- 投稿日:2019-11-28T23:38:41+09:00
Ecllipseのエラーの件
コードを書いて実行すると、問題が検出されましたとのウィンドウが開き、
下記のメッセージが表示されます。
org.eclipse.epp.logging.aeri.ide
解決方法ご教授願います。
- 投稿日:2019-11-28T21:36:17+09:00
dbunit 2.6.0ならpoiは勝手に入ってくる
雑なメモ
dbUnitでxlsxからテストデータ流すぞってときには、2.6.0を使うと、dbUnitの中で必要なPOIとかのDependency書いててくれるから、自分では特に書かなくていい。
- 投稿日:2019-11-28T21:32:38+09:00
自主勉1日目
はじめに言っておかなければいけないのは、
「いくら良い先生がついたところで、わたしのポンコツ具合は変わらない」
ということだ。いつも「なに考えてるのかわかんない」と言われる謎回路変換がかかっているので、間違いもあるかもしれない。
しかし出力しないと気づかないので、それも含めて勉強していきたいと思う。テキストは『スッキリわかるJava入門』
https://book.impress.co.jp/books/1113101090
ほかの本は見たことがなく、比較できない。
ちなみに、JVM君のイラストがめちゃくちゃかわいいので、個人的には100点。1章を見返してみたけど、もうfinal(+大文字)で定数とか、そういえばあったな状態になってて怖い!
そのくらい何も知らないところからのスタートなのは、いつも通りだけど。今日はここまで。
- 投稿日:2019-11-28T19:03:55+09:00
Oracle Code One 2019に行ってきました
この記事はSRA Advent Calendar 2019の1日目の記事です。
こんにちは! 関西事業部の佐々木です。
今年のOracle Code Oneの印象
1996年から20年以上続いてきたJavaOneは2018年からOracle Code Oneになりました。
今年はOracle Code Oneになってから2回目で、2019年の9/16から9/19にサンフランシスコで開催されました。
私は2015年のJavaOneから5年連続の参加です。さて、カンファレンス名から「Java」の文字が消えてしまったOracle Code Oneですが、私の印象としては去年よりさらにJava以外の言語、GoやPythonなどのセッションが増えたように思えます。
JavaOne時代からJava言語以外のセッションもありましたが、ScalaやKotlinなどのJVM言語やJavaScriptが多かった印象です。
もちろん、コンテナ技術やDevOpsなどプログラミング言語に特化しないセッションもJavaOne時代から多くあるのですが、Oracle Code OneになってJava色が薄まったように感じます。それから今年は日本人登壇のセッションが多かったようにも思います。
Oracle Code OneのFacebookグループにもまとめたのですが、毎日日本人が参加しているセッションがありました。
皆さんカッコよかったです。今年のミッション
去年のOracle Code Oneでは「Amazon.comで買い物をする」というミッションを自分に課しました。(去年の記事)
この内容はOracle Code One 2018 報告会 in 大阪の登壇時にも話をしたのですが、その時に初代Java Championのさくらばさんから来年はAmazon Goで買い物ですねww #kanjava
— Yuichi Sakuraba (@skrb) 2018年11月24日との言葉をいただき
逆らうと怖いのでAmazon Goに興味があったので今年のミッションは「Amazon Goで買い物する」にしました。
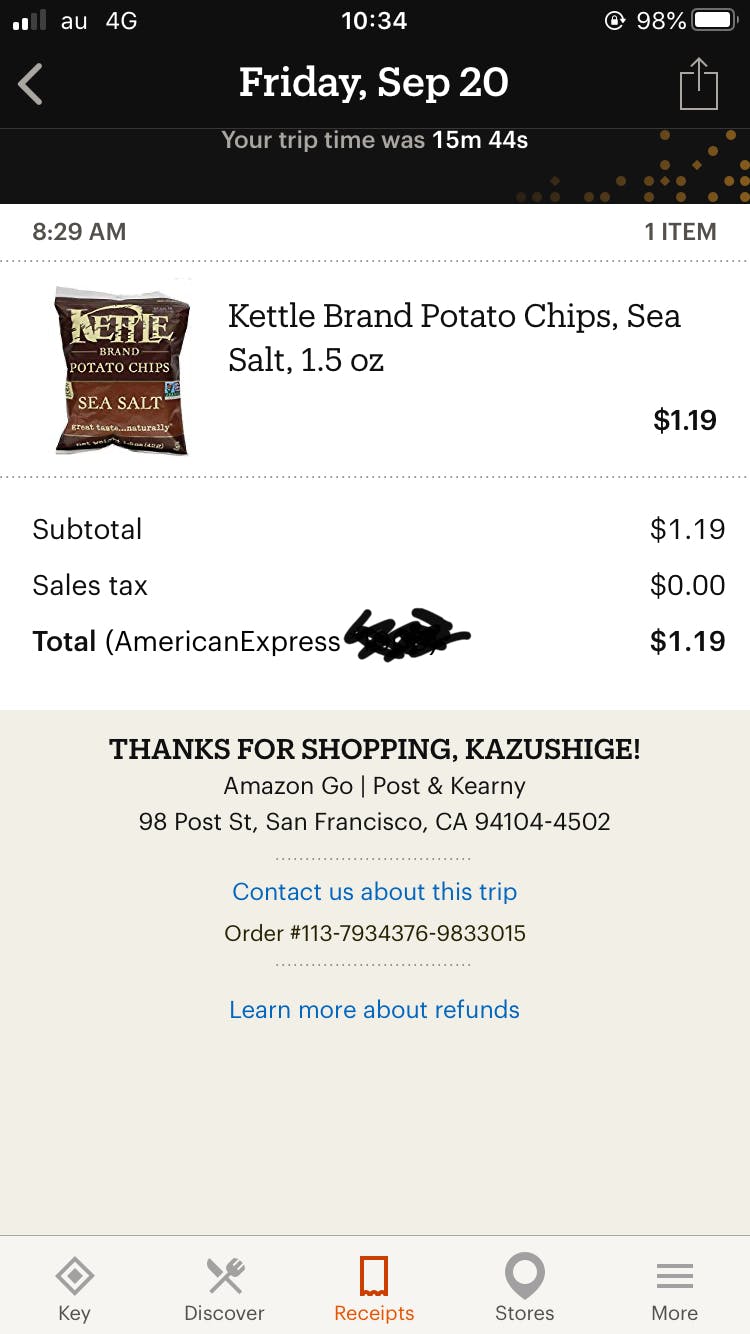
(さくらばさんは去年のOracle Code Oneの時に行ったとのことです)今年のミッションAmazon Goに来た pic.twitter.com/4gKDgePF9t
— 佐々木和繁@3391 (@kazsharp) September 19, 2019事前にAmazon Goのアプリをインストールしておき、表示されたQRコードをゲートにかざして入店します。
棚に商品がずらっと並んでいるので、勝手に商品を取って再びゲートをくぐって店を出ます。
アプリを確認すると決済されていることがわかります。
一度取った商品を戻したり、取るフリをしたりしてみましたが間違って購入とかにはならなかったです。ボビーフィッシャーを探して
最後に、個人的には今年一番の収穫だと思っているストリートチェスについてです。
(屋外でプレイするチェスのことを何と言うのかわからないけど、ストリートファイターⅡが好きなのでストリートチェスと呼びます)
今年のOracle Code Oneのセッションは大体Moscone Southってところでやってたのですが、そのすぐ近くにYerba Buena Gardensという公園があります。
その公園の東の端でチェスをやっている人たちがいました。
これは映画「ボビーフィッシャーを探して」でみた場面じゃないか!
パッと見、定職を持ってなさそうなおっちゃんたちですが、一人のおっちゃんに声をかけて一局お手合わせ願いました。
あっさり負けたのですが「一日中、毎日おるからまた来いよ」と言われました。
(やっぱり定職持ってないんや)
そして次の日はセッション最終日で夕方には蟹Oneがあるのですが、最後に予約していたセッションがキャンセルになってしまいました。
「時間空いたやん! チェスできるやん!!」
ということで再びおっちゃんのもとへ
今度は先手後手を交代して一局ずつの二局プレイしましたが、やはり勝てませんでした。
終わってからおっちゃんに「カンファレンスは今日で終わりなんでもう来れない」と言ったら「来年またおいで」と言われました。どうやら来年のミッションは決まったようです。


- 投稿日:2019-11-28T17:44:19+09:00
Jetty のログを任意のディレクトリに出力する方法
概要
軽量WebサーバーのJettyでは以下の2つのログファイルが出力されます。
- 標準出力/標準エラー出力
- アクセスログ
これらのログファイルはデフォルト状態では
jetty.baseプロパティで指定されたディレクトリ直下のlogsに出力されます。Jettyのリファレンス Default Logging with Jetty’s StdErrLog や Configuring Jetty Request Logs を参照しましたが、出力先を任意のディレクトリに変更する方法が分かりにくかったので本記事でまとめました。
内容
1. 標準出力/標準エラー出力ログの出力先の変更方法
ログファイルの設定は
etc/jetty-logging.xmlから行います。jetty-logging.xml<?xml version="1.0"?> <!DOCTYPE Configure PUBLIC "-//Jetty//Configure//EN" "http://www.eclipse.org/jetty/configure_9_0.dtd"> <!-- =============================================================== --> <!-- Configure stderr and stdout to a Jetty rollover log file --> <!-- this configuration file should be used in combination with --> <!-- other configuration files. e.g. --> <!-- java -jar start.jar etc/jetty-logging.xml --> <!-- =============================================================== --> <Configure id="logging" class="org.eclipse.jetty.util.log.Log"> <New id="ServerLog" class="java.io.PrintStream"> <Arg> <New class="org.eclipse.jetty.util.RolloverFileOutputStream"> <Arg><Property name="jetty.logs" default="./logs"/>/yyyy_mm_dd.stderrout.log</Arg> <Arg type="boolean">false</Arg> <Arg type="int">90</Arg> <Arg><Call class="java.util.TimeZone" name="getTimeZone"><Arg>GMT</Arg></Call></Arg> <Get id="ServerLogName" name="datedFilename"/> </New> </Arg> </New> <Get name="rootLogger"> <Call name="info"><Arg>Redirecting stderr/stdout to <Ref refid="ServerLogName"/></Arg></Call> </Get> <Call class="java.lang.System" name="setErr"><Arg><Ref refid="ServerLog"/></Arg></Call> <Call class="java.lang.System" name="setOut"><Arg><Ref refid="ServerLog"/></Arg></Call> </Configure>変更箇所
<Arg><Property name="jetty.logs" default="./logs"/>/yyyy_mm_dd.stderrout.log</Arg>
jetty.logsプロパティで指定されたディレクトリ直下(プロパティがなければ $pwd/logs)にyyyy_mm_dd.stderrout.logとして出力されるようになっています。対応方法としては Jetty 起動コマンドのシステムプロパティに
LOG_DIR=/test/logsという値を指定してjetty-logging.xmlでLOG_DIRを参照することでログを任意のディレクトリに出力できるようになります。$ java -DLOG_DIR=/test/logs -jar start.jar<Arg><Property name="LOG_DIR"/>/yyyy_mm_dd.stderrout.log</Arg>この例では標準出力/標準エラー出力ログが
/test/logs/yyyy_mm_dd.stderrout.logに出力されます。2. アクセスログの出力先の変更方法
ログファイルの設定は
etc/jetty-requestlog.xmlから行います。jetty-requestlog.xml<?xml version="1.0"?> <!DOCTYPE Configure PUBLIC "-//Jetty//Configure//EN" "http://www.eclipse.org/jetty/configure_9_0.dtd"> <!-- =============================================================== --> <!-- Configure the Jetty Request Log --> <!-- =============================================================== --> <Configure id="Server" class="org.eclipse.jetty.server.Server"> <!-- =========================================================== --> <!-- Configure Request Log --> <!-- =========================================================== --> <Ref refid="Handlers"> <Call name="addHandler"> <Arg> <New id="RequestLog" class="org.eclipse.jetty.server.handler.RequestLogHandler"> <Set name="requestLog"> <New id="RequestLogImpl" class="org.eclipse.jetty.server.AsyncNCSARequestLog"> <Set name="filename"><Property name="jetty.base" default="." /><Property name="requestlog.filename" default="/logs/yyyy_mm_dd.request.log"/></Set> <Set name="filenameDateFormat"><Property name="requestlog.filenameDateFormat" default="yyyy_MM_dd"/></Set> <Set name="retainDays"><Property name="requestlog.retain" default="90"/></Set> <Set name="append"><Property name="requestlog.append" default="false"/></Set> <Set name="extended"><Property name="requestlog.extended" default="false"/></Set> <Set name="logCookies"><Property name="requestlog.cookies" default="false"/></Set> <Set name="LogTimeZone"><Property name="requestlog.timezone" default="GMT"/></Set> </New> </Set> </New> </Arg> </Call> </Ref> </Configure>変更箇所
<Set name="filename"><Property name="jetty.base" default="." /><Property name="requestlog.filename" default="/logs/yyyy_mm_dd.request.log"/></Set>
jetty.baseプロパティで指定されたディレクトリ直下(プロパティがなければ $pwd)に/logs/yyyy_mm_dd.request.logとして出力されるようになっています。アクセスログは標準出力/標準エラー出力ログと違って出力先ディレクトリと出力ファイル名が個別に指定されています。
注意点としては、出力ファイル名にlogsディレクトリの指定がデフォルトで含まれているところです。対応方法としては標準出力/標準エラー出力ログと同じように Jetty 起動コマンドのシステムプロパティに
LOG_DIR=/test/logsという値を指定してjetty-requestlog.xmlでLOG_DIRを参照することでログを任意のディレクトリに出力できるようになります。$ java -DLOG_DIR=/test/logs -jar start.jar<Set name="filename"><Property name="LOG_DIR"/><Property name="requestlog.filename" default="/yyyy_mm_dd.request.log"/></Set>
requestlog.filenameプロパティの出力ファイル名からはlogsディレクトリの指定を取り除いてファイル名のみとしています。この例ではアクセスログが
/test/logs/yyyy_mm_dd.request.logに出力されます。
- 投稿日:2019-11-28T16:44:55+09:00
Java暗号化、Word文書の解読
いくつかの重要な文書に対して,文書の内容が漏れないように保証します,常にファイルを暗号化する必要があります。ファイルを表示する時,パスワードを正しく入力してからファイルを開く必要があります。 本論文では、Word文書に対してSpire.Doc for Javaを使ってパスワード保護を設定し、パスワードを削除する方法を紹介します。
【示例1】Wordパスワード保護設定
import com.spire.doc.Document; import com.spire.doc.FileFormat; public class EncryptWord { public static void main(String[] args) { // Word文書を読み込む Document document = new Document(); document.loadFromFile("sample.docx"); // パスワードで文書を保護します document.encrypt("abc-123"); //文書を保存 document.saveToFile("Encrypt.docx", FileFormat.Docx); } }ファイルの暗号化結果:
【示例2】Wordパスワードの保護を解除します
import com.spire.doc.Document; import com.spire.doc.FileFormat; public class DecryptWord { public static void main(String[] args) { //パスワード付きのファイルを読み込み、元のパスワードを入力して解除します Document document = new Document(); document.loadFromFile("Encrypt.docx", FileFormat.Docx, "abc-123"); //文書を保存 document.saveToFile("Decrypt.docx", FileFormat.Docx); } }プログラムを実行すると、作成されたファイルはパスワード保護されなくなります。
- 投稿日:2019-11-28T15:30:17+09:00
args4j defaultを表示させない方法
概要
先日args4jを使っていて、以下のような現象に悩まされました。
defaultの部分が自動生成される。-h (--help) : print usage message and exit (default: true) -v (--version) : print version (default: false)解決策
API仕様を見たところ、withShowDefaultsというメソッドがデフォルトでtrueを返しているようなので、falseを渡してあげます。
ParserProperties parserProps = ParserProperties.defaults().withShowDefaults(false);-h (--help) : print usage message and exit -v (--version) : print versiondefaultが表示されないようになりました。
参考
API仕様
https://args4j.kohsuke.org/args4j/apidocs/org/kohsuke/args4j/ParserProperties.html
- 投稿日:2019-11-28T10:01:24+09:00
Sourcetrail(win版)をJavaコードで使ってみる
Sourcetrail(win版)をJavaコードで使ってみる
https://qiita.com/cloudsnow/items/7d7f3b859186667379ef
macOS版を参考にしてやってみました。
最終確認してCreateを選択までしたのですが動作しなかったのでどこがおかしいか調べてみると
)Editにあるpreferencesを開くとjava Path(64Bit)のアドレスパスが違ったので
"C:/Program Files/Java/jdk1.8.0_102/jre/bin/server/jvm.dll"に変更したら動作しました
- 投稿日:2019-11-28T09:14:48+09:00
stream中にエラーハンドリングできなくてこまるやつ
例外catchしてくださいって怒られるやつ
ぐぬぬ一行で書けない...
っていうのをどうにか綺麗に書くためのやつです
準備
準備.java/** --------------------準備-------------------- */ /** 例外を投げるインターフェース */ private static interface Throwable<T, S> { S apply(T t) throws NullPointerException, NumberFormatException, Exception; } /** 例外に応じて実行する関数を切り替えるメソッド */ private static <T, S> Function<T, S> switchFunction(Throwable<T, S> tf, BiFunction<Exception, T, S> npe, BiFunction<Exception, T, S> nfe, Function<Exception, S> other) { return v -> { try { return tf.apply(v); } catch (NullPointerException e) { return npe.apply(e, v); } catch (NumberFormatException e) { return nfe.apply(e, v); } catch (Exception e) { return other.apply(e); } }; }例外を投げられるFunctionを作りまして
とあるFunctionを実行しようとしたときに例外がでたらこっちのFunctionにするーっていうメソッドを作ります
- やりたい処理
- ぬるぽならこの処理
- NumberFormatExceptionならこの処理
- その他ならこの処理
の4つを実装していきます
内部の処理の実装
内部.java/** --------------------具体的な処理の実装-------------------- */ /** メイン処理 */ private static final Throwable<String, Integer> tf = v -> { if (v.equals("5")) { return Integer.parseInt(v); } else if (v.equals("999")) { throw new NullPointerException(); } else if (v.equals("ddd")){ throw new NumberFormatException(); } else { throw new IOException(); } }; /** ぬるぽの時の処理 */ private static final BiFunction<Exception, String, Integer> npe = (e, v) -> { e.printStackTrace(); return 0; }; /** 数値変換だめなときの処理 */ private static final BiFunction<Exception, String, Integer> nfe = (e, v) -> { e.printStackTrace(); return v.length(); }; /** その他の例外時の処理 */ private static final Function<Exception, Integer> other = e -> { e.printStackTrace(); return 1; };今回は全パターンみたいので強制的にException投げるようにしました
それじゃ実行していきましょう実行
実行.java/** --------------------実行-------------------- */ public static void main(String[] args) { Arrays.asList("5", "ddd", "999", "0").stream().map(switchFunction(tf, npe, nfe, other)) .forEach(System.out::println); }5 java.lang.NumberFormatException at test1.Test1.lambda$0(Test1.java:35) at test1.Test1.lambda$4(Test1.java:18) at java.util.stream.ReferencePipeline$3$1.accept(Unknown Source) at java.util.Spliterators$ArraySpliterator.forEachRemaining(Unknown Source) at java.util.stream.AbstractPipeline.copyInto(Unknown Source) at java.util.stream.AbstractPipeline.wrapAndCopyInto(Unknown Source) at java.util.stream.ForEachOps$ForEachOp.evaluateSequential(Unknown Source) at java.util.stream.ForEachOps$ForEachOp$OfRef.evaluateSequential(Unknown Source) at java.util.stream.AbstractPipeline.evaluate(Unknown Source) at java.util.stream.ReferencePipeline.forEach(Unknown Source) at test1.Test1.main(Test1.java:55) 3 java.lang.NullPointerException at test1.Test1.lambda$0(Test1.java:33) at test1.Test1.lambda$4(Test1.java:18) at java.util.stream.ReferencePipeline$3$1.accept(Unknown Source) at java.util.Spliterators$ArraySpliterator.forEachRemaining(Unknown Source) at java.util.stream.AbstractPipeline.copyInto(Unknown Source) at java.util.stream.AbstractPipeline.wrapAndCopyInto(Unknown Source) at java.util.stream.ForEachOps$ForEachOp.evaluateSequential(Unknown Source) at java.util.stream.ForEachOps$ForEachOp$OfRef.evaluateSequential(Unknown Source) at java.util.stream.AbstractPipeline.evaluate(Unknown Source) at java.util.stream.ReferencePipeline.forEach(Unknown Source) at test1.Test1.main(Test1.java:55) 0 java.io.IOException at test1.Test1.lambda$0(Test1.java:37) at test1.Test1.lambda$4(Test1.java:18) at java.util.stream.ReferencePipeline$3$1.accept(Unknown Source) at java.util.Spliterators$ArraySpliterator.forEachRemaining(Unknown Source) at java.util.stream.AbstractPipeline.copyInto(Unknown Source) at java.util.stream.AbstractPipeline.wrapAndCopyInto(Unknown Source) at java.util.stream.ForEachOps$ForEachOp.evaluateSequential(Unknown Source) at java.util.stream.ForEachOps$ForEachOp$OfRef.evaluateSequential(Unknown Source) at java.util.stream.AbstractPipeline.evaluate(Unknown Source) at java.util.stream.ReferencePipeline.forEach(Unknown Source) at test1.Test1.main(Test1.java:55) 1想定通りですね
弱点
まぁ見てわかる通り、実装できるFunctionの引数、戻り値の型が
せっかくジェネリクスでとってるのに、全部一致してないとダメってことですね現実的な実装だと困るケースも出てきそうです
っていうかこんなにFunction重ねるとなんか重くなりそうです...いいのかこれ実行部分、内部の処理が綺麗に分かれているので
可読性はめっちゃ高いんじゃないでしょうか
けどね、うん 準備長すぎな一連のstreamに対する中間操作でどうしてもExceptionを吐くケースが複数あるなら
こういった実装をした方がきれいにまとまるとかありそうですこれをメソッドでやってみる
これでしょ.javapublic class Test7 { private static <T>void switchMethod(T t) { try { s1(t); } catch (NumberFormatException e) { s2(t); } } private static <T>void s1(T t) throws NumberFormatException{ System.out.println(Integer.parseInt((String) t)); } private static <T>void s2(T t) { System.out.println(t + "すうちむり"); } public static void main(String[] args) { List<String> list = new ArrayList<>(Arrays.asList("a", null, "2")); list.stream().forEachOrdered(Test7::switchMethod); } }aすうちむり nullすうちむり 2やっぱ準備段階でメソッドは増えまくるんですよねぇ
例外吐いた場合の挙動が同じなら使った方が綺麗ですけども...
うーむ、難しい...
- 投稿日:2019-11-28T08:54:09+09:00
Java Artery-数値配列の処理-集約(最大値、最小値、合計、平均、標準偏差)、変換(移動平均、変化率など)、ヒストグラムなど
目次 ⇒ Javaアルゴリズムライブラリ-Artery-サンプル
概要
ArMathには計算処理のメソッドが集められている。その中から配列に関係するものを紹介する。本稿の内容は次の通り。
・関連enum、インターフェースの説明
・集約処理-最大値、最小値、合計、平均、標準偏差
・変換処理-指定数値との加減乗除
・変換処理-指定ロジックによる変換
・変換処理-移動平均、変化率など
・二つの配列の合成-二つの配列の値の加減乗除
・二つの配列の合成-二つの配列の値の計算(ロジックは外部指定)
・ヒストグラムの作成-境界値は直接またはArValidatorで指定する
・おまけ(逆順とランダマイズ、Map・二次元Map上の数値の加減乗除)ラッパー型配列とプリミティブ型の配列を変換することが必要だったりするが、(紹介はしないが)このようなメソッドも含まれている。一次元配列と二次元配列の変換もできる。
なおArListには、ここに示したようなメソッドが用意されているが、ArListではオブジェクトの中の特定フィールドを指定して、このような計算を行うことができる。
一次元配列と二次元配列について同様の機能があるが、サンプルは一次元配列で示している。
関連enum、インターフェースの説明
ArReduceTo
ArReduceTo.java/** 数値列の集約方法の定義 */ public enum ArReduceTo { /** 最大値 */ MAX, /** 最小値 */ MIN, /** 合計値 */ SUM, /** 平均値 */ AVG, /** 標準偏差 */ STD_DEV, /** 予備-0 */ YOBI_0, /** 予備-1 */ YOBI_1, }ArCalc
ArCalc.java/** 演算の種類の定義 */ public enum ArCalc { /** 加算 */ ADD, /** 減算 */ SUB, /** 乗算 */ MUL, /** 除算 */ DIV, /** 代入 */ SET, /** 逆減算 */ ISUB, /** 逆除算 */ IDIV, /** 交換 */ SWAP, }ArConvertTo
ArConvertTo.java/** 数値列の変換方法の定義 */ public enum ArConvertTo { /** 移動平均 */ MOVING_AVG, /** 変動率 */ CHANGE_RATE, /** 変動幅 */ CHANGE_WIDTH, /** パーセント */ PERCENT, /** 累積値 */ ACCUMULATION, /** ヒストグラム */ HISTOGRAM, /** 期間集計(四半期⇒年間などに使用) */ PERIOD_SUM, /** 予備-0 */ YOBI_0, /** 予備-1 */ YOBI_1, }ArTableRC
ArTableRC.java/** ROW,COLUMNの区別の定義 */ public enum ArTableRC { /** ROW */ ROW, /** COLUMN */ COLUMN; }ArCreator
ArCreator.java/** 指定されたオブジェクトから別のオブジェクトを生成するインタフェース. */ public interface ArCreator<T0,T1> { /** argからT1クラスのオブジェクトを生成する.実装がどのような処理をしているか分からないのでExceptionをthrowしておく. */ public T1 convert(T0 arg) throws Exception; }ArCreator2d
ArCreator2d.java/** 二つの値を元に別の値を生成するインターフェース */ public interface ArCreator2D<$arg0,$arg1,$value> { /** arg0とarg1から$valueクラスのオブジェクトを生成する.実装がどのような処理をしているか分からないのでExceptionをthrowしておく. */ public $value convert($arg0 arg0,$arg1 arg1) throws Exception; }ArValidator
ArValidator.java/** 指定されたオブジェクトの正当性を判定するインターフェース. */ public interface ArValidator<T> { /** * 指定されたオブジェクトを判定する. * @param value 判定対象オブジェクト. */ public boolean check(T value); }集約処理-最大値、最小値、合計、平均、標準偏差
メソッド定義
二次元配列ではROWまたはCOLUMNを指定して集約することができる。
ArMath.java/** 一次元配列の集約(最大最小など) */ public static double calc(double[] doubleArray,ArReduceTo kind) /** 二次元配列の集約(最大最小など) */ public static double[] calc(double[][] doubleArray,ArReduceTo kind,ArTableRC rowCol)サンプルプログラム
Q09_00.javapackage jp.avaj.lib.algo; import jp.avaj.lib.def.ArReduceTo; import jp.avaj.lib.test.L; /** 数値配列の集約処理-最大値、最小値、合計、平均、標準偏差 */ public class Q09_00 { public static void main(String[] args) { double[] array = new double[]{1,2,3,4,5,6,7,8,9,10}; // 念のためランダマイズ array = ArMath.randomize(array); L.p("array="+ArObj.toString(array)); L.p("最大値="+ArMath.calc(array,ArReduceTo.MAX)); L.p("最小値="+ArMath.calc(array,ArReduceTo.MIN)); L.p("合計="+ArMath.calc(array,ArReduceTo.SUM)); L.p("平均="+ArMath.calc(array,ArReduceTo.AVG)); L.p("標準偏差="+ArMath.calc(array,ArReduceTo.STD_DEV)); } }サンプル実行結果
result.txtarray=[1, 5, 10, 7, 2, 4, 6, 8, 3, 9] 最大値=10.0 最小値=1.0 合計=55.0 平均=5.5 標準偏差=2.8722813232690143変換処理-指定数値との加減乗除
メソッド定義
ArMath.java/** 一次元配列の変換 */ public static double[] convert(double[] doubleArray,ArCalc kind,double value) /** 二次元配列の変換 */ public static double[][] convert(double[][] doubleArray,ArCalc kind,double value)サンプルプログラム
Q09_01.javapackage jp.avaj.lib.algo; import jp.avaj.lib.def.ArCalc; import jp.avaj.lib.test.L; /** 数値配列の変換処理-指定数値との加減乗除. 本サンプルでは加算処理のみを行う. */ public class Q09_01 { public static void main(String[] args) { double[] array = ArMath.doubleArray(10,new ArGeneratorDoubleRandom(10D,20D)); L.p("array="+ArObj.toString(array)); array = ArMath.convert(array,ArCalc.ADD,3D); L.p("array="+ArObj.toString(array)); } }サンプル実行結果
result.txtarray=[13.348039840199508, 14.896592857645892, 17.333929293408378, 13.588269785858508, 16.036528261560278, 13.983347639430207, 12.002249957043128, 19.93148386395162, 12.337109159822935, 14.39586704149562] array=[16.348039840199508, 17.896592857645892, 20.333929293408378, 16.588269785858508, 19.036528261560278, 16.983347639430207, 15.002249957043128, 22.93148386395162, 15.337109159822935, 17.39586704149562]変換処理-指定ロジックによる変換
ロジックはArCreatorで指定するものと、ArCreator2Dで指定するものがある。前者は当該の数値を使って変換し、後者は当該の数値と配列のインデックスを使って変換する。
メソッド定義
ArMath.java/** 一次元配列の変換 */ public static double[] convert(double[] doubleArray,ArCreator<Double,Double> creator) throws Exception /** 一次元配列の変換.creatorのInteger引数には配列のインデックスが指定される. */ public static double[] convert(double[] doubleArray,ArCreator2D<Double,Integer,Double> creator) throws Exception /** 二次元配列の変換 */ public static double[][] convert(double[][] doubleArray,ArCreator<Double,Double> creator) throws Exception /** 二次元配列の変換 */ public static double[][] convert(double[][] doubleArray,ArCreator2D<Double,Integer,Double> creator) throws Exceptionサンプルプログラム
Q09_02.javapackage jp.avaj.lib.algo; import jp.avaj.lib.test.L; /** 数値配列の変換処理-指定ロジックによる変換 */ public class Q09_02 { public static void main(String[] args) throws Exception { // テストデータ double[] array = ArMath.doubleArray(10,new ArGeneratorDoubleRandom(5D,10D)); L.p("array="+ArObj.toString(array)); double[] newArray; // ArCreator<Double,Double>を利用した変換 { // ArCreatorの定義 ArCreator<Double,Double> creator = new ArCreator<Double,Double>() { @Override public Double convert(Double obj) throws Exception { return obj+2D; } }; newArray = ArMath.convert(array,creator); L.p("newArray="+ArObj.toString(newArray)); } // ArCreator2D<Double,Integer,Double>を利用した変換 { // ArCreator2Dの定義、Integerのパラメータには配列のインデックスが渡される ArCreator2D<Double,Integer,Double> creator = new ArCreator2D<Double,Integer,Double>() { @Override public Double convert(Double arg0,Integer arg1) throws Exception { return ((arg1%2)==0) ? arg0 : -arg0; } }; newArray = ArMath.convert(array,creator); L.p("newArray="+ArObj.toString(newArray)); } } }サンプル実行結果
result.txtarray=[5.852138560225006, 9.75606457517308, 5.4476666795846, 8.750541556076218, 9.276962894000498, 5.419291907356978, 8.018936197987681, 9.885258841879601, 8.406859998877785, 5.572972359413988] newArray=[7.852138560225006, 11.75606457517308, 7.4476666795846, 10.750541556076218, 11.276962894000498, 7.419291907356978, 10.018936197987681, 11.885258841879601, 10.406859998877785, 7.572972359413988] newArray=[5.852138560225006, -9.75606457517308, 5.4476666795846, -8.750541556076218, 9.276962894000498, -5.419291907356978, 8.018936197987681, -9.885258841879601, 8.406859998877785, -5.572972359413988]変換処理-移動平均、変化率など
メソッド定義
ArMath.java/** * ArConvertToを利用した数値の変換.ただしkindのうちヒストグラムは指定不可. * paramは次の場合のみ意味がある.MOVING_AVG,CHANGE_RATE,CHANGE_WIDTH,PERIOD_SUM. * またCHANGE_RATE,CHANGE_WIDTHでparamに0を指定した場合は初期値に対する変動となる. */ public static double[] convert(double[] array,ArConvertTo kind,int param) throws Exception /** * ArConvertToを利用した数値の変換.ただしkindのうちヒストグラムは指定不可. * paramは次の場合のみ意味がある.MOVING_AVG,CHANGE_RATE,CHANGE_WIDTH,PERIOD_SUM. * またCHANGE_RATE,CHANGE_WIDTHでparamに0を指定した場合は初期値に対する変動となる. */ public static double[] convert(double[][] array,ArConvertTo kind,int param,ArTableRC rowCol,int index) throws Exceptionサンプルプログラム
Q09_03.javapackage jp.avaj.lib.algo; import jp.avaj.lib.def.ArConvertTo; import jp.avaj.lib.test.L; /** 数値配列の変換処理-移動平均、変化率など 本サンプルでは移動平均と合計値に対するパーセントを求める. */ public class Q09_03 { public static void main(String[] args) throws Exception { // テストデータ double[] array = ArMath.doubleArray(10,new ArGeneratorDoubleRandom(5D,10D)); L.p("array="+ArObj.toString(array)); double[] newArray; // 四個の移動平均 { newArray = ArMath.convert(array,ArConvertTo.MOVING_AVG,4); L.p("newArray="+ArObj.toString(newArray)); } // 合計値に対するパーセント { newArray = ArMath.convert(array,ArConvertTo.PERCENT,0); // 最後の引数は無意味 L.p("newArray="+ArObj.toString(newArray)); } } }サンプル実行結果
result.txtarray=[5.985380144134761, 7.575355662184555, 7.8352635477308015, 5.149850038794702, 9.389332364999511, 5.035633917916596, 7.484603584807374, 6.847220004442178, 8.15795801332105, 9.350653554342703] newArray=[5.985380144134761, 6.780367903159658, 7.131999784683373, 6.6364623482112055, 7.487450403427393, 6.8525199673604025, 6.764854976629546, 7.189197468041415, 6.881353880121799, 7.960108789228326] newArray=[8.220405604471235, 10.40410043166721, 10.761061591616974, 7.072876759979646, 12.895441648951902, 6.916010726815919, 10.27946024716367, 9.404068637932905, 11.204254727155634, 12.842319624244903]二つの配列の合成-二つの配列の値の加減乗除
メソッド定義
ArMath.java/** 一次元配列同士の演算 */ public static double[] calc(double[] doubleArray0,double[] doubleArray1,ArCalc kind) /** 二次元配列の行・列と一次元配列の加減乗除.元の二次元配列が書き換えられる. */ public static void calc(double[][] doubleArray0,double[] doubleArray1,int index,ArCalc kind,ArTableRC rowCol)サンプルプログラム
Q09_04.javapackage jp.avaj.lib.algo; import jp.avaj.lib.def.ArCalc; import jp.avaj.lib.test.L; /** 数値配列の変換処理-二つの配列の合成-二つの配列の値の加減乗除 本サンプルでは加算と乗算を行う */ public class Q09_04 { public static void main(String[] args) { // テストデータ double[] array0 = ArMath.doubleArray(10,new ArGeneratorDoubleRandom(5D,10D)); L.p("array0="+ArObj.toString(array0)); double[] array1 = ArMath.doubleArray(10,new ArGeneratorDoubleRandom(5D,10D)); L.p("array1="+ArObj.toString(array1)); double[] newArray; // 加算処理 { newArray = ArMath.calc(array0,array1,ArCalc.ADD); L.p("newArray="+ArObj.toString(newArray)); } // 乗算処理 { newArray = ArMath.calc(array0,array1,ArCalc.MUL); L.p("newArray="+ArObj.toString(newArray)); } } }サンプル実行結果
result.txtarray0=[8.786527250579027, 8.475128917235198, 6.570863590659945, 9.095151921000824, 5.810489054840153, 8.574370760082004, 9.513894390034038, 7.928853544903687, 8.364814697141732, 7.496390955771403] array1=[9.825877092616365, 6.40624152776633, 8.091125641955209, 7.508234716238508, 9.254752954661516, 6.5836384715162835, 6.050855953787648, 5.823069794583683, 7.791340507005785, 7.748951867821722] newArray=[18.612404343195394, 14.881370445001528, 14.661989232615154, 16.603386637239332, 15.06524200950167, 15.158009231598289, 15.564750343821686, 13.75192333948737, 16.156155204147517, 15.245342823593125] newArray=[86.3353368351139, 54.29372282276542, 53.16568288817856, 68.28853540272175, 53.77464074831031, 56.450557205120205, 57.56720451364436, 46.170267583006414, 65.1731195834377, 58.08917269864668]二つの配列の合成-二つの配列の値の計算(ロジックは外部指定)
メソッド定義
変換ロジックArCreator2Dの引数には、それぞれの配列の値が指定される。
ArMath.java/** 一次元配列同士の演算 */ public static double[] calc(double[] doubleArray0,double[] doubleArray1,ArCreator2D<Double,Double,Double> creator) throws Exception /** 二次元配列の行・列と一次元配列の演算.元の二次元配列が書き換えられる.*/ public static void calc(double[][] doubleArray0,double[] doubleArray1,int index,ArCreator2D<Double,Double,Double> creator,ArTableRC rowCol) throws Exceptionサンプルプログラム
Q09_05.javapackage jp.avaj.lib.algo; import jp.avaj.lib.def.ArCalc; import jp.avaj.lib.test.L; /** 数値配列の変換処理-二つの配列の合成-二つの配列の値の計算(ロジックは外部指定) */ public class Q09_05 { public static void main(String[] args) throws Exception { // テストデータ double[] array0 = ArMath.doubleArray(10,new ArGeneratorDoubleRandom(5D,10D)); L.p("array0="+ArObj.toString(array0)); double[] array1 = ArMath.doubleArray(10,new ArGeneratorDoubleRandom(5D,10D)); L.p("array1="+ArObj.toString(array1)); double[] newArray; ArCreator2D<Double,Double,Double> creator; // サンプル0 { creator = new ArCreator2D<Double,Double,Double>() { @Override public Double convert(Double arg0,Double arg1) throws Exception { return arg0 + arg1; } }; newArray = ArMath.calc(array0,array1,creator); L.p("newArray="+ArObj.toString(newArray)); } // サンプル1 { creator = new ArCreator2D<Double,Double,Double>() { @Override public Double convert(Double arg0,Double arg1) throws Exception { return arg0 * arg1; } }; newArray = ArMath.calc(array0,array1,ArCalc.MUL); L.p("newArray="+ArObj.toString(newArray)); } } }サンプル実行結果
result.txtarray0=[5.494186340089856, 7.735644497901893, 9.972069234046275, 7.934361174668532, 9.917112507755494, 5.151322997853091, 9.188756724966979, 6.353024733860859, 8.223364931681369, 5.106895727778108] array1=[9.363650797189873, 7.332827778640875, 9.2790020579598, 5.158181941401007, 5.763411771209263, 6.158648211398885, 9.22867429510773, 9.781626836497223, 8.291547420073364, 5.795528562585907] newArray=[14.857837137279729, 15.068472276542767, 19.251071292006074, 13.092543116069539, 15.680524278964757, 11.309971209251977, 18.41743102007471, 16.13465157035808, 16.51491235175473, 10.902424290364014] newArray=[51.44564230329209, 56.72414885990545, 92.530850944833, 40.926878527728505, 57.15640296360463, 31.725186167065885, 84.80004299170105, 62.142917229664, 68.18442028360442, 29.597160056485965]ヒストグラムの作成-境界値は直接またはArValidatorで指定する
なおArListでは数値ではなく、任意のオブジェクトに対するヒストグラムを作成するメソッドが用意されている。境界値はArValidatorで指定する。
メソッド定義
ArMath.java/** * ヒストグラムを作成する.doudaryのlength-1の値が戻される. * boundary[0],boundary[length-1]にはnullを指定できる.その場合は無限値と解釈される. */ public static int[] histogram(double[] array,Double[] boundary) throws Exception /** ヒストグラムを作成する.validators.lendth-1の値が戻される. */ public static int[] histogram(double[] array,ArValidator<Double>[] validators) throws Exceptionサンプルプログラム
Q09_06.javapackage jp.avaj.lib.algo; import jp.avaj.lib.test.L; /** ヒストグラムの作成-境界値は直接またはArValidatorで指定する */ public class Q09_06 { public static void main(String[] args) throws Exception { // テストデータ ⇒ 1.0~10.0の配列を作成する double[] array = ArMath.doubleArray(10,new ArGeneratorDoubleSeq(1D,1D)); // あらぬ疑いを避けるためにランダマイズする array = ArMath.randomize(array); L.p("array="+ArObj.toString(array)); int[] result; // 境界値を直接指定する { // 両端をnullにすれば無限値となる Double[] boundary = new Double[] { null,4.0D,8.0D,null }; result = ArMath.histogram(array,boundary); L.p("result="+ArObj.toString(result)); } // 境界値をArValidatorで指定する { // ArValidatorの配列の作成 ⇒ 一例なのでよろしく Double[][] boundary = new Double[][] { {null,4.0D}, {4.0D,8.0D}, {8.0D,null}, }; ArValidator<Double>[] validators = ArValidatorUtil.createArValidatorDoubleRangeArray(boundary); result = ArMath.histogram(array,validators); L.p("result="+ArObj.toString(result)); } } }サンプル実行結果
result.txtarray=[6, 9, 1, 3, 5, 7, 2, 8, 10, 4] result=[3, 4, 3] result=[3, 4, 3]おまけ
逆順とランダマイズ
ArMath.java/** 一次元配列の逆順 */ public static double[] reverse(double[] doubleArray) /** 一次元配列のランダマイズ */ public static double[] randomize(double[] doubleArray) /** 二次元配列の行・列の逆順,indexが-1の時はすべてのRowまたはColumn */ public static double[][] reverse(double[][] doubleArray,int index,ArTableRC rowCol) /** 二次元配列の行・列のランダマイズ,indexが-1の時はすべてのRowまたはColumn */ public static double[][] randomize(double[][] doubleArray,int index,ArTableRC rowCol)Q09_07.javapackage jp.avaj.lib.algo; import jp.avaj.lib.test.L; /** 逆順とランダマイズ */ public class Q09_07 { public static void main(String[] args) { // テストデータ ⇒ 1.0~10.0の配列を作成する double[] array = ArMath.doubleArray(10,new ArGeneratorDoubleSeq(1D,1D)); L.p("array="+ArObj.toString(array)); double[] newArray; // 逆順 newArray = ArMath.reverse(array); L.p("newArray="+ArObj.toString(newArray)); // ランダマイズ newArray = ArMath.randomize(array); L.p("newArray="+ArObj.toString(newArray)); } }result.txtarray=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10] newArray=[10, 9, 8, 7, 6, 5, 4, 3, 2, 1] newArray=[8, 1, 7, 9, 10, 6, 5, 4, 2, 3]Map、二次元Map上の数値の加減乗除
Mapあるいは二次元Map(ArMatrix)上のInteger値を更新する。返値は更新後の値。
ArMath.java/** * 値がIntegerのMapの加減乗除.指定されたキーに対応する値とvalueの演算を行う. * 除算の場合は、切り捨てて整数化する. * Mapにキーが存在しない場合は、加減の場合は0、乗除の場合は1を仮定する. */ public static <$Key> int calc(Map<$Key,Integer> map,$Key key,ArCalc op,Integer value) /** * 値がIntegerのArMatrixの加減乗除.指定されたキーに対応する値とvalueの演算を行う. * 除算の場合は、切り捨てて整数化する. * ArMatrixにキーが存在しない場合は、加減と交換の場合は0、乗除の場合は1を仮定する. */ public static <$Key0, $Key1> int calc(ArMatrix<$Key0,$Key1,Integer> mat,$Key0 key0,$Key1 key1,ArCalc op,Integer value)Q09_08.javapackage jp.avaj.lib.algo; import java.util.HashMap; import java.util.Map; import jp.avaj.lib.def.ArCalc; import jp.avaj.lib.test.L; /** Map、二次元Map上の数値の加減乗除 */ public class Q09_08 { public static void main(String[] args) { int result; L.p("Mapの場合"); { // 初期値を適当に入れておく Map<String,Integer> map = new HashMap<String,Integer>(); map.put("a",3); map.put("b",4); map.put("c",5); // 加減算では存在しないキーでは0が設定されていると仮定、徐除算では1. result = ArMath.calc(map,"d",ArCalc.ADD,2); L.p("result="+result); result = ArMath.calc(map,"d",ArCalc.MUL,3); L.p("result="+result); } L.p("二次元Map(ArMatrix)の場合"); { // 初期値を適当に入れておく ArMatrix<String,String,Integer> mat = new ArMatrix<String,String,Integer>(); mat.put("a0","b0",7); mat.put("a1","b1",3); mat.put("a0","b1",5); mat.put("a1","b0",6); result = ArMath.calc(mat,"a","b",ArCalc.ADD,2); L.p("result="+result); result = ArMath.calc(mat,"a","b",ArCalc.MUL,3); L.p("result="+result); } } }result.txtMapの場合 result=2 result=6 二次元Map(ArMatrix)の場合 result=2 result=6==== end.
- 投稿日:2019-11-28T07:48:31+09:00
Java (WebSphere Application Server)メモ[1]
WebSphere Application Server とは
IBMが開発・販売する、Java EE対応のアプリケーションサーバであり、IBMソフトウェアのWebSphereブランドの中核をなす製品(以下、WASと略)
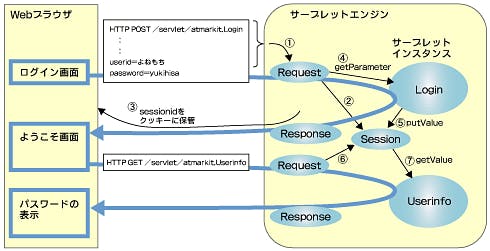
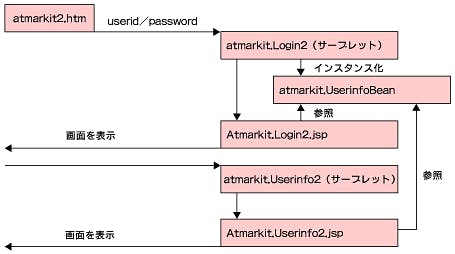
JSPとどう連携して使うのか
- ログイン画面を表示するJSPを作成する
- ようこそ画面を表示するJSPを作成する
- ユーザー情報画面を表示するJSPを作成する
- ユーザー情報を保存するBeanを作成する
それぞれのサーブレットでは、データをBeanに保存し、画面を表示するためにJSPを呼び出す。
詳しくは、参考[3]へ
参考
[1]WAS導入向け
https://qiita.com/TTakakiyo/items/05dfdb020249699d9849[2]JSP エンジン・パラメーター
https://www.ibm.com/support/knowledgecenter/ja/SSEQTP_9.0.5/com.ibm.websphere.base.doc/ae/rweb_jspengine.html[3]WASとサーブレット、JSPの連携
https://www.atmarkit.co.jp/ait/spv/0201/10/news001.html[4] JSPカスタムタグ
https://nablarch.github.io/docs/5u9/doc/application_framework/application_framework/libraries/tag.html#id3
- 投稿日:2019-11-28T02:51:59+09:00
HomebrewでインストールできるJDKまとめ(2019年11月時点)
はじめに
AdoptOpenJDK と Cask-Versions が衝突するなどしていた、homebrewでインストールできるJDK界隈ですが、一応の整理がついたようです。
ここでは、その記念(?)にhomebrewでインストールできるJDKとそのコマンドをまとめておきます。
なお、この記事の執筆時点で、最新バージョンは Java 13 です。
Homebrew
openjdk
brew install oepnjdkOpenJDK の最新バージョンが手元でビルド&インストールされます。
ただし、keg-only指定なので、インストール後に$JAVA_HOME用のフォルダへのシンボリックリンクを貼る必要があります。sudo ln -sfn /usr/local/opt/openjdk/libexec/openjdk.jdk /Library/Java/JavaVirtualMachines/openjdk.jdk.bashrcなど(PATHの通し方)# xx はインストールしたJDKのバージョン(例:13) export JAVA_HOME=`/usr/libexec/java_home -v xx`@バージョン番号で、11以降のリリース済みバージョンもビルド&インストールできるようです。
(もちろん、サポート期間はリリーススケジュール準拠です)# OpenJDK 11 brew install openjdk@11 # OpenJDK 12 brew install openjdk@12Homebrew Cask
java
brew cask install javaOracle OpenJDK Build (OracleがビルドしたOpenJDK)の最新バージョンがインストールされます。
brew install javaとの違いは、
- オラクルがビルドしたものがそのままダウンロードされる点
$JAVA_HOME用のフォルダへ直接配置されるので、JAVA_HOMEのPATHを通すだけでよい点
(※恐らく、以後のcaskでインストールできるJDKは全てそう)です。
(PATHの通し方再掲)# xx はインストールしたJDKのバージョン(例:13) export JAVA_HOME=`/usr/libexec/java_home -v xx`次バージョンのEarly Access版や、Oracle Open JDK 11をインストールすることもできます。
# Oracle OpenJDK 次バージョンのEarly Access版 brew cask install java-beta # Oracle OpenJDK 11 brew cask install java11Note That:
Oracle Open JDK(
https://jdk.java.net/) をダウンロードするのに、caskのhomepageの値 がhttps://openjdk.java.net/になっていて、設定ミスかな?という感じがします。java6
brew cask install java6なんで11の次が6なの...と思っていたら、これは過去にAppleが提供していた JavaForOSX.dmg でした。
oracle-jdk
brew cask install oracle-jdkOracleが提供する Oracle JDK の最新バージョンがインストールされます。
利用には Oracle JDK License が適用されます。
zulu
brew cask install zuluMicrosoft Azureにも採用されている、Azul社が提供するZulu JDKの最新バージョンがインストールされます。
バージョン番号をつけて、Zuluが独自にLTSを提供している旧バージョンもインストールできるようです。
# Azul Zulu JDK 11 brew cask install zulu11 # Azul Zulu JDK 8 brew cask install zulu8 # Azul Zulu JDK 7 brew cask install zulu7adoptopenjdk
brew cask install adoptopenjdkAdoptOpenJDK.net Community がビルドした OpenJDK の最新バージョンがインストールされます。
AdoptOpenJDK/openjdk をtapすることで、バージョンの指定や、HotSpot VM版以外にも、J9版などがインストールできるようになります。
brew tap AdoptOpenJDK/openjdk# AdoptOpenJDK, HotSpot版の11 brew cask install adoptopenjdk11 # AdoptOpenJDK, HotSpot版のJREのみ brew cask install adoptopenjdk11-jre # AdoptOpenJDK, OpenJ9版の11 adoptopenjdk11-openj9他、沢山あるので https://github.com/AdoptOpenJDK/homebrew-openjdk/tree/master/Casks を参照してください。
corretto
brew cask install correttoAmazon Linuxなどにも採用されているAmazon Correto の最新バージョンがインストールされます。
この記事の執筆時点では、リリースされている11と8が用意されています。
# Amazon Correto 11 brew cask install corretto # Amazon Correto 8 brew cask install corretto8sapmachine-jdk
brew cask install sapmachine-jdkドイツのSAP社が提供するOpenJDK(SapMachine)の最新バージョンがインストールされます。
LTS(11)のcaskは(まだ)ないようです。
どのJDKをインストールすれば良いか?
OpenJDKソムリエに関連するまとめ あたりの資料ややりとりをウォッチしつつ、ビルド元やライセンス、LTSの提供状況で自分の環境に合うディストリビューターのものを選ぶ(orビルドする)のが良い感じです。
複数のJDKを使い分け・切り替えしたい場合は SDKMAN! や JEnv の利用も検討したほうが良さそうですね。
Homebrew でまだインストールできないディストリビューターのJDKもあるので、ほしいなと思った人はぜひHomebrew Caskにコミットしていきましょう。
おわりに
これもインストールできるよ? などあれば教えてください。