- 投稿日:2019-08-27T23:33:37+09:00
ggplot2のまとめ【備忘録】
はじめに
データ分析形の仕事の際、膨大なエクセルデータを誰かに見せる際に
表形式のまま提示すると、伝えたいことも伝えにくいことがある。
最近はRを使っているので、ggplot2を学んだ。備忘録的に書きます。扱うデータ
使い慣れているアボカドデータを使います。
URLはhttps://www.kaggle.com/neuromusic/avocado-pricesです。
カテゴリカルデータ、実数値、時系列と揃っているので扱いやすいです。
しかもデータ自体も軽いので、個人的におすすめです。ggplot2について
色々なことが記事を書いているので、わざわざ書くまでもありませんが、
Rの可視化パッケージです。pythonでいうSeabornだと認識しております。
ggplot2のほうが簡単だなと思いました。。というよりもRstudio上で画像が確認できるのが楽でいいなと思いました。「Pythonだってnotebookのインラインで画像出せるよ!」と言われそうですが、私の使っているパソコンでは
スペックが足りないのか重く感じます。とりあえずEDA
Rの記事で恐縮ですが、一旦pandas-profilingsでデータ探索しました。(Rでも似たようなパッケージはないのでしょうか。。あると嬉しいのですが)
どんなデータなのか、ざっくり見ると面白いです。
pandas-profilingsは、各変数ごとの相関が高いものは分析してくれないです。これは、重回帰分析をする際、高すぎる相関を持つ変数を説明変数とするとモデルの当てはまりが悪くなるだと思います。わざわざ消してくれているのですね。今回の場合、4225と4046が0.9以上の相関を持つため、4225は処理していないです。
※4225などの数字はavocadoの種類を指します。
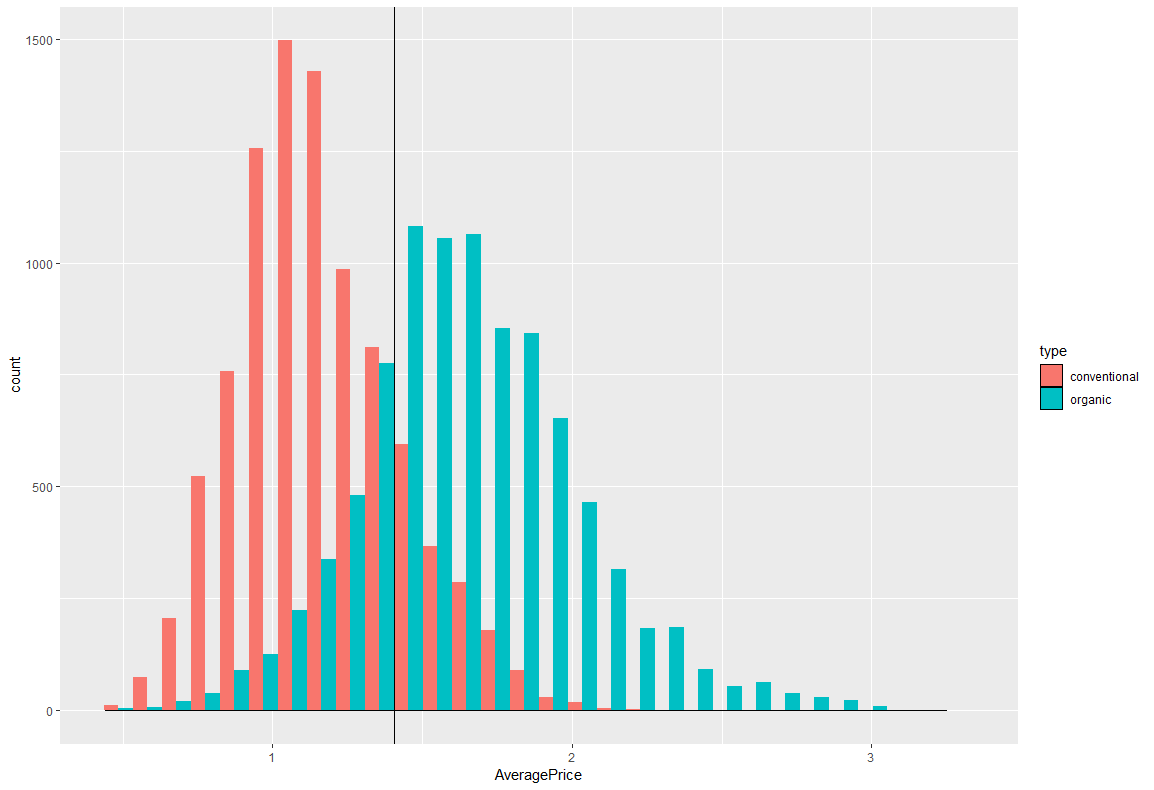
詳細はこちらAveragePriceをみると、正規分布っぽい形をしています。1~1.5あたりが最も多いみたいですね。
regionは、valueをみるとわかるかもしれませんがアメリカの都市が格納されているみたいです。たとえば、ChicagoやLosAngelesなどです。これはカテゴライズ変数のようですね。typeもカテゴライズで、本データセットのアボカドはconventionalかorganicに属するみたいですね。なんとなくですが、organicのAveragePriceのほうが高そうです。
Pandas-Profilingsでもある程度はわかるかもしれません。ただ、やはりまだまだ詳細に見てみたい部分が出てくるかと思います。それをggplot2でコーディングしながら見ていきたいと思います。ggplot
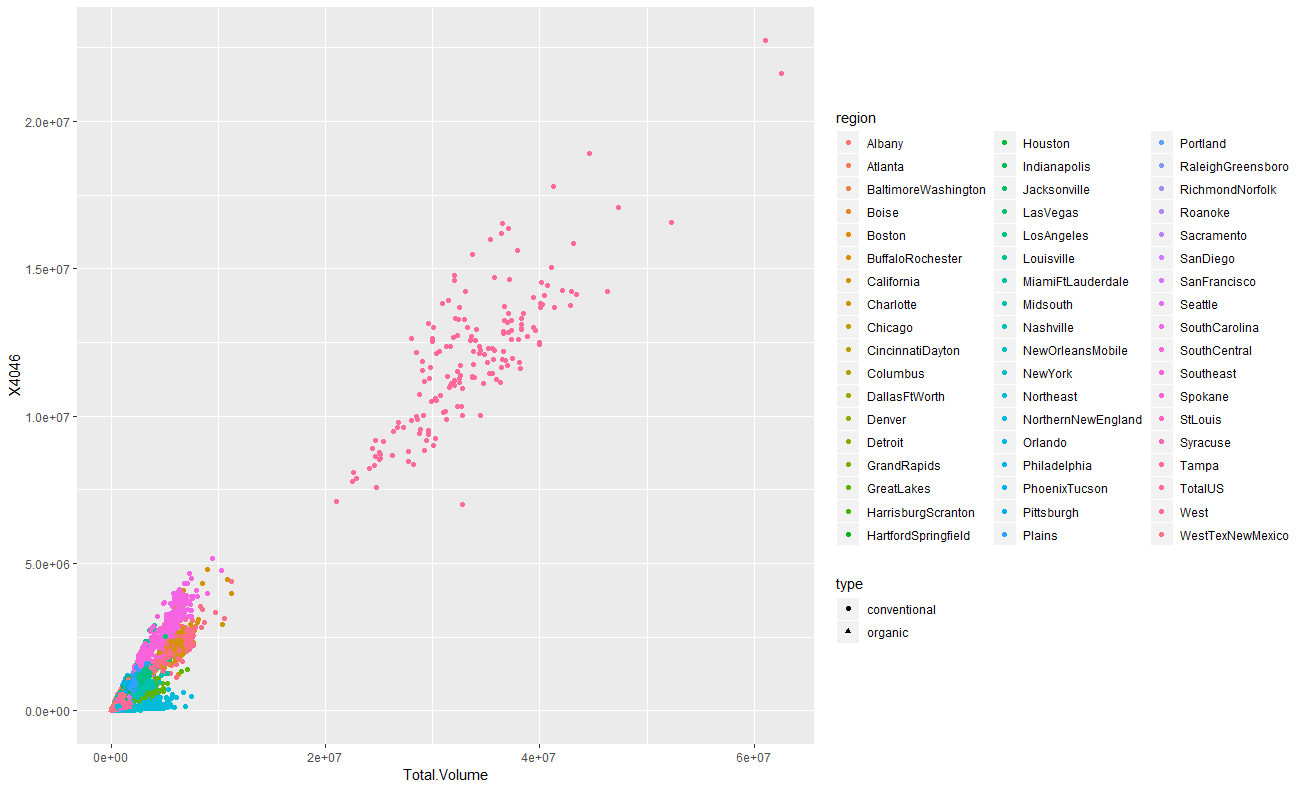
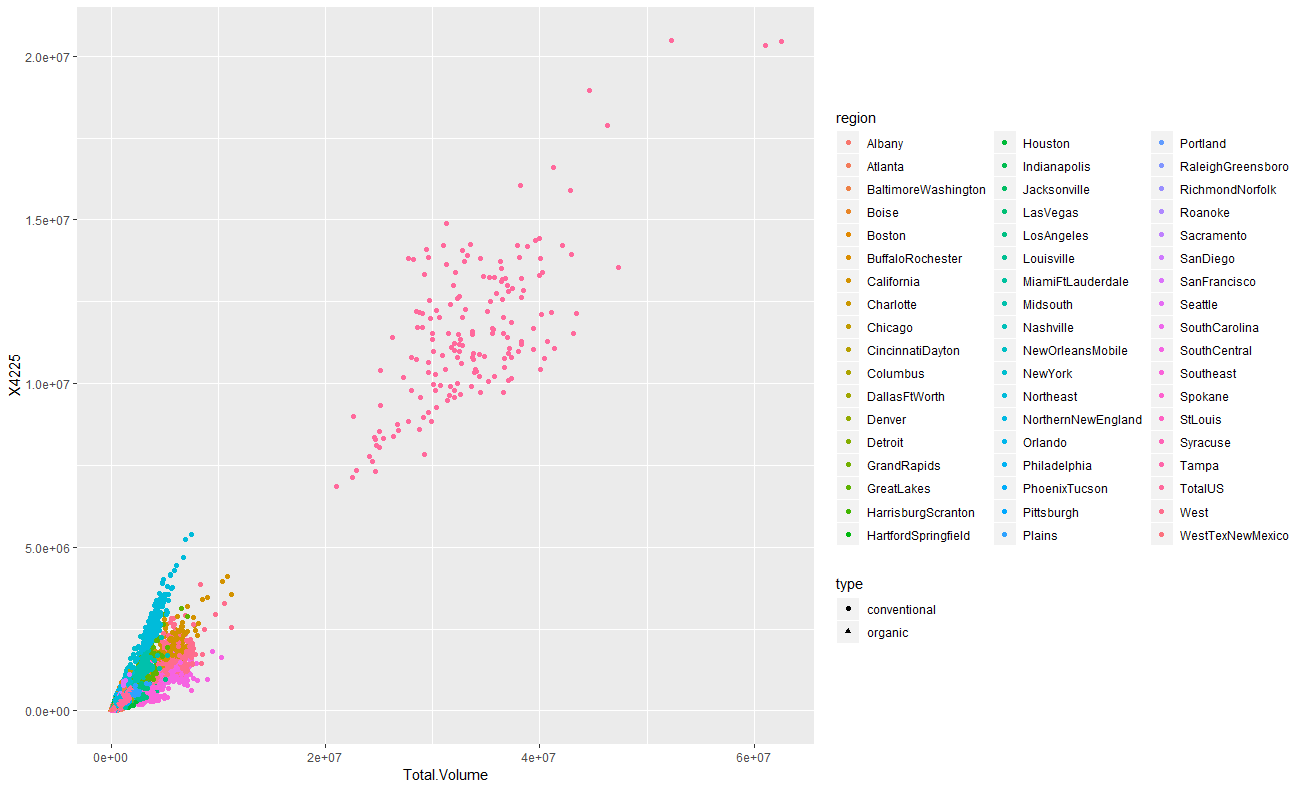
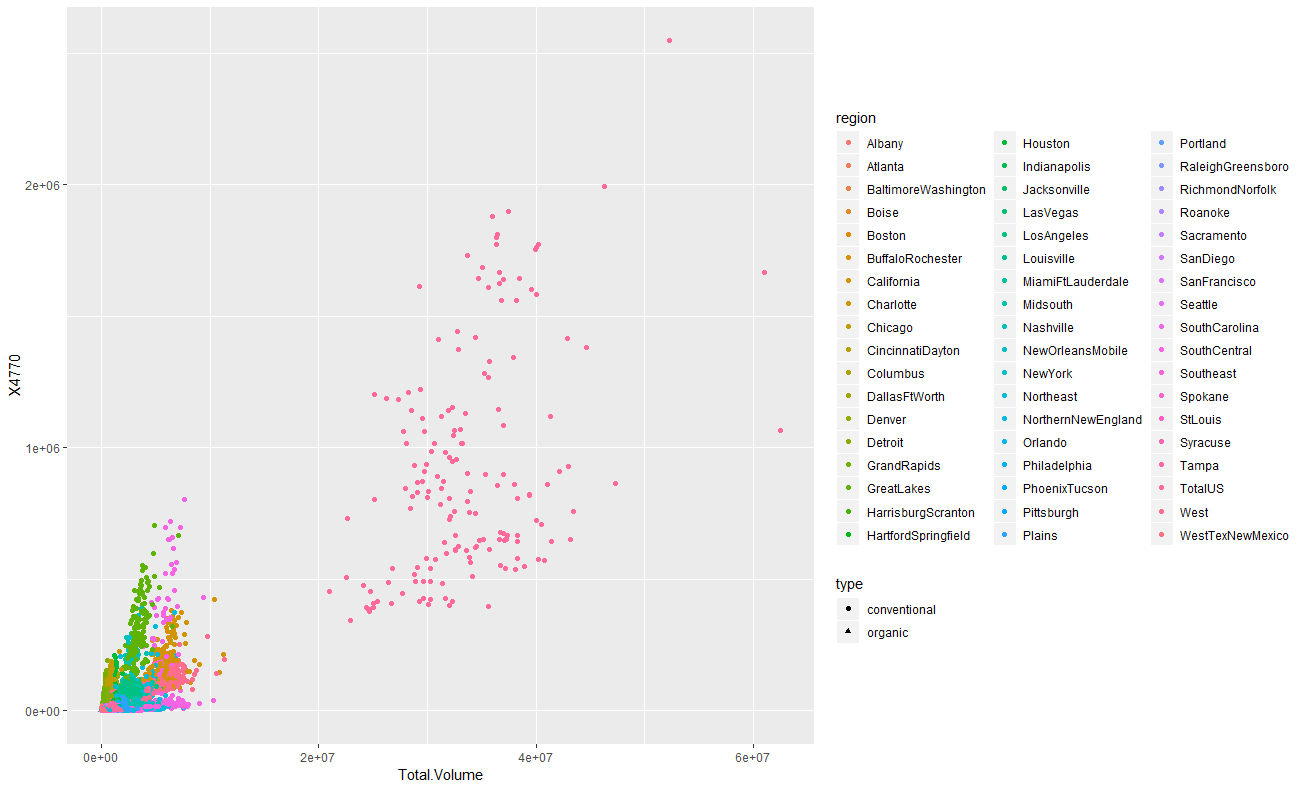
散布図
main.rggplot(df,aes(x=Total.Volume,y=X4046,colour=region,shape=type))+ geom_point() ggplot(df,aes(x=Total.Volume,y=X4225,colour=region,shape=type))+ geom_point() ggplot(df,aes(x=Total.Volume,y=X4770,colour=region,shape=type))+ geom_point()
geom_pointで散布図を描画します。横軸はTotal.Volumeで縦軸は4046と4225と4770です。regionで色付けしてみると、TotalUSという区分の
データが広範囲に渡って散らばっています。4046と4225はなんとなく相関がありそうな形をしていますね。今度はregionで色分けをせずに、3つのアボカドをプロットしてみます。
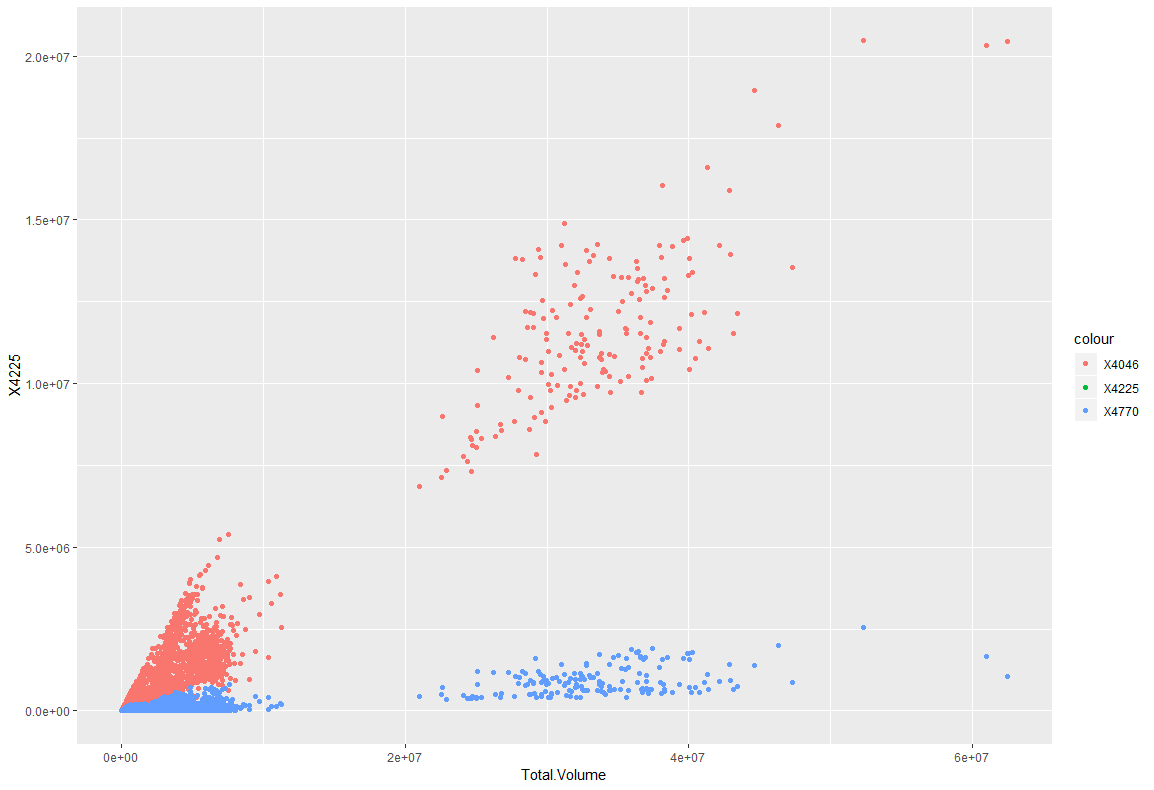
main.rggplot(df,aes(x=Total.Volume))+ geom_point(aes(y=X4225,color="X4046"))+ geom_point(aes(y=X4770,color="X4225"))+ geom_point(aes(y=X4770,color="X4770"))
x軸を4046,4225,4225のTotal.Volumeとし、y軸を4046,4225,4225として描画した結果、最もTotal.Volumeに影響しているのは4046ということがわかりました。4225が見えないのは、データの値がかなり小さいため、表示できていないだけだと考えられます。
ヒストグラム
横軸をAveragePriceにし、ヒストグラムを描画してみました。
main.rggplot(df,aes(x=AveragePrice,fill=type))+ geom_histogram(position="dodge")+ geom_density(alpha=0.5)+ geom_vline(xintercept=mean(df$AveragePrice),linetype=1)
最初に書いたとおり、organicの高いですね。
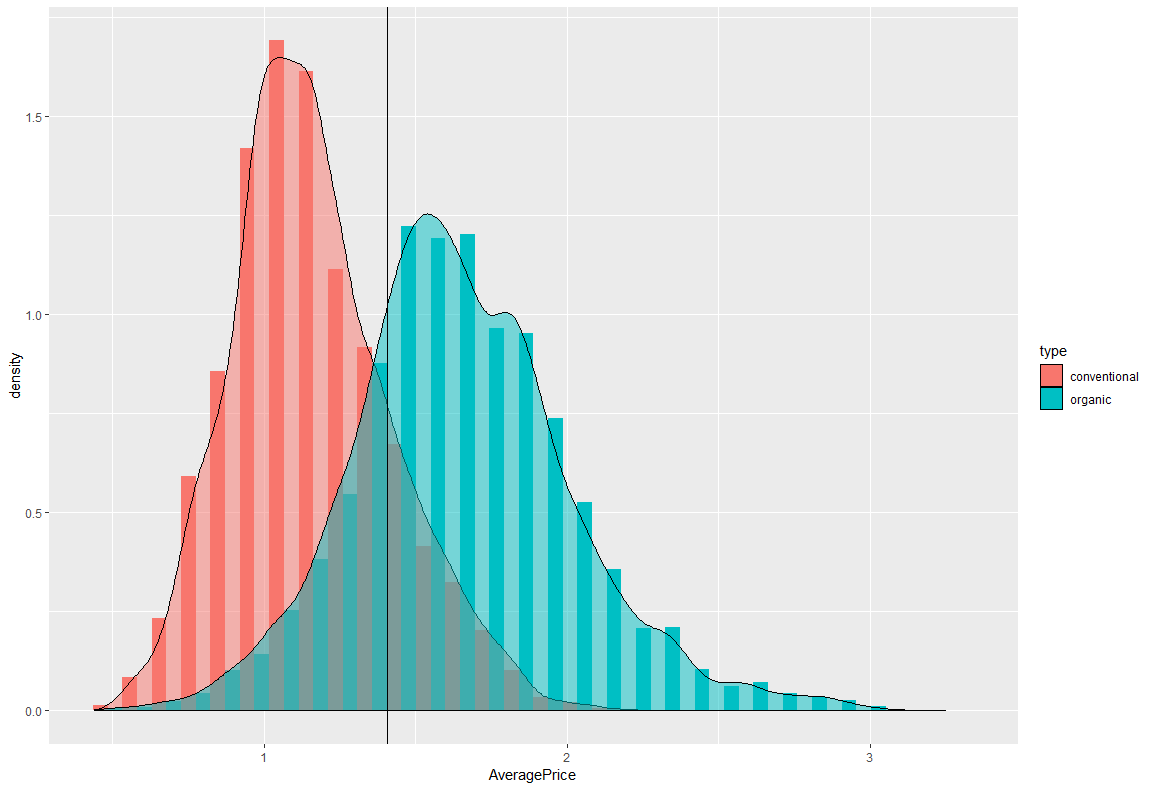
ただ、これじゃあ少し見にくいので、確率密度分布に変更してみます。main.rggplot(df,aes(x=AveragePrice,y=..density..,fill=type))+ geom_histogram(position="dodge")+ geom_density(alpha=0.5)+ geom_vline(xintercept=mean(df$AveragePrice),linetype=1)
少し見やすくなりました。また、縦棒の線はAveragePriceの平均線です。ちょうど山と山の間に線があるのは面白いですね。価格調整などしているのでしょうか。
線グラフ
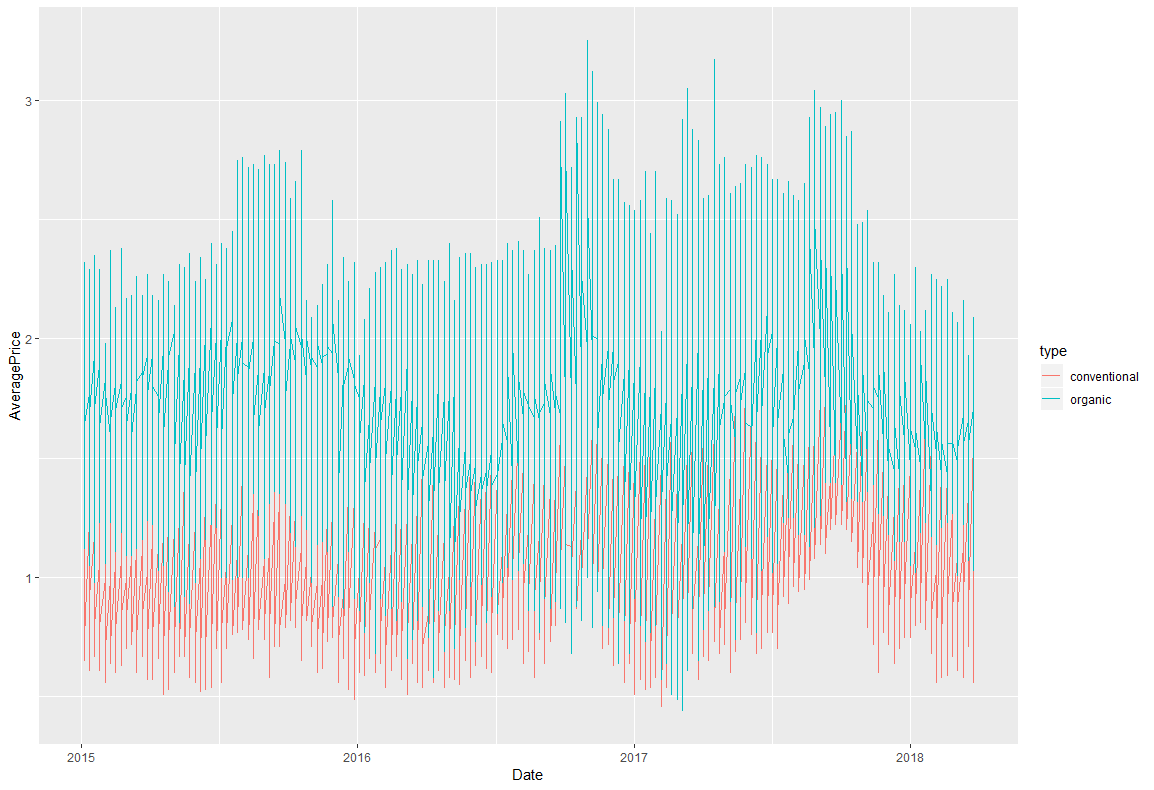
時系列のグラフです。
まず、POSIXct型に変更する必要があります。main.rdf$Date <- as.POSIXct(df$Date) ggplot(df,aes(x=Date,y=AveragePrice,colour=type))+ geom_line()+ #なぜかdate_breaksでエラーがおきるため、コメントアウト #scale_x_datetime(breaks=date_breaks("100 days"))
全体的な傾向としても、organicがずっと高いですね。
2017年の後半にconventionalが急激に高くなっているのが気になります。棒グラフ
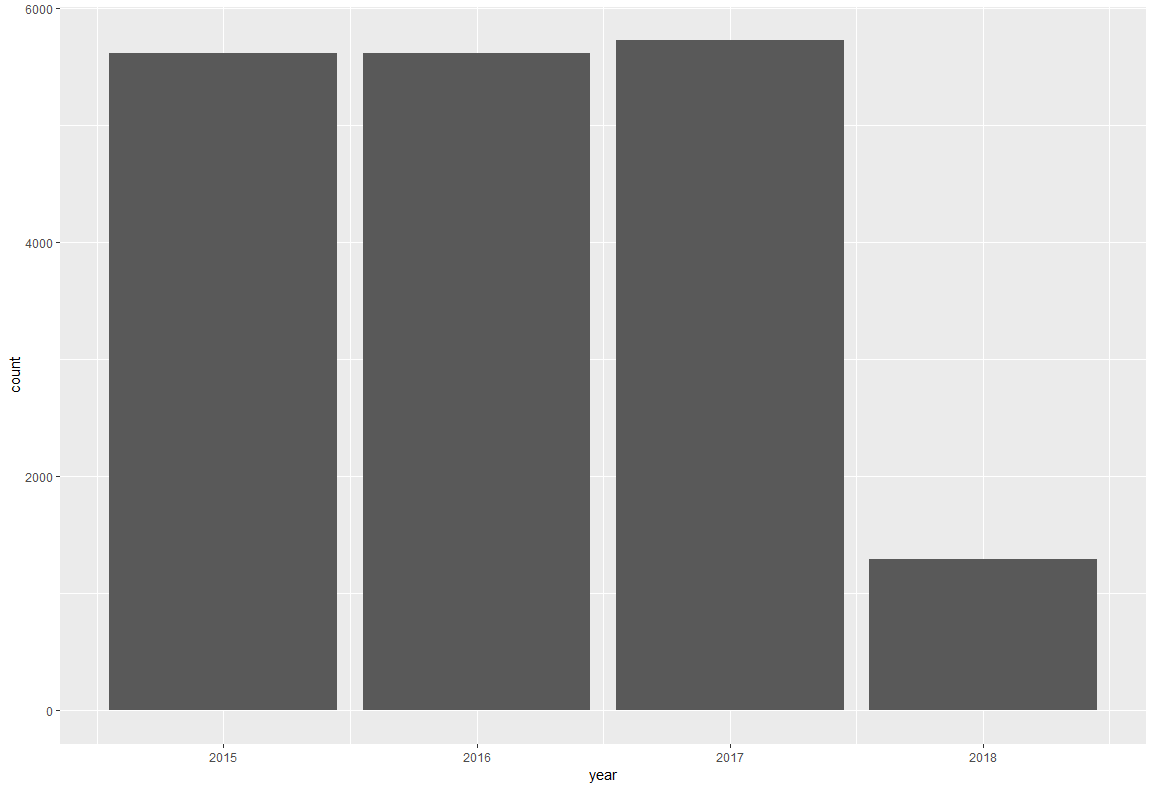
年ごとの分布を見てみました。単なるカウント値をみています。
main.rggplot(df,aes(x=year))+ geom_bar()
2018年のデータはほとんどないことがわかりました。
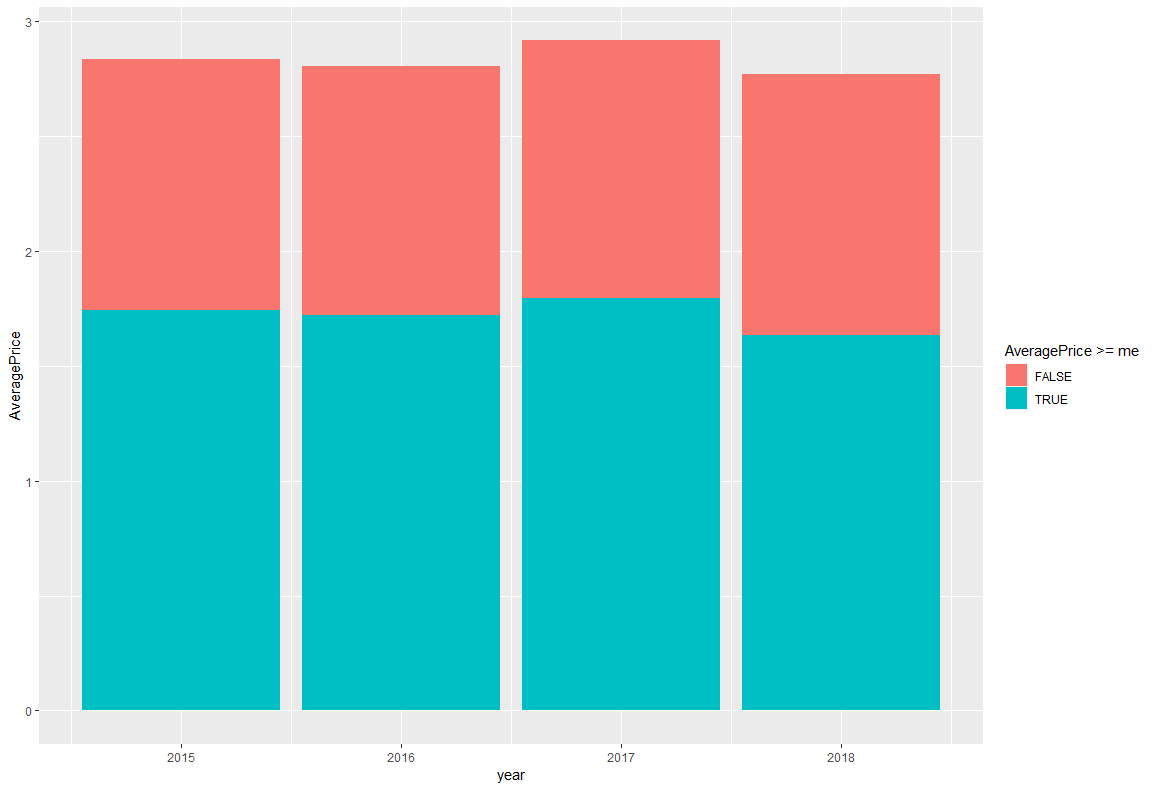
こうやって並べてみると、かなりわかりやすいですね。次はカウント値ではなく、AveragePriceを年ごとに見ました。さらに、各年の平均値を予め計算しておき、平均値以下のところは色を変更しました。
main.rggplot(df,aes(x=year,y=AveragePrice,fill=AveragePrice>=me))+ geom_bar(stat = "summary",fun.y = "mean")
グリッド上に描画させています。前年比などを見る際には見やすそうですね。
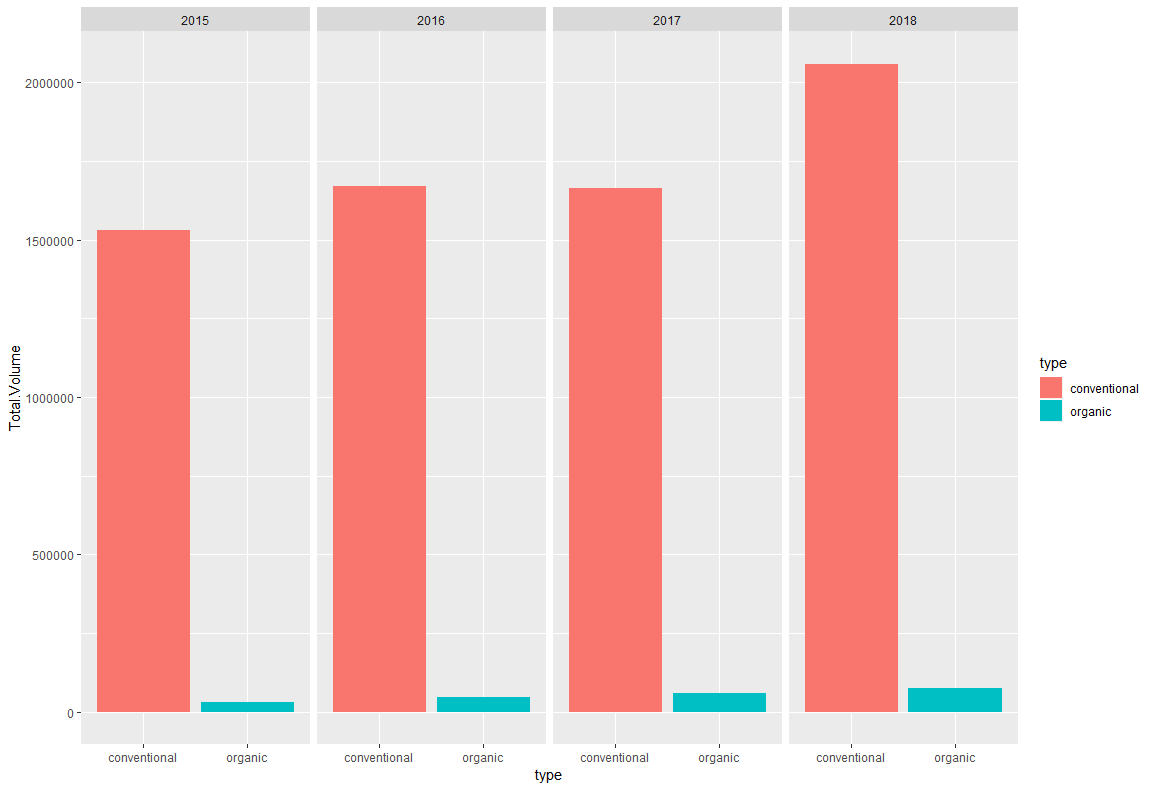
main.rggplot(df,aes(x=type,y=Total.Volume))+ geom_bar(stat="summary",fun.y = "mean",aes(fill=type))+ facet_grid(. ~year)
おわりに
まだまだ色々なグラフが書けそうです。他にもどのようなグラフが書けるのか引き続き調べてみたいなと思いました。
また、今回感じたのは、グラフを作成する際には自分の中で何らかの仮説がないと、ただ作るだけになってしまうと感じました。
なぜか可視化するのか、X軸y軸はどうするのか。グルーピング粒度はどうするのか。などなど、可視化をする前にやらなきゃいけないことが多くあります。
可視化という単なる”作業”に入る前に、まずは可視化するための整理をしっかりやろうと感じました。参考サイト
http://motw.mods.jp/R/ggplot_geom_bar.html
https://mrunadon.github.io/images/geom_kazutanR.html

- 投稿日:2019-08-27T22:59:17+09:00
【kaggleで機械学習勉強・第四回】pseudo-labeling-qda【kaggle,python,半教師あり学習】
前回に引き続き、第四回目です。
疑似ラベリングとQDA(判別分析)を使用した予測
疑似ラベリングというと、半教師あり学習のイメージがあります。
今回はカーネル中の図がコード付きでないためそのまま引っ張ってきています。本編
過去にローマンさんが疑似ラベルを使ったカーネルを作成しています。
https://www.kaggle.com/nroman/i-m-overfitting-and-i-know-it/notebookカーネルの解説と改善を行い、疑似ラベルの威力を実証します。
サンタンデールのコンペでは、疑似ラベルを使用したチームが二位に入賞し、25000ドル(250万円くらい?)を獲得しました。
疑似ラベルって?
疑似ラベル手法は5つのステップからなります
1:トレーニングデータを使用してモデルを作成
2:テストデータをモデルで予測
3:テストデータとトレーニングデータを混ぜる
4:混ぜたデータでモデルを作る
5:このモデルを使いさらに正確に予測するstep1 モデル作成
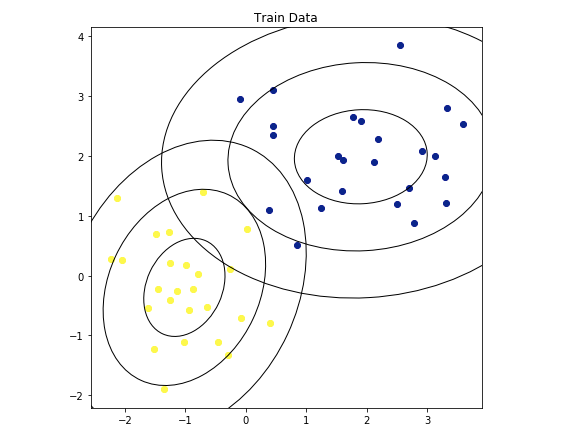
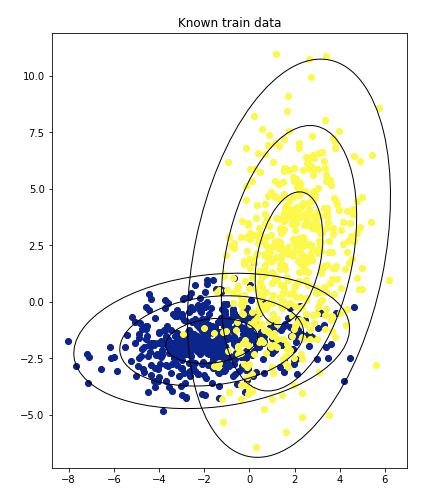
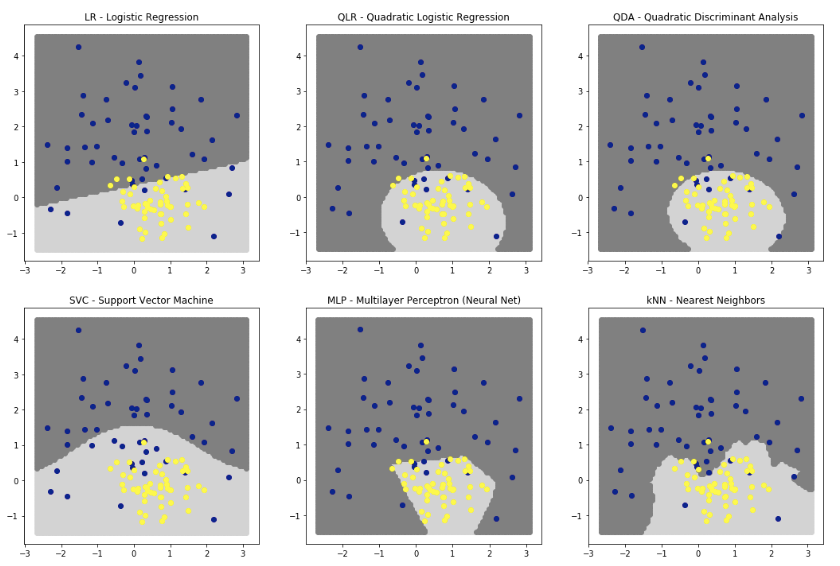
50個のトレーニングデータがある。
ターゲット=1なら黄
ターゲット=0なら青QDAを使用してモデルを構築します。 QDAは多変量ガウス分布を計算し、target = 1とtarget = 0を予測するモデルを作ります。
分布ごとに1σ、2σ、3σの楕円として表されます。
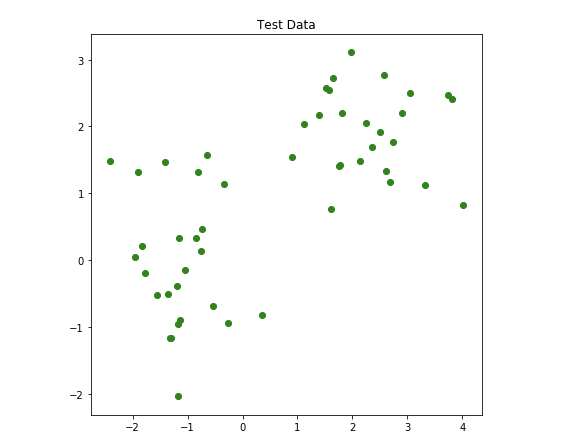
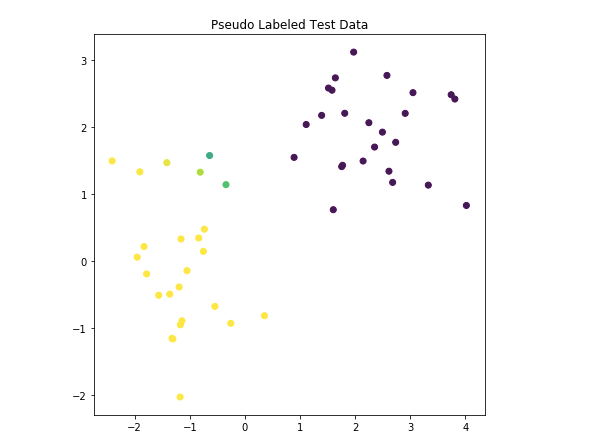
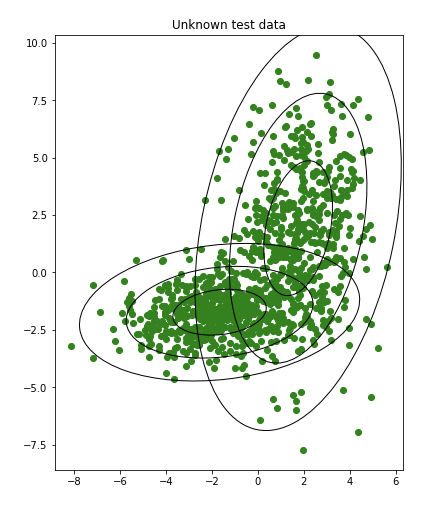
step2 テストデータを予測
モデル(楕円)を使用して、50個の未知のデータを予測します。
下の写真は、分類子が行った予測の結果を示しています。
(黄色か青かを予測して色付けしていると思われる)
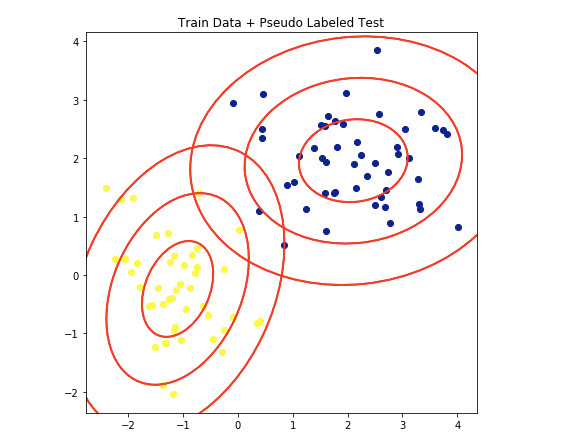
step3と4 改善モデルを作るために、疑似ラベルデータを使う
確信度が0.99の予測データをトレーニングデータに結合させました。
こうして結合した90点のデータを使い、新しいモデルを作ります。赤い楕円はQDAによる新しいガウス分布の範囲を示しています。
最初よりもいい分類をする楕円を描いているので、いいモデルといえるでしょう。
step5テストデータの予測
テストデータに二度目のモデルを適応させましょう。
疑似ラベルは何故働くのか
疑似ラベルを最初に学んだのはwizardyさんの記事からでした。
モデルの精度をさらに高めることが出来ることに驚きました。一度目のモデルで作成した確信度の高い予測データを含めて、モデルを作成したため、テストデータの予測精度はさらに向上するのです。
疑似ラベルの仕組みは、QDAによって理解しやすくなります。
QDAはp次元空間の点を使用して超楕円を見つける手法です。
こちらで説明します。先にリンク先の内容から。
QDAの説明
異なる2つの多変量ガウス分布からデータを生成します。
一つの分布からの観測値にtarget=1というラベルを付け、
もう一方の分布の観測値にtarget=0というラベルを付けましょう。
こういうデータにはQDA(Quadratic Discriminant Analysis)が良き分類器になります。QDAはtarget=1,0のガウス分布を見つけます。
データは多変量ガウス分布から得られたデータであり、p次元空間の超楕円体です。(p=変数の数)2次元(p=2)の場合を図示します。
黄色はtarget=1,青色はtarget=0,緑は不明。データにQDAを行うと、楕円体を見つけてくれます。
図は1,2,3σを円として書いています。
判別のつかない不明データ(緑)が見つかった場合、どの楕円体に分類される確率が高いかを考えてくれます。
この時の計算は、P1/(P0 + P1)を計算しています。
target=1である確率 / 0である確率 + 1である確率
P1=データが楕円1(target=1)に含まれる確率
P0=データが楕円0(target=0)に含まれる確率もとに戻って
疑似ラベルはより多くのデータを使って、各超楕円の中心と形状を正確に推定することにより、良い予測ができるようになるのです。
モデルはp次元空間でのtarget=1およびtarget=0の形状を可視化できます。
疑似ラベルの試みはすべてのタイプのモデルに役立ちます。
多くのデータがあればより正確な形を推定できるのです。
こちらで詳しくまたまたリンクに飛びます。
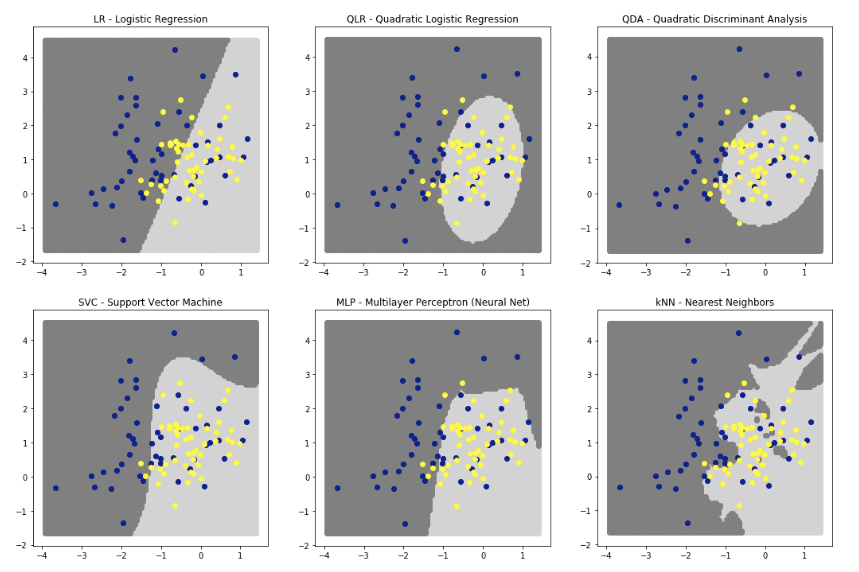
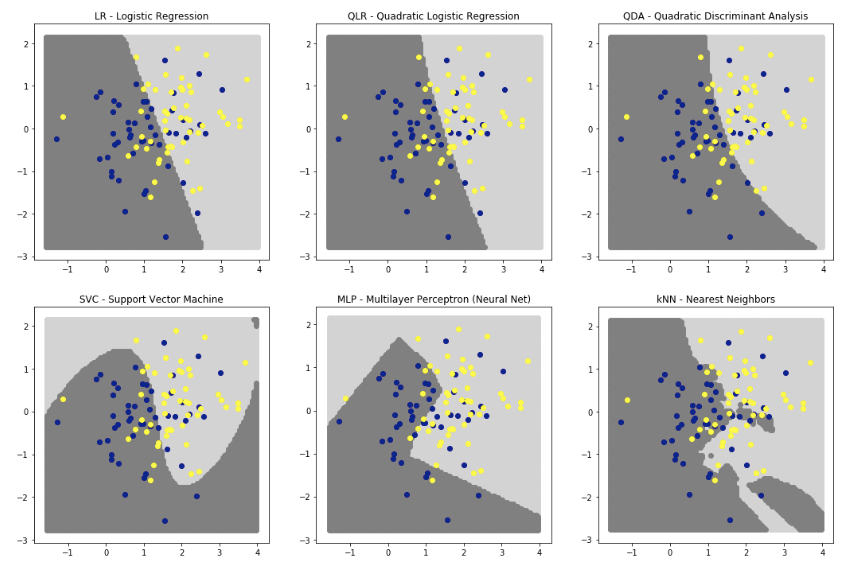
コンペ上位6つの分類器の分類結果を判別境界で確認してみましょう。
1:ロジスティク回帰
分類には超平面を使用する。2:二次ロジスティク回帰
3:二次判別分析(QDA)
どちらも曲面・円・楕円・双曲線などを使用する4:サポートペクトルマシン
多項式曲面を使用。5:ニューラルネット
多数の直線を使用。ReLUを使っています。
ハイパボリックtanや、シグモイドで滑らかになる。6:近傍法
ギザギザな面を使う。これまでのところ、
3番QDAは、超楕円形にデータが存在するため、最高のパフォーマンスを発揮してくれます。
QDAを使うことが最善と考えます。QDAとQLRを比較するためのplotも作成しました。
どちらもシグモイド関数で予測しますが、係数はそれぞれ異なったものを使用しています。sigmoid(a1x1^2 + a2x2^2 + a3x1x2 + a4x1 + a5x2 + b)よく似た曲線になっていることがわかります。
QDAは多変量ガウス分布の分離には精度よく対応してくれます。
None-the-less QLRも非常にいいです。vladislavさんのQDAカーネルと、YirunさんのQLRのカーネルや、Bojanさんのカーネルを参考にしましょう。
https://www.kaggle.com/tunguz/ig-pca-nusvc-knn-qda-lr-stack https://www.kaggle.com/gogo827jz/pseudo-labelled-polylr-and-qda https://www.kaggle.com/speedwagon/quadratic-discriminant-analysis
図の出し方はこんな感じ
xres = 100 yres = 100 xx = np.linspace(xmin,xmax,xres) yy = np.linspace(ymin,ymax,yres) grid = np.zeros((xres*yres,2)) for i in range(yres): grid[i*xres:(i+1)*xres,0] = xx for i in range(yres): for j in range(xres): grid[i*xres+j,1] = yy[i] clf = QuadraticDiscriminantAnalysis() clf.fit(X,y) preds = clf.predict(grid) from matplotlib.colors import LinearSegmentedColormap colors = [(0.5, 0.5, 0.5), (0.65, 0.65, 0.65), (0.8, 0.8, 0.8)] cm = LinearSegmentedColormap.from_list('mycolors', colors, N=100) plt.scatter(grid[:,0], grid[:,1], c=preds, cmap=cm) plt.scatter(X[:,0], X[:,1], c=y) plt.show()またまた本編にもどって
コンペデータに疑似ラベルを試す
import numpy as np, pandas as pd, os from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis from sklearn.model_selection import StratifiedKFold from sklearn.feature_selection import VarianceThreshold from sklearn.metrics import roc_auc_score train = pd.read_csv('../input/train.csv') test = pd.read_csv('../input/test.csv') train.head()step 1, 2
# INITIALIZE VARIABLES cols = [c for c in train.columns if c not in ['id', 'target']] cols.remove('wheezy-copper-turtle-magic') oof = np.zeros(len(train)) preds = np.zeros(len(test)) # BUILD 512 SEPARATE MODELS for i in range(512): # ONLY TRAIN WITH DATA WHERE WHEEZY EQUALS I train2 = train[train['wheezy-copper-turtle-magic']==i] test2 = test[test['wheezy-copper-turtle-magic']==i] idx1 = train2.index; idx2 = test2.index train2.reset_index(drop=True,inplace=True) # FEATURE SELECTION (USE APPROX 40 OF 255 FEATURES) sel = VarianceThreshold(threshold=1.5).fit(train2[cols]) train3 = sel.transform(train2[cols]) test3 = sel.transform(test2[cols]) # STRATIFIED K-FOLD skf = StratifiedKFold(n_splits=11, random_state=42, shuffle=True) for train_index, test_index in skf.split(train3, train2['target']): # MODEL AND PREDICT WITH QDA clf = QuadraticDiscriminantAnalysis(reg_param=0.5) clf.fit(train3[train_index,:],train2.loc[train_index]['target']) oof[idx1[test_index]] = clf.predict_proba(train3[test_index,:])[:,1] preds[idx2] += clf.predict_proba(test3)[:,1] / skf.n_splits #if i%64==0: print(i) # PRINT CV AUC auc = roc_auc_score(train['target'],oof) print('QDA scores CV =',round(auc,5))結果
QDA scores CV = 0.96541step3,4
# INITIALIZE VARIABLES test['target'] = preds oof = np.zeros(len(train)) preds = np.zeros(len(test)) # BUILD 512 SEPARATE MODELS for k in range(512): # ONLY TRAIN WITH DATA WHERE WHEEZY EQUALS I train2 = train[train['wheezy-copper-turtle-magic']==k] train2p = train2.copy(); idx1 = train2.index test2 = test[test['wheezy-copper-turtle-magic']==k] # ADD PSEUDO LABELED DATA test2p = test2[ (test2['target']<=0.01) | (test2['target']>=0.99) ].copy() test2p.loc[ test2p['target']>=0.5, 'target' ] = 1 test2p.loc[ test2p['target']<0.5, 'target' ] = 0 train2p = pd.concat([train2p,test2p],axis=0) train2p.reset_index(drop=True,inplace=True) # FEATURE SELECTION (USE APPROX 40 OF 255 FEATURES) sel = VarianceThreshold(threshold=1.5).fit(train2p[cols]) train3p = sel.transform(train2p[cols]) train3 = sel.transform(train2[cols]) test3 = sel.transform(test2[cols]) # STRATIFIED K FOLD skf = StratifiedKFold(n_splits=11, random_state=42, shuffle=True) for train_index, test_index in skf.split(train3p, train2p['target']): test_index3 = test_index[ test_index<len(train3) ] # ignore pseudo in oof # MODEL AND PREDICT WITH QDA clf = QuadraticDiscriminantAnalysis(reg_param=0.5) clf.fit(train3p[train_index,:],train2p.loc[train_index]['target']) oof[idx1[test_index3]] = clf.predict_proba(train3[test_index3,:])[:,1] preds[test2.index] += clf.predict_proba(test3)[:,1] / skf.n_splits #if k%64==0: print(k) # PRINT CV AUC auc = roc_auc_score(train['target'],oof) print('Pseudo Labeled QDA scores CV =',round(auc,5))結果
Pseudo Labeled QDA scores CV = 0.97033予測値を出力
sub = pd.read_csv('../input/sample_submission.csv') sub['target'] = preds sub.to_csv('submission.csv',index=False) import matplotlib.pyplot as plt plt.hist(preds,bins=100) plt.title('Final Test.csv predictions') plt.show()
まとめ
このカーネルでは、疑似ラベルについて、なぜ機能するのか、使いかたを学びました。
コンペのデータに使用してみると、スコアが0.005増加しました。
疑似ラベリングとQDAはCV=0.970,LB=0.969でした。
疑似ラベルが無しならCV=0.965,LB=0.965でした。カーネルをローカルで実行すると、パブリックのtestにのみ適応されるので、CVとLBは異なるのです。
以上

- 投稿日:2019-08-27T22:56:42+09:00
LeetCode / Excel Sheet Column Number
[https://leetcode.com/problems/excel-sheet-column-number/]
Given a column title as appear in an Excel sheet, return its corresponding column number.
For example:
A -> 1
B -> 2
C -> 3
...
Z -> 26
AA -> 27
AB -> 28
...先日の記事はFrom列インデックスTo列名でしたが、今回はFrom列名To列インデックスの変換がお題です。
From列インデックスTo列名の問題が解ければ、こちらも易しいです。解答・解説
解法1
英字に相当する値を、26のn乗(nは1の位であれば0, 10の位であれば1, 100の位であれば2,,,)に掛け、合計を取ればOKです。
from string import ascii_uppercase class Solution(object): def titleToNumber(self, s): """ :type s: str :rtype: int """ d = {} for i,e in enumerate(ascii_uppercase): d[e] = i+1 ans = 0 for i,e in enumerate(s[::-1]): ans += d[e] * pow(26,i) return ansこちらの解法が先に思いついてしまいましたが、文字列数分のループを2度回してしまっているところが改善すべき点です。
解法2
アスキーコードを取得するord関数を使えば、ord(char) - 64 に対して26のn乗を掛けるだけで済むので、1度のループで済みます。
class Solution(object): def titleToNumber(self, s): """ :type s: str :rtype: int """ return sum((ord(char) - 64) * (26 ** exp) for exp, char in enumerate(s[::-1]))
- 投稿日:2019-08-27T22:21:45+09:00
Nuxt,Netlify,Contentful,Python,Firebase,Herokuを使ったサーバレスな複業メディアサイトを作った話
何を作ったか
エンジニア向けの複業(副業)メディアサイトを作りました。
複業(副業)関連のニュースを毎日自動で更新して配信してます。
https://fukugyou.dev/自分自身2年ほどエンジニアとして複業をしていて、今後もっと複業(副業)をする、興味を持つエンジニアは増えると思いますし、個人的にはもっと複業の良さを知ってほしいという思いがあります。
もちろん複業にはメリットデメリット、色々な意見があると思っていますが、そこも含めて世の中の複業にまつわるニュースを集約してフラットに情報提供出来る場があると良いなと思い当サイトを作りました。個人で開発を進めておりましたがフロントエンドとバックエンド含めて、ある程度形になったので全体の構成についてまとめようと思います。
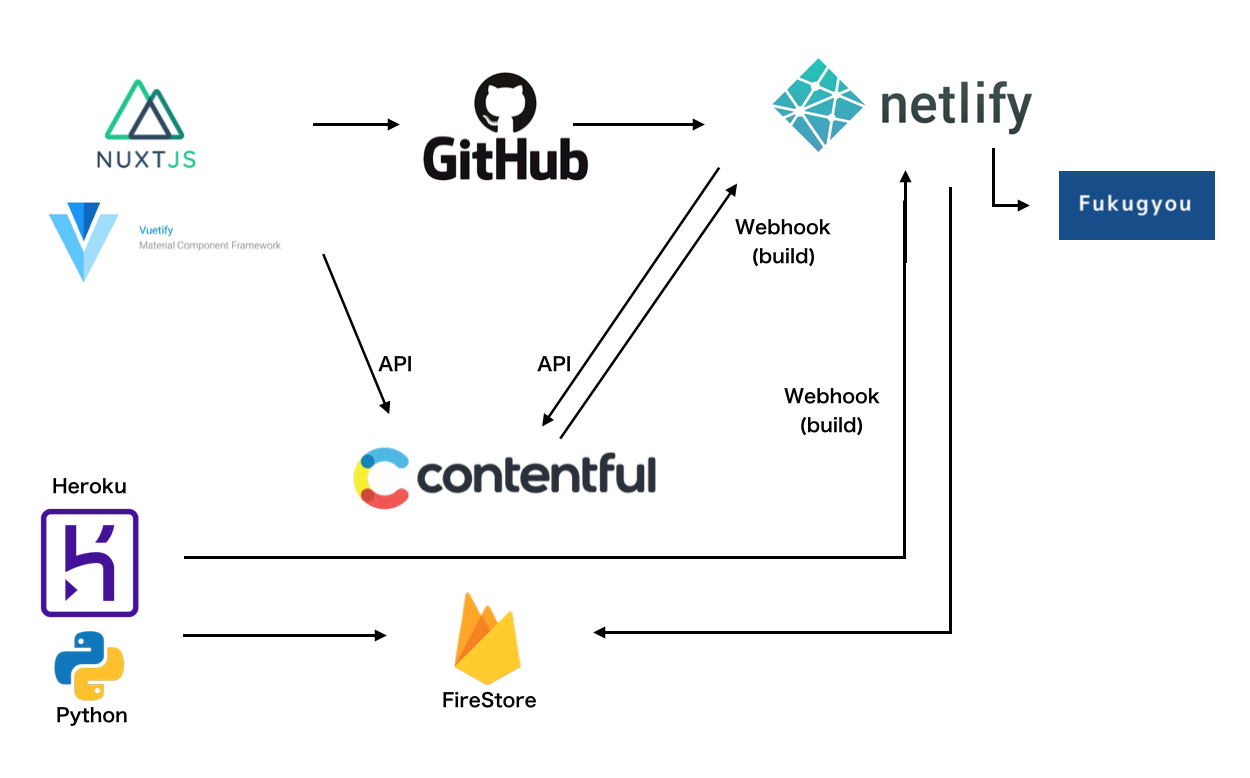
どう作ったか
概要
アーキテクチャ、プラットフォームの選定基準
まず個人開発なのでインフラの構築等、本来のアプリケーション開発以外で時間を使うのが嫌だったのでなるべくサーバレス(インフラの事は考えない)構成にしたいという思いはありました。
また出来るだけ無料で使えるものに収めたいというのも個人的には重要な選定基準でした。この手の個人開発サービスはリリースしても多くの場合がそんなに使われる事なく自然と消えていくものだと思っています。
(以前個人でiOSアプリを作ってリリースした時もそうでした。。)
そこで大事なのは個人で改善や開発を継続し続けるモチベーション管理だと思いますが、個人的には「ユーザー数が少なくマネタイズも出来ないのにサービスの維持コストだけかかる」という状態がモチベーション低下になると思っていたので、初期段階は出来るだけ無料で運用できるようにしたいと思ってました。ここは単に個人開発のモチベーションコントロールの問題なので、逆にAWSなどを使ってお金を払いながらも個人サービスを開発した方がお尻に火がついて良いみたいな場合もあるかもしれません。
今回選定しているサービスやプラットフォームは全て無料で使える範囲で利用しているので
同じように無料でできる範囲内で個人サービスを開発してリリースしたいという方のご参考になればと思います。(※無料といいつつドメイン代だけはお金を払っています。ドメインも気にしない方であれば完全無料にする事もできます)
フロントエンド
Nuxt
Nuxt自体の説明は省略しますが、Nuxtを選択した理由を簡単にまとめます。
ここはほぼ個人的な理由なのであまり一般化できないですが、本業や自分が今やっている複業などの環境含めて、Nuxtを使う(見る)機会が多かったのでNuxtにしましたというのが1番大きい理由です。あとは今回は高速化のため静的ファイルをベースにサイトを作りたかったので静的ファイルを簡単にジェネレートできるNuxt(nuxt generate)を選択したというのも大きいです。後述するNetlifyとも相性が良いです。
ただこの理由もおそらく全てNuxtじゃないと出来ない、というわけではないのでReactなどを使っても同様の事は可能だと思いますので最終的には個人のスキルセットや環境に合わせて選択するのが良いかなと思ってます。
また今回はNuxtと合わせてUIフレームワークでVuetifyを使っています。
デザインスキルが低く、ゼロベースでUIを作るのが厳しいと思っていたので何かしらのUIフレームワーク(cssフレームワーク)を使おうと思っていました。
BulmaやBootstrap等検討しましたがVue.jsのアプリケーションと相性が良さそうなVuetifyを選定しています。Netlify
Netlifyは静的ファイルのホスティングサービスです。
webサイトを公開するのに自分でインスタンスを立ててサーバを用意するというのがめんどくさかったので静的ファイルとセットでホスティングできるサービスを使ってフロントエンドのサーバを用意できるプラットフォームを選定しました。(サーバレス構成)
ホスティングサービスに関しては、GitHub PagesやFirebaseホスティング、AWSのs3+CloudFrontなどありますが、それらと比べてNetlifyが良かったのはこの辺です。
- Nuxtと相性が良い(Nuxt ジェネレートで簡単に静的ファイルをホスティングできる。Nuxtの公式ドキュメントもNetlifyを使っている)
- GitHubと連携してデプロイが簡単にできる
- GitHubのプルリクエスト単位でテスト環境を用意できる
- Netlifyフォームなどホスティング以外の機能も利用できる(お問い合わせ機能で使ってます)
またNetlifyは無料プランも用意されているので個人で簡単なサイトを公開する程度であれば無料の範囲内で十分問題ないのも大きい理由です。
Contentful
ContentfulとはヘッドレストCMSです。(UIを持たずにAPIベースでブログの投稿、参照などの機能を提供するプラットフォーム)
今回のサイトは自分でもブログ的にエンジニア向けの複業関連記事を提供したかったので、ブログの投稿、参照機能が必要でした。
ブログといえばWordPressが1番有名ではありますが使うモチベーションがほぼなかったので、こちらもNuxt、Netlifyとも相性がよくてサーバレスで運用出来るContentfulを使ってます。
またNuxt,Netlify,Contentfulを使ったCMS構築の記事があったので技術選定と実装面も含めて参考にさせて頂きました。バックエンド
Python
APIからデータの取得、スクレイピング、Firebase操作、Herokuのデプロイなどを行うだけなので正直言語としてはなんでも良かったです。
個人的に最近はPythonが書きたい気分だったのでPythonにしました、以外の理由はほぼないです。。
一応FirebaseやHerokuでPythonも言語としてサポートされているので使っても大丈夫そうだなという裏どりくらいはした程度です。Firebase
FirebaseはもともとはmBaaS(mobile backend as a Service)と言われるモバイルのバックエンド構築をサポートするプラットフォームですが、最近はモバイル以外のwebアプリケーションでも使える機能が増えてきています。
今回使ったのはその中でFirestoreだけです。
データストアとして使えるプラットフォームを探していましたがなかなか無料で使えるものが多くない(自分で探した範囲内では。。)のとRDSまで行かなくても単純なKVSレベルでも十分だったのでFirebaseを使うことにしました。
またFirestoreも無料で使える範囲があるのでそこにうまく収めれば良さそうだったのと、個人的にFirebaseをもうちょっと使ってみたかった(過去Firebaseのリアルタイムデータベースをちょっとだけ触った事があるくらい)というのも理由としてありました。また今回のFirestoreは無料枠だと50,000リクエスト/日しかなかったので、なるべくFirestoreへのリクエストを減らすための工夫をしてます。
具体的にはクライアント側から直接Firestoreを見ずに、Nuxtのジェネレートのタイミングで一度だけFirestoreのデータを参照し、結果をjsonファイルに保存し、クライアント側ではjsonファイルを参照するようにしてます。
そうする事で毎回Firestoreへリクエストを飛ばす必要がなくなるので、無料枠も使いきる事がなくなるはずです。
詳しくはこちらをご参照ください。Heroku
HerokuとはPaaS(Platform as a Service)と呼ばれるプラットホームでwebアプリケーションを構築するうえで様々な機能を提供してくれるサービスです。
今回使ったのは一部分だけで、cron処理による定期実行を実現したかったので
Heroku Schedulerを使っています。
最近だとFirebaseでもcronのような定期実行ができるようなので、そちらでも良さそうです。ただFirebaseのcronだと無料では使えない?(ここ正確にためしてないので違ってたらすまません。。)
ですがHerokuであれぼwebアプリケーションと合わせて一定のdynoであれば無料で使えます。
1回1分以内で、1日2,3回動くバッチ処理であればHerokuの無料枠を使ってHeroku Schedulerが使えるのでとても便利です。
1000dyno/月までが無料の範囲内ですが実績としては1日1分以内のバッチ処理が2,3回動いて3dyno/月くらいしか使ってないのでかなり余裕だと思ってます。Heroku schedulerについては数年前に個人的に使った事があり、その実績もあったので今回も採用しました。
(数年前と同じ技術選定をするのが変化の早いこの業界で良いのか悪いのかが微妙な気分にはなりますが。。。)最後に
正直作ったものもや使っているプラットフォーム等も目新しいものはありせん。
ただ色々と組み合わせて使う事でフロントエンド、バックエンドが組み合わさったそれなりのアーキテクチャのウェブアプリケーションが作れると思います。
今回使ったサービスやプラットホームはどれも非常に使いやすいですし、難しいものもあまりないので
これくらいであれば比較的短期間で簡単なサービス公開までできると思うので個人開発の参考になればと思います。
- 投稿日:2019-08-27T21:23:43+09:00
[スクレイピング]ResponseがShift_jisだった
はじめに
Shift_jisとかいう
古代文字コードを拾得してしまった場合の対処法
ちなみにWindows環境の場合です。今回は某5ちゃんねるを例にさせてもらう。
Responseを出力する
そのまま出力してみる
test.pyheaders = { 'connection': 'keep-alive' } response = requests.get(target_url, headers=headers, stream=False) print(response.text)UnicodeEncodeError: 'cp932' codec can't encode character '\x93' in position 33: illegal multibyte sequenceUnicodeEncodeErrorがでる。
案外知られてないが、Pythonで出力する場合cp932というshift_jisの亜種ともいえる文字コードに変換してから出力されるわけだが
その際、cp932に変換できない文字が含まれているとエラーが出る。test.pyprint("?")ただ無視して出力することもできる。
test.pyprint("?".encode('cp932','ignore').decode('cp932', 'ignore'))ただ今回のResponseを無視して出力してみると
<a href="1440930335/l50">1: VBvO}XiVer.6.0 j part65 []~]©2ch.net (487)</a> <a href="1529199088/l50">2: X§¢±± 149C (635)</a> <a href="1556284220/l50">3: E}/KXbh 83 (75)</a> sequence文字化けしてしまう
そもそも今回はShift_jisを取得したはずなのに
Unicodeを変換しようとしていること自体がおかしいつまりResponseの文字コードの設定がいかれてるので
response.encodingを正しく設定してあげる。test.pyresponse.encoding = 'shift_jis'<a href="javascript:changeSubbackStyle();" target="_self" class="js">表示スタイル切替</a> <a href="/tech/kako/kako0000.html"><b>過去ログ倉庫はこちら</b></a> <a href="/tech/"><b>板TOPはこちら</b></a></small></div> <div><small id="trad"> <a href="1551746188/l50">1: 人工知能ディープラーニング機械学習の数学 ★2 (224)</a> …できました。
Beautiful Soupに渡す
test.pyresponse.encoding = 'shift_jis' soup = bs4.BeautifulSoup(response.text, 'html.parser') print(soup.prettify().encode('cp932','ignore').decode('cp932', 'ignore'))返ってくるのはUnicode
また
Beautiful SoupはUnicodeDammitと呼ばれるクラスを使って与えられたドキュメントのエンコーディングを調べ、元のエンコーディングがなにであろうともUnicodeに変換します。と便利な機能があるのでresponse.content(bytes型)を渡す。
test.pysoup = bs4.BeautifulSoup(response.content, 'html.parser') print(soup.prettify().encode('cp932','ignore').decode('cp932', 'ignore'))… <a href="1411797173/l50"> 371: 【C/C++】統合開発環境CLion【JetBrains】 (49) </a> …BeautifulSoupにはbytes型を渡そう。
また今回はWindowsに標準出力するために
.encode('cp932','ignore').decode('cp932', 'ignore')
というめんどくさいことをしているが、返ってくるのはUnicodeなので
普通に操作するだけならそのままで扱える。まとめ
実際、文字コードは難しい
- 投稿日:2019-08-27T20:51:39+09:00
俺はRustのDebugをしようとしていた。そうしたらpython 3.6.9をWindows10でx64 Release buildしていた
はじまり(ポエム)
私はRustのプログラムを愛用しているVisual Studio Codeで書いていた。
デバッグするかーとどうやってデバッグするか調べた。
Visual Studio CodeでRustのコード補完・タスク・Debug実行
なるほど、CodeLLDBというのがあるらしい。
私はCodeLLDBをポチッと導入し、設定を書き起動しようとした。
CodeLLDB requires Python 3.6(64bit), but looks like it is not installed on this machine
Python必要なの!?あれ、でもPython入れてなかったっけ・・・
python -V Python 3.2.2古すぎ!
はいはい、chocolateyで入れましょうね~
choco install python3 -ypython -V Python 3.7.4あれ、なんか3.7が降ってきた。まあ3.6って言ってたけど動くでしょ!
CodeLLDB requires Python 3.6(64bit), but looks like it is not installed on this machine
希望は打ち砕かれた。
I got the same error,
I have found a difference in registry. Python is registered under "HKEY_CURRENT_USER" but not under "HKEY_LOCAL_MACHINE" .
なるほど、レジストリ見てんのか。偽装してみるか。
ところが
python36.dllが見つからないとのたまってきた。
なんでDLLの場所設定でいじれないの?
私はIssueを投げた。
Why does the python version is locked as 3.6 only for Windows? · Issue #205 · vadimcn/vscode-lldbしかしそうはいっても始まらぬ。なんとかしてPython3.6を手に入れねばならぬ。
Python Releases for Windows | Python.org
3.6系統の最新リリースは・・・3.6.9か。リンクを踏んだ私に待ち受けていたのは・・・
Python Release Python 3.6.9 | Python.org
ソースコードしか配布されていないという現実だった
・・・これはビルドするしかない! 一つ前の3.6.8を使うという発想が何故かなかった私はビルドする道へ進んだ。最近はC++書いてなくてTypeScriptばっか書いてるけどVisual Studioくらい入ってるし余裕でしょ、そう思っていた。
開発者コマンドプロンプトで配布されているソースコードを展開したディレクトリの中の
PCbuildに移動してbuild.bat -p x64 -c Releaseとし、ビルドした。なんかエラーが出たり型変換周りの(
intをvoid*にキャストして配列に格納しまたintにキャストして使うとかいうコードが原因、これ書いたやつ正気か?これだからC言語使い共は・・・)警告がどっさり出たが、とにかく終わった。レジストリを偽装し、VSCodeの設定で"lldb.launch.env"の
PATHを書いて動かした。Fatal Python error: Py_Initialize: unable to load the file system codec Import Error: No module named 'encodings'これなにか足りてないやつだ、そう悟った私はとりあえず眠り、リフレッシュした脳みそで本気で取り組むことにした。
本気でビルドする
ビルドの準備
改めてビルドの準備をしていく。
.NET 3.5
Windows10では.NET 3.5がデフォルトで無効になっている。
.NET Framework 3.5 を有効化する手順について ( Windows 10 ) | Ask CORE
に従って有効化する。Visual Studio
2015以上であればよい。私はVisual Studio 2019を選んだ。C#とC++のコンパイルが普通にできれば十分だとは思うが、なんせ私の環境にはいろいろ入れているので最小構成がよくわからない。
MSVC v140 - VS2015 C++ ビルドツールとかも必要である可能性はある。まあなんなら下にVS installerの構成ファイル置いておくので適宜いじって読み込ませてほしい。
https://gist.github.com/yumetodo/c48152a7512356db33bb2c0994610359
choclatey
必須というわけではないが、ないと説明が面倒くさいので。
https://chocolatey.org/install
にあるとおりに入れてほしい。
Mercurial
管理者権限のあるPowershellないしコマンドプロンプトで
choco install hg -yPython
PythonをビルドするにはPythonが必要である。おおっと、鶏と卵の問題というかブートストラップ問題だ。
choco install python3 -ysphinx
さっそくPythonについてくるpipの出番だ。
pip install SphinxTcl
これがなんなのかわかっていないがとにかく必要らしい。なんとなくIDLEのためじゃないかという気がするが・・・。
ftp://ftp.tcl.tk/pub/tcl/tcl8_6/
から
tcl-core8.6.6-src.tar.gzをダウンロードする。HTML Help Workshop
Visual Studio 2017以降のインストーラーでは入れられないので自分で持ってくる必要がある。
Microsoft HTML Help Downloads | Microsoft Docs
Download Htmlhelp.exeをクリック。ダウンロードしたら実行してどんどん次に進んでいけば終わる。Build
Download & 展開
Python Release Python 3.6.9 | Python.org
XZ compressed source tarballを落として展開する。
追加のファイル配置
その中に
externalsというディレクトリを作る。そこにtcl-core8.6.6-src.tar.gzを展開する。フォルダー名はtcl-core-8.6.6.0に。これをやらないと、下のようなエラーに見舞われる。
環境変数の設定
VSの開発者コマンドプロンプトを立ち上げる。以下の環境変数を設定する。
set PYTHON="C:\Python37\python.exe"python2.7もしくは3.4以降の
python.exeのフルパス。
今回はchocolateyで入れているから"C:\Python37\python.exe"set SPHINXBUILD="C:\Python37\Scripts\sphinx-build.exe"
where sphinx-buildすれば教えてくれるだろう。set PATH="C:\Program Files\Mercurial\hg.exe";"C:\Program Files (x86)\HTML Help Workshop\hhc.exe";%PATH%1つ目はhg.exeの場所。
where hgすれば教えてくれるだろう
もう一つはhhc.exeの場所。デフォルトでは"C:\Program Files (x86)\HTML Help Workshop\hhc.exe"ビルド
ビルドにはとても時間がかかる。PCを放置して別の作業をしたいが、PGOビルドをするときにネットワーク接続をしようとしてWindowsのファイアウォールから許諾画面が出てくる。ただまあビルドの最終盤で気がついて許可したけど多分間に合ってなかったろうし、やっぱり放置してもいい気がする。
ビルドコマンドは極めてシンプルだ。
-oにはビルド成果物を置く場所を指定する。cd Tools\msi buildrelease.bat -x64 -o "C:\tmp\python"最終的に
Total Copied Skipped Mismatch FAILED Extras Dirs : 1 0 1 0 0 0 Files : 71 28 43 0 0 0 Bytes : 96.69 m 49.61 m 47.08 m 0 0 0 Times : 0:00:00 0:00:00 0:00:00 0:00:00 Speed : 481735111 Bytes/sec. Speed : 27565.104 MegaBytes/min. Ended : 2019年8月27日 17:26:31のようなログが出て終わった。
install
先程
-oで指定したディレクトリにamd64というディレクトリが作られているはずだ。python-3.6.9-amd64.exeがよくお見かけするpythonのインストーラーだ。これを実行する。
CodeLLDBよ、動け
VSCodeの設定を
"lldb.launch.env": { "PATH": "C:\\Python36", "PYTHONPATH": "C:\\Python36\\Lib", }見直してリベンジだ。
動いた。
余談
大体同じ話が
- python 3.6.9をWindowsでx64 Release buildした - yumetodoの旅とプログラミングとかの記録
- python 3.6.9をもっとガチでWindows10でx64 Release buildした - yumetodoの旅とプログラミングとかの記録
に書いてあるのですが、せっかくなのでQiitaにもあげようとこの記事を書いたわけです。


- 投稿日:2019-08-27T20:44:47+09:00
Ratio CutとNormalized Cutについて(2次元)
最近この2つについて学んだのでそのメモ書きです。もっと効率的なプログラムの書き方があったら教えてもらいたいです。。。
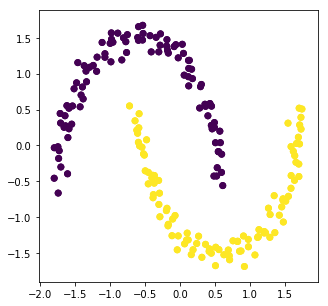
お馴染みのこちらのデータセットですが、これをk-NNなどで分類しようとするとどうしても原点付近のデータがうまいこと分離されません。そこで利用できるのが Ratio CutやNormalized Cutといった点の間のつながりに重みを持たせることでその重みからクラスタに分類しようといった考え方です。点同士に重みを持たせる方法としては次の3つのようなものがあります。
1. $\varepsilon$-neighborhood graph
2. k-nearest neighbor graph
3. Fully connected graph1つ目は、ある1点からある距離$\varepsilon$内にある点の間全てに重みを持たせるものです。
2つ目は、ある1点から最も近いk点との間に重みを持たせるものです。この方法はそのままだと$v_i$からみて$v_j$には重みがあるけど、その逆は重みがないといったことがおきる場合があります。そのため、片方から見て重みがあるのならその逆にも重みを持たせることにより無向グラフを作成することができます。
3つ目は、全ての点の間に重みをもたせるものです。点同士の距離が遠くなるにつれ重みを小さくするためにガウス分布が使われることが多いです。$$W_{ij}=\rm{exp}\left(-\frac{||v_i-v_j||^2}{2\sigma^2}\right)$$
1つ目と2つ目を実装すると次のようになります。
Similarity_Graph.pyclass Similarity_Graph: def __init__(self,N): self.W=np.zeros((N,N)) def epsilon_nearest(self,data,r): W=self.W for i in range(N): distance2=np.sum((data-data[i])**2,axis=1) for j in range(N): if distance2[j]==0: W[i][j]=0 elif distance2[j]<r: W[i][j]=0 else: W[i][j]=1 return W def k_nearest(self,data,k): W=self.W for i in range(N): distance2=np.sum((data-data[i])**2,axis=1) nbrs=np.argsort(distance2)[1:k+1] W[i,nbrs]=1 W[nbrs,i]=1 return WRatio Cut
Ratio Cutで最小化したい目的関数は次の式です。
$$RatioCut(A_1,A_2)=\frac{1}{2}\sum_i \frac{W\left(A_i,\bar{A_i}\right)}{|A_i|}$$
ここでLをGraph Laplacianとし、$f$を次のように定めます。
$$f=
\sqrt{\frac{|\bar{A}|}{|A|}} (v_i \in A),\
\sqrt{\frac{|A|}{|\bar{A}|}} (v_i \in \bar{A})\
$$
このように定めた上で$f^TLf$を計算すると次のようになります。
$$f^TLf=|V|RatioCut(A,\bar{A})$$
すなわち、$RatioCut(A,\bar{A})$を最小化することは$f^TLf$を最小化することに等しくなります。
結果として求めたい最小化問題は次のようになります。
$$\rm{min}_{A \subset V}\ f^TLf \ \ \ \rm{subject\ \ to}\ \ \ \ f\perp 1,||f||=\sqrt{n}$$
Rayleigh-Ritz theoremからGraph Laplacian Lの2番目に小さい固有値への固有ベクトル$f$が解を与えることになります。実際の実装では$f$の値の符号によって領域を分割します。実装は後のNormalized Cutと合わせて行います。Normalized Cut
Normalized Cutで最小化したい目的関数は次の式です。
$$NCut(A_1,A_2)=\frac{1}{2}\sum_i \frac{W(A_i,\bar{A_i})}{vol(A_i)}$$
$vol(A_i)$は次のように定義されます。
$$vol(A_i)=\sum_{i \in A_i,j\in V} W_{ij}$$
こちらでは求めたい最小化問題は次のようなものです。
$$\rm{min}_{f \in R^n}\ f^TLf \ \ \ \rm{subject\ \ to}\ \ \ \ Df\perp 1,\ f^TDf=vol(V)$$ここで$g=D^{1/2}f$を代入すると次のようになります。
$$\rm{min}_{g \in R^n}\ g^TD^{-1/2}LD^{-1/2}g \ \ \ \rm{subject\ \ to}\ \ \ \ g\perp D^{1/2}1,\ ||g||^2=vol(V)$$
これより$\rm{Lsym}=D^{-1/2}LD^{-1/2}$とおくとこれは$\rm{Lsym}$の2番目の固有値に対する固有ベクトルが解を与えることになります。$\rm{Lsym}$はNormalized Graph Laplacianと呼ばれるものです。
以上の2つをk-nearest neighbor graphで実装すると次のようになります。
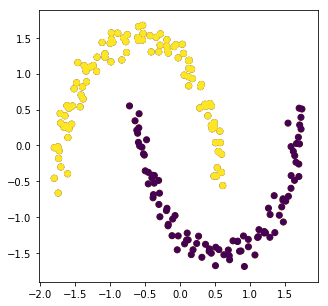
Cuts.pyimport numpy as np import matplotlib.pyplot as plt from sklearn import datasets import scipy.linalg X,z=datasets.make_moons(n_samples=200,noise=0.05,random_state=0) X_norm=(X-np.mean(X,axis=0))/np.std(X,axis=0) x=X_norm[:,0] y=X_norm[:,1] figure=plt.figure(figsize=(5,5)) plt.scatter(x,y,c=z) N=len(X_norm) Similarity=Similarity_Graph(N) W=Similarity.k_nearest(data=X_norm,k=10) D=np.zeros((N,N)) for i in range(N): D[i][i]=np.sum(W,axis=1)[i] L=D-W Dsqrt=scipy.linalg.sqrtm(D) Dsqrt_inv=np.linalg.inv(Dsqrt) Lsym=np.dot(Dsqrt_inv,L,Dsqrt) U,sig,VT=np.linalg.svd(Lsym) #NormalizedCut# #U,sig,VT=np.linalg.svd(L) #RatioCut Y=VT[N-2,:].T for i in range(N): if Y[i]>0: Y[i]=1 else: Y[i]=0 plt.scatter(x,y,c=Y)
結果はどちらを用いても今回はきれいに2つに分かれました。しかし、それぞれの領域の点数が大きく異なっている場合、Ratio Cutは点数がほぼ同じになるように調整するのでうまくいきません。なのでNormalized Cutを用いるほうが良いと考えています。
参考
[1]機械学習とかコンピュータビジョンとか
- 投稿日:2019-08-27T20:23:33+09:00
Coral DevBoardでOpenCVをビルドしてインストールする
【内容】
前回の記事でCoral DevBoardをセットアップして使えるようになりました。
早速過去のプログラムを使ってパフォーマンスを比較したかったのですが、Webカメラの入力や結果画像の出力にOpenCVを使っているためそのまま利用することは出来ません。
手っ取り早くインストールを試みましたがpip3もaptも該当モジュールが存在しません。ということでCoral DevBoardでOpenCVをソースからビルドしてインストールします。
【注意点】
DevBoardでOpenCVをビルドするには2つ注意点があります。
まず1つ目はメモリ容量が足らない。
2つ目は内蔵ストレージ(eMMC)の容量が足らないです。1つ目の解決方法としてはスワップ領域を設定します。
実際にビルドしたところ、最大で1GB以上のスワップ領域を使いましたので、本手順では安全を見て2GBで設定しています。2つ目の解決方法としてはSDカードをマウントして、ソースの取得およびビルドをSDカード上で行います。
こちらは最終的に11GB以上の容量を必要としましたので、16GBのSDカードを使いました。【概要】
実行した手順は概ね以下の手順になります。
- スワップ設定
- 依存モジュールのインストール
- SDカードのマウント
- ソースの取得
- cmakeの実行
- build & install
- 動作確認
【0.DevBoardへの接続】
まずはDevBoardに接続してください。
前回の記事を参考にSerial Consoleまたはsshで繋いでください。なお、今回作業後に気がついたのですが、DevBoardのHDMI出力にTVをつなぐと、左上のアイコンからターミナルを起動できるのですね。
恐らくこちらで作業しても良いと思います。【1.スワップ領域の設定】
まずはスワップ領域を設定します。
下記のコマンドを実行することでスワップ領域を設定できます。スワップ領域の設定# スワップ領域の設定 (2GB) sudo dd if=/dev/zero of=/swapfile bs=100M count=20 sudo mkswap /swapfile sudo swapon /swapfile最初1GBでビルドを行ったところ最後の最後で溢れて固まってしまいました。
ですので安全を見て2GBを指定しています。【2. 依存モジュールのインストール】
ビルドに必要なモジュールをインストールします。
下記コマンドを実行してください。依存モジュールのインストール# 依存モジュールのインストール sudo apt-get install build-essential cmake unzip pkg-config sudo apt-get install libjpeg-dev libpng-dev libtiff-dev sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev sudo apt-get install libxvidcore-dev libx264-dev sudo apt-get install libgtk-3-dev sudo apt-get install libcanberra-gtk* sudo apt-get install libatlas-base-dev gfortran sudo apt-get install python3-dev【3. SDカードのマウント】
OpenCVを内蔵ストレージ上でビルドするには容量が足りないため、SDカードをマウントしてその上で作業します。
SDカードは16GBのものを利用しました。SDカードの挿入とデバイスの確認
まずはSDカードをカードスロットに挿入します。
シリアルコンソールに繋いでいる場合はその時点で以下のようなメッセージが表示されます。
sshで繋いでいる場合はdmesgの最後の方に表示されます。SDカード挿入ログ[ 6250.755801] mmc1: host does not support reading read-only switch, assuming write-enable [ 6250.917963] mmc1: new ultra high speed SDR104 SDHC card at address aaaa [ 6250.925514] mmcblk1: mmc1:aaaa SL16G 14.8 GiB [ 6250.938402] mmcblk1: p1この表示からSDカードのデバイス名を取得します。
最終行のmmcblk1が今回挿入されたSDカードのデバイス名です。
このあと、SDカードにアクセスする場合は/dev/mmcblk1でアクセスします。パティションの削除
SDカード挿入ログの最終行に表示された
mmcblk1: p1のp1はパティションを表しています。
今回挿入したSDカードにはすでにパティションが切られていたようです。事前にこのパティションを削除します。
fdiskコマンドでSDカードにアクセスし、pコマンドでパティション情報を取得します。
その後、dコマンドでパティションを削除し、wコマンドでパティション情報を書き込んでいます。パティションの削除# fdisk sudo fdisk /dev/mmcblk1 Welcome to fdisk (util-linux 2.29.2). Changes will remain in memory only, until you decide to write them. Be careful before using the write command. Command (m for help): p Disk /dev/mmcblk1: 14.9 GiB, 15931539456 bytes, 31116288 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0x7b12e7a8 Device Boot Start End Sectors Size Id Type /dev/mmcblk1p1 8192 31116287 31108096 14.9G c W95 FAT32 (LBA) Command (m for help): d Selected partition 1 Partition 1 has been deleted. Command (m for help): p Disk /dev/mmcblk1: 14.9 GiB, 15931539456 bytes, 31116288 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0x7b12e7a8 Command (m for help): w The partition table has been altered. Calling ioctl() to re-read partition table. Syncing disks.SDカードのフォーマット
SDカードをフォーマットします。
本来は新たにパティションを作ってフォーマットすべきでしょうが、今回は単純に作業用なのでSDカードごとフォーマットします。
フォーマットタイプはext4としています。SDカードのフォーマット# format sudo mkfs.ext4 /dev/mmcblk1 mke2fs 1.43.4 (31-Jan-2017) Found a dos partition table in /dev/mmcblk1 Proceed anyway? (y,N) y Discarding device blocks: done Creating filesystem with 3889536 4k blocks and 972944 inodes Filesystem UUID: 2dd25c14-ce4e-4fda-ad71-12aa7643b64e Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208 Allocating group tables: done Writing inode tables: done Creating journal (16384 blocks): done Writing superblocks and filesystem accounting information: doneSDカードのマウント
SDカードのフォーマットが完了したら、SDカードをマウントします。
事前にマウントポイントとして/mnt/sdcardを作成した上で、SDカードをマウントしています。SDカードのマウント# マウントポイントの作成 sudo mkdir /mnt/sdcard # SDカードのマウント sudo mount /dev/mmcblk1 /mnt/sdcard/【4. ソースの取得】
GithubからOpenCVのソースを取得します。
今回は最新のリリースバージョンである4.1.1をダウンロードしました。ソースの取得# 事前にSDカードのマウントポイントに移動 cd /mnt/sdcard/ # 作業フォルダの作成と移動 sudo mkdir opencv cd opencv # Release version 4.1.1 をダウンロード sudo wget -O opencv.zip https://github.com/opencv/opencv/archive/4.1.1.zip sudo wget -O opencv_contrib.zip https://github.com/opencv/opencv_contrib/archive/4.1.1.zip # ファイルの解凍 sudo unzip opencv.zip sudo unzip opencv_contrib.zip # フォルダ名の変更 sudo mv opencv-4.1.1 opencv sudo mv opencv_contrib-4.1.1 opencv_contrib最新のソースを使いたい場合は上記コマンドの代わりにgitからcloneしてください。
git_cloneの例# git から最新版をcloneする git clone https://github.com/opencv/opencv git clone https://github.com/opencv/opencv_contrib【5. cmakeの実行】
cmakeを実行してビルドの準備をします。
必要に応じてビルドオプションを変更してください。
ここでエラーが出る場合は依存ファイルが足りないなど、環境に問題があります。# makeファイルを作成する cd opencv sudo mkdir build cd build sudo cmake -D CMAKE_BUILD_TYPE=RELEASE \ -D CMAKE_INSTALL_PREFIX=/usr/local \ -D INSTALL_PYTHON_EXAMPLES=ON \ -D INSTALL_C_EXAMPLES=OFF \ -D OPENCV_ENABLE_NONFREE=ON \ -D OPENCV_EXTRA_MODULES_PATH=../../opencv_contrib/modules \ -D BUILD_opencv_python2=OFF \ -D BUILD_opencv_python3=ON \ -D PYTHON_EXECUTABLE=/usr/bin/python3 \ -D ENABLE_FAST_MATH=1 \ -D ENABLE_NEON=ON -D WITH_LIBV4L=ON \ -D WITH_V4L=ON \ -D BUILD_EXAMPLES=OFF \ ../最終的に以下のように表示されればOKです。
Python用のライブラリを使う場合はログ内Python 3の項目がきちんと埋まっているかを確認してください。cmake結果-- General configuration for OpenCV 4.1.1 ===================================== -- Version control: unknown -- -- Extra modules: -- Location (extra): /home/mendel/opencv/opencv_contrib/modules -- Version control (extra): unknown -- -- Platform: -- Timestamp: 2019-08-27T01:25:57Z -- Host: Linux 4.9.51-imx aarch64 -- CMake: 3.7.2 -- CMake generator: Unix Makefiles -- CMake build tool: /usr/bin/make -- Configuration: RELEASE -- -- CPU/HW features: -- Baseline: NEON FP16 -- required: NEON -- disabled: VFPV3 -- -- C/C++: -- Built as dynamic libs?: YES -- C++ Compiler: /usr/bin/c++ (ver 6.3.0) -- C++ flags (Release): -fsigned-char -ffast-math -W -Wall -Werror=return-type -Werror=non-virtual-dtor -Werror=address -Werror=sequence-point -Wformat -Werror=format-security -Wmissing-declarations -Wundef -Winit-self -Wpointer-arith -Wshadow -Wsign-promo -Wuninitialized -Winit-self -Wno-delete-non-virtual-dtor -Wno-comment -fdiagnostics-show-option -pthread -fomit-frame-pointer -ffunction-sections -fdata-sections -fvisibility=hidden -fvisibility-inlines-hidden -O3 -DNDEBUG -DNDEBUG -- C++ flags (Debug): -fsigned-char -ffast-math -W -Wall -Werror=return-type -Werror=non-virtual-dtor -Werror=address -Werror=sequence-point -Wformat -Werror=format-security -Wmissing-declarations -Wundef -Winit-self -Wpointer-arith -Wshadow -Wsign-promo -Wuninitialized -Winit-self -Wno-delete-non-virtual-dtor -Wno-comment -fdiagnostics-show-option -pthread -fomit-frame-pointer -ffunction-sections -fdata-sections -fvisibility=hidden -fvisibility-inlines-hidden -g -O0 -DDEBUG -D_DEBUG -- C Compiler: /usr/bin/cc -- C flags (Release): -fsigned-char -ffast-math -W -Wall -Werror=return-type -Werror=non-virtual-dtor -Werror=address -Werror=sequence-point -Wformat -Werror=format-security -Wmissing-declarations -Wmissing-prototypes -Wstrict-prototypes -Wundef -Winit-self -Wpointer-arith -Wshadow -Wuninitialized -Winit-self -Wno-comment -fdiagnostics-show-option -pthread -fomit-frame-pointer -ffunction-sections -fdata-sections -fvisibility=hidden -O3 -DNDEBUG -DNDEBUG -- C flags (Debug): -fsigned-char -ffast-math -W -Wall -Werror=return-type -Werror=non-virtual-dtor -Werror=address -Werror=sequence-point -Wformat -Werror=format-security -Wmissing-declarations -Wmissing-prototypes -Wstrict-prototypes -Wundef -Winit-self -Wpointer-arith -Wshadow -Wuninitialized -Winit-self -Wno-comment -fdiagnostics-show-option -pthread -fomit-frame-pointer -ffunction-sections -fdata-sections -fvisibility=hidden -g -O0 -DDEBUG -D_DEBUG -- Linker flags (Release): -Wl,--gc-sections -- Linker flags (Debug): -Wl,--gc-sections -- ccache: NO -- Precompiled headers: YES -- Extra dependencies: dl m pthread rt -- 3rdparty dependencies: -- -- OpenCV modules: -- To be built: aruco bgsegm bioinspired calib3d ccalib core datasets dnn dnn_objdetect dpm face features2d flann freetype fuzzy gapi hfs highgui img_hash imgcodecs imgproc line_descriptor ml objdetect optflow phase_unwrapping photo plot python3 quality reg rgbd saliency shape stereo stitching structured_light superres surface_matching text tracking ts video videoio videostab xfeatures2d ximgproc xobjdetect xphoto -- Disabled: world -- Disabled by dependency: - -- Unavailable: cnn_3dobj cudaarithm cudabgsegm cudacodec cudafeatures2d cudafilters cudaimgproc cudalegacy cudaobjdetect cudaoptflow cudastereo cudawarping cudev cvv hdf java js matlab ovis python2 sfm viz -- Applications: tests perf_tests apps -- Documentation: NO -- Non-free algorithms: YES -- -- GUI: -- GTK+: YES (ver 3.22.11) -- GThread : YES (ver 2.50.3) -- GtkGlExt: NO -- VTK support: NO -- -- Media I/O: -- ZLib: /usr/lib/aarch64-linux-gnu/libz.so (ver 1.2.8) -- JPEG: /usr/lib/aarch64-linux-gnu/libjpeg.so (ver 62) -- WEBP: build (ver encoder: 0x020e) -- PNG: /usr/lib/aarch64-linux-gnu/libpng.so (ver 1.6.28) -- TIFF: /usr/lib/aarch64-linux-gnu/libtiff.so (ver 42 / 4.0.8) -- JPEG 2000: build (ver 1.900.1) -- OpenEXR: build (ver 2.3.0) -- HDR: YES -- SUNRASTER: YES -- PXM: YES -- PFM: YES -- -- Video I/O: -- DC1394: NO -- FFMPEG: YES -- avcodec: YES (57.64.101) -- avformat: YES (57.56.101) -- avutil: YES (55.34.101) -- swscale: YES (4.2.100) -- avresample: NO -- GStreamer: NO -- v4l/v4l2: YES (linux/videodev2.h) -- -- Parallel framework: pthreads -- -- Trace: YES (with Intel ITT) -- -- Other third-party libraries: -- Lapack: NO -- Eigen: NO -- Custom HAL: YES (carotene (ver 0.0.1)) -- Protobuf: build (3.5.1) -- -- OpenCL: YES (no extra features) -- Include path: /home/mendel/opencv/opencv/3rdparty/include/opencl/1.2 -- Link libraries: Dynamic load -- -- Python 3: -- Interpreter: /usr/bin/python3 (ver 3.5.3) -- Libraries: /usr/lib/aarch64-linux-gnu/libpython3.5m.so (ver 3.5.3) -- numpy: /usr/local/lib/python3.5/dist-packages/numpy/core/include (ver 1.17.0) -- install path: lib/python3.5/dist-packages/cv2/python-3.5 -- -- Python (for build): /usr/bin/python3 -- -- Java: -- ant: NO -- JNI: NO -- Java wrappers: NO -- Java tests: NO -- -- Install to: /usr/local -- ----------------------------------------------------------------- -- -- Configuring done -- Generating done -- Build files have been written to: /home/mendel/opencv/opencv/build【6. build & install】
cmakeコマンドが正常に完了したら、ビルド及びインストールを行います。
OpenCVのビルド
実際に
makeコマンドでビルドを実行します。
今回は4プロセス並列でビルドし、処理時間を測定してみました。OpenCVのビルドtime sudo make -j4ビルド時間結果real 275m9.931s user 277m17.536s sys 37m11.680s今回は約4時間半程かかりました。
途中失敗したり条件を変えたため、この手順を5回行いました…OpenCVのインストール
正常にビルドが完了したら、下記コマンドでインストールします。
OpenCVのインストールsudo make install sudo ldconfig以上で、OpenCVのインストールは完了です。
【7. 動作確認】
正常にインストールできているか確認します。
下記コマンドを実行して、エラーなくバージョンが表示されれば正常にインストールできています。動作確認python3 -c "import cv2;print(cv2.__version__);"出力結果4.1.1【片付け】
必要に応じてSDカードのアンマウントとスワップ領域を削除します。
片付け# SDカードのアンマウント sudo umount /mnt/sdcard # swap領域の削除 sudo swapoff /swapfile sudo rm /swapfileswap領域を削除することで内蔵ストレージ(eMMC)の容量をあけることが出来ます。
【最後に】
これで過去のプログラムを実行する環境が整いました。
実際に動作することも確認できましたので、このあとパフォーマンスを比較したいと思います。なお、今回の作業を行ったあとの各パティションの空き容量は以下のとおりです。
空き容量の確認df -h Filesystem Size Used Avail Use% Mounted on /dev/root 7.0G 2.1G 4.6G 32% / devtmpfs 332M 0 332M 0% /dev tmpfs 492M 0 492M 0% /dev/shm tmpfs 492M 17M 476M 4% /run tmpfs 5.0M 4.0K 5.0M 1% /run/lock tmpfs 492M 0 492M 0% /sys/fs/cgroup tmpfs 492M 492K 492M 1% /var/log /dev/mmcblk0p1 124M 29M 89M 25% /boot tmpfs 99M 13M 86M 13% /run/user/1000 /dev/mmcblk1 15G 11G 2.9G 80% /mnt/sdcard内蔵ストレージは4.6GB空いています。
もう少しカスタマイズ可能かな。なお、今回作業で使ったSDカードは16GBですが、最終的に11GB以上消費してしまいました。
以前はもっと少ない容量でもビルドできていたので、初めは内蔵ストレージだけでビルドできるかと試してみたのですが、まったく足りなかったですね…
Contrib moduleなどを削ればビルド行けるのでしょうか?
ちょっと今は試す気になれません。
- 投稿日:2019-08-27T20:21:48+09:00
Pythonでジャガード係数を求める【Jaccard係数】
ジャガード係数とは
ジャガード係数は分母に和集合、分子に積集合の大きさをそれぞれ入れて計算することができます。
これにより、集合同士の類似度を計算することができます。数式は次の通りです。$$
J( A, B ) = \frac { \mid A \cap B \mid } { \mid A \cup B \mid } = \frac { \mid A \cap B \mid } { |A| + |B| - \mid A \cap B \mid }
$$このジャガード係数をPythonで書くと以下のようなコードになります。
jaccard.pydef jaccard(data1, data2): items = 0 for item in data1: if item in data2: items += 1 return items / (len(data1) + len(data2) - items) data1 = ['Action', 'Comedy', 'Parody', 'Sci-Fi', 'Seinen', 'Super Power', 'Supernatural'] #One Punch Man data2 = ['Action', 'Comedy', 'Historical', 'Parody', 'Samurai', 'Sci-Fi', 'Shounen'] #Gintama° jaccard(data1, data2) #0.4追記
集合体を使うとよりわかりやすいです。
jaccard2.pydata1 = ['Action', 'Comedy', 'Parody', 'Sci-Fi', 'Seinen', 'Super Power', 'Supernatural'] #One Punch Man data2 = ['Action', 'Comedy', 'Historical', 'Parody', 'Samurai', 'Sci-Fi', 'Shounen'] #Gintama° set_data1 = set(data1) set_data2 = set(data2) numerator = len(set_data1 & set_data2) # {'Action', 'Comedy', 'Parody', 'Sci-Fi'} denominator = len(set_data1 | set_data2) # {'Action', 'Comedy', ..., 'Super Power', 'Supernatural'} print(numerator / denominator) # 4 / 10 --> 0.4参考
pythonでデータ間の類似度を計算する方法いろいろ
【技術解説】集合の類似度(Jaccard係数,Dice係数,Simpson係数)
pythonでJaccard係数を実装
自然言語処理する時に計算するJaccard係数をPythonで計算する方法まとめ
- 投稿日:2019-08-27T19:15:42+09:00
【コピペでOK!】PythonでCSVファイルへの読み込み、書き込み
tl;dr
PythonでCSVファイルを読み書きする方法をまとめます。
用意するもの・環境
- macOS Mojave 10.14.6
- Python 3.7(ANACONDA3)
- PyCharm 2019.2
開発環境の構築は下記の記事を参考にしてください。
【これさえ読めばOK】MacでPythonを使って開発するための準備
https://qiita.com/ryoichiro001/items/35a232a430c41dd512fa公式ドキュメント
CSV ファイルの読み書き
https://docs.python.org/ja/3/library/csv.htmlパラメータの詳細はこちらを参照してください。
CSVパッケージを使用する
import csvCSVファイルの読み込み
import csv import os def get_info_from_csv(dir_name, file_name, delimiter=','): p_file = os.path.join(dir_name, file_name) with open(p_file, 'r', encoding='utf-8') as f: reader = csv.reader(f, delimiter=delimiter) lists = [row for row in reader] return listsこの例ではencodingをutf-8にしているが、これは読み込む対象のファイルに合わせる必要がある。
# 呼び出し例 url_list = get_info_from_csv('inputs_files', 'input.txt')CSVファイルの書き込み
import csv import os def put_info_to_csv(lists, dir_name, file_name, header=[], delimiter=','): """二次元配列をCSVファイルに出力 :param lists:出力したい二次元配列 :param dir_name:ディレクトリ名(1階層下を想定) :param file_name:ファイル名 :param header:ファイルのヘッダ :param delimiter:CSVの区切り文字 :return:なし """ p_file = os.path.join(dir_name, file_name) with open(p_file, "w", encoding='utf-8') as f: writer = csv.writer(f, delimiter=delimiter, quoting=csv.QUOTE_MINIMAL) if header: writer.writerow(header) writer.writerows(lists)# 呼び出し例 out_info = [[]] out_info.clear() # 2次元配列を初期化 count = 1 out_line = [] out_line.append(count) out_line.append('A') out_info.append(out_line) count += 1 out_line = [] out_line.append(count) out_line.append('B') out_info.append(out_line) count += 1 out_line = [] out_line.append(count) out_line.append('C') out_info.append(out_line) put_info_to_csv(out_info, 'temporary_files', 'output.txt')output.txt1,A 2,B 3,C参考URL
PythonでCSVファイルを読み込み・書き込み(入力・出力)
https://note.nkmk.me/python-csv-reader-writer/Pythonで2次元配列の静的確保と動的確保
http://sonickun.hatenablog.com/category/%E3%83%97%E3%83%AD%E3%82%B0%E3%83%A9%E3%83%9F%E3%83%B3%E3%82%B0?page=1402667101Pythonでリスト(配列)の要素を削除するclear, pop, remove, del
https://note.nkmk.me/python-list-clear-pop-remove-del/
- 投稿日:2019-08-27T18:50:14+09:00
Pythonでグーグルニュースをスクレイピングして、Rで編集。
グーグルニュースは関心があるキーワードや文章で検索すると、関連度順とリリース日時順で整理して100件の記事を表示してくれます。
食品のヒット商品出現の経緯を探るために、ヒットした食品に関係しそうなキーワードや文章で検索して過去のニュースを調査して、それらのニュースリリース時の関心の上昇度をグーグルトレンドで確認することで、ヒットに至る経緯を探ることができそうです。
今春にローソンから発売された「バスチー」は発売後4か月で1,900万個売れた大ヒット商品となりました。そこで、「バスチー」の由来となった「バスクチーズケーキ」でグーグルニュースをプログラムで自動的に検索、編集してデータ化することを検討しました。
こちらも参照ください。
データサイエンスで食のヒットの種を見つけ出そう(1)これまで、Rをベースに統計解析用にプログラミングをしてきましたが、ウェブ情報の取得や機械学習を広く利用する場合にはPythonを使い始めています。 Rでグーグルニュースのウェブページをスクレイピングしていましたが、PythonでグーグルニュースのRSSをパースする方法を知りこちらを使うようになりました。
グーグルニュースをキーワードで自動的にPythonで取得して、Rで集計するプログラムを紹介します。
Pythonのコーディングは下記の記事を参考にしました。とても丁寧で分かり易く書かれています。
【Python】Googleニュースをスクレイピングする環境
Windows10
Python3.6.5
R3.6.1Pythonでグーグルニュースを取得
グーグルニュースの情報取得のためにfeedparserをコマンドプロンプトでpipを用いてインストール
$ pip install feedparserライブラリのインポート
import feedparser import json import pprintグーグルニュースを検索ワードで検索するためのURLを作成する。
今回は検索ワードは今春に発売されて大ヒットしたローソンの「バスチー」の元となった「バスクチーズケーキ」にします。
s = 'バスクチーズケーキ' #検索ワードをURLエンコードに変換 s_quote = urllib.parse.quote(s) #グーグルニュース検索のURLの間に挟む url = "https://news.google.com/news/rss/search/section/q/" + s_quote + "/" + s_quote + "?ned=jp&hl=ja&gl=JP"urlをfeedparserでパースする
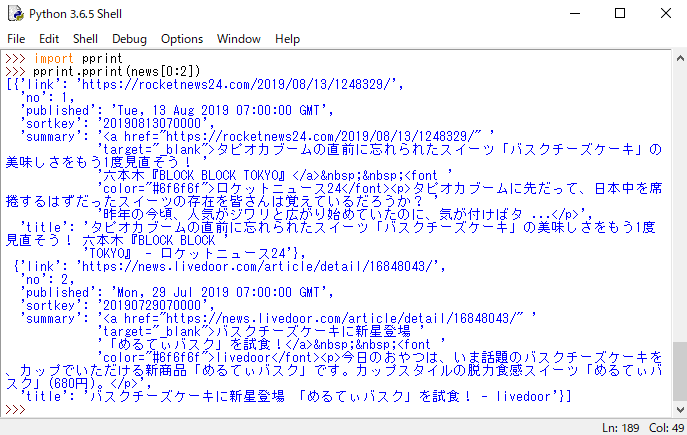
d = feedparser.parse(url)ニュース記事リストを、for文で繰り返し各記事のtitle、summary, link, published,sortkeyを取得
for i, entry in enumerate(d.entries, 1): p = entry.published_parsed sortkey = "%04d%02d%02d%02d%02d%02d" % (p.tm_year, p.tm_mon, p.tm_mday, p.tm_hour, p.tm_min, p.tm_sec) tmp = { "no": i, "title": entry.title, "summary": entry.summary, "link": entry.link, "published": entry.published, "sortkey": sortkey } news.append(tmp)取得したニュースの最初の2件を表示してみる
pprint.pprint(news[0:2])以下の実行結果が表示されました。
項目のsummaryに'<a href="http://・・"とニュースのリンク先が記載されているので、これを削除したり、項目の順番を変えたり、日時順にソートするために、手慣れているRにデータを渡します。
json形式で保存
PythonからRへのデータの受け渡しにはjson形式のファイルを使うと簡単で便利です。
with open('news.json', 'w') as f: json.dump(news, f)Rでjsonファイルをcsvファイルに変換
パッケージのインストール
install.packages("jsonlite") #json形式のデータを扱う install.packages("formattable") #データフレームをHTMLに表示パッケージを読み込む
library(jsonlite) library(formattable)json形式のファイルを読み込んで、データを編集
news <- fromJSON("news.json")項目summaryから不要な文字を除きます。
項目summaryには、ニュースのリンク先のURL他のHTML由来の不要な文字が含まれているのでこれをgsub()を使って除きます。
(rownum <- nrow(news)) #次のfor文設定のためにニュース件数を代入 for (i in 1:rownum){ dev <- strsplit(news[i, 3], ">") #分割 dev.c <- dev[[1]] summary <- paste(dev.c[2], dev.c[6]) #必要な文章を結合 summary <- gsub("</a", "。", summary) # "</a"を除く summary <- gsub("</p", "。", summary) # "</p"を除く news[i, 3] <- summary #修正した文章を戻す }リリース日時でニュースを降順にソート
項目sortkeyを使います
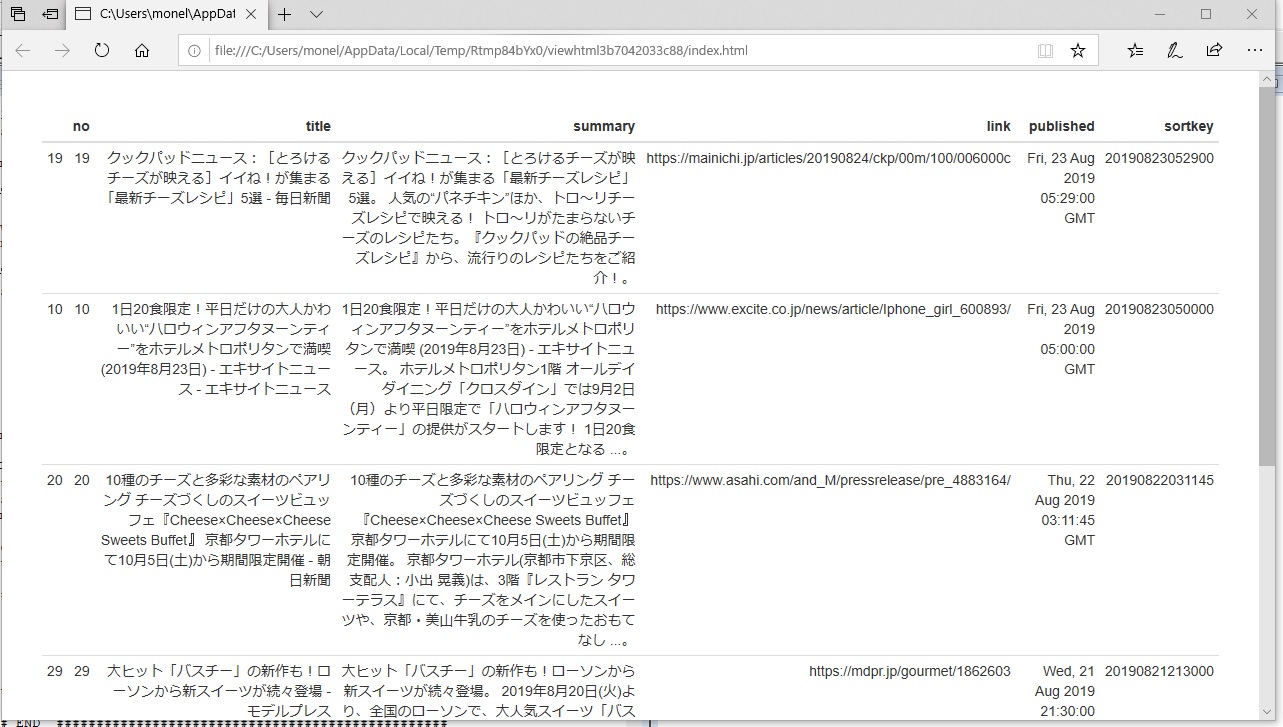
sortlist <- order(news$sortkey, decreasing=TRUE) news.sort <- news[sortlist,]初めの6件のニュースをHTMLに表示
formattable::formattable(head(news.sort))実行結果
csvファイルで保存
## csvファイルで保存 write.csv(news.sort, "バスクチーズケーキのグーグルニュース.csv")以上
ある期間に絞りたいときも、同じくsortkeyを使えばできます。

- 投稿日:2019-08-27T18:40:28+09:00
pythonで音声を並列で再生する方法
やったこと
今回、Pythonにおいて、音声を並列で再生する(Aの音声を再生し、再生の終了を待つ前にBの音声を並列で再生する)方法を検討しました。
・環境:
Python3.6.5
Mac OS Mojave方法
様々検討したのですが、最終的にはsubprocessを使ってMacのターミナル上での音声再生コマンドであるmplayerを叩く方法で実現しました。
mplayerは
brew install mplayerでインストールできます。Linuxを利用されている方ですと aplay で良いと思います。
実際のコード
import subprocess A = '○○○.mp3' B = '●●●.mp3' subprocess.Popen(['mplayer', A]) subprocess.Popen(['mplayer', B])実行すると、AとBの音声がほぼ同時に再生されます。
これを利用して、aの信号を受け取るとAの音声を流し、bの信号を受け取るとBの音声を流す。
などの処理を実行することができます。簡潔ですが、以上です。
ご参考になれば幸いです。補足
pythonで音声を再生する際はpyAudioを使うのが一般的ですが、これをthreadingなどで並列処理化しても、うまく並列再生されず、しまいにはおそらくメモリーエラーでSegmentation Faultになりました(信号の取得等の処理を入れています)。
もしかしたら、他の方法もあるのかもしれませんが、とりあえず上記で実現できたため投稿します。
- 投稿日:2019-08-27T18:26:25+09:00
与えられた木が二分探索木か判定するアルゴリズム
この記事は何か?
入力として木構造が渡されたとき、それが二分探索木かどうか調べるアルゴリズムについて紹介する。
二分探索木
二分探索木は二分木であり、節の左側の子には節と同じか小さい要素しか含まず、右側の子には節と同じか大きい要素しか含まないものを指す。
次の木は二分探索木の例である。
すべての部分木で左側の子が節と同じかそれより小さく、右側の子が節と同じかそれより大きい要素を持っている。
二分探索木かどうか判定するアルゴリズム
二分探索木の子の節が取りうる値の幅は、親の節よりも狭くなる。上の二分探索木を例に考えよう。
根の要素が取りうる値の幅は
[-∞, ∞]である。つまり、どのような値でも問題がない。根から左側の子である 7 の節が取りうる値は[-∞, 19]である。なぜなら、根の左側の子は根よりも大きい値であってはならないからである。次に 7 の節の右側の子について考えよう。この節の取りうる値は[7, 19]で、実際の値は 11 である。親が 7 なので、右側の子は 7 より大きい値でなければならず、親が 19 より小さいという制約を持っているため、この節も同じ制約を引き継ぐためである。このように、根から葉に向かって取りうる値のレンジを更新しつつ、実際の値がそのレンジにおさまっているかどうかを調べることで、与えられた木が二分探索木かどうかを判定できる。
具体的な実装は次のようになる。
# 木のノードは BstNode クラスで表現する class BstNode: def __init__(self, data=None, left=None, right=None): self.data, self.left, self.right = data, left, right def is_binary_tree_bst(tree: BstNode, low_range=float('-inf'), high_range=float('inf')) -> bool: if not tree: return True if not (low_range <= tree.data <= high_range): return False return \ is_binary_tree_bst(tree=tree.left, low_range=low_range, high_range=tree.data) and \ is_binary_tree_bst(tree=tree.right, low_range=tree.data, high_range=high_range)根から再帰的に左右の子の部分木を探索し、すべての節の値がレンジの範囲内におさまっていれば
is_binary_tree_bstはTrueを返す。

- 投稿日:2019-08-27T18:14:06+09:00
[Python]たった4行で英文間の類似度を出すモジュールを作る
はじめに
コサイン類似度を使用します
コサイン類似度についての詳しい説明は以前書いたQiitaを見てください↓
pythonで「君とはベクトルが合わない」を数値で出そう笑今回は2文章間の類似度を4行の簡単なpythonで出してみようと思います!
2文章間の類似度
例えばこんな2つの文があったとします
text1 = ”I like apple and lemon” text2 = ”I like apple and banana”この2つの文章を表でまとめると
I like apple and lemon banana text1 1 1 1 1 1 0 text2 1 1 1 1 0 1 2つのテキストをベクトルで表すと
α = (1,1,1,1,1,0)
β = (1,1,1,1,0,1)
α・β = 4
|α| = √5
|β| = √5これらからコサイン類似度をもとめる。
cosθ = (α・β)/|α||β|
であるからcosθ = 4 / (√5 ✕ √5) = 0.8
Pythonで書いてみる
環境
ubuntu 18.04
python3
分かち書きに必要なモジュールのインストール polyglot
$ sudo apt-get update $ sudo apt-get install libicu-dev $ sudo apt-get install python3-pip $ sudo -H pip3 install --upgrade pip $ sudo -H pip3 install numpy $ sudo -H pip3 install polyglot $ sudo -H pip3 install pyicu $ sudo -H pip3 install pycld2 $ sudo -H pip3 install morfessor主な使い方はここを見てください↑
以下がコサイン類似度を求める4行のモジュールです
cos_sentence.pyimport math from polyglot.text import Text def calc_cos(text1,text2): return len([i for i in Text(text1).words if i in Text(text2).words])/(math.sqrt(len(Text(text1).words)*len(Text(text2).words)))
はい、無理やり4行にしたので見やすくしますw
cos_sentence.pyimport math from polyglot.text import Text def calc_cos(text1,text2): # テキストを分かち書きしてlistに格納 list1 = Text(text1).words list2 = Text(text2).words # コサイン類似度の分母 denominator = math.sqrt(len(list1)*len(list2)) # コサイン類似度の分子 numerator = len([i for i in list1 if i in list2]) return numerator/denominator
このモジュールを呼んで上の2文の類似度を出す
test.pyimport cos_sentence print(cos_sentence.calc_cos("I like apple and lemon","I like apple and banana"))結果↓
0.8あとがき(text1,2が短文でないとき)
この分かち書きだと "."とか"?"とか"!" も含んじゃうので、数文ある記事ならreplace("!","")とかするか、正確にやりたいなら形態素解析してリストに格納する必要があります
形態素解析もpolyglotでできます、"."とか"?"とか"!" の品詞名は'PUNCT'です
text内に複数文ある場合はこんな感じでしょうか
cos_sentence.pyimport math from polyglot.text import Text def calc_cos(text1,text2): # テキストを分かち書きしてlistに格納 list1 = text_to_list(text1) list2 = text_to_list(text2) # コサイン類似度の分母 denominator = math.sqrt(len(list1)*len(list2)) # コサイン類似度の分子 numerator = 0 for word in list1: if word in list2: numerator += 1 # 既出の単語を消去 list2.remove(word) return numerator/denominator def text_to_list(text): #textからlistに単語を格納する関数 list = [] for token in Text(text).pos_tags: if u'PUNCT' != token[1]: list.append(token[0]) return list
- 投稿日:2019-08-27T17:14:26+09:00
numpyでヒストグラムを作る
問題
最も簡単なやり方は
matplotlibを使うことです。例えば、[Python]Matplotlibでヒストグラムを描画する方法もしかしたらナンセンスかもしれないけど、numpyの
np.histogramからやりたかったのでここにメモする。np.histogramから値を取ってくるには、hist, bins = np.histgram(data)のようにすればいいけれど、
binsにはbinの両端の値が入っていて、だからplt.bar(bins, hist) plt.show()とやっても、配列の長さが一致していないと怒られる。どうしたらいいのだろうか。
方法
binsの値の代わりにbinの中央値の値を吐き出す関数を書けば良い。以下のコードを書いた。import matplotlib.pyplot as plt import numpy as np def hist(arr, nbins=10, weights=None, isNormed=False): """ Args: arr: 1d array bins: the number of bins Returns: hist: 1d array, histogram bins[:-1]: 1d array, centers of bins """ hist, bins = np.histogram(arr, bins=nbins, weights=weights) if isNormed == True: hist = hist/hist.sum() halfDeltaBin = np.diff(bins)[0]/2 bins = bins + halfDeltaBin return hist, bins[:-1]
- 投稿日:2019-08-27T17:11:34+09:00
Pandas の代表的データ操作 *memo
良く自分が使うものを中心に備忘録としてまとめ。
更新頻度高めで更新していきます。apply+lambda
df.apply(lambda x: func(x['col1'],x['col2']),axis=1)指定した列に定義した関数を一気に適用
groupby
同要素を集約
applyと組み合わせることで複雑な処理も可能に#同要素を持つ、文字列を連結 df_Split.groupby("result").agg({"Word":lambda x: ",".join(x)})stack,unstack
unstack
行→列
インデックスを行から列に変換する
unstackの方が良く使うイメージvalue_counts
ユニークな値毎にその個数をカウント
1行1列をピンポイントで取得
df.loc['行名', 'カラム名'] # 出力は値のみ1列の#番目を取得
df.iloc[:, [1]] # カッコ内の数値は先頭を0とするカラム番号drop
#1列削除 df.drop('カラム名', axis =1) #複数列削除 df.drop(['カラム名','カラム名'], axis =1)isnull().sum()
Nullが含まれている列を調査し、列ごとのnull数を出す
concat
二つのデータフレームを結合
pd.concat([df1, df2], axis =1)as_matrix
データフレームをアレイに変換
ランダムフォレストに入力するときや、ディープラーニングに入力するときに使えるpd.series
アレイをデータフレームに変換
- 投稿日:2019-08-27T15:34:42+09:00
optuna入門
機械学習モデルのハイパーパラメーターの最適化の為に作られたベイズ最適化packageであるoptunaの使い方を調べたのでまとめます
optunaには何ができるか
ベイズ最適化の中でも新しい手法であるTPEを用いた最適化をやってくれます。シングルプロセスで手軽に使う事もできますし、多数のマシンで並列に学習する事もできます。並列処理を行う場合はデータベース上にoptunaファイルを作成して複数マシンから参照する事でこれを実現いますので、当該DBにアクセスできるマシンすべてが学習に参加できるのが素晴らしいところです。optunaファイルがあれば途中再開も出来ますのでお盆に会社が停電になって連休明けに再開するような場合にも安心です。
公式チュートリアル
https://optuna.readthedocs.io/en/stable/tutorial/first.html
APIリファレンス
https://optuna.readthedocs.io/en/stable/reference/index.html本記事の内容
- シングルプロセスでの基本的な使い方
- 最適化の様子を可視化するコードと結果
データベースを使うやり方はこの記事では扱いません。
基本の使い方
ざっくり以下のような手順で使います
1. optuna.create_study()でoptuna.studyインスタンスをつくる
2. 最小化したいスコアを返り値とする関数を定義する
3. studyインスタンスのoptimize()に2でつくった関数を渡して最適化する例として公式チュートリアルのコードを示します
pythonimport optuna def objective(trial): x = trial.suggest_uniform('x', -10, 10) score = (x - 2) ** 2 print('x: %1.3f, score: %1.3f' % (x, score)) return score study = optuna.create_study() study.optimize(objective, n_trials=100)何をどう最適化するかはすべて関数に書いて渡す仕組みです。最適化する変数はまとめてoptuna.trial.Trialとして受け取り、関数内で[x = trial.suggest_uniform('x', -10, 10)]のようにして変数に置き換えて使います。複数の変数を渡したい場合も[x2 = trial.suggest_loguniform('x2', 0.0001, 1000)]などのように書き足していけばoptuna.studyインスタンスの方でtrialに追加してくれます。どういう動作なのか分からなくて最初戸惑ったんですが、めちゃめちゃ簡潔に書けるのが素晴らしいです。
デバッグするときの変数の渡し方
optuna用の関数は変数をoptuna.trial.Trialオブジェクトとして渡さないといけないので、引数に定数を与えて動作を確認したい場合はTrialオブジェクトに変換しなければなりません。その為にあるのがoptuna.trial.FixedTrial()で、辞書型にして放り込めば変換してくれます。
pythonobjective(optuna.trial.FixedTrial({'x': 1}))結果の見方
ベストスコアが得られたときの結果は以下のように見られます
python>>> study.best_params # best_valueを出したときのparameter {'x': 1.9515800599830937} >>> study.best_value # 一番良いスコア 0.0023444905912408044 >>> study.best_trial #best_valueを出したときの試行内容 FrozenTrial(number=95, state=<TrialState.COMPLETE: 1>, value=0.0023444905912408044, datetime_start=datetime.datetime(2019, 8, 27, 14, 14, 46, 915766), datetime_complete=datetime.datetime(2019, 8, 27, 14, 14, 46, 922766), params={'x': 1.9515800599830937}, user_attrs={}, system_attrs={'_number': 95}, intermediate_values={}, params_in_internal_repr={'x': 1.9515800599830937}, trial_id=95)各試行の結果もすべて保存されています
python>>> type(study.trials) # 試行結果はlist型で入ってます list >>> study.trials[0] # 1回目の試行結果 FrozenTrial(number=0, state=<TrialState.COMPLETE: 1>, value=13.19350872351688, datetime_start=datetime.datetime(2019, 8, 27, 14, 14, 45, 722910), datetime_complete=datetime.datetime(2019, 8, 27, 14, 14, 45, 727912), params={'x': 5.6322869825382575}, user_attrs={}, system_attrs={'_number': 0}, intermediate_values={}, params_in_internal_repr={'x': 5.6322869825382575}, trial_id=0) >>> study.trials[0].value # 1回目の試行でのスコア 13.19350872351688 >>> study.trials[0].datetime_start # 開始時間 2019-08-27 14:14:45.722910 >>> study.trials[0].datetime_complete # 終了時間 2019-08-27 14:14:45.727912 >>> study.trials[0].params_in_internal_repr # 1回目の試行のparameter {'x': 5.6322869825382575}個人的に開始終了時間が入っているのがポイント高いです
変数の設定方法いろいろ
最初のサンプルコードで使ったtrial.suggest_uniform()による均一分布の探索以外にもいろいろ種類があります。
pythondef objective(trial): # Categorical parameter optimizer = trial.suggest_categorical('optimizer', ['MomentumSGD', 'Adam']) # Int parameter num_layers = trial.suggest_int('num_layers', 1, 3) # Uniform parameter dropout_rate = trial.suggest_uniform('dropout_rate', 0.0, 1.0) # Loguniform parameter learning_rate = trial.suggest_loguniform('learning_rate', 1e-5, 1e-2) # Discrete-uniform parameter drop_path_rate = trial.suggest_discrete_uniform('drop_path_rate', 0.0, 1.0, 0.1)listから選ぶ、指定範囲の整数から選ぶ、指定範囲の均一分布から選ぶ、指定範囲の指数分布から選ぶ、指定範囲の離散値から選ぶなどがありますので、普通にハイパーパラメーターの最適化をするのに不足する事はないと思います。
これ以外にもいくつかありますので詳しくは以下を参照してください
https://optuna.readthedocs.io/en/stable/reference/trial.html最適化の様子を可視化してみる
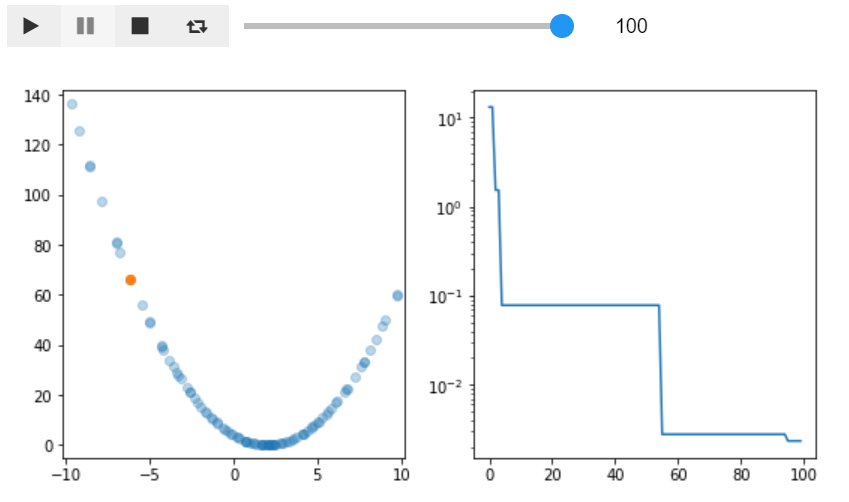
ipywidgetsで最適化していく様子を確認してみました。再生ボタンを押すと1つずつ点を打っていく様子が確認できます。
pythonimport numpy as np import matplotlib.pyplot as plt from ipywidgets import Play, IntSlider, jslink, HBox, interactive_output values = [each.value for each in study.trials] best_values = [np.min(values[:k+1]) for k in range(len(values))] x = [each.params_in_internal_repr['x'] for each in study.trials] def f(k): plt.figure(figsize=(9,4.5)) ax = plt.subplot(121) ax.set_xlim(np.min(x)-0.5, np.max(x)+0.5) ax.set_ylim(np.min(values)-5, np.max(values)+5) ax.scatter(x[:k], values[:k], alpha=0.3) ax.scatter(x[k-1], values[k-1]) ax = plt.subplot(122) ax.plot(best_values[:k]) ax.set_yscale('log') plt.show() play = Play(value=1, min=0, max=len(study.trials), step=1, interval=500, description="Press play",) slider = IntSlider(min=0, max=len(study.trials)) jslink((play, 'value'), (slider, 'value')) ui = HBox([play, slider]) out = interactive_output(f, {'k': slider}) display(ui, out)
とりあえず見たい方はこちらもどうそ
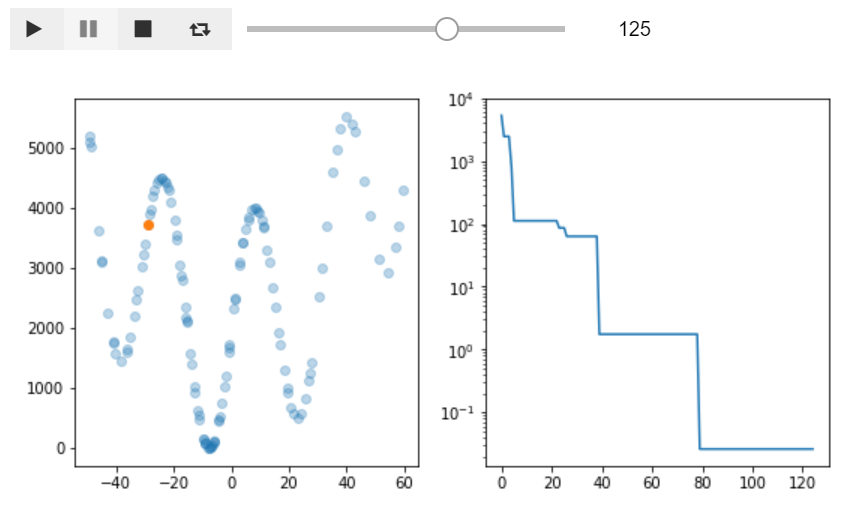
https://twitter.com/studio_haneya/status/1166195464984616961最適化の様子を可視化してみる
pythonimport optuna import numpy as np import matplotlib.pyplot as plt from ipywidgets import Play, IntSlider, jslink, HBox, interactive_output # 正弦波を足してlocal minimumのある関数を作成 def objective(trial): x = trial.suggest_uniform('x', -50, 60) score = x ** 2 + np.sin(x/5)*2000 + 1939.7 print('x: %1.3f, score: %1.3f' % (x, score)) return score # 最適化を実行 study = optuna.create_study() study.optimize(objective, n_trials=200) # 結果をプロットする為に値を加工 values = [each.value for each in study.trials] best_values = [np.min(values[:k+1]) for k in range(len(values))] x = [each.params_in_internal_repr['x'] for each in study.trials] # プロットする関数 def f(k): plt.figure(figsize=(9,4.5)) ax = plt.subplot(121) ax.set_xlim(np.min(x)-5, np.max(x)+5) ax.set_ylim(np.min(values)-300, np.max(values)+300) ax.scatter(x[:k], values[:k], alpha=0.3) ax.scatter(x[k-1], values[k-1]) ax = plt.subplot(122) ax.plot(best_values[:k]) ax.set_yscale('log') plt.show() # ipywidgetで表示 play = Play(value=1, min=0, max=len(study.trials), step=1, interval=500, description="Press play",) slider = IntSlider(min=0, max=len(study.trials)) jslink((play, 'value'), (slider, 'value')) ui = HBox([play, slider]) out = interactive_output(f, {'k': slider}) display(ui, out)
全体像を的確に探りつつlocal minimumにひっかかる事なく最適値付近にたどり着いているのが素晴らしいです。
まとめ
optunaめっちゃ良いのでみんな使うべき
- 投稿日:2019-08-27T15:23:17+09:00
【初心者】pythonで0から Project Euler を解いてみた 18,67
おはこんばんにちわ!!
夏休み終わりました。地元の花火大会の日私はコンビニでカップルのレジをピッピピッピやってましたよ(泣)
今回はeuler18と67を解くわよ!
問題文はここみなさい!!
18問目
http://odz.sakura.ne.jp/projecteuler/index.php?cmd=read&page=Problem%2018
67問目
http://odz.sakura.ne.jp/projecteuler/index.php?cmd=read&page=Problem%2067
今回はアルゴリズムが同じなので一緒に作っちゃう?アルゴリズム
まずはこれぇ!
まず、スカートをめくるようにしたから見ていくわよっ!!
2と4を比べて大きいほうを一つ上のものに足していくわ!
少し難しく書くとlist使って
list[2][0]とlist[2][1]をくらべるのよ
ちなみに今回二次元配列を使ってくわ❕
次に青のところを比べて大きいのを上に足すわ!!
そしたら7と4が11と10になったの、わかるぅ??
そしたら私のだいすきなピンクちゃんの11,10を比べて大きいのを足して完成だわ!!コード
 pro = """75 95 64 17 47 82 18 35 87 10 20 04 82 47 65 19 01 23 75 03 34 88 02 77 73 07 63 67 99 65 04 28 06 16 70 92 41 41 26 56 83 40 80 70 33 41 48 72 33 47 32 37 16 94 29 53 71 44 65 25 43 91 52 97 51 14 70 11 33 28 77 73 17 78 39 68 17 57 91 71 52 38 17 14 91 43 58 50 27 29 48 63 66 04 68 89 53 67 30 73 16 69 87 40 31 04 62 98 27 23 09 70 98 73 93 38 53 60 04 23""" pro = pro.strip().split("\n") for i in range(len(pro)): pro[i] = pro[i].strip().split(" ") pro[i] = [int(x) for x in pro[i]] num = [] ne_num = 0 for x in range(len(pro)-1,0,-1): for y in range(len(pro[x])- 1): pro[x-1][y] += max(pro[x][y],pro[x][y+1]) print(pro[0])pro = pro.strip().split("\n") for i in range(len(pro)): pro[i] = pro[i].strip().split(" ") pro[i] = [int(x) for x in pro[i]]
pro = """75 95 64 17 47 82 18 35 87 10 20 04 82 47 65 19 01 23 75 03 34 88 02 77 73 07 63 67 99 65 04 28 06 16 70 92 41 41 26 56 83 40 80 70 33 41 48 72 33 47 32 37 16 94 29 53 71 44 65 25 43 91 52 97 51 14 70 11 33 28 77 73 17 78 39 68 17 57 91 71 52 38 17 14 91 43 58 50 27 29 48 63 66 04 68 89 53 67 30 73 16 69 87 40 31 04 62 98 27 23 09 70 98 73 93 38 53 60 04 23""" pro = pro.strip().split("\n") for i in range(len(pro)): pro[i] = pro[i].strip().split(" ") pro[i] = [int(x) for x in pro[i]] num = [] ne_num = 0 for x in range(len(pro)-1,0,-1): for y in range(len(pro[x])- 1): pro[x-1][y] += max(pro[x][y],pro[x][y+1]) print(pro[0])pro = pro.strip().split("\n") for i in range(len(pro)): pro[i] = pro[i].strip().split(" ") pro[i] = [int(x) for x in pro[i]]ここで一つ一つをリストの要素にして二次元配列にするわ!!
ここ大切?私ここで一日悩んで結局調べてしまったわ(泣)num = [] ne_num = 0 for x in range(len(pro)-1,0,-1): for y in range(len(pro[x])- 1): pro[x-1][y] += max(pro[x][y],pro[x][y+1]) print(pro[0])ここでさっきのアルゴリズムの登場だわっ!
range(len(pro)-1,0,-1): で赤い矢印の役目をはたしているわっ!!!
二重ループ使ってガンガンゴリゴリ計算していくわっ!!!
そして最後にlist[0]が答えになるってわけ?
どぉ??みんな分かったぁ??
67問目コードも載せ解くわ?txet_deta = open("triangle.txt") txet = txet_deta.read() txet = txet.strip().split("\n") for x in range(len(txet)): txet[x] = txet[x].strip().split(" ") txet[x] = [int(y) for y in txet[x]] #print(txet) for i in range(len(txet)-1,0,-1): for n in range(0,i): txet[i-1][n] += max(txet[i][n],txet[i][n+1]) print(txet[0])やり方は一緒よ?
みんな頑張のよ?みんなも暑さには気を付けるのよ!
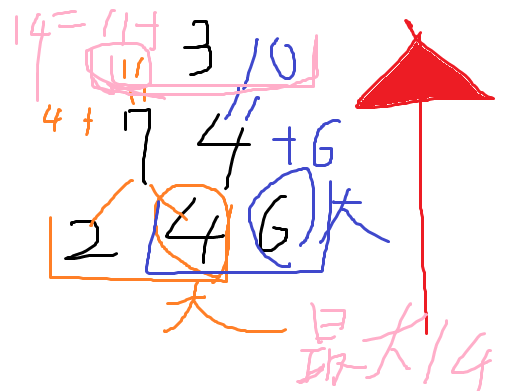
水分補給しなさいね!!
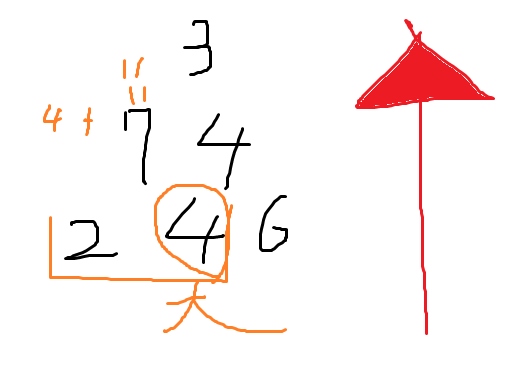
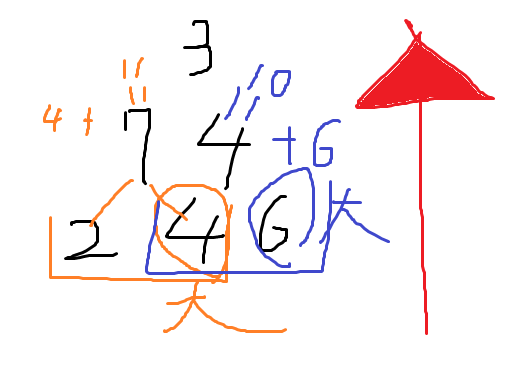
- 投稿日:2019-08-27T15:22:11+09:00
python Bottle chrome icon エラーが出たとき!
python Bottle chrome icon エラーが出たとき!
Failed to load resource: the server responded with a status of 404 (Not Found)
なんとも気分の悪いエラーである。
「icoファイルがないというエラー」
icoファイルを作ったけどどこに入れればいいの!
解決方法いろいろあるが、Bottleの立場に立って考えよう。bottle.pyfrom bottle import * @route('/favicon.ico') def favcon(): return static_file('favicon.ico', root='./static')favicon.icoを呼びに来た時にstaticフォルダの下に置いたicoをロードしてあげよう。
C:. │ app.py │ bottle4j_ico.pyproj │ bottle4j_ico.pyproj.user │ requirements.txt │ routes.py ├─static │ │ favicon.ico ### ここにICOファイルを配置 │ ├─content │ │ bootstrap-grid.css │ │ bootstrap-grid.css.map │ │ bootstrap-grid.min.css │ │ bootstrap-grid.min.css.map │ │ bootstrap-reboot.css │ │ bootstrap-reboot.css.map │ │ bootstrap-reboot.min.css │ │ bootstrap-reboot.min.css.map │ │ bootstrap.css │ │ bootstrap.css.map │ │ bootstrap.min.css │ │ bootstrap.min.css.map │ │ jumbotron.css │ │ site.css │ │ │ ├─fonts │ │ glyphicons-halflings-regular.eot │ │ glyphicons-halflings-regular.svg │ │ glyphicons-halflings-regular.ttf │ │ glyphicons-halflings-regular.woff │ │ │ └─scripts │ bootstrap.bundle.js │ bootstrap.bundle.js.map │ bootstrap.bundle.min.js │ bootstrap.bundle.min.js.map │ bootstrap.js │ bootstrap.js.map │ bootstrap.min.js │ bootstrap.min.js.map │ jquery-1.10.2.intellisense.js │ jquery-1.10.2.js │ jquery-1.10.2.min.js │ jquery-1.10.2.min.map │ jquery.validate-vsdoc.js │ jquery.validate.js │ jquery.validate.min.js │ jquery.validate.unobtrusive.js │ jquery.validate.unobtrusive.min.js │ modernizr-2.6.2.js │ respond.js │ respond.min.js │ _references.js │ ├─views │ about.tpl │ contact.tpl │ index.tpl │ layout.tpl │
はい消えたよ!
「いいよね」してね。
- 投稿日:2019-08-27T14:52:30+09:00
大規模日本語ビジネスニュースコーパスを学習したELMo(MeCab利用)モデルの利用方法と精度比較検証
こんにちは、ストックマークの kaerururu (@kaeru_nantoka) です。
今回は、
1 ) 弊社の森長がビジネスドメインのニュース記事で学習し、先日ご紹介した 事前学習済みELMo を Google Colaboratory 上で動かす方法のご紹介
2 ) 単語単位埋め込みモデルと文字単位・単語単位埋め込みモデル、両モデルの精度比較検証
について書いていきます。
精度比較検証のソースコードは私の GitHub リポジトリ に置いておりますので、よろしければご覧ください。
目次
ELMo とは
ELMo を Google Colaboratory で使う
単語単位埋め込みモデルと文字単位・単語単位埋め込みモデル、両モデルの精度比較検証
まとめ
1. ELMo とは
森長の こちらの記事 をご参照ください。
2. ELMo を Google Colaboratory で使う
# まず GoogleCoraboratory の実行環境上で Google Drive にアップロードしているファイル等を使用できるように同期します。 (マウント) # 以下のコードを実行すると /content/drive/My\Drive のパスで 'マイドライブ' にアクセスできるようになります。 from google.colab import drive drive.mount('/content/drive') # 必要なライブラリをインストールします。 !pip install overrides !git clone https://github.com/HIT-SCIR/ELMoForManyLangs.git !sudo python 'ELMoForManyLangs/setup.py' install # 必要なライブラリをインポートします。 import numpy as np import pandas as pd from ELMoForManyLangs.elmoformanylangs import Embedder from overrides import overrides# https://drive.google.com/drive/u/1/folders/1sau1I10rFeAn8BDk8eZDL5qaEjTlNghp # こちらからダウンロードし、マイドライブにアップロードします。 # ディレクトリ構成図は以下のようにしました。 マイドライブ/ | ┗ ELMo(MeCab+NEologd,大規模日本語ビジネスニュースコーパス) | ┝ 単語単位埋め込みモデル | ┗ 文字単位・単語単位埋め込みモデルword_model_path = "drive/My Drive/ELMo(MeCab+NEologd,大規模日本語ビジネスニュースコーパス)/単語単位埋め込みモデル" char_model_path = "drive/My Drive/ELMo(MeCab+NEologd,大規模日本語ビジネスニュースコーパス)/文字単位・単語単位埋め込みモデル" # 検証を簡単にするために以下の分かち書き済みの文章をベクトル化してみます。 sentence = [["私", "は", "かえるるる", "です", "。"]] # 二文以上を入力とする場合は以下のような形式にします。 #sentence = [["私", "は", "かえるるる", "です", "。"], ["今日", "は", "良い", "日", "です", "。"]] # 文字ベースモデルを読み込みます。 char_e = Embedder(char_model_path) # ベクトル化します。 char_e.sents2elmo(sentence) ''' [array([[-0.4960455 , 0.23145533, -0.68693703, ..., -1.8998976 , 0.12295818, 0.84103614], [-0.5553099 , 0.38843736, 1.1085998 , ..., -1.2523936 , 0.3710082 , 0.47726187], [ 0.66378814, 0.7664747 , -0.7795389 , ..., 0.15099259, 0.5987463 , 0.25316635], [ 1.6014119 , -0.8411358 , 0.14325786, ..., -1.3320394 , -0.28175083, -0.13953142], [ 0.06204838, -0.19042088, 0.03529637, ..., 0.43587098, -0.3109077 , 0.8177585 ]], dtype=float32)] ''' # 上記のケースだと次元数は以下のようになります。 # (文章数, 文章の単語数, 各単語ベクトルの次元数) # (1, 5, 1024) # 単語ベースモデルを読み込みます。 word_e = Embedder(word_model_path) # ベクトル化します。 word_e.sents2elmo(sentence) ''' [array([[-0.9826827 , 1.348456 , -0.10182356, ..., 0.08225163, 0.2174012 , 0.19200923], [-1.1222464 , 1.0925405 , 0.21446343, ..., 0.2424735 , -0.10293475, -1.7148284 ], [-0.84306383, 1.1494427 , 0.45648345, ..., -0.00976461, 0.15618794, 0.3466216 ], [-0.6785489 , 1.3507837 , -0.01715413, ..., 0.27897805, -0.16935939, -1.5792443 ], [-0.3811637 , 1.2148697 , 1.1317929 , ..., 0.31342533, -0.4075661 , -0.68974656]], dtype=float32)] ''' # 上記のケースだと次元数は以下のようになります。 # (文章数, 文章の単語数, 各単語ベクトルの次元数) # (1, 5, 1024)以上、簡単に ELMo を Google Colaboratory で使用することができました。
3. 単語単位埋め込みモデルと文字単位・単語単位埋め込みモデル、両モデルの精度比較検証
入力の文章を単語単位で入力としているモデルが単語単位埋め込みモデルで、入力の文章を文字単位及び単語単位で入力としているモデルが文字単位・単語単位埋め込みモデルです。
単語単位と文字単位のモデルの違いについての説明は、こちらの記事 が分かりやすいです。
文字単位の入力も受け付けている分、文字単位・単語単位埋め込みモデルの方が、表現力が高そうです。そこで、簡単な検証で精度比較をしてみました。
検証設定
検証コード : GitHub リポジトリ
データセット : Livedoor ニュースコーパス
タスク : 記事のトピック9値分類
使用フレームワーク : PyTorch
使用ニューラルネットワークモデル : 双方向 LSTM
形態素解析器 ( janome 利用) (学習には Mecab + Neologd を使用しておりますが、本検証では GoogleColaboratry で簡単に pip install できる janome を利用しております。)
評価指標 : accuracy, f1-score
比較モデル
( 1 ) 日本語 wiki 事前学習済み word2vec (以下 : 日本語 w2v) (単語ベクトルの次元数 : 200次元)
東北大学の乾・岡崎研究室が公開してくださっている「日本語 Wikipedia エンティティベクトル」を使用させていただきました。
( 2 ) 日本語 w2v + 日本語 ELMo 単語単位埋め込みモデル (単語ベクトルの次元数 : 200次元(w2v)と 1024次元(ELMo)を連結した 1224次元)
( 3 ) 日本語 w2v + 日本語 ELMo 文字単位・単語単位埋め込みモデル (単語ベクトルの次元数 : 200次元(w2v)と 1024次元(ELMo)を連結した 1224次元)
検証結果
比較モデル accuracy f1-score (1) 0.811397557666214 0.816528911339967 (2) 0.825644504748982 0.827270317269987 (3) 0.835820895522388 0.832877040710358 簡単な検証でも、w2v モデルで獲得したベクトルに ELMo で獲得したベクトルを結合させた方が w2v 単体で獲得したベクトル使用時よりも accuracy と f1-score 両方の指標で 1~2% 程度精度が向上しました。
また、文字単位でも学習している ELMo モデルは未知語でも文字構成からベクトルを生成できるので、未知語が多いタスクでも有用です。本検証で使用した Livedoor ニュースコーパスはビジネスニュース以外のドメインのニュース記事も含まれておりましたので、今回の ELMo モデルにとって未知語が多くあったことから、文字単位で学習させた ELMo を利用したモデルが一番良い精度が出たと思われます。
4. まとめ
今回は、弊社の森長が先日紹介しましたビジネスニュースで学習した ELMo を GoogleColaboratory 上で使用する方法と、単語単位、文字単位・単語単位の両モデルについて 日本語 w2v モデルに結合した時の効果と精度検証の結果をご紹介しました。
この記事をきっかけに弊社の ELMo モデルを使用して楽しく NLP できる方が増えれば大変嬉しいです。
- 投稿日:2019-08-27T14:21:50+09:00
【Python】プロジェクトオイラー Problem 9
ピタゴラス数(ピタゴラスの定理を満たす自然数)とは a < b < c で以下の式を満たす数の組である.
a2 + b2 = c2
例えば, 32 + 42 = 9 + 16 = 25 = 52 である.
a + b + c = 1000 となるピタゴラスの三つ組が一つだけ存在する.
これらの積 abc を計算しなさい.
problem8はこちらから
つまり、a*a + b*b == c*c and a + b + c == 1000ということのはず
a,b,cはそれぞれ1000以下のはずだからrange(1000)でいいはず
かつ、a + b + c == 1000だということは
kotae = 0 for a in range(1,1000): for b in range(a,1000): for c in range(b,1000): if a*a + b*b == c*c and a + b + c == 1000: kotae = a*b*c print(kotae) 31875000正解---
- 投稿日:2019-08-27T13:54:03+09:00
【Python】 プロジェクトオイラー plobrem8
次の1000桁の数字のうち, 隣接する4つの数字の総乗の中で, 最大となる値は, 9 × 9 × 8 × 9 = 5832である.
73167176531330624919225119674426574742355349194934
96983520312774506326239578318016984801869478851843
85861560789112949495459501737958331952853208805511
12540698747158523863050715693290963295227443043557
66896648950445244523161731856403098711121722383113
62229893423380308135336276614282806444486645238749
30358907296290491560440772390713810515859307960866
70172427121883998797908792274921901699720888093776
65727333001053367881220235421809751254540594752243
52584907711670556013604839586446706324415722155397
53697817977846174064955149290862569321978468622482
83972241375657056057490261407972968652414535100474
82166370484403199890008895243450658541227588666881
16427171479924442928230863465674813919123162824586
17866458359124566529476545682848912883142607690042
24219022671055626321111109370544217506941658960408
07198403850962455444362981230987879927244284909188
84580156166097919133875499200524063689912560717606
05886116467109405077541002256983155200055935729725
71636269561882670428252483600823257530420752963450この1000桁の数字から13個の連続する数字を取り出して, それらの総乗を計算する. では、それら総乗のうち、最大となる値はいくらか.
problem6はこちらから
とりあえず1000桁の数字それぞれからそこから12個先までをかけていき、
その最大値を更新したときだけを記録していけば答えがだせるはず
プログラム的には、
for文二回重ねて使って1000桁それぞれの12個先までをかける...①
(自分を含めたら13回繰り返すプログラムを作る)if分を使って最大値のみを記録する...②
とりあえず①からプログラムを書いてみる
sen = 1000 kakeru = 12 for a in range(sen): for b in range(12): print(b) 0.1.2.3.4.5.6.7.8.9.10.11.12.0.1.....これで自分をふくめて13個繰り返したプログラムができた
あとは例の1000桁をリストにして抜き出したいから
sen = 1000 senketa = [731671765~752963450](省略) for a in range(sen): x = 0 hokan = 1 for b in range(12): print(senketa[x]) x += 1エラーが出てしまった...
一応上のプログラムでは一周するたびにxの値が増えていってsenketa[x]から抜き出す値が変わっていくはずだったけど
調べてみたらsenketaのリストはあの1000桁をまとめてひとまとまりということになっているらしい
ならば
7,3,1,6,7,1,7,6,5,3,1,3,3,0,6,2,4,9,1,9,2,2,5,1,1,9,6,7,4,4,2,6,5,7,4,7,4,2,3,5,5,3,4,9,1,9,4,9,3,4,9,6,9,8,3,5,2,0,3,1,2,7,7,4,5,0,6,3,2,6,2,3,9,5,7,8,3,1,8,0,1,6,9,8,4,8,0,1,8,6,9,4,7,8,8,5,1,8,4,3,8,5,8,6,1,5,6,0,7,8,9,1,1,2,9,4,9,4,9,5,4,5,9,5,0,1,7,3,7,9,5,8,3,3,1,9,5,2,8,5,3,2,0,8,8,0,5,5,1,1,1,2,5,4,0,6,9,8,7,4,7,1,5,8,5,2,3,8,6,3,0,5,0,7,1,5,6,9,3,2,9,0,9,6,3,2,9,5,2,2,7,4,4,3,0,4,3,5,5,7,6,6,8,9,6,6,4,8,9,5,0,4,4,5,2,4,4,5,2,3,1,6,1,7,3,1,8,5,6,4,0,3,0,9,8,7,1,1,1,2,1,7,2,2,3,8,3,1,1,3,6,2,2,2,9,8,9,3,4,2,3,3,8,0,3,0,8,1,3,5,3,3,6,2,7,6,6,1,4,2,8,2,8,0,6,4,4,4,4,8,6,6,4,5,2,3,8,7,4,9,3,0,3,5,8,9,0,7,2,9,6,2,9,0,4,9,1,5,6,0,4,4,0,7,7,2,3,9,0,7,1,3,8,1,0,5,1,5,8,5,9,3,0,7,9,6,0,8,6,6,7,0,1,7,2,4,2,7,1,2,1,8,8,3,9,9,8,7,9,7,9,0,8,7,9,2,2,7,4,9,2,1,9,0,1,6,9,9,7,2,0,8,8,8,0,9,3,7,7,6,6,5,7,2,7,3,3,3,0,0,1,0,5,3,3,6,7,8,8,1,2,2,0,2,3,5,4,2,1,8,0,9,7,5,1,2,5,4,5,4,0,5,9,4,7,5,2,2,4,3,5,2,5,8,4,9,0,7,7,1,1,6,7,0,5,5,6,0,1,3,6,0,4,8,3,9,5,8,6,4,4,6,7,0,6,3,2,4,4,1,5,7,2,2,1,5,5,3,9,7,5,3,6,9,7,8,1,7,9,7,7,8,4,6,1,7,4,0,6,4,9,5,5,1,4,9,2,9,0,8,6,2,5,6,9,3,2,1,9,7,8,4,6,8,6,2,2,4,8,2,8,3,9,7,2,2,4,1,3,7,5,6,5,7,0,5,6,0,5,7,4,9,0,2,6,1,4,0,7,9,7,2,9,6,8,6,5,2,4,1,4,5,3,5,1,0,0,4,7,4,8,2,1,6,6,3,7,0,4,8,4,4,0,3,1,9,9,8,9,0,0,0,8,8,9,5,2,4,3,4,5,0,6,5,8,5,4,1,2,2,7,5,8,8,6,6,6,8,8,1,1,6,4,2,7,1,7,1,4,7,9,9,2,4,4,4,2,9,2,8,2,3,0,8,6,3,4,6,5,6,7,4,8,1,3,9,1,9,1,2,3,1,6,2,8,2,4,5,8,6,1,7,8,6,6,4,5,8,3,5,9,1,2,4,5,6,6,5,2,9,4,7,6,5,4,5,6,8,2,8,4,8,9,1,2,8,8,3,1,4,2,6,0,7,6,9,0,0,4,2,2,4,2,1,9,0,2,2,6,7,1,0,5,5,6,2,6,3,2,1,1,1,1,1,0,9,3,7,0,5,4,4,2,1,7,5,0,6,9,4,1,6,5,8,9,6,0,4,0,8,0,7,1,9,8,4,0,3,8,5,0,9,6,2,4,5,5,4,4,4,3,6,2,9,8,1,2,3,0,9,8,7,8,7,9,9,2,7,2,4,4,2,8,4,9,0,9,1,8,8,8,4,5,8,0,1,5,6,1,6,6,0,9,7,9,1,9,1,3,3,8,7,5,4,9,9,2,0,0,5,2,4,0,6,3,6,8,9,9,1,2,5,6,0,7,1,7,6,0,6,0,5,8,8,6,1,1,6,4,6,7,1,0,9,4,0,5,0,7,7,5,4,1,0,0,2,2,5,6,9,8,3,1,5,5,2,0,0,0,5,5,9,3,5,7,2,9,7,2,5,7,1,6,3,6,2,6,9,5,6,1,8,8,2,6,7,0,4,2,8,2,5,2,4,8,3,6,0,0,8,2,3,2,5,7,5,3,0,4,2,0,7,5,2,9,6,3,4,5,0
千分割しました
これならいけるはず
sen = 1000 senketa = [7,3,1,6,7,~6,3,4,5,0](省略) for a in range(sen): x = 0 hokan = 1 for b in range(12): print(senketa[x]) x += 1大量に数字が出てきているから成功しているっぽい
次は掛け合わせてみる
sen = 1000 kakeru = 13 senketa = [7,3,1,6,7,~6,3,4,5,0](省略) for a in range(sen): x = 0 hokan = 1 for b in range(12): hokan *= senketa[x] x += 1 print(hokan) 7 21 21 126 882 882 6174 37044 185220 555660 555660 1666980この答えをひたすら出している
なるほどxが一回目のforぶんで0に戻っているから先に進まなかったみたい
xの最初の値を12にしてfor文一回目で-12して、
二回目のfor文でxを一回ごとに1ずつ増やしていけばうまくいくはず
そしてあとはif文を使って最大値を記録する
sen = 1000 kakeru = 13 x = 0 kotae = 1 senketa = [7,3,1,6,7,1,7,6,5,3,1,3,3,0,6,2,4,9,1,9,2,2,5,1,1,9,6,7,4,4,2,6,5,7,4,7,4,2,3,5,5,3,4,9,1,9,4,9,3,4,9,6,9,8,3,5,2,0,3,1,2,7,7,4,5,0,6,3,2,6,2,3,9,5,7,8,3,1,8,0,1,6,9,8,4,8,0,1,8,6,9,4,7,8,8,5,1,8,4,3,8,5,8,6,1,5,6,0,7,8,9,1,1,2,9,4,9,4,9,5,4,5,9,5,0,1,7,3,7,9,5,8,3,3,1,9,5,2,8,5,3,2,0,8,8,0,5,5,1,1,1,2,5,4,0,6,9,8,7,4,7,1,5,8,5,2,3,8,6,3,0,5,0,7,1,5,6,9,3,2,9,0,9,6,3,2,9,5,2,2,7,4,4,3,0,4,3,5,5,7,6,6,8,9,6,6,4,8,9,5,0,4,4,5,2,4,4,5,2,3,1,6,1,7,3,1,8,5,6,4,0,3,0,9,8,7,1,1,1,2,1,7,2,2,3,8,3,1,1,3,6,2,2,2,9,8,9,3,4,2,3,3,8,0,3,0,8,1,3,5,3,3,6,2,7,6,6,1,4,2,8,2,8,0,6,4,4,4,4,8,6,6,4,5,2,3,8,7,4,9,3,0,3,5,8,9,0,7,2,9,6,2,9,0,4,9,1,5,6,0,4,4,0,7,7,2,3,9,0,7,1,3,8,1,0,5,1,5,8,5,9,3,0,7,9,6,0,8,6,6,7,0,1,7,2,4,2,7,1,2,1,8,8,3,9,9,8,7,9,7,9,0,8,7,9,2,2,7,4,9,2,1,9,0,1,6,9,9,7,2,0,8,8,8,0,9,3,7,7,6,6,5,7,2,7,3,3,3,0,0,1,0,5,3,3,6,7,8,8,1,2,2,0,2,3,5,4,2,1,8,0,9,7,5,1,2,5,4,5,4,0,5,9,4,7,5,2,2,4,3,5,2,5,8,4,9,0,7,7,1,1,6,7,0,5,5,6,0,1,3,6,0,4,8,3,9,5,8,6,4,4,6,7,0,6,3,2,4,4,1,5,7,2,2,1,5,5,3,9,7,5,3,6,9,7,8,1,7,9,7,7,8,4,6,1,7,4,0,6,4,9,5,5,1,4,9,2,9,0,8,6,2,5,6,9,3,2,1,9,7,8,4,6,8,6,2,2,4,8,2,8,3,9,7,2,2,4,1,3,7,5,6,5,7,0,5,6,0,5,7,4,9,0,2,6,1,4,0,7,9,7,2,9,6,8,6,5,2,4,1,4,5,3,5,1,0,0,4,7,4,8,2,1,6,6,3,7,0,4,8,4,4,0,3,1,9,9,8,9,0,0,0,8,8,9,5,2,4,3,4,5,0,6,5,8,5,4,1,2,2,7,5,8,8,6,6,6,8,8,1,1,6,4,2,7,1,7,1,4,7,9,9,2,4,4,4,2,9,2,8,2,3,0,8,6,3,4,6,5,6,7,4,8,1,3,9,1,9,1,2,3,1,6,2,8,2,4,5,8,6,1,7,8,6,6,4,5,8,3,5,9,1,2,4,5,6,6,5,2,9,4,7,6,5,4,5,6,8,2,8,4,8,9,1,2,8,8,3,1,4,2,6,0,7,6,9,0,0,4,2,2,4,2,1,9,0,2,2,6,7,1,0,5,5,6,2,6,3,2,1,1,1,1,1,0,9,3,7,0,5,4,4,2,1,7,5,0,6,9,4,1,6,5,8,9,6,0,4,0,8,0,7,1,9,8,4,0,3,8,5,0,9,6,2,4,5,5,4,4,4,3,6,2,9,8,1,2,3,0,9,8,7,8,7,9,9,2,7,2,4,4,2,8,4,9,0,9,1,8,8,8,4,5,8,0,1,5,6,1,6,6,0,9,7,9,1,9,1,3,3,8,7,5,4,9,9,2,0,0,5,2,4,0,6,3,6,8,9,9,1,2,5,6,0,7,1,7,6,0,6,0,5,8,8,6,1,1,6,4,6,7,1,0,9,4,0,5,0,7,7,5,4,1,0,0,2,2,5,6,9,8,3,1,5,5,2,0,0,0,5,5,9,3,5,7,2,9,7,2,5,7,1,6,3,6,2,6,9,5,6,1,8,8,2,6,7,0,4,2,8,2,5,2,4,8,3,6,0,0,8,2,3,2,5,7,5,3,0,4,2,0,7,5,2,9,6,3,4,5,0] for a in range(sen): x -= 12 hokan = 1 for b in range(kakeru): hokan *= senketa[x] x += 1 if hokan > kotae: kotae = hokan print(kotae) 23514624000おわり
problem9はこちらから
- 投稿日:2019-08-27T13:07:02+09:00
Python: コメント文を認識してスキップする
以下の入力ファイルがあり、コメント文を
#で示しているとする。# title # subtitile aaa bbb cccコメント文だと認識させるには、文字列のメソッドである
startswithを使用すれば良い。
例えば、以下のPythonのコードを動かしてみる:with open("test.txt") as fin: for line in fin: if line.startswith("#"): continue print(line.rstrip())すると
# aaa bbb cccおや、これでは
#の前に空白があるとコメント文だと認識してくれないようだ。この問題を解決するためには、line.startswith("#")をline.strip().startswith("#")に変えれば良い:with open("test.txt") as fin: for line in fin: if line.strip().startswith("#"): continue print(line.rstrip())すると
aaa bbb cccとなり解決。
- 投稿日:2019-08-27T12:57:52+09:00
【疑問解決】Python __init__.pyってなに?
tl;dr
Pythonのソースコードのディレクトリの下に
__init__.pyというファイルがあります。
このファイルの役割をまとめます。用意するもの・環境
- macOS Mojave 10.14.6
- Python 3.7(ANACONDA3)
- PyCharm 2019.2
開発環境の構築は下記の記事を参考にしてください。
【これさえ読めばOK】MacでPythonを使って開発するための準備
https://qiita.com/ryoichiro001/items/35a232a430c41dd512faディレクトリ(フォルダ)をパッケージとして利用できる
このようなディレクトリ構成があったとします。
. ├── README.md ├── inputs_files │ └── urls.txt ├── main.py ├── outputs_files │ └── out_csv.txt └── scripts ├── __init__.py └── file_utils.pyそうすると下記のようにして利用できます。
from scripts import file_utilsこの場合、
__init__.pyの中身は空(0KB)で構いません。インポートした際に実行されるプログラムを実行
外部のプログラムからimportされた際に実行されるプログラムを書いておくことができます。
必ず動かす初期処理を記述しておくと便利です。Python3.3以降では
__init__.pyがなくてもフォルダをパッケージとして認識してくれるここまで書いておいてアレですが、Python3.3以降では、
__init__.pyファイルがなくてもパッケージとして利用できます。Python公式ドキュメント
https://docs.python.org/ja/dev/whatsnew/3.3.html#pep-420-implicit-namespace-packages参考URL
Python
__init__.pyの機能について
https://www.kangetsu121.work/entry/2018/09/16/004008
- 投稿日:2019-08-27T12:21:48+09:00
ハノイの塔のアルゴリズムをやってみた
会社でアルゴリズムの話題でハノイの塔のアルゴリズム考える話を聞いて、ちょっと前にやったのでQiitaの記事にしてみようかなと
ハノイの塔とは
wiki
https://ja.wikipedia.org/wiki/%E3%83%8F%E3%83%8E%E3%82%A4%E3%81%AE%E5%A1%94ピラミッド状に重なってるものを、小さいものの上に大きいものは乗せてはいけないってルールで最初の一から別の位置へ、三つの位置を移動させながら移し替えるパズルです。
以下では言葉を統一するために移動させるものを円盤、円盤を置ける場所を杭とします円盤の数によらず三つの杭で移し替えることは可能なのか
数学的帰納法的な論理展開で証明できます。
(1) 円盤が一枚の時
自明(2) 円盤が1..n-1枚の時、移し替えることが可能だと仮定(n>=2)
円盤がn枚の時
n枚目以外のn-1枚の円盤は別の杭に移動させることは仮定より可能
n-1枚を別の杭に移動させたのちに、n枚目の円盤を残る空いている杭に移し替え、再度n枚目の円盤の上にn-1枚の円盤を移し替えればn枚の円盤を三つの杭でうつしかえることができる。以上より三つで移し替えることができる。
アルゴリズムを考えてみた
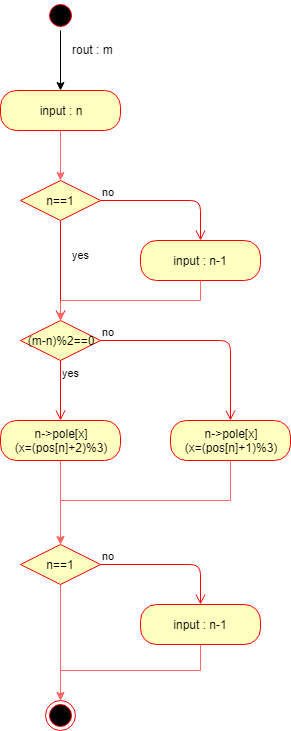
アルゴリズムを考える際に、上記の円盤の塊を別の杭に移し替えるイメージがあって何となく再帰関数を用いてうまいことやれそうだなって思って考えてました。
ただ、n枚の円盤の塊を動かす関数をうまく定義できずにうまくいかずに悩むこと半日。1枚目の円盤の上には何も置けないのでそいつの動きに注目してみようと思い、円盤3枚とか4枚とかで動きを確認したところ何やら規則的な動きをしてるような感じがあり、他の円盤に対しても確認してみたところ、他も同様の規則性が!!
このあたりの規則性に関しては実際にお手を動かして確認された方が感動するかと思います。で、私がそこから導いたアルゴリズムは以下のような感じです。
円盤を塊で見るのではなく、円盤一つ一つを規則的にうごかす形式です。
書き方悪いので補足します。
routってあるのは何枚の円盤を動かすかって話です。
input:n-1ってあるのは、この関数をinput:n-1で実行させろってことです。で、これをpythonで記述したのが以下のコードになります
import sys pos = [0]*int(sys.argv[1]) pole = [list(range(1,int(sys.argv[1])+1)),[],[]] print(pole) def move(n,m): if n!=1 : move(n-1,m) next = (pos[n-1]+2)%3 if (m-n)%2==0 else (pos[n-1]+1)%3 pole[next].insert(0,pole[pos[n-1]].pop(0)) pos[n-1]=next print(pole) if n!=1 : move(n-1,m) move(int(sys.argv[1]),int(sys.argv[1]))できる限り短く書いてやろうと頑張りましたが、自分にはこれが限界でした...
そもそも円盤の位置を保持する配列が必要なのかどうか、個人的には疑問だったのですが、その配列なしでうまくやる方法を思いつかなかったので...そのあたりまだまだ改良できそうです。まとめ
Pythonの勉強がてらハノイの塔のアルゴリズムに挑戦しましたが、Pythonの勉強よりも頭の体操になった感じでした。
- 投稿日:2019-08-27T11:32:47+09:00
立ちあがっているビットを数え上げるアルゴリズム
この記事は何か?
立ちあがっているビットを数え上げるアルゴリズムについて取り上げる。
たとえば十進数で
7という数はPythonでは0b111と表現できる。0bは単に数が二進数であることを表現しているだけなので、数値表現部分は111である。つまり、立ちあがっているビットは3つである。このように、数を十進数で与えられたときに、それを二進数で表現した場合に立ちあがっているビット数を返す方法を探求したい。最下位ビットからナイーブに数え上げる方法
次のような方法がもっともナイーブだろう。
def count_bits(n): count = 0 while n: if n & 1 == 1: count += 1 n >>= 1 return countなんのことはない。数を 1 ビットずつ右にシフトしながら、最下位ビットと
1の AND が1になるものを数えているだけである。立ち上がっているビットを右から落としていく方法
x = x & (x - 1)で x の最下位ビットを落とせる。したがってxが0になるまでx = x & (x - 1)を繰り返すことで、立ち上がっているビットを数えられる。具体的には次のように書ける。
def count_bits(n): count = 0 while n: count += 1 n = n & (n - 1) return count数と立ち上がっているビット数のマップをあらかじめ作っておく方法
あらかじめ
Pythonのリストに「立ち上がっているビット数」を計算してつめておく方法も考えられる。CPythonのリストはC 言語での配列で実装されているため、この方法であれば与えられた数を二進数表現した際に立ち上がっているビットの数をO(1)で返せる。仮に 64 ビットの整数が入力される場合、この方法を単純に適用するとリストが大きくなりすぎるため現実的ではない。そういうときは全体のビット列を n 分割するとよい。入力が 64 ビットの整数である場合、16 ビットごとに分割して考えると、2^16 (すなわち 65536) 個の要素を持つリストさえあればよい。
具体的には、まず次のように 16 ビットの整数に対応するリストを作成する。
def _count_bits(n): count = 0 while n: count += 1 n = n & (n - 1) return count PRE_CALCULATED_COUNT = [] for i in range(65536): # 65536 = 2^16 PRE_CALCULATED_COUNT.append(_count_bits(i))ここで計算した
PRE_CALCULATED_COUNTを使い、ビットマスクを使いながら 16 ビットずつ立ち上がりビット数を調べて足し合わせればよい。def count_bits(n): bitmask = 0xffff return (PRE_CALCULATED_COUNT[(n & bitmask)] + PRE_CALCULATED_COUNT[(n >> 16 & bitmask)] + PRE_CALCULATED_COUNT[(n >> (16 * 2) & bitmask)] + PRE_CALCULATED_COUNT[(n >> (16 * 3) & bitmask)])
- 投稿日:2019-08-27T10:36:16+09:00
Jupyter Notebookの開発環境整備[memo]
Jupyterを使い始める時に参考にしたサイトのメモ
フォント、背景色など
https://qiita.com/uratatsu/items/cdc83308ce85a32d0512
白背景色を変更する。上の記事をそのままパクりました。pip install jupyterthemes jt -t onedork -f inconsolata -T -N -cellw 90% -tfs 11キーバインド
https://www.g104robo.com/entry/jupyter-notebook-vim
$ pip install jupyter_contrib_nbextensions $ jupyter contrib nbextension install --user $ mkdir -p $(jupyter --data-dir)/nbextensions $ cd $(jupyter --data-dir)/nbextensions $ git clone https://github.com/lambdalisue/jupyter-vim-binding vim_binding $ jupyter nbextension enable vim_binding/vim_bindingでvim 風のキーバインディングにできるそうです。
ショートカット
https://qiita.com/masafumi_miya/items/6524dbd227705351a00c
コマンドモードでhを押すとショートカットキーの一覧がみれます。
matplotlibでのfigの表示
https://qiita.com/gyu-don/items/062fd82e4dd2a9b6dfbb
matplotlib.use('tkAgg') %matplotlib inline import matplotlib import matplotlib.pyplot as pltのような形で
matplotlib.use('tkAgg')を
%matplotlib inlineimport matplotlib.pyplot as pltの前に書く。importの後だと反映されない。
逆にファイルに出力したい場合は、
https://qiita.com/koichifukushima/items/e63e642431db92178188matplotlib.use('Agg')をimport matplotlibの後につける
ファイルの保存は
plt.savefig('figure.png')その他まとめ
https://qiita.com/ishizakiiii/items/b98bbf8997f039f40058
テーマやデバッグのやり方、レポートをJupyterから作成する方法など色々まとまっています。
- 投稿日:2019-08-27T10:24:37+09:00
ゼロから作るDeepLearning作業ログ001
3章【ニューラルネットワーク 〜NNの基礎と活性化関数〜】
Introduction
前章までではANDやORなどの簡単な線形関数を組み合わせることで(層を重ねることで)複雑な非線形識別関数(XOR)を実装可能なことを見ました。
しかしこの方法の非効率的なポイントとして重みパラメータを自分でいちいち設定する必要があることが挙げられます。そこで今回はパラメータ調整を自動で行えるように設定された多重層の線形合成関数(いわゆるニューラルネット)について学習していきます。
ニューラルネットは上記のように入力層、中間層、出力層からなる、線形関数を多層化した関数のことです。
前章でみてきたように単純な関数でも組み合わせるとコンピュータのような複雑な演算が可能なものが完成するのでその威力は期待できそうです。ニューラルネットは数学的に「入力が与えられたら期待する出力を出すような関数を求める」機械学習の世界において線形関数と活性化関数を多重に合成した(人間の脳を真似て作成した)形の関数のことと認識しています。
パーセプトロンの復習

上記の図は二つの信号を受け取ってyを出力するパーセプトロンです。
これを数式で表現すると以下のようになります。y = \left\{ \begin{array}{ll} 0 & (b+w_1x_1+w_2x_2 \leq 0) \\ 1 & (b+w_1x_1+w_2x_2 > 0) \end{array} \right.bのことをバイアス(人によっては重み)と呼ぶのでした。
これはニューロンの発火(値が1となるか0となるか)しやすさを決定する変数であったので、通常重みとは少しニュアンスが異なる場合が多そうです。ここでこの式をよりシンプルに
h(x) = \left\{ \begin{array}{ll} 0 & (x \leq 0) \\ 1 & (x > 0 ) \end{array} \right.を用いて
y = h(b+w_1x_1+w_2x_2)と表示することができます。このように入力信号$(b+w_1x_1+w_2x_2)$を関数によって変換して出力するものとして捉えることができます。この考え方を進めたものが次に出てくる活性化関数です。
活性化関数
活性化関数として様々なものが種類としてあるそうですが、ここでは代表的なもののみ学習します。
ステップ関数
パーセプトロンの実装で用いた、ガウス関数のような階段状のグラフを描く関数のことです。
以下で実際にPythonを用いて実装してみます。def step_function(x) if x > 0: return 1 else: return 0この実装だとNumpyのような多次元配列を引数に取ることはできません。
そこで以下のように実装を修正しましょう。def step_function(x): y = x > 0 return y.astype(np.int)ここでは省略されていますが、二つのことが起こっています。
一つ目はy = x > 0という評価で配列xが全てTrue、Falseのみを引数にもつ配列に変換されています。
二つ目にはastype()というメソッドで引数にとった希望の型に配列を変換しています。デフォルトではTrueは1に、Falseは2に変換されて、結果としては条件を満たして発火した出力ニューロンの部分のみ1になる配列が出力されます。以下でステップ関数のグラフを作成してみましょう。
通常グラフ作成や描画などはmatplotlibというライブラリを用いて行います。import numpy as np import matplotlib.pylab as plt def step_function(x): y = x > 0 return y.astype(np.int) x = np.arange(-5.0,5.0,0.1) y = step_function(x) plt.plot(x,y) plt.ylim(-0.1,1.1) #y軸の範囲を指定している plt.show()コードの解説をしておくと、
np.arange()では-5.0から0.5までの間を0.1区切りにした要素を持つ配列を表示しています。
その他matplotlibのコードについてはある程度の描画のための決まり文句です。
図は以下のように出力されます。
シグモイド関数
続いて少し複雑なシグモイド関数という活性化関数を考えます。
シグモイド関数は以下のように実装されます。import numpy as np def sigmoid(x): return 1/(1+np.exp(-x))注意点として、このシグモイド関数も階段関数と同様に配列を引数にとる関数であることに注意しましょう。
つまり配列の各要素にシグモイド関数を作用させたものとして捉えられます。このコードには後述するNumpyのブロードキャスト機能が関わってきます。
ブロードキャスト機能とは簡単にいうと配列とスカラーの演算結果が、配列の各要素にスカラーを演算させたものと同じになるという機能です。では今回もシグモイド関数をグラフにしてみましょう。
コードとグラフは以下のようになります。
import numpy as np import matplotlib.pylab as plt def sigmoid(x): return 1/(1+np.exp(-x)) x = np.arange(-5.0,5.0,0.1) y = sigmoid(x) plt.plot(x,y) plt.ylim(-0.1,1.1) #y軸の範囲を指定している plt.show()
このシグモイド関数が先ほどの階段関数と大きく異なる点として、返り値が離散的でないこと、グラフが滑らか(数学的には微分可能)ということが挙げられます。この性質が後ほどわかるように大きな意味を持ってきます。
しかし両者の重要な共通点として非線形な関数であることが挙げられます。この非線形性がニューラルネットにとってとても重要である。
なぜなら仮に線形な活性化関数を用いてしまうと、線形関数の合成は線形関数であるので、全体として線形関数になってしまいます。これでは単一の線形関数と変わらず、層を重ねる意味が無くなってしまします。ReLu関数
近年よく用いられている人気の活性化関数がReLuです。
これはシグモイドや階段関数ににている非線形関数ですが、関数としてはとても単純です。
そのため実装も以下のように簡単に行うことができます。def relu(x) return np.maximum(0,x)上記コードの
np.maximumは0とxの配列の各要素を比べています。
つまりは配列の各要素に線形にReLu関数を実行していることになります。またグラフもシンプルで以下のように実装、描画できます。
import numpy as np import matplotlib.pylab as plt def relu(x): return np.maximum(0,x) x = np.arange(-5.0,5.0,0.1) y = relu(x) plt.plot(x,y) plt.ylim(-0.1,1.1) #y軸の範囲を指定している plt.show()
おわり
今回はQitaの練習も兼ねてここまでにします!
次回は多次元配列の計算から書いていきます。



- 投稿日:2019-08-27T08:37:26+09:00
SSDで動画の物体検出をやってみた!
やること
- 動画における物体検出をやってみた
- 物体検出のアルゴリズムはSSD(Single Shot MultiBox Detector)を利用
手順概要
- 1. ソースコードのダウンロード
- 2. 学習済モデルのダウンロード
- 3. 環境構築
- 4. ソースコードの修正
- 5. 動画ファイルの指定
- 6. 物体検出の実行
- 7. 実行結果の変換(png -> gif)
動作環境
- macOS Catalina 10.15 beta
- anaconda 4.6.14
- Python 3.5.4
- tensorflow 1.3.0
- keras 1.2.2
- opencv-python 3.3.0.9
- imageio 2.4.1
1. ソースコードのダウンロード
- 下記コマンドでソースコードをダウンロードします
$ git clone https://github.com/rykov8/ssd_keras.git $ cd ssd_keras2. 学習済モデルのダウンロード
- こちらに学習済モデルが公開されているので、
weights_SSD300.hdf5をダウンロードします
- ダウンロードしたファイルは、プロジェクトの直下に格納します
3. 環境構築
- こちらのAnaconda環境構築用の設定ファイルをダウンロードして、プロジェクトの直下に格納します
- ダウンロードした設定ファイル(.yaml)を元に下記のコマンドでAnacondaの環境を構築します
- また、「imageio」を個別にインストールします
- その後、環境をアクティベートします
$ conda env create -f ykov8_ssd_keras.yaml $ conda install imageio $ source activate rykov8_ssd_keras4. ソースコードの修正
- 私の環境では、以下部分を修正しました
- コンソール上にも物体検出の結果を出力しています
- 物体検出した結果は「testing_utils」の「image」フォルダにpng形式で保存します(182行目)
/testing_utils/videotest.py#-------------- # 12行目 #-------------- # before from scipy.misc import imread, imresize # after from imageio import imread #-------------- # 87行目 #-------------- # before vidw = vid.get(cv2.cv.CV_CAP_PROP_FRAME_WIDTH) vidh = vid.get(cv2.cv.CV_CAP_PROP_FRAME_HEIGHT) # after vidw = vid.get(cv2.CAP_PROP_FRAME_WIDTH) vidh = vid.get(cv2.CAP_PROP_FRAME_HEIGHT) #-------------- # 99行目 #-------------- # before # after num_frame = 0 #-------------- # 162行目 #-------------- # before # after print(text) #-------------- # 182行目 #-------------- # before # after print(text) cv2.imwrite("./image/frame_" + str('{0:04d}'.format(num_frame)) +".png", to_draw) num_frame += 15. 動画ファイルの指定
videotest_example.pyで動画ファイルの指定を行います- 動画ファイルはPexels(フリー動画サイト)からダウンロードしました
/testing_utils/videotest_example.py#-------------- # 24行目 #-------------- # before vid_test.run('path/to/your/video.mkv') # after vid_test.run('../movie/1.mp4')6. 物体検出の実行
- 指定した動画で物体検出の実行をします
- 4.の182行目で記載した通り、「testing_utils」フォルダ内に「image」フォルダを作成しておきます
$ python videotest_example.py7. 実行結果の変換(png -> gif)
- 実行が完了したら、「image」フォルダのpngファイルをgifに変換します
- gifへの変換はPicGIF Liteを使いました
結果(gifファイル)
人混み
歩道と車道
観光地
談笑
ソースコード
https://github.com/hiraku00/ssd_keras_test
参考文献



- 投稿日:2019-08-27T08:27:49+09:00
djangoバージョン
Djangoは環境依存しているモジュールが多々あり、バージョンにより処理が稼働しない可能性がある為、設定環境を書いておくことにしました。
Python3.6.8
理由:一部pcではtensorflowが正常に稼働しない場合がある為
django2.2.4
まずdjango2.1以下だと以下のように存在しない親ノードを見に行きエラーが出る場合があります。
djangoエラー
django.db.migrations.exceptions.NodeNotFoundError: Migration app.0001_initial dependencies reference nonexistent parent node ('auth', '0011_update_proxy_permissions')しかしdjango2.2でも以下エラーが発生するケースがあります。
systemctlでエラー sqlからMariaDBへ
サーバー上でsystemctlするとエラーが発生
sudo systemctl status hoge.comエラー内容
$ sudo systemctl status hoge.com ● hoge.com.service - hoge.com Loaded: loaded (/etc/systemd/system/hoge.com.service; disabled; vendor preset: disabled) Active: failed (Result: exit-code) since 火 2019-08-27 13:58:15 JST; 14s ago Process: 9245 ExecStart=/usr/local/bin/gunicorn --bind 127.0.0.0:8000 hogehogehoge.wsgi:application (code=exited, status=3) Main PID: 9245 (code=exited, status=3) 8月 27 13:58:15 tk2-401-41950.vs.sakura.ne.jp gunicorn[9245]: check_sqlite_version() 8月 27 13:58:15 tk2-401-41950.vs.sakura.ne.jp gunicorn[9245]: File "/usr/local/lib64/python3.6/site-packages/django/db/backends/sqlite3/base.py", line 63, in check_sqlite_version 8月 27 13:58:15 tk2-401-41950.vs.sakura.ne.jp gunicorn[9245]: raise ImproperlyConfigured('SQLite 3.8.3 or later is required (found %s).' % Database.sqlite_version) 8月 27 13:58:15 tk2-401-41950.vs.sakura.ne.jp gunicorn[9245]: django.core.exceptions.ImproperlyConfigured: SQLite 3.8.3 or later is required (found 3.7.17). 8月 27 13:58:15 tk2-401-41950.vs.sakura.ne.jp gunicorn[9245]: [2019-08-27 13:58:15 +0900] [9249] [INFO] Worker exiting (pid: 9249) 8月 27 13:58:15 tk2-401-41950.vs.sakura.ne.jp gunicorn[9245]: [2019-08-27 13:58:15 +0900] [9245] [INFO] Shutting down: Master 8月 27 13:58:15 tk2-401-41950.vs.sakura.ne.jp gunicorn[9245]: [2019-08-27 13:58:15 +0900] [9245] [INFO] Reason: Worker failed to boot. 8月 27 13:58:15 tk2-401-41950.vs.sakura.ne.jp systemd[1]: hoge.com.service: main process exited, code=exited, status=3/NOTIMPLEMENTED 8月 27 13:58:15 tk2-401-41950.vs.sakura.ne.jp systemd[1]: Unit hoge.com.service entered failed state. 8月 27 13:58:15 tk2-401-41950.vs.sakura.ne.jp systemd[1]: hoge.com.service failed.raise ImproperlyConfigured('SQLite 3.8.3 or later is required (found %s).' % Database.sqlite_version) 8月 27 13:58:15 tk2-401-41950.vs.sakura.ne.jp gunicorn[9245]: django.core.exceptions.ImproperlyConfigured: SQLite 3.8.3 or later is required (found 3.7.17).解決方法
解決方法は2つあります。
1.django2.2を利用する
これはSQLiteのバージョンが古いために起きているので、MariaDBを導入しdjango2.2系で稼働するように設定しましょう
2.django2.1にダウングレードする
pip3 install django==2.1.xxxx --user
MariaDB 5.5.60
mysql Ver 15.1 Distrib 5.5.60-MariaDB, for Linux (x86_64) using readline 5.1