- 投稿日:2019-11-28T23:40:58+09:00
命名の大事さを遠回りに体感してみる
命名の大事さを遠回りに体感してみる
メディアドゥ アドベントカレンダーの記事です。
私は医者でも学者でもありませんが、今回は認識とかそういったものから、分かりやすい命名とは、というものを遠回りに体感してみます。
はじめに
私は、文字を読むことが苦手です。気合いを入れれば人並みの速度で読むことができます。例えば、紙に印刷された文字などは、歪みが発生すると、読むことが困難になります。そのため、技術書は電子版で購入することがほとんどです。また、マンガを読むことは大変です。絵と、吹き出しの中の文字と、オノマトペの文字が入り混じり、そのうちに絵と文字の区別がつかず、なかなか苦労をします。アクション要素強めのマンガでも、単行本1冊に3時間などかかりますが、ジョジョの奇妙な冒険は、6部まで読みました。現在7部の途中です。ジョナサン・ジョースターが最も好きなキャラクターです。絵柄は2部が好きなため、初期のゴツい絵柄とキャラクターが、私の趣向にあっているのだと思います。
ただ、プログラムのコードは、日々触れていることによる慣れからか、読むことに苦労を覚えません。プログラムのコードは、英数字と、使用可能な記号で、構成されています。
そうして日々を過ごし、チームで開発する上で、可読性を意識したコードの事を考えますが、人にとって読みやすい命名というのはどういうことかを、改めて考えてみると、本記事の内容が頭の中に浮かびました。
文字の認識
プログラムのコードは文字ですが、私達が普段触れ合う文書と同じ用に脳の中では扱われるのでしょうか。
音声化
人間は、文字から意味を認識する際に、文字から意味へと直接マッピングしているわけではないようです。文字を視覚により認識した後、音声化が行われ、介して意味へとつながっているということらしいです。言われてみれば、確かにそのように思います。
文字の順番
タイポグリセミアというものがあるようです。
タイポグリセミア(Typoglycemia)は、文章中のいくつかの単語で最初と最後の文字以外の順番が入れ替わっても正しく読めてしまう現象である。
試しに、本記事の文章の一部を単語ごとで分割し、バラバラにしてみます。
ジョョ冒の妙奇ジな険 は 、 6ま部読でましみた。 現7の途在中部です 。 ジナジサンョ・ターョスー が 最好きもなキタクャラーです 。 絵は部2柄がきた好なめ 、 初ゴ期ツのい絵と柄キクラャターが 、 私にの趣あって向るだいとの思まいす。
ひらがなでやってみます。
じじょょ の きょみう な ぼけうん は ろくぶ まで よましみた。げざんい ななぶ の とゅでうちす。じさなょん じすょーたー が もっすきともな きくゃらたー です。えらがは にぶ が すたきなめ しきょの ごつい えがら と きゃらたくー が わしたの しこゅう に あっている の だと おいまもす。
何となく読めるといえば読めますが、しっくりくるかというとそうでもないと感じます。ひらがなの方が、単語の区切りで分けていることもあり、読みやすく感じます。上述の音声化を加味すると、文字の順番がバラバラであっても、それを脳内で再構成し、意味の通る順番へ並べ替え、音声化する際には、好ましい順番に直した状態になっていると考えられます。
ここで言えること
- 文字は頭の中で音声化されている (と言える)
- 文字の順番はそれほど重要ではない (と言える)
プログラム コードへの転用
サンプルに、挨拶するプログラムを思うままに書きました。本来であれば、エンティティと値オブジェクトと、処理はサービスとして分けて・・・とコード自体をパッケージやファイルで分割するので1ファイルあたりはエディタのスクロールが発生しないレベルまで小さくします。今回は掲載が記事であることから、一望しやすいように一つのファイルにまとめています。
// あいさつプログラム package main import "fmt" func main() { f := &greeterFactory{} g := &greeting{ from: f.makeHuman("kent"), to: f.makeDog(shiba), } g.start() g = &greeting{ from: f.makeDog(golden), to: f.makeDog(dalmatian), } g.start() } // モデルとなる、インターフェースと構造体の定義 type greeter interface { greet() string } type human struct { name string } func (h *human) greet() string { return fmt.Sprintf("こんにちは、わたしは %s です", h.name) } type dog struct { roar string } func (d *dog) greet() string { return fmt.Sprintf("%s だワン!", d.roar) } // ファクトリーの定義 type breed int const ( shiba breed = iota + 1 golden dalmatian ) type greeterFactory struct{} func (g *greeterFactory) makeHuman(n string) greeter { return &human{name: n} } func (g *greeterFactory) makeDog(b breed) greeter { switch b { case shiba: return &dog{roar: "ワン"} case golden: return &dog{roar: "ガオー"} case dalmatian: return &dog{roar: "ニャー"} default: return &dog{roar: "我は何者"} } } // ロジックの定義 type greeting struct { from greeter to greeter } func (g *greeting) start() { fmt.Println("あいさつ かいし!") fmt.Println(g.from.greet()) fmt.Println(g.to.greet()) fmt.Println("あいさつ おわり!") }実行結果あいさつ かいし! こんにちは、わたしは kent です ワン だワン! あいさつ おわり! あいさつ かいし! ガオー だワン! ニャー だワン! あいさつ おわり!それほどの処理もないため、変化させても効果は乏しいような気がしますが、色々と変えて実験してみます。
タイポグリセミア化
読みにくくなるだけですが、タイポグリセミア化してみます。
// あさいつプラグロム package main import "fmt" func main() { f := &greteerFcatroy{} g := &greeting{ form: f.mkaeHmaun("knet"), to: f.mkaeDog(sbhia), } g.sartt() g = &greeting{ form: f.mkaeDog(gloedn), to: f.mkaeDog(damiatlan), } g.sartt() } // モデルとなる、インーフターェスと構造体の定義 type geterer interface { geret() string } type hmaun struct { nmae string } func (h *hmaun) geret() string { return fmt.Sprintf("こちんには、わしたは %s です", h.nmae) } type dog struct { raor string } func (d *dog) geret() string { return fmt.Sprintf("%s だワン!", d.raor) } // フクァリトーの定義 type beerd int const ( sbhia beerd = iota + 1 gloedn damiatlan ) type greteerFcatroy struct{} func (g *greteerFcatroy) mkaeHmaun(n string) geterer { return &hmaun{nmae: n} } func (g *greteerFcatroy) mkaeDog(b beerd) geterer { switch b { case sbhia: return &dog{raor: "ワン"} case gloedn: return &dog{raor: "ガオー"} case damiatlan: return &dog{raor: "ニャー"} default: return &dog{raor: "我何は者"} } } // ロッジクの定義 type greeting struct { form geterer to geterer } func (g *greeting) sartt() { fmt.Println("あさいつ かいし!") fmt.Println(g.form.geret()) fmt.Println(g.to.geret()) fmt.Println("あさいつ おわり!") }実行結果あさいつ かいし! こちんには、わしたは knet です ワン だワン! あさいつ おわり! あさいつ かいし! ガオー だワン! ニャー だワン! あさいつ おわり!意外と読めますね。fromがformになる辺りは、単語として成り立ったままのため、困惑しますが、いけそうです。文字の順番より、音より何より、言語構文のおかげで読むことができるという感じがしますが。関数や構造体の名前などが重要でなければ、変数名だけでなく、それらも1文字でも良さそうです。
全て1文字にする
アルファベットですと使える文字数が少なく、重複によりコンパイルエラーとなるため、一部は2文字にしています。頭の中では音声化する必要もありません。
// あいさつプログラム package main import "fmt" func main() { f := &f{} g := &gg{ f: f.h("kent"), t: f.d(bs), } g.s() g = &gg{ f: f.d(bg), t: f.d(bd), } g.s() } // モデルとなる、インターフェースと構造体の定義 type g interface { g() string } type h struct { n string } func (h *h) g() string { return fmt.Sprintf("こんにちは、わたしは %s です", h.n) } type d struct { r string } func (d *d) g() string { return fmt.Sprintf("%s だワン!", d.r) } // ファクトリーの定義 type b int const ( bs b = iota + 1 bg bd ) type f struct{} func (f *f) h(n string) g { return &h{n: n} } func (f *f) d(b b) g { switch b { case bs: return &d{r: "ワン"} case bg: return &d{r: "ガオー"} case bd: return &d{r: "ニャー"} default: return &d{r: "我は何者"} } } // ロジックの定義 type gg struct { f g t g } func (g *gg) s() { fmt.Println("あいさつ かいし!") fmt.Println(g.f.g()) fmt.Println(g.t.g()) fmt.Println("あいさつ おわり!") }割と読むことができます。このコードを作成している間、半分ほど過ぎたところでスラスラと書くことができました。頭の中に「〜〜〜は***のコード」と、辞書が出来上がってくれば、難なく読み書きできました。この場合、コメントがかなり助けていると考えられます。初めてこのコードを読むとコメントがないと全くわかりません、特にmain関数は呪文です。しかし、文字数が少ないため、前述のコードよりも、この1文字〜2文字の名前で構成されたコードのほうが、字面はスッキリとしています。
日本語にする
(私にとって)母国語であれば、最も読みやすそうです。
// あいさつプログラム package main import "fmt" func main() { 製造機 := &挨拶さん製造機{} 処理 := &挨拶処理{ 先に言う人: 製造機.人間を作る("kent"), 後に言う人: 製造機.犬を作る(柴犬), } 処理.始める() 処理 = &挨拶処理{ 先に言う人: 製造機.犬を作る(ゴールデンレトリバー), 後に言う人: 製造機.犬を作る(ダルメシアン), } 処理.始める() } // モデルとなる、インターフェースと構造体の定義 type 挨拶さん interface { 挨拶する() string } type 人間 struct { 名前 string } func (この人の *人間) 挨拶する() string { return fmt.Sprintf("こんにちは、わたしは %s です", この人の.名前) } type 犬 struct { 鳴き声 string } func (この犬の *犬) 挨拶する() string { return fmt.Sprintf("%s だワン!", この犬の.鳴き声) } // ファクトリーの定義 type 犬種 int const ( 柴犬 犬種 = iota + 1 ゴールデンレトリバー ダルメシアン ) type 挨拶さん製造機 struct{} func (この製造機 *挨拶さん製造機) 人間を作る(渡す名前 string) 挨拶さん { return &人間{名前: 渡す名前} } func (この製造機 *挨拶さん製造機) 犬を作る(渡す犬種 犬種) 挨拶さん { switch 渡す犬種 { case 柴犬: return &犬{鳴き声: "ワン"} case ゴールデンレトリバー: return &犬{鳴き声: "ガオー"} case ダルメシアン: return &犬{鳴き声: "ニャー"} default: return &犬{鳴き声: "我は何者"} } } // ロジックの定義 type 挨拶処理 struct { 先に言う人 挨拶さん 後に言う人 挨拶さん } func (この挨拶処理の *挨拶処理) 始める() { fmt.Println("あいさつ かいし!") fmt.Println(この挨拶処理の.先に言う人.挨拶する()) fmt.Println(この挨拶処理の.後に言う人.挨拶する()) fmt.Println("あいさつ おわり!") }英語で書かれている部分は、言語ルール上必ずそうなる部分や、外部パッケージであり、日本語である部分は自前で書いた部分ということがすぐに読み取ることができます。読みやすいかどうかはわかりませんが、「この〜の.〜.〜()」と、日常の言葉のように流れているあたりは意図が伝わりやすそうです。字面は、ごちゃごちゃとしています。形のシンプルさではアルファベットにかないません。ロジック中の処理は、流れがある方がわかりやすく、定義など独立している部分は、字面がスッキリしていることが良さそうです。
説明をつける
ここまでで下記のことが大事であることがわかりました。
- 頭の中に定義の辞書が出来上がっていること
- 字面はスッキリしている方が良い
それであれば、命名が極端に短縮されたものでも、一定のルールがあり、そのルールが説明されていれば、すんなりと読むことができるかを試してみます。
/* あいさつプログラム 型 命名、関数 命名 型名 末尾 F : インスタンス生成のための、ファクトリを表します 返却する型名がそのまま関数名になっています 型名 末尾 L : 処理本体である、ロジックを表します 処理の実行はdo関数です */ package main import "fmt" func main() { f := &greeterF{} g := &greetL{ from: f.human("kent"), to: f.dog(shiba), } g.do() g = &greetL{ from: f.dog(golden), to: f.dog(dalmatian), } g.do() } // モデルとなる、インターフェースと構造体の定義 type greeter interface { greet() string } type human struct { name string } func (h *human) greet() string { return fmt.Sprintf("こんにちは、わたしは %s です", h.name) } type dog struct { roar string } func (d *dog) greet() string { return fmt.Sprintf("%s だワン!", d.roar) } // ファクトリーの定義 type breed int const ( shiba breed = iota + 1 golden dalmatian ) type greeterF struct{} func (g *greeterF) human(n string) greeter { return &human{name: n} } func (g *greeterF) dog(b breed) greeter { switch b { case shiba: return &dog{roar: "ワン"} case golden: return &dog{roar: "ガオー"} case dalmatian: return &dog{roar: "ニャー"} default: return &dog{roar: "我は何者"} } } // ロジックの定義 type greetL struct { from greeter to greeter } func (g *greetL) do() { fmt.Println("あいさつ かいし!") fmt.Println(g.from.greet()) fmt.Println(g.to.greet()) fmt.Println("あいさつ おわり!") }特に読みやすさは変わらないように感じます。また、それほど字面もスッキリしませんでした。
まとめ
有名なオープンソースのコードなどを見ても、上述したような妙な命名は殆どありませんし、GoDocでパッケージや型に説明をつけるため、結局は普通が一番ということになります。
ありきたりな言葉になりますが、つまるところ重要なのは・・・。
- シンプルであること
- 意図が説明されていること
- 全体で一貫したルールがあること
ということであり、それをチームで遵守することと言えます。命名で迷ったら、それらの基準に立ち返ると、悩みも解決できるかもしれません。
なお、ドメイン駆動設計の場合は、ドメイン知識を中心に命名をするため、そもそもそういった議論はユビキタス言語の策定のフェーズで殆ど終わります。
そういうところで、あえて命名を普段ではやらない形をいくつか試してみましたが、改めて大事さを体感することができました。
- 投稿日:2019-11-28T18:37:21+09:00
MySQL/PostgreSQLに対応したdump/recreate/validateツールを作りました
概要
- MySQL/PostgreSQLに対応したdump/recreate/validateツールを作りました。
- Dump機能はデータベース単位でDDLを生成し、テーブル毎にDDL+Insert文を出力します。
- Recreate機能はデータベースをDrop and Restoreすることでdumpファイルが正常に復元できることをチェックします。
- Validate機能はテーブル単位でCheckSumまたはMD5値を取得して保存し、リストア前後でデータの欠損や変更がないことをチェックします。
- github.com/m22r/chronicleにてコードを公開してます。
インストール方法
$ git clone git@github.com:m22r/chronicle.git $ make build使い方
dump
Store dump files of all databases and tables Usage: chronicle dump [flags] Flags: -h, --help help for dump --only-info Create only information file --skip-info Skip creating information file Global Flags: --bucket string Bucket which store dump and information files (required only if store at not local) --dbms string Type of the database management system (choice "mysql", "postgres")) (default "mysql") --dir string Directory which store dump and information files (required) -H, --host string Hostname of database (default "127.0.0.1") -p, --pass string Password of database -P, --port int Port of database (default 3306) --retry int Maximum number of tries (default 5) --storage string Type of storage which store dump and information files (choice "s3", "local") (default "local") --thread int Maximum number of threads (default 10) -u, --user string Username of database (default "root")recreate
Recreate all databases and tables with dumped files and informations. Usage: chronicle recreate [flags] Flags: -h, --help help for recreate Global Flags: --bucket string Bucket which store dump and information files (required only if store at not local) --dbms string Type of the database management system (choice "mysql", "postgres")) (default "mysql") --dir string Directory which store dump and information files (required) -H, --host string Hostname of database (default "127.0.0.1") -p, --pass string Password of database -P, --port int Port of database (default 3306) --retry int Maximum number of tries (default 5) --storage string Type of storage which store dump and information files (choice "s3", "local") (default "local") --thread int Maximum number of threads (default 10) -u, --user string Username of database (default "root")validate
Validate all restored tables and databases. Usage: chronicle validate [flags] Flags: -h, --help help for validate Global Flags: --bucket string Bucket which store dump and information files (required only if store at not local) --dbms string Type of the database management system (choice "mysql", "postgres")) (default "mysql") --dir string Directory which store dump and information files (required) -H, --host string Hostname of database (default "127.0.0.1") -p, --pass string Password of database -P, --port int Port of database (default 3306) --retry int Maximum number of tries (default 5) --storage string Type of storage which store dump and information files (choice "s3", "local") (default "local") --thread int Maximum number of threads (default 10) -u, --user string Username of database (default "root")想定しているユースケース
- テーブル毎のdumpファイルをテキストベースで取得したい
- 取得したdumpファイルがきちんと復元できることをチェックしたい
- MySQLとPostgreSQLを両方利用しているが、同じようなフォーマットでdumpファイルを取得したい
参考資料
- 投稿日:2019-11-28T18:04:37+09:00
SSMパラメータストアに対するアクセス検知ツール
概要
- SSMパラメータストアに対するアクセス検知ツールを作りました。
- 任意の期間中のアクセスをCloudTrail APIから取得し、ユーザ名、UserAgent, 対象のパラメータ, 期間中のアクセス件数, ソースIPアドレスなどをSlackに通知します。
- github.com/m22r/dobermanにてコードを公開しています。
slackへの通知サンプル
terraformでSSMパラメータ内の値を閲覧したときの通知内容
対象期間中にアクセスがなかった時の通知内容
インストール方法
$ git clone git@github.com:m22r/doberman.git $ make build使い方
Detection Tool against attempt to put/get SSM secure parameter Usage: doberman [flags] doberman [command] Available Commands: help Help about any command version Print version Flags: --channel string slack channel --end string end time of detection (format:2006-01-02T15:04:05-07:00) -h, --help help for doberman --icon-url string slack icon URL --ignore-system-user don't detect system users --log-format string logging format (text or json) (default "text") --start string start time of detection (format:2006-01-02T15:04:05-07:00) --token string slack app's OAuth access token Use "doberman [command] --help" for more information about a command.継続的に検知する構成例
- Cloudwatch EventとCodebuildをつかって1日1回、過去24時間分のアクセスを解析してslackに通知するように仕込んでおくと良い感じです。
参考資料


- 投稿日:2019-11-28T17:21:18+09:00
GolangでRDSをPITR(ポイントインタイムリカバリ)するCLI
概要
- RDSのポイントインリカバリを簡単に実行するツールをGoで作りました。
- 復元元のDBインスタンス/クラスターの設定を復元先にも引き継ぐようにしています。
- github.com/m22r/phoenixにてコードを公開してます。
インストール方法
$ git clone git@github.com:m22r/phoenix.git $ make build使い方
$ ./phoenix -h Point In Time Recovery Tool for Amazon RDS, Aurora Usage: phoenix [flags] phoenix [command] Available Commands: help Help about any command version Print version Flags: --cluster If you restore Aurora Cluster, Use this option. --delay int Interval between each tries (default 30) -h, --help help for phoenix --log-format string Log format (text or json) (default "text") --restore-time string Restore point of recovery (ex. 2019-07-07T12:00:00+0900) -s, --source string Source DB instance or cluster -t, --target string Target DB instance or cluster --tries int Max count of tries (default 180) Use "phoenix [command] --help" for more information about a command.参考資料
- 投稿日:2019-11-28T17:00:41+09:00
GOMODULE--Goのパッケージ管理
Goのパッケージ管理
GOMODULEが誕生される前に
GOPATHとGOVENDORを使用してパッケージの管理をするのが一般的でした。
GOPATH: Go言語一度でも使用したことがあれば、お馴染みがあると思います、GOROOTと一緒に、Go言語の環境構築時にセットしてると思います。また、配下にsrcフォルダが存在することが必須とされています
GOVENDOR: パッケージ管理を専門フォルダーvendorに一任する、glide, dep,go dep...などの管理ツールもありますでも、どっちを使用しても、便利とは言えない
GOPATH
- 全てのプロジェクトは
srcに置かなければならない、すぐディレクトリがパンパンになりますGOVENDOR
- ディレクトリに対しての依存性が厳しい、場合によって
vendorの配下にまたvendorが存在しますGOMODULE goモジュール
Go1.11バージョン以降追加された機能です。またバージョン上げてない方はバージョンアップしてください
公式の説明は以下になります リンク
Go 1.13には、Goモジュールのサポートが含まれています。モジュール対応モードは、現在のディレクトリまたはその親にgo.modファイルが見つかった場合にデフォルトでアクティブになります。 モジュールサポートを利用する最も簡単な方法は、リポジトリをチェックアウトし、そこにgo.modファイル(次のセクションで説明)を作成し、そのファイルツリー内からgoコマンドを実行することです。 より細かく制御するために、Go 1.13は一時的な環境変数GO111MODULEを引き続き尊重します。これは、off、on、またはauto(デフォルト)の3つの文字列値のいずれかに設定できます。GO111MODULE = onの場合、goコマンドではモジュールを使用する必要があり、GOPATHを参照することはありません。これを、モジュール対応または「モジュール対応モード」で実行されるコマンドと呼びます。GO111MODULE = offの場合、goコマンドはモジュールサポートを使用しません。代わりに、ベンダーのディレクトリとGOPATHを調べて依存関係を見つけます。これを「GOPATHモード」と呼びます。GO111MODULE = autoまたは未設定の場合、goコマンドは現在のディレクトリに基づいてモジュールサポートを有効または無効にします。モジュールのサポートは、現在のディレクトリにgo.modファイルが含まれる場合、またはgo.modファイルが含まれるディレクトリの下にある場合にのみ有効になります。 モジュール対応モードでは、GOPATHはビルド中のインポートの意味を定義しなくなりましたが、ダウンロードされた依存関係(GOPATH / pkg / mod)とインストールされたコマンド(GOBINが設定されていない場合はGOPATH / bin)を保存します。では、早速使ってみます、まずgoの環境変数を確認します
go envset GO111MODULE= set GOARCH=amd64 set GOBIN= set GOCACHE=C:\Users\user\AppData\Local\go-build set GOENV=C:\Users\user\AppData\Roaming\go\env set GOEXE=.exe set GOFLAGS= set GOHOSTARCH=amd64 set GOHOSTOS=windows set GONOPROXY= set GONOSUMDB= set GOOS=windows set GOPATH=C:\Users\user\go set GOPRIVATE= set GOPROXY=https://proxy.golang.org,direct set GOROOT=C:\Go set GOSUMDB=sum.golang.org set GOTMPDIR= set GOTOOLDIR=C:\Go\pkg\tool\windows_amd64 set GCCGO=gccgo set AR=ar set CC=gcc set CXX=g++ set CGO_ENABLED=1 set GOMOD= set CGO_CFLAGS=-g -O2 set CGO_CPPFLAGS= set CGO_CXXFLAGS=-g -O2 set CGO_FFLAGS=-g -O2 set CGO_LDFLAGS=-g -O2 set PKG_CONFIG=pkg-config下記のようにgomoduleの値は空になってます
それはどういう意味かというとと
goのプロジェクトがGOPATHの配下に存在すれば=off,でなければ=onset GO111MODULE=でもそのまましておくと、一部エラーを引き起こす可能性があります。
下記のコマンドを実行して修正しましょうgo env -w GO111MODULE=on実行後、再度env情報確認すれば、下記のようにonになってるはずです
set GO111MODULE=onGOMODULE実際使ってみます
任意のディレクトリでフォルダを新規に作ってください
mkdir gomodtest && cd gomodtestgomodをセット、名前を何にするのかは任意
go mod init gomodtest実行後、
go.modファイルが作られたと思います、中身を見てみますとmodule gomodtest go 1.13
- プロジェクト名
- 使用してるgoのバージョン
が確認できるはずです、早速パッケージを
getしましょうgo get -u go.uber.org/zap終了後、また
go.modの中身をみてみましょう、先ほどgetしたパッケージ内容が記録されてることが確認できます。module gomodtest go 1.13 require ( go.uber.org/atomic v1.5.1 // indirect go.uber.org/multierr v1.4.0 // indirect go.uber.org/zap v1.13.0 // indirect golang.org/x/lint v0.0.0-20191125180803-fdd1cda4f05f // indirect golang.org/x/tools v0.0.0-20191127201027-ecd32218bd7f // indirect )また、同じディレクトリに
go.sumファイルが増えてると思います、中身を確認すると省略 ... github.com/BurntSushi/toml v0.3.1 h1:WXkYYl6Yr3qBf1K79EBnL4mak0OimBfB0XUf9Vl28OQ= github.com/BurntSushi/toml v0.3.1/go.mod h1:xHWCNGjB5oqiDr8zfno3MHue2Ht5sIBksp03qcyfWMU= ... 省略パッケージのバージョンとそのhash値が入ってます、それは、パッケージが不正なカイゼンされないことが確保しますとの用途です
下記のコマンド実行すれば
go.sumの内容をgo.modに同期できますgo mod tidygoモジュール使用する場合、パッケージは下記のディレクトリに存在します
/gopath/pkg/mod/go.uber.org/zap@v1.13.0/field.go最後
インストールしたパッケージを使ってみましょう、
Uberさんがオープンソースしたlog出力用のパッケージです
gomodtestディレクトリの配下でgoファイルを新規に作りますvim main.gogomodtest/main.gopackage main import "go.uber.org/zap" func main(){ logger, _ := zap.NewProduction() logger.Warn("warning test") }実行すれば、以下の出力が確認できます
{"level":"warn","ts":1574911209.375762,"caller":"gomodtest/main.go:7","msg":"warning test"}既存プロジェクトのGOMODULE使用
cd [とあるgomod使用していないgoプロジェクト] && go mod init [プロジェクト名]その後、ディレクトリ内の全てのファイルをbuildします
go build ./...以上、完了です

- 投稿日:2019-11-28T16:21:45+09:00
03. 円周率
03. 円周率
"Now I need a drink, alcoholic of course, after the heavy lectures involving quantum mechanics."という文を単語に分解し,各単語の(アルファベットの)文字数を先頭から出現順に並べたリストを作成せよ.
Go
package main import ( "fmt" "regexp" "strings" ) func main() { var src string = "Now I need a drink, alcoholic of course, after the heavy lectures involving quantum mechanics." var wlen []int rex := regexp.MustCompile("([a-zA-Z]+)") // 単語に分割 words := strings.Split(src, " ") for _, word := range words { // アルファベットのみを抽出 match := rex.FindStringSubmatch(word) // アルファベットの文字数を保存 wlen = append(wlen, len(match[1])) } // 結果を表示 fmt.Println(wlen) }python
# -*- coding: utf-8 -*- import re src = "Now I need a drink, alcoholic of course, after the heavy lectures involving quantum mechanics." wlen = [] # 正規表現パターン定義(アルファベットのみ) pattern = re.compile('([a-zA-Z]+)') # 単語に分割 words = src.split(" ") for word in words: # アルファベットのみ抽出 result = re.search(pattern, word).group() # アルファベットの文字数を保存 wlen.append(len(result)) # 結果を表示 print(wlen)Javascript
var src = "Now I need a drink, alcoholic of course, after the heavy lectures involving quantum mechanics." var wlen = []; // ループ版 var words = src.split(' '); for (var i = 0; i < words.length; i++) { val = words[i].match(/[a-zA-Z]+/); wlen.push(val[0].length); } console.log(wlen); // forEach 版 var wlen = []; src.split(' ').forEach(function (value) { this.push(value.match(/[a-zA-Z]+/)[0].length); }, wlen) console.log(wlen);まとめ
以外と簡単と作ったが、他の人の結果を見て間違ってることに気づいた。 "." や "," は抜くのか。
アルファベット判別は少し悩んだが、正規表現で対応。Goの正規表現処理は遅いんだったかな?。問題の円周率の意味が解った時は、なんとなく嬉しかった。w
- 投稿日:2019-11-28T16:21:19+09:00
02. 「パトカー」+「タクシー」=「パタトクカシーー」
02. 「パトカー」+「タクシー」=「パタトクカシーー」
「パトカー」+「タクシー」の文字を先頭から交互に連結して文字列「パタトクカシーー」を得よ.
Go
package main import ( "fmt" "strings" ) func main() { var p1 string = "パトカー"; var p2 string = "タクシー"; var result string; // 文字を配列にする p1s := strings.Split(p1,""); p2s := strings.Split(p2,""); // 配列数ループ(「パトカー」に合わせる。同じ文字数だから・・・) for i := range(p1s) { // 各文字を1文字づつ連結 result += p1s[i] + p2s[i]; } // 結果を表示 fmt.Println(result); }python
# -*- coding: utf-8 -*- p1 = u"パトカー" p2 = u"タクシー" p1s = [] p2s = [] # 文字列を配列へ(「パトカー」に合わせる。同じ文字数だから・・・) for i in range(len(p1)): p1s.append(p1[i]) p2s.append(p2[i]) # 配列数ループ(「パトカー」に合わせる) result = "" for i in range(len(p1s)): # 各文字を1文字づつ連結 result += p1s[i] + p2s[i] # 結果を表示 print (result)Javascript
let p1 = "パトカー"; let p2 = "タクシー"; var result = ""; // 文字を配列にする let p1s = p1.split(""); let p2s = p2.split(""); // 配列数ループ(「パトカー」に合わせる。同じ文字数だから・・・) for (var i = 0; i < p1s.length; i++) { // 各文字を1文字づつ連結 result += p1s[i] + p2s[i]; } // 結果を表示 console.log(result);まとめ
どれも、イマイチ感がすごい。
他の人のソースを覗いてみる。
- 投稿日:2019-11-28T15:43:35+09:00
Golang Mac環境構築メモ
Goのバージョンを混在させるためgoenvからGoを入れる
brew install --HEAD goenv更新時
brew upgrade --fetch-HEAD goenvbash_profileにgoenv関連のパスを通しておく
vim ~/.bash_profile以下を記載して
:qw#goenv export PATH="$HOME/.goenv/bin:$PATH" export GOPATH=$HOME/go eval "$(goenv init -)"bash_profileの変更を反映
source ~/.bash_profilegoenvコマンドが叩けることの確認
goenv -vここからGoの構築
goenvでインストールできるGoのバージョンを確認goenv install -lバージョン指定で入れる
goenv install 1.11.4有効なバージョンに今回入れたバージョンが表示されれば成功
goenv versionsマシン全体で入れたバージョンを有効にする
goenv global 1.11.4 goenv rehash所定のディレクトリのみで有効にしたい場合
goenv local 1.11.4
- 投稿日:2019-11-28T14:50:59+09:00
mockeryのOn()にはTimes()を指定しよう
TL;DR
https://github.com/vektra/mockery のmock指定時の注意点。
- 同じ引数
- 返り値が場合によって異なる
の条件を満たすmockを使いまわす場合は
On()のメソッドチェーンでTimes()をつける。
それが難しければt.Runのなかでnewすること。回数を指定しない場合
On()の上書きが効かないので、最初にセットされたReturn()を返し続けることになる。例
func TestHoge(t *testing.T) { mockFoo := new(mocks.Foo) mockBar := new(mocks.Bar) t.Run("test - first", func(t *testing.T) { mockFoo.On("FuncA", mock.Anything).Return(1) mockBar.On("FuncB", 1).Return(1) // テストコード }) t.Run("test - second", func(t *testing.T) { mockFoo.On("FuncA", mock.Anything).Return(2) mockBar.On("FuncB", 2).Return(2) // テストコード }) }(
test - first→test - secondの順にテストが流れると想定する。)
上記のようなテストがあったとき、mockが返す値は以下のようになる。
mockFoo.FuncA mockBar.FuncB test - first 1 1 test - second 1 2 原因は、モックが 同じ引数 で
On()を上書きできないため。
Return()指定時にあらかじめ回数を指定されない限り、最初にセットされたReturn()をずっと返し続ける様子。どちらのテスト内でも引数
mock.Anythingを渡されているFuncAはtest - secondの中でも1を返している(test - firstでセットされたため)が、
t.Run()の中で毎回違う引数を渡されているFuncBはそれぞれ期待の値でモックできている。対応策
呼び出し回数を指定する。
Times()など。
回数を指定すると、その回数に到達したときに自動的にモックを解除してくれる。ちなみに、指定の回数 < 実際に呼ばれた回数になるとPanicになる。
mock.AssertExpectations(t)を指定しておくと、
実際に呼ばれた回数 < 指定の回数だったときにもエラーにできる。
これらもテストとして有効利用できるかも。
Once()
- 1回だけ呼ぶ
Twice()
- 2回だけ呼ぶ
Times(i int)
iで指定した回数だけ呼ぶ。3回以上指定したい時はこれfunc TestHoge(t *testing.T) { mockFoo := new(mocks.Foo) mockBar := new(mocks.Bar) t.Run("test - first", func(t *testing.T) { mockFoo.On("FuncA", mock.Anything).Return(1).Once() // 1回 mockBar.On("FuncB", 1).Return(1).Once() // 1回 }) t.Run("test - second", func(t *testing.T) { mockFoo.On("FuncA", mock.Anything).Return(2).Twice() // 2回 mockBar.On("FuncB", 2).Return(2).Times(3) // 3回 }) }どうしても
Times()の指定が難しい場合は、t.Run()の中で毎回mockを作り直したほうが事故を防げる。
- 投稿日:2019-11-28T13:33:57+09:00
Slackで誰かの承認をもらえたらRDSにクエリ実行して結果を返す仕組み
概要
- SlashコマンドでAWSのアカウントがなくてもRDSにクエリ実行する仕組みを作りました。
- 同じチャンネルで実行者以外の誰かの承認をもらえないと実行できません。
- 実行結果をslackにそのままPostするのではなく、s3にcsv形式で保存し、署名付きURL(有効期限15分)をslackにPostします。
- 特定のチャンネルからのslashコマンドしか受け付けないので、悪意のある第3者がこっそりクエリ実行して結果を閲覧することはできません。
コードは以下に公開しています。
https://github.com/m22r/sequelcatコマンド実行時の流れ
コマンド実行時
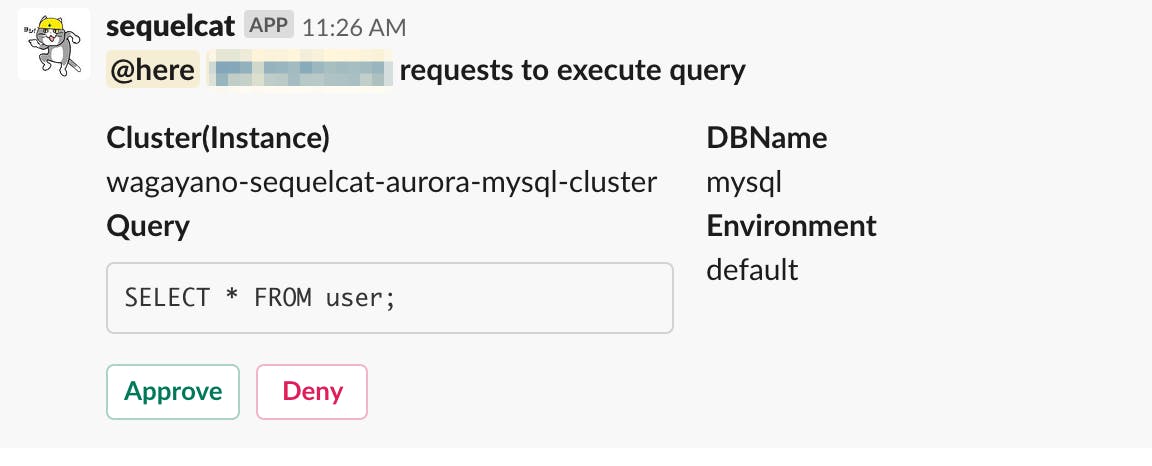
クエリを流したい人が特定のチャンネルでslashコマンドを入力します。承認画面
同じチャンネルに承認確認のメッセージが投稿されます。
承認者は実行対象のDBが間違ってないかざっくり確認して、Approveをポチッとします。結果通知
- Approveされると、lambdaで動作しているバックエンドアプリがRDSに対してSQLを実行し、終わったら結果を同じチャンネルに通知します。
- 15分以内にDownloadLinkからcsvをダウンロードして、結果を確認します。
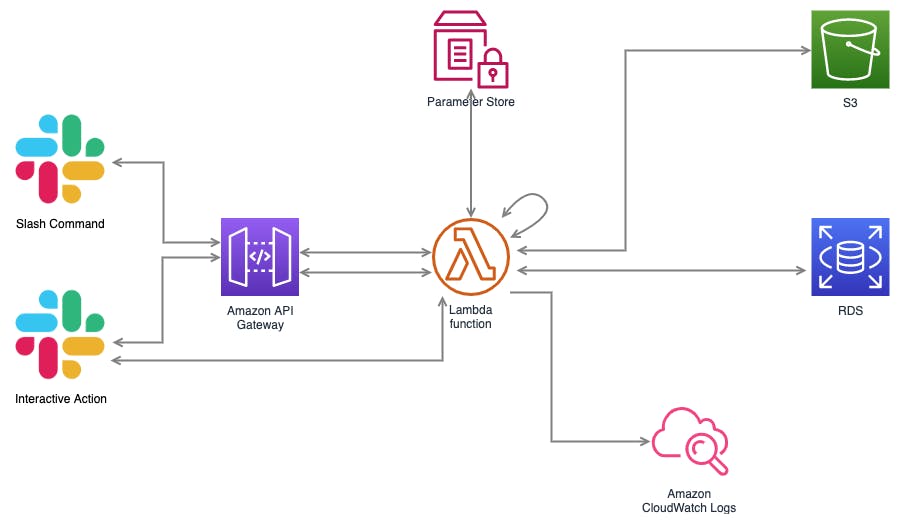
構成図
2つのAPIエンドポイントと1つのジョブ処理をモノリシックな1つのコードで記述し、lambdaで動作させています。
- slashコマンドを受け付けるAPI
- interactionを処理するAPI
- RDSに対してクエリ実行、結果をs3に保存、slackに通知するジョブ
機能要件
slackからRDSに対してクエリ実行できるということは、一種のセキュリティホールを空けるということなので、導入する際は熟慮した上で慎重にすべきだと思います。
今回この仕組みを作るにあたって実装した機能要件を列挙します。
- 承認フロー
- 依頼者本人がApproveしようとしてもエラーとする(デフォルト)
- mysql, postgres, mariadb対応
- RDS, Aurora両方対応
- 一度approve or denyされるとボタンを押せないようにする
- 依頼者、承認者、実行クエリをCloudWatch Logsとslackに記録
- 実行結果をCSV形式でS3に保存し、期限付きのDownloadリンクをslackに返す
- 指定したチャンネル以外からの要求にはエラーを返す
参考資料


- 投稿日:2019-11-28T01:36:50+09:00
Goの実装例で理解するダックタイピング
ダックタイピングという単語を聞いたことがあるものの、アヒル以外何も頭に思い浮かばないという方向けの記事です。ダックタイピングについてGoでの実装例と共に初心者の方でも分かるようにやさしく書いていきます。
以前書いたポリモーフィズムの記事の焼き直し感が否めませんが、まあ前回の記事と今回の記事を読めばダックタイピングとポリモーフィズム両方理解できるってことで気にせず書いていきます。
Wikipediaで理解するダックタイピング
まずはWikipediaのダックタイピングの説明を引用します。この説明を読んでよく分からなくても、記事を読み終わった後に再び読んでみると腑に落ちるはずですので、まずはさらっと読んでみてください。
ダック・タイピング(duck typing)とは、Smalltalk、Perl、Python、Rubyなどのいくつかの動的型付けオブジェクト指向プログラミング言語に特徴的な型付けの作法のことである。それらの言語ではオブジェクト(変数の値)に何ができるかはオブジェクトそのものが決定する。これによりポリモーフィズム(多態性)を実現することができる。つまり、静的型付け言語であるJavaやC#の概念で例えると、オブジェクトがあるインタフェースのすべてのメソッドを持っているならば、たとえそのクラスがそのインタフェースを宣言的に実装していなくとも、オブジェクトはそのインタフェースを実行時に実装しているとみなせる、ということである。それはまた、同じインタフェースを実装するオブジェクト同士が、それぞれがどのような継承階層を持っているのかということと無関係に、相互に交換可能であるという意味でもある。
"If it walks like a duck and quacks like a duck, it must be a duck"
(もしもそれがアヒルのように歩き、アヒルのように鳴くのなら、それはアヒルに違いない)この説明でダックタイピングがなんであるかを理解できなくても気にしないでください。実装例を見た方がわかりやすいので、これからGoでの実装例を見ていきます。
ダックタイピングの実装
type Income interface { calculate() string } type google struct { workingYear, baseSalary, performance int } type yahoo struct { performance, workingYear, baseSalary int } (g google) calculate() int { return g.baseSalary + (1000 * g.performance) } func (y yahoo) calculate() int { return y.baseSalary + (20000 * y.workingYear) }上記では、calculateメソッドを持つIncomeインターフェースを定義し、YahooとGoogleという二つの構造体型にcalculateメソッドを定義しました。
すると、以下のようなことができるようになります。func main() { hanako := google{ workingYear: 5, baseSalary: 100000, performance: 190, } choko := yahoo{ baseSalary: 60000, workingYear: 50, } motoko := yahoo{ baseSalary: 40000, workingYear: 25, } workers := []Income{hanako, choko, motoko} //yahoo, google型がincomeインターフェースを満たしているから渡せる fmt.Printf("Total income: %d\n", calculateIncome(workers)) } func calculateIncome(ic []Income) int { sum := 0 for _, worker := range ic { sum += worker.calculate() } return sum }google型もyahoo型も共にcalculateメソッドを実装しているため、Incomeインターフェースを満たしているということになります。すると、このように違う型の構造体(ここではyahoo型、google型)も、同じIncome型として扱うことが可能になるのです。
最後にもう一度Wikipediaで理解するダックタイピング
ここで、先ほどのWikipediaの説明の一部をもう一度読んでみましょう。
オブジェクトがあるインタフェースのすべてのメソッドを持っているならば、たとえそのクラスがそのインタフェースを宣言的に実装していなくとも、オブジェクトはそのインタフェースを実行時に実装しているとみなせる、ということである。それはまた、同じインタフェースを実装するオブジェクト同士が、それぞれがどのような継承階層を持っているのかということと無関係に、相互に交換可能であるという意味でもある。
これを先の実装例と照らして読み替えてみると理解が深まると思います。
Wikipediaを実装例で読み替え
オブジェクトがあるインタフェースのすべてのメソッドを持っているならば、
読み替え:構造体(yahoo型、google型)がIncomeインターフェースの全てのメソッド(ここでは
calculate()だけ)を持っているならば *1たとえそのクラスがそのインタフェースを宣言的に実装していなくとも、
読み替え:GoにはJavaなどの言語と違ってインターフェースの宣言的実装はなく、インターフェースが持つメソッドを全て実装した時点でインターフェースを実装したとみなす。
オブジェクトはそのインタフェースを実行時に実装しているとみなせる、ということである。
読み替え:yahoo型、google型は両方ともIncomeインターフェースを実装しているとみなせる。(だからIncome型のスライスの要素にhanako, choko, motokoを入れられた)
もし、それがアヒルのように歩き、アヒルのように鳴くのなら、それはアヒルに違いない
読み替え:もしyahoo型、google型が計算ができるのなら、それはincomeに違いない
最後の読みかえはかなり微妙でしたが、ダックタイピングについて理解できたのではないかと思います。Goでは明示的なインターフェースの宣言がないので、インターフェースを扱おうとすると勝手にダックタイピングになりますがダックタイピングとは何なのかしっかりと理解しておくことはいずれ役に立つでしょう。
本記事で引用したWikipeiaの説明には、
それらの言語ではオブジェクト(変数の値)に何ができるかはオブジェクトそのものが決定する。これによりポリモーフィズム(多態性)を実現することができる。
とあります。ポリモーフィズムについての説明記事も以前に書いてありますので、Goでポリモーフィズムを理解したいという方はそちらもお読みください。今回の記事と説明がほとんど同じですので、すんなりと理解できると思います。Go言語でポリモーフィズムとその便利さを理解する
それでは、最後までお読みいただきありがとうございました。
注釈
*Goにはオブジェクトはありませんが、構造体を代わりに使って似たような振る舞いを実現できます。