- 投稿日:2019-07-08T23:14:20+09:00
Docker でコンテナ間の通信をする
0. はじめに
Dockerの初歩的なところ。
1. Dockerでコンテナ間の通信をしたい
別の言い方をすると、別のコンテナに接続したい。
例) GitLabのコンテナを立てたので、devコンテナから git pull したい2. 解決策
ネットワークを作って、通信させたいコンテナを同一ネットワークに接続すればよい。
(1) ネットワークの作成
docker network create <network名>(2) ネットワークにコンテナを追加
docker network connect <network名> <container1>
docker network connect <network名> <container2>(3) 各コンテナのipアドレスの確認
docker network inspection <network名>以上です。
- 投稿日:2019-07-08T23:14:13+09:00
ElasticBeanstalk(MultiContainer)の利用方法
概要
Dockerを利用した本番運用をしたくなり、ElasticBeanstalkについて調べたのでまとめる。
ElasticBeanstalkとは
定義ファイルを準備する事で、AWS上のリソース(EC2,ECS,ELB...etc)を利用した環境を構築してくれるサービスであり、MultiContainerパターンではCloudFormation + ECSと同等の環境を設定ファイルのみで構築できる。
マルチコンテナパターン概要
- Dockerrun.aws.jsonにコンテナの関係を定義して、ElasticBeanstalkのコマンドを叩けばデプロイされる。
- 冗長化構成やスケール設定をしたい場合は.ebextensions内に追加設定を書いていくことで実現できる。
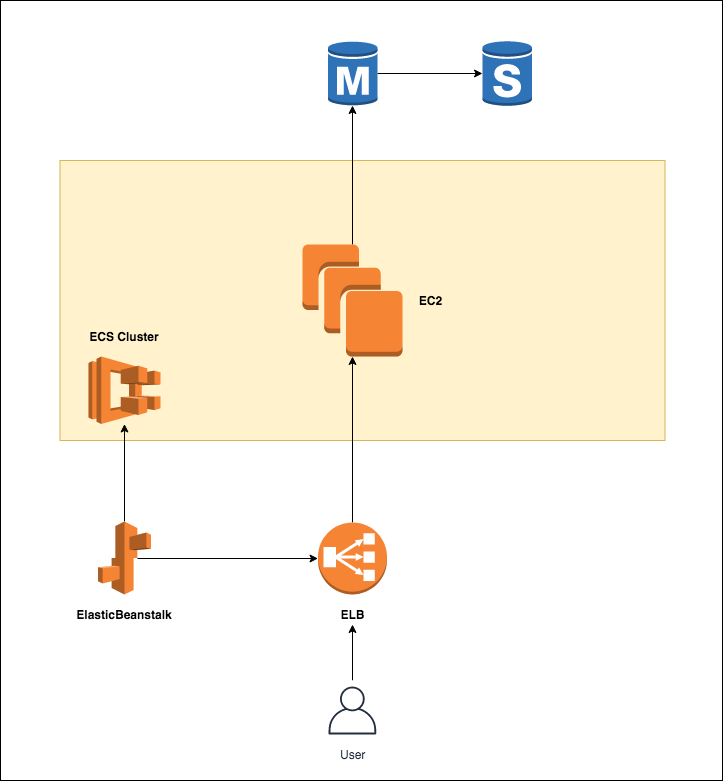
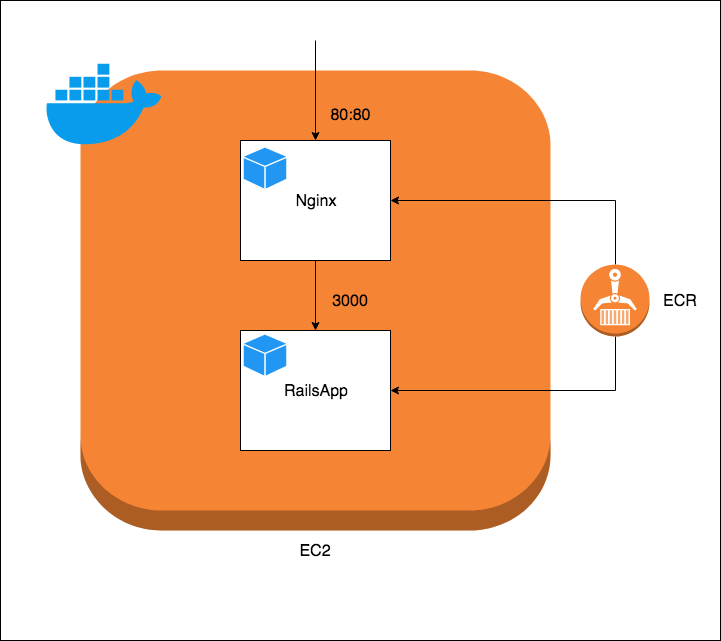
サンプルの構成図
サンプルのリソース関係図・構成図は下記のようになる
AWSリソース関係図
EC2内のContainer構成図
Dockerrun.aws.jsonのサンプル
ECRを利用したサンプルを下記に示す(書き方はdocker-composeのjson版?)
Dockerrun.aws.json{ "AWSEBDockerrunVersion": 2, "containerDefinitions": [ { "name": "nginx", "image": "xxxxx.amazonaws.com/xxxxx/nginx:latest", "essential": true, "memory": 128, "portMappings": [ { "hostPort": 80, "containerPort": 80 } ], "links": [ "rails-app" ], // Log設定(今回はCloudWatchLogsを利用する) "logConfiguration" : { "logDriver": "awslogs", "options": { "awslogs-region": "ap-northeast-1", "awslogs-group": "/xxxxx/develop/nginx" } } }, { "name": "rails-app", "image": "xxxxx.amazonaws.com/xxxxx/rails-app:latest", "essential": true, "memory": 256, "portMappings": [ { "containerPort": 3000 } ], "logConfiguration" : { "logDriver": "awslogs", "options": { "awslogs-region": "ap-northeast-1", "awslogs-group": "/xxxxx/develop/rails-app" } } } ] }ログの運用について
デフォルトでは各コンテナの標準出力がS3に保存されるが、それだと見づらいためCloudWatchLogsを利用する。
設定方法はこちらを参照
※ ElasticBeanstalkを利用する場合はLoggingDriverとしてFluentdを指定できない(カスタムAMIでなんとかいけるがオススメできない)Deployまでの流れ
- AWS-CLIとEB-CLIの準備
- DockerImageの作成(説明省略)
- ImageをECRにPush(こちらを参照)
- EB-CLIでcreate or deploy
AWS-CLIとEB-CLIの準備
AWS-CLIのインストール
$ brew install awscliEB-CLIのインストール
$ brew install awsebcliEB-CLIでDeploy
初期設定
$ eb init 9) ap-northeast-1 : Asia Pacific (Tokyo) 2) [ Create new Application ] 8) Multi-container Docker 残りはお好きなように設定新規作成
$ eb create rails-app-developデプロイ
$ eb deploy rails-app-developオートスケールなどの細かい設定について
- Docker.run.jsonと同階層に.ebextensionsを作成し、そこに追加設定ファイルを置く
- 「ファイル名.config」としないと認識しないため注意
- 拡張設定値はこちらを参照
階層サンプル
. ├── .ebextensions │ ├── 00-vpc.config │ └── 01-autoscaling.config ├── .elasticbeanstalk │ └── config.yml └── Dockerrun.aws.json
- 投稿日:2019-07-08T21:49:50+09:00
はじめてのDocker for Windows - イメージの入手と削除、コンテナの生成から削除まで
来るべきRailsチュートリアルへの着手に向けて、はじめてDocker for Windowsなるものを使ってみました。その結果まとめです。
Docker for Windowsのインストール
私の場合は、Chocolatey経由でDocker for Windowsをインストールしました。Chocolateyを使ったアプリケーションのインストールを行う場合、Powershellに管理者権限が必要となります。
powershell$ choco install docker-desktopDocker for Windowsがインストールされているか確認
Windows Powershellで以下のコマンドを実行します。管理者権限は必要ありません。
powershell$ docker -vDocker for Windowsが正しくインストールされていれば、実行結果は以下のようになります。
powershellDocker version 18.09.2, build 6247962バージョンが表示されていますね。
Dockerイメージ
Dockerイメージの入手 - nginx latest
powershell$ docker pull nginx実行結果は以下の通りになりました。
powershellUsing default tag: latest latest: Pulling from library/nginx fc7181108d40: Pull complete d2e987ca2267: Pull complete 0b760b431b11: Pull complete Digest: sha256:96fb261b66270b900ea5a2c17a26abbfabe95506e73c3a3c65869a6dbe83223a Status: Downloaded newer image for nginx:latestnginx latestのDockerイメージが正常に入手できたようです。
Dockerイメージの一覧表示
powershell$ docker image ls
docker image lsコマンドにより、現在Docker上に追加済みのDockerイメージを一覧表示することができます。powershell$ docker image ls REPOSITORY TAG IMAGE ID CREATED SIZE nginx latest f68d6e55e065 6 days ago 109MBnginx latestのイメージがDocker上にある状態です。
Dockerイメージの削除
powershell$ docker image rm
docker image rmコマンドにより、現在Docker上に追加済みのDockerイメージを削除することができます。powershell$ docker image ls REPOSITORY TAG IMAGE ID CREATED SIZE nginx latest f68d6e55e065 6 days ago 109MB $ docker image rm nginx Untagged: nginx:latest Untagged: nginx@sha256:96fb261b66270b900ea5a2c17a26abbfabe95506e73c3a3c65869a6dbe83223a Deleted: sha256:f68d6e55e06520f152403e6d96d0de5c9790a89b4cfc99f4626f68146fa1dbdc Deleted: sha256:1b0c768769e2bb66e74a205317ba531473781a78b77feef8ea6fd7be7f4044e1 Deleted: sha256:34138fb60020a180e512485fb96fd42e286fb0d86cf1fa2506b11ff6b945b03f Deleted: sha256:cf5b3c6798f77b1f78bf4e297b27cfa5b6caa982f04caeb5de7d13c255fd7a1e $ docker image ls REPOSITORY TAG IMAGE ID CREATED SIZE現在実行中のDocker上にDockerイメージはなくなりました。
Dockerコンテナ
Dockerコンテナの作成
powershell$ docker run -d -p 80:80 --name webserver nginx
-dコンテナをデタッチド・モード(バックグラウンド実行)で生成する-p {ホスト側TCPポート}:{コンテナ側TCPポート}ポート番号の指定
- 今回は、ホスト側・コンテナ側ともTCP80番ポートを使用
--name {コンテナ名}生成するコンテナ名の指定- 最後にイメージ名を指定する(今回は
nginx)このあとWebブラウザで
http://localhostにアクセスしたら、nginxサーバーの初期画面がきちんと表示されました。Dockerコンテナの一覧表示
powershell$ docker container ls
-aオプションなしのdocker container lsは、現在実行中のコンテナの一覧を表示します。例えば
webserverという名前のnginxイメージによるコンテナがサービス実行中の場合、実行結果は以下のようになります。powershell$ docker container ls CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES c36d096e5202 nginx "nginx -g 'daemon of…" 13 seconds ago Up 12 seconds 0.0.0.0:80->80/tcp webserver続いて
docker container ls -aです。powershell$ docker container ls -a
docker container ls -aは、実行中・停止中問わず、現在自環境上に存在するコンテナの一覧を表示します。例えば
webserverという名前のnginxイメージによるサービス停止中のコンテナが存在する場合、実行結果は以下のようになります。powershell$ docker container ls -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES c36d096e5202 nginx "nginx -g 'daemon of…" 46 seconds ago Exited (0) 4 seconds ago webserver4秒前に正常に停止されたという状態も表示されていますね。
Dockerコンテナのサービス停止
powershell$ docker container stop webserver
docker container stop {コンテナ名}コマンドにより、Dockerコンテナを削除することなくサービス停止することができます。上記コマンドは、webserverという名前のdockerコンテナのサービスを停止するコマンドです。powershell$ docker container start webserver $ docker container ls CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES c36d096e5202 nginx "nginx -g 'daemon of…" 13 seconds ago Up 12 seconds 0.0.0.0:80->80/tcp webserver $ docker container stop webserver webserver $ docker container ls -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES c36d096e5202 nginx "nginx -g 'daemon of…" About a minute ago Exited (0) 2 seconds ago webserver一連の動作は以上のようになります。
Dockerコンテナの削除
powershell$ docker container rm webserver
docker container rm {コンテナ名}コマンドにより、Dockerコンテナを完全に削除することができます。上記コマンドは、webserverという名前のdockerコンテナのサービスを削除するコマンドです。powershell$ docker container stop webserver webserver $ docker container ls -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES c36d096e5202 nginx "nginx -g 'daemon of…" About a minute ago Exited (0) 2 seconds ago webserver $ docker container rm webserver webserver $ docker container ls -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES全体としての実行結果は、以上のようになります。
- 投稿日:2019-07-08T15:57:57+09:00
Docker Composeの初めの一歩
はじめに
こんにちは!
私は、大学4回生です。
現在、未来電子テクノロジーでプログラミング開発コースでインターンを行っています。
今回は、私自身が詰まった「Docker Composeのコンポーネントを定義するところ」についてお話しします。
(プログラミング初心者であるため、内容に誤りがあるかもしれません。
もし、誤りがあれば修正するのでどんどん指摘してください。)Docker Composeとは
Docker Composeとは、複数のコンテナからなるサービスを構築、実行する手順をを自動的に管理する機能のことです。
つまり、仮想環境を作り出し、そこでサイトやアプリを作るために必要なものです。Docker Composeのコンポーネントを定義するところまで
まず、Macの場合、ターミナルが必要になります。
(vimとzshを使用しています)
1.空のディレクトリーを作るmkdir test(ファイル名)2.この空のディレクトリーの中に、「Dockerfile」というファイルを作成します。
mkdir Dockerfile※DockerfileのDは、大文字
3.この「Dockerfile」に以下のコードを写します。
vi Dockerfile(以下のコード⬇︎)
FROM python:3 ENV PYTHONUNBUFFERED 1 RUN mkdir /code WORKDIR /code COPY requirements.txt /code/ RUN pip install -r requirements.txt COPY . /code/4.次に、一度「Dockerfile」を保存し閉じた後、新たに「requirements.txt」というファイルを作成します。
touch requirements.txt5.この「requirements.txt」に、以下のコードを写します。
vi requirements.txt(以下のコード⬇︎)
Django>=2.0,<3.0 psycopg2>=2.7,<3.06.この「requirements.txt」を保存し閉じた後、「docker-compose.yml」というファイルを作成します。
touch docker-compose.yml7.そして「docker-compose.yml」に以下のコードを写すと、Docker Composeのコンポーネントを定義するところまでは完了です。
vi docker-compose.yml(以下のコード⬇️)
version: '3' services: db: image: postgres web: build: . command: python manage.py runserver 0.0.0.0:8000 volumes: - .:/code ports: - "8000:8000" depends_on: - dbまとめ
サイトを作る際に、Docker Composeを使用しました。
これからDockerをマスターしたいです。参考文献
「Quickstart: Compose and Django」https://docs.docker.com/compose/django/
- 投稿日:2019-07-08T15:30:01+09:00
golang でgo modを使う場合のDockerfile
golangでgo mod(Go Modules) を使う場合のDockerfile情報があまりなかったのと、マルチステージビルドを試したかったのでやってみた。
マルチステージビルドを使いたかったのは、普通にDockerでビルドするとえらく大容量になってしまうので、容量を削減したかったのが主な理由。ちなみに、マルチステージを使う前のイメージサイズは283.6 MB。
go自体は main.go の1ファイルだけ。
以下がDockerfile
#Step 1 ビルド処理のみ FROM golang:alpine as builder RUN apk update \ && apk add git RUN mkdir /app WORKDIR /app COPY go.mod . COPY go.sum . RUN go mod download COPY . . RUN go build -o /main #Step2 ビルドしたファイルを実際に使うために移動 FROM alpine:3.9 COPY --from=builder /main . ENTRYPOINT ["/main"]こちらでビルドすると、8.6 MBぐらいになってかなり軽量化できた。
- 投稿日:2019-07-08T15:30:01+09:00
golang でgo modを使う場合のDcokerfile
golangでgo mod(Go Modules) を使う場合のDockerfile情報があまりなかったのと、マルチステージビルドを試したかったのでやってみた。
マルチステージビルドを使いたかったのは、普通にDockerでビルドするとえらく大容量になってしまうので、容量を削減したかったのが主な理由。ちなみに、マルチステージを使う前のイメージサイズは283.6 MB。
go自体は main.go の1ファイルだけ。
以下がDockerfile
#Step 1 ビルド処理のみ FROM golang:alpine as builder RUN apk update \ && apk add git RUN mkdir /app WORKDIR /app COPY go.mod . COPY go.sum . RUN go mod download COPY . . RUN go build -o /main #Step2 ビルドしたファイルを実際に使うために移動 FROM alpine:3.9 COPY --from=builder /main . ENTRYPOINT ["/main"]こちらでビルドすると、8.6 MBぐらいになってかなり軽量化できた。
- 投稿日:2019-07-08T15:04:38+09:00
DockerHubのイメージはバージョンのタグが付いてても上書きされている
はじめに
- DockerHubなどのイメージについて「バージョンのタグを指定してればイメージが変わることはない」というのは勘違いです。
- 「
latestじゃなきゃ大丈夫」ではないです- むしろかなりのイメージで上書きが行われています。
- 公式イメージでも結構変更されてます。
- この記事では実際に公式イメージの変更履歴を集めているGitHubリポジトリで調べてみます
イメージ変更履歴を集めているGitHubリポジトリで見れます
DockerHubのwebサイトでは変更日時ぐらいしか見れませんが、
docker-library/repo-infoというリポジトリで公式イメージの変更履歴が見れます変更履歴の見方
repo-info/repos/配下から調べたいイメージ名のディレクトリを見つけます- その配下の
remoteかlocalの中にあるタグ名のmdファイルを見ます
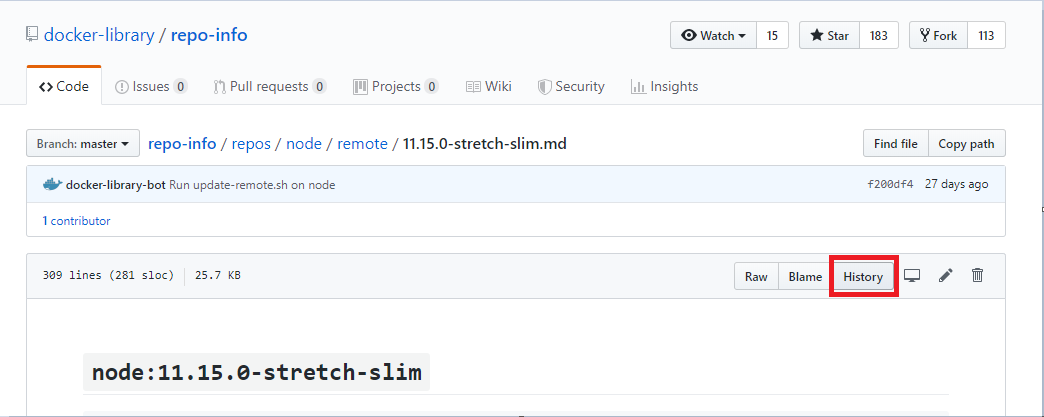
localはpull実行で差分を検知した際に収集したもので、remoteはapiで変更を検知した際のものです。たぶん定期実行でpollingしてるんだと思います。(ほぼ違いはないはず?)- 「History」ボタンでコミットログから変更が追えます
- イメージのshaがmdファイルに記録されているので、それを使って古いものをpullすることもできます。(消されていなければ)
例えば、
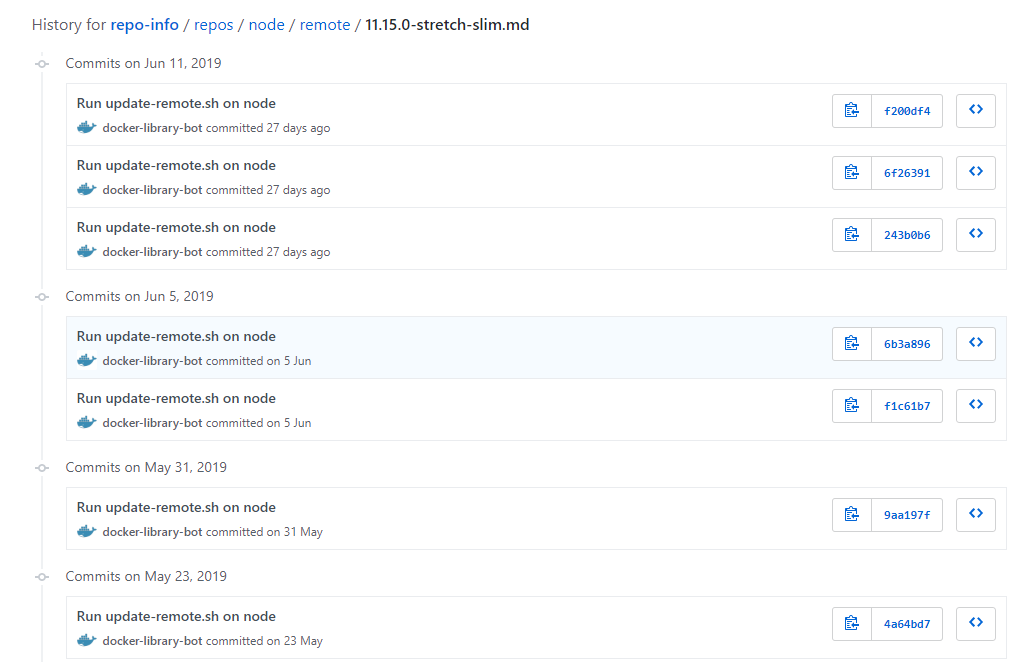
node:11.15.0-stretch-slimイメージの変更履歴を見てみるdocker-library/repo-info の node/remote/11.15.0-stretch-slim.mdを見てみます。
- 思ったよりたくさん更新されてました
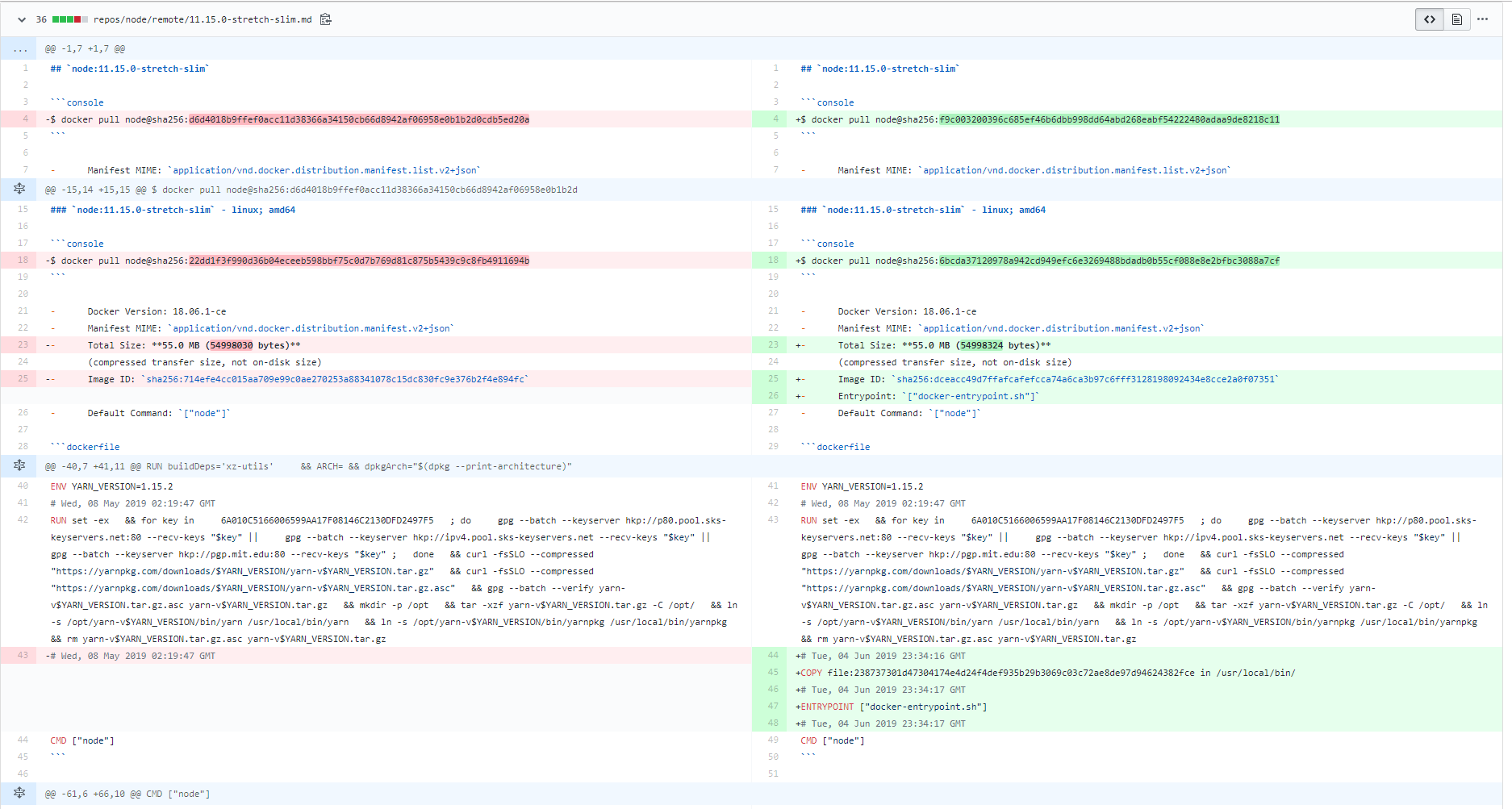
Jun5 2019の変更を見てみると、新しくファイル追加やEntrypoint変更がされたようです
両方runして追加ファイルを調べてみます
- 追加されたのは
docker-entrypoint.shみたいです
- ちなみに、今回はDockerfile自体が変更されているので、nodeのdockerfileリポジトリでも変更が見れます
他にどんな変更があるのか
完全にイメージに依りますが、次のケースが多そうです。
- セキュリティアップデート
- セマンティックバージョンでマイナーバージョンまで指定しているタグの場合、パッチアップデートで上書きされる
2.0タグのイメージの中身が2.0.0から2.0.1に代わる- セマンティックバージョンでメジャーバージョンまで指定しているタグの場合、マイナーアップデートで上書きされる
2タグのイメージの中身が2.0.3から2.1.0に代わるまとめ
- 「latest以外のタグを指定していればイメージが書き換わることはない」は勘違いです
- 書き換わって困るのであれば自分のレジストリでイメージ管理したほうがいいでしょう


- 投稿日:2019-07-08T15:04:38+09:00
DockerHubのイメージはタグ指定でも変更されてるよ
はじめに
- DockerHubなどのイメージについて「タグを指定してればイメージが変わることはない」というのは勘違いです。
- 「
latestじゃなきゃ大丈夫」ではないです- むしろかなりのイメージで上書きが行われています。
- 公式イメージでも結構変更されてます。
- そういった変更履歴を見ることができるGitHubリポジトリの紹介です
イメージ変更履歴を集めているGitHubリポジトリで見れます
DockerHubのwebサイトでは変更日時ぐらいしか見れませんが、
docker-library/repo-infoというリポジトリで公式イメージの変更履歴が見れます変更履歴の見方
repo-info/repos/配下から調べたいイメージ名のディレクトリを見つけます- その配下の
remoteかlocalの中にあるタグ名のmdファイルを見ます
localはpull実行で差分を検知した際に収集したもので、remoteはapiで変更を検知した際のものです。たぶん定期実行でpollingしてるんだと思います。(ほぼ違いはないはず?)- 「History」ボタンでコミットログから変更が追えます
- イメージのshaがmdファイルに記録されているので、それを使って古いものをpullすることもできます。(消されていなければ)
例えば、
node:11.15.0-stretch-slimイメージの変更履歴を見てみるdocker-library/repo-info の node/remote/11.15.0-stretch-slim.mdを見てみます。
- 思ったよりたくさん更新されてました
Jun5 2019の変更を見てみると、新しくファイル追加やEntrypoint変更がされたようです
両方runして追加ファイルを調べてみます
- 追加されたのは
docker-entrypoint.shみたいです- ちなみに、今回はDockerfile自体が変更されているので、nodeのdockerfileリポジトリでも変更が見れます
他にどんな変更があるのか
完全にイメージに依りますが、次のケースが多そうです。
- セキュリティアップデート
- セマンティックバージョンでマイナーバージョンまで指定しているタグの場合、パッチアップデートで上書きされる
2.0タグのイメージの中身が2.0.0から2.0.1に代わる- セマンティックバージョンでメジャーバージョンまで指定しているタグの場合、マイナーアップデートで上書きされる
2タグのイメージの中身が2.0.3から2.1.0に代わる困るのか
上書きされるイメージ次第です
- 私の経験ではnpmのティーポット事件でイメージが変更され、CIの
npm installがこけたぐらいなので、そこまで大ごとでないかもしれません。- むしろセキュリティアップデートもしてくれるという点では上書きしてくれる方が楽かも
- 外部に影響受けるのがまずいようなサービスでは自前でイメージ管理をしたほうがいいでしょう
- 特にKubernetesを使っていると、
imagePullPolicy: Never以外ではpod障害で別Nodeにpodを立て直すときなどにpullが発生する可能性があります
- 投稿日:2019-07-08T14:54:19+09:00
Cognitive Services Custom Vision から画像解析モデルを Dockerimage に Export して利用する
Custom Vision を利用すると、最小で画像5枚から画像解析モデルを作成し、Web API や CoreML、TensorFlow、ONNX のフォーマットで Export して利用できるほか、そのままお手持ちの Docker 環境で Image Build して Web API サービスとして利用できる Dockerfile としても Export 可能です。
今回は Custom Vision で作成したモデルを Dockerfile として Export し、ローカルの Docker 環境で動かして画像解析してみるまでの手順を紹介します。
準備
- Custom Vision の利用環境
- Cognitive Services Custom Vision で画像解析モデルを作成します。
- 利用準備: Microsoft Azure & Cognitive Services 利用準備
- Docker 環境 (Windows または Linux)
- 以下の手順では、Windows10 + Docker for Windows (ver 18.09.2)、Linux コンテナーで確認しています。
手順
Custom Vision で画像解析モデルを作成、Export
Custom Vision で画像解析モデルを作成
Custom Vision を利用した独自の画像分類およびオブジェクト検出のアルゴリズム構築 の手順を参考に、画像分類(Classification) または オブジェクト検出(Object Detection) モデルを作成します。
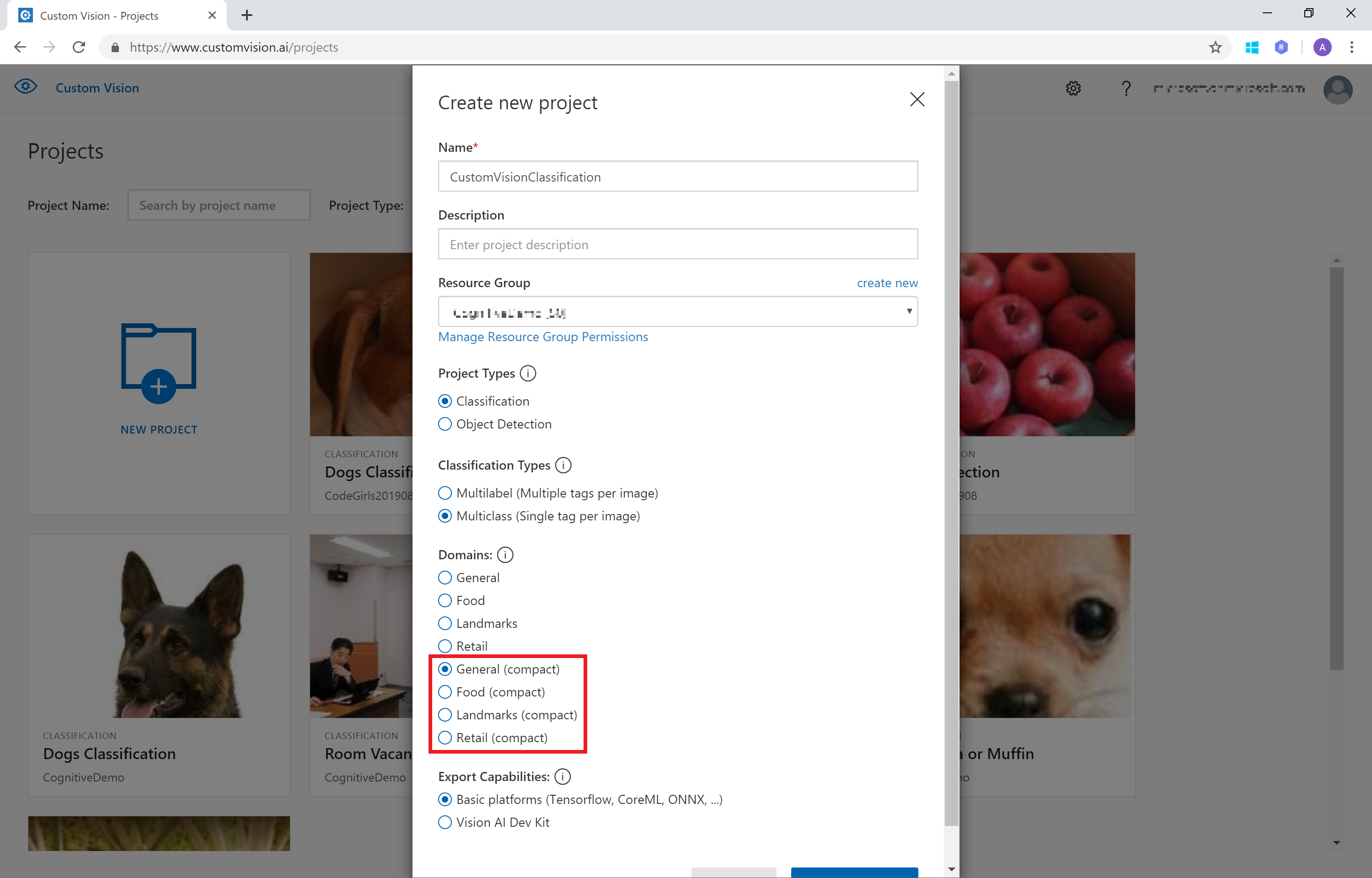
モデルの Export を行いたいときは、Project 作成時に "compact" と書かれている Domain を選択します。
作成済みの Project を使いたい場合は、設定画面で "compact" と記されている Domain を選択し、Train すると Compact モデルが作成されます。
Dockerimage で Export
モデルを作成した Project で [Performance] 画面を開きます。
上部バーの [Export] をクリックします。
Export する形式は [Dockerfile] を選択します。
Docker Version は Linux または Windows をお手持ちの環境に合わせて選択します。
モデルが準備できて [Download] と表示されたらクリックしてダウンロードします。
ダウンロードした Dockerfile の ZIP ファイルを展開すると、以下のような構造になっています。
Web サービスのアプリ部分も含まれているため、Image Build してすぐに利用できます。CVDockerImage
┗ app
┗ app.py
┗ labels.txt
┗ model.pb
┗ predict.py
┗ requirements.txt
┗ azureml
┗ README.txt
┗ score.py
┗ Dockerfile
┗ README.txtDockerfile から Image Build、Web API でアクセス
ダウンロードした dockerfile (ZIP ファイル) を展開しておきます。
docker コマンドで Image Build を行います。
設定 ※ご自身の環境に合わせて変更してください dockerfile を展開したディレクトリ C:\data\CVDockerImage 作成する Docker Image の名前 cvclassification > docker build -t cvclassification C:\data\CVDockerImageしばらくして、以下のようなイメージ作成が成功したメッセージが表示されたら OK です。
> docker build -t cvclassification C:\data\CVDockerImage Sending build context to Docker daemon 5.105MB Step 1/7 : FROM python:3.5 3.5: Pulling from library/python : Successfully built 0000a00a0000 Successfully tagged cvclassification:latestls コマンドでイメージが作成されていることを確認します。
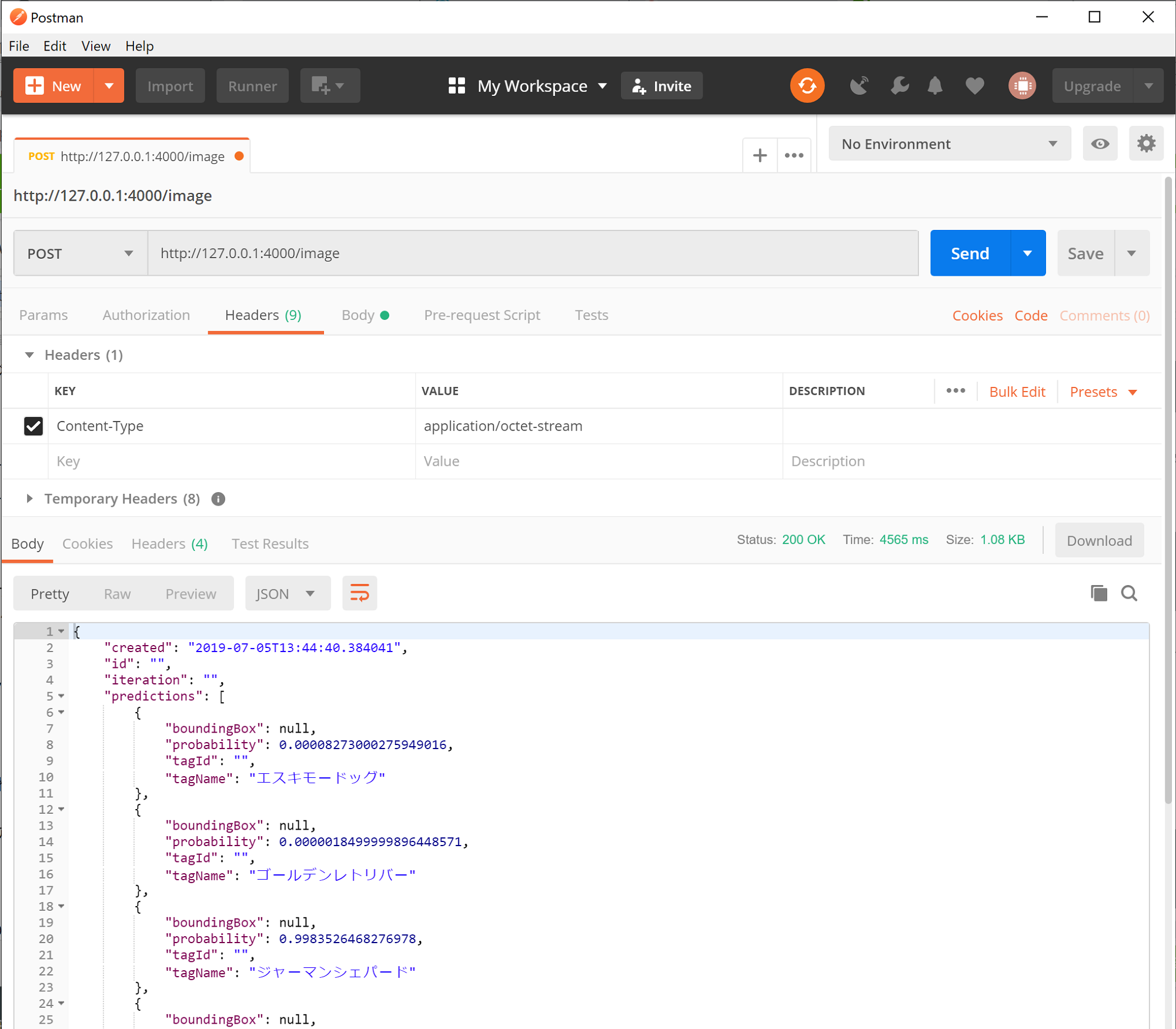
> docker image ls REPOSITORY TAG IMAGE ID CREATED SIZE cvclassification latest 0000a00a0000 About 5 minutes ago 1.51GBrun コマンドでコンテナーを起動します。以下では Web サービスを localhost (127.0.0.1)、Port: 4000 に設定しています。
> docker run -p 127.0.0.1:4000:80 -d cvclassification 000a00aa000aブラウザーで
http://localhost:4000にアクセスすると、Custom Vision の Host メッセージが表示されれば OK です。
では Web API としてアクセスしてみます。
- 画像ファイル(バイナリ)を送信する場合:
http://localhost:4000/image- 画像ファイル URL を送信する場合:
http://localhost:4000/urlPOST http://127.0.0.1:4000/image Content-Type: application/octet-stream Body: /*画像ファイル(バイナリ)*/解析結果が取得できればOKです。
ps -a コマンドで作成されているコンテナーを確認できます。
> docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 000a00aa000a cvclassification "/bin/sh -c 'python …" 21 minutes ago Up 20 minutes 127.0.0.1:4000->80/tcp heuristic_banach起動したコンテナーは stop コマンドで停止できます。
> docker stop 000a00aa000a参考
- 投稿日:2019-07-08T13:44:23+09:00
dockerでjenkins構築(plugin install errorを出さない)
はじめに
本通りだと、pluginがインストール出来なかったので書きます
この本読んでます
Docker/Kubernetes 実践コンテナ開発入門(山田 明憲)
この記事で手順が丸々書き写してくれてます
参考:https://qiita.com/i_whammy_/items/84b71c56d70817803472
早速構築
1. 適当にjenkins試す用のディレクトリ作って、
docker-compose.yml作成するdocker-compose.ymlversion: "3" services: master: container_name: master # (library/)jenkins:2.60.3(公式)だと依存プラグインの関係でインストールがエラるので、jenkins/jenkins使う image: jenkins/jenkins:lts ports: - 18080:8080 - 50000:50000 volumes: - ./jenkins_home:/var/jenkins_home # links: # - slave01 # # slave01: # container_name: slave01 # image: jenkinsci/ssh-slave # environment: # - JENKINS_SLAVE_SSH_PUBKEY=ssh-rsa AAAxxxxxxxxxxxxイメージ作成&起動
docker-compose up --build -djenkinsの起動ログが見たい場合
下記のコマンドで確認できます。
docker logs master2. master側のSSHキー作成
sshキー作成
docker exec -it master ssh-keygen -t rsa -C ""hostマシンの./jenkins_home/.ssh/id_rsa.pubか
docker内の/var/jenkins_home/.ssh/id_rsa.pubで確認ができます。
3. slaveを作成する
1. 適当にjenkins試す用のディレクトリ作って、docker-compose.yml作成する
で作成したdocker-compose.ymlのslaveの欄をコメントアウトをなおすdocker-compose.ymlversion: "3" services: master: container_name: master # (library/)jenkins:2.60.3(公式)だと依存プラグインの関係でインストールがエラるので、jenkins/jenkins使う image: jenkins/jenkins:lts ports: - 18080:8080 - 50000:50000 volumes: - ./jenkins_home:/var/jenkins_home links: - slave01 slave01: container_name: slave01 image: jenkinsci/ssh-slave environment: - JENKINS_SLAVE_SSH_PUBKEY=ssh-rsa AAAAxxxxxxxxxxxxxxxx再度、イメージ作成&起動
docker-compose up --build -d4. 適当にjenkinsの画面でポチポチ設定してください
秘密鍵の入力を[Jenkinsのマスター上の~/.sshから]にしたいんですが、ないので直接入力しました。
おわりに
本通りに進んで詰まるの辛い
jenkinsまだ何もわからない友人と開発してるowntimeぜひ使ってみてください
辛口でもいいのでコメントお願いします〜
- 投稿日:2019-07-08T10:20:36+09:00
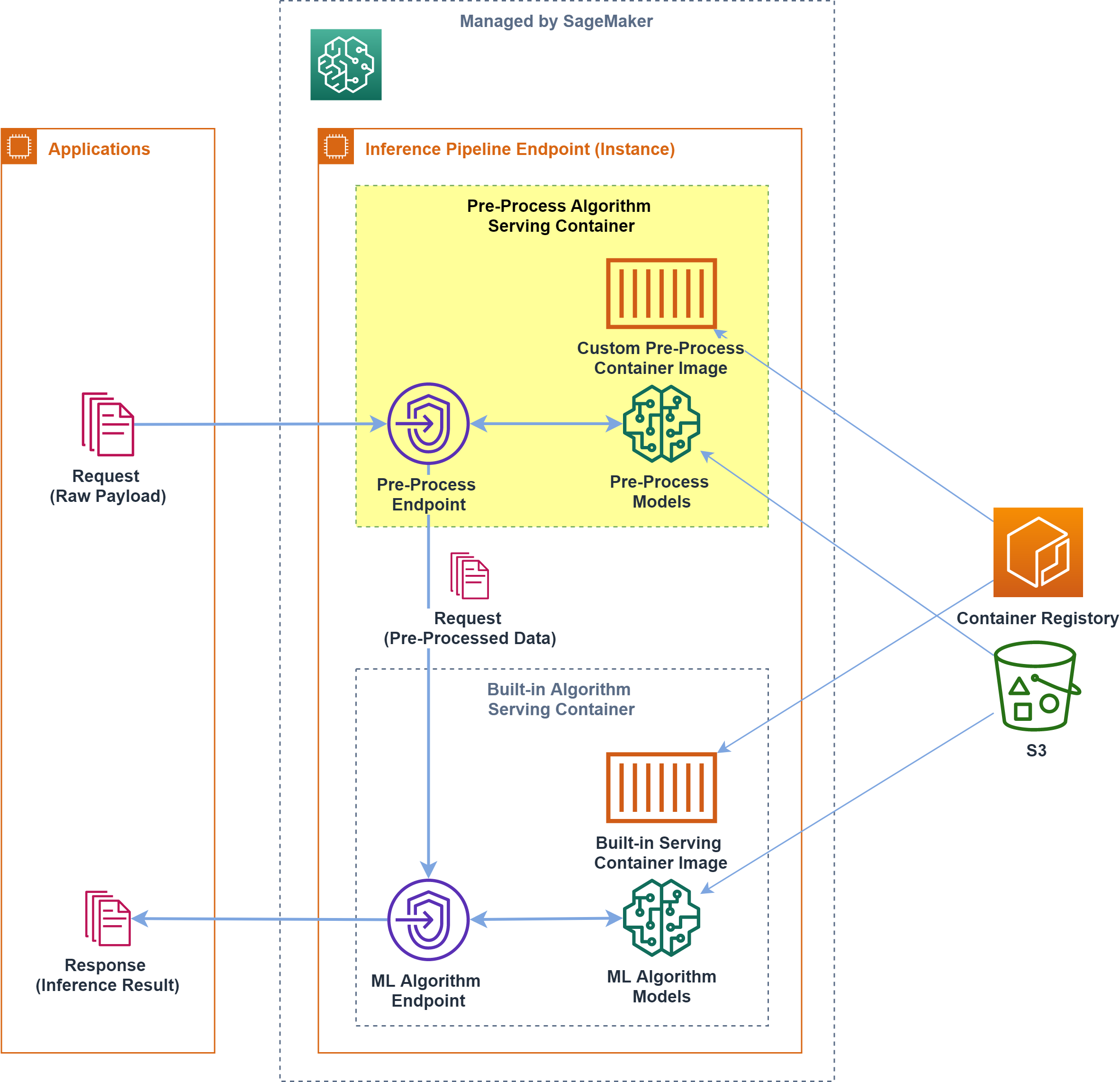
Amazon SageMaker の推論パイプラインで、独自コンテナを組み合わせる方法
概要
Amazon SageMaker で、独自コンテナを含む 推論パイプラインエンドポイントを構築する 方法について書きます
SageMaker で提供されるコンテナで所望の前処理が実現できず、独自コンテナによる前処理をしたい場合、カスタム前処理コンテナはどのようにつくるか、どのように組み込むか 調べた際のメモです
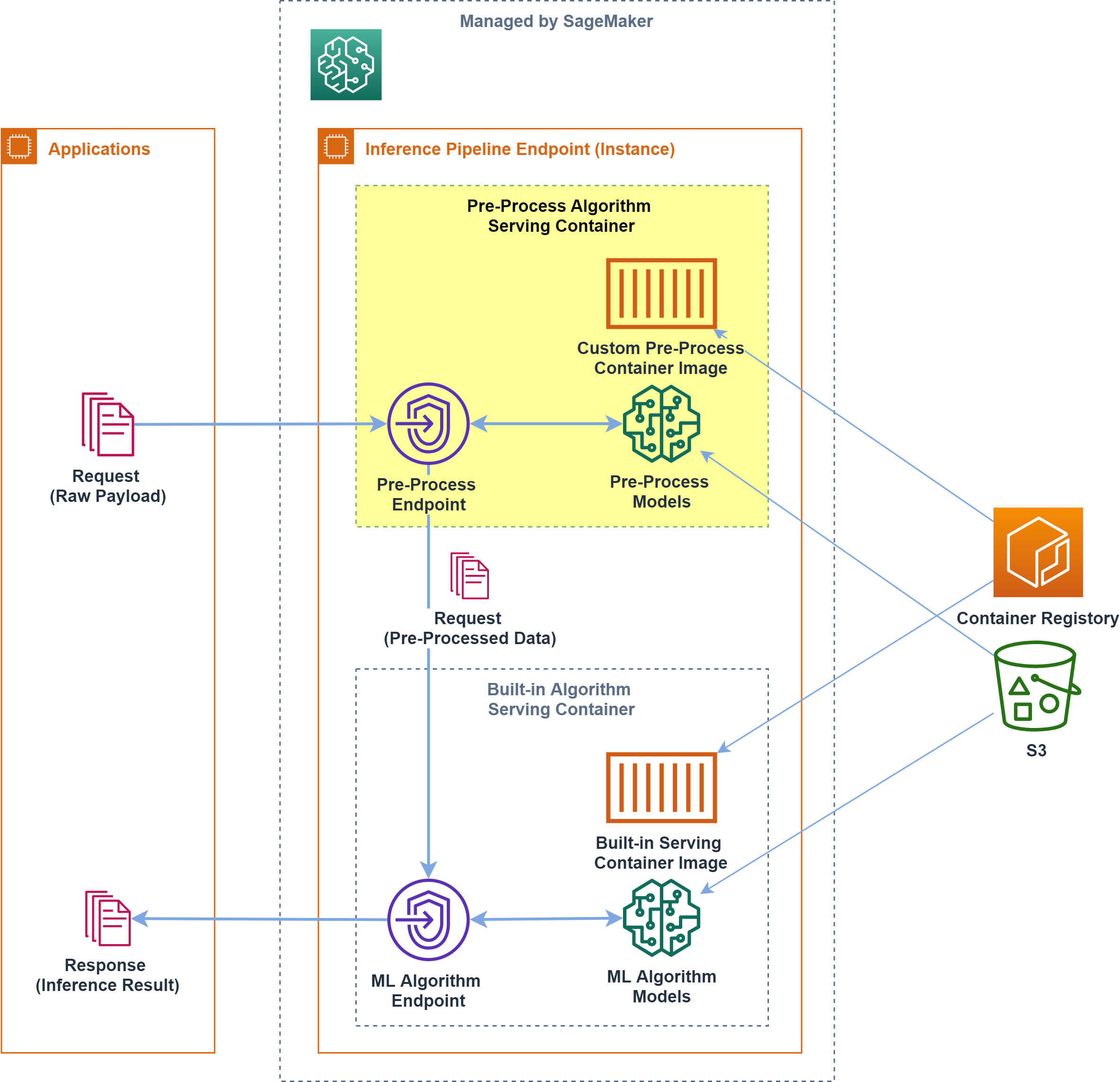
組み込みアルゴリズムと推論パイプライン
Amazon SageMaker では組み込みアルゴリズムが提供されており、解きたい問題にフィットするものがあれば、MLアルゴリズムに関するコードを書かずに手軽にMLモデルを作れるようになっています
組み込みアルゴリズムに引き渡す入力形式はアルゴリズムごとに決まっており、基本的には、保有するデータを整形する前処理が必要です
こうした 前処理は学習/推論で同じ処理なため、共通化されていることが望ましい ということで、SageMaker では前処理アルゴリズムをコンテナ化して学習/推論時に実行させる仕組みが提供されています前処理コンテナでは SageMaker でのコンテナの挙動を踏襲し、
fitでインスタンス上に前処理コンテナを展開してデータ整形/S3バケットへ出力したり、deployでインスタンス上に前処理コンテナを展開してリクエストデータ整形/次処理へ渡す、といった挙動をさせます
とくに推論処理では、エンドポイントへ届いたリクエストを前処理して後続の推論アルゴリズムへ渡すために、「前処理+推論処理(+後処理等)」をセットにした 推論パイプラインエンドポイント が構築できるようになっています
- Amazon SageMaker 組み込みアルゴリズムを使用する
- Amazon SageMaker 推論パイプライン
- Amazon SageMaker トレーニングと推論でデータ処理コードの一貫性を確保する
前処理で独自コンテナが必要になるケース
推論パイプラインのサンプル には、SageMaker で MLフレームワークを使うときと同様
sagemaker.sklearn.estimator.SKLearnなどEstimatorを利用して、任意のスクリプトを所定のコンテナ環境下で実行させる例が載っています
提供されているコンテナで所望の処理が実現できれば、カスタムコンテナは不要ですfrom sagemaker.sklearn.estimator import SKLearn script_path = 'sklearn_abalone_featurizer.py' sklearn_preprocessor = SKLearn( entry_point=script_path, role=role, train_instance_type="ml.c4.xlarge", sagemaker_session=sagemaker_session)しかし提供されるコンテナにないライブラリや、インストールされていないミドルウェアを使いたい場合には、独自の環境をコンテナ化して実行させる必要があります
たとえば自然言語を扱う課題で MeCab で形態素解析したいといった場合には、MeCab が動作してかつ Amazon SageMaker の仕様に従ったコンテナが必要になります
前処理コンテナのつくりかた
Amazon SageMaker で提供されているコンテナ群は GitHub で公開されているので、ライブラリを追加する程度であれば、既存コンテナを拡張するのが楽かもしれません
用意されているコンテナをFROM文で呼び出した上に、追加のインストールやセットアップを施しますそうした提供済みコンテナで都合が悪い(ミドルウェアのバージョンが合わないとか、既存の資産を使いたいとか)場合には独自コンテナを作ります
前処理コンテナの要件
基本的な挙動は SageMaker の 独自のトレーニングイメージ の仕様にあわせる必要があります
fitやdeployといった命令をうけて所定の処理が RUN される必要があるため、scikit_bring_your_ownなどをベースに、枠組みそのままで中身の処理を書き換えるのがよさそうです
また、パイプラインエンドポイントのための独自の設定がいくつか必要です
- 構成要素
- train:トレーニング(fit)時に呼び出される処理
- serve:エンドポイント構築(deploy)時に呼び出される処理
- predictor.py:推論エンドポイントで呼び出される処理
- その他の要件
- Dockerfile に次のコードが必要
LABEL com.amazonaws.sagemaker.capabilities.accept-bind-to-port=true- エンドポイントのリクエスト受け付けポートが次の環境変数に依存する
SAGEMAKER_BIND_TO_PORT- Dockerコンテナリポジトリに、次のポリシー付与が必要
前処理コンテナに実装する内容
scikit_bring_your_own 等をベースに、下記の機能を実装します
train
生データを受け取って整形加工し、MLモデルトレーニングに使用する訓練データをつくり、S3へ配置します
訓練データ生成の際に作成される「辞書データ」や「ベクトライザ」は推論時にも同じものを使うため、推論エンドポイントへ引き継ぐ必要がありますが、SageMaker のアルゴリズムで/opt/ml/model以下を共有する仕組みにのせて、推論エンドポイントの同一ディレクトリへ展開させるようにします
Estimator.fitで呼び出される- 指定されたタイプのインスタンスに、
inputs={'raw':'s3://'}で引き渡した S3 パスのデータが/opt/ml/input/data/{channel}以下へ 自動的に 展開される/opt/ml/input/data/{channel}からデータを参照して一括整形する- MLトレーニングで使用する、加工整形した訓練データを S3 上の任意のパスへアップロードする
- 推論エンドポイントでデータの整形処理に必要になるモデルデータ(辞書やベクトライザなど)を
/opt/ml/modelへ出力する
joblib.dumpなど/opt/ml/model以下のファイル群がtar.gz形式でアーカイブされてoutput_pathで指定された S3 パスへ 自動的に アップロードされるserve
train時に生成したモデルファイルをインスタンス上に配置し、/invocationsのリクエストを受け付ける web サーバを起動します
Estimator.deployで呼び出される
output_pathに指定された S3 パスから、Training 時に生成済みのモデル群をインスタンスの/opt/ml/model以下へ 自動的に 展開する/invocationsと/pingに応答するウェブサーバー を起動する
- パイプラインモデルのエンドポイントは、リクエストを受け付けるポートを環境変数
SAGEMAKER_BIND_TO_PORTで指定されるため、web サーバの設定でポートを環境変数を参照するようにする(環境変数がなければ 8080 を使う)predict
serveで起動したエンドポイントで、推論を行いたい生データを所定の書式で受け取り、後続の推論アルゴリズムが要求する書式に整形して返します
serveの際に配置したモデルファイル群を/opt/ml/model以下から取得し、コード上へ読み出す
joblib.loadなど- 推論リクエストに含まれる生データを取得し、文字列の正規化を行う
- 正規化したデータについて、先に取得したベクトライザ等を使用して推論アルゴリズムが要求する形式のデータへ変換する
- 変換した形式のデータをレスポンスとして返す
コンテナのビルド、ECRへのPUSH
上記実装したコード群をコンテナ化し、ECR のリポジトリへ push します
push した ECR のリポジトリには、SageMaker のパイプラインモデルからの呼び出しを許可するポリシーを付与する必要があります(推論パイプラインの Amazon ECR アクセス許可のトラブルシューティング)
ECR コンソールから
Repositories > 該当リポジトリリンク > Permissionsと進んで、アクセス許可ポリシーを下記 JSON の通り追加します{ "Version": "2008-10-17", "Statement": [ { "Sid": "allowSageMakerToPull", "Effect": "Allow", "Principal": { "Service": "sagemaker.amazonaws.com" }, "Action": [ "ecr:GetDownloadUrlForLayer", "ecr:BatchGetImage", "ecr:BatchCheckLayerAvailability" ] } ] }ここまででパイプライン用の前処理コンテナができました
MLプロセスへの組み込み
組み込みMLアルゴリズムと、独自コンテナによる前処理を組み合わせ、MLフローを実行します
前処理(訓練データの準備)
生データを用意してS3へアップロードし、以下のようなコードによって、訓練データへ変換します
&前処理で生成した ベクトライザ 等の生成物を S3 へ格納しますimport sagemaker sess = sagemaker.Session() role = sagemaker.get_execution_role() preprocess_image_name = 'preprocess_ecr_container_image' preprocess_job_name = '{preprocess_id}' rawdata_input_path = 's3_rawdata_path' train_dataset_path = 's3_preprocessed_data_path' preprocessor = sagemaker.estimator.Estimator( image_name = preprocess_image_name, role = role, train_instance_count = preprocess_instance_count, train_instance_type = preprocess_instance_type, train_volume_size = preprocess_volume_size, output_path = train_dataset_path, sagemaker_session = sess ) preprocessor.fit( inputs={'rawdata': rawdata_input_path}, job_name = preprocess_job_name )学習
前処理で訓練に必要なデータはすべて S3 上の所定の場所へアップロードされている状態です
下記のコードによって、組み込みアルゴリズムによるトレーニングを実行しますimport sagemaker algorithm_name = 'ml_hoge' ml_container_name = get_image_uri(boto3.Session().region_name, algorithm_name) ml_model_path = 's3_ml_model_path' ml_training_job_name = '{algorithm_name}-{preprocess_id}-{timestamp}' ml = sagemaker.estimator.Estimator( image_name = ml_container_name, role = role, sagemaker_session = sess, train_instance_count = train_instance_count, train_instance_type = train_instance_type, output_path = ml_model_path ) ml.fit( inputs={ 'train': train_dataset_path_train, 'validation': train_dataset_path_valid, 'auxiliary': train_dataset_path_aux, 'test': train_dataset_path_test }, job_name = ml_training_job_name )エンドポイント構築
前処理で生成した ベクトライザ 等を利用するデータ前処理コンテナと、組み込みアルゴリズムの学習済モデルを参照する推論コンテナをセットにして、推論パイプラインエンドポイントを構築します
(sagemaker.pipeline.PipelineModelのmodels変数へ渡した配列のモデル順に、リクエストに応答するエンドポイントが構築されます)import sagemaker preprocessor = sagemaker.estimator.Estimator.attach(preprocess_job_name) preprocess_model = preprocessor.create_model() ml = sagemaker.estimator.Estimator.attach(ml_training_job_name) ml_model = ml.create_model() pipeline_endpoint_name = '{algorithm_name}-pipeline-endpoint-{version}' pipeline_model = sagemaker.pipeline.PipelineModel( name = pipeline_model_name, role = role, models = [ preprocess_model, ml_model ] ) pipeline_model.deploy( initial_instance_count = pipeline_instance_count, instance_type = pipeline_instance_type, endpoint_name = pipeline_endpoint_name )ここまでで、独自コンテナによる前処理を組み込んだ推論エンドポイントが起動します
推論リクエストへの応答
生データを所定の形式で引き渡せば、
前処理コンテナで整形 -> 組み込みアルゴリズムの推論コンテナで推論した結果が返りますimport sagemaker from sagemaker.content_types import CONTENT_TYPE_JSON ml_predictor = sagemaker.predictor.RealTimePredictor( endpoint = pipeline_endpoint_name, serializer = sagemaker.predictor.json_serializer, deserializer= sagemaker.predictor.json_deserializer, content_type= CONTENT_TYPE_JSON, accept = CONTENT_TYPE_JSON ) payload = {'target':'日本語文字列'} pprint(ml_predictor.predict(payload))トラブルシューティング
エンドポイント構築時に ping health check に失敗する
エンドポイント構築時に
pingに失敗して構築できないというエラーが発生する場合ValueError: Error hosting endpoint pipeline-endpoint-vXX: Failed Reason: The container-1 for production variant AllTraffic did not pass the ping health check. Please check CloudWatch logs for this endpoint.独自コンテナで起動させたWebサーバが、環境変数
SAGEMAKER_BIND_TO_PORTポートでリクエストを受け付けていない可能性があります(CloudWatchLogs にも何の情報も出ず途方に暮れるのですが、落ち着いて)
Webサーバ( nginx など)の設定を見直し、SAGEMAKER_BIND_TO_PORT環境変数が存在する場合には、環境変数の指定するポートで受け付けるようにしますECR コンテナリポジトリに必要な権限が付与されていない
パイプラインエンドポイントを構築しようとする際、権限が足りないといったエラーが出る場合
ValueError: Error hosting endpoint pipeline-endpoint-vXX: Failed Reason: The repository of your image 111111111.dkr.ecr.xxxxx.amazonaws.com/XXXXXXXXXXXXXXXXXXXX does not grant ecr:GetDownloadUrlForLayer, ecr:BatchGetImage, ecr:BatchCheckLayerAvailability permission to sagemaker.amazonaws.com service principal.推論パイプラインエンドポイントを構築する際には、パイプラインに組み込む独自コンテナのリポジトリに SageMaker からの読み出しを許可するポリシー付与が必要です
推論パイプラインの Amazon ECR アクセス許可 を参考に、ECR コンソールから必要なポリシーを付与します{ "Version": "2008-10-17", "Statement": [ { "Sid": "allowSageMakerToPull", "Effect": "Allow", "Principal": { "Service": "sagemaker.amazonaws.com" }, "Action": [ "ecr:GetDownloadUrlForLayer", "ecr:BatchGetImage", "ecr:BatchCheckLayerAvailability" ] } ] }その他
まとめ
独自コンテナを含む推論パイプラインエンドポイントを構築する際、次の点に注意してください
- 基本的な挙動は SageMaker のカスタムコンテナと同じ
- エンドポイントのリクエスト受け付けポートは次の環境変数に依存する
SAGEMAKER_BIND_TO_PORT- 推論パイプラインでリアルタイム予測を実行
- Dockerコンテナリポジトリに、次のポリシー付与が必要
日本語処理など独自コンテナを必要とするケースで、ぜひ参考にしていただければと思います
参考資料
パイプラインのコンテナは、(8080 ではなく) SAGEMAKER_BIND_TO_PORT 環境変数で指定されたポートでリッスンします。
コンテナがこの要件に準拠していることを示すには、次のコマンドを使用して Dockerfile にラベルを追加します
LABEL com.amazonaws.sagemaker.capabilities.accept-bind-to-port=true
- Amazon SageMaker がトレーニングイメージを実行する方法
- Amazon SageMaker ホスティングサービスでの独自の推論コードの使用
- pipeline.PipelineModel
- 推論パイプラインのトラブルシューティング
Amazon SageMaker 組み込みアルゴリズムを含むパイプラインでカスタム Docker イメージを使用する場合は、Amazon ECR ポリシーが必要です。ポリシーは、イメージをプルするために Amazon SageMaker のアクセス許可を Amazon ECR レポジトリに与えます。
- 投稿日:2019-07-08T09:28:42+09:00
【複数プロジェクト対応】Laravel開発環境をDockerを使って用意する
Laravel
Vagrantを使った開発環境 Homestead
Vagrant仮想環境を使って開発をする場合はこちらを参照してください。
https://readouble.com/laravel/5.8/ja/homestead.htmlDockerを使った開発環境 Laradock
今回のドキュメントはDockerを使った開発環境の構築を行います。
https://laradock.io/複数プロジェクトに対応した構成でインストールする
仕事として使い始める方、趣味の延長でウェブサービスを作りたい方など、開発マシン上に複数のプロジェクトを作ることがあります。
上記の場合、プロジェクト毎にミドルウェアのバージョンが指定される場合があり、他のプロジェクトに影響させたくない場合は仮想環境を個別に用意することになります。
ここで示す例は個別に仮想環境を用意する方法の手順を示します。
構築例
プロジェクトfugaとプロジェクトmogeを共存させ、仮想環境はそれぞれ独自で動くものとする。
構成─ Laravel # ここの名前はお好きに。Laravelプロジェクトを入れる的な。 │ ├── fuga | ├── app | ├── data | └── laradock │ ├── .env │ └── docker-compose.yml ├── moge | ├── app | ├── data | └── laradock │ ├── .env │ └── docker-compose.yml注意点は複数プロジェクトでdockerコンテナがバッティングする
複数プロジェクトをdockerで立ち上げるとき、コンテナのバッティングが発生して作成に失敗するので、それを回避するためいくつかポイントがあります。
最初にプロジェクトfugaを作る
最初に作ったプロジェクトを、以降のプロジェクトの雛形にするため、注意深く作成しましょう。
まずプロジェクトをまとめるディレクトリ
fugaを作成し、その中にlaradockをgit cloneします。$ mkdir fuga;cd $_ $ git clone https://github.com/Laradock/laradock.gitこの段階で以下の構成になります。
構成─ Laravel │ ├── fuga | └── laradock │ ├── env-example │ └── docker-compose.ymldocker-compose実行
docker-compose.ymlに値を注入するため、env-exampleをコピーして.envを作り、fugaプロジェクト用の設定を行います。$ cp env-example .env $ vi .env書き換える場所は以下の部分で。 最初の2行はfugaプロジェクト内を指すように変更して、PORTはプロジェクトごとにバッティングしないように利用するミドルウェアのPORTを変更します。
APP_CODE_PATH_HOST=../app/ DATA_PATH_HOST=../data COMPOSE_PROJECT_NAME=fugalaradock # ポイント! 一意にしてコンテナ名のバッティングを防ぐ! NGINX_HOST_HTTP_PORT=8099 NGINX_HOST_HTTPS_PORT=4499 APACHE_HOST_HTTP_PORT=8099 APACHE_HOST_HTTPS_PORT=4499 WORKSPACE_SSH_PORT=2299 MYSQL_PORT=3399コンテナ立ち上げの準備ができました。 さっそく立ち上げてみましょう!
一番最初に実行したときはかなりの時間がかかるので、気長に待ちましょう( ´ー`)y-~~$ docker-compose up -d nginx mysql workspace : : Creating fugalaradock_docker-in-docker_1 ... done Creating fugalaradock_mysql_1 ... done Creating fugalaradock_workspace_1 ... done Creating fugalaradock_php-fpm_1 ... done Creating fugalaradock_nginx_1 ... done最後にエラーが出なかったら成功です。 ただしこの状態ではサーバ環境が揃っただけなので、
http://localhost:8099でアクセスしても何も表示されません。この段階で以下の構成になります。
構成─ Laravel │ ├── fuga | ├── app # .envのAPP_CODE_PATH_HOSTの設定により生成 # コンテナ内の /var/wwwの位置になる | ├── data # .envのDATA_PATH_HOSTの設定により生成 | └── laradock │ ├── .env │ └── docker-compose.ymlLaravelプロジェクトの雛形を生成する
この状態で開発(&実行)環境はコンテナ内(ゲスト側)に生成されましたので、Laravelのプロジェクトを生成するためにコンテナ内へ入ります。
開発作業環境(workspace)
docker psでworkspaceがついたコンテナを探します。$ docker ps A*********** fugalaradock_nginx B*********** fugalaradock_php-fpm C*********** fugalaradock_workspace # <--- これ D*********** fugalaradock_mysql E*********** docker:dindコンテナに入ります。
$ docker exec -it C*********** bash root@C***********:/var/www# # プロンプトが出てくればOKcomposerを使ってLaravelプロジェクトを作成します。
# composer create-project laravel/laravel . # <-- ホスト側のfuga/app内に作る : : Package manifest generated successfully. > @php artisan key:generate --ansi Application key set successfully.これでLaravelの雛形が/var/www/app内に生成され
http://localhost:8099で以下のページが表示されれば成功です。
別プロジェクト(moge)を作る
注意する部分まで。
$ mkdir moge;cd $_ $ git clone https://github.com/Laradock/laradock.git $ cp env-example .env $ vi .env
.envの設定を他のプロジェクトと重ならないように変更しておきます。APP_CODE_PATH_HOST=../app/ DATA_PATH_HOST=../data COMPOSE_PROJECT_NAME=mogelaradock # ポイント! 一意にしてコンテナ名のバッティングを防ぐ! NGINX_HOST_HTTP_PORT=8090 NGINX_HOST_HTTPS_PORT=4490 APACHE_HOST_HTTP_PORT=8090 APACHE_HOST_HTTPS_PORT=4490 WORKSPACE_SSH_PORT=2290 MYSQL_PORT=3390あとはプロジェクトの雛形を生成して終わり!
$ docker ps $ docker exec -it {containerID} bash root@{containerID}:/var/www# # composer create-project laravel:laravel .

- 投稿日:2019-07-08T06:14:00+09:00
Dockerでよく使用するコマンドをまとめ
何かを表示させる系のコマンド
//Dockerのバージョン表示 docker version //ダウンロードされているイメージ表示 docker images //起動しているコンテナを表示 docker ps //これまでに起動した(起動している)コンテナ表示 ※exited=過去 up=今 docker ps -a //コンテナの中身表示 docker exec -it コンテナ名 ls //今までの動かした軌跡が全て表示 history //今までの動かした軌跡の単語検索結果表示 history|grep "見たい単語"イメージを扱うときのコマンド
//DockerHubからイメージをダウンロード docker pull イメージ名:タグ //イメージからコンテナを作成・起動 docker run -it -d --name コンテナ名 イメージ名:タグコンテナを扱うときのコマンド
//コンテナの操作許可 docker exec -it コンテナ名 pwd //コンテナ内に入場 docker exec -it コンテナ名 /bin/bash //コンテナの起動開始 docker start コンテナ名 //コンテナの起動終了 docker stop コンテナ名 //コンテナの削除 docker rm コンテナ名 //フォルダの頂点 /(ルート)(新規)開発作業時に使うコマンド
//今いるディレクトリの参照(Dockerfileのみで使用可能) ./ //コンテナを作成 docker build ./ -t コンテナ名:タグ //マウント docker run -d -p 8080:80 -v $PWD/PCのマウントしたいフォルダ名:コンテナのマウントしたいフォルダ名までのツリー --name サーバー名 コンテナ名:タグDockerfile 関連
# build するときに基にするイメージの指定 FROM イメージ名
- 投稿日:2019-07-08T01:25:13+09:00
Docker swarm mode でDockerのオーケストレーションツール入門
この記事では、Dockerは触ったことあるけど、k8sみたいなオーケストレーションツールは使ったことないよって人向けに、Dockerのswarm modeでマルチホストなクラスタを構築し、いくつかの代表的な機能(スケールアウトとかローリングアップデートとか)を使うところまでをハンズオン形式で紹介します。
オーケストレーションツール触ってみたいけど、k8sはチョット敷居が高い・・・って人向けです。swarm mode、お手軽でいいよ
今回試す環境は以下のとおりです。
環境
- Ubuntu 18.04 LTS 3台
- Docker version 18.09.7
- docker-compose version 1.24.0
Docker swarm modeとは
Dockerのver 1.12以降で組み込まれたオーケストレーションツールです。
これを用いることで、Dockerの機能に加えて、ざっくり以下のようなことができるようになります。
- 複数ホスト間でのクラスタの構築
- コンテナレベルでのスケールアウト
- ローリングアップデートを用いた無停止デプロイ
- コンテナレベルでの迅速なロールバック
また、Swarmはdocker-composeとの相性が非常に良く、上記のような機能を
docker-compose.ymlファイルベースで定義したコンテナ群に対して、一括で適用することができます。
(docker-composeのversion 3以降では、deployというswarm mode専用の記法が用意されているぐらいです)
これが非常に強力で、普段からdocker-composeを使っている人であれば既存のワークフローを壊すことなく、簡単にクラスタ環境を手に入れることができます。コンテナオーケストレーションツールとしては、ココ最近はkubernetesが一強になってしまった感はありますが、Docker swarm modeは、CE版のDockerにデフォルトで組み込まれているので、Dockerをインストールするだけで簡単に使い始めることができます。
クラスタの構築もコマンドを数行打つだけの簡単なものなので、コンテナオーケストレーションとはなんぞや?というのを理解する入り口として、とりあえず使って見る分にはとても良いのではないでしょうか。
ちなみにEnterPrise版のDockerでは、kubernetesがswarmと同じようにDockerに組み込まれたようなので、そちらが使える環境であればそちらを使ってみても良いかもしれません。
今回は公式のswarmチュートリアルをベースに、わかりやすいよう多少内容を変えながらハンズオンを行っていきたいと思います。
詳しい人はそちらを見たほうがわかりやすいかもしれません。環境準備
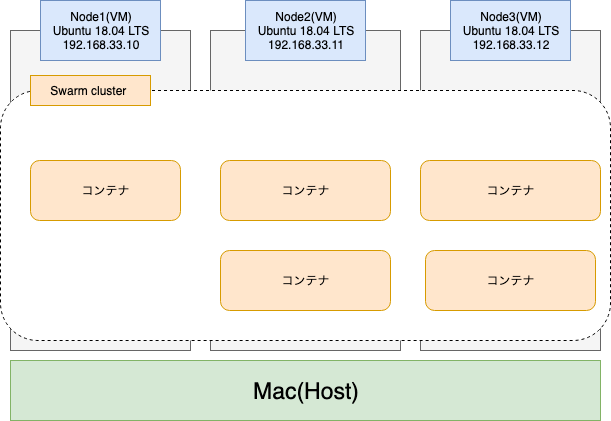
さて、今回は3台のLinuxサーバー(Ubuntu 18.04LTS)を使ってクラスタを組んでいきたいと思います。
なのでまずは、3台のLinuxマシンを用意しなければいけません。
AWSやAzureで仮想マシンを借りても良いのですが、今回はお試しなのでローカル環境にVirtualboxとVagrantを使って、3台の仮想マシンを立てちゃいたいと思います。構成は以下のような感じです
なお、今回仮想マシンを立てるホストマシンはmacです。Windows環境での動作は検証していないのでご了承ください。。まあ結局の所、仮想マシンを3台建てられさえすれば良いので、方法は何でも良いと思います。
1. Virtual boxとVagrantのインストール
公式サイトからそれぞれインストーラーを落としてきてインストールします
2. 仮想マシンの作成
インストールが終わったら、仮想マシンを作成します。まず、Vagrant用のディレクトリを仮想マシンの台数分作ります。ここでは
node1node2node3と名付けることにしますディレクトリ構成.. ├── node1 │ └── data // VMとホストの共有フォルダ docker-compose.ymlなどの構築資材を置く ├── node2 │ └── data └── node3 └── dataそれぞれのnodeディレクトリの直下に移動し、以下のコマンドを実行します。
console.$ cd ./node1 $ vagrant init ubuntu/bionic64すると以下のような
Vagrantfileが作成されると思うので、それぞれのnodeにIPアドレスを割り振るために以下のように書き換えます。IPアドレスはnodeごとに別のものを設定するようにしてください# -*- mode: ruby -*- # vi: set ft=ruby : # All Vagrant configuration is done below. The "2" in Vagrant.configure # configures the configuration version (we support older styles for # backwards compatibility). Please don't change it unless you know what # you're doing. Vagrant.configure("2") do |config| # The most common configuration options are documented and commented below. # For a complete reference, please see the online documentation at # https://docs.vagrantup.com. # Every Vagrant development environment requires a box. You can search for # boxes at https://vagrantcloud.com/search. config.vm.box = "ubuntu/bionic64" # Disable automatic box update checking. If you disable this, then # boxes will only be checked for updates when the user runs # `vagrant box outdated`. This is not recommended. # config.vm.box_check_update = false # Create a forwarded port mapping which allows access to a specific port # within the machine from a port on the host machine. In the example below, # accessing "localhost:8080" will access port 80 on the guest machine. # NOTE: This will enable public access to the opened port # config.vm.network "forwarded_port", guest: 80, host: 8080 # Create a forwarded port mapping which allows access to a specific port # within the machine from a port on the host machine and only allow access # via 127.0.0.1 to disable public access # config.vm.network "forwarded_port", guest: 80, host: 8080, host_ip: "127.0.0.1" # Create a private network, which allows host-only access to the machine # using a specific IP. config.vm.network "private_network", ip: "192.168.33.10" ## ここのコメントアウトを外し、一意なipアドレスを各nodeに割り振る # Create a public network, which generally matched to bridged network. # Bridged networks make the machine appear as another physical device on # your network. # config.vm.network "public_network" # Share an additional folder to the guest VM. The first argument is # the path on the host to the actual folder. The second argument is # the path on the guest to mount the folder. And the optional third # argument is a set of non-required options. # dataディレクトリをVMにマウントする config.vm.synced_folder "./data", "/home/vagrant/vagrant_data" # Provider-specific configuration so you can fine-tune various # backing providers for Vagrant. These expose provider-specific options. # Example for VirtualBox: # # config.vm.provider "virtualbox" do |vb| # # Display the VirtualBox GUI when booting the machine # vb.gui = true # # # Customize the amount of memory on the VM: # vb.memory = "1024" # end # # View the documentation for the provider you are using for more # information on available options. # Enable provisioning with a shell script. Additional provisioners such as # Puppet, Chef, Ansible, Salt, and Docker are also available. Please see the # documentation for more information about their specific syntax and use. # config.vm.provision "shell", inline: <<-SHELL # apt-get update # apt-get install -y apache2 # SHELL end最後に以下を実行することで仮想マシンの作成と立ち上げを行います。
$ vagrant up立ち上げた仮想マシンには以下のコマンドでssh接続することができます
$ vagrant sshサーバーに接続できたら、わかりやすいように各Nodeサーバーのhostnameを
node1node2node3に変更しておきましょう$ sudo hostnamectl set-hostname ubuntu-node1 // node1の場合 $ hostname ubuntu-node1 // 変わったことを確認以上の操作を3つのNode全てに行ってください。最終的なディレクトリ構成は以下のような感じになると思います。
. ├── node1 │ ├── data │ ├── Vagrantfile │ └── ubuntu-bionic-18.04-cloudimg-console.log ├── node2 │ ├── data │ ├── Vagrantfile │ └── ubuntu-bionic-18.04-cloudimg-console.log └── node3 ├── data ├── Vagrantfile └── ubuntu-bionic-18.04-cloudimg-console.logDockerとDockerComposeのインストール
swarmを動作させるために各NodeにDockerとdocker-composeをインストールします。
docker-composeは入れなくても使えるのですが、Dockerのswarm modeではdocker-composeのyaml記法で定義されたコンテナ群をまとめてデプロイできるので、あったほうがいろいろ便利です。Dockerのインストール
基本的には公式サイトに従ってインストールするのが一番間違いがないです。一応現時点(2019/07)でのインストール方法をメモしておきます
- インストールされている古いDockerの削除
$ sudo apt-get remove docker docker-engine docker.io containerd runc
- Dockerのインストール
$ sudo apt-get update $ sudo apt-get install \ apt-transport-https \ ca-certificates \ curl \ gnupg-agent \ software-properties-common $ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - $ sudo apt-key fingerprint 0EBFCD88 $ sudo add-apt-repository \ "deb [arch=amd64] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) \ stable" $ sudo apt-get update $ sudo apt-get install docker-ce docker-ce-cli containerd.io最後に現在のユーザー(vagrant)をdocker groupに所属させ、
dockerコマンドをsudoなしで実行できるようにします。# dockerグループがなければ作る $ sudo groupadd docker # 現行ユーザをdockerグループに所属させる $ sudo gpasswd -a $USER docker # dockerをrestert $ sudo service docker restart # 一度ログアウトして入り直す $ exit $ vagrant ssh # dockerコマンドが実行できることを確認 $ docker ps -aDocker composeのインストール
こちらも公式サイトのやり方に従うのが一番良いでしょう。
一応現時点(2019/07)でのインストール方法をメモしておきます。
$ sudo curl -L "https://github.com/docker/compose/releases/download/1.24.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose $ sudo chmod +x /usr/local/bin/docker-compose $ sudo ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose上記の作業を3つのNode全てに行います。
Docker Swarmの初期設定とクラスタの構築
まずはNode1をManagerNodeとしてswarmに登録する必要があります。
Node1にsshでログインし、以下のコマンドを実行しましょう。Node1で実行.$ docker swarm init --advertise-addr="192.168.33.10" --listen-addr=0.0.0.0:2377 Swarm initialized: current node (ql8aefbw7rg8nfmznejnzfeus) is now a manager. To add a worker to this swarm, run the following command: docker swarm join --token SWMTKN-1-66qe5cyf31fd8rktwvjbrtpd63l32789aqpbfheauwgfh38g8wrf2ey-bob77wfdnrkpcmqtxfgkiu47a 192.168.33.10:2377 To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
--advertise-addrには自分自身のIPアドレス。--listen-addrにはクラスタ間の通信に使用するport番号を指定しましょう。このポートでクラスタ間の通信を行うので、事前にVM上で、各クラスタに対してこのポートを開けておく必要があります。これでSwarmのクラスタが作成されます。今後は、上記で作ったクラスタに他のNodeをjoinさせることで、クラスタをどんどん広げていくことができます。
クラスタに参加しているnodeの一覧を見るには以下を実行します。
今は自分自身だけですね$ docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION ql8aefbw7rg8nfmznejnzfeus * ubuntu-node1 Ready Active Leader 18.09.7さっそく
Node2とNode3をworker nodeとしてjoinさせてみましょう。swarm init時に発行された
tokenを使ってクラスタにjoinすることができます。Node2,3で実行.$ docker swarm join --token SWMTKN-1-66qe5cyf31fd8rktwvjbrtpd63l32789aqpbfheauwgfh38g8wrf2ey-bob77wfdnrkpcmqtxfgkiu47a 192.168.33.10:2377もしもtokenを忘れてしまった場合は以下のコマンドで見ることができます。
$ docker swarm join-token -q workerもう一度
docker node lsを実行すると、クラスタに参加しているNodeが増えていることがわかります。$ docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION ql8aefbw7rg8nfmznejnzfeus * ubuntu-node1 Ready Active Leader 18.09.7 uusz619ly0y6zp3zsdh0br31y ubuntu-node2 Ready Active 18.09.7 pgouhk6cndlxddjhll1vo1rfv ubuntu-node3 Ready Active 18.09.7これで、manager node1個とworker node2個の計3個のVMでクラスタを組むことができました。
(補足) manager nodeとworker nodeについて
Swarmでは、クラスタを構成するDocker Engineインスタンスのことをノードと呼びます。
今までnode = LinuxVMみたいな書き方をしてきましたが、正確にはLinuxの上で動いているDocker Engineでクラスタを組んでいる。という表現が正しいです。
このクラスタを構成するnodeには、manager nodeとworker nodeの2種類が存在し、それぞれ以下のような役割を担います。
- maneger nodeは一つのリーダー(leader node)を選出し、コンテナのオーケストレーションや管理指示をworker nodeに送信する。デフォルトではmanager nodeもworker nodeとして動作する
- worker nodeはmanager nodeからの指示を受け取り、コンテナをデプロイしたり削除したりする。
詳しくは以下を読んでみてください
Portainerの構築
Swarmの構築には必要ないのですが、コンテナの状態をGUI上から監視できるPortainerというツールがあるのでこれを各Nodeに構築しておきます。 portainerというディレクトリを作り、以下の
docker-compose.ymlを作ります。. ├── node1 │ ├── Vagrantfile │ └── data │ └── portainer │ └── docker-compose.yml // 追加 ├── node2 │ ├── Vagrantfile │ └── data │ └── portainer │ └── docker-compose.yml // 追加 └── node3 ├── Vagrantfile └── data └── portainer └── docker-compose.yml // 追加docker-compose.ymlversion: '3' services: portainer: container_name: my-portainer hostname: my_portainer image: portainer/portainer ports: - "9000:9000" command: -H unix:///var/run/docker.sock volumes: - /var/run/docker.sock:/var/run/docker.sock - data:/data restart: always volumes: data:最後に以下のコマンドを実行して、Portainerのコンテナを立ち上げましょう
$ cd ./<Portainerのdocker-composeファイルをおいたディレクトリ> $ docker-compose up -d以下のURLにアクセスするとPortainerにログインできます。
http://<NodeのIP>:9000コンテナのデプロイ
さて、では先ほど作成したクラスタ上でコンテナをデプロイしましょう。コンテナのデプロイは
docker serviceコマンドを用いて行う事ができますが、複雑な構成のコンテナをデプロイする場合は、コマンドが長くなってしまって使いにくいです。swarmはdocker-composeの
yaml形式で定義されたファイルを使ってコンテナのデプロイを行うことができるので、こちらを使うようにしましょう。まず、Node1の配下に以下のような
docker-compose.ymlファイルを用意しますdocker-compose.ymlversion: '3.7' services: nginx: image: nginx ports: - target: 80 published: 8080 protocol: tcp mode: ingress. ├── node1 │ ├── Vagrantfile │ └── data │ ├── nginx │ │ └── docker-compose.yml // 追加 │ └── portainer │ └── docker-compose.yml ├── node2 │ ├── Vagrantfile │ └── data │ └── portainer │ └── docker-compose.yml └── node3 ├── Vagrantfile └── data └── portainer └── docker-compose.ymlDocker composeを使い慣れた人にとっては見慣れた形式のファイルだと思います。
今回は簡単のために空のnginxコンテナを使って動作確認することにします。以下のコマンドをNode1上で実行しましょう。
$ cd <docker-compose.ymlを用意した場所> $ docker stack deploy nginx --compose-file ./docker-compose.yml以下にアクセスしてコンテナが起動したことを確認します。nginxのデフォルトの画面が表示されれば成功です。
http://<Node1のIP>:8080(上記の手順に従ってNodeServerを作った場合は http://192.168.33.10:8080 のハズ)さて今回は
ingressモードでコンテナのポートを公開しました。この場合、コンテナが立ち上がっているhost(今回はNode1)以外のNodeからでもこのコンテナにアクセスできます。以下のURLにも接続してみて、ページが表示されることを確かめてみましょう。
http://<Node2のIP>:8080
http://<Node3のIP>:8080
Portainerを使うと、swarmクラスタ上でどのようにコンテナがデプロイされているかを見ることができます。
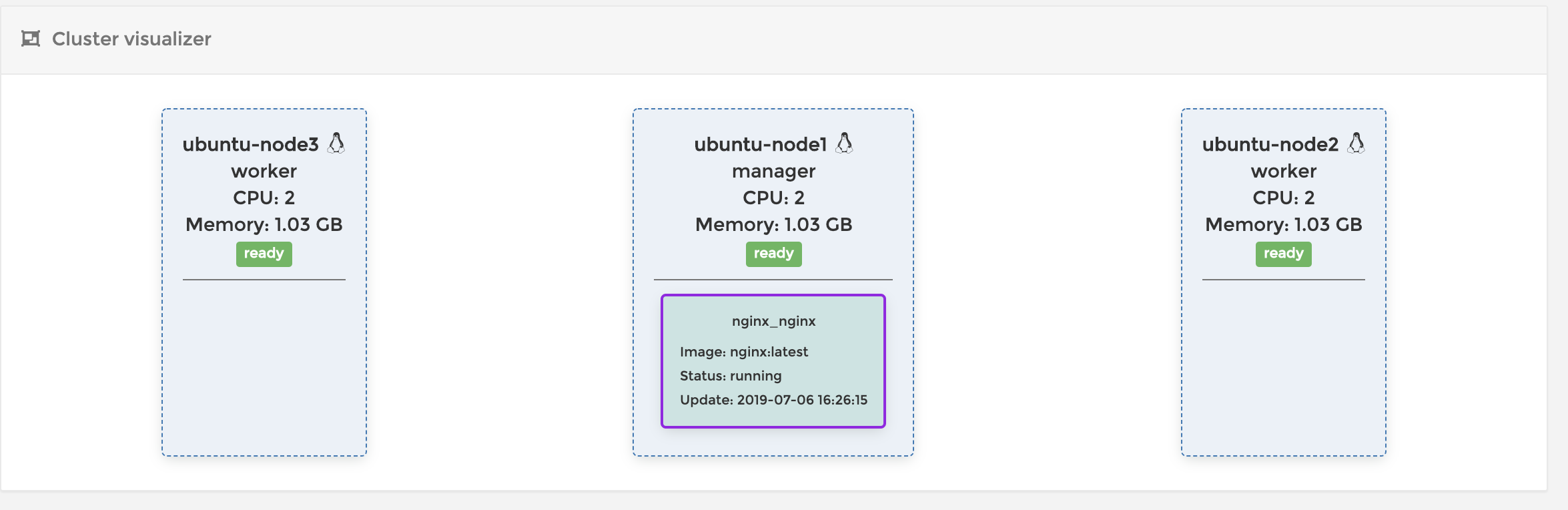
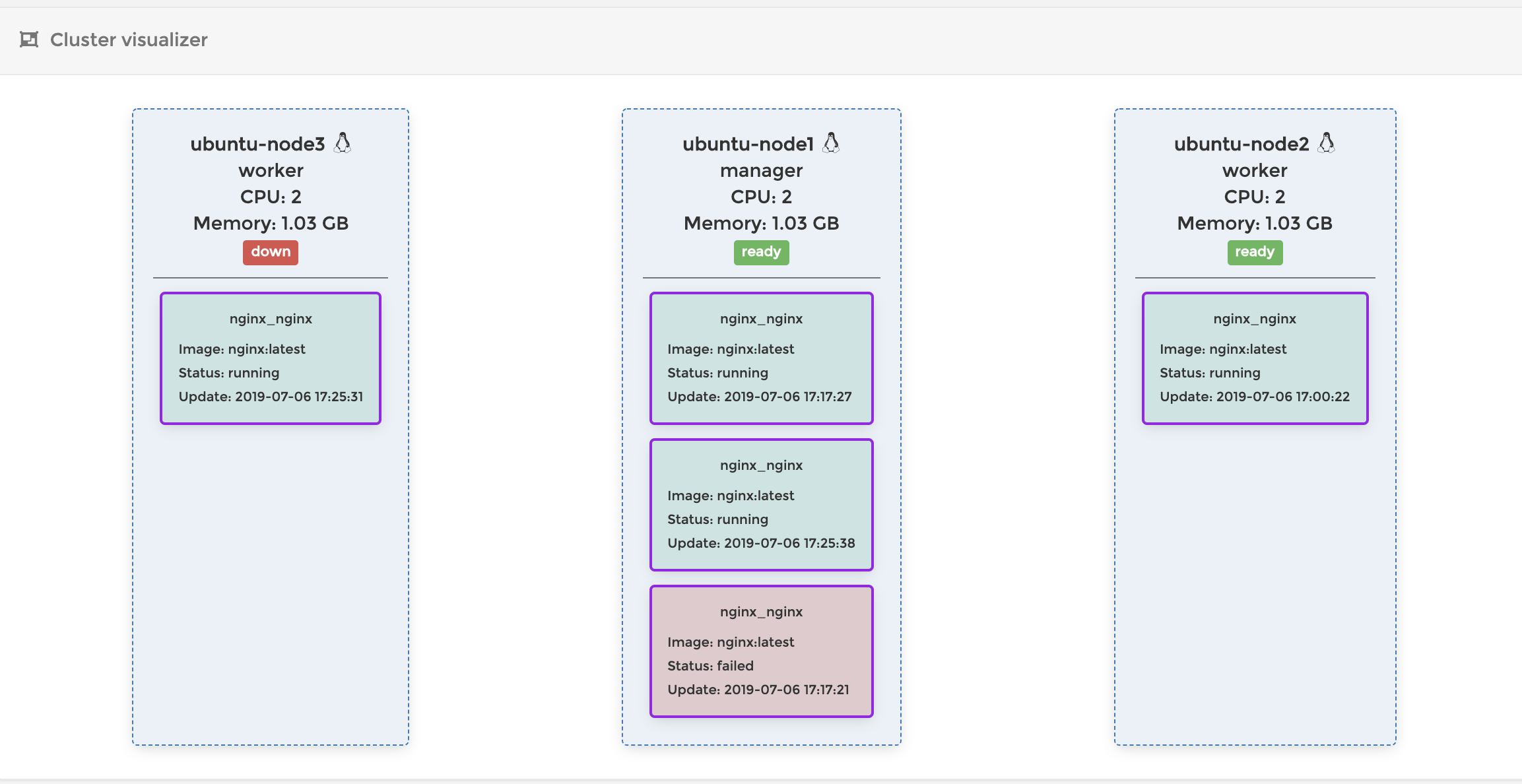
サイドバーから「swarm」を選び、「Go to cluster visualizer」のリンクをクリックしてみましょう
今はコンテナをひとつだけデプロイしたので以下のような感じですね
ちなみに今回は、簡単のためにServiceを1種類しか定義しませんでしたが、swarmでは
docker-compose.ymlで使える記法はよほど特殊なものでない限りすべてサポートしているので、serviceを複数定義すれば、複数のコンテナを連携させてデプロイすることももちろん可能です。既存の
docker-compose.ymlファイルがそのまま使えるのは嬉しいですねスケールアウト
現在、1個だけコンテナが立ち上がっているわけですが、実際のサービスでは、利用状況によってコンテナをスケールアウトしたくなる場合があります。
その場合は以下のコマンド打つことで簡単スケールアウトすることができます。
まずはスケールアウトしたいService(docker-composeで定義したService)の名前を見つけます
$ docker stack ps nginx ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS p1syqxgwanpy nginx_nginx.1 nginx:latest ubuntu-node1 Running Running 27 minutes agodocker-composeを使ってコンテナをデプロした場合、各Serviceの名前は
composefileのあるディレクトリ名_composeで定義したservice名になります。今回の場合はnginxディレクトリの下にdocker-compose.ymlを作っちゃったのでnginx_nginxですね。(なんでこの名前にしちゃったんだろ?)上のコマンドでは
.1が末尾についていますが、これはServiceがスケールアウトして同じコンテナが複数立った場合に見分けるためのものです。なので実際のサービス名はnginx_nginxですねこのサービスをスケールアウトするには以下の
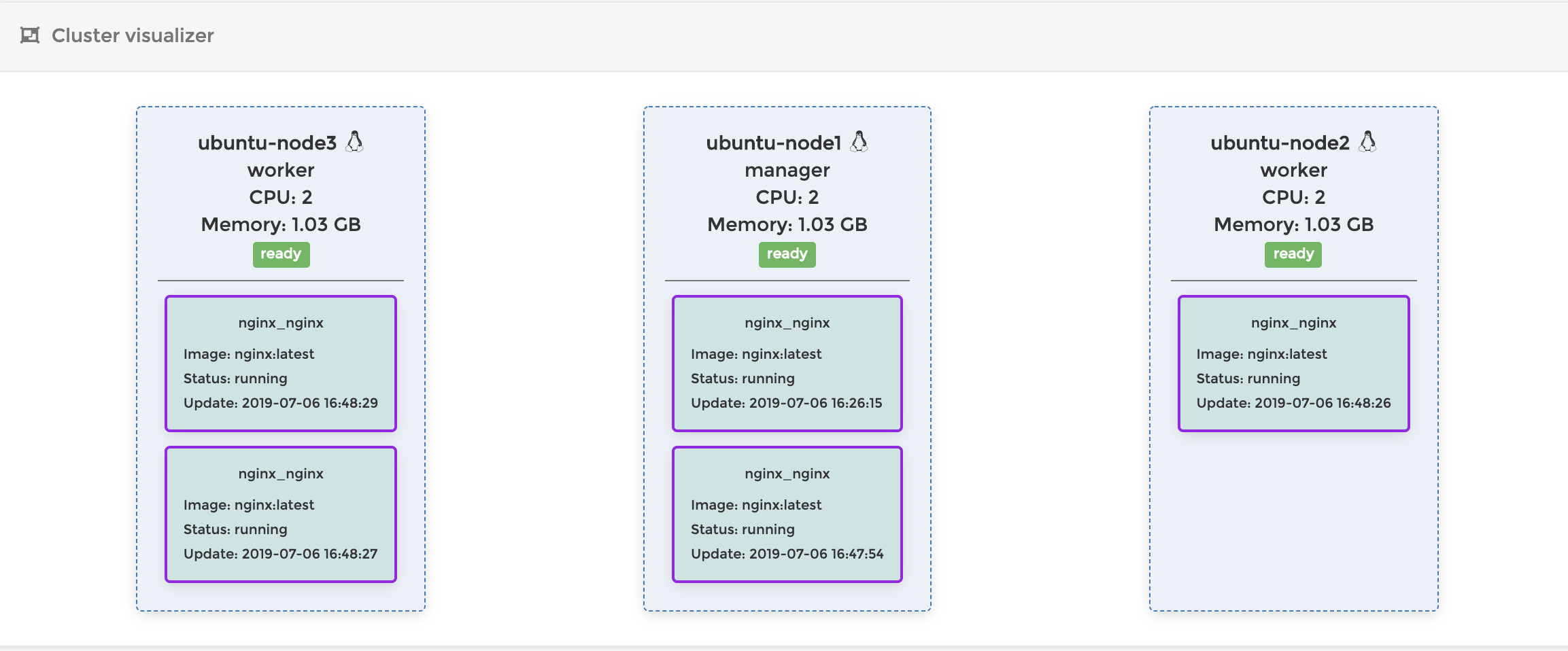
service scaleコマンドをNode1で実行します。$ docker service scale nginx_nginx=5 // コンテナの数を5個にスケールアウトする nginx_nginx scaled to 5 overall progress: 5 out of 5 tasks 1/5: running 2/5: running 3/5: running 4/5: running 5/5: running verify: Service convergedPortainerで確認すると、コンテナが5つに増えていることがわかります。
composefileを使ったスケールアウト
上記の方法でもスケールアウトはできるのですが、compose fileに予め、作成するコンテナ数を定義する事もできます。
docker-compose.ymlを以下のように書き換えてみましょうdocker-compose.ymlversion: '3.7' services: nginx: image: nginx ports: - target: 80 published: 8080 protocol: tcp mode: ingress deploy: mode: replicated replicas: 3 ## コンテナを3つ作成するdocker-composeを書き換えた後、もう一度
stack deployを実行することで、docker-compose.ymlの差分を自動的に検知して、その状態にコンテナをデプロイし直してくれます。宣言的で良い感じですね
$ cd <docker-compose.ymlを用意した場所> $ docker stack deploy nginx --compose-file ./docker-compose.yml
リカバリー
さて、これで同じコンテナを複数個立てて、ロードバランシングすることができました。
じゃあこの状態で、コンテナやNodeを落とすとどうなってしまうのでしょう?ちょっとやってみたいと思います。
コンテナを削除する
まず削除対象のコンテナを探します
$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 7e504778aab7 nginx:latest "nginx -g 'daemon of…" About an hour ago Up About an hour 80/tcp nginx_nginx.1.p1syqxgwanpys3c64kx9dlwsl今回はnode1のコンテナを削除してみましょう
$ docker rm 7e504778aab7すると、以下のように削除したはずのコンテナが復活します。
実はDocker swarmは
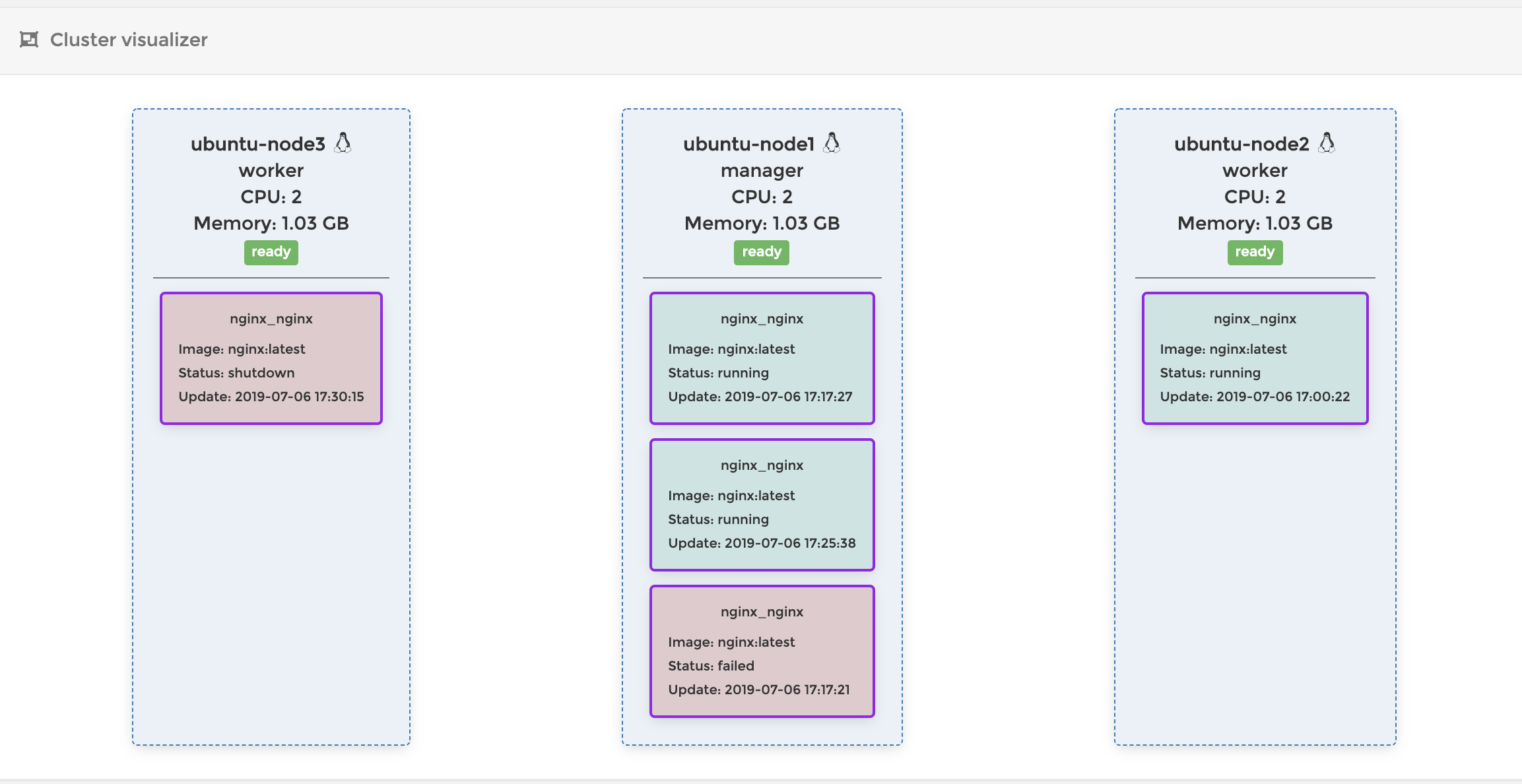
docker-compose.ymlのreplicasで指定した数のコンテナが起動するように常に維持しようとします。なので、もしもコンテナが止まったり、削除されたりした場合は、新しいコンテナを作成してこれを補おうとします。上では一度コンテナの作成に失敗しているようですが、最終的には起動しているコンテナが3つになるように常に調整してくれます。Worker Nodeを減らす
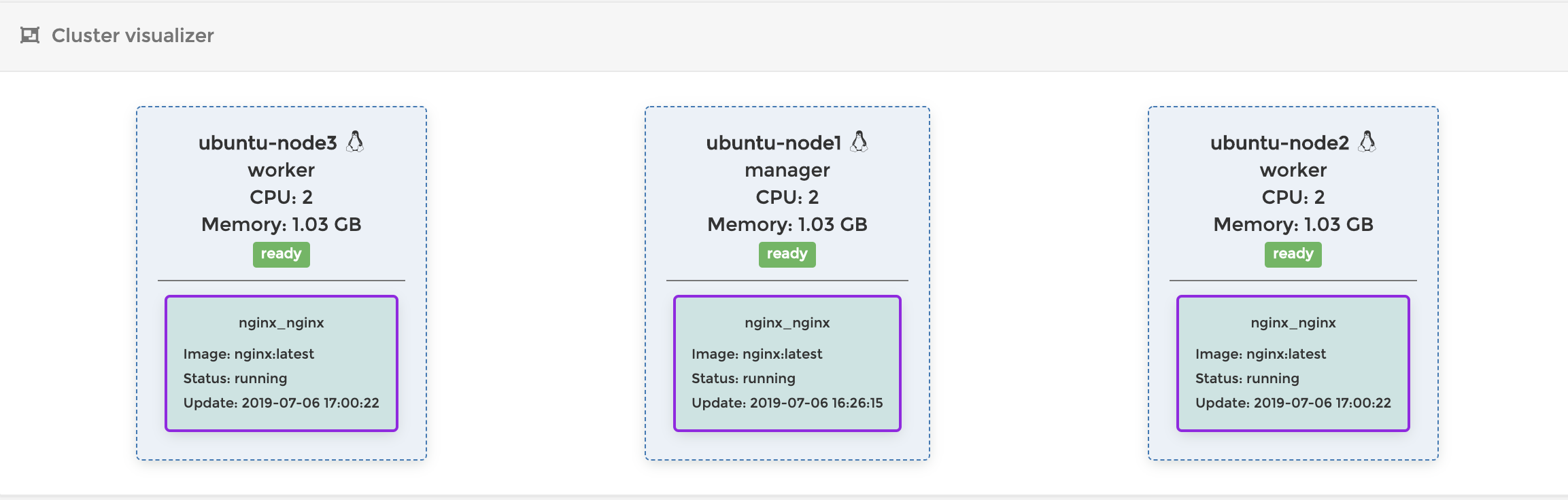
では今度はworker nodeを減らして挙動を見てみましょう。この状態で
Node3のVMの電源を落としますNode3.$ sudo init 0 // Node3の電源を落とすすると以下のような状態になります。Node3がdown状態になって、Node1にもう一つコンテナが立ち上がっているのがわかります。
このようにNodeがダウンすると、Swarmはそこにデプロイされていたコンテナを別のNodeで起動して数を調整します。賢いですね
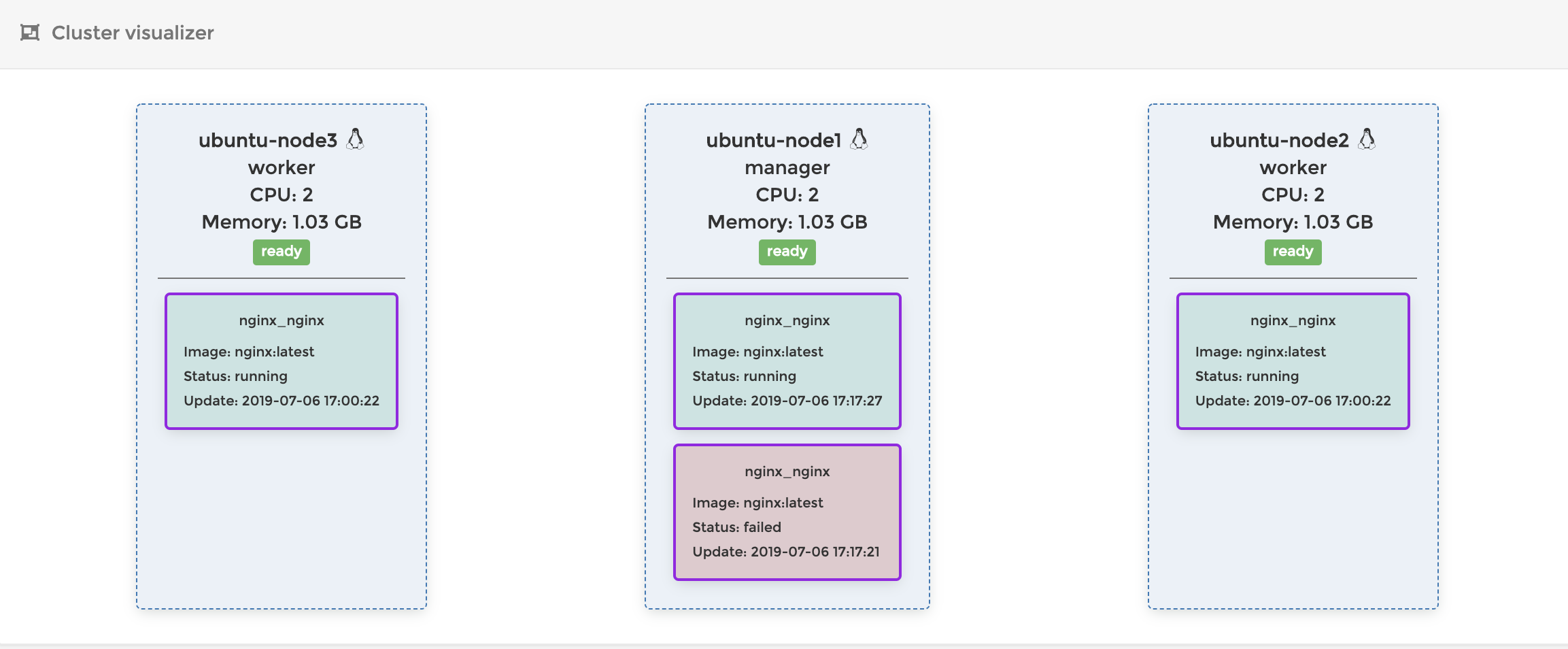
この状態でもう一度Node3を起動すると以下のような状態になります。
あれ、Node3にデプロイされていたコンテナがshatdownされちゃいましたね。なんだかNode1にデプロイ先が偏っていて微妙な感じです。うーん。。。
SwarmがNodeの再接続を検知しても、現在のコンテナの状態が正しい場合は、既存のコンテナを移動してrebalanceするようなことはしてくれないみたいですね。
なのでもしも偏っちゃったコンテナをrelocateしたい場合は以下のコマンドを実行してください。
$ docker service update --force nginx_nginxでもこのコマンドって、既存のコンテナを順番に破棄して、全て新しく入れ替えるコマンドなんですよね。主にあとで紹介するローリングアップデートとかに使うやつです。なので停止したコンテナが大量にできちゃってますね
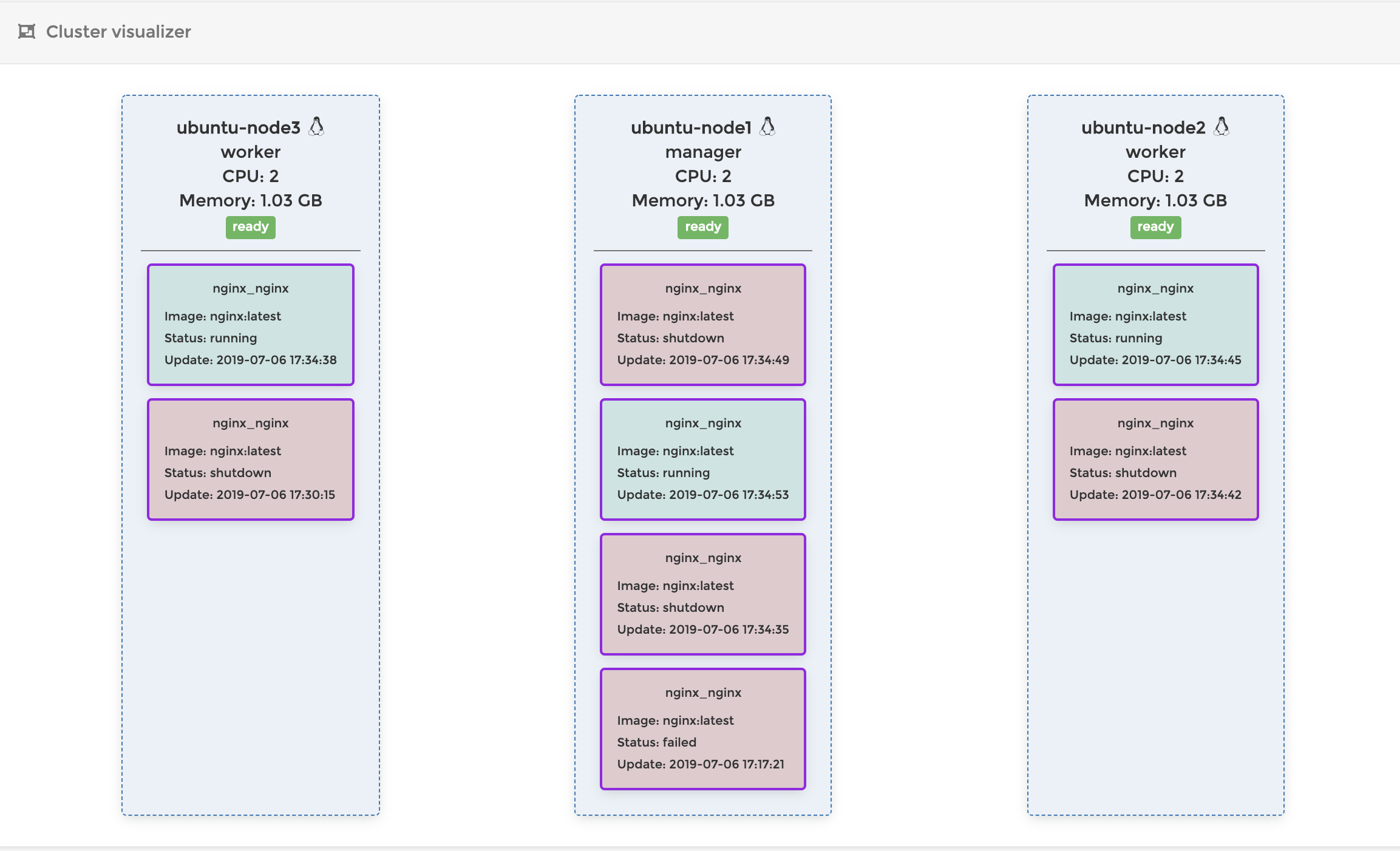
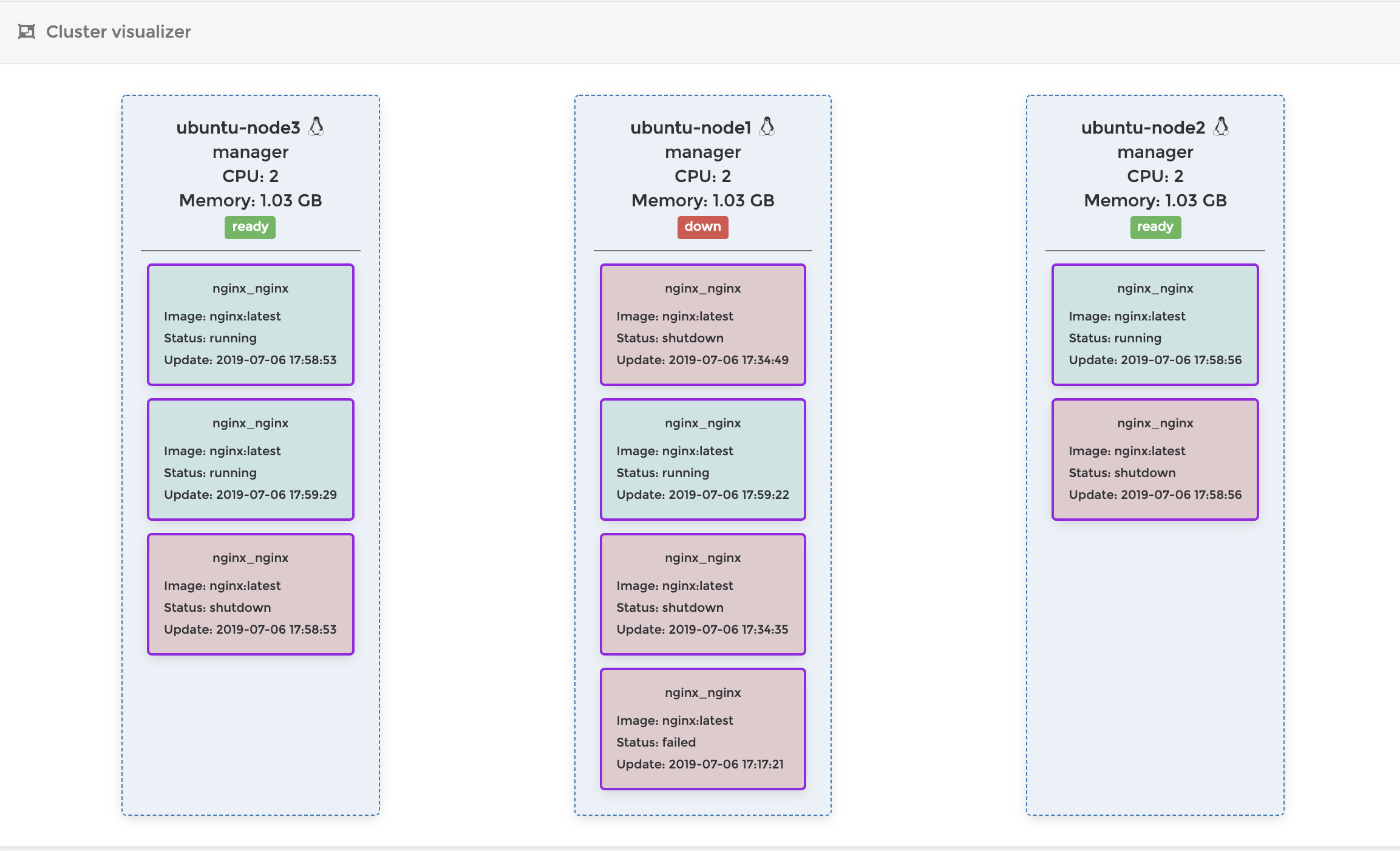
Manager Nodeを落とす
ではworker nodeではなくmanager nodeを落とすとどうなってしまうのでしょう?
Swarmでは現在リーダーとなっているノード(manager nodeの中から一つ選ばれる)が落ちると、残りのmanager nodeの中から一つを選出し、そのnodeがleader node(Swarmをコントロールするノード)になります。
現在はmanager node1、 worker node2の環境なので、まずはmanager nodeの数を増やします。
このとき、manager nodeの数は最低でも3つないと新しいリーダーを選出できません。なのでまずは今回作ったNode2とNode3を両方共manager nodeに昇格させます。昇格させる場合は、Node1で以下を実行します。
$ docker node promote ubuntu-node2 // node2をManagerに昇格 $ docker node promote ubuntu-node3 // node3をManagerに昇格
docker node lsを実行すると、MANAGER STATUSがReachableになっているのがわかるでしょうか?$ docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION ql8aefbw7rg8nfmznejnzfeus * ubuntu-node1 Ready Active Leader 18.09.7 uusz619ly0y6zp3zsdh0br31y ubuntu-node2 Ready Active Reachable 18.09.7 pgouhk6cndlxddjhll1vo1rfv ubuntu-node3 Ready Active Reachable 18.09.7この状態でNode1を落としてみます。
Node2の上で
docker node lsを実行してみるとnode3がLeaderに昇格していることがわかります。$ docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION ql8aefbw7rg8nfmznejnzfeus ubuntu-node1 Unknown Active Unreachable 18.09.7 uusz619ly0y6zp3zsdh0br31y * ubuntu-node2 Ready Active Reachable 18.09.7 pgouhk6cndlxddjhll1vo1rfv ubuntu-node3 Ready Active Leader 18.09.7Node3のPortainerを見てみると、以下のようになっています。
ダウンしたNode1の代わりに、Node3が適切にコンテナを起動して、コンテナの数を維持していることがわかります。
(補足) Leader Node選出ロジックについて
Swarmでは、Swarmを管理するleader nodeが落ちてしまった場合、新しいleader nodeをRaftと呼ばれるロジックに従って選出します。
この場合、ロスト可能なNodeの最大数は、manager nodeの数をNとして
(N-1)/2で計算されます。
3台の場合は(3-1)/2 = 1なので1台までなら落ちても大丈夫です。ただし多ければ良いというものでもないみたいで、主にパフォーマンス上の理由から、Docker swarmではmanager nodeの数は最大でも7台までに抑えることが推奨されています。
詳しくは以下を参照して見てください
https://docs.docker.com/engine/swarm/how-swarm-mode-works/nodes/・A three-manager swarm tolerates a maximum loss of one manager.
・A five-manager swarm tolerates a maximum simultaneous loss of two manager nodes.
・An N manager cluster tolerates the loss of at most (N-1)/2 managers.
・Docker recommends a maximum of seven manager nodes for a swarm.ローリングアップデート
さて、個人的にSwarmの目玉機能だと思っているローリングアップデートを紹介したいと思います。今まで見てきたように、Swarmでは同じイメージのコンテナを複数立ててロードバランシングすることができます。
そして複数コンテナを立てている環境では、デプロイされているコンテナを順番に更新していくことで、無停止デプロイを実現することができます。俗に言うローリングアップデートと言うやつですね。
さっそく試してみましょう
docker-compose.ymlを以下のように書き換えますdocker-compose.ymlversion: '3.7' services: nginx: image: httpd ## => イメージをnginxからApacheに変更 ports: - target: 80 published: 8080 protocol: tcp mode: ingress deploy: mode: replicated replicas: 3そして再び
docker stack deployを実行しましょう。これだけでローリングアップデートによって、3つのコンテナが順番にApache serverに差し替わります。$ cd <docker-compose.ymlを用意した場所> $ docker stack deploy nginx --compose-file ./docker-compose.yml実行した後、今までnginxが動いていたURLを更新してみてください。どこかのタイミングでnginxがhttpdに差し替わっているのが確認できると思います。
http://<NodeのIP>:8080httpdの初期画面
ちなみに
docker stack deployは、実行時にdocker-compose.ymlの差分を検知して、差分のあったserviceだけをdocker service updateするような動きになっています。
なので実際に実行されているのはdocker service updateですね。ロールバック
上で無事
nginxをhttpdに「アップデート」できました。しかし世は大nginx時代、皆さんの中にはこのアップデートを快く思わない人もいるでしょう。今すぐ、Apacheを窓から投げ捨て、サーバーのアップデートをなかったコトにして、もとのnginxに戻したくなるかもしれません
そんなときでもSwarmなら安心です。SwarmにはService単位でのrollback機能が実装されています。
以下のコマンドを実行してみてください。アップデートはなかったことにされ、再びnginxの初期画面を目にすることができるでしょう
$ docker service rollback nginx_nginx
余談
作成されるコンテナの数を制限したい
ローリングアップデートを繰り返していると、過去のイメージで作られた停止済みコンテナが大量にできてしまいます。
それが嫌な場合は、swarmのoptionでこれを制限することができます。$ docker swarm update --task-history-limit 5 // 一つのServiceについてコンテナを5世代前まで残すこの設定が効果を発揮するのは次回の
docker service update時であることに注意してください。
つまりこの設定を有効にしただけでは古いコンテナは削除されません。もしも古いコンテナを削除したいのであれば、以下のコマンドを実行してみてください。
現在存在する古いコンテナが削除され、現時点のコンテナだけになることがわかると思います$ docker swarm update --task-history-limit 0 // コンテナ履歴を残さない $ docker service update --force nginx_nginxただし、停止されたコンテナが大量にできたからと言って、大量のストレージが消費されているわけではありません。
以下のコマンドを実行して、停止されているコンテナのストレージ容量を見てみてください
$ docker ps -a -s CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES SIZE 3bb6e4eac2a7 nginx:latest "nginx -g 'daemon of…" 42 seconds ago Up 35 seconds 80/tcp nginx_nginx.2.nd8v1m97djhykqhe1jd7xoopb 2B (virtual 109MB) cf9d34de148f nginx:latest "nginx -g 'daemon of…" About a minute ago Exited (0) 38 seconds ago nginx_nginx.2.z7h14vx534milfsml9zddyvu7 0B (virtual 109MB) 1369522e3aca portainer/portainer "/portainer -H unix:…" 30 hours ago Up About a minute 0.0.0.0:9000->9000/tcp my-portainer 0B (virtual 75.4MB)
size 0B (virtual 109MB)となっているのがわかるでしょうか?実はDockerのコンテナのストレージは元となったcontainer imageとの差分のみを保持する仕組みになっています。なので同じイメージのコンテナがいくら増えようが、使われる容量は0Bです。
むしろDockerを運用するときにはconatiner imageの方を気にするようにしましょう。特に自分が作っているアプリのconatiner imageがエンハンスによって増えていくと、新たなイメージをデプロイするたびにどんどんストレージ容量が使われている可能性があります。
その場合は、定期的にストレージに保存されている古いイメージを削除するなどしたほうが良いでしょう。まとめ
以上でDocker Swarm modeのハンズオンは終わりです。
ここで紹介した以外にも、様々な機能がswarmには備わっているので興味がある人は調べてみてください。
ちなみにここでは紹介しませんでしたが、DockerのSwarm modeはシングルノードでも実行できます。
その場合は、引数なしでdocker swarm initと打つだけで、単一のサーバーの上でローリングアップデートやロールバックなどの魅力的な機能を利用することができます。クラスタ組むほどじゃないんだけど、ローリングアップデートはしたいんだよな〜ってときはとてもお手軽で便利です。(Single node docker swarm でお手軽 rolling updateなんかは参考になります)
ココらへんはk8sにはない利点なんじゃないでしょうか?以上
参考URL

- 投稿日:2019-07-08T00:38:10+09:00
Dockerコンテナのフロントテスト環境構築(Selenium-Grid×docker-compose)
概要
フロントエンドコンテナとSelenium-Gridコンテナをdoccker-composeで構築、連携し、ローカルDockerでフロントテストを実行
背景
・ローカルのdocker環境のフロントのテストをしたい。
・なんとなくSeleniumGridを触ってみたい。構成
▽用意するコンテナ
・フロントページのコンテナ(PHP)→以前作成したPHP×Apacheのコンテナ
・SeleniumHubコンテナ →公式イメージをそのまま使う
・SeleniumNodeコンテナ →公式イメージをそのまま使う↑に同じdocker-networkを設定、対象IPとドメイン名をhosts設定
ディレクトリ構成
front-test-env ├ php_web_container // ウェブコンテナモジュール() ├ frontTest-1.0-SNAPSHOT.jar // フロントテストスクリプト └ docker-compose.ymlversion: "3" services: web_container: container_name: php_web_container build: ./php_web_container ports: - "443:443" - "80:80" volumes: - ./php_web_container/src:/var/www/html environment: ENVIRONMENT: development extra_hosts: - "nishimu.com:127.0.0.1" networks: container_net: ipv4_address: 172.16.238.6 selenium-hub: image: selenium/hub:3.6.0-bromine ports: - "4444:4444" networks: container_net: ipv4_address: 172.16.238.7 selenium-node-chrome-debug: image: selenium/node-chrome-debug:3.6.0-bromine ports: - "0.0.0.0:32768:5900" environment: - HUB_PORT_4444_TCP_ADDR=172.16.238.7 - HUB_PORT_4444_TCP_PORT=4444 networks: container_net: extra_hosts: - "nishimu.com:172.16.238.6" # Connect 'vnc://localhost:32768/', default pass to 'secret'. networks: container_net: driver: bridge ipam: driver: default config: - subnet: 172.16.238.0/24コンテナ起動
# コンテナビルド docker-compose build # コンテナ起動 docker-compose up -d # コンテナ起動確認 docker-compose ps $ docker-compose ps Name Command State Ports --------------------------------------------------------------------------------------------------------------------------------------------- nishimu_containers_selenium-hub_1 /opt/bin/entry_point.sh Up 0.0.0.0:4444->4444/tcp nishimu_containers_selenium-node-chrome-debug_1 /opt/bin/entry_point.sh Up 0.0.0.0:32768->5900/tcp php_web_container /bin/sh -c /usr/sbin/httpd ... Up 0.0.0.0:443->443/tcp, 0.0.0.0:80->80/tcp, 8000/tcp ※Web(php_web_container), Hub(nishimu_containers_selenium-hub_1), Node(nishimu_containers_selenium-node-chrome-debug_1) のコンテナが立ち上がっていることを確認VNC起動
hostsに以下を設定
127.0.0.1 localhost 127.0.0.1 nishimu.com[Finder]を右クリック→[サーバへ接続]を押下 →
vnc://localhost:32768
※画面共有でnishimu_containers_selenium-node-chrome-debug_1にVNC接続テストスクリプト
テキトーにリンクを押して、フォーム入力するスクリプトをKotlin作成。。
package com.nishimu.seleniumtest import org.springframework.boot.autoconfigure.SpringBootApplication import org.springframework.boot.runApplication import org.openqa.selenium.remote.DesiredCapabilities import org.openqa.selenium.remote.RemoteWebDriver import java.net.URL @SpringBootApplication class SeleniumTestApplication fun main(args: Array<String>) { runApplication<SeleniumTestApplication>(*args) val driver = RemoteWebDriver(URL("http://127.0.0.1:4444/wd/hub"), DesiredCapabilities.chrome()) try { driver.run { // HOME get("http://nishimu.com/tp_biz48_skyblue/index.html") Thread.sleep(3000) findElementById("menu5").click() Thread.sleep(3000) // CONTACT findElementByName("お名前").sendKeys("テスト したろう") findElementByName("メールアドレス").sendKeys("test@example.com") findElementByName("お問い合わせ詳細").sendKeys("テストです!!!") Thread.sleep(3000) close() println("[INFO]:Test successfully passed!!") } } catch (e: Exception) { println("[ERROR]:" + e.message) } finally { driver.quit() } }実行結果
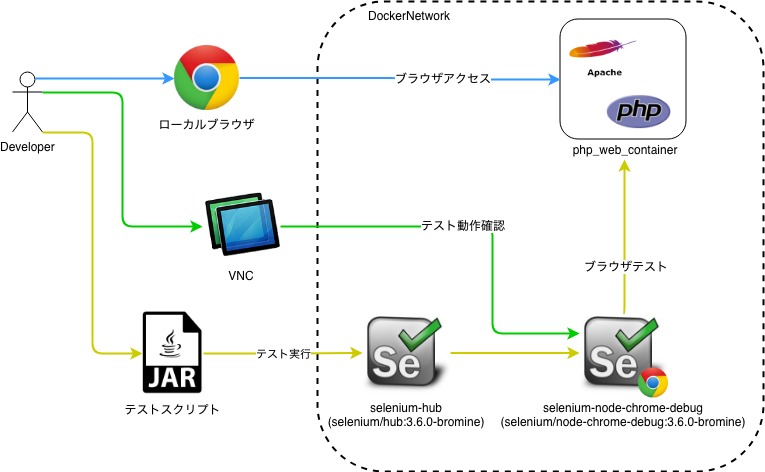
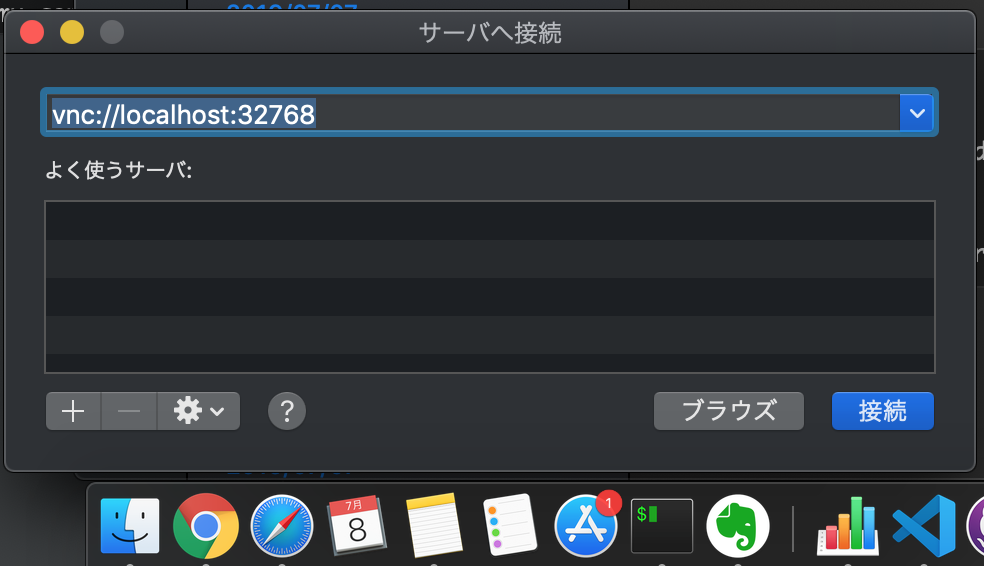
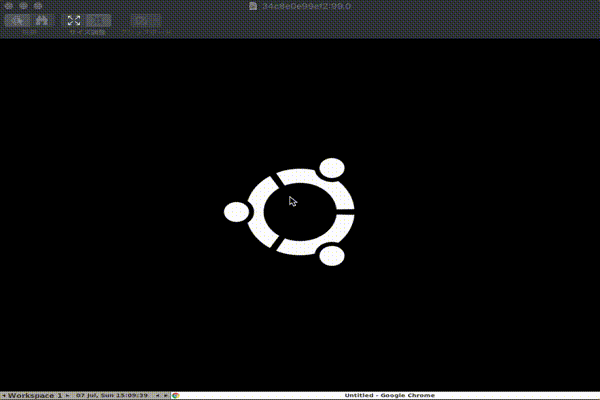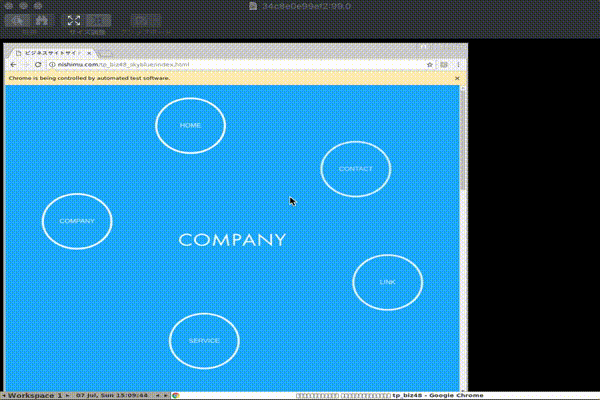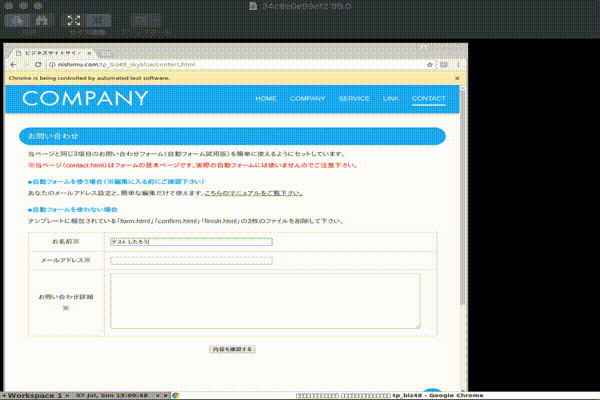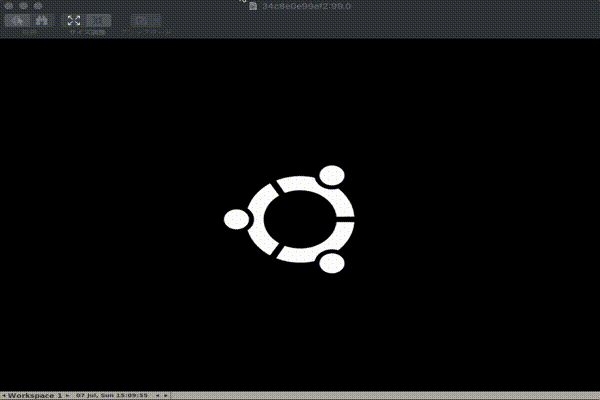
- 投稿日:2019-07-08T00:35:07+09:00
【初学者向け】MacでDockerを使うための最低限の事
はじめに
今更ですがDockerの魅力を知ったので、
ローカル環境(Mac)にインストールしてみました。その際に行った初期設定などを、備忘録を含めてまとめます。
ローカル環境でMacOSを使用している前提とします。
また、dockerをインストールした後の操作などは対象外です。開発環境
- Macbook Pro (Core i5)
- MacOS
DockerをMacで使う
macにアプリケーションをインストールするだけです。
(カップラーメンを作るより早く終わります。)Dockerのインストール
1.Docker for MacのDL & Install
https://hub.docker.com/editions/community/docker-ce-desktop-mac
上記のdockerhubより、Get Dockerをクリックし、Docker Desktop for MacをDLする。
(dockerhubにログインしないとDL出来ません。登録&ログインを済ませておいてください。)
DLしたdocker.dmgファイルを開き、Docker.appをApplicationsへ追加する。
その後は流れに沿ってインストールしてください。
2.Dockerの動作確認
MacのTerminalより下記のコマンドでバージョンを確認する。
$ docker --version Docker version 18.09.2, build 6247962 $ docker-compose --version docker-compose version 1.24.0, build 0aa59064 $ docker-machine --version docker-machine version 0.16.1, build cce350d7上記のような出力がされれば、dockerが正常作動しているのでOK!
まとめ
これだけで、macでdockerを使用出来ます。
今回は本当に最低限の事のみを記事にしました。
docker,docker-composeの操作などは、別記事にて更新予定です。

- 投稿日:2019-07-08T00:25:36+09:00
debian buster (arm64) に docker install
古いバージョンの docker を削除
# apt-get remove docker docker-engine docker.io containerd runcarm64 は docker本家のリポジトリを設定する
# apt-get update # apt-get install \ apt-transport-https \ ca-certificates \ curl \ gnupg2 \ software-properties-common # curl -fsSL https://download.docker.com/linux/debian/gpg | apt-key add - OK # add-apt-repository \ "deb [arch=arm64] https://download.docker.com/linux/debian \ $(lsb_release -cs) \ stable"docker インストール
# apt-get update # apt-get install docker-ce docker-ce-cli containerd.iodocker-compose インストール
# apt-get install python-setuptools python-pip # pip install docker-compose # pip uninstall backports.ssl-match-hostname # apt-get install python-backports.ssl-match-hostname vi /etc/sysctl.conf net.ipv4.ip_forward=1
- 投稿日:2019-07-08T00:17:29+09:00
コンテナで良い感じにDjangoを動かす構成を考える
概要
Djangoの環境をコンテナで作って動かしていたが、クラウドネイティブを目指してImmutableでマイクロサービスな構成を作ろうとすると一般的なDjangoの作り方ではいまいちに感じる部分が多かった。
いろいろ弄ってみて良い感じにできたので逆引き的な書き方で記事にしておく。
コード一式は以下のリポジトリ参照
https://github.com/sensq/container_django構成
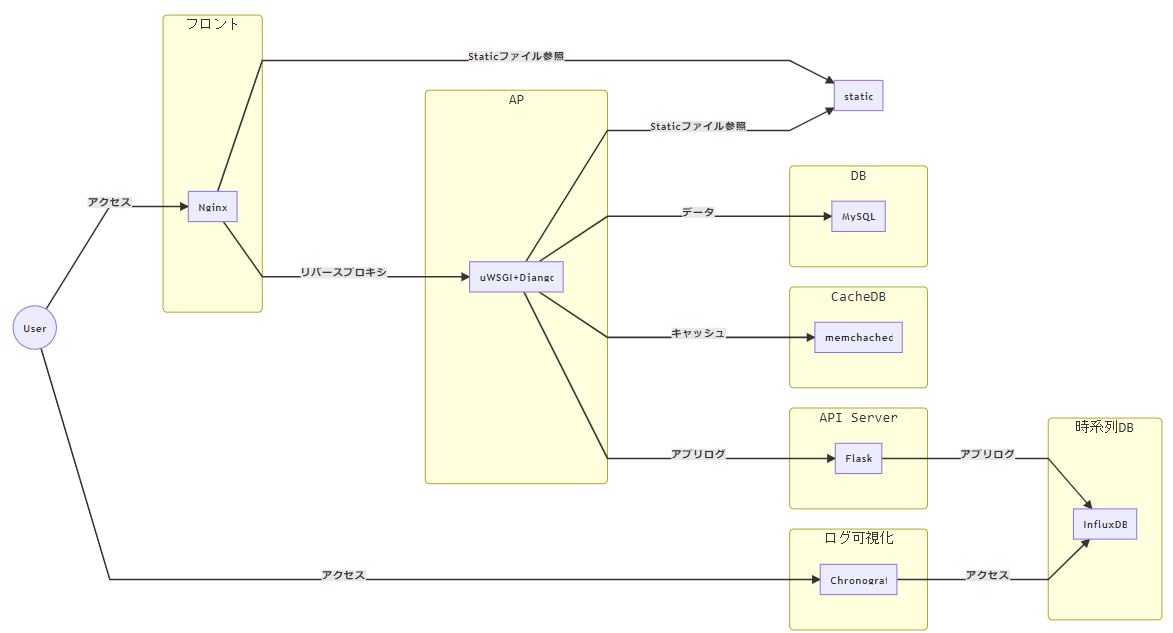
最終的な構成は以下の図を参照
一見難しそうだが、コンテナを使うと割と簡単に構築できる。
データ、キャッシュ、アプリログはすべて別々のDBに保存するようにし、アプリケーションには一切のデータを持たせないようにした。StaticファイルはDjangoが生成するものをNginxで参照させる必要があるため、両方から見える場所に置くようにする。あらかじめ生成物をすべて用意しておけばNginxから見えるだけでもよいが、その場合は管理するファイルが増える。今回は単純にホストの適当なディレクトリにマウントさせているだけ。
API-ServerはDjangoに機能追加していくとごてごてして辛くなった経験から、依存性の低い機能を別出しできる場所として作った。一つのコンテナにAPIを追加していってもいいし、1機能ごとにコンテナを作ってもいいし、とりあえずあると便利だと思う。今回はアプリのログをInfluxDBに保存する部分だけ実装した。
コンテナの監視はやらない。
上の画像のmermaid(Qiitaだと対応していなかった)
graph LR User((User)) User -->|"アクセス"| Nginx User -->|"アクセス"| Chronograf subgraph フロント Nginx end Nginx -->|"Staticファイル参照"| static uWSGI -->|"Staticファイル参照"| static Nginx -->|"リバースプロキシ"| uWSGI uWSGI -->|"データ"| MySQL uWSGI -->|"キャッシュ"| memchached uWSGI -->|"アプリログ"| Flask Chronograf -->|"アクセス"| InfluxDB Flask -->|"アプリログ"| InfluxDB subgraph AP uWSGI["uWSGI+Django"] end subgraph API Server Flask end subgraph CacheDB memchached end subgraph DB MySQL end subgraph 時系列DB InfluxDB end subgraph ログ可視化 Chronograf end static使用するミドルウェアと用途
- Docker(コンテナ管理)
- 下記すべてを一つのサーバで良い感じに動かしてくれる凄いクジラ
- Kubernetesの前座
- Nginx(Webサーバ)
- Webアクセスする入り口
- URLでバックエンドにルーティングさせる
- uWSGI+Django(アプリケーションサーバ)
- アプリケーションが動くところ
- Nginxがルーティングさせてくるところ
DjangoはPythonのWebアプリケーションフレームワークuWSGIはPythonのWebアプリを動かすためのアプリケーションサーバ
Gunicorn,Nginx Unitなどでも代替可- MySQL(RDBMS)
- アプリのデータを保存するところ
- どのRDBMSも使い方はほとんど変わらないので好きなものを使えばいい
- memcached(KVS = Key-Value-Store)
- アプリのキャッシュ(ログイン情報とか)を保存するところ
- アプリのコンテナをステートレスにするために必要
Redisでもたぶん代替可- InfluxDB(TSDB = Time-Series-DataBase)
- アプリのログを保存するところ
- Chronograf
- InfluxDBを可視化するツール
ディレクトリ構成
tree. ├── .env # docker-composeの環境変数を定義するファイル ├── .gitignore ├── README.md ├── docker-compose.yml └── build/ ├── api/ # API Serverコンテナ関連のファイル │ ├── Dockerfile │ ├── apiserver.py │ └── requirements.txt ├── db/ # MySQLコンテナ関連のファイル │ ├── Dockerfile │ └── my.cnf # MySQLの設定ファイル ├── sample_app/ # AP(Django)コンテナ関連のファイル │ ├── Dockerfile │ ├── requirements.txt │ ├── check_admin.py # 管理者ユーザの存在をチェックするスクリプト │ ├── docker-entrypoint.sh # コンテナ起動時に毎回実行されるスクリプト │ └── project/ # Djangoプロジェクトディレクトリ │ ├── manage.py │ ├── prj/ # Djangoプロジェクト全体の設定ファイル │ │ ├── settings.py │ │ ├── urls.py │ │ └── wsgi.py │ └── app/ # Djangoアプリケーションディレクトリ │ ├── __init__.py │ ├── admin.py │ ├── apps.py │ ├── models.py │ ├── tests.py │ ├── urls.py │ ├── views.py │ └── templates/ └── web/ # Nginxコンテナ関連のファイル ├── Dockerfile ├── default.conf.template # Nginxの設定ファイル └── uwsgi_paramsdocker-compose.yml
環境変数で各種設定を行えるようにしておき、設定変更やコード変更した場合はコンテナを作り直す。とはいえ、コード変更の確認で毎回ビルドするのは面倒なので開発中は
volumesでコードのディレクトリを永続化させておく方が楽でよい。
実際に使う場合は、dbとinfluxdbのコンテナにはvolumesで永続化させる設定を記載することdocker-compose.ymlversion: '3' services: web: build: ./build/web depends_on: - sample_app volumes: - ./data/static:/codes/static:ro ports: - "80:80" - "443:443" command: > /bin/sh -c "envsubst ' $$NGINX_LOCATION_SUBDIR $$WSGI_CONTAINER_NAME $$WSGI_PORT ' < /etc/nginx/conf.d/default.conf.template > /etc/nginx/conf.d/default.conf && nginx -g 'daemon off;'" environment: NGINX_LOCATION_SUBDIR: ${NGINX_LOCATION_SUBDIR} # Webアクセスするサブディレクトリ名 WSGI_CONTAINER_NAME: ${WSGI_CONTAINER_NAME} # WSGIを動かすコンテナの名前 WSGI_PORT: ${WSGI_PORT} # WSGIを動かすポート sample_app: build: context: ./build/sample_app args: DJANGO_PROJECT_NAME: ${DJANGO_PROJECT_NAME} depends_on: - db volumes: - ./data/static:/static # - ./hoge-dir-path:/${DJANGO_PROJECT_NAME} environment: WSGI_PORT: ${WSGI_PORT} # WSGIを動かすポート WSGI_PROCESSES: ${WSGI_PROCESSES} # WSGIを動かすプロセス数 WSGI_THREADS: ${WSGI_THREADS} # WSGIを動かすスレッド数 NGINX_LOCATION_SUBDIR: ${NGINX_LOCATION_SUBDIR} # Webアクセスするサブディレクトリ名 DJANGO_DEBUG: ${DJANGO_DEBUG} # DjangoのDEBUGモードの有効化 DJANGO_ALLOWED_HOSTS: ${DJANGO_ALLOWED_HOSTS} # Djangoに接続を許可するホスト名またはIP DJANGO_PROJECT_NAME: ${DJANGO_PROJECT_NAME} # Djangoプロジェクトの名前(フォルダ名と合わせる) DJANGO_APPLICATION_NAME: ${DJANGO_APPLICATION_NAME} # Djangoアプリケーションの名前(フォルダ名と合わせる) DJANGO_ADMIN_EMAIL: ${DJANGO_ADMIN_EMAIL} # Django管理者ユーザのEMAIL DJANGO_ADMIN_PASSWORD: ${DJANGO_ADMIN_PASSWORD} # Django管理者ユーザのパスワード DATABASE_CONTAINER_NAME: ${DATABASE_CONTAINER_NAME} # Djangoで使用するDBコンテナの名前 DATABASE_PORT: ${DATABASE_PORT} # Djangoで使用するDBコンテナの公開ポート MYSQL_DATABASE: ${MYSQL_DATABASE} # Djangoで使用するDBの名前 MYSQL_USER: ${MYSQL_USER} # Djangoで使用するDBのログインユーザ MYSQL_PASSWORD: ${MYSQL_PASSWORD} # Djangoで使用するDBのログインパスワード APISERVER_HOST: ${APISERVER_HOST} # API Serverが稼働しているホストやコンテナの名前 db: build: ./build/db # volumes: # - ./hoge-dir-path:/var/lib/mysql environment: MYSQL_ROOT_PASSWORD: ${MYSQL_ROOT_PASSWORD} MYSQL_ROOT_HOST: ${MYSQL_ROOT_HOST} MYSQL_DATABASE: ${MYSQL_DATABASE} # Djangoで使用するDBの名前 MYSQL_USER: ${MYSQL_USER} # Djangoで使用するDBのログインユーザ MYSQL_PASSWORD: ${MYSQL_PASSWORD} # Djangoで使用するDBのログインパスワード cache: image: memcached:alpine apiserver: build: ./build/api environment: INFLUXDB_HOST: ${INFLUXDB_HOST} # InfluxDBが稼働しているホストやコンテナの名前 INFLUXDB_PORT: ${INFLUXDB_PORT} # InfluxDBが稼働しているポート番号 INFLUXDB_DB: ${INFLUXDB_DB} # InfluxDBに初期作成するDB名 APISERVER_PORT: ${APISERVER_PORT} # API Serverを稼働させるポート番号 APISERVER_DEBUG: ${APISERVER_DEBUG} # API ServerのDEBUGモードの有効化 influxdb: image: influxdb:alpine # volumes: # - ./hoge-dir-path:/var/lib/influxdb environment: INFLUXDB_DB: ${INFLUXDB_DB} # InfluxDBに初期作成するDB名 INFLUXDB_ADMIN_USER: ${INFLUXDB_ADMIN_USER} # InfluxDBの管理者ユーザ名 INFLUXDB_ADMIN_PASSWORD: ${INFLUXDB_ADMIN_PASSWORD} # InfluxDBの管理者ユーザのパスワード chronograf: image: chronograf:alpine ports: - "${CHRONOGRAF_PORT}:8888" environment: INFLUXDB_URL: ${INFLUXDB_URL} # InfluxDBのURL INFLUXDB_USERNAME: ${INFLUXDB_USERNAME} # InfluxDBに接続するユーザ名 INFLUXDB_PASSWORD: ${INFLUXDB_PASSWORD} # InfluxDBに接続するユーザのパスワード.envの記載例
.envNGINX_LOCATION_SUBDIR=sample WSGI_CONTAINER_NAME=sample_app WSGI_PORT=5000 WSGI_PROCESSES=5 WSGI_THREADS=3 DJANGO_DEBUG=True DJANGO_ALLOWED_HOSTS=192.168.1.100 DJANGO_PROJECT_NAME=prj DJANGO_APPLICATION_NAME=sample DJANGO_ADMIN_EMAIL=admin@localhost.com DJANGO_ADMIN_PASSWORD=admin DATABASE_CONTAINER_NAME=db DATABASE_PORT=3306 MYSQL_ROOT_PASSWORD=P@ssw0rd MYSQL_ROOT_HOST=% MYSQL_DATABASE=django MYSQL_USER=django MYSQL_PASSWORD=dj@ng0 KEYCLOAK_USER=admin KEYCLOAK_PASSWORD=admin APISERVER_HOST=apiserver APISERVER_PORT=4000 APISERVER_DEBUG=True INFLUXDB_HOST=influxdb INFLUXDB_PORT=8086 INFLUXDB_URL=http://influxdb:8086 INFLUXDB_DB=sample INFLUXDB_ADMIN_USER=admin INFLUXDB_ADMIN_PASSWORD=admin INFLUXDB_USERNAME=admin INFLUXDB_PASSWORD=admin CHRONOGRAF_PORT=8888ざっくりとした各コンテナの構築説明
- Nginxコンテナ
- 基本的にはコンフィグファイル(HTTPS化する場合は証明書と鍵も)を送るだけ
- DjangoでWSGIを使うために
uwsgi_paramsというファイルも送る- ただし、コンフィグファイルで環境変数を使うために下記の細工がいる
- Djangoコンテナ
- コンテナで良い感じに使うためにいろいろと細工がいる(下記参照)
- API-Serverコンテナ
- Post用のメソッドを1つ作成して
FlaskでWebサーバとして起動しておくだけ- 具体的には下記参照
- MySQLコンテナ
- 環境変数のみで設定が完結するため、ビルド不要だった
- どこかのバージョンから以下の設定を行わないとDjangoから使えなくなったため、my.cnfを送るだけのDockerfileが必要
default_authentication_plugin=mysql_native_password- memcachedコンテナ
- 環境変数のみで設定が完結するため、ビルド不要
- InfluxDBコンテナ
- 環境変数のみで設定が完結するため、ビルド不要
- Chronografコンテナ
- 環境変数のみで設定が完結するため、ビルド不要
API-Server補足
InfluxDBのClientを使うために
pipでinfluxdbのインストールが必要。flask-corsも入れておいた方がいい。
あとは以下のようなコードでAPIを作成できる。apiserver.pyfrom flask import Flask, jsonify, abort, make_response, render_template, request from flask_cors import CORS import os api = Flask(__name__) CORS(api) # CORS有効化 @api.route('/add_influxdb', methods=['POST']) def post(): influxdb_host = os.environ.get("INFLUXDB_HOST") influxdb_port = os.environ.get("INFLUXDB_PORT") influxdb_database = os.environ.get("INFLUXDB_DB") from influxdb import InfluxDBClient client = InfluxDBClient(host=influxdb_host, port=influxdb_port, database=influxdb_database) # Postで渡されたパラメータを受け取る # 以下はタグ1つ、フィールド2つのパラメータを受け取るの場合の例 measurement = request.form["measurement"] type = request.form["type"] value1 = request.form["value1"] value2 = request.form["value2"] # InfluxDBに書き込むデータを作成する # RDBMSのように事前にテーブル定義をしておかなくても、柔軟にデータを書き込める data = [{ "measurement": measurement, "tags": {"type": type}, "fields": { "value1": value1, "value2": value2 } }] # InfluxDBに書き込む client.write_points(data) return make_response(data[0]) # Webサーバを起動する if __name__ == '__main__': port = os.environ.get("APISERVER_PORT") from distutils.util import strtobool debug = strtobool(os.environ.get("APISERVER_DEBUG")) api.run(host='0.0.0.0', port=port, debug=debug)curlでAPI実行する場合のコマンド例
bashcurl -POST http://apiserver:4000/add_influxdb -d "measurement=ipmgr&type=Hoge&value1=val1&value2=val2"PythonでAPI実行する場合のコード例
pythonimport os import urllib.request import urllib.parse host = os.environ.get("APISERVER_HOST") port = os.environ.get("APISERVER_PORT") api_url = "http://" + host + ":" + port + "/add_influxdb" data = { "measurement": measurement, "type": type, "value1": value1, "value2": value2 } encoded_data = urllib.parse.urlencode(data).encode('utf-8') req = urllib.request.Request(api_url, encoded_data) res = urllib.request.urlopen(req)逆引きDjango問題
プロジェクト名とアプリ名を環境変数化したい
変更の必要なファイルは以下に配置されている4つのpythonファイル。
tree"<デフォルトがプロジェクト名だけど実はなんでもいい>/" ├── manage.py ├── "<プロジェクト名>/" │ ├── settings.py │ ├── urls.py # 上部のコメント部分だけなので適当な文字列に書き換える │ └── wsgi.py └── "<アプリケーション名>/" └── # ここに配置されるファイルには該当する部分無しどれもpythonスクリプトのため、
os.environ.get("KEY_NAME")で環境変数から値を取得できる。また、取得した値を使って文字列結合することでプロジェクト名やアプリ名の含まれるパスなどを作成できる。
manage.pyとwsgi.py
理由わからないがDJANGO_SETTINGS_MODULEという環境変数に値をsetしているので、該当部分を以下のように書き換える。# DJANGO_PROJECT_NAMEはdocker-compose.ymlで定義した環境変数 prj_name = os.environ.get("DJANGO_PROJECT_NAME") os.environ.setdefault('DJANGO_SETTINGS_MODULE', (prj_name + '.settings'))
settings.py
主に以下の部分を書き換える。他に必要な部分があれば同様に書き換え可能。settings.py# DJANGO_PROJECT_NAMEとDJANGO_APPLICATION_NAMEはdocker-compose.ymlで定義した環境変数 PRJ_NAME = os.environ.get("DJANGO_PROJECT_NAME") APP_NAME = os.environ.get("DJANGO_APPLICATION_NAME") INSTALLED_APPS = [ # 省略 APP_NAME, ] ROOT_URLCONF = (PRJ_NAME + '.urls') WSGI_APPLICATION = (PRJ_NAME + '.wsgi.application')
urls.py
アプリケーション内のurls.pyを参照させるように書き換える。urls.pyurlpatterns = [ path('admin/', admin.site.urls), path('', include(os.environ.get("DJANGO_APPLICATION_NAME") + '.urls')) ]settings.pyをいろいろ環境変数化したい
os.environ.get("KEY_NAME")で環境変数から値を取得できるため、環境変数化したい部分をdocker-compose.ymlで定義することで好きなように環境変数化可能
他のファイルで環境変数の値を使いたい場合も同様import文でアプリケーション名を書く必要がある
importlibを使うと動的にimportできる。以下のように書くことで環境変数の値からimportするモジュールを決定させられる。import os app_name = os.environ.get("DJANGO_APPLICATION_NAME") module_path = app_name + ".models" from importlib import import_module module = import_module(module_path) Hoge = getattr(module, "Hoge") # これで以下を記載した場合と同様にimportされる # from app_name.models import HogeDBにMySQLを使いたい
settings.pyに以下のように記載する。
一般的には各パラメータには固定値を記載するが、環境変数を参照させるようにすることでコンテナを汎用的に扱いやすくする。
※事前にpip installでpymysqlを入れておくことsettings.pyimport pymysql pymysql.install_as_MySQLdb() DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': os.environ.get("MYSQL_DATABASE"), 'USER': os.environ.get("MYSQL_USER"), 'PASSWORD': os.environ.get("MYSQL_PASSWORD"), 'HOST': os.environ.get("DATABASE_CONTAINER_NAME"), 'PORT': os.environ.get("DATABASE_PORT", "3306"), 'OPTIONS': { 'charset': 'utf8mb4', }, } }キャッシュにmemcachedを使いたい
settings.pyに以下のように記載する。
LOCATIONのサーバ名とポート番号は固定でよいと思っているが、環境変数化したかったらMySQLと同様にos.environ.getを使って環境変数を参照させるようにすればよい。
※事前にpip installでpython-memcachedを入れておくことsettings.pySESSION_ENGINE = 'django.contrib.sessions.backends.cache' CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache', 'LOCATION': 'cache:11211', } }DBの初期セットアップが終わる前にDjangoが起動してしまう
DBに接続できない状態でDjangoが起動してしまうとMigrationが上手くいかず正常に起動しない。
docker-composeでdepend_onを使えば起動順を設定できるが、あくまでコンテナの起動順のため、初期セットアップが終わるまでは待ってくれない。
そのため、docker-entrypoint.shの最初でDBコンテナにアクセスできるようになるまで待つwhileループを入れておく。docker-entrypoint.shDATABASE_HOSTNAME=${DATABASE_CONTAINER_NAME} DATABASE_PORT=${DATABASE_PORT:-'3306'} echo "Waiting for database" while ! nc -zv $DATABASE_HOSTNAME $DATABASE_PORT do sleep 0.1 doneDB作成するたびに管理者ユーザを作らないといけない
docker-entrypoint.shでadminユーザの存在をチェックし、存在していなかったら作成する。
一般的にはpython manage.py createsuperuserで作成するが、対話形式になってしまうのでDjango shellから作成する。
docker-entrypoint.sh
該当部分のみ抜粋docker-entrypoint.shPRJ_NAME=${DJANGO_PROJECT_NAME} # Create Admin User EXIST_ADMIN=`python manage.py shell < /check_admin.py` if [ ${EXIST_ADMIN} = 'True' ]; then : else echo "Does not exist admin user." /${PRJ_NAME}/manage.py shell -c "from django.contrib.auth.models import User; User.objects.create_superuser('admin', os.environ.get('DJANGO_ADMIN_EMAIL','admin@localhost.com'), os.environ.get('DJANGO_ADMIN_PASSWORD','admin'))" echo "Created admin user!! ('admin', ${DJANGO_ADMIN_EMAIL:-'admin@localhost.com'}, ${DJANGO_ADMIN_PASSWORD:-'admin'})" fi
check_admin.py
存在チェックのスクリプトも埋め込めるが、流石に長いので別ファイルにしておく。check_admin.pyfrom django.contrib.auth.models import User try: User.objects.get(username="admin") print('True') except User.DoesNotExist: print('False')