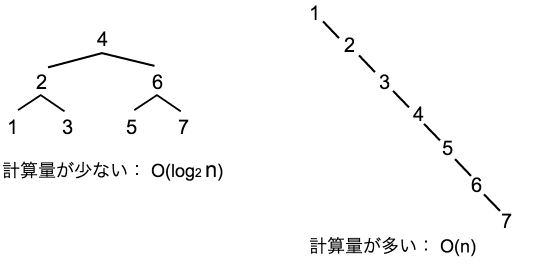
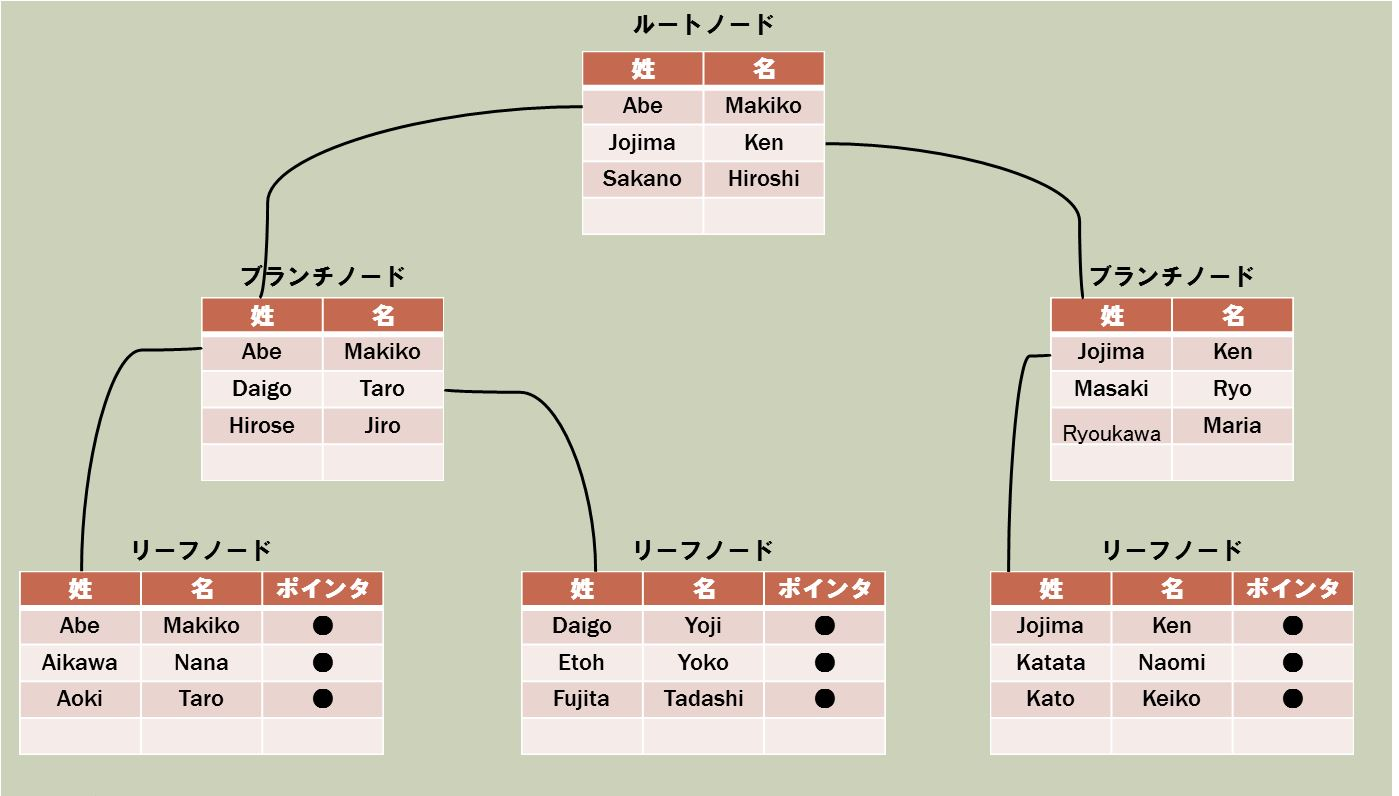
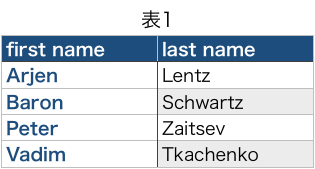
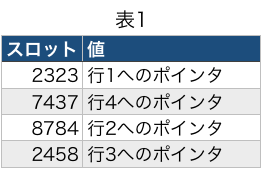
ALTER TABLE テーブル名 AUTO_INCREMENT = 値でテーブルのオートインクリメントの値を変更できます。
なのに、SELECT AUTO_INCREMENT FROM information_schema.TABLES WHERE table_name = テーブル名で変更前のオートインクリメントの値が取れてしまう…
対策
information_schema.INNODB_TABLESTATSには変更後の値が入っていました。 SELECT AUTOINC FROM information_schema.INNODB_TABLESTATS WHERE NAME = DB名/テーブル名で取得できました。カラム名がAUTOINCな点に注意です。