- 投稿日:2019-07-01T18:08:51+09:00
究極に分かるNoise_shapeの動作
0. 概要
Dropoutの適用範囲を決めるNoise_shapeの動作であるが、以下のKerasの公式から詳細な処理を読み解くのは不可能に近い。
https://keras.io/ja/layers/core/
rate: 0と1の間の浮動小数点数.入力ユニットをドロップする割合. noise_shape: 入力と乗算されるバイナリドロップアウトマスクのshapeは1階の整数テンソルで表す.例えば入力のshapeを(batch_size, timesteps, features)とし,ドロップアウトマスクをすべてのタイムステップで同じにしたい場合,noise_shape=(batch_size, 1, features)を使うことができる. seed: random seedとして使うPythonの整数.そこで、実験的に試して分かった動作をまとめる。
1. Noise_shapeの動作
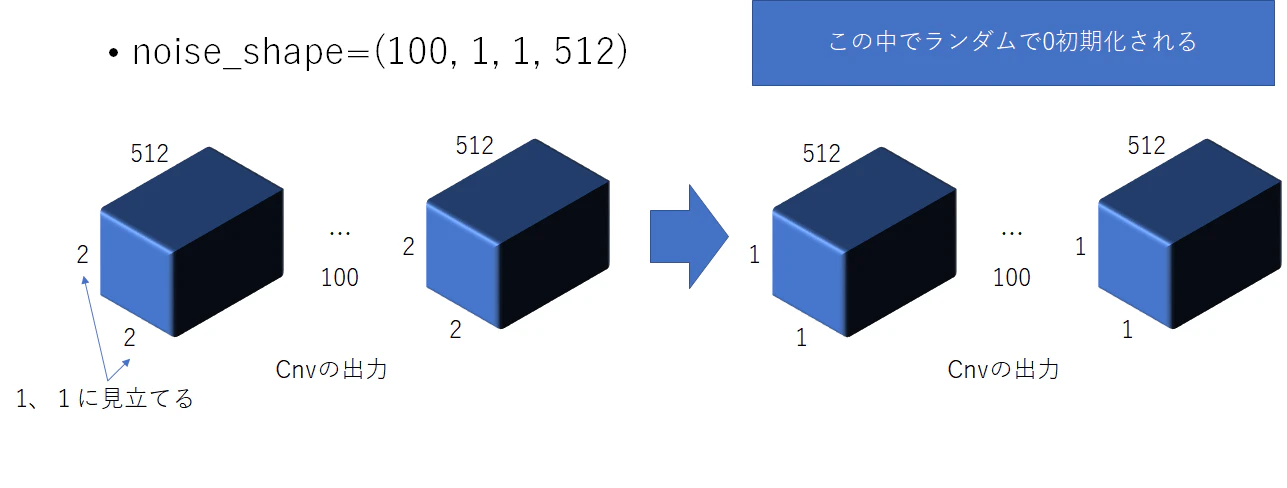
まず、CNNから出力されたShepが以下だとする。
そこでNoise_shapeを指定し、Dropoutを掛ける。
この時、1x1を指定すると、2x2を1x1のように扱ってくれる。
もう少し詳しく説明するとこんな感じである。
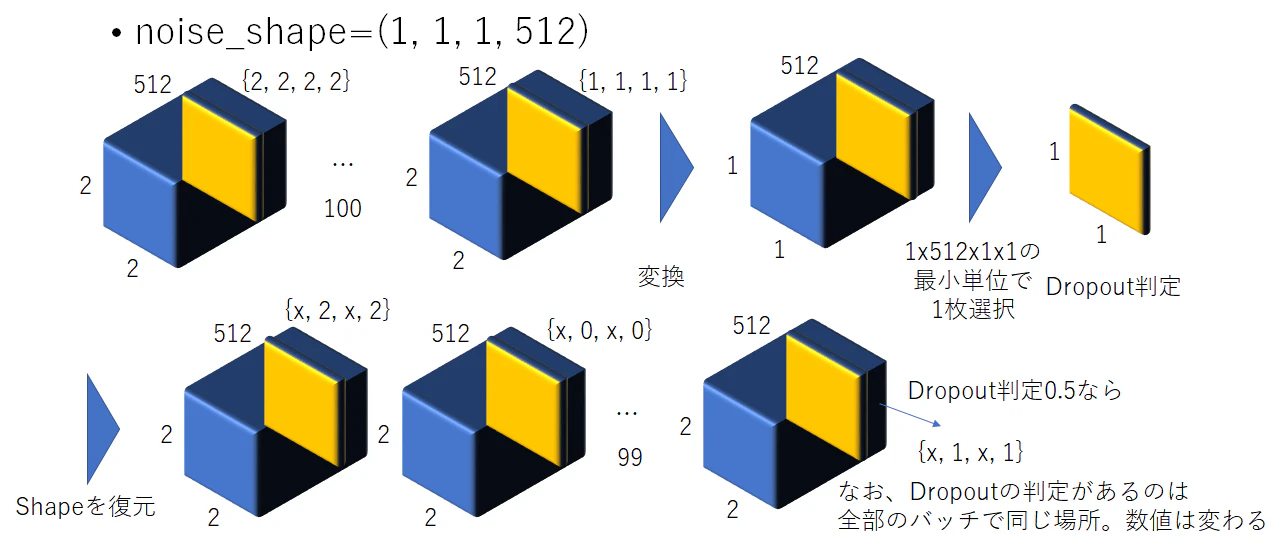
因みに2x2を指定すると、以下のように各画素に対してDropoutを設定できる。
これまではバッチサイズを入力数分確保して、独立的にDropoutを行っていたが、これを1つに見立てると以下のような感じの処理になる。
中々、慣れない表記である。



- 投稿日:2019-07-01T11:30:32+09:00
TensorFlowで音声変換
やりたいこと
TensorFlowを使って日本語文字データ→音声データへの変換を学習させたい。
1.教師データのサンプルを作成する
2.生成された学習データの特性を確認、加工する
3.文字データ→音声データへの変換を学習させる
4.少ない教師データ数、短い学習時間で効率的に学習させる方法を考える1.教師データのサンプルを作成する
素人の作る非効率な学習モデルでは、おそらく膨大な教師データが必要になると思われるので、voiceroidを自動化して大量の音声データを作成する。
使用したソフト:voiceroid2
https://www.ah-soft.net/shopbrand/ct92/アプリの実行パスに、読み上げる単語を記録したinput.txtを用意しておく。
あ あー あーうぃん あーかーと あーかいばー あーかいぶ あーかむ あーかん あーかんそー あーがー上記単語は、『現代日本語書き言葉均衡コーパス』語彙表サイトから短単位語彙表データを入手し、その「読み」の項目を使用。
https://pj.ninjal.ac.jp/corpus_center/bccwj/freq-list.html後で学習データとして使うのに便利にするため、すべての読みをひらがなに変更後、以下のようなデータを削除
・「ひとつ(数)」「ひと・・・」のように。「(」や「・」を含む単語
・「う゛」を含む単語
・sortすると先頭にくる、制御文字や記号からはじまる単語
また、学習時にはinputを固定長にする必要があるため、15文字以上の単語は一括で削除した。上記データに個人的に学習させたい固有名詞を含めた合計138423個をinput.txtに用意し、
以下のスクリプトでVOICEROID2による自動音声化を行う。自動化のために以下ページが大変参考になった。
Qiita# -*- coding: utf-8 -*- import pywinauto import time import os import subprocess #子エレメントをclassnameで検索し、見つかったエレメントを返す関数 def search_child_byclassname(class_name, uiaElementInfo, target_all = False, waitcount = 50): for loop in range(waitcount): #見つからなかった場合にも、少し待って何度か繰り返すためのループ target = [] # 全ての子要素検索 for childElement in uiaElementInfo.children(): # ClassNameの一致確認 if childElement.class_name == class_name: if target_all == False: return childElement else: target.append(childElement) if target_all == False: print ( 'LOOP:' + str(uiaElementInfo.name) + ' searchclass:' + class_name) #見つからなかったらループ else: return target time.sleep(0.2) #0.2秒ごとにリトライ # 0.2秒x50回=10秒待っても見つからなかったらFalse。あまり待つ必要がない処理の場合はwaitcountを指定してすぐにfalseを返すようにする return False #子エレメントをnameで検索し、見つかったエレメントを返す関数 def search_child_byname(name, uiaElementInfo, waitcount = 50): for loop in range(waitcount): #見つからなかった場合にも、少し待って何度か繰り返すためのループ # 全ての子要素検索 for childElement in uiaElementInfo.children(): # Nameの一致確認 if childElement.name == name: return childElement time.sleep(0.2) #0.2秒ごとにリトライ print ( 'LOOP:' + str(uiaElementInfo.name) + ' searchname:' + name ) #見つからなかったらループ # 0.2秒x50回=10秒待っても見つからなかったらFalse。あまり待つ必要がない処理の場合はwaitcountを指定してすぐにfalseを返すようにする return False #子エレメントをnameとclassnameの両方で検索し、両方一致したエレメントを返す関数 def search_child_bynameandclassname(name, class_name, uiaElementInfo, target_all = False, waitcount = 50): for loop in range(waitcount): #見つからなかった場合にも、少し待って何度か繰り返すためのループ target = [] # 全ての子要素検索 for childElement in uiaElementInfo.children(): # ClassNameの一致確認 if childElement.class_name == class_name and childElement.name == name: if target_all == False: return childElement else: target.append(childElement) if target_all == False: print ( 'LOOP:' + str(uiaElementInfo.name) + ' searchname:' + name + ' searchclass:' + class_name) #見つからなかったらループ else: return target time.sleep(0.2) #0.2秒ごとにリトライ # 0.2秒x50回=10秒待っても見つからなかったらFalse。あまり待つ必要がない処理の場合はwaitcountを指定してすぐにfalseを返すようにする return False #アプリの起動および接続 def app_start1(app1,path1,t1): try: app1.Connect(path = path1) except: app1.Start(cmd_line = path1) time.sleep(t1) app1.Connect(path = path1) ## Voiceroid Editorの起動からトップ画面まで def startVOICEROID2(): # アプリ起動 app = pywinauto.Application() path1 = u"C:\Program Files (x86)\\AHS\\VOICEROID2\\VoiceroidEditor.exe" t1 = 2 app_start1(app,path1,t1) ## Voiceroid2 Editor強制終了(ハングアップ時対応) def killVOICEROID2(): cmd = 'taskkill /f /im VoiceroidEditor.exe' returncode = subprocess.call(cmd) ## 引数の文字列を入力して「再生」 def talkVOICEROID2(speakPhrase): # デスクトップのエレメント parentUIAElement = pywinauto.uia_element_info.UIAElementInfo() # voiceroidを捜索する voiceroid2 = search_child_byname("VOICEROID2",parentUIAElement,waitcount=1) # *がついている場合 if voiceroid2 == False: voiceroid2 = search_child_byname("VOICEROID2*",parentUIAElement,waitcount=1) # テキスト要素のElementInfoを取得 TextEditViewEle = search_child_byclassname("TextEditView",voiceroid2) textBoxEle = search_child_byclassname("TextBox",TextEditViewEle) # コントロール取得 textBoxEditControl = pywinauto.controls.uia_controls.EditWrapper(textBoxEle) # テキスト登録 textBoxEditControl.set_edit_text(speakPhrase) # ボタン取得 buttonsEle = search_child_byclassname("Button",TextEditViewEle,target_all = True) # 再生ボタンを探す playButtonEle = "" for buttonEle in buttonsEle: # テキストブロックを捜索 textBlockEle = search_child_byclassname("TextBlock",buttonEle) if textBlockEle.name == "再生": playButtonEle = buttonEle break # ボタンコントロール取得 playButtonControl = pywinauto.controls.uia_controls.ButtonWrapper(playButtonEle) # 再生ボタン押下 playButtonControl.click() ## 引数の文字列を音声化して「音声保存」。保存先のフルパスファイル名も指定。拡張子はwav固定なので省略可 def saveVOICEROID2(speakPhrase,filename): # デスクトップのエレメント parentUIAElement = pywinauto.uia_element_info.UIAElementInfo() # voiceroidを捜索する voiceroid2 = search_child_byname("VOICEROID2",parentUIAElement,waitcount=1) # *がついている場合 if voiceroid2 == False: voiceroid2 = search_child_byname("VOICEROID2*",parentUIAElement,waitcount=1) # テキスト要素のElementInfoを取得 print("voiceroid2 classname = "+str(voiceroid2.children()) ) TextEditViewEle = search_child_byclassname("TextEditView",voiceroid2) textBoxEle = search_child_byclassname("TextBox",TextEditViewEle) # コントロール取得 textBoxEditControl = pywinauto.controls.uia_controls.EditWrapper(textBoxEle) # テキスト登録 textBoxEditControl.set_edit_text(speakPhrase) # ボタン取得 buttonsEle = search_child_byclassname("Button",TextEditViewEle,target_all = True) # 音声保存ボタンを探す playButtonEle = "" for buttonEle in buttonsEle: # テキストブロックを捜索 textBlockEle = search_child_byclassname("TextBlock",buttonEle) if textBlockEle.name == "音声保存": playButtonEle = buttonEle break # ボタンコントロール取得 playButtonControl = pywinauto.controls.uia_controls.ButtonWrapper(playButtonEle) # 音声保存ボタン押下 playButtonControl.click() # 音声保存ウィンドウが開くまで少し待つ(ウィンドウが開く前にsearch_child_bynameすると、bool値falseが返ってくる) time.sleep(0.3) # 音声保存ウィンドウと、その中の"OK"ボタンを探して押す onseihozon = search_child_byname("音声保存",voiceroid2) buttonEle = search_child_byname("OK",onseihozon) playButtonControl = pywinauto.controls.uia_controls.ButtonWrapper(buttonEle) playButtonControl.click() time.sleep(0.3) # ファイル名を入力。深いエレメントなので1つずつ潜る。nameがあるものはbynameで、nameが空白のものはbyclassnameで、類似エレメントが多いものは両方で検索。 savefile1 = search_child_byname("名前を付けて保存",onseihozon) savefile2 = search_child_byclassname("DUIViewWndClassName",savefile1) savefile3 = search_child_bynameandclassname("ファイル名:","AppControlHost",savefile2) #"ファイル名:"コンボボックス savefile4 = search_child_byname("ファイル名:",savefile3) #"ファイル名:"テキストボックス textBoxEditControl = pywinauto.controls.uia_controls.EditWrapper(savefile4) textBoxEditControl.set_edit_text(filename) #"保存(S)"ボタンを押す。"名前を付けて保存"ダイヤログの配下にある。 buttonEle = search_child_byname("保存(S)",savefile1) playButtonControl = pywinauto.controls.uia_controls.ButtonWrapper(buttonEle) playButtonControl.click() time.sleep(1.0) #「合成音声をファイルに保存しました」ダイヤログのOKボタンを押す savefile1 = search_child_byname("情報",onseihozon) buttonEle = search_child_byname("OK",savefile1) playButtonControl = pywinauto.controls.uia_controls.ButtonWrapper(buttonEle) playButtonControl.click() time.sleep(0.3) FILEPATH='C:\work\output' #出力先フォルダ inputfile = open('input.txt','r') line = inputfile.readline() while line: #ファイルを1行ずつループ try: #エラー時には、voiceroidを再起動してからリトライ saveVOICEROID2(line.strip(),FILEPATH + '\\' + line.strip() ) #.strip()で各行末尾の改行コードを消す except: killVOICEROID2() time.sleep(5) startVOICEROID2() time.sleep(10) saveVOICEROID2(line.strip(),FILEPATH + '\\' + line.strip() ) #.strip()で各行末尾の改行コードを消す line = inputfile.readline() inputfile.close()上記処理を回していると、数日に1回ほど以下のエラーが出て処理が止まることがある。
VOICEROID2 Editorは動作を停止しました 問題が発生したため、プログラムが正しく動作しなくなりました。上記エラーが記録されたことを検出した際、タスクスケジューラから
voiceroid.exeと、メッセージBOXの両方をtaskkillするバッチをキックするようにしてみた。ping -n 5 localhost >NUL taskkill /f /im WerFault.exe taskkill /f /im VoiceroidEditor.exeVOICEROID2が強制終了されると、startVOICEROID2()によりアプリが再起動され、処理が継続する。
これで処理が止まることなく10日間、全単語を音声化するまで安定して動くようになった。2.生成された学習データの特性を確認、加工する
先はVOICEROID2を使用する都合上Windows環境だったが、ここからはCentos7環境を使用する。
今回の学習データは以下になる
input:日本語文字データ(text:utf-8)
output:音声データ(wav)これをそのままTensorFlowに入力することはできないので、input/outputそれぞれについて、0~1.0の範囲内の数値を使用したnumpy行列に変換するための処理を作成する。
まずはinputを変換する。
作成した教師データについて文字数ごとのデータ数を数えると以下のような感じ。
12文字以上はデータ数が極端に少なかったので、手動で作った単語表を加えてデータ数を増やしている。[root@osk-cent01 work]# LENGTH1=0;LENGTH2=0;LENGTH3=0;LENGTH4=0;LENGTH5=0;LENGTH6=0;LENGTH7=0;LENGTH8=0;LENGTH9=0;LENGTH10=0;LENGTH11=0;LENGTH12=0;LENGTH13=0;LENGTH14=0 [root@osk-cent01 work]# while read line > do LENGTH=$((`echo $line | wc -m` - 1)) > if [ $LENGTH -gt 14 ] > then echo $line $LENGTH #念のために15文字以上の長さの文字が残っていた場合に表示 > fi > eval LENGTH$LENGTH=`eval expr '$'LENGTH$LENGTH + 1` > done < input.txt [root@osk-cent01 work]# echo $LENGTH1 $LENGTH2 $LENGTH3 $LENGTH4 $LENGTH5 $LENGTH6 $LENGTH7 $LENGTH8 $LENGTH9 $LENGTH10 $LENGTH11 $LENGTH12 $LENGTH13 $LENGTH14 66 3002 24038 53049 30415 14848 6658 3179 1406 522 292 367 303 278 [root@osk-cent01 work]#input変換(text→numpy)のルールとしては、
すべての文字を、それぞれ11~211の数字を割り当てる。
同じ母音の音は近い数字になるように、以下のルールで割り当てる
あ行:11~50
い行:51~90
う行:91~130
え行:131~170
お行:171~210
ん:211濁音、半濁音は、それぞれの清音と近い数字になるように割り当てる。
また、「ぁ」「ぃ」「ぅ」「ぇ」「ぉ」「ゃ」「ゅ」「ょ」は、同じ母音の文字と近い数字になるように割り当てる。
11:あ
12:うぁ
13:か
14:きゃ
15:が
16:ぎゃそれぞれの音の後に、長音「ー」および「っ」を表すデータを付与する。
通常の長さの音=128、長音「ー」=200、「っ」=30これにより、
「ぎょーざ」は、以下のように変換される
175 (ぎょ)
200 (長音「ー」)
18 (ざ)
128 (通常の長さ)「あっぷる」は以下のように変換される
11 (あ)
30 (「っ」)
110 (ぷ)
128 (通常の長さ)
115 (る)
128 (通常の長さ)TensorFlowの入出力は固定長にする必要があるので、必ず指定文字数になるようにする。
今回は14文字なので、1文字あたり2要素の合計28個の数字のlistを返す。
14文字に足りない文字数分は、すべて「0」(無音)で埋める。単語の文字列を引数に、対応する数字のlistを返す関数
/work/char2num.py#charの文字列を、規則に従ってlistに変換。listのサイズは発音文字数numで揃える(不足は0で埋める)。 def exchange(char,num): output = [] # 帰り値用list。1音を2つの数字で表す。詳細は別途説明書に記載 oto = 0 # 何音入れたか?のカウント「ば」「あっ」「ぎゃー」文字数は1-3だが、すべて1音でカウント for n in range(len(char)): # 文字列の長さだけループ m = char[n] #今回ループで処理する文字 oto += 1 #1文字1音の言葉→そのまま入れる。次の文字が「ゃ」「ゅ」「ょ」の場合の場合も一旦入れて、後で書き換える #「っ」「ー」を含まない通常の長さを示す数字「128」も仮入れする if m == 'あ':output += [11,128] elif m == 'か':output += [13,128] elif m == 'が':output += [15,128] elif m == 'さ':output += [17,128] elif m == 'ざ':output += [20,128] elif m == 'た':output += [23,128] elif m == 'だ':output += [29,128] elif m == 'な':output += [34,128] elif m == 'は':output += [36,128] elif m == 'ば':output += [39,128] elif m == 'ぱ':output += [42,128] elif m == 'ま':output += [44,128] elif m == 'や':output += [46,128] elif m == 'ら':output += [47,128] elif m == 'わ':output += [50,128] elif m == 'い':output += [51,128] elif m == 'き':output += [53,128] elif m == 'ぎ':output += [55,128] elif m == 'し':output += [57,128] elif m == 'じ':output += [60,128] elif m == 'ち':output += [63,128] elif m == 'ぢ':output += [69,128] elif m == 'に':output += [74,128] elif m == 'ひ':output += [76,128] elif m == 'び':output += [79,128] elif m == 'ぴ':output += [82,128] elif m == 'み':output += [84,128] elif m == 'り':output += [87,128] elif m == 'う':output += [91,128] elif m == 'く':output += [93,128] elif m == 'ぐ':output += [95,128] elif m == 'す':output += [97,128] elif m == 'ず':output += [100,128] elif m == 'つ':output += [103,128] elif m == 'づ':output += [109,128] elif m == 'ぬ':output += [114,128] elif m == 'ふ':output += [116,128] elif m == 'ぶ':output += [119,128] elif m == 'ぷ':output += [122,128] elif m == 'む':output += [124,128] elif m == 'ゆ':output += [126,128] elif m == 'る':output += [127,128] elif m == 'え':output += [131,128] elif m == 'け':output += [133,128] elif m == 'げ':output += [135,128] elif m == 'せ':output += [137,128] elif m == 'ぜ':output += [140,128] elif m == 'て':output += [143,128] elif m == 'で':output += [149,128] elif m == 'ね':output += [154,128] elif m == 'へ':output += [156,128] elif m == 'べ':output += [159,128] elif m == 'ぺ':output += [162,128] elif m == 'め':output += [164,128] elif m == 'れ':output += [167,128] elif m == 'お':output += [171,128] elif m == 'こ':output += [173,128] elif m == 'ご':output += [175,128] elif m == 'そ':output += [177,128] elif m == 'ぞ':output += [180,128] elif m == 'と':output += [183,128] elif m == 'ど':output += [189,128] elif m == 'の':output += [194,128] elif m == 'ほ':output += [196,128] elif m == 'ぼ':output += [199,128] elif m == 'ぽ':output += [202,128] elif m == 'も':output += [204,128] elif m == 'よ':output += [206,128] elif m == 'ろ':output += [207,128] elif m == 'を':output += [210,128] elif m == 'ん':output += [211,128] else: oto-=1 #上記以外の文字(「ゃ」「ゅ」「ょ」「ぁ」「ぃ」「ぅ」「ぇ」「ぉ」「っ」「ー」)の場合は、oto+=1をキャンセル if oto == 0 : return ([0]* (num*2)) #1文字目が上記以外の場合はall 0で即return(エラー扱い) #「ゃ」「ゅ」「ょ」「ぁ」「ぃ」「ぅ」「ぇ」「ぉ」の場合は、1つ前の音(listでは2つ前)を変更する if m == 'ゃ': if output[(oto*2)-2] == 53:output[(oto*2)-2] = 14 #「53=き」の場合、「14=きゃ」に変更 elif output[(oto*2)-2] == 55:output[(oto*2)-2] = 16 elif output[(oto*2)-2] == 57:output[(oto*2)-2] = 18 elif output[(oto*2)-2] == 60:output[(oto*2)-2] = 21 elif output[(oto*2)-2] == 63:output[(oto*2)-2] = 24 elif output[(oto*2)-2] == 69:output[(oto*2)-2] = 30 elif output[(oto*2)-2] == 74:output[(oto*2)-2] = 35 elif output[(oto*2)-2] == 76:output[(oto*2)-2] = 37 elif output[(oto*2)-2] == 79:output[(oto*2)-2] = 40 elif output[(oto*2)-2] == 82:output[(oto*2)-2] = 43 elif output[(oto*2)-2] == 84:output[(oto*2)-2] = 45 elif output[(oto*2)-2] == 87:output[(oto*2)-2] = 48 elif m == 'ゅ': if output[(oto*2)-2] == 53:output[(oto*2)-2] = 94 elif output[(oto*2)-2] == 55:output[(oto*2)-2] = 96 elif output[(oto*2)-2] == 57:output[(oto*2)-2] = 98 elif output[(oto*2)-2] == 60:output[(oto*2)-2] = 101 elif output[(oto*2)-2] == 63:output[(oto*2)-2] = 104 elif output[(oto*2)-2] == 69:output[(oto*2)-2] = 110 elif output[(oto*2)-2] == 74:output[(oto*2)-2] = 115 elif output[(oto*2)-2] == 76:output[(oto*2)-2] = 117 elif output[(oto*2)-2] == 79:output[(oto*2)-2] = 120 elif output[(oto*2)-2] == 82:output[(oto*2)-2] = 123 elif output[(oto*2)-2] == 84:output[(oto*2)-2] = 125 elif output[(oto*2)-2] == 87:output[(oto*2)-2] = 128 elif m == 'ょ': if output[(oto*2)-2] == 53:output[(oto*2)-2] = 174 elif output[(oto*2)-2] == 55:output[(oto*2)-2] = 176 elif output[(oto*2)-2] == 57:output[(oto*2)-2] = 178 elif output[(oto*2)-2] == 60:output[(oto*2)-2] = 181 elif output[(oto*2)-2] == 63:output[(oto*2)-2] = 184 elif output[(oto*2)-2] == 69:output[(oto*2)-2] = 190 elif output[(oto*2)-2] == 74:output[(oto*2)-2] = 195 elif output[(oto*2)-2] == 76:output[(oto*2)-2] = 197 elif output[(oto*2)-2] == 79:output[(oto*2)-2] = 200 elif output[(oto*2)-2] == 82:output[(oto*2)-2] = 203 elif output[(oto*2)-2] == 84:output[(oto*2)-2] = 205 elif output[(oto*2)-2] == 87:output[(oto*2)-2] = 208 elif m == 'ぁ': if output[(oto*2)-2] == 91:output[(oto*2)-2] = 12 elif output[(oto*2)-2] == 57:output[(oto*2)-2] = 19 elif output[(oto*2)-2] == 60:output[(oto*2)-2] = 22 elif output[(oto*2)-2] == 103:output[(oto*2)-2] = 26 elif output[(oto*2)-2] == 143:output[(oto*2)-2] = 27 elif output[(oto*2)-2] == 109:output[(oto*2)-2] = 31 elif output[(oto*2)-2] == 149:output[(oto*2)-2] = 32 elif output[(oto*2)-2] == 116:output[(oto*2)-2] = 38 elif output[(oto*2)-2] == 119:output[(oto*2)-2] = 41 elif m == 'ぃ': if output[(oto*2)-2] == 91:output[(oto*2)-2] = 52 elif output[(oto*2)-2] == 57:output[(oto*2)-2] = 59 elif output[(oto*2)-2] == 60:output[(oto*2)-2] = 62 elif output[(oto*2)-2] == 63:output[(oto*2)-2] = 65 elif output[(oto*2)-2] == 103:output[(oto*2)-2] = 66 elif output[(oto*2)-2] == 143:output[(oto*2)-2] = 67 elif output[(oto*2)-2] == 109:output[(oto*2)-2] = 71 elif output[(oto*2)-2] == 149:output[(oto*2)-2] = 72 elif output[(oto*2)-2] == 116:output[(oto*2)-2] = 78 elif output[(oto*2)-2] == 119:output[(oto*2)-2] = 81 elif output[(oto*2)-2] == 87:output[(oto*2)-2] = 89 elif m == 'ぅ': if output[(oto*2)-2] == 103:output[(oto*2)-2] = 106 elif output[(oto*2)-2] == 143:output[(oto*2)-2] = 107 elif output[(oto*2)-2] == 183:output[(oto*2)-2] = 108 elif output[(oto*2)-2] == 109:output[(oto*2)-2] = 111 elif output[(oto*2)-2] == 149:output[(oto*2)-2] = 112 elif output[(oto*2)-2] == 189:output[(oto*2)-2] = 113 elif output[(oto*2)-2] == 116:output[(oto*2)-2] = 118 elif output[(oto*2)-2] == 119:output[(oto*2)-2] = 121 elif output[(oto*2)-2] == 87:output[(oto*2)-2] = 129 elif m == 'ぇ': if output[(oto*2)-2] == 91:output[(oto*2)-2] = 132 elif output[(oto*2)-2] == 57:output[(oto*2)-2] = 139 elif output[(oto*2)-2] == 60:output[(oto*2)-2] = 142 elif output[(oto*2)-2] == 63:output[(oto*2)-2] = 145 elif output[(oto*2)-2] == 103:output[(oto*2)-2] = 146 elif output[(oto*2)-2] == 109:output[(oto*2)-2] = 151 elif output[(oto*2)-2] == 116:output[(oto*2)-2] = 158 elif output[(oto*2)-2] == 119:output[(oto*2)-2] = 161 elif m == 'ぉ': if output[(oto*2)-2] == 91:output[(oto*2)-2] = 172 elif output[(oto*2)-2] == 183:output[(oto*2)-2] = 188 elif output[(oto*2)-2] == 189:output[(oto*2)-2] = 193 elif output[(oto*2)-2] == 116:output[(oto*2)-2] = 198 elif output[(oto*2)-2] == 119:output[(oto*2)-2] = 201 elif output[(oto*2)-2] == 87:output[(oto*2)-2] = 209 #「ー」「っ」の場合は、今回の発音長(listでは1つ前)を変更する elif m == 'っ':output[(oto*2)-1] = 30 elif m == 'ー':output[(oto*2)-1] = 200 #固定長5文字(len()=num*2)に揃えて、不足分は0で埋める output += [0] * ((num*2)-len(output)) return (output)また、出力もwavファイルの波形データをそのまま入れてもまともに学習できないので、以下サイトを参考に、「基本周波数」「スペクトル包絡」「非周期性指標」を抽出する
Qiita/work/wav2numpy.py
# -*- coding: utf-8 -*- from scipy.io import wavfile import pyworld as pw import numpy as np # wavファイル名を引数に、f0,sp,apのnumpyを返す関数wav2numpy(wavfilename) def wav2numpy(wavfilename): fs, data = wavfile.read( wavfilename ) data = data.astype(np.float) # WORLDはfloat前提のコードになっているのでfloat型にしておく _f0, t = pw.dio(data, fs) # 基本周波数の抽出 f0 = pw.stonemask(data, _f0, t, fs) # 基本周波数の修正 sp = pw.cheaptrick(data, f0, t, fs) # スペクトル包絡の抽出 ap = pw.d4c(data, f0, t, fs) # 非周期性指標の抽出 return ( f0 , sp , ap ) # f0,sp,apおよび任意のwavファイル名を引数。f0,sp,apからwavファイルを出力する def numpy2wav(f0,sp,ap,wavfilename): fs = 44100 synthesized = pw.synthesize(f0, sp, ap, fs).astype(np.int16) wavfile.write( wavfilename ,fs,synthesized)これらデータをTensorFlowに投入したいが、先程生成したf0,spを0~1.0の範囲内に収めるために、どの程度の範囲なのか、特性を確認する必要がある。(apは最初から0~1.0の範囲内に収まるので加工不要)
import numpy as np import matplotlib.pyplot as plt import csv import pandas as pd import wav2numpy wavdir = '/home/d9840yh/work/wavfiles2' maxf0 = 0 minf0 = 1e100 maxsp = 0 minsp = 1e100 inputfile = open('input.txt','r') line = inputfile.readline() while line: f0=[] sp=[] ap=[] f0 , sp , ap = wav2numpy.wav2numpy(wavdir + '/' + line.strip() + '.wav') #wavからf0,sp,apを抽出 if f0.max() > maxf0 : #f0 max更新 maxf0=f0.max() print("new max f0 : max f0=",maxf0," min f0=",minf0," max sp=",maxsp," min sp=",minsp," file:",line.strip()) if f0.min() < minf0 : #f0 min更新 minf0=f0.min() print("new min f0 : max f0=",maxf0," min f0=",minf0," max sp=",maxsp," min sp=",minsp," file:",line.strip()) if sp.max() > maxsp : #sp max更新 maxsp=sp.max() print("new max sp : max f0=",maxf0," min f0=",minf0," max sp=",maxsp," min sp=",minsp," file:",line.strip()) if sp.min() < minsp : #sp min更新 minsp=sp.min() print("new min sp : max f0=",maxf0," min f0=",minf0," max sp=",maxsp," min sp=",minsp," file:",line.strip()) line = inputfile.readline()実行結果
[root@osk-cent01 work]# python3.6 ./03_search_max.py new max f0 : max f0= 265.4438671748281 min f0= 1e+100 max sp= 0 min sp= 1e+100 file: あ new min f0 : max f0= 265.4438671748281 min f0= 0.0 max sp= 0 min sp= 1e+100 file: あ new max sp : max f0= 265.4438671748281 min f0= 0.0 max sp= 657068294.401034 min sp= 1e+100 file: あ new min sp : max f0= 265.4438671748281 min f0= 0.0 max sp= 657068294.401034 min sp= 0.027947641201406224 file: あ new max f0 : max f0= 302.4288177772 min f0= 0.0 max sp= 657068294.401034 min sp= 0.027947641201406224 file: あー new max sp : max f0= 302.4288177772 min f0= 0.0 max sp= 837133555.222678 min sp= 0.027947641201406224 file: あー new min sp : max f0= 302.4288177772 min f0= 0.0 max sp= 837133555.222678 min sp= 0.0063757402892679615 file: あー new max f0 : max f0= 344.4078989932586 min f0= 0.0 max sp= 837133555.222678 min sp= 0.0063757402892679615 file: あーうぃん new max sp : max f0= 344.4078989932586 min f0= 0.0 max sp= 1931761024.0156083 min sp= 0.0063757402892679615 file: あーうぃん (中略) new max f0 : max f0= 692.524084004494 min f0= 0.0 max sp= 12431307878.277342 min sp= 8.294699504145247e-18 file: えいこさのいど new min sp : max f0= 692.524084004494 min f0= 0.0 max sp= 12431307878.277342 min sp= 5.7318239325174266e-18 file: さきのり new min sp : max f0= 692.524084004494 min f0= 0.0 max sp= 12431307878.277342 min sp= 4.4569279355354585e-18 file: しぇるどれいく new max sp : max f0= 692.524084004494 min f0= 0.0 max sp= 16109683177.383907 min sp= 4.4569279355354585e-18 file: ぜねらりf0は最大692.5なので、単純に/1024すれば0~1.0の範囲内に収まる。
ただ、spは対数的な特性をもつデータなので、単純に/10e11すると、小さなレンジのデータがまともに学習できなくなると思われる。
(実際に、サンプルの学習データとして10e-20 ~ 1.0までの20桁のレンジのデータを学習させてみたところ、小さなレンジのデータは≒0として扱われて、結果に反映されなかった。)そのため、spについては対数計算した上で、0~1.0の範囲内に収める必要がある。
元データが4.4e-18~1.6e10の範囲なので、単純にlog10を取ると-19~11のデータ範囲に収まる。
それを+19して、さらに/30すれば、良い感じに収まりそう。なお、fp,sp,apのサイズは音声の長さに依存するが、もっともサイズの大きいwavファイルを確認したところ以下だった。
f0.shape=(475,)
sp.shape=(475, 1025)
ap.shape=(475, 1025)なお、1025は音声の中身にかかわらずで、475の部分が音声の長さに比例して増える。
学習前にこれをflat化する必要があるので、sp,apは475x1025=486875。
余裕をもって500x1025=512500としておけば問題無い3.文字データ→音声データへの変換を学習させる
以上の結果をふまえて、学習用の仕組みを作成する。
用意した音声wavファイルは138423個あるが、これをいきなり放り込んで失敗すると嫌なので、使用する教師データ数を動的に変更できるようにする。ついでにBatchsizeやepochsも変更できるようにする。
# cat 03_larning06_all.ini [general] DATASIZE=50000 BATCHSIZE=10 EPOCHS=2 #学習用のスクリプトを用意。
最初、モデルは以下のように考えていた。
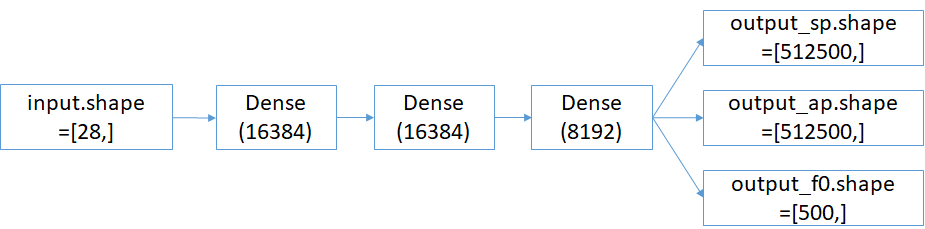
input.shape=[28,]
→ Dense(16384)
→ Dense(16384)
→ Dense(8192)
→ output_sp.shape=[512500,]
→ output_ap.shape=[512500,]
→ output_sp.shape=[500,]しかし、上記だと100GB超のメインメモリを消費する。
おそらく、最後のDense(16384)→output_sp.shape=[205000,]の箇所で、
sp用だけでも単純に8,192*512,500=4,198,400,000の変数を学習させることになるのが原因と思われる。
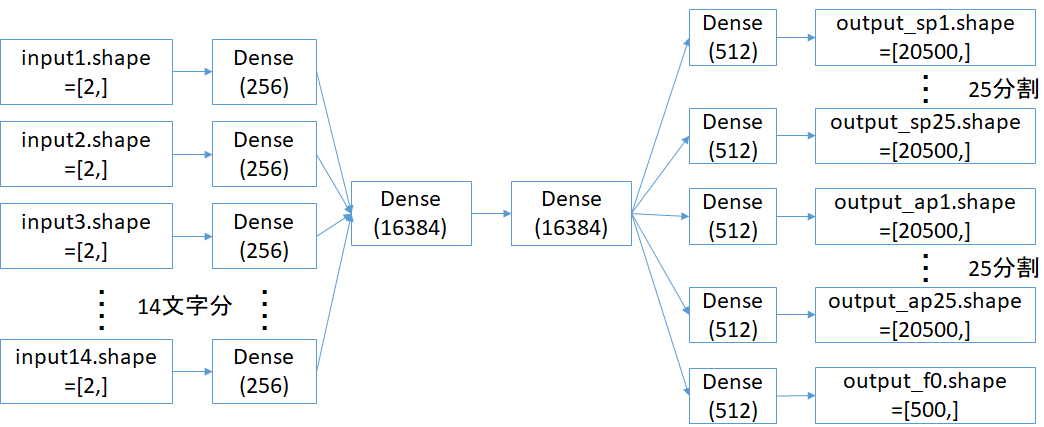
そこで、以下のように最後のDenseを25分割した。
ついでにinputも1文字([2,])単位で分割し、最初のDenseとの間に1層追加する。(ここで、各1音ごとの音特性を学習してくれたら、その後のDenseは音韻長や繋ぎなどの全体をまとめる学習に専念できないかな?と)input1.shape=[2,]
→Dense(256)
input2.shape=[2,]
→Dense(256)
input3.shape=[2,]
→Dense(256)
(中略、input14まで続く。)
→ Dense(16384)
→ Dense(16384)
→ Dense(512)
→ output_sp1.shape=[20500,]
→ Dense(512)
→ output_sp2.shape=[20500,]
→ Dense(512)
→ output_sp3.shape=[20500,]
(中略、output_sp25まで同じように作成)
→ Dense(512)
→ output_ap1.shape=[20500,]
→ Dense(512)
→ output_ap2.shape=[20500,]
(中略、output_ap25まで同じように作成)
→ Dense(512)
→ output_sp.shape=[500,]これで、最終Denseのセル数は8192 → 512*25=12,800と実質増えているにもかかわらず、そこで学習される変数数は512*20500*25=262,400,000 となり、1/10以下に落とせた。
このあたりのコーディングがゴリ押しなのだが、なにか良い感じにDenseを分割できる方法は無いものか。
あと、教師データ量が膨大なので、学習と平行して教師データを加工できるようにfit_generatorを使っているのだが、通常のfitでいうところのVALIDSPLITがつかえない。これも自分でon_epoch_end()内に実装するしか無いのかな・・・活性関数は、いまいち効果が分からないので、とりあえずreluをつっこんでおく。
from __future__ import absolute_import, division, print_function, unicode_literals # TensorFlow と tf.keras のインポート import tensorflow as tf from tensorflow import keras config = tf.ConfigProto(log_device_placement=True) sess = tf.Session(config=config) keras.backend.set_session(sess) # ヘルパーライブラリのインポート import numpy as np import math from datetime import datetime import gc import configparser # 自作スクリプト #charの文字列を、規則に従ってlistに変換 exchange(char,num) import char2num #wavファイルからf0,sp,apのnumpy arrayを取り出す import wav2numpy wavdir = '/home/d9840yh/work/wavfiles2' inifile = '03_larning06_all.ini' config = configparser.SafeConfigParser() # input.txtの各行を1要素としたlist:wordlistを生成 wordlist = [] with open("input.txt", "r",encoding="utf-8") as f: wordlist.extend(f.read().split()) #モデルを定義する関数。 inputは28の数字、outputは[sp,ap=512500つの数字][f0=500つの数字] model_input1 = keras.Input(shape=(2,), name='in1') model_input2 = keras.Input(shape=(2,), name='in2') model_input3 = keras.Input(shape=(2,), name='in3') model_input4 = keras.Input(shape=(2,), name='in4') model_input5 = keras.Input(shape=(2,), name='in5') model_input6 = keras.Input(shape=(2,), name='in6') model_input7 = keras.Input(shape=(2,), name='in7') model_input8 = keras.Input(shape=(2,), name='in8') model_input9 = keras.Input(shape=(2,), name='in9') model_input10 = keras.Input(shape=(2,), name='in10') model_input11 = keras.Input(shape=(2,), name='in11') model_input12 = keras.Input(shape=(2,), name='in12') model_input13 = keras.Input(shape=(2,), name='in13') model_input14 = keras.Input(shape=(2,), name='in14') x1_1 = keras.layers.Dense(256, activation='relu', name='1st_layer1')(model_input1) x1_2 = keras.layers.Dense(256, activation='relu', name='1st_layer2')(model_input2) x1_3 = keras.layers.Dense(256, activation='relu', name='1st_layer3')(model_input3) x1_4 = keras.layers.Dense(256, activation='relu', name='1st_layer4')(model_input4) x1_5 = keras.layers.Dense(256, activation='relu', name='1st_layer5')(model_input5) x1_6 = keras.layers.Dense(256, activation='relu', name='1st_layer6')(model_input6) x1_7 = keras.layers.Dense(256, activation='relu', name='1st_layer7')(model_input7) x1_8 = keras.layers.Dense(256, activation='relu', name='1st_layer8')(model_input8) x1_9 = keras.layers.Dense(256, activation='relu', name='1st_layer9')(model_input9) x1_10 = keras.layers.Dense(256, activation='relu', name='1st_layer10')(model_input10) x1_11 = keras.layers.Dense(256, activation='relu', name='1st_layer11')(model_input11) x1_12 = keras.layers.Dense(256, activation='relu', name='1st_layer12')(model_input12) x1_13 = keras.layers.Dense(256, activation='relu', name='1st_layer13')(model_input13) x1_14 = keras.layers.Dense(256, activation='relu', name='1st_layer14')(model_input14) x1_merge = keras.layers.concatenate([x1_1,x1_2,x1_3,x1_4,x1_5,x1_6,x1_7,x1_8,x1_9,x1_10,x1_11,x1_12,x1_13,x1_14], axis=-1) x2 = keras.layers.Dense(16384, activation='relu', name='2nd_layer')(x1_merge) x3 = keras.layers.Dense(16384, activation='relu', name='3rd_layer')(x2) x4_sp1 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp1')(x3) x4_sp2 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp2')(x3) x4_sp3 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp3')(x3) x4_sp4 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp4')(x3) x4_sp5 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp5')(x3) x4_sp6 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp6')(x3) x4_sp7 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp7')(x3) x4_sp8 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp8')(x3) x4_sp9 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp9')(x3) x4_sp10 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp10')(x3) x4_sp11 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp11')(x3) x4_sp12 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp12')(x3) x4_sp13 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp13')(x3) x4_sp14 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp14')(x3) x4_sp15 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp15')(x3) x4_sp16 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp16')(x3) x4_sp17 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp17')(x3) x4_sp18 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp18')(x3) x4_sp19 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp19')(x3) x4_sp20 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp20')(x3) x4_sp21 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp21')(x3) x4_sp22 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp22')(x3) x4_sp23 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp23')(x3) x4_sp24 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp24')(x3) x4_sp25 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp25')(x3) model_output_sp1 = keras.layers.Dense(20500, name='out_sp1')(x4_sp1) model_output_sp2 = keras.layers.Dense(20500, name='out_sp2')(x4_sp2) model_output_sp3 = keras.layers.Dense(20500, name='out_sp3')(x4_sp3) model_output_sp4 = keras.layers.Dense(20500, name='out_sp4')(x4_sp4) model_output_sp5 = keras.layers.Dense(20500, name='out_sp5')(x4_sp5) model_output_sp6 = keras.layers.Dense(20500, name='out_sp6')(x4_sp6) model_output_sp7 = keras.layers.Dense(20500, name='out_sp7')(x4_sp7) model_output_sp8 = keras.layers.Dense(20500, name='out_sp8')(x4_sp8) model_output_sp9 = keras.layers.Dense(20500, name='out_sp9')(x4_sp9) model_output_sp10 = keras.layers.Dense(20500, name='out_sp10')(x4_sp10) model_output_sp11 = keras.layers.Dense(20500, name='out_sp11')(x4_sp11) model_output_sp12 = keras.layers.Dense(20500, name='out_sp12')(x4_sp12) model_output_sp13 = keras.layers.Dense(20500, name='out_sp13')(x4_sp13) model_output_sp14 = keras.layers.Dense(20500, name='out_sp14')(x4_sp14) model_output_sp15 = keras.layers.Dense(20500, name='out_sp15')(x4_sp15) model_output_sp16 = keras.layers.Dense(20500, name='out_sp16')(x4_sp16) model_output_sp17 = keras.layers.Dense(20500, name='out_sp17')(x4_sp17) model_output_sp18 = keras.layers.Dense(20500, name='out_sp18')(x4_sp18) model_output_sp19 = keras.layers.Dense(20500, name='out_sp19')(x4_sp19) model_output_sp20 = keras.layers.Dense(20500, name='out_sp20')(x4_sp20) model_output_sp21 = keras.layers.Dense(20500, name='out_sp21')(x4_sp21) model_output_sp22 = keras.layers.Dense(20500, name='out_sp22')(x4_sp22) model_output_sp23 = keras.layers.Dense(20500, name='out_sp23')(x4_sp23) model_output_sp24 = keras.layers.Dense(20500, name='out_sp24')(x4_sp24) model_output_sp25 = keras.layers.Dense(20500, name='out_sp25')(x4_sp25) x4_ap1 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap1')(x3) x4_ap2 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap2')(x3) x4_ap3 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap3')(x3) x4_ap4 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap4')(x3) x4_ap5 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap5')(x3) x4_ap6 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap6')(x3) x4_ap7 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap7')(x3) x4_ap8 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap8')(x3) x4_ap9 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap9')(x3) x4_ap10 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap10')(x3) x4_ap11 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap11')(x3) x4_ap12 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap12')(x3) x4_ap13 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap13')(x3) x4_ap14 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap14')(x3) x4_ap15 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap15')(x3) x4_ap16 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap16')(x3) x4_ap17 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap17')(x3) x4_ap18 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap18')(x3) x4_ap19 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap19')(x3) x4_ap20 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap20')(x3) x4_ap21 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap21')(x3) x4_ap22 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap22')(x3) x4_ap23 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap23')(x3) x4_ap24 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap24')(x3) x4_ap25 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap25')(x3) model_output_ap1 = keras.layers.Dense(20500, name='out_ap1')(x4_ap1) model_output_ap2 = keras.layers.Dense(20500, name='out_ap2')(x4_ap2) model_output_ap3 = keras.layers.Dense(20500, name='out_ap3')(x4_ap3) model_output_ap4 = keras.layers.Dense(20500, name='out_ap4')(x4_ap4) model_output_ap5 = keras.layers.Dense(20500, name='out_ap5')(x4_ap5) model_output_ap6 = keras.layers.Dense(20500, name='out_ap6')(x4_ap6) model_output_ap7 = keras.layers.Dense(20500, name='out_ap7')(x4_ap7) model_output_ap8 = keras.layers.Dense(20500, name='out_ap8')(x4_ap8) model_output_ap9 = keras.layers.Dense(20500, name='out_ap9')(x4_ap9) model_output_ap10 = keras.layers.Dense(20500, name='out_ap10')(x4_ap10) model_output_ap11 = keras.layers.Dense(20500, name='out_ap11')(x4_ap11) model_output_ap12 = keras.layers.Dense(20500, name='out_ap12')(x4_ap12) model_output_ap13 = keras.layers.Dense(20500, name='out_ap13')(x4_ap13) model_output_ap14 = keras.layers.Dense(20500, name='out_ap14')(x4_ap14) model_output_ap15 = keras.layers.Dense(20500, name='out_ap15')(x4_ap15) model_output_ap16 = keras.layers.Dense(20500, name='out_ap16')(x4_ap16) model_output_ap17 = keras.layers.Dense(20500, name='out_ap17')(x4_ap17) model_output_ap18 = keras.layers.Dense(20500, name='out_ap18')(x4_ap18) model_output_ap19 = keras.layers.Dense(20500, name='out_ap19')(x4_ap19) model_output_ap20 = keras.layers.Dense(20500, name='out_ap20')(x4_ap20) model_output_ap21 = keras.layers.Dense(20500, name='out_ap21')(x4_ap21) model_output_ap22 = keras.layers.Dense(20500, name='out_ap22')(x4_ap22) model_output_ap23 = keras.layers.Dense(20500, name='out_ap23')(x4_ap23) model_output_ap24 = keras.layers.Dense(20500, name='out_ap24')(x4_ap24) model_output_ap25 = keras.layers.Dense(20500, name='out_ap25')(x4_ap25) x4_f0 = keras.layers.Dense(512, activation='relu', name='4th_layer_f0')(x3) model_output_f0 = keras.layers.Dense(500, name='out_f0')(x4_f0) model = keras.models.Model(inputs=[model_input1,model_input2,model_input3,model_input4,model_input5,model_input6,model_input7,model_input8,model_input9,model_input10,model_input11,model_input12,model_input13,model_input14], outputs=[model_output_sp1,model_output_sp2,model_output_sp3,model_output_sp4,model_output_sp5,model_output_sp6,model_output_sp7,model_output_sp8,model_output_sp9,model_output_sp10,model_output_sp11,model_output_sp12,model_output_sp13,model_output_sp14,model_output_sp15,model_output_sp16,model_output_sp17,model_output_sp18,model_output_sp19,model_output_sp20,model_output_sp21,model_output_sp22,model_output_sp23,model_output_sp24,model_output_sp25,model_output_ap1,model_output_ap2,model_output_ap3,model_output_ap4,model_output_ap5,model_output_ap6,model_output_ap7,model_output_ap8,model_output_ap9,model_output_ap10,model_output_ap11,model_output_ap12,model_output_ap13,model_output_ap14,model_output_ap15,model_output_ap16,model_output_ap17,model_output_ap18,model_output_ap19,model_output_ap20,model_output_ap21,model_output_ap22,model_output_ap23,model_output_ap24,model_output_ap25,model_output_f0]) class FitGenSequence(keras.utils.Sequence): def __init__(self, batch_size , data_size , word_list ): #word_listはwavファイルのリスト。そのうちdata_size個を学習に使うが、batch_size個単位で分割して学習する self.batch_size = batch_size self.word_list = word_list self.length = data_size // batch_size # batch_size個単位でに分割学習されるため、data_size / batch_size回に分割される # 余剰分は切り捨て(data_size=5100 , batch_size=1000の場合、1000個x5回の5000個だけ学習に使う) def __getitem__(self, idx): start_idx = idx * self.batch_size last_idx = start_idx + self.batch_size # 今回のループで使用するwavファイルのリストは self.word_list[start_idx:last_idx] print (self.word_list[start_idx:last_idx]) inputdata = [] outputdata_sp = [] outputdata_ap = [] outputdata_f0 = [] for word in self.word_list[start_idx:last_idx]: # inputデータ生成 28xデータ数の2d arrray inputdata.append((char2num.exchange(word.strip(),14))) outdata_f0 , outdata_sp , outdata_ap = wav2numpy.wav2numpy(wavdir + '/' + word.strip() + '.wav') #wavファイルからf0,sp,ap抽出 #outputデータ整形 固定長にする outdata_sp2=[flatten for inner in outdata_sp for flatten in inner] #sp,apは1025x可変長の2d arrayなので1d arrayに展開。同時にnumpy→lisst変換される outdata_sp2 += [0] * (512500-len(outdata_sp2)) #sp,apは1025x可変長(max500)=512500で固定長になるように0埋め outputdata_sp.append(outdata_sp2) outdata_ap2=[flatten for inner in outdata_ap for flatten in inner] #sp,apは1025x可変長の2d arrayなので1d arrayに展開。同時にnumpy→llist変換される outdata_ap2 += [0] * (512500-len(outdata_ap2)) #sp,apは1025x可変長(max500)=512500で固定長になるように0埋め outputdata_ap.append(outdata_ap2) outdata_f02 = outdata_f0.tolist() #f0はもともと1d arrayなのでflatten不要。単純にnumpy→list変換だけ outdata_f02 += [0] * (500-len(outdata_f02)) #f0は1x可変長(max500)=500で固定長になるように0埋め outputdata_f0.append(outdata_f02) #listをinput/outputに指定すると「Please provide as model inputs either a single array or a list of arrays.」になるのでnumpy変換 #input(14文字)を14等分。outputは25等分。 self.input1 , self.input2 , self.input3 , self.input4 , self.input5 , self.input6 , self.input7 , self.input8 , self.input9 , self.input10 , self.input11 , self.input12 , self.input13 , self.input14 = np.hsplit( np.array(inputdata) /256 , 14 ) outputdata_sp_np = np.array([[(math.log10(i)+19)/30 if i!=0 else 0 for i in j ] for j in outputdata_sp]) #4.4e-18~1.6e10を対数(-19~+11),+19して/30で0.0~1.0内に収める。 self.sp1 , self.sp2 , self.sp3 , self.sp4 , self.sp5 , self.sp6 , self.sp7 , self.sp8 , self.sp9 , self.sp10 , self.sp11 , self.sp12 , self.sp13 , self.sp14 , self.sp15 , self.sp16 , self.sp17 , self.sp18 , self.sp19 , self.sp20 , self.sp21 , self.sp22 , self.sp23 , self.sp24 , self.sp25 = np.hsplit( outputdata_sp_np , 25 ) del outputdata_sp del outputdata_sp_np gc.collect() self.ap1 , self.ap2 , self.ap3 , self.ap4 , self.ap5 , self.ap6 , self.ap7 , self.ap8 , self.ap9 , self.ap10 , self.ap11 , self.ap12 , self.ap13 , self.ap14 , self.ap15 , self.ap16 , self.ap17 , self.ap18 , self.ap19 , self.ap20 , self.ap21 , self.ap22 , self.ap23 , self.ap24 , self.ap25 = np.hsplit( np.array(outputdata_ap) , 25 ) del outputdata_ap gc.collect() self.f0 = np.array(outputdata_f0) /1024 #0~692 del outputdata_f0 gc.collect() return {'in1':self.input1,'in2':self.input2,'in3':self.input3,'in4':self.input4,'in5':self.input5,'in6':self.input6,'in7':self.input7,'in8':self.input8,'in9':self.input9,'in10':self.input10,'in11':self.input11,'in12':self.input12,'in13':self.input13,'in14':self.input14} , {'out_sp1':self.sp1,'out_sp2':self.sp2,'out_sp3':self.sp3,'out_sp4':self.sp4,'out_sp5':self.sp5,'out_sp6':self.sp6,'out_sp7':self.sp7,'out_sp8':self.sp8,'out_sp9':self.sp9,'out_sp10':self.sp10,'out_sp11':self.sp11,'out_sp12':self.sp12,'out_sp13':self.sp13,'out_sp14':self.sp14,'out_sp15':self.sp15,'out_sp16':self.sp16,'out_sp17':self.sp17,'out_sp18':self.sp18,'out_sp19':self.sp19,'out_sp20':self.sp20,'out_sp21':self.sp21,'out_sp22':self.sp22,'out_sp23':self.sp23,'out_sp24':self.sp24,'out_sp25':self.sp25,'out_ap1':self.ap1,'out_ap2':self.ap2,'out_ap3':self.ap3,'out_ap4':self.ap4,'out_ap5':self.ap5,'out_ap6':self.ap6,'out_ap7':self.ap7,'out_ap8':self.ap8,'out_ap9':self.ap9,'out_ap10':self.ap10,'out_ap11':self.ap11,'out_ap12':self.ap12,'out_ap13':self.ap13,'out_ap14':self.ap14,'out_ap15':self.ap15,'out_ap16':self.ap16,'out_ap17':self.ap17,'out_ap18':self.ap18,'out_ap19':self.ap19,'out_ap20':self.ap20,'out_ap21':self.ap21,'out_ap22':self.ap22,'out_ap23':self.ap23,'out_ap24':self.ap24,'out_ap25':self.ap25,'out_f0':self.f0} def __len__(self): return self.length def on_epoch_end(self): pass model.compile(loss='mean_squared_error', optimizer='adam') #モデルのコンパイル #model.load_weights('03_larning05_all_a.h5') #訓練済みモデルを読み込み while True: config.read(inifile) fitgen_sequence = FitGenSequence(batch_size=config.getint('general', 'BATCHSIZE') , data_size=config.getint('general', 'DATASIZE') , word_list=wordlist ) model.fit_generator(generator=fitgen_sequence , epochs=config.getint('general', 'EPOCHS') ) model.save('/data/03_larning05_all_' + datetime.now().strftime("%Y%m%d_%H%M%S") +'.h5')4.少ない教師データ数、短い学習時間で効率的に学習させる方法を考える
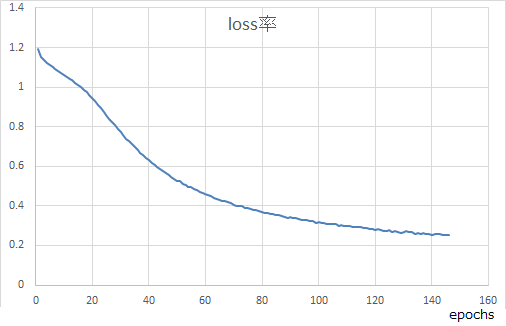
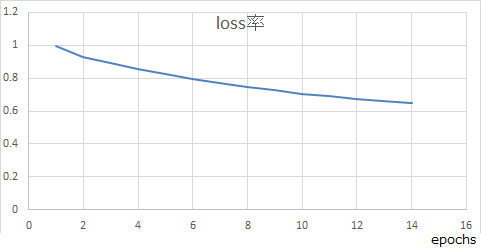
10000単語、batchsize=10で学習させたところ、84epochsくらいでloss率が下がりづらくなり、
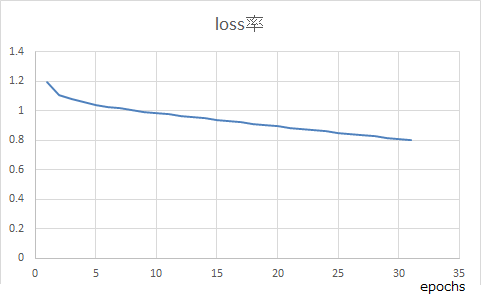
149epochs程度経過後、loss=0.25くらいで頭打ちになった。(6core:12thread/1.9GHz。メモリ32GB環境で約20日間)1000/1000 [==============================] - 13431s 13s/step - loss: 0.2511 - out_sp1_loss: 0.0014 - out_sp2_loss: 0.0070 - out_sp3_loss: 0.0096 - out_sp4_loss: 0.0088 - out_sp5_loss: 0.0135 - out_sp6_loss: 0.0151 - out_sp7_loss: 0.0091 - out_sp8_loss: 0.0034 - out_sp9_loss: 0.0014 - out_sp10_loss: 4.7735e-04 - out_sp11_loss: 2.7430e-04 - out_sp12_loss: 1.6851e-04 - out_sp13_loss: 9.2398e-05 - out_sp14_loss: 5.4483e-05 - out_sp15_loss: 5.0145e-05 - out_sp16_loss: 3.5160e-05 - out_sp17_loss: 1.8517e-05 - out_sp18_loss: 1.7576e-05 - out_sp19_loss: 7.4513e-06 - out_sp20_loss: 9.8959e-07 - out_sp21_loss: 2.2931e-07 - out_sp22_loss: 1.7947e-07 - out_sp23_loss: 1.2095e-11 - out_sp24_loss: 1.8030e-11 - out_sp25_loss: 5.6759e-12 - out_ap1_loss: 0.0187 - out_ap2_loss: 0.0239 - out_ap3_loss: 0.0251 - out_ap4_loss: 0.0263 - out_ap5_loss: 0.0286 - out_ap6_loss: 0.0283 - out_ap7_loss: 0.0161 - out_ap8_loss: 0.0066 - out_ap9_loss: 0.0026 - out_ap10_loss: 0.0011 - out_ap11_loss: 6.4949e-04 - out_ap12_loss: 3.1281e-04 - out_ap13_loss: 1.8863e-04 - out_ap14_loss: 1.2824e-04 - out_ap15_loss: 9.1774e-05 - out_ap16_loss: 6.1045e-05 - out_ap17_loss: 2.9133e-05 - out_ap18_loss: 2.2714e-05 - out_ap19_loss: 6.3900e-06 - out_ap20_loss: 1.7681e-06 - out_ap21_loss: 3.3528e-07 - out_ap22_loss: 1.5480e-07 - out_ap23_loss: 7.4649e-12 - out_ap24_loss: 9.2365e-12 - out_ap25_loss: 7.8836e-12 - out_f0_loss: 0.0018それに対して最初から50000単語、batchsize=10で学習させたところ、同じく20日間放置して31epochs経過するも、loss:0.80程度。まだ1epochあたり0.008程度下がり続けているが、収束が遅すぎる。
(性能は同じく6core:12thread/1.9GHz。メモリ32GBと同じスペック)5000/5000 [==============================] - 74533s 15s/step - loss: 0.8005 - out_sp1_loss: 0.0042 - out_sp2_loss: 0.0253 - out_sp3_loss: 0.0330 - out_sp4_loss: 0.0297 - out_sp5_loss: 0.0424 - out_sp6_loss: 0.0539 - out_sp7_loss: 0.0460 - out_sp8_loss: 0.0279 - out_sp9_loss: 0.0146 - out_sp10_loss: 0.0072 - out_sp11_loss: 0.0035 - out_sp12_loss: 0.0018 - out_sp13_loss: 0.0011 - out_sp14_loss: 6.8459e-04 - out_sp15_loss: 5.0065e-04 - out_sp16_loss: 3.8773e-04 - out_sp17_loss: 2.3878e-04 - out_sp18_loss: 1.3287e-04 - out_sp19_loss: 8.1552e-05 - out_sp20_loss: 4.5552e-05 - out_sp21_loss: 3.8080e-05 - out_sp22_loss: 1.0064e-05 - out_sp23_loss: 1.0051e-06 - out_sp24_loss: 2.4118e-11 - out_sp25_loss: 2.4103e-11 - out_ap1_loss: 0.0452 - out_ap2_loss: 0.0565 - out_ap3_loss: 0.0599 - out_ap4_loss: 0.0613 - out_ap5_loss: 0.0667 - out_ap6_loss: 0.0770 - out_ap7_loss: 0.0608 - out_ap8_loss: 0.0367 - out_ap9_loss: 0.0195 - out_ap10_loss: 0.0093 - out_ap11_loss: 0.0047 - out_ap12_loss: 0.0024 - out_ap13_loss: 0.0015 - out_ap14_loss: 9.9513e-04 - out_ap15_loss: 7.5172e-04 - out_ap16_loss: 5.4091e-04 - out_ap17_loss: 3.3179e-04 - out_ap18_loss: 1.6043e-04 - out_ap19_loss: 8.7130e-05 - out_ap20_loss: 6.2652e-05 - out_ap21_loss: 3.1422e-05 - out_ap22_loss: 1.4057e-05 - out_ap23_loss: 7.1795e-07 - out_ap24_loss: 1.8263e-11 - out_ap25_loss: 1.9893e-11 - out_f0_loss: 0.0032そこで、最初から10000単語、20日後の149epochs経過のloss=0.25で頭打ちになったモデルに対して、途中から教師データを10000単語→50000単語に増やしてみたところ、増加後最初の1回はloss:0.9971だったが、10日で12epochs経過すると0.67まで一気に改善して、最初から50000単語で学習していた方を追い抜いた。
5000/5000 [==============================] - 63167s 13s/step - loss: 0.6756 - out_sp1_loss: 0.0037 - out_sp2_loss: 0.0212 - out_sp3_loss: 0.0292 - out_sp4_loss: 0.0264 - out_sp5_loss: 0.0377 - out_sp6_loss: 0.0465 - out_sp7_loss: 0.0374 - out_sp8_loss: 0.0207 - out_sp9_loss: 0.0099 - out_sp10_loss: 0.0046 - out_sp11_loss: 0.0024 - out_sp12_loss: 0.0013 - out_sp13_loss: 8.7149e-04 - out_sp14_loss: 5.9194e-04 - out_sp15_loss: 4.3575e-04 - out_sp16_loss: 2.7581e-04 - out_sp17_loss: 1.4421e-04 - out_sp18_loss: 1.2563e-04 - out_sp19_loss: 7.0380e-05 - out_sp20_loss: 6.7398e-05 - out_sp21_loss: 4.6027e-05 - out_sp22_loss: 1.7514e-05 - out_sp23_loss: 1.0061e-06 - out_sp24_loss: 1.6893e-11 - out_sp25_loss: 1.6380e-11 - out_ap1_loss: 0.0391 - out_ap2_loss: 0.0465 - out_ap3_loss: 0.0524 - out_ap4_loss: 0.0542 - out_ap5_loss: 0.0595 - out_ap6_loss: 0.0680 - out_ap7_loss: 0.0513 - out_ap8_loss: 0.0285 - out_ap9_loss: 0.0139 - out_ap10_loss: 0.0067 - out_ap11_loss: 0.0035 - out_ap12_loss: 0.0019 - out_ap13_loss: 0.0012 - out_ap14_loss: 7.7377e-04 - out_ap15_loss: 6.2020e-04 - out_ap16_loss: 3.7930e-04 - out_ap17_loss: 2.4824e-04 - out_ap18_loss: 1.5485e-04 - out_ap19_loss: 9.1987e-05 - out_ap20_loss: 5.5130e-05 - out_ap21_loss: 3.6122e-05 - out_ap22_loss: 1.5816e-05 - out_ap23_loss: 8.1232e-07 - out_ap24_loss: 1.4804e-11 - out_ap25_loss: 1.5227e-11 - out_f0_loss: 0.0030おそらく、40000/50000のデータが未学習だったためloss率が悪化したものの、未学習データ分は学習が早いため、一気に改善したと思われる。
(追記待ち)
- 投稿日:2019-07-01T11:30:32+09:00
TensorFlowで文字列から音声に変換するモデルを試す
やりたいこと・方針
TensorFlowを使って日本語文字データ→音声データへの変換を学習させたい。
1.教師データのサンプルを作成する
2.生成された学習データの特性を確認、加工する
3.文字データ→音声データへの変換を学習させる
4.学習結果を使用して文字データ→音声データ変換を試す
5.少ない教師データ数、短い学習時間で効率的に学習させる方法を考えるやっていることは、音声読み上げソフトと同じことです。
音声加工の知識を全く持たない自分でも、機械学習に頼れば似たような仕組みを真似できるのか?という興味から始まっています。学習データに関しては、音声加工についての知識などもっておりませんので、機械学習のゴリ押しでなんとかする方針です。
音韻長など処理済みのデータを教師にしたほうが間違いなく高効率ですが、そういった処理済みのデータを大量に用意する方法も思いつかないですし、1データずつ人間の耳で聞いて加工するような入手の手間が大きい学習データは使わない方針とします。また、音声加工ではRNN/LSTMを使ってリアルタイム処理するのが定石のようですが、上記のとおりinputデータは音韻長を考慮していない単なるテキストデータのため、inputの各文字を時系列にそって並べられない。(=RNNに適さないと思っています。自分がRNNを理解できていないだけかもしれません。)
そのため今回はRNN/LSTMは使わず、基本的なTensorFlowの機能のみで処理します。あと、自分はpythonもTensorFlowも触りだして間もないので、モデルはKerasに頼って簡単に書きます。
1.教師データのサンプルを作成する
素人の作る非効率な学習モデルでは、おそらく膨大な教師データが必要になると思われるので、voiceroidを自動化して大量の音声データ(wav)を作成する。
使用したソフト:voiceroid2
https://www.ah-soft.net/shopbrand/ct92/pythonで自動化するが、実行ファイルと同じ場所に作成する単語をリストしたinput.txtを用意しておく。
あ あー あーうぃん あーかーと あーかいばー あーかいぶ あーかむ あーかん あーかんそー あーがー上記単語は、『現代日本語書き言葉均衡コーパス』語彙表サイトから短単位語彙表データを入手し、その「読み」の項目を使用。
https://pj.ninjal.ac.jp/corpus_center/bccwj/freq-list.html後で学習データとして使うのに便利にするため、すべての読みをひらがなに変更後、以下のようなデータを削除(VOICEROIDがうまく読めなかったり、今回の目的にふさわしくないもの)
・「ひとつ(数)」「ひと・・・」のように。「(」や「・」を含む単語
・「う゛」を含む単語
・sortすると先頭にくる、制御文字や記号からはじまる単語
また、学習時にはinputを固定長にする必要があるため、15文字以上の単語は一括で削除した。上記データに個人的に学習させたい固有名詞を含めた合計138423個をinput.txtに用意し、
以下のスクリプトでVOICEROID2による自動音声化を行う。自動化のために以下ページが大変参考になった。
VOICEROID2(紲星あかり)をプログラムから動かしてみる# -*- coding: utf-8 -*- import pywinauto import time import os import subprocess #子エレメントをclassnameで検索し、見つかったエレメントを返す関数 def search_child_byclassname(class_name, uiaElementInfo, target_all = False, waitcount = 50): for loop in range(waitcount): #見つからなかった場合にも、少し待って何度か繰り返すためのループ target = [] # 全ての子要素検索 for childElement in uiaElementInfo.children(): # ClassNameの一致確認 if childElement.class_name == class_name: if target_all == False: return childElement else: target.append(childElement) if target_all == False: print ( 'LOOP:' + str(uiaElementInfo.name) + ' searchclass:' + class_name) #見つからなかったらループ else: return target time.sleep(0.2) #0.2秒ごとにリトライ # 0.2秒x50回=10秒待っても見つからなかったらFalse。あまり待つ必要がない処理の場合はwaitcountを指定してすぐにfalseを返すようにする return False #子エレメントをnameで検索し、見つかったエレメントを返す関数 def search_child_byname(name, uiaElementInfo, waitcount = 50): for loop in range(waitcount): #見つからなかった場合にも、少し待って何度か繰り返すためのループ # 全ての子要素検索 for childElement in uiaElementInfo.children(): # Nameの一致確認 if childElement.name == name: return childElement time.sleep(0.2) #0.2秒ごとにリトライ print ( 'LOOP:' + str(uiaElementInfo.name) + ' searchname:' + name ) #見つからなかったらループ # 0.2秒x50回=10秒待っても見つからなかったらFalse。あまり待つ必要がない処理の場合はwaitcountを指定してすぐにfalseを返すようにする return False #子エレメントをnameとclassnameの両方で検索し、両方一致したエレメントを返す関数 def search_child_bynameandclassname(name, class_name, uiaElementInfo, target_all = False, waitcount = 50): for loop in range(waitcount): #見つからなかった場合にも、少し待って何度か繰り返すためのループ target = [] # 全ての子要素検索 for childElement in uiaElementInfo.children(): # ClassNameの一致確認 if childElement.class_name == class_name and childElement.name == name: if target_all == False: return childElement else: target.append(childElement) if target_all == False: print ( 'LOOP:' + str(uiaElementInfo.name) + ' searchname:' + name + ' searchclass:' + class_name) #見つからなかったらループ else: return target time.sleep(0.2) #0.2秒ごとにリトライ # 0.2秒x50回=10秒待っても見つからなかったらFalse。あまり待つ必要がない処理の場合はwaitcountを指定してすぐにfalseを返すようにする return False #アプリの起動および接続 def app_start1(app1,path1,t1): try: app1.Connect(path = path1) except: app1.Start(cmd_line = path1) time.sleep(t1) app1.Connect(path = path1) ## Voiceroid Editorの起動からトップ画面まで def startVOICEROID2(): # アプリ起動 app = pywinauto.Application() path1 = u"C:\Program Files (x86)\\AHS\\VOICEROID2\\VoiceroidEditor.exe" t1 = 2 app_start1(app,path1,t1) ## Voiceroid2 Editor強制終了(ハングアップ時対応) def killVOICEROID2(): cmd = 'taskkill /f /im VoiceroidEditor.exe' returncode = subprocess.call(cmd) ## 引数の文字列を入力して「再生」 def talkVOICEROID2(speakPhrase): # デスクトップのエレメント parentUIAElement = pywinauto.uia_element_info.UIAElementInfo() # voiceroidを捜索する voiceroid2 = search_child_byname("VOICEROID2",parentUIAElement,waitcount=1) # *がついている場合 if voiceroid2 == False: voiceroid2 = search_child_byname("VOICEROID2*",parentUIAElement,waitcount=1) # テキスト要素のElementInfoを取得 TextEditViewEle = search_child_byclassname("TextEditView",voiceroid2) textBoxEle = search_child_byclassname("TextBox",TextEditViewEle) # コントロール取得 textBoxEditControl = pywinauto.controls.uia_controls.EditWrapper(textBoxEle) # テキスト登録 textBoxEditControl.set_edit_text(speakPhrase) # ボタン取得 buttonsEle = search_child_byclassname("Button",TextEditViewEle,target_all = True) # 再生ボタンを探す playButtonEle = "" for buttonEle in buttonsEle: # テキストブロックを捜索 textBlockEle = search_child_byclassname("TextBlock",buttonEle) if textBlockEle.name == "再生": playButtonEle = buttonEle break # ボタンコントロール取得 playButtonControl = pywinauto.controls.uia_controls.ButtonWrapper(playButtonEle) # 再生ボタン押下 playButtonControl.click() ## 引数の文字列を音声化して「音声保存」。保存先のフルパスファイル名も指定。拡張子はwav固定なので省略可 def saveVOICEROID2(speakPhrase,filename): # デスクトップのエレメント parentUIAElement = pywinauto.uia_element_info.UIAElementInfo() # voiceroidを捜索する voiceroid2 = search_child_byname("VOICEROID2",parentUIAElement,waitcount=1) # *がついている場合 if voiceroid2 == False: voiceroid2 = search_child_byname("VOICEROID2*",parentUIAElement,waitcount=1) # テキスト要素のElementInfoを取得 print("voiceroid2 classname = "+str(voiceroid2.children()) ) TextEditViewEle = search_child_byclassname("TextEditView",voiceroid2) textBoxEle = search_child_byclassname("TextBox",TextEditViewEle) # コントロール取得 textBoxEditControl = pywinauto.controls.uia_controls.EditWrapper(textBoxEle) # テキスト登録 textBoxEditControl.set_edit_text(speakPhrase) # ボタン取得 buttonsEle = search_child_byclassname("Button",TextEditViewEle,target_all = True) # 音声保存ボタンを探す playButtonEle = "" for buttonEle in buttonsEle: # テキストブロックを捜索 textBlockEle = search_child_byclassname("TextBlock",buttonEle) if textBlockEle.name == "音声保存": playButtonEle = buttonEle break # ボタンコントロール取得 playButtonControl = pywinauto.controls.uia_controls.ButtonWrapper(playButtonEle) # 音声保存ボタン押下 playButtonControl.click() # 音声保存ウィンドウが開くまで少し待つ(ウィンドウが開く前にsearch_child_bynameすると、bool値falseが返ってくる) time.sleep(0.3) # 音声保存ウィンドウと、その中の"OK"ボタンを探して押す onseihozon = search_child_byname("音声保存",voiceroid2) buttonEle = search_child_byname("OK",onseihozon) playButtonControl = pywinauto.controls.uia_controls.ButtonWrapper(buttonEle) playButtonControl.click() time.sleep(0.3) # ファイル名を入力。深いエレメントなので1つずつ潜る。nameがあるものはbynameで、nameが空白のものはbyclassnameで、類似エレメントが多いものは両方で検索。 savefile1 = search_child_byname("名前を付けて保存",onseihozon) savefile2 = search_child_byclassname("DUIViewWndClassName",savefile1) savefile3 = search_child_bynameandclassname("ファイル名:","AppControlHost",savefile2) #"ファイル名:"コンボボックス savefile4 = search_child_byname("ファイル名:",savefile3) #"ファイル名:"テキストボックス textBoxEditControl = pywinauto.controls.uia_controls.EditWrapper(savefile4) textBoxEditControl.set_edit_text(filename) #"保存(S)"ボタンを押す。"名前を付けて保存"ダイヤログの配下にある。 buttonEle = search_child_byname("保存(S)",savefile1) playButtonControl = pywinauto.controls.uia_controls.ButtonWrapper(buttonEle) playButtonControl.click() time.sleep(1.0) #「合成音声をファイルに保存しました」ダイヤログのOKボタンを押す savefile1 = search_child_byname("情報",onseihozon) buttonEle = search_child_byname("OK",savefile1) playButtonControl = pywinauto.controls.uia_controls.ButtonWrapper(buttonEle) playButtonControl.click() time.sleep(0.3) FILEPATH='C:\work\output' #出力先フォルダ inputfile = open('input.txt','r') line = inputfile.readline() while line: #ファイルを1行ずつループ try: #エラー時には、voiceroidを再起動してからリトライ saveVOICEROID2(line.strip(),FILEPATH + '\\' + line.strip() ) #.strip()で各行末尾の改行コードを消す except: killVOICEROID2() time.sleep(5) startVOICEROID2() time.sleep(10) saveVOICEROID2(line.strip(),FILEPATH + '\\' + line.strip() ) #.strip()で各行末尾の改行コードを消す line = inputfile.readline() inputfile.close()上記処理を回していると、数日に1回ほど以下のエラーが出て処理が止まることがある。
VOICEROID2 Editorは動作を停止しました 問題が発生したため、プログラムが正しく動作しなくなりました。上記エラーが記録されたことを検出した際、タスクスケジューラから
voiceroid.exeと、メッセージBOXの両方をtaskkillするバッチをキックするようにしてみた。ping -n 5 localhost >NUL taskkill /f /im WerFault.exe taskkill /f /im VoiceroidEditor.exeVOICEROID2が強制終了されると、startVOICEROID2()によりアプリが再起動され、処理が継続する。
これで処理が止まることなく10日間、全単語を音声化するまで安定して動くようになった。なお、voiceroidの仕様上、長い単語は、1つの単語のつもりでinputしても途中で発音が区切られている場合があるが妥協する。
最初からすべてひらがなでinputしているので、読み間違いは無いはず。生成された138423個のwavファイルの合計容量は7.8GiB程度でした。
2.生成された学習データの特性を確認、加工する
先はVOICEROID2を使用する都合上Windows環境だったが、ここからはCentos7環境を使用する。
今回の学習データは以下になる
input:日本語文字データ(text:utf-8)
output:音声データ(wav)これをそのままTensorFlowに入力することはできないので、input/outputそれぞれについて、0~1.0の範囲内の数値を使用したnumpy行列に変換するための処理を作成する。
inputの加工
まずはinputを変換する。
作成した教師データについて文字数ごとのデータ数を数えると以下のような感じ。
12文字以上はデータ数が極端に少なかったので、手動で作った単語表を加えてデータ数を増やしている。[work]# LENGTH1=0;LENGTH2=0;LENGTH3=0;LENGTH4=0;LENGTH5=0;LENGTH6=0;LENGTH7=0;LENGTH8=0;LENGTH9=0;LENGTH10=0;LENGTH11=0;LENGTH12=0;LENGTH13=0;LENGTH14=0 [work]# while read line > do LENGTH=$((`echo $line | wc -m` - 1)) > if [ $LENGTH -gt 14 ] > then echo $line $LENGTH #念のために15文字以上の長さの文字が残っていた場合に表示 > fi > eval LENGTH$LENGTH=`eval expr '$'LENGTH$LENGTH + 1` > done < input.txt [work]# echo $LENGTH1 $LENGTH2 $LENGTH3 $LENGTH4 $LENGTH5 $LENGTH6 $LENGTH7 $LENGTH8 $LENGTH9 $LENGTH10 $LENGTH11 $LENGTH12 $LENGTH13 $LENGTH14 66 3002 24038 53049 30415 14848 6658 3179 1406 522 292 367 303 278 [work]#input変換(text→numpy)のルールとしては、
すべての文字を、それぞれ11~211の数字を割り当てる。
同じ母音の音は近い数字になるように、以下のルールで割り当てる
あ行:11~50
い行:51~90
う行:91~130
え行:131~170
お行:171~210
ん:211濁音、半濁音は、それぞれの清音と近い数字になるように割り当てる。
また、「ぁ」「ぃ」「ぅ」「ぇ」「ぉ」「ゃ」「ゅ」「ょ」は、同じ母音の文字と近い数字になるように割り当てる。
11:あ
12:うぁ
13:か
14:きゃ
15:が
16:ぎゃそれぞれの音の後に、長音「ー」および「っ」を表すデータを付与する。
通常の長さの音=128、長音「ー」=200、「っ」=30これにより、
「ぎょーざ」は、以下のように変換される
175 (ぎょ)
200 (長音「ー」)
18 (ざ)
128 (通常の長さ)「あっぷる」は以下のように変換される
11 (あ)
30 (「っ」)
110 (ぷ)
128 (通常の長さ)
115 (る)
128 (通常の長さ)TensorFlowの入出力は固定長にする必要がある。
今回の教師データが最大14文字なので、1文字あたり2要素の合計28個の数字のlistを返す。
14文字に足りない文字数分は、すべて「0」(無音扱い)で埋める。単語の文字列を引数に、対応する数字のlistを返す関数を作成
char2num.py#charの文字列を、規則に従ってlistに変換。listのサイズは発音文字数numで揃える(不足は0で埋める)。 def exchange(char,num): output = [] # 帰り値用list。1音を2つの数字で表す。詳細は別途説明書に記載 oto = 0 # 何音入れたか?のカウント「ば」「あっ」「ぎゃー」文字数は1-3だが、すべて1音でカウント for n in range(len(char)): # 文字列の長さだけループ m = char[n] #今回ループで処理する文字 oto += 1 #1文字1音の言葉→そのまま入れる。次の文字が「ゃ」「ゅ」「ょ」の場合の場合も一旦入れて、後で書き換える #「っ」「ー」を含まない通常の長さを示す数字「128」も仮入れする if m == 'あ':output += [11,128] elif m == 'か':output += [13,128] elif m == 'が':output += [15,128] elif m == 'さ':output += [17,128] elif m == 'ざ':output += [20,128] elif m == 'た':output += [23,128] elif m == 'だ':output += [29,128] elif m == 'な':output += [34,128] elif m == 'は':output += [36,128] elif m == 'ば':output += [39,128] elif m == 'ぱ':output += [42,128] elif m == 'ま':output += [44,128] elif m == 'や':output += [46,128] elif m == 'ら':output += [47,128] elif m == 'わ':output += [50,128] elif m == 'い':output += [51,128] elif m == 'き':output += [53,128] elif m == 'ぎ':output += [55,128] elif m == 'し':output += [57,128] elif m == 'じ':output += [60,128] elif m == 'ち':output += [63,128] elif m == 'ぢ':output += [69,128] elif m == 'に':output += [74,128] elif m == 'ひ':output += [76,128] elif m == 'び':output += [79,128] elif m == 'ぴ':output += [82,128] elif m == 'み':output += [84,128] elif m == 'り':output += [87,128] elif m == 'う':output += [91,128] elif m == 'く':output += [93,128] elif m == 'ぐ':output += [95,128] elif m == 'す':output += [97,128] elif m == 'ず':output += [100,128] elif m == 'つ':output += [103,128] elif m == 'づ':output += [109,128] elif m == 'ぬ':output += [114,128] elif m == 'ふ':output += [116,128] elif m == 'ぶ':output += [119,128] elif m == 'ぷ':output += [122,128] elif m == 'む':output += [124,128] elif m == 'ゆ':output += [126,128] elif m == 'る':output += [127,128] elif m == 'え':output += [131,128] elif m == 'け':output += [133,128] elif m == 'げ':output += [135,128] elif m == 'せ':output += [137,128] elif m == 'ぜ':output += [140,128] elif m == 'て':output += [143,128] elif m == 'で':output += [149,128] elif m == 'ね':output += [154,128] elif m == 'へ':output += [156,128] elif m == 'べ':output += [159,128] elif m == 'ぺ':output += [162,128] elif m == 'め':output += [164,128] elif m == 'れ':output += [167,128] elif m == 'お':output += [171,128] elif m == 'こ':output += [173,128] elif m == 'ご':output += [175,128] elif m == 'そ':output += [177,128] elif m == 'ぞ':output += [180,128] elif m == 'と':output += [183,128] elif m == 'ど':output += [189,128] elif m == 'の':output += [194,128] elif m == 'ほ':output += [196,128] elif m == 'ぼ':output += [199,128] elif m == 'ぽ':output += [202,128] elif m == 'も':output += [204,128] elif m == 'よ':output += [206,128] elif m == 'ろ':output += [207,128] elif m == 'を':output += [210,128] elif m == 'ん':output += [211,128] else: oto-=1 #上記以外の文字(「ゃ」「ゅ」「ょ」「ぁ」「ぃ」「ぅ」「ぇ」「ぉ」「っ」「ー」)の場合は、oto+=1をキャンセル if oto == 0 : return ([0]* (num*2)) #1文字目が上記以外の場合はall 0で即return(エラー扱い) #「ゃ」「ゅ」「ょ」「ぁ」「ぃ」「ぅ」「ぇ」「ぉ」の場合は、1つ前の音(listでは2つ前)を変更する if m == 'ゃ': if output[(oto*2)-2] == 53:output[(oto*2)-2] = 14 #「53=き」の場合、「14=きゃ」に変更 elif output[(oto*2)-2] == 55:output[(oto*2)-2] = 16 elif output[(oto*2)-2] == 57:output[(oto*2)-2] = 18 elif output[(oto*2)-2] == 60:output[(oto*2)-2] = 21 elif output[(oto*2)-2] == 63:output[(oto*2)-2] = 24 elif output[(oto*2)-2] == 69:output[(oto*2)-2] = 30 elif output[(oto*2)-2] == 74:output[(oto*2)-2] = 35 elif output[(oto*2)-2] == 76:output[(oto*2)-2] = 37 elif output[(oto*2)-2] == 79:output[(oto*2)-2] = 40 elif output[(oto*2)-2] == 82:output[(oto*2)-2] = 43 elif output[(oto*2)-2] == 84:output[(oto*2)-2] = 45 elif output[(oto*2)-2] == 87:output[(oto*2)-2] = 48 elif m == 'ゅ': if output[(oto*2)-2] == 53:output[(oto*2)-2] = 94 elif output[(oto*2)-2] == 55:output[(oto*2)-2] = 96 elif output[(oto*2)-2] == 57:output[(oto*2)-2] = 98 elif output[(oto*2)-2] == 60:output[(oto*2)-2] = 101 elif output[(oto*2)-2] == 63:output[(oto*2)-2] = 104 elif output[(oto*2)-2] == 69:output[(oto*2)-2] = 110 elif output[(oto*2)-2] == 74:output[(oto*2)-2] = 115 elif output[(oto*2)-2] == 76:output[(oto*2)-2] = 117 elif output[(oto*2)-2] == 79:output[(oto*2)-2] = 120 elif output[(oto*2)-2] == 82:output[(oto*2)-2] = 123 elif output[(oto*2)-2] == 84:output[(oto*2)-2] = 125 elif output[(oto*2)-2] == 87:output[(oto*2)-2] = 128 elif m == 'ょ': if output[(oto*2)-2] == 53:output[(oto*2)-2] = 174 elif output[(oto*2)-2] == 55:output[(oto*2)-2] = 176 elif output[(oto*2)-2] == 57:output[(oto*2)-2] = 178 elif output[(oto*2)-2] == 60:output[(oto*2)-2] = 181 elif output[(oto*2)-2] == 63:output[(oto*2)-2] = 184 elif output[(oto*2)-2] == 69:output[(oto*2)-2] = 190 elif output[(oto*2)-2] == 74:output[(oto*2)-2] = 195 elif output[(oto*2)-2] == 76:output[(oto*2)-2] = 197 elif output[(oto*2)-2] == 79:output[(oto*2)-2] = 200 elif output[(oto*2)-2] == 82:output[(oto*2)-2] = 203 elif output[(oto*2)-2] == 84:output[(oto*2)-2] = 205 elif output[(oto*2)-2] == 87:output[(oto*2)-2] = 208 elif m == 'ぁ': if output[(oto*2)-2] == 91:output[(oto*2)-2] = 12 elif output[(oto*2)-2] == 57:output[(oto*2)-2] = 19 elif output[(oto*2)-2] == 60:output[(oto*2)-2] = 22 elif output[(oto*2)-2] == 103:output[(oto*2)-2] = 26 elif output[(oto*2)-2] == 143:output[(oto*2)-2] = 27 elif output[(oto*2)-2] == 109:output[(oto*2)-2] = 31 elif output[(oto*2)-2] == 149:output[(oto*2)-2] = 32 elif output[(oto*2)-2] == 116:output[(oto*2)-2] = 38 elif output[(oto*2)-2] == 119:output[(oto*2)-2] = 41 elif m == 'ぃ': if output[(oto*2)-2] == 91:output[(oto*2)-2] = 52 elif output[(oto*2)-2] == 57:output[(oto*2)-2] = 59 elif output[(oto*2)-2] == 60:output[(oto*2)-2] = 62 elif output[(oto*2)-2] == 63:output[(oto*2)-2] = 65 elif output[(oto*2)-2] == 103:output[(oto*2)-2] = 66 elif output[(oto*2)-2] == 143:output[(oto*2)-2] = 67 elif output[(oto*2)-2] == 109:output[(oto*2)-2] = 71 elif output[(oto*2)-2] == 149:output[(oto*2)-2] = 72 elif output[(oto*2)-2] == 116:output[(oto*2)-2] = 78 elif output[(oto*2)-2] == 119:output[(oto*2)-2] = 81 elif output[(oto*2)-2] == 87:output[(oto*2)-2] = 89 elif m == 'ぅ': if output[(oto*2)-2] == 103:output[(oto*2)-2] = 106 elif output[(oto*2)-2] == 143:output[(oto*2)-2] = 107 elif output[(oto*2)-2] == 183:output[(oto*2)-2] = 108 elif output[(oto*2)-2] == 109:output[(oto*2)-2] = 111 elif output[(oto*2)-2] == 149:output[(oto*2)-2] = 112 elif output[(oto*2)-2] == 189:output[(oto*2)-2] = 113 elif output[(oto*2)-2] == 116:output[(oto*2)-2] = 118 elif output[(oto*2)-2] == 119:output[(oto*2)-2] = 121 elif output[(oto*2)-2] == 87:output[(oto*2)-2] = 129 elif m == 'ぇ': if output[(oto*2)-2] == 91:output[(oto*2)-2] = 132 elif output[(oto*2)-2] == 57:output[(oto*2)-2] = 139 elif output[(oto*2)-2] == 60:output[(oto*2)-2] = 142 elif output[(oto*2)-2] == 63:output[(oto*2)-2] = 145 elif output[(oto*2)-2] == 103:output[(oto*2)-2] = 146 elif output[(oto*2)-2] == 109:output[(oto*2)-2] = 151 elif output[(oto*2)-2] == 116:output[(oto*2)-2] = 158 elif output[(oto*2)-2] == 119:output[(oto*2)-2] = 161 elif m == 'ぉ': if output[(oto*2)-2] == 91:output[(oto*2)-2] = 172 elif output[(oto*2)-2] == 183:output[(oto*2)-2] = 188 elif output[(oto*2)-2] == 189:output[(oto*2)-2] = 193 elif output[(oto*2)-2] == 116:output[(oto*2)-2] = 198 elif output[(oto*2)-2] == 119:output[(oto*2)-2] = 201 elif output[(oto*2)-2] == 87:output[(oto*2)-2] = 209 #「ー」「っ」の場合は、今回の発音長(listでは1つ前)を変更する elif m == 'っ':output[(oto*2)-1] = 30 elif m == 'ー':output[(oto*2)-1] = 200 #固定長5文字(len()=num*2)に揃えて、不足分は0で埋める output += [0] * ((num*2)-len(output)) return (output)母音と子音で別の数字に分けたほうが良かったかな?と思ったが、、とりあえず最低限の加工はできたはず。
上記スクリプトの返り値は1文字あたり2つの数字のlist。各数字の範囲は0~211の整数なので、TensorFlowに入れる際には/256して0~1.0まで範囲に収める必要がある。
outputの加工
次に出力(wav)をnumpyに変換する
wavファイルの波形データをそのまま入れてもまともに学習できないので、以下サイトを参考に、「基本周波数(f0)」「スペクトル包絡(sp)」「非周期性指標(ap)」を抽出する
音声合成システム WORLD に触れてみる今回用意した138423個のwavファイルの合計容量は7.8GiB程度だが、これを上記のように3種のnumpyに変換すると、numpy.saveでbinary保管しても10倍以上の容量に膨れる。
最初から全wavをnumpyに変換してディスク上においておく方法も考えられるが、自分の環境はSSD容量が小さいので、学習中に、必要なデータを都度wav→f0,sp,ap変換する仕組みを採用する。以下は、その変換部分のスクリプト。逆変換(numpy→wav)の処理もついでに作っておく
wav2numpy.py
# -*- coding: utf-8 -*- from scipy.io import wavfile import pyworld as pw import numpy as np # wavファイル名を引数に、f0,sp,apのnumpyを返す関数wav2numpy(wavfilename) def wav2numpy(wavfilename): fs, data = wavfile.read( wavfilename ) data = data.astype(np.float) # WORLDはfloat前提のコードになっているのでfloat型にしておく _f0, t = pw.dio(data, fs) # 基本周波数の抽出 f0 = pw.stonemask(data, _f0, t, fs) # 基本周波数の修正 sp = pw.cheaptrick(data, f0, t, fs) # スペクトル包絡の抽出 ap = pw.d4c(data, f0, t, fs) # 非周期性指標の抽出 return ( f0 , sp , ap ) # f0,sp,apおよび任意のwavファイル名を引数。f0,sp,apからwavファイルを出力する def numpy2wav(f0,sp,ap,wavfilename): fs = 44100 synthesized = pw.synthesize(f0, sp, ap, fs).astype(np.int16) wavfile.write( wavfilename ,fs,synthesized)これらデータをTensorFlowに投入したいが、先程生成したf0,spを0~1.0の範囲内に収めるために、どの程度の範囲なのか、特性を確認する必要がある。(apは最初から0~1.0の範囲内に収まるので加工不要)
以下、データの特性を確認するためだけのスクリプト
import numpy as np import matplotlib.pyplot as plt import csv import pandas as pd import wav2numpy wavdir = '/home/d9840yh/work/wavfiles2' maxf0 = 0 minf0 = 1e100 maxsp = 0 minsp = 1e100 inputfile = open('input.txt','r') line = inputfile.readline() while line: f0=[] sp=[] ap=[] f0 , sp , ap = wav2numpy.wav2numpy(wavdir + '/' + line.strip() + '.wav') #wavからf0,sp,apを抽出 if f0.max() > maxf0 : #f0 max更新 maxf0=f0.max() print("new max f0 : max f0=",maxf0," min f0=",minf0," max sp=",maxsp," min sp=",minsp," file:",line.strip()) if f0.min() < minf0 : #f0 min更新 minf0=f0.min() print("new min f0 : max f0=",maxf0," min f0=",minf0," max sp=",maxsp," min sp=",minsp," file:",line.strip()) if sp.max() > maxsp : #sp max更新 maxsp=sp.max() print("new max sp : max f0=",maxf0," min f0=",minf0," max sp=",maxsp," min sp=",minsp," file:",line.strip()) if sp.min() < minsp : #sp min更新 minsp=sp.min() print("new min sp : max f0=",maxf0," min f0=",minf0," max sp=",maxsp," min sp=",minsp," file:",line.strip()) line = inputfile.readline()実行結果
[work]# python3.6 ./03_search_max.py new max f0 : max f0= 265.4438671748281 min f0= 1e+100 max sp= 0 min sp= 1e+100 file: あ new min f0 : max f0= 265.4438671748281 min f0= 0.0 max sp= 0 min sp= 1e+100 file: あ new max sp : max f0= 265.4438671748281 min f0= 0.0 max sp= 657068294.401034 min sp= 1e+100 file: あ new min sp : max f0= 265.4438671748281 min f0= 0.0 max sp= 657068294.401034 min sp= 0.027947641201406224 file: あ new max f0 : max f0= 302.4288177772 min f0= 0.0 max sp= 657068294.401034 min sp= 0.027947641201406224 file: あー new max sp : max f0= 302.4288177772 min f0= 0.0 max sp= 837133555.222678 min sp= 0.027947641201406224 file: あー new min sp : max f0= 302.4288177772 min f0= 0.0 max sp= 837133555.222678 min sp= 0.0063757402892679615 file: あー new max f0 : max f0= 344.4078989932586 min f0= 0.0 max sp= 837133555.222678 min sp= 0.0063757402892679615 file: あーうぃん new max sp : max f0= 344.4078989932586 min f0= 0.0 max sp= 1931761024.0156083 min sp= 0.0063757402892679615 file: あーうぃん (中略) new max f0 : max f0= 692.524084004494 min f0= 0.0 max sp= 12431307878.277342 min sp= 8.294699504145247e-18 file: えいこさのいど new min sp : max f0= 692.524084004494 min f0= 0.0 max sp= 12431307878.277342 min sp= 5.7318239325174266e-18 file: さきのり new min sp : max f0= 692.524084004494 min f0= 0.0 max sp= 12431307878.277342 min sp= 4.4569279355354585e-18 file: しぇるどれいく new max sp : max f0= 692.524084004494 min f0= 0.0 max sp= 16109683177.383907 min sp= 4.4569279355354585e-18 file: ぜねらりf0は最大692.5なので、単純に/1024すれば0~1.0の範囲内に収まる。
spは対数的な特性をもつデータなので、単純に/10e11すると、小さなレンジのデータがまともに学習できなくなると思われる。
(実際に、サンプルの学習データとして10e-20 ~ 1.0までの20桁のレンジのデータがoutputになるように超シンプルなモデルに学習させてみたところ、小さなレンジのデータは≒0として扱われて、10e-3以上のデータしか結果に反映されなかった。)そのため、spについては対数計算した上で、0~1.0の範囲内に収める必要がある。
元データが4.4e-18~1.6e10の範囲なので、単純にlog10を取ると-19~11のデータ範囲に収まる。
それを+19して、さらに/30すれば、良い感じに収まりそう。なお、fp,sp,apのサイズは音声の長さに依存するが、もっともサイズの大きいwavファイルを確認したところ以下だった。
f0.shape=(475,)
sp.shape=(475, 1025)
ap.shape=(475, 1025)なお、1025は音声の中身にかかわらずで、475の部分が音声の長さに比例して増える。
学習前にこれをflat化する必要があるので、sp,apは475x1025=486875。
余裕をもって500x1025=512500としておけば問題無い3.文字データ→音声データへの変換を学習させる
以上の結果をふまえて、学習用の仕組みを作成する。
用意した音声wavファイルは138423個あるが、これをいきなり放り込んで失敗すると嫌なので、使用する教師データ数を動的に変更できるようにする。ついでにBatchsizeやepochsも変更できるようにする。
# cat 03_larning05_all.ini [general] DATASIZE=10000 BATCHSIZE=10 EPOCHS=3 #学習用のスクリプトを用意。
最初、モデルは以下のように考えていた。
しかし、上記だと100GB超のメインメモリを消費する。
おそらく、最後のDense(8192)→output_sp.shape=[205000,]の箇所で、
sp用だけでも単純計算8,192*512,500=4,198,400,000の変数を学習させることになるのが原因と思われる。(Dense=全層結合だからそういうことだよね?)
最後のoutputは、ある程度時系列に沿ったデータ配列になっているので、np.hsplitで分割しても、個々はそれなりにまとまった時間軸のデータになっているはず。そこで、以下のように最後のDenseより後を25分割した。
ついでにinputも1文字([2,])単位で分割し、最初のDenseとの間に1層追加する。(ここで、各1音ごとの音特性を学習してくれたら、その後のDenseは音韻長や繋ぎなどの全体をまとめる学習に専念できないかな?という狙い)
これで、最終Denseのセル数は8192 → 512*25=12,800と実質増えているにもかかわらず、最終Denseからoutput_spとの間で学習する変数は512*20500*25=262,400,000 となり、1/10以下に落とせた。
このあたりのコーディングがゴリ押しなのだが、なにか良い感じにDenseを分割できる方法は無いものか。
また、教師データ量が膨大なので、全データを一斉にメモリに格納することはできない。
そこで学習と平行して教師データを加工できるようにfit_generatorを使っているのだが、通常のfitでいうところのVALIDSPLITがつかえない。これも自分でon_epoch_end()内に実装するしか無いのかな・・・活性関数は、いまいち効果が分からないので、とりあえずreluをつっこんでおく。
単語のリストであるinput.txtはスクリプトと同じディレクトリ内に配置。
VOICEROIDにより生成されたwavファイルは、/home/d9840yh/work/wavfiles2/以下に配置。from __future__ import absolute_import, division, print_function, unicode_literals # TensorFlow と tf.keras のインポート import tensorflow as tf from tensorflow import keras config = tf.ConfigProto(log_device_placement=True) sess = tf.Session(config=config) keras.backend.set_session(sess) # ヘルパーライブラリのインポート import numpy as np import math from datetime import datetime import gc import configparser # 自作スクリプト #charの文字列を、規則に従ってlistに変換 exchange(char,num) import char2num #wavファイルからf0,sp,apのnumpy arrayを取り出す import wav2numpy wavdir = '/home/d9840yh/work/wavfiles2' inifile = '03_larning05_all.ini' config = configparser.SafeConfigParser() # input.txtの各行を1要素としたlist:wordlistを生成 wordlist = [] with open("input.txt", "r",encoding="utf-8") as f: wordlist.extend(f.read().split()) #モデルを定義する関数。 inputは28の数字、outputは[sp,ap=512500つの数字][f0=500つの数字] model_input1 = keras.Input(shape=(2,), name='in1') model_input2 = keras.Input(shape=(2,), name='in2') model_input3 = keras.Input(shape=(2,), name='in3') model_input4 = keras.Input(shape=(2,), name='in4') model_input5 = keras.Input(shape=(2,), name='in5') model_input6 = keras.Input(shape=(2,), name='in6') model_input7 = keras.Input(shape=(2,), name='in7') model_input8 = keras.Input(shape=(2,), name='in8') model_input9 = keras.Input(shape=(2,), name='in9') model_input10 = keras.Input(shape=(2,), name='in10') model_input11 = keras.Input(shape=(2,), name='in11') model_input12 = keras.Input(shape=(2,), name='in12') model_input13 = keras.Input(shape=(2,), name='in13') model_input14 = keras.Input(shape=(2,), name='in14') x1_1 = keras.layers.Dense(256, activation='relu', name='1st_layer1')(model_input1) x1_2 = keras.layers.Dense(256, activation='relu', name='1st_layer2')(model_input2) x1_3 = keras.layers.Dense(256, activation='relu', name='1st_layer3')(model_input3) x1_4 = keras.layers.Dense(256, activation='relu', name='1st_layer4')(model_input4) x1_5 = keras.layers.Dense(256, activation='relu', name='1st_layer5')(model_input5) x1_6 = keras.layers.Dense(256, activation='relu', name='1st_layer6')(model_input6) x1_7 = keras.layers.Dense(256, activation='relu', name='1st_layer7')(model_input7) x1_8 = keras.layers.Dense(256, activation='relu', name='1st_layer8')(model_input8) x1_9 = keras.layers.Dense(256, activation='relu', name='1st_layer9')(model_input9) x1_10 = keras.layers.Dense(256, activation='relu', name='1st_layer10')(model_input10) x1_11 = keras.layers.Dense(256, activation='relu', name='1st_layer11')(model_input11) x1_12 = keras.layers.Dense(256, activation='relu', name='1st_layer12')(model_input12) x1_13 = keras.layers.Dense(256, activation='relu', name='1st_layer13')(model_input13) x1_14 = keras.layers.Dense(256, activation='relu', name='1st_layer14')(model_input14) x1_merge = keras.layers.concatenate([x1_1,x1_2,x1_3,x1_4,x1_5,x1_6,x1_7,x1_8,x1_9,x1_10,x1_11,x1_12,x1_13,x1_14], axis=-1) x2 = keras.layers.Dense(16384, activation='relu', name='2nd_layer')(x1_merge) x3 = keras.layers.Dense(16384, activation='relu', name='3rd_layer')(x2) x4_sp1 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp1')(x3) x4_sp2 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp2')(x3) x4_sp3 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp3')(x3) x4_sp4 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp4')(x3) x4_sp5 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp5')(x3) x4_sp6 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp6')(x3) x4_sp7 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp7')(x3) x4_sp8 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp8')(x3) x4_sp9 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp9')(x3) x4_sp10 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp10')(x3) x4_sp11 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp11')(x3) x4_sp12 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp12')(x3) x4_sp13 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp13')(x3) x4_sp14 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp14')(x3) x4_sp15 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp15')(x3) x4_sp16 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp16')(x3) x4_sp17 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp17')(x3) x4_sp18 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp18')(x3) x4_sp19 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp19')(x3) x4_sp20 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp20')(x3) x4_sp21 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp21')(x3) x4_sp22 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp22')(x3) x4_sp23 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp23')(x3) x4_sp24 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp24')(x3) x4_sp25 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp25')(x3) model_output_sp1 = keras.layers.Dense(20500, name='out_sp1')(x4_sp1) model_output_sp2 = keras.layers.Dense(20500, name='out_sp2')(x4_sp2) model_output_sp3 = keras.layers.Dense(20500, name='out_sp3')(x4_sp3) model_output_sp4 = keras.layers.Dense(20500, name='out_sp4')(x4_sp4) model_output_sp5 = keras.layers.Dense(20500, name='out_sp5')(x4_sp5) model_output_sp6 = keras.layers.Dense(20500, name='out_sp6')(x4_sp6) model_output_sp7 = keras.layers.Dense(20500, name='out_sp7')(x4_sp7) model_output_sp8 = keras.layers.Dense(20500, name='out_sp8')(x4_sp8) model_output_sp9 = keras.layers.Dense(20500, name='out_sp9')(x4_sp9) model_output_sp10 = keras.layers.Dense(20500, name='out_sp10')(x4_sp10) model_output_sp11 = keras.layers.Dense(20500, name='out_sp11')(x4_sp11) model_output_sp12 = keras.layers.Dense(20500, name='out_sp12')(x4_sp12) model_output_sp13 = keras.layers.Dense(20500, name='out_sp13')(x4_sp13) model_output_sp14 = keras.layers.Dense(20500, name='out_sp14')(x4_sp14) model_output_sp15 = keras.layers.Dense(20500, name='out_sp15')(x4_sp15) model_output_sp16 = keras.layers.Dense(20500, name='out_sp16')(x4_sp16) model_output_sp17 = keras.layers.Dense(20500, name='out_sp17')(x4_sp17) model_output_sp18 = keras.layers.Dense(20500, name='out_sp18')(x4_sp18) model_output_sp19 = keras.layers.Dense(20500, name='out_sp19')(x4_sp19) model_output_sp20 = keras.layers.Dense(20500, name='out_sp20')(x4_sp20) model_output_sp21 = keras.layers.Dense(20500, name='out_sp21')(x4_sp21) model_output_sp22 = keras.layers.Dense(20500, name='out_sp22')(x4_sp22) model_output_sp23 = keras.layers.Dense(20500, name='out_sp23')(x4_sp23) model_output_sp24 = keras.layers.Dense(20500, name='out_sp24')(x4_sp24) model_output_sp25 = keras.layers.Dense(20500, name='out_sp25')(x4_sp25) x4_ap1 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap1')(x3) x4_ap2 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap2')(x3) x4_ap3 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap3')(x3) x4_ap4 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap4')(x3) x4_ap5 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap5')(x3) x4_ap6 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap6')(x3) x4_ap7 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap7')(x3) x4_ap8 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap8')(x3) x4_ap9 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap9')(x3) x4_ap10 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap10')(x3) x4_ap11 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap11')(x3) x4_ap12 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap12')(x3) x4_ap13 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap13')(x3) x4_ap14 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap14')(x3) x4_ap15 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap15')(x3) x4_ap16 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap16')(x3) x4_ap17 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap17')(x3) x4_ap18 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap18')(x3) x4_ap19 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap19')(x3) x4_ap20 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap20')(x3) x4_ap21 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap21')(x3) x4_ap22 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap22')(x3) x4_ap23 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap23')(x3) x4_ap24 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap24')(x3) x4_ap25 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap25')(x3) model_output_ap1 = keras.layers.Dense(20500, name='out_ap1')(x4_ap1) model_output_ap2 = keras.layers.Dense(20500, name='out_ap2')(x4_ap2) model_output_ap3 = keras.layers.Dense(20500, name='out_ap3')(x4_ap3) model_output_ap4 = keras.layers.Dense(20500, name='out_ap4')(x4_ap4) model_output_ap5 = keras.layers.Dense(20500, name='out_ap5')(x4_ap5) model_output_ap6 = keras.layers.Dense(20500, name='out_ap6')(x4_ap6) model_output_ap7 = keras.layers.Dense(20500, name='out_ap7')(x4_ap7) model_output_ap8 = keras.layers.Dense(20500, name='out_ap8')(x4_ap8) model_output_ap9 = keras.layers.Dense(20500, name='out_ap9')(x4_ap9) model_output_ap10 = keras.layers.Dense(20500, name='out_ap10')(x4_ap10) model_output_ap11 = keras.layers.Dense(20500, name='out_ap11')(x4_ap11) model_output_ap12 = keras.layers.Dense(20500, name='out_ap12')(x4_ap12) model_output_ap13 = keras.layers.Dense(20500, name='out_ap13')(x4_ap13) model_output_ap14 = keras.layers.Dense(20500, name='out_ap14')(x4_ap14) model_output_ap15 = keras.layers.Dense(20500, name='out_ap15')(x4_ap15) model_output_ap16 = keras.layers.Dense(20500, name='out_ap16')(x4_ap16) model_output_ap17 = keras.layers.Dense(20500, name='out_ap17')(x4_ap17) model_output_ap18 = keras.layers.Dense(20500, name='out_ap18')(x4_ap18) model_output_ap19 = keras.layers.Dense(20500, name='out_ap19')(x4_ap19) model_output_ap20 = keras.layers.Dense(20500, name='out_ap20')(x4_ap20) model_output_ap21 = keras.layers.Dense(20500, name='out_ap21')(x4_ap21) model_output_ap22 = keras.layers.Dense(20500, name='out_ap22')(x4_ap22) model_output_ap23 = keras.layers.Dense(20500, name='out_ap23')(x4_ap23) model_output_ap24 = keras.layers.Dense(20500, name='out_ap24')(x4_ap24) model_output_ap25 = keras.layers.Dense(20500, name='out_ap25')(x4_ap25) x4_f0 = keras.layers.Dense(512, activation='relu', name='4th_layer_f0')(x3) model_output_f0 = keras.layers.Dense(500, name='out_f0')(x4_f0) model = keras.models.Model(inputs=[model_input1,model_input2,model_input3,model_input4,model_input5,model_input6,model_input7,model_input8,model_input9,model_input10,model_input11,model_input12,model_input13,model_input14], outputs=[model_output_sp1,model_output_sp2,model_output_sp3,model_output_sp4,model_output_sp5,model_output_sp6,model_output_sp7,model_output_sp8,model_output_sp9,model_output_sp10,model_output_sp11,model_output_sp12,model_output_sp13,model_output_sp14,model_output_sp15,model_output_sp16,model_output_sp17,model_output_sp18,model_output_sp19,model_output_sp20,model_output_sp21,model_output_sp22,model_output_sp23,model_output_sp24,model_output_sp25,model_output_ap1,model_output_ap2,model_output_ap3,model_output_ap4,model_output_ap5,model_output_ap6,model_output_ap7,model_output_ap8,model_output_ap9,model_output_ap10,model_output_ap11,model_output_ap12,model_output_ap13,model_output_ap14,model_output_ap15,model_output_ap16,model_output_ap17,model_output_ap18,model_output_ap19,model_output_ap20,model_output_ap21,model_output_ap22,model_output_ap23,model_output_ap24,model_output_ap25,model_output_f0]) class FitGenSequence(keras.utils.Sequence): def __init__(self, batch_size , data_size , word_list ): #word_listはwavファイルのリスト。そのうちdata_size個を学習に使うが、batch_size個単位で分割して学習する self.batch_size = batch_size self.word_list = word_list self.length = data_size // batch_size # batch_size個単位でに分割学習されるため、data_size / batch_size回に分割される # 余剰分は切り捨て(data_size=5100 , batch_size=1000の場合、1000個x5回の5000個だけ学習に使う) def __getitem__(self, idx): start_idx = idx * self.batch_size last_idx = start_idx + self.batch_size # 今回のループで使用するwavファイルのリストは self.word_list[start_idx:last_idx] print (self.word_list[start_idx:last_idx]) inputdata = [] outputdata_sp = [] outputdata_ap = [] outputdata_f0 = [] for word in self.word_list[start_idx:last_idx]: # inputデータ生成 28xデータ数の2d arrray inputdata.append((char2num.exchange(word.strip(),14))) outdata_f0 , outdata_sp , outdata_ap = wav2numpy.wav2numpy(wavdir + '/' + word.strip() + '.wav') #wavファイルからf0,sp,ap抽出 #outputデータ整形 固定長にする outdata_sp2=[flatten for inner in outdata_sp for flatten in inner] #sp,apは1025x可変長の2d arrayなので1d arrayに展開。同時にnumpy→lisst変換される outdata_sp2 += [0] * (512500-len(outdata_sp2)) #sp,apは1025x可変長(max500)=512500で固定長になるように0埋め outputdata_sp.append(outdata_sp2) outdata_ap2=[flatten for inner in outdata_ap for flatten in inner] #sp,apは1025x可変長の2d arrayなので1d arrayに展開。同時にnumpy→llist変換される outdata_ap2 += [0] * (512500-len(outdata_ap2)) #sp,apは1025x可変長(max500)=512500で固定長になるように0埋め outputdata_ap.append(outdata_ap2) outdata_f02 = outdata_f0.tolist() #f0はもともと1d arrayなのでflatten不要。単純にnumpy→list変換だけ outdata_f02 += [0] * (500-len(outdata_f02)) #f0は1x可変長(max500)=500で固定長になるように0埋め outputdata_f0.append(outdata_f02) #listをinput/outputに指定すると「Please provide as model inputs either a single array or a list of arrays.」になるのでnumpy変換 #input(14文字)を14等分。outputは25等分。 self.input1 , self.input2 , self.input3 , self.input4 , self.input5 , self.input6 , self.input7 , self.input8 , self.input9 , self.input10 , self.input11 , self.input12 , self.input13 , self.input14 = np.hsplit( np.array(inputdata) /256 , 14 ) outputdata_sp_np = np.array([[(math.log10(i)+19)/30 if i!=0 else 0 for i in j ] for j in outputdata_sp]) #4.4e-18~1.6e10を対数(-19~+11),+19して/30で0.0~1.0内に収める。 self.sp1 , self.sp2 , self.sp3 , self.sp4 , self.sp5 , self.sp6 , self.sp7 , self.sp8 , self.sp9 , self.sp10 , self.sp11 , self.sp12 , self.sp13 , self.sp14 , self.sp15 , self.sp16 , self.sp17 , self.sp18 , self.sp19 , self.sp20 , self.sp21 , self.sp22 , self.sp23 , self.sp24 , self.sp25 = np.hsplit( outputdata_sp_np , 25 ) del outputdata_sp del outputdata_sp_np gc.collect() self.ap1 , self.ap2 , self.ap3 , self.ap4 , self.ap5 , self.ap6 , self.ap7 , self.ap8 , self.ap9 , self.ap10 , self.ap11 , self.ap12 , self.ap13 , self.ap14 , self.ap15 , self.ap16 , self.ap17 , self.ap18 , self.ap19 , self.ap20 , self.ap21 , self.ap22 , self.ap23 , self.ap24 , self.ap25 = np.hsplit( np.array(outputdata_ap) , 25 ) del outputdata_ap gc.collect() self.f0 = np.array(outputdata_f0) /1024 #0~692 del outputdata_f0 gc.collect() return {'in1':self.input1,'in2':self.input2,'in3':self.input3,'in4':self.input4,'in5':self.input5,'in6':self.input6,'in7':self.input7,'in8':self.input8,'in9':self.input9,'in10':self.input10,'in11':self.input11,'in12':self.input12,'in13':self.input13,'in14':self.input14} , {'out_sp1':self.sp1,'out_sp2':self.sp2,'out_sp3':self.sp3,'out_sp4':self.sp4,'out_sp5':self.sp5,'out_sp6':self.sp6,'out_sp7':self.sp7,'out_sp8':self.sp8,'out_sp9':self.sp9,'out_sp10':self.sp10,'out_sp11':self.sp11,'out_sp12':self.sp12,'out_sp13':self.sp13,'out_sp14':self.sp14,'out_sp15':self.sp15,'out_sp16':self.sp16,'out_sp17':self.sp17,'out_sp18':self.sp18,'out_sp19':self.sp19,'out_sp20':self.sp20,'out_sp21':self.sp21,'out_sp22':self.sp22,'out_sp23':self.sp23,'out_sp24':self.sp24,'out_sp25':self.sp25,'out_ap1':self.ap1,'out_ap2':self.ap2,'out_ap3':self.ap3,'out_ap4':self.ap4,'out_ap5':self.ap5,'out_ap6':self.ap6,'out_ap7':self.ap7,'out_ap8':self.ap8,'out_ap9':self.ap9,'out_ap10':self.ap10,'out_ap11':self.ap11,'out_ap12':self.ap12,'out_ap13':self.ap13,'out_ap14':self.ap14,'out_ap15':self.ap15,'out_ap16':self.ap16,'out_ap17':self.ap17,'out_ap18':self.ap18,'out_ap19':self.ap19,'out_ap20':self.ap20,'out_ap21':self.ap21,'out_ap22':self.ap22,'out_ap23':self.ap23,'out_ap24':self.ap24,'out_ap25':self.ap25,'out_f0':self.f0} def __len__(self): return self.length def on_epoch_end(self): pass model.compile(loss='mean_squared_error', optimizer='adam') #モデルのコンパイル #model.load_weights('03_larning05_all_a.h5') #訓練済みモデルを読み込み while True: config.read(inifile) fitgen_sequence = FitGenSequence(batch_size=config.getint('general', 'BATCHSIZE') , data_size=config.getint('general', 'DATASIZE') , word_list=wordlist ) model.fit_generator(generator=fitgen_sequence , epochs=config.getint('general', 'EPOCHS') ) model.save('/data/03_larning05_all_' + datetime.now().strftime("%Y%m%d_%H%M%S") +'.h5')iniファイルに「EPOCHS=3」としているので、3EPOCHSごとに学習済みモデルが保管されていく。
[work]# ls -ltr /data/03_larning05* -rw-r--r--. 1 root root 15021867824 1月 30 00:20 /data/03_larning05_all_20190130_001833.h5 -rw-r--r--. 1 root root 15021867824 1月 30 11:32 /data/03_larning05_all_20190130_113049.h5 -rw-r--r--. 1 root root 15021867824 1月 30 22:44 /data/03_larning05_all_20190130_224258.h5 -rw-r--r--. 1 root root 15021867824 1月 31 09:59 /data/03_larning05_all_20190131_095735.h5 -rw-r--r--. 1 root root 15021867824 1月 31 21:13 /data/03_larning05_all_20190131_211253.h5 -rw-r--r--. 1 root root 15021867824 2月 1 08:26 /data/03_larning05_all_20190201_082558.h5 -rw-r--r--. 1 root root 15021867824 2月 1 19:39 /data/03_larning05_all_20190201_193900.h5 -rw-r--r--. 1 root root 15021867824 2月 2 06:52 /data/03_larning05_all_20190202_065203.h5 -rw-r--r--. 1 root root 15021867824 2月 2 18:08 /data/03_larning05_all_20190202_180720.h5 -rw-r--r--. 1 root root 15021867824 2月 3 05:23 /data/03_larning05_all_20190203_052226.h5 -rw-r--r--. 1 root root 15021867824 2月 3 16:38 /data/03_larning05_all_20190203_163813.h5 -rw-r--r--. 1 root root 15021867824 2月 4 03:54 /data/03_larning05_all_20190204_035411.h5 -rw-r--r--. 1 root root 15021867824 2月 4 15:10 /data/03_larning05_all_20190204_151004.h5 #loss: 0.6556 -rw-r--r--. 1 root root 15021867824 2月 5 02:24 /data/03_larning05_all_20190205_022323.h5 -rw-r--r--. 1 root root 15021867824 2月 5 13:37 /data/03_larning05_all_20190205_133640.h5 -rw-r--r--. 1 root root 15021867824 2月 6 00:52 /data/03_larning05_all_20190206_005158.h5 -rw-r--r--. 1 root root 15021867824 2月 6 12:08 /data/03_larning05_all_20190206_120800.h5 #loss: 0.5280 -rw-r--r--. 1 root root 15021867824 2月 6 23:22 /data/03_larning05_all_20190206_232153.h5 -rw-r--r--. 1 root root 15021867824 2月 7 10:36 /data/03_larning05_all_20190207_103541.h5 -rw-r--r--. 1 root root 15021867824 2月 7 21:50 /data/03_larning05_all_20190207_214935.h5 -rw-r--r--. 1 root root 15021867824 2月 8 09:03 /data/03_larning05_all_20190208_090312.h5 #loss: 0.4476 -rw-r--r--. 1 root root 15021867824 2月 8 20:18 /data/03_larning05_all_20190208_201737.h5 -rw-r--r--. 1 root root 15021867824 2月 9 07:32 /data/03_larning05_all_20190209_073134.h5 -rw-r--r--. 1 root root 15021867824 2月 9 18:44 /data/03_larning05_all_20190209_184421.h5 -rw-r--r--. 1 root root 15021867824 2月 10 05:58 /data/03_larning05_all_20190210_055747.h5 #loss: 0.3895 -rw-r--r--. 1 root root 15021867824 2月 10 17:12 /data/03_larning05_all_20190210_171123.h5 -rw-r--r--. 1 root root 15021867824 2月 11 04:25 /data/03_larning05_all_20190211_042439.h5 #loss: 0.3714 -rw-r--r--. 1 root root 15021867824 2月 11 15:38 /data/03_larning05_all_20190211_153738.h5 #「loss: 0.3631」→「loss: 0.3631」→「loss: 0.3581」と、初めて下がらないepochがあった -rw-r--r--. 1 root root 15021867824 2月 12 02:52 /data/03_larning05_all_20190212_025121.h5 #loss: 0.3518 1/3epochは「loss: 0.3596」で、前epochより初めて上がった -rw-r--r--. 1 root root 15021867824 2月 12 14:05 /data/03_larning05_all_20190212_140437.h5 -rw-r--r--. 1 root root 15021867824 2月 13 01:29 /data/03_larning05_all_20190213_012856.h5 #loss: 0.3367 -rw-r--r--. 1 root root 15021867824 2月 13 12:41 /data/03_larning05_all_20190213_124109.h5 -rw-r--r--. 1 root root 15021867824 2月 13 23:55 /data/03_larning05_all_20190213_235432.h5 #loss: 0.3218 -rw-r--r--. 1 root root 15021867824 2月 14 11:08 /data/03_larning05_all_20190214_110811.h5 -rw-r--r--. 1 root root 15021867824 2月 14 22:23 /data/03_larning05_all_20190214_222224.h5 #loss: 0.3074 -rw-r--r--. 1 root root 15021867824 2月 15 09:36 /data/03_larning05_all_20190215_093552.h5 -rw-r--r--. 1 root root 15021867824 2月 15 20:49 /data/03_larning05_all_20190215_204907.h5 #loss: 0.2976 -rw-r--r--. 1 root root 15021867824 2月 16 08:01 /data/03_larning05_all_20190216_080118.h5 -rw-r--r--. 1 root root 15021867824 2月 16 19:14 /data/03_larning05_all_20190216_191345.h5 #loss: 0.2865 -rw-r--r--. 1 root root 15021867824 2月 17 06:27 /data/03_larning05_all_20190217_062718.h5 -rw-r--r--. 1 root root 15021867824 2月 17 17:42 /data/03_larning05_all_20190217_174205.h5 #loss: 0.2774 -rw-r--r--. 1 root root 15021867824 2月 18 04:57 /data/03_larning05_all_20190218_045644.h5 #loss: 0.2785 初めて前の3/3epochよりも上がった -rw-r--r--. 1 root root 15021867824 2月 18 16:12 /data/03_larning05_all_20190218_161148.h5 #loss: 0.2690 -rw-r--r--. 1 root root 15021867824 2月 19 03:25 /data/03_larning05_all_20190219_032452.h5 #loss: 0.2719 -rw-r--r--. 1 root root 15021867824 2月 19 14:36 /data/03_larning05_all_20190219_143621.h5 #loss: 0.2594 -rw-r--r--. 1 root root 15021867824 2月 20 01:48 /data/03_larning05_all_20190220_014726.h5 #loss: 0.2606 -rw-r--r--. 1 root root 15021867824 2月 20 13:00 /data/03_larning05_all_20190220_125926.h5 #loss: 0.2526 -rw-r--r--. 1 root root 15021867824 2月 21 00:13 /data/03_larning05_all_20190221_001300.h5 #loss: 0.2556 -rw-r--r--. 1 root root 15021867824 2月 21 11:26 /data/03_larning05_all_20190221_112533.h5 #loss: 0.25114.学習結果を使用して文字データ→音声データ変換を試す
教師データに含まれている「'ふぃねがんず','あ','かたりうったえる'」の3音の他にも、いくつかの単語をwav化してみる。
from __future__ import absolute_import, division, print_function, unicode_literals # TensorFlow と tf.keras のインポート import tensorflow as tf from tensorflow import keras config = tf.ConfigProto(log_device_placement=True) sess = tf.Session(config=config) keras.backend.set_session(sess) # ヘルパーライブラリのインポート from scipy.io import wavfile import numpy as np import pyworld as pw import csv # 自作スクリプト charの文字列を、規則に従ってlistに変換 exchange(char,num) import char2num #モデルを定義する関数。 model_input1 = keras.Input(shape=(2,), name='in1') model_input2 = keras.Input(shape=(2,), name='in2') model_input3 = keras.Input(shape=(2,), name='in3') model_input4 = keras.Input(shape=(2,), name='in4') model_input5 = keras.Input(shape=(2,), name='in5') model_input6 = keras.Input(shape=(2,), name='in6') model_input7 = keras.Input(shape=(2,), name='in7') model_input8 = keras.Input(shape=(2,), name='in8') model_input9 = keras.Input(shape=(2,), name='in9') model_input10 = keras.Input(shape=(2,), name='in10') model_input11 = keras.Input(shape=(2,), name='in11') model_input12 = keras.Input(shape=(2,), name='in12') model_input13 = keras.Input(shape=(2,), name='in13') model_input14 = keras.Input(shape=(2,), name='in14') x1_1 = keras.layers.Dense(256, activation='relu', name='1st_layer1')(model_input1) x1_2 = keras.layers.Dense(256, activation='relu', name='1st_layer2')(model_input2) x1_3 = keras.layers.Dense(256, activation='relu', name='1st_layer3')(model_input3) x1_4 = keras.layers.Dense(256, activation='relu', name='1st_layer4')(model_input4) x1_5 = keras.layers.Dense(256, activation='relu', name='1st_layer5')(model_input5) x1_6 = keras.layers.Dense(256, activation='relu', name='1st_layer6')(model_input6) x1_7 = keras.layers.Dense(256, activation='relu', name='1st_layer7')(model_input7) x1_8 = keras.layers.Dense(256, activation='relu', name='1st_layer8')(model_input8) x1_9 = keras.layers.Dense(256, activation='relu', name='1st_layer9')(model_input9) x1_10 = keras.layers.Dense(256, activation='relu', name='1st_layer10')(model_input10) x1_11 = keras.layers.Dense(256, activation='relu', name='1st_layer11')(model_input11) x1_12 = keras.layers.Dense(256, activation='relu', name='1st_layer12')(model_input12) x1_13 = keras.layers.Dense(256, activation='relu', name='1st_layer13')(model_input13) x1_14 = keras.layers.Dense(256, activation='relu', name='1st_layer14')(model_input14) x1_merge = keras.layers.concatenate([x1_1,x1_2,x1_3,x1_4,x1_5,x1_6,x1_7,x1_8,x1_9,x1_10,x1_11,x1_12,x1_13,x1_14], axis=-1) x2 = keras.layers.Dense(16384, activation='relu', name='2nd_layer')(x1_merge) x3 = keras.layers.Dense(16384, activation='relu', name='3rd_layer')(x2) x4_sp1 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp1')(x3) x4_sp2 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp2')(x3) x4_sp3 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp3')(x3) x4_sp4 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp4')(x3) x4_sp5 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp5')(x3) x4_sp6 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp6')(x3) x4_sp7 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp7')(x3) x4_sp8 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp8')(x3) x4_sp9 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp9')(x3) x4_sp10 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp10')(x3) x4_sp11 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp11')(x3) x4_sp12 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp12')(x3) x4_sp13 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp13')(x3) x4_sp14 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp14')(x3) x4_sp15 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp15')(x3) x4_sp16 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp16')(x3) x4_sp17 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp17')(x3) x4_sp18 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp18')(x3) x4_sp19 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp19')(x3) x4_sp20 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp20')(x3) x4_sp21 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp21')(x3) x4_sp22 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp22')(x3) x4_sp23 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp23')(x3) x4_sp24 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp24')(x3) x4_sp25 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp25')(x3) model_output_sp1 = keras.layers.Dense(20500, name='out_sp1')(x4_sp1) model_output_sp2 = keras.layers.Dense(20500, name='out_sp2')(x4_sp2) model_output_sp3 = keras.layers.Dense(20500, name='out_sp3')(x4_sp3) model_output_sp4 = keras.layers.Dense(20500, name='out_sp4')(x4_sp4) model_output_sp5 = keras.layers.Dense(20500, name='out_sp5')(x4_sp5) model_output_sp6 = keras.layers.Dense(20500, name='out_sp6')(x4_sp6) model_output_sp7 = keras.layers.Dense(20500, name='out_sp7')(x4_sp7) model_output_sp8 = keras.layers.Dense(20500, name='out_sp8')(x4_sp8) model_output_sp9 = keras.layers.Dense(20500, name='out_sp9')(x4_sp9) model_output_sp10 = keras.layers.Dense(20500, name='out_sp10')(x4_sp10) model_output_sp11 = keras.layers.Dense(20500, name='out_sp11')(x4_sp11) model_output_sp12 = keras.layers.Dense(20500, name='out_sp12')(x4_sp12) model_output_sp13 = keras.layers.Dense(20500, name='out_sp13')(x4_sp13) model_output_sp14 = keras.layers.Dense(20500, name='out_sp14')(x4_sp14) model_output_sp15 = keras.layers.Dense(20500, name='out_sp15')(x4_sp15) model_output_sp16 = keras.layers.Dense(20500, name='out_sp16')(x4_sp16) model_output_sp17 = keras.layers.Dense(20500, name='out_sp17')(x4_sp17) model_output_sp18 = keras.layers.Dense(20500, name='out_sp18')(x4_sp18) model_output_sp19 = keras.layers.Dense(20500, name='out_sp19')(x4_sp19) model_output_sp20 = keras.layers.Dense(20500, name='out_sp20')(x4_sp20) model_output_sp21 = keras.layers.Dense(20500, name='out_sp21')(x4_sp21) model_output_sp22 = keras.layers.Dense(20500, name='out_sp22')(x4_sp22) model_output_sp23 = keras.layers.Dense(20500, name='out_sp23')(x4_sp23) model_output_sp24 = keras.layers.Dense(20500, name='out_sp24')(x4_sp24) model_output_sp25 = keras.layers.Dense(20500, name='out_sp25')(x4_sp25) x4_ap1 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap1')(x3) x4_ap2 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap2')(x3) x4_ap3 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap3')(x3) x4_ap4 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap4')(x3) x4_ap5 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap5')(x3) x4_ap6 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap6')(x3) x4_ap7 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap7')(x3) x4_ap8 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap8')(x3) x4_ap9 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap9')(x3) x4_ap10 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap10')(x3) x4_ap11 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap11')(x3) x4_ap12 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap12')(x3) x4_ap13 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap13')(x3) x4_ap14 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap14')(x3) x4_ap15 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap15')(x3) x4_ap16 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap16')(x3) x4_ap17 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap17')(x3) x4_ap18 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap18')(x3) x4_ap19 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap19')(x3) x4_ap20 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap20')(x3) x4_ap21 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap21')(x3) x4_ap22 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap22')(x3) x4_ap23 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap23')(x3) x4_ap24 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap24')(x3) x4_ap25 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap25')(x3) model_output_ap1 = keras.layers.Dense(20500, name='out_ap1')(x4_ap1) model_output_ap2 = keras.layers.Dense(20500, name='out_ap2')(x4_ap2) model_output_ap3 = keras.layers.Dense(20500, name='out_ap3')(x4_ap3) model_output_ap4 = keras.layers.Dense(20500, name='out_ap4')(x4_ap4) model_output_ap5 = keras.layers.Dense(20500, name='out_ap5')(x4_ap5) model_output_ap6 = keras.layers.Dense(20500, name='out_ap6')(x4_ap6) model_output_ap7 = keras.layers.Dense(20500, name='out_ap7')(x4_ap7) model_output_ap8 = keras.layers.Dense(20500, name='out_ap8')(x4_ap8) model_output_ap9 = keras.layers.Dense(20500, name='out_ap9')(x4_ap9) model_output_ap10 = keras.layers.Dense(20500, name='out_ap10')(x4_ap10) model_output_ap11 = keras.layers.Dense(20500, name='out_ap11')(x4_ap11) model_output_ap12 = keras.layers.Dense(20500, name='out_ap12')(x4_ap12) model_output_ap13 = keras.layers.Dense(20500, name='out_ap13')(x4_ap13) model_output_ap14 = keras.layers.Dense(20500, name='out_ap14')(x4_ap14) model_output_ap15 = keras.layers.Dense(20500, name='out_ap15')(x4_ap15) model_output_ap16 = keras.layers.Dense(20500, name='out_ap16')(x4_ap16) model_output_ap17 = keras.layers.Dense(20500, name='out_ap17')(x4_ap17) model_output_ap18 = keras.layers.Dense(20500, name='out_ap18')(x4_ap18) model_output_ap19 = keras.layers.Dense(20500, name='out_ap19')(x4_ap19) model_output_ap20 = keras.layers.Dense(20500, name='out_ap20')(x4_ap20) model_output_ap21 = keras.layers.Dense(20500, name='out_ap21')(x4_ap21) model_output_ap22 = keras.layers.Dense(20500, name='out_ap22')(x4_ap22) model_output_ap23 = keras.layers.Dense(20500, name='out_ap23')(x4_ap23) model_output_ap24 = keras.layers.Dense(20500, name='out_ap24')(x4_ap24) model_output_ap25 = keras.layers.Dense(20500, name='out_ap25')(x4_ap25) x4_f0 = keras.layers.Dense(512, activation='relu', name='4th_layer_f0')(x3) model_output_f0 = keras.layers.Dense(500, name='out_f0')(x4_f0) model = keras.models.Model(inputs=[model_input1,model_input2,model_input3,model_input4,model_input5,model_input6,model_input7,model_input8,model_input9,model_input10,model_input11,model_input12,model_input13,model_input14], outputs=[model_output_sp1,model_output_sp2,model_output_sp3,model_output_sp4,model_output_sp5,model_output_sp6,model_output_sp7,model_output_sp8,model_output_sp9,model_output_sp10,model_output_sp11,model_output_sp12,model_output_sp13,model_output_sp14,model_output_sp15,model_output_sp16,model_output_sp17,model_output_sp18,model_output_sp19,model_output_sp20,model_output_sp21,model_output_sp22,model_output_sp23,model_output_sp24,model_output_sp25,model_output_ap1,model_output_ap2,model_output_ap3,model_output_ap4,model_output_ap5,model_output_ap6,model_output_ap7,model_output_ap8,model_output_ap9,model_output_ap10,model_output_ap11,model_output_ap12,model_output_ap13,model_output_ap14,model_output_ap15,model_output_ap16,model_output_ap17,model_output_ap18,model_output_ap19,model_output_ap20,model_output_ap21,model_output_ap22,model_output_ap23,model_output_ap24,model_output_ap25,model_output_f0]) model.compile(loss='mean_squared_error', optimizer='adam') #モデルのコンパイル def sampleout(): for word in ['あいうえお','ふぃねがんず','あ','かたりうったえる','まほうじんぐるぐる','どうしましょうか']: inputdata_np1 , inputdata_np2 , inputdata_np3 , inputdata_np4 , inputdata_np5 , inputdata_np6 , inputdata_np7 , inputdata_np8 , inputdata_np9 , inputdata_np10 , inputdata_np11 , inputdata_np12 , inputdata_np13 , inputdata_np14 = np.hsplit( np.array([char2num.exchange(word,14)]) /256 , 14 ) sp1 , sp2 , sp3 , sp4 , sp5 , sp6 , sp7 , sp8 , sp9 , sp10 , sp11 , sp12 , sp13 , sp14 , sp15 , sp16 , sp17 , sp18 , sp19 , sp20 , sp21 , sp22 , sp23 , sp24 , sp25 , ap1 , ap2 , ap3 , ap4 , ap5 , ap6 , ap7 , ap8 , ap9 , ap10 , ap11 , ap12 , ap13 , ap14 , ap15 , ap16 , ap17 , ap18 , ap19 , ap20 , ap21 , ap22 , ap23 , ap24 , ap25 , f0 = model.predict({'in1':inputdata_np1,'in2':inputdata_np2,'in3':inputdata_np3,'in4':inputdata_np4,'in5':inputdata_np5,'in6':inputdata_np6,'in7':inputdata_np7,'in8':inputdata_np8,'in9':inputdata_np9,'in10':inputdata_np10,'in11':inputdata_np11,'in12':inputdata_np12,'in13':inputdata_np13,'in14':inputdata_np14}) print ("sp1.shape=",sp1.shape) print ("ap1.shape=",ap1.shape) result_out_sp = np.concatenate([sp1 , sp2 , sp3 , sp4 , sp5 , sp6 , sp7 , sp8 , sp9 , sp10 , sp11 , sp12 , sp13 , sp14 , sp15 , sp16 , sp17 , sp18 , sp19 , sp20 , sp21 , sp22 , sp23 , sp24 , sp25], 1) result_out_ap = np.concatenate([ap1 , ap2 , ap3 , ap4 , ap5 , ap6 , ap7 , ap8 , ap9 , ap10 , ap11 , ap12 , ap13 , ap14 , ap15 , ap16 , ap17 , ap18 , ap19 , ap20 , ap21 , ap22 , ap23 , ap24 , ap25], 1) print ("result_out_sp.shape=",result_out_sp.shape) print ("result_out_ap.shape=",result_out_ap.shape) result_out_sp = [[10**((i*30)-19) if i!=0 else 0 for i in j ] for j in result_out_sp] result_out_f0 = f0 *1024 synthesized = pw.synthesize( np.reshape(result_out_f0, (500,)).astype(np.float64) , np.reshape(result_out_sp, (500,1025)) , np.reshape(result_out_ap, (500,1025)).astype(np.float64) , 44100 ).astype(np.int16) wavfile.write(headword+word+'.wav',44100,synthesized) model.load_weights('/data/03_larning05_all_20190621_021938.h5') headword='03_larning05_1_loss0851_' sampleout()5.少ない教師データ数、短い学習時間で効率的に学習させる方法を考える
教師データ数の調整について
教師データとして10000単語を使用した場合、50000単語を使用した場合で比較してみる。
10000単語、batchsize=10で学習させたところ、84epochsくらいでloss率が下がりづらくなり、
149epochs程度経過後、loss=0.25くらいで頭打ちになった。
(GPUなし、6core:12thread/1.9GHz。メモリ32GB環境で約20日間)
1000/1000 [==============================] - 13431s 13s/step - loss: 0.2511 - out_sp1_loss: 0.0014 - out_sp2_loss: 0.0070 - out_sp3_loss: 0.0096 - out_sp4_loss: 0.0088 - out_sp5_loss: 0.0135 - out_sp6_loss: 0.0151 - out_sp7_loss: 0.0091 - out_sp8_loss: 0.0034 - out_sp9_loss: 0.0014 - out_sp10_loss: 4.7735e-04 - out_sp11_loss: 2.7430e-04 - out_sp12_loss: 1.6851e-04 - out_sp13_loss: 9.2398e-05 - out_sp14_loss: 5.4483e-05 - out_sp15_loss: 5.0145e-05 - out_sp16_loss: 3.5160e-05 - out_sp17_loss: 1.8517e-05 - out_sp18_loss: 1.7576e-05 - out_sp19_loss: 7.4513e-06 - out_sp20_loss: 9.8959e-07 - out_sp21_loss: 2.2931e-07 - out_sp22_loss: 1.7947e-07 - out_sp23_loss: 1.2095e-11 - out_sp24_loss: 1.8030e-11 - out_sp25_loss: 5.6759e-12 - out_ap1_loss: 0.0187 - out_ap2_loss: 0.0239 - out_ap3_loss: 0.0251 - out_ap4_loss: 0.0263 - out_ap5_loss: 0.0286 - out_ap6_loss: 0.0283 - out_ap7_loss: 0.0161 - out_ap8_loss: 0.0066 - out_ap9_loss: 0.0026 - out_ap10_loss: 0.0011 - out_ap11_loss: 6.4949e-04 - out_ap12_loss: 3.1281e-04 - out_ap13_loss: 1.8863e-04 - out_ap14_loss: 1.2824e-04 - out_ap15_loss: 9.1774e-05 - out_ap16_loss: 6.1045e-05 - out_ap17_loss: 2.9133e-05 - out_ap18_loss: 2.2714e-05 - out_ap19_loss: 6.3900e-06 - out_ap20_loss: 1.7681e-06 - out_ap21_loss: 3.3528e-07 - out_ap22_loss: 1.5480e-07 - out_ap23_loss: 7.4649e-12 - out_ap24_loss: 9.2365e-12 - out_ap25_loss: 7.8836e-12 - out_f0_loss: 0.0018それに対して最初から50000単語、batchsize=10で学習させたところ、同じく20日間放置して31epochs経過した時点でloss:0.80程度。まだ1epochあたり0.008程度コンスタントに下がり続けているが、収束が遅すぎる。
(マシン性能は先のものとほぼ同じ環境なので、単純に学習データ数が増えたことによる影響と思われる。予想では10000単語よりも高いloss率で頭打ちになるかと思っているが、それを確かめるには時間がかかりすぎる。)しかし学習後のモデルで未学習単語をいくつかwav化して聴き比べたところ、loss=0.25まで下がった先ほどのモデルより、loss=0.8のこのモデルのほうが聴き取りやすい。
教師データが多いため、より汎用性の高い学習ができているということだろうか?
現状、教師データのloss率でしか評価できていないので、fitのVALIDSPLIT的な仕組みを作るか、あるいはvalidation dataを別途用意してepochごとに検証してみたほうが良いかも。
5000/5000 [==============================] - 74533s 15s/step - loss: 0.8005 - out_sp1_loss: 0.0042 - out_sp2_loss: 0.0253 - out_sp3_loss: 0.0330 - out_sp4_loss: 0.0297 - out_sp5_loss: 0.0424 - out_sp6_loss: 0.0539 - out_sp7_loss: 0.0460 - out_sp8_loss: 0.0279 - out_sp9_loss: 0.0146 - out_sp10_loss: 0.0072 - out_sp11_loss: 0.0035 - out_sp12_loss: 0.0018 - out_sp13_loss: 0.0011 - out_sp14_loss: 6.8459e-04 - out_sp15_loss: 5.0065e-04 - out_sp16_loss: 3.8773e-04 - out_sp17_loss: 2.3878e-04 - out_sp18_loss: 1.3287e-04 - out_sp19_loss: 8.1552e-05 - out_sp20_loss: 4.5552e-05 - out_sp21_loss: 3.8080e-05 - out_sp22_loss: 1.0064e-05 - out_sp23_loss: 1.0051e-06 - out_sp24_loss: 2.4118e-11 - out_sp25_loss: 2.4103e-11 - out_ap1_loss: 0.0452 - out_ap2_loss: 0.0565 - out_ap3_loss: 0.0599 - out_ap4_loss: 0.0613 - out_ap5_loss: 0.0667 - out_ap6_loss: 0.0770 - out_ap7_loss: 0.0608 - out_ap8_loss: 0.0367 - out_ap9_loss: 0.0195 - out_ap10_loss: 0.0093 - out_ap11_loss: 0.0047 - out_ap12_loss: 0.0024 - out_ap13_loss: 0.0015 - out_ap14_loss: 9.9513e-04 - out_ap15_loss: 7.5172e-04 - out_ap16_loss: 5.4091e-04 - out_ap17_loss: 3.3179e-04 - out_ap18_loss: 1.6043e-04 - out_ap19_loss: 8.7130e-05 - out_ap20_loss: 6.2652e-05 - out_ap21_loss: 3.1422e-05 - out_ap22_loss: 1.4057e-05 - out_ap23_loss: 7.1795e-07 - out_ap24_loss: 1.8263e-11 - out_ap25_loss: 1.9893e-11 - out_f0_loss: 0.0032そこで、最初から10000単語、20日後の149epochs経過のloss=0.25で頭打ちになったモデルに対して、途中から教師データを10000単語→50000単語に増やしてみたところ、増加後最初の1回はloss:0.9971に劇的に下がったが、11日で14epochs経過すると0.67まで改善。最初から50000単語で20日間学習していた方を5日目の時点で追い抜いていた。
5000/5000 [==============================] - 72708s 13s/step - loss: 0.6503 - out_sp1_loss: 0.0036 - out_sp2_loss: 0.0203 - out_sp3_loss: 0.0282 - out_sp4_loss: 0.0255 - out_sp5_loss: 0.0365 - out_sp6_loss: 0.0450 - out_sp7_loss: 0.0357 - out_sp8_loss: 0.0193 - out_sp9_loss: 0.0091 - out_sp10_loss: 0.0042 - out_sp11_loss: 0.0022 - out_sp12_loss: 0.0011 - out_sp13_loss: 7.4244e-04 - out_sp14_loss: 5.2103e-04 - out_sp15_loss: 3.9318e-04 - out_sp16_loss: 2.4515e-04 - out_sp17_loss: 1.3115e-04 - out_sp18_loss: 1.1614e-04 - out_sp19_loss: 5.5201e-05 - out_sp20_loss: 5.5209e-05 - out_sp21_loss: 4.2189e-05 - out_sp22_loss: 1.6384e-05 - out_sp23_loss: 1.0061e-06 - out_sp24_loss: 1.3750e-11 - out_sp25_loss: 1.3883e-11 - out_ap1_loss: 0.0379 - out_ap2_loss: 0.0451 - out_ap3_loss: 0.0507 - out_ap4_loss: 0.0527 - out_ap5_loss: 0.0581 - out_ap6_loss: 0.0662 - out_ap7_loss: 0.0495 - out_ap8_loss: 0.0268 - out_ap9_loss: 0.0130 - out_ap10_loss: 0.0062 - out_ap11_loss: 0.0032 - out_ap12_loss: 0.0018 - out_ap13_loss: 0.0010 - out_ap14_loss: 6.5772e-04 - out_ap15_loss: 5.5738e-04 - out_ap16_loss: 3.3696e-04 - out_ap17_loss: 2.2287e-04 - out_ap18_loss: 1.3068e-04 - out_ap19_loss: 7.3644e-05 - out_ap20_loss: 4.2706e-05 - out_ap21_loss: 3.4859e-05 - out_ap22_loss: 1.5254e-05 - out_ap23_loss: 8.1234e-07 - out_ap24_loss: 1.6548e-11 - out_ap25_loss: 1.5406e-11 - out_f0_loss: 0.0030おそらく、40000/50000のデータが未学習だったためloss率が悪化したものの、未学習データ分は学習が早いため、一気に改善したと思われる。
あくまで教師データに対するloss率を見ただけだが、最初から大量の教師データを学習させるより、少ないデータである程度loss率を下げた後に教師データ数を段階的に増やしていく方が効率的ということになる。
いわれてみれば当たり前で、最初から50000の教師データを投入すると、50000の教師データ全てに最適化されるように学習する必要があるため、1データ処理するごとのパラメータの変化が抑えられる動きになるはず。(そうしないとパラメータが暴れて、もっと早い段階でloss率が乱高下することになるはず。)
最初は少ない教師データによって、汎用性は低くても、ある程度それっぽい収束をさせた後、過学習の弊害が出る前を見計らって教師データ数を増やしていくことで効率的に学習できると思われる。(追記待ち)