- 投稿日:2020-06-30T23:46:47+09:00
【Pytorch】MaxPool2dのceil_mode
ceil_modeとは
Pytorchの学習済モデルtorchvision.models.googlenetをKerasに移植してみようと思ったら、気になることが。
MaxPool2dのceil_modeってなんでしょか。
ドキュメントをみると、「Trueの場合、出力シェイプの計算でfloor(切り捨て)ではなくceil(切り上げ)を使う」とある。
torch.nn — PyTorch master documentation
ceil_mode – when True, will use ceil instead of floor to compute the output shape
以下は、torchvision.models.googlenetで最初にでてくるMaxPool2D。
# 入力は (112, 112, 64) MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=True)出力サイズを計算してみると、55.5
output\_shape = \frac{input\_shape + 2 \times padding - kernel\_size}{stride} + 1 \\ = \frac{112 + 2 \times 0 - 3}{2} + 1 = 55.5torchsummaryで実際の出力サイズを見てみると、(ch=64, 56, 56)なので、確かに小数点以下を切り上げ(ceil)してるっぽい。
MaxPool2d-4 [-1, 64, 56, 56]PyTorchの結果を確認してみる
kernel=(3,3), stride=(2,2)のMaxPool2dに以下の(10,10)サイズのサンプルデータを突っ込んで結果をみてみる。
サンプルデータ
import torch import torch.nn as nn >>> x = torch.arange(1, 101).view(1, 10, 10).float() >>> x tensor([[[ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.], [ 11., 12., 13., 14., 15., 16., 17., 18., 19., 20.], [ 21., 22., 23., 24., 25., 26., 27., 28., 29., 30.], [ 31., 32., 33., 34., 35., 36., 37., 38., 39., 40.], [ 41., 42., 43., 44., 45., 46., 47., 48., 49., 50.], [ 51., 52., 53., 54., 55., 56., 57., 58., 59., 60.], [ 61., 62., 63., 64., 65., 66., 67., 68., 69., 70.], [ 71., 72., 73., 74., 75., 76., 77., 78., 79., 80.], [ 81., 82., 83., 84., 85., 86., 87., 88., 89., 90.], [ 91., 92., 93., 94., 95., 96., 97., 98., 99., 100.]]]) >>> x.shape torch.Size([1, 10, 10])ceil_mode = False
padding = 1
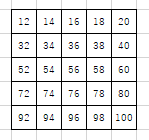
>>> nn.MaxPool2d((3,3), stride=2, padding=1, ceil_mode=False)(x) # 出力サイズ (5, 5) tensor([[[ 12., 14., 16., 18., 20.], [ 32., 34., 36., 38., 40.], [ 52., 54., 56., 58., 60.], [ 72., 74., 76., 78., 80.], [ 92., 94., 96., 98., 100.]]])output\_shape = \frac{input\_shape + 2 \times padding - kernel\_size}{stride} + 1 \\ = \frac{10 + 2 \times 1 - 3}{2} + 1 = 5.5小数点以下を切り捨てて、5.5 → 5
padding = 0
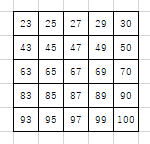
>>> nn.MaxPool2d((3,3), stride=2, padding=0, ceil_mode=False)(x) # 出力サイズ (4, 4) tensor([[[23., 25., 27., 29.], [43., 45., 47., 49.], [63., 65., 67., 69.], [83., 85., 87., 89.]]])output\_shape = \frac{input\_shape + 2 \times padding - kernel\_size}{stride} + 1 \\ = \frac{10 + 2 \times 0 - 3}{2} + 1 = 4.5小数点以下を切り捨てて、4.5 → 4
ceil_mode = True
padding = 1
>>> nn.MaxPool2d((3,3), stride=2, padding=1, ceil_mode=True)(x) # 出力サイズ (6, 6) tensor([[[ 12., 14., 16., 18., 20., 20.], [ 32., 34., 36., 38., 40., 40.], [ 52., 54., 56., 58., 60., 60.], [ 72., 74., 76., 78., 80., 80.], [ 92., 94., 96., 98., 100., 100.], [ 92., 94., 96., 98., 100., 100.]]])output\_shape = \frac{input\_shape + 2 \times padding - kernel\_size}{stride} + 1 \\ = \frac{10 + 2 \times 1 - 3}{2} + 1 = 5.5小数点以下を切り上げて、5.5 → 6
padding = 0
>>> nn.MaxPool2d((3,3), stride=2, padding=0, ceil_mode=True)(x) # 出力サイズ (5, 5) tensor([[[ 23., 25., 27., 29., 30.], [ 43., 45., 47., 49., 50.], [ 63., 65., 67., 69., 70.], [ 83., 85., 87., 89., 90.], [ 93., 95., 97., 99., 100.]]])output\_shape = \frac{input\_shape + 2 \times padding - kernel\_size}{stride} + 1 \\ = \frac{10 + 2 \times 0 - 3}{2} + 1 = 4.5小数点以下を切り上げて、4.5 → 5
ceil_modeのTrue/Falseでの違い
以下の出力サイズはいずれも(5, 5)となるが、違いは何か。
* padding=1, ceil_mode=False
* padding=0, ceil_mode=Truepadding=1, ceil_mode=False
MaxPoolingの様子
出力
padding=0, ceil_mode=True
MaxPoolingの様子
パディングなしなので、左上からプーリングを行っている。
出力シェイプが切り上げされることにより、結果右と下のみパディングしたのと同じ結果となっている。
出力
Kerasの結果を確認してみる
kernel=(3,3), stride=(2,2)のMaxPool2dに以下の(10,10)サイズのサンプルデータを突っ込んで結果をみてみる。
KerasのMaxPooling2Dには、ceil_mode的なパラメータはない。Kerasはいつも出力シェイプの計算結果を小数点以下切り捨てしている模様(Pytorchでいうところのceil_mode=False)。
サンプルデータ
Pytorchのときと同じく、10x10のデータを生成。
from tensorflow.keras.layers import MaxPooling2D import numpy as np x = np.arange(1, 101).reshape(1, 10, 10, 1).astype(np.float)padding=1
Pytorchでの、padding=1, ceil_mode=Falseと同じ出力。
>>> out = MaxPooling2D((3,3), strides=(2,2))(ZeroPadding2D((1,1))(x)) >>> out = tf.transpose(out, perm=[0,3,1,2]) >>> with tf.Session() as sess: >>> out_value = sess.run(out) >>> print(out_value) # 出力サイズ (5, 5) [[[[ 12. 14. 16. 18. 20.] [ 32. 34. 36. 38. 40.] [ 52. 54. 56. 58. 60.] [ 72. 74. 76. 78. 80.] [ 92. 94. 96. 98. 100.]]]]padding=0
Pytorchでの、padding=0, ceil_mode=Falseと同じ出力。
>>> out = MaxPooling2D((3,3), strides=(2,2))(x) >>> out = tf.transpose(out, perm=[0,3,1,2]) >>> with tf.Session() as sess: >>> out_value = sess.run(out) >>> print(out_value) # 出力サイズ (4, 4) [[[[23. 25. 27. 29.] [43. 45. 47. 49.] [63. 65. 67. 69.] [83. 85. 87. 89.]]]]kerasで、ceil_mode=Trueと同じ出力を出すには?
ZeroPadding2Dは以下の様に設定すると、上下および左右に対しゼロパディングする。
ZeroPadding2D((1,1))(x)
以下のように、上と下、左と右、それぞれパディングの設定を変えることも可能。
(下と右にだけゼロパディングを適用している)ZeroPadding2D(((0,1), (0,1)))(x)
下と右にだけゼロパディング適用することにより、ceil_mode=Trueと同じ出力を得ることができた。
>>> out = MaxPooling2D((3,3), strides=(2,2))(ZeroPadding2D(((0,1), (0,1)))(x)) >>> out = tf.transpose(out, perm=[0,3,1,2]) >>> with tf.Session() as sess: >>> out_value = sess.run(out) >>> print(out_value) # 出力サイズ (5, 5) [[[[ 23. 25. 27. 29. 30.] [ 43. 45. 47. 49. 50.] [ 63. 65. 67. 69. 70.] [ 83. 85. 87. 89. 90.] [ 93. 95. 97. 99. 100.]]]]



- 投稿日:2020-06-30T23:01:57+09:00
atom(仮想環境)のhydrogenを設定する手順
はじめに
atomで開発をしていく中で、途中までのコードを実行したいときありませんか?調べるとAtomをjupyterのように使用できるhydrogenというpackageがあったのでその設定方法を書いていこうと思います。私のような初心者ではエラーがなかなか解消できず、解決できた時は正直泣きました。笑
はじめての投稿かつ独学でやっているもので間違い等あれば指摘していただけると幸いです。対象とする人
・atomのhydrogenを仮想環境下で設定したい方
・atomでhydrogenを設定する際に以下のようなエラー文が出た方(atomでhydrogenを実行しようとしたきとにでるエラーです)
Traceback (most recent call last): File "C:\Program Files\WindowsApps\PythonSoftwareFoundation.Python.3.7_3.7.2032.0_x64__qbz5n2kfra8p0\lib\runpy.py", line 193, in _run_module_as_main "main", mod_spec) File "C:\Program Files\WindowsApps\PythonSoftwareFoundation.Python.3.7_3.7.2032.0_x64__qbz5n2kfra8p0\lib\runpy.py", line 85, in _run_code exec(code, run_globals) File
・・・・・・・中略・・・・・・・・ "C:\Users\username\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.7_qbz5n2kfra8p0\LocalCache\local-packages\Python37\site-packages\jupyter_core\paths.py", line 361, in win32_restrict_file_to_user import win32api ImportError: DLL load failed: �w�肳�ꂽ���W���[����������܂���B
自分が陥ったエラーについて
自分が一通り設定を完了してからatomでhydrogenを実行したときに上記のエラーコードで出できて、ほんとうに苦労しました。
いろいろ試した結果解決策は以下のとおりでした。(詳細は以下の手順⑧からみてください)
・Atom/環境設定/hydrogen/settingsから設定ができる「startup code」「Kernel Gateways」へjupyter Kernel のjsonを張り付ける手順の際に仮想環境のjsonではなくbase環境のjsonを張り付けていたためこのようなエラーがでていたと思われます。(base環境はpython3.7です。)
環境
・Windows10
・Atom 1.48.0
・hydrogen 2.14.3
・仮想環境 conda python3.6.10
※anaconda,atom,hydrogenはインストール済みであることとします。
仮想環境を構築した理由としては、python3.7だとhydrogenが上手く動かない?といった記事がいくつかあったため、python3.6の仮想環境を構築することにしました。(実際にpython3.7での設定は試みていないため真偽は不明)手順
①仮想環境を構築
・anaconda promptを起動
・以下のコードを実行
Anaconda_prompt>conda create -n py36_fxpractice python=3.6※
py36_fxpracticeの部分は仮想環境名になる箇所であるため任意の名称で構いません。
※今回はpython3.6の仮想環境を構築したいので仮想環境を構築する際pythonのversionを指定しています。・実行後いろんな文章が表示された後、以下の文が表示されます。
Proceed ([y]/n)?
yを入力しEnter②:構築した環境の確認
以下のコードを実行
Anaconda_prompt>conda info -e出力結果# conda environments: # base * C:\Users\UsersName\Anaconda3 py36_fxpractice C:\Users\UsersName\Anaconda3\envs\py36_fxpractice※このコードで先ほど作成した仮想環境ができているかの確認および、どこの環境にいるのかの確認をします。
※出力結果からbase環境と先ほど作成したpy36_fxpractice環境があることがわかります。base環境に*印があるため現在はbase環境にいることもわかります。③:仮想環境への切替え
以下のコードを実行
Anaconda_prompt>activate py36_fxpractice実行後(py36_fxpractice) C:\Users\Kawahara>※実行後環境が仮想環境に切り替わります。
(base)⇒(py36_fxpractice)に替わります。④:jupyterのインストール
以下のコードを実行
Anaconda_prompt>conda install jupyter※仮想環境でjupyterをインストールします。jupyterをインストールする際に、同時に必要なものが④のコード実行後「これも一緒にインストールするよ?」って感じで表示されます。
・実行後いろんな文章が表示された後、以下の文が表示されます。
Proceed ([y]/n)?
yを入力しEnter⑤:jupyterのkernelを作成
以下のコードを実行
Anaconda_promptipython kernel install --user --name py36_fxpractice --display-name py36_fxpractice※
$ipython kernel install --user --name=環境名 --display-name=環境名であるため、環境名の箇所は任意のもので構いません。⑥:jupyter kernelの確認
以下のコードを実行
Anaconda_promptjupyter kernelspec list出力結果Available kernels: py36_fxpractice C:\Users\UserName\AppData\Roaming\jupyter\kernels\py36_fxpractice python3 C:\Users\UserName\AppData\Roaming\jupyter\kernels\python3※作成した仮想環境のパスのようなものが表示されていれば成功です。
⑦必要なライブラリのインストール
Anaconda_prompt〈例〉conda install numpy
conda install 【ライブラリ名】でインストールできます。①④同様にProceed ([y]/n)?と聞かれるのでyを入力しEnterをします。上記は例としてnumpyをインストールしています。⑧:jupyter notebookの起動
以下のコードを実行
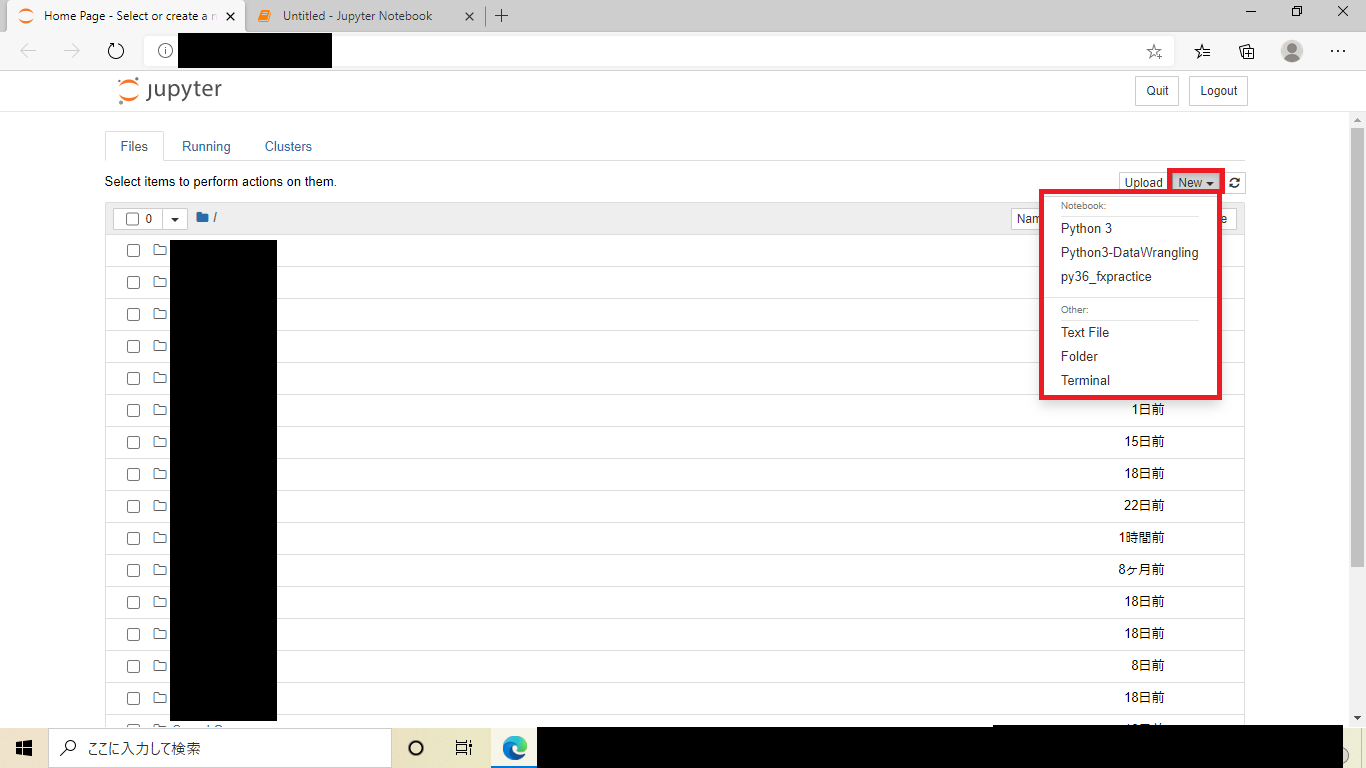
Anaconda_promptjupyter notebookコード実行後ブラウザでjupyteが起動します。(以下のような画面が表示されます。)
・上記の画像の
Newをクリックし⑤で作成したカーネルのdisplay-nameがあるはずなのでそれを選択します。実際にコードを実行してみてjupyterが正常に動くのか確認します。
確認後jupyterおよびanaconda promptを閉じます。(画面右上の×で私は閉じています。)⑨:jupyter kernelのjsonを取得
再度anaconda promptを開き以下のコードを実行
Anaconda_promptjupyter kernelspec list --json※コードを実行後にjsonコードが表示されます。jsonとはたくさんの[]で囲まれて中に、パスなどが表示されています。その中に上記の手順で作成した仮想環境名であったり、display名があれば成功っぽいです。
⑩:Atomの設定
anaconda promptよりAtomを開く(以下のコードを実行)
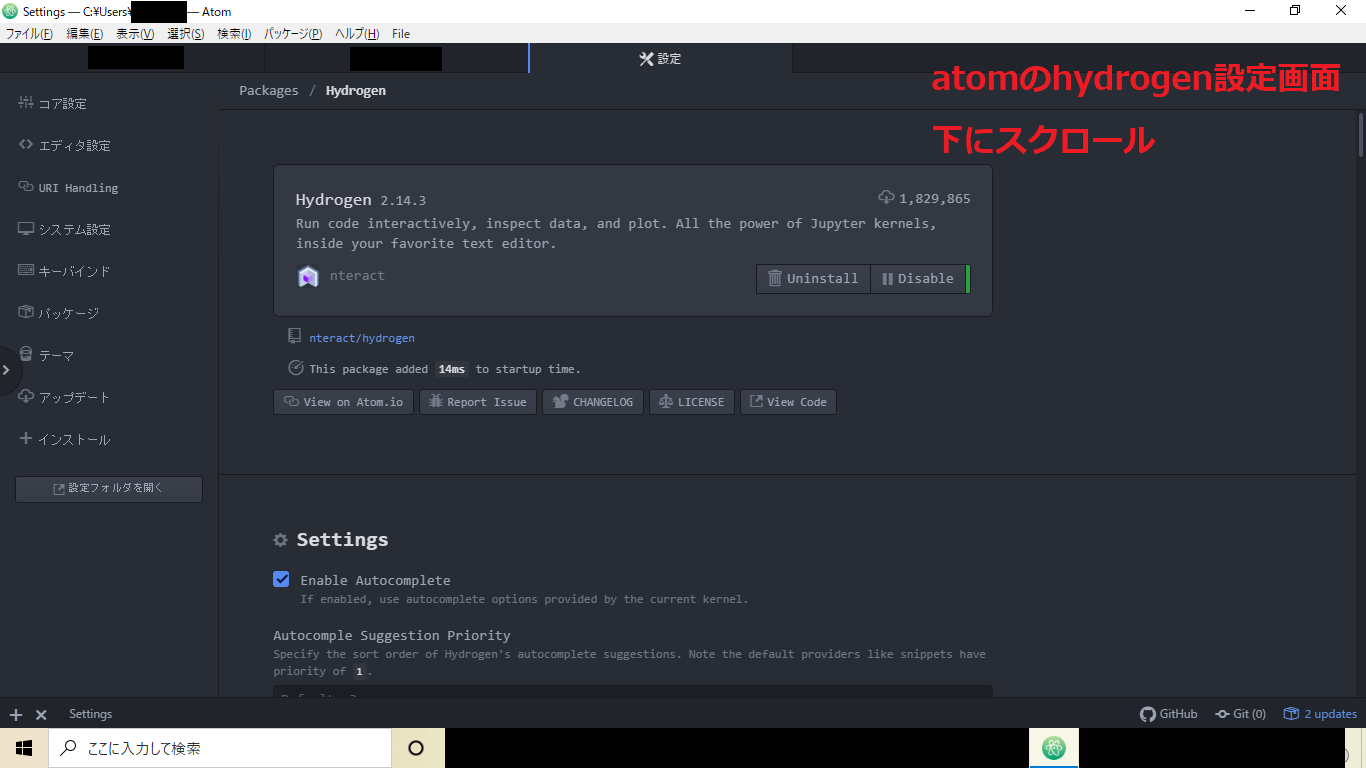
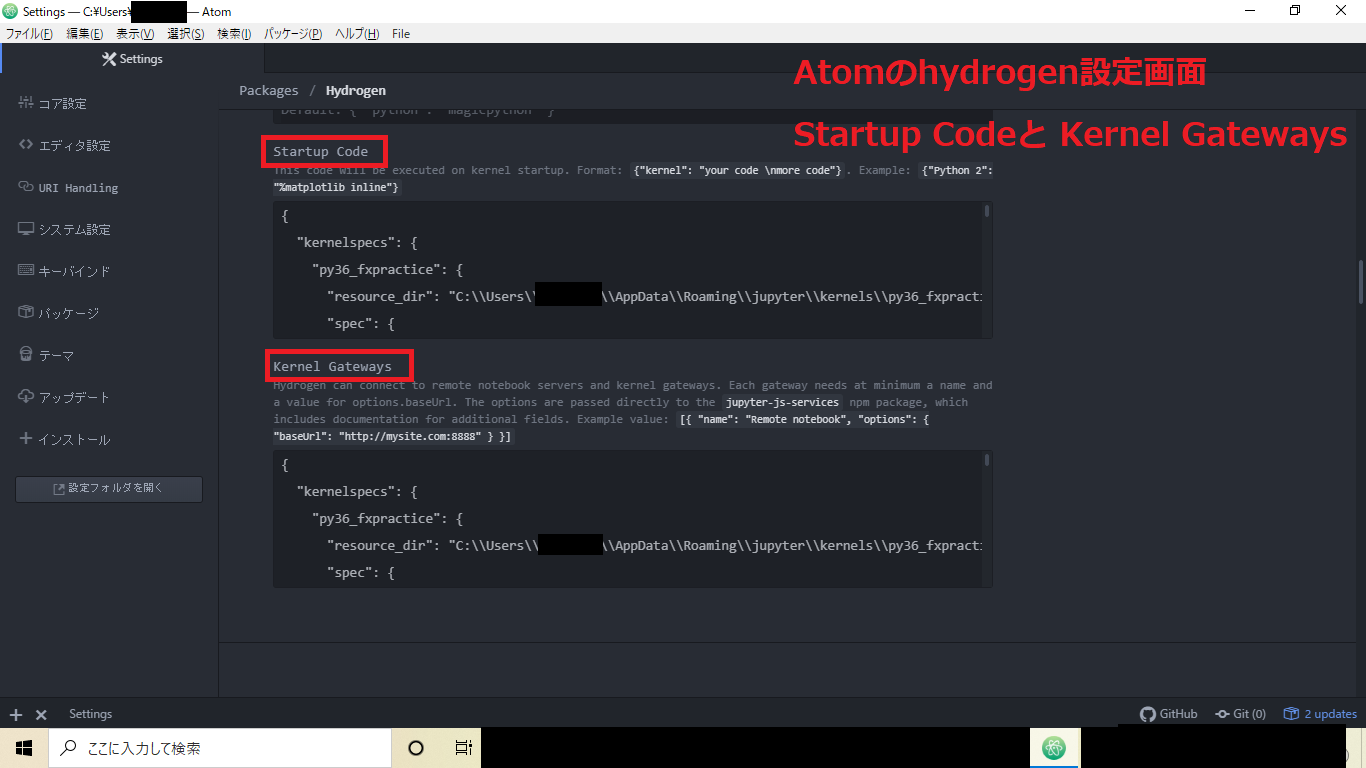
※anaconda promptから開かないとhydrogenが起動しないっぽいです。Anaconda_promptatom .Atom起動後、Atom/環境設定/hydrogen/settingsから設定ができる「startup code」「Kernel Gateways」へjupyter Kernel のjsonを張り付ける。
一度atomを終了し再度同じ方法でAtomを開く。
適当なファイルを開いてshift + Enterを押すと画面のようにAtom上でjupyterみたいにコードが実行されるはずです。
参照URL
以下の方のHPを参考にしましたので載せておきます。
Jupyter関連
・ [Qiita] Miniconda・Atom Hydrogenを用いたPython環境構築
仮想環境について
[Qiita] 【初心者向け】Anacondaで仮想環境を作ってみる
path設定
これは記事に書いてはいませんが、上記の手順をしてもダメだった場合、この記事を参考にして仮想環境でPathを通してみてください。
・[Qiita] AtomでHydrogenを動かす手順メモ

- 投稿日:2020-06-30T22:24:04+09:00
ゼロから始めるLeetCode Day72 「1498. Number of Subsequences That Satisfy the Given Sum Condition」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
どうやら多くのエンジニアはその対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイトであり、海外のテックカンパニーでのキャリアを積みたい方にとっては避けては通れない道である。
と、仰々しく書いてみましたが、私は今のところそういった面接を受ける予定はありません。
ただ、ITエンジニアとして人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
Python3で解いています。
前回
ゼロから始めるLeetCode Day71 「1496. Path Crossing」今はTop 100 Liked QuestionsのMediumを優先的に解いています。
Easyは全て解いたので気になる方は目次の方へどうぞ。Twitterやってます。
技術ブログ始めました!!
技術はLeetCode、Django、Nuxt、あたりについて書くと思います。こちらの方が更新は早いので、よければブクマよろしくお願いいたします!問題
1498. Number of Subsequences That Satisfy the Given Sum Condition
難易度はMedium。問題としては、整数の配列
numsと整数targetが与えられます。
numsの最小値と最大値の和が目標値以下になるような、空ではない部分列の数を返します。答えが大きすぎるかもしれないので、10^9 + 7の剰余演算を返します。
Example 1:
Input: nums = [3,5,6,7], target = 9
Output: 4
Explanation: There are 4 subsequences that satisfy the condition.
[3] -> Min value + max value <= target (3 + 3 <= 9)
[3,5] -> (3 + 5 <= 9)
[3,5,6] -> (3 + 6 <= 9)
[3,6] -> (3 + 6 <= 9)Example 2:
Input: nums = [3,3,6,8], target = 10
Output: 6
Explanation: There are 6 subsequences that satisfy the condition. (nums can have repeated numbers).
[3] , [3] , [3,3], [3,6] , [3,6] , [3,3,6]Example 3:
Input: nums = [2,3,3,4,6,7], target = 12
Output: 61
Explanation: There are 63 non-empty subsequences, two of them don't satisfy the condition ([6,7], [7]).
Number of valid subsequences (63 - 2 = 61).Example 4:
Input: nums = [5,2,4,1,7,6,8], target = 16
Output: 127
Explanation: All non-empty subset satisfy the condition (2^7 - 1) = 127Constraints:
- 1 <= nums.length <= 10^5
- 1 <= nums[i] <= 10^6
- 1 <= target <= 10^6
解法
class Solution: def numSubseq(self, nums: List[int], target: int) -> int: ans,mod = 0,10**9+7 nums.sort() for i,j in enumerate(nums): if target < j*2: break b = bisect.bisect(nums,target-j,lo=i) ans += pow(2, b-i-1, mod) return ans % mod # Runtime: 888 ms, faster than 82.84% of Python3 online submissions for Number of Subsequences That Satisfy the Given Sum Condition. # Memory Usage: 25.2 MB, less than 100.00% of Python3 online submissions for Number of Subsequences That Satisfy the Given Sum Condition.問題文で指定されている通り、最初に
mod(10**9+7)を指定し、for文の中で二分探索をする、という書き方をしました。
bisectの引数は以下の通りです。bisect(a,b,(lo,hi)) a: リスト b: 挿入する値 lo: 探索範囲の下限 hi: 探索範囲の上限なお、この記事を読む方の中にははご存知の方が多いと思いますが、二分探索はソートされていることが前提条件なので、コードの最初の方でリストをソートしてあります。例を見る限りソートされてない場合も多そうだったしね・・・
ちなみに10**9+7、というのは他の競技プログラミングをやる上で(たくさんサイトがあるのでどれか一つに限らず)結構出てきたりします。
それについての分かりやすい解説記事を書いてくださっている方もいるので気になる方は是非そちらもどうぞ。では今回はここまで。お疲れ様でした。
- 投稿日:2020-06-30T21:52:03+09:00
アナログメーターの読取りは、例題のMNISTで出来ます。
人工知能を用いて アナログメーターの読取りを行うのに 教科書の例題にあるMNISTで出来ます。
まずは、カメラと照明を固定して撮影条件が一定となるように設置をします。一定の範囲内で撮影出来る事を保証できると、人工知能による予測精度が向上します。
次に、特定のアナログメーターを 事前に撮影して針の位置の状態をそれぞれ準備します。どの程度のデーターを準備するかは、要求する分解能に従いますが、20-30分解能もあれば、十分と思われます。
なぜなら、アナログメーター自体の精度(誤差)は、±2.5%や±1.6%程度あり、つまり、約5%や3%程度の誤差は、アナログメーターを使う時点で、許容されています。
有効桁数3桁、4桁の測定には、アナログメーターは向いていません。事前のデーターを多く用意するため、撮影条件や照明条件を振って、許容範囲内の状態を可能な限り撮影したり、画像処理でデーターを水増しましょう。
プログラム自体は、MNISTと同等のクラス分類です。データーが十分あれば、トレーニングとテストに分けたり、過剰適合の検証をしたり、パラメーターの調整をしたり、色々できます。
ana00.png
ana01.png
ソースコード
データー準備import numpy as np
import matplotlib.pyplot as plt
import cv2i=np.ndarray([32,32,3])
data=np.ndarray([10,32,32,3])
data[:]=0i=plt.imread("ana00.png")
plt.imshow(i)
plt.show()
i = cv2.resize(i, (32,32))
data[0,:,:,:]=i
plt.imshow(i)
plt.show()i=plt.imread("ana01.png")
i = cv2.resize(i, (32,32))
data[1,:,:,:]=ii=plt.imread("ana02.png")
i = cv2.resize(i, (32,32))
data[2,:,:,:]=ii=plt.imread("ana03.png")
i = cv2.resize(i, (32,32))
data[3,:,:,:]=ii=plt.imread("ana04.png")
i = cv2.resize(i, (32,32))
data[4,:,:,:]=ii=plt.imread("ana05.png")
i = cv2.resize(i, (32,32))
data[5,:,:,:]=ii=plt.imread("ana06.png")
i = cv2.resize(i, (32,32))
data[6,:,:,:]=ii=plt.imread("ana07.png")
i = cv2.resize(i, (32,32))
data[7,:,:,:]=ii=plt.imread("ana08.png")
i = cv2.resize(i, (32,32))
data[8,:,:,:]=ii=plt.imread("ana09.png")
i = cv2.resize(i, (32,32))
data[9,:,:,:]=i学習と予測
import matplotlib.pyplot as plt
from sklearn import datasets, svm, metrics
from sklearn.model_selection import train_test_splitx = data.reshape((10,-1))
y=np.array([0,1,2,3,4,5,6,7,8,9])X_train=x
X_test=x
y_train=y
y_test=yclassifier = svm.SVC(gamma=0.001)
classifier.fit(X_train, y_train)
predicted = classifier.predict(X_test)print("Classification report for classifier %s:\n%s\n"
% (classifier, metrics.classification_report(y_test, predicted)))人工知能は、画像を見てクラス分類しているだけです。アナログメーターの概念を認識したり針や目盛を理解しているわけではありません。過剰な要求仕様を求めなければ、アナログメーターの読取りは、例題のMNISTで出来ますね。


- 投稿日:2020-06-30T21:34:48+09:00
SPSS Modelerの再構成ノードをPythonで書き換える。購入商品カテゴリごとの集計
SPSS Modelerで縦持ちデータを横持ちに変換する再構成ノードをPythonのpandasで書き換えてみます。
1.加工のイメージ
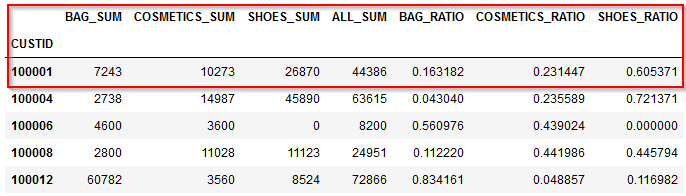
以下のID付POSデータから各顧客毎に①商品カテゴリごとの購入額合計と②商品カテゴリごとの購入割合を集計してみます。
■加工前
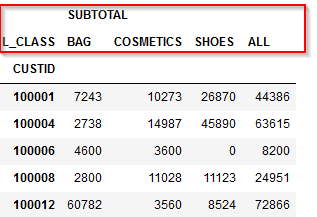
誰(CUSTID)がいつ(SDATE)何(PRODUCTID、L_CLASS商品大分類、M_CLASS商品中分類)をいくら(SUBTOTAL)購入したかが記録されたID付POSデータを使います。
■加工後
顧客毎(CUSTID)に商品大分類(L_CLASS)の①商品カテゴリごとの購入額合計と②商品カテゴリごとの購入割合を集計します。
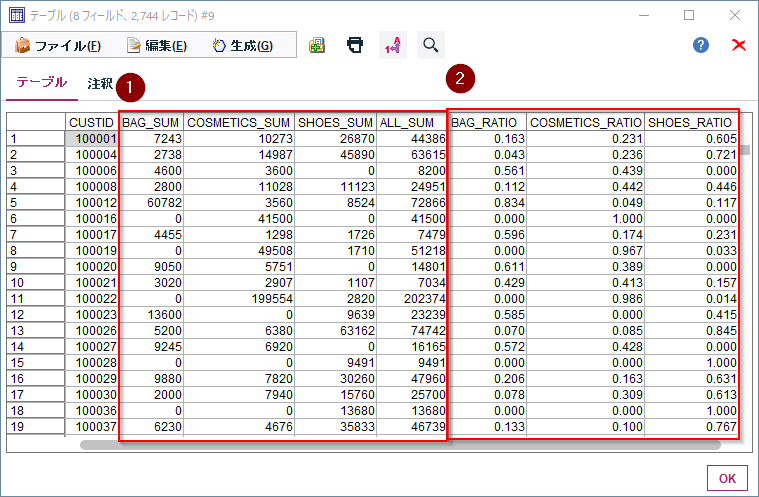
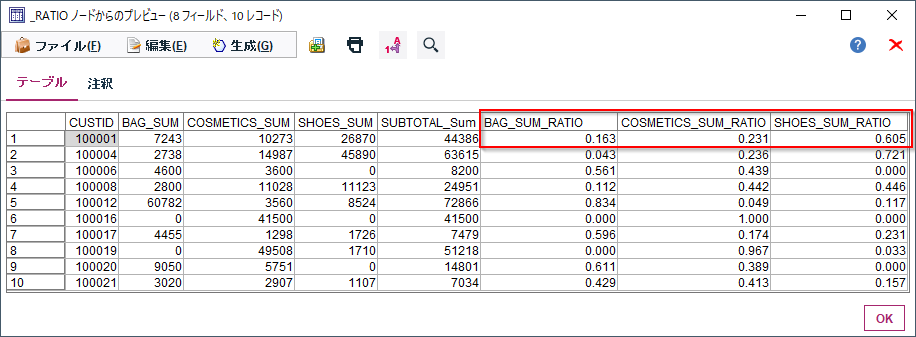
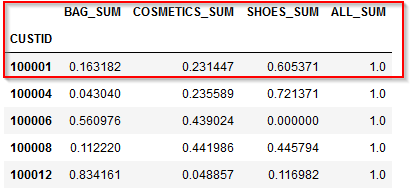
商品大分類にはBAG、COMETICS、SHOESの3つがあり、100001番の顧客はBAGで7243円、COSMETICSで10273円、SHOESで26870円の購入があります。それを金額の割合で計算するとBAG16.3%、COSMETICS23.1%、SHOES60.5%となります。このような集計を行うと顧客の特徴が浮かび上がってきます。
2.Modeler再構成ノードでの設定①商品カテゴリごとの購入額合計
まず、①商品カテゴリごとの購入額合計までを求めてみます。
再構成ノードは、データ型ノード、レコード集計、また置換ノードまでの組合せで通常使われます。
さらに今回は総購入金額まで計算するために、レコード集計とレコード結合ノードも組み合わせます。
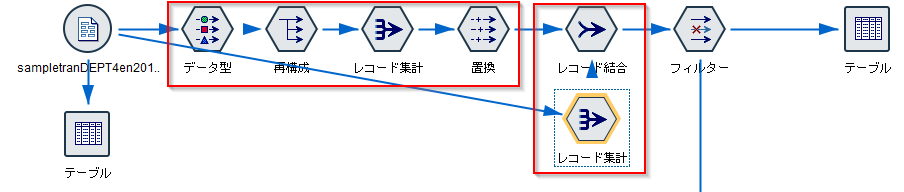
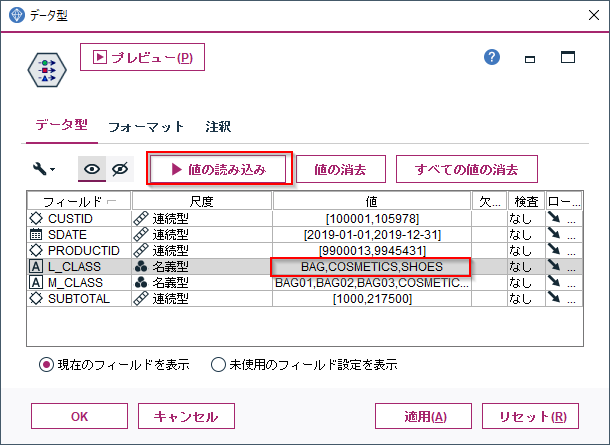
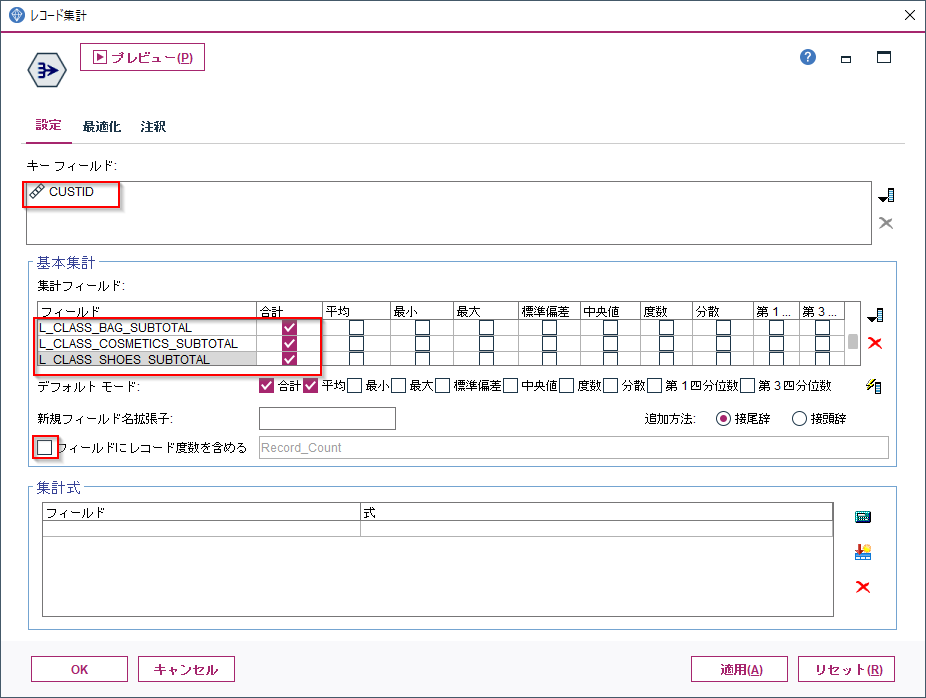
まずデータ型ノードで商品大分類(L_CLASS)にどんなカテゴリ値があるかを認識します。データ型ノードで「値の読み込み」を行うと、自動で大分類のすべてのカテゴリが認識されます。
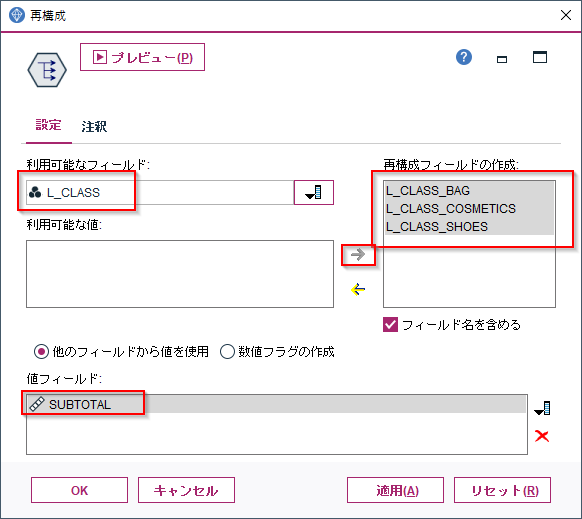
次に再構成ノードで横持ちさせたいフィールドの値を選びます。以下の例では商品大分類(L_CLASS)にはBAG、COMETICS、SHOES、これらを列として展開して値には小計(SUBSTOTAL)をセットしています。
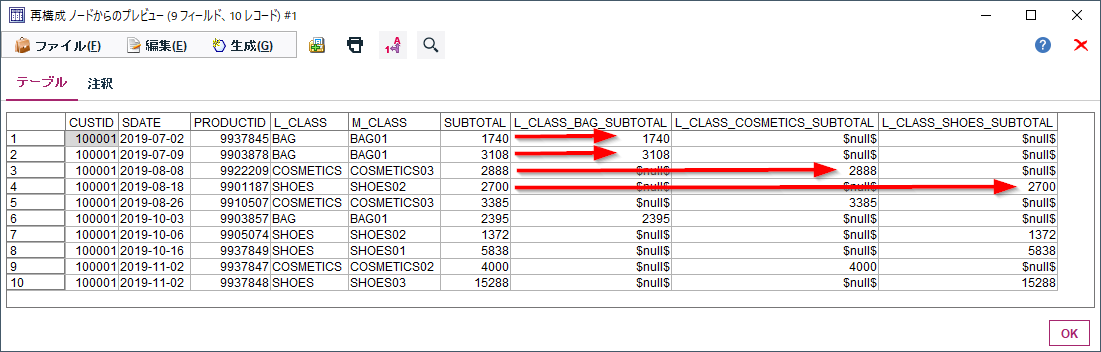
この設定の結果をプレビューすると下のようになります。小計(SUBSTOTAL)が各商品大分類(L_CLASS)の列に振り分けられたことがわかります。
次に「レコード集計」ノードをつかってこのBAG、COMETICS、SHOESの小計値を顧客で1レコードに集計します(レコード度数は不要なのでチェックを外します)。
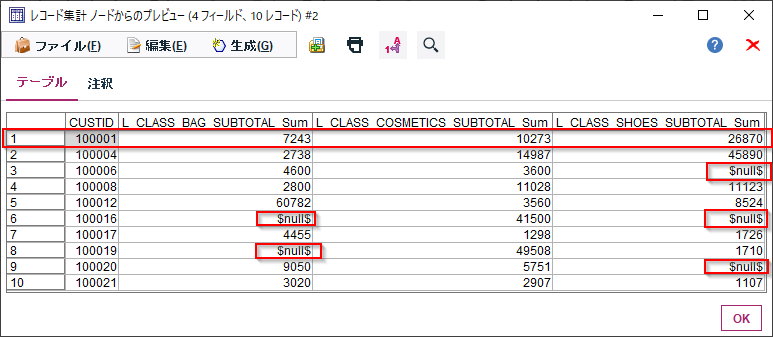
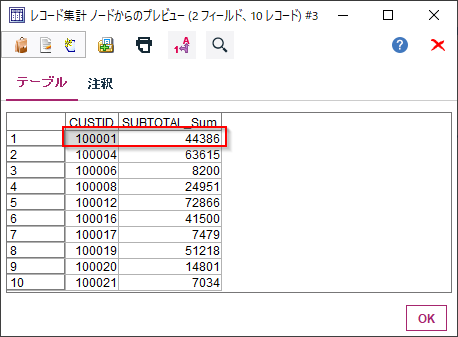
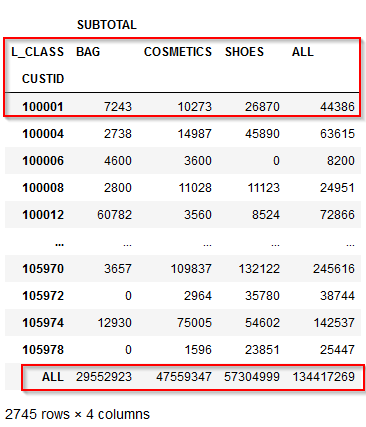
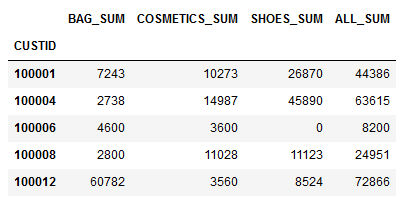
これで各顧客毎のBAG、COMETICS、SHOESの商品大分類ごとの購入総額が集計されました。100001番の顧客はBAGで7243円、COSMETICSで10273円、SHOESで26870円の購入があることが計算できました。
これでほぼ完成なのですが、いくつかNULLの値があります。これはこの顧客はこの商品大分類での購入が一度もなかったことを意味しています。このままだと計算に使いづらいので、NULLを0に置き換えます。
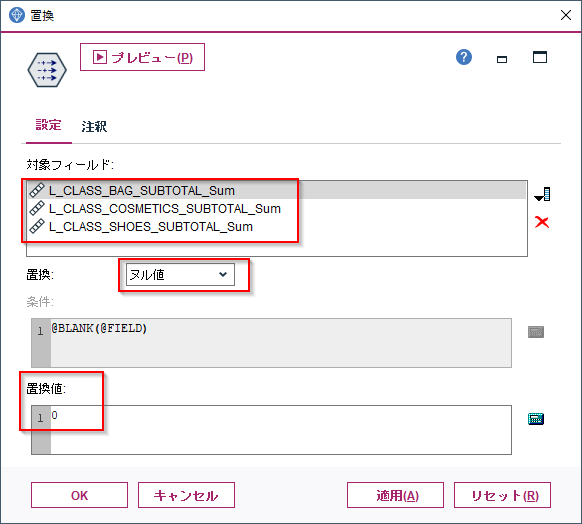
それを行うのが置換ノードです。
BAG、COMETICS、SHOESの合計値のノードを選択し、ヌル値の場合に0に設定します。
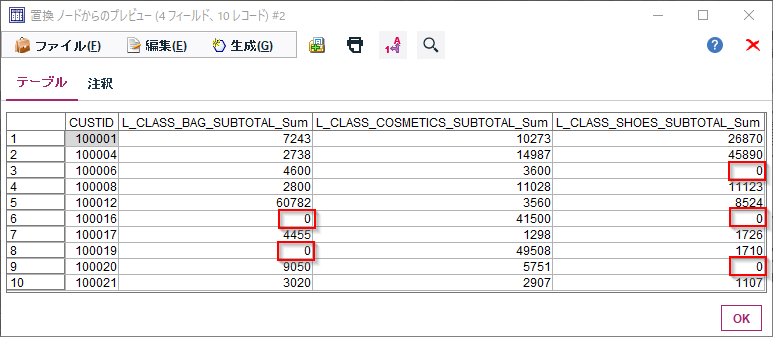
以下のようにヌルが0に変換されました。
次に顧客毎の総購入額を、レコード集計とレコード結合のノードを追加して算出します。
まず、レコード集計ノードで各顧客(CUSTID)の小計(SUBTOTAL)の合計、つまり総購入金額を算出します(やはりレコード度数は不要です)。
100001番の顧客は全部で44,386円の購入しています。
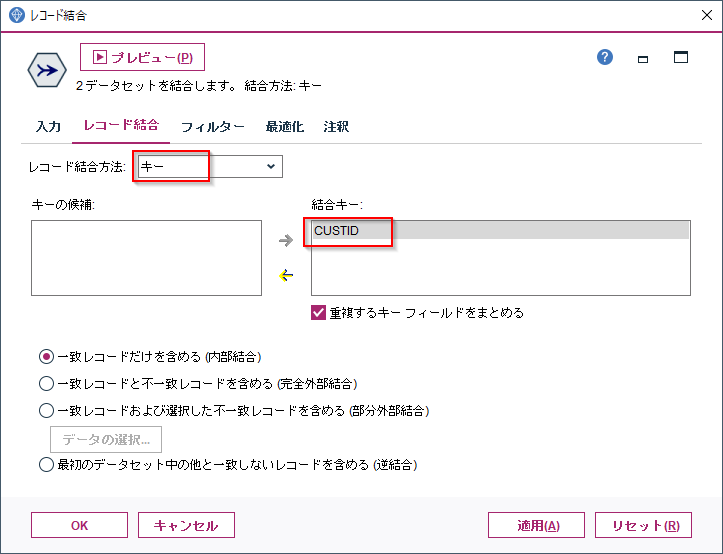
この集計結果と先ほどのBAG、COMETICS、SHOESの合計額の集計をレコード結合ノードで結合します。
そうすると各顧客毎のBAG、COMETICS、SHOESの合計額の集計の後ろに総購入額が結合できました。
最後はフィルターノードで長くなった列名を短くしておきました(この作業は必須ではありません)。
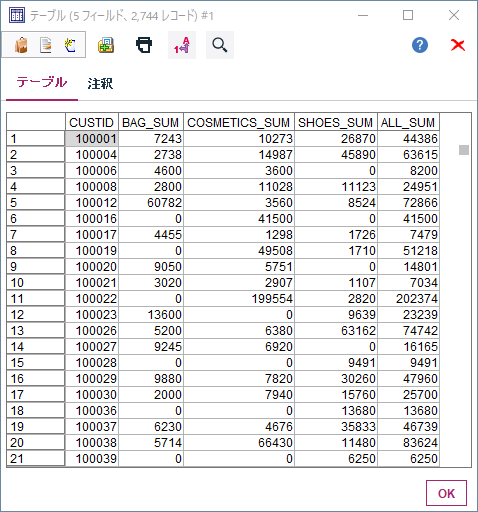
最終的なデータは以下のようになりました。
2.Modeler再構成ノードでの設定②商品カテゴリごとの購入割合
ここからは、再構成ノードとしては少し応用的な使い方ですが、他の顧客と比較しやすい「割合」を計算したいことはよくありますのでご紹介します。
先ほど作ったデータを見てみましょう。
100001番の顧客はBAGは7243円÷44,386円、COSMETICSは10273円÷44,386円、SHOESは26870円÷44,386円の各割り算を行うことで購入額の割合が計算できます。
この計算をフィールド作成ノードで行います。
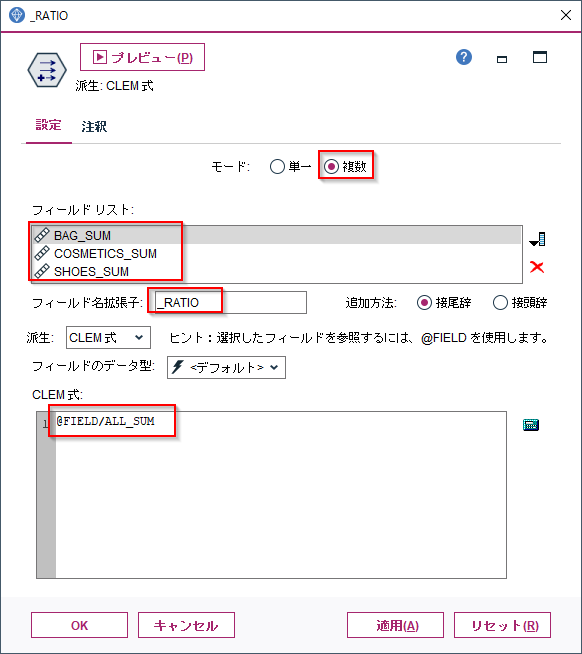
モードを複数とし、フィールドリストにBAG_SUM、COSMETICS_SUM、SHOES_SUMを選択します。こうするとCLEM式の中で、@FIELDをつかって、BAG_SUM、COSMETICS_SUM、SHOES_SUMの各列を参照できます。
ここでは
@FIELD/ALL_SUM
を指定することで、
BAG_SUM/ALL_SUM、COSMETICS_SUM/ALL_SUM、SHOES_SUM/ALL_SUMの3つの割合が求められます。
これで各顧客毎のBAG、COMETICS、SHOESの商品大分類ごとの購入割合が集計されました。100001番の顧客の購入割合はBAG16.3%、COSMETICS23.1%、SHOES60.5%となります。
3.pandasでの設定①商品カテゴリごとの購入額合計
同じデータ加工をpandasでもやってみます。実は①商品カテゴリごとの購入額合計の算出は、pandasではpivot_tableというメソッド一つで非常に簡単にできます。
pivot_tran_df= df.pivot_table( index=['CUSTID'],columns=['L_CLASS'],values=['SUBTOTAL'], aggfunc='sum', fill_value=0, margins=True, margins_name='ALL')
- index=['CUSTID'],columns=['L_CLASS'],values=['SUBTOTAL']でCUSTIDをキーにしてL_CLASSに含まれるBAG、COMETICS、SHOESの商品大分類ごとにSUBTOTALを展開します。ここまでが再構成ノードの設定のイメージです。
- aggfunc='sum'でSUBTOTALの合計値を算出することを示します。ここが集計ノードのイメージです。
- fill_value=0はNULLになった箇所を0埋めすることを示します。ここが置換ノードのイメージです。
- margins=True, margins_name='ALL'は列合計と行合計を追加することを示します。ここが集計ノードとレコード結合ノードの役割を果たしています。
以下のようにCUSTID毎にBAG、COMETICS、SHOESの購入額と総購入金額が計算できています。
- 参考
- pandas.pivot_table — pandas 1.0.5 documentation https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.pivot_table.html
- pandasのピボットテーブルでカテゴリ毎の統計量などを算出 | note.nkmk.me https://note.nkmk.me/python-pandas-pivot-table/
列の合計列は必要ですが、行の合計行は今回は不要なので以下で削除します。
pivot_tran_df=pivot_tran_df[:-1]
- 参考
pivot_tableをつかうと列が階層構造になりマルチカラムになります。
マルチカラムのままだと結合などがしづらく扱いづらいので、フラットなスネーク形式(アンダースコアで連結)の列名に変換します。Modelerの命名規則に合わせると以下のようになります。
pivot_tran_df.columns = [ pivot_tran_df.columns.names[1]+"_"+levels[1]+"_"+levels[0] for levels in pivot_tran_df.columns]
ここではさらに正規表現を使って、BAG_SUMのような短い列名に変更しました。
import re pivot_tran_df=pivot_tran_df.rename( columns= lambda str: re.sub('L_CLASS_(.+)_SUBTOTAL',r'\1_SUM',str))
3.pandasでの設定②商品カテゴリごとの購入割合
②商品カテゴリごとの購入割合をModelerでは@FIELD/ALL_SUMで計算しました。
pandasではdivメソッドを使います。Modelerの置換ノードのイメージに近くて、すべての列がALL_SUMで除算されて置き換えられます。ALL_SUM自身も割られて1.0になっています。
pivot_tran_ratio_df=pivot_tran_df.div(pivot_tran_df["ALL_SUM"], axis=0)
- 参考
- pandas.DataFrame.div — pandas 0.24.2 documentation https://pandas.pydata.org/pandas-docs/version/0.24.2/reference/api/pandas.DataFrame.div.html
- python - データフレームの複数列を一つの列で割る - スタック・オーバーフロー https://ja.stackoverflow.com/questions/52834/%E3%83%87%E3%83%BC%E3%82%BF%E3%83%95%E3%83%AC%E3%83%BC%E3%83%A0%E3%81%AE%E8%A4%87%E6%95%B0%E5%88%97%E3%82%92%E4%B8%80%E3%81%A4%E3%81%AE%E5%88%97%E3%81%A7%E5%89%B2%E3%82%8B
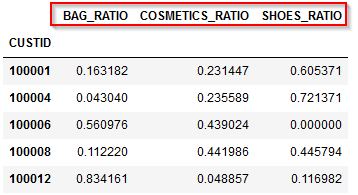
ALL_SUMを削除(drop)し、SUM(合計)ではなくRATIO(割合)なので列名を変更します(rename)。
import re pivot_tran_ratio_df=pivot_tran_ratio_df\ .drop(columns=['ALL_SUM'])\ .rename(columns= lambda str:re.sub('_SUM','_RATIO',str))
最後に①商品カテゴリごとの購入額合計のDataFrameに結合しなおして完成です。
pivot_tran_df=pivot_tran_df.join(pivot_tran_ratio_df)
4. サンプル
サンプルは以下に置きました。
ストリーム
https://github.com/hkwd/200611Modeler2Python/blob/master/Restructure/Restructure.str?raw=true
notebook
https://github.com/hkwd/200611Modeler2Python/blob/master/Restructure/restructure.ipynb
データ
https://raw.githubusercontent.com/hkwd/200611Modeler2Python/master/data/sampletranDEPT4en2019S.csv■テスト環境
Modeler 18.2.1
Windows 10 64bit
Python 3.6.9
pandas 0.24.15. 参考情報
【リレー連載】わたしの推しノード - ID付POSやIoT時系列データから特徴量を生成するスゴ技職人「再構成ノード」 | IBM ソリューション ブログ https://www.ibm.com/blogs/solutions/jp-ja/spssmodeler-push-node-4/








- 投稿日:2020-06-30T21:34:04+09:00
Pythonで実装するアヒル本「StanとRでベイズ統計モデリング」
Pythonで実装するアヒル本
アヒル本とは
アヒル本「StanとRでベイズ統計モデリング」、ベイズ界隈では有名な書籍です。
ベイズ推定を実装したい、と思ったときにまず最初に手に取ると良いでしょう。
しかし、ベイズとは何かという点について解説している本ではないため、ベイズの枠組みで事例を積み重ねることで事後分布を更新できるために得られる利点などについて納得ができていない方は、ベイズ自体の基礎的な解説を読んでからチャレンジしたほうが良いと思います。なぜPythonか
上記本のオフィシャルでは、タイトルどおり実装はRなんですね。
Pythonで実装したい方も多いと思います。
私もその一人でしたので、Python実装をつくりました。Python実装にあたって
Stanのインターフェイスについては、PyStanでRとほぼ変わらない使いごこちを実現できます。
一方で、データ整形についてはPandasを使うので、Rとはかなり異なるコードとなります。利用するPythonライブラリ
- Python > 3
- PyStan
など、詳しくは以下をご覧ください。
requirements.txt
https://github.com/MasazI/python-r-stan-bayesian-model-2/blob/master/exec/requirements.txt
コード
すべてのコードはGithubに上がっていますので、実行自体はすぐできるかと思います。
練習問題もすべてPythonで解いてあります。Github
https://github.com/MasazI/python-r-stan-bayesian-model-2
何かありましたらプルリクエストをいただけるとありがたいです。

- 投稿日:2020-06-30T21:09:36+09:00
PycharmでDjangoでアプリケーションを作成する手順~具体的な中身に入っていく前編~
はじめに
この記事はPycharmでDjangoを使ってアプリケーションを作成する準備の段階を書いていきます。
あくまで僕の手順なので、他の方の記事も見るとより理解が深まると思います。新しいPycharmプロジェクトを作成する
- Pycharmの左上のメニューバーから「ファイル」を選んでクリック。
- その中の一番上の「新規プロジェクトを作成」をクリック。
- ロケーションの部分にデフォルトで「untitled」とは言っているのでその部分を削除して、自分の好きなプロジェクト名を入れる。
- 右下の作成を押すと新規のウィンドウに作成するか、今いるウィンドウで作成するか聞いてくるので、好きな方を選ぶ。 これでプロジェクトの作成は完了です。
仮想環境構築
今回はPipenvを用いて仮想環境の構築を行なっていきます。
Pycharmの左下のあるターミナルを開いてください。インストールされているかの確認
まずインストールされているか確認します。
pipenv --version数字が出ればインストールされています。
インストールされていない時
pip install pipenvこのように入力すればインストールができます。
Djangoを追加
pipenv install djangoこのように入力することで、最新のdjangoをインストールできます。
仮想環境有効化
pipenv shellこのように入力すると、ターミナルの一番左の部分の「(base)」となっていた部分が、プロジェクト名に変わっていることが確認できます。
ここまでで仮想環境の構築は終了です。Djangoのプロジェクトとアプリケーションを作成
まずはプロジェクトを作成していきましょう。
①django-admin startproject プロジェクト名 -> プロジェクト名のディレクトリの上に同じ名前のディレクトリができてしまう ②django-admin startproject プロジェクト名 . -> Pycharmのプロジェクトの直下に作成できる①だとやってみるとわかるのですが、余計なディレクトリができてしまうので、②のように最後に「.」をつけるのがおすすめです。
次にアプリケーションを作成していきます。
python manage.py startapp アプリ名これでアプリが作成できます。
ついでに
あとで作成することになるので、あらかじめ作成しておくと良いものを書いておきます。
Pycharmプロジェクト | |___templates | |___djangoプロジェクトディレクトリ | |___djangoアプリケーションディレクトリ___ | |___urls.py |___manage.py | |___その他のファイル類urls.pyの作成
アプリの方には「urls.py」がないので、アプリのディレクトリを右クリックして、一番上の「新規」から「urls.py」と入力してファイルを作成しましょう。
templatesの作成
htmlファイルを入れておくtemplatesディレクトリを作成しましょう。
Pycharmプロジェクトのディレクトリを右クリックして「新規ボタン」を押して「templates」ディレクトリを作成しましょう。Pycharmプロジェクト | |___templates | |___djangoプロジェクトディレクトリ | |___djangoアプリケーションディレクトリ | |___manage.py | |___その他のファイル類順番はバラバラで良いのでこんな感じになっていれば十分です。
最後に
今回はPycharmでのdjangoを使ったアプリケーション作成の準備段階の手順を解説してきました。
参考になれば幸いです。
今後続きの記事を作成していく予定ですのでよければ見ていってください。
- 投稿日:2020-06-30T21:09:36+09:00
PycharmでDjangoでアプリケーションを作成する手順~準備編~
はじめに
この記事はPycharmでDjangoを使ってアプリケーションを作成する準備の段階を書いていきます。
あくまで僕の手順なので、他の方の記事も見るとより理解が深まると思います。新しいPycharmプロジェクトを作成する
- Pycharmの左上のメニューバーから「ファイル」を選んでクリック。
- その中の一番上の「新規プロジェクトを作成」をクリック。
- ロケーションの部分にデフォルトで「untitled」とは言っているのでその部分を削除して、自分の好きなプロジェクト名を入れる。
- 右下の作成を押すと新規のウィンドウに作成するか、今いるウィンドウで作成するか聞いてくるので、好きな方を選ぶ。 これでプロジェクトの作成は完了です。
仮想環境構築
今回はPipenvを用いて仮想環境の構築を行なっていきます。
Pycharmの左下のあるターミナルを開いてください。インストールされているかの確認
まずインストールされているか確認します。
pipenv --version数字が出ればインストールされています。
インストールされていない時
pip install pipenvこのように入力すればインストールができます。
Djangoを追加
pipenv install djangoこのように入力することで、最新のdjangoをインストールできます。
仮想環境有効化
pipenv shellこのように入力すると、ターミナルの一番左の部分の「(base)」となっていた部分が、プロジェクト名に変わっていることが確認できます。
ここまでで仮想環境の構築は終了です。Djangoのプロジェクトとアプリケーションを作成
まずはプロジェクトを作成していきましょう。
①django-admin startproject プロジェクト名 -> プロジェクト名のディレクトリの上に同じ名前のディレクトリができてしまう ②django-admin startproject プロジェクト名 . -> Pycharmのプロジェクトの直下に作成できる①だとやってみるとわかるのですが、余計なディレクトリができてしまうので、②のように最後に「.」をつけるのがおすすめです。
次にアプリケーションを作成していきます。
python manage.py startapp アプリ名これでアプリが作成できます。
ついでに
あとで作成することになるので、あらかじめ作成しておくと良いものを書いておきます。
Pycharmプロジェクト | |___templates | |___djangoプロジェクトディレクトリ | |___djangoアプリケーションディレクトリ___ | |___urls.py |___manage.py | |___その他のファイル類urls.pyの作成
アプリの方には「urls.py」がないので、アプリのディレクトリに作成します。
#アプリケーションディレクトリに移動 cd アプリケーションディレクトリ名 #urls.pyファイルを作成 touch urls.pyこれで完了です。
templatesの作成
HTMLファイルを入れておくtemplatesディレクトリを作成しましょう。
#Pycharmのプロジェクトに移動 cd Pycharmプロジェクト名 #templatesディレクトリの作成 mkdir templatesこれでOKです。
Pycharmプロジェクト | |___templates | |___djangoプロジェクトディレクトリ | |___djangoアプリケーションディレクトリ | |___manage.py | |___その他のファイル類順番はバラバラで良いのでこんな感じになっていれば十分です。
staticディレクトリを作成
CSSファイルやJavaScriptファイル、画像ファイルなどを保存する「static」ディレクトリを作成しましょう。
#アプリケーションディレクトリに移動 cd アプリケーションディレクトリ名 #staticディレクトリを作成 mkdir static #staticディレクトリに移動 cd static #cssディレクトリ作成 mkdir css #javascruptディレクトリ作成 mkdir javascrupt #画像を入れておくディレクトリ作成 mkdir imgこれで「static」ディレクトリの用意は完了です。
実行できるか確認
最後に実行できるか確認しましょう。
#データベース構成のバージョン管理をするための、マイグレーションファイルというものを作成 python manage.py makemigrations #データベース構成を変更したり、変更を取り消す python manage.py migrateこの2つをターミナルに打ち込みましょう。
#実行!!! python manage.py runserverこれを無事に実行できると
http://127.0.0.1:8000/と表示されるのでクリックするとブラウザに飛びます。
ブラウザが開いた時にロケットが飛んでいれば無事に実行できています!終わりに
今回はPycharmでのdjangoを使ったアプリケーション作成の準備段階の手順を解説してきました。
参考になれば幸いです。
今後続きの記事を作成していく予定ですのでよければ見ていってください。
続き
↓
↓
settings.py編
- 投稿日:2020-06-30T21:08:03+09:00
[光-Hikari-のPython]09章-01 クラス(オブジェクトの基礎)
[Python]09章-01 オブジェクトの基礎
今まで、文字列や数値、データ構造の分野ではリストやタプルなどに触れました。データ構造の個所で触れましたが、これらはオブジェクトと言いました。
さて、このオブジェクトとは何でしょう。まずはオブジェクトについて説明して少し掘り下げていきたいと思います。
オブジェクトとは
まずはPython Consoleにて以下のコードを入力して確認してみましょう。
>>> S = 'hello' >>> type(S) <class 'str'>Sという変数に'hello'という文字列を代入しています。さて、次にtype()関数により、<class 'str'>が出力されています。
これは、S変数がが現在str型のオブジェクトであることを意味しています。では、strオブジェクトの詳細を見てみましょう。以下のURLから閲覧できます。
https://docs.python.org/ja/3/library/stdtypes.html#text-sequence-type-strマニュアルを見てみると、str型はテキストシーケンス型と書かれています。要するに文字列型のオブジェクトということです。
さて、マニュアルを少し下に送ると、「文字列メソッド」というものが出てきます。
例えば、一番最初にあるstr.capitalize()メソッドを実行してみましょう。
なお、このマニュアルにある、strはstr型のオブジェクトを表すので、今回実際に入力するときにはSという変数名となります。>>> S 'hello' >>> S.capitalize() 'Hello'先頭のみ、大文字になったことが確認できたと思います。詳細はstr.capitalize()メソッドマニュアルを見てください。
また、ほかのメソッドも見てみましょう。str.capitalize()メソッドを実行してみましょう。指定方法はマニュアルを参照してください。
>>> S.replace('l', 'L') 'heLLo'replaceメソッドにより、文字列中の文字を変更ができます。詳細はマニュアルを見てみましょう。
他にもいろいろなメソッドをマニュアルを見ながらやってみましょう。今後、マニュアルに書いてある内容は一部を除き、割愛していきたいと思います。
さて、このstr型だけではないですが、オブジェクトの型にはほかにもあります。以下のコマンドでいろいろな方を確認してみましょう。
以下はint型オブジェクトとなります。
>>> num1 = 100 >>> type(num1) <class 'int'>以下はfloat型オブジェクトとなります。
>>> num2 = 10.5 >>> type(num2) <class 'float'>以下はlist型オブジェクトとなります。
>>> ls = ['Japan', 'America', 'China'] >>> type(ls) <class 'list'>以下はtuple(タプル)型オブジェクトとなります。
>>> tp = (10, 20, 30) >>> type(tp) <class 'tuple'>以下はdict(ディクショナリ)型オブジェクトとなります。
>>> dc = {'jp':'Japan','us':'America', 'ch':'Chine'} >>> type(dc) <class 'dict'>これらそれぞれの型のオブジェクトにはメソッドを持ちます。実際に調べてみましょう。ほとんどは以下のURLに記載してあります。
https://docs.python.org/ja/3/library/stdtypes.html<重要>
実は、あるデータとその振る舞い(メソッド)が一塊になっているものを一般にオブジェクトと言います。
基本的にPythonにおける値はオブジェクトと言えます。また、関数もオブジェクトと言えます。出漁結果はとなります。
def calc_func(x): print('関数内で実行します') f = (x ** 2) + (3 * x) + 4 ##計算結果fを返す return f print(type(calc_func))オリジナルのオブジェクト
先ほどはint型やstr型、そしてlist型などのオブジェクトがありましたが、実はオブジェクトは自分で作成することができます。
これについては次回触れていきたいと思います。最後に
このオブジェクトの概念は非常に取り扱いの難しいものなので、最初は壁を感じるかと思います。ポイントは先ほどのURLにもあった、いろいろなマニュアルを読んでみることです。
最初は意味が分からなくても、読んでいくことで意味が分かってくるようになりますので、ポイントはマニュアルを見ながら実際に実行してみることです。【目次リンク】へ戻る
- 投稿日:2020-06-30T20:02:26+09:00
数学記号がわからないならプログラムを書けばいいじゃない。
とある数学(というか数字)嫌いマンの伝説
- 数IIIと数Cをなんとなくのコレクション精神で履修してみるも、何もかも意味がわからない
- 原因をたどったらそもそも数Iあたりから既によくわかっていなかった
- 飲み会に行くと割り勘の計算ができない
- むしろ1000円上乗せぐらいならあげるからよしなにやっといてという気持ち
- なぜかプログラムは一般人レベルぐらいには書ける
で、なんで今更?
- なんか分析とかやってみたいの!かっこよさそうじゃん?
- 最終的には未来を予測してこの世界の神になるんじゃ!
というわけで神を目指す数学嫌いマンは着々と数学の復習をしていったわけですが....。
数学記号あるじゃないですか。なんすか、あれ。知らんし。そこで思いついたのです。
数学記号がよくわからないならプログラムで実装してみたら良いのでは、と。Σを実装してみる
とりあえず手始めにΣの意味を忘れてしまったので、自分で実装してみることにしました。
※本記事はわからない人がわからないなりに理解しようとした内容のため、用語等が正確でない場合がありますそもそもΣの目的とは
目的が不明確だと勉強しても全くしっくり来ませんね。
Σの意味は総和、つま数の一覧(配列)を作成して合計値を求めることです。たとえば[1,2,3,4,5,6,7,8,9,10]の合計値は55ですが、この合計値を一文字で書き表すために使う記号ということになるでしょう。いや、わかりますよ。でもそれなら1~10までの合計って書けばいいじゃん。
では仮に数の一覧が[2,4,6,8,10]だったら。「1~10の中の偶数値のみの合計」となるでしょうけれど、長い。条件が複雑化すればするほど読みにくくなるらしいです。個人的には文章化してくれたほうが読みやすいんですけどね。
ともかくここでΣが登場します。
Σは繰り返し処理である
たとえば、[1,2,3,4,5,6,7,8,9,10]の合計値はこのように表すことができます。
つまり、1から10まで繰り返しながら、繰り返し毎に1から10までの値をそのまま配列に追加して行き、最後に配列内の全要素の合計を求めるという意味になります。
私の場合は合計をいきなり求めようとするとアレルギー反応を起こしますので、まずは落ち着いて先に数列を作ります。というわけで1~10までの配列(リスト)をpythonで実装してみます。array = [] for i in range(1, 11): array.append(i)うん、全然問題ないですね。
あとは合計値を求めるのであれば、sum(array) # => 55と書けば合計値が求まるはずです。
コードに落とすと余裕なのにΣだと一瞬意味不明に見える。
これは数学記号が格好つけて可読性の低い記号や文字を使っているからです。
本当は多分由来とかあるんだと思います....。
ではこの一般的なpythonコードとΣ記号の差を埋めていきましょう。同じ役割を持つ変数や値を色分けしてみました。
これで多少はわかりやすくなります。「どこまで繰り返すか」はrange()関数の仕様上11になりますが仕方ないです。
この場合だと、kとiは同じ役割を担っていますね。
どうせなら変数名は統一しましょう。array = [] for k in range(1, 11): array.append(k)これで少しわかりやすくなりました。
こころのこえ
kとかnとかaとか使わずに"start_from"とか"end"とか"element"とかわかりやすい変数名にしてくれたらいいのにな。そもそもΣ自体、英語で総和を表す"Summation"のSをギリシャ文字のΣにしたものらしいですよ。じゃあSummationでいいじゃん。なんで略すのよ。そもそもsummationの語源ってラテン語だからね?なんでギリシャ文字にするのよ。かっこいいけどさ!
処理部分のカスタマイズ
さて話を戻します。
Σの右側が先程は"k"と書いてありましたが、このようにまた別の式が入ってくることもあります。
これは、コードにすれば非常にシンプルです。
最終的にリストに含めたい値がどのように加工されるのかを示していると考えると良いでしょう。array = [] for k in range(1, 11): array.append(k) #ここのkの部分に当たるですので、今回の例であれば
array = [] for k in range(1, 11): array.append(2 * k)このように書けるわけです。
非常にシンプルな式しか扱っていませんが、あとはこれの応用でいけるのではないでしょうか。
ちょっと遊んでみる(おまけ)
さて、基礎はわかったのでプログラム的な視点で調整してみようと思います。
まず、毎回書くのは面倒なので関数化してみます。安直な関数化
安直に関数化するとこうなりますね。戻り値はちゃんと総和を返すようにしています。
def sigma(): array = [] for k in range(1, 11): array.append(2 * k) return sum(array)値を外から受け取る
このままだと柔軟性に欠けるので、値はちゃんと外から受け取るようにしましょう。
def sigma(k, n): array = [] for k in range(k, (n + 1)): array.append(2 * k) return sum(array) #関数の呼び出し例 print(sigma(1, 10)) # => 1から10それぞれに2を掛けたものの総和なので110式も外から受け取る
式も外から受け取れるようにしましょう。ここはラムダ式を使ってみます。
def sigma(k, n, func): array = [] for k in range(k, (n + 1)): array.append(func(k, n)) return sum(array) #関数の呼び出し例 print(sigma(1, 10, lambda k, n : 2 * k)) # => 1から10それぞれに2を掛けたものの総和なので110ここで察しました。
あれ、リスト内包表記ってもしかして....リスト内包表記の場合
array = [2 * k for k in range(1, 11)] print(sum(array))なるほど.....。
print(sum([2 * k for k in range(1, 11)]))なんと1行にまで縮まりました。
実行速度が早いとかは知ってましたが、リスト内包表記ってこういう意味でも楽なんですね。
なんならこのあと条件分岐とかも挟めますし!結論
プログラムが書けるけど数学ができない人はプログラムを書いてみるのも手かもしれません!
Σが便利だとは思いませんでしたが、少なくとも理解はできましたしリスト内包表記が素晴らしいことはわかりました(笑)。



- 投稿日:2020-06-30T19:56:09+09:00
【初心者向け】Raspberry Piで人感センサー作ってLINEに通知してみた!
はじめに
Raspberry Piをセンサーモジュールに接続して、検知情報を自分のLINEに通知する人感センサーを作ってみました。
経緯
社内の試作アプリ作成の一環として、人感センサーの構築を担当することになりました。
ラズパイってなあに?Pythonって聞いたことあるけど何ができるの?状態からスタートして、センサーが反応したらLINEにお知らせしてくれるものを作ってみました。
自社への作業報告を兼ねて記事を投稿してますが、ラズパイを使って電子工作をしてみたい!という方の参考になれば幸いです。作るにあたり必要なもの
・RaspBerry Pi Zero
・Ren He HC-SR501人体赤外線感応モジュール
( URL:https://www.amazon.co.jp/gp/product/B07DCKZS5S )
・SDカード
・ブレッドボード・ジャンパーワイヤー(メス-メス)
( URL:https://www.amazon.co.jp/gp/product/B01A4DDUTA )
・USBハブ
・モニター
・USBキーボード
・プラスチックハンマー
・GPIOハンマーヘッダー
( https://www.amazon.co.jp/gp/product/B0711MPHVF/ )OSのインストール
ラズパイの公式サイトからOSをダウンロードします。
今回はNOOBS Liteを利用しました。
ダウンロードしたOSのZipファイルを解凍して、SDカードに書き込みます。ラズパイとセンサーモジュールの接続
GPIO Hammer Header使ってGPIOピンをラズパイにプラスチックハンマーでトントンしたら、センサーモジュールと同じ役割のGPIOピンにジャンパーワイヤーで接続します。
今回使用したRaspBerry Pie Zeroではこんな感じで接続します。
センサーモジュールの検知時間と検知範囲はこのぐらいに設定しました。
初期設定
ラズパイにSDカードを挿入します。
モニター、USBキーボード、マウス、電源を接続してラズパイを起動します
こちらの記事を参考に、初期設定を行いますセンサーモジュール動作確認
PythonでラズパイのGPIOの制御設定を行い、センサーモジュールの動作確認をします。
以下のプログラムを実行しますsensor_test.pyimport RPi.GPIO as GPIO GPIO_PIN = 12 GPIO.setmode(GPIO.BCM) GPIO.setup(GPIO_PIN,GPIO.IN) while True: if(GPIO.input(GPIO_PIN) == GPIO.HIGH): print("1") break GPIO.cleanup()プログラム実行後、センサーモジュールに手をかざしてみて、以下の結果になれば動作確認完了です
pi@raspberrypi:~ $ python /home/pi/work/sensor_test.py 1LINE Notifyでアクセストークンの発行
- LINE Notifyにアクセスして、通知を送りたいLINEのアカウントでログインしマイページを開きます
2.「トークンを発行する」をクリックします
3.トークン名を任意のトークン名に設定し、「1:1でLINE Notify 通知を受け取る」を選択する
4.発行されたトークンをメモします
人感センサーの検知情報をLINEへ通知
いよいよプログラム実装します!
センサーモジュールからの感知情報をラズパイでうけとり、LINE Notifyに向かってAPIをたたきます。detection_LINE.pyimport requests import RPi.GPIO as GPIO import time SLEEPTIME = 30 GPIO_PIN = 12 GPIO.setmode(GPIO.BCM) GPIO.setup(GPIO_PIN,GPIO.IN) def main(): url = "https://notify-api.line.me/api/notify" token = "先ほどメモしたアクセストークン" headers = {"Authorization" : "Bearer "+ token} message = 'IN USE!!!!!' payload = {"message" : message} requests.post(url ,headers = headers ,params=payload) try: while True: if(GPIO.input(GPIO_PIN) == GPIO.HIGH): main() time.sleep(SLEEPTIME) finally: GPIO.cleanupラズパイ起動時に自動で実行されるようにCronの設定をします。
crontab -ecronの設定ファイルが開いたら、最終行に以下を追加します。
@reboot python /home/pi/work/detection_LINE.pyラズパイ再起動
ラズパイを再起動して、センサーモジュールに手をかざしたら通知が来ました!
つくってみての感想
ちんぷんかんぷんな状態からスタートしましたが、GPIO取り付けるのに意外に力使ったり、センサーモジュールの検知範囲マックスにした状態+スリープタイム挟まずにスクリプト実行して爆竹のごとくLINE通知鳴りやまなかったりと、初心者ならではの周り道もたくさんしましたが、夏休みの自由研究感覚で楽しめました!
次はAWSのLambdaあたりを使って何か作れたらなあ~と思います。






- 投稿日:2020-06-30T19:52:34+09:00
Oracle NoSQL Database Cloudシミュレータ を使い PythonでNoSQLをさわってみる
本投稿の背景
Oracle Cloud にも NoSQL(Oracle NoSQL Database Cloud) があるのですが、
NoSQLの場合、Pythonで DDLや DMLはどうやって実行するのか?を調査したいと思ったのがきっかけです。Oracle NoSQL Database Cloudシミュレータというのがあり、
ローカルPCで試すことができますので、Oracle NoSQL Database Cloudシミュレータを使用する手順とPythonでDDLやDMLをどうやって実行するのかをまとめました。
本投稿では
Windows10環境で Pythonから Oracle NoSQL Database Cloud シミュレータを触ってみる内容となります。前提はWindows10環境にAnaconda-Python 3.7 versionがインストールしている状態からの手順です。
Oracle NoSQL Database Cloudシミュレータとは
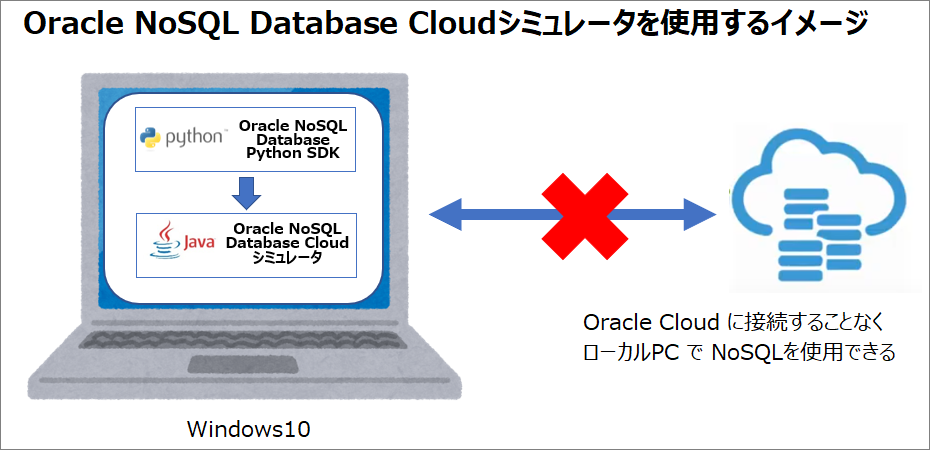
Oracle NoSQL Database Cloudシミュレータでは、クラウド・サービスをシミュレートし、
Oracle NoSQL Database Cloud Serviceにアクセスせずにローカルでアプリケーションを記述およびテストできます。
Oracle NoSQL Database Java SDKには、開発者が使用するサンプルがいくつか含まれています。Oracle NoSQL Database Cloud Serviceを使用して開始する前に、
Oracle NoSQL Database Cloud Simulatorでアプリケーションを開発し、基本的な例を理解できます。⇒Oracle NoSQL Database Cloudシミュレータは、Oracle Cloud に接続せずに、ローカル環境(ノートPC)で、アプリ(Python、Java、Node.js、Go)を試せる環境が準備できます。
環境準備
環境準備は以下2つを準備します
1.Oracle NoSQL Database Cloudシミュレータのダウンロード
2.Oracle NoSQL Database Python SDK のインストール前提はWindows10環境にAnaconda-Python 3.7 versionがインストールしている状態からの手順です。Anacondaのインストールは こちら から
1.Oracle NoSQL Database Cloudシミュレータのダウンロード
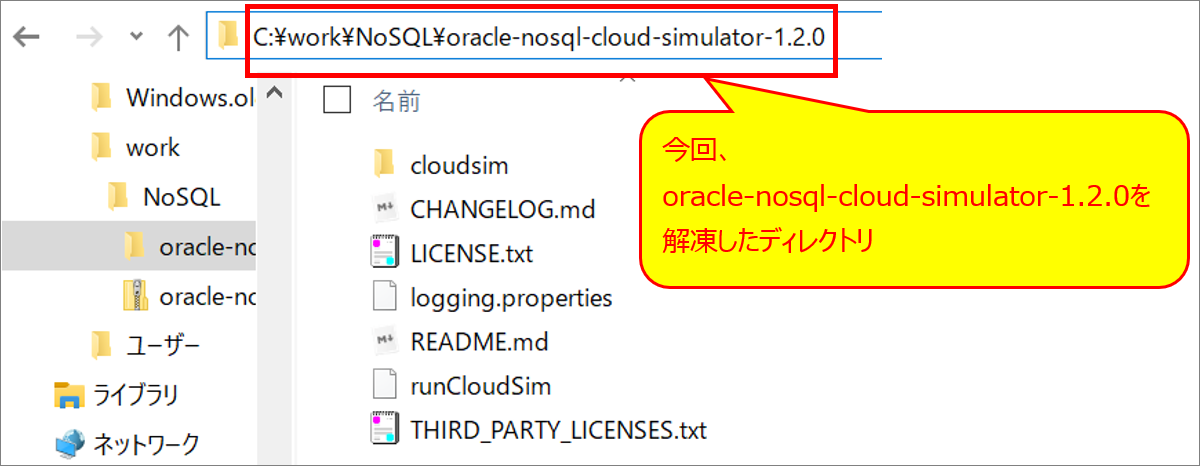
oracle-nosql-cloud-simulator-1.2.0.zip を任意のフォルダにダウンロードして解凍します。
Oracle NoSQL Database Cloudシミュレータを動かすための要件
・使用しているマシンにJava JDKバージョン10以上がインストールされていること。
・Oracle NoSQL Database Cloud Simulatorをインストールする5 GB以上の使用可能なディスク領域。Java JDKバージョン10以上インストールされていない場合
※私の環境ではJava JDKが未インストールでしたので、新規インストール手順となります。例は新規インストールとなります。
https://www.oracle.com/java/technologies/javase-downloads.html
こちらの[ JDK Download ]をクリックして、Windows x64 Installer をダウンロード。
1.ダウンロードした jdk-14.0.1_windows-x64_bin.exe をダブルクリック。
2.以下手順でJava SDKをインストール
2.Oracle NoSQL Database Python SDK のインストール
Anaconda プロンプトを起動
Anaconda プロンプトで
pip install borneoと入力して [Enter]
※Successfully installed borneo-5.2.0 が出ればOKOracle NoSQL Database Cloudシミュレータの起動
1.コマンドプロンプトを起動
コマンドプロンプトを起動される
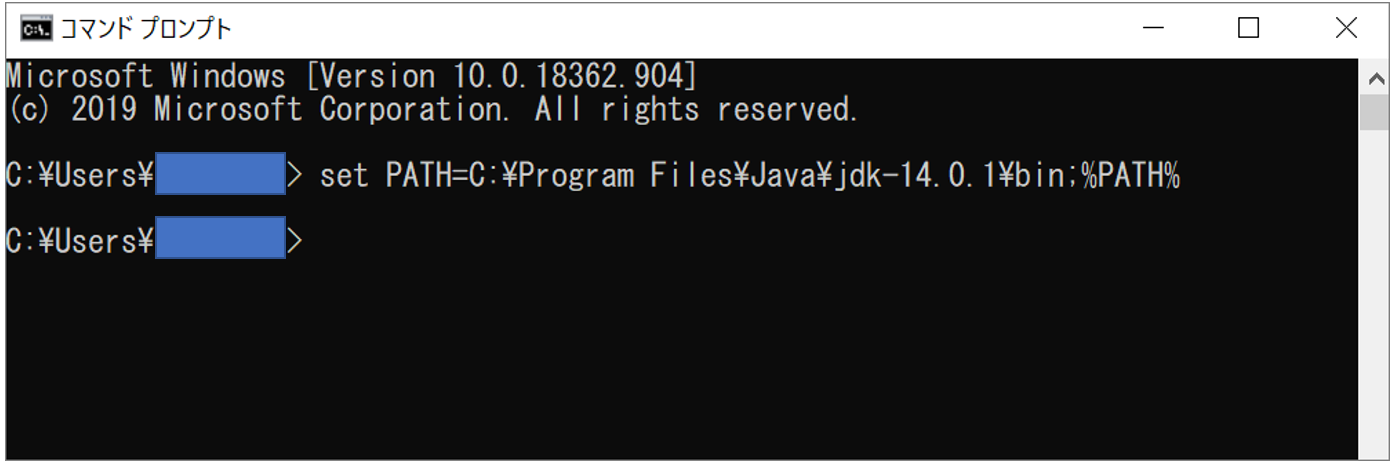
2.環境変数(PATH)に Java JDK のパスをいれる
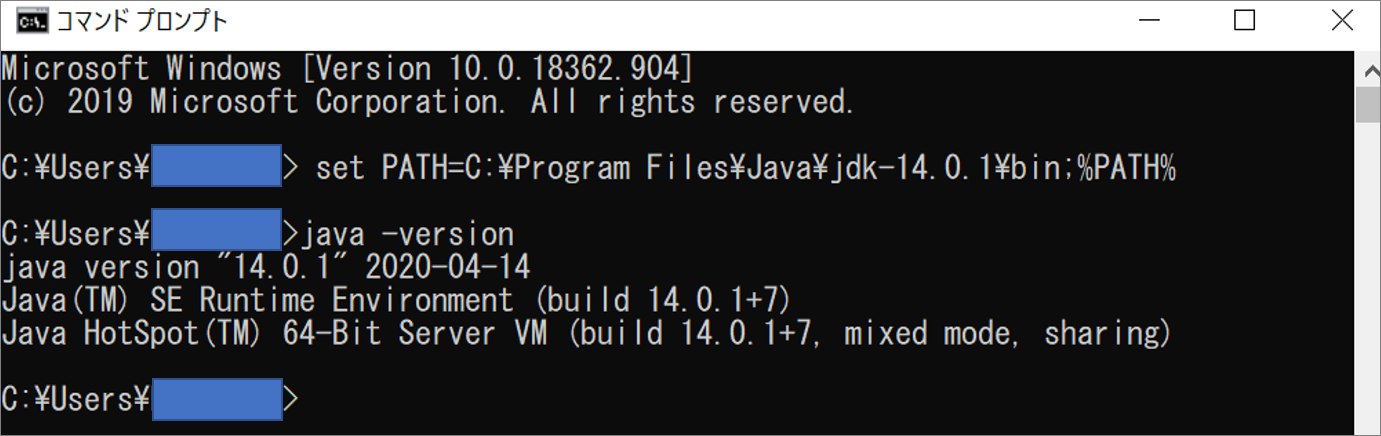
今回インストールしたJava JDKのパスは、C:\Program Files\Java\jdk-14.0.1\bin
set PATH=C:\Program Files\Java\jdk-14.0.1\bin;%PATH% で環境変数PATHにJava JDKのパスを設定
Java -version と入力して、Java JDKのバージョンを確認
⇒今回インストールした Java JDK 14になっていることを確認
コマンドプロンプトで
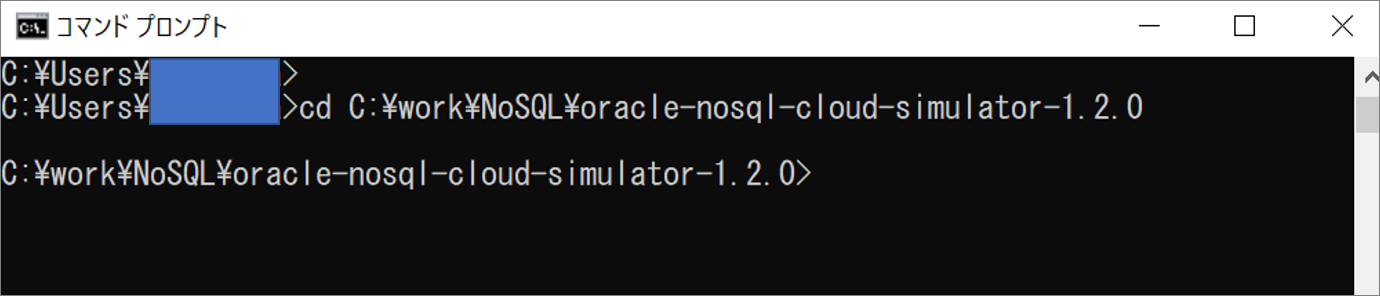
oracle-nosql-cloud-simulator-1.2.0を解凍したディレクトリに移動
cdコマンドで、oracle-nosql-cloud-simulator-1.2.0を解凍したディレクトリに移動
コマンドプロンプトで以下のコマンドを入力
※マニュアルでは Linux のコマンドしかない。実行ファイル「runCloudSim」 をメモ帳で開き中に書いてあるコマンドを確認。 必須パラメータ -root は 現在のディレクトリとするため . としています。java -Djava.util.logging.config.file=logging.properties -jar cloudsim/lib/cloudsim.jar -root .「Oracle NoSQL Cloud Simulator is ready」で 起動されている状態になります
Oracle NoSQL Database Cloudシミュレータの停止方法
[Ctrl]+C で停止になります。
サンプルスクリプトを実行してみる
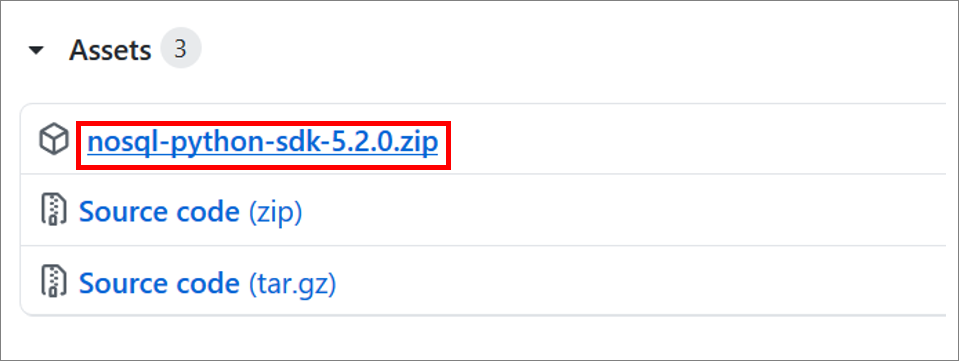
GitHubから pythonのサンプルスクリプト(nosql-python-sdk-5.2.0.zip)をダウンロードします。
https://github.com/oracle/nosql-python-sdk/releases
nosql-python-sdk-5.2.0.zipを任意のフォルダに解凍します。
サンプルスクリプトは [examples]フォルダに格納されています。
Anaconda プロンプトを起動
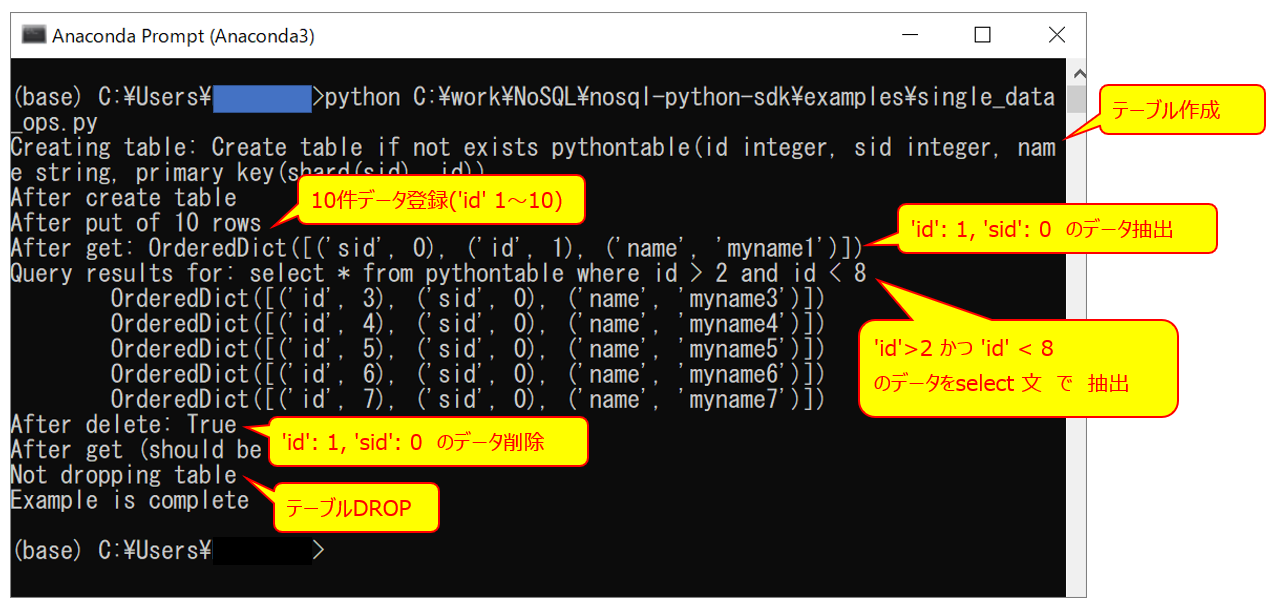
サンプルスクリプトを実行(試しにsingle_data_ops.pyを実行)
サンプルスクリプトをドラッグして[Enter]キーを押下します。
※Oracle NoSQL Database Cloudシミュレータは起動しておく必要があります
single_data_ops.py の 実行結果
※single_data_ops.py の中で、各処理実行後、結果を表示しています。
single_data_ops.pyの中に
テーブル作成、データ登録、データ抽出、データ削除、テーブルDropの処理が記載されておりましたので、single_data_ops.pyを参考にして頂ければと思います。また詳細は、Oracle NoSQL Database Python SDK(日本語) 、SQL Reference for Oracle NoSQL Database(SELECT Expression) も参考になりました。
multi_data_ops.py、table_ops.py もサンプルスクリプトとして実行することができます。
参考
・Oracle NoSQL Database Python SDK
https://docs.oracle.com/cd/E83857_01/paas/nosql-cloud/sdk/index.html・SQL Reference for Oracle NoSQL Database(SELECT Expression)
https://docs.oracle.com/en/database/other-databases/nosql-database/19.5/sqlreferencefornosql/select-expression.html・NoSQLデータベース マニュアル
https://docs.cloud.oracle.com/ja-jp/iaas/nosql-database/index.html・NoSQLデータベース マニュアル (Oracle NoSQL Database Cloudシミュレータでの開発)
https://docs.cloud.oracle.com/ja-jp/iaas/nosql-database/doc/developing-oracle-nosql-database-cloud-simulator.html





- 投稿日:2020-06-30T19:14:07+09:00
Pyhtonの基礎復習はこれだけ ~3~
6.文字列操作
シングルクォート、ダブルクォート
文字列にシングルクォートを含む場合、文字列をダブルクォートで囲むことでエラーを回避できる。
spam = "That is Alice's cat"エスケープ文字
しかし、シングルクォートとダブルクォートの両方を使いたいときはエスケープ文字を用いることで回避できる。
エスケープ文字 意味 \' シングルクォート \" ダブルクォート \t タブ \n 改行 \\ バックスラッシュ print("Hello there!\nHow are you?\nI\'m doing fine\t." Hello there! How are you? I'm doing fine .windowsでは、 \ は ¥ になる。
raw文字列
クォート文字の前 r に付けると文字列のエスケープ文字を無視する。
print(r'That is Carol\'s cat.') That is Carol\'s cat.三連クォート
三連クォートを用いればエスケープ文字を使う必要がなくなる。
Pythonの字下げルールも適用されない。print('''Dear Alice, Eve's cat has been arrested for catnapping, cat burglary, and extortion. Sincerely, Bob''') Dear Alice, Eve's cat has been arrested for catnapping, cat burglary, and extortion. Sincerely, Bob複数行コメント
#記号はつけた場所から文末までコメントを挟み込むことができる。
複数行にわたってコメントを入れたいとき以下のようには"""で囲む。def spam(): """これはspam()関数の動きを説明するための、 複数行コメントです。""" print('Hell!')文字列のインデックスとスライス
文字列もリストと同様にインデックスとスライスを適用することができる。
便利な文字列メソッド
- upper()
文字列の全てを大文字にして返す。
spam = 'Hello world' sapam = spam.upper() spam 'HELLO WORLD'
- lower()
文字列の全てを小文字にして返す。
spam = 'Hello world' sapam = spam.lower() spam 'hello world'
- isupper()
1文字以上の全ての英字が大文字ならTrueを返す。
HELLO.isupper() True
- islower()
1文字以上の全ての英字が小文字ならTrueを返す。
hello.islower() TrueisXという文字列メソッド
- isalpha()
一文字以上の英字のみで構成されているときTrueを返す。
'hello'.isalpha() True
- isalnum
一文字以上の英字、数字のみのときTrueを返す。
'hello123'.isalnum() True
- isdecimal
一文字以上の数字のみで構成されているときTrueを返す。
'123'.isdecimal() True
- isspace
スペースかタブか改行だけで構成されているときTrueを返す。
' '.isspace() True
- istitle
大文字から始まり残り全ての英字が小文字で構成されているときTrueを返す。
Apple.istitle() Truestartswith()メソッド、endswith()メソッド
対称の文字列がメソッドに渡された文字列から始まるか、終わる場合にTrueを返す。
'Hello world!'.startswith('Hello') True 'Hello world!'.endswith('World!') Truejoin()メソッド、split()メソッド
- join()メソッド
文字列のリストを一つの文字列に連結する。
','.join(['cats','rats','bats']) 'cats,rats,bats' 'ABC'.join(['cats','rats','bats']) 'catsABCratsABCbats'
- split()メソッド
文字列を指定した文字で区切り、リストにする。
'My name is Simon'.split() ['My','name','is','Simon'] 'MyABCnameABCisABCSimon'.split(ABC) ['My','name','is','Simon']テキストをそろえる
- rjust()メソッド
- ljust()メソッド
文字列が指定した数値より大きいとき、その分だけ指定した文字を右、もしくは左に加える。
'Hello'.rjust(10, '*') '*****Hello' 'Hello'.ljust(10, '*') 'Hello*****'
- center()メソッド
文字列が指定した数値より大きいとき、その分だけ指定した文字を左右に加える。
'Hello'.center(10, '*') '**Hello***' 'Hello'.center(10) ' Hello 'strip()メソッド、rstrip()メソッド、lstrip()メソッド
文字列の左端、右端、両端から指定した文字を消すときに用いる。
spam = ' Hello world ' spam.strip() 'Hello world' spam.lstrip() 'Hello world ' spam.rstrip() ' Hello world'また、引数を渡すことで以下のように文字を消すこともできる。
引数のアルファベットの順番は任意になるので以下のようになる。spam = 'SpamSpamBaconSpamEggsSpamSpam' spam.strip(ampS) BaconSpamEggspyperclipモジュール
pyperclipモジュールにはcopy()、paste()関数がある。
コンピュータのクリップボードにコピーしたり、ペーストすることができる。import pyperclip pyperclip.copy('Hello world!') pyperclip.paste() 'Hello world!'続き
初めから
Pythonの基礎復習はこれだけ~1~
- 投稿日:2020-06-30T18:04:08+09:00
C言語で16文字でセグフォらせる
↓PythonをSegmentation Faultで落とすのが最近流行っているようなので。
pythonを三行でセグフォらせる
pythonを2行でセグフォらせる
pythonを1行でセグフォらせる
Pythonを33文字でセグフォらせる
Pythonをctypesを使わずに1行でセグフォらせる
Rustを5行でセグフォらせる
主語(Python)をC言語に変えるだけで途端につまらなくなりますが、やってることは同じです。コード
gcc 10.1.0で動作確認(警告は出ます)
*a;main(){*a=0;}> gcc segf.c segf.c:3:4: 警告: データ定義が型または記憶域クラスを持っていません 3 | *a;main(){*a=0;} | ^ segf.c:3:5: 警告: 型がデフォルトの ‘int’ に ‘a’ の宣言内でなります [-Wimplicit-int] 3 | *a;main(){*a=0;} | ^ segf.c:3:7: 警告: 戻り値の型をデフォルトの ‘int’ にします [-Wimplicit-int] 3 | *a;main(){*a=0;} | ^~~~ > ./a.out zsh: segmentation fault (core dumped) ./a.out簡単な解説
これだけだとQiitaの記事要件を満たさないため、簡単に解説します。
まず最初に観るコードは↓です。int main(void) { int *a = 0; *a = 0; // ←ここで落ちる return 0; }C言語にはポインタという概念があり、これを用いるとメモリの好きな番地にアクセスすることができます。
int *a = 0のところでaという名前のポインタを宣言し、メモリ番地0を代入します。2行目で*aに値を代入すると、実際には存在しないアドレス1 にアクセスすることになり、CPU例外が発生します。ショートコーディング
それでは、上のコードを短くしていきましょう。まず、C言語の規約上
return 0は省略できます。2また、返り値の型intも互換性の観点から省略できます。(省略すると暗黙的にintになります。)さらに、引数のvoidも書かなくても動きます。
これらを踏まえると以下のようになります。main() { int *a = 0; *a = 0; // ←ここで落ちる }ここで、ローカル変数
aはグローバル変数として定義してもよいです。さらに、グローバル変数として定義すると、(よほど特殊な環境でない限り)0で初期化してくれるため初期化のための代入が不要です3。int *a; main() { *a = 0; // ←ここで落ちる }さらに、グローバル変数の型指定子
intも省略できます。これで冒頭のコードになりました。おまけ。番地
*(0p00000000)は本当に存在しないか?古典的なコンピュータにおいて、メモリはたくさんの情報を保管しておくことができる装置です。しかしながら、たくさんの情報をメモリに送ったり、メモリから受け取るためには、直感的には送受信したい情報の個数分だけ電線が必要になります。しかしながら、CPUの動作速度に耐えられるような細い電線をたくさん用意するのはコスト面で不可能なので、メモリアドレスという概念を導入します。これにより、一度に読み書きできる情報の個数(1Byteという)4は少ないながら、メモリアドレスを変更することによってたくさんの情報をメモリに保管することができます。
このように、メモリ大容量時代に欠かすことのできないメモリアドレスという概念ですが、これは
0から始まる正の整数で表されるため、実際には0番地というアドレスは存在するのです。では、なぜセグメンテーションフォルトが起きたか、というと、OSが利用しているページングというCPUの機能が原因です。コンピュータにおいてメモリアドレスはユニークです。よって、特に工夫しない場合、マルチタスキングOSにおいて複数のプロセスが同じメモリアドレス空間を所有することになります。この場合、メモリにアクセスする場合は、他のプロセスが利用しているメモリに間違ってアクセスしないように気をつけなければなりません。このような不便を解消するのがページングで、ページングを用いると各プロセスがそれぞれ別個の仮想アドレス空間を所有できます。このとき、仮想アドレス空間5と物理(メモリ)アドレス空間の間を変換する表をOSが管理しています。
よって、本来プロセスは存在するすべてのアドレスにアクセスできるはずです。しかしながら、実際はそうはいかず、仮想アドレス空間においてもOSが幅を利かしています。プログラムから利用できるメモリの範囲を制限しているのです。このような仮想アドレス空間の区画分けをメモリマップといいます。この記事にあるように、0番地の周辺は使用しないこととなっており(対応する物理メモリアドレスが割り当てられていない)、そのためセグメンテーションフォルトが発生します。6
おわりに
さらっと書くつもりが20分くらい掛かった。書かなきゃよかった。
- 投稿日:2020-06-30T18:01:16+09:00
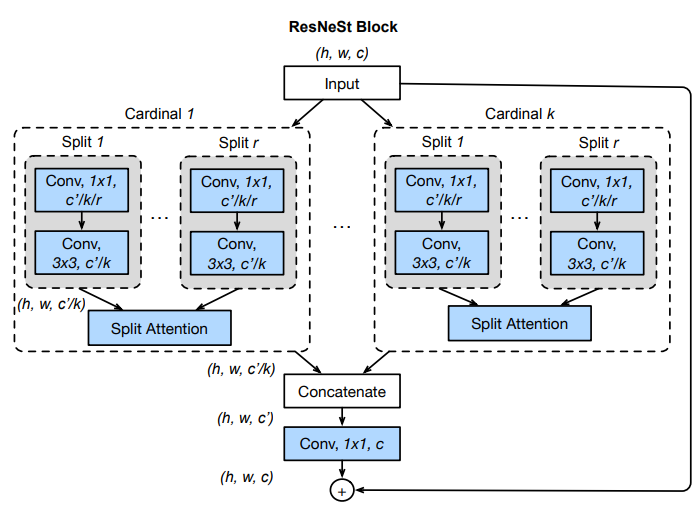
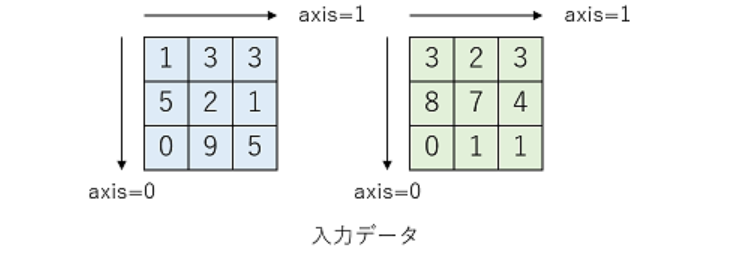
Concatenateの理解
はじめに
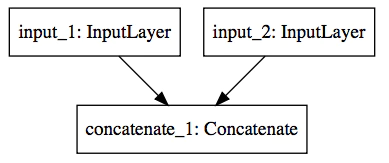
KerasのF.Cholletの本を読むと、Concatenate Layerの説明がされている部分がある。下記の絵で表現されているが、この中でどんな演算が行われているかさっぱりしたまなであった。
ところで、U-NET, ResnetなどにConcatenate Layerが重要な役割をしていることから、これ以上にConcatenate Layerを理解せず放置することは良くない判断で、簡単なテンソルを利用し、Concatenate Layerの挙動を確認することにした。
理解
Excelで、文字列結合の時に、Concatenate関数を使ったことがあったので、何となく複数の配列を何の演算もせず、くっつけるイメージは持っていたが、Teratailにわかりやすい図があったので、ここで紹介する。
ここで、青と緑二つの行列がある。
これらの行列は2次元(2D)テンソルで、これらの行列のShapeは(3,3)である。
axisとは、テンソルの次元(Dimension)を言う。[テンソル(Tensor)の理解(2) : Shape]axisは、テンソルの次元の軸も指す。(物理でのモーメントを表記するときのベクトルを考えるといいかもしれない。)
2次元テンソルの場合、axis = 0が垂直方向、 axis = 1が水平方向を意味する。
ただし、axis = -1とした場合は、一番最後の軸を意味する。Pythonのリストのスライスを考えるといい。
そして、Concatenate Layerの時、結合方向を指定することが可能である。
(1) axis = 0の場合、垂直方向に結合する。
(2) axis = 1の場合、水平方向に結合する。(ただし、2次元の場合、axis = -1も同じ意味)
プログラムコード
import tensorflow as tf import numpy as np #2D Tensorの準備 x1 = np.array([[1,3,3], [5,2,1], [0,9,5]]) x2 = np.array([[3,2,3], [8,7,4], [0,1,1]]) print('x1=',x1) print('x2=',x2)Concatenate Layer
垂直結合
#Concantenate Layer # axis = 0, 垂直方向結合 y1 = tf.keras.layers.Concatenate(axis=0)([x1,x2]) print('y1=',y1)垂直結合結果y1= tf.Tensor( [[1 3 3] [5 2 1] [0 9 5] [3 2 3] [8 7 4] [0 1 1]], shape=(6, 3), dtype=int32)水平結合
# axis = 1 (or axis = -1) 水平方向結合 y2 = tf.keras.layers.Concatenate(axis=-1)([x1,x2]) print('y2=',y2)水平結合結果y2= tf.Tensor( [[1 3 3 3 2 3] [5 2 1 8 7 4] [0 9 5 0 1 1]], shape=(3, 6), dtype=int32)まとめ
やっとConcatenate Layerの動作を理解した。(気がする。)
ただし、Concatenateのスペリングがなかなか頭に入らない。(涙)参考資料

- 投稿日:2020-06-30T17:56:44+09:00
なろう小説APIを試してみた2
なろう小説APIを読んでいたら面白いコマンドを見つけたので紹介と分析をしてみる
会話率
パラメータ 値 説明 kaiwaritu int string 抽出する小説の会話率を%単位で指定できます。範囲指定する場合は、最低数と最大数をハイフン(-)記号で区切ってください。 なるほど。会話率……
会話ばっかりとか地の分とかそういうのかなではでは早速
ロードの準備とライブラリの読み込みをし
before_load.pyimport pandas as pd import requests import numpy as np import seaborn as sns from scipy import stats import matplotlib.pyplot as plt %matplotlib inline url = "http://api.syosetu.com/novelapi/api/"narou_load.pyst = 1 lim = 500 data = [] while st < 2000: payload = {'of': 't-gp-gf-n-ka', 'order': 'hyoka', 'out':'json','lim':lim,'st':st} r = requests.get(url,params=payload) x = r.json() data.extend(x[1:]) st = st + lim df = pd.DataFrame(data) df.head()
payload = {'of': 't-gp-gf-n
この部分にkaという部分を追加すればロードができる。(上では追加済み)
そして出てくるデータが
title kaiwaritu(%) 転生したらスライムだった件 14 ありふれた職業で世界最強 40 とんでもスキルで異世界放浪メシ 36 無職転生 - 異世界行ったら本気だす - 22 デスマーチからはじまる異世界狂想曲( web版 ) 38 なるほど。ありふれ結構高いな(ファン)
ただ、そもそもこれがどれくらい高いのか分からないのでdescribe()してみる
kaiwaritu count 2000.00000 mean 38.00800 std 10.66831 min 0.00000 25% 31.00000 50% 38.00000 75% 45.00000 max 96.00000 なるほど。平均が38%となると平均くらいなのか。
というか、ありふれくらい文字数が多くてこの割合って結構多いのか?文字数を少し絞ってみようか。
読了時間
あえて文字数を指定せずに読了時間というものを使ってみる
といっても読了時間とは
パラメータ 値 説明 time int string 抽出する小説の読了時間を指定できます。読了時間は小説文字数÷500を切り上げした数字です。範囲指定する場合は、最小文字数と最大文字数をハイフン(-)記号で区切ってください。 と、ある通り文字数に比例した数字なので数字が小さくなる以外はそこまで問題はないはず。
payloadのofにtiを追加して早速ロードせっかくなので
timeをdescribe()してみて
time count 2000.000000 mean 1395.985500 std 1823.680635 min 11.000000 25% 434.750000 50% 889.500000 75% 1608.250000 max 26130.000000 一応最低でも5001文字以上はあるようだ。
(...というかmaxってサモナーさんじゃないだろうな)
df[['title','time']].sort_values('time').tail()
title time マギクラフト・マイスター 14868 境界迷宮と異界の魔術師 16410 異世界料理道 17653 サモナーさんが行く 25536 レジェンド 26130 違いました
読了時間(文字数)と会話率の関連性
doku_kai.py#時間で四分位する df['part']=pd.qcut(df.time,4,labels=['D','C','B','A']) #パート毎に平均する df.groupby('part').agg({'kaiwaritu':['mean']})※文字数はD<C<B<A
part kaiwaritu(平均:%) D 36.990 C 38.180 B 38.322 A 38.540 これは驚いた。特に長編だろうが短編だろうが会話率は変わらないようだ。
文体
悔しかったので、もう一つ文体という機能を使ってみた
これはまだ試作段階のようで、はっきりとデータが出ない場合がある(そもそもあいまい)のと、ofに設定ができないのでデータフレーム読み込みを2種類作ることにする
パラメータ 値 説明 buntai int string 文体を指定できます。ハイフン(-)記号で区切ればOR検索できます。 1:字下げされておらず、連続改行が多い作品 2:字下げされていないが、改行数は平均な作品 4:字下げが適切だが、連続改行が多い作品 6:字下げが適切でかつ改行数も平均な作品 まず、それぞれ
df1、df2、df4、df6にわける
- df1
失格紋の最強賢者 ~世界最強の賢者が更に強くなるために転生しました~
公爵令嬢の嗜み
転生賢者の異世界ライフ ~第二の職業を得て、世界最強になりました~
乙女ゲームの破滅フラグしかない悪役令嬢に転生してしまった…
ライブダンジョン!
- df2
異世界食堂
誰かこの状況を説明してください
針子の乙女
私はおとなしく消え去ることにします
中堅(中年)サラリーマンのまったり異世界産業革命
- df4
ありふれた職業で世界最強
無職転生 - 異世界行ったら本気だす -
デスマーチからはじまる異世界狂想曲( web版 )
Re:ゼロから始める異世界生活
陰の実力者になりたくて!【web版】
- df6
転生したらスライムだった件
とんでもスキルで異世界放浪メシ
私、能力は平均値でって言ったよね!
蜘蛛ですが、なにか?
聖女の魔力は万能です一部納得いかない分類もあるが、ここは我慢する
df1 df2 df4 df6 count 500.000000 500.000000 500.00000 500.000000 mean 36.506000 35.246000 38.74200 37.668000 std 11.489211 14.927396 9.70091 13.106691 min 1.000000 0.000000 6.00000 0.000000 25% 28.000000 25.000000 32.75000 30.000000 50% 36.000000 35.000000 39.00000 38.000000 75% 44.000000 44.250000 45.00000 46.000000 max 70.000000 98.000000 71.00000 96.000000 この結果を見ると、大きな差は無いもののdf2が全体的に少なく、逆にdf6が多い結果になった。
尚、母数を500ずつにしているのは最初の母数が2000だったからであって、2000ずつ表示にしたときdf2はさらに下がり34%であった。こうみると会話率は文体にもかかわってないようだ。
やっぱりジャンルなのかな感想
あまり上手くいかない分析結果になってしまったが、今後仕事としてやっていくときの練習にはなったのかなとは思った。
また面白いデータ分析を思いついたらやってみたいと思う。
読み返してみたら転スラの会話率の低さに驚いた。心の中の会話が多いからか?
- 投稿日:2020-06-30T17:43:08+09:00
cx_Oracle が使える Docker イメージ
Python アプリから Oracle データベースに繋ぐ必要があり Python クライアントを入れる Dockerfile を書いたのだが、やたら苦労したので備忘録として書いておく。
DockerfileFROM python:3.7 RUN pip install cx_Oracle # Install Oracle Client ENV ORACLE_HOME=/opt/oracle ENV LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$ORACLE_HOME/lib RUN apt-get update && apt-get install -y libaio1 && rm -rf /var/lib/apt/lists/* \ && wget -q https://download.oracle.com/otn_software/linux/instantclient/19600/instantclient-basic-linux.x64-19.6.0.0.0dbru.zip \ && unzip instantclient-*.zip \ && mkdir -p $ORACLE_HOME \ && mv instantclient_19_6 $ORACLE_HOME/lib \ && rm -f instantclient-*.zipcx_Oracle 8 Initialization — cx_Oracle 8.0.0 documentation
公式ドキュメントによると、cx_Oracle を利用するためには Oracle Client ライブラリがインストールされている必要があり、cx_Oracle は次の順序でライブラリの読み込みを試行する。
cx_Oracle.init_oracle_client(lib_dir="...")で指定したパス- OS のライブラリパス (
$LD_LIBRARY_PATH)$ORACLE_HOME/libこのうち
1.と3.の方法で試したときに、他のライブラリは読み込めるのにlibnnz19.soだけ「そんなファイルは無い」などとエラーが出て大変困った。
原因はいまだにわからない。
2.の方法を試したところ問題なく読み込まれた。
- 投稿日:2020-06-30T17:32:57+09:00
スライドパズル・15パズルの解法
概要
スライドパズル・15パズルの解法を試してみたいと思っています。
使用言語はpython です。
ここで遊べます(リンクあり)。
空いているマスに、数字マスを移動させる事で1,2,3,・・・と順に並べることを目的とします。完全ランダム
20回移動して、一致していなかったらさらに移動を繰り返します。
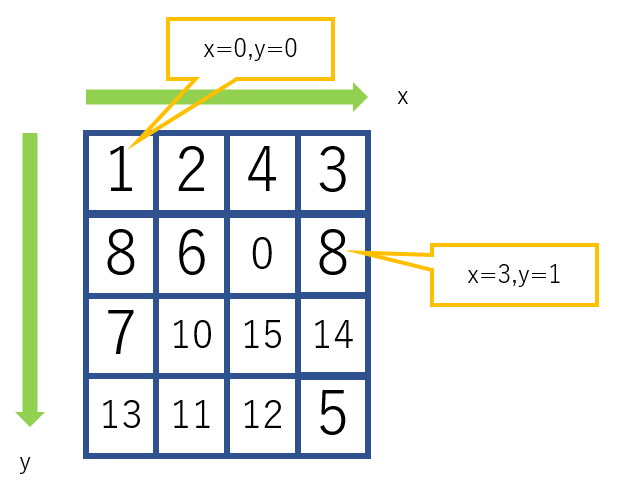
100セットごとに現状をprintします。座標系
クラスの関数
slide.move(direction)操作マスをdirectionの方向に動かす
0:上
1:右
2:下
3:左slide.shuffle(num)num回、ランダムで移動する
結果
10分ほど回しましたが一致する事はありませんでした。
10105300times [2, 7, 4, 1] [3, 10, 8, 12] [6, 5, 14, 15] [0, 11, 9, 13] 10105400times [0, 9, 2, 3] [14, 1, 8, 7] [13, 15, 11, 12] [5, 10, 6, 4] 10105500times [9, 10, 5, 6] [15, 2, 13, 8] [12, 7, 0, 1] [4, 3, 11, 14]実行プログラムは次のようになります。
import random import numpy as np # Numpyライブラリ class Slide(): """ 0 が 操作マス 左上を原点とする 横に x 縦に y トスル """ def __init__(self): self.puzzle = [[1,2,3,4], [5,6,7,8], [9,10,11,12], [13,14,15,0]] self.x = 3 self.y = 3 def shuffle(self,num): for i in range(num): j=0 while True: j = random.randint(0,3) break self.move(j) def move(self,direction): """ 0 3 1 2 """ if direction == 0: if self.y != 0: if self.fixed[self.y-1][self.x] == 0: self.puzzle[self.y][self.x] = self.puzzle[self.y-1][self.x] self.y = self.y - 1 self.puzzle[self.y][self.x] = 0 if direction == 1: if self.x != 3: if self.fixed[self.y][self.x+1] == 0: self.puzzle[self.y][self.x] = self.puzzle[self.y][self.x+1] self.x = self.x + 1 self.puzzle[self.y][self.x] = 0 if direction == 2: if self.y != 3: if self.fixed[self.y+1][self.x] == 0: self.puzzle[self.y][self.x] = self.puzzle[self.y+1][self.x] self.y = self.y + 1 self.puzzle[self.y][self.x] = 0 if direction == 3: if self.x != 0: if self.fixed[self.y][self.x-1] == 0: self.puzzle[self.y][self.x] = self.puzzle[self.y][self.x-1] self.x = self.x - 1 self.puzzle[self.y][self.x] = 0 def check(self): for i in range(4): for j in range(4): if self.puzzle[i][j] != j+1+i*4: return -1 return 0 if __name__ == '__main__' : hoge = Slide() hoge.shuffle(500) print(hoge.puzzle) n=0 while True: hoge.shuffle(20) flag = hoge.check() if flag == 0: break n=n+1 if n%100 == 0: print(str(n)+"times") print(hoge.puzzle[0]) print(hoge.puzzle[1]) print(hoge.puzzle[2]) print(hoge.puzzle[3]) print("find") print(str(n) + "times") print(hoge.puzzle)一致している部分を固定しながら・ランダム
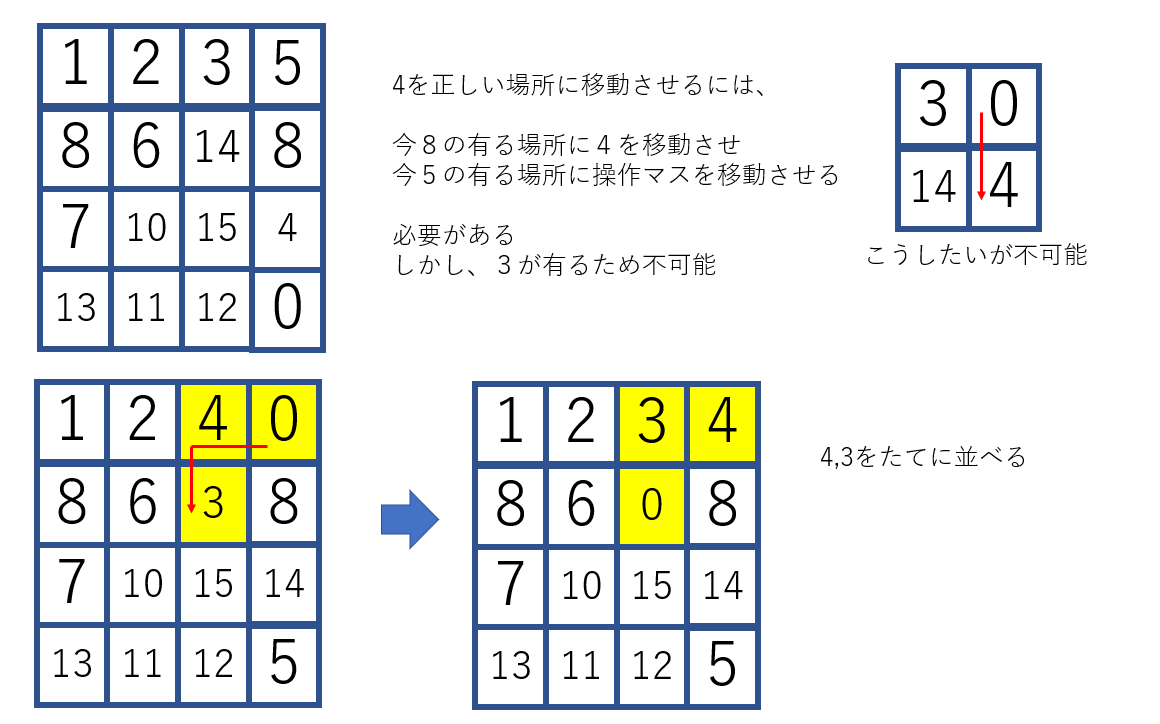
正しい位置に移動できたマスから固定する方法を使います。
ただし、[1, 2, 3, 11] [5, 6, 7, 8] [12, 11, 10, 9] [15, 13, 4, 0]で、1,2,3を固定すると、4を正しい位置に移動させることができなります。
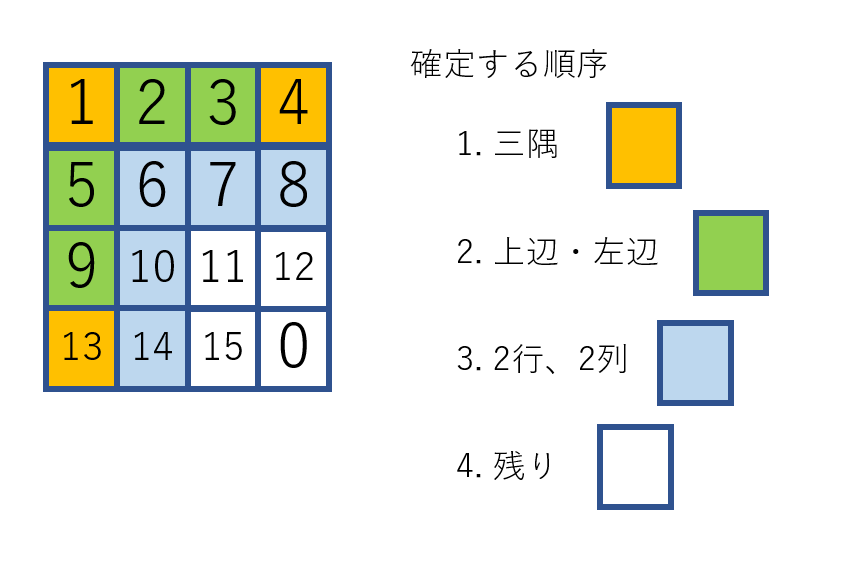
そこで、
1. 3隅(右下隅は空なので)
2. 3隅の間2マス(同時出ないとアウト):上辺、左辺
3. 2行
4. 2列の順に完成させます。(ランダムで回し、成立したら固定し、次に行く)
この段階で、左下4マスのみなので、6通り(確定しているかも)でここはランダムでも解けます。
結果としては、かなり良くなります。
shuffled puzzle [11, 5, 2, 7] [1, 6, 12, 14] [0, 13, 9, 3] [8, 15, 4, 10] start analyze 3652times [1, 2, 3, 4] [5, 6, 7, 8] [9, 10, 11, 12] [13, 14, 15, 0]3652セット(3652*20回移動)で完成できました。完全ランダムだと、10105500セットを超えても完成しないので、かなりいいと思います。
何回かやりましたが、1秒もかかりませんが、セット数はまばらです。import random import numpy as np # Numpyライブラリ class Slide(): """ 0 が 操作マス 左上を原点とする 横に x 縦に y トスル """ def __init__(self): self.puzzle = [[1,2,3,4], [5,6,7,8], [9,10,11,12], [13,14,15,0]] self.x = 3 self.y = 3 self.fixed = np.zeros((4,4)) def shuffle(self,num): for i in range(num): j=0 while True: j = random.randint(0,3) break self.move(j) def move(self,direction): """ 0 3 1 2 """ if direction == 0: if self.y != 0: if self.fixed[self.y-1][self.x] == 0: self.puzzle[self.y][self.x] = self.puzzle[self.y-1][self.x] self.y = self.y - 1 self.puzzle[self.y][self.x] = 0 if direction == 1: if self.x != 3: if self.fixed[self.y][self.x+1] == 0: self.puzzle[self.y][self.x] = self.puzzle[self.y][self.x+1] self.x = self.x + 1 self.puzzle[self.y][self.x] = 0 if direction == 2: if self.y != 3: if self.fixed[self.y+1][self.x] == 0: self.puzzle[self.y][self.x] = self.puzzle[self.y+1][self.x] self.y = self.y + 1 self.puzzle[self.y][self.x] = 0 if direction == 3: if self.x != 0: if self.fixed[self.y][self.x-1] == 0: self.puzzle[self.y][self.x] = self.puzzle[self.y][self.x-1] self.x = self.x - 1 self.puzzle[self.y][self.x] = 0 def check_corner(self): if self.puzzle[0][0] == 1: if self.puzzle[0][3] == 4: if self.puzzle[3][0] == 13: return 1 return 0 def check_upperside(self): if self.puzzle[0][1] == 2: if self.puzzle[0][2] == 3: return 1 return 0 def check_lowerside(self): if self.puzzle[1][0] == 5: if self.puzzle[2][0] == 9: return 1 return 0 def check_line2(self): if self.puzzle[1][1] == 6: if self.puzzle[1][2] == 7: if self.puzzle[1][3] == 8: return 1 return 0 def check_row2(self): if self.puzzle[1][1] == 6: if self.puzzle[2][1] == 10: if self.puzzle[3][1] == 14: return 1 return 0 def check_else(self): if self.puzzle[2][2] == 11: if self.puzzle[2][3] == 12: if self.puzzle[3][2] == 15: return 1 return 0 if __name__ == '__main__' : hoge = Slide() hoge.shuffle(500) print("shuffled puzzle") print(hoge.puzzle[0]) print(hoge.puzzle[1]) print(hoge.puzzle[2]) print(hoge.puzzle[3]) print("start analyze") n=0 #隅 flag = 0 while True: hoge.shuffle(20) n=n+1 flag = hoge.check_corner() if flag == 1: break hoge.fixed[0][0] = 1 hoge.fixed[0][3] = 1 hoge.fixed[3][0] = 1 #上辺・左辺 flag1 = 0 flag2 = 0 while True: hoge.shuffle(20) n=n+1 if flag1 == 0: flag1 = hoge.check_upperside() if flag1 == 1: hoge.fixed[0][1] = 1 hoge.fixed[0][2] = 1 if flag2 == 0: flag2 = hoge.check_lowerside() if flag2 == 1: hoge.fixed[1][0] = 1 hoge.fixed[2][0] = 1 else: if flag1 == 1: break #2行・2列 flag1 = 0 flag2 = 0 while True: hoge.shuffle(20) n=n+1 if flag1 == 0: flag1 = hoge.check_line2() if flag1 == 1: hoge.fixed[1][1] = 1 hoge.fixed[1][2] = 1 hoge.fixed[1][3] = 1 if flag2 == 0: flag2 = hoge.check_row2() if flag2 == 1: hoge.fixed[1][1] = 1 hoge.fixed[2][1] = 1 hoge.fixed[3][1] = 1 else: if flag1 == 1: break #左下4マス flag = 0 while True: hoge.shuffle(20) n=n+1 flag = hoge.check_else() if flag == 1: break print(str(n)+"times") print(hoge.puzzle[0]) print(hoge.puzzle[1]) print(hoge.puzzle[2]) print(hoge.puzzle[3])ランダムでなく、計算により目標位置に移動させる
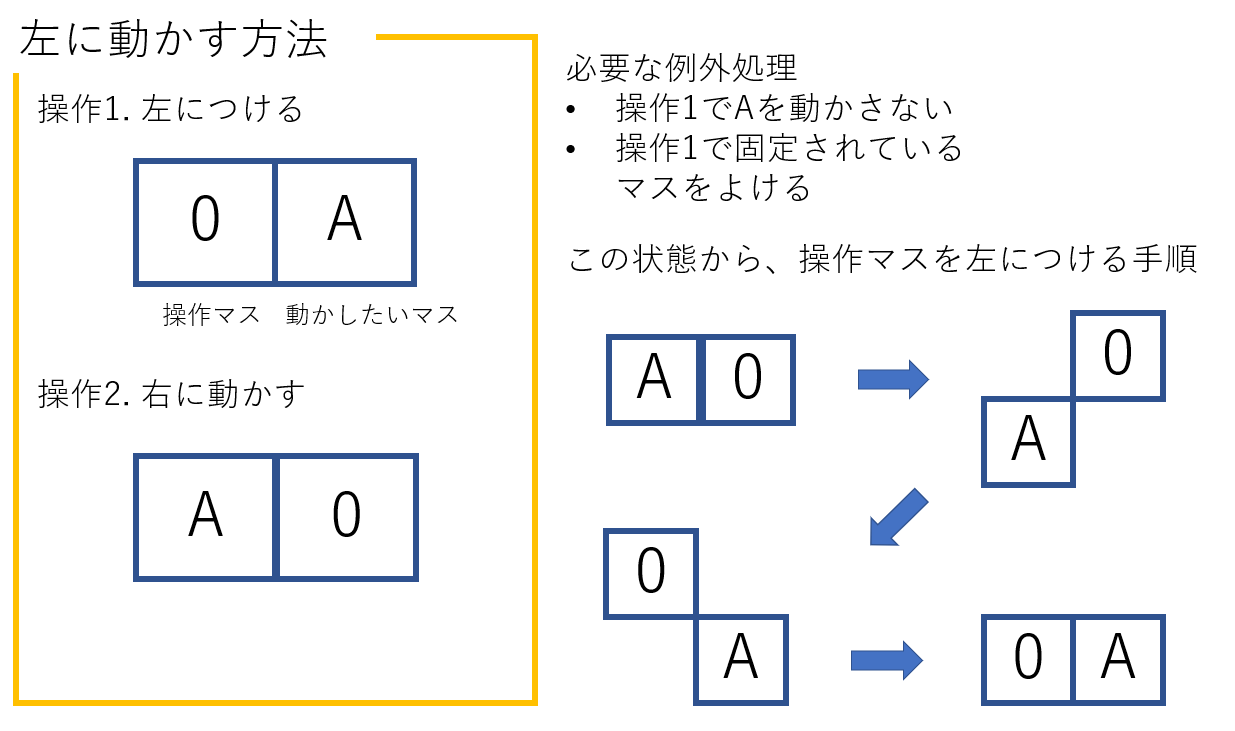
任意の場所Aにある"数字"を任意の場所Bに移動させる手順の作成法を考えます。
Aを左に移動させるには、操作マス(0マス)をAの左に移動させ、操作マスを右に移動させればよいです。
Aや固定しているマスを動かさないように、操作マスを移動させるルートはA*アルゴリズムによって解きます。
最後に、作成したA*アルゴリズムを貼っておきます。Astar(goal_x,goal_y,start_x,start_y,obstacle)を与えると、最短ルートを返します。
このルートに基づき、操作マスを動かしたいマスのとなりに付け、上下左右へ動かします。
この関数によって、Aを任意の場所に動かす事ができるようになりました。次に、どのマスから確定させていくか決めます。
- 1
- 2
- 4と3 :3を固定すると4が入らなくなるため
- 5
- 9と13
- 6 (ここから先は、ゲーム木探索で解ける、後で実装したい)
- 7と8
- 10と14
- 11と12と15 : ここは0を右下隅に移動させた場合、次の3通りしか有りません。
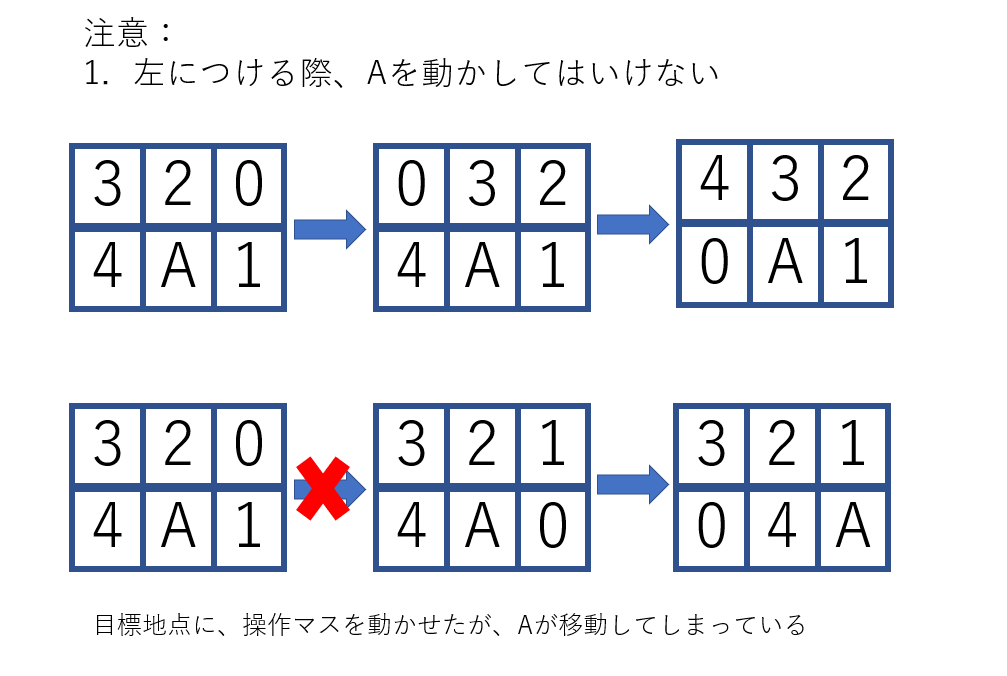
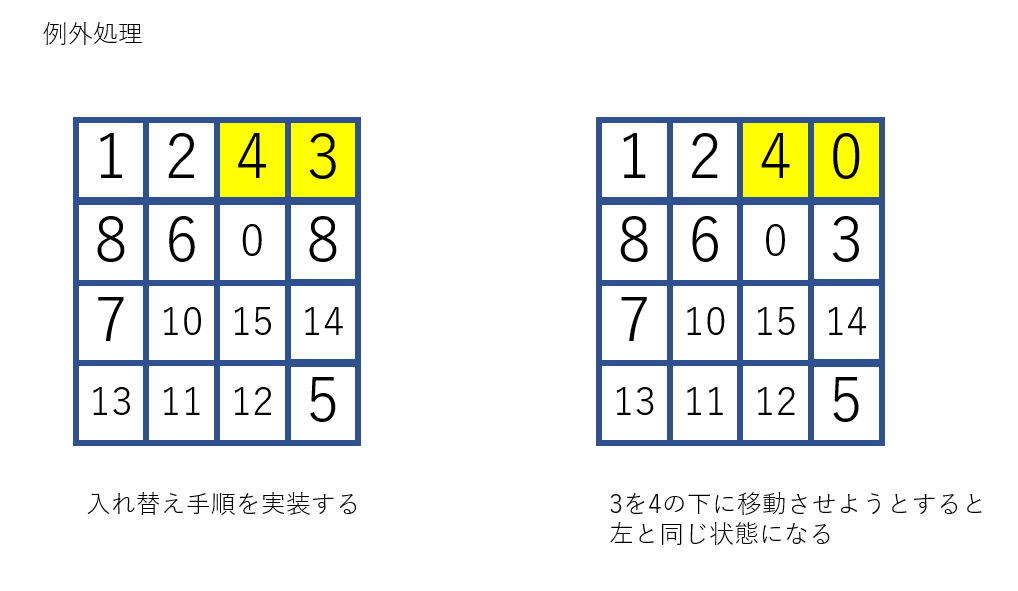
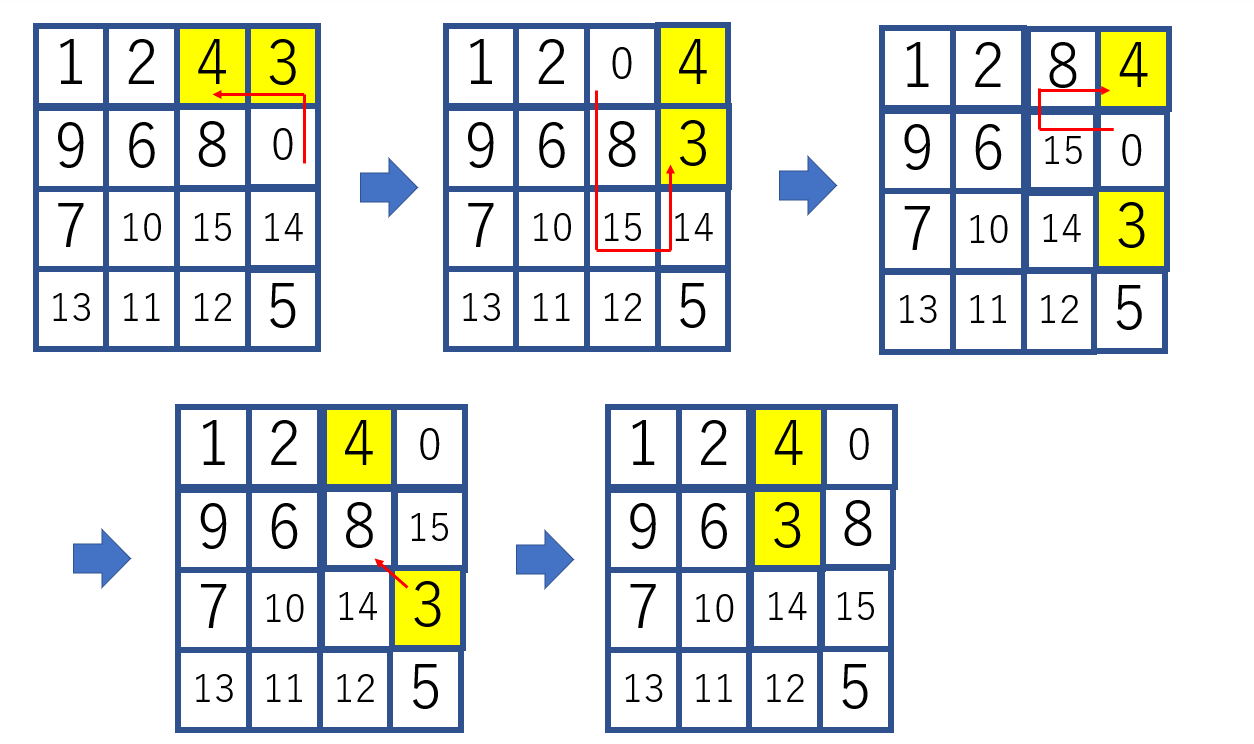
よって、各パターンで場合分けしてやれば完成します。二カ所同時に埋める必要がある場所(3,4など)のアルゴリズムを示します。
例外として、4を2のとなりに置いた時点で3が右上隅に移動していた場合
入れ替え手順を考えると、次のようになります。
3を遠くに移動させてから、4-3の縦の列を作るという手順です。以上で完全に解けるようになりました。手数としては200~50ぐらいです。固定しながらのランダムで8万ぐらい使っていたので、かなりの進歩だと思います。
以上をプログラムにすると
# -*- coding: utf-8 -*- """ Created on Mon Jun 29 13:35:47 2020 @author: kisim """ """ スライドパズルの解法を探す 最終的には、パズドラに応用したい。そして10combo を目指す """ """ Astar アルゴリズムにより、fixed をよけながら移動する 場合分けはエラーの原因で面倒のため """ import random import numpy as np # Numpyライブラリ import copy import Astar as As class Slide(): """ 0 が 操作マス 左上を原点とする 横に x 縦に y トスル """ def __init__(self): self.puzzle = [[1,2,3,4], [5,6,7,8], [9,10,11,12], [13,14,15,0]] self.x = 3 #操作マス 0 の場所 self.y = 3 self.fixed = np.zeros((4,4)) self.route = [[self.x,self.y]] def route_clear(self): self.route = [[self.x,self.y]] def shuffle(self,num): for i in range(num): j=0 while True: j = random.randint(0,3) break self.move(j) def move(self,direction): """ 0 3 1 2 動くのに失敗したら -1 動いたら 0 """ if direction == 0: if self.y != 0: if self.fixed[self.y-1][self.x] == 0: self.puzzle[self.y][self.x] = self.puzzle[self.y-1][self.x] self.y = self.y - 1 self.puzzle[self.y][self.x] = 0 self.route.append([self.x,self.y]) return 0 else: return -1 if direction == 1: if self.x != 3: if self.fixed[self.y][self.x+1] == 0: self.puzzle[self.y][self.x] = self.puzzle[self.y][self.x+1] self.x = self.x + 1 self.puzzle[self.y][self.x] = 0 self.route.append([self.x,self.y]) return 0 else: return -1 if direction == 2: if self.y != 3: if self.fixed[self.y+1][self.x] == 0: self.puzzle[self.y][self.x] = self.puzzle[self.y+1][self.x] self.y = self.y + 1 self.puzzle[self.y][self.x] = 0 self.route.append([self.x,self.y]) return 0 else: return -1 if direction == 3: if self.x != 0: if self.fixed[self.y][self.x-1] == 0: self.puzzle[self.y][self.x] = self.puzzle[self.y][self.x-1] self.x = self.x - 1 self.puzzle[self.y][self.x] = 0 self.route.append([self.x,self.y]) return 0 else: return -1 return -1 def move_0(self,x,y): """ 操作マス("0"マス) を x,y に動かす 先にルートを考え、fixに引っかからないとわかってから、移動を行います。 これはある種の迷路です。 別の関数で 迷路を解くための A* アルゴリズムを実装し、それを利用して解きましょう """ hoge = As.Astar(x,y,self.x,self.y,self.fixed) result = hoge.explore() route = [] if result == 0: route = hoge.route else: return -1 for i in range(len(route)-1): if route[i][0] < route[i+1][0]: self.move(1) elif route[i+1][0] < route[i][0]: self.move(3) elif route[i+1][1] < route[i][1]: self.move(0) elif route[i+1][1] > route[i][1]: self.move(2) if self.x !=x or self.y != y: return -1 else: return 0 def move_any(self,position,direction): x=position[0] y=position[1] """ 任意の "数"(x,y) を direction の方向に動かす 0 3 1 2 動くのに失敗したら -1 動いたら 0 """ if direction == 0: #上に移動させる 操作マスを上に付ける self.fixed[y][x] = 1 hoge = self.move_0(x,y-1) self.fixed[y][x] = 0 if hoge == -1: return -1 else: self.move_0(x,y) return 0 elif direction == 2: # 下に移動させる self.fixed[y][x] = 1 hoge = self.move_0(x,y+1) self.fixed[y][x] = 0 if hoge == -1: return -1 else: self.move_0(x,y) return 0 elif direction == 1: # 右に移動させる self.fixed[y][x] = 1 hoge = self.move_0(x+1,y) self.fixed[y][x] = 0 if hoge == -1: return -1 else: self.move_0(x,y) return 0 elif direction == 3: # 左に移動させる self.fixed[y][x] = 1 hoge = self.move_0(x-1,y) self.fixed[y][x] = 0 if hoge == -1: return -1 else: self.move_0(x,y) return 0 def find_position(self,num): for i in range(4): for j in range(4): if self.puzzle[i][j] == num: return (j,i) def move_x(self,number,position): target_x = position[0] target_y = position[1] """ def move_any(self,position,direction): 任意の "数"(x,y) を direction の方向に動かす 0 3 1 2 動くのに失敗したら -1 動いたら 0 """ position2 = self.find_position(number) now_x = position2[0] now_y = position2[1] """ Astar アルゴリズムで number の ルート 見つけ ルートに従い、move_anyで動かし 但し、道幅が広くないと成立しないので、move_anyが失敗する可能性がある ->Astar , fixする順序で対処 """ hoge = As.Astar(target_x,target_y,now_x,now_y,self.fixed) result = hoge.explore() route = [] if result == 0: route = hoge.route else: return -1 for i in range(len(route)-1): position2 = self.find_position(number) now_x = position2[0] now_y = position2[1] if route[i][0] < route[i+1][0]: result = self.move_any((now_x,now_y),1) if result == -1: return -1 elif route[i+1][0] < route[i][0]: result = self.move_any((now_x,now_y),3) if result == -1: return -1 elif route[i+1][1] < route[i][1]: result = self.move_any((now_x,now_y),0) if result == -1: return -1 elif route[i+1][1] > route[i][1]: result = self.move_any((now_x,now_y),2) if result == -1: return -1 position2 = self.find_position(number) now_x = position2[0] now_y = position2[1] if target_x != now_x or target_y != now_y: return -1 else: return 0 def exchange_row(self): """ 4 3 x 0 y z で入れ替える """ self.move(0) self.move(3) """ 0 4 x 3 y z """ self.move(2) self.move(2) self.move(1) """ x 4 y 3 z 0 """ self.move(0) """ x 4 y 0 z 3 """ self.move(3) self.move(0) self.move(1) """ 4 0 x y z 3 """ def exchange_line(self): """ 13 0 y 9 x z """ self.move(3) self.move(2) """ 9 13 y 0 x z """ self.move(1) self.move(1) self.move(0) """ 9 13 0 x y z """ self.move(3) """ 9 0 13 x y z """ self.move(2) self.move(3) self.move(0) """ 0 y 13 9 x z """ def route_test(slide,route): if route == []: return -1 else: for i in range(len(route)-1): if route[i][0] < route[i+1][0]: slide.move(1) elif route[i+1][0] < route[i][0]: slide.move(3) elif route[i+1][1] < route[i][1]: slide.move(0) elif route[i+1][1] > route[i][1]: slide.move(2) return slide if __name__ == '__main__' : hoge = Slide() hoge.shuffle(600) hoge.route_clear() print(hoge.puzzle[0]) print(hoge.puzzle[1]) print(hoge.puzzle[2]) print(hoge.puzzle[3]) #test用 hoge2 = Slide() hoge2.puzzle = copy.deepcopy(hoge.puzzle) hoge2.x = hoge.x hoge2.y = hoge.y #1 hoge.move_x(1,(0,0)) hoge.fixed[0][0] =1 #2 hoge.move_x(2,(1,0)) hoge.fixed[0][1] =1 #3,4 hoge.move_x(4,(2,0)) hoge.fixed[0][2] =1 if hoge.x == 3 and hoge.y == 0 and hoge.puzzle[1][3] == 3: hoge.move(2) if hoge.puzzle[0][3] == 3: hoge.fixed[0][2] = 0 hoge.move_0(3,1) hoge.exchange_row() print("errored 3-4") hoge.move_x(3,(2,1)) hoge.fixed[1][2] = 1 hoge.move_0(3,0) hoge.fixed[1][2] = 0 hoge.fixed[0][2] = 0 hoge.move(3) hoge.move(2) hoge.fixed[0][2] = 1 hoge.fixed[0][3] = 1 #5 hoge.move_x(5,(0,1)) hoge.fixed[1][0] =1 #9,13 hoge.move_x(9,(0,3)) hoge.fixed[3][0] =1 if hoge.x == 0 and hoge.y == 2 and hoge.puzzle[2][1] == 13: hoge.move(1) if hoge.puzzle[2][0] == 13: hoge.fixed[3][0] = 0 hoge.move_0(1,2) hoge.exchange_line() print("error 9-13") hoge.fixed[3][0] = 1 hoge.move_x(13,(1,3)) hoge.fixed[3][1] = 1 hoge.move_0(0,2) hoge.fixed[3][1] = 0 hoge.fixed[3][0] = 0 hoge.move(2) hoge.move(1) hoge.fixed[2][0] = 1 hoge.fixed[3][0] = 1 #6 hoge.move_x(6,(1,1)) hoge.fixed[1][1] =1 #7,8 hoge.move_x(8,(2,1)) hoge.fixed[1][2] =1 if hoge.x == 3 and hoge.y == 1 and hoge.puzzle[2][3] == 7: hoge.move(2) if hoge.puzzle[1][3] == 7: hoge.fixed[1][2] = 0 hoge.move_0(3,2) hoge.exchange_row() print("error 7-8") hoge.move_x(7,(2,2)) hoge.fixed[2][2] = 1 hoge.move_0(3,1) hoge.fixed[2][2] = 0 hoge.fixed[1][2] = 0 hoge.move(3) hoge.move(2) hoge.fixed[1][3] = 1 hoge.fixed[1][2] = 1 #6マスなので もう ゲーム木探索でも解けるのでは? #10,14 result = hoge.move_x(10,(1,3)) print(str(result)+"result") hoge.fixed[3][1] =1 if hoge.x == 1 and hoge.y == 2 and hoge.puzzle[2][2] == 14: hoge.move(1) if hoge.puzzle[2][1] == 14: hoge.fixed[3][1] = 0 hoge.move_0(2,2) hoge.exchange_line() print("error10-14") hoge.fixed[3][1] = 1 hoge.move_x(14,(2,3)) hoge.fixed[3][2] = 1 hoge.move_0(1,2) hoge.fixed[3][2] = 0 hoge.fixed[3][1] = 0 hoge.move(2) hoge.move(1) hoge.fixed[2][1] = 1 hoge.fixed[3][1] = 1 # これで行けるかと思ったが 、ちょっと違った hoge.move_0(3,3) print("a") print(hoge.puzzle[0]) print(hoge.puzzle[1]) print(hoge.puzzle[2]) print(hoge.puzzle[3]) print(hoge.fixed[0]) print(hoge.fixed[1]) print(hoge.fixed[2]) print(hoge.fixed[3]) if hoge.puzzle[3][2] == 11: #反時計回り一周 hoge.move(0) hoge.move(3) hoge.move(2) hoge.move(1) elif hoge.puzzle[3][2] == 12: #時計回り一周 hoge.move(3) hoge.move(0) hoge.move(1) hoge.move(2) print(hoge.puzzle[0]) print(hoge.puzzle[1]) print(hoge.puzzle[2]) print(hoge.puzzle[3]) print(len(hoge.route)) hoge2 = route_test(hoge2,hoge.route) if hoge2 == -1: print("error") else: print(hoge2.puzzle[0]) print(hoge2.puzzle[1]) print(hoge2.puzzle[2]) print(hoge2.puzzle[3])A*アルゴリズム
Aster.pyimport numpy as np # Numpyライブラリ import random import copy class Node(): def __init__(self,x,y,cost,parent,num): self.x = x self.y = y self.state = 1 # 0:none 1:open 2:closed self.score = 0 self.cost = cost self.parent = parent self.expect_cost = 0 self.num = num self.calculated = 0 def close(self): self.state = 2 class Astar(): def __init__(self,g_x,g_y,s_x,s_y,obstacle): self.width = obstacle.shape[1] self.height = obstacle.shape[0] self.g_x = g_x self.g_y = g_y self.s_x = s_x self.s_y = s_y self.x = s_x self.y = s_y self.obstacle_list = copy.deepcopy(obstacle) self.maked_list = [] self.num = 0 start = Node(s_x,s_y,0,-1,self.num) self.Node_list = [start] self.num = self.num + 1 self.now = start #現在のノード self.route = [] self.goal = -1 #gaal の ノード self.finished = 0 #goal したかどうか if g_x == s_x and g_y == s_y: self.finished == 1 self.goal = start self.route = [[s_x,s_y]] def open(self): self.now.close() #周りをopen """ 壁・障害 が有るときはopen できない ->obstacle_list 既に作っていないか?->maked_list """ cost = self.now.cost parent = self.now.num if self.x!=0: if self.maked_list.count([self.x-1,self.y]) == 0 and self.obstacle_list[self.y][self.x-1] == 0 : self.Node_list.append(Node(self.x-1,self.y,cost+1,parent,self.num)) self.num = self.num + 1 self.maked_list.append([self.x-1,self.y]) if self.x!=self.width-1: if self.maked_list.count([self.x+1,self.y]) == 0 and self.obstacle_list[self.y][self.x+1] == 0 : self.Node_list.append(Node(self.x+1,self.y,cost+1,parent,self.num)) self.num = self.num + 1 self.maked_list.append([self.x+1,self.y]) if self.y!=0: if self.maked_list.count([self.x,self.y-1]) == 0 and self.obstacle_list[self.y-1][self.x] == 0 : self.Node_list.append(Node(self.x,self.y-1,cost+1,parent,self.num)) self.num = self.num + 1 self.maked_list.append([self.x,self.y-1]) if self.y!=self.height-1: if self.maked_list.count([self.x,self.y+1]) == 0 and self.obstacle_list[self.y+1][self.x] == 0 : self.Node_list.append(Node(self.x,self.y+1,cost+1,parent,self.num)) self.num = self.num + 1 self.maked_list.append([self.x,self.y+1]) """ #デバッグ print("test") for i in self.Node_list: print(i.state) """ #open しているものを計算 for i in self.Node_list: if i.state == 1 and i.calculated == 0: i.calculated = 1 i.expect_cost = abs(i.x - self.g_x)+abs(i.y-self.g_y) i.score = i.cost + i.expect_cost #open しているもののうち、スコアの小さいものをリストにまとめる min_cost = 100 min_cost_list = [] for i in self.Node_list: if i.state == 1: if i.cost < min_cost: min_cost = i.cost min_cost_list = [i] elif i.cost == min_cost: min_cost_list.append(i) if min_cost_list != []: self.now = min_cost_list[random.randint(0,len(min_cost_list)-1)] self.x = self.now.x self.y = self.now.y else: print("none min") return -1 if self.now.x == self.g_x and self.now.y == self.g_y: return 1 else: return 0 def explore(self): """ 0 :goal -1:goal できない """ if self.finished == 1: return 0 else: while True: hoge = self.open() if hoge == 1: #print("goal!") self.goal = self.now self.finished = 1 self.Route() return 0 elif hoge == -1: return -1 def Route(self): if self.finished == 1: while True: self.route.append((self.now.x,self.now.y)) if self.now.parent == -1: break else: self.now = self.Node_list[self.now.parent] self.route.reverse() #print(self.route) def Express(self): if self.finished == 1: if self.route ==[]: print("not goaled") else: graph = self.obstacle_list for i in self.route: graph[i[1]][i[0]] = 2 print(graph) if __name__ == '__main__' : width = 5 height = 5 obstacle =np.zeros((height,width)) """ obstacle[2][1] = 1 obstacle[2][2] = 1 obstacle[1][2] = 1 obstacle[3][2] = 1 """ obstacle[1][0] = 1 print(obstacle) g_x = 0 g_y = 2 s_x = 0 s_y = 0 hoge = Astar(g_x,g_y,s_x,s_y,obstacle) result = hoge.explore() if result == 0: hoge.Express()

- 投稿日:2020-06-30T17:30:59+09:00
だから僕はpandasをやめた【データサイエンス100本ノック(構造化データ加工編)篇 #2】
だから僕はpandasをやめた【データサイエンス100本ノック(構造化データ加工編)篇 #2】
データサイエンス100本ノック(構造化データ加工編)のPythonの問題を解いていきます。この問題群は、模範解答ではpandasを使ってデータ加工を行っていますが、私達は勉強がてらにNumPyの構造化配列を用いて処理していきます。
はじめに
NumPyの構造化配列の勉強として、データサイエンス100本ノック(構造化データ加工編)のPythonの問題を解いていきます。
Pythonでデータサイエンス的なことをする人の多くはpandas大好き人間かもしれませんが、実はpandasを使わなくても、NumPyで同じことができます。そしてNumPyの方がたいてい高速です。
pandas大好き人間だった僕もNumPyの操作には依然として慣れていないので、今回この『データサイエンス100本ノック』をNumPyで操作することでpandasからの卒業を試みて行きたいと思います。
なおnp.vectorize()やnp.frompyfunc()等による関数のベクトル化は行わない方針です。今回は10~16問目をやっていきます。文字列の条件インデックスというテーマのようです。
初期データは以下のようにして読み込みました(データ型指定はとりあえず後回し)。import numpy as np import pandas as pd # 模範解答用 df_store = pd.read_csv('data/store.csv') df_customer = pd.read_csv('data/customer.csv') # 僕たちが扱うデータ arr_store = np.genfromtxt( 'data/store.csv', delimiter=',', encoding='utf-8', names=True, dtype=None) arr_customer = np.genfromtxt( 'data/customer.csv', delimiter=',', encoding='utf-8', names=True, dtype=None)P_010
P-010: 店舗データフレーム(df_store)から、店舗コード(store_cd)が"S14"で始まるものだけ全項目抽出し、10件だけ表示せよ。
文字列の先頭が一致するかどうかは
np.char.startswith()を用います。第一引数に文字列の配列、第二引数に検索するワードを与えます。In[010]arr_store[np.char.startswith(arr_store['store_cd'], 'S14')][:10]
np.char.xxx()のような関数を使うのは簡単ですが、NumPyにおいて文字列関連の操作は苦手分野なので、速度を求める場合はPython標準のforループを使う方が良いことがしばしばあります。その場合NumPy配列をわざわざリストに変換すると速くなります。In[010]arr_store[[item[:3] == 'S14' for item in arr_store['store_cd'].tolist()]][:10]先頭の数文字だけを見る場合は、より簡単かつ高速に処理する方法が存在します。店舗コード(store_cd)列を確認すると、
arr_store['store_cd'] # array(['S12014', 'S13002', 'S14010', 'S14033', 'S14036', 'S13051', # ... # 'S13003', 'S12053', 'S13037', 'S14024', 'S14006'], dtype='<U6')すべて6桁の文字列で構成されていることがわかります。必要なのは先頭3文字だけなので、これを
U3データ型で読み直します。すると、4文字目以降が読み取られず捨てられて以下のようになります。arr_store['store_cd'].astype('<U3') # array(['S12', 'S13', 'S14', 'S14', 'S14', 'S13', 'S13', 'S14', 'S13', # ... # 'S14', 'S13', 'S12', 'S13', 'S12', 'S13', 'S14', 'S14'], # dtype='<U3')これが“S14”のものを引っこ抜けばいいので、解答は以下のようになります。
In[010]arr_store[arr_store['store_cd'].astype('<U3') == 'S14'][:10]出力は以下の通り。
Out[010]array([('S14010', '菊名店', 14, '神奈川県', '神奈川県横浜市港北区菊名一丁目', 'カナガワケンヨコハマシコウホククキクナイッチョウメ', '045-123-4032', 139.6326, 35.50049, 1732.), ('S14033', '阿久和店', 14, '神奈川県', '神奈川県横浜市瀬谷区阿久和西一丁目', 'カナガワケンヨコハマシセヤクアクワニシイッチョウメ', '045-123-4043', 139.4961, 35.45918, 1495.), ('S14036', '相模原中央店', 14, '神奈川県', '神奈川県相模原市中央二丁目', 'カナガワケンサガミハラシチュウオウニチョウメ', '042-123-4045', 139.3716, 35.57327, 1679.), ('S14040', '長津田店', 14, '神奈川県', '神奈川県横浜市緑区長津田みなみ台五丁目', 'カナガワケンヨコハマシミドリクナガツタミナミダイゴチョウメ', '045-123-4046', 139.4994, 35.52398, 1548.), ('S14050', '阿久和西店', 14, '神奈川県', '神奈川県横浜市瀬谷区阿久和西一丁目', 'カナガワケンヨコハマシセヤクアクワニシイッチョウメ', '045-123-4053', 139.4961, 35.45918, 1830.), ('S14028', '二ツ橋店', 14, '神奈川県', '神奈川県横浜市瀬谷区二ツ橋町', 'カナガワケンヨコハマシセヤクフタツバシチョウ', '045-123-4042', 139.4963, 35.46304, 1574.), ('S14012', '本牧和田店', 14, '神奈川県', '神奈川県横浜市中区本牧和田', 'カナガワケンヨコハマシナカクホンモクワダ', '045-123-4034', 139.6582, 35.42156, 1341.), ('S14046', '北山田店', 14, '神奈川県', '神奈川県横浜市都筑区北山田一丁目', 'カナガワケンヨコハマシツヅキクキタヤマタイッチョウメ', '045-123-4049', 139.5916, 35.56189, 831.), ('S14022', '逗子店', 14, '神奈川県', '神奈川県逗子市逗子一丁目', 'カナガワケンズシシズシイッチョウメ', '046-123-4036', 139.5789, 35.29642, 1838.), ('S14011', '日吉本町店', 14, '神奈川県', '神奈川県横浜市港北区日吉本町四丁目', 'カナガワケンヨコハマシコウホククヒヨシホンチョウヨンチョウメ', '045-123-4033', 139.6316, 35.54655, 890.)], dtype=[('store_cd', '<U6'), ('store_name', '<U6'), ('prefecture_cd', '<i4'), ('prefecture', '<U4'), ('address', '<U19'), ('address_kana', '<U30'), ('tel_no', '<U12'), ('longitude', '<f8'), ('latitude', '<f8'), ('floor_area', '<f8')])色んな方法で、それぞれ速度を比較してみます。
Time[010]# 模範解答 %timeit df_store.query("store_cd.str.startswith('S14')", engine='python').head(10) # 3.46 ms ± 23.2 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) # pandasのほかの方法 %timeit df_store[df_store['store_cd'].str.startswith('S14')][:10] # 876 µs ± 18.1 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each) %timeit df_store.loc[[index for index, item in enumerate(df_store['store_cd']) if item[:3] == 'S14']][:10] # 732 µs ± 17.5 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each) # NumPyを使った方法 %timeit arr_store[np.char.startswith(arr_store['store_cd'], 'S14')][:10] # 54.3 µs ± 3.17 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each) %timeit arr_store[[item[:3] == 'S14' for item in arr_store['store_cd'].tolist()]][:10] # 22.8 µs ± 377 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each) %timeit arr_store[arr_store['store_cd'].astype('<U3') == 'S14'][:10] # 5.55 µs ± 91.4 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
pd.DataFrame.query()を使った文字列条件インデックスはおそいことで有名です。P_011
P-011: 顧客データフレーム(df_customer)から顧客ID(customer_id)の末尾が1のものだけ全項目抽出し、10件だけ表示せよ。
前問と同じですね。
np.char.endswith()関数を使います。In[011]arr_customer[np.char.endswith(arr_customer['customer_id'], '1')][:10]速度が気になる場合はforループ。
In[011]arr_customer[[item[-1] == '1' for item in arr_customer['customer_id']]][:10]より速い方法を考えます。
文字列の最後の字を見る場合は.astype()戦法は使えません。しかし、今回の例では、また別の方法で高速処理することが可能です。顧客ID(customer_id)列を確認すると、arr_customer['customer_id'] # array(['CS021313000114', 'CS037613000071', 'CS031415000172', ..., # 'CS012403000043', 'CS033512000184', 'CS009213000022'], dtype='<U14')すべての行が同じ文字数(14桁)になっていることがわかります。この最後が“1”のものを探せばいいわけです。
これを実行するには、まず配列arr_customer['customer_id']を.tobytes()メソッドを用いてバイト列に変換し、データ型'U14'で読まれていたこの配列をnp.frombuffer()関数を用いて'U1'データ型で読み直します。それをさらにreshape()メソッドで14列の配列に組み替えると、以下のようになります。# 顧客IDの全データを1文字ずつに分解 np.frombuffer(arr_customer['customer_id'].tobytes(), dtype='<U1') # array(['C', 'S', '0', ..., '0', '2', '2'], dtype='<U1') # 1行14文字ずつに戻す np.frombuffer(arr_customer['customer_id'].tobytes(), dtype='<U1').reshape(len(arr_customer), -1) # array([['C', 'S', '0', ..., '1', '1', '4'], # ['C', 'S', '0', ..., '0', '7', '1'], # ..., # ['C', 'S', '0', ..., '1', '8', '4'], # ['C', 'S', '0', ..., '0', '2', '2']], dtype='<U1')この配列の「最後の列が“1”の行」が求める行なので、以下のようになります。この手法はかなり応用がききます。
In[011]arr_customer[np.frombuffer(arr_customer['customer_id'].tobytes(), dtype='<U1') .reshape(len(arr_customer), -1)[:, -1] == '1'][:10]出力は以下の通りです。
Out[011]array([('CS037613000071', '六角 雅彦', 9, '不明', '1952-04-01', 66, '136-0076', '東京都江東区南砂**********', 'S13037', 20150414, '0-00000000-0'), ('CS028811000001', '堀井 かおり', 1, '女性', '1933-03-27', 86, '245-0016', '神奈川県横浜市泉区和泉町**********', 'S14028', 20160115, '0-00000000-0'), ('CS040412000191', '川井 郁恵', 1, '女性', '1977-01-05', 42, '226-0021', '神奈川県横浜市緑区北八朔町**********', 'S14040', 20151101, '1-20091025-4'), ('CS028314000011', '小菅 あおい', 1, '女性', '1983-11-26', 35, '246-0038', '神奈川県横浜市瀬谷区宮沢**********', 'S14028', 20151123, '1-20080426-5'), ('CS039212000051', '藤島 恵梨香', 1, '女性', '1997-02-03', 22, '166-0001', '東京都杉並区阿佐谷北**********', 'S13039', 20171121, '1-20100215-4'), ('CS015412000111', '松居 奈月', 1, '女性', '1972-10-04', 46, '136-0071', '東京都江東区亀戸**********', 'S13015', 20150629, '0-00000000-0'), ('CS004702000041', '野島 洋', 0, '男性', '1943-08-24', 75, '176-0022', '東京都練馬区向山**********', 'S13004', 20170218, '0-00000000-0'), ('CS041515000001', '栗田 千夏', 1, '女性', '1967-01-02', 52, '206-0001', '東京都多摩市和田**********', 'S13041', 20160422, 'E-20100803-F'), ('CS029313000221', '北条 ひかり', 1, '女性', '1987-06-19', 31, '279-0011', '千葉県浦安市美浜**********', 'S12029', 20180810, '0-00000000-0'), ('CS034312000071', '望月 奈央', 1, '女性', '1980-09-20', 38, '213-0026', '神奈川県川崎市高津区久末**********', 'S14034', 20160106, '0-00000000-0')], dtype=[('customer_id', '<U14'), ('customer_name', '<U10'), ('gender_cd', '<i4'), ('gender', '<U2'), ('birth_day', '<U10'), ('age', '<i4'), ('postal_cd', '<U8'), ('address', '<U26'), ('application_store_cd', '<U6'), ('application_date', '<i4'), ('status_cd', '<U12')])速度を比較してみます。
Time[011]%timeit df_customer.query("customer_id.str.endswith('1')", engine='python').head(10) # 12.2 ms ± 454 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) %timeit arr_customer[np.char.endswith(arr_customer['customer_id'], '1')][:10] # 20.7 ms ± 847 µs per loop (mean ± std. dev. of 7 runs, 10 loops each) %timeit arr_customer[[item[-1] == '1' for item in arr_customer['customer_id']]][:10] # 9.44 ms ± 185 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) %timeit arr_customer[np.frombuffer(arr_customer['customer_id'].tobytes(), dtype='<U1').reshape(len(arr_customer), -1)[:, -1] == '1'][:10] # 1.83 ms ± 77 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
np.char.xxx()は場合によってはpd.query()よりも遅いようです……。P_012
P-012: 店舗データフレーム(df_store)から横浜市の店舗だけ全項目表示せよ。
In[012]arr_store[np.char.find(arr_store['address'], '横浜市') >= 0]または、
In[012]arr_store[['横浜市' in item for item in arr_store['address'].tolist()]]住所欄は文字数が不定ですが「横浜市」は必ず5・6・7文字目に現れるので、
.astype('<U7')で先頭7文字だけに切ったあとで最後の3文字だけの配列を作って、In[012]arr_store[np.frombuffer(arr_store['address'].astype('<U7').view('<U1') .reshape(len(arr_store), -1)[:, 4:].tobytes(), dtype='<U3') == '横浜市']とすることもできます。
Out[012]array([('S14010', '菊名店', 14, '神奈川県', '神奈川県横浜市港北区菊名一丁目', 'カナガワケンヨコハマシコウホククキクナイッチョウメ', '045-123-4032', 139.6326, 35.50049, 1732.), ('S14033', '阿久和店', 14, '神奈川県', '神奈川県横浜市瀬谷区阿久和西一丁目', 'カナガワケンヨコハマシセヤクアクワニシイッチョウメ', '045-123-4043', 139.4961, 35.45918, 1495.), ('S14040', '長津田店', 14, '神奈川県', '神奈川県横浜市緑区長津田みなみ台五丁目', 'カナガワケンヨコハマシミドリクナガツタミナミダイゴチョウメ', '045-123-4046', 139.4994, 35.52398, 1548.), ('S14050', '阿久和西店', 14, '神奈川県', '神奈川県横浜市瀬谷区阿久和西一丁目', 'カナガワケンヨコハマシセヤクアクワニシイッチョウメ', '045-123-4053', 139.4961, 35.45918, 1830.), ('S14028', '二ツ橋店', 14, '神奈川県', '神奈川県横浜市瀬谷区二ツ橋町', 'カナガワケンヨコハマシセヤクフタツバシチョウ', '045-123-4042', 139.4963, 35.46304, 1574.), ('S14012', '本牧和田店', 14, '神奈川県', '神奈川県横浜市中区本牧和田', 'カナガワケンヨコハマシナカクホンモクワダ', '045-123-4034', 139.6582, 35.42156, 1341.), ('S14046', '北山田店', 14, '神奈川県', '神奈川県横浜市都筑区北山田一丁目', 'カナガワケンヨコハマシツヅキクキタヤマタイッチョウメ', '045-123-4049', 139.5916, 35.56189, 831.), ('S14011', '日吉本町店', 14, '神奈川県', '神奈川県横浜市港北区日吉本町四丁目', 'カナガワケンヨコハマシコウホククヒヨシホンチョウヨンチョウメ', '045-123-4033', 139.6316, 35.54655, 890.), ('S14048', '中川中央店', 14, '神奈川県', '神奈川県横浜市都筑区中川中央二丁目', 'カナガワケンヨコハマシツヅキクナカガワチュウオウニチョウメ', '045-123-4051', 139.5758, 35.54912, 1657.), ('S14042', '新山下店', 14, '神奈川県', '神奈川県横浜市中区新山下二丁目', 'カナガワケンヨコハマシナカクシンヤマシタニチョウメ', '045-123-4047', 139.6593, 35.43894, 1044.), ('S14006', '葛が谷店', 14, '神奈川県', '神奈川県横浜市都筑区葛が谷', 'カナガワケンヨコハマシツヅキククズガヤ', '045-123-4031', 139.5633, 35.53573, 1886.)], dtype=[('store_cd', '<U6'), ('store_name', '<U6'), ('prefecture_cd', '<i4'), ('prefecture', '<U4'), ('address', '<U19'), ('address_kana', '<U30'), ('tel_no', '<U12'), ('longitude', '<f8'), ('latitude', '<f8'), ('floor_area', '<f8')])P_013
P-013: 顧客データフレーム(df_customer)から、ステータスコード(status_cd)の先頭がアルファベットのA〜Fで始まるデータを全項目抽出し、10件だけ表示せよ。
こうなると面倒です。模範解答では正規表現で検索していますが、とりあえず正規表現を使わずやっていきます。
np.char.startswith()で行くならこうなります。In[013]arr_customer[ np.char.startswith(arr_customer['status_cd'], np.array(list('ABCDEF'))[:, None]) .any(0)][:10]相当しんどい感じがします。forを使ったほうが簡単です。
In[013]arr_customer[[item[0] in set('ABCDEF') for item in arr_customer['status_cd'].tolist()]][:10]文字列の先頭だけ読み込んで
np.in1d()。速いし簡単です。In[013]arr_customer[np.in1d(arr_customer['status_cd'].astype('<U1'), np.fromiter('ABCDEF', dtype='<U1'))][:10]ちなみにここでは検索ワードもNumPy配列にしていますが、
list('ABCDEF')にしても速度はたいして変わりませんでした。Out[013]array([('CS031415000172', '宇多田 貴美子', 1, '女性', '1976-10-04', 42, '151-0053', '東京都渋谷区代々木**********', 'S13031', 20150529, 'D-20100325-C'), ('CS015414000103', '奥野 陽子', 1, '女性', '1977-08-09', 41, '136-0073', '東京都江東区北砂**********', 'S13015', 20150722, 'B-20100609-B'), ('CS011215000048', '芦田 沙耶', 1, '女性', '1992-02-01', 27, '223-0062', '神奈川県横浜市港北区日吉本町**********', 'S14011', 20150228, 'C-20100421-9'), ('CS029415000023', '梅田 里穂', 1, '女性', '1976-01-17', 43, '279-0043', '千葉県浦安市富士見**********', 'S12029', 20150610, 'D-20100918-E'), ('CS035415000029', '寺沢 真希', 9, '不明', '1977-09-27', 41, '158-0096', '東京都世田谷区玉川台**********', 'S13035', 20141220, 'F-20101029-F'), ('CS031415000106', '宇野 由美子', 1, '女性', '1970-02-26', 49, '151-0053', '東京都渋谷区代々木**********', 'S13031', 20150201, 'F-20100511-E'), ('CS029215000025', '石倉 美帆', 1, '女性', '1993-09-28', 25, '279-0022', '千葉県浦安市今川**********', 'S12029', 20150708, 'B-20100820-C'), ('CS033605000005', '猪股 雄太', 0, '男性', '1955-12-05', 63, '246-0031', '神奈川県横浜市瀬谷区瀬谷**********', 'S14033', 20150425, 'F-20100917-E'), ('CS033415000229', '板垣 菜々美', 1, '女性', '1977-11-07', 41, '246-0021', '神奈川県横浜市瀬谷区二ツ橋町**********', 'S14033', 20150712, 'F-20100326-E'), ('CS008415000145', '黒谷 麻緒', 1, '女性', '1977-06-27', 41, '157-0067', '東京都世田谷区喜多見**********', 'S13008', 20150829, 'F-20100622-F')], dtype=[('customer_id', '<U14'), ('customer_name', '<U10'), ('gender_cd', '<i4'), ('gender', '<U2'), ('birth_day', '<U10'), ('age', '<i4'), ('postal_cd', '<U8'), ('address', '<U26'), ('application_store_cd', '<U6'), ('application_date', '<i4'), ('status_cd', '<U12')])P_014
P-014: 顧客データフレーム(df_customer)から、ステータスコード(status_cd)の末尾が数字の1〜9で終わるデータを全項目抽出し、10件だけ表示せよ。
In[014]arr_customer[[item[-1] in set('123456789') for item in arr_customer['status_cd'].tolist()]][:10]In[014]arr_customer[np.in1d(np.frombuffer(arr_customer['status_cd'].tobytes(), dtype='<U1') .reshape(len(arr_customer), -1)[:, -1], np.fromiter('123456789', dtype='<U1'))][:10]Out[014]array([('CS001215000145', '田崎 美紀', 1, '女性', '1995-03-29', 24, '144-0055', '東京都大田区仲六郷**********', 'S13001', 20170605, '6-20090929-2'), ('CS033513000180', '安斎 遥', 1, '女性', '1962-07-11', 56, '241-0823', '神奈川県横浜市旭区善部町**********', 'S14033', 20150728, '6-20080506-5'), ('CS011215000048', '芦田 沙耶', 1, '女性', '1992-02-01', 27, '223-0062', '神奈川県横浜市港北区日吉本町**********', 'S14011', 20150228, 'C-20100421-9'), ('CS040412000191', '川井 郁恵', 1, '女性', '1977-01-05', 42, '226-0021', '神奈川県横浜市緑区北八朔町**********', 'S14040', 20151101, '1-20091025-4'), ('CS009315000023', '皆川 文世', 1, '女性', '1980-04-15', 38, '154-0012', '東京都世田谷区駒沢**********', 'S13009', 20150319, '5-20080322-1'), ('CS015315000033', '福士 璃奈子', 1, '女性', '1983-03-17', 36, '135-0043', '東京都江東区塩浜**********', 'S13015', 20141024, '4-20080219-3'), ('CS023513000066', '神戸 そら', 1, '女性', '1961-12-17', 57, '210-0005', '神奈川県川崎市川崎区東田町**********', 'S14023', 20150915, '5-20100524-9'), ('CS035513000134', '市川 美帆', 1, '女性', '1960-03-27', 59, '156-0053', '東京都世田谷区桜**********', 'S13035', 20150227, '8-20100711-9'), ('CS001515000263', '高松 夏空', 1, '女性', '1962-11-09', 56, '144-0051', '東京都大田区西蒲田**********', 'S13001', 20160812, '1-20100804-1'), ('CS040314000027', '鶴田 きみまろ', 9, '不明', '1986-03-26', 33, '226-0027', '神奈川県横浜市緑区長津田**********', 'S14040', 20150122, '2-20080426-4')], dtype=[('customer_id', '<U14'), ('customer_name', '<U10'), ('gender_cd', '<i4'), ('gender', '<U2'), ('birth_day', '<U10'), ('age', '<i4'), ('postal_cd', '<U8'), ('address', '<U26'), ('application_store_cd', '<U6'), ('application_date', '<i4'), ('status_cd', '<U12')])P_015
P-015: 顧客データフレーム(df_customer)から、ステータスコード(status_cd)の先頭がアルファベットのA〜Fで始まり、末尾が数字の1〜9で終わるデータを全項目抽出し、10件だけ表示せよ。
条件が複数あってもforループで簡単に取得できます。
In[015]arr_customer[[item[0] in set('ABCDEF') and item[-1] in set('123456789') for item in arr_customer['status_cd'].tolist()]][:10]文字列を切って
np.in1d()を使う方法は条件が多くなり書くのが面倒になってきました。わざわざ以下のようなコードを書く人はいないでしょう。(もっといい方法がないだろうか……?)In[015]statud_cd_split = np.frombuffer(arr_customer['status_cd'].tobytes(), dtype='<U1').reshape(len(arr_customer), -1) arr_customer[np.in1d(statud_cd_split[:, 0], np.fromiter('ABCDEF', dtype='<U1')) & np.in1d(statud_cd_split[:, -1], np.fromiter('123456789', dtype='<U1'))][:10]Out[015]array([('CS011215000048', '芦田 沙耶', 1, '女性', '1992-02-01', 27, '223-0062', '神奈川県横浜市港北区日吉本町**********', 'S14011', 20150228, 'C-20100421-9'), ('CS022513000105', '島村 貴美子', 1, '女性', '1962-03-12', 57, '249-0002', '神奈川県逗子市山の根**********', 'S14022', 20150320, 'A-20091115-7'), ('CS001515000096', '水野 陽子', 9, '不明', '1960-11-29', 58, '144-0053', '東京都大田区蒲田本町**********', 'S13001', 20150614, 'A-20100724-7'), ('CS013615000053', '西脇 季衣', 1, '女性', '1953-10-18', 65, '261-0026', '千葉県千葉市美浜区幕張西**********', 'S12013', 20150128, 'B-20100329-6'), ('CS020412000161', '小宮 薫', 1, '女性', '1974-05-21', 44, '174-0042', '東京都板橋区東坂下**********', 'S13020', 20150822, 'B-20081021-3'), ('CS001215000097', '竹中 あさみ', 1, '女性', '1990-07-25', 28, '146-0095', '東京都大田区多摩川**********', 'S13001', 20170315, 'A-20100211-2'), ('CS035212000007', '内村 恵梨香', 1, '女性', '1990-12-04', 28, '152-0023', '東京都目黒区八雲**********', 'S13035', 20151013, 'B-20101018-6'), ('CS002515000386', '野田 コウ', 1, '女性', '1963-05-30', 55, '185-0013', '東京都国分寺市西恋ケ窪**********', 'S13002', 20160410, 'C-20100127-8'), ('CS001615000372', '稲垣 寿々花', 1, '女性', '1956-10-29', 62, '144-0035', '東京都大田区南蒲田**********', 'S13001', 20170403, 'A-20100104-1'), ('CS032512000121', '松井 知世', 1, '女性', '1962-09-04', 56, '210-0011', '神奈川県川崎市川崎区富士見**********', 'S13032', 20150727, 'A-20100103-5')], dtype=[('customer_id', '<U14'), ('customer_name', '<U10'), ('gender_cd', '<i4'), ('gender', '<U2'), ('birth_day', '<U10'), ('age', '<i4'), ('postal_cd', '<U8'), ('address', '<U26'), ('application_store_cd', '<U6'), ('application_date', '<i4'), ('status_cd', '<U12')])書くのは面倒ですが、forループより高速です。
Time[015]%timeit df_customer.query("status_cd.str.contains('^[A-F].*[1-9]$', regex=True)", engine='python').head(10) # 31 ms ± 1.25 ms per loop (mean ± std. dev. of 7 runs, 10 loops each) %timeit arr_customer[[item[0] in set('ABCDEF') and item[-1] in set('123456789') for item in arr_customer['status_cd'].tolist()]][:10] # 16.7 ms ± 1.37 ms per loop (mean ± std. dev. of 7 runs, 100 loops each) %%timeit statud_cd_split = np.frombuffer(arr_customer['status_cd'].tobytes(), dtype='<U1').reshape(len(arr_customer), -1) arr_customer[np.in1d(statud_cd_split[:, 0], np.fromiter('ABCDEF', dtype='<U1')) & np.in1d(statud_cd_split[:, -1], np.fromiter('123456789', dtype='<U1'))][:10] # 3.94 ms ± 17.5 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)P_016
P-016: 店舗データフレーム(df_store)から、電話番号(tel_no)が3桁-3桁-4桁のデータを全項目表示せよ。
ここまでくると正規表現モジュール
reを使うべきでしょうか。In[016]import re arr_store[[bool(re.fullmatch(r'[0-9]{3}-[0-9]{3}-[0-9]{4}', item)) for item in arr_store['tel_no'].tolist()]]今回の場合、データを見ると10桁の電話番号しかなく、またバグった値もなかったので、「4文字目と8文字目が“-”の行」という問題に置換することができました。データに合わせて柔軟に問題を読み替えるのも解法の1つということで……。
In[016]tel_no_split = np.frombuffer(arr_store['tel_no'].tobytes(), dtype='<U1').reshape(len(arr_store), -1) arr_store[(tel_no_split[:, 3] == '-') & (tel_no_split[:, 7] == '-')]Out[016]array([('S12014', '千草台店', 12, '千葉県', '千葉県千葉市稲毛区千草台一丁目', 'チバケンチバシイナゲクチグサダイイッチョウメ', '043-123-4003', 140.118 , 35.63559, 1698.), ('S13002', '国分寺店', 13, '東京都', '東京都国分寺市本多二丁目', 'トウキョウトコクブンジシホンダニチョウメ', '042-123-4008', 139.4802, 35.70566, 1735.), ('S14010', '菊名店', 14, '神奈川県', '神奈川県横浜市港北区菊名一丁目', 'カナガワケンヨコハマシコウホククキクナイッチョウメ', '045-123-4032', 139.6326, 35.50049, 1732.), ('S14033', '阿久和店', 14, '神奈川県', '神奈川県横浜市瀬谷区阿久和西一丁目', 'カナガワケンヨコハマシセヤクアクワニシイッチョウメ', '045-123-4043', 139.4961, 35.45918, 1495.), ('S14036', '相模原中央店', 14, '神奈川県', '神奈川県相模原市中央二丁目', 'カナガワケンサガミハラシチュウオウニチョウメ', '042-123-4045', 139.3716, 35.57327, 1679.), ('S14040', '長津田店', 14, '神奈川県', '神奈川県横浜市緑区長津田みなみ台五丁目', 'カナガワケンヨコハマシミドリクナガツタミナミダイゴチョウメ', '045-123-4046', 139.4994, 35.52398, 1548.), ('S14050', '阿久和西店', 14, '神奈川県', '神奈川県横浜市瀬谷区阿久和西一丁目', 'カナガワケンヨコハマシセヤクアクワニシイッチョウメ', '045-123-4053', 139.4961, 35.45918, 1830.), ('S13052', '森野店', 13, '東京都', '東京都町田市森野三丁目', 'トウキョウトマチダシモリノサンチョウメ', '042-123-4030', 139.4383, 35.55293, 1087.), ('S14028', '二ツ橋店', 14, '神奈川県', '神奈川県横浜市瀬谷区二ツ橋町', 'カナガワケンヨコハマシセヤクフタツバシチョウ', '045-123-4042', 139.4963, 35.46304, 1574.), ('S14012', '本牧和田店', 14, '神奈川県', '神奈川県横浜市中区本牧和田', 'カナガワケンヨコハマシナカクホンモクワダ', '045-123-4034', 139.6582, 35.42156, 1341.), ('S14046', '北山田店', 14, '神奈川県', '神奈川県横浜市都筑区北山田一丁目', 'カナガワケンヨコハマシツヅキクキタヤマタイッチョウメ', '045-123-4049', 139.5916, 35.56189, 831.), ('S14022', '逗子店', 14, '神奈川県', '神奈川県逗子市逗子一丁目', 'カナガワケンズシシズシイッチョウメ', '046-123-4036', 139.5789, 35.29642, 1838.), ('S14011', '日吉本町店', 14, '神奈川県', '神奈川県横浜市港北区日吉本町四丁目', 'カナガワケンヨコハマシコウホククヒヨシホンチョウヨンチョウメ', '045-123-4033', 139.6316, 35.54655, 890.), ('S13016', '小金井店', 13, '東京都', '東京都小金井市本町一丁目', 'トウキョウトコガネイシホンチョウイッチョウメ', '042-123-4015', 139.5094, 35.70018, 1399.), ('S14034', '川崎野川店', 14, '神奈川県', '神奈川県川崎市宮前区野川', 'カナガワケンカワサキシミヤマエクノガワ', '044-123-4044', 139.5998, 35.57693, 1318.), ('S14048', '中川中央店', 14, '神奈川県', '神奈川県横浜市都筑区中川中央二丁目', 'カナガワケンヨコハマシツヅキクナカガワチュウオウニチョウメ', '045-123-4051', 139.5758, 35.54912, 1657.), ('S12007', '佐倉店', 12, '千葉県', '千葉県佐倉市上志津', 'チバケンサクラシカミシヅ', '043-123-4001', 140.1452, 35.71872, 1895.), ('S14026', '辻堂西海岸店', 14, '神奈川県', '神奈川県藤沢市辻堂西海岸二丁目', 'カナガワケンフジサワシツジドウニシカイガンニチョウメ', '046-123-4040', 139.4466, 35.32464, 1732.), ('S13041', '八王子店', 13, '東京都', '東京都八王子市大塚', 'トウキョウトハチオウジシオオツカ', '042-123-4026', 139.4235, 35.63787, 810.), ('S14049', '川崎大師店', 14, '神奈川県', '神奈川県川崎市川崎区中瀬三丁目', 'カナガワケンカワサキシカワサキクナカゼサンチョウメ', '044-123-4052', 139.7327, 35.53759, 962.), ('S14023', '川崎店', 14, '神奈川県', '神奈川県川崎市川崎区本町二丁目', 'カナガワケンカワサキシカワサキクホンチョウニチョウメ', '044-123-4037', 139.7028, 35.53599, 1804.), ('S13018', '清瀬店', 13, '東京都', '東京都清瀬市松山一丁目', 'トウキョウトキヨセシマツヤマイッチョウメ', '042-123-4017', 139.5178, 35.76885, 1220.), ('S14027', '南藤沢店', 14, '神奈川県', '神奈川県藤沢市南藤沢', 'カナガワケンフジサワシミナミフジサワ', '046-123-4041', 139.4896, 35.33762, 1521.), ('S14021', '伊勢原店', 14, '神奈川県', '神奈川県伊勢原市伊勢原四丁目', 'カナガワケンイセハラシイセハラヨンチョウメ', '046-123-4035', 139.3129, 35.40169, 962.), ('S14047', '相模原店', 14, '神奈川県', '神奈川県相模原市千代田六丁目', 'カナガワケンサガミハラシチヨダロクチョウメ', '042-123-4050', 139.3748, 35.55959, 1047.), ('S12013', '習志野店', 12, '千葉県', '千葉県習志野市芝園一丁目', 'チバケンナラシノシシバゾノイッチョウメ', '047-123-4002', 140.022 , 35.66122, 808.), ('S14042', '新山下店', 14, '神奈川県', '神奈川県横浜市中区新山下二丁目', 'カナガワケンヨコハマシナカクシンヤマシタニチョウメ', '045-123-4047', 139.6593, 35.43894, 1044.), ('S12030', '八幡店', 12, '千葉県', '千葉県市川市八幡三丁目', 'チバケンイチカワシヤワタサンチョウメ', '047-123-4005', 139.924 , 35.72318, 1162.), ('S14025', '大和店', 14, '神奈川県', '神奈川県大和市下和田', 'カナガワケンヤマトシシモワダ', '046-123-4039', 139.468 , 35.43414, 1011.), ('S14045', '厚木店', 14, '神奈川県', '神奈川県厚木市中町二丁目', 'カナガワケンアツギシナカチョウニチョウメ', '046-123-4048', 139.3651, 35.44182, 980.), ('S12029', '東野店', 12, '千葉県', '千葉県浦安市東野一丁目', 'チバケンウラヤスシヒガシノイッチョウメ', '047-123-4004', 139.8968, 35.65086, 1101.), ('S12053', '高洲店', 12, '千葉県', '千葉県浦安市高洲五丁目', 'チバケンウラヤスシタカスゴチョウメ', '047-123-4006', 139.9176, 35.63755, 1555.), ('S14024', '三田店', 14, '神奈川県', '神奈川県川崎市多摩区三田四丁目', 'カナガワケンカワサキシタマクミタヨンチョウメ', '044-123-4038', 139.5424, 35.6077 , 972.), ('S14006', '葛が谷店', 14, '神奈川県', '神奈川県横浜市都筑区葛が谷', 'カナガワケンヨコハマシツヅキククズガヤ', '045-123-4031', 139.5633, 35.53573, 1886.)], dtype=[('store_cd', '<U6'), ('store_name', '<U6'), ('prefecture_cd', '<i4'), ('prefecture', '<U4'), ('address', '<U19'), ('address_kana', '<U30'), ('tel_no', '<U12'), ('longitude', '<f8'), ('latitude', '<f8'), ('floor_area', '<f8')])なんでこの問題は全部出力しないといけないんでしょうか。
- 投稿日:2020-06-30T16:10:21+09:00
だから僕はpandasをやめた【データサイエンス100本ノック(構造化データ加工編)篇 #1】
だから僕はpandasをやめた【データサイエンス100本ノック(構造化データ加工編)篇 #1】
データサイエンス100本ノック(構造化データ加工編)のPythonの問題を解いていきます。この問題群は、模範解答ではpandasを使ってデータ加工を行っていますが、私達は勉強がてらにNumPyの構造化配列を用いて処理していきます。
はじめに
Pythonでデータサイエンス的なことをする人の多くはpandas大好き人間かもしれませんが、実はpandasを使わなくても、NumPyで同じことができます。そしてNumPyの方がたいてい高速です。
pandas大好き人間だった僕もNumPyの操作には依然として慣れていないので、今回この『データサイエンス100本ノック』をNumPyで操作することでpandasからの卒業を試みて行きたいと思います。今回は8問目までをやっていきます。
今回使うのはreceipt.csvだけみたいです。初期データは以下のようにして読み込みました(データ型指定はとりあえず後回し)。import numpy as np import pandas as pd # 模範解答用 df_receipt = pd.read_csv('data/receipt.csv') # 僕たちが扱うデータ arr_receipt = np.genfromtxt( 'data/receipt.csv', delimiter=',', encoding='utf-8', names=True, dtype=None)省メモリです。
import sys sys.getsizeof(df_receipt) # 26065721 sys.getsizeof(arr_receipt) # 15074160P_001
P-001: レシート明細のデータフレーム(df_receipt)から全項目の先頭10件を表示し、どのようなデータを保有しているか目視で確認せよ。
スライスで取ります。
In[001]arr_receipt[:10]次のように、データが取得できます。しかも賢いのでカンマの位置を揃えてくれます(全角文字列がなければ)。
Out[001]array([(20181103, 1257206400, 'S14006', 112, 1, 'CS006214000001', 'P070305012', 1, 158), (20181118, 1258502400, 'S13008', 1132, 2, 'CS008415000097', 'P070701017', 1, 81), (20170712, 1215820800, 'S14028', 1102, 1, 'CS028414000014', 'P060101005', 1, 170), (20190205, 1265328000, 'S14042', 1132, 1, 'ZZ000000000000', 'P050301001', 1, 25), (20180821, 1250812800, 'S14025', 1102, 2, 'CS025415000050', 'P060102007', 1, 90), (20190605, 1275696000, 'S13003', 1112, 1, 'CS003515000195', 'P050102002', 1, 138), (20181205, 1259971200, 'S14024', 1102, 2, 'CS024514000042', 'P080101005', 1, 30), (20190922, 1285113600, 'S14040', 1102, 1, 'CS040415000178', 'P070501004', 1, 128), (20170504, 1209859200, 'S13020', 1112, 2, 'ZZ000000000000', 'P071302010', 1, 770), (20191010, 1286668800, 'S14027', 1102, 1, 'CS027514000015', 'P071101003', 1, 680)], dtype=[('sales_ymd', '<i4'), ('sales_epoch', '<i4'), ('store_cd', '<U6'), ('receipt_no', '<i4'), ('receipt_sub_no', '<i4'), ('customer_id', '<U14'), ('product_cd', '<U10'), ('quantity', '<i4'), ('amount', '<i4')])模範解答(pandas)と速度を比較してみます。
Time[001]# 模範解答 %timeit df_receipt.head(10) # 130 µs ± 5.02 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each) %timeit arr_receipt[:10] # 244 ns ± 8.23 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)模範解答の 1/500 の速さで取得できました。
P_002
P-002: レシート明細のデータフレーム(df_receipt)から売上日(sales_ymd)、顧客ID(customer_id)、商品コード(product_cd)、売上金額(amount)の順に列を指定し、10件表示させよ。
NumPyの構造化配列は、私達が慣れ親しんだ
pd.DataFrameと同じように操作できます。In[002]arr_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']][:10]Out[002]array([(20181103, 'CS006214000001', 'P070305012', 158), (20181118, 'CS008415000097', 'P070701017', 81), (20170712, 'CS028414000014', 'P060101005', 170), (20190205, 'ZZ000000000000', 'P050301001', 25), (20180821, 'CS025415000050', 'P060102007', 90), (20190605, 'CS003515000195', 'P050102002', 138), (20181205, 'CS024514000042', 'P080101005', 30), (20190922, 'CS040415000178', 'P070501004', 128), (20170504, 'ZZ000000000000', 'P071302010', 770), (20191010, 'CS027514000015', 'P071101003', 680)], dtype={'names':['sales_ymd','customer_id','product_cd','amount'], 'formats':['<i4','<U14','<U10','<i4'], 'offsets':[0,40,96,140], 'itemsize':144})
pd.DataFrameを操作するよりも高速です。Time[002]%timeit df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']].head(10) # 5.19 ms ± 43.5 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) %timeit arr_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']][:10] # 906 ns ± 17.5 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)P_003
P-003: レシート明細のデータフレーム(df_receipt)から売上日(sales_ymd)、顧客ID(customer_id)、商品コード(product_cd)、売上金額(amount)の順に列を指定し、10件表示させよ。ただし、sales_ymdはsales_dateに項目名を変更しながら抽出すること。
名前の変更は地味に面倒臭いことです。
np.lib.recfunctions.rename_fields()を介すのが一番簡単ですが、それでもこの関数は結構使い勝手が悪かったりします。In[003]np.lib.recfunctions.rename_fields(arr_receipt, {'sales_ymd': 'sales_date'})[ ['sales_date', 'customer_id', 'product_cd', 'amount']][:10]Out[003]array([(20181103, 'CS006214000001', 'P070305012', 158), (20181118, 'CS008415000097', 'P070701017', 81), (20170712, 'CS028414000014', 'P060101005', 170), (20190205, 'ZZ000000000000', 'P050301001', 25), (20180821, 'CS025415000050', 'P060102007', 90), (20190605, 'CS003515000195', 'P050102002', 138), (20181205, 'CS024514000042', 'P080101005', 30), (20190922, 'CS040415000178', 'P070501004', 128), (20170504, 'ZZ000000000000', 'P071302010', 770), (20191010, 'CS027514000015', 'P071101003', 680)], dtype={'names':['sales_date','customer_id','product_cd','amount'], 'formats':['<i4','<U14','<U10','<i4'], 'offsets':[0,40,96,140], 'itemsize':144})とはいえ、pandasに比べてとても高速に処理してくれます。
Time[003]%timeit df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']].rename(columns={'sales_ymd': 'sales_date'}).head(10) # 12.8 ms ± 252 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) %timeit np.lib.recfunctions.rename_fields(arr_receipt, {'sales_ymd': 'sales_date'})[['sales_date', 'customer_id', 'product_cd', 'amount']][:10] # 6.19 µs ± 132 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)pandasは処理のたびに新しいデータフレームオブジェクトをどんどこ作っているので遅いかつ重いわけです。
P_004
P-004: レシート明細のデータフレーム(df_receipt)から売上日(sales_ymd)、顧客ID(customer_id)、商品コード(product_cd)、売上金額(amount)の順に列を指定し、以下の条件を満たすデータを抽出せよ。
- 顧客ID(customer_id)が"CS018205000001"
これも直感的操作で取得できます。
In[004]arr_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']][ arr_receipt['customer_id'] == 'CS018205000001']Out[004]arr_receipt[['sales_ymd','customer_id','product_cd','amount']][arr_receipt['customer_id'] == 'CS018205000001'] array([(20180911, 'CS018205000001', 'P071401012', 2200), (20180414, 'CS018205000001', 'P060104007', 600), (20170614, 'CS018205000001', 'P050206001', 990), (20170614, 'CS018205000001', 'P060702015', 108), (20190216, 'CS018205000001', 'P071005024', 102), (20180414, 'CS018205000001', 'P071101002', 278), (20190226, 'CS018205000001', 'P070902035', 168), (20190924, 'CS018205000001', 'P060805001', 495), (20190226, 'CS018205000001', 'P071401020', 2200), (20180911, 'CS018205000001', 'P071401005', 1100), (20190216, 'CS018205000001', 'P040101002', 218), (20190924, 'CS018205000001', 'P091503001', 280)], dtype={'names':['sales_ymd','customer_id','product_cd','amount'], 'formats':['<i4','<U14','<U10','<i4'], 'offsets':[0,40,96,140], 'itemsize':144})模範解答は
pd.DataFrame.query()が大好きのようです。普通にインデックスすればいいと思うんですけどね。Time[004]%timeit df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']].query('customer_id == "CS018205000001"') # 11.6 ms ± 477 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) %timeit df_receipt.loc[df_receipt['customer_id'] == 'CS018205000001', ['sales_ymd', 'customer_id', 'product_cd', 'amount']] # 9.49 ms ± 212 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) %timeit arr_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']][arr_receipt['customer_id'] == 'CS018205000001'] # 2.7 ms ± 475 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)P_005
P-005: レシート明細のデータフレーム(df_receipt)から売上日(sales_ymd)、顧客ID(customer_id)、商品コード(product_cd)、売上金額(amount)の順に列を指定し、以下の条件を満たすデータを抽出せよ。
- 顧客ID(customer_id)が"CS018205000001"
- 売上金額(amount)が1,000以上
条件が複数あっても同じです。
In[005]arr_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']][ (arr_receipt['customer_id'] == 'CS018205000001') & (arr_receipt['amount'] >= 1000)]Out[005]array([(20180911, 'CS018205000001', 'P071401012', 2200), (20190226, 'CS018205000001', 'P071401020', 2200), (20180911, 'CS018205000001', 'P071401005', 1100)], dtype={'names':['sales_ymd','customer_id','product_cd','amount'], 'formats':['<i4','<U14','<U10','<i4'], 'offsets':[0,40,96,140], 'itemsize':144})P_006
P-006: レシート明細データフレーム「df_receipt」から売上日(sales_ymd)、顧客ID(customer_id)、商品コード(product_cd)、売上数量(quantity)、売上金額(amount)の順に列を指定し、以下の条件を満たすデータを抽出せよ。
- 顧客ID(customer_id)が"CS018205000001"
- 売上金額(amount)が1,000以上または売上数量(quantity)が5以上
なんだか行が長くなってきたので分けます。
In[006]col_list = ['sales_ymd', 'customer_id', 'product_cd', 'quantity', 'amount'] cond = ((arr_receipt['customer_id'] == 'CS018205000001') & ((arr_receipt['amount'] >= 1000) | (arr_receipt['quantity'] >= 5))) arr_receipt[col_list][cond]Out[006]array([(20180911, 'CS018205000001', 'P071401012', 2200), (20180414, 'CS018205000001', 'P060104007', 600), (20170614, 'CS018205000001', 'P050206001', 990), (20190226, 'CS018205000001', 'P071401020', 2200), (20180911, 'CS018205000001', 'P071401005', 1100)], dtype={'names':['sales_ymd','customer_id','product_cd','amount'], 'formats':['<i4','<U14','<U10','<i4'], 'offsets':[0,40,96,140], 'itemsize':144})P_007
P-007: レシート明細のデータフレーム(df_receipt)から売上日(sales_ymd)、顧客ID(customer_id)、商品コード(product_cd)、売上金額(amount)の順に列を指定し、以下の条件を満たすデータを抽出せよ。
- 顧客ID(customer_id)が"CS018205000001"
- 売上金額(amount)が1,000以上2,000以下
In[007]col_list = ['sales_ymd', 'customer_id', 'product_cd', 'quantity', 'amount'] cond = ((arr_receipt['customer_id'] == 'CS018205000001') & ((1000 <= arr_receipt['amount']) & (arr_receipt['amount'] <= 2000))) arr_receipt[col_list][cond]Out[007]array([(20180911, 'CS018205000001', 'P071401005', 1, 1100)], dtype={'names':['sales_ymd','customer_id','product_cd','quantity','amount'], 'formats':['<i4','<U14','<U10','<i4','<i4'], 'offsets':[0,40,96,136,140], 'itemsize':144})P_008
P-008: レシート明細のデータフレーム(df_receipt)から売上日(sales_ymd)、顧客ID(customer_id)、商品コード(product_cd)、売上金額(amount)の順に列を指定し、以下の条件を満たすデータを抽出せよ。
- 顧客ID(customer_id)が"CS018205000001"
- 商品コード(product_cd)が"P071401019"以外
In[008]col_list = ['sales_ymd', 'customer_id', 'product_cd', 'quantity', 'amount'] cond = ((arr_receipt['customer_id'] == 'CS018205000001') & (arr_receipt['product_cd'] != 'P071401019')) arr_receipt[col_list][cond]Out[008]array([(20180911, 'CS018205000001', 'P071401012', 1, 2200), (20180414, 'CS018205000001', 'P060104007', 6, 600), (20170614, 'CS018205000001', 'P050206001', 5, 990), (20170614, 'CS018205000001', 'P060702015', 1, 108), (20190216, 'CS018205000001', 'P071005024', 1, 102), (20180414, 'CS018205000001', 'P071101002', 1, 278), (20190226, 'CS018205000001', 'P070902035', 1, 168), (20190924, 'CS018205000001', 'P060805001', 1, 495), (20190226, 'CS018205000001', 'P071401020', 1, 2200), (20180911, 'CS018205000001', 'P071401005', 1, 1100), (20190216, 'CS018205000001', 'P040101002', 1, 218), (20190924, 'CS018205000001', 'P091503001', 1, 280)], dtype={'names':['sales_ymd','customer_id','product_cd','quantity','amount'], 'formats':['<i4','<U14','<U10','<i4','<i4'], 'offsets':[0,40,96,136,140], 'itemsize':144})Time[008]col_list = ['sales_ymd', 'customer_id', 'product_cd', 'quantity', 'amount'] %timeit df_receipt[col_list].query('customer_id == "CS018205000001" & product_cd != "P071401019"') # 15.6 ms ± 1.19 ms per loop (mean ± std. dev. of 7 runs, 10 loops each) %timeit arr_receipt[col_list][((arr_receipt['customer_id'] == 'CS018205000001') & (arr_receipt['product_cd'] != 'P071401019'))] # 4.28 ms ± 86.3 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)おわりに
ほいよ
これ、NumPyで作った高速・アチアチ・データ加工ね
処理後にcsvに吐き出してもいいし、pandasで重い処理することはないんだよ
だから僕はpandasをやめた
- 投稿日:2020-06-30T15:54:25+09:00
データサイエンス100本ノック~初心者未満の戦いpart11
これはデータサイエンティストの卵がわけもわからないまま100本ノックを行っていく奮闘録である。
完走できるか謎。途中で消えてもQiitaにあげてないだけと思ってください。ネタバレも含みますのでやろうとされている方は注意
しばらく更新できない可能性有り。消えたらスマンヌ
コレは見づらい!この書き方は危険!等ありましたら教えていただきたいです。
心にダメージを負いながら糧とさせていただきます。この解き方は間違っている!この解釈の仕方は違う!等もありましたらコメントください。
今回は57~62まで。
[前回]52~56
[目次付き初回]57本目
P-057: 前問題の抽出結果と性別(gender)を組み合わせ、新たに性別×年代の組み合わせを表すカテゴリデータを作成せよ。組み合わせを表すカテゴリの値は任意とする。先頭10件を表示させればよい。
自分のプログラムと先頭行だけ表示
mine56.pydf=df_customer.copy() df_bins=pd.cut(df.age,[10,20,30,40,50,60,150],right=False,labels=[10,20,30,40,50,60]) df=pd.concat([df[['customer_id','birth_day']],df_bins],axis=1) df.head(10)
customer_id birth_day age CS021313000114 1981-04-29 30 mine57.pydf=pd.concat([df_customer[['customer_id','birth_day','gender_cd']],df_bins],axis=1) df['age_gen']=df.gender_cd.astype('str')+df.age.astype('str') df.head(10) '''模範解答''' df_customer_era['era_gender'] = df_customer['gender_cd'] + df_customer_era['age'].astype('str') df_customer_era.head(10)
pd.concatしたので正直別に前回の流用しなくてもいい気もした。尚、
このage列の30のに性別を表す桁を加え
1(女性)+30(年代)= 130
とするのが今回の目的と、いうのが分からず書いたのが
miss57.pydf=pd.concat([df_customer[['customer_id','birth_day','gender_cd']],df_bins],axis=1) df=df.groupby(['age','gender_cd']).agg({'customer_id':'count'}) pd.pivot_table(df,index='age',columns='gender_cd')
思わずクロス集計してしまったぜ58本目
P-058: 顧客データフレーム(df_customer)の性別コード(gender_cd)をダミー変数化し、顧客ID(customer_id)とともに抽出せよ。結果は10件表示させれば良い。
mine58.pydf=df_customer.copy() pd.concat([df['customer_id'],pd.get_dummies(df['gender_cd'])],axis=1).head(10) '''模範解答''' pd.get_dummies(df_customer[['customer_id', 'gender_cd']], columns=['gender_cd']).head(10)ダミー変数ってなんだ?と思い、調べたところ
先頭列に該当項目を作り、表中はtrueorfalseで要素の有無を出すことらしいというか、表を見たほうが早い
男性 女性 不明 0 1 0 0 0 1 0 1 0 0 1 0 0 1 0 こういうこと
59本目
P-059: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、合計した売上金額を平均0、標準偏差1に標準化して顧客ID、売上金額合計とともに表示せよ。標準化に使用する標準偏差は、不偏標準偏差と標本標準偏差のどちらでも良いものとする。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。結果は10件表示させれば良い。
…
……
………
標準化ってなによ
いろんなサイトを読んで理解しようとしたが、
当時数学をサボっていた自分は理解が追い付かず、先輩に聞いて参考になるWebサイトを教えてもらいこうかな?と書くも
df['hyou1'] =df['amount_sum'] - df.amount_sum.mean()
※(合計-平均)/ 1(標準偏差)のつもりと書いて間違える。
何とか理解しようと逆引き的に回答の
preprocessing.scaleを調べようとしていたところhttps://note.nkmk.me/python-list-ndarray-dataframe-normalize-standardize/ 後半
pandas.DataFrame, pandas.Seriesの正規化・標準化
pandasのメソッドを利用
~中略~プログラム内
print( (df.T - df.T.mean()) / df.T.std() )
# col1 col2 col3
# a -1.0 0.0 1.0
# b -1.0 0.0 1.0
# c -1.0 0.0 1.0これかッッッ
つまり
(データ/.mean())/.std()
とすればッmine59.pydf=df_receipt.copy() df=df.query('not customer_id.str.startswith("Z")',engine='python') df=df.groupby('customer_id').agg({'amount':'sum'}).reset_index() df['hyou1'] =(df['amount'] - df.amount.mean()) / df.amount.std() df.head(10) '''模範解答''' # skleanのpreprocessing.scaleを利用するため、標本標準偏差で計算されている df_sales_amount = df_receipt.query('not customer_id.str.startswith("Z")', engine='python'). \ groupby('customer_id').agg({'amount':'sum'}).reset_index() df_sales_amount['amount_ss'] = preprocessing.scale(df_sales_amount['amount']) df_sales_amount.head(10)一致しました。
60本目
P-060: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、合計した売上金額を最小値0、最大値1に正規化して顧客ID、売上金額合計とともに表示せよ。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。結果は10件表示させれば良い。
同一サイトにて
print((df - df.min()) / (df.max() - df.min()))
# col1 col2 col3
# a 0.0 0.0 0.0
# b 0.5 0.5 0.5
# c 1.0 1.0 1.0と、あるのでこれを流用
mine60.pydf=df_receipt.copy() df=df.query('not customer_id.str.startswith("Z")',engine='python') df=df.groupby('customer_id').agg({'amount':'sum'}).reset_index() df['minmax'] =(df['amount'] - df.amount.min()) / (df.amount.max()-df.amount.min()) df.head(10) '''模範解答''' # skleanのpreprocessing.scaleを利用するため、標本標準偏差で計算されている df_sales_amount = df_receipt.query('not customer_id.str.startswith("Z")', engine='python'). \ groupby('customer_id').agg({'amount':'sum'}).reset_index() df_sales_amount['amount_mm'] = preprocessing.minmax_scale(df_sales_amount['amount']) df_sales_amount.head(10)61、62本目
P-061: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、合計した売上金額を常用対数化(底=10)して顧客ID、売上金額合計とともに表示せよ。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。結果は10件表示させれば良い。
P-062: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、合計した売上金額を自然対数化(底=e)して顧客ID、売上金額合計とともに表示せよ。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。結果は10件表示させれば良い。
対数化は指数関数を使えばいいので
mine61_62.pydf=df_receipt.copy() df=df.query('not customer_id.str.startswith("Z")',engine='python') df=df.groupby('customer_id').agg({'amount':'sum'}).reset_index() #60、常用対数比 df['jouyou']=df.amount.apply(lambda x: math.log10(x)) #61、自然対数比 df['shizen']=df.amount.apply(lambda x: math.log(x)) df.head(10)で出せる
mohan61_62.py# skleanのpreprocessing.scaleを利用するため、標本標準偏差で計算されている df_sales_amount = df_receipt.query('not customer_id.str.startswith("Z")', engine='python'). \ groupby('customer_id').agg({'amount':'sum'}).reset_index() df_sales_amount['amount_log10'] = np.log10(df_sales_amount['amount'] + 1) df_sales_amount.head(10) # skleanのpreprocessing.scaleを利用するため、標本標準偏差で計算されている df_sales_amount = df_receipt.query('not customer_id.str.startswith("Z")', engine='python'). \ groupby('customer_id').agg({'amount':'sum'}).reset_index() df_sales_amount['amount_loge'] = np.log(df_sales_amount['amount'] + 1) df_sales_amount.head(10)………
+1ってなぁに?今回はここまで
logは高校数学でよくわからなくなり始めた部分なので、ホントにお手上げです。
この、+1についてわかる方、コメントおねがいします。ホントニワカラナイ
- 投稿日:2020-06-30T15:53:50+09:00
Seleniumでページ内のiframeを操作できない
問題
Selenium/BeautifulSoupを使ってページ内のiframeの内容を取得しようとしたが、できない。
BeautifulSoupでHTMLを全取得すると以下のような結果になる。
HTMLを取得するコードBeautifulSoup(driver.page_source, 'html.parser')取得結果<html> <head> <!-- head --> </head> <body> <!-- body --> <iframe id="iframe" scrolling="yes" src="https://example.com/iframe" src_data="https://example.com/iframe"> </iframe> </body> </html>やりたいこと
iframeのなかを見たい、操作したい。
解決方法
以下のコードで、driverがiframeにフォーカスする。
iframe = driver.find_element_by_id('#iframe') driver.switch_to.frame(iframe)HTMLを取得するコードBeautifulSoup(driver.page_source, 'html.parser')でHTMLがiframeになっていることを確認してください。
参考
https://www.selenium.dev/documentation/ja/webdriver/browser_manipulation/#webelementを使う
追記
元のウィンドウに戻る際は以下のコードで戻ります。
driver.switchTo().defaultContent();
- 投稿日:2020-06-30T15:44:18+09:00
rubyistがpycallでpython::Dictデータで苦労した話
rubyistがpycallでpython::Dictデータで苦労した話
PyCall Ruby版
Tipsにほぼ完璧な対応報告がある.
さらに,numpy特有の記法# 最後の行へのアクセス pythonだと m[-1,:] と書くところなどと,rubyistにわかりやるいnumpyの解説まで付いている.
という風に簡単にできそうに見える...
複雑なデータ構造だとお手上げ
ところが,複雑なpythonのデータ構造を扱う時には
非常に苦労する.原因はdictのkeyがよくわからないから.
単純な文字を取る時にはいいが,少し複雑な文字ではうまく取れないようだ.以下の通りにしてpymatgenにあるVasprun::tdosあるいは
Vasprun::compolete_dos などが取れる.ところが,
p spd_dos = dosrun.complete_dos.get_spd_dos() とすると,
{<OrbitalType.s: 0>: <pymatgen.electronic_structure.dos.Dos
object at 0x102dd4710>, <OrbitalType.p: 1>:
<pymatgen.electronic_structure.dos.Dos object at 0x102dc2dd8>,
<OrbitalType.d: 2>: <pymatgen.electronic_structure.dos.Dos
object at 0x102d962b0>}と出力される.これはspd_dos('OrbitalType.s')で取れそうに思うが
だめ.そこで,p s_d = spd_dos.to_a[0][1].densitiesとして
array([ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ... ])python::arrayにして,さらに
s_list = PyCall::List.(s_d.to_a[0][1]).to_aとしてhashをarrayにしてvalsを取り出し,さらにそれをto_aでrubyが解釈できるdata構造に変換している.
慣れると同じcodeの繰り返しなんでそれほど苦労しなくなるが,
多分時間が経てば忘れるね.
そこをlibに組み込んで欲しいが,dictを直接読むのは文字だけのよう...
code書いて,pull reqかけてみるか.densitiesやenergyはnameがわからないとどうしようもなくて,
これは,pymatgenのsource codeを読んで見つける.
どうもpycallを使うには,こういうのを繰り返す必要がありそうだ.require 'pycall/import' include PyCall::Import pyimport :sys pyimport 'numpy', as: :np pyfrom 'pymatgen.io.vasp.outputs', import: :Vasprun # dos dosrun = Vasprun.("../dos_calc_fine/vasprun.xml") e_object = (dosrun.tdos.energies - dosrun.efermi) energy = PyCall::List.(e_object).to_a spd_dos = dosrun.complete_dos.get_spd_dos() spd = PyCall::Dict.(spd_dos) s_d = spd.to_a[0][1].densities s_list = PyCall::List.(s_d.to_a[0][1]).to_a p_d = spd.to_a[1][1].densities p_list = PyCall::List.(p_d.to_a[0][1]).to_a d_d = spd.to_a[2][1].densities d_list = PyCall::List.(d_d.to_a[0][1]).to_a tdos = dosrun.tdos.densities t_list = PyCall::List.(tdos.to_a[0][1]).to_a require 'numo/gnuplot' Numo.gnuplot do set yrange: '[-10:10]' plot [s_list, energy, w: :l, title: 's'], [p_list, energy, w: :l, title: 'p'], [d_list, energy, w: :l, title: 'd'], [t_list, energy, w: :l, title: 'total'] end
- 投稿日:2020-06-30T14:46:05+09:00
データサイエンス100本ノック~初心者未満の戦いpart10
これはデータサイエンティストの卵がわけもわからないまま100本ノックを行っていく奮闘録である。
完走できるか謎。途中で消えてもQiitaにあげてないだけと思ってください。ネタバレも含みますのでやろうとされている方は注意
統計学の問題がわからないんじゃぁああああ!(59~)
コレは見づらい!この書き方は危険!等ありましたら教えていただきたいです。
心にダメージを負いながら糧とさせていただきます。この解き方は間違っている!この解釈の仕方は違う!等もありましたらコメントください。
今回は52~56まで。
[前回]45~51
[目次付き初回]52本目
P-052: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計の上、売上金額合計に対して2000円以下を0、2000円超を1に2値化し、顧客ID、売上金額合計とともに10件表示せよ。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。
mine52.pydf=df_receipt[df_receipt['customer_id'].str.contains('^[^Z]')].reset_index() df=df.groupby('customer_id').agg({'amount':'sum'}).reset_index() df['amount']=df['amount'].apply(lambda x : 0 if x<=2000 else 1) df.head(10) '''模範解答''' df_sales_amount = df_receipt.query('not customer_id.str.startswith("Z")', engine='python') df_sales_amount = df_sales_amount[['customer_id', 'amount']].groupby('customer_id').sum().reset_index() df_sales_amount['sales_flg'] = df_sales_amount['amount'].apply(lambda x: 1 if x > 2000 else 0) df_sales_amount.head(10)
groupbyをしてから合計出し、それを比較しながら0と1に振り分ける。どちらかといえば
lambdaを使いこなせるかの問題なので、久々のpython問題でした。pythonってこの問題だけじゃないけど、型を意識しない文で型を意識して解かないといけないのがホントにめんどくさい。
この場合の
lambda x:~のxにどの階層の型のデータが入っているのかを把握できるようになるのにすごく時間がかかりました。53本目
P-053: 顧客データフレーム(df_customer)の郵便番号(postal_cd)に対し、東京(先頭3桁が100〜209のもの)を1、それ以外のものを0に2値化せよ。さらにレシート明細データフレーム(df_receipt)と結合し、全期間において買い物実績のある顧客数を、作成した2値ごとにカウントせよ。
mine53.pydf=df_customer.copy() df['postal_cd']=df.postal_cd.apply(lambda x: 1 if 100<=int(x[:3])<=209 else 0) df=pd.merge(df,df_receipt,how='inner',on='customer_id') df.groupby('postal_cd').agg({'customer_id':'nunique'}) '''模範解答''' df_tmp = df_customer[['customer_id', 'postal_cd']].copy() df_tmp['postal_flg'] = df_tmp['postal_cd'].apply(lambda x: 1 if 100 <= int(x[0:3]) <= 209 else 0) pd.merge(df_tmp, df_receipt, how='inner', on='customer_id'). \ groupby('postal_flg').agg({'customer_id':'nunique'})
lambda内のif文で 100<=x<=209 の形が書けるの便利すぎる。elseに集中しすぎてifを書き忘れたのは内緒。54本目
P-054: 顧客データデータフレーム(df_customer)の住所(address)は、埼玉県、千葉県、東京都、神奈川県のいずれかとなっている。都道府県毎にコード値を作成し、顧客ID、住所とともに抽出せよ。値は埼玉県を11、千葉県を12、東京都を13、神奈川県を14とすること。結果は10件表示させれば良い。
mine54.pydf=df_customer.copy() df['to_cd']=df['address'].apply(lambda x:11 if x.startswith('埼玉県')\ else 12 if x.startswith('千葉県')\ else 13 if x.startswith('東京都') \ else 14 if x.startswith('神奈川県') else 0) df[['customer_id','address','to_cd']].head(10) '''模範解答''' pd.concat([df_customer[['customer_id', 'address']], df_customer['address'].str[0:3].map({'埼玉県': '11', '千葉県':'12', '東京都':'13', '神奈川':'14'})], axis=1).head(10)いやぁ、
startwith()便利ですねぇ(containsのスペルを忘れてた)
気を付けないといけないとはbool型で返ることですかね55本目
P-055: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、その合計金額の四分位点を求めよ。その上で、顧客ごとの売上金額合計に対して以下の基準でカテゴリ値を作成し、顧客ID、売上金額と合計ともに表示せよ。カテゴリ値は上から順に1〜4とする。結果は10件表示させれば良い。
- 最小値以上第一四分位未満
- 第一四分位以上第二四分位未満
- 第二四分位以上第三四分位未満
- 第三四分位以上
mine55.pydf=df_receipt.copy() df=df.groupby('customer_id')['amount'].sum().reset_index() si=df.quantile(q=[0.25,0.5,0.75]).T #float(si[0.25]) df['sibun']=df['amount'].apply(lambda x:1 if x<float(si[0.25]) else 2 if x<float(si[0.5]) else 3 if x<float(si[0.75]) else 4) df.head(10) '''模範解答''' # コード例1 df_sales_amount = df_receipt[['customer_id', 'amount']].groupby('customer_id').sum().reset_index() pct25 = np.quantile(df_sales_amount['amount'], 0.25) pct50 = np.quantile(df_sales_amount['amount'], 0.5) pct75 = np.quantile(df_sales_amount['amount'], 0.75) def pct_group(x): if x < pct25: return 1 elif pct25 <= x < pct50: return 2 elif pct50 <= x < pct75: return 3 elif pct75 <= x: return 4 df_sales_amount['pct_group'] = df_sales_amount['amount'].apply(lambda x: pct_group(x)) df_sales_amount.head(10) # コード例2 df_temp = df_receipt.groupby('customer_id')[['amount']].sum() df_temp['quantile'], bins = pd.qcut(df_receipt.groupby('customer_id')['amount'].sum(), 4, retbins=True) display(df_temp.head()) print('quantiles:', bins)合計から四分位点を出して、以上未満で分けていく……
というやり方でやりましたが、コード例2ではpd.cutの中にそのまま合計を入れて4分割指定してますね。四分位点は32本目でやっている内容でしたが、案の定忘れていました。フクシュウシナキャ
56本目
P-056: 顧客データフレーム(df_customer)の年齢(age)をもとに10歳刻みで年代を算出し、顧客ID(customer_id)、生年月日(birth_day)とともに抽出せよ。ただし、60歳以上は全て60歳代とすること。年代を表すカテゴリ名は任意とする。先頭10件を表示させればよい。
mine56.pydf=df_customer.copy() df_bins=pd.cut(df.age,[10,20,30,40,50,60,150],right=False,labels=[10,20,30,40,50,60]) df=pd.concat([df[['customer_id','birth_day']],df_bins],axis=1) df.head(10) '''模範解答''' # コード例1 df_customer_era = pd.concat([df_customer[['customer_id', 'birth_day']], df_customer['age'].apply(lambda x: min(math.floor(x / 10) * 10, 60))], axis=1) df_customer_era.head(10) # コード例2 df_customer['age_group'] = pd.cut(df_customer['age'], bins=[0, 10, 20, 30, 40, 50, 60, np.inf], right=False) df_customer[['customer_id', 'birth_day', 'age_group']].head(10)今度は43本目の復習ですね。
np,infの存在を知らなかったので明らかにとりえない数字の150を入れました。また、df.age.min()で最低年齢を出して10~でいいことを確認してから0を抜きました。
pd.cutにlabelsという項目があるので入れるときれいな数字が出ます。
また、right=Falseで10<=x<20という範囲を取るようになります今回はここまで
- 投稿日:2020-06-30T13:40:28+09:00
ホテリングのT^2法による多変量正規分布を仮定した異常検知
はじめに
本連載について
こんにちは,(株)日立製作所 Lumada Data Science Lab. の露木です。
化学プラントや工場設備,あるいはもっと身近なモーターや冷蔵庫などの故障予兆検知を行う際に,振動や音,温度,圧力,電圧,消費電力のような値を取得できる複数のセンサーで測定した多次元の時系列数値データを分析することがあります。このような故障予兆検知は,機械学習の分野では異常検知問題として解くことができます。
そこで本連載では時系列数値データの異常検知を題材とし,数回の記事に分けてアルゴリズムの基礎的な説明と実装を示していきます。
- 第1回. scipyを使って特徴量の相関を考慮したマハラノビス距離を計算する
- 第2回. ホテリングの$T^2$法による多変量正規分布を仮定した異常検知
- 第3回. GMMによる多峰性分布にもとづいたデータの異常検知
- 第4回. 移動窓を使った多次元時系列データの異常検知
今回扱う内容: ホテリングのT^2法
今回は「ホテリングの $T^2$ 法」による異常検知を紹介します。ホテリングの $T^2$ 法は,アメリカの経済学者ハロルド・ホテリング が確立した古典的な手法です 1 2 3 4 。この異常検知技術は 初回の記事 で説明したユースケースに必要な4つの要素技術のうち
2.に相当します。
- 時系列数値データの異常検知に必要な4つの要素技術
- 要素技術1. 特徴量空間における距離の定義
- 要素技術2. 正常データの分布を仮定し,異常なデータと正常なデータを分ける閾値を設定する方法 (本稿)
- 要素技術3. 複数のモードに対応できるクラスタリング
- 要素技術4. 時系列データに対応するための移動窓の活用
この
2.の要素技術をさらに分解すると以下の4つの手順に細分化できます。本記事では以下の手順のそれぞれについて説明を加えながら実装の紹介を行います。
- 手順1. 母集団の分布を推定する: 統計量として標本の平均値と分散共分散行列を計算する
- 手順2. 異常度を計算する: 標本ごとにマハラノビスの2乗値を計算する
- 手順3. 閾値を計算する: 所望の異常検知確率から異常度の閾値を逆算する
- 手順4. 異常を判定する: 異常度が閾値より大きい場合は異常と判定
データセットの準備
実際のデータを測定すると時間がかかりますから,ここでは人工的なデータセットを作成して異常検知技術を試します。初回の記事で説明した異常検知のユースケース にもとづけば,図1における各モードに応じた4つ程度の正規分布を作るべきといえます。
図1. 期待される分析結果一方で,ホテリングの$T^2$法の理論では母集団が1つの正規分布に従うことを仮定します1234。そこで,本記事ではクラスタリング等の何らかの手段によって「図1の運転モードに相当するデータだけ分離できた」と仮定して2次元の正規分布に従ったデータセットを作成することにします。
正規分布は平均$\mu$と分散$\sigma$の2つのパラメータで定義される確率分布ですので,それらの値を設定すればデータセットを作成できます。ただし,今回は2次元の正規分布を作りたいので分散はスカラーではなく行列 (分散共分散行列 $\Sigma$) になります。この分散共分散行列はその対角項に分散,非対角項に共分散 (次元間の相関を表す行列要素) を含む行列です。
実装
以下のコードでは平均 $\mu = (0,0)$ と分散に 50, 共分散に 35 の値を設定し,念のため多めに10万点のデータセットを作成します。データ数は,後に計算する標本の平均と分散共分散行列の精度が十分に高くなる程度の数があれば良いので,必ずしも10万点も必要とは限りません。
pythonimport matplotlib.pyplot as plt import numpy as np # 2次元の正規分布からデータセットを作成する mean = np.array((0,0)) # 平均値をゼロに設定 cov = np.array([(50, 35), (35, 50)]) # 分散共分散行列を設定 # データを10万点作成する X = np.random.multivariate_normal(mean, cov, 100000)可視化
このデータセットを可視化すると図2のようになります。先程のコードでは分散共分散行列を表す変数
covで 35 という比較的大きな共分散を指定していますので,右肩上がりのような相関を持った2次元の正規分布となっています。python# データセットの分布を可視化 plt.plot(X.T[0], X.T[1], 'x', alpha=0.01) plt.axis('equal') plt.show()
図2. データセットの分布異常検知の実装
手順1. 母集団の分布を推定する
実装
作成したデータセット (母集団) から,その分布を推定します。具体的には,標本の平均${\bf \hat \mu}$と分散共分散行列 $\hat \Sigma$ を計算することで,元になっている正規分布の形状を明らかにします。この計算はホテリングの$T^2$法において異常度として用いる「マハラノビス距離の2乗値」を求めるために必要な準備です。
python# 標本の平均を計算 mu = X.mean(axis=0) # 標本の分散共分散行列を計算 cov2 = np.cov(X.T)可視化
念の為,計算結果を真値 (母集団の平均と分散共分散行列) と比較すると,平均については 0 であるべきところを -0.00602358,分散については 50 であるべきところを 50.18772103 などと比較的良く推定できていることがわかります。
pythonprint("母集団の平均") print(mean) print("標本平均") print(mu) print("\n母集団の分散共分散行列") print(cov) print("標本による分散共分散行列") print(cov2)実行結果母集団の平均 [0 0] 標本平均 [-0.00602358 0.00186333] 母集団の分散共分散行列 [[50 35] [35 50]] 標本による分散共分散行列 [[50.18772103 35.14373908] [35.14373908 49.97181938]]手順2. 異常度を計算する
次に標本 ${\bf x'}$ の異常度 $a({\bf x}')$ を計算します。ホテリングの$T^2$法では,式(1)で計算できる「標本$\bf x'$と 標本平均$\bf \hat \mu$ の間のマハラノビス距離の2乗値」を異常度として用います。マハラノビス距離は前回の記事で説明したように,母集団の分散を考慮した距離の定義方法です。一般的なユークリッド距離の代わりに,マハラノビス距離を使うことで特徴量間に強い相関がある場合でも正常データと異常データを分離しやすくなる利点があります。
a({\bf x}') \equiv({\bf x'} - {\bf \hat \mu})^{\rm T} {\hat \Sigma^{-1}} ({\bf x'} - {\bf \hat \mu}) \tag{1}実装
式(1)の標本平均$\hat \mu$や標本の分散共分散行列 $\hat \Sigma$は,先程の手順1で計算済みです。したがって,例えば
(1,1)の特徴量を持つ標本の異常度は以下のコードで計算できます。pythonfrom scipy.spatial import distance from scipy.stats import chi2 # 分散共分散行列の逆行列を計算 cov_i = np.linalg.pinv(cov2) # 異常度を計算したい点を設定 x = (1, 1) # 異常度を計算 (マハラノビス距離の2乗値を計算) anomaly_score = distance.mahalanobis(x, mu, cov_i)**2 # 異常度を表示 print("異常度 = %.2f" % anomaly_score)実行結果異常度 = 0.02なお,先に作成したデータセットの全データについて異常度を計算する処理は,Pythonのリスト内包表記を使って以下のように書けます。
python# データセット (変数X) に含まれる全データについて異常度を計算 anomaly_scores = np.array([x for x in X if distance.mahalanobis(x, mu, cov_i)**2])手順3. 閾値を計算する
異常度が計算できたら,次は異常検知のための閾値を設定します。マハラノビス距離と正規分布の性質から,式(1)で定義される異常度は「特徴量の次元 (自由度) $m$ に対してデータ数$N$が十分に大きい」とき,近似的に自由度$m$のカイ二乗分布に従うことが知られています3 4 。これは異常データが検知される確率から,異常度の閾値を逆算できることを意味します。
例えば自由度$m=3$のとき,異常データの数を全体の10%に設定したい場合は
\int^\infty_{6.25} f(a,3) {\rm d}a = 1 - \int^{6.25}_0 f(a,3) {\rm d}a = 0.10 \tag{2}であるので,異常度 $a({\bf x}')= 6.25$ を閾値に設定すれば良いと逆算できます。ただし,$f(a,m)$はカイ二乗分布の確率密度関数です。
この閾値と異常検知確率の関係は図3のように可視化できます 5 。図3の縦軸は自由度3のカイ二乗分布の確率密度を表しており,横軸は異常度です。先程の例のように横軸の異常度 $a({\bf x}')= 6.25$ を閾値として設定すれば,異常データが出現する確率 (青色部分の面積) は全体の 10% になります。
クリックして描画コードを開く
ソースコードimport matplotlib.pyplot as plt import matplotlib as mpl from scipy.stats import chi2 import numpy as np # 日本語フォント設定 font = {'family':'IPAexGothic'} mpl.rc('font', **font) # 自由度 m = 3 plt.rcParams["font.size"] = 18 plt.figure(figsize=(20,5)) # カイ二乗分布の確率密度関数を可視化 chi_pdf = np.array([(x, chi2.pdf(x, m)) for x in np.linspace(0, 8, 100)]) plt.plot(chi_pdf[:,0], chi_pdf[:,1]) x1 = np.arange(6.25, 8, 0.01) y1 = chi2.pdf(x1, m) y2 = np.zeros(x1.shape) plt.fill_between(x1, y1, y2, where=y1>y2, facecolor='blue') plt.annotate("異常検知の閾値を\n$a(x')=6.25$ にすると", xy=(6.25, 0.05), xytext=(5.55, 0.20), arrowprops=dict()) plt.annotate("異常データが出現する確率\n(青色部分の面積) は\n$p=10\%$ になる", xy=(7.4, 0.035), xytext=(6.55, 0.1), arrowprops=dict()) plt.xlabel("異常度 $a(x')$") plt.ylabel("確率密度 $f(a(x'), %d)$" % m) plt.show()
図3. 自由度3のカイ二乗分布の確率密度関数と異常検知される確率の関係実装
PythonのScipyライブラリでは,式(2)の積分の逆関数は
scipy.stats.chi2.isf()の関数として提供されています。したがって,以下のコードで閾値を計算できます。pythonm = 3 # 自由度 (特徴量の次元) を設定 p = 0.1 # 異常検知される確率を設定 threshold = chi2.isf(p, m) # 異常検知の閾値を計算 print("自由度 %d で異常検知される確率を %1.2f %%に設定したければ,閾値は %1.2f" % (m, 100 * p, threshold))実行結果自由度 3 で異常検知される確率を 10.00 %に設定にしたければ,閾値は 6.25可視化
参考までに,異常度の閾値を等高線図として可視化した結果を図4に示します。図4の等高線は,内側からそれぞれ異常検知される確率を10%,5%,1%に設定した場合を表しています (これら確率の値は理解を深めるための例示であり,実用上の意味があるものではありません)。ホテリングの$T^2$法に従って異常検知を行う場合,これらの等高線よりも外側にある標本を異常と判定することになります。
python# 可視化したい「異常検知される確率」の値を設定 probs = [0.1, 0.05, 0.01] # 確率に対応する等高線の値を計算 levels = [chi2.isf(x, X.shape[-1]) for x in probs] # 表示範囲の指定 r = 30 # z軸値(異常度)を計算 z = np.array( [ [(i, j, distance.mahalanobis([i,j], mu, cov_i)**2) for i in np.linspace(-r, r, 100)] for j in np.linspace(-r, r, 100)] ) # グラフ描画 myfig = plt.figure() myax = myfig.add_subplot(1, 1, 1) myax.set_aspect('equal') plt.ylim(-r, r) plt.xlim(-r, r) # 等高線図を描画 cont = plt.contour(z.transpose()[0], z.transpose()[1], z.transpose()[2], levels=levels, colors=['k']) # 散布図の描画 plt.plot(X[:,0], X[:,1], '.', alpha=0.01) plt.show()
図4. 異常検知される確率と正常データの範囲。等高線は内側から10%,5%,1%の標本が異常として検知される場合に対応する
手順4. 異常を判定する
実装
閾値を使って異常判定する方法を示します。この判定はif文で,手順2の異常度と手順3の閾値について大小関係を比較するだけで簡単に実装できます。
pythonif anomaly_score > threshold: print("このデータは異常です")また,データセットに含まれるすべての標本について異常判定する場合は,以下のようにリスト内包表記で記述すると異常度の計算から判定まで1行で行えるので便利です。
pythonanomaly_data = np.array([x for x in X if distance.mahalanobis(x, mu, cov_i)**2 > threshold])可視化
ここまでに紹介したコードを使って,異常検知される確率を1%とした場合の異常検知を行い,散布図で可視化します。1%という数値は仮に選択したものですが,実際にはユースケースに応じて定めます。つまり,異常データを見逃さないこと (あるいは何%の確率なら見逃しても許容されるか) といった要件や,例えば観測されるデータが1ヶ月で10万件あったとして,その1%に相当する1000件が異常として検知されたとき,1000件/月の詳細を確認する人員数を確保できるのか?といった案件固有の事情を加味しながら総合的に判断します。
この可視化は以下のPythonコードで実現でき,実行結果として図5を得ます。図5中のオレンジ色のプロット点が,異常と判定された標本を示します。等高線図の外側の出現確率の低い (具体的には1%以下の) 標本が異常と判定されていることがわかります。
python# 異常検知の実施 ## 異常検知される確率を1%に設定 p = 0.01 ## 確率に対応する異常度の閾値を計算 threshold = chi2.isf(p, X.shape[-1]) ## データセットについて異常検知を実施 anomaly_data = np.array([x for x in X if distance.mahalanobis(x, mu, cov_i)**2 > threshold]) ## 可視化用に正常データのみを含むリストも作る normal_data = np.array([x for x in X if distance.mahalanobis(x, mu, cov_i)**2 <= threshold]) # 散布図として異常検知結果を可視化する ## 表示範囲の指定 r = 30 ## z軸値(異常度)を計算 z = np.array( [ [(i, j, distance.mahalanobis([i,j], mu, cov_i)**2) for i in np.linspace(-r, r, 100)] for j in np.linspace(-r, r, 100)] ) ## グラフ描画 myfig = plt.figure() myax = myfig.add_subplot(1, 1, 1) myax.set_aspect('equal') plt.ylim(-r, r) plt.xlim(-r, r) ## 等高線図を描画 cont = plt.contour(z.transpose()[0], z.transpose()[1], z.transpose()[2], levels=[threshold], colors=['k']) ## 散布図の描画 plt.plot(normal_data[:,0], normal_data[:,1], '.', alpha=0.1) plt.plot(anomaly_data[:,0], anomaly_data[:,1], '.', alpha=0.1) plt.show()
図5. 異常検知結果異常検知結果の検算
最後に,実際に異常検知された確率 (実績値) が閾値設定時の想定 (設定値) と一致するか検算します。この検算が合わない場合は母集団の分布を正しく推定できていないことが示唆され,原因として以下のような可能性を考えることができます。
- 母集団が単一の正規分布に従わない可能性
- 対策: 収集したデータセットの可視化などを行って分布を確認します。そのうえで,前処理の工夫やホテリングの$T^2$法以外のアルゴリズムの採用を検討します。
- 標本平均・標本分散の推定が誤っている可能性
- 対策: データ収集を継続してデータセットの標本数を増やします。
- 診断対象のデータ数が少なすぎる可能性
- 対策: 診断対象のデータ数を増やして再度検算を行います。
今回の例であれば,以下のように異常検知確率の設定値 1.00% に対して実績値 0.99% となり,ほぼ一致します。これは「データセットの準備」の章で単一の正規分布から十分に多い標本数を作成しており,ホテリングの$T^2$法の仮定を満たすデータセットであるからです。
pythonprint("異常検知された標本数: %10d個" % len(anomaly_data)) print("異常検知確率 (設定値): %10.2f%%" % (p * 100)) print("異常検知確率 (実績値): %10.2f%%" % (len(anomaly_data)/len(X) * 100))実行結果異常検知された標本数: 988個 異常検知確率 (設定値): 1.00% 異常検知確率 (実績値): 0.99%おわりに
本記事では,ホテリングの $T^2$ 法の手順を追いながら,その考え方と実装を示しました。ホテリングの$T^2$法による異常検知は理論的に明確で扱いやすいですが,何度も述べているように母集団が単一の正規分布に従う強い仮定を求めます。しかし,実世界の異常検知問題では複数の状態を背景に持ち,単一の正規分布ではうまく表現できない系を扱うことも少なくありません。
このような場合は,k-means法や混合正規分布モデル(GMM)によるクラスタリングや,1クラスサポートベクトルマシンといった別のアルゴリズムの利用も検討しなければなりません3 。そこで,次回の記事ではGMMを使って多峰的な正規分布 (複数の正規分布) にもとづいたデータの異常検知を行う方法を示します。
参考文献
NIST/SEMATECH. "Hotelling T Squared." §6.5.4.3 in NIST/Sematech Engineering Statistics Internet Handbook. . ↩
Hotelling, H. Multivariate Quality Control. In C. Eisenhart, M. W. Hastay, and W. A. Wallis, eds. Techniques of Statistical Analysis. New York: McGraw-Hill, 1947. ↩
井手, 入門 機械学習による異常検知 Rによる実践ガイド, コロナ社, 2015. ↩

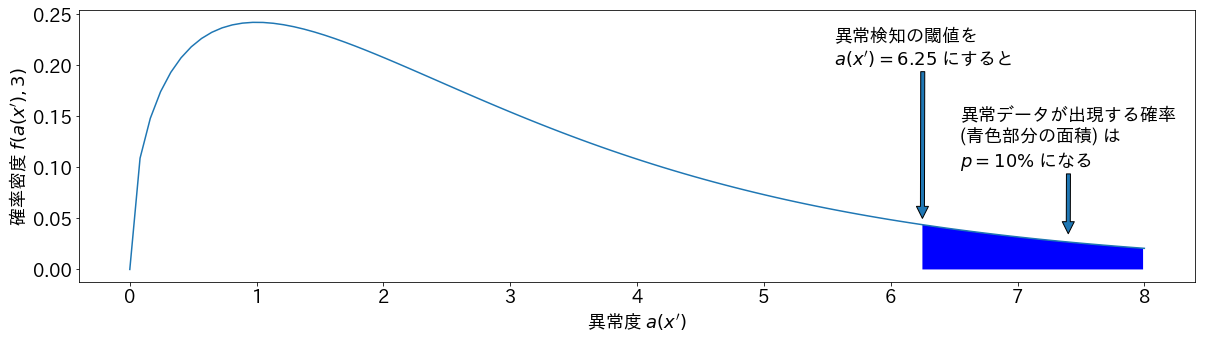
- 投稿日:2020-06-30T13:16:09+09:00
Djangoプロジェクトを作成して実行
このPycharm公式ドキュメントの手順をもう少し分かりやすくかみ砕いたページです。
プロジェクトの作成
まずは新規プロジェクトを作成します
プロジェクトタイプはDjangoを選択し、プロジェクト名(ProjctTest)とApplication name(Poppo)はお好きなものを・・・
CreateをクリックしこれでDjangoプロジェクトが準備完了。
プロジェクトの構造
作成したプロジェクトにはすでにフレームワーク固有のファイルとディレクトリが含まれています。
プロジェクトツールウィンドウのプロジェクトビューを見てみましょう。
これはDjango固有のプロジェクト構造を示しています。
PoPPo と ProjectTest ディレクトリ(さっき設定したお好きな名前で作成されている)
また、manage.py および settings.py ファイルが表示今回中身を編集するファイルは
- ProjectTest/urls.py
- Poppo/models.py
- Poppo/views.py
になります。Djangoサーバーの起動
では早速Djangoサーバーを起動してみましょう!
manage.py ユーティリティの runserver タスクを起動するだけです。まずTerminalを開き
python manage.py runserver
と入力
次にコンソールに表示されたURLをクリック
この画面が表示されたら成功です?
モデルの作成
次にmodels.pyを開いて、下記のコードを入力します。
このとき既にimport文があることに注意
from django.db import models # the following lines added: import datetime from django.utils import timezone class Question(models.Model): question_text = models.CharField(max_length=200) pub_date = models.DateTimeField('date published') def __str__(self): return self.question_text def was_published_recently(self): now = timezone.now() return now - datetime.timedelta(days=1) <= self.pub_date <= now was_published_recently.admin_order_field = 'pub_date' was_published_recently.boolean = True was_published_recently.short_description = 'Published recently?' class Choice(models.Model): question = models.ForeignKey(Question, on_delete=models.DO_NOTHING,) choice_text = models.CharField(max_length=200) votes = models.IntegerField(default=0) def __str__(self): return self.choice_textデータベースの作成
新しいモデル用のテーブルを作成する必要があります。
そこでmanage.pyコンソールをCtrl+Alt+Rで呼び出し、makemigrations Poppoを入力。
Djangoに2つの新しいモデル、つまり Choice と Questionが作成されたことを伝え、migrationsフォルダを作成しました。
models.py
作成されたmigrationフォルダ
次に再びmanage.pyコンソールで
sqlmigrate Poppo 0001
と入力。
最後に
migrateコマンドを実行して、データベースにこれらのテーブルを作成します。
スーパーユーザーの作成
manage.py コンソールで
createsuperuserコマンドを入力し、自分のメールアドレスとパスワードを指定します。
Superuser created successfully.と出たら作成完了。
実行/デバッグ構成の準備
これで管理者ページに移動する準備が整いました。
Djangoサーバーを実行し、ブラウザにアクセスし、アドレスバーにURL全体を入力することは可能ですが、PyCharmを使用すると簡単です。
あらかじめ設定されたDjangoサーバーの実行構成を少し変更して使用します。ここを選択。
Run/Debug Configurations ダイアログで、このRun/Debug Configurationsに名前(ここでは ProjectTest)を付け、デフォルトブラウザでアプリケーションの実行を有効にし(チェックボックスRun browserを選択)、デフォルトで開くサイトのページを指定します(ここでは http://127.0.0.1:8000/admin/です)。
これでOKをクリック
管理サイトの起動
アプリケーションを起動するには、Shift+F10を押すか、メインツールバーの Runボタン をクリックして、標準のDjangoサイトログインページを開きます。
作成したスーパーユーザーでログイン。
ログインすると、管理ページ(上の画像)が表示されます。認証と認可 (GroupsとUsers)セクションがありますが、投票(Questionの追加)は使用できません。なぜそうなるのでしょうか?
Question オブジェクトには管理インターフェースがあることを管理者に伝える必要があります。
そのために、Poppo/admin.py を開き、次のコードを入力します。from django.contrib import admin from .models import Question #this line added admin.site.register(Question)#this line addedページをリフレッシュし、質問の投票セクションが表示されていることを確認します。
追加完了。
適当に質問を追加してみましょう。
質問が追加されました。
admin.pyの編集
質問に対しての選択肢はまだありません。
そこで再度 Poppo/admin.py を開き、次のように変更します。from django.contrib import admin from .models import Choice, Question class ChoiceInline(admin.TabularInline): model = Choice extra = 3 class QuestionAdmin(admin.ModelAdmin): fieldsets = [ (None, {'fields': ['question_text']}), ('Date information', {'fields': ['pub_date'], 'classes': ['collapse']}), ] inlines = [ChoiceInline] admin.site.register(Question, QuestionAdmin)
ページをリフレッシュし、追加した質問をクリックし、選択肢の追加が表示されていることを確認。
選択肢や投票数を追加し保存する。
Viewの作成
ViewではIf文やWhile文、リスト、その他どのような構文もここで扱うことができるようになります。
そして関数化することで次のtemplateに渡すことができるのです。さらにViewでは、関数ごとにどのHTMLファイルに情報を渡すのかを指定します。
それによりそれぞれの関数をtemplateに紐付けていくことになります。Poppo/views.py を開き、次のコードを入力します。
from django.http import HttpResponse def index(request): return HttpResponse("Hello, world. You're at the polls index.")
次に、urls.py という名前の新しいファイルを Poppo ディレクトリに追加し
次のコードを入力します。from django.conf.urls import url from . import views urlpatterns = [ url(r'^$', views.index, name='index'), ]
最後に ProjectTest/urls.py (PyCharmがすでに作成している)を編集し、インデックスページのURLを末尾に追加します。from django.conf.urls import include, url from django.contrib import admin urlpatterns = [ url(r'^Poppo/', include('Poppo.urls')), #this line added url(r'^admin/', admin.site.urls), ]127.0.0.1:8000/Poppo/ を開いてみると・・・
次により多くのViewを追加してみます。
再度、Poppo/views.pyに次のコードを追加します。def detail(request, question_id): return HttpResponse("You're looking at question %s." % question_id) def results(request, question_id): response = "You're looking at the results of question %s." return HttpResponse(response % question_id) def vote(request, question_id): return HttpResponse("You're voting on question %s." % question_id)次の url() 呼び出しを追加する新しいViewを Poppo/urls.py モジュールに配線(末尾に追記)します。
from django.conf.urls import url from . import views urlpatterns = [ url(r'^$', views.index, name='index'), # ex: /Poppo/5/ url(r'^(?P<question_id>[0-9]+)/$', views.detail, name='detail'), # ex: /Poppo/5/results/ url(r'^(?P<question_id>[0-9]+)/results/$', views.results, name='results'), # ex: /Poppo/5/vote/ url(r'^(?P<question_id>[0-9]+)/vote/$', views.vote, name='vote'), ]ブラウザで対応するページを開くと、次のように表示されます。
Djangoテンプレートの作成
以上の通り、これらのページのデザインはビューにハードコードされています。
読みやすくするために、対応するPythonコードを編集する必要があります。
次に、Pythonからの出力の視覚的表現を分離しましょう。
そうするために、templateを作成しましょう。Poppo/views.py を開き、その内容を次のコードに置き換えます。
from django.http import HttpResponse, HttpResponseRedirect from django.shortcuts import get_object_or_404, render from django.urls import reverse from .models import Question, Choice def index(request): latest_question_list = Question.objects.order_by('-pub_date')[:5] context = {'latest_question_list': latest_question_list} return render(request, 'Poppo/index.html', context) def detail(request, question_id): question = get_object_or_404(Question, pk=question_id) return render(request, 'Poppo/detail.html', {'question': question}) def results(request, question_id): question = get_object_or_404(Question, pk=question_id) return render(request, 'Poppo/results.html', {'question': question}) def vote(request, question_id): question = get_object_or_404(Question, pk=question_id) try: selected_choice = question.choice_set.get(pk=request.POST['choice']) except (KeyError, Choice.DoesNotExist): return render(request, 'Poppo/detail.html', { 'question': question, 'error_message': "You didn't select a choice.", }) else: selected_choice.votes += 1 selected_choice.save() return HttpResponseRedirect(reverse('Poppo:results', args=(question.id,)))ここで作成していないindex.htmlページを参照していることに気付くと思います。
PyCharmはクイックフィックスという機能があります。
電球をクリックするか Alt+Enterを押すと、対応するテンプレートファイルがtemplatesフォルダーに作成されます(PyCharmはこのテンプレートが存在するはずのディレクトリ Poppo も作成します)。
同様にしてdetail.htmlとresults.htmlも作成します。
今のところ index.html は空です。次のコードを追加します。
{% load static %} <link rel="stylesheet" type="text/css" href="{% static 'Poppo/style.css' %}" /> {% if latest_question_list %} <ul> {% for question in latest_question_list %} <li><a href="{% url 'detail' question.id %}">{{ question.question_text }}</a></li> {% endfor %} </ul> {% else %} <p>No polls are available.</p> {% endif %}スタイルシートの作成
Viewファイル index.htmlに見られるように、スタイルシート(.cssファイル)の参照があり、そしてまだ作成していません。
次のように作成します。
ディレクトリを作成します。これを行うには、プロジェクトビューで、Pythonパッケージ Poppo を選択し、Alt+Insertを押します。
表示されるポップアップメニューでディレクトリを選択し、ディレクトリ構造 static/Poppoを指定します。
次に、このディレクトリにスタイルシートを作成します。これを行うには、最も内側のディレクトリ Poppo/static/Poppoを選択し、Alt+Insertを押し、Stylesheetを選択して、表示されるダイアログでstyleを入力します。
好みに応じて、作成されたスタイルシートに下記のコードを追加(例:質問のリストを緑色の文字で表示)。
li a {
color: green;
}
実行結果の確認
Runボタンをクリックしブラウザの
http://127.0.0.1:8080/admin/を
http://127.0.0.1:8080/Poppo/に変更し入力して確認してみましょう。
出来ました。
これを参考に自分のページを育ててみましょう?
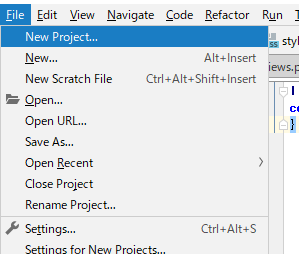

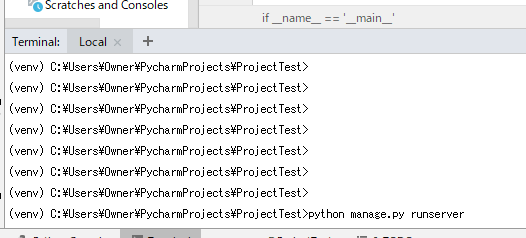

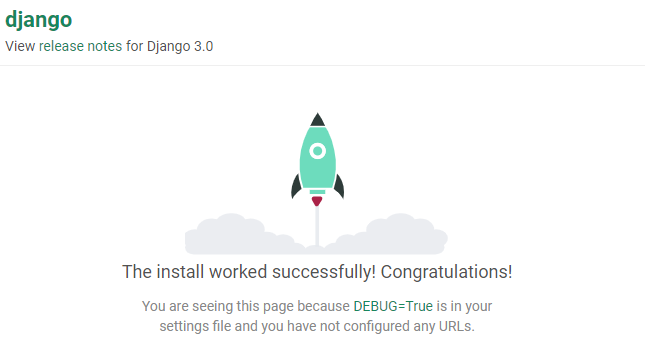
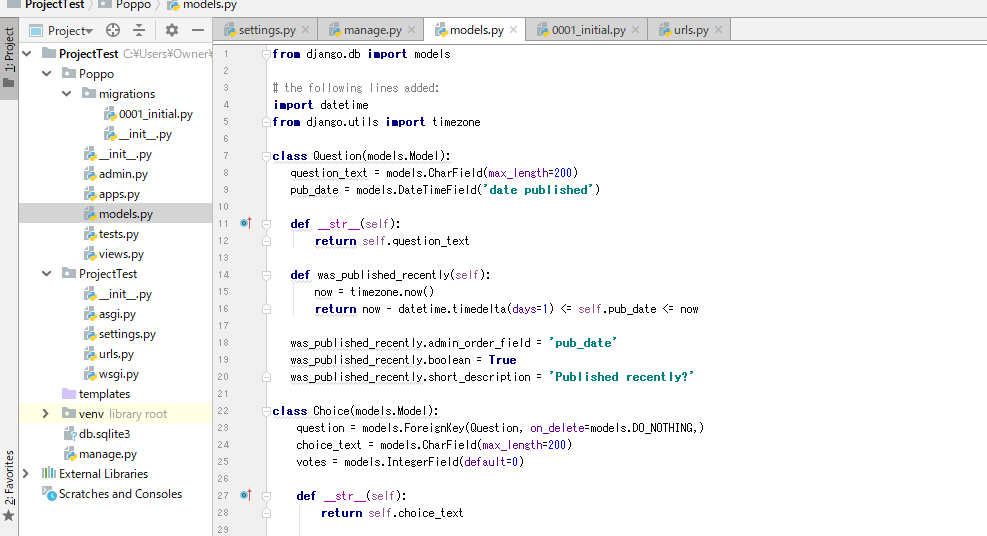
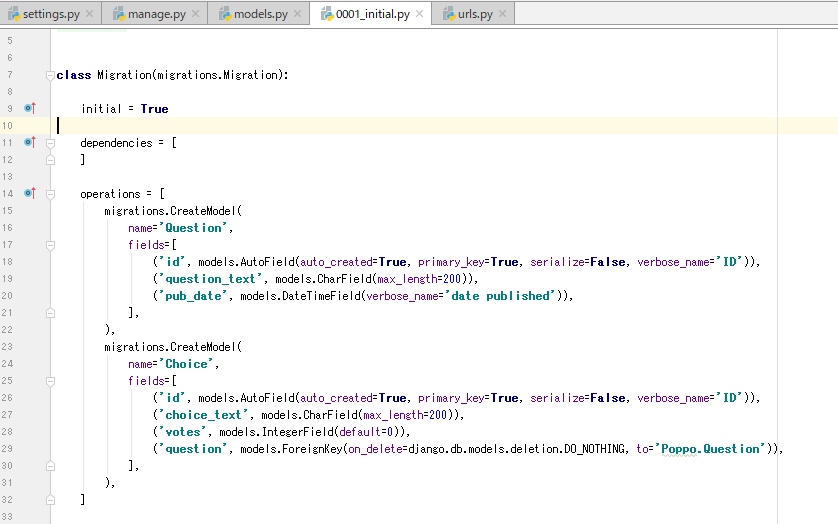

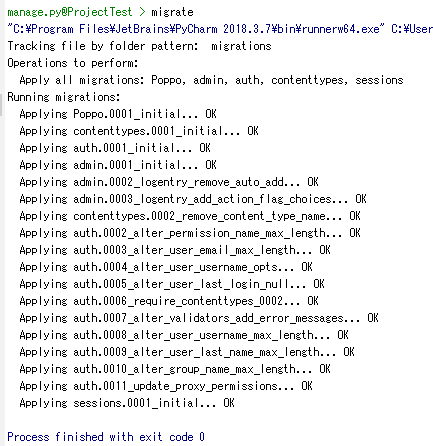






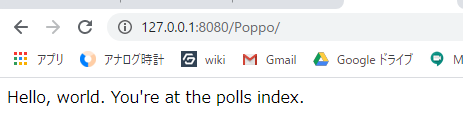
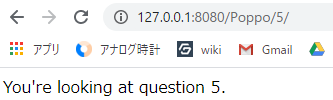
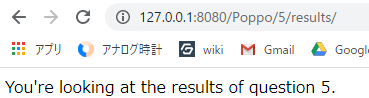
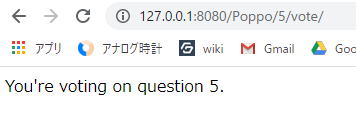

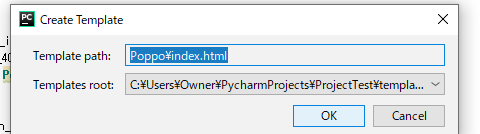

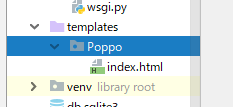
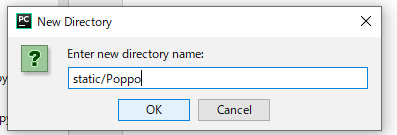

- 投稿日:2020-06-30T13:16:09+09:00
Djangoプロジェクトを作成して実行【2020新卒】
この記事は2020年の新卒IT未経験の者が書きました。
少しでも分かりやすくこのPycharm公式ドキュメントの手順をかみ砕いた記事です。プロジェクトの作成
まずは新規プロジェクトを作成します
プロジェクトタイプはDjangoを選択し、プロジェクト名(ProjctTest)とApplication name(Poppo)はお好きなものを・・・
CreateをクリックしこれでDjangoプロジェクトが準備完了。
プロジェクトの構造
作成したプロジェクトにはすでにフレームワーク固有のファイルとディレクトリが含まれています。
プロジェクトツールウィンドウのプロジェクトビューを見てみましょう。
これはDjango固有のプロジェクト構造を示しています。
PoPPo と ProjectTest ディレクトリ(さっき設定したお好きな名前で作成されている)
また、manage.py および settings.py ファイルが表示今回中身を編集するファイルは
- ProjectTest/urls.py
- Poppo/models.py
- Poppo/views.py
になります。Djangoサーバーの起動
では早速Djangoサーバーを起動してみましょう!
manage.py ユーティリティの runserver タスクを起動するだけです。まずTerminalを開き
python manage.py runserver
と入力
次にコンソールに表示されたURLをクリック
この画面が表示されたら成功です?
モデルの作成
次にmodels.pyを開いて、下記のコードを入力します。
このとき既にimport文があることに注意
from django.db import models # the following lines added: import datetime from django.utils import timezone class Question(models.Model): question_text = models.CharField(max_length=200) pub_date = models.DateTimeField('date published') def __str__(self): return self.question_text def was_published_recently(self): now = timezone.now() return now - datetime.timedelta(days=1) <= self.pub_date <= now was_published_recently.admin_order_field = 'pub_date' was_published_recently.boolean = True was_published_recently.short_description = 'Published recently?' class Choice(models.Model): question = models.ForeignKey(Question, on_delete=models.DO_NOTHING,) choice_text = models.CharField(max_length=200) votes = models.IntegerField(default=0) def __str__(self): return self.choice_textデータベースの作成
新しいモデル用のテーブルを作成する必要があります。
そこでmanage.pyコンソールをCtrl+Alt+Rで呼び出し、makemigrations Poppoを入力。
Djangoに2つの新しいモデル、つまり Choice と Questionが作成されたことを伝え、migrationsフォルダを作成しました。
models.py
作成されたmigrationフォルダ
次に再びmanage.pyコンソールで
sqlmigrate Poppo 0001
と入力。
最後に
migrateコマンドを実行して、データベースにこれらのテーブルを作成します。
スーパーユーザーの作成
manage.py コンソールで
createsuperuserコマンドを入力し、自分のメールアドレスとパスワードを指定します。
Superuser created successfully.と出たら作成完了。
実行/デバッグ構成の準備
これで管理者ページに移動する準備が整いました。
Djangoサーバーを実行し、ブラウザにアクセスし、アドレスバーにURL全体を入力することは可能ですが、PyCharmを使用すると簡単です。
あらかじめ設定されたDjangoサーバーの実行構成を少し変更して使用します。ここを選択。
Run/Debug Configurations ダイアログで、このRun/Debug Configurationsに名前(ここでは ProjectTest)を付け、デフォルトブラウザでアプリケーションの実行を有効にし(チェックボックスRun browserを選択)、デフォルトで開くサイトのページを指定します(ここでは http://127.0.0.1:8000/admin/です)。
これでOKをクリック
管理サイトの起動
アプリケーションを起動するには、Shift+F10を押すか、メインツールバーの Runボタン をクリックして、標準のDjangoサイトログインページを開きます。
作成したスーパーユーザーでログイン。
ログインすると、管理ページ(上の画像)が表示されます。認証と認可 (GroupsとUsers)セクションがありますが、投票(Questionの追加)は使用できません。なぜそうなるのでしょうか?
Question オブジェクトには管理インターフェースがあることを管理者に伝える必要があります。
そのために、Poppo/admin.py を開き、次のコードを入力します。from django.contrib import admin from .models import Question #this line added admin.site.register(Question)#this line addedページをリフレッシュし、質問の投票セクションが表示されていることを確認します。
追加完了。
適当に質問を追加してみましょう。
質問が追加されました。
admin.pyの編集
質問に対しての選択肢はまだありません。
そこで再度 Poppo/admin.py を開き、次のように変更します。from django.contrib import admin from .models import Choice, Question class ChoiceInline(admin.TabularInline): model = Choice extra = 3 class QuestionAdmin(admin.ModelAdmin): fieldsets = [ (None, {'fields': ['question_text']}), ('Date information', {'fields': ['pub_date'], 'classes': ['collapse']}), ] inlines = [ChoiceInline] admin.site.register(Question, QuestionAdmin)
ページをリフレッシュし、追加した質問をクリックし、選択肢の追加が表示されていることを確認。
選択肢や投票数を追加し保存する。
Viewの作成
ViewではIf文やWhile文、リスト、その他どのような構文もここで扱うことができるようになります。
そして関数化することで次のtemplateに渡すことができるのです。さらにViewでは、関数ごとにどのHTMLファイルに情報を渡すのかを指定します。
それによりそれぞれの関数をtemplateに紐付けていくことになります。Poppo/views.py を開き、次のコードを入力します。
from django.http import HttpResponse def index(request): return HttpResponse("Hello, world. You're at the polls index.")
次に、urls.py という名前の新しいファイルを Poppo ディレクトリに追加し
次のコードを入力します。from django.conf.urls import url from . import views urlpatterns = [ url(r'^$', views.index, name='index'), ]
最後に ProjectTest/urls.py (PyCharmがすでに作成している)を編集し、インデックスページのURLを末尾に追加します。from django.conf.urls import include, url from django.contrib import admin urlpatterns = [ url(r'^Poppo/', include('Poppo.urls')), #this line added url(r'^admin/', admin.site.urls), ]127.0.0.1:8000/Poppo/ を開いてみると・・・
次により多くのViewを追加してみます。
再度、Poppo/views.pyに次のコードを追加します。def detail(request, question_id): return HttpResponse("You're looking at question %s." % question_id) def results(request, question_id): response = "You're looking at the results of question %s." return HttpResponse(response % question_id) def vote(request, question_id): return HttpResponse("You're voting on question %s." % question_id)次の url() 呼び出しを追加する新しいViewを Poppo/urls.py モジュールに配線(末尾に追記)します。
from django.conf.urls import url from . import views urlpatterns = [ url(r'^$', views.index, name='index'), # ex: /Poppo/5/ url(r'^(?P<question_id>[0-9]+)/$', views.detail, name='detail'), # ex: /Poppo/5/results/ url(r'^(?P<question_id>[0-9]+)/results/$', views.results, name='results'), # ex: /Poppo/5/vote/ url(r'^(?P<question_id>[0-9]+)/vote/$', views.vote, name='vote'), ]ブラウザで対応するページを開くと、次のように表示されます。
Djangoテンプレートの作成
以上の通り、これらのページのデザインはビューにハードコードされています。
読みやすくするために、対応するPythonコードを編集する必要があります。
次に、Pythonからの出力の視覚的表現を分離しましょう。
そうするために、templateを作成しましょう。Poppo/views.py を開き、その内容を次のコードに置き換えます。
from django.http import HttpResponse, HttpResponseRedirect from django.shortcuts import get_object_or_404, render from django.urls import reverse from .models import Question, Choice def index(request): latest_question_list = Question.objects.order_by('-pub_date')[:5] context = {'latest_question_list': latest_question_list} return render(request, 'Poppo/index.html', context) def detail(request, question_id): question = get_object_or_404(Question, pk=question_id) return render(request, 'Poppo/detail.html', {'question': question}) def results(request, question_id): question = get_object_or_404(Question, pk=question_id) return render(request, 'Poppo/results.html', {'question': question}) def vote(request, question_id): question = get_object_or_404(Question, pk=question_id) try: selected_choice = question.choice_set.get(pk=request.POST['choice']) except (KeyError, Choice.DoesNotExist): return render(request, 'Poppo/detail.html', { 'question': question, 'error_message': "You didn't select a choice.", }) else: selected_choice.votes += 1 selected_choice.save() return HttpResponseRedirect(reverse('Poppo:results', args=(question.id,)))ここで作成していないindex.htmlページを参照していることに気付くと思います。
PyCharmはクイックフィックスという機能があります。
電球をクリックするか Alt+Enterを押すと、対応するテンプレートファイルがtemplatesフォルダーに作成されます(PyCharmはこのテンプレートが存在するはずのディレクトリ Poppo も作成します)。
同様にしてdetail.htmlとresults.htmlも作成します。
今のところ index.html は空です。次のコードを追加します。
{% load static %} <link rel="stylesheet" type="text/css" href="{% static 'Poppo/style.css' %}" /> {% if latest_question_list %} <ul> {% for question in latest_question_list %} <li><a href="{% url 'detail' question.id %}">{{ question.question_text }}</a></li> {% endfor %} </ul> {% else %} <p>No polls are available.</p> {% endif %}スタイルシートの作成
Viewファイル index.htmlに見られるように、スタイルシート(.cssファイル)の参照があり、そしてまだ作成していません。
次のように作成します。
ディレクトリを作成します。これを行うには、プロジェクトビューで、Pythonパッケージ Poppo を選択し、Alt+Insertを押します。
表示されるポップアップメニューでディレクトリを選択し、ディレクトリ構造 static/Poppoを指定します。
次に、このディレクトリにスタイルシートを作成します。これを行うには、最も内側のディレクトリ Poppo/static/Poppoを選択し、Alt+Insertを押し、Stylesheetを選択して、表示されるダイアログでstyleを入力します。
好みに応じて、作成されたスタイルシートに下記のコードを追加(例:質問のリストを緑色の文字で表示)。
li a {
color: green;
}
実行結果の確認
Runボタンをクリックしブラウザの
http://127.0.0.1:8080/admin/を
http://127.0.0.1:8080/Poppo/に変更し入力して確認してみましょう。
出来ました。
これを参考に自分のページを育ててみましょう?
- 投稿日:2020-06-30T12:49:13+09:00
ubuntu20.04LTSにてpython-pip インストールさせる方法
Sudo nano /etc/apt/sources.listで
コピペ
deb http://archive.ubuntu.com/ubuntu bionic main universe
deb http://archive.ubuntu.com/ubuntu bionic-security main universe
deb http://archive.ubuntu.com/ubuntu bionic-updates main universe
を追加してapt update apt upgrade -y
python-pip-whl_9.0.1-2.3~ubuntu1.18.04.1等のファイルがないので
wget http://ports.ubuntu.com/pool/universe/p/python-pip/python-pip-whl_9.0.1-2.3~ubuntu1.18.04.1_all.deb
でDLし
dpkg -i python-pip-whl_9.0.1-2.3~ubuntu1.18.04.1_all.debでインスコ
あと残りの関連をインスコ
apt install -y build-essential python-all-dev python-setuptools python-wheel
これで無事にpython-pip起動できます
あとは試しに防犯カメラソフト motioneye
sudo apt install -y python-pip curl libssl-dev libcurl4-openssl-dev libjpeg-dev
sudo apt install -y motion
sudo pip install motioneye
mkdir -p /etc/motioneye
cp /usr/local/share/motioneye/extra/motioneye.conf.sample /etc/motioneye/motioneye.conf
mkdir -p /var/lib/motioneye
cp /usr/local/share/motioneye/extra/motioneye.systemd-unit-local /etc/systemd/system/motioneye.service
systemctl daemon-reload
systemctl enable motioneye
systemctl start motioneye
入れると起動できるかと思います
- 投稿日:2020-06-30T12:08:19+09:00
工作機械ソムリエ - Machine Sommelier by Keras -
本記事では深層学習に対する不信感を抱いた筆者が、深層学習の分類能力について検証します。検証の上でWebサイトやYoutubeからの画像を引用している箇所があります(ソース記載)。学術目的ではありますが、問題があれば削除します。また、プログラムを使用する際は自分で画像を集めてください。
はじめに
はじめのはじめに
なぜバキュームと判断したのか・・・
Figure 0. R2D2を操作する男性の画像をニューラルネット(VGG16)によりクラス分類した結果。下のグラフは左から確信度の高い順に予測クラスを並べてある。 工作機械 主要7社 (2020/3/11 日刊工業新聞に詳細あり)
Figure 1. 工作機械主要7社(の受注 2020年2月) この記事の内容が気になる方は実際のWebページをご覧ください。https://www.nikkan.co.jp/articles/view/00551108 深層学習の分類の力とは・・・
- 記事の内容(各社売上)とは全然関係ないですが、この7社の製品が深層学習で分類できるか気になったのでやってみました。
- 工作機械は製品なのでデータが集まりそうだし簡単には数理モデル化できないかなと思ったので分類の様子を見たいと思いました。
- 今回の問題設定の実用性は無いですが、この分類フレームワークは使えると思います。
Grad-CAMによるニューラルネットの注目箇所
最後にはGrad-CAMによる画像分類の判断基準を示しますが、公開するプログラムでは載せていません。今後何かの折に投稿するかもしれません。明示的にロゴで学習するように設定しなくてもロゴをもとに判断するのか、あるいは変なところを手掛かりに判断するのか。まあすべての製品にロゴがついているわけではないので、そこは深層学習の力の見せ所かもしれないです。
タイトルについて
ソムリエという言葉はワイン限定で使われる言葉ですが最近では「~ソムリエ」という形でワイン以外にも用いられるそうです。
プログラム実行環境
- Windows10
- CPU:Core i7-7700HQ
- Memory: 16GB
- Graphic board: GTX1060 6GB
- Strage: NVMe M.2 SSD 1TB
- CUDA 9.0.176
工作機械大手7社の製品を画像分類するモデルをKerasで作成
- 画像はネット上で収集(主に各社のホームページの製品ページより収集)
- ある程度統一的なものに絞る(門型などは外します。特に東芝機械さんはTUE-100だけです。他のもの入れるとさすがにバラバラで分類できないような気がしたので。)
- データセットは1_0001.jpg(公開プログラム冒頭の説明)のように名付けてプログラム内のdatasetフォルダーに入れます(Figure2-a, Figure2-b)
- Jupyter notebookでは学習するか推測するか、BackboneにResNet50かMobilenet V1(後述)のどちらを用いるかをGUIで選択可能(Tkinter)
- Jupyter notebookのパラメータや使い方の詳細はノートブック冒頭に説明してあります。
- プログラムはgithubのページにあります。 https://github.com/moriitkys/MachineSommelier
Figure 2-a Figure 2-b
用語まとめ
Deep Learning 深層学習
深層学習は機械学習の一つの手法です。機械学習はサンプルデータを与えてデータ に潜むパターンを学習し、入力と出力の関係を求める手法です。その中でもニューラルネットワークは人間の神経回路を真似することで学習を実現しようとするモデルです。ニューラルネットワークの起源とも呼べるようなものが 1958 年に提案された単純パーセプトロンです。
ニューラルネットワークの層を深くしたものが深層学習であり、その基本となるのが順伝播型ニューラルネットワーク(Figure 3-b.)です。単純パーセプトロンはFigure 3-a. に示すように $n$ 個の入力ノードに対し $n$ 個の重み $w$ を掛け合わせて、関数 $f_{(x)}$ によってすべて足し合わせて $w_{n+1}$ も足した結果、出力がある一定値以上なら 1、それ以下なら 0 を出力するというような仕組みです。
Figure 3-a. 単純パーセプトロンの概念図 Figure 3-b. 順伝播ニューラルネットワークの概念図 さらに、画像認識における順伝播型ニューラルネットワークは畳み込みニューラルネットワークと呼ばれるものが広く使用されています。
畳み込みニューラルネットワーク
畳み込みニューラルネットワーク(Convolutional Neural Network、CNN)は出力層側のユニットが隣接する入力層側の特定のユニットに結合されている順伝播型ニューラルネットワークです。CNN は畳み込み層、プーリング層という特殊な層を持ち、畳み込み層ではフィルター (カーネル) を入力データに対し適用することで特徴マップを得ます。本記事では割愛しますが、CNNは画像認識では非常に重要な処理です。以下のFigure 4.にCNNの処理の例を示します。
Figure 4. CNNの処理の例 Classification 画像分類
画像認識の分野では主に4種類くらいあるかなと思っています。応用によってはより複雑な出力を持つものもありますが今回は省略します。
・Classification 画像分類 入力が何のクラスに相当するかを推測する(各々確率を出力)、(Figure5-a)
Figure 5-a. Classificationの例。ImageNet(後述)で学習済みVGG16(ネットワークの一種、後述)でのクラス分類で、この例の結果としては失敗(最後に解説あり)。
【折り畳みです。▶をクリック】ちなみに(vacuum)
以下のサイトのようなデータがImageNetには含まれているようです。これはvacuumと誤認識するのも無理はないです...
https://www.myhenry.co.uk/
・Detection 物体検出 入力に対して何のクラスのオブジェクトがどこの座標領域に存在するかを矩形で推測する (Figure5-b)
Figure 5-b. Detectionの例。Pascal VOC2012(後述)で学習済みYolo(学習アーキテクチャの一種)によるDetectionで、この例では人をうまく検出できているが、ロボットは"parking meter"と誤認識されています。
【折り畳みです。▶をクリック】ちなみに(parking meter)
parking meterがどんなものかというと、以下の論文内にありました。
https://arxiv.org/pdf/2003.07003.pdf
言われてみればロボットっぽいですが・・・
・Semantic Segmentation 領域意味分割 入力の各画素をクラス分類 (Figure5-c)
Figure 5-c. Semantic Segmentationの例。Pascal VOC2018で学習済みのDeeplab V3+によるSemantic Segmentationで、この例では人間領域を正しく推測できています。ロボットは背景として認識されています。 ・Instance Segmentation = Detection + Segmentation (Figure5-d)
Figure 5-d. Instance Segmentationの例。Microsoft COCO(後述)で学習済みのMask R-CNNによるInstance Segmentationで、この例では人間領域を推測できているが、粗い。ロボットは背景として認識されています。 今回はネットワークの最後でsoftmaxを適用し、入力が何のクラスに相当するかを推測する"Classification"を行います。
Backbone
Backboneとは特徴抽出ネットワークのことです。入力部分の層と出力部分(Head)を取り除いた部分です。今回はResNet50とMobilenet(後述)を用います。どちらもKerasで用意されているため、自分でネットワークを構築する必要はありません。以下のようにしてインポートできます。
from keras.applications.resnet50 import ResNet50 base_model = ResNet50( include_top = False, weights = "imagenet", input_shape = INPUT_SHAPE )Backboneはニューラルネットワークなので、あるデータセットにおける学習によって何かしらの重み(上記プログラムのweights)が決まります。
- 「あるデータセット」はいくつかネット上に公開されており、ダウンロードが可能です(数GBから数十GBのように非常に大きなデータ量ですが)。例えば、Microsoft COCOやImageNet、Pascal VOCなどが有名所でしょうか。
- 「何かしらの重み」についても、公開されています。ただし、これは「何のネットワーク」で「何のデータセット」を使って学習したかが重要です。例えば、今回のResNet50とMobilenet V1ではそれぞれImageNetで学習された重みを用います。今回はKerasの機能で楽々と実行が可能ですが、自分で問題設定をして重みを調達する場合はネットワークとデータセットの二つに注意する必要があります。Head (Top)
ニューラルネットワークの出力付近の部分です。既存のBackboneを読み込んだときにinclude_top = Falseとすると、出力部分を変更できます。層を増やして精度向上のため工夫したり、分類クラス数を変更したりと、目的に応じた変更が可能となります(クラス数の変更は引数で変更できると思いますが...)。
今回Headの部分は以下のように構築しました。top_model.add(Flatten(input_shape=base_model.output_shape[1:])) top_model.add(Dropout(0.5)) top_model.add(Dense(nb_classes, activation='softmax')) # Concatenate base_model(backbone) with top model model = Model(input=base_model.input, output=top_model(base_model.output))Grad-CAM
Grad-CAMの論文は以下です。詳しくは読んでください。
Ramprasaath R. Selvaraju · Michael Cogswell · Abhishek Das · Ramakrishna Vedantam · Devi Parikh · Dhruv Batra, Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization, arXiv:1610.02391v4 [cs.CV] 3 Dec 2019
(https://arxiv.org/abs/1610.02391)
この論文を以下ではGrad-CAM論文と呼びます。Grad-CAM論文のアブストラクトの一部は以下です。We propose a technique for producing ‘visual explanations’ for decisions from a large class of Convolutional Neural Network (CNN)-based models, making them more transparent and explainable.
Our approach–Gradient-weighted Class Activation Mapping (Grad-CAM), uses the gradients of any target concept (say ‘dog’ in a classification network or a sequence of words in captioning network) flowing into the final convolutional layer to produce a coarse localization map highlighting the important regions in the image for predicting the concept.→(訳)提案した手法はCNNベースのモデルの大規模クラスからの決定を視覚的に説明するものであり、モデルの透明性や解釈性を向上する。Grad-CAMは対象の概念(犬のようなラベルなど)の勾配を使うが、その勾配は最終層に入って粗い特徴マップを生成し、予測する際の画像上の重要な位置をハイライトする。
Figure 6. Grad-CAM論文内のFig. 2の画像 「予測する際の画像上の重要な位置をハイライト」した結果は上の画像のGrad-CAMと書かれたカラーマップ(Figure 6.の中のa)です。今回はこのカラーマップを生成してクラス予測時に入力画像のどこを注目したのかを確認します。
Grad-CAMの処理の流れをまとめました(間違ってたらすみません)。
1. CNNへの入力と予測 : 深層学習アーキテクチャでは、入力画像がCNNを通ることで特徴マップを出力され、それをもとに入力が何のクラスに相当するかを確率の配列として出力します(Figure 6.の中のb)。plobs_pred = model.predict(input_tests) cls_idx = np.argmax(model.predict(x)) cls_output = model.output[:, cls_idx] conv_output = model.get_layer(layer_name).output2. 勾配$\frac{\partial y^{c}}{\partial A_{i j}^{k}}$の計算 : 対象となるクラスのみ1,それ以外を0として逆伝播を行います。最終層との勾配を取ればよいので以下のようにして計算します。変数layer_nameには今回であればResNet50の場合activation_49, Mobilenetの場合はconv_pw_13_reluとしました。Grad-CAM論文中の$A_{i j}^{k}$は以下のfmap_activationで求めました。$\frac{\partial y^{c}}{\partial A_{i j}^{k}}$は$A_{i j}^{k}$に関してのクラス$c$のスコア$y^{c}$の勾配であり、fmap_activationを使って勾配計算をするわけではないです。意味の問題だと思ってます。
grads = keras.backend.gradients(cls_output, conv_output)[0] gradient_function = keras.backend.function([model.input], [conv_output, grads]) fmap_activation, grads_val = gradient_function([x]) fmap_activation, grads_val = output[0], grads_val[0]注意 上記の入力xはimg_to_arrayなどで前処理する必要があります。
3. 重み$\alpha_{k}^{c}$の計算 : 各チャンネルで勾配の平均をとり、重みとします。以下のGrad-CAM論文の式(1)に相当する部分の処理です。Grad-CAM以前のClass Activation Mapping(CAM)ではGlobal average pooling層(GAP)を追加しなければなりませんでした(CAMは特徴マップと最終層の重みの積で計算され、特徴マップはGAPにより重み付けを得ます)。しかしGrad-CAMではGAPの部分を逆伝播の勾配計算により代替できるというものであり、モデルの修正をせずとも可視化が可能になりました。
$$\alpha_{k}^{c}=\frac{1}{Z} \sum_{i} \sum_{j} \frac{\partial y^{c}}{\partial A_{i j}^{k}}$$
alpha = np.mean(grads_val, axis=(0, 1))4. クラス識別局所マップ(Grad-CAM)$L_{\text {Grad }-\mathrm{C} A \mathrm{M}}^{c}$の計算 : Grad-CAM論文中の式(2)の計算を以下のように行います。シグマの部分はnumpyの内積で計算し、ReLUはFigure 7.のように負がゼロであることからnumpyのmaximumを使えばよいという事がわかります。
Figure 7. ReLUのグラフ $$L_{\mathrm{Grad}-\mathrm{CAM}}^{c}=\operatorname{ReLU}\left(\sum_{k} \alpha_{k}^{c} A^{k}\right)$$
l_gradcam = np.dot(fmap_activation, alpha)#シグマ部分 l_gradcam = cv2.resize(l_gradcam, (img_h, img_w), cv2.INTER_LINEAR) l_gradcam = np.maximum(l_gradcam, 0) #ReLU計算に相当 l_gradcam = l_gradcam / l_gradcam.max()あとはcv2.applyColorMapなどを使ってJET変換してカラーマップとすればできあがりです。
ドロップアウト
ネットワークが過学習(トレーニングデータのみにフィッティングしすぎてバリデーションデータで精度が悪くなる現象)が生じるのを防ぐためにドロップアウトと呼ばれる手法を適用します。ネットワークの一部のノードを無効にして学習することを繰り返し、汎化性能を向上させます。
損失関数
前回(Kerasでワイン分類)軽く説明していますので、省略します。今回も多クラス分類なのでcategorical_crossentropyを用います。
Kerasでワイン分類 : https://qiita.com/moriitkys/items/2ac240437a31131108c7最適化関数
前回(Kerasでワイン分類)軽く説明していますので、省略します。今回はいろいろ試した結果SGDが最もよく学習できたので、これを採用します。
以上の損失関数、最適化関数はgithubにアップするコードのセル2でモデルをコンパイルする部分にあります。
model.compile( optimizer = SGD(lr=0.001), loss = 'categorical_crossentropy', metrics = ["accuracy"] )Tkinter
Python からGUIを構築・操作するための標準ライブラリ(ウィジェット・ツールキット)であるので、何もしなくてもPythonを入れたら使えるライブラリです。
今回githubに投稿したノートブックで動作するGUIウィンドウは以下のような感じです。そのプログラムは以下です。そのままコピペしても動くと思います。
ボタンは3種類あり、click_flag_train関数では押されると赤色になり、フラグの値が変わるようになっています。はじめはInferenceモード、押すとTrainモード、また押すとInferenceモード、・・・となります。ラベルも変わります。
ラジオボタンも設置しており、tkinter.Radiobuttonでどちらのバックボーンを使うか選択できます。
最後に一番下のStartボタンを押すとウィンドウが終了してその下のプログラムへと進行します。
Figure 8. Tkinterの実行時の様子 import os import numpy as np flag_train = False type_backbone = "ResNet50" layer_name_gradcam = "activation_49" # --- Setting buttons --- import tkinter tki = tkinter.Tk() tki.geometry('300x400') tki.title('Settings') radio_value_aug = tkinter.IntVar() radio_value_split = tkinter.IntVar() radio_value = tkinter.IntVar() label = tkinter.Label(tki, text='Mode: Inference') label.place(x=50, y=60) def callback(event): if event.widget["bg"] == "SystemButtonFace": event.widget["bg"] = "red" else: event.widget["bg"] = "SystemButtonFace" def click_flag_train(): global flag_train if flag_train == True: label['text'] = 'Mode: Inference' flag_train = False else: label['text'] = 'Mode: Train' flag_train = True def click_start(): tki.destroy() # Create buttons btn_flag_train = tkinter.Button(tki, text='Train', command = click_flag_train) btn_start = tkinter.Button(tki, text='Start', command = click_start) label1 = tkinter.Label(tki,text="1. Select Train or Inference") label1.place(x=50, y=30) btn_flag_train.place(x=50, y=100) label2 = tkinter.Label(tki,text="2. Select ResNet50 or Mobilenet") label2.place(x=50, y=150) rdio_one = tkinter.Radiobutton(tki, text='ResNet', variable=radio_value, value=1) rdio_two = tkinter.Radiobutton(tki, text='Mobilenet', variable=radio_value, value=2) rdio_one.place(x=50, y=180) rdio_two.place(x=150, y=180) label3 = tkinter.Label(tki,text="3. Start") label3.place(x=50, y=250) btn_start.place(x=50, y=280) # Display the button window btn_flag_train.bind("<1>",callback) btn_start.bind("<1>",callback) tki.mainloop() if radio_value.get() == 1: type_backbone = "ResNet50" layer_name_gradcam = "activation_49" elif radio_value.get() == 2 : type_backbone = "Mobilenet" layer_name_gradcam = "conv_pw_13_relu" print(flag_train) print(type_backbone)今回の本題ではないのですが、Tkinterが長くなってしまいました。
用語まとめ終わり
ResNet50 VS Mobilenet V1
二つの違いをざっくり述べると、ResNetは重くて高精度、Mobilenetは軽くてやや低精度、という感じでしょうか。以下に詳細な比較をまとめます。
ResNet
- 2015年にILSVRCで優勝したネットワーク
- モデルの構造 Figure 9-a.のような176層のDeep CNN
- 残差構造を用いる(Figure 9-b.)
- 今回のプログラムでのパラメータ数 23548935 (Figure 10-a.)
- 1 epochあたり 126s (Figure 10-b.)
- 参考 Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Deep Residual Learning for Image Recognition, arXiv:1512.03385 [cs.CV] 10 Dec 2015, (https://arxiv.org/abs/1512.03385) -
Figure 9-a. ResNetモデル構造 Figure 9-b. 残差構造
Figure 10-a. ResNetのパラメータ数 Figure 10-b. ResNetの学習中の様子 残差構造はFigure9-b.のようにidentity関数が出力にそのまま足されるような構造があり、層を深くした場合に勾配消失しにくくなります。したがってResNetはより複雑な表現力を獲得しています。
Mobilenet V1
- 2015年にGoogleが論文を発表
- モデル構造 Figure 11-a.のような97層のDeep CNN
- Depthwise Separable Convolutionを用いる(Figure 11-b.)
- 今回のプログラムでの学習パラメータ数 3465031 (Figure 12-a.)
- 1 epochあたり 65s (Figure 12-b.)
- 参考 Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam, MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications, arXiv:1704.04861 [cs.CV] 17 Apr 2017, (https://arxiv.org/abs/1704.04861)
Figure 11-a. Mobilenet V1の構造 Figure 11-b. Depthwise Separable Convolution
Figure 12-a. Mobilenet V1のパラメータ数 Figure 12-b. Mobilenet V1の学習中の様子 Depthwise Separable Convolutionの構造はFigure 11-b.に示すように空間方向(縦横)での畳み込みの後にチャンネル方向の畳み込みをするという二段階で畳み込み処理を実行します。通常はこれを一度にします。なぜ二段階で軽量化されるのかという原理は論文を読むか、他の方が書いたQiitaの記事にも詳しく説明されていますので、今回は省略します(今後書くかも)。
学習の設定
・クラス数はcategories=["Makino", "Okuma", "OKK", "Toshiba", "JTEKT", "Tsugami", "Mitsubishi" ]の7種類
・データセットは以下の表Table 1.に枚数を記載。拡張は輝度変化、ペッパーノイズ、カットアウト、変形を実行。
・データセットの分割 train:validation=6:4
・画像の縦横サイズはResNet50で197x197、Mobilenetで192x192
・ドロップアウト、損失関数、最適化関数は既に説明済み
・すべての層が学習対象
・ResNet50またはMobilenet V1のそれぞれでbatch_size=32、30 epochsの学習を実行Table 1. データセットの内訳
クラス 拡張前の枚数 拡張後の枚数 1 Makino 105 2088 2 Okuma 72 1368 3 OKK 75 1800 4 Toshiba 7 504 5 JTEKT 60 2160 6 Tsugami 45 1620 7 Mitsubishi 24 1152 結果
LossとAccuracy
LossやAccuracyの推移から両者とも学習は収束したと思います。(評価が1.0になっているのは不穏ですが)
まずResNet50で学習30epochした場合のLossとAccuracyの推移が以下です。Lossは小さいほど、Accuracyは大きいほど学習が順調に進んだことになります。青色がtrainデータでの精度、オレンジ色がvalodationデータでの精度です。ドロップアウトの効果も確認できます(trainデータでの精度が低い)。
Figure 13-a. ResNet50の各Epochに対するLoss Figure 13-b. ResNet50の各Epochに対するAccuracy 続いてMobilenet V1で学習30epochした場合のLossとAccuracyの推移が以下です。青色がtrainデータでの精度、オレンジ色がvalodationデータでの精度です。
Figure 14-a. Mobilenetの各Epochに対するLoss Figure 14-b. Mobilenetの各Epochに対するAccuracy 未知のテスト画像を用いた推測結果
この30epoch学習させた重みを用いて、学習にも評価にも用いていない未知の画像を28枚集めてきて推測させた結果を以下Table2にまとめました。
Table 2. 各モデルの各テスト画像に対する推測の結果
総テスト画像数 ResNet50 総正解数 Mobilenet 総正解数 28 26 23 正解率 0.929 0.821 このことから、ResNetの方が10%ほど精度が良い結果となりました。
Grad-CAMによる可視化
また、Grad-CAMにより注目領域を可視化させていますが、若干ロゴっぽい部分に着目しているようです(特にResNet)。
Figure 15-1. Makinoのテスト画像の推測結果と可視化 https://www.youtube.com/watch?v=mMgyLnV7l6M
Figure 15-2. Okumaのテスト画像の推測結果と可視化 https://www.youtube.com/watch?v=f_qI1sxj9fU
Figure 15-3. Tsugamiのテスト画像の推測結果と可視化 https://www.youtube.com/watch?v=rSTW2hEfSns そうでもないかも・・・
Figure 15-4. JTEKTのテスト画像の推測結果と可視化 https://www.youtube.com/watch?v=SVtN08ASIrI 多くの可視化の結果では、ResNetはロゴや色、特徴的な形状(エッジなど)をシャープに注目している印象でしたが、Mobilenetでは全体的にボヤっとしていてうまく特徴を掴みきれていないいないようにも見えます。
OKKさんのやつは色で判別してる感じはあるそうです。
Figure 15-5. OKKのテスト画像の推測結果と可視化 https://www.youtube.com/watch?v=Xfk3wXWleUs&t=21s 「はじめのはじめに」について
なぜ冒頭の画像がVacuumと判断されたかについては、ネットワークの構造が悪いというわけではなく、データセットの問題だと考えられます。そして以下の3つの理由を考えました。
- ImageNetに使われたVacuumの画像と画像中のロボットの形状が似ていた(上述の「ちなみに」の部分に記載したサイト)
- ImageNetでは人間が横を向いたデータが少ない(?)(未確認)
- ImageNetではマスクをつけた人間のデータが少ない(?)(未確認)
- ただ、トップ10の中にPersonが入っていないのが気になります。そこで人間が正面を向いた状態の画像を推測させたところ、シャツやタイ、スーツなどのような衣服の推測が多く入っていました。このことからも、マスクをつけるとImageNetでは人の推測精度が下がるのではないかと思います。
感想
- データセットを集めるには牧野フライスさんのサイトが一番良かったです。なぜなら製品の外観を角度を変えて撮影したものがあったり、似た見た目の画像が多かったりということが挙げられます。OKKさんも一部除いて色が特徴的なのでNN的にはありがたいかもしれません。
- 転移学習なので似た画像であれば100枚に満たない程度でもある程度学習できましたが、今回の例は特殊すぎてあまり参考にならないかもしれないです。特に、LossやAccuracyの推移があまりにも綺麗すぎるので、データセットやパラメータチューニングが適切ではないように思います。
- 一番実感しているのはデータセットが非常に重要だということですが、今回の可視化の結果や精度の点から考えると、ネットワークもそれなりに影響しているということがわかりました。
- 可視化について、ロゴや色のような特徴ではなくすぐには気づかないような特徴を発見するかと期待していましたが、まだ全部は見れていません。できたとしても画像をここで多数公開するのは良くないと思うので・・・
- 今回の検証は問題設定自体が実用的ではありませんが、サクッと学習結果を見たい場合には使いやすいノートブックになったかなと思っています。
- 記事やプログラムは粗い部分が残ってしまいましたが、一区切りつけなければなりません。訂正やご意見がありましたら、ご連絡ください。
参考
https://www.ling.upenn.edu/courses/cogs501/Rosenblatt1958.pdf
https://keras.io/ja/models/sequential/
https://keras.io/ja/applications/
https://www.bigdata-navi.com/aidrops/2611/
https://qiita.com/simonritchie/items/f6d6196b1b0c41ca163c
https://qiita.com/kinziro/items/69f996065b4a658c42e8
http://www.image-net.org/
https://cocodataset.org/#home
http://host.robots.ox.ac.uk/pascal/VOC/
https://arxiv.org/pdf/1409.1556.pdf
https://pjreddie.com/darknet/yolo/
https://github.com/tensorflow/models/tree/master/research/deeplab
https://arxiv.org/abs/1703.06870https://docs.python.org/ja/3/library/tkinter.html
https://qiita.com/simonritchie/items/da54ff0879ad8155f441https://www.makino.co.jp/ja-jp/
https://www.okuma.co.jp/mold-industry/index.html
https://www.okk.co.jp/product/index.html
https://www.shibaura-machine.co.jp/jp/product/machinetool/
https://www.jtekt.co.jp/
https://www.tsugami.co.jp/
https://www.mhi-machinetool.com/




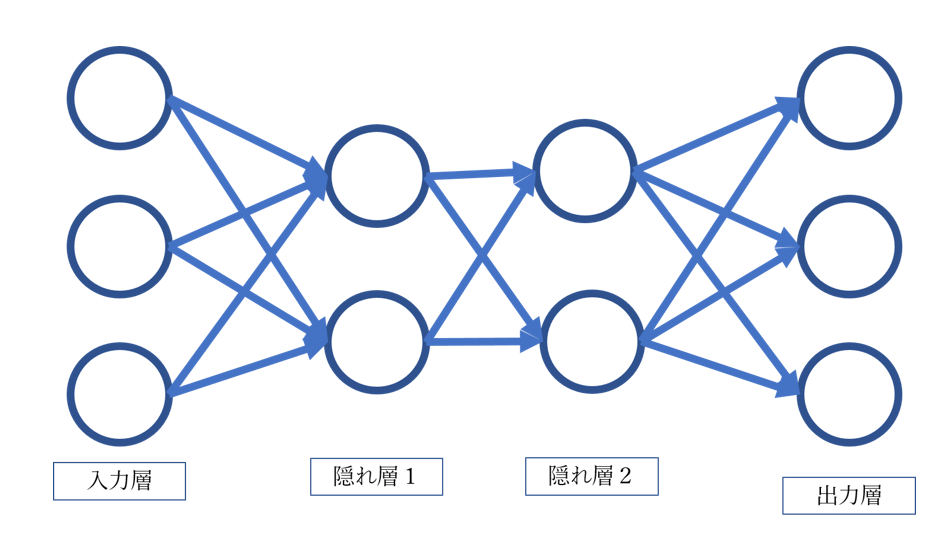
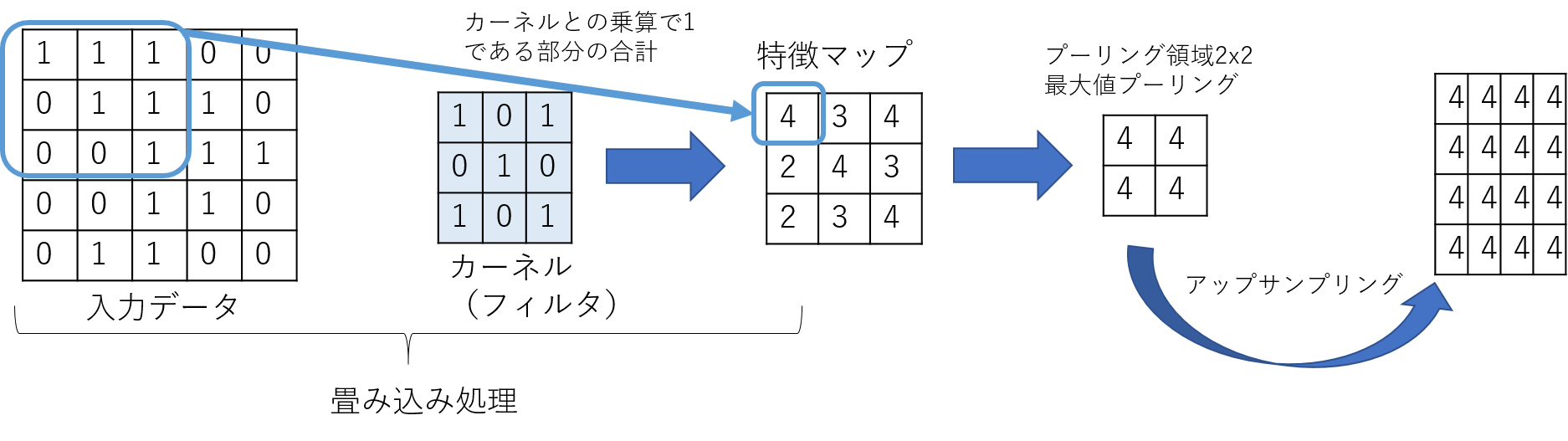



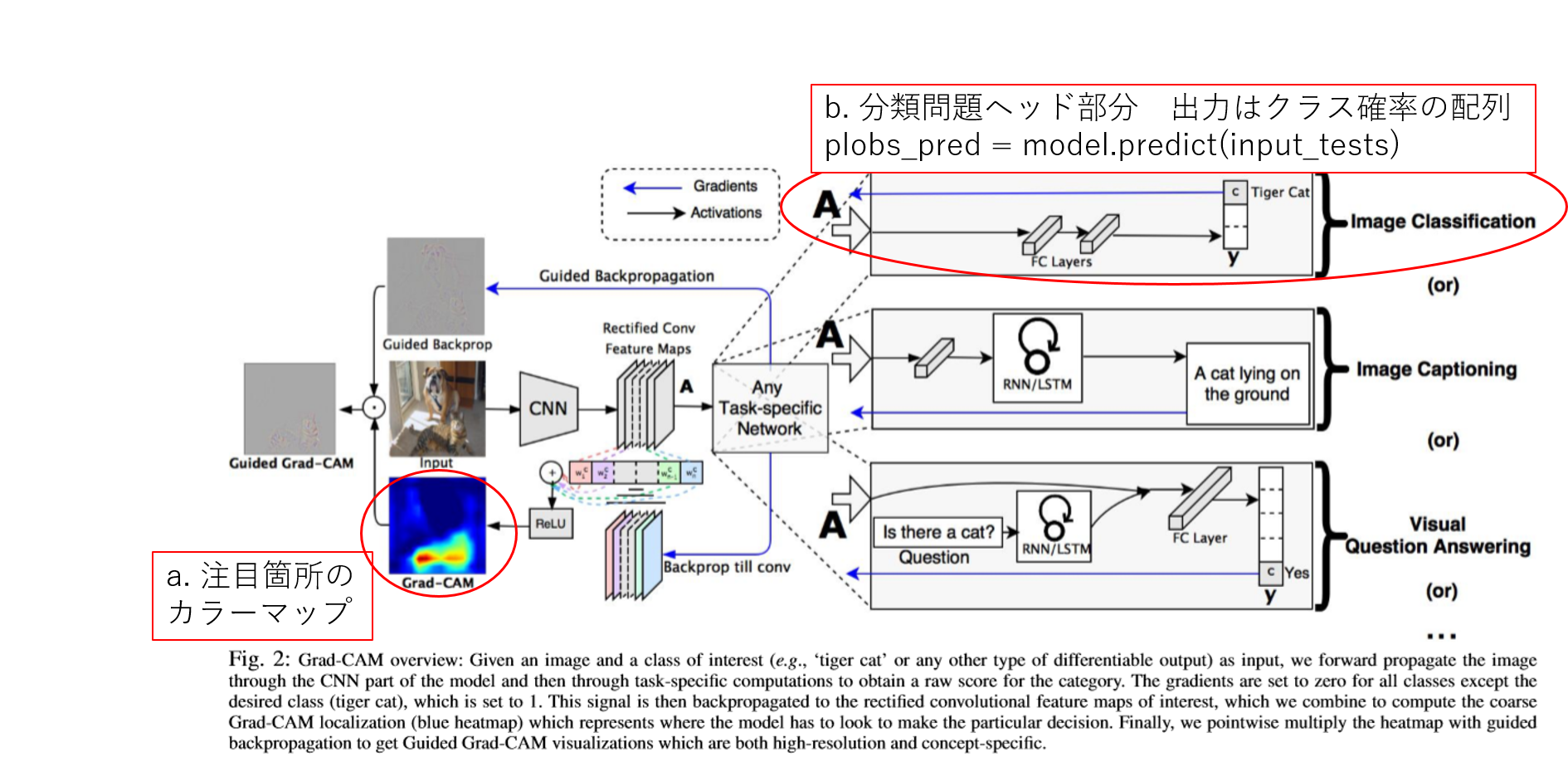

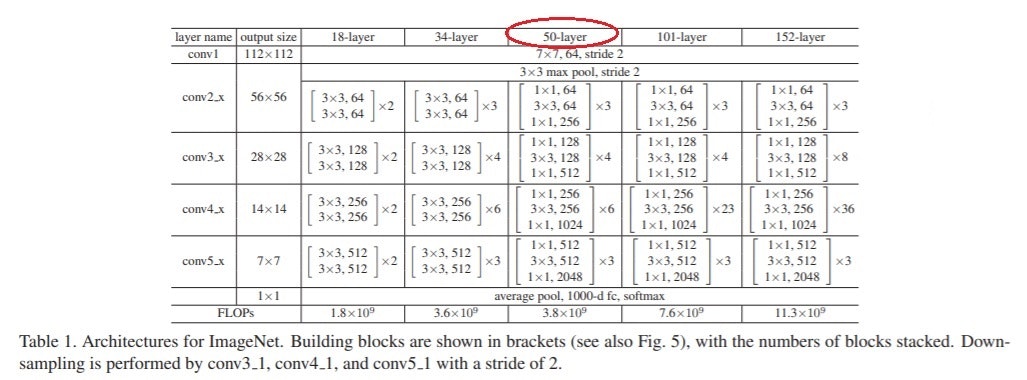
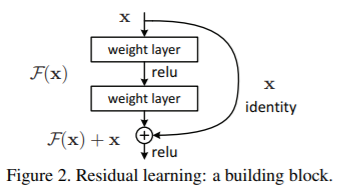





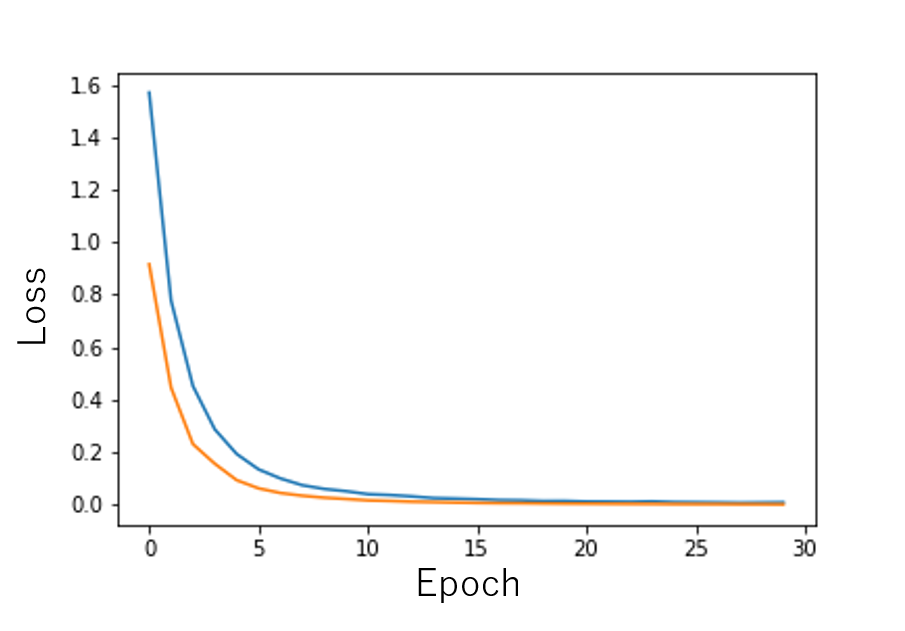

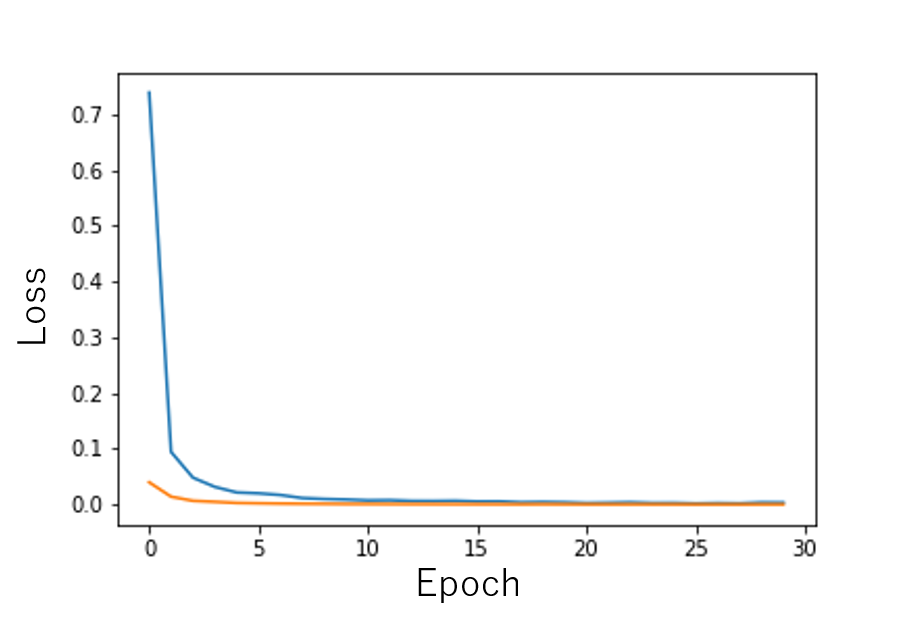

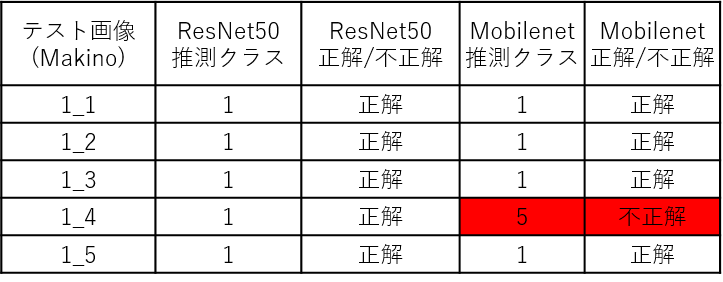
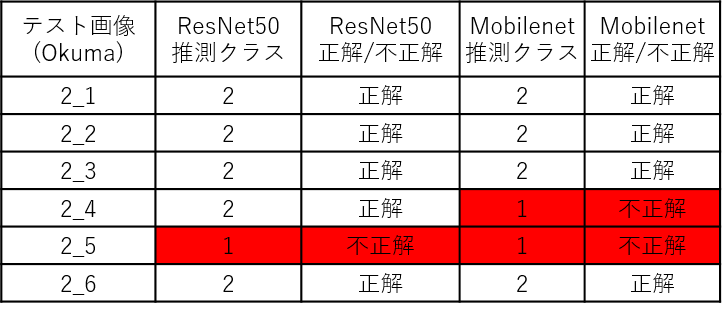
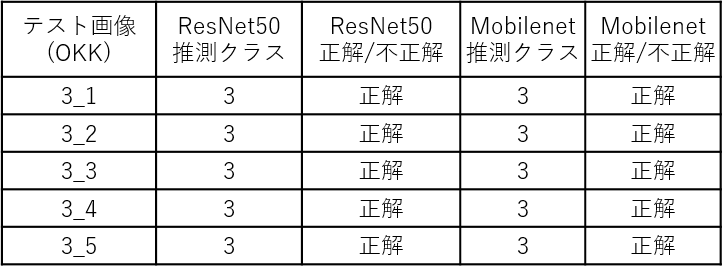

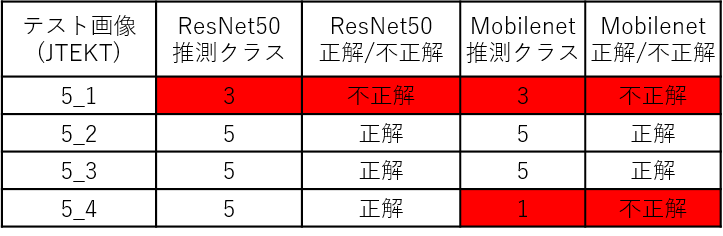
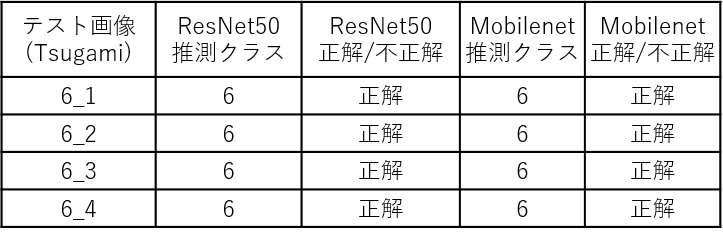
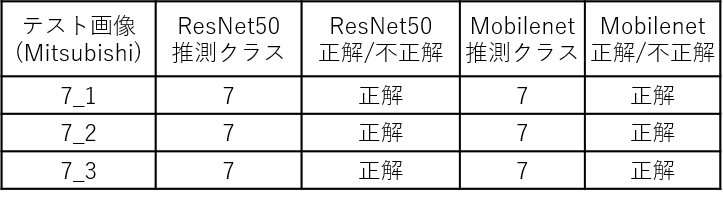
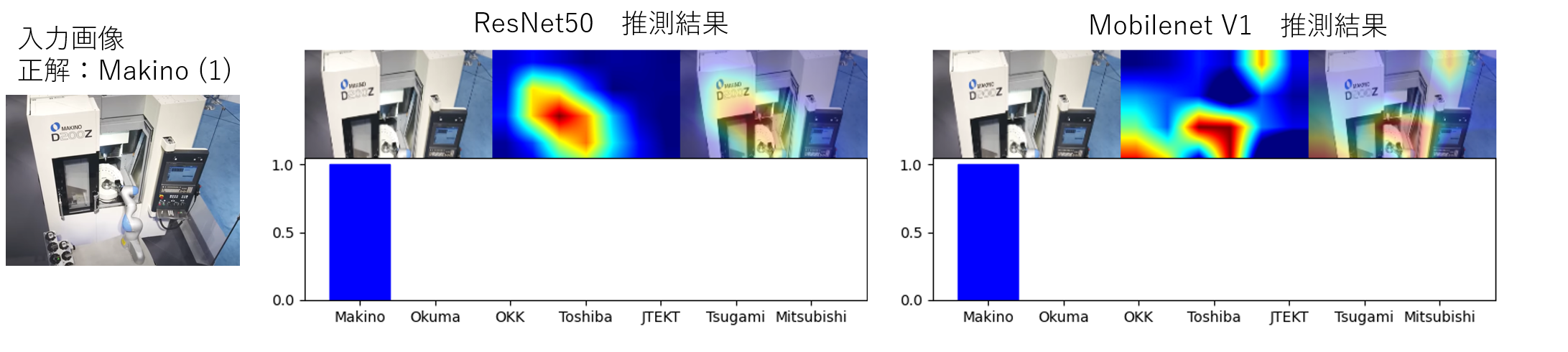
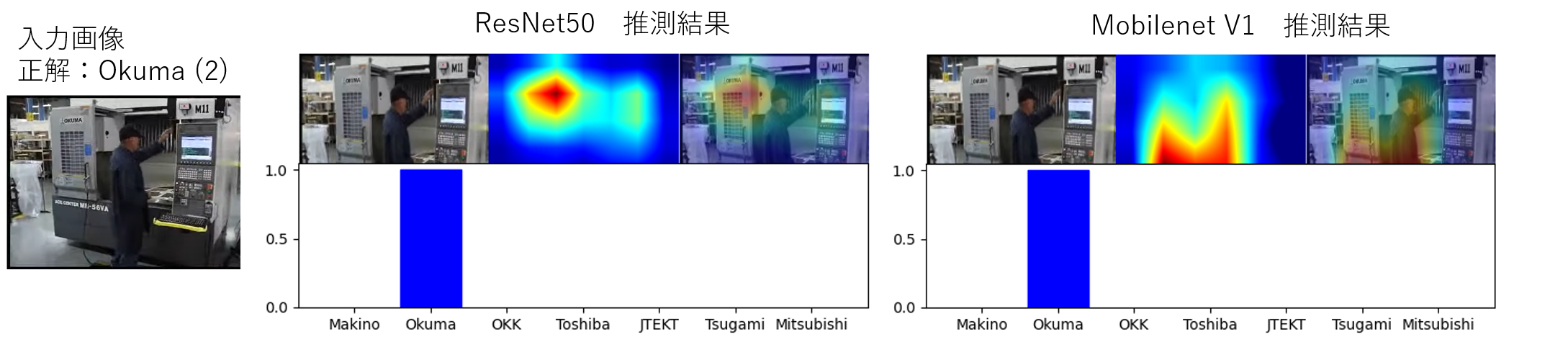
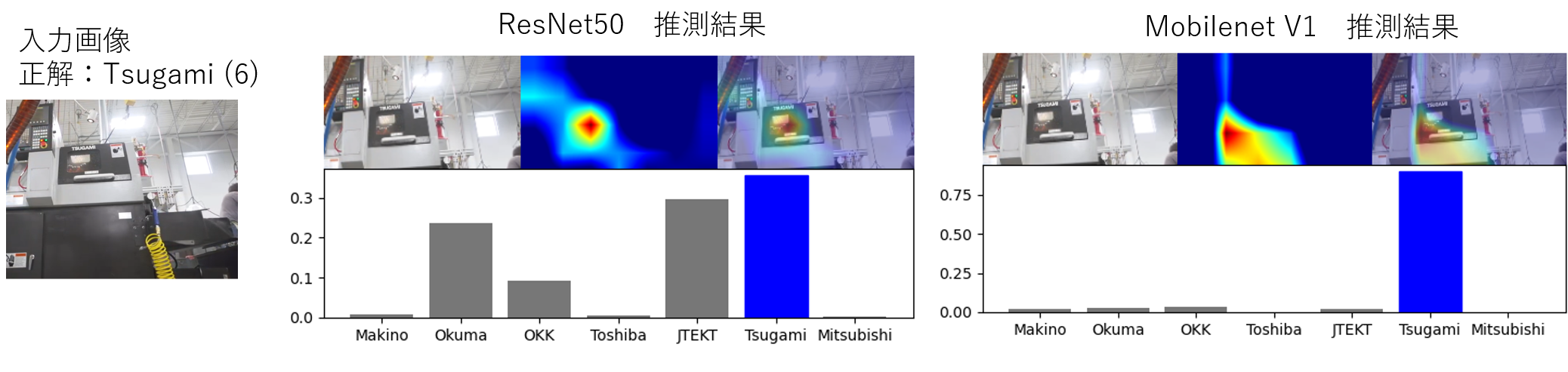

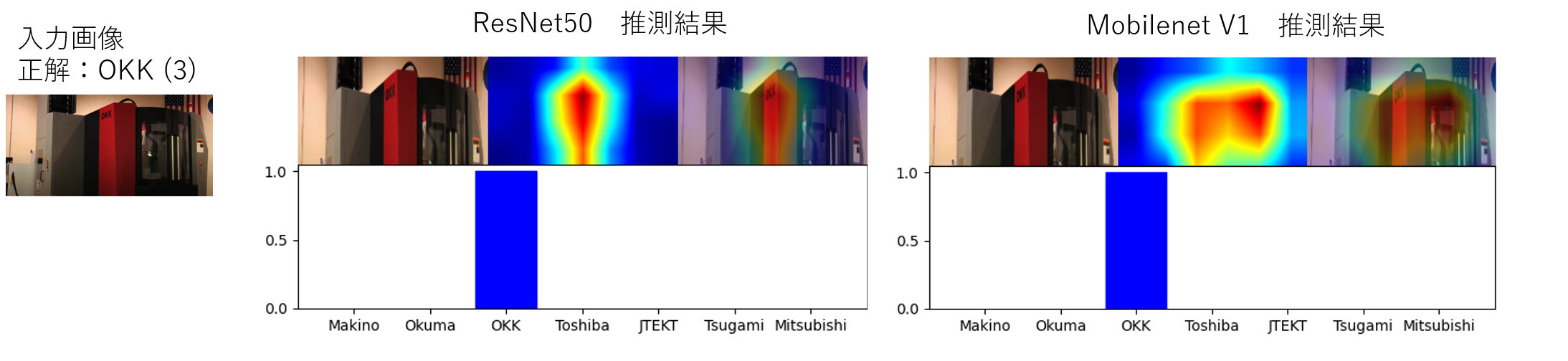
- 投稿日:2020-06-30T11:38:29+09:00
Pythonで書くフーリエ級数の検算用コード
理工系の学部生にとって厄介なのはフーリエ級数の手計算である。
一通り計算したはいいものの、結果が汚すぎて自信がないということはよくある。
そこでPythonで検算できるコードを書いたので備忘録も兼ねて掲載する。例えば
f(x)=x \ \ \ \ (-\pi \le x \le \pi)をフーリエ級数展開すると
f(x)=-\Sigma_{n=1}^{\infty}\frac{(-1)^n}{n}\sin(nx)となる。これを検算してみよう。
import numpy as np import matplotlib.pyplot as plt #x軸を定義する x = np.arange(-np.pi,np.pi,0.01) #シグマの中身の関数 def func(k): return -1*(((-1)**k)/k)*np.sin(k*x) #シグマ演算の関数. 引数で和の範囲を指定. def sigma(func,frm,to): ret = np.zeros_like(x) for i in range(frm,to): ret += func(i) return ret #フーリエ級数展開の関数 f = sigma(func,1,100) #結果の表示 fig, ax = plt.subplots(1,1) ax.set_aspect('equal') ax.plot(x,f) plt.show() #こっちは足されていく過程をみるためのグラフ #この設定では高々9回まで """ fig, axes = plt.subplots(3,3,figsize=(7,7)) for i,ax in enumerate(axes.ravel()): ax.set_aspect('equal') ax.set_title('n={}'.format(i)) f = sigma(func,1,i) ax.plot(x,f) plt.show() """結果はこのようになる。
100個の項を足し合わせたものだが、そこそこ再現できている。ついでにコード中でコメントアウトしている部分を実行すると結果は次のようになる。
n=0,1についてはfor文の関係で表示されないが、ここは各々変更して欲しい。参考文献