- 投稿日:2019-07-08T23:07:37+09:00
【備忘録】WindowsでPythonファイルを自動実行する
こんばんは、@0yanです。
先日、別の部署の課長から「毎月第1営業日に、Eラーニングの研修受講履歴を送って欲しいのだけど」と依頼を受け、「忘れそうだな・・・」と思ったため、早速、Seleniumで研修受講履歴をダウンロード&Gmail送信するコードを書き、Windows上で自動実行することにしました(サーバを自由にたてる権限はないため)。
以下、WindowsでPythonファイルを自動実行するための備忘録です。流れ
1.pythonファイルを作成する
2.batファイルを作成する
3.タスクスケジューラに登録するbatファイルを作成する
任意の場所にbatファイルを作成します。例えば、
- PC123というユーザー名で、PycharmProjects直下のtest.pyを自動実行したい
- Anaconda3フォルダ直下にpython.exeがある
という場合、以下のように記述します。
※batファイルでコメントアウトする際は、シングルクオーテーションを先頭につけます。test.bat'実行したいファイルが格納されているディレクトリの絶対パス cd C:\Users\PC123\PycharmProjects 'python.exeの絶対パス 実行したいファイル名 C:\Users\PC123\Anaconda3\python.exe test.pyタスクスケジューラに登録する
@Richard_Roe さんの記事が分かり易かったので、そちらに譲ります。
(参考になりました。ありがとうございました!)
- 投稿日:2019-07-08T22:16:18+09:00
デイリーポータルZの渋谷の交差点から人をじわじわ消すプログラムを書いてみた
目的
https://dailyportalz.jp/kiji/shibuya-nobodify
ここの記事のプログラムを実装してみよう準備
pythonで実装しようと思うので、anacondaにopencv3をインストール
アルゴリズム
定点撮影した写真を準備する。この写真を順番に読みだして、前のn個の写真と画素ごとに比較してもっとも頻度の高い画素に置き換える。
置き換え方法としては、平均、中央値、最頻などが考えられたが中央値を採用するプログラム
激重プログラムなのでもっと改善が必要ですがなんとか動いたものができた
import cv2 import glob import statistics import numpy as np class PHOTO_REMOVE(): """description 写真で背景のみ抽出する """ output_file = "./output.mp4" hist = 10 is_First = True stack_index = 0 read_img_count = 0 def __init__(self,param=None): """ 初期化 hist : 背景判定を何フレームで行うか? path : 写真があるフォルダのパス """ if param != None: self.hist = param["hist"] self.set_photo_file(param["path"]) else: self.set_photo_file("./sample") self.set_output_video(self.output_file) self.image_stack = [None for _ in range(self.hist)] print(len(self.image_stack)) def run(self): self.read_jpg_files(self.path) def main_analize(self,image): print("test") def set_photo_file(self,name): self.is_photo = True self.is_video = False self.path = glob.glob('{}/*.JPG'.format(name)) self.file_num = len(self.path) #print(self.path) def read_jpg_files(self,files): self.fill_stack_data(files) self.img_height, self.img_width, self.img_channels = cv2.resize(cv2.imread(files[0]),(640,480)).shape[:3] print(self.img_height, self.img_width, self.img_channels) #for img in cv2.resize(cv2.imread(files[0]),(640,480)): # for rgb in img: # print(rgb) for f in files: img = cv2.imread(f) img = cv2.resize(img, (640,480)) self.read_img_count = self.read_img_count + 1 print("FRAME {0}番目".format(self.read_img_count)) ret_img = self.photo_remove(img) cv2.imshow("frame",ret_img) self.make_output_video(ret_img) if cv2.waitKey(1) & 0xFF == ord('q'): break cv2.destroyAllWindows() self.output_video.release() def set_output_video(self,name): fourcc = cv2.VideoWriter_fourcc(*'mp4v') self.output_video = cv2.VideoWriter(name,fourcc, 2.0, (640,480)) def make_output_video(self,img): self.output_video.write(img) def fill_stack_data(self,files): for i in range(self.hist-1): self.image_stack[i] = cv2.resize(cv2.imread(files[i]), (640,480)) def photo_remove(self,img): ret_img = img self.image_stack[self.stack_index] = img if self.stack_index == self.hist-1: self.stack_index = 0 else: self.stack_index = self.stack_index + 1 for h in range(self.img_height-1): for w in range(self.img_width-1): tmp = [] for i in range(self.hist-1): tmp.append(np.linalg.norm(self.image_stack[i][h,w])) #tmp.append(self.image_stack[i][h,w]) median = statistics.median(tmp) for i in range(self.hist-1): if median == tmp[i]: ret_img[h,w] = self.image_stack[i][h,w] break return ret_img if __name__ == "__main__": test_obj = PHOTO_REMOVE() test_obj.run()追記
中央値を採用するアルゴリズムだとじわじわ消すことはできないので件名に偽りあり。
- 投稿日:2019-07-08T21:24:49+09:00
コーフェン相関係数を用いて、階層的クラスタリングにおける最適な距離と方法を考える。
はじめに
階層的クラスタリングを行うときに迷うのが、どの距離と方法を使うのがよいのかという点です。正解の用意されていないクラスタリングでは、特にです。
今回は、距離と方法ごとにコーフェン相関係数を計算して、クラスタリングの妥当性を調べてみます。この値が1に近いほど良いとされています。(詳しくはこちら)データの準備
今回は、irisのデータセットを使いました。
# irisのデータセットを得る。 from sklearn import datasets dataset = datasets.load_iris() dataset_data = dataset.data dataset_target = dataset.target target_names = dataset.target_names dataset_labels = target_names[dataset_target] # データの標準化を行う。 from sklearn.preprocessing import scale data = scale(dataset_data)コーフェン相関係数の計算
まず、クラスタリングで使いそうな距離や方法をリストアップします。データの形に合うものをいくつか用意します。
METORICS = ['euclidean', 'minkowski', 'cityblock', 'seuclidean', 'sqeuclidean', 'cosine', 'correlation', 'hamming', 'jaccard', 'chebyshev', 'canberra', 'braycurtis', 'mahalanobis'] METHODS = ['single', 'complete', 'average', 'weighted', 'centroid', 'median', 'ward'] # minkowski距離に使うノルム。デフォルトだと2で、ユークリッド距離となるので、とりあえず3。 P_NORM = 3コーフェン相関係数の計算には
scipyのcophenetを使いました。(詳しくはこちら)# 距離と方法を変えてコーフェン相関係数(CPCC)を計算する。 import itertools from scipy.spatial.distance import pdist from scipy.cluster.hierarchy import linkage, cophenet result = [] for metric, method in itertools.product(METORICS, METHODS): distance_matrix = pdist(X=data, metric=metric, p=P_NORM) linkage_matrix = linkage(y=distance_matrix, method=method) cpcc, _ = cophenet(linkage_matrix, distance_matrix) result.append([metric, method, cpcc])データ処理のために、
pandasのDataframeに計算結果を入れます。コーフェン相関係数が最大となった距離と方法を得ます。import pandas as pd cpcc_df = pd.DataFrame(result, columns=['metric', 'method', 'CPCC']) # コーフェン相関係数が最大である距離と方法を得る best_metoric = cpcc_df.loc[cpcc_df['CPCC'].idxmax(), 'metric'] best_method = cpcc_df.loc[cpcc_df['CPCC'].idxmax(), 'method'] print ("距離:{0}, 方法:{1} でコーフェン相関係数が最大。".format(best_metoric,best_method))実行結果は、以下のとおり。
距離:correlation, 方法:average でコーフェン相関係数が最大。これだけではよくわからないので、
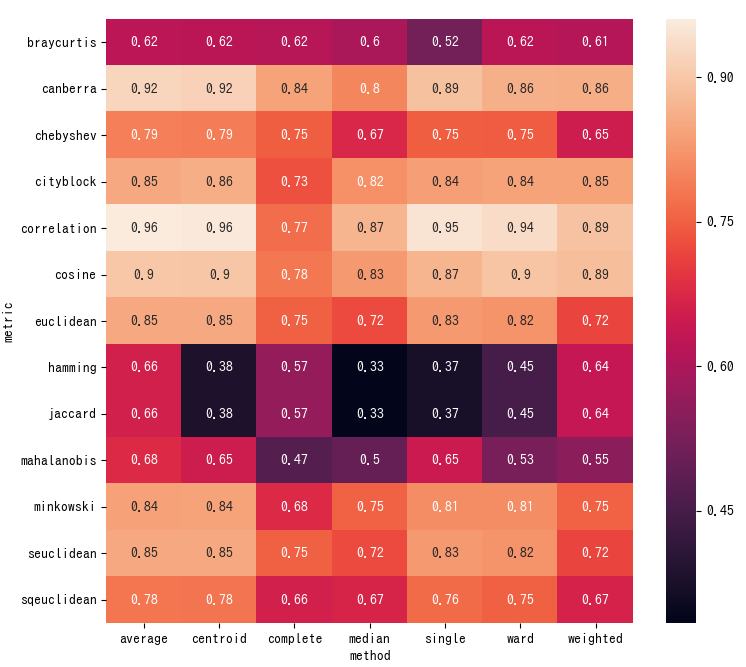
seabornのheatmapを使って、全体を見てみました。# DataFrameを整形。 cpcc_df = cpcc_df.set_index(keys=['metric', 'method']).unstack() cpcc_df.columns = cpcc_df.columns.droplevel() # heatmapで表示。 import matplotlib.pyplot as plt import seaborn as sns fig, ax = plt.subplots(figsize=(8.5, 8)) ax = sns.heatmap(data=cpcc_df, annot=True) fig.show()
heatmapを見てみると、方法よりも距離の方がコーフェン相関係数に影響している傾向があります。この傾向は、クラスタリングするデータによって変わってくるかもしれません。デンドログラムの作図
計算結果から得たベストな距離と方法でデンドログラムを描いて完成です。
# コーフェン相関係数が最大である距離と方法でデンドログラムを描く。 from scipy.cluster.hierarchy import linkage, dendrogram best_linkage = linkage(y=data, metric=best_metoric, method=best_method) fig, ax = plt.subplots(figsize=(5,13)) ax = dendrogram(Z=best_linkage, orientation='right', labels=dataset_labels) fig.show()
最後に
今回計算したコーフェン相関係数も、これだけで完璧なクラスタリングができるわけではなく、指標の一つでしかありません。複数の指標を使ったクラスタリングを目指して勉強していきたいと思います。最後までお付き合いいただき、ありがとうございました。

- 投稿日:2019-07-08T21:10:07+09:00
量子アルゴリズムの基本:算術演算の確認(べき剰余)
$$
\def\bra#1{\mathinner{\left\langle{#1}\right|}}
\def\ket#1{\mathinner{\left|{#1}\right\rangle}}
\def\braket#1#2{\mathinner{\left\langle{#1}\middle|#2\right\rangle}}
$$はじめに
加算、剰余加算、制御-剰余乗算という具合に見てきましたが、それは「Shorのアルゴリズム」で重要な役割を果たす「べき剰余」を実行するための準備として、という位置づけでした。今回はその「べき剰余」について見ていきます。アルゴリズムを説明した後、自作の量子計算シミュレータqlazyで、動作を確認します。
参考にさせていただいた論文は以下です。
べき剰余の実現方法
参考論文に全体の回路図が出ているので、まずそれを掲載します。
$a^x \space mod \space N$という「べき剰余」を実行する回路です(図には$x^a \space mod \space N$と書いてありますが、$a^x \space mod \space N$の間違いではないかと思われます)。
図を見てわかる通り、前回の記事で確認した「制御-剰余乗算(以下CMMと省略)」とスワップ(以下SWAPと表記)とCMMの逆演算(以下iCMMと表記)をセットにして繰り返し適用していくだけなので、考え方はそれほど難しくないです。
説明のため、レジスタに名前をつけます。図の左側の上にxと記載してあるレジスタを<x>、1と記載してあり最終結果が格納されるレジスタを<xx>、一番下の0と記載されている レジスタを<y>と名付けておきます。aを格納するレジスタが記載されていないですが、この量子計算を実現するために外から与えるパラメータのようなもので、あえて言うなら古典レジスタに格納されていると思えば良いと思います。その他、CMMを実現するために必要になるレジスタもありますが、詳細は前回の記事を参照してください。
では、左から順に、レジスタ<xx>とレジスタ<y>の状態変化を表にして示します。状態なのでケット記号を使って$\ket{A}$のように記載すべきなのですが、簡単のため$A$とのみ記載します。また、各段階での計算は$mod \space N$前提で実行しているものと思ってください。xの値によって、各段階のCMMやSWAPやiCMMがONになったりOFFになったりするので、場合分けをして表にしてみました。
- $x=0$ ($x_{0}=0,x_{1}=0$)の場合
レジスタ 初期状態 0番目のCMM SWAP 0番目のiCMM 1番目のCMM SWAP 1番目のiCMM <xx> $1$ $1$ $1$ $1$ $1$ $1$ $1$ <y> $0$ $0$ $0$ $0$ $0$ $0$ $0$
- $x=1$ ($x_{0}=1,x_{1}=0$)の場合
レジスタ 初期状態 0番目のCMM SWAP 0番目のiCMM 1番目のCMM SWAP 1番目のiCMM <xx> $1$ $a$ $1$ $a$ $a$ $a$ $a$ <y> $0$ $1$ $a$ $0$ $0$ $0$ $0$
- $x=2$ ($x_{0}=0,x_{1}=1$)の場合
レジスタ 初期状態 0番目のCMM SWAP 0番目のiCMM 1番目のCMM SWAP 1番目のiCMM <xx> $1$ $1$ $1$ $1$ $1$ $a^{2}$ $a^{2}$ <y> $0$ $0$ $0$ $0$ $a^{2}$ $1$ $0$
- $x=3$ ($x_{0}=1,x_{1}=1$)の場合
レジスタ 初期状態 0番目のCMM SWAP 0番目のiCMM 1番目のCMM SWAP 1番目のiCMM <xx> $1$ $a$ $1$ $a$ $a$ $a^{3}$ $a^{3}$ <y> $0$ $1$ $a$ $0$ $a^{3}$ $a$ $0$ というわけで、レジスタ<xx>に$a^{x} \space mod \space N$の値が入ることがわかります。ここで1点注意しておきたいのがSWAPの動作です。回路図のSWAPには制御ビットとつながる線が書かれていませんが、CMM-SWAP-iCMMが一体となって制御ビットとつながっていることを意味しています。つまり、SWAPは厳密に言うと、制御SWAP(正式名称は知りません。フレドキンゲートの拡張みたいですがちょっと違うかな?)です。
さて、"CMM-SWAP-iCMM"のセットを2回繰り返したところまで書けたので、あとはこれを延長すれば、任意のべき剰余が計算できるというわけです。
数式で説明すると、以下のような量子計算を$i=0,1,2,...$と繰り返していると思えば良いです。
\begin{align} & \ket{a^{2^0 x_0 + 2^1 x_1 + \cdots 2^{i-1} x_{i-1}}, 0} \\ & \rightarrow \ket{a^{2^0 x_0 + 2^1 x_1 + \cdots 2^{i-1} x_{i-1}},a^{2^0 x_0 + 2^1 x_1 + \cdots 2^{i} x_{i}}} \\ & \rightarrow \ket{a^{2^0 x_0 + 2^1 x_1 + \cdots 2^{i} x_{i}},a^{2^0 x_0 + 2^1 x_1 + \cdots 2^{i-1} x_{i-1}}} \\ & \rightarrow \ket{a^{2^0 x_0 + 2^1 x_1 + \cdots 2^{i} x_{i}}, 0} \end{align}ここで、1行目から2行目はCMM、2行目から3行目はSWAP、3行目から4行目はiCMMの演算を表しています。これを$n$回繰り返すと、最大で$x=2^{n}-1$までのべき剰余$a^{x} \space mode \space N$が実行できることがわかります。
シミュレータで動作確認
それでは、シミュレータで動作確認をしていくのですが、その前に各レジスタに必要となるビット数を見積もってみます。上の図だけ見ると、とてもシンプルに見えるのですが、CMMやiCMMを実現するためには内部で「剰余加算」を実行していて、「剰余加算」を実行するために内部で「加算」を実行していて、各々を実行するために多くの補助レジスタが必要になります。シミュレータでの実行は限定されたメモリ範囲内でやるしかないため、今回はとても小さい数での動作確認になります。具体的には、$a=2,N=3,x=0,1,2$で動作させることを前提にします。
まず、$a=2$については外部パラメータということで量子レジスタとして割り当てることはしません。$x$については2ビットで十分なので、レジスタ<x>には2ビットを割り当てます。レジスタ<xx>には、$mod \space 3$の結果が格納されるので2ビット割り当てることにします。CMMを実行するために、内部で剰余加算を実行しますが、それへの入力レジスタが別途必要になり、今回レジスタ<xxx>と名付けることにします(前回の制御-剰余乗算の記事では<xx>と呼んでいました)。<xxx>には最大で$a^2=4$が入るので、3ビット割り当てます。<y>は、CMMの内部で剰余加算をするもう一方の入力レジスタなので、<xxx>よりも1つ多いビット数を用意しておく必要があるため、4ビットとします。加算を実行するためには桁上げ情報格納のためのレジスタ<c>がさらに必要になります。それには<y>と同じ数のビットを用意しておき、最上位の1ビットを<y>と共有するため、追加で3ビット必要になります。$N=3$を格納するためのレジスタも、上の回路図には書かれていないですが、必要です。剰余加算回路の内部で<xxx>とスワップするため同じビット数、すなわち3ビットを割り当てます。その他、剰余加算でアンダーフロー記述のための補助レジスタが1ビット必要になります。以上、すべてを合わせると「18量子ビット」となります。ちょっとややこしい説明になってしまいましたが、前回までの、加算、剰余加算、制御-剰余乗算の記事をよく見ればわかると思います(と言いつつ、間違っていたらすみません、汗)。
それではシミュレータで、「べき剰余」の動作を確認してみます。先程説明したように、$a=2,N=3,x=0,1,2$で動作させます。x=3の場合は、今回ビット数の関係で諦めましたので、xのすべての値に対して重ね合わせることはせず、$x=0,1,2$でforループを回して結果を逐一表示するようにしました。全体のPythonコードは以下の通りです。
from qlazypy import QState def swap(self,id_0,id_1): dim = min(len(id_0),len(id_1)) for i in range(dim): self.cx(id_0[i],id_1[i]).cx(id_1[i],id_0[i]).cx(id_0[i],id_1[i]) return self def ctr_swap(self,id_ctr,id_0,id_1): dim = min(len(id_0),len(id_1)) for i in range(dim): self.ccx(id_ctr[0],id_0[i],id_1[i]) self.ccx(id_ctr[0],id_1[i],id_0[i]) self.ccx(id_ctr[0],id_0[i],id_1[i]) return self def sum(self,q0,q1,q2): self.cx(q1,q2).cx(q0,q2) return self def i_sum(self,q0,q1,q2): self.cx(q0,q2).cx(q1,q2) return self def carry(self,q0,q1,q2,q3): self.ccx(q1,q2,q3).cx(q1,q2).ccx(q0,q2,q3) return self def i_carry(self,q0,q1,q2,q3): self.ccx(q0,q2,q3).cx(q1,q2).ccx(q1,q2,q3) return self def plain_adder(self,id_a,id_b,id_c): depth = len(id_a) for i in range(depth): self.carry(id_c[i],id_a[i],id_b[i],id_c[i+1]) self.cx(id_a[depth-1],id_b[depth-1]) self.sum(id_c[depth-1],id_a[depth-1],id_b[depth-1]) for i in reversed(range(depth-1)): self.i_carry(id_c[i],id_a[i],id_b[i],id_c[i+1]) self.sum(id_c[i],id_a[i],id_b[i]) return self def arrow(self,N,q,id): for i in range(len(id)): if (N>>i)%2 == 1: self.cx(q,id[i]) return self def arrow2(self,i,a,id_ctr,id_x,id_xx): aa = a * 2**i for j in range(len(id_xx)): if (aa>>j)%2 == 1: self.ccx(id_ctr[0],id_x[i],id_xx[j]) return self def arrow3(self,id_ctr,id_x,id_y): for j in range(len(id_x)): self.ccx(id_ctr[0],id_x[j],id_y[j]) return self def i_plain_adder(self,id_a,id_b,id_c): depth = len(id_a) for i in range(depth-1): self.i_sum(id_c[i],id_a[i],id_b[i]) self.carry(id_c[i],id_a[i],id_b[i],id_c[i+1]) self.i_sum(id_c[depth-1],id_a[depth-1],id_b[depth-1]) self.cx(id_a[depth-1],id_b[depth-1]) for i in reversed(range(depth)): self.i_carry(id_c[i],id_a[i],id_b[i],id_c[i+1]) return self def modular_adder(self,N,id_a,id_b,id_c,id_N,id_t): self.plain_adder(id_a,id_b,id_c) self.swap(id_a,id_N) self.i_plain_adder(id_a,id_b,id_c) self.x(id_b[len(id_b)-1]) self.cx(id_b[len(id_b)-1],id_t[0]) self.x(id_b[len(id_b)-1]) self.arrow(N,id_t[0],id_a) self.plain_adder(id_a,id_b,id_c) self.arrow(N,id_t[0],id_a) self.swap(id_a,id_N) self.i_plain_adder(id_a,id_b,id_c) self.cx(id_b[len(id_b)-1],id_t[0]) self.plain_adder(id_a,id_b,id_c) return self def i_modular_adder(self,N,id_a,id_b,id_c,id_N,id_t): self.i_plain_adder(id_a,id_b,id_c) self.cx(id_b[len(id_b)-1],id_t[0]) self.plain_adder(id_a,id_b,id_c) self.swap(id_a,id_N) self.arrow(N,id_t[0],id_a) self.i_plain_adder(id_a,id_b,id_c) self.arrow(N,id_t[0],id_a) self.x(id_b[len(id_b)-1]) self.cx(id_b[len(id_b)-1],id_t[0]) self.x(id_b[len(id_b)-1]) self.plain_adder(id_a,id_b,id_c) self.swap(id_a,id_N) self.i_plain_adder(id_a,id_b,id_c) return self def ctr_modular_multiplier(self,a,N,id_ctr,id_x,id_xx,id_y,id_c,id_N,id_t): depth = len(id_x) for i in range(depth): self.arrow2(i,a,id_ctr,id_x,id_xx) self.modular_adder(N,id_xx,id_y,id_c,id_N,id_t) self.arrow2(i,a,id_ctr,id_x,id_xx) self.x(id_ctr[0]) self.arrow3(id_ctr,id_x,id_y) self.x(id_ctr[0]) return self def i_ctr_modular_multiplier(self,a,N,id_ctr,id_x,id_xx,id_y,id_c,id_N,id_t): depth = len(id_x) self.x(id_ctr[0]) self.arrow3(id_ctr,id_x,id_y) self.x(id_ctr[0]) for i in reversed(range(depth)): self.arrow2(i,a,id_ctr,id_x,id_xx) self.i_modular_adder(N,id_xx,id_y,id_c,id_N,id_t) self.arrow2(i,a,id_ctr,id_x,id_xx) return self def modular_exponentiation(self,a,N,id_x,id_xx,id_xxx,id_y,id_c,id_N,id_t): depth = len(id_x) id_ctr = [0] for i in range(depth): aa = a**(2**i) id_ctr[0] = id_x[i] self.ctr_modular_multiplier(aa,N,id_ctr,id_xx,id_xxx,id_y,id_c,id_N,id_t) self.ctr_swap(id_ctr,id_xx,id_y) self.i_ctr_modular_multiplier(aa,N,id_ctr,id_xx,id_xxx,id_y,id_c,id_N,id_t) return self def encode(self,decimal,id): for i in range(len(id)): if (decimal>>i)%2 == 1: self.x(id[i]) return self def decode(self,id): iid = id[::-1] return self.m(id=iid,shots=1).lst def create_register(): num = 0 id_x = [i for i in range(2)] num += len(id_x) id_xx = [i+num for i in range(2)] num += len(id_xx) id_xxx = [i+num for i in range(3)] num += len(id_xxx) id_y = [i+num for i in range(4)] num += len(id_y) id_c = [i+num for i in range(4)] id_c[len(id_c)-1] = id_y[len(id_y)-1] num += (len(id_c)-1) id_N = [i+num for i in range(3)] num += len(id_N) id_t = [i+num for i in range(1)] num += len(id_t) id_r = id_xx return (num,id_x,id_xx,id_xxx,id_y,id_c,id_N,id_t,id_r) if __name__ == '__main__': # add methods QState.swap = swap QState.ctr_swap = ctr_swap QState.sum = sum QState.i_sum = i_sum QState.carry = carry QState.i_carry = i_carry QState.arrow = arrow QState.arrow2 = arrow2 QState.arrow3 = arrow3 QState.plain_adder = plain_adder QState.i_plain_adder = i_plain_adder QState.modular_adder = modular_adder QState.i_modular_adder = i_modular_adder QState.ctr_modular_multiplier = ctr_modular_multiplier QState.i_ctr_modular_multiplier = i_ctr_modular_multiplier QState.modular_exponentiation = modular_exponentiation QState.encode = encode QState.decode = decode # set input numbers a = 2 N = 3 x_list = [0,1,2] # create registers num,id_x,id_xx,id_xxx,id_y,id_c,id_N,id_t,id_r = create_register() for x in x_list: # initialize quantum state qs = QState(num) qs.encode(x,id_x) qs.encode(N,id_N) qs.encode(1,id_xx) # execute controlled modular multiplier qs.modular_exponentiation(a,N,id_x,id_xx,id_xxx,id_y,id_c,id_N,id_t) res = qs.decode(id_r) print("{0:}^{1:} mod {2:} -> {3:}".format(a,x,N,res)) qs.free()前回までの記事(加算、剰余加算、制御-剰余乗算)で、大半の関数は説明済なので、今回の差分だけを説明します。
def ctr_swap(self,id_ctr,id_0,id_1): dim = min(len(id_0),len(id_1)) for i in range(dim): self.ccx(id_ctr[0],id_0[i],id_1[i]) self.ccx(id_ctr[0],id_1[i],id_0[i]) self.ccx(id_ctr[0],id_0[i],id_1[i]) return selfで、制御ビットつきのスワップを定義しています。通常のスワップは制御NOTを3つ組み合わせますが、さらに別の制御ビットによってON/OFF制御するため、制御-制御NOT、つまりToffoliゲート3つに置き換えています。
def modular_exponentiation(self,a,N,id_x,id_xx,id_xxx,id_y,id_c,id_N,id_t): depth = len(id_x) id_ctr = [0] for i in range(depth): aa = a**(2**i) id_ctr[0] = id_x[i] self.ctr_modular_multiplier(aa,N,id_ctr,id_xx,id_xxx,id_y,id_c,id_N,id_t) self.ctr_swap(id_ctr,id_xx,id_y) self.i_ctr_modular_multiplier(aa,N,id_ctr,id_xx,id_xxx,id_y,id_c,id_N,id_t) return selfで、べき剰余を定義しています。上で示した回路図をそのまま実行しています。
def create_register(): num = 0 id_x = [i for i in range(2)] num += len(id_x) id_xx = [i+num for i in range(2)] num += len(id_xx) id_xxx = [i+num for i in range(3)] num += len(id_xxx) id_y = [i+num for i in range(4)] num += len(id_y) id_c = [i+num for i in range(4)] id_c[len(id_c)-1] = id_y[len(id_y)-1] num += (len(id_c)-1) id_N = [i+num for i in range(3)] num += len(id_N) id_t = [i+num for i in range(1)] num += len(id_t) id_r = id_xx return (num,id_x,id_xx,id_xxx,id_y,id_c,id_N,id_t,id_r)で、各レジスタに割り当てる量子ビット番号と全体の量子ビット数を計算してリターンする関数を定義しています。
というわけで、プログラム本体の説明です。
# set input numbers a = 2 N = 3 x_list = [0,1,2] # create registers num,id_x,id_xx,id_xxx,id_y,id_c,id_N,id_t,id_r = create_register()$a,N$の値と$x$の値を入れるリストを設定して、各レジスタおよび必要となる全体量子ビット数を適当な変数に格納します。
for x in x_list: # initialize quantum state qs = QState(num) qs.encode(x,id_x) qs.encode(N,id_N) qs.encode(1,id_xx) # execute controlled modular multiplier qs.modular_exponentiation(a,N,id_x,id_xx,id_xxx,id_y,id_c,id_N,id_t) res = qs.decode(id_r) print("{0:}^{1:} mod {2:} -> {3:}".format(a,x,N,res))xの値を変えながら、べき剰余の計算を実行し、その結果を逐次表示します。
実行結果は、以下の通りです。
2^0 mod 3 -> 1 2^1 mod 3 -> 2 2^2 mod 3 -> 1というわけで、べき剰余が正しく計算できることが確認できました。
おわりに
結局、とても小さい数でしか実行できませんでしたが、とりあえず確認できたことにします。今回18量子ビットという見積りのもとで実行しましたが、参考論文には$N$のビット数$n$に対して、$7n+1$量子ビットで良いという記載があります。だとすると、本当は15量子ビットで実行可能なはず、ということでしょうか?ちょっとわかりませんが、もしかすると何らかの誤まった解釈から余分な量子ビットを使ってしまっているのかもしれません(が、すみません。今回はここまでとします。みなさま、お使いのシミュレータで実行してみて、量子ビット削減できたよ!ということが、もしあれば、後で教えて下さい)。
「べき剰余」のアルゴリズムについては、今回参考にした論文が発表された1990年代半ば以降、研究の進展がとてもあるようなので、今後余裕があれば見ておこうと思います。
次回は、予定では「Shorのアルゴリズム」なのですが、べき剰余の部分をどうしようか、考え中です。
以上

- 投稿日:2019-07-08T20:34:04+09:00
気象×Python 〜AMeDASの地点データ自動取得〜
Seleniumを使って、気象データのダウンロード自動化を目指したいと、思います。
1. 経緯
▶任意の地点である一定期間の気象データ(気温・降水量など)が欲しい場合、気象庁のアメダス(AMeDAS:Automated Meteorological Data Acquisition System:自動気象データ収集システム)をよく利用している。
▶手軽にダウンロードできる反面、一度に取得できるデータ量には上限がある。
▶仮に長期間の1時間間隔のデータを取得しようとした場合、期間を区切りながら手動でダウンロードするのはめんどう。地点が増えればなおさらである。
⇒ある地点を選択してダウンロードして、また地点を変えてダウンロードして、、、この作業を全部自動化できないのか。2. Seleniumによるブラウザ自動操作
2.1 Chromedriverの導入
Chromedriver導入に関しては、多くの参考記事があると思うのでここでは省略します。
https://sites.google.com/a/chromium.org/chromedriver/downloads
2.2 ダウンロードするアメダス地点の選定
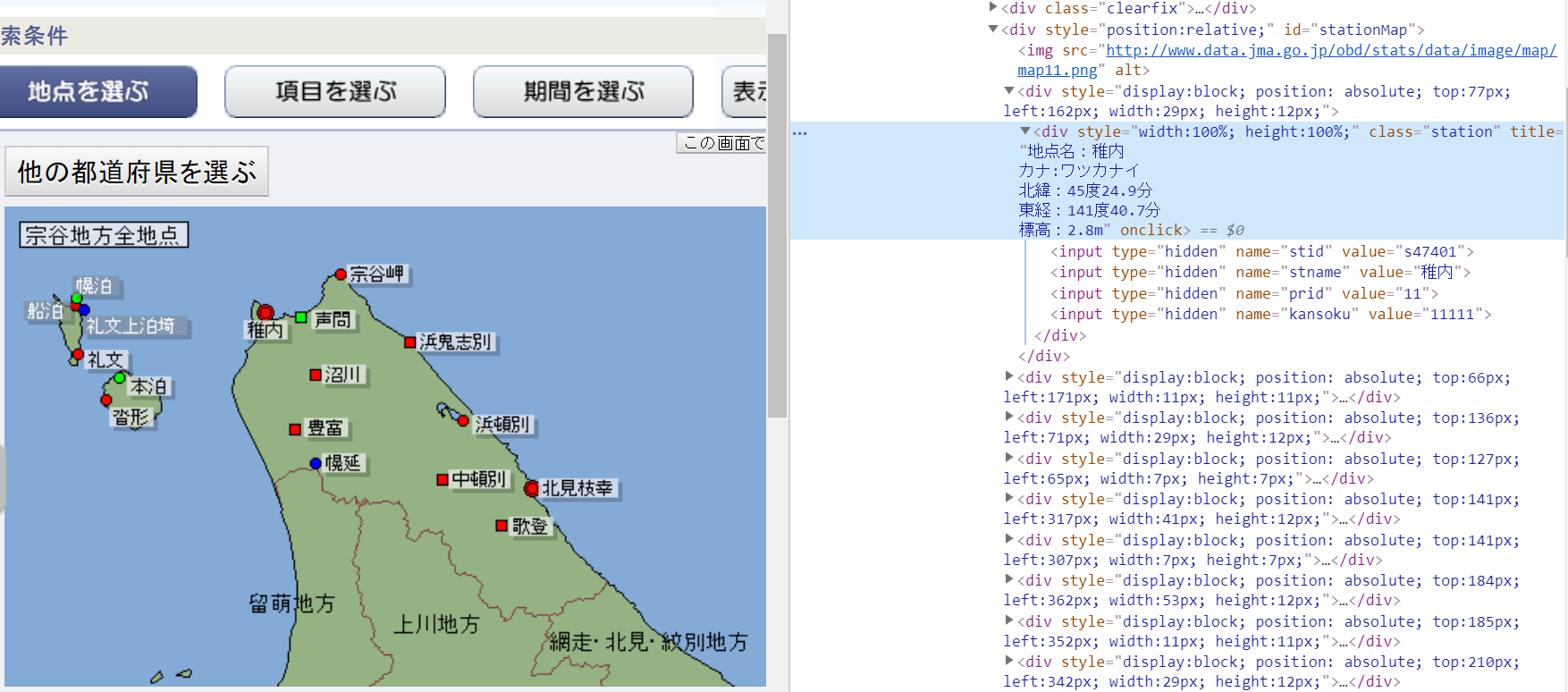
①まず目的のダウンロードサイトから、地域を選択する操作をしなければならないので、各地域の場所情報をリスト化する。
今回は各地域のid属性値(id=pr××)を取得した(=計61地域)
②各地域の観測地点を1地点ずつ選択するための情報をリスト化する。
今回はname="stname"のvalue="××"を取得した(=計1300地点)
get_list.py# -*- coding: utf-8 -*- from selenium import webdriver from selenium.webdriver.chrome.options import Options import time options = Options() options.add_argument('--headless') driver = webdriver.Chrome('C:/selenium/chromedriver', options=options) html = driver.get("https://www.data.jma.go.jp/gmd/risk/obsdl/index.php") time.sleep(1) #各地域のid属性取得========================================================== pr_list = [] prefecture = driver.find_elements_by_class_name("prefecture") for pr in prefecture: pr = pr.get_attribute("id") pr_list.append(pr) #========================================================================== #各地域の観測地点名取得========================================================== stname_list = [] for i in pr_list: #順番に各地域へアクセス driver.find_element_by_xpath('//*[@id="{}"]'.format(i)).click() time.sleep(1) #その地域の観測地点情報の取得 stations = driver.find_elements_by_xpath('//*[@class="station"]') for station in stations: station.click() #地点選択 time.sleep(1) #地点名取得 stname = station.find_element_by_name("stname").get_attribute("value") stname_list.append(stname) #全部選択し終わったらその地域から離れ、別の地域へ driver.find_element_by_css_selector("#buttonSelectStation").click() time.sleep(1) #==============================================================================各地域・地点情報のリストは以下の通り。稼働中の地点は1300ヶ所、この中から各自ダウンロードしたい地点を選定する。
※リスト化のプログラムは時間かかります。
2.3 AMeDASデータダウンロード
実際にデータをダウンロードするには物理量や期間などを選択する必要があります。
以下のプログラムでは2017年12月1日から2019年3月31日の冬季期間における時間降雪量を取得しています。
各要素をクリックするためのidやxpathを丁寧に指定してあげてください。get_amedas.py# -*- coding: utf-8 -*- from selenium import webdriver import time driver = webdriver.Chrome('C:/selenium/chromedriver') html = driver.get("https://www.data.jma.go.jp/gmd/risk/obsdl/index.php") time.sleep(1) #ダウンロードするデータの詳細設定============================================================================== #項目を選ぶ driver.find_element_by_id('elementButton').click() time.sleep(1) #時間降雪量を選択 driver.find_element_by_xpath('//*[@id="aggrgPeriod"]/div/div[1]/div[1]/label/input').click() time.sleep(1) driver.find_element_by_xpath('//*[@id="降雪の深さ"]').click() time.sleep(1) #期間を選ぶ driver.find_element_by_id('periodButton').click() time.sleep(1) driver.find_element_by_xpath('//*[@id="selectPeriod"]/div/div[2]/div[1]/label/span').click() time.sleep(1) driver.find_element_by_xpath( '//*[@id="selectPeriod"]/div/div[2]/div[2]/div[2]/select[1]/option[3]').click() # 2017年 time.sleep(1) driver.find_element_by_xpath('//*[@id="selectPeriod"]/div/div[2]/div[2]/div[1]/select[1]/option[12]').click() #12月 time.sleep(1) driver.find_element_by_xpath('//*[@id="selectPeriod"]/div/div[2]/div[2]/div[1]/select[2]/option[1]').click() #1日 time.sleep(1) driver.find_element_by_xpath('//*[@id="selectPeriod"]/div/div[2]/div[2]/div[2]/select[2]/option[1]').click() #2018年 time.sleep(1) driver.find_element_by_xpath('//*[@id="selectPeriod"]/div/div[2]/div[2]/div[1]/select[3]/option[3]').click() #3月 time.sleep(1) driver.find_element_by_xpath('//*[@id="selectPeriod"]/div/div[2]/div[2]/div[1]/select[4]/option[31]').click() #31日 time.sleep(1) #表示オプションを選ぶ driver.find_element_by_id('optionButton').click() time.sleep(1) driver.find_element_by_xpath('//*[@id="selectOp"]/div[1]/div/div[2]/p/label/input').click() time.sleep(1) driver.find_element_by_xpath('//*[@id="selectOp"]/div[2]/div/div[2]/p/label/input').click() time.sleep(1) driver.find_element_by_xpath('//*[@id="selectOp"]/div[3]/p[3]/label/input').click() time.sleep(1) driver.find_element_by_xpath('// *[@id="selectOp"]/div[4]/div/div[2]/label/input').click() time.sleep(1) #================================================================================================== #地点を選ぶ driver.find_element_by_id('stationButton').click() time.sleep(1) #今回は試しに以下のリストに示した観測地点のデータをダウンロードする select_list = ['稚内', '北見枝幸', '歌登', '中頓別', '豊富', '沼川', '浜鬼志別'] for i in pr_list: driver.find_element_by_xpath('//*[@id="{}"]'.format(i)).click() time.sleep(1) stations = driver.find_elements_by_xpath('//*[@class="station"]') time.sleep(1) for station in stations: station.click() time.sleep(1) stname = station.find_element_by_name("stname").get_attribute("value") #選択中の地点がselect_listになければ、その地点をスキップする if not stname in select_list: print(stname + " skip") else: driver.find_element_by_xpath('//*[@id="csvdl"]/img').click() time.sleep(5) #ダウンロードには多少時間がかかる print(stname + " DL") #選択した地点を解除する driver.find_element_by_id("deleteAllStPref").click() time.sleep(1) driver.find_element_by_css_selector("#buttonSelectStation").click() time.sleep(1)$ python get_amedas.py 稚内 DL 沓形 skip 浜頓別 skip 北見枝幸 DL 歌登 DL 中頓別 skip 豊富 DL 沼川 DL 宗谷岬 skip 浜鬼志別 DL 本泊 skip : :上記プログラム実行すると、ダウンロードフォルダなどに保存されます。
あとは、ループしつつも、同時にデータ整形して別フォルダに保存し、元のファイルは削除しておくようなプログラムを組み込むといいと思います。
ではでは。


- 投稿日:2019-07-08T20:01:15+09:00
Flaskの練習として簡単なToDoリストWebアプリを作成
はじめに
Pythonで書くWebアプリケーションフレームワークFlaskの練習として、簡単なToDoリストを作成しました。
概要
- ルートページ(
index.html)にはToDoリストの一覧を表示- それぞれの項目に詳細ページ(
show.html)- 他に、項目編集ページ(
edit.html)と新規項目追加フォームページ(new.html)- 見た目はBootstrapを使いました
環境
OS macOS mojave Python 3.7.3 Flask 1.0.3 ソースコード
https://github.com/TaroNoguchi/flask-app-practice
アプリの作成
まずはアプリの根幹になるファイル
app.pyを作成します。モジュールのインポートなど
app.pyfrom flask import Flask, render_template, request, redirect, url_for from flask_sqlalchemy import SQLAlchemy from datetime import datetime app = Flask(__name__) app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///todo.db' app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True db = SQLAlchemy(app) db.create_all()作業ディレクトリを整理
以下は完成したディレクトリ構造。
*はbootstrapのファイルです。
その他ページの見た目をhtmlでtemplatesに、cssでstaticに作成しました。. ├── Procfile ├── app.py ├── requirements.txt ├── static │ ├── css │ │ └── bootstrap.css * │ └── js │ ├── bootstrap.js * │ └── jquery-3.4.1.js * ├── templates │ ├── edit.html │ ├── favicon.png │ ├── index.html │ ├── layout.html │ ├── new.html │ └── show.html └── todo.dbデータベースの作成
SQLAlchemyというモジュールを用いて、SQL文を書かずとも操作ができるスタイルで作ります。
まずはtouch todo.dbでデータベースファイルを作り、以下のクラスに対応するようにテーブルを作成します。app.pyclass Post(db.Model): __tablename__ = "posts" id = db.Column(db.Integer, primary_key=True, autoincrement=True) date = db.Column(db.Text()) title = db.Column(db.Text()) content = db.Column(db.Text()) commit = db.Column(db.Integer)このクラスを外部から呼び出すことでデータベースへの操作を行うことができます。
ルートページの作成
app.py
app.py@app.route('/') # ルート(/)ページURLにリクエストが送られた時の処理 def index(): posts = Post.query.all() return render_template("index.html", posts = posts)
- 変数postsにPostクラスの全てのクエリを代入
index.htmlのテンプレートを呼び出してレンダリングし、表示。index.html
続いて
index.htmlを編集します。
layout.htmlで共通部分を作成し、{% block content %}と{% endblock %}で挟み込んだ所のみを記述することで余計にコードを書かないようにします。index.html{% extends "layout.html" %} {% block content %} <div class="container"> <h1>ToDo</h1> <table class="table table-hover table-responsive"> <tr><th>Last Update</th><th>Title</th><th></th><th></th><th></th></tr> {% for post in posts %} <div class="row"> <tr> <td>{{ post.date }}</td> {% if post.commit == 1 %} <td><del>{{ post.title }}</del></td> {% else %} <td>{{ post.title }}</td> {% endif %} <td><a href="/show/{{ post.id }}" class="btn btn-success far fa-file-alt"> 詳細 </a></td> <td><a href="/done/{{ post.id }}" class="btn btn-info fas fa-check-circle"> Done </a></td> <td><a href="/undone/{{ post.id }}" class="btn btn-success fas fa-undo-alt"> Undone </a></td> </tr> </div> {% endfor %} </table> <p> <a href="/new" class="btn btn-primary far fa-file"> 新規 </a> <a href="/destroy/alldone" class="btn btn-danger fas fa-trash" onclick="return confirm('完了済みの項目を全て削除します。よろしいですか?')"> 完了済みをすべて削除 </a> </p> </div> {% endblock %}
- forループとtableタグを使ってクエリの一覧表示
- Postクラス変数commitが1の時完了を、0の時未完了を表し、1の時は横線を入れるよう条件分岐で記述
- 各種ボタンを作成
詳細ページの作成
app.py
/show/(Postクラスのインスタンスのid)にアクセスした時の振る舞いをapp.pyに記述します。app.py@app.route('/show/<int:id>') def show(id): post = Post.query.get(id) return render_template("show.html", post = post)
/showの後に記述されたint型の値を変数idに格納- この変数idとDBのidカラムのデータを変数postに代入
show.htmlをテンプレートとしてれ呼び出し、レンダリングshow.html
show.html{% extends "layout.html" %} {% block content %} <div class="container"> <div class="card bg-light"> <div class="card-header"> <h2>{{ post.title }}</h2> </div> <div class="card-body"> <blockquote class="blockquote mb-0"> <p>{{ post.content }}</p> <footer class="blockquote-footer"><cite title="Source Title">(Last Update: {{ post.date }})</cite></footer> </blockquote> {% if post.commit == 1 %} <div class="alert alert-success" role="alert"> 完了しています </div> {% endif %} </div> </div> <br> <div> <a href="/edit/{{ post.id }}" class="btn btn-warning far fa-edit"> 編集 </a> <a href="/destroy/{{ post.id }}" class="btn btn-danger fas fa-trash-alt" onclick="return confirm('この項目を削除します。よろしいですか?')"> 削除 </a> <a href="/done/{{ post.id }}" class="btn btn-info fas fa-check-circle"> Done </a> <a href="/undone/{{ post.id }}" class="btn btn-success fas fa-undo-alt"> Undone </a> </div> <br> <p><a href="/" class="btn btn-default">一覧に戻る</a></p> </div> {% endblock %}
- タイトルと、さらに詳しく情報が表示されます
- 完了しているもの(commit == 1)にはブロックが表示されます
新規追加・編集ページの作成
新規追加・編集ページのレイアウトと、そこに記述された内容をPOSTメソッドで送るロジックを組みます。
new.html
先にテンプレートを作ります。
new.html{% extends "layout.html" %} {% block content %} <div class="container"> <form action="/create" method="POST"> <div class="form-group"> <label for="title">ToDo</label> <input type="text" name="title" value="" class="form-control" placeholder="What do you do next?"> </div> <div class="form-group"> <label for="content">備考</label> <textarea class="form-control" name="content" cols="40" rows="10" placeholder="If you have options, write down here."></textarea> </div> <button type="submit" class="btn btn-primary">保存</button> <button type="button" class="btn btn-danger" onclick="history.back()">キャンセル</button> </form> </div> {% endblock %}
/createへPOSTリクエストを送ります- 送り先ではname属性で指定した値で取り出せます
app.py
app.py@app.route('/new') def new_post(): return render_template("new.html")このメソッドに
/newにアクセスされた時の動きを記述します。
といってもnew.htmlのテンプレートをレンダリングするだけです。app.py@app.route('/create', methods=["POST"]) def create_post(): new_post = Post() new_post.title = request.form["title"] new_post.content = request.form["content"] new_post.date = str(datetime.today().year) + "-" + str(datetime.today().month) + "-" + str(datetime.today().day) new_post.commit = 0 db.session.add(new_post) db.session.commit() return redirect(url_for('.index'))こちらで、実際に
new.htmlで入力された値をDBに格納します。
- 変数new_postをPostクラスでインスタンス化
- title, contentにPOSTリクエストで送られてきた値を格納
- dateは今日の日付
- 未完了なのでcommitは0に
- session.addでデータベースへ値を追加
- session.commitでデータベースの変更を実行します
- 編集後にわざわざレンダリングせず
index.htmlを表示させます。こうすることでリロードした時に同じものが登録されてしまうのを防げますedit.html
edit.html{% extends "layout.html" %} {% block content %} <div class="container"> <form action="/update/{{ post.id }}" method="POST"> <div class="form-group"> <label for="title">ToDo</label><br> <input type="text" name="title" value="{{ post.title }}" class="form-control"> </div> <div class="form-group"> <label for="content">詳細</label><br> <textarea name="content" cols="40" rows="10" class="form-control">{{ post.content }}</textarea> </div> <button type="submit" class="btn btn-primary">保存</button> <button type="button" class="btn btn-danger" onclick="history.back()">キャンセル</button> </form> </div> {% endblock %}こちらも
new.htmlと見た目は一緒ですが、一緒にレンダリングした変数postを使って現在のデータを入力ボックス内に表示してあげないといけません。
/update/{{ post.id }}へリクエストを送りますapp.py
app.py@app.route('/edit/<int:id>') def edit_post(id): post = Post.query.get(id) return render_template("edit.html", post = post)こちらは編集ページなので指定したデータも一緒にレンダリングしてあげないといけません。
app.py@app.route('/update/<int:id>', methods=["POST"]) def update_post(id): post = Post.query.get(id) post.title = request.form["title"] post.content = request.form["content"] post.date = str(datetime.today().year) + "-" + str(datetime.today().month) + "-" + str(datetime.today().day) db.session.commit() return redirect(url_for('.index'))
/createの時と同じような要領で記述します- 今回も編集後にわざわざレンダリングせず
index.htmlを表示します項目の完了(make item done)・削除のロジック
リクエストがdestroy, done, undoneに送られた時の動きを
app.pyに記述します。これらに関するURLにリクエストが送られた時の「動き」を記述すれば良いだけなので、とくに新たなhtmlファイルを書く必要はありません。Done, Undone
app.py@app.route('/done/<int:id>') def done_post(id): post = Post.query.get(id) post.commit = 1 post.date = str(datetime.today().year) + "-" + str(datetime.today().month) + "-" + str(datetime.today().day) db.session.commit() posts = Post.query.all() return redirect(url_for('.index')) @app.route('/undone/<int:id>') def undone_post(id): post = Post.query.get(id) post.commit = 0 post.date = str(datetime.today().year) + "-" + str(datetime.today().month) + "-" + str(datetime.today().day) db.session.commit() posts = Post.query.all() return redirect(url_for('.index'))
- 変数commitが0か1かで、完了・未完了を分けているのでそれをリクエストによって変更する記述をします
削除
一件のみの削除
app.py@app.route('/destroy/<int:id>') def destroy(id): post = Post.query.get(id) db.session.delete(post) db.session.commit() posts = Post.query.all() return redirect(url_for('.index'))
- 新規追加や編集の時と記述の仕方はほとんど一緒です
- session.deleteで削除してコミットします
完了済みを全削除
app.py@app.route('/destroy/alldone') def destroy_alldone(): posts_done = Post.query.filter_by(commit=1).all() for i in posts_done: db.session.delete(i) db.session.commit() posts = Post.query.all() return redirect(url_for('.index'))
- ルートページにこのボタンがあります
Post.query.filter_byで変数commitが1のもの(完了しているもの)をとりだし- 削除してコミットします
- 最後にルートページに飛んで終了
最後に
GitHubではHerokuに公開したURLも記述していますがユーザー管理を導入していないので完全に一人用です。
Herokuの使い方はRailsのチュートリアルドキュメントを参考にしました。
- 投稿日:2019-07-08T19:45:22+09:00
PythonでError Handlingをどのような場合でコード上に書くべきか
What is this?
備忘録的なあれです。
Golangを書いている後、Pythonを書き始めるとエラーをどうあつかったらいいかわからなくなりました。Golangは基本的に、なにかメソッドを書く際には、必ずといっていい程、エラーも同時に返り値として設定します。そのおかげで、「このエラーはraiseさせよう」とか、「ここはpanicでええやろ」とか、「ここは例外的に処理させねばとか」、逐一考える機会が与えらえて良いなあという印象を受けました。
一方で、Pythonはコード上にて明示的吐き出されません。プログラムを実行した際に、ようやく「ああ、ここはこういうエラーが吐き出されのね、ふーん」みたいなことが多々ありました。
Golangから改めてPythonを触った自分は、エラー出た場合に、
try exceptで例外処理として、エラーを吐き出すべきなのか、そのままエラーをシステムに吐かせればいいのか、わからなくなりました。そこで、今回では、どのような場合にエラーを
try exceptでログを吐き出すべきなのか、備忘録的に記載していきます。エラーを例外処理する場合
結論からいうと、
「エラーログに付加要素を付け加えたい場合に例外処理をするべき」
です。どういうこっちゃかというと、例えばデータベースに接続して検索するケースを挙げます。
下記のような、Mysqlに接続するとします。import mysql.connector class DataBaseRepository: def __init__(self): self.conn = mysql.connector.connect( database=MYSQL_DATABASE, host=MYSQL_HOST, user=MYSQL_USER, password=MYSQL_PASS, charset='utf8mb4', autocommit=True, connection_timeout=60, ) def get_users(self, user_id: int, group_id: int) -> [str]: """ get username :return list of username """ cursor = self.conn.cursor sql = f""" SELECT name FROM users WHERE user_id = {user_id} AND group_id = {group_id} """ cursor.execute(sql) return cursor.fetchall() def close(self): self.conn.close() def __del__(self): self.close()DataBaseに接続して、
get_usersでuser_idとgroup_idが一致するuserのnameを取得します。(そのほかのメソッドは、説明は省きます)このコードを用いた下記のような2種類実行のコードがあるとします。
- 例外処理を書く場合
from logging import getLogger if __name__ == '__main__': logger = getLogger(__name__) repo = DataBaseRepository() user_id = 100 group_id = 1 try: user_names = repo.get_users(group_id, gender_id) except: """ ここにどうような処理を書くべき? """ if len(user_names) == 0 { logger.warn('user_name size is zero!') }
- 例外処理を書かない場合
from logging import getLogger if __name__ == '__main__': repo = DataBaseRepository() user_id = 100 group_id = 1 user_names = repo.get_users(group_id, gender_id) if len(user_names) == 0 { logger.warn('user_name size is zero!') }どっちがいいと思いますか?
どっちでも、エラーがでるときは十分ありうるコードなのです。DataBaseのカラムが存在しないかもしれないし、Connectionが確立されてないかもしれないし、そもそもレコードがないこともありえますね。その場合、より多くの情報があった方が不足の事態に対処しやすいです。
この情報が付加要素となるわけです。例えば、今回の場合だと、
group_idとgender_idがあった方が、断然エラー対応しやすいです。
なので、エラーがでる部分を例外処理でくくって、付加要素を加えます。
- 例外処理を書く場合
from logging import getLogger if __name__ == '__main__': logger = getLogger(__name__) repo = DataBaseRepository() user_id = 100 group_id = 1 try: user_names = repo.get_users(group_id, gender_id) except Exception as e: """ ここにどうような処理を書くべき? """ logger.error(f'Failed to get user_name of group_id:{group_id} and gender_id:{gender_id}') raise(e) if len(user_names) == 0 { logger.warn('user_name size is zero!') }これで、エラー対応が楽になるはず。。。
まとめ
要約すると
「エラー対応がしやすいように、付加要素的なエラーログを意識しましょう」
以上。何か、ご意見やご指摘あれば、何卒コメント欄にご記入いただけますと幸いです。
- 投稿日:2019-07-08T19:24:28+09:00
tracebackの取得にはTracebackExceptionを使おう
TL;DR
''.join(traceback.TracebackException.from_exception(exc).format())従来の方法
tracebackを文字列で取得する方法として traceback.format_exception() がよく紹介されています。
import traceback try: 1/0 except Exception as e: t = traceback.format_exception(type(e), e, e.__traceback__) print(t) # ['Traceback (most recent call last):\n', # ' File "/path/to/script.py", line 4, in <module>\n 1/0\n', # 'ZeroDivisionError: division by zero\n']この書き方は冗長です。エラーひとつに対して
etype,value,tbの3つの引数を与えなくてはなりません。
(実は引数e_typeは Python3.5 からは無視される仕様となっているため、Noneなどで代用できます)より単純な書き方
Python3.5 から TracebackException が導入され、より単純に同じことを実現できるようになりました。
import traceback try: 1/0 except Exception as e: t = list(traceback.TracebackException.from_exception(e).format()) print(t) # ['Traceback (most recent call last):\n', # ' File "/path/to/script.py", line 4, in <module>\n 1/0\n', # 'ZeroDivisionError: division by zero\n']
TracebackException.format()は文字列のジェネレータを返すという点に注意してください。
- 投稿日:2019-07-08T19:24:28+09:00
tracebackを文字列で取得する時はTracebackExceptionを使おう
TL;DR
''.join(traceback.TracebackException.from_exception(exc).format())従来の方法
tracebackを文字列で取得する方法として traceback.format_exception() がよく紹介されています。
import traceback try: 1/0 except Exception as e: t = traceback.format_exception(type(e), e, e.__traceback__) print(t) # ['Traceback (most recent call last):\n', # ' File "/path/to/script.py", line 4, in <module>\n 1/0\n', # 'ZeroDivisionError: division by zero\n']この書き方は冗長です。エラーひとつに対して
etype,value,tbの3つの引数を与えなくてはなりません。
(引数e_typeは Python3.5 からは無視される仕様となったため、Noneで代用できます)より単純な書き方
Python3.5 から TracebackException が導入され、より単純に同じことを実現できるようになりました。
import traceback try: 1/0 except Exception as e: t = list(traceback.TracebackException.from_exception(e).format()) print(t) # ['Traceback (most recent call last):\n', # ' File "/path/to/script.py", line 4, in <module>\n 1/0\n', # 'ZeroDivisionError: division by zero\n']
TracebackException.format()は文字列のジェネレータを返す点に注意してください。謝辞
TracebackExceptionについて教えてくださった python.jp の atsuoishimoto さんに感謝申し上げます。
の
- 投稿日:2019-07-08T18:56:53+09:00
ロジスティック回帰(Logistic Regression)
はじめに
これは筆者の勉強まとめページですので、指摘しまくってい頂けると幸いです
ロジスティック回帰
線形回帰を二値分類に使用する方法で、とある閾値を超えたものを1クラス、その他のクラスを0クラスとして分類していく手法で、今回は0.5を閾値として、損失関数が以下のように設定される。
$$ y = w・x + b $$
$$ sigmoid(x) = \frac{1}{1 + \exp(-x)} $$
$$ loss = \sum^{n}_{k = 1}{(t・log(sigmoid(y) + (1 - t)・log(1 - sigmoid(y))} $$
これを用いて2クラス分類をしていきます
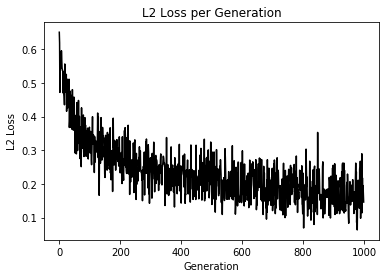
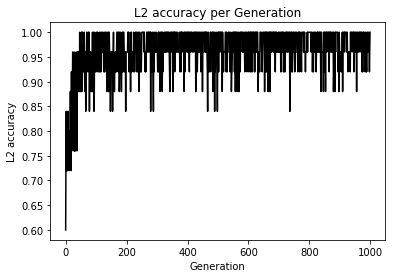
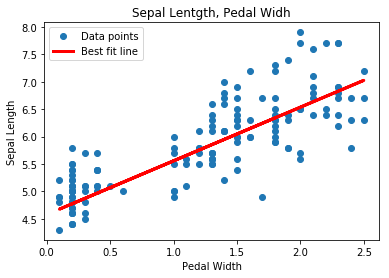
import matplotlib.pyplot as plt import tensorflow as tf import numpy as np from sklearn import datasets sess = tf.Session() # [setosa, versicolor] と [virginica] の分類を行う iris = datasets.load_iris() x_vals = iris.data target = iris.target y1 = [0 for i in target if i != 2] y2 = [1 for i in target if i == 2] y_vals = np.array(y1+y2) learning_rate = 0.05 batch_size = 25 x_data = tf.placeholder(shape = [None, 4], dtype = tf.float32) y_target = tf.placeholder(shape = [None, 1], dtype = tf.float32) A = tf.Variable(tf.random_normal(shape = [4, 1])) b = tf.Variable(tf.random_normal(shape = [1, 1])) model_output = tf.add(tf.matmul(x_data, A), b) loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits = model_output, labels = y_target)) init = tf.global_variables_initializer() sess.run(init) optimizer = tf.train.GradientDescentOptimizer(learning_rate) train = optimizer.minimize(loss) prediction = tf.round(tf.sigmoid(model_output)) prediction_correct = tf.cast(tf.equal(prediction, y_target), tf.float32) accuracy = tf.reduce_mean(prediction_correct) loss_vec = [] accuracy_vec = [] for i in range(1000): rand_index = np.random.choice(len(x_vals), size = batch_size) rand_x = x_vals[rand_index] rand_y = np.transpose([y_vals[rand_index]]) sess.run(train, feed_dict = {x_data: rand_x, y_target: rand_y}) tmp_accuracy, temp_loss = sess.run([accuracy, loss], feed_dict = {x_data: rand_x, y_target: rand_y}) loss_vec.append(temp_loss) accuracy_vec.append(tmp_accuracy) if (i + 1) % 25 == 0: print("Step #" + str(i + 1) + " A = " + str(sess.run(A)) + " b = " + str(sess.run(b))) print("Loss = " + str(temp_loss)) print("Acc = " + str(tmp_accuracy)) plt.plot(loss_vec, "k-") plt.title("L2 Loss per Generation") plt.xlabel("Generation") plt.ylabel("L2 Loss") plt.show() plt.plot(accuracy_vec, "k-") plt.title("L2 accuracy per Generation") plt.xlabel("Generation") plt.ylabel("L2 accuracy") plt.show()
こんな感じで学習が進んでいれば成功
うまく分類できている模様(テストデータで検証してないけど...)
ロジスティック回帰で他クラスにする手法とかないかな(ボソッ)
- 投稿日:2019-07-08T16:50:38+09:00
BoW ✕ ロジスティック回帰で誰がツイートしたかを当てる
環境
ubuntu 16.04 LTS
python 3.7.3やること
Python機械学習プログラミング(第一版)の「第8章 | 機械学習の適用1-感情分析」を参考に、2人のユーザーによるツイートを正解ラベルありで学習させ、ツイートからどちらのユーザーがツイートしたかを判定します。ちなみにこの本は第二版が出ているので買う場合はそっちを選んでください。特に深層学習のトピックが増えているらしいです。
学習するツイートについて
ともにライターで、ツイッターを利用していれば1度は見たことがあるであろうARuFaさんとヨッピーさんのツイートを使います。
服屋で店員さんに声をかけられるのが怖いので、同じ根暗たちを集めて『店員に声をかけられる前に爆速で服を買い、その服だけでコーディネートをする大会』をした記事を書きました。緊張感すごい
— ARuFa (@ARuFa_FARu) 2019年7月1日
【挑戦】店員に声をかけられる前に服を買え!「即買いコーディネート選手権」!https://t.co/ZuNp1vvNy7 pic.twitter.com/ZtFcRXQ5za
笹のコスプレ pic.twitter.com/vIsbRdAyWT
— ヨッピー (@yoppymodel) 2019年7月7日Twitter APIのstatuses/user_timelineでそれぞれツイートを取得し、ツイート内のユーザーIDとURLはここで取り除きます。ツイート、ユーザー(正解ラベル:0,1)のDataFrameにしてCSVで保存します。
ここでstatuses/user_timelineについて、指定したユーザーのツイートを新しい順に3200個取得するのですが、それにはRTも含まれます。include_rts=FalseでRTは除いているのですが、カウント時には含まれるので、例えばRTが200個あればレスポンスとして取得できるツイートは3000個になります。さらにその後の処理でリプライも除いているので、RTやリプライ数により結果として取得できるツイートは3200から大きく減る場合があります。
Twitter APIの概要やsearch/tweetsの使い方等はこちら
import urllib import io from requests_oauthlib import OAuth1Session, OAuth1 import requests import sys import re import pandas as pd def main(): # APIの認証キー CK = 'xxxxxxxxxxxxxxxx' CKS = 'xxxxxxxxxxxxxxxx' AT = 'xxxxxxxxxxxxxxxx' ATS = 'xxxxxxxxxxxxxxxx' # ユーザーID user_id = 'ARuFa_FARu' # 正確にはscree_nameのこと。本来のuser_idは数字だけで表現される # 取得時のパラメーター range = 200 # 検索回数の上限値(最大200) # インスタンス作成 get = Get_User_Timeline() save = Save_Data() # タイムライン取得 tweets = get.get_tl(CK, CKS, AT, ATS, user_id, range) # 前処理 tweets = get.preprocess(tweets) # DataFrameの作成 user_label = 0 # ユーザーラベル df = save.to_DF(tweets, user_label) # CSVとして保存 path = "ARuFa.csv" save.save_as_csv(df, path) class Get_User_Timeline: def get_tl(self, CK, CKS, AT, ATS, user_id, range): user_id = urllib.parse.quote_plus(user_id) sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8') url = "https://api.twitter.com/1.1/statuses/user_timeline.json?screen_name="+user_id+"&include_rts=False&tweet_mode=extended" auth = OAuth1(CK, CKS, AT, ATS) response = requests.get(url, auth=auth) data = response.json() cnt = 0 tweets = [] count_tweets = 0 while True: if len(data) == 0: break if cnt > range: break cnt += 1 for tweet in data: if tweet['in_reply_to_status_id'] == None: tweets.append(tweet['full_text']) count_tweets += 1 max_id = int(tweet["id"]) - 1 url = "https://api.twitter.com/1.1/statuses/user_timeline.json?screen_name="+user_id+"&include_rts=False&tweet_mode=extended&max_id="+str(max_id) response = requests.get(url, auth=auth) try: data = response.json() except KeyError: print('上限まで検索しました') break print('取得したツイート数 :', count_tweets) return tweets def preprocess(self, tweets): for i in range(len(tweets)): tweets[i] = re.sub(r'@\w+', '', tweets[i]) tweets[i] = re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-]+', '', tweets[i]) return tweets class Save_Data(): def to_DF(self, tweets, user_label): cols = ['tweet', 'user'] df = pd.DataFrame(index=[], columns=cols) for tweet in tweets: record = pd.Series([tweet, user_label], index=df.columns) df = df.append(record, ignore_index=True) return df def save_as_csv(self, df, path): df.to_csv(path, index=False) if __name__ == '__main__': main()テキストデータのベクトル化について
BoWというモデルでテキストをベクトル化し,さらにTF-IDFが適用されるsklearnのTfidfVectorizerを使用します。同じくsklearnのCountVectorizerのようなシンプルなBoWモデルでは、各テキストにおける単語の出現頻度をそのままベクトルに反映し、その出現頻度を
tf(t,d)で表します。dは各テキストで、tはその中の各単語の出現回数です。ここで、「が」「は」といったような助詞など多くのテキストに頻繁に出現するような単語は判断材料として乏しいので過剰な重みを与えないようにしたいと考え、IDFを次にように定義します。
idf(t, d) = log\frac{n_d}{1 + df(t, d)}nはテキストの総数です。単語の出現頻度が大きいほど重みが抑えられます。また、出現頻度が低い単語にも過剰な重みが与えられることを防ぐために対数をとっています。そして、TF-IDFはdfとidfの積で定義されます。
tfーidf(t, d) = tf(t, d) × idf(t, d)さらにこの後の学習では、ベクトルを正規化するべきかの検証も行われます。詳しいことは参考文献を読んでください。
データの前処理
さきほど作成したCSVをそれぞれ読み込み、欠損値のある列を削除します。ここからは全てjupyter-notebookで実行しています。
import pandas as pd df_y = pd.read_csv('Yoppi.csv') df_a = pd.read_csv('ARuFa.csv') df_y = df_y[~df_y['tweet'].isnull()] df_a = df_a[~df_a['tweet'].isnull()]ここでデータをチェックしてみます。
print('ヨッピー') print(df_y.info()) print(df_y.head(5))ヨッピー <class 'pandas.core.frame.DataFrame'> Int64Index: 1198 entries, 0 to 1205 Data columns (total 2 columns): tweet 1198 non-null object user 1198 non-null int64 dtypes: int64(1), object(1) memory usage: 28.1+ KB None tweet user 0 【定期】ヨッピーが書いた記事が全部届くLINE@(スマホから)はこっち→ たまにダラダラ長... 0 1 坦坦担麺\n\n元RADWIMPSの斉木さん、ギターを置いてなぜ汁なし担々麺屋になったんですか? 0 2 Twitterで見かけたあの件、マジだったのか……!\n\nお悔やみ欄見て遺族に虚偽請求の手... 0 3 「ハイヒール履いてみた」って動画が話題だけど、自分でやってみて当事者のしんどさを知るっていう... 0 4 【定期】ヨッピーが書いた記事が全部届くLINE@(スマホから)はこっち→ たまにダラダラ長... 0print('ARuFa') print(df_a.info()) print(df_a.head())ARuFa <class 'pandas.core.frame.DataFrame'> Int64Index: 1952 entries, 0 to 1971 Data columns (total 2 columns): tweet 1952 non-null object user 1952 non-null int64 dtypes: int64(1), object(1) memory usage: 45.8+ KB None tweet user 0 服屋で店員さんに声をかけられるのが怖いので、同じ根暗たちを集めて『店員に声をかけられる前に爆... 1 1 周りのタピオカユーザーに差をつけたいので、クッソでかいタピオカを吸ってるように見えるストロー... 1 2 ムチャクチャな理由で会社が休みになりました 1 3 最近カレーばっかりで飽きてきたので、カレーを構成する『カレールー』『白米』『スプーン』の位置... 1 4 ?????????????? 1ヨッピーさんのツイート数が1198に対してARuFaさんは1952です。前述の通り、statuses/user_timelineの仕様及びリプライを除いていることからRT数やリプライ数が多いほどここでのツイート数は少なくなります。この差に関する検証は後ほどやっていきたいと思います。
またヨッピーさんの方は定期ツイートが設定されているのでこれも除きます。df_y = df_y[df_y['tweet']!='【定期】ヨッピーが書いた記事が全部届くLINE@(スマホから)はこっち→ たまにダラダラ長文を投下するFB(5000人到達したからフォローしてね)はこっち→'] df_y.info()<class 'pandas.core.frame.DataFrame'> Int64Index: 898 entries, 1 to 1205 Data columns (total 2 columns): tweet 898 non-null object user 898 non-null int64 dtypes: int64(1), object(1) memory usage: 21.0+ KBさらに300ほど少なくなりました。
最後に、2つのDataFrameを縦に結合し、学習・テストデータに分割します。
df = pd.concat([df_y, df_a]) X_train, X_test, Y_train, Y_test = train_test_split(df.tweet, df.user, test_size=0.3, random_state=0)ロジスティック回帰で学習させる
Pipelineでパラメータの比較をまとめて行い、先ほど触れたベクトルの正規化についても検証します。基本的に元のプログラムと同じですが、TfidfVectorizerのtokenizerとstop_wordsは変えています。
①tokenizerについて、これはテキストをトークンごとに分割する処理です。英語の場合は素直に単語を空白で区切ればOKですが、日本語ではMeCabの分かち書きで分割する場合が多く、ここでもそうしています。また元のプログラムでは単純な単語の分割に加えて単語を原形に変換した場合(例:runnner, running, run → run)も検証していますが、ここでそのような処理は行いません。
②stop_wordsについて、これはどんなテキストにも出現しうるありふれた単語のことで、英語の場合isやandなどのことを指します。これを除く処理はNLTKというライブラリを使えば簡単に実装できるのですが、日本語は用意されていません。ただし、TF-IDFを適用した段階でストップワードのような単語の重みはあらかじめ抑えられているので、ストップワードを除く必要性はあまりないと参考文献でも言及されています。これについては後で検証しますので、ここではストップワードを除かずそのまま学習させます。
import MeCab import sys from sklearn.model_selection import GridSearchCV from sklearn.model_selection import train_test_split from sklearn.pipeline import Pipeline from sklearn.linear_model import LogisticRegression from sklearn.feature_extraction.text import TfidfVectorizer def tokenizer(text): m = MeCab.Tagger('-Owakati') wakati_text = m.parse(text) return wakati_text.split() tfidf = TfidfVectorizer(strip_accents=None, lowercase=False, preprocessor=None) param_grid = [{'vect__ngram_range': [(1, 1)], 'vect__stop_words': [None] 'vect__tokenizer': [tokenizer], 'clf__penalty': ['l1', 'l2'], 'clf__C': [1.0, 10.0, 100.0]}, {'vect__ngram_range': [(1, 1)], 'vect__stop_words': [None] 'vect__tokenizer': [tokenizer], 'vect__use_idf': [False], 'vect__norm': [None], 'clf__penalty': ['l1', 'l2'], 'clf__C': [1.0, 10.0, 100.0]} ] lr_tfidf = Pipeline([('vect', tfidf), ('clf', LogisticRegression(random_state=0))]) gs_lr_tfidf = GridSearchCV(lr_tfidf, param_grid, scoring='accuracy', cv=5, verbose=1, n_jobs=-1) gs_lr_tfidf.fit(X_train, Y_train)実行結果
gs_lr_tfidf.best_params_ # {'clf__C': 100.0, # 'clf__penalty': 'l2', # 'vect__ngram_range': (1, 1), # 'vect__stop_words': None, # 'vect__tokenizer': <function __main__.tokenizer(text)>}gs_lr_tfidf.best_score_ # 0.8751879699248121clf = gs_lr_tfidf.best_estimator_ clf.score(X_test, Y_test) # 0.8783625730994152best_params_で最適なパラメータが見れます。まずTfidfVectorizerについて、TF−IDFが適用され、ベクトルにはL2正則化(デフォルト)が適用されています。次にLogisticRegressionについて、L2正則化が適用され、その正則化項のパラメータCは100.0となっています。下の3つは共通です。
学習データでの正解率は約87.5%、テストデータでは約87.8%です。参考文献では学習・テストデータがそれぞれ25000個あったので足りるかなと思ったのですが、割といい感じになりました。
参考文献の内容としてはここまでですが、以降はこれまでに触れた今回の分析で気になる2つの点について検証していきます。
データの偏りについて
前処理後のデータ数は、ヨッピーさんが898、ARuFaさんが1952と倍近い偏りがあります。一般的にこの場合はARuFaさんと判定される確率の方が高くなると考えられ、実際に先ほどの学習結果についてテストデータをヨッピーさんとARuFaさんで分けて検証してみると、
X_y_test = X_test[Y_test==0] Y_y_test = Y_test[Y_test==0] X_a_test = X_test[Y_test==1] Y_a_test = Y_test[Y_test==1]clf.score(X_y_test, Y_y_test) # 0.7509157509157509clf.score(X_a_test, Y_a_test) # 0.9381443298969072ヨッピーさんのツイート正しく判定できる確率は約75.1%、ARuFaさんのツイートを正しく判定できる確率は約93.8%と、20%近い差がありました。
このような偏りを前処理の段階で抑えるには、基本的にデータを削るか補うかの2択になると思います。数値データであれば平均値などで補えますが、テキストデータでは難しく、今回は少ない方でも約900個あるのでそれに合わせて大きい方のデータを削ります。
df_a2 = df_a.sample(n=len(df_y), random_state=0) df = pd.concat([df_y, df_a2]) X_train, X_test, Y_train, Y_test = train_test_split(df.tweet, df.user, test_size=0.3, random_state=0)ヨッピーさんのデータの数だけARuFaさんのデータからランダムに抽出し、それを結合して学習・テストデータに分割しています。
あとは先程と同じように学習させるので、コードは省略します。
実行結果
gs_lr_tfidf.best_params_ # {'clf__C': 100.0, # 'clf__penalty': 'l2', # 'vect__ngram_range': (1, 1), # 'vect__stop_words': None, # 'vect__tokenizer': <function __main__.tokenizer(text)>}gs_lr_tfidf.best_score_ # 0.8480509148766905clf = gs_lr_tfidf.best_estimator_ clf.score(X_test, Y_test) # 0.862708719851577データ数を減らしたためか、学習データでは約2.7%・テストデータでは約1.6%正解率が下がっています。
続いて、テストデータをヨッピーさんとARuFaさんで分けて検証してみましょう。
X_y_test = X_test[Y_test==0] Y_y_test = Y_test[Y_test==0] X_a_test = X_test[Y_test==1] Y_a_test = Y_test[Y_test==1]clf.score(X_y_test, Y_y_test) # 0.8717948717948718clf.score(X_a_test, Y_a_test) # 0.85338345864661662つの正解率の差を約1.8%まで縮めることができました。どのような課題かにもよるとは思いますが、データ数の偏りは抑えるべきだと確認できましたね。次の検証でも同じようにデータ数は揃えます。
ストップワードについて
元のプログラムと今回のプログラムの違いとして、stop_wordsを除くかどうかの検証について説明しました。
stop_wordsについて、これはどんなテキストにも出現しうるありふれた単語のことで、英語の場合isやandなどのことを指します。これを除く処理はNLTKというライブラリを使えば簡単に実装できるのですが、日本語は用意されていません。ただし、TF-IDFを適用した段階でストップワードのような単語の重みはあらかじめ抑えられているので、ストップワードを除く必要性はあまりないと参考文献でも言及されています。これについては後で検証しますので、ここではストップワードを除かずそのまま学習させます。
ということで、ここではストップワードを除く場合も検証してみます。前述のようにNLTKのストップワードには日本語のものはないので、
http://svn.sourceforge.jp/svnroot/slothlib/CSharp/Version1/SlothLib/NLP/Filter/StopWord/word/Japanese.txt
をstopwords.txtとしてダウンロード(コピペ)します。これは京都大学が作成したSlothLibというライブラリに登録されている単語ベースによるストップワードです。分かち書きで分割された単語のうちこのストップワードに含まれるものを除きます。今回はTfidfVectorizerのパラメータstop_wordsはNoneのままで、tokenizerにストップワードを除くものを追加します。with open('stopwords.txt', 'r') as f: stopwords = [] line = f.readline() while line: if line != '\n': stopwords.append(line.strip()) line = f.readline() def tokenizer(text): m = MeCab.Tagger('-Owakati') wakati_text = m.parse(text) return wakati_text.split() def tokenizer_not_stopwords(text): m = MeCab.Tagger('-Owakati') wakati_text = m.parse(text) wakati_list = wakati_text.split() drop_words = set(wakati_list) & set(stopwords) return list(set(wakati_list) - drop_words)また、tokenizerとtokenizer_not_stopwordsをまとめて検証するためparam_gridを以下のように変更します。
param_grid = [{'vect__ngram_range': [(1, 1)], 'vect__stop_words': [None], 'vect__tokenizer': [tokenizer, tokenizer_not_stopwords], # 追加 'clf__penalty': ['l1', 'l2'], 'clf__C': [1.0, 10.0, 100.0]}, {'vect__ngram_range': [(1, 1)], 'vect__stop_words': [None], 'vect__tokenizer': [tokenizer, tokenizer_not_stopwords], # 追加 'vect__use_idf': [False], 'vect__norm': [None], 'clf__penalty': ['l1', 'l2'], 'clf__C': [1.0, 10.0, 100.0]} ]実行結果
gs_lr_tfidf.best_params_ # {'clf__C': 10.0, # 'clf__penalty': 'l2', # 'vect__ngram_range': (1, 1), # 'vect__stop_words': None, # 'vect__tokenizer': <function __main__.tokenizer_not_stopwords(text)>}gs_lr_tfidf.best_score_ # 0.863961813842482clf = gs_lr_tfidf.best_estimator_ clf.score(X_test, Y_test) # 0.8589981447124304パラメータはtokenizer_not_stopwordsの方になっていますが、正解率には最初と比べて有意な差は見られません(先ほどの検証を踏まえARuFaさんのデータ数を削っているので若干下がっています)。TF-IDFを適用する場合、やはりストップワードを除く必要性は低そうですね。
以上で終わりです。ありがとうございました!
- 投稿日:2019-07-08T16:24:17+09:00
SiloファイルをPythonから作りたいだけのはずだったのに...
概要
この記事はPythonの計算結果をsiloファイルとして出力し、それをVisItで可視化しようと奮闘したときに生まれた副産物です。
インストール
pyvisfile
pip install pyvisfileで
pyvisfileをインストールします。これがsiloファイルを作成するために必要なモジュールです。その他もろもろをインストール、と思いきや...
pyvisfileを動作させるにはboost-pythonとPyUbrasというモジュールも必要らしいことがわかりました。
brew install boost-pythonの後に
pip install pyublasとすると
boost/python.hppがありませんとエラー。そんなはずはない、と思いネットサーフィンをしていると...同じくpyublasのインストールができないとの報告を発見。NumPy・SciPyを用いた数値計算の高速化 : 落ち穂拾いのBoost/Pythonの章にて、「boostやPyUblasのビルドがPython3ではできなかった」と書かれています。
そのほかにも、こんなStackOverFlowの記事を発見。
結言
PyUblasやBoostの開発がPython3で行われてないっぽい?なんともモヤっとした終わり方ですが、Pythonからsiloファイルを書き出して、それをVisItで描画するという方法はあまり推奨できないのかなぁという感じでした。それでもmatPlotlibやMayaviがありますから、まぁ困らないんですけどね。
- 投稿日:2019-07-08T15:37:37+09:00
デミング回帰(Demming Regression)
はじめに
これは筆者の勉強まとめページですので、指摘しまくってい頂けると幸いです
デミング回帰
今回は https://qiita.com/raso0527/items/ba4bef9b1271428afbfc の記事のコードの損失関数を改良して学習をする
デミング回帰も線形回帰の一種で、損失関数を以下のように設定したもの
$$ loss = \frac{|t - (w・x + b)|}{\sqrt{w^2 + 1}} $$
これは数学IIで習った点と直線の距離の公式を変形した形になっていて、これを適用することにより、距離の大きさを誤差として極小値に近づけるよう学習をしていく。
点と直線の距離の公式
https://ja.wikipedia.org/wiki/%E7%82%B9%E3%81%A8%E7%9B%B4%E7%B7%9A%E3%81%AE%E8%B7%9D%E9%9B%A2以下TensorFlowによるコード
demming_numerator = tf.abs(tf.subtract(y_target , tf.add(tf.matmul(x_data, A), b))) demming_demoinator = tf.sqrt(tf.add(tf.square(A), 1)) loss = tf.reduce_mean(tf.truediv(demming_numerator, demming_demoinator))
- 投稿日:2019-07-08T15:37:37+09:00
線形回帰4
はじめに
これは筆者の勉強まとめページですので、指摘しまくってい頂けると幸いです
デミング回帰
今回は https://qiita.com/raso0527/items/ba4bef9b1271428afbfc の記事のコードの損失関数を改良して学習をする
デミング回帰も線形回帰の一種で、損失関数を以下のように設定したもの
$$ loss = \frac{|t - (w・x + b)|}{\sqrt{w^2 + 1}} $$
これは数学IIで習った点と直線の距離の公式を変形した形になっていて、これを適用することにより、距離の大きさを誤差として極小値に近づけるよう学習をしていく。
点と直線の距離の公式
https://ja.wikipedia.org/wiki/%E7%82%B9%E3%81%A8%E7%9B%B4%E7%B7%9A%E3%81%AE%E8%B7%9D%E9%9B%A2以下TensorFlowによるコード
demming_numerator = tf.abs(tf.subtract(y_target , tf.add(tf.matmul(x_data, A), b))) demming_demoinator = tf.sqrt(tf.add(tf.square(A), 1)) loss = tf.reduce_mean(tf.truediv(demming_numerator, demming_demoinator))
- 投稿日:2019-07-08T15:02:05+09:00
屋外など独立環境下での使用を想定したヘッドレス Raspberry Pi の作りかた
はじめに
モニタやキーボードを必要としないコンピュータの運用形態をヘッドレスというそうです。ここでは、天体観測時に望遠鏡に取り付ける Raspberry Pi(以下ラズパイ)のような、ヘッドレスかつ広域インターネットに接続しない、独立型の実行環境の作り方について説明します。
目標
ラズパイ自体を Wi-fi のアクセスポイントとして機能するようにします。アクセスポイント化したラズパイに、ノートパソコンから接続し、ウィンドウシステム経由でラズパイを操作できるようにします。この設定により、以下に示すような条件および操作方法にてラズパイが操作できるようになりますので、結果的にラズパイのヘッドレスな状況での運用が可能となります(天体撮影などでは、ノートパソコンとラズパイとバッテリだけ持っていけば良いので、持ち運ばなければならない荷物の量も少なくなります):
- インターネットに接続できる環境がなくても(スマフォでテザリング等しなくても)、
- アクセスポイント化したラズパイにノートパソコンから VNC 接続し、
- GUI でラズパイを操作したり、
- Web カメラ画像などを確認するプログラムなどを、
- ノートパソコンより操作
ラズパイにはバックアップされた時計が搭載されていないので、通常は NTP を活用して正しい時刻を保持するようにしています。インターネットに接続しない場合、正確な時刻が分からなくなってしまいます。もちろん、そもそも正確な時刻は要らない、という運用形態であれば何も問題はありませんが、例えば、撮影日時をファイル名として記録したい等、現在時刻をある程度正確に知りたい場合などは困ってしまいます。そこで、本稿では、あくまでもオプションとしてですが、バッテリーパックアップされたリアルタイムクロックモジュールを活用する方法についても記しておきます。
なお、本稿では mac からラズパイに接続することを想定して、各種の設定について記しています。Windows マシンからの VNC 接続については、今後の更新にて追記される…かもしれません。
Step 0 システムソフトウェアの更新
まずはシステムを最新版にしておきます。
sudo apt-get update sudo apt-get upgrade sudo apt-get dist-upgradStep 1 必要なソフトウェアのインストール
本稿の設定では、最終的にラズパイはインターネットには接続できない状況になります。なので、インターネットに接続できる標準設定の時に、必要となる各種のソフトウェアのインストールを済ませておきます。
1.1 VNC Server - Tight VNC Server
1.1.1 インストール
今回は、ssh などのターミナルではなく、VNC 接続に対応します。標準の設定でも VNC 接続へは対応しているようですが、mac の場合、標準のソフトウェアで接続することができませんでした。そのため、Tight VNC Server をインストールしておきます。
sudo apt install tightvncserver無事インストールできたら、tightvncserver として、Tight VNC サーバーを起動します。するとパスワードを聞かれるので、入力します。このパスワードは mac から接続する時に入力するパスワードとなります。
ちなみに、もし、パスワードの入力で何か失敗してしまったら、~/.vnc/passwd ファイルを削除して、再度 tighvncserver を起動します。するとパスワードを聞いてくれますので、今度は失敗しないように、パスワードを入力(設定)しましょう。
1.1.2 接続テスト
mac は標準で VNC クライアントを有していますので、ファインダーメニューの「移動」→「サーバへ接続」と移動し、
vnc://ラズパイのIPアドレス:5901として接続してみます。もし、ラズパイのアドレスが 192.168.123.45 であれば、
vnc://192.168.123.45:5901で接続できるハズです。ここで VNC 接続できないと、ヘッドレス設定を行ったラズパイにも接続できず、困ったこととなります。この段階で、しっかりテスト&確認するようにしましょう。…とはいえ、ネットワークの設定によっては、もしかすると VNC 接続できない場合もあるかもしれません。その場合は、全ての設定完了後に再度 VNC 接続を試みてみましょう。
1.1.3 Tight VNC Server 関連で参考にしたページ
以下のページにお世話になりました。感謝。
MacからRaspberry PiにVNCでリモートデスクトップ接続する方法
https://darmus.net/raspberry-pi-mac-vnc/VNCで接続用パスワードを忘れたときは
http://blogcdn.rutake.com/blog/techmemo/2007/09/vnc.htmlTightVNC:Mac から Raspberry Pi 3 を リモートデスクトップ
https://homemadegarbage.com/mac-raspi3-vnc1.2 アクセスポイント化ソフトウェア - hostapd
ここではインストールだけを行います(設定は後ほど)。
sudo apt install hostapd1.3 DNS 用ソフトウェア - dnsmasq
同じくインストールだけを行います(設定は後ほど)。
sudo apt install dnsmasq1.4 オプションその1 - バッテリーパックアップされたリアルタイムクロックモジュールを使う場合
私の場合は、ある程度正確な時刻が必要でしたので、バッテリーパックアップ可能なリアルタイムクロックモジュール(RTC)を使用しました。RTC モジュールはスイッチサイエンスで売っている約 500 円の PiRTC (DS1307) を使用しました。https://www.switch-science.com/catalog/5334/
以下、DS1307 を用いた PiRTC の設定方法です(左側の三角形をクリックすると展開します)
1.4.1 正しい時刻の取得 - ntpdate
RTC モジュールの情報を使うには、まず正しい時刻を RTC に保存しなければなりません。起動後、ある程度時間が経つと、いつの間にかラズパイの時刻が正確になっていますが、せっかちな私は ntpdate を用いて強制的に時刻を同期するようにしています。というわけで、ntpdate のインストールを行います。
sudo apt install ntpdatentpdate の使い方は簡単で、「sudo ntpdate ntpサーバーのアドレス」とすれば時刻同期は完了です。ntp サーバーのアドレスですが、NICT が公開しているものがありますので、
sudo ntpdate -v ntp.nict.jpとすれば十分です。オプション v をつけると、同期に関する情報を表示してくれるものです。無事に同期が完了すると、最後の出力の行頭に現在の時刻が表示されているはずです。
参考資料
Linux基本コマンドTips(315):【 ntpdate 】コマンド――時刻をNTPサーバと同期する
https://www.atmarkit.co.jp/ait/articles/1906/21/news013.html1.4.2 I2C の有効化
PiRTC は I2C により通信を行うので、I2C を有効にします。
sudo raspi-configとして raspi-config を立ち上げ、"5 Interfacing Options" → "P5 I2C" へと進み、I2C を有効化しておきます。
1.4.3 RTC ドライバのインストール
スイッチサイエンスのページからもドライバのインストールに関する説明がありますが、当方の環境では、さらに追加の設定が必要でしたので、それも合わせて記しておきます。まず、Seeed-Studio よりインストーラを入手します(今回、以下の作業はホームディレクトリで行うものとします)。この段階では、まだ RTC モジュールはラズパイに装着しません。
cd ~ git clone https://github.com/Seeed-Studio/pi-hats.gitなお、Seeed-Studio の Seeed は Seed ではなく、Seeed (e が 3 つ)なので注意して下さい。
次に、pi-hats/tools ディレクトリに移動して、インストールスクリプトを実行します:
cd ~/pi-hats/tools sudo ./install.sh -u rtc_ds1307 syncRTC モジュールを装着するため、ラスパイの電源をオフにします:
sudo shutdown now1.4.4 RTC モジュールの装着
バックアップ用の電池をもジュルに入れて、Pi RTC DS1307 をラズパイに装着し、ラズパイの電源を入れます。
1.4.5 /dev/rtc の作成
/etc/modules に rtc-ds1307 を追加します。追加後は多分、以下のような状況になっているかと思います:
# /etc/modules: kernel modules to load at boot time. # # This file contains the names of kernel modules that should be loaded # at boot time, one per line. Lines beginning with "#" are ignored. i2c-dev rtc-ds1307書き込んだら一旦リブートします(sudo reboot now)。その後、
ls /etc/r*などとして、/dev に rtc というディレクトリがあるか確認します。/dev/rtc というファイルが確認できれば OK です。
1.4.5 DS1307 との通信の確認
正しくドライバが動作していることを確認するために、今しがた取り付けた PiRTC の時刻を読み出してみます:
sudo hwclock -rとして、何か値が表示されれば OK です。渡しの場合は 2000 年 1 月 1 日である旨を示す表示が出てきました。
1.4.6 現在時刻を RTC に保存
ntpdate などを用いて、ラズパイの時計を正しい時刻にしておきます。続いて、
sudo hwclock -wとして、DS1307 に現在のシステム時刻を書き込みます。これで、電池が有効である間、ラズパイの電源を切っても PiRTC は(ほぼ)正確な時刻を報告してくれるようになりました。
1.5 オプションその2 - その他必要なソフトのインストール(例:Python 関係)
Step 2 ではアクセスポイント化してしまうため、広域インターネットへの接続が断たれてしまいます。その前に、必要なソフトウェアは全てインストールしておきましょう。私の場合は Python から OpenCV を使う必要があったので、libopencv-dev と python-opencv をインストールしておきました。
sudo apt install libopencv-dev sudo apt install python-opencv参考:「Raspberry Pi B+にOpenCV-Python環境を構築する」
https://qiita.com/jh3rox/items/be803f9171db8fe737deあと、VideoForLinux も使うので、もしなかった場合はこの段階でインストールしておきます:
sudo apt-get install v4l-utils参考:Raspberry PiとPythonで複数のUSBカメラを取り扱う方法
https://qiita.com/sudamasahiko/items/09c19addcbf23816390bもちろん、インストールするだけでなく、念のため動作確認もしておきましょう。
渡しの場合は、ロジクールの C270 という Web カメラを Python で操作したかったので、以下のプログラムを作って確認しました:
import cv2 cap=cv2.VideoCapture(0) while True: ret, frame = cap.read() If ret==False: continue cv2.imshow('frame',frame) if cv2.waitKey(1) & 0xFF == ord('q'): break capture.release() cv2.destroyAllWindows()1.6 オプションその3
mac とラズパイを接続し、かつ、ファイルのやりとりを mac-ラズパイ間で行う場合には、netatalk をインストールしておきましょう。
sudo apt install netatalkStep 2 ラズパイのアクセスポイント化
ここからはラズパイのアクセスポイント化を進めていきます。この作業を行うと、広域インターネットには接続できなくなりますので、必要なソフトのインストールなどは Step1 の段階で全て済ましておきましょう。
※ なお、2.1 および 2.2 については以下のページを参考にしました…というか、ほぼそのままです。
一箇所にまとまっていた方が便利かと思い、本文書に記しております。参考:Raspberry Pi3 wifiのAP/Clientを切り替え
https://qiita.com/yamato225/items/4c17bfdbda6ce57104de2.1 hostapd の設定を行う
アクセスポイント化を担う hostapd の設定を行います。具体的には、/etc/hostapd/hostapd.conf に以下の内容を記述します:
interface=wlan0 driver=nl80211 ssid=AstroPi ##SSID名 hw_mode=g channel=6 ieee80211n=1 wmm_enabled=1 ht_capab=[HT40][SHORT-GI-20][DSSS_CCK-40] macaddr_acl=0 auth_algs=1 ignore_broadcast_ssid=0 wpa=2 wpa_key_mgmt=WPA-PSK wpa_passphrase=raspberry ##SSIDパスワード rsn_pairwise=CCMP2.2 dhcpcd の設定を行う
DHCP 機能を担う dhcpcd の設定を行います。具体的には /etc/dhcpcd.conf を以下のように記述します。Step 1 の時にも補足しましたが、dhcpd.conf ではなく dhcpcd.conf と最後の d の前に c がひとつ入りますので、間違えないようにしましょう。
interface eth0 fallback static_eth0 denyinterface wlan0 interface wlan0 static ip_address=192.168.123.1/24 static routers=192.168.123.123.1 static domain_name_servers=192.168.123.1 static broadcast 192.168.123.1.255この例では、アクセスポイント化したラズパイから渡される IP アドレスを 192.168.123.* にしています。123 では都合が悪い、という人は適当に該当部分を書き換えて下さい。
2.3 rc.local への追加
起動時にアクセスポイントとしてラズパイが機能するように、いくつかのプログラムを起動時に実行するようにします。ここでは /etc/rc.local に以下の内容を記述する例を紹介します。/etc/rc.local の最後には exit 0 という記述があるので、その直前に以下の内容を記述します(なお、rc.local は root にて実行されるため sudo は不要です)。
# --- AstroPi - begin here --- # hwclock -s systemctl stop wpa_supplicant systemctl stop dhcpcd ifconfig wlan0 down && sudo ifconfig wlan0 up hostapd /etc/hostapd/hostapd.conf & sleep 5 systemctl start dhcpcd systemctl start dnsmasq sudo -u pi tightvncserver -geometry 1024x768 -depth 24 # --- AstroPi - end here ---hostapd の起動の後、sleep しているのは、直後に dhcpcd を起動しても上手く動作しなかったためです。もしこの設定で上手くいかない場合はスリープする秒数を伸ばしてみて下さい(私の環境では 3 だと時々失敗してしまいます)。
なお、下から 2 行目にて sudo していますが、これは root での実行のためではなく、ユーザー pi にて tightvncserver を起動するためです(-u pi)。tightvncserver の起動には環境変数の USER と HOME が必要とのことで、それらが設定された状況にて実行するようしています。
参考
【sudo】Linuxで指定したユーザーでコマンドを実行する
https://uxmilk.jp/53095Raspberry Pi で TightVNC サーバ
https://raspberrypi.akaneiro.jp/archives/455オプション:Pi RTC DS1307 を使用している場合
2 行目の hwclock に関する行の行頭の # を削除し、hwclock -s を有効化して下さい。これにより、RTC が保持している日時がラズパイの日時として設定されます。Step 3 動作確認
ここまでの設定を行ったら、一度ラズパイをリブートさせ(sudo reboot now)、アクセスポイント化したラズパイに接続(Wifi を AstroPi-AP に接続)できることを確認します。Wifi 経由でラズパイへの接続が無事終了したら、念のため
ping 192.168.123.1を実行し、アクセスポイント化(AP 化)したラズパイと通信できていることを確認して下さい。
次に、Mac の場合、ファインダ→移動→サーバーへ接続…、とし、
vnc://192.168.123.1:5901/VNC にて、ラズパイのデスクトップ画面が表示されることを確認してみて下さい。
以上にて、独立環境下でのヘッドレスなラズパイができあがりました。もし、アプリケーションプログラムのインストールし忘れなどに気がついた場合は、先にも記した @yamato225 さんの分かりやすい解説ページ 「Raspberry Pi3 wifiのAP/Clientを切り替え」https://qiita.com/yamato225/items/4c17bfdbda6ce57104de を参考に、一度クライアントモードにして再起動してみて下さい。
おわりに
当方の環境では、ここに示した設定で(いまのところ)問題なく動作しております。しかし、私自身は Linux に関してあまり詳しくはありませんので、誤解している部分や間違っているところがありましたらご指摘いただければ幸いです。
- 投稿日:2019-07-08T12:27:11+09:00
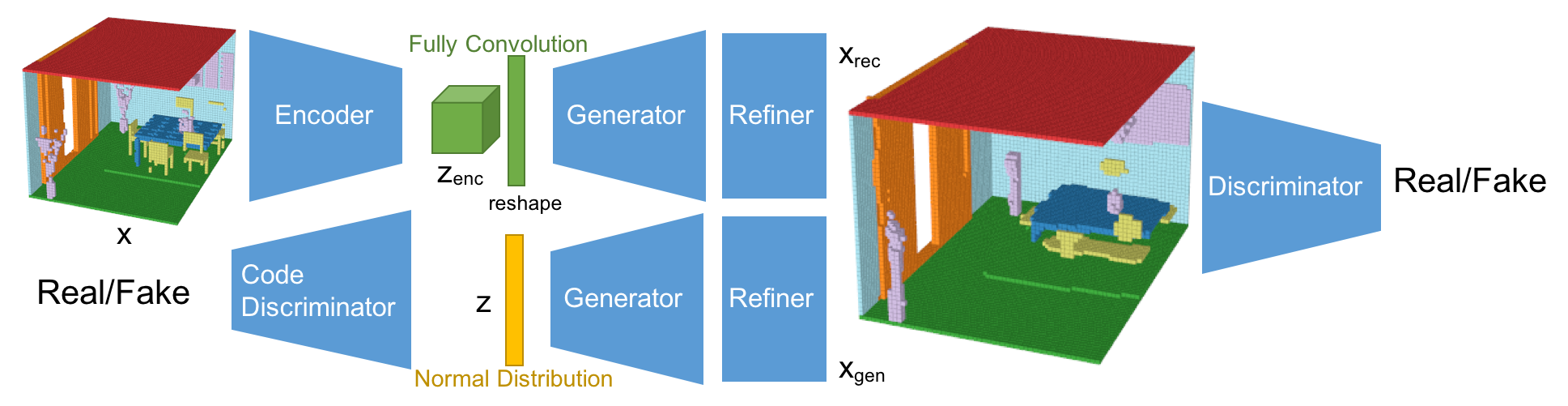
GANを活用した3Dマルチオブジェクトの生成モデル
今更ながら私がVisiting Scholarでやっていた研究を日本語版で投稿します。
この内容は約2年前(2017年9月)のMediumを日本語訳した内容です。
Githubのソースコードはコチラです。
Fully Convolutional Refined Auto-Encoding Generative Adversarial Networks for 3D Multi Object Scenes
-Special thanks to Christopher Choy and Prof. Silvio Savarese, and Stanford Vision and Learning Lab.
Introduction
GAN(Generative Adversarial Networks)やVAE(Variational Auto-Encoder)を活用した生成モデルは、ディープラーニングやコンピュータービジョンの領域で非常に注目されているテーマの一つである。これらの生成モデルは、高品質の生成を可能にするだけでなく、表現学習や特徴量抽出、さらには潜在空間を活用した認識タスクなどへの応用可能性を秘めている。
特に今回は3Dマルチオブジェクトの生成モデルに注目した。3Dマルチオブジェクトの生成モデルは、多様な新規の3Dオブジェクトを生成でき、かつ、オブジェクト種類、形状やレイアウトを潜在空間として表現することができる。このような3Dマルチオブジェクトの生成モデルは、AR/VR,グラフィクスの領域で極めて重要なタスクになると考えられる。
ただ、3Dの生成モデルはいまだに発展途上である。(2年後の今はRGBD->3Dや、3D Completionなどのタスクで活用されるようになってきました。) 単一オブジェクトの基本的な生成モデル[1][2] はあるが、マルチオブジェクトはない。
そこで、本研究では、End to Endで新規のGANsアーキテクチャを活用して、3Dマルチオブジェクトの生成モデルに取り組んだ。Dataset
正解のVoxelデータとして、SUNCG Datasetを活用した[3]。
SUNCGデータセットを、以下のように変更した。
- 240x144x240から80x48x80に圧縮。
- カメラアングルによるトリミングを削除。
- Empty以外のクラスが10000voxel以上存在するシーンのみを抽出。結果、12のクラスをもつ185K以上のシーンが集まった。
12クラス:empty, ceiling, floor, wall, window, chair, bed, sofa, table, tvs, furn, objs
このデータセットは平均92%のVoxelがEmptyクラスであり、非常にスパースである。さらに、リビング、風呂場、寝室、ダイニング、ガレージ等シーンの種類は多種多様であるため、非常に難易度の高いデータセットとなっている。
Models
ネットワーク構造
今回のネットワーク構造は、Fully Convolutional Refined Auto-Encoding Generative Adversarial Networksである。3DGAN[1], alphaGAN[4], SimGAN[5]を参考にしている。そして、Fully Convolutional Layerとマルチオブジェクトの分類が生成モデルとしては新規の構造となる。
このネットワークは、VAEとGANの構造を混合させている。VAEで使われるKLダイバージェンスロスは、alphaGANの構造のように、code discriminatorとしてAAE(Adversarial Auto-Encoder)構造に置き換えている[4]。 加えて、生成されたシーンはRefinerによってより綺麗な形になるようにしている[5]。 今回、潜在空間は5x3x5x16としており、これはFully Convolutional Layerによって算出されている。Fully Convolution構造は、セマンティックセグメンテーションのタスクで使われるように、特徴量をより厳密に取り出すことができる。結果として、Fully Convolution構造は再構成の性能を向上させている。また、AAE構造は、分布への制約条件を緩め、分布をより潜在的に扱うことができるようになり、再構成と生成の性能を向上させることができている。また、Refinerはオブジェクトの形状をスムーズにして、よりリアルな見た目にする効果がある。
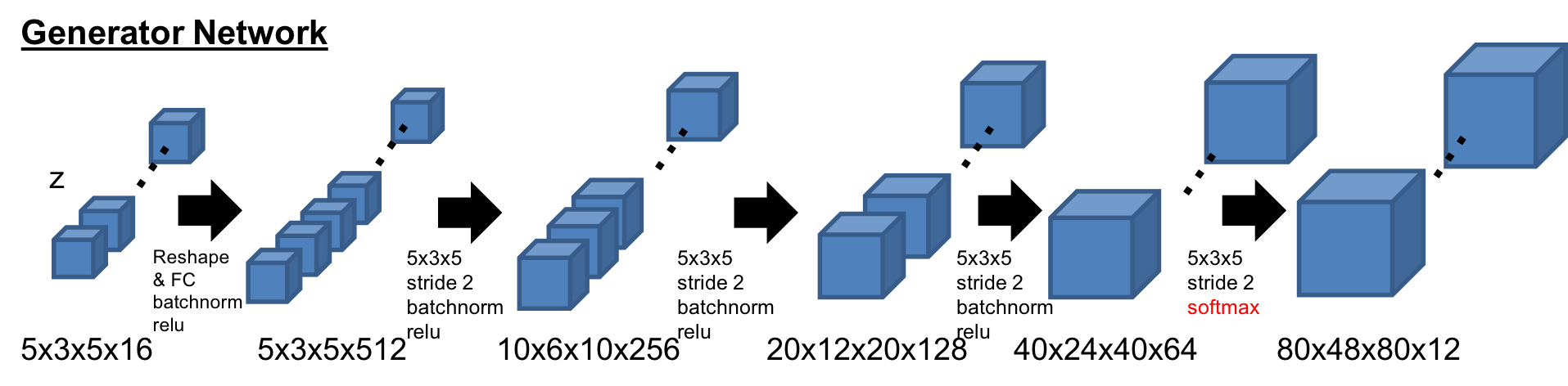
-Encoder
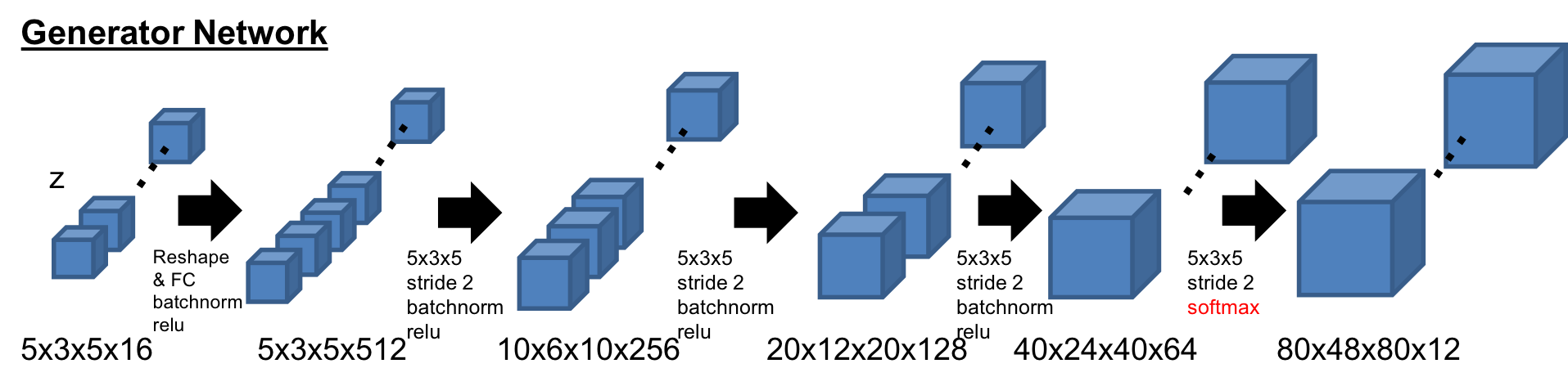
Encoderの基本構造は3DGAN[1]のDiscriminatorネットワークを踏襲している。最後のレイヤーが1x1x1のFully Convolution層のところが違いである。
-Generator
Generatorの基本構造も同様に3DGAN[1]の構造。最後のレイヤーが12チャンネルになっており、Softmaxで活性化されている。また、最初の潜在空間は展開させている。
-Discriminator
Discriminatorの基本構造も同様に3DGAN[1]の構造。ただ、活性化の前にはLayer Normalizationを活用している。
-Code Discriminator
潜在空間の分布を判定するCode discriminatorは、alphaGAN[4]と同様の構造で、750次元の2層の隠れ層を持つ。
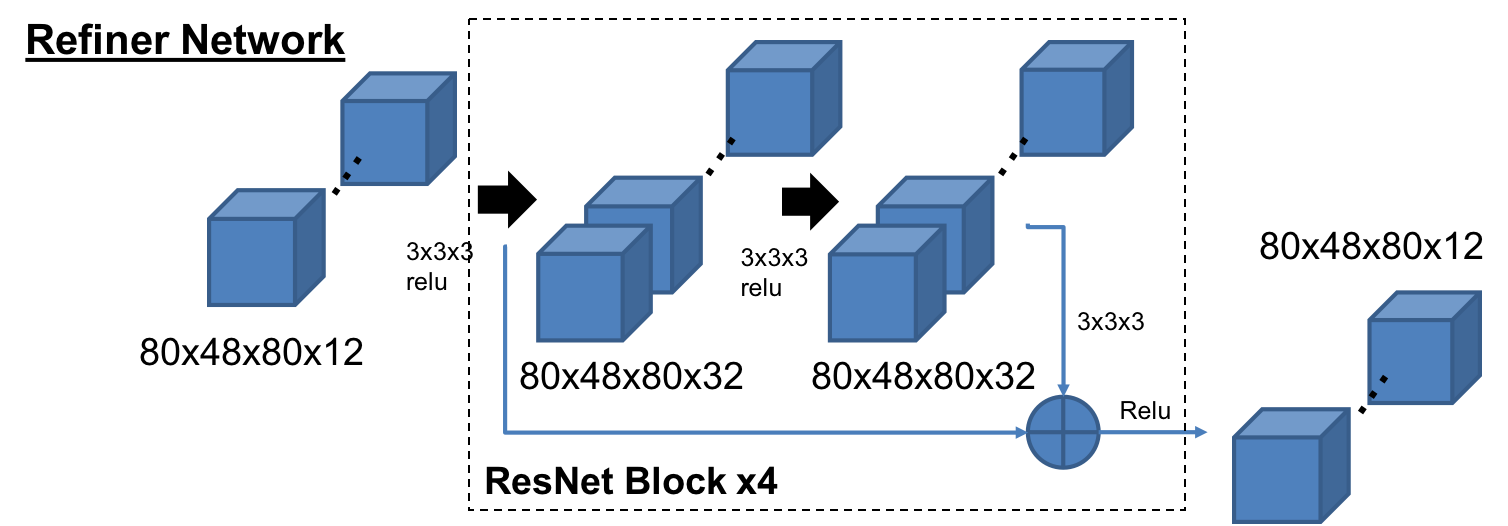
-Refiner
RefinerはSimGAN[5]の構造をベースにしており、4つのResNetブロックで構成されている。メモリーの負荷を減らすため、チャネル数は32にしている。
Loss Functions
ロス関数は、基本的には再構成のロス(Reconstruction Loss)、生成されたオブジェクトのGANロス(GAN Loss)、AAE構造の分布に対するGANロス(Distribution GAN Loss)で構成されている。
Reconstruction loss
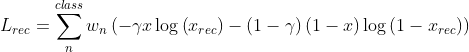
は小さいオブジェクトのロスを埋もれさせないため、バッチごとのオブジェクトの専有率で正規化された重みである。
はスパースな空間でPositiveなVoxel(1)のロスの重みを調整するハイパーパラメータである。
GAN loss
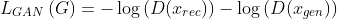
Distribution GAN loss
Optimization
各ネットワーク構造ごとに以下のロス関数を使って学習する。
Encoder
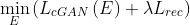
Generator and Refiner
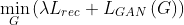
Discriminator
Code Discriminator
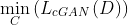
は再構成ロスの重み。
Experiments
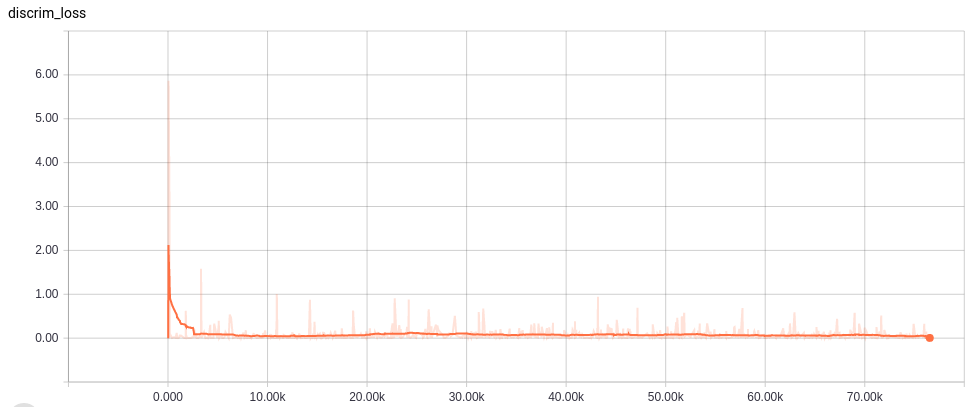
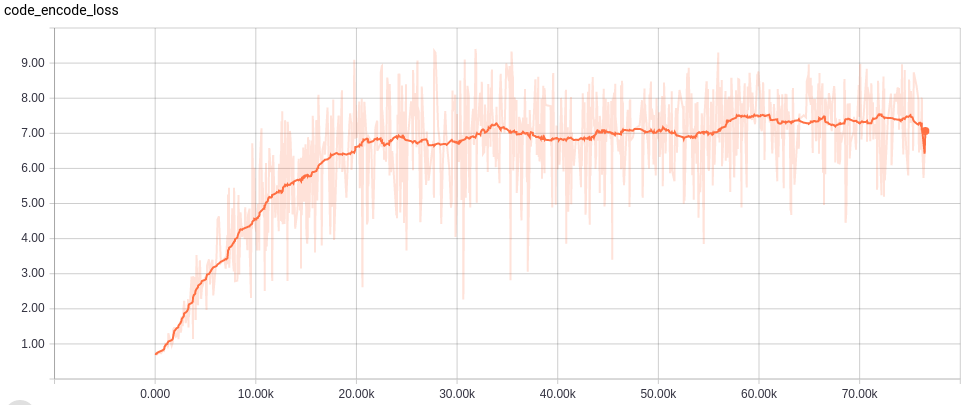
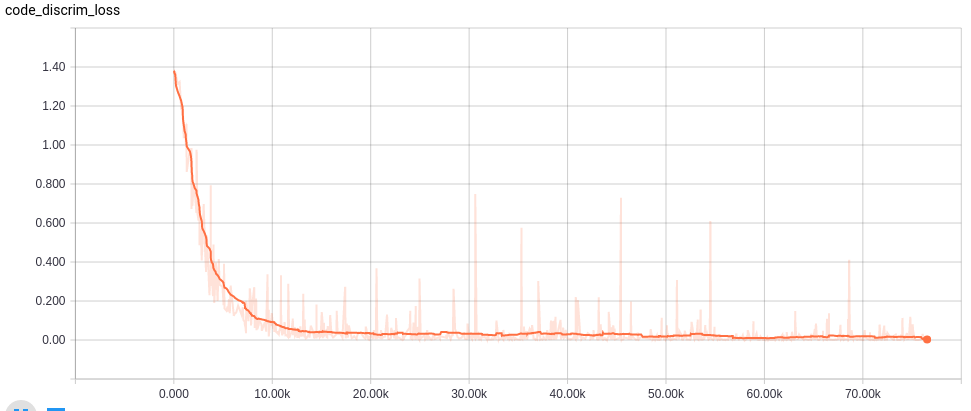
それぞれのネットワーク構造に置いて、OptimizerにAdamを使い、Learning Rateは0.0001とした。まず、Refinerなして75000 iterationトレーニングを行い、その後Refienerを追加し、さらに25000 iterationを実行した。初めのトレーニングはバッチサイズ20、Refiner込みのトレーニングはバッチサイズ8とした。また、GPUにはNVIDIA GeForce GTX TITAN Xを活用した。
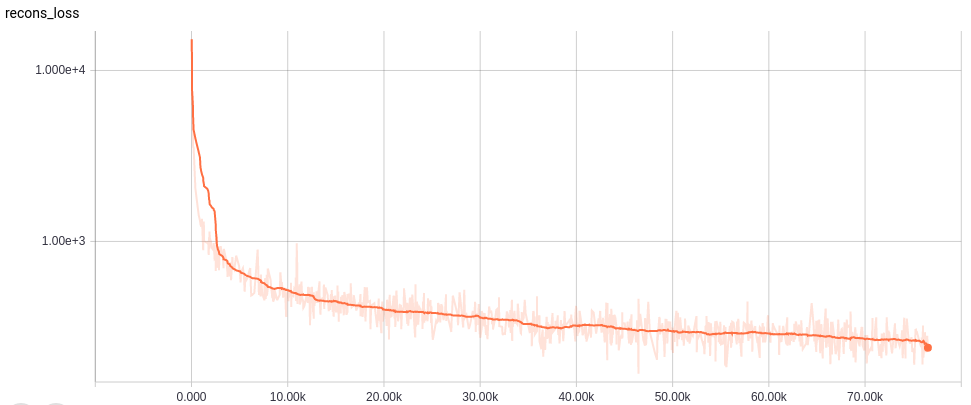
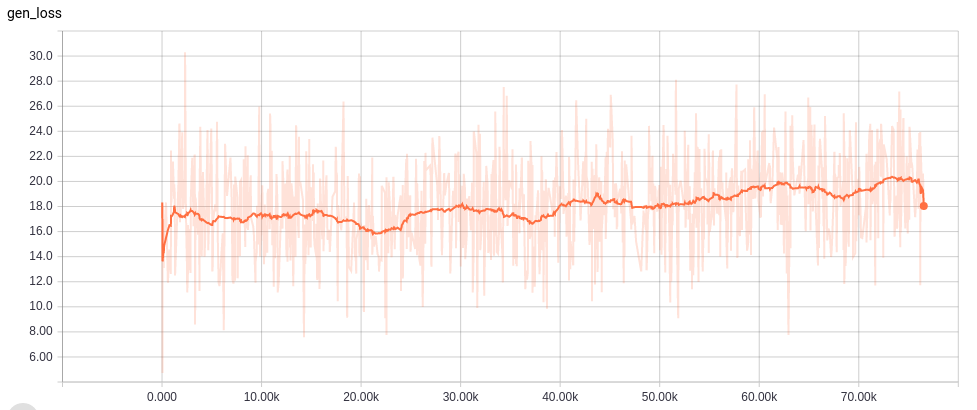
Learning curves
各ネットワークの学習カーブは以下。
Visualization
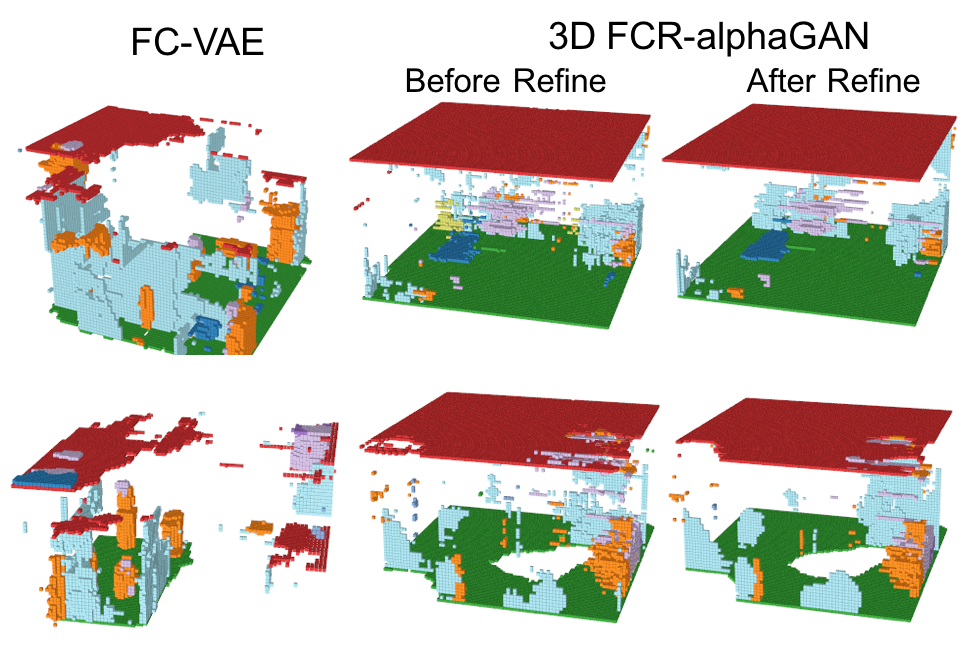
-Reconstruction
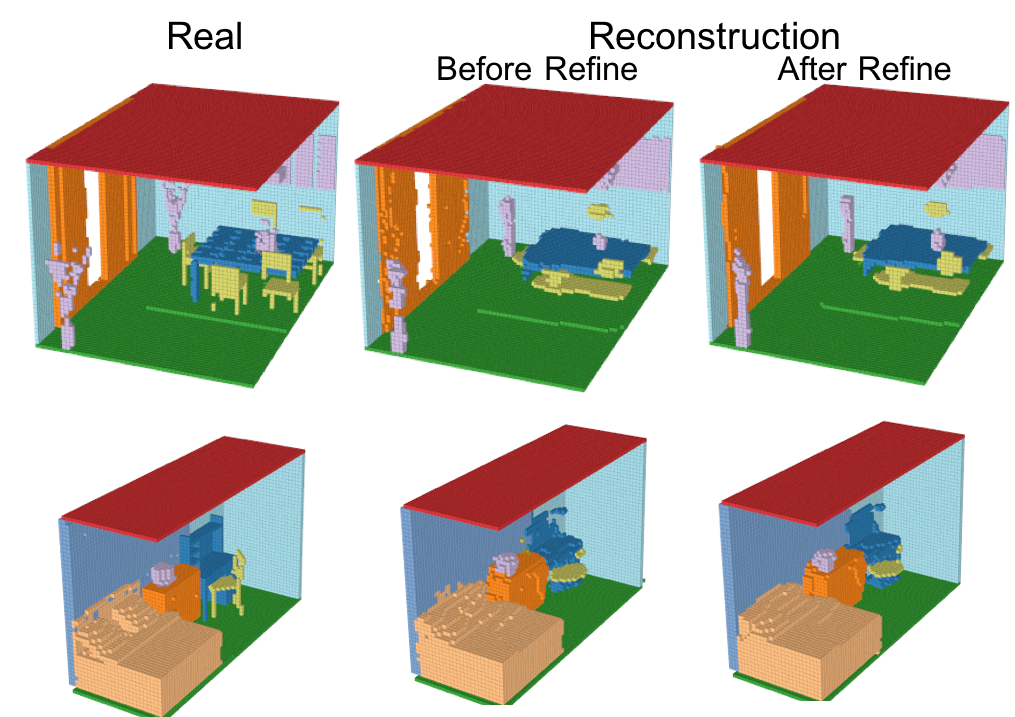
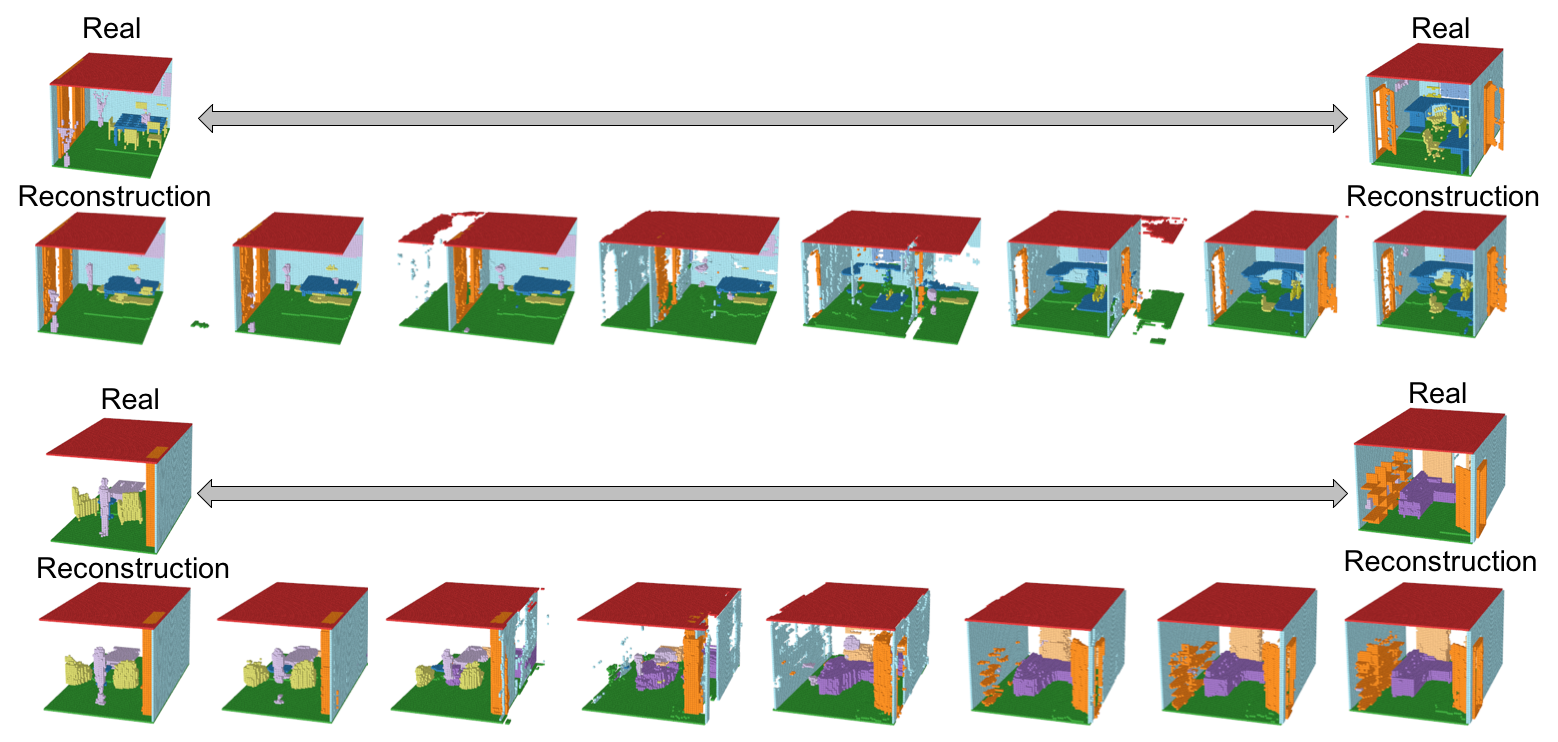
Encoder、Generator、Refinerを活用して再構成したシーンの結果を以下に示す。
小さいオブジェクトは消えてしまっているものの、多くのVoxelは再構成されている。さらに、Refinerによってよりリアルなシーンに再構成されている。IoUとmAPを使った定量評価は後述する。
-Generation from normal distribution
GeneratorとRefinerを活用した標準分布からの生成の結果を以下に示す。
このように、FCR-alphaGANの構造は、通常のFully Convolutional VAEに比べて生成のクオリティが上がっているが、その表現能力は十分とは言えない。これは、Encoderにより生成される分布が、標準分布に分散できていないこと、データセットのスパース性やマルチオブジェクトにより、非常に複雑な潜在空間が想定されることが考えられる。潜在空間をレイアウトとオブジェクトに分離することでこの問題を解決できるかもしれない。Reconstruction Performance
再構成の定量的な評価を以下に示す。
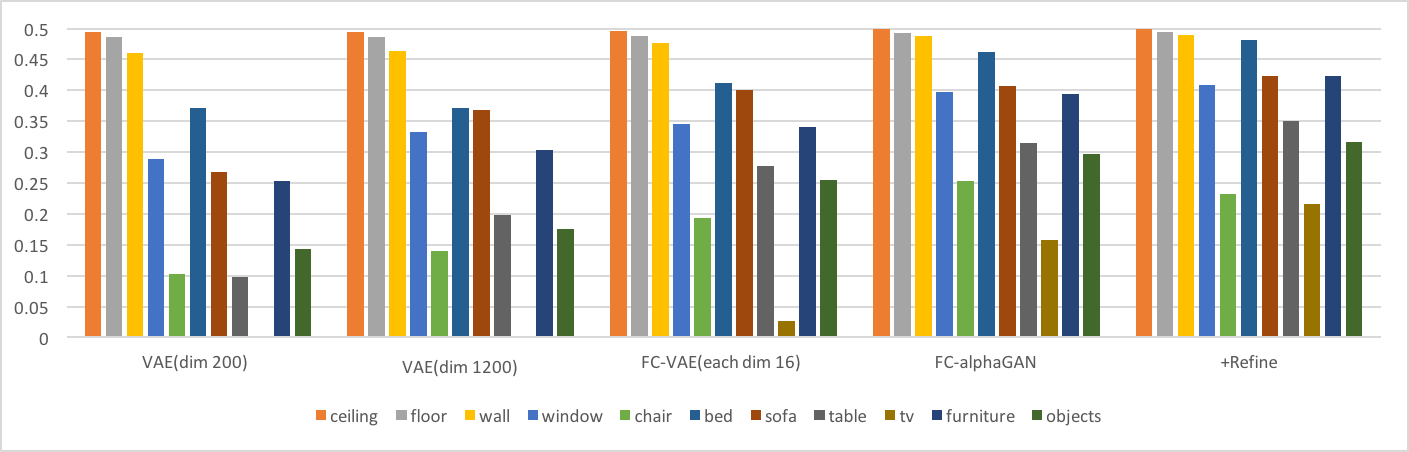
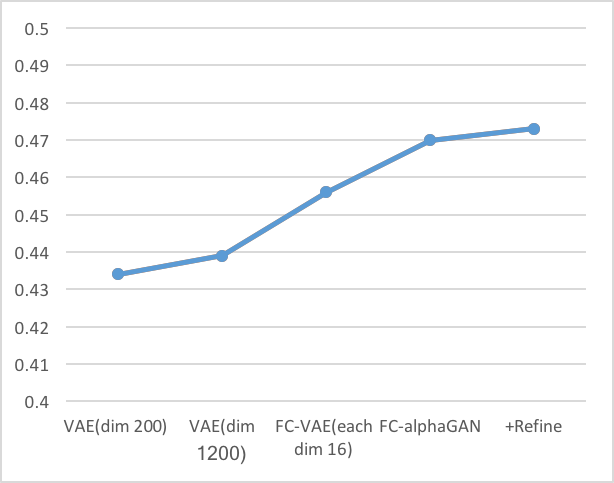
-Intersection over Union(IoU)
以下の棒グラフは、それぞれのクラスのIoU性能を示す。折れ線グラフはオーバーオールでの結果である。(IoUの定義は[6]参照)
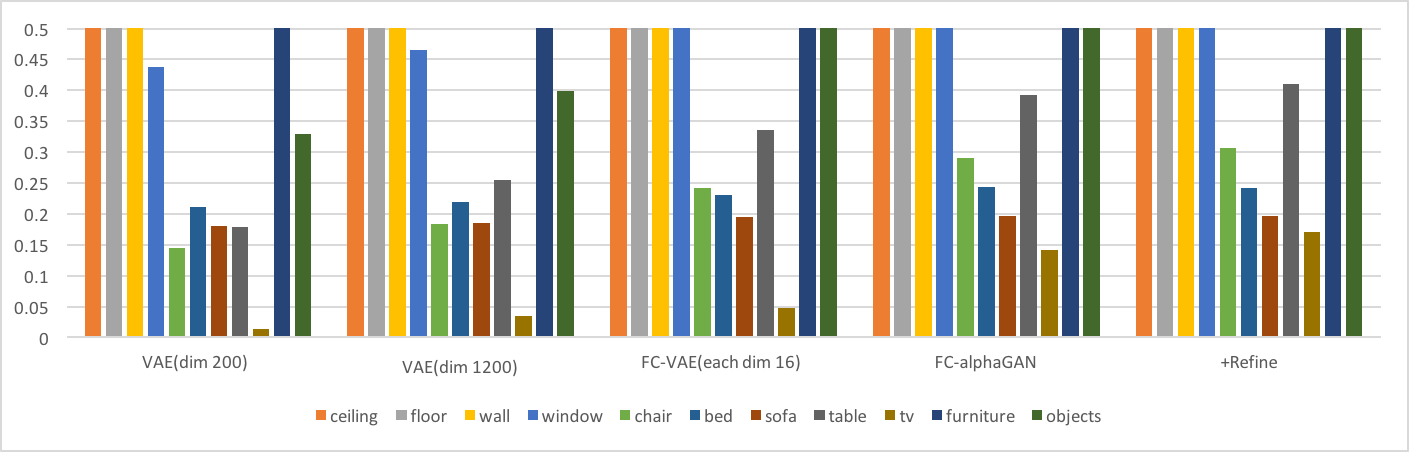
-mean Average Precision(mAP)
IoUと同様にmAPの棒グラフと折れ線グラフを以下に示す。
これらの結果より以下の考察ができる。
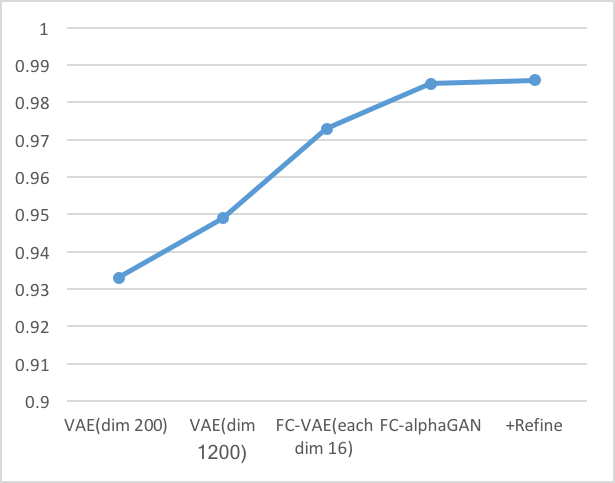
- 同じ潜在空間の次元数を持つVAE(dim1200)とFC-VAE(each dim16)の比較からわかるように、Fully Convolutionは再構成性能を向上させている。
- AlphaGAN構造が再構成性能の向上に貢献している。
Evaluations
Interpolation
Interpolation(潜在空間の遷移)の結果を以下に示す。(遷移のgif画像はトップに示している)
シーン間の潜在空間の遷移は、流れるように移行している。ただし、遷移間のシーンも意味のあるシーンとして保たれておらず、シーンが破壊されてしまっているため、本来期待したManifoldが作られているとは言い難い。マルチオブジェクトの難易度の高さが見て取れる。
Interpretation of latent space
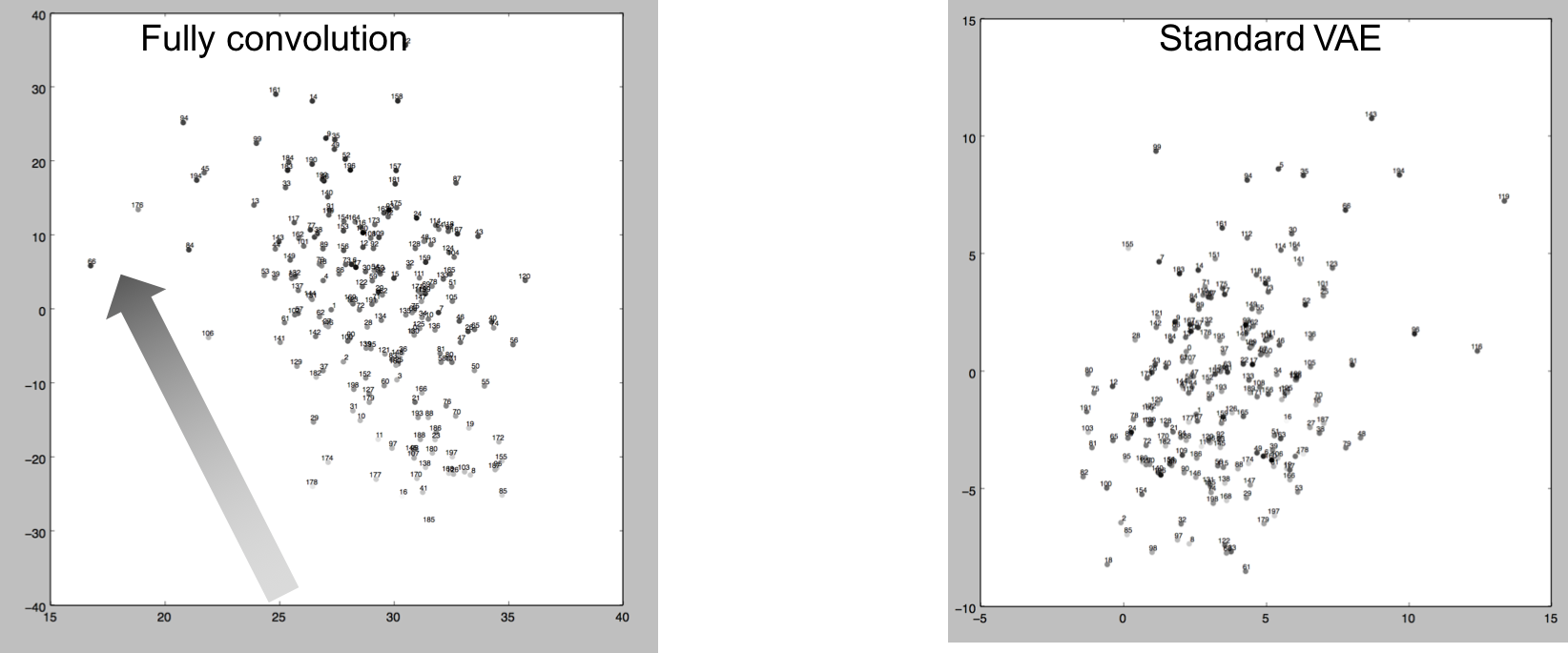
以下に、エンコーダーによりエンコードされた200サンプルを、SVDにより2Dマップしたグラフを示す。プロットのグレースケールは、各シーンの重心座標をSVDにより1Dに落とした数値を示している。左がFully Convolution、右が1200次元の通常のVAEベクトルである。
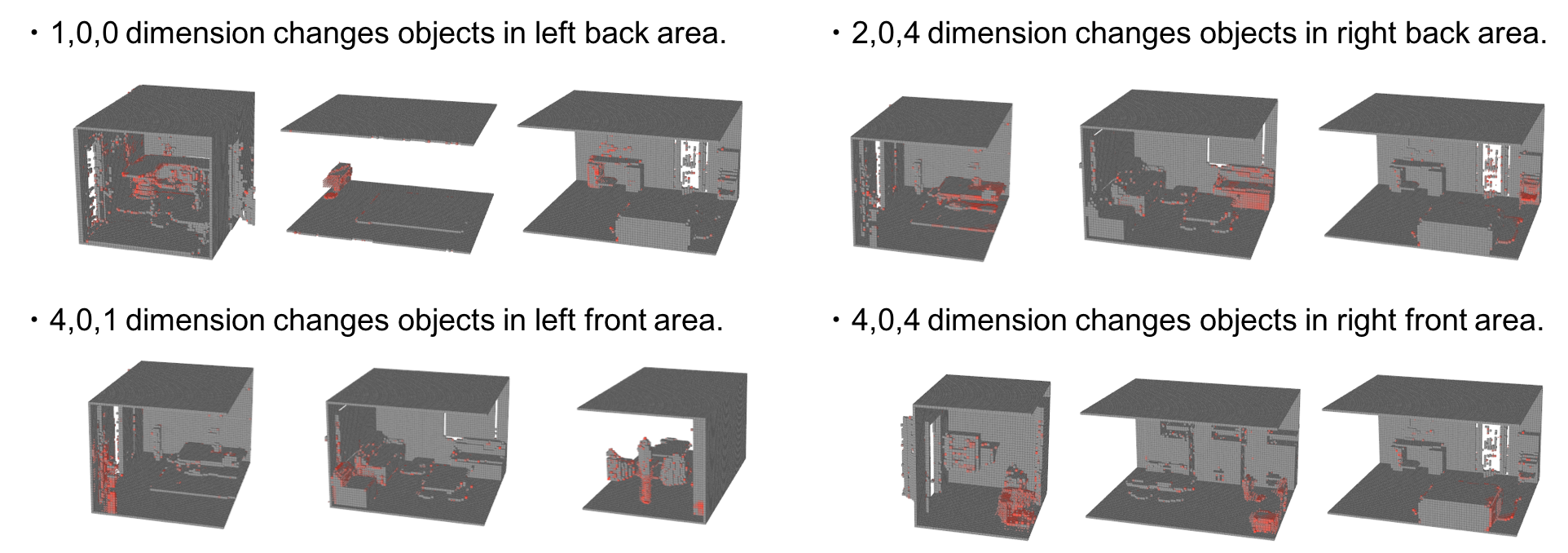
Fully Convolutionによる分布は、重心座標の1Dエンべディングに習って、右下から左上へ繊維していることがわかる。これは、Fully Convlution構造による潜在空間が通常のVAEと比べて空間的な意味合いに関係付けられていることを意味している。以下の図は、5x3x5の潜在空間の各次元の影響を表現している。個々の次元に標準分布のノイズを与えて、それが生成されたシーンへ及ぼす影響を、赤色の濃度で表現している。
この結果より、潜在空間の各次元が生成されるシーンの特定の位置に集中して変化させていることを意味しており、Fully Convolution構造が空間的な情報を潜在空間に表現していることを示している。
Suggestions of future work
-Revise the dataset
前述した通り、このデータセットは非常にスパースで、たくさんのシーンの種類が存在している。床や小さい構造は様々な位置に配置されており、椅子の足のような小さいパーツはダウンサイジングによって破壊されている。これらは潜在空間の予測を非常に難しくしている。
そのため、さらなる精度向上のためには、オブジェクトのポジションの調整や、種類の限定、ダウンサイジングの方法の変更など、データセットを再考することが必要と考えられる。-Redefine the latent space
今回は、潜在空間を形状やオブジェクトの位置など全ての情報を含む1つの空間として定義した。そのため、いくつかの小さいオブジェクトは生成モデルでは消えてしまうことも多く、たくさんのリアリティに欠けるオブジェクトが生成された。これを解決するために、レイアウトと各オブジェクトの情報を潜在空間として分割するなど、潜在空間の再定義が重要と考えられる。ただし、1つのオブジェクトクラスの中でも、1つのシーンに複数のオブジェクト種類があったり、オブジェクトの個数の増減を考慮する必要が出てくるため、クラス間の文脈の考慮も必要であると考えられ、課題である。
References
[1]Jiajun Wu, Chengkai Zhang, Tianfan Xue, William T. Freeman, Joshua B. Tenenbaum; Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling; arXiv:1610.07584v1
[2]Andrew Brock, Theodore Lim, J.M. Ritchie, Nick Weston; Generative and Discriminative Voxel Modeling with Convolutional Neural Networks; arXiv:1608.04236v2
[3]Shuran Song, Fisher Yu, Andy Zeng, Angel X. Chang, Manolis Savva, Thomas Funkhouser; Semantic Scene Completion from a Single Depth Image; arXiv:1611.08974v1
[4]Mihaela Rosca, Balaji Lakshminarayanan, David Warde-Farley, Shakir Mohamed; Variational Approaches for Auto-Encoding Generative Adversarial Networks; arXiv:1706.04987v1
[5]Ashish Shrivastava, Tomas Pfister, Oncel Tuzel, Josh Susskind, Wenda Wang, Russ Webb; Learning from Simulated and Unsupervised Images through Adversarial Training; arXiv:1612.07828v1
[6]Christopher B. Choy, Danfei Xu, JunYoung Gwak, Kevin Chen, Silvio Savarese; 3D-R2N2: A Unified Approach for Single and
Multi-view 3D Object Reconstruction; arXiv:1604.00449v1
以上でした。
2016~2017年当時、DCGANが有名になり、mode collapseの問題がいまだ大きな課題で、毎日のようにGAN関連論文が出て手法がアップデートされていました。GANへの理解も乏しい中で、色々あって3Dのマルチオブジェクトの生成モデルというテーマに挑戦したのですが、想像していた以上に難易度が高く、後から思い返すと「こうしておけばよかった」と後悔することも多いのです。(初めはノイズしか生成されてこなくて、どうしようかと思っていました。) この研究はまだまだ課題も多く、志半ばで終了してしまいましたが、GANや生成モデルについて実践的で最高の経験でした。


- 投稿日:2019-07-08T11:51:16+09:00
TensorFlowのhe_normalとtruncated_normalは標準偏差が違う
CNNの重み初期化にHeの初期値を使おうと思ったら、TensorFlow(Keras)の
tf.initializers.he_normalを使う場合とtf.initializers.truncated_normalで学習結果が異なったので調べた話。環境
- Python 3.7.3
- TensorFlow 1.14.0
- numpy 1.16.2
- matplotlib 3.0.3
Heの初期値
Heの初期値とは、活性化関数にReLUを使用するニューラルネットワークにおいて学習がうまく進むような重みの初期値の決め方で、Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classificationという論文の中で示されています。
この論文以前にXavierの初期値と呼ばれる重み初期化が提唱されていましたが、近年一般的なReLUや畳み込みニューラルネットワークに適していなかったことが背景にあります。導出等は論文を参照していただくとして、結果はとてもシンプルで
Var = \frac{2}{N_{in}}を満たす分散の正規分布から重みの初期値をサンプリングする、というものです。ここで$N_{in}$は重みの入力次元で、全結合層なら入力要素数、2次元の畳み込みならフィルターサイズと入力チャンネル数の積です。
現在ではReLUは標準的な活性化関数で、畳み込みニューラルネットワークも非常によく使われるということもあり、Heの初期値は重み初期化のスタンダードとなっています。TensorFlow(Keras)で使う
tf.initializers.he_normalを使うTensorFlowではHeの初期値が
tf.initializers.he_normalとして実装されていて、簡単に使うことができます。# tensorflowの場合 W_shape = [filter_row, filter_col, ch_in, ch_out] initializer = tf.initializers.he_normal() W = tf.get_variable(name='W', shape=W_shape, initializer=initializer) h = tf.nn.conv2d(input, W, padding='SAME') # kerasの場合 initializer = tf.initializers.he_normal() h = K.layers.Conv2D(ch_out, [filter_row, filter_col], kernel_initializer=initializer)(input)ただし、
tf.initializers.he_normalは通常の正規分布ではなく、標準偏差の2倍でカットした切断正規分布からサンプリングする点に注意が必要です。
tf.initializers.truncated_normalから計算する
tf.initializers.he_normalを使わない場合は以下のようになります。公式実装に合わせて切断正規分布からサンプリングしています。W_shape = [filter_row, filter_col, ch_in, ch_out] stddev = (2 / (filter_row * filter_col * ch_in)) ** 0.5 initializer = tf.initializers.truncated_normal(mean=0.0, stddev=stddev) W = tf.get_variable(name='W', shape=W_shape, initializer=initializer) h = tf.nn.conv2d(input, W, padding='SAME')2つのパターンを比較
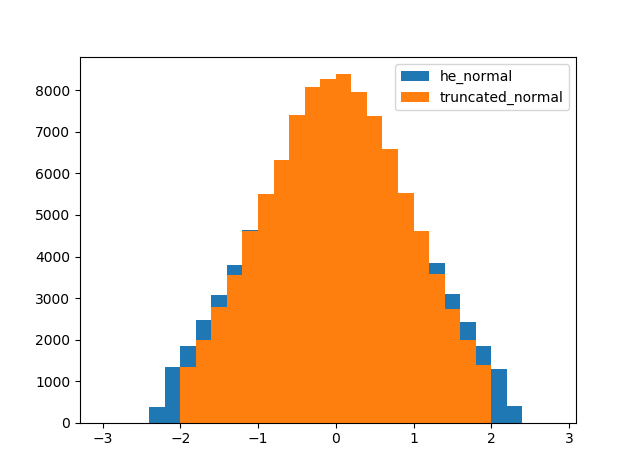
tf.initializers.he_normalとtf.initializers.truncated_normalの分布を比較してみます。簡単のため、重みは全結合層を想定しています。また、標準偏差が1となることを期待して$N_{in}$を2としています。import numpy as np import tensorflow as tf import matplotlib.pyplot as plt shape = [2, 50000] seed = 1 # he_normalを使う場合 initializer = tf.initializers.he_normal(seed=seed) tf_W = tf.get_variable(name='he_normal', shape=shape, initializer=initializer) # truncated_normalを使う場合 stddev = (2 / shape[0]) ** 0.5 initializer = tf.initializers.truncated_normal(mean=0.0, stddev=stddev, seed=seed) my_W = tf.get_variable(name='my_he_normal', shape=shape, initializer=initializer) # 結果を比較 init = tf.global_variables_initializer() with tf.Session() as sess: sess.run(init) tf_W_value = sess.run(tf_W) my_W_value = sess.run(my_W) bins = np.arange(-3.0, 3.0, 0.2) plt.figure() plt.hist(tf_W_value.flatten(), bins=bins, label='he_normal') plt.hist(my_W_value.flatten(), bins=bins, label='truncated_normal') plt.legend() plt.show()
あれ…? 分布の裾がおかしいですね。
原因
公式のドキュメントを読んで違いが生まれる原因を探ります。
tf.initializers.he_normalのドキュメントを読むkeras公式では大した記述はありません。しかし、tensorflow公式では
It draws samples from a truncated normal distribution centered on 0 with standard deviation (after truncation) given by stddev = sqrt(2 / fan_in) where fan_in is the number of input units in the weight tensor.
とあり、正規分布を切断後の標準偏差をスケーリングすることがわかります。
tf.initializers.truncated_normalのドキュメントを読む
tf.initializers.he_normalを使わない場合ではtf.initializers.truncated_normalの標準偏差を指定したので、ドキュメントを確認してみると、These values are similar to values from a random_normal_initializer except that values more than two standard deviations from the mean are discarded and re-drawn. This is the recommended initializer for neural network weights and filters.
とありますが、特に有益な情報はなさそう。
そこでソースコードを見てみると、中でtf.random.truncated_normalを呼び出しています。そちらのドキュメントを確認してみたところ、stddev: A 0-D Tensor or Python value of type dtype. The standard deviation of the normal distribution, before truncation.
ありました。
tf.initializers.truncated_normalでは、切断前の正規分布の標準偏差を指定するようです。まとめ
tf.initializers.he_normalでは、切断後の正規分布の標準偏差をスケーリングするのに対し、tf.initializers.truncated_normalでは、切断前の正規分布の標準偏差を指定することがわかりました。
確かに結果のヒストグラムでは、tf.initializers.truncated_normalは絶対値が2以下の範囲に収まっていて、切断前の正規分布の標準偏差が1であることがわかります。一方で、tf.initializers.he_normalは絶対値が2以下の範囲からはみ出してしまっています。
tf.initializers.he_normalは切断正規分布を1つの確立分布として考えているのに対し、tf.initializers.truncated_normalでは、切断正規分布はあくまで正規分布をカットしただけ、って考えなのかもしれません。
この違いが学習に与える影響は未知数ですが、自分で24層のCNNを作って遊んでいた時には学習曲線に明確な違いが出たので、学習がうまくいかない時はもう一方の初期化のやり方を試してみるといいかもしれません。公式ドキュメントとソースコード確認するの大事。
おまけ
tf.initializers.he_normalってどうなってんの
tf.initializers.he_normalのソースコードを追ってみると、中でtf.initializers.VarianceScalingを呼び出しています。そちらのソースコードを確認してみると…# constant taken from scipy.stats.truncnorm.std(a=-2, b=2, loc=0., scale=1.) stddev = math.sqrt(scale) / .87962566103423978 return random_ops.truncated_normal(shape, 0.0, stddev, dtype, seed=self.seed)力業で標準偏差を補正して
tf.random.truncated_normalを呼び出してますね…正規分布じゃなくて切断正規分布を使う理由って何よ
TensorFlowやTensorFlowバックエンドのKerasでは切断正規分布が標準的で、Heの初期値も切断正規分布で実装されていますが、PyTorchやChainerではそもそも切断正規分布が実装されておらず、Heの初期値は通常の正規分布で実装されているようです。
じゃあ切断正規分布を使うメリットって何よ?って話なのですが、StackOverflow等では、活性化関数にsigmoidやtanhを使う場合に、重みの初期値の絶対値が大きいと活性化関数の入力が大きくなって勾配が小さくなり、学習が遅くなってしまうことを防ぐため、との説明がありました。(明確な文献は見つけられなかったので、ご存知の方は教えていただけると嬉しいです。)
この場合、絶対値が大きい初期値を排除することが目的であり、切断後の標準偏差だと分布が広がってしまうので、切断正規分布の標準偏差は切断前の正規分布で考えるべきのように思えます。
しかし、これはあくまで活性化関数がsigmoidやtanhの場合であり、ReLUの場合には活性化関数の入力が大きくても勾配は変わらないので、この理屈は通じません。
そうなるとHeの初期値以前に、TensorFlowが切断正規分布を標準的としている意味がわかりません。
謎は深まるばかりじゃ…
- 投稿日:2019-07-08T11:45:13+09:00
Certificates.command for python on macOS
機材の環境
Mac OS 10.12.6
brewをbrew_managerというIDで導入。
Administratorという管理者IDで実行中StackOverflow
How to make Python use CA certificates from Mac OS TrustStore?
https://stackoverflow.com/questions/40684543/how-to-make-python-use-ca-certificates-from-mac-os-truststoreurllib and “SSL: CERTIFICATE_VERIFY_FAILED” Error
https://stackoverflow.com/questions/27835619/urllib-and-ssl-certificate-verify-failed-errorAnaconda
を入れてある。
macOS$ /Applications/Python\ 3.6/Install\ Certificates.commandではうまく入らない。pipで入るらしい。
macOS$ sudo pip install certifi Password: WARNING: The directory '/Users/administrator/Library/Caches/pip/http' or its parent directory is not owned by the current user and the cache has been disabled. Please check the permissions and owner of that directory. If executing pip with sudo, you may want sudo's -H flag. WARNING: The directory '/Users/administrator/Library/Caches/pip' or its parent directory is not owned by the current user and caching wheels has been disabled. check the permissions and owner of that directory. If executing pip with sudo, you may want sudo's -H flag. Requirement already satisfied: certifi in /Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages (2019.6.16)もう入って要るらしい。
- 投稿日:2019-07-08T11:41:00+09:00
modを使った平方数の効率的な判定と可視化
概要
平方数の判定を
modを使うと効率よくできるという記事 を5年くらい前に @hnw が ブログでまとめてた 。私は 数論をあまり知らないので、手を動かしながら確かめたい(Python3 on Google Colab)。「平方数の
mod 256の値は 44 種類しかない」という性質がある。これを逆に使う。「ある数
Nをmod 256してみて 結果が 44 種類のどれにも該当しないならNは平方数でない」を判定の先頭に配置すると、 (256-44)/256 ≒ 83% くらいの確率で 平方数でないと早めに判定ができる。mod 256って結局0xff との ANDというビット演算なので、高速で嬉しい。44種類?
mod 256だと 44種類だしmod 100だと 22種類だし(出典:Wikipedia)、mod 19だと 10種類らしい。これを確かめよう。全ての自然数について調べる必要はない。
mod 256でkとなる数は、二乗したときに同じ値になるから(なぜなら $(Q\cdot 256+k)^2$ を 256 で割った余りは $k^2$ を256で割った余り となり $k$のみに依存し$Q$に依存しない)。つまり、0..255 の整数について二乗したときの余りを調べれば十分:Python3でのワンライナー.py>>> set(map(lambda x: x * x % 256, range(0,256))) {0, 1, 129, 4, 132, 9, 137, 16, 144, 17, 145, 25, 153, 33, 161, 36, 164, 169, 41, 49, 177, 185, 57, 64, 193, 65, 196, 68, 73, 201, 81, 209, 217, 89, 225, 97, 100, 228, 249, 105, 233, 113, 241, 121}上記ワンライナーにより 確かに 44 種類しかないことがわかる。mod100についても同様に 22 種類だとわかる:
>>> set(map(lambda x: x * x % 100, range(0,100))) {0, 1, 4, 9, 16, 21, 24, 25, 29, 36, 41, 44, 49, 56, 61, 64, 69, 76, 81, 84, 89, 96}こうなると 色々な数について、この方法での効率を調べたくなってくる。
効率性の可視化
前章では
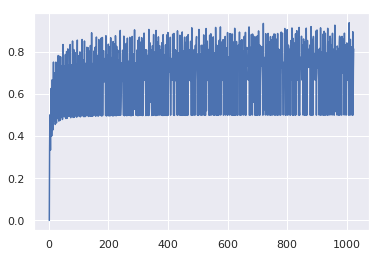
mod 256とmod 100のみを調べた。そしてmod 256での効率がおおよそ 83% であることを見た。このパーセンテージは 高めたり低めたりすることができるのだろうか?というのを Google Colab で可視化してみた:可視化.pydef efficiency (n): L = len(set(map(lambda x: x * x % n, range(0,n)))) return float(n - L)/n xs = list(range(2, 1024)) ys = list(map(efficiency, range(2, 1024))) import matplotlib.pyplot as plt import seaborn as sns sns.set() plt.plot(xs,ys)チャートは以下のようになる:
ここから言えそうなのは
mod 256の 83% っていうのはまあ悪くない数字- 数によって振れ幅があるけど 50% くらいに下限がある
ということくらいなので、以下若干の考察
83%→94%
どうも 1024 まで調べた範囲だと
mod 1008が一番高効率になり、そのときのパーセンテージは 94% 程度になった。print (max(ys), ys.index(max(ys))) print efficiency(1008) # 0.9365079365079365 1006 # 0.936507936507936550%弱が下限で 素数だと下限に近い
これは hnw の記事でも指摘していた事象だと思う。つまり、
mod 素数の時は、ちょうど半分が候補から外れることを反映している。以下より、たしかに 全ての素数の効率が 50% 以下であることがわかる:def is_prime (n): return all(map((lambda m: n % m != 0), range(2,n))) zs = [ i+2 for i, y in enumerate(ys) if y < 0.5] primes = list(filter(is_prime, range(3,1024))) all(list(map(lambda p: p in zs, primes))) # true逆に効率が低いからといって素数というわけではない
print (list(map(is_prime, zs)).count(True)) # 172 print (list(map(is_prime, zs)).count(False)) # 96まとめ
平方数の判定に
mod 256を使うことで効率が上がりそうだということを確かめた。
- 投稿日:2019-07-08T11:25:01+09:00
今日のcondo error(3)
機材の環境
Mac OS 10.12.6
brewをbrew_managerというIDで導入。
Administratorという管理者IDで実行中conda install
macOS$ conda install Certificates.command Traceback (most recent call last): File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/conda/exceptions.py", line 1043, in __call__ return func(*args, **kwargs) File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/conda/cli/main.py", line 84, in _main exit_code = do_call(args, p) File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/conda/cli/conda_argparse.py", line 80, in do_call module = import_module(relative_mod, __name__.rsplit('.', 1)[0]) File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/importlib/__init__.py", line 126, in import_module return _bootstrap._gcd_import(name[level:], package, level) File "<frozen importlib._bootstrap>", line 978, in _gcd_import File "<frozen importlib._bootstrap>", line 961, in _find_and_load File "<frozen importlib._bootstrap>", line 950, in _find_and_load_unlocked File "<frozen importlib._bootstrap>", line 655, in _load_unlocked File "<frozen importlib._bootstrap_external>", line 678, in exec_module File "<frozen importlib._bootstrap>", line 205, in _call_with_frames_removed File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/conda/cli/main_install.py", line 8, in <module> from .install import install File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/conda/cli/install.py", line 19, in <module> from ..core.index import calculate_channel_urls, get_index File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/conda/core/index.py", line 9, in <module> from .package_cache_data import PackageCacheData File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/conda/core/package_cache_data.py", line 15, in <module> from conda_package_handling.api import InvalidArchiveError File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/conda_package_handling/api.py", line 3, in <module> from libarchive.exception import ArchiveError as _LibarchiveArchiveError File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/libarchive/__init__.py", line 1, in <module> from .entry import ArchiveEntry File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/libarchive/entry.py", line 6, in <module> from . import ffi File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/libarchive/ffi.py", line 197, in <module> c_int, check_int) File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/libarchive/ffi.py", line 108, in ffi f = getattr(libarchive, 'archive_'+name) File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/ctypes/__init__.py", line 361, in __getattr__ func = self.__getitem__(name) File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/ctypes/__init__.py", line 366, in __getitem__ func = self._FuncPtr((name_or_ordinal, self)) AttributeError: dlsym(0x7f9ad103cd80, archive_read_open_filename_w): symbol not found During handling of the above exception, another exception occurred: Traceback (most recent call last): File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/bin/conda", line 13, in <module> sys.exit(main()) File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/conda/cli/main.py", line 150, in main return conda_exception_handler(_main, *args, **kwargs) File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/conda/exceptions.py", line 1335, in conda_exception_handler return_value = exception_handler(func, *args, **kwargs) File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/conda/exceptions.py", line 1046, in __call__ return self.handle_exception(exc_val, exc_tb) File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/conda/exceptions.py", line 1090, in handle_exception return self.handle_unexpected_exception(exc_val, exc_tb) File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/conda/exceptions.py", line 1101, in handle_unexpected_exception self.print_unexpected_error_report(error_report) File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/conda/exceptions.py", line 1171, in print_unexpected_error_report from .cli.main_info import get_env_vars_str, get_main_info_str File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/conda/cli/main_info.py", line 19, in <module> from ..core.index import _supplement_index_with_system File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/conda/core/index.py", line 9, in <module> from .package_cache_data import PackageCacheData File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/conda/core/package_cache_data.py", line 15, in <module> from conda_package_handling.api import InvalidArchiveError File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/conda_package_handling/api.py", line 7, in <module> from .tarball import CondaTarBZ2 as _CondaTarBZ2 File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/conda_package_handling/tarball.py", line 7, in <module> import libarchive File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/libarchive/__init__.py", line 1, in <module> from .entry import ArchiveEntry File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/libarchive/entry.py", line 6, in <module> from . import ffi File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/libarchive/ffi.py", line 197, in <module> c_int, check_int) File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/site-packages/libarchive/ffi.py", line 108, in ffi f = getattr(libarchive, 'archive_'+name) File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/ctypes/__init__.py", line 361, in __getattr__ func = self.__getitem__(name) File "/Users/administrator/.pyenv/versions/anaconda3-4.3.0/lib/python3.6/ctypes/__init__.py", line 366, in __getitem__ func = self._FuncPtr((name_or_ordinal, self)) AttributeError: dlsym(0x7f9ad103cd80, archive_read_open_filename_w): symbol not found
- 投稿日:2019-07-08T11:06:26+09:00
今日のconda error(2)
機材の環境
Mac OS 10.12.6
brewをbrew_managerというIDで導入。
Administratorという管理者IDで実行中tensorflow導入
macOS$ conda install tensorflow Fetching package metadata ........... Solving package specifications: . Package plan for installation in environment /Users/administrator/.pyenv/versions/anaconda3-4.3.0: The following NEW packages will be INSTALLED: _anaconda_depends: 5.0.1-py36h6e48e2d_1 _tflow_select: 2.3.0-mkl absl-py: 0.7.1-py36_0 astor: 0.7.1-py36_0 backports.shutil_get_terminal_size: 1.0.0-py36_2 bkcharts: 0.2-py36h073222e_0 bzip2: 1.0.7-h1de35cc_0 ca-certificates: 2019.5.15-0 certifi: 2019.6.16-py36_0 conda-package-handling: 1.3.10-py36_0 dask-core: 2.0.0-py_0 dbus: 1.13.6-h90a0687_0 expat: 2.2.6-h0a44026_0 filelock: 3.0.12-py_0 gast: 0.2.2-py36_0 gettext: 0.19.8.1-h15daf44_3 glib: 2.56.2-hd9629dc_0 glob2: 0.7-py_0 gmp: 6.1.2-hb37e062_1 gmpy2: 2.0.8-py36h6ef4df4_2 grpcio: 1.12.1-py36hd9629dc_0 imageio: 2.5.0-py36_0 intel-openmp: 2019.4-233 jupyterlab: 0.35.5-py36hf63ae98_0 jupyterlab_launcher: 0.13.1-py36_0 jupyterlab_server: 0.2.0-py36_0 keras-applications: 1.0.8-py_0 keras-preprocessing: 1.1.0-py_1 libarchive: 3.3.3-h786848e_5 libcxx: 4.0.1-hcfea43d_1 libcxxabi: 4.0.1-hcfea43d_1 libedit: 3.1.20181209-hb402a30_0 libffi: 3.2.1-h475c297_4 libgfortran: 3.0.1-h93005f0_2 libprotobuf: 3.8.0-hd9629dc_0 libsodium: 1.0.16-h3efe00b_0 libssh2: 1.8.0-h1218725_2 lz4-c: 1.8.1.2-h1de35cc_0 lzo: 2.10-h362108e_2 markdown: 3.1.1-py36_0 mccabe: 0.6.1-py36_1 mock: 3.0.5-py36_0 mpc: 1.1.0-h6ef4df4_1 mpfr: 4.0.1-h3018a27_3 ncurses: 6.1-h0a44026_1 pandoc: 2.2.3.2-0 pcre: 8.43-h0a44026_0 pkginfo: 1.5.0.1-py36_0 protobuf: 3.8.0-py36h0a44026_0 pycodestyle: 2.5.0-py36_0 pysocks: 1.7.0-py36_0 python-libarchive-c: 2.8-py36_9 sphinxcontrib: 1.0-py36_1 sphinxcontrib-websupport: 1.1.2-py_0 tbb: 2019.4-h04f5b5a_0 tensorboard: 1.13.1-py36haf313ee_0 tensorflow: 1.13.1-mkl_py36haf07a9b_0 tensorflow-base: 1.13.1-mkl_py36hc36dc97_0 tensorflow-estimator: 1.13.0-py_0 termcolor: 1.1.0-py36_1 tqdm: 4.32.1-py_0 typing: 3.6.4-py36_0 urllib3: 1.24.2-py36_0 webencodings: 0.5.1-py36_1 zeromq: 4.3.1-h0a44026_3 zstd: 1.3.7-h5bba6e5_0 The following packages will be UPDATED: anaconda: 4.4.0-np112py36_0 --> custom-py36_1 astropy: 1.3.2-np112py36_0 --> 2.0.14-py36h1de35cc_0 bottleneck: 1.2.1-np112py36_0 --> 1.2.1-py36h1d22016_1 conda: 4.3.30-py36h173c244_0 --> 4.7.5-py36_0 conda-env: 2.6.0-0 --> 2.6.0-1 h5py: 2.7.0-np112py36_0 --> 2.7.0-np113py36_0 libiconv: 1.14-0 --> 1.15-hdd342a3_7 libxml2: 2.9.4-0 --> 2.9.9-hf6e021a_1 llvmlite: 0.18.0-py36_0 --> 0.29.0-py36h98b8051_0 lxml: 3.7.3-py36_0 --> 4.1.1-py36h6c891f4_0 matplotlib: 2.0.2-np112py36_0 --> 2.0.2-np113py36_0 numba: 0.33.0-np112py36_0 --> 0.44.1-py36h6440ff4_0 numexpr: 2.6.2-np112py36_0 --> 2.6.2-np113py36_0 numpy: 1.12.1-py36_0 --> 1.13.3-py36ha726252_3 pandas: 0.20.1-np112py36_0 --> 0.24.2-py36h0a44026_0 pycosat: 0.6.2-py36_0 --> 0.6.3-py36h1de35cc_0 pytables: 3.3.0-np112py36_0 --> 3.4.2-np113py36_0 pywavelets: 0.5.2-np112py36_0 --> 1.0.3-py36h1d22016_1 requests: 2.14.2-py36_0 --> 2.22.0-py36_0 scikit-image: 0.13.0-np112py36_0 --> 0.13.1-py36h1de35cc_1 scikit-learn: 0.18.1-np112py36_1 --> 0.19.0-np113py36_0 scipy: 0.19.0-np112py36_0 --> 0.19.1-np113py36_0 setuptools: 27.2.0-py36_0 --> 41.0.1-py36_0 statsmodels: 0.8.0-np112py36_0 --> 0.10.0-py36h1d22016_0 xz: 5.2.2-1 --> 5.2.4-h1de35cc_4 zlib: 1.2.8-3 --> 1.2.11-h1de35cc_3 The following packages will be DOWNGRADED: libxslt: 1.1.29-0 --> 1.1.28-2 Proceed ([y]/n)? y _tflow_select- 100% |################################| Time: 0:00:00 2.92 MB/s bzip2-1.0.7-h1 100% |################################| Time: 0:00:00 15.91 MB/s ca-certificate 100% |################################| Time: 0:00:00 16.68 MB/s conda-env-2.6. 100% |################################| Time: 0:00:00 3.84 MB/s intel-openmp-2 100% |################################| Time: 0:00:00 8.43 MB/s libcxxabi-4.0. 100% |################################| Time: 0:00:00 5.30 MB/s libgfortran-3. 100% |################################| Time: 0:00:00 5.14 MB/s libiconv-1.15- 100% |################################| Time: 0:00:00 17.60 MB/s libsodium-1.0. 100% |################################| Time: 0:00:00 46.26 MB/s libssh2-1.8.0- 100% |################################| Time: 0:00:00 14.16 MB/s lz4-c-1.8.1.2- 100% |################################| Time: 0:00:00 39.00 MB/s lzo-2.10-h3621 100% |################################| Time: 0:00:00 5.12 MB/s pandoc-2.2.3.2 100% |################################| Time: 0:00:01 11.83 MB/s xz-5.2.4-h1de3 100% |################################| Time: 0:00:00 40.76 MB/s zlib-1.2.11-h1 100% |################################| Time: 0:00:00 25.89 MB/s libcxx-4.0.1-h 100% |################################| Time: 0:00:00 16.56 MB/s libxml2-2.9.9- 100% |################################| Time: 0:00:00 20.77 MB/s zstd-1.3.7-h5b 100% |################################| Time: 0:00:00 37.93 MB/s astor-0.7.1-py 100% |################################| Time: 0:00:00 30.90 MB/s certifi-2019.6 100% |################################| Time: 0:00:00 44.47 MB/s dask-core-2.0. 100% |################################| Time: 0:00:00 41.36 MB/s expat-2.2.6-h0 100% |################################| Time: 0:00:00 38.33 MB/s filelock-3.0.1 100% |################################| Time: 0:00:00 15.06 MB/s gast-0.2.2-py3 100% |################################| Time: 0:00:00 8.91 MB/s glob2-0.7-py_0 100% |################################| Time: 0:00:00 16.60 MB/s gmp-6.1.2-hb37 100% |################################| Time: 0:00:00 39.71 MB/s libarchive-3.3 100% |################################| Time: 0:00:00 18.28 MB/s libffi-3.2.1-h 100% |################################| Time: 0:00:00 26.63 MB/s libprotobuf-3. 100% |################################| Time: 0:00:00 15.19 MB/s libxslt-1.1.28 100% |################################| Time: 0:00:00 16.60 MB/s llvmlite-0.29. 100% |################################| Time: 0:00:01 13.60 MB/s mccabe-0.6.1-p 100% |################################| Time: 0:00:00 12.96 MB/s ncurses-6.1-h0 100% |################################| Time: 0:00:00 16.31 MB/s numpy-1.13.3-p 100% |################################| Time: 0:00:00 6.84 MB/s pcre-8.43-h0a4 100% |################################| Time: 0:00:00 20.28 MB/s pkginfo-1.5.0. 100% |################################| Time: 0:00:00 22.08 MB/s pycodestyle-2. 100% |################################| Time: 0:00:00 23.38 MB/s pycosat-0.6.3- 100% |################################| Time: 0:00:00 18.99 MB/s pysocks-1.7.0- 100% |################################| Time: 0:00:00 27.39 MB/s sphinxcontrib- 100% |################################| Time: 0:00:00 4.61 MB/s tbb-2019.4-h04 100% |################################| Time: 0:00:00 17.64 MB/s termcolor-1.1. 100% |################################| Time: 0:00:00 10.58 MB/s tqdm-4.32.1-py 100% |################################| Time: 0:00:00 20.50 MB/s typing-3.6.4-p 100% |################################| Time: 0:00:00 30.96 MB/s webencodings-0 100% |################################| Time: 0:00:00 18.79 MB/s zeromq-4.3.1-h 100% |################################| Time: 0:00:00 16.51 MB/s absl-py-0.7.1- 100% |################################| Time: 0:00:00 4.23 MB/s backports.shut 100% |################################| Time: 0:00:00 10.30 MB/s bottleneck-1.2 100% |################################| Time: 0:00:00 9.81 MB/s gettext-0.19.8 100% |################################| Time: 0:00:00 9.05 MB/s h5py-2.7.0-np1 100% |################################| Time: 0:00:00 15.60 MB/s libedit-3.1.20 100% |################################| Time: 0:00:00 17.50 MB/s lxml-4.1.1-py3 100% |################################| Time: 0:00:00 15.76 MB/s mock-3.0.5-py3 100% |################################| Time: 0:00:00 19.15 MB/s mpfr-4.0.1-h30 100% |################################| Time: 0:00:00 16.11 MB/s numba-0.44.1-p 100% |################################| Time: 0:00:00 3.43 MB/s numexpr-2.6.2- 100% |################################| Time: 0:00:00 6.71 MB/s python-libarch 100% |################################| Time: 0:00:00 17.54 MB/s pywavelets-1.0 100% |################################| Time: 0:00:00 9.08 MB/s scipy-0.19.1-n 100% |################################| Time: 0:00:01 13.42 MB/s setuptools-41. 100% |################################| Time: 0:00:00 16.45 MB/s sphinxcontrib- 100% |################################| Time: 0:00:00 21.62 MB/s conda-package- 100% |################################| Time: 0:00:00 16.18 MB/s glib-2.56.2-hd 100% |################################| Time: 0:00:00 15.57 MB/s grpcio-1.12.1- 100% |################################| Time: 0:00:00 3.91 MB/s imageio-2.5.0- 100% |################################| Time: 0:00:00 15.39 MB/s keras-applicat 100% |################################| Time: 0:00:00 11.90 MB/s keras-preproce 100% |################################| Time: 0:00:00 21.23 MB/s markdown-3.1.1 100% |################################| Time: 0:00:00 18.67 MB/s matplotlib-2.0 100% |################################| Time: 0:00:01 7.01 MB/s mpc-1.1.0-h6ef 100% |################################| Time: 0:00:00 16.36 MB/s pandas-0.24.2- 100% |################################| Time: 0:00:00 15.22 MB/s protobuf-3.8.0 100% |################################| Time: 0:00:00 16.60 MB/s pytables-3.4.2 100% |################################| Time: 0:00:00 5.14 MB/s scikit-learn-0 100% |################################| Time: 0:00:00 8.53 MB/s tensorflow-est 100% |################################| Time: 0:00:00 17.41 MB/s astropy-2.0.14 100% |################################| Time: 0:00:00 6.98 MB/s bkcharts-0.2-p 100% |################################| Time: 0:00:00 16.84 MB/s dbus-1.13.6-h9 100% |################################| Time: 0:00:00 14.07 MB/s gmpy2-2.0.8-py 100% |################################| Time: 0:00:00 16.90 MB/s statsmodels-0. 100% |################################| Time: 0:00:00 11.36 MB/s tensorboard-1. 100% |################################| Time: 0:00:00 15.55 MB/s tensorflow-bas 100% |################################| Time: 0:00:08 11.03 MB/s tensorflow-1.1 100% |################################| Time: 0:00:00 3.62 MB/s urllib3-1.24.2 100% |################################| Time: 0:00:00 19.04 MB/s requests-2.22. 100% |################################| Time: 0:00:00 16.54 MB/s conda-4.7.5-py 100% |################################| Time: 0:00:00 15.57 MB/s jupyterlab_lau 100% |################################| Time: 0:00:00 24.79 MB/s jupyterlab_ser 100% |################################| Time: 0:00:00 24.02 MB/s jupyterlab-0.3 100% |################################| Time: 0:00:00 15.46 MB/s scikit-image-0 100% |################################| Time: 0:00:02 10.49 MB/s _anaconda_depe 100% |################################| Time: 0:00:00 5.26 MB/s anaconda-custo 100% |################################| Time: 0:00:00 3.63 MB/s ERROR conda.core.link:_execute_actions(337): An error occurred while uninstalling package 'defaults::astropy-1.3.2-np112py36_0'. PermissionError(13, 'Permission denied') Attempting to roll back. PermissionError(13, 'Permission denied')同じ間違いを二度する。
sudoつけて実行。macOS$ sudo conda install tensorflow Password: Fetching package metadata ........... Solving package specifications: . Package plan for installation in environment /Users/administrator/.pyenv/versions/anaconda3-4.3.0: The following NEW packages will be INSTALLED: _anaconda_depends: 5.0.1-py36h6e48e2d_1 _tflow_select: 2.3.0-mkl absl-py: 0.7.1-py36_0 astor: 0.7.1-py36_0 backports.shutil_get_terminal_size: 1.0.0-py36_2 bkcharts: 0.2-py36h073222e_0 bzip2: 1.0.7-h1de35cc_0 ca-certificates: 2019.5.15-0 certifi: 2019.6.16-py36_0 conda-package-handling: 1.3.10-py36_0 dask-core: 2.0.0-py_0 dbus: 1.13.6-h90a0687_0 expat: 2.2.6-h0a44026_0 filelock: 3.0.12-py_0 gast: 0.2.2-py36_0 gettext: 0.19.8.1-h15daf44_3 glib: 2.56.2-hd9629dc_0 glob2: 0.7-py_0 gmp: 6.1.2-hb37e062_1 gmpy2: 2.0.8-py36h6ef4df4_2 grpcio: 1.12.1-py36hd9629dc_0 imageio: 2.5.0-py36_0 intel-openmp: 2019.4-233 jupyterlab: 0.35.5-py36hf63ae98_0 jupyterlab_launcher: 0.13.1-py36_0 jupyterlab_server: 0.2.0-py36_0 keras-applications: 1.0.8-py_0 keras-preprocessing: 1.1.0-py_1 libarchive: 3.3.3-h786848e_5 libcxx: 4.0.1-hcfea43d_1 libcxxabi: 4.0.1-hcfea43d_1 libedit: 3.1.20181209-hb402a30_0 libffi: 3.2.1-h475c297_4 libgfortran: 3.0.1-h93005f0_2 libprotobuf: 3.8.0-hd9629dc_0 libsodium: 1.0.16-h3efe00b_0 libssh2: 1.8.0-h1218725_2 lz4-c: 1.8.1.2-h1de35cc_0 lzo: 2.10-h362108e_2 markdown: 3.1.1-py36_0 mccabe: 0.6.1-py36_1 mock: 3.0.5-py36_0 mpc: 1.1.0-h6ef4df4_1 mpfr: 4.0.1-h3018a27_3 ncurses: 6.1-h0a44026_1 pandoc: 2.2.3.2-0 pcre: 8.43-h0a44026_0 pkginfo: 1.5.0.1-py36_0 protobuf: 3.8.0-py36h0a44026_0 pycodestyle: 2.5.0-py36_0 pysocks: 1.7.0-py36_0 python-libarchive-c: 2.8-py36_9 sphinxcontrib: 1.0-py36_1 sphinxcontrib-websupport: 1.1.2-py_0 tbb: 2019.4-h04f5b5a_0 tensorboard: 1.13.1-py36haf313ee_0 tensorflow: 1.13.1-mkl_py36haf07a9b_0 tensorflow-base: 1.13.1-mkl_py36hc36dc97_0 tensorflow-estimator: 1.13.0-py_0 termcolor: 1.1.0-py36_1 tqdm: 4.32.1-py_0 typing: 3.6.4-py36_0 urllib3: 1.24.2-py36_0 webencodings: 0.5.1-py36_1 zeromq: 4.3.1-h0a44026_3 zstd: 1.3.7-h5bba6e5_0 The following packages will be UPDATED: anaconda: 4.4.0-np112py36_0 --> custom-py36_1 astropy: 1.3.2-np112py36_0 --> 2.0.14-py36h1de35cc_0 bottleneck: 1.2.1-np112py36_0 --> 1.2.1-py36h1d22016_1 conda: 4.3.30-py36h173c244_0 --> 4.7.5-py36_0 conda-env: 2.6.0-0 --> 2.6.0-1 h5py: 2.7.0-np112py36_0 --> 2.7.0-np113py36_0 libiconv: 1.14-0 --> 1.15-hdd342a3_7 libxml2: 2.9.4-0 --> 2.9.9-hf6e021a_1 llvmlite: 0.18.0-py36_0 --> 0.29.0-py36h98b8051_0 lxml: 3.7.3-py36_0 --> 4.1.1-py36h6c891f4_0 matplotlib: 2.0.2-np112py36_0 --> 2.0.2-np113py36_0 numba: 0.33.0-np112py36_0 --> 0.44.1-py36h6440ff4_0 numexpr: 2.6.2-np112py36_0 --> 2.6.2-np113py36_0 numpy: 1.12.1-py36_0 --> 1.13.3-py36ha726252_3 pandas: 0.20.1-np112py36_0 --> 0.24.2-py36h0a44026_0 pycosat: 0.6.2-py36_0 --> 0.6.3-py36h1de35cc_0 pytables: 3.3.0-np112py36_0 --> 3.4.2-np113py36_0 pywavelets: 0.5.2-np112py36_0 --> 1.0.3-py36h1d22016_1 requests: 2.14.2-py36_0 --> 2.22.0-py36_0 scikit-image: 0.13.0-np112py36_0 --> 0.13.1-py36h1de35cc_1 scikit-learn: 0.18.1-np112py36_1 --> 0.19.0-np113py36_0 scipy: 0.19.0-np112py36_0 --> 0.19.1-np113py36_0 setuptools: 27.2.0-py36_0 --> 41.0.1-py36_0 statsmodels: 0.8.0-np112py36_0 --> 0.10.0-py36h1d22016_0 xz: 5.2.2-1 --> 5.2.4-h1de35cc_4 zlib: 1.2.8-3 --> 1.2.11-h1de35cc_3 The following packages will be DOWNGRADED: libxslt: 1.1.29-0 --> 1.1.28-2 Proceed ([y]/n)? y
- 投稿日:2019-07-08T11:03:58+09:00
今日のjupiter error
macOS$ jupiter notebook [I 10:26:54.511 NotebookApp] The port 8888 is already in use, trying another port. [I 10:26:54.864 NotebookApp] Serving notebooks from local directory: /Users/administrator/Desktop/ai_study_nagao [I 10:26:54.864 NotebookApp] 0 active kernels [I 10:26:54.864 NotebookApp] The Jupyter Notebook is running at: http://localhost:8889/?token=e85d11576be3a551e8f2ada804cbd11742cb82b6565f722c [I 10:26:54.864 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation). [C 10:26:54.865 NotebookApp] Copy/paste this URL into your browser when you connect for the first time, to login with a token: http://localhost:8889/?token=e85d11576be3a551e8f2ada804cbd11742cb82b6565f722c [I 10:26:57.004 NotebookApp] Accepting one-time-token-authenticated connection from ::1 [W 10:27:02.044 NotebookApp] Notebook ai_study.ipynb is not trusted [I 10:27:06.185 NotebookApp] Kernel started: 98446682-d81f-44b3-86b5-90130e3f6caa [I 10:29:05.934 NotebookApp] Saving file at /ai_study.ipynb [W 10:29:05.936 NotebookApp] Saving untrusted notebook ai_study.ipynbdocker で8888使ってた。
jupyterでファイル選択
# MNISTのダウンロード from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("/tmp/data/") C:\Users\sakata\Anaconda3\envs\studyML-gpu\lib\site-packages\dask\config.py:168: YAMLLoadWarning: calling yaml.load() without Loader=... is deprecated, as the default Loader is unsafe. Please read https://msg.pyyaml.org/load for full details. data = yaml.load(f.read()) or {} WARNING:tensorflow:From <ipython-input-22-f05f99d671a3>:3: read_data_sets (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version. Instructions for updating: Please use alternatives such as official/mnist/dataset.py from tensorflow/models. WARNING:tensorflow:From C:\Users\sakata\Anaconda3\envs\studyML-gpu\lib\site-packages\tensorflow\contrib\learn\python\learn\datasets\mnist.py:260: maybe_download (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version. Instructions for updating: Please write your own downloading logic. WARNING:tensorflow:From C:\Users\sakata\Anaconda3\envs\studyML-gpu\lib\site-packages\tensorflow\contrib\learn\python\learn\datasets\mnist.py:262: extract_images (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version. Instructions for updating: Please use tf.data to implement this functionality. Extracting /tmp/data/train-images-idx3-ubyte.gz WARNING:tensorflow:From C:\Users\sakata\Anaconda3\envs\studyML-gpu\lib\site-packages\tensorflow\contrib\learn\python\learn\datasets\mnist.py:267: extract_labels (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version. Instructions for updating: Please use tf.data to implement this functionality. Extracting /tmp/data/train-labels-idx1-ubyte.gz Extracting /tmp/data/t10k-images-idx3-ubyte.gz Extracting /tmp/data/t10k-labels-idx1-ubyte.gz WARNING:tensorflow:From C:\Users\sakata\Anaconda3\envs\studyML-gpu\lib\site-packages\tensorflow\contrib\learn\python\learn\datasets\mnist.py:290: DataSet.__init__ (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version. Instructions for updating: Please use alternatives such as official/mnist/dataset.py from tensorflow/models.もう1箇所
from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("./tmp/data/") C:\Users\sakata\Anaconda3\envs\studyML-gpu\lib\site-packages\dask\config.py:168: YAMLLoadWarning: calling yaml.load() without Loader=... is deprecated, as the default Loader is unsafe. Please read https://msg.pyyaml.org/load for full details. data = yaml.load(f.read()) or {} WARNING:tensorflow:From <ipython-input-5-235989482ffe>:2: read_data_sets (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version. Instructions for updating: Please use alternatives such as official/mnist/dataset.py from tensorflow/models. WARNING:tensorflow:From C:\Users\sakata\Anaconda3\envs\studyML-gpu\lib\site-packages\tensorflow\contrib\learn\python\learn\datasets\mnist.py:260: maybe_download (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version. Instructions for updating: Please write your own downloading logic. WARNING:tensorflow:From C:\Users\sakata\Anaconda3\envs\studyML-gpu\lib\site-packages\tensorflow\contrib\learn\python\learn\datasets\mnist.py:262: extract_images (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version. Instructions for updating: Please use tf.data to implement this functionality. Extracting ./tmp/data/train-images-idx3-ubyte.gz WARNING:tensorflow:From C:\Users\sakata\Anaconda3\envs\studyML-gpu\lib\site-packages\tensorflow\contrib\learn\python\learn\datasets\mnist.py:267: extract_labels (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version. Instructions for updating: Please use tf.data to implement this functionality. Extracting ./tmp/data/train-labels-idx1-ubyte.gz Extracting ./tmp/data/t10k-images-idx3-ubyte.gz Extracting ./tmp/data/t10k-labels-idx1-ubyte.gz WARNING:tensorflow:From C:\Users\sakata\Anaconda3\envs\studyML-gpu\lib\site-packages\tensorflow\contrib\learn\python\learn\datasets\mnist.py:290: DataSet.__init__ (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version. Instructions for updating: Please use alternatives such as official/mnist/dataset.py from tensorflow/models.tensorflowが入っていなかったからかと思い導入。
あ、フォルダが存在しない。macOS^C[I 10:40:31.374 NotebookApp] interrupted Serving notebooks from local directory: /Users/administrator/Desktop/ai_study_nagao 1 active kernels The Jupyter Notebook is running at: http://localhost:8889/?token=e85d11576be3a551e8f2ada804cbd11742cb82b6565f722c Shutdown this notebook server (y/[n])? y [C 10:40:34.644 NotebookApp] Shutdown confirmed [I 10:40:34.686 NotebookApp] Shutting down kernels [I 10:40:35.102 NotebookApp] Kernel shutdown: 98446682-d81f-44b3-86b5-90130e3f6caa $conda install tensorflow
- 投稿日:2019-07-08T10:20:36+09:00
Amazon SageMaker の推論パイプラインで、独自コンテナを組み合わせる方法
概要
Amazon SageMaker で、独自コンテナを含む 推論パイプラインエンドポイントを構築する 方法について書きます
SageMaker で提供されるコンテナで所望の前処理が実現できず、独自コンテナによる前処理をしたい場合、カスタム前処理コンテナはどのようにつくるか、どのように組み込むか 調べた際のメモです
組み込みアルゴリズムと推論パイプライン
Amazon SageMaker では組み込みアルゴリズムが提供されており、解きたい問題にフィットするものがあれば、MLアルゴリズムに関するコードを書かずに手軽にMLモデルを作れるようになっています
組み込みアルゴリズムに引き渡す入力形式はアルゴリズムごとに決まっており、基本的には、保有するデータを整形する前処理が必要です
こうした 前処理は学習/推論で同じ処理なため、共通化されていることが望ましい ということで、SageMaker では前処理アルゴリズムをコンテナ化して学習/推論時に実行させる仕組みが提供されています前処理コンテナでは SageMaker でのコンテナの挙動を踏襲し、
fitでインスタンス上に前処理コンテナを展開してデータ整形/S3バケットへ出力したり、deployでインスタンス上に前処理コンテナを展開してリクエストデータ整形/次処理へ渡す、といった挙動をさせます
とくに推論処理では、エンドポイントへ届いたリクエストを前処理して後続の推論アルゴリズムへ渡すために、「前処理+推論処理(+後処理等)」をセットにした 推論パイプラインエンドポイント が構築できるようになっています
- Amazon SageMaker 組み込みアルゴリズムを使用する
- Amazon SageMaker 推論パイプライン
- Amazon SageMaker トレーニングと推論でデータ処理コードの一貫性を確保する
前処理で独自コンテナが必要になるケース
推論パイプラインのサンプル には、SageMaker で MLフレームワークを使うときと同様
sagemaker.sklearn.estimator.SKLearnなどEstimatorを利用して、任意のスクリプトを所定のコンテナ環境下で実行させる例が載っています
提供されているコンテナで所望の処理が実現できれば、カスタムコンテナは不要ですfrom sagemaker.sklearn.estimator import SKLearn script_path = 'sklearn_abalone_featurizer.py' sklearn_preprocessor = SKLearn( entry_point=script_path, role=role, train_instance_type="ml.c4.xlarge", sagemaker_session=sagemaker_session)しかし提供されるコンテナにないライブラリや、インストールされていないミドルウェアを使いたい場合には、独自の環境をコンテナ化して実行させる必要があります
たとえば自然言語を扱う課題で MeCab で形態素解析したいといった場合には、MeCab が動作してかつ Amazon SageMaker の仕様に従ったコンテナが必要になります
前処理コンテナのつくりかた
Amazon SageMaker で提供されているコンテナ群は GitHub で公開されているので、ライブラリを追加する程度であれば、既存コンテナを拡張するのが楽かもしれません
用意されているコンテナをFROM文で呼び出した上に、追加のインストールやセットアップを施しますそうした提供済みコンテナで都合が悪い(ミドルウェアのバージョンが合わないとか、既存の資産を使いたいとか)場合には独自コンテナを作ります
前処理コンテナの要件
基本的な挙動は SageMaker の 独自のトレーニングイメージ の仕様にあわせる必要があります
fitやdeployといった命令をうけて所定の処理が RUN される必要があるため、scikit_bring_your_ownなどをベースに、枠組みそのままで中身の処理を書き換えるのがよさそうです
また、パイプラインエンドポイントのための独自の設定がいくつか必要です
- 構成要素
- train:トレーニング(fit)時に呼び出される処理
- serve:エンドポイント構築(deploy)時に呼び出される処理
- predictor.py:推論エンドポイントで呼び出される処理
- その他の要件
- Dockerfile に次のコードが必要
LABEL com.amazonaws.sagemaker.capabilities.accept-bind-to-port=true- エンドポイントのリクエスト受け付けポートが次の環境変数に依存する
SAGEMAKER_BIND_TO_PORT- Dockerコンテナリポジトリに、次のポリシー付与が必要
前処理コンテナで実装する内容
scikit_bring_your_own 等をベースに、下記の機能を実装します
train
生データを受け取って整形加工し、MLモデルトレーニングに使用する訓練データをつくり、S3へ配置します
訓練データ生成の際に作成される「辞書データ」や「ベクトライザ」は推論時にも同じものを使うため、推論エンドポイントへ引き継ぐ必要がありますが、SageMaker のアルゴリズムで/opt/ml/model以下を共有する仕組みにのせて、推論エンドポイントの同一ディレクトリへ展開させるようにします
Estimator.fitで呼び出される- 指定されたタイプのインスタンスに、
inputs={'raw':'s3://'}で引き渡した S3 パスのデータが/opt/ml/input/data/{channel}以下へ 自動的に 展開される/opt/ml/input/data/{channel}からデータを参照して一括整形する- MLトレーニングで使用する、加工整形した訓練データを S3 上の任意のパスへアップロードする
- 推論エンドポイントでデータの整形処理に必要になるモデルデータ(辞書やベクトライザなど)を
/opt/ml/modelへ出力する
joblib.dumpなど/opt/ml/model以下のファイル群がtar.gz形式でアーカイブされてoutput_pathで指定された S3 パスへ 自動的に アップロードされるserve
train時に生成したモデルファイルをインスタンス上に配置し、/invocationsのリクエストを受け付ける web サーバを起動します
Estimator.deployで呼び出される
output_pathに指定された S3 パスから、Training 時に生成済みのモデル群をインスタンスの/opt/ml/model以下へ 自動的に 展開する/invocationsと/pingに応答するウェブサーバー を起動する
- パイプラインモデルのエンドポイントは、リクエストを受け付けるポートを環境変数
SAGEMAKER_BIND_TO_PORTで指定されるため、web サーバの設定でポートを環境変数を参照するようにする(環境変数がなければ 8080 を使う)predict
serveで起動したエンドポイントで、推論を行いたい生データを所定の書式で受け取り、後続の推論アルゴリズムが要求する書式に整形して返します
serveの際に配置したモデルファイル群を/opt/ml/model以下から取得し、コード上へ読み出す
joblib.loadなど- 推論リクエストに含まれる生データを取得し、文字列の正規化を行う
- 正規化したデータについて、先に取得したベクトライザ等を使用して推論アルゴリズムが要求する形式のデータへ変換する
- 変換した形式のデータをレスポンスとして返す
コンテナのビルド、ECRへのPUSH
上記実装したコード群をコンテナ化し、ECR のリポジトリへ push します
push した ECR のリポジトリには、SageMaker のパイプラインモデルからの呼び出しを許可するポリシーを付与する必要があります(推論パイプラインの Amazon ECR アクセス許可のトラブルシューティング)
ECR コンソールから
Repositories > 該当リポジトリリンク > Permissionsと進んで、アクセス許可ポリシーを下記 JSON の通り追加します{ "Version": "2008-10-17", "Statement": [ { "Sid": "allowSageMakerToPull", "Effect": "Allow", "Principal": { "Service": "sagemaker.amazonaws.com" }, "Action": [ "ecr:GetDownloadUrlForLayer", "ecr:BatchGetImage", "ecr:BatchCheckLayerAvailability" ] } ] }ここまででパイプライン用の前処理コンテナができました
MLプロセスへの組み込み
組み込みMLアルゴリズムと、独自コンテナによる前処理を組み合わせ、MLフローを実行します
前処理(訓練データの準備)
生データを用意してS3へアップロードし、以下のようなコードによって、訓練データへ変換します
&前処理で生成した ベクトライザ 等の生成物を S3 へ格納しますimport sagemaker sess = sagemaker.Session() role = sagemaker.get_execution_role() preprocess_image_name = 'preprocess_ecr_container_image' preprocess_job_name = '{preprocess_id}' rawdata_input_path = 's3_rawdata_path' train_dataset_path = 's3_preprocessed_data_path' preprocessor = sagemaker.estimator.Estimator( image_name = preprocess_image_name, role = role, train_instance_count = preprocess_instance_count, train_instance_type = preprocess_instance_type, train_volume_size = preprocess_volume_size, output_path = train_dataset_path, sagemaker_session = sess ) preprocessor.fit( inputs={'rawdata': rawdata_input_path}, job_name = preprocess_job_name )学習
前処理で訓練に必要なデータはすべて S3 上の所定の場所へアップロードされている状態です
下記のコードによって、組み込みアルゴリズムによるトレーニングを実行しますimport sagemaker algorithm_name = 'ml_hoge' ml_container_name = get_image_uri(boto3.Session().region_name, algorithm_name) ml_model_path = 's3_ml_model_path' ml_training_job_name = '{algorithm_name}-{preprocess_id}-{timestamp}' ml = sagemaker.estimator.Estimator( image_name = ml_container_name, role = role, sagemaker_session = sess, train_instance_count = train_instance_count, train_instance_type = train_instance_type, output_path = ml_model_path ) ml.fit( inputs={ 'train': train_dataset_path_train, 'validation': train_dataset_path_valid, 'auxiliary': train_dataset_path_aux, 'test': train_dataset_path_test }, job_name = ml_training_job_name )エンドポイント構築
前処理で生成した ベクトライザ 等を利用するデータ前処理コンテナと、組み込みアルゴリズムの学習済モデルを参照する推論コンテナをセットにして、推論パイプラインエンドポイントを構築します
(sagemaker.pipeline.PipelineModelのmodels変数へ渡した配列のモデル順に、リクエストに応答するエンドポイントが構築されます)import sagemaker preprocessor = sagemaker.estimator.Estimator.attach(preprocess_job_name) preprocess_model = preprocessor.create_model() ml = sagemaker.estimator.Estimator.attach(ml_training_job_name) ml_model = ml.create_model() pipeline_endpoint_name = '{algorithm_name}-pipeline-endpoint-{version}' pipeline_model = sagemaker.pipeline.PipelineModel( name = pipeline_model_name, role = role, models = [ preprocess_model, ml_model ] ) pipeline_model.deploy( initial_instance_count = pipeline_instance_count, instance_type = pipeline_instance_type, endpoint_name = pipeline_endpoint_name )ここまでで、独自コンテナによる前処理を組み込んだ推論エンドポイントが起動します
推論リクエストへの応答
生データを所定の形式で引き渡せば、
前処理コンテナで整形 -> 組み込みアルゴリズムの推論コンテナで推論した結果が返りますimport sagemaker from sagemaker.content_types import CONTENT_TYPE_JSON ml_predictor = sagemaker.predictor.RealTimePredictor( endpoint = pipeline_endpoint_name, serializer = sagemaker.predictor.json_serializer, deserializer= sagemaker.predictor.json_deserializer, content_type= CONTENT_TYPE_JSON, accept = CONTENT_TYPE_JSON ) payload = {'target':'日本語文字列'} pprint(ml_predictor.predict(payload))トラブルシューティング
エンドポイント構築時に ping health check に失敗する
エンドポイント構築時に
pingに失敗して構築できないというエラーが発生する場合ValueError: Error hosting endpoint pipeline-endpoint-vXX: Failed Reason: The container-1 for production variant AllTraffic did not pass the ping health check. Please check CloudWatch logs for this endpoint.独自コンテナで起動させたWebサーバが、環境変数
SAGEMAKER_BIND_TO_PORTポートでリクエストを受け付けていない可能性があります(CloudWatchLogs にも何の情報も出ず途方に暮れるのですが、落ち着いて)
Webサーバの設定を見直し、SAGEMAKER_BIND_TO_PORT環境変数が存在する場合には、環境変数の指定するポートで受け付けるように設定しますECR コンテナリポジトリに必要な権限が付与されていない
パイプラインエンドポイントを構築しようとする際、権限が足りないといったエラーが出る場合
ValueError: Error hosting endpoint pipeline-endpoint-vXX: Failed Reason: The repository of your image 111111111.dkr.ecr.xxxxx.amazonaws.com/XXXXXXXXXXXXXXXXXXXX does not grant ecr:GetDownloadUrlForLayer, ecr:BatchGetImage, ecr:BatchCheckLayerAvailability permission to sagemaker.amazonaws.com service principal.推論パイプラインエンドポイントを構築する際には、パイプラインに組み込む独自コンテナのリポジトリに SageMaker からの読み出しを許可するポリシー付与が必要です
推論パイプラインの Amazon ECR アクセス許可 を参考に、ECR コンソールから必要なポリシーを付与します{ "Version": "2008-10-17", "Statement": [ { "Sid": "allowSageMakerToPull", "Effect": "Allow", "Principal": { "Service": "sagemaker.amazonaws.com" }, "Action": [ "ecr:GetDownloadUrlForLayer", "ecr:BatchGetImage", "ecr:BatchCheckLayerAvailability" ] } ] }その他
まとめ
独自コンテナを含む推論パイプラインエンドポイントを構築する際、次の点に注意してください
- 基本的な挙動は SageMaker のカスタムコンテナと同じ
- エンドポイントのリクエスト受け付けポートは次の環境変数に依存する
SAGEMAKER_BIND_TO_PORT- 推論パイプラインでリアルタイム予測を実行
- Dockerコンテナリポジトリに、次のポリシー付与が必要
日本語処理など独自コンテナを必要とするケースで、ぜひ参考にしていただければと思います
参考資料
パイプラインのコンテナは、(8080 ではなく) SAGEMAKER_BIND_TO_PORT 環境変数で指定されたポートでリッスンします。
コンテナがこの要件に準拠していることを示すには、次のコマンドを使用して Dockerfile にラベルを追加します
LABEL com.amazonaws.sagemaker.capabilities.accept-bind-to-port=true
- Amazon SageMaker がトレーニングイメージを実行する方法
- Amazon SageMaker ホスティングサービスでの独自の推論コードの使用
- pipeline.PipelineModel
- 推論パイプラインのトラブルシューティング
Amazon SageMaker 組み込みアルゴリズムを含むパイプラインでカスタム Docker イメージを使用する場合は、Amazon ECR ポリシーが必要です。ポリシーは、イメージをプルするために Amazon SageMaker のアクセス許可を Amazon ECR レポジトリに与えます。
- 投稿日:2019-07-08T09:15:31+09:00
Packer, Ansible, Terraformで作るBlue-Greenデプロイメント (AWS)
概要
AWS環境で、デプロイメントのフローを自動化する仕事を任されたので、成果物をここにメモしておきます。
デプロイをするシステムは、以下のように構成されています。
Blue/Greenの2環境を用意し、普段は片方のみを使用しています。使用していないほうの環境にデプロイをして、ELBの振り分け先を変更することで、ダウンタイムのないデプロイメントを目指します。また、packerやAnsible, Terraformなどのツールを使うことで、このフローを自動化していきます。
尚、こちらの記事やこちらの記事などを参考にして作成しました。
作業手順
- アプリケーションや必要なミドルウェアなどをインストールした、ゴールデンAMIを作成する
- ゴールデンAMIを参照する起動設定を新規作成し、デプロイ先のAutoScaling Groupにそれを読み込ませる
- Elastic Load BalancerのListenerが転送するTargetGroupを変更し、本番環境をBlueからGreenに(もしくはGreenからBlueに)切り替える
AMIの作成
PackerとAnsibleを使って、ゴールデンAMIを作成します。AMIの基本的な設定はPackerで、ツールのインストール等の構成管理はAnsibleで、それぞれ行います。
まずは、Packerの設定です。
packer.json{ "variables":{ "version":"" //デプロイのたびに変わる値は、変数としておきます }, "builders": // AMIを作成するために一時的に立てられるEC2インスタンスについて定義 [ { "type":"amazon-ebs", "ami_name": "test-AMI-v{{user `version`}}", "region": "ap-northeast-1", "source_ami": "ami-xxxxxxxxxxx", // 基とするAMI "instance_type": "t2.micro", "ssh_username": "centos", "tags":{ "version":"{{user `version`}}" // 起動設定を作成するときに、見つけやすいようにタグをつけておく }, "force_deregister": true, "force_delete_snapshot": true, "security_group_ids":["sg-xxxxxxx","sg-xxxxxxx"], "iam_instance_profile": "xxxxxxx", "subnet_id":"subnet-xxxxxxxx" } ], "provisioners": // AMI作成用のインスタンスの中で行いたい処理を定義 [ { "type":"shell", "inline": [ // Ansibleを動かすためのツールをインストール "sudo -E yum -y update", "sudo -E yum -y install epel-release", "sudo -E yum -y install python-pip", "sudo -E yum -y install ansible" ] }, { "type":"ansible-local", // Ansibleの起動 "playbook_file":"setup.yml" } ] }上のファイルの中から呼ばれている、Ansibleの設定ファイル(playbook)の設定は、以下の通りです。
尚、以下ではS3上のmavenリポジトリから成果物をとってくるようにしてあります。setup.yml- hosts: all become: yes vars: proxy_env: # すべてに共通するプロキシ設定は、変数化しておく https_proxy: xxxxxxxxx http_PROXY: xxxxxxxxx HTTPS_PROXY: xxxxxxxxx HTTP_PROXY: xxxxxxxxx no_proxy: xxxxxxxxx tasks: - environment: "{{proxy_env}}" name: "install boto3 (required by aws-s3)" # boto3のインストール pip: name: boto3 - pip: name: lxml name: "install lxml" # Ansibleのs3モジュールを動かすのに必要 environment: "{{proxy_env}}" - maven_artifact: # S3上のmavenリポジトリから成果物を取得 repository_url: 's3://xxxxxxxx' group_id: jp.co.xx.xx artifact_id: xxxxxx version: 1.0.0 extension: tgz dest: /tmp/xxxxxx.tgz
packerコマンドで上記のpackerおよびAnsibleを実行すると、AMIが作成されるはずですASGの設定変更
Terraformを用いて、まず上で作成したAMIを読み込む起動設定を作成し、そしてデプロイ先のASG(使用中でない環境のASG)にその起動設定を読み込ませるようにします。
deploy.tfprovider "aws" { region = "ap-northeast-1" } variable "target_version" {} // デプロイのたびに値が変わるものは、変数化しておく data "aws_ami" "centos" { // packerとAnsibleで作成したAMIを取得 most_recent = true owners = ["xxx"] filter { // タグで検索 name = "version" values = ["${var.target_version}"] } } resource "aws_launch_configuration" "test" { // 起動設定を新規作成 name = "config-test-v${var.target_version}" image_id = "${data.aws_ami.centos.id}" // 作成したAMIを指定 instance_type = "t2.micro" enable_monitoring = false security_groups = ["sg-xxxxxxx", "sg-xxxxxxxxx","sg-xxxxxxx"] key_name = "xxxxxxxxx" iam_instance_profile = "xxxxxxxxx" root_block_device { delete_on_termination = true iops = 100 volume_size = 30 volume_type = "gp2" } } resource "aws_autoscaling_group" "test_resource" { // デプロイ先のASGが上の起動設定を読みこむよう、設定変更 name = "asg-test" launch_configuration = "${aws_launch_configuration.test.name}" // 上で作成した起動設定を指定 min_size = 2 max_size = 2 desired_capacity = 2 target_group_arns = ["xxxxx","xxxxxx"] vpc_zone_identifier = ["xxxxxxx","xxxxxxxx"] lifecycle { create_before_destroy = true } }
terraformコマンドで上の設定を反映させると、使用中でない環境のASGに設定が反映されます。Blue/Greenの切り替え
最後に、ELBの振り分けの設定を変えます。適当なスクリプト言語でシェルを書くのですが、今回はCentOSにデフォルトで入っているPythonの2系で書きます(
今時Python2かよ、って感じですが)。処理の手順は、以下の通りです
1. ASGに紐づくEC2のインスタンスのリストを取得
2. EC2がすべて立ち上がって、テストをパスしたか確認する
3. EC2がすべて立ち上がっていれば、ELBのListenerのリクエストの転送先のTargetGroupを変更し、Blue/Greenを切り替える以下がコードです。
switch_elb.sh#! /bin/python # -*- coding: utf-8 -*- from time import sleep import json import subprocess # ASGに紐づくEC2インスタンスのリストの取得 GET_INSTANCE_LIST = """aws ec2 describe-instances --filters "Name=tag:version,Values=%s""" # EC2インスタンスがヘルシーな状態であるか確認 GET_INSTANCE_STATUS = "aws ec2 describe-instance-status --instance-id %s" # ELBの切り替え SWITCH_ELB_LISTENER = "aws elbv2 modify-rule --rule-arn %s --actions Type=forward,TargetGroupArn=%s" # EC2のリストを取得し、ヘルスチェック def get_ec2_health(version): instance_ids = [] # インスタンスのリスト取得 instance_list = subprocess.check_output(GET_INSTANCE_LIST % version,shell=True) instance_dict = json.loads(instance_list) for instance in instance_dict["Reservations"]: # 停止中のインスタンスは除く if instance["Instances"][0]["State"]["Code"] != 48: instance_ids.append(instance["Instances"][0]["InstanceId"]) for i in range(30): # 一つずつインスタンスをヘルスチェックし、一つでもダメであれば、15秒後に再チェック result = check_ec2_status(instance_ids) if result == True: return True else: sleep(15) return False # EC2のヘルスチェック def check_ec2_status(instance_ids): for instance_id in instance_ids: result = commands.getoutput(GET_INSTANCE_STATUS % instance_id) status_dict = json.loads(result) # 一つでもヘルスチェックに失敗すれば、Falseを返す if status_dict["InstanceStatuses"][0]["SystemStatus"]["Details"][0]["Status"] != "passed" or status_dict["InstanceStatuses"][0]["InstanceStatus"]["Details"][0]["Status"] != "passed": return False return True # ELBの切り替え def switch_elb(): ELB_rules = {} try: # ELBのListenerのRuleのarnをjson形式で羅列しておくファイル file = open("../../ELB_rules_arns.json","r") ELB_rules = json.load(file) except: print("ELBのルールの情報が読み込めませんでした") return target_group_arns = {} try: # デプロイ先の環境の、TargetGroupのarnをjson形式で羅列しておくファイル file = open("./target_group_arns.json","r") target_group_arns = json.load(file) except: print("ターゲットグループの情報が読み込めませんでした") return for key in ELB_rules: result = subprocess.call(SWITCH_ELB_LISTENER % (ELB_rules[key],target_group_arns[key]),shell=True) if result == 0: print("切り替え成功") return 0 # メインの関数 def main(): version = input("デプロイのバージョンを指定してください") ec2_health = get_ec2_health(version) if ec2_health == True: switch_elb_status = switch_elb() if switch_elb_status != 0: print("ELBの切り替えがうまくいきませんでした") else: print("ELBの切り替えに成功しました") else: print("EC2のヘルスチェックが失敗したため、切り替えを行いません") if __name__ == "__main__": main()
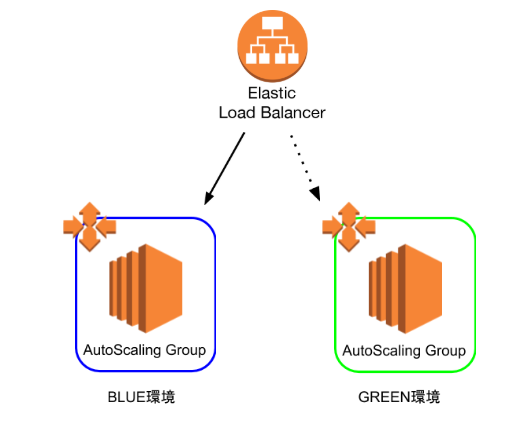
- 投稿日:2019-07-08T09:00:14+09:00
AWS CloudFormationのLambda-backedカスタムリソースでリソースの更新・削除をする方法
AWS CloudFormationのLambda-backedカスタムリソースを利用するとAWS CloudFormationで管理できないリソースも管理することができますが、Lambda-backedで作成したリソースの更新・削除するのにリソースのIDをどうやって取り回そうか悩みました。
下記は解決策の1案となりますが、他に良い方法があれば教えてほしいです!
前提
- AWSアカウントがある
- AWS CLIが利用できる
- AWS Lambda、CloudFormationの作成権限がある
CloudFormationのテンプレート作成
> mkdir 任意のディレクトリ > cd 任意のディレクトリ > touch cfn-template.yamlLambda-backedカスタムリソースを利用して何かしらのリソースを作成・更新・削除するテンプレートとなります。
ポイントとしてはCreateResourceのひとつで完結できたら良かったのですが、CreateResourceで作成したリソースのIDを自前で取り回せなかったので、更新と削除を別リソースUpdateResourceで行うようにしました。うーん、めんどうですcfn-template.yamlResources: CreateResource: Type: Custom::CustomResource Properties: ServiceToken: !GetAtt CreateResourceFunction.Arn UpdateResource: Type: Custom::CustomResource Properties: ServiceToken: !GetAtt UpdateResourceFunction.Arn ResourceId: !GetAtt CreateResource.Id CreateResourceFunction: Type: AWS::Lambda::Function Properties: Handler: index.handler Role: !GetAtt FunctionExecutionRole.Arn Code: ZipFile: !Sub | import cfnresponse def handler(event, context): if event['RequestType'] == 'Create': # なんかリソース作成 response = {'Id': 'hoge'} print('create resources ' + response['Id']) cfnresponse.send(event, context, cfnresponse.SUCCESS, response) return # 他のRequestTypeは無視 cfnresponse.send(event, context, cfnresponse.SUCCESS, {}) Runtime: python3.7 UpdateResourceFunction: Type: AWS::Lambda::Function Properties: Handler: index.handler Role: !GetAtt FunctionExecutionRole.Arn Code: ZipFile: !Sub | import cfnresponse def handler(event, context): Id = event['ResourceProperties']['ResourceId'] if event['RequestType'] == 'Update': # なんかリソース更新 print('update resources ' + Id) cfnresponse.send(event, context, cfnresponse.SUCCESS, {}) return if event['RequestType'] == 'Delete': # なんかリソース削除 print('delete resources ' + Id) cfnresponse.send(event, context, cfnresponse.SUCCESS, {}) return # 他のRequestTypeは無視 cfnresponse.send(event, context, cfnresponse.SUCCESS, {}) Runtime: python3.7 FunctionExecutionRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Principal: Service: - lambda.amazonaws.com Action: - sts:AssumeRole Path: "/" Policies: - PolicyName: root PolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Action: - logs:CreateLogGroup - logs:CreateLogStream - logs:PutLogEvents Resource: "arn:aws:logs:*:*:*"動作確認
スタック作成
> aws cloudformation create-stack \ --stack-name cfn-lambda-backed-test \ --template-body file://cfn-template.yaml \ --capabilities CAPABILITY_IAM { "StackId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-lambda-backed-test/3bed13d0-96e9-11e9-90fb-122d883fe268" }スタック作成して各リソースが作成できたらLambda関数のログを確認します。
各リソースと関数のPhysicalResourceIdをパラメータにaws logs get-log-eventsコマンドで取得します。> aws cloudformation list-stack-resources \ --stack-name cfn-lambda-backed-test { "StackResourceSummaries": [ { "LogicalResourceId": "CreateResource", "PhysicalResourceId": "2019/06/25/[$LATEST]587b7bbfa5b74a38a54846ff44a9a592", "ResourceType": "Custom::CustomResource", "LastUpdatedTimestamp": "2019-06-25T01:33:55.358Z", "ResourceStatus": "CREATE_COMPLETE", "DriftInformation": { "StackResourceDriftStatus": "NOT_CHECKED" } }, { "LogicalResourceId": "CreateResourceFunction", "PhysicalResourceId": "cfn-lambda-backed-test-CreateResourceFunction-LBG1WB6FV88B", "ResourceType": "AWS::Lambda::Function", "LastUpdatedTimestamp": "2019-06-25T01:33:49.819Z", "ResourceStatus": "CREATE_COMPLETE", "DriftInformation": { "StackResourceDriftStatus": "NOT_CHECKED" } }, { "LogicalResourceId": "FunctionExecutionRole", "PhysicalResourceId": "cfn-lambda-backed-test-FunctionExecutionRole-17PMYTJ3NS41Z", "ResourceType": "AWS::IAM::Role", "LastUpdatedTimestamp": "2019-06-25T01:33:46.370Z", "ResourceStatus": "CREATE_COMPLETE", "DriftInformation": { "StackResourceDriftStatus": "NOT_CHECKED" } }, { "LogicalResourceId": "UpdateResource", "PhysicalResourceId": "2019/06/25/[$LATEST]59ec7f3b07ec48f5b5feab288384b268", "ResourceType": "Custom::CustomResource", "LastUpdatedTimestamp": "2019-06-25T01:34:01.068Z", "ResourceStatus": "CREATE_COMPLETE", "DriftInformation": { "StackResourceDriftStatus": "NOT_CHECKED" } }, { "LogicalResourceId": "UpdateResourceFunction", "PhysicalResourceId": "cfn-lambda-backed-test-UpdateResourceFunction-BMXD99ZLKXP0", "ResourceType": "AWS::Lambda::Function", "LastUpdatedTimestamp": "2019-06-25T01:33:49.516Z", "ResourceStatus": "CREATE_COMPLETE", "DriftInformation": { "StackResourceDriftStatus": "NOT_CHECKED" } } ] } > aws logs get-log-events \ --log-group-name /aws/lambda/cfn-lambda-backed-test-CreateResourceFunction-LBG1WB6FV88B \ --log-stream-name '2019/06/25/[$LATEST]587b7bbfa5b74a38a54846ff44a9a592' \ --output=text \ --query "events[*].message" START RequestId: e8ad68ad-86be-4ea1-ad3f-736617882ce7 Version: $LATEST create resources hoge https://cloudformation-custom-resource-response-useast1.s3.amazonaws.com/(略) Response body: {"Status": "SUCCESS", "Reason": "See the details in CloudWatch Log Stream: 2019/06/25/[$LATEST]587b7bbfa5b74a38a54846ff44a9a592", "PhysicalResourceId": "2019/06/25/[$LATEST]587b7bbfa5b74a38a54846ff44a9a592", "StackId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-lambda-backed-test/3bed13d0-96e9-11e9-90fb-122d883fe268", "RequestId": "1cb162f1-979f-4e6f-b277-dd7e729d23cc", "LogicalResourceId": "CreateResource", "NoEcho": false, "Data": {"Id": "hoge"}} Status code: OK END RequestId: e8ad68ad-86be-4ea1-ad3f-736617882ce7 REPORT RequestId: e8ad68ad-86be-4ea1-ad3f-736617882ce7 Duration: 292.74 ms Billed Duration: 300 ms Memory Size: 128 MB Max Memory Used: 29 MB > aws logs get-log-events \ --log-group-name /aws/lambda/cfn-lambda-backed-test-UpdateResourceFunction-BMXD99ZLKXP0 \ --log-stream-name '2019/06/25/[$LATEST]59ec7f3b07ec48f5b5feab288384b268' \ --output=text \ --query "events[*].message" START RequestId: d593f33a-9231-4284-8157-97b5b799f70e Version: $LATEST https://cloudformation-custom-resource-response-useast1.s3.amazonaws.com/(略) Response body: {"Status": "SUCCESS", "Reason": "See the details in CloudWatch Log Stream: 2019/06/25/[$LATEST]59ec7f3b07ec48f5b5feab288384b268", "PhysicalResourceId": "2019/06/25/[$LATEST]59ec7f3b07ec48f5b5feab288384b268", "StackId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-lambda-backed-test/3bed13d0-96e9-11e9-90fb-122d883fe268", "RequestId": "fe1b2ba8-0aff-44a6-ac1f-f46863594b0f", "LogicalResourceId": "UpdateResource", "NoEcho": false, "Data": {}} Status code: OK END RequestId: d593f33a-9231-4284-8157-97b5b799f70e REPORT RequestId: d593f33a-9231-4284-8157-97b5b799f70e Duration: 242.26 ms Billed Duration: 300 ms Memory Size: 128 MB Max Memory Used: 29 MBスタック作成時には
CreateResourceでリソースの作成、UpdateResourceは呼び出しのみとなることが確認できました。スタック削除
スタックを削除して動作を確認します。
> aws cloudformation delete-stack \ --stack-name cfn-lambda-backed-test { "StackId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-lambda-backed-test/3bed13d0-96e9-11e9-90fb-122d883fe268" }スタック削除すると当然のことながらリソースが取得できなくなるので、ログストリーム名を取得してからログを確認します。
> aws logs describe-log-streams \ --log-group-name /aws/lambda/cfn-lambda-backed-test-CreateResourceFunction-LBG1WB6FV88B \ --output=text \ --query "logStreams[*].logStreamName" 2019/06/25/[$LATEST]587b7bbfa5b74a38a54846ff44a9a592 2019/06/25/[$LATEST]8d6fac4288674ecbb7b6f7a577b8b932 > aws logs get-log-events \ --log-group-name /aws/lambda/cfn-lambda-backed-test-CreateResourceFunction-LBG1WB6FV88B \ --log-stream-name '2019/06/25/[$LATEST]8d6fac4288674ecbb7b6f7a577b8b932' \ --output=text \ --query "events[*].message" START RequestId: 8a0c34a7-8c3a-47b5-9128-3a49748aca52 Version: $LATEST > aws logs describe-log-streams \ --log-group-name /aws/lambda/cfn-lambda-backed-test-UpdateResourceFunction-BMXD99ZLKXP0 \ --output=text \ --query "logStreams[*].logStreamName" 2019/06/25/[$LATEST]0c2223e7635d4ee0b04c508e0fc76511 2019/06/25/[$LATEST]59ec7f3b07ec48f5b5feab288384b268 > aws logs get-log-events \ --log-group-name /aws/lambda/cfn-lambda-backed-test-UpdateResourceFunction-BMXD99ZLKXP0 \ --log-stream-name '2019/06/25/[$LATEST]0c2223e7635d4ee0b04c508e0fc76511' \ --output=text \ --query "events[*].message" START RequestId: fcde5258-b444-4e33-aef6-d2dcff63e2c2 Version: $LATEST delete resources hoge https://cloudformation-custom-resource-response-useast1.s3.amazonaws.com/(略) Response body: {"Status": "SUCCESS", "Reason": "See the details in CloudWatch Log Stream: 2019/06/25/[$LATEST]0c2223e7635d4ee0b04c508e0fc76511", "PhysicalResourceId": "2019/06/25/[$LATEST]0c2223e7635d4ee0b04c508e0fc76511", "StackId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-lambda-backed-test/3bed13d0-96e9-11e9-90fb-122d883fe268", "RequestId": "5d390a57-55b6-4ddd-8820-0104c94ab705", "LogicalResourceId": "UpdateResource", "NoEcho": false, "Data": {}} Status code: OK END RequestId: fcde5258-b444-4e33-aef6-d2dcff63e2c2 REPORT RequestId: fcde5258-b444-4e33-aef6-d2dcff63e2c2 Duration: 644.07 ms Billed Duration: 700 ms Memory Size: 128 MB Max Memory Used: 56 MBスタック削除時には
CreateResourceは呼び出しのみ、UpdateResourceでリソースの削除がされることが確認できました。まとめ
若干定義が面倒になりますがAWS CloudFormationのLambda-backedカスタムリソースを利用してリソースを更新・削除できることが確認できました。
参考
Blue21: lambdaのログを aws-cli で見る
https://blue21neo.blogspot.com/2018/02/lambda-aws-cli.html
- 投稿日:2019-07-08T08:17:25+09:00
【新発見】「最近はいいねの獲得が難しくなっている」は本当か? 〜 Qiitaのいいねを可視化して分かった7つの驚愕 〜
「Qiitaでいいねしたら草生えるページ」を作った副産物として全いいねの日時データを取得できました。
いいねした日時を使った分析をすると今までわからなかった驚愕の事実が見えてきました。今までのQiita分析記事とこの記事では何が違うのか?
今までにもQiitaのいいねを分析した記事はいくつもありましたが、これらの中では記事データを使った分析を行なっていました。
データの取得元はAPIでいうと /api/v2/items になります。
このデータでは記事の投稿日時はわかってもいいねした日時まではわかりませんでした。これに対してこの記事で使用するデータは、各記事についたいいねを /api/v2/items/:item_id/likes から取得しています。
このデータではいいねした日時までわかります。
この記事では今までわからなかったいいねした日時を使った分析を行なっています。今までの投稿日ベース時系列いいね分析は問題あり
今までのQiita分析記事では以下のようなグラフが使用されていました。
これは月毎の1記事あたり平均いいね数をグラフ化したものです。
x軸は投稿した日付になっています。つまり、いつ投稿された記事が「今現在」どれだけのいいねを獲得しているかのグラフになります。これらの記事では以下のような考察をしているものがあります。
- 2014年の記事は2018年の記事より3倍のいいねを獲得している(データを取得した日で値が変わるので5倍と言ってる記事もある)
- 2014年以降はいいねの獲得が難しくなっている
- 原因は2016年11月のいいね導入
まず1と2ですが、冷静に考えるとおかしな話です。
例えて言うならこういう事です。
2014年生まれの子(現在5歳)と2018年生まれの子(現在1歳)の「今現在の身長」を比較して、
「2014年の子の方が背が高い。だから最近の子は成長が遅いんだ。」
と言っているようなものです。話を元に戻します。
2014年の記事に付いたいいねは2014年だけではなくそれ以降に付いたいいねも含まれていて、2019年7月現在、合計約5.5年分です。
これに対して2018年の記事に付いたいいねは2018年から現在までの約1.5年です。
この期間が違う2つのいいね数を単純に比較するに意味があるでしょうか?
「最初の1年でついたいいね数」や「年数で割ったいいね数」で比較するなら分かりますが、そのまま比較するのは無意味です。
(自分も一度似たような発言をしてしまいましたが...)最後の3についてですが、このデータからはとても読み取れません。
これは「はじめに結論ありき」で強引に結びつけているように思えます。知りたいこと
今までの投稿日ベースの時系列いいね分析は明らかに間違いがありました。
しかし「最近はいいねの獲得が難しくなっている」というのは体感として事実です。
2016年11月のいいね導入についても、その後のいいね数に全く影響がないということはないでしょう。そこでこの記事ではいいねの日時を使って
- いいね数は減少しているのか?
- 2016年11月のいいね導入はいいね数に影響はあったのか?
- いいね数が減少している、またはそう感じるこれ以外の原因はあるのか?
を中心に調べていきます。
分析
データは2019年6月24日頃に取得したものを使用します。
ここで使用したデータと分析結果はkaggleで公開しています。
- Dataset: https://www.kaggle.com/tag1216/qiita-items-and-likes-20190624
- Kernel: https://www.kaggle.com/tag1216/qiita-likes-analytics
この記事ではその中からいくつかピックアップして紹介していきます。
もし他の情報も知りたい方はkaggleで公開しているkernelを参照してください。
(説明を書いていないのでわかりにくいかもしれませんが)それでは結果を見ていきましょう。
驚愕① 2017年のいいね数は前年比マイナス30%だが2018年には回復している
以下は月次いいね数のグラフです。
x軸は記事の投稿日ではなくいいねした日になります。
なお、12月はアドベントカレンダーの影響で大きく変動するのでグラフでは異常値として除外しています。
明確に2016年11月ごろからいいね数が大幅に減少しているのがわかります。
しかし2017年後半には持ち直してきており、2018年には2017年の水準を超えています。このことから、「2016年11月のいいね導入」はその後のいいね数に大きな影響を与えたことがわかりますが、すでにその影響はなくなっていると見ていいでしょう。
その他の数値も見てみましょう。
「いいねした人のUU数」
「いいねした人一人当たりのいいね数」
「1記事あたりのいいね数」
「いいねした人のUU数」はいいね数とほぼ同じです。
「いいねした人一人当たりのいいね数」と「1記事あたりのいいね数」は2017年以降もピークよりは若干低い値に留まっています。
「1記事あたりのいいね数」は上昇傾向にあったので、現在も「2016年11月のいいね導入」の影響が残っていると言えます。
なお、「1記事あたりのいいね数」はその年に発生したいいね数をその年に投稿された記事数で割って算出したものです。
その年に投稿された記事以外へのいいねも含まれています。驚愕② 1年目の平均いいね数は2014年が12.5、2018年が8.1
ここからは、いいねした日と記事の投稿日の関係を見るために、いいね数を「いいねした年」と「投稿した年」で集計したデータを使用します。
grouped_likes = ( likes_items .groupby([ pd.Grouper(key="liked_at", freq="YS"), pd.Grouper(key="created_at", freq="YS"), ]) .liker.count() .rename("likes") ) likes_matrix = grouped_likes.reset_index().pivot_table( index="liked_at", columns="created_at", values="likes", aggfunc="sum", )以下は上記データをヒートマップで可視化したものです。
x軸が記事の投稿年、y軸がいいねした年です。
この表は縦に見ると「その年に投稿された記事がいついいねされたか」が分かります。
横に見ると「その年に発生したいいねがいつ投稿された記事についたか」が分かります。
このままだと分かりにくいので各年の1記事あたりいいね数にしてみます。
各年の1記事あたりいいね数(平均いいね数)は以下の通りです。
投稿日 1記事あたりいいね数 2011 24.1 2012 19.4 2013 27.5 2014 34.2 2015 26.6 2016 20.2 2017 13.4 2018 10.6 2019 6.8 2014年は34.2、2018年は10.6で3倍以上の差がありますが、最初の1年のいいね数で見ると...
1年目で獲得したいいね数で見ると2014年は12.5、2018年は8.1で1.5倍程度の差になります。
統計値で見ると差があることはわかりましたが、この程度の差だと普段違いを感じることは無いと思います。
「最近はいいねの獲得が難しくなっている」と感じるのは他に何らかの原因がありそうです。驚愕③ 過去の記事は2年目以降に獲得したいいねの割合が大きい
次は「いついいねされたかの割合」で出してみます。
先ほどと同じように1年目だけ見ると、過去のほうが1年目で獲得した割合が少なくなっています。
逆に言うと、過去の記事は2年目以降に獲得したいいねの割合が大きいということになります。過去記事のいいね数が大きいのは毎年いいねが積み上げられた結果だということです。
驚愕④ 最近は過去の記事にいいねする割合が増えている
次は「いつ投稿された記事にいいねしたかの割合」をみていきます。
1年目だけ見ると、最近は同年に投稿された記事に対するいいねの割合が減少しています。
つまり、過去の記事にいいねする割合が徐々に増えていることが分かります。
驚愕⑤ いいね総数の6割は1ヶ月以上前の記事に付いている
ここからはいいねが何日前の記事に付いたのかを可視化します。
この期間を以下の区分で分割して割合を見ていきます。
- 0〜1日未満
- 1日〜1週間未満
- 1週間〜1ヶ月未満
- 1ヶ月以上
likes_items["time_delta"] = likes_items.liked_at - likes_items.created_at def cut_time_delta(df): return pd.cut( df.time_delta.dt.days, bins=[0, 1, 7, 30, 99999], labels=["1day", "1week", "1month", "1month over"], right=False, ).value_counts().sort_index() period_stats = ( likes_items .groupby(pd.Grouper(key="liked_at", freq="YS")) .apply(lambda x: cut_time_delta(x) / len(x)) .stack() .rename("value") ) sns.heatmap( period_stats.unstack("time_delta"), annot=True, fmt=".1%", yticklabels=yearly_likes_stats.index.year, )
最近は約6割のいいねが1ヶ月以上前の記事に付いています。
これって結構意外な数字ではないでしょうか。もっと最新の記事にいいねが付いていると思っていませんでしたか?驚愕⑥ 2018年以降トレンドの影響で特定の記事にいいねが偏っている
先ほどの期間の区分ですが、大雑把で無意味な括りのようで実は以下のような意味で区切ってあります。
- 0〜1日未満 : 「タグフィード」や「全ての記事」など最新記事をチェックしていいねが付いたもの
- 1日〜1週間未満 : トレンドからいいねが付いたもの
- 1週間〜1ヶ月未満 : 毎週水曜配信のQiitaニュースからいいねが付いたもの
- 1ヶ月以上 : オーガニック検索やサイト内検索からいいねが付いたもの
これを踏まえて先ほどの表を見るといくつか気づくことがあります。
a. 2015年以降検索からのいいねが増えて、以後60%前後で安定。
b. Qiitaニュースからのいいねは減少傾向にある。
c. 2018年以降、最新記事からのいいねとトレンドからのいいねが入れ替わった。a.の2015年からの変化の原因は何でしょうか?今のところ想像がつきません。
b.の数値が意外です。もう少し多い感覚がありましたが週一なので全体に対する影響は小さかったんですね。
そういえば最近Qiitaニュースに関するアンケートがありましたが、トレンドと差別化できてないこともあり、何らかのテコ入れがありそうです。c.についてはもう少し詳しく見ていきます。
この期間のいいね(1〜7日前の記事についたいいね)を記事単位で集計し、記事毎のいいね数の分布を出してみます。いいね数分布の区分は
- 1以上10未満
- 10以上100未満
- 100以上
です。
trend_likes = likes_items[ ("1days" <= likes_items.time_delta) & (likes_items.time_delta < "7days") ] trend_items = trend_likes.groupby([ pd.Grouper(key="created_at", freq="YS"), "item_id" ]).liker.count().rename("likes") trend_likes_dist = ( trend_items.groupby([ "created_at", pd.cut(trend_items, bins=[1, 10, 100, 99999], right=False) ]) .sum() .groupby("created_at") .apply(lambda x: x / x.sum()) .rename("value") )
2018年以降、つまりトップページがトレンドになってから以降、いいね数が100件を超える
記事が記事のいいね総数が 倍増しています。
このことから、トレンド導入によって最新記事へのいいへは特定の記事(トレンドに載った記事)に大きく偏っていると考えられます。「最近はいいねの獲得が難しくなっている」と感じる最大の原因はここにあるのではないでしょうか。
驚愕⑦ Qiiaのトレンドは...
可視化の趣向が違うのと衝撃的な内容なので別記事にします。
おまけ① 初いいねが付くまでの日数
pd.cut( (likes_items .groupby("item_id") .time_delta.min() .dt.days ), bins=[0, 1, 7, 30, 365, 99999], labels=["1day", "1week", "1month", "1year", "1year over"], right=False, ).value_counts().sort_index() / len(items)1day 0.539090 1week 0.082175 1month 0.038557 1year 0.098697 1year over 0.028684約5割の記事は1日以内にいいねが付いています。
1年以上前の記事で現在0いいねでも3%の確率でいいねが付くようなので気長に待ちましょう。おまけ② 投稿から3分以内のいいね
投稿から3分以内に付いたいいね数が多いユーザーです。
(likes_items[ (likes_items.created_at >= "2018") & (likes_items.time_delta <= "3minutes") ] .groupby("author") .liker.count().rename("quick liked") .sort_values(ascending=False) .reset_index() [:30] ).style.hide_index().format({"author": "@{:s}"})
author quick liked @suin 62 @KanNishida 45 @kaizen_nagoya 24 @creaith 24 @sj-i 24 @takuya_tsurumi 23 @tanabee 19 @reoisym 18 @takahirom 16 @ucan-lab 16 @mizchi 14 @Hailee 14 @yoshinori_hisakawa 14 @kaityo256 14 @piacerex 13 @kyogom 13 @uhyo 11 @reoring 11 @miyumiyu 11 @shsssskn 11 @shuhey_fujiwara 11 @naoya_matsuda 11 @kahirokunn 11 @nunulk 10 @4_mio_11 9 @ababup1192 9 @nouphet 8 @superyusuke 8 @Gaccho 8 @tatsuya_yamamura 8 QiitaやTwitterでフォロワーが多いユーザーはわからないでもないですが、それ以外は例のOrganizationパワーでしょうかね。
Pandasを使ったデータ分析の実践例 - やはりQiitaアドベントカレンダーの「企業・学校・団体」カテゴリーにはヘビーライカーが多かった
きっと社内Slackでこんなやりとりがあるのかも知れません。
書いた人 「Qiitaに記事書いたで〜 みんな17時までにいいねしてくれやで〜」
いいねした人 「一番乗りでいいねしといたで〜(読んでへんけど)」
書いた人 「無事トレンドに載ったやで〜 ありがとな〜」
いいねした人 「お互い様やで〜 次にワイが書くクソ記事もよろしくやで〜」
書いた人 「任せとき〜 (読まへんけど)」最後に
いかがでしたか?
いいねした日時を使うことで今まで見えなかったことが色々とわかったと思います。
他にも
- 曜日時間帯別いいね数
- コホート分析
- 短期間だけ注目される記事と長期間愛される記事の違い
- 怪しげないいねの検出
など、今までできなかった色々な分析ができると思います。
データは公開しているので興味のある方はぜひチャレンジしてください。
参考
他のQiita分析記事
以下を参照してください。
Qiitaで起きた出来事
- 2016/06/29頃 人気の投稿ページ(トレンドの前身) https://blog.qiita.com/146688745654-2/
- 2016/11/14頃 いいね導入 https://blog.qiita.com/153200849029-2/
- 2017/11/25頃 トップ画面がトレンドに(β) https://qiita.com/mizchi/items/290973cd1f68fcbe035c
- 2018前後? トップ画面がトレンドに
- 2018/04/19頃 トレンドロジック変更 https://blog.qiita.com/173120067699-2/
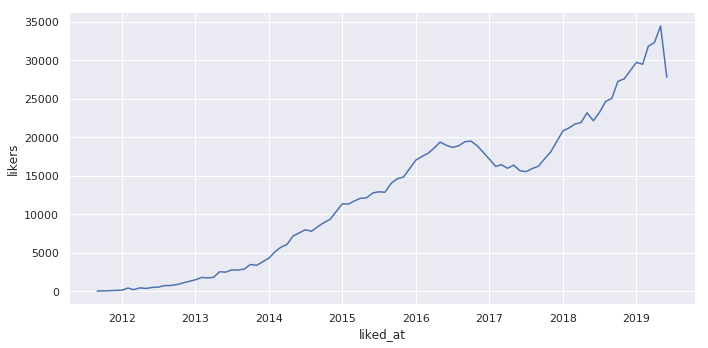
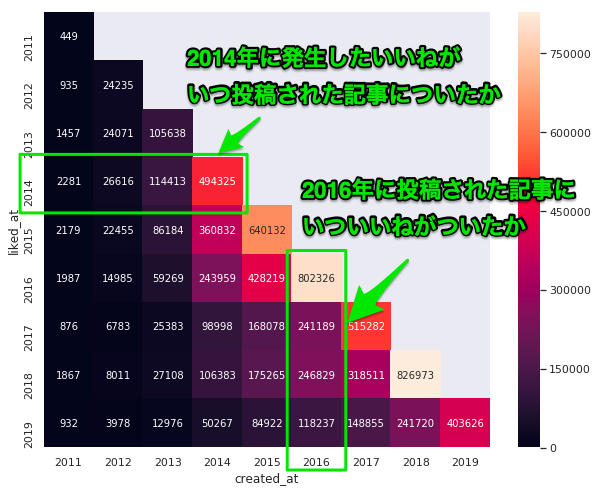
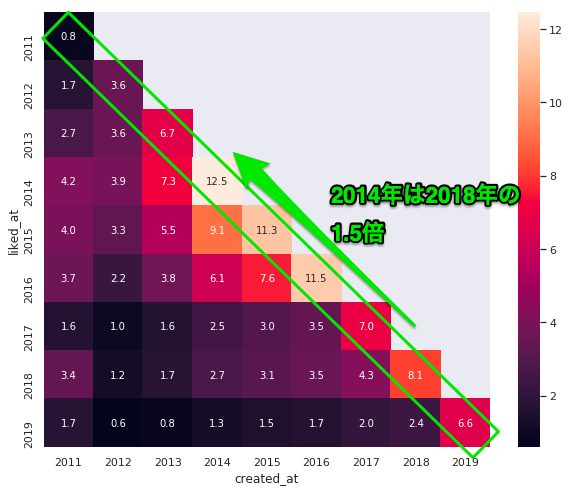
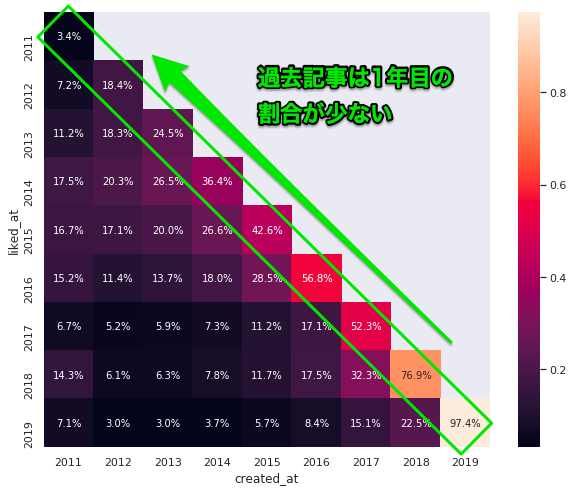
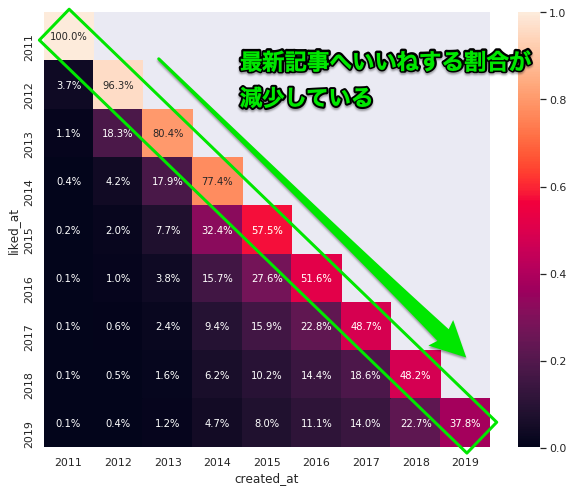
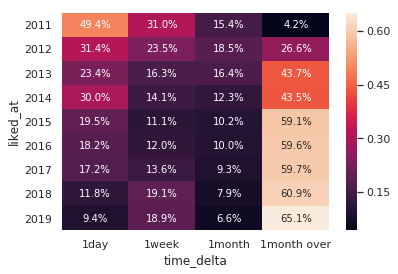
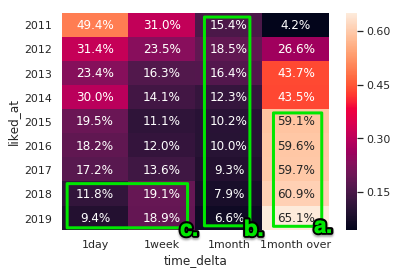
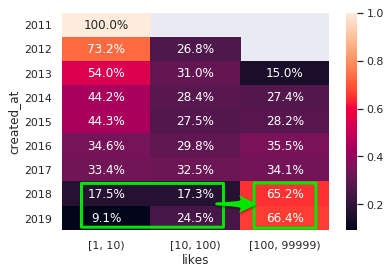
- 投稿日:2019-07-08T08:00:17+09:00
YouTube Liveの生放送から盛り上がった箇所を自動抽出するCLIを作った話
作ったもの
YouTubeLiveの生放送から盛り上がった箇所を自動抽出するCLI
PyPlに公開してます。
GitHubpython=>3.5
使い方$ pip install pylive_jp $ pylive 動画URL=>https://www.youtube.com/watch?v=7BAcdKhvkPc ハイライト抽出数(何箇所抽出するか?)=>3 処理中:ハイライトを抽出したいYouTubeLiveのアーカイブの動画URLを指定して、抽出数を入力すると最も盛り上がったシーンから順に動画が生成される。
上記の例だと指定URLの動画から、盛り上がった箇所ベスト3の動画3本が生成される。(あまり多く指定すると処理に時間がかかるので3~6くらいがベスト)開発期間
半月くらい
開発人数
一人
なぜ作ったのか
生放送は再生時間が長く全て見るのに時間がかかる、そこで盛り上がった箇所だけ自動で抽出できたら便利だと思ったので作成
また、事前に使えそうなパッケージなどを探していたらいい感じのが見つかったのも開発に踏み切った要因の一つ処理内容
大きく分けて、動画DL、チャットの解析、動画切り出し、という3つの処理を行っている。また、動画のDLとチャットの解析は互いに独立した処理なので平行処理で実装した。
以下に概要図を示す。
チャット解析
YouTube Liveのチャットを解析することで盛り上がり箇所を抽出している。
チャットデータの取得
YouTube Liveの生放送からのチャットデータの取得方法はこちらのサイトが詳しく解説しているので参考にさせていただきました。詳しい解説などはこちらのサイトをご覧下さいhttp://watagassy.hatenablog.com/entry/2018/10/06/002628
やっていることはBeautiful SoupでのHTMLの解析、1チャットにはあらゆるデータが含まれているのでこの中からチャット文と投稿時間を取得する
チャット文と投稿時間(msec)#チャット文 #※チャット文の場所が変更されたのを確認 2019/6/27 samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["message"]["simpleText"] ↓ samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["message"]["runs"][0]["text"] #チャット投稿時間(ミリ秒) samp["replayChatItemAction"]["videoOffsetTimeMsec"]
1チャットから取得できるデータ一覧
取得できるチャットデータsamp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["message"]["runs"][0]["text"] samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["authorName"]["simpleText"] samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["authorPhoto"]["thumbnails"][0]["url"] samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["authorPhoto"]["thumbnails"][0]["width"] samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["authorPhoto"]["thumbnails"][0]["height"] samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["authorPhoto"]["thumbnails"][1]["url"] samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["authorPhoto"]["thumbnails"][1]["width"] samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["authorPhoto"]["thumbnails"][1]["height"] samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["contextMenuEndpoint"]["clickTrackingParams"] samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["contextMenuEndpoint"]["commandMetadata"]["webCommandMetadata"]["ignoreNavigation"] samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["contextMenuEndpoint"]["liveChatItemContextMenuEndpoint"]["params"] samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["id"] samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["timestampUsec"] samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["authorExternalChannelId"] samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["contextMenuAccessibility"]["accessibilityData"]["label"] samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["timestampText"]["simpleText"] samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["clientId"] samp["replayChatItemAction"]["videoOffsetTimeMsec"]
チャット取得コード(長いので一部省略)
from bs4 import BeautifulSoup import requests import datetime import lxml def analysis(target_url): session = requests.Session() #ユーザーエージェント情報(ブラウザとかの情報) headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36 '} # まず動画ページにrequestsを実行しhtmlソースを手に入れてlive_chat_replayの先頭のurlを入手 html = requests.get(target_url) soup = BeautifulSoup(html.text, "html.parser") #html解析 for iframe in soup.find_all("iframe"): if("live_chat_replay" in iframe["src"]): next_url= iframe["src"] (・・・略) while(1): try: html = session.get(next_url, headers=headers) soup = BeautifulSoup(html.text,"lxml")#パーサーは処理を高速化するためにlxmlを選択 # 次に飛ぶurlのデータがある部分をfind_allで探してsplitで整形 for scrp in soup.find_all("script"): if "window[\"ytInitialData\"]" in scrp.text: dict_str = scrp.text.split(" = ")[1] # javascript表記なので更に整形. falseとtrueの表記を直す dict_str = dict_str.replace("false","False") dict_str = dict_str.replace("true","True") # 辞書形式と認識すると簡単にデータを取得できるが, 末尾に邪魔なのがあるので消しておく(「空白2つ + \n + ;」を消す) dict_str = dict_str.rstrip(" \n;") # 辞書形式に変換 dics = eval(dict_str) # "https://www.youtube.com/live_chat_replay?continuation=" + continue_url が次のlive_chat_replayのurl continue_url = dics["continuationContents"]["liveChatContinuation"]["continuations"][0]["liveChatReplayContinuationData"]["continuation"] next_url = "https://www.youtube.com/live_chat_replay?continuation=" + continue_url # dics["continuationContents"]["liveChatContinuation"]["actions"]がコメントデータのリスト。先頭はノイズデータなので[1:]で保存 #コメント情報を取得 for samp in dics["continuationContents"]["liveChatContinuation"]["actions"][1:]: #print("コメント探索") comment_data.append(str(samp)+"\n") """ コメントデータの場所が変更されたのを確認 2019/6/27 samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["message"]["simpleText"] ↓ samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["message"]["runs"][0]["text"] """ #コメント取得 try: coment=str(samp["replayChatItemAction"]["actions"][0]["addChatItemAction"]["item"]["liveChatTextMessageRenderer"]["message"]["runs"][0]["text"]) #print(coment) except: #print("取得できないコメントです") continue #コメント時間の取得 time_msec=int(samp["replayChatItemAction"]["videoOffsetTimeMsec"])#コメントした時間のミリ秒を取得 time_msec=int(time_msec/1000)#ミリ秒→秒に変換 #print(str(time_msec)+"秒") (・・・略)盛り上がりの定義
チャットの取得方法がわかったので次は、生放送における「盛り上がり」の定義とはなにか?について考えた。
ここで最初に思いついたのが秒間チャット数だ、秒間チャット数が多ければそこは盛り上がったシーンだと考えたが必ずしもそうではなかった。というのも、配信者が視聴者に対して質問を投げかける場面や、配信者の疑問にユーザーが応答する場面などではチャット数が増加するからだ。そこで、特定のワードに着目することで「盛り上がり」を定義することにした。というのも、ネット上では面白いという感情を表現するワードとして「草」や「w」のような文字が使われているからだ、上記のワードが語尾に含まれる場合や、これらのワードのみで構成されるチャットを秒間でカウントして数値が大きい個所を盛り上がり箇所として抽出することにした。
実際に「草」や「w」の含まれる1秒間のチャット数をカウントしてグラフ化した画像を以下に示す。
ここで、本当に1秒間の頻度で判断していいのかと疑問に感じた。というのも、チャットは連続性があり配信者の1アクションに対して数秒に渡ってチャットが流れるからだ。ある程度の時間的な幅が必要だと考え、10秒単位でカウントすることにした。
10秒単位でカウントしてグラフ化した画像を以下に示す。
1秒単位では現れなかった部分が確認できる。
ではなぜ10秒単位なのか?正直言うとここは適当に設定した。ここの時間幅はもう少し考察する必要があるかもしれない後はコメント数の多い順に盛り上がった箇所の時間リストを生成
動画のダウンロード
YouTubeから動画をDLするのにはpytubeというパッケージを使用した。https://python-pytube.readthedocs.io/en/latest/
動画URLからDLできる便利なパッケージ
仕組みは、動画URLリクエスト(動画視聴用のURL)のレスポンスから動画のダイレクトURL(実際に動画ファイルがある場所)を取得してYouTubeサーバーにリクエストすることで動画をDLしているらしい
pytubeについてもっと詳しく知りたい人はここ→ https://github.com/nficano/pytube
動画切り出し
時間を指定して動画を切り出すのにはMoviePyというパッケージを使用した。https://zulko.github.io/moviepy/
開始時刻と終了時刻を指定すれば指定動画ファイルから動画を切り出してくれる。今回開発したCLIでは切り出し位置は盛り上がり時間のリストの各要素に対して、盛り上がった時間が中央になるように各要素±1分の合計2分間を切り出している。(切り出し時間はCLIで指定できるようにした方がいいかもしれない)
なぜ2分に設定したかと言うと、動画は2分くらいが丁度いいというデータがあるらしいから(正直この辺の時間設定は適当)
参考URL:https://blog.hubspot.com/marketing/how-long-should-videos-be-on-instagram-twitter-facebook-youtube並行処理
動画DLとチャット解析は独立した処理なので並行処理を行うことにした。しかし、pythonにはGIL(Global Interpreter Lock)という仕組みがあり、1プロセスに1つのインタプリタしか割り当てられないので1プロセスでは平行処理ができないことが判明した。(もっと正確には、GILを取得している1スレッドはPythonのコードの実行を行えるが他スレッドは動かせないとのこと)、どうやら複数プロセスを扱う必要があるらしい
そこで、複数のプロセスを扱うためのモジュールであるmultiprocessingを用いた。
multiprocessingドキュメント
以下コード(長いので一部省略)
from multiprocessing import Process, Queue, Pool #動画DL def videodl(q,video_objct): v_path=video_objct.dounlord_video() #動画のダウンロード処理 q.put(v_path) return #コメント解析 def analysis(q2,target_url): c_count=coment_analysis.analysis(target_url) q2.put(c_count) return (・・・略) def main(): (・・・略) #プロセス間のデータ受け渡しがキューかパイプでしかできない q=Queue() #DLパス記録用のキュー q2=Queue() #秒間コメント数記録用のキュー #並行処理 pros=Process(target=videodl, args=(q,video_objct)) #動画DL pros2=Process(target=analysis, args=(q2,target_url)) #コメント解析 pros.start() pros2.start() (・・・略) #joinするまえにデータを受け取らないとerrorになる video_path=q.get() pros.join() comment_count=q2.get() pros2.join()複数プロセスを扱うのでデータの受け渡しはキューで行った。joinでプロセスが消滅するのでその前にデータを受け取る必要がある
苦労した点・感想
外部パッケージのpytubeがYouTubeの仕様変更の影響を受ける為、pytubeを起因としたエラーが発生する時がある。
しかしこれはもう仕方がない事だと思う、今後はpytubeのOSS開発に貢献できるように勉強していこうと思っている。今回は発想したシステムの機能を細分化した結果、機能に当てはまる技術が見つかったので比較的スムーズに開発できた。
やはり外部パッケージのpytubeとMoviePyの存在が大きかったと思う、自分のタスクとしてはチャットの解析と平行処理の部分で、動画DLと動画の切り出しに関しては外部パッケージに依存している。
スムーズに開発できるのはいいが外部パッケージに依存することでデメリットもある。可用性が低かったり保守が難しいという点だ、外部パッケージを起因としたエラーは修正に時間がかかる場合があり、また、修正後の最新verのリリースを待たなければならない今後何かやる際はこういった部分も考慮して開発できたらと感じた。
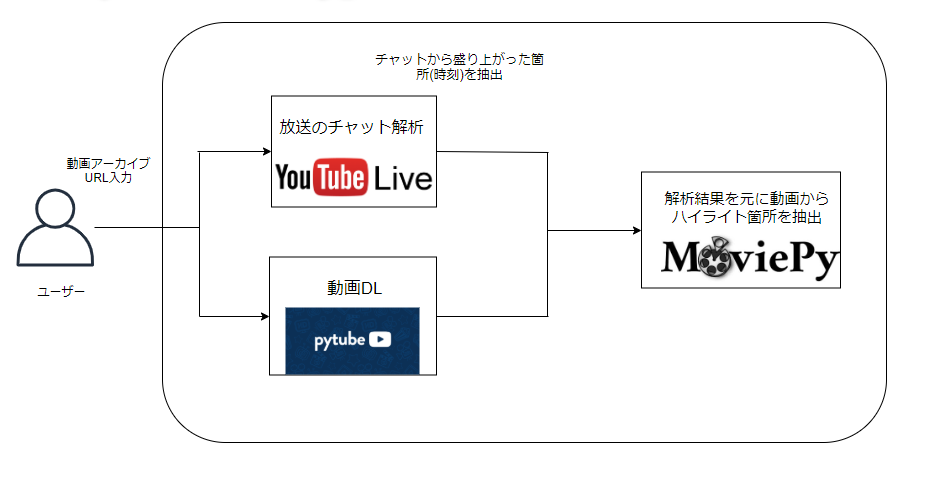
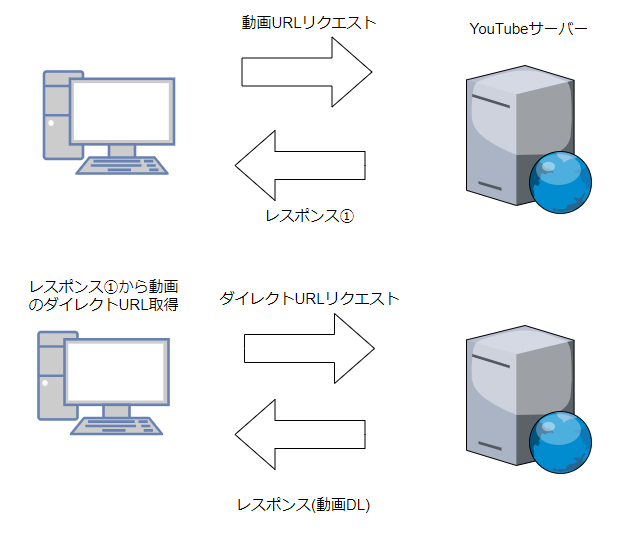
- 投稿日:2019-07-08T02:25:18+09:00
Selenium for Python 画像が読み込まれるまで待機する
はじめに
Seleniumで処理を自動化しました。
しばしば画像の読み込みが完了する前に、処理を始めてしまい例外が発生していました。
そこで画像の読み込みが完了するまで待機する処理を考えてみました。環境
Python 3.7.3
selenium 3.141.0
Firefox: 67.0.4 (64 ビット)
geckodriver 0.24.0 ( 2019-01-28)ソース
JavaScript
画像の読み込みが完了したかどうかを判定する処理は、JavaScriptで実装しました。
以下のようになります。
ここでは、Document配下の全ての画像を対象にしています。
適宜、修正してください。JavaScriptfunction isLoadedAllImges() { const imges = document.getElementsByTagName("img"); let completed = true; for (const img of imges) { if (img.complete === false) { completed = false; break; } } return completed; }Python
上で定義したJavaScriptをSelenium(Python)側から呼び出します。
単純な事ですが、重要なのは、画像が読み込まれるまでSelenium側でsleepをしてやることです。
理由は、
- JavaScriptには、単純なSleepがない
- JavaScript側がビジー状態になっていると画像の読み込みが完了しない
からです。
Sleepをしてくれるライブラリ等あればそれを使えば良いのでしょうが、それの設定をするのも面倒なのでこのような実装にしました。PythonJavaScriptIsLoadedAllImges = ''' function isLoadedAllImges() { const imges = document.getElementsByTagName("img"); let completed = true; for (const img of imges) { if (img.complete === false) { completed = false; break; } } return completed; } return isLoadedAllImges() ''' def isLoadedAllImges(timeOut=300, interval=1): start = time.time() completed = False while time.time() - start < timeOut and completed == False: completed = driver.execute_script(JavaScriptIsLoadedAllImges) time.sleep(interval) return completed最後に
単純なサイトではこれでうまく行くと思います。
実際には、アクセスしているサイトの挙動によってはうまく行かないことも出てくるかと思います。余談ですが、Selenium等での自動化にはまると楽しいですね。
これを仕事や収入に結び付ければ良いのでしょうが。
- 投稿日:2019-07-08T01:28:10+09:00
【データ分析編】RaspberryPi + 物体検出 で室内の人数を slack へ可視化
概要
【構築編】RaspberryPi + 物体検出 で室内の人数を slack へ可視化 の続きです.
Slack のチャンネルに,室内の人数が流れるようになりました.
今回は,このチャンネルのログから過去の人数データを取得し,そのデータの分析を試みます.
手順
チャンネルのログを取得し,csv形式で保存する
事前に Slack API でデータ取得用の App を作成し,トークンを控えます.
- 与える権限
- channels:history
- channels:read
また,チャンネルIDを調べておきます.
参考:SlackのチャンネルIDを確認する方法必要な情報を取り出して csv 形式で保存するPythonスクリプトを作りました.
logall.pyimport requests import re import time import json import pandas as pd url = "https://slack.com/api/channels.history" token = "(あなたのトークン)" channel_id = "(あなたのチャンネルID)" prog = re.compile("現在ゼミ室には [0-9]+名います.") # 他の発言を拾わないように,正規表現でマッチングする def is_match(text: str) -> bool: return prog.fullmatch(text) is not None # 人数抽出 def text2people_num(text: str) -> int: return int(text.split('現在ゼミ室には ')[1].split('名います.')[0]) def main(): payload = { "token": token, "channel": channel_id, "count": 1000, } response = requests.get(url, params=payload) df = pd.DataFrame(columns=["timestamp", "people_num",]) json_data = response.json() messages = json_data["messages"] for message in messages[::-1]: if is_match(message['text']): # 欲しいデータであるとき ts = time.ctime(int(message['ts'].split('.')[0])) people_n = text2people_num(message["text"]) print(ts, people_n) df = df.append(pd.Series([ts, people_n], index=df.columns), ignore_index=True) df.to_csv("room_log.csv") if __name__ == '__main__': main()csvファイルの中身はだいたいこんな感じになります(Jupyter Notebook で開いたためidが振られている点に注意).実際にはもっと行があります.
csv形式のデータを Jupyter Notebook で開き分析する
[1]import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline[2]df = pd.read_csv('room_log.csv', index_col=0) dfデータを確認したら,前処理を行います.
タイムスタンプをそのまま使うのは難しいので,日付と時刻のカラムを追加します.
また,あとで先月の記録を可視化するので,月のカラムも追加します.
今回,元のタイムスタンプはここで捨てました.[3]from calendar import month_abbr def timestamp2disc_time(ts: str) -> str: elms = ts.split()[-2] elms = elms.split(':') correct_minute = int(elms[1]) // 15 * 15 return elms[0] + ':' + "%02d" % correct_minute def timestamp2date(ts: str) -> str: elms = ts.split() day = str("%02d" % int(elms[2])) elms = [elms[4], elms[1], day, '(' + elms[0] + ')'] return " ".join(elms) month2int = dict() for i, key in enumerate(month_abbr): month2int[key] = i df['month'] = df['timestamp'].apply(lambda elm: month2int[elm.split()[1]]) df['time'] = df['timestamp'].apply(timestamp2disc_time) df['date'] = df['timestamp'].apply(timestamp2date) df = df.drop('timestamp', axis=1) dfこの時点でのデータフレームは次のようになります.
seaborn のヒートマップを用いて,このデータをわかりやすく可視化します.
ヒートマップの作成にあたり,seabornに与えるデータフレームを作成します.
参考:Python でデータ可視化 - カッコいいヒートマップを描こう[4]df_pivot = pd.pivot_table(data=df[df['month'] == 6], values='people_num', columns='date', index='time', aggfunc=np.mean) df_pivotヒートマップを描画します.縦に長くなるので figsize を変更して見やすくします.
[5]plt.figure(figsize=(9, 20)) sns.heatmap(df_pivot, annot=True, fmt='2g', cmap='Reds')
ヒートマップですので,室内の人数が多かった時間帯ほど色が濃く表示されます,
まとめ
データを取得して処理し,可視化する手順を示しました.
今後は曜日ごとの利用状況を見たり,機械学習によって利用傾向のモデル化を行なうとおもしろいかもしれないと考えています.