, 1, numLabels); //この例では、テストフォルダには他と同じようなフォルダ階層がないので、テストデータに関してはラベルはなしのままにします。 DataSetIterator testdataIter = new RecordReaderDataSetIterator(recordReaderTest, 1);//1 is a batchsize正規化
学習を始める最終段階として、モデルに入力するデータを正規化します。
正規化とはよく統計学で利用される手法で、外れ値や、データごとの最大値・最小値のズレなど、モデルが学習する上で混乱をさせるようなものを省くための処理です。
ここでは、画像のピクセル値を0から1の間の数値に変換するスケーラを設定しています。
スケーラにはいろいろな種類がありますが、一般に、訓練用に調整されたスケーラを、検証やテストのデータにも適用します。
(とはいえ、ここで利用しているのは0-1範囲変換なので、調整の必要がない単純なものですが、お作法的に。)// Normalization DataNormalization scaler = new ImagePreProcessingScaler(0, 1); scaler.fit(traindataIter); traindataIter.setPreProcessor(scaler); valdataIter.setPreProcessor(scaler); testdataIter.setPreProcessor(scaler);モデルのトレーニングと検証
モデルの訓練をepochs回繰り返します。
準備したDatasetIteraterをモデルのfit()という関数に渡すのみです。
あとは自動的に繰り返しでデータ取得→学習データリセットをやってくれます。
(モデルによっては、1epoch内でさらにiteraterの繰り返しが必要なことがあるので、DL4JのExampleなどを注意して見てください。)訓練ごとに、同時に検証も行っていきます。
network.evaluate(valdataIter);でよく知られている評価指標と混合行列が計算されます。System.out.println("Start training model...."); int i = 0; while (i < epochs) { while (traindataIter.hasNext()) { DataSet trained = traindataIter.next(); // System.out.println(trained.numExamples());//same as batch size network.fit(trained); } System.out.println("Evaluate model at iteration " + i + " ...."); Evaluation eval = network.evaluate(valdataIter);//use nd4j's Evaluation System.out.println(eval.stats()); valdataIter.reset();//Iteraterを最初に戻す traindataIter.reset();//Iteraterを最初に戻す i++; }モデルのテスト
最後に、トレーニングにもテストにも用いていないデータでテストしてみます。
ここでは、画像を単体で入力して、Evaluationを使わずに、自分で確認する方法を示します。/* * 元画像があるフォルダ階層をトレーニングデータのフォルダ階層と同じにした場合、 * 上記のように評価できます。 * フォルダが整理されていなくても、 * 以下のように画像ごとに評価できます。 */ System.out.println("Test model...."); while(testdataIter.hasNext()) { DataSet testData = testdataIter.next(); System.out.println("testing... :"+testData.id()); INDArray input = testData.getFeatures(); INDArray pred = network.output(input); System.out.println(pred); int predLabel = Nd4j.argMax(pred).getInt(0);//labelある場合 if(predLabel == 0) { System.out.println("ABDOMEN"+" with praba "+pred.getDouble(predLabel)); }else { System.out.println("CHEST"+" with praba "+pred.getDouble(predLabel)); } } System.out.println("Finish....");実行
途中の計算過程はこのように可視化出来ます。
途中の評価は、以下のとおりです。epoch16で結構良い成績になっています。
一部省略。
Evaluate model at iteration 15 ....
# of classes: 2
Accuracy: 0.9000
Precision: 0.9167
Recall: 0.9000
F1 Score: 0.8889最後のテストの出力は、以下のとおりです。
Test model....
testing... :
[[ 5.7758e-5, 0.9999]]
CHEST with praba 0.9999421834945679
testing... :
[[ 0.5547, 0.4453]]
ABDOMEN with praba 0.5546808838844299
Finish....お腹はギリギリ判定できたようです。まだまだ怪しいモデルですね。
コードの外観
以下のようになります。
ChestOrAbd.javapublic class ChestOrAbd { protected static final Logger log = LoggerFactory.getLogger(ChestOrABd.class); public static void main(String[] args) { long seed = 42; final Random RAND_NUM_GEN = new Random(seed); final String[] ALLOWED_FORMATS = BaseImageLoader.ALLOWED_FORMATS; ParentPathLabelGenerator LABEL_GENERATOR_MAKER = new ParentPathLabelGenerator(); BalancedPathFilter PATH_FILTER = new BalancedPathFilter(RAND_NUM_GEN, ALLOWED_FORMATS, LABEL_GENERATOR_MAKER); int numLabels = 2;// chest or abd int height = 64;// image size for train int width = 64;// image size for train int channels = 3;// image channels(in this case, image type is RGB, so 3 channels) int[] inputShape = new int[] {channels, height, width}; int batchSize = 32;// train data size in 1 epoch int epochs = 50; System.out.println("Preparing data...."); // Prepare train File trainDir = new File("./Open_I_abd_vs_CXRs/TRAIN/"); FileSplit trainSplit = new FileSplit(trainDir, NativeImageLoader.ALLOWED_FORMATS, RAND_NUM_GEN); InputSplit train = trainSplit.sample(PATH_FILTER, 1.0)[0]; // Prepare val File valDir = new File("./Open_I_abd_vs_CXRs/VAL/"); FileSplit valSplit = new FileSplit(valDir, NativeImageLoader.ALLOWED_FORMATS, RAND_NUM_GEN); InputSplit val = valSplit.sample(PATH_FILTER, 1.0)[0]; // Prepare test File testDir = new File("./Open_I_abd_vs_CXRs/TEST/"); FileSplit testSplit = new FileSplit(testDir, NativeImageLoader.ALLOWED_FORMATS, RAND_NUM_GEN); InputSplit test = testSplit.sample(PATH_FILTER, 1.0)[0]; System.out.println("train data total sample size " + train.length()); System.out.println("validation total data sample size " + val.length()); System.out.println("test data total sample size " + test.length()); System.out.println("Prepare augumentation...."); ImageTransform flipTransform1 = new FlipImageTransform(new Random(seed)); ImageTransform flipTransform2 = new FlipImageTransform(new Random(seed)); ImageTransform warpTransform = new WarpImageTransform(new Random(seed), inputShape[1]/10); boolean shuffle = false; List<Pair<ImageTransform, Double>> pipeline = Arrays.asList(new Pair<>(flipTransform1, 0.9), new Pair<>(flipTransform2, 0.8), new Pair<>(warpTransform, 0.9)); ImageTransform transform = new PipelineImageTransform(pipeline, shuffle); // data reader setup ImageRecordReader recordReaderTrain = new ImageRecordReader(height, width, channels, LABEL_GENERATOR_MAKER); ImageRecordReader recordReaderVal = new ImageRecordReader(height, width, channels, LABEL_GENERATOR_MAKER); /* * 今回は配布元のデータ構造に合わせるので、 * テストデータは階層のラベルを自動計算させない。 * (利用する際は、データのフォルダ階層を他と同じにして利用する。) */ // ImageRecordReader recordReaderTest = new ImageRecordReader(height, width, channels, LABEL_GENERATOR_MAKER); ImageRecordReader recordReaderTest = new ImageRecordReader(height, width, channels); try { // recordReaderTrain.initialize(train);// Train without transformations recordReaderTrain.initialize(train,transform);// Train with transformations recordReaderVal.initialize(val);//検証データにはオーグメンテーションをしない recordReaderTest.initialize(test); } catch (IOException e) { e.printStackTrace(); } System.out.println("Start construct SimpleCNN model..."); MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder().trainingWorkspaceMode(WorkspaceMode.ENABLED) .inferenceWorkspaceMode(WorkspaceMode.ENABLED).seed(seed).activation(Activation.IDENTITY) .weightInit(WeightInit.RELU).optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT) .updater(new AdaDelta()).convolutionMode(ConvolutionMode.Same).list() // block 1 .layer(0, new ConvolutionLayer.Builder(new int[] { 7, 7 }).name("image_array").nIn(inputShape[0]).nOut(16) .build()) .layer(1, new BatchNormalization.Builder().build()) .layer(2, new ConvolutionLayer.Builder(new int[] { 7, 7 }).nIn(16).nOut(16).build()) .layer(3, new BatchNormalization.Builder().build()) .layer(4, new ActivationLayer.Builder().activation(Activation.RELU).build()) .layer(5, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.AVG, new int[] { 2, 2 }).build()) .layer(6, new DropoutLayer.Builder(0.5).build()) // block 2 .layer(7, new ConvolutionLayer.Builder(new int[] { 5, 5 }).nOut(32).build()) .layer(8, new BatchNormalization.Builder().build()) .layer(9, new ConvolutionLayer.Builder(new int[] { 5, 5 }).nOut(32).build()) .layer(10, new BatchNormalization.Builder().build()) .layer(11, new ActivationLayer.Builder().activation(Activation.RELU).build()) .layer(12, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.AVG, new int[] { 2, 2 }).build()) .layer(13, new DropoutLayer.Builder(0.5).build()) // block 3 .layer(14, new ConvolutionLayer.Builder(new int[] { 3, 3 }).nOut(64).build()) .layer(15, new BatchNormalization.Builder().build()) .layer(16, new ConvolutionLayer.Builder(new int[] { 3, 3 }).nOut(64).build()) .layer(17, new BatchNormalization.Builder().build()) .layer(18, new ActivationLayer.Builder().activation(Activation.RELU).build()) .layer(19, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.AVG, new int[] { 2, 2 }).build()) .layer(20, new DropoutLayer.Builder(0.5).build()) // block 4 .layer(21, new ConvolutionLayer.Builder(new int[] { 3, 3 }).nOut(128).build()) .layer(22, new BatchNormalization.Builder().build()) .layer(23, new ConvolutionLayer.Builder(new int[] { 3, 3 }).nOut(128).build()) .layer(24, new BatchNormalization.Builder().build()) .layer(25, new ActivationLayer.Builder().activation(Activation.RELU).build()) .layer(26, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.AVG, new int[] { 2, 2 }).build()) .layer(27, new DropoutLayer.Builder(0.5).build()) // block 5 .layer(28, new ConvolutionLayer.Builder(new int[] { 3, 3 }).nOut(256).build()) .layer(29, new BatchNormalization.Builder().build()) .layer(30, new ConvolutionLayer.Builder(new int[] { 3, 3 }).nOut(256).build()) .layer(31, new GlobalPoolingLayer.Builder(PoolingType.AVG).build()) //output .layer(32, new OutputLayer.Builder().nIn(256).nOut(2) .lossFunction(LossFunctions.LossFunction.MCXENT) .weightInit(WeightInit.XAVIER) .activation(Activation.SOFTMAX) .build()) .setInputType(InputType.convolutional(inputShape[2], inputShape[1], inputShape[0])) .backpropType(BackpropType.Standard) .build(); MultiLayerNetwork network = new MultiLayerNetwork(conf); network.init(); System.out.println(network.summary()); // visualize train process // URL:http://localhost:9000/train/overview UIServer uiServer = UIServer.getInstance(); StatsStorage statsStorage = new InMemoryStatsStorage(); uiServer.attach(statsStorage); // set Stats Listener, to check confusion matrix for each epoch network.setListeners(new StatsListener(statsStorage), new ScoreIterationListener(1)); /* * 今回は2クラスしか無いのですが、 * 教師ラベルには、画像の種類(フォルダごと)によって画像に教師ラベルが付きます。 * 例えば、画像1(答えは腹部):(胸部:0, 腹部:1)です。 * このように、対応する方に「1」がつきます。 * この「1」という数字がラベルインデックスです。 * DataSetIteratorの引数には4つセットされています。 * recordReaderTrain, batchSize, 1, numLabelsです。 * このうち、1の部分がラベルインデックスです。 */ DataSetIterator traindataIter = new RecordReaderDataSetIterator(recordReaderTrain, batchSize, 1, numLabels); DataSetIterator valdataIter = new RecordReaderDataSetIterator(recordReaderVal, batchSize, 1, numLabels); //この例では、テストフォルダには他と同じようなフォルダ階層がないので、テストデータに関してはラベルはなしのままにします。 DataSetIterator testdataIter = new RecordReaderDataSetIterator(recordReaderTest, 1);//1 is a batchsize // // Normalization DataNormalization scaler = new ImagePreProcessingScaler(0, 1); scaler.fit(traindataIter); traindataIter.setPreProcessor(scaler); valdataIter.setPreProcessor(scaler); testdataIter.setPreProcessor(scaler); System.out.println("Start training model...."); int i = 0; while (i < epochs) { while (traindataIter.hasNext()) { DataSet trained = traindataIter.next(); // System.out.println(trained.numExamples());//same as batch size network.fit(trained); } System.out.println("Evaluate model at iteration " + i + " ...."); Evaluation eval = network.evaluate(valdataIter);//use nd4j's Evaluation System.out.println(eval.stats()); valdataIter.reset();//Iteraterを最初に戻す traindataIter.reset();//Iteraterを最初に戻す i++; } /* * テストデータのフォルダ階層を他と同じにした場合は、 * 上記のように評価できます。 * フォルダが整理されていなくても、 * 以下のように画像ごとに評価できます。 */ System.out.println("Test model...."); while(testdataIter.hasNext()) { DataSet testData = testdataIter.next(); System.out.println("testing... :"+testData.id()); INDArray input = testData.getFeatures(); INDArray pred = network.output(input); System.out.println(pred); int predLabel = Nd4j.argMax(pred).getInt(0);//labelある場合 if(predLabel == 0) { System.out.println("ABDOMEN"+" with praba "+pred.getDouble(predLabel)); }else { System.out.println("CHEST"+" with praba "+pred.getDouble(predLabel)); } } System.out.println("Finish...."); } }感想
私の場合は、ここまでできたら、あれはどうだ、こうやったらどうだなど、いろんなことを妄想し始めることが出来ました。
次のステップには、転移学習や、今回うまく活用できていないレイヤーの組み込み方法、複雑なモデル(ComputationGraph)へのレベルアップ(あるいは簡素化のための試行錯誤)、RNNやLSTMの活用、分類問題以外の課題への挑戦、などがあります。
時代の流れに乗って、こういう話題にもついていけるように頑張りたいものです。Reference
- Hello World Deep Learning in Medical Imaging
- QiitaのDL4J関連の記事を書いてくれた先人たちの知恵
- 投稿日:2020-07-31T12:42:53+09:00
【Effective Javaを読む】 第2章 項目5 『不必要なオブジェクトの生成を避ける』
不必要なオブジェクトの生成を避ける
タイトルの通り。オブジェクトを不用意に生成しまくることはパフォーマンスの劣化につながる。
ちょっと工夫して無駄なオブジェクトを生成しない書き方をしましょうって話。用語集
自動ボクシング
Javaではプリミティブ型(基本型)と参照型の2つの型がある。
プリミティブ型、例えばintをコレクションに置くことはできない。
コレクションはオブジェクト参照だけを保持できるため、プリミティブ値は適切なラッパークラス (int の場合はInteger) に「詰める (box)」必要がある。
オブジェクトをコレクションから取り出すときは、格納した Integer を取得します。int が必要な場合は、intValue メソッドを使用して、Integer から「取り出す (unbox)」必要がある。
これを明示的に実装することは煩雑さの原因であるため、自動ボクシング、アンボクシングの機能がJavaには存在する。
プリミティブ型→ラッパークラスの自動変換を自動ボクシング
ラッパークラス→プリミティブ型の自動変換をアンボクシングと呼ぶ。
プリミティブ型 ラッパークラス boolean Boolean char Character byte Byte short Short int Integer long Long float Float double Double 不変(immutable)
作成後にその状態を変えることのできないオブジェクトのこと。
サンプルコード
このコードはこの箇所が実行されるたびに新しいStringインスタンスを生成してしまう。
例1String s = new String("stringette"); //これをやってはいけないこれならOK
例2String s = "stringette";その人がベビーブーム世代かどうかを判定するisBabyBoomerメソッドをもったPersonクラスを例に考えてみる。
↓の書き方だと、isBabyBoomerメソッドが呼ばれるたびに、不必要に新たなCalenderインスタンス、TimeZoneインスタンス、boomStart、boomEndのDateインスタンスを生成している。これはやってはいけない。例3public class Person { private final Date birthDate; //他のフィールド、メソッド、コンストラクタは省略 //これをやってはいけない! public boolean isBabyBoomer() { //コストの高いオブジェクトの不必要な生成 Calender gmtCal = Calender.getInstance(TimeZone.getTimeZone("GMT")); gmtCal.set(1946, Calender.JANUARY, 1, 0, 0, 0); Date boomStart = gmtCal.getTime(); gmtCal.set(1965, Calender.JANUARY, 1, 0, 0, 0); Date boomEnd = gmtCal.getTime(); return birthDate.compareTo(boomStart) >= 0 && birthDate.compareTo(boomEnd) < 0 ; } }例3の悪いところを改善したのが例4。
クラスが初期化された時点で1度だけCalenderインスタンス、TimeZoneインスタンス、BoomStart、BoomEndのDateインスタンスを生成している。
これによってisBabyBoomerメソッドが頻繁に呼ばれるのであればかなりのパフォーマンス向上になります。例4public class Person { private final Date birthDate; //他のフィールド、メソッド、コンストラクタは省略 /** * ベビーブームの開始と終わりの日付。 */ private static final Date BOOM_START; private static final Date BOOM_END; static { Calender gmtCal = Calender.getInstance(TimeZone.getTimeZone("GMT"); gmtCal.set(1946, Calender.JANUARY, 1, 0, 0, 0); BoomStart = gmtCal.getTime(); gmtCal.set(1965, Calender.JANUARY, 1, 0, 0, 0); BoomEnd = gmtCal.getTime(); } public boolean osBabyBoomer() { return birthDate.compareTo(BoomStart) >= 0 && birthDate.compareTo(BoomEnd) < 0 ; } }例5は1文字の誤字のせいでかなり遅いです。
変数sumがlongではなくLongで宣言されています。
そのせいでプログラムは約2^31個の不必要なLongインスタンスを生成する。
(long i をLong sum に加算するごとに1つのインスタンスが増える)
教訓:ボクシングされた基本データ型よりも基本データ型を選び、意図しない自動ボクシングに注意すること例5//恐ろしく遅いプログラム! オブジェクト生成を指摘できますか? public static void main(String[] args) { Long sum = OL; for (long i = 0; i <= Integer.MAX_VALUE; i++) { sum += i; } System.out.println(sum); }続く
【Effective Javaを読む】 第2章 項目6 『廃れたオブジェクト参照を取り除く』
https://qiita.com/Natsukii/items/5f2edd6a9bcdb94b03e5
- 投稿日:2020-07-31T01:10:27+09:00
JavaFXのドロップボックスの更新遅延の問題
概要
JavaFXのChoiceBoxインスタンス(ComboBoxについても同様と予想します)
の選択肢リストを入れ替える際の
遅延とメモリ使用量が問題でした。環境
Win10
Java8症状
1000個程度のStringリストをchoiceBox.getItems().addAll( items );
とかで渡すのですが
choiceBoxがすでにシーングラフ上に表示済みの場合にこの操作すると、
数10秒単位で固まるうえに 使用メモリ量が500MBとか数GBとかいう単位で増加します。
おそらくリスト中のアイテム一個足されるたびにリスナーが働いてシーングラフにアクセスするのだと思う。
choiceBoxが一度でも描画されたらそれまで。
setVisible(false);にしたり親ノードから外して非表示にしても症状は変わらない。↑ これが納得いかないのですね。なんでグラフ更新を無効化できないの?
choiceBox.setItems();からObservableListをセットし直すという方法も試したが
このメソッドが有効なのは最初の一回だけのようです。結論
いろいろためしましたが
ChoiceBoxインスタンスを使い捨てにして「表示後のインスタンスに対するリスト更新はしない」のが一番まともなようです。choiceBoxをfinal にしたいのだが、当面あきらめます。
ぼやき
Java は
こういった実験に時間を費やして進捗が止まる。
なにか間違ってるのだろうか。
- 投稿日:2020-07-31T00:10:25+09:00
MacでHomebrewを使えばEclipseがなくてもすぐTomcatを使える
Tomcatの環境設定で困りませんか?
MacでTomcatの環境設定をする際、Tomcatのtar.gzまたはzipファイルを公式サイトからダウンロードしてjava_homeやcatalina_homeのパスを色々設定したりと色々めんどくさくて、嫌になりませんか?
私は一度嫌になって、Eclipseに頼りました。でもEclipseも不具合があったら、また問題を見つけるの大変そうだなと思いました。
そこで、今回一番シンプルなTomcat導入方法を見かけたので紹介します。
ソース
Installing Apache Tomcat on MacOS Mojave using Homebrew(2019/8/29)
https://medium.com/@fahimhossain_16989/installing-apache-tomcat-on-macos-mojave-using-homebrew-28ce039b4b2e設定方法
「Installing and Running Apache Tomcat on Mac OS using Homebrew」の見出しから参照してください。(cask云々と書いてある箇所は割愛して進めました。)
Step1:Tomcatをインストール
Tomcatのインストールのために以下のコマンドをターミナルで実行します。
###Step2:Tomcatを開始するbrew update brew install tomcat
Homebrewのコマンドを使って、自動的に開始(停止)する場合は以下のコマンドbrew services start tomcat brew services stop tomcatマニュアルでTomcatを開始(停止)する場合は以下のコマンド
以上で、Tomcatを開始することができます。catalina run catalina stopLast login: Thu Jul 30 22:52:31 on ttys001 AkihironoMacBook-puro% catalina run Using CATALINA_BASE: /usr/local/Cellar/tomcat/9.0.37/libexec Using CATALINA_HOME: /usr/local/Cellar/tomcat/9.0.37/libexec Using CATALINA_TMPDIR: /usr/local/Cellar/tomcat/9.0.37/libexec/temp Using JRE_HOME: /usr/local/opt/openjdk Using CLASSPATH: /usr/local/Cellar/tomcat/9.0.37/libexec/bin/bootstrap.jar:/usr/local/Cellar/tomcat/9.0.37/libexec/bin/tomcat-juli.jar NOTE: Picked up JDK_JAVA_OPTIONS: --add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=java.base/java.io=ALL-UNNAMED --add-opens=java.rmi/sun.rmi.transport=ALL-UNNAMED . . . . 31-Jul-2020 00:08:31.077 情報 [main] org.apache.catalina.startup.HostConfig.deployDirectory ディレクトリ [/usr/local/Cellar/tomcat/9.0.37/libexec/webapps/host-manager] の Web アプリケーションの配備は [18] ms で完了しました。 31-Jul-2020 00:08:31.080 情報 [main] org.apache.coyote.AbstractProtocol.start プロトコルハンドラー ["http-nio-8080"] を開始しました。 31-Jul-2020 00:08:31.090 情報 [main] org.apache.catalina.startup.Catalina.start サーバーの起動 [829]ms