- 投稿日:2020-07-04T23:56:43+09:00
Raspberry-piメモ
色々作ってもらっていると、自分でも触りたくなったので休日に勉強を始めた
とりあえず買って放置していたものを掘り起こす
Raspberry Pi4 ModelB Rev1.2 とラズパイカメラv2
Raspbian 10 buster
たぶんまたしばらくしたら同じことで詰まるので、自分の手順を記録する
1.とりあえずカメラをつないで画像を保存してみる
参考URL様
http://igarashi-systems.com/sample/translation/raspberry-pi/usage/python-camera.html
IDEのthonny?とかいうのでサンプルプログラムのコピペを動かす
→ 問題なくできる2.openCVで画像を触ってみたかったのでインストール
何も考えず pip install python-opencv
→ import cv2ができず地獄が始まる
pythonのデフォルトをpython3にした
参考URL様
https://www.souichi.club/raspberrypi/python3-default/
$ sudo unlink python $ sudo ln -s python3 pythonちゃんとimportできるかターミナル触りまくっててpython3と打つのがだるかっただけ。結局ターミナルで触らなくなったのであんまり意味がなくなったかも
キーボードがなんかおかしいので直す
参考URL様
https://qiita.com/sukinasaki/items/426068d6e87169fa3d88
$ sudo raspi-configから同じ感じで
ちょっとconfigの最初だけ名前違ったけど4番目なのは変わらず
設定できたと思ったら何かたまに元に戻る、USB切り替え器でキーボードつないでるのが良くないのかなあ。メインPCとラズパイの接続を切り替えたりしてると元に戻る
追記)よくわからないが元の設定は日本語配列に変わってなかった?
入力メソッドが並んでいるところの英語キーボードを削除、日本語キーボードに変更したら調子がよくなった。たまにできてたのはなぜなんだろう
python3 + openCV
import cv2が使えない
参考URL様
関係ありそうなところをマネする
ImportError: libjasper.so.1: cannot open shared object file: No such file or directory
$ sudo apt-get install libjasper-devImportError: libQtGui.so.4: cannot open shared object file: No such file or directory
$ sudo apt-get install libqt4-testImportError: libcblas.so.3: cannot open shared object file: No such file or directory
$ sudo apt-get install libatlas-base-devImportError: /lib/python3.7/site-packages/cv2/cv2.cpython-37m-arm-linux-gnueabihf.so: undefined symbol: _atomic_fetchadd_8
export LD_PRELOAD=/usr/lib/arm-linux-gnueabihf/libatomic.so.1を追記
コマンドのやり方がよくわからなかった(ただ開かれたファイルの中身を大量のエラーだと勘違いしていた)ので
/home/pi にあった.bashrcをテキストエディタで開いて一番下の行に上記の1文をコピペして保存した。.profileのほうにも入れた
どっちが正解?
ここでターミナルではimport cv2が通る
IDEのサンプルプログラムにimport cv2を書き足してみる→またImportErrorが出る
標準入っていたやつで悩みたくないので、少し触れたことがあるソフトに切り替える
Visual Studio Codeを入れる
参考URL様
簡単に入れることができた。
普通にimport cv2はOKになったが、import picameraが動かなくなった
→VS Codeの作業フォルダとして名前をimportするものと同じpicameraにしたせいでエラーが出ていた?そういうの関係あるんだ
無事にサンプルプログラムが動いて画像が保存できる。
import cv2も通るよし、スタートライン
- 投稿日:2020-07-04T23:36:47+09:00
Python3チートシート(基本編)
本記事の内容
- Pythonの基本
- 制御構造
- データ構造
- 関数
- クラス/インスタンス
- モジュール/パッケージ/名前空間/スコープ
- 組み込み関数/特殊メソッド
- ファイル操作と入出力
1. Pythonの基本
基本文法
インデントimport os def function(): # インデントはPEP8(*)に従い、半角スペース4つ print('Hello world')(*)PEP8(Python Enhancement Proposal)
https://www.python.org/dev/peps/pep-0008/
Indentation
Use 4 spaces per indentation level.変数宣言# 数値 num = 1 # 文字列 name = 'Tanaka' # リスト list = [1, 2, 3, 4, 5] # 明示的な型宣言 num: int = 1 name: str = 'Tanaka' # 型変換 old_num = '1' # String型 new_num = int(num) # integer型に変換してnew_numに代入
- Pythonで変数宣言が不要な理由は、Pythonが動的型付き言語の為。動的型付き言語はプログラムの実行中に型を自動で判定しながら処理を行っていく。型を明示しなくても実行時には決まっているが、暗黙的な型変換は行われない為、コード記述時には型を意識する必要がある。
コメント# 1行単位のコメント """ 複数行を まとめて コメント """Docstringdef test_function(param1, param2): """二つの引数を加算して返却するtest_function Args: param1(int): 第一引数の説明 param2(int): 第二引数の説明 Returns: param1とparam2の加算結果を返却する """ return param1 + param2
- Docstringはコメントと違い様々なツールからも参照できるドキュメント。モジュールの冒頭と関数、クラス、メソッドの定義のみで利用可能。(関数等の途中では使えない。)
数値の操作
数値計算# 整数の加算 >>> 1 + 1 2 # 整数の減算 >>> 2 - 1 1 # 整数の乗算 >>> 5 * 6 30 # 整数の除算 ※除算は常に浮動小数点を返す >>> 6 / 5 1.2 # 評価順は数学と同様 >>> 50 - 5 * 6 20 >>> (50 - 5 * 6) / 4 5.0 # 標準の除算はfloatを返す >>> 17 / 3 5.666666666666667 # 「//」:切り下げ除算は小数点以下を切り捨てる >>> 17 // 3 5 # 「%」:剰余(除算の余り)を返す >>> 17 % 3 2 >>> # 5の2乗 >>> 5 ** 2 25 # 2の7乗 >>> 2 ** 7 128 # 小数点以下を丸める(小数点以下を2桁で丸める) >>> pie = 3.1415926535 >>> pie 3.1415926535 >>> round(pie, 2) 3.14文字列の操作
文字列# シングルクオートで囲む >>> print('Hello world') Hello world # ダブルクオートで囲む >>> print("Hello world") Hello world # 文字列として「'」を使う場合(ダブルクオートで囲む) >>> print("I'm from Japan.") I'm from Japan. ' # 文字列として「'」を使う場合(エスケープする) >>> print('I\'m from Japan.') I'm from Japan. ' # 改行する(\n) >>> print('Hello! \nHow are you doing?') Hello! How are you doing? # 特殊文字としての解釈を防ぐ(「\n」部分が改行として解釈される為、rawデータとして処理させる) >>> print(r'C:\name\name') C:\name\name # 複数行の出力(「"""」で囲む) >>> print(""" ... line1 ... line2 ... line3 ... """) line1 line2 line3 # 改行をさせない(「\」を記載する) >>> print("""\ ... line1 ... line2 ... line3\ ... """) line1 line2 line3 # 文字の繰り返し >>> print('Yes.' * 3 + '!!!') Yes.Yes.Yes.!!! # 文字列の結合(リテラル同士は「+」がなくてもOK) >>> print('Py''thon') Python # 文字列の結合(変数 + リテラルは「+」が必要) >>> prefix = 'Py' >>> print(prefix + 'thon') Python文字列のインデックス/スライシング# 変数定義 >>> word = 'Python' # wordの0番目の位置の文字を取得 >>> print(word[0]) P # wordの5番目の位置の文字を取得 >>> print(word[5]) n # wordの最後から1番目の位置の文字を取得(先頭からは、0,1,2・・・ 最後からは-1,-2,-3・・・) >>> print(word[-1]) n # wordの最後から3番目の位置の文字を取得(先頭からは、0,1,2・・・ 最後からは-1,-2,-3・・・) >>> print(word[-3]) h # wordの0(0含む)から2(2は含まない)の位置まで文字を取得 >>> print(word[0:2]) Py # wordの2(2含む)から5(5は含まない)の位置まで文字を取得 >>> print(word[2:5]) tho # wordの最初から2(2含む)の位置まで文字を取得 >>> print(word[:2]) Py # wordの2(2含む)の位置から最後までの文字を取得 >>> print(word[2:]) thon # wordの最初から最後までの文字を取得 >>> print(word[:]) Python文字に関するメソッド# 文字列sを定義 >>> s = 'Hello Tom. How are you doing.' >>> print(s) Hello Tom. How are you doing. # 文字列に特定の文字列が含まれるかを確認 >>> print(s.startswith('Hello')) True >>> print(s.startswith('Tom')) False # 文字列に特定の文字(or文字列)が含まれる位置を確認(先頭から) >>> print(s.find('o')) 4 # 文字列に特定の文字(or文字列)が含まれる位置を確認(最後から) >>> print(s.rfind('o')) 24 # 文字列に含まれる特定の文字(or文字列)の数を確認 >>> print(s.count('o')) 5 # 文字列の先頭の文字を大文字に変換 >>> print(s.capitalize()) Hello tom. how are you doing. # 文字列の各単語の先頭の文字を大文字に変換 >>> print(s.title()) Hello Tom. How Are You Doing. # 文字列を大文字に変換 >>> print(s.upper()) HELLO TOM. HOW ARE YOU DOING. # 文字列を小文字に変換 >>> print(s.lower()) hello tom. how are you doing. # 特定の文字列を置換 >>> print(s.replace('Tom', 'Bob')) Hello Bob. How are you doing.2. 制御構造
条件分岐(if文)
条件分岐(if文)if 条件式1: 条件式1が真の場合に実行される処理 elif 条件式2: 条件式1が偽かつ条件式2が真の場合に実行される処理 else: 全ての条件式が偽の場合に実行される処理
- ifは上から順に評価され、最初に真になった節の処理が実行される。条件式1が真の場合、条件式2の結果が真でも条件式2の処理は実行されない。
条件式で偽となる値- None - False - 数値型のゼロ 、 0 、 0.0 、 0j(複素数) - 文字列、リスト、辞書、集合などのコンテナオブジェクトの空オブジェクト - メソッド__bool__()がFalseを返すオブジェクト - メソッド__bool__()を定義しておらず、メソッド__len__()が0を返すオブジェクト
- Pythonでは、偽となるオブジェクト以外が真と評価される。つまり上記以外は全て真となる。
数値の比較# 等価の場合にTrue >>> 1 == 1 True # 等価でない場合にTrue >>> 1 != 1 False # 左辺が大きい場合にTrue >>> 1 > 0 True # 右辺が大きい場合にTrue >>> 1 < 0 False # 左辺が大きいまたは等価の場合にTrue >>> 1 >= 0 True # 右辺が大きいまたは等価の場合にTrue >>> 1 <= 0 False # x < y and y < z と等価 >>> x, y, z = 1, 2, 3 >>> x < y < z Trueオブジェクトの比較>>> x = 'red' >>> y = 'green' # 等価の場合にTrue >>> x == y False # 等価でない場合にTrue >>> x != y True # 同じオブジェクトの場合にTrue >>> x is None False # 同じオブジェクトでない場合にTrue >>> x is not None True >>> items = ['pen', 'note', 'book'] # itemsに'book'が含まれている場合にTrue >>> 'book' in items True # itemsに'note'が含まれていない場合にTrue >>> 'note' not in items Falseループ(for文)
for文>>> items = [1, 2, 3] >>> for i in items: ... print(f'変数iの値は{i}') ... 変数iの値は1 変数iの値は2 変数iの値は3 # range()関数 >>> for i in range(3): ... print(f'{i}番目の処理') ... 0番目の処理 1番目の処理 2番目の処理 # enumerate()関数 >>> chars = 'word' >>> for count, char in enumerate(chars): ... print(f'{count}番目の文字は{char}') ... 0番目の文字はw 1番目の文字はo 2番目の文字はr 3番目の文字はd # ディクショナリのループ(items()メソッド) >>> sports = {'baseball': 9, 'soccer': 11, 'tennis': 2} >>> for k, v in sports.items(): ... print(k, v) ... baseball 9 soccer 11 tennis 2 # 二つのシーケンスの同時ループ(zip()関数) >>> questions = ['name', 'quest', 'favorite color'] >>> answers = ['lancelot', 'the holy grail', 'blue' ] >>> for q, a in zip(questions, answers): ... print('What is your {0}? It is {1}.'.format(q, a)) ... What is your name? It is lancelot. What is your quest? It is the holy grail. What is your favorite color? It is blue.for文のelse節の挙動>>> nums = [2, 4, 6, 8] >>> for n in nums: ... if n % 2 == 1: ... break ... else: ... print('奇数がありません') ... 奇数がありません
- else節にはfor文が終了した後に一度だけ実行したい処理を記述する。
- else節を使用すると、for文、あるいはwhile文の処理中でbreak文を使用しなかった時、else節のブロックを実行する。
例外処理
try文try: 例外が発生する可能性のある処理 except 捕捉したい例外クラス: 捕捉したい例外が発生した時に実行される処理 else: 例外が発生しなかった時のみ実行される処理 finally: 例外の発生有無にかかわらず実行したい処理
- try節:例外が発生する可能性のある処理をtry-except節の間に記載する
try-except節# 配列の存在しない要素へのアクセスを行い例外を発生させ、except節で捕捉する >>> l = [1, 2, 3] >>> i = 5 >>> try: ... l[i] ... except: ... print('It is no problem') ... It is no problem # 特定の例外をexcept節で捕捉する >>> try: ... l[i] ... except IndexError: ... print('You got an IndexError') ... You got an IndexError # 例外の原因を出力させる >>> try: ... l[i] ... except IndexError as ex: ... print('You got an IndexError : {}'.format(ex)) ... You got an IndexError : list index out of range # 全ての例外を捕捉する >>> try: ... () + l ... except IndexError: ... print('You got an IndexError') ... except BaseException as ex: ... print('You got an Exception : {}'.format(ex)) ... You got an Exception : can only concatenate tuple (not "list") to tuple例外のクラス階層
https://docs.python.org/ja/3/library/exceptions.html#exception-hierarchy
- else節:例外が発生しなかった場合に実行する処理をelse節に記述する
else節# 例外が発生しなかった場合に実行する処理をelse節に記述する >>> try: ... 1 + 1 ... except BaseException: ... print('You got an Exception.') ... else: ... print('There are no Exceptions!') ... 2 There are no Exceptions!
- finally節:例外が発生しても発生しなくても実行する処理をfinally節に記述する
finally節# 例外が発生しても発生しなくても実行する処理をfinally節に記述する >>> try: ... raise NameError('It is a NameError!!!') ... except NameError as ne: ... print(ne) ... finally: ... print('NameError Program finished!!!') ... It is a NameError!!! NameError Program finished!!!例外の送出(意図的な例外の発生)
raise文# 単純にraiseのみを記載すると、例外を再送出することができる。(例外の送出は知りたいが、その場では処理をさせない場合) >>> try: ... raise NameError('It is a NameError!!!') ... except NameError: ... print('Name Error.') ... raise ... Name Error. Traceback (most recent call last): File "<stdin>", line 2, in <module> NameError: It is a NameError!!!3. データ構造
リスト型
リスト型# リスト「l」の定義 >>> l = [1, 2, 3, 4, 5] >>> print(l) [1, 2, 3, 4, 5] # リストの特定の要素の取得 >>> print(l[0]) 1 >>> print(l[-1]) 5 # リストの最初から3番目(0番目、1番目、2番目)の要素まで(3番目は含まない)を取得 >>> print(l[:3]) [1, 2, 3] # リストの最後から3番目(3番目は含む)の要素から最後までを取得 >>> print(l[-3:]) [3, 4, 5] # リストの全ての要素を取得 >>> print(l[:]) [1, 2, 3, 4, 5] # リストの結合 >>> l2 = [6, 7, 8, 9, 10] >>> print(l + l2) [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] # リストの要素の変更 >>> l[2] = 300 >>> print(l) [1, 2, 300, 4, 5]
- 文字列は変更不能体(immutable)であり、特定の要素を変更することはできないが、リストは変更可能体(mutable)であり、要素を入れ替えることができる。
リストの操作
リストの操作# リストの要素の追加(最後に追加) >>> l.append(600) >>> print(l) [1, 2, 300, 4, 5, 600] # リストの要素の追加(先頭に追加:0番目のインデックスに「0」を追加) >>> l.insert(0, 0) >>> print(l) [0, 1, 2, 300, 4, 5, 600] # リストの要素の取得(最後の要素の取得、リストからは消える) >>> l.pop() 600 >>> print(l) [0, 1, 2, 300, 4, 5] # リストの要素の取得(0番目の要素の削除、リストからは消える) >>> l.pop(0) 0 >>> print(l) [1, 2, 300, 4, 5] # リストの要素の削除(2番目の要素の削除) >>> del l[2] >>> print(l) [1, 2, 4, 5] # リストの削除(リストごと削除) >>> del l >>> print(l) Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'l' is not defined # リストの全要素の削除(リストは削除しない) >>> print(l) [['A', 'B', 'C'], [1, 2, 3]] >>> l.clear() >>> print(l) [] # リストの指定した値に合致した要素を削除 >>> l = [0, 1, 2, 3, 3, 3, 4, 5] >>> l.remove(3) >>> print(l) [0, 1, 2, 3, 3, 4, 5] # リストの指定した値に合致した要素を削除(合致する要素がないとエラーとなる) >>> l.remove(3) >>> l.remove(3) >>> l.remove(3) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: list.remove(x): x not in list >>> print(l) [0, 1, 2, 4, 5] # リストの要素数の取得 >>> print(len(l)) 5 # リストの入れ子(リストを要素とするリストを作成) >>> l1 = ['A', 'B', 'C'] >>> l2 = [1, 2, 3] >>> l = [l1, l2] >>> print(l) [['A', 'B', 'C'], [1, 2, 3]] # 指定した値に合致するインデックスの取得(アイテムが存在しない場合はエラー) >>> l = [1, 2, 3, 4, 5] >>> l.index(3) 2 >>> l.index(6) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: 6 is not in list # 指定した値に合致する要素数を取得 >>> l.count(4) 1 # リストの要素を逆順に変更 >>> print(l) [1, 2, 3, 4, 5] >>> l.reverse() >>> print(l) [5, 4, 3, 2, 1] # リストの要素を昇順に並び替え >>> l = [4, 5, 2, 1, 3] >>> print(l) [4, 5, 2, 1, 3] >>> l.sort(key=None, reverse=False) >>> print(l) [1, 2, 3, 4, 5] # リストの要素を降順に並び替え >>> l = [4, 5, 2, 1, 3] >>> print(l) [4, 5, 2, 1, 3] >>> l.sort(key=None, reverse=True) >>> print(l) [5, 4, 3, 2, 1] # 特定の文字で区切ってリストに格納 >>> s = 'Hi, Tom. How are you doing?' >>> print(s.split(' ')) ['Hi,', 'Tom.', 'How', 'are', 'you', 'doing?'] >>> print(s.split('.')) ['Hi, Tom', ' How are you doing?']タプル型
- リストとタプルの違いは、リストは各要素に対して値を変更できる(mutable)のに対し、タプルは値を変更できない(immutable)。
- その為、タプルは値を一度入れたら書き換えられたくない時など、読み込み専用の用途で利用する。
タプル型# タプルの宣言(括弧ありでもなしでもタプルとして定義される) >>> t = (1, 2, 3, 4, 5) >>> print(t) (1, 2, 3, 4, 5) >>> t2 = 1, 2, 3 >>> print(t2) (1, 2, 3) # タプルの宣言(定義の最後に「,」があるとタプルとして定義される為注意) # 要素数が一つのみの場合にも最後に「,」を記述する必要がある。 >>> t3 = 1, >>> t3 (1,) >>> type(t3) <class 'tuple'> # タプルはリストと違い、値を変更できない >>> t[0] = 100 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object does not support item assignment # タプルにリストを格納し、そのリストの値は変更可能 >>> t = ([1, 2, 3], [4, 5, 6]) >>> t ([1, 2, 3], [4, 5, 6]) >>> t[0][0] 1 >>> t[0][0] = 100 >>> t ([100, 2, 3], [4, 5, 6])タプルのアンパッキング# タプルの値を変数に代入 >>> t = (1, 2, 3) >>> t (1, 2, 3) >>> x, y, z = t >>> print(x, y, z) 1 2 3 # 特定の変数の値を入れ替える場合等に有効 >>> X = 100 >>> Y = 200 >>> print(X, Y) 100 200 >>> X, Y = Y, X >>> print(X, Y) 200 100辞書型(ディクショナリ型)
辞書型(ディクショナリ型)# 辞書型(ディクショナリ型)の宣言① >>> d = {'x': 10, 'y': 20, 'z': 30} >>> d {'x': 10, 'y': 20, 'z': 30} # 辞書型(ディクショナリ型)の宣言② >>> dict(a=100, b=200, c=300) {'a': 100, 'b': 200, 'c': 300} # 辞書型(ディクショナリ型)の特定のキーの値の取得 >>> d['y'] 20 # 辞書型(ディクショナリ型)にキーと値の追加 >>> d['a'] = 40 >>> d {'x': 10, 'y': 20, 'z': 30, 'a': 40} # 辞書型(ディクショナリ型)の特定のキーの削除 >>> del d['a'] >>> d {'x': 10, 'y': 20, 'z': 30}辞書型(ディクショナリ型)の操作
辞書型(ディクショナリ型)の操作# 辞書型(ディクショナリ型)のキーリストの取得 >>> d {'x': 10, 'y': 20, 'z': 30} >>> d.keys() dict_keys(['x', 'y', 'z']) >>> list(d.keys()) ['x', 'y', 'z'] # 辞書型(ディクショナリ型)の更新(結合) # キーが存在している項目は値の更新、キーが存在していない項目はキーと値の追加 >>> d {'x': 10, 'y': 20, 'z': 30} >>> d2 {'x': 100, 'a': 1, 'b': 2} >>> d.update(d2) >>> d {'x': 100, 'y': 20, 'z': 30, 'a': 1, 'b': 2} # 特定のキーの値を取得 >>> d.get('x') 100 # 特定のキーの値を取得(取り出したキーと値は辞書定義からはなくなる) >>> d {'x': 100, 'y': 20, 'z': 30, 'a': 1, 'b': 2} >>> d.pop('a') 1 >>> d.pop('b') 2 >>> d {'x': 100, 'y': 20, 'z': 30} # 特定のキーが辞書に含まれるか確認 >>> d {'x': 100, 'y': 20, 'z': 30} >>> 'x' in d True集合
- リストやタプルとの違いは、集合は要素の重複を許さず、要素の順番を保持しない。
- 組み込み型の集合型には、set型とfrozenset型の二種類がある。
set型>>> items = {'note', 'notebook', 'pen'} >>> type(items) <class 'set'> >>> items {'notebook', 'note', 'pen'} # 重複している要素は1つになる >>> items = {'note', 'notebook', 'pen', 'pen', 'note'} >>> items {'notebook', 'note', 'pen'} # 要素の追加 >>> items.add('book') >>> items {'notebook', 'note', 'pen', 'book'} # 要素の削除 >>> items.remove('pen') >>> items {'notebook', 'note', 'book'} # 要素を取り出して集合から削除 # 順序がない為、取り出される要素は不定 >>> items.pop() 'notebook' >>> items {'note', 'book'}
- frozenset型は、set型を不変にした型(不変な集合を扱う型)
frozenset型>>> items = frozenset(['note', 'notebook', 'pen']) >>> type(items) <class 'frozenset'> >>> items frozenset({'notebook', 'note', 'pen'}) # 不変な型の為変更はできない >>> items.add('book') Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'frozenset' object has no attribute 'add'集合の演算>>> set_a = {'note', 'notebook', 'pen'} >>> set_b = {'note', 'book', 'file'} # 和集合 >>> set_a | set_b {'notebook', 'note', 'file', 'book', 'pen'} >>> set_a.union(set_b) {'notebook', 'note', 'file', 'book', 'pen'} # 差集合 >>> set_a - set_b {'notebook', 'pen'} >>> set_a.difference(set_b) {'notebook', 'pen'} # 積集合 >>> set_a & set_b {'note'} >>> set_a.intersection(set_b) {'note'} # 対称差 >>> set_a ^ set_b {'notebook', 'book', 'file', 'pen'} >>> set_a.symmetric_difference(set_b) {'notebook', 'book', 'file', 'pen'} # 部分集合か判定 >>> {'note', 'pen'} <= set_a True >>> {'note', 'pen'}.issubset(set_a) True内包表記
- 内包表記は、リストや集合、辞書等を生成できる構文。
リスト内包表記(リストの作成)# for文を使ったリストの作成 >>> numbers = [] >>> for i in range(10): ... numbers.append(str(i)) ... >>> numbers ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'] # リスト内包表記を使ったリストの作成 >>> [str(v) for v in range(10)] ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'] # ネストしたリストの内包表記 # for文を使った記述 >>> tuples = [] >>> for x in [1, 2, 3]: ... for y in [4, 5, 6]: ... tuples.append((x, y)) ... >>> tuples [(1, 4), (1, 5), (1, 6), (2, 4), (2, 5), (2, 6), (3, 4), (3, 5), (3, 6)] # リスト内包表記を使ったネストしたリストの作成 >>> [(x, y) for x in [1, 2, 3] for y in [4, 5, 6]] [(1, 4), (1, 5), (1, 6), (2, 4), (2, 5), (2, 6), (3, 4), (3, 5), (3, 6)] # if文のある内包表記 # for文を使った記述 >>> even = [] >>> for i in range(10): ... if i % 2 == 0: ... even.append(i) ... >>> even [0, 2, 4, 6, 8] # 内包表記を使った記述 >>> [x for x in range(10) if x % 2 == 0] [0, 2, 4, 6, 8]4. 関数
関数の定義# 関数の定義(引数なし) >>> def say_hello(): ... print('Hello') ... >>> say_hello() Hello # 関数の定義(引数あり) >>> def say_something(str): ... print(str) ... >>> say_something('Good morning') Good morning # 関数の定義(引数あり、デフォルト引数指定あり) >>> def say_something(str='Hi!'): ... print(str) ... # 引数を指定しない場合は、デフォルト引数が使われる >>> say_something() Hi! # 引数を指定した場合は、その引数が使われる。 >>> say_something('Hello') Hello # 関数の定義(戻り値あり) >>> def increment(num): ... return num + 1 ... >>> increment(1) 2
- 関数の中で、return文が実行されるとそこで処理が終了される為、その後の処理は実行されない。
- returnがない関数の戻り値は、Noneとなる。
関数の引数# 位置引数 -> 関数呼び出し時に渡された順序通りに変数に格納される(引数の数が異なるとエラー) >>> def increment(num1, num2): ... return num1 + num2 ... >>> increment(2, 4) 6 # キーワード引数 -> 呼び出し時にキーワード引数を指定(順序は関係ない) >>> def greeting(name, str): ... print(str + ', ' + name + '!') ... >>> greeting(str='Hello', name='Tom') Hello, Tom! # デフォルト引数 -> 仮引数にデフォルト値を指定可能(ただし、デフォルト値のある仮引数は、デフォルト値のない仮引数よりも後に記述する必要がある。) >>> def greeting(name, str='Hi'): ... print(str + ', ' + name + '!') ... >>> greeting('Tom') Hi, Tom! # 可変長の位置引数 -> 任意の数の引数を受け取ることが可能(指定位置は、位置引数の最後で、デフォルト値のある引数よりも前) >>> def say_something(name, *args): ... for str in args: ... print("I'm " + name + ". " + str + "!") ... >>> say_something('Tom', 'Hello', 'Hi', 'Good morning') I'm Tom. Hello! I'm Tom. Hi! I'm Tom. Good morning! ' # 可変長のキーワード引数 -> 仮引数に割当てられなかったキーワード引数を辞書型で受け取る(指定位置は、一番最後) >>> def print_birthday(family_name, **kwargs): ... print("Birthday of " + family_name + " family") ... for key, value in kwargs.items(): ... print(f'{key}: {value}') ... >>> print_birthday('Smith', Nancy='1990/1/1', Tom='1993/1/1', Julia='2010/1/1') Birthday of Smith family Nancy: 1990/1/1 Tom: 1993/1/1 Julia: 2010/1/1 # 可変長の位置引数とキーワード引数 -> どのような引数の呼び出しにも対応可能 >>> def say_something(*args, **kwargs): ... for s in args: ... print(s) ... for key, value in kwargs.items(): ... print(f'{key}: {value}') ... >>> say_something('Hello', 'Hi', 'Bye', Nancy='29 years old', Tom='26 years old') Hello Hi Bye Nancy: 29 years old Tom: 26 years old # キーワードのみ引数 -> 呼び出し時に仮引数名が必須になる引数 # 「*」以降がキーワードのみ引数となる >>> def increment(num, lsat, *, ignore_error=False): ... pass ... # 位置引数ではエラーとなる >>> increment(1, 2, True) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: increment() takes 2 positional arguments but 3 were given # キーワード引数でのみ指定できる >>> increment(1, 2, ignore_error=True) >>> # 位置のみ引数 -> 呼び出し時に仮引数名を指定できない引数 # 「/」より前が位置のみ引数となる。仮にabs関数で仮引数名を指定するとエラーになる。 >>> help(abs) abs(x, /) Return the absolute value of the argument. >>> abs(x=-1) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: abs() takes no keyword arguments引数リストのアンパック# リストに格納された値を引数に渡す >>> def greeting(x, y, z): ... print(x) ... print(y) ... print(z) ... >>> contents = ['Hello', 'Good morning', 'Bye'] # 関数呼び出し時に「*」演算子でリストから引数を展開する >>> greeting(*contents) Hello Good morning Bye # 辞書に格納された値を引数に渡す >>> def say_something(name, greeting): ... print(name) ... print(greeting) ... >>> dict = {'greeting': 'Hello'} # 関数呼び出し時に「**」演算子で辞書から引数を展開する >>> say_something('Julia', **dict) Julia Hellolambda式
- lambda式を使うと、1行で無名関数を作成できる。
- 無名関数は関数の引数として関数オブジェクトを渡す時によく利用される。
lambda式の構文lambda 引数1, 引数2, 引数3, ...: 戻り値になる式lambda式の例>>> increment = lambda num1, num2: num1 + num2 >>> increment(1, 2) 3 # 以下と同義 >>> def increment(num1, num2): ... return num1 + num2 ... >>> increment(1, 2) 3 # 第一引数の関数が真になるもののみが残る。 >>> nums = ['one', 'two', 'three'] >>> filterd = filter(lambda x: len(x) == 3, nums) >>> list(filterd) ['one', 'two']型ヒント
- アノテーションで関数に型情報を付与する。
- コードの保守性を高めるために利用する。また、mypyなどの静的解析ツールによる型チェックの利用もできる。
- 実行時に型チェックが行われる訳ではないので、指定した意外の型を使ってもエラーにはならない。
型情報を付与する為の構文def 関数名(arg1: arg1の型, arg2: arg2の型, ...) -> 戻り値の型: # 関数で実行したい処理 return 戻り値 >>> def say_something(name: str, age: int) -> str: ... print(name) ... print(age) ... return name ... >>> say_something('Tom', 29) Tom 29 'Tom'5. クラス/インスタンス
クラス定義
クラス定義class クラス名(基底クラス名): def メソッド名(引数1, 引数2, ...): メソッドで実行したい処理 return 戻り値 >>> class Person(object): ... def say_something(self): ... print('Hello!!!') ... # クラスをインスタンス化 >>> person = Person() # インスタンスメソッドの呼び出し >>> person.say_something() Hello!!!インスタンスの初期化
インスタンスの初期化>>> class Person: ... def __init__(self): ... print('Init completed!') ... def say_something(self): ... print('Hello!!!') ... # インスタンスを生成した時に、初期化処理(__init__に定義した処理)が呼ばれる >>> person = Person() Init completed! >>> person.say_something() Hello!!!プロパティ
- インスタンスメソッドに「@property」を付けると、そのインスタンスメソッドは、「()」を付けずに呼び出せる
- 「@property」が付いたメソッド -> 値の取得時に呼び出される(読み取り専用) -> getter
- 「@メソッド名.setter」 -> 値を代入する時に呼び出される -> setter
- setterのメソッド名には、「@property」を付けたメソッド名をそのまま利用しなくてはならない。
@property(setter)>>> class Person: ... @property ... def name(self): ... return self._name ... @name.setter ... def name(self, name): ... self._name = name ... >>> person = Person() >>> person.name = 'Tom' >>> person.name 'Tom'
- アンダースコアから始まる属性(_name):プライベートな属性であることを表現する。
- アンダースコア2つから始まる属性(__name):名前修飾が行われる。(例:Personクラスの変数「__name」を「_Person__name」に変換する。)サブクラスでの名前衝突を防ぐために利用される。
クラスの継承
クラスの継承>>> class Person: ... def greeting(self): ... print('Hello') ... def say_something(self): ... print('I am human') ... >>> class Man(Person): ... # メソッドのオーバーライド ... def say_something(self): ... print('I am a man') ... >>> man = Man() >>> man.say_something() I am a man # 基底クラス(Personクラス)のメソッドも利用可能 >>> man.greeting() Hello6. モジュール/パッケージ/名前空間/スコープ
モジュール
- コードを記述した .py ファイル
- クラスや関数の定義が記載されたファイルをモジュールと呼ぶ
モジュールの作成(モジュール名:sample.py)import sys def say_something_upper(s): # 大文字に変換 upper_s = s.upper() return upper_s str = sys.argv[1] print(say_something_upper(str))モジュール(sample.py)の呼び出し$ python sample.py hello HELLO $直接実行した時のみに動くコードの記述
直接実行した時のみに動くコードの記述import sys def say_something_upper(s): # 大文字に変換 upper_s = s.upper() return upper_s def main(): str = sys.argv[1] print(say_something_upper(str)) if __name__ == '__main__': main()
- 「if __name__ == '__main__'」 の記述がない場合、他のモジュールからimportされた場合等でも実行されてしまう。
- そのため、スクリプトとして直接実行された場合にのみ処理が呼ばれるように、上記の通り条件文を記載する。
- グローバル変数「__name__」に格納される値は以下の通り
- 対話モードで実行した場合の変数「__name__」 -> 「__main__」
- スクリプトとして実行した場合の変数「__name__」 -> 「__main__」
- モジュールとしてimportされた場合の変数「__name__」 -> 「モジュール名」
- よって、スクリプトとして実行された場合は、条件文が「真」となりモジュールが実行され、モジュールとしてimportされた場合は、条件文は「偽」となり、モジュールは実行されない。
パッケージの作成
- パッケージを作成するためには、ディレクトリを作成し、そのディレクトリをパッケージとして扱うために、「__init__.py」ファイルを配置する。(空ファイルでもOK)
- 「__init__.py」にはパッケージの初期化コードを記述したり、「all.py」変数をセットしたりすることも可能。
__init__.py# 空ファイルでOKパッケージ内のモジュールのインポート
python_programming/sample.pyfrom python_package import hello def say_hello(): print(hello.return_hello()) def main(): say_hello() if __name__ == '__main__': main()python_programming/python_package/hello.pydef return_hello(): return 'Hello!!!'実行結果$ python sample.py Hello!!! $
- importの記述方法
importの記述方法# パッケージをimport import パッケージ名 import sample_package # パッケージから特定のモジュールをimport(from指定なし) import パッケージ名.モジュール名 import sample_package.greeting # パッケージから特定のモジュールをimport(from指定あり) from パッケージ名 import モジュール名 from sample_package import greeting # パッケージやモジュールから特定の属性だけをimport from パッケージ名/モジュール名 import 関数名 from sample_package.greeting import say_something # importしたパッケージ/モジュール/関数に別名を付与 from パッケージ名 import モジュール名 as 別名 from sample_package.greeting import say_something as sワイルドカードを利用した複数属性の一括importと「__all__」
一括import# ワイルドカード(*)を利用した一括import from パッケージ名 import * from sample_package import *
- 上記のようにワイルドカードを利用したimportは、可読性が低下したり、意図しない名前の上書きによって不具合が発生する可能性があるため、基本的には利用しない。
- パッケージの「__init__.py」のコードが、「__all__」というリストを定義していれば、それは「from パッケージ import *」の際にimportすべきモジュールのリストとなる。
- 例として、下記を定義した場合、「from sample_package import *」を実行されても、"morning", "evening", "night"のモジュールのみがimportされる。
__init__.py__all__ = ["morning", "evening", "night"]
前提:sample_packageの中に、"morning", "evening", "night"を含む多数のモジュールが存在7. 組み込み関数/特殊メソッド
組み込み関数
組み込み関数とは、Pythonに組み込まれている関数で、何もimportすることなく利用することが可能。
- isinstance() : 第一引数に渡したインスタンスオブジェクトが、第二引数に渡したクラスに属していれば、Trueを返す。
isinstance()>>> d = {} # 第一引数はインスタンスオブジェクト >>> isinstance(d, dict) True # 第二引数をタプルにすると複数のクラスで同時に比較 >>> isinstance(d, (list, int, dict)) True
- issubclass() : isinstance()とほぼ同じだが、第一引数にクラスオブジェクトを取る。
issubclass()# 第一引数はクラスオブジェクト >>> issubclass(dict, object) True # bool型はint型のサブクラス >>> issubclass(bool, (list, int, dict)) True
- callable() : 呼び出し可能オブジェクトを判定(関数やクラス、メソッド等、()を付けて呼び出せるオブジェクト)
callable()>>> callable(isinstance) # 関数 True >>> callable(Exception) # クラス True >>> callable(''.split) # メソッド True
- getattr() / setattr() / delattr() : オブジェクトの属性を操作
getattr()/setattr()/delattr()# サンプルクラス定義 >>> class Mutable: ... def __init__(self, attr_map): ... for k, v in attr_map.items(): ... setattr(self, str(k), v) ... # mに属性を設定 >>> m = Mutable({'a': 1, 'b': 2}) >>> m.a 1 >>> attr = 'b' # 値の取得 >>> getattr(m, attr) 2 # 値の削除 >>> delattr(m, 'a') >>> m.a Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'Mutable' object has no attribute 'a' # getattr()はメソッドも取得可能 >>> str = 'python' >>> instance_method = getattr(str, 'upper') >>> instance_method() 'PYTHON'
- zip() : 複数のイテラブルの要素を同時に返す
zip()# それぞれのイテラブルのi番目の要素どうしをまとめる >>> a = [1, 2, 3] >>> b = [4, 5, 6] >>> zip(a, b) <zip object at 0x10827a7d0> >>> list(zip(a, b)) [(1, 4), (2, 5), (3, 6)] # zip()は一番短いイテラブルの長さまでしか結果を返さない >>> d = [1, 2, 3] >>> e = [4, 5, 6, 7, 8] >>> f = [9, 10] >>> zip(d, e, f) <zip object at 0x10827a7d0> >>> list(zip(d, e, f)) [(1, 4, 9), (2, 5, 10)] # 一番長いイテラブルに合わせる場合は、標準ライブラリのitertools.zip_longest()関数を利用 >>> from itertools import zip_longest >>> list(zip_longest(d, e, f, fillvalue=0)) [(1, 4, 9), (2, 5, 10), (3, 6, 0), (0, 7, 0), (0, 8, 0)]
- sorted() : イテラブルの要素を並べ替える
sorted()>>> a = [3, 2, 5, 1, 4] >>> b = [2, 1, 4, 5, 3] # list.sort()は自分自身を並べ替える >>> a.sort() >>> a [1, 2, 3, 4, 5] # sorted()は新しいリストを返す >>> sorted(b) [1, 2, 3, 4, 5] >>> b [2, 1, 4, 5, 3] # reverse=Trueを指定すると逆順になる >>> sorted(b, reverse=True) [5, 4, 3, 2, 1]
sorted()では要素同士を直接比較するため、数値と文字列が混在しているとエラーになるその他の組み込み関数は以下ご参照
Python組み込み関数一覧
https://docs.python.org/ja/3/library/functions.html特殊メソッド
特殊メソッドとは、メソッド名の前後にアンダースコアが二つ( __ )ついているメソッドで、Pythonから暗黙的に呼び出される。
特殊メソッド# クラス「Word」の中に特殊メソッド、「__init__」「__str__」「__len__」を定義 >>> class Word(object): ... def __init__(self, text): ... self.text = text ... def __str__(self): ... return 'Word!!!' ... def __len__(self): ... return len(self.text) # クラスをインスタンス化 >>> w = Word('test') # wを文字列として扱おうとすると、暗黙的に「__str__」が呼ばれる >>> print(w) Word!!! # wの長さを取得するために「len」を実行しようとすると、暗黙的に「__len__」が呼ばれる >>> print(len(w)) 4 # 本来の記述方法(wというインスタンスのtextという属性にアクセスしlenの値を取得) >>> print(len(w.text)) 4その他の特殊メソッドは以下ご参照
Python特殊メソッド名
https://docs.python.org/ja/3/reference/datamodel.html#special-method-names8. ファイル操作と入出力
open()を使ったファイルの書き込み
open()を使ったファイルの書き込み# 第一引数はファイル名、第二引数はモード # モード(引数はオプションであり、省略すれば「r」となる) # 「r」:読み込み専用 # 「w」:書き出し専用 # 「a」:追記(ファイルの末尾への追記) # 「r+」:読み書き両方 >>> f = open('test.txt', 'w') >>> f.write('Test!') >>> f.close() # 以下の通り「test.txt」が生成され、「Test!」が書き込まれている。 [localhost]$ cat test.txt Test! [localhost]$ # printでもファイルへの書き込みを実施することが可能 >>> f = open('test.txt', 'w') >>> print('Print!', file=f) >>> f.close() # 以下の通り「test.txt」が生成され、「Print!」が書き込まれている。 [localhost]$ cat test.txt Print! [localhost]$ # printを使った場合のオプション >>> f = open('test.txt', 'w') >>> print('My', 'name', 'is', 'Tom', sep='###', end='!!!', file=f) >>> f.close() # 区切り文字はsepで指定した「###」(デフォルトは半角スペース)、最後はendで指定した「!!!」が書き込まれている。 [localhost]$ cat test.txt My###name###is###Tom!!! [localhost]$read()を使ったファイルの読み込み
read()を使ったファイルの読み込み# 事前準備として「test.txt」を準備 >>> f = open('test.txt', 'w') >>> print('My', 'name', 'is', 'Tom', end='!\n', file=f) >>> print('My', 'name', 'is', 'Nancy', end='!\n', file=f) >>> print('My', 'name', 'is', 'Julia', end='!\n', file=f) >>> f.close() [localhost]$ cat test.txt My name is Tom! My name is Nancy! My name is Julia! [localhost]$ # read()を使ってファイルの内容を読み込む >>> f = open('test.txt', 'r') >>> f.read() 'My name is Tom!\nMy name is Nancy!\nMy name is Julia!\n' >>> f.close() # readline()を使って一行づつ読み込む >>> f = open('test.txt', 'r') >>> f.readline() 'My name is Tom!\n' >>> f.readline() 'My name is Nancy!\n' >>> f.readline() 'My name is Julia!\n' >>> f.close()withステートメントを使ったファイルの操作
withステートメントを使ったファイルの操作# with open()を使ってファイルを操作するとclose()処理が不要となる。 >>> with open('test.txt', 'a') as f: ... print('with open statement!', file=f) ... >>> [localhost]$ cat test.txt My name is Tom! My name is Nancy! My name is Julia! with open statement! [localhost]$
- open()によってファイル操作を行う場合、close()を実行するまでメモリを使っているため、必ず最後にclose()してメモリを開放する必要がある。
- 一方、with open()の場合、with open()節のインデントの中の処理が終わると、勝手にclose()してくれる為、close()忘れがなくなる。
参考文献/教材
- [O'REILY]『Pythonチュートリアル』【著者】Guido van Rossum
- [技術評論社]『Python実践入門』【著者】陶山 嶺
- [Udemy]『現役シリコンバレーエンジニアが教えるPython3入門+応用+アメリカのシリコンバレー流コードスタイル』【作者】酒井 潤
- 投稿日:2020-07-04T23:32:30+09:00
Python 正規表現で文字列置換
reモジュールのsub 関数を使って置換していきます。
reモジュールの使い方
参考 https://note.nkmk.me/python-re-match-search-findall-etc/プログラム
プログラムのの挙動は以下の通りです。
response1, response3, response4 の値は以下のように変換されます。
1)
target_str 及び tmp_json が 以下の場合、
target_str = "asdasdasd ${key1} asdasdasdasd %key2% asdasdasd |key1| asdasdasd"
tmp_json = {"key1" : "value1","key2" : "value2"}
置換後の値は以下のように、tmp_json のキーに対応する値で書き換えられます。
asdasdasd value1 asdasdasdasd value2 asdasdasd value1 asdasdasd2)
target_str 及び tmp_json が 以下の場合、
target_str = "asdasdasd ${k1} asdasdasdasd %k2% asdasdasd |key1| asdasdasd"
tmp_json = {"key1" : "value1","key2" : "value2"}
置換後の値は以下のように、tmp_json のキーそのもので書き換えられます。
asdasdasd k1 asdasdasdasd k2 asdasdasd value1 asdasdasd3)
target_str 及び tmp_json が 以下の場合、
target_str = "asdasdasd $key1} asdasdasdasd key2% asdasdasd key1| asdasdasd"
tmp_json = {"key1" : "value1","key2" : "value2"}
正規表現パターンにマッチしないので、元の値と変わりません。response2の値はtmp_json の値関係なく、正規表現にマッチした値で書き換えられます。マッチしない場合、上記3と同じく、元の値と変わりません。
#-*- encoding:utf-8 -*- from functools import partial import re def call_back(match: re.match,tmp_dict=None) -> str: """ call back Args: match: match object of re module tmp_dict: something dict object Returns: value """ value = match.group("param") if tmp_dict != None and value in tmp_dict: return tmp_dict[value] return value def search_and_convert(expression: str, tmp_json: dict) -> str: """ Search specified string value, and replace it to the specified one Args: expression: would be converted string tmp_json: something dict value Returns: expression """ l = [ { "reg" : re.finditer(r"(?<=\$\{)\w+(?=\})",expression), "prefix" : "${", "suffix" : "}" }, { "reg" : re.finditer(r"(?<=%)\w+(?=%)",expression), "prefix" : "%", "suffix" : "%" }, { "reg" : re.finditer(r"(?<=\|)\w+(?=\|)",expression), "prefix" : "|", "suffix" : "|" } ] for item in l: match_iterator = item["reg"] if match_iterator: for match in match_iterator: value = match.group() converted_value = value if value in tmp_json: converted_value = tmp_json[value] expression = expression.replace( item["prefix"] + value + item["suffix"], converted_value ) return expression if __name__ == "__main__": target_str = "asdasdasd ${key1} asdasdasdasd %key2% asdasdasd |key1| asdasdasd" tmp_json = {"key1" : "value1","key2" : "value2"} #re.sub with lambda print(f"target_str = {target_str}") response1 = re.sub(r"\$\{(?P<param>\w+)\}",lambda x: tmp_json[x.group("param")] if x.group("param") in tmp_json else x.group("param"),target_str) response1 = re.sub(r"%(?P<param>\w+)%",lambda x: tmp_json[x.group("param")] if x.group("param") in tmp_json else x.group("param"),response1) response1 = re.sub(r"\|(?P<param>\w+)\|",lambda x: tmp_json[x.group("param")] if x.group("param") in tmp_json else x.group("param"),response1) print(f"response1 = {response1}") #re.sub with call back. print(f"\033[33mtarget_str = {target_str}") response2 = re.sub(r"\$\{(?P<param>\w+)\}",call_back,target_str) response2 = re.sub(r"%(?P<param>\w+)%",call_back,response2) response2 = re.sub(r"\|(?P<param>\w+)\|",call_back,response2) print(f"response2 = {response2}\033[0m") #re.sub with call back which has a fixed augument. print(f"target_str = {target_str}") response3 = re.sub(r"\$\{(?P<param>\w+)\}",partial(call_back,tmp_dict=tmp_json),target_str) response3 = re.sub(r"%(?P<param>\w+)%",partial(call_back,tmp_dict=tmp_json),response3) response3 = re.sub(r"\|(?P<param>\w+)\|",partial(call_back,tmp_dict=tmp_json),response3) print(f"response3 = {response3}") #re.search & replace print(f"\033[33mtarget_str = {target_str}") response4 = search_and_convert(target_str,tmp_json) print(f"response4 = {response4}\033[0m") if response1 == response3 == response4: print("OK") else: raise Exception("Failed")
- 投稿日:2020-07-04T23:00:30+09:00
tkinterで干支を自動算出してくれるプログラムを作ってみた
干支自動算出機を作ってみた
- 最近、なんとなく思ったことや考えたことを調べることが多くて(暇だから)。。。
- ふいに干支について調べてみました。→ 干支別性格診断発見
- 案外当たってました。(特徴をうまくつかんでいたように感じた)
- 干支が分かれば人間関係も良好に築けるのではないかと思い、さらに調べると簡単に求める方法が出てきたのでプログラミングしてみました。[1]
コーディング内容
今回は
tkinterを利用してプログラムを作成しました[2]# coding:utf-8 import tkinter as tk
ウインドウ
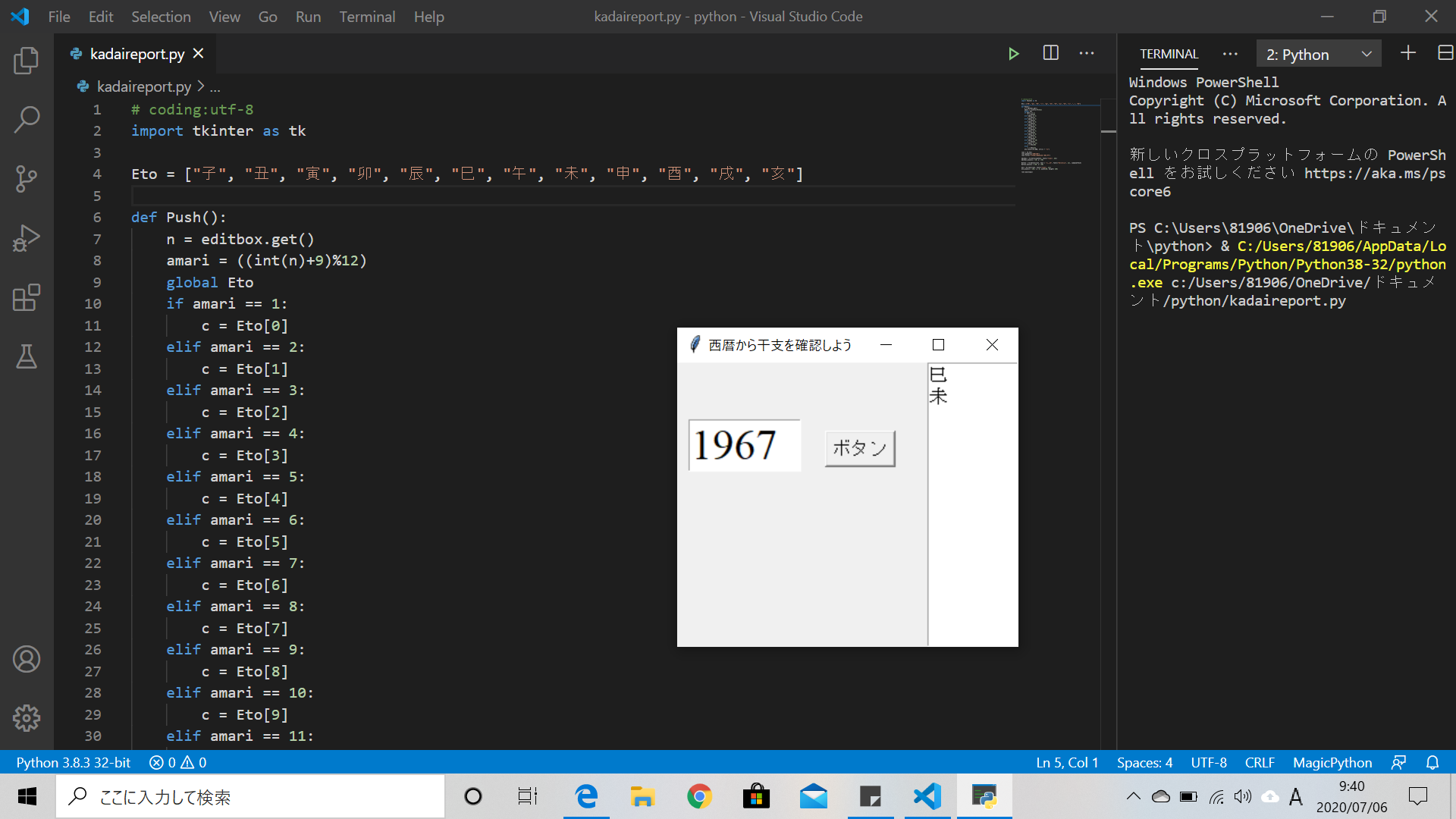
自動算出してくれるプログラムを作るにあたって、基礎となるウインドウを作成しました
サイズを横300の縦250に、タイトルを西暦から干支を確認しようという名前に設定しましたroot = tk.Tk() root.geometry("300x250") root.title("西暦から干支を確認しよう")
入力欄・実行ボタンの配置
入力欄は
Entryを、ボタンはButtonを使って配置しましたeditbox = tk.Entry(width=5, font=("Times", 28)) editbox.place(x = 10, y = 50) Button = tk.Button(root, text = "ボタン", font=("Helvetica", 12), command=Push) Button.place(x = 130, y = 60)
干支の表示
干支を表示するテキスト欄を
Textで配置しました
今回。テキスト欄の幅(width)を80、高さを(height)を250としましたeto = tk.Text(root, font=("Times", 12)) eto.place(x = 220, y = 0, width=80, height= 250)
ボタンが押されたときの操作
まず
Etoという名のリストを作り、
ボタンが押されたときに干支をリストから算出をしてその結果をテキスト欄に表示するという操作(プログラム)をPushという関数にdefで定義したEto = ["子", "丑", "寅", "卯", "辰", "巳", "午", "未", "申", "酉", "戌", "亥"] def Push(): n = editbox.get() amari = ((int(n)+9)%12) global Eto if amari == 1: c = Eto[0] elif amari == 2: c = Eto[1] elif amari == 3: c = Eto[2] elif amari == 4: c = Eto[3] elif amari == 5: c = Eto[4] elif amari == 6: c = Eto[5] elif amari == 7: c = Eto[6] elif amari == 8: c = Eto[7] elif amari == 9: c = Eto[8] elif amari == 10: c = Eto[9] elif amari == 11: c = Eto[10] else: c = Eto[11] eto.insert(tk.END, str(c) + "\n")
実行結果
完成形
# coding:utf-8 import tkinter as tk Eto = ["子", "丑", "寅", "卯", "辰", "巳", "午", "未", "申", "酉", "戌", "亥"] def Push(): n = editbox.get() amari = ((int(n)+9)%12) global Eto if amari == 1: c = Eto[0] elif amari == 2: c = Eto[1] elif amari == 3: c = Eto[2] elif amari == 4: c = Eto[3] elif amari == 5: c = Eto[4] elif amari == 6: c = Eto[5] elif amari == 7: c = Eto[6] elif amari == 8: c = Eto[7] elif amari == 9: c = Eto[8] elif amari == 10: c = Eto[9] elif amari == 11: c = Eto[10] else: c = Eto[11] eto.insert(tk.END, str(c) + "\n") root = tk.Tk() root.geometry("300x250") root.title("西暦から干支を確認しよう") editbox = tk.Entry(width=5, font=("Times", 28)) editbox.place(x = 10, y = 50) Button = tk.Button(root, text = "ボタン", font=("Helvetica", 12), command=Push) Button.place(x = 130, y = 60) eto = tk.Text(root, font=("Times", 12)) eto.place(x = 220, y = 0, width=80, height= 250) root.mainloop()
感想
- フォントは自分がしっくりくるものを使う
Push関数の中身はもう少し簡単にできそうだからもう少し考えてみるEtoリスト内は文字なはずなのに表示するときにstr関数が必要なのはなんでだろう?
参考文献
[1]. 「知っておくと便利な計算11選」
[2].「いちばんやさしいPython入門教室」, 大沢文孝著, 株式会社ソーテック社発行
- 投稿日:2020-07-04T22:40:15+09:00
vimを閉じずにpythonを実行して結果を表示する話
やりたいこと
- pythonをvimを閉じずに実行する
- 実行結果を新しいバッファに表示する
できたもの
- pythonファイルの場合のみ
<F5>を押すと実行される- 実行結果が新しいバッファに表示される
- 複数回実行した場合は追記される
- 複数のpythonファイルが開かれていいる場合カーソルがあるファイルが実行される
場所
この内容は
vimrcに書き込みました.vimrcは:edit $MYVIMRCで開くことが出来ます.特に設定を変更していない方は
:vnew $HOME/_vimrcこちらでも開けます.
:versionで設定を確認することができます.
vimrcのヘルプ:h vimrcでは推奨: Vimの設定ファイルは全て
$HOME/.vim/ディレクトリ(MS-Windowsでは$HOME/vimfiles/)に置くこと。そうすれば設定ファイルを別のシステムにコ ピーするのが容易になる。となっています.
$HOMEは:echo $HOMEで確認できます.$HOME/vimfiles下にvimrcを作る場合はvimrcという名前ですが$HOMEの下に置く場合は_vimrcという名前になるようです.やったこと
素朴な方法
:!python %Exコマンド
:! hogeはcmdhogeを実行してくれます.これを<F5>へ割り当てます.autocmd BufRead,BufNewFile *.py inoremap <F5> <Esc>:w<CR>:! python %<CR> autocmd BufRead,BufNewFile *.py nnoremap <F5> :w<CR>:! python %<CR>これで
<F5>を押すことで開いているファイルを実行できます.問題点
実行結果が
ENTERを押すことで消えてしまう.新しいバッファを開く方法
上記の問題を解決するため新しいバッファを開くように設定しました.ただし、既に開いている場合を除かないと
<F5>を押すたびに増殖するのでこれを解決するために場合分けが必要です.長くなったのでPyexe()という関数を作りました.
このとき、先程使った:! hogeは実行するだけなので出力を文字列として得られるsystem(hoge)を使います."関数を定義 function Pyexe() "結果を出力用のバッファに入力後戻ってくる準備 "カーソルの現在位置を取得 :let pos=getpos(".") "現在のウィンドウのidを取得 :let cwinid=win_getid() "現在のウィンドウのバッファのファイル名を取得 :let fileName=expand('%') "出力用のバッファの設定 "表示するファイル名を決定 :let outFileName="~pyOut" "既に出力用のウィンドが開かれているか確認する準備 "出力用のバッファが存在している場合バッファ番号を得る.存在しない場合-1. :let bnr=bufnr(outFileName) "出力用のバッファのウィンドウidを取得(リスト形式).存在しない場合は空のリスト. :let wids=win_findbuf(bnr) "出力用のバッファが存在する場合ウィンドウidをoutWindidへ.存在しない場合作る. if bnr == -1 || len(wids)==0 "存在しない場合 "pythonのファイルを閉じた時に同時に出力用のバッファが閉じられるようにする :autocmd QuitPre <buffer> exe(':bwipeout!') g:bnr "ウィンドウを分割して出力用のバッファを作る :exe 'vertical rightbelow new' outFileName "ユーザーは書き込まないのでnofileにバッファタイプを設定します :set buftype=nofile "ノーマルモードでqを押すだけで終了するように設定します. "<buffer>オプションは今回てき作った出力用のバッファでのみ適用されるようにします. :nmap <buffer> q <C-u>:bwipeout!<CR> "ウィンドウのサイズを調整 :vertical resize 70 "出力用のバッファバッファ番号を得る :let bnr=bufnr(outFileName) else "存在する場合 "出力用のバッファのウィンドウidをリストから取り出す :let outWinid=wids[0] "出力用のバッファのウィンドウへ移動 :call win_gotoid(outWinid) endif "出力 "出力用のバッファの末行へ移動 :call setpos(bnr,"$") "cmdを呼び出してpythonを実行 :let @r=system('python '.fileName) "出力用のバッファへプットする :put r "再描写 :redraw! "開始位置へ戻る "pythonファイルのウィンドウへ移動 :call win_gotoid(cwinid) "開始位置へカーソルを移動 :call setpos(".",pos) endfunctionあとはこれをpythonの場合のみ
<F5>へ割り当てます."pythonファイルの場合のみ<F5>キーを押すことで実行できるようにする autocmd BufRead,BufNewFile *.py inoremap <F5> <Esc>:w<CR>:call Pyexe()<CR> autocmd BufRead,BufNewFile *.py nnoremap <F5> :w<CR>:call Pyexe() <CR>

- 投稿日:2020-07-04T22:20:59+09:00
製薬企業研究者がPythonのコーディング規約についてまとめてみた
はじめに
ここでは、Pythonのコーディング規約について解説します。
PEP8で定められたコーディング規約
Pythonでは、PEP8というコーディング規約が定められています。
PEP8で定められている概要について以下に示します。import文
import文では、
import os, sysなどとせず以下のように複数行に分けるようにします。
また、標準ライブラリ、サードパーティ製ライブラリ、ローカルのモジュール等は区別できるよう1行の空白行を入れるようにします。import os import sys from django.utils import timezone from my_app.models import User文中の空白文字
a = 1 b = a + 2 list_nums = [a, b] dict_nums = {'a': a, 'b': b}
=の前後には半角スペースを入れ、リストや辞書などの,の後にも半角スペースを入れます。
また、辞書の:の後にも半角スペースを入れます。インデント
if文やfor文、関数やクラス定義の際には、:の後の行は半角スペース4つ(およびその倍数)分だけインデントして書き始めます。if True: print("It's true.")空白行
トップレベルの関数やクラス定義の前には、2行空けるようにします。
クラス内のメソッドの場合は1行空けます。def my_func(): return 'my_func' class MyClass(): name = my_class def print_name(self): return self.name1行の文字数
1行の文字数は基本的に79文字以下にします。
docstringの場合は72文字以下にします。Flake8を用いたチェック
ソースコードがPEP8に従っているかチェックするツールとして、
flake8があります。
以下のコマンドで実行することができます。$ flake8 ファイル名.py実行すると、ソースコードのどの部分がどのようなコーディング規約に合っていないかを表示してくれます。
まとめ
ここでは、Pythonのコーディング規約について解説しました。
Pythonは可読性を重視する言語ですので、他の人が読んでも分かりやすいコードを書くのに不可欠です。
- 投稿日:2020-07-04T22:06:47+09:00
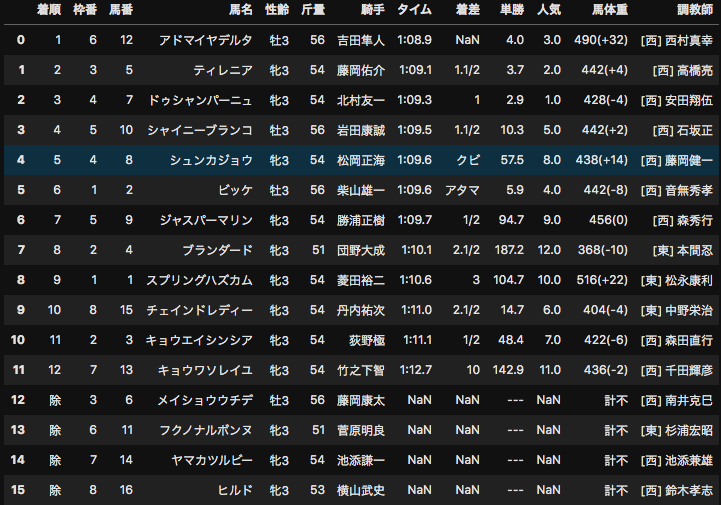
pandasのread_htmlを用いて競馬データをスクレイピングする方法
やること
netkeiba.comから2019年の全レース結果をスクレイピングする。tableタグがついているデータはpandasのread_htmlを使うと、1行でスクレイピングできるので便利。
pd.read_html("https://db.netkeiba.com/race/201902010101")[0]
ソースコード
netkeiba.comでは1レースごとにrace_idが付与されているので、race_idのリストを入れたらそれぞれのレース結果をまとめてスクレイピングして辞書型で返してくれる関数を作る。
import pandas as pd import time from tqdm.notebook import tqdm def scrape_race_results(race_id_list, pre_race_results={}): race_results = pre_race_results for race_id in tqdm(race_id_list): if race_id in race_results.keys(): continue try: url = "https://db.netkeiba.com/race/" + race_id race_results[race_id] = pd.read_html(url)[0] time.sleep(1) except IndexError: continue except: break return race_results今回は、2019年の全レース結果をスクレイピングしたいので、2019年の全race_idのリストを作る。
race_id_list = [] for place in range(1, 11, 1): for kai in range(1, 6, 1): for day in range(1, 9, 1): for r in range(1, 13, 1): race_id = ( "2019" + str(place).zfill(2) + str(kai).zfill(2) + str(day).zfill(2) + str(r).zfill(2) ) race_id_list.append(race_id)スクレイピングできたら、pandasのDataFrame型に変換してpickleファイルで保存する。
results = scrape_race_results(race_id_list) for key in results: results[key].index = [key] * len(results[key]) results = pd.concat([results[key] for key in results], sort=False) results.to_pickle('results.pickle')動画で詳しい解説をしています!
競馬予想で始めるデータ分析・機械学習

- 投稿日:2020-07-04T20:32:39+09:00
libscipsのプログラムレベルのお話①(α0.0.1)
注意 このコンテンツは旧サイトを移行したものです。なので内容がおかしいかもしれませんがご了承ください。
注意2 このコンテンツは自分のツールをより多くの人に知ってもらうためにkumitatepazuru's blogから複製したものです。使ってね!今回は、自分が作っているライブラリlibscipsについて説明しようと思う。
作成経緯
僕達zyo_senチームはこれまでagent2d(gliders2d)を使っていた。しかし、agent2dはC++で僕達の専門(?)はpythonなので解読が大変だった。そして、もとAI教室のチームということもあり、AIで戦わせたかった。でもC++の情報は少ない...さてどうしよう。
そんなときに思いついたのがこのライブラリだった。
agent2dがベースとして使っているのはlibrcscと言うサーバーとの通信等をやってくれているライブラリ。それを自分たちで作ればいいのではないかと思い作ったものだ。幸い、昔にagent2dベースではない手法を使っていたこともあり、それを参考にしながら作成していった。そしてできたのが
lib
soccer
communicate
in
python
system
でlibscips
だった。このライブラリは
全体の90%以上をサッカーの計算等のプログラムにする
と言うことを目標にしてやっていく予定だ。
player.pyを見る。
まず、player.pyを見てもらおう。
import json from socket import socket, AF_INET, SOCK_DGRAM class analysis: def __init__(self, error, analysis_log): self.error = error self.analysis_log = analysis_log def msg_analysis(self, text, log_show=None): text = text[0] if text[0] == "error": text = text[1].replace("_", " ") log = "\033[38;5;1m[ERR]" + ( "\033[38;5;13mno \033[4m" + self.no + "\033[0m ") * ( self.no != "") + "\t\033[4m" + text + "\033[0m" r = {"type": "error", "value": str(self.error.get(text) + (self.error.get(text) is None))} elif text[0] == "init": self.no = text[2] log = "\033[38;5;10m[OK]" + ( "\033[38;5;13mno \033[4m" + self.no + "\033[0m ") * ( self.no != "") + "\t\033[38;5;10minit msg.\t\033[4m" + "\033[38;5;11mleft team" * ( text[1] == "l") + \ "\033[38;5;1mright team" * (text[1] == "r") + "\033[0m\033[38;5;6m no \033[4m" + text[2] + "\033[0m" r = {"type": "init", "value": text[:-2]} elif text[0] == "server_param" or text[0] == "player_param" or text[0] == "player_type": log = "\033[38;5;12m[INFO]" + ( "\033[38;5;13mno \033[4m" + self.no + "\033[0m ") * ( self.no != "") + "\t\033[38;5;10m" + text[0] + " msg.\033[0m" r = {"type": text[0], "value": text[1:]} elif text[0] == "see" or text[0] == "sense_body": log = "\033[38;5;12m[INFO]" + ( "\033[38;5;13mno \033[4m" + self.no + "\033[0m ") * ( self.no != "") + "\t\033[38;5;10m" + text[0] + " msg. \033[38;5;9mtime \033[4m" + text[ 1] + "\033[0m" r = {"type": text[0], "time": int(text[1]), "value": text[2:]} elif text[0] == "hear": log = "\033[38;5;12m[INFO]" + ( "\033[38;5;13mno \033[4m" + self.no + "\033[0m ") * ( self.no != "") + "\t\033[38;5;10mhear msg. \033[38;5;9mtime \033[4m" + text[1] + "\033[0m " + \ "\033[38;5;6mspeaker \033[4m" + text[2] + "\033[0m " + "\033[38;5;13mcontents \033[4m" + text[3] + \ "\033[0m" r = {"type": "hear", "time": int(text[1]), "speaker": text[2], "contents": text[3]} elif text[0] == "change_player_type": log = "\033[38;5;12m[INFO]" + ( "\033[38;5;13mno \033[4m" + self.no + "\033[0m ") * ( self.no != "") + "\t\033[38;5;10mhear msg. \033[0m" r = {"type": "change_player_type", "value": text[1]} else: log = "\033[38;5;12m[INFO]" + ( "\033[38;5;13mno \033[4m" + self.no + "\033[0m ") * ( self.no != "") + "\t\033[38;5;10mUnknown return value \033[0m\033[4m" + str(text) + "\033[0m" r = {"type": "unknown", "value": text} if log_show is None: log_show = r["type"] in self.analysis_log if log_show: print(log) return r def see_analysis(self, text, hit, log_show=None): if type(hit) == str: hit = [hit] text = text[0] for i in text[2:]: if i[0] == hit: if log_show is None: log_show = hit in self.analysis_log or hit[0] in self.analysis_log if log_show: print("\033[38;5;12m[INFO]\t\033[38;5;10mThere was a " + str( hit) + " in the visual information.\033[0m") return i[1:] if log_show: print("\033[38;5;12m[INFO]\t\033[38;5;10mThere was no " + str(hit) + " in the visual information.\033[0m") return None class player_signal(analysis): def __init__(self, ADDRESS="127.0.0.1", HOST="", send_log=False, recieve_log=False, analysis_log=("unknown", "init", "error")): self.ADDRESS = ADDRESS self.s = socket(AF_INET, SOCK_DGRAM) ok = 0 i = 0 print("\033[38;5;12m[INFO]\t\033[38;5;13mSearching for available ports ...\033[0m") while ok == 0: try: self.s.bind((HOST, 1000 + i)) ok = 1 except OSError: i += 1 self.recieve_port = 1000 + i self.recieve_log = recieve_log self.send_log = send_log self.analysis_log = analysis_log self.no = "" self.player_port = 0 self.error = {"no more player or goalie or illegal client version": 0} super().__init__(self.error, self.analysis_log) def __del__(self): self.s.close() def send_msg(self, text, PORT=6000, log=None): self.s.sendto((text + "\0").encode(), (self.ADDRESS, PORT)) self.send_logging(text, PORT, log=log) def send_logging(self, text, PORT, log=None): if log is None: log = self.send_log if log: print("\033[38;5;12m[INFO]\t" + ( "\033[38;5;13mno \033[4m" + self.no + "\033[0m ") * (self.no != "") + "\033[38;5;10mSend msg.\t" + "\033[38;5;9mPORT \033[4m" + str(self.recieve_port) + "\033[0m\033[38;5;9m → \033[4m" + str(PORT) + "\033[0m\t\033[38;5;6mTEXT \033[4m" + text + "\033[0m") def send_init(self, name, goalie=False, version=15, log=None): msg = "(init " + name + " (goalie)" * goalie + " (version " + str(version) + "))" self.send_msg(msg, log=log) r = self.recieve_msg(log=log) self.player_port = r[1][1] return r def send_move(self, x, y, log=None): msg = "(move " + str(x) + " " + str(y) + ")" self.send_msg(msg, self.player_port, log=log) def send_dash(self, power, log=None): msg = "(dash " + str(power) + ")" self.send_msg(msg, self.player_port, log=log) def send_turn(self, moment, log=None): msg = "(turn " + str(moment) + ")" self.send_msg(msg, self.player_port, log=log) def send_turn_neck(self, angle, log=None): msg = "(turn_neck " + str(angle) + ")" self.send_msg(msg, self.player_port, log=log) def send_kick(self, power, direction, log=None): msg = "(kick " + str(power) + " " + str(direction) + ")" self.send_msg(msg, self.player_port, log=log) def recieve_msg(self, log=None): msg, address = self.s.recvfrom(8192) if log is None: log = self.recieve_log if log: print("\033[38;5;12m[INFO]" + ( "\033[38;5;13mno \033[4m" + self.no + "\033[0m ") * ( self.no != "") + "\t\033[0m\033[38;5;10mGet msg.\t\033[38;5;9mPORT \033[4m" + str( self.recieve_port) + "\033[0m\033[38;5;9m ← \033[4m" + str(address[1]) + "\033[0m\t\033[38;5;6mIP \033[4m" + address[0] + "\033[0m") return json.loads(msg[:-1].decode("utf-8").replace(" ", " ").replace("(", '["').replace(")", '"]'). replace(" ", '","').replace('"[', "[").replace(']"', "]").replace("][", "],["). replace('""', '"')), address156行の短いプログラムだ。これを一つづつ説明していく。
このプログラムは今の所外部ライブラリは使っていない。
また各クラス等の使い方はlibscips WIKIを参照してほしい。
analysisクラス
まず、analysisから、説明していく。
普通は後述のplayer_signalに継承して使われる。ただ見やすくするためにクラスを分けている。
なので一番最初の__init__関数
def __init__(self, error, analysis_log): self.error = error self.analysis_log = analysis_logは完全にNameError回避&Pycharm警告出さなくする用。なくても大丈夫。
次のmsg_analysisは引数textを分解して、コマンドの種類を分類し、条件分岐をして扱いやすい辞書型にして返すプログラム。
引数textの中身は
(["see", "0", [["b"], "10", "0"], ...], (127.0.0.1, 6000))こんな感じ。
def msg_analysis(self, text, log_show=None): text = text[0] if text[0] == "error": text = text[1].replace("_", " ") log = "\033[38;5;1m[ERR]" + ( "\033[38;5;13mno \033[4m" + self.no + "\033[0m ") * ( self.no != "") + "\t\033[4m" + text + "\033[0m" r = {"type": "error", "value": str(self.error.get(text) + (self.error.get(text) is None))} elif text[0] == "init": self.no = text[2] log = "\033[38;5;10m[OK]" + ( "\033[38;5;13mno \033[4m" + self.no + "\033[0m ") * ( self.no != "") + "\t\033[38;5;10minit msg.\t\033[4m" + "\033[38;5;11mleft team" * ( text[1] == "l") + \ "\033[38;5;1mright team" * (text[1] == "r") + "\033[0m\033[38;5;6m no \033[4m" + text[2] + "\033[0m" r = {"type": "init", "value": text[:-2]} # --- 条件分岐が続く --- if log_show is None: log_show = r["type"] in self.analysis_log if log_show: print(log) return rコマンドの条件分岐が永遠と続く関数だ。
変数textは解析するもとデータが入っている。なぜ、一番最初に
text = text[0]が入っているかと言うと上に書いてある引数textの例を見てわかるとおり、元データだと送信元の情報も入っていて邪魔だから消している。変数logはlog_showまたはself.analysis_logにコマンドが当てはまる場合にその中身が表示される。
変数rはreturnされる辞書型が入っている。
次はsee_analysis。see情報の中に特定のオブジェクトがあるか調べてあったら扱いやすい情報にして返すという関数だ。
def see_analysis(self, text, hit, log_show=None): if type(hit) == str: hit = [hit] text = text[0] for i in text[2:]: if i[0] == hit: if log_show is None: log_show = hit in self.analysis_log or hit[0] in self.analysis_log if log_show: print("\033[38;5;12m[INFO]\t\033[38;5;10mThere was a " + str( hit) + " in the visual information.\033[0m") return i[1:] if log_show: print("\033[38;5;12m[INFO]\t\033[38;5;10mThere was no " + str(hit) + " in the visual information.\033[0m") return None最初の
if type(hit) == str: hit = [hit]はオブジェクトデータがリスト化されているから、string形式のままで処理をするとエラーが起こってしまう。なのでstring形式の場合はリストに変換する、という部分だ。
あとは、オブジェクトデータをあさってあったらオブジェクト情報を返す。そして、log_showがTrueなら、ログを出すというすごい簡単な関数だ。
player_signalクラス
次は、player_signalクラスだ。
一番最初の__init__関数
def __init__(self, ADDRESS="127.0.0.1", HOST="", send_log=False, recieve_log=False, analysis_log=("unknown","init", "error")): self.ADDRESS = ADDRESS self.s = socket(AF_INET, SOCK_DGRAM) ok = 0 i = 0 print("\033[38;5;12m[INFO]\t\033[38;5;13mSearching for available ports ...\033[0m") while ok == 0: try: self.s.bind((HOST, 1000 + i)) ok = 1 except OSError: i += 1 self.recieve_port = 1000 + i self.recieve_log = recieve_log self.send_log = send_log self.analysis_log = analysis_log self.no = "" self.player_port = 0 self.error = {"no more player or goalie or illegal client version": 0} super().__init__(self.error, self.analysis_log)は初期設定をしてポートを確保する関数だ。引数をselfにぶち込んで
while ok == 0: try: self.s.bind((HOST, 1000 + i)) ok = 1 except OSError: i += 1ここでOSErrorがでなくなるまで回して空いているポートを探す&確保をする。
そして、
super().__init__(self.error, self.analysis_log)ここで先程のエラー回避initを実行する。
__init__関数はこんな感じ。
次に__del__関数。
def __del__(self): self.s.close()プログラムが終了したときなどにポートを開放する関数。一応自動的に開放されるが、念の為。
次はsend_msg関数。
def send_msg(self, text, PORT=6000, log=None): self.s.sendto((text + "\0").encode(), (self.ADDRESS, PORT)) self.send_logging(text, PORT, log=log)この関数はメッセージを送る関数だが、やっていることは、2行目でメッセージを送信、3行目でログを表示する場合は表示(後述のsend_loggingを呼び出し)している。たったそれだけ。
つぎは、先程にも出たsend_logging。ただprint文を使ってログを出しているだけ。
def send_logging(self, text, PORT, log=None): if log is None: log = self.send_log if log: print("\033[38;5;12m[INFO]\t" + ( "\033[38;5;13mno \033[4m" + self.no + "\033[0m ") * (self.no != "") + "\033[38;5;10mSend msg.\t" + "\033[38;5;9mPORT \033[4m" + str(self.recieve_port) + "\033[0m\033[38;5;9m → \033[4m" + str(PORT) + "\033[0m\t\033[38;5;6mTEXT \033[4m" + text + "\033[0m")logがNoneだったら__init__関数で指定したsend_logを参照してTrueだったら表示、Trueだったら問答無用で表示するというプログラム。
次は、send_init。名前の通りinitコマンドを送るだけの関数。
def send_init(self, name, goalie=False, version=15, log=None): msg = "(init " + name + " (goalie)" * goalie + " (version " + str(version) + "))" self.send_msg(msg, log=log) r = self.recieve_msg(log=log) self.player_port = r[1][1] return rざっくり言うと
2行目で送るmsgを作成
3行目で実際に送る(send_msg関数を呼び出し)
4行目でサーバーのレスポンスを確認(後述のrecieve_msg関数を呼び出し)
5行目で移動コマンド等のサーバーのポートを確認(サーバーのポート6000番は確かinitコマンドしか受け付けない)
6行目で戻り値としてレスポンスを返す。
といった感じ。
次は、send_move・send_dash・send_turn・send_turn_neck・send_kick。プレイヤーを動かす関数。
中身は(send_move)
def send_move(self, x, y, log=None): msg = "(move " + str(x) + " " + str(y) + ")" self.send_msg(msg, self.player_port, log=log)ただ、msgを作って送る(send_msgを呼び出し)しているだけ。
最後にrecieve_msg。その名の通りサーバーから送られてくる情報を受信する関数。自分の一番の力作関数でもある。
def recieve_msg(self, log=None): msg, address = self.s.recvfrom(8192) if log is None: log = self.recieve_log if log: print("\033[38;5;12m[INFO]" + ( "\033[38;5;13mno \033[4m" + self.no + "\033[0m ") * ( self.no != "") + "\t\033[0m\033[38;5;10mGet msg.\t\033[38;5;9mPORT \033[4m" + str( self.recieve_port) + "\033[0m\033[38;5;9m ← \033[4m" + str(address[1]) + "\033[0m\t\033[38;5;6mIP \033[4m" + address[0] + "\033[0m") return json.loads(msg[:-1].decode("utf-8").replace(" ", " ").replace("(", '["').replace(")", '"]'). replace(" ", '","').replace('"[', "[").replace(']"', "]").replace("][", "],["). replace('""', '"')), address説明をすると
2行目でサーバーからのメッセージ受信
3~8行目で必要ならばログを表示
9~11行目で戻り値として扱いやすい情報にメッセージを直す。
何がすごいかと言うと扱いやすい情報にするのに実質1行で済ませているから。(Pycharmの自動整形で3行になっているだけ。)
なぜ、json.loadsを使っているかと言うと、jsonは以下のように辞書型以外に、リストも扱える。
なので、json.loadsを使い、文字列のリストから、リストに変換してもらっている。
しかし、受信した情報はリスト型に変換できないのでリスト型に変換できるようにしてからリスト型にしている。
[ { "hello":"jobs" }, [ "contents" ] ]現段階である機能はこれだけ。もし、アップデートで機能追加がされたら、随時②や③で増やしていこうと思う。
最後に
そのうちcszp版も作りたいな...一生終わらなさそうだけど。
ていうか書いていて思ったけれどこの記事のフォント読みやすいしほのぼのしているしブログに最適!すごい合ってる。ちょっと嬉しい。
それでは、またいつか。
個人的な質問等はこちらまで。
https://forms.gle/V6NRhoTooFw15hJdA
また、自分が参加しているRobocup soccer シミュレーションリーグのチームでは参加者募集中です!活動の見学、活動に参加したい方、ご連絡お待ちしております!
- 投稿日:2020-07-04T19:37:59+09:00
現在のディレクトリ構成
ディレクトリ構造(暫定)
project3 ├──dancesite │ ├──dancesite │ │ ├──_pycache_ │ │ ├──__init__.py │ │ ├──asgi.py │ │ ├──settings.py │ │ ├──urls.py │ │ └──wsgi.py │ │ │ ├──matching │ │ ├──__pycache__ │ │ ├──media │ │ ├──migrations │ │ ├──static │ │ │ └──matching │ │ │ └──css │ │ │ └──style.css │ │ │ │ │ ├──templates │ │ │ ├──matching │ │ │ │ ├──mypage/ │ │ │ │ ├──board │ │ │ │ ├──index.html │ │ │ │ ├──board.html │ │ │ │ ├──Recruitment.html │ │ │ │ └──serch.html │ │ │ │ │ │ │ ├──user_app │ │ │ │ ├──login.html │ │ │ │ ├──logout.html │ │ │ │ └──sighup.html │ │ │ │ │ │ │ └──base.html │ │ │ │ │ ├──__init__.py │ │ ├──admin.py │ │ ├──apps.py │ │ ├──forms.py │ │ ├──models.py │ │ ├──tests.py │ │ ├──urls.py │ │ └──views.py │ │ │ ├──user_app │ │ ├──__pycache__/ │ │ ├──migrations/ │ │ ├──__init__.py │ │ ├──admin.py │ │ ├──apps.py │ │ ├──forms.py │ │ ├──models.py │ │ ├──tests.py │ │ ├──urls.py │ │ └──views.py │ │ │ ├──db.sqlite3 │ │ │ └── manage.py │ └──venv/現状
現状ではuse_appでサインアップ、リダイレクトは問題なくできてはいるが、djangoの認証機能上アプリ名はaccounts、templateのパスはtemplates/registration/login.htmlとあらかじめきめられてるらしい…??
(参照:https://docs.djangoproject.com/ja/3.0/topics/auth/default/#all-authentication-views)ただ、accontsアプリとuser_appアプリの中身を見ても違いは下記の点ぐらいなので、アプリ名は何でもいいのかも…
accounts/apps.pyclass AccountsConfig(AppConfig): name = 'accounts'user_app/apps.pyclass UserAppConfig(AppConfig): name = 'user_app'今後の課題
・ユーザー認証機能の完全な実装
・ログインしたユーザーがマイページで詳細な情報の登録をできるようにする。
- 投稿日:2020-07-04T18:17:40+09:00
クラウド上のPython2系のスクリプトを3系に移行しアップデートする作業メモ
これは何
いまだに動いているPython2系のスクリプトを3系にアップデートするときの作業(事前準備含む)の備忘メモ前提
- pyenvを使用してPythonのバージョン管理を行っている
- Dockerやvirtualenv, Pipenvは未使用
概要
- 移行するPythonを決める
- ローカルで検証する
- 本番(stg)でバージョンを上げる
手順
- 以下で簡単に移行手順を示します
事前調査
現在の動作環境を確認
- 使用しているOSによってアップデートする先のPythonのバージョンが限られているので、事前に調査する
- サーバ上で
pyenv install --listして、移行できるPythonのバージョンを確認する- 以下はLinuxのOSが
Linux: Amazon Linux AMI release 2016.03だった場合の例[ec2-user@app]$ pyenv install --list Available versions: # 中略 3.6.0 3.6-dev 3.6.1 3.6.2 3.6.3 3.6.4 3.7.0b2 3.7-dev 3.8-dev # 後略移行先のPythonバージョンを決定
- 先ほどの
pyenv install --listでアップデートできるバージョンの中から、Pythonのバージョンを選定する
- パッチバージョンの数字の後に
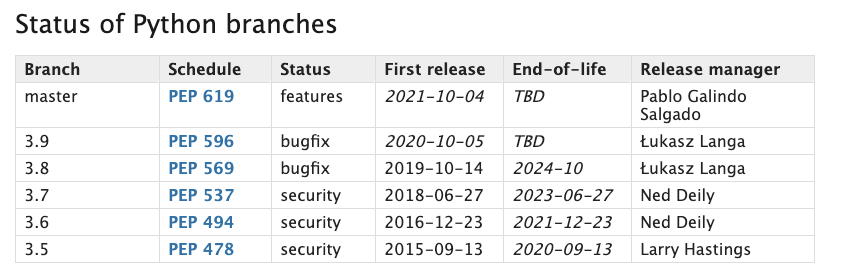
devやb*が入っているものは、stableでないバージョンなので避ける- Python Developer’s Guideに各バージョンのメンテナンス期限などが書かれているので、EOLができる限り長いものを選ぶ
- 先ほどの
Linux: Amazon Linux AMI release 2016.03の例では、 上記の理由より3.6.4にするのが妥当
- Python Developer’s Guide: https://devguide.python.org/#status-of-python-branches
ローカルでの動作検証
Python3系で使用できないロジックの洗い出し
- futurizeでPythonのコードのアップデートを試みます
- applyされなかったファイルやメソッドをについて検証していきます
- Pythonの公式でも推奨されているやり方っぽいです
- Python 2 から Python 3 への移植: https://docs.python.org/ja/3/howto/pyporting.html#porting-python-2-code-to-python-3
- futurize Py2 to Py2/3: http://python-future.org/automatic_conversion.html#stage-1-safe-fixes
Python3系の記法に自動変換を行ってみる
- 2to3というライブラリで、Python2でのみ通用する記法を(ある程度)自動的に3系の記法に変換してくれます
- 3系への影響範囲が大きい場合は、こちらで一気に変換してみても良いかもしれません(過信は禁物、動作検証はすべき)
- これも、Python3の公式ドキュメントで記載されている方法論になります
- 2to3 Python 2 から 3 への自動コード変換: https://docs.python.org/ja/3/library/2to3.html#module-lib2to3
Pythonバージョンの切り替え&スクリプト実行
- 上記のライブラリでのコードやロジックの移行にある程度目処がついたら、実際にローカルで動かしていきます
- 主な順序は「
pyenvでバージョン切り替え」「ライブラリのインストール」「スクリプトの実行」となります- DBとの接続が必要な部分など、ローカルだけでは完結しないロジックがある場合はスキップするなど、実行可能な部分だけでも実行する
コケた場合のバックアップ方法をメモする
- ローカルで問題なく動作した場合、stgや本番環境のアップデートを行うことになります
- その前に、「仮にPython3のコードでの動作に問題があった場合」の切り戻しオペレーションをドキュメントか何かに記載しておきましょう
- 具体的に想定される切り戻し作業
pyenvで旧バージョンのPythonに切り替え- アップデートしたコードのcommitをrevertする
- 旧バージョンでライブラリをインストールし直す
移行実施
- 以降でいよいよ本番のスクリプトのPythonバージョンを変更していきます
- stg環境があればstg環境で先に実施する
Pythonバージョンの切り替え
pyenvでPythonのバージョンを切り替えていきます# 3.6.4をインストール $ pyenv install 3.6.4 $ pyenv versions system * 2.7 (set by /home/ec2-user/.pyenv/version) 3.6.4 # 追加されているはず $ pyenv local 3.6.4 $ pyenv rehash $ pyenv versions system 2.7 (set by /home/ec2-user/.pyenv/version) * 3.6.4 # 変更されているはず $ python --version Python 3.6.4 # 変更されているはずライブラリの再インストール
- Python3環境にライブラリをインストールします
- 以下は
requirements.txtを用いてインストールする例です$ pip install -r requirements.txt Collecting urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 (from requests->-r requirements.txt (line 5)) Cache entry deserialization failed, entry ignored Downloading https://files.pythonhosted.org/packages/e1/e5/df302e8017440f111c11cc41a6b432838672f5a70aa29227bf58149dc72f/urllib3-1.25.9-py2.py3-none-any.whl (126kB) 100% |████████████████████████████████| 133kB 9.1MB/s Collecting certifi>=2017.4.17 (from requests->-r requirements.txt (line 5)) Cache entry deserialization failed, entry ignored Cache entry deserialization failed, entry ignored Downloading https://files.pythonhosted.org/packages/57/2b/26e37a4b034800c960a00c4e1b3d9ca5d7014e983e6e729e33ea2f36426c/certifi-2020.4.5.1-py2.py3-none-any.whl (157kB) 100% |████████████████████████████████| 163kB 7.3MB/s # 以下略スクリプトの動作確認
- 手動で動かせるスクリプトの場合は、実際にスクリプトを動かしてみます
- エラーを吐かずに想定通り動作する場合は、移行成功です
- 一応動作ログを取得してファイルに吐き出すなり、ドキュメントに貼り付けておくなりしておくとベストです
[ec2-user@app]$ python main.py参考ドキュメント



- 投稿日:2020-07-04T17:35:16+09:00
Serverless Framework & Python 環境変数の使い方
この記事は、私の個人ブログ Practical Cloud Python - SERVERLESS FRAMEWORK & PYTHON 環境変数の使い方 を Qiita に移植したものです。Practical Cloud Python の方もよろしくお願いします。
Abstract
ステージ管理とコーディングで楽できる環境変数の管理方法を説明します。
ソース
例題となるソースを公開していますので、実装例はこちらを見てください。
https://github.com/hassaku63/sls-env-example
Lambda (scheduled) -> SQS -> Lambda (Queue consumer) の構成になっています。
前提
以下のパッケージ、プラグインを利用しています。
Serverless Framework
Python
環境変数は .env.と serverless.yml で宣言
例示のソースは Slack へのポストを想定したコードです。Tokenやチャンネル名が秘匿情報にあたりますので、 .env に記述しています。
Serverless Framework では、Serverless Dotenv Plugin を使うことで .env ファイルの定義をデプロイパッケージングの時に provider.environment に組み込んでくれます。
Dotenv plugin では、指定したステージの名前をサフィックスとする .env ファイルを自動でロードします。例えば、dev ステージであれば .env.dev を環境変数の定義として読み込みます( Automatic Env file name resolution のセクションを参照)。ステージごとにAPI Tokenなどを変更する設定はこの機能を利用します。
SQS や DynamoDB のリソース名の管理にも環境変数で宣言します。これは、コードの中から boto3 のクライアントを使う場合にキューやテーブルのリソース名が必要になるからです。
https://gist.github.com/hassaku63/0e4e61db60bd48b5d86459ceabb9dd34
provider: name: aws runtime: python3.8 profile: ${opt:profile, default} stage: ${opt:stage, dev} region: ${opt:region, us-east-1} timeout: 30 environment: # To tell lambda function to AWS AccountId by use pseudo-parameters plugin. # AccountId is used to construct SQS Queue URL AWS_ACCOUNT_ID: '#{AWS::AccountId}' # MY_QUEUE_NAME is used to construct Queue URL in lambda. # And also convenient to reference resource ARN in IAM Policy statement MY_QUEUE_NAME: ${self:service}-my-queue-${self:provider.stage}
${self:service}-my-queue-${self:provider.stage}としている部分が今回のソースで利用しているキューの名前です。service や ステージ名を含めるのは、複数のデプロイステージを利用する場合にリソース名のユニーク性を確保するためです。Python から SQS への Enqueue を行う場合は、ターゲットリソースの識別子として QueueUrl を指定する必要があります。QueueUrl を組み立てるためには AWS アカウント ID, AWS リージョン, QueueName の3つが必要です。Lambda の中でそれらを参照できるようにしたいので、環境変数で宣言しているというわけです(なお、リージョンだけは Lambda が実行時にデフォルトで環境変数として自動でセットしてくれるため自前で定義する必要がありません)。
環境変数を .env に書くべきか serverless.yml に書くべきか、という話もありますが、これは秘匿したい情報かどうか、という軸で判断すれば良いと思います。環境変数の数が多くなりすぎて冗長になってしまう、という場合は本当に環境変数じゃないと困るものだけをピックアップして、それだけを環境変数として宣言すると良いでしょう。(リソース名の一部分を構成する部分文字列など)本質的に重要でない部分などがあれば、それらは custom セクションで定義しておくのなどすると良いのではないかと思います。
Python での環境変数の定義は settings.py に寄せる
Python から環境変数を扱う場合は os.environ を利用すると思います。しかし、この書き方では IDE の自動補完が効かないため、コーディング時に変数名の Typo に気づく方法がありません。デプロイして初めて環境変数のミスタイピングに気づく…というのはあまり開発体験がよろしくありません。また、Lambda handler の数が増えてきたとき、その都度 os.environ を使うのはなんだか DRY に違反しているような感じもしますね。
これを防ぐために、環境変数のロード、および Python 定数として定義してしまうための settings.py を作ります。すべての Python コードは、環境変数をこのモジュールから読み込むようにします。こうすることで、DRY を守りつつ、IDE の自動補完を活用できるようになり、ミスタイピングの可能性をへらすことができます。
https://gist.github.com/hassaku63/0e971fb0823aea561f33db880d0269e4
""" Declare all environment variables defined in .env.<stage-name> and serverless.yml as python variables. If you would like to use environment variables in your code, you import this module then reference as constants of python variable. By use this technique, you are able to use IDE auto-completion effectively when you writing python code. It is useful to reduce miss-typing of environment variables. """ import os import pathlib import json import dotenv project_root_dir = pathlib.Path(__file__).parent / '../' dotenv.load_dotenv() MYAPP_STAGE_NAME = os.environ.get('MYAPP_STAGE_NAME') stage_env_path = project_root_dir / f'.env.{MYAPP_STAGE_NAME}' dotenv.load_dotenv(stage_env_path.resolve()) # Slack SLACK_BOT_TOKEN = os.environ.get('SLACK_BOT_TOKEN') SLACK_CHANNEL = os.environ.get('SLACK_CHANNEL') # AWS AWS_ACCOUNT_ID = os.environ.get('AWS_ACCOUNT_ID') # Notice: You don't need to define AWS_REGION in .env and serverless.yml # because of lambda runtime automatically set AWS_REGION env var when execute. AWS_REGION = os.environ.get('AWS_REGION') # SQS MY_QUEUE_NAME = os.environ.get('MY_QUEUE_NAME', '')このとき、ステージに応じた .env を読み込むために python-dotenv を利用しています。プロジェクトルートに .env が存在することを期待しています。Pathlib で settings の相対ディレクトリを探し、MYAPP_STAGE_NAME 環境変数を使ってステージ名を決定し、その名前を .env のサフィックスとして使用します。
※serverless-dotenv-plugin は NODE_ENV の定義をステージ名として使用することもできるので、独自のステージ管理用変数 (MYAPP_STAGE_NAME) ではなくこちらを使っても良いかもしれません。
まとめ
Serverless Framework にも Python にも、.env を扱うための追加パッケージが使えます。これらを利用して環境変数をうまく使っていきましょう。
DynamoDB や SQS のリソース識別子など、コード中でリソース名への参照がいる場合があります。このような場合にも環境変数が使えます。環境変数として定義しておくことで、テンプレート中のリソース名参照においても変数を再利用することができます。
os.environ を使って環境変数をPython の定数にまとめるためのモジュールを作りましょう。IDE の自動補完も使えるし、記述が一箇所に集約されるのでミスタイピングが起こりづらくなり、楽です。
- 投稿日:2020-07-04T17:21:42+09:00
イカサマコインである確率をベイズの定理で計算する【python】
問題
コインが二枚ある
一枚は1/2の確率で表が出るコイン
もう一枚はイカサマで70%が表になるコイン
イカサマのコインかどうかを当てられたら勝ち今追加で50回試行したとき35回表だった
さて、この時イカサマコインといえるか?
古典統計の場合
イカサマコインではない場合、50回中25回表になるはず。
比率の差の検定を行うと、
カイ二乗値は4.16
p値は0.04
危険率5%で検定すると、「イカサマでないコインを投げたとして35回表が出る」ことは起きても4%くらいだからイカサマでないコインと言い切ることはできない
という解釈になる「言い切れない」とか曖昧な結果でなく、
イカサマコインであるかどうかというような1,0の確率が欲しいベイズ統計では
P(X|Y) = \frac{P(Y|X)P(X)}{P(Y)}この場合
二項分布\begin{align} {}_n C_{x} p^x (1-p)^{n-x} \end{align}を尤度P(Y|X)
として扱う事前確率P(X)はイカサマコインである確率、もしくは公正なコインである確率を置く
今回はイカサマコインも公正なコインもどちらも等しく選ばれるものとして
P(X)=0.5
として考えておく。起こりうる事象は、
イカサマコインが選ばれて35回表がでる
公正コインが選ばれて35回表がでるこれを計算式で表すと
公正
\begin{align} {}_{50} C_{35} (0.5)^{35} (1-0.5)^{50-35}=0.0019 \end{align}イカサマ
\begin{align} {}_{50} C_{35} (0.7)^{35} (1-0.7)^{50-35}=0.1223 \end{align}となる。
それぞれの値に事前確率としてイカサマコインが選ばれる確率をかける
これだけでは確率として考えられないので、両者の値を足して周辺分布とする公正
\frac{0.1223×0.5}{0.1223×0.5+0.0019×0.5}=0.016イカサマ
\frac{0.0019×0.5}{0.1223×0.5+0.0019×0.5}=0.984import math import numpy as np import random def combinations_count(n, r): return math.factorial(n) // (math.factorial(n - r) * math.factorial(r)) loaded_prior=0.5 loaded_heads=0.7 loaded_tails=0.3 fair_prior=1-loaded_prior fair_heads=0.5 fair_tails=0.5 n=50 x=35 n_x=n-x def coin(n,x,n_x,lp,lh,lt,fp,fh,ft): loaded_likelihood=combinations_count(n, x)*(loaded_heads**x)*(loaded_tails**n_x) fair_likelihood=combinations_count(n, x)*(fair_heads**x)*(fair_tails**n_x) marginal = loaded_likelihood*loaded_prior + fair_likelihood*fair_prior load_prob=(loaded_likelihood*loaded_prior)/marginal fair_prob=(fair_likelihood*fair_prior)/marginal return load_prob, fair_prob load_prob,fair_prob= coin(n=n,x=x,n_x=n_x,lp=loaded_prior,lh=loaded_heads,lt=loaded_tails,fp=fair_prior,fh=fair_heads,ft=fair_tails) print("loaded coin "+str(round(load_prob,3))+"%, fair coin "+str(round(fair_prob,3))+"%")loaded coin 0.984%, fair coin 0.016%こうして計算すると、イカサマコインである確率は事前には0.5だったが0.98まで上昇した。
ちなみに33回表が出たら90%を超えるtry_time = 50 for o in range(try_time): n_x=try_time-o lo_p,fa_p=coin(n=try_time,x=o,n_x=n_x, lp=loaded_prior,lh=loaded_heads,lt=loaded_tails, fp=fair_prior,fh=fair_heads,ft=fair_tails) print("head "+str(o)+" loaded coin "+str(round(lo_p,3))+"%, fair coin "+str(round(fa_p,3))+"%")head 0 loaded coin 0.0%, fair coin 1.0% head 1 loaded coin 0.0%, fair coin 1.0% head 2 loaded coin 0.0%, fair coin 1.0% head 3 loaded coin 0.0%, fair coin 1.0% head 4 loaded coin 0.0%, fair coin 1.0% head 5 loaded coin 0.0%, fair coin 1.0% head 6 loaded coin 0.0%, fair coin 1.0% head 7 loaded coin 0.0%, fair coin 1.0% head 8 loaded coin 0.0%, fair coin 1.0% head 9 loaded coin 0.0%, fair coin 1.0% head 10 loaded coin 0.0%, fair coin 1.0% head 11 loaded coin 0.0%, fair coin 1.0% head 12 loaded coin 0.0%, fair coin 1.0% head 13 loaded coin 0.0%, fair coin 1.0% head 14 loaded coin 0.0%, fair coin 1.0% head 15 loaded coin 0.0%, fair coin 1.0% head 16 loaded coin 0.0%, fair coin 1.0% head 17 loaded coin 0.0%, fair coin 1.0% head 18 loaded coin 0.0%, fair coin 1.0% head 19 loaded coin 0.0%, fair coin 1.0% head 20 loaded coin 0.0%, fair coin 1.0% head 21 loaded coin 0.0%, fair coin 1.0% head 22 loaded coin 0.001%, fair coin 0.999% head 23 loaded coin 0.002%, fair coin 0.998% head 24 loaded coin 0.005%, fair coin 0.995% head 25 loaded coin 0.013%, fair coin 0.987% head 26 loaded coin 0.029%, fair coin 0.971% head 27 loaded coin 0.065%, fair coin 0.935% head 28 loaded coin 0.14%, fair coin 0.86% head 29 loaded coin 0.275%, fair coin 0.725% head 30 loaded coin 0.469%, fair coin 0.531% head 31 loaded coin 0.674%, fair coin 0.326% head 32 loaded coin 0.828%, fair coin 0.172% head 33 loaded coin 0.918%, fair coin 0.082% head 34 loaded coin 0.963%, fair coin 0.037% head 35 loaded coin 0.984%, fair coin 0.016% head 36 loaded coin 0.993%, fair coin 0.007% head 37 loaded coin 0.997%, fair coin 0.003% head 38 loaded coin 0.999%, fair coin 0.001% head 39 loaded coin 0.999%, fair coin 0.001% head 40 loaded coin 1.0%, fair coin 0.0% head 41 loaded coin 1.0%, fair coin 0.0% head 42 loaded coin 1.0%, fair coin 0.0% head 43 loaded coin 1.0%, fair coin 0.0% head 44 loaded coin 1.0%, fair coin 0.0% head 45 loaded coin 1.0%, fair coin 0.0% head 46 loaded coin 1.0%, fair coin 0.0% head 47 loaded coin 1.0%, fair coin 0.0% head 48 loaded coin 1.0%, fair coin 0.0% head 49 loaded coin 1.0%, fair coin 0.0%以上
- 投稿日:2020-07-04T16:53:27+09:00
flaskで投稿掲示板作成
今回はflaskを使用し投稿掲示板を作成してみました。
ディレクトリ構成は以下のようになっています。app.py form_arrange.py templates |__main_page.html static |__css |__style.css data |__save_data.jsonコードについてはgithubにアップしています。
javascriptについては慣れていませんので記事を参考にし作成しています。実装画面
実装コード
app.pyfrom flask import Flask,render_template,request , Markup import json import time from form_arrange import form app = Flask(__name__) @app.route('/', methods=["GET" , "POST"]) def main_page(): method = request.method save_json_path = "data/save_data.json" if method == "POST": former = form(form_input=dict(request.form) , save_json_path=save_json_path) if "clear" in dict(request.form).keys(): former.save_json_clear() return render_template("main_page.html" , save_list=former.save_list, method=method) form_input = former.form_input former.write_save_json() return render_template("main_page.html" , save_list=former.save_list,form_input=form_input , method=method) else: former = form(save_json_path) save_list = former.save_list return render_template("main_page.html" , save_list=save_list, method=method) if __name__ == "__main__": app.run(debug=True)form_arrange.pyimport json import os,sys class form: def __init__(self , save_json_path , form_input=None): self.save_list = self.read_save_json(save_json_path) self.save_json_path = save_json_path if form_input != None: self.form_input = form_input def read_save_json(self , save_json_path): save_list = [] if os.path.exists(save_json_path): with open(save_json_path , "r") as f: save_list = json.load(f) return save_list else: with open(self.save_json_path , "w") as f: save_list = json.dump(save_list, f, indent=4) return save_list def write_save_json(self): self.save_list.append(self.form_input) with open(self.save_json_path , "w") as f: save_list = json.dump(self.save_list, f, indent=4) def save_json_clear(self): self.save_list = [] with open(self.save_json_path , "w") as f: json.dump(self.save_list, f, indent=4)/templates/main_page.html<!DOCTYPE HTML> <html lang="ja"> <head> <meta charset="utf-8"> <title>書き込み掲示板</title> <link href="/static/css/style.css" rel="stylesheet" type="text/css"> <script type="text/javascript" src="/static/js/main.js"></script> </head> <body> <div id="so_far_post_id" class="so_far_post_class"> <p>過去の投稿を表示</p> </div> <body onload="start()"> <script> var save_list = {{ save_list|tojson }}; function start() { // 追加 for(let i = 0; i < save_list.length; i++) { console.log(save_list[i]) var hoge = JSON.stringify(save_list[i]); var pHoge = JSON.parse(hoge); var newElement = document.createElement("p"); // p要素作成 var newContent = document.createTextNode("---------------------------"); // テキストノードを作成 newElement.appendChild(newContent); // p要素にテキストノードを追加 newElement.setAttribute("id",i); // p要素にidを設定 var parentDiv = document.getElementById("so_far_post_id"); // 子要素3への参照を取得 var childP3 = document.getElementById(i); parentDiv.insertBefore(newElement, childP3); var newElement = document.createElement("p"); // p要素作成 var newContent = document.createTextNode("投稿 " + pHoge.write_text); // テキストノードを作成 newElement.appendChild(newContent); // p要素にテキストノードを追加 newElement.setAttribute("id",i); // p要素にidを設定 var parentDiv = document.getElementById("so_far_post_id"); // 子要素3への参照を取得 var childP1 = document.getElementById(i); parentDiv.insertBefore(newElement, childP1); var newElement = document.createElement("p"); // p要素作成 var newContent = document.createTextNode("名前 " + pHoge.name); // テキストノードを作成 newElement.appendChild(newContent); // p要素にテキストノードを追加 newElement.setAttribute("id",i); // p要素にidを設定 var parentDiv = document.getElementById("so_far_post_id"); // 子要素3への参照を取得 var childP2 = document.getElementById(i); parentDiv.insertBefore(newElement, childP2); } } </script> </body> <p>method name {{method}}</p> <form method="get" action="/"> <input type="submit" value="GET"> </form> <br> <form method="post" action="/"> <input type="submit" name="clear" value="登録内容clear"> </form> <form method="post" action="/"> <p>お名前</p> <input type="text" name="name"> <p>内容</p> <textarea name="write_text" cols="50" rows="10"></textarea> <br><br> <input type="submit" value="投稿する"> </form> </body> </html>/static/css/style.css.so_far_post_class { float: right; list-style: none; margin: 30px; }

- 投稿日:2020-07-04T16:53:02+09:00
【Python】Lambdaで定期的にCloudWatch LogsからS3へエクスポートする
【AWS】CloudFormationでS3バケット作成とライフサイクルルールを設定する で作成したS3にCloudWatch Logsに保存しているログを定期的にエクスポートするLambdaをPythonで開発したお話です。
簡単に試せるようにGitHubリポジトリを作成しておきました -> homoluctus/lambda-cwlogs-s3
要件
- 毎日JST14:00に前日のログをエクスポート
- 複数のロググループをエクスポート可能
開発
言語
- Python3.8
開発ライブラリ
- isort
- mypy
- flake8
- autopep8
本番ライブラリ
- boto3
- boto3-stubs (type annotation用)
デプロイメントツール
- Serverless Framework
- GitHub Actions
AWSサービス
- Lambda
- CloudWatch Events
- CloudWatch Logs
- S3
コード
コード全部を載せるのは無理なので、メインとなるコードだけ解説用に載せます
完全なソースコードはリポジトリをみてねエクスポートするロググループ設定用のクラス
TypeScriptのInterface風にエクスポートしたいロググループを複数設定できるようにしました。
エクスポートするロググループを追加する場合はLogGroupクラスを継承するだけでOKです。エクスポートするS3のオブジェクトキーがどのロググループのログでいつのかわかりやすくなるようにしています。
docstringにも書いていますがdest_bucket/dest_obj_first_prefix or log_group/dest_obj_final_prefix/*というような階層構造になります。dest_obj_first_prefixが指定してなければ、log_groupの名前が入ります。*以降はエクスポートタスクのID/ログストリーム/ファイルみたいな感じになります。これは自動で付加されるのでコントロールできません.class LogGroup(object, metaclass=ABCMeta): """CloudWatch LogsをS3へエクスポートするための設定用基底クラス エクスポートするロググループの追加方法 class Example(LogGroup): log_group = 'test' """ # log_groupは必須でそれ以外はオプション log_group: ClassVar[str] log_stream: ClassVar[str] = '' start_time: ClassVar[int] = get_specific_time_on_yesterday( hour=0, minute=0, second=0) end_time: ClassVar[int] = get_specific_time_on_yesterday( hour=23, minute=59, second=59) dest_bucket: ClassVar[str] = 'lambda-cwlogs-s3' dest_obj_first_prefix: ClassVar[str] = '' dest_obj_final_prefix: ClassVar[str] = get_yesterday('%Y-%m-%d') @classmethod def get_dest_obj_prefix(cls) -> str: """完全なS3のobject prefixを取得 S3の階層構造 dest_bucket/dest_obj_first_prefix/dest_obj_final_prefix/* Returns: str """ first_prefix = cls.dest_obj_first_prefix or cls.log_group return f'{first_prefix}/{cls.dest_obj_final_prefix}' @classmethod def to_args(cls) -> Dict[str, Union[str, int]]: args: Dict[str, Union[str, int]] = { 'logGroupName': cls.log_group, 'fromTime': cls.start_time, 'to': cls.end_time, 'destination': cls.dest_bucket, 'destinationPrefix': cls.get_dest_obj_prefix() } if cls.log_stream: args['logStreamNamePrefix'] = cls.log_stream return argsCloudWatch Logsのクライアント
CloudWatch LogsのAPIで使用するのは以下の2つ
- create_export_task
- S3へエクスポートするタスクを作成
- タスクを作成するとCloudWatch LogsがS3へエクスポートしてくれる
- レスポンスには作成したタスクのIDが含まれている
- describe_export_tasks
- 作成したタスクのtaskIdを引数としてタスクの情報を取得
- タスクの進捗を確認するために使用する
- ステータスコード
COMPLETEDならエクスポート完了CANCELLEDとFAILEDはエラー扱いにする- それ以外ならまだ未完了とする
@dataclass class Exporter: region: InitVar[str] client: CloudWatchLogsClient = field(init=False) def __post_init__(self, region: str): self.client = boto3.client('logs', region_name=region) def export(self, target: Type[LogGroup]) -> str: """CloudWatch Logsの任意のロググループをS3へエクスポート Args: target (Type[LogGroup]) Raises: ExportToS3Error Returns: str: CloudWatch Logs APIからのレスポンスに含まれるtaskId """ try: response = self.client.create_export_task( **target.to_args()) # type: ignore return response['taskId'] except Exception as err: raise ExportToS3Error(err) def get_export_progress(self, task_id: str) -> str: try: response = self.client.describe_export_tasks(taskId=task_id) status = response['exportTasks'][0]['status']['code'] return status except Exception as err: raise GetExportTaskError(err) @classmethod def finishes(cls, status_code: str) -> bool: """エクスポートタスクが終了したかをステータスコードから判別する Args: status_code (str): describe_export_tasksのレスポンスに含まれるステータスコード Raises: ExportToS3Failure: ステータスコードがCANCELLEDかFAILEDの場合 Returns: bool """ uppercase_status_code = status_code.upper() if uppercase_status_code == 'COMPLETED': return True elif uppercase_status_code in ['CANCELLED', 'FAILED']: raise ExportToS3Failure('S3へのエクスポート失敗') return Falsemain
LogGroup.__subclasses__()でエクスポートしたいロググループの設定子クラスを取得します。
__subclasses__()はリストを返すので、それをfor文で回します。
CloudWatch Logsのエクスポートタスクはアカウントで1つしか同時に実行できないので、describe_export_tasks APIを叩いてタスクが完了しているか確認します。未完了であれば5s待つようにしています。create_export_taskが非同期APIなのでそのようにポーリングするしかありません。def export_to_s3(exporter: Exporter, target: Type[LogGroup]) -> bool: task_id = exporter.export(target) logger.info(f'{target.log_group}をS3へエクスポート中 ({task_id=})') while True: status = exporter.get_export_progress(task_id) if exporter.finishes(status): return True sleep(5) def main(event: Any, context: Any) -> bool: exporter = Exporter(region='ap-northeast-1') targets = LogGroup.__subclasses__() logger.info(f'エクスポート対象のロググループは{len(targets)}個') for target in targets: try: export_to_s3(exporter, target) except GetExportTaskError as err: logger.warning(err) logger.warning(f'{target.log_group}の進捗状況の取得失敗') except Exception as err: logger.error(err) logger.error(f'{target.log_group}のS3へエクスポート失敗') else: logger.info(f'{target.log_group}のS3へエクスポート完了') return Trueserverless.yml
以下は一部を抜粋したものです。
Lambdaがエクスポートタスク作成とタスク情報の取得ができるようにIAM Roleを設定します。
それから、毎日JST14:00でエクスポートを実行したいので、eventsにcron(0 5 * * ? *)を指定します。CloudWatch EventsはUTCで動いているので、-9hすれば期待通りのJST14:00に実行してくれます。iamRoleStatements: - Effect: 'Allow' Action: - 'logs:createExportTask' - 'logs:DescribeExportTasks' Resource: - 'arn:aws:logs:${self:provider.region}:${self:custom.accountId}:log-group:*' functions: export: handler: src/handler.main memorySize: 512 timeout: 120 events: - schedule: cron(0 5 * * ? *) environment: TZ: Asia/Tokyoおわりに
homoluctus/lambda-cwlogs-s3にはGitHub Actionsやエクスポート先のS3を作成するためのCloudFormationテンプレートもあります。ぜひ参照してみてください。
Reference
- 投稿日:2020-07-04T15:44:49+09:00
keras-yolo3をonnxに変換する
TL;DR
- YOLOv3のKeras版実装を利用したオリジナルデータ学習手順(2020年6月24日時点)で作成したHDF5形式(*.h5)をONNX形式に変換する方法
参考とするサイト
axinc-ai/yolov3-face
onnx/keras-onnx1. 環境の作成
1.1. ソースの準備
axinc-ai/yolov3-faceからgitでクローンする
git clone https://github.com/axinc-ai/yolov3-face.git続けて、yolov3-face内でリンクしているkeras-yolo3をクローンする
cd .\yolov3-face git clone https://github.com/qqwweee/keras-yolo3.git1.2. 変換用python環境作成
condaで仮想環境「yolov3-face」を作成する
conda create -n yolov3-face python=3.6 -y必要なモジュールをインストールする。
axinc-ai/yolov3-faceで細かいバージョンが指定されており、condaのリポジトリに用意されていないため、pipでインストールするconda activate yolov3-face pip install tensorflow==1.13.2 pip install keras==2.2.4 pip install keras2onnx==1.5.1 pip install opencv-python pip install pillow pip install matplotlib1.3. 推論用python環境作成
condaで仮想環境「yolov3-face-inference」を作成する
conda create -n yolov3-face-inference python=3.6 -y必要なモジュールをインストールする。
axinc-ai/yolov3-faceで細かいバージョンが指定されており、condaのリポジトリに用意されていないため、pipでインストールするconda activate yolov3-face-inference pip install tensorflow==1.13.2 pip install onnxruntime pip install keras==2.2.4 pip install pillow2. 変換および判定(用意されている例で検証)
まずは用意されているサンプルで検証する
2.1. 変換
書式
python keras-yolo3-to-onnx.py <h5-model-filepath> <classes-filepath> <anchors-filepath> <onnx-filepath>
パラメータ 指定する内容 h5-model-filepath kerasで作成したモデルファイル classes-filepath モデル作成時に使用したクラス名を記載したファイル anchors-filepath モデル作成時に使用したアンカーファイル onnx-filepath 変換後ONNXファイル 実行
cd .\keras-onnx conda activate yolov3-face python keras-yolo3-to-onnx.py ../model_data/logs/trained_weights_final.h5 ../model_data/face_classes.txt ../model_data/tiny_yolo_anchors.txt ../model_data/ax_face.onnx2.2. 推論
書式
python inference.py <onnx-filepath> <classes-filepath> <targetimage-filepath> <outputimage-filepath>
パラメータ 指定する内容 onnx-filepath 変換後ONNXファイル classes-filepath モデル作成時に使用したクラス名を記載したファイル inputimage-filepath 推論する画像ファイル outputimage-filepath 推論結果を描画したファイル 実行
cd .\keras-onnx conda activate yolov3-face-inference python inference.py ../model_data/ax_face.onnx ../model_data/face_classes.txt ../images/couple.jpg output.jpg3. YOLOv3のKeras版実装を利用したオリジナルデータ学習手順(2020年6月24日時点)で処理したファイルの場合
※ファイルは記載の場所にコピーしておく
ファイル 値 kerasで作成したモデルファイル ../model_data/yolo_logs/models/Step2_yolo_weight_mAP_best.h5 クラスファイル ../model_data/voc_classes.txt アンカーファイル ../model_data/yolo_anchors.txt 変換後ONNXファイル ../model_data/ax_yolov3.onnx 3.1. 変換
cd .\keras-onnx conda activate yolov3-face python keras-yolo3-to-onnx.py ../model_data/yolo_logs/models/Step2_yolo_weight_mAP_best.h5 ../model_data/voc_classes.txt ../model_data/yolo_anchors.txt ../model_data/ax_yolov3.onnx3.2. 推論
python inference.py ../model_data/ax_yolov3.onnx ../model_data/voc_classes.txt ../images/couple.jpg output.jpg
参考
keras-yolo3 + JetsonNano
https://qiita.com/rhene/items/b2a8ebe1f003e1107f63
http://mirai-tec.hatenablog.com/entry/2019/08/24/102129
http://mirai-tec.hatenablog.com/entry/2019/09/03/235156YOLOv3(Darknet) + JetsonNano
https://soralab.space-ichikawa.com/2019/06/jetson-tx2-tensorrt-yolov3/
https://www.nakasha.co.jp/future/ai/vol2_yolov3nvidia_jetson_nano.htmlTensorRT + Jetson Nano
https://qiita.com/tsutof/items/f81d3900fa77d954ef39
kerassからONNXに変換する
https://medium.com/axinc/yolov3-66c9b998c096
その他
https://qiita.com/agumon/items/114da6921c5dc4f7d7f9
https://github.com/zzh8829/yolov3-tf2
https://qiita.com/plseal/items/f493c67b2e810f2f876e
http://mirai-tec.hatenablog.com/entry/2020/01/12/115546
https://rightcode.co.jp/blog/information-technology/tensorflow2-yolov3-run
- 投稿日:2020-07-04T15:39:44+09:00
法学部生のマッチグサービス開発(途中経過)
自己紹介
まず簡単に自己紹介をさせていただきます。
・中央大学法学部在籍中(2020年現在)
・大学では公共法務を専攻。
・プログラミング歴、トータル約5か月。(progate、PyQ、書籍)
・言語はpython、フレームワークはdjangoを使用。
・目標はマッチングサイトの作成。バージョン
Package Version Python 3.8.3 asgiref 3.2.9 beautifulsoup4 4.9.1 Django 3.0.7 mysqlclient 1.4.6 pip 20.1.1 PyMySQL 0.9.3 pytz 2020.1 setuptools 41.2.0 soupsieve 2.0.1 sqlparse 0.3.1途中経過
・ログイン機能の実装中
これまでにつまずいた所
※web開発、djangoに関する前提知識なしでインプットとアウトプットを同時進行しています。
・djangoのview、formについての勉強不足。
(個人情報登録のタグ等をtemplateに全部手書きしていた。base.htmlも使用していなかったため修正必須。)・MySQLとdjangoの連携。
(デフォルトがSqliteだったため各種のインストールが必要だった。IT知識のなさを痛感。)
(githubのリポジトリに思いっきりMySQLの情報をcommitしてしまいプロジェクト全消し。gitignoreについて詳しく知らなかった…)・djangoのユーザー認証機能の存在を知らなかった
(moels.pyやforms.pyでの試行錯誤に時間をかけすぎた…)反省とこれから
・フレームワークについてあまりにも知識がなく無駄に無駄を重ねているので、適度にdjangoについてのインプットの比重を上げる。
- 投稿日:2020-07-04T15:12:52+09:00
【無料】freeCodeCampにPythonの認定コースが追加されました!
freeCodeCampとは
コース毎に用意された5つのプロジェクトを完了させると認定証がもらえるサービスで、プロジェクト達成に必要な技術を身につけるためのレッスンも含めて無料です。
ただ、全文英語です。
Mouse Dictionaryとか使えばだいぶ楽になると思います本題
freeCodeCampに既にあった6コースに、
- Pythonでの科学計算
- Pythonでのデータ分析
- Pythonでの機械学習
- 情報セキュリティ
の4コースが追加されました。カリキュラムとか詳細は公式サイトを確認してください。
アカウント登録しなくてもコースを見ることはできますが、進捗の保存や証明書の発行には登録が必要です(もちろん無料)。
- 投稿日:2020-07-04T15:08:11+09:00
Python + Selenium よく使う操作メソッドまとめ
はじめに
Webスクレイピング等でSeleniumを使っております。
開発時に「あれ?これどうやって書くんだっけ?」と、忘れては調べている項目についてのみ本記事にまとていくことにしました。ChromeOptions
必要なオプションが設定されていないと、稀に下記のようなタイムアウトエラーが発生します、
Timed out receiving message from renderer: 600.000この件について、Stack Overflowの回答では、以下のオプション設定を行えば問題ないそうです。(ちなみに「役に立たない増え続ける引数オプション」と呼ばれており、まさにその通り・・・)
options.addArguments("start-maximized"); options.addArguments("enable-automation"); options.addArguments("--headless"); options.addArguments("--no-sandbox"); options.addArguments("--disable-infobars"); options.addArguments("--disable-dev-shm-usage"); options.addArguments("--disable-browser-side-navigation"); options.addArguments("--disable-gpu"); driver = new ChromeDriver(options);明示的な待機処理
WebDriverWait.untilメソッドで、任意のHTMLの要素が特定の状態になるまで待つ明示的な待機時間を設定することができます。詳細はこちら。
クリック可能か判定
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.ID, "cnfm_btn")))選択可能か判定
WebDriverWait(driver, 10).until(EC.element_located_to_be_selected((By.ID, "cnfm_btn")))
- 投稿日:2020-07-04T15:04:58+09:00
Pythonで写真のExifから焦点距離情報とレンズ情報を抽出した話
概要
「自分はどのレンズをよく使ってるんだろう?」
カメラ好きなら一度は思ったことでしょう。
写真1枚について調べたい場合は、RAW現像ソフトを使えばExifに記録された情報を確認できます。
しかし、写真フォルダーにある大量の写真となると、カウントするだけでも一苦労です。……そこで、Python 3とPillowを使用し、情報を自動で収集するプログラムを書いてみました。以下、その際のポイントについて。
Exif抽出だけなら難しくない
幸い、Exif情報を辞書形式で取り出すだけなら、Pillowを使うだけで簡単に書けます。
焦点距離についても、実焦点距離、および35mm判換算焦点距離を別々に取り出すことができます。from PIL import Image from PIL.ExifTags import TAGS from PIL.MpoImagePlugin import MpoImageFile # 読み込みたい画像ファイルのパス path = 'test.jpg' # 読み込み im: MpoImageFile = Image.open(path) # Exif情報を取り出す exif = im.getexif() # tag_idはExif情報のキー、valueはExif情報の値。 # tag_idはstr型ではないので、TAGS.getメソッドによってstr型に変換する for tag_id, value in exif.items(): tag = TAGS.get(tag_id, tag_id) if tag == 'FocalLength': print(f'実焦点距離:{value}') if tag == 'FocalLengthIn35mmFilm': print(f'35mm判換算焦点距離:{value}')また、レンズ名についての情報は、MakerNoteと呼ばれる、各カメラメーカー毎に固有のフォーマットを持つバイナリ文字列で記録されています。
Exif情報のフォーマットと異なり書式は公開されていませんが、非公式な解析結果がググれば幾らでも出てきます。今回はパナ社のカメラで記録した写真についての情報のみ考えることにします。maker = '' maker_note = b'' for tag_id, value in exif.items(): tag = TAGS.get(tag_id, tag_id) if tag == 'MakerNote': maker_note = value if tag == 'Make': maker = value if maker == 'Panasonic' and maker_note != b'': # 以下、解析処理MakerNoteとの格闘
ググって出てきた情報を見る限り、パナの場合、「固有のヘッダー文字列」+「TIFF IFDっぽいバイナリ列」+「その他バイナリデータ」で表現されます。
固有のヘッダー文字列は読み飛ばせばいいのですが、問題はTIFF IFD。こちらもググって出てきた情報を読んだ感じ、次のような書式になっているようです。
- 12バイトの固定長なレコードがn個並んでおり、それらの先頭に「何個レコードが並んでいるか」を示す情報が2バイト分使用して記録されている
- バイナリはいずれもリトルエンディアン
- 各レコードについて、
- 先頭2バイトが「レコードの種類」
- 次の2バイトが「レコードに含まれる値の型」
- 次の4バイトが「レコードに含まれる値の個数 or 値の全長(バイト単位)」
- 次の4バイトが「レコードに含まれる値 or "先頭"からのオフセット(バイト単位)」
つまり、処理としては、「何個レコードが並んでいるか」を読み取り、その個数分だけIFDを読み取る……といった動きになります。厄介なのは、「IFDには実際のデータが収録されている」のか、「IFDには実際のデータへの参照が収録されている」のかを判別する必要があるということです。
例えば、あるIFDが16進数で「03 00 03 00 01 00 00 00 03 00 00 00」と記録されていた場合、
- 先頭「03 00」=「0x0003」=「ホワイトバランスの情報」
- 次の「03 00」=「0x0003」=「short型(2バイト整数)」
- 次の「01 00 00 00」=「0x00000001」=「データ数は1個(データ長からしても間違いない)」
- 次の「03 00 00 00」=「0x00000003」=「ホワイトバランス設定は3("曇り"プリセット)」
だと分かります。しかし、IFDが16進数で「51 00 02 00 22 00 00 00 64 0D 00 00」と記録されていた場合、
- 先頭「51 00」=「0x0051」=「レンズ名の情報」
- 次の「02 00」=「0x0002」=「char型(1バイト整数、ASCII文字列となる)」
- 次の「22 00 00 00」=「0x0000002」=「データ長は34文字(レコードに34個も値は入らないのでデータ長である)」
- 次の「64 0D 00 00」=「0x00000D64」=「0スタートで3428オフセット目にデータが存在する」
となります。さて問題、「3428オフセット目」はどこからが基準でしょうか?
……これに対応するには、Exifファイルフォーマットについて知る必要があります。今までExifと言ってきましたが、これは単に「JPEGファイルに引っ付いたメタ情報」と言うだけではなく、メタ情報を含ませた上でJPEG(JFIF)規格に準拠したファイルフォーマットを指します。これによると、Exifと一般に呼ばれるメタデータは、「
Exif\x00\x00」というシグネチャーから始まるバイナリ列です。で、前述した「オフセット」の基準は、この「Exif」シグネチャーが終わった直後です(試行錯誤して確認)。つまり、JPGファイルをバイナリで読み込んで「Exif」シグネチャーを検索し、その直後の位置を記憶しておく必要があります。
ただ、大変残念なことに、上記PillowによるExifデータ読み取り処理では「Exifデータが画像ファイル全体からどれぐらいのオフセット位置に存在するか」を読み取ってくれないので、コードが次のように煩雑になります。つらい。
exif_signature = b'Exif\x00\x00' with open(path, 'rb') as f: # バイナリデータと、必要なオフセット値を取得 raw_data = f.read() raw_exif_base_index = raw_data.find(exif_signature) + len(exif_signature) # Exif情報を取得 im: MpoImageFile = Image.open(path) exif = im.getexif() # 中略。maker_noteにMakerNoteのバイナリが収められているとする ifd_count = int.from_bytes(maker_note[12:14], byteorder='little') for x in range(0, ifd_count): # IFDを順に読んでいく pointer = 12 + 2 + x * 12 ifd_data = maker_note[pointer:pointer + 12] tag_name = ifd_data[0:2].hex() if tag_name == '5100': # レンズ名についてのIFDならば # レンズ名をバイナリデータから抽出 # (末尾に不要な\x00があるので取り除く) name_length = int.from_bytes(ifd_data[4:8], byteorder='little') name_offset = int.from_bytes(ifd_data[8:], byteorder='little') start_index = raw_exif_base_index + name_offset end_index = start_index + name_length lens_name = raw_data[start_index:end_index].decode('ascii').replace('\0', '') print(f'レンズ名:{lens_name}') breakおまけ:抽出結果
上記のようにして抽出した上で、pandasを使い、頻度分析を実施しました。
これ自体はExcelも併用したやっつけ仕事ですが、Pythonはグラフ化も得意なので、頑張れば「分析結果をPDFに書き出す」ぐらいまで実装できるかもしれません。今まで使ってきたレンズの使用率、およびレンズごとによく使用した焦点距離(35mm換算)を可視化。こういう時はPythonが便利ですね。 pic.twitter.com/MTp0IoDH64
— YSR@ものべのプレイ中 (@YSRKEN) July 4, 2020おまけ2:自動分析用コード
上記のコードをより洗練させて、実行して放置すればCSV形式で標準出力に書き出すやつを作りました。以下、ソースコードと出力例。
https://gist.github.com/YSRKEN/832267d8fb810817ec233bc7f63e54df
(前略) 写真枚数:4293 レンズ名,使用率(%),焦点距離毎の使用率(%) OLYMPUS M.12-40mm F2.8,20.6,80mm(36.2) 24mm(29.0) 50mm(3.3) 42mm(2.9) 48mm(2.8) 64mm(1.9) 60mm(1.8) 68mm(1.7) 54mm(1.6) 30mm(1.5) 34mm(1.5) 58mm(1.4) 76mm(1.2) 40mm(1.2) 28mm(1.2) 36mm(1.2) 52mm(1.1) 62mm(1.0) 46mm(1.0) 38mm(0.9) 158mm(0.8) 72mm(0.7) 56mm(0.7) 44mm(0.6) 70mm(0.5) 82mm(0.5) 32mm(0.5) 63mm(0.3) 94mm(0.3) 26mm(0.2) 73mm(0.2) 47mm(0.1) 89mm(0.1) LUMIX G VARIO 14-140/F3.5-5.6 ,15.5,28mm(26.1) 280mm(19.5) 92mm(7.6) 80mm(4.0) 52mm(3.9) 30mm(3.4) 305mm(3.3) 68mm(3.0) 42mm(2.4) 110mm(2.2) 38mm(2.2) 74mm(1.9) 48mm(1.9) 122mm(1.6) 64mm(1.5) 204mm(1.3) 60mm(1.2) 162mm(1.0) 138mm(1.0) 146mm(1.0) 34mm(1.0) 130mm(0.9) 56mm(0.7) 176mm(0.7) 32mm(0.6) 132mm(0.4) 184mm(0.4) 154mm(0.4) 168mm(0.4) 41mm(0.3) 100mm(0.3) 150mm(0.3) 119mm(0.3) 159mm(0.3) 230mm(0.3) 218mm(0.3) 222mm(0.1) 284mm(0.1) 87mm(0.1) 211mm(0.1) 200mm(0.1) 191mm(0.1) 69mm(0.1) 257mm(0.1) 295mm(0.1) 260mm(0.1) LUMIX G VARIO 100-300/F4.0-5.6II,12.7,600mm(58.1) 200mm(15.5) 428mm(3.3) 300mm(3.1) 446mm(2.2) 1212mm(2.0) 272mm(1.8) 376mm(1.5) 216mm(1.1) 572mm(1.1) 254mm(1.1) 386mm(1.1) 480mm(1.1) 228mm(0.9) 366mm(0.7) 468mm(0.5) 240mm(0.5) 400mm(0.5) 324mm(0.5) 342mm(0.5) 394mm(0.5) 500mm(0.4) 528mm(0.4) 420mm(0.4) 492mm(0.4) 410mm(0.2) 436mm(0.2) 456mm(0.2) OLYMPUS M.12-100mm F4.0,9.9,200mm(31.8) 24mm(18.4) 100mm(11.1) 395mm(9.0) 70mm(7.5) 50mm(5.2) 108mm(2.1) 140mm(1.9) 36mm(1.4) 68mm(1.4) 122mm(1.2) 48mm(1.2) 62mm(0.9) 47mm(0.7) 58mm(0.7) 32mm(0.7) 76mm(0.7) 114mm(0.5) 82mm(0.5) 94mm(0.5) 88mm(0.5) 40mm(0.2) 279mm(0.2) 339mm(0.2) 132mm(0.2) 150mm(0.2) 184mm(0.2) 160mm(0.2) 46mm(0.2) 34mm(0.2) (後略)参考資料
- 投稿日:2020-07-04T13:05:39+09:00
結局、統計モデリングとは何なのか
先日、つれづれなるままに
時系列分析の勉強法の記事『統計初心者が時系列分析を学ぶための勉強法』
を書き殴ってみたところ、反響の大きさに驚きました。正直、時系列分析なんてかなりニッチな分野だ(3人ぐらいしか読まないだろう)と思ってたからです。
ステイホームしているみなさんが、暇だから時系列分析を使ってFXで一儲けしようとでも考えているんでしょうか。時系列分析のトピックである、状態空間モデルも統計モデリングの一種なわけですが、本日は、「統計モデリングとは何なのか」について、あらためて考えてみたいと思います。
統計モデリングといえば、みんな大好き緑本『データ解析のための統計モデリング入門――一般化線形モデル・階層ベイズモデル・MCMC (確率と情報の科学)』です。
緑本はたしかに素晴らしい本ですが、緑本を読んだだけでは、「何が統計モデリングで、何が統計モデリングではないのか」「統計学におけるモデルとはなにか」という私の長年の疑問は晴れませんでした。
その他、下記のような素晴らしい記事もたくさん読みましたが、書いてあることが難しく、玄人向けの説明に感じてしまいます。
ここでは、もう少し簡単なところから話をはじめ、「結局、統計モデリングとは何なのか」といった深淵な問いに迫ってみましょう。
この記事の対象者
この記事は、「統計学とは」「統計学でいうところのモデルとは」「統計学と機械学習の違いとは」といった取るに足らない疑問に、ただでさえ取るに足らない人生を浪費したことのあるみなさんが対象です。
統計学の知識はほとんどなくても、理解可能な内容になっています。
それではさっそく始めましょう!
統計モデリングとはなにか
統計モデリングの基本パーツは確率分布である
統計モデリングを語る上で欠かせないのは、確率分布です。
確率分布というと、読者のみなさんは、正規分布、二項分布、ポアソン分布、ガンマ分布……etc といったものを思い浮かべるでしょう。
(確率分布界の皇帝として君臨している正規分布様の神々しい御姿……)これら確率分布の数学的な性質について学ぶが統計学だと思っている方も多いようです。
それは、大学などの統計学のカリキュラムが、これら代表的な確率分布に関する数学理論から始まるためでしょう。
(だから、統計学をクソつまらないものだと思っている人が多いのでしょう。)ですが、確率分布に関する数学理論など、統計学の本質でもなんでもありません。
重要なのは、「統計学では、確率分布を使ってどのようにモデリングをおこなうのか」です。
この記事では、「何が統計モデリングで、何が統計モデリングではないのか」を明らかにすることで、
「統計学では、確率分布を使ってどのようにモデリングをおこなうのか」。つまり、「統計モデリングとはなにか」という問いに迫っていきます。では、これから、いくつかの質問を通して、「何が統計モデリングで、何が統計モデリングではないのか」ということを明らかにしていきましょう。
何が統計モデリングで、何が統計モデリングではないのか
Q1. 日本の全中学生男子の身長のデータがあります。これらの平均や分散を求めることは、統計モデリングと言えるでしょうか。
A1. 私の考えでは、ただ、平均や分散を計算するだけでは、統計モデリングとはいえません。
なぜなら、平均や分散は、得られたデータからそのまま計算することができるからです。
全中学生男子の身長データが手元にあるのなら、それを全部足して人数で割れば、平均を計算できます。
平均を計算できれば、分散も計算可能です。たしかに、平均や分散を統計量といいます。
平均という概念自体が、統計学的な世界観で重要視される指標であり、
平均を求めることは、統計学的な営みだと言うこともできるかもしれません。ですが、「モデリング」しているとは言えないと思います。
では、
Q2. 日本の全中学生男子の身長のデータに対して、どんな操作をすれば統計「モデリング」と呼べるようになるでしょうか
A2. 観測データのヒストグラムの形が正規分布っぽい?と考え、ヒストグラムに正規分布を重ねあわせたら統計モデリングの世界に一歩足を踏み入れています
どうやら、全中学生男子の身長の分布は、正規分布に近似できるのではないか。
そう考えたあなたは、統計モデリングをはじめています。正規分布
\frac {1}{\sqrt{2\pi\sigma^2}} \exp(-\frac {(x-\mu)^2}{2\sigma^2})\\ \\ \mu: 平均\\ \sigma^2: 分散の平均と分散に、観測データの平均と分散を当てはめれば、上記の図のようにヒストグラムの上に正規分布をきれいに重ね合わせることができます。
得られたデータの確率分布を考える。
この観測データは、正規分布から生み出されているのではないかと考える。
それはもう立派な「統計モデリング」です。でも、これだけで「統計モデリング」を名乗ったところで、あまり有意義なことをしたようには思えませんね。
Q3. では、統計モデリングはどんな場面で使うと意味があるのでしょうか?
A3. 日本の全中学生男子ではなく、一部の中学生男子の身長のデータしか手に入らなかったとき
これまでは、全中学生男子の身長が得られたことを前提にしてきましたが、実際のデータ分析の現場ではそんな幸運なことは滅多にありません。
私たちには、全体のうちのごく一部のデータ(標本、サンプル)から、全体(母集団)の平均や分散の値(ベイズ統計学なら分布)について想いを巡らせるという高度に知的な営みが要求されます。
それこそが、統計学で行ないたいことです。手元のデータから母集団について想いを巡らせるためには、まず母集団の分布を仮定する必要があります。
例えば、日本の全中学生男子の身長の分布を正規分布だと仮定したとします。
ここでは、手元のデータしかヒントがない中で、母集団の分布を仮定する必要があります。
あなたは、これまでの経験や知識を総動員し、最も妥当だと思う確率分布を選ぶでしょう。これこそが、統計モデリングです。
そして、ここが統計学の難しいところでもあります。
なぜその統計モデリングを行ったのかは、あなたの主観が入り込むとこでもあります。
そして、その統計モデリングが説得感を持つかどうかは、あなたの主張を聞く人の主観が入ります。ここではこれ以上の深入りはしませんが、「モデリング」の世界には、多くの場合、完全な客観だけでは判断できない余地が残ります。
一旦、統計モデリングができたら、手元にある100人の身長データは、正規分布する母集団(= 全中学生男子の身長)から生み出されたのだと考え、手元のデータから母集団の正規分布の形を想像しようとします。
これこそが、統計モデリングに基づく『統計学』的推定です。
母集団の分布が正規分布であれば、母集団の平均と分散が分かると、分布の形を描くことができます。
ここでは詳しく説明しませんが、
母集団である全中学生男子の身長の平均値は、手元にある100人の身長の平均値で推定するのが、統計学的には最もリーズナブルな推定になります。
直感的には、納得感がありますよね。分散の推定値については、少しややこしいので、興味のある方はご自身で勉強してみてください。
母集団の正規分布の形が分かれば、今回の100人のデータがどの程度の確率で生み出されたものなのか(どの程度珍しいものなのか)がわかります。
それはつまり、確率論的に手元のデータを説明する手段を得たということです。統計学と確率論は切っても切れない関係にあります。
なぜなら、統計学とは、得られたデータの生起確率を統計モデリングによって扱う学問でもあるからです。このように統計モデリングすることができたみなさんなら、次は、どのような問題に興味が湧くでしょうか。
例えば、他の集団(日本の中学生女子や高校生男子)のデータと比較してみたいと思うかもしれません。
他の集団との比較で活躍する分析手法が、「検定」と呼ばれるものです。
検定も、母集団の確率分布を仮定することで可能になる統計学的手法です。このように、「統計モデリング」をすることで、その先に豊かな世界が広がっています。
その世界を統計学と呼ぶのです。一般化線形モデルなどの回帰モデルとここで説明した統計モデリングの関係
結論から言えば、多くの方が統計モデリングと言われて思い浮かべる、
線形モデル(LM)、一般化線形モデル(GLM)、一般化線形混合モデル(GLMM)
といった統計モデルは、ここで説明した統計モデリングを回帰の世界に拡張したに過ぎません。これらの発展的モデルも、基本パーツは、あくまで確率分布です。
例えば、冒頭でもあげた緑本や 「統計モデリングとは何なのか」をいま一度整理してみると言った記事では、主に回帰モデルを扱っています。
ですが、
真の分布を仮定して、そのパラメータの値(平均や分散。ベイズ統計学なら平均や分散自体も値ではなく分布)を手元のデータを用いて推測する
という統計モデリングの本質は、何ら変わりません。まとめ
本日は、「結局、統計モデリングとは何なのか」という問いについて考えてみました。
統計学の本はたくさん読んできましたが、
統計学におけるモデルの意味についてここまでくどくどと説明してくれてる本はありませんでした。
特に、ここで取り上げた「何が統計モデリングで、何が統計モデリングではないのか」ということがよく分かりませんでした。そこで、自分の考えをまとめてみようと思ったのが、この記事を書いたきっかけです。
本記事が、「統計学」という深淵な学問に挑むみなさまの参考になることを願います。
- 投稿日:2020-07-04T12:58:58+09:00
Optunaを使ったRandomforestの設定方法
Optunaを使ったRandomforestの設定方法
修正200704
よく考えたら、max_depth,n_estimators等は、離散値suggest_discrete_uniform(name, low, high, q)で与えるべきでしたので、スクリプトを修正しました。
max_depth,n_estimators,max_leaf_nodesは離散値suggest_discrete_uniformだと、型がfloatになってしまうので、int(suggest_discrete_uniform())にして、型を整数型に変更して渡しています。
修正前
前回Optunaの使い方を書いたので、これからは個別の設定方法について記載しようと思う。。
Randomforestで渡せる引数は、いろいろあるが、主なものをすべてOptunaで設定してみた。
max_depth,n_estimatorsを整数で渡すべきか、数をカテゴリーとして渡すべきか、悩んだが、今回は整数で渡した。def objective(trial): criterion = trial.suggest_categorical('criterion', ['mse', 'mae']) bootstrap = trial.suggest_categorical('bootstrap',['True','False']) max_depth = int(trial.suggest_discrete_uniform('max_depth', 10, 1000,10)) max_features = trial.suggest_categorical('max_features', ['auto', 'sqrt','log2']) max_leaf_nodes = int(trial.suggest_discrete_uniform('max_leaf_nodes', 10, 1000,10)) n_estimators = int(trial.suggest_discrete_uniform('n_estimators', 10, 1000,10)) regr = RandomForestRegressor(bootstrap = bootstrap, criterion = criterion, max_depth = max_depth, max_features = max_features, max_leaf_nodes = max_leaf_nodes,n_estimators = n_estimators,n_jobs=2) score = cross_val_score(regr, X_train, y_train, cv=3, scoring="r2") r2_mean = score.mean() print(r2_mean) return r2_mean#optunaで学習 study = optuna.create_study(direction='maximize') study.optimize(objective, n_trials=1000) # チューニングしたハイパーパラメーターをフィット optimised_rf = RandomForestRegressor(bootstrap = study.best_params['bootstrap'], criterion = study.best_params['criterion'], max_depth = int(study.best_params['max_depth']), max_features = study.best_params['max_features'], max_leaf_nodes = int(study.best_params['max_leaf_nodes']),n_estimators = int(study.best_params['n_estimators']), n_jobs=2) optimised_rf.fit(X_train ,y_train)これを使って、Bostonのデータセットを使って、ハイパーパラメーターをチューニングしてみました。
いい感じにフィットしました。
- 投稿日:2020-07-04T12:31:40+09:00
[Python] クラス変数をもつクラスを継承する
クラス変数をもつ親クラスを継承するクラスが複数あった場合,
子クラスがクラス変数にアクセスするときの挙動が怪しかったのでメモ.結論(?):
- 継承先の子クラスでも,mutableなクラス変数は共有されてそう
- 別々に管理したければ子クラスで同じ変数を上書きする
症状
# 親クラス class AbstClass: class_number = 0 dict_number = {'class': 0} # 子クラス1 class Class1(AbstClass): def __init__(self): self.class_number = 1 self.dict_number['class'] = 1 # 子クラス2 class Class2(AbstClass): def __init__(self): self.class_number = 2 self.dict_number['class'] = 2 obj1 = Class1() print(obj1.class_number, obj1.dict_number['class']) # 1, 1 ←わかる obj2 = Class2() print(obj2.class_number, obj2.dict_number['class']) # 2, 2 ←わかる print(obj1.class_number, obj1.dict_number['class']) # 1, 2 ←!?「2つの子クラスが同じ親クラスのクラス変数にアクセスしている」なら分かりやすいが,
上記の例では
class_numberは2つのクラスで別々に管理dict_numberは2つのクラスで共有→Class2()をしたときにClass1で書き換えたdict_numerを上書きになっている.
原因の仮説
mutable/immutableが関係している?と推測.つまり,
- mutableなクラス変数(上記の
dict_number): 子クラスでも共有- immutableなクラス変数(上記の
class_number): 子クラスでは別々に管理実際,AbstClassに
class_number_tuple = (0,)というタプルを定義すると,
class_numberと同様の振る舞いが確認された.
(※intはimmutable.参考:
GAMMASOFT: Pythonの組み込みデータ型の分類表(ミュータブル等))対策
子クラス内でクラス変数を再定義する:
class Class1(AbstClass): class_number = 0 dict_kv = {'class': 0} class Class2(AbstClass): class_number = 0 dict_kv = {'class': 0}と,各インスタンスではそれぞれのクラスのクラス変数を優先する=別々に管理することになる.
ただし,欲を言えば言語として自動的に例外を出してほしい.
- 実際,辞書のキーにリストを入れるとunhashableと怒られる
- ABCの
@abstractmethodのように,「共有すべきクラス変数」「子クラスで上書きすべきクラス変数」を明示できるようにできれば…現状の対策としては,
- 継承されることが前提の抽象クラスにはクラス変数を定義しない(上記の通り結局子クラスで再定義する方が安全なので単純に行数の無駄)
- そうでないクラスのクラス変数にアクセスする必要がある時は,継承ではなく委譲を使う(理想)
- 継承するクラスのソースコードは冒頭だけでも読む(現実)
ぐらいでしょうか….何か良い方策などございましたらご教示頂ければ幸いです.
- 投稿日:2020-07-04T12:19:31+09:00
ゼロから始めるLeetCode Day76「3. Longest Substring Without Repeating Characters」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
どうやら多くのエンジニアはその対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイトであり、海外のテックカンパニーでのキャリアを積みたい方にとっては避けては通れない道である。
と、仰々しく書いてみましたが、私は今のところそういった面接を受ける予定はありません。
ただ、ITエンジニアとして人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
Python3で解いています。
前回
ゼロから始めるLeetCode Day75 「15. 3Sum」今はTop 100 Liked QuestionsのMediumを優先的に解いています。
Easyは全て解いたので気になる方は目次の方へどうぞ。Twitterやってます。
技術ブログ始めました!!
技術はLeetCode、Django、Nuxt、あたりについて書くと思います。こちらの方が更新は早いので、よければブクマよろしくお願いいたします!問題
3. Longest Substring Without Repeating Characters
難易度はMedium。問題としては、文字列が与えられたとき、文字を繰り返さずに最長の部分文字列の長さを求めなさいというものです。
Example 1:
Input: "abcabcbb"
Output: 3
Explanation: The answer is "abc", with the length of 3.Example 2:
Input: "bbbbb"
Output: 1
Explanation: The answer is "b", with the length of 1.Example 3:
Input: "pwwkew"
Output: 3Explanation: The answer is "wke", with the length of 3.
Note that the answer must be a substring, "pwke" is a subsequence and not a substring.解法
class Solution: def lengthOfLongestSubstring(self, s: str) -> int: dic,length,start = {},0,0 for i,j in enumerate(s): if j in dic: sums = dic[j] + 1 if sums > start: start = sums num = i - start + 1 if num > length: length = num dic[j] = i return length # Runtime: 60 ms, faster than 76.33% of Python3 online submissions for Longest Substring Without Repeating Characters. # Memory Usage: 13.9 MB, less than 55.58% of Python3 online submissions for Longest Substring Without Repeating Characters.
lengthで最大の長さを保持し、startで部分文字列の開始位置を保持しています。そこまで書くことはないですね・・・
そういえば組み込み関数が便利っていうのはPython特有なのでしょうか?
言語によっては組み込み関数によって実装が楽だったりするとかありそうですが・・・・他の言語で解いてみるのも面白いのでJavaで書いたりもたまにしていますがなかなか慣れないものですね。
では今回はここまで。
お疲れ様でした。
- 投稿日:2020-07-04T12:19:21+09:00
分数式から係数を取り出す方法
多項式の係数を取り出すときはcoeff()メソッドを使えば良いが、分数式になると単純に使うだけではダメで、expand()メソッドで展開する必要がある。
how_to_get_coeff_from_fractional_expression.py# coding:utf-8 import sympy as sp # f(x)/g(y) のx**aの次数の取り方 # sympy の変数を作る x, y = sp.symbols('x y') # sympy.Symbol の関数(分数式)を作る symbolFunc = (x**2 + 2*x + 3) / (4*y + 5) # x**1 の係数として、 2/(4y + 5) を期待するが 0 になる print(symbolFunc.coeff(x, 1)) # ==> 0 # expand() メソッドを噛ませるとうまくいく print(symbolFunc.expand().coeff(x, 1)) # ==> 2/(4y + 5)
- 投稿日:2020-07-04T12:16:06+09:00
Target WSGI script '/var/www/xxx/xxx.wsgi' cannot be loaded as python module というエラーが発生した場合の対処方法
Pythonを使った簡単なアプリケーションを作成&公開する場合、WebサーバはApache、Webアプリケーションフレームワークはflaskという組み合わせはよくあると思います。
そして、Apacheとflaskを繋ぐWSGI(Web Server Gateway Interface)はmod_wsgiを使うことになります。AWSでEC2のインスタンスを立て、Apacheをインストールし、flaskで書いたアプリを動かすぞ!mod_wsgiもインストールしたから問題なく動くはず!と思っていたのに、次のようなエラーが発生することがあります。
mod_wsgi (pid=8711): Target WSGI script '/var/www/xxx/xxx.wsgi' cannot be loaded as Python module. mod_wsgi (pid=8711): Exception occurred processing WSGI script '/var/www/xxx/xxx.wsgi'.あれ、mod_wsgiをインストールしたのに何で?となりますが、結論から言うと
yum install mod_wsgiでインストールしたmod_wsgiはバージョンが古くPython2系にしか対応していないためです(Cent OS系のOSの場合)。ですので、
yum install mod_wsgiでmod_wsgiをインストールした場合は、yum remove mod_wsgiでアンインストールする必要があります。その上で、pip install mod_wsgiのようにpip経由でインストールすればPython3系に対応したmod_wsgiをインストールできます。例えば、
venvを使ってPython3.7の仮想環境を作成している場合、上記のpipコマンドを実行すると$VENVHOME/lib/python3.7/site-packages/mod_wsgi/server/mod_wsgi-py37.cpython-37m-x86_64-linux-gnu.soという場所にmod_wsgiの共有ライブラリファイルを作成されます。そして、Apacheのconfファイルに次のように記述すると、Python3に対応したmod_wsgiが実行されます。
LoadModule wsgi_module $VENVHOME/lib/python3.7/site-packages/mod_wsgi/server/mod_wsgi-py37.cpython-37m-x86_64-linux-gnu.soめでたし、めでたし。それにしても、Pythonのバージョンに関しては色々な所に落とし穴がありますね…。
- 投稿日:2020-07-04T11:36:45+09:00
webスクレイピングで画像収集
今回はwebスクレイピングを使用し指定したURLから画像を収集するコードを書き、説明していきたいと思います。
実装コード
import requests from requests.compat import urljoin from bs4 import BeautifulSoup import time from PIL import Image import urllib.request import sys.os class web_scryping: def __init__(self , url): self.url = url self.soup = BeautifulSoup(requests.get(self.url).content, 'lxml') class download_images(web_scryping): def download(self , max_down_num): self.down_num = 0 self.max_down_num = max_down_num self.save_path = './img/' + str(self.down_num+1) + '.jpg' now_num = 0 for link in self.soup.find_all("img"): src_attr = link.get("src") target = urljoin(self.url, src_attr) resp = requests.get(target) image = resp.content #breakpoint() print(str(resp) + ' ' + str(now_num)) now_num = now_num + 1 if str(resp) != '<Response [404]>': with open(self.save_path, 'wb') as f: f.write(image) self.down_num = self.down_num + 1 time.sleep(1) self.save_path = './img/' + str(self.down_num+1) + '.jpg' if self.down_num == self.max_down_num: break def img_resize(self , img_path): try: im = Image.open(img_path) print("元の画像サイズ width: {}, height: {}".format(im.size[0], im.size[1])) im_resize = im.resize(size=(800,1200)) im_resize.save(save_path) print('image resize sucess') except: print('image resize failed') def main(): url = sys.argv[0] di = download_images(url) di.download(50) if __name__ == '__main__': main()プログラムの流れについて
手順1
def main(): url = sys.argv[0] di = download_images(url) di.download(50)コマンドライン引数にて第一引数にURLを指定します。
URLをweb_scrypingクラスを継承したdownload_imagesクラスに渡します。手順2
class web_scryping: def __init__(self , url): self.url = url self.soup = BeautifulSoup(requests.get(self.url).content, 'lxml')download_imagesクラスはweb_scrypingクラスを継承し、なおかつdownload_imagesクラスにはinitメソッドがないためweb_scrypingクラスのinitメソッドが起動します。
ここではURLをrequests.getメソッドで内容を取得し、BeautifulSoupでhtmlの内容を解析します。解析結果をself.soupというクラス変数に入れます。手順3
class download_images(web_scryping): def download(self , max_down_num): self.down_num = 0 self.max_down_num = max_down_num self.save_path = './img/' + str(self.down_num+1) + '.jpg' now_num = 0 for link in self.soup.find_all("img"): src_attr = link.get("src") target = urljoin(self.url, src_attr) resp = requests.get(target) image = resp.content #breakpoint() print(str(resp) + ' ' + str(now_num)) now_num = now_num + 1 if str(resp) != '<Response [404]>': with open(self.save_path, 'wb') as f: f.write(image) self.down_num = self.down_num + 1 time.sleep(1) self.save_path = './img/' + str(self.down_num+1) + '.jpg' if self.down_num == self.max_down_num: break手順1のdownload_imagesクラスのdownloadメソッドを使用し、downloadを開始します。
self.save_pathはimgディレクトリの中に数字.jpgという感じでどんどん画像ファイルの名前を指定していきます。
self.soup.find_all("img"): htmlの中からimgタグを探します。
src_attr = link.get("src"): imgタグからsrcの項目を取得します。
image = resp.content: image変数に画像オブジェクトが入ります。
if str(resp) != '': resp変数にレスポンスの結果が入っているため404でなければ画像を保存します。
time.sleep(1): スクレイピングを行う時はwebサイトに負担をかけることは好ましくないためsleepメソッドを使用し時間を空けます。おまけ
def img_resize(self , img_path): try: im = Image.open(img_path) print("元の画像サイズ width: {}, height: {}".format(im.size[0], im.size[1])) im_resize = im.resize(size=(800,1200)) im_resize.save(save_path) print('image resize sucess') except: print('image resize failed')このメソッドは画像のサイズを調整するメソッドなんですが大きくすると解像度があまりよくなかったため使用していません。
- 投稿日:2020-07-04T10:49:23+09:00
Django-TodoList①~一覧を表示してみよう~
はじめに
今回の記事では、TodoListの「タイトル」、「内容」、「期日」についてブラウザに表示させることを目標として進めていきます。
できれば前回までの記事を読むとわかりやすいです。前回までの記事
↓
↓
↓
PycharmでDjangoでアプリケーションを作成する手順~準備編~'urls.py'の編集
まずはアプリケーションの'urls.py'に追記していきます。
アプリケーションの'urls.py'はデフォルトでは用意されていないため、まだ作ってない人は作っていきましょう。#アプリケーションディレクトリに移動 $ cd アプリケーション名 #urls.pyファイルを作成 $ touch urls.py作ることができたら開いてください。
'urls.py'はブラウザに表示する材料を集めるための指示書です。
中身は何も書かれていないと思うので、指示書として活用できるように、次のように書き込んでいきます。from django.urls import path from .views import TodoList #views.pyからTodoListを持ってくる urlpatterns = [ path('list/', TodoList.as_view()), #URlの末尾にに'list/'と追記すると'views.py'の'TodoList'が表示される。 ]'views.py'に存在するTodoList(これから作成していきます)を読み込んで、URLの末尾に'list/'とすることで、'TodoList'が実行されるようにする。
ちなみに'as_view()'というのは、クラス汎用ビューを使用する場合つけられるものなので、そういうものと思っておいてください。views.pyの編集
次に'views.py'を編集していきます。
'urls.py'(指示書)に沿って必要な材料を揃えるために行動するのが、この'views.py'の役割です。
下のように追記してください。from django.shortcuts import render from django.views.generic import ListView #modelオブジェクトの一覧を表示させる'ListView'をインポート from .models import TodoModel #'models.py'の'TodoModel'クラスをインポート class TodoList(ListView): template_name = 'list.html' #'list.html'を表示する model = TodoModel #'TodoModelを引っ張ってくるHTMLファイルと'models.py'ファイルを指定して、'views.py'が呼び出された時に一緒に呼び出してくれます。
models.pyの編集
必要となる素材を用意するのがこの'models.py'の役割です。
'models.py'をしたのように書き換えてください。from django.db import models from django.utils import timezone #時間を設定できるものをインんポート class TodoModel(models.Model): #'django.db.models.Model'クラスの継承 title = models.CharField(max_length=50) #タイトルの設定 content = models.TextField() #内容の設定 deadline = models.DateTimeField(default=timezone.now) #期限を24時間後に設定 def __str__(self): return self.title #管理画面でタイトルを表示させる(言葉ではわかりづらいと思うので、次の章で詳しく説明します。)追記したら、ターミナルに次のように入力してください。
$ python manage.py makemigrations #マイグレーションファイルの作成 $ python manage.py migrate #モデルをデータベースに反映もっとフィールドの種類が知りたい人は、この方の記事を読んでみるとわかりやすいです。
Django: モデルフィールドリファレンスの一覧(nachashinさん)admin.pyの編集
ここではモデルの登録をしていきます。
'admin.py'に次のように追記してください。from django.contrib import admin from todo.models import TodoModel admin.site.register(TodoModel)これで登録が完了しました。
管理者ユーザーの登録
ここから管理画面を利用できる管理者ユーザー(今回は自分)を登録をしていきます。
ターミナルに次のように入力してください$ python manage.py createsuperuserそうすると次のようなものが1行ずつ表示されるので、入力していきましょう。
#管理者名登録 Username (leave blank to use 'user1'): #ここに自分の好き名前を入力してください #Emailアドレスの登録 Email address: #ここに自分のメアドを入力してください(今回は練習なので入力しないでも大丈夫です) #管理者のパスワード Password: # Password (again): <img width="427" alt="スクリーンショット 2020-07-03 13.28.24.png" src="https://qiita-image-store.s3.ap-northeast-1.amazonaws.com/0/570269/e196962e-8dde-b60e-07c6-8bcde6fa2e52.png"> This password is too common. #パスワードが単純過ぎる場合はエラー発生 Password: #ここに管理画面に入る時のパスワードを入力してください Password (again): #パスワードの確認です。 #もしかすると次のような警告が出るかもしれません このパスワードは ユーザー名 と似すぎています。 このパスワードは短すぎます。最低 8 文字以上必要です。 このパスワードは一般的すぎます。 #今回は練習なので無視して大丈夫ですが、本番の時はしっかり作り直しましょう。 #無視する時は'y'を入力し、作り直す時は'N'を入力しましょう。 Bypass password validation and create user anyway? [y/N]: y #これが出れば管理者ユーザーの登録ができてます。 superuser created successfully.管理画面にログインし、モデルに追加する
早速管理画面にログインしていきたいと思うます。
ターミナルを開いてください。$ python manage.py runserverそうすると
Starting development server at http://127.0.0.1:8000/と出るのでクリックするとブラウザに飛びます。
ブラウザのURLの末尾に「admin/」と入力してください。
そうすると下のような管理画面のログインフォームが現れます。
①この画面が表示されたら、先ほど登録した「ユーザー名」と「パスワード」を入力して、ログインしてください。
②ログインすると、「TODO」というところに「Todo models」と表示されていると思います。
そこをクリックしてください。
③右上に「TODO MODEL」を追加とあるでクリックします。
④「タイトル」、「内容」、「期日」を入力したら、「保存してもう一つ追加」をクリックして、もう一つ好きなものを追加して「保存」を押してください。
⑤そうするとタイトルが表示されているのを確認できるはずです。
ここでいったんPycharmに戻りましょう。HTMLファイルを作成
ここからはHTMLファイルを作成していきます。
まずターミナルで「control」ボタンと「c」ボタンを同時に押して、サーバーを止めましょう。
HTMLの知識がない方もコピペで実装できるので、ひとまずは大丈夫です。
アプリケーションディレクトリの'templates'ディレクトリに移動します。
まだ作成しいない人は作成していきましょう。#アプリケーションに移動 $ cd アプリケーション名 #tempaltesディレクトリの作成 $ mkdir templates作成できたら次はHTMLファイルを作っていきます。
#templatesディレクトリに移動 $ cd templates #HTMLファイル作成 $ touch list.htmlこれでHTMLファイルfが作成できたので、書き込んでいきます。
<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> {% for list in object_list %} #モデルのデータを一つずつ取り出す。 <h1>{{ list.title }}</h1> #タイトルを表示 <p>{{ list.content }}</p> #内容を表示 <p>{{ list.deadline }}</p> #期日を表示 {% endfor %} </body> </html>djangoの中身をHTMLで表示するには、「{{}}」や「{% %}」を使います。
これでHTMLファイルの編集は完了です。ブラウザに一覧を表示
さて早速表示できる確認してみましょう。
$ python manage.py runserverとターミナルに入力して、ブラウザに移動します。
URLの末尾に'list/'と追加すると、先ほど登録したものが一覧表示されているはずです。
無事教示できている子音が確認できたら目標達成です。
今回はここまでです!
お疲れ様でした。終わりに
今回はTodoListに登録したものの一覧を表示させることをしてきました。
今後も記事を追加していくのでよかったらみていってください。
- 投稿日:2020-07-04T09:53:53+09:00
Calmar Ratio(カルマーレシオ)とは
1 目的
Calmar Ratio(カルマーレシオ)の意味と計算方法を説明します。
2 内容
2-1 Returnの計算方法
ある銘柄の開始日から当日までのReturnはこちらの定義に従います。
2-2 Maxdrowdownの計算方法
Returnが最大になった以降で、どの程度の割合でReturnが下落し底を打つのかを評価する式のことです。
具体的に開始日からn営業日の期間において、Returnの最大値を$R_{max}^{(n)}$とする。
R_{max}^{(n)}=max\left\{R_{i} | 0<i≦n \right\}ここで、Maxdrowdown $MDD_{max}^{(n)}$は下記式で定義する。
MDD_{max}^{(n)}=max\left\{\frac{R_{max}^{(n)}}{R_{i}} | 0<i≦n \right\}
2-3 Calmar Ratioの計算方法
Calmar Ratio(カルマーレシオ)の定義式
Calmar Ratio=\frac{CAGR(n)}{MDD_{max}^{(n)}}補足 : Shapen Ratioに比べて、Calmar Ratioは最悪の下落率を考慮した指標になっている。
2-4 Calmar Ratioの計算式コード例
test.pydef CAGR(DF): df = DF.copy() df["daily_ret"] = DF["Close"].pct_change() #株価終値の前日との変化率を計算する。 df["cum_return"] = (1 + df["daily_ret"]).cumprod() #cumprod(全要素の累積積を スカラーyに返します. n = len(df)/252 #1年の取引日を252日に設定している。 print( "df[cum_return]" ) print( df["cum_return"] ) print( "df[cum_return][-1] ") print( df["cum_return"][-1] ) CAGR = (df["cum_return"][-1])**(1/n) - 1 return CAGR def max_dd(DF): "function to calculate max drawdown" df = DF.copy() df["daily_ret"] = DF["Close"].pct_change() df["cum_return"] = (1 + df["daily_ret"]).cumprod() #cumprod()全要素の掛け算を行う。 print(df["cum_return"]) #ax.legend() #凡例を描写する df["cum_roll_max"] = df["cum_return"].cummax() df["drawdown"] = df["cum_roll_max"] - df["cum_return"] df["drawdown_pct"] = df["drawdown"]/df["cum_roll_max"] max_dd = df["drawdown_pct"].max() ax=df["cum_return"].plot(marker="*",figsize=(10, 5)) ax=df["cum_roll_max"].plot(marker="*",figsize=(10, 5)) ax=df["drawdown"].plot(marker="*",figsize=(10, 5)) ax=df["drawdown_pct"].plot(marker="*",figsize=(10, 5)) ax.legend() #凡例を描写する return max_dd def calmar(DF): "function to calculate calmar ratio" df = DF.copy() clmr = CAGR(df)/max_dd(df) return clmr
- 投稿日:2020-07-04T08:55:44+09:00
【初心者】Pythonの配列
Pythonで配列を使ってみる
split()に何も指定しないと、空白で区切ってリストを作ってくれる。
>>> s1 = "The quick brown fox jumps over the lazy dog." >>> s_list = s1.split() >>> print(s_list) ['The', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog.'] >>> print(s_list[1]) quick >>> len(s_list) 9 >>> while i < len(s_list): print(s_list[i]) i += 1 The quick brown fox jumps over the lazy dog >>> for w in s_list: print(w) The quick brown fox jumps over the lazy dog.
- 投稿日:2020-07-04T05:10:39+09:00
名古屋で開催されいている技術イベント・勉強会
はじめに
この度、名古屋を離れ、関東へ引っ越すことになりました。名古屋(東海圏)エンジニアを増やして地元を盛り上げていくという夢が叶わなくなってしまいました。
名古屋でもエンジニアコミュニティを盛り上げようと頑張っている企業さんや、エンジニアさんがたくさんいることを多くの人に共有したくこの記事を書いています。
名古屋へのUターンを考えていたり、リモートができるようになり都心を離れようかなぁと考えている人は、ぜひ次の拠点として名古屋を選択に入れる参考にしてみてください。
*以下イベント情報の概要はリンクページから一部引用させていただいています。
定期開催編
以下、定期開催されている勉強会です。
Yahoo! JAPAN Nagoya
主催:Yahoo! JAPAN
概要:ヤフー株式会社の名古屋オフィスで開催するクリエイター向け勉強会コミュニティ。 多種多様なクリエイター同士が交流できる場所として、開発スキルやノウハウについて学びながら、社内外のクリエイターがアウトプット/インプットできる機会になるべく、2019年3月にスタート。フロントエンドもくもく会
主催:Nagoya Frontend User Group
概要:フロントエンドを中心にしたもくもく会。名古屋の企業・団体からの会場提供を受けている。名古屋アジャイル勉強会
概要:アジャイルの考え方や方法を体験的に学び、職場で活かすことを応援する、誰でも参加できるグループ。
Mobile Act
主催:フェンリル
概要:モバイルアプリ開発関連の情報共有や参加者同士の交流を目的とした勉強会。Nagoya.Swift+
概要:技術者としての好奇心や向上心を満たすために技術的な挑戦をするふりをして遊びます。
nagoya.go
概要:名古屋のGoコミュニティ。もくもく会やGo勉強会が開催されている。
OthloTech
主催:OthloTech
概要:OthloTech<オスロテック>は東海圏の学生エンジニア・デザイナーによる学校を超えたコミュニティ。 月に1〜2回、学生限定の勉強会やハッカソンを開催。JAWS-UG名古屋
主催:JAWS-UG名古屋支部
概要:Amazon Web Services(AWS)のユーザグループ、JAWS-UGの名古屋支部のイベント。
AWSに興味があるんだけど周りに知ってる人がいない、がっつり勉強したい!という人たちが集い、一緒に勉強する場を企画。MISO MOKU
主催:Misoca Developer Meetup
概要:毎週ベースで行われていた、エンジニア・デザイナー向けのもくもく会。弥生株式会社と合併したため、2020年7月以降の開催は未定。Nagoya.unity
概要:名古屋を中心に活動を行うUnityユーザのコミュニティで、主に勉強会などの開催を行っています。
名古屋ギークバー
概要:技術的なものから、アナログゲーム、LT大会、生ハムを食べるなど、幅広くイベントを開催され、名古屋のギークな人達に会える。
番外編
開催頻度が低いけど大規模だったり、面白い試みをしているイベントを書いていきます。
NGK
概要:NGKは、東海地方IT系コミュニティ合同の大新年会。普段から東海地方の勉強会に参加している人、今まで参加したことがない人、他地域の人など、 誰にとっても、さまざまなコミュニティとつながりを広げ、深める良い機会になることを目指すイベント。
東海のエンジニアはみんな参加しているのではないか?と思うぐらい大規模なイベント。
みそかつウェブ
概要:名古屋という土地を生かし、エンジニア&デザイナーコミュニティを盛り上げるため、 IT業界に関わる人同士の交流の場として似た境遇の仲間を探したり、相談できる友人を作ったりできるコミュニティです。
最後に
思いついたイベントをばっと書いているので、どんどん追記していきます。他もあるよ~みたいなご意見ありましたら是非いただけますと嬉しいです。
コミュニティも盛り上がっているので、ぜひ色々参加してみてください。
割とアットホームな土地(外からはそう思われていないかもしれないが)なので、いいですよ~。