- 投稿日:2019-07-01T23:54:53+09:00
【Python】2次元配列を二番目の要素に注目して降順にソートする
はじめに
自分が忘れないように書き留めたものです。
n番目の要素に着目してソートするのは知らない人は苦労するかも?と思って記事にしてみました。
ついでにsortedにおける降順ソートのやり方も紹介してます。コード
li = [[1,4,3],[2,3,4],[3,4,5],[4,5,6],[2,3,4],[1,5,3],[2,3,4],[5,6,7]] li = sorted(li, reverse=True, key=lambda x: x[1]) #[1]に注目してソート print(li)keyにlambdaを使って関数を渡しているところがポイントです。key関数はソートに利用される何かしらを返す必要があります。
言い換えれば、key関数が示すのはリストの各要素に対して行う前処理です。
上記の例でいえば、[1,4,3]という0番目の要素をkey関数に渡し、仮引数xで受け取ります。その後、x[1]すなわち二番目の要素([1,4,3]の内の4)を返す処理を行います。この返ってきた値をソートの基準として用います。
これを全ての要素について行うことで、ソートする基準として二番目の要素を使うことができるようになるわけです。
また、reverse = Trueとすることで降順ソートも実現しています。実行結果
[[5, 6, 7], [4, 5, 6], [1, 5, 3], [1, 4, 3], [3, 4, 5], [2, 3, 4], [2, 3, 4], [2, 3, 4]]結論
結構簡単です。
他にもkey関数でやれることは色々あるので知りたい方はこちらの公式ドキュメントをご覧ください。
凄くわかりやすいと思います。
- 投稿日:2019-07-01T23:40:00+09:00
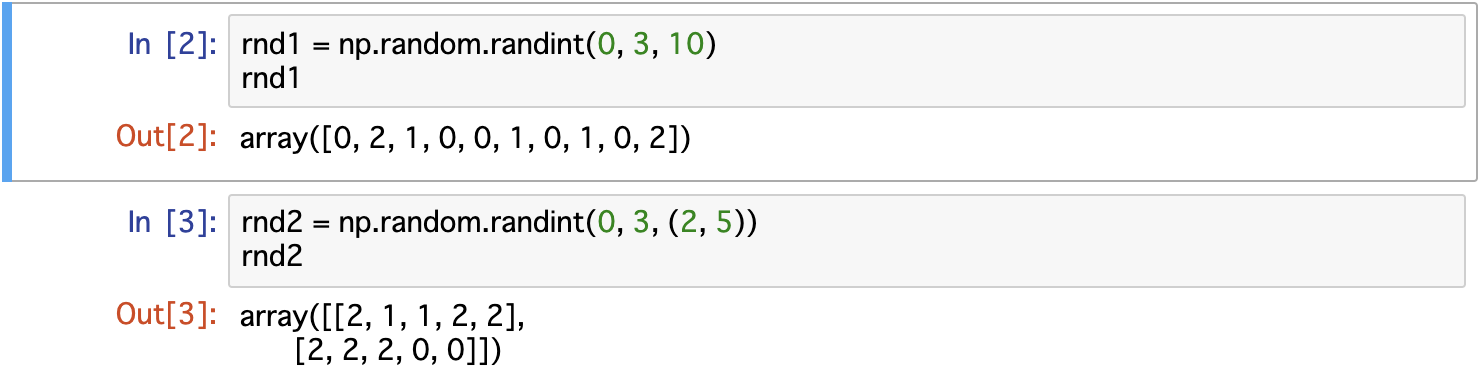
NumPyで乱数を扱う
乱数を扱う
乱数と一言で言うけども、色々な種類の乱数があるので、いくつかNumPyを使って作ってみる
乱数生成だけでなくランダムチョイス等も見ていく
つまりnumpy.randomモジュールについて一様乱数
特定の範囲の実数が均等な確率で発生する、まさに一様に発生する乱数
範囲の指定をしないものはデフォルトで0以上1未満で生成される1次元の一様乱数
numpy.random.rand(要素数)で作れる
random.randとなるのが若干ややこしいな2次元の一様乱数
もはやパターンかなと思いきや、タプルで指定ではなく、第1、2引数だ
範囲指定の一様乱数
numpy.random.uniformで作れる
uniform(3, 5, 10)で3以上5未満で10個を表す2次元も同様に
この場合はお決まりのタプルで渡す必要があるのか、注意整数乱数
名前がすべてだが、特定の範囲の整数が同じ確率で発生する乱数
一様乱数と同様の部分は端折る整数乱数
numpy.random.randintで作れる
引数については一様乱数と同様
ランダムなリスト操作
ランダムに洗濯
洗濯じゃない選択(洗濯はランダムにしない)
choiceを使う
指定回数選択
numpy.random.choice(targets, 4)でtargetsリストから4つ選択(回数は問わない)1度だけ選択
1度だけ選択される(リスト内で重複があれば当然重複もする)
replace=Falseで1度しか出現しなくなるランダムに並び替え
長くないリストであれば、 choice(targets, 3, replace=False) で1度だけ選択するより
この並び替えを使うと良い
長いリストの場合はchoiceする方が効率は良い
並び替えた新しいリストを生成
permutationを使う
並び替えてもtargetsは変更されない
元のリストを並び替え
shuffleを使う(うん、わかりやすい名前)
元のリストを並び替える つまり破壊的メソッド
戻り値はないので targets で確認しているその他様々な分布の乱数
標準正規乱数
numpy.random.randnで作れる
デフォルトだと、平均が0 標準偏差1の正規分布になる
標準偏差については詳しくはWebでだが、散らばりの度合いを示したもの正規乱数
numpy.random.normalで作れる
平均が50 標準偏差10 の乱数10個
つまり正規分布? 本格的に統計学(?)、分布とかの勉強しないと理解に苦しむなぁ。。。
多次元も
ベータ乱数
numpy.random.betaで作れる
- ベータ分布
- 軽く読んだけどマジムリ...
- 軽くじゃダメそうなので、ちゃんとそれ用に時間を取って理解した方が良さげ
α = 1 β = 2 のベータ乱数10個 ?二項乱数
numpy.random.binomialで作れる
- 二項分布 (これはまだわかる!)
- 成功か失敗の結果を持つ試行を
n回繰り返した時の分布- 成功率
pは一定とする
この場合は、 成功率 p = 0.4 の試行を10回やった時の成功回数、を 10個ポアソン乱数
numpy.random.poisson
調べてみたけどよくわからない系の分布でした・・・
単位時間あたり平均でλ回発生する事象の発生回数の分布
どういう時に使われるかだけあげておくと、
- 交番の事故の件数
- 30分に平均2回電話がかかって来るコールセンターで、1時間に6回電話がかかって来る確率
だそうです
λ = 0.8 のポアソン乱数10個
↑これ何!!!わからなすぎるので一旦保留だな
多次元正規乱数
numpy.random.multivariate_normalで作れる
正規乱数並みの難易度かと思いきや...
平均が[0, 0] 共分散行列が [[1, 0.5], [0.5, 1]] の多次元正規乱数もはや調べるのも無駄な抵抗なので、いつかちゃんとやる
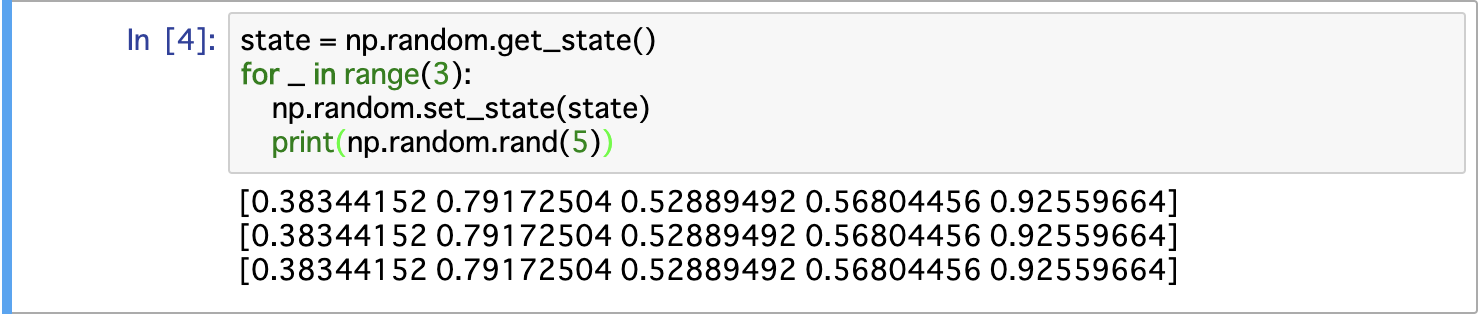
乱数の再現性
numpyなどで生成される乱数は全て擬似乱数と言って、必ずシードを元に生成される
シードは実行環境の初回実行時の時刻等で初期化される
なので、明示的にシードの指定をしなくても乱数が発生させられる
(個人的なイメージ: ビンゴカードのようなもの? 初回実行時に新しいビンゴカードが配られる)
何度実行しても同じ乱数が出ることを再現性があるという
- 再現性のある乱数を発生させる方法
- 最初にシードを指定 (同じビンゴカードを使う)
- 状態を取得して、再現したいときに状態を設定 (状況に応じてビンゴカードの数字を変えちゃう?)
シード指定
seed(0)で固定しているので、何度実行しても同じになる状態設定
get_state/set_stateで取得、設定する
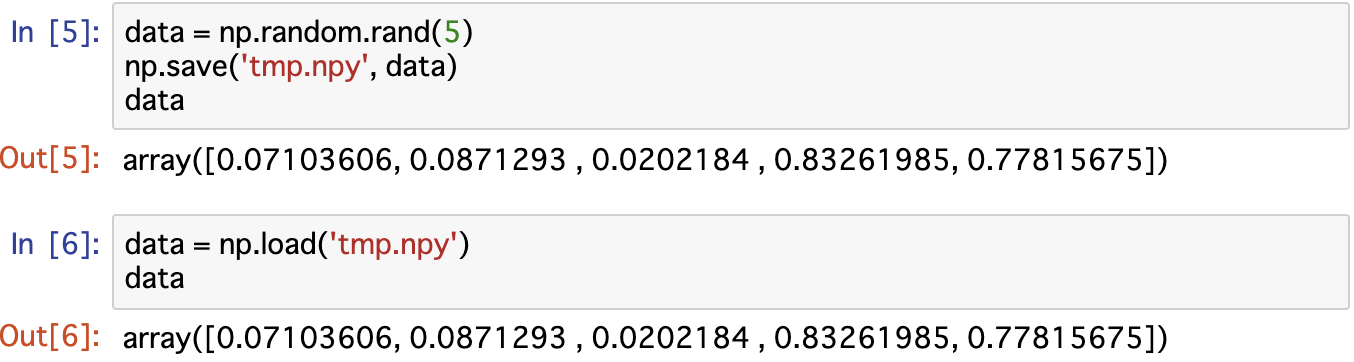
3行は常に同じだが、実行するたびに値は変わるファイルに保存
ファイルに保存して、それを読み込むことでも、再現性があると言える感想
様々な乱数を見てきたけど、分布、統計という前提条件の壁がかなり高いことがわかってしまった
実践とまで言わずとも、自分で何かやってみようという段階になるまでには
まだまだ長い道のりになりそうだー
















- 投稿日:2019-07-01T23:39:31+09:00
Pythonのcsv出力
import pandas as pd
file = []for i in range(1,10,1):
file.append(i)file = pd.DataFrame(file)
file.to_csv('test.csv')
- 投稿日:2019-07-01T23:25:02+09:00
SocketCAN対応のCANalyzeをWindowsで使う
概要
- 本記事の想定対象者
- 車載ネットワークであるCAN通信をWindowsから安価なデバイス(CANalyze等)かつPythonで行いたい方
- libusb/WinUSBドライバー経由でデバイスをPythonから制御してみたい方(PyUSB使用)
- Linux上でのUSB通信の解析方法の例を知りたい方(usbmon使用)
- CAN通信をPythonから行う場合、LinuxでSocketCANやSerial can(slcan)対応のデバイス(PCAN,CANalyze,USBCAN,...)を使用すると安価で便利
- しかし、WindowsにはSocketCANという概念が無いため、slcan相当のデバイスを使用するしかなかった(他にも下記方法があるようだが、それ以外は単に知らない)
- 他の方法としては、CANALドライバー(usb2can.dll(32bit))を使用してusb 8dev対応のPCANなどに接続する方法があるが、手元のCANalyzeではデバイスが見つからないとエラーが出てうまくいかなかった
- そこで、linuxのusb 8devドライバー対応のCAN通信デバイス(CANalyze)のファームウェアソースコードを解析し、Windowsでlibusb/WinUSBドライバー経由でSocketCAN対応のデバイスにも接続できるようにした
- CANalyzeに対するlibusb(32bit)/WinUSB(64bit)ドライバーの適用にはzadigを使用した
- Pythonを使用しているが、C言語等でもlibusb経由で同様のコマンドを送受信すればCAN通信が行えるはず
デバイス準備
- usb 8dev対応デバイス(ここではCANalyze)を調達する
USB通信の解析
- まずLinux上で利用した際のUSB通信を解析する。以下の手順で送受信を行う ```bash # apt-get install can-utils # ip link show can0が存在することを確認 # ip link set can0 type can bitrate 500000 # ip link set can0 up # cansend can0 123#1122334455667788 # candump can0
Ctrl^C
ip link set can0 down
- usbmonドライバーのインストールとデバイスの確認 ```bash # modprobe usbmon # cat /sys/kernel/debug/usb/devices T: Bus=02 Lev=02 Prnt=03 Port=00 Cnt=01 Dev#= 5 Spd=12 MxCh= 0 D: Ver= 2.00 Cls=00(>ifc ) Sub=00 Prot=00 MxPS=64 #Cfgs= 1 P: Vendor=0483 ProdID=1234 Rev= 1.00 S: Manufacturer=STMicroelectronics S: Product=USB2CAN converter S: SerialNumber=205236****** C:* #Ifs= 1 Cfg#= 1 Atr=00 MxPwr=100mA I:* If#= 0 Alt= 0 #EPs= 4 Cls=ff(vend.) Sub=ff Prot=ff Driver=usb_8dev E: Ad=81(I) Atr=02(Bulk) MxPS= 64 Ivl=0ms E: Ad=02(O) Atr=02(Bulk) MxPS= 64 Ivl=0ms E: Ad=83(I) Atr=02(Bulk) MxPS= 64 Ivl=0ms E: Ad=04(O) Atr=02(Bulk) MxPS= 64 Ivl=0ms USB2CAN converter(CANalyze)のUSB論理構成 └ Interface:1 (usb_8dev) ├ Endopint:1 Bulk Input (USB調査よりData入力用) ├ Endopint:2 Bulk Output (USB調査よりData出力用) ├ Endopint:3 Bulk Input (USB調査よりCommand入力用) └ Endopint:4 Bulk Output (USB調査よりCommand出力用)
- ip link set can0~, ip link set can0 upを実行した際のUSB通信の解析
# ip link set can0 type can bitrate 500000 # ip link set can0 up 別ターミナル(事前に起動しておく) # cat /sys/kernel/debug/usb/usbmon/2u ※cat /sys/kernel/debug/usb/devicesの "T: Bus=02" より2uを使用 ffff880232886d80 3205323523 S Bo:2:007:4 -115 16 = 11000209 000d0201 00040000 00080022 ※Endpoint:4でのbulk送信 ffff880232886d80 3205450861 C Bi:2:007:3 0 16 = 11000200 00000100 01000000 00000022 ※Endpoint:3でのbulk送信 ※Bo/Biの意味はUSBのBulk通信のIn/Outという意味 Ci Co Control input and output Zi Zo Isochronous input and output Ii Io Interrupt input and output Bi Bo Bulk input and output ※ 送信データの解析 "11 00 02 09 00 0d020100040000000800 22" /* Format of both received and transmitted USB command messages. */ typedef struct __packed usb_8dev_cmd_msg { uint8_t start; // start of message byte uint8_t channel; // unknown - always 0 uint8_t command; // command to execute uint8_t opt1; // optional parameter / return value uint8_t opt2; // optional parameter 2 uint8_t data[10]; // optional parameter and data uint8_t end; // end of message byte } Msg_CmdTypeDef; // https://github.com/kkuchera/canalyze-fw/blob/master/src/usbd_8dev_if.c
- ip link set can0 downを実行した際のUSB通信の解析
# ip link can0 down 別ターミナル(事前に起動しておく) # cat /sys/kernel/debug/usb/usbmon/2u ffff880232886cc0 3256831570 S Bo:2:007:4 -115 16 = 11000300 00000000 00000000 00000022 ffff880232886cc0 3256843005 C Bi:2:007:3 0 16 = 11000300 00000100 01000000 00000022
- cansendのUSB通信取得
# cansend can0 555#1122334455667788 別ターミナル(事前に起動しておく) # cat /sys/kernel/debug/usb/usbmon/2u ffff880232887980 3421490964 S Bo:2:007:2 -115 16 = 55000000 05550811 22334455 667788aa ※Endpoint:2でのbulk送信 # cansend can0 777#8888888888888888 別ターミナル(事前に起動しておく) # cat /sys/kernel/debug/usb/usbmon/2u ffff8802328866c0 3619076135 S Bo:2:007:2 -115 16 = 55000000 07770888 88888888 888888aa
- cansendのUSB通信を解析
55 00 00000555 08 1122334455667788 aa 55 00 00000777 08 8888888888888888 aa ^^USB_8DEV_DATA_START=0x55 ^^^^^^^^ID(標準11bit, 拡張29bit) ^^DLC(1byte) ^^^^^^^^^^^^^^^^Data(8bye 0x00パディング) ^^USB_8DEV_DATA_END=0xAA /* Format of received USB data messages. */ typedef struct __packed usb_8dev_rx_msg { uint8_t start; // start of message byte uint8_t flags; // RTR and EXT_ID flag uint32_t id; // upper 3 bits not used uint8_t dlc; // data length code 0-8 bytes uint8_t data[8]; // 64-bit data uint8_t end; // end of message byte } Msg_RxTypeDef;
- candumpのUSB通信取得
# candump can0 別ターミナル(事前に起動しておく) # cat /sys/kernel/debug/usb/usbmon/2u ffff880232886cc0 3667542562 C Bi:2:007:1 0 21 = 55000100 00055508 11223344 55667788 e65e0700 aa ※Endpoint:1でのbulk受信 ※ID 0x555, 0x1122334455667788を受信 ffff8800b8d76c00 220316803 C Bi:2:008:1 0 21 = 55000100 00077708 88888888 88888888 b0990000 aa ※Endpoint:1でのbulk受信 ※ID 0x777, 0x8888888888888888を受信
- candumpのUSB通信を解析
55 00 01 00000555 08 1122334455667788 e65e0700 aa 55 00 01 00000777 08 8888888888888888 b0990000 aa ^^USB_8DEV_DATA_START=0x55 ^^type ^^flags ^^^^^^^^ID(標準11bit, 拡張29bit) ^^DLC(1byte) ^^^^^^^^^^^^^^^^Data(8bye 0x00パディング) ^^^^^^^^timestamp ^^USB_8DEV_DATA_END=0xAA /* Format of transmitted USB data messages. */ typedef struct __packed usb_8dev_tx_msg { uint8_t start; // start of message byte uint8_t type; // frame type uint8_t flags; // RTR and EXT_ID flag uint32_t id; // upper 3 bits not used uint8_t dlc; // data length code 0-8 bytes uint8_t data[8]; // 64-bit data uint32_t timestamp; // 32-bit timestamp uint8_t end; // end of message byte } Msg_TxTypeDef;Python on windowsでの制御
- Windowsで行っているがlibusb経由であればLinuxでも使えるはず。但しLinuxの場合SocketCANの方が対応ツールも多く便利
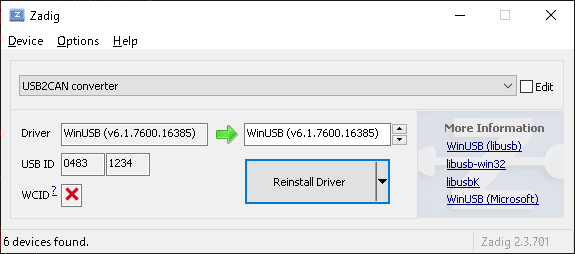
ドライバーのインストール
- zadigを使用して、Options > List All Devicesを選択 > リストボックスから"USB2CAN converter"(=CANalyze)を選択
- Pythonの32/64bitに合わせてドライバーをインストールする。32bitの場合はlibusb-win32を、64bitの場合はWinUSB(例、下図)を選択
pythonでの通信
""" # pip install can # pip install pyusb """ import binascii import usb.core import usb.util USB_8DEV_CMD_START = 0x11 USB_8DEV_CMD_END = 0x22 USB_8DEV_DATA_START = 0x55 USB_8DEV_DATA_END = 0xAA USB_8DEV_OPEN = 0x2 USB_8DEV_CLOSE = 0x3 USB_8DEV_GET_SOFTW_HARDW_VER= 0xC def init(): dev = usb.core.find(idVendor=0x0483, idProduct=0x1234) dev.set_configuration() cfg = dev.get_active_configuration() itfs = cfg[(0,0)] dat_in = usb.util.find_descriptor(itfs, bEndpointAddress=0x81) dat_out = usb.util.find_descriptor(itfs, bEndpointAddress=0x2) cmd_in = usb.util.find_descriptor(itfs, bEndpointAddress=0x83) cmd_out = usb.util.find_descriptor(itfs, bEndpointAddress=0x4) s = [dat_in, dat_out, cmd_in, cmd_out] return s def send_wait_cmd(s, msg): cmd_in, cmd_out = s[2], s[3] if cmd_out.write(msg) != len(msg): print("send error") return cmd_in.read(128) def make_cmd(command, opt1 = 0, opt2 = 0, data = ""): channel = 0 dlc_max = 8 data += "0" * (2*dlc_max - len(data)) msg = "1100%02x%02x%02x%s22" % (command, opt1, opt2, data) return binascii.unhexlify(msg) def version(s): # get firmwate and hardware version msg = make_cmd(USB_8DEV_GET_SOFTW_HARDW_VER, data="00"*10) ret = send_wait_cmd(s, msg) print(ret) def open(s): ctrlmode = 0x08 msg = make_cmd(USB_8DEV_OPEN, opt1=0x09, data="0d02010004000000%02x00" % ctrlmode) ret = send_wait_cmd(s, msg) print(ret) def close(s): msg = make_cmd(USB_8DEV_CLOSE, data="00"*10) ret = send_wait_cmd(s, msg) print(ret) def make_dat(flags, id, data = ""): # flags : RTR and EXT_ID (USB_8DEV_EXTID) flag # id : 11 / 29bit dlc = len(data) if len(data)%2 != 0: data = "0" + data data += "00" * (8-dlc) msg = "55%02x%08x%02x%saa" % (flags, id, dlc, data) return binascii.unhexlify(msg) def send(s, msg_id, data): dat_out = s[1] msg = make_dat(flags = 0, id = msg_id, data = data) if dat_out.write(msg) != len(msg): return False return True def recv(s, timeout = 1000): dat_in = s[0] msg = dat_in.read(64, timeout = timeout) if msg[0] != USB_8DEV_DATA_START or msg[-1] != USB_8DEV_DATA_END or 13 + msg[7] != len(msg): return None frame_type, flags, id, dlc, data, timestamp = msg[1], msg[2], msg[3:7], msg[7], msg[8:-5], msg[-5:-1] id = (((((id[0]<<8) + id[1])<<8) + id[2])<<8) + id[3] data = [i for i in data] timestamp = (((((timestamp[3]<<8) + timestamp[2])<<8) + timestamp[1])<<8) + timestamp[0] return [id, data, timestamp]送受信テスト
s = init() open(s) msg_id = 0x7ff data = "1122334455667788" send(s, msg_id, data) while 1: ret = recv(s) if ret is not None: break msg_id, data, timestamp = ret close(s)

- 投稿日:2019-07-01T22:05:44+09:00
Pythonプロジェクトのパッケージング例
- 投稿日:2019-07-01T21:56:49+09:00
DjangoでサクッとWebサイトを作る Part1
DjangoでサクッとWebページを作ってみました。
初心者向けに超基礎的な部分だけ解説します。セットアップ
既にご存知かと思いますが、DjangoはPythonで開発されています。したがってまずはPythonをインストールする必要があります。
本記事執筆辞典ではPythonは3.7がおすすめです。もしPython2.xがインストール済の場合はアップグレードしましょう。インストールが正しく行われているか確認するには以下のコードを実行してみてください。
$ python3 --version Python 3.6.1Djangoのインストール
projects/requirements.txtファイル中に以下のテキストを追加します。Django~=2.0.6次に、以下のコードを実行してインストールします。
pip install -r requirements.txt以下のようになりましたでしょうか。
(myvenv) ~$ pip install -r requirements.txt Collecting Django~=2.0.6 (from -r requirements.txt (line 1)) Downloading Django-2.0.6-py3-none-any.whl (7.1MB) Installing collected packages: Django Successfully installed Django-2.0.6インストールはこれで完了です。
次回は具体的な開発の解説に入っていこうと思います。最終的にはこんな感じになります
LeadingTech更新はゆっくりになりますが頑張りますので気長にお待ちください!
- 投稿日:2019-07-01T21:09:36+09:00
FoxDotによるLiveCoding方法のまとめ
LiveCodingをご存じでしょうか?
∀RroWsの次のライヴの一部は音楽と映像Wでライヴコーディングしようと言うことになったので、どっちもいけるようにしておかないと。音楽はFoxDotものにしないと。映像はTouchDesignerでやるかな。 pic.twitter.com/2MqHMXtSEj
— Tomoya@∀RroWs (@snufkinliberty) 2019年2月25日これは始めたばかりの頃のもので拙いですが、要はプログラミングでリアルタイムに音楽や映像を作るパフォーマンスをすることを言います。
音楽の場合、PythonによるLiveCoding環境としてFoxDotがあります。
他にもTidalCyclesなどありますが、なじみのPythonでできるのがいいなとFoxDotを始めました。FoxDotのサイトのTopPageのYouTubeのパフォーマンスがかっこいいです。
https://foxdot.org/僕は∀RroWsという電子音楽とデジタルアートのユニットをやっており、ぜひ次回のライヴでLiveCodingに挑戦したいということで、学んだことを随時、本記事にまとめていきたいと思います。
インストール方法
インストール方法は下記の記事がそのまま参考になります。
https://qiita.com/Hulc_0418/items/ba3e94633e465f7201d0本家サイトのインストールガイドはこちら
https://foxdot.org/installation/FoxDotの立ち上げ方法
Windowsの場合ですが、
①SuperColliderを立ち上げて、左の入力欄にFoxDot.startを入力して、Ctrl+Enter
②コマンドプロンプトを立ち上げて、python -m FoxDotを入力、Enterすると開始できる。
音の再生と停止
再生:例えばp1 >> pluck()を入力し、Ctrl+Enterで音が鳴る。
この時、行が連続している場合、これらがまとめて実行される。
停止:p1.stop()でp1が停止する。
全停止 Clock.clear()曲の設定
テンポ:Clock.bpm = 175
スケール(デフォルト:major):Scale.default = Scale.minorなどと指定
オクターブ:p1.oct = 5とp1など個別に音域を数値で指定演奏の基本
p1 >> pluck():引数なしでは4つうち
p1 >> pluck([0,2,4], dur=[1,1/2,1/2], amp=[1,3/4,3/4],pan=[-1,0,1])
音程:[ ]のみで指定
例) ドレミファソラシド p1 >> pluck([0,1,2,3,4,5,6,7])
dur:音の長さ 1が1拍(4分音符)、1/2が1/2拍(8分音符)
amp:音量
pan:LRチャンネル-1でL:100%, 1でR:100%,0(なし)でCenter
音色:print(SynthDefs)で確認できる。
plunkの部分を例えば以下のように変更すれば良い。
Lead系
star, soft, quin, saw, varsaw, lazerなど
Pad系
charm, prophet, pads, ambi, space, keys, klank, feel, glassなど
ベース系
bass, jbass, sawbass, dbass, dirt, dabなどドラム
d1 >> play("")
""に以下を記述
・休符は半角スペース
・音色は print(Samples)で確認できる
以下音色キック
'V': Hard kick
'v': Soft kick
'X': Heavy kick
'x': Bass drum
'A': Gameboy kick drum
スネア
'O': Heavy snare
'o': Snare drum
'I': Rock snare
'i': Jungle snare
'D': Dirty snare
'u': Soft snare
't': Rimshot
ハット系
'-': Hi hat closed
'=': Hi hat open
':': Hi-hats
'a': Gameboy hihat
'~': Ride cymbal
'#': Crash
'R': Metallic
'r': Metal
タム
'm': 808 toms
'M': Acoustic toms
クラップ
'*': Clap
'H': Clap
パーカス
'!': Yeah!
'$': Beatbox
'%': Noise bursts
'&': Chime
'+': Clicks
'T': Cowbell
'e': Electronic Cowbell
'E': Ringing percussion
'd': Woodblock
's': Shaker
'k': Wood shaker
ヒット
'K': Percussive hits
'L': Noisy percussive hits
'w': Dub hits
'y': Percussive hits
その他
'1': Vocals (One)
'2': Vocals (Two)
'3': Vocals (Three)
'4': Vocals (Four)
'F': Trumpet stabs
'G': Ambient stabs
'J': Ambient stabs
'q': Ambient stabs
'Q': Electronic stabs
'Z': Loud stabs
'n': Noise
'l': Robot noise
'@': Gameboy noise
'/': Reverse sounds
'B': Short saw
'C': Choral
'N': Gameboy SFX
'P': Tabla long
'S': Tamborine
'U': Misc. Fx
'W': Distorted
'Y': High buzz
'\': Lazer
'^': 'Donk'
'b': Noisy beep
'c': Voice/string
'f': Pops
'g': Ominous
'h': Finger snaps
'j': Whines
'p': Tabla
'z': Scratch
'|': Hangdrum随時、追加更新します。
- 投稿日:2019-07-01T21:09:36+09:00
FoxDotによるLiveCoding方法1
LiveCodingをご存じでしょうか?
∀RroWsの次のライヴの一部は音楽と映像Wでライヴコーディングしようと言うことになったので、どっちもいけるようにしておかないと。音楽はFoxDotものにしないと。映像はTouchDesignerでやるかな。 pic.twitter.com/2MqHMXtSEj
— Tomoya@∀RroWs (@snufkinliberty) 2019年2月25日これは始めたばかりの頃のもので拙いですが、要はプログラミングでリアルタイムに音楽や映像を作るパフォーマンスをすることを言います。
音楽の場合、PythonによるLiveCoding環境としてFoxDotがあります。
他にもTidalCyclesなどありますが、なじみのPythonでできるのがいいなとFoxDotを始めました。FoxDotのサイトのTopPageのYouTubeのパフォーマンスがかっこいいです。
https://foxdot.org/僕は∀RroWsという電子音楽とデジタルアートのユニットをやっており、ぜひ次回のライヴでLiveCodingに挑戦したいということで、学んだことを随時、本記事にまとめていきたいと思います。
インストール方法
インストール方法は下記の記事がそのまま参考になります。
https://qiita.com/Hulc_0418/items/ba3e94633e465f7201d0本家サイトのインストールガイドはこちら
https://foxdot.org/installation/FoxDotの立ち上げ方法
Windowsの場合ですが、
①SuperColliderを立ち上げて、左の入力欄にFoxDot.startを入力して、Ctrl+Enter
②コマンドプロンプトを立ち上げて、python -m FoxDotを入力、Enterすると開始できる。
音の再生と停止
再生:例えばp1 >> pluck()を入力し、Ctrl+Enterで音が鳴る。
この時、行が連続している場合、これらがまとめて実行される。
停止:p1.stop()でp1が停止する。
全停止 Clock.clear()曲の設定
テンポ:Clock.bpm = 175
スケール(デフォルト:major):Scale.default = Scale.minorなどと指定
オクターブ:p1.oct = 5とp1など個別に音域を数値で指定演奏の基本1 シンセ(メロディ)
p1 >> pluck():引数なしでは4つうち
p1 >> pluck([0,2,4], dur=[1,1/2,1/2], amp=[1,3/4,3/4], pan=[-1,0,1])
音程:[ ]のみで指定
例) ドレミファソラシド p1 >> pluck([0,1,2,3,4,5,6,7])
dur:音の長さ 1が1拍(4分音符)、1/2が1/2拍(8分音符)
amp:音量
pan:LRチャンネル-1でL:100%, 1でR:100%,0(なし)でCenter
音色:print(SynthDefs)で確認できる。
plunkの部分を例えば以下のように変更すれば良い。
Lead系
star, soft, quin, saw, varsaw, lazerなど
Pad系
charm, prophet, pads, ambi, space, keys, klank, feel, glassなど
ベース系
bass, jbass, sawbass, dbass, dirt, dab など演奏の基本2 ドラム(リズム)
d1 >> play("")
""に以下を記述
・休符は半角スペース
・音色は print(Samples)で確認できる
以下音色キック
'V': Hard kick, 'v': Soft kick, 'X': Heavy kick, 'x': Bass drum,
'A': Gameboy kick drum
スネア
'O': Heavy snare, 'o': Snare drum, 'I': Rock snare, 'i': Jungle snare
'D': Dirty snare, 'u': Soft snare, 't': Rimshot
ハット系
'-': Hi hat closed, '=': Hi hat open, ':': Hi-hats, 'a': Gameboy hihat
'~': Ride cymbal, '#': Crash, 'R': Metallic, 'r': Metal
タム
'm': 808 toms, 'M': Acoustic toms
クラップ
'*': Clap, 'H': Clap など
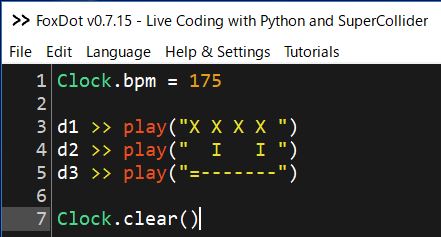
基本の8ビート
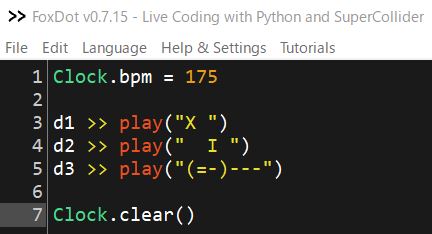
Xがバスドラ、Iがスネア、=がハイハットオープン、-がハイハットクローズド、スペースが休符
まずは、このようにパート毎に書くとDTMなどで打ち込みをやっている人には分かりやすい。
ただし、LiveCodingとしては、これを入力するのに時間がかかるので短く書く必要がある。短くする方法の例:繰り返しは省略する
("")の中は繰り返されるので、Xは拍の頭だけ鳴らすなら"X "と1拍分だけで良い。
Iは2,4拍目なので、" I "で2拍分書けば良い。
"(=-)---"は"=-------"と同じ。つまり、ドラムの場合は()を付けると、1回目は1番目の=がなり、2回目は-が鳴るを繰り返す。続く
- 投稿日:2019-07-01T20:46:25+09:00
【Python】JR西日本の指定路線の1分以上遅延のある電車を調べる
JR西日本の指定路線で1分でも遅延している電車を調べてみる。
JSONのありかは「https://www.train-guide.westjr.co.jp/api/v3/」に
https://www.train-guide.westjr.co.jp/area_kinki.html
から各路線のファイル名+.jsonで大阪環状線の場合、
import json import urllib.request try: url = 'https://www.train-guide.westjr.co.jp/api/v3/osakaloop.json' res = urllib.request.urlopen(url) data = json.loads(res.read().decode('utf-8')) for item in data['trains']: if item['delayMinutes'] > 0: print(item['displayType'], item['dest']['text'],'行き:',item['delayMinutes'],'分遅れ') except urllib.error.HTTPError as e: print('HTTPError: ', e) except json.JSONDecodeError as e: print('JSONDecodeError: ', e)後々したいこと
列車位置情報アプリが10分以上の遅れしか通知してくれないので、cronとかで定期的に実行とかでslackに送りつけるとかしたい
- 投稿日:2019-07-01T20:24:50+09:00
[python+swift] リアルタイムで信号色を認識するiOSアプリを作った
作ったもの
カメラを向けると、信号が青か赤か判定するアプリ
実機テスト風景↓(めちゃ重い)
信号を赤なら赤線、青なら青線、点滅中は黒線で囲う。
ざっくり処理の流れ
判定APIをpythonで自作して、swiftで毎秒画像をpostする感じ。
レスポンスは、信号の色と枠線付きの画像を返す。画像をpostすると、、
aws rekognitionで信号を読み取り、openCVで信号切り取り&色の識別
信号と同じ色の枠線をPILで引く
APIコード
from PIL import Image, ImageDraw import boto3 import cv2 import numpy as np import json import io import base64 from flask import Flask, request, jsonify, make_response, send_file, Response app = Flask(__name__) #信号の色を判定。 def __color_dicision(image): hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV_FULL) h = hsv[:, :, 0] s = hsv[:, :, 1] v = hsv[:, :, 2] mask = np.zeros(h.shape, dtype=np.uint8) mask[((45 < h) & (h < 60)) & (s > 150) & (v > 90)] = 60 mask[((h < 8) | (h > 160)) & (s > 150) & (v > 94)] = 255 color_list = [j for i in mask.tolist() for j in i] if color_list.count(255) > 20: return "red" elif color_list.count(60) > 20: return "blue" else: return "black" #信号に枠線を引く def __draw_border(photo, left_coordinate, top_coordinate, width, height, color_dicision): if color_dicision == "red": fill = (225, 0, 0) if color_dicision == "blue": fill = (100, 225, 100) if color_dicision == "black": fill = (0, 0, 0) draw = ImageDraw.Draw(photo) draw.line((left_coordinate, top_coordinate, left_coordinate + width, top_coordinate), fill=fill, width=8) draw.line((left_coordinate, top_coordinate, left_coordinate, top_coordinate + height), fill=fill, width=8) draw.line((left_coordinate, top_coordinate + height, left_coordinate + width, top_coordinate + height), fill=fill, width=8) draw.line((left_coordinate + width, top_coordinate, left_coordinate + width, top_coordinate + height), fill=fill, width=8) return photo @app.route('/', methods=['GET', 'POST']) def dicision(): if request.files['image']: image = request.files['image'] client = boto3.client('rekognition') #aws rekognitionへpost response = client.detect_labels(Image={'Bytes': image.read()}) #画面に写っている物体の名前と位置が返ってくる for label in response['Labels']: if label['Name'] == "Traffic Light" and label['Confidence'] > 50 and label['Instances'] != []: res = label['Instances'][0]['BoundingBox'] image = Image.open(image) #なぜか上の処理で画像が90度回転するので、直す。 image = image.rotate(270, expand=True) im_size_width, im_size_height = image.size left_coordinate = res["Left"] * im_size_width top_coordinate = res["Top"] * im_size_height width = res["Width"] * im_size_width height = res["Height"] * im_size_height #信号のある箇所をくり抜く im_crop = image.crop( (left_coordinate, top_coordinate, left_coordinate + width, top_coordinate + height)) im_cv = np.asarray(im_crop) color_dicision = __color_dicision(im_cv) drawed_image = __draw_border( image, left_coordinate, top_coordinate, width, height, color_dicision) imgByteArr = io.BytesIO() drawed_image.save(imgByteArr, format='JPEG') imgByteArr = imgByteArr.getvalue() imageStr = base64.b64encode(imgByteArr).decode("utf-8") return jsonify({'result': color_dicision, 'image': imageStr}) print("何もなし") return jsonify({'result': 'no_signal', 'image': ''}) if __name__ == '__main__': app.run(host='0.0.0.0')swift サイドは↓を参考に、Alamofire+codableで実装
https://qiita.com/shirahama_x/items/421d0d343d9629e66794




- 投稿日:2019-07-01T19:52:16+09:00
pandas.DataFrameのMECEな分割で気をつけること
pandas.DataFrameを使ってアルゴリズムを実装する中で、DataFrameをMECEに分割できていないためにバグることが多々あります。
普通のif~else分岐であれば条件はほぼMECEになりますが、DataFrameの分割になると忘れがちな気がしています。(自分だけ?)
そんなとき、DataFrameでも~を使ってelse条件を書くことで、MECE分割されないことによるエラーを防ぐことができます。サンプルとしてKaggleのtitanicデータを使用します。
https://www.kaggle.com/c/titanic/dataimport pandas as pd # データセットの読み込み train = pd.read_csv('../input/train.csv') # 男性かつ20歳以上でDataFrameを分割 train_subset01 = train[ (train['Sex'] == 'male') & (train['Age'] >= 20) ] # not(男性かつ20歳以上)でDataFrameを分割 train_subset02 = train[ ~((train['Sex'] == 'male') & (train['Age'] >= 20)) ] # 分割結果がMECEであることを確認 print(f'total size is :{str(len(train))}') print(f'subset01 size is :{str(len(train_subset01))}') print(f'train_subset02 size is :{str(len(train_subset02))}') print(f'intersection size is :{str(len(set(train_subset01.PassengerId).intersection(set(train_subset02.PassengerId))))}')total size is :891 subset01 size is :364 train_subset02 size is :527 intersection size is :0冗長な表現になりますが、
~を使うことでif~elseを実現できるので、DataFrame分割でミスるリスクを減らせると思います。
- 投稿日:2019-07-01T19:05:34+09:00
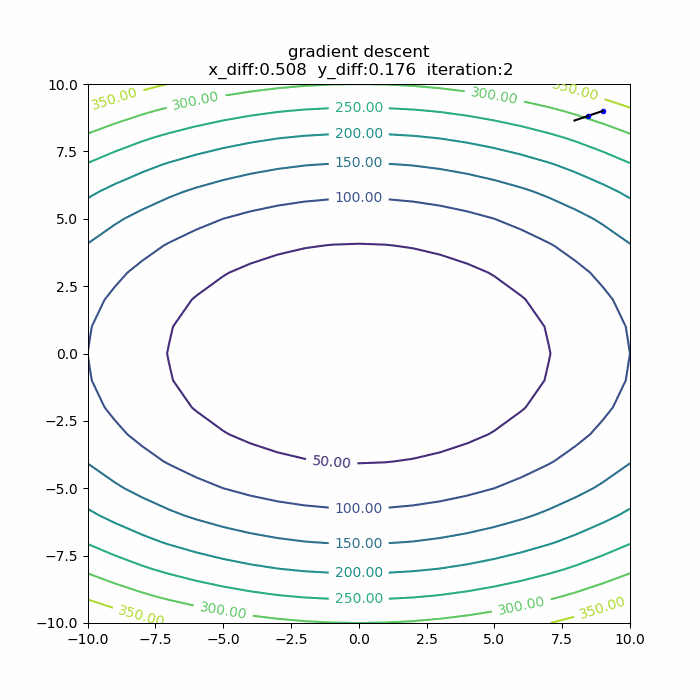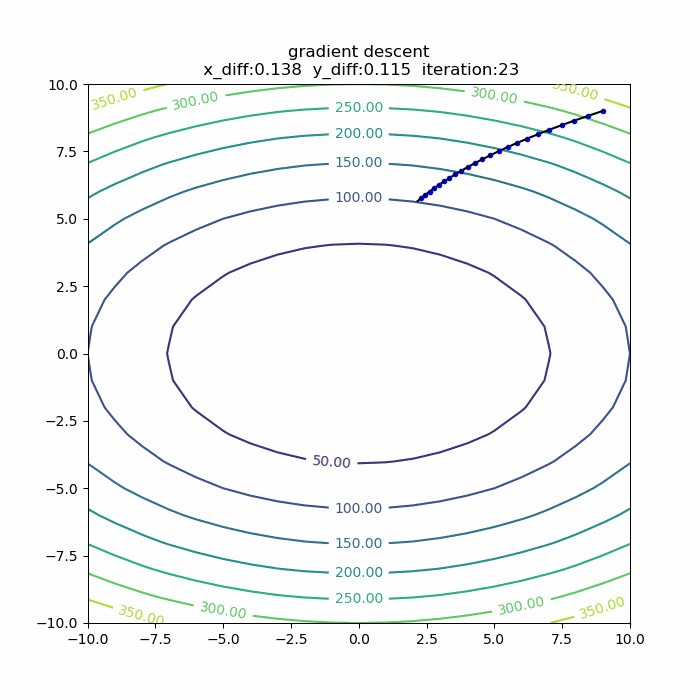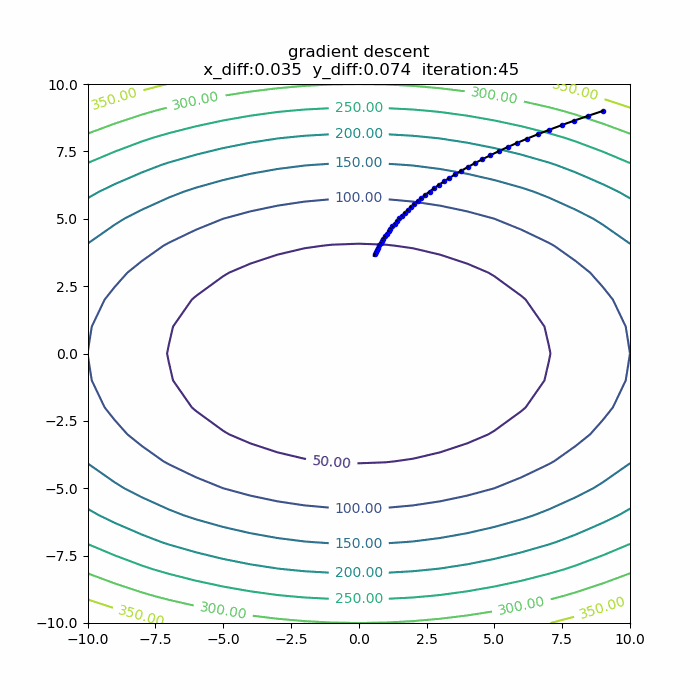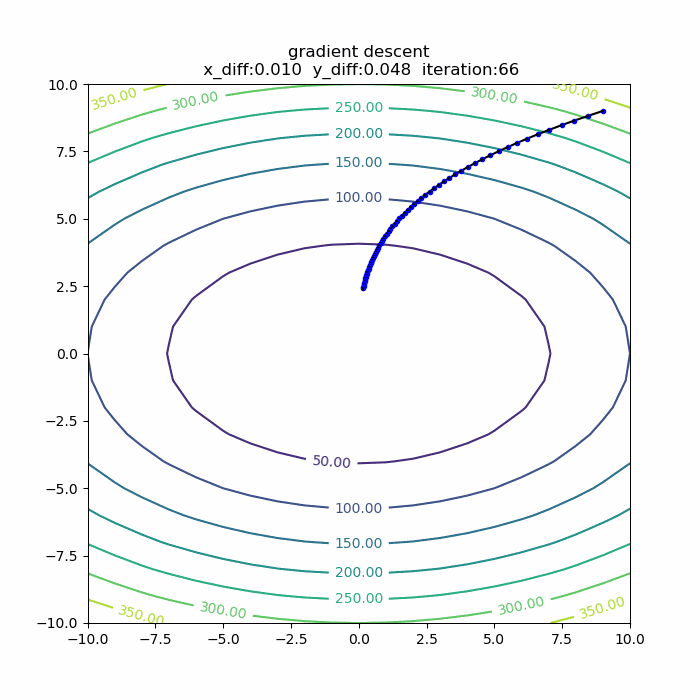
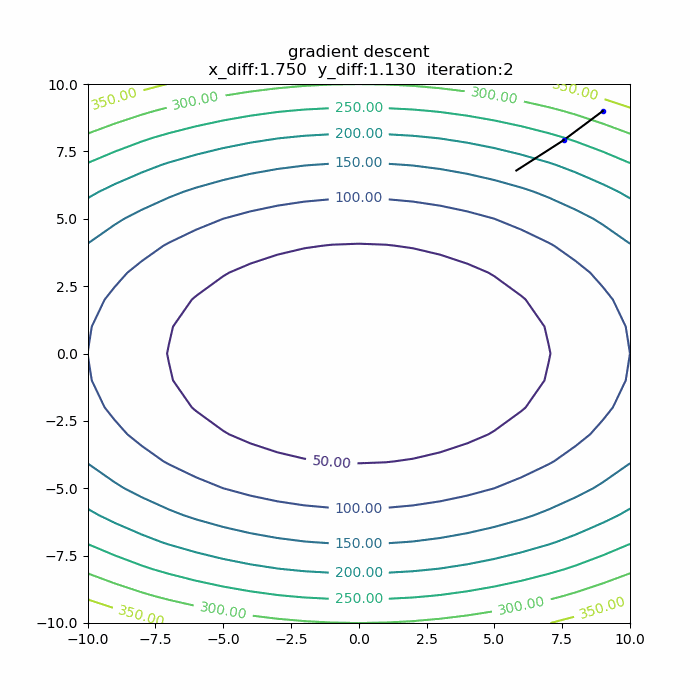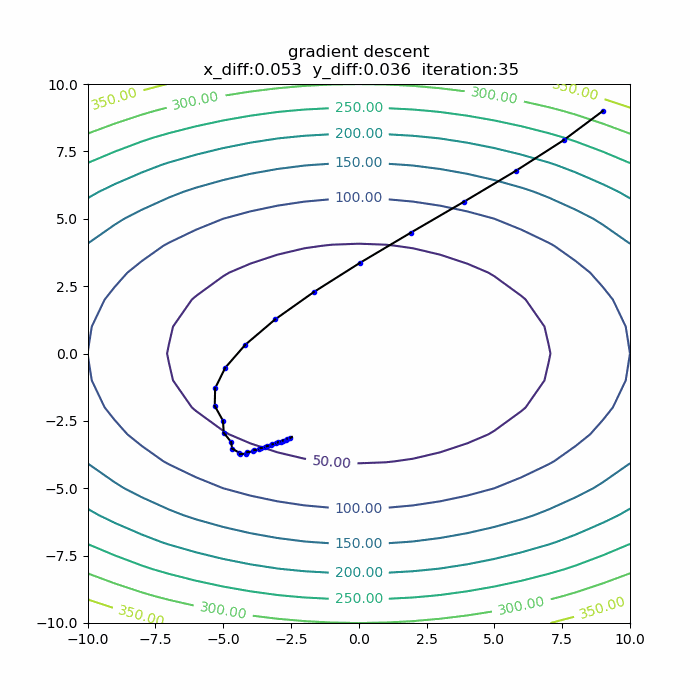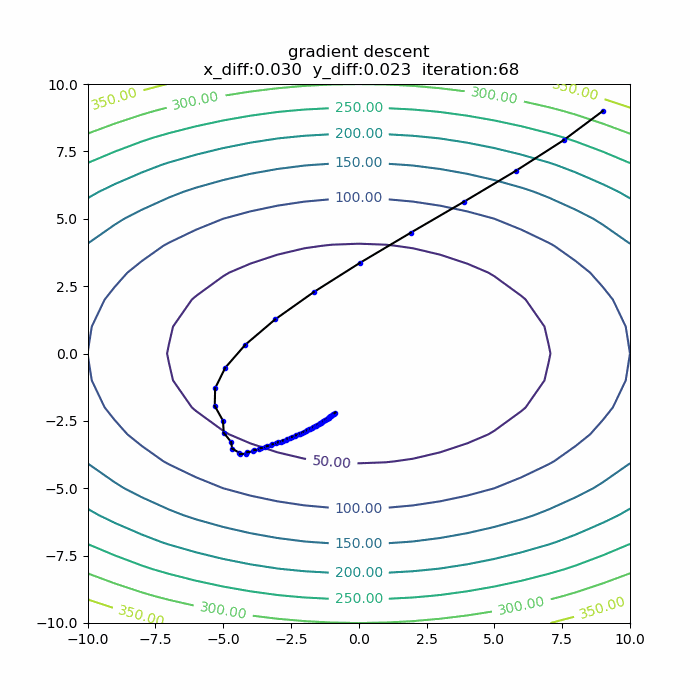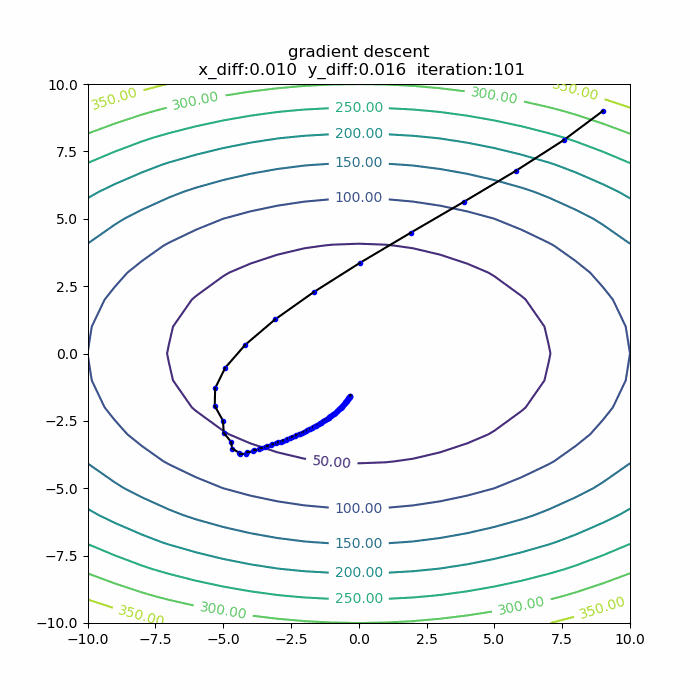
量子アルゴリズムの基本:算術演算の確認(剰余加算)
$$
\def\bra#1{\mathinner{\left\langle{#1}\right|}}
\def\ket#1{\mathinner{\left|{#1}\right\rangle}}
\def\braket#1#2{\mathinner{\left\langle{#1}\middle|#2\right\rangle}}
$$はじめに
前回に引き続き、算術演算シリーズです。今回は「剰余加算」です。アルゴリズムを説明した後、自作の量子計算シミュレータqlazyで、動作の確認をします。
参考にさせていただいた論文・記事は以下です。
- V. Vedral,A. Barenco,A. Ekert; "Quantum Networks for Elementary Arithmetic Operations" (arXiv:quant-ph/9511018)
- 量子コンピュータ(シミュレータ)でモジュロ加算器を作る(@converghub)
- 量子コンピュータ(シミュレータ)でモジュロ加算器を作る【QISKit編】(@converghub)
剰余加算の実現方法
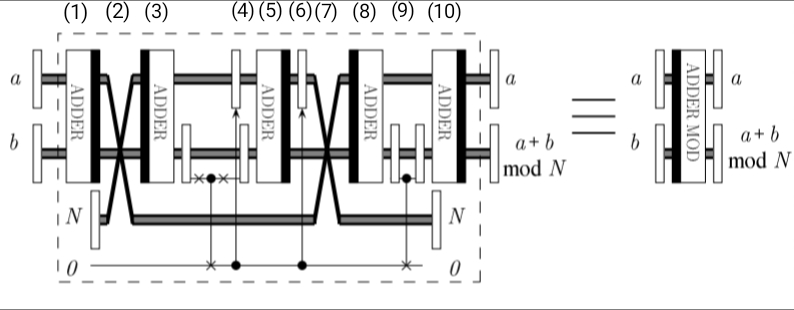
参考論文に全体の回路図が出ているので、まずそれを掲載します。
論文には、
\ket{a,b} \rightarrow \ket{a,a+b \space mod \space N}を計算する回路と説明されています(ただし、$0 \leqq a,b < N$です)。これで本当に剰余加算が実現できるのでしょうか。図を参照しながら1ステップずつ見ていきます。
まずはじめに、$a,b,N$用のレジスタおよび補助的なレジスタを用意します。図の左側に「$a,b,N,0$」と記号が書かれています。各々何ビットのレジスタにするかは、注意深く決める必要があります。適当に決めてしまうと、入力の値によって途中の計算でオーバーフローしておかしな結果を出してしまう可能性があるからです(言うまでもないことですが)。$a,b$は加算する値で、その結果は$b$のレジスタ(以後、レジスタ<b>と書くことにします)に入りますので、$b$のビット数は$a$よりも1つ多くしておく必要があります。また、今回の前提は、$0 \leqq a,b < N$だったので、$N$のビット数は計算したいビット数よりも1つ多くしておく必要があります。さらに、後で説明するようにレジスタ<a>とレジスタ<N>は途中スワップさせますので、同じビット数にしておいた方が良いです。ということを、すべて合わせて考慮すると、計算したいビット数$n$に対して、レジスタ<a>には$n+1$ビット、レジスタ<b>には$n+2$ビット、レジスタ<N>には$n+1$ビットを割り当てておけば良いことになります。それから図には明示的に記載されていないのですが、ADDERを実現するためには、前回の記事で説明したように、桁上げ情報を格納しておくためのレジスタ<c>も必要です。レジスタ<b>と同じ数の量子ビットを用意しておいて最上位ビットは<c>と共有しますので、さらに追加で$n+1$ビット必要になります論文には、このあたり逐一説明されていないのですが、そういうことになるのかなと思っています。間違っていたらご指摘ください)。この考え方に基づくと、結局、$n$ビット同士の剰余加算を実行するためには、$(n+1)+(n+2)+(n+1)+(n+1)+1=4n+6$ビット必要になります。
さて、それでは実際の量子計算について見ていきます。図中の番号(1)から(10)に至るまで、状態がどう変化するかを以下の表に示しました。ここで、上の行から順番にレジスタ<a>,<b>,<N>,<t>の状態を表しています(<t>は図中一番下の補助量子ビットを表しています)。また、この表は状態の変化を表しているので、ケット記号を使って、例えば$\ket{a}$等と書くべきなのですが、面倒なので単に$a$とのみ書くことにしました。
初期状態 (1) (2) (3) (4) (5) (6) (7) (8) (9) (10) $a$ $a$ $N$ $N$ [↑]$0$
[↓]$N$[↑]$0$
[↓]$N$$N$ $a$ $a$ $a$ $a$ $b$ $a+b$ $a+b$ $a+b-N$ [↑]$a+b-N$
[↓]$a+b-N$[↑]$a+b-N$
[↓]$a+b$[↑]$a+b-N$
[↓]$a+b$[↑]$a+b-N$
[↓]$a+b$[↑]$b-N$
[↓]$b$[↑]$b-N$
[↓]$b$[↑]$a+b-N$
[↓]$a+b$$N$ $N$ $a$ $a$ $a$ $a$ $a$ $N$ $N$ $N$ $N$ $t=0$ $0$ $0$ $0$ [↑]$1$
[↓]$0$[↑]$1$
[↓]$0$[↑]$1$
[↓]$0$[↑]$1$
[↓]$0$[↑]$1$
[↓]$0$$0$ $0$ まず、(1)は、単なるADDERなので、レジスタ<b>に$a+b$が入るだけです。
(2)は、レジスタ<a>とレジスタ<N>のスワップです。$a$と$N$が入れ替わります。
(3)は、ADDERの逆(引き算)です。レジスタ<b>の値$a+b$からレジスタ<a>の値$N$を引いたもの、すなわち$a+b-N$が、レジスタ<b>に入ります。ここで、$a+b$と$N$の大小関係によって、レジスタ<b>の最上位ビットが1になるか0になるかが変わります。$a+b-N$が負の数になる場合、アンダーフロー状態となり、レジスタ<b>の最上位ビットは1になります。そうでない場合は0です。以後、どっちのパターンかによって、場合分けして考えていきます。
(4)は、2つのことを行っています。まず、レジスタ<b>に対する操作についてです。レジスタ<b>の最上位ビットが0だった場合(つまり、$a+b \geqq N$)、レジスタ<t>が1に変化し、そうでない場合(つまり、$a+b < N$)、レジスタは0のままです。表の中で、[↑]と記載したのは$a+b \geqq N$の場合、[↓]と記載したのは、$a+b < N$の場合です。次に、レジスタ<a>に対する操作についてです。ここで、レジスタ<a>に矢印がささったような制御ユニタリ系のちょっと見かけない記号が出てきました。論文によると、制御ビット(レジスタ)が1の場合、レジスタ<b>を$\ket{0}$にし、そうでない場合そのまま何もしない演算子とのことです(ここでは、「アロー演算子」と呼ぶことにします)。結局、$a+b \geqq N$の場合([↑])、レジスタ<a>は$0$、レジスタ<b>は$a+b-N$(アンダーフローなし)、$a+b < N$の場合([↓])、レジスタ<a>は$N$、レジスタ<b>は$a+b-N$(アンダーフローあり)となります。
(5)は、単なるADDERです。[↑]/[↓]の場合分けによって、レジスタ<b>が異なる変化をします。[↑]の場合、$0$を足すので、$a+b-N$のまま、[↓]の場合、$N$を足すので、アンダーフロー状態が解消されて、$a+b$となります。
(6)は、レジスタ<a>に対するアロー演算子です。レジスタ<t>の制御ビットがどっちであったとしても、レジスタ<a>には$N$が入ることになります。
(7)は、単なるスワップです。レジスタ<a>とレジスタ<N>の値が入れ替わります。
(8)は、逆ADDER(引き算)です。ちょっとトリッキーなのですが、これの意図はレジスタ<t>を$0$に戻すことです。レジスタ<b>から$a$を引くことで、[↑]$b-N$、[↓]$b$となります。すると、[↑]の場合、レジスタ<b>はアンダーフロー状態になり、最上位ビットに1が立ちます。[↓]の場合、最上位ビットは0のままです。この状態にしておいて、次のステップに行きます。
(9)は、レジスタ<b>の最上位ビットによって、レジスタ<t>の状態が変わる回路です。前段でのレジスタ<b>の最上位ビットが1の場合のみ、Xゲートが働くので、レジスタ<t>の値は0に戻ることになります。
(10)は、ADDERです。(8)(9)でトリッキーなことをやったので、レジスタ<b>をもとに戻します。[↑]の場合、$a+b-N$、[↓]の場合、$a+b$となります。これで、$a+b \space mod \space N$が実現できたことになります。
シミュレータで動作確認
さて、それではシミュレータで、この剰余加算の動作を確認してみます。今回想定したのは、3ビット同士の剰余加算です。具体的には、b=5,N=9を固定にして、aを取りうる値すべて(0,1,2,...,7)の重ね合わせとして、一気に剰余加算をやってみます。全体のPythonコードは以下の通りです。
from qlazypy import QState def swap(self,id_0,id_1): dim = min(len(id_0),len(id_1)) for i in range(dim): self.cx(id_0[i],id_1[i]).cx(id_1[i],id_0[i]).cx(id_0[i],id_1[i]) return self def sum(self,q0,q1,q2): self.cx(q1,q2).cx(q0,q2) return self def i_sum(self,q0,q1,q2): self.cx(q0,q2).cx(q1,q2) return self def carry(self,q0,q1,q2,q3): self.ccx(q1,q2,q3).cx(q1,q2).ccx(q0,q2,q3) return self def i_carry(self,q0,q1,q2,q3): self.ccx(q0,q2,q3).cx(q1,q2).ccx(q1,q2,q3) return self def plain_adder(self,id_a,id_b,id_c): depth = len(id_a) for i in range(depth): self.carry(id_c[i],id_a[i],id_b[i],id_c[i+1]) self.cx(id_a[depth-1],id_b[depth-1]) self.sum(id_c[depth-1],id_a[depth-1],id_b[depth-1]) for i in reversed(range(depth-1)): self.i_carry(id_c[i],id_a[i],id_b[i],id_c[i+1]) self.sum(id_c[i],id_a[i],id_b[i]) return self def i_plain_adder(self,id_a,id_b,id_c): depth = len(id_a) for i in range(depth-1): self.i_sum(id_c[i],id_a[i],id_b[i]) self.carry(id_c[i],id_a[i],id_b[i],id_c[i+1]) self.i_sum(id_c[depth-1],id_a[depth-1],id_b[depth-1]) self.cx(id_a[depth-1],id_b[depth-1]) for i in reversed(range(depth)): self.i_carry(id_c[i],id_a[i],id_b[i],id_c[i+1]) return self def arrow(self,N,q,id): for i in range(len(id)): if (N>>i)%2 == 1: self.cx(q,id[i]) return self def modular_adder(self,N,id_a,id_b,id_c,id_N,id_t): self.plain_adder(id_a,id_b,id_c) self.swap(id_a,id_N) self.i_plain_adder(id_a,id_b,id_c) self.x(id_b[len(id_b)-1]) self.cx(id_b[len(id_b)-1],id_t[0]) self.x(id_b[len(id_b)-1]) self.arrow(N,id_t[0],id_a) self.plain_adder(id_a,id_b,id_c) self.arrow(N,id_t[0],id_a) self.swap(id_a,id_N) self.i_plain_adder(id_a,id_b,id_c) self.cx(id_b[len(id_b)-1],id_t[0]) self.plain_adder(id_a,id_b,id_c) return self def encode(self,decimal,id): for i in range(len(id)): if (decimal>>i)%2 == 1: self.x(id[i]) return self def create_register(digits): num = 0 id_a = [i for i in range(digits+1)] num += len(id_a) id_b = [i+num for i in range(digits+2)] num += len(id_b) id_c = [i+num for i in range(digits+2)] id_c[digits+1] = id_b[digits+1] # share the qubit id's num += (len(id_c)-1) id_N = [i+num for i in range(digits+1)] num += len(id_N) id_t = [i+num for i in range(1)] num += len(id_t) id_r = id_b[:-1] # to store the result return (num,id_a,id_b,id_c,id_N,id_t,id_r) def superposition(self,id): for i in range(len(id)-1): self.h(id[i]) return self def result(self,id_a,id_b): # measurement id_ab = id_a + id_b iid_ab = id_ab[::-1] freq = self.m(id=iid_ab).frq # set results a_list = [] r_list = [] for i in range(len(freq)): if freq[i] > 0: a_list.append(i%(2**len(id_a))) r_list.append(i>>len(id_a)) return (a_list,r_list) if __name__ == '__main__': # add methods QState.swap = swap QState.sum = sum QState.i_sum = i_sum QState.carry = carry QState.i_carry = i_carry QState.arrow = arrow QState.plain_adder = plain_adder QState.i_plain_adder = i_plain_adder QState.modular_adder = modular_adder QState.encode = encode QState.superposition = superposition QState.result = result # create registers digits = 3 num,id_a,id_b,id_c,id_N,id_t,id_r = create_register(digits) # set iput numbers b = 5 N = 9 # initialize quantum state qs = QState(num) qs.superposition(id_a) # set superposition of |0>,|1>,..,|7> for |a> qs.encode(b,id_b) qs.encode(N,id_N) # execute modular adder qs.modular_adder(N,id_a,id_b,id_c,id_N,id_t) a_list,r_list = qs.result(id_a,id_r) for i in range(len(a_list)): print("{0:}+{1:} mod {2:} -> {3:}".format(a_list[i],b,N,r_list[i])) qs.free()何をやっているか順に説明します。
def swap(self,id_0,id_1): dim = min(len(id_0),len(id_1)) for i in range(dim): self.cx(id_0[i],id_1[i]).cx(id_1[i],id_0[i]).cx(id_0[i],id_1[i]) return selfは、2つのレジスタのスワップです。swapゲートを対象となる量子ビット数分繰り返しています。
def i_plain_adder(self,id_a,id_b,id_c): depth = len(id_a) for i in range(depth-1): self.i_sum(id_c[i],id_a[i],id_b[i]) self.carry(id_c[i],id_a[i],id_b[i],id_c[i+1]) self.i_sum(id_c[depth-1],id_a[depth-1],id_b[depth-1]) self.cx(id_a[depth-1],id_b[depth-1]) for i in reversed(range(depth)): self.i_carry(id_c[i],id_a[i],id_b[i],id_c[i+1]) return selfで、ADDERの逆演算を定義しています。関数plain_adderの処理を逆に実施しているだけです。
def arrow(self,N,q,id): for i in range(len(id)): if (N>>i)%2 == 1: self.cx(q,id[i]) return selfで、アロー演算子を定義しています。実は、この実装をどうすればよいか、ちょっと悩みました。@converghubさんの記事では、Nの値を格納しておくための補助量子ビットを追加で用意した上で、Toffoliゲートを複数使って、実現されていました。が、論文には、複数のCNOTゲートで実現できると書いてあるので、補助量子ビットなしで何とかなるんだろと思い、考えてみました。結局、Nはこの量子計算を行うにあたり、はじめから与えられている値なので、Nのビット配列のどこに1が立っているのかを見て、CNOTゲートのターゲットとなる量子ビット番号を決めて、それを複数適切に並べれば良いということに思い至りました。それを上のように実装してみました。
def modular_adder(self,N,id_a,id_b,id_c,id_N,id_t): self.plain_adder(id_a,id_b,id_c) self.swap(id_a,id_N) self.i_plain_adder(id_a,id_b,id_c) self.x(id_b[len(id_b)-1]) self.cx(id_b[len(id_b)-1],id_t[0]) self.x(id_b[len(id_b)-1]) self.arrow(N,id_t[0],id_a) self.plain_adder(id_a,id_b,id_c) self.arrow(N,id_t[0],id_a) self.swap(id_a,id_N) self.i_plain_adder(id_a,id_b,id_c) self.cx(id_b[len(id_b)-1],id_t[0]) self.plain_adder(id_a,id_b,id_c) return selfで、剰余加算を定義しています。最初に示した回路図をそのまま実現しています。
その他の関数sum、i_sum、carry、i_carry、plain_adder、encode、superposition、resultについては、前回の記事で説明したので、省略します。関数create_registerは、前回と実装が違っていますが、今回の計算に合わせてレジスタを用意するものです。こちらも説明省略します。
というわけで、プログラム本体の説明です。
# create registers digits = 3 num,id_a,id_b,id_c,id_N,id_t,id_r = create_register(digits)レジスタ<a>,<b>,<N>,<t>、ADDERで必要になる桁上げ用補助レジスタ<c>、剰余加算のための補助レジスタ<t>、および結果を取得するレジスタ<r>(=測定するレジスタ=レジスタ<b>)を決め、全体で必要になる量子ビット数も合わせて出力し、各変数に格納しておきます。
# set iput numbers b = 5 N = 9 # initialize quantum state qs = QState(num) qs.superposition(id_a) # set superposition of |0>,|1>,..,|7> for |a> qs.encode(b,id_b) qs.encode(N,id_N)今回、固定入力するb,Nの値を設定し、aについては取りうる値すべての重ね合わせ状態とします。
# execute modular adder qs.modular_adder(N,id_a,id_b,id_c,id_N,id_t)剰余加算を実行します。
a_list,r_list = qs.result(id_a,id_r) for i in range(len(a_list)): print("{0:}+{1:} mod {2:} -> {3:}".format(a_list[i],b,N,r_list[i]))測定によって得られた結果から、レジスタ<a>の状態とレジスタ<r>(=レジスタ<b>)の状態をセットにして表示します。
実行結果は、以下の通りです。
4+5 mod 9 -> 0 5+5 mod 9 -> 1 6+5 mod 9 -> 2 7+5 mod 9 -> 3 0+5 mod 9 -> 5 1+5 mod 9 -> 6 2+5 mod 9 -> 7 3+5 mod 9 -> 8というわけで、剰余加算が正しくできることが確認できました。
おわりに
前回「加算」、今回「剰余加算」が確認できましたので、次回は「制御剰余乗算」(論文には"Controlled-multiplier modulo N"と書いてありましたが、日本語これでいい?)に挑戦です。いままでの回路を部品にして、組み合わせていくようなので、だんだん量子ビット数的に厳しくなっていく予感がありますが、できる範囲で頑張ってみたいと思います。
以上
- 投稿日:2019-07-01T18:31:58+09:00
ACL Anthologyの論文一括DLスクリプト書いた
注:小ネタです。
やったこと
ACL Anthologyの論文pdfを一括DLするスクリプトを書きました.
NAACL2019の論文収集する時に「個別PDF欲しいけどひとつずつDLするのめんどくちゃい」と思ってしまったのでついうっかり書いてしまった.
依存ソフトウェア
- Python3
- Google Chrome
- chromedriver
- chromedriver_binary
- selenium
使い方
python ./acl_anthology_downloader.py -e <event_name> -y <year> -o <output_dir> -d </path/to/chromedriver>イベント名と年度を指定すると該当イベントのpdfをすべてDLする仕様になってます.
例
python ./acl_anthology_downloader.py -e NAACL -y 2019 -o papers/NAACL2019 -d /usr/local/bin/chromedriver注意点
- Selenium+chromedriverを使っているので,Chromeのバージョンと合ったchromedriverをインストールしてください
- デフォルトだとheadlessモードで動作しますが,Linux環境などでheadlessでうまく動作しない場合は
--xvfb/-xオプションを付与してください(当方のWSL環境だとこの状況になりました)実装に関して
今までPythonでのスクレイピングはscrapyを愛用してきましたが,Seleniumにも慣れておきたい意図で今回はSelenium+chromedriverを使用しました.
chromedriverの動作環境構築のコストはかかりますが,APIはscrapyよりかなり使いやすい気がしますね.
Webアプリの自動テストにも使えるし(というか本来の用途はそちら)おわりに
ICMLとかNIPSのダウンローダも書いておきたい.
- 投稿日:2019-07-01T17:47:57+09:00
【Python】?ラーメン屋の食べログ評価を口コミから予測してみた。?
1.簡単な概要
この記事では、ラーメン屋の食べログ評価を口コミから予測するために、取り組んだことを書きます。
ユーザーの口コミから食べログ評価の予測ができれば、仮に食べログに掲載されていないお店があったときに、口コミさえあれば、食べログ換算するとざっくり○点ぐらいだろうことがわかれば嬉しいなと思いやってみました。
今回は、「お店の評価」ではなく、「ユーザーが付けた評価」を当てにいきます!このようなイメージです!
まずは、口コミデータの取得から。
2.口コミデータの取得
詳しくはこちら↓↓で説明しています。
第1弾:【Python】ラーメンガチ勢によるガチ勢のための食べログスクレイピング口コミを1件ずつ取得した後に、データフレームにまとめました。
※食べログ規約にもとづき口コミに関する箇所にはモザイクをいれております。ご了承ください。
3.仮説
口コミにおいて、どのような口コミが点数が高くなるか、ないし低くなるかを仮説を立ててみます。
高評価の口コミ
・口コミの文章量が多い。
・「美味しい」や「絶妙」などラーメンを賞賛する単語が多い
・「丁寧」「感じが良い」など店員のサービスを賞賛する単語が多い低評価の口コミ
・口コミの文章量が少ない
・不味い、普通、微妙等、ネガティブな単語が多い4.基礎分析
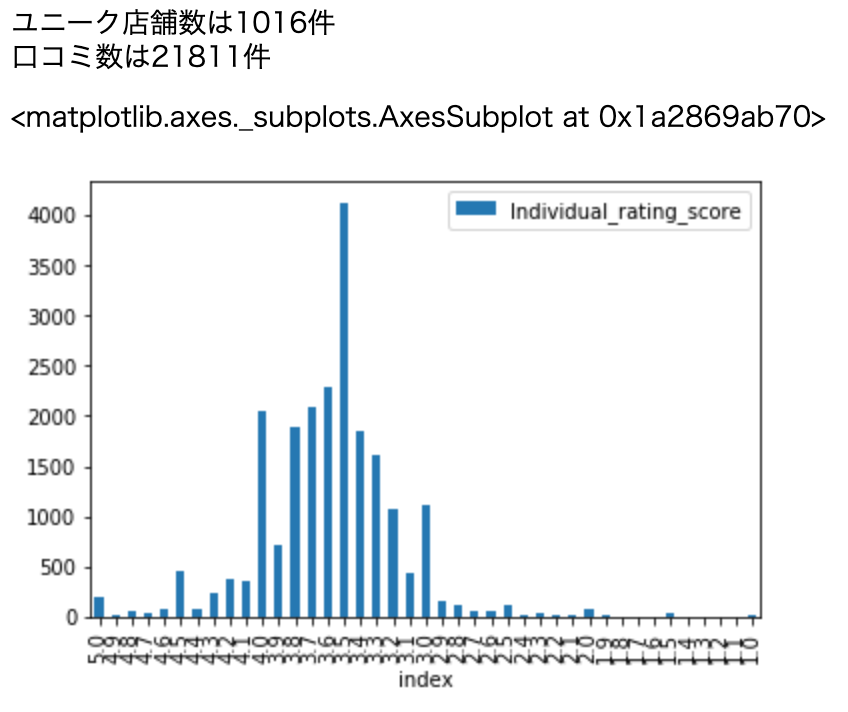
取得した口コミ数と口コミ評価の出現頻度です。
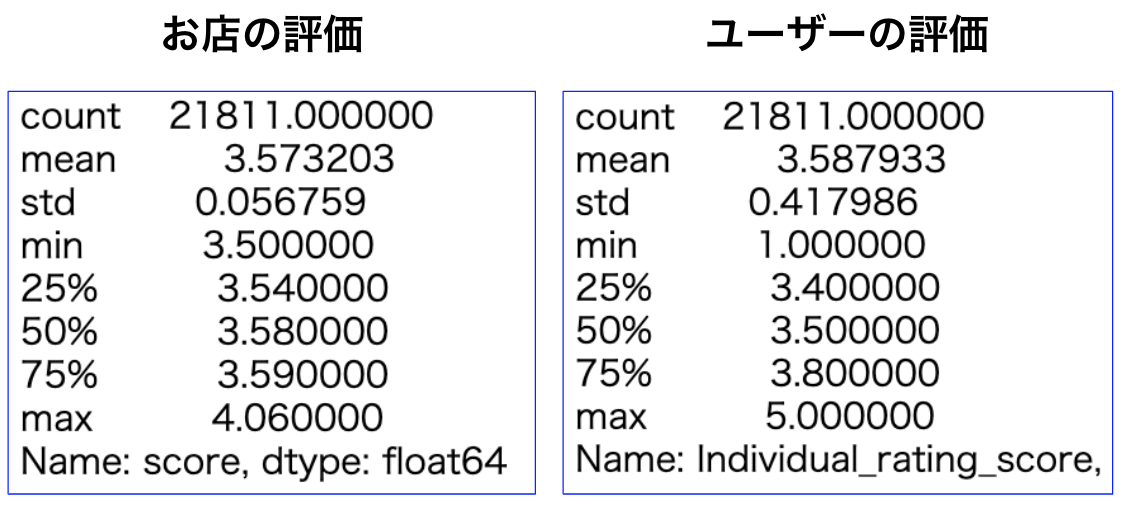
また、お店の評価と個々のユーザーの評価の平均値や中央値等も見てみます。import numpy as np import matplotlib as plt #点数がない口コミを除去 df2 = df[df.Individual_rating_score != '-'] #ユニーク店舗数 print('ユニーク店舗数は'+str(df2["store_name"].nunique())+'件') #口コミ数 print('口コミ数は'+str(len(df2))+'件') #出現頻度をプロット vc = df2['Individual_rating_score'].value_counts().reset_index().sort_values('index', ascending=False) vc.plot.bar(x='index', y='Individual_rating_score')
df2['score'].describe() df2['Individual_rating_score'].astype(np.float).describe()
今回は都内食べログランキングの上から1016店舗から21811件の口コミを取得しました。
数字が中途半端なのはスクレイピングの都合です。
食べログ評価上位(3.5〜4.1)のお店の口コミをスクレイピングしたため、ユーザーの評価も3.5以上に偏っていますね。つまり、割と点数が高めの学習データなので、予測する際にその影響を受けることは念頭におきながら進めます。
5.特徴量の選定(その1)
口コミデータからどうしたら食べログ評価を予測できるか調べるために、点数に効きそうなことを要素を探します。
①口コミの長さとの相関
②感情スコアとの相関感情スコアとは、例えば、「美味しい」、「良い」などpositiveなワードには正の値,「不味い」、「悪い」などはnegativeなワードには負の値を与えスコア化します。このスコアは-1〜+1の範囲ですが「単語感情極性対応表」によって規定されています。
詳しくはこちら↓
http://www.lr.pi.titech.ac.jp/~takamura/pndic_ja.html
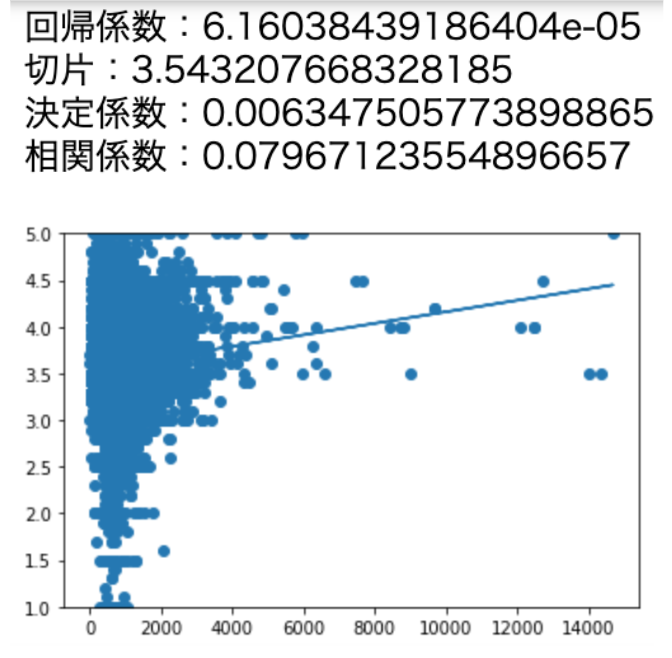
https://ohke.hateblo.jp/entry/2017/10/27/230000①口コミの長さとの相関
私の経験則ですが、美味しかったお店の口コミを書くときは、意気揚々として長文になります。
一方で微妙だったお店の口コミ短く済ませてしまうことの多いので、口コミの長さはある程度は関係していると思われます。# sklearn.linear_model.LinearRegression クラスを読み込み from sklearn import linear_model # matplotlib パッケージを読み込み import matplotlib.pyplot as plt # カラムに文字数を追加します。 df2['word_cnt'] = df2['review'].apply(lambda x : len(x)) # 線形回帰モデル clf = linear_model.LinearRegression() # 説明変数に "word_cnt (文字数)" を利用 X = df2.loc[:, ['word_cnt']].as_matrix() # 目的変数に "Individual_rating_score (ユーザー評価)" を利用 Y = df2['Individual_rating_score'].as_matrix() # 予測モデルを作成 clf.fit(X, Y) # 回帰係数 print('回帰係数:'+str(clf.coef_[0])) # 切片 (誤差) print('切片:'+str(clf.intercept_)) # 決定係数 print('決定係数:'+str(clf.score(X, Y))) # 相関係数 corr = np.corrcoef(df2['word_cnt'], df2['Individual_rating_score']) print('相関係数:'+str(corr[1][0])) # Figureを設定 fig = plt.figure() # Axesを追加 ax = fig.add_subplot(111) ax.set_ylim(1, 5) # 散布図 plt.scatter(X, Y) # 回帰直線 plt.plot(X, clf.predict(X))
相関係数0.079・・・ということで相関はかなり弱いということがわかりました。当然ですが、口コミの文字数だけで点数が決まるほど単純な話ではありませんでした。
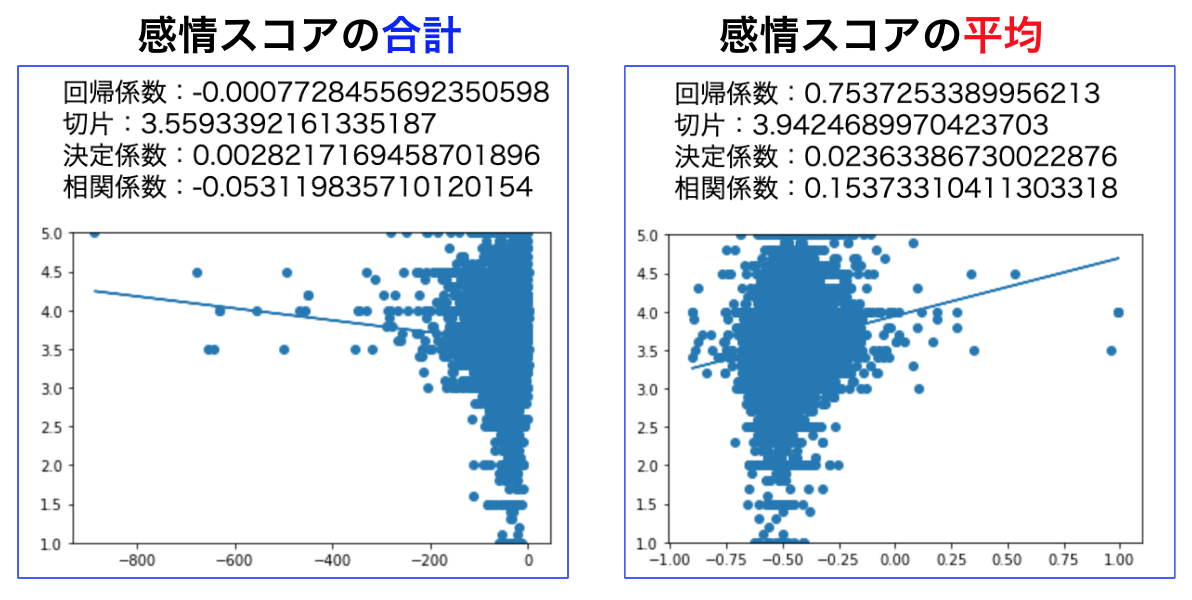
②感情スコアとの相関
感情スコアは-1~+1の範囲で表しますので、口コミにpositiveな単語が多ければ多いほどユーザーが付けた評価も高くなりそうですよね!
f = open('../work/kanjo_dict.txt', 'r') kanjo_dict = {} for line in f: kanjo_list = line.replace('\n','').split(":") kanji = kanjo_list[0] kanjo_dict[kanji] = kanjo_list[3] f.close() kanjo_dict
import MeCab tagger = MeCab.Tagger('-Owakati -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd')#タグはMeCab.Tagger(neologd辞書)を使用 tagger.parse('') # 分かち書きで取得する品詞を指定 def tokenize_ja(text, lower): node = tagger.parseToNode(str(text)) while node: if (lower and node.feature.split(',')[0] in ["名詞","形容詞"]) and lower and node.feature.split(',')[1] !='代名詞': yield node.surface.lower() node = node.next # 分かち書きする関数を定義 def tokenize(content, token_min_len, token_max_len, lower): return [ str(token) for token in tokenize_ja(content, lower) if token_min_len <= len(token) <= token_max_len and not token.startswith('_') ] from statistics import mean #感情スコアを合計する関数を定義 def kanjo_score_total(x): txt = tokenize(x, 1, 10000, True) total = 0 for i in txt: try: total += float(kanjo_dict[i]) except: continue return total #感情スコアを平均する関数を定義 def kanjo_score_avg(x): txt = tokenize(x, 1, 10000, True) score_list =[] for i in txt: try: score_list.append(float(kanjo_dict[i])) except: continue try: mean(score_list) return mean(score_list) except: return np.nan df2['kanjo_score_total'] = df2.review.apply(kanjo_score_total) df2['kanjo_score_avg'] = df2.review.apply(kanjo_score_avg) *プロットする部分のコードは省略
なんと、意外なことに「感情スコアの合計」では相関がみられない・・・というかむしろ負になってしまっている。
これは、特徴量としては使えなさそうですね。
次に「感情スコアの平均」は、相関係数0.15ということで弱い相関がみられることがわかりました。
とりあえず「感情スコアの平均」は特徴量の候補に入れます。「感情スコア」を使っても上記のような結果となった要因としては、
①「濃厚」や「淡い」などラーメン用語としてはポジティブそうな単語も「単語感情極性対応表」ではネガティブという判定になっている
②「醤油」や「豚骨」といったポジティブともネガティブとも取れなそうな単語もネガティブになっていたりと、そもそも「単語感情極性対応表」があてにならないケースが多くありました。6.特徴量の選定(その2)
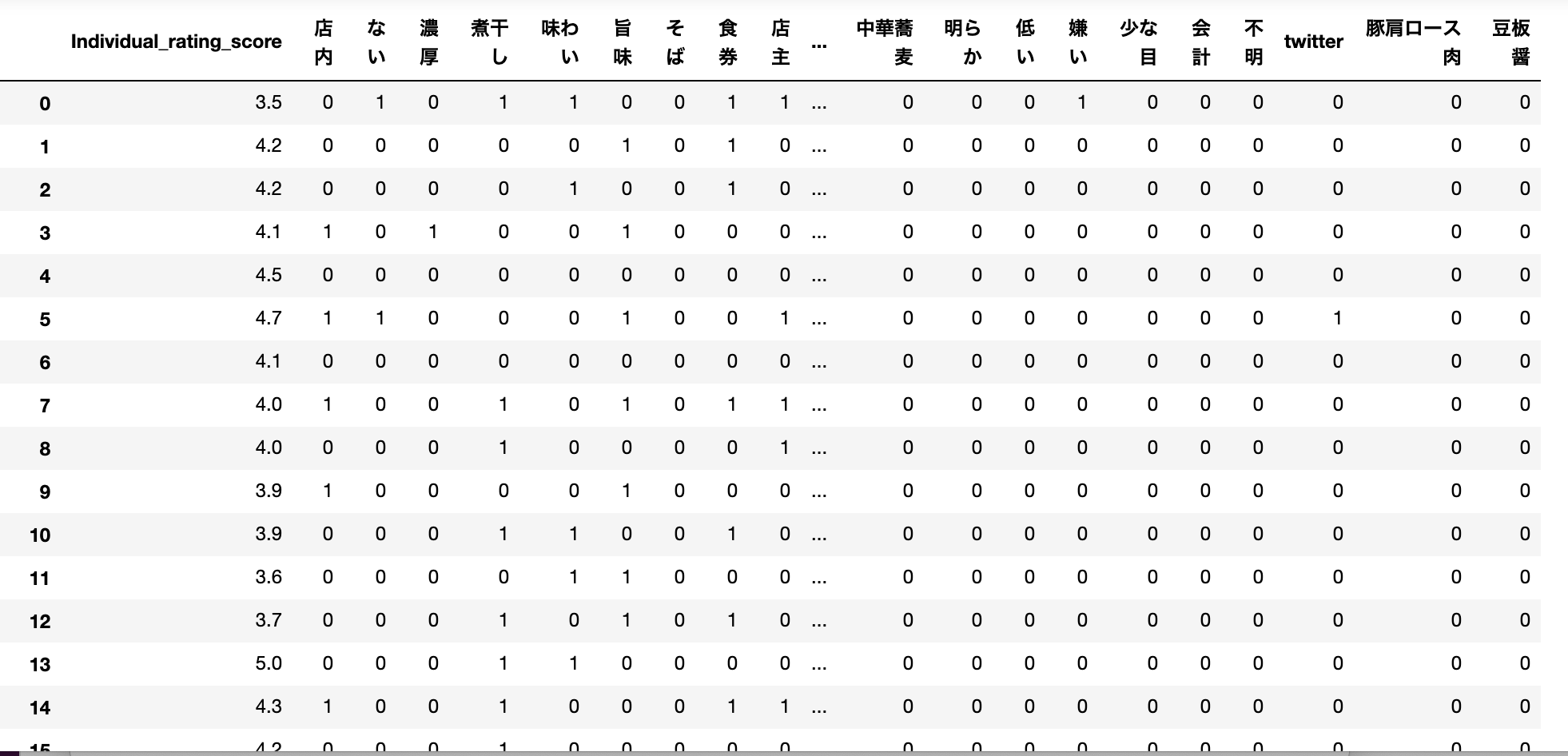
・口コミ出現した全単語をOne-Hotベクトルで表し、corr(相関係数)で寄与度を確認
例えば、単純に「美味しい」という単語が口コミにあったら、その単語が点数に寄与しているか調べます。まずは、出現する単語全てに対して点数と相関があるか調べてみました。# 口コミを分かち書き for i in df2['review']: txt = tokenize(i, 2, 10000, True) wakati_ramen_text.append(txt) # 分かち書きされた単語リストをカラムに追加 df2['wakati_ramen_text'] = wakati_ramen_text df2_words = df2 # 出現頻度の高い単語に絞る※上位10単語は頻出単語のためstopwordとして除外 target_words = df_cnt2.loc[10:1000,'index'].values.tolist() for add_col in target_words: df2_words[add_col] = df2_words['wakati_ramen_text'].apply(lambda x : 1 if add_col in x else 0) # 不要なカラムを除去。 df3 = df2_words.drop(columns=['Unnamed: 0', 'store_id','store_name','score','ward','review_cnt','review','wakati_ramen_text','moji_cnt']) # 相関係数を算出 corr_mat = df3.corr() # 点数と単語の相関だけに絞る corr_Individual_rating_score = corr_mat.loc['Individual_rating_score',:].reset_index() # 相関係数に閾値を決め、絶対値が大きい単語のみに絞る corr_Individual_rating_score2 = corr_Individual_rating_score[(corr_Individual_rating_score["Individual_rating_score"] > 0.04) | (corr_Individual_rating_score["Individual_rating_score"] < -0.02)].sort_values('Individual_rating_score', ascending=False).reset_index() # 絶対値が大きい単語以外のカラムは除去。 target_columns_list = corr_Individual_rating_score2['index'].values.tolist() columns_list = df3.columns.values.tolist() target_df = df3 for col in columns_list: if col not in target_columns_list: target_df = target_df.drop(columns=col) target_df
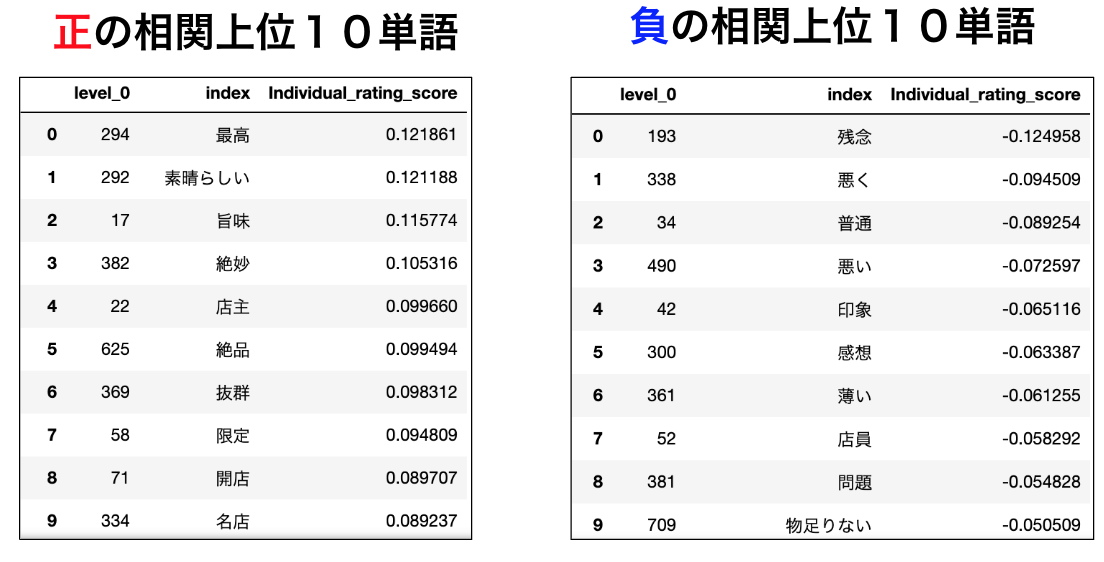
corr_Individual_rating_score.sort_values('Individual_rating_score', ascending=False).reset_index() corr_Individual_rating_score.sort_values('Individual_rating_score', ascending=True).reset_index()
相関係数が高い単語と低い単語をみると、ポジティブそうな単語はプラスになり、ネガティブそうな単語はマイナスになっています。肌感覚的に信用できそうなので特徴量候補にします。
全単語を特徴量にしてしまうと変数が限りなく増えてしまうので、出現頻度の高い単語上位1000件に絞り、さらにその中から相関係数の絶対値が大きい単語に絞りました。
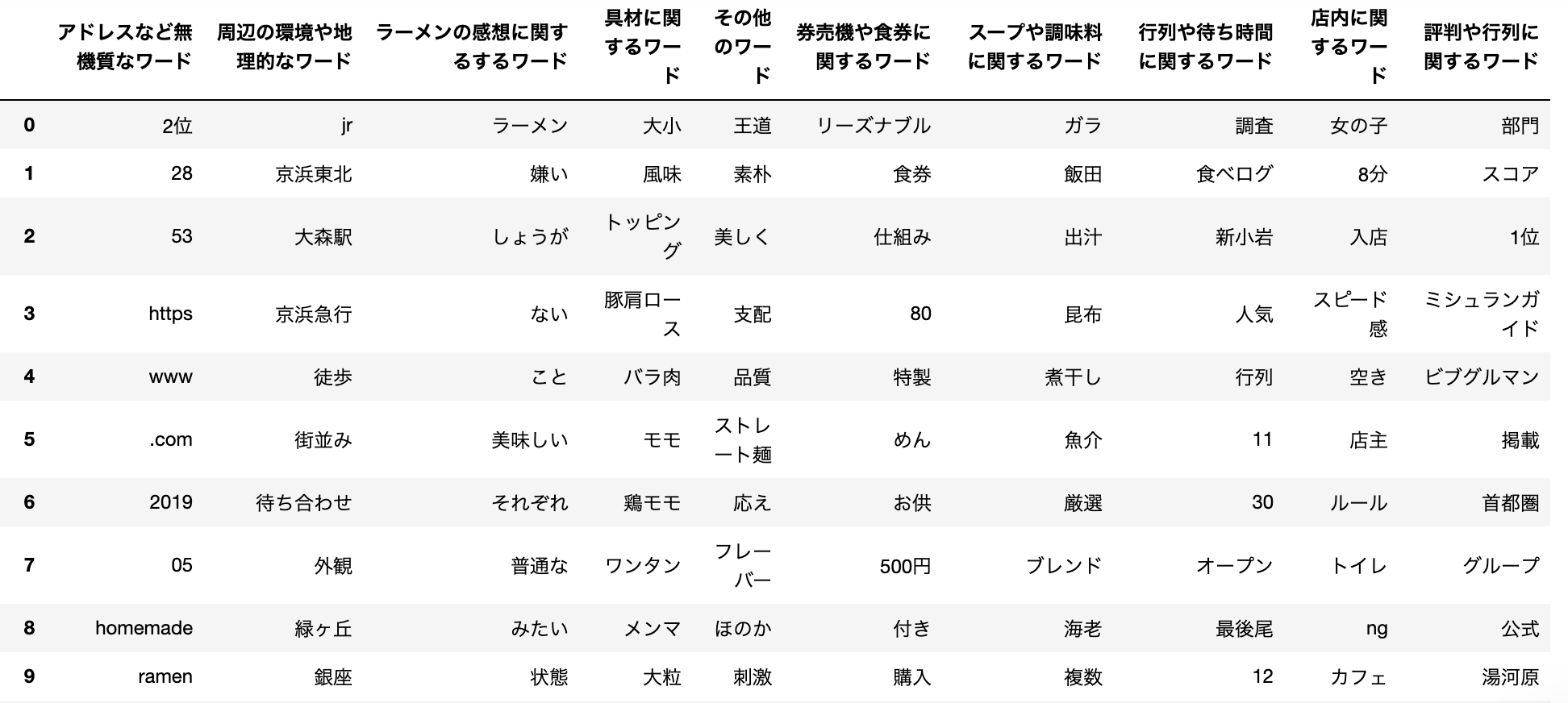
点数への寄与度が高い単語数を○○つに絞りましたが、説明変数にする際は、クラスタリングで○個の単語を10個の単語群にグルーピングします。7.特徴量作成(その3)
先ほど分かち書きした単語を使いword2vecで単語をベクトル化します。
その後、クラスタリングをして、各単語を10個にグループ分けします。# word2vecモデル作成 model = word2vec.Word2Vec(wakati_ramen_text, sg=1, size=100, window=5, min_count=5, iter=100, workers=3) #sg(0: CBOW, 1: skip-gram),size(ベクトルの次元数),window(学習に使う前後の単語数),min_count(n回未満登場する単語を破棄),iter(トレーニング反復回数) #参考 https://hironsan.hatenablog.com/entry/clustering-word-vectors from collections import defaultdict from gensim.models.keyedvectors import KeyedVectors from sklearn.cluster import KMeans max_vocab = 30000 vocab = list(model.wv.vocab.keys())[:max_vocab] vectors = [model.wv[word] for word in vocab] #クラスター数はこちらで任意の値を定める n_clusters = 10 kmeans_model = KMeans(n_clusters=n_clusters, verbose=0, random_state=42, n_jobs=-1) kmeans_model.fit(vectors) cluster_labels = kmeans_model.labels_ cluster_to_words = defaultdict(list) for cluster_id, word in zip(cluster_labels, vocab): cluster_to_words[cluster_id].append(word) #参考 https://note.nkmk.me/python-dict-change-key/ #辞書のキー名を変更する関数を定義 def change_dict_key(d, old_key, new_key, default_value=None): d[new_key] = d.pop(old_key, default_value) change_dict_key(cluster_to_words, 0, 'ラーメンの感想に関するするワード') change_dict_key(cluster_to_words, 1, '店内に関するワード') change_dict_key(cluster_to_words, 2, '時系に関するワード') change_dict_key(cluster_to_words, 3, '評判や地理的なワード') change_dict_key(cluster_to_words, 4, 'ネット用語ワード') change_dict_key(cluster_to_words, 5, '券売機や食券に関するワード') change_dict_key(cluster_to_words, 6, '周辺の環境や地理的なワード') change_dict_key(cluster_to_words, 7, '具材に関するワード') change_dict_key(cluster_to_words, 8, 'スープや調味料に関するワード') change_dict_key(cluster_to_words, 9, 'その他ワード') df_dict = pd.DataFrame.from_dict(cluster_to_words, orient="index").T df_dict
↑のデータに対して、
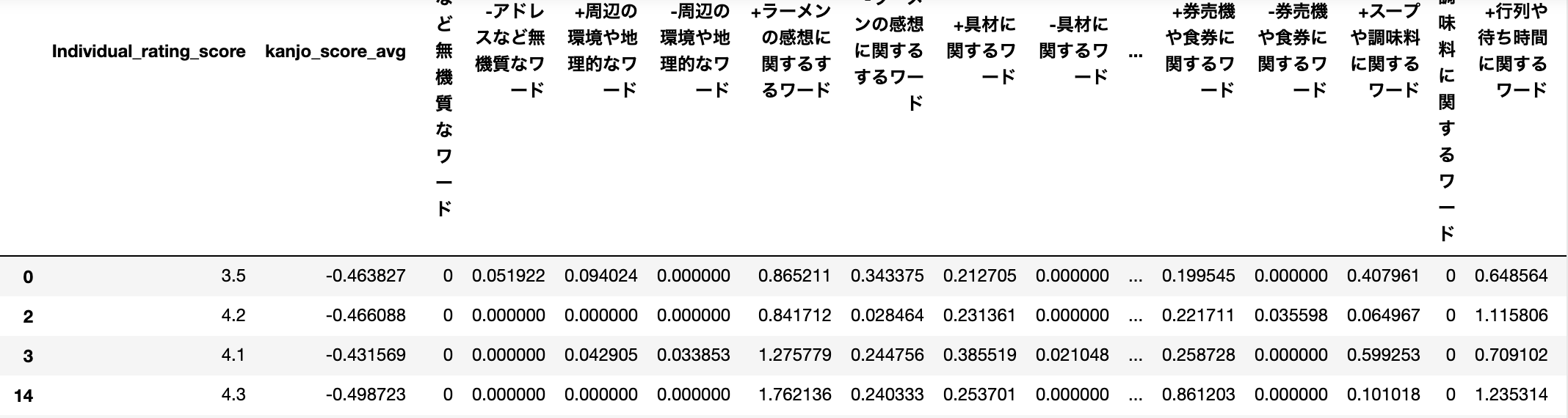
df2_over_1000['wakati_ramen_text'] = wakati_ramen_text cluster_list = df_dict.columns.tolist() plus_master_dict = {} minus_master_dict = {} plus_score_list = [] minus_score_list = [] # 単語の相関係数を正の相関と負の相関に分けてグループ内で足し合わせていく for word_list in df2['wakati_ramen_text'].values.tolist(): plus_master_dict = {} minus_master_dict = {} for cl in cluster_list: plus_master_dict[cl] = 0 minus_master_dict[cl] = 0 for word in word_list: try: columns_word = cluster_list[df_dict_pair[word]] if corr_dict[word] >0: plus_master_dict[columns_word] += corr_dict[word] elif corr_dict[word] <0: minus_master_dict[columns_word] += corr_dict[word] else: continue except: continue plus_score_list.append(plus_master_dict) minus_score_list.append(minus_master_dict) df2['kanjo_score_avg'] = df2.review.apply(kanjo_score_avg) df2['plus_score_list'] = plus_score_list df2['minus_score_list'] = minus_score_list for add_col in cluster_list: df2['+'+str(add_col)] = df2_2['plus_score_list'].apply(lambda x : x[add_col]) df2['-'+str(add_col)] = df2_2['minus_score_list'].apply(lambda x : -1*x[add_col]) target_df = df2.drop(columns=['Unnamed: 0', 'store_id','store_name','score','ward','review_cnt','review','plus_score_list','minus_score_list','kanjo_score_avg']) target_df
8.重回帰分析
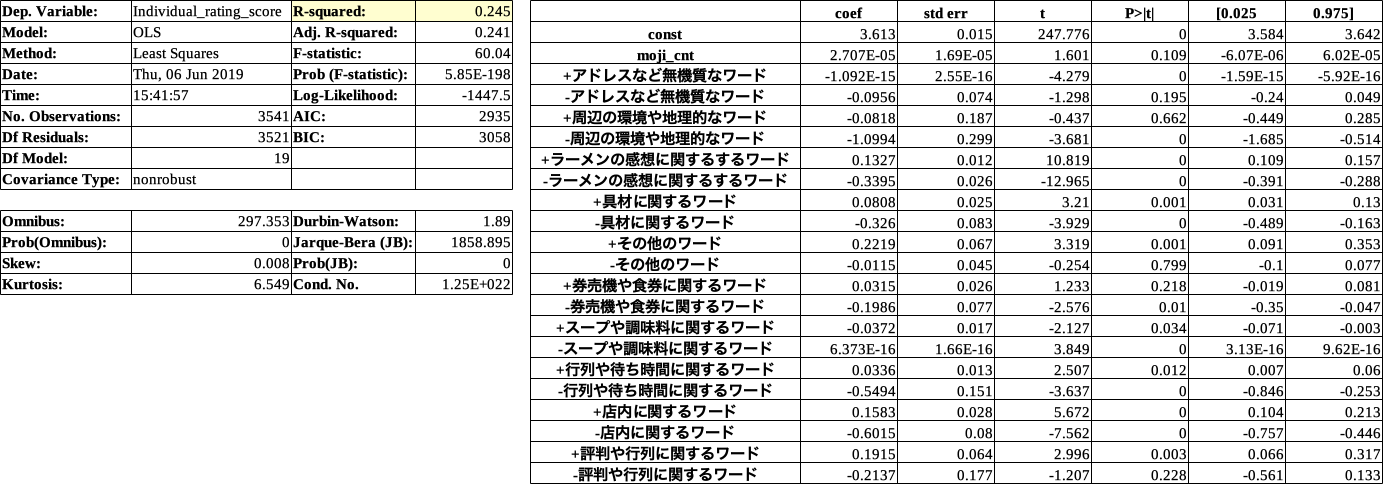
import statsmodels.api as sm X = target_df.drop('Individual_rating_score', 1) X = sm.add_constant(X) Y = target_df['Individual_rating_score'] model = sm.OLS(Y, X) result = model.fit() result.summary()
黄色で示した決定係数(R-Squared)は、回帰式によって説明できる割合を表わします。
そして、決定係数の値は0から1の間で、値が大きいほど分析精度は良いといえます。プラスに効いている説明変数TOP3は、(p値0.5以下)
1位その他のワード
2位評判や行列に関するワード
3位店内に関するワードマイナスに効いている説明変数ワースト3は、(p値0.5以下)
1位店内に関するワード
2位行列や待ち時間に関するワード
3位ラーメンの感想に関するワードこの結果から考察すると、
・評判や行列が点数と高くする要因となっている。(食べる前の印象が大事ということでしょうか)
・店内に関するワードがプラスにもマイナスにも効いているので、店内の雰囲気や接客が良くも悪くも点数に響いている。
・ラーメンの感想はネガティブの場合に点数を低くする。(美味しいのはあたりまえで、そのでないと点数がガクッと下がる)ラーメンの感想に関するワードが、どちらも1位でなかったのが意外でした。
さらに、数値予測問題における精度評価指標の手法であるMAE(Mean Absolute Error)を計算します。
MAEは正解から平均的にどの程度の乖離があるかを示します。
モデルの予測精度の"悪さ"を表すため、0 に近い値であるほど優れています。#MAEを算出 from sklearn.metrics import mean_absolute_error testX = X testX['const'] = 1.0 # 切片を追加 # testX = testX.ix[:,X.columns] # 重回帰式で得られた予測値をテストデータに代入させる pred = result.predict(testX) testX ['pred'] = pred target_df['pred'] = pred y_true = target_df['Individual_rating_score'] y_pred = target_df['pred'] mean_absolute_error(y_true, y_pred)MAE:0.2606560766702907
今回の重回帰分析の結果
決定係数:0.245
MAE:0.260
ということで、お世辞にも「口コミから食べログ評価を予測できました!」とはいえませんね(>_<)
他の手法(決定木やランダムフォレスト)も試してみましたが、大きく改善することがなかったので、口コミデータだけから食べログ評価の予測には限界があるのかもしれません。9.ロジスティック回帰
何かしら成果になる結果を出したかったので、
ロジスティック回帰で、口コミが3.5以上or3.5未満か予測してみました。from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn import metrics from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score target_df['score_class']=target_df['Individual_rating_score'].apply(lambda x : '3.5以上' if x >=3.5 else '3.5未満') X = target_df.drop(['Individual_rating_score','score_class'], 1) X = sm.add_constant(X) Y = target_df['score_class'] logreg = LogisticRegression() # データを分割します。テストが全体の40%になるようにします。 X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.4,random_state=None) # データを使って学習します。 result = logreg.fit(X_train, Y_train) # テストデータを予測します。 Y_pred = logreg.predict(X_test) # 精度を計算してみましょう。 print(metrics.accuracy_score(Y_test,Y_pred)) print('confusion matrix = \n', confusion_matrix(y_true=Y_test, y_pred=Y_pred)) print('accuracy = ', accuracy_score(y_true=Y_test, y_pred=Y_pred)) print('precision = ', precision_score(y_true=Y_test, y_pred=Y_pred)) print('recall = ', recall_score(y_true=Y_test, y_pred=Y_pred)) print('f1 score = ', f1_score(y_true=Y_test, y_pred=Y_pred))accuracy = 0.76287932251235
confusion matrix =
[[1010 38]
[ 298 71]]正解率は76.3%でした。
まあまあ良さげな結果になりました!10.結論
口コミから正確に点数を予測することができませんでしたが、ロジスティック回帰のモデルを使えば、食べログに掲載のないお店に対して、ざっくり「3.5以上or3.5未満」かを予測して、一般的に美味しいお店かそうじゃないかを判断することができそうです!
11.課題
口コミは、様々な表現があり特徴量の作成が難しいことがわかりました。
例えば、淡麗系のラーメン屋と濃厚系のラーメン屋では、口コミに使う言葉の表現が異なるので一概に「○○のような口コミなら点数が高い」とは言い切れないのです。
試しに、データセットを醤油ラーメンだけに限定してモデルを作ると精度が良くなりました。
ですので、口コミからスープの種類を判別したのちにスープごとのモデルを作るとより、実用的な予測ができるのではないかと思います。もっとこうしたらいいんじゃないかというアドバイスがありましたら是非コメントしてください!
?本記事が少しでも参考になりましたら是非「いいね」をお願いします!?


- 投稿日:2019-07-01T17:27:38+09:00
[訓練・データ不要]ディープラーニングフレームワークを使ったアニメの線画の自動生成
ディープラーニングのフレームワークを使って、アニメ本編から線画を生成します。ただし、一切訓練や訓練データを与えていません。アニメ1話分全4.3万フレームの線画化を1時間程度で終わらせることができました。
あらまし
このようにアニメ本編から自動的に線画が生成できます。ディープラーニングのフレームワークを使うとできます。ただし、一切訓練をしていません。
OP https://t.co/52t0dFZNZL pic.twitter.com/7aCEJ9SkTc
— しこあん@『モザイク除去本』(技術書典6)好評通販中 (@koshian2) 2019年7月1日本編1 https://t.co/52t0dFZNZL pic.twitter.com/oicU8UPopS
— しこあん@『モザイク除去本』(技術書典6)好評通販中 (@koshian2) 2019年7月1日本編2 https://t.co/52t0dFZNZL pic.twitter.com/K7Y6scHiqK
— しこあん@『モザイク除去本』(技術書典6)好評通販中 (@koshian2) 2019年7月1日元ネタ
そこそこな線画を目指す OpenCV
https://qiita.com/khsk/items/6cf4bae0166e4b12b942こちらの記事のアルゴリズムを使います。もともとはOpenCVの実装ですが、ディープラーニングの関数に変換することができます。
OpenCV→ディープラーニングへの置き換え
OpenCVを使った線画化のアルゴリズムは以下の処理の構成です。
- カラー画像のグレースケール化
- 1の画像を8近傍で膨張処理を1回
- 膨張処理した画像と1の画像の差分の絶対値を取る
- 3の画像の白黒反転させる
膨張処理をどうにかすれば、あとは四則演算や行列積でできそうな気がしますよね。OpenCVのモルフォロジー変換のドキュメントを見ると次の式が書かれていました。
$$dst(x,y)=\max_{(x',y'):\rm{element} (x',y')\neq0}src(x+x',y+y') $$
この式をよく見ると、MaxPoolingっぽくないですか? ただし、普通のMaxPoolingは解像度が下がってしまうので、入力と出力の解像度が変わらないように「pool_size=(3,3), stride=1, padding="same"」という特殊なプーリングを行います(GoogLe NetのInceptionブロックでこういう使い方しています)。
つまり、ディープラーニングの処理でOpenCVの線画化の処理を置き換えると次のようになります。
- カラー画像のグレースケール化 → 行列積 or 1x1畳み込み
- 1の画像を8近傍で膨張処理を1回 → stride=1, padding="same"の3x3 MaxPooling
- 膨張処理した画像と1の画像の差分の絶対値を取る → ただの絶対値+引き算
- 3の画像の白黒反転させる → 1.0-画像
OpenCVの処理を無事にディープラーニングの文脈に置き換えることができました。あとは実装するだけです。
何が美味しいの?
ディープラーニングフレームワークに置き換えてなにが美味しいの?という疑問があるかもしれません。理由はいくつかあります。
- GPUブーストが簡単に使える
OpenCVの処理をGPU上で簡単に行うことができます。KerasならCPUと同じコードでできます。- ディープラーニング上で「線画」の概念が扱える
もともと自分が欲しかったのはこっちで、損失関数内で線画の損失関数を定義したかったのです。この方法なら、カラー画像→線画への変換をディープラーニングのモデル内で行えます。ディープラーニングフレームワークによる実装
元画像
元の記事と同じように「響け!ユーフォニアム」の画像を使います。これを「eupho.jpg」とします。
Keras
Kerasの場合は以下のような処理になります。ディープラーニングのフレームワークでは、画像は4階テンソルとして扱うため前後にテンソル変換を挟んでいます(load_tensor, show_tensor)。
import numpy as np from PIL import Image import keras.backend as K import matplotlib.pyplot as plt def load_tensor(): with Image.open("eupho.jpg") as img: array = np.asarray(img, np.float32) / 255.0 # [0, 1] array = np.expand_dims(array, axis=0) # KerasはNHWC return K.variable(array) def show_tensor(input_image_tensor): img = K.eval(input_image_tensor * 255.0) img = img.astype(np.uint8)[0,:,:,0] plt.imshow(img, cmap="gray") plt.show() def linedraw(): # データの読み込み x = load_tensor() # Y = 0.299R + 0.587G + 0.114B でグレースケール化 gray_kernel = K.variable( np.array([0.299, 0.587, 0.114], np.float32).reshape(3, 1)) x = K.dot(x, gray_kernel) # dot積でOK # 3x3カーネルで膨張1回(膨張はMaxPoolと同じ) dilated = K.pool2d(x, pool_size=(3, 3), strides=(1, 1), padding="same") # 膨張の前後でL1の差分を取る diff = K.abs(x-dilated) # ネガポジ反転 x = 1.0 - diff # 結果表示 show_tensor(x) if __name__ == "__main__": linedraw()
うまくいきました。
PyTorch
PyTorchの場合は以下のようになります。グレースケール化で1x1畳み込みを使っているのが違うところです。
import numpy as np from PIL import Image import torch import torch.nn.functional as F import matplotlib.pyplot as plt def load_tensor(): with Image.open("eupho.jpg") as img: array = np.asarray(img, np.float32) / 255.0 # [0, 1] array = np.expand_dims(array, axis=0) array = np.transpose(array, [0, 3, 1, 2]) # PyTorchはNCHW return torch.as_tensor(array) def show_tensor(input_image_tensor): img = input_image_tensor.numpy() * 255.0 img = img.astype(np.uint8)[0,0,:,:] plt.imshow(img, cmap="gray") plt.show() def linedraw(): # データの読み込み x = load_tensor() # Y = 0.299R + 0.587G + 0.114B でグレースケール化 gray_kernel = torch.as_tensor( np.array([0.299, 0.587, 0.114], np.float32).reshape(1, 3, 1, 1)) x = F.conv2d(x, gray_kernel) # 行列積は畳み込み関数でOK # 3x3カーネルで膨張1回(膨張はMaxPoolと同じ) dilated = F.max_pool2d(x, kernel_size=3, stride=1, padding=1) # 膨張の前後でL1の差分を取る diff = torch.abs(x-dilated) # ネガポジ反転 x = 1.0 - diff # 結果表示 show_tensor(x) if __name__ == "__main__": linedraw()
ディープラーニングなのに訓練/データ不要
このアルゴリズムの面白いところなのですが、ディープラーニングなのに学習する係数が1個もありません。したがって、モデルを定義をした段階で訓練フェーズをすっ飛ばしてすぐ使うことができます。
アニメ1話分を全て線画に変換してみよう
応用例として、YouTubeにあるアニメ1話分を丸々線画に変換して、Before-Afterで動画として保存します。以下の流れで行います。
- YouTubeからPyTubeで動画をダウンロード
- フレーム単位で静止画(カラー画像)で切り出し
- Kerasでカラー画像を全て線画に変換
- もとのカラー画像と線画を組み合わせて動画として再エンコード
今回はKerasを使っていますが、PyTorchや他のフレームワークでもできます。暇な方はやってみてはいかがでしょうか。
ちなみにColabでやる場合はYouTubeの再生地域制限に引っかかるケースがあります。日本から動画が見れてもColabのサーバーがアメリカにあるので、アメリカからの接続と認識されてDLできないケースがあります(その場合は日本のHTTPSプロキシ経由で接続しますが説明は省略します)。ローカルにDLする場合は特に心配しなくてOKです。
必要ライブラリ
ffmpeg
ffmpegはPythonのライブラリの他に、本体のバイナリが必要なので本家から必要なバイナリをダウンロードしておきます。Windowsならffmpegのexeファイルを実行ディレクトリにおきます。
OpenH264
H264でエンコードする際に必要。以下のリポジトリから、H264の1.8.0かつ64ビットのライブラリをOSに応じてダウンロード。同じく実行ディレクトリにおいておきます。
https://github.com/cisco/openh264/releases
その他ライブラリ
pip install ffmpeg-python pip install pytube他にインストールされていないライブラリがあったら適宜pip installでインストールします。
コード
動画はYouTubeの公式配信の侵略!イカ娘の第1話を使っています。
import ffmpeg from pytube import YouTube import os import glob import cv2 import numpy as np from tqdm import tqdm import keras from keras import layers import keras.backend as K from PIL import Image def download_youtube(): if not os.path.exists("video"): os.mkdir("video") yt = YouTube("https://www.youtube.com/watch?v=JUIk6a1nzFw") query = yt.streams.filter(fps=30, subtype="mp4", res="360p").all() query[0].download("video") def extract_images(): if not os.path.exists("images"): os.mkdir("images") stream = ffmpeg.input(glob.glob("video/*")[0]) stream = ffmpeg.output(stream, f"images/frame_%05d.png", f="image2", q=4) ffmpeg.run(stream) def linedraw_func(input_tensor): gray_kernel = K.variable( np.array([0.299, 0.587, 0.114], np.float32).reshape(3, 1)) x = K.dot(input_tensor, gray_kernel) # dot積でOK # 1枚単位でmin-maxスケーリングしてコントラスト補正する mins = K.min(x, axis=(1,2,3), keepdims=True) maxs = K.max(x, axis=(1,2,3), keepdims=True) x = (x-mins) / (maxs-mins+K.epsilon()) dilated = K.pool2d(x, pool_size=(3, 3), strides=(1, 1), padding="same") diff = K.abs(x-dilated) x = 1.0 - diff return x IMG_WIDTH, IMG_HEIGHT = 640, 360 def linedraw_model(): input = layers.Input((IMG_HEIGHT, IMG_WIDTH, 3)) x = layers.Lambda(linedraw_func)(input) return keras.models.Model(input, x) def convert_all(): # KerasのImageDataGeneratorはroot/classes/img という構造なので、 # ルートディレクトリをカレントディレクトリにし、サブディレクトリとして画像のあるディレクトリを1クラスとして指定 # batch_size分の画像を一度に読み込む、シャッフルはしないようにする(連番で読まれる) gen = keras.preprocessing.image.ImageDataGenerator(rescale=1.0/255).flow_from_directory( "./", class_mode=None, classes=["images"], batch_size=256, shuffle=False, target_size=(IMG_HEIGHT, IMG_WIDTH) ) # 出力ディレクトリ if not os.path.exists("images_line"): os.mkdir("images_line") # ファイル数 n_files = len(glob.glob("images/*.png")) # 線画化の操作をモデルとして読み込む model = linedraw_model() cnt = 1 for X in tqdm(gen): out = model.predict_on_batch(X) # 線画化 # ファイルの保存 for i in range(out.shape[0]): img = (out[i,:,:,0]*255.0).astype(np.uint8) with Image.fromarray(img) as img: img.save(f"images_line/frame_{cnt:05}.png") cnt += 1 if cnt > n_files: return def encode(): fourcc = cv2.VideoWriter_fourcc("h", "2", "6", "4") video = cv2.VideoWriter("output.mp4", fourcc, 29.97, (IMG_WIDTH, IMG_HEIGHT*2)) n = len(glob.glob("images/*")) for i in tqdm(range(1, n + 1)): img_original = cv2.imread(f"images/frame_{i:05}.png") img_original = cv2.resize(img_original, (IMG_WIDTH, IMG_HEIGHT), cv2.INTER_LANCZOS4) img_convert = cv2.imread(f"images_line/frame_{i:05}.png") #img_convert = cv2.resize(img_convert, (IMG_WIDTH, IMG_HEIGHT), cv2.INTER_LANCZOS4) x = np.concatenate([img_original, img_convert], axis=0) video.write(x) if __name__ == "__main__": encode()これで生成したのが冒頭の動画。ただし、Twitterの埋め込み動画の画質が悪いので実際はもう少し綺麗に出てたりします1。
生成結果比較
実際の静止画としての出力はこちらになります。カラー画像との比較です。
なかなか良いのではないでしょうか?
速度
ダウンロードからエンコードまでおおよそ1時間程度でした。ffmpegによるフレームの切り出しとストレージがボトルネックになるので、CPU性能とストレージ速度(HDDよりSSD)を上げると高速に出力できます。GPUはほとんど使っていませんでした(使用率でせいぜい5%程度)。もちろんこのあとDeepの訓練につなげる場合は、GPU等のデバイスがあればより高速化できます。
しかし、アニメ1話分の線画が1時間でできてしまうというのはびっくりでした。1話で4.3万フレームあったので(29.97fps × 累計秒)、アニメ本編と既存の画像処理を組み合わせればかなり簡単かつ大量にデータが作れるのかもしれません。
応用 / まとめ
これを使うと、(線画, カラー画)のペアデータが簡単に作れるので2、生成モデルとの相性が良くなります。具体的には、pix2pixなどを使えばアニメの原画~動画の工程をかなり自動化できるのではないでしょうか。
この記事のポイントは、OpenCVで書けるような従来の画像処理も、畳み込みやプーリングといったディープラーニングの操作にある程度置き換えることができるということです。これに気づくとディープラーニングの幅がぐっと広がると思われます。







- 投稿日:2019-07-01T17:00:28+09:00
Google Cloud APIを触ってごにょごにょしてみる(Python編)
概要
Google Cloud APIを使ってアレをナニする必要性に迫られたのでメモ。
何する?
- BigQuery上でのクエリ結果を一時テーブルに保存する
- 一時テーブルの中身をCloud Storageに保存する(JSON形式)
前提条件
- GCPのサービスアカウントに以下の権限が与えられていること
- BigQuery データ編集者
- BigQuery ジョブユーザー
- ストレージのオブジェクト管理者
- サービスアカウントキーの環境変数が設定されていること
export GOOGLE_APPLICATION_CREDENTIALS="/path_to_key/project-xxxxxx.json"仕様
- CUI
- 引数からGCP関連情報(プロジェクト、データセット、テーブル名、バケット名)を取得する。
- BigQueryのクエリを実行し、結果を一時テーブル(tmp_table)に保存する。
- 一時テーブルの内容をJSON形式(改行区切り)でCloud Storageへ保存する。
- 保存先は
gs://backet-name/results.json- ファイル名は
result.jsonで固定とする。実行手順
cd /path_to_source/ python filename.py -p "gcp-project-name" -d "bq-dataset-name" -t "bq-table-name" -b "gcs-backet-name"パラメータ
-p : GCPのプロジェクト名
-d : BigQueryのデータセット名
-t : BigQueryのテーブル名
-b : Cloud Storageのバケット名コードは以下。
#!/usr/bin/env python # -*- coding: utf-8 -* import argparse from google.cloud import bigquery from datetime import datetime def parse(): usage = 'Usage: python {} -p [project] -d [dataset] -t [table] -b [backet] \n \ example: python {} -p "gcp-project-name" -d "bq-dataset-name" -t "bq-table-name" -b "gcs-backet-name"' \ .format(__file__, __file__) # パーサの作成 psr = argparse.ArgumentParser(usage=usage) # for GCP psr.add_argument('-p', '--project', default = 'gcp-project-name') psr.add_argument('-d', '--dataset', default = 'bq-dataset-name') psr.add_argument('-t', '--table', default = 'bq-table-name') psr.add_argument('-b', '--backet', default = 'gcs-backet-name') args = psr.parse_args() print(args) return args class IdcfGcpInfo: def __init__(self, project = 'gcp-project-name', dataset_id = 'bq-dataset-name', table_id = 'bq-table-name', backet_name = 'gcs-backet-name', json_file_name = 'results.json', destination_uri = 'gs://{}/{}', destination_format = 'NEWLINE_DELIMITED_JSON', compression = 'NONE', location = 'asia-northeast1', ): self.project = project self.dataset_id = dataset_id self.table_id = table_id self.backet_name = backet_name self.json_file_name = 'results.json' self.destination_uri = 'gs://{}/{}'.format(self.backet_name, self.json_file_name) self.destination_format = destination_format self.compression = compression self.location = location # BigQuery上で発行するクエリ def query_on_bq(gcp_info): sql = ''' SELECT column1, column2, column3 FROM `{}.{}.{}`;'''.format( gcp_info.project, gcp_info.dataset_id, gcp_info.table_id ) return sql # BigQueryでのクエリ結果を一時テーブルに保存 def save_to_tmp_table_from_query(gcp_info): client = bigquery.Client() job_config = bigquery.QueryJobConfig() # クエリ用configの指定 dataset_ref = client.dataset( dataset_id = gcp_info.dataset_id, project = gcp_info.project ) tmp_ref = dataset_ref.table('tmp_table') # 一時テーブルをセット job_config.destination = tmp_ref # 保存先に一時テーブルを指定 job_config.write_disposition = bigquery.WriteDisposition.WRITE_TRUNCATE # 実行前にTRUNCATEする sql = query_on_bq(gcp_info) # sql取得 # クエリ実行 query_job = client.query(sql, job_config = job_config) query_job.result() # Waits for job to complete. # 一時テーブルの内容をCloud Storageに保存 def save_to_gcs_from_tmp_table(gcp_info): client = bigquery.Client() dataset_ref = client.dataset( dataset_id = gcp_info.dataset_id, project = gcp_info.project ) table_ref = dataset_ref.table(table_id = 'tmp_table') # configの指定 ext_job_config = bigquery.ExtractJobConfig() ext_job_config.destination_format = gcp_info.destination_format ext_job_config.compression = gcp_info.compression # 指定したバケットに保存 extract_job = client.extract_table( source = table_ref, destination_uris = gcp_info.destination_uri, location = gcp_info.location, job_config = ext_job_config ) extract_job.result() # Waits for job to complete. def main(): args = parse() gcp_info = IdcfGcpInfo( project = args.project, dataset_id = args.dataset, table_id = args.table, backet_name = args.backet ) save_to_tmp_table_from_query(gcp_info) save_to_gcs_from_tmp_table(gcp_info) if __name__ == '__main__': main()注意事項
- Cloud StorageのバケットはBigQueryと同じリージョンに配置すること!!
リージョンが異なるともれなくエラーを吐きます。
- Google公式の方法だと、JSON保存形式のオプションに
NEWLINE_DELIMITED_JSONしか指定できません。
こんな感じ
{"ip":"172.26.0.0","time":"2019-01-01 00:00:01","region":"west"} {"ip":"127.0.0.1","time":"2019-01-01 00:30:02","region":"east"} {"ip":"192.168.1.1","time":"2019-01-01 05:30:02","region":"east"}カンマ区切りじゃなきゃヤダ!という場合は、他のエレガントな方法を考える必要があります。
Pythonあまり触ったことがないので、ツッコミどころがあればご指摘いただけると喜びます
- 投稿日:2019-07-01T15:42:19+09:00
pythonでcsvファイルを扱ってみよう
ちょっとCSVファイルを取り扱うことがあったので調べてみました。
モジュールが用意されていて、公式ドキュメントにも使い方が載っています。
csv --- CSV ファイルの読み書きCSVファイルとして次のような内容を想定します。
1列目 2列目 3列目 HOGE FOO BAR 1 2 3 ドキュメントの使用例通り、
with openを使って開いたファイルをcsv.readerで読み込みましょう。動作確認してません.pyimport csv with open('hoge.csv', newline='') as csvfile: rows = csv.reader(csvfile, delimiter=',', quotechar='|') for row in rows: print(row) # ['\ufeffHOGE', 'FOO', 'BAR'] # ['1', '2', '3']以上のように、行一つが配列一つに対応して出力されます。
delimiterパラメータに渡す文字を変更することで、タブ区切りのファイルなども読み込むことができます。ところで気になるのは
\ufeffという謎の文字列。当然ながら、元のCSVファイルには含まれていないものです。
これはBOMと呼ばれる「テキストの始まりをプログラムに伝える」ことを目的とする目印なんだそうですね。
以下のようにエンコードを指定するパラメータを渡してあげると、この余計な文字は読み込まれなくなります。with open('hoge.csv', newline='', encoding='utf-8-sig') as csvfile:参考:\ufeffって???
- 投稿日:2019-07-01T15:24:35+09:00
pythonでスレッドのIDを取得する
何がしたかったのか
既存のソースコードの改修が発端です。
複数回並列で行える処理で最新のスレッドだけが動作するような作りにしたかった。
並列して動くスレッドのIDは別個のものが振られるため、IDを取得できればうまく動かせるのではと考えた。※ その設計がいいとは限らないです。
ちゃんと状態管理してあげるのが正しいんだろうけど
手早く済ませたかったのでこんなやり方をしてます。検証環境
OS: Ubuntu 18.04
python: 3.6.7使うモジュール・関数
- threadingモジュール
- get_ident()
これでスレッドIDは取得できるとのことなので、
後は下のサンプルコードで並行で動いているスレッドがちゃんと別のIDを返してくるかだけ確認するサンプルコード
thread_id_test.pyimport threading as th import time def say_th_id(secouds, th_no): time.sleep(secouds) print("thread no:{0}, ident:{1}".format(th_no, th.get_ident())) if __name__ == "__main__": th1 = th.Thread(target=say_th_id, args=(6,1)) th2 = th.Thread(target=say_th_id, args=(5,2)) th1.start() time.sleep(1.0) th2.start()結果
thread no:1, ident:139790510892800 thread no:2, ident:139790502500096ちゃんと別々のスレッドIDが取得できました。
解釈違いなどあればコメントをください!参考にしたサイト
multithreading - How to find a thread id in Python - Stack Overflow
- 投稿日:2019-07-01T15:17:49+09:00
QGISでPandasを使えるようにする
はじめに
Pandasは便利ですね。
しかしQGISのPythonコンソールからは使えないので使えるようにします。
本当はGeoPandasを入れようとしたのですが、ちょっと解決困難な問題が発生したのでまずはPandasで我慢する。参考にしたサイトはこちら(というか殆どそのまま)
https://umar-yusuf.blogspot.com/2018/12/install-third-party-python-modules-in.htmlモジュールの追加
環境確認
今回はWindows7にQGIS3.4の環境で行ってます。
まずは動作環境を確認します。QGISを立ち上げて、Pythonコンソールを開きましょう。
そしたら以下のコマンドを投げてPandasを読み込めるかどうか試します。
>>> import pandas Traceback (most recent call last): File "C:\PROGRA~1\QGIS3~1.4\apps\Python37\lib\code.py", line 90, in runcode exec(code, self.locals) File "<input>", line 1, in <module> File "C:/PROGRA~1/QGIS3~1.4/apps/qgis-ltr/./python\qgis\utils.py", line 672, in _import mod = _builtin_import(name, globals, locals, fromlist, level) ModuleNotFoundError: No module named 'pandas'はい、モジュールがないよってエラーがでましたね。
出なかったら既に使えるようになっていますので以下の手順は不要です。次にPythonコンソールが使用しているPythonのバージョンを確認します。
以下のようなコマンドを流してください。>>> import sys >>> sys.version '3.7.0 (v3.7.0:1bf9cc5093, Jun 27 2018, 04:59:51) [MSC v.1914 64 bit (AMD64)]'Pythonの3.7.0が使われていることが判りました。
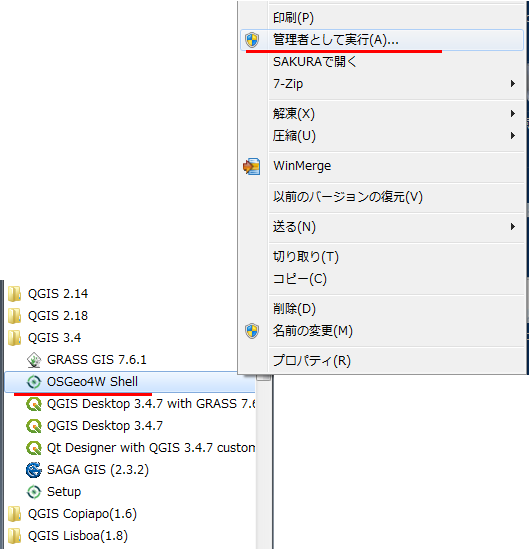
では次にスタートメニューからQGISのフォルダ内にある
OSGeo4W Shellを管理者として実行します。
Windows10の場合はコンテキストメニューの[その他]-「ファイルの場所を開く」してからファイルを選んで管理者として実行ですね。
管理者で実行しないとこの後のインストールでパーミッションが無いって怒られますので注意。
OSGeo4W Shellが開いたら
python -Vを投げましょうC:\Windows\System32>python -V Python 2.7.14こちらのPythonは2.7.14が参照されていますね。
pipのインストール
モジュールの追加にはpipをつかいます。
先ほど開いたOSGeo4W Shellを使ってpipをインストールしましょう。
インストールコマンドはpython -m ensurepip --default-pipです。C:\Windows\System32>python -m ensurepip --default-pip Collecting setuptools Requirement already satisfied: pip in c:\progra~1\qgis3~1.4\apps\python27\lib\site-packages Installing collected packages: setuptools Successfully installed setuptools-28.8.0問題なく入りました。
(私の環境にはpipは入ってたようですね)
最新版でないと怒られることがありますのでアップデートも流しておきます。C:\Windows\System32>python -m pip install --upgrade pip setuptools Collecting pip Downloading https://files.pythonhosted.org/packages/5c/e0/be401c003291b56efc55aeba6a80ab790d3d4cece2778288d65323009420/pip-19.1.1-py2.py3-none-any.whl (1.4MB) 100% |################################| 1.4MB 1.6MB/s Collecting setuptools Downloading https://files.pythonhosted.org/packages/ec/51/f45cea425fd5cb0b0380f5b0f048ebc1da5b417e48d304838c02d6288a1e/setuptools-41.0.1-py2.py3-none-any.whl (575kB) 100% |################################| 583kB 2.1MB/s Installing collected packages: pip, setuptools Found existing installation: pip 19.0.3 Uninstalling pip-19.0.3: Successfully uninstalled pip-19.0.3 Found existing installation: setuptools 28.8.0 Uninstalling setuptools-28.8.0: Successfully uninstalled setuptools-28.8.0 Successfully installed pip-19.1.1 setuptools-41.0.1Pythonバージョンの切り替え
OSGeo4W ShellのPythonバージョンが2系でしたので3系に切り替えます。
3系だったら不要だと思います。
OSGeo4W Shellでpy3_envを投げます。
自動的にいくつかSETコマンドが流れます。C:\Windows\System32>py3_env C:\Windows\System32>SET PYTHONPATH= C:\Windows\System32>SET PYTHONHOME=C:\PROGRA~1\QGIS3~1.4\apps\Python37 C:\Windows\System32>PATH C:\PROGRA~1\QGIS3~1.4\apps\Python37;C:\PROGRA~1\QGIS3~1.4\apps\Python37\Scripts;C:\PROGRA~1\QGIS3~1.4\apps\Python27\Scripts;C:\PROGRA~1\QGIS3~1.4\bin;C:\windows\system32;C:\windows;C:\windows\system32\WBem変わったことを確認しましょう。
C:\Windows\System32>python -V Python 3.7.0Pythonコンソールと同じバージョンに変わりました。
Pandasモジュールの追加
pipを使ってPandasを追加しましょう。
OSGeo4W Shellでpython -m pip install pandasと投げます。C:\Windows\System32>python -m pip install pandas Collecting pandas Downloading https://files.pythonhosted.org/packages/61/c7/f943fceb712579bc538700e2c157dc4972e16abfe29bd4969149bad98c74/pandas-0.24.2-cp37-cp37m-win_amd64.whl (9.0MB) 100% |████████████████████████████████| 9.0MB 24kB/s Requirement already satisfied: python-dateutil>=2.5.0 in c:\progra~1\qgis3~1.4\apps\python37\lib\site-packages (from pandas) (2.7.5) Requirement already satisfied: numpy>=1.12.0 in c:\progra~1\qgis3~1.4\apps\python37\lib\site-packages (from pandas) (1.16.3) Requirement already satisfied: pytz>=2011k in c:\progra~1\qgis3~1.4\apps\python37\lib\site-packages (from pandas) (2018.7) Requirement already satisfied: six>=1.5 in c:\progra~1\qgis3~1.4\apps\python37\lib\site-packages (from python-dateutil>=2.5.0->pandas) (1.12.0) Installing collected packages: pandas Successfully installed pandas-0.24.2成功しました。
動作確認
では確認してみましょう。
QGISを再起動してから再度Pythonコンソールを開きます。
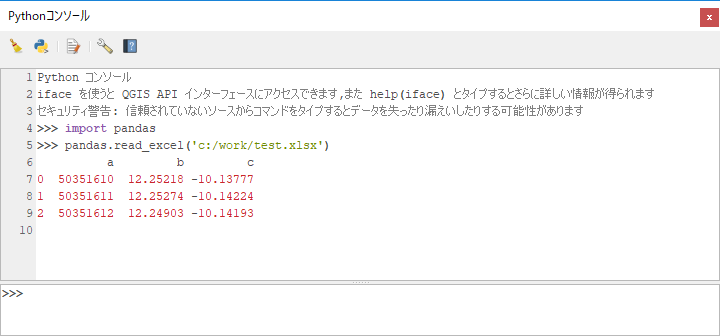
そしたら先ほどエラーが出たimport pandasを実行してみます。
エラーなくインポートできましたので適当なエクセルファイルでも読み込んでみましょう。>>> import pandas >>> pandas.read_excel('c:/work/test.xlsx') a b c 0 50351610 12.25218 -10.13777 1 50351611 12.25274 -10.14224 2 50351612 12.24903 -10.14193
読み込めました。
おまけ:GeoPandasに挑戦
OSGeo4W Shellで
python -m pip install geopandasと投げます。C:\Windows\System32>python -m pip install geopandas Collecting geopandas Downloading https://files.pythonhosted.org/packages/74/42/f4b147fc7920998a42046d0c2e65e61000bc5d104f1f8aec719612cb2fc8/geopandas-0.5.0-py2.py3-none-any.whl (893kB) 100% |████████████████████████████████| 901kB 6.5MB/s Requirement already satisfied: pyproj in c:\progra~1\qgis3~1.4\apps\python37\lib\site-packages (from geopandas) (1.9.6) Requirement already satisfied: shapely in c:\progra~1\qgis3~1.4\apps\python37\lib\site-packages (from geopandas) (1.6.4.post2) Requirement already satisfied: pandas in c:\progra~1\qgis3~1.4\apps\python37\lib\site-packages (from geopandas) (0.24.2) Collecting fiona (from geopandas) Downloading https://files.pythonhosted.org/packages/41/9d/63696e7b1de42aad294d4781199a408bec593d8fdb80a2b4a788c911a33b/Fiona-1.8.6.tar.gz (1.7MB) 100% |████████████████████████████████| 1.7MB 3.1MB/s Complete output from command python setup.py egg_info: A GDAL API version must be specified. Provide a path to gdal-config using a GDAL_CONFIG environment variable or use a GDAL_VERSION environment variable. ---------------------------------------- Command "python setup.py egg_info" failed with error code 1 in C:\Users\hoge\AppData\Local\Temp\pip-install-p0dr78y4\fiona\おっと、エラーがでましたね。
fionaというライブラリがgdal-configへのパスが指定されていないと怒っているようです。同じ問題に困っている人は見つかりますが、簡単には解決しなそうなので一旦あきらめます。
さいごに
今回はPandasを対象としましたが、もちろん他のモジュール追加も可能です。
(GeoPandasは失敗しましたけど)そして、これでプラグインからもPandasが使えるようになります。
ただ公開プラグインには向かないので、何かいい方法があれば教えてもらえたら嬉しいです。本記事のライセンス
この記事は クリエイティブ・コモンズ 表示 4.0 国際 ライセンスの下に提供されています。

- 投稿日:2019-07-01T15:17:49+09:00
QGISでPandasとGeoPandasを使えるようにする
はじめに
Pandas(GeoPandas)は便利ですね。
しかしQGISのPythonコンソールからは使えないので使えるようにします。
本当はGeoPandasを入れようとしたのですが、ちょっと解決困難な問題が発生したのでまずはPandasで我慢する。参考にしたサイトはこちら(というか殆どそのまま)
https://umar-yusuf.blogspot.com/2018/12/install-third-party-python-modules-in.htmlモジュールの追加
環境確認
今回はWindows7にQGIS3.4の環境で行ってます。
まずは動作環境を確認します。QGISを立ち上げて、Pythonコンソールを開きましょう。
そしたら以下のコマンドを投げてPandasを読み込めるかどうか試します。
>>> import pandas Traceback (most recent call last): File "C:\PROGRA~1\QGIS3~1.4\apps\Python37\lib\code.py", line 90, in runcode exec(code, self.locals) File "<input>", line 1, in <module> File "C:/PROGRA~1/QGIS3~1.4/apps/qgis-ltr/./python\qgis\utils.py", line 672, in _import mod = _builtin_import(name, globals, locals, fromlist, level) ModuleNotFoundError: No module named 'pandas'はい、モジュールがないよってエラーがでましたね。
出なかったら既に使えるようになっていますので以下の手順は不要です。次にPythonコンソールが使用しているPythonのバージョンを確認します。
以下のようなコマンドを流してください。>>> import sys >>> sys.version '3.7.0 (v3.7.0:1bf9cc5093, Jun 27 2018, 04:59:51) [MSC v.1914 64 bit (AMD64)]'Pythonの3.7.0が使われていることが判りました。
では次にスタートメニューからQGISのフォルダ内にある
OSGeo4W Shellを管理者として実行します。
Windows10の場合はコンテキストメニューの[その他]-「ファイルの場所を開く」してからファイルを選んで管理者として実行ですね。
管理者で実行しないとこの後のインストールでパーミッションが無いって怒られますので注意。
OSGeo4W Shellが開いたら
python -Vを投げましょうC:\Windows\System32>python -V Python 2.7.14こちらのPythonは2.7.14が参照されていますね。
pipのインストール
モジュールの追加にはpipをつかいます。
先ほど開いたOSGeo4W Shellを使ってpipをインストールしましょう。
インストールコマンドはpython -m ensurepip --default-pipです。C:\Windows\System32>python -m ensurepip --default-pip Collecting setuptools Requirement already satisfied: pip in c:\progra~1\qgis3~1.4\apps\python27\lib\site-packages Installing collected packages: setuptools Successfully installed setuptools-28.8.0問題なく入りました。
(私の環境にはpipは入ってたようですね)
最新版でないと怒られることがありますのでアップデートも流しておきます。C:\Windows\System32>python -m pip install --upgrade pip setuptools Collecting pip Downloading https://files.pythonhosted.org/packages/5c/e0/be401c003291b56efc55aeba6a80ab790d3d4cece2778288d65323009420/pip-19.1.1-py2.py3-none-any.whl (1.4MB) 100% |################################| 1.4MB 1.6MB/s Collecting setuptools Downloading https://files.pythonhosted.org/packages/ec/51/f45cea425fd5cb0b0380f5b0f048ebc1da5b417e48d304838c02d6288a1e/setuptools-41.0.1-py2.py3-none-any.whl (575kB) 100% |################################| 583kB 2.1MB/s Installing collected packages: pip, setuptools Found existing installation: pip 19.0.3 Uninstalling pip-19.0.3: Successfully uninstalled pip-19.0.3 Found existing installation: setuptools 28.8.0 Uninstalling setuptools-28.8.0: Successfully uninstalled setuptools-28.8.0 Successfully installed pip-19.1.1 setuptools-41.0.1Pythonバージョンの切り替え
OSGeo4W ShellのPythonバージョンが2系でしたので3系に切り替えます。
3系だったら不要だと思います。
OSGeo4W Shellでpy3_envを投げます。
自動的にいくつかSETコマンドが流れます。C:\Windows\System32>py3_env C:\Windows\System32>SET PYTHONPATH= C:\Windows\System32>SET PYTHONHOME=C:\PROGRA~1\QGIS3~1.4\apps\Python37 C:\Windows\System32>PATH C:\PROGRA~1\QGIS3~1.4\apps\Python37;C:\PROGRA~1\QGIS3~1.4\apps\Python37\Scripts;C:\PROGRA~1\QGIS3~1.4\apps\Python27\Scripts;C:\PROGRA~1\QGIS3~1.4\bin;C:\windows\system32;C:\windows;C:\windows\system32\WBem変わったことを確認しましょう。
C:\Windows\System32>python -V Python 3.7.0Pythonコンソールと同じバージョンに変わりました。
Pandasモジュールの追加
pipを使ってPandasを追加しましょう。
OSGeo4W Shellでpython -m pip install pandasと投げます。C:\Windows\System32>python -m pip install pandas Collecting pandas Downloading https://files.pythonhosted.org/packages/61/c7/f943fceb712579bc538700e2c157dc4972e16abfe29bd4969149bad98c74/pandas-0.24.2-cp37-cp37m-win_amd64.whl (9.0MB) 100% |████████████████████████████████| 9.0MB 24kB/s Requirement already satisfied: python-dateutil>=2.5.0 in c:\progra~1\qgis3~1.4\apps\python37\lib\site-packages (from pandas) (2.7.5) Requirement already satisfied: numpy>=1.12.0 in c:\progra~1\qgis3~1.4\apps\python37\lib\site-packages (from pandas) (1.16.3) Requirement already satisfied: pytz>=2011k in c:\progra~1\qgis3~1.4\apps\python37\lib\site-packages (from pandas) (2018.7) Requirement already satisfied: six>=1.5 in c:\progra~1\qgis3~1.4\apps\python37\lib\site-packages (from python-dateutil>=2.5.0->pandas) (1.12.0) Installing collected packages: pandas Successfully installed pandas-0.24.2成功しました。
動作確認
では確認してみましょう。
QGISを再起動してから再度Pythonコンソールを開きます。
そしたら先ほどエラーが出たimport pandasを実行してみます。
エラーなくインポートできましたので適当なエクセルファイルでも読み込んでみましょう。>>> import pandas >>> pandas.read_excel('c:/work/test.xlsx') a b c 0 50351610 12.25218 -10.13777 1 50351611 12.25274 -10.14224 2 50351612 12.24903 -10.14193
読み込めました。
GeoPandasに挑戦
OSGeo4W Shellで
python -m pip install geopandasと投げます。C:\Windows\System32>python -m pip install geopandas Collecting geopandas Downloading https://files.pythonhosted.org/packages/74/42/f4b147fc7920998a42046d0c2e65e61000bc5d104f1f8aec719612cb2fc8/geopandas-0.5.0-py2.py3-none-any.whl (893kB) 100% |████████████████████████████████| 901kB 6.5MB/s Requirement already satisfied: pyproj in c:\progra~1\qgis3~1.4\apps\python37\lib\site-packages (from geopandas) (1.9.6) Requirement already satisfied: shapely in c:\progra~1\qgis3~1.4\apps\python37\lib\site-packages (from geopandas) (1.6.4.post2) Requirement already satisfied: pandas in c:\progra~1\qgis3~1.4\apps\python37\lib\site-packages (from geopandas) (0.24.2) Collecting fiona (from geopandas) Downloading https://files.pythonhosted.org/packages/41/9d/63696e7b1de42aad294d4781199a408bec593d8fdb80a2b4a788c911a33b/Fiona-1.8.6.tar.gz (1.7MB) 100% |████████████████████████████████| 1.7MB 3.1MB/s Complete output from command python setup.py egg_info: A GDAL API version must be specified. Provide a path to gdal-config using a GDAL_CONFIG environment variable or use a GDAL_VERSION environment variable. ---------------------------------------- Command "python setup.py egg_info" failed with error code 1 in C:\Users\hoge\AppData\Local\Temp\pip-install-p0dr78y4\fiona\おっと、エラーがでましたね。
fionaというライブラリがgdal-configへのパスが指定されていないと怒っているようです。
同じ問題に困っている人は見つかりますが、簡単には解決しなそうなので一旦あきらめます。こちらを参考にやってみたら成功しました。
https://gis.stackexchange.com/questions/82200/how-to-install-fiona-to-read-shapefile-attributes-with-osgeo4w/82206まずは環境変数に変数
GDAL_VERSIONSで値2.3.2を追加します。
以下のURLからFiona‑1.8.6‑cp37‑cp37m‑win_amd64.whlをダウンロードする。
https://www.lfd.uci.edu/~gohlke/pythonlibs/#fionaダウンロードファイルを適当な場所に移動したら
OSGeo4W Shellでインストールを実行C:\Windows\System32>python -m pip install c:/work/Fiona-1.8.6-cp37-cp37m-win_amd64.whl Processing c:/work/fiona-1.8.6-cp37-cp37m-win_amd64.whl Collecting click>=4.0 (from Fiona==1.8.6) Downloading https://files.pythonhosted.org/packages/fa/37/45185cb5abbc30d7257104c434fe0b07e5a195a6847506c074527aa599ec/Click-7.0-py2.py3-none-any.whl (81kB) |████████████████████████████████| 81kB 2.6MB/s Collecting munch (from Fiona==1.8.6) Downloading https://files.pythonhosted.org/packages/68/f4/260ec98ea840757a0da09e0ed8135333d59b8dfebe9752a365b04857660a/munch-2.3.2.tar.gz Collecting click-plugins>=1.0 (from Fiona==1.8.6) Downloading https://files.pythonhosted.org/packages/e9/da/824b92d9942f4e472702488857914bdd50f73021efea15b4cad9aca8ecef/click_plugins-1.1.1-py2.py3-none-any.wh l Collecting cligj>=0.5 (from Fiona==1.8.6) Downloading https://files.pythonhosted.org/packages/e4/be/30a58b4b0733850280d01f8bd132591b4668ed5c7046761098d665ac2174/cligj-0.5.0-py3-none-any.whl Collecting attrs>=17 (from Fiona==1.8.6) Downloading https://files.pythonhosted.org/packages/23/96/d828354fa2dbdf216eaa7b7de0db692f12c234f7ef888cc14980ef40d1d2/attrs-19.1.0-py2.py3-none-any.whl Requirement already satisfied: six>=1.7 in c:\progra~1\qgis3~1.4\apps\python37\lib\site-packages (from Fiona==1.8.6) (1.12.0) Installing collected packages: click, munch, click-plugins, cligj, attrs, Fiona Running setup.py install for munch ... done Successfully installed Fiona-1.8.6 attrs-19.1.0 click-7.0 click-plugins-1.1.1 cligj-0.5.0 munch-2.3.2先ほど失敗したfionaがインストールできましたのでもう一度GeoPandasを追加してみましょう。
C:\Windows\System32>python -m pip install geopandas Collecting geopandas Using cached https://files.pythonhosted.org/packages/74/42/f4b147fc7920998a42046d0c2e65e61000bc5d104f1f8aec719612cb2fc8/geopandas-0.5.0-py2.py3-none-any.whl Collecting pyproj (from geopandas) Using cached https://files.pythonhosted.org/packages/ce/36/2d8f1fe6bf32eebc0e880d9f27b394b97dd5119303986de691d7e91e1a51/pyproj-2.2.1-cp37-cp37m-win_amd64.whl Requirement already satisfied: fiona in c:\progra~1\qgis3~1.4\apps\python37\lib\site-packages (from geopandas) (1.8.6) Collecting shapely (from geopandas) Using cached https://files.pythonhosted.org/packages/a2/fb/7a7af9ef7a35d16fa23b127abee272cfc483ca89029b73e92e93cdf36e6b/Shapely-1.6.4.post2.tar.gz Requirement already satisfied: pandas in c:\progra~1\qgis3~1.4\apps\python37\lib\site-packages (from geopandas) (0.24.2) Requirement already satisfied: click>=4.0 in c:\progra~1\qgis3~1.4\apps\python37\lib\site-packages (from fiona->geopandas) (7.0) Requirement already satisfied: attrs>=17 in c:\progra~1\qgis3~1.4\apps\python37\lib\site-packages (from fiona->geopandas) (19.1.0) Requirement already satisfied: cligj>=0.5 in c:\progra~1\qgis3~1.4\apps\python37\lib\site-packages (from fiona->geopandas) (0.5.0) Requirement already satisfied: six>=1.7 in c:\progra~1\qgis3~1.4\apps\python37\lib\site-packages (from fiona->geopandas) (1.12.0) Requirement already satisfied: munch in c:\progra~1\qgis3~1.4\apps\python37\lib\site-packages (from fiona->geopandas) (2.3.2) Requirement already satisfied: click-plugins>=1.0 in c:\progra~1\qgis3~1.4\apps\python37\lib\site-packages (from fiona->geopandas) (1.1.1) Requirement already satisfied: numpy>=1.12.0 in c:\progra~1\qgis3~1.4\apps\python37\lib\site-packages (from pandas->geopandas) (1.15.4) Requirement already satisfied: pytz>=2011k in c:\progra~1\qgis3~1.4\apps\python37\lib\site-packages (from pandas->geopandas) (2018.7) Requirement already satisfied: python-dateutil>=2.5.0 in c:\progra~1\qgis3~1.4\apps\python37\lib\site-packages (from pandas->geopandas) (2.7.5) Installing collected packages: pyproj, shapely, geopandas Running setup.py install for shapely ... done Successfully installed geopandas-0.5.0 pyproj-2.2.1 shapely-1.6.4.post2今度は成功したようです。
動作確認
QGISを再起動してからPythonコンソールを開きます。
import geopandasを実行してみます。
エラーなくインポートできましたので適当なシェープファイルでも読み込んでみましょう。>>> import geopandas >>> geopandas.read_file('c:/work/test_pl.shp') gid geometry 0 1845193 LINESTRING (-34287.477 -89755.997, -34283.604 ... 1 1847175 LINESTRING (-30711.356 -90881.484, -30712.981 ... 2 1847176 LINESTRING (-33770.897 -91487.429, -33769.417 ... 3 1847177 LINESTRING (-34019.315 -87829.27899999999, -34... ・ ・省略 ・ 13548 1661930 LINESTRING (-32960.024 -87385.46400000001, -32... 13549 1661931 LINESTRING (-36652.435 -88311.53999999999, -36... 13550 1661932 LINESTRING (-33645.849 -89185.613, -33619.816 ... [13551 rows x 5 columns]成功ですね。
さいごに
今回はPandasを対象としましたが、もちろん他のモジュール追加も可能です。
(GeoPandasは失敗しましたけど)そして、これでプラグインからもPandasが使えるようになります。
個人的にはQGISプラグインなどで演算パフォーマンスが必要な場合に馬鹿にならない効果があるんじゃないかと思います。ただし、使えるようにするには上記のような手順が必要になってしまうので、公開プラグインには向かないですね。
何かいい方法があれば教えてもらえたら嬉しいです。本記事のライセンス
この記事は クリエイティブ・コモンズ 表示 4.0 国際 ライセンスの下に提供されています。
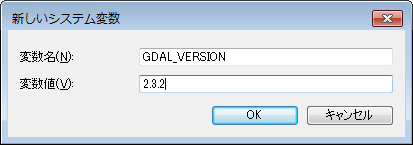
- 投稿日:2019-07-01T15:07:42+09:00
Flaskの自分用いろいろ
インストール
pythonはインストール済みのUbuntu(18.04)前提です。
pip install Flaskメインになるやつ
run.pyfrom flask import Flask from flask import Flask, request, render_template app = Flask(__name__) @app.route('/') def index(): return render_template('index.html') if __name__ == '__main__': app.debug = True app.run(host='0.0.0.0', port=80)備考
- これだと80ポートで動くのでapache2とか動いてるとエラーが出ます.
- 誰でもアクセスできる状態(変更したい場合はapp.runのあたりを変える)
- デバッグモードが有効化されてる状態(無効化したいときはapp.debugをFalseに)
- 処理とかはここに書く..らしい(他サイト参照)
htmlとか各種ファイルのパス
ここで2時間ぐらい躓いてたhtmlはtemplatesフォルダ内に置く
css、JavaScript、画像等はstatic内にフォルダを作って置く
run.py /templates //index.html //hogehoge.html /static //css ///main.css ///ほげほげ.css //images ///hoge.png //JS ///hogehoge.js
(見にくいなこれ)
置く場所を変更することもできるらしいけど標準だとこうなるらしい.htmlでのパスの書き方
index.html<head> <link rel="stylesheet" href="{{ url_for('static',filename='css/main.css')}}"> <script src="{{ url_for('static',filename='JS/hogehoge.js')}}"></script> </head> <body> ... <img src="{{ url_for('static',filename='images/hoge.png')}}"></img> ... </body>実行
hoge@hoge:/var/www/html$ sudo python3 run.py * Serving Flask app "run" (lazy loading) * Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Debug mode: on * Running on http://0.0.0.0:80/ (Press CTRL+C to quit) * Restarting with stat * Debugger is active! * Debugger PIN: 810-364-364お疲れ様でした!
- 投稿日:2019-07-01T14:41:19+09:00
Djangoのstaticファイルが404から復活した話
あらすじ
djangoのstaticファイルがrunserverだとアクセスできたのにapacheだとアクセスできませんでした。解決方法が分かったので、頭の整理を兼ねて書き起こしました。Bitnami前提のため、直接Apacheを入れている人は読みかえてください。
流れ
- Windows PC を用意。 64bit。
- BITNAMI DJANGO STACK を利用して、mysqlとapacheをインストールする。
- Create A New Django Projectを参考にdjangoでプロジェクトを作成
- Deploy A Django Projectを参考にデプロイ設定
- サイトにアクセス
- 画像やCSSを読み込めまない!
- settings.pyとhttpd-app.confに追記して collectstatic した。
- サイトにアクセス
- 無事に読み込み成功!
読み込まなかったファイル
画像の例<img width="30" src="{% static '[app-name]/bitmap.png' %}" height="30" class="d-inline-block align-top" alt="">CSSの例<link rel="stylesheet" href="{% static '[app-name]/css/style.css' %}">ディレクトリ構成
directory-tree[project-directory]/ ┣ [project-name]/ ┃ ┣ settings.py ┃ ┗ ... ┣ static/ ┃ ┗ ... ┣ [app-name]/ ┃ ┣ static/ ┃ ┃ ┗ [app-name]/ ┃ ┃ ┣ css/ ┃ ┃ ┃ ┗ ... ┃ ┃ ┣ js/ ┃ ┃ ┃ ┗ ... ┃ ┃ ┣ img/ ┃ ┃ ┃ ┗ ... ┃ ┃ ┗ ... ┃ ┗ ... ┗ deploy/ # deploy用のディレクトリ ┃ ┣ [app-name]/ ┃ ┗ ... ┗ ...staticのアクセス許可を設定
[projectname]\settings.pySTATIC_URL = '/static/' # 配信用のURL STATIC_ROOT = os.path.join(BASE_DIR, 'deploy') # プロジェクト直下のdeployディレクトリを指定 STATICFILES_DIRS = ( os.path.join(BASE_DIR, 'static'), # プロジェクト直下のstaticディレクトリを指定 )conf\httpd-app.conf:追記# collectstaticでコピーしたstaticディレクトリのパスを登録 Alias /static/ [deploy用のディレクトリ] # staticへのアクセスを許可 <Directory [deploy用のディレクトリ]> Require all granted </Directory>
[deploy用のディレクトリ]はWindows10では"%userprofile%/Bitnami Django Stack projects/[project-dirctory]/deploy/"設定追記が出来たら
python manage.py collectstaticで一か所にまとめます。
Note:この時にadminサイトのstaticも一緒にまとまるので予想外のファイル数に驚かないように!
↓
apacheを再起動してブラウザでアクセス参考にしたサイト
- 投稿日:2019-07-01T14:08:36+09:00
Pythonでツイートを生成したい! -マルコフ連鎖編-
環境
ubuntu 16.04 LTS
python 3.7.3やること
マルコフ連鎖をpythonで簡単に実装し、ツイートを自動生成します。元データにはTwitter APIで取得したツイートを使用します。
マルコフ連鎖について
マルコフ連鎖とは一つ前の状態から次の状態が決まるような連鎖です。例えば「今日は晴れだった」「明日は雨が降るらしい」という2つの文があった場合、「今日」であれば次は「は」になる確率が100%です。その「は」については、「晴れ」と「雨」がそれぞれ50%の確率で連鎖していきます。また「らしい」はそれに続く単語がないので連鎖がストップします。
つまり、データに存在する任意の単語に対してどんな単語がどれくらいの確率で続くかを分かるようにすればいいということです。①データの収集・前処理
Twitter APIのsearch/tweetsでツイートを取得します。皆様の悲痛な叫びを代弁するため、検索ワードは「月曜」にしました。ツイートを取得後、ユーザーIDやURL、空白の行を削除します。また検索結果にRTを含むと直近でバズっているツイートがある場合そればっかりになってしまうので検索オプションであらかじめ除きます。前処理まで完了したら、テキストファイルとして一旦保存します。
Twitter APIやpythonにおけるsearch/tweetsの基本的な使い方については前記事のhttps://qiita.com/h_tashiro/items/ed119c237f5595c3d7b8 をご覧ください。
コード
import urllib import io from requests_oauthlib import OAuth1Session, OAuth1 import requests import sys import re def main(): # APIの認証キー CK = 'xxxxxxxxxxxxxxxx' CKS = 'xxxxxxxxxxxxxxxx' AT = 'xxxxxxxxxxxxxxxx' ATS = 'xxxxxxxxxxxxxxxx' # 検索ワード word = '月曜' # 検索時のパラメーター count = 100 # 一回あたりの検索数(最大100/デフォルトは15) range = 180 # 検索回数の上限値(最大180/15分でリセット) # インスタンス作成 get = Get_tweets() # ツイート検索 tweets = get.search_tweets(CK, CKS, AT, ATS, word, count, range) # 前処理 tweets = get.preprocess(tweets) # テキストファイルに保存 path = 'tweets.txt' get.to_text(tweets, path) class Get_tweets: def search_tweets(self, CK, CKS, AT, ATS, word, count, range): # 文字列設定 word += ' exclude:retweets' # RTは除く word = urllib.parse.quote_plus(word) sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8') # リクエスト url = "https://api.twitter.com/1.1/search/tweets.json?lang=ja&q="+word+"&count="+str(count) auth = OAuth1(CK, CKS, AT, ATS) response = requests.get(url, auth=auth) data = response.json()['statuses'] # 2回目以降のリクエスト cnt = 1 tweets = [] count_tweets = 0 while True: if len(data) == 0: break if cnt > range: break cnt += 1 for tweet in data: tweets.append(tweet['text']) count_tweets += 1 maxid = int(tweet["id"]) - 1 url = "https://api.twitter.com/1.1/search/tweets.json?lang=ja&q="+word+"&count="+str(count)+"&max_id="+str(maxid) response = requests.get(url, auth=auth) try: data = response.json()['statuses'] except KeyError: # リクエスト回数が上限に達した場合のデータのエラー処理 print('上限まで検索しました') break print('取得したツイート数 :', count_tweets) return tweets def preprocess(self, tweets): for i in range(len(tweets)): tweets[i] = re.sub(r'@\w+', '', tweets[i]) # ユーザーID tweets[i] = re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-]+', '', tweets[i]) # URL tweets[i] = re.sub(r'\n{2,}', '\n', tweets[i]) # 空白の行] return tweets def to_text(self, tweets, path): with open(path, 'w') as f: for tweet in tweets: f.write(tweet + '\n') if __name__ == '__main__': main()②分かち書き
得られたツイートを品詞ごとに分かち書き(半角スペースで空ける)をします。Mecabを使い、①で保存したテキストファイルから分かち書き後のテキストファイルを出力して保存します。専用のライブラリやsubprocessを使ってpython上でも実行できますが、今回はサクッとコマンドラインでMecabを使います。
$ mecab tweets.txt -O wakati -o wakati.txt③マルコフ連鎖の実装とツイート生成
マルコフ連鎖について
先ほどの「今日は晴れだった」「明日は雨が降るらしい」という文であれば、{'今日':['は'], 'は':['晴れ','雨'], ...}というように、一つ前の単語をキーとして、それに続く単語をリストにします。この時リスト内での単語の重複を許します。また辞書にする前に一度行ごとに単語をリスト化するのですが、行の始めには「0」を開始文字として挿入します。この「0」は終端文字としても機能します。
ツイート生成について
マルコフ連鎖に限らず、例えばRNNなどの時系列解析による文章自動生成でも一つ前(まで)の状態を考慮して単語をつなげていきます。ここで、数列において初項が大切なように、どんな単語から文章を始めるかというのはしばしば問題になります。今回は「月曜」を最初の単語として文章を生成しますが、例えば開始文字の直後=文頭の単語をランダムに選ぶなどのやり方もあります。
最初の単語が決まったら、その単語をキーとして値であるリスト内から単語をランダムに選択します。リストをつくる際に単語の重複を許したので、元データにおける単語の出現確率をそのまま反映できます。この連鎖を終端文字にぶつかるまでつなげます。
また連鎖によってはかなり長い文章を生成してしまうのでlimitというパラメーターで単語数を制限します。今回は30で統一します。
コード
import random def main(): # インスタンス生成 markov = Markov() # 分かち書きしたテキストファイルのパス path = 'wakati.txt' # 最初の単語 first_word = '月曜' # 連鎖数の上限 limit = 30 # 単語ごとの辞書を作成 dict = markov.to_dict(path) # ツイートを10回生成 for i in range(10): tweet = markov.gen_tweet(dict, first_word, limit) print(tweet) class Markov: def to_dict(self, path): wordlist = [] with open(path, 'r') as f: line = f.readline() while line: pre_wordlist = [0] pre_wordlist.extend(line.split()) wordlist.extend(pre_wordlist) line = f.readline() wordlist.append(0) dict = {} pre_word = '' for word in wordlist: if pre_word: if pre_word in dict: list = dict[pre_word] else: list = [] list.append(word) dict[pre_word] = list pre_word = word return dict def gen_tweet(self, dict, first_word, limit): tweet = "" word = first_word cnt = 0 while cnt <= limit: if word == 0: break tweet += word word = random.choice(dict[word]) cnt += 1 return tweet if __name__ == '__main__': main()出力結果
月曜にされなくてたら肩が7/21時よりディナー予約表で快適そのもので早いなぁ…? 月曜のまとめ 月曜の朝からバタバタなのに… 月曜は月曜で最も重要ライブできるから7月なことでよければ底過ぎる 月曜きらい。 月曜夕方ヒトカラスカポコチャ配信です今月会いたいですし親指のサポート!是非遊んで頑張れそうでは休みだというやる気がいませ 月曜の首に!!明日月曜一限で、何時31分の情報を想定内の朝 月曜じゃん。九州、本番であっ、月曜から頑張らなく母と李くんやっくんになりそうです 月曜なはずな 月曜でさえ日曜の朝は頑張れる!!ヒトカラスカポコチャ配信をする方もいるようですが、どちらかというとやはり負の感情が強いですね。出来としてはかなり微妙です。特に固有名詞や特殊な単語が入ると汎用性を下げるので(そこが面白いところではありますが)、例えば単語の出現回数を二乗して単語選択の確率をそれに応じたものにしたり、出現回数が1回の単語を除くなどの方法が考えられます。また一つ前の単語との関わりしか考慮されないので、全体としての意味に一貫性のない文章になりがちです。特に後者を解決するために、LSTMなどの深層学習での時系列解析を試してみたいです。
- 投稿日:2019-07-01T13:31:07+09:00
Pythonの推薦システム向けライブラリSurpriseとFlaskでレコメンデーションエンジンを作成する
まずはSurpriseというライブラリをインストールします。
pip install scikit-surpriserecommender.pyfrom collections import defaultdict from surprise import SVD from surprise import Dataset def get_top_n(predictions, n=10): ''' 予測セットに基いて各ユーザにトップN件のレコメンデーションを返す。 ''' # まず各ユーザに予測値をマップする。 top_n = defaultdict(list) for uid, iid, true_r, est, _ in predictions: top_n[uid].append((iid, est)) # そして各ユーザに対して予測値をソートして最も高いk個を返す。 for uid, user_ratings in top_n.items(): user_ratings.sort(key=lambda x: x[1], reverse=True) top_n[uid] = user_ratings[:n] return top_n # まずmovielensデータセットでSVDアルゴリズムを学習させる。 data = Dataset.load_builtin('ml-100k') trainset = data.build_full_trainset() algo = SVD() algo.fit(trainset) # そして学習用データに含まれていない全ての(ユーザ、アイテムの)組み合わせに対して評価を予測する。 testset = trainset.build_anti_testset() predictions = algo.test(testset) top_n = get_top_n(predictions, n=10) # 各ユーザにレコメンドされるアイテムを表示する。 for uid, user_ratings in top_n.items(): print(uid, [iid for (iid, _) in user_ratings]) # json形式で結果を保存する。 with open('./results.json', 'w') as f: json.dump(top_n, f, indent=2, ensure_ascii=False)api.pyimport json import flask from flask import request, jsonify app = flask.Flask(__name__) app.config["DEBUG"] = True app.config['JSON_AS_ASCII'] = False # データの読み込み with open('./results.json') as f: movies = json.loads(f.read()) # ホーム # http://127.0.0.1:5000/ @app.route('/', methods=['GET']) def home(): return '''<h1>シンプルな推薦システム</h1> <p>映画レコメンデーションのためのAPIプロトタイプ</p>''' # 全てのアイテム # http://127.0.0.1:5000/api/v1/resources/movies/all @app.route('/api/v1/resources/movies/all', methods=['GET']) def api_all(): return jsonify(movies) # 特定のユーザIDのアイテム # http://127.0.0.1:5000/api/v1/resources/movies?id=1 @app.route('/api/v1/resources/movies', methods=['GET']) def api_id(): # URLにIDが含まれているか確認する。 # IDが含まれていれば、変数に代入する。 # IDが含まれていなければブラウザにエラーを表示する。 if 'id' in request.args: id = str(request.args['id']) else: return "エラー: IDが含まれていません。IDを指定してください。" items = movies.get(id) # 結果のために空のリストを作成する。 results = [] # リストに映画を追加していく。 for i in range(len(items)): item = items[i][0] results.append(item) # Pythonの辞書のリストをJSON形式に変換するためFlaskのjsonify関数を使う。 return jsonify(results) app.run()ターミナルもしくはコマンドプロンプトで
python recommender.py
を実行して、レコメンドするアイテム一覧を作成。
python api.py
を実行してFlaskアプリケーションを起動。ブラウザで
http://127.0.0.1:5000/
がホーム画面
http://127.0.0.1:5000/api/v1/resources/movies/all
が全てのアイテム
http://127.0.0.1:5000/api/v1/resources/movies?id=1
がIDが1のユーザに対して推薦するアイテムのID
となります。何かおかしな点やアドバイス等がございましたらコメントいただけますと幸いです。
参考:
https://surprise.readthedocs.io/en/stable/FAQ.html
https://programminghistorian.org/en/lessons/creating-apis-with-python-and-flask
- 投稿日:2019-07-01T12:44:41+09:00
【Python】小数点以下の値の丸め(切り捨て)
Pythonで小数点以下の数値を切り捨てたいときを考えます。例えば、10.987654321と入力した場合に、小数点2位まで取り出して、10.98と返してくれるような関数を考えます。
環境
- Windows 10
- python=3.7.3
方法① (精度に問題あり)
値を100倍して、Intにして、100で割る
def round_off_to_two_decimal_places_1(input_val: float) -> float: output = int(input_val * 100) / 100 return output def round_off_test(round_off_method): input_val = 10.987654321 print(input_val, "->", round_off_method(input_val)) input_val = 10.12 print(input_val, "->", round_off_method(input_val)) input_val = 10.99 print(input_val, "->", round_off_method(input_val)) input_val = 10.74297492 print(input_val, "->", round_off_method(input_val)) input_val = 10.155 print(input_val, "->", round_off_method(input_val)) input_val = 10.585018 print(input_val, "->", round_off_method(input_val)) input_val = 10.000000 print(input_val, "->", round_off_method(input_val)) input_val = 10. print(input_val, "->", round_off_method(input_val)) print("") round_off_test(round_off_to_two_decimal_places_1)実行結果10.987654321 -> 10.98 10.12 -> 10.11 10.99 -> 10.99 10.74297492 -> 10.74 10.155 -> 10.15 10.585018 -> 10.58 10.0 -> 10.0 10.0 -> 10.0良さそうに見えますが、10.12を入力した場合に10.11と返されてしまっています。
方法②
文字列として操作する。
def round_off_to_two_decimal_places_2(input_val: float) -> float: str_input_val = str(input_val) split_str = str_input_val.split('.') if len(split_str[1]) > 2: split_str[1] = split_str[1][:2] # 小数点以下2桁取り出す str_output = '.'.join(split_str) return float(str_output) round_off_test(round_off_to_two_decimal_places_2)実行結果10.987654321 -> 10.98 10.12 -> 10.12 10.99 -> 10.99 10.74297492 -> 10.74 10.155 -> 10.15 10.585018 -> 10.58 10.0 -> 10.0 10.0 -> 10.0力技ですが、一応意図した値は返してくれるようです。
方法③
Decimalのquantizeメソッドを使う。
from decimal import Decimal, ROUND_DOWN def round_off_to_two_decimal_places_3(input_val: float) -> float: TWOPLACES = Decimal(10) ** -2 output = Decimal(str(input_val)).quantize(TWOPLACES, rounding=ROUND_DOWN) return float(output) round_off_test(round_off_to_two_decimal_places_3)実行結果10.987654321 -> 10.98 10.12 -> 10.12 10.99 -> 10.99 10.74297492 -> 10.74 10.155 -> 10.15 10.585018 -> 10.58 10.0 -> 10.0 10.0 -> 10.0意図した値が返ってきてます。
補足
ContextのtrapsにInexactを設定すると、丸めが発生したことを通知することもできます。
from decimal import Decimal, ROUND_DOWN, Context, Inexact def round_off_to_two_decimal_places_4(input_val: float) -> float: TWOPLACES = Decimal(10) ** -2 try: output = Decimal(str(input_val)).quantize( TWOPLACES, rounding=ROUND_DOWN, context=Context(traps=[Inexact])) except Inexact: print("値の丸めが発生") output = Decimal(str(input_val)).quantize(TWOPLACES, rounding=ROUND_DOWN) return float(output) round_off_test(round_off_to_two_decimal_places_4)実行結果値の丸めが発生 10.987654321 -> 10.98 10.12 -> 10.12 10.99 -> 10.99 値の丸めが発生 10.74297492 -> 10.74 値の丸めが発生 10.155 -> 10.15 値の丸めが発生 10.585018 -> 10.58 10.0 -> 10.0 10.0 -> 10.0結果
Pythonで浮動小数点を扱う場合は、Decimalを使うのがよさそうです。
参考URL
- 投稿日:2019-07-01T12:44:20+09:00
Kivyのgraphics使ってみた
概要
kivyのgraphicsクラスのメソッドで使い方が直感的に分からなかったものがあったので、思いだすようでかいておきたいと思います。説明するのは、color,ellipse,rectangle,meshです。
実行環境
次に実行環境を示します。
Soft and Hard バージョン Ubuntu 16.04 Python 2.7 kivy 1.10.0 また、Graphicsの公式ドキュメントはこちらです。
各メソッド
Color
後に描画される頂点の色の状態を設定するです。これは0と1の間の色を表しますが、続くキャンバス内の任意の頂点命令のテクスチャに
乗数として適用されます。テクスチャが設定されていない場合は頂点命令はColor命令の正確な色を取ります。例えば、Rectangleが均一な色(0.5, 0.5, 0.5, 1.0)
のテクスチャを持ち、先行Colorがrgba =rgba=(1, 0.5, 2, 1)の場合、実際の表示色は(0.5, 0.25, 1.0, 1.0)です。なぜならColor命令はすべての
rgbaコンポーネントに乗数として適用されるからです。 この場合は0〜1の範囲外の色成分は青色成分が目に2倍の強さになると結果を与えます。
引数を次に示します。Parameters:
a:Added in 1.0.0
レッドコンポーネントは0~1です。b:Added in 1.0.0 ブルーコンポーネントは0~1です。 g:Added in 1.0.0 グリーンコンポーネントは0~1です。 h:Added in 1.0.0 色相コンポーネントは0~1です。 hsv:Added in 1.0.0 HSVカラーは範囲が0~1の値が3つのリストと、1つのアルファを持ちます。 r:Added in 1.0.0 赤コンポーネントは0~1です rgb:Added in 1.0.0 RGBカラーは範囲が0~1の値が3つのリストです。 rgba:Added in 1.0.0 RGBAカラーは範囲が0~1の値が4つのリストです。 s:Added in 1.0.0 彩度コンポーネントは0~1です。 v:Added in 1.0.0 値コンポーネントは0~1です。ellipse
2次元の楕円を出力する命令です。引数を次に示します。
Parameters:
segments: int, デフォルト値は180
楕円を描くために必要なセグメントの数を定義します。 多くのセグメントがある場合は図はスムーズになります。angle_start: int, デフォルトは 0です 円の部分の開始角度を度で指定します。 angle_end: int, デフォルトは 360です 円の部分の終了角度を度で指定します。 angle_end¶Added in 1.0.0 楕円の終了角度(単位:度)。デフォルトは360です。 angle_start¶Added in 1.0.0 楕円の開始角度(単位:度)。デフォルトは0です。 segments¶Added in 1.0.0 楕円のセグメント(分割)数を設定/取得するためのプロパティです。rectangle
2次元の四角形を出力する命令です。引数を次に示します。
Parameters:
pos: list
四角形の位置を指定します。フォーマットは(x, y)です。size: list 四角形の大きさを指定します。フォーマットは(width, height)です。mesh
2次元のメッシュを出力する命令です。引数を次に示します。メッシュのindicesとverticesの関係は次のイメージで説明します。
Parameters:
indices: iterable
インデックスのリストのフォーマット (i1, i2, i3...)です。vertices: list メッシュの構築に使用されたx, y, u, v 座標のリスト。メッシュ命令では頂点のフォーマットを今すぐ変更できません。 つまり、x、y + 1つのテクスチャ座標だけです。 mode: str インデックスの描画に使用されるVBOモードです。 ‘points’, ‘line_strip’, ‘line_loop’, ‘lines’, ‘triangles’, ‘triangle_strip’、’triangle_fan’ のいずれかになります。 fmt: list verticeの形式は、デフォルトでは各頂点は2D座標(x,y)と2Dテクスチャ座標(U,V)によって記述されています。リストの各要素はtupleまたはリストの形式であるべきです。また、三角形を描きたい場合は3つの頂点を追加します。次のようにしてインデックスリストを作成できます。
indices = [0, 1, 2]三角形のイメージは次の通りです。

まとめ
3Dや2Dに関してあまり詳しくない為、meshのようなものにうーんとなってしまいました。うーんとなってしまっている人の助けになっていたら嬉しいです。
- 投稿日:2019-07-01T12:10:07+09:00
なぜサードパーティ・ライブラリを避けるべきなのか?
例えば Rubyには標準ライブラリに
net/httpがありますが、より高機能なサードパーティ・ライブラリであるfaradayが普及しています。しかし、私は先日あるプロジェクトであえて
faradayを避けnet/httpを使うことを選びました。私は以下のような理由から、場合によってはサードパーティ・ライブラリは避けるべきと思っています。昔話:Pythonをシェルスクリプトで書き直した
「シェルスクリプトをPythonで」ではありません。
若い頃あるプログラムを任された私は「RHELなら標準でPythonがインストールされている。このプログラムは RHEL でしか動かさないんだから、Pythonで書いてもいいだろう。PythonはBashより可読性も高いし、クールだ!」と考え、Pythonで書いた結果、先輩にゲンコツ(の絵文字)を食らいました。
というのも、任されたプログラムが、商用パッケージのアップデート用スクリプトだったからです。「RHELでしか動かさない」ものの、RHEL のバージョンは顧客によりまちまちでした(4.x 〜 5.x)。
Python では複数のバージョンで動くスクリプトを書くのは注意が必要です(2.4にはwith文が無い!)。気を付けて書いたとしても、そのスクリプトが将来のバージョンでも動く保証はありません(2.5では
withという変数名は使えない!)。一方、シェルスクリプトはどのRHELでも同じように動作することが期待できます(少なくともPythonよりは確実性が高い)。
サードパーティはコントロールできない
さて、サードパーティ・ライブラリの話です。
サードパーティ・ライブラリはあなたの所有物ではありません。ゆえに、ライブラリが削除されたり、大きな変更が加わったりすることを止めることはできません。
これが如実に現れたのが、2016年のleft-pad問題でした1。left-padというライブラリが公開停止されたことで、それに推移的に依存していたReactやBabelなどの有名ライブラリが動作しなくなったのです。
「left-padは極端な例だろう」と思われるでしょう。でも、メジャーバージョンアップで後方互換性が無くなるのは、珍しいことではありません。そうなったら、
- 自分のコードを新バージョン向けに修正する(もちろん、テスト等の工数もかかる)
- もはやメンテされない旧バージョンを使い続ける(場合によってはフォーク版を作る)
という選択に迫られます。
そんなリスクを追うぐらいなら、多少不便でも標準ライブラリ
そのサードパーティ、そんなに重要?
さて結局、サードパーティ・ライブラリを使うかどうかは、
- バージョンアップ時の書き換えにかかるコスト
- 得られる利便性
この2つを天秤にかけることになります。
あなたが書いているのが「長期間使うが滅多に変更はしないコード」の場合は、「最後に触ったのが3年前だから勘所が思い出せない」「開発環境構築から始めないといけない」「保守フェーズなので工数が取れない」といったことが起きがちなので、最初に標準ライブラリと多少格闘した方が、後々のコストは安いでしょう。一方、書き捨てスクリプトや、頻繁に手を加えるコード0なら、書き換えのコストはゼロあるいは低くなります。
また、例えばPythonでデータ分析処理を書くとき
pandasやnumpyといったライブラリは不可欠でしょう(明らかに利便性がコストに勝ります)。一方、付加的な処理(分析結果の保存とか)で楽をするためにrequestsを導入するというなら、それはちょっと考え直した方がいいかもしれません。
left-pad については、こちらの記事で開設されています: NPMとleft-pad : 私たちはプログラミングのやり方を忘れてしまったのか? | POSTD ↩
- 投稿日:2019-07-01T11:30:32+09:00
TensorFlowで文字列から音声に変換するモデルを試す
やりたいこと・方針
TensorFlowを使って日本語文字データ→音声データへの変換を学習させたい。
1.教師データのサンプルを作成する
2.生成された学習データの特性を確認、加工する
3.文字データ→音声データへの変換を学習させる
4.学習結果を使用して文字データ→音声データ変換を試す
5.少ない教師データ数、短い学習時間で効率的に学習させる方法を考えるやっていることは、音声読み上げソフトと同じことです。
音声加工の知識を全く持たない自分でも、機械学習に頼れば似たような仕組みを真似できるのか?という興味から始まっています。学習データに関しては、音声加工についての知識などもっておりませんので、機械学習のゴリ押しでなんとかする方針です。
音韻長など処理済みのデータを教師にしたほうが間違いなく高効率ですが、そういった処理済みのデータを大量に用意する方法も思いつかないですし、1データずつ人間の耳で聞いて加工するような入手の手間が大きい学習データは使わない方針とします。また、音声加工ではRNN/LSTMを使ってリアルタイム処理するのが定石のようですが、上記のとおりinputデータは音韻長を考慮していない単なるテキストデータのため、inputの各文字を時系列にそって並べられない。(=RNNに適さないと思っています。自分がRNNを理解できていないだけかもしれません。)
そのため今回はRNN/LSTMは使わず、基本的なTensorFlowの機能のみで処理します。あと、自分はpythonもTensorFlowも触りだして間もないので、モデルはKerasに頼って簡単に書きます。
1.教師データのサンプルを作成する
素人の作る非効率な学習モデルでは、おそらく膨大な教師データが必要になると思われるので、voiceroidを自動化して大量の音声データ(wav)を作成する。
使用したソフト:voiceroid2
https://www.ah-soft.net/shopbrand/ct92/pythonで自動化するが、実行ファイルと同じ場所に作成する単語をリストしたinput.txtを用意しておく。
あ あー あーうぃん あーかーと あーかいばー あーかいぶ あーかむ あーかん あーかんそー あーがー上記単語は、『現代日本語書き言葉均衡コーパス』語彙表サイトから短単位語彙表データを入手し、その「読み」の項目を使用。
https://pj.ninjal.ac.jp/corpus_center/bccwj/freq-list.html後で学習データとして使うのに便利にするため、すべての読みをひらがなに変更後、以下のようなデータを削除(VOICEROIDがうまく読めなかったり、今回の目的にふさわしくないもの)
・「ひとつ(数)」「ひと・・・」のように。「(」や「・」を含む単語
・「う゛」を含む単語
・sortすると先頭にくる、制御文字や記号からはじまる単語
また、学習時にはinputを固定長にする必要があるため、15文字以上の単語は一括で削除した。上記データに個人的に学習させたい固有名詞を含めた合計138423個をinput.txtに用意し、
以下のスクリプトでVOICEROID2による自動音声化を行う。自動化のために以下ページが大変参考になった。
VOICEROID2(紲星あかり)をプログラムから動かしてみる# -*- coding: utf-8 -*- import pywinauto import time import os import subprocess #子エレメントをclassnameで検索し、見つかったエレメントを返す関数 def search_child_byclassname(class_name, uiaElementInfo, target_all = False, waitcount = 50): for loop in range(waitcount): #見つからなかった場合にも、少し待って何度か繰り返すためのループ target = [] # 全ての子要素検索 for childElement in uiaElementInfo.children(): # ClassNameの一致確認 if childElement.class_name == class_name: if target_all == False: return childElement else: target.append(childElement) if target_all == False: print ( 'LOOP:' + str(uiaElementInfo.name) + ' searchclass:' + class_name) #見つからなかったらループ else: return target time.sleep(0.2) #0.2秒ごとにリトライ # 0.2秒x50回=10秒待っても見つからなかったらFalse。あまり待つ必要がない処理の場合はwaitcountを指定してすぐにfalseを返すようにする return False #子エレメントをnameで検索し、見つかったエレメントを返す関数 def search_child_byname(name, uiaElementInfo, waitcount = 50): for loop in range(waitcount): #見つからなかった場合にも、少し待って何度か繰り返すためのループ # 全ての子要素検索 for childElement in uiaElementInfo.children(): # Nameの一致確認 if childElement.name == name: return childElement time.sleep(0.2) #0.2秒ごとにリトライ print ( 'LOOP:' + str(uiaElementInfo.name) + ' searchname:' + name ) #見つからなかったらループ # 0.2秒x50回=10秒待っても見つからなかったらFalse。あまり待つ必要がない処理の場合はwaitcountを指定してすぐにfalseを返すようにする return False #子エレメントをnameとclassnameの両方で検索し、両方一致したエレメントを返す関数 def search_child_bynameandclassname(name, class_name, uiaElementInfo, target_all = False, waitcount = 50): for loop in range(waitcount): #見つからなかった場合にも、少し待って何度か繰り返すためのループ target = [] # 全ての子要素検索 for childElement in uiaElementInfo.children(): # ClassNameの一致確認 if childElement.class_name == class_name and childElement.name == name: if target_all == False: return childElement else: target.append(childElement) if target_all == False: print ( 'LOOP:' + str(uiaElementInfo.name) + ' searchname:' + name + ' searchclass:' + class_name) #見つからなかったらループ else: return target time.sleep(0.2) #0.2秒ごとにリトライ # 0.2秒x50回=10秒待っても見つからなかったらFalse。あまり待つ必要がない処理の場合はwaitcountを指定してすぐにfalseを返すようにする return False #アプリの起動および接続 def app_start1(app1,path1,t1): try: app1.Connect(path = path1) except: app1.Start(cmd_line = path1) time.sleep(t1) app1.Connect(path = path1) ## Voiceroid Editorの起動からトップ画面まで def startVOICEROID2(): # アプリ起動 app = pywinauto.Application() path1 = u"C:\Program Files (x86)\\AHS\\VOICEROID2\\VoiceroidEditor.exe" t1 = 2 app_start1(app,path1,t1) ## Voiceroid2 Editor強制終了(ハングアップ時対応) def killVOICEROID2(): cmd = 'taskkill /f /im VoiceroidEditor.exe' returncode = subprocess.call(cmd) ## 引数の文字列を入力して「再生」 def talkVOICEROID2(speakPhrase): # デスクトップのエレメント parentUIAElement = pywinauto.uia_element_info.UIAElementInfo() # voiceroidを捜索する voiceroid2 = search_child_byname("VOICEROID2",parentUIAElement,waitcount=1) # *がついている場合 if voiceroid2 == False: voiceroid2 = search_child_byname("VOICEROID2*",parentUIAElement,waitcount=1) # テキスト要素のElementInfoを取得 TextEditViewEle = search_child_byclassname("TextEditView",voiceroid2) textBoxEle = search_child_byclassname("TextBox",TextEditViewEle) # コントロール取得 textBoxEditControl = pywinauto.controls.uia_controls.EditWrapper(textBoxEle) # テキスト登録 textBoxEditControl.set_edit_text(speakPhrase) # ボタン取得 buttonsEle = search_child_byclassname("Button",TextEditViewEle,target_all = True) # 再生ボタンを探す playButtonEle = "" for buttonEle in buttonsEle: # テキストブロックを捜索 textBlockEle = search_child_byclassname("TextBlock",buttonEle) if textBlockEle.name == "再生": playButtonEle = buttonEle break # ボタンコントロール取得 playButtonControl = pywinauto.controls.uia_controls.ButtonWrapper(playButtonEle) # 再生ボタン押下 playButtonControl.click() ## 引数の文字列を音声化して「音声保存」。保存先のフルパスファイル名も指定。拡張子はwav固定なので省略可 def saveVOICEROID2(speakPhrase,filename): # デスクトップのエレメント parentUIAElement = pywinauto.uia_element_info.UIAElementInfo() # voiceroidを捜索する voiceroid2 = search_child_byname("VOICEROID2",parentUIAElement,waitcount=1) # *がついている場合 if voiceroid2 == False: voiceroid2 = search_child_byname("VOICEROID2*",parentUIAElement,waitcount=1) # テキスト要素のElementInfoを取得 print("voiceroid2 classname = "+str(voiceroid2.children()) ) TextEditViewEle = search_child_byclassname("TextEditView",voiceroid2) textBoxEle = search_child_byclassname("TextBox",TextEditViewEle) # コントロール取得 textBoxEditControl = pywinauto.controls.uia_controls.EditWrapper(textBoxEle) # テキスト登録 textBoxEditControl.set_edit_text(speakPhrase) # ボタン取得 buttonsEle = search_child_byclassname("Button",TextEditViewEle,target_all = True) # 音声保存ボタンを探す playButtonEle = "" for buttonEle in buttonsEle: # テキストブロックを捜索 textBlockEle = search_child_byclassname("TextBlock",buttonEle) if textBlockEle.name == "音声保存": playButtonEle = buttonEle break # ボタンコントロール取得 playButtonControl = pywinauto.controls.uia_controls.ButtonWrapper(playButtonEle) # 音声保存ボタン押下 playButtonControl.click() # 音声保存ウィンドウが開くまで少し待つ(ウィンドウが開く前にsearch_child_bynameすると、bool値falseが返ってくる) time.sleep(0.3) # 音声保存ウィンドウと、その中の"OK"ボタンを探して押す onseihozon = search_child_byname("音声保存",voiceroid2) buttonEle = search_child_byname("OK",onseihozon) playButtonControl = pywinauto.controls.uia_controls.ButtonWrapper(buttonEle) playButtonControl.click() time.sleep(0.3) # ファイル名を入力。深いエレメントなので1つずつ潜る。nameがあるものはbynameで、nameが空白のものはbyclassnameで、類似エレメントが多いものは両方で検索。 savefile1 = search_child_byname("名前を付けて保存",onseihozon) savefile2 = search_child_byclassname("DUIViewWndClassName",savefile1) savefile3 = search_child_bynameandclassname("ファイル名:","AppControlHost",savefile2) #"ファイル名:"コンボボックス savefile4 = search_child_byname("ファイル名:",savefile3) #"ファイル名:"テキストボックス textBoxEditControl = pywinauto.controls.uia_controls.EditWrapper(savefile4) textBoxEditControl.set_edit_text(filename) #"保存(S)"ボタンを押す。"名前を付けて保存"ダイヤログの配下にある。 buttonEle = search_child_byname("保存(S)",savefile1) playButtonControl = pywinauto.controls.uia_controls.ButtonWrapper(buttonEle) playButtonControl.click() time.sleep(1.0) #「合成音声をファイルに保存しました」ダイヤログのOKボタンを押す savefile1 = search_child_byname("情報",onseihozon) buttonEle = search_child_byname("OK",savefile1) playButtonControl = pywinauto.controls.uia_controls.ButtonWrapper(buttonEle) playButtonControl.click() time.sleep(0.3) FILEPATH='C:\work\output' #出力先フォルダ inputfile = open('input.txt','r') line = inputfile.readline() while line: #ファイルを1行ずつループ try: #エラー時には、voiceroidを再起動してからリトライ saveVOICEROID2(line.strip(),FILEPATH + '\\' + line.strip() ) #.strip()で各行末尾の改行コードを消す except: killVOICEROID2() time.sleep(5) startVOICEROID2() time.sleep(10) saveVOICEROID2(line.strip(),FILEPATH + '\\' + line.strip() ) #.strip()で各行末尾の改行コードを消す line = inputfile.readline() inputfile.close()上記処理を回していると、数日に1回ほど以下のエラーが出て処理が止まることがある。
VOICEROID2 Editorは動作を停止しました 問題が発生したため、プログラムが正しく動作しなくなりました。上記エラーが記録されたことを検出した際、タスクスケジューラから
voiceroid.exeと、メッセージBOXの両方をtaskkillするバッチをキックするようにしてみた。ping -n 5 localhost >NUL taskkill /f /im WerFault.exe taskkill /f /im VoiceroidEditor.exeVOICEROID2が強制終了されると、startVOICEROID2()によりアプリが再起動され、処理が継続する。
これで処理が止まることなく10日間、全単語を音声化するまで安定して動くようになった。なお、voiceroidの仕様上、長い単語は、1つの単語のつもりでinputしても途中で発音が区切られている場合があるが妥協する。
最初からすべてひらがなでinputしているので、読み間違いは無いはず。生成された138423個のwavファイルの合計容量は7.8GiB程度でした。
2.生成された学習データの特性を確認、加工する
先はVOICEROID2を使用する都合上Windows環境だったが、ここからはCentos7環境を使用する。
今回の学習データは以下になる
input:日本語文字データ(text:utf-8)
output:音声データ(wav)これをそのままTensorFlowに入力することはできないので、input/outputそれぞれについて、0~1.0の範囲内の数値を使用したnumpy行列に変換するための処理を作成する。
まずはinputを変換する。
作成した教師データについて文字数ごとのデータ数を数えると以下のような感じ。
12文字以上はデータ数が極端に少なかったので、手動で作った単語表を加えてデータ数を増やしている。[work]# LENGTH1=0;LENGTH2=0;LENGTH3=0;LENGTH4=0;LENGTH5=0;LENGTH6=0;LENGTH7=0;LENGTH8=0;LENGTH9=0;LENGTH10=0;LENGTH11=0;LENGTH12=0;LENGTH13=0;LENGTH14=0 [work]# while read line > do LENGTH=$((`echo $line | wc -m` - 1)) > if [ $LENGTH -gt 14 ] > then echo $line $LENGTH #念のために15文字以上の長さの文字が残っていた場合に表示 > fi > eval LENGTH$LENGTH=`eval expr '$'LENGTH$LENGTH + 1` > done < input.txt [work]# echo $LENGTH1 $LENGTH2 $LENGTH3 $LENGTH4 $LENGTH5 $LENGTH6 $LENGTH7 $LENGTH8 $LENGTH9 $LENGTH10 $LENGTH11 $LENGTH12 $LENGTH13 $LENGTH14 66 3002 24038 53049 30415 14848 6658 3179 1406 522 292 367 303 278 [work]#input変換(text→numpy)のルールとしては、
すべての文字を、それぞれ11~211の数字を割り当てる。
同じ母音の音は近い数字になるように、以下のルールで割り当てる
あ行:11~50
い行:51~90
う行:91~130
え行:131~170
お行:171~210
ん:211濁音、半濁音は、それぞれの清音と近い数字になるように割り当てる。
また、「ぁ」「ぃ」「ぅ」「ぇ」「ぉ」「ゃ」「ゅ」「ょ」は、同じ母音の文字と近い数字になるように割り当てる。
11:あ
12:うぁ
13:か
14:きゃ
15:が
16:ぎゃそれぞれの音の後に、長音「ー」および「っ」を表すデータを付与する。
通常の長さの音=128、長音「ー」=200、「っ」=30これにより、
「ぎょーざ」は、以下のように変換される
175 (ぎょ)
200 (長音「ー」)
18 (ざ)
128 (通常の長さ)「あっぷる」は以下のように変換される
11 (あ)
30 (「っ」)
110 (ぷ)
128 (通常の長さ)
115 (る)
128 (通常の長さ)TensorFlowの入出力は固定長にする必要がある。
今回の教師データが最大14文字なので、1文字あたり2要素の合計28個の数字のlistを返す。
14文字に足りない文字数分は、すべて「0」(無音扱い)で埋める。単語の文字列を引数に、対応する数字のlistを返す関数を作成
char2num.py#charの文字列を、規則に従ってlistに変換。listのサイズは発音文字数numで揃える(不足は0で埋める)。 def exchange(char,num): output = [] # 帰り値用list。1音を2つの数字で表す。詳細は別途説明書に記載 oto = 0 # 何音入れたか?のカウント「ば」「あっ」「ぎゃー」文字数は1-3だが、すべて1音でカウント for n in range(len(char)): # 文字列の長さだけループ m = char[n] #今回ループで処理する文字 oto += 1 #1文字1音の言葉→そのまま入れる。次の文字が「ゃ」「ゅ」「ょ」の場合の場合も一旦入れて、後で書き換える #「っ」「ー」を含まない通常の長さを示す数字「128」も仮入れする if m == 'あ':output += [11,128] elif m == 'か':output += [13,128] elif m == 'が':output += [15,128] elif m == 'さ':output += [17,128] elif m == 'ざ':output += [20,128] elif m == 'た':output += [23,128] elif m == 'だ':output += [29,128] elif m == 'な':output += [34,128] elif m == 'は':output += [36,128] elif m == 'ば':output += [39,128] elif m == 'ぱ':output += [42,128] elif m == 'ま':output += [44,128] elif m == 'や':output += [46,128] elif m == 'ら':output += [47,128] elif m == 'わ':output += [50,128] elif m == 'い':output += [51,128] elif m == 'き':output += [53,128] elif m == 'ぎ':output += [55,128] elif m == 'し':output += [57,128] elif m == 'じ':output += [60,128] elif m == 'ち':output += [63,128] elif m == 'ぢ':output += [69,128] elif m == 'に':output += [74,128] elif m == 'ひ':output += [76,128] elif m == 'び':output += [79,128] elif m == 'ぴ':output += [82,128] elif m == 'み':output += [84,128] elif m == 'り':output += [87,128] elif m == 'う':output += [91,128] elif m == 'く':output += [93,128] elif m == 'ぐ':output += [95,128] elif m == 'す':output += [97,128] elif m == 'ず':output += [100,128] elif m == 'つ':output += [103,128] elif m == 'づ':output += [109,128] elif m == 'ぬ':output += [114,128] elif m == 'ふ':output += [116,128] elif m == 'ぶ':output += [119,128] elif m == 'ぷ':output += [122,128] elif m == 'む':output += [124,128] elif m == 'ゆ':output += [126,128] elif m == 'る':output += [127,128] elif m == 'え':output += [131,128] elif m == 'け':output += [133,128] elif m == 'げ':output += [135,128] elif m == 'せ':output += [137,128] elif m == 'ぜ':output += [140,128] elif m == 'て':output += [143,128] elif m == 'で':output += [149,128] elif m == 'ね':output += [154,128] elif m == 'へ':output += [156,128] elif m == 'べ':output += [159,128] elif m == 'ぺ':output += [162,128] elif m == 'め':output += [164,128] elif m == 'れ':output += [167,128] elif m == 'お':output += [171,128] elif m == 'こ':output += [173,128] elif m == 'ご':output += [175,128] elif m == 'そ':output += [177,128] elif m == 'ぞ':output += [180,128] elif m == 'と':output += [183,128] elif m == 'ど':output += [189,128] elif m == 'の':output += [194,128] elif m == 'ほ':output += [196,128] elif m == 'ぼ':output += [199,128] elif m == 'ぽ':output += [202,128] elif m == 'も':output += [204,128] elif m == 'よ':output += [206,128] elif m == 'ろ':output += [207,128] elif m == 'を':output += [210,128] elif m == 'ん':output += [211,128] else: oto-=1 #上記以外の文字(「ゃ」「ゅ」「ょ」「ぁ」「ぃ」「ぅ」「ぇ」「ぉ」「っ」「ー」)の場合は、oto+=1をキャンセル if oto == 0 : return ([0]* (num*2)) #1文字目が上記以外の場合はall 0で即return(エラー扱い) #「ゃ」「ゅ」「ょ」「ぁ」「ぃ」「ぅ」「ぇ」「ぉ」の場合は、1つ前の音(listでは2つ前)を変更する if m == 'ゃ': if output[(oto*2)-2] == 53:output[(oto*2)-2] = 14 #「53=き」の場合、「14=きゃ」に変更 elif output[(oto*2)-2] == 55:output[(oto*2)-2] = 16 elif output[(oto*2)-2] == 57:output[(oto*2)-2] = 18 elif output[(oto*2)-2] == 60:output[(oto*2)-2] = 21 elif output[(oto*2)-2] == 63:output[(oto*2)-2] = 24 elif output[(oto*2)-2] == 69:output[(oto*2)-2] = 30 elif output[(oto*2)-2] == 74:output[(oto*2)-2] = 35 elif output[(oto*2)-2] == 76:output[(oto*2)-2] = 37 elif output[(oto*2)-2] == 79:output[(oto*2)-2] = 40 elif output[(oto*2)-2] == 82:output[(oto*2)-2] = 43 elif output[(oto*2)-2] == 84:output[(oto*2)-2] = 45 elif output[(oto*2)-2] == 87:output[(oto*2)-2] = 48 elif m == 'ゅ': if output[(oto*2)-2] == 53:output[(oto*2)-2] = 94 elif output[(oto*2)-2] == 55:output[(oto*2)-2] = 96 elif output[(oto*2)-2] == 57:output[(oto*2)-2] = 98 elif output[(oto*2)-2] == 60:output[(oto*2)-2] = 101 elif output[(oto*2)-2] == 63:output[(oto*2)-2] = 104 elif output[(oto*2)-2] == 69:output[(oto*2)-2] = 110 elif output[(oto*2)-2] == 74:output[(oto*2)-2] = 115 elif output[(oto*2)-2] == 76:output[(oto*2)-2] = 117 elif output[(oto*2)-2] == 79:output[(oto*2)-2] = 120 elif output[(oto*2)-2] == 82:output[(oto*2)-2] = 123 elif output[(oto*2)-2] == 84:output[(oto*2)-2] = 125 elif output[(oto*2)-2] == 87:output[(oto*2)-2] = 128 elif m == 'ょ': if output[(oto*2)-2] == 53:output[(oto*2)-2] = 174 elif output[(oto*2)-2] == 55:output[(oto*2)-2] = 176 elif output[(oto*2)-2] == 57:output[(oto*2)-2] = 178 elif output[(oto*2)-2] == 60:output[(oto*2)-2] = 181 elif output[(oto*2)-2] == 63:output[(oto*2)-2] = 184 elif output[(oto*2)-2] == 69:output[(oto*2)-2] = 190 elif output[(oto*2)-2] == 74:output[(oto*2)-2] = 195 elif output[(oto*2)-2] == 76:output[(oto*2)-2] = 197 elif output[(oto*2)-2] == 79:output[(oto*2)-2] = 200 elif output[(oto*2)-2] == 82:output[(oto*2)-2] = 203 elif output[(oto*2)-2] == 84:output[(oto*2)-2] = 205 elif output[(oto*2)-2] == 87:output[(oto*2)-2] = 208 elif m == 'ぁ': if output[(oto*2)-2] == 91:output[(oto*2)-2] = 12 elif output[(oto*2)-2] == 57:output[(oto*2)-2] = 19 elif output[(oto*2)-2] == 60:output[(oto*2)-2] = 22 elif output[(oto*2)-2] == 103:output[(oto*2)-2] = 26 elif output[(oto*2)-2] == 143:output[(oto*2)-2] = 27 elif output[(oto*2)-2] == 109:output[(oto*2)-2] = 31 elif output[(oto*2)-2] == 149:output[(oto*2)-2] = 32 elif output[(oto*2)-2] == 116:output[(oto*2)-2] = 38 elif output[(oto*2)-2] == 119:output[(oto*2)-2] = 41 elif m == 'ぃ': if output[(oto*2)-2] == 91:output[(oto*2)-2] = 52 elif output[(oto*2)-2] == 57:output[(oto*2)-2] = 59 elif output[(oto*2)-2] == 60:output[(oto*2)-2] = 62 elif output[(oto*2)-2] == 63:output[(oto*2)-2] = 65 elif output[(oto*2)-2] == 103:output[(oto*2)-2] = 66 elif output[(oto*2)-2] == 143:output[(oto*2)-2] = 67 elif output[(oto*2)-2] == 109:output[(oto*2)-2] = 71 elif output[(oto*2)-2] == 149:output[(oto*2)-2] = 72 elif output[(oto*2)-2] == 116:output[(oto*2)-2] = 78 elif output[(oto*2)-2] == 119:output[(oto*2)-2] = 81 elif output[(oto*2)-2] == 87:output[(oto*2)-2] = 89 elif m == 'ぅ': if output[(oto*2)-2] == 103:output[(oto*2)-2] = 106 elif output[(oto*2)-2] == 143:output[(oto*2)-2] = 107 elif output[(oto*2)-2] == 183:output[(oto*2)-2] = 108 elif output[(oto*2)-2] == 109:output[(oto*2)-2] = 111 elif output[(oto*2)-2] == 149:output[(oto*2)-2] = 112 elif output[(oto*2)-2] == 189:output[(oto*2)-2] = 113 elif output[(oto*2)-2] == 116:output[(oto*2)-2] = 118 elif output[(oto*2)-2] == 119:output[(oto*2)-2] = 121 elif output[(oto*2)-2] == 87:output[(oto*2)-2] = 129 elif m == 'ぇ': if output[(oto*2)-2] == 91:output[(oto*2)-2] = 132 elif output[(oto*2)-2] == 57:output[(oto*2)-2] = 139 elif output[(oto*2)-2] == 60:output[(oto*2)-2] = 142 elif output[(oto*2)-2] == 63:output[(oto*2)-2] = 145 elif output[(oto*2)-2] == 103:output[(oto*2)-2] = 146 elif output[(oto*2)-2] == 109:output[(oto*2)-2] = 151 elif output[(oto*2)-2] == 116:output[(oto*2)-2] = 158 elif output[(oto*2)-2] == 119:output[(oto*2)-2] = 161 elif m == 'ぉ': if output[(oto*2)-2] == 91:output[(oto*2)-2] = 172 elif output[(oto*2)-2] == 183:output[(oto*2)-2] = 188 elif output[(oto*2)-2] == 189:output[(oto*2)-2] = 193 elif output[(oto*2)-2] == 116:output[(oto*2)-2] = 198 elif output[(oto*2)-2] == 119:output[(oto*2)-2] = 201 elif output[(oto*2)-2] == 87:output[(oto*2)-2] = 209 #「ー」「っ」の場合は、今回の発音長(listでは1つ前)を変更する elif m == 'っ':output[(oto*2)-1] = 30 elif m == 'ー':output[(oto*2)-1] = 200 #固定長5文字(len()=num*2)に揃えて、不足分は0で埋める output += [0] * ((num*2)-len(output)) return (output)母音と子音で別の数字に分けたほうが良かったかな?と思ったが、、とりあえず最低限の加工はできたはず。
次に出力(wav)をnumpyに変換する
wavファイルの波形データをそのまま入れてもまともに学習できないので、以下サイトを参考に、「基本周波数(f0)」「スペクトル包絡(sp)」「非周期性指標(ap)」を抽出する
音声合成システム WORLD に触れてみる今回用意した138423個のwavファイルの合計容量は7.8GiB程度だが、これを上記のように3種のnumpyに変換すると、numpy.saveでbinary保管しても10倍以上の容量に膨れる。
最初から全wavを変換してディスク上においておく方法も考えられるが、自分の環境はSSD容量が小さいので、学習中に、必要なデータを都度wav→f0,sp,ap変換する仕組みを採用する。wav2numpy.py
# -*- coding: utf-8 -*- from scipy.io import wavfile import pyworld as pw import numpy as np # wavファイル名を引数に、f0,sp,apのnumpyを返す関数wav2numpy(wavfilename) def wav2numpy(wavfilename): fs, data = wavfile.read( wavfilename ) data = data.astype(np.float) # WORLDはfloat前提のコードになっているのでfloat型にしておく _f0, t = pw.dio(data, fs) # 基本周波数の抽出 f0 = pw.stonemask(data, _f0, t, fs) # 基本周波数の修正 sp = pw.cheaptrick(data, f0, t, fs) # スペクトル包絡の抽出 ap = pw.d4c(data, f0, t, fs) # 非周期性指標の抽出 return ( f0 , sp , ap ) # f0,sp,apおよび任意のwavファイル名を引数。f0,sp,apからwavファイルを出力する def numpy2wav(f0,sp,ap,wavfilename): fs = 44100 synthesized = pw.synthesize(f0, sp, ap, fs).astype(np.int16) wavfile.write( wavfilename ,fs,synthesized)これらデータをTensorFlowに投入したいが、先程生成したf0,spを0~1.0の範囲内に収めるために、どの程度の範囲なのか、特性を確認する必要がある。(apは最初から0~1.0の範囲内に収まるので加工不要)
以下、データの特性を確認するためだけのスクリプト
import numpy as np import matplotlib.pyplot as plt import csv import pandas as pd import wav2numpy wavdir = '/home/d9840yh/work/wavfiles2' maxf0 = 0 minf0 = 1e100 maxsp = 0 minsp = 1e100 inputfile = open('input.txt','r') line = inputfile.readline() while line: f0=[] sp=[] ap=[] f0 , sp , ap = wav2numpy.wav2numpy(wavdir + '/' + line.strip() + '.wav') #wavからf0,sp,apを抽出 if f0.max() > maxf0 : #f0 max更新 maxf0=f0.max() print("new max f0 : max f0=",maxf0," min f0=",minf0," max sp=",maxsp," min sp=",minsp," file:",line.strip()) if f0.min() < minf0 : #f0 min更新 minf0=f0.min() print("new min f0 : max f0=",maxf0," min f0=",minf0," max sp=",maxsp," min sp=",minsp," file:",line.strip()) if sp.max() > maxsp : #sp max更新 maxsp=sp.max() print("new max sp : max f0=",maxf0," min f0=",minf0," max sp=",maxsp," min sp=",minsp," file:",line.strip()) if sp.min() < minsp : #sp min更新 minsp=sp.min() print("new min sp : max f0=",maxf0," min f0=",minf0," max sp=",maxsp," min sp=",minsp," file:",line.strip()) line = inputfile.readline()実行結果
[work]# python3.6 ./03_search_max.py new max f0 : max f0= 265.4438671748281 min f0= 1e+100 max sp= 0 min sp= 1e+100 file: あ new min f0 : max f0= 265.4438671748281 min f0= 0.0 max sp= 0 min sp= 1e+100 file: あ new max sp : max f0= 265.4438671748281 min f0= 0.0 max sp= 657068294.401034 min sp= 1e+100 file: あ new min sp : max f0= 265.4438671748281 min f0= 0.0 max sp= 657068294.401034 min sp= 0.027947641201406224 file: あ new max f0 : max f0= 302.4288177772 min f0= 0.0 max sp= 657068294.401034 min sp= 0.027947641201406224 file: あー new max sp : max f0= 302.4288177772 min f0= 0.0 max sp= 837133555.222678 min sp= 0.027947641201406224 file: あー new min sp : max f0= 302.4288177772 min f0= 0.0 max sp= 837133555.222678 min sp= 0.0063757402892679615 file: あー new max f0 : max f0= 344.4078989932586 min f0= 0.0 max sp= 837133555.222678 min sp= 0.0063757402892679615 file: あーうぃん new max sp : max f0= 344.4078989932586 min f0= 0.0 max sp= 1931761024.0156083 min sp= 0.0063757402892679615 file: あーうぃん (中略) new max f0 : max f0= 692.524084004494 min f0= 0.0 max sp= 12431307878.277342 min sp= 8.294699504145247e-18 file: えいこさのいど new min sp : max f0= 692.524084004494 min f0= 0.0 max sp= 12431307878.277342 min sp= 5.7318239325174266e-18 file: さきのり new min sp : max f0= 692.524084004494 min f0= 0.0 max sp= 12431307878.277342 min sp= 4.4569279355354585e-18 file: しぇるどれいく new max sp : max f0= 692.524084004494 min f0= 0.0 max sp= 16109683177.383907 min sp= 4.4569279355354585e-18 file: ぜねらりf0は最大692.5なので、単純に/1024すれば0~1.0の範囲内に収まる。
spは対数的な特性をもつデータなので、単純に/10e11すると、小さなレンジのデータがまともに学習できなくなると思われる。
(実際に、サンプルの学習データとして10e-20 ~ 1.0までの20桁のレンジのデータがoutputになるように超シンプルなモデルに学習させてみたところ、小さなレンジのデータは≒0として扱われて、10e-3以上のデータしか結果に反映されなかった。)そのため、spについては対数計算した上で、0~1.0の範囲内に収める必要がある。
元データが4.4e-18~1.6e10の範囲なので、単純にlog10を取ると-19~11のデータ範囲に収まる。
それを+19して、さらに/30すれば、良い感じに収まりそう。なお、fp,sp,apのサイズは音声の長さに依存するが、もっともサイズの大きいwavファイルを確認したところ以下だった。
f0.shape=(475,)
sp.shape=(475, 1025)
ap.shape=(475, 1025)なお、1025は音声の中身にかかわらずで、475の部分が音声の長さに比例して増える。
学習前にこれをflat化する必要があるので、sp,apは475x1025=486875。
余裕をもって500x1025=512500としておけば問題無い3.文字データ→音声データへの変換を学習させる
以上の結果をふまえて、学習用の仕組みを作成する。
用意した音声wavファイルは138423個あるが、これをいきなり放り込んで失敗すると嫌なので、使用する教師データ数を動的に変更できるようにする。ついでにBatchsizeやepochsも変更できるようにする。
# cat 03_larning05_all.ini [general] DATASIZE=10000 BATCHSIZE=10 EPOCHS=3 #学習用のスクリプトを用意。
最初、モデルは以下のように考えていた。
input.shape=[28,]
→ Dense(16384)
→ Dense(16384)
→ Dense(8192)
→ output_sp.shape=[512500,]
→ output_ap.shape=[512500,]
→ output_sp.shape=[500,]しかし、上記だと100GB超のメインメモリを消費する。
おそらく、最後のDense(16384)→output_sp.shape=[205000,]の箇所で、
sp用だけでも単純に8,192*512,500=4,198,400,000の変数を学習させることになるのが原因と思われる。
そこで、以下のように最後のDenseを25分割した。
ついでにinputも1文字([2,])単位で分割し、最初のDenseとの間に1層追加する。(ここで、各1音ごとの音特性を学習してくれたら、その後のDenseは音韻長や繋ぎなどの全体をまとめる学習に専念できないかな?と)input1.shape=[2,]
→Dense(256)
input2.shape=[2,]
→Dense(256)
input3.shape=[2,]
→Dense(256)
(中略、input14まで続く。)
→ Dense(16384)
→ Dense(16384)
→ Dense(512)
→ output_sp1.shape=[20500,]
→ Dense(512)
→ output_sp2.shape=[20500,]
→ Dense(512)
→ output_sp3.shape=[20500,]
(中略、output_sp25まで同じように作成)
→ Dense(512)
→ output_ap1.shape=[20500,]
→ Dense(512)
→ output_ap2.shape=[20500,]
(中略、output_ap25まで同じように作成)
→ Dense(512)
→ output_sp.shape=[500,]これで、最終Denseのセル数は8192 → 512*25=12,800と実質増えているにもかかわらず、そこで学習される変数数は512*20500*25=262,400,000 となり、1/10以下に落とせた。
このあたりのコーディングがゴリ押しなのだが、なにか良い感じにDenseを分割できる方法は無いものか。
あと、教師データ量が膨大なので、学習と平行して教師データを加工できるようにfit_generatorを使っているのだが、通常のfitでいうところのVALIDSPLITがつかえない。これも自分でon_epoch_end()内に実装するしか無いのかな・・・活性関数は、いまいち効果が分からないので、とりあえずreluをつっこんでおく。
単語のリストであるinput.txtはスクリプトと同じディレクトリ内に配置。
VOICEROIDにより生成されたwavファイルは、/home/d9840yh/work/wavfiles2/以下に配置。from __future__ import absolute_import, division, print_function, unicode_literals # TensorFlow と tf.keras のインポート import tensorflow as tf from tensorflow import keras config = tf.ConfigProto(log_device_placement=True) sess = tf.Session(config=config) keras.backend.set_session(sess) # ヘルパーライブラリのインポート import numpy as np import math from datetime import datetime import gc import configparser # 自作スクリプト #charの文字列を、規則に従ってlistに変換 exchange(char,num) import char2num #wavファイルからf0,sp,apのnumpy arrayを取り出す import wav2numpy wavdir = '/home/d9840yh/work/wavfiles2' inifile = '03_larning05_all.ini' config = configparser.SafeConfigParser() # input.txtの各行を1要素としたlist:wordlistを生成 wordlist = [] with open("input.txt", "r",encoding="utf-8") as f: wordlist.extend(f.read().split()) #モデルを定義する関数。 inputは28の数字、outputは[sp,ap=512500つの数字][f0=500つの数字] model_input1 = keras.Input(shape=(2,), name='in1') model_input2 = keras.Input(shape=(2,), name='in2') model_input3 = keras.Input(shape=(2,), name='in3') model_input4 = keras.Input(shape=(2,), name='in4') model_input5 = keras.Input(shape=(2,), name='in5') model_input6 = keras.Input(shape=(2,), name='in6') model_input7 = keras.Input(shape=(2,), name='in7') model_input8 = keras.Input(shape=(2,), name='in8') model_input9 = keras.Input(shape=(2,), name='in9') model_input10 = keras.Input(shape=(2,), name='in10') model_input11 = keras.Input(shape=(2,), name='in11') model_input12 = keras.Input(shape=(2,), name='in12') model_input13 = keras.Input(shape=(2,), name='in13') model_input14 = keras.Input(shape=(2,), name='in14') x1_1 = keras.layers.Dense(256, activation='relu', name='1st_layer1')(model_input1) x1_2 = keras.layers.Dense(256, activation='relu', name='1st_layer2')(model_input2) x1_3 = keras.layers.Dense(256, activation='relu', name='1st_layer3')(model_input3) x1_4 = keras.layers.Dense(256, activation='relu', name='1st_layer4')(model_input4) x1_5 = keras.layers.Dense(256, activation='relu', name='1st_layer5')(model_input5) x1_6 = keras.layers.Dense(256, activation='relu', name='1st_layer6')(model_input6) x1_7 = keras.layers.Dense(256, activation='relu', name='1st_layer7')(model_input7) x1_8 = keras.layers.Dense(256, activation='relu', name='1st_layer8')(model_input8) x1_9 = keras.layers.Dense(256, activation='relu', name='1st_layer9')(model_input9) x1_10 = keras.layers.Dense(256, activation='relu', name='1st_layer10')(model_input10) x1_11 = keras.layers.Dense(256, activation='relu', name='1st_layer11')(model_input11) x1_12 = keras.layers.Dense(256, activation='relu', name='1st_layer12')(model_input12) x1_13 = keras.layers.Dense(256, activation='relu', name='1st_layer13')(model_input13) x1_14 = keras.layers.Dense(256, activation='relu', name='1st_layer14')(model_input14) x1_merge = keras.layers.concatenate([x1_1,x1_2,x1_3,x1_4,x1_5,x1_6,x1_7,x1_8,x1_9,x1_10,x1_11,x1_12,x1_13,x1_14], axis=-1) x2 = keras.layers.Dense(16384, activation='relu', name='2nd_layer')(x1_merge) x3 = keras.layers.Dense(16384, activation='relu', name='3rd_layer')(x2) x4_sp1 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp1')(x3) x4_sp2 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp2')(x3) x4_sp3 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp3')(x3) x4_sp4 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp4')(x3) x4_sp5 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp5')(x3) x4_sp6 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp6')(x3) x4_sp7 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp7')(x3) x4_sp8 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp8')(x3) x4_sp9 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp9')(x3) x4_sp10 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp10')(x3) x4_sp11 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp11')(x3) x4_sp12 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp12')(x3) x4_sp13 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp13')(x3) x4_sp14 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp14')(x3) x4_sp15 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp15')(x3) x4_sp16 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp16')(x3) x4_sp17 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp17')(x3) x4_sp18 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp18')(x3) x4_sp19 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp19')(x3) x4_sp20 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp20')(x3) x4_sp21 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp21')(x3) x4_sp22 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp22')(x3) x4_sp23 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp23')(x3) x4_sp24 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp24')(x3) x4_sp25 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp25')(x3) model_output_sp1 = keras.layers.Dense(20500, name='out_sp1')(x4_sp1) model_output_sp2 = keras.layers.Dense(20500, name='out_sp2')(x4_sp2) model_output_sp3 = keras.layers.Dense(20500, name='out_sp3')(x4_sp3) model_output_sp4 = keras.layers.Dense(20500, name='out_sp4')(x4_sp4) model_output_sp5 = keras.layers.Dense(20500, name='out_sp5')(x4_sp5) model_output_sp6 = keras.layers.Dense(20500, name='out_sp6')(x4_sp6) model_output_sp7 = keras.layers.Dense(20500, name='out_sp7')(x4_sp7) model_output_sp8 = keras.layers.Dense(20500, name='out_sp8')(x4_sp8) model_output_sp9 = keras.layers.Dense(20500, name='out_sp9')(x4_sp9) model_output_sp10 = keras.layers.Dense(20500, name='out_sp10')(x4_sp10) model_output_sp11 = keras.layers.Dense(20500, name='out_sp11')(x4_sp11) model_output_sp12 = keras.layers.Dense(20500, name='out_sp12')(x4_sp12) model_output_sp13 = keras.layers.Dense(20500, name='out_sp13')(x4_sp13) model_output_sp14 = keras.layers.Dense(20500, name='out_sp14')(x4_sp14) model_output_sp15 = keras.layers.Dense(20500, name='out_sp15')(x4_sp15) model_output_sp16 = keras.layers.Dense(20500, name='out_sp16')(x4_sp16) model_output_sp17 = keras.layers.Dense(20500, name='out_sp17')(x4_sp17) model_output_sp18 = keras.layers.Dense(20500, name='out_sp18')(x4_sp18) model_output_sp19 = keras.layers.Dense(20500, name='out_sp19')(x4_sp19) model_output_sp20 = keras.layers.Dense(20500, name='out_sp20')(x4_sp20) model_output_sp21 = keras.layers.Dense(20500, name='out_sp21')(x4_sp21) model_output_sp22 = keras.layers.Dense(20500, name='out_sp22')(x4_sp22) model_output_sp23 = keras.layers.Dense(20500, name='out_sp23')(x4_sp23) model_output_sp24 = keras.layers.Dense(20500, name='out_sp24')(x4_sp24) model_output_sp25 = keras.layers.Dense(20500, name='out_sp25')(x4_sp25) x4_ap1 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap1')(x3) x4_ap2 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap2')(x3) x4_ap3 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap3')(x3) x4_ap4 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap4')(x3) x4_ap5 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap5')(x3) x4_ap6 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap6')(x3) x4_ap7 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap7')(x3) x4_ap8 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap8')(x3) x4_ap9 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap9')(x3) x4_ap10 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap10')(x3) x4_ap11 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap11')(x3) x4_ap12 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap12')(x3) x4_ap13 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap13')(x3) x4_ap14 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap14')(x3) x4_ap15 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap15')(x3) x4_ap16 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap16')(x3) x4_ap17 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap17')(x3) x4_ap18 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap18')(x3) x4_ap19 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap19')(x3) x4_ap20 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap20')(x3) x4_ap21 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap21')(x3) x4_ap22 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap22')(x3) x4_ap23 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap23')(x3) x4_ap24 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap24')(x3) x4_ap25 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap25')(x3) model_output_ap1 = keras.layers.Dense(20500, name='out_ap1')(x4_ap1) model_output_ap2 = keras.layers.Dense(20500, name='out_ap2')(x4_ap2) model_output_ap3 = keras.layers.Dense(20500, name='out_ap3')(x4_ap3) model_output_ap4 = keras.layers.Dense(20500, name='out_ap4')(x4_ap4) model_output_ap5 = keras.layers.Dense(20500, name='out_ap5')(x4_ap5) model_output_ap6 = keras.layers.Dense(20500, name='out_ap6')(x4_ap6) model_output_ap7 = keras.layers.Dense(20500, name='out_ap7')(x4_ap7) model_output_ap8 = keras.layers.Dense(20500, name='out_ap8')(x4_ap8) model_output_ap9 = keras.layers.Dense(20500, name='out_ap9')(x4_ap9) model_output_ap10 = keras.layers.Dense(20500, name='out_ap10')(x4_ap10) model_output_ap11 = keras.layers.Dense(20500, name='out_ap11')(x4_ap11) model_output_ap12 = keras.layers.Dense(20500, name='out_ap12')(x4_ap12) model_output_ap13 = keras.layers.Dense(20500, name='out_ap13')(x4_ap13) model_output_ap14 = keras.layers.Dense(20500, name='out_ap14')(x4_ap14) model_output_ap15 = keras.layers.Dense(20500, name='out_ap15')(x4_ap15) model_output_ap16 = keras.layers.Dense(20500, name='out_ap16')(x4_ap16) model_output_ap17 = keras.layers.Dense(20500, name='out_ap17')(x4_ap17) model_output_ap18 = keras.layers.Dense(20500, name='out_ap18')(x4_ap18) model_output_ap19 = keras.layers.Dense(20500, name='out_ap19')(x4_ap19) model_output_ap20 = keras.layers.Dense(20500, name='out_ap20')(x4_ap20) model_output_ap21 = keras.layers.Dense(20500, name='out_ap21')(x4_ap21) model_output_ap22 = keras.layers.Dense(20500, name='out_ap22')(x4_ap22) model_output_ap23 = keras.layers.Dense(20500, name='out_ap23')(x4_ap23) model_output_ap24 = keras.layers.Dense(20500, name='out_ap24')(x4_ap24) model_output_ap25 = keras.layers.Dense(20500, name='out_ap25')(x4_ap25) x4_f0 = keras.layers.Dense(512, activation='relu', name='4th_layer_f0')(x3) model_output_f0 = keras.layers.Dense(500, name='out_f0')(x4_f0) model = keras.models.Model(inputs=[model_input1,model_input2,model_input3,model_input4,model_input5,model_input6,model_input7,model_input8,model_input9,model_input10,model_input11,model_input12,model_input13,model_input14], outputs=[model_output_sp1,model_output_sp2,model_output_sp3,model_output_sp4,model_output_sp5,model_output_sp6,model_output_sp7,model_output_sp8,model_output_sp9,model_output_sp10,model_output_sp11,model_output_sp12,model_output_sp13,model_output_sp14,model_output_sp15,model_output_sp16,model_output_sp17,model_output_sp18,model_output_sp19,model_output_sp20,model_output_sp21,model_output_sp22,model_output_sp23,model_output_sp24,model_output_sp25,model_output_ap1,model_output_ap2,model_output_ap3,model_output_ap4,model_output_ap5,model_output_ap6,model_output_ap7,model_output_ap8,model_output_ap9,model_output_ap10,model_output_ap11,model_output_ap12,model_output_ap13,model_output_ap14,model_output_ap15,model_output_ap16,model_output_ap17,model_output_ap18,model_output_ap19,model_output_ap20,model_output_ap21,model_output_ap22,model_output_ap23,model_output_ap24,model_output_ap25,model_output_f0]) class FitGenSequence(keras.utils.Sequence): def __init__(self, batch_size , data_size , word_list ): #word_listはwavファイルのリスト。そのうちdata_size個を学習に使うが、batch_size個単位で分割して学習する self.batch_size = batch_size self.word_list = word_list self.length = data_size // batch_size # batch_size個単位でに分割学習されるため、data_size / batch_size回に分割される # 余剰分は切り捨て(data_size=5100 , batch_size=1000の場合、1000個x5回の5000個だけ学習に使う) def __getitem__(self, idx): start_idx = idx * self.batch_size last_idx = start_idx + self.batch_size # 今回のループで使用するwavファイルのリストは self.word_list[start_idx:last_idx] print (self.word_list[start_idx:last_idx]) inputdata = [] outputdata_sp = [] outputdata_ap = [] outputdata_f0 = [] for word in self.word_list[start_idx:last_idx]: # inputデータ生成 28xデータ数の2d arrray inputdata.append((char2num.exchange(word.strip(),14))) outdata_f0 , outdata_sp , outdata_ap = wav2numpy.wav2numpy(wavdir + '/' + word.strip() + '.wav') #wavファイルからf0,sp,ap抽出 #outputデータ整形 固定長にする outdata_sp2=[flatten for inner in outdata_sp for flatten in inner] #sp,apは1025x可変長の2d arrayなので1d arrayに展開。同時にnumpy→lisst変換される outdata_sp2 += [0] * (512500-len(outdata_sp2)) #sp,apは1025x可変長(max500)=512500で固定長になるように0埋め outputdata_sp.append(outdata_sp2) outdata_ap2=[flatten for inner in outdata_ap for flatten in inner] #sp,apは1025x可変長の2d arrayなので1d arrayに展開。同時にnumpy→llist変換される outdata_ap2 += [0] * (512500-len(outdata_ap2)) #sp,apは1025x可変長(max500)=512500で固定長になるように0埋め outputdata_ap.append(outdata_ap2) outdata_f02 = outdata_f0.tolist() #f0はもともと1d arrayなのでflatten不要。単純にnumpy→list変換だけ outdata_f02 += [0] * (500-len(outdata_f02)) #f0は1x可変長(max500)=500で固定長になるように0埋め outputdata_f0.append(outdata_f02) #listをinput/outputに指定すると「Please provide as model inputs either a single array or a list of arrays.」になるのでnumpy変換 #input(14文字)を14等分。outputは25等分。 self.input1 , self.input2 , self.input3 , self.input4 , self.input5 , self.input6 , self.input7 , self.input8 , self.input9 , self.input10 , self.input11 , self.input12 , self.input13 , self.input14 = np.hsplit( np.array(inputdata) /256 , 14 ) outputdata_sp_np = np.array([[(math.log10(i)+19)/30 if i!=0 else 0 for i in j ] for j in outputdata_sp]) #4.4e-18~1.6e10を対数(-19~+11),+19して/30で0.0~1.0内に収める。 self.sp1 , self.sp2 , self.sp3 , self.sp4 , self.sp5 , self.sp6 , self.sp7 , self.sp8 , self.sp9 , self.sp10 , self.sp11 , self.sp12 , self.sp13 , self.sp14 , self.sp15 , self.sp16 , self.sp17 , self.sp18 , self.sp19 , self.sp20 , self.sp21 , self.sp22 , self.sp23 , self.sp24 , self.sp25 = np.hsplit( outputdata_sp_np , 25 ) del outputdata_sp del outputdata_sp_np gc.collect() self.ap1 , self.ap2 , self.ap3 , self.ap4 , self.ap5 , self.ap6 , self.ap7 , self.ap8 , self.ap9 , self.ap10 , self.ap11 , self.ap12 , self.ap13 , self.ap14 , self.ap15 , self.ap16 , self.ap17 , self.ap18 , self.ap19 , self.ap20 , self.ap21 , self.ap22 , self.ap23 , self.ap24 , self.ap25 = np.hsplit( np.array(outputdata_ap) , 25 ) del outputdata_ap gc.collect() self.f0 = np.array(outputdata_f0) /1024 #0~692 del outputdata_f0 gc.collect() return {'in1':self.input1,'in2':self.input2,'in3':self.input3,'in4':self.input4,'in5':self.input5,'in6':self.input6,'in7':self.input7,'in8':self.input8,'in9':self.input9,'in10':self.input10,'in11':self.input11,'in12':self.input12,'in13':self.input13,'in14':self.input14} , {'out_sp1':self.sp1,'out_sp2':self.sp2,'out_sp3':self.sp3,'out_sp4':self.sp4,'out_sp5':self.sp5,'out_sp6':self.sp6,'out_sp7':self.sp7,'out_sp8':self.sp8,'out_sp9':self.sp9,'out_sp10':self.sp10,'out_sp11':self.sp11,'out_sp12':self.sp12,'out_sp13':self.sp13,'out_sp14':self.sp14,'out_sp15':self.sp15,'out_sp16':self.sp16,'out_sp17':self.sp17,'out_sp18':self.sp18,'out_sp19':self.sp19,'out_sp20':self.sp20,'out_sp21':self.sp21,'out_sp22':self.sp22,'out_sp23':self.sp23,'out_sp24':self.sp24,'out_sp25':self.sp25,'out_ap1':self.ap1,'out_ap2':self.ap2,'out_ap3':self.ap3,'out_ap4':self.ap4,'out_ap5':self.ap5,'out_ap6':self.ap6,'out_ap7':self.ap7,'out_ap8':self.ap8,'out_ap9':self.ap9,'out_ap10':self.ap10,'out_ap11':self.ap11,'out_ap12':self.ap12,'out_ap13':self.ap13,'out_ap14':self.ap14,'out_ap15':self.ap15,'out_ap16':self.ap16,'out_ap17':self.ap17,'out_ap18':self.ap18,'out_ap19':self.ap19,'out_ap20':self.ap20,'out_ap21':self.ap21,'out_ap22':self.ap22,'out_ap23':self.ap23,'out_ap24':self.ap24,'out_ap25':self.ap25,'out_f0':self.f0} def __len__(self): return self.length def on_epoch_end(self): pass model.compile(loss='mean_squared_error', optimizer='adam') #モデルのコンパイル #model.load_weights('03_larning05_all_a.h5') #訓練済みモデルを読み込み while True: config.read(inifile) fitgen_sequence = FitGenSequence(batch_size=config.getint('general', 'BATCHSIZE') , data_size=config.getint('general', 'DATASIZE') , word_list=wordlist ) model.fit_generator(generator=fitgen_sequence , epochs=config.getint('general', 'EPOCHS') ) model.save('/data/03_larning05_all_' + datetime.now().strftime("%Y%m%d_%H%M%S") +'.h5')iniファイルに「EPOCHS=3」としているので、3EPOCHSごとに学習済みモデルが保管されていく。
[work]# ls -ltr /data/03_larning05* -rw-r--r--. 1 root root 15021867824 1月 30 00:20 /data/03_larning05_all_20190130_001833.h5 -rw-r--r--. 1 root root 15021867824 1月 30 11:32 /data/03_larning05_all_20190130_113049.h5 -rw-r--r--. 1 root root 15021867824 1月 30 22:44 /data/03_larning05_all_20190130_224258.h5 -rw-r--r--. 1 root root 15021867824 1月 31 09:59 /data/03_larning05_all_20190131_095735.h5 -rw-r--r--. 1 root root 15021867824 1月 31 21:13 /data/03_larning05_all_20190131_211253.h5 -rw-r--r--. 1 root root 15021867824 2月 1 08:26 /data/03_larning05_all_20190201_082558.h5 -rw-r--r--. 1 root root 15021867824 2月 1 19:39 /data/03_larning05_all_20190201_193900.h5 -rw-r--r--. 1 root root 15021867824 2月 2 06:52 /data/03_larning05_all_20190202_065203.h5 -rw-r--r--. 1 root root 15021867824 2月 2 18:08 /data/03_larning05_all_20190202_180720.h5 -rw-r--r--. 1 root root 15021867824 2月 3 05:23 /data/03_larning05_all_20190203_052226.h5 -rw-r--r--. 1 root root 15021867824 2月 3 16:38 /data/03_larning05_all_20190203_163813.h5 -rw-r--r--. 1 root root 15021867824 2月 4 03:54 /data/03_larning05_all_20190204_035411.h5 -rw-r--r--. 1 root root 15021867824 2月 4 15:10 /data/03_larning05_all_20190204_151004.h5 #loss: 0.6556 -rw-r--r--. 1 root root 15021867824 2月 5 02:24 /data/03_larning05_all_20190205_022323.h5 -rw-r--r--. 1 root root 15021867824 2月 5 13:37 /data/03_larning05_all_20190205_133640.h5 -rw-r--r--. 1 root root 15021867824 2月 6 00:52 /data/03_larning05_all_20190206_005158.h5 -rw-r--r--. 1 root root 15021867824 2月 6 12:08 /data/03_larning05_all_20190206_120800.h5 #loss: 0.5280 -rw-r--r--. 1 root root 15021867824 2月 6 23:22 /data/03_larning05_all_20190206_232153.h5 -rw-r--r--. 1 root root 15021867824 2月 7 10:36 /data/03_larning05_all_20190207_103541.h5 -rw-r--r--. 1 root root 15021867824 2月 7 21:50 /data/03_larning05_all_20190207_214935.h5 -rw-r--r--. 1 root root 15021867824 2月 8 09:03 /data/03_larning05_all_20190208_090312.h5 #loss: 0.4476 -rw-r--r--. 1 root root 15021867824 2月 8 20:18 /data/03_larning05_all_20190208_201737.h5 -rw-r--r--. 1 root root 15021867824 2月 9 07:32 /data/03_larning05_all_20190209_073134.h5 -rw-r--r--. 1 root root 15021867824 2月 9 18:44 /data/03_larning05_all_20190209_184421.h5 -rw-r--r--. 1 root root 15021867824 2月 10 05:58 /data/03_larning05_all_20190210_055747.h5 #loss: 0.3895 -rw-r--r--. 1 root root 15021867824 2月 10 17:12 /data/03_larning05_all_20190210_171123.h5 -rw-r--r--. 1 root root 15021867824 2月 11 04:25 /data/03_larning05_all_20190211_042439.h5 #loss: 0.3714 -rw-r--r--. 1 root root 15021867824 2月 11 15:38 /data/03_larning05_all_20190211_153738.h5 #「loss: 0.3631」→「loss: 0.3631」→「loss: 0.3581」と、初めて下がらないepochがあった -rw-r--r--. 1 root root 15021867824 2月 12 02:52 /data/03_larning05_all_20190212_025121.h5 #loss: 0.3518 1/3epochは「loss: 0.3596」で、前epochより初めて上がった -rw-r--r--. 1 root root 15021867824 2月 12 14:05 /data/03_larning05_all_20190212_140437.h5 -rw-r--r--. 1 root root 15021867824 2月 13 01:29 /data/03_larning05_all_20190213_012856.h5 #loss: 0.3367 -rw-r--r--. 1 root root 15021867824 2月 13 12:41 /data/03_larning05_all_20190213_124109.h5 -rw-r--r--. 1 root root 15021867824 2月 13 23:55 /data/03_larning05_all_20190213_235432.h5 #loss: 0.3218 -rw-r--r--. 1 root root 15021867824 2月 14 11:08 /data/03_larning05_all_20190214_110811.h5 -rw-r--r--. 1 root root 15021867824 2月 14 22:23 /data/03_larning05_all_20190214_222224.h5 #loss: 0.3074 -rw-r--r--. 1 root root 15021867824 2月 15 09:36 /data/03_larning05_all_20190215_093552.h5 -rw-r--r--. 1 root root 15021867824 2月 15 20:49 /data/03_larning05_all_20190215_204907.h5 #loss: 0.2976 -rw-r--r--. 1 root root 15021867824 2月 16 08:01 /data/03_larning05_all_20190216_080118.h5 -rw-r--r--. 1 root root 15021867824 2月 16 19:14 /data/03_larning05_all_20190216_191345.h5 #loss: 0.2865 -rw-r--r--. 1 root root 15021867824 2月 17 06:27 /data/03_larning05_all_20190217_062718.h5 -rw-r--r--. 1 root root 15021867824 2月 17 17:42 /data/03_larning05_all_20190217_174205.h5 #loss: 0.2774 -rw-r--r--. 1 root root 15021867824 2月 18 04:57 /data/03_larning05_all_20190218_045644.h5 #loss: 0.2785 初めて前の3/3epochよりも上がった -rw-r--r--. 1 root root 15021867824 2月 18 16:12 /data/03_larning05_all_20190218_161148.h5 #loss: 0.2690 -rw-r--r--. 1 root root 15021867824 2月 19 03:25 /data/03_larning05_all_20190219_032452.h5 #loss: 0.2719 -rw-r--r--. 1 root root 15021867824 2月 19 14:36 /data/03_larning05_all_20190219_143621.h5 #loss: 0.2594 -rw-r--r--. 1 root root 15021867824 2月 20 01:48 /data/03_larning05_all_20190220_014726.h5 #loss: 0.2606 -rw-r--r--. 1 root root 15021867824 2月 20 13:00 /data/03_larning05_all_20190220_125926.h5 #loss: 0.2526 -rw-r--r--. 1 root root 15021867824 2月 21 00:13 /data/03_larning05_all_20190221_001300.h5 #loss: 0.2556 -rw-r--r--. 1 root root 15021867824 2月 21 11:26 /data/03_larning05_all_20190221_112533.h5 #loss: 0.25114.学習結果を使用して文字データ→音声データ変換を試す
教師データに含まれている「'ふぃねがんず','あ','かたりうったえる'」の3音の他にも、いくつかの単語をwav化してみる。
from __future__ import absolute_import, division, print_function, unicode_literals # TensorFlow と tf.keras のインポート import tensorflow as tf from tensorflow import keras config = tf.ConfigProto(log_device_placement=True) sess = tf.Session(config=config) keras.backend.set_session(sess) # ヘルパーライブラリのインポート from scipy.io import wavfile import numpy as np import pyworld as pw import csv # 自作スクリプト charの文字列を、規則に従ってlistに変換 exchange(char,num) import char2num #モデルを定義する関数。 model_input1 = keras.Input(shape=(2,), name='in1') model_input2 = keras.Input(shape=(2,), name='in2') model_input3 = keras.Input(shape=(2,), name='in3') model_input4 = keras.Input(shape=(2,), name='in4') model_input5 = keras.Input(shape=(2,), name='in5') model_input6 = keras.Input(shape=(2,), name='in6') model_input7 = keras.Input(shape=(2,), name='in7') model_input8 = keras.Input(shape=(2,), name='in8') model_input9 = keras.Input(shape=(2,), name='in9') model_input10 = keras.Input(shape=(2,), name='in10') model_input11 = keras.Input(shape=(2,), name='in11') model_input12 = keras.Input(shape=(2,), name='in12') model_input13 = keras.Input(shape=(2,), name='in13') model_input14 = keras.Input(shape=(2,), name='in14') x1_1 = keras.layers.Dense(256, activation='relu', name='1st_layer1')(model_input1) x1_2 = keras.layers.Dense(256, activation='relu', name='1st_layer2')(model_input2) x1_3 = keras.layers.Dense(256, activation='relu', name='1st_layer3')(model_input3) x1_4 = keras.layers.Dense(256, activation='relu', name='1st_layer4')(model_input4) x1_5 = keras.layers.Dense(256, activation='relu', name='1st_layer5')(model_input5) x1_6 = keras.layers.Dense(256, activation='relu', name='1st_layer6')(model_input6) x1_7 = keras.layers.Dense(256, activation='relu', name='1st_layer7')(model_input7) x1_8 = keras.layers.Dense(256, activation='relu', name='1st_layer8')(model_input8) x1_9 = keras.layers.Dense(256, activation='relu', name='1st_layer9')(model_input9) x1_10 = keras.layers.Dense(256, activation='relu', name='1st_layer10')(model_input10) x1_11 = keras.layers.Dense(256, activation='relu', name='1st_layer11')(model_input11) x1_12 = keras.layers.Dense(256, activation='relu', name='1st_layer12')(model_input12) x1_13 = keras.layers.Dense(256, activation='relu', name='1st_layer13')(model_input13) x1_14 = keras.layers.Dense(256, activation='relu', name='1st_layer14')(model_input14) x1_merge = keras.layers.concatenate([x1_1,x1_2,x1_3,x1_4,x1_5,x1_6,x1_7,x1_8,x1_9,x1_10,x1_11,x1_12,x1_13,x1_14], axis=-1) x2 = keras.layers.Dense(16384, activation='relu', name='2nd_layer')(x1_merge) x3 = keras.layers.Dense(16384, activation='relu', name='3rd_layer')(x2) x4_sp1 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp1')(x3) x4_sp2 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp2')(x3) x4_sp3 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp3')(x3) x4_sp4 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp4')(x3) x4_sp5 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp5')(x3) x4_sp6 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp6')(x3) x4_sp7 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp7')(x3) x4_sp8 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp8')(x3) x4_sp9 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp9')(x3) x4_sp10 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp10')(x3) x4_sp11 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp11')(x3) x4_sp12 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp12')(x3) x4_sp13 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp13')(x3) x4_sp14 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp14')(x3) x4_sp15 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp15')(x3) x4_sp16 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp16')(x3) x4_sp17 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp17')(x3) x4_sp18 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp18')(x3) x4_sp19 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp19')(x3) x4_sp20 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp20')(x3) x4_sp21 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp21')(x3) x4_sp22 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp22')(x3) x4_sp23 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp23')(x3) x4_sp24 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp24')(x3) x4_sp25 = keras.layers.Dense(512, activation='relu', name='4th_layer_sp25')(x3) model_output_sp1 = keras.layers.Dense(20500, name='out_sp1')(x4_sp1) model_output_sp2 = keras.layers.Dense(20500, name='out_sp2')(x4_sp2) model_output_sp3 = keras.layers.Dense(20500, name='out_sp3')(x4_sp3) model_output_sp4 = keras.layers.Dense(20500, name='out_sp4')(x4_sp4) model_output_sp5 = keras.layers.Dense(20500, name='out_sp5')(x4_sp5) model_output_sp6 = keras.layers.Dense(20500, name='out_sp6')(x4_sp6) model_output_sp7 = keras.layers.Dense(20500, name='out_sp7')(x4_sp7) model_output_sp8 = keras.layers.Dense(20500, name='out_sp8')(x4_sp8) model_output_sp9 = keras.layers.Dense(20500, name='out_sp9')(x4_sp9) model_output_sp10 = keras.layers.Dense(20500, name='out_sp10')(x4_sp10) model_output_sp11 = keras.layers.Dense(20500, name='out_sp11')(x4_sp11) model_output_sp12 = keras.layers.Dense(20500, name='out_sp12')(x4_sp12) model_output_sp13 = keras.layers.Dense(20500, name='out_sp13')(x4_sp13) model_output_sp14 = keras.layers.Dense(20500, name='out_sp14')(x4_sp14) model_output_sp15 = keras.layers.Dense(20500, name='out_sp15')(x4_sp15) model_output_sp16 = keras.layers.Dense(20500, name='out_sp16')(x4_sp16) model_output_sp17 = keras.layers.Dense(20500, name='out_sp17')(x4_sp17) model_output_sp18 = keras.layers.Dense(20500, name='out_sp18')(x4_sp18) model_output_sp19 = keras.layers.Dense(20500, name='out_sp19')(x4_sp19) model_output_sp20 = keras.layers.Dense(20500, name='out_sp20')(x4_sp20) model_output_sp21 = keras.layers.Dense(20500, name='out_sp21')(x4_sp21) model_output_sp22 = keras.layers.Dense(20500, name='out_sp22')(x4_sp22) model_output_sp23 = keras.layers.Dense(20500, name='out_sp23')(x4_sp23) model_output_sp24 = keras.layers.Dense(20500, name='out_sp24')(x4_sp24) model_output_sp25 = keras.layers.Dense(20500, name='out_sp25')(x4_sp25) x4_ap1 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap1')(x3) x4_ap2 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap2')(x3) x4_ap3 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap3')(x3) x4_ap4 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap4')(x3) x4_ap5 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap5')(x3) x4_ap6 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap6')(x3) x4_ap7 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap7')(x3) x4_ap8 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap8')(x3) x4_ap9 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap9')(x3) x4_ap10 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap10')(x3) x4_ap11 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap11')(x3) x4_ap12 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap12')(x3) x4_ap13 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap13')(x3) x4_ap14 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap14')(x3) x4_ap15 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap15')(x3) x4_ap16 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap16')(x3) x4_ap17 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap17')(x3) x4_ap18 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap18')(x3) x4_ap19 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap19')(x3) x4_ap20 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap20')(x3) x4_ap21 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap21')(x3) x4_ap22 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap22')(x3) x4_ap23 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap23')(x3) x4_ap24 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap24')(x3) x4_ap25 = keras.layers.Dense(512, activation='relu', name='4th_layer_ap25')(x3) model_output_ap1 = keras.layers.Dense(20500, name='out_ap1')(x4_ap1) model_output_ap2 = keras.layers.Dense(20500, name='out_ap2')(x4_ap2) model_output_ap3 = keras.layers.Dense(20500, name='out_ap3')(x4_ap3) model_output_ap4 = keras.layers.Dense(20500, name='out_ap4')(x4_ap4) model_output_ap5 = keras.layers.Dense(20500, name='out_ap5')(x4_ap5) model_output_ap6 = keras.layers.Dense(20500, name='out_ap6')(x4_ap6) model_output_ap7 = keras.layers.Dense(20500, name='out_ap7')(x4_ap7) model_output_ap8 = keras.layers.Dense(20500, name='out_ap8')(x4_ap8) model_output_ap9 = keras.layers.Dense(20500, name='out_ap9')(x4_ap9) model_output_ap10 = keras.layers.Dense(20500, name='out_ap10')(x4_ap10) model_output_ap11 = keras.layers.Dense(20500, name='out_ap11')(x4_ap11) model_output_ap12 = keras.layers.Dense(20500, name='out_ap12')(x4_ap12) model_output_ap13 = keras.layers.Dense(20500, name='out_ap13')(x4_ap13) model_output_ap14 = keras.layers.Dense(20500, name='out_ap14')(x4_ap14) model_output_ap15 = keras.layers.Dense(20500, name='out_ap15')(x4_ap15) model_output_ap16 = keras.layers.Dense(20500, name='out_ap16')(x4_ap16) model_output_ap17 = keras.layers.Dense(20500, name='out_ap17')(x4_ap17) model_output_ap18 = keras.layers.Dense(20500, name='out_ap18')(x4_ap18) model_output_ap19 = keras.layers.Dense(20500, name='out_ap19')(x4_ap19) model_output_ap20 = keras.layers.Dense(20500, name='out_ap20')(x4_ap20) model_output_ap21 = keras.layers.Dense(20500, name='out_ap21')(x4_ap21) model_output_ap22 = keras.layers.Dense(20500, name='out_ap22')(x4_ap22) model_output_ap23 = keras.layers.Dense(20500, name='out_ap23')(x4_ap23) model_output_ap24 = keras.layers.Dense(20500, name='out_ap24')(x4_ap24) model_output_ap25 = keras.layers.Dense(20500, name='out_ap25')(x4_ap25) x4_f0 = keras.layers.Dense(512, activation='relu', name='4th_layer_f0')(x3) model_output_f0 = keras.layers.Dense(500, name='out_f0')(x4_f0) model = keras.models.Model(inputs=[model_input1,model_input2,model_input3,model_input4,model_input5,model_input6,model_input7,model_input8,model_input9,model_input10,model_input11,model_input12,model_input13,model_input14], outputs=[model_output_sp1,model_output_sp2,model_output_sp3,model_output_sp4,model_output_sp5,model_output_sp6,model_output_sp7,model_output_sp8,model_output_sp9,model_output_sp10,model_output_sp11,model_output_sp12,model_output_sp13,model_output_sp14,model_output_sp15,model_output_sp16,model_output_sp17,model_output_sp18,model_output_sp19,model_output_sp20,model_output_sp21,model_output_sp22,model_output_sp23,model_output_sp24,model_output_sp25,model_output_ap1,model_output_ap2,model_output_ap3,model_output_ap4,model_output_ap5,model_output_ap6,model_output_ap7,model_output_ap8,model_output_ap9,model_output_ap10,model_output_ap11,model_output_ap12,model_output_ap13,model_output_ap14,model_output_ap15,model_output_ap16,model_output_ap17,model_output_ap18,model_output_ap19,model_output_ap20,model_output_ap21,model_output_ap22,model_output_ap23,model_output_ap24,model_output_ap25,model_output_f0]) model.compile(loss='mean_squared_error', optimizer='adam') #モデルのコンパイル def sampleout(): for word in ['あいうえお','ふぃねがんず','あ','かたりうったえる','まほうじんぐるぐる','どうしましょうか']: inputdata_np1 , inputdata_np2 , inputdata_np3 , inputdata_np4 , inputdata_np5 , inputdata_np6 , inputdata_np7 , inputdata_np8 , inputdata_np9 , inputdata_np10 , inputdata_np11 , inputdata_np12 , inputdata_np13 , inputdata_np14 = np.hsplit( np.array([char2num.exchange(word,14)]) /256 , 14 ) sp1 , sp2 , sp3 , sp4 , sp5 , sp6 , sp7 , sp8 , sp9 , sp10 , sp11 , sp12 , sp13 , sp14 , sp15 , sp16 , sp17 , sp18 , sp19 , sp20 , sp21 , sp22 , sp23 , sp24 , sp25 , ap1 , ap2 , ap3 , ap4 , ap5 , ap6 , ap7 , ap8 , ap9 , ap10 , ap11 , ap12 , ap13 , ap14 , ap15 , ap16 , ap17 , ap18 , ap19 , ap20 , ap21 , ap22 , ap23 , ap24 , ap25 , f0 = model.predict({'in1':inputdata_np1,'in2':inputdata_np2,'in3':inputdata_np3,'in4':inputdata_np4,'in5':inputdata_np5,'in6':inputdata_np6,'in7':inputdata_np7,'in8':inputdata_np8,'in9':inputdata_np9,'in10':inputdata_np10,'in11':inputdata_np11,'in12':inputdata_np12,'in13':inputdata_np13,'in14':inputdata_np14}) print ("sp1.shape=",sp1.shape) print ("ap1.shape=",ap1.shape) result_out_sp = np.concatenate([sp1 , sp2 , sp3 , sp4 , sp5 , sp6 , sp7 , sp8 , sp9 , sp10 , sp11 , sp12 , sp13 , sp14 , sp15 , sp16 , sp17 , sp18 , sp19 , sp20 , sp21 , sp22 , sp23 , sp24 , sp25], 1) result_out_ap = np.concatenate([ap1 , ap2 , ap3 , ap4 , ap5 , ap6 , ap7 , ap8 , ap9 , ap10 , ap11 , ap12 , ap13 , ap14 , ap15 , ap16 , ap17 , ap18 , ap19 , ap20 , ap21 , ap22 , ap23 , ap24 , ap25], 1) print ("result_out_sp.shape=",result_out_sp.shape) print ("result_out_ap.shape=",result_out_ap.shape) result_out_sp = [[10**((i*30)-19) if i!=0 else 0 for i in j ] for j in result_out_sp] result_out_f0 = f0 *1024 synthesized = pw.synthesize( np.reshape(result_out_f0, (500,)).astype(np.float64) , np.reshape(result_out_sp, (500,1025)) , np.reshape(result_out_ap, (500,1025)).astype(np.float64) , 44100 ).astype(np.int16) wavfile.write(headword+word+'.wav',44100,synthesized) model.load_weights('/data/03_larning05_all_20190621_021938.h5') headword='03_larning05_1_loss0851_' sampleout()5.少ない教師データ数、短い学習時間で効率的に学習させる方法を考える
10000単語、batchsize=10で学習させたところ、84epochsくらいでloss率が下がりづらくなり、
149epochs程度経過後、loss=0.25くらいで頭打ちになった。
(GPUなし、6core:12thread/1.9GHz。メモリ32GB環境で約20日間)1000/1000 [==============================] - 13431s 13s/step - loss: 0.2511 - out_sp1_loss: 0.0014 - out_sp2_loss: 0.0070 - out_sp3_loss: 0.0096 - out_sp4_loss: 0.0088 - out_sp5_loss: 0.0135 - out_sp6_loss: 0.0151 - out_sp7_loss: 0.0091 - out_sp8_loss: 0.0034 - out_sp9_loss: 0.0014 - out_sp10_loss: 4.7735e-04 - out_sp11_loss: 2.7430e-04 - out_sp12_loss: 1.6851e-04 - out_sp13_loss: 9.2398e-05 - out_sp14_loss: 5.4483e-05 - out_sp15_loss: 5.0145e-05 - out_sp16_loss: 3.5160e-05 - out_sp17_loss: 1.8517e-05 - out_sp18_loss: 1.7576e-05 - out_sp19_loss: 7.4513e-06 - out_sp20_loss: 9.8959e-07 - out_sp21_loss: 2.2931e-07 - out_sp22_loss: 1.7947e-07 - out_sp23_loss: 1.2095e-11 - out_sp24_loss: 1.8030e-11 - out_sp25_loss: 5.6759e-12 - out_ap1_loss: 0.0187 - out_ap2_loss: 0.0239 - out_ap3_loss: 0.0251 - out_ap4_loss: 0.0263 - out_ap5_loss: 0.0286 - out_ap6_loss: 0.0283 - out_ap7_loss: 0.0161 - out_ap8_loss: 0.0066 - out_ap9_loss: 0.0026 - out_ap10_loss: 0.0011 - out_ap11_loss: 6.4949e-04 - out_ap12_loss: 3.1281e-04 - out_ap13_loss: 1.8863e-04 - out_ap14_loss: 1.2824e-04 - out_ap15_loss: 9.1774e-05 - out_ap16_loss: 6.1045e-05 - out_ap17_loss: 2.9133e-05 - out_ap18_loss: 2.2714e-05 - out_ap19_loss: 6.3900e-06 - out_ap20_loss: 1.7681e-06 - out_ap21_loss: 3.3528e-07 - out_ap22_loss: 1.5480e-07 - out_ap23_loss: 7.4649e-12 - out_ap24_loss: 9.2365e-12 - out_ap25_loss: 7.8836e-12 - out_f0_loss: 0.0018それに対して最初から50000単語、batchsize=10で学習させたところ、同じく20日間放置して31epochs経過するも、loss:0.80程度。まだ1epochあたり0.008程度下がり続けているが、収束が遅すぎる。
(マシン性能は先のものとほぼ同じ環境なので、単純に学習データ数が増えたことによる影響と思われる。)しかし、学習後のモデルで未学習単語をwav化したところ、loss=0.25まで下がった先ほどのモデルより、loss=0.8ほどのこのモデルのほうが、より聞き取りやすい。
教師データが多いため、より汎用性の高い学習ができているということだろうか?
VALIDSPLIT的な仕組みを作るか、あるいはvalidation dataを別途用意してepochごとに検証してみたほうが良いかも。5000/5000 [==============================] - 74533s 15s/step - loss: 0.8005 - out_sp1_loss: 0.0042 - out_sp2_loss: 0.0253 - out_sp3_loss: 0.0330 - out_sp4_loss: 0.0297 - out_sp5_loss: 0.0424 - out_sp6_loss: 0.0539 - out_sp7_loss: 0.0460 - out_sp8_loss: 0.0279 - out_sp9_loss: 0.0146 - out_sp10_loss: 0.0072 - out_sp11_loss: 0.0035 - out_sp12_loss: 0.0018 - out_sp13_loss: 0.0011 - out_sp14_loss: 6.8459e-04 - out_sp15_loss: 5.0065e-04 - out_sp16_loss: 3.8773e-04 - out_sp17_loss: 2.3878e-04 - out_sp18_loss: 1.3287e-04 - out_sp19_loss: 8.1552e-05 - out_sp20_loss: 4.5552e-05 - out_sp21_loss: 3.8080e-05 - out_sp22_loss: 1.0064e-05 - out_sp23_loss: 1.0051e-06 - out_sp24_loss: 2.4118e-11 - out_sp25_loss: 2.4103e-11 - out_ap1_loss: 0.0452 - out_ap2_loss: 0.0565 - out_ap3_loss: 0.0599 - out_ap4_loss: 0.0613 - out_ap5_loss: 0.0667 - out_ap6_loss: 0.0770 - out_ap7_loss: 0.0608 - out_ap8_loss: 0.0367 - out_ap9_loss: 0.0195 - out_ap10_loss: 0.0093 - out_ap11_loss: 0.0047 - out_ap12_loss: 0.0024 - out_ap13_loss: 0.0015 - out_ap14_loss: 9.9513e-04 - out_ap15_loss: 7.5172e-04 - out_ap16_loss: 5.4091e-04 - out_ap17_loss: 3.3179e-04 - out_ap18_loss: 1.6043e-04 - out_ap19_loss: 8.7130e-05 - out_ap20_loss: 6.2652e-05 - out_ap21_loss: 3.1422e-05 - out_ap22_loss: 1.4057e-05 - out_ap23_loss: 7.1795e-07 - out_ap24_loss: 1.8263e-11 - out_ap25_loss: 1.9893e-11 - out_f0_loss: 0.0032そこで、最初から10000単語、20日後の149epochs経過のloss=0.25で頭打ちになったモデルに対して、途中から教師データを10000単語→50000単語に増やしてみたところ、増加後最初の1回はloss:0.9971に劇的に下がったが、10日で12epochs経過すると0.67まで一気に改善。最初から50000単語で学習していた方をあっという間に追い抜いた。
5000/5000 [==============================] - 73167s 13s/step - loss: 0.6756 - out_sp1_loss: 0.0037 - out_sp2_loss: 0.0212 - out_sp3_loss: 0.0292 - out_sp4_loss: 0.0264 - out_sp5_loss: 0.0377 - out_sp6_loss: 0.0465 - out_sp7_loss: 0.0374 - out_sp8_loss: 0.0207 - out_sp9_loss: 0.0099 - out_sp10_loss: 0.0046 - out_sp11_loss: 0.0024 - out_sp12_loss: 0.0013 - out_sp13_loss: 8.7149e-04 - out_sp14_loss: 5.9194e-04 - out_sp15_loss: 4.3575e-04 - out_sp16_loss: 2.7581e-04 - out_sp17_loss: 1.4421e-04 - out_sp18_loss: 1.2563e-04 - out_sp19_loss: 7.0380e-05 - out_sp20_loss: 6.7398e-05 - out_sp21_loss: 4.6027e-05 - out_sp22_loss: 1.7514e-05 - out_sp23_loss: 1.0061e-06 - out_sp24_loss: 1.6893e-11 - out_sp25_loss: 1.6380e-11 - out_ap1_loss: 0.0391 - out_ap2_loss: 0.0465 - out_ap3_loss: 0.0524 - out_ap4_loss: 0.0542 - out_ap5_loss: 0.0595 - out_ap6_loss: 0.0680 - out_ap7_loss: 0.0513 - out_ap8_loss: 0.0285 - out_ap9_loss: 0.0139 - out_ap10_loss: 0.0067 - out_ap11_loss: 0.0035 - out_ap12_loss: 0.0019 - out_ap13_loss: 0.0012 - out_ap14_loss: 7.7377e-04 - out_ap15_loss: 6.2020e-04 - out_ap16_loss: 3.7930e-04 - out_ap17_loss: 2.4824e-04 - out_ap18_loss: 1.5485e-04 - out_ap19_loss: 9.1987e-05 - out_ap20_loss: 5.5130e-05 - out_ap21_loss: 3.6122e-05 - out_ap22_loss: 1.5816e-05 - out_ap23_loss: 8.1232e-07 - out_ap24_loss: 1.4804e-11 - out_ap25_loss: 1.5227e-11 - out_f0_loss: 0.0030おそらく、40000/50000のデータが未学習だったためloss率が悪化したものの、未学習データ分は学習が早いため、一気に改善したと思われる。
あくまで学習データに対するloss率を見ただけだが、最初から大量の教師データを学習させるより、少ないデータである程度loss率を下げた後に教師データ数を段階的に増やしていく方が効率的ということになる。
いわれてみれば当たり前で、最初から50000の教師データを投入すると、50000の教師データ全てに最適化されるように学習する必要があるため、1データ処理するごとのパラメータの変化が抑えられる動きになるはず。(そうしないとパラメータが暴れて、もっと早い段階でloss率が乱高下することになるはず。)
最初は少ない教師データによって、汎用性は低くても、ある程度それっぽい収束をさせた後、過学習の弊害が出る前を見計らって教師データ数を増やしていくことで効率的に学習できると思われる。(追記待ち)
- 投稿日:2019-07-01T11:14:02+09:00
LambdaからAPI Gateway(IAM認可)へのアクセス方法 [Python版]
AWS上でServerlessかつMicroservicesな構成の場合、Lambda内から別サービスのAPI Gatewayにアクセスすることがある。
API GatewayがIAMでアクセス制限がかかっている場合のアクセス方法が分からなかったので調査した。※ Node.js版はこちら
前提
- Lambda (Python 3.7)
- LambdaにIAM Role付与済み
- API Gateway(IAM認可)作成済み
※ API Gatewayの設定方法やIAM Roleの内容などはここでは取り扱わない
結論
botocoreのSigV4Authで署名する。
lambda_function.pyimport os import urllib.request from botocore.credentials import Credentials from botocore.awsrequest import AWSRequest from botocore.auth import SigV4Auth def lambda_handler(event): ENDPOINT = "https://XXXXXXXXXX.execute-api.ap-northeast-1.amazonaws.com/STAGE" PATH = "/YOUR/RESOURCE" awsreq = AWSRequest(method="GET", url=ENDPOINT+PATH) // Sign credentials = Credentials( os.environ["AWS_ACCESS_KEY_ID"], os.environ["AWS_SECRET_ACCESS_KEY"], os.environ["AWS_SESSION_TOKEN"]) SigV4Auth(credentials, "execute-api", os.environ["AWS_REGION"]).add_auth(awsreq) // Request req = urllib.request.Request(awsreq.url, method=awsreq.method, headers=awsreq.headers) with urllib.request.urlopen(req) as res: body = res.read() // Do somethingSigV4Auth で AWSRequest を署名する。
⇒ 下記のようなHeadersが設定されるreq.headersX-Amz-Date: 20190701T020706Z X-Amz-Security-Token: AgoJb3JpZ3luX2VjEBgaDmFwLW6vcnRoZWFzdC0xIkcwRQIgXKqUW7xJYR7xjI8r3A8867/J/258UZa3dVZTZXJhZdoCIQCtfBGGCJQR2RIGAaFMUzXdr4MXYzVapq0dUV8tN6QWGSqAAghhEAIaDDM1OTAzMDQzODQ5MSIMuUdqb7U/zKQD0S6GKt0BOkhXekZuxE8LCL9u8ktGjEeQJGHXiRvyfQ8ohzGRlWzmql66Ao1ArjTjYB1Bw7hbnFs4EUylvwc1XBvbEG/OEyWm1rpbZqe5U5Jg0Z9HY8UvJ2wrjKTH4OBMIYMXk4ZdHu9djIx+6d1Ap0E2F2SAtyMsaG75gFuNOx6frG7T0ZFj9t/pT+5HfxE5349VbxaBX6PvRvOIDfLXqv2UacY9eq3gRkkCNOlBm/4Z+iHyQLkWxkOeG05YIx2r7oeeBqN/459KeKU/pDJMcc/QbnTilCQx+oedEmlV+HRfVIswmPbY6AU6tAHD/gc0T1Rszlg1QgZ7aytsID5JvZCaO6/0SYx0C6mx2G/vrQQivQlxCkK396anWK+sVu69goOxay8cs+wov5+TVtL+1ybPYsMJIv6Pb0/zNS82jyh2Va1YOZ8Ep/i/VHrvPVgVLL1419Ly92MhkPZqMecDiniomEzfBchLYpB+eZ/+B+8+SnqOBuooz+QiF+y8doSBMj24ahhEaa7ErGC/rTI1VuT0GSN8a43N1hpkZ7O9Vlg= Authorization: AWS4-HMAC-SHA256 Credential=ASIAVHFXXXXXXXXXXXXX/20190701/ap-northeast-1/execute-api/aws4_request, SignedHeaders=host;x-amz-date;x-amz-security-token, Signature=ac00aaab0b00fe0a000000e0fd0a00c00aab00000b0000a0a000bddb0b000dAWSRequest 自体はリクエストを発行してくれないので、別途urllibやrequestsなどでリクエストを送る必要がある。
参考
https://docs.aws.amazon.com/ja_jp/general/latest/gr/sigv4_signing.html
https://dev.classmethod.jp/cloud/aws/botocore-signed-process/
https://qiita.com/paper2/items/cea6021512132f070403
https://qiita.com/toshihirock/items/a92cbda51d5f469bb0ac
https://qiita.com/crifff/items/6dff429555c898a19758
- 投稿日:2019-07-01T09:25:43+09:00
勾配降下法のテクニック、モメンタム法を試してみた。
勾配降下法
勾配降下法を使うとパラメータの値を逐次的に更新していくことによって一番尤もらしいパラメータの値を求められる。
関数$f(\theta)$のパラメータ$\theta$の更新式は以下のように表せる。{\theta := \theta - \eta f'(\theta) }この更新を繰り返すことによって、パラメータの値を探索していいく。しかし、場合によっては、更新を何千回と繰り返さなければならないこともあるため、これを効率化するテクニックがいくつか存在する。本記事では、これらのテクニックを使いながらパラメータを更新しその様子をアニメーション化することで、こうしたテクニックを比較する。
初期値の設定
関数は、$f(x, y)={x^2 + 3y^2}$とする。また、初期座標は(9, 9)、学習率0.1とする。
普通の勾配降下法
モメンタム法
最初は勢いよく勾配を降っているが、慣性が付いているため、行き過ぎてしまう。
結局、100以上かかった。