- 投稿日:2019-07-01T23:29:52+09:00
TemplateMethodパターンをPHPで書いてみた
TemplateMethodパターンとは?
このパターンの役割は、重複した実装の洗練・整理です。
流れは一緒だけれども、内部の処理が違う処理においてそれぞれの処理を分けることが出来ます。なので、使い所としては、複数種類のフォーマットで出力をするとき(.txt, .html, .csvなど)などに使えます。
- AbstractClass : 処理の枠組みを定義するクラス。このクラスの中に、枠組みを決めるTemplateMethodが存在しています。
- ConcreteMethod : AbstractClassを継承するサブクラス。Abstractで定義された抽象メソッドの中身を実装しています。
サンプルコード
今回は、こちらの本のに書かれているコードを参考に作成しました。
こちらはJavaで書かれていますので、それをPHPに書き直してみました。今回は、例としてコーヒーと紅茶を淹れるプログラムを作ります。
テンプレートメソッドパターンを適用させる前に、一度そのままコードを書いてみましょう。
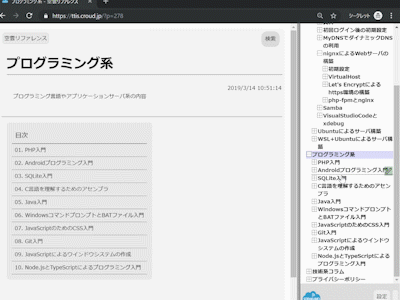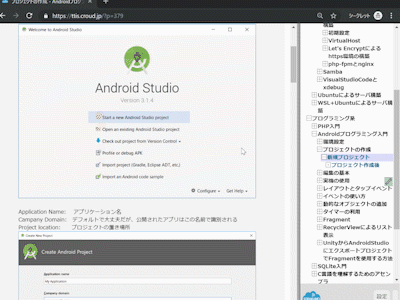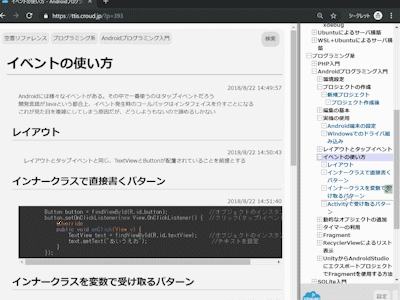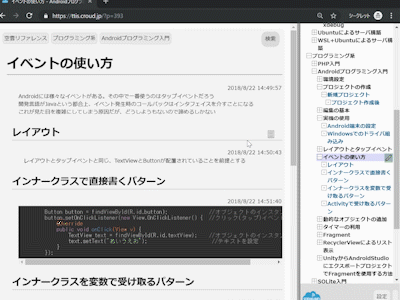
<?php class Coffee { public function describeBeverage() { echo "--------------------------------\n"; echo 'コーヒーを作ります。\n'; } public function boilWater() { echo'お湯を沸かします。\n'; } public function brew() { echo 'コーヒー豆を挽き、ドリップします。\n'; } public function pourInCup() { echo 'カップに注ぎます。\n'; } public function addContents() { echo '砂糖とミルクを足します。\n'; } public function makeBeverage() { $this->describeBeverage(); $this->boilWater(); $this->brew(); $this->pourInCup(); $this->addContents(); } }<?php class Tea { public function describeBeverage() { echo "--------------------------------\n"; echo "紅茶を作ります。\n"; } public function boilWater() { echo "お湯を沸かします。\n"; } public function brew() { echo "ティーバッグを浸します。\n"; } public function pourInCup() { echo "カップに注ぎます。\n"; } public function addContents() { echo "レモンを足します。\n"; } public function makeBeverage() { $this->describeBeverage(); $this->boilWater(); $this->brew(); $this->pourInCup(); $this->addContents(); } }<?php require_once 'Coffee.php'; require_once 'Tea.php'; $coffee = new Coffee(); $tea = new Tea(); $coffee->makeBeverage(); $tea->makeBeverage();-------------------------------- 【コーヒーを作ります】 お湯を沸かします コーヒー豆を挽き、ドリップします カップに注ぎます 砂糖とミルクを足します -------------------------------- 【紅茶を作ります】 お湯を沸かします ティーパックを浸します カップに注ぎます レモンを足します出来ましたか?確かに動いていますね!では、なぜテンプレートメソッドを使う必要があるのでしょうか?
CoffeeクラスとTeaクラス、よく見ると同じ処理をそれぞれで書いていますね。
少なくともboilWater()とpourInCup()は全く同じことをやっています。
他に飲み物が増えた時、全てのクラスに同じ処理を書くのはしんどいですよね…そこで、これらの共通する処理を枠組みとして定義するのがテンプレートメソッドパターンです!!!!!まず、共通する処理を定義する抽象クラスを作成しましょう。
ここでは、各クラスの共通処理をメソッドとして定義し、クラスによって異なる処理を抽象メソッドとして定義します。
これを行うことによって、サブクラスはクラス独自の処理(今回の場合だと、brew()とaddContents())だけを記述するだけで良くなります。<?php abstract class CaffeineBeverage { /** * 各クラスの共通の処理 */ public function describeBeverage($beverage_name) { echo "--------------------------------\n"; echo "【" . $beverage_name . "を作ります】\n"; } public function boilWater() { echo "お湯を沸かします\n"; } public function pourInCup() { echo "カップに注ぎます\n"; } /** * 各クラスによって異なる処理。抽象クラスとして定義 * 中身はサブクラスで実装してもらう */ abstract protected function brew(); abstract protected function addContents(); /** * TemplateMethod */ public function makeBeverage($beverage_name) { //一連の動作を定義 $this->describeBeverage($beverage_name); $this->boilWater(); $this->brew(); $this->pourInCup(); $this->addContents(); } }そして、この抽象クラスを継承したサブクラス(CoffeeクラスとTeaクラス)は、それぞれ独自の処理を記述するだけです。
<?php require_once 'CaffeineBeverage.php'; class Coffee extends CaffeineBeverage { //それぞれのクラス独自の処理のみを実装する protected function brew() { echo "コーヒー豆を挽き、ドリップします\n"; } protected function addContents() { echo "砂糖とミルクを足します\n"; } }<?php require_once 'CaffeineBeverage.php'; class Tea extends CaffeineBeverage { //それぞれのクラス独自の処理のみを実装する protected function brew() { echo "ティーバッグを浸します\n"; } protected function addContents() { echo "レモンを足します\n"; } }どうでしょう?テンプレートメソッドを適用させたことによって、CoffeeクラスとTeaクラスがだいぶスッキリして見えませんか?
飲み物が増えたとしても、CaffeineBeverageクラスを継承して独自の処理だけ付け足せば良いので、とても楽ですね。
ただ、作り方が全く違ってたり、独自のステップ(例えば30分蒸らすとか)がある場合は、テンプレートメソッドの管轄外から外れてしまうので出来ません。参考書籍
- 投稿日:2019-07-01T21:03:09+09:00
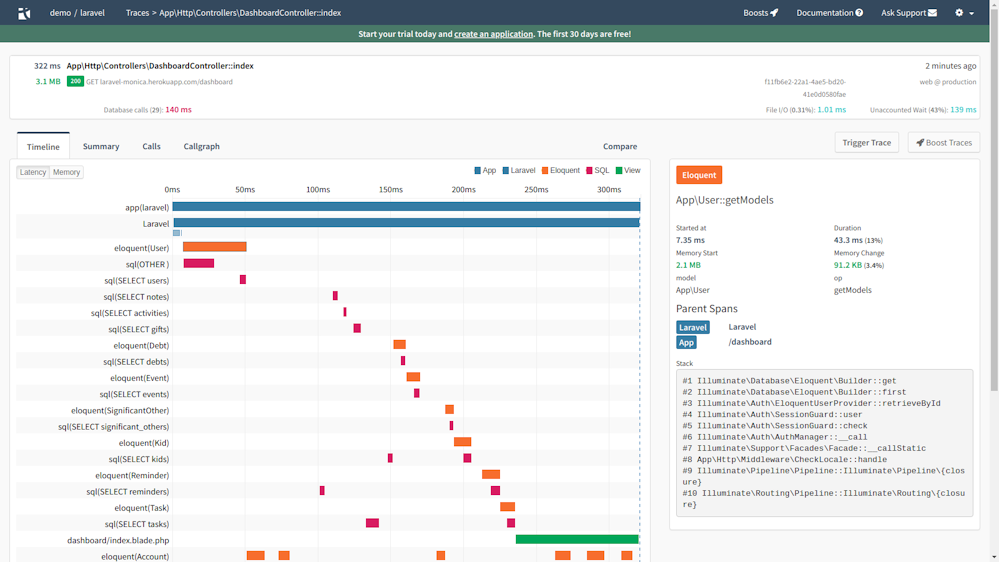
PHP の関数実行とその計測(記事版)
PHP カンファレンス福岡 2019 にて、「PHP の関数実行とその計測」という題でお話させていただきました。
使ったスライドは slideshare に上げていますが、話の内容の方もテキストとしてネット上にあった方がよい部分もあるかな、と思い、登壇時の原稿とスライドで使った画像から雑に記事を用意してみました。自己紹介のように明らかに不要な部分は抜いています。元が原稿なため、やや話し言葉っぽい部分があります。
内容の誤り等にお気づきの際はお気軽にコメント / PR いただければ助かります。
PHP の関数実行とその計測
今回話す内容は以下です。
- 1 つは PHP の関数実行の仕組みについて
- もう1つはその性能計測について
PHP で関数というのは、プログラムに行わせる一連の処理のまとまりです。
<?php function sum(int $a, int $b): int { return $a + $b; } echo sum(1, 2);こんなコードのものですね。
まずはこのコードが処理系によってどう実行されているかの話からです。
Zend Engine の概要
この中に Zend Engine というのを聞いたことがある方はどのくらいいらっしゃいますでしょうか。
(けっこう手が上がる筈)ありがとうございます、では Zend Engine が何のことか、雑になんとなく分かる、という方はどのくらいいらっしゃいますでしょうか。
(けっこう減る筈)ありがとうございます。
Zend Engine は PHP の公式処理系のコア部分です。php.net で配布されている、いわゆる公式処理系です。かつて PHP 4 の頃に、 Zeev さんという人と Andi さんという人が中心となって、PHP 3 までの処理系を大きくリニューアルしました。彼らの名前から 2 文字ずつとって、Zend Engine と処理系のコアが名付けられました。
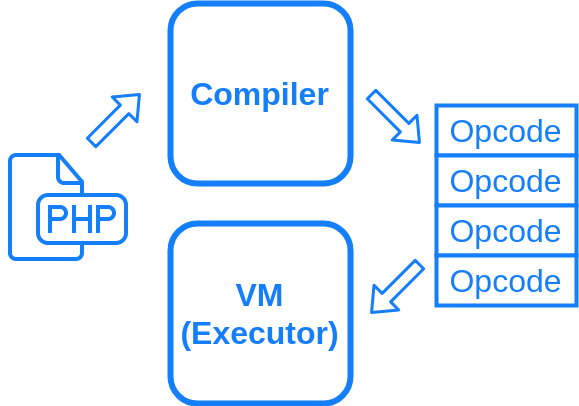
Zend Engineは、ざっくり言ってバイトコードコンパイラとバイトコードを実行するVM、仮想マシンから成ります。
バイトコードというのは仮想マシンの命令です。オペコードとも呼びます。PHP コードが実行される際、Zend Engine のコンパイラがコードを ZendVM のオペコードの列にコンパイルします。ZendVM がこのオペコードの列から一つ一つ命令を取り出し、対応する処理を実行していきます。
大体こんな図になります。
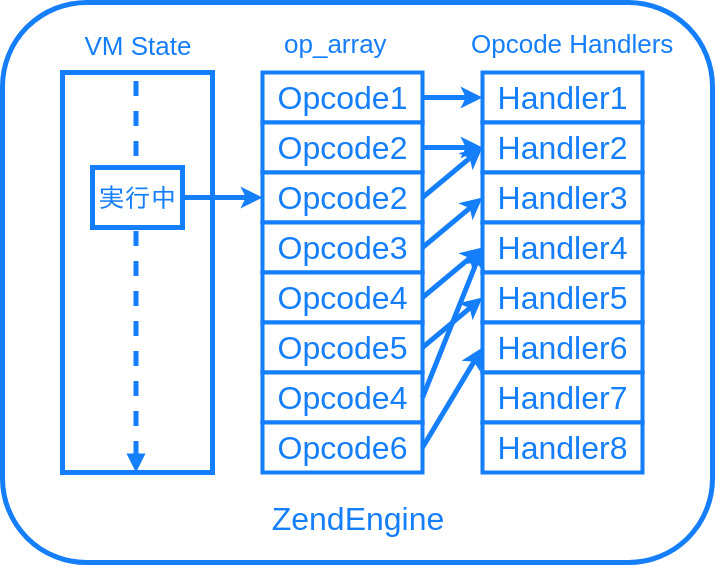
実行部分をもう少し細かく見ると、だいたいこんな図になります。
オペコードの列、VM の命令列を、Zend Engine では op_array と呼びます。オペコードの配列、ということです。op_array は関数ごとに作られます。
PHP コードをコンパイルした結果 op_array が作られて、VM が一つ一つ命令を取り出し、各命令に対応する C 言語側処理であるオペコードハンドラというものが、一つ一つ呼び出されていきます。PHP っぽい疑似コードで表すと、大体こんな流れになります。
// 実際にはもう少し複雑 foreach ($op_array as $opline) { // 例: [ADD, [1, 2]] [$opcode, $operands] = $opline; $handler = $opcode_handlers[$opcode]; $handler($operands); }op_array からオペコードとオペランドを取り出し、オペコードに対応したハンドラを取り出して、その処理を呼び出します。
なお、オペランドというのは命令にくっつけるパラメータです。例えば足し算。1 足す 2 を表すコードがあるとして、足す、ADD という命令に対応する 1 と 2 というのがオペランドです。
実際の処理系は最適化のためオペランドの種類に応じて特化したオペコードハンドラがあったりと、もう少し複雑です。が、概念的には大体こんな流れです。PHP スクリプトがどうにかして仮想マシンの命令列に変換され、仮想マシンが命令列を実行していく、というのが、今のところの話の流れです。
その PHP コードがどう仮想マシンの命令に変換されるか、というコンパイル処理についても、少し駆け足で説明します。
コード実行の流れ
まず大まかな流れです。PHP のソースコードは最初に字句解析と呼ばれる処理で、言語の規則に従った単語みたいなものの集まりへと分解されます。次に構文解析と呼ばれる処理で、字面として言語のルールにちゃんと則ったプログラムになっているか、正しい文法で書かれている感じがするか、というのを判定します。同時に抽象構文木、AST と呼ばれるデータ構造をメモリ上に構築し、コード生成と呼ばれる処理がこの AST をてっぺんから解釈しつつ、op_array を構築していきます。
それでは、各段階についてもう少し細かく見ていきます。字句解析
字句解析というのは、プログラムのソースコードを字句というものの集まりに分類し、分解することです。
さっきの PHP コードをもう一度ここで使います。
<?php function sum(int $a, int $b): int { return $a + $b; } echo sum(1, 2);この PHP コードのそれぞれの部分は、↓のような形で字句に分割されます。
T_OPEN_TAG T_FUNCTION T_STRING (T_STRING T_VARIABLE, T_STRING T_VARIABLE): T_STRING { T_RETURN T_VARIABLE + T_VARIABLE; } T_ECHO T_STRING(T_LNUMBER, T_LNUMBER);構文解析
構文規則
構文解析の処理はソースコードの先頭から字句を取り出していって、決められた構文規則に当てはめることができるか、PHP プログラムとして正しく書かれているか、というのをチェックする処理です。
処理系内で構文規則の定義には BNF という記法が使われています。
ざっくりいって、左側にルールの名前、右側にその構成要素と並び方が書いてあるような記法です。関数定義に関する構文規則のみを、処理系のソースコードからはしょりつつ一部抜粋します。
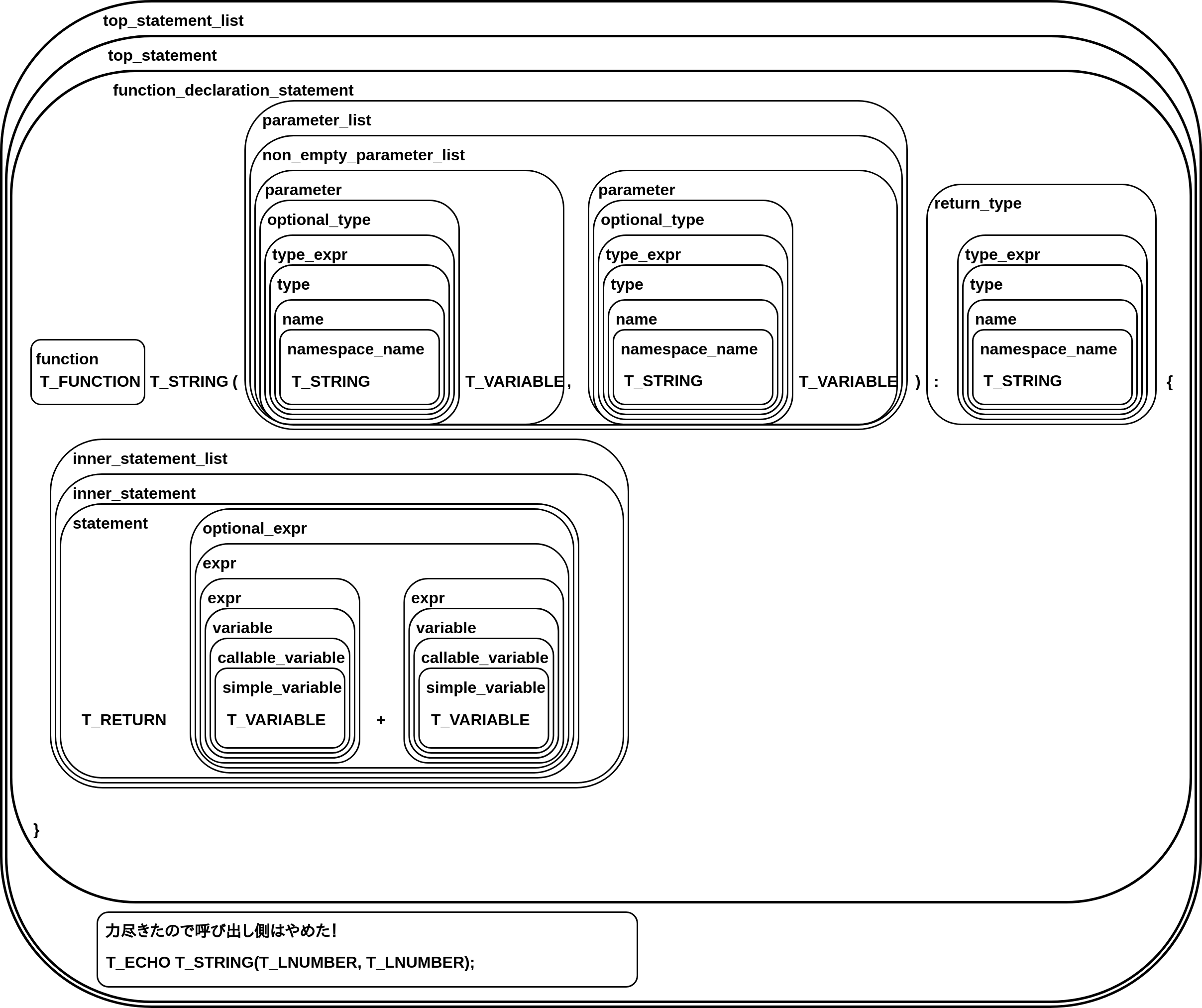
top_statement: function_declaration_statement function_declaration_statement: function returns_ref T_STRING '(' parameter_list ')' return_type '{' inner_statement_list '}' returns_ref: /* empty */ | '&' parameter_list: non_empty_parameter_list | /* empty */ non_empty_parameter_list: parameter | non_empty_parameter_list ',' parameter parameter: optional_type is_reference is_variadic T_VARIABLE | optional_type is_reference is_variadic T_VARIABLE '=' expr optional_type: /* empty */ | type_expr type_expr: type | '?' type type: T_ARRAY | T_CALLABLE | name name: namespace_name | T_NAMESPACE T_NS_SEPARATOR namespace_name | T_NS_SEPARATOR namespace_name namespace_name: T_STRING | namespace_name T_NS_SEPARATOR T_STRING return_type: /* empty */ | ':' type_expr ;top_statement、つまり <?php から始まるトップレベルの PHP コードを指すルールがあります。その中では function_declaration_statement、つまり関数定義を書くことができます。関数定義は function から始まり、参照を返すかどうかの & 、関数名と続いて、引数をくくる括弧があって、parameter_list、つまり引数リストがあります。その後波括弧があり、inner_statement_list、つまり関数の中身の文のリストがあって、という構造になっています。
この parameter_list とか inner_statement_list というのにも同様の形でルール定義があります。このルールはこういう内容から成り、そこに出てくるこのルールはこういう内容から成って、というのを繰り返していくと、最終的には字句解析で切り出されるような言語の字句の集まりが残るようになっています。具象構文木
さっきの字句解析結果に構文規則を当てはめると、
こんな感じになります。
構文解析の処理は、このようにプログラムへ構文規則を当てはめて、コードが正しく書かれているか、というのを判定する処理となっています。これは字句の列からプログラム全体を表す構文規則へ収束していく、ある種のツリー構造を構築することが出来るかを確かめていくような処理となっています。
「コードのこの部分はこういう構文規則の一部で、またその部分は別の構文規則の一部で、それがまた別の構文規則の一部で」という入れ子構造のデータからツリー構造を導き出すのは、日頃から入れ子構造の HTML と DOM ツリーの間を行ったりきたりしてきた PHP 使いの皆さんには、案外馴染みのある話なんじゃないかな、とも思います。
構文規則をソースコードへ当てはめることで作ることのできるツリー構造を、具象構文木と呼びます。コードを正しくツリー構造へ当てはめられるなら、コードの各部分がどういう役割と対応しているか、の分類が、そこそこできている状態ということにもなります。実マシンや仮想マシンで実行するコードを生成する際、この情報を使えると便利そうです。
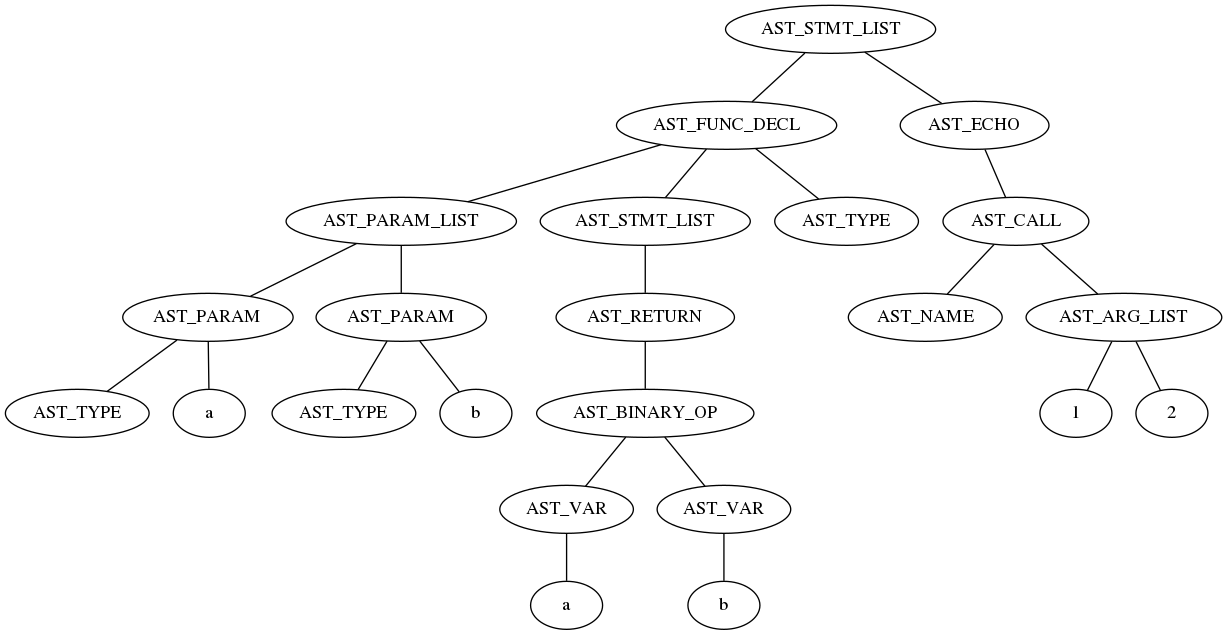
AST(Abstract Syntax Tree)、抽象構文木
具象構文木からコード生成に使える情報だけを残したものを、抽象構文木、Abstract Syntax Tree とか AST とか呼びます。PHP の構文解析処理は、この AST の生成をプログラムの構文上の正しさの検証と同時に行っていきます。
上図は nikic/php-ast でのダンプ内容から、 php-ast 側で利便性のために追加するノードを取り除いて Graphviz で出力したものですが、具象構文木からだいぶ内容が簡略化されているのが分かります。
AST からのコード生成
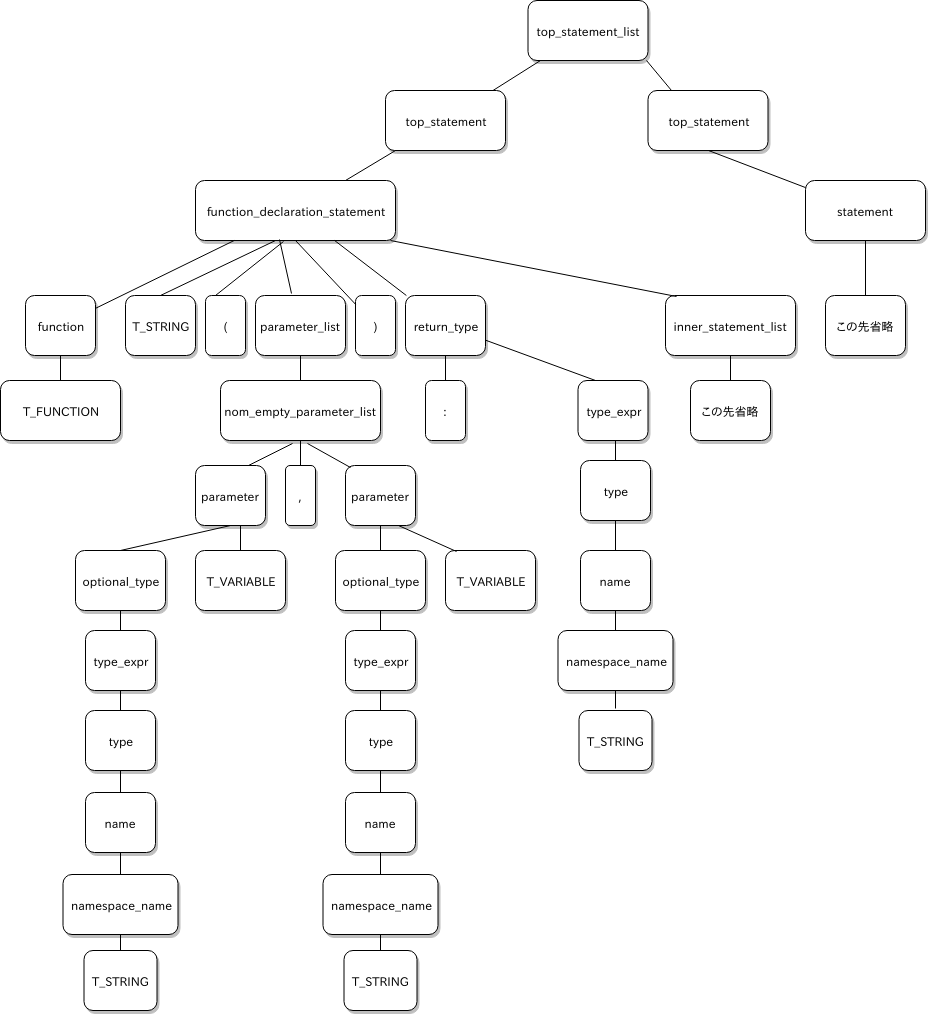
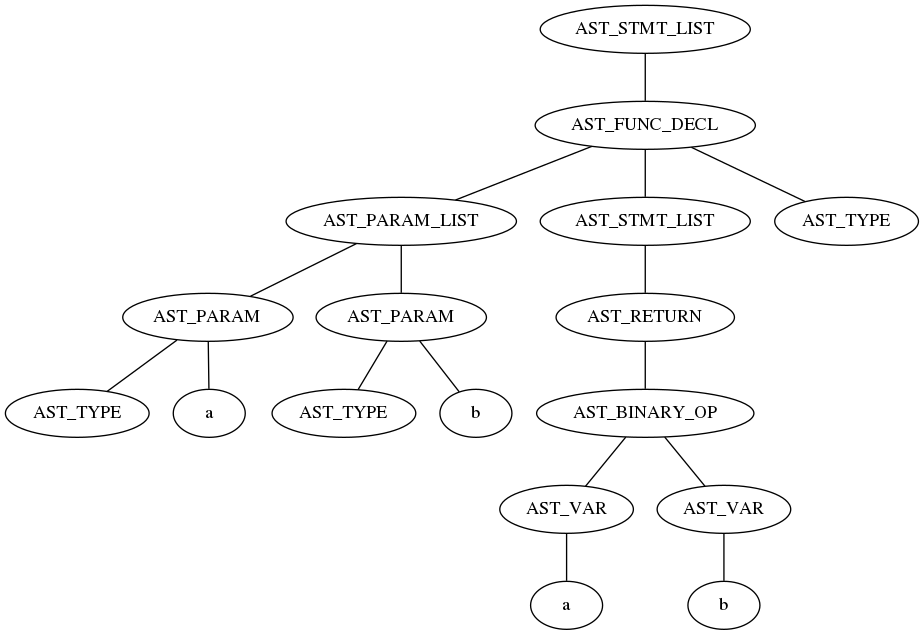
最終的に、コンパイル処理は AST を上から順にたどって、オペコードを生成していきます。
これは先ほどの AST から関数の定義部分のみを抜き出したものです。
これがこんな感じ↓に処理されます。
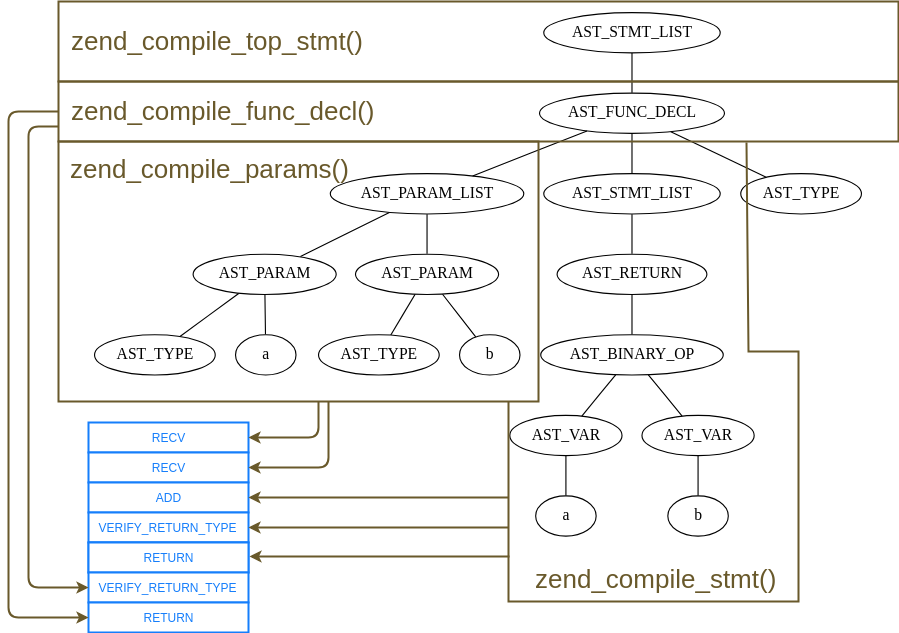
まず zend_compile_top_stmt() という関数が処理系内で呼ばれて、これが top_statement、トップレベルのコードと対応します。
zend_compile_top_stmt() は AST の子ノードを順繰りにたどり、ZEND_AST_FUNC_DECL、つまり関数定義と対応するノードがあれば、zend_compile_func_decl() を呼び出します。そこで新たな op_array を用意したり、処理系内部の関数登録表へその op_array を登録します。その後 AST の子ノードから更に引数リストや処理本体と対応するノードを取り出して 、zend_compile_params() や zend_compile_stmt() といった、それぞれのノードを処理するための関数を呼び出していきます。こうして少しずつ op_array へオペコードを詰めていきます。※ 作図の問題で返り値型宣言と対応する AST_FUNC_DECL の子ノード AST_TYPE が処理されていないように見えますが、本当は zend_compile_params() で引数ノードの AST_PARAM_LIST とあわせて読み込まれて処理されています
今回のコードは結果としてはこんなオペコードとなります。
$_main: INIT_FCALL 2 128 string("sum") SEND_VAL int(1) 1 SEND_VAL int(2) 2 V0 = DO_UCALL ECHO V0 RETURN int(1) sum: CV0($a) = RECV 1 CV1($b) = RECV 2 T2 = ADD CV0($a) CV1($b) VERIFY_RETURN_TYPE T2 RETURN T2 VERIFY_RETURN_TYPE RETURN null関数と op_array
さて、このような過程で PHP のソースコードがオペコードの配列へ変換されるわけですが、先程の説明でちょっと触れたように、このオペコードの配列、op_array は関数ごとに作られます。では関数定義の中にない PHP ファイルのトップレベルのコードはどうなるでしょうか。これについては、ファイルを読み込んでコンパイルした直後に呼び出す擬似的な main() 関数があるかのように、独立した op_array へコンパイルされます。
だいたいこんなイメージです。
<?php // function 擬似的なmain関数() { function sum(int $a, int $b): int { return $a + $b; } echo sum(1, 2); // }まとめるとこのようになります。
トップレベルの疑似main関数用の op_array があって、そこから呼び出す関数には別の op_array があります。もちろん、さらにそこから呼び出す関数にも独立した op_array があります。関数呼び出し命令で VM の実行は別の op_array へジャンプして、リターンすると呼び出し元へジャンプする、というような形になります。
こんな感じで関数ごとに op_array が存在します。
関数呼び出しのオペコード
さて、ここまで説明したところで、あらためて先程の PHP コードとそのコンパイル結果をもう一度見てみます。
<?php function sum(int $a, int $b): int { return $a + $b; } echo sum(1, 2);$_main: INIT_FCALL 2 128 string("sum") SEND_VAL int(1) 1 SEND_VAL int(2) 2 V0 = DO_UCALL ECHO V0 RETURN int(1) sum: CV0($a) = RECV 1 CV1($b) = RECV 2 T2 = ADD CV0($a) CV1($b) VERIFY_RETURN_TYPE T2 RETURN T2 VERIFY_RETURN_TYPE RETURN nullトップレベルのコード、疑似 main 関数は INIT_FCALL 'sum' という命令から始まり、SEND_VAL 1 と SEND_VAL 2 が続き、DO_FCALL、RETURN で終わります。関数 sum では RECV という命令が 2 つ続き、その結果を ADD という命令に渡した後、更にその結果を VERIFY_RETURN_TYPE 命令に与え、RETURN 命令に渡します。
DO_FCALL が関数を呼び出す、つまり VM の次の命令実行を別の op_array へジャンプさせる命令で、ADD が 2 つのオペランドの加算結果を出力する命令、VERIFY_RETURN_TYPE が返り値の型検査を行う命令、ということは、命令の名前からなんとなく分かりやすいのではないかな、と思います。少し分かり辛いかもしれないのが、INIT_FCALL と SEND_VAL、RECV です。これらは VM のスタックに関する命令です。
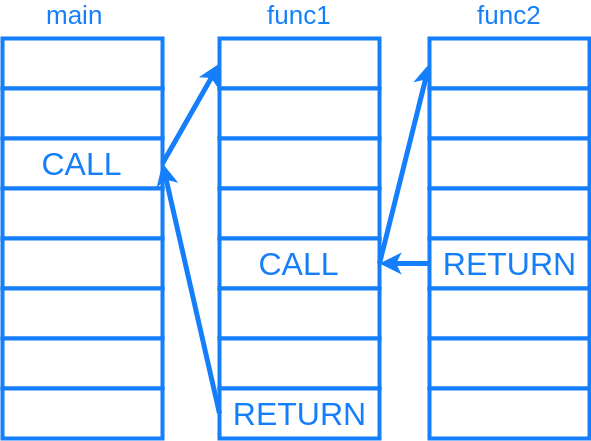
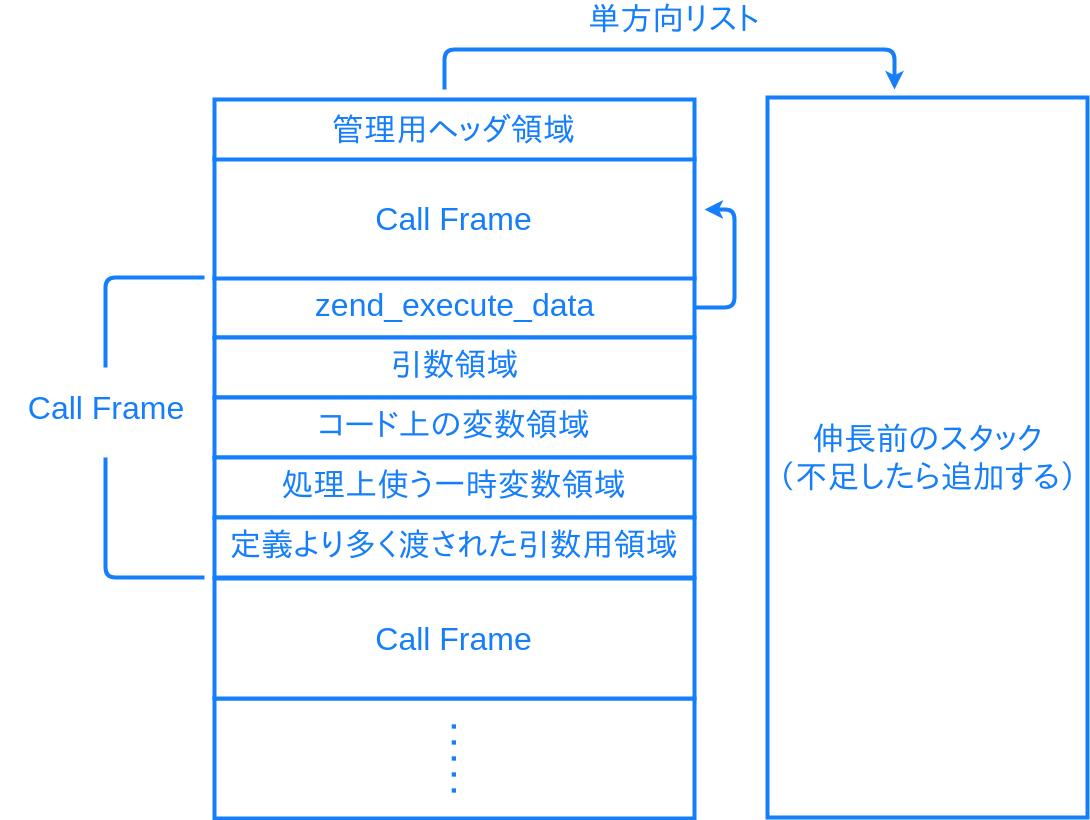
VM スタック
ZendVM は実マシンのスタックと別に、VM の実行状態を保持するためのスタックを持ちます。使っている内に確保したメモリ領域を足りなくなったら、新たに確保して単方向リストでつなぐ、という形で管理されています。VM スタックには関数の呼び出し状況や変数等、VM の実行状態が保持されます。関数が呼び出されるたび、INIT_FCALL の実行によって、この VM スタック内へコールフレームと呼ばれる領域が確保されます。
だいたい上図のような内容です。
コールフレームの先頭には zend_execute_data という、実行中の関数やオペコード、RETURN 先を得るための呼び出し元コールフレームへのポインタなどの情報を持つ構造体があります。続いてその関数の引数用のメモリ領域、変数や一時変数用のメモリ領域がコールフレーム内に配置されます。関数の呼び出し側は SEND_VAL 命令でこのコールフレーム内の引数用の領域へデータをコピーし、呼び出された側は RECV 命令で引数用の領域から値を取り出して、必要な型検査を行います。
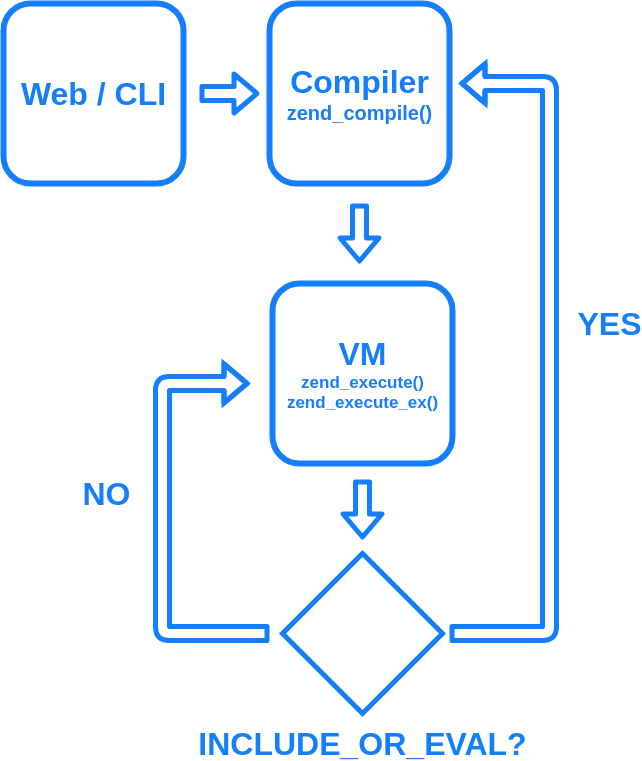
ファイルがコンパイルされる時
あらためて PHP コードがコンパイルされるタイミングからの流れをまとめると、このようになります。
コマンドラインなら起動時に与えるファイル名で、Web なら Web サーバがアクセスされた URL に対応するパスを与える形で、処理系へ実行する PHP ファイルが指示されます。
まずソースコードを zend_compile() という内部処理でコンパイルし、関数ごとの op_array が生成されます。zend_execute() という処理が zend_execute_ex() という別処理を呼び出し、疑似的な main 関数に対応する op_array 内の命令を、VM が順繰りに実行していきます。もしその op_array 中で、INCLUDE_OR_EVAL、 という PHP コードの include や eval に対応する命令が実行されると、別の PHP スクリプトが読み込まれ、コンパイルされます。そして読み込んだファイルに対応する擬似的な main 関数が呼び出されます。
と、いう感じにスクリプトの処理が進んでいきます。
executor_globals (EG)
処理系がその時々でどういう状態にあるか、どの op_array のどのオペコードを実行しているか、という情報は、executor_globalsという構造体に格納されています。VM の全ての実行状態を取得できる、非常に重要な構造体です。executor_globals にはシンボルテーブルや関数テーブル、VM スタックへのポインターといった情報があります。current_execute_data という構造体へのポインタをフィールドとして持っていて、これを通して実行中の関数、そしてその op_array のどこを実行しているか、といった情報が得られます。ポイント先は関数呼び出し時に VM スタックのコールフレーム先頭へ確保される構造体そのもので、関数呼び出しやファイル読み込みで実行中の op_array が切り替わるたび、つど更新されます。ZendVM が命令を実行していくに従って、これらの情報がメモリ上で都度更新されていくわけです。
処理系の標準処理のフック
ここまで話してきた Zend Engine の動作は、拡張を通してある程度カスタマイズすることが可能です。
例えば、先の話に出てきた zend_compile、zend_execute_ex、といった処理は処理系内部では関数ポインタになっており、拡張からその実装をフックして差し替えることが可能です。標準のコンパイラが AST を構築した後のタイミングには zend_ast_process という関数ポインタが呼び出されますし、zend_set_user_opcode_hadler では特定のオペコードに対応するオペコードハンドラを差し替えるようなこともできます。このように、拡張から内部処理をフックできるポイントは幾つかあります。
実際に xdebug や opcache といった拡張は、これらの処理を目的に応じて差し替えることで機能しています。zend_execute_ex をフックすると、例えば PHP の全関数呼び出しの前後へ時間計測関数を挟み込み、差分を記録していく拡張を作ることも可能です。
Zend Engine の話のまとめ
以上、少し駆け足でしたが、Zend Engine における関数実行のされ方について説明をしてきました。
Zend Engine における関数実行の仕組み、なんとなくのイメージはできましたでしょうか。
PHP のソースコードが字句に分解され、構文が検査されるとともに AST が構築され、関数ごとオペコードの配列へコンパイルされます。VM が一つ一つオペコードを取り出し、executor_globals や VM スタックといった内部状態を更新しながら動作していきます。そしてそれらコンパイラや VM の処理の一部は、拡張を通して差し替えることができます。
それでは次に、PHP コード、関数の実行性能はどのようにして計測できるか、というお話をさせていただきます。関数実行の計測
趣味やお仕事でプログラムの高速化をしよう、という話があったとします。
例えば PHP のファミコンエミュレータで、マリオが 6 FPS しか出ないから、60 FPS 目指してみようか、とかそういう時ですね。
こんな時、とりあえず何をすればいいか分かりますでしょうか?「推測するな、計測せよ」
はい、とりあえず計測です。誰がこんなオヤジギャグみたいなうまいこと言ったのか分かりませんが、きっと日本人なのでしょうね。しかしそれにしてもうまいこと言ったものです。
ボトルネック
システムの中で特に遅く、他の足を引っ張っているような部分を、そのシステムのボトルネックと呼びます。
ボトルネックを見つけ出し、遅くなっている原因を取り除いてやることで、効率的にプログラムの性能改善を行っていくことができます。ボトルネックを見つけ出すには計測が必要です。原始的計測
先のコードを使い回し、関数 sum の実行時間を計測してみます。
<?php function sum(int $a, int $b): int { return $a + $b; } $start = microtime(true); $result = sum(1, 2); $end = microtime(true) - $start; }実行前に Unix エポックからのマイクロ秒で現在時刻を取得します。
実行後同様に時間を取得して、実行前の値との差をとります。
これは PHP プログラムを計測する際の、非常に原始的な方法です。
このやり方には良い部分も悪い部分もあります。原始的計測の良いところ
例えば良いところは、追加のライブラリやツールのインストールが要らないことです。
また、だいたい Controller の処理が実行される前まで、とか、View のレンダリングが開始してからリクエストが終了するまで、とか、任意の区間を対象に計測をとることができます。
DB アクセスやキャッシュアクセス等の共通コードに仕込むことで、実行時間の大枠をつかめるようにもなります。原始的計測のびみょいところ
ただし、この方法では計測箇所ごとにコード修正が必要です。
細かく見た時にどこがボトルネックになっていそうかな、というのを推測したり、外れた時や改修の過程でボトルネックが変わった際は人力二分探索気味に、計測区間を変えながら計測用の実行を繰り返す必要ができたりします。
DB アクセスがボトルネックな場合は、クエリを実行する共通コードへ時間計測を仕掛けて、クエリごとに実行時間を記録することで性能改善に取り組むこともできます。が、ボトルネックが PHP コード側にある場合、「うーんこの array_map() が遅いんだろうか……?」というように、見るもの全てが容疑者に思え、どこに時間計測を仕掛ければいいのか分からなくなってしまいます。ここでプロファイラを使うことで、人力でコードを修正してつどつど時間計測処理を仕込むことなく、ほぼ無修正のプログラムをいい感じの区間で計測することができます。
Profiler とは
プロファイラは性能解析のためのツールです。プログラムの各処理の実行時間を収集し、統計情報を出力します。
2 種類の計測方式
PHP には大きく分けて 2 種類のプロファイラが存在します。
一つは関数呼び出しフック方式(以下フック方式)、もう一つがサンプリング方式です。
それぞれ特徴があり、この記事の前半で説明した Zend Engine に関する知識が少しあると、理解が若干簡単になります。それではまず、フック方式の話から始めます。
フック方式
Zend Engine についての説明の最後の方で、zend_execute_ex()、つまり op_array 内のオペコードを VM に実行させる処理は、処理系内で関数ポインタとなっており、拡張から差し替えることができる、という話をしました。
この zend_execute_ex() を差し替え、まず開始時刻を取得し、元々の zend_execute_ex() のオペコード実行処理を呼び、終了時刻を取得して、その差分を記録する、という処理へ替えます。
全関数呼び出しの実行時間が自動的に記録され、呼び出し階層のどの部分で何から呼ばれた何に処理時間がどれだけかかった、ということが、ほとんど全て把握できるようになります。
これがよくあるフック方式のプロファイラの仕組みの例です。フック方式のプロファイラは幾つか存在し、いずれも処理系へ組み込んで使うC言語拡張として提供されています。デバッガの xdebug に付いているのもフック方式ですし、xhprof や xhprof から派生した tideways、blackfire、spx といったプロファイラもあります。
この中で特に他への影響が大きいと言えるのは xhprof なので、とりあえず xhprof についての話から始めます。xhprof
xhprof は Facebook 製の拡張です。
基本的な動作原理は、先にフック方式のプロファイラの仕組みの例として話した通りのもので、全関数呼び出しをフックするものです。OSS として公開されていたことで、後に blackfire や tideways といった他プロファイラへ派生しています。
xhprof が出るまでは xdebug が唯一のPHPプロファイラでしたが、xdebug のプロファイラは尋常でなく重く、一方 xhprof はたまに動かす分には本番環境でさえ使える軽さ、というのがウリでした。
しかしFacebook が HHVM へ移行し ZendVM を捨てたことで、PHP7 をサポートしないまま破棄されてしまいました。
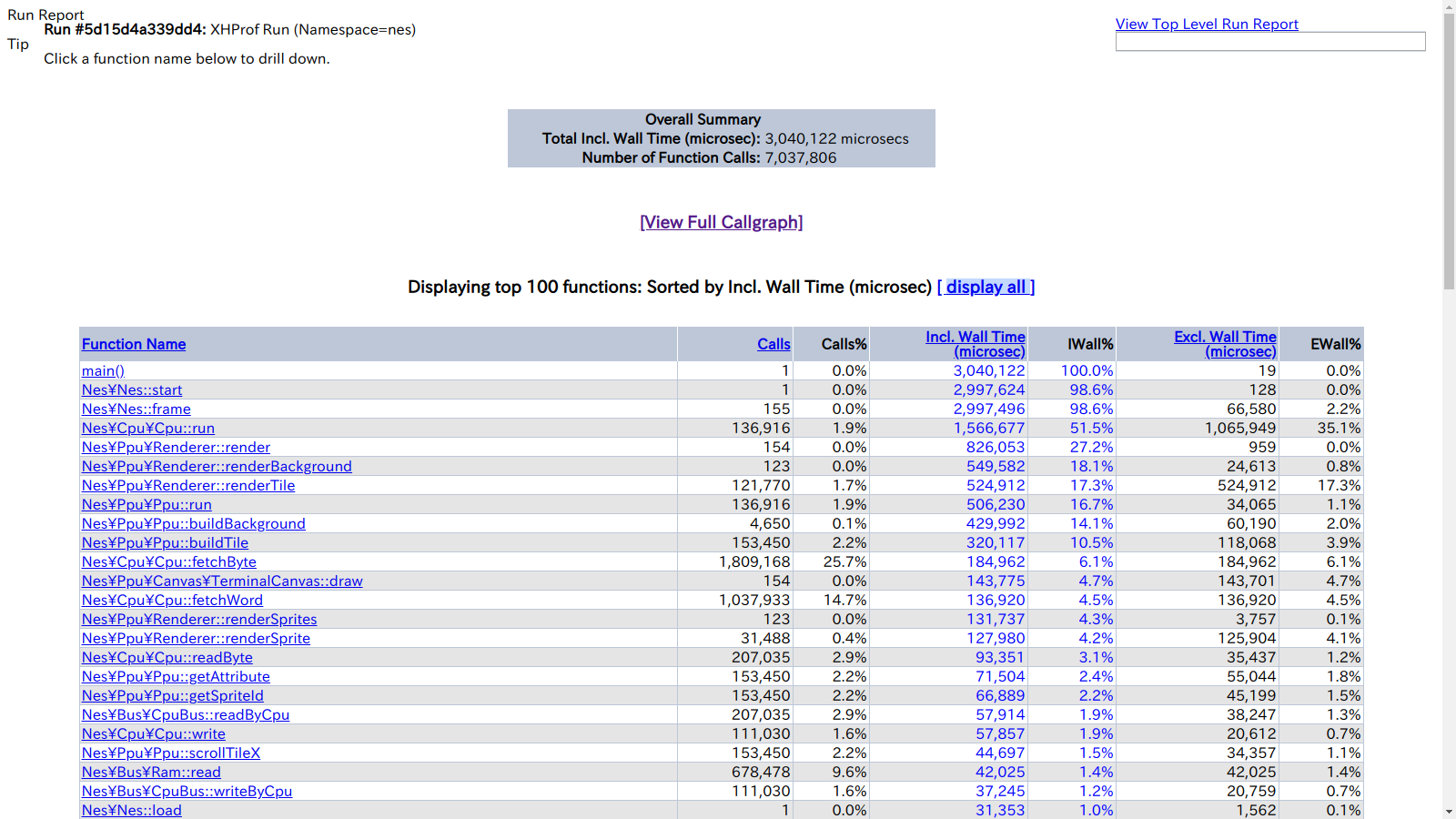
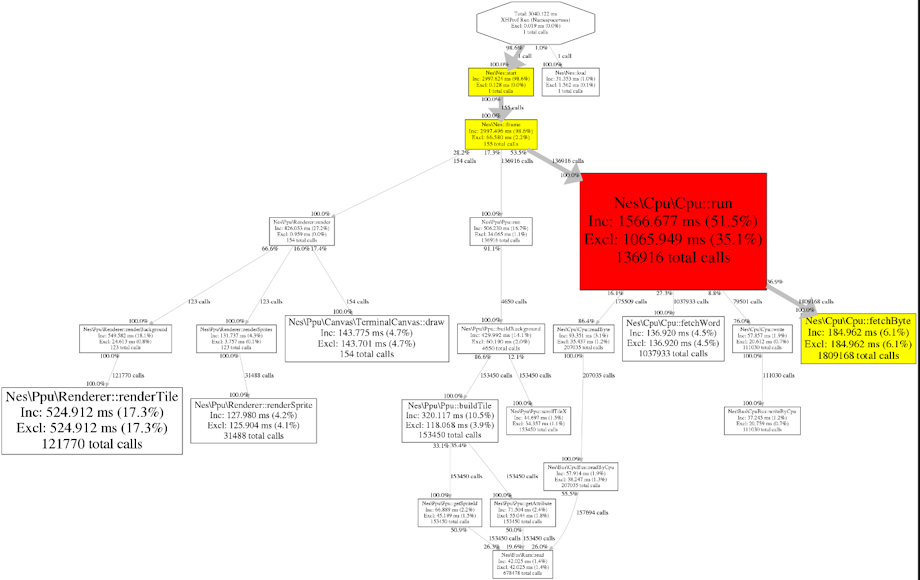
こんな感じにブラウザからプロファイル結果を見ることができます。
標準ではファイルへプロファイル結果を吐き出すのですが、データベースへ蓄積したプロファイル結果を見るためのサードパーティのビューアも幾つか存在します。コールグラフとかも見れます。
tideways
xhprof から派生したプロファイラの 1 つに、tideways というプロファイラがあります。
tideways は xhprof 派生の拡張と PHP 側から利用するクラスライブラリ、SaaS のセットです。
拡張側は元は xhprof へ区間計測機能のような新機能を追加したオープンソースのものでしたが、後に 0 からコードがリライトされ、同時に拡張のコードもクローズドソースになっています。
しかし tideways 本体の拡張がクローズドソースになってからも、xhprof 互換機能のみを切り出した tideways_xhprof が OSS として公開されています。
tideways_xhprof は PHP7.3 にも対応しており、xhprof 互換の無料で使えるプロファイラの中では特によくメンテされてるものです。
中のコードは元の xhprof よりきれいですし、性能も元の xhprof より良いです。
SaaS の方の tideways は大体こんな感じです。xhprof 形式で実行時間を集計する機能と別に、区間計測データを集めて視覚的に表示するような機能も付いています。これは xhprof 形式の計測より計測負荷も低いみたいです。
要件やコスト感が合えばぜひ SaaS の方を契約して買い支えてあげてください。フック型の計測オーバーヘッド
これらフック型のプロファイラに共通して言えるのは、計測時のオーバーヘッドに注意する必要がある、ということです。
例えば Zend Engine には、zend_execute_ex が拡張によってフックされている場合に限って無効になってしまう最適化があります。拡張からのフックがない場合、ユーザ定義関数の呼び出しは他命令と同じ VM のループの中で、 zend_execute_data を差し替えながら実行されます。が、これは再帰をループへ展開する類の最適化が行われた結果の現状実装であり、zend_execute_ex がフックされている場合はこの最適化が無効となり、関数呼び出しごとに zend_execute_ex を再帰的に呼び出すという古い挙動へフォールバックします(これのおかげで、 zend_execute_ex をフックして関数実行を監視する拡張が動作し続けられています)。
当然、実行時間を取得して記録する処理自体にもわずかながらオーバーヘッドがあります。
関数本体の実行時間が長い場合には誤差でしかないようなものですが、これらがほぼ固定時間で全ての関数呼び出しにかかる、というのが問題です。
※ この図どうせならもう少しやばそうな差にした方がよかったですね、気が向いたら差し替えます
1 つ 1 つの実行は高速であるような関数が、何万回も大量に呼び出されることを考えてみてください。
チリツモで計測負荷が大きく効いてくることになり、なんなら本体の処理より計測負荷の方が大きいような状況になってしまうこともあります。
本当は大した時間のかからない速い処理なのが、呼び出し回数が多いばかりに計測負荷の分で遅く見えてしまい、本来のボトルネックを隠してしまうことさえあり得ます。
呼び出し回数に応じ計測負荷が各関数に対して非対称な影響を与えてしまう、というのは、フック型プロファイラで広範囲な計測を取ろうとすると避けられない問題です。
※ 一応、多く呼ばれる関数を計測対象から除外するという軽減策はあります。PHP 8 の JIT
来年冬にリリースされる PHP8 には JIT コンパイラが導入されることが決まっています。I/O バウンドな処理についての負荷はあまり変わりませんが、CPU 負荷の高い、それこそ速い関数が大量に呼び出されるようなユースケースも今後ある程度増えていくのではないかと思われます。この際、VM の実行方式が変わることで zend_execute_ex のフックによる性能計測は機能しなくなる可能性があります。zend_ast_process あたりのフックにより拡張から AST 操作を行う等して、関数呼び出しごとに自動で計測処理を挟み込むようにする、という手はあります。が、命令の実行速度が上がり、その恩恵を受けられる(PHP 側処理を多く行う)コードを実行する以上、計測処理のオーバーヘッドは割合としては上がりがちとなり、合計オーバーヘッドがやばくなる問題はおそらくますます避けがたくなります。
フック方式まとめ
フック方式のプロファイラについてまとめます。あらゆる関数呼び出しを計測可能で、計測する箇所ごとに計測コードを差し込まなくても使えます。ただし計測対象を大量に呼び出す場合は計測オーバーヘッドが大きくなってしまいます。重めの I/O 等、1 回あたりの実行時間が長い分かりやすいボトルネックがある場合に便利です。
サンプリング方式
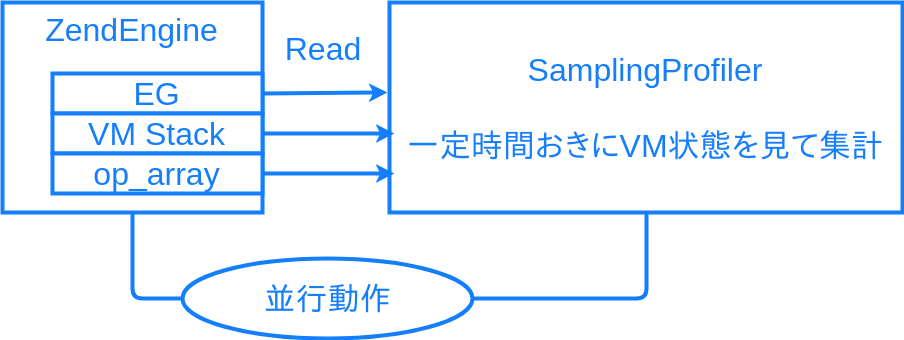
フック型の問題を解決できるのが、サンプリング方式のプロファイラです。
計測対象と平行動作するプログラムにより、VM の実行状態をサンプリングして監視します。
ExecutorGlobals から実行中の命令位置などの内容を定期的に読み取り、よく実行されている箇所が重い箇所、ということになります。サンプリング方式の例
サンプリング方式のプロファイラは今のところあまり種類がありません。知る限りでは nikic/sample_prof、そして adsr/phpspy、その他に krakjoe/trace というものもあります。
今回はこのうち sample_prof、phpspy を順に取り上げます。sample_prof
sample_prof はフック型のプロファイラと同様 、C 言語拡張として作られています。フック型プロファイラは関数レベルの解像度でしか計測をとれませんが、sample_prof ではソースコードの行レベルでコードのどのあたりが頻繁に実行されているかを計測することができます。行レベルでの計測がとれることで、各関数に散在する変数代入がチリツモで遅い、とか、極度に CPU バウンドな処理で型検査のコストが重い可能性とかにも気付くことができます。
内部ではプロファイラの開始時に pthread_create() でスレッドを起動し、指定したサンプリングレートで計測スレッドが VM の内部状態を監視するようになっています。
// 起動自体は他プロファイラと似たような方法でいける sample_prof_start(50); // ここでスレッド生成 register_shutdown_function(function(){ sample_prof_end(); $data = sample_prof_get_data(); file_put_contents(uniqid() . 'prof.txt', serialize($data)); });スレッドはメモリ空間を共有するので、別スレッドから普通に ExecutorGlobals が読めるわけです。
また PHP スクリプト本体の処理と別スレッドで計測スレッドが動くということは、CPU コアが余っていればあまり本体の処理に影響を与えずに計測がとれます。仮にコアが余っていなくても、OS がいい感じにスケジューリングしてくれる限り、少なくとも計測対象の関数が速く多く呼ばれる場合の負荷の非対称性は生まれません。sample_prof はスレッドで動く C 言語拡張なので、ある種のなるほど感があります。まあ動くだろうな、という感じです。
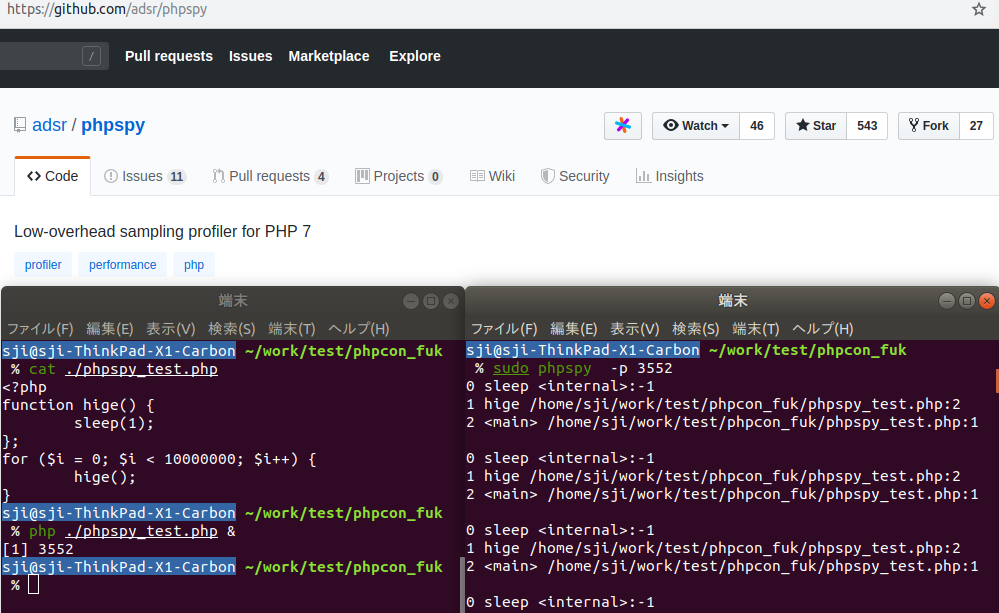
sample_prof と違い、明らかに頭がおかしいことをやっているのが phpspy です。phpspy
phpspy はスタンドアロンの C 言語プログラムで、PHP の拡張ではありません。
どういうことかというと、こんなふうに実行中の PHP プログラムが何をしているかを別プロセスから覗き見ることができます。
もうパッと見で意味が分からない、という感じがします。
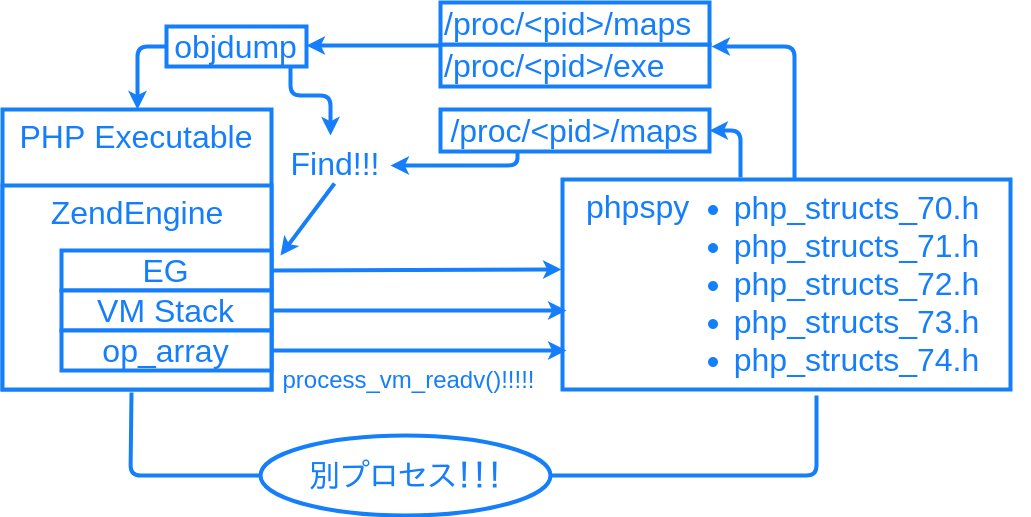
phpspy は各バージョンの PHP 処理系の ExecutorGlobals 等、構造体のメモリレイアウトについて自前で情報を持っています。/proc/<PID>/maps や PHP バイナリの ELF ヘッダ等の情報を読み取って強引に各構造体のアドレスを特定し、process_vm_readv() で読み取って、完全にプロセス外から VM の実行状態を解析します。
各関数の実行性能を読み取れるばかりか、実行中のスクリプトの変数の値を覗き見ることさえできるのです。
それも、拡張インストールやスクリプト中での計測の開始処理などを一切必要とせずにです。元々は Ruby で同様のことをやっている rbspy というのがあり、それのパクリだそうです。
rbspy を作った人が超楽しそうに解説をしてる動画があるので、興味のある方はぜひ見てみてください。サンプリング方式のまとめ
サンプリングプロファイラについてのまとめです。サンプリングプロファイラは計測対象の処理に影響を与えずに、性能解析を行うことができます。サンプリングのため、サンプリングレートによっては取りこぼしてしまう関数実行もあり、全ての呼び出しを確実に記録してプログラムの実行のされ方を観察する、という使い方には向きません。大量に呼び出される関数でも計測オーバーヘッドの累積が起きず、どのあたりがボトルネックになっていそうか、という点については比較的正確なイメージを得ることができます。
おしまい
気が向いたらたまに内容を拡充したり説明を丁寧にしたり図を親切化したり実際のコードへのハイパーリンクを足したりしたい、という気持ちだけはあります。気持ちだけはね!



- 投稿日:2019-07-01T19:39:52+09:00
PHPでTwitter APIのアクセストークンを取得する
はじめに
初投稿です。
初めて触ったWebAPIなので備忘録がてらに書き残しておきます。前準備
TwitterDeveloppersから開発者アカウントを取得します。Appを作成しConsumerKeyの生成を取得までを済ませてください。
開発者アカウントの取得方法については割愛します。今日の時点(2019年7月1日)では私が申請した頃と申請フローが変更されていました…それからTwitterOAuthのライブラリを導入してください。TwitterAPIのリクエストが格段に便利になるすごいライブラリです。
導入方法はComposerでも何でもいいですがComposerが楽だと思います。公式のWith Composerが参考になるはずです。手順
oauth/request_tokenからリクエストトークンを取得するhttps://api.twitter.com/oauth/authorizeに取得したリクエストトークンを合わせて飛ばす- Twitter上でログイン→連携アプリを認証→コールバックに指定したページに戻ってくる
oauth/access_tokenで認証だいたいこんな流れです。
実装
access_token.php<?php session_start(); require_once($_SERVER['DOCUMENT_ROOT'] . "/vendor/autoload.php"); use Abraham\TwitterOAuth\TwitterOAuth; // 設定項目 $con_key = "*****"; // Consumer Key $con_secret = "*****"; // Consumer Secret $callback_url = "http://" . $_SERVER["HTTP_HOST"] . "access_token.php"; // Callback URL // 3. コールバックに指定したページに戻ってくる if ($_GET) { // $twitter = new TwitterOAuth($con_key, $con_secret, $_GET['oauth_token'], $_SESSION['oauth_secret']); // 4. oauth/access_tokenで認証 $params = [ 'oauth_verifier' => $_GET["oauth_verifier"], ]; $access_token = $twitter->oauth('oauth/access_token', $params); foreach ($access_token as $key => $value) { echo $account_status[$key] = $value; echo "<br/>"; } session_destroy(); ?> <a href="<?= $callback_url ?>">もう一度認証する</a> <?php // 1. oauth/request_tokenからリクエストトークンを取得する } else { //TwitterOAuthの仕様準備 $twitter = new TwitterOAuth($con_key, $con_secret); $params = [ "oauth_callback" => $callback_url, "x_auth_access_type" => "write" ]; $request_token = $twitter->oauth('oauth/request_token', $params); $_SESSION["oauth_secret"] = $request_token["oauth_token_secret"]; // 2. https://api.twitter.com/oauth/authorizeに取得したリクエストトークンを合わせて飛ばす header("Location: https://api.twitter.com/oauth/authorize?oauth_token=" . $request_token["oauth_token"]); }解説
手順辿りつつピックアップ。
$callback_url = "http://" . $_SERVER["HTTP_HOST"] . "access_token.php"; // Callback URL1枚のページでアクセストークンの取得を行うため
$callback_urlにはこのページを指定。$request_token = $twitter->oauth('oauth/request_token', $params);oauthメソッドで手順1.のリクエストトークンを取得。
$_SESSION["oauth_secret"] = $request_token["oauth_token_secret"];この後Twitterに遷移するためセッションに
oauth_token_secretを保存。header("Location: https://api.twitter.com/oauth/authorize?oauth_token=" . $request_token["oauth_token"]);
headerでTwitterの認証ページへ飛ばす。パラメータにさっき取得したリクエストトークンをつける。
ここからTwitter上の認証ページから戻ってきた処理
$twitter = new TwitterOAuth($con_key, $con_secret, $_GET['oauth_token'], $_SESSION['oauth_secret']);TwitterOAuthを再度newする。今度は引数にConsumer Keyと取得したOAuth Key指定する。
$params = [ 'oauth_verifier' => $_GET["oauth_verifier"], ]; $access_token = $twitter->oauth('oauth/access_token', $params);戻ってきた際に取得した
oauth_verifierをパラメータにoauth/access_tokenへリクエスト。これでアクセストークンが取得できました!これさえあれば好きなようにTwitterAPIが叩けます!
TwitterOauthがすごい話
初めて触ったときはCurlでリクエストしてたんでもう必死でした。TwitterOAuthが無かったら生きていけなかった。
今回はアクセストークンを取得する話でしたが,個人で使う分にベアラートークンさえあればAPIは叩けます。
以前はAPI叩くのにいちいちベアラートークンを取得してられっかよ!という状態だったので,1度取得してからローカルに大事に大事に保存していました。
しかしこのTwitterOAuthはConsumer Keyさえあれば勝手にベアラートークンを取得してgetなりpostのリクエストを飛ばしてくれるすごいやつなんです。すごい!
いつかTwitterOAuthがすごいって紹介記事書きたい。ちなみにtmhOAuthという同様にTwitterAPIを叩くライブラリがあるのですが,こちらは5,6年前に更新が止まってます。
時間があるときにTwitterOAuthとtmhOAuthの比較記事も書けたらなーと考えています。まとめ
うまくまとめられないなー至らないなーとぼやきながら四苦八苦で初投稿してみました。
引き出し開けつつこれはこれだよなあれはあれって頭の整理ができたことは事実なので今後も続けていきたいですね。
あとTwitterAPIの情報探してるとログイン認証だとかアプリ認証だとかコンシューマーキーだとかAPIキーだとか同じモノを指していても言葉が違ったりします。
その辺の認識?定義?を自分で整理できていると情報探すのが楽。参考
- 投稿日:2019-07-01T19:00:47+09:00
Laravel Excel 3.1 レイアウトまとめ
概要
Laravel Excel 3.1で設定できるレイアウトのまとめです.
シート全体に対して適用されます.
ビューを使用時に各セルごとで設定できるスタイルはここにまとめています.環境
- Laravel 5.8
- Laravel Excel 3.1
実装
以下はすべて
php artisan make:export ModelExport --model=Modelで作成したファイルの
use Maatwebsite\Excel\Concerns\WithEvents; use Maatwebsite\Excel\Events\AfterSheet; use Maatwebsite\Excel\Events\BeforeSheet; class BookExport implements FromCollection , WithEvents { public function registerEvents() : array { return [ //ここに追加する ]; } }に
return [ AfterSheet::class => function(AfterSheet $event) { //処理 }, ];このように追加します.キーが同じものは処理をまとめてください.
印刷の向き
use PhpOffice\PhpSpreadsheet\Worksheet\PageSetup; AfterSheet::class => function(AfterSheet $event) { $sheet = $event->getSheet()->getDelegate(); $sheet->getPageSetup()->setOrientation(PageSetup::ORIENTATION_LANDSCAPE); }
PageSetup::XXXの部分はORIENTATION_DEFAULT = 'default'; //デフォルト ORIENTATION_LANDSCAPE = 'landscape'; //横 ORIENTATION_PORTRAIT = 'portrait'; //縦から選びます.
目盛線の有無
AfterSheet::class => function(AfterSheet $event) { $sheet = $event->getSheet()->getDelegate(); $sheet->setShowGridlines(false); //trueで表示する }フォント
BeforeSheet::class => function(BeforeSheet $event) { $sheet = $event->getSheet()->getDelegate(); $sheet->getParent()->getDefaultStyle()->applyFromArray([ 'font' => [ 'name' => 'MS Pゴシック', 'size' => 10, ], ]); },設定できる項目は
'font' => [ 'name' => 'フォント名', //フォント 'bold' => true, //ボールド体 'italic' => true, //イタリック体 'superscript' => true, //上付き文字 'subscript' => false, //下付き文字 'underline' => \PhpOffice\PhpSpreadsheet\Style\Font::UNDERLINE_DOUBLE, //下線 'strikethrough' => true, //取り消し線 'color' => [ 'rgb' => 'FF0000' //色 ], 'size' => 12, //文字サイズ ],これだけあります.
セルの幅
BeforeSheet::class => function(BeforeSheet $event) { $sheet = $event->getSheet()->getDelegate(); $width = [ 'A' => 10, 'B' => 12, 'C' => 11, ]; // Disable the autosize and set column width foreach ($width as $column => $value) { $sheet->getColumnDimension($column) ->setAutoSize(false) ->setWidth($value); } // Set autosized to true $sheet->hasFixedSizeColumns = true; },セルの高さ
BeforeSheet::class => function(BeforeSheet $event) { $sheet = $event->getSheet()->getDelegate(); $sheet->getDefaultRowDimension()->setRowHeight(20); },配置
use PhpOffice\PhpSpreadsheet\Style\Alignment; BeforeSheet::class => function(BeforeSheet $event) { $sheet = $event->getSheet()->getDelegate(); $sheet->getParent()->getDefaultStyle()->applyFromArray([ 'alignment' => [ 'horizontal' => Alignment::HORIZONTAL_CENTER, //水平 'vertical' => Alignment::VERTICAL_CENTER, //垂直 'textRotation' => 0, //回転 'wrapText' => FALSE, //折返し ], ]); }配置は水平方向は
Alignment::XXXX 配置 HORIZONTAL_GENERAL 通常 HORIZONTAL_LEFT 左寄せ HORIZONTAL_RIGHT 右寄せ HORIZONTAL_CENTER 中央揃え HORIZONTAL_CENTER_CONTINUOUS 選択範囲で中央揃え HORIZONTAL_JUSTIFY 両端揃え HORIZONTAL_FILL 繰り返し から選び,垂直方向は
Alignment::XXXX 配置 VERTICAL_BOTTOM 下揃え VERTICAL_TOP 上揃え VERTICAL_CENTER 中央揃え VERTICAL_JUSTIFY 両端揃え から選びます.
その他
その他
applyFromArrayメソッドで適用できるスタイルに
- fill
- borders
- numberformat
- protection
- quotePrefix
があります(調査中).
参考
- 投稿日:2019-07-01T12:22:24+09:00
PHPのヒアドキュメントをシンタックスハイライトする
- 投稿日:2019-07-01T10:55:27+09:00
Laravel Excel 3.1 導入 + 使用例
概要
Laravel-Excelの導入方法と使い方の紹介です.公式ドキュメントに同じものがあります.
目盛線や印刷の向きなどの設定方法はこちらにまとめています.
環境
- Laravel 5.8
- Laravel-Excel 3.1
インストール
次のコマンドを打ちます:
composer require maatwebsite/excelこれでvender以下にLaravel-Excel用のファイルが追加されます.
次にLaravelの設定をしていきます.まずconfig/app.phpに
config/app.php'providers' => [ /* * Package Service Providers... */ Maatwebsite\Excel\ExcelServiceProvider::class, //追加 ]config/app.php'aliases' => [ 'Excel' => Maatwebsite\Excel\Facades\Excel::class, //追加 ]この2行を追加します.追加後コンソールで
php artisan vendor:publish --provider="Maatwebsite\Excel\ExcelServiceProvider"を実行して,インストール完了です.
使用例
Userを出力してみます.まず
php artisan make:export UsersExport --model=Userを実行して,必要なファイルを作成します.ファイルは app/Exports/UsersExport.php に作成されます.作成されたファイルは
App/Exports/UsersExports.php<?php namespace App\Exports; use App\User; use Maatwebsite\Excel\Concerns\FromCollection; class UsersExport implements FromCollection { public function collection() { return User::all(); } }のようになっています.
次にコントローラに
UserController.phpuse App\Exports\UsersExport; use Maatwebsite\Excel\Facades\Excel; class UsersController extends Controller { public function export() { return Excel::download(new UsersExport, 'users.xlsx'); } }を追加します.あとはルートを
routes/web.phpRoute::get('/users/export','UserController@export');追加すれば完了です.
出力形式の指定
出力形式を指定する場合は次のようにします:
UserController.phpuse App\Exports\UsersExport; use Maatwebsite\Excel\Facades\Excel; use Maatwebsite\Excel\Excel as ExcelType class UsersController extends Controller { public function export() { return Excel::download(new UsersExport, 'users.xlsx', ExcelType::XLSX); } }ちなみに
return Excel::download(new UsersExport, 'users.xlsx', 'Xlsx');としても動きます(推奨はしません).対応している形式は
ExcelType::XXXX 実体 XLSX 'Xlsx' CSV 'Csv' TSV 'Csv' ODS 'Ods' XLS 'Xls' SLK 'Slk' XML 'Xml' GNUMERIC 'Gnumeric' HTML 'Html' MPDF 'Mpdf' DOMPDF 'Dompdf' TCPDF 'Tcpdf' です.
参考
- 投稿日:2019-07-01T09:07:45+09:00
php-master-changes 2019-06-30
今日は fileinfo の二重解放を避けるための修正、ドキュメントの更新、timelib を更新する修正があった!
2019-06-30
weltling: Set buffer to NULL to prevent double free (Kamil Dudka at redhat)
- https://github.com/php/php-src/commit/5ae0a6b784e90e5c2aa6723b404a7bb91cd5fecc
- [7.4~]
- ext/fileinfo で、二重解放を避けるよう解放後バッファのポインタに NULL を突っ込む修正
weltling: Update libmagic.patch [ci skip]
- https://github.com/php/php-src/commit/dacf9ecc46243b8e61dcd1988443f4a57b413f43
- [7.4~]
- ext/fileinfo で、libmagic のパッチを更新
weltling: Update NEWS [ci skip]
- https://github.com/php/php-src/commit/a149f9f3c087fb99dae217653d705aa4fc1d0c66
- [7.2~]
- NEWS へ前日の修正を追記
derickr: Update timelib to 2018.02
- https://github.com/php/php-src/commit/aae5907cb7e775f16bedf61b010b8692c12a2843
- [7.3~]
- ext/date で、timelib を 2018.02 へ更新
derickr: Fixed tests due to changed timezone data
- https://github.com/php/php-src/commit/cc3fe3bd30ecd94e7eec5075f25f7cd4c5b806e2
- [7.3~]
- ext/date で、タイムゾーンデータの更新に伴うテストの期待出力の修正
- 投稿日:2019-07-01T09:07:26+09:00
# Node.jsとTypeScriptによる高速かつ軽量なWebシステム構築1 ~ 地獄の門前 ~
Node.jsとTypeScriptによる高速かつ軽量なWebシステム構築1 ~ 地獄の門前 ~
1.はじめに
ツリー型情報掲載システム(Node.js+TypeScript版)
ソースコードNode.jsとTypeScriptで上記のものを作ったので、このあたりの開発に関する話をしていきます。今回は導入部分です。
2.Node.jsによる完全包囲
Node.jsはJavaScriptを好きな場所で走らせることが出来るフレームワークとして、様々な場所で使われている。
- VSCodeのようなデスクトップアプリとそのプラグイン
- 開発ツールと制御用スクリプト
- バックエンドサービス
- 色々なツール類
VSCodeにはかなりお世話になっている。初期バージョンの頃はあんまり使えないという認識だったのだが、その後の進化は凄まじいものがあった。Node.jsを使えばそんなデスクトップアプリから、ちょっとしたコマンドまで色々なものが開発可能だ。もちろんWebアプリを作るときのバックエンドのプログラムを作ることも出来る。そして、そういったプログラムを作るときの開発環境も一通りNode.jsで作られている。既にNode.jsからは逃げられない世界が構築されているのだ。
Node.jsで何に使うのと聞かれたら、「作れるものが多すぎて、一概には答えられない」という、質問した人間が不満にしか思わないような回答になってしまうのである。
3.異世界転移のJavaScriptと自らを縛るTypeScript
JavaScriptはクセの強い言語だ。書きたい処理を書くのは簡単なのだが、実は仕様が複雑で、なんだかよく分からないけれど動いているから大丈夫なのだろうというプログラムを書いてしまいがちである。コールバックされたときに今持っているthisが何のインスタンスを示すのか、外側のブロックから拾ってきた変数のデータがいつのものなのか、気を抜いてうっかりしていると命を取られかねない。
受け取った変数のパラメータの取り方は本当に正しいのか、オブジェクトの中身がどうなっているのか、うろ覚えのプロパティ名前が本当に合っているのか、実は一瞬たりとも気を休められない。しかし本当に恐ろしいのは、実は間違っているのに何事も無かったかのように動くことにある。好き勝手に色々書いていたら、いつの間にかそこが異世界と化しているのだ。
この危険を回避するにはJavaScript単体の使用をやめ、TypeScriptで自らを拘束する以外に方法が無い。自らの意思で手かせを付け、足に鉄球と鎖を巻き付けるのだ。身動きがとれない苦しみと引き換えに、突然の異世界転移は防ぐことが出来る。異世界で無双するのは「なろう」だけで十分である。
4.PHPからNode.jsへの移植作業とその理由
以前はバックエンドをPHPで作っていたのだが、それをNode.jsに移植することにした。理由は単純で、現行のほとんどの処理をTypeScript化したかったからだ。TypeScriptならバックエンドとフロントエンドを同じ言語で書くことが出来る。それによってデータ構造の記述が両方で使い回せるのだ。これは非常に大きなアドバンテージである。二度手間を防げる上に、移植に伴うミスも発生しなくなる。これでデータのやりとりがぐっと楽になるのだ。
ただしPHPからNode.jsへの移行には重大な注意点がある。速度はPHPの方が圧倒的に速いことだ。初期化処理とか色々込みのPHPプログラムが、準備万端で待ち受けしているNode.jsのプログラムと互角以上にやり合うのだ。色々と実験を繰り返しみたが、PHP7系統の速度がおかしいぐらいに速い。
ということでNode.jsでプログラムを組む場合は、速度的な優位を期待してはいけない。細かい処理でPHPと互角、重い処理ほどPHPの方が優位性を増していく。ただし大量のアクセスをさばく際のメモリ消費量に関してはNode.jsの方が優れているので、貧弱なリソース下で動かすなら考慮に入れるべきだろう。
5.Node.jsの特徴
向いてない作業
Node.jsの特徴は、細かい処理を大量に捌くことだ。たとえば受付のオペレータのように、用件を聞いたら対象の部署へ内線を回すという作業などが該当する。間違っても重い荷物を持たせてはいけない。Node.jsは荷物を持った瞬間に腰痛を発症し、手痛い損害賠償を請求されることになるだろう。
重い処理とはなんなのか。画像加工とか機械学習とか動画編集とかはもちろんこれに該当する。そういうWebサービスを作るなら、別の言語で作ったプロセスにいったん投げた方が幸せになれる。
そしてもっと一般的に行われている中でやってはいけない仕事、それはDOMを組み合わせてHTMLデータを作成する作業だ。ぶっちゃけこれをやらせるなら、PHPとかに処理を任せた方がよい。その方がよっぽど高速だ。
HTMLデータを生成する作業を主体とするのなら、はっきりいってNode.jsという選択は愚策といってよい。踵を返して他の言語の門を叩いて欲しい。Node.jsで開発しても、面倒なだけでちっとも作業は効率化しない。
向いてる作業
Node.jsに向いている作業は最初に書いた通り、受付オペレータである。Webシステムならば、クライアントからの要求を聞き、それをDBに投げ、結果が返って来たらクライアントにデータを送り返すのだ。できるだけ内容に関知しないことが理想だ。しかしこれだけは最低限処理しないといけないというのがある。クライアントが誰なのか、問い合わせが正当なものなのかの確認だ。つまり向いている作業とは、WebAPIを構築する部分である。
ではHTMLは誰が作るのという疑問を抱くかもしれない。初期ページ以外はフロントエンド側で動的に生成すれば良いのだ。バックエンド側は生成に必要なデータを返してやるだけで良い。場合によってはサーバサイドレンダリングが必要なこともあるかもしれない。しかしそれを主体とするシステムに導入するのは考え直した方が良いだろう。
まとめ
- 軽量の処理ならNode.js
- Webサービスを作る上で重い処理ほどPHPの方が速くなるし、さらに重い処理はネイティブ言語系に投げた方が良い
- 大量アクセス時の省メモリの動作はNode.jsが有利
- 金をかけても問題なく、GB単位でメモリが用意できる環境なら、省メモリがあまりアドバンテージにならない
- 本気の同時一万アクセスとかは、普通に組んでたら無理なので夢は見ないこと
6.非同期地獄と入門と門前
Node.jsはシングルスレッドかつ非同期を前提に動作する。非同期は必要なデータが返ってくるまでラグのある処理をタスクプールに積んでいく。ファイルの入出力からDBアクセスまで、その場で欲しいデータをことごとくその場でもらうことが出来ない。データ受け取り後に必要となる処理を切り分けて、ひたすらプールにため込んでいくのだ。これが非同期地獄というやつだ。ただしこの非同期地獄はPromise/async/awaitによって、一応は抜け出すことが出来る。ただし非同期処理にPromiseを返してこないライブラリを扱う場合は、そのまま使うかPromise化するかという面倒な作業が待っている。
この非同期処理に慣れることや、自分が必要とするライブラリのPromise化が終わったら、ようやく開発の門の前に立った状態となる。そう、門前に立っただけである。つまり、まだ入門すらしていないのだ。
ちなみにシングルスレッドだと、複数CPUがあっても、そのリソースを活用できないという認識はしなくて大丈夫だ。プロセスを増やせばリソースは使い切れるし、それを簡単に行う仕組みも用意されている。どのみちスクリプト系の言語はマルチスレッド対応言語でも、変数などの排他制御の問題で性能が頭打ちになる。そうなると結局マルチプロセスしか選択肢が残らない。マルチスレッドで性能を追求したければ、ネイティブ系の言語か、Javaを使った方が幸せになれるだろう。
まとめ
- 非同期処理は、使用するライブラリを全てPromise化してからが始まり
- とにかく慣れるまでが辛い
- シングルスレッドでもマルチプロセスにすればCPU資源を生かすことは出来る
- 非同期処理の同期をとらずに気軽に大量のループで回すと不幸が訪れる
- ガチで性能を追求するなら別の言語へ
7.TypeScriptと流星
非同期処理による問題も解決し、いよいよ入門を果たしても、所詮は門を通り抜けたに過ぎない。そこからTypeScriptという地獄が始まる。フロントエンドとバッグエンドを同じ言語で書けるという利点を生かすため、以前に別言語で作った資産を移植する作業をしなければならない。つまり、以前作った資産が多い人間ほど、重い荷物を背負うのだ。
私の場合、ブラウザ上でウインドウシステムを実現するというフロントエンドフレームワークという資産があった。これを移植しなければならないのだ。荷物があまりに重すぎたので、単純移植を諦め、ほとんどの部分を作り直した。
フロントエンドで書いていたJavaScriptのTypeScriptへの移植は、同じ系統の言語だからすぐに出来るだろうとか安易に考えてはいけない。コンパイルした瞬間、流星のごときエラーメッセージによって、自分の甘さをとことん教えられるのだ。ここで必要なのは、エラーの数に心を折られない精神力だ。
こんなに型でカタカタしなくてもいいだろうにと思って、一つ一つ修正していくと、実は馬鹿をやっていた記述をいくつも発見することになる。そう、ここでたまたま動いていたコードを見つけることになるのだ。さらに段階的にstrictを有効にして、チェックを厳しくしていく必要がある。最終的にeslintを導入してanyすら禁止すれば、ようやく入門を完了した状態となる。anyが一個でも残っていたら、入門から脱したとは言えない。
PHPからTypeScriptの移植は文法が似ているおかげもあって、非同期への対処が終わっていれば、意外にあっさり出来る。JavaScriptで食らったペガ○ス流星拳に比べれば衝撃の度合いは低い。
まとめ
- JavaScriptから移行するのは、それなりの覚悟が必要
- TypeScriptの型の仕様を本気で突き詰めると、実はシャレにならないほど複雑
- TypeScriptの言語仕様はこうしている間にも増え続け、気がつくと背後に知らないキーワードが立っている
- anyを自分のソースコードから完全に除去しないかぎり、素のJavaScriptの呪縛からは抜け出せない
- エラー流星拳に対して、身を守るためにクロスを纏うことは出来ないが苦労はするだろう
というかクロスって肝心な場所を守ってない気がする8.必要となる知識
今回の開発で必要となった知識をざっと挙げてみたいと思う。
- HTML/CSS
- JavaScriptの文法と特性
- ブラウザでJavaScriptを動かすためのDOMを操作や、イベント
- Ajaxや人を殺さない方のJSON
- TypeScriptの文法と特性
- Node.jsの基本的な使い方とランタイムライブラリ
- WebPackなどの開発ツールやプラグイン、必要なpolyfill
- npmで呼び出す、大海の中に投げ出された中から掴み取るモジュール
- DBとSQLとそれを操作するモジュール
なんだかんだでWebPackが鬼門だ。情報はたくさんあるのだが、内容が新旧入り交じり、プラグインも混沌としている。自分が必要としているものがなんなのか、最適解を見つけるまで試行錯誤することになるだろう。この辺りの話もこの後の記事でしていきたい。
9.次回の予定
次回はバックエンドとフロントエンドで導入した開発手法の話になる予定