- 投稿日:2019-11-28T20:26:19+09:00
OpenVPNとVPC(RouteTable)の設定だけで特定ドメインのみAlibaba CloudにルーティングさせるNW構成を作る
この記事の目的
特定のドメインやG-IP向けの通信経路だけAlibaba Cloud網を通したいときの手段として検証してみました。
VPC間にCENを通して2つのVPCをつなげたうえで試してみました。
VPN接続後、NATサーバ(ECS)を通ってアクセスするようになります。リソース構成図とNWフロー
下図のとおりです。
手順
OpenVPN:ECSの作成
GUIコンソールから作成しました。
- サーバー情報
機能 Hostname Zone InstanceType Spec P-IP NATサーバ nat01 日本東京(ゾーンB) ecs.t5-lc1m1.small 1vCPU 1GiB 10.68.30.153 VPNサーバ openvpn01 日本東京(ゾーンA) ecs.t5-lc1m1.small 1vCPU 1GiB 10.68.10.238
セキュリティグループ(OpenVPN)
便宜上一旦anyしてます
セキュリティグループ(NATサーバ)
便宜上一旦anyにしてます
VPCのルートテーブル情報(OpenVPN)
VPCのルートテーブル情報(NATサーバ)
OpenVPN:Configure
CAは腹持ちで建てました。
ECS上のOpenVPNの構築は別の記事に起こしているので、↓のリンクをご参照ください。
https://qiita.com/tnoce/items/b5765b38aeacc8f92269
- ポイント
- push "route 13.112.0.0 255.252.0.0" ※qiitaのipアドレスをVPN接続したクライアントにpushする
/etc/openvpn/default.conf※コメントアウトとオプションoff項目を除く[root@openvpn]# grep '^[^#]' 'server_r.conf' port 1194 proto udp dev tun ca /etc/openvpn/easy-rsa/pki/ca.crt cert /etc/openvpn/easy-rsa/pki/issued/server_r.crt key /etc/openvpn/easy-rsa/pki/private/server_r.key # This file should be kept secret dh /etc/openvpn/easy-rsa/pki/dh.pem server 10.8.0.0 255.255.255.0 ifconfig-pool-persist ipp.txt push "route 13.112.0.0 255.252.0.0"ECS(NATサーバ):Configure
eth0 の firewalld zone を external に変更
# firewall-cmd --zone=external --change-interface=eth0 --permanent successexternalゾーン に IPマスカレード設定
# firewall-cmd --zone=external --add-masquerade --permanent success変更の反映
# firewall-cmd --reload successFirewalldを常に起動
# systemctl enable firewalldFirewalldを起動
# systemctl start firewalldFirewalldのステータスを確認(RunningになっていればOK)
# systemctl status firewalld irewalld.service - firewalld - dynamic firewall daemon Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor preset: enabled) Active: active (running) since 木 2019-11-28 08:00:13 CST; 10h ago Docs: man:firewalld(1) Main PID: 542 (firewalld) CGroup: /system.slice/firewalld.service └─542 /usr/bin/python2 -Es /usr/sbin/firewalld --nofork --nopid 11月 28 08:00:13 nginx02 systemd[1]: Starting firewalld - dynamic firewall daemon... 11月 28 08:00:13 nginx02 systemd[1]: Started firewalld - dynamic firewall daemon. 11月 28 18:02:38 nginx02 firewalld[542]: WARNING: ALREADY_ENABLED: masquerade検証
VPN接続
vpnuxやtunnelblickなどのGUIアプリでVPN接続します。
接続後にNW設定を確認
OpenVPNに設定しいてたクライアントサブネットが割り当てられていることを確認します。
User:~$ ifconfig | grep 10.8 inet 10.8.0.6 --> 10.8.0.5 netmask 0xffffffffQiita向けの経路が適切にpublishされているか確認します。
User:~$ netstat -rn | grep 13.112/14 13.112/14 10.8.0.5 UGSc utun8特定ドメイン向けの経路を確認
これでVPN接続時はAlibaba CloudのVPC網を通ってNATサーバからQiitaにアクセスするようになりました!
注意点としてIPアドレスが複数ある場合は、丸めて記載するか単体でそれぞれ記載するなど工夫が必要です。
OpenVPNがドメインで経路をpushできれば良さそうなんですけど、今のところはできなさそう...?しかし、特定IP範囲であれば、クライアントのProxy設定不要でVPN接続さえすればローカルスプリットします。
そして、特定経路だけVPCにルーティングしてくれるので、ユーザーにルーティングを意識させたくないとき有効的に使える構成だと思います。







- 投稿日:2019-11-28T20:26:19+09:00
OpenVPNとVPC(RouteTable)の設定だけで特定サイトにのみルーティングさせるネットワーク構成をAlibaba Cloudで作る
この記事の目的
特定のドメインやG-IP向けの通信経路だけAlibaba Cloud網を通したいときの手段として検証してみました。
間にCENを通して2つのVPCをつなげたうえで試してみました。
VPN接続後、NATサーバ(ECS)を通ってアクセスするようになります。リソース構成図とNWフロー
下図のとおりです。
手順
OpenVPN:ECSの作成
GUIコンソールから作成しました。
- サーバー情報
機能 Hostname Zone InstanceType Spec P-IP NATサーバ nat01 日本東京(ゾーンB) ecs.t5-lc1m1.small 1vCPU 1GiB 10.68.30.153 VPNサーバ openvpn01 日本東京(ゾーンA) ecs.t5-lc1m1.small 1vCPU 1GiB 10.68.10.238
セキュリティグループ(OpenVPN)
便宜上一旦anyしてます
セキュリティグループ(NATサーバ)
便宜上一旦anyにしてます
VPCのルートテーブル情報(OpenVPN)
VPCのルートテーブル情報(NATサーバ)
OpenVPN:Configure
CAは腹持ちで建てました。
ECS上のOpenVPNの構築は別の記事に起こしているので、↓のリンクをご参照ください。
https://qiita.com/tnoce/items/b5765b38aeacc8f92269
- ポイント
- push "route 13.112.0.0 255.252.0.0" ※qiitaのipアドレスをVPN接続したクライアントにpushする
/etc/openvpn/default.conf※コメントアウトとオプションoff項目を除く[root@openvpn openvpn]# grep '^[^#]' 'server_r.conf' port 1194 proto udp dev tun ca /etc/openvpn/easy-rsa/pki/ca.crt cert /etc/openvpn/easy-rsa/pki/issued/server_r.crt key /etc/openvpn/easy-rsa/pki/private/server_r.key # This file should be kept secret dh /etc/openvpn/easy-rsa/pki/dh.pem server 10.8.0.0 255.255.255.0 ifconfig-pool-persist ipp.txt push "route 13.112.0.0 255.252.0.0"ECS(NATサーバ):Configure
eth0 の firewalld zone を external に変更
# firewall-cmd --zone=external --change-interface=eth0 --permanent successexternalゾーン に IPマスカレード設定
# firewall-cmd --zone=external --add-masquerade --permanent success変更の反映
# firewall-cmd --reload successFirewalldを常に起動
# systemctl enable firewalldFirewalldを起動
# systemctl start firewalldFirewalldのステータスを起動(RunningになっていればOK)
# systemctl status firewalld irewalld.service - firewalld - dynamic firewall daemon Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor preset: enabled) Active: active (running) since 木 2019-11-28 08:00:13 CST; 10h ago Docs: man:firewalld(1) Main PID: 542 (firewalld) CGroup: /system.slice/firewalld.service └─542 /usr/bin/python2 -Es /usr/sbin/firewalld --nofork --nopid 11月 28 08:00:13 nginx02 systemd[1]: Starting firewalld - dynamic firewall daemon... 11月 28 08:00:13 nginx02 systemd[1]: Started firewalld - dynamic firewall daemon. 11月 28 18:02:38 nginx02 firewalld[542]: WARNING: ALREADY_ENABLED: masquerade検証
VPN接続
vpnuxやtunnelblickなどのGUIアプリでVPN接続します。
接続後にNW設定を確認
OpenVPNに設定しいてたクライアントサブネットが割り当てられていることを確認します。
User:~$ ifconfig | grep 10.8 inet 10.8.0.6 --> 10.8.0.5 netmask 0xffffffffQiita向けの経路が適切にpublishされているか確認します。
User:~$ netstat -rn | grep 13.112/14 13.112/14 10.8.0.5 UGSc utun8特定ドメイン向けの経路を確認
これでVPN接続時はQiitaにアクセスする場合Alibaba CloudのVPC網を通ってNATサーバからQiitaにアクセスするようになりました!
注意点としてIPアドレスが複数ある場合は、丸めて記載するか単体でそれぞれ記載するなど工夫が必要です。
OpenVPNがドメインで経路をpushできれば良さそうなんですけど、今のところはできなさそう...?しかし、特定IP範囲であれば、クライアントのProxy設定不要でVPN接続さえすればローカルスプリットします。
そして、特定経路だけVPCにルーティングしてくれるので、ユーザーにルーティングを意識させたくないとき有効的に使える構成だと思います。
- 投稿日:2019-11-28T20:26:19+09:00
OpenVPNとVPC(RouteTable)の設定だけで特定ドメインのみAlibaba Cloud VPCにルーティングさせるNW構成を作る
この記事の目的
特定のドメインやG-IP向けの通信経路だけAlibaba Cloud網を通したいときの手段として検証してみました。
間にCENを通して2つのVPCをつなげたうえで試してみました。
VPN接続後、NATサーバ(ECS)を通ってアクセスするようになります。リソース構成図とNWフロー
下図のとおりです。
手順
OpenVPN:ECSの作成
GUIコンソールから作成しました。
- サーバー情報
機能 Hostname Zone InstanceType Spec P-IP NATサーバ nat01 日本東京(ゾーンB) ecs.t5-lc1m1.small 1vCPU 1GiB 10.68.30.153 VPNサーバ openvpn01 日本東京(ゾーンA) ecs.t5-lc1m1.small 1vCPU 1GiB 10.68.10.238
セキュリティグループ(OpenVPN)
便宜上一旦anyしてます
セキュリティグループ(NATサーバ)
便宜上一旦anyにしてます
VPCのルートテーブル情報(OpenVPN)
VPCのルートテーブル情報(NATサーバ)
OpenVPN:Configure
CAは腹持ちで建てました。
ECS上のOpenVPNの構築は別の記事に起こしているので、↓のリンクをご参照ください。
https://qiita.com/tnoce/items/b5765b38aeacc8f92269
- ポイント
- push "route 13.112.0.0 255.252.0.0" ※qiitaのipアドレスをVPN接続したクライアントにpushする
/etc/openvpn/default.conf※コメントアウトとオプションoff項目を除く[root@openvpn]# grep '^[^#]' 'server_r.conf' port 1194 proto udp dev tun ca /etc/openvpn/easy-rsa/pki/ca.crt cert /etc/openvpn/easy-rsa/pki/issued/server_r.crt key /etc/openvpn/easy-rsa/pki/private/server_r.key # This file should be kept secret dh /etc/openvpn/easy-rsa/pki/dh.pem server 10.8.0.0 255.255.255.0 ifconfig-pool-persist ipp.txt push "route 13.112.0.0 255.252.0.0"ECS(NATサーバ):Configure
eth0 の firewalld zone を external に変更
# firewall-cmd --zone=external --change-interface=eth0 --permanent successexternalゾーン に IPマスカレード設定
# firewall-cmd --zone=external --add-masquerade --permanent success変更の反映
# firewall-cmd --reload successFirewalldを常に起動
# systemctl enable firewalldFirewalldを起動
# systemctl start firewalldFirewalldのステータスを確認(RunningになっていればOK)
# systemctl status firewalld irewalld.service - firewalld - dynamic firewall daemon Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor preset: enabled) Active: active (running) since 木 2019-11-28 08:00:13 CST; 10h ago Docs: man:firewalld(1) Main PID: 542 (firewalld) CGroup: /system.slice/firewalld.service └─542 /usr/bin/python2 -Es /usr/sbin/firewalld --nofork --nopid 11月 28 08:00:13 nginx02 systemd[1]: Starting firewalld - dynamic firewall daemon... 11月 28 08:00:13 nginx02 systemd[1]: Started firewalld - dynamic firewall daemon. 11月 28 18:02:38 nginx02 firewalld[542]: WARNING: ALREADY_ENABLED: masquerade検証
VPN接続
vpnuxやtunnelblickなどのGUIアプリでVPN接続します。
接続後にNW設定を確認
OpenVPNに設定しいてたクライアントサブネットが割り当てられていることを確認します。
User:~$ ifconfig | grep 10.8 inet 10.8.0.6 --> 10.8.0.5 netmask 0xffffffffQiita向けの経路が適切にpublishされているか確認します。
User:~$ netstat -rn | grep 13.112/14 13.112/14 10.8.0.5 UGSc utun8特定ドメイン向けの経路を確認
これでVPN接続時はAlibaba CloudのVPC網を通ってNATサーバからQiitaにアクセスするようになりました!
注意点としてIPアドレスが複数ある場合は、丸めて記載するか単体でそれぞれ記載するなど工夫が必要です。
OpenVPNがドメインで経路をpushできれば良さそうなんですけど、今のところはできなさそう...?しかし、特定IP範囲であれば、クライアントのProxy設定不要でVPN接続さえすればローカルスプリットします。
そして、特定経路だけVPCにルーティングしてくれるので、ユーザーにルーティングを意識させたくないとき有効的に使える構成だと思います。
- 投稿日:2019-11-28T19:20:30+09:00
文系初心者が半年で AWS を触れるようになるまでの記録
NAVITIME JAPAN Advent Calendar 2019 6日目の記事です。
はじめに
今年4月に新卒でナビタイムジャパンに入社したふみぽんです。
サーバーって何?という状態からどうやって AWS を扱えるようになったのかをよく聞かれるので、記事にしてみました。
ちなみに、AWS で好きなサービスは CloudFront です。今のレベル感
【今できること】
- AWS のサービス名を聞いて何のサービスか分かる
- コンソールからの構築
- CloudFormation を用いた構築
- AWS CLI を用いたツールの開発
【まだできないこと】
- 障害調査
- データベース自体の理解
- 社内で利用していないAWSサービスの理解
勉強方法
- AWS の公式動画、AWS Black Beltを見る
- 無料
- サービス毎にそれぞれ1時間で説明してくれるから短時間で学習できる
- Developers IO
- 実際に使ってみた経験を記事にしてくれている
- 最新のアップデート情報もすぐに記事に
- シェルの勉強
- クラウド業務の自動化をするならシェルの知識は必須
- オススメの本:新しいLinuxの教科書
- スラスラ読めて、基礎から勉強できるので初心者におすすめです。
AWS に関して、本で勉強は一切していません。ひたすら動画を見ました。
機能や UI がすぐに変わるので、本が出た頃には情報が古くなっているなんてこともあります。(動画も更新頻度が2年に1度くらいなので情報が古い場合がありますが)
クラウドの中でシェア No.1なだけあって、ネットにも情報がたくさん落ちていますので、お金を出さなくても業務レベルの知識が身につくと思います!記録
配属1ヶ月目
ありがたいことに配属されて1ヶ月くらいは業務の9割を AWS の学習にあてさせていただきました。 この1ヶ月は初めましてのことだらけで、分からない単語が出てくる度に動画を止めて調べていたところ、1つの動画を見終わるのに1日以上かかってました。辛い。
- 動画視聴の順番 : IAM Part1/Part2、VPC、EC2(EC2、AWS のコスト最適化/リザーブドインスタンス)、 Amazon EC2 スポットインスタンス、ELB、CloudWatch、SNS、Auto Scaling、CloudFront、S3 ※リンクがあるものは私が特に重要だと思った動画です
配属2ヶ月目
この頃から動画で学習が終わったサービスの構築を割り振っていただいたり、MTG に同行させてもらうようになりました。 勉強は業務の3割くらい。 この頃になると、なんとなく MTG 中の話が理解できるようになり、動画もサラッと頭に入ってくるようになります。壁を乗り越えた感。
配属3ヶ月目以降
できることが増え、業務 100%になりました。 これだけ AWS に触れていると単純接触効果で AWS が大好きになります。その勢いのまま、勉強します。 業務中に疑問に思ったところを実際に試してみたり、ドキュメントを読みながら実際に構築するのがオススメです。
- 動画視聴の順番 : CloudTrail & AWS Config、Amazon Athena、AWS Glue、RDS、Amazon Aurora with MySQL Compatibility、Amazon Aurora with PostgreSQL Compatibility、GuardDuty、 Amazon CloudSearch and Amazon Elasticsearch Service、Cognito、ElastiCache、Code Services、EMR
これから
動画はあくまで基礎学習です。動画を全て見終わったからといってどんな業務でもできるようになるかというと、そうでもなかったです。さらに知識を深めるにしても範囲が広すぎてどこから手をつけたらいいのか分からないので、これからは業務で知らないことが出てきたら調べる方法で知識を増やしていきます。
また、今月中にソリューションアーキテクトの資格取得にも挑戦しようと思います!私と AWS の戦いはまだまだ続く。
- 投稿日:2019-11-28T18:43:15+09:00
SAML2.0シングルサインオン対応したアプリからサインアウトする4つの方法
シングルサインオンについては解説サイトがたくさんありますが、サインアウトについては言及されていないケースが多いような気がします(個人の感想です)。
ということで、シングルサインオン対応したSaaSアプリケーションをサインアウトするの4つのパターンについて整理しました。
- SPからサインアウトする
- SPからサインアウトしたら、IdPからもサインアウトする
- SPからサインアウトしたら、IdP・他のSPからもサインアウトする
- IdPからサインアウトしたら、他のSPからもサインアウトする
前提
- 共通のIdPを利用してシングルサインオンを行うSPが2つあるとします
- SPはそれぞれサインアウト機能を持ちます
- ユーザは2つのSPにシングルサインオンしています
- 動作確認はIdP=AzureAD, SP=AWS Cognitoで行なっています。他のIdP/SPでは異なる動きになる可能性があります
IdP/SPの設定項目
AzureAD, AWS Cognitoの場合、サインアウトに関する以下のような設定項目があります。
それぞれに何を設定した時にどのような動きになるのか、見ていきたいと思います。IdPのサインアウト設定項目
項目 内容 サインアウトURL SPをログアウトさせるURLを指定する
SAMLログアウト要求/応答の送付先となるSPのサインアウト設定項目
項目 内容 サインアウトURL SPからログアウトした後のリダイレクト先 シングルサインアウト(IdPサインアウトフロー)の有効/無効 シングルサインアウトの有効/無効を設定する
この項目がない場合、SPがシングルサインアウトに対応していないことが考えられるIdP/SPで同じような名前の項目がありますが、役割が全く違うのがややこしいところです。
SPからサインアウトする
1つ目のパターンを見ていきます。(といってもこれはサインアウトと呼べないものですが…)
設定項目 設定内容 IdP-サインアウトURL 設定なし SP-サインアウトURL 任意のURL SP-シングルサインアウト有効/無効 無効
1. ユーザはSP1からサインアウトします。
2. SPのサインアウトURLで設定したURLにリダイレクトします(※図では省略)。この状態だと、SP1のセッションは破棄されますが、IdPのセッションは残ったままです。
このままもう一度SP1(認証済でないと閲覧できないページ)にアクセスすると、IdPとのセッションが残っている=サインイン済と判断され、クレデンシャルを入力せずサインインが完了してしまいます。
ユーザから見ると、「あれ、サインアウトしたはずのにSP1が開ける…?サインアウトできてない…?」という動きになってしまいます。SPからサインアウトしたら、IdPからもサインアウトする
上のパターンの「サインアウトしたはずなのに…」を解消するため、同時にIdPからもサインアウトしたいと思います。
設定項目 設定内容 IdP-サインアウトURL 設定なし SP-サインアウトURL IdPからサインアウトするURL SP-シングルサインアウト有効/無効 無効
1. ユーザはSP1からサインアウトします。
2. SPのサインアウトURLで設定した「IdPからサインアウトするURL」にリダイレクトします。
IdPからサインアウトします。SPサインアウト後のリダイレクト先として「IdPからサインアウトするURL」を指定することで、両方からサインアウトすることができます。
「IdPからサインアウトするURL」は、例えばAzureADだとhttps://login.microsoftonline.com/common/wsfederation?wa=wsignout1.0というURLです(シングルサインオンのセットアップページに記載されています)。
AzureADにサインインした状態でこのURLを叩くと、AzureADからサインアウトされます。混乱しやすいですが、このパターンはSAML2.0で定義されたシングルサインアウトではありません。
IdPとのセッションが切れていても、SP2とのセッションは残っているため、このまましばらくSP2は使い続けることができます。
やがてSP2のセッションが切れた時、再度IdPへのサインインが必要になります。cybozu.comをSPとしてシングルサインオンを構成する場合、このパターンの動きになるのではないかと思います。
(「SAML認証ができるまで - SPが信頼するIdPの登録」より)SPからサインアウトしたら、IdP・他の全てのSPからもサインアウトする
このパターンがSAML2.0仕様で定義された「シングルサインアウト」です。
IdPによっては、シングルサインアウトに対応していない場合もあります。
設定項目 設定内容 IdP-サインアウトURL SP1, SP2それぞれからサインアウトするURL SP-サインアウトURL SP1, SP2それぞれ任意のURL SP-シングルサインアウト有効/無効 有効
- ユーザはSP1からサインアウトし、セッションを破棄します。
- SPはログアウト要求SAMLメッセージを作成し、IdPがシングルサインアウトを行うURLへリダイレクトします。 IdPは、ユーザとのセッションを破棄します。
- 他にもSSOしているSPがある場合、IdPはログアウト要求SAMLメッセージを作成し、IdPで設定した「SP2のサインアウトURL」へリダイレクトします。
SP2はユーザとのセッションを破棄します。- IdPはログアウト応答SAMLメッセージを作成し、IdPで設定した「SP1のサインアウトURL」へリダイレクトします。
- SP1で設定した「サインアウトURL」へリダイレクトします
補足: ログアウト要求の署名
IdPによっては、SPからIdPへログアウト要求を送る際、署名つきのSAMLメッセージを想定している場合があります。
その場合、SPが提供する署名用証明書(公開鍵)をIdPに事前に登録する必要があります。
(私が試したAzureADでは署名用証明書は不要でした)補足: IdPがシングルサインアウトを行うURL
AzureADの場合、IdPがシングルサインアウトを行うURLは、最初にSPに設定するメタデータの中に含まれています。
バインディングがHTTPリダイレクトであることもここに明記されています。<SingleLogoutService Binding="urn:oasis:names:tc:SAML:2.0:bindings:HTTP-Redirect" Location="https://login.microsoftonline.com/[テナントID]/saml2" />IdPからサインアウトしたら、他の全てのSPからもサインアウトする
最後に、直接IdPのポータル等からサインアウトするパターンです。
設定項目 設定内容 IdP-サインアウトURL SP1, SP2それぞれからサインアウトするURL SP-サインアウトURL 任意のURL SP-シングルサインアウト有効/無効 任意
- ユーザはIdPからサインアウトします。
- SSOしているSPがあれば、IdPはログアウト要求SAMLメッセージを作成し、IdPで設定した「SP1,2のサインアウトURL」へリダイレクトします。
SP1,2はそれぞれユーザとのセッションを破棄します。おわりに
本稿は、AzureADをIdP、AWS CognitoをSPとして構成し、設定を変えながら挙動を確認した結果を元に作成しています。
別のIdP、SPでは設定項目が異なる・動作が異なる可能性があります。資料
Security Assertion Markup Language (SAML) V2.0 Technical Overview
AWS Cognito ユーザープールの ID プロバイダーの設定
LINE WORKS ログアウト
Oracle Eloqua シングル・ログアウト
AzureAD シングル サインアウトの SAML プロトコル




- 投稿日:2019-11-28T18:04:37+09:00
SSMパラメータストアに対するアクセス検知ツール
概要
- SSMパラメータストアに対するアクセス検知ツールを作りました。
- 任意の期間中のアクセスをCloudTrail APIから取得し、ユーザ名、UserAgent, 対象のパラメータ, 期間中のアクセス件数, ソースIPアドレスなどをSlackに通知します。
- github.com/m22r/dobermanにてコードを公開しています。
slackへの通知サンプル
terraformでSSMパラメータ内の値を閲覧したときの通知内容
対象期間中にアクセスがなかった時の通知内容
インストール方法
$ git clone git@github.com:m22r/doberman.git $ make build使い方
Detection Tool against attempt to put/get SSM secure parameter Usage: doberman [flags] doberman [command] Available Commands: help Help about any command version Print version Flags: --channel string slack channel --end string end time of detection (format:2006-01-02T15:04:05-07:00) -h, --help help for doberman --icon-url string slack icon URL --ignore-system-user don't detect system users --log-format string logging format (text or json) (default "text") --start string start time of detection (format:2006-01-02T15:04:05-07:00) --token string slack app's OAuth access token Use "doberman [command] --help" for more information about a command.継続的に検知する構成例
- Cloudwatch EventとCodebuildをつかって1日1回、過去24時間分のアクセスを解析してslackに通知するように仕込んでおくと良い感じです。
参考資料


- 投稿日:2019-11-28T16:16:39+09:00
非エンジニアが「AWS Amplify Console」でWEBサイトを公開する環境を作ってみた
こんにちは。フォトクリエイトでオールスポーツコミュニティのプロダクトマネージャーを担当している@takuyamajpです。
この記事はフォトクリエイト Advent Calendar 2019の 4日目 の記事です。
自己紹介
WEBディレクターとして制作会社2社を経て、小さなWEB制作会社を経営しておりました。この時に縁がありフォトクリエイトとは業務委託契約でお仕事をさせて頂いており、2019年1月に正式にジョインしました。プロダクトマネージャーというポジションで仕事をするのは現職が初めてです。
ちなみにマラソンのタイムはハーフ1:44:22です。次はフルマラソンでサブ4を目指します。
フォトクリエイトのことも少し紹介
僕はカスタマーバリュー開発部に所属しています。顧客への提供価値を高めることをミッションとした部門です。UX体験を一気通貫で作れる体制となっており、エンジニアやデザイナーを中心とした様々な触手のメンバーで構成されています。職能別のグループから成り立っており、プロジェクト単位で各グループからメンバーをアサインして開発を進めていくという働き方をしています。
※当社サービスの「スナップスナップ」のみPdM、アナリスト、エンジニア、デザイナーといった異なる職能を持ったメンバーで構成されたマトリックス組織として活動しています。
オールスポーツコミュニティは部分的に様々なメンバーにサポート頂いているのですが、フルコミットしているのは今のところ僕一人です。(ちょっと寂しい)
なのでユーザーインタビュー、簡単なUIのイメージ作り、仕様書作成やデータ分析など、コードを書くこと以外は幅広く出来ることはやろう。というスタンスで働いています。そこでコードが書けない僕でも簡単にWEBサイトを公開する環境を作れる方法があるよ!ってことを社内のエンジニアに教えてもらいましたので記事にしてみました。
インフラ担当が不在の制作会社の方々や、社内が人手不足で困っている僕と似た境遇の方の一助になれたら嬉しいです。
この記事を読んで出来るようになること
- 非エンジニアでもスタティックなWEBサイトを公開する環境を構築出来るようになります
ランディングページを公開する環境などはこれで十分です。静的なサーバ構築で制作会社に数万支払ってる方などは、今後は自分でやりましょう。簡単です。
説明していきます。
構築する環境の概要
GitHubのリポジトリとAWS Amplifyを組み合わせて作ります。
特定のブランチにプッシュするとWEBサイトが公開される仕組みになります。AWS Amplify とは
AWS Amplifyとは静的なWEBサイトを公開する環境を簡単に作ることが出来るサービスです。
- ドメインを割り当てることが出来る。(本番の環境として使える)
- プッシュするだけでWEBサイトを公開出来る (FTPとか使わないで良い)
- ブランチごとのデプロイ〜公開 (別の確認用のディレクトリを作ったりしないでOK)
- ベーシック認証も出来る (.htaccess書く必要なし)
- スケーラビリティもバッチリ(ストレージはS3なので容量などを気にしないで良い)
素晴らしいですね。
構築手順
1.ソースコードを準備
公開したいWebサイトを用意します。今回はGitHubで説明します。
2.GitHubとAWS Amplifyを連携する
AWSマネジメントコンソールにログインしてサービスへ移動します。
AWSはサービスが沢山ありますね。検索フォームで
AWS Amplifyと検索しましょう。
Amplify Console の方の
GET STARTEDを選択します。
GitHubを選択して
Continueをクリック。
GitHubのログインアカウントを入力して
Sign inします。
Authorize aws-amplify-consoleをクリック。
これでGitHubアカウントとAWS Amplifyの連携ができました。3.AWS AmplifyでWEBサイトを公開
公開したいリポジトリを選択して
次へをクリック。
続いてブランチを選択して
次へ。
次へです。
リポジトリの詳細を確認してください。公開したいリポジトリとブランチは間違いありませんか?
問題なければ保存してデプロイを選択します。
ビルドが始まりました。
ファイル数が少ないので15秒くらいで終わりました。
それでは赤枠部分のURLをクリックします。
公開されました。
とても簡単ですね?これならスタティックなWEBサイトも簡単に公開、運用していくことができます。
独自ドメインで公開したい場合は
ドメイン管理から行います。route53で管理しているドメインを割り当てることができます。最後に
2020年はオールスポーツコミュニティの顧客体験を向上させる為に、プロダクトをしっかり磨き込んで行く予定です。フォトクリエイトでは一緒にプロダクトを盛り上げてくださる方を募集しております。少しでもご興味をお持ちいただけたようでしたら、人事部門の担当者 twitter: @tetsunosuke へお知らせください。
















- 投稿日:2019-11-28T16:05:59+09:00
SlackでAWS Chatbotを使ってawsコマンドがたたけるようになったそうなので、試してみた
下記の記事にて AWS ChatbotがSlackからのコマンド実行をβ版サポートしたとのことで、早速試しました
[引用] re:Invent 2019に向けて 2019年11月後半アップデートのまとめ 第四弾 | Amazon Web Services ブログ
画像キャプチャなどもある対応方法は下記のブログ記事で確認したので、操作手順は下記を参照してください。※英語ですが、、、、
Running AWS commands from Slack using AWS Chatbot | AWS DevOps Blog
上記ブログの「2. Test AWS Chatbot in Slack and get help」のところまできて、
@aws helpを実行してみたところ
1つのSlack内で複数のAWSアカウントのAWS Chatbotを利用している場合なんでしょうか。最初にどちらのAWSアカウントをデフォルトアカウントとして、利用するかを確認されました。
マスキングしてますが、アカウントIDの書かれた2つのボタンが表示されてボタンを押すだけです。その後、
@aws helpしたところ上記ブログと同様のレスポンスがかえってきました
aws cliとほぼ似たようなコマンドで対応できるので、わかりやすいですね

取り急ぎ、EC2まわりを試したいので、@aws ec2 --helpしてみたところ、結構いろんなコマンドがでてきました。
使えるコマンドたちHere are all the operations I know about for ec2: • accept-reserved-instances-exchange-quote • accept-transit-gateway-vpc-attachment • accept-vpc-endpoint-connections • accept-vpc-peering-connection • advertise-byoip-cidr • allocate-address • allocate-hosts • apply-security-groups-to-client-vpn-target-network • assign-ipv6-addresses • assign-private-ip-addresses • associate-address • associate-client-vpn-target-network • associate-dhcp-options • associate-iam-instance-profile • associate-route-table • associate-subnet-cidr-block • associate-transit-gateway-route-table • associate-vpc-cidr-block • attach-classic-link-vpc • attach-internet-gateway • attach-network-interface • attach-volume • attach-vpn-gateway • authorize-client-vpn-ingress • authorize-security-group-egress • authorize-security-group-ingress • bundle-instance • cancel-bundle-task • cancel-capacity-reservation • cancel-conversion-task • cancel-export-task • cancel-import-task • cancel-reserved-instances-listing • cancel-spot-fleet-requests • cancel-spot-instance-requests • confirm-product-instance • copy-fpga-image • copy-image • copy-snapshot • create-capacity-reservation • create-client-vpn-endpoint • create-client-vpn-route • create-customer-gateway • create-default-subnet • create-default-vpc • create-dhcp-options • create-egress-only-internet-gateway • create-fleet • create-flow-logs • create-fpga-image • create-image • create-instance-export-task • create-internet-gateway • create-key-pair • create-launch-template • create-launch-template-version • create-nat-gateway • create-network-acl • create-network-acl-entry • create-network-interface • create-network-interface-permission • create-placement-group • create-reserved-instances-listing • create-route • create-route-table • create-security-group • create-snapshot • create-snapshots • create-spot-datafeed-subscription • create-subnet • create-tags • create-traffic-mirror-filter • create-traffic-mirror-filter-rule • create-traffic-mirror-session • create-traffic-mirror-target • create-transit-gateway • create-transit-gateway-route • create-transit-gateway-route-table • create-transit-gateway-vpc-attachment • create-volume • create-vpc • create-vpc-endpoint • create-vpc-endpoint-connection-notification • create-vpc-endpoint-service-configuration • create-vpc-peering-connection • create-vpn-connection • create-vpn-connection-route • create-vpn-gateway • delete-client-vpn-endpoint • delete-client-vpn-route • delete-customer-gateway • delete-dhcp-options • delete-egress-only-internet-gateway • delete-fleets • delete-flow-logs • delete-fpga-image • delete-internet-gateway • delete-key-pair • delete-launch-template • delete-launch-template-versions • delete-nat-gateway • delete-network-acl • delete-network-acl-entry • delete-network-interface • delete-network-interface-permission • delete-placement-group • delete-queued-reserved-instances • delete-route • delete-route-table • delete-security-group • delete-snapshot • delete-spot-datafeed-subscription • delete-subnet • delete-tags • delete-traffic-mirror-filter • delete-traffic-mirror-filter-rule • delete-traffic-mirror-session • delete-traffic-mirror-target • delete-transit-gateway • delete-transit-gateway-route • delete-transit-gateway-route-table • delete-transit-gateway-vpc-attachment • delete-volume • delete-vpc • delete-vpc-endpoint-connection-notifications • delete-vpc-endpoint-service-configurations • delete-vpc-endpoints • delete-vpc-peering-connection • delete-vpn-connection • delete-vpn-connection-route • delete-vpn-gateway • deprovision-byoip-cidr • deregister-image • describe-account-attributes • describe-addresses • describe-aggregate-id-format • describe-availability-zones • describe-bundle-tasks • describe-byoip-cidrs • describe-capacity-reservations • describe-classic-link-instances • describe-client-vpn-authorization-rules • describe-client-vpn-connections • describe-client-vpn-endpoints • describe-client-vpn-routes • describe-client-vpn-target-networks • describe-conversion-tasks • describe-customer-gateways • describe-dhcp-options • describe-egress-only-internet-gateways • describe-elastic-gpus • describe-export-image-tasks • describe-export-tasks • describe-fast-snapshot-restores • describe-fleet-history • describe-fleet-instances • describe-fleets • describe-flow-logs • describe-fpga-image-attribute • describe-fpga-images • describe-host-reservation-offerings • describe-host-reservations • describe-hosts • describe-iam-instance-profile-associations • describe-id-format • describe-identity-id-format • describe-image-attribute • describe-images • describe-import-image-tasks • describe-import-snapshot-tasks • describe-instance-attribute • describe-instance-credit-specifications • describe-instance-status • describe-instances • describe-internet-gateways • describe-key-pairs • describe-launch-template-versions • describe-launch-templates • describe-moving-addresses • describe-nat-gateways • describe-network-acls • describe-network-interface-attribute • describe-network-interface-permissions • describe-network-interfaces • describe-placement-groups • describe-prefix-lists • describe-principal-id-format • describe-public-ipv4-pools • describe-regions • describe-reserved-instances • describe-reserved-instances-listings • describe-reserved-instances-modifications • describe-reserved-instances-offerings • describe-route-tables • describe-scheduled-instance-availability • describe-scheduled-instances • describe-security-group-references • describe-security-groups • describe-snapshot-attribute • describe-snapshots • describe-spot-datafeed-subscription • describe-spot-fleet-instances • describe-spot-fleet-request-history • describe-spot-fleet-requests • describe-spot-instance-requests • describe-spot-price-history • describe-stale-security-groups • describe-subnets • describe-tags • describe-traffic-mirror-filters • describe-traffic-mirror-sessions • describe-traffic-mirror-targets • describe-transit-gateway-attachments • describe-transit-gateway-route-tables • describe-transit-gateway-vpc-attachments • describe-transit-gateways • describe-volume-attribute • describe-volume-status • describe-volumes • describe-volumes-modifications • describe-vpc-attribute • describe-vpc-classic-link • describe-vpc-classic-link-dns-support • describe-vpc-endpoint-connection-notifications • describe-vpc-endpoint-connections • describe-vpc-endpoint-service-configurations • describe-vpc-endpoint-service-permissions • describe-vpc-endpoint-services • describe-vpc-endpoints • describe-vpc-peering-connections • describe-vpcs • describe-vpn-connections • describe-vpn-gateways • detach-classic-link-vpc • detach-internet-gateway • detach-network-interface • detach-volume • detach-vpn-gateway • disable-ebs-encryption-by-default • disable-fast-snapshot-restores • disable-transit-gateway-route-table-propagation • disable-vgw-route-propagation • disable-vpc-classic-link • disable-vpc-classic-link-dns-support • disassociate-address • disassociate-client-vpn-target-network • disassociate-iam-instance-profile • disassociate-route-table • disassociate-subnet-cidr-block • disassociate-transit-gateway-route-table • disassociate-vpc-cidr-block • enable-ebs-encryption-by-default • enable-fast-snapshot-restores • enable-transit-gateway-route-table-propagation • enable-vgw-route-propagation • enable-volumeio • enable-vpc-classic-link • enable-vpc-classic-link-dns-support • export-client-vpn-client-certificate-revocation-list • export-client-vpn-client-configuration • export-image • export-transit-gateway-routes • get-capacity-reservation-usage • get-console-output • get-ebs-default-kms-key-id • get-ebs-encryption-by-default • get-host-reservation-purchase-preview • get-launch-template-data • get-password-data • get-reserved-instances-exchange-quote • get-transit-gateway-attachment-propagations • get-transit-gateway-route-table-associations • get-transit-gateway-route-table-propagations • import-client-vpn-client-certificate-revocation-list • import-image • import-instance • import-key-pair • import-snapshot • import-volume • modify-capacity-reservation • modify-client-vpn-endpoint • modify-ebs-default-kms-key-id • modify-fleet • modify-fpga-image-attribute • modify-hosts • modify-id-format • modify-identity-id-format • modify-image-attribute • modify-instance-attribute • modify-instance-capacity-reservation-attributes • modify-instance-credit-specification • modify-instance-event-start-time • modify-instance-metadata-options • modify-instance-placement • modify-launch-template • modify-network-interface-attribute • modify-reserved-instances • modify-snapshot-attribute • modify-spot-fleet-request • modify-subnet-attribute • modify-traffic-mirror-filter-network-services • modify-traffic-mirror-filter-rule • modify-traffic-mirror-session • modify-transit-gateway-vpc-attachment • modify-volume • modify-volume-attribute • modify-vpc-attribute • modify-vpc-endpoint • modify-vpc-endpoint-connection-notification • modify-vpc-endpoint-service-configuration • modify-vpc-endpoint-service-permissions • modify-vpc-peering-connection-options • modify-vpc-tenancy • modify-vpn-connection • modify-vpn-tunnel-certificate • modify-vpn-tunnel-options • monitor-instances • move-address-to-vpc • provision-byoip-cidr • purchase-host-reservation • purchase-reserved-instances-offering • purchase-scheduled-instances • reboot-instances • register-image • reject-transit-gateway-vpc-attachment • reject-vpc-endpoint-connections • reject-vpc-peering-connection • release-address • release-hosts • replace-iam-instance-profile-association • replace-network-acl-association • replace-network-acl-entry • replace-route • replace-route-table-association • replace-transit-gateway-route • report-instance-status • request-spot-fleet • request-spot-instances • reset-ebs-default-kms-key-id • reset-fpga-image-attribute • reset-image-attribute • reset-instance-attribute • reset-network-interface-attribute • reset-snapshot-attribute • restore-address-to-classic • revoke-client-vpn-ingress • revoke-security-group-egress • revoke-security-group-ingress • run-instances • run-scheduled-instances • search-transit-gateway-routes • send-diagnostic-interrupt • start-instances • stop-instances • terminate-client-vpn-connections • terminate-instances • unassign-ipv6-addresses • unassign-private-ip-addresses • unmonitor-instances • update-security-group-rule-descriptions-egress • update-security-group-rule-descriptions-ingress • withdraw-byoip-cidrコマンド多すぎてやばい・・・

ついでに、@aws ec2 describe-instance --region ap-northeast-1してみたら、結構表示が細かい情報まで表示される仕組みのようで、
「Show more」も出るしで、インスタンスがたくさんあると大変そうでした・・・もう少し見やすい表示にならないかなー
まとめ
まあまだ導入したばかりなので、もっと使い倒してみます。その流れで NoOpsが加速するといいですね

lambda使えたりとか、サポートへ質問できたりもするみたいなので、便利そうですね。
サポートへ質問できるところはSlackの/feedbackと同じようにしてたくさん意見もらえるようにしたのかなー





- 投稿日:2019-11-28T15:45:18+09:00
EC2のReserved InstanceからSavings Planに移行すべきなのかの判断フロー
先日、AWSからSavings Plansというとても良さそうなサービスの発表がありました。
https://aws.amazon.com/jp/blogs/news/new-savings-plans-for-aws-compute-services/早速、クラスメソッドさんやserverworksさんが解説記事も書かれていて、大変参考になります。
https://dev.classmethod.jp/cloud/aws/new-savings-plans-for-compute/
http://blog.serverworks.co.jp/tech/2019/11/11/sp-vs-ri/ただ、このSavings Plan、とても良さそうなものには見えるんだけど、カバー範囲が広くて複雑で、
「結局、これまでやってきたEC2のReserved Instance購入オペレーションはどうすればいいの? どんどん切り替えていくべきなの??」
って所が、1番気になるんだけど、そこに対しての明確な解が良く分からないままに、自分の会社でのRI更新のタイミングが訪れたので、↑に対する答えを求めて自分なりに調べてみたのでまとめてみます。それぞれがどんなものなの?ってのは、ここでは解説しませんので、上記に紹介したリンクを始め、公式ドキュメントや各種関連記事等をご覧いただければと。
なお、この記事は、2019/11/28 時点での私個人での調査結果/判断で、
認識違いもあるかもしれませんので、皆様の組織での最終決定にあたっては、ご自身のユースケースに照らし合わせて改めてご確認ください。
また、こんな視点が漏れてるよ!みたいのがあったらご指摘いただけると嬉しいです。tl;dr
- Convertible RIは、Compute Savings Planへの移行一択
- Standard RIは、EC2 Instance Savings Plansへの移行 or そのままStandard RI。
- (状況によっては、Compute Savings Planに切り替えちゃうのもあり)
以下、このような結論に至った理由を記載していきます。
Convertible RI
Compute Savings Planに移行すべき理由
- 割引率はConvertible RIとCompute Savings Planで同じ。
- 機能面の大きな違いとして、Compute Savings Planでは、
Automatically applies pricing to any instance familyというのがあり、instance familyを移動した時、自動的にコミット金額の割り当てを行ってくれるが、Convertible RIでは自分でオペレーションして、instance familyの切り替えを行わなければならない。この2つを考慮すると、切り替えないという選択肢は無いかなと思う。
あえて、Compute Savings Planの穴を探すとすると、Convertible RIのinstance family変更時、金額が追加になった場合は、その差額はAWS側で計算されて支請いが発生するのに対して、Compute Savings Planでは、自分で差額を計算したり、Cost Explorerとにらめっこしながら、追加分を購入しないといけない所かな〜と思う。
が、これもRIの交換という手間を省けるというCompute Savings Planのメリットと総合して考えると、移行をためらう理由にはならないでしょう。Standard RI
EC2 Instance Savings Plansへの移行 or そのままStandard RI
- Convertible RI vs Compute Savings Planでは、後者に切り替えることで、instance familyの変更時に、透過的に適用先が切り替わってくれるようになるという、決定的な差が存在したけれど、Standard RIとEC2 Instance Savings Plansの間では、これといった機能差は無いように思える。
- 違いとしては、購入の単位が、Standard RIではfamily内でのコア数、EC2 Instance Savings Plansではfamily内での1時間あたりの利用料金ということになるくらい?
- 特に差がないのであれば、新しいものに乗っかっていく方がいいかな、、?というのはあるけど、私が今いる会社でのユースケースを考えると、EC2 instanceとRIが1対1で紐づくことが多いので、Standard RIの方式の方がマッピングがしやすそうと感じる。
- Standard RIでは、ちょっと前にRIの予約購入機能なるものが発表されて、RIが切れたタイミングに合わせて買う!みたいな作業をしなくて良くなった。
書き出してみると、現状では、従来通りのStandard RIで更新してしまう方がやや優位かもしれない、、? ただ、AWSの進化を考えると、新しい流れに乗っておいた方が今後新たなメリットを色々と享受出来る可能性もあり、決定打にかけるかな〜という感じ。
Compute Savings Planにしちゃう!?
これは、Savings Planを調べながら、改めて自分たちのRI運用を考えながら思ったこと。
Convertible RIではなく、 Standard RIを使っている人のほとんどは、割引率の大きさを理由として挙げると思う。Compute Savings PlanはConvertible RI相当の割引率なので、切り替えると、そのメリットは失われる。
ただ、サービス規模が拡大して、EC2 instanceが増えるにつれて、Standard RIでは以下のようなデメリットが発生していて、何らかの改善は必要とずっと感じていた。 (同様の問題を抱えている人は多いはず?)
- 複雑化していく一方のStandard RIの購入運用
- 複雑化しすぎて、書い漏れ等が発生して、RIのコストメリットを最大限に享受できない
- せっかく新しいinstance typeが発表されて、技術的には大したコストをかけずに切り替えることもできるのに、RIの制限で切り替えることが出来ないちょっとした残念な気持ち
- RIの更新タイミングと、instance family変更のタイミングを合わせないといけないという調整の手間
Convertible RIへの切り替えはこれらの問題への大きな解決策となるかもしれない。
仮にConvertible RIを導入しても、RI変換の手間は発生するので、割引率を超えるほどのメリットがあるか?、、というと、微妙な所があった。それが、先に書いた通り、Compute Savings Planでは、適用するinstance familyの切り替えは透過的に行ってくれるようになる!これによって、全てをCompute Savings Planにしちゃえば、今後のオペレーションは定期的にCost Explorerをチェックし、RIの買い漏れを発見したら、何も考えずに、コミット金額を超えてon-demandになっている分のCompute Savings Plan買い増すだけという、相当に単純なオペレーションに集約することができそう。ということで、Compute Savings Planに切り替えちゃうか否かは、
割引率の低下 vs RIの買い漏れ等による余剰な支払い、複雑なRIオペレーションの削減
を天秤にかけて、エイやで決める!という感じになるのかな〜と想像したのでした。または、変更の可能性がない独立したコンポーネントで、金額のでかい部分 (e.g. 巨大の自前hadoop cluster) だけはスタンダードRI or EC2 Instance Savings Plansを使って、それ以外の部分をCompute Savings Planへ!という合いの子というのもありかもしれません。
以上、Savings Planのことを調べつつ、RI運用について思うことをツラツラと書いてみました。
事実を誤認している所や、何か考慮足りない部分などありましたら、ご指摘いただけると嬉しいです!皆さま、良いRI or Savings Plan 生活を!!
- 投稿日:2019-11-28T15:45:18+09:00
EC2のRI(Reserved Instance)からSavings Planに移行すべきなのかの判断フロー
先日、AWSからSavings Plansというとても良さそうなサービスの発表がありました。
https://aws.amazon.com/jp/blogs/news/new-savings-plans-for-aws-compute-services/早速、クラスメソッドさんやserverworksさんが解説記事も書かれていて、大変参考になります。
https://dev.classmethod.jp/cloud/aws/new-savings-plans-for-compute/
http://blog.serverworks.co.jp/tech/2019/11/11/sp-vs-ri/ただ、このSavings Plan、とても良さそうなものには見えるんだけど、カバー範囲が広くて複雑で、
「結局、これまでやってきたEC2のReserved Instance購入オペレーションはどうすればいいの? どんどん切り替えていくべきなの??」
って所が、1番気になるんだけど、そこに対しての明確な解が良く分からないままに、自分の会社でのRI更新のタイミングが訪れたので、↑に対する答えを求めて自分なりに調べてみたのでまとめてみます。それぞれがどんなものなの?ってのは、ここでは解説しませんので、上記に紹介したリンクを始め、公式ドキュメントや各種関連記事等をご覧いただければと。
なお、この記事は、2019/11/28 時点での私個人での調査結果/判断で、
認識違いもあるかもしれませんので、皆様の組織での最終決定にあたっては、ご自身のユースケースに照らし合わせて改めてご確認ください。
また、こんな視点が漏れてるよ!みたいのがあったらご指摘いただけると嬉しいです。tl;dr
- Convertible RIは、Compute Savings Planへの移行一択
- Standard RIは、EC2 Instance Savings Plansへの移行 or そのままStandard RI。
- (状況によっては、Compute Savings Planに切り替えちゃうのもあり)
以下、このような結論に至った理由を記載していきます。
Convertible RI
Compute Savings Planに移行すべき理由
- 割引率はConvertible RIとCompute Savings Planで同じ。
- 機能面の大きな違いとして、Compute Savings Planでは、
Automatically applies pricing to any instance familyというのがあり、instance familyを移動した時、自動的にコミット金額の割り当てを行ってくれるが、Convertible RIでは自分でオペレーションして、instance familyの切り替えを行わなければならない。この2つを考慮すると、切り替えないという選択肢は無いかなと思う。
あえて、Compute Savings Planの穴を探すとすると、Convertible RIのinstance family変更時、金額が追加になった場合は、その差額はAWS側で計算されて支請いが発生するのに対して、Compute Savings Planでは、自分で差額を計算したり、Cost Explorerとにらめっこしながら、追加分を購入しないといけない所かな〜と思う。
が、これもRIの交換という手間を省けるというCompute Savings Planのメリットと総合して考えると、移行をためらう理由にはならないでしょう。Standard RI
EC2 Instance Savings Plansへの移行 or そのままStandard RI
- Convertible RI vs Compute Savings Planでは、後者に切り替えることで、instance familyの変更時に、透過的に適用先が切り替わってくれるようになるという、決定的な差が存在したけれど、Standard RIとEC2 Instance Savings Plansの間では、これといった機能差は無いように思える。
- 違いとしては、購入の単位が、Standard RIではfamily内でのコア数、EC2 Instance Savings Plansではfamily内での1時間あたりの利用料金ということになるくらい?
- 特に差がないのであれば、新しいものに乗っかっていく方がいいかな、、?というのはあるけど、私が今いる会社でのユースケースを考えると、EC2 instanceとRIが1対1で紐づくことが多いので、Standard RIの方式の方がマッピングがしやすそうと感じる。
- Standard RIでは、ちょっと前にRIの予約購入機能なるものが発表されて、RIが切れたタイミングに合わせて買う!みたいな作業をしなくて良くなった。
書き出してみると、現状では、従来通りのStandard RIで更新してしまう方がやや優位かもしれない、、? ただ、AWSの進化を考えると、新しい流れに乗っておいた方が今後新たなメリットを色々と享受出来る可能性もあり、決定打にかけるかな〜という感じ。
Compute Savings Planにしちゃう!?
これは、Savings Planを調べながら、改めて自分たちのRI運用を考えながら思ったこと。
Convertible RIではなく、 Standard RIを使っている人のほとんどは、割引率の大きさを理由として挙げると思う。Compute Savings PlanはConvertible RI相当の割引率なので、切り替えると、そのメリットは失われる。
ただ、サービス規模が拡大して、EC2 instanceが増えるにつれて、Standard RIでは以下のようなデメリットが発生していて、何らかの改善は必要とずっと感じていた。 (同様の問題を抱えている人は多いはず?)
- 複雑化していく一方のStandard RIの購入運用
- 複雑化しすぎて、書い漏れ等が発生して、RIのコストメリットを最大限に享受できない
- せっかく新しいinstance typeが発表されて、技術的には大したコストをかけずに切り替えることもできるのに、RIの制限で切り替えることが出来ないちょっとした残念な気持ち
- RIの更新タイミングと、instance family変更のタイミングを合わせないといけないという調整の手間
Convertible RIへの切り替えはこれらの問題への大きな解決策となるかもしれない。
仮にConvertible RIを導入しても、RI変換の手間は発生するので、割引率を超えるほどのメリットがあるか?、、というと、微妙な所があった。それが、先に書いた通り、Compute Savings Planでは、適用するinstance familyの切り替えは透過的に行ってくれるようになる!これによって、全てをCompute Savings Planにしちゃえば、今後のオペレーションは定期的にCost Explorerをチェックし、RIの買い漏れを発見したら、何も考えずに、コミット金額を超えてon-demandになっている分のCompute Savings Plan買い増すだけという、相当に単純なオペレーションに集約することができそう。ということで、Compute Savings Planに切り替えちゃうか否かは、
割引率の低下 vs RIの買い漏れ等による余剰な支払い、複雑なRIオペレーションの削減
を天秤にかけて、エイやで決める!という感じになるのかな〜と想像したのでした。または、変更の可能性がない独立したコンポーネントで、金額のでかい部分 (e.g. 巨大の自前hadoop cluster) だけはスタンダードRI or EC2 Instance Savings Plansを使って、それ以外の部分をCompute Savings Planへ!という合いの子というのもありかもしれません。
ただ、AWS Cost Managementの画面を見ると、"Savings Plan" と "Reservations"で項目が分かれていて、それぞれでレポートが表示されるようなので、運用考えると、統一しちゃった方がいいのかもしれないけど、実際に購入して使い始めみないと分からない。。
以上、Savings Planのことを調べつつ、RI運用について思うことをツラツラと書いてみました。
事実を誤認している所や、何か考慮足りない部分などありましたら、ご指摘いただけると嬉しいです!皆さま、良いRI or Savings Plan 生活を!!
- 投稿日:2019-11-28T15:09:30+09:00
SAML2.0シングルサインオンの流れと設定項目の意味をちゃんと理解する
(๑╹ヮ╹๑)「ウチのWebアプリ、SAMLでシングルサインオンできるようにしたいんだよね〜よろしく!」
(๏д๏)「えっあっはい(SAMLってなんだ…?)」ということである日突然SAMLと戦う羽目になり、苦しみつつ調べたことを記します。
SAMLとは
SAMLとは、異なるドメイン間で認証情報を連携するためのXMLベースの仕様です。
SAMLを利用することで、社内ネットワーク上のActiveDirectory(ADFS)やAzureADの認証情報を利用して、クラウドサービスへのシングルサインオンが可能になります。
クラウドサービスごとに複数ログインする必要がなくなるということです。動きのイメージは下記ページの説明がたいへんわかりやすいです。
SAML認証ができるまで
SAMLとはちなみに、シングルサインオンのプロトコルは、SAMLのほかにもあります。
よく見かける「TwitterIDでログイン」「LINEIDでログイン」はOpenID Connectですね。
プロトコル 特徴 利用シーン SAML2.0 XMLベース エンタープライズの主流 ws-federation SAMLと似たXMLベースの仕様 ほぼMicrosoft製品のみ? OpenID Connect OAuth2.0ベース。トークンはJSON Web Token コンシューマ系が中心 以下、断りのない限り、ユースケースとして最も多い「一般的なWebブラウザーを用いてシングルサインオンを行うシナリオ」について述べます。
(WebブラウザーではないUserAgent向けのECP(Enhanced Client and Proxy)なども仕様にありますが本記事では省略)SAMLの登場人物
IdP(Identity Provider)
- 認証情報を管理する人。要求に応じて認証情報を渡す
- ActiveDirectory(ADFS)など
- OneLogin, Okta, AzureADなどクラウドサービスもあり、IDaaSと呼ばれる
SP(Service Provider)
- IdPから認証情報を受け取って使う人
- 認証したいSaaSアプリケーションはこっち
ユーザ(ブラウザ)
- シングルサインオンでアプリケーションを使いたい人
SAML認証方式の種類
一般的なWebブラウザーを用いたSAMLの認証は、SAMLフローがSPとIdPどちらから開始されるかによって2種類に分類されます。
SAMLフローがSPから開始されるものをSP-Initiated、IdPから開始されるものをIdP-Initiatedと呼びます。SPによって、対応しているかどうかはまちまちです。
例えば、salesforce.comは両方に対応していますが、AWS CognitoはSP-Initiatedのみ対応しています。(Discussion Forums: IdP initiated auth with Okta)まずは、それぞれのざっくりした流れを紹介します(シンプルさを優先して色々と端折っています)。
SP-Initiatedをユーザから見た流れ
- ユーザはまずSPにアクセス
- IdPのログイン画面にリダイレクトされる
- 認証情報を入力してログイン
- 認証OKであれば、SPの画面が表示される
ユーザが最初にSPにアクセスするので、SP-Initiatedと呼ばれます。
もし既にIdPにログインしていれば、
SPにアクセス→(認証済なので)すぐSPの画面が表示される
という動きになります。IdP-Initiatedをユーザから見た流れ
- ユーザはまずIdPのログイン画面で認証情報を入力してログイン
- IdPのポータル画面(AzureADならアクセスパネル(myapps.microsoft.com)など)からアプリのアイコンを押す
- SPの画面が表示される
ユーザが最初にIdPにアクセスするので、IdP-Initiatedと呼ばれます。
※ややこしいのですが、ユーザから見た動作がこのパターンでもSP-Initiatedの場合があります。後述の「補足:サインオンURL」参照SP-Initiatedによるシングルサインオン
設定手順書があれば、SSOの設定は問題なくできると思いますが、IdP/SPの設定項目の意味や役割を把握するために、もう少し詳しくシングルサインオンのフローを整理することにします。
まずはSP-Initiatedによるシナリオを見てみたいと思います。
ここでは、最も多いパターンの「リダイレクト/POSTバインディングによるSP-Initiated SSO」を取り上げます。
(「POST/ArtifactバインディングによるSP-Initiated SSO」というパターンもありますが、ガラケーなどブラウザで扱えるデータサイズに限界がある頃に使われていたもので、最近はあまり使われていません)
(出典:Security Assertion Markup Language (SAML) V2.0 Technical Overview)1. ユーザ(ブラウザ)がSPにアクセスします。
2. SPはブラウザにIdPへのリダイレクト応答を返し、ブラウザは、IdPへリダイレクトします。
クエリストリングには、SAMLRequest(認証要求)を含みます。SAML認証完了後のリダイレクト先情報を示すRelayStateが含まれることもあります。3. IdPは、該当ユーザが既にIdPにログイン済かどうかを判断します。
もし未ログインであれば、ログイン画面を表示し、ユーザにID/パスワードなどのクレデンシャルを要求します。4. ユーザは正しいクレデンシャルを入力します。
5. IdPは、HTMLformを含んだHTTPレスポンスをブラウザに返します。HTTPレスポンスには、フォームを自動的にPOSTするスクリプトコードが添付されています。
HTMLformには、SAMLResponse(認証応答)を含みます。認証応答には、IdPから連携されるID情報が含まれています。
認証要求にRelayStateが含まれていた場合は、認証応答にもそのままRelayStateを付与します。<form method = "post" action = "https://sp.example.com/SAML2/SSO/POST" ...> <input type = "hidden" name = "SAMLResponse" value = "response" /> <input type = "hidden" name = "RelayState" value = "token" /> ... <input type = "submit" value = "Submit" /> </ form>6. ブラウザでフォームを自動的にPOSTするスクリプトコードが実行され、ブラウザは宛先(SPのアサーションコンシューマサービスURL)へPOSTリクエストを行います。
SPは、認証応答に含まれるデジタル署名を検証し、認証応答の発行元がIdPであることを確認します。
確認OKであれば、SPはRelayStateに含まれるリダイレクト先URLを取り出し、ブラウザにリダイレクト応答を返します。7. ユーザがリソースにアクセスするための正しい権限を持っている場合、リソースはブラウザに返されます。
IdP-Initiatedによるシングルサインオン
続いて、IdP-Initiatedによるシナリオを簡単に見てみます。
(出典:Security Assertion Markup Language (SAML) V2.0 Technical Overview)
- IdPはログインページを表示し、ユーザにID/パスワードなどのクレデンシャルを要求します。
- ユーザは正しいクレデンシャルを入力します。
- ユーザはIdPのポータルなどからリンクをクリックして、SPへのアクセスを要求します。
- IdPは、HTMLformを含んだHTTPレスポンスをブラウザに返します。HTMLformには、SAMLResponse(認証応答)、RelayStateが含まれます。
- ブラウザでフォームを自動的にPOSTするスクリプトコードが実行され、ブラウザは宛先(SPのアサーションコンシューマサービスURL)へPOSTリクエストを行います。
SPは、認証応答に含まれるデジタル署名を検証し、認証応答の発行元がIdPであることを確認します。
確認OKであれば、SPはRelayStateに含まれるリダイレクト先URLを取り出し、ブラウザにリダイレクト応答を返します。- ユーザがリソースにアクセスするための正しい権限を持っている場合、リソースはブラウザに返されます。
SSOのための準備
フローを押さえたところで、実際にシングルサインオンを構成するための設定項目を見ていきます。
SAMLによるシングルサインオンを行うには、IdPとSPの間で事前に信頼関係を構築しておく必要があります。
本項はIdP/SPの実装によって大きく変わる部分のため、詳細はIdP/SPのドキュメントをご覧ください。
なお、筆者はIdPとしてAzureAD/TrustLogin、SPとしてAWS Cognitoユーザープールを利用しています。SPに登録するIdPの情報
SP側に登録する主な項目です。
項番 項目 説明 1 エンティティID IdPを一意に識別するID 2 IDプロバイダーURL(SSOエンドポイントURL) IdPが認証要求メッセージを受け取るURL
SP-Initatedによるシングルサインオンフロー2「SPはIdPページへのリダイレクト要求を返す」時に使う3 証明書 IdPが認証応答メッセージの署名に用いる秘密鍵に対応する公開鍵
SP-Initatedによるシングルサインオンフロー6でデジタル署名を検証する時に使う4 メタデータ 1~3の情報が入ったXMLファイルまたはメタデータにアクセスできるURL 5 IdPから受け取るユーザー属性 IdPが持つ属性(メールアドレス、名前、電話番号etc...)を、どんな名前で受け取るか定義する 1-3と5、または4と5をIdPに登録します。
どちらかといえば、4のメタデータファイルをアップロードしたりURL指定したりするケースが多いと思います。補足:証明書の有効期限
証明書には有効期限があり、期限が切れるとシングルサインオンができなくなってしまいます。
証明書または(証明書情報を含んだ)メタデータをファイルアップロードした場合、期限が切れる前に更新する必要があります。AzureADの場合、証明書の有効期限は最大3年間です。期限が切れる 60日前、30日前、7日前に通知メールが送信されます。
更新するためには、コンソールから新しい証明書を作成して切り替えを行う必要があります。
Azure Active Directory でのフェデレーション シングル サインオンの証明書の管理メタデータにアクセスできるURLを指定した場合は証明書は自動更新されるため、可能であればエンドポイントURLを指定するとよいです。
補足:バインディング
SPによっては、バインドタイプ(SAML Binding)を設定できる場合があります。
SAML Bindingとは、認証要求や認証応答をどのような方法で行うかの定義です。
ほとんどの場合、認証要求ではHTTP Redirect、認証応答ではHTTP POSTを使用します。
バインドタイプの設定や、バインドタイプが合わない場合のエラーについては、「Azure AD とアプリケーションを SAML 連携して SAML Binding の動作を見てみる。」が詳しいです。IdPに登録するSPの情報
項番 項目 説明 1 エンティティID SPを一意に識別するID 2 応答URL(Assertion Consumer Service URL) 認証応答のPOST先URL 3 サインオンURL SP側でサインインを開始するURL 4 リレー状態(RelayState/SP認証成功後の移行URL) SP認証成功後のリダイレクト先 5 Named ID ユーザーを一意に識別するための項目。IdPのアカウントとSPのアカウントを紐づけるために使う 6 Named ID Format Named IDの形式。
SP-Initiatedの認証要求メッセージ内で形式が指定されている場合、同じフォーマットを指定する。7 SPに渡すユーザー属性 IdPが持つ属性(メールアドレス、名前、電話番号etc...)を、どんな名前でSPに渡すかを定義する 個人的に「サインオンURL」と「リレー状態」で混乱したので補足です。
補足:サインオンURL
サインオンURLは、IdPのポータル上からアプリケーションを起動した時にリダイレクトされるURLです。
項目を設定した場合、IdPのポータル上からアプリケーションを起動した時にSPにリダイレクトし、SSOを開始するのでSP-Initiatedになります。
項目を設定しない場合、IdPのポータル上からアプリケーションを起動した時はIdPのサインインページにリダイレクトするので、IdP-Initiatedになります。あまり意識することはないのかもしれませんが、IdPに先にログインしてポータルからアプリを起動してもSP-Initiatedの場合があるということですね。
あくまで、「IdPのポータル上からアプリケーションを起動する時」用の設定のため、このようなケースがない場合は設定不要です。補足:リレー状態
IdP-Initiatedの場合は文字通り「SP認証成功後のリダイレクト先」です。
通常、ログイン認証後はSPの認証後トップページが表示されますが、特定のページにリダイレクトしたい場合にURLを設定します。一方、SP-Initiatedの場合は少し複雑です。
リレー状態(RelayState)は、SPからIdPに認証要求を送る際に付与することができます。(SP-Initiatedによるシングルサインオン2参照)
SPがRelayStateを付与して認証要求を行った場合、SAML2.0の仕様により、IdPは値を変更せずに認証応答を返します。
SPは認証応答のRelayStateからリダイレクト先URLを取得し、ブラウザにリダイレクト応答を送信するのです。このように認証要求に既にRelayStateが指定されている場合、IdPにもRelayStateが設定されていると、双方が一致しないためにエラーとなる場合があります。
ちなみに、SPが付与するRelayStateは、必ずしもURLの形式ではないようです。
AWS Cognitoの場合、RelayStateを復号するとJSONでした。動かしてみると、認証成功後は"redirectURI"へリダイレクトされます。RelayState{ "userPoolId": "[ユーザープールID]", "providerName": "[ユーザープール名]", "clientId": "[アプリクライアントID]", "redirectURI": "https://abc.sample.net/", "responseType": "token", "providerType": "SAML", "scopes": [ "aws.cognito.signin.user.admin", "email", "openid", "phone", "profile" ], "state": null, "codeChallenge": null, "codeChallengeMethod": null, "nonce": "[hash値]", "serverHostPort": "[ドメイン名].auth.ap-northeast-1.amazoncognito.com", "creationTimeSeconds": 1574826098, "session": null, "userAttributes": null, "isStateForLinkingSession": false }仕組みを整理する中で出てきた疑問
2回目のログインの時、なぜIdPは認証済とわかるのか?
シングルサインオン対応したSPにアクセスする時、既にIdPにログイン済であれば、再度ログイン画面でID/Passwordを入力する必要はありません。Cookieによるセッション管理がされているためです。
- SP1へアクセスするためIdPにログイン
- IdPからセッションIDが発行され、ブラウザのCookieに保存される
- 別のSP2にアクセス→IdPにリダイレクトした時、一緒にCookieのセッションIDが送信される
- IdPは送信されてきたセッションIDが有効かチェック
チェックOKなら、その人は既にIdPにログイン済のため、ログイン画面をスキップという感じです。
AzureADの場合、ログイン時に「サインイン状態を保持しますか?」とダイアログが表示され、「はい」を選択すると、期間3ヶ月の永続的セッションCookieが保存されます。
セッションCookieが有効な間、再度ログイン操作を行う必要はありません。
「いいえ」を選択すると、ブラウザを閉じるまでの非永続セッションCookieとなります。
Azure AD が発行するトークンの有効期間についておわりに
先人の解説を読み、OASISのSAML2.0仕様を読み、IdPやSPの設定に失敗し、ネットワークキャプチャを取って通信内容を確認し、やっと納得できた気がします。勉強になりました。
通信内容の確認はChromeやFirefoxの拡張が使いやすいです。
今回はChromeの「SAML Tracer」を主に使いましたが、「SAML Chrome Panel」も良さそうです。参考資料
SAML2.0仕様
Security Assertion Markup Language (SAML) V2.0 Technical Overview
Profiles for the OASIS Security Assertion Markup Language (SAML) V2.0
Assertions and Protocols for the OASIS Security Assertion Markup Language(SAML) V2.0
Metadata for the OASIS Security Assertion Markup Language (SAML) V2.0SAMLのフロー・用語などの解説。とてもお世話になりました。
便利なSaaSをもっと安全に使うには?(番外編:SAML解説)
SAML2.0でのシングルサインオン実装と戦うあなたに(.NET編)
Azure AD の SAML 構成に必要な設定項目とその意味、動作の説明についてセッションCookieについて
Cookieとセッションをちゃんと理解するデジタル署名について
Digital Signature



- 投稿日:2019-11-28T13:52:56+09:00
EC2インスタンスのOSの種類を調べる
[マネコン]
→[SSM(System Manager)]
→[インスタンスとノード]
→[マネージドインスタンス]
→「AWS:InstanceInformation.PlatformName: Equal:"OS名"」でフィルタ
→OS名でフィルタされたインスタンス一覧が表示される
- 投稿日:2019-11-28T13:29:43+09:00
cloud9って何なの?
cloud9の使い方
1.environmentはパソコンのローカル環境のこと
以下の画像のPythonとかpracticeがenvironmentと呼ばれていて、environmentの一つ一つが仮想的な環境になっている。パソコン一台を仮想空間に持っているみたいなイメージ。environmentを4つ以上作ると有料なので注意してください!
environmentを起動(OPEN IDEを押す)する度にEC2と呼ばれているAWSのサーバーのインスタンス(仮想サーバーの一部)が生成されて仮想サーバーを使うことが出来ます。逆にログアウトするとサーバーは返却される。environmentを使うときだけサーバーを借りて、使わないときは返却するというイメージ。大規模開発とかでは使う分だけお金を払うのでお得にサーバを利用できます。
environmentは個別の環境なので、言語のバージョンの設定やMysqlの準備などはenvironmentごとに行う必要があります。アプリごとに環境を設定するのはめんどくさいと思うのでenvironmentごとの容量(1GB)超えないまでは複数のアプリ開発も同じenvironmentでやっちゃった方がいいと思います。
2.ターミナルを使おう!
緑のプラスボタンを押して"New Terminal"を押すとターミナルを起動でき、仮想的なパソコン(environment)に命令を出すことが出来ます。コマンドはLinuxコマンドになるので、Windowsユーザの方は一通りLinuxコマンド勉強してから使った方がいいかもしれないです。
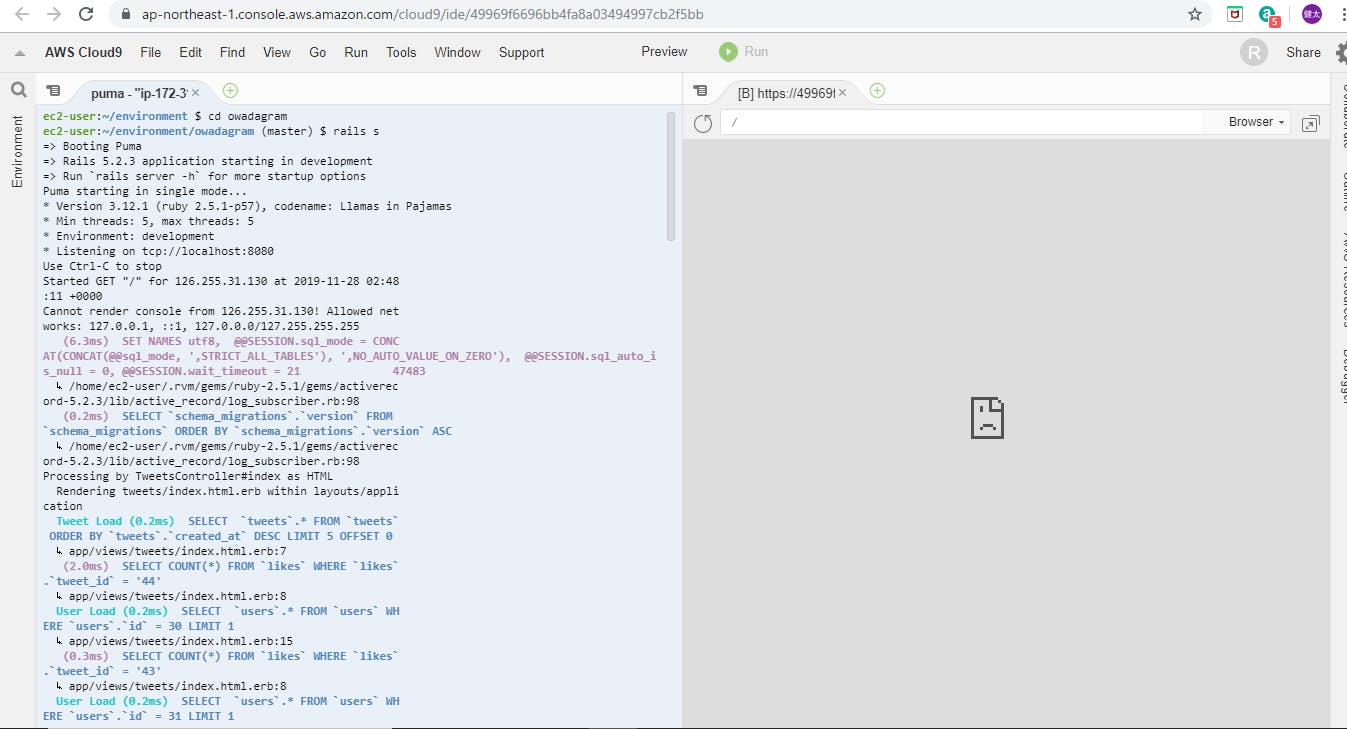
3.作成したアプリケーションをプラウザで確認しよう
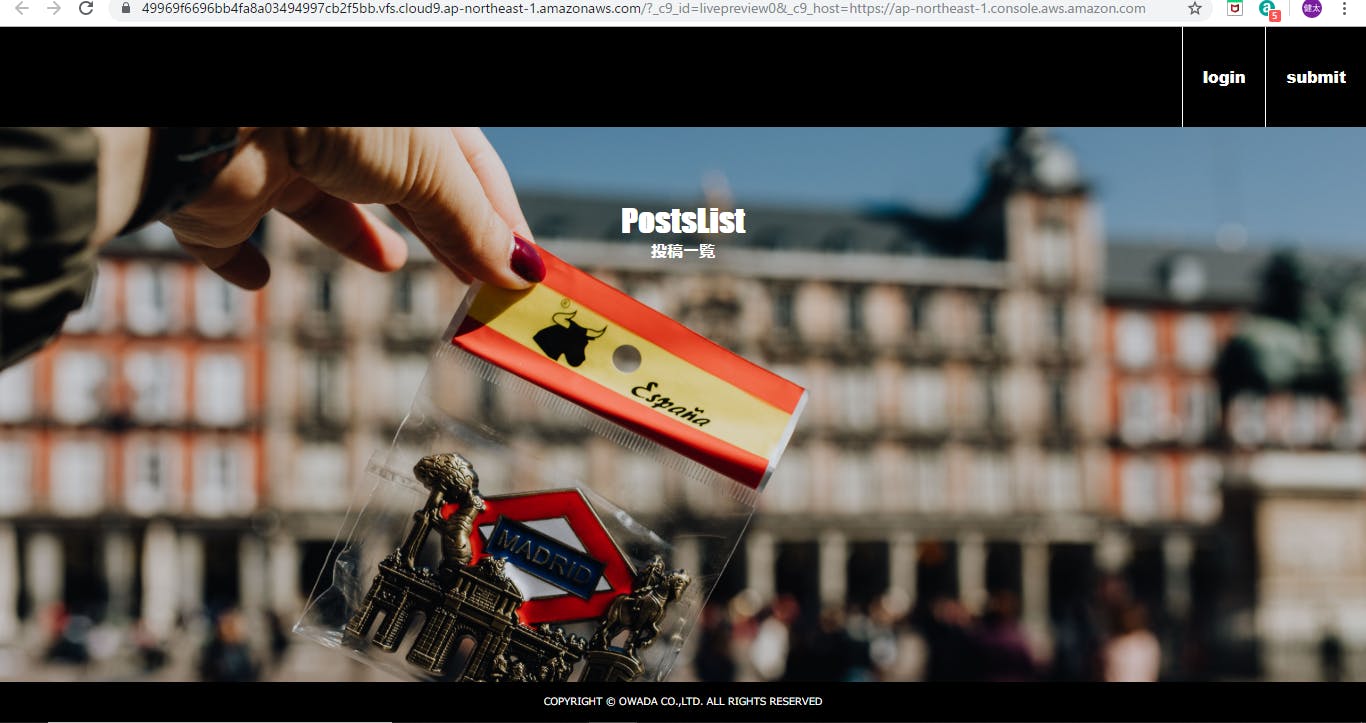
2番で起動したターミナルで、作成したアプリケーションをAWSのプラウザで確認できます。以下の画像の左画面で、表示したいアプリケーションのディレクトリに移動してサーバを起動します(railsの場合は"rails s")。その後、上の一覧のPreviewを押して、”Preview running application”を押すと作成したアプリケーションを以下の画像の右側の表示が出て来ます。
その右上の矢印ボタンを押すとcloud9のプラウザで以下のようにアプリケーションの確認が出来ます。
※注意
cloud9のプラウザはたまにCSSの適用がされなかったり、明らかに通っているパスが通らなかったりという不具合があるので、そういう時はサーバの再起動をすると大抵直ります。

- 投稿日:2019-11-28T11:17:54+09:00
Amazon Transcribe

- 投稿日:2019-11-28T11:17:54+09:00
Amazon TranscribeにVirtual Insanityを文字起こしさせてみた
TL;DR
曲の歌詞を抽出するのはダメそう。
きっかけ
翻訳制度が高いというなら歌詞付き音楽もいけるんじゃないか?
とかふと思ったのでやってみた感選曲
とりあえず洋楽で好きなjamiroquaiのVirtualInsanityをチョイス。
やってみた
MP3ファイルを用意する。
あとはAmazon Transcribeの説明の通りに翻訳にかける。言語:Englishで翻訳した結果
操作ミスで言語:日本語で翻訳させちゃった結果・・・
感想
なんか惜しいっておもうところもあるけど大抵ダメ。
音楽の歌詞翻訳は難しい・・・
※当初翻訳サービスだと勘違いしていたので文字起こしに改めて更新しています。VirtualInsanityの歌詞サイト

- 投稿日:2019-11-28T01:21:38+09:00
AWS経由でPepperの聞き取りをAlexaに任せてみた
はじめに
この記事は2019/11/19のIoTLTで発表した内容をもとに
AWS経由でPepperとAlexaを連携させた会話システムを作った際の
- Alexaスキルを作る過程で参考にした記事
- Alexaと他のアプリを連携させる際にハマったポイント
についてまとめたものになります。
メインはAlexaスキルにおけるDynamoDBを使った他のアプリとの連携についての説明なので、Alexaに興味がある方のお役に立てれば幸いです。
LTの時のスライドはこちらPepperは聞き取りができない
Pepperはマイクの性能がイマイチで*聞き取りができません。
つまり、Pepperはコミュニケーションロボットであるにも関わらず人と会話ができません。
これは致命的、、、ということで今回はPepperの聞き取り機能を実用的なレベルに引き上げる方法として
AlexaにPepperの聞き取りを任せるシステムを作りました。これにより欠点だった聞き取り能力をAlexaに補ってもらい、
持ち前の親しみやすさを存分に発揮できる最強のPepperが出来上がるはずです。
多分。以下AlexaとAndroidアプリであるPepperのシステムとの連携をする上で
参考にした記事やハマったところをまとめていきます。*雑音がない環境で真正面から話しかければ聞き取れます。
しかし複数人が話しかけてきたり雑音がある環境では実用的出ないのが実情です。。Alexaスキル作成時のハマりどころ
Alexaスキルの開発にはAmazonの提供するAlexa Skill Kitと*AWS Lambdaを使います。
なおLambdaではNode.jsを使いました。僕はAlexaスキルの開発は未経験だったのですが、以下の一連の記事がとても参考になりました。
Alexa SDK for Node.js Ver2入門(その1)はじめの一歩Alexaスキルの開発を始めた時に盛大にハマったのがAlexaスキルSDKのバージョンについてです。
現在のNode.jsのSDKのバージョンはVer2ですが、初心者向けの記事はVer1のものが多く
Ver1でのスキルの作成の基本を学んだ後Ver2の記事をみて混乱、、ということが多々ありました。上の記事はVer2に対応した初心者向けの記事なので、混乱することなくスキル開発の基本が習得できるためおすすめです。
初めてのスキル作成から会話の作り方、Alexaスキルから*AWS DynamoDBへのデータの格納までスキル開発で必要な知識が一通り網羅されているので、これをベースに様々なスキルへ応用ができると思います。*Lambdaに触ったことがない方でも上の記事に概要があります。
*DynamoDBについてはあまり説明がないので、触ったことのなかった僕は適宜調べながら進めました。DynamoDBでのデータ共有
今回はDynamoDBへデータを格納できるというところに目をつけ、
DynamoDBを通してPepperのAndroidアプリとの連携に応用してみました。
システムの全体像は以下のようになります。
AlexaスキルのLambdaからDynamoDBに格納したデータに
PepperのAndroidアプリからAPI Gateway経由でアクセスします。AndroidアプリからDynamoDBのデータを一定時間ごとにGETし、
それを元にAlexaが聞き取った音声のデータや会話の状態を取得します。
Androidアプリの方で受け取ったデータを元に返すメッセージを決定し
その内容をPepperに発話させるという流れです。まず上で紹介した記事を参考にDynamoDBにアクセスするためのAdapterを用意します。
const config = {tableName: 'xxx', // <= DynamoDBのテーブル名 createTable: true}; // <= テーブルを自動生成する場合true const DynamoDBAdapter = new Adapter.DynamoDbPersistenceAdapter(config);exports.handlerの設定に 'withPersistenceAdapter(DynamoDBAdapter)' を追加します。
let skill; exports.handler = async function (event, context) { if (!skill) { skill = Alexa.SkillBuilders.custom() .addRequestHandlers( LaunchRequestHandler, xxx, // スキルで使うHandlerを設定 xxx) .withPersistenceAdapter(DynamoDBAdapter) .addErrorHandlers(ErrorHandler) .create(); } return skill.invoke(event); }SDKではデフォルトでid、attributeという要素が設定されます。
idはプライマリキーで"amzn1.ask.account.xxxx"というようにAlexaスキルのスキルIDになっています。
attributeはMap型でこの中に複数の要素を設定することができます。
なので例えばString型のhoge, Number型のhugaというデータを格納したい時はattributeの要素として設定してやることになります。
データへのアクセスについては、任意のインテントのHandlerで行います。
最初のアクセスの際にattributeに要素が追加されます。
以下は呼び出された時に「わー」と発話しつつ、このattributeのhogeの中身を"ほげほげ"に設定するインテントのサンプルです。const xxxxxxxHandler = { canHandle(handlerInput) { return handlerInput.requestEnvelope.request.type === 'IntentRequest' && handlerInput.requestEnvelope.request.intent.name === 'xxxxxxxIntent'; }, handle(handlerInput) { return new Promise((resolve, reject) => { handlerInput.attributesManager.getPersistentAttributes() .then((attributes) => { attributes.hoge = "ほげほげ"; handlerInput.attributesManager.setPersistentAttributes(attributes); return handlerInput.attributesManager.savePersistentAttributes(); }) .then(() => { resolve(handlerInput.responseBuilder .speak("わー") .getResponse()); }) .catch((error) => { reject(error); }); }); } };上で紹介した記事のコードを参考にしてやってみたところLambdaでエラーが出てしまったため、同期処理にPromiseを使っています。
もし紹介した記事のコードでうまくいかない場合は参考にしてみてください。Pepper側の処理
ここまででAlexaスキルからDynamoDBへデータをアップするところまでができました。
あとはPepperのAndroidアプリからこのデータへアクセスできるようにしてやります。まず以下のようにAPI Gatewayを使いLambda経由で以下のようにDynamoDBにアクセスできるようにしてやります。
この設定についてはこの記事を参考にしました。
そして設定したURLにAndroidアプリから一定周期でアクセスしてやることでAlexaとAndroidアプリ間でデータを共有することができ、連携を取ることができるようになります!Android側の処理は今回のメインでないので省略いたします。
終わりに
実際にデモを作ってみたところ問題なく連携が取れるようになりました。
Alexaを補聴器がわりに従えたPepperがこれから躍進することに期待しましょう。今回はAlexaとPepperとの連携でしたが、API GatewayでURLにアクセスできればどんなアプリケーションでもAlexaと連携が取れるので応用の幅は広そうですね。
Pepperが最近Androidアプリとして開発できるようになりました。
Androidアプリを開発したことがある方は簡単に作ることができると思います。
Pepper開発についてはアトリエ秋葉原というところが無料でワークショップをやっているのでおすすめです。
Pepperの開発も新鮮で楽しいのでぜひ一度やってみてください!



- 投稿日:2019-11-28T01:04:24+09:00
Terraformアンチパターン(2019年版)
はじめに
- Infrastructure as Code(以下IaCと略します)って最近では当たり前のように実践されてますよね。特にterraformはかなりユーザが多く、開発のスピードも速い印象です。
- IaCを実現できたインフラエンジニアの皆さんの多くが次に直面する問題はコードの保守運用に関する事柄ではないでしょうか?
- terraformもコードなので、アプリケーションのコードと同じように保守性(テスト容易性、理解容易性、変更容易性)を意識する必要があります。ただコード化しただけでは属人性を排除したとは言えないと思います。
- 保守性の高いterraformって具体的にどう書けばいいの?と周りに聞いてみても、巷には「ぼくのかんがえた最強のterraformベストプラクティス」が乱立していて、自転車置き場の議論になりがちです。
- また、v0.12前後でterraformの記法が大きく変わったので、古い情報はあまり参考にならなかったりします。
- 一方で、terraformのつらい話をするとみんなウンウン頷いてくれるので、アンチパターンについては共有認識を作りやすいのかな
- これまで、複数の現場で中規模以上のterraformの運用保守をやってきて、何度かこれはイケてないなと思うterraformを読んだり書いたり(ゴメンナサイ
)直したりしてきたので、terraformのアンチパターンをまとめてみました。
Terraformアンチパターン集
依存関係が足りていないresource
- マネジメントコンソールをポチポチしながらリソースを作成し、後でterraform化した時にありがちなパターンです。
- terraformで依存関係の定義が足りておらず、別の環境で試してみるとエラーとなってしまいます。
- 途中まで手動でリソースを作成したときは、一度関連するリソースを全て削除してテストしてみましょう。
moduleを使わず1つの階層内で全てのresouceを定義する
構成例
## [補足]実際にはもっとファイル数が多かったり、命名規則がぐちゃぐちゃだったりします。 . ├── bar.tf ├── ec2.tf ├── ecs.tf ├── elb.tf ├── foo.tf ├── iam.tf ├── lambda.tf ├── outputs.tf ├── rds.tf ├── s3.tf ├── security_group.tf ├── ssm.tf ├── subnet.tf ├── variables.tf └── vpc.tf
- terraformは1つの階層内でNamespaceを共有するため、名前の衝突が起きる可能性が高いです。これを避けるためにはresource名を長くしてしまいがちです。
- moduleを使わないと抽象化ができないため、大きなプロジェクトになると全体を把握しづらくなります。
大規模プロジェクトを1つのstateで管理する
- 「1アカウントにつき1stateで運用しなければならない」なんてルールはどこにも存在しないのに、なぜか先入観を持ってこの構成にしてしまうケースが多いです。
- この構成にすると1か所変更してplanするだけで、全てのリソースの現在の状態を確認してしまうため、実行時に非常に時間がかかります。
- 1つのモジュールや変数を変更した時の影響範囲が大きくなって、変更容易性が失われます。
DRYでないコード
- 複数のstateを分けて運用し始めると今度は同じリソース定義を何度も記述しがちです。
- DRYでないコードを書くと変更容易性が落ちる上に、古い設定が残り続けてトラブルの元になります。
- 別のstateで管理しているリソースの状態を参照したい場合はData Sourcesを使いましょう。
古い記法で記述されたコード
- terraformはかなり開発の流れが早く、古い記法をつかっていると最新のバージョンが使えないこともあります。
resource, variables, outputsを同じファイルに書く
- terraformではvariablesだけ参照したいケースが多発するため、ファイルを分けたほうが読みやすいです。
秘匿情報をハードコードしてしまう
- terraformに限らずやめたほうがいいです。
- terraform実行時のログに秘匿情報が残ってしまいます。
- プライベートリポジトリで運用していたとしても、意図せず秘匿情報をそのままコピー/フォークして事故が起きる危険性があります。
- SSMパラメータストア, Hashicorp vaultなど秘匿情報を管理するSaaSにデータを格納しておきましょう。
再利用しづらいmodule
- 抽象化を意識せずにmoduleを作ると、再利用しづらいmoduleができてしまいます。
- module内部にハードコードされた設定があると、他のサービスでmoduleを再利用するときにも無理して同じ設定を使うか、任意の設定値を投入できるようにリファクタする必要が出てきます。
- 変数にはdefault値を設定することができるので、よく使われるであろう設定値をdefaultとして定義しておくと使いやすいmoduleができます。
- 抽象度を下げて特定のユースケースに特化したmoduleを作る場合は、それがわかるようなディレクトリ名にしておかないと、想定外の利用をされてしまう可能性があります。
Default値のない変数
- module内でvariablesを設定したものの、default値を定義しない場合、moduleを呼び出す時に必ず値を代入しなければならず、コード量が増大します。
- もちろん全ての変数にDefault値を設定すべきとは思いませんが、積極的に使うべきだと思います。
Typeの指定のない変数
- string型以外の型を期待する変数では、変数を定義する時に型を明示したほうが可読性が高いです。
- 型を明示しておくことで、想定外の型を代入された場合、実行前にエラーに気づくことができます。
深すぎる階層構造
- 必要以上に深い階層構造を作ると全体の見通しが悪くなります。
module in module
- terraformではmodule内部にmoduleを定義することができますが、大抵の問題は他の方法で解決できます。
- コードの見通しが悪くなりますし、階層構造も深くなりがちです。
- 循環参照してしまう危険もありますので、乱用するのはおすすめしません。
- 抽象度レベルの異なるmoduleを作って、命名の工夫でわかりやすくすれば、使い所もあるかもしれません。
アンチパターンを避けた無難な構成
- 下の例は私が最近よくやる構成です。
. ├── api_a │ ├── backend.tf │ ├── main.tf │ └── variables.tf ├── api_b │ ├── backend.tf │ ├── main.tf │ └── variables.tf ├── common │ ├── backend.tf │ ├── iam_users.tf │ ├── route_tables.tf │ ├── security_groups.tf │ ├── subnets.tf │ ├── variables.tf │ └── vpc.tf ├── job_a │ ├── backend.tf │ ├── main.tf │ └── variables.tf ├── job_b │ ├── backend.tf │ ├── main.tf │ └── variables.tf └── modules ├── alb │ ├── main.tf │ ├── outputs.tf │ └── variables.tf ├── api_gateway │ ├── main.tf │ ├── outputs.tf │ └── variables.tf ├── aurora │ ├── main.tf │ ├── outputs.tf │ └── variables.tf ├── cloudwatch_event │ ├── main.tf │ ├── outputs.tf │ └── variables.tf ├── codebuild │ ├── main.tf │ ├── outputs.tf │ └── variables.tf ├── fargate │ ├── main.tf │ ├── outputs.tf │ └── variables.tf ├── lambda │ ├── main.tf │ ├── outputs.tf │ └── variables.tf ├── rds │ ├── main.tf │ ├── outputs.tf │ └── variables.tf └── s3 ├── main.tf ├── outputs.tf └── variables.tf運用例
- 例えばAPIを増やしたい時は、api_aをディレクトリごとコピーしてapi_cを作成、variables.tfでパラメータを調整、backend.tfでstateファイルの保存先を変更するだけでセットアップが完了します。
- stateファイルの保存先をapiごとに分けることで、既存APIのstateファイルに影響を与えることなく新規構築できます。
- APIの数が100個に増えたとしても、moduleを再利用しているので、コード量はそれほど増えません。
- ネットワーク関連の設定をcommonでまとめて設定することで、CIDR重複などのリスクを防げます。
- IAMユーザ関連の設定をcommonでまとめて設定することで、ユーザごとの権限を把握しやすくしています。
- 一方でlambdaやfargateなどに付与するIAMロールに関してはそれぞれのmodule内で定義した方が依存関係を理解しやすいです。variablesでIAMポリシーの内容を渡せるように定義すれば、各APIごとに別の権限を割り当てたいときにも対応できます。
- dev,stg,prdで同じコードベースを使ったデプロイをしたい場合はworkspaceを使います。
参考資料
- 投稿日:2019-11-28T00:44:27+09:00
Googleカレンダーの予定からバイトの給料を計算して教えてくれるSlack botが欲しい!
はじめに
Googleカレンダーとても便利ですよね.Gmailと連動できるし,PCから開けるし,シンプルだし.ただ,不満に思う点があります.それがバイトの給料を計算してくれないことです.シフト管理アプリと連動してくれれば良いのに...
と言うことで,気になってた各種APIとかAWSとかを初心者なりに使いつつ,作ってみました.使ったもの
- Slack
- AWS
- Googleカレンダー
- Python
アーキテクチャ全体像
以下のような構成でbotを作成しました.
手順
- Slack APIのサイト上でbot作成用のアプリを作成する
- AWS上にSlackイベントを受け取るエンドポイントを作成する
- GoogleAPIを使って,Googleカレンダーからバイトの給料を計算するプログラムを作成
- AWS lambdaに導入
【手順1】【手順2】Slack botを作成し,AWS上にエンドポイントを作成する
この手順は,以下の記事にとてもお世話になりました.記事の通りに進めると,問題なくできると思います.
AWS初心者でもわかる! ブラウザ上で完結! AWS+Slack Event APIを使ったSlackボット超入門【手順3】Googleカレンダーからバイトの給料を計算するプログラムを作成
Googleカレンダーの予定をPythonを使って取得する方法は以下の記事を参考にしました.
Google Calenderの予定をPython3から取得する次に,公式のサンプルと公式リファレンスを参考に,給料を計算するプログラムを作っていきます.
プログラムは大きく以下に分かれます.
- handle_slack_event():エントリポイント
- MakePayMsg():ユーザテキストに対応した給料を計算し,メッセージを作成
- CalculatePay():日給を計算
フルコードはgithubにあるので,そちらを参照してください.
handle_slack_event()
エントリポイントです.ユーザが送信したテキストを解析し,それを元にメッセージを投稿します.
# -----エントリポイント----- def handle_slack_event(slack_event, context): # 受け取ったイベント情報をCloud Watchログに出力 logging.info(json.dumps(slack_event)) # Event APIの認証 if "challenge" in slack_event: return slack_event.get("challenge") # ボットによるイベントまたはメッセージ投稿イベント以外の場合 # 反応させないためにそのままリターンする # Slackには何かしらのレスポンスを返す必要があるのでOKと返す # (返さない場合、失敗とみなされて同じリクエストが何度か送られてくる) if is_bot(slack_event) or not is_message_event(slack_event): return "OK" # ユーザからのメッセージテキストを取り出す text = slack_event.get("event").get("text") # 給料計算クラスの宣言 pay_msg = MakePayMsg() # ユーザからのテキストを解析して,メッセージを作成 if 'help' in text: msg = '知りたい情報に対応する番号を入力してください!\n' msg += '(1)来月の給料\n' msg += '(2)今年の給料\n' msg += '(3)給料のログ\n' elif text == '1': msg = '来月の給料は¥{}です!'.format(pay_msg.monthpay()) elif text == '2': msg = '{}'.format(pay_msg.yearpay()) elif text == '3': msg = '給料ログ\n{}'.format(pay_msg.paylog()) else: msg = '\\クエー/' # メッセージの投稿 post_message_to_slack_channel(msg, slack_event.get("event").get("channel")) # メッセージの投稿とは別に、Event APIによるリクエストの結果として # Slackに何かしらのレスポンスを返す必要があるのでOKと返す # (返さない場合、失敗とみなされて同じリクエストが何度か送られてくる) return "OK"MakePayMsg()
ユーザテキストに対応した給料を計算し,メッセージを作成します.
# -----給料を計算し,メッセージを作成する----- class MakePayMsg(): def __init__(self): self.SCOPES = ['https://www.googleapis.com/auth/calendar.readonly'] self.now = datetime.datetime.now() self.events = self.get_event() # Googleカレンダーから取り出したイベント self.pay_log = self.make_paylog() # 今年分の給料ログ # ---Googleカレンダーからイベントを取り出す--- def get_event(self): creds = None if os.path.exists('token.pickle'): with open('token.pickle', 'rb') as token: creds = pickle.load(token) # If there are no (valid) credentials available, let the user log in. if not creds or not creds.valid: if creds and creds.expired and creds.refresh_token: creds.refresh(Request()) else: flow = InstalledAppFlow.from_client_secrets_file( 'credentials.json', self.SCOPES) creds = flow.run_local_server(port=0) # Save the credentials for the next run with open('/tmp/token.pickle', 'wb') as token: pickle.dump(creds, token) service = build('calendar', 'v3', credentials=creds) # バイトのシフトを登録しているカレンダーを選択 calender_id = os.environ['CALENDER_ID'] page_token = None events = service.events().list(calendarId=calender_id, pageToken=page_token).execute() return events # ---今年分の給料ログを作成する--- def make_paylog(self): pay_log = [] cal = CalculatePay(1013, 1063, 1.25, 22) # 時給情報を入力 # eventからバイトの開始時間と終了時間を取り出し,給料計算する for event in self.events['items']: # 開始時間と終了時間をdatetimeに変形 stime = event['start']['dateTime'] stime = datetime.datetime( int(stime[0:4]), int(stime[5:7]), int(stime[8:10]), int(stime[11:13]), int(stime[14:16])) etime = event['end']['dateTime'] etime = datetime.datetime( int(etime[0:4]), int(etime[5:7]), int(etime[8:10]), int(etime[11:13]), int(etime[14:16])) # 給料計算をする期間 # (x-1)年12月~x年11月に働いた分がx年の給料 if self.now.month != 12: sdate = datetime.date(self.now.year-1, 12, 1) edate = datetime.date(self.now.year, 11, 30) else: sdate = datetime.date(self.now.year, 12, 1) edate = datetime.date(self.now.year+1, 11, 30) # 1年分の給料をログとして記録 if (stime.date() >= sdate) and (etime.date() <= edate): # 開始時間と終了時間から1日分の給料計算 daypay = cal.calculate(stime, etime) # 働いた分が翌月の給料になるように調整 if stime.month==12: daypay_dir = {'date':stime.date(), 'month':1, 'pay':daypay} else: daypay_dir = {'date':stime.date(), 'month':stime.month+1, 'pay':daypay} pay_log += [daypay_dir] return pay_log # ---来月の給料を表示するメッセージを作成--- def monthpay(self): mpay = 0 for i in self.pay_log: if i['month'] == (self.now.month+1): mpay += i['pay'] return mpay # ---1年分の給料を表示するメッセージを作成--- def yearpay(self): mpay_list = [0] * 12 for i in self.pay_log: mpay_list[i['month']-1] += i['pay'] msg = '' for i, mpay in enumerate(mpay_list): msg += '{}月 ¥{:,}\n'.format(i+1, mpay) msg += '\n合計¥{}'.format(sum(mpay_list)) return msg # ---1年分のログを表示するメッセージを作成--- def paylog(self): msg = '' month = 0 for i in self.pay_log: while i['month'] != month: msg += '\n{}月\n'.format(month+1) month += 1 msg += '{} ¥{:,}\n'.format(i['date'], i['pay']) return msgここで注意点ですが,Lambda が書き込みできるのは
/tmp配下のファイルのみです.
そのため,あるファイルへの書き込み処理をする場合,ローカルで実行した時にはエラーが起きなかったのに,Lambdaで実行したところ[Errno 30] Read-only file systemが発生すると言うことがあります.
このプログラムでもエラーが出たため,以下のように変更しました.変更前with open('token.pickle', 'wb') as token: pickle.dump(creds, token)変更後with open('/tmp/token.pickle', 'wb') as token: pickle.dump(creds, token)CalculatePay()
日給を計算します.
# -----日給を計算する----- class CalculatePay(): def __init__( self, basic_pay, irregular_pay, night_rate, night_time): self.basic_pay = basic_pay # 平日の時給 self.irregular_pay = irregular_pay # 土日祝日の時給 self.night_rate = night_rate # 深夜給の増額率 self.night_time = night_time # 深夜給になる時間 # ---日給を計算--- def calculate(self, stime, etime): night_time = datetime.datetime(stime.year, stime.month, stime.day, self.night_time) if stime.weekday() >= 5 or jpholiday.is_holiday(stime.date()): pay = self.irregular_pay else: pay = self.basic_pay if etime >= night_time: normal_time = self.get_h(night_time - stime) night_time = self.get_h(etime - night_time) daypay = normal_time * pay + night_time * (pay * self.night_rate) else: normal_time = self.get_h(etime - stime) daypay = normal_time * pay return round(daypay) # ---x時間y分→h時間表示に変換--- def get_h(self, delta_time): h = delta_time.seconds / 3600 return h【手順4】AWS lambdaに導入
Googleカレンダーから給料を計算するプログラムを書く上で,いくつかのモジュールをインストールしました.
何もせずにAWS Lambdaでこのプログラムを実行すると,ModuleNotFoundErrorが出ます.
様々なモジュールををAWS Lambda上でも使用できるようにするために,Python用のAWS Lambdaデプロイパッケージを作成します.簡潔に言うと,プロジェクトディレクトリにすべての依存モジュールをインストールし,実行ファイルと一緒にzipでアップロードします.
これは,以下のサイトの通りに実行すれば良いです.
【Python】AWS Lambdaで外部モジュールを使用する実行結果
最近Googleカレンダーにバイトのシフトを記録し始めたので,データが少ないです.
このbotを導入したので,今後はシフト管理もGoogleカレンダーでしていきたいと思います.
(バイト先がどこかわかりやすいアイコンだなあ)helpの表示
来月の給料の表示
今年の給料
給料のログ
その他





