- 投稿日:2019-07-08T18:56:53+09:00
ロジスティック回帰(Logistic Regression)
はじめに
これは筆者の勉強まとめページですので、指摘しまくってい頂けると幸いです
ロジスティック回帰
線形回帰を二値分類に使用する方法で、とある閾値を超えたものを1クラス、その他のクラスを0クラスとして分類していく手法で、今回は0.5を閾値として、損失関数が以下のように設定される。
$$ y = w・x + b $$
$$ sigmoid(x) = \frac{1}{1 + \exp(-x)} $$
$$ loss = \frac{1}{n}\sum^{n}_{k = 1}{(t・log(sigmoid(y) + (1 - t)・log(1 - sigmoid(y))} $$
これを用いて2クラス分類をしていきます
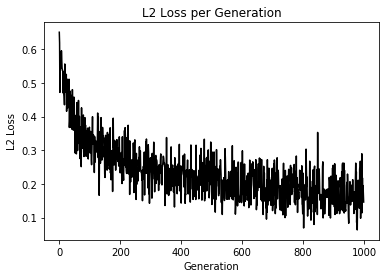
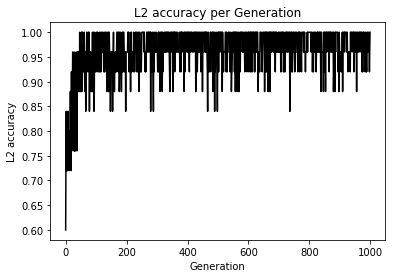
import matplotlib.pyplot as plt import tensorflow as tf import numpy as np from sklearn import datasets sess = tf.Session() # [setosa, versicolor] と [virginica] の分類を行う iris = datasets.load_iris() x_vals = iris.data target = iris.target y1 = [0 for i in target if i != 2] y2 = [1 for i in target if i == 2] y_vals = np.array(y1+y2) learning_rate = 0.05 batch_size = 25 x_data = tf.placeholder(shape = [None, 4], dtype = tf.float32) y_target = tf.placeholder(shape = [None, 1], dtype = tf.float32) A = tf.Variable(tf.random_normal(shape = [4, 1])) b = tf.Variable(tf.random_normal(shape = [1, 1])) model_output = tf.add(tf.matmul(x_data, A), b) loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits = model_output, labels = y_target)) init = tf.global_variables_initializer() sess.run(init) optimizer = tf.train.GradientDescentOptimizer(learning_rate) train = optimizer.minimize(loss) prediction = tf.round(tf.sigmoid(model_output)) prediction_correct = tf.cast(tf.equal(prediction, y_target), tf.float32) accuracy = tf.reduce_mean(prediction_correct) loss_vec = [] accuracy_vec = [] for i in range(1000): rand_index = np.random.choice(len(x_vals), size = batch_size) rand_x = x_vals[rand_index] rand_y = np.transpose([y_vals[rand_index]]) sess.run(train, feed_dict = {x_data: rand_x, y_target: rand_y}) tmp_accuracy, temp_loss = sess.run([accuracy, loss], feed_dict = {x_data: rand_x, y_target: rand_y}) loss_vec.append(temp_loss) accuracy_vec.append(tmp_accuracy) if (i + 1) % 25 == 0: print("Step #" + str(i + 1) + " A = " + str(sess.run(A)) + " b = " + str(sess.run(b))) print("Loss = " + str(temp_loss)) print("Acc = " + str(tmp_accuracy)) plt.plot(loss_vec, "k-") plt.title("L2 Loss per Generation") plt.xlabel("Generation") plt.ylabel("L2 Loss") plt.show() plt.plot(accuracy_vec, "k-") plt.title("L2 accuracy per Generation") plt.xlabel("Generation") plt.ylabel("L2 accuracy") plt.show()
こんな感じで学習が進んでいれば成功
うまく分類できている模様(テストデータで検証してないけど...)
ロジスティック回帰で他クラスにする手法とかないかな(ボソッ)
- 投稿日:2019-07-08T15:37:37+09:00
デミング回帰(Demming Regression)
はじめに
これは筆者の勉強まとめページですので、指摘しまくってい頂けると幸いです
デミング回帰
今回は https://qiita.com/raso0527/items/ba4bef9b1271428afbfc の記事のコードの損失関数を改良して学習をする
デミング回帰も線形回帰の一種で、損失関数を以下のように設定したもの
$$ loss = \frac{|t - (w・x + b)|}{\sqrt{w^2 + 1}} $$
これは数学IIで習った点と直線の距離の公式を変形した形になっていて、これを適用することにより、距離の大きさを誤差として極小値に近づけるよう学習をしていく。
点と直線の距離の公式
https://ja.wikipedia.org/wiki/%E7%82%B9%E3%81%A8%E7%9B%B4%E7%B7%9A%E3%81%AE%E8%B7%9D%E9%9B%A2以下TensorFlowによるコード
demming_numerator = tf.abs(tf.subtract(y_target , tf.add(tf.matmul(x_data, A), b))) demming_demoinator = tf.sqrt(tf.add(tf.square(A), 1)) loss = tf.reduce_mean(tf.truediv(demming_numerator, demming_demoinator))
- 投稿日:2019-07-08T15:37:37+09:00
線形回帰4
はじめに
これは筆者の勉強まとめページですので、指摘しまくってい頂けると幸いです
デミング回帰
今回は https://qiita.com/raso0527/items/ba4bef9b1271428afbfc の記事のコードの損失関数を改良して学習をする
デミング回帰も線形回帰の一種で、損失関数を以下のように設定したもの
$$ loss = \frac{|t - (w・x + b)|}{\sqrt{w^2 + 1}} $$
これは数学IIで習った点と直線の距離の公式を変形した形になっていて、これを適用することにより、距離の大きさを誤差として極小値に近づけるよう学習をしていく。
点と直線の距離の公式
https://ja.wikipedia.org/wiki/%E7%82%B9%E3%81%A8%E7%9B%B4%E7%B7%9A%E3%81%AE%E8%B7%9D%E9%9B%A2以下TensorFlowによるコード
demming_numerator = tf.abs(tf.subtract(y_target , tf.add(tf.matmul(x_data, A), b))) demming_demoinator = tf.sqrt(tf.add(tf.square(A), 1)) loss = tf.reduce_mean(tf.truediv(demming_numerator, demming_demoinator))
- 投稿日:2019-07-08T14:29:23+09:00
TensorFlowLiteで1枚の画像の物体認識するたぶん最小構成 for Android
はじめに
前にTensorFlow Mobileでの物体認識はやったんですが、今やるならTensorFlowLiteでしょうということでやってみた
検証環境
- Android Studio 3.2.1
- CompileSdkVersion:28
- MinSdkVersion:18
- TargetSdkVersion:28
- TensorFlowLite
プロジェクト作成
まずはプロジェクトの作成お好きなプロジェクト名で
minumum SDKはAPI 18未満だとエラーが出るんで、18以上を選択
初期Activityは何でもいいですが、ここでは最小構成ということでEmpty Activity
build.gradleの設定
build.gradle(app)apply plugin: 'com.android.application' android { compileSdkVersion 28 defaultConfig { applicationId "com.anadreline.android.peopleaicounter" minSdkVersion 18 targetSdkVersion 28 versionCode 1 versionName "1.0" testInstrumentationRunner "android.support.test.runner.AndroidJUnitRunner" } buildTypes { release { minifyEnabled false proguardFiles getDefaultProguardFile('proguard-android.txt'), 'proguard-rules.pro' } } aaptOptions { noCompress "tflite" } } dependencies { implementation fileTree(dir: 'libs', include: ['*.jar']) implementation 'com.android.support:appcompat-v7:28.0.0' implementation 'com.android.support.constraint:constraint-layout:1.1.3' implementation 'org.tensorflow:tensorflow-lite:0.0.0-nightly' implementation 'org.tensorflow:tensorflow-lite-gpu:0.0.0-nightly' testImplementation 'junit:junit:4.12' androidTestImplementation 'com.android.support.test:runner:1.0.2' androidTestImplementation 'com.android.support.test.espresso:espresso-core:3.0.2' }ポイントは2つだけ
TensorFlowLiteの依存設定と
implementation 'org.tensorflow:tensorflow-lite:0.0.0-nightly'
implementation 'org.tensorflow:tensorflow-lite-gpu:0.0.0-nightly'
tfliteファイルを圧縮させないためのnoCompress設定
aaptOptions {
noCompress "tflite"
}認識関連クラス
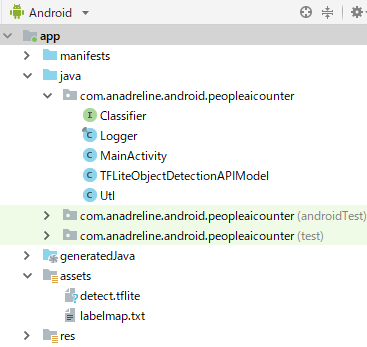
公式のサンプルからClassifier.javaとTensorFlowObjectDetectionAPIModel.javaとLogger.javaの3つ
それにassetsフォルダに公式サイトのモデルファイル(detect.tflite)とラベルファイル(label_map.txt)を入れますレイアウト
あとは画像選択させるためMainActivityにボタンを設置してー
activity_main.xml<?xml version="1.0" encoding="utf-8"?> <android.support.constraint.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:app="http://schemas.android.com/apk/res-auto" xmlns:tools="http://schemas.android.com/tools" android:layout_width="match_parent" android:layout_height="match_parent" tools:context=".MainActivity"> <Button android:layout_width="wrap_content" android:layout_height="wrap_content" android:text="Detect" android:onClick="onClick" app:layout_constraintBottom_toBottomOf="parent" app:layout_constraintLeft_toLeftOf="parent" app:layout_constraintRight_toRightOf="parent" app:layout_constraintTop_toTopOf="parent" /> </android.support.constraint.ConstraintLayout>物体認識
最後に画像を取得して認識する処理を作成して完成
MainActivity.javapackage com.anadreline.android.objectdetection; import android.content.Intent; import android.graphics.Bitmap; import android.graphics.Canvas; import android.graphics.Paint; import android.graphics.Rect; import android.net.Uri; import android.os.Build; import android.os.Bundle; import android.support.v7.app.AppCompatActivity; import android.util.Log; import android.view.View; import android.widget.Toast; import java.io.IOException; import java.util.List; public class MainActivity extends AppCompatActivity { private static final int TF_OD_API_INPUT_SIZE = 300; private static final boolean TF_OD_API_IS_QUANTIZED = true; private static final String TF_OD_API_MODEL_FILE = "detect.tflite"; private static final String TF_OD_API_LABELS_FILE = "file:///android_asset/labelmap.txt"; private final int REQUEST_FILE = 1; private final int REQUEST_CAMERA = 2; @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); } public void onClick(View view) { Intent intentGallery; if (Build.VERSION.SDK_INT < 19) { intentGallery = new Intent(Intent.ACTION_GET_CONTENT); intentGallery.setType("image/*"); } else { intentGallery = new Intent(Intent.ACTION_OPEN_DOCUMENT); intentGallery.addCategory(Intent.CATEGORY_OPENABLE); intentGallery.setType("image/*"); } startActivityForResult(intentGallery, REQUEST_FILE); } @Override protected void onActivityResult(int requestCode, int resultCode, Intent data) { super.onActivityResult(requestCode, resultCode, data); if (resultCode == RESULT_OK) { Uri resultUri = data.getData(); if (resultUri == null) { return;} Bitmap image = Utl.decodeUri(this, resultUri, 1200, 0); int height = image.getHeight(); int width = image.getWidth(); Bitmap crop = Bitmap.createBitmap(TF_OD_API_INPUT_SIZE, TF_OD_API_INPUT_SIZE, Bitmap.Config.ARGB_8888); Canvas canvas = new Canvas(crop); canvas.drawBitmap(image, new Rect(0, 0, width, height), new Rect(0, 0, TF_OD_API_INPUT_SIZE, TF_OD_API_INPUT_SIZE), new Paint()); try { Classifier detector = TFLiteObjectDetectionAPIModel.create( getAssets(), TF_OD_API_MODEL_FILE, TF_OD_API_LABELS_FILE, TF_OD_API_INPUT_SIZE, TF_OD_API_IS_QUANTIZED); final List<Classifier.Recognition> results = detector.recognizeImage(crop); for (final Classifier.Recognition result : results) { Log.v("Detect", "Title:" + result.getTitle()); Log.v("Detect", "Confidence:" + result.getConfidence()); Log.v("Detect", "Location:" + result.getLocation()); } } catch (final IOException e) { e.printStackTrace(); Toast toast = Toast.makeText(getApplicationContext(), "Classifier could not be initialized", Toast.LENGTH_SHORT); toast.show(); finish(); } } } }ここでのポイントは認識クラスに投げる画像は決められたサイズにする必要があること
上記のこのへんで変形してますMainActivity.java//TF_OD_API_INPUT_SIZE=300; Bitmap crop = Bitmap.createBitmap(TF_OD_API_INPUT_SIZE, TF_OD_API_INPUT_SIZE, Bitmap.Config.ARGB_8888); Canvas canvas = new Canvas(crop); canvas.drawBitmap(image, new Rect(0, 0, width, height), new Rect(0, 0, TF_OD_API_INPUT_SIZE, TF_OD_API_INPUT_SIZE), new Paint());以上TensorFlowLiteによる物体認識のたぶん最小構成
- 投稿日:2019-07-08T12:27:11+09:00
GANを活用した3Dマルチオブジェクトの生成モデル
今更ながら私がVisiting Scholarでやっていた研究を日本語版で投稿します。
この内容は約2年前(2017年9月)のMediumを日本語訳した内容です。
Githubのソースコードはコチラです。
Fully Convolutional Refined Auto-Encoding Generative Adversarial Networks for 3D Multi Object Scenes
-Special thanks to Christopher Choy and Prof. Silvio Savarese, and Stanford Vision and Learning Lab.
Introduction
GAN(Generative Adversarial Networks)やVAE(Variational Auto-Encoder)を活用した生成モデルは、ディープラーニングやコンピュータービジョンの領域で非常に注目されているテーマの一つである。これらの生成モデルは、高品質の生成を可能にするだけでなく、表現学習や特徴量抽出、さらには潜在空間を活用した認識タスクなどへの応用可能性を秘めている。
特に今回は3Dマルチオブジェクトの生成モデルに注目した。3Dマルチオブジェクトの生成モデルは、多様な新規の3Dオブジェクトを生成でき、かつ、オブジェクト種類、形状やレイアウトを潜在空間として表現することができる。このような3Dマルチオブジェクトの生成モデルは、AR/VR,グラフィクスの領域で極めて重要なタスクになると考えられる。
ただ、3Dの生成モデルはいまだに発展途上である。(2年後の今はRGBD->3Dや、3D Completionなどのタスクで活用されるようになってきました。) 単一オブジェクトの基本的な生成モデル[1][2] はあるが、マルチオブジェクトはない。
そこで、本研究では、End to Endで新規のGANsアーキテクチャを活用して、3Dマルチオブジェクトの生成モデルに取り組んだ。Dataset
正解のVoxelデータとして、SUNCG Datasetを活用した[3]。
SUNCGデータセットを、以下のように変更した。
- 240x144x240から80x48x80に圧縮。
- カメラアングルによるトリミングを削除。
- Empty以外のクラスが10000voxel以上存在するシーンのみを抽出。結果、12のクラスをもつ185K以上のシーンが集まった。
12クラス:empty, ceiling, floor, wall, window, chair, bed, sofa, table, tvs, furn, objs
このデータセットは平均92%のVoxelがEmptyクラスであり、非常にスパースである。さらに、リビング、風呂場、寝室、ダイニング、ガレージ等シーンの種類は多種多様であるため、非常に難易度の高いデータセットとなっている。
Models
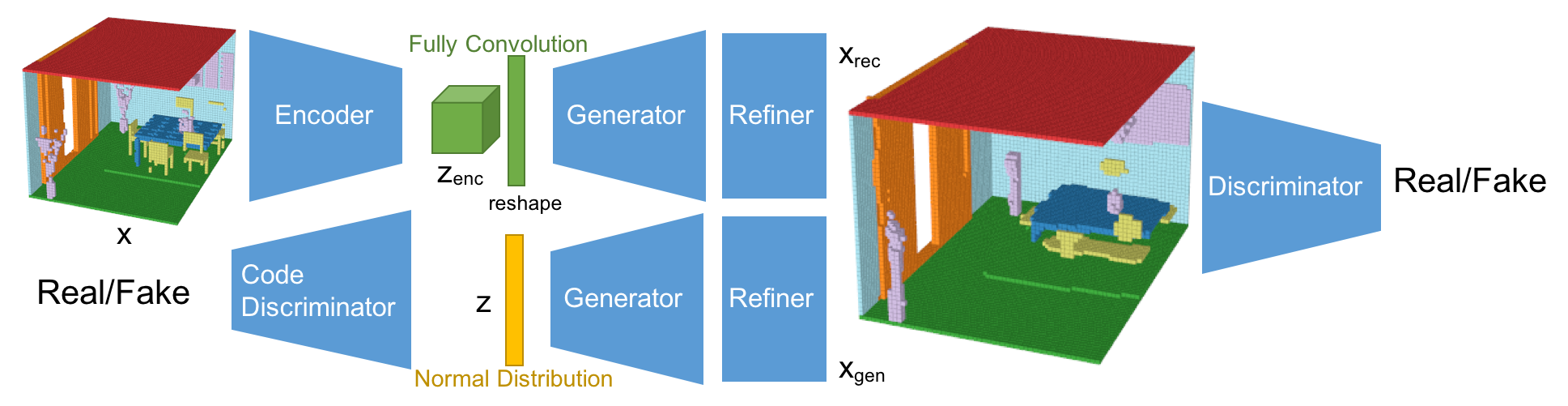
ネットワーク構造
今回のネットワーク構造は、Fully Convolutional Refined Auto-Encoding Generative Adversarial Networksである。3DGAN[1], alphaGAN[4], SimGAN[5]を参考にしている。そして、Fully Convolutional Layerとマルチオブジェクトの分類が生成モデルとしては新規の構造となる。
このネットワークは、VAEとGANの構造を混合させている。VAEで使われるKLダイバージェンスロスは、alphaGANの構造のように、code discriminatorとしてAAE(Adversarial Auto-Encoder)構造に置き換えている[4]。 加えて、生成されたシーンはRefinerによってより綺麗な形になるようにしている[5]。 今回、潜在空間は5x3x5x16としており、これはFully Convolutional Layerによって算出されている。Fully Convolution構造は、セマンティックセグメンテーションのタスクで使われるように、特徴量をより厳密に取り出すことができる。結果として、Fully Convolution構造は再構成の性能を向上させている。また、AAE構造は、分布への制約条件を緩め、分布をより潜在的に扱うことができるようになり、再構成と生成の性能を向上させることができている。また、Refinerはオブジェクトの形状をスムーズにして、よりリアルな見た目にする効果がある。
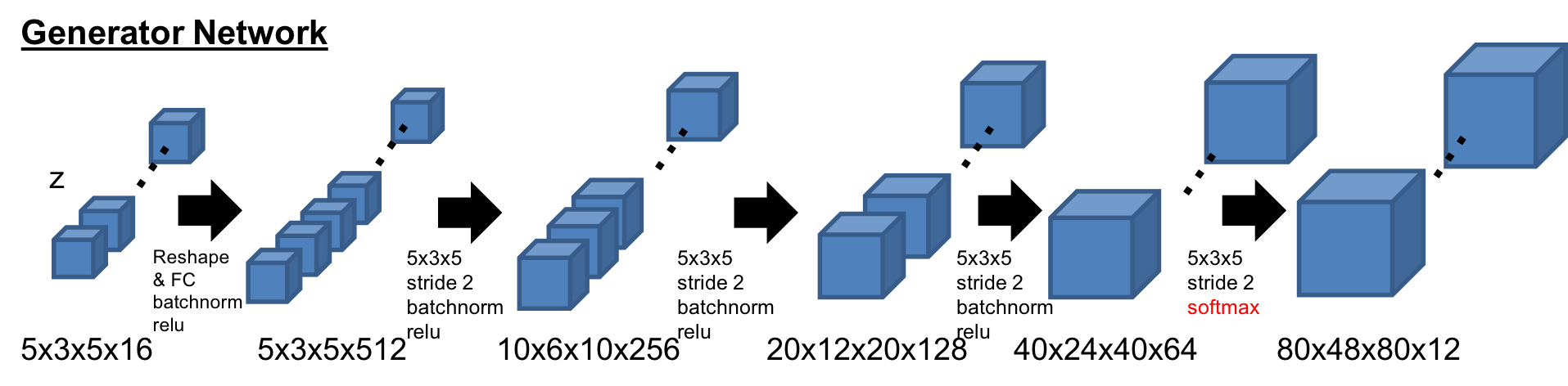
-Encoder
Encoderの基本構造は3DGAN[1]のDiscriminatorネットワークを踏襲している。最後のレイヤーが1x1x1のFully Convolution層のところが違いである。
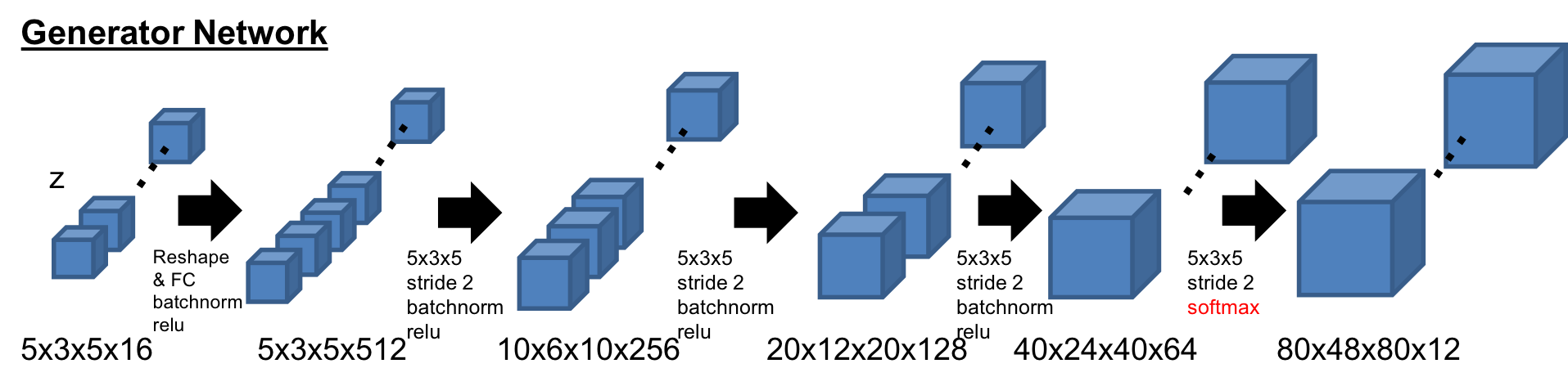
-Generator
Generatorの基本構造も同様に3DGAN[1]の構造。最後のレイヤーが12チャンネルになっており、Softmaxで活性化されている。また、最初の潜在空間は展開させている。
-Discriminator
Discriminatorの基本構造も同様に3DGAN[1]の構造。ただ、活性化の前にはLayer Normalizationを活用している。
-Code Discriminator
潜在空間の分布を判定するCode discriminatorは、alphaGAN[4]と同様の構造で、750次元の2層の隠れ層を持つ。
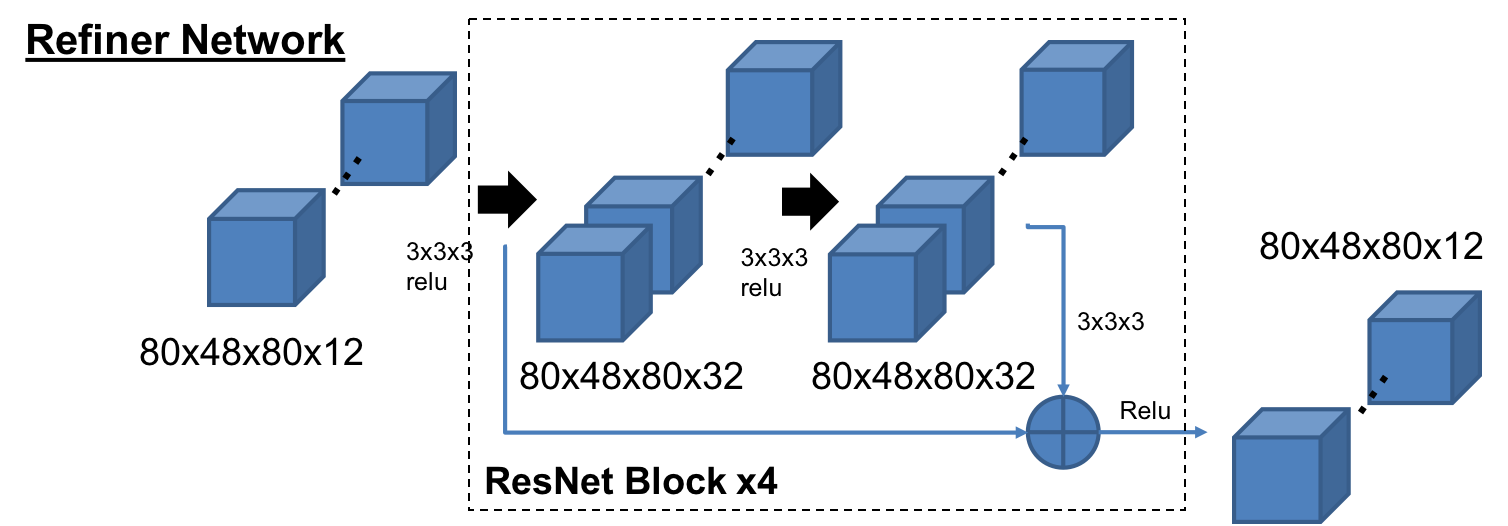
-Refiner
RefinerはSimGAN[5]の構造をベースにしており、4つのResNetブロックで構成されている。メモリーの負荷を減らすため、チャネル数は32にしている。
Loss Functions
ロス関数は、基本的には再構成のロス(Reconstruction Loss)、生成されたオブジェクトのGANロス(GAN Loss)、AAE構造の分布に対するGANロス(Distribution GAN Loss)で構成されている。
Reconstruction loss
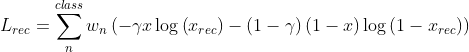
は小さいオブジェクトのロスを埋もれさせないため、バッチごとのオブジェクトの専有率で正規化された重みである。
はスパースな空間でPositiveなVoxel(1)のロスの重みを調整するハイパーパラメータである。
GAN loss
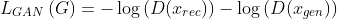
Distribution GAN loss
Optimization
各ネットワーク構造ごとに以下のロス関数を使って学習する。
Encoder
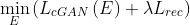
Generator and Refiner
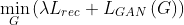
Discriminator
Code Discriminator
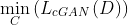
は再構成ロスの重み。
Experiments
それぞれのネットワーク構造に置いて、OptimizerにAdamを使い、Learning Rateは0.0001とした。まず、Refinerなして75000 iterationトレーニングを行い、その後Refienerを追加し、さらに25000 iterationを実行した。初めのトレーニングはバッチサイズ20、Refiner込みのトレーニングはバッチサイズ8とした。また、GPUにはNVIDIA GeForce GTX TITAN Xを活用した。
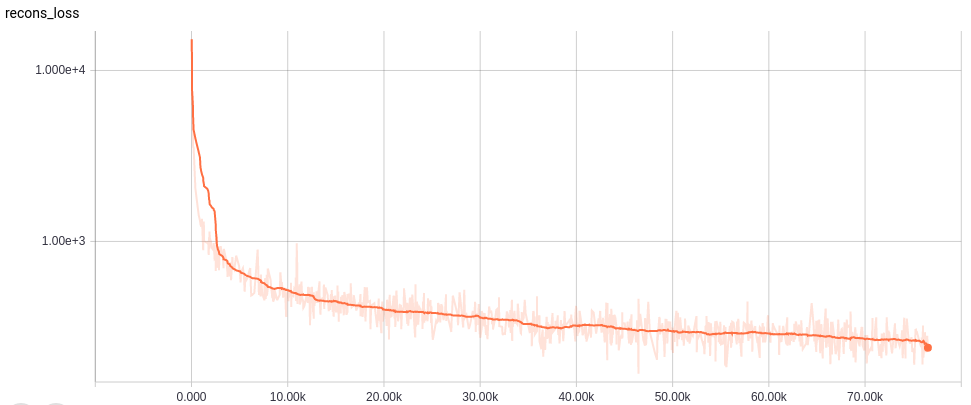
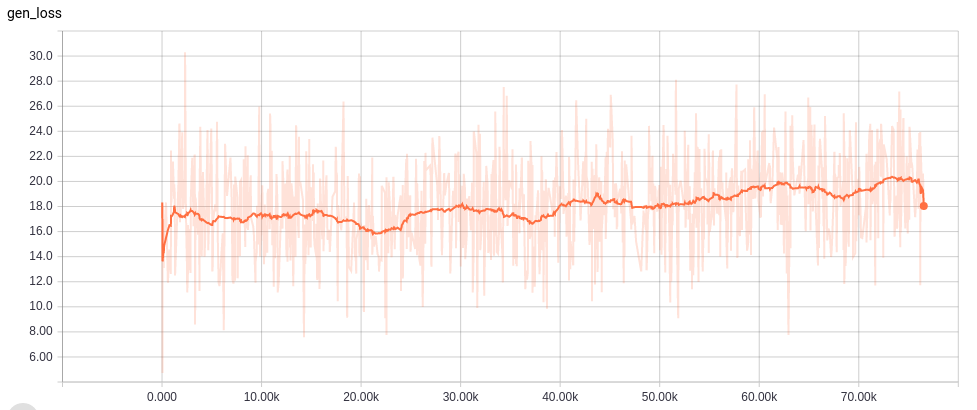
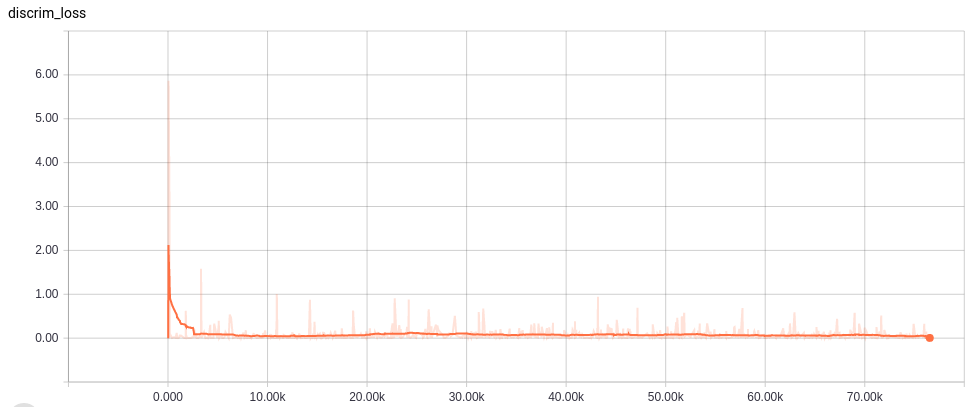
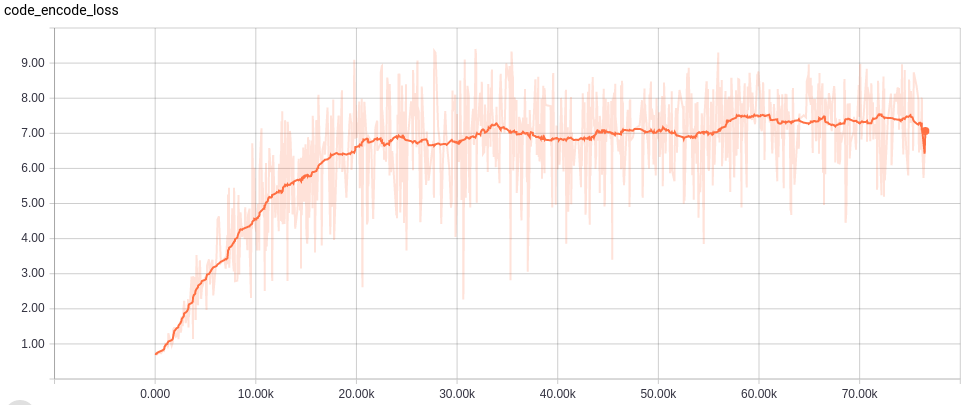
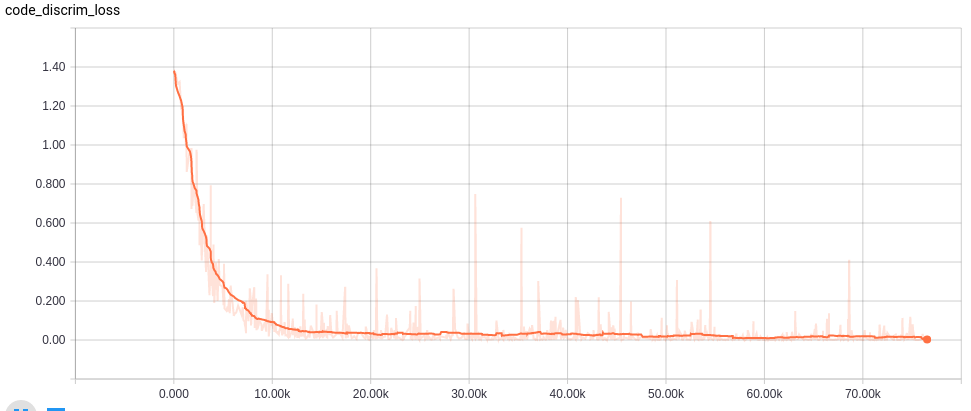
Learning curves
各ネットワークの学習カーブは以下。
Visualization
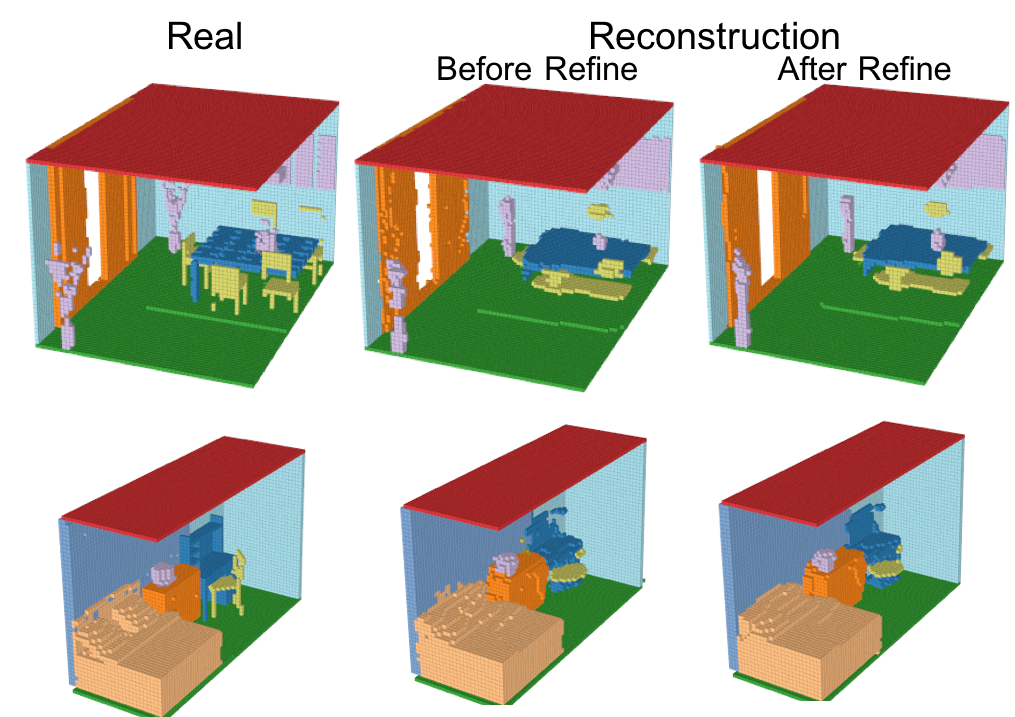
-Reconstruction
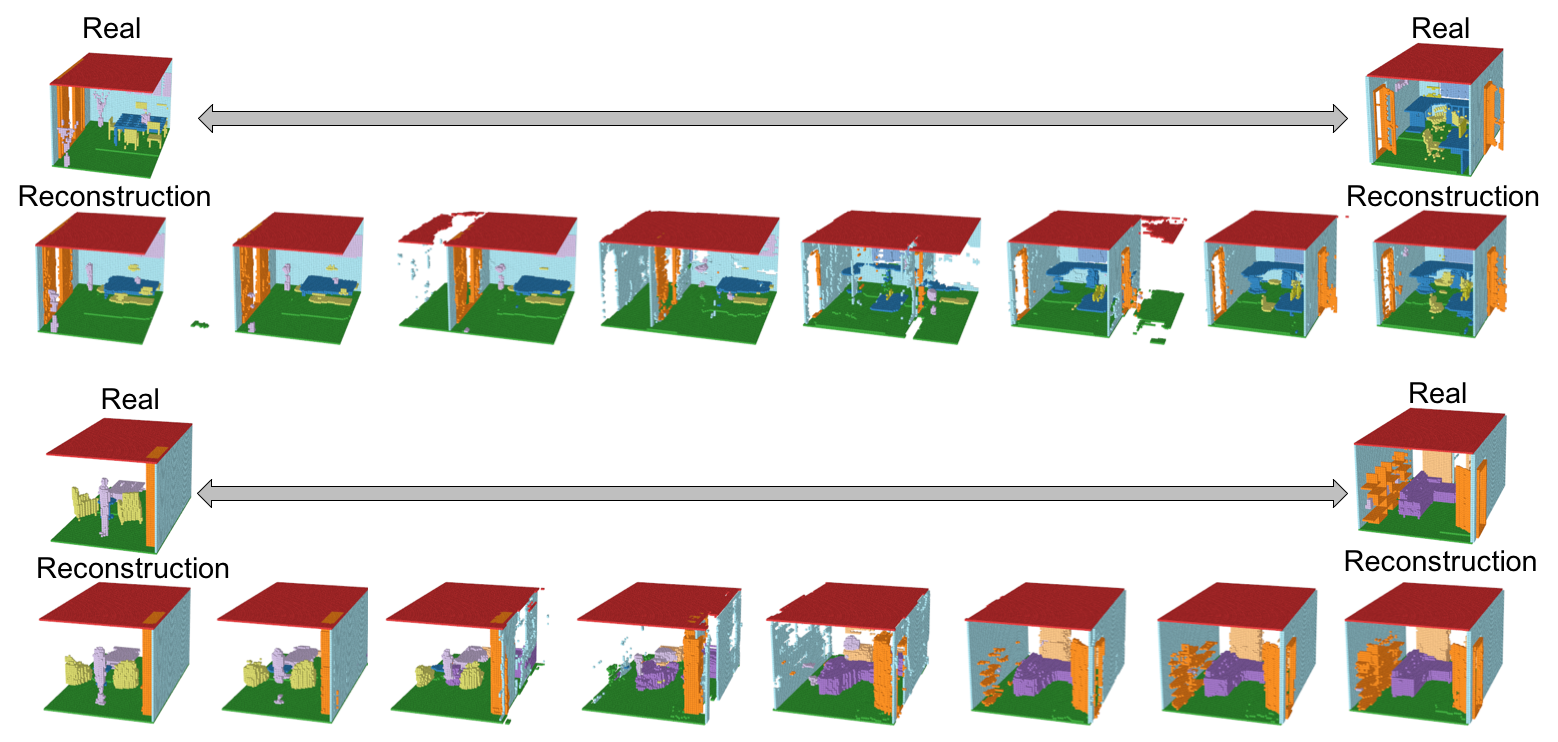
Encoder、Generator、Refinerを活用して再構成したシーンの結果を以下に示す。
小さいオブジェクトは消えてしまっているものの、多くのVoxelは再構成されている。さらに、Refinerによってよりリアルなシーンに再構成されている。IoUとmAPを使った定量評価は後述する。
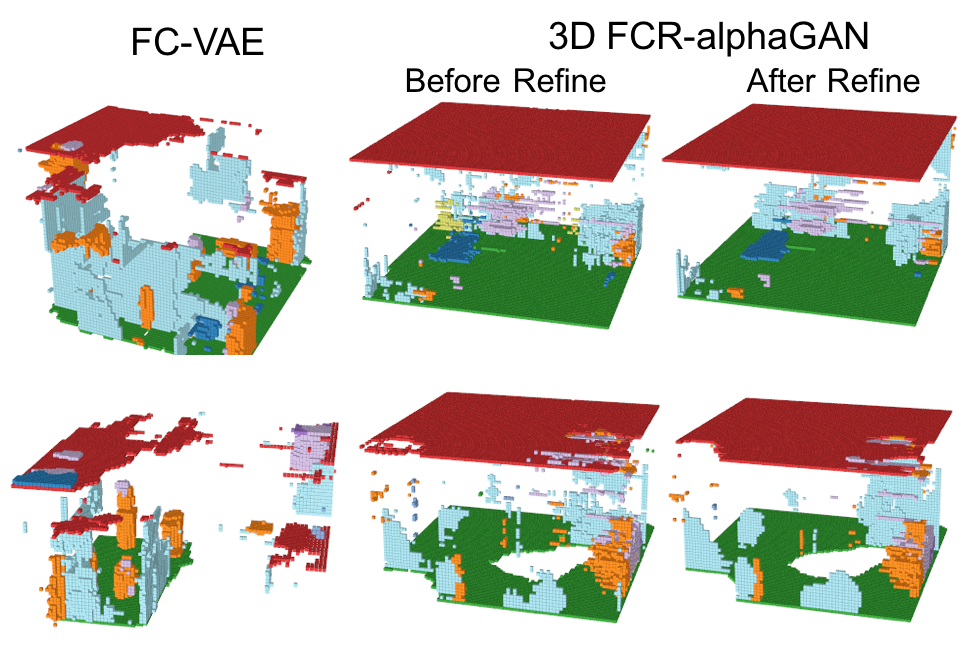
-Generation from normal distribution
GeneratorとRefinerを活用した標準分布からの生成の結果を以下に示す。
このように、FCR-alphaGANの構造は、通常のFully Convolutional VAEに比べて生成のクオリティが上がっているが、その表現能力は十分とは言えない。これは、Encoderにより生成される分布が、標準分布に分散できていないこと、データセットのスパース性やマルチオブジェクトにより、非常に複雑な潜在空間が想定されることが考えられる。潜在空間をレイアウトとオブジェクトに分離することでこの問題を解決できるかもしれない。Reconstruction Performance
再構成の定量的な評価を以下に示す。
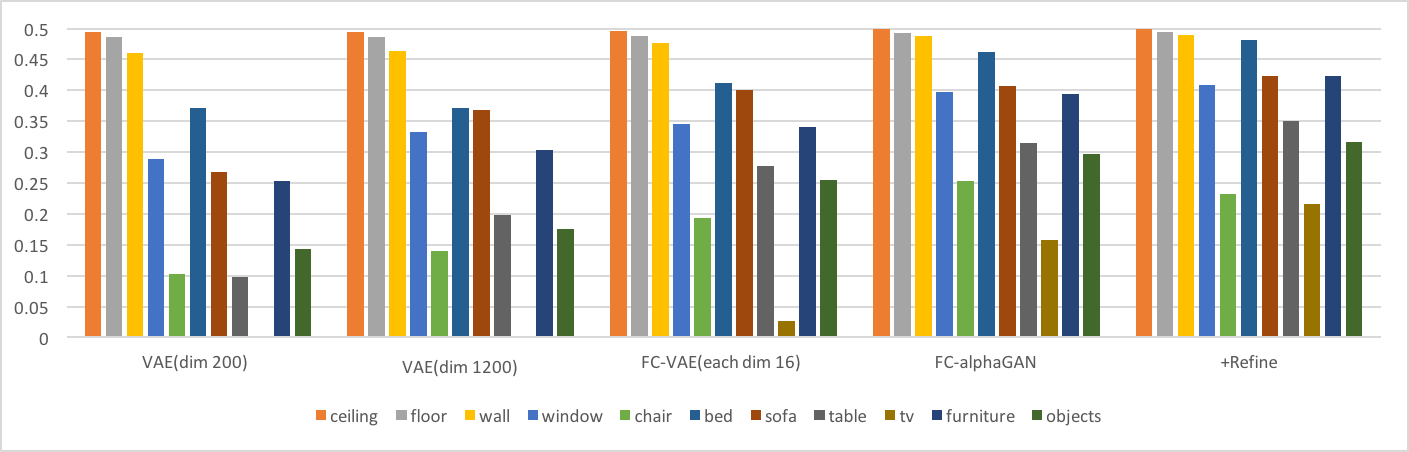
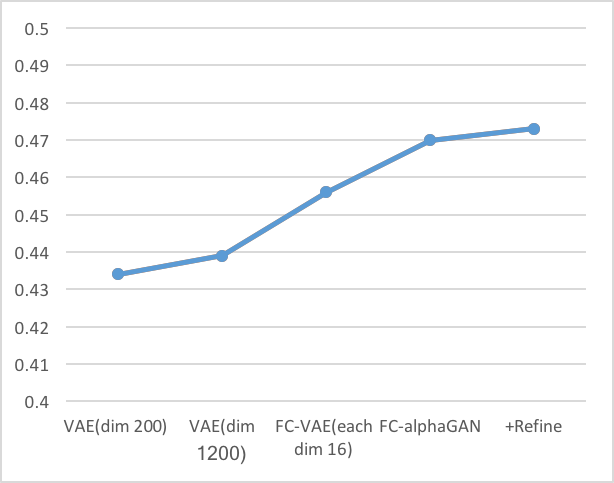
-Intersection over Union(IoU)
以下の棒グラフは、それぞれのクラスのIoU性能を示す。折れ線グラフはオーバーオールでの結果である。(IoUの定義は[6]参照)
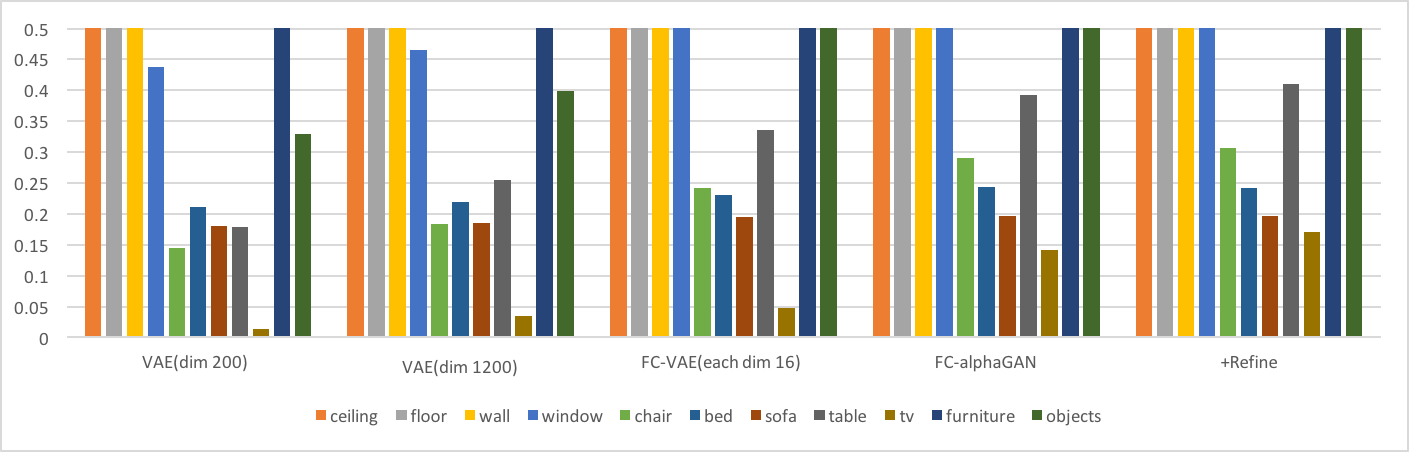
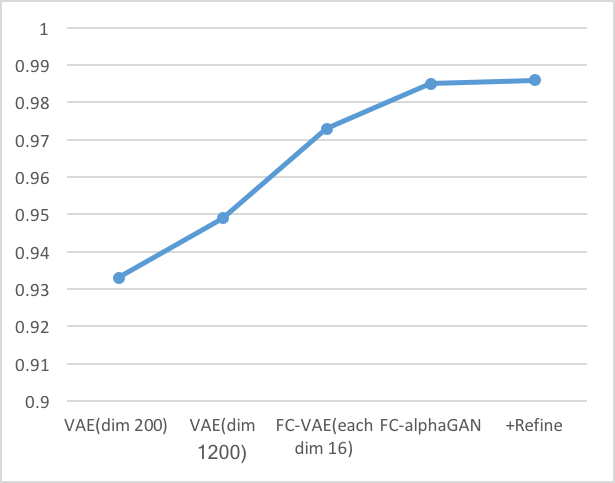
-mean Average Precision(mAP)
IoUと同様にmAPの棒グラフと折れ線グラフを以下に示す。
これらの結果より以下の考察ができる。
- 同じ潜在空間の次元数を持つVAE(dim1200)とFC-VAE(each dim16)の比較からわかるように、Fully Convolutionは再構成性能を向上させている。
- AlphaGAN構造が再構成性能の向上に貢献している。
Evaluations
Interpolation
Interpolation(潜在空間の遷移)の結果を以下に示す。(遷移のgif画像はトップに示している)
シーン間の潜在空間の遷移は、流れるように移行している。ただし、遷移間のシーンも意味のあるシーンとして保たれておらず、シーンが破壊されてしまっているため、本来期待したManifoldが作られているとは言い難い。マルチオブジェクトの難易度の高さが見て取れる。
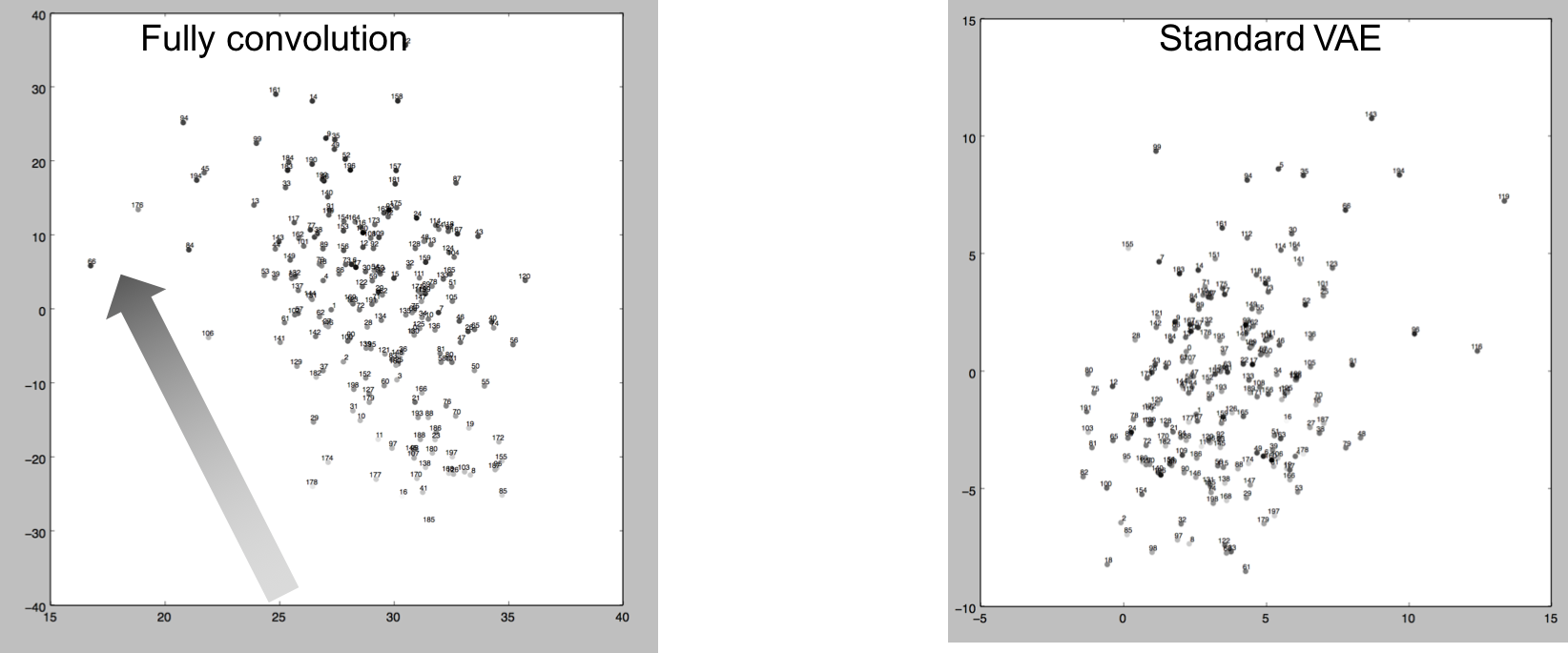
Interpretation of latent space
以下に、エンコーダーによりエンコードされた200サンプルを、SVDにより2Dマップしたグラフを示す。プロットのグレースケールは、各シーンの重心座標をSVDにより1Dに落とした数値を示している。左がFully Convolution、右が1200次元の通常のVAEベクトルである。
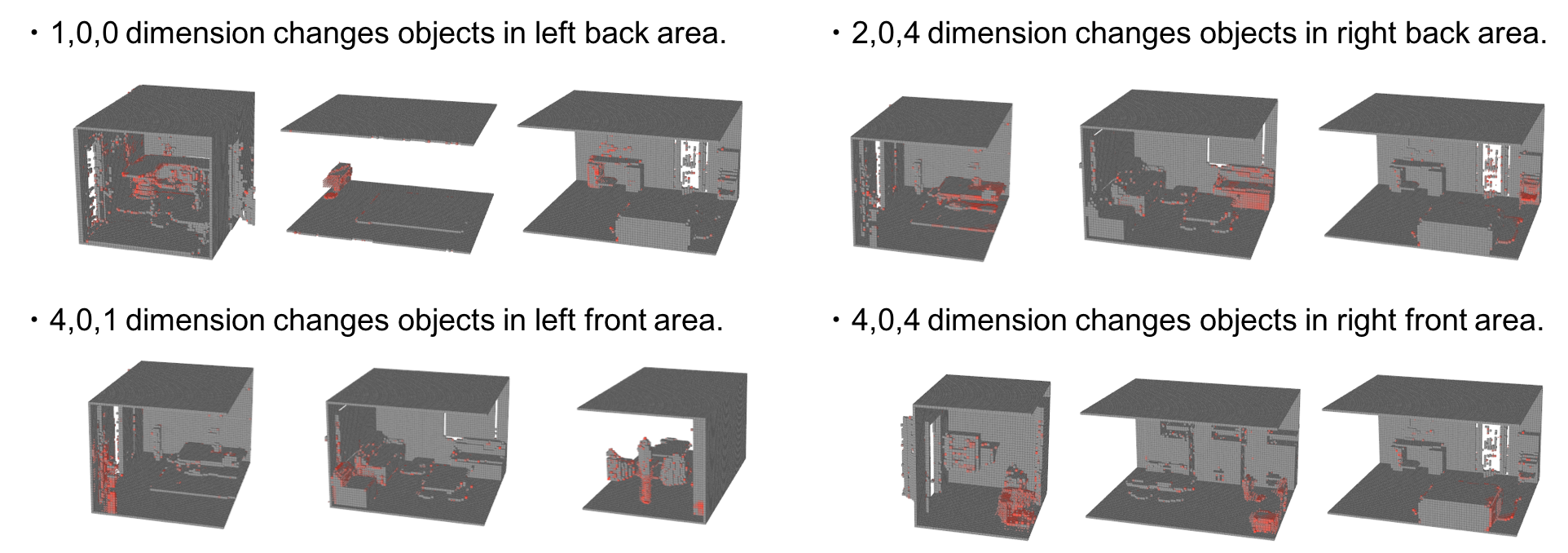
Fully Convolutionによる分布は、重心座標の1Dエンべディングに習って、右下から左上へ繊維していることがわかる。これは、Fully Convlution構造による潜在空間が通常のVAEと比べて空間的な意味合いに関係付けられていることを意味している。以下の図は、5x3x5の潜在空間の各次元の影響を表現している。個々の次元に標準分布のノイズを与えて、それが生成されたシーンへ及ぼす影響を、赤色の濃度で表現している。
この結果より、潜在空間の各次元が生成されるシーンの特定の位置に集中して変化させていることを意味しており、Fully Convolution構造が空間的な情報を潜在空間に表現していることを示している。
Suggestions of future work
-Revise the dataset
前述した通り、このデータセットは非常にスパースで、たくさんのシーンの種類が存在している。床や小さい構造は様々な位置に配置されており、椅子の足のような小さいパーツはダウンサイジングによって破壊されている。これらは潜在空間の予測を非常に難しくしている。
そのため、さらなる精度向上のためには、オブジェクトのポジションの調整や、種類の限定、ダウンサイジングの方法の変更など、データセットを再考することが必要と考えられる。-Redefine the latent space
今回は、潜在空間を形状やオブジェクトの位置など全ての情報を含む1つの空間として定義した。そのため、いくつかの小さいオブジェクトは生成モデルでは消えてしまうことも多く、たくさんのリアリティに欠けるオブジェクトが生成された。これを解決するために、レイアウトと各オブジェクトの情報を潜在空間として分割するなど、潜在空間の再定義が重要と考えられる。ただし、1つのオブジェクトクラスの中でも、1つのシーンに複数のオブジェクト種類があったり、オブジェクトの個数の増減を考慮する必要が出てくるため、クラス間の文脈の考慮も必要であると考えられ、課題である。
References
[1]Jiajun Wu, Chengkai Zhang, Tianfan Xue, William T. Freeman, Joshua B. Tenenbaum; Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling; arXiv:1610.07584v1
[2]Andrew Brock, Theodore Lim, J.M. Ritchie, Nick Weston; Generative and Discriminative Voxel Modeling with Convolutional Neural Networks; arXiv:1608.04236v2
[3]Shuran Song, Fisher Yu, Andy Zeng, Angel X. Chang, Manolis Savva, Thomas Funkhouser; Semantic Scene Completion from a Single Depth Image; arXiv:1611.08974v1
[4]Mihaela Rosca, Balaji Lakshminarayanan, David Warde-Farley, Shakir Mohamed; Variational Approaches for Auto-Encoding Generative Adversarial Networks; arXiv:1706.04987v1
[5]Ashish Shrivastava, Tomas Pfister, Oncel Tuzel, Josh Susskind, Wenda Wang, Russ Webb; Learning from Simulated and Unsupervised Images through Adversarial Training; arXiv:1612.07828v1
[6]Christopher B. Choy, Danfei Xu, JunYoung Gwak, Kevin Chen, Silvio Savarese; 3D-R2N2: A Unified Approach for Single and
Multi-view 3D Object Reconstruction; arXiv:1604.00449v1
以上でした。
2016~2017年当時、DCGANが有名になり、mode collapseの問題がいまだ大きな課題で、毎日のようにGAN関連論文が出て手法がアップデートされていました。GANへの理解も乏しい中で、色々あって3Dのマルチオブジェクトの生成モデルというテーマに挑戦したのですが、想像していた以上に難易度が高く、後から思い返すと「こうしておけばよかった」と後悔することも多いのです。(初めはノイズしか生成されてこなくて、どうしようかと思っていました。) この研究はまだまだ課題も多く、志半ばで終了してしまいましたが、GANや生成モデルについて実践的で最高の経験でした。


- 投稿日:2019-07-08T11:51:16+09:00
TensorFlowのhe_normalとtruncated_normalは標準偏差が違う
CNNの重み初期化にHeの初期値を使おうと思ったら、TensorFlow(Keras)の
tf.initializers.he_normalを使う場合とtf.initializers.truncated_normalで学習結果が異なったので調べた話。環境
- Python 3.7.3
- TensorFlow 1.14.0
- numpy 1.16.2
- matplotlib 3.0.3
Heの初期値
Heの初期値とは、活性化関数にReLUを使用するニューラルネットワークにおいて学習がうまく進むような重みの初期値の決め方で、Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classificationという論文の中で示されています。
この論文以前にXavierの初期値と呼ばれる重み初期化が提唱されていましたが、近年一般的なReLUや畳み込みニューラルネットワークに適していなかったことが背景にあります。導出等は論文を参照していただくとして、結果はとてもシンプルで
Var = \frac{2}{N_{in}}を満たす分散の正規分布から重みの初期値をサンプリングする、というものです。ここで$N_{in}$は重みの入力次元で、全結合層なら入力要素数、2次元の畳み込みならフィルターサイズと入力チャンネル数の積です。
現在ではReLUは標準的な活性化関数で、畳み込みニューラルネットワークも非常によく使われるということもあり、Heの初期値は重み初期化のスタンダードとなっています。TensorFlow(Keras)で使う
tf.initializers.he_normalを使うTensorFlowではHeの初期値が
tf.initializers.he_normalとして実装されていて、簡単に使うことができます。# tensorflowの場合 W_shape = [filter_row, filter_col, ch_in, ch_out] initializer = tf.initializers.he_normal() W = tf.get_variable(name='W', shape=W_shape, initializer=initializer) h = tf.nn.conv2d(input, W, padding='SAME') # kerasの場合 initializer = tf.initializers.he_normal() h = K.layers.Conv2D(ch_out, [filter_row, filter_col], kernel_initializer=initializer)(input)ただし、
tf.initializers.he_normalは通常の正規分布ではなく、標準偏差の2倍でカットした切断正規分布からサンプリングする点に注意が必要です。
tf.initializers.truncated_normalから計算する
tf.initializers.he_normalを使わない場合は以下のようになります。公式実装に合わせて切断正規分布からサンプリングしています。W_shape = [filter_row, filter_col, ch_in, ch_out] stddev = (2 / (filter_row * filter_col * ch_in)) ** 0.5 initializer = tf.initializers.truncated_normal(mean=0.0, stddev=stddev) W = tf.get_variable(name='W', shape=W_shape, initializer=initializer) h = tf.nn.conv2d(input, W, padding='SAME')2つのパターンを比較
tf.initializers.he_normalとtf.initializers.truncated_normalの分布を比較してみます。簡単のため、重みは全結合層を想定しています。また、標準偏差が1となることを期待して$N_{in}$を2としています。import numpy as np import tensorflow as tf import matplotlib.pyplot as plt shape = [2, 50000] seed = 1 # he_normalを使う場合 initializer = tf.initializers.he_normal(seed=seed) tf_W = tf.get_variable(name='he_normal', shape=shape, initializer=initializer) # truncated_normalを使う場合 stddev = (2 / shape[0]) ** 0.5 initializer = tf.initializers.truncated_normal(mean=0.0, stddev=stddev, seed=seed) my_W = tf.get_variable(name='my_he_normal', shape=shape, initializer=initializer) # 結果を比較 init = tf.global_variables_initializer() with tf.Session() as sess: sess.run(init) tf_W_value = sess.run(tf_W) my_W_value = sess.run(my_W) bins = np.arange(-3.0, 3.0, 0.2) plt.figure() plt.hist(tf_W_value.flatten(), bins=bins, label='he_normal') plt.hist(my_W_value.flatten(), bins=bins, label='truncated_normal') plt.legend() plt.show()
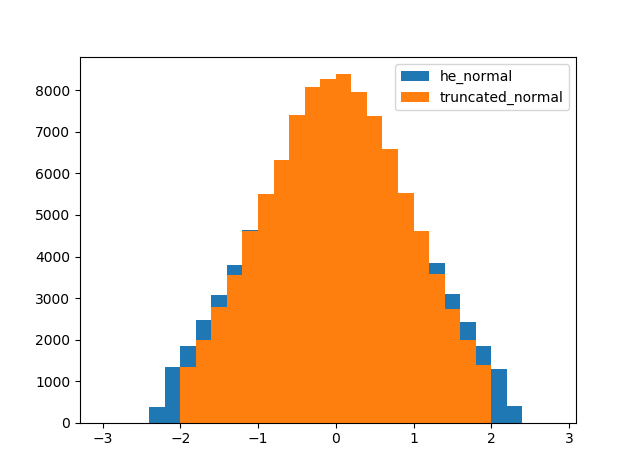
あれ…? 分布の裾がおかしいですね。
原因
公式のドキュメントを読んで違いが生まれる原因を探ります。
tf.initializers.he_normalのドキュメントを読むkeras公式では大した記述はありません。しかし、tensorflow公式では
It draws samples from a truncated normal distribution centered on 0 with standard deviation (after truncation) given by stddev = sqrt(2 / fan_in) where fan_in is the number of input units in the weight tensor.
とあり、正規分布を切断後の標準偏差をスケーリングすることがわかります。
tf.initializers.truncated_normalのドキュメントを読む
tf.initializers.he_normalを使わない場合ではtf.initializers.truncated_normalの標準偏差を指定したので、ドキュメントを確認してみると、These values are similar to values from a random_normal_initializer except that values more than two standard deviations from the mean are discarded and re-drawn. This is the recommended initializer for neural network weights and filters.
とありますが、特に有益な情報はなさそう。
そこでソースコードを見てみると、中でtf.random.truncated_normalを呼び出しています。そちらのドキュメントを確認してみたところ、stddev: A 0-D Tensor or Python value of type dtype. The standard deviation of the normal distribution, before truncation.
ありました。
tf.initializers.truncated_normalでは、切断前の正規分布の標準偏差を指定するようです。まとめ
tf.initializers.he_normalでは、切断後の正規分布の標準偏差をスケーリングするのに対し、tf.initializers.truncated_normalでは、切断前の正規分布の標準偏差を指定することがわかりました。
確かに結果のヒストグラムでは、tf.initializers.truncated_normalは絶対値が2以下の範囲に収まっていて、切断前の正規分布の標準偏差が1であることがわかります。一方で、tf.initializers.he_normalは絶対値が2以下の範囲からはみ出してしまっています。
tf.initializers.he_normalは切断正規分布を1つの確立分布として考えているのに対し、tf.initializers.truncated_normalでは、切断正規分布はあくまで正規分布をカットしただけ、って考えなのかもしれません。
この違いが学習に与える影響は未知数ですが、自分で24層のCNNを作って遊んでいた時には学習曲線に明確な違いが出たので、学習がうまくいかない時はもう一方の初期化のやり方を試してみるといいかもしれません。公式ドキュメントとソースコード確認するの大事。
おまけ
tf.initializers.he_normalってどうなってんの
tf.initializers.he_normalのソースコードを追ってみると、中でtf.initializers.VarianceScalingを呼び出しています。そちらのソースコードを確認してみると…# constant taken from scipy.stats.truncnorm.std(a=-2, b=2, loc=0., scale=1.) stddev = math.sqrt(scale) / .87962566103423978 return random_ops.truncated_normal(shape, 0.0, stddev, dtype, seed=self.seed)力業で標準偏差を補正して
tf.random.truncated_normalを呼び出してますね…正規分布じゃなくて切断正規分布を使う理由って何よ
TensorFlowやTensorFlowバックエンドのKerasでは切断正規分布が標準的で、Heの初期値も切断正規分布で実装されていますが、PyTorchやChainerではそもそも切断正規分布が実装されておらず、Heの初期値は通常の正規分布で実装されているようです。
じゃあ切断正規分布を使うメリットって何よ?って話なのですが、StackOverflow等では、活性化関数にsigmoidやtanhを使う場合に、重みの初期値の絶対値が大きいと活性化関数の入力が大きくなって勾配が小さくなり、学習が遅くなってしまうことを防ぐため、との説明がありました。(明確な文献は見つけられなかったので、ご存知の方は教えていただけると嬉しいです。)
この場合、絶対値が大きい初期値を排除することが目的であり、切断後の標準偏差だと分布が広がってしまうので、切断正規分布の標準偏差は切断前の正規分布で考えるべきのように思えます。
しかし、これはあくまで活性化関数がsigmoidやtanhの場合であり、ReLUの場合には活性化関数の入力が大きくても勾配は変わらないので、この理屈は通じません。
そうなるとHeの初期値以前に、TensorFlowが切断正規分布を標準的としている意味がわかりません。
謎は深まるばかりじゃ…