- 投稿日:2020-07-04T23:40:06+09:00
[Processing×Java] ループの使いかた2---入れ子構造,座標変換
この記事はプログラムの構造をProcessingを通じて理解していくための記事です。
今回はループについて少しだけ詳しく書いていきます。
目次
0.forループ0.forループ
0-0. forループと座標変換
Processingでは、"図形を描くときの基準点"や"座標そのもの"を自分の都合のいいようにカスタマイズできます。
◯"図形"の基準点を移動するプログラム
for00.javasize(500,500); background(255); //四角形の中心を基準にして図形を描けるようにする。 rectMode(CENTER); //5回繰り返す(i = 0,1,2,3,4) for(int i = 0;i < 5;i++){ //四角形の辺の大きさを表すint型の変数 s を定義する。 int s = 400 -i * 80; noFill(); stroke(115,237,201); //枠線の太さを決める strokeWeight(3); //中心が(width/2,height/2)で、辺がsの四角形を描く。 rect(width/2,height/2,s,s); }
Point : rectMode(CENTER)
これを使うと、四角形の中心を基準にして図形を描くことができます。
(デフォルトの基準点は、四角形の左上端)◯"座標"の基準点をずらすプログラム
次のプログラムでは、translate()を使って座標の中心を(width/2,height/2)にずらしています。
つまり、画面(Processingのウィンドウ)の中心の座標が(0,0)になったということです。for01.javasize(500,500); background(255); //座標の基準点(原点)を画面の中心(width/2,height/2)にずらす translate(width/2,height/2); //3回繰り返す for(int i = 0;i < 3;i++){ //TWO_PI/6 = 60度、ループの度に回転する rotate(TWO_PI/6); noFill(); stroke(12,232,178); //画面の中心が(0,0)なので... ellipse(0,0,150,375); }
Point : translate();
座標の基準点をずらすための関数。
今回は基準点を画面の中央にずらした。Point : rotate();
座標の基準点を軸に回転する。
今回は基準点が画面の中央なので、そこを軸に回転した。
引数は、PIやTWO_PIを使って指定する。Point : TWO_PI
2π = 360度
ラジアン(孤度,radian)と呼ばれる形式で円弧の長さで角度を表現する。
半径1の単位円の円周の長さは、2 * π = 2π。
単位円の円弧2πは円1周分の角度 = 360度。0-1. forループと入れ子構造
◯二重入れ子のプログラム
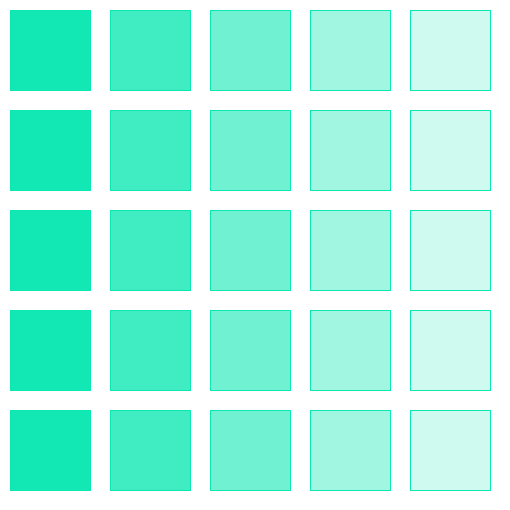
for02.javasize(510,510); background(255); stroke(12,232,178); //横の移動を5回繰り返す(i = 10,110,210,310,410) for(int i = 10;i < width;i += 100){ //縦の移動を5回繰り返す(j = 10,110,210,310,410) for(int j = 10;j < height;j += 100){ fill(12,232,178,255-i * 0.5); rect(i,j,80,80); } }
Point : プログラムの実行順番
このプログラムの場合は、1番左の列(の上から)から順番に実行されていきます。
つまり
◯i = 10のとき
・j = 10 : 実行
・j = 110 : 実行
・j = 210 : 実行
・j = 310 : 実行
・j = 410 : 実行
◯i = 110のとき
・j = 10 : 実行
・j = 110 : 実行
・j = 210 : 実行
・j = 310 : 実行
・j = 410 : 実行
◯i = 210のとき
:◯二重入れ子のプログラム(アニメーション)
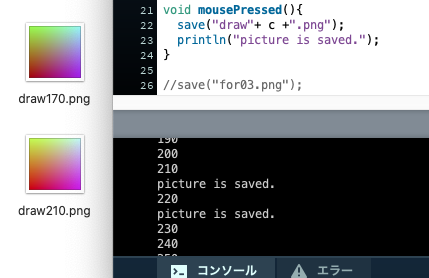
draw.java//色を変化させたいので変数cを用意する int c = 0; void setup(){ size(510,510); } //変数cを徐々にずらしていく。 void draw(){ //横の移動を500回繰り返す(i = 0,1,2...508,509) for(int i = 0;i < width;i ++){ //縦の移動を500回繰り返す(j = 0,1,2...508,509) for(int j = 0;j < height;j ++){ stroke(c,255-j/2,i/2); //1ピクセルの点を描く point(i,j); } } //色を徐々に変えていく c += 10; //色を書き出す println(c); //もし変数cの値が255を超えたら if(c > 255){ //cを0にする c = 0; } } //マウスが押されたときに1度だけ実行される void mousePressed(){ //マウスが押されたときのウィンドウをpng形式で保存する save("draw"+ c +".png"); //画像が保存されましたと出力する println("picture is saved."); }
Point :save()
画像を保存することができる。
save("~.png");などという形で、名前と保存形式を""の中に書く。
保存した画像は、メニューバーの[スケッチ]から、[スケッチフォルダーを開く]で確認できる。◯三重入れ子のプログラム
for03.javasize(510,510); background(255); noFill(); stroke(12,232,178); //四角形の中心を基準に描けるようにする rectMode(CENTER); //5回繰り返す(i = 55,155,255,355,455) for(int i = 55;i < width;i += 100){ //5回繰り返す(j = 55,155,255,355,455) for(int j = 55;j < height;j += 100){ //4回繰り返す(s = 10,30,50,70)ことで、四角形の1区画が完成する。 for(int s = 10;s < 90;s += 20){ //座標(i,j)で、辺の大きさsの正方形を描く rect(i,j,s,s); } } }
Point :
マトリョーシカのような大きさの異なる4つの四角形のかたまりがfor(int s = 10;s < 90;s += 20){ rect(,,s,s); }の部分。
このかたまりを、並べていく(二重ループの時と同じ)。
最後に
読んでいただきありがとうございました。
より良い記事にしていくために御意見、ご指摘のほどよろしくお願いいたします。





- 投稿日:2020-07-04T23:21:13+09:00
AndroidStudioのAlarmManager実装時に苦戦した点
AndroidStudioでAlarmManagerを使う方法について
自分がコードを書いていた時につまずいた点などを踏まえて紹介します。※Qiita初投稿です、ちょくちょく変なところや違うところがあるかもしれませんが多めにみてください…
AlarmManagerの設定の仕方
今回作るのは何分後(秒、時間、etc...)かに処理するというコードを作ります。
まずは、AlarmManagerの設定の仕方を見ていきます。重要!
1: AndroidManifestに設定を加えていきます。
AndroidManifest.xml<manifest xmlns:android="http://schemas.android.com/apk/res/android" <uses-permission android:name="android.permission.WAKE_LOCK" /> <application <receiver android:name=".AlarmManagerを受け取るクラス." android:process=":remote" > </receiver> </application> </manifest>AndroidManifestに
uses-permission android:name="android.permission.WAKE_LOCK"
とreceiver android:name=".AlarmManagerを受け取るクラス"を書くことでAlarmManagerが動きます。
android:process=":remote"私は、ここを書くの忘れていてめっちゃ苦労しました。公式サイトもAlarmManagerのところになかったので…
2: AlarmManagerを送るためのIntentを作る
AlarmManagerを置きたいところに.java... AlarmManager alarmManager = (AlarmManager)context.getSystemService(Context.ALARM_SERVICE); Intent intent = new Intent(context, AlarmManagerを受け取る場所.class); PendingIntent pendingIntent = PendingIntent.getBroadcast(context, 0, intent, 0); alarmManager.setExact(AlarmManager.RTC_WAKEUP, お好きな時間を「ミリ秒!」で, pendingIntent );Intentを使って何分後にデータを送るか設定します。
上の3つのコードのcontextは、だいたいgetApplicationContext()となっていることが多いです。
最後の行の第2引数はミリ秒となっていることが多いのでミリ秒で書くことをおすすめします。3: BroadcastReceiverをextends(継承)したクラスを作成する
AlarmManagerを受け取る場所.java// BoardcastReceiverを継承 public class AlarmManagerを受け取る場所 extends BroadcastReceiver { @Override public void onReceive(Context context, Intent intent) { // 作りたい処理を書く } }
BroadcastReceiverを継承してあとはonReceiveメゾットを作ってそこに処理を作ったら完成です。最後まで見ていただきありがとうございます。
最初なので何かとおかしいところがあれば申し訳ありません。twitterもやっていますのでフォローしていただければ幸いです。
https://twitter.com/tomfumy_dev
- 投稿日:2020-07-04T18:26:49+09:00
utf8mb3に入るようにJavaで制限をかけたい
やりたいことは簡単なのに。。。
MySqlのvarcharが扱える文字コード(character set)は、デフォルトでutf8であり、これはutf8mb3(3バイト文字)のエイリアスでもあるようです(バージョンがあがるごとにだんだんutf8mb4に移行しつつあるようですが)。
で、業務で使うmysql5.7には、utf8で接続することになっているため、4バイト文字が入りません。
というわけで、サーバー側(java)で文字を切ってあげればよいことになりました。調べてみたものの、なんかスマートな方法がぱっと出てこなかったので、なんとなく調べたことをまとめておきます。
サロゲートペアと4バイト文字の違い
まずこれがわからなかった。
上司に言われた指示は「絵文字を使えないようにしたい」だった。
自分の会社の先達が作ったコードでは、バリデーションでサロゲートペアをひっかけており、これを参考にしろと提示された。で、サロゲートペアって?
わからんので調べてみる
いったんUnicodeとutf8、サロゲートペアの話をある程度理解してから進みます。
- ある文字があったとき、Unicodeとutf8では、それぞれ違う符号であらわす
- 通信上はUnicodeで行い、実際プログラムが利用するときにutf8の符号にする
- utf8は1~3バイトで表す
- データ通信等ではUnicodeを使用し、実際のプログラムでは符号化(1~3バイト)して使う
- 文字「あ」は、Unicodeでは「3042」、utf8では「E3 81 82」
- Unicodeは当初の設計上、2バイト一文字で表現しようとしていたが、表現する文字が増えてきたため、2バイト*2で 一文字で表現する方法が追加された
- これがサロゲートペアで、前半がU+D800~U+DBFF、後半がU+DC00~U+DFFFの範囲と定義されている
- UTF-16ではサロゲートペアで表されるような、基本多言語面外の符号位置をUTF-8で表す時は(中略)U+10000~U+10FFFFの符号位置にデコードしてから変換する(Wiki参照)
- BPMの表現 = UTF8では3バイト文字で表現可能
- 1~3バイト内で表現しきれなかったutf8の文字を表現するために4バイト使って表現する
- utf8mb3ではこの4バイト文字が入らない
こちらの話から、utf8においては、Unicodeのサロゲートペアはutf8で4バイトで符号化されるのと同義であることがわかりました(でいいのかな?たぶん)。
理解力が乏しいせいか、なかなか把握できず困りました。。。。でこれをいざJavaでかいてみるとするとどうなるか。
いったん、上記の話を確かめるためJshellで確認してみます。import java.util.stream.IntStream; String word = "?"; System.out.println("this word has length of " + word.length()); if (word.length() != word.codePointCount(0, word.length())) { System.out.println("code point count " + word.codePointCount(0, word.length())); } IntStream.range(0, word.length()).forEach(i -> { System.out.println("code point is " + Integer.toHexString(word.codePointAt(i))); var target = word.charAt(i); if (Character.isSurrogate(target)){ System.out.println("this is surrogate pair"); } System.out.println("check "+ target); }); ------------------- this word has length of 2 code point count 1 code point is 20bb7 this is surrogate pair check ? code point is dfb7 this is surrogate pair check ?ちなみに?は「つちよし」で変換できます。
ためしにMysql5.7のvarcharにいれるとエラーになりました。
Incorrect string value: '\xF0\xA0\xAE\xB7' for column 'name' at row 1
名前にいれられないとか。。。。
まあ、今回の要件はそこではないのでよいのです。javaのcharには2バイト文字が格納されるので、string.length()は文字数でなく、左記ユニット数がカウントされます。
コードポイントが実際のUnicodeで表現する文字1つにあたるため、サロゲートペアを確認する時はcodePointCountと比較することも可能です。結論?
ということで、結局サロゲートペア = UTF8の4バイト文字の認識でよい、のかな?
どちらにしろ、Character.isSurrogate()が最も便利そうなので、これでサロゲートペアを確認し、4バイト文字を制限することとします。参考
- 【図解】【3分解説】UnicodeとUTF-8の違い!【今さら聞けない】
- Unicodeがどんな風にUTF-8に割当てられているか
- UTF-8の符号化方法について
- Unicode 【 ユニコード 】
- 符号化文字集合と文字符号化方式 - 「プログラマのための文字コード技術入門」を読んだ
- MySQL で utf8 と utf8mb4 の混在で起きること
- 投稿日:2020-07-04T17:36:48+09:00
【Java】equals()メソッド実装に「同一性」のチェックは不要なのか?
はじめに
ご覧いただきありがとうございます.Javaのequals()メソッドについて,同一の場合即座にtrueを返す以下の実装の有り無しで実行時間を比較してみました.
// equals()の冒頭で同一性チェック if (this == obj){ return true; }いきさつ(長くてすみません)
私は現在SIerの新卒SEということで研修を受けています.Java未経験者前提の内容であるため少し退屈ではありますが楽しくやっております.
(少しでも隙間時間に自分のための勉強もしなければならないという危機感を持っていたりもしますが...)さて,いま研修では開発演習というものを行っています.作成済みの外部設計書をもとに,単体,結合テスト,内部設計書(コンポーネント仕様書)作成,コーディングを行うといったプロジェクト体験のようなものです.
内部設計ではすでに決められたフィールド名メソッド名をもとに,コーディングできるようメソッドのフローチャートを作成します.
とあるDTOの仕様書に取り掛かるとそこには
「equals()メソッドをオーバーライドしてください」
とありました.あ,これ進●ゼミでやったところだ.equals()メソッドのオーバーライド
equals()メソッドはObjectクラスで以下のように定義されています.
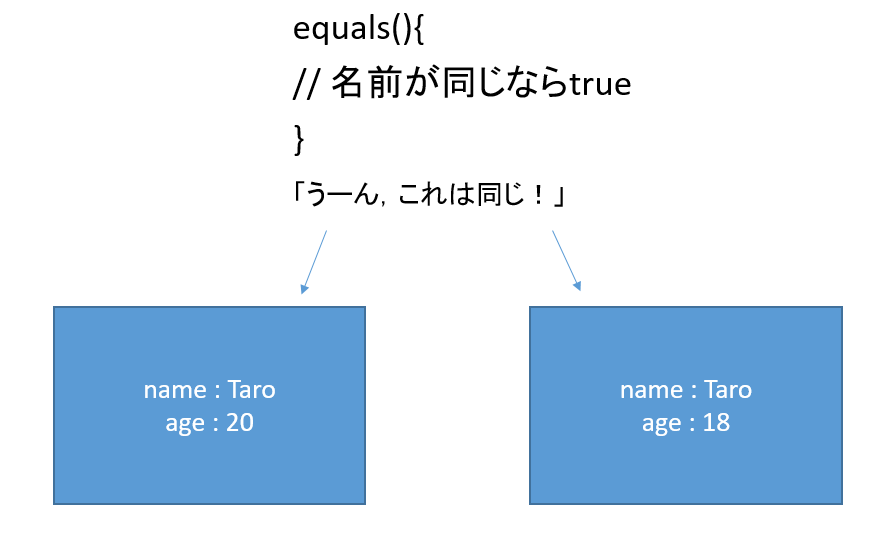
// Java 11のソースコードより抜粋 public boolean equals(Object obj) { return (this == obj); }これは単に同一性を返すのみなので自作クラスでは適切に実装する必要があります.この場合の同値性は仕様で決まるので,例えば自作クラスPersonではageフィールドが異なってもnameさえ同値なら同値判定することも(やろうと思えば)自由です.
そしてここからがこの記事の本題です.
equals()メソッドではまず最初に同一性をチェックします.// equals()の冒頭で同一性チェック(再掲) if (this == obj){ return true; }つまり,
a.equals(a)の場合即座にtrueを返します.これは必須ではないのですが,パフォーマンスに影響するので実装するのが通例だとEclipseの自動生成が言っています.これが無いと,aのフィールドがaのフィールドと等しいかを判定する必要があるわけですね.この処理は何?
equals()メソッドのフローチャートをせっせせっせと作りPM役の講師の方に提出すると,該当の同一性チェック処理の部分にこんなコメントを頂きました.
「この処理は何?」
equals()を実装する際は当然含める処理だと思っていたのでつっこまれるとは思っていませんでした.つっこむにしても,同一性チェックという概念自体は知っていて「今回は小規模なのでここまで厳密な処理は要らないかな」という指摘なら腑に落ちるのですが,「こんな処理は知らない,現場でも見たことがないし返す結果は同じだから意味ないよ」とのことでした.
もちろん私はつい最近まで学生であり現場など全く知らないので,もしかすると同一性チェックなんてこの世に存在しないのでは・・・?と疑心暗鬼になったとともに,これじゃ単に冗長なロジックを書いたただの馬鹿扱いされてしまうと思い,この記事を書いてみました.
とりあえず実行時間によるメリットを実感できれば私の勝ちとします(強引).環境
Windows10
Eclipse方法
以下のPerson.javaを使います.本来はObjectクラスのequals()メソッドをオーバーライドしなければならないのですが,比較のために同一性チェックがあるequalsWithSelfCheck()と,同一性チェックが無いequalsWithoutSelfCheck()メソッドを作成して比較しました.どちらもEclipse自動生成のequals()メソッドをもとにしています.
Person.javapublic class Person { private String name; private int age; public Person(String name, int age) { this.name = name; this.age = age; } public boolean equalsWithoutSelfCheck(Object obj) { if (obj == null) return false; if (getClass() != obj.getClass()) return false; Person other = (Person) obj; if (age != other.age) return false; if (name == null) { if (other.name != null) return false; } else if (!name.equals(other.name)) return false; return true; } public boolean equalsWithSelfCheck(Object obj) { if (this == obj) return true; if (obj == null) return false; if (getClass() != obj.getClass()) return false; Person other = (Person) obj; if (age != other.age) return false; if (name == null) { if (other.name != null) return false; } else if (!name.equals(other.name)) return false; return true; } }また,以下のMainで条件を同じにして実行時間の差を出力します.10回繰り返して計測しました.
Main.javapublic class Main { public static void main(String[] args) { ArrayList<Person> list = new ArrayList<>(); Person person = new Person("Taro", 20); //全部同一のpersonが入っているリスト for(int i = 0; i < 10000000; i++) { list.add(person); } for (int i = 0; i < 10; i++) { long time1 = 0; long time2 = 0; for (Person p : list) { long start = System.nanoTime(); person.equalsWithoutSelfCheck(p); long end = System.nanoTime(); time1 = time1 + end - start; } for (Person p : list) { long start = System.nanoTime(); person.equalsWithSelfCheck(p); long end = System.nanoTime(); time2 = time2 + end - start; } System.out.println("実行時間差:" + (time1 - time2) * 0.000001 + "ミリ秒"); } } }結果
実行時間差:7.8233999999999995ミリ秒 実行時間差:5.2443ミリ秒 実行時間差:3.8985ミリ秒 実行時間差:4.9727ミリ秒 実行時間差:5.5971ミリ秒 実行時間差:2.7468ミリ秒 実行時間差:10.9687ミリ秒 実行時間差:5.1853ミリ秒 実行時間差:5.4607ミリ秒 実行時間差:3.6744ミリ秒いずれも同一性チェックを含めたメソッドのほうが速い結果となりました.若干ばらつきはあります.
実行順が原因の可能性もあるため順序を入れ替えて試しましたが,いずれも実行時間差がマイナスになり,同じ結論になりました.ちなみに
以下のようにリストの中身が同値ではあるが同一でないケースも試してみました.
//全要素が同値(同一ではない)リスト for(int i = 0; i < 10000000; i++) { list.add(new Person("Taro", 20)); }その結果,以下のように平均した実行時間差はありませんでした.
実行時間差:3.5603ミリ秒 実行時間差:-0.223ミリ秒 実行時間差:1.0935ミリ秒 実行時間差:0.5618ミリ秒 実行時間差:-0.006999999999999999ミリ秒 実行時間差:-1.4681ミリ秒 実行時間差:-0.8628ミリ秒 実行時間差:1.5103ミリ秒 実行時間差:-1.9932999999999998ミリ秒 実行時間差:0.3394ミリ秒このことから,equals()メソッドにおける同一性チェックはパフォーマンスに十分寄与することが確認できました.
結論
equals()メソッドにおける同一性チェックはパフォーマンスに十分寄与することが確認でき,有用な実装だということがわかりました.(私の勝ち(?))
さいごに
最後までお読みいただきありがとうございました.何かございましたらぜひご指摘,ご指導よろしくお願いいたします.
- 投稿日:2020-07-04T17:21:41+09:00
ソース変更もブレークもせずにデバッグで変数の値を変更する(条件付きブレークポイント使用)
プログラムを作ったあと、通常は通らないルートをテストしたいとき、皆さんはどうしていますか?
一般的には以下のような形で実行すると思います。
- 特定の箇所にブレークポイントを設定する
- テストしたいアクションを実行する
- ブレークポイントに止まるのを待つ
- ブレークポイントに止まったら、手動で値を変更する
でも、値を変更した状態を何度か操作を繰り返したいときってありまして、こういう場合は値が自動で書き換わってほしいと思うわけなんですよ。
思ったことありませんか?実はこれは条件付きブレークポイントを使用することで実現できますが、ベテラン勢でも割と知らない人も多いので残しておきます。
前提条件と予備知識
サンプルコードと想定パターン
RestAPIを実行して、状態チェック→パース→モデル変換を行うメソッド。(内容は特に重要ではありません)
public JmaFeed getFeed() { ResponseEntity<String> response = restTemplate.getForEntity(uri, String.class); if (!response.hasBody()) { return null; } String responseBody = response.getBody(); if (isNull(responseBody)) { return null; } JmaXmlFeed xml = xmlParser.read(response.getBody(), JmaXmlFeed.class); if (isNull(xml.getTitle())) { return null; } return modelMapper.map(xml, JmaFeed.class); }このメソッドで、普段は起こり得ない
isNull(responseBody)isNull(xml.getTitle())となる条件を何度も確認したいと仮定します。
なお、xml.getTitle()はxml.setTitle()で値を書き換え可能、ソースコードは変更しないという条件も加えておきます。予備知識:条件付きブレークポイント
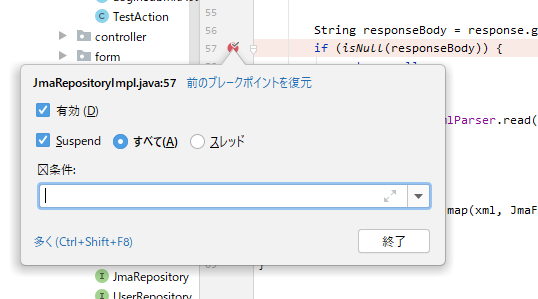
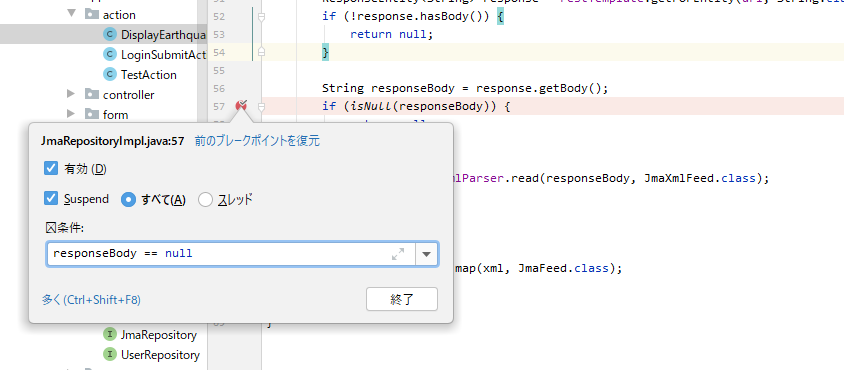
IDEでデバッグする際、ブレークポイントには条件を設定することが可能です。
これは条件付きブレークポイントと呼ばれたりもします。■IntelliJのブレークポイントで右クリックしたときの画面
この条件の普通の使い方は、「変数がAが0の場合」とか「変数Bがnullの場合」とかを設定します。
つまり、以下のような書き方をします。■例: 変数 responseBodyがnullの場合にブレークする
これで
responseBody = nullのときにブレークポイントで止めることができます。デバッグ時にソース変更もブレークもせずに変数の値を変更する方法
ここからが本題です。
2つの方法を説明していきます。条件付きブレークポイントで変数値に代入をする
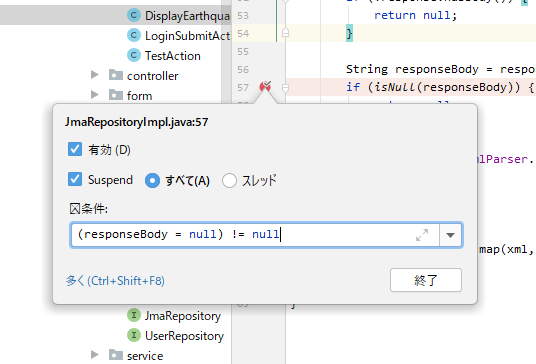
条件付きブレークポイントの条件は最終的にtrue/falseを返せば良いのであって、途中は何をしてもOK。
なので、こういう条件を設定することも可能。条件(responseBody = null) != null
この式は見ての通り
- responseBodyにnullを代入
- responseBodyがnullでないことを判定
を行うので、条件は必ずfalseになりブレークすることはありません。
つまり、ブレークポイントで止まることなく、自動でresponseBodyを書き換えることができたというわけです。条件付きブレークポイントでsetterを呼び出す
次に2.の条件
isNull(xml.getTitle()))を満たす方法ですが、さっきよりも工夫が必要です。
というのも、今回のプログラムではxml.setTitle(null)で値を変更できますが、setterの多くはvoidメソッドです。
ということは、メソッド結果を何かと比較することができず、xml.setTitle(null) != nullのような式は条件に設定できません。したがって、以下のような式にしてみます。
条件Optional.of("a").map(x -> { xml.setTitle(null); return false; }).get()
xml.setTitle(null)を実行をしつつ、falseを返す方法として、メソッドを引数にできるOptional#mapを使って実現しました。
ラムダ式を引数に持って任意の値を返すことができれば、他の方法でも実現できると思います。ちなみに、Eclipseの場合は
xml.setTitile(null)を設定するだけでも期待通りに値を書き換えてくれます。
IDEによって条件に差があるようですので、自分で使用されているIDEの挙動を確認してみてください。まとめ
デバッグ時にブレークせずに変数の値を変更する方法のまとめです。
1. 条件付きブレークポイントで変数値に代入をする
代入をして、falseとなる条件を書く
条件例(responseBody = null) != null2. 条件付きブレークポイントでsetterを呼び出す
Optional#map でsetterを呼び出してfalseを返す
条件Optional.of("a").map(x -> { xml.setTitle(null); return false; }).get()他の言語でも同様の仕組みを用いれば、同じことはできると思います。
- 投稿日:2020-07-04T17:21:41+09:00
デバッグでブレークせずに変数の値を変更する(条件付きブレークポイント使用)
プログラムを作ったあと、通常は通らないルートをテストしたいとき、皆さんはどうしていますか?
一般的には以下のような形で実行すると思います。
- 特定の箇所にブレークポイントを設定する
- テストしたいアクションを実行する
- ブレークポイントに止まるのを待つ
- ブレークポイントに止まったら、手動で値を変更する
これはこれで何も問題はありません。
僕も普通に使用します。しかしながら、値を変更した状態を何度か繰り返したいときってありまして、こういう場合は値が自動で書き換わってほしいと思うわけなんですよ。
思ったことありませんか?実はこれは条件付きブレークポイントを使用することで実現できますが、ベテラン勢でも割と知らない人も多いので残しておきます。
前提条件と予備知識
サンプルコードと想定パターン
RestAPIを実行して、状態チェック→パース→モデル変換を行うメソッド。
public JmaFeed getFeed() { ResponseEntity<String> response = restTemplate.getForEntity(uri, String.class); if (!response.hasBody()) { return null; } String responseBody = response.getBody(); if (isNull(responseBody)) { return null; } JmaXmlFeed xml = xmlParser.read(response.getBody(), JmaXmlFeed.class); if (isNull(xml.getTitle())) { return null; } return modelMapper.map(xml, JmaFeed.class); }このメソッドで、普段は起こり得ない
isNull(responseBody)isNull(xml.getTitle())となる条件を何度も確認したいと仮定します。
なお、xml.getTitle()はxml.setTitle()で値を書き換え可能、ソースコードは変更しないという条件も加えておきます。予備知識:条件付きブレークポイント
IDEでデバッグする際、ブレークポイントには条件を設定することが可能です。
これは条件付きブレークポイントと呼ばれたりもします。■IntelliJのブレークポイントで右クリックしたときの画面
この条件の普通の使い方は、「変数がAが0の場合」とか「変数Bがnullの場合」とかを設定します。
つまり、以下のような書き方をします。■例: 変数 responseBodyがnullの場合にブレークする
デバッグ時にブレークせずに変数の値を変更する方法
条件付きブレークポイントで変数値に代入をする
ここからが本題ですが、この条件は最終的にtrue/falseを返せば良いのであって、途中は何をしてもOK。
なので、こういう条件を設定することも可能。条件(responseBody = null) != null
この式は見ての通り
- responseBodyにnullを代入
- responseBodyがnullでないことを判定
を行うので、条件は必ずfalseになりブレークすることはありません。
つまり、ブレークポイントで止まることなく、自動でresponseBodyを書き換えることができたというわけです。条件付きブレークポイントでsetterを呼び出す
次に2.の条件
isNull(xml.getTitle()))を満たす方法ですが、さっきよりも工夫が必要です。
というのも、xml.setTitle(null)で値を変更できますが、setterの多くはvoidメソッドなので、メソッド結果を何かと比較することができず、条件に設定できないから。なので、以下のような式にしてみます。
条件Optional.of("a").map(x -> { xml.setTitle(null); return false; }).get()もっと良い方法があるかもしれません。
ちなみに、Eclipseの場合は
xml.setTitile(null)を設定するだけでも動いたりするので、IDEによって差があるようですね。。まとめ
デバッグ時にブレークせずに変数の値を変更する方法のまとめです。
条件付きブレークポイントで変数値に代入をする
代入をして、falseとなる条件を書く
条件例(responseBody = null) != null条件付きブレークポイントでsetterを呼び出す
Optional#map でsetterを呼び出してfalseを返す
条件Optional.of("a").map(x -> { xml.setTitle(null); return false; }).get()
- 投稿日:2020-07-04T15:22:48+09:00
JAVA Silverの学習方法を参考にして合格してみた
はじめに
Java SE 8 Programmer I(JAVA Silver)の学習方法を参考にして勉強し、合格できたので、Java Silverを取りたい方はご参考ください。
試験について、試験までの手続き
まず試験申込が意外と大変。
下記の記事は試験をとる意味や手続きまで把握できるので是非ご参考ください。参考にした記事
「Java Silver受験手続きの仕方と学習方法」自分もこちらの記事をまるまる参考にしてます。
勉強資料
以下の2冊のみを使い倒しました。
「徹底攻略Java SE 8 Silver問題集」
こちらはごりごり問題を解いていく用です。基本的にはこちらしか使いませんでした。「スッキリわかるJava入門」
こちらは問題集の解説見てもわからない時用の参考書です。学習の流れ
「徹底攻略Java SE 8 Silver問題集」の内容は1〜9章がトピック別の問題集、10・11章は総合問題(模擬試験)が入っています。
それを踏まえて下記の流れで勉強しました。(1) 1章〜9章をまず解く → 答えだけチェック(自分の実力チェック) 正答率は10%
(2) 1章〜9章を解く → じっくり解説理解(単語の定義や処理の流れを知る) 正答率20%
(3) 1章〜9章を解く → 間違ったところを特にじっくり解説理解(理解が深まった気がする) 正答率50%
(4) 10・11章(模擬試験)を解く → じっくり解説理解 正答率20% ここで心が1回心が折れる
(5) 10・11章を解く → じっくり解説理解 正答率40%
(6) 10・11章を解く → どのトピックが苦手かわかってくる 正答率70%
(7) 苦手な問題を暗記する
(8) 苦手な問題ジャンルの章にもどって復習
あとは(6)〜(8)を繰り返すのみです。時短術
わからないところが出た時、わからないところをそのままの言葉でGoogle検索。
→調べ方がわからないため、いろいろ考えずにまずは検索する
→考える時間を削減!何回も調べたものもその場で分からなくなったら何度も調べる。
→何度も同じフローを辿って記憶の定着。
→復習時間を削減!それでも分からなかったら分かる人に聞く。
→理解する時間を削減!
※オンライン・オフラインどちらでもいいので質問できる環境はおすすめ。問題を繰り返す段階で、答えも合う、解説も自分でできる問題は繰り返し解かない。
→周回の時短ここら辺は短い期間で理解を深めるための方法として有効だと思います。
勉強時間
自分は15日間で約120時間ほど
受験した方の情報を集計したところ、最低でも100〜150時間ほどの勉強時間を確保しているようです。まとめ
結果は合格ラインが65%に対し、75%で合格しました。
勉強環境を作ること
勉強時間を確保すること
やること言いたいことはこれに尽きます。
そもそも座学が苦手だと言う人はまたその対策記事も書こうかと思います。
それでは、また!
- 投稿日:2020-07-04T15:22:48+09:00
Javaを知らずに、Java Silverを2週間で合格してみた
はじめに
Javaをほぼ知らない状態でJava Silverに受かるか挑戦してみました。
Java SE 8 Programmer I(JAVA Silver)の学習方法を参考にして勉強し、合格できたので、Java Silverを取りたい方はご参考ください。試験について、試験までの手続き
まず試験申込が意外と大変。
下記の記事は試験をとる意味や手続きまで把握できるので是非ご参考ください。参考にした記事
「Java Silver受験手続きの仕方と学習方法」自分もこちらの記事をまるまる参考にしてます。
勉強資料
以下の2冊のみを使い倒しました。
「徹底攻略Java SE 8 Silver問題集」
こちらはごりごり問題を解いていく用です。基本的にはこちらしか使いませんでした。「スッキリわかるJava入門」
こちらは問題集の解説見てもわからない時用の参考書です。学習の流れ
「徹底攻略Java SE 8 Silver問題集」の内容は1〜9章がトピック別の問題集、10・11章は総合問題(模擬試験)が入っています。
それを踏まえて下記の流れで勉強しました。(1) 1章〜9章をまず解く → 答えだけチェック(自分の実力チェック) 正答率は10%
(2) 1章〜9章を解く → じっくり解説理解(単語の定義や処理の流れを知る) 正答率20%
(3) 1章〜9章を解く → 間違ったところを特にじっくり解説理解(理解が深まった気がする) 正答率50%
(4) 10・11章(模擬試験)を解く → じっくり解説理解 正答率20% ここで心が1回心が折れる
(5) 10・11章を解く → じっくり解説理解 正答率40%
(6) 10・11章を解く → どのトピックが苦手かわかってくる 正答率70%
(7) 苦手な問題を暗記する
(8) 苦手な問題ジャンルの章にもどって復習
あとは(6)〜(8)を繰り返すのみです。時短術
わからないところが出た時、わからないところをそのままの言葉でGoogle検索。
→調べ方がわからないため、いろいろ考えずにまずは検索する
→考える時間を削減!何回も調べたものもその場で分からなくなったら何度も調べる。
→何度も同じフローを辿って記憶の定着。
→復習時間を削減!それでも分からなかったら分かる人に聞く。
→理解する時間を削減!
※オンライン・オフラインどちらでもいいので質問できる環境はおすすめ。問題を繰り返す段階で、答えも合う、解説も自分でできる問題は繰り返し解かない。
→周回の時短ここら辺は短い期間で理解を深めるための方法として有効だと思います。
勉強時間
自分は15日間で約120時間ほど
受験した方の情報を集計したところ、最低でも100〜150時間ほどの勉強時間を確保しているようです。まとめ
結果は合格ラインが65%に対し、75%で合格しました。
勉強環境を作ること
勉強時間を確保すること
やること言いたいことはこれに尽きます。
そもそも座学が苦手だと言う人はまたその対策記事も書こうかと思います。
それでは、また!
- 投稿日:2020-07-04T14:28:22+09:00
ProgateでJava 勉強メモ2
型の話
データの型は結構いろんな種類があるみたい。
intとか数字ってざっくり思ってたけど、正確には「整数」。
少数点以下を持つ数字はdouble型に分類される。
int型同士の計算は結果はint型で返ってくるし、double型同士の計算はdouble型で返ってくる。System.out.println(5/2); 2 //int型 System.out.println(5.0/2.0); 2.5 //double型結果が変わるので、注意
データ型が違うもの同士を
+などで処理することはできないので、型を変換する必要がある。型変換
自動型変換
//String型+int型 System.out.println("今日は" + 6 + "月です") =>("今日は" + "6" + "月です") int型がString型に自動で変換されるint型とdouble型 ⇒ double型
int型がdouble型に自動変換されるため。
強制型変換(キャスト)
整数同士の計算で答えを正確に(小数点以下も含めて)出したいときは、強制型変換を行う。
たとえば、10/4 の計算変換したいとき→どちらかもint型なので、どっちかの値をdouble型にする。
すると、自動型変換がかかって、両方ともdouble型になり、得られる値もdouble型になる。
型変換なしであれば小数点は切られて2になるSystem.out.println((double)10/4); 10をint型からdouble型に変更 //2.5
- 投稿日:2020-07-04T13:36:58+09:00
【Spring Boot】独自のプロパティファイルを追加して、env.getProperty()で値を取得したい。
デモアプリの構成
src/main/resources/test.properties
が追加したプロパティファイル。
このファイルから、値を取得する。
プロパティファイル内は、↑の状態。@PropertySource でEnvironmentにプロパティファイルを追加する
import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.context.annotation.PropertySource; @SpringBootApplication @PropertySource("classpath:test.properties") public class PropertyTestApplication { public static void main(String[] args) { SpringApplication.run(PropertyTestApplication.class, args); } }@PropertySource()の引数に、プロパティファイルのパスを指定してやれば、Environmentに追加できる。
@PropertySourceは、@Configurationと一緒に宣言する必要があるが、
@SpringBootApplication内で、@Configurationが宣言されているため特別に宣言する必要はない。env.getProperty()で取得する。
import org.springframework.beans.factory.annotation.Autowired; import org.springframework.core.env.Environment; import org.springframework.stereotype.Component; @Component public class PropertyGetComponent { @Autowired Environment env; public void printProperty() { String value = env.getProperty("test.property.key"); System.out.println("取得した値は[ " + value + " ] です。"); } }printProperty()の実行結果は↓
取得した値は[ test value ] です。env.getProperty()で追加したプロパティファイルから、値を取得することができた
参考にした記事


- 投稿日:2020-07-04T12:32:13+09:00
簡単な学習 Java
初心者がJavaをより速く、より速く学ぶために一歩一歩
https://www.amazon.co.jp/dp/B08C7XJGRF
Javaは強力なプログラミング言語です。 習得が簡単で楽しいJava。 この本はJavaを生き生きとさせ、風変わりでフルカラーのイラストが物事をより明るい面に保ちます。 オブジェクト指向プログラミングを整理し、クラスとメソッドでコードを再利用する方法、ループや条件ステートメントなどの制御構造を使用する方法、Javaでシェイプとパターンを描画する方法、キャンバスでゲーム、アニメーション、グラフィックを作成する方法を学びます。
ほんの少しの時間で、Javaを使用して設計および開発する方法を学ぶことができます。 この本の各レッスンは、わかりやすいステップバイステップのアプローチを使用して、前のレッスンに基づいており、基本を基礎から学ぶことができます。 明確な指示と実践的で実践的な例は、Javaと対話する方法を示しています。
この本は、Javaの主なスキルとコーディングを理解するための段階的なガイダンスを教えています。 本の終わりまでに、独自のアプリケーションとゲームを作成できます。 あなたはそれを簡単かつ迅速に学びます。

- 投稿日:2020-07-04T12:16:07+09:00
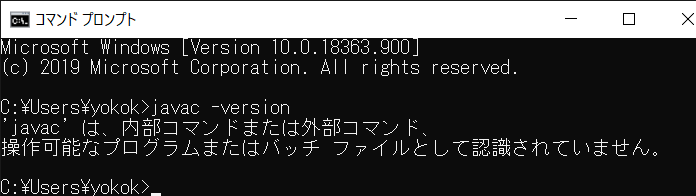
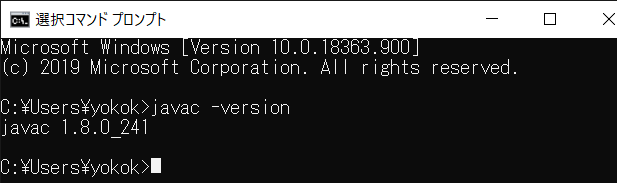
PATHが通らない…原因は文字コード
新しく買ったPCにJDKをインストールし、環境変数を設定しました。そしてjavacコマンドを実行、、、
うーん、環境変数の設定を再確認してみても間違いは見当たらない。
そこで文字コードの問題かもしれないと思い、入力したパスの文字コードを確認してみると
どうやら円マークがU+005Cではなく、U+00A5になっていたようです。
そもそも私たちがWindowsの日本語キーボードで入力している円マークは実は円マークではなくバックスラッシュの仮の姿です。(正確にはあれこれすると円マークも入力できますが)
なぜこんなことが起きるのかというと、もともとのASCIIでバックスラッシュの文字が割り振られていた5Cという文字コードに日本では円マークを割り振り、JIS X 0201として規格化してしまったからです。
その後、全世界の文字コードを統一しようということで、Unicodeの規格が生まれ、バックスラッシュと円マークをきちんと区別して定義しようとなりました。その際、U+005Cにバックスラッシュが、U+00A5に円マークが割り当てられます。
しかし、WindowsがUnicode化するにあたって「U+005Cの文字コードはバックスラッシュだが、日本語の表示では円マークとする」としました。
そのため、日本語キーボードでバックスラッシュを入力すると、フォントによって画面上には円マークだったりバックスラッシュだったりが表示されたりします。(実際はバックスラッシュ)
つまり、私たちが普段日本語キーボードで入力するときは入力した文字が円マークで表示されていても、本当はバックスラッシュ(文字コードがU+005C)なのです。
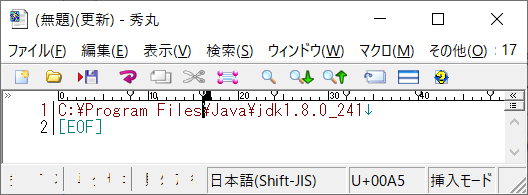
しかし、どっかからコピペなどをしてきたときに本物の円マーク(文字コードがU+00A5)を持ってきてしまうことがあるのです。さて、説明が長くなりましたが、今回の私の場合はパスをコピペして設定していたため、(なぜか)本物の円マークを使ってしまっていました。なので、きちんとキーボードから入力して環境変数を設定してあげると、
このように無事、javacコマンドが実行できました。
- 投稿日:2020-07-04T11:41:12+09:00
【Java】ジェネリクスクラスおよびジェネリクスメソッド
はじめに
ListやMapでお馴染みのジェネリクスについて、なんとなく利用しているが、自作クラスに対してジェネリクスを使用する場合にあやふやになることがあるので最低限覚えておきたいことを残しておく。
検証環境
- Eclipse Oxygen.3a Release (4.7.3a)
- Java8
検証用ソースコード
Generics.javapackage generics; import java.util.ArrayList; import java.util.List; public class Generics { public static void main(String[] args) { Bean<String> beanForStr1 = new Bean<String>(); beanForStr1.setValue("文字列"); System.out.println(beanForStr1.getValue()); Bean<Integer> beanForInt1 = new Bean<Integer>(); beanForInt1.setValue(1000); System.out.println(beanForInt1.getValue()); ExpandBean<Integer> beanForInt2 = new ExpandBean<Integer>(); beanForInt2.setValue(1000); System.out.println(beanForInt2.getValue()); System.out.println(getAnyBean(beanForStr1).get(0).getValue()); System.out.println(getAnyBean(beanForInt1).get(0).getValue()); System.out.println(getAnyBean(beanForInt2).get(0).getValue()); } /** * ジェネリクスメソッド */ public static <T> List<T> getAnyBean(T args){ List<T> list = new ArrayList<T>(); list.add(args); return list; } }Bean.java/** * ジェネリクスクラス */ public class Bean<T> { private T value; public T getValue() { return value; } public void setValue(T value) { this.value = value; } }ExpandBean.javapackage generics; /** * ジェネリクスクラス * 「Numberクラスを継承した何らかのクラス」といった指定(制限)ができる */ public class ExpandBean<T extends Number> { private T value; public T getValue() { return value; } public void setValue(T value) { this.value = value; } }メモ
基盤部分を作ったり、共通処理をまとめたりするのに覚えておくと役立つ。
ジェネリクスクラスはシックリ来るが、ジェネリクスメソッドの戻り値指定の直前にジェネリクスを書く点がなんかシックリ来ない。ではまた(^_^)ノシ
- 投稿日:2020-07-04T10:35:55+09:00
Javaのメソッドバインディングについて
今日はJavaのメソッドバインディングに関して記事を書こうと思います。
普段Javaを勉強していてあまり意識していなかったのでこの際ちゃんと整理することにします。事前知識
事前知識としてキャストについて復習しておきましょう。キャストには明示的な型変換と暗黙的な型変換があります。詳しくは以下のURLを見てみてください。
https://techacademy.jp/magazine/28486
それとコンパイル時と実行時のタイミングについても知っておいた方がいいでしょう。コンパイル時とは自分が書いたJavaファイルがバイトコードに変換されるタイミング。実行時とはそのバイトコードをJVMが実際に実行するタイミングです。Eclipseで開発している場合は通常コードを書いたら勝手にコンパイルされ、実行ボタンを押したタイミングでコードが実行されます。ターミナルなどで開発してる時はjavacコマンドでコンパイルしてclassファイルを作ったらjavaコマンドで実際に実行しますね。
それと記事内で使用してる「結びつける」とか「バインドする」っていうのは全部同じ意味で使っています。(紛らわしくてごめんなさい。。)そもそもメソッドバインディングって?
僕自身この言葉の意味も知らなかったのですが簡単にいうと、Javaにおいてメソッドの呼び出しとその呼び出されたメソッドのシグニチャ、および実装部分を結びつける(バインディングする)仕組みのようなものです。シグニチャとはメソッド名+引数のことで、実装部分とは{}の中の処理のことです。メソッドはこの2つで一塊りとなっていますが今は分けて考えてください。これを理解していないと思わぬところでつまづく可能性があります(まだエンジニアではないので偉そうなことは言えませんが・・・)。具体的に見ていきましょう。
Animal.javapublic class Animal { public void eat(double quantity) { System.out.println("動物は" + quantity + "g食べました。"); } }Human.javapublic class Human extends Animal { public void eat(int quantity) { System.out.println("人間は" + quantity + "g食べました。"); } }Test.javapublic class Test { public static void main(String[] args) { Animal animal = new Human(); int quantity = 500; animal.eat(quantity); // ? } }クラスは全て同じパッケージ内にあるとします。ここでTest.javaを実行すると何が出力されるでしょうか?そしてその理由は?
メソッドバインディング
正解は「動物は500.0g食べました。」と出力されます。なぜでしょうか。自分は最初Humanが参照先として代入されているのだから「人間は500g食べました。」と出力されるはずだ、と考えました。Testクラスで引数に渡されているのもint型ですし。でも実際には答えは違いました。
何が起こったかを理解するためにJavaにおけるメソッドのバインディング(結び付け)が起こるタイミングを見ていきましょう。以下の表を見てください。
メソッドタイプ コンパイル時にバインディング 実行時にバインディング non-staticメソッド メソッドシグニチャ メソッド実装 staticメソッド メソッドシグニチャ、メソッド実装 今回はeatがnon-staticメソッドなのでこれを元に説明していこうと思います(staticメソッドでも考え方は同じです)。
コンパイル時のバインディング
Javaではコンパイル時に、呼び出されたメソッドとそのシグニチャを結びつけます。つまり、コンパイラが毎回呼び出されたメソッドのシグニチャを決めていると言っても良いかもしれません。このルールを今自分たちが見ているコードに沿って考えてみましょう。Test.javaの最後の行はこうなっていました。
Test.javaanimal.eat(quantity);まず、コンパイラは変数animalの宣言タイプ(型)を見にいきます。animalの型はAnimal型です。次にコンパイラは「うん、うん。この変数はAnimalクラスの型だな。じゃあ、このクラスの中に今呼び出されているメソッドがあるのか探してみよう。」と捜索を開始します。この時、呼び出されているメソッドと互換性があるメソッドも検索範囲に含まれます。実際にAnimalクラスの中には
Animal.javaeat(double quantity)というシグニチャが定義されています。呼び出し元では引数にはint型が渡されていますがint→doubleの変換は暗目的に勝手に行われるので(明示的にキャストしなくていい)、コンパイラが「これは今呼び出されているメソッドと互換性のあるメソッドだ」と判断して、animal.eat(quantity)のメソッド呼び出しとdouble型を引数に取るeatメソッド(シグニチャ)を結びつけます。この時点でeatの引数はdouble型だということがコンパイラによって決定されました。そしてそれはもう実行時には変更することはできません。実際に確かめてみましょう。
Compiled from "Test.java" public class Test { public Test(); Code: 0: aload_0 1: invokespecial #1 // Method java/lang/Object."<init>":()V 4: return public static void main(java.lang.String[]); Code: 0: new #2 // class Human 3: dup 4: invokespecial #3 // Method Human."<init>":()V 7: astore_1 8: sipush 500 11: istore_2 12: aload_1 13: iload_2 14: i2d 15: invokevirtual #4 // Method Animal.eat:(D)V 18: return }これはターミナルからjavacコマンドでそれぞれのファイルをコンパイルした後、javap -c Testとやってコンパイルしたコードの中身を見ています。ここで気にして欲しいのは以下の行です。
15: invokevirtual #4 // Method Animal.eat:(D)VこれはTestクラスの中のメソッドの呼び出し部分、animal.eat(quantity)と対応しています。(D)は引数はdouble型、Vは戻り値はvoidである、ということを示しています。invokevirtualというのは実際の実装部分は実行時に決定されるっていう意味です。このバイトコードの指示にしたがってRuntimeにコードが実行されます。つまり、コンパイラでは上記のように「呼び出されているメソッドはAnimalのeatメソッドだよ」と結びつけだけを行って実行時にJVMによって処理の中身が決定されます。
実行時のバインディング
あとはバイトコードの指示にしたがってanimal.eat(quantity)のメソッドを実行すれば良いだけです。
先ほど、コンパイラは変数animalの宣言タイプを見にいくと言いました。JVMは代入されるオブジェクトから捜索を開始します。つまり、Test.javaAnimal animal = new Human();コンパイラはこの式の左側(Animal)を参照して一連のバインディングを行うのに対して、JVMはまず右側(Human)のオブジェクトを見にいきます。
そうするとこれはHumanクラスのオブジェクトなのでHumanクラスの中で、eat:(D)Vのメソッドを探そうとします。一方で、Humanクラスの中にあるのは、eat:(I)Vなので(Iはint型のこと)、マッチするメソッドは見当たりません。そこでJVMはその継承関係から該当のメソッドを探しに行きます。つまり、そのクラスが継承している親クラスを見てそこにもなかったらさらにその親クラスを見にいくと言った具合でどんどん階層を上がりながらeat:(D)Vを探しに行くのです。今回だと一階層上がったAnimalクラスに該当のメソッドがあったのでこの中の実装部分を呼び出し元のメソッド(animal.eat(quantity))とバインディングして処理を実行しています。結果として、「動物は500.0g食べました。」と出力されたわけです。メソッドバインディングの例
最後にメソッドバインディングの一例を見てみましょう。
List<Integer> list = new ArrayList<>(); list.add(1); list.add(2); list.add(3); list.add(4); System.out.println(list); // [1, 2, 3, 4] list.remove(3); System.out.println(list); // [1, 2, 3]List型のremoveメソッドにはList.remove(int index)とList.remove(Object o)の違う型の引数を取るメソッドが2つオーバーロードされています(https://docs.oracle.com/javase/jp/8/docs/api/java/util/List.html )。ここではremoveにint型の引数が入れられているのでlist.remove(3)とList.remove(int index)がコンパイル時にバインディングされます。そして実行時にArrayList.remove(int index)の中の処理(実装部分)がlist.remove(3)とバインディングされます。結果として、このリストの3番目のindexにある4が削除され、[1, 2, 3]と表示されるわけです。
ここまでは別に何も変わったことはありません。しかし次の例はどうでしょう。Collection<Integer> list = new ArrayList<>(); list.add(1); list.add(2); list.add(3); list.add(4); System.out.println(list); // [1, 2, 3, 4] list.remove(3); System.out.println(list); // [1, 2, 4] ← ??変わったのはlistの入れ物がList型からCollection型になっただけです。結果は[1, 2, 4]と表示されました。indexの3番目ではなく、数値の3そのものが削除されたのです。なぜならCollectionにはCollection.remove(Object o)の1つしかremoveメソッドがないからです。コンパイラはこのObject型を引数に取るremoveメソッドとlist.remove(3)をバインディングします。これにより、list.remove(3)の引数の3というのはindexではなく、Objectとして扱われます。実際に先ほどと同様javapコマンドで確認してみると、Collection.remove:(Ljava/lang/Object;)Zと表示されます(ZはBoolean型のこと)。そしてバイトコードの指示に従って今度はArrayList.remove(int index)ではなく、ArrayList.remove(Object o)がJVMによって実行されます。結果として[1, 2, 4]が画面に表示されたわけです。もしメソッドバインディングについて知らなかったら普通にindexの3番目が削除される想定でプログラムを組んでいたかもしれません。そうなれば障害の原因になります。それを回避するためにもこのメカニズムを知っておくことは大きなメリットがあると思い、今回記事を書かせていただきました。
ここまで読んでいただきありがとうございました。
- 投稿日:2020-07-04T09:40:02+09:00
【Java】Adapterパターン
検証環境
- Eclipse Oxygen.3a Release (4.7.3a)
- Java8
検証用ソースコード
例えば下記のようなOimoクラスがあったとしましょう。このクラスは味を感じることができます。
Oimo.javapackage adapter; public class Oimo { public String feelTaste() { return "おいしい"; } }しかしながら、私はお芋を食べるときにお芋の情報が欲しいので
下記のように宣言します。ここで出てくるNewAbilityクラスとNewOimoクラスがAdapterパターンの主役たちです。User.javapackage adapter; public class User { public static void main(String[] args) { NewAbility oimo = new NewOimo("紅あずま"); System.out.println(oimo.oimoInfo()); } }まずはOimoクラスを継承したNewOimoクラスを作成しましょう。
ついでにお芋情報を取得できるように新しい能力を授けましょう。NewOimo.javapackage adapter; public class NewOimo extends Oimo implements NewAbility { public final String name; public NewOimo(String name) { this.name = name; } @Override public String oimoInfo() { return getName() + feelTaste(); } private String getName() { return this.name; } }続いて、UserクラスとNewOimoクラスの架け橋となるNewAbilityインタフェースを作成してNewOimoクラスに委譲しましょう。
NewAbility.javapackage adapter; public interface NewAbility { public String oimoInfo(); }クラス図
感想
既存コードを利用したいけど、IFが違うから直接は利用できないときに、このAdapterパターンが役に立ちそう。覚えておこう!
ド新規の開発だと使うことはないのかな?ではまた(^_^)ノシ

- 投稿日:2020-07-04T00:05:34+09:00
【Apache POI】対応するExcelのバージョン
本記事の内容
JavaでExcelを読み書きためにApache POIを使っているときに、Excelのバージョンによって対応するコンポーネントの種類が異なったり、使えないバージョンがあったので忘備録としてまとめることにしました。
(もし、間違いがあれば教えていただけると嬉しいです。)Apache POIとは
初めに、簡単にApache POIについて説明します。
Apache POIとは、JavaのプログラムでOfficeのファイルを読み書きできるライブラリです。
>Apache POI公式サイトExcelの読み書きに使うコンポーネント
Excelの読み書きを行うためのコンポーネントは3種類あり、拡張子や用途によって使用するものが異なります。
コンポーネント 読込 書込 拡張子 対応バージョン HSSF 〇 〇 .xls Excel 97-Excel 2003 (BIFF 8) XSSF 〇 〇 .xlsx Excel 2003- (OOXML) SXSSF × 〇 .xlsx Excel 2003- (OOXML) HSSFやXSSFはExcelのバージョンに合わせて通常の読み書き時に使用します。
※Excel 97より前のバージョン(BIFF 5.0,7.0)では使用できないのでご注意ください。
SXSSFは読み込みはできませんが、ファイルサイズの大きいExcelを書き込む際にメモリを最適化してくれます。
(Apache POIの公式のものではありませんが、読み込み時はStreaming Readerというライブラリが便利です。)おわりに
今回は簡単にApache POIが使用できるExcelのバージョンとコンポーネントについてまとめてみましたが、後日、Apache POIの使用方法についてもまとめていけたらと思います。