- 投稿日:2020-06-30T23:47:46+09:00
CloudFormationに日本語コメントを含めるとエラーになる場合の解決方法
前提条件
- Windowsで*.ymlに日本語コメントを含めてAWS CLIを叩いた場合のみ起こる
- マネコンから*.ymlをアップロードした場合は不明
- AWS CLIをインストーラからインストールしている場合のみ起こる
- 結論から言うとインストーラからインストールしているAWS CLIをアンインストールしてpipでgithubからインストールすればいい
テンプレートに日本語コメントを含めるとエラーになる
# これは日本語だ AWSTemplateFormatVersion: '2010-09-09' Parameters: Parameter: Type: Number Resources: # 日本語だ、これは Lambda: Type: 'AWS::Lambda::Function'こういうテンプレートファイルを
aws cloudformation create-stack --template-body file://hoge.yml --stack-name fooと実行するとError parsing parameter '--template-body': Unable to load paramfile (hoge.yml), text contents could not be decoded. If this is a binary file, please use the fileb:// prefix instead of the file:// prefix.いったエラーが出ることがある。fileb://とあるが、もちろんテンプレートはバイナリではない。AWS CLI実行時に
--debugをつけるとこのようなエラーが見える。UnicodeDecodeError: 'cp932' codec can't decode byte 0xef in position 89: illegal multibyte sequence文字コード関連のエラーらしい
VS Codeで記述したので、テンプレートファイルはUTF8である。根本的解決にならないが、テンプレートファイルをShift_JISに変換してAWS CLIを実行すれば問題ない。ただ、JISのままだと、GithubにPushすると文字化けする等、いろいろと面倒。というかつい先日にMicrosoftからUnicodeを使ってくれとお触れが出たばっかりである。
AWS CLIが食っている文字コードをUTF8にする
調べたところ、AWS CLIは後ろでboto(Python)が動いているらしい。
C:\> aws --version aws-cli/2.0.3 Python/3.7.5 Windows/10 botocore/2.0.0dev7管理者権限を持つCMDなりPowershellで環境変数を付加してやる。参考にしたのはこの記事。
setx /m PYTHONUTF8 1何も変わらん( ^ω^)…
'cp932' codec can't decode byte 0xef in position 89: illegal multibyte sequenceCLIが使っているPythonは環境変数を読んでないらしい
インストーラから入れたAWS CLIをアンインストールする。
参考にした記事はこの記事、要するにPythonが環境変数を読んでないなら、環境変数を読ませたいPythonのパッケージマネージャであるpipから、botoとAWS CLIをインストールしてやればいい。pip install https://github.com/boto/botocore/archive/v2.tar.gz pip install https://github.com/aws/aws-cli/archive/v2.tar.gz解決した
aws cloudformation create-stack --template-body file://lambda.yml --stack-name foo { "StackId": "arn:aws:cloudformation:ap-northeast-1:111111111111:stack/foo/00000000-1111-1111-1111-111111111111" }環境構築でハマるのもストレスマッハだけど、文字コード関連もそれに準ずるくらいイラつく。
参考記事
WindowsでCP932(Shift-JIS)エンコード以外のファイルを開くのに苦労した話
https://qiita.com/Yuu94/items/9ffdfcb2c26d6b33792e
Windows 上の Python で UTF-8 をデフォルトにする
https://qiita.com/methane/items/9a19ddf615089b071e71
AWS CLI v2をpipからインストールしてみた
https://dev.classmethod.jp/cloud/aws/install-aws-cli-v2-from-sourcecode/
- 投稿日:2020-06-30T22:42:23+09:00
AWSで学ぶクラウドの超基礎①〜クラウドの特徴についてまとめる〜
なんとなくでAWSを使っていたので、改めてクラウドについてまとめながら復習したいなって思っています。
クラウドとは?
クラウドコンピューティング(英: cloud computing)は、インターネットなどのコンピュータネットワークを経由して、コンピュータ資源をサービスの形で提供する利用形態である。 略してクラウドと呼ばれることも多く、cloud とは英語で「雲」を意味する。
wikipediaの説明だと掴みきれなかったので、
NISTの資料
を読みました。NISTの資料の中身を紹介しながら、クラウドの理解を深めていこうと思います。
クラウドの特徴
- オンデマンド・セルフサービス
- 幅広いネットワークアクセス
- リソースの共用
- スピーディな拡張性
- サービスが計測可能である NISTの資料より
オンデマンド・セルフサービス
クラウドサービスは、物理世界を意識せず、ユーザが利用したい時に利用したいだけのリソースを調達できる。
そのため、オンプレと違い、環境構築を1週間でできる。
AWSでは、Webインターフェイスのマネジメントコンソール、各種プログラムで利用するSDK(ソフトウェア開発キット)が用意されている。幅広いネットワークアクセス
コンピューティングリソースへのアクセスはネットワーク経由でアクセスが前提。
また、端末関係なく、アクセスできる。リソースの共用
クラウドの先には、データセンターとして、物理的な設備が存在する。
集約された物理的な設備を複数のユーザに共有している。スピーディな拡張性
スピーディに需要に応じてサーバの追加や削除が可能。
AWSではサーバは1台1分程度で起動するサービスが計測可能である
AWSなどのクラウド環境では計測環境がデフォルトで用意されている。
まとめ
クラウドを使っていると物理サーバを忘れがちですが、ちゃんと意識して使う必要がありますね、、、。
オンプレはやっぱ大変ですね、、。
- 投稿日:2020-06-30T20:19:35+09:00
AWS, GCP, Heroku 本当の無料は Heroku だけになった。
AWS, GCP, Heroku、どれも無料枠がある。
私は全部使用したことがあるが、AWS は、よくわからんけど金がかかった。GCP と Heroku は無料だ。
ただ、GCP は、請求先の登録が必須になった。
もちろん、登録したからと言って、金がかかるわけではない。
過去にAWSで金がかかったので、私はちょっと抵抗がある。
少し前までは、請求先の登録は不要で、本当に無料でGCPを使えてた。なので、今回、サービスを開発するために、Heroku を使用した。
請求先の登録も不要で使える。Heroku は無料だが、ダウンタイムが発生する。
ユーザーが30分いないと、サーバーが停止する。
なので、ユーザーが30分以降に訪れた際に、起動までページが表示されない。
あと、起動時間は500時間/月。
請求先の登録で、1000時間/月になる。
PostgreSQL を使えるが、1万レコードまでである。
日本にリージョンはない。無料で制限があるものの、趣味程度なら充分すぎる。
作ったサービスはこれ
https://deau-project.herokuapp.com/
- 投稿日:2020-06-30T19:29:44+09:00
【Nyantech ハンズオンシリーズ】機械学習を使って写真に写っている猫を見分けてみよう!をやってみた。ハマりポイントを補足
概要
【Nyantech ハンズオンシリーズ】機械学習を使って写真に写っている猫を見分けてみよう!をやってみました。
いろいろとハマってしまったので、補足します。環境
リージョン
「us-east-1」のバージニアに統一する必要があります。(オレゴンとかでも大丈夫らしい)
私は説明をよく読まずにS3を東京リージョンにして進めてしまい途中でエラーとなり、やり直しました。
また、SageMakerも東京リージョンにしてしまったため再度やり直しました。画像のサイズ
使用する画像のサイズに制限があるようです。私が最初に準備した画像は4896x3672ピクセルでした。
このサイズでもRekognitionで「Train model」を開始するまでは問題なく進みます。しかし、Train Modelを開始して数秒後にTrain Failとなり、無効なデータが多すぎるとメッセージされてしまいます。
Rekognitionの要件には画像サイズは最大で4096x4096ピクセルとなっていますので、準備する画像はサイズを確認する必要があります。
画像の枚数
学習に使う画像は1種類のラベルに付き10枚程度はあったほうが良いようです。理由は(推測)、RekognitionのTrain Modelの際に学習用データセットを2:8にテスト用と学習用に振り分ける設定を選択するためと思われます。
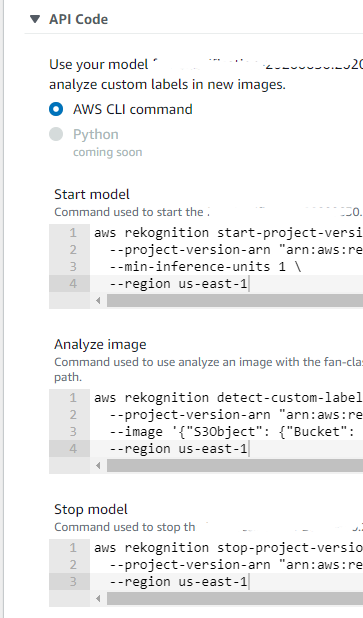
APIを実行して判定結果を確認する
学習が完了してモデルができあがると好きな画像を判定させることができます。
操作はすべてAWS CLIからAPIを実行するようになっています。
画像は事前にS3へアップロードしておく必要があります。Rekognitionが発行してくれるAPIは、「Start Model」「Analyze image」「Stop model」の3つです。
使い始めるときに「Start Model」のAPIを実行して、判定時には「Analyze image」、停止するときは「Stop model」のAPIを実行します。「Stop model」しないと利用料金が発生し続けるようです。
「Analyze image」時の注意
Start、StopのAPIはすぐに応答があったのですが、「Analyze image」のAPIを実行した初期は「準備ができていない」というエラーが返ってきました。StartのAPIでは「Starting」という返答があり、Rekognitionのコンソール上でもStartingと表示されていたので何がおかしいのか全くわかりませんでしたが、数分後には正常に動作できたので、おそらく「Analyze image」できるまでには時間がかかるようです。
まとめ
以上の補足事項があれば、おそらく2~3時間で完了できるハンズオンかと思います。
ちなみに私の環境では19枚の画像を学習させて約50分の学習時間でした。
精度は50%でした。(画像の問題)誰かの助けになれれば最高です。


- 投稿日:2020-06-30T19:07:35+09:00
[Terraform] AWSのEC2インスタンスを、コードで一発構築する!
今回はTerraformをご紹介します
Terraformは、HashiCorpさんが開発しているオープンソースソフトウェアです。
(ビジネス向けの有料版もあります。)AWSやGCPなどのクラウド上にサーバーなどを構築する作業を、コードで書いて実行するだけで出来るようになります。
最初は大変かもですが、一回慣れれば↓のようなメリットがあります。
- AWSコンソールをいちいちポチポチしなくても環境構築ができるようになる。
- コピーしてちょっといじれば他のケースにも流用できる。
- Gitなどのソース管理ソフトが使えるので、
- 更新履歴が取れる。
- 万が一のとき前のバージョンにすぐ戻せる。
- 複数人で開発作業ができる
etc...なおHCLという言語で書く必要がありますが、全然難しくないです。
今回はこのTerraformでAWSのEC2インスタンスを構築してみましょう。
おことわり
記事中に登場する固有ID値などは全部ダミーです。
ご自分の環境における値に読み替える、などしてくださいね。必要なもの
Terraformバージョン 0.12.XX。
インストール方法は本記事でご紹介しますのでご安心を。
ちなみに本記事は↓のバージョンで執筆しました。$ terraform --version Terraform v0.12.26 + provider.aws v2.68.0AWS関連
AWSアカウント。
もちろんご用意下さい。
本記事くらいの操作なら無料枠で全然可能です。
(ただし、AWS会員登録にはクレジットカードが必須です。)AWS初期設定。
おすすめ記事 > AWSアカウントを取得したら速攻でやっておくべき初期設定まとめ
AWSの基本的な機能(VPC,サブネット,IAM,EC2,AMI,セキュリティグループ)の把握。
おすすめ記事 > 0から始めるAWS入門:概要
プログラムからEC2インスタンス作成する権限を持ったIAMユーザー。
および、そのIAMユーザーのアクセスキーとシークレットキーを、お手元にご用意ください。
具体的には
- プログラムからAWSを操作することを許可されている。
- 必要なポリシー(できれば最低限必要なものだけに絞る)を付与している。
- こちらを参考にさせて頂きました > IAMポリシーによるEC2インスタンス操作制限
(ちょっと試すだけなら管理者権限で実施しても良いですが、後始末は重々ご注意を。)ポリシー設定サンプル
ポリシーはAWSコンソールでポチポチする他にJSON形式で設定できますが、↓このポリシー設定で本記事の作業ができることを確認済みです。
パーフェクトとまでは行かないですが、かなり権限を絞ってみました。{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "ec2:TerminateInstances", "ec2:StartInstances", "ec2:StopInstances" ], "Resource": "arn:aws:ec2:*:*:instance/*" }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": [ "ec2:RevokeSecurityGroupIngress", "ec2:AuthorizeSecurityGroupIngress", "ec2:RevokeSecurityGroupEgress", "ec2:DeleteSecurityGroup" ], "Resource": "arn:aws:ec2:*:*:security-group/*" }, { "Sid": "VisualEditor2", "Effect": "Allow", "Action": "ec2:RunInstances", "Resource": [ "arn:aws:ec2:*::image/ami-*", "arn:aws:ec2:*:*:subnet/*", "arn:aws:ec2:*:*:key-pair/*", "arn:aws:ec2:*:*:instance/*", "arn:aws:ec2:*:*:volume/*", "arn:aws:ec2:*:*:security-group/*", "arn:aws:ec2:*:*:network-interface/*" ] }, { "Sid": "VisualEditor3", "Effect": "Allow", "Action": [ "ec2:Describe*", "iam:PassRole", "iam:Get*", "iam:List*", "ec2:GetConsole*", "ec2:ImportKeyPair", "ec2:CreateKeyPair", "ec2:CreateSecurityGroup", "ec2:DeleteKeyPair" ], "Resource": "*" } ] }操作端末
- Mac
- Linux
この記事では、上記OSのコマンドインターフェースで、
tfenvというツールを一段かませてTerraformを使う方法をご紹介します。※ もし純粋にTerraform本体だけを使うなら、こちらがダウンロードページ。
こちらの方法では、ページに載っているOS端末なら大体動くと思います。
Terraformの話をしていたのにいきなり
tfenvとか出てきたぞ!?
tfenvは、Terraformの複数バージョンを管理して、好きなバージョンのTerraformを呼び出すようにワンクッションかませられるツールです。「Terraformをバージョンアップしたら、同じコードなのに動かなくなっちゃった…」
こんな事が発生したら、アワアワしちゃいますよね。
そういった問題を回避できるツールなのです。
便利なのでtfenvを使う前提で進めてまいりましょう。tfenvインストール編
Macの場合
brewコマンド(Homebrew)インストール
Homebrewは、コマンド操作でMacにソフトウェアをインストールするのに便利なツールで、とても有名です。
この記事の手順を実施するのにも必要なので、もし未導入でしたら↓こちらの記事をご紹介するのでインストールをすませておきましょう。tfenvインストールの前に
もしすでにTerraform単体でインストールしてしまっていたら、以下のコマンドを実行しておきましょう。
tfenvインストール
MacですでにTerraformが入ってしまっている場合に事前に行う手順.# もしすでにTerraformが入っていて tfenv install がコケたら、これをする。 brew unlink terraformでは改めまして...
Macに tfenv をインストールするには、以下のコマンドを打てばOKです。Macでtfenvをインストールするコマンド.brew install tfenvLinuxの場合
Linuxの場合は、githubから tfenv 一式をまんま取得してしまいましょう。
その中の/binディレクトリに、ビルド済のtfenvコマンドファイルがあるので、tfenvのbinディレクトリにPATHを通してどこからでもtfenvコマンドを打てるようにしてあげれば、インストール完了です。
Linuxでtfenvをインストールする一連のコマンド.git clone https://github.com/tfutils/tfenv ~/.tfenv echo 'export PATH="$HOME/.tfenv/bin:$PATH"' >> ~/.bash_profile source ~/.bash_profiletfenvを使ってTerraformをインストール
Terraformのバージョン一覧を見る
以下のコマンドで出来ます。
Terraformのバージョン一覧を見るコマンド.tfenv list-remoteTerraformインストール
せっかくバージョン一覧を調べたところですが、latest (「正式版で一番新しいやつを頼む」) という指定でインストールしてしまいましょう。
tfenvでTerraform最新版をインストールするコマンド.tfenv install latest使用するTerraformバージョンを指定しておく
インストールしただけではダメです、これも忘れずに。
複数バージョンのTerraformが扱えるtfenvならではですね。Terraformバージョンを指定するコマンド.tfenv use latest実践編
作業ディレクトリを作る
Terraformでは基本、1プロジェクト1ディレクトリという風になっています。
ので、ディレクトリを作りましょう。mkdir hogehogeそして、ディレクトリの中に入っておきましょう。
cd hogehogeAWSアクセス情報ファイルを作る
まずはTerraformにAWSアクセス情報を与えてあげないと何も出来ません。
というわけでやっていきましょう。viなどのテキストエディタで
terraform.tfvarsというファイル名で編集を開始します。(この名前にしておけば、自動的に読み込んでくれるのです。)vi terraform.tfvars中身はというと、
terraform.tfvarsaccess_key_sample = "AKAOFUOAE92AFHGHESY" //←ご自分のAWSアクセスキーに書き換えてね secret_key_sample = "RHaZsoghSOGH93ShlgihhrilirsrurhEzg+" //←ご自分のAWSシークレットキーに書き換えてね region_sample = "ap-northeast-1" //←日本国外でご利用なら、お好みで書き換えてねこんな感じ。(ちなみに↑のキーはデタラメのダミーです。)
余談: HCL言語でのコメントの書き方
↓こういう書き方をすると、Terraformは無視してくれます。
Terraformのコメント記法.# #の後に何を書いても無効 // //の後に何を書いても無効 /* /*(半角)と */(半角)のあいだに何を書いても無効(複数行もOK) /*(半角)と */(半角)のあいだに何を書いても無効(複数行もOK) /*(半角)と */(半角)のあいだに何を書いても無効(複数行もOK) */メモを書きとめておくのに利用しましょう。
SSH接続用鍵ファイルを作成しておく
EC2インスタンスが起動したあとSSH接続するのに必要な鍵ファイルを作成しておきましょう。これがないと、せっかくEC2インスタンスを作っても肝心の接続ができなくなってしまいます。
ご承知の方もいらっしゃると思いますが、念のためコマンド例を↓に書いておきます。
SSH鍵ファイル作成コマンド例.ssh-keygen -t rsa -b 4096 -C "foo@example.com" -f aws_key_pair_example実行すると、英語で質問が2回ほど来ますが、今回は例なので、何も入力せずリターンキーを押せばOKです。そうすると以下2つのファイルができあがります。
- aws_key_pair_example ←秘密鍵ファイル。
- aws_key_pair_example.pub ←公開鍵ファイル。
※ AWSコンソールの「キーペア」画面で作成もできますが、今回はコマンドで作成したものを使う方法で説明していきます。
ソースコード本体を書く
それではいよいよTerraformのコードを書いていきます。
テキストエディタなどで
main.tfというファイル名でコードを書いていきましょう。(ファイル名の拡張子を.tfにしておけば、Terraformが実行対象として認識してくれるのです。)vi main.tfコードの中身は↓こちら。
2ヶ所ほど、ご自分の環境に合わせて書き換えて頂く必要があります。
//★という目印をつけてあるので、コード内を検索してみて下さい。main.tf//terraform.tfvars に書いたアクセスキーなどを格納する変数を宣言しています。 variable access_key_sample {} variable secret_key_sample {} variable region_sample {} /* この宣言により、AWS操作を実行する際のアクセスキーなどを 自動的に参照してくれるようになります。 */ provider "aws" { access_key = var.access_key_sample secret_key = var.secret_key_sample region = var.region_sample } /* Amazon公式AMIのAmazon Linux2の最新版を取得するための条件を宣言しています。 */ data "aws_ami" "al2_latest" { most_recent = true owners = ["amazon"] filter { name = "architecture" values = ["x86_64"] } filter { name = "root-device-type" values = ["ebs"] } filter { name = "name" values = ["amzn2-ami-hvm-*"] } filter { name = "virtualization-type" values = ["hvm"] } filter { name = "block-device-mapping.volume-type" values = ["gp2"] } filter { name = "state" values = ["available"] } } /* SSH鍵ファイルの"公開鍵"の方を指定します。 秘密鍵の方を指定してしまわないようご注意! */ resource "aws_key_pair" "example" { key_name = "example" public_key = file("aws_key_pair_example.pub") } //新たにセキュリティグループを作成するための宣言です。 resource "aws_security_group" "example" { name = "example" vpc_id = "vpc-hoge2222222" //★ご自分のVPCのIDを入力してください。 } /* 上で宣言した "example"セキュリティグループにインバウンドルールを追加します。 ポート:22でSSH接続をどこのIPからでも許可するよう設定します。 (本来はIP制限をかけた方がセキュリティ上良いですが、今回は例なので良しとしましょう。) これがないと、SSH接続がAWSのファイアウォールにブロックされてしまいます。 */ resource "aws_security_group_rule" "example_sg_inbound" { type = "ingress" //インバウンドルールである。 from_port = "22" //接続元(=皆さんの端末)から発信する際のポート番号。 to_port = "22" //接続先(=EC2インスタンス側)で待ち受けるポート番号。 protocol = "tcp" //TCPプロトコル通信である。 cidr_blocks = ["0.0.0.0/0"] //どこのIPからでも接続を許可する。 security_group_id = aws_security_group.example.id } //ここから、実際にEC2インスタンスを構築する設定が書かれています。 resource "aws_instance" "example" { /* 【必須】 ベースにしたいAMIのIDを指定します。 ここでは、上の方で宣言しておいた「最新のAmazon Linux2」という設定を動的に指定しています。 */ ami = data.aws_ami.al2_latest.image_id /* 【必須】 インスタンスタイプを指定します。 今回は、一番安くて低スペックな t2.micro にしましょう。 */ instance_type = "t2.micro" /* EC2インスタンスに適用するセキュリティグループをIDで指定します。 カンマ区切りで複数指定もできます。 今回は、上の方で宣言した "example"セキュリティグループ のIDを指定しておきます。 */ security_groups = [ aws_security_group.example.id ] /* 構築先のネットワークのサブネットをお好みで指定できます。 省略するとデフォルトサブネットが適用されます。 ただしセキュリティグループの作成もTerraformで行う場合は、指定しないとエラーになります。 */ subnet_id = "subnet-hoge2222222" //★ご自分のVPCに紐づくサブネットのIDを入力してください。 //上の方で作ったキーペア設定のIDを動的に指定しています。 key_name = aws_key_pair.example.id /* プライベートIPをお好みで指定することもできます。 (サブネットルールに従わないIPや、すでに使われているIPを指定したらエラー) */ // private_ip = "172.31.0.1" //パブリックIPもお好みで指定可能。(こちらも、ルールに合わないIPを指定したらエラー) // public_ip = "xxx.xxx.xxx.xxx" //ここでは、ルートディスクの容量やタイプを指定できます。 root_block_device { volume_size = "20" //容量:20GiB volume_type = "gp2" //タイプ:gp2 delete_on_termination = "true" //EC2インスタンスを破棄するとき、このディスクも一緒に破棄する:YES //...今回書いた以外にも、色々オプションがあります。 } }実行
ディレクトリを初期化する
Terraformの都合上、最初だけちょっとした準備が必要なので、↓のコマンドを実行してあげましょう。
(Terraform作業ディレクトリの最上位階層にて1回だけ実行すればOKです。)terraform init実行計画を確認する
次に↓のコマンドを実行してみてください。
terraform plan↓こんな感じで色々表示されます。
Refreshing Terraform state in-memory prior to plan... The refreshed state will be used to calculate this plan, but will not be persisted to local or remote state storage. data.aws_ami.al2_latest: Refreshing state... ------------------------------------------------------------------------ An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: + create Terraform will perform the following actions: # aws_instance.example will be created + resource "aws_instance" "example" { + ami = "ami-hogehogehoge22222" + arn = (known after apply) + associate_public_ip_address = (known after apply) + availability_zone = (known after apply) + cpu_core_count = (known after apply) + cpu_threads_per_core = (known after apply) + get_password_data = false ... ... ...「もし実行したら、こうなるよ」という情報を教えてくれます。
今回はあまり細かく指定していないので、大体の項目が(known after apply)(構築後に分かるよ)となっています。実際に実行する
今度こそ実行です。
↓のコマンドを打ってください。terraform applyそうすると↓のように「本当に実行していい?」と聞かれるので
yesと打ってリターンキーを押しましょう。... ... ... Plan: 2 to add, 0 to change, 0 to destroy. Do you want to perform these actions? Terraform will perform the actions described above. Only 'yes' will be accepted to approve. Enter a value: ←ここに yes と打ち込む!そうするとズラーっとコマンドログが流れていき...
aws_key_pair.example: Creating... aws_key_pair.example: Creation complete after 0s [id=example] aws_instance.example: Creating... aws_instance.example: Still creating... [10s elapsed] aws_instance.example: Still creating... [20s elapsed] aws_instance.example: Creation complete after 23s [id=i-hogehogehoge] Apply complete! Resources: 4 added, 0 changed, 0 destroyed.こんな感じで終われば成功です!
今の状況を確認する
↓のコマンドで、今の状況を確認できます。
terraform show振られたIPアドレスなんかもこれで知ることができます。
(terraform applyの結果にも表示されますけれども。)SSHで接続して見る
ついでにぜひ、実際にEC2インスタンスに接続も試してみてください。
ssh -l ec2-user -i ./aws_key_pair_example XXX.XXX.XXX.XXX接続IPは、少し前の手順で確認したIPを指定してください。
作ったEC2インスタンスを破棄する
今度は↓のコマンドを打ってみましょう。
terraform destroy「破棄を実行したら、こうなっちゃうよ」という情報がズラーっと表示されます。
最後に「本当に破棄する?」と聞いてくるのでyesと打ってリターンキーを押しましょう。... ... ... - tags = {} -> null } Plan: 0 to add, 0 to change, 2 to destroy. Do you really want to destroy all resources? Terraform will destroy all your managed infrastructure, as shown above. There is no undo. Only 'yes' will be accepted to confirm. Enter a value: ←ここに yes と打ち込む!そうするとコマンドログがズラーっと流れていき...
... ... ... aws_instance.example: Still destroying... [id=i-hogehogehoge, 30s elapsed] aws_instance.example: Destruction complete after 35s aws_key_pair.example: Destroying... [id=example] aws_key_pair.example: Destruction complete after 0s Destroy complete! Resources: 4 destroyed.
Destroy complete!と表示されたら成功です!AWSコンソールのEC2画面で、実際にインスタンスが破棄されていることを確認してみてください。
またEC2インスタンス以外にも、Terraformにより作成されたリソース(セキュリティグループ、キーペアなど)も合わせて削除してくれます。あとがき
いかがでしたでしょうか?
Terraformではこの他にも、VPCそのものやロードバランサーの作成まで出来てしまいます。
ぜひ活用してみて下さい。
- 投稿日:2020-06-30T18:39:26+09:00
IAMの学習のまとめ
IAMの5大機能
- IAMユーザ
- IAMグループ
- IAMポリシー
- IAMロール
- パーミッション・バウンダリー
IAMユーザ
アクセスキーの発行は原則しない。
IAMグループ
- 管理ポリシー
- 新しい
- 推奨
- インラインポリシー
- 古い
- 原則使わない
複数のポリシーを付与したグループの挙動
明示的なDeny > 明示的なAllow > 暗黙的なDeny(デフォルト)
例えば、s3:PutObject を明示的にDenyしたポリシーと明示的にAllowしたポリシーを同じグループにつけると、Denyになる
IAMポリシー
Versionは"2012-10-17"を明示的に指定する。
しないと、"2008-10-17"がデフォルト値として設定されてしまうため。IAMロール
IAMロールはユーザではなく、AWSサービスやアプリに対して、AWSの操作権限を与える仕組み。
随時追記。
- 投稿日:2020-06-30T17:01:04+09:00
AWS Batchを使うまでのまとめ
はじめに
AWS Batchを使って、S3に静的コンテンツをアップロードして配信してみたかったのですが、初歩的な所で引っかかる部分がいくつかあったので、備忘録的にまとめておきます。
作りたい構成はざっくり以下のようなものです。
IAMロールを用いたAWS CLIの認証
公式の説明はこちら
ですが、これを行う前にIAMへアクセスし、アクセスキーを生成するようにしてください。AWS CLIを使ってECRへログイン
公式の説明はこちらにあるのですが、まずログイン部分のここ
aws ecr get-login-password --region region | docker login --username AWS --password-stdin aws_account_id.dkr.ecr.region.amazonaws.comの
--username AWSはそのままでいいです。赤字の部分だけ置き換えればいいのですが、ちょっと悩みました。Batch実行
公式の説明はこちら
ECRへのPUSHが成功したら、Batchの作成時にECR上のイメージのフルパスをコピペするだけ。
実行からログが出るまでしばらく時間かかるので焦らず待ちましょう。
なお、ログはCloud Watchに出力されるようです。スポットインスタンスでの実行
スポットフリートロールが必要なようです。公式の説明はこちら
以下の2コマンドをポチポチ実行すると、スポットインスタンスを実行するためのロールができるようです。
後はコンピューティング環境を設定する際にスポットを選択すれば、スポットインスタンスで実行できます。$ aws iam create-role --role-name AmazonEC2SpotFleetRole \ --assume-role-policy-document '{"Version":"2012-10-17","Statement":[{"Sid":"","Effect":"Allow","Principal":{"Service":"spotfleet.amazonaws.com"},"Action":"sts:AssumeRole"}]}' $ aws iam attach-role-policy \ --policy-arn arn:aws:iam::aws:policy/service-role/AmazonEC2SpotFleetTaggingRole \ --role-name AmazonEC2SpotFleetRoleS3へのファイル送信
以下のようにDockerFileを作成し、hello-worldイメージを更新します。
FROM ubuntu:18.04 # Install dependencies RUN apt-get update && \ apt-get -y install curl unzip && \ curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" && \ unzip awscliv2.zip && \ ./aws/install # Create Index File & POST To S3 RUN echo 'echo "Hello World From ECR!" `date` > /root/index.html' > /root/run_awscli.sh && \ echo 'aws s3 cp --acl public-read /root/index.html $AWS_BUCKET_URI' >> /root/run_awscli.sh && \ chmod 755 /root/run_awscli.sh CMD /root/run_awscli.sh環境変数を与えて起動すれば、S3にファイルが配置され、ブラウザからファイルを参照できます(実行時の環境変数についてはこちらを参照。
AWS_BUCKET_URIは自前です)。$ docker run -e AWS_ACCESS_KEY_ID=xxxx -e AWS_SECRET_ACCESS_KEY=xxxx -e AWS_BUCKET_URI=xxxx hello-world後は、このイメージをECRにPUSHして、AWSBatchのジョブ定義を再作成すればS3にファイルがPUT出来ます。
定期実行
公式の説明はこちら
CloudWatchのイベント-ルールから書いてある通り設定するだけ。
とても簡単でした。おわりに
Dockerさえ使い慣れていれば、かなり簡単にバッチ実行をすることができました。
もっとやりやすい方法などあれば教えてくださいmm

- 投稿日:2020-06-30T17:00:31+09:00
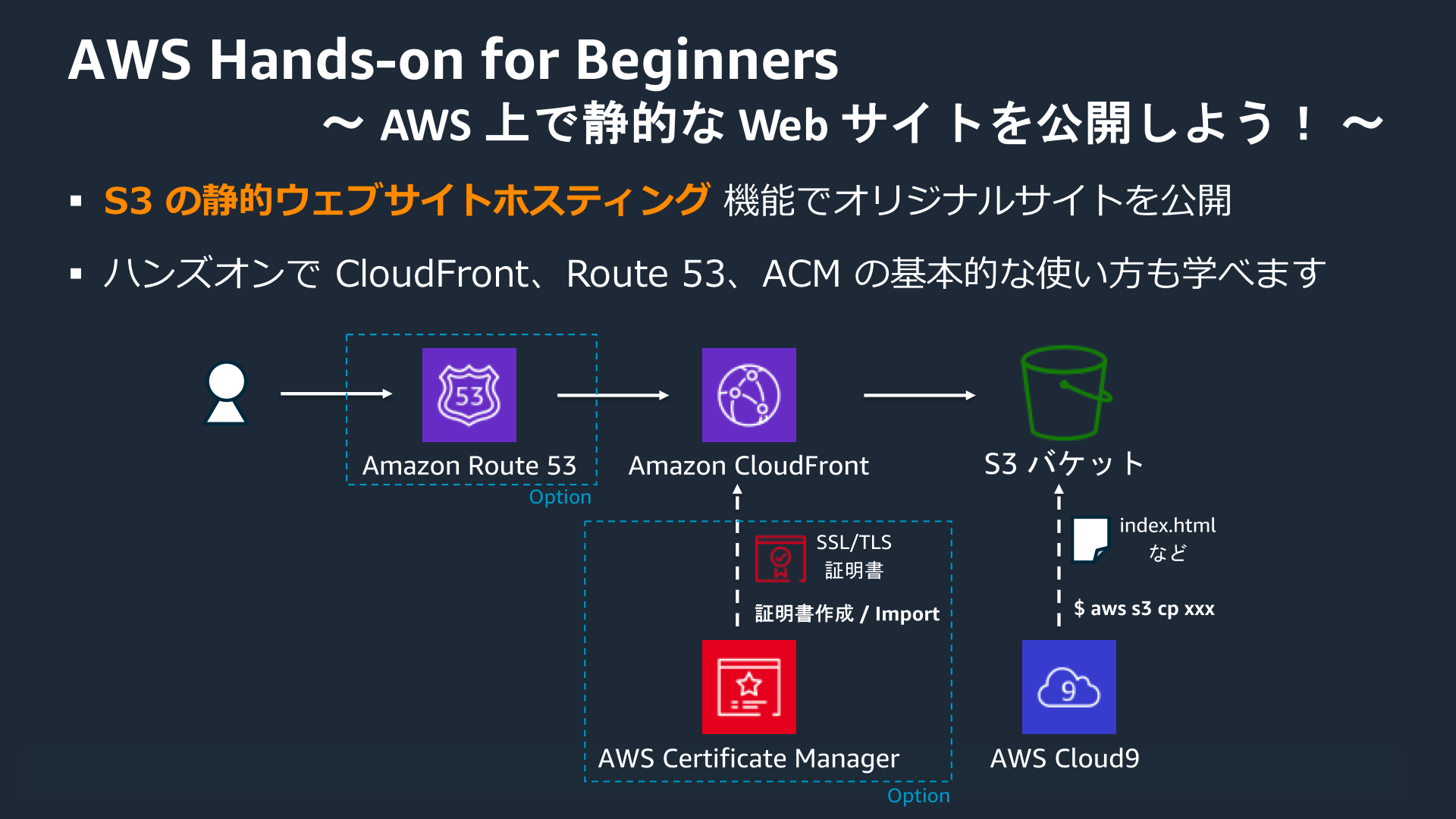
AWSハンズオン実践メモ 〜AWS 上で静的な Web サイトを公開しよう!〜
はじめに
AWS公式のハンズオンシリーズの中から、Amazon S3 の静的ウェブサイトホスティング機能を用いて、静的な Web サイトをインターネット上に公開するハンズオンを実施しました。
本記事は自身のハンズオン学習メモとして投稿します。
目次
ハンズオンの目的
Amazon S3 の静的ウェブサイトホスティング機能を用いて、簡単な Web サイトをインターネット上に公開するハンズオンを実施。
- S3の静的Webホスティング機能を利用して、簡単なwebサイトを作成し、公開できるようになる
- CloudFrontを用いて、コンテンツキャッシュの仕組みを学ぶ
- Route53を用いて、独自ドメインの設定方法を学ぶ
- ACMを使い、SSL/TLS証明書のプロビジョニング、管理、デプロイの方法を学ぶ
Amazon S3 の静的ウェブサイトホスティング機能を用いて、簡単な Web サイトをインターネット上に公開するハンズオンを行います。HTML や CSS を用いて作成したサイト、例えば新規プロタクトのランディングページや個人のポートフォリオサイトなどを容易にホスティングすることができるようになります。
あわせて、Amazon CloudFront という CDN サービスを用いたコンテンツキャッシュ、Amazon Route 53 という DNS サービスを用いた独自ドメインの取得 & ネームサーバーへのレコード登録、AWS Certificate Manager を用いた証明書の作成 & 配置の手順についても学ぶことができます。
(https://aws.amazon.com/jp/aws-jp-introduction/aws-jp-webinar-hands-on/?trk=aws_blog より引用)本編
S3 の静的ホスティング機能を使ってみる
- S3作成。パブリックアクセスを許可
- バケットポリシー記述(json形式)
- プロパティの"Static website hosting"から、インデックスドキュメントにindex.htmlを設定
- index.htmlをアップロード
- エンドポイントにアクセス
Cloud9 環境を立ち上げて静的コンテンツを開発する + AWS CLI で S3 にファイルアップロードする
- Cloud9を起動
- index.htmlを編集
- CLIでindex.htmlをs3にアップロード
- 再度エンドポイントにアクセス。index.htmlが更新されている事を確認
続・静的コンテンツの開発 + AWS CLI で S3 に複数のファイルを一括アップロードする
- index.htmlを編集し、画像を表示させる
- faviconを表示させる
- CSSを使い、画像位置を調整する
- 編集したファイルを一括でS3アップロード(オプション--recursiveを使用)
- 再度エンドポイントにアクセス。index.htmlが更新されている事を確認
CloudFront を使って、画像をキャッシュさせる
- CloudFrontのDistributionを作成
- CloudFront経由でS3のindex.htmlを表示出来る事を確認
- CloudFrontにアクセスした際、デベロッパーツールのネットワークの項目に、X-Cacheの項目が追加されている事を確認
Route 53 で独自ドメインを取得し、S3 に HTTP アクセスする
- Route53でドメインを取得
- エイリアスレコードとして、S3のバケット名を登録
- エイリアスでS3にアクセス出来る事を確認
ACM を使い、Route 53 - CloudFront - S3 で HTTPS アクセスする
通信のHTTPS化
- ACMで証明書作成。(バージニア北部で作成する必要がある。)DNSで検証。(CNAMEを追加することで検証を行う)
- CloudfrontのViewer Protocol PolicyをRedirect HTTP to HTTPSに変更
- Alternate Domain Names(CNAMEs)にドメイン名を入力
- SSL Certificateの項目でCustom SSL Certificateを選択
- Route53のエイリアスレコードをCloudFrontに変更
- ブラウザでアクセス。HTTPSでの通信になっている事を確認
S3の直接アクセスを無効化
- S3への直接アクセスを無効にする(バケットポリシー削除&ウェブサイトのホスティングを無効にする)
- CloudFrontの設定を変更
- CloudFrontのDistributionからOrigin Domain NameをS3のドメインに変更
- Restrict Bucket AccessをYesに変更
- Origin Access IdentityをCreate a New Identityに設定
- Grant Read Permissions on BucketをYesに設定
作成した AWS リソースの削除
粛々と削除。特筆すべきことはなし。
おわりに
CloudFront、Route53、ACMを触った事がなかったので、いい経験になった。
静的なwebサイトであればS3で手軽に公開できるし、Sorryページも工数かけずに作れる事が分かった。
- CloudFrontのキャッシュの設計
- ACMの証明書の種類と細かな認証の仕組み
あたりの理解が不十分なので、今後学習していきたい。
- 投稿日:2020-06-30T15:43:14+09:00
さくらインターネットからAWS Lightsail に引っ越しした個人的所感
- 投稿日:2020-06-30T15:42:04+09:00
さくらインターネットからAWS Lightsail に引っ越しした個人的所感
- 投稿日:2020-06-30T14:43:39+09:00
動画分析とメタデータ抽出のチュートリアル【初心者】
はじめに
Amazon Rekognition という画像分析ができるサービスがありますが、更に動画分析ができるのはご存知でしょうか?
このチュートリアルでは、AWS コンソール上で、Amazon Rekognition Video の動画分析機能を使用する方法について紹介していきます。Amazon Rekognition Videoは
- ストリーミング動画のリアルタイムの分析
- 活動を検知
- オブジェクト、有名人の顔
- 不適切なコンテンツ
を認識したりする、ディープラーニングを使用した動画分析サービスです。
なにをするのか
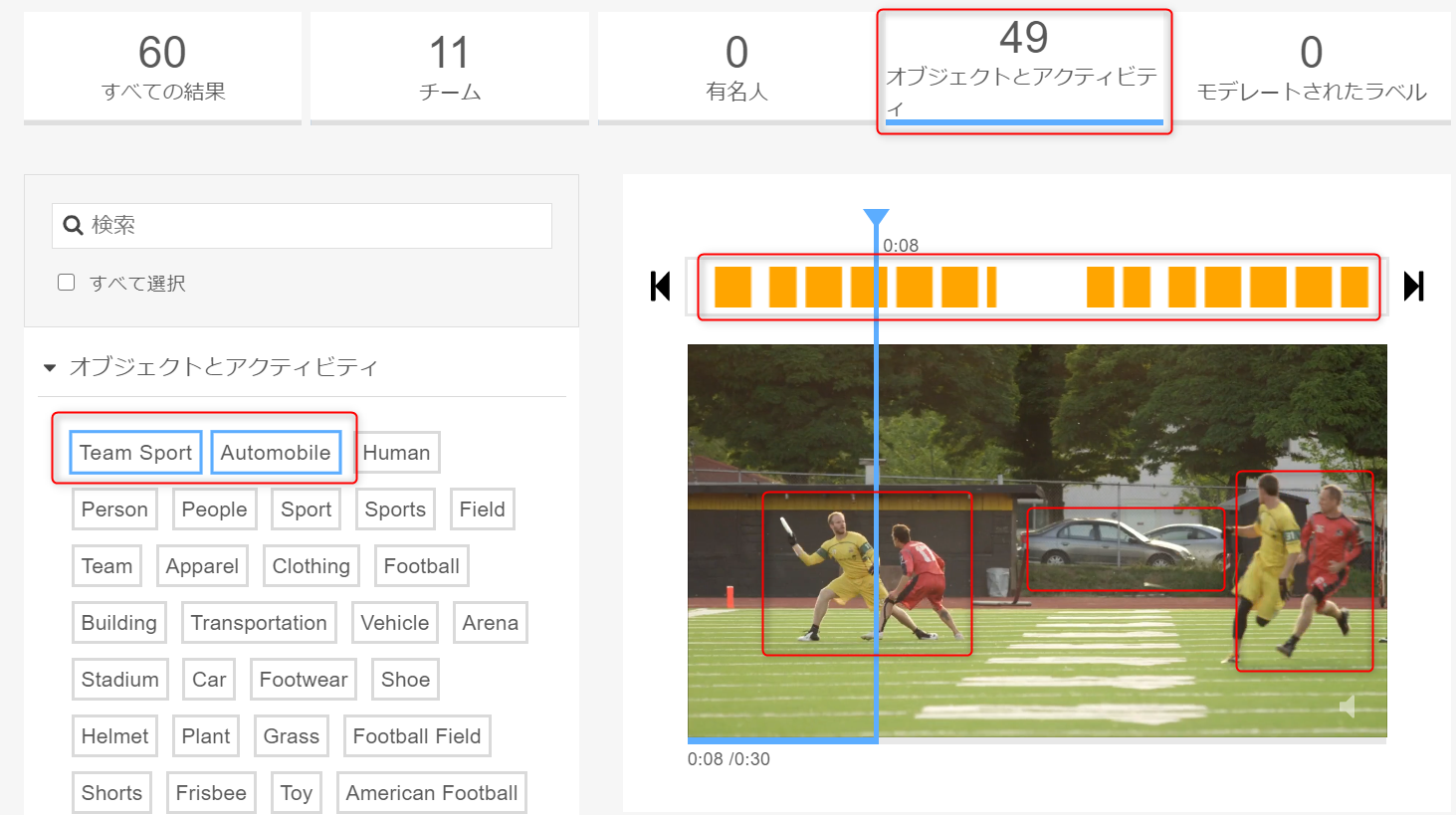
Ultimate Frisbee ゲームの 30 秒のクリップを分析します。
動画を分析すると、リッチメタデータを自動的に抽出し、検索可能な動画ライブラリの構築、コンテンツのモデレーションの実行ができます。このチュートリアルは、AWS CLI または Rekognition APIを使用する際に利用可能な機能のデモです。
ステップ1 分析の見方を知る
Amazon Rekognition コンソールに入り、左側にある「ビデオ分析(Video analysis )」を選択します。
動画を分析すること、 JSON 応答を受け取ることができます。
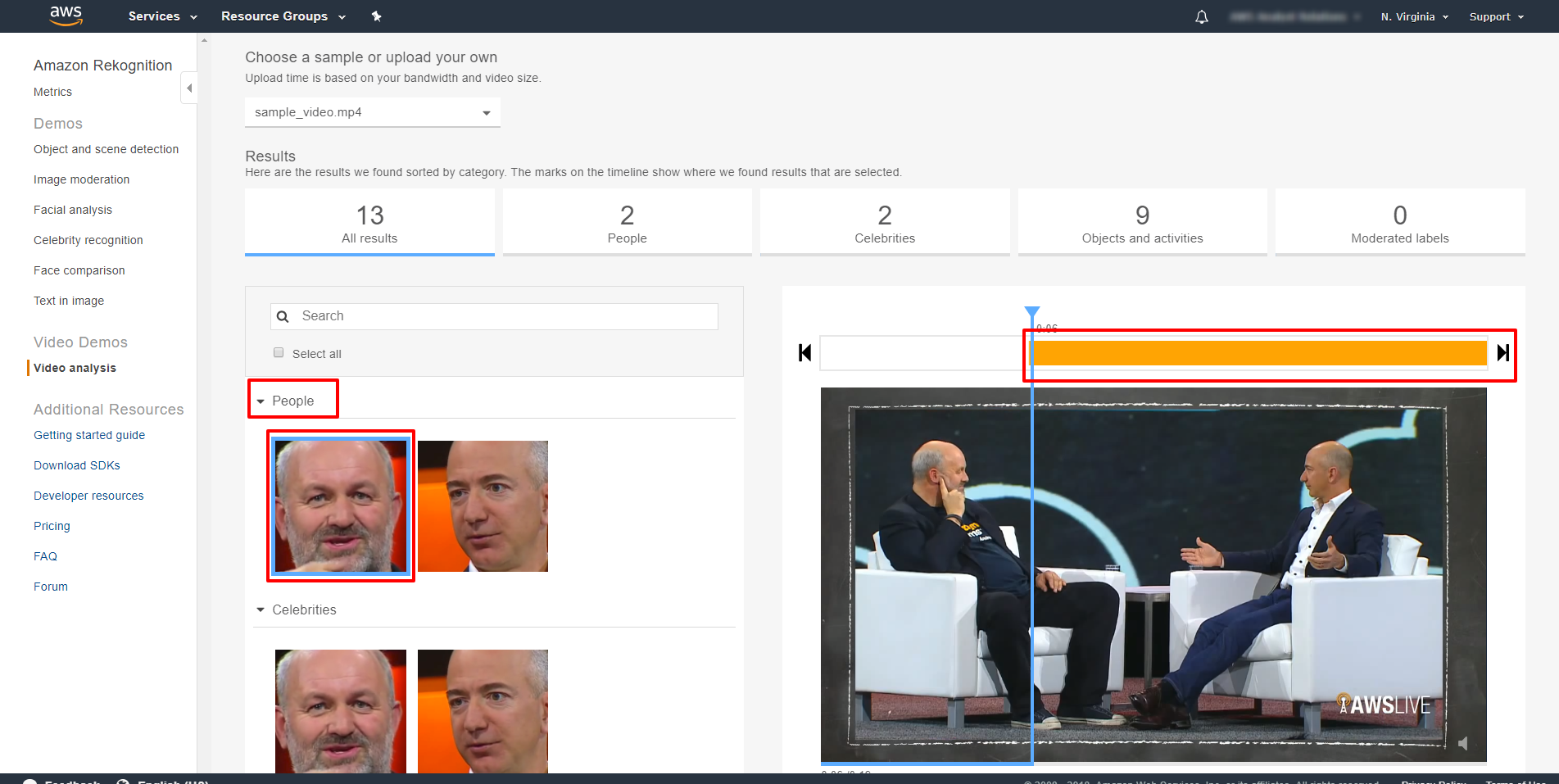
あらかじめアップロードされた Jeff Bezos と Werner Vogels の動画は、Rekognition Video がいかにして人々を追跡できるか、いかに行動を検知し、いかに対象物や有名人、不適切なコンテントを認知できるかを、試すことができます。最初に People の下、 Werner Vogels のアイコンをクリックします。
そうすると画面右側の動画は、Werner が登場するクリップを映し出します。
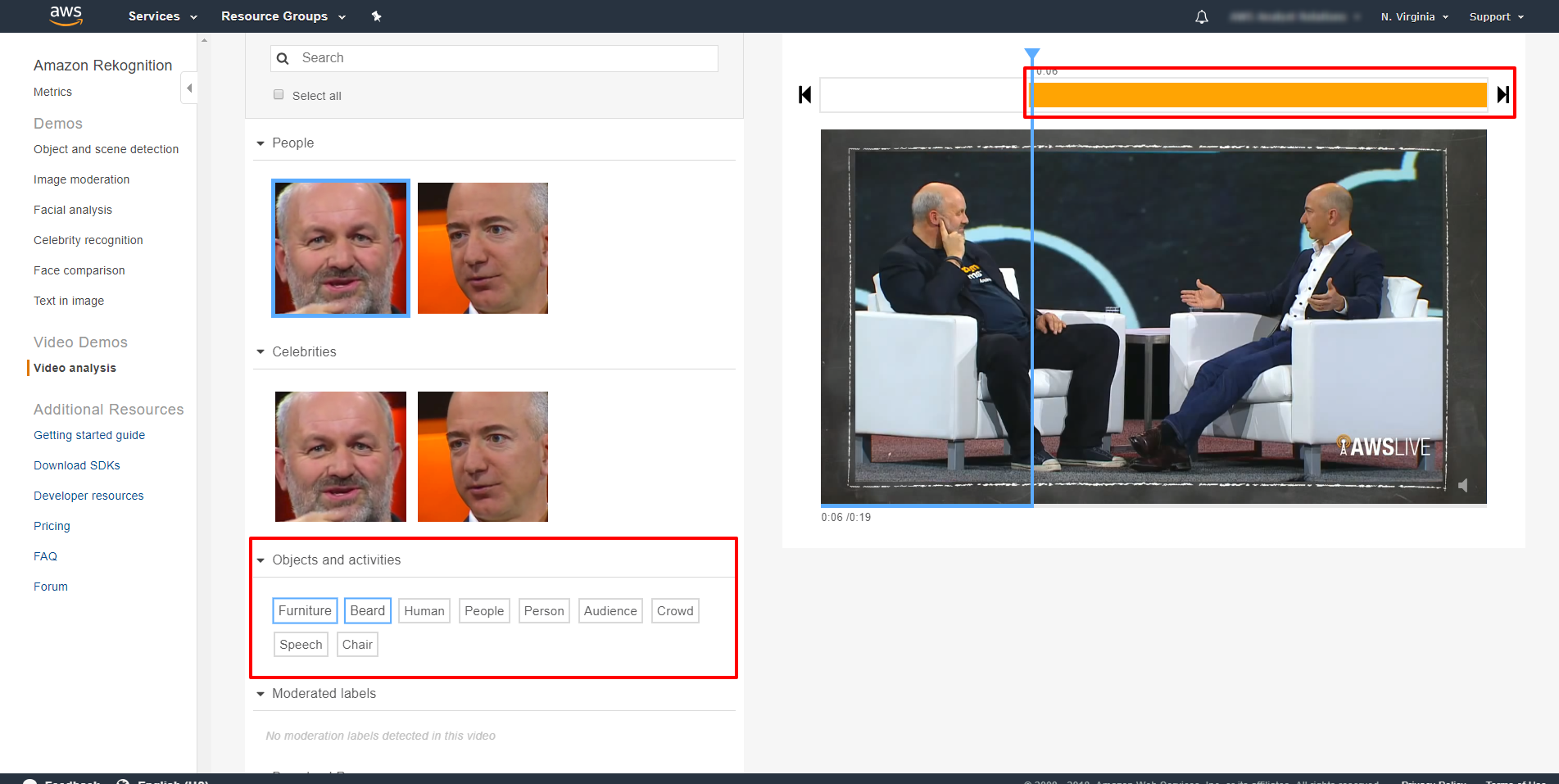
このクリップで検出されたオブジェクトとアクティビティを確認します。
「Beard」 をクリックして Werner のあごひげが検知された正確な時間を確認。
「Furniture」 をクリックしていつ椅子が検出されたのかを確認できます。
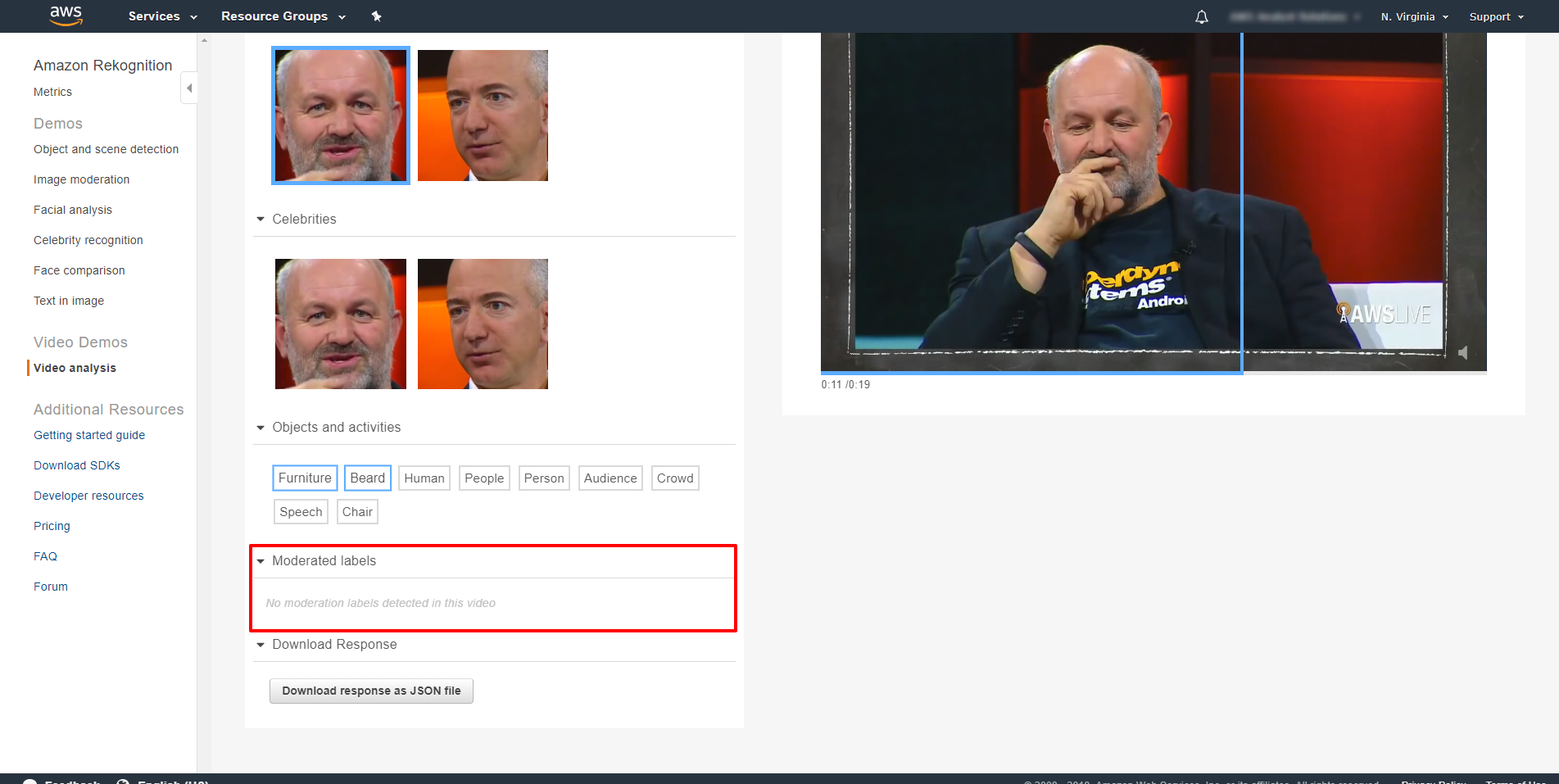
moderated labels(不適切な投稿を除外する)が全く見つからないことも見て取れます。
本機能は、自分の判断で不適切なコンテンツにフィルターをかけることを可能にします。
例えば、ヌードを含む画像にフィルターをかけたい、といったときに使えます。
ステップ2 動画のアップロード
30 秒の動画 1 本をダウンロードして、それを分析するために Rekognition コンソールにアップロードします。
こちらからダウンロードして保存
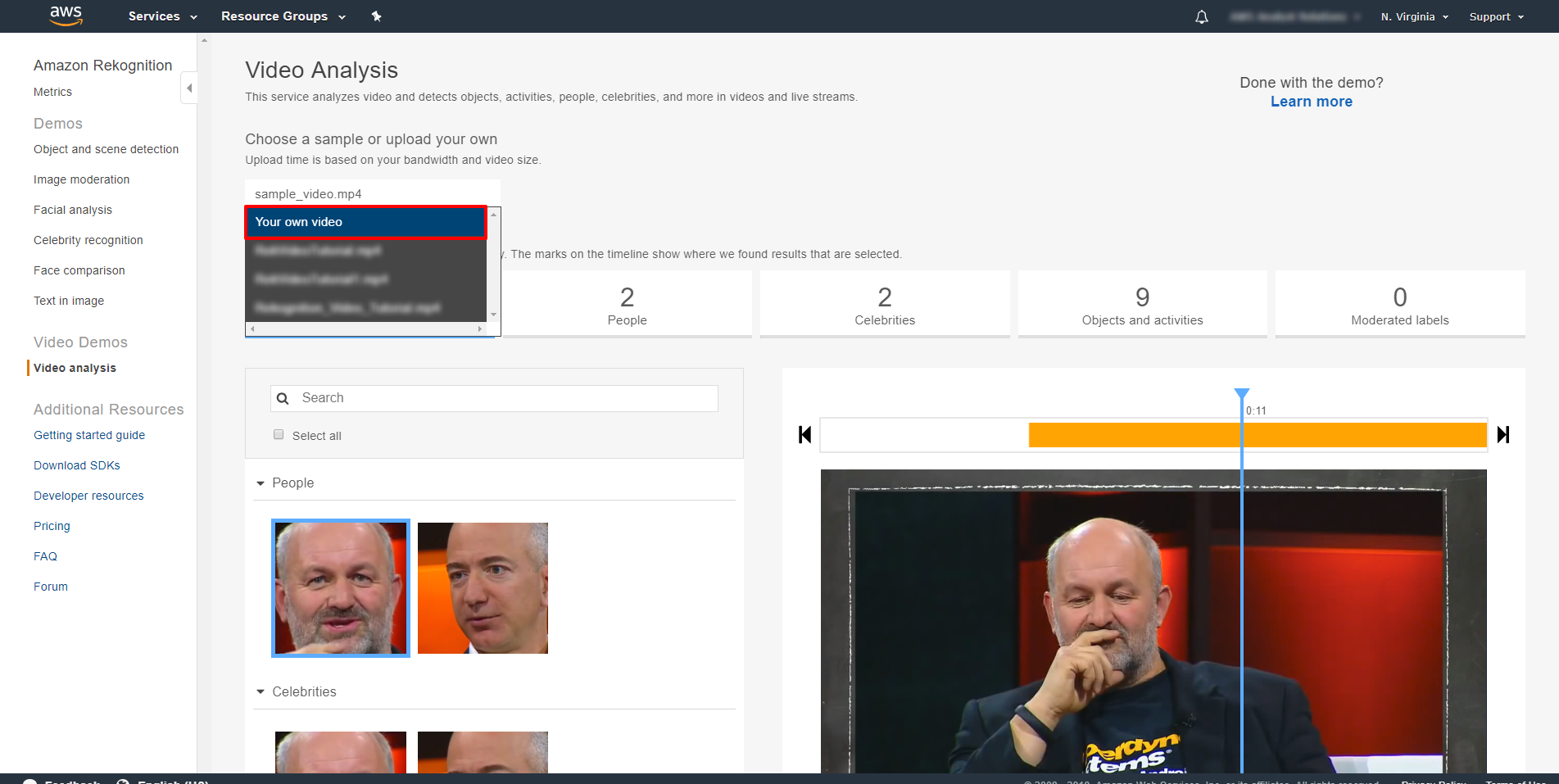
「Choose a sample」 または 「upload your own」 の下にある下向きの矢印をクリックして、「Your own video」 をクリックし、ビデオ映像を選択してデスクトップに保存します。
コンソールにて無料デモを流すに当たり、動画ファイルは、60 mb または 60 秒を超えてはならない点をご留意下さい。40 ~ 50 秒後、動画が分析され、その結果がコンソールにて見られるようになります。
スッテプ3 分析結果を見る
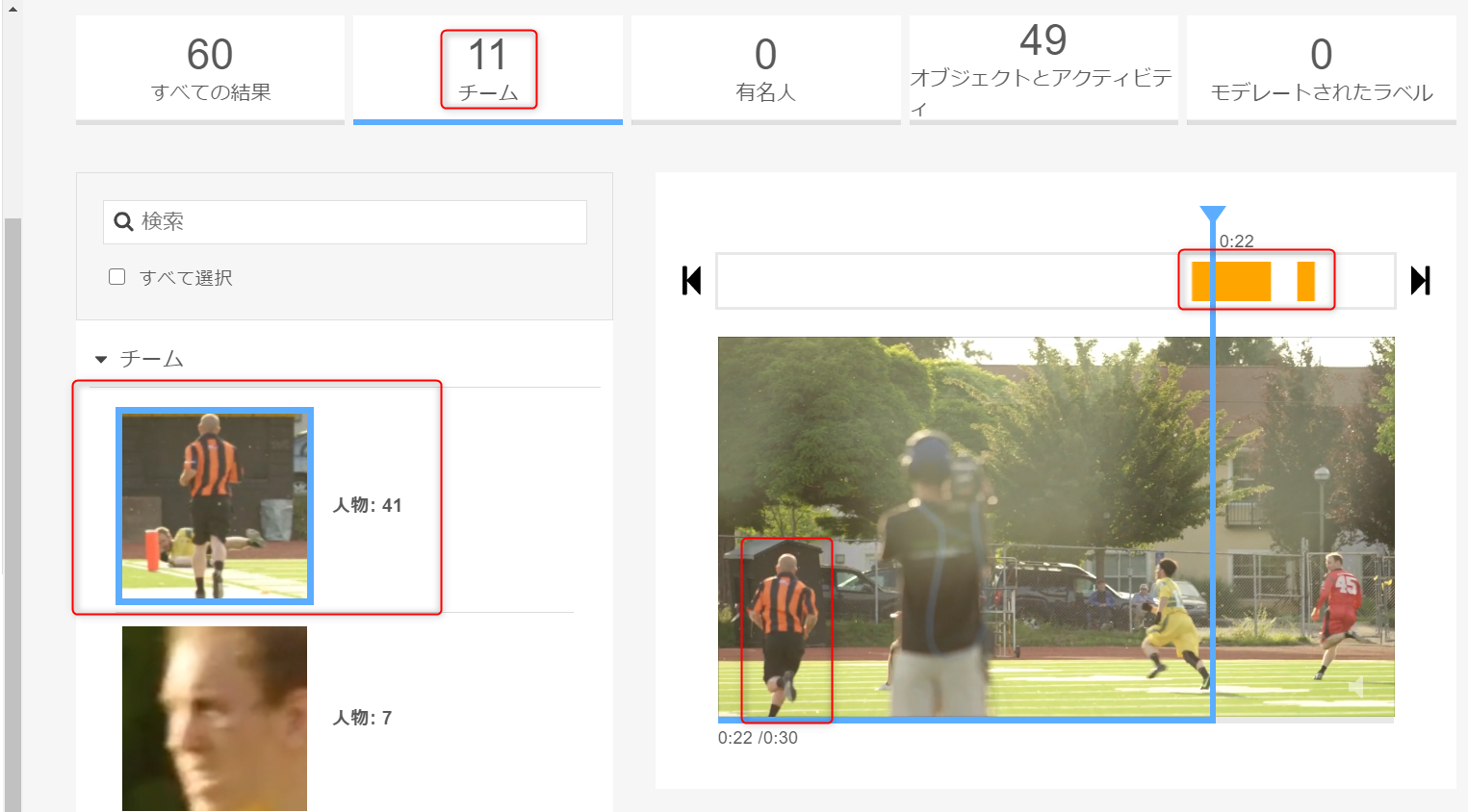
Rekognition がクリップから 11 名を検出したことに注目します。
例えば、「People」 下の 「Show more」 をクリックし、オレンジと黒の縦縞シャツを着たレフリーを選択します。
この特定のレフリーがビデオにて検知された時を、右側の動画分析にて見ることができます。
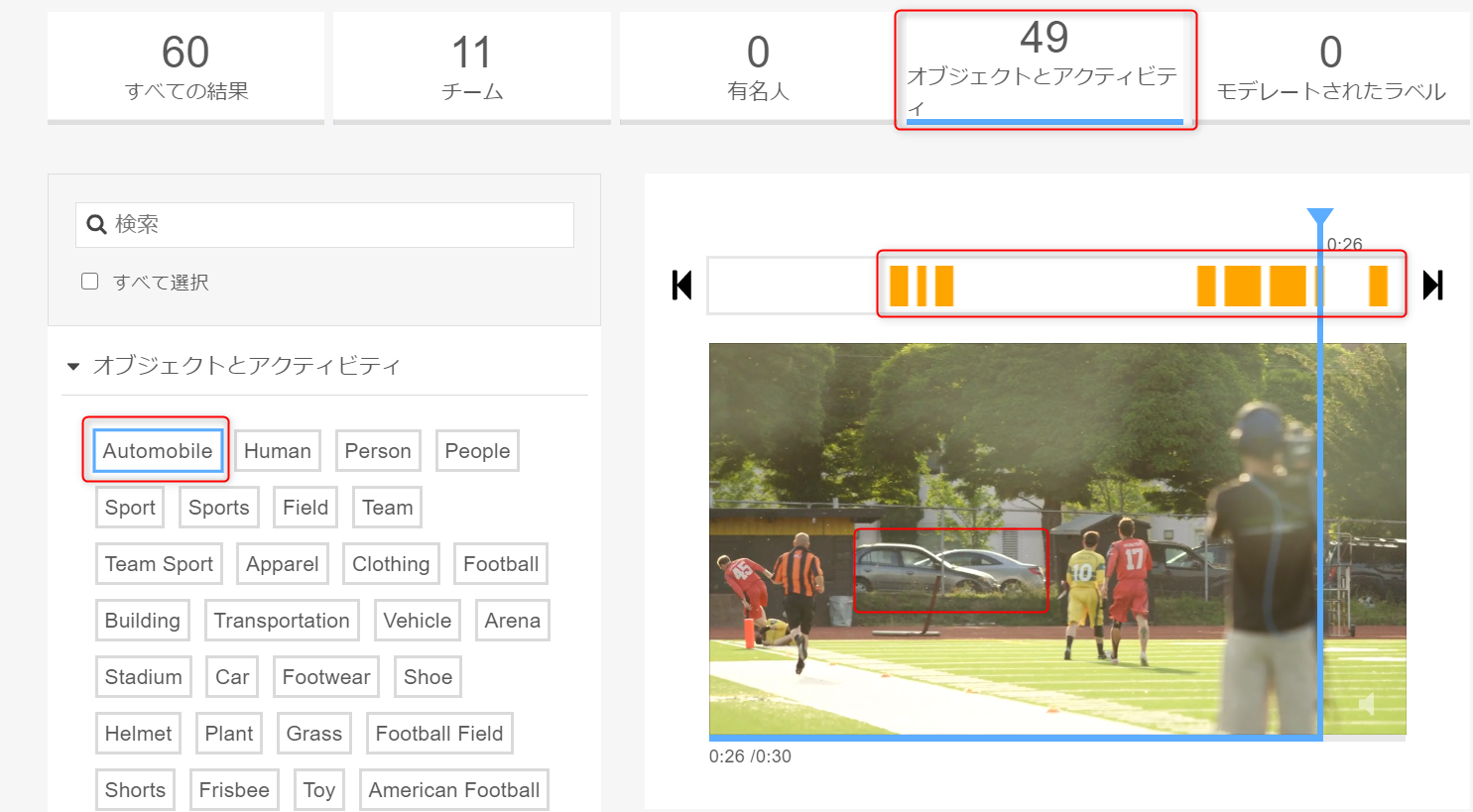
「Objects and activities」をクリックします。
自動的にタグが付けられた 49 の物体およびアクティビティが検出されています。
例えば 「Automobile」 をクリックして、自動車が検出された動画の各シーンを閲覧します。
次に、「Team Sport」をクリックして、右手の動画分析におけるフラッグが立てられた各クリップが、本ステップを通じて選択してきたラベルの内少なくともひとつを含むことになることに注目します。
レフリーは People 、そして自動車は Object 、
「Team Sport 」は Activity の下に属します。
ステップ4 リソースの削除
アップロードされた動画は、 S3 bucket に自動的に保存されますので、費用を発生させないために、それを消去する必要があります。
S3 buckets から 「rekognition-video-console-demo」で始まる bucket を見つけます。
この bucket および「select all media」をクリックして、次に右クリックをし「Delete」を選択します。まとめ
ビデオ映像からの自動メタデータは、マーケティングや広告活動に活かしたり
検索可能な動画ライブラリの構築、またはスポーツ競技で豊かな分析を提供する、スポーツトラッキングを立ち上げるためのアプリケーションにおいて活躍できると思います。
全然難しくないので、気軽に試してみてくださいね!公式サイトリンク

- 投稿日:2020-06-30T11:44:34+09:00
モノリスはクラピカ
Reactを学習中のRailsエンジニアです。学習していて思うのは、Reactは(サービス開発全体のことを考えると)Railsよりはるか学習コストが高いということ。似たようなサービスを作るために必要な手数も、考えなければいけないこともかなり多いです。
正直最初は「技術が大好きなエンジニアの自己満だろ」「Railsに飽きた奴らがやってるだけだろ」くらいに思っていたのですが、そうとも限らないことが腹落ちして理解できるようになったので、現在の考えをまとめてみようと思います。
おことわり
この記事の中で登場する
SPAという単語はフロントエンドとバックエンドを明確に分けて開発されるアプリケーションくらいの意味として解釈してください。フロントエンドのロジックをNuxt.jsで作ってNetlifyにデプロイして、Goで作ったAPIをAWSで動かす、みたいな構成のやつです。乱暴ですみません。他に良い表現があればコメントください。
モノリスはRailsやLarabelでviewファイルの生成まで行っているアプリケーションを指します。SPA⇄MPA
マイクロサービス⇄モノリス
で比較しろよ、って話ですが、マイクロサービスについて語れるほどの知識はないし、MPAというよりモノリスの話がしたかったので、雰囲気で読んでください。SPAが台頭した理由
よりリッチな表現ができる(UXの向上)
ページ遷移が高速、DOMを色々動かしてもコードがカオスになりにくいなど。SPAのメリットとして真っ先にあげられることが多いので、みなさんもよくご存知かと思います。
フロントエンドとバックエンドが疎結合になる
疎結合になると、新技術を部分的に採用することが容易になります。またサービスの規模が大きくなっても、コードがカオスになりづらいです。Railsエンジニアをやっていると、成長し大規模化したRailsアプリ開発者がつらそうにしている記事をよく見かけます。
クロスプラットフォーム対応
SPAを採用すると、web、iOS、Android、macOS用アプリ、windows用アプリで同じAPIを使うことができます。
元々web以外のプラットフォームでは、表示周りやページ切り替え等のロジックを先にインストールして、他に必要なデータのやりとりだけをAPIを使って行う、というスタイルで統一されていました。webも同じスタイルに揃うと構成がキレイになってすっきりしますね。マネージドサービスの充実
この記事を書くに至った理由です。この視点を得て、SPAが普及したことの必然性を理解しました。
2020年現在、ざっと思いつくだけでも以下のようなマネージドサービスが存在します。認証: Firebase Auth, Auth0, Cognito
決済: Stripe
検索: Algolia
サーバーレスコンピューティング: Lambda, Cloud Functions
NoSQL: CloudFirestore, DynamoDB
ストレージ: S3
メール送信: SendGridここで言えるのは、バックエンドで自前で実装しなければいけない機能が大幅に減ったということです。
「外部サービスをどれだけ有効に活用できるか」が重要になってくると、モノリスの魅力は相対的に薄れていきます。そもそもRuby on Railsが登場した2004年にはAWSすら存在しておらず、モノリスがwebアプリ開発のど真ん中に鎮座していた2010年代前半にも、上記で紹介したサービスの多くは存在していませんでした。
いくらRuby on Railsも進化しているとはいえ、これだけ状況が変わってしまえば、開発のメインストリームから外れてしまうのは仕方のないことだと感じます。
また余談ですが、Rubyの認証ライブラリで1番人気があるDeviseを使っている人は、全員つらそうな顔をしています。
その他
- コンポーネント単位で分割することで保守性や再利用性が高くなったり、デザイナーとの協業がしやすくなる
- TypeScriptとVSCodeの連携がすごい
などなど他にもSPAのメリットは色々とありそうですが、これらはどちらかというと副産物に近く、SPAが台頭したメインの理由では無いと考えています。
モノリスは用済みになったのか
全くそんなことは無いと考えています。
以下の条件を満たすアプリケーション開発では、今でもモノリスがファーストチョイスです。
「モノリスでも問題ない」ではなく、「モノリスの方が圧倒的に良い」です。
- webだけで良い
- 関わる開発者が少ない
- UXの要件がそれほど厳しくない
具体的な場面としては
- 多くのwebアプリののプロトタイプ
- リリース後の修正が少ないと予想されるシステム
- 機能要件が指定された受託開発など
- 「この機能を削ればこの予算で実現できます」など仕様をモノリスに寄せることで双方が得をする場面は必ず存在する
- 小~中規模のwebアプリの一部
- 必要な要件や、想定されるユーザー数などから技術選定。モノリスの方が効率良く開発できるサービスは、今後もそこそこの割合で残り続けるはず。
などが考えられます。
モノリスの最大の弱点とされる密結合は、必ずしも悪ではないのです。
分割は短期的な生産性を下げます。
密結合は短期的な生産性を上げます。
この点を考慮して技術選定をするべきです。結論
特定の制約の上で、モノリスはもの凄い力を発揮します。
参考
- 投稿日:2020-06-30T09:22:18+09:00
TerraformでALBを作成する
はじめに
この記事の続きです。今回はALBを作成します。
TerraformでEC2、セキュリティグループを作成する以下がディレクトリ構成です。
% tree +[master] . ├── README.md ├── main.tf ├── modules #追記 │ ├── alb │ │ ├── Create-alb.tf #作成 │ │ ├── outputs.tf #作成 │ │ └── variables.tf #作成 │ ├── ec2 │ │ ├── Create-ec2.tf │ │ ├── outputs.tf │ │ └── variables.tf │ ├── rds │ │ ├── Create-rds.tf │ │ ├── outputs.tf │ │ └── variables.tf │ ├── security_group │ │ ├── Create-securitygroup.tf │ │ ├── outputs.tf │ │ └── variables.tf │ └── vpc │ ├── Create-vpc.tf │ ├── outputs.tf │ └── variables.tf ├── outputs.tf ├── terraform.tfstate ├── terraform.tfstate.backup └── variables.tfコードの作成
main.tfにモジュールの利用を宣言
main.tfにて、alb用のセキュリティグループの作成、ALBの作成を行います。
セキュリティグループは前回作成したものを再利用。
ALBのパラメータは他モジュールからのinputや変わりそうなパラメータだけ抜き出しています。
terrarform destroyで簡単に削除できる様に、enable_deletion_protection = falseにしています。./main.tf########以下を追記######## module lb-sg { source = "./modules/security_group" sg_config = { name = "lb-sg" vpc_id = module.vpc.vpc_id protocol = "tcp" port = [80, 443] cidr_blocks = ["0.0.0.0/0"] } } module lb { source = "./modules/alb" lb_base_config = { public_subnet_id = module.vpc.public_subnet_id sg_id = module.lb-sg.sg_id NameTag = "Terraform" enable_deletion_protection = false } lb_target_config = { port = 80 protocol = "HTTP" vpc_id = module.vpc.vpc_id path = "/" instance_id = module.ec2.instance_id } }変数のinput
moduleで定義した変数を読み込みます。
セキュリティグループは前回の記事でinputしているので行う必要は無いです。./modules/alb/valiables.tfvariable "lb_base_config" { type = object({ public_subnet_id = list(string) sg_id = string NameTag = string enable_deletion_protection = string }) } variable "lb_target_config" { type = object({ port = string protocol = string vpc_id = string path = string instance_id = any }) }ALBの作成
health_checkの数値など一部ハードコートされてますが、この辺は変数化するなりすれば良いでしょう。
でも、あんまり変数化しすぎると訳がわからなくなります。。
aws_lb_target_group_attachmentについては、target_idがインスタンスIDのリストを受け入れてくれなかったのでcount方式にしています。terraform./modules/alb/Create-alb.tfresource "aws_lb" "mylb" { name = var.lb_base_config.NameTag load_balancer_type = "application" internal = false idle_timeout = 60 enable_deletion_protection = var.lb_base_config.enable_deletion_protection subnets = var.lb_base_config.public_subnet_id } resource "aws_lb_target_group" "myapp" { name = var.lb_base_config.NameTag port = var.lb_target_config.port protocol = var.lb_target_config.protocol vpc_id = var.lb_target_config.vpc_id deregistration_delay = "10" health_check { protocol = var.lb_target_config.protocol path = var.lb_target_config.path port = var.lb_target_config.port healthy_threshold = 5 unhealthy_threshold = 2 timeout = 5 interval = 10 matcher = 200 } } resource "aws_alb_listener" "myapp-http" { load_balancer_arn = aws_lb.mylb.arn port = "80" protocol = "HTTP" default_action { target_group_arn = aws_lb_target_group.myapp.arn type = "forward" } } resource "aws_lb_target_group_attachment" "myinstance" { count = length(var.lb_target_config.instance_id) target_group_arn = aws_lb_target_group.myapp.arn target_id = element(var.lb_target_config.instance_id, count.index % length(var.lb_target_config.instance_id)) port = 80 }output
あとでわかりやすい様にALBのDNS名をoutputします。
terraform./modules/alb/outputs.tfoutput "alb_dns_name" { value = aws_lb.mylb.dns_name }
- 投稿日:2020-06-30T08:45:37+09:00
サーバレスアーキテクチャにおけるアクセス制御について
はじめに
Webサービスには、認証・認可が必要な場合が多く、それをアプリで実現しようとすると手間が掛かります。
サーバレスアーキテクチャでは、認証・認可をAWSのサービスをうまく使って実装することで、開発にかかる期間を短縮できます。
また、IDやパスワード忘れなどのよくある問い合わせにも、一切コードを書かずに対応できる仕組みがあります。認証と認可
混同しがちなのですが、認証と認可を改めて確認してください。
よくわかる認証と認可
https://dev.classmethod.jp/articles/authentication-and-authorization/認証
通信の相手が誰(何)であるかを確認すること。
認可
とある特定の条件に対して、リソースアクセスの権限を与えること。
AWSサービスそれぞれの役割
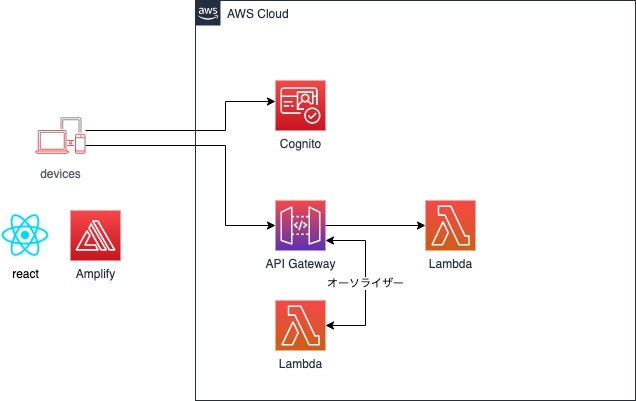
API Gateway、Cognito、Lambdaの3つの役割を記載します。
- API Gatewayは、アプリケーションがバックエンドサービスからのデータ、ビジネスロジック、機能にアクセスするための「フロントドア」として機能します。
- Cognitoは、ウェブアプリケーションおよびモバイルアプリに素早く簡単にユーザーのサインアップ/サインインおよびアクセスコントロールの機能を追加できます。
- AWS Lambda を使用することで、サーバーのプロビジョニングや管理をすることなく、コードを実行できます。料金は、コンピューティングに使用した時間に対してのみ発生します。
Cognitoから発行されるトークン
Cognitoから発行されるトークンは、3種類あります。
認証で必要となるので、覚えておいてください。
- IDトークン(IDToken)
- アクセストークン(AccessToken)
- 更新トークン(RefreshToken)
IDトークン(IDToken)
Cognito User Poolsのユーザー属性を含めたトークンです。
API Gatewayでは、こちらのトークンを使用します。
認証後、3600秒後(1時間後)で有効期限切れになります。アクセストークン(AccessToken)
Cognito User Poolsの最低限のユーザー情報を含めたトークンです。
認証後、3600秒後(1時間後)で有効期限切れになります。更新トークン(RefreshToken)
IDトークンは、1時間後に有効期限切れになるため、有効期限が切れたら更新トークンを使用して、新しいIDトークンを発行します。
更新トークンは、デフォルトで30日後に有効期限切れとなり、有効期限が切れたらサインインが必要となります。
- デフォルトで30日になっていますが、1日〜3650日まで期間を変更することが出来ます。
- AWS SDK(Amplify)を使用している場合は、更新トークンによって自動的にIDトークンが更新されますので、特に操作(ロジック)は不要です。
API Gatewayの認証方法
いくつかパターンがあるので、1つずつ解説していきます。
- IAM認証 + Cognito
- Cognitoユーザープールオーソライザー
- Lambdaオーソライザー
- APIキー
- Cognito + Lambdaオーソライザー
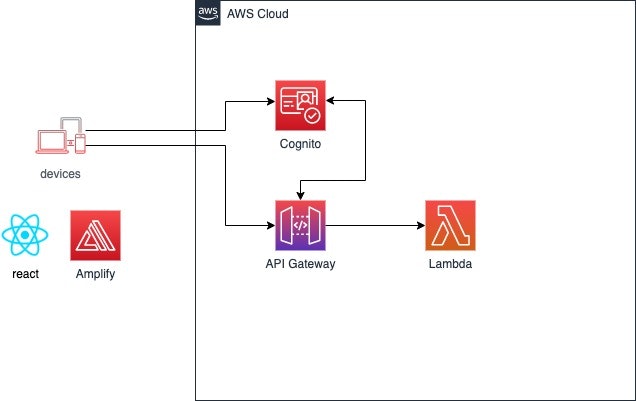
IAM認証 + Cognito
IAM認証とCognitoを組み合わせる方法。
CognitoがIAMを返して、そのIAMに基づいて、API GatewayはLambdaを実行しようとします。
Cognitoユーザープールオーソライザー
Cognitoでユーザ認証ができるか確認する方法。
IAM認証 + Cognitoと異なり、フェデレーティッドアイデンティティは使用しないし、IAMも使用しません。
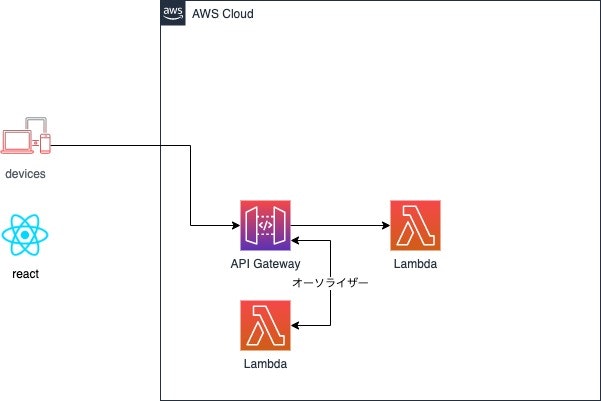
Lambdaオーソライザー
Lambdaに独自の認証ロジックを書く方法。
Lambdaに独自の認証ロジック(Authorizationヘッダにセットしたトークンの検証等)を記述でき、認証する場合、Lambdaを実行可能なIAMポリシーを生成してreturnすると、Lambdaを実行する
APIキー
APIキーでアクセス制限する。APIキーをx-api-keyヘッダに設定したときのみLambdaを実行する。
AWSは認証機能として使用しないようにドキュメントに記載しているが、一般ユーザ間の通信ではなくサーバ間のAPI通信などAPIキーが外部に漏れない状況であれば、簡易的な認証として使用できる。
Cognito + Lambdaオーソライザー
Cognitoでユーザ認証ができるか確認し、Lambdaオーソライザーで認可の処理を実装する方法。
認証方式と利用方法
ユーザーにAPI Gateway コンポーネントサービスを呼び出す権限が与えられ、Lambdaの実行が可能となります。
認証方法 利用用途 IAM認証 + Cognito ログイン済みユーザと、ゲストユーザーの2種類で、Lambdaの実行可否を制御するのに向いている。 Cognitoユーザープールオーソライザー 認証できれば、Lambdaを実行可能とするのに向いている。 Lambdaオーソライザー 独自の認証・認可ロジックを書けるが、それなりにしんどい。 APIキー APIキーが漏洩する可能性が低い、サーバ間API連係等に向いている。 Cognito + Lambdaオーソライザー クライアントでCognito認証を行い、Lambdaで独自認可処理を行う場合に向いている。認証と認可のロジックが分離できる。 まとめ
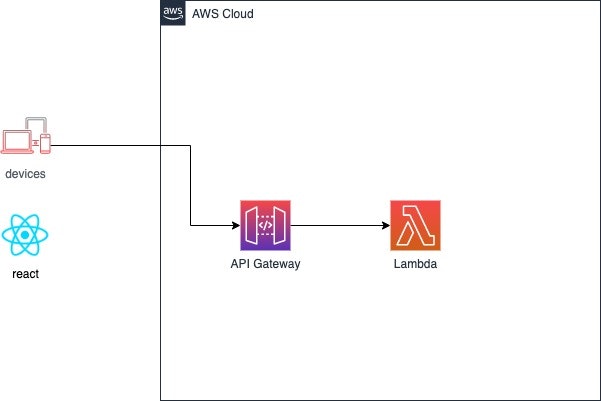
- 認証不要な場合は、API Gateway+Lambdaの構成
- サーバー間通信の場合は、シンプルなAPIキー
- 認証済みの場合に限り、特定のLambdaを実行したい場合は、IAM認証+Cognito
- 認証できれば誰でも使っていい場合は、Cognitoユーザープールオーソライザー
- WebクライアントでAWS SDKが使えない場合は、Lambdaオーソライザーで頑張る
- WebクライアントでAWS SDKが使える場合は、Cognito認証を実装し、Lambdaオーソライザーで認可

- 投稿日:2020-06-30T08:36:12+09:00
【AWS】VPCってなに?
AWS VPCとは何か
個人的なメモです。
Amazon VPCは仮想ネットワークを構築できるAWSサービスの一つです。
ネットワークはリージョン毎に構築します。
EC2などでサーバーをたてる際は、VPCで構築したネットワーク内に設置します。リージョン
- AWSのサービスが提供されている各地域のこと。参照
- リージョンによって、提供されているサービスは異なるが、基本的なサービスは使える。参照
- 値段やその地域の法律、また物理的距離の違いでリージョンを決定する。
- 例:安定的にサービスを稼働したいなら東京。テストサーバーは値段の安いバージニア北部など。
下記は2020/7時点
コード 名前 us-east-2 米国東部 (オハイオ) us-east-1 米国東部(バージニア北部) us-west-1 米国西部 (北カリフォルニア) us-west-2 米国西部 (オレゴン) af-south-1 アフリカ (ケープタウン) ap-east-1 アジアパシフィック (香港) ap-south-1 アジアパシフィック (ムンバイ) ap-northeast-3 アジアパシフィック (大阪: ローカル) ap-northeast-2 アジアパシフィック (ソウル) ap-southeast-1 アジアパシフィック (シンガポール) ap-southeast-2 アジアパシフィック (シドニー) ap-northeast-1 アジアパシフィック (東京) ca-central-1 カナダ (中部) eu-central-1 欧州 (フランクフルト) eu-west-1 欧州 (アイルランド) eu-west-2 欧州 (ロンドン) eu-south-1 ヨーロッパ (ミラノ) eu-west-3 欧州 (パリ) eu-north-1 欧州 (ストックホルム) me-south-1 中東 (バーレーン) sa-east-1 南米 (サンパウロ) アベイラビリティゾーン
- リージョン内にある独立したデータセンターのこと。
- リージョン内には複数のアベイラビリティゾーンがあり、地理的冗長化が可能。
VPC作成
- 仮想ネットワークを構築する際にリージョンを選択。
- ネットワークを区切りたいとき、サブネットを使う。
- Publicサブネットにwebサーバーを置き、PrivateサブネットにDBサーバーを置くなど。
- Publicサブネットは外部からアクセスできるが、Privateはできない。
- サブネットはアベイラビリティゾーン内に作る。
- 複数のアベイラビリティゾーンに作成し、地理的冗長化ができる。
- 投稿日:2020-06-30T02:06:19+09:00
消せいないプロセスID(PID)の消去方法!(Vim、Viでの操作不能の対処)
$ sudo visudoのコマンド入力できなくなり凄く困ったので解決方法を記載します!
何かの不具合で、
.ssh %の状態もしくは[ec2-user@ip-xx-x-x-xxx] $から強制終了されるとターミナルでのコマンド入力ができなくなる時があります。私も、過去に似たような経験をしたことがあり、多分プロセスIDが正常に切られなかったため、
ec2-userにログインした際、$ sudo visudoが入力できないと予測しました。
発生したエラーは下記ですエラー文visudo: /etc/sudoers がビジー状態です。後で再試行してくださいこの問題を可決するのに凄く時間を費やしたので、プロセスID(PID)の一般的な消去方法とプロセスID(PID)が無限に増殖する際の消去方法について記載したいと思います。
1. 基本のプロセスID(PID)の消去方法!
1. ターミナルでルートディレクトリーに移動する。または、
.ssh %の状態もしくは[ec2-user@ip-xx-x-x-xxx] $にする。ターミナルの初期画面の状態xxxxxxxxx@xxxxxxxxxxMacBook-xxx ~ % (例です)2.psを入力する
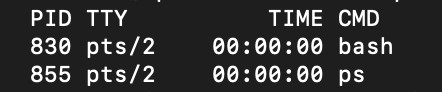
ルートディレクトリーxxxxxxxxx@xxxxxxxxxxMacBook-xxx ~ % ps.sshxxxxxxxxx@xxxxxxxxxxMacBook-xxx ~ .ssh % psec2-use[ec2-user@ip-xx-xx-xx-xxx ~]$ ps3.PID(プロセスID)が表示されるのを確認する
psを入力すると下記の図のような画面が表示されると思います。
4.PID(プロセスID)を
killorkill -9で削除する(私はec2-userの状態でエラーが発生したため、ec2-user状態での記載例を載せる)
[ec2-user@ip-xx-xx-xx-xxx ~]$ kill PIDの数値 or kill -9 PIDの数値 [ 入力例 ~] $ kill *** or kill -9 *** (*** = PID)
kill -9 (PID番号)で入力すると強制的に終了させる事ができる。5.PID(プロセスID)が消去できれば、問題なく動作可能
私の場合、この手順ではPID(プロセスID)の消去ができませんでした。実際に起きていた問題は、PID(プロセスID)を消去しても無限に再生される状態でした。
2. PID(プロセスID)の無限出現の消去方法
ここからが本題です!
私を苦しめたPID(プロセスID)の無限出現です。消し方が分かればすごく簡単に直せます!1. ターミナルでルートディレクトリーに移動する。または、
.ssh %の状態もしくは[ec2-user@ip-xx-x-x-xxx] $にする。ec2-use[ec2-user@ip-xx-xx-xx-xxx ~]$ (例です)私は、ec2-user内で発生したので、上記の状態で説明を続ける
2.
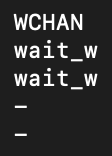
ps lを入力するec2-use[ec2-user@ip-xx-xx-xx-xxx ~]$ ps l3.プロセスごとの実行状態を確認する
- 下記のような画面が表示されると思います

4.
WCHANの列にあるwait_wのPID(プロセスID)をkillで消去する詳細画面を載せておきます
killやり方[ec2-user@ip-xx-xx-xx-xxx ~]$ kill PIDの数値 or kill -9 PIDの数値 [ 入力例 ~] $ kill *** or kill -9 *** (*** = PID)5.無限増殖するプロセスID(PID)の消去ができたため、無事に入力可能となる!
参考資料
psのコマンドの種類は下記の
ps コマンド集に記載されてます。
もし、ご興味がありましたら見て下さい!
ps コマンド集最後に
以上で、消せいないプロセスID(PID)の消去方法(プロセスID無限増殖)の説明を終わりたいと思います。間違っているてん、不明点があればご指摘頂けると助かります。
最後までご覧いただき、ありがとうございました。
- 投稿日:2020-06-30T02:06:19+09:00
消せないプロセスID(PID)の消去方法!(Vim、Viでの操作不能の対処)
$ sudo visudoのコマンド入力できなくなり凄く困ったので解決方法を記載します!
何かの不具合で、
.ssh %の状態もしくは[ec2-user@ip-xx-x-x-xxx] $から強制終了されるとターミナルでのコマンド入力ができなくなる時があります。私も、過去に似たような経験をしたことがあり、多分プロセスIDが正常に切られなかったため、
ec2-userにログインした際、$ sudo visudoが入力できないと予測しました。
発生したエラーは下記ですエラー文visudo: /etc/sudoers がビジー状態です。後で再試行してくださいこの問題を可決するのに凄く時間を費やしたので、プロセスID(PID)の一般的な消去方法とプロセスID(PID)が無限に増殖する際の消去方法について記載したいと思います。
1. 基本のプロセスID(PID)の消去方法!
1. ターミナルでルートディレクトリーに移動する。または、
.ssh %の状態もしくは[ec2-user@ip-xx-x-x-xxx] $にする。ターミナルの初期画面の状態xxxxxxxxx@xxxxxxxxxxMacBook-xxx ~ % (例です)2.psを入力する
ルートディレクトリーxxxxxxxxx@xxxxxxxxxxMacBook-xxx ~ % ps.sshxxxxxxxxx@xxxxxxxxxxMacBook-xxx ~ .ssh % psec2-use[ec2-user@ip-xx-xx-xx-xxx ~]$ ps3.PID(プロセスID)が表示されるのを確認する
psを入力すると下記の図のような画面が表示されると思います。
4.PID(プロセスID)を
killorkill -9で削除する
(私はec2-userの状態でエラーが発生したため、ec2-user状態での記載例を載せる)[ec2-user@ip-xx-xx-xx-xxx ~]$ kill PIDの数値 or kill -9 PIDの数値 [ 入力例 ~] $ kill *** or kill -9 *** (*** = PID)
kill -9 (PID番号)で入力すると強制的に終了させる事ができる。5.PID(プロセスID)が消去できれば、問題なく動作可能
私の場合、この手順ではPID(プロセスID)の消去ができませんでした。実際に起きていた問題は、PID(プロセスID)を消去しても無限に再生される状態でした。
2. PID(プロセスID)の無限増殖の消去方法!
ここからが本題です!
私を苦しめたPID(プロセスID)の無限増殖です。消し方が分かればすごく簡単に直せます!1. ターミナルでルートディレクトリーに移動する。または、
.ssh %の状態もしくは[ec2-user@ip-xx-x-x-xxx] $にする。
言語:ec2-use
[ec2-user@ip-xx-xx-xx-xxx ~]$ (例です)
私は、ec2-user内で発生したので、上記の状態で説明を続ける
2.
ps lを入力する
言語:ec2-use
[ec2-user@ip-xx-xx-xx-xxx ~]$ ps l
3.プロセスごとの実行状態を確認する
- 下記のような画面が表示されると思います
4.
WCHANの列にあるwait_wのPID(プロセスID)をkillで消去する詳細画面を載せておきます
killやり方[ec2-user@ip-xx-xx-xx-xxx ~]$ kill PIDの数値 or kill -9 PIDの数値 [ 入力例 ~] $ kill *** or kill -9 *** (*** = PID)5.無限増殖するプロセスID(PID)の消去ができたため、無事に入力可能となる!
参考資料
psのコマンドの種類は下記の
ps コマンド集に記載されてます。
もし、ご興味がありましたら見て下さい!
ps コマンド集最後に
以上で、消せないプロセスID(PID)の消去方法(プロセスID無限増殖)の説明を終わりたいと思います。間違っている点がありましたらご指摘頂けると助かります。
最後までご覧いただき、ありがとうございました。
- 投稿日:2020-06-30T01:16:50+09:00
S3に保存されたMP3ファイルをLambdaでGoogle Cloud Speech-to-Textを使って文字起こしする
S3に保存されたMP3ファイルをLambdaでGoogle Cloud Speech-to-Textを使って文字起こしする
はじめに
前回のS3に保存されたwavファイルをLambdaでGoogle Cloud Speech-to-Textを使って文字起こしするに引き続き、
今回はMP3ファイルを対象に、S3に保存されたMP3ファイルをLambdaでGoogle Cloud Speech-to-Textを使って文字起こしする手順をまとめます。重複する点が非常に多いので、相違点になるコードの部分だけ(前回でいう5-9のみ)ご紹介します。
Code
実行するコードは以下になります。
const AWS = require('aws-sdk'); const speech = require('@google-cloud/speech').v1p1beta1; const client = new speech.SpeechClient(); const s3 = new AWS.S3({ apiVersion: '2012-09-25' }); exports.handler = function(event, context) { const bucket = event.Records[0].s3.bucket.name; const key = event.Records[0].s3.object.key; const params = { Bucket: bucket, Key: key }; s3.getObject(params, async (err, data) => { if (err) { console.log(err, err.stack); } else { const audioBytes = data.Body.toString('base64'); const audio = { content: audioBytes }; const config = { encoding: 'MP3', sampleRateHertz: 44100, languageCode: 'ja-JP', }; const request = { audio: audio, config: config, }; const [response] = await client.recognize(request); const transcription = response.results.map(result => result.alternatives[0].transcript).join('\n'); console.log(transcription); }; }); }ポイント
1. Cloud Speech-to-TextをMPx3で使うにはβ版を使う
音声エンコードの概要に記されている通り、MP3ファイルの場合はベータ版のみが使用できます。 なので2行目に変更があります。
const speech = require('@google-cloud/speech').v1p1beta1;2. async/awaitで非同期処理対策
認識をしているときに、非同期で処理が行われてしまいうまく文字起こしできない可能性があるので、前回は入れなかったasync/awaitを入れてその対策をしました
const [response] = await client.recognize(request);3. sampleRateHertzの調整
お好みのツールを使ってsampleRateHertzを確認して調整していただければと。もしかしらこのパラメータ設定しなくても行けるかもしれません。
結果
transcriptionの中に入っています。個人的には結構な認識精度で驚いています。
最後に
今回は、前回の記事に続いて、MP3のデータを扱ってみました。
正直、JavaScript、Node.jsを雰囲気でやってる人間なので間違いなどあったらぜひ教えていただきたいです。参考