- 投稿日:2019-07-08T23:43:51+09:00
基本的なシステム構成図を理解するためのAWS基礎を初心者がまとめてみた
はじめに
4月からの業務でAWSのシステム構成図を見ることが多くなり、AWS上で動いているシステムのシステム構成図を理解できるようになるために個人的に知っておきたいと思ったAWSの用語・サービスをまとめてみました。
2018年10月に新しくなったAWSアーキテクチャアイコンを使用しています。サーバ・クライアントなどの説明については以下がとてもわかりやすいです!
超絶初心者のためのサーバとクライアントの話知っておきたい用語
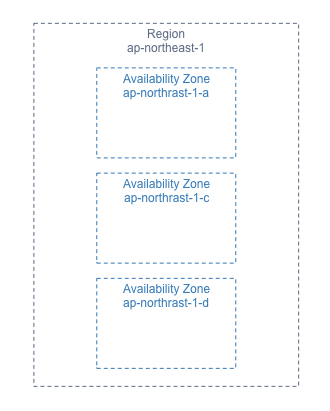
リージョン
- AWSがサービスを提供している拠点(国と地域)
- リージョン同士はそれぞれ地理的に離れている
- 日本だとap-northeast-1(リージョン名はアジアパシフィック(東京))
アベイラビリティゾーン
- リージョン内のさらに細かい拠点
- 1つのアベイラビリティゾーンは複数のデータセンターから構成されている
- ap-northeast-1には3つのアベイラビリティゾーンがある(a,c,d なぜかbが無い)
- ごく稀にアベイラビリティゾーン全体で障害が発生することがあり、その時にリソースが1つのAZに固まっているとサービスが停止してしまうため、アベイラビリティゾーンをまたがってインスタンスを配置する設計にする必要がある
リージョンとアベイラビリティゾーンの関係性
主なサービス
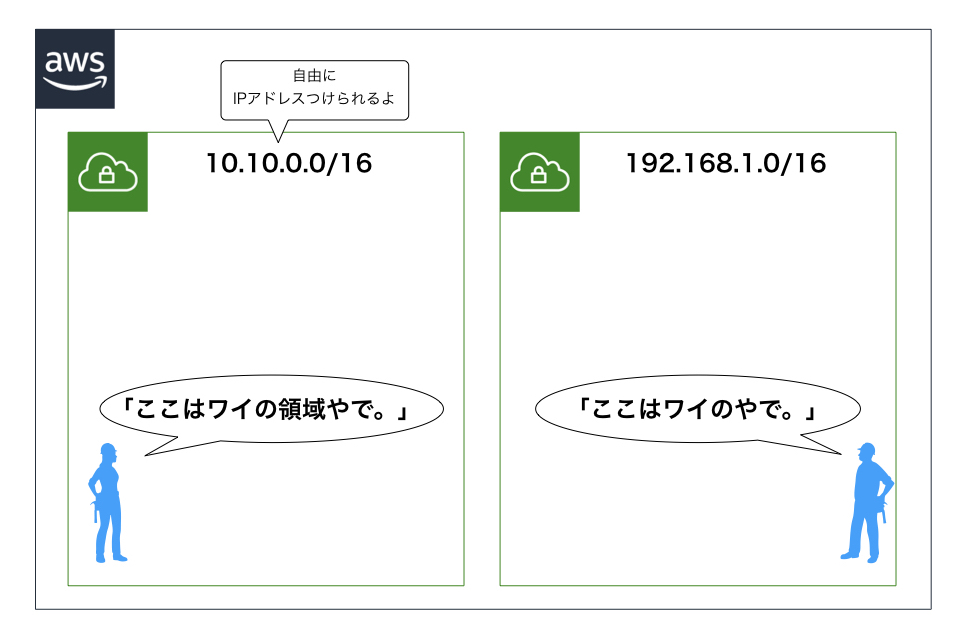
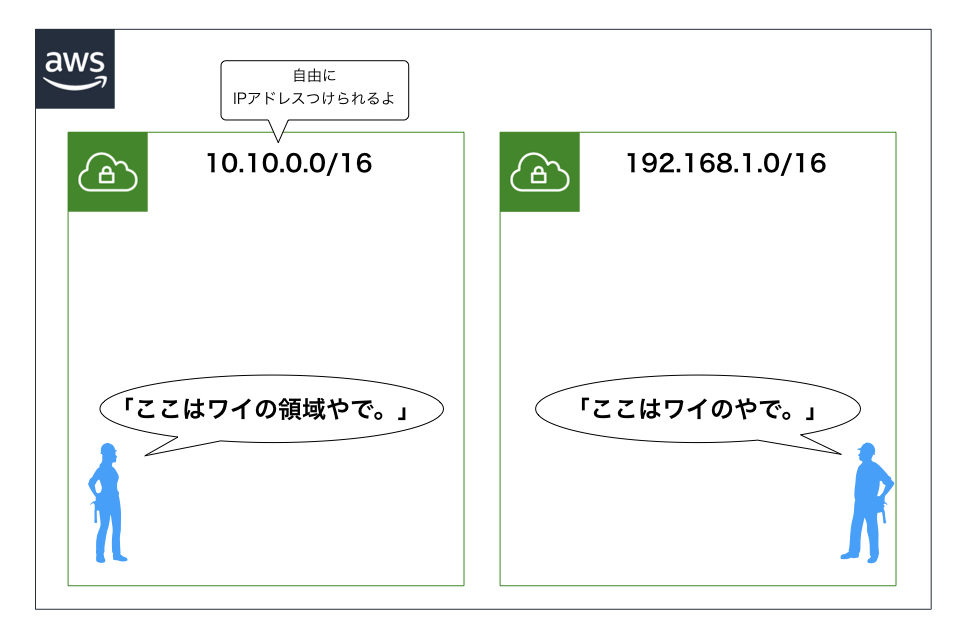
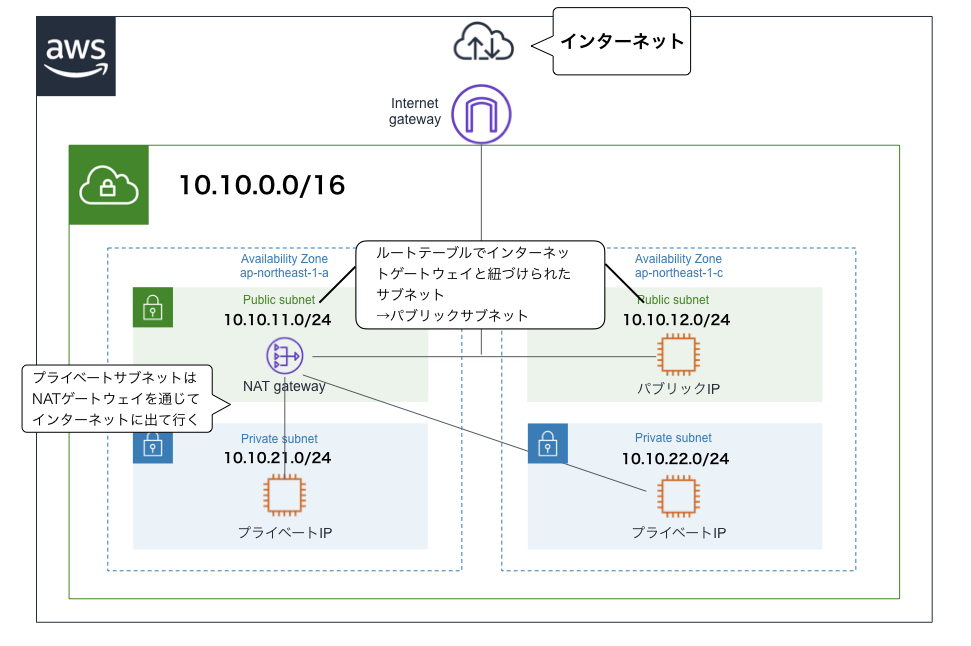
VPC
- Virtual Private Cloudの略
- VPCを使うことで、AWS内にプライベートなネットワークを作成できる
- 自由にIPアドレス(CIDRブロック)を割り当てることができる
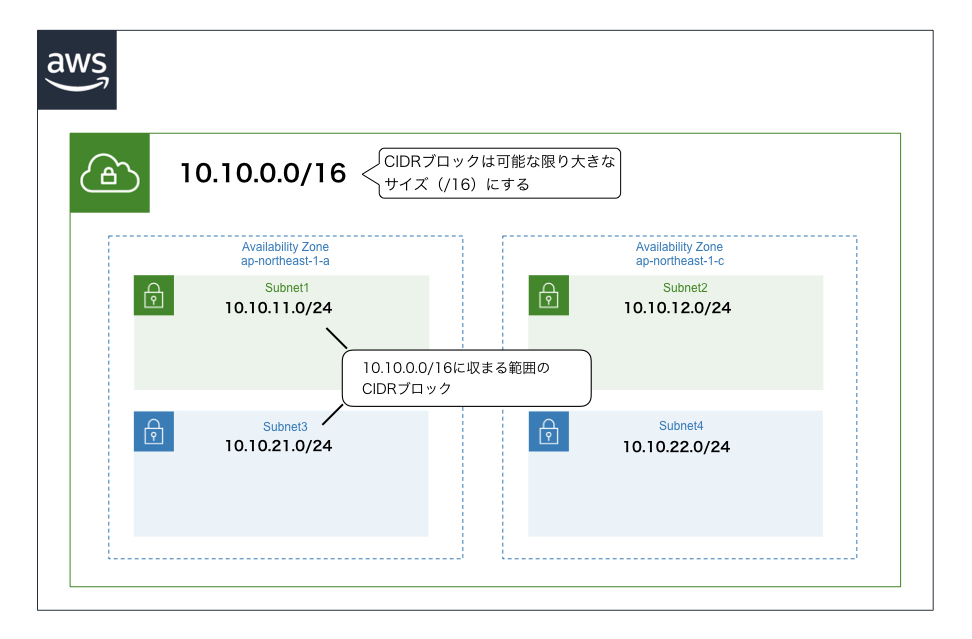
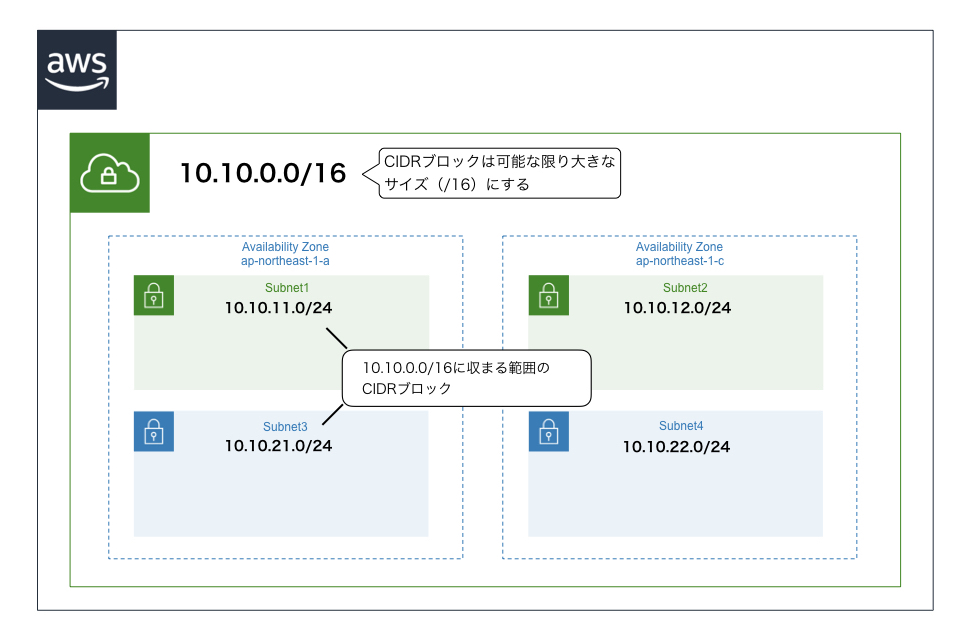
サブネット
- VPCのさらに内側につくる、EC2インスタンス(※後述)などを起動するための領域
- VPCに設定したCIDRブロックに収まるCIDRブロックを割り当てる
- サブネット作成時にアベイラビリティゾーンを指定する
- パブリックサブネットとプライベートサブネットがあり、それらの違いはインターネットゲートウェイ(※後述)から直接アクセスできるかできないかである(アクセスできるのがパブリックで、アクセスできないのがプライベート)
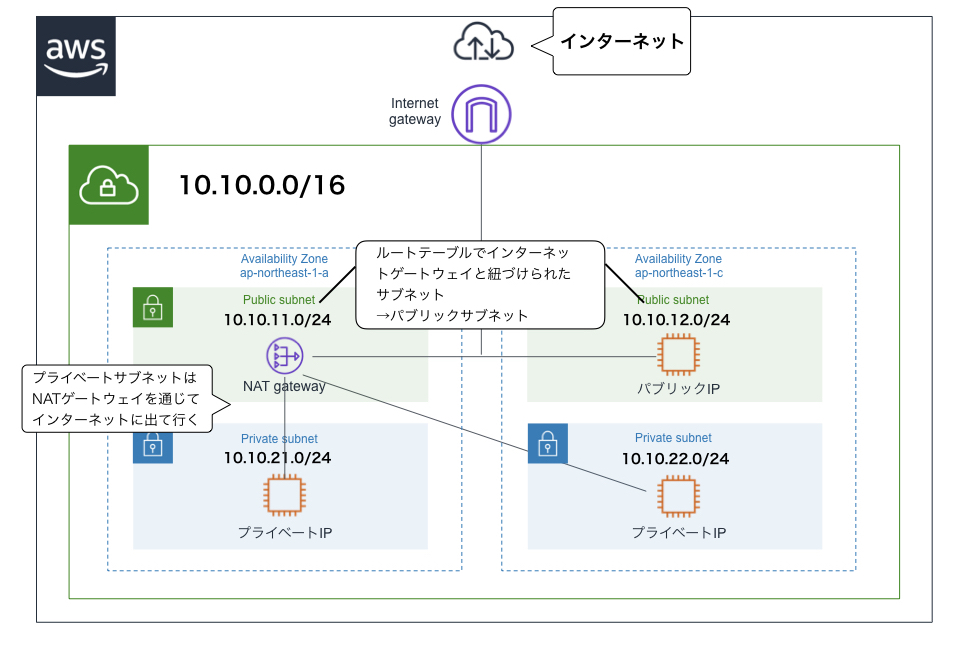
ルートテーブル
- サブネット内のインスタンスの通信先のルールを定めたもの(表)
- 個々のサブネットに1つずつ設定する
- 各サブネットをルートテーブルに関連付ける必要がある(指定しない場合はデフォルトのルートテーブルになる)
- ルートテーブルで、サブネットの通信先にインターネットゲートウェイを指定することで、サブネットがインターネットに接続できる
ゲートウェイ
- VPCの内部と外部との通信をやり取りする出入り口
インターネットゲートウェイ
- VPCとインターネットを接続するためのゲートウェイ
- 各VPCに1つだけ取り付けられる
NATゲートウェイ
- プライベートIPしか持っていないEC2インスタンスがインターネットと通信できるようにするためのもの
- プライベートIPをNATゲートウェイが持つグローバルIPに変換し、外部と通信する
ゲートウェイエンドポイント
- S3やDynamoDBといったVPCの中に入れられないサービスに、VPC内から接続する際に利用する
EC2
- Amazon Elastic Compute Cloudの略でAWSの基幹サービス
- 仮装サーバを提供する
- 仮装サーバの1つ1つの実体は「インスタンス」と呼ばれる
- ボタンワンクリックでインスタンスをつくることができるので便利
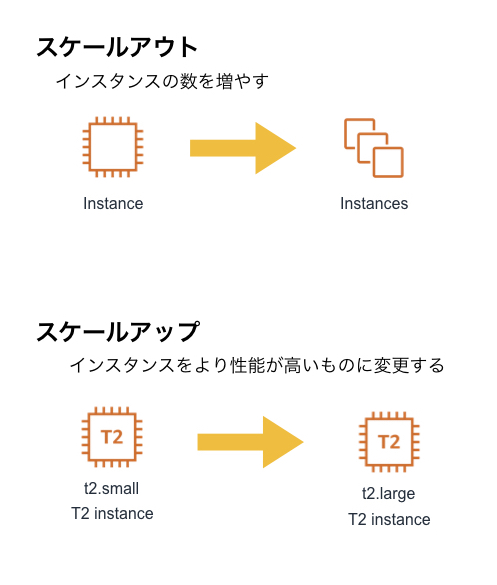
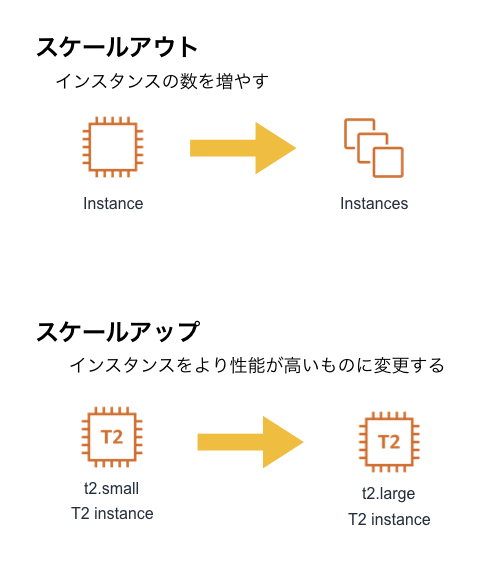
- クライアントからのリクエスト数が増えたらインスタンスの数を増やしたり(スケールアウト)、インスタンスの性能を上げたり(スケールアップ)も簡単にできるため、サーバ調達のための時間やコストを削減できる

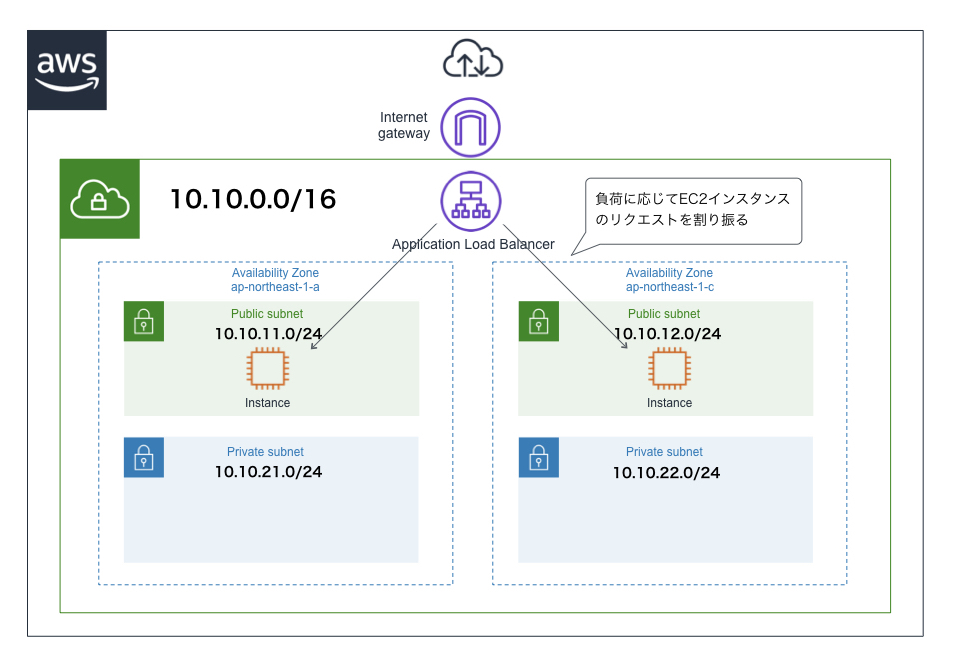
ELB
- Elastic Load Balancingの略
- その名の通りロードバランサーのマネージドサービス(管理とかを一括して請け負ってくれるサービス)
- EC2インスタンスがスケールアウトされて複数ある場合、ELBがクライアントからリクエストを受け取り、それを各インスタンスに分散させる
- ELB自体もスケーリングができ、負荷に応じてスケールする設計になっている
ELBの種類
- Classic Load Balancer(CLB)
- L4/L7レイヤーで負荷分散を行う。現在はあまり使わない。
- Application Load Balancer(ALB)
- L7レイヤーでの負荷分散を行う。CLBより後に登場。
- Network Load Balancer(NLB)
- L4レイヤーでの負荷分散を行う。HTTP以外のプロトコル通信の負荷分散をしたい時に利用する。

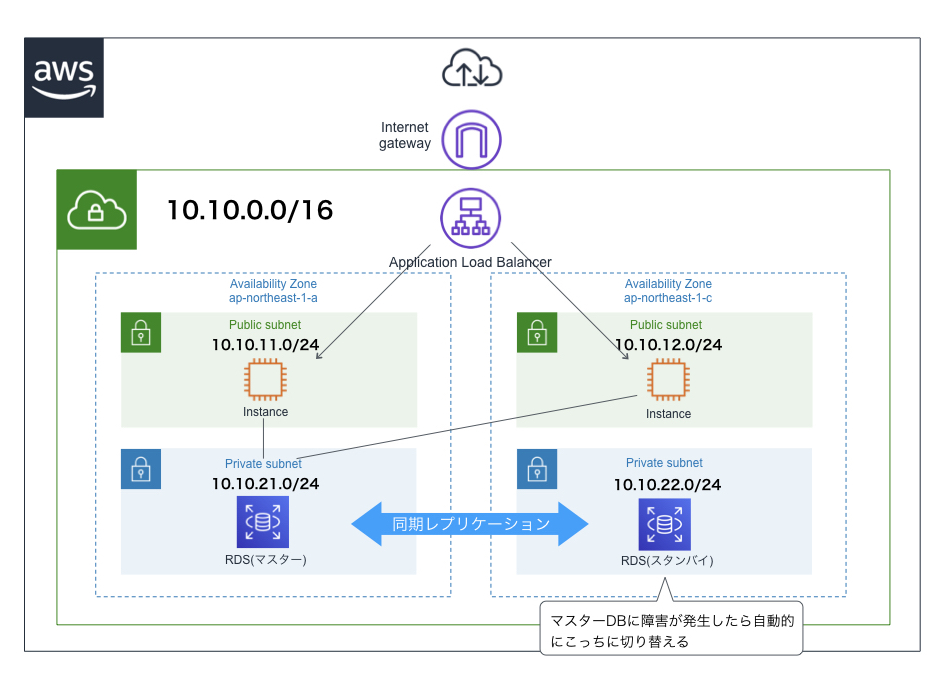
RDS
- RDB(リレーショナルデータベース、関係データベース)と呼ばれる、SQL文でデータを操作するデータベースのマネージドサービス
- Amazon Aurora、MySQL、MariaDB、PostgresSQL、Oracleなどのデータベースエンジンから好きなものを選べる
- データ保存用ストレージはEBS(Elastic Block Store)を使用している
- インターネットからの接続はデフォルトでオフになっているため、EC2などの他のAWSサービスから通信することが多い
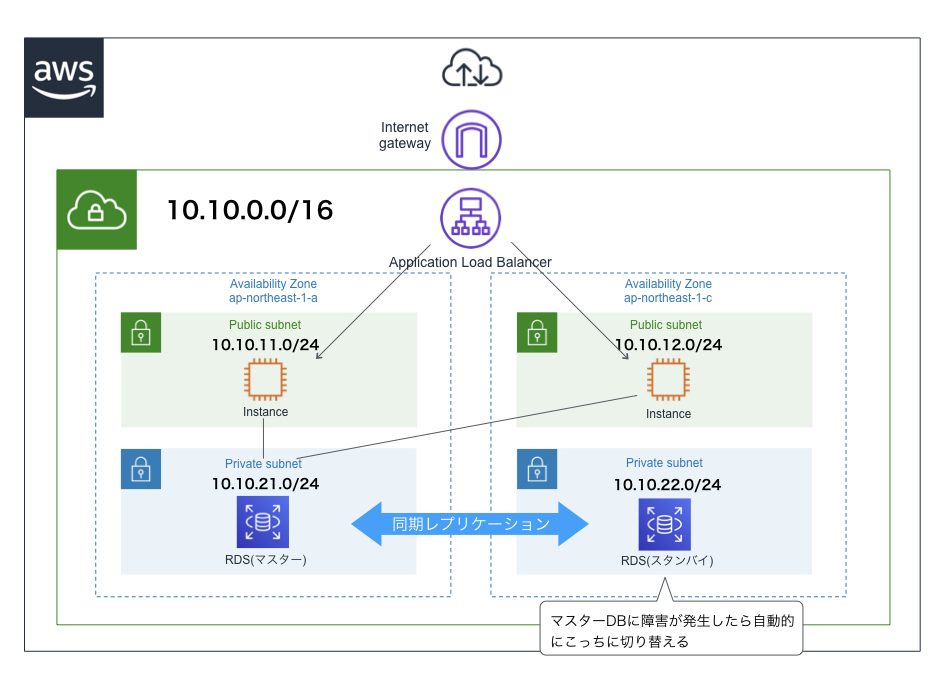
マルチAZ構成
- 1つのリージョン内の2つのアベイラビリティゾーンにDBインスタンス(データベースの実体)をそれぞれ配置する構成
- 1つのアベイラビリティゾーンで障害が発生しても、もう一つのアベイラビリティゾーンが生きていればシステムのダウンタイムを短くすることができる
- DBインスタンス作成時にマルチAZ構成を選択したら、あとはAWSが勝手に冗長化してくれて便利
S3
- Simple Storage Serviceの略
- 容量無制限のストレージ(補助記憶)サービス
- 保存するファイルにメタデータを追加し、「オブジェクト」として管理する
- S3に保存されている各オブジェクトには、RESTやSOAPといったWeb APIでアクセスする
- データのバックアップや、静的コンテンツ(HTMLファイルなど)のホスティングとしても利用される
- VPCの中には入れられないため、ゲートウェイエンドポイントを通じてVPC内のEC2インスタンスと通信する
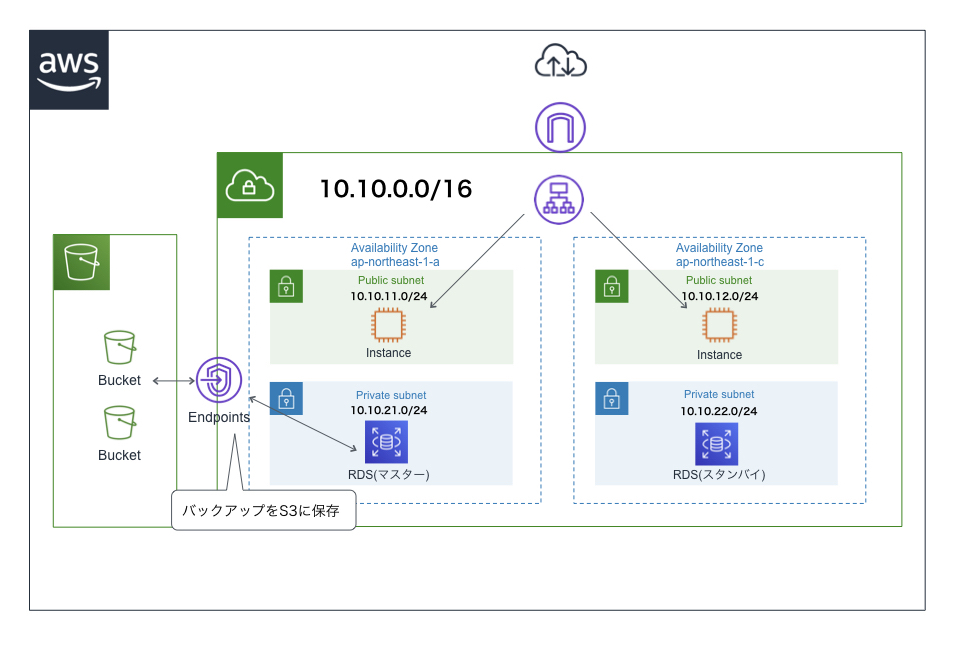
バケット
- オブジェクトを保存するための領域
- バケット名はAWS内(全世界)で一意にしなければならない
オブジェクト
- S3に格納されるデータそのもの
- 各オブジェクトには必ず一意になるURLが作成される
Route53
- ドメイン管理機能と権威DNS機能を持つ
- 権威DNSとは、ドメイン名とIPアドレスの変更情報を保持しているDNS
- DNSのポート番号が53であることからこの名前が付いている
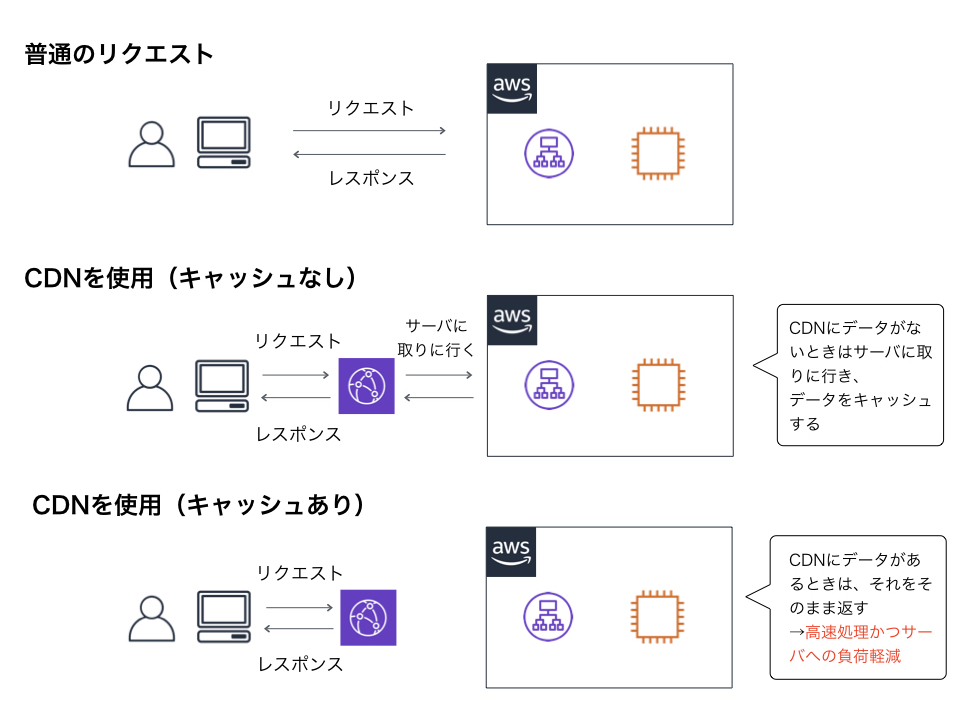
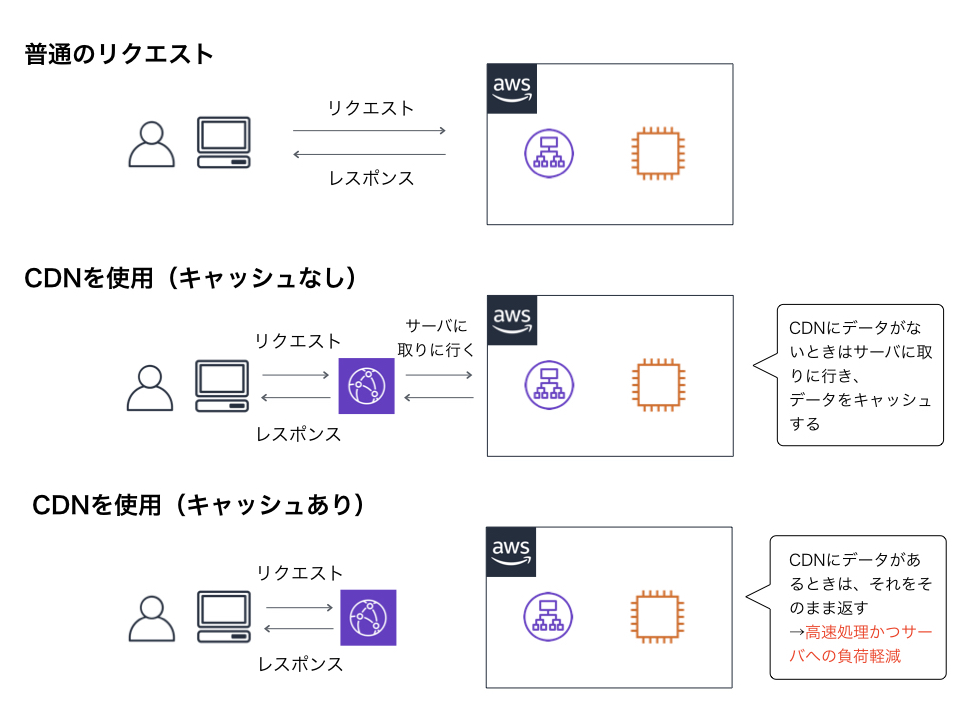
CloudFront
- 静的コンテンツをキャッシュして配信するサービス
- ロードバランサーの前段に配置し、元のサーバにあるデータをキャッシュしておくことで、次回に同じリクエストが来たらキャッシュしたものを返す
- サーバの負荷を軽減できる
- 利用者から最も近いロケーションからコンテンツを高速に配信することができる
- キャッシュの期間は拡張子やURLごとに設定することができる
- 頻繁にアップデートされるコンテンツはキャッシュを短くし、あまり更新されないコンテンツは長くするなど
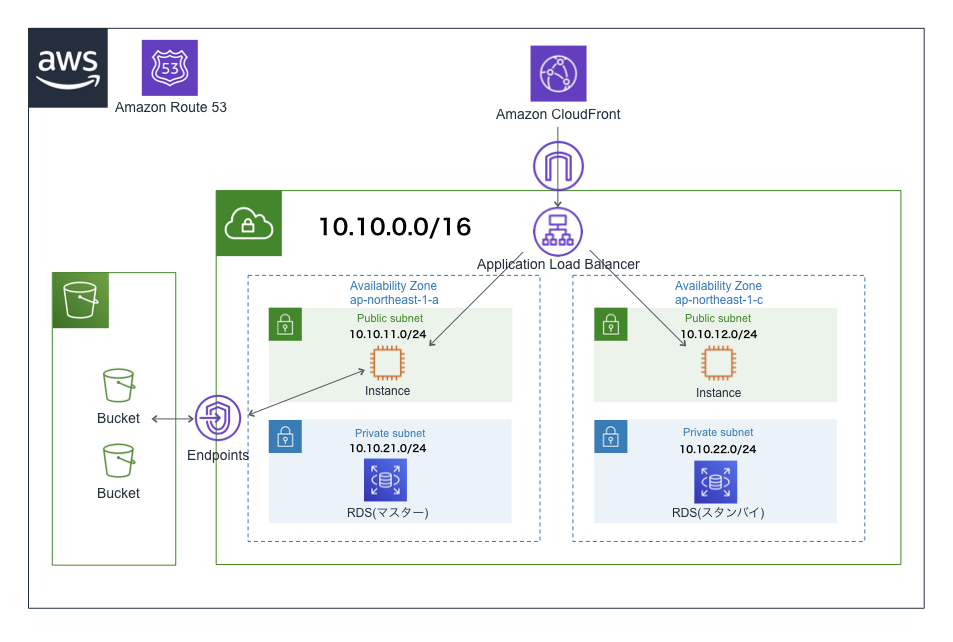
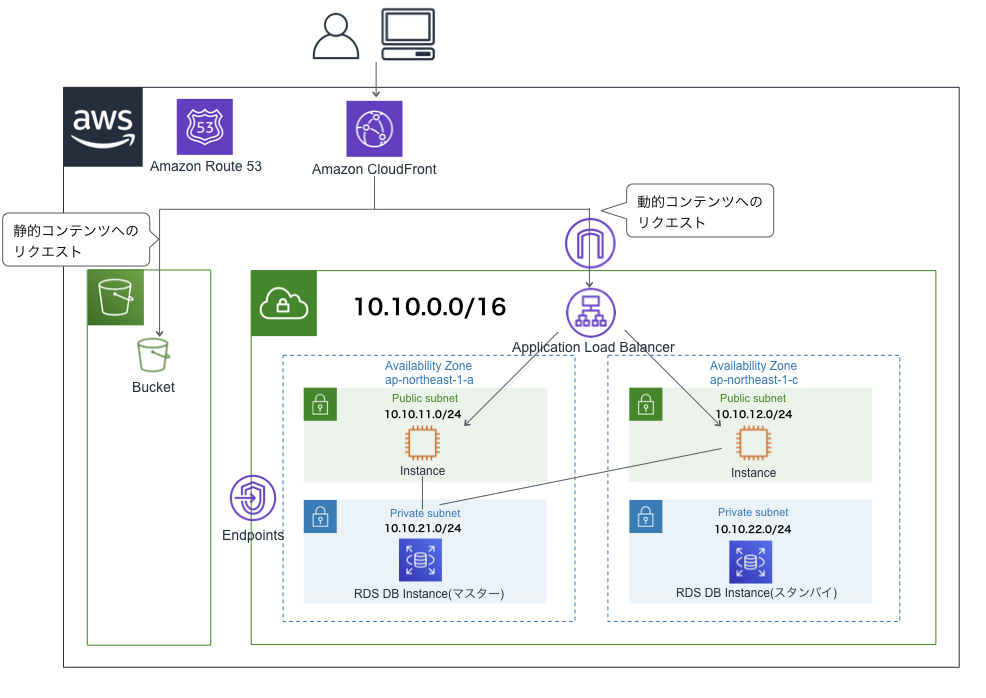
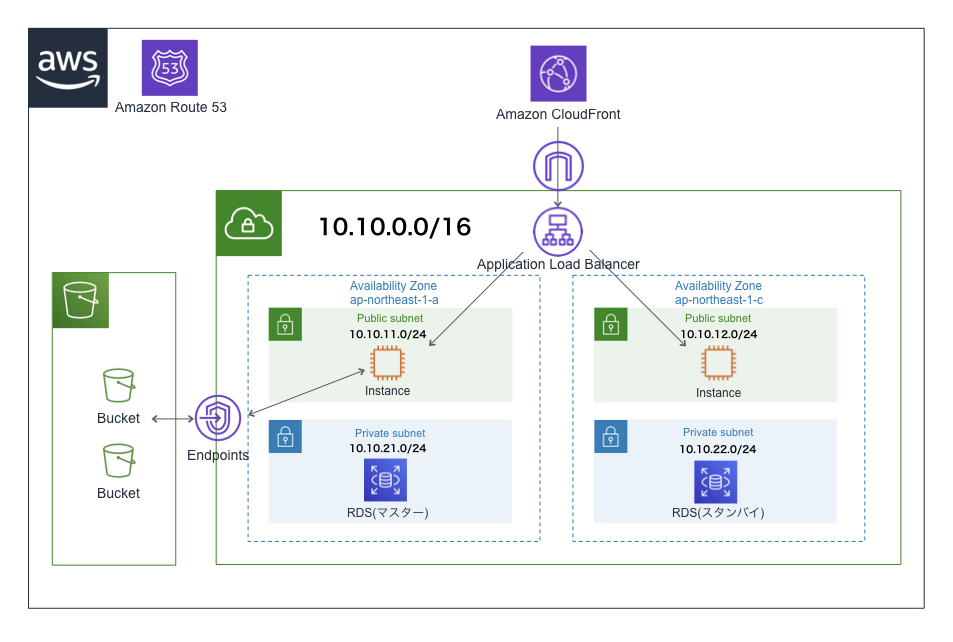
オーソドックスなアーキテクチャ
- 簡易的なブログのシステム構成図を想定
- S3にはエラーページなどの静的コンテンツを配置
参考資料



- 投稿日:2019-07-08T23:43:51+09:00
基本的なシステム構成図を理解するためのAWS基礎をまとめてみた
はじめに
最近、AWSのシステム構成図を見ることが多くなり、AWS上で動いているシステムのシステム構成図を理解できるようになるために個人的に知っておきたいと思ったAWSの用語・サービスをまとめてみました。
私自身も勉強がてら作成したので、わかりづらい部分も多くあると思いますが、AWSのサービス全くわからん→なんとなく雰囲気把握した、となっていただけたらと思います。
2018年10月に新しくなったAWSアーキテクチャアイコンを使用しています。サーバ・クライアントなどの説明についてはここではしていませんが、以下の記事でとてもわかりやすくまとめてくださっています!
超絶初心者のためのサーバとクライアントの話知っておきたい用語
リージョン
- AWSがサービスを提供している拠点(国と地域)
- リージョン同士はそれぞれ地理的に離れている(例えば日本とオレゴンとか)
- 日本はap-northeast-1(リージョン名はアジアパシフィック(東京))
アベイラビリティゾーン
- リージョン内のさらに細かい拠点
- 1つのアベイラビリティゾーンは複数のデータセンターから構成されている
- ap-northeast-1には3つのアベイラビリティゾーンがある(a,c,d なぜかbが無い)
- ごく稀にアベイラビリティゾーン全体で障害が発生することがあり、その時にリソースが1つのアベイラビリティゾーンに固まっているとサービスが停止してしまうため、アベイラビリティゾーンをまたがってインスタンスを配置する設計にする必要がある
リージョンとアベイラビリティゾーンの関係性
主なサービス
VPC
- Virtual Private Cloudの略
- AWSの中のプライベートゾーンのようなもの
- VPCを使うことで、AWS内にプライベートなネットワークを作成できる
- 自由にIPアドレス(CIDRブロック)を割り当てることができる
サブネット
- VPCのさらに内側につくる、EC2インスタンス(※後述)などを起動するための領域
- VPCに設定したCIDRブロックに収まるCIDRブロックを割り当てる
- サブネット作成時にアベイラビリティゾーンを指定する
- パブリックサブネットとプライベートサブネットがあり、それらの違いはインターネットゲートウェイ(※後述)から直接アクセスできるかできないかである(アクセスできるのがパブリックで、アクセスできないのがプライベート)
ルートテーブル
- サブネット内のインスタンスの通信先のルール(サブネットがどこと通信するか)を定めた表のようなもの
- 個々のサブネットに1つずつ設定する
- 各サブネットをルートテーブルに関連付ける必要がある(指定しない場合はデフォルトのルートテーブルになる)
- ルートテーブルで、サブネットの通信先にインターネットゲートウェイを指定することで、サブネットがインターネットに接続できる

ゲートウェイ
- VPCの内部と外部との通信をやり取りする出入り口
インターネットゲートウェイ
- VPCとインターネットを接続するためのゲートウェイ
- 各VPCに1つだけ取り付けられる
NATゲートウェイ
- プライベートIPしか持っていないEC2インスタンスがインターネットと通信できるようにするためのもの
- プライベートIPをNATゲートウェイが持つグローバルIPに変換し、外部と通信する
ゲートウェイエンドポイント
- S3やDynamoDBといったVPCの中に入れられないサービスに、VPC内から接続する際に利用する
EC2
- Amazon Elastic Compute Cloudの略でAWSの基幹サービス
- 仮想サーバを提供する
- 仮想サーバの1つ1つの実体は「インスタンス」と呼ばれる
- EC2インスタンス≒サーバ という感覚
- ボタンワンクリックでインスタンスをつくることができるので便利
- クライアントからのリクエスト数が増えたらインスタンスの数を増やしたり(スケールアウト)、インスタンスの性能を上げたり(スケールアップ)も簡単にできるため、サーバ調達のための時間やコストを削減できる
ELB
- Elastic Load Balancingの略
- その名の通りロードバランサーのマネージドサービス(管理とかを一括して請け負ってくれるサービス)
- ロードバランサー→サーバへの負荷を分散させるやつ
- EC2インスタンスがスケールアウトされて複数ある場合、ELBがクライアントからリクエストを受け取り、それを各インスタンスに分散させる
- ELB自体もスケーリングができ、負荷に応じてスケールする設計になっている
ELBの種類
- Classic Load Balancer(CLB)
- L4/L7レイヤーで負荷分散を行う。現在はあまり使わない。
- Application Load Balancer(ALB)
- L7レイヤーでの負荷分散を行う。CLBより後に登場。
- Network Load Balancer(NLB)
- L4レイヤーでの負荷分散を行う。HTTP以外のプロトコル通信の負荷分散をしたい時に利用する。
RDS
- RDB(リレーショナルデータベース、関係データベース)と呼ばれる、SQL文でデータを操作するデータベースのマネージドサービス
- Amazon Aurora、MySQL、MariaDB、PostgresSQL、Oracleなどのデータベースエンジンから好きなものを選べる
- データ保存用ストレージはEBS(Elastic Block Store)を使用している
- インターネットからの接続はデフォルトでオフになっている(多分セキュリティを保つため)ため、EC2などの他のAWSサービスから通信することが多い
マルチAZ構成
- 1つのリージョン内の2つのアベイラビリティゾーンにDBインスタンス(データベースの実体)をそれぞれ配置する構成
- 1つのアベイラビリティゾーンで障害が発生しても、もう一つのアベイラビリティゾーンが生きていればシステムのダウンタイムを短くすることができる
- DBインスタンス作成時にマルチAZ構成を選択したら、あとはAWSが勝手に冗長化してくれて便利
S3
- Simple Storage Serviceの略
- 容量無制限のストレージ(補助記憶)サービス
- なんかめっちゃ色々なものが大量に入る箱のようなもの
- 保存するファイルにメタデータを追加し、「オブジェクト」として管理する
- S3に保存されている各オブジェクトには、RESTやSOAPといったWeb APIでアクセスする
- データのバックアップや、静的コンテンツ(HTMLファイルなど)のホスティング(置き場)としても利用される
- VPCの中には入れられないため、ゲートウェイエンドポイントを通じてVPC内のEC2インスタンスと通信する
バケット
- オブジェクトを保存するための領域
- バケット名はAWS内(全世界)で一意にしなければならない
オブジェクト
- S3に格納されるデータそのもの
- 各オブジェクトには必ず一意になるURLが作成される
Route53
- DNSのサービス
- ドメイン管理機能と権威DNS機能を持つ
- 権威DNSとは、ドメイン名とIPアドレスの変更情報を保持しているDNS
- DNSのポート番号が53であることからこの名前が付いている
CloudFront
- 静的コンテンツをキャッシュして配信するサービス
- ロードバランサーの前段に配置し、元のサーバにあるデータをキャッシュしておく(記憶しておく)ことで、次回に同じリクエストが来たらキャッシュしたものを返す
- サーバの負荷を軽減できる
- 利用者から最も近いロケーションからコンテンツを高速に配信することができる
- キャッシュの期間は拡張子やURLごとに設定することができる
- 頻繁にアップデートされるコンテンツはキャッシュを短くし、あまり更新されないコンテンツは長くするなど
オーソドックスなアーキテクチャ
- 簡易的なブログのシステム構成図を想定
- S3にはエラーページなどの静的コンテンツを配置
参考資料
以下を参考にさせていただきました。ありがとうございました。

- 投稿日:2019-07-08T23:14:13+09:00
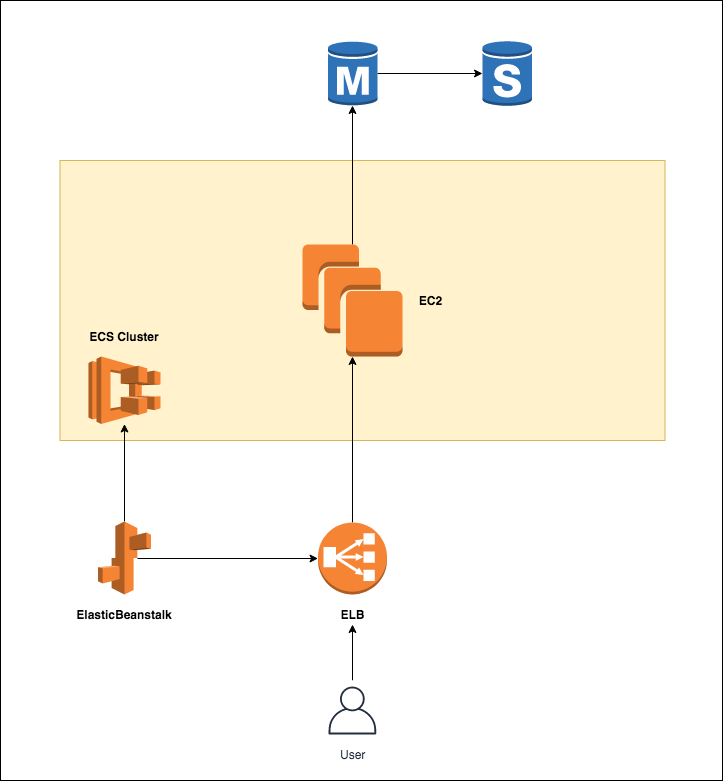
ElasticBeanstalk(MultiContainer)の利用方法
概要
Dockerを利用した本番運用をしたくなり、ElasticBeanstalkについて調べたのでまとめる。
ElasticBeanstalkとは
定義ファイルを準備する事で、AWS上のリソース(EC2,ECS,ELB...etc)を利用した環境を構築してくれるサービスであり、MultiContainerパターンではCloudFormation + ECSと同等の環境を設定ファイルのみで構築できる。
マルチコンテナパターン概要
- Dockerrun.aws.jsonにコンテナの関係を定義して、ElasticBeanstalkのコマンドを叩けばデプロイされる。
- 冗長化構成やスケール設定をしたい場合は.ebextensions内に追加設定を書いていくことで実現できる。
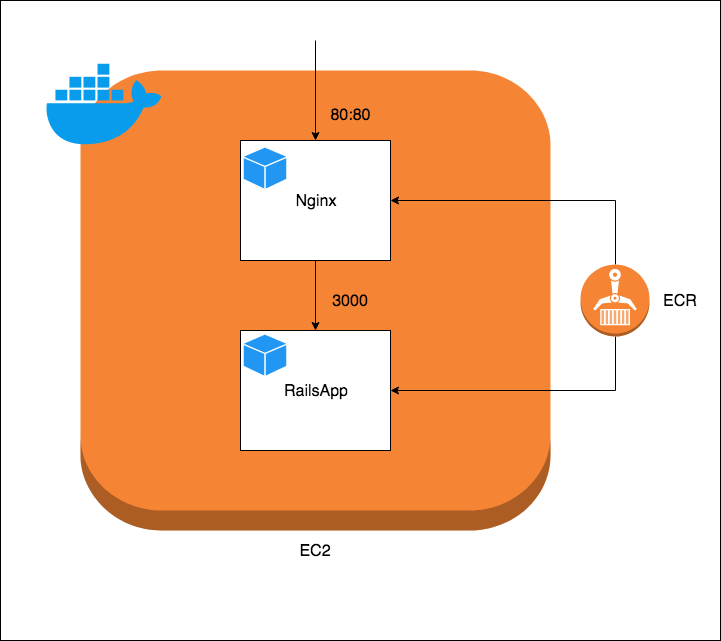
サンプルの構成図
サンプルのリソース関係図・構成図は下記のようになる
AWSリソース関係図
EC2内のContainer構成図
Dockerrun.aws.jsonのサンプル
ECRを利用したサンプルを下記に示す(書き方はdocker-composeのjson版?)
Dockerrun.aws.json{ "AWSEBDockerrunVersion": 2, "containerDefinitions": [ { "name": "nginx", "image": "xxxxx.amazonaws.com/xxxxx/nginx:latest", "essential": true, "memory": 128, "portMappings": [ { "hostPort": 80, "containerPort": 80 } ], "links": [ "rails-app" ], // Log設定(今回はCloudWatchLogsを利用する) "logConfiguration" : { "logDriver": "awslogs", "options": { "awslogs-region": "ap-northeast-1", "awslogs-group": "/xxxxx/develop/nginx" } } }, { "name": "rails-app", "image": "xxxxx.amazonaws.com/xxxxx/rails-app:latest", "essential": true, "memory": 256, "portMappings": [ { "containerPort": 3000 } ], "logConfiguration" : { "logDriver": "awslogs", "options": { "awslogs-region": "ap-northeast-1", "awslogs-group": "/xxxxx/develop/rails-app" } } } ] }ログの運用について
デフォルトでは各コンテナの標準出力がS3に保存されるが、それだと見づらいためCloudWatchLogsを利用する。
設定方法はこちらを参照
※ ElasticBeanstalkを利用する場合はLoggingDriverとしてFluentdを指定できない(カスタムAMIでなんとかいけるがオススメできない)Deployまでの流れ
- AWS-CLIとEB-CLIの準備
- DockerImageの作成(説明省略)
- ImageをECRにPush(こちらを参照)
- EB-CLIでcreate or deploy
AWS-CLIとEB-CLIの準備
AWS-CLIのインストール
$ brew install awscliEB-CLIのインストール
$ brew install awsebcliEB-CLIでDeploy
初期設定
$ eb init 9) ap-northeast-1 : Asia Pacific (Tokyo) 2) [ Create new Application ] 8) Multi-container Docker 残りはお好きなように設定新規作成
$ eb create rails-app-developデプロイ
$ eb deploy rails-app-developオートスケールなどの細かい設定について
- Docker.run.jsonと同階層に.ebextensionsを作成し、そこに追加設定ファイルを置く
- 「ファイル名.config」としないと認識しないため注意
- 拡張設定値はこちらを参照
階層サンプル
. ├── .ebextensions │ ├── 00-vpc.config │ └── 01-autoscaling.config ├── .elasticbeanstalk │ └── config.yml └── Dockerrun.aws.json
- 投稿日:2019-07-08T22:21:38+09:00
ALBのOIDC認証をSpring Securityで使用してみた。
認証が辛い!! もっと楽に安全に認証したい。したいですよね?
そういえば、ALBがOIDC認証に対応していたな、Spring Securityに食わせれば手間いらずで認証できるんじゃ・・・?事前準備
- ALBのhttps設定は以下を参考に設定
https://qiita.com/Yuki_BB3/items/fd410ef29935169aad9d- Amazon CognitoやGoogle Identity PlatformでOIDCの設定をする
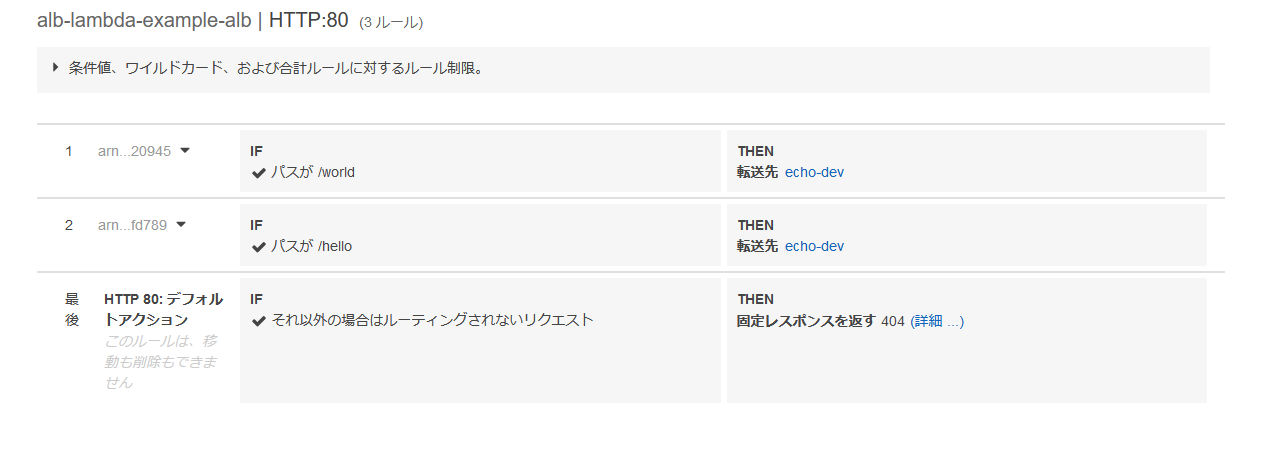
ALBの仕様
検証が成功してターゲットグループ(Spring Securityが載ってるアプリ)を呼ぶときにはヘッダーの
x-amzn-oidc-dataにJWTを乗せて送ってくる。
- 2回目以降もセッションが有効であれば毎回ちゃんと乗せてくれる。
- 有効期限(exp)は3分ぐらいとかなり短い(厳密には計ってない)
- 署名はECDSA + P-256 + SHA256
Spring Securityの設定
まず、主となるのが以下のフィルターこのフィルターが今回すべての起点となる。
org.springframework.security.oauth2.server.resource.web.BearerTokenAuthenticationFilter見ての通り本来はbearerトークン用ではあるもののトークンはJWTが入ってくることが決め打ちになってるので、今回はこれを活用する。
その際、JWTの検証や詰め替えは次のアーティファクトが担っている。
org.springframework.security:spring-security-oauth2-josebearerトークンではなく
x-amzn-oidc-dataをトークンとして認識させる以下を継承したクラスを作成
org.springframework.security.oauth2.server.resource.web.BearerTokenResolverALBTokenResolverpublic class ALBTokenResolver implements BearerTokenResolver { @Override public String resolve(HttpServletRequest request) { return request.getHeader("x-amzn-oidc-data"); } }このような形で任意のヘッダーやリクエストボディもトークンとして認識させることができる。
JWTの検証
org.springframework.security.oauth2.jwt.JwtDecoderがJWTのパースから検証までを行っている。
実体はorg.springframework.security.oauth2.jwt.NimbusJwtDecoderJwkSupportである。公開鍵の取得
まず、JWTを署名した公開鍵は所定のURLからPEMでEC公開鍵が得られるので、それに合わせて
com.nimbusds.jose.proc.JWSVerificationKeySelectorを継承したクラスを作成する。
実装はcom.nimbusds.jose.util.X509CertUtilsを参考に作成する。
長いので以下のリンクを参照
https://github.com/tac-yacht/Sample_SpringSecurityForAWSALB/blob/master/src/main/java/com/example/auth/ALBPublicKeySelector.java
※JwtDecoderから来るjwkSetUrlを流用しているため、application.ymlに以下を設定すること(決め打ちとする場合はこの限りでは無い)application.ymlspring: security: oauth2: resourceserver: jwt: jwk-set-uri: https://public-keys.auth.elb.us-west-2.amazonaws.com/JwtDecoderへの取得処理の設定
実体は前述したとおり
NimbusJwtDecoderJwkSupportなのだが、任意の署名アルゴリズムと鍵取得が設定できない。
そのためまるごとコピーして以下の部分に先ほどのKeySelectorで初期化する。private_constractor(String,String)JWSKeySelector<SecurityContext> jwsKeySelector = new ALBPublicKeySelector<SecurityContext>(this.jwsAlgorithm, jwkSource); //ここアルゴリズムは以下の部分を書き換える
public_constractorpublic ALBJwtDecoder(@Value("${spring.security.oauth2.resourceserver.jwt.jwk-set-uri}") String jwkSetUrl) { this(jwkSetUrl, JwsAlgorithms.ES256); }処理利用の設定
あとはほかのSpring Security同様ConfigJavaを記述
OAuth2ResourceServerSecurityConfiguration.java@EnableWebSecurity public class OAuth2ResourceServerSecurityConfiguration extends WebSecurityConfigurerAdapter { @Autowired private ALBTokenResolver resolver; @Autowired private ALBJwtDecoder decoder; @Override protected void configure(HttpSecurity http) throws Exception { http .authorizeRequests() .anyRequest().authenticated() .and() .oauth2ResourceServer() .bearerTokenResolver(resolver) .jwt() .decoder(decoder) ; } }ちなみにdecoderからメソッドチェインできる
jwtAuthenticationConverterを実装することでコントローラーの@AuthenticationPrincipalから得られるオブジェクトを任意のものに変更できる。ユーザーの詳細情報をDBやRedisから引いたものを設定したりまとめ
残念ながら設定だけとは行かなかったが、ALBが行った認証を受け取って利用できることがわかった。
Issueを見ると、今後はNimbusJwtDecoderJwkSupportは非推奨になり、OidcIdTokenDecoderFactoryに置き換わることで先ほどの署名アルゴリズムといったところが設定可能になるようだ。
https://github.com/spring-projects/spring-security/issues/6883ソースコード
https://github.com/tac-yacht/Sample_SpringSecurityForAWSALB
参考文献
- https://www.slideshare.net/masatoshitada7/oauth-20spring-security-51-121418814
- https://www.slideshare.net/masatoshitada7/spring-security-meetup
- https://qiita.com/suke_masa/items/0f75fa75a22a6551065b
- https://qiita.com/Yuki_BB3/items/fd410ef29935169aad9d
- https://docs.aws.amazon.com/ja_jp/elasticloadbalancing/latest/application/listener-authenticate-users.html
余談
以下を読むとLet's EncryptはEC2はダメとのこと。ALBならドメイン違うし(elb.amazonaws.com)、リスナールールで適当に静的応答すれば行けるんじゃね?!→ダメでした。
https://hacknote.jp/archives/37697/
短期間でいいからAWS Certificate ManagerからXXX.elb.amazonaws.com向けの電子署名払い出してくれないかな……
- 投稿日:2019-07-08T21:51:08+09:00
Heroku CLIをAWSで使えるようにする
https://devcenter.heroku.com/articles/heroku-cli
からダウンロードします。
Other installation methodsのリンクからページに飛び。
(
$ cd ~/environment/で移動してからやるとよい)TarballsのLinux(x64)のリンクアドレスをコピー
$ curl -OL "(URL)を貼る。"ダウンロードが始まる。
.
.
.
.
.
.Heroku CLIのインストールしていく
$tar zxf heroku-linux-x64.tar.gz $ sudo mv heroku /usr/local/ $ ls /usr/local/heroku/ (確認) $echo 'PATH=/usr/local/heroku/bin:$PATH' >> $HOME/.bash_profile $source $HOME/.bash_profile > /dev/null最後に確認する
$ heroku -vバージョンが表示されたらOK!
.
.
.
.
.
.終わったら消そう!
$ rm -f heroku-linux-x64.tar.gzこれで完了です。
- 投稿日:2019-07-08T20:59:37+09:00
Amazon DocumentDBにRobo3T(Robomongo)で繋ぎたいンゴ
ローカルからRobo3TでAmazon DocumentDBに繋ぐために四苦八苦した非エンジニアの備忘録メモ。
前置き
Amazon DocumentDBとは?
AWSが提供しているMongoDB互換のドキュメント指向データベースサービス。
※MongoDBのフルマネージドサービスという訳ではない。Robo3Tとは?
旧名: Robomongo。
オープンソースのMongoDB用GUIツール。
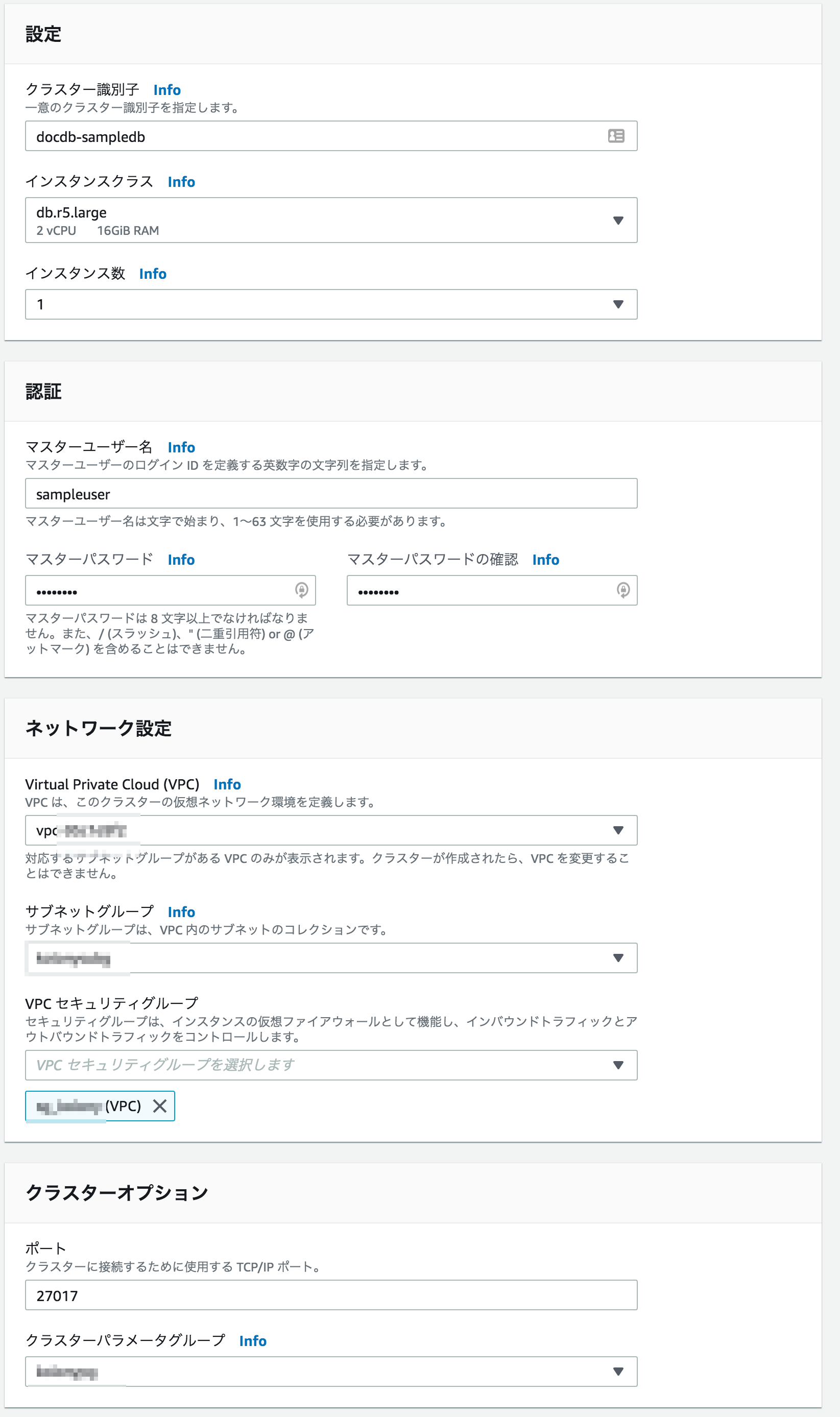
※非エンジニアはCLIなんて操作できないので必須アイテム。①DocumentDBのクラスターを作成
- サブネットグループやパラメーターグループは事前に作っておく。作成後に変更するのはしんどいので作成段階でセットする。
- VPCは後ほど作成するEC2と同じVPCをセットする。
②EC2を作成
トンネル用のEC2を作成する。
VPSとセキュリティグループさえ気をつければ、他は適当で良い。③EC2に接続
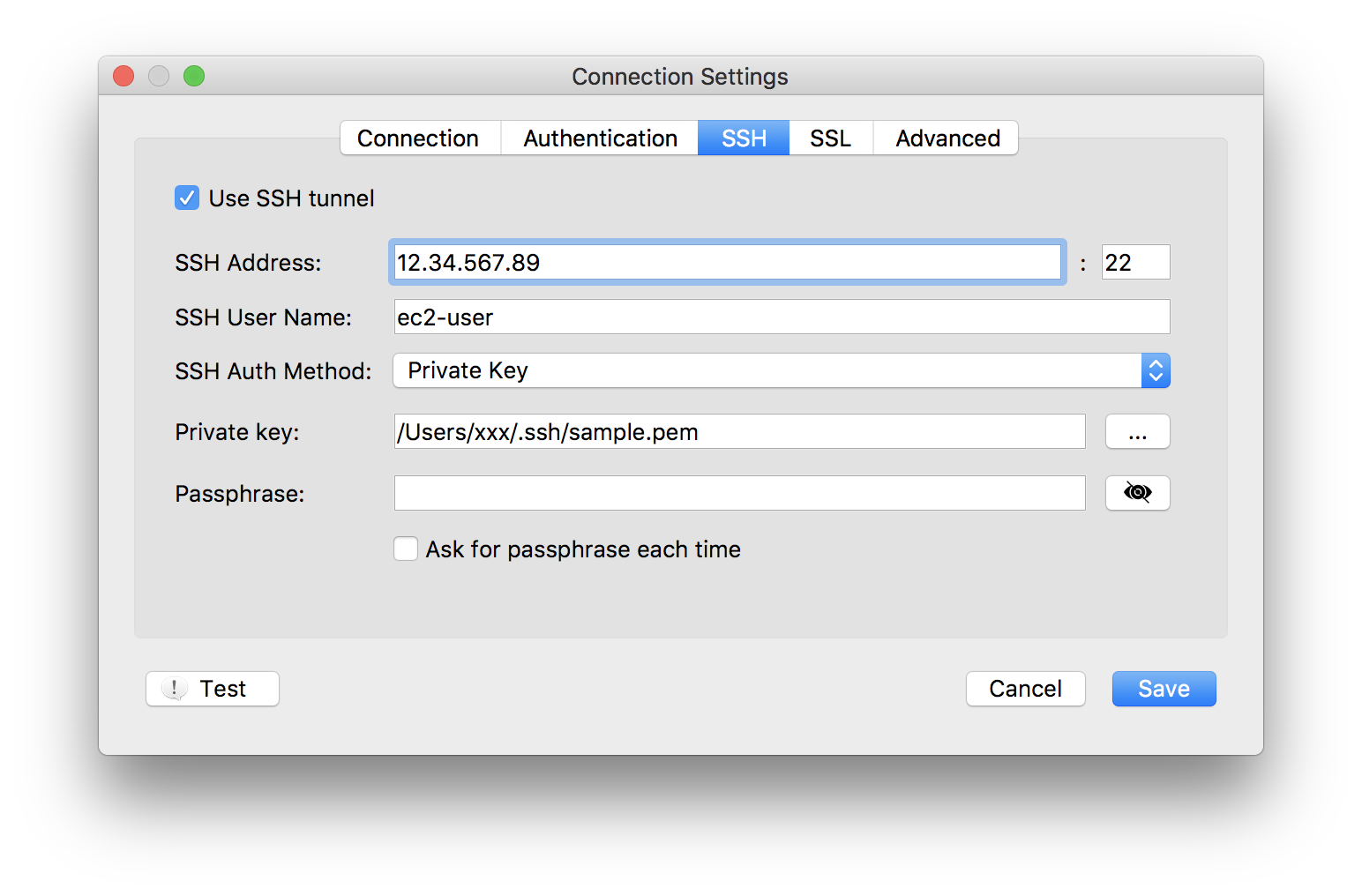
下記を参考に裏で接続しておく。
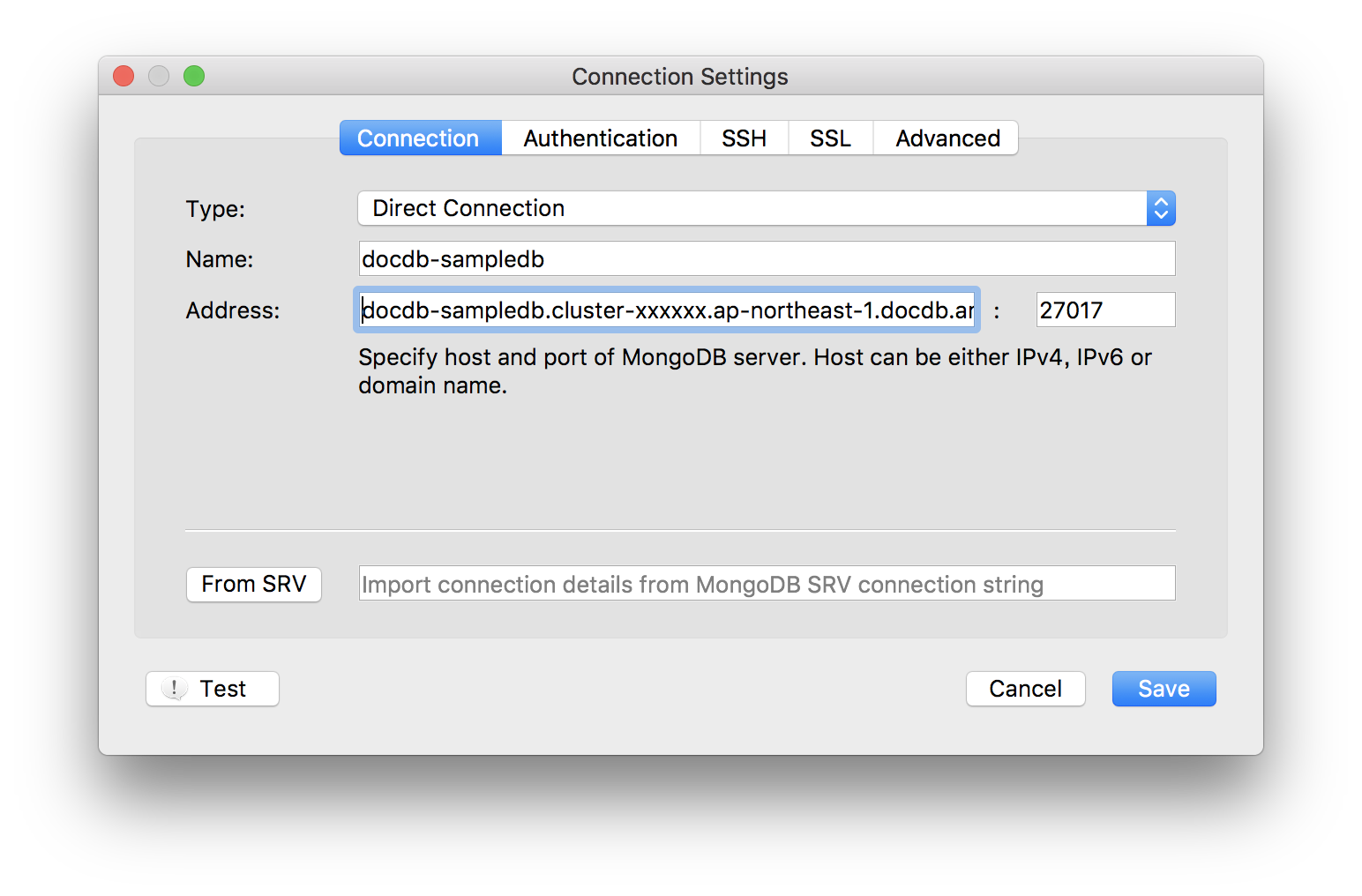
ssh ec2-user@12.34.567.89 -p22 -L27018:172.20.0.1:27017 -i /.ssh/sample.pem④Robo3Tを設定
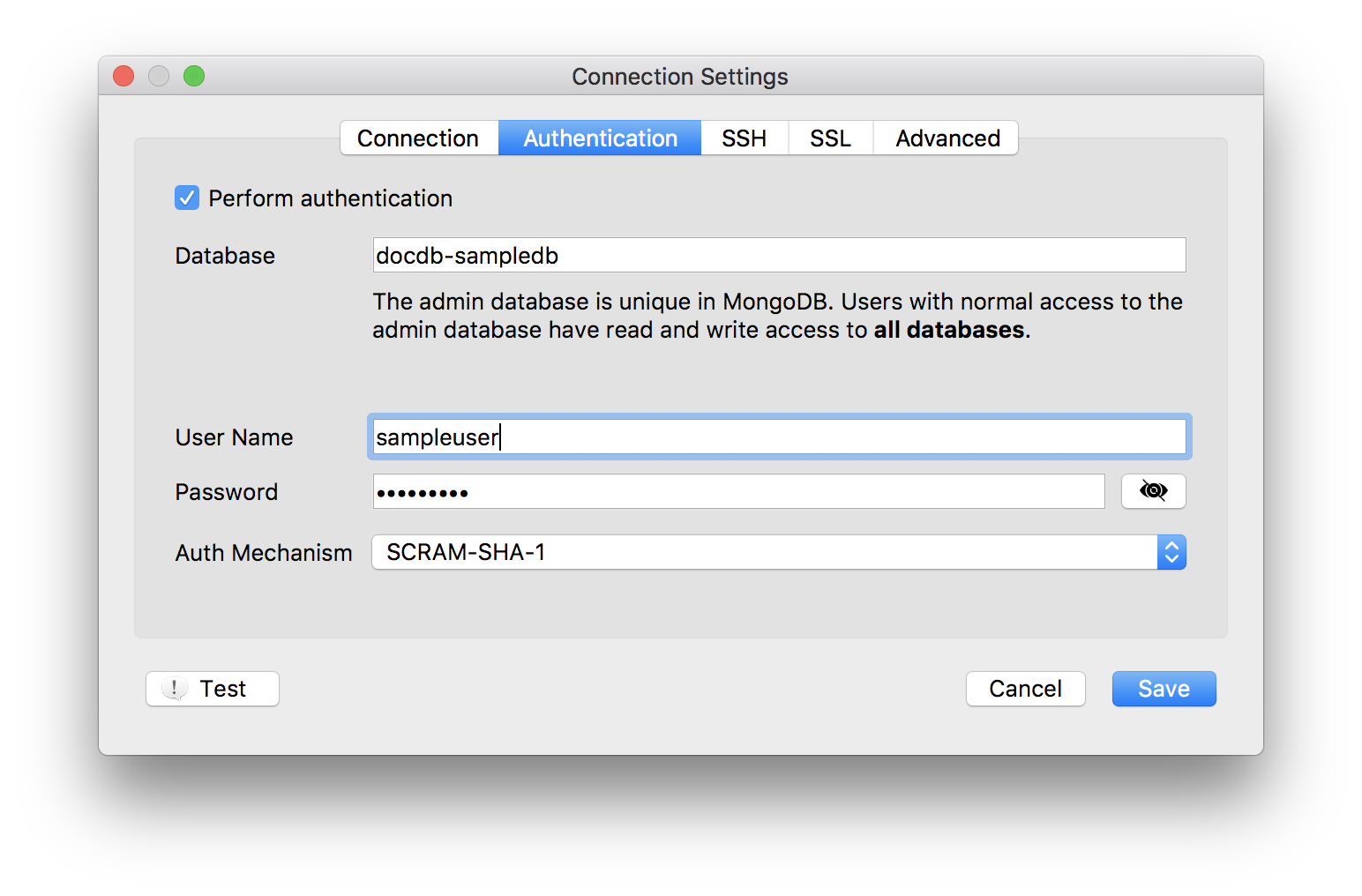
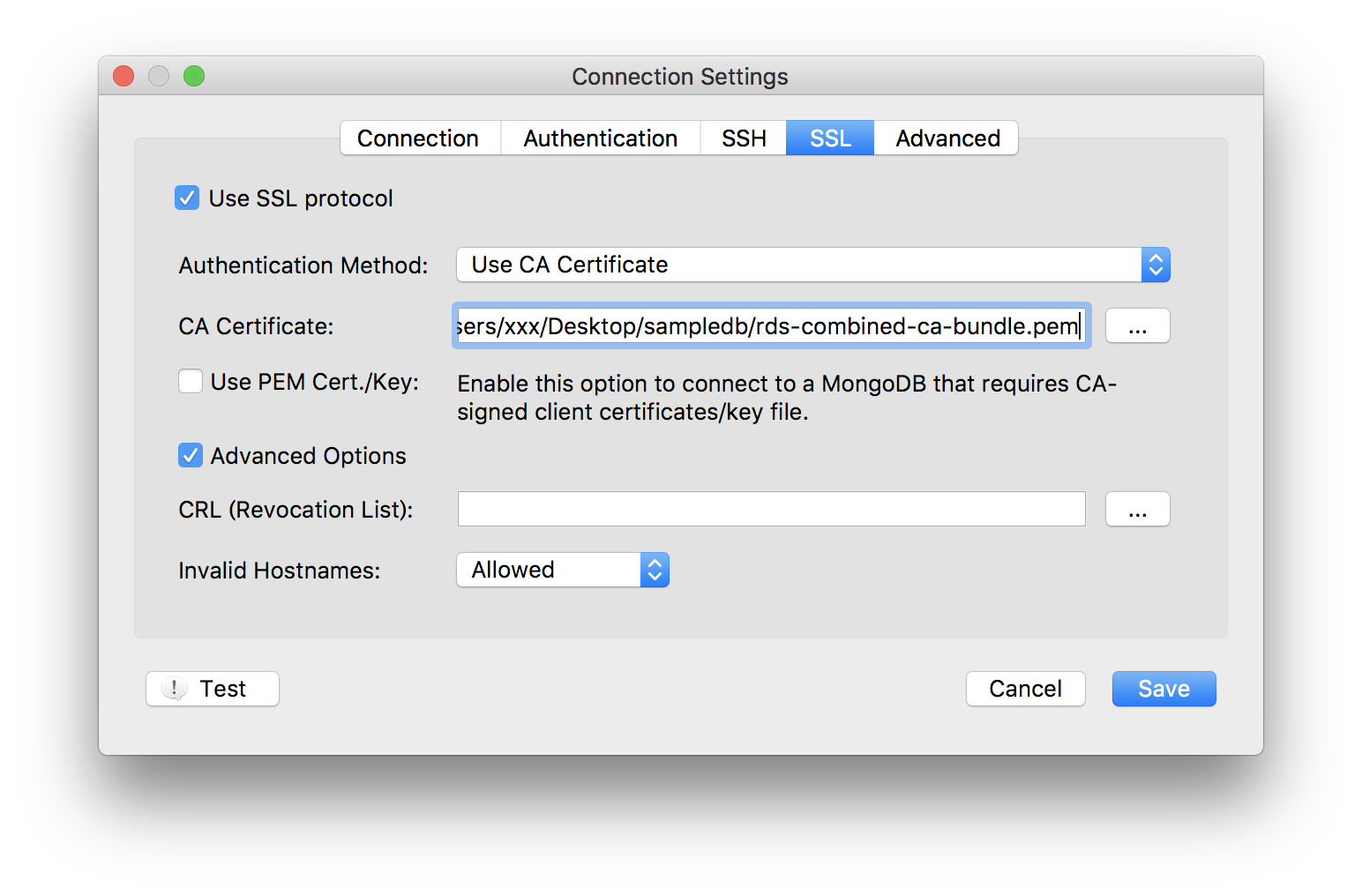
下記を参考に新規プロファイルを作成する。
DocumentDB用のpemはhttps://s3.amazonaws.com/rds-downloads/rds-combined-ca-bundle.pemからダウンロードしておく。
⑤Robo3Tで接続
無事繋がったンゴ
参考
amazon web services - AWS DocumentDB with Robo 3T (Robomongo) - Stack Overflow
https://stackoverflow.com/questions/54384253/aws-documentdb-with-robo-3t-robomongo
- 投稿日:2019-07-08T20:36:16+09:00
S3のオブジェクトの更新をトリガーとして発火する LambdaFunctionを作成する。
はじめに
以前、CloudFrontの配信元のファイル(S3)が更新されたら自動的にキャッシュをクリアする仕組みを作るという記事を作成しました。
その対応の中で「S3のオブジェクトの更新をトリガーとして発火する LambdaFunction」が必要となります。
当記事では具体的な設定方法を紹介します。
具体的な設定方法
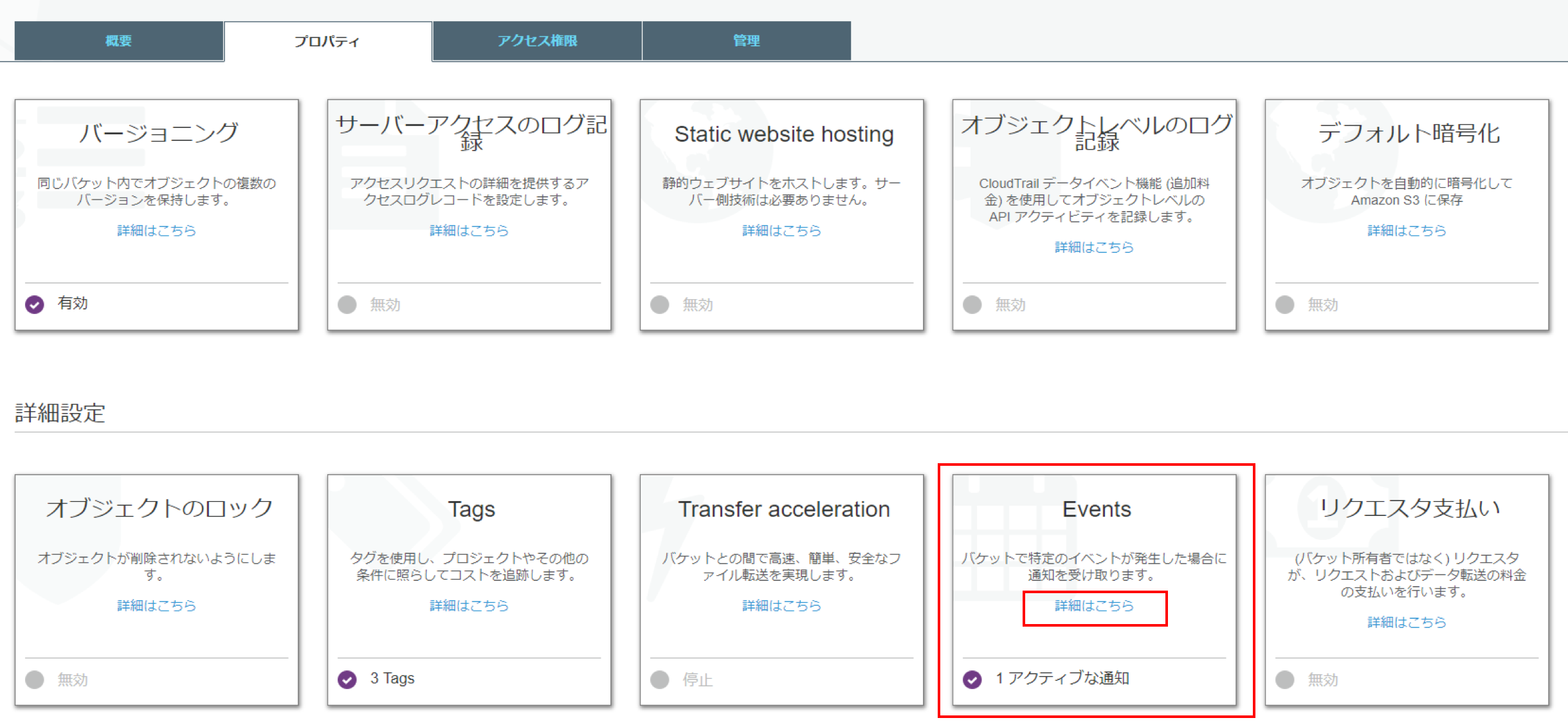
- イベント発火元のS3バケットを選択
- 「プロパティ」-「Events」-「詳細はこちら」をクリック
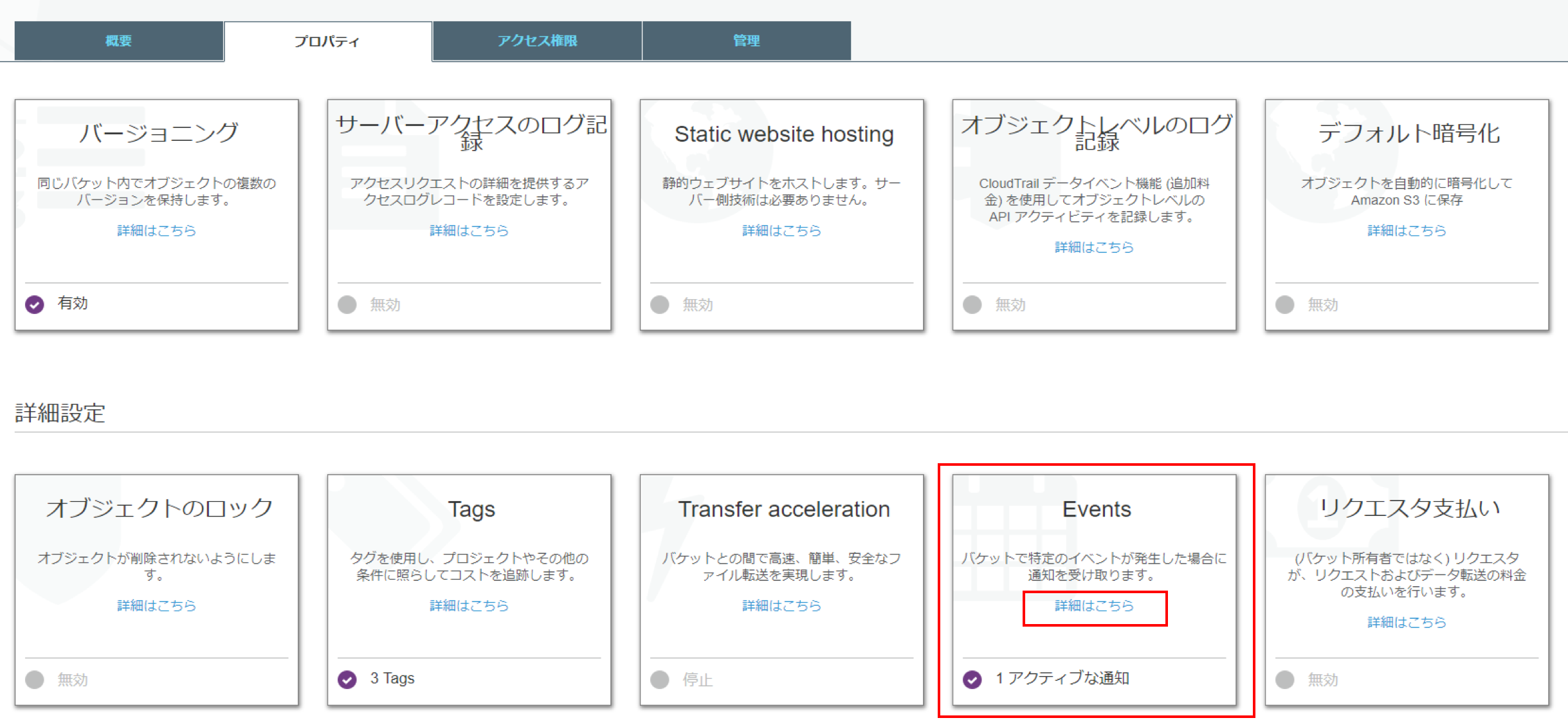
- 「通知の追加」をクリックして、[送信先]にLambdaFunctionを選択、[Lambda]に自分の実行したいLambdaFunction名を選択する
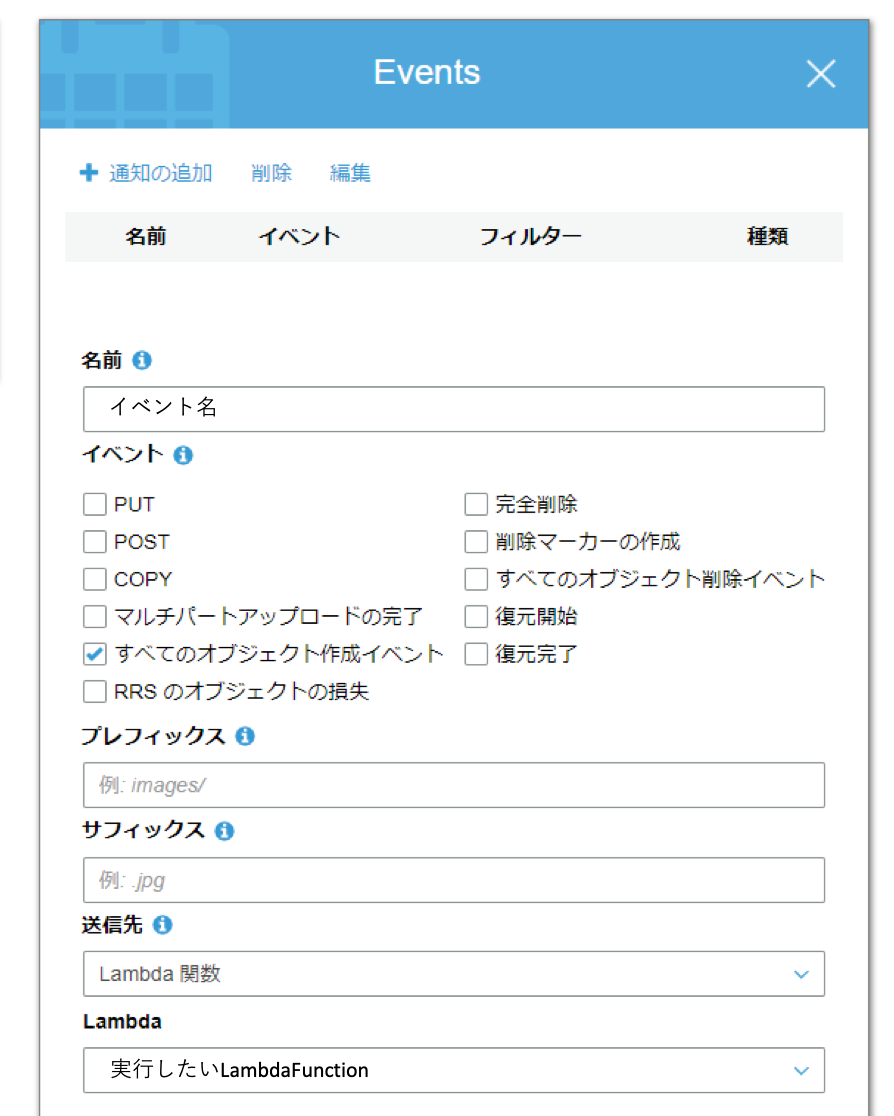
以上で完了です。
終わりに
設定自体は見つけてしまえば簡単です。
設定が反映されるまでは3分くらいかかる為、留意して下さい。
※実はLambdaFunction側からでも簡単に設定できます。
- 投稿日:2019-07-08T20:36:16+09:00
AWS S3のオブジェクトの更新をトリガーとして発火する LambdaFunctionを作成する。
はじめに
以前、CloudFrontの配信元のファイル(S3)が更新されたら自動的にキャッシュをクリアする仕組みを作るという記事を作成しました。
その対応の中で「S3のオブジェクトの更新をトリガーとして発火する LambdaFunction」が必要となります。
当記事では具体的な設定方法を紹介します。
具体的な設定方法
- イベント発火元のS3バケットを選択
- 「プロパティ」-「Events」-「詳細はこちら」をクリック
- 「通知の追加」をクリックして、[送信先]にLambdaFunctionを選択、[Lambda]に自分の実行したいLambdaFunction名を選択する
以上で完了です。
終わりに
設定自体は見つけてしまえば簡単です。
設定が反映されるまでは3分くらいかかる為、留意して下さい。
※実はLambdaFunction側からでも簡単に設定できます。
- 投稿日:2019-07-08T20:36:16+09:00
AWS S3のオブジェクトの更新をトリガーとして発火する LambdaFunctionを作成する
はじめに
以前、CloudFrontの配信元のファイル(S3)が更新されたら自動的にキャッシュをクリアする仕組みを作るという記事を作成しました。
その対応の中で「S3のオブジェクトの更新をトリガーとして発火する LambdaFunction」が必要となります。
当記事では具体的な設定方法を紹介します。
LambdaFunctionの中身の件についてはこちらの記事にて記載しております。
AWS S3バケット名からCloufFrontのキャッシュをクリア(CreateInvalidation)するAPIをコールする具体的な設定方法
- イベント発火元のS3バケットを選択
- 「プロパティ」-「Events」-「詳細はこちら」をクリック
- 「通知の追加」をクリックして、[送信先]にLambdaFunctionを選択、[Lambda]に自分の実行したいLambdaFunction名を選択する
以上で完了です。
終わりに
設定自体は見つけてしまえば簡単です。
設定が反映されるまでは3分くらいかかる為、留意して下さい。
※実はLambdaFunction側からでも簡単に設定できます。
- 投稿日:2019-07-08T17:56:18+09:00
【RDS for Oracle】Performance Insights(パフォーマンスインサイト)メモ
メモ
チューニングの手前までができる。チューニング自体はしないRDSで提供しているすべてのエンジン(Oracleなど)でつかえる。
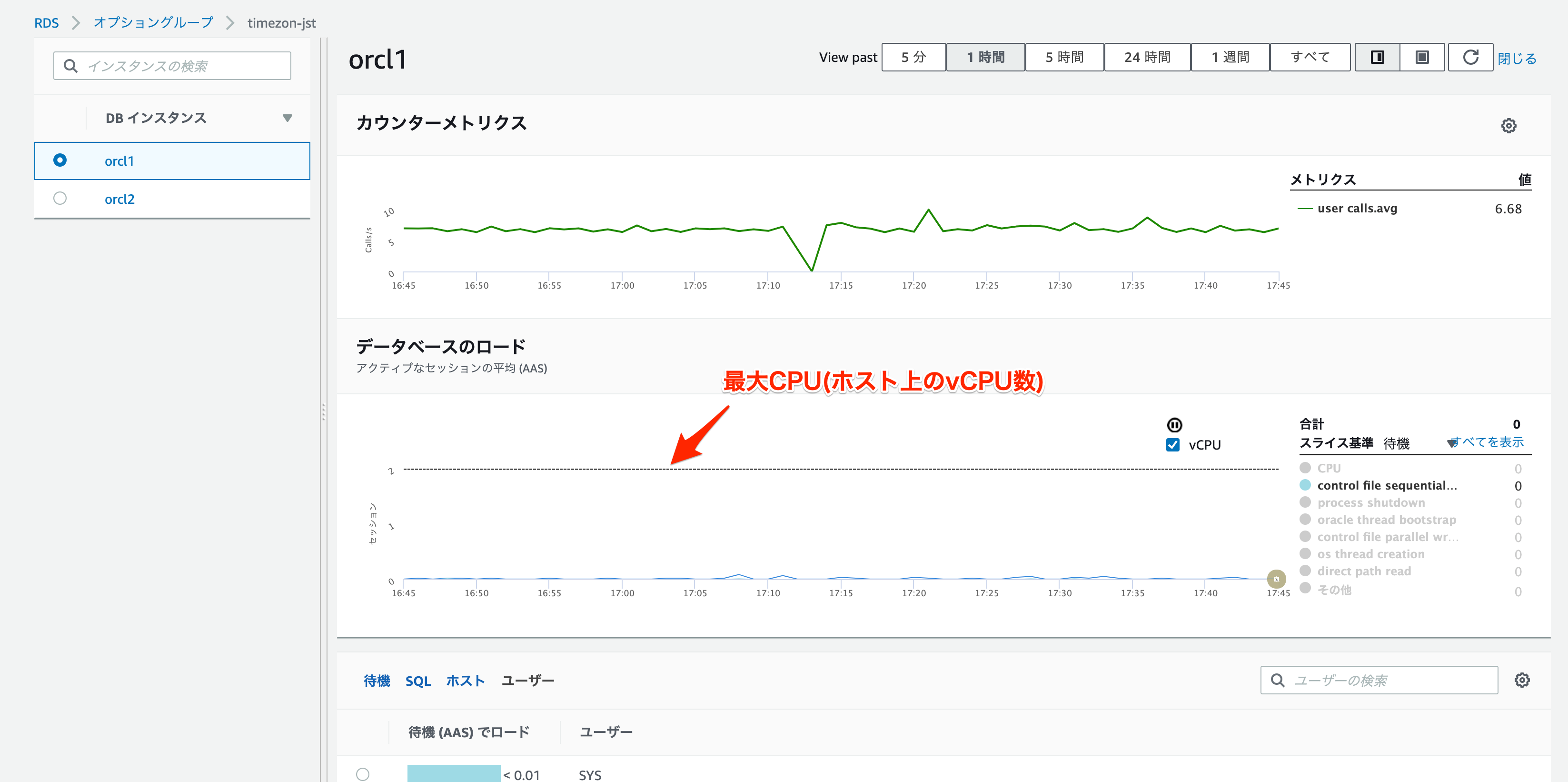
データベースロード:アクティブなセッション数(CPU使用率、アイドルの2つのステータス)。1秒おきにアクティブなセッションの詳細な情報をサンプリング
カウンターメトリクス:OSよりのメトリクス(CPU使用率)
Top N ディメンション:その時間帯のパフォーマンスに影響していたTop NのSQL。データ保持基幹デフォルト7日(2年間の長期保持も)パフォーマンス問題の有無は
データベースロードがインスタンスの最大vCPUを超えているかどうかが基準分析
- どんな待機イベントが多かったのか。
- 高負荷SQL
- 接続元ホスト(システム全体の中で問題の比率の多いアプリケーションは?)
- 接続ユーザ
クエリのパフォーマンス管理
SQLヒント
SQL Plan Stability
SQL Plan管理
→OracleだとSPM(SQL Plan Manager)重要なとこ
負荷グラフでの重要な視覚的手がかりは「最大CPU」ラインです。このラインはホスト上のvCPUの数を表します。vCPUよりも多くのアクティブセッションがCPU待機している場合、CPUの許容量を超えてインスタンスが実行されていることを意味します。負荷全体が「最大CPU」のラインを超えると、ボトルネックが発生する可能性があります。ボトルネックはCPUの飽和が原因かもしれませんし、データベース内でセッションが待機するその他の多くの理由によって引き起こされているかもしれません。
参考
Amazon RDSパフォーマンスインサイトの使用
Performance Insights を使用した Amazon RDS データベースの負荷分析
- 投稿日:2019-07-08T17:18:07+09:00
AWSのS3をマウントしたい人に。(Goofys)
はじめに
私はS3をマウントすることになりました。ググると主にStorageGateway、goofys、s3fsの3つのうちのどれかを使用するようです。試行錯誤の末、goofysを使用することにしました。
ちなみに私の場合最初、StorageGatewayを使おうとしましたが、ファイルゲートウェイ設定の際VMwareEsxiをインストールする必要があり、なぜか詰まりました。VMwareの環境構築の苦労についてはまた別の機会で、、
環境はLinuxです。go,fuseのインストール
goofysの使用にあたってgo,fuseが必要になるため、先にインストールします。
sudo apt-get update sudo apt-get install golangPATHを通す
export GOPATH =$HOME/goこの時色々ググって試した結果、いつのまにかGOPATHとGOROOTが同じパスになってエラーになったため注意。
echo $GOPATH echo $GOROOT echo $PATH上記のようにパスを確認しながら進めるとよかったです。
goofysのインストール
go get github.com/kahing/goofys go install github.com/kahing/goofys1行目を実行しても反応がなく、2行目を先に試したりすると、”permissiondenied”や”許可がありません”というエラーが出た。rootユーザーで試したり、awsconfigureの設定をし直したり、PATHの確認したり試行錯誤した。さらによく調べると、この部分の処理には時間がかかることがあると分かりました。そこで、しばらく待ってみると正常に実行されました。2行目の実行に関しては私の場合、2,3秒で終わりました。
(goofysのインストールver2)
wget https://github.com/kahing/goofys/releases/download/v0.0.5/goofys -P /usr/local/bin/上記の方法も試してみたりしました。ですが、これは必要なかったと思います。
マウントの確認
$aws s3 mb s3://shangben-goofys //S3バケット作成 $mkdir ~/mount-goofys //ローカルディレクトリ作成上のようにS3バケットとマウント先のローカルディレクトリを作ります。
ちょっとファイルを作ってみます。
$touch ~/mount-goofys/testS3やボリュームを確認してみます。
$aws s3 ls s3://マウントしたバケット名 $ps auxf|grep goofys //プロセス確認 $df -h //ボリュームの確認おわり
- 投稿日:2019-07-08T17:18:07+09:00
GoofysでAWSのS3をマウントする。
はじめに
私はS3をマウントすることになりました。ググると主にStorageGateway、goofys、s3fsの3つのうちのどれかを使用するようです。試行錯誤の末、goofysを使用することにしました。
ちなみに私の場合最初、StorageGatewayを使おうとしましたが、ファイルゲートウェイ設定の際VMwareEsxiをインストールする必要があり、なぜか詰まりました。VMwareの環境構築の苦労についてはまた別の機会で、、
環境はLinuxです。go,fuseのインストール
goofysの使用にあたってgo,fuseが必要になるため、先にインストールします。
sudo apt-get update sudo apt-get install golangPATHを通す
export GOPATH =$HOME/goこの時色々ググって試した結果、いつのまにかGOPATHとGOROOTが同じパスになってエラーになったため注意。
echo $GOPATH echo $GOROOT echo $PATH go env GOPATH //これでもできる。上記のようにパスを確認しながら進めるとよかったです。
goofysのインストール
go get github.com/kahing/goofys go install github.com/kahing/goofys1行目を実行しても反応がなく、2行目を先に試したりすると、”permissiondenied”や”許可がありません”というエラーが出た。rootユーザーで試したり、awsconfigureの設定をし直したり、PATHの確認したり試行錯誤した。さらによく調べると、この部分の処理には時間がかかることがあると分かりました。そこで、しばらく待ってみると正常に実行されました。2行目の実行に関しては私の場合、2,3秒で終わりました。
(goofysのインストールver2)
wget https://github.com/kahing/goofys/releases/download/v0.0.5/goofys -P /usr/local/bin/上記の方法も試してみたりしました。ですが、これは必要なかったと思います。
マウントの確認
$aws s3 mb s3://shangben-goofys //S3バケット作成 $mkdir ~/mount-goofys //ローカルディレクトリ作成上のようにS3バケットとマウント先のローカルディレクトリを作ります。
ちょっとファイルを作ってみます。
$touch ~/mount-goofys/testS3やボリュームを確認してみます。
$aws s3 ls s3://マウントしたバケット名 $ps auxf|grep goofys //プロセス確認 $df -h //ボリュームの確認おわり
- 投稿日:2019-07-08T15:36:05+09:00
AWS DeepRacer Virtual Circuit 6月の優勝者Fumiakiに聞いてみた
はじめに
AWS DeepRacerリーグの6月の仮想サーキットで登場した新たなコースは、社内でも勉強会をはじめとして多くの話題に挙がりました。特に
- トレーニング用トラック(Kumo Torakku Training)が、なかなか完走できない問題
- レース用トラック(KumoTorakku)は形が異なる問題
については、闊達な議論が飛び交いました。
この癖のある6月のバーチャルサーキットで1位を獲得することができたFumiakiの走行記録とヒアリングした学習方針を公開します。
今回も分析にはAWS DeepRacerワークショップのGitHubで公開されているlog-analysisノートブックを使いました。
https://github.com/aws-samples/aws-deepracer-workshops/
ログ分析ツールの導入方法や使い方は
AWS DeepRacerのログ分析ツールを使ってみた
を参考にしてください。注意
- 以下の内容は 2019 年 7 月 4 日時点のサンプルノートブックを対象にしています。その他のバージョンのノートブックでは利用できない可能性があります。
- ログの分析は、6月の仮想サーキットで1位を獲得したデータ、モデルを対象にしています。
- 本記事は、あくまで個人の見解に基づいて記載しております。
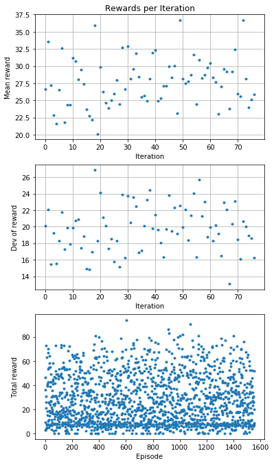
トレーニングモデルの分析結果
Plot rewards per Iteration
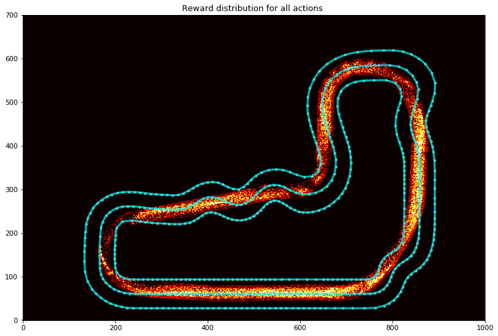
1stepあたりの最大報酬は1です。Reward distribution for all actions
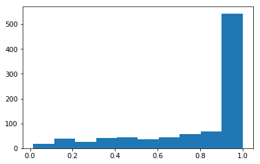
Probability distribution on decisions (actions)
仮想サーキットの走行記録
仮想サーキットで送信した記録はCloudWatchLogsの
/aws/deepracer/leaderboard/SimulationJobs/以下に走行後にログとして残されています。Evaluation Run Analysis
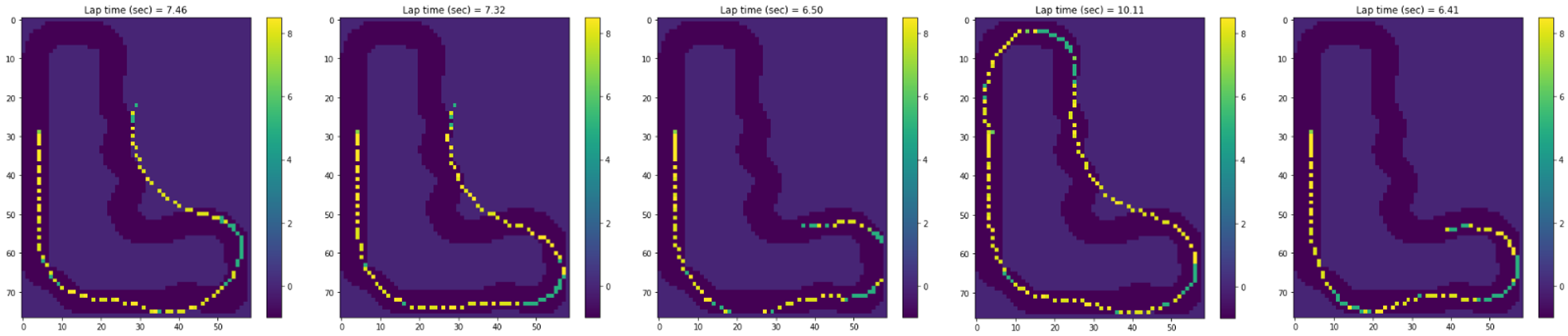
全エピソード中、完走したのは4回目の1回だけでした。
結果中のLaptimeは10.11秒とありますが分析では最初のステップがタイムとして含まれていないため、公式記録は10.312秒です。また、分析用にトレーニングトラック用を利用しているのでコースアウトしているように見えますが、実際のレース用トラックは以下の図(右)のように急なヘアピン、シケインはありません。
完走したエピソードのstep数は149です。
感想と考察
以下はあくまで個人的な見解となります。
Reward distribution for all actionsを見ると、トラック上のカーブやシケインに沿うのではなくショートカットコースに沿っていることがわかります。(Fumiakiは5月のLondonLoopでも同じ手法をとっていました)
トレーニングトラックで左曲がりになる以下のポイントは、レーストラックでは右曲がりになっています。
トレーニング中においてシミュレーションでは、左に曲がるコース映像のハズです。
このポイントだけあえてコースラインとは逆の方向、右に曲がれる学習をし、且つ他のポイントではコース通りに曲がれるような学習をしていることがわかりました。
これらは仮想サーキットの完走率(1/5)にも現れており、コースアウトしやすいポイントにもなっています。
このことから、仮想サーキットへはこの可能性を信じておそらく何度も挑戦したのだと思います。学習方針
ログやデータから読み取れないところは、直接Fumiakiに聞いてみました。
1. トレーニング用のKumoTorakkuを完走するには?
まずは完走させることを目的に学習した後で、速いスロットルが選ばれやすくなるように追加学習をしました。
具体的にはKumo Torakkuをメインに他のトラックを少し組み入れてトレーニングしました。
正直、これ以外にもいろいろと試行錯誤を繰り返しているので、何が効いているのか分からない部分はありますが。。2. トレーニングとレース(仮想サーキット)トラックの違いについて
トレーニングトラックよりレーストラックの方が走りやすいので、トレーニングトラックが殆ど走れなくてもレース用のトラックで完走出来たりするケースもありました。
リーダーズボードのEvaluationを見るとレースは全5回走行で、Kumo Torakkuはそのうち1回完走すれば良いので、奇跡の1周に頼りやすいと思いました。
(※5月のLondonLoopでは3回以上の完走が記録として必須でした。)また、トレーニングのトラックではもっと完走率の高く、速いモデルができていたのですが、それは仮想サーキットコースでは一度も完走できませんでした。
トレーニングトラックに特化し過ぎるのも注意が必要かもしれません。最後に
今月のバーチャルレース当初はそれぞれの課題を個人で抱えていましたが、今回のトラックが比較的難しかったことが共通の課題となり、勉強会以外でも、職場・部署の壁を越えてより積極的にコミュニケーションをとり、議論を深めあう機会になりました。
エンジニア同士お互いに敬意を持って、わからないことを聞いてみる、知っていることを教える、ということも良かったと思います。Congratulations! Fumiaki!



- 投稿日:2019-07-08T15:26:57+09:00
AmazonLinuxのEC2上でHIDSのAIDEを構築する
IDSとは?
IDSは、侵入検知システム(Intrusion Detection System)の略称。
似たような概念として、IPSがありますが、こちらは侵入防止システム(Intrusion Prevention System)の略称で、侵入されたことを検知するか、それとも侵入自体を防止するか分けられています。IDSにはNIDSとHIDSの二種類があり、一般的にIDSと呼ぶと前者のことをさすことが多いです。
NIDSは、Network-based Intrusion Detection Systemの頭文字を取ったもので、ネットワーク上で侵入検知を行うシステムです。
HIDSは、その頭にHost-basedが付いたもので、ホスト型の侵入検知システムのことをさします。
本ポストでは、オープンソースで提供されるHIDSのひとつである、AIDEのインストール方法について述べます。AIDEとは?
HIDSの一つで、ファイルの改ざん検知を実施するツールです。
Advanced Intrusion Detection Environmentの頭文字を取っているそうです。
https://aide.github.io/似たようなツールとして、OSSECというのがあります。
https://ossec.github.io/
そっちの方はAWSさんの公式ドキュメントに構築手順が載っているので、そちらを参照。
https://aws.amazon.com/jp/blogs/news/how-to-monitor-host-based-intrusion-detection-system-alerts-on-amazon-ec2-instances/インストール&初期設定
まずは、yumを使ってインストールをしていきましょう。
今回は、OSとしてAmazonLinuxを利用しました。yum install -y aide/etcの下に、どこのフォルダを検知対象とするかを書くためのコンフィグファイルが
出来ているはずです。/etc/aide.conf@@define DBDIR /var/lib/aide @@define LOGDIR /var/log/aide database=file:@@{DBDIR}/aide.db.gz database_out=file:@@{DBDIR}/aide.db.new.gz gzip_dbout=yes verbose=5 report_url=file:@@{LOGDIR}/aide.log report_url=stdout FIPSR = p+i+n+u+g+s+m+c+acl+selinux+xattrs+sha256 ALLXTRAHASHES = sha1+rmd160+sha256+sha512+tiger EVERYTHING = R+ALLXTRAHASHES NORMAL = FIPSR+sha512 DIR = p+i+n+u+g+acl+selinux+xattrs PERMS = p+i+u+g+acl+selinux LOG = > LSPP = FIPSR+sha512 DATAONLY = p+n+u+g+s+acl+selinux+xattrs+sha256 /boot NORMAL /bin NORMAL /sbin NORMAL /lib NORMAL /lib64 NORMAL …上の方はいじらなくてよいですが、/boot NORMAL等ディレクトリがずらっと記述されているはずです。
これは、検知対象のディレクトリを表しています。検知対象としたいディレクトリはそのままにして、検知したくないディレクトリの行の先頭には!を付けてあげましょう。
(今回はテストなので、/usr以外すべてのディレクトリを検知対象外としました。)/etc/aide.conf/boot NORMAL ↓ ! /boot NORMAL次に、現状のファイル状態を保存したデータベースファイルを作成します。
aide --initconsole### AIDE database at /var/lib/aide/aide.db.new.gz initialized.結構時間がかかります。現状のファイル構造が複雑であれば複雑であるほど時間がかかるんだと思います。
終わったら、早速ファイルを変更してみて検査…をしようとすると、エラーが出ます。
↑でやった初期化だけでは、検知に利用するためのデータベースファイルの元しかできないので、自分で名前を変更してあげる必要があります。mv /var/lib/aide/aide.db.new.gz /var/lib/aide/aide.db.gzようやく、検知する準備ができました。
さっそく適当に一つファイルを作ってみて、検知ができるか見てみましょう。touch /usr/testfile.txt/usrの直下にtestfile.txtという名前のテキストファイルを置きました。
(あくまで例ですので、ご自身の都合のいいディレクトリで試してみてください)検査してみます。
aide --checkconsoleAIDE found differences between database and filesystem!! Start timestamp: 2019-07-08 06:21:37 Summary: Total number of files: 36082 Added files: 1 Removed files: 0 Changed files: 1 --------------------------------------------------- Added files: --------------------------------------------------- added: /usr/testfile.txt --------------------------------------------------- Changed files: --------------------------------------------------- changed: /usr -------------------------------------------------- Detailed information about changes: --------------------------------------------------- Directory: /usr Mtime : 2019-05-13 17:54:02 , 2019-07-08 06:18:33 Ctime : 2019-05-13 17:54:02 , 2019-07-08 06:18:33やはり少し時間はかかりますが、検知できました!
実際に利用する場合は、cronに検査とデータベースファイルの更新処理を書いたシェルを登録することになるかと思います。
- 投稿日:2019-07-08T15:25:14+09:00
【RDS for Oracle】Enterprise Managerを使う
前提
- RDS for Oracle で使用できるEnterprise Manager(EM)は以下です。
Oracleバージョン EMの種類 デフォルト・ポート 12c EM Express 5500 11g EM Database Control 1158
- 検証環境(ORCL1)が12cなのEMはEM Expressになります。
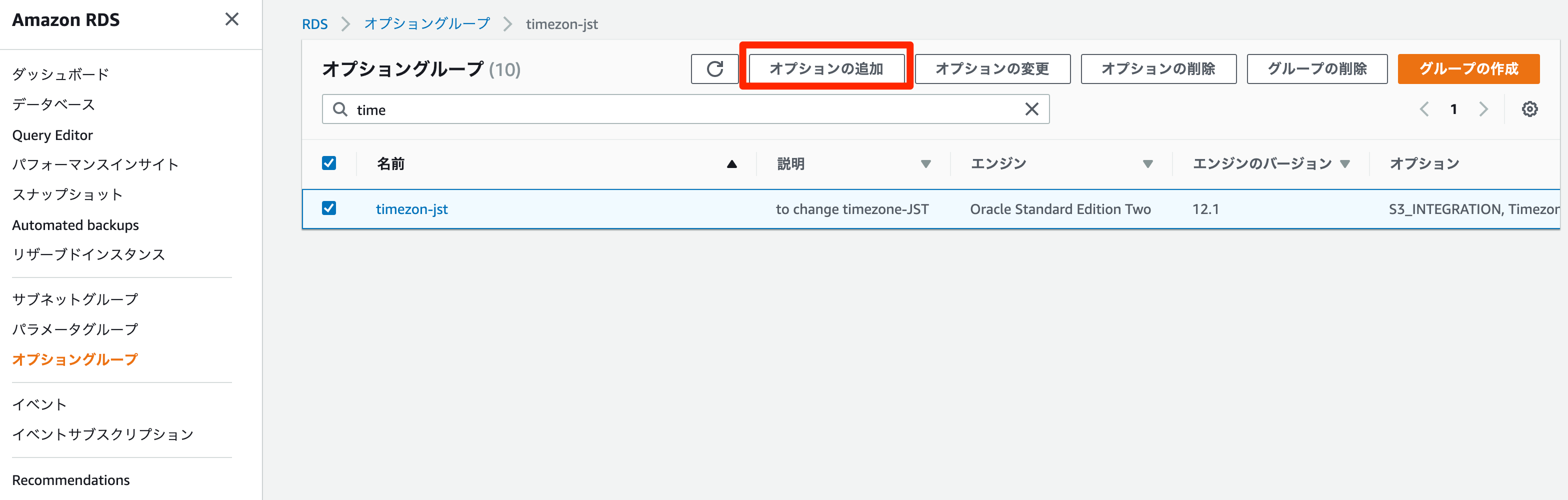
RDSでEMを使うにはオプショングループを設定します。以前の記事でオプショングループを作っているので、今回はこちらにオプションを追加していきます。
注意点
- 次のDB インスタンスクラスではEMはサポートされない
- db.t2.micro
- db.t2.smal
- db.m1.small
事前準備
- RDSのセキュリティグループのインバウンドにEMのポート(5500 or 1158)を追加する
- オプショングループの設定
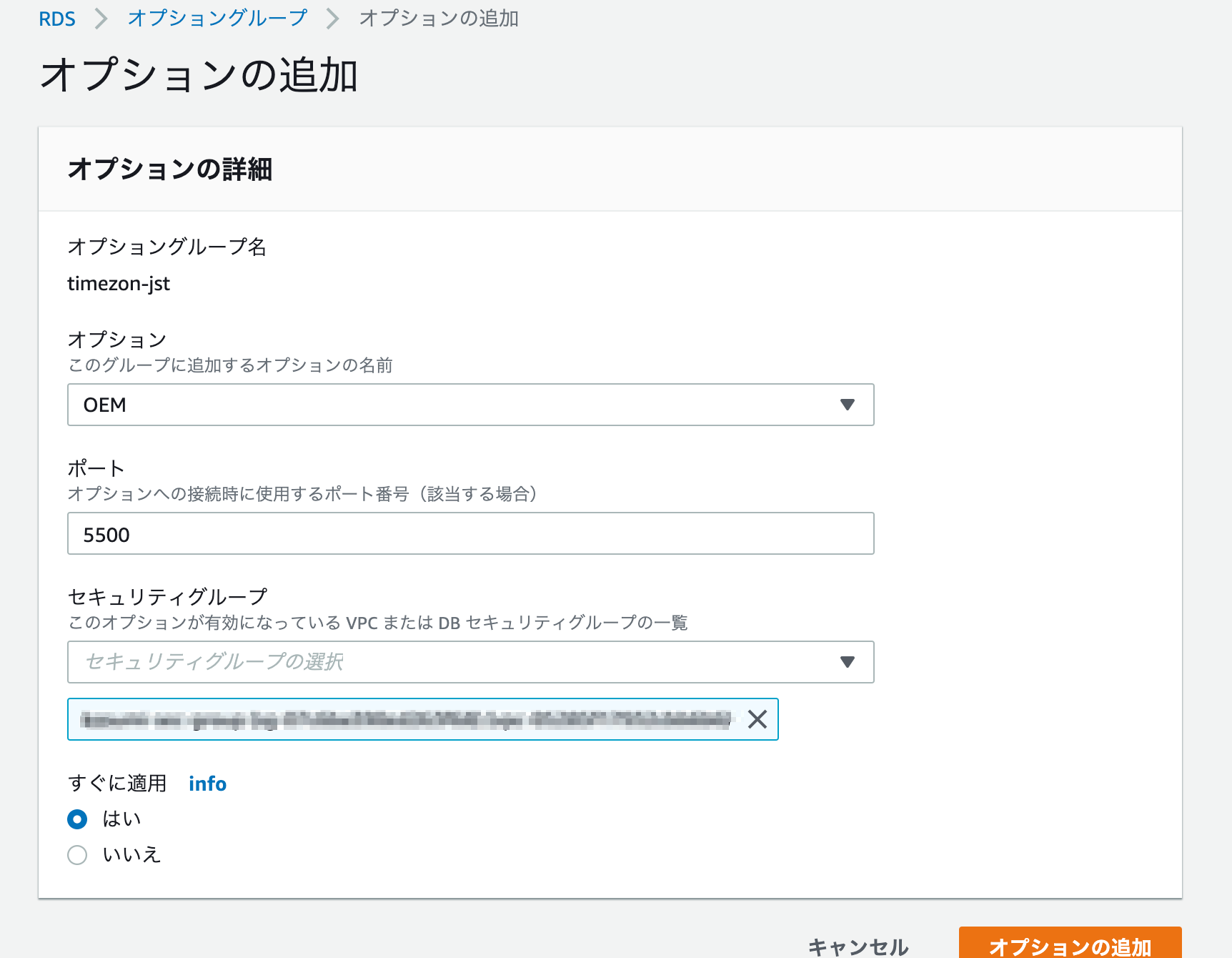
オプショングループの設定
RDSのコンソールから
オプショングループ→オプションに追加
オプションに
OEMを選択
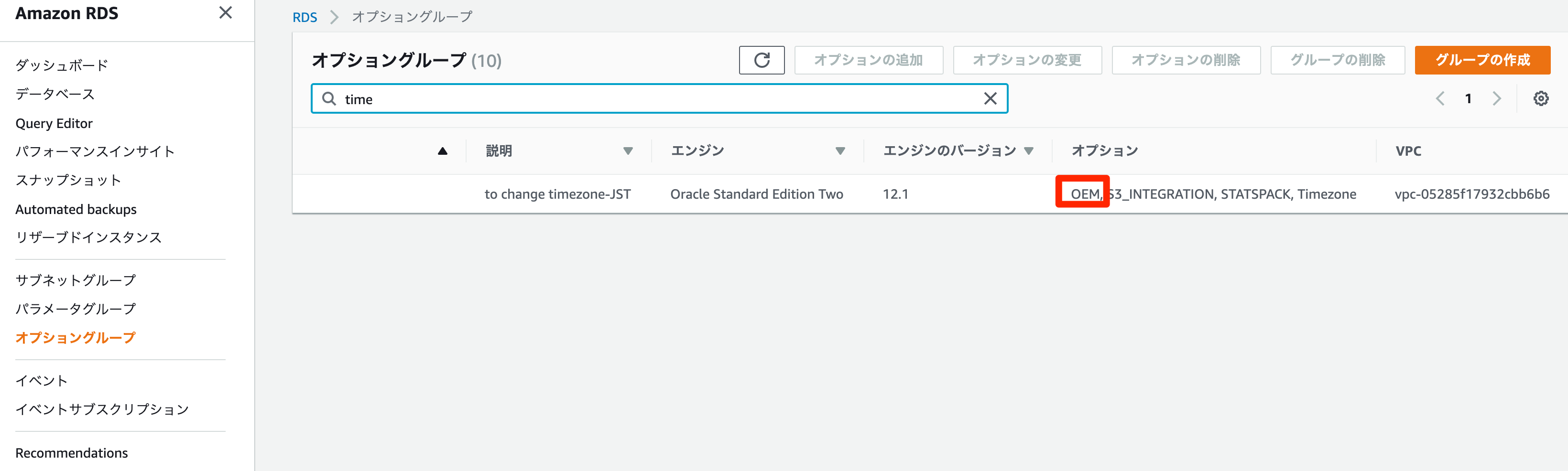
すでにオプショングループがインスタンスに紐付いているので、インスタンスに反映されます(インスタンスの再起動はありません)。
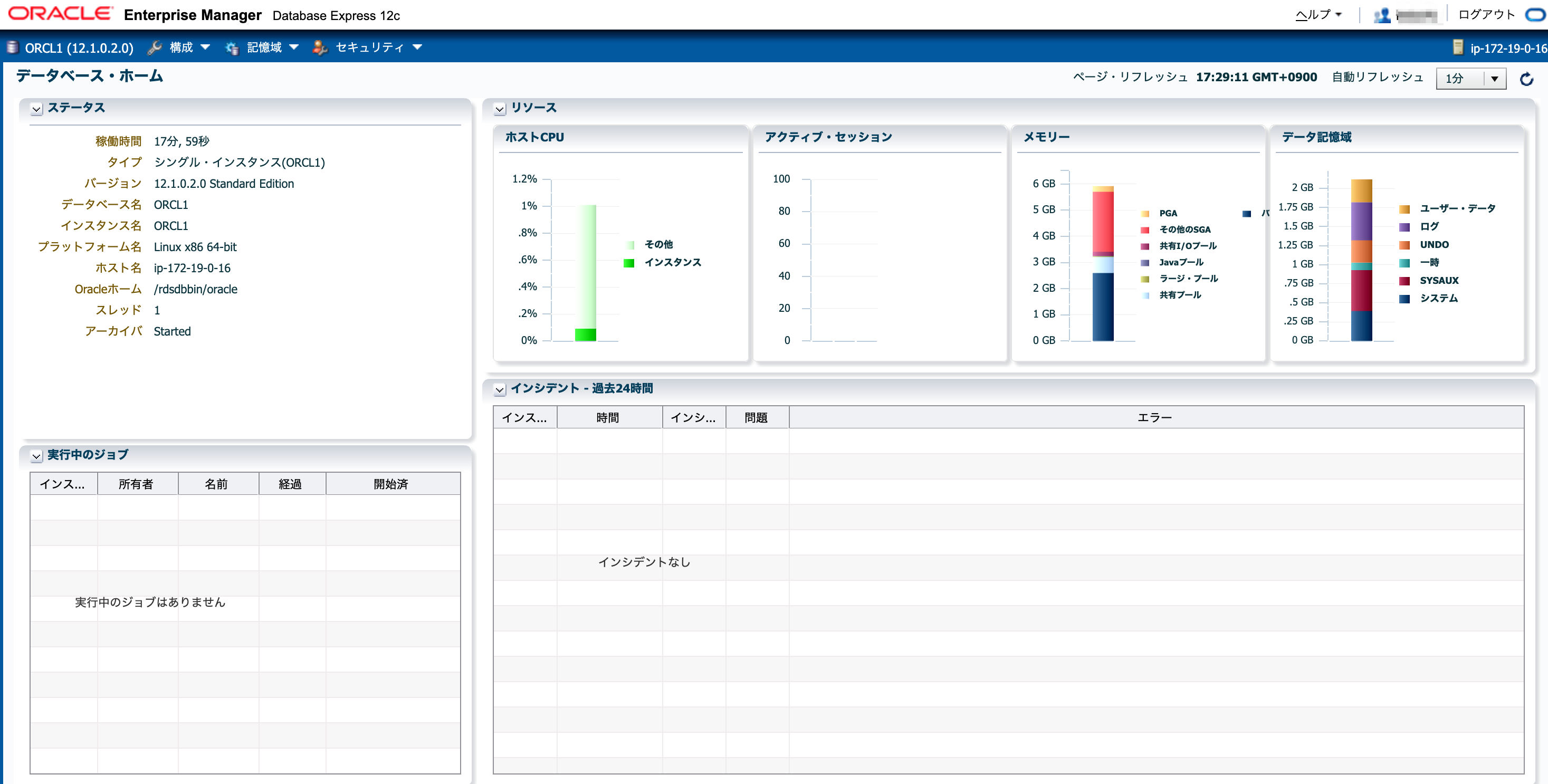
EMにアクセス
ブラウザ経由でEMにアクセスします。
今回、パブリックサブネット上に踏み台サーバ(Amazon Linux)、プライベートサブネット上にRDS(Oracle)があるためポートフォワードして続します。
- ローカルPC(今回はmac)でポートフォワード
$ ssh -L 13389:orcl1.xxxx.us-west-2.rds.amazonaws.com:5500 -i <踏み台のキーペア> ec2-user@<踏み台のパブリックIPアドレス> Last login: Mon Jul 8 08:14:36 2019 from 210.227.234.114 __| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/ 7 package(s) needed for security, out of 13 available Run "sudo yum update" to apply all updates. [ec2-user@ip-10-0-0-223 ~]$
- この状態で下記URLをブラウザに入れます
https://localhost:13389/em
ユーザ名とパスワードに
マスターユーザのユーザ名とパスワードを入れログインします
無事ログインできました
参考


- 投稿日:2019-07-08T15:06:24+09:00
【RDS for Oracle】初期化パラメータの変更
はじめに
RDSでは
alter system文での初期化パラメータの変更ができない。
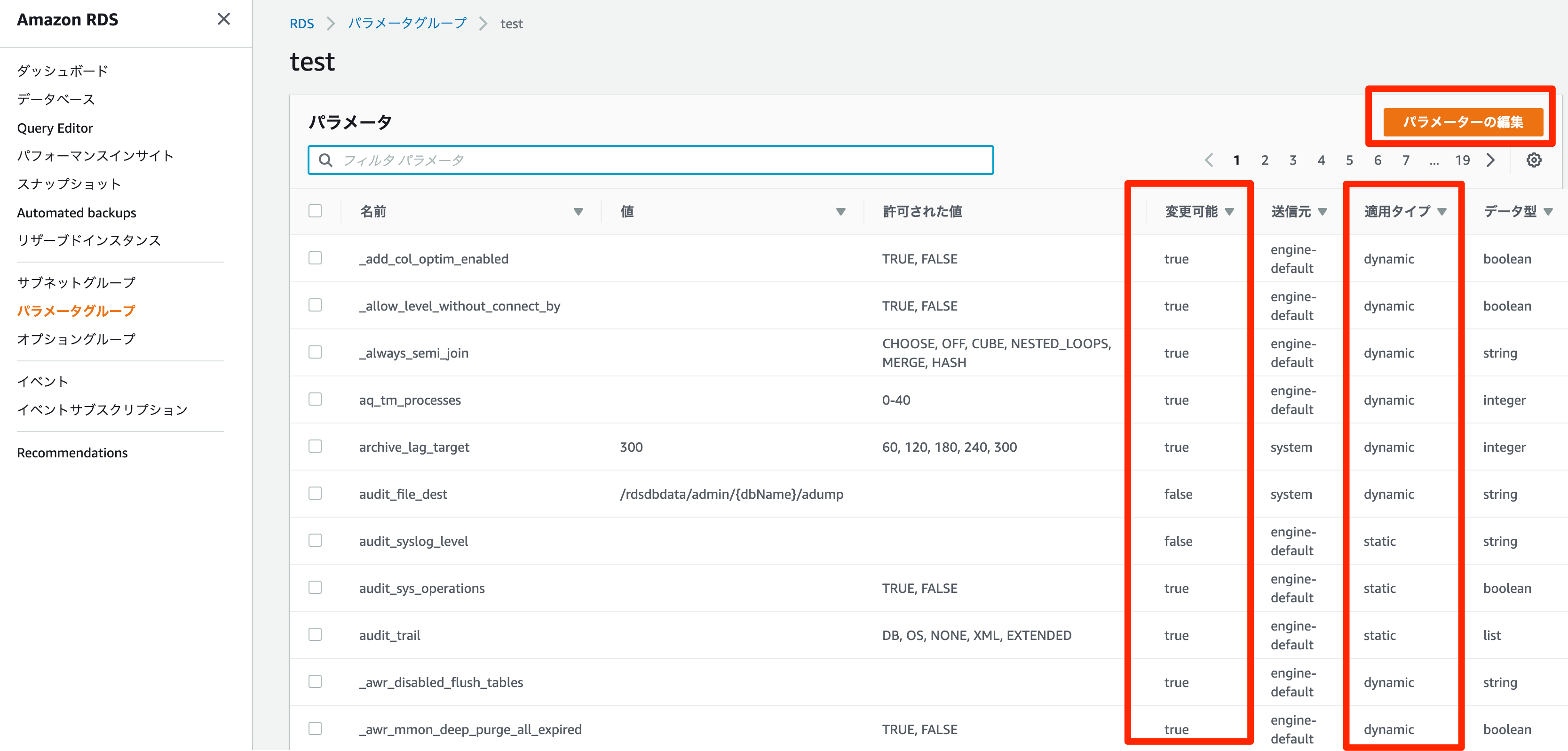
RDSの場合パラメータグループを作成し初期化パラメータを変更する。変更できる初期化パラメータは
変更可能列がtrueの初期化パラメータのみとなる。
また、パラメータグループの適用タイプにより、変更時の動作が変わる。
適用タイプ 初期化パラメータ変更時の動作 dynamic 即時変更が有効 static インスタンス再起動後変更が有効 パラメータグループの作成
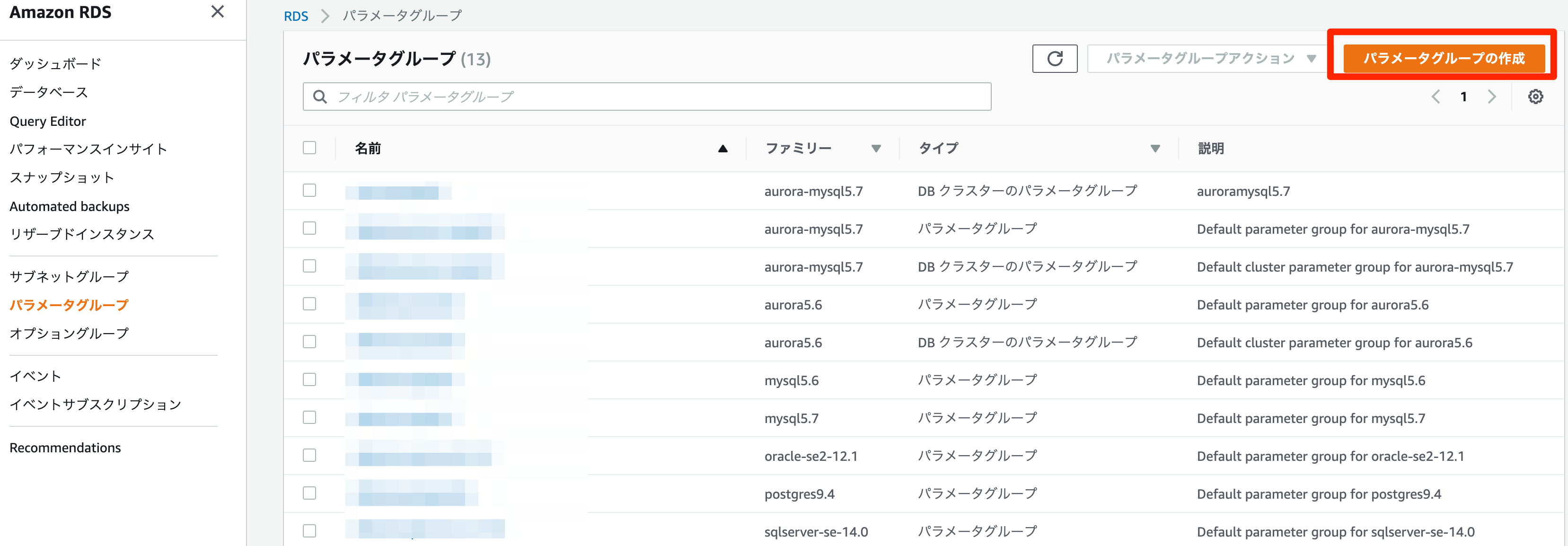
パラメータグループからパラメータグループの作成
パラメータグループファミリーを選択し、グループ名と説明を記入し作成
パラメータの編集から初期化パラメータを変更できる。
作成したパラメータグループをインスタンスに付け替える。
参考
- 投稿日:2019-07-08T14:46:57+09:00
【RDS for Oracle】リストアのやりかた
はじめに
AWSのユーザガイド「DB スナップショットの復元」によると。。。
復元すると新しい DB インスタンスが作成
されるらしいです。なので
エンドポイントも変わるみたい。マネージメントコンソールからのリカバリ方法
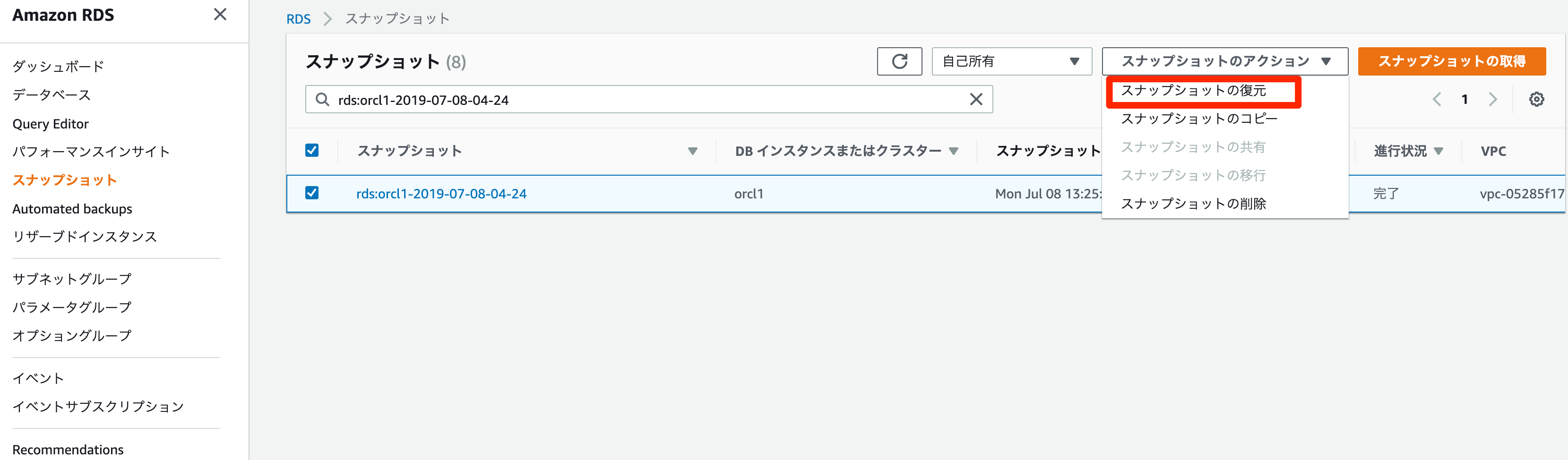
- RDS コンソールから
Snapshotsを選択- 復元の元にする DB スナップショットを選択
スナップショットのアクション、スナップショットの復元の順に選択
DB インスタンスの復元ページで、DB インスタンス識別子に、復元された DB インスタンスの名前を入力DBインスタンスの復元を選択
- スナップショットが作成された DB インスタンスの DB インスタンス機能を復元する場合は、セキュリティグループを使用するために DB インスタンスを変更します。次のステップは、DB インスタンスが VPC 内にあることを前提としています。DB インスタンスが VPC 内にない場合は、EC2 マネジメントコンソールを使用して、DB インスタンスに必要な DB セキュリティグループを見つけます。
- VPC コンソールから
セキュリティグループを選択- DB インスタンスで使用するセキュリティグループを選択
- 必要に応じて、EC2 インスタンスのセキュリティグループにセキュリティグループをリンクするためのルールを追加します。詳細については、VPC 内の DB インスタンスに同じ VPC 内の EC2 インスタンスがアクセスするを参照してください
AWS CLIでのリカバリ方法
- Linux、OS X、Unix の場合:
aws rds restore-db-instance-from-db-snapshot \ --db-instance-identifier <Newインスタンス名> \ --db-snapshot-identifier <mydbsnapshot>
- Windows の場合
aws rds restore-db-instance-from-db-snapshot ^ --db-instance-identifier <Newインスタンス名> ^ --db-snapshot-identifier <mydbsnapshot>https://www.cloud-koubou.jp/archives/1175
補足
AWSのDBサービスのバックアップ取得時間などは「AWS データベースサービスの自動バックアップ設定まとめ」にまとまってます。

- 投稿日:2019-07-08T14:05:35+09:00
一番意識の低いAWS CloudWatch Insights入門
昨年末にAWSに追加されたAmazon CloudWatch Logs Insightsが結構便利です。
せっかくなので、最低限のやる気でなんとなく使えるようになっておきましょう。5分くらいで。インサイトを開いてみる
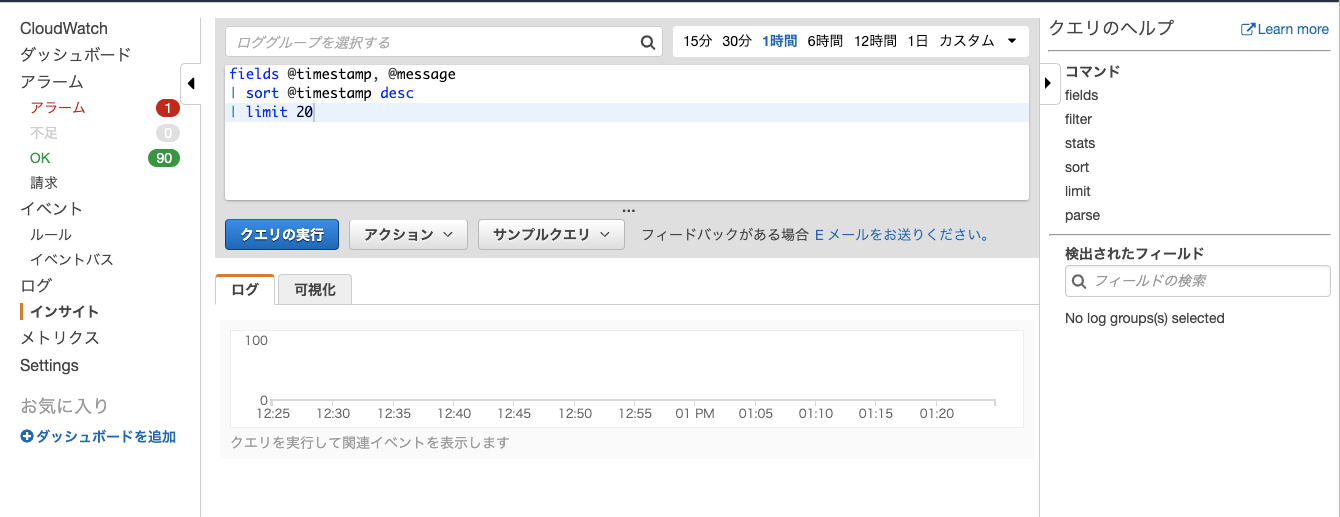
ひとまずマネコンのCloudWatchの左のメニューからインサイトを開いてみるとこんな感じの画面になります。
ログを表示してみる
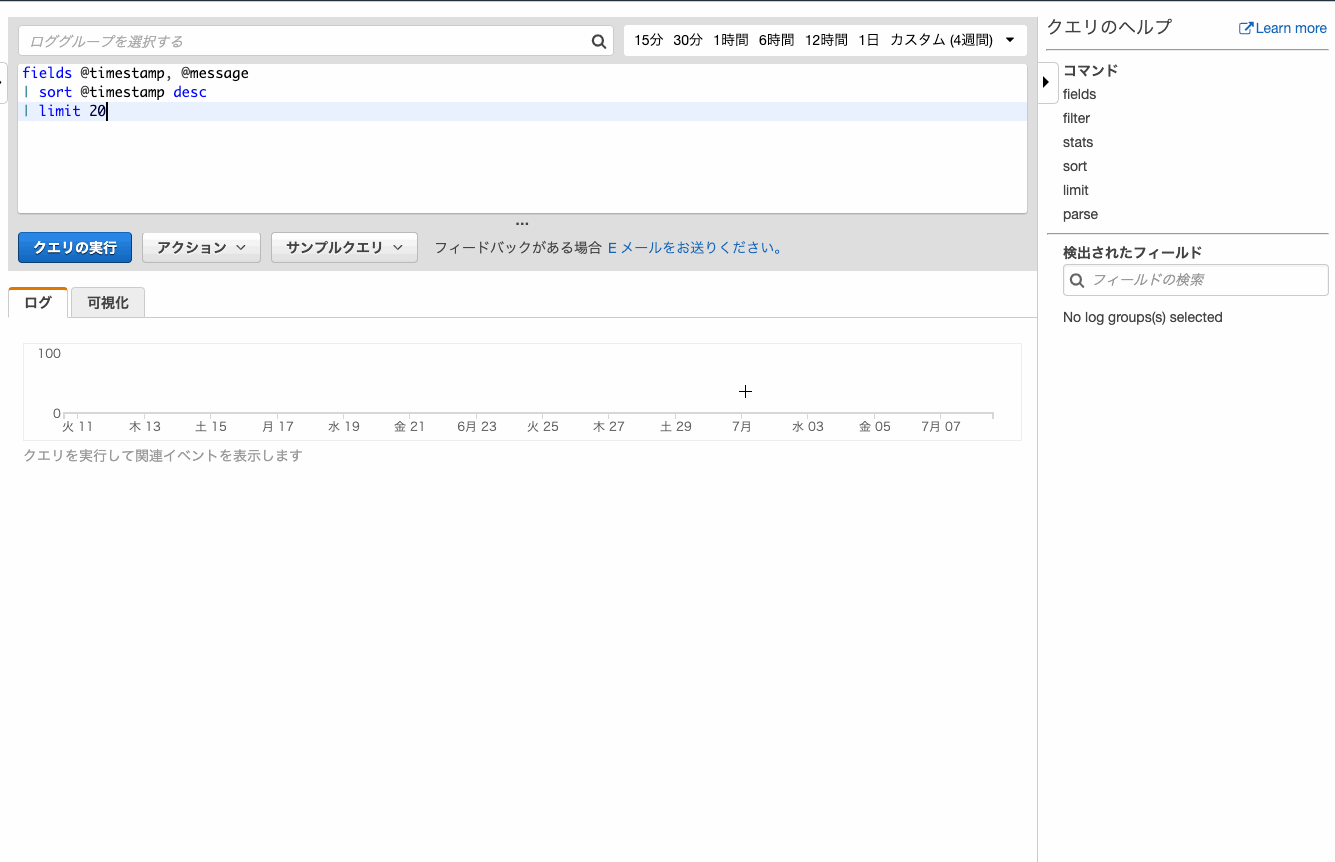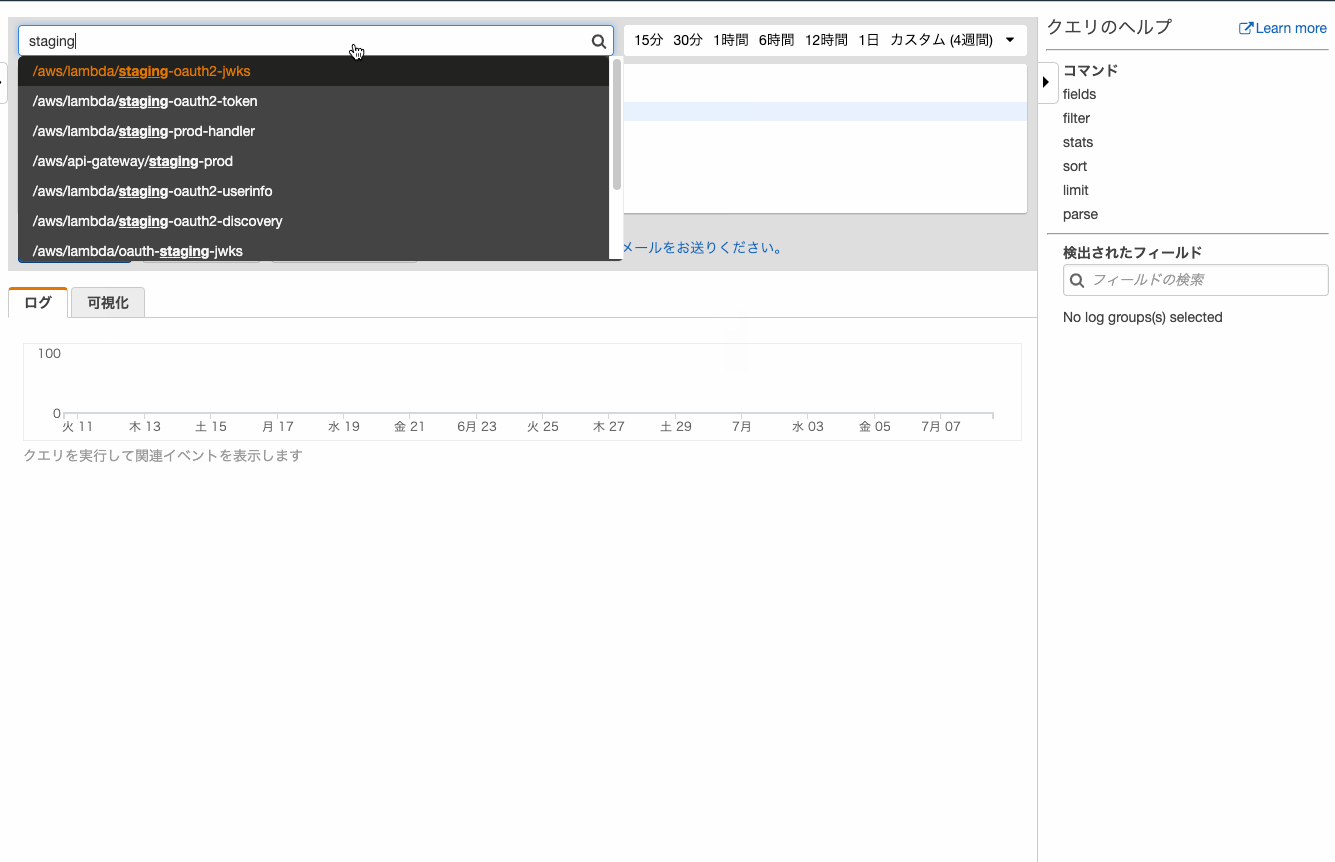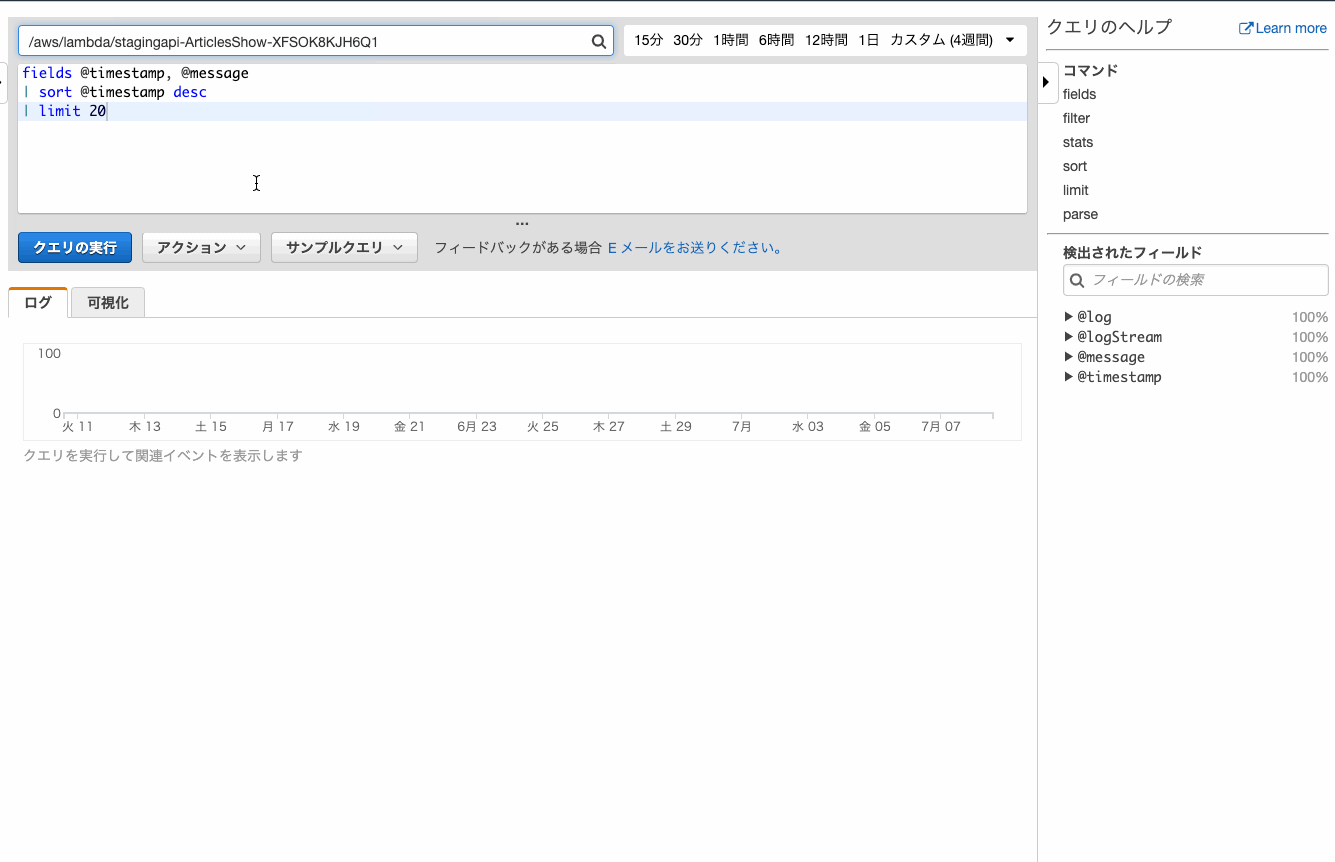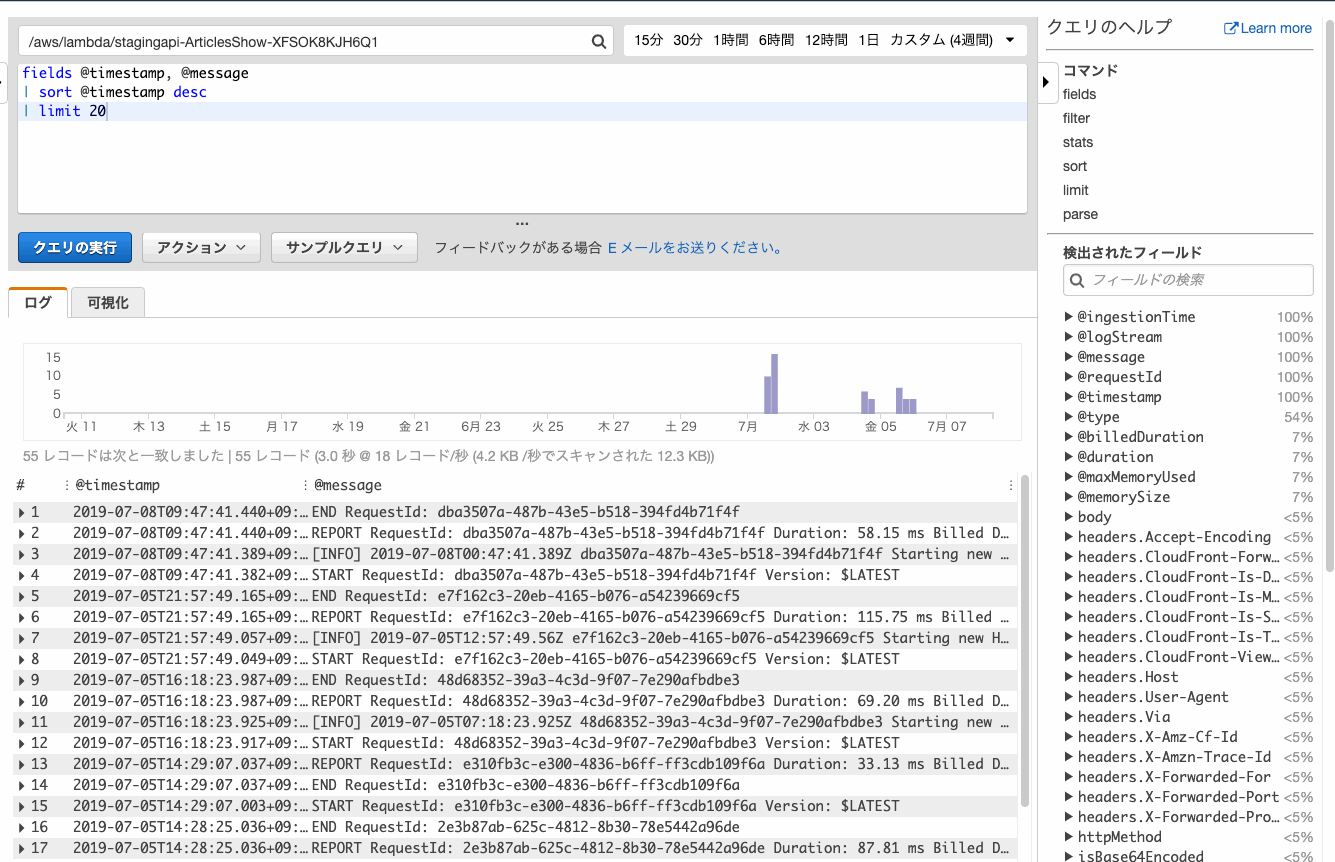
まずは何も考えずにログを表示してみましょう。
AWSのマネコンにしては珍しく、部分一致のインクリメンタルサーチをしてくれるので快適に目的のロググループにたどり着けます。
エラーを探してみる
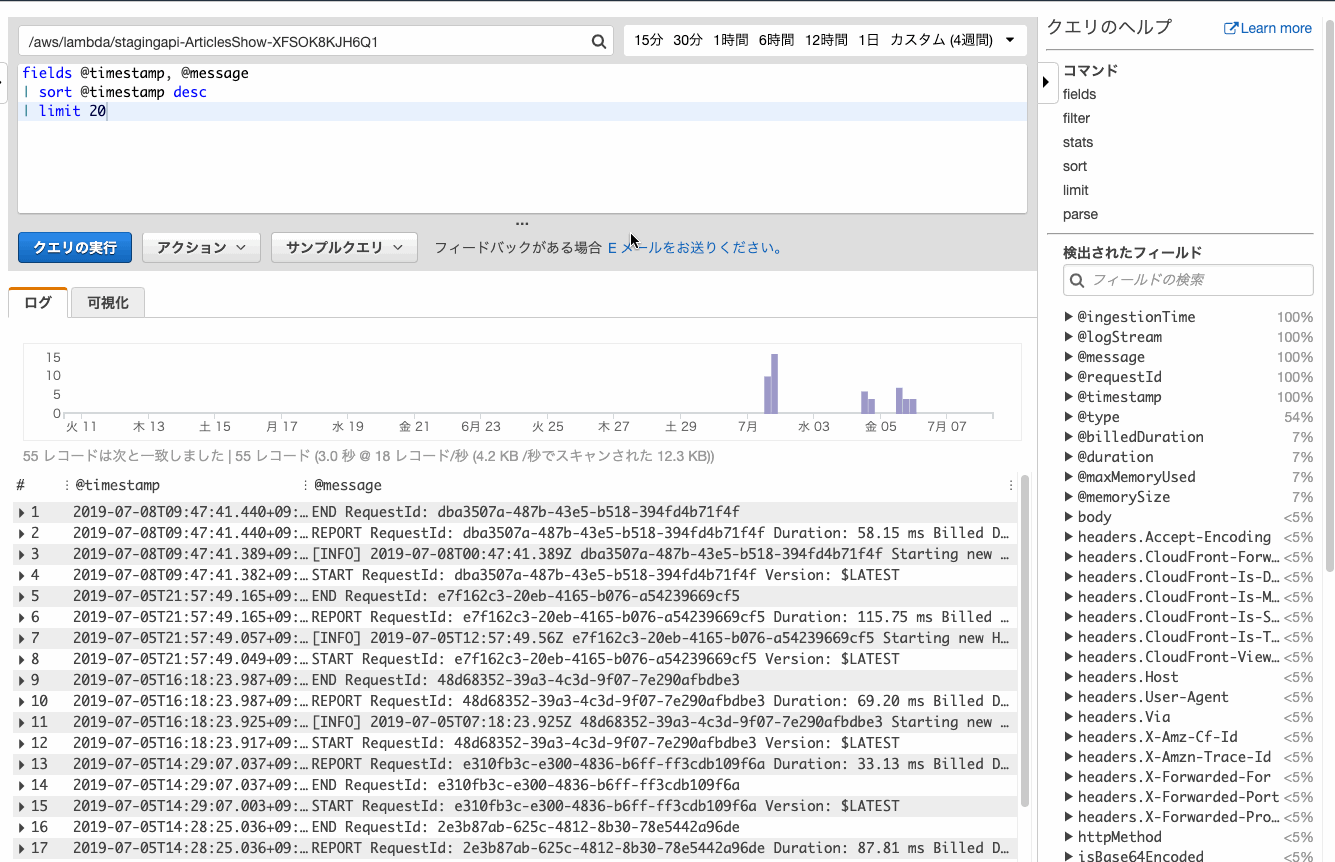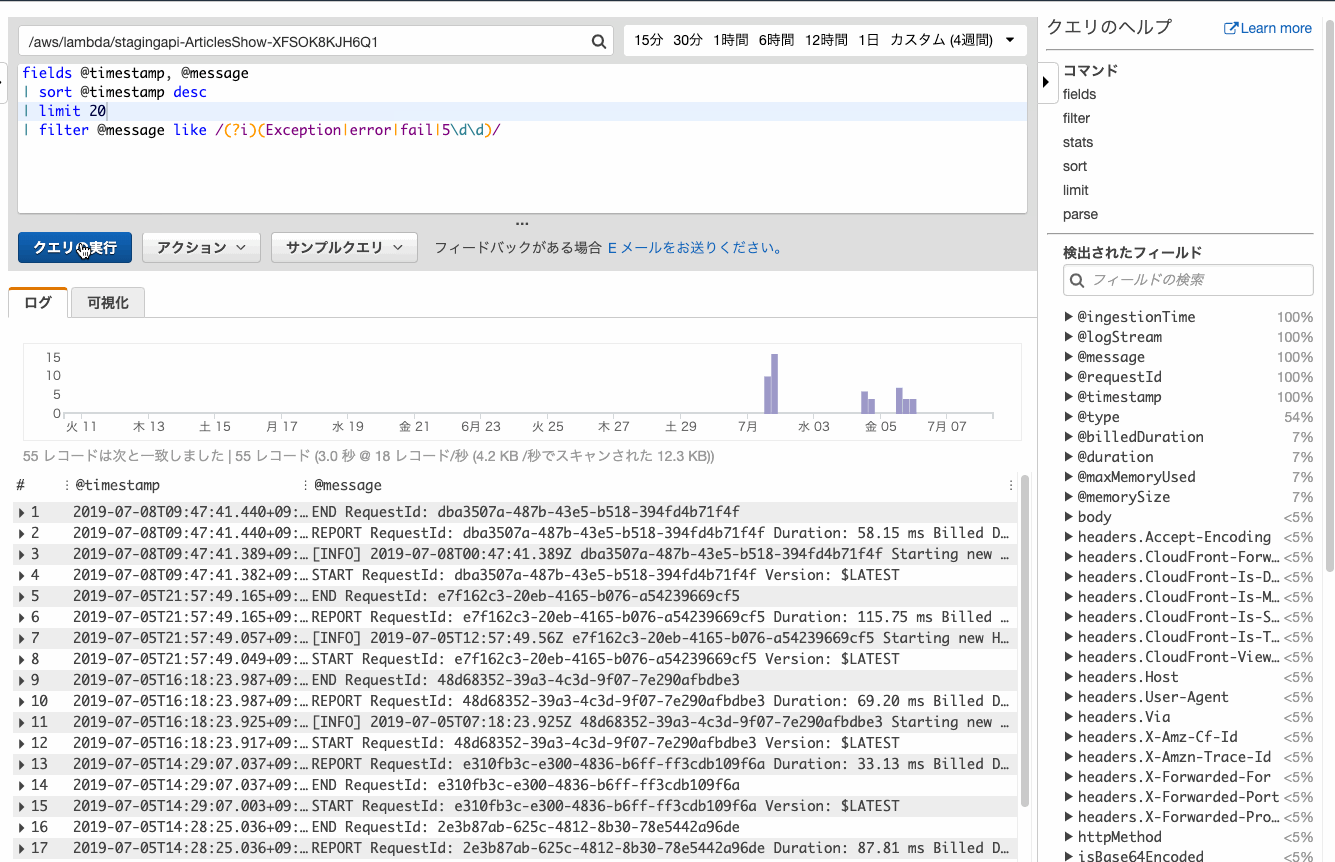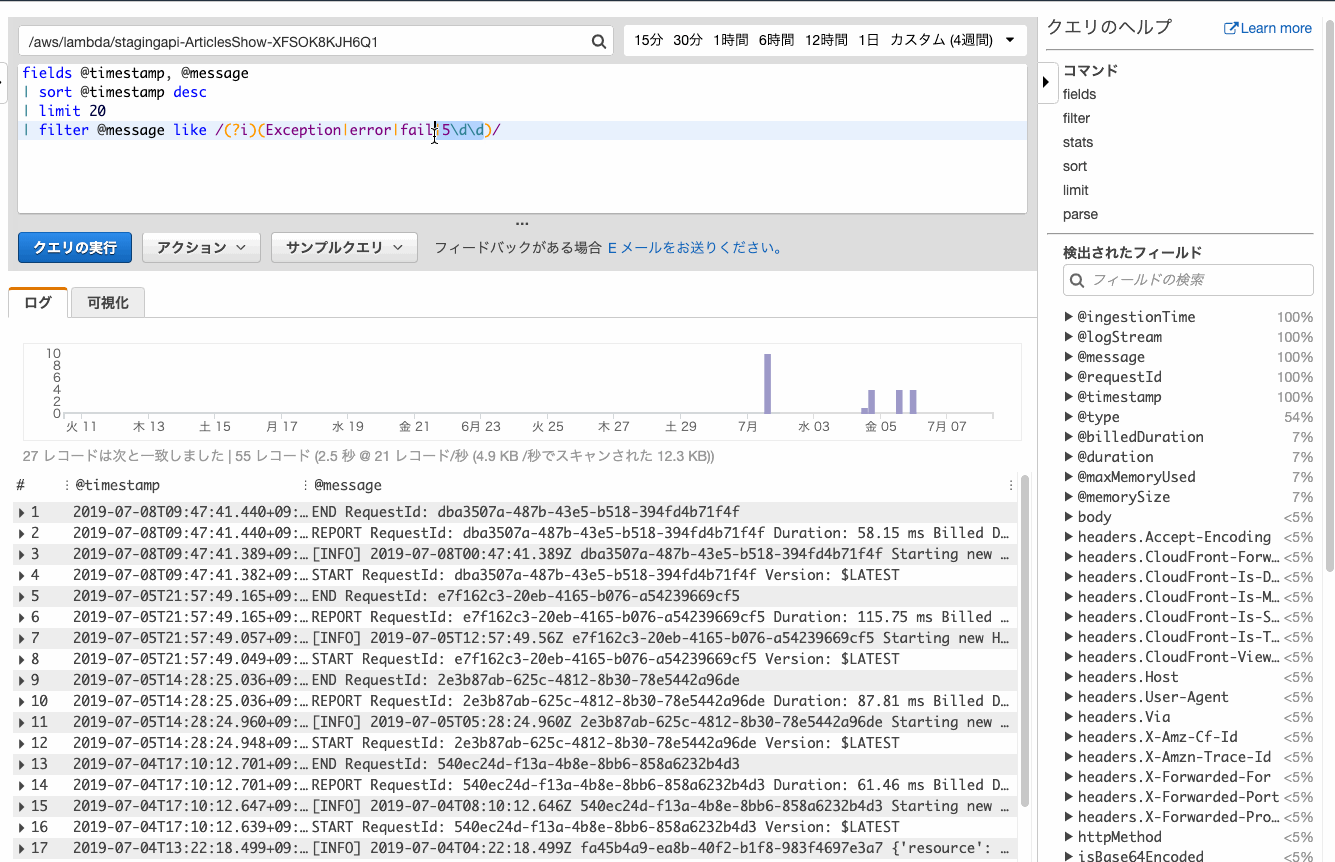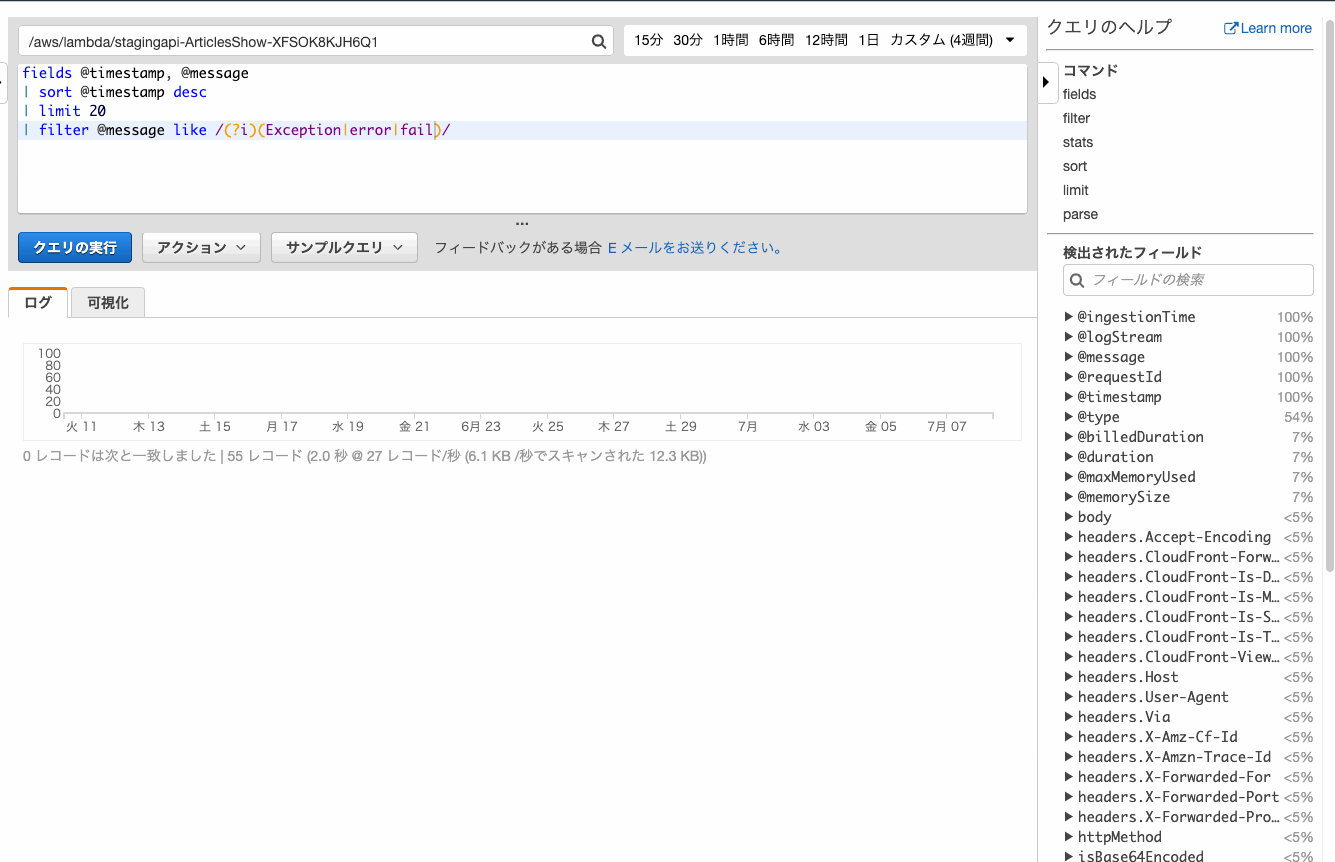
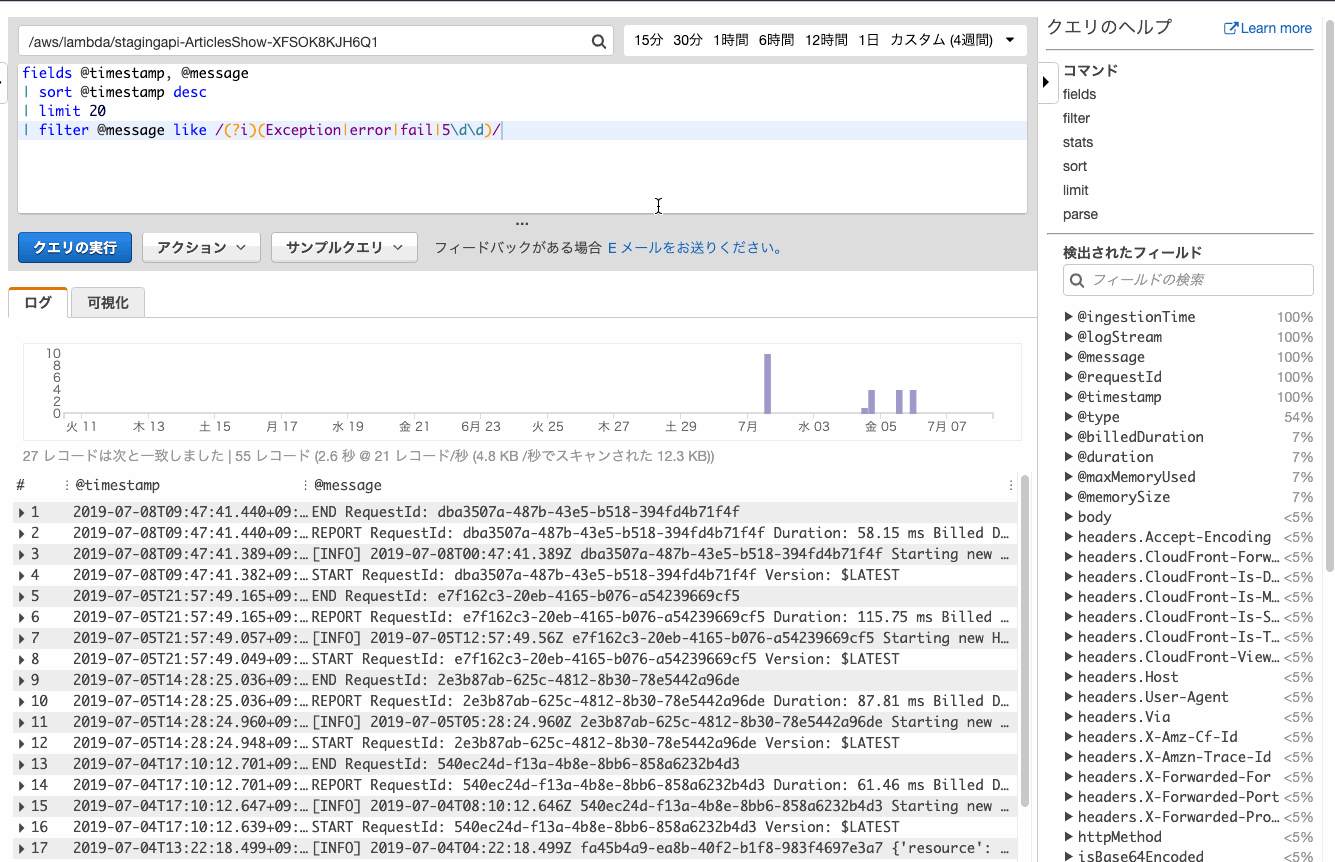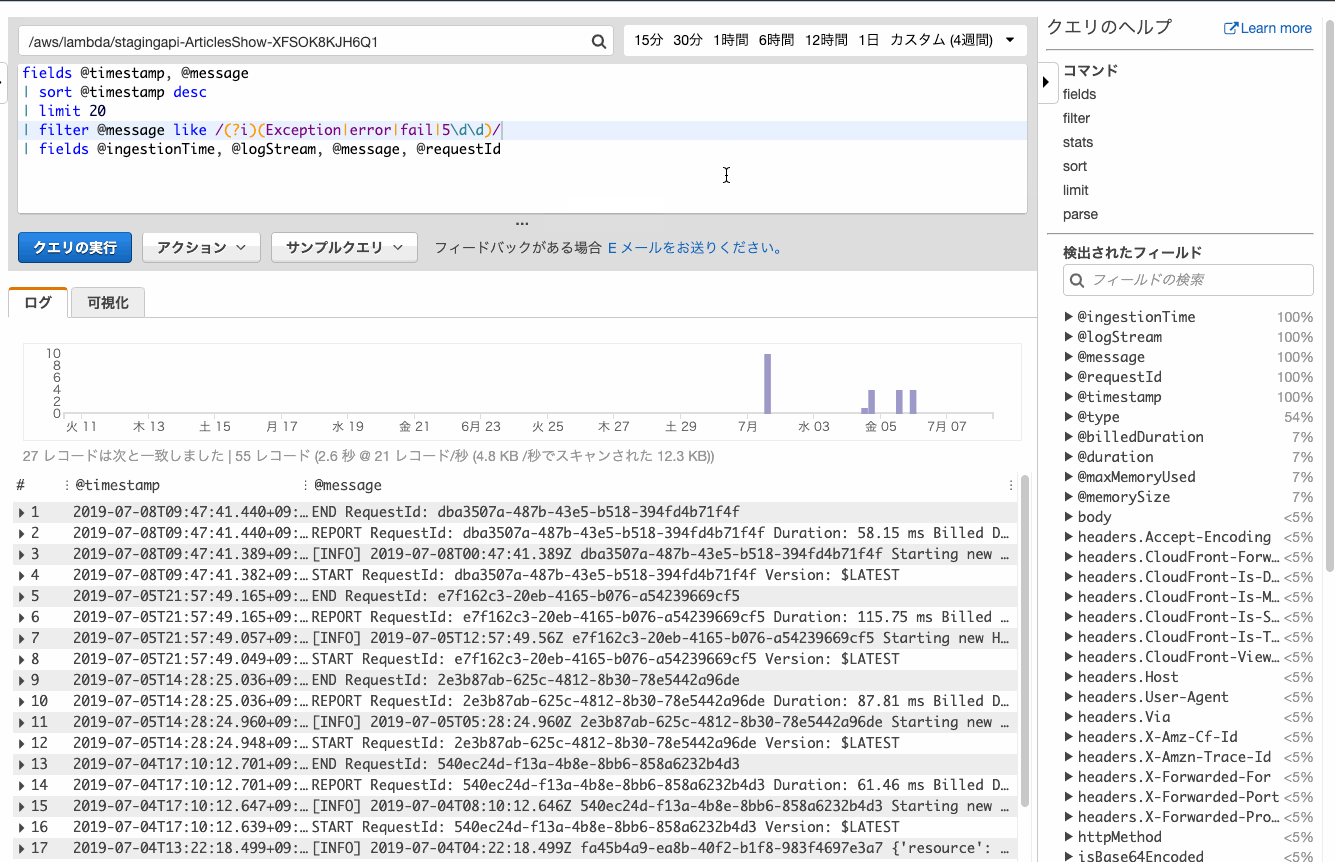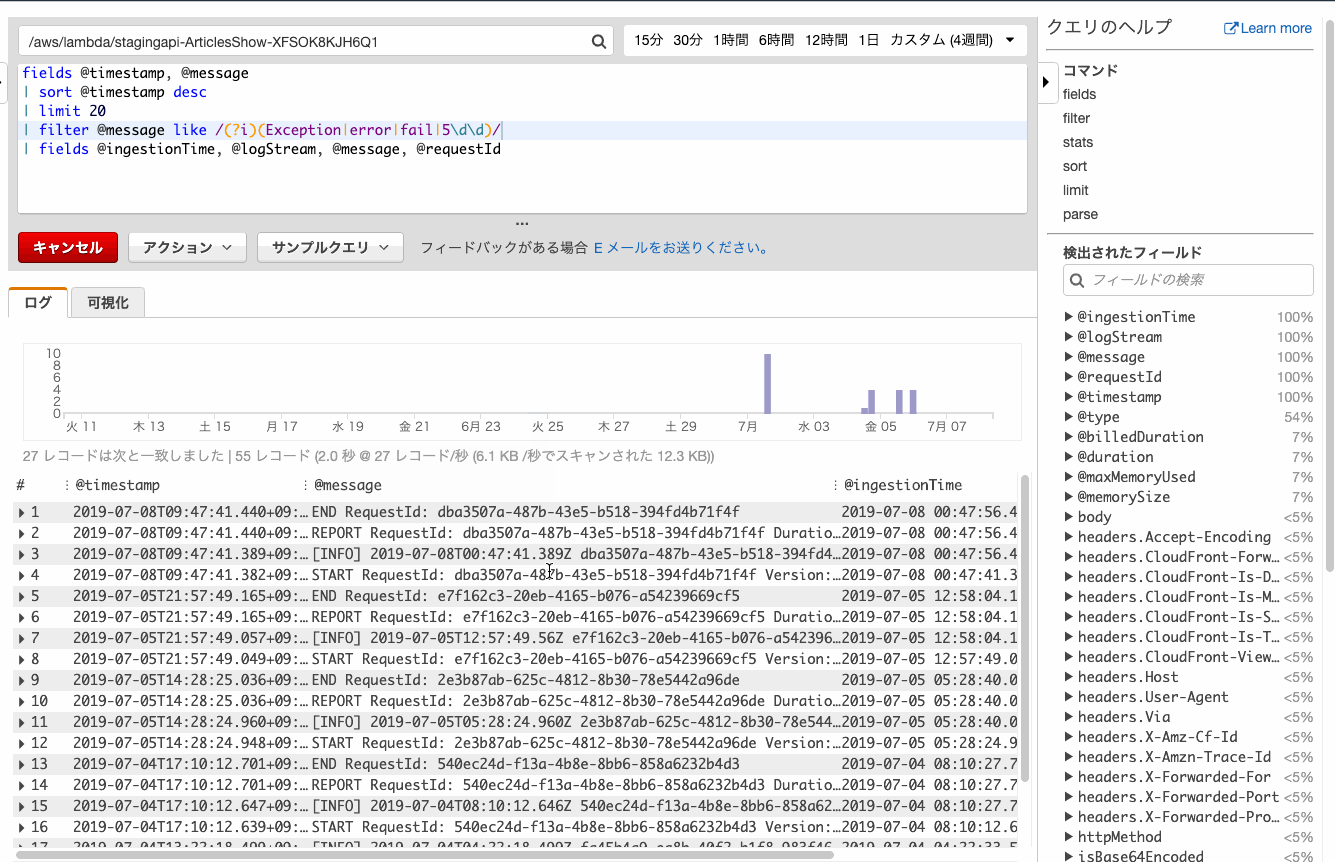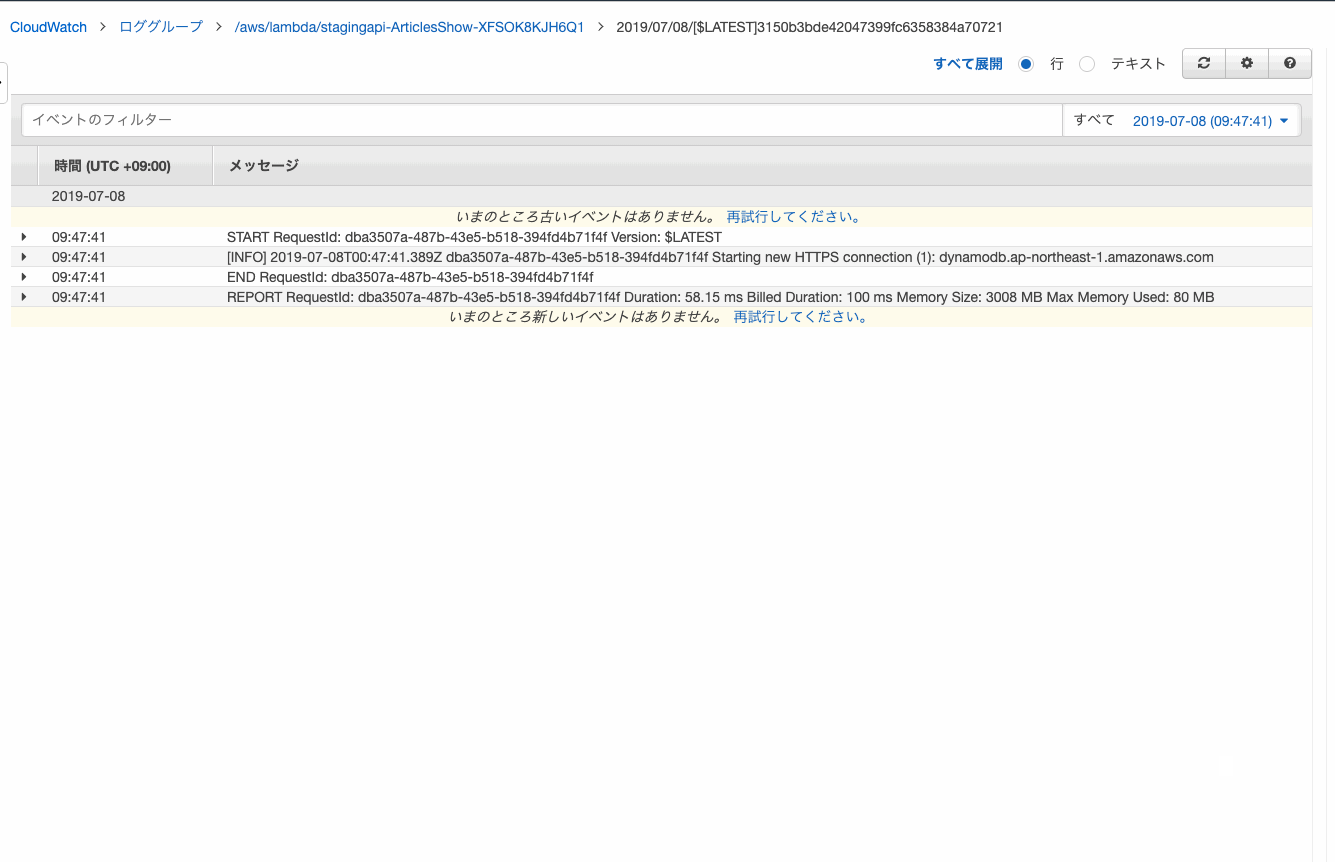
ログからエラーを抽出してみます。
何も考えずにデフォルトのfilterを追加すると、親切にエラーっぽい文字列の正規表現が追加されます。
⬆の手順では5\d5\dはノイズが混じることが多いので除却しています。
ヒットしたログの詳細を確認する
ヒットしたログの前後を見たい場合も多いでしょう。
そんな場合は何も考えずにfieldsを追加しましょう。クエリでいろいろ重複しててもOKぽいです。
@logStreamのフィールドがリンクとなり、おなじみログストリームでの確認ができました。時間を絞ってログを確認する
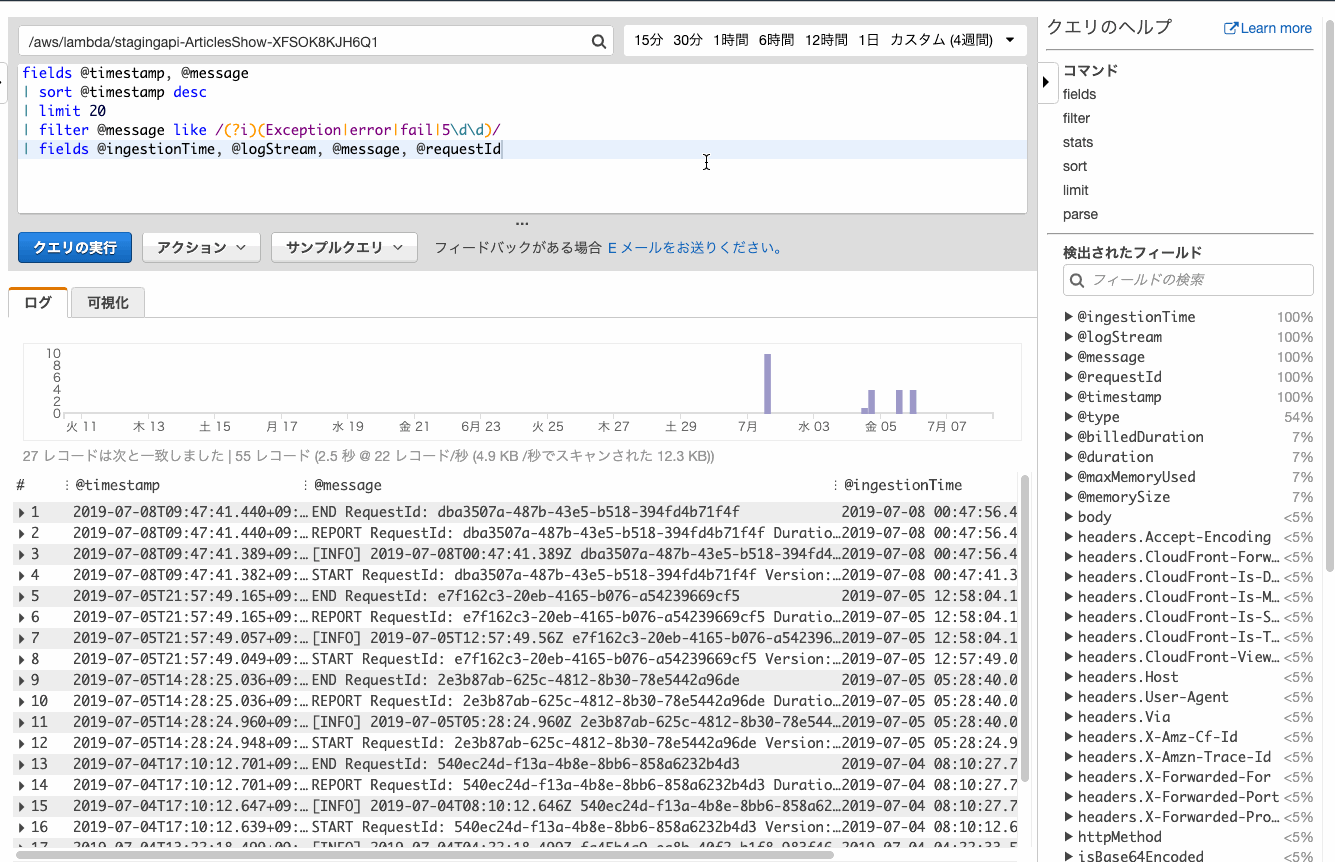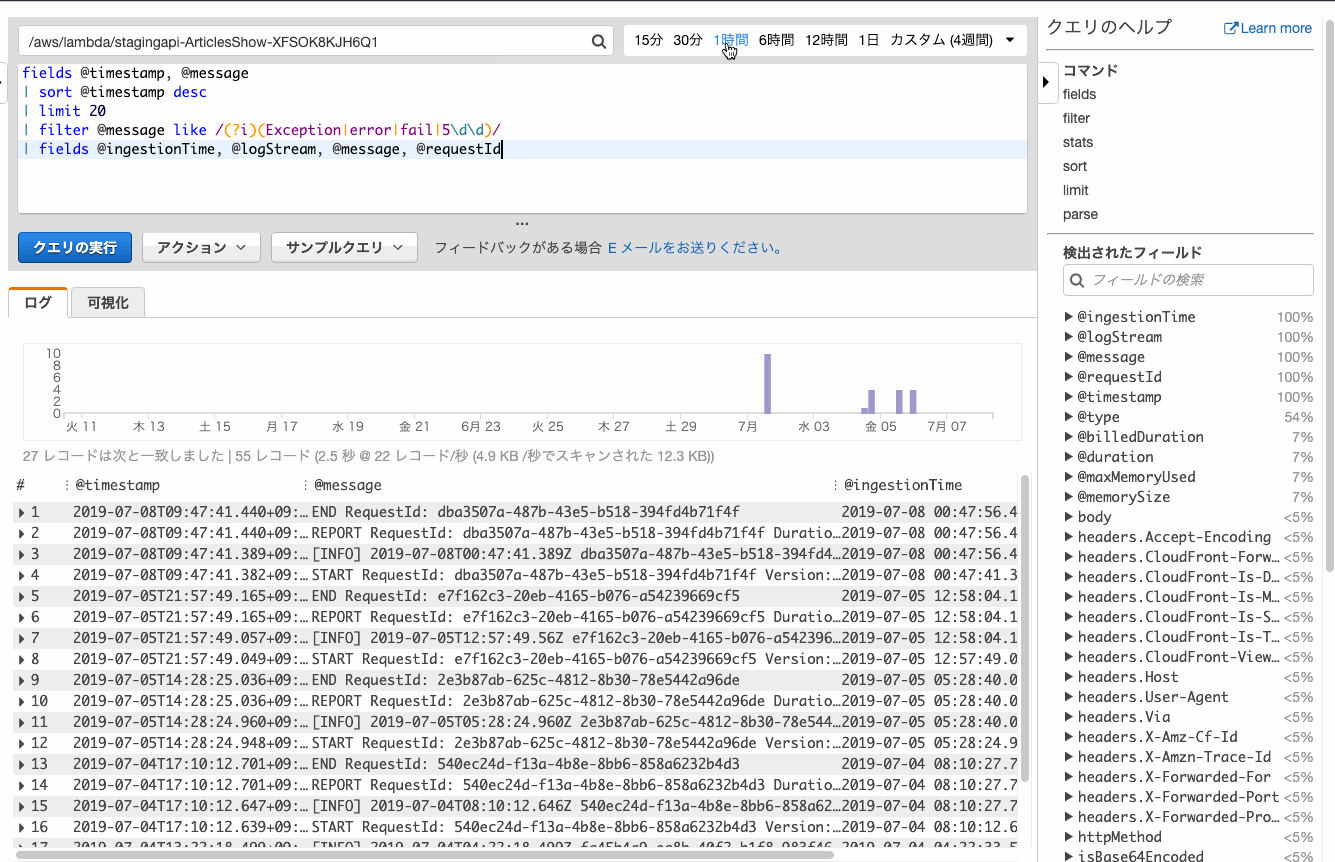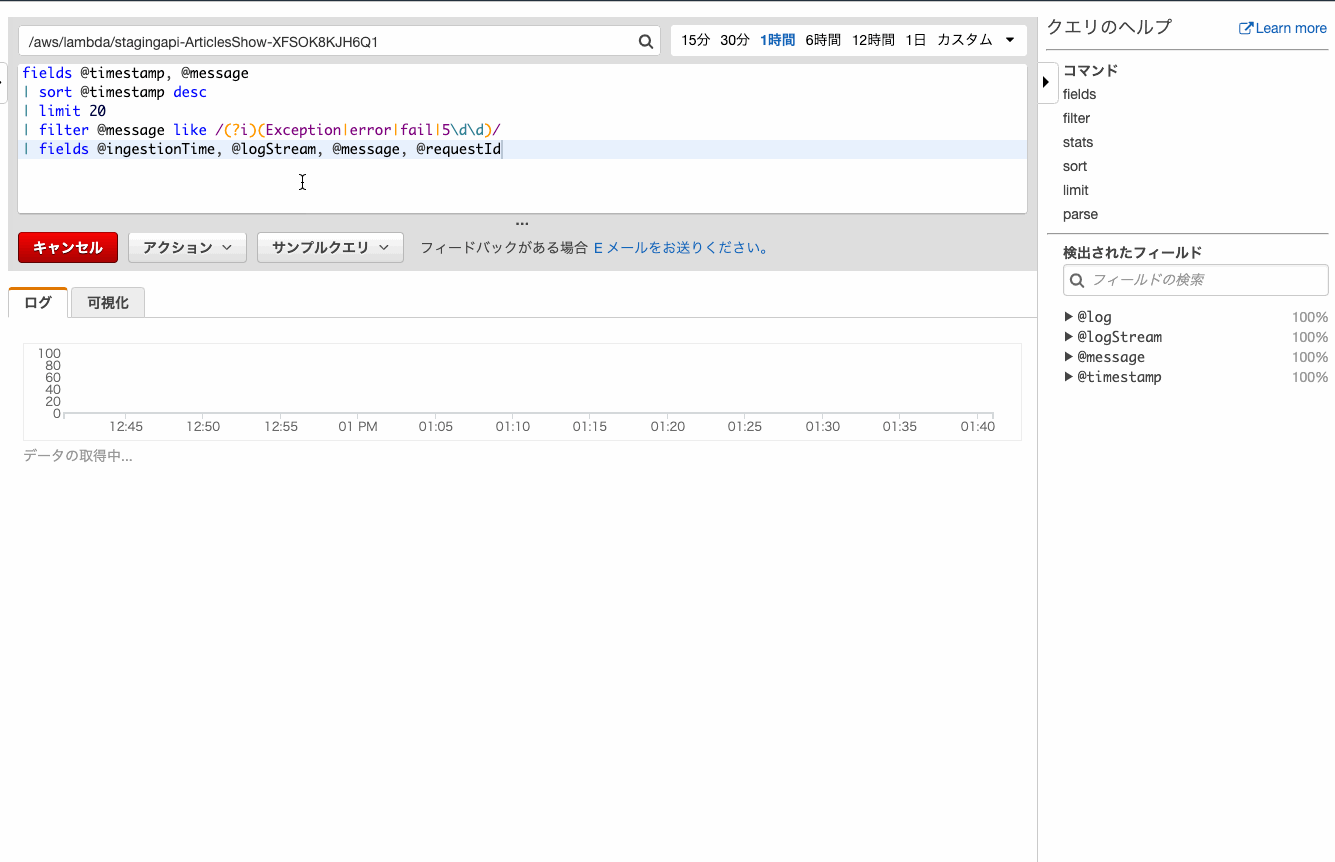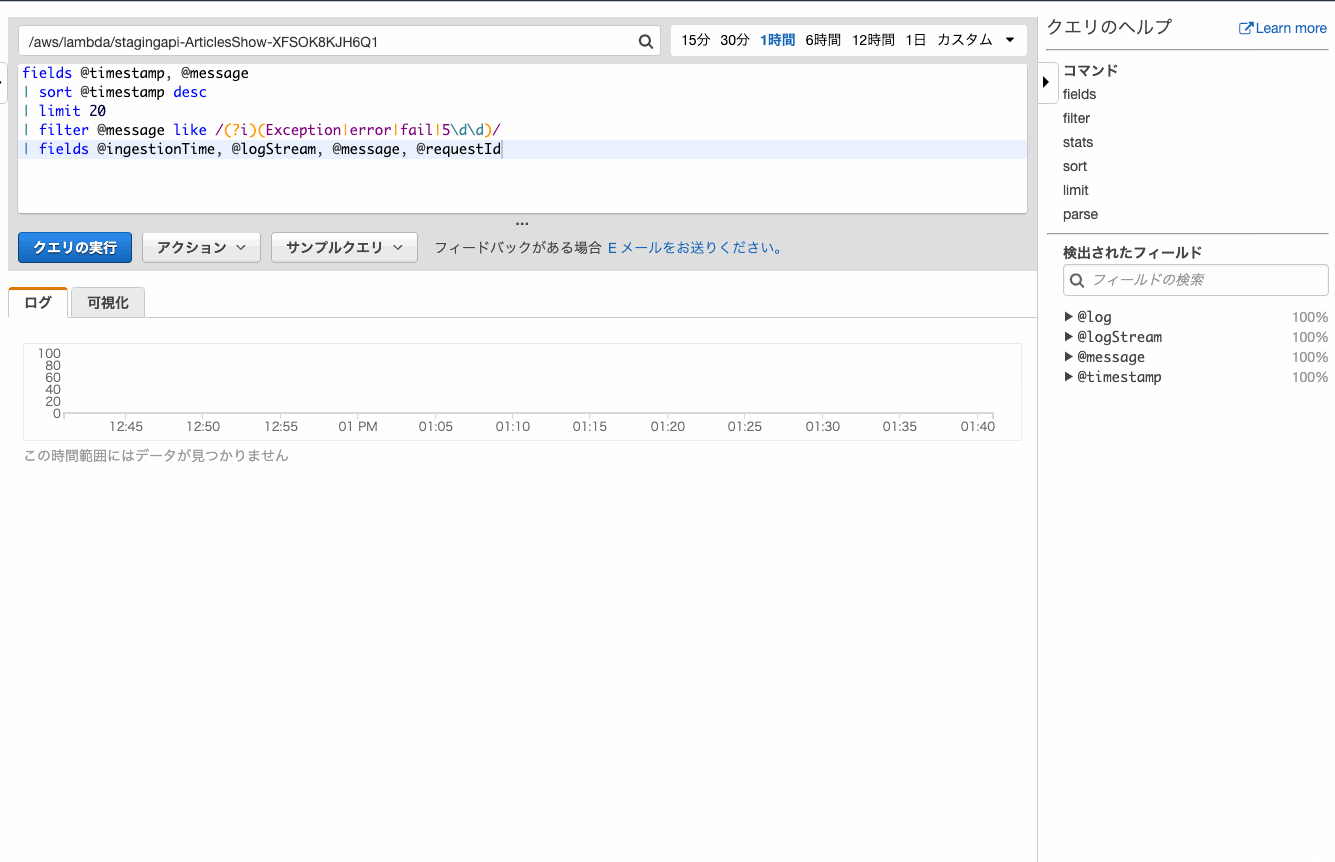
数分前に起こったエラーが確認したい、という場合は時間を絞ると効率が良いです。
1時間以内にはエラーが起こっていないことが確認できました。
所感
- CloudWatchを利用するなら使うべき
- 手軽にログ調査の時間が短縮できます
- AWSにしては珍しく親切な仕様
- 部分一致のインクリメンタルサーチとかコマンドからクエリを追加した時にいい感じのデフォルト値が入ってることとか、使い勝手がかなり良いです
- おかげでなんとなく使うだけでも効用が得られます
- 投稿日:2019-07-08T13:34:34+09:00
【RDS for Oracle】ノーアーカイブログモードへ変更
はじめに
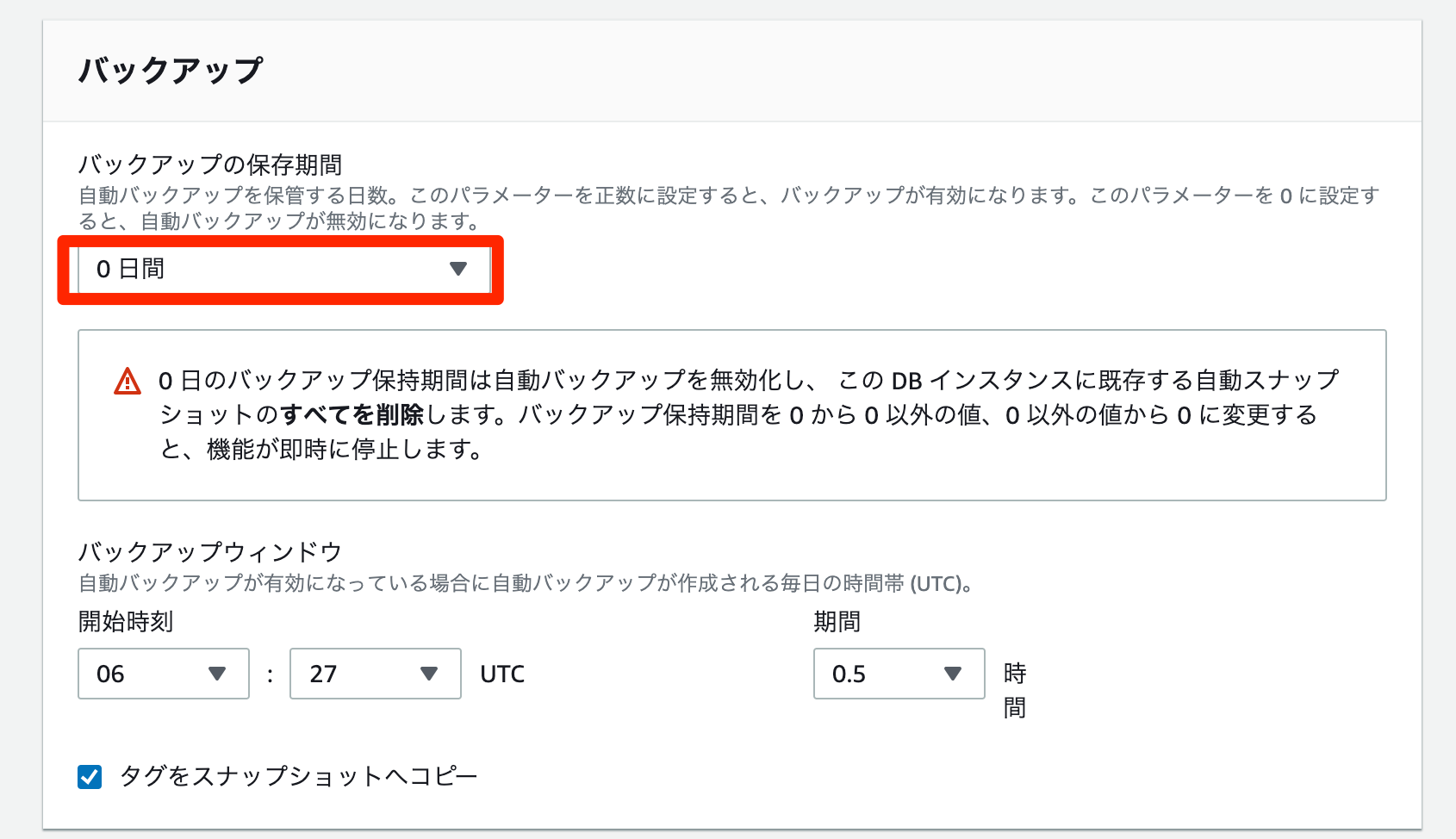
AWSのユーザガイドを確認すると。。。
大量のデータをロードしている間など、特定の状況では、自動バックアップを一時的に無効にすることをお勧めします。
とあります。
デフォルトはアーカイブログモードのため、DataPumpなどでインポートしたとき、アーカイブログが大量に生成されディスクを圧迫する恐れがあるということですね。オンプレのOracleでもインポート前に
SQL> alter database noarchivelog;で、ノーアーカイブログモードにしてました。しかし、RDSではSYSやSYSTEMユーザでログインできず、alter database文も実行できません。
どうやら、RDS for Oracleのばあい、自動バックアップを無効化することで、アーカイブログモード(デフォルト)から
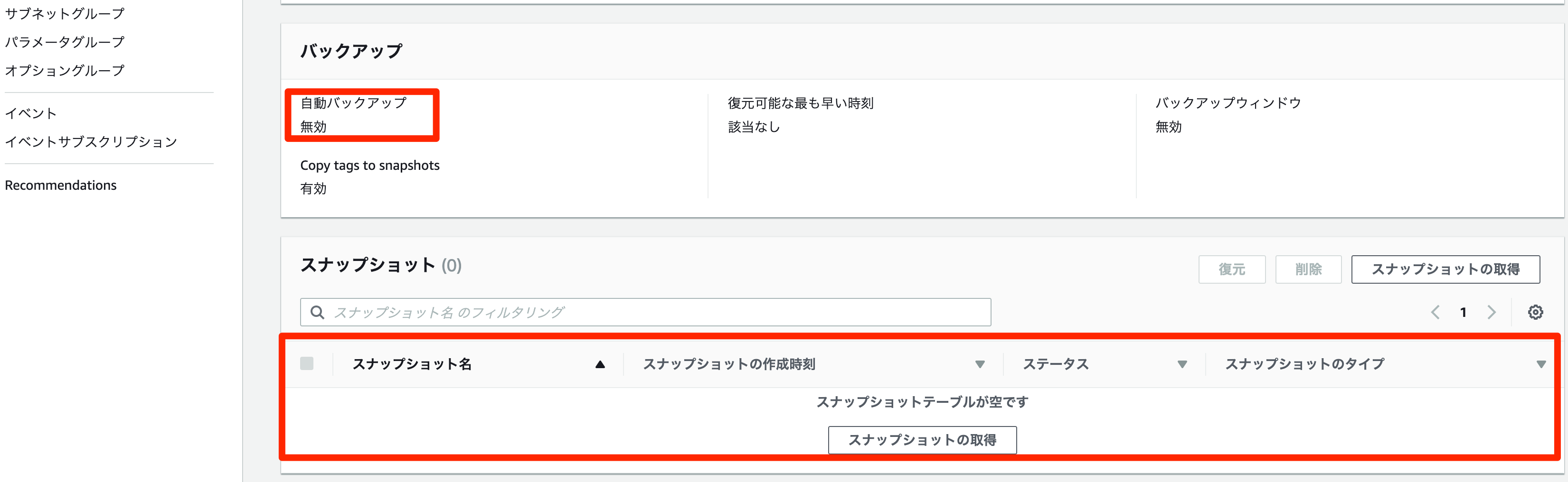
ノーアーカイブログモードに変更できるようです。自動バックアップを無効化した場合、以下の注意点があります。
移行などの作業時に一時的に無効するのがよさそうです。重要
自動バックアップは、無効にするとポイントインタイムリカバリも無効になるため、無効にしないことを強くお勧めします。DB インスタンスの自動バックアップを無効にすると、そのインスタンスの既存の自動バックアップがすべて削除されます。自動バックアップを無効にしてから再度有効にした場合、自動バックアップを再度有効にした時点からしか復元できません。また、自動バックアップの無効化(ノーアーカイブログモードへの変更)時にはDBインスタンスが
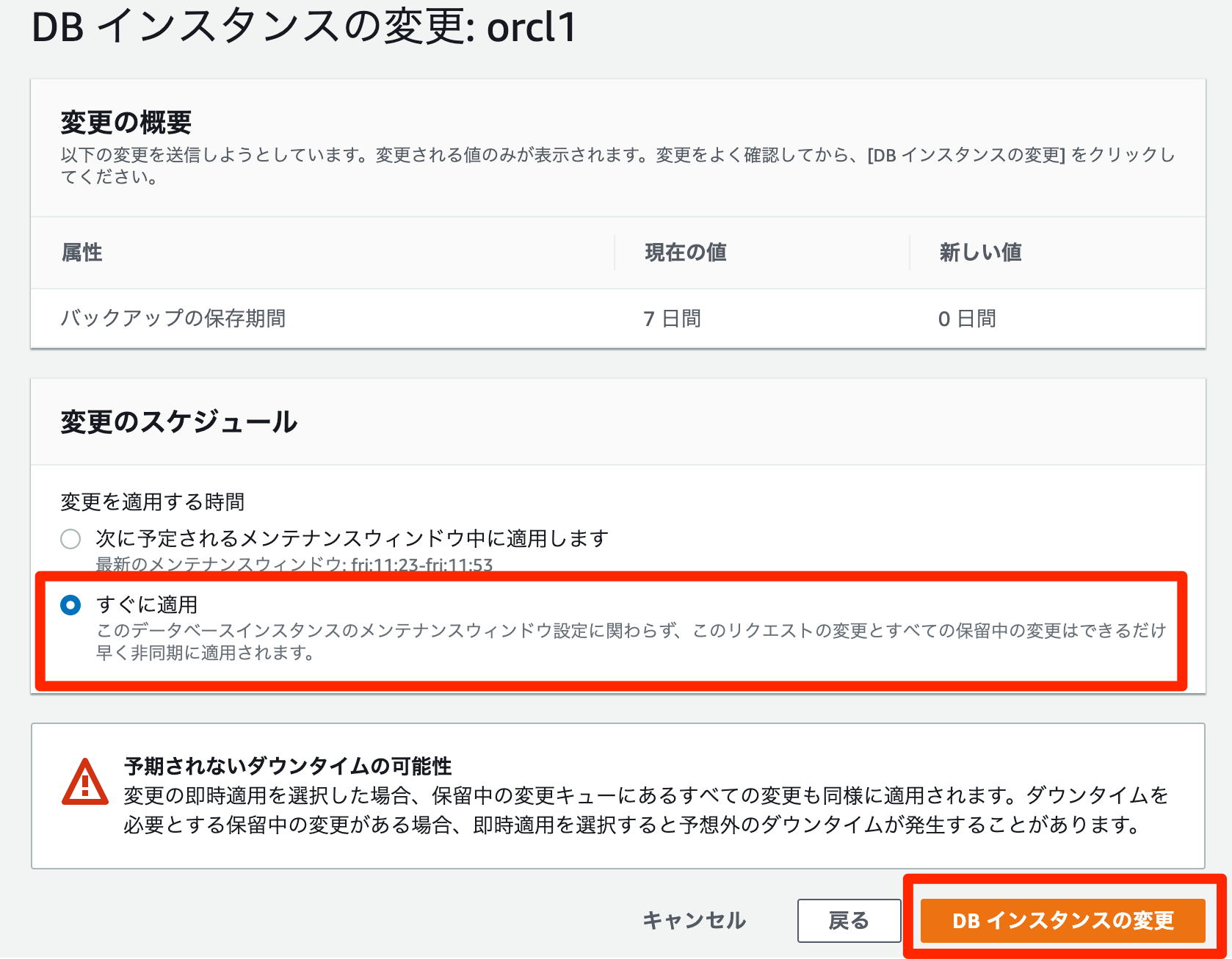
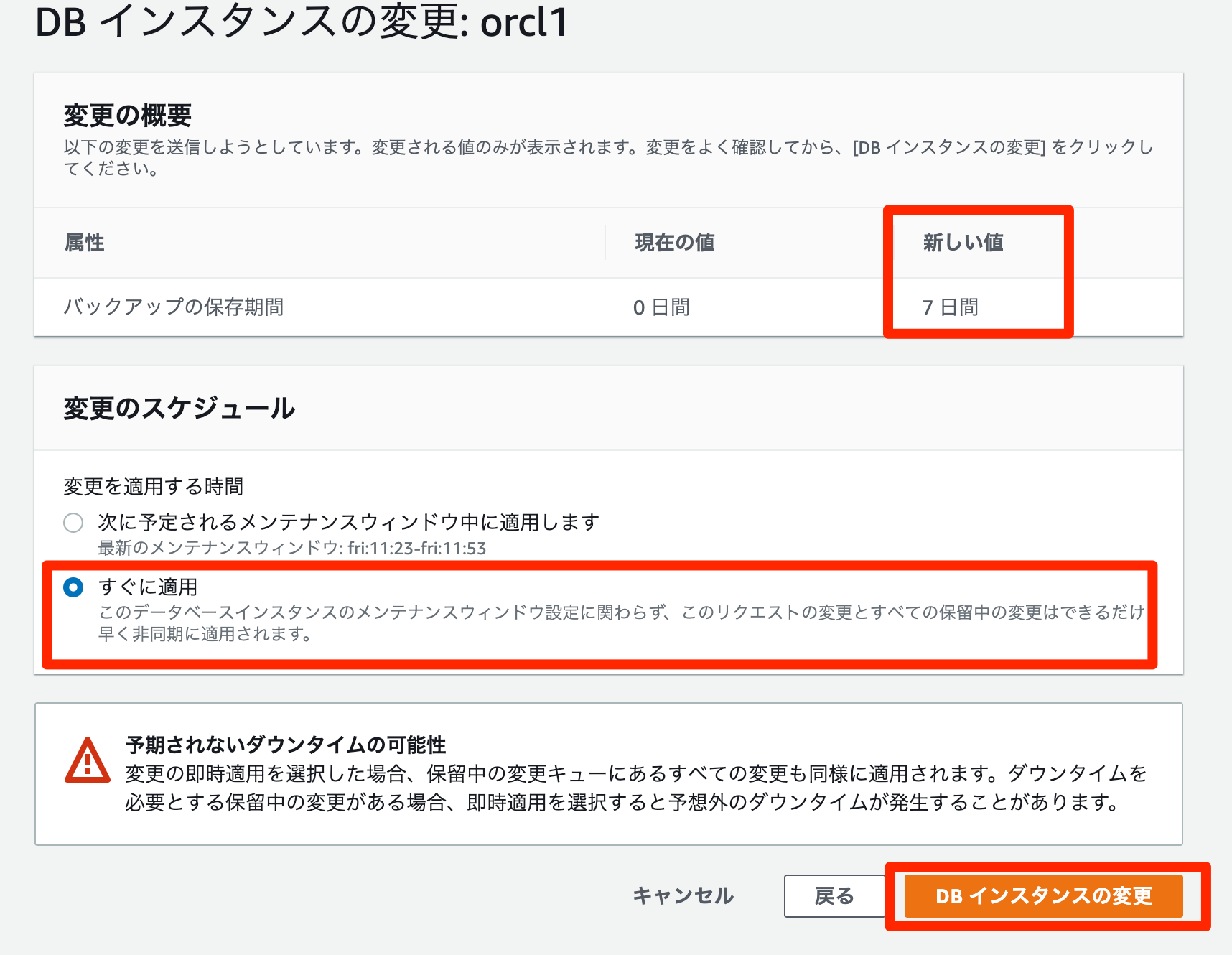
再起動するようです。自動バックアップの無効方法(ノーアーカイブログモード)
- RDSコンソールで対象インスタンスを選択
変更を選択すると、DBインスタンスの変更ページが表示される
バックアップの保存期間で0 days (0 日)を選択
次へを選択
すぐに適用を選択- 確認ページで、
DBインスタンスの変更を選択して変更を保存し、自動バックアップを無効にします
対象インスタンスのステータスが
変更中になります
利用可能となったので変更が反映されます
メンテナンスとバックアップからスナップショットを確認すると削除されています
インスタンスに接続しノーアーカイブログモードになったか確認します。
SQL> select name,log_mode from v$database; NAME LOG_MODE --------- ------------ ORCL1 NOARCHIVELOG ★ARCHIVELOGからNOARCHIVELOGに変わった自動バックアップの有効方法(アーカイブログモード)
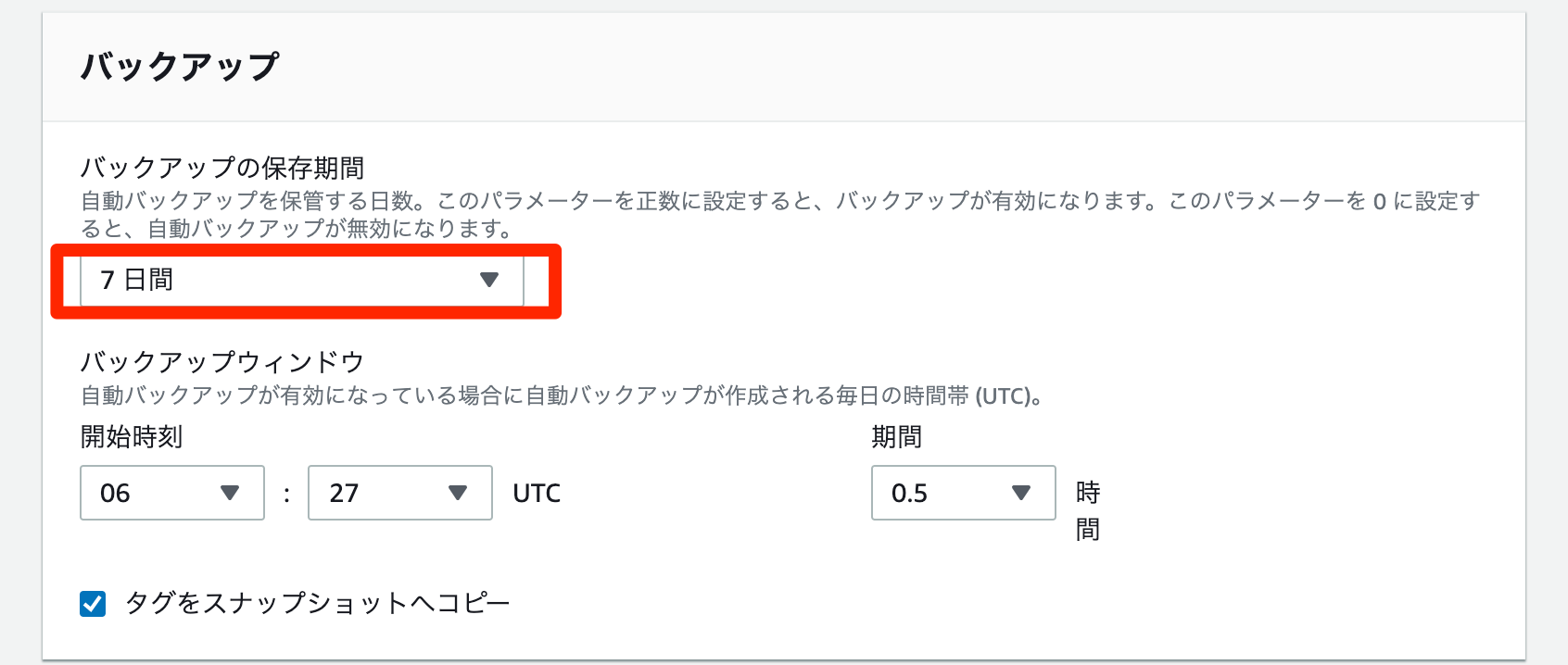
- RDSコンソールで対象インスタンスを選択
変更を選択するとDBインスタンスの変更ページが表示されます。
バックアップの保存期間で、ゼロ以外の正の値 (7 日など) を選択
次へを選択
すぐに適用を選択確認ページで、
DBインスタンスの変更を選択して変更を保存し、自動バックアップを有効化
- 対象インスタンスの
ステータスが変更中から利用可能になったら変更が反映される- インスタンスに接続しアーカイブログモードになったか確認します。
SQL> select name,log_mode from v$database; NAME LOG_MODE --------- ------------ ORCL1 ARCHIVELOG
- 自動バックアップを有効化した場合、スナップショットも自動で取得してくれるようです。

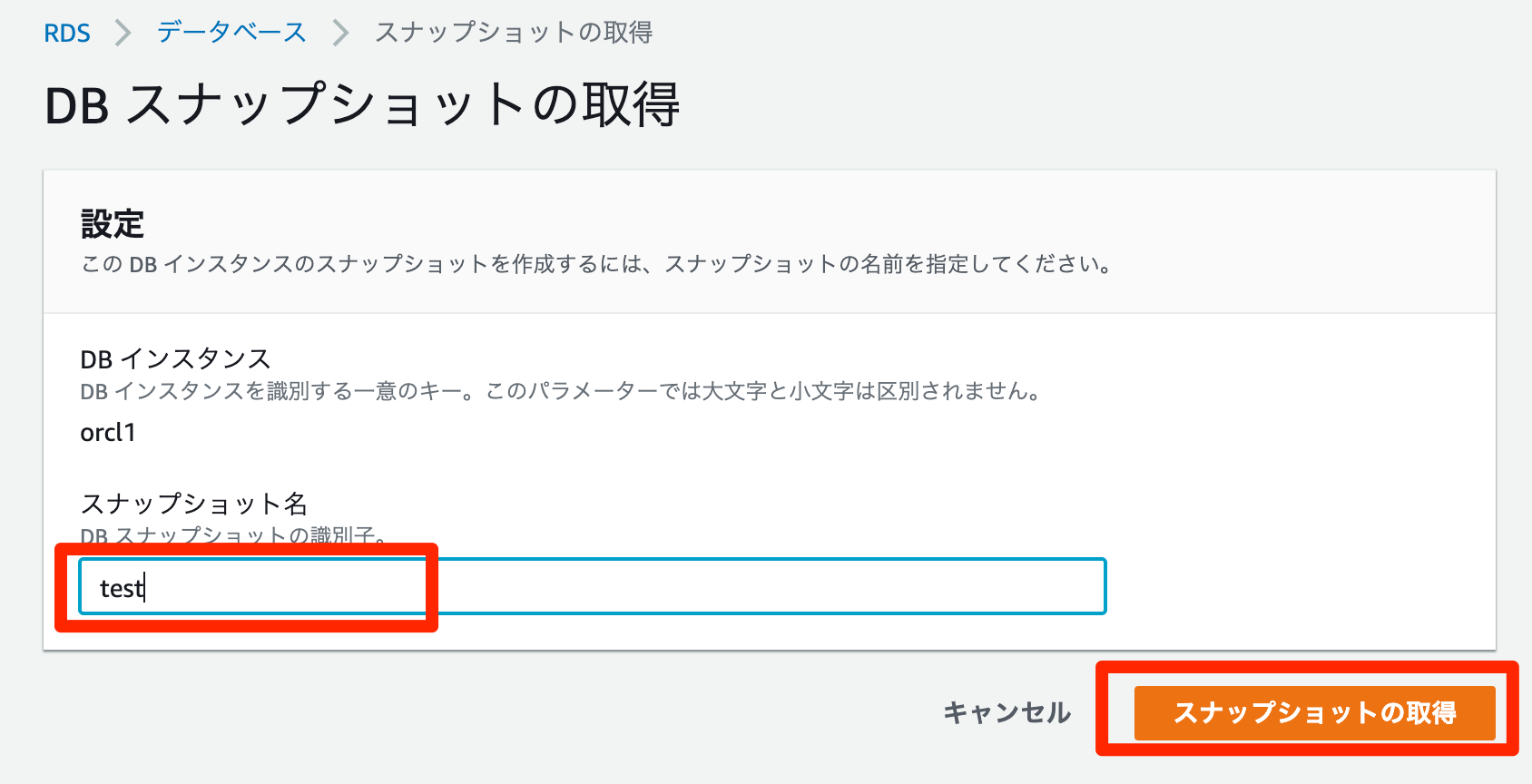
手動でスナップショットを取る場合
- RDSコンソールで対象インスタンスを選択
アクションで、スナップショットの取得を選択
DB スナップショットの取得ウィンドウが表示されます
スナップショット名ボックスにスナップショットの名前を入力します。
スナップショットの取得を選択
メンテナンスとバックアップからスナップショットが取得されたことが確認できます
AWS CLIでの自動バックアップの無効/有効方法
AWS CLIでの自動バックアップの無効
modify-db-instance コマンドを使用して、バックアップ保持期間を0に設定し--apply-immediatelyを指定します。
- Linux、OS X、Unix の場合
aws rds modify-db-instance \ --db-instance-identifier <インスタンス名> \ --backup-retention-period 0 \ --apply-immediately
- Windows の場合
aws rds modify-db-instance ^ --db-instance-identifier <インスタンス名> ^ --backup-retention-period 0 ^ --apply-immediately変更が有効になるタイミングを確認するには、バックアップ保持期間の値が
0になり mydbinstance のステータスがavailableになるまで、DB インスタンスに対して describe-db-instances を呼び出します。aws rds describe-db-instances --db-instance-identifier <インスタンス名>AWS CLIでの自動バックアップの有効
自動バックアップをすぐに有効にするには、
modify-db-instance コマンドを使用します。
(例)バックアップ保持期間を 3 日に設定することで、自動バックアップを有効にします。
- Linux、OS X、Unix の場合
aws rds modify-db-instance \ --db-instance-identifier <インスタンス名> \ --backup-retention-period 3 \ --apply-immediately
- Windows の場合:
aws rds modify-db-instance ^ --db-instance-identifier <インスタンス名> ^ --backup-retention-period 3 ^ --apply-immediately






- 投稿日:2019-07-08T12:37:26+09:00
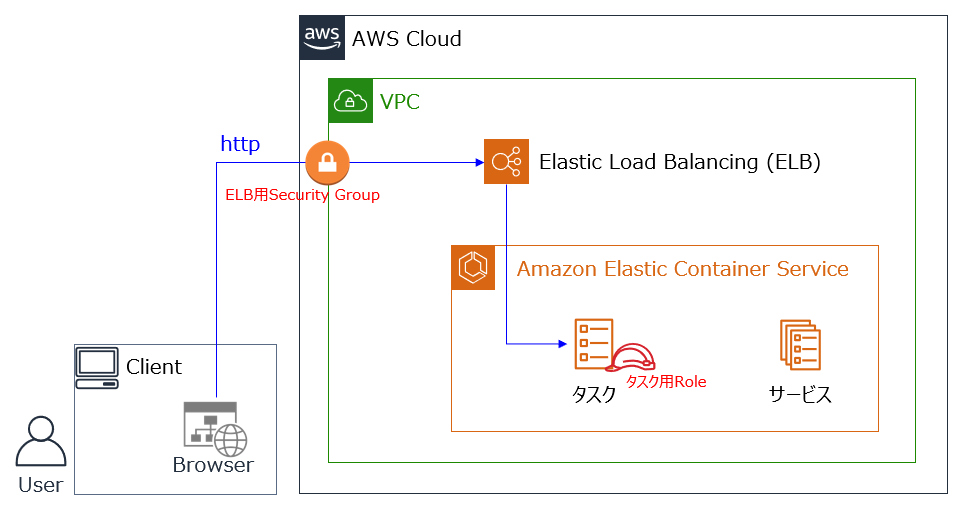
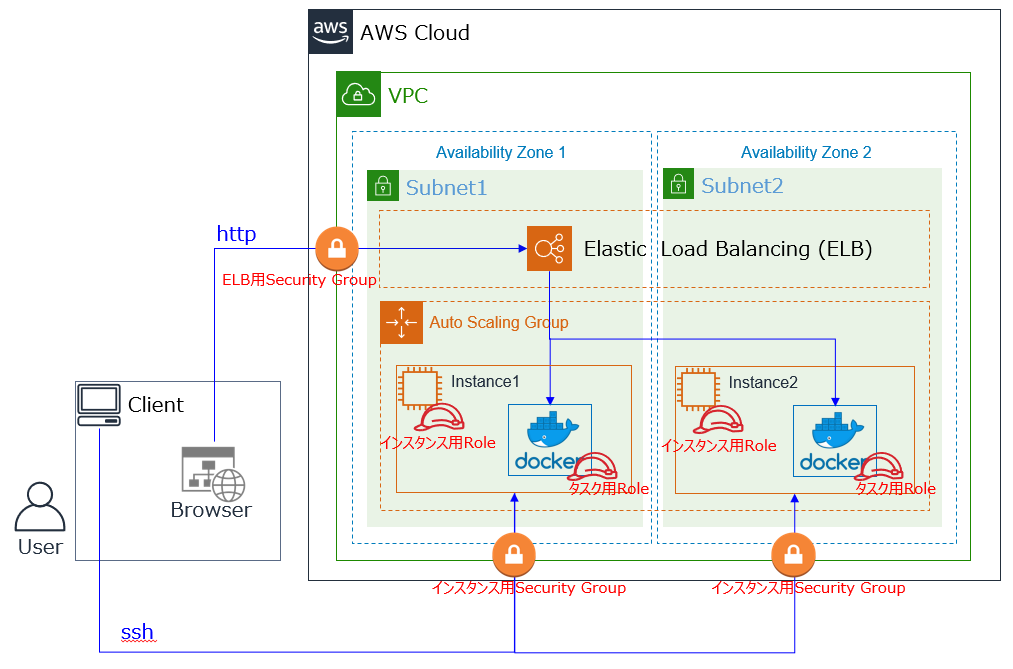
[AWS] Amazon ECS(EC2タイプ)のちょっと長めのチュートリアル(第3回)
※本記事は Amazon ECS(EC2タイプ)のちょっと長めのチュートリアル(第1回) および (第2回) の続きです。
前回までで、ECSクラスターが作成できました。今回はサービスとタスクを作成して、Dockerコンテナが起動されることを確認します。
注:このチュートリアルでは前回同様に、ELB 1台 と、t3.microのEC2 2台 のAWS利用料が発生します。
サービス、タスクとは
毎回使っている簡単な方の図:
これから残りのサービスとタスクを作成していくわけですが、正確には"タスク定義"というものを先に作成するため、
- タスク定義(Task Definition):1つ以上のコンテナ設定が記述されたJSONファイル、具体的には以下のような設定を記述します。
- 実行するDocker(ECR)イメージ
- Docker起動オプション(環境変数/マウントポイント/ログ設定/ヘルスチェックなど)
- IAMロール
- ネットワークモード
- CPU/メモリの制限
- サービス(Service):定義されたタスクを、ECSクラスターで動作させるための設定
- クラスターと、起動させるタスクの数
- デプロイ設定
- インスタンス配置設定
- VPC、ロードバランサ設定
- タスク(Task):サービスによって、実際に実行されたコンテナ(群)。今回の例では1タスク=1 Dockerイメージで起動されます。
の順で作成していきます。ざっくり言うと、タスクの方がコンテナの起動設定(多くがDockerのパラメタで指定可能なもの)で、サービスの方がAWS環境の設定となります。
タスク定義は図で表現されることはほとんどありませんが、実際の設定の多くはここにあります。(慣れると気にならなくなりますが、サービスの方にもサービス定義があった方が分かりやすいんじゃないかと最初は思いました。)
難しい方の図。ようやく 第1回 で作成したコンテナの動作確認ができるようになります。
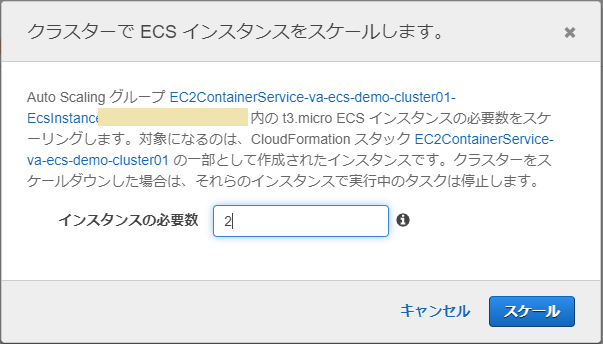
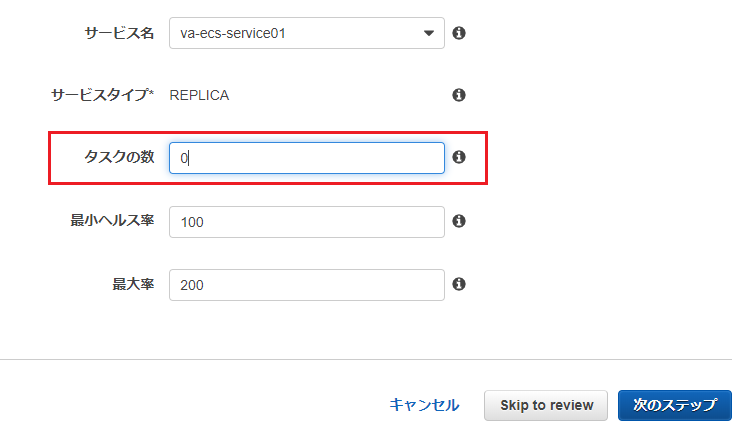
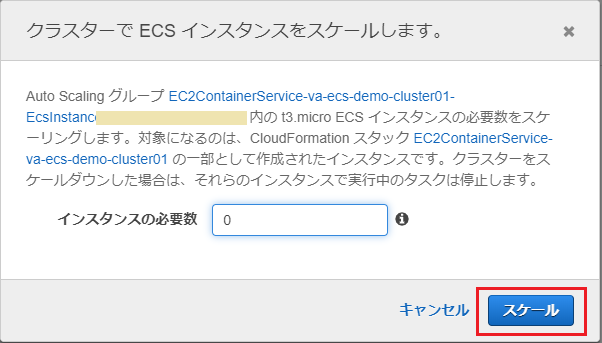
インスタンスを起動
まず、前回 EC2の課金が発生しないようインスタンス数を0にしておいたのを、戻します。
ECSクラスターの設定から「ECSインスタンス」タブ→「ECSインスタンスのスケール」で台数を2に設定しておきます。
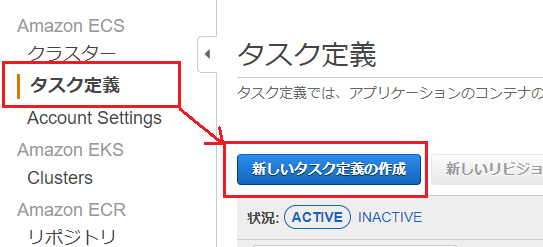
4) タスク定義の作成
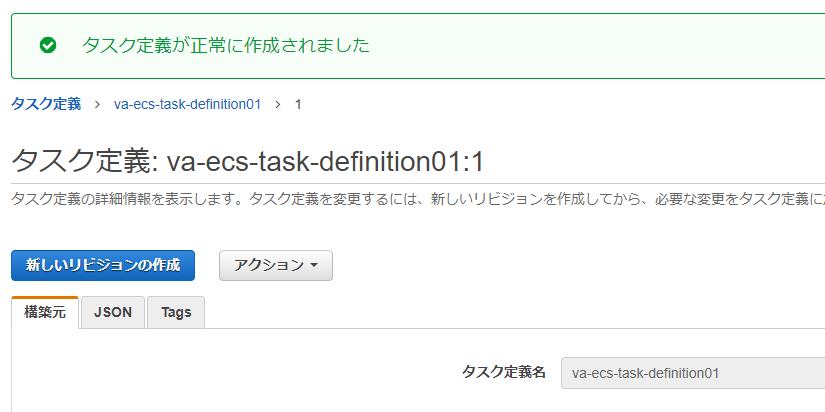
ECSのメニューから、「タスク定義」→「新しいタスク定義の作成」を選択します。
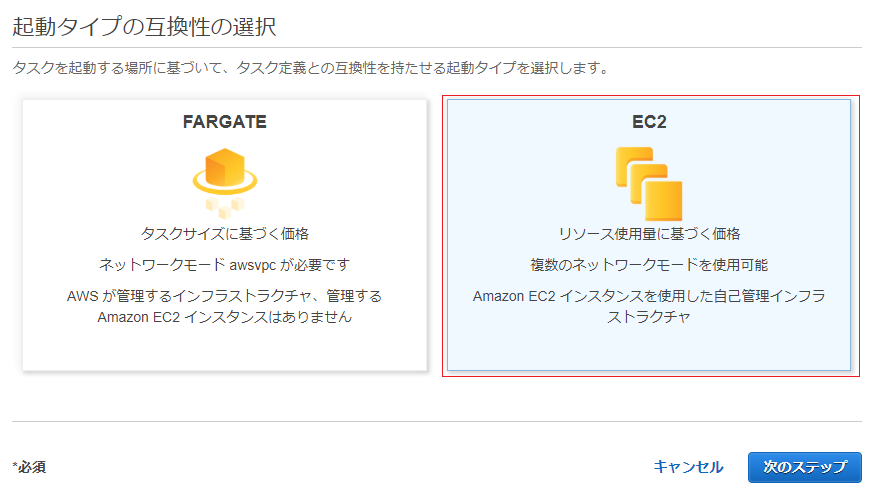
起動タイプでEC2を選択して次のステップに進みます。
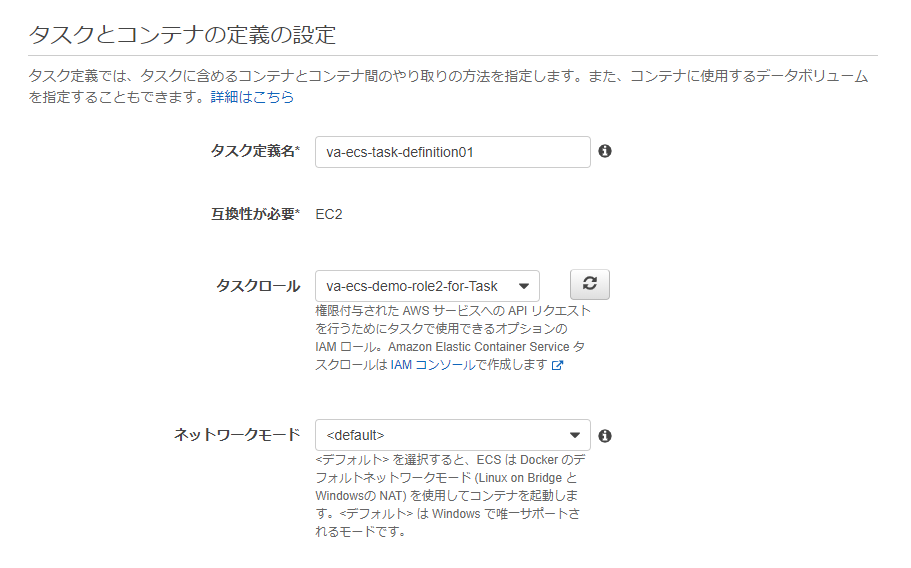
「タスクとコンテナ定義の設定」で必要な情報を入力します。
- タスク定義名 : 任意の名前
- タスクロール : 前回作成した タスク用ロール を指定
- ネットワークモード : "<default>" を選択
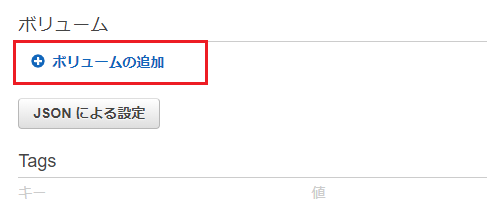
次に、EC2インスタンスのストレージをコンテナにマウントする設定を追加します(テスト用コンテナの動作に必要ありませんが説明のため)。
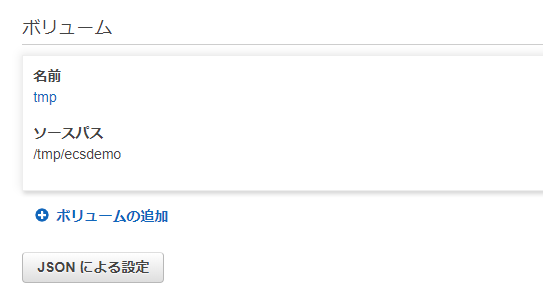
画面の下(縦長の画面なので一番下までスクロールします)にある「ボリュームの追加」を選択します。
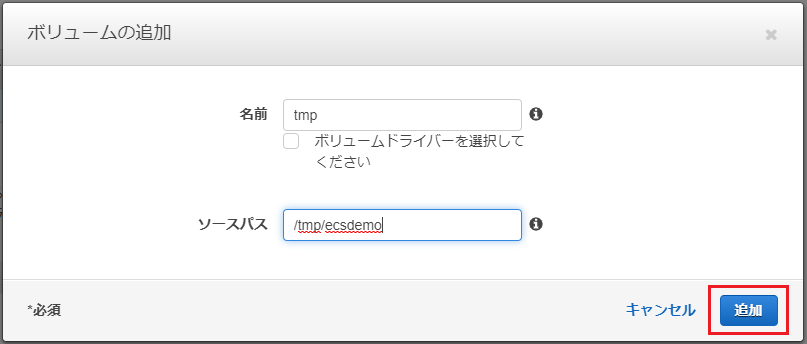
「ソースパス」がEC2インスタンスのパスになります。ここでは
/tmp/ecsdemoを指定しています。
「追加」を押すと元の設定画面に戻り、設定が追加されたことが確認できます。
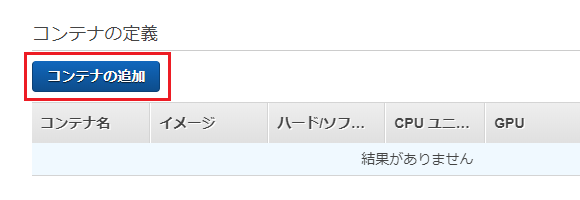
次に、画面を少し上に戻って、コンテナ定義の項目で「コンテナの追加」ボタンを押します。
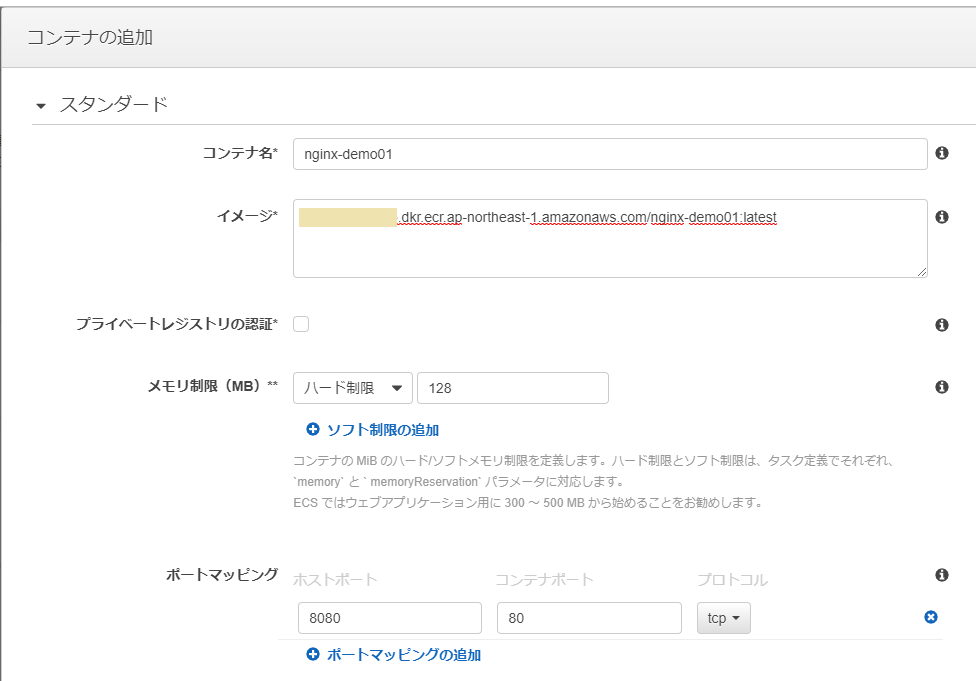
必要な情報を入力します。
- コンテナ名 : 任意の名前
- イメージ : 第1回で作成したECRイメージのパス(AWSアカウント名からダグまで含むフルパスを設定します)
- メモリ制限 : 128
- ポートマッピング:ホストポート8080、コンテナポート80
入力画面を下に進み、環境変数を設定します(これもテスト用コンテナの動作に必要ありませんが説明のため)。ここでは
TEST_ENV01という変数を設定しています。ここの画面が少し分かりづらいですが、キーと値の間にある"Value"というプルダウンも明示的に選択する必要があるので注意して下さい。
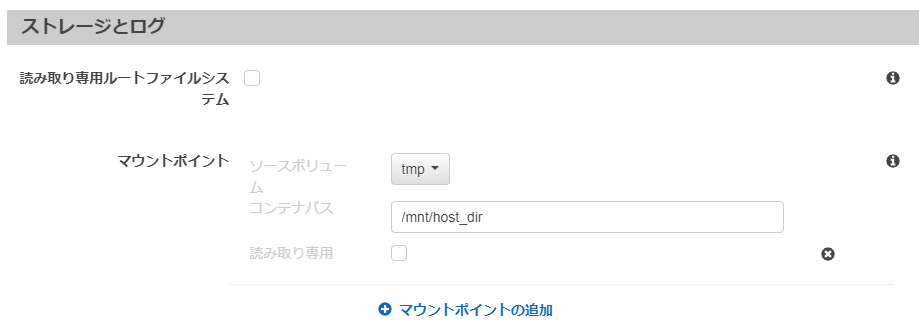
最後に「ストレージとログ」で、マウントポイントを設定します。
こちらはコンテナ内のパスで、例として/mnt/host_dirというディレクトリを指定しています(事前に存在しなくても構いません)。
「追加」ボタンを押してタスク定義の作成画面に戻り、そこで「作成」を押してタスク定義の作成は完了となります。
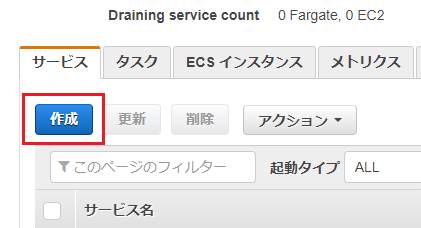
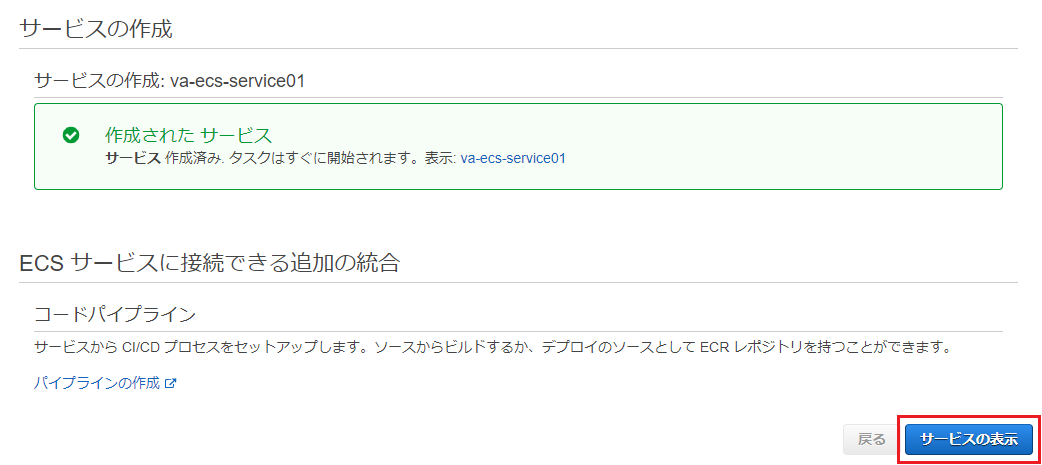
5) サービスの作成
サービスはECSクラスターの「サービス」タブから「作成」を選択します。
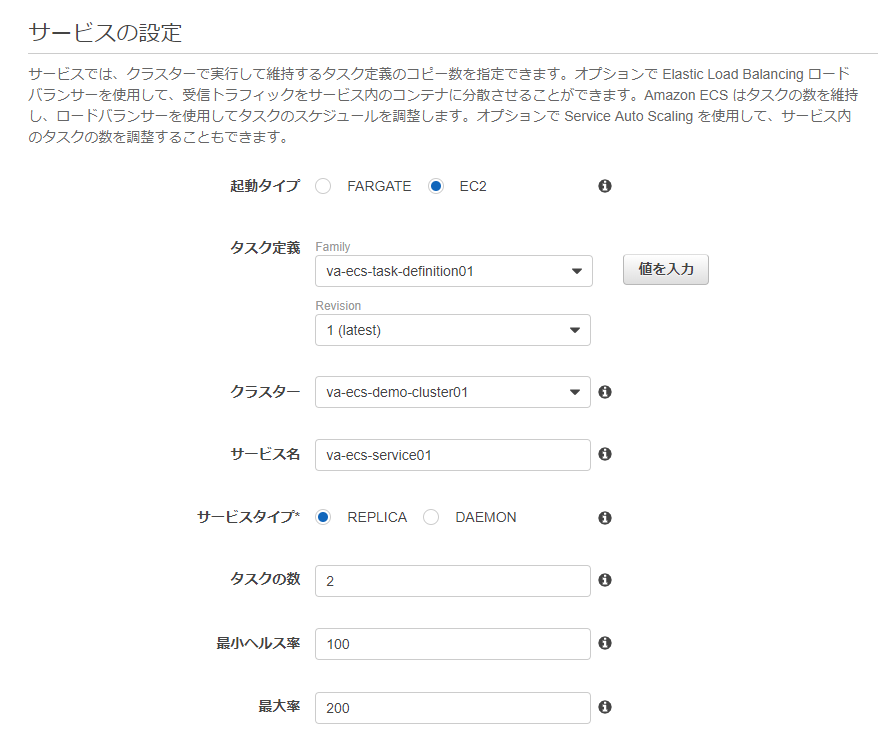
サービスの設定画面で必要な情報を入力します。
- 起動タイプ : EC2
- タスク定義 : 4)で作成したタスク定義
- クラスター : 前回作成したクラスター
- サービス名 : 任意の名前
- タスクの数 : 2
その他の設定はデフォルトでOKです。
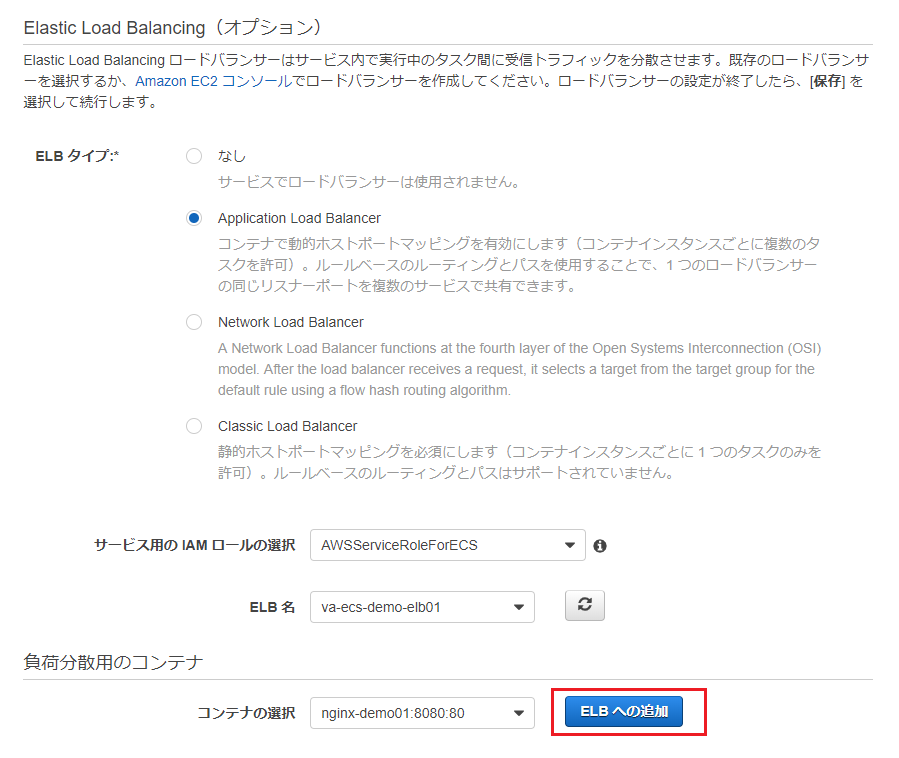
次に進み、ALBの設定を行います。
- ELBタイプ : "Application Load Balancer"を選択
- サービス用のIAMロールの選択 : "AWSServiceRoleForECS"(デフォルト)
- ELB名 : 前回作成したELB を選択
をそれぞれ選択します。続いて下にある「負荷分散コンテナ」で、先ほど作成したコンテナが表示されていることを確認して「ELBへの追加」を押します。
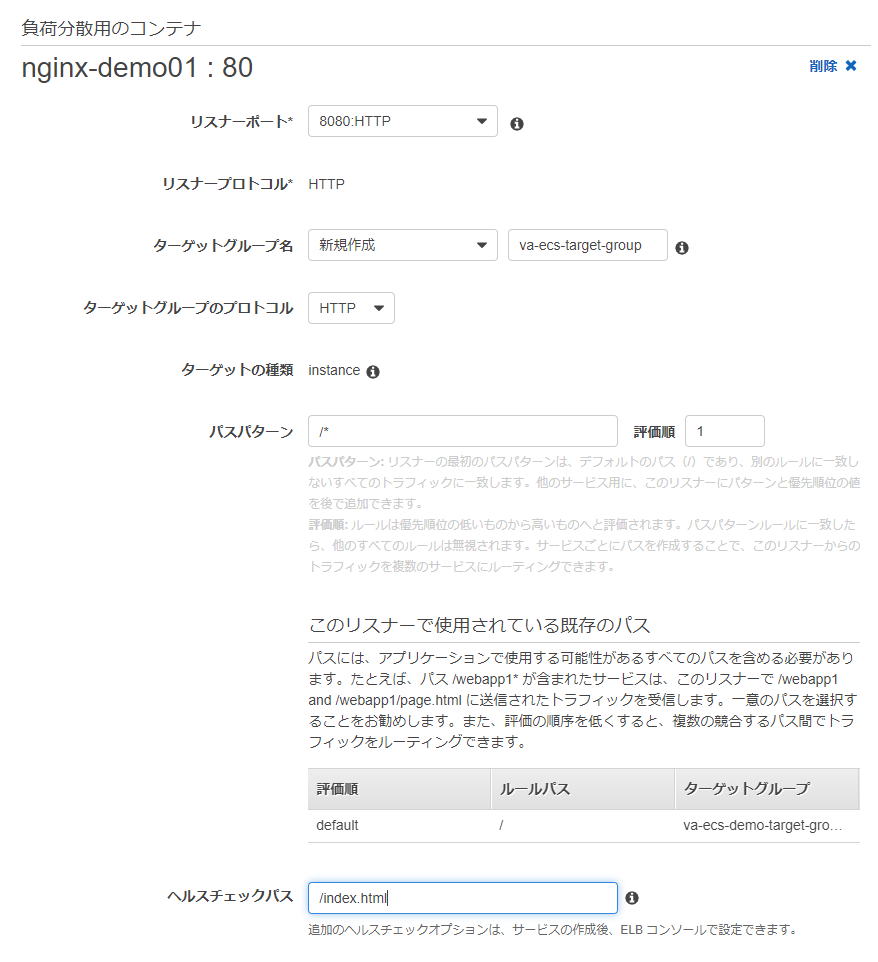
負荷分散コンテナの設定を入力します。
- リスナーポート : 8080:HTTP
- ターゲットグループ名 : 新規作成を選択し、任意の名前を入力
- ターゲットグループのプロトコル : HTTP
- パスパターン :/*(スラッシュとアスタリスク)を入力
- 評価値 : 1
- ヘルスチェックパス :/index.html
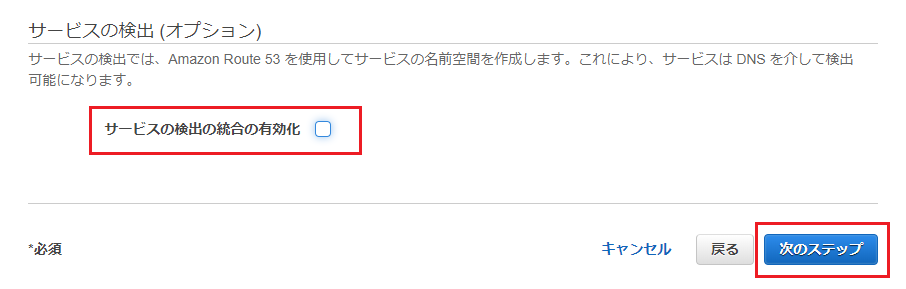
画面下に進み、サービスの検出オプションは外して次のステップに進みます。
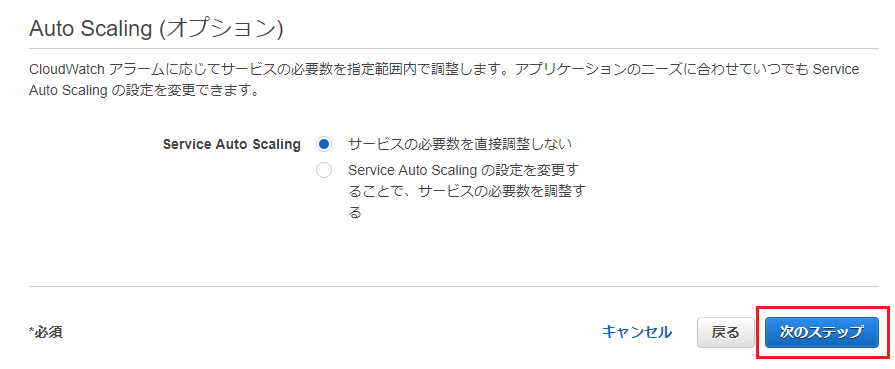
Auto Schaingオプションはデフォルトのまま
次のステップに進みます。
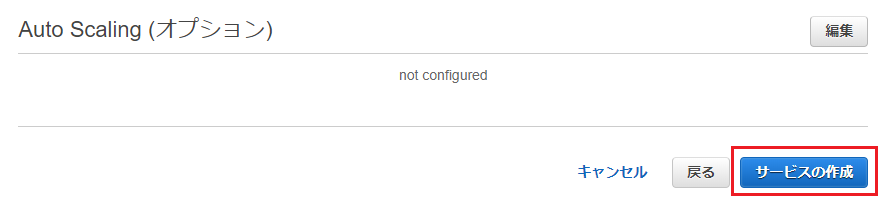
最後に確認画面で「サービスの作成」を押します。
サービスが作成されたら「サービスの表示」ボタンを押します。
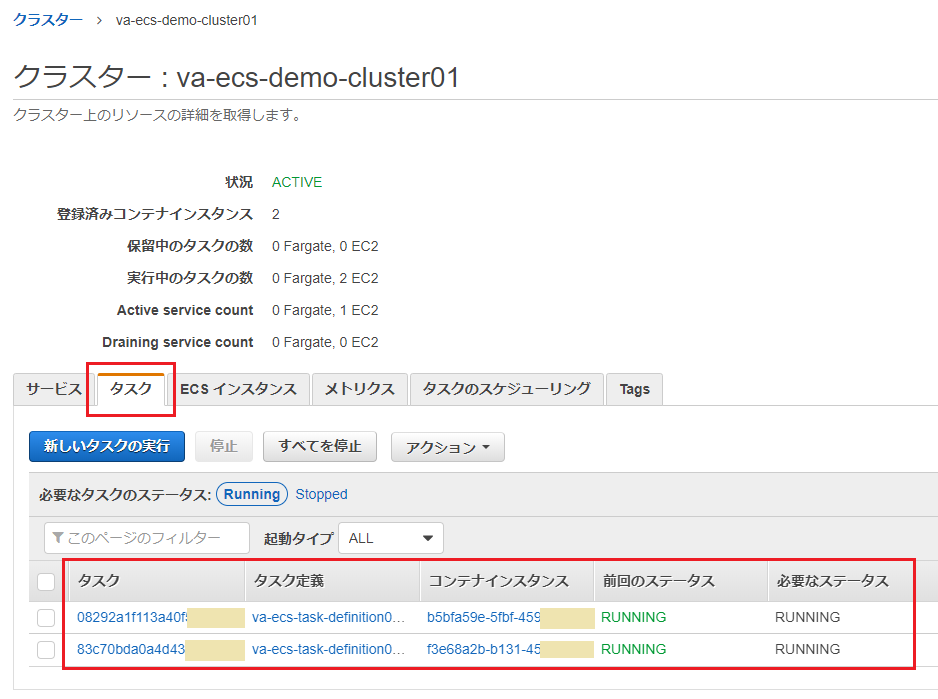
クラスターの画面に遷移し、(サービスではなく)「タスク」タブが表示されます。2つのインスタンスで、それぞれタスクが起動していれば作成は完了となります。
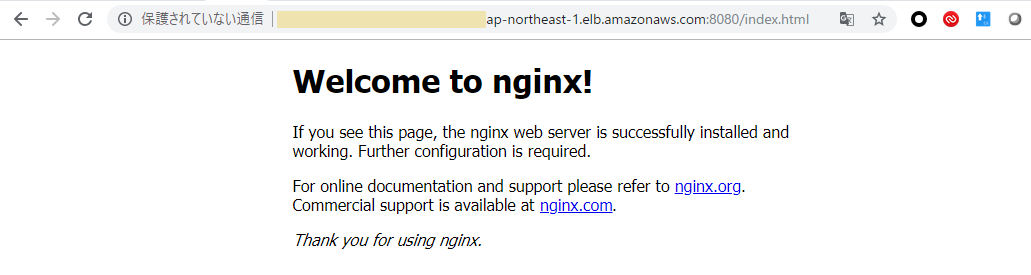
動作確認:ブラウザでの確認
ようやくこの構成ができたので、ブラウザでnginxのテストページにアクセスしてみます。
EC2 → ロードバランサから ELBのDNS名 を確認し、
http://<ELBのDNS名>:8080/index.htmlにアクセスします。
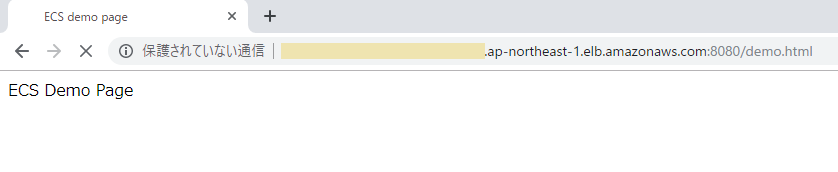
次に、テスト用に追加したhtmlが表示されることを確認します。
http://<ELBのDNS名>:8080/demo.htmlにアクセスします。
うまく接続できない場合は、第2回で作成した ELB用セキュリティグループ の設定をまず確認して下さい。マイIPに限定して作成してあったので、お使いのネットワーク環境によってはアクセス元をもう少し広く設定する必要があるかもしれません。
動作確認:EC2にログインして確認してみる
EC2タイプなので、ログインして確認することが可能です。前回作成した鍵を使って、ECSインスタンスにsshでログインして確認します。
※Dockerプロセスの確認※ # docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 5aa208dd78ff <AWSアカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/nginx-demo01:latest "nginx -g 'daemon of…" 40 minutes ago Up 40 minutes 0.0.0.0:8080->80/tcp ecs-va-ecs-task-definition01-1-nginx-demo01-faa6d1db8188b2ae4900 1aa15ba1a11f amazon/amazon-ecs-agent:latest "/agent" 2 hours ago Up 2 hours ecs-agent ※テスト用のコンテナにログイン※ # docker exec -it 5aa208dd78ff /bin/bash ※環境変数が設定されていることの確認※ root@5aa208dd78ff:/# export | grep TEST_ENV01 declare -x TEST_ENV01="This_is_test" ※マウントポイントを確認するため、ファイルを作成※ root@5aa208dd78ff:/# ls -l /mnt/host_dir/ total 0 root@5aa208dd78ff:/# export > /mnt/host_dir/container_export.txt root@5aa208dd78ff:/# ls -l /mnt/host_dir/container_export.txt -rw-r--r-- 1 root root 599 Jul 2 07:51 /mnt/host_dir/container_export.txt root@5aa208dd78ff:/# cat /mnt/host_dir/container_export.txt declare -x AWS_CONTAINER_CREDENTIALS_RELATIVE_URI="/v2/credentials/221a631f-ecee-4ec0-8539-921f512c0efa" declare -x AWS_EXECUTION_ENV="AWS_ECS_EC2" declare -x ECS_CONTAINER_METADATA_URI="http://169.254.170.2/v3/5c8ca5e4-8043-4aad-ba1f-aca76518f101" declare -x HOME="/root" declare -x HOSTNAME="5aa208dd78ff" declare -x NGINX_VERSION="1.13.1-1~stretch" declare -x NJS_VERSION="1.13.1.0.1.10-1~stretch" declare -x OLDPWD declare -x PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin" declare -x PWD="/" declare -x SHLVL="1" declare -x TERM="xterm" declare -x TEST_ENV01="This_is_test" ※ホストOSに戻る※ root@5aa208dd78ff:/# exit exit ※マウントポイントにコンテナで作成したファイルがあることを確認※ # ls -l /tmp/ecsdemo/ total 4 -rw-r--r-- 1 root root 599 Jul 2 07:51 container_export.txt # cat /tmp/ecsdemo/container_export.txt declare -x AWS_CONTAINER_CREDENTIALS_RELATIVE_URI="/v2/credentials/221a631f-ecee-4ec0-8539-921f512c0efa" declare -x AWS_EXECUTION_ENV="AWS_ECS_EC2" declare -x ECS_CONTAINER_METADATA_URI="http://169.254.170.2/v3/5c8ca5e4-8043-4aad-ba1f-aca76518f101" declare -x HOME="/root" declare -x HOSTNAME="5aa208dd78ff" declare -x NGINX_VERSION="1.13.1-1~stretch" declare -x NJS_VERSION="1.13.1.0.1.10-1~stretch" declare -x OLDPWD declare -x PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin" declare -x PWD="/" declare -x SHLVL="1" declare -x TERM="xterm" declare -x TEST_ENV01="This_is_test" ※イメージの確認※ # docker images REPOSITORY TAG IMAGE ID CREATED SIZE <AWSアカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/nginx-demo01 latest de6344632e81 2 weeks ago 109MB amazon/amazon-ecs-agent latest 267bac512a39 3 weeks ago 57.1MB amazon/amazon-ecs-pause 0.1.0 54d8403124ce 3 weeks ago 954kBスケールインしておく
以上で、一通りの構築作業は完了しました。次回以降コンテナの更新処理や異常系を試す予定ですが、それまではインスタンス費用がからないよう台数をまた0にしておきます。
これまでのようにインスタンス台数を減らすだけで課金は発生しませんが、それではタスクの再起動が繰り返されることになるので、まずタスクの数を0に設定します。サービスの設定で「更新」を選択します。
タスクの数を0に変更して更新します。
その後、クラスターの設定からインスタンスを0に変更します。
Link
参考資料



- 投稿日:2019-07-08T11:22:48+09:00
【RDS for Oracle】自動統計情報収集(自動オプティマイザ統計収集)変更方法
Oracleでは3つの自動メンテナンス・タスクがあります
- 自動統計情報収集(自動オプティマイザ統計収集)
- 自動セグメント・アドバイザ
- 自動SQLチューニング・アドバイザ
これらのタスクはメンテナンス・ウィンドウ(メンテナンス可能として設定した時間帯)で実行されます。
自動化メンテナンス・タスクの有効/無効の確認
SQL> col CLIENT_NAME for a40 SQL> select client_name, status from dba_autotask_client; CLIENT_NAME STATUS ---------------------------------------- -------- auto optimizer stats collection ENABLED auto space advisor ENABLED sql tuning advisor ENABLED
※注意
自動SQLチューニング・アドバイザを使用するにはEnterprise EditionのオプションのOracle Tuning Packオプションが必要です。このオプションがない場合は自動SQLチューニング・アドバイザを無効化する必要があります。
自動メンテナンス・タスク CLIENT_NAME 自動統計情報収集 auto optimizer stats collection 自動セグメント・アドバイザ auto space advisor 自動SQLチューニング・アドバイザ sql tuning advisor
- 自動メンテナンス・タスクの無効化の方法
- 例:自動SQLチューニング・アドバイザの無効
BEGIN dbms_auto_task_admin.disable( client_name => 'sql tuning advisor', operation => NULL, window_name => NULL); END; /
- 自動SQLチューニング・アドバイザの確認
SQL> select client_name, status from dba_autotask_client; CLIENT_NAME STATUS ---------------------------------------- -------- auto optimizer stats collection ENABLED auto space advisor ENABLED sql tuning advisor DISABLED ★無効化されてる
- 自動メンテナンス・タスクの有効化の方法
- 例:自動SQLチューニング・アドバイザの有効
BEGIN dbms_auto_task_admin.enable( client_name => 'sql tuning advisor', operation => NULL, window_name => NULL); END; /
- 自動SQLチューニング・アドバイザの確認
SQL> select client_name, status from dba_autotask_client; CLIENT_NAME STATUS ---------------------------------------- -------- auto optimizer stats collection ENABLED auto space advisor ENABLED sql tuning advisor ENABLEDD ★有効化に戻った
メンテナンス・ウィンドウのスケジュールを確認
デフォルトの実行時間
曜日 実行時間 月〜金 22:00〜翌日2:00(4時間) 土〜日 06:00〜翌日2:00(20時間) SQL> col REPEAT_INTERVAL for a70 SQL> col DURATION for a30 SQL> select WINDOW_NAME ,REPEAT_INTERVAL ,DURATION, ENABLED from DBA_SCHEDULER_WINDOWS; WINDOW_NAME REPEAT_INTERVAL DURATION ENABL -------------------- ---------------------------------------------------------------------- ------------------------------ ----- WEEKEND_WINDOW freq=daily;byday=SAT;byhour=0;byminute=0;bysecond=0 +002 00:00:00 FALSE WEEKNIGHT_WINDOW freq=daily;byday=MON,TUE,WED,THU,FRI;byhour=22;byminute=0; bysecond=0 +000 08:00:00 FALSE SUNDAY_WINDOW freq=daily;byday=SUN;byhour=6;byminute=0; bysecond=0 +000 20:00:00 TRUE SATURDAY_WINDOW freq=daily;byday=SAT;byhour=6;byminute=0; bysecond=0 +000 20:00:00 TRUE FRIDAY_WINDOW freq=daily;byday=FRI;byhour=22;byminute=0; bysecond=0 +000 04:00:00 TRUE THURSDAY_WINDOW freq=daily;byday=THU;byhour=22;byminute=0; bysecond=0 +000 04:00:00 TRUE WEDNESDAY_WINDOW freq=daily;byday=WED;byhour=22;byminute=0; bysecond=0 +000 04:00:00 TRUE TUESDAY_WINDOW freq=daily;byday=TUE;byhour=22;byminute=0; bysecond=0 +000 04:00:00 TRUE MONDAY_WINDOW freq=daily;byday=MON;byhour=22;byminute=0; bysecond=0 +000 04:00:00 TRUE 9 rows selected.
- メンテナンス・ウィンドウの実行予定時間を確認
SQL> set pages 100 line 200 SQL> col WINDOW_NAME for a20 SQL> col WINDOW_NEXT_TIME for a40 SQL> select WINDOW_NAME,to_char(WINDOW_NEXT_TIME,'yyyy/mm/dd hh24:mm;ss'),WINDOW_ACTIVE,AUTOTASK_STATUS,OPTIMIZER_STATS,SEGMENT_ADVISOR,SQL_TUNE_ADVISOR,HEALTH_MONITOR from DBA_AUTOTASK_WINDOW_CLIENTS order by 1; WINDOW_NAME TO_CHAR(WINDOW_NEXT WINDO AUTOTASK OPTIMIZE SEGMENT_ SQL_TUNE HEALTH_M -------------------- ------------------- ----- -------- -------- -------- -------- -------- FRIDAY_WINDOW 2019/07/12 22:07;00 FALSE ENABLED ENABLED ENABLED ENABLED DISABLED MONDAY_WINDOW 2019/07/08 22:07;00 FALSE ENABLED ENABLED ENABLED ENABLED DISABLED SATURDAY_WINDOW 2019/07/13 06:07;00 FALSE ENABLED ENABLED ENABLED ENABLED DISABLED SUNDAY_WINDOW 2019/07/14 06:07;00 FALSE ENABLED ENABLED ENABLED ENABLED DISABLED THURSDAY_WINDOW 2019/07/11 22:07;00 FALSE ENABLED ENABLED ENABLED ENABLED DISABLED TUESDAY_WINDOW 2019/07/09 22:07;00 FALSE ENABLED ENABLED ENABLED ENABLED DISABLED WEDNESDAY_WINDOW 2019/07/10 22:07;00 FALSE ENABLED ENABLED ENABLED ENABLED DISABLED 7 rows selected.
- メンテナンス・ウィンドウの開始時刻を変更
- (例)日曜のメンテナンス・ウィンドウの開始時間を2:00に変更
BEGIN DBMS_SCHEDULER.SET_ATTRIBUTE( NAME =>'SYS.SUNDAY_WINDOW' ,ATTRIBUTE =>'REPEAT_INTERVAL' ,VALUE =>'freq=daily;byday=SUN;byhour=2;byminute=0; bysecond=0' ); END; /
- 実行時間を変更
- (例)日曜のメンテナンス・ウィンドウの実行時間を6時間に変更
BEGIN DBMS_SCHEDULER.SET_ATTRIBUTE( NAME =>'SYS.SUNDAY_WINDOW' ,ATTRIBUTE =>'DURATION' ,VALUE => NUMTODSINTERVAL(6, 'HOUR') ); END; /
- 確認
SQL> select WINDOW_NAME ,REPEAT_INTERVAL ,DURATION, ENABLED from DBA_SCHEDULER_WINDOWS; WINDOW_NAME REPEAT_INTERVAL DURATION ENABL -------------------- ---------------------------------------------------------------------- ------------------------------ ----- WEEKEND_WINDOW freq=daily;byday=SAT;byhour=0;byminute=0;bysecond=0 +002 00:00:00 FALSE WEEKNIGHT_WINDOW freq=daily;byday=MON,TUE,WED,THU,FRI;byhour=22;byminute=0; bysecond=0 +000 08:00:00 FALSE SUNDAY_WINDOW freq=daily;byday=SUN;byhour=2;byminute=0; bysecond=0 +000 06:00:00 TRUE ★2:00〜8:00(6時間)に変更 SATURDAY_WINDOW freq=daily;byday=SAT;byhour=6;byminute=0; bysecond=0 +000 20:00:00 TRUE FRIDAY_WINDOW freq=daily;byday=FRI;byhour=22;byminute=0; bysecond=0 +000 04:00:00 TRUE THURSDAY_WINDOW freq=daily;byday=THU;byhour=22;byminute=0; bysecond=0 +000 04:00:00 TRUE WEDNESDAY_WINDOW freq=daily;byday=WED;byhour=22;byminute=0; bysecond=0 +000 04:00:00 TRUE TUESDAY_WINDOW freq=daily;byday=TUE;byhour=22;byminute=0; bysecond=0 +000 04:00:00 TRUE MONDAY_WINDOW freq=daily;byday=MON;byhour=22;byminute=0; bysecond=0 +000 04:00:00 TRUE 9 rows selected.参考
- 投稿日:2019-07-08T10:20:36+09:00
Amazon SageMaker の推論パイプラインで、独自コンテナを組み合わせる方法
概要
Amazon SageMaker で、独自コンテナを含む 推論パイプラインエンドポイントを構築する 方法について書きます
SageMaker で提供されるコンテナで所望の前処理が実現できず、独自コンテナによる前処理をしたい場合、カスタム前処理コンテナはどのようにつくるか、どのように組み込むか 調べた際のメモです
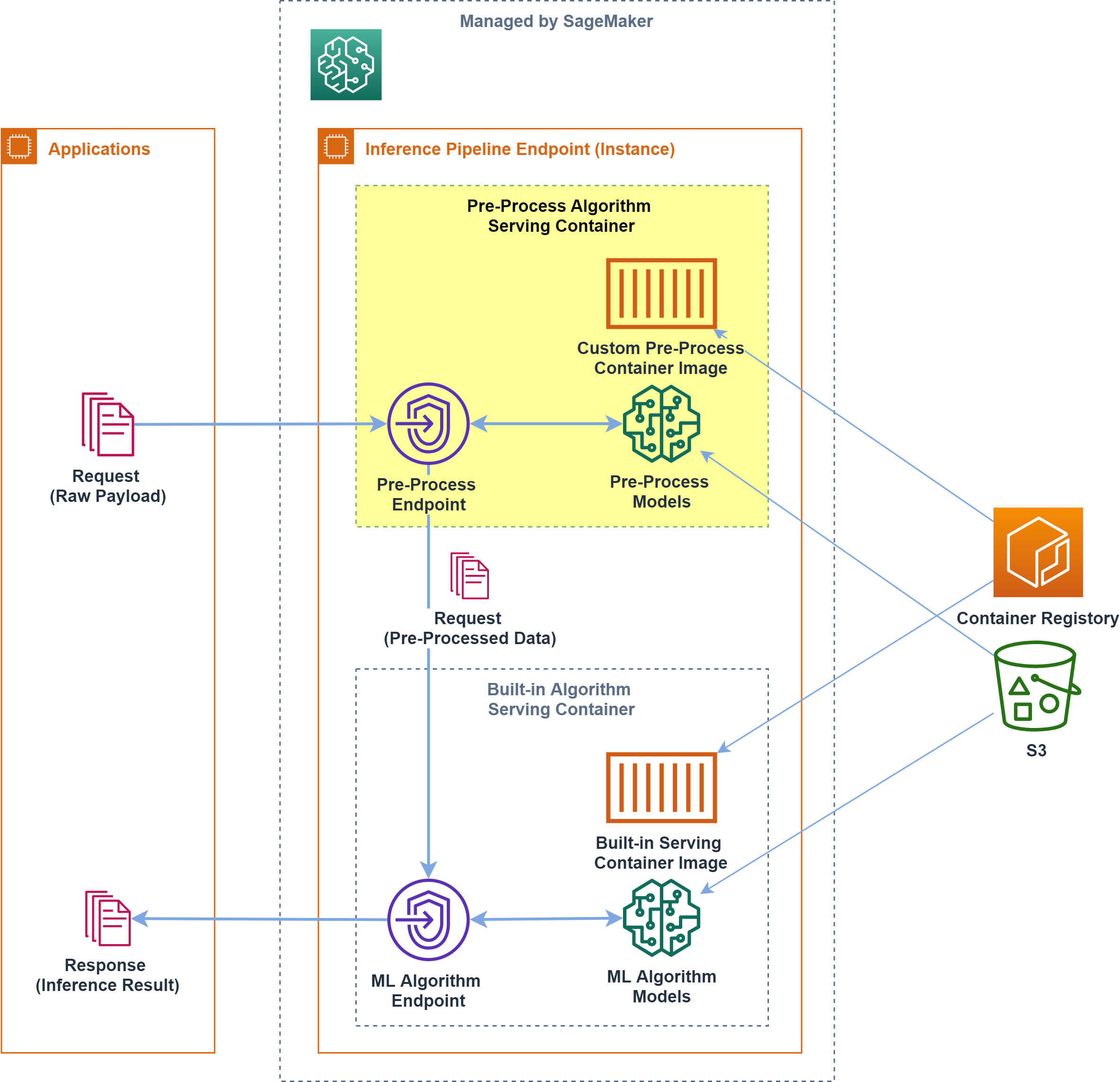
組み込みアルゴリズムと推論パイプライン
Amazon SageMaker では組み込みアルゴリズムが提供されており、解きたい問題にフィットするものがあれば、MLアルゴリズムに関するコードを書かずに手軽にMLモデルを作れるようになっています
組み込みアルゴリズムに引き渡す入力形式はアルゴリズムごとに決まっており、基本的には、保有するデータを整形する前処理が必要です
こうした 前処理は学習/推論で同じ処理なため、共通化されていることが望ましい ということで、SageMaker では前処理アルゴリズムをコンテナ化して学習/推論時に実行させる仕組みが提供されています前処理コンテナでは SageMaker でのコンテナの挙動を踏襲し、
fitでインスタンス上に前処理コンテナを展開してデータ整形/S3バケットへ出力したり、deployでインスタンス上に前処理コンテナを展開してリクエストデータ整形/次処理へ渡す、といった挙動をさせます
とくに推論処理では、エンドポイントへ届いたリクエストを前処理して後続の推論アルゴリズムへ渡すために、「前処理+推論処理(+後処理等)」をセットにした 推論パイプラインエンドポイント が構築できるようになっています
- Amazon SageMaker 組み込みアルゴリズムを使用する
- Amazon SageMaker 推論パイプライン
- Amazon SageMaker トレーニングと推論でデータ処理コードの一貫性を確保する
前処理で独自コンテナが必要になるケース
推論パイプラインのサンプル には、SageMaker で MLフレームワークを使うときと同様
sagemaker.sklearn.estimator.SKLearnなどEstimatorを利用して、任意のスクリプトを所定のコンテナ環境下で実行させる例が載っています
提供されているコンテナで所望の処理が実現できれば、カスタムコンテナは不要ですfrom sagemaker.sklearn.estimator import SKLearn script_path = 'sklearn_abalone_featurizer.py' sklearn_preprocessor = SKLearn( entry_point=script_path, role=role, train_instance_type="ml.c4.xlarge", sagemaker_session=sagemaker_session)しかし提供されるコンテナにないライブラリや、インストールされていないミドルウェアを使いたい場合には、独自の環境をコンテナ化して実行させる必要があります
たとえば自然言語を扱う課題で MeCab で形態素解析したいといった場合には、MeCab が動作してかつ Amazon SageMaker の仕様に従ったコンテナが必要になります
前処理コンテナのつくりかた
Amazon SageMaker で提供されているコンテナ群は GitHub で公開されているので、ライブラリを追加する程度であれば、既存コンテナを拡張するのが楽かもしれません
用意されているコンテナをFROM文で呼び出した上に、追加のインストールやセットアップを施しますそうした提供済みコンテナで都合が悪い(ミドルウェアのバージョンが合わないとか、既存の資産を使いたいとか)場合には独自コンテナを作ります
前処理コンテナの要件
基本的な挙動は SageMaker の 独自のトレーニングイメージ の仕様にあわせる必要があります
fitやdeployといった命令をうけて所定の処理が RUN される必要があるため、scikit_bring_your_ownなどをベースに、枠組みそのままで中身の処理を書き換えるのがよさそうです
また、パイプラインエンドポイントのための独自の設定がいくつか必要です
- 構成要素
- train:トレーニング(fit)時に呼び出される処理
- serve:エンドポイント構築(deploy)時に呼び出される処理
- predictor.py:推論エンドポイントで呼び出される処理
- その他の要件
- Dockerfile に次のコードが必要
LABEL com.amazonaws.sagemaker.capabilities.accept-bind-to-port=true- エンドポイントのリクエスト受け付けポートが次の環境変数に依存する
SAGEMAKER_BIND_TO_PORT- Dockerコンテナリポジトリに、次のポリシー付与が必要
前処理コンテナに実装する内容
scikit_bring_your_own 等をベースに、下記の機能を実装します
train
生データを受け取って整形加工し、MLモデルトレーニングに使用する訓練データをつくり、S3へ配置します
訓練データ生成の際に作成される「辞書データ」や「ベクトライザ」は推論時にも同じものを使うため、推論エンドポイントへ引き継ぐ必要がありますが、SageMaker のアルゴリズムで/opt/ml/model以下を共有する仕組みにのせて、推論エンドポイントの同一ディレクトリへ展開させるようにします
Estimator.fitで呼び出される- 指定されたタイプのインスタンスに、
inputs={'raw':'s3://'}で引き渡した S3 パスのデータが/opt/ml/input/data/{channel}以下へ 自動的に 展開される/opt/ml/input/data/{channel}からデータを参照して一括整形する- MLトレーニングで使用する、加工整形した訓練データを S3 上の任意のパスへアップロードする
- 推論エンドポイントでデータの整形処理に必要になるモデルデータ(辞書やベクトライザなど)を
/opt/ml/modelへ出力する
joblib.dumpなど/opt/ml/model以下のファイル群がtar.gz形式でアーカイブされてoutput_pathで指定された S3 パスへ 自動的に アップロードされるserve
train時に生成したモデルファイルをインスタンス上に配置し、/invocationsのリクエストを受け付ける web サーバを起動します
Estimator.deployで呼び出される
output_pathに指定された S3 パスから、Training 時に生成済みのモデル群をインスタンスの/opt/ml/model以下へ 自動的に 展開する/invocationsと/pingに応答するウェブサーバー を起動する
- パイプラインモデルのエンドポイントは、リクエストを受け付けるポートを環境変数
SAGEMAKER_BIND_TO_PORTで指定されるため、web サーバの設定でポートを環境変数を参照するようにする(環境変数がなければ 8080 を使う)predict
serveで起動したエンドポイントで、推論を行いたい生データを所定の書式で受け取り、後続の推論アルゴリズムが要求する書式に整形して返します
serveの際に配置したモデルファイル群を/opt/ml/model以下から取得し、コード上へ読み出す
joblib.loadなど- 推論リクエストに含まれる生データを取得し、文字列の正規化を行う
- 正規化したデータについて、先に取得したベクトライザ等を使用して推論アルゴリズムが要求する形式のデータへ変換する
- 変換した形式のデータをレスポンスとして返す
コンテナのビルド、ECRへのPUSH
上記実装したコード群をコンテナ化し、ECR のリポジトリへ push します
push した ECR のリポジトリには、SageMaker のパイプラインモデルからの呼び出しを許可するポリシーを付与する必要があります(推論パイプラインの Amazon ECR アクセス許可のトラブルシューティング)
ECR コンソールから
Repositories > 該当リポジトリリンク > Permissionsと進んで、アクセス許可ポリシーを下記 JSON の通り追加します{ "Version": "2008-10-17", "Statement": [ { "Sid": "allowSageMakerToPull", "Effect": "Allow", "Principal": { "Service": "sagemaker.amazonaws.com" }, "Action": [ "ecr:GetDownloadUrlForLayer", "ecr:BatchGetImage", "ecr:BatchCheckLayerAvailability" ] } ] }ここまででパイプライン用の前処理コンテナができました
MLプロセスへの組み込み
組み込みMLアルゴリズムと、独自コンテナによる前処理を組み合わせ、MLフローを実行します
前処理(訓練データの準備)
生データを用意してS3へアップロードし、以下のようなコードによって、訓練データへ変換します
&前処理で生成した ベクトライザ 等の生成物を S3 へ格納しますimport sagemaker sess = sagemaker.Session() role = sagemaker.get_execution_role() preprocess_image_name = 'preprocess_ecr_container_image' preprocess_job_name = '{preprocess_id}' rawdata_input_path = 's3_rawdata_path' train_dataset_path = 's3_preprocessed_data_path' preprocessor = sagemaker.estimator.Estimator( image_name = preprocess_image_name, role = role, train_instance_count = preprocess_instance_count, train_instance_type = preprocess_instance_type, train_volume_size = preprocess_volume_size, output_path = train_dataset_path, sagemaker_session = sess ) preprocessor.fit( inputs={'rawdata': rawdata_input_path}, job_name = preprocess_job_name )学習
前処理で訓練に必要なデータはすべて S3 上の所定の場所へアップロードされている状態です
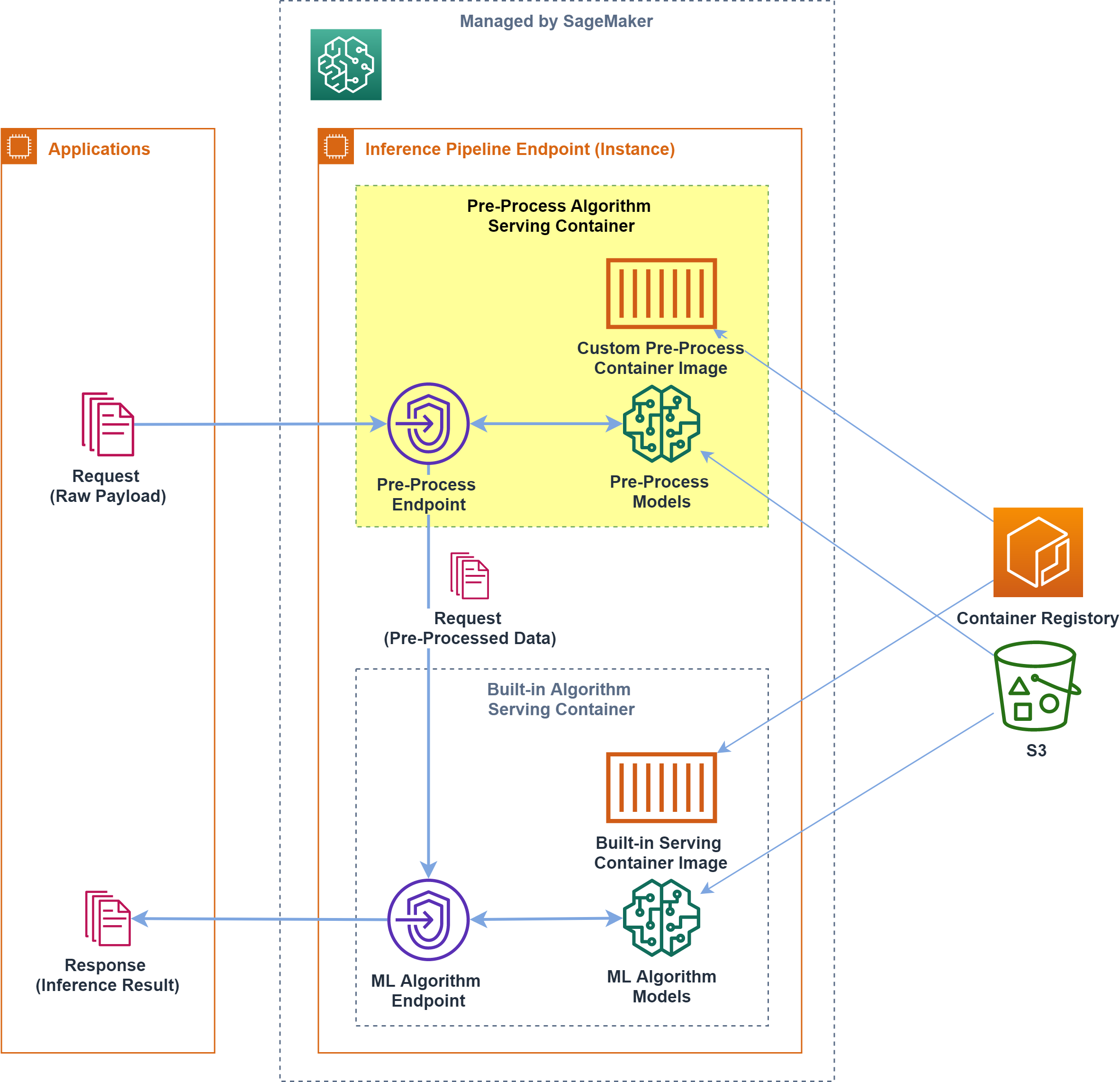
下記のコードによって、組み込みアルゴリズムによるトレーニングを実行しますimport sagemaker algorithm_name = 'ml_hoge' ml_container_name = get_image_uri(boto3.Session().region_name, algorithm_name) ml_model_path = 's3_ml_model_path' ml_training_job_name = '{algorithm_name}-{preprocess_id}-{timestamp}' ml = sagemaker.estimator.Estimator( image_name = ml_container_name, role = role, sagemaker_session = sess, train_instance_count = train_instance_count, train_instance_type = train_instance_type, output_path = ml_model_path ) ml.fit( inputs={ 'train': train_dataset_path_train, 'validation': train_dataset_path_valid, 'auxiliary': train_dataset_path_aux, 'test': train_dataset_path_test }, job_name = ml_training_job_name )エンドポイント構築
前処理で生成した ベクトライザ 等を利用するデータ前処理コンテナと、組み込みアルゴリズムの学習済モデルを参照する推論コンテナをセットにして、推論パイプラインエンドポイントを構築します
(sagemaker.pipeline.PipelineModelのmodels変数へ渡した配列のモデル順に、リクエストに応答するエンドポイントが構築されます)import sagemaker preprocessor = sagemaker.estimator.Estimator.attach(preprocess_job_name) preprocess_model = preprocessor.create_model() ml = sagemaker.estimator.Estimator.attach(ml_training_job_name) ml_model = ml.create_model() pipeline_endpoint_name = '{algorithm_name}-pipeline-endpoint-{version}' pipeline_model = sagemaker.pipeline.PipelineModel( name = pipeline_model_name, role = role, models = [ preprocess_model, ml_model ] ) pipeline_model.deploy( initial_instance_count = pipeline_instance_count, instance_type = pipeline_instance_type, endpoint_name = pipeline_endpoint_name )ここまでで、独自コンテナによる前処理を組み込んだ推論エンドポイントが起動します
推論リクエストへの応答
生データを所定の形式で引き渡せば、
前処理コンテナで整形 -> 組み込みアルゴリズムの推論コンテナで推論した結果が返りますimport sagemaker from sagemaker.content_types import CONTENT_TYPE_JSON ml_predictor = sagemaker.predictor.RealTimePredictor( endpoint = pipeline_endpoint_name, serializer = sagemaker.predictor.json_serializer, deserializer= sagemaker.predictor.json_deserializer, content_type= CONTENT_TYPE_JSON, accept = CONTENT_TYPE_JSON ) payload = {'target':'日本語文字列'} pprint(ml_predictor.predict(payload))トラブルシューティング
エンドポイント構築時に ping health check に失敗する
エンドポイント構築時に
pingに失敗して構築できないというエラーが発生する場合ValueError: Error hosting endpoint pipeline-endpoint-vXX: Failed Reason: The container-1 for production variant AllTraffic did not pass the ping health check. Please check CloudWatch logs for this endpoint.独自コンテナで起動させたWebサーバが、環境変数
SAGEMAKER_BIND_TO_PORTポートでリクエストを受け付けていない可能性があります(CloudWatchLogs にも何の情報も出ず途方に暮れるのですが、落ち着いて)
Webサーバ( nginx など)の設定を見直し、SAGEMAKER_BIND_TO_PORT環境変数が存在する場合には、環境変数の指定するポートで受け付けるようにしますECR コンテナリポジトリに必要な権限が付与されていない
パイプラインエンドポイントを構築しようとする際、権限が足りないといったエラーが出る場合
ValueError: Error hosting endpoint pipeline-endpoint-vXX: Failed Reason: The repository of your image 111111111.dkr.ecr.xxxxx.amazonaws.com/XXXXXXXXXXXXXXXXXXXX does not grant ecr:GetDownloadUrlForLayer, ecr:BatchGetImage, ecr:BatchCheckLayerAvailability permission to sagemaker.amazonaws.com service principal.推論パイプラインエンドポイントを構築する際には、パイプラインに組み込む独自コンテナのリポジトリに SageMaker からの読み出しを許可するポリシー付与が必要です
推論パイプラインの Amazon ECR アクセス許可 を参考に、ECR コンソールから必要なポリシーを付与します{ "Version": "2008-10-17", "Statement": [ { "Sid": "allowSageMakerToPull", "Effect": "Allow", "Principal": { "Service": "sagemaker.amazonaws.com" }, "Action": [ "ecr:GetDownloadUrlForLayer", "ecr:BatchGetImage", "ecr:BatchCheckLayerAvailability" ] } ] }その他
まとめ
独自コンテナを含む推論パイプラインエンドポイントを構築する際、次の点に注意してください
- 基本的な挙動は SageMaker のカスタムコンテナと同じ
- エンドポイントのリクエスト受け付けポートは次の環境変数に依存する
SAGEMAKER_BIND_TO_PORT- 推論パイプラインでリアルタイム予測を実行
- Dockerコンテナリポジトリに、次のポリシー付与が必要
日本語処理など独自コンテナを必要とするケースで、ぜひ参考にしていただければと思います
参考資料
パイプラインのコンテナは、(8080 ではなく) SAGEMAKER_BIND_TO_PORT 環境変数で指定されたポートでリッスンします。
コンテナがこの要件に準拠していることを示すには、次のコマンドを使用して Dockerfile にラベルを追加します
LABEL com.amazonaws.sagemaker.capabilities.accept-bind-to-port=true
- Amazon SageMaker がトレーニングイメージを実行する方法
- Amazon SageMaker ホスティングサービスでの独自の推論コードの使用
- pipeline.PipelineModel
- 推論パイプラインのトラブルシューティング
Amazon SageMaker 組み込みアルゴリズムを含むパイプラインでカスタム Docker イメージを使用する場合は、Amazon ECR ポリシーが必要です。ポリシーは、イメージをプルするために Amazon SageMaker のアクセス許可を Amazon ECR レポジトリに与えます。
- 投稿日:2019-07-08T09:15:31+09:00
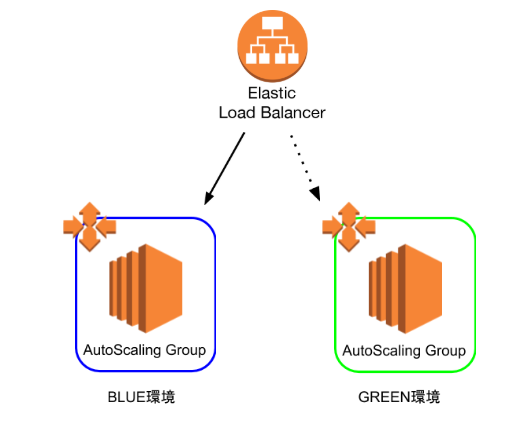
Packer, Ansible, Terraformで作るBlue-Greenデプロイメント (AWS)
概要
AWS環境で、デプロイメントのフローを自動化する仕事を任されたので、成果物をここにメモしておきます。
デプロイをするシステムは、以下のように構成されています。
Blue/Greenの2環境を用意し、普段は片方のみを使用しています。使用していないほうの環境にデプロイをして、ELBの振り分け先を変更することで、ダウンタイムのないデプロイメントを目指します。また、packerやAnsible, Terraformなどのツールを使うことで、このフローを自動化していきます。
尚、こちらの記事やこちらの記事などを参考にして作成しました。
作業手順
- アプリケーションや必要なミドルウェアなどをインストールした、ゴールデンAMIを作成する
- ゴールデンAMIを参照する起動設定を新規作成し、デプロイ先のAutoScaling Groupにそれを読み込ませる
- Elastic Load BalancerのListenerが転送するTargetGroupを変更し、本番環境をBlueからGreenに(もしくはGreenからBlueに)切り替える
AMIの作成
PackerとAnsibleを使って、ゴールデンAMIを作成します。AMIの基本的な設定はPackerで、ツールのインストール等の構成管理はAnsibleで、それぞれ行います。
まずは、Packerの設定です。
packer.json{ "variables":{ "version":"" //デプロイのたびに変わる値は、変数としておきます }, "builders": // AMIを作成するために一時的に立てられるEC2インスタンスについて定義 [ { "type":"amazon-ebs", "ami_name": "test-AMI-v{{user `version`}}", "region": "ap-northeast-1", "source_ami": "ami-xxxxxxxxxxx", // 基とするAMI "instance_type": "t2.micro", "ssh_username": "centos", "tags":{ "version":"{{user `version`}}" // 起動設定を作成するときに、見つけやすいようにタグをつけておく }, "force_deregister": true, "force_delete_snapshot": true, "security_group_ids":["sg-xxxxxxx","sg-xxxxxxx"], "iam_instance_profile": "xxxxxxx", "subnet_id":"subnet-xxxxxxxx" } ], "provisioners": // AMI作成用のインスタンスの中で行いたい処理を定義 [ { "type":"shell", "inline": [ // Ansibleを動かすためのツールをインストール "sudo -E yum -y update", "sudo -E yum -y install epel-release", "sudo -E yum -y install python-pip", "sudo -E yum -y install ansible" ] }, { "type":"ansible-local", // Ansibleの起動 "playbook_file":"setup.yml" } ] }上のファイルの中から呼ばれている、Ansibleの設定ファイル(playbook)の設定は、以下の通りです。
尚、以下ではS3上のmavenリポジトリから成果物をとってくるようにしてあります。setup.yml- hosts: all become: yes vars: proxy_env: # すべてに共通するプロキシ設定は、変数化しておく https_proxy: xxxxxxxxx http_PROXY: xxxxxxxxx HTTPS_PROXY: xxxxxxxxx HTTP_PROXY: xxxxxxxxx no_proxy: xxxxxxxxx tasks: - environment: "{{proxy_env}}" name: "install boto3 (required by aws-s3)" # boto3のインストール pip: name: boto3 - pip: name: lxml name: "install lxml" # Ansibleのs3モジュールを動かすのに必要 environment: "{{proxy_env}}" - maven_artifact: # S3上のmavenリポジトリから成果物を取得 repository_url: 's3://xxxxxxxx' group_id: jp.co.xx.xx artifact_id: xxxxxx version: 1.0.0 extension: tgz dest: /tmp/xxxxxx.tgz
packerコマンドで上記のpackerおよびAnsibleを実行すると、AMIが作成されるはずですASGの設定変更
Terraformを用いて、まず上で作成したAMIを読み込む起動設定を作成し、そしてデプロイ先のASG(使用中でない環境のASG)にその起動設定を読み込ませるようにします。
deploy.tfprovider "aws" { region = "ap-northeast-1" } variable "target_version" {} // デプロイのたびに値が変わるものは、変数化しておく data "aws_ami" "centos" { // packerとAnsibleで作成したAMIを取得 most_recent = true owners = ["xxx"] filter { // タグで検索 name = "version" values = ["${var.target_version}"] } } resource "aws_launch_configuration" "test" { // 起動設定を新規作成 name = "config-test-v${var.target_version}" image_id = "${data.aws_ami.centos.id}" // 作成したAMIを指定 instance_type = "t2.micro" enable_monitoring = false security_groups = ["sg-xxxxxxx", "sg-xxxxxxxxx","sg-xxxxxxx"] key_name = "xxxxxxxxx" iam_instance_profile = "xxxxxxxxx" root_block_device { delete_on_termination = true iops = 100 volume_size = 30 volume_type = "gp2" } } resource "aws_autoscaling_group" "test_resource" { // デプロイ先のASGが上の起動設定を読みこむよう、設定変更 name = "asg-test" launch_configuration = "${aws_launch_configuration.test.name}" // 上で作成した起動設定を指定 min_size = 2 max_size = 2 desired_capacity = 2 target_group_arns = ["xxxxx","xxxxxx"] vpc_zone_identifier = ["xxxxxxx","xxxxxxxx"] lifecycle { create_before_destroy = true } }
terraformコマンドで上の設定を反映させると、使用中でない環境のASGに設定が反映されます。Blue/Greenの切り替え
最後に、ELBの振り分けの設定を変えます。適当なスクリプト言語でシェルを書くのですが、今回はCentOSにデフォルトで入っているPythonの2系で書きます(
今時Python2かよ、って感じですが)。処理の手順は、以下の通りです
1. ASGに紐づくEC2のインスタンスのリストを取得
2. EC2がすべて立ち上がって、テストをパスしたか確認する
3. EC2がすべて立ち上がっていれば、ELBのListenerのリクエストの転送先のTargetGroupを変更し、Blue/Greenを切り替える以下がコードです。
switch_elb.sh#! /bin/python # -*- coding: utf-8 -*- from time import sleep import json import subprocess # ASGに紐づくEC2インスタンスのリストの取得 GET_INSTANCE_LIST = """aws ec2 describe-instances --filters "Name=tag:version,Values=%s""" # EC2インスタンスがヘルシーな状態であるか確認 GET_INSTANCE_STATUS = "aws ec2 describe-instance-status --instance-id %s" # ELBの切り替え SWITCH_ELB_LISTENER = "aws elbv2 modify-rule --rule-arn %s --actions Type=forward,TargetGroupArn=%s" # EC2のリストを取得し、ヘルスチェック def get_ec2_health(version): instance_ids = [] # インスタンスのリスト取得 instance_list = subprocess.check_output(GET_INSTANCE_LIST % version,shell=True) instance_dict = json.loads(instance_list) for instance in instance_dict["Reservations"]: # 停止中のインスタンスは除く if instance["Instances"][0]["State"]["Code"] != 48: instance_ids.append(instance["Instances"][0]["InstanceId"]) for i in range(30): # 一つずつインスタンスをヘルスチェックし、一つでもダメであれば、15秒後に再チェック result = check_ec2_status(instance_ids) if result == True: return True else: sleep(15) return False # EC2のヘルスチェック def check_ec2_status(instance_ids): for instance_id in instance_ids: result = commands.getoutput(GET_INSTANCE_STATUS % instance_id) status_dict = json.loads(result) # 一つでもヘルスチェックに失敗すれば、Falseを返す if status_dict["InstanceStatuses"][0]["SystemStatus"]["Details"][0]["Status"] != "passed" or status_dict["InstanceStatuses"][0]["InstanceStatus"]["Details"][0]["Status"] != "passed": return False return True # ELBの切り替え def switch_elb(): ELB_rules = {} try: # ELBのListenerのRuleのarnをjson形式で羅列しておくファイル file = open("../../ELB_rules_arns.json","r") ELB_rules = json.load(file) except: print("ELBのルールの情報が読み込めませんでした") return target_group_arns = {} try: # デプロイ先の環境の、TargetGroupのarnをjson形式で羅列しておくファイル file = open("./target_group_arns.json","r") target_group_arns = json.load(file) except: print("ターゲットグループの情報が読み込めませんでした") return for key in ELB_rules: result = subprocess.call(SWITCH_ELB_LISTENER % (ELB_rules[key],target_group_arns[key]),shell=True) if result == 0: print("切り替え成功") return 0 # メインの関数 def main(): version = input("デプロイのバージョンを指定してください") ec2_health = get_ec2_health(version) if ec2_health == True: switch_elb_status = switch_elb() if switch_elb_status != 0: print("ELBの切り替えがうまくいきませんでした") else: print("ELBの切り替えに成功しました") else: print("EC2のヘルスチェックが失敗したため、切り替えを行いません") if __name__ == "__main__": main()
- 投稿日:2019-07-08T09:00:14+09:00
AWS CloudFormationのLambda-backedカスタムリソースでリソースの更新・削除をする方法
AWS CloudFormationのLambda-backedカスタムリソースを利用するとAWS CloudFormationで管理できないリソースも管理することができますが、Lambda-backedで作成したリソースの更新・削除するのにリソースのIDをどうやって取り回そうか悩みました。
下記は解決策の1案となりますが、他に良い方法があれば教えてほしいです!
前提
- AWSアカウントがある
- AWS CLIが利用できる
- AWS Lambda、CloudFormationの作成権限がある
CloudFormationのテンプレート作成
> mkdir 任意のディレクトリ > cd 任意のディレクトリ > touch cfn-template.yamlLambda-backedカスタムリソースを利用して何かしらのリソースを作成・更新・削除するテンプレートとなります。
ポイントとしてはCreateResourceのひとつで完結できたら良かったのですが、CreateResourceで作成したリソースのIDを自前で取り回せなかったので、更新と削除を別リソースUpdateResourceで行うようにしました。うーん、めんどうですcfn-template.yamlResources: CreateResource: Type: Custom::CustomResource Properties: ServiceToken: !GetAtt CreateResourceFunction.Arn UpdateResource: Type: Custom::CustomResource Properties: ServiceToken: !GetAtt UpdateResourceFunction.Arn ResourceId: !GetAtt CreateResource.Id CreateResourceFunction: Type: AWS::Lambda::Function Properties: Handler: index.handler Role: !GetAtt FunctionExecutionRole.Arn Code: ZipFile: !Sub | import cfnresponse def handler(event, context): if event['RequestType'] == 'Create': # なんかリソース作成 response = {'Id': 'hoge'} print('create resources ' + response['Id']) cfnresponse.send(event, context, cfnresponse.SUCCESS, response) return # 他のRequestTypeは無視 cfnresponse.send(event, context, cfnresponse.SUCCESS, {}) Runtime: python3.7 UpdateResourceFunction: Type: AWS::Lambda::Function Properties: Handler: index.handler Role: !GetAtt FunctionExecutionRole.Arn Code: ZipFile: !Sub | import cfnresponse def handler(event, context): Id = event['ResourceProperties']['ResourceId'] if event['RequestType'] == 'Update': # なんかリソース更新 print('update resources ' + Id) cfnresponse.send(event, context, cfnresponse.SUCCESS, {}) return if event['RequestType'] == 'Delete': # なんかリソース削除 print('delete resources ' + Id) cfnresponse.send(event, context, cfnresponse.SUCCESS, {}) return # 他のRequestTypeは無視 cfnresponse.send(event, context, cfnresponse.SUCCESS, {}) Runtime: python3.7 FunctionExecutionRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Principal: Service: - lambda.amazonaws.com Action: - sts:AssumeRole Path: "/" Policies: - PolicyName: root PolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Action: - logs:CreateLogGroup - logs:CreateLogStream - logs:PutLogEvents Resource: "arn:aws:logs:*:*:*"動作確認
スタック作成
> aws cloudformation create-stack \ --stack-name cfn-lambda-backed-test \ --template-body file://cfn-template.yaml \ --capabilities CAPABILITY_IAM { "StackId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-lambda-backed-test/3bed13d0-96e9-11e9-90fb-122d883fe268" }スタック作成して各リソースが作成できたらLambda関数のログを確認します。
各リソースと関数のPhysicalResourceIdをパラメータにaws logs get-log-eventsコマンドで取得します。> aws cloudformation list-stack-resources \ --stack-name cfn-lambda-backed-test { "StackResourceSummaries": [ { "LogicalResourceId": "CreateResource", "PhysicalResourceId": "2019/06/25/[$LATEST]587b7bbfa5b74a38a54846ff44a9a592", "ResourceType": "Custom::CustomResource", "LastUpdatedTimestamp": "2019-06-25T01:33:55.358Z", "ResourceStatus": "CREATE_COMPLETE", "DriftInformation": { "StackResourceDriftStatus": "NOT_CHECKED" } }, { "LogicalResourceId": "CreateResourceFunction", "PhysicalResourceId": "cfn-lambda-backed-test-CreateResourceFunction-LBG1WB6FV88B", "ResourceType": "AWS::Lambda::Function", "LastUpdatedTimestamp": "2019-06-25T01:33:49.819Z", "ResourceStatus": "CREATE_COMPLETE", "DriftInformation": { "StackResourceDriftStatus": "NOT_CHECKED" } }, { "LogicalResourceId": "FunctionExecutionRole", "PhysicalResourceId": "cfn-lambda-backed-test-FunctionExecutionRole-17PMYTJ3NS41Z", "ResourceType": "AWS::IAM::Role", "LastUpdatedTimestamp": "2019-06-25T01:33:46.370Z", "ResourceStatus": "CREATE_COMPLETE", "DriftInformation": { "StackResourceDriftStatus": "NOT_CHECKED" } }, { "LogicalResourceId": "UpdateResource", "PhysicalResourceId": "2019/06/25/[$LATEST]59ec7f3b07ec48f5b5feab288384b268", "ResourceType": "Custom::CustomResource", "LastUpdatedTimestamp": "2019-06-25T01:34:01.068Z", "ResourceStatus": "CREATE_COMPLETE", "DriftInformation": { "StackResourceDriftStatus": "NOT_CHECKED" } }, { "LogicalResourceId": "UpdateResourceFunction", "PhysicalResourceId": "cfn-lambda-backed-test-UpdateResourceFunction-BMXD99ZLKXP0", "ResourceType": "AWS::Lambda::Function", "LastUpdatedTimestamp": "2019-06-25T01:33:49.516Z", "ResourceStatus": "CREATE_COMPLETE", "DriftInformation": { "StackResourceDriftStatus": "NOT_CHECKED" } } ] } > aws logs get-log-events \ --log-group-name /aws/lambda/cfn-lambda-backed-test-CreateResourceFunction-LBG1WB6FV88B \ --log-stream-name '2019/06/25/[$LATEST]587b7bbfa5b74a38a54846ff44a9a592' \ --output=text \ --query "events[*].message" START RequestId: e8ad68ad-86be-4ea1-ad3f-736617882ce7 Version: $LATEST create resources hoge https://cloudformation-custom-resource-response-useast1.s3.amazonaws.com/(略) Response body: {"Status": "SUCCESS", "Reason": "See the details in CloudWatch Log Stream: 2019/06/25/[$LATEST]587b7bbfa5b74a38a54846ff44a9a592", "PhysicalResourceId": "2019/06/25/[$LATEST]587b7bbfa5b74a38a54846ff44a9a592", "StackId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-lambda-backed-test/3bed13d0-96e9-11e9-90fb-122d883fe268", "RequestId": "1cb162f1-979f-4e6f-b277-dd7e729d23cc", "LogicalResourceId": "CreateResource", "NoEcho": false, "Data": {"Id": "hoge"}} Status code: OK END RequestId: e8ad68ad-86be-4ea1-ad3f-736617882ce7 REPORT RequestId: e8ad68ad-86be-4ea1-ad3f-736617882ce7 Duration: 292.74 ms Billed Duration: 300 ms Memory Size: 128 MB Max Memory Used: 29 MB > aws logs get-log-events \ --log-group-name /aws/lambda/cfn-lambda-backed-test-UpdateResourceFunction-BMXD99ZLKXP0 \ --log-stream-name '2019/06/25/[$LATEST]59ec7f3b07ec48f5b5feab288384b268' \ --output=text \ --query "events[*].message" START RequestId: d593f33a-9231-4284-8157-97b5b799f70e Version: $LATEST https://cloudformation-custom-resource-response-useast1.s3.amazonaws.com/(略) Response body: {"Status": "SUCCESS", "Reason": "See the details in CloudWatch Log Stream: 2019/06/25/[$LATEST]59ec7f3b07ec48f5b5feab288384b268", "PhysicalResourceId": "2019/06/25/[$LATEST]59ec7f3b07ec48f5b5feab288384b268", "StackId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-lambda-backed-test/3bed13d0-96e9-11e9-90fb-122d883fe268", "RequestId": "fe1b2ba8-0aff-44a6-ac1f-f46863594b0f", "LogicalResourceId": "UpdateResource", "NoEcho": false, "Data": {}} Status code: OK END RequestId: d593f33a-9231-4284-8157-97b5b799f70e REPORT RequestId: d593f33a-9231-4284-8157-97b5b799f70e Duration: 242.26 ms Billed Duration: 300 ms Memory Size: 128 MB Max Memory Used: 29 MBスタック作成時には
CreateResourceでリソースの作成、UpdateResourceは呼び出しのみとなることが確認できました。スタック削除
スタックを削除して動作を確認します。
> aws cloudformation delete-stack \ --stack-name cfn-lambda-backed-test { "StackId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-lambda-backed-test/3bed13d0-96e9-11e9-90fb-122d883fe268" }スタック削除すると当然のことながらリソースが取得できなくなるので、ログストリーム名を取得してからログを確認します。
> aws logs describe-log-streams \ --log-group-name /aws/lambda/cfn-lambda-backed-test-CreateResourceFunction-LBG1WB6FV88B \ --output=text \ --query "logStreams[*].logStreamName" 2019/06/25/[$LATEST]587b7bbfa5b74a38a54846ff44a9a592 2019/06/25/[$LATEST]8d6fac4288674ecbb7b6f7a577b8b932 > aws logs get-log-events \ --log-group-name /aws/lambda/cfn-lambda-backed-test-CreateResourceFunction-LBG1WB6FV88B \ --log-stream-name '2019/06/25/[$LATEST]8d6fac4288674ecbb7b6f7a577b8b932' \ --output=text \ --query "events[*].message" START RequestId: 8a0c34a7-8c3a-47b5-9128-3a49748aca52 Version: $LATEST > aws logs describe-log-streams \ --log-group-name /aws/lambda/cfn-lambda-backed-test-UpdateResourceFunction-BMXD99ZLKXP0 \ --output=text \ --query "logStreams[*].logStreamName" 2019/06/25/[$LATEST]0c2223e7635d4ee0b04c508e0fc76511 2019/06/25/[$LATEST]59ec7f3b07ec48f5b5feab288384b268 > aws logs get-log-events \ --log-group-name /aws/lambda/cfn-lambda-backed-test-UpdateResourceFunction-BMXD99ZLKXP0 \ --log-stream-name '2019/06/25/[$LATEST]0c2223e7635d4ee0b04c508e0fc76511' \ --output=text \ --query "events[*].message" START RequestId: fcde5258-b444-4e33-aef6-d2dcff63e2c2 Version: $LATEST delete resources hoge https://cloudformation-custom-resource-response-useast1.s3.amazonaws.com/(略) Response body: {"Status": "SUCCESS", "Reason": "See the details in CloudWatch Log Stream: 2019/06/25/[$LATEST]0c2223e7635d4ee0b04c508e0fc76511", "PhysicalResourceId": "2019/06/25/[$LATEST]0c2223e7635d4ee0b04c508e0fc76511", "StackId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-lambda-backed-test/3bed13d0-96e9-11e9-90fb-122d883fe268", "RequestId": "5d390a57-55b6-4ddd-8820-0104c94ab705", "LogicalResourceId": "UpdateResource", "NoEcho": false, "Data": {}} Status code: OK END RequestId: fcde5258-b444-4e33-aef6-d2dcff63e2c2 REPORT RequestId: fcde5258-b444-4e33-aef6-d2dcff63e2c2 Duration: 644.07 ms Billed Duration: 700 ms Memory Size: 128 MB Max Memory Used: 56 MBスタック削除時には
CreateResourceは呼び出しのみ、UpdateResourceでリソースの削除がされることが確認できました。まとめ
若干定義が面倒になりますがAWS CloudFormationのLambda-backedカスタムリソースを利用してリソースを更新・削除できることが確認できました。
参考
Blue21: lambdaのログを aws-cli で見る
https://blue21neo.blogspot.com/2018/02/lambda-aws-cli.html
- 投稿日:2019-07-08T08:13:27+09:00
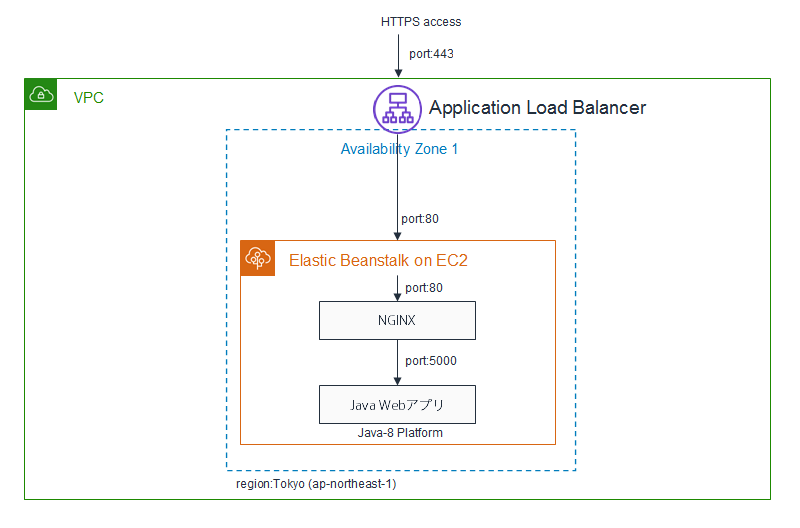
ゼロから始めるAWS Elastic Beanstalk #2~ 独自ドメイン対応、HTTPS対応、HTTP→HTTPSへのリダイレクト対応、Auto Scaling設定 ~
概要
- ゼロから始めるJavaでAWS Elastic Beanstalk #1~ EB CLIを使ったJava Webアプリ環境構築 ~の続編です
Elastic Beanstalkで構築するWebアプリを以下のようにします
- HTTPS対応
- 独自ドメイン対応
- うっかりHTTPでリクエスト来たらHTTPSにリダイレクト
- Auto Scalingは不要
ということで、以下のように構成するときの設定例をみていきます
本編
ALB(Application Load Balancer)をHTTPSに対応する
Elastic BeanstalkでつくったWebアプリをHTTPSに対応させるため、拡張設定用のYAMLファイルを作る。
プロジェクトのルートに .ebextensionsというディレクトリをつくり、そこにalb-secure-listener.configというファイルを作成する。elastic-beantalk-java-app ├── .ebextensions │ └── alb-secure-listener.config ・ ・ その他のファイル達 ・alb-secure-listener.configは以下のようにする
alb-secure-listener.configoption_settings: aws:elbv2:listener:default: ListenerEnabled: 'false' aws:elbv2:listener:443: DefaultProcess: https ListenerEnabled: 'true' Protocol: HTTPS SSLCertificateArns: arn:aws:acm:ap-northeast-1:123456789:certificate/abcdef-01234-6123-caca-123456789b aws:elasticbeanstalk:environment:process:https: Port: '80' Protocol: HTTP
以下、設定内容の説明をしていく。設定その1:「HTTPは受け付けません」
aws:elbv2:listener:default: ListenerEnabled: 'false'aws:elbv2:listener:defaultはデフォルトのリスナー(ポート80)の設定を意味する。
ここでListenerEnabled: 'false'としていったんポート80、つまり、HTTPは利用不可とした。つまりHTTPでのアクセスを受け付けない設定にした。(「こういう設定もアリだよね」という例のためで、後で変更してHTTP(ポート80)でアクセス来たらHTTPS(ポート443)にリダイレクトするように構成する。)
設定その2:「HTTPSを受け付けます、証明書はこれです。」
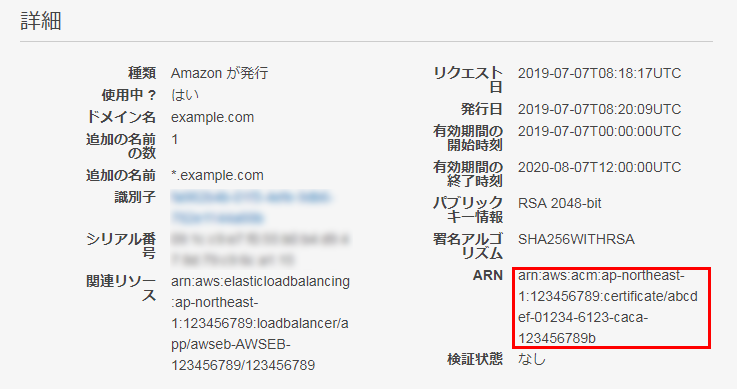
aws:elbv2:listener:443: DefaultProcess: https ListenerEnabled: 'true' Protocol: HTTPS SSLCertificateArns: arn:aws:acm:ap-northeast-1:123456789:certificate/abcdef-01234-6123-caca-123456789baws:elbv2:listener:443はポート443の設定。
ここでは、HTTPSでつかうポート443についての設定で、HTTPSプロトコルで使うことを指定している。
SSLCertificateArnsにはACM(Certificate Mangaer)で取得した証明書のARNを指定する
設定その3:「ロードバランサーにHTTPSでアクセス来たら、ロードバランサーはEC2のポート80番にHTTPでつなぎます」
aws:elbv2:listener:443:以下にあったDefaultProcess: httpsの部分だが、
このhttpsというのは、以下の設定にあるaws:elasticbeanstalk:environment:process:https:のhttpsに対応している。つまり単なる名前。httpsじゃなくてもOK。aws:elasticbeanstalk:environment:process:https: Port: '80' Protocol: HTTPこれで、ロードバランサーにHTTPSでアクセスがきたら、その先にあるEC2の80番ポートにつなぎに行くという設定ができた。
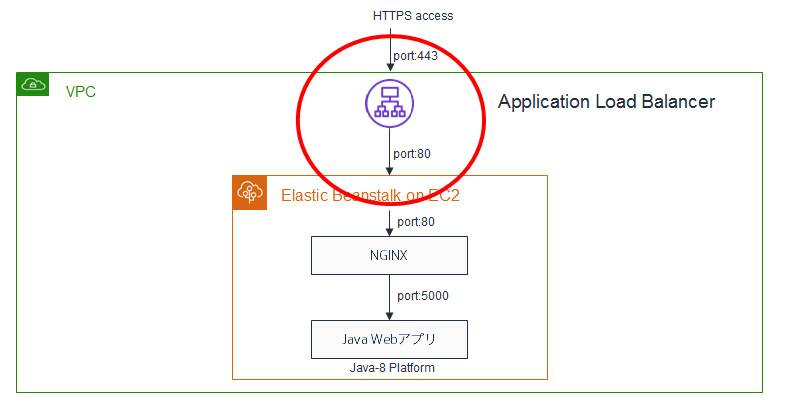
つまり、以下の赤マルの部分の設定ができた。
Auto Scalingを構成する
aws:autoscaling:asg: Availability Zones: Any MaxSize: '1' MinSize: '1'っこではaws:autoscaling:asgでAuto Scalingグループで使用するインスタンスの最小数と最大数を、それぞれ1に設定した。つまりこれはスケールしない設定。
最大数を2以上に設定した場合、Availability Zones: Anyになってるときは、使用可能なAvailability Zone間で均等にインスタンスを起動するようになる。
HTTPSのみ有効で、AutoScaleしないalb-secure-listener.configの内容
ここまでの内容まとめると
alb-secure-listener.configは以下のようにするファイルの置き場所elastic-beantalk-java-app ├── .ebextensions │ └── alb-secure-listener.config ・ ・ その他のファイル達 ・HTTPSのみ有効で、AutoScaleしないalb-secure-listener.configの内容
alb-secure-listener.configoption_settings: aws:elbv2:listener:default: ListenerEnabled: 'false' aws:elbv2:listener:443: DefaultProcess: https ListenerEnabled: 'true' Protocol: HTTPS SSLCertificateArns: arn:aws:acm:ap-northeast-1:456509554684:certificate/fa982b4b-01f3-4efe-9db6-782e1144a88b aws:elasticbeanstalk:environment:process:https: Port: '80' Protocol: HTTP aws:autoscaling:asg: Availability Zones: Any MaxSize: '1' MinSize: '1'アプリをデプロイする
さて、ここまで設定したところでアプリをデプロイする
eb create my-jetty-app-test2 --instance_type t2.small --elb-type application --vpc.id vpc-xxxxxxxxxxxxxxxxx --vpc.elbpublic --vpc.elbsubnets subnet-xxxxxxxxxxxxxxxxx,subnet-yyyyyyyyyyyyyyyyy --vpc.publicip --vpc.ec2subnets subnet-xxxxxxxxxxxxxxxxx,subnet-yyyyyyyyyyyyyyyyy独自ドメイン対応
アプリのデプロイが終わったら、Elastic Beanstalkを独自ドメインに対応する
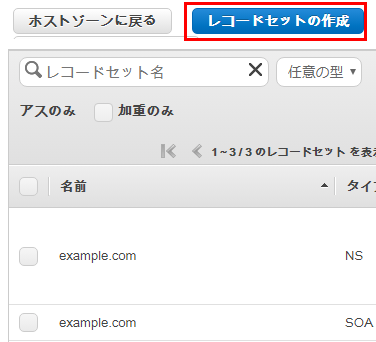
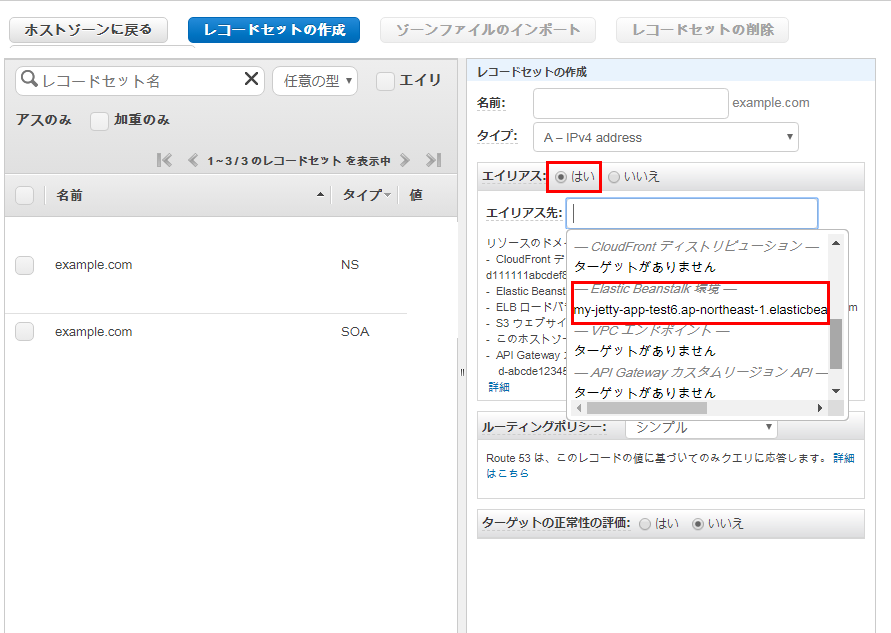
Webコンソールから Route 53 に行き、対象ドメインを選択してレコードセットの作成をクリック
エイリアス を選択し、エイリアス先から Elastic Beanstalk環境グループのなかから、このドメインを割り当てたい環境を選択し作成をクリックすればOK
これで、ドメインがElastic Beanstalkに作った環境にひもづいた。
ドメイン名は仮にexample.comとすると
で無事アプリが公開できた。
ここまでで独自ドメイン+HTTPS化が終了。HTTPアクセスのHTTPSへのリダイレクト対応
ALB(Application Loadbalancer)の機能アップにより、ALBの設定だけでHTTP→HTTPSへのダイレクトができるようになっている。
さきほどは、alb-secure-listener.configの設定で以下のようにHTTPを無効にしてしまったが、これを有効にする
alb-secure-listener.config(HTTP無効)option_settings: aws:elbv2:listener:default: ListenerEnabled: 'false'↓
alb-secure-listener.config(HTTP有効)option_settings: aws:elbv2:listener:default: ListenerEnabled: 'true'既にデプロイしているなら、Webコンソールから有効にしてもOK
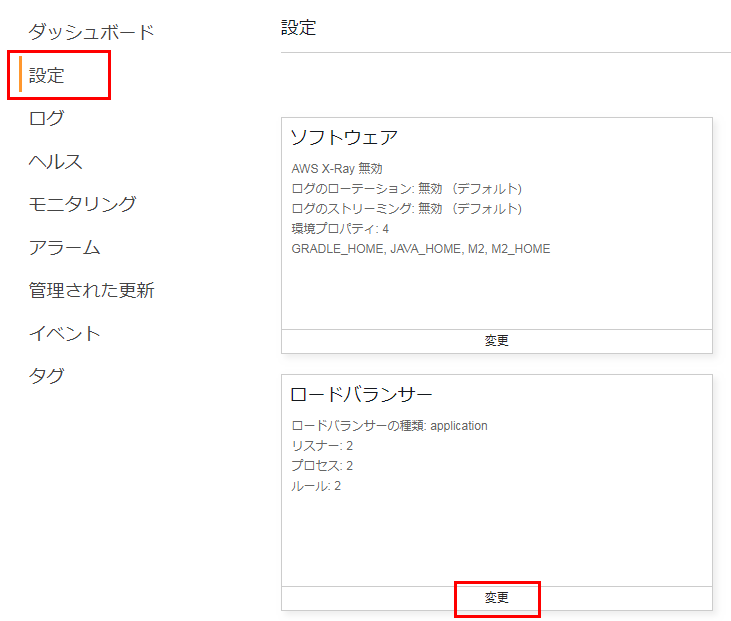
Webコンソールから有効にするには、Elastic Beanstalkにアクセスし、
https://ap-northeast-1.console.aws.amazon.com/elasticbeanstalk
ElasticBeanstalk>変更したい環境>設定>ロードバランサーとメニューを選択して、変更をクリック
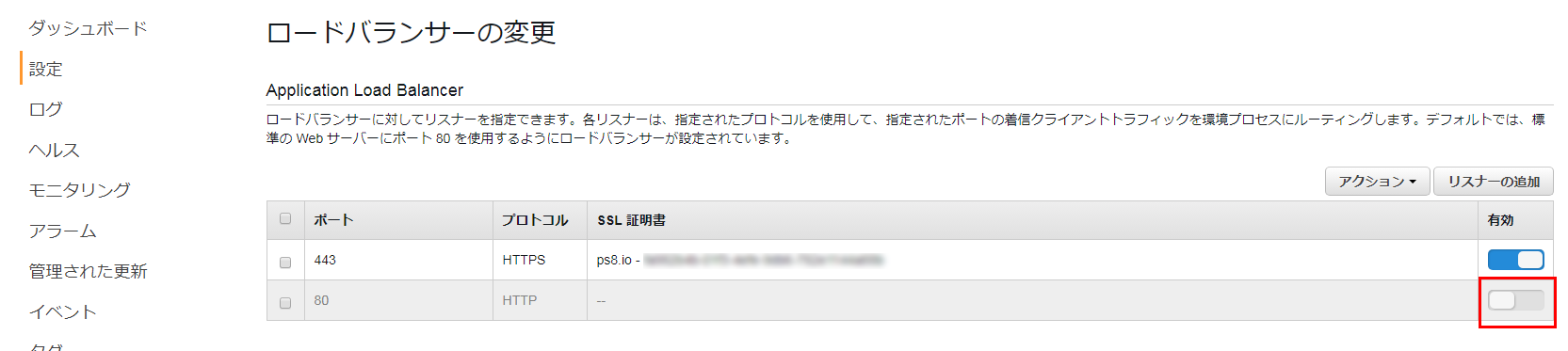
ロードバランサーの変更画面で、無効になっているポート80を有効にして、適用をクリックすればOK
5分程度まつと、構成の更新が終了する。
ポート80のリスナーが有効になったらロードバランサーのリダイレクト設定をする
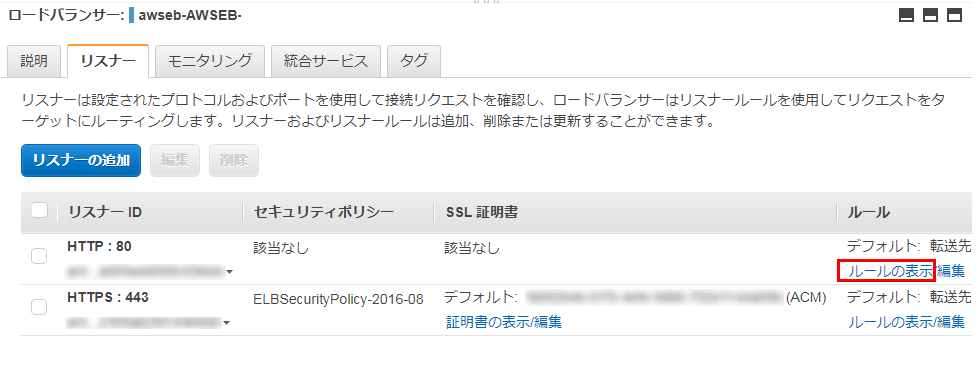
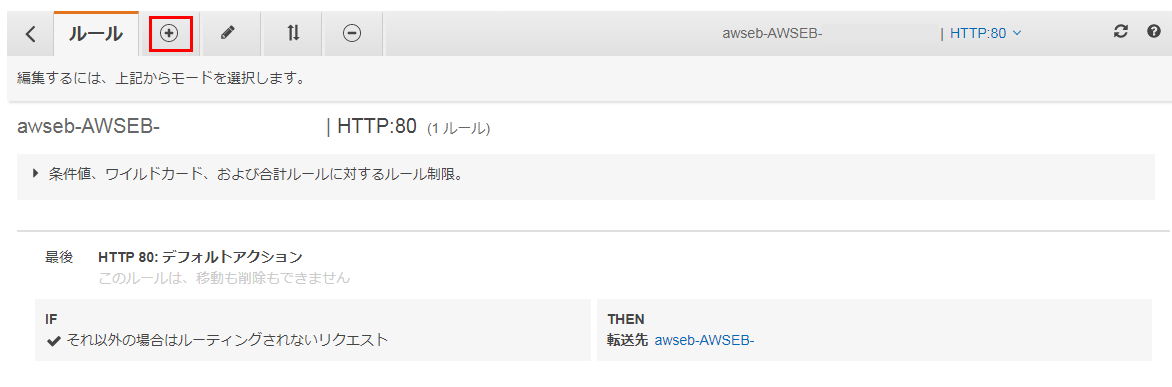
https://ap-northeast-1.console.aws.amazon.com/ec2/v2/home?region=ap-northeast-1#LoadBalancers:
Elastic Beanstalkが自動生成したロードバランサーを選択し、リスナータブを選択する。
HTTP:80のリスナーのルールを表示をクリックする
ルール設定画面で
ボタンをクリックする
次に、
をクリック
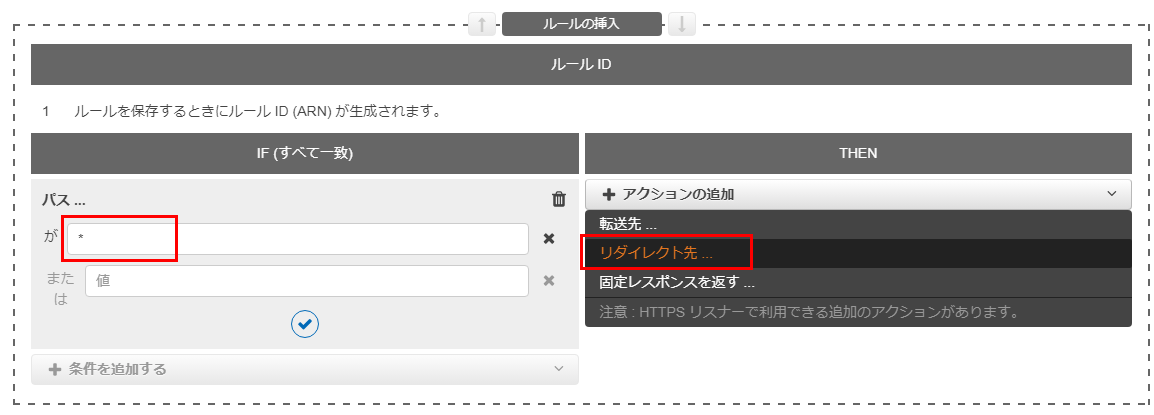
IFとTHENの条件式を設定できるので、
- IFにはパスが・・・を選択し、値として *(アスタリスク=ワイルドカード) を入力
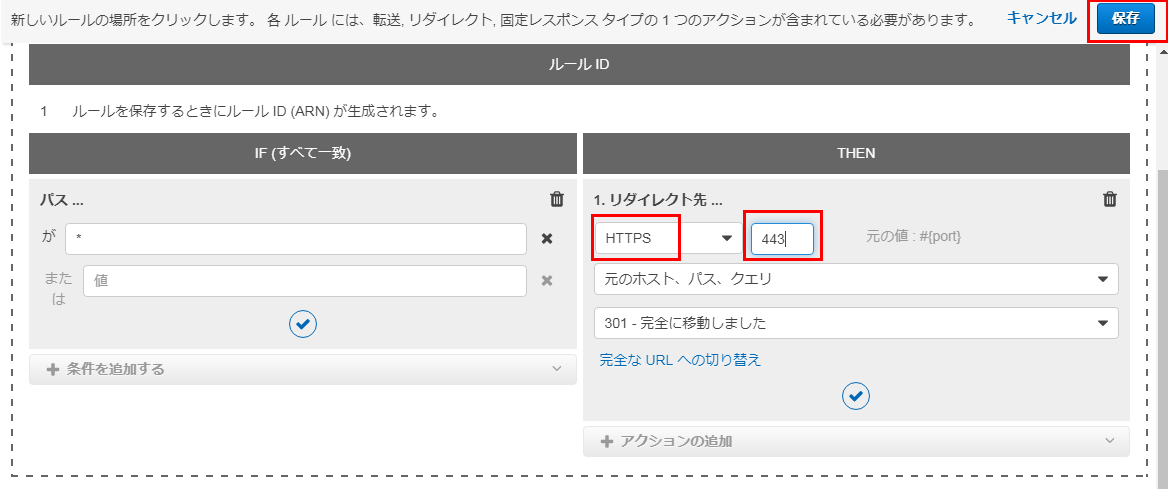
- THENには、アクションの追加で リダイレクト先 を選択する
リダイレクト先として HTTPSを選択し、ポート番号として443と入力する
できたら、保存をクリック。
これで、HTTPにアクセスが来たらHTTPSにリダイレクトする設定は完了。
実際に、
http://example.com にアクセスしてみると、ちゃんと https://example.com にリダイレクトされる。
まとめ
ゼロから始めるJavaでAWS Elastic Beanstalk #1~ EB CLIを使ったJava Webアプリ環境構築 ~の続編として、Elastic BeanstalkのWebアプリを独自ドメイン、HTTPS、HTTPからのリダイレクトに対応するための方法について説明しました
シンプルな設定・操作で実用に耐える環境を構築できるElastic Beanstalkは本番環境構築だけでなく、プロトタイピングなどのラピッドな開発にも向いており色々なシーンで重宝しそうです。
説明した構成
本稿で使用したソースコード
https://github.com/riversun/java-jetty-app-on-elasticbeanstalk/tree/https_conf_with_ebextensions_dir



- 投稿日:2019-07-08T08:10:14+09:00
ゼロから始めるJavaでAWS Elastic Beanstalk #1~ EB CLIを使ったJava Webアプリ環境構築 ~
概要
- AWS Elastic Beanstalkを使えば、EC2でのOSやミドルウェアのセットアップ不要でコマンド1つでWebアプリ実行環境を構築することができます。セキュリティパッチ等も自動適用できるため運用が軽くなるメリットもある上、ベースはEC2等AWSのコンポーネントの組み合わせなので、その気になれば色々カスタマイズもできるという、とても使い勝手の良いサービスです。
- 本稿ではEB CLIというツールをつかってコマンド1つでJava Web アプリの実行環境を構築します。
- Java Webアプリは、Tomcatで動作するWARではなく、Java SEでつくったスッピンのWebアプリ(JAR)が対象です。
(つまり概念さえ理解できればWebアプリFrameworkはSpring BootでもPlay frameworkでもかまいませんし、アプリサーバーもTomcatでもJettyでもGlassfishでもOKです)- また、続編で独自ドメイン対応、HTTPS対応、HTTP→HTTPSへのリダイレクト対応、Auto Scaling設定をします。
環境・構成
以下のような構成をコマンドラインから作ります
(コマンドラインから作るので環境の量産、再構築もカンタン)
- アプリ・プラットフォーム
- AWS Elastic Beanstalkの Java 8 プラットフォーム
- 本稿ではJSP/ServletのWebアプリをJetty9で実行
- クラウド環境
- サービス:AWS Elastic Beanstalk (EC2 + Application Loadbalancer on VPC)
- リージョン:東京(ap-northeast-1) →東京じゃなくてもOK
ソースコード
本稿で紹介する全ソースコードはこちらにあります
https://github.com/riversun/java-jetty-app-on-elasticbeanstalk本編
Elastic Beanstalk コマンドラインインターフェイス(EB CLI)のインストール
Elastic BeanstalkアプリはWeb GUIをつかっても構築できるが、環境構築の自動化など本番運用を考えるとコマンドラインを使うと同じような操作を何度もせずにすみ手間もへるし、アプリ・環境の構築・変更がコマンド一発で済のでCIに組み込むなどすれば安定した運用が可能となる。
1.EB CLIをインストールする
EB CLIのインストールにはPythonが必要となる。
もし、PCにPythonがインストールされていなければ、
https://www.anaconda.com/distribution/
などからインストールしておく。最新版をインストールしておけばOKPythonがインストールが完了していれば、以下のコマンドで EB CLI をインストールできる
pip install awsebcli --upgrade --user2.以下のコマンドでインストール終了チェック
EB CLIがインストールされ、コマンドラインで利用可能になっているかどうか、以下のコマンドで確認する
eb --version EB CLI 3.15.2 (Python 3.7.1)ちゃんとインストールできた模様
TIPS
Windows環境の場合、eb コマンドがみつからない場合がある。
そのときは、C:\Users\[ユーザー名]\AppData\Roaming\Python\Python37\Scriptsをパスに追加する
JavaでWebアプリを作る
Elastic Beanstalkで作るJavaアプリは FAT JAR形式で作る
Elastic BeanstalkでJava Webアプリを実行するにはいくつかの方法がある。
- warファイルをアップロード(Tomcatで実行する)
- JARファイルをアップロード(Java SE環境で実行する)
本稿では JARファイルをアップロード する方式を採用する。
JARファイルとは、Javaで作ったアプリ(Webアプリ)のソースコード+依存ファイルを1つのJARにまとめたモノの事を言う。全部1つにしてサイズの大きなJARを作るので「FAT JAR」とも言う。
JARを使うメリットは、作ったWebアプリをJARファイルにさえできれば、何でもOKということ。
FrameworkはPlay Frameworkでも、Spring Bootでも、Strutsでも、JSFでも良いし(もちろん素のJSP/ServletでもOK)、APサーバーもTomcatでもJettyでもGlassfishでもUndertow(Wildfly)でもOK。
ただしJARをつくってElastic Beanstalkで動かすには、「Elastic Beanstalkのお作法」があるので、そちらをみていく。
といっても、難しくはない。
Elastic Beanstalk用のJavaソースコード構成
Web APサーバーとしてJettyを使ったJava Webアプリを考える。
まず、全体像は以下のとおり。「★」印がついているところが Elastic Beanstalkのための構成
その他はJavaのMavenプロジェクトの標準的なソースコード構成となるElasticBeanstalk用Javaソースコード構成elastic-beantalk-java-app ├── src/main/java ・・・Javaのソースコードのルートディレクトリ │ └── myserver │ └── StartServer.java ├── src/main/resources │ └── webroot ・・・静的WebコンテンツやJSPのルートディレクトリ │ ├── index.html │ └── show.jsp ├── src/main/assembly │ └── zip.xml ・・・★elastic beanstalkにアップロードするZIPファイルの生成ルールを記述 ├── .elasticbeanstalk ・・・★Elastic Beanstalkへのデプロイ情報を格納するディレクトリ │ └── config.yml ・・・★Elastic Beanstalkへのデプロイ情報のYAMLファイル ├── target ・・・ビルドした結果(jarなど)が生成されるディレクトリ ├── Procfile ・・・★Elastic BeanstalkのEC2上でJARファイルを実行するためのスクリプトを記述する └── pom.xml ・・・Maven用設定ファイルソースコードや設定ファイル等の中身については後で説明するとして、
先にこのソースコードがどのようにビルドされて Elastic Beanstalkにアップロードされるかをみておく。Elastic BeanstalkにアップロードするZIPファイルの構造
本稿では、手元のPCでソースコードをビルドして、それを1つのJARファイルにパッケージし、さらにJARファイル以外にもElastic Beanstalkに必要なファイル含めてZIPファイルを生成する。
ここで、JavaのソースコードをビルドしてできたFAT JARのファイル名をeb-app-jar-with-dependencies.jarとする。(maven-assembly-pluginで生成する、後で説明)
ElasticBeanstalkにアップロードするためのZIPファイル名をmy-jetty-app-eb.zipとすると、そのZIPファイルの中身構造は以下となる。my-jetty-app-eb.zipの中身my-jetty-app-eb.zip ├── my-jetty-app-jar-with-dependencies.jar ・・・Javaのソースコードを1つのJARにパッケージしたもの └── Procfile ・・・Elastic BeanstalkのEC2内でJARを実行するためのスクリプトZIPファイルの中には、ソースをまとめたJARファイルと、実行スクリプトの書いてあるファイルであるProcfileの2つとなる。
ということで、この形式のZIPファイルをEB CLI経由でElastic Beanstalkにアップロードすればデプロイできる。
これが「Elastic Beanstalkのお作法」の1つということになる。次は、Javaアプリのソースをみていく。
とくに「Elastic Beanstalkのお作法」に関連する部分を中心に説明するJavaアプリのソースコードの作り方
これからJavaアプリを動かそうとしているElastic Beanstalk環境は以下のようなもので、Java Webアプリとしてケアしておくべき点はポート番号 5000をListenするところ
つまり、Javaでポート番号 5000をListenするサーバープログラムを作ってあげればひとまずOK
サンプルコード
ということでサンプルコードを以下のリポジトリに置いた
https://github.com/riversun/java-jetty-app-on-elasticbeanstalkこのサンプルはServlet/JSP/プッシュ通知機能をJetty上動作させている
このコードをクローンすると
clone https://github.com/riversun/java-jetty-app-on-elasticbeanstalk.git前述したとおり以下のようなソースコード構成となっている。
(一部ファイルは省略)ElasticBeanstalk用Javaソースコード構成elastic-beantalk-java-app ├── src/main/java ・・・Javaのソースコードのルートディレクトリ │ └── myserver │ └── StartServer.java ├── src/main/resources │ └── webroot ・・・静的WebコンテンツやJSPのルートディレクトリ │ ├── index.html │ └── show.jsp ├── src/main/assembly │ └── zip.xml ・・・★elastic beanstalkにアップロードするZIPファイルの生成ルールを記述 ├── .elasticbeanstalk ・・・★Elastic Beanstalkへのデプロイ情報を格納するディレクトリ │ └── config.yml ・・・★Elastic Beanstalkへのデプロイ情報のYAMLファイル ├── target ・・・ビルドした結果(jarなど)が生成されるディレクトリ ├── Procfile ・・・★Elastic BeanstalkのEC2上でJARファイルを実行するためのスクリプトを記述する └── pom.xml ・・・Maven用設定ファイル※「★」印がついているところが Elastic Beanstalkのための構成
Javaアプリとしてのメインクラス(エントリーポイント)は StartServer.javaとなる。
これをローカル実行して http://localhost:5000/ にアクセスすれば、以下のようになり
JSPやServletなどのシンプルな実装を試すことができるサンプルとなっている。
ここからは、ソースコードで重要なところを以下に説明する
src/main/java myserver.StartServer.java
メインクラス。
Jettyを起動してServlet/JSPをホストしポート5000で待ち受ける/pom.xml
pom.xml(抜粋)<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.riversun</groupId> <artifactId>my-jetty-app</artifactId> <version>1.0.0</version> <packaging>jar</packaging> <name>my-jetty-app</name> <description>jetty app on elastic beanstalk</description>pom.xml<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.riversun</groupId> <artifactId>my-jetty-app</artifactId> <version>1.0.0</version> <packaging>jar</packaging> <name>my-jetty-app</name> <description>jetty app on elastic beanstalk</description> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <jetty-version>9.4.19.v20190610</jetty-version> </properties> <dependencies> <!-- for server --> <dependency> <groupId>javax.servlet</groupId> <artifactId>javax.servlet-api</artifactId> <version>3.1.0</version> </dependency> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-annotations</artifactId> <version>${jetty-version}</version> </dependency> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-webapp</artifactId> <version>${jetty-version}</version> </dependency> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>apache-jsp</artifactId> <version>${jetty-version}</version> <type>jar</type> </dependency> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>apache-jstl</artifactId> <version>${jetty-version}</version> <type>pom</type> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> <version>2.9.9</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.8.1</version> <configuration> <source>1.8</source> <target>1.8</target> <excludes> <exclude>examples/**/*</exclude> </excludes> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-javadoc-plugin</artifactId> <version>3.1.0</version> <executions> <execution> <id>attach-javadocs</id> <goals> <goal>jar</goal> </goals> </execution> </executions> <configuration> <author>true</author> <source>1.7</source> <show>protected</show> <encoding>UTF-8</encoding> <charset>UTF-8</charset> <docencoding>UTF-8</docencoding> <doclint>none</doclint> <additionalJOption>-J-Duser.language=en</additionalJOption> </configuration> </plugin> <!-- add source folders --> <plugin> <groupId>org.codehaus.mojo</groupId> <artifactId>build-helper-maven-plugin</artifactId> <version>3.0.0</version> <executions> <execution> <phase>generate-sources</phase> <goals> <goal>add-source</goal> </goals> <configuration> <sources> <source>src/main/java</source> </sources> </configuration> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <executions> <!-- ソースコードをfat-jar化する --> <execution> <id>package-jar</id> <phase>package</phase> <goals> <goal>single</goal> </goals> <configuration> <appendAssemblyId>true</appendAssemblyId> <archive> <manifest> <mainClass>myserver.StartServer</mainClass> </manifest> </archive> <finalName>${project.artifactId}</finalName> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> </execution> <!-- Elastic Beanstalkにアップロードするzip(fat.jarや関連ファイルを含む)を作成する --> <execution> <id>package-zip</id> <phase>package</phase> <goals> <goal>single</goal> </goals> <configuration> <appendAssemblyId>true</appendAssemblyId> <finalName>${project.artifactId}</finalName> <descriptors> <descriptor>src/main/assembly/zip.xml</descriptor> </descriptors> </configuration> </execution> </executions> </plugin> </plugins> <resources> <resource> <directory>src/main/resources</directory> </resource> </resources> </build> </project>以下、ポイントだけみていく。
mavenのartifactId
以下はartifactIdとしてmy-jetty-appとした。
この後のビルドで生成されるファイル名などもこのartifactIdの値が使われる<groupId>org.riversun</groupId> <artifactId>my-jetty-app</artifactId>maven-assembly-pluginの設定
以下はmaven-assembly-pluginの設定を行っている。
maven-assembly-pluginとは、配布用のjarファイルやzipファイルを作るためのmavenプラグイン。
このmaven-assembly-pluginには2つのタスクをさせている。<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <executions> <!-- ソースコードをfat-jar化する --> <execution> <id>package-jar</id> <phase>package</phase> <goals> <goal>single</goal> </goals> <configuration> <appendAssemblyId>true</appendAssemblyId> <archive> <manifest> <mainClass>myserver.StartServer</mainClass> </manifest> </archive> <finalName>${project.artifactId}</finalName> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> </execution> <!-- Elastic Beanstalkにアップロードするzip(fat.jarや関連ファイルを含む)を作成する --> <execution> <id>package-zip</id> <phase>package</phase> <goals> <goal>single</goal> </goals> <configuration> <appendAssemblyId>true</appendAssemblyId> <finalName>${project.artifactId}</finalName> <descriptors> <descriptor>src/main/assembly/zip.xml</descriptor> </descriptors> </configuration> </execution> </executions> </plugin>その1 JARファイル生成
まず前半の設定に注目。<execution> <id>package-jar</id> <phase>package</phase> <goals> <goal>single</goal> </goals> <configuration> <appendAssemblyId>true</appendAssemblyId> <archive> <manifest> <mainClass>myserver.StartServer</mainClass> </manifest> </archive> <finalName>${project.artifactId}</finalName> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> </execution>ここで記述しているのはJavaソースコードを1つのJARファイルにまとめること。
つまり、FAT JARを作るためのタスク設定となる。
<mainClass>myserver.StartServer</mainClass>はJARファイルを実行するときの起動クラス。
<finalName>${project.artifactId}</finalName>は、最終的にできあがるJARファイルのファイル名がartifactIdで指定された値=my-jetty-app-[AssemblyId].jarとなる。
<descriptorRef>jar-with-dependencies</descriptorRef>はmavenのdependenciesに記載した依存ライブラリも一緒にJARファイルとしてパッケージする。
<appendAssemblyId>true</appendAssemblyId>は、生成されるJARファイルのファイル名にAssemblyIdをつけるか否かをセットする。もしこれをtrueにすると、JARファイル名はmy-jetty-app-jar-with-dependencies.jarとなる。ここで設定した条件でJARファイルを生成するには
mvn packageとすればよい。するとtargetディレクトリにmy-jetty-app-jar-with-dependencies.jarが生成される
その2 ZIPファイルの生成
次は後半の設定
<execution> <id>package-zip</id> <phase>package</phase> <goals> <goal>single</goal> </goals> <configuration> <appendAssemblyId>true</appendAssemblyId> <finalName>${project.artifactId}</finalName> <descriptors> <descriptor>src/main/assembly/zip.xml</descriptor> </descriptors> </configuration> </execution>ここで記述しているのは、上でつくったJARファイルとElastic Beanstalk関連ファイル(Procfileなど)をZIPファイルにまとめるタスクとなる。
<finalName>${project.artifactId}</finalName>としているところはJARのときと同じく生成されるファイル名を指定している。ZIPの生成ルールは外だしされた設定ファイルである
<descriptor>src/main/assembly/zip.xml</descriptor>で設定する。src/main/assembly/zip.xml
さて、その外だしされた zip.xmlをみてみる。
これは最終的にZIPファイルを生成するときの生成ルールとなる。
<include>でJARファイルとProcfileなどを指定して、Elastic Beanstalkにアップロードする形式のZIPファイルの生成方法を指示している。zip.xml<?xml version="1.0" encoding="UTF-8"?> <assembly xmlns="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.2" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.2 http://maven.apache.org/xsd/assembly-1.1.2.xsd"> <id>eb</id> <baseDirectory>/</baseDirectory> <formats> <format>zip</format> </formats> <fileSets> <fileSet> <directory>${project.basedir}</directory> <outputDirectory>/</outputDirectory> <includes> <include>Procfile</include> <include>Buildfile</include> <include>.ebextensions/*</include> </includes> </fileSet> <fileSet> <directory>${project.build.directory}</directory> <outputDirectory>/</outputDirectory> <includes> <include>my-jetty-app-jar-with-dependencies.jar</include> <!-- <include>*.jar</include> --> </includes> </fileSet> </fileSets> </assembly>最終的に生成されるZIPファイルのファイル名はmy-jetty-app-[id].zipとなる。
zip.xmlでは、<id>eb</id>と指定しているので、生成されるZIPファイル名はmy-jetty-app-eb.zipとなる。まとめると必要パッケージを生成するためのmavenコマンド
mvn packageを実行するとmy-jetty-app-jar-with-dependencies.jarとmy-jetty-app-eb.zipの両方がtargetディレクトリ以下に生成されることになる。ここは、あとで実際にdeployファイルを生成するところでもう一度確認する。
/Procfile
ProcfileはElastic BeanstalkのEC2内でJARを実行するためのファイル。
Elastic BeanstalkのEC2上でアプリを起動するためのコマンドを
web:以下に記載する。Procfileweb: java -jar my-jetty-app-jar-with-dependencies.jar↓のように起動オプションを記述してもOK
web: java -jar my-jetty-app-jar-with-dependencies.jar -Xms256m詳細は公式参照
.elasticbeanstalk/config.yml
config.ymlにはデプロイ情報を記述する
ここにはElastic Beansalkにデプロイするファイルtarget/my-jetty-app-eb.zipを指定している。config.ymldeploy: artifact: target/my-jetty-app-eb.zipElastic Beanstalkにデプロイする際に、このファイルが参照される。
いまは
deploy:artifact:しか記述していないが、これからEB CLIをつかってElastic Beanstalkのデプロイ設定をしていく過程でこのconfig.ymlに必要な値が追加されていく。EB CLIを使ってアプリをデプロイする
ファイルの意味をざっくり理解できたところで、さっそくElastic Beanstalkにアプリをデプロイする。
EB CLIを使ってElastic BeanstalkアプリケーションをAWS上に作る
1.アプリのディレクトリに移動する
cd java-jetty-app-on-elasticbeanstalk2.Elastic BeanstalkにJava用の箱*を作る
(* 箱=アプリケーション)そのためのEB CLIのコマンドは以下の形式となる。
eb init アプリ名 --region リージョン名 --platform プラットフォーム ここではアプリ名をmy-eb-app、リージョンは東京リージョン(ap-northeast-1)、プラットフォームをjava-8とする
コマンドは以下のようになる。
eb init my-eb-app --region ap-northeast-1 --platform java-8すると
Application my-eb-app has been created.というメッセージがでて、
AWS Elasticbeanstalk上にアプリケーションの箱ができるさっそくWebコンソールで確認すると箱(アプリケーション)ができている
https://ap-northeast-1.console.aws.amazon.com/elasticbeanstalk/home
さて、ソースコードにある/.elasticbeanstalk/config.ymlを見てみる。
上記コマンドで、config.ymlも更新され、以下のようになっている。
config.ymlbranch-defaults: master: environment: null deploy: artifact: target/my-jetty-app-eb.zip global: application_name: my-eb-app branch: null default_ec2_keyname: null default_platform: java-8 default_region: ap-northeast-1 include_git_submodules: true instance_profile: null platform_name: null platform_version: null profile: eb-cli repository: null sc: git workspace_type: ApplicationTIPS
------------もし、Credential情報が登録されていなければ、以下のようにaws-access-idとaws-secret-keyを聞かれるので入力する。
eb init my-eb-app --region ap-northeast-1 --platform java-8 You have not yet set up your credentials or your credentials are incorrect You must provide your credentials. (aws-access-id): xxxxx (aws-secret-key): xxxxx Application my-eb-app has been created.1回入力すれば、
[user]/.awsディレクトリ以下にconfigファイルができるので、次からは聞かれない。------------
デプロイ用のパッケージを作る
さきほどみてきたように、Elastic BeanstalkにデプロイするためのZIPファイルを生成する。
ZIP生成はMavenでやるので
maven packageコマンドをたたく(cleanもついでにやっておくと、コマンドは以下のとおり)
mvn clean package以下のようになり、無事 target/ディレクトリにmy-jetty-app-eb.zipが生成できた。
[INFO] --- maven-assembly-plugin:2.2-beta-5:single (package-zip) @ my-jetty-app --- [INFO] Reading assembly descriptor: src/main/assembly/zip.xml [INFO] Building zip: jetty-app-on-eb\target\my-jetty-app-eb.zip [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 32.984 s [INFO] Finished at: 2019-07-01T15:55:14+09:00 [INFO] Final Memory: 37M/449M [INFO] ------------------------------------------------------------------------Elastic Beanstalkにデプロイし環境を構築する
いまから、つくったZIPファイルをEB CLIをつかってElastic Beanstalkにデプロイする
Elastic Beanstalkにデプロイするには、eb createコマンドを使う
eb createコマンドの使い方
eb createコマンドは以下のように指定する。
オプションは以下のとおり
eb create 環境の名前 [オプション][オプション]・・・[オプション]
オプション 説明 --cname URLのCNAMEを指定。
例 CNAMEにmy-jetty-app-test を指定すると
http://my-jetty-app-test.ap-northeast-1.elasticbeanstalk.com/
としてアクセスできる--instance_type インスタンスタイプ。
t2シリーズを指定する場合はVPC必須--elb-type ロードバランサーのタイプ
「application」を指定すると
アプリケーションロードバランサーになる。
あとで、独自ドメインやHTTPS対応するときにも
ロードバランサーあると楽--vpc.id VPCのID --vpc.elbpublic ロードバランサーを
パブリックサブネットに置く--vpc.elbsubnets ロードバランサーのサブネットIDを指定。
複数指定するときはカンマ区切り--vpc.publicip Elastic BeanstalkのEC2を
パブリックサブネットに置く--vpc.ec2subnets Elastic Beanstalkの
EC2のサブネットIDを指定。
複数指定するときはカンマ区切り詳しくは公式参照
それでは、
コマンドラインから以下を実行する。eb create my-jetty-app-test --cname my-jetty-app-test --instance_type t2.small --elb-type application --vpc.id vpc-xxxxxxxxxxxxxxxxx --vpc.elbpublic --vpc.elbsubnets subnet-xxxxxxxxxxxxxxxxx,subnet-yyyyyyyyyyyyyyyyy --vpc.publicip --vpc.ec2subnets subnet-xxxxxxxxxxxxxxxxx,subnet-yyyyyyyyyyyyyyyyy上記は実際のID等はダミーだが、環境名my-jetty-app-test、cnameがmy-jetty-app-testでEC2のインスタンスタイプがt2.small、ELB(ロードバランサー)がapplicationロードバランサー、VPCのIDがvpc-xxxxxxxxxxxxxxxxxとしてさきほどのZIPファイルをデプロイするコマンドとなる。
(どのZIPファイルがアップロードされるかは、.elasticbeanstalk/config.ymlで指定されているのでそれが参照される)
また、--vpc.elbpublic、--vpc.publicipはELB(ロードバランサー)とElastic BeanstalkのEC2が指定したVPC内のパブリックサブネットで実行されることを示している。--vpc.elbsubnetsと--vpc.ec2subnetsそれぞれおなじパブリック・サブネット(2つ)を指定してある。ELBはパブリックにアクセスできないとアプリにアクセスできないのでパブリックサブネットに置く。EC2側はパブリックサブネットに置く方法とプライベートサブネットにおく方法がある。本稿の例では、パブリックサブネットにおいているが、自動生成されたセキュリティグループによってELBからしかアクセスできないようになっている。ただし、パブリックIPは割り当てられる。
(よりセキュアにするにはEC2はプライベートサブネットに置くなど工夫ができるが、これはElastic BeanstalkというよりEC2,VPCまわりのセキュリティイシューなのでここでは割愛とする。)さて、上記コマンドを実行すると、以下のようにアップロードから環境構築までが自動的に実行される。
Uploading: [##################################################] 100% Done... Environment details for: my-jetty-app-test Application name: my-eb-app Region: ap-northeast-1 Deployed Version: app-1d5f-190705_00000 Environment ID: e-2abc Platform: arn:aws:elasticbeanstalk:ap-northeast-1::platform/Java 8 running on 64bit Amazon Linux/2.8.6 Tier: WebServer-Standard-1.0 CNAME: my-jetty-app-test.ap-northeast-1.elasticbeanstalk.com Updated: 2019-07-01 07:08:01.989000+00:00 Printing Status: 2019-07-01 07:08:00 INFO createEnvironment is starting. 2019-07-01 07:08:02 INFO Using elasticbeanstalk-ap-northeast-1-000000000000 as Amazon S3 storage bucket for environment data. 2019-07-01 07:08:23 INFO Created target group named: arn:aws:elasticloadbalancing:ap-northeast-1:000000000000:targetgroup/awseb-AWSEB-LMAAAA/000000000 2019-07-01 07:08:23 INFO Created security group named: sg-11111111111111111 2019-07-01 07:08:39 INFO Created security group named: sg-22222222222222222 2019-07-01 07:08:39 INFO Created Auto Scaling launch configuration named: awseb-e-xxxxxxxxxx-stack-AWSEBAutoScalingLaunchConfiguration-3V 2019-07-01 07:09:41 INFO Created Auto Scaling group named: awseb-e-xxxxxxxxxx-stack-AWSEBAutoScalingGroup-XXXXXXXXXXXX 2019-07-01 07:09:41 INFO Waiting for EC2 instances to launch. This may take a few minutes. 2019-07-01 07:09:41 INFO Created Auto Scaling group policy named: arn:aws:autoscaling:ap-northeast-1:000000000000:scalingPolicy:4e:autoScalingGroupName/awseb-e- xxxxxxxxxx-stack-AWSEBAutoScalingGroup-XXXXXXXXXXXX:policyName/awseb-e-xxxxxxxxxx-stack-AWSEBAutoScalingScaleUpPolicy-FA 2019-07-01 07:09:42 INFO Created Auto Scaling group policy named: arn:aws:autoscaling:ap-northeast-1:000000000000:scalingPolicy:8a:autoScalingGroupName/awseb-e- xxxxxxxxxx-stack-AWSEBAutoScalingGroup-XXXXXXXXXXXX:policyName/awseb-e-xxxxxxxxxx-stack-AWSEBAutoScalingScaleDownPolicy-SSZW 2019-07-01 07:09:57 INFO Created CloudWatch alarm named: awseb-e-xxxxxxxxxx-stack-AWSEBCloudwatchAlarmHigh-H0N 2019-07-01 07:09:57 INFO Created CloudWatch alarm named: awseb-e-xxxxxxxxxx-stack-AWSEBCloudwatchAlarmLow-BX 2019-07-01 07:10:34 INFO Created load balancer named: arn:aws:elasticloadbalancing:ap-northeast-1:000000000000:loadbalancer/app/awseb-AWSEB-1BQ 2019-07-01 07:10:34 INFO Created Load Balancer listener named: arn:aws:elasticloadbalancing:ap-northeast-1:000000000000:listener/app/awseb-AWSEB-1BQ 2019-07-01 07:11:05 INFO Application available at my-jetty-app-test.ap-northeast-1.elasticbeanstalk.com. 2019-07-01 07:11:05 INFO Successfully launched environment: my-jetty-app-test環境構築が開始されると、Webコンソールでも状況を把握することができる。
デプロイできた模様
無事アプリが http://my-jetty-app-test.ap-northeast-1.elasticbeanstalk.com/ にデプロイされた模様
アクセスすると、
ちゃんとJSPやServletも動いている模様
まとめ
Java SEをつかったWebアプリをEB CLIをつかって、AWS Elastic Beanstalkにデプロイするまでの手順をハンズオン方式で紹介しました
結果、以下のような構成をコマンドから構築することができました
紹介した全ソースコードはこちらです
https://github.com/riversun/java-jetty-app-on-elasticbeanstalk.git続編「ゼロから始めるAWS Elastic Beanstalk #2」では、独自ドメイン対応、HTTPS対応、HTTP→HTTPSへのリダイレクト対応、Auto Scaling設定について、取り扱います。








- 投稿日:2019-07-08T04:06:49+09:00
ServerlessFrameworkでLambda+ALBを使う
はじめに
API Gatewayを利用するのであれば
functionsに記載するだけであったが
ALBをLambdaのトリガーとする場合別途ALBを作成する必要がありそうだったのでやってみたサービス構成
ALB -> Lambda
Lambdaは引数をそのままレスポンスとして返すだけのものを作成。
ALBは2つのパスでのルーティングをそれぞれ同じLambdaへ、それ以外を404とするものを作成。※事前に用意したもの
- LambdaにつけるIAMロール
- ALBにつけるVPC(のサブネットID2つとセキュリティグループID)フォルダ構成
. ├── handler.js └── serverless.ymlLambdaソースコード
コードは内容には特に関係ないので別になんでもよい
handler.jsmodule.exports.main = async (event) => { return response = { headers: { 'Content-Type': 'application/json' }, body: JSON.stringify(event), statusCode: 200 } }serverless.yml
API Gatewayと若干書き方は変わるが
単純にALBをLambdaのAPIとしての口としたいだけなら
ALBとリスナーをresourcesで作成して
functionsでそれに紐づけるだけでよさそう。serverless.ymlservice: alb-lambda-example provider: name: aws runtime: nodejs10.x region: ap-northeast-1 functions: echo: handler: handler.main role: arn:aws:iam::00000000000:role/iam_role # IAMロールのARN events: - alb: listenerArn: Ref: exampleLoadBalancerListener priority: 2 conditions: path: /hello - alb: listenerArn: Ref: exampleLoadBalancerListener priority: 1 conditions: path: /world resources: Resources: exampleLoadBalancer: Type: AWS::ElasticLoadBalancingV2::LoadBalancer Properties: Name: alb-lambda-example-alb Scheme: internet-facing Subnets: - subnet-XXXXXXXXXXXXX # サブネットID - subnet-YYYYYYYYYYYYY # サブネットID SecurityGroups: - sg-ZZZZZZZZZZZZZZ # セキュリティグループID exampleLoadBalancerListener: Type: "AWS::ElasticLoadBalancingV2::Listener" Properties: DefaultActions: - Type: fixed-response FixedResponseConfig: ContentType: text/html MessageBody: <h1>Not Found</h1> StatusCode: 404 LoadBalancerArn: Ref: exampleLoadBalancer Port: 80 Protocol: HTTP結果
AWSコンソール上のALBの振り分けルール
作成されたALBのDNSにブラウザでアクセスすると
/helloと/worldではJSONがレスポンスされそれ以外ではNot Foundページが表示された。トラブルシュート
sls deployに成功するがLambdaがALBと関連付けられてない
serverlessをアップデートすると治るかも