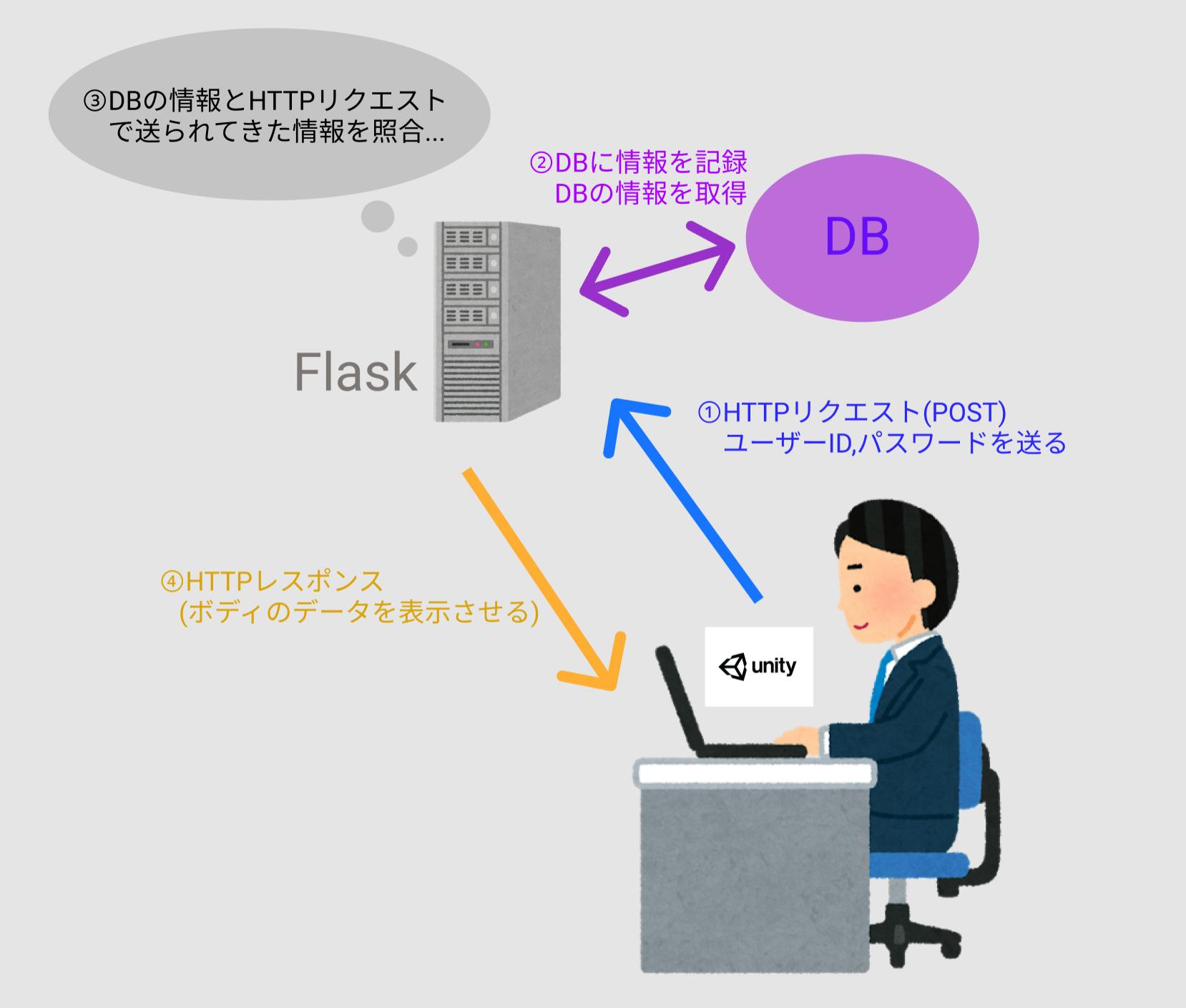
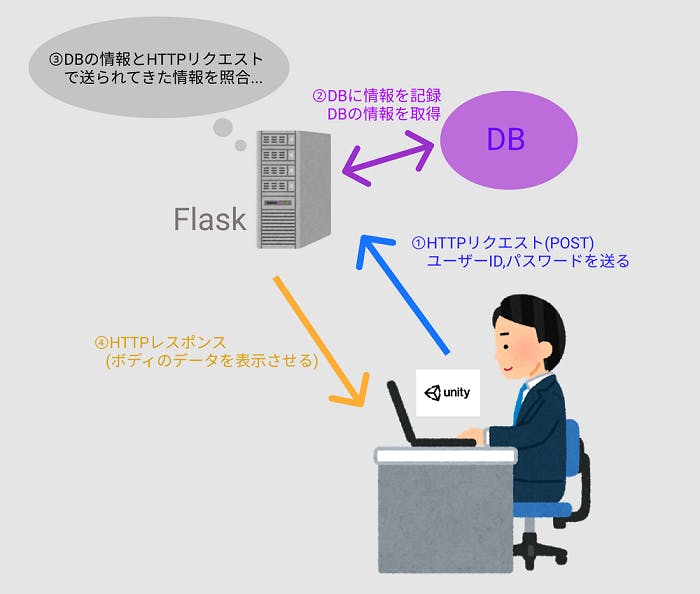
- 投稿日:2019-11-28T23:51:46+09:00
薬理学実習_鎮静睡眠麻酔薬
time.shname=$1 conc=$2 sleep 540; say "{$1}、1分前です" sleep 60; say "{$1}、時間です" say "次の投与濃度は{$2}分の1です"time.pyimport numpy as np import os,sys import pickle import pandas as pd import argparse #最初の引数受付 parser = argparse.ArgumentParser() parser.add_argument('-n', '--name', type=str, default=None, help='person name') parser.add_argument('-d', '--drug', type=str, default=None, help='drug name') args = parser.parse_args(sys.argv[1:]) name = args.name drug = args.drug time_path = 'time.sh' os.system(f'chmod +x {time_path}') result = [] import time print('実験を開始します。モニターの時間を教えて下さい') base_time = input() print(f'{base_time}より実験開始') #base time bt = time.time() conc_lis = [64,32,16,8,4,2,1,0] #input()関数で、ただエンターを押すことで次に進むことを実装する。 inp='' #各投与濃度について繰り返し for i in range(6): if inp=='': next_conc = conc_lis[i+1] #時間経過を数え、音声読み上げを行う os.system(f'bash {time_path} {name} {str(next_conc)}') #投与後10分経過した段階を記録しておく time_past = time.time() - bt print('スコアを教えて下さい') score = input() conc = conc_lis[i] print(f'睡眠スコア:{score},濃度:{conc}') result.append(np.array([time_past,score,conc])) print('注射が終わったらリターンキーを押してください') inp = input() if inp!='': inp = '' #毎回データを保存 path = f'{drug}.pickle' with open(path, 'wb') as f: pickle.dump([result, base_time],f) print(f'{path} に保存します') df = pd.DataFrame(result) df.columns=['時間経過','睡眠スコア','濃度'] print(f'{drug}.csvに保存します') df.to_csv(f'{drug}.csv') print('次の実験に移ります')
- 投稿日:2019-11-28T23:08:00+09:00
Python GoogleMapsAPIで逆ジオコーディングを日本語で出す
始まりは「緯度・経度」から
たまたまだが、仕事でデータ処理チームのExcelのVBAを色々と直しているうちに、「atsukinovさん、VBAでAPIって使ったことありますか?」と聞かれた。
「え、使ったことないですね。どうしましたか」
「VBAで、緯度・経度から住所を調べるGoogle MapのAPIを使ってるんですが、なかなかうまくいかなくて…」
「ほうほう」
ということでコード画面を見せてもらったところ
(さっぱりわからん)
というのが正直な感想だった。
こちとら画像ダウンロードでちょいとflickrのAPIをチュートリアルに沿って使ったことがあるだけで、そもそもAPIとか使わんのじゃ!!
「因みにそのデータはどのくらい処理するんですか」
「8万行です」
Oh...
そりゃ確かにAPIとかそういう機能も使いたくなるだろうな。
でも、API使うなら正直Pythonとかで処理しちゃった方が楽だなと思ったので、
「とりあえず、俺Pythonで何かできないか調べてみますよ」
と言って、まずはGoogleMapsAPIというものについて調べることにした。Geocodingの記事は見飽きたんじゃ!!
ということで早速ググってみるわけだけど、どうやら「緯度・経度」から住所を探知するのは「逆ジオコーティング(Reverse-Geocoding)」ということがわかった。
物件名や名称から住所、緯度・経度を探すのは普通の「ジオコーディング」らしい。
しかし困ったことに、この「逆ジオコーディング」でヒットする記事は少なく、求めていたコードは中々見当たらなかった。
正規のジオコーディングの記事は見飽きたんじゃ!!
さらに、逆ジオコーディングのそれっぽいコードが乗っていたとして、得られる住所は英語表記、つまり番地→都道府県という形で、アルファベットで表記されてしまうことがネックだった。
例えば「東京タワー」で調べたら、
・〒105-0011 東京都港区芝公園4丁目2−8
と表示されるのではなく、
・4-2-8, Shibakoen, Minato-ku, Tokyo
みたいな感じで表記されてしまう。
これでは住所を次に読む人が困ってしまうので、なんとか日本語表記にする方法を探した。
そして見つかった以下、コードを載せるので参考になれば幸いである。
参考にしたわかりやすい解説(Pythonでジオコーディング(Geocoder/Googlemaps))逆ジオコーディング(緯度・経度)から住所を日本語で探す
import googlemaps #GoogleMapsAPI用に取得したAPIキーを変数に格納する Key = XXXXX #GoogleMapsAPI用にAPIキーを返す gmaps = googlemaps.Client(key=Key) #リストにいくつか緯度・経度を格納する list = [ "35.65858645, 139.745440057962", #東京タワー "35.71005425, 139.810714099926" #東京スカイツリー ] #リストの中から順番に住所を探していく for i in list: results = gmaps.reverse_geocode((i), language='ja') add = [d.get('formatted_address') for d in results] print(add[1]) #=>日本、〒105-0011 東京都港区芝公園4丁目2−8 #=>日本、〒131-0045 東京都墨田区押上1丁目1−83問題はこのままだと、文頭に「日本、」という若干余計な文字が入っていること。
これをスライスで途中から記載するできるようにちょっとコードを改変する。for i in list: results = gmaps.reverse_geocode((i), language='ja') add = [d.get('formatted_address') for d in results] Jusho = add[1] print(Jusho[3:]) #=>〒105-0011 東京都港区芝公園4丁目2−8 #=>〒131-0045 東京都墨田区押上1丁目1−83うん、素晴らしい出来栄えだ。求めていた形そのものである。
ただ、問題はGoogleMapsAPIがどうやら月に無料でアクセス可能なAPIの件数が40,000件までということらしい(参照元)
まぁそれを超えるヘビーユーザーは中々いないかもしれないが、それを超えると料金が請求されてしまうので頭に入れておこう。
- 投稿日:2019-11-28T23:01:09+09:00
MSの安全確認を突破し、証明書もムリヤリ提出する、ゴリラseleniumライブラリ
なんで作ったの?
ブラウザをコードで動かすseleniumは大変便利。だが、システム毎に毎回書くのも面倒。
だったら自分の使い勝手のいいラッパー、ライブラリを作ろうじゃないか。先に結果だけ見たい人
- システムに合わせて1ファイル(systemspecific.py)だけ改修
- テストするシナリオを作ってフォルダに配置
- コードを実行して、一晩待って、スクショで確認
https://github.com/ofbear/pyAutoTest
どんなものが欲しい?
優先したいこと
- 使い回したいので、システム毎に改修すべき部分はくくりだしたい
- システムに合わせて改修したら、あとは非エンジニアでも使えるようにしたい
- オレオレ証明書で使っても文句を言われないようにしたい(物理で)
- クライアント証明書の提出もしたい(物理で)
捨ててもいいこと
- テストはどうせ夜中に走らせるので、処理は遅くてもOK
- 結果はとりあえずスクショの目視でOK
特徴は?
だいたいのところは、みなさんが各自で作ってるラッパーと一緒だと思います。
設計は好みによるところが大きいので、これから作る人の参考になるかな、程度。
一番の特徴は↓だと思う。
- オレオレ証明書で使っても文句を言われないようにしたい(物理で)
- クライアント証明書の提出もしたい(物理で)オレオレ証明書で使っても文句を言われないようにする
結論だけ書くと、ページのタイトルを見て、忠告している時は、ムリヤリOKを押していく処理。
「素直に証明書入れろ」というのはごもっともなんですが、あくまでデバッグ用なので。
(sleepを入れているのは、遷移に結構時間がかかるので、余裕を作るため)def avoid_security_check(self): ok_flg = True if self.__driver.title: # ie if self.__driver.title == "このサイトは安全ではありません": ok_flg = self.click("moreInfoContainer") ok_flg &= self.click("overridelink") time.sleep(0.5) # edge elif self.__driver.title == "証明書エラー: ナビゲーションはブロックされました": ok_flg = self.click("moreInformationDropdownSpan") ok_flg &= self.click("invalidcert_continue") time.sleep(0.5) return ok_flgクライアント証明書の提出をする
どうもクライアント証明書提出のポップアップが出ると、対応するまで、seleniumは待機状態になる模様。
つまり、selenium単独ではクライアント証明書提出はできない。
そこで、pyautoguiというos操作モジュールを使うことで、ムリヤリでもポップアップに対応しようという話。要点は3つ
- 指定時間内はポップアップ画像を検索し、見つかったらクリックする処理を作る
- ポップアップが出現するボタンを押す処理を作る
- これらが同時に走るように、並列処理を行う
これによってムリヤリにでもポップアップを処理するという仕組みです。def cert(self, cmd): self.__pki_flg = False ok_flg = True with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor: futures = [] futures.append(executor.submit(self.post_cert_chrome, cmd)) futures.append(executor.submit(self.submit, cmd)) for future in concurrent.futures.as_completed(futures): ok_flg &= future.result() return ok_flg def submit(self): ok_flg = self.click("submit") return ok_flg def post_cert_chrome(self, cmd): # cmd check is practiced if cmd == "ok": ok_flg = self.move_click("img/chrome/ok.png") elif cmd == "cancel": ok_flg = self.move_click("img/chrome/cancel.png") elif cmd.isdecimal(): diff = 80 + (int(cmd) * 40) ok_flg = self.move_click("img/chrome/next.png", 0, diff) ok_flg &= self.move_click("img/chrome/ok.png") return ok_flg def move_click(self, img_path, x=0, y=0, seconds=0.2): # search from image pos, ok_flg = self.search_from_image(img_path) if ok_flg: # move mouse pyautogui.moveTo(pos.x + x, pos.y + y, seconds) # click pyautogui.click() return ok_flg def search_from_image(self, img_path): # check image if not os.path.isfile(img_path): self.__log.printLog(LOG_LEVEL.EEROR, "failed to setting") return None, False i = 30 while i > 0: i -= 1 # get position pos = pyautogui.locateCenterOnScreen(img_path) if pos: break time.sleep(0.2) if not pos: return None, False return pos, True最後に
seleniumラッパーはともかく、安全確認とポップアップを突破したい人はちらほらいて。
その解決がネットにはあまりなかったようなので、記事にしてみました。いつか誰かの参考になれば幸い。とりあえず、やりたいことができれば、強引でもよかろうというスタンスの。ゴリラコーディングでした。
- 投稿日:2019-11-28T22:33:52+09:00
PythonのUnittestでmotoによるmockを共通化する
1. 動機
テストコード作成中に各テストコードでmockを作成するのが冗長的だなと思い、共通化できないか試行錯誤してみた。
以下、スタート時点のサンプルアプリとサンプルテストコード。
テストコードのEC2作成部分を共通化する。
- アプリ:EC2の情報を取得して出力する
app.pyimport boto3 def main(): client = boto3.client('ec2') # 全てのインスタンス情報を取得する。 instances = client.describe_instances() # インスタンス名を抽出する。 instace_name = [instance['KeyName'] for r in instances.get('Reservations') for instance in r.get('Instances')] # インスタンス名を出力する print(instace_name)
- テストコード:mockでEC2を作成しアプリを実行する
test.pyimport unittest import boto3 from moto import mock_ec2 from app import app class MyTestCase(unittest.TestCase): @mock_ec2 def test_case_1(self): client = boto3.client('ec2') # 作成するEC2の条件を設定 ec2objects = [ {'KeyName': 'test_ec2_name_1'} ] # EC2を作成 for o in ec2objects: client.run_instances( ImageId='ami-03cf127a', MinCount=1, MaxCount=1, KeyName=o.get('KeyName')) # アプリを実行 app.main() @mock_ec2 def test_case_2(self): client = boto3.client('ec2') # 作成するEC2の条件を設定 ec2objects = [ {'KeyName': 'test_ec2_name_2'} ] # EC2を作成 for o in ec2objects: client.run_instances( ImageId='ami-03cf127a', MinCount=1, MaxCount=1, KeyName=o.get('KeyName')) # アプリを実行 app.main() if __name__ == '__main__': unittest.main()2. setUpメソッドを使用してみる
setUpメソッドにEC2を作成するコードを記述し、テストケース実行前にEC2が作成されるか試してみる。
test.pyimport unittest import boto3 from moto import mock_ec2 from app import app class MyTestCase(unittest.TestCase): @mock_ec2 def setUp(self): client = boto3.client('ec2') # 作成するEC2の条件を設定 ec2objects = [ {'KeyName': 'test_ec2_name_1'} ] # EC2を作成 for o in ec2objects: client.run_instances( ImageId='ami-03cf127a', MinCount=1, MaxCount=1, KeyName=o.get('KeyName')) @mock_ec2 def test_case_1(self): # アプリを実行 app.main() @mock_ec2 def test_case_2(self): # アプリを実行 app.main() if __name__ == '__main__': unittest.main()result.test_case_1 (tests.test_setUp.MyTestCase) ... [] ok test_case_2 (tests.test_setUp.MyTestCase) ... [] ok ---------------------------------------------------------------------- Ran 2 tests in 0.458s OKEC2名は出力されない。
motoによるmockの有効期限はメソッドの終了までのようで、setUpメソッドに記述してしまうとsetUpメソッド終了時点でmockが消えてしまう。
結果、テストケース実行時にはmockが存在していない。3. 共通クラスを作成し、各メソッドから実行する
前項の結果からmockはテストケースないで作成しなければならないとわかったので、共通クラスを作って各ケースから共通クラス内のメソッドを実行できないか試してみる。
test.pyimport unittest import boto3 from moto import mock_ec2 from app import app class common: @staticmethod def enviroment_1(name): client = boto3.client('ec2') # 作成するEC2の条件を設定 ec2objects = [ {'KeyName': name} ] # EC2を作成 for o in ec2objects: client.run_instances( ImageId='ami-03cf127a', MinCount=1, MaxCount=1, KeyName=o.get('KeyName')) class MyTestCase(unittest.TestCase): @mock_ec2 def setUp(self): self.common = common @mock_ec2 def test_case_1(self): # EC2を作成 self.common.enviroment_1('test_ec2_name_1') # アプリを実行 app.main() @mock_ec2 def test_case_2(self): # EC2を作成 self.common.enviroment_1('test_ec2_name_2') # アプリを実行 app.main() if __name__ == '__main__': unittest.main()result.test_case_1 (tests.test_common.MyTestCase) ... ['test_ec2_name_1'] ok test_case_2 (tests.test_common.MyTestCase) ... ['test_ec2_name_2'] ok ---------------------------------------------------------------------- Ran 2 tests in 0.489s OKいい感じに共通化できて、思った通りの結果が返ってきた。
ただ共通クラスを作るのはコード数増えるのでもう少し簡単にしたい。3. テストクラス内に共通メソッドを作成する
そもそもテストクラス内でテストケース以外の共通メソッドが作成できれば一番手っ取り早いことにやっと気づく。
test.pyimport unittest import boto3 from moto import mock_ec2 from app import app class MyTestCase(unittest.TestCase): @mock_ec2 def test_cace_1(self): # EC2を作成 self.__common('test_ec2_name_1') # アプリを実行 app.main() @mock_ec2 def test_cace_2(self): # EC2を作成 self.__common('test_ec2_name_2') # アプリを実行 app.main() def __common(self, name): client = boto3.client('ec2') # 作成するEC2の条件を設定 ec2objects = [ {'KeyName': name} ] # EC2を作成 for o in ec2objects: client.run_instances( ImageId='ami-03cf127a', MinCount=1, MaxCount=1, KeyName=o.get('KeyName')) if __name__ == '__main__': unittest.main()result.test_case_1 (tests.test.MyTestCase) ... ['test_ec2_name_1'] ok test_case_2 (tests.test.MyTestCase) ... ['test_ec2_name_2'] ok ---------------------------------------------------------------------- Ran 2 tests in 0.361s OKできた。
これが今できる一番スマートな共通化。
- 投稿日:2019-11-28T21:43:02+09:00
pythonのmodels.pyで設定するテーブルを関連付ける
やりたい事
pythonでdjangoを使ってブログを作っている。
models.pyにテーブルの設定を行う際に、
カテゴリー>記事のような親と子の関係にあるテーブルを作りたい。やり方
各テーブルを紐づけるには、
各テーブルに存在する変数を用いる。
その際指定される変数をforeign_keyとして設定する。実際にやってみた
ブログに投稿する記事には以下のclassとデータが入っている。
postクラスには
id,title,cantent,created_at,category
その際categoryクラスは別で作り、
id,name,created_at
で構成されている。これらをデータ型も決めてコードに落とすと、
class Category(models.Model): name = models.CharField('カテゴリ名',max_length=255) created_at = models.DateTimeField('日付',default=timezone.now) class Day(models.Model): title = models.CharField('タイトル',max_length=200) text = models.TextField('本文') date = models.DateTimeField('日付',default=timezone.now) category = models.ForeignKey(Category,verbose_name='カテゴリ',on_delete=models.PROTECT)Dayクラスのcategoryインスタンスに代入しているのはmodelsにForeignKey関数を掛け合わせたものである。
その際に第一引数にcategoryを取り、verbose_nameでモデルの名前を任意のものに変えられます。
そしてon_deleteにPROTECT関数を代入する事でcategoryクラスで消去の処理を行った際でもpostクラスが存在する限り消去が行われなくなる(カテゴリを消しても投稿した記事は消えない)。まとめ
ForeignKey関数を使う事で、
設定元が親テーブル、参照される側は小テーブルとなり関連づけられる。参考記事
ForeignKey:https://www.sejuku.net/blog/54072
verbose_name:https://codor.co.jp/django/how-to-use-verbose-name
- 投稿日:2019-11-28T19:53:21+09:00
デジタル世界で時を刻む、ブロックチェーンのちょっと深い話
そろそろ年末が近づき、良くも悪くも時間の流れを感じる時期になってきました。現代人は時間に追われ、忙しい毎日を送っていますが、人間と時間は密接な関係があります。
ところで、ブロックチェーンといえば、改ざんできないとか、分散型であるとか、いろいろな形で評価されていますが、他にも「デジタル世界に時間の流れを作り出した」とみることもできます。
先日登壇したイベントでもこの話題についてお話しましたが、あらためてQiitaでもまとめてみます!
上記画像をクリックすると登壇した時の様子のダイジェストがyoutubeで視聴できます!時間って深い
そもそも、時間って概念はいつ誕生したのでしょうか? 一説によれば、紀元前3500年頃、今から5000年以上も前に、エジプトで誕生したと言われています。太陽が上って沈むまでを、太陽が作る影を使って、1日を分割して時間を表現し始めたようです。当時のエジプトは1年を365日にした地でもあり、人類史でみても重要な転換点でもありました。
ちなみに、今我々が使っている1秒という単位は、セシウムという元素の状態遷移を利用しています。また、世界中の時刻の基準になるのはグリニッジ標準時です。これまでにたくさんの人が正確な「時間」を計測して定義しようと努力してきたことが伺えます。
時間の流れそのものは人の目でみることはできません。そこで、太古の昔から一定の間隔で印をつけることで、時間の流れを表現してきました。影の場所、星の位置、時刻などなど、実にたくさんの道具や概念を使って、時間の流れを可視化してきたのです。
デジタル世界の時間
ここまでの話は、リアルな世界での話でした。視点を変えてみて、デジタル世界ではどうでしょうか?
デジタル世界は情報が"光の速さ"で飛び交い、人と人をつなげることができました。しかし、データのコピペが簡単にできるが故に、どのデータが正しいのか分からなくなりやすいという性質も持っています。そこで、データを作られた順番に並べ、リアルな世界と同じように時間の流れに合わせて整理してあげればいいのではないか、と考えることができます。あるタイミングで誰が何をどのくらい持っているのかが分かったとして、その状態は後にも先にもそのタイミングだけであると保証することができればデータの唯一性を保つことができます。
ブロックチェーンは管理者のいない分散型のネットワークにおいて、このようにデータを時間の流れに沿って並べるための方法を作り出しました。だからこそ、誰がどのくらい持っているのかという情報が肝になる「通貨」や、そのタイミングで誰が持っていたのかという「所有権」などが、デジタルの分散型ネットワーク上で扱えるようになったのです。
具体的には、実にさまざまな技術を連携させてこれを実現しているわけなのですが、その中でも重要な役割を果たしているのがハッシュ関数です
ハッシュ関数を連鎖させる
ブロックチェーンではハッシュ関数と呼ばれる関数が非常によく使われます。ブロックチェーンでは、ハッシュ関数を工夫して使うことで、時間の流れを作り出しました。
ハッシュ関数?
ハッシュ関数は端的に説明すると、「入力されたデータを一定の長さのデータに変えて出力する」ものです。
例えば、
Qiitaという文字をハッシュ関数にかけてやると、b352ef02eddfbe535b1a502a7753987ed139b2db30f215d7a793462d69e1570bというデータとなって返ってきます。
Qiita最高なら、388e0bb2085247e440e97f9f0cfab7aac6e05c4032c3763c33ac17b0d8d50da4です。他にも、入力データが少しでも変わると、出てくるデータが大きく変わる性質があります。Qiitaの大文字を小文字に変えて
qiitaにすると、e54e4c85c3aab2dfe3782e6bee5742d39899e227edc1b437d7fd30b1f1f7c3a8となります。ハッシュ値の比較Qiita ---> b352ef02eddfbe535b1a502a7753987ed139b2db30f215d7a793462d69e1570b Qiita最高 ---> 388e0bb2085247e440e97f9f0cfab7aac6e05c4032c3763c33ac17b0d8d50da4 qiita ---> e54e4c85c3aab2dfe3782e6bee5742d39899e227edc1b437d7fd30b1f1f7c3a8しかも、入力した値と出力した値は一対一の関係で、一つの入力値には、1つの出力値しか紐づきません。また、出力されたハッシュ値から入力された値を逆算することも基本できません。
ハッシュの鎖
このハッシュ関数、ある工夫をして使うと面白いことができます。
ちょっとやってみましょう。
まず関数で適当なワードをハッシュ化してみます。今回は、東京駅にしましょう。このハッシュ値はこちらです。
b1da97b0d5652c7498c02f717fa6be043b6b519f801732f8f4c0d7cafd41153e次に、
品川駅をハッシュ化しますが、そこでひと工夫します。その工夫は、先ほど作ったハッシュ値と合体させてハッシュ化するというものです。つまり、b1da97b0d5652c7498c02f717fa6be043b6b519f801732f8f4c0d7cafd41153e品川駅とします。最後にちゃんと品川駅がついていますよね。こちらをハッシュ化すると11ca45f31c305dce198643dbde9bc9981d4763d578f4aa3cac459a820bbdcac4となります。ハッシュ関数の特徴に同じ長さのデータを出力するというものがありましたが、ちゃんと同じ長さになっていますね。同じように
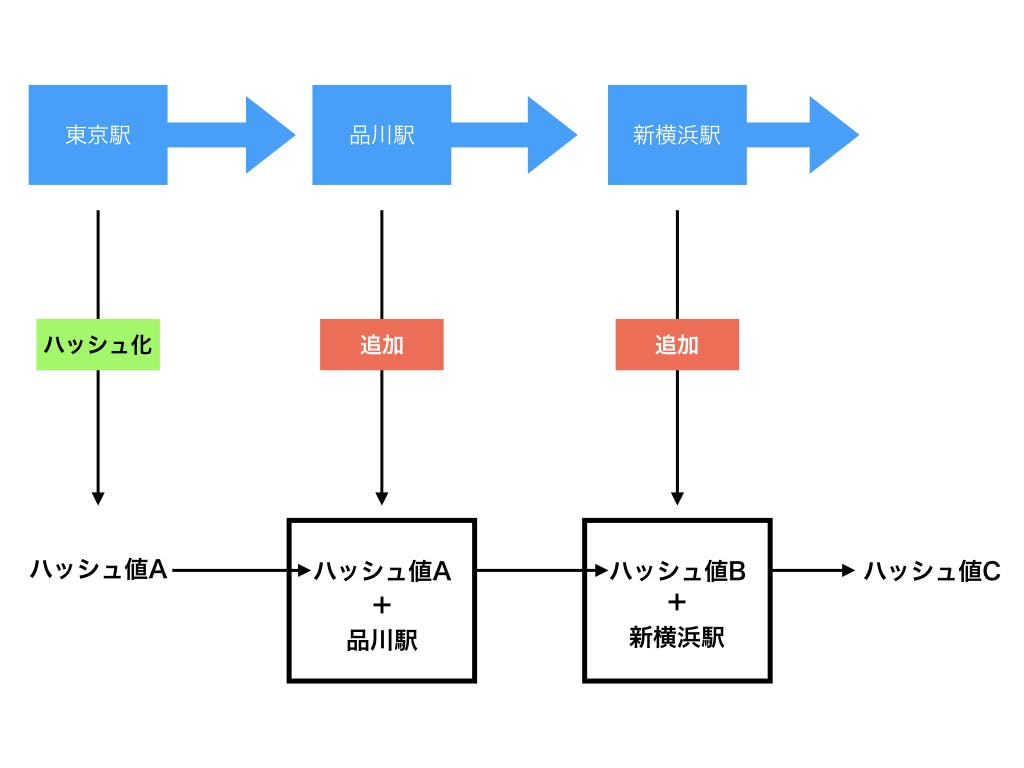
新横浜でやってみましょう。先ほどのハッシュ値11ca45f31c305dce198643dbde9bc9981d4763d578f4aa3cac459a820bbdcac4に新横浜を合体させてハッシュ化するとfc2acfecbd366054ee1a547108a8399133399b22e55d0123715efefdc173b4b5となります。何故こんな形でハッシュ関数を使ったのか、以下の図を見るとわかりやすくなると思います。
こんな感じで、前のデータを使ってハッシュ値を出し、次のデータでそのハッシュ値を利用してさらに計算しています。そのため、データの前後関係に依存関係が生まれます。ということは、今回の場合、品川駅の前は東京駅であり、品川駅の後ろは新横浜駅であり、それ以外はありえないと言い切れます。新横浜駅の次に東京駅がくることはありえないというわけですね。
ブロックチェーンは「デジタル世界に時間の流れを作った」
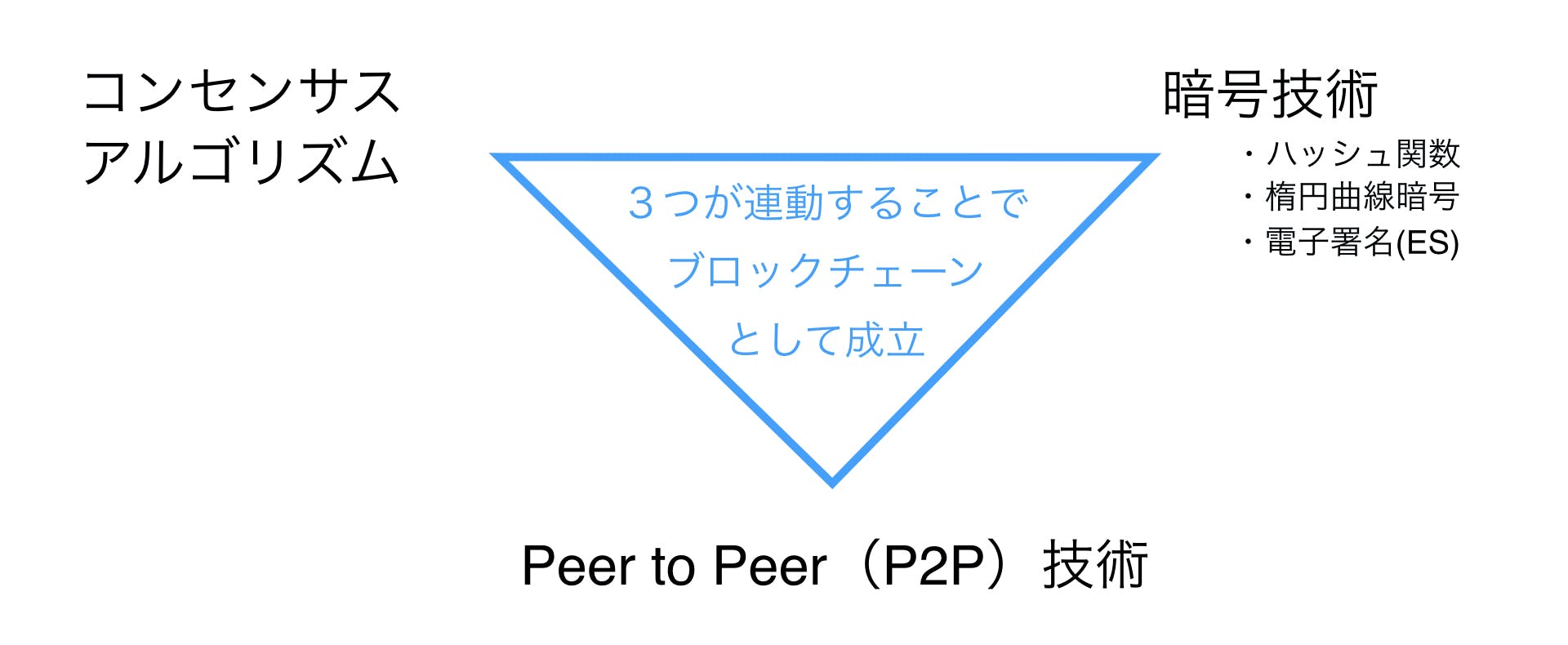
ブロックチェーンは、上記のようにハッシュを鎖のようにつなげていくことで、時間の流れを表現しました。ブロックチェーンの基本的なコンセプトをまとめているサトシナカモトの論文でも、全体を通してTimestampというキーワードが登場し、そこでハッシュ関数が使われています。
実際には、コンセンサスアルゴリズムや電子署名、楕円曲線暗号などさまざまな技術を連携させて、より安全性や真正性を高めて、全体としてブロックチェーン技術として機能しています。
Time goes by...
時間の流れは巻き戻すことができません。過去の失敗、今の怠慢、将来の不安、時間は時に全ての人に残酷なものです。しかし、時の流れは平等でもあります。時間というものを考えてみると、今をどう生きるかということに思いをはせてしまいます。
最後は、故スティーブジョブスの名言で終わることにしましょう。
あなたの時間は限られている。
だから他人の人生を生きたりして無駄に過ごしてはいけない。
ドグマ(教義、常識、既存の理論)にとらわれるな。
それは他人の考えた結果で生きていることなのだから。
他人の意見が雑音のようにあなたの内面の声をかき消したりすることのないようにしなさい。
そして最も重要なのは、自分の心と直感を信じる勇気を持つことだ。文系ビジネスパーソンのためのブロックチェーンプログラミング入門
ブロックチェーンは概念を知るだけだと、とても分かりにくい技術です。しかし、実際に簡単なプログラムによって実際に動かし、技術の核心を目で見て確認することで、より深く理解することができます。ブロックチェーンを"体感"すれば、ブロックチェーンの可能性やどう生活を変えてくれるのかを生き生きと考えることができます。今回、エンジニアでない文系のビジネスパーソンの方でも、ブロックチェーンを感じられるようプログラミングの基本的な部分やエンジニアの考え方から、ブロックチェーンの仕組みまで学ぶことができる講座を用意しました!
この講座で、シンプルで人気の開発言語 Pythonで書かれたコードを動かして、ブロックチェーンとプログラミングの両方を学びながら技術に強いビジネスパーソンを目指してみませんか?


- 投稿日:2019-11-28T18:56:32+09:00
【Python】CSVデータの形態素解析からCSV出力まで【GiNZA】
CSVデータを収集する
まずは、CSVデータをとってきます。
何のデータを取ってこようか悩みましたが、
大好きなヨルシカの歌詞をスクレイピングして取ってきます。まず、スクレイピングに必要なモジュールのインストール
pip install requests pip install bs4 pip install lxml pip install pandasスクレイピング!
ここを参考にしました。
【https://qiita.com/yuuuusuke1997/items/122ca7597c909e73aad5#%E3%81%8A%E3%82%8F%E3%82%8A%E3%81%AB】import requests from bs4 import BeautifulSoup import pandas as pd import time #スクレイピングしたデータを入れる表を作成 list_df = pd.DataFrame(columns=['歌詞']) for page in range(10): try: #曲ページ先頭アドレス base_url = 'https://www.uta-net.com' #歌詞一覧ページ artist = "22653" url = 'https://www.uta-net.com/artist/'+artist+'/0/' + str(page) + '/' response = requests.get(url) soup = BeautifulSoup(response.text, 'lxml') links = soup.find_all('td', class_='side td1') for link in links: a = base_url + (link.a.get('href')) #歌詞詳細ページ response = requests.get(a) soup = BeautifulSoup(response.text, 'lxml') song_lyrics = soup.find('div', itemprop='lyrics') song_lyric = song_lyrics.text song_lyric = song_lyric.replace('\n','') #サーバーに負荷を与えないため1秒待機 time.sleep(1) #取得した歌詞を表に追加 tmp_se = pd.DataFrame([song_lyric], index=list_df.columns).T list_df = list_df.append(tmp_se) except: print(page) import traceback traceback.print_exc() print(list_df) #csv保存 list_df.to_csv('list.csv', mode = 'a', encoding='utf_8_sig')形態素解析の必要なインストール
まずは必要なものをインストール
pip install "https://github.com/megagonlabs/ginza/releases/download/v1.0.2/ja_ginza_nopn-1.0.2.tgz" pip install matplotlib pip install wordcloudmatplotlibの日本語化
これを参考に【https://qiita.com/osakasho/items/7408d031ca0b2192422f】
解析とグラフの表示!
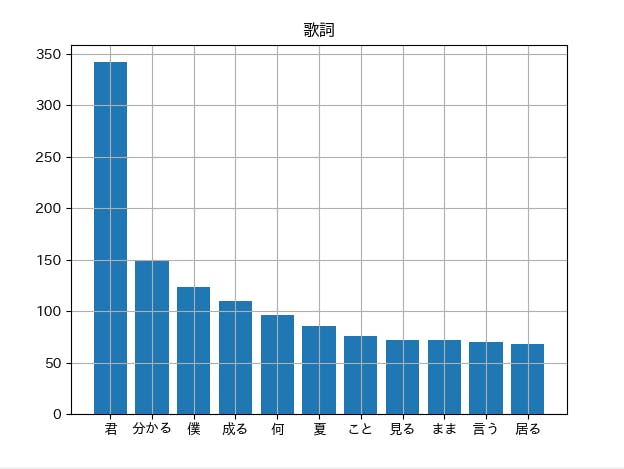
# coding: utf-8 import spacy nlp = spacy.load('ja_ginza_nopn') import pandas as pd import matplotlib.pyplot as plt import collections from wordcloud import WordCloud def ginza(word): doc = nlp(word) # 調査結果 total_ls = [] Noun_ls = [chunk.text for chunk in doc.noun_chunks] Verm_ls = [token.lemma_ for token in doc if token.pos_ == "VERB"] for n in Noun_ls: total_ls.append(n) for v in Verm_ls: total_ls.append(v) return total_ls, Noun_ls, Verm_ls """--------------- CSV読み込みと前セット --------------""" csv_read_path = "list.csv" df = pd.read_csv(csv_read_path) target_categories = ["歌詞"] black_list = ["test"] """-------------------------------------------------------------""" """--------------- 形態素の処理 ------------------------""" for target in target_categories: total_voc = []#文字を入れる箱を用意 for data in df[target]: try: word_ls, noun_ls, verm_ls = ginza(data) except:#もし、分解できない場合は、一単語とする。 word_ls = [data] for w in word_ls: if not w in black_list:#その単語がブラックリストに入っていないかチェックする。 total_voc.append(w) print("単語数は、", len(total_voc), "でした。") # 最頻単語を順位づけ c = collections.Counter(total_voc) # CSVに書き込む c_data = (c.most_common()) csvdf = pd.DataFrame(c_data) filename = target + ".csv" csvdf.to_csv(filename, encoding='utf_8_sig') print("----------------------------") # 一応グラフ化する # 追加部分 フォントを指定する。 plt.rcParams["font.family"] = "IPAexGothic" plt.title(target) plt.grid(True) graph_x_list = [] graph_y_list = [] top_num = 0 for key, value in c.most_common(): graph_x_list.append(key) graph_y_list.append(value) if top_num >= 10: break top_num += 1 try: plt.bar(graph_x_list, graph_y_list) # グラフの表示 plt.show() except: print(target, " に関して、データを描画できませんでした。") # WordCloud で描画する font = 'C:/Windows/Fonts/YuGothM.ttc' wordcloud = WordCloud(background_color="white", width=1000, height=600, font_path=font) wordcloud.generate(" ".join(wordcloud_ls)) wordcloud.to_file(target+'.png') """-------------------------------------------------------------"""グラフの結果
棒グラフの結果
WordCloudの結果
めっちゃ分かってそうだね
お疲れ様でした。

- 投稿日:2019-11-28T18:56:32+09:00
【Python】CSVデータの形態素解析からCSV出力・グラフ表示まで【GiNZA】
CSVデータを収集する
まずは、CSVデータをとってきます。
何のデータを取ってこようか悩みましたが、
大好きなヨルシカの歌詞をスクレイピングして取ってきます。まず、スクレイピングに必要なモジュールのインストール
pip install requests pip install bs4 pip install lxml pip install pandasスクレイピング!
ここを参考にしました。
【https://qiita.com/yuuuusuke1997/items/122ca7597c909e73aad5#%E3%81%8A%E3%82%8F%E3%82%8A%E3%81%AB】import requests from bs4 import BeautifulSoup import pandas as pd import time #スクレイピングしたデータを入れる表を作成 list_df = pd.DataFrame(columns=['歌詞']) for page in range(10): try: #曲ページ先頭アドレス base_url = 'https://www.uta-net.com' #歌詞一覧ページ artist = "22653" url = 'https://www.uta-net.com/artist/'+artist+'/0/' + str(page) + '/' response = requests.get(url) soup = BeautifulSoup(response.text, 'lxml') links = soup.find_all('td', class_='side td1') for link in links: a = base_url + (link.a.get('href')) #歌詞詳細ページ response = requests.get(a) soup = BeautifulSoup(response.text, 'lxml') song_lyrics = soup.find('div', itemprop='lyrics') song_lyric = song_lyrics.text song_lyric = song_lyric.replace('\n','') #サーバーに負荷を与えないため1秒待機 time.sleep(1) #取得した歌詞を表に追加 tmp_se = pd.DataFrame([song_lyric], index=list_df.columns).T list_df = list_df.append(tmp_se) except: print(page) import traceback traceback.print_exc() print(list_df) #csv保存 list_df.to_csv('list.csv', mode = 'a', encoding='utf_8_sig')形態素解析の必要なインストール
まずは必要なものをインストール
pip install "https://github.com/megagonlabs/ginza/releases/download/v1.0.2/ja_ginza_nopn-1.0.2.tgz" pip install matplotlib pip install wordcloudmatplotlibの日本語化
これを参考に【https://qiita.com/osakasho/items/7408d031ca0b2192422f 】
解析とグラフの表示!
# coding: utf-8 import spacy nlp = spacy.load('ja_ginza_nopn') import pandas as pd import matplotlib.pyplot as plt import collections from wordcloud import WordCloud def ginza(word): doc = nlp(word) # 調査結果 total_ls = [] Noun_ls = [chunk.text for chunk in doc.noun_chunks] Verm_ls = [token.lemma_ for token in doc if token.pos_ == "VERB"] for n in Noun_ls: total_ls.append(n) for v in Verm_ls: total_ls.append(v) return total_ls, Noun_ls, Verm_ls """--------------- CSV読み込みと前セット --------------""" csv_read_path = "list.csv" df = pd.read_csv(csv_read_path) target_categories = ["歌詞"] black_list = ["test"] """-------------------------------------------------------------""" """--------------- 形態素の処理 ------------------------""" for target in target_categories: total_voc = []#文字を入れる箱を用意 for data in df[target]: try: word_ls, noun_ls, verm_ls = ginza(data) except:#もし、分解できない場合は、一単語とする。 word_ls = [data] for w in word_ls: if not w in black_list:#その単語がブラックリストに入っていないかチェックする。 total_voc.append(w) print("単語数は、", len(total_voc), "でした。") # 最頻単語を順位づけ c = collections.Counter(total_voc) # CSVに書き込む c_data = (c.most_common()) csvdf = pd.DataFrame(c_data) filename = target + ".csv" csvdf.to_csv(filename, encoding='utf_8_sig') print("----------------------------") # 一応グラフ化する # 追加部分 フォントを指定する。 plt.rcParams["font.family"] = "IPAexGothic" plt.title(target) plt.grid(True) graph_x_list = [] graph_y_list = [] top_num = 0 for key, value in c.most_common(): graph_x_list.append(key) graph_y_list.append(value) if top_num >= 10: break top_num += 1 try: plt.bar(graph_x_list, graph_y_list) # グラフの表示 plt.show() except: print(target, " に関して、データを描画できませんでした。") # WordCloud で描画する font = 'C:/Windows/Fonts/YuGothM.ttc' wordcloud = WordCloud(background_color="white", width=1000, height=600, font_path=font) wordcloud.generate(" ".join(wordcloud_ls)) wordcloud.to_file(target+'.png') """-------------------------------------------------------------"""グラフの結果
棒グラフの結果
WordCloudの結果
めっちゃ分かってそうだね
お疲れ様でした。
- 投稿日:2019-11-28T18:55:32+09:00
誰にも教えたくない超カンタン分子系統樹作成術
系統樹推定
ETE Toolkitを使った超簡便な分子系統樹作成法を紹介します。
(図: http://etetoolkit.org/documentation/ete-build/ より)使用するツール
- BLAST (配列類似性検索)
- MAFFT (アライメント) https://mafft.cbrc.jp/alignment/server/
- trimAl (アライメントの修正 for 系統樹構築), optional http://trimal.cgenomics.org/
- RAxML (系統樹計算) https://sco.h-its.org/exelixis/web/software/raxml/index.html
- FigTree or iTOL (系統樹描画)
大まかな流れ
- 近縁種との系統関係を見たい対象生物種の16S rRNA配列(?)を配列データベース (16S rRNA,RefSeqやnr等)に対してBLASTによる配列類似性検索を行い,その結果から対象種が所属する属とかの他の種の配列を取ってくる. ※勝手にバクテリア16S対象にしてますが自身の配列にしてください。
- 対象属じゃない奴の16S rRNA配列を取ってくる (系統樹のoutgroupにするため).
- ↑1.2.の配列全部をFASTAファイルにまとめ,MAFFT L-INS-iによるマルチプルアライメントを行う.
- アライメント結果をtrimAlを用いて系統樹構築用の調整をする (系統樹計算に際して,ギャップばかり等不向きな領域を取り除く).この段階はoptionalで,やらなくても良い。
- RAxMLを用いて最尤法系統樹を構築する.bootstrap値も計算する.
- 構築した系統樹をFigTreeに読み込ませて描画する. またはiTOLで描画する (webベースだけどこっちのほうが綺麗).
- たのしい (✿╹◡╹)v
キーワード
系統樹の種類:無根系統樹 (unrooted tree),有根系統樹 (rooted tree),
系統樹の計算手法:NJ法,最尤法,ベイズ法裏ルート
ETE Toolkitを使って一瞬で系統樹を構築する方法。
楽すぎてホントにビビりました。本当は有料の情報商材としたかったのですが,正直,めちゃくちゃ悩みました。そしてほんまに真剣に、真剣に考えて気づいたんです。それを今回特別に公開したいと思います。PythonとAnacondaは入ってる前提です。
入ってない/怪しい場合→
macOS: HomebrewのインストールからpyenvでPythonのAnaconda環境構築までメモ
Linux: Linux環境でのpyenvでPythonのAnaconda環境構築メモ環境構築
$ pip install ete3 #ETE toolkitのインストール $ conda install -c etetoolkit ete_toolchain #必要なツールのインストール系統樹構築
文法は
$ ete3 build -w ワークフロー名 -n 入力配列ファイル(アライメント前) -o 出力先ディレクトリ名 --clearall例:
$ ete3 build -w mafft_linsi-none-none-raxml_default -n input.fasta -o output_tree --clearallこのワークフローの文法はハイフン区切りで
aligner-trimmer-tester-builderとなっている。
例えば,ワークフローが
mafft_linsi-none-none-raxml_default
だったら,mafftのL-INS-iアルゴリズムでアライメントして,RAxMLで系統樹を構築する..となる。
もしラボのパイセン殿がアライメントはclustalを使うのじゃー!と仰るならclustalo_default-none-none-raxml_defaultとすればclustal omega(clustal wの後継)を使ってアライメントしてくれる。
trimAl使った配列のギャップ領域トリミングの工程を入れたかったら,
mafft_linsi-trimal01-none-raxml_defaultとすれば良い。
系統樹推定の際にbootstrap値の計算も入れたかったら
mafft_linsi-none-none-raxml_default_bootstrapとする (少し時間はかかる)。・たぶん
mafft_linsi-none-none-raxml_default_bootstrapとするのが安牌かな (ごめんなさいごめんなさい)使えるツールは
$ ete3 build appsとすれば表示してくれる。参考: Composing custom workflows
結果ファイル
上記例の系統樹構築コマンドを実行すると,
./output_tree/mafft_linsi-none-none-raxml_default内に結果ファイルを色々と生成してくれる。
その中のファイルに色々あって,
・input.fasta.final_tree.png
→系統樹と,アライメントされた配列の模式図を合わせて表してくれるチャラい図
・input.fasta.final_tree.fa
→アライメントされたfastaファイル
・input.fasta.final_tree.nw
→推定された系統樹のファイル。これをFigTreeだったりiTOLに読み込ませると綺麗な図が出せる。

- 投稿日:2019-11-28T18:55:24+09:00
エクセルがタブ文字を認識してくれなくて困ったら
- 投稿日:2019-11-28T18:55:24+09:00
エクセルがタブ文字を認識してくれなくて困った
- 投稿日:2019-11-28T18:49:01+09:00
【データサイエンス向け】Jupyterチートシート(随時更新)【Jupyter Notebook/Lab】
自分は普段データ分析やモデル構築を主にJupyter上で行なっています。
その中で何回調べんねん、ってやつをメモっておきます。(随時更新)開発編
修正した.pyモジュールをリロードしたい
既にimportしたモジュールはキャッシュされるのか、普通にimportしなおしても更新されません。
以下でリロード(再import)できます。import importlib importlib.reload(hoge) # hoge はimport済みのモジュールこれ割と最近まで知らなくて、毎回再起動してたのでマジで目からウロコです。
他にも%autoreloadでモジュールを自動更新する方法があります。描画編
matplotlibで日本語を描画したい
fontにこだわりがなければ、japanize-matplotlib が一番手取り早いと思います。
pip install japanize-matplotlibimport matplotlib.pyplot as plt import japanize_matplotlib plt.plot([1, 2, 3, 4]) plt.xlabel('日本語を簡単に使える喜び') plt.show()
Log編
pdbでデバッグしたい
2つ方法があります。
ブレークポイント指定してデバッガ起動
以下コードを差し込むfrom IPython.core.debugger import Pdb; Pdb().set_trace()バグ発生時にデバッガ起動
以下マジックコマンドを実行セル先頭に差し込む%%debugtqdmを表示したい
一旦これでいけるかと
from tqdm._tqdm_notebook import tqdm_notebook import numpy as np # tqdm_notebook で囲う for i in tqdm_notebook(np.arange(1, 100000, 1)): # ここに処理 pass※ JupyterLabではプラグインをインストールしておかないと上手く表示されない場合があります。参考
pandas編
applyでtqdmを表示したい
# pandasのapplyへ適用 import pandas as pd from tqdm._tqdm_notebook import tqdm_notebook # set description tqdm_notebook.pandas(desc="これをやります") # apply df = pd.DataFrame({'hoge': np.arange(1, 100000, 1)}) df['hoge'] = df['hoge'].progress_apply(lambda x: x + 1)※ JupyterLabではプラグインをインストールしておかないと上手く表示されない場合があります。参考
DataFrameの表示が省略されるのを防ぎたい
表示件数や、一つのセルの中で表示できる文字数の上限を増やします。
import pandas as pd pd.set_option("display.max_colwidth", 500) # 1セルに500文字入る pd.set_option("display.max_rows", 100) # 100行表示できる※ JupyterLabでset_optionが効かない場合、
df[:100]のようにmax_rows以下のレコードを表示するようにすると上手く動作します(個人的な経験より)DataFrameをMarkdownの表形式で出力したい
DataFrameをマークダウンで出力してコピペできます。地味に使います
pip install pytablewriterimport pytablewriter writer = pytablewriter.MarkdownTableWriter() writer.from_dataframe(df) writer.write_table() # | col1 | col2 | # |------|--------| # |hoge1 |line1 | # |hoge2 |line2 |ショートカット系
コマンドパレットへのショートカット
- Jupyter:Cmd + Option + P
- JupyterLab:Ctrl/Cmd + Shift + C

- 投稿日:2019-11-28T18:49:01+09:00
【データサイエンス向け】Jupyterチートシート(随時更新)【JupyterNotebook/Lab】
自分は普段データ分析やモデル構築を主にJupyter上で行なっています。
その中で何回調べんねん、ってやつをメモっておきます。(随時更新)開発編
修正した.pyモジュールをリロードしたい
既にimportしたモジュールはキャッシュされるのか、普通にimportしなおしても更新されません。
以下でリロード(再import)できます。import importlib importlib.reload(hoge) # hoge はimport済みのモジュールこれ割と最近まで知らなくて、毎回再起動してたのでマジで目からウロコです。
他にも%autoreloadでモジュールを自動更新する方法があります。描画編
matplotlibで日本語を描画したい
fontにこだわりがなければ、japanize-matplotlib が一番手取り早いと思います。
pip install japanize-matplotlibimport matplotlib.pyplot as plt import japanize_matplotlib plt.plot([1, 2, 3, 4]) plt.xlabel('日本語を簡単に使える喜び') plt.show()
Log編
pdbでデバッグしたい
2つ方法があります。
ブレークポイント指定してデバッガ起動
以下コードを差し込むfrom IPython.core.debugger import Pdb; Pdb().set_trace()バグ発生時にデバッガ起動
以下マジックコマンドを実行セル先頭に差し込む%%debugtqdmを表示したい
一旦これでいけるかと
from tqdm._tqdm_notebook import tqdm_notebook import numpy as np # tqdm_notebook で囲う for i in tqdm_notebook(np.arange(1, 100000, 1)): # ここに処理 pass※ JupyterLabではプラグインをインストールしておかないと上手く表示されない場合があります。参考
pandas編
applyでtqdmを表示したい
# pandasのapplyへ適用 import pandas as pd from tqdm._tqdm_notebook import tqdm_notebook # set description tqdm_notebook.pandas(desc="これをやります") # apply df = pd.DataFrame({'hoge': np.arange(1, 100000, 1)}) df['hoge'] = df['hoge'].progress_apply(lambda x: x + 1)※ JupyterLabではプラグインをインストールしておかないと上手く表示されない場合があります。参考
DataFrameの表示が省略されるのを防ぎたい
表示件数や、一つのセルの中で表示できる文字数の上限を増やします。
import pandas as pd pd.set_option("display.max_colwidth", 500) # 1セルに500文字入る pd.set_option("display.max_rows", 100) # 100行表示できる※ JupyterLabでset_optionが効かない場合、
df[:100]のようにmax_rows以下のレコードを表示するようにすると上手く動作します(個人的な経験より)DataFrameをMarkdownの表形式で出力したい
DataFrameをマークダウンで出力してコピペできます。地味に使います
pip install pytablewriterimport pytablewriter writer = pytablewriter.MarkdownTableWriter() writer.from_dataframe(df) writer.write_table() # | col1 | col2 | # |------|--------| # |hoge1 |line1 | # |hoge2 |line2 |ショートカット系
コマンドパレットへのショートカット
- Jupyter:Cmd + Option + P
- JupyterLab:Ctrl/Cmd + Shift + C
- 投稿日:2019-11-28T18:30:38+09:00
【Python】機械学習用にIcrawlerで画像を収集【1000枚】
結論
# coding: utf-8 import os from icrawler.builtin import GoogleImageCrawler """---------------- Settings ------------------""" search_word = u"猫"#日本語の場合は、頭に"u"をつける dir_ = "./images/"+search_word+"/" download_num = 1000 #ダウンロードする枚数 """--------------------------------------------------""" if not os.path.exists(dir_):#フォルダが無ければ作る os.makedirs(dir_) crawler = GoogleImageCrawler(storage={"root_dir": dir_}) crawler.crawl(keyword=search_word, max_num=download_num)
- 投稿日:2019-11-28T18:30:33+09:00
AnacondaとPyCharmで、MacにPythonの環境構築をしよう
はじめに
はじめまして、まさなり(@log_masanari)といます。web系を主に勉強している大学2年生です。
大学の授業でpythonを書くことになったので、pythonの環境構築やってみました。
同じような境遇の方の参考になると嬉しいです。環境
MacOS Catalina 10.15.1
なぜAnacondaなのか
もちろんMac環境にも最初からPython 2.X がインストールされています。しかし、Python 2.X は
というわけで、Python 3.X を使っていきましょう。
https://www.python.org/downloads/
こちらからPython 3 をインストールするのも良いですが、後々ライブラリを集めるのが面倒なので、一括してライブラリをインストールしてくれるAnacondaを使ってPython 3 の環境を構築していきます。やっていきましょう環境構築していきます
Anacondaのインストール
まずはここからAnacondaをインストール
https://www.anaconda.com/ダウンロードできたパッケージを起動し、インストラクションに従ってインストールします。
10分〜20分かかると思います(長い...。)
これで、python 3 のインストールができました。
python 3 の確認
Terminalを起動してみましょう。
(base) macmac:~ hogehoge$macmacは、使っているMacの名前です。hogehogeは、ログインしているユーザーの名前です。
あれっ、(base)ってなに?
これは、Anacondaによって作られた仮想環境の名前です。
ん、なにそれって人は、この記事を読んでください。pythonpythonと打ち込んで、実行すると、
Python 3.7.4 (default, Aug 13 2019, 15:17:50) [Clang 4.0.1 (tags/RELEASE_401/final)] :: Anaconda, Inc. on darwinはい。Anaconda, Inc.のpython 3 が確認できました。対話型シェルが起動している状態なので、抜けます。
>>> exit()抜けました。続いて、pythonの場所を確認します。
which pythonこれで、pythonの場所を確認できます。
/Users/hogehoge/opt/anaconda3/bin/pythonこんな感じ。
これで、anacondaによってpython 3 がインストールされました。PyCharmのインストール
PyCharmは、JetBrainsが提供するIDE(総合開発環境)です。
Professional(有償) と Community(無償) があります。
Professionalは、 $199(20000円くらい)/年 のサブスクリプション形式で利用できます。最初の30日間は無料で使えるようですが、ProfessionalからCommunityに移行するのが結構めんどうみたいです。無料の期間だけProfessional使おうって人は注意が必要。今回は、無償のCommunityのほうを使っていきます。
まずはここからPyCharmをインストール
https://www.jetbrains.com/pycharm/downloadダウンロードして起動すると、
こんな感じの指示があります。従いましょう。
これで、PyCharmが使えるようになります。
ただ、これだとまだ問題があります。PyCharmからpythonを実行すると、Mac環境に最初から入っているpythonが実行されてしまいます。なので、Anacondaでインストールしたpythonを実行できるように設定してあげます。
このように、Existing interpreterに、先程確認したpythonのパスを指定してあげましょう。
Locationに作業用フォルダを指定して、Createを押すと...はい、これでpythonを書ける環境が整いました。Hello World! をする
指定したフォルダにpythonファイルを作成して、
hello.pyprint('Hello World!')PyCharmが勝手に保存してくれます。最高ですね。
実行は、右上のAdd Configurationから行います。
適当に名前をつけて、OK
Script Pathには、実行したいファイルを指定してあげます。(ここでは、hello.py)
Ctrl-Rで実行!!!!
無事にHello World!できましたね。
こんな感じに実行画面を移動させたり、Terminalを起動したりもできます。かっこいい!!!!
以上で、AnacondaとPyCharmを使ったpythonの環境構築を終わります。お疲れさまでした。
おわりに
ここまで読んでいただき、ありがとうございました。
はじめて記事を書いてみたのですが、ノリと勢いでササッと書けちゃうものですね。
わかりにくい点、間違っている点があれば、コメントにて教えていただけると嬉しいです。
また、感想や要望なども待っています。これからも自分のアウトプットを兼ねて、初学者にもわかりやすい記事を書いていこうと思います。
QiitaとTwitterのフォロー、よろしくおねがいします。

- 投稿日:2019-11-28T18:10:49+09:00
【Python】CSVデータの形態素解析からCSV出力まで【GiNZA】
CSVデータを収集する
まずは、CSVデータをとってきます。
何のデータを取ってこようか悩みましたが、
大好きなヨルシカの歌詞をスクレイピングして取ってきます。まず、スクレイピングに必要なモジュールのインストール pip install requests pip install bs4 pip install lxml pip install pandasスクレイピング!
ここを参考にしました。
【https://qiita.com/yuuuusuke1997/items/122ca7597c909e73aad5#%E3%81%8A%E3%82%8F%E3%82%8A%E3%81%AB】import requests from bs4 import BeautifulSoup import pandas as pd import time #スクレイピングしたデータを入れる表を作成 list_df = pd.DataFrame(columns=['歌詞']) for page in range(10): try: #曲ページ先頭アドレス base_url = 'https://www.uta-net.com' #歌詞一覧ページ artist = "22653" url = 'https://www.uta-net.com/artist/'+artist+'/0/' + str(page) + '/' response = requests.get(url) soup = BeautifulSoup(response.text, 'lxml') links = soup.find_all('td', class_='side td1') for link in links: a = base_url + (link.a.get('href')) #歌詞詳細ページ response = requests.get(a) soup = BeautifulSoup(response.text, 'lxml') song_lyrics = soup.find('div', itemprop='lyrics') song_lyric = song_lyrics.text song_lyric = song_lyric.replace('\n','') #サーバーに負荷を与えないため1秒待機 time.sleep(1) #取得した歌詞を表に追加 tmp_se = pd.DataFrame([song_lyric], index=list_df.columns).T list_df = list_df.append(tmp_se) except: print(page) import traceback traceback.print_exc() print(list_df) #csv保存 list_df.to_csv('list.csv', mode = 'a', encoding='utf_8_sig')形態素解析の必要なインストール
まずは必要なものをインストール
pip install "https://github.com/megagonlabs/ginza/releases/download/v1.0.2/ja_ginza_nopn-1.0.2.tgz" pip install matplotlib pip install wordcloudmatplotlibの日本語化
これを参考に【https://qiita.com/osakasho/items/7408d031ca0b2192422f】
解析とグラフの表示!
# coding: utf-8 import spacy nlp = spacy.load('ja_ginza_nopn') import pandas as pd import matplotlib.pyplot as plt import collections from wordcloud import WordCloud def ginza(word): doc = nlp(word) # 調査結果 total_ls = [] Noun_ls = [chunk.text for chunk in doc.noun_chunks] Verm_ls = [token.lemma_ for token in doc if token.pos_ == "VERB"] for n in Noun_ls: total_ls.append(n) for v in Verm_ls: total_ls.append(v) return total_ls, Noun_ls, Verm_ls """--------------- CSV読み込みと前セット --------------""" csv_read_path = "list.csv" df = pd.read_csv(csv_read_path) target_categories = ["歌詞"] black_list = ["test"] """-------------------------------------------------------------""" """--------------- 形態素の処理 ------------------------""" for target in target_categories: total_voc = []#文字を入れる箱を用意 for data in df[target]: try: word_ls, noun_ls, verm_ls = ginza(data) except:#もし、分解できない場合は、一単語とする。 word_ls = [data] for w in word_ls: if not w in black_list:#その単語がブラックリストに入っていないかチェックする。 total_voc.append(w) print("単語数は、", len(total_voc), "でした。") # 最頻単語を順位づけ c = collections.Counter(total_voc) # CSVに書き込む c_data = (c.most_common()) csvdf = pd.DataFrame(c_data) filename = target + ".csv" csvdf.to_csv(filename, encoding='utf_8_sig') print("----------------------------") # 一応グラフ化する # 追加部分 フォントを指定する。 plt.rcParams["font.family"] = "IPAexGothic" plt.title(target) plt.grid(True) graph_x_list = [] graph_y_list = [] top_num = 0 for key, value in c.most_common(): graph_x_list.append(key) graph_y_list.append(value) if top_num >= 10: break top_num += 1 try: plt.bar(graph_x_list, graph_y_list) # グラフの表示 plt.show() except: print(target, " に関して、データを描画できませんでした。") # WordCloud で描画する font = 'C:/Windows/Fonts/YuGothM.ttc' wordcloud = WordCloud(background_color="white", width=1000, height=600, font_path=font) wordcloud.generate(" ".join(total_voc)) wordcloud.to_file(target+'.png') """-------------------------------------------------------------"""
- 投稿日:2019-11-28T18:03:21+09:00
AIエンジニアに直ぐになる!Python / AI / 機械学習 / 深層学習 / 統計分析を数日で網羅的に習得!
絶対に読んでほしい、手元に置いておきたい3冊(実務で使えること勉強しません?)
事業会社にいるITスタッフとして事業会社の実務で使えるコンパクトな網羅的な書籍や情報がなくかなり悩んでおりました。本屋に行ってもネットの情報を見ても多くの本や情報が溢れていますが、実際のソースコードが乏しく情報がかなり断片的、「網羅的な情報」(これ重要!)でなく理解に苦しむことが多かったです。プログラミングスクールのカリキュラムと比較しましたが、これら3冊の本を読破して実務で実践した方がよっぽどか身に付くと思いました。大規模書店に出向き本を徹底的に比較しクイックに(私のイメージでは数日で)網羅的に習得したい場合にお勧めな書籍がこちら、次の3冊になりました。実際に私も買いましたが、数日で読み切り基本的な機械学習、深層学習のコードが書けるレベルまで成長できました。初心者が網羅的なAIのフルスタックエンジニアとしてすぐに自立するには必携なはずです!
(1)すぐに使える! 業務で実践できる! Pythonによる AI・機械学習・深層学習アプリのつくり方
https://amzn.to/2OSFeSh断然この一冊は一押しです!実務への応用がすぐにイメージがつきました。Google Colaboratoryの説明だけではなくほぼ全ての演習で実際にColaboratory上でコピペして流せるコードがついています(手元にJupyter Notebook環境を構築した場合も想定されています)。NumPy, SciPy, Pandas, scikit-learn (学習とテストケース分け), OpenCV (OCR, 手書きや画像認識、ぼかし処理、動画解析),自然言語処理、スパム判定への応用、TensorFlowやKeras, MNIST, CNNなどのライブラリを活用した深層学習についても網羅的に学べてすぐに実行可能なソースコードがついています。TensorFlowやKeras, CNNライブラリなどを使った場合や使わなかった場合のコードの違いにまで言及されており、この一冊で誰もが明日からAIエンジニアになれそうです。 https://amzn.to/2OSFeSh
(2)東京大学のデータサイエンティスト育成講座 ~Pythonで手を動かして学ぶデ―タ分析~
https://amzn.to/2R4BIY1東京大学松尾研究室がネットで公開している情報をより詳細を加えて書籍化されたもの。Pythonの言語特性や統計分析、機械学習のエントリーレベルとしてすごく役立ちます。 Google Colaboratoryで実行可能。大方の内容が研究室で公開はされていてそれだけでも勉強できなくもないのですが、とにかく量が多いので、ネットのファイルだけでは混乱し復習が大変だと思いましたし頭の中にスーッと入れるには本があった方が助かりました。そんなに高くないので時間短縮を考えると手元に本があった方がいいです。 https://amzn.to/2R4BIY1
(3)統計学図鑑
https://amzn.to/2R0zys3一番コンパクトで一番網羅的に統計学の基礎が書かれている本に見えました。データサイエンティスト必携だと思います。記述統計学、確率分布、推測統計学、信頼区間、仮説検定、分散分析と多重比較、ノンパラメトリック、実験計画、回帰分析、多変量解析、ベイズ統計学とビッグデータと誰もが何かしら聞いたことがあるキーワードについて網羅的に図などを活用しコンパクトにまとめられています。https://amzn.to/2R0zys3
私の場合は経済学で統計学を一部学んでいたこととプログラミングの知識もゼロではなかったというバックグラウンドではあるもののどちらもゼロベースでも十分に使える書籍だなあと思いました。バックグラウンドが少しでもあれば復習や知らない知識の補完が非常に楽な3冊だと思います。
統計学の知識はAI処理で必須ではないこともあると思いますが、電算処理の業務要件によっては統計分析のエリアになるので信頼を得るにも基礎固めはしておいた方が良さそうです。
- 投稿日:2019-11-28T18:02:09+09:00
【Python】Matplotlibを日本語化するメモ【Windows】
結論
1.( https://ipafont.ipa.go.jp/node26 )からIPAexゴシック(Ver.----)をダウンロードする
2. zipファイルを解凍し、中のipaexg.ttfをコピーする。
3. Pythonの環境フォルダの\Lib\site-packages\matplotlib\mpl-data\fonts\ttfのフォルダ内に張り付ける。
4. C:User/name/.matplotlibフォルダ内のデータを全て消す。OK
- 投稿日:2019-11-28T17:40:50+09:00
pythonを触りながら基礎を学んでいく 変数編
Pythonしてますか?
私ははじめました
question = あってます?あってますよね!そうですよね!progateというサイトで学んでいます
学んだこと
変数なんだかあだ名みたいなものかなという認識です
あってます?あってますよね!そうですよね!
aaa = 15
と先に指定しておけば
bbb = aaa * aaaと
繰り返し使えるそうですでも、なんか回りくどいなって印象もあります
なんで
変数を指定するの?その数字が何を表すものかを明確にしたいからです
あってます?あってますよね!そうですよね!先に言っていた変数はあだ名みたいなもの
というイメージとちょっと変わってきましたね
あだ名は明確なものをある意味わかりづらくしてます
(知ってる人だけがわかる感じ)つまり
aaa = 15これは良くない
aaaも15も何を表しているのかわかりませんものねこう書けばわかりやすいんじゃね?
my_age = 15
これで私の年齢は15才なんだなっていう意味がわかってきますね
年齢、ばれちゃいましたねコレは便利という考え方
じゃあ私が5年後何歳になっているのかな?
という疑問を答えたい場合私は15才…そう…私は15才…絶対私は15才…my_age = 15 five_years = 5 my_future = my_age + five_years # 15 + 5 っていう数字より意味がわかりやすい print(my_future) # 何を知りたいのかわかりやすい 20二十歳になりました
ヤッピー!マンモスうれピー!ちなみに
print(ホニャララ)で結果を表示することができますっていうことで…いいのかな…
どうですか?
みなさんこういうことで
print(question)
- 投稿日:2019-11-28T17:39:06+09:00
初心者が機械学習をできるようになるための全て
はじめに
この記事は僕がインターン志望先で課題として出された、「機械学習をするために必要な知識」として提示されたものをこなしつつ、機械学習をできるようにするというための記事です。
この記事の全てを行うことで初めて見習い機械学習エンジニアとなることができるでしょう。
逆に、この記事の全てを行うだけで簡単に機械学習の基礎をさらうことができます。自分用としての性質も含むため、完璧な解説ではありません。
開発環境
色々言う前にまずは私の開発環境から参りましょう。
OS
・Windows
・Windows Subsystem for Linux(Ubuntuでも動かせるようにしています)
IDE
Pycharm初心者が機械学習をするために何が必要?
以下、インターン志望先から提示された課題を箇条書きします。これが「必要な物」です。
のちに一個一個説明していきますが、まずは全容を抑えましょう。①エンジニアとして絶対必要な能力
すらすらと使いこなせるようにする。
・python3の基礎知識
・command line
・Git②セットアップ
以下の物を把握する。
・Python系統
・pip
・pipenv
・Ubuntuの端末(コマンドライン)で効率化の為に必須なもの
・tmux
・その他
・マークダウン記法(Qiita用)・デバッグ作業
・Pycharmによるデバッグ③機械学習
ライブラリとして、以下の物を把握する。
・scikit-learn
・Numpy
・Pandas
・Matplotlib
・Keras④本
Must
・リーダブルコード
・機械学習のエッセンス
・仕事で始める機械学習
その他個人的に良かった本
・やさしく学ぶ 機械学習を理解するための数学のきほん
・Pythonで動かして学ぶ! あたらしい深層学習の教科書 機械学習の基本から深層学習まで①エンジニアとして絶対必要な能力
・python3の基礎知識
・command line
・Gitこれらの能力なしでは実際のところ何もできないのと同じようなものです。
まずは何よりも最初にこの3つをやってしまいましょう。
Progateが志望先でお勧めされていました。無料でやることが可能ですし、自分では環境開発の必要がないのも最初の一歩として魅力的です。僕自身、1日で全て終わらせましたので難なく進められると思います。
後々多用するであろう早見表をProgateを参考に作ってみましたので是非ご活用ください。
・Git基本・早見表
・コマンドライン基本・早見表②セットアップ
Python系統
・pip
・pipenvこれらはPythonで必要なライブラリを手に入れるためのツールです。
実際問題としては、pipを使うのはpipenvをインストールするためだけです。
pipについては以下をご覧ください。
・pipの早見表
pipenvについては他の方が書かれた良い記事をご覧ください。
Anacondaやpyenvなどがある中で何故Pipenvを使うのかという理由が記されている記事です。
・pyenv、pyenv-virtualenv、venv、Anaconda、Pipenv。私はPipenvを使う。
Pipenvのインストールについては次の記事を参考にさせて頂きました。
・Pipenvを使ったPython開発まとめUbuntuの端末(コマンドライン)で効率化の為に必須なもの
・tmuxtmuxは開発を効率化してくれる道具です。
ターミナルで複数個のウインドウを作る必要がなく、同じ一画面で操作できるようにするものです。
以下のウェブサイトを参照させていただきました。
・インフラエンジニアならtmuxを使いこなしているか!?その他
・マークダウン記法(Qiita用)この「マークダウン記法」、最初はプログラムの記法か何かかと思いましたが単純に今私が現在進行形で行っているQiitaを書く作業で便利な記法です。文字を大きくする方法や段落の作り方、ただそれだけあります。
以下の記事を参照すればすべてがまとまっております。
・Qiita マークダウン記法 一覧表・チートシートデバッグ作業
・Pycharmによるデバッグこれも効率化の問題ですが、単なる効率化で済ませてはいけません。Pythonのデバッグ作業は有用な方法があります。それが「Pycharmを使う」ことです。
志望先からは以下の記事の内容を理解し、使いこなせることが求められました。
・【ノンプログラマー向けPython】PyCharmでデバッグをする基本中の基本③機械学習系
Pythonの文法ではなくて、ライブラリを使いこなそうという話です。
機械学習を学ぶ中で重要なのは「何ができるのかわかったら十分」ということでしょう。
私も最初はとても時間をかけてライブラリの一つ一つを勉強していたのですが、そのような必要はないように思えます。
何ができるのか理解して知っていれば、片手に本が一冊あったりQiitaのチートシートの様なものを見れば実装することができるでしょう。プログラミングの実装は試験ではありません。カンニングしたい放題です。ですから僕は「自分用」の意味も含めて早見表の記事などを書いています。僕が説明する必要などなく、素晴らしいまとめ記事があふれていますので、ぜひご自分で調べてみてください。
公式Tutorialこそが全てでもあるので貼っておきますね。今の僕から思えば1週間ほどで全てできたのではないかなと少し後悔しています。
以下の順番で学習したら良いでしょう。
①scikit-learn
②Numpy
③Pandas
④Matplotlib
⑤Keras
もう一度言いますよ!重要なのは
「何ができるか分かったらOK!」ですよ!!④本
機械学習を学ぶ上で読んだ本を紹介します。
機械学習のエッセンス
機械学習のエッセンス
この本はPythonの基本、機械学習に必要な数学の話、Pythonを使った数値計算、機械学習アルゴリズムを取り扱っています。これ以上ないほど機械学習の全てがまとまっているように思えます。
大学で数学を学んだ方はPythonによる数値計算から読み進めたら良いでしょう。仕事で始める機械学習
仕事で始める機械学習
その名の通り実務のイメージがつきます。理論だけ勉強しても何に使えるのかわからないですよね。
そんな時に良い道しるべとなってくれると思います。また、2冊目に読むべき本ですので、基礎は抑えてから読むのが良いでしょう。とはいえ、まとめ本としての性質も持つので機械学習手法の復習に最適だと思います。やさしく学ぶ 機械学習を理解するための数学のきほん
やさしく学ぶ 機械学習を理解するための数学のきほん
この本のおかげで基本的な機械学習における数学の知識が理解できました。
機械学習のエッセンスが難しいと感じるならばこれから始めれば問題ないでしょう。Pythonで動かして学ぶ! あたらしい深層学習の教科書 機械学習の基本から深層学習まで
Pythonで動かして学ぶ! あたらしい深層学習の教科書 機械学習の基本から深層学習まで
僕がメインで勉強したのはこの本です。どのように人工知能を学ぼうかと、教授に相談しに研究室に行ったときに頂いた本です。
(理論的な話は置いといて)深層学習の全てが記されています。環境開発から実装まで全てを行います。この本をまず第一にやってから上記の本をやるというのが本当の初心者の方におすすめです。また、僕が上記に記したライブラリ(Numpyとかです)のことも全て学べるようにできております。さいごに
僕が今までしてきたことの全てをこの記事に詰めさせていただきました。
これからは論文を読みながら人工知能の最先端技術に触れられればと思います。
長ったらしくなりましたが、読んでいただいてありがとうございました。
- 投稿日:2019-11-28T16:21:45+09:00
03. 円周率
03. 円周率
"Now I need a drink, alcoholic of course, after the heavy lectures involving quantum mechanics."という文を単語に分解し,各単語の(アルファベットの)文字数を先頭から出現順に並べたリストを作成せよ.
Go
package main import ( "fmt" "regexp" "strings" ) func main() { var src string = "Now I need a drink, alcoholic of course, after the heavy lectures involving quantum mechanics." var wlen []int rex := regexp.MustCompile("([a-zA-Z]+)") // 単語に分割 words := strings.Split(src, " ") for _, word := range words { // アルファベットのみを抽出 match := rex.FindStringSubmatch(word) // アルファベットの文字数を保存 wlen = append(wlen, len(match[1])) } // 結果を表示 fmt.Println(wlen) }python
# -*- coding: utf-8 -*- import re src = "Now I need a drink, alcoholic of course, after the heavy lectures involving quantum mechanics." wlen = [] # 正規表現パターン定義(アルファベットのみ) pattern = re.compile('([a-zA-Z]+)') # 単語に分割 words = src.split(" ") for word in words: # アルファベットのみ抽出 result = re.search(pattern, word).group() # アルファベットの文字数を保存 wlen.append(len(result)) # 結果を表示 print(wlen)Javascript
var src = "Now I need a drink, alcoholic of course, after the heavy lectures involving quantum mechanics." var wlen = []; // ループ版 var words = src.split(' '); for (var i = 0; i < words.length; i++) { val = words[i].match(/[a-zA-Z]+/); wlen.push(val[0].length); } console.log(wlen); // forEach 版 var wlen = []; src.split(' ').forEach(function (value) { this.push(value.match(/[a-zA-Z]+/)[0].length); }, wlen) console.log(wlen);まとめ
以外と簡単と作ったが、他の人の結果を見て間違ってることに気づいた。 "." や "," は抜くのか。
アルファベット判別は少し悩んだが、正規表現で対応。Goの正規表現処理は遅いんだったかな?。問題の円周率の意味が解った時は、なんとなく嬉しかった。w
- 投稿日:2019-11-28T16:21:19+09:00
02. 「パトカー」+「タクシー」=「パタトクカシーー」
02. 「パトカー」+「タクシー」=「パタトクカシーー」
「パトカー」+「タクシー」の文字を先頭から交互に連結して文字列「パタトクカシーー」を得よ.
Go
package main import ( "fmt" "strings" ) func main() { var p1 string = "パトカー"; var p2 string = "タクシー"; var result string; // 文字を配列にする p1s := strings.Split(p1,""); p2s := strings.Split(p2,""); // 配列数ループ(「パトカー」に合わせる。同じ文字数だから・・・) for i := range(p1s) { // 各文字を1文字づつ連結 result += p1s[i] + p2s[i]; } // 結果を表示 fmt.Println(result); }python
# -*- coding: utf-8 -*- p1 = u"パトカー" p2 = u"タクシー" p1s = [] p2s = [] # 文字列を配列へ(「パトカー」に合わせる。同じ文字数だから・・・) for i in range(len(p1)): p1s.append(p1[i]) p2s.append(p2[i]) # 配列数ループ(「パトカー」に合わせる) result = "" for i in range(len(p1s)): # 各文字を1文字づつ連結 result += p1s[i] + p2s[i] # 結果を表示 print (result)Javascript
let p1 = "パトカー"; let p2 = "タクシー"; var result = ""; // 文字を配列にする let p1s = p1.split(""); let p2s = p2.split(""); // 配列数ループ(「パトカー」に合わせる。同じ文字数だから・・・) for (var i = 0; i < p1s.length; i++) { // 各文字を1文字づつ連結 result += p1s[i] + p2s[i]; } // 結果を表示 console.log(result);まとめ
どれも、イマイチ感がすごい。
他の人のソースを覗いてみる。
- 投稿日:2019-11-28T16:05:55+09:00
WagtailでRichTextFieldを表示すると<p>タグがついてしまう
RichTextFieldを表示しようとすると、HTMLタグが表示されてしまう
とても初歩的な問題かもしれませんが、RichTextFieldを表示しようとして
html{{ page.body }}このように、HTMLファイルでCharFieldなどと同じように書いてしまうと、
<p>body content</p>このように
<p></p>タグも表示されてしまいます。解決方法
html{% load wagtailcore_tags %} ... {{ page.body|richtext }}このようにrichtextフィルターを使って書くことで、
body content
<p></p>タグをなくして表示できました。
- 投稿日:2019-11-28T15:37:30+09:00
Twilio の SMS サービスでメッセージを送ってみる
目的
Amazon SMS でのメッセージ送信を GCP のサービスで代用できないか調査したところ、Twilio というサードパーティサービスを Google が推奨していたので試しに使ってみました。
・Twilio による SMS サービスおよび音声サービスの使用
Twilio について
Twilio がどんなものか知らない方も多いと思います。
簡単に言うと音声通話、SMS、チャット、ビデオなどの機能を持つクラウド API サービスです。
特徴としてプログラムで電話、SMS、FAX などを制御可能なので、アプリやシステムと絡めたサービスを作りたいときに検討してみるのがいいかと思います。Twilio のパートナーである KDDI が詳しい情報をウェブに公開しているので気になる方はどうぞ。
https://twilio.kddi-web.com/Twilio アカウント作成
Twilio の利用にはまずアカウントを作成する必要があります。
上記リンクの無料サインアップからアカウント登録を行います。
サイトの説明に従ってアカウント作成を完了させてください。一般的な手順なので特に難しくはないと思います。アメリカの電話番号を取得
Twilio アカウントで利用する電話番号を取得します。
注意点として、SMS を使いたい場合国番号1から始まるアメリカの電話番号を取得する必要があります(日本の電話番号が SMS 未対応の為)。以下が電話番号取得手順
1.ログイン後のホーム画面から、画面左の#タブを選択し、Get Started をクリック
2.最初の Twilio 電話番号を取得をクリック
3.デフォルトでアメリカの電話番号が割り当てられているのでそのまま「この番号を選択」をクリック
※デフォルトの番号が+81から始まる日本の電話番号だった場合は、「Search for a different number」のリンクからアメリカの番号を取得してください。
これで電話番号の取得が完了し、SMSを使用できる状態になりました。
SMSでメッセージを送ってみよう!!
それでは実際に Twilio の Programmable SMS というサービスを使ってメッセージを送ってみます。
以下のサイト(英語)が参考になりました。
https://www.twilio.com/docs/sms/quickstart
画像のようにプログラミング言語ごとに内容がまとめられているので、自分の好みにあった言語を参考にすればいいかと思います。
今回は Python でやってみます。1. Python 環境の準備
python をローカル環境にインストールしていない場合下記のコマンドでインストールできます。
pip install python;2. Twilio ライブラリーのインストール
下記のコマンドでライブラリーをインストールします。
pip install twilio;pip: command not found が表示された場合は、下記のコマンドを実行してください。
easy_install twilio参考 URL:https://jp.twilio.com/docs/libraries/python
3. Twilio アカウントに対して SMS をリクエストするための Python ファイルを作成
下のリンクで ACCOUNT SID と AUTH TOKEN を確認しておきます。
https://jp.twilio.com/console/project/settings下記のコードをエディタやメモ帳にコピーします。
sms_message.py# Download the helper library from https://www.twilio.com/docs/python/install from twilio.rest import Client # Your Account Sid and Auth Token from twilio.com/console # DANGER! This is insecure. See http://twil.io/secure account_sid = 'ACXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX' auth_token = 'your_auth_token' client = Client(account_sid, auth_token) message = client.messages \ .create( body="Hello from Python!", from_='+発信元電話番号(国番号含む)', to='+メッセージ送り先の電話番号(国番号含む)' ) print(message.sid)
- account_sid と auth_token の部分に確認しておいた情報を入力
- body に送りたいメッセージ、from に Twilio の登録した電話番号、to にメッセージを送りたい端末の電話番号を入力
- send_sms.py の名前で保存
4. コマンドでファイルを叩き、メッセージを送信
コマンドで、先ほど作成した Python ファイルを叩くとメッセージが送信されます。
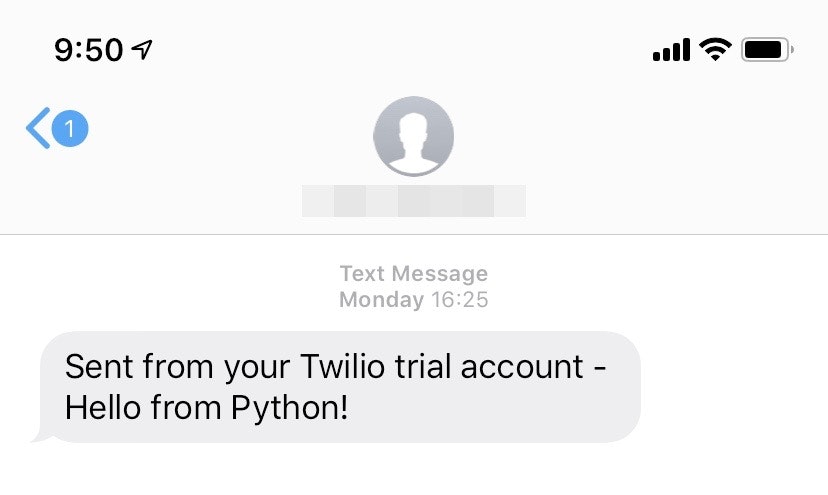
python send_sms.py5. 端末が受信した SMS
無事メッセージが確認できました。
終わりに
以上が SMS を送るまでの一覧の流れになります。
料金体系やSMS以外の Twilioサービスについては次回以降があればまとめようと思います。




- 投稿日:2019-11-28T15:12:33+09:00
強化学習22 Colaboratory+CartPole+ChainerRL+A3C
強化学習21まで終了していることが前提です。
A3Cは、
Asynchronous Advantage Actor-Critic
の略です。
詳しい説明は、こちらをどうぞ。
【強化学習】実装しながら学ぶA3C【CartPoleで棒立て:1ファイルで完結】https://qiita.com/sugulu/items/acbc909dd9b74b043e4521と同じように、chainerRLをそのままnotebookにしました。
それなりに時間がかかり、90分ルールにひっかかるので、スモールサイズでやりました。Google drive mount
import google.colab.drive google.colab.drive.mount('gdrive') !ln -s gdrive/My\ Drive mydriveprogram install
!apt-get install -y xvfb python-opengl ffmpeg > /dev/null 2>&1 !pip install pyvirtualdisplay > /dev/null 2>&1 !pip -q install JSAnimation !pip -q install chainerrlMain program
An example of training A3C against OpenAI Gym Envs.
This script is an example of training a A3C agent against OpenAI Gym envs.
Both discrete and continuous action spaces are supported.modules import
from __future__ import division from __future__ import print_function from __future__ import unicode_literals from __future__ import absolute_import from builtins import * # NOQA from future import standard_library standard_library.install_aliases() # NOQA import argparse import os import sys import chainer from chainer import functions as F from chainer import links as L import gym import numpy as np import chainerrl from chainerrl.agents import a3c from chainerrl import experiments from chainerrl import links from chainerrl import misc from chainerrl.optimizers.nonbias_weight_decay import NonbiasWeightDecay from chainerrl.optimizers import rmsprop_async from chainerrl import policies from chainerrl.recurrent import RecurrentChainMixin from chainerrl import v_functionClass A3CFFSoftmax
An example of A3C feedforward softmax policy.
class A3CFFSoftmax(chainer.ChainList, a3c.A3CModel): def __init__(self, ndim_obs, n_actions, hidden_sizes=(200, 200)): self.pi = policies.SoftmaxPolicy( model=links.MLP(ndim_obs, n_actions, hidden_sizes)) self.v = links.MLP(ndim_obs, 1, hidden_sizes=hidden_sizes) super().__init__(self.pi, self.v) def pi_and_v(self, state): return self.pi(state), self.v(state)Class A3CFFMellowmax
An example of A3C feedforward mellowmax policy.
class A3CFFMellowmax(chainer.ChainList, a3c.A3CModel): def __init__(self, ndim_obs, n_actions, hidden_sizes=(200, 200)): self.pi = policies.MellowmaxPolicy( model=links.MLP(ndim_obs, n_actions, hidden_sizes)) self.v = links.MLP(ndim_obs, 1, hidden_sizes=hidden_sizes) super().__init__(self.pi, self.v) def pi_and_v(self, state): return self.pi(state), self.v(state)Class A3CLSTMGaussian
An example of A3C recurrent Gaussian policy.
class A3CLSTMGaussian(chainer.ChainList, a3c.A3CModel, RecurrentChainMixin): def __init__(self, obs_size, action_size, hidden_size=200, lstm_size=128): self.pi_head = L.Linear(obs_size, hidden_size) self.v_head = L.Linear(obs_size, hidden_size) self.pi_lstm = L.LSTM(hidden_size, lstm_size) self.v_lstm = L.LSTM(hidden_size, lstm_size) self.pi = policies.FCGaussianPolicy(lstm_size, action_size) self.v = v_function.FCVFunction(lstm_size) super().__init__(self.pi_head, self.v_head, self.pi_lstm, self.v_lstm, self.pi, self.v) def pi_and_v(self, state): def forward(head, lstm, tail): h = F.relu(head(state)) h = lstm(h) return tail(h) pout = forward(self.pi_head, self.pi_lstm, self.pi) vout = forward(self.v_head, self.v_lstm, self.v) return pout, voutMain
args
import logging parser = argparse.ArgumentParser() parser.add_argument('--processes', type=int,default=8) parser.add_argument('--env', type=str, default='CartPole-v0') parser.add_argument('--arch', type=str, default='FFSoftmax',choices=('FFSoftmax', 'FFMellowmax', 'LSTMGaussian')) parser.add_argument('--seed', type=int, default=0) parser.add_argument('--outdir', type=str, default='mydrive/OpenAI/CartPole/result-a3c') parser.add_argument('--t-max', type=int, default=5) parser.add_argument('--beta', type=float, default=1e-2) parser.add_argument('--profile', action='store_true') parser.add_argument('--steps', type=int, default=8 * 10 ** 7) parser.add_argument('--eval-interval', type=int, default=10 ** 5) parser.add_argument('--eval-n-runs', type=int, default=10) parser.add_argument('--reward-scale-factor', type=float, default=1e-2) parser.add_argument('--rmsprop-epsilon', type=float, default=1e-1) parser.add_argument('--render', action='store_true', default=False) parser.add_argument('--lr', type=float, default=7e-4) parser.add_argument('--weight-decay', type=float, default=0.0) parser.add_argument('--demo', action='store_true', default=False) parser.add_argument('--load', type=str, default='') parser.add_argument('--logger-level', type=int, default=logging.INFO) parser.add_argument('--monitor', action='store_true')変更したいところは、
args =parser.parse_args([--env].[CartPole-v0'])
のようにする。
args = parser.parse_args(['--steps','300000','--eval-interval','10000']) logging.basicConfig(level=args.logger_level, stream=sys.stdout, format='')Set a random seed used in ChainerRL.
If you use more than one processes, the results will be no longer
deterministic even with the same random seed.
misc.set_random_seed(args.seed)Set different random seeds for different subprocesses.
If seed=0 and processes=4, subprocess seeds are [0, 1, 2, 3].
If seed=1 and processes=4, subprocess seeds are [4, 5, 6, 7].
process_seeds = np.arange(args.processes) + args.seed * args.processes assert process_seeds.max() < 2 ** 32 if not os.path.exists(args.outdir): os.makedirs(args.outdir)function
def make_env(process_idx, test): env = gym.make(args.env) # Use different random seeds for train and test envs process_seed = int(process_seeds[process_idx]) env_seed = 2 ** 32 - 1 - process_seed if test else process_seed env.seed(env_seed) # Cast observations to float32 because our model uses float32 env = chainerrl.wrappers.CastObservationToFloat32(env) if args.monitor and process_idx == 0: env = chainerrl.wrappers.Monitor(env, args.outdir) if not test: # Scale rewards (and thus returns) to a reasonable range so that # training is easier env = chainerrl.wrappers.ScaleReward(env, args.reward_scale_factor) if args.render and process_idx == 0 and not test: env = chainerrl.wrappers.Render(env) return envactionのタイプでモデルを選択します。
sample_env = gym.make(args.env) timestep_limit = sample_env.spec.tags.get( 'wrapper_config.TimeLimit.max_episode_steps') obs_space = sample_env.observation_space action_space = sample_env.action_space # Switch policy types accordingly to action space types if args.arch == 'LSTMGaussian': model = A3CLSTMGaussian(obs_space.low.size, action_space.low.size) elif args.arch == 'FFSoftmax': model = A3CFFSoftmax(obs_space.low.size, action_space.n) elif args.arch == 'FFMellowmax': model = A3CFFMellowmax(obs_space.low.size, action_space.n)optimizer
opt = rmsprop_async.RMSpropAsync( lr=args.lr, eps=args.rmsprop_epsilon, alpha=0.99) opt.setup(model) opt.add_hook(chainer.optimizer.GradientClipping(40)) if args.weight_decay > 0: opt.add_hook(NonbiasWeightDecay(args.weight_decay))Agent
agent = a3c.A3C(model, opt, t_max=args.t_max, gamma=0.99, beta=args.beta) if args.load: agent.load(args.load)train
experiments.train_agent_async( agent=agent, outdir=args.outdir, processes=args.processes, make_env=make_env, profile=args.profile, steps=args.steps, eval_n_steps=None, eval_n_episodes=args.eval_n_runs, eval_interval=args.eval_interval, max_episode_len=timestep_limit) agent.save(args.outdir+'/agent')import pandas as pd import glob import os score_files = glob.glob(args.outdir+'/scores.txt') score_files.sort(key=os.path.getmtime) score_file = score_files[-1] df = pd.read_csv(score_file, delimiter='\t' ) dfdf.plot(x='steps',y='average_value')from pyvirtualdisplay import Display display = Display(visible=0, size=(1024, 768)) display.start()from JSAnimation.IPython_display import display_animation from matplotlib import animation import matplotlib.pyplot as plt %matplotlib inlineframes = [] env = gym.make(args.env) process_seeds = np.arange(args.processes) + args.seed * args.processes assert process_seeds.max() < 2 ** 32 env_seed = int(process_seeds[0]) env.seed(env_seed) env = chainerrl.wrappers.CastObservationToFloat32(env) env = chainerrl.wrappers.ScaleReward(env, args.reward_scale_factor) envw = gym.wrappers.Monitor(env, args.outdir, force=True) for i in range(3): obs = envw.reset() done = False R = 0 t = 0 while not done and t < 200: frames.append(envw.render(mode = 'rgb_array')) action = agent.act(obs) obs, r, done, _ = envw.step(action) R += r t += 1 print('test episode:', i, 'R:', R) agent.stop_episode() envw.close() from IPython.display import HTML plt.figure(figsize=(frames[0].shape[1]/72.0, frames[0].shape[0]/72.0),dpi=72) patch = plt.imshow(frames[0]) plt.axis('off') def animate(i): patch.set_data(frames[i]) anim = animation.FuncAnimation(plt.gcf(), animate, frames=len(frames),interval=50) anim.save(args.outdir+'/test.mp4') HTML(anim.to_jshtml())
- 投稿日:2019-11-28T15:08:43+09:00
Pipenvを使っていたらハッシュエラーが出るようになった話
これはなに
Pipenvを使っていたらある日謎のエラーが出るようになりました。
原因を突き止めるのに苦労したのでメモ的に書いていこうかと思った次第です。
最終的には解決したので、同じような症状で悩んでいて、対処法だけ知りたい方は解決までどうぞ。Pipenvを使っていたらある日謎のエラーが出ていることに気づく
最初にこのエラーに気づいたのはCIで自動テストを設定しようと思ったときでした。
docker環境内で自動テストを実行するコードを書いていたのですが、docker内でpipenv syncやpipenv installを実行する時に以下のエラーが出ていることに気づきました。An error occurred while installing readme-renderer==24.0 --hash=sha256:bb16f55b259f27f75f640acf5e00cf897845a8b3e4731b5c1a436e4b8529202f --hash=sha256:c8532b79afc0375a85f10433eca157d6b50f7d6990f337fa498c96cd4bfc203d! Will try again. An error occurred while installing requests==2.22.0 --hash=sha256:11e007a8a2aa0323f5a921e9e6a2d7e4e67d9877e85773fba9ba6419025cbeb4 --hash=sha256:9cf5292fcd0f598c671cfc1e0d7d1a7f13bb8085e9a590f48c010551dc6c4b31 --hash=sha256:11e007a8a2aa0323f5a921e9e6a2d7e4e67d9877e85773fba9ba6419025cbeb4 --hash=sha256:9cf5292fcd0f598c671cfc1e0d7d1a7f13bb8085e9a590f48c010551dc6c4b31! Will try again. An error occurred while installing requests-toolbelt==0.9.1 --hash=sha256:380606e1d10dc85c3bd47bf5a6095f815ec007be7a8b69c878507068df059e6f --hash=sha256:968089d4584ad4ad7c171454f0a5c6dac23971e9472521ea3b6d49d610aa6fc0! Will try again. An error occurred while installing secretstorage==3.1.1 ; sys_platform == 'linux' --hash=sha256:20c797ae48a4419f66f8d28fc221623f11fc45b6828f96bdb1ad9990acb59f92 --hash=sha256:7a119fb52a88e398dbb22a4b3eb39b779bfbace7e4153b7bc6e5954d86282a8a! Will try again. An error occurred while installing sphinx==2.2.1 --hash=sha256:31088dfb95359384b1005619827eaee3056243798c62724fd3fa4b84ee4d71bd --hash=sha256:52286a0b9d7caa31efee301ec4300dbdab23c3b05da1c9024b4e84896fb73d79! Will try again. An error occurred while installing sphinx-git==11.0.0 --hash=sha256:6bf9d837de108c79fb7db585ebd590fd48f4d1f830b540420d0ca675f3b9f800! Will try again. An error occurred while installing twine==3.1.0 --hash=sha256:1a87ae3f1e29a87a8ac174809bf0aa996085a0368fe500402196bda94b23aab3 --hash=sha256:ba8ba1b39987f1c22d9162f7dd3b4668388640e5f7158c15226624f88e464836! Will try again.色々ためして、venv環境が無い状態で
pipenv installやpipenv syncを実行するとエラーが発生することがわかりました。
hashが出ているのでひとまずPipfile.lockも消してみてから、pipenv install`を実行したがそれでもエラーが出る。
この時確認した状況は以下の通りです。
- venv環境、Pipfile.lockがなくても同様のエラーが出る。
- 上記でエラーが出ているモジュールを別のPipfileでインストールしてもこのエラーは発生しない。
- エラーは出ているがインストールは完了している。
さてさてこれはなんなんだ...
Pipfileを眺めてみる
venv環境もPipfile.lockも消してなお、エラーが出るのでPipfileに原因があるのはほぼ確定です。
このときのPipfileが以下になります。[[source]] name = "pypi" url = "https://pypi.org/simple" verify_ssl = true [dev-packages] flake8 = "*" autopep8 = "*" isort = "*" autoflake = "*" pytest = "*" pytest-cov = "*" qiitacli = {path = "."} twine = "*" sphinx = "*" sphinx-git = "*" pypandoc = "*" [packages] click = ">=7.0" qiita_v2 = ">=0.2.1" [requires] python_version = "3" [scripts] main = "python qiitacli/client.py"僕の脳みそじゃどこがおかしいかわからないよ...
ログを見てみる
pipenv install時に-vオプションを付けて出力を眺めてみました。
思ったより出力が多くてびっくりしましたwその中で原因と思われるログが出ていたのがこちら。
ERROR: In --require-hashes mode, all requirements must have their versions pinned with ==. These do not: tqdm>=4.14 from https://files.pythonhosted.org/packages/bb/62/6f823501b3bf2bac242bd3c320b592ad1516b3081d82c77c1d813f076856/tqdm-4.39.0-py2.py3-none-any.whl#sha256=5a1f3d58f3eb53264387394387fe23df469d2a3fab98c9e7f99d5c146c119873 (from twine==3.1.0->-r /tmp/pipenv-pbslpsa_-requirements/pipenv-u629hk8s-requirement.txt (line 1)) readme-renderer>=21.0 from https://files.pythonhosted.org/packages/c3/7e/d1aae793900f36b097cbfcc5e70eef82b5b56423a6c52a36dce51fedd8f0/readme_renderer-24.0-py2.py3-none-any.whl#sha256=c8532b79afc0375a85f10433eca157d6b50f7d6990f337fa498c96cd4bfc203d (from twine==3.1.0->-r /tmp/pipenv-pbslpsa_-requirements/pipenv-u629hk8s-requirement.txt (line 1)) requests-toolbelt!=0.9.0,>=0.8.0 from https://files.pythonhosted.org/packages/60/ef/7681134338fc097acef8d9b2f8abe0458e4d87559c689a8c306d0957ece5/requests_toolbelt-0.9.1-py2.py3-none-any.whl#sha256=380606e1d10dc85c3bd47bf5a6095f815ec007be7a8b69c878507068df059e6f (from twine==3.1.0->-r /tmp/pipenv-pbslpsa_-requirements/pipenv-u629hk8s-requirement.txt (line 1)) secretstorage; sys_platform == "linux" from https://files.pythonhosted.org/packages/82/59/cb226752e20d83598d7fdcabd7819570b0329a61db07cfbdd21b2ef546e3/SecretStorage-3.1.1-py3-none-any.whl#sha256=7a119fb52a88e398dbb22a4b3eb39b779bfbace7e4153b7bc6e5954d86282a8a (from keyring>=15.1->twine==3.1.0->-r /tmp/pipenv-pbslpsa_-requirements/pipenv-u629hk8s-requirement.txt (line 1)) Exception information: Traceback (most recent call last): File "/hoge/.venv/lib/python3.6/site-packages/pip/_internal/cli/base_command.py", line 153, in _main status = self.run(options, args) File "/hoge/.venv/lib/python3.6/site-packages/pip/_internal/commands/install.py", line 382, in run resolver.resolve(requirement_set) File "/hoge/.venv/lib/python3.6/site-packages/pip/_internal/legacy_resolve.py", line 208, in resolve raise hash_errors pip._internal.exceptions.HashErrors: In --require-hashes mode, all requirements must have their versions pinned with ==. These do not: tqdm>=4.14 from https://files.pythonhosted.org/packages/bb/62/6f823501b3bf2bac242bd3c320b592ad1516b3081d82c77c1d813f076856/tqdm-4.39.0-py2.py3-none-any.whl#sha256=5a1f3d58f3eb53264387394387fe23df469d2a3fab98c9e7f99d5c146c119873 (from twine==3.1.0->-r /tmp/pipenv-pbslpsa_-requirements/pipenv-u629hk8s-requirement.txt (line 1)) readme-renderer>=21.0 from https://files.pythonhosted.org/packages/c3/7e/d1aae793900f36b097cbfcc5e70eef82b5b56423a6c52a36dce51fedd8f0/readme_renderer-24.0-py2.py3-none-any.whl#sha256=c8532b79afc0375a85f10433eca157d6b50f7d6990f337fa498c96cd4bfc203d (from twine==3.1.0->-r /tmp/pipenv-pbslpsa_-requirements/pipenv-u629hk8s-requirement.txt (line 1)) requests-toolbelt!=0.9.0,>=0.8.0 from https://files.pythonhosted.org/packages/60/ef/7681134338fc097acef8d9b2f8abe0458e4d87559c689a8c306d0957ece5/requests_toolbelt-0.9.1-py2.py3-none-any.whl#sha256=380606e1d10dc85c3bd47bf5a6095f815ec007be7a8b69c878507068df059e6f (from twine==3.1.0->-r /tmp/pipenv-pbslpsa_-requirements/pipenv-u629hk8s-requirement.txt (line 1)) secretstorage; sys_platform == "linux" from https://files.pythonhosted.org/packages/82/59/cb226752e20d83598d7fdcabd7819570b0329a61db07cfbdd21b2ef546e3/SecretStorage-3.1.1-py3-none-any.whl#sha256=7a119fb52a88e398dbb22a4b3eb39b779bfbace7e4153b7bc6e5954d86282a8a (from keyring>=15.1->twine==3.1.0->-r /tmp/pipenv-pbslpsa_-requirements/pipenv-u629hk8s-requirement.txt (line 1))内部で
pip installする時に--require-hashesオプション付けてるんですね。
hash checking modeというらしい、このログ見るまで存在を知りませんでした。
In --require-hashes mode, all requirements must have their versions pinned with ==. These do not要約するとhash checking modeの時はすべてのモジュールのバージョンを==で指定しなきゃだめよ!!ってことっぽいですね。(英語ワカラナイ)そもそもエラーの出ていないモジュールもPipfileでバージョン指定してないし、謎は深まるばかり。
requirements.txtを眺めてみる
ログを見るにPipenvコマンドはrequirements.txt相当のファイルを/tmp配下に生成しては、pipコマンドに
-rオプションを付けて実行しているよう。
それらのファイルの中身を実際に見てました。方法としてはPipenv実行時にひたすら
sudo cp -rf /tmp/pipenv* .を連打。絶対にもっといい方法があるはずだけれどひとまずこれで。コピーしたファイルのなかの一つを見てみるとこんな感じ
twine==3.1.0 --hash=sha256:1a87ae3f1e29a87a8ac174809bf0aa996085a0368fe500402196bda94b23aab3 --hash=sha256:ba8ba1b39987f1c22d9162f7dd3b4668388640e5f7158c15226624f88e464836ほー、モジュールひとつずつにハッシュ値を付けたrequirements.txtを生成して、
-rオプションに渡しているんだ。ハッシュ値を確認してみましたが、実際に公開されているファイルと同値でした。
試しにこのrequirements.txtファイルを使って手で作ったvenv環境にインストールしてみます。
$ echo -n ' twine==3.1.0 --hash=sha256:1a87ae3f1e29a87a8ac174809bf0aa996085a0368fe500402196bda94b23aab3 --hash=sha256:ba8ba1b39987f1c22d9162f7dd3b4668388640e5f7158c15226624f88e464836' > requirements.txt $ python3 -m venv venv $ ./venv/bin/pip install -r requirements.txt --require-hashes Collecting twine==3.1.0 Using cached https://files.pythonhosted.org/packages/74/45/1016cad7eb7cbda959a701d1dfa88b9118306677018ac3de224a6a6e7751/twine-3.1.0-py3-none-any.whl Collecting readme-renderer>=21.0 Collecting requests-toolbelt!=0.9.0,>=0.8.0 Collecting tqdm>=4.14 Collecting requests>=2.20 Collecting keyring>=15.1 Collecting importlib-metadata; python_version < "3.8" Requirement already satisfied: setuptools>=0.7.0 in ./venv/lib/python3.6/site-packages (from twine==3.1.0->-r requirements.txt (line 1)) (42.0.1) Collecting pkginfo>=1.4.2 ERROR: In --require-hashes mode, all requirements must have their versions pinned with ==. These do not: readme-renderer>=21.0 from https://files.pythonhosted.org/packages/c3/7e/d1aae793900f36b097cbfcc5e70eef82b5b56423a6c52a36dce51fedd8f0/readme_renderer-24.0-py2.py3-none-any.whl#sha256=c8532b79afc0375a85f10433eca157d6b50f7d6990f337fa498c96cd4bfc203d (from twine==3.1.0->-r requirements.txt (line 1)) requests-toolbelt!=0.9.0,>=0.8.0 from https://files.pythonhosted.org/packages/60/ef/7681134338fc097acef8d9b2f8abe0458e4d87559c689a8c306d0957ece5/requests_toolbelt-0.9.1-py2.py3-none-any.whl#sha256=380606e1d10dc85c3bd47bf5a6095f815ec007be7a8b69c878507068df059e6f (from twine==3.1.0->-r requirements.txt (line 1)) tqdm>=4.14 from https://files.pythonhosted.org/packages/bb/62/6f823501b3bf2bac242bd3c320b592ad1516b3081d82c77c1d813f076856/tqdm-4.39.0-py2.py3-none-any.whl#sha256=5a1f3d58f3eb53264387394387fe23df469d2a3fab98c9e7f99d5c146c119873 (from twine==3.1.0->-r requirements.txt (line 1)) requests>=2.20 from https://files.pythonhosted.org/packages/51/bd/23c926cd341ea6b7dd0b2a00aba99ae0f828be89d72b2190f27c11d4b7fb/requests-2.22.0-py2.py3-none-any.whl#sha256=9cf5292fcd0f598c671cfc1e0d7d1a7f13bb8085e9a590f48c010551dc6c4b31 (from twine==3.1.0->-r requirements.txt (line 1)) keyring>=15.1 from https://files.pythonhosted.org/packages/b1/08/ad1ae7262c8146bee3be360cc766d0261037a90b44872b080a53aaed4e84/keyring-19.2.0-py2.py3-none-any.whl#sha256=f5bb20ea6c57c2360daf0c591931c9ea0d7660a8d9e32ca84d63273f131ea605 (from twine==3.1.0->-r requirements.txt (line 1)) importlib-metadata; python_version < "3.8" from https://files.pythonhosted.org/packages/f6/d2/40b3fa882147719744e6aa50ac39cf7a22a913cbcba86a0371176c425a3b/importlib_metadata-0.23-py2.py3-none-any.whl#sha256=d5f18a79777f3aa179c145737780282e27b508fc8fd688cb17c7a813e8bd39af (from twine==3.1.0->-r requirements.txt (line 1)) pkginfo>=1.4.2 from https://files.pythonhosted.org/packages/e6/d5/451b913307b478c49eb29084916639dc53a88489b993530fed0a66bab8b9/pkginfo-1.5.0.1-py2.py3-none-any.whl#sha256=a6d9e40ca61ad3ebd0b72fbadd4fba16e4c0e4df0428c041e01e06eb6ee71f32 (from twine==3.1.0->-r requirements.txt (line 1))お!再現したぞ!
でもエラーが出ているのはrequirements.txtに記述されてるモジュールとは別のモジュール...
このhash checking modeってのは依存パッケージもすべてバージョン指定で記述する必要があるんですね。
でもじゃあなぜ普通にpipenv installする時はエラーが出ないのか。--no-depsとは
もうしばらくログを確認していると正常に動作している時はpipでインストールする時に
--no-depsというオプションが付いていることを見つけました。
- エラー時のログ
$ ['/hoge/.venv/bin/pip', 'install', '--verbose', '--upgrade', '-r', '/tmp/pipenv-9owwlzhi-requirements/pipenv-65yqxf03-requirement.txt', '-i', 'https://pypi.org/simple', '--require-hashes']
- 正常時のログ
$ ['/hoge/.venv/bin/pip', 'install', '--verbose', '--upgrade', '--no-deps', '-r', '/tmp/pipenv-5dvxlnyt-requirements/pipenv-pvatvj5c-requirement.txt', '-i', 'https://pypi.org/simple', '--require-hashes']おおおこれっぽい!
--no-depsはDon't install package dependencies.つまり依存パッケージをインストールしないオプションですね。
なるほでこれならさっきのrequirements.txtでも正常に動作しそうです。$ ./venv/bin/pip install -r requirements.txt --require-hashes --no-deps Collecting twine==3.1.0 Using cached https://files.pythonhosted.org/packages/74/45/1016cad7eb7cbda959a701d1dfa88b9118306677018ac3de224a6a6e7751/twine-3.1.0-py3-none-any.whl Installing collected packages: twine Successfully installed twine-3.1.0できた。
少しずつ原因がつかめてきました。
あと残るは謎は なぜ
--no-depsオプションを付けてくれなかったのか だけですね。最後の鍵はeditable
最後はPipenvのソースを読むしかありません。
https://github.com/pypa/pipenv
pipenv installを実行した時に実際にpip install ...コマンドを実行している場所を見てみましょう。実際にpipコマンドを実行している箇所は
pipenv/core.py内のpip_installという関数でした。
呼び出される順番としてdo_install -> do_init -> do_install_dependencies -> batch_install -> pip_installとまあ色々有りましたが、、、
結論だけいうとbatch_install関数内の以下の箇所で--no-depsのオプションを付けるか否かのフラグが設定されていました。if not PIPENV_RESOLVE_VCS and is_artifact and not dep.editable: install_deps = True no_deps = Falsedepってのはインストールするモジュールの情報が入ったクラスです。
PIPENV_RESOLVE_VCSじゃなくて、is_artifactで、モジュールがeditableじゃなくて、、、さっぱりわからん
なんとなく「ソースからインストールするモジュールでeditableのフラグが付いていないもの」が
--no-depsの付与に関係してそうですね。
pipenv install -hしたらこんなものがありました。$ pipenv install -h 略 -e, --editable TEXT An editable python package URL or path, often to a VCS repo.あ、、、
解決
エラーの原因となったPipfileをもう一度見てみましょう。
[[source]] name = "pypi" url = "https://pypi.org/simple" verify_ssl = true [dev-packages] flake8 = "*" autopep8 = "*" isort = "*" autoflake = "*" pytest = "*" pytest-cov = "*" qiitacli = {path = "."} twine = "*" sphinx = "*" sphinx-git = "*" pypandoc = "*" [packages] click = ">=7.0" qiita_v2 = ">=0.2.1" [requires] python_version = "3" [scripts] main = "python qiitacli/client.py"はい原因は
qiitacli = {path = "."}こいつでしたね。
開発中のモジュールをローカルにインストールするときによく
pipenv install .とかしてたんですがこれが問題でした。
正しくはpipenv install -e .こう。その結果できたPipfileがこう。qiitacli = {editable = true,path = "."}editableフラグが付いてますね。
この状態なら正常にインストールが完了しました。
まとめ
これ昔はちゃんと
-eオプション付けて入れてたんですけど、オプションなくてもインストール出来ることに気がついてからはそのままインストールするようにしちゃってました。(多分)ちなみに公式のドキュメントにもしっかり書いてありました。 https://pipenv-ja.readthedocs.io/ja/translate-ja/basics.html#editable-dependencies-e-g-e
せめて使ってるオプションの意味くらいは理解しようね。自分。
- 投稿日:2019-11-28T14:38:47+09:00
Python初心者の下克上勉強方法
自己紹介
- 来年から未経験で大手slerのエンジニアとして就職予定
- 世間的にはMARCHレベルの大学の大学4年生
- 大学受験は理系だが、学部は経営学部
- 大学では統計学や経営情報の分野の専攻
- Pythonの本格的な勉強は2019/10月から
- それまでは軽くRを使っていたのとHTML\CSSで簡単なwebサイトを作ったことがある程度
機械学習の勉強のきっかけ
- ゼミの卒論で高度な分析をしたかったから
- 完全に未経験ではなくエンジニアとしてスキルを身につけたかったため
- 大学生として残りの期間本気でなにかを勉強したかったため
- 数学的なアプローチがすごく興味がある
- 今のホットの分野の機械学習に元々興味があったから
- slerという業界がそのままなくなると言われていることへの不安
- web業界に正直なところ憧れがある
自分が学ぶこんなところです!将来に対して投資という一面が一番大きいと思います
学び始めて2ヶ月経たないくらいですが徐々にわかってきたのでとても楽しくなってきました。下克上にむけての勉強方法
今までやってきたこと
さて、ここからが本題です!!
箇条書きなのでとても見づらいと思いますがご了承ください①独学プログラマー(移動時間で少し読む程度)
→最初にプログラミングとはみたいなところに興味があったので購入
②ProgateのPythonコース(4日間で2週)
→ざっくりと記述方法がわかる程度。プログラミング特有のオブジェクト指向の意味があまりわかっていない感じ
③Udemyの株式会社キカガクの『脱ブラックボックスセミナー』初級編
2日間で計5時間くらいだと思います!
④Udemyの株式会社キカガクの『脱ブラックボックスセミナー』中級偏
上記の続きの講座です。同じく2日間で計5時間くらいだと思います!
2つの講座を通じて教師あり学習・教師なし学習などの理論や実務で使えるレベルの回帰分析が学べたので本当に良かったです!初心者の方には非常におすすめです!⑤読書:機械学習になりたい人のための本
上記の4つでざっくり理解した上でまだ勉強したいと思ったのでプロになるにはどうやって残りの期間勉強していけばよいかをしるために読みました。3時間ほどで一通り読み終えました。
⑥プログラミングスクールの無料体験
プログラミングスクールと言えば、web系がメインですが具体的な勉強の方法を知りたかったので、AIに力を入れているAidemyと侍エンジニアに体験に行きました。codecampさんにも行きましたがAIを本格的にやっていなかったのであまり話しを覚えていません。侍エンジニアさんは特に無料体験して良かったと感じました。スクールでの学習も考えましたが、金銭的にかなりきつかったのと、今仮に学習したとしてもコードがかけなさすぎて、講師に質問することもなければ自分で独学することがメインとなり、コスパが悪いと思いやめました。将来的にもう少し力をつけてから、スクールは検討しようと思います。
⑦PYQでの学習
11月はほとんどこれがメインでした。
コースがいろいろあるのですが、未経験からのPython文法(勉強時間の目安が82時間~)コースを一通りやりました。
基本的なコードはかけるようになりましたが、どこまで覚えるべきかいう線引きが難しいです。
これが終わった後は機械学習コース(勉強時間の目安が42時間~)をやっています。現在進行形です。⑧読書:人工知能プログラミングのための数学がわかる本
Aidemyさんの無料体験をした際に進めてもらった本を買って読みました。
だらだら読んでいたのと載っている問題を解いていたりしていたので2週間くらいかかりました。⑨読書:人工知能は人間を超えるか ディープラーニングの先にあるもの
11月20日くらいから読み始めました。人工知能関連でもっとも有名な書籍だと思います。5日くらいで読めそうです。
とても面白かったです。⑩数学:線形代数のキャンパスゼミ
機械学習になりたい人のための本で記載がありました。
線形代数の知識は機械学習の理解には必須とのことなので大学2年生以来ですが、学習をしています。
2週間くらいかかると思います。*その他
①タイピングの練習
勉強の生産性の向上のために必須だと思います。e-typinngというサイトを使っています。
2019/11/20くらいから毎日30分やっています。②英語の学習
2019/11/24のTOEIC(L/R)を受験。10月中は平均1.5時間。11月の試験前は3時間くらい使って勉強してました。
1年前に700点だったので800点目標で勉強してました。
社会人になったら仕様書が英語なのと今後Couseraなど海外のサイトで勉強していこうと思っていたので勉強していました。③ゼミの卒論(大学の後期の期間)
もともとRを使ってやっていたのですがせっかくpythonを勉強しているのでpythonで分析をして卒論を書いています。
サッカーのJリーグのデータ分析をやっています。貴重なアウトプットの場になっています。これからやっていきたいこと(2019年12月中)
①TEAM AIの勉強会への参戦
②試しにKagguleに挑戦→これも勉強会の参戦予定
③pyqで機械学習をメインに演習問題をやってみる
④線形代数のキャンパスゼミ(12月10日までに1周)
⑤統計検定2級を調べ、勉強の開始最後に
これからも試行錯誤しながら頑張っていきたいと思います!!!
- 投稿日:2019-11-28T13:12:54+09:00
DjangoのModelAdminでlist_displayの項目をリンクにする
やりたかったこと
DjangoのModelAdminで、list_displayのある項目をリンクにしてその項目の詳細ページに飛べるようにしたかった。
list_displayの項目をlinkにする方法
例えば、リンクにする前のコードがこんな感じだったとする。
from django.contrib import admin class FooModelAdmin(admin.ModelAdmin): list_display = ('foo','bar')上のコードで、list_displayの'foo'をリンクにしたいときは、以下のようにする。
from django.contrib import admin from django.utils.safestring import mark_safe class FooModelAdmin(admin.ModelAdmin): list_display = ('foo','bar') def foo_link(self, obj): return mark_safe( f'<a href="/foo/{obj.pk}/">{obj.foo}</a>' ) foo_link.short_description = "foo" foo_link.admin_order_field = "foo"
foo_link.short_description = "foo"とすることで、foo_linkと表示されるのではなく、fooと表示されるようにできる。
また、foo_link.admin_order_field = "foo"とすることで、fooによる並び順にすることができる。こんな感じでうまくリンクにできると思います。
間違いやもっといい書き方があればコメントください。参考
https://stackoverflow.com/questions/3998786/change-list-display-link-in-django-admin
https://stackoverflow.com/questions/47953705/how-do-i-use-allow-tags-in-django-2-0-admin/47953774補足:mypyに引っかかる
先述のコードの以下の部分に対して、mypyがエラーを吐いてしまいます。
foo_link.short_description = "foo" foo_link.admin_order_field = "foo"error: "Callable[[FooModelAdmin, Any], str]" has no attribute "short_description"error: "Callable[[FooModelAdmin, Any], str]" has no attribute "admin_order_field"こんな感じのエラーです。
解決策
調べて見ると、この問題はmypyのバグのようで、githubなんかで結構議論されたものの解決するのが難しいみたいです。
現状では、# type: ignoreを文末につけmypyに型チェックを無視させる方法で対応するしかないようです。from django.contrib import admin from django.utils.safestring import mark_safe class FooModelAdmin(admin.ModelAdmin): list_display = ('foo','bar') def foo_link(self, obj): return mark_safe( f'<a href="/foo/{obj.pk}/">{obj.foo}</a>' ) foo_link.short_description = "foo" # type: ignore foo_link.admin_order_field = "foo" # type: ignoreこのように書くとmypyのエラーはなくなります。
- 投稿日:2019-11-28T11:39:30+09:00
Wikidataの知識をNeo4jで可視化してみる
NTTドコモサービスイノベーション部AdventCalendar2019の8日目の記事です。
今回は、構造化された知識ベースのひとつであるWikidataのデータを、グラフDBのひとつであるNeo4jを使って可視化してみます。グラフDBとは
簡単にいえば、グラフ構造を扱えるデータベースのことです。一般によく普及しているRDBと比べて、データ間の関係を扱うためにデザインされたデータベースと言えます1。ちなみに、グラフとは折れ線グラフや棒グラフのことではなく、ノード(接点)とエッジ(枝)の集合で表される、下図のようなデータ構造を指します(Wikipediaより引用)。
この図だけ見ると何の役に立つのかイマイチ分かりませんが、グラフ構造は現実世界の様々なモノゴトを表現するのに大変便利です。例えば、駅をノード、線路をエッジとみれば路線図もグラフで表現できますし、都市をノード、道路をエッジとみれば輸送問題も表現できるでしょう。また、アカウントをノード、アカウント間の関係をエッジとみればSNSもグラフで表現できます。実応用的なところでいえば、購買履歴をグラフ構造で表現して商品の推薦にも利用できるようです2。
表現できるモノゴト ノード エッジ 路線図 駅 線路 物流 都市 道路 SNS アカウント アカウント間の関係 社内人事 社員 社員同士の関係 Wikipedia ページ ページ間のリンク 最近は言語処理界隈でもグラフ構造への注目が高まっているようで、例えば、自然言語処理のトップ国際会議であるACLでは、GCN (Graph Convolutional Netowrk) 関連論文の投稿件数が、昨年は3件だったのが今年は11件と大きく増加しています。
このグラフDBを使って、ある事実とある事実の間の関係を可視化してみます。
Wikidataからの情報抽出
可視化するためには可視化するデータが必要ですが、イチから人手でデータを作成するのは大変です。
そこで今回は、あらかじめ構造化されている知識ベースであるWikidata3のダンプを利用して、グラフDBにインポートするデータを作成します。「構造化」というのは、「計算機で扱いやすくなっている」くらいの意味です。Wikidataは共同編集型の知識ベースで、Wikipediaと同じウィキメディア・プロジェクトのひとつです。
Wikidataでは、例えば「ジョン・レノンの国籍はイギリスである」という「知識」を(ジョン・レノン, 国籍, イギリス)のような3つ組で表現します。このような(エンティティ1, プロパティ, エンティティ2)の形式を関係トリプルと呼びます。ここでいうエンティティは、Wikipediaにあるページのタイトルだとおもってもらってかまいません。それぞれのエンティティには"Q"から始まるWikidata固有の識別子がふられています(例えば、Q5は「ヒト」を指します)。同様に、プロパティには"P"から始まるWikidata固有の識別子がふられています。Wikidataの全データは毎週水曜日頃にJSON形式でダンプされているので、これをグラフDBにインポートするデータとして使いましょう。ここから、
latest-all.json.bz2かlatest-all.json.gzのいずれかをダウンロードしてください。
中身のJSONの構造については、ここが詳しいです。とりあえず、下に示すような
Pythonスクリプトを実行すれば、ダンプからエンティティやプロパティの情報、ないし関係トリプルを抽出できます(それなりに時間とメモリを消費する気がするので注意してください)。
サンプルスクリプト
#!/usr/bin/env python # coding: utf-8 import bz2 import json import codecs triples = [] qs = [] with bz2.BZ2File('latest-all.json.bz2', 'r') as rf, \ codecs.open('rdf.tsv', 'w', 'utf-8') as rdff, \ codecs.open('q_id.tsv', 'w', 'utf-8') as qf: next(rf) # 1行目を飛ばす for i, line in enumerate(rf, 1): try: line = json.loads(line[:-2]) except json.decoder.JSONDecodeError: print(i) rdff.write('\n'.join(['\t'.join(x) for x in triples]) + '\n') qf.write('\n'.join(['\t'.join(x) for x in qs]) + '\n') triples = [] qs = [] continue try: ett_id = line['id'] except KeyError: ett_id = None try: ett_name = line['labels']['ja']['value'] except KeyError: ett_name = None if ett_id is not None and ett_name is not None: qs.append((ett_id, ett_name)) triple = [] for _, props in line['claims'].items(): for prop in props: p_id = prop['mainsnak']['property'] try: id_ = prop['mainsnak']['datavalue']['value']['id'] except Exception as e: # print(ett_id, p_id, e) continue triple.append((ett_id, p_id, id_)) triples.extend(triple) triple = [] if i % 10000000 == 0: print(i) rdff.write('\n'.join(['\t'.join(x) for x in triples]) + '\n') qf.write('\n'.join(['\t'.join(x) for x in qs]) + '\n') rdff.write('\n'.join(['\t'.join(x) for x in triples]) + '\n') qf.write('\n'.join(['\t'.join(x) for x in qs]) + '\n')
q_id.tsvは下表のようなタブ区切りのファイルです(このファイルにはQ IDだけではなくP IDも含まれます)。
Q ID エンティティ名 Q31 ベルギー Q8 幸福 Q23 ジョージ・ワシントン Q24 ジャック・バウアー Q42 ダグラス・アダムズ また、
rdf.tsvは下表のようなタブ区切りのデータです。
エンティティ1 プロパティ エンティティ2 Q31 P1344 Q1088364 Q31 P1151 Q3247091 Q31 P1546 Q1308013 Q31 P5125 Q7112200 Q31 P38 Q4916 上記2ファイルを組み合わせて、2種類のファイルを作ります。
まずは、q_id.tsvにヘッダを加えて、下表のようなタブ区切りのデータnodes.tsvを作成し保存しましょう(3列目の:LABELはあってもなくてもかまわないので、実はファイル名をrenameするだけでもよかったりします)。
id:ID name :LABEL Q31 ベルギー Entity Q8 幸福 Entity Q23 ジョージ・ワシントン Entity Q24 ジャック・バウアー Entity Q42 ダグラス・アダムズ Entity 併せて、エンティティ間のプロパティも、下表のようなタブ区切りのデータ
relationships.tsvとして保存します。rdf.tsvにヘッダをつけて、2列目の:TYPEをq_id.tsvを参照して"P000"から文字列に置換するだけです(実はこちらもわざわざ置換する必要性はないので、ファイル名をrenameするだけでよかったりします)。
:START_ID :TYPE :END_ID Q23 配偶者 Q191789 Q23 父親 Q768342 Q23 母親 Q458119 Q23 兄弟姉妹 Q850421 Q23 兄弟姉妹 Q7412891 プロパティには「国籍」や「配偶者」、「出生地」、「誕生日」など様々な種類があるのですが、このままでは数が多すぎるので、今回の可視化では、人と人の間に定義付けられるプロパティにしぼりました。例えば「親族」や「父親」「母親」「師匠」「弟子」などです。また、エンティティも日本語名のあるエンティティに限定しています。
Neo4jを使ってみる
グラフDBにはいろいろな種類があるのですが、ここでは比較的ポピュラーなNeo4j4を紹介します。
Neo4jの他には例えばAmazon Neptuneが有名だと思います(名前がかっこいい)5。インストール
macOSの場合はHomebrewでインストールするのがオススメです。
$ brew cask install homebrew/cask-versions/adoptopenjdk8 # Javaが入っていない場合 $ brew install neo4j
Javaのバージョンが違うとneo4j: Java 1.8 is required to install this formula. Install AdoptOpenJDK 8 with Homebrew Cask: brew cask install homebrew/cask-versions/adoptopenjdk8 Error: An unsatisfied requirement failed this build.と怒られるので注意してください。
$ which neo4jと入力して/usr/local/bin/neo4jのように表示されればインストール完了です。データのインポート
先ほど作成した
nodes.tsvとrelationships.tsvをNeo4jにインポートします。データのインポートは下記のようなコマンドを叩きます。$ neo4j-admin import --nodes ./Downloads/nodes.tsv --relationships ./Downloads/relationships.tsv --delimiter="\t"インポートがうまくいけば、
IMPORT DONE in 9s 735ms. Imported: 2269484 nodes 201763 relationships 6808452 properties Peak memory usage: 1.05 GBのように表示されます。
Neo4jサーバの起動や停止は下記コマンドで行います。
$ neo4j start # サーバを起動するとき $ neo4j stop # サーバを停止するときサーバを起動させたら
http://localhost:7474にアクセスしてみてください。初めてアクセスしたときはログインを求められると思いますので、ユーザー名とパスワードにそれぞれ"neo4j"と入力してください。その後、パスワードの変更を求められますので、任意のパスワードに変更してください。Cypherでデータを処理する
これで準備は整いました。早速Neo4jを使ってみましょう。Neo4jではクエリとして、Cypherと呼ばれる、SQLライクな言語を使います(以下、CypherをCQLと記載します)。なお、本記事ではCQLの詳説はいたしませんのでご了承ください。
この記事が投稿される12月8日はジョン・レノンの命日ですので、ジョン・レノンを題材に取り上げましょう。余談ですが、僕は"Jealous Guy"がいちばん好きです。
n-hop探索
例えば、「ジョン・レノン」に紐づくエンティティを見たいときは、次のようなCQLを発行します。このCQLは、「ジョン・レノン」ノードから3-hopまで先にある全てのEntityノードを返却します。
match p=((:Entity{name:"ジョン・レノン"})-[*1..3]-()) return p
やや分かりづらいですが、中央から少し左下にある「ジョン...」が「ジョン・レノン」ノードです。例えば「ジョン・レノン」から上に向かって「オノ・ヨーコ」(1)→「安田善三郎」(2)→「片岡仁左衛門」(3)と3-hop先まで関係が伸びているのが分かります。右下のかたまりは、おなじみポール・マッカートニーとその家族です。
残念ながらこのグラフ中に、ザ・ビートルズのメンバーだったリンゴ・スターやジョージ・ハリソンの名前はありません。
最短経路探索
Neo4jでは最短経路を探索することができ、これが目玉機能のひとつだそうです。
試みに、明治時代を代表する文豪である「夏目漱石」と「森鴎外」の間の最短経路を探索してみましょう。12月8日はぜんぜん関係ありません。余談ですが、僕は『虞美人草』がいちばん好きです。
次のようなCQLを発行します。「『夏目漱石』と『森鴎外』の間にある全てのノードを返却する」というCQLを
shortestpathでくくるだけです。match p=shortestpath((:Entity{name:"夏目漱石"})-[*]-(:Entity{name:"森鴎外"})) return p
上の方に出ている「ジョン...」はジョン・レノンではなくて「ジョン万次郎」です。
同時代に生きたふたりですが、Wikidataの知識に基づけば、その関係は意外にも遠いことが分かります。史実によってみても、お互いに顔見知り程度で交流らしい交流はなかったそうです。
それでは、一見関係のなさそうな「ジョン・レノン」と「夏目漱石」の間にはどんな最短経路があるでしょうか。
match p=shortestpath((:Entity{name:"夏目漱石"})-[*]-(:Entity{name:"ジョン・レノン"})) return p
「夏目漱石」から「芥川龍之介」、「サミュエル・ベケット」(戯曲『ゴドーを待ちながら』の作者)などを経て、「ボブ・ディラン」("Like a Rolling Stone"で有名、ノーベル文学賞受賞者)で文学と音楽の橋が渡された後、「ジミ・ヘンドリックス」、「プリンス」、「シャキーラ」、そして「ジョン・レノン」へとたどり着くようです。正直、少々唐突で迂遠な感じが否めません6。
Wikidataはそれなりに大規模な構造化データですが、知識ベースとしてすぐに使うには多少不十分だと考えられます。例えば関係抽出を使って知識ベースを拡充する必要があるでしょう。関係抽出とは、例えば「『坊つちやん』の作者である夏目漱石は~」という文から(夏目漱石, 作者, 『坊つちやん』)という関係トリプルを抽出する技術です。
まとめ
Neo4jを使ってWikidataの知識を可視化してみました。
Neo4jで描画したグラフはブラウザ上でうねうね動かせて楽しいのでぜひご自身で実践して触ってみてください。
昨年の弊社アドベントカレンダーで林さんが記事を書いてくれています→ https://qiita.com/dcm_hayashi/items/9b2536b6fbffa0118fad ↩
「夏目漱石」の一高時代からの親友である「中村是公」は、満鉄総裁や東京市長を歴任した「後藤新平」の腹心のひとりとして知られています。その後藤が提唱した都市計画に賛同したのが「安田善次郎」でした(ちなみにこのとき建てられたのが日比谷公会堂です)。そして、安田のひ孫はご存知「オノ・ヨーコ」で彼女の配偶者は「ジョン・レノン」です、という具合に辿ったほうがWikidataの結果よりもだいぶ短縮できます。 ↩
- 投稿日:2019-11-28T11:38:00+09:00
【Unity(C#),Python】API通信勉強メモ③簡易版ログイン機能の実装
今回やること
Unity側から入力した情報を登録 & ログインする機能を作ります。
前回同様、Flaskでローカルにアプリケーションサーバーを立てて利用します。【前回】:【Unity(C#),Python】API通信勉強メモ②Flaskでローカルサーバー立ち上げ
なんもわからんなりの解釈が山盛りなのでマサカリ、オールオッケーです。
特にセキュリティ面に関してはエンジニアと名乗るのが恥ずかしいくらい疎いので
超巨大マサカリで一刀両断してもらってもしっかりと受け止めます。実際に作成したもの
ID、パスワードを入力してのアカウント登録が行えて、
ログイン画面で実際にログインっぽいことが可能です。行っていることのイメージです。
DBに情報が保存されているので、Editorを閉じてもアカウント情報は消えません。(たぶん)
Unity側
Unity側が行う処理としては入力した情報をローカルサーバーに送って、
レスポンスに応じてテキストを表示するだけです。登録ボタンに関する処理using System.Collections; using UnityEngine.Networking; using UnityEngine; using System.Text; using UnityEngine.UI; public class RegistraionHTTPPost : MonoBehaviour { [SerializeField, Header("LogText")] Text m_logText; [SerializeField, Header("IDInputField")] InputField m_idInputField; [SerializeField, Header("PassInputField")] InputField m_passInputField; //接続するURL private const string RegistrationURL = "http://localhost:5000/registration"; //ゲームオブジェクトUI > ButtonのInspector > On Click()から呼び出すメソッド public void Registration() { StartCoroutine(RegistrationCoroutine(RegistrationURL)); } IEnumerator RegistrationCoroutine(string url) { //POSTする情報 WWWForm form = new WWWForm(); form.AddField("user_id", m_idInputField.text, Encoding.UTF8); form.AddField("password", m_passInputField.text, Encoding.UTF8); //URLをPOSTで用意 UnityWebRequest webRequest = UnityWebRequest.Post(url, form); //UnityWebRequestにバッファをセット webRequest.downloadHandler = new DownloadHandlerBuffer(); //URLに接続して結果が戻ってくるまで待機 yield return webRequest.SendWebRequest(); //エラーが出ていないかチェック if (webRequest.isNetworkError) { //通信失敗 Debug.Log(webRequest.error); m_logText.text = "通信エラー"; } else { //通信成功 Debug.Log("Post"+" : "+webRequest.downloadHandler.text); m_logText.text = webRequest.downloadHandler.text; } } }ローカルサーバーに対して情報を送る処理は下記箇所が担っています。
ローカルサーバー側が受け取る情報として
formにuser_id、passwordなどをリクエスト情報として追加しています。リクエスト時に送る情報//POSTする情報 WWWForm form = new WWWForm(); form.AddField("user_id", m_idInputField.text, Encoding.UTF8); form.AddField("password", m_passInputField.text, Encoding.UTF8);詳細に理解できてはいませんが、
formというのはリクエストの種類(POST,GETなど)に加えて、何かしらの情報を渡せるもののようです。
WWWFormはPOST専用のクラスです。ローカルのアプリケーションサーバー(Flask)
こっちは本当に難しくて、
そもそも私は何をやればいいんだろうという状態が長く続いてしんどかったです。まずはアカウント情報を登録する上でDB(データベース)というものを利用する必要があるとわかりました。
DBって何?
データベース(英: database, DB)とは、検索や蓄積が容易にできるよう整理された情報の集まり。 通常はコンピュータによって実現されたものを指すが、紙の住所録などをデータベースと呼ぶ場合もある。コンピュータを使用したデータベース・システムでは、データベース管理用のソフトウェアであるデータベース管理システムを使用する場合も多い。
【引用元】:ウィキペディア(Wikipedia)
データベースってのはソフトウェアのことらしいです。
そのデータはどこにあってどういう仕組みで成り立っているのか完全に理解するために深堀りすると、
帰ってこられなくなるって偉い人が言ってたので深くは考えません。
【参考リンク】:そもそもデータベースって何で出来ていて、どこの何にどう保存されるのでしょうか。。DBにもいろいろと種類があって、今回利用するのはRDB(リレーショナルデータベース)っぽいです。
SQLAlchemy
データベースを実際に操作するにはSQLという言語を用いるのですが、それをPython内からやってくれる、というライブラリ
【引用元】:はじめての Flask #4 ~データベースをSQLAlchemyでいじってみよう~
だそうです。便利ですね~。今回はこちらを使います。
実装
いよいよFlask及びDBの実装です。
import hashlib from flask import * from sqlalchemy import create_engine, Column, String, Integer from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.orm import sessionmaker, scoped_session app = Flask(__name__) engine = create_engine('sqlite:///user.db') Base = declarative_base() # DBの設定 class User(Base): __tablename__ = 'users' id = Column(Integer, primary_key=True, unique=True) user_id = Column(String) password = Column(String) Base.metadata.create_all(engine) SessionMaker = sessionmaker(bind=engine) session = scoped_session(SessionMaker) # DBにIDとパスワード登録する @app.route("/registration", methods=["POST"]) def registration(): user = request.form["user_id"].strip() check_users = session.query(User).filter(User.user_id == user).all() if check_users: return "そのユーザー名は使用済みです" else: user = User(user_id=request.form["user_id"], password=str(hashlib.sha256( request.form["password"].strip().encode("utf-8")).digest())) session.add(user) session.commit() return str(user.user_id.strip() + "様\nご登録ありがとうございます") # ログインできるID、パスワードの組合わせかどうかDBを見て照合 @app.route("/login", methods=["POST"]) def login_check(): user = request.form["user_id"].strip() check_users = session.query(User).filter(User.user_id == user).all() try: for login_user in check_users: login_user_pass = login_user.password if login_user_pass == str(hashlib.sha256( request.form["password"].strip().encode("utf-8")).digest()): return "ログイン完了です" else: return "パスワードが異なります" except: return "登録情報が異なります" if __name__ == "__main__": app.run(debug=True) # User.__table__.drop(engine) # テーブル削除用テーブルの消し方
下記箇所のコメントアウトを解除して動かせば消えます。
User.__table__.drop(engine) # テーブル削除用Pylintと仲良くする
VSCでpyhtonを書いているのですが、FlaskがPylintと仲良くしてくれませんでした。
そのため、Setting.jsonを開いて下記設定を追記しました。
"python.linting.pylintArgs": [ "--load-plugins", "pylint_flask" ],ハッシュ化
今回、ハッシュ化してセキュリティ対策もばっちりだぜ!ってのをやってみたかったんですが、
現状、②の箇所しかできていないので全く意味がないような気がしてます。
POSTを使うだけではセキュリティ不十分だよ~って記事がいっぱい出てくるので
やりとりする情報は全てハッシュ化しないとダメなのかな~と勝手に思ってます。
この辺り、詳しく知ってる方いたら教えてください。
Basic認証とDigest認証
セキュリティうんぬんを調べている際に知りました。
認証にも種類があるそうです。Digest認証はセキュリティの観点でBasic認証より優れています。しかし、すべての環境に対応しているわけではありません。ページを利用するユーザーの環境がある程度分かっていて、対応しているブラウザを使っている場合には問題はありません。しかし、不特定多数のユーザーに向けたページで設定をする場合、Digest認証は向いていません。
一方Basic認証はセキュリティ面でDigest認証に劣っています。しかし、あらかじめセキュリティ対策が行われている環境下、例えばSSLやローカルネットワーク内などで利用する分には特に問題はないでしょう。ユーザーの環境にも左右されません。
このように、不特定多数のユーザーが使うページにユーザー認証を設定する場合はSSLと合わせたBasic認証、管理者など接続する環境が特定されている場合にはDigest認証、と状況によって使い分けるのが一般的です。
【引用元】:Basic認証(基本認証)とDigest認証、それぞれの役割と違いについて
今回実装したものはBasic認証と呼ばれるものに該当するのでしょうか。
よくわかりませんので、"お前が作ったのはどちらでもない"とかでいいので知りたいです。参考リンク