- 投稿日:2019-08-27T22:18:14+09:00
AWSでサーバーを準備してみる。
目的
AWSでWEBサーバー、DBサーバーを作成する。
個人的にAWSを試してみるために行った作業手順をまとめた記事になります。はじめに
AWSのアカウントを作成する。
https://portal.aws.amazon.com/billing/signup#/startネットワークの構築
VPCを作成する。
AWSマネジメントコンソールからVPCをクリックし、VPCの作成ページに移動し、
vps-sampleというVPCを作成する。VPC作成をクリックすると下記の様なページが表示されるので、それぞれの項目を入力する。
(画像は入力後)
subnetを作成する。
publicSubnetを作成する。
インターネットにつながる設定のサブネット。WEBサーバーなど外部からアクセスがある場合に使う。
サブネットのページより作成をクリック。
名前:public-subnet-sample-1a
VPC:vpc-sample
アベイラビリティーゾーン:ap-northeast-1a
IPv4 CIDR ブロック:10.0.10.0/24privateSubnetを作成する。
上記と同様にして、名前:private-subnet-sample-1aを作成する。
下記だけ変更しておく。
IPv4 CIDR ブロック:10.0.20.0/24ルーティングを作成する。
作成したpublic-subnet-sample-1aからインターネットに接続できる様に設定する。
インターネットゲートウェイを作成する。
インターネットゲートウェイからインターネットゲートウェイを作成をクリックし作成する。
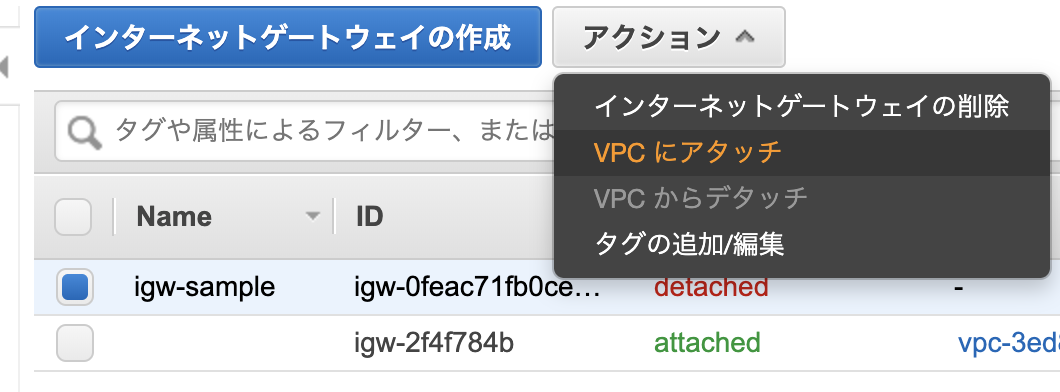
名前:igw-sampleインターネットゲートウェイをVPCにアタッチする。
アクションよりVPCをアタッチをクリックする。
作成したvpc-sampleを選択しアタッチする。
ルートテーブルを作成
ルートテーブルをクリックし、ルートテーブル作成をクリックする。
作成画面が表示されるので、作成したvpc-sampleを選択し作成。subnetを関連づける。
作成したルートテーブルを選択すると、下に詳細が表示されるので
サブネットを関連づけるを選択し、サブネットの関連付けを編集をクリックして、public-subnet-sample-1aを選択する。ルートの編集を行う。
サブネットを関連づけるの隣にあるルートをクリックし、ルートの編集をクリックする。
送信先に「0.0.0.0/0」を入力し、ターゲットには、先ほど作成した、インターネットゲートウェイを選択する。作成したVPC上にサーバーを設置する。
EC2インスタンス
EC2インスタンスはWebサーバーとして使用できる仮想サーバー。
EC2のインスタンスを作成し、必要なものをインストールしていく。EC2インスタンスを作成する。
AMIを選択する。
今回は無料枠で使えるAMI(Amazonが提供しているテンプレートの様なもの)を選択。
インスタンスタイプを選択する。
こちらも無料枠であるt2.microを選択する。
詳細設定
VPCは作成したvpc-sampleを選択し、サブネットはpublic-subnet-sample-1aを選択する。
privateに設置してしまうと外部からアクセスできなくなる。インターネットインターフェイスでは、プライベートipの設定ができる。
サブネットのIPを10.0.10.0/16にしたので、10.0.10.10を設定しておく。ストレージを選択する。
デフォルトの設定のまま進める。(汎用SSD)
セキュリティグループを作成する。
セキュリティグループのページを開き、セキュリティーグループを作成をクリックする。
キーペアを選択し、インスタンスを作成する。
キーペアは、サーバーにアクセスするために必要。こちらは、なくすと作り直す必要があるので注意する。
まとめ
これで、一旦WEBサーバーのインスタンスの作成は完了しました。
作成したEC2インスタンスには、apacheやnginxや、PHPなどを入れていけばWEBサーバーとして稼働できます。
RDSなどデータベースを使用しない場合はここまでやれば完了です。


- 投稿日:2019-08-27T21:23:43+09:00
AWSのサービスいくつかを3分で掴む
AWSについて無知すぎたため自分基準で調べてみました。
優しめのマサカリください!
AWSの特徴
- Amazonが運営するクラウドコンピューティングサービス
- 柔軟にスケーリングが可能
- 各サービスを簡単に連携できる
主なサービス
サーバ、コンピューティング
EC2 - Elastic Compute Cloud
- クラウドコンピューティングサービス
- サーバー置き場
Lambda
- サーバレスで必要時のみコードを実行可能
データベース
RDS - Amazon Relational Database Service
- よくあるリレーショナルデータベース
- 自動バックアップ
ElastiCashe
- 高いパフォーマンスのインメモリデータストア、メモリキャッシュ
- DBの問い合わせ結果を一時的にキャッシュすることで高速化
- Redis/Memcachedに対応
- Redis - 高速なKeyValueデータストア
- Memcached - 分散メモリキャッシュサーバ
ストレージ
S3 - Amazon Simple Storage Service
- ストレージサービス
- 99.999999999%の耐久性(設計上)
EBS - Elastic Block Store
- EC2用のストレージサービス
ネットワーク系
Route53
- DNSシステム
ELB - Elastic Load Balancer
- ロードバランサー
- トラフィック分散
- 複数のアベイラビリティーゾーンの複数のEC2インスタンスに分散
VPC - Virtual Private Cloud
- 仮想ネットワークの作成
- インターネットへの公開
- 社内LANとの接続
- 基本的に必須
CloudWatch
- AWSのモニタリング(ログ)サービス
- しきい値でのアラートなどを設定可能
- Logs
- EC2やS3のログファイル監視
- Events
- AWS環境の変化時にイベントを生成可能
コンテナ
ECS - Elastic Container Service
- コンテナを動かせる
- EC2のクラスタ構成を作りロードバランサーで負荷分散、コンテナの死活管理と自動復旧などを行ってくれる
Fargate
- ECSから派生したサービス
- EC2インスタンスが不要なコンテナサービス
EKS - Elastic Kubernetes Service
- コンテナアプリのデプロイなどをKubernetesを用いて簡単に実行できる
- Kubernetes
- クラウド上のコンテナを一元管理できる
セキュリティ
IAM - Identity and Access Management
- AWSのユーザアカウントやグループに対するアクセス権を設定
- 無料
ACM - AWS Certificate Manager
- SSL,TSL証明書の作成と管理
特にお世話になった参考文献様
- ELB
- ネットワーク視点で見るAWS ELB(Elastic Load Balancing)のタイプ別比較[NLB対応] / Classmethhod
- ELBの比較表に補足事項を書き加えてみる(NLB編) / Serverworks
- ECS
- ECSの概念を理解しよう / まーぽんって誰がつけたの?
- Fargate
- AWS FargateとECSの違いは? / Qiita @ABCompany1
- 投稿日:2019-08-27T21:13:05+09:00
AWS東京リージョンの障害を回避するインフラ構成とは?
WS東京リージョンの大規模障害で多数のサービスに影響がでました。
今回の障害はなぜ起きたのか?そして回避策はなかったのか?
AWSからも公式メッセージがでたので、検証してみます。今回の障害は東京リージョンの1つのゾーンで発生した障害です。
これはインフラ構成によっては回避できる事案です。では、どの様にすればサービス停止を回避できたのでしょうか?
以下詳細に検証していきます。目次
- AWS東京リージョンの障害の原因と影響
- EC2をマルチAZとマルチリージョンにする
- DBはAuroraを使う
- 責任の所在について
1. AWS東京リージョンの障害の原因と影響
今回の東京リージョンの障害の原因は冷却システムの不具合でした。
冷却システムが動かなくなり、サーバーがオーバーヒートしてしまいました。その影響で、EC2(サーバー機能)とRDS(データベース)が使えなくなりました。
東京リージョンの1つのゾーンで広範囲のサーバーに影響範囲が広がり、
多数のサービス、アプリ、ゲームに影響がでて一時サービス停止を余儀なくされました。2. EC2をマルチAZとマルチリージョンにする
ではどのような構成にすれば、今回の障害が起きても、
サービス停止を回避できたのでしょうか?AWSのデータセンターにはリージョンとゾーンという概念があります。
リージョンは東京、大阪、オレゴン、台湾などのエリア別、国別の場所。
ゾーンは東京リージョンの範囲内の独立した別の場所の事です。東京リージョンには複数のゾーンが存在します。
今回は東京リージョンの1つのゾーンで起きた障害なので、
複数箇所のゾーンにEC2をおいて、分散しておけば良かったのです。しかしそれだけではなく、マルチリージョンといって、
大阪リージョンにもEC2を分散しておくとより安全でした。3.DBはAuroraを使う
東京リージョンのRDSの障害を回避するにはどうすれば良かったのでしょうか?
ゲームや、Webサービスで一番大切なデータはユーザーのデータです。
なぜなら、課金して買ったダイヤやレベル、ユーザの投稿内容、フォロアー情報
などが消えたり、不整合を起こして使えなくなってはいけないのです。それに、なるべくEC2と地理的に近いゾーンに置いて、
すこしでもアクセス速度を速くする必要があります。なので殆どの国内向けゲームとWebサービスのRDSが、
東京リージョンに集中していました。今回の障害でも回避を難しくしたのはこのRDSの障害だったでしょう。
AWSのRDSのドキュメントにはこのように記載されています。AWS リージョン間でのリソースのレプリケーションは自動的に実行されないため、ユーザーが特に指定して行う必要があります。
Amazon は、アベイラビリティーの高い最新のデータセンターを運用しています。しかし、非常にまれですが、同じ場所にあるインスタンスすべての可用性に影響する障害が発生することもあります。もし、すべてのインスタンスを 1 か所でホストしている場合、そのような障害が起きたとき、インスタンスがすべて利用できなくなります。まさに今回の障害がその非常にまれなパターンに当てはまるでしょう。
ではどの様に回避すれば良かったのか?
結論はAurora(高性能のセキュリティ、可用性、信頼性があるデータベース)を
最初から選択すべきでした。可用性というのは、複数箇所に分散していて、障害に強い性能の事です。
結果論ですが、東京リージョンのRDSを使っている時点で、
今回の障害は回避不可能でした。なぜならデータベースはEC2のように複数リージョンに分散して、
データの整合性と速度を保つのは非常に難しく、通常そんな事はしません。じゃあ、高可用性 (マルチAZ)で複数ゾーンにまたいで
設置するれば良いという意見もありますよね?しかし今回の障害では、マルチAZでもレプリケーションに失敗した報告がありました。
なので、完全に回避するにはAuroraの高可用性マネージドサービスDBを使えば良かったのです。
4. 責任の所在について
AWSでは「責任共有モデル」といって、AWSと利用者の責任を共有して分担するモデルがあります
今回の障害はハード側でサーバーのオーバーヒートというAWS側の果たすべき責任です。
しかしながら、東京リージョンの一部のゾーンの障害です。
利用者側の責任でマルチゾーンなどの構成を組む事で、回避できた障害でもあります。[東京リージョン(AP-NORTHEAST-1)で発生したAmazon EC2とAmazonEBSの事象概要](https://aws.amazon.com/jp/message/56489/)
この度の事象発生時、異なるアベイラビリティゾーンの EC2 インスタンスや EBS ボリュームへの影響はございませんでした。複数のアベイラビリティゾーンでアプリケーションを稼働させていたお客様は、事象発生中も可用性を確保できている状況でした。アプリケーションで最大の可用性を必要とされるお客様には、この複数アベイラビリティゾーンのアーキテクチャに則ってアプリケーションを稼働させることを引き続き推奨します(お客様にとって高可用性に課題を生じ得る全てのアプリケーションのコンポーネントは、この耐障害性を実現する方法の下で稼働させることを強く推奨します)。
AWS側のアナウンスでも、最大限の可用性を考慮してインフラ構成を組んでねって言ってます。
Amazonの利用規約でもサービスレベルアグリーメント(SLA)を設定しています。
EC2ではマルチAZ構成で99.99% です。
0.01%は落ちるかもしれないけど、
ゆるしてねってAmazonは規約で決めています。月で計算すると、24時間 × 30日 × 0.01% = 7.2時間です。
7.2時間ってけっこう落ちる余裕ありますよね。今回はシングルAZで約6時間の障害です。
そもそもマルチAZでは障害回避できましたっていってるので、SLAの範囲内です。RDSのSLAはマルチAZで99.95%でした。
月で計算すると、24時間 × 30日 × 0.05% = 36時間です。RDSはマルチAZでも使えなかったとしても
復旧まで9.5時間でしたので、これもSLAの範囲内ですね。計算してみると、けっこうAWSといえども落ちてもいい時間の許容範囲がデカイですね。
RDSに関しては1年間で438時間(約18日)落ちても許してねって規約で決めてます。ただそれに甘んじる事なく、
オーバーヒートと一部基盤破棄する規模の物理障害を
9.5時間で完全復旧させてしまうのは、かなり手早い復旧でしたね。まとめ
今回の東京リージョンの大規模障害は本当にレアケースで、
多大な影響範囲でしたよね。対応したインフラエンジニアの方々はかなり焦ったのではないでしょうか?
今回学んだのはAWSでも落ちるときは落ちるんですね。
なのでマルチAZ、マルチリージョンで冗長構成にしましょうって事ですね。そしてDBはAurora一択ですね。
Auroraと同じような冗長構成を自分で組むとコストが5倍かかります。
それとそもそも難しすぎて、同じ冗長構成を普通は組めません。
おとなしくAuroraに課金して安心、安全をお金で買いましょう。以上、AWS東京リージョンの障害についてでした。
- 投稿日:2019-08-27T21:08:48+09:00
AnsibleでJenkinsをインストールするPlaybookを書いた
AWS EC2へJenkinsをインストールPlaybookを書きました。
検証環境
- AMI
- ・ CentOS 7 x86_64 - with Updates HVM
- インスタンスタイプ
- ・ t2.medium
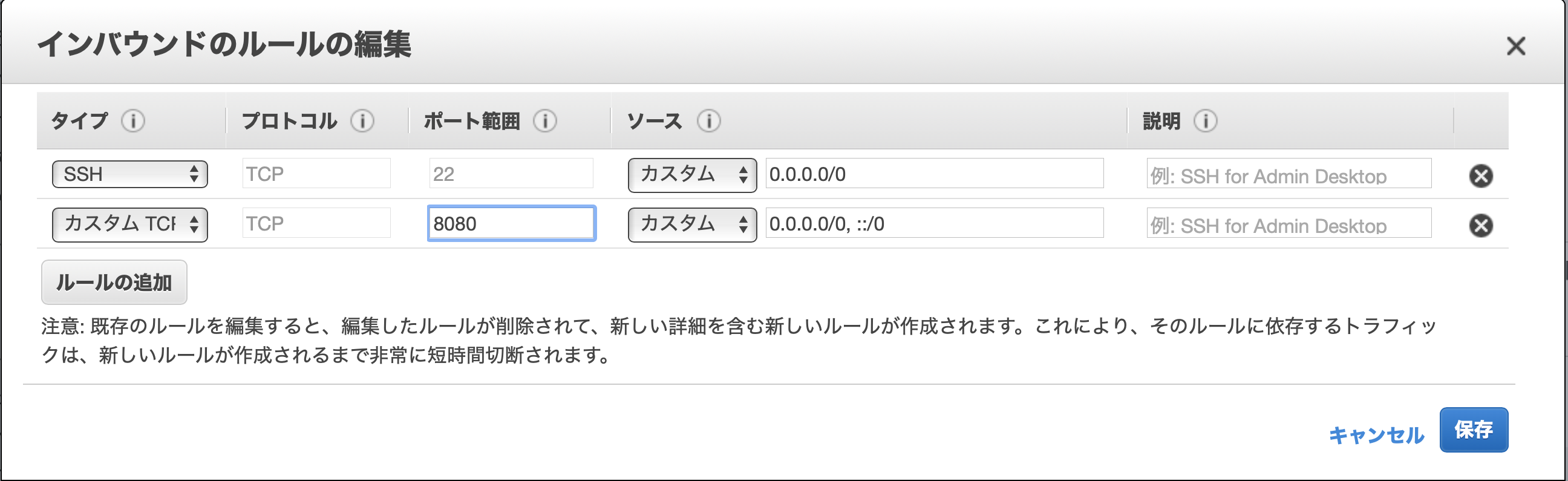
- セキュリティーグループ
- ・ SSH 22番
- ・ カスタムTCP 8080番を開放
- 利用するAnsibleのバージョン
- ・ 2.8.4
利用するAnsible Galaxy role
- geerlingguy.repo-epel
- geerlingguy.pip
- geerlingguy.docker
- geerlingguy.git
- robertdebock.bootstrap
- robertdebock.locale
Jenkinsサーバにインストールされる主なライブラリ
・ Ansible | 最新の安定バージョン
・ Docker | 最新の安定バージョン
・ Docker Compose | 最新の安定バージョン
・ Git | yum install gitでインストールされるバージョン構築されるJenkinsの設定
・ ユーザー「jenkins」をDockerグループへ追加
・ https無効
・ http://jenkins-url:8080 にてアクセス
・ Javaは「yum install java」でインストールしたものと同一のもの
インストール方法
EC2を起動しSSHで接続、以下のコマンドを実行する
# rootに変更する sudo su # システムをアップデートする yum -y update # 必要なパッケージをインストールする yum install -y git ansible # JenkinsをインストールするPlaybookを取得する git clone https://github.com/ansible-centos7/jenkins_install.git # Jenkinsをインストールする cd jenkins_install ansible-galaxy install -r roles/requirements.yml ansible-playbook -i localhost, -c local install.yml関連サイト
- 投稿日:2019-08-27T21:05:34+09:00
AWSでNATインスタンスを構築してみよう!
はじめに
AWSではVPCとサブネットを上手く使い分けることでネットワーク公開領域と非公開領域を分けることができる。ネットワーク公開領域をパブリックサブネット、非公開領域をプライベートサブネットとそれぞれ呼び、プライベートサブネットにサーバーを立てることでセキュアなサーバーを構築することが可能。
この性質とNATインスタンスを利用することで、
プライベートサブネットに配置されたサーバーに対して以下のネットワーク要件が可能となる。
- ロードバランサー経由でのみアクセス可能
- 外部からサーバーに直接アクセス不可能(HTTP, HTTPS, SSHなど全て)
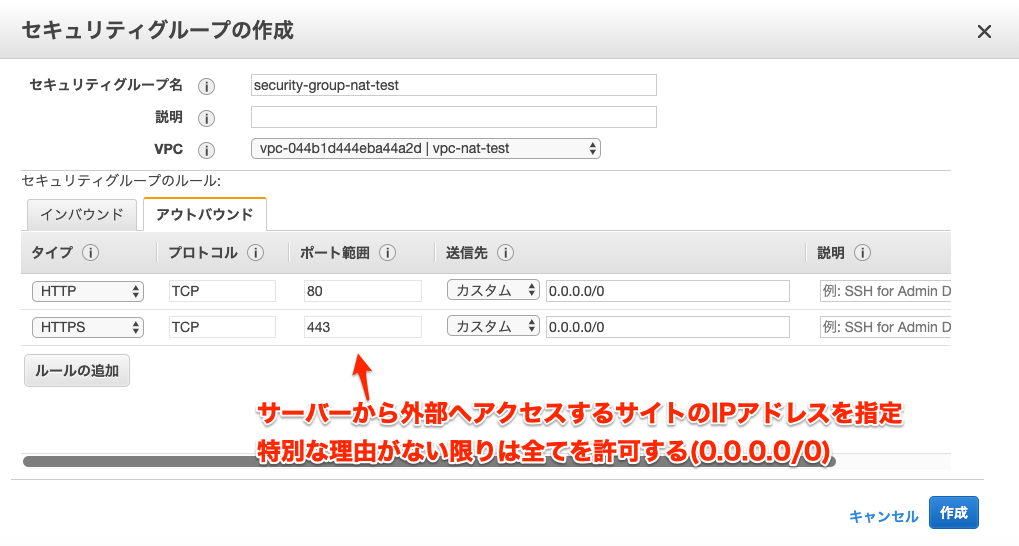
- サーバーからの外部サイトはアクセス可能
NATインスタンスとは?
簡単に言うとプライベートサブネットに配置されたサーバーから外部サイトへアクセスするときに踏み台となるサーバーのこと。
例
データベースに接続してJSONを返す内部APIサーバーを構築したい要件。
このAPIサーバーは外部決済機能を持っていてStripeと通信を行う必要があり、今後も要件次第ではFacebookやSendgridなどの外部サイトと通信が増える可能性がある。APIサーバーをパブリックサブネットに配置すると誰でもサーバーに接続することができてしまい、認証情報さえあればAPIサーバー経由で情報が取得できてしまうかもしれないので危険なので、セキュアなプライベートサブネットにAPIを立てることにした。
この場合だと、ネットワーク設定されていないプライベートサブネットにサーバーを配置するのでStripeなどの外部へ通信を行うことができない。そんな要件の時に活用できる救世主がNATインスタンスである!!!!!
APIサーバーが外部通信を行いたい場合、NATインスタンスを通してネットワークにアクセスすること可能。
APIサーバーの代わりにNATインスタンスがStripeへ通信を行い決済完了の通知を受け取る。
そして決済完了の通知をAPIサーバーに伝達するという仕組み。もう少し具体的にNATインスタンスを知りたい場合は公式サイトをみてね。
そもそもNATを知りたい人はこちら(図があって個人的に分かりやすかった)NATインスタンスとNAT Gatewayの違い
AWSにはNAT Gatewayが存在する。NATインスタントと何が違うの?と疑問に思う人もいるだろう。NATインスタンスの構築を自動でやってAWSコンソールから管理できるのがNAT Gatewayである。
じゃあ、最初から自分で構築せずにNAT Gateway使えばいいのではないか。
と思うかもしれないが、問題なのは料金である。NATインスタンスはスペックにも寄るが1000円〜3000円くらい、
NAT Gatewayは7000円以上となり結構なコストになってしまう。私が携わっているプロジェクトではコスト削減のために少々管理が面倒でもNATインスタンスを立てることにしている。
補足
プライベートサブネットに配置されるサーバーをECSで管理してコンテナを自動的に起動させたりしたい場合はAWSにアクセスできる必要があるため、NATインスタンスを構築する必要がある。
そうしないとECSからEC2インスタンスの紐付けができない点に注意が必要!
構築手順
正直なところこちらの記事の方が説明が詳しい気もするが、今回はアウトプットも兼ねて。
ネットワークの構築
VPC
まずはネットワークの基礎となる、VPCを作成する。
ネットワークのクラスとサブネットについての参考記事
Subnet(public, private)
ネットワーク公開設定を行うサブネット(パブリックサブネット)と、
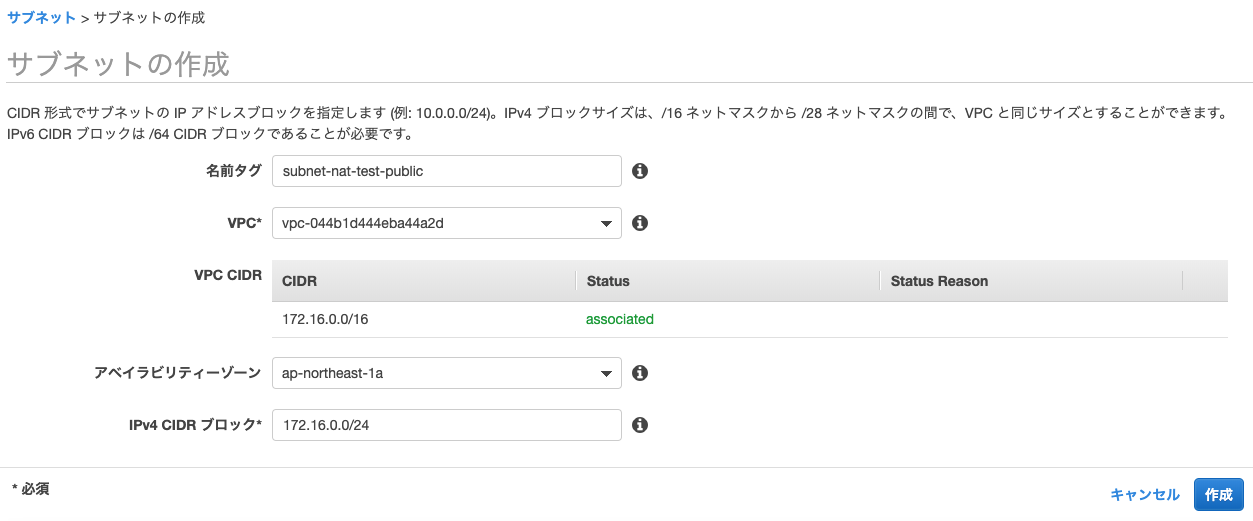
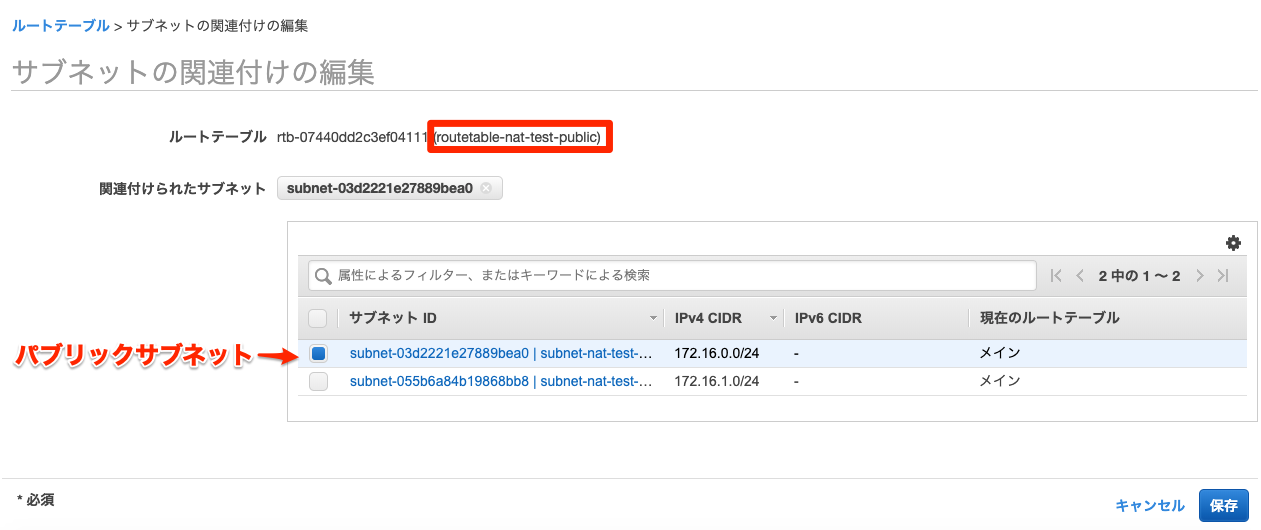
ネットワークに接続できない設定を行うサブネット(プライベートサブネット)を作成する。パブリックサブネットの作成
サブネットのネットワーク部を
172.16.0.Xに設定する。今回の場合は、東京リージョンのアベイラビリティゾーン(AZ)は1aを指定する。
可用性を高める構成にしたい場合は1cにも同じようにサブネットを作成する。
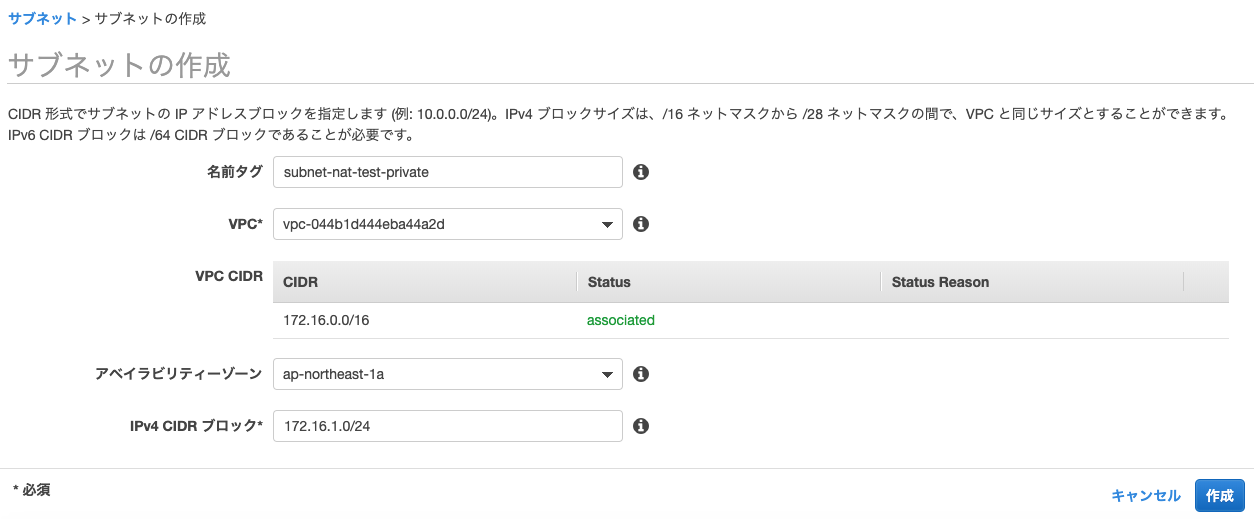
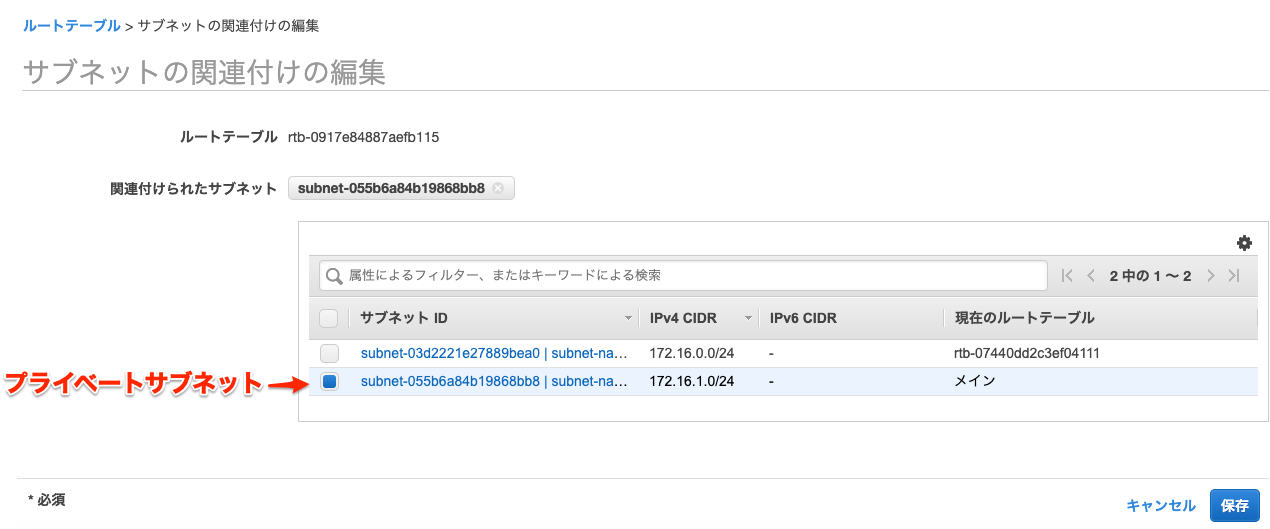
プライベートサブネットの作成
サブネットのネットワーク部を
172.16.1.Xに設定する。
ルートテーブルなどの接続経路設定
ネットワークの経路を設定するルートテーブルはサブネット単位で紐づけることが可能。
VPCを作成した時にメインテーブルと呼ばれるルートテーブルが作成されるので、デフォルトでプライベートサブネットの経路に設定する。サブネットとルートテーブルの関連付け
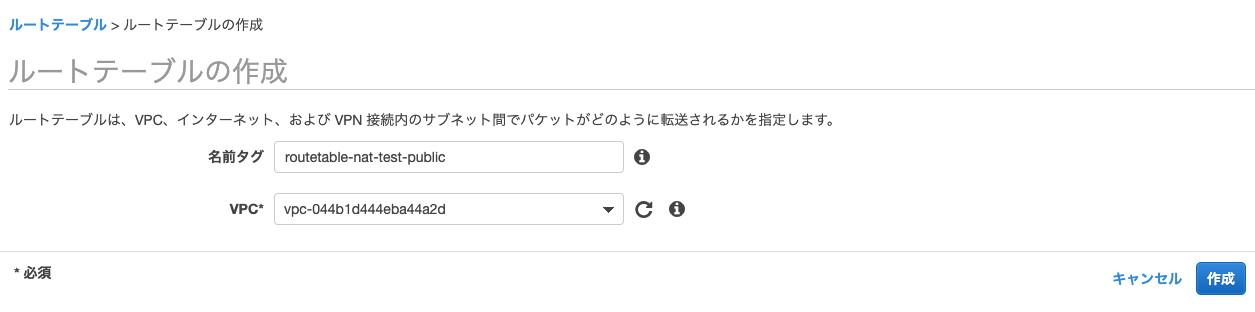
パブリックサブネットに紐づけるルートテーブルを作成する。
作成したルートテーブルをパブリックサブネットに紐づける。
これでパブリックサブネットのネットワーク経路はこのルートテーブルの設定が適用される。
メインルートテーブルにプライベートサブネットに紐づける。
メインルートテーブルはすでに作成されているため、新規で作成する必要はない。
Nameタグにroutetable-xxx-privateと設定すると後々分かりやすい!
インターネット接続経路を確保する
インターネットに接続するためにはインターネットゲートウェイを作成して、経路を許可するIPアドレス範囲を指定する必要がある。
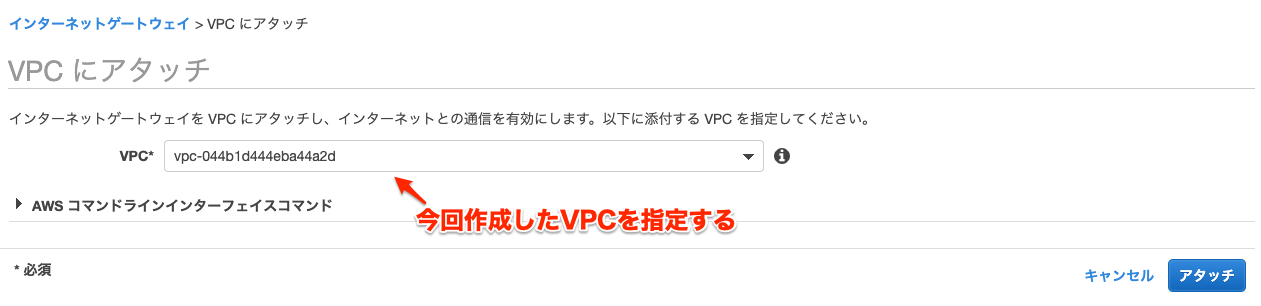
インターネットゲートウェイを作成
インターネットゲートウェイとVPCを紐付ける。
デフォルトではVPCが設定されていないので個別で紐づける必要があることに注意。
インターネットゲートウェイの状態がattachedに変化すれば正しく設定されたことになる。
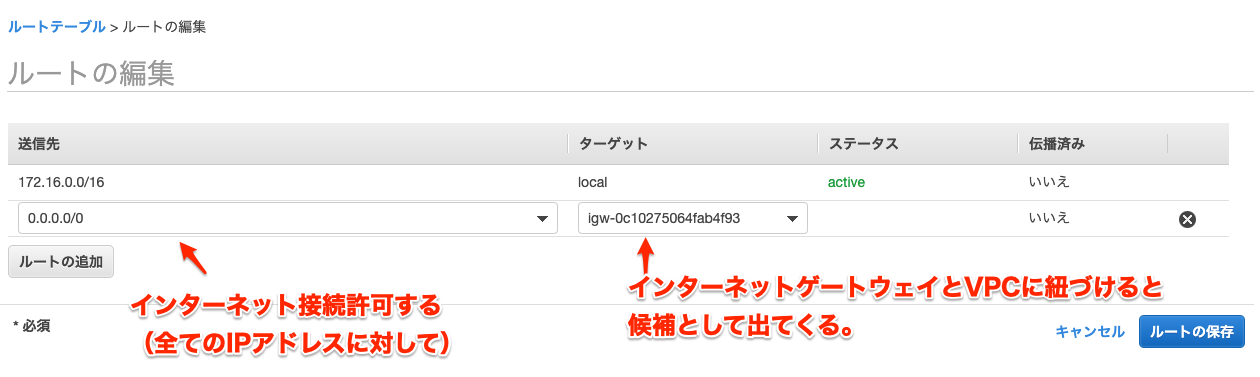
パブリックのルートテーブルに紐付ける。
特に通信制御せずにインターネットアクセスすると言う意味で0.0.0.0/0を設定する。
これでネットワーク関連の設定は完了。
その他のネットワーク許可設定は後述にあるセキュリティグループで設定する。NATインスタンス作成
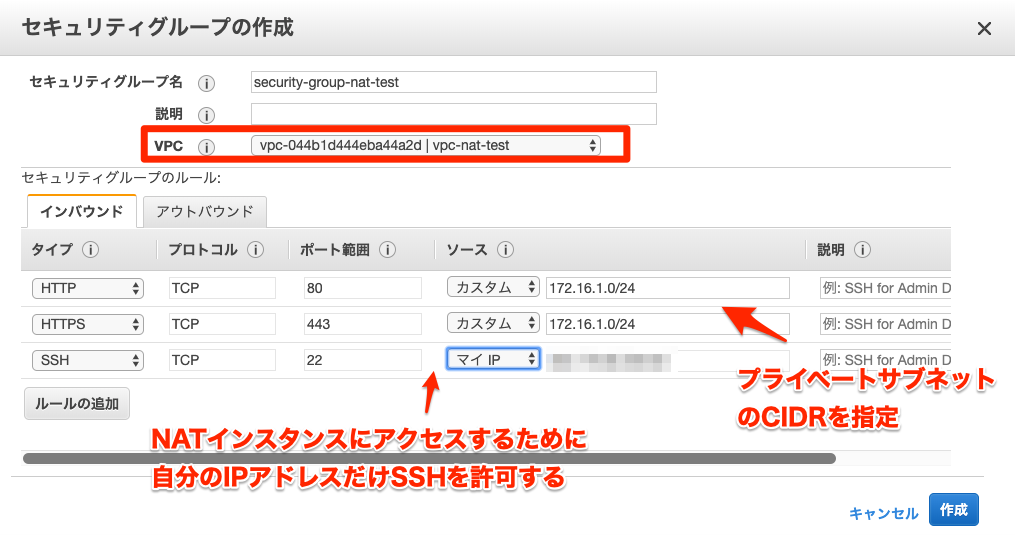
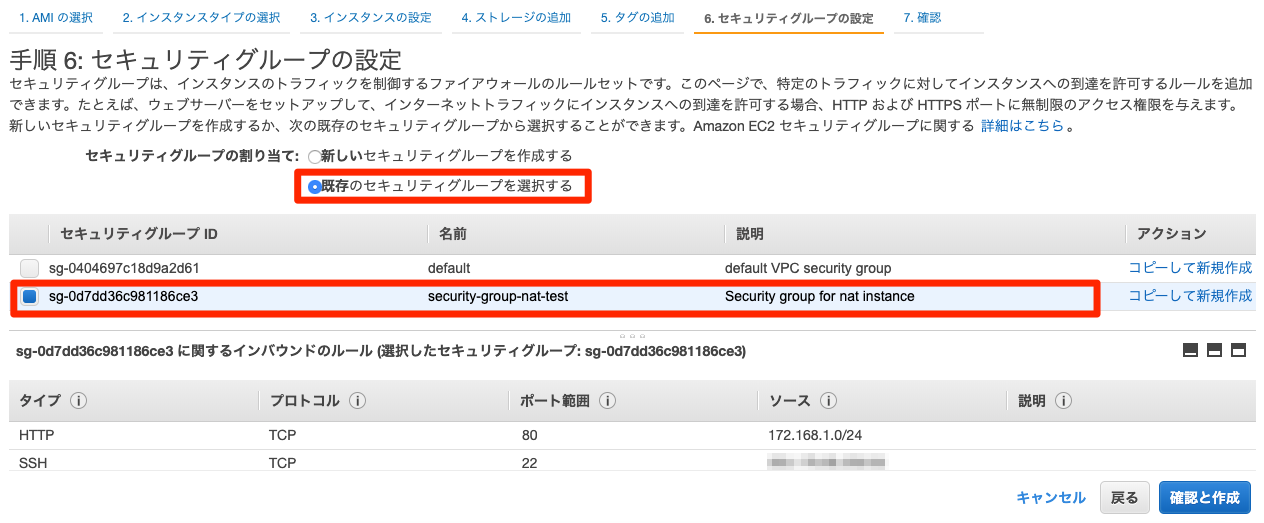
セキュリティグループの作成
NATインスタンスに紐づけるセキュリティグループを作成する。(参考)
サブネットを1a,1c両方に作成している場合はHTTP,HTTPSそれぞれ許可するCIDRを設定する。
(画像上はセキュリティグループの説明ないですが、適当に設定すること)
インバウンド
アウトバウンド
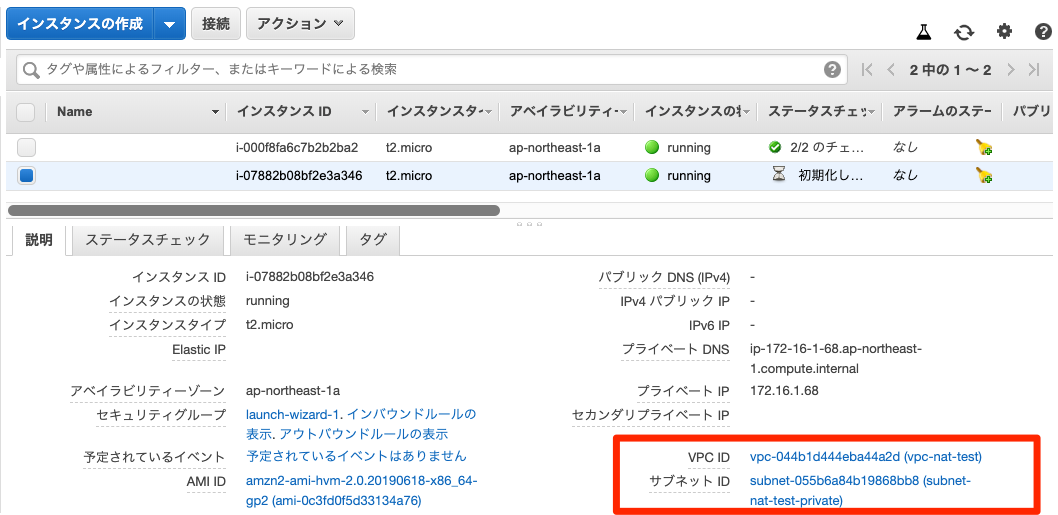
EC2インスタンスの作成とIPアドレスの割り当て
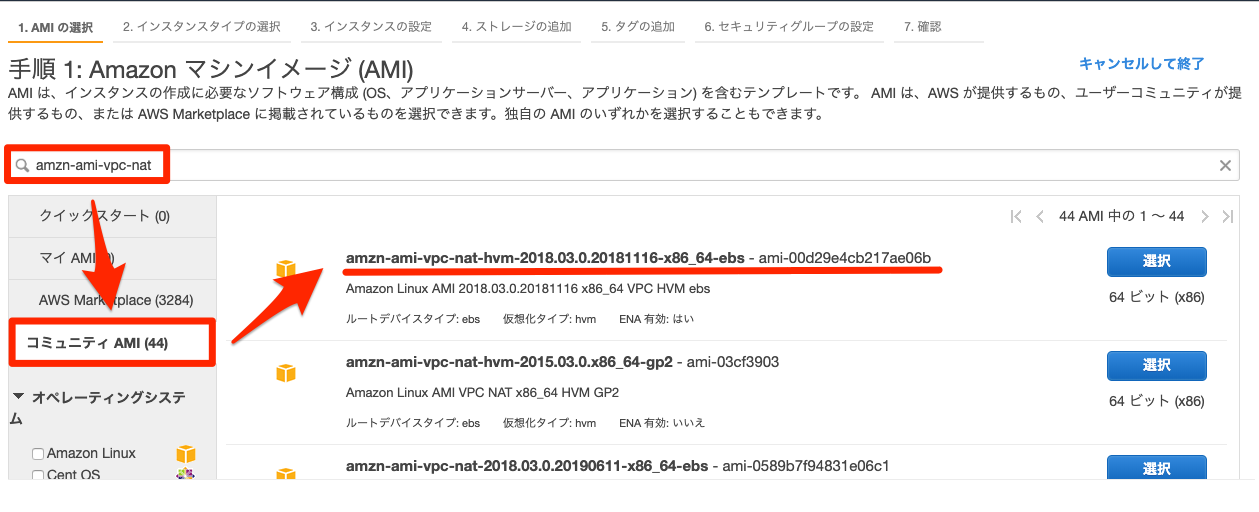
NAT用のEC2インスタンス専用のイメージが提供されている。(参考)
マシンイメージ(AMI)の選択
Amazonマシンイメージの選択ウィンドウで検索するとNAT用のイメージが表示される。(amzn-ami-vpc-nat)今回は最新版っぽい一番上のインスタンスを利用するが、バージョンは常に更新されるのでマシンイメージ名の日付が最新のものを選択するのがおすすめ。
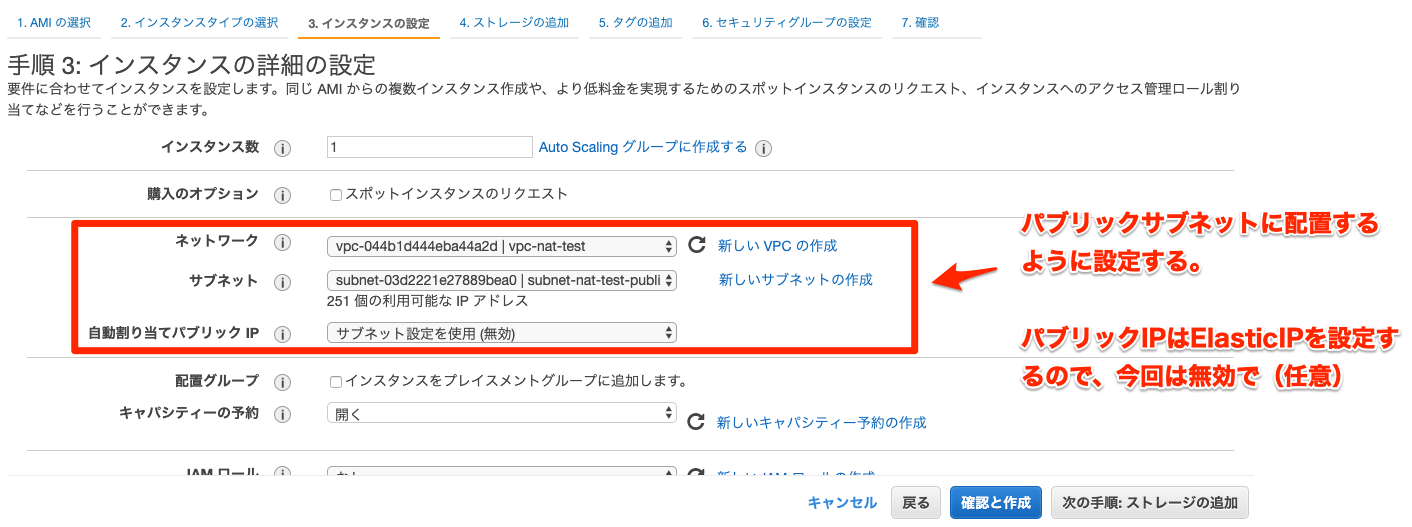
インスタンスを配置するネットワーク設定
パブリックインスタンスにNATインスタンスを配置することが必要。
APIサーバーはプライベートに配置するが、NATインスタンスは代わりに接続を行う必要があるためパブリックサブネットの必要がある、と覚えておく。
セキュリティグループの設定
さっき作ったNATインスタンス用のセキュリティグループを設定する。
あとはキー情報を作成してEC2インスタンスの起動を待つ。
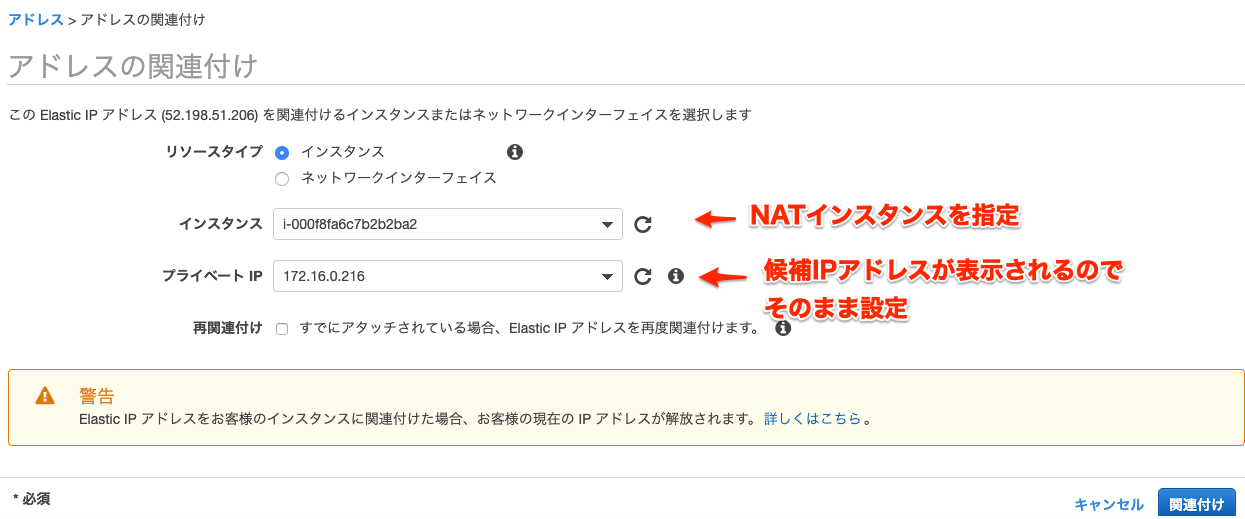
その間にNATインスタンスがパブリックIPを持つのに必要な固定IPアドレスの設定を。固定IPの紐付け
割り当てボタンを押すと自動的にパブリックIPアドレスを取得してくれる。
固定IPとNATインスタンスを紐づける。
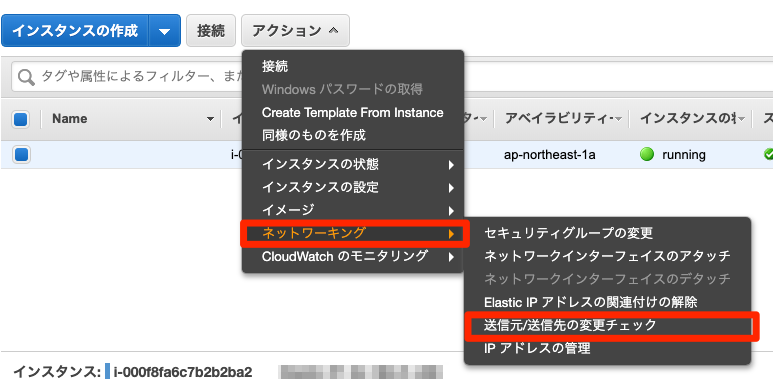
送信元/送信先チェックの無効化
この設定作業はとても大切です!!!(忘れがちなだけ)
送信元/送信先チェックは
NATインスタンスに対して送信しますよ!
と外部サーバーが応答してくれるかどうかをチェックしている機能です。しかし、今回はプライベートサブネットに配置されたインスタンスに送信するため、
あなたのサーバーのxxさんに対して送信するので後はよろしく!
のようにNATインスタンス宛ての応答ではないです。
そのためこの機能を有効のままにしておくと「自分宛じゃないから無理!!」となるわけです。
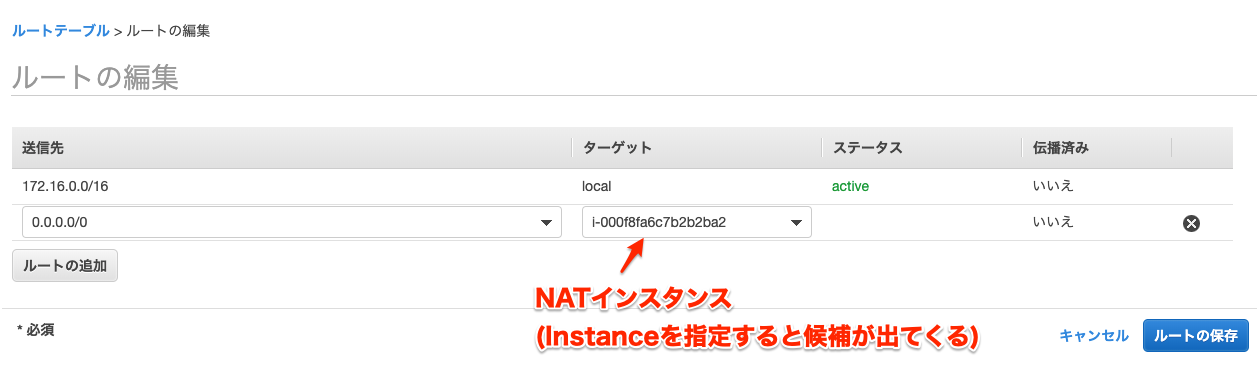
プライベートサブネットからのインターネット接続をNATインスタンス経由にする
プライベートサブネットに紐づいているルートテーブルに対してネットワーク経路を追加する。
以下の設定を行うことでプライベートサブネットから外部への接続はNATインスタンスを経由するようになります。
これでNATインスタンスの設定は完了です!!!
NATインスタンスの接続確認
サーバーを立てる
プライベートサブネットにEC2インスタンスが配置されていない場合は仮にサーバーを立ててテストを実施する。
Amazon Linux2をパブリックサブネットに配置する。
基本的に設定はデフォルトでOK。
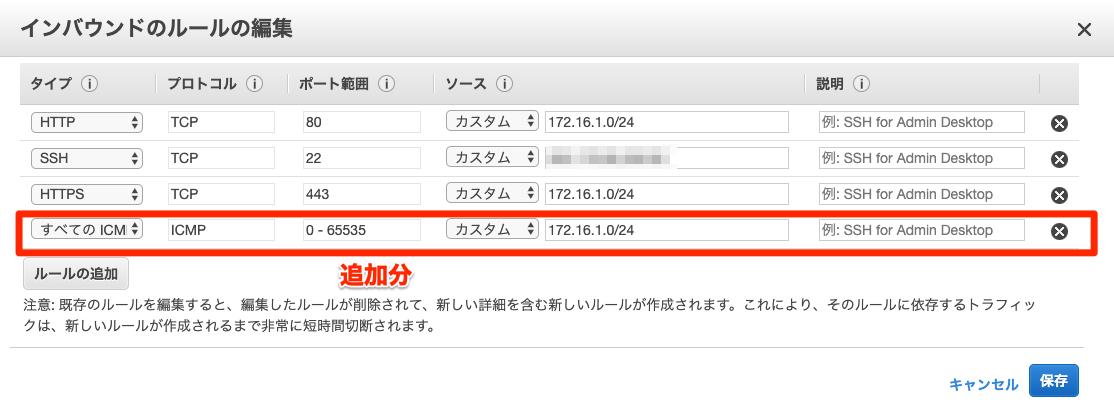
NATインスタンスのセキュリティグループを変更
セキュリティグループにテスト用IPアドレスの許可設定を行う。
インバウンド
今回のテストではpingによる接続確認を行うため
すべてのICMP IPv4を許可する必要がある。
サーバーからNATインスタンス経由でのpingになるため許可するのはプライベートサブネットに配置されているインスタンスのみ許可。
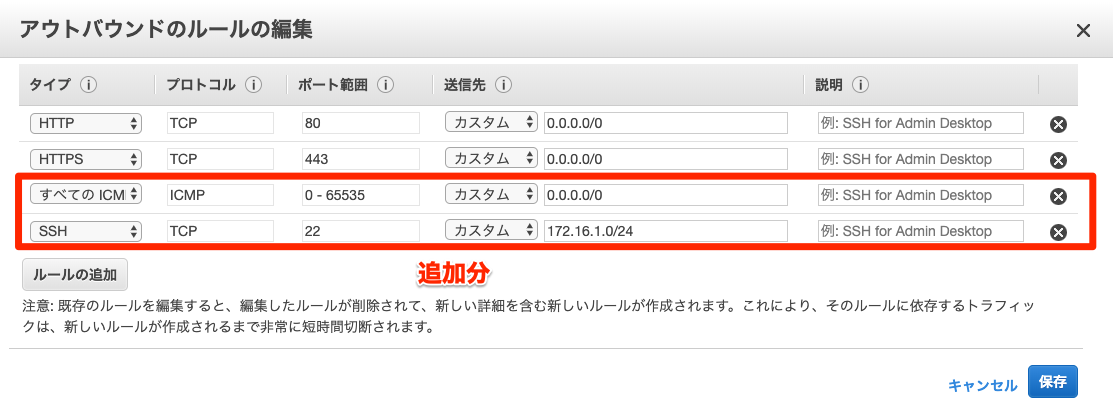
アウトバウンド
ping接続した応答を受診する必要があるため
すべてのICMP IPv4の接続を全て許可する必要がある。
またプライベートサブネットに配置されたインスタンスにSSHの応答を返す必要もあるため設定。
テスト実施
SSH接続確認
まずはNATインスタンス経由でプライベートサブネットに配置したサーバーにSSH接続を行う。
ssh -o ProxyCommand='ssh -i [NATインスタンスの公開鍵] ec2-user@[NATインスタンス固定IP] -W [サーバーのプライベートIP]:22' -i [サーバーの公開鍵] ec2-user@[サーバーのプライベートIP]例えば、以下のような接続情報の場合
- NATインスタンス固定IP:
52.198.51.206- サーバーのプライベートIP:
172.16.1.68- NATインスタンスの公開鍵の場所: (MAC上)
~/.ssh/nat-test.pem- サーバーの公開鍵の場所: (MAC上)
~/.ssh/nat-test-server.pem実行するコマンドは
ssh -o ProxyCommand='ssh -i ~/.ssh/nat-test.pem ec2-user@52.198.51.206 -W 172.16.1.68:22' -i ~/.ssh/nat-test-server.pem ec2-user@172.16.1.68ネットワーク接続確認
ping確認
プライベートサブネットに配置したサーバーでping接続確認を行う。
[ec2-user@ip-172-16-1-68 ~]$ ping yahoo.co.jp PING yahoo.co.jp (183.79.135.206) 56(84) bytes of data. 64 bytes from f1.top.vip.kks.yahoo.co.jp (183.79.135.206): icmp_seq=1 ttl=40 time=17.1 ms 64 bytes from f1.top.vip.kks.yahoo.co.jp (183.79.135.206): icmp_seq=2 ttl=40 time=17.1 ms 64 bytes from f1.top.vip.kks.yahoo.co.jp (183.79.135.206): icmp_seq=3 ttl=40 time=17.1 ms ^C --- yahoo.co.jp ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2002ms rtt min/avg/max/mdev = 17.168/17.186/17.199/0.107 mscurl確認
ステータス200が返ることを確認。
[ec2-user@ip-172-16-1-68 ~]$ curl -I https://www.yahoo.co.jp/ HTTP/2 200 date: Tue, 27 Aug 2019 11:50:37 GMT p3p: policyref="http://privacy.yahoo.co.jp/w3c/p3p_jp.xml", CP="CAO DSP COR CUR ADM DEV TAI PSA PSD IVAi IVDi CONi TELo OTPi OUR DELi SAMi OTRi UNRi PUBi IND PHY ONL UNI PUR FIN COM NAV INT DEM CNT STA POL HEA PRE GOV" x-content-type-options: nosniff x-xss-protection: 1; mode=block x-frame-options: SAMEORIGIN expires: -1 pragma: no-cache cache-control: private, no-cache, no-store, must-revalidate content-type: text/html; charset=UTF-8 age: 0 via: http/1.1 edge1604.img.bbt.yahoo.co.jp (ApacheTrafficServer [c sSf ]) server: ATS [ec2-user@ip-172-16-1-68 ~]$フローログの確認
今回はフローログの設定方法まで詳しくは書かないが、VPCフローログを確認すると以下のような経路になっていることも確認できるので調べながら確認するのも良い。
- サーバー(172.16.1.xxx)からNATインスタンス(172.16.0.xxx)
- NATインスタンス(172.16.0.xxx)からyahooサイト(183.79.135.206)
- yahooサイト(183.79.135.206)からNATインスタンス(172.16.0.xxx)
- NATインスタンス(172.16.0.xxx)からサーバー(172.16.1.xxx)
まとめ
NATインスタンスを構築することで安価でかつセキュアな作りにすることができる。
試す価値大いにあり!!!!



- 投稿日:2019-08-27T20:07:25+09:00
[AWS] Amazon ECS(EC2タイプ)のちょっと長めのチュートリアル(第4回)
※本記事は Amazon ECS(EC2タイプ)のちょっと長めのチュートリアル( 第1回 , 第2回 , 第3回 )の続きです。
前回までで、ECSの実行環境は一通り作成できました。今回はDockerイメージの更新手順を確認します。
これまで例としてnginxのコンテナを使っていましたが、それをapacheのコンテナに差し替えてみます。
図にするとこんな感じです。
インスタンスとサービスのスケール
第2回,第3回と同様に、作業前にインスタンスをスケールアウトしておきます。
最初にインスタンス数を2に増やし、
その次に、サービスの更新でタスク数を2に変更しておきます。
1) 更新用イメージの作成
apache2のイメージを作成し、ビルドします。第1回と同様に、テスト用のhtmlを追加しただけの簡単なものです。
DockerfileFROM httpd COPY demo.html /usr/local/apache2/htdocs/demo.html# ls -l total 8 -rw-r--r-- 1 root root 389 Aug 2 19:37 demo.html -rw-r--r-- 1 root root 63 Aug 2 19:37 Dockerfile # cat Dockerfile FROM httpd COPY demo.html /usr/local/apache2/htdocs/demo.html # cat demo.html <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /> <title>ECS demo page</title> </head> <body> <div class="main_page"> ECS Demo Page for httpd </div> </body> </html> ## ※Dockerコンテナをビルドする※ # docker build -t apache-demo01 . Sending build context to Docker daemon 3.072kB Step 1/2 : FROM httpd latest: Pulling from library/httpd f5d23c7fed46: Pull complete b083c5fd185b: Pull complete bf5100a89e78: Pull complete 98f47fcaa52f: Pull complete 622a9dd8cfed: Pull complete Digest: sha256:dc4c86bc90593c6e4c5b06872a7a363fc7d4eec99c5d6bfac881f7371adcb2c4 Status: Downloaded newer image for httpd:latest ---> ee39f68eb241 Step 2/2 : COPY demo.html /usr/local/apache2/htdocs/demo.html ---> 81d38acb42a3 Removing intermediate container a653dd92bbd8 Successfully built 81d38acb42a3 Successfully tagged apache-demo01:latest ## ※動作確認のため実行してみる※ # docker run -itd --privileged -p8888:80 apache-demo01 1ca3fc48ee4de32a06edd1d8feeec959870e934f5d96194d2ab324e983721716 ## ※起動したことを確認する※ # docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 1ca3fc48ee4d apache-demo01 "httpd-foreground" 21 minutes ago Up 21 minutes 0.0.0.0:8888->80/tcp cranky_goldwasser ## ※追加したdemo.htmlが参照できることを確認する※ # curl http://localhost:8888/demo.html <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /> <title>ECS demo page</title> </head> <body> <div class="main_page"> ECS Demo Page for httpd </div> </body> </html> ## ※動作確認したコンテナを停止しておく※ # docker stop 1ca3fc48ee4d 1ca3fc48ee4d2) 更新手順(ECR)
ここも第1回とほぼ同様の手順となります。今回作成したイメージは"apachetest"というタグを付けておきます。
ECRへのログイン:profileオプションが他のコマンド同様に指定可能です。
# $(aws ecr get-login --no-include-email --region ap-northeast-1 --profile vatest) Login Succeededタグ付け:ビルドしたイメージに、ECR形式でのタグを付与します。リポジトリ名に"nginx"を入れていたため少し違和感のある名称になってしまいましたが・・・"nginx-demo01(リポジトリ名):apachetest(タグ名)" が付与した名称です。
# docker tag apache-demo01:latest <AWSアカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/nginx-demo01:apachetest # docker images | grep nginx-demo01 <AWSアカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/nginx-demo01 apachetest 81d38acb42a3 25 minutes ago 154MB <AWSアカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/nginx-demo01 latest de6344632e81 7 weeks ago 109MB nginx-demo01 latest de6344632e81 7 weeks ago 109MBECRへのプッシュ:先ほど付与したタグの通りに指定し、ECRにプッシュします。
# docker push <AWSアカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/nginx-demo01:apachetest The push refers to a repository [<AWSアカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/nginx-demo01] 781884c43489: Pushed 635721fc6973: Pushed bea448567d6c: Pushed bfaa5f9c3b51: Pushed 9d542ac296cc: Pushed d8a33133e477: Pushed apachetest: digest: sha256:9fb40d7d1c0a9f28438bc997765518b55e735c242b3bacf7ad4fe6bf468c58ff size: 1574最後に、コンソールでイメージが追加されたことを確認します。
3) 更新手順(ECS)
タスク定義の更新、サービスの更新の順に実行して変更を反映します。第3回と同様の手順となります。
3-1) タスク定義の更新
タスク定義にチェックを入れ、「新しいリビジョンの作成」を選択します。
コンテナをクリックして出てくるダイアログ内で、イメージのタグ名を変更します。
保存して、新しいリビジョン(2)が作成されたことを確認します。
3-2) サービスの更新
サービスを表示し、「更新」ボタンを押します。
サービスの設定で、タスク定義の新しいリビジョン(2)を選択します。
保存し、更新されたことを確認します。
3-3) 動作確認
少し待ってブラウザで
http://<ELBのDNS名>:8080/index.htmlにアクセスし、apacheのデフォルトページに変更になったことを確認します。
http://<ELBのDNS名>:8080/demo.htmlにアクセスし、テスト用に追加したhtmlも更新されたことを確認します。
インスタンスにログインし、Dockerコマンドでも更新されたことが確認できます。
## ※イメージの確認※ # docker images REPOSITORY TAG IMAGE ID CREATED SIZE <AWSアカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/nginx-demo01 apachetest 81d38acb42a3 About an hour ago 154MB amazon/amazon-ecs-agent latest b5b4bfd5a2aa 3 weeks ago 57.1MB amazon/amazon-ecs-pause 0.1.0 c5d9a481de06 3 weeks ago 954kB <AWSアカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/nginx-demo01 latest de6344632e81 7 weeks ago 109MB ## ※Dockerプロセスの確認※ # docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 5613cf288fbd <AWSアカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/nginx-demo01:apachetest "httpd-foreground" 11 minutes ago Up 11 minutes 0.0.0.0:8080->80/tcp ecs-va-ecs-task-definition01-2-nginx-demo01-b4fcfb81e5de8c89a401 5ecdc50a96f7 amazon/amazon-ecs-agent:latest "/agent" 25 minutes ago Up 25 minutes ecs-agent以上でDockerイメージの更新が確認できました。
コマンドでスケールインしておく
作業後はいつものようにタスクとインスタンス数を0にしておきますが、今回からCLIで実行してみます。インスタンスの方のスケールはawsコマンドではなくecs-cliコマンドでの実行となるため、先にインストールします。
ecs-cliコマンドのインストール
$ which ecs-cli $ sudo curl -o /usr/local/bin/ecs-cli https://s3.amazonaws.com/amazon-ecs-cli/ecs-cli-linux-amd64-latest % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 29.9M 100 29.9M 0 0 8826k 0 0:00:03 0:00:03 --:--:-- 8826k $ sudo chmod +x /usr/local/bin/ecs-cli $ which ecs-cli /usr/local/bin/ecs-cliサービスのスケールイン(タスク数を0にする)
サービスの方はawsコマンドで実行可能です。
aws ecs update-service --cluster <クラスタ名> --service <サービス名> --desired-count <変更後のタスク数> --profile <awsプロファイル>$ aws ecs update-service --cluster va-ecs-demo-cluster01 --service va-ecs-service01 --desired-count 0 --profile vatest ※サービス定義が出力されるが長いので省略※インスタンスのスケールイン
インスタンスはecs-cliコマンドで変更します。先にecs-cli configureコマンドを実行する必要があるのですが、ここでのポイントは --cfn-stack-name オプションで、"EC2ContainerService-"+クラスタ名 を指定する 必要があります。これは CLIでクラスタを作成した場合とデフォルトのプレフィックスが違うため、その差によるエラーが出ないようにする設定です。
## ecs-cli configure --cluster <クラスタ名> --cfn-stack-name "EC2ContainerService-"<クラスタ名> --region <リージョン> --config-name <Config名(何でもよい)> $ ecs-cli configure --cluster va-ecs-demo-cluster01 --cfn-stack-name EC2ContainerService-va-ecs-demo-cluster01 --region ap-northeast-1 --config-name vapractice-ecs INFO[0000] Saved ECS CLI cluster configuration vapractice-ecs. ## ecs-cli scale --capability-iam --size <変更後のインスタンス数> --cluster <クラスタ名> --region <リージョン> --aws-profile <awsプロファイル> $ ecs-cli scale --capability-iam --size 0 --cluster va-ecs-demo-cluster01 --region ap-northeast-1 --aws-profile vatest INFO[0000] Waiting for your cluster resources to be updated... INFO[0000] Cloudformation stack status stackStatus=UPDATE_IN_PROGRESS以上で実行インスタンス数を0にできました。
Link














- 投稿日:2019-08-27T18:33:50+09:00
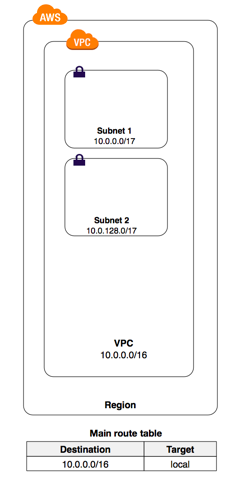
[AWS] VPC MEMO
VPCの概要
Virtual Private Cloud
後で復習がてらにまとめろ
- 仮想ネットワークを構築するサービス
- クラウド内外のネットワーク間を接続も可能
- VPCは基本は一つのAZ内で構築されるが複数のAZにリソースを置くことができる。
CIDR(Classless Inter-Domain Routing)
グローバル部とホスト部の範囲設定。ローカルIPの範囲設定サブネットマスクのこと。
16〜28を設定可能。VPC内のサブネットは200こまで。
196.32.100.???/16の
16 = 255.255.000.000のサブネット
ネットワーク部が196.32、ホスト部100.???。
CIDRはVPCとサブネットの2つに定義できる。こんな感じ。
サブネットの種類
・パブリックサブネット
インターネットゲートウェイとルーティングされている
・プライベートサブネット
インターネットゲートウェイとルートしてないNATゲートウェイ
プライベートサブネットへ接続する際はNATゲートウェイをパブリックサブネットへ設定し、経由してアクセスする必要がある。
VPC外部接続
・エンドポイント
・パブリックAWSネットワーク(or プライベートの場合はNATゲートウェイ設置)ルートテーブルでネット経路作成
ルートテーブルとCIDRアドレスでルーティングを設定。
VPCのトラフィック設定
セキュリティグループの設定
- ステートフル:戻りトラフィック考慮せずOK
- サーバー単位
- 許可をIn/Out設定
- デフォでは同一セキュリティグループのみ通信可能
- 必要な通信は許可設定必要
ネットワークACLs
- サブネット単位
- ステートレス:戻りトラフィックも許可設定可能。
- 許可拒否をIn/Out設定
- デフォでは全てのIPを許可
- 番号の順序通りに適用
VPC設計ポイント
- 将来の拡張性を考慮したCIDR
- 既存のアドレス帯などとかぶらいないように注意
- VPCの組織的な構成を予め考えておく。
- サブネットはPLとPVを使い分けてセキュリティの可用性UP
- VPCFlowLogsでモニタリングする
VPCとのオンプレミス接続
Direct Connect
個別のデータセンターや社内オフィスなどを専用線を介してAWSへプライベート接続する。
- 安いアウトバウンドトラフィック価格
- ネットワーク信頼性・帯域幅の向上
- 使用リージョン付近のDirect Connectロケーションに自社機器を物理的に設置して専用線を引く。設置などはどうすんのかは謎。どっかに頼むんだろうね。
- 専用線のため通常のネット障害は受けない。専用線の障害は受けるが。とにかく信頼性高し。VPN接続
- Direct Connectより安い
- リードタイムは短い。物理的な設置がないため
- 帯域幅はDirectConnectより制限がある
- インターネット経由のためネットワーク影響を受ける。
- インターネット接続のため障害の切り分けが難しい。
VPCエンドポイント
VPCエンドポイントはグローパルIPをもつAWSサービスに対してVPC無いから直接アクセスするための出口。S3などはVPCに属さず、VPC内同士の接続にはならないため。
いかの2つの形式がある。違いがよくわからねえGateway型
- 基本無料
- サブネットに特殊なルーティングを設定し、VPC内部から直接通信する。
PrivateLink型
- 有料
余談
Direct Connect Gateway
リージョン間をまたいだ接続を可能にする。VPC Peering
2つのVPC間でのトラフィックルーティングを可能にする
- 異なるAWSアカウント間のVPC間も接続可能
- 一部のリージョン間ならば異なるVPC間の接続可能
- マネージド・サービス。冗長性はAWSが対応してる。VPC Flow logs
ネットワークトラフィックを取得してCloudWatchでモニタリングできるようにする。
- 利用自体は無料VPCを分割するケース
- アプリーケーションごとの分割
- 監査のスコープによる分割
- リスクレベルの分割
- 本番検証開発フェーズの分割
- 部署による分割
結構重要ーVPCの設定上限
リージョンあたりのVPC数 = 5
VPCあたりのサブネット数 = 200
AWSアカウントあたりの1リージョンのElasticIP数 = 5
ルートテーブルあたりのルート上限数 = 100
VPCあたりのセキュリティグループの上限 = 500
セキュリティグループあたりのルール上限 = 50
- 投稿日:2019-08-27T16:20:34+09:00
Cloud9でデバッグ時の「A newer version of the AWS SAM CLI is available!」を解決する方法
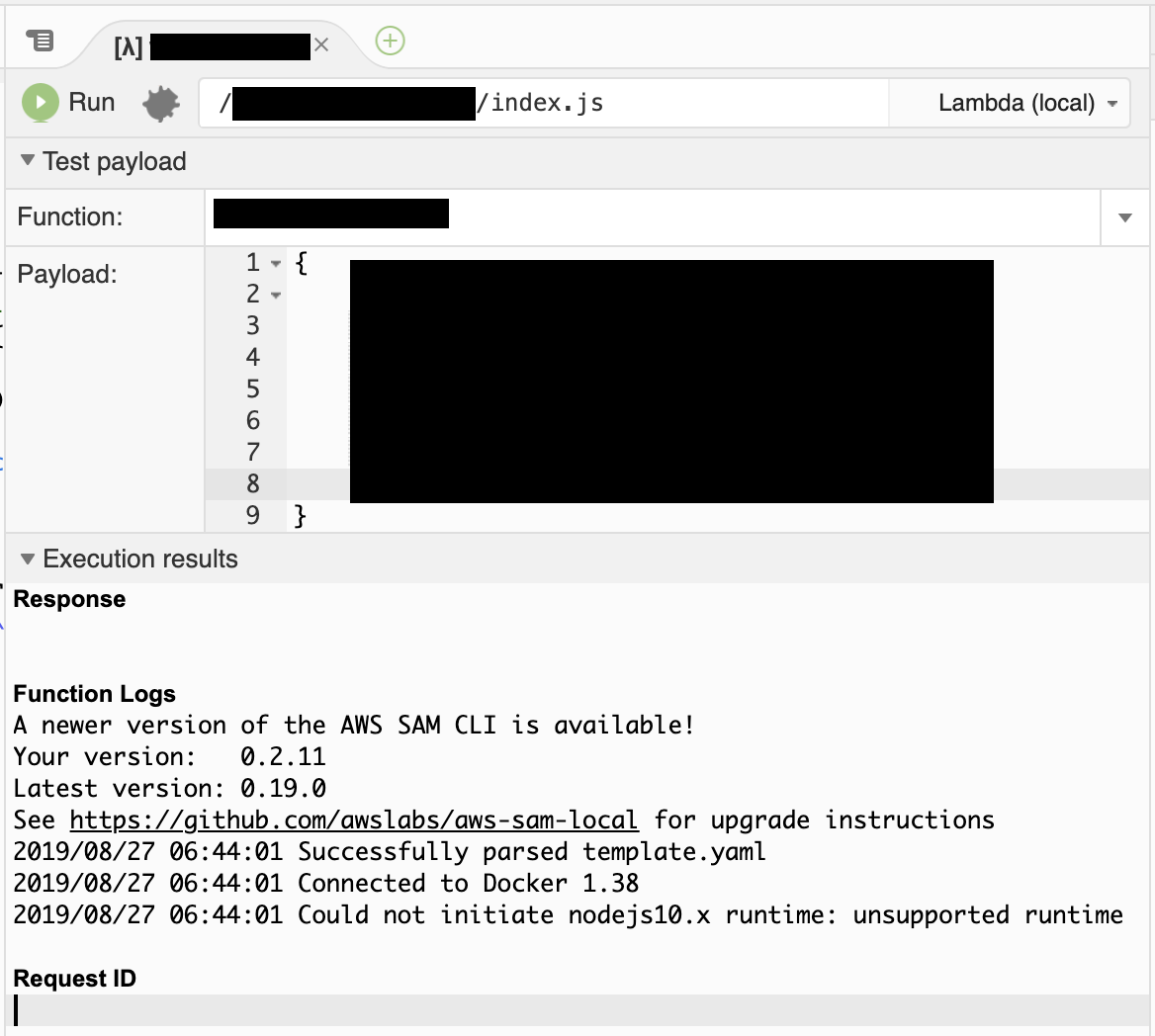
?現象
Cloud9でデバッグを行うと、「A newer version of the AWS SAM CLI is available!」という文言が表示されて、デバッグが実行できない。
?原因
ログに書いてある事が全てです。
Cloud9で使っているAWS SAM CLIのバージョンが古いため、Lambda関数のランタイムにNode.js 10.xを選択したものに対応していないため、エラーになっています。A newer version of the AWS SAM CLI is available! Your version: 0.2.11 Latest version: 0.19.0 See https://github.com/awslabs/aws-sam-local for upgrade instructions 2019/08/27 06:49:39 Successfully parsed template.yaml 2019/08/27 06:49:39 Connected to Docker 1.38 2019/08/27 06:49:39 Could not initiate nodejs10.x runtime: unsupported runtime?解決方法
以下のコマンドでSAM CLIのバージョンアップを行う。
pip install --user --upgrade aws-sam-cli以下のコマンドで、SAM CLIが利用できるように、シンボリックリンクを変更する。
ln -sf $(which sam) ~/.c9/bin/samこれで、最新のAWS SAM CLIが有効になり、デバッグができるようになります。
- 投稿日:2019-08-27T16:02:57+09:00
AWS DMSを使ってみた(ノウハウ)
はじめに
ちょっと前に仕事でAWS DMSを使ったので、その時のノウハウです。
DMSはDatabase Migration Serviceの略で、(基本的には)DBからDBへ移行するためのツールです。自分が実際に使ったのはOracle→Autora MySQLの移行です。
ターゲットDBのテーブルは予め作っておく
DMSは、ソースDBからデータを抜き取り、一度DMSのデータ型に変換して、
更にターゲットDBのデータ型に直してデータを入れていきます。この過程で意図しないデータ型に変換されてしまうことがあるので、
ターゲットDBには予め意図した型のテーブル・カラムを作成しておいてから、データ移行を行ったほうが良いです。データの変換テーブルは以下のページなどを参照。
AWS Database Migration Service のデータ型
OracleがソースDBの時のデータ型
Aurora MySQLがターゲットDBの時のデータ型またテーブルの移行にはSCT(Schema Conversion Tool)を使うこともできます。
AWS Schema Conversion Tool
※これで変換されたDDLをそのまま使うのではなく、意図した型になっていることを確認してからターゲットDBに適用した方が良いです。トリガーなどは無効化
大量のデータがインサートされる時はできるならトリガーは無効化しておきます。
(もしトリガーの挙動が別テーブルへのデータインサートなら、そのテーブルも同期しておけばOK)
でないと、いちいちトリガーが動いてデータ同期に時間がかかります。
(フルロードのときはload data infileでロードするからトリガは動かない気もする。)もっと言うと、インデックスもフルロード時には一時的に外しておいた方が効率的です。
タスク作成はスクリプトなどで自動化
AWSコンソールからタスクを作成できますが、テーブルが多いときには現実的ではありません。
API/SDKなどを使って自動化できるようにしましょう。
最低限はタスクですが、DMSインスタンスなども簡単に作れるようにスクリプトを用意しておいても良いです。
CreateReplicationTask
CreateReplicationInstance
あたりを参照。CreateReplicationTask についてもうちょっと深堀り
CreateReplicationTaskと、タスク作成に関するポイントをいくつか。
移行のタイプ
FullLoadとCDC(change data capture)とFullLoad+CDCから選択できます。
要件にも寄りますが、ほとんどの場合はFullLoad+CDCを選ぶことになります。
FullLoadだけを選ぶのは、もう更新されないDB(静止断面)をソースDBとするとき。
CDCを選ぶのは、DMS以外でFullLoadをするとき。同期開始地点を時間やSCN(Oracle)で指定可能(cdc-start-position/cdc-start-time)だけど、
ちゃんと環境を整えてやらないと、整合性を保つのは難しいと思われます。※データ移行はFullLoadとCDCの2フェーズに見えますが、実はこの間にはキャッシュ適用というタイミングもあります。
これはFullLoad実施中に発生した変更をキャッシュしておき、FullLoadが終わったらそれを適用します。
キャッシュ適用が終わったら、CDCに移行します。タスク設定(ReplicationTaskSettings)
APIのページではさらっと書いてありますが、結構たくさんのことをJSON形式で指定する必要があります。
大きくは、FullLoad設定、CDC設定、ログ設定、エラー時の挙動など。
詳細はこちら→AWS Database Migration Service タスク設定の指定
個別のパラメータについては、更に以下にて。TargetMetadata.ParallelLoadThreads
ターゲットDBへのロード処理を何多重で実行するかです。(1テーブルを複数スレッドで処理します。)
Aurora MySQLの場合、auto_commitをonにしておかないとロードされないレコードが発生します。(他のDBも同様?)
(最近のDMSでは強制的にonにするようになっているとも聞きました。)TargetMetadata.BatchApplyEnabled
BatchApplyを有効にするかどうか。有効にすると結果整合性が取られる。
無効にするとTransactionModeになって、トランザクションの順序性が保証されます。
ChangeProcessingTuning内のBatchApply...パラメータで細かいチューニングができます。FullLoadSettings.TargetTablePrepMode
FullLoad開始前に対象テーブルをどうするかを設定します。
何もしない(DO_NOTHING)、Dropする(DROP_AND_CREATE)、Truncateする(TRUNCATE_BEFORE_LOAD)
の3択です。
手動でtruncateしてからDO_NOTHINGをするか、TRUNCATE_BEFORE_LOADにしておきます。
Dropすると、DMSがよしなにデータ型を決めてしまうのでおすすめしません。FullLoadSettings.MaxFullLoadSubTasks
FullLoadを何多重(何テーブル)同時にロードするかを設定します。
先のParallelLoadThreadsとは別の話です。FullLoadSettings.TransactionConsistencyTimeout
タスク開始時、残存トランザクションがあれば何秒待つか、という設定です。
デフォルトは10分(600秒)なので、その場合は最長10分待ちます。
その間にトランザクションが完了しなければ、そのトランザクションの完了を待たずにフルロードが開始されます。
タスク開始以降に開始したトランザクションについては、キャッシュで変更が反映されますが、
タイムアウトしてしまったトランザクションは・・・・。ChangeProcessingDdlHandlingPolicy.*
それぞれDrop、Truncate、Alterを同期するかどうかです。
データ同期中にソースDBにDDL適用するのはおすすめしません。。。
カラム追加などすると、うまくデータ同期が動かなくなったりします。
ただ、大量にDeleteするよりTruncateした方が色々効率は良いので、これだけ有効化しても良いと思います。
また、ソースDB、ターゲットDBそれぞれのDBによって、同期されるDDLに制約があります。
特にPatition系は注意が必要です。ドキュメントを良く確認する必要があります。ErrorBehavior.*
数が多いので割愛しますが、エラー時の挙動はちゃんと考えておいたほうが良いです。
テーブルマッピング(TableMappings)
対象テーブルや対象外テーブルや、フィルタを設定したり、変換ルールなどをJSON形式で指定します。
APIのページの例ではJSONファイルを指定していますが、Python SDK(Boto)ではできなかったので、
JSON形式でコマンドに埋め込みました。詳細はこちら→テーブルマッピングを使用して、タスクの設定を指定する
OracleのCapture(Extract)するツール
ソースDBがOracleの場合は、CaptureするツールとしてLogMinerとBinary Reader があります。
LogMinerの方が機能的には優れていますが、スピードはBinary Readerの方が早いです。
またLogMinerはソースDBに負荷がかかりますが、Binary Readerはネットワーク帯域とDMSインスタンスに負荷がかかります。
それぞれの挙動の概要は以下のとおりです。
詳細はこちらのページで→AWS DMS のソースとして Oracle データベースを使用するLogMiner
LogMiner自体はOracleDBに付随するツールです。LogMiner経由でREDOを読み込み必要な変更をDMSに転送します。
そのためソースDBに負荷がかかります。Binary Reader
Binary ReaderはAWS独自(?)のツールです。
REDOログ(アーカイブREDOログも含む)をDMSに転送して、Binary Readerで変更を読み取ります。
REDOログをすべて転送しDMSで変更を読み取るため、ネットワークとDMSインスタンスに負荷がかかります。
確かタスク分だけ同じREDOログを転送することになるので、ネットワーク負荷はタスク分だけ倍増します。
またREDOログがASMにあったりすると、それはそれは大変な苦労を見ることになります。Active Data GuardのスタンバイDBをソースDBにする
スタンバイDBは読み取り専用ですが、ソースDBに指定することができます。
ただスタンバイDB自体もデータ同期していて遅延が発生するので、ターゲットDBへのデータ同期は更に遅延が発生します。
またADGとDMSを長い間停止しておくと、同期の再開時にDMSがタスクを止めていた間の変更を
移行しないことがあります。(standbyDelayTimeを参照)parallelLoadThreads(Autora MySQLの追加の接続属性)
Aurora MySQLをターゲットDBとした時の、追加の接続属性に「parallelLoadThreads」があります。
タスクのTargetMetadata.ParallelLoadThreadsが優先だった気がするのですが、
もしタスクで設定しても有効にならなければ、こちらでも設定しておきます。詳細はこちら→AWS Database Migration Service のターゲットとしての MySQL 互換データベースの使用
おわりに
リアルタイムデータ同期はかなり難しかったです。
DB移行時だけ利用するという用途であれば良いと思います。
どうしても恒久的にデータ同期する必要があるのであれば、
同期するテーブルの選定、タイミング(リアルタイム、バッチ)を良く精査しなければなりません。
またバッチであれば、ファイル連携などDMS以外の手段でも良いと思います。
(リアルタイムもDMS以外の手段がありますが。)大量のテーブル・データを全てリアルタイムで常にデータ同期するなんて、
運用が大変(というか無理)なので、絶対にお勧めしません。
- 投稿日:2019-08-27T13:15:42+09:00
社内ネットワーク機器をCloudWatchで監視する
社内にあるルータやスイッチなどのsnmpしかないネットワーク機器をCloudWatchで監視したい欲求にかられてやってみたので設定方法のまとめです。
TL;DR
VPNなどでVPCと直接つながっていないsnmp機器をCollectdとCloudWatch Agent 経由でCloudWatchにデータを投げて、メトリクスをグラフにします。
もう一度試す気力がないので設定した際の記録をもとに書いています。collectdはデータ収集ツールです。グラフを描画する機能はありません。
https://collectd.org前提
- AWSのVPCと直接つながっていない。
- 踏み台にできるマシンがある。
- 複数のネットワーク機器を1台の踏み台を経由してCloudWatchにポイポイする。
踏み台サーバの準備
collectdのインストール
collectdとsnmp pluginをインストールします。centos7を利用していて下記をインストールしました。
collectd-snmp-5.8.1-1.el7.x86_64 collectd-5.8.1-1.el7.x86_64こちらEC2へのインストールですが、参考になります。https://dev.classmethod.jp/cloud/aws/collectd-cloudwatch/
CloudWatch AgentでCollectdを有効にする。
踏み台サーバのCloudWatch Agent のCollectdを有効にします。
ウィザードを使ってもいいですし、設定ファイルをいじってもいいです。とりあえず踏み台サーバ自身のメトリクスがCloudWatchにあがるところまで確認しておいてください。
意外としくったりします。
参考) https://qiita.com/murata-tomohide/items/3e66d63b21c08d6481a2Collectd CloudWatch Pluginをインストールする。
CollectdからデータをCloudWatchに流すためのプラグインを入れます。
https://github.com/awslabs/collectd-cloudwatch
git clone してsetup.pyを動かします。
collectd.confにsnmp設定追加
/etc/collectd.confで↓のディレクトリを読むようにして、ディレクトリ配下にsnmp.confを置きました。
上のsetup.pyが/etc/collectd.confをいじるので注意してください。/etc/collectd.conf~snip #</Plugin> Include "/etc/collectd-cloudwatch.conf" Include "/etc/collectd.d/"/etc/collectd.d/snmp.confLoadPlugin snmp <Plugin snmp> # <Data "powerplus_voltge_input"> # Type "voltage" ~snip # ORESW006 <Data "uptime_ORESW006"> Type "uptime" Table false Instance "ORESW006-UPTIME" Values "DISMAN-EVENT-MIB::sysUpTimeInstance" </Data> <Data "std_traffic_ORESW006"> Type "if_octets" Table true InstancePrefix "ORESW006-" Instance "IF-MIB::ifDescr" Values "IF-MIB::ifInOctets" "IF-MIB::ifOutOctets" </Data> <Data "std_errors_ORESW006"> Type "if_errors" Table true InstancePrefix "ORESW006-" Instance "IF-MIB::ifDescr" Values "IF-MIB::ifInErrors" "IF-MIB::ifOutErrors" </Data> <Data "std_discards_ORESW006"> Type "if_dropped" Table true InstancePrefix "ORESW006-" Instance "IF-MIB::ifDescr" Values "IF-MIB::ifInDiscards" "IF-MIB::ifOutDiscards" </Data> <Host "ORESW006.netgear"> Address "192.168.0.6" Version 2 Community "onesatoshi" Collect "uptime_ORESW006" "std_traffic_ORESW006" "std_errors_ORESW006" "std_discards_ORESW006" Interval 60 Timeout 10 Retries 1 </Host>どんな値があるのか確認するにはsnmpwalkなどでMIBを調べます。
snmpwalk -v 2c -c oregaichiban 192.168.0.6 systemとか。
InstancePrefix でわざわざ機器名を指定しているのは、後述のwhitelistに記述する際にどの機器のメトリクスか判別できないので、めんどくさいですがやっておいたほうがいいです。
今回10台ぐらいのルータやスイッチを設定したのですが、3台目ぐらいからわけわかめになります。
設定し終わったらsystemctl restart collectd.serviceをしてください。CloudWatchにぶん投げるデータを選定 whitelistを調整
今のままだと、CloudWatchのpluginによって、データがせき止められているので、CloudWatchに流すデータを指定してあげます。
具体的には
/opt/collectd-plugins/cloudwatch/config/blocked_metricsにリストが入っていますので、必要そうなデータを/opt/collectd-plugins/cloudwatch/config/whitelist.confにコピーします。/opt/collectd-plugins/cloudwatch/config/blocked_metrics~snip snmp--if_octets-ORESW006-lag 3.tx snmp--if_octets-ORESW006-lag 4.rx snmp--if_octets-ORESW006-lag 4.tx snmp--if_octets-ORESW006-lag 5.rx snmp--if_octets-ORESW006-lag 5.tx snmp--if_errors-ORESW006-1 Gigabit - Level.rx snmp--if_errors-ORESW006-1 Gigabit - Level.tx snmp--if_errors-ORESW006-2 Gigabit - Level.rx snmp--if_errors-ORESW006-2 Gigabit - Level.tx snmp--if_errors-ORESW006-3 Gigabit - Level.rx snmp--if_errors-ORESW006-3 Gigabit - Level.tx snmp--if_errors-ORESW006-4 Gigabit - Level.rx snmp--if_errors-ORESW006-4 Gigabit - Level.tx snmp--if_errors-ORESW006-5 Gigabit - Level.rx snmp--if_errors-ORESW006-5 Gigabit - Level.tx snmp--if_errors-ORESW006-6 Gigabit - Level.rx snmp--if_errors-ORESW006-6 Gigabit - Level.tx snmp--if_errors-ORESW006-7 Gigabit - Level.rx snmp--if_errors-ORESW006-7 Gigabit - Level.tx snmp--if_errors-ORESW006-8 Gigabit - Level.rx snmp--if_errors-ORESW006-8 Gigabit - Level.tx snmp--if_errors-ORESW006-9 Gigabit - Level.rx snmp--if_errors-ORESW006-9 Gigabit - Level.tx snmp--if_errors-ORESW006-10 Gigabit - Level.rx snmp--if_errors-ORESW006-10 Gigabit - Level.tx snmp--if_errors-ORESW006-lag 1.rx snmp--if_errors-ORESW006-lag 1.tx snmp--if_errors-ORESW006- CPU Interface for Slot: 3 Port: 1.rx snmp--if_errors-ORESW006- CPU Interface for Slot: 3 Port: 1.tx snmp--if_errors-ORESW006-lag 2.rx snmp--if_errors-ORESW006-lag 2.tx snmp--if_errors-ORESW006-lag 3.rx snmp--if_errors-ORESW006-lag 3.tx snmp--if_errors-ORESW006-lag 4.rx snmp--if_errors-ORESW006-lag 4.tx snmp--if_errors-ORESW006-lag 5.rx snmp--if_errors-ORESW006-lag 5.tx snmp--if_dropped-ORESW006-1 Gigabit - Level.rx snmp--if_dropped-ORESW006-1 Gigabit - Level.tx snmp--if_dropped-ORESW006-3 Gigabit - Level.rx snmp--if_dropped-ORESW006-3 Gigabit - Level.tx snmp--if_dropped-ORESW006-lag 4.rx snmp--if_dropped-ORESW006-lag 4.tx snmp--if_dropped-ORESW006-7 Gigabit - Level.rx snmp--if_dropped-ORESW006-7 Gigabit - Level.tx snmp--if_dropped-ORESW006-5 Gigabit - Level.rx snmp--if_dropped-ORESW006-5 Gigabit - Level.tx snmp--if_dropped-ORESW006-8 Gigabit - Level.rx snmp--if_dropped-ORESW006-8 Gigabit - Level.tx snmp--if_dropped-ORESW006-4 Gigabit - Level.rx snmp--if_dropped-ORESW006-4 Gigabit - Level.tx ~snipこんな感じで入ってきますので、whitelist.conf に書いていきます。この時にPrefixがついていないとわけわかめになるんですよ。
正規表現が使えるので楽ですね。/opt/collectd-plugins/cloudwatch/config/whitelist.conf~snip # ORESW006 snmp--uptime-ORESW006-UPTIME snmp--if_octets-ORESW006-[0-9].* snmp--if_dropped-ORESW006-[0-9].* snmp--if_errors-ORESW006-[0-9].* ~snip拾ったものをすべて流す設定もあります。setup.pyを実行する際に‘whitelist_pass_through ‘って項目があったかとおもいますが、それをtrueにすれば全部ぶん投げます。
※10,000メトリクスまで月額$0.3/metricです。金額に注意しましょう。ちなみにその辺のconfは
/opt/collectd-plugins/cloudwatch/config/plugin.confですhostの項目が設定されていたら空欄にしましょう。(CloudWatchのHost部分にsnmpのhostが表示されるようになります。)CloudWatchのグラフを作成
↑の設定がちゃんとできていれば、CloudWatchにデータが流れてきていると思います。メトリクスを確認してみてください。
こんな感じですべてのメトリクスにcollectdって項目ができていると思います。
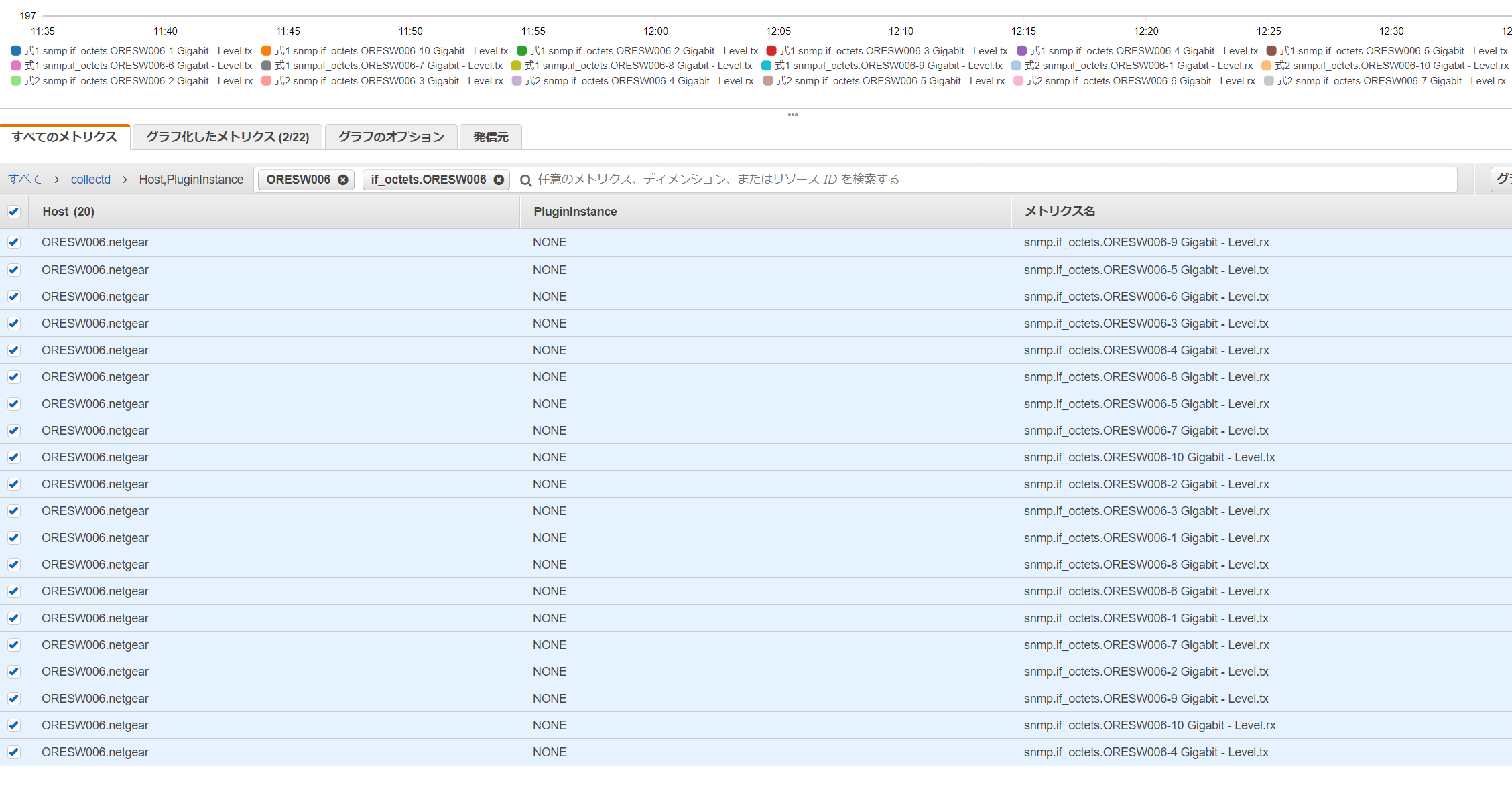
スイッチのメトリクスを選択
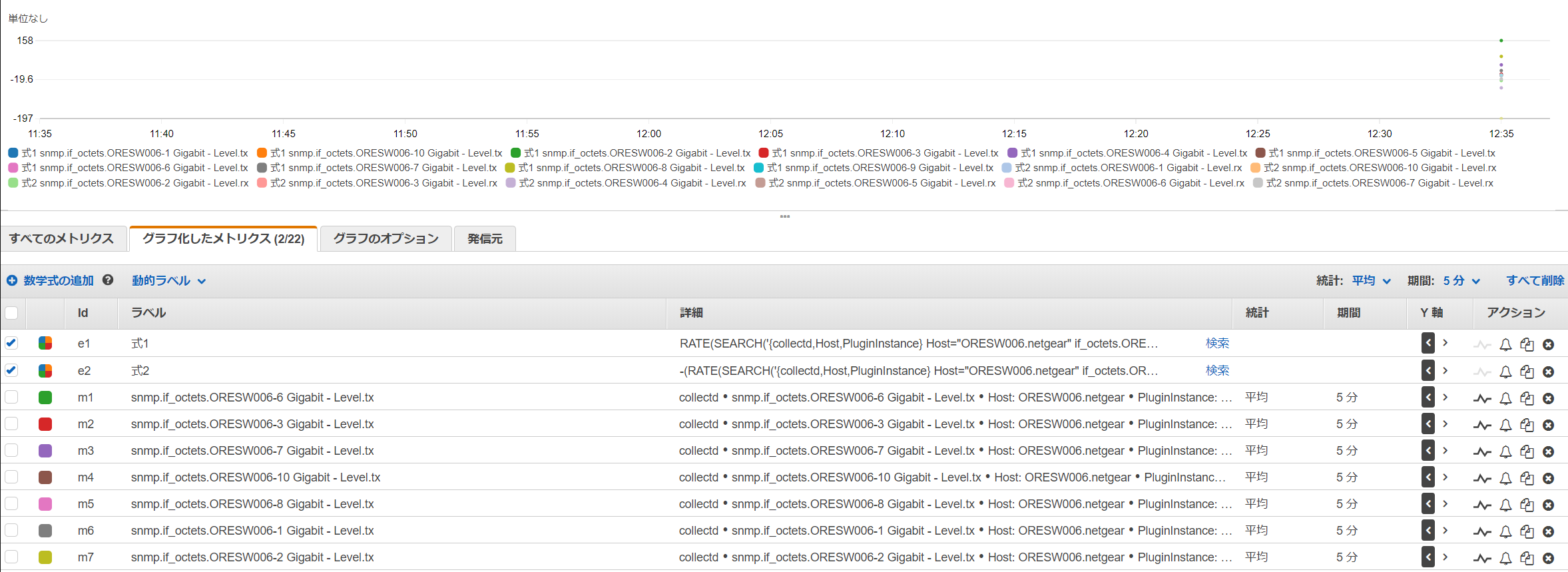
例としてスイッチのトラフィックをグラフにしてみましょう。
if_octetsのtxとrxを拾います。
Metric Mathで調整
Metric Mathを使ってrxは負の値にします。このままだとbit per sec なので8で割ってbyteにしてみます。
まだデータが取れていないのでこれで計算が合っているのかよくわかっていません。どなたかヘルプ!https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/using-metric-math.html
RATE(SEARCH('{collectd,Host,PluginInstance} Host="ORESW006.netgear" if_octets.ORESW006 tx', 'Average', 300)) / 8
-(RATE(SEARCH('{collectd,Host,PluginInstance} Host="ORESW006.netgear" if_octets.ORESW006 rx', 'Average', 300)) / 8)
あとはグラフのオプションなどのラベルを調整したりしてダッシュボードに追加してください。
入れすぎるとダッシュボードに入れすぎ!って怒られるので注意です。まとめ
ストレージを気にしなくていい。
こーいうののモニタリングサーバを自前で持つと結構なストレージ容量が必要になってくるのですが、踏み台はawsにデータをぶん投げているだけなのであまり気にする必要ありません。
踏み台サーバの負荷が結構低くてうれしい。
collectdが優秀なのか、1000メトリクス超えてもCPU負荷は3-5%ぐらいでした。
Intel(R) Xeon(R) CPU E3-1241 v3 @ 3.50GHz
メモリもほとんど使っていません。snmpのCloudWatchのプラグインがいまいち
whitelistの関係上、Collectdのsnmpプラグインでホストごとに取得する項目を書かないといけないので設定ファイルがでかくなってしまいます。
まったく同じ製品が結構な量あるって場合には1か所に書いてもいいかもしれませんが、寄せ集めてきな感じだとつらいです。取得できるもの全部上げるわけにいかない。
お金とかの問題。でも1000メトリクスで月額$300ぐらい。スイッチだと1ポートにつきrx, tx, dropped, errorsとなる。
~utとかリクエストの金額は誤差だけど。。。1メトリクスあたりで課金って思うと必要なものだけ上げたくなるよね。
最初は請求をこまめにチェックしましょう。AmazonCloudWatch APN1-TimedStorage-ByteHrs $0.033 per GB-mo of log storage - Asia Pacific (Tokyo)データの保持期間がCloudWatch依存になる
メトリクスの保持
昔は14日で消えていましたが、今はMAX455日間保持してくれます。(徐々に細かいデータは消えていく感じ)
保持されたデータをDL等することはできなさそうなので、一度使い始めたら移行期間は併用するしかないためしばらくはロックインされます。CloudWatch には、メトリクスデータが次のように保持されます。
期間が 60 秒未満のデータポイントは、3 時間使用できます。これらのデータポイントは高解像度カスタムメトリクスです。
期間が 60 秒 (1 分) のデータポイントは、15 日間使用できます。
期間が 300 秒 (5 分) のデータポイントは、63 日間使用できます。
期間が 3600 秒 (1 時間) のデータポイントは、455 日 (15 か月) 間使用できます。最初は短い期間で発行されるデータポイントは、長期的なストレージのため一緒に集計されます。たとえば、1 分の期間でデータを収集する場合、データは 1 分の解像度で 15 日にわたり利用可能になります。15 日を過ぎてもこのデータはまだ利用できますが、集計され、5 分の解像度のみで取得可能になります。63 日を過ぎるとこのデータはさらに集計され、1 時間の解像度のみで利用できます。
CloudWatch は、2016 年 7 月 9 日の時点で 5 分および 1 時間のメトリクスデータを保持し始めました。
まだ試し始めて間もないためわかっていない部分もありますが、とりあえずこんな感じでした。
View部分はgrafanaとか別のツールを使ったほうがいい気がしているこの頃。
(だったらPrometheusでsnmp-exporterでいいのでは?あれ?あれれ?)
- 投稿日:2019-08-27T11:29:34+09:00
AWS CodeBuild をローカルでデバッグする CodeBuild Local 入門
簡単に
- https://github.com/aws/aws-codebuild-docker-images を clone
aws-codebuild-docker-images/ubuntu/standard/2.0/Dockefileをビルド ( これがビルド用イメージになる )
- マシンスペックにもよりますが、 Core i7 の Macbook で 20 分程度かかりました
- ヘルパースクリプト
aws-codebuild-docker-images/local_builds/codebuild_build.shを利用して CodeBuild Local 起動Getting-started$ git clone https://github.com/aws/aws-codebuild-docker-images.git $ docker build -t aws/codebuild/standard:2.0 ./aws-codebuild-docker-images/ubuntu/standard/2.0/ $ ./aws-codebuild-docker-images/local_builds/codebuild_build.sh -i aws/codebuild/standard:2.0 -s /path/to/src -a ./artifactsCodeBuild の
buildspec.ymlのデバッグがつらい!!CodeBuild の
buildspec.ymlを書いているとき、こんなことありませんか?
buildspec.ymlのちょっとした修正の動作確認をしたいけど、この修正でいいかわからない- 修正途中のコミットを push したくない、後でコミットログを整理したくない
- 修正途中のソースでパイプラインが走りきって、ビルドされたコンテナイメージをリポジトリに push してしまうとまずい
- CodeBuild の待ち時間が長い
それ、 CodeBuild Local なら解決できるかもしれません。
CodeBuild Local とは ?
aws/aws-codebuild-docker-images - GitHub
- AWS が提供する CodeBuild のビルド用イメージの Docker ファイルと、それを動かすための Agent Docker イメージとヘルパースクリプト
- ローカルで
buildspec.ymlを走らせてデバッグできる- 本物の CodeBuild 同様、複数ソースをインプットとしたり、アーティファクトの出力もできる
やってみよう !
CodeBuild Local を簡単に体験できる Makefile を書きました。
使い方がわかってきたら、実際にプロダクトに組み込んでみると良いと思います。ikasam/codebuild-local-getting-started - GitHub
getting-startedの使い方$ git clone https://github.com/ikasam/codebuild-local-getting-started.git $ cd codebuild-local-getting-started $ make動作確認環境
- Docker Desktop for Mac v2.1.0.1 (37199)
- Engine: 19.03.1
- GNU Make 3.81
ヘルパースクリプト
codebuild_build.shの使い方がわかれば CodeBuild Local が分かる!!ヘルパースクリプトがやっていること
スクリプトに渡されたオプションから、実際に実行する
dockerコマンドを組み立てて実行します。最終的にどういうコマンドが実行されるかは、スクリプト実行時の最初に表示されます。$ ./aws-codebuild-docker-images/local_builds/codebuild_build.sh \ -i aws/codebuild/standard:2.0 -e ./codebuild.local.env -s . -a ./artifacts Build Command: docker run -it -v /var/run/docker.sock:/var/run/docker.sock -e \ "IMAGE_NAME=aws/codebuild/standard:2.0" \ -e "ARTIFACTS=/Users/m_kanno/ikasama/codebuild-local-getting-started/artifacts" \ -e "SOURCE=/Users/m_kanno/ikasama/codebuild-local-getting-started/." \ -v "/Users/m_kanno/ikasama/codebuild-local-getting-started:/LocalBuild/envFile/" \ -e "ENV_VAR_FILE=codebuild.local.env" \ -e "INITIATOR=m_kanno" amazon/aws-codebuild-local:latest※ 見やすさのために出力を改行しています
少しクセのあるオプションたち
ここの README にだいたいのことが書いてありますが、少しクセがあるので補足説明をしておきます。
https://github.com/aws/aws-codebuild-docker-images/tree/master/local_builds
オプション 意味 必須? -iビルド用イメージ ○ -aアーティファクト出力先 ○ -lagent イメージを指定する -cAWS CLI の設定 -pAWS CLI のプロファイル -bbuildspec.ymlの指定-e環境変数 -mソースディレクトリをホストから Volume Mount -sソースディレクトリの指定
-iビルド用イメージ
- カスタム用ビルドイメージはここで指定します
-c,-pAWS CLI の設定、プロファイル
~/.aws/config,~/.aws/credentialをビルド用イメージ内にコピーします- 例えば、 AWS のリソースにアクセスする際に必要です
- ECR からイメージを pull するとか
- プロファイルを指定したい場合は
-cに加えて-p your_profileも指定します
-e環境変数
- ファイルだけ渡せる
-e MYENV=hogeというような渡し方はできません- 一般的な env ファイルフォーマット
- 細かい仕様は README に書いてあります
- ローカルで走らせたくない処理があるときは、環境変数で制御すると良いです
CODEBUILD_CIは CodeBuild 上ではtrueとなるので、ローカルではfalseを渡して if で分岐するとか環境変数で制御する例if $CODEBUILD_CI; then echo This line is executed only in the real CodeBuild environment; fi
-mソースディレクトリをホストから Volume Mount
- うまく使うとソース転送時間を短縮できます
- マウント先にビルドの中間生成物を作ったあと削除しないと、ホスト上に中間生成物が残ります
-sソースディレクトリの指定
- 省略するとカレントディレクトリをソースとします
- 複数ソースを指定する場合、 2 つ目以降は
-s <sourceIdentifier>:<sourceLocation>の形式で指定しますbuildspec.ymlの中では、$CODEBUILD_SRC_DIR_<sourceIdentifier>で参照できます 12 つの異なる Docker イメージ
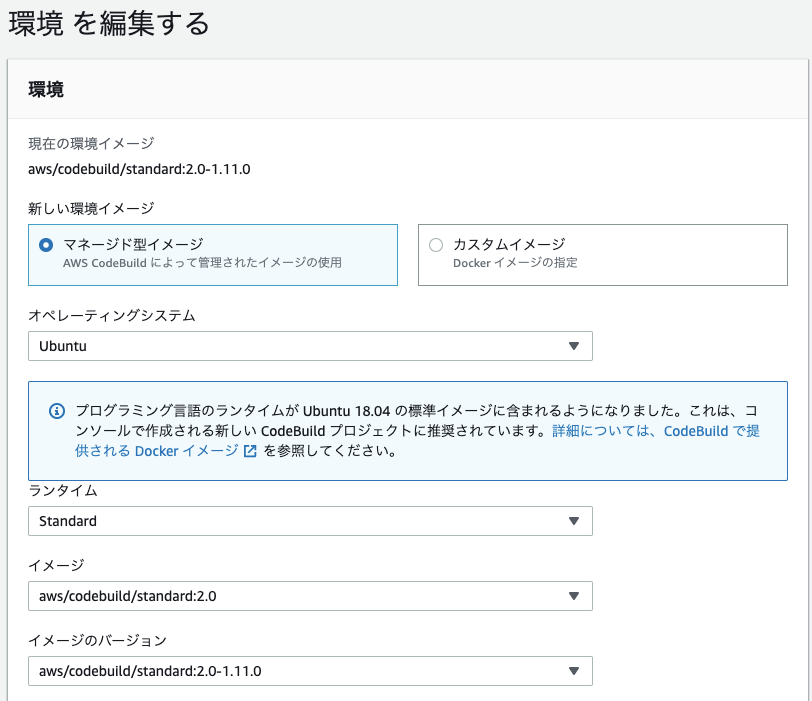
ビルド用イメージ
ビルド環境となる Docker イメージです。
CodeBuild が標準で提供しているイメージを利用したり、プロジェクトによってはカスタムイメージを用意します。 getting-started では CodeBuild 標準のaws/codebuild/standard:2.0を利用しています。
aws/codebuild/standard:2.0は、CodeBuild のコンソールでは環境設定で設定します。
CodeBuild Local Agent (agent イメージ)
CodeBuild をエミュレートする Docker イメージです。
こいつがbuildspec.ymlを解釈し、ビルド用イメージ上でのビルドを指示します。
Dockerfile などは公開されていおらず2、 Docker Hub からイメージを pull して利用します。CodeBuild Local の制限事項
buildspec.yml上での Docker の Volume mount がうまく動きません。
これは、以下の環境差異によるものです。
- CodeBuild: OS 3上の Docker でビルド用イメージを動かす
- CodeBuild Local: Docker コンテナ (agent) からホスト OS の Docker でビルド用イメージを動かす
Docker デーモンが動いている場所とマウントしようとする場所が違うので、 CodeBuild Local では Volume mount がうまく動きません。4
まとめ
- CodeBuild Local で
buildspec.ymlを手軽に動作確認できます- CodeBuild Local を簡単に体験できる Makefile を作りました。ぜひ試してみてください!
- ヘルパースクリプト
codebuild_build.shの使い方をマスターしよう!- 一部制限事項があるので、気をつけましょう
参考
- 投稿日:2019-08-27T09:49:34+09:00
ECRのライフサイクルの設定メモ
これはなに?
AWSのECSを使う前提で、ECRを利用しています。
こちらはDockerイメージのリポジトリで、CIやパイプラインで定期的にビルドしたイメージをpush & 登録する設定を試しています。ここでは、ECSについてはまだ触れません。
(ECSを起動すると思いがけず課金が発生するので、個人枠では慎重に進めています....)やりたいこと
さて、ECRもAWSの1年間の無償枠の中の1つとして利用ができます。
ただし、サイズ制限があり、リポジトリの利用サイズが0.5GBを越えてしまうと、課金対象になってしまいます。今実験しているDockerのイメージは、サイズが450MB程度...。
CIでの定期的なpushは実施できそうなので、更新した単位でイメージの登録はできますが、2世代分は保持はできません。ということで、やりたいのはこちら。
- 最新の1つを残して、うまく削除できるようにしたい
注意点
スクリーンショットや設定方法は変更される可能性があります。
また、実際にちゃんと消えているか、課金状況はどうかというのは、こまめに確認することをお勧めします...。方法: ライフサイクルの設定
設定にあたっては、こちらの記事を参考にさせていただきました。
- Amazon ECR ライフサイクルポリシー / ライフサイクルポリシーの作成 (AWS公式)
- ECRのライフサイクルポリシー設定によるリポジトリ容量の節約 (Classmethod DevelopersIO)
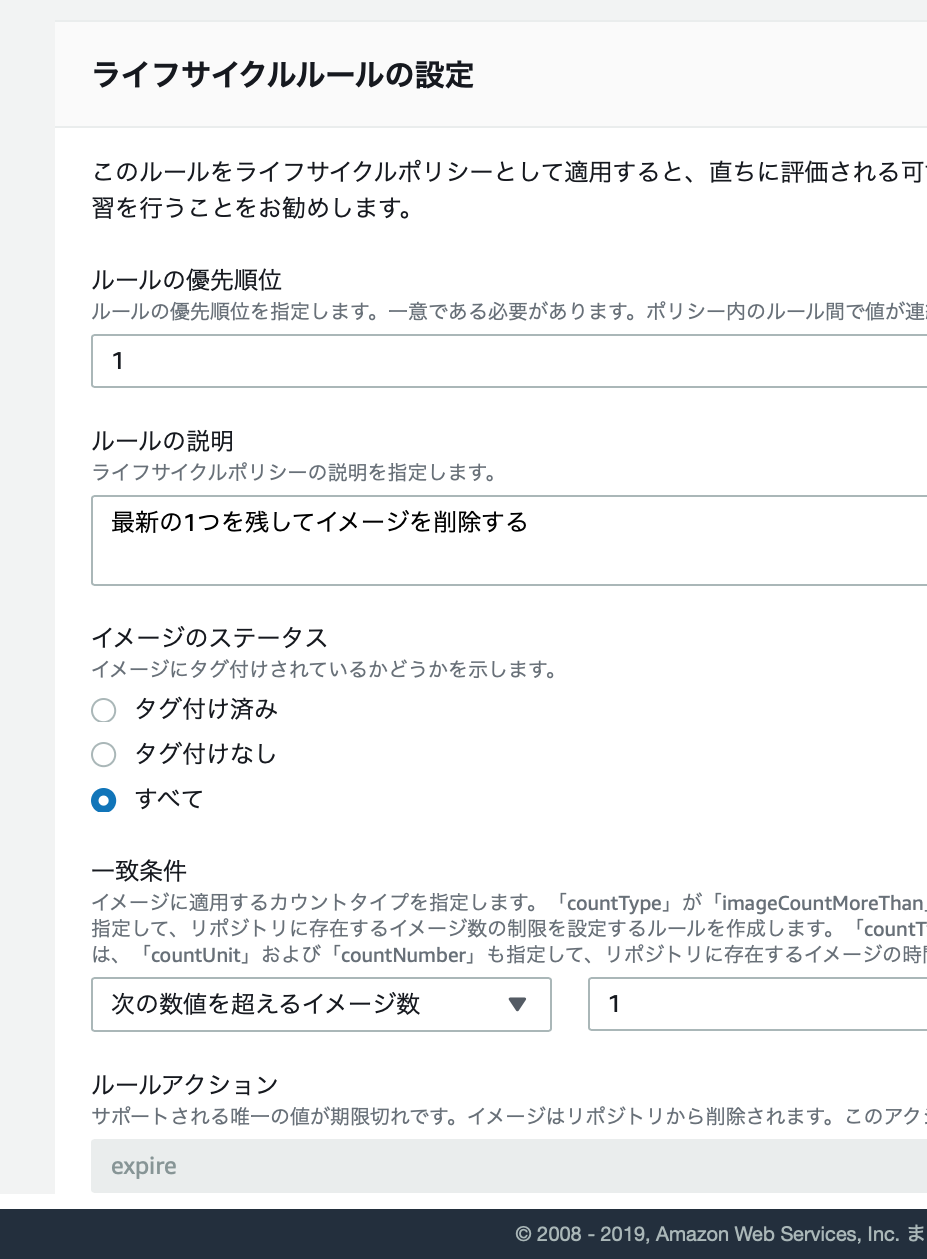
設定画面
「最新の1つを残して」を条件にしたので、「次の数値を超えるイメージ数」に1を設定。さらに、タグ付けの有無は問わずに指定しています。
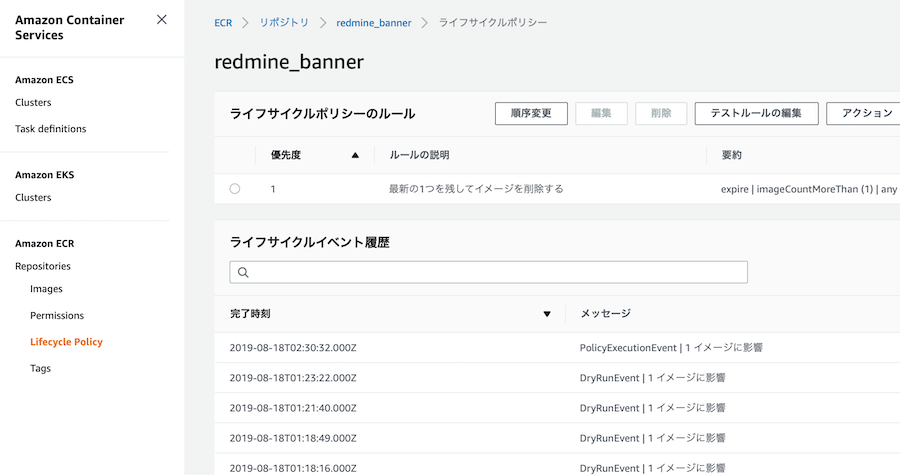
適用の結果
リポジトリに複数イメージが溜まった状態で、テストのポリシーを実行すると、該当するイメージがあれば以下のように表示されます。
実際には、新しいイメージがプッシュされた直後に削除が発生するのではなく、削除フラグ的なものが設定された上で、2〜3時間くらい経ってから削除になっています。
Terraformで設定する
コンソールでの設定がうまく行ったので、設定をTerraform側に落とし込んでみます。
ECR作成やライフサイクルポリシーの設定も、リソースとして定義ができるので、terraform importをしてから、以下のような形で書き出しています。
- ECRのリポジトリ名は akiko/redmine_banner
- メンテナ&イメージ名的に / が使えるので、あえてこうしてみる
- ECRのリポジトリ作成後に、
aws_ecr_lifecycle_policyで、ポリシーを設定
- 対象は
repository =で設定しますresource "aws_ecr_repository" "akiko_redmine_banner" { name = "akiko/redmine_banner" } resource "aws_ecr_lifecycle_policy" "akiko_redmine_banner_policy" { policy = jsonencode( { rules = [ { action = { type = "expire" } description = "最新の1つを残してイメージを削除する" rulePriority = 1 selection = { countNumber = 1 countType = "imageCountMoreThan" tagStatus = "any" } }, ] } ) repository = "${aws_ecr_repository.akiko_redmine_banner.name}" }補足:AWSからのアラート
課金のアラームを設定しているので、ECRに関しても警告メッセージが届きました。抜粋ですがこんな感じ。
補足:CircleCIからのイメージのビルドと登録
以下は抜粋ですが、CircleCIからaws-cliを使ってイメージのビルドとECRへの登録を行う部分です。
- CircleCIのAWS ECR用のOrbsを使ってみています
- 基本的にはjobsのところで細かいスクリプト処理を記載したりするのですが、Orbsを使っている場合は、環境変数と呼び出したい処理の名前を記載するぐらいでOK
- 以下の例だとbuildではソースのチェックアウトしかしてません
個人的には、CodePipelone & CodeBuildで同じ処理をするよりは、手元でcliを操作する感覚に近いので、こちらのほうが好きかも...です。
orbs: aws-ecr: circleci/aws-ecr@6.2.0 version: 2.1 jobs: build: docker: # specify the version you desire here (ruby 2.4.x) - image: circleci/ruby:2.5-browsers-legacy steps: - checkout workflows: build_test_push: jobs: - build: filters: branches: ignore: - /ignore-build-.*/ - master - aws-ecr/build-and-push-image: account-url: AWS_ECR_ACCOUNT_URL aws-access-key-id: AWS_ACCESS_KEY_ID aws-secret-access-key: AWS_SECRET_ACCESS_KEY create-repo: true dockerfile: Dockerfile path: . region: AWS_REGION repo: akiko/redmine_banner extra-build-args: '--build-arg COMMIT=$CIRCLE_SHA1 --build-arg=BRANCH=$CIRCLE_BRANCH' requires: - build filters: branches: only: - ecs-trial

- 投稿日:2019-08-27T09:42:27+09:00
使われていないEC2インスタンスを停止するにはcronで十分だと思った
EC2インスタンス料金、ちりつもですよね。
Lambdaを使って夜間は停止しておくことも可能ですが、開発用や個人用ならcronで十分かなと思いました。
起動は手動で。crontabSHELL=/bin/bash PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/opt/aws/bin:/root/bin:/opt/aws/bin # 20時~翌9時までの間、ログインユーザがいなければシャットダウンする * 20-23 * * * if [ `who | wc -l` -eq 0 ] ; then shutdown -h now ; fi * 00-08 * * * if [ `who | wc -l` -eq 0 ] ; then shutdown -h now ; fi
- cron実行時のデフォルトシェルはbashではなく
/bin/shになるので明示的に宣言しているshutdownコマンドのパスも通しておくwhoコマンドを使ってログインユーザがいるか確認し、出力がなければ(=ログインユーザがいない)シャットダウン- 「20時~翌9時まで」ならcron式で「00-08」とすることに注意
- Ansible でやるなら if文を
-eq 1にすれば良いけど、それならLambdaで良いと思う
- 投稿日:2019-08-27T00:20:10+09:00
AWS | ssh接続できない permission denied (publickey).
ec2-userでログインはできる、でも新規ユーザを作成後(ここではappという名前のユーザーを作ったこととする)、そのユーザでssh接続を試みると、、、
permission denied (publickey).WTF ...
* 公開鍵も適切に設置されている
* ユーザー名やホスト名が間違っているわけではない(IPアドレスも正しい)
* アクセス権限も問題なし
* セキュリティグループも問題ない
原因がわからず、エラーログを追ってググっても権限関係の解決方法がほとんどで大分ハメられたので、誰か同じように悩まれてる方がいたらと思い、解決方法をシェアしたいと思います。# ちなみにssh接続のログの出し方 # -vvv をつける $ ssh -i "~/.ssh/id_rsa" app@88.90.10.10 -vvv # ちなみにIPアドレスのこの数字は "ハヤクイレテ" って読めるappユーザーにパスワードを設定
(1)まずec2-userでとりあえずEC2に入り、管理者権限に切り替える
(2)パスワードを設定
# パスワードの状態を確認 $ passwd -S app # こんな感じの出力結果になると思われ app LK 2019-06-26 0 99999 7 -1 # LK => パスワードがロック状態という意味 # appユーザのパスワードのロックを解除 # -uがロック解除 -fが強制的に というオプション # -fがないと"危険な操作"として弾かれる $ passwd -u -f app # もう一度パスワードの状態を確認 $ passwd -S app # こんな感じの出力結果になると思われ app PS 2019-06-26 0 99999 7 -1 # LKからPSとなっていることを確認 # パスワードを設定 $ passwd app # Enter New Password: # Confirm New Password:(EC2)sshd_config 以下の通りとなるようコメントアウトまたは追記
# /etc/ssh/sshd_config RSAAuthentication yes PubkeyAuthentication yes PasswordAuthentication yes AuthorizedKeysFile .ssh/authorized_keys* sshd再読み込み
$ sudo service sshd restart
これでappユーザで再びssh接続を試みてみてください。
ssh接続時にパスワードの入力が求められますので、そのときは↑で設定したパスワードを入力。
参考にした記事
追伸
某スクールでメンターをやっていて、20人近くの受講生さんをみていますが今のところ二人同じ問題につまづいて、この方法で解決しました。
しかしながら、当方インフラが全然でなぜこのようなエラーとなるのか、なぜパスワードを設定すれば解決するのか、根拠を示せませんw
そのため、どなたかこの問題について違うアプローチ方法または知見を共有していただければ幸いです。