- 投稿日:2019-07-01T16:07:06+09:00
Amazon Linux 2018.3で最新バージョン(1.17.1)のNginXにアップデートする
nginx.repoを
/etc/yum.repos.d/以下に作成します。このとき各項目にpriority=1を追加しましょう。/etc/yum.repos.d/nginx.repo[nginx-stable] name=nginx stable repo baseurl=http://nginx.org/packages/centos/6/$basearch/ priority=1 gpgcheck=1 enabled=1 gpgkey=https://nginx.org/keys/nginx_signing.key [nginx-mainline] name=nginx mainline repo baseurl=http://nginx.org/packages/mainline/centos/6/$basearch/ priority=1 gpgcheck=1 enabled=1 gpgkey=https://nginx.org/keys/nginx_signing.keyそして
yum --showduplicate list nginxで$ yum --showduplicate list nginx Installed Packages nginx.x86_64 1.17.1-1.el6.ngx @nginx-mainline Available Packages nginx.x86_64 1.8.0-1.el6.ngx nginx-stable nginx.x86_64 1.8.1-1.el6.ngx nginx-stable (中略) nginx.x86_64 1.16.0-1.el6.ngx nginx-stable nginx.x86_64 1.17.0-1.el6.ngx nginx-mainline nginx.x86_64 1.17.1-1.el6.ngx nginx-mainline利用可能なパッケージのバージョンの一覧が表示されるのですが、この中のパッケージを指定して新しいバージョンにアップデートしようとしても
$ sudo yum --disablerepo=amzn-updates install nginx-1.17.1-1.el6.ngx.x86_64 Loaded plugins: priorities, update-motd, upgrade-helper 1 packages excluded due to repository priority protections Package nginx-1.17.1-1.el6.ngx.x86_64 is obsoleted by 1:nginx-all-modules-1.12.1-1.33.amzn1.x86_64 which is already installedと表示されてしまい、アップデートできません。
Package XXX is obsoleted by YYY which is already installedと表示されてしまう原因としてyumが本来古いはずのNginxのパッケージを最新版と認識するために古いバージョン扱いとなるパッケージがインストールできないようです。ということで$ sudo yum downgrade nginx-1.17.1これでインストール(アップデート)できます。
おまけ
ElasticBeanstalk(およびCloudFormation)用の設定ファイルです。
ebextensions/upgrade_nginx.configcommands: update_nginx: command: | NGINX_VER=$(yum list nginx | grep nginx | awk '{print $2}') if ! [ NGINX_VER = "1.17.1-1.el6.ngx" ] ; then yum --disablerepo=amzn-updates downgrade nginx-1.17.1 -y fi nginx -V files: /etc/yum.repo.d/nginx.repo: mode: "000644" owner: root group: root content: | [nginx-stable] name=nginx stable repo baseurl=http://nginx.org/packages/centos/6/$basearch/ priority=1 gpgcheck=1 enabled=1 gpgkey=https://nginx.org/keys/nginx_signing.key [nginx-mainline] name=nginx mainline repo baseurl=http://nginx.org/packages/mainline/centos/6/$basearch/ priority=1 gpgcheck=1 enabled=1 gpgkey=https://nginx.org/keys/nginx_signing.key
- 投稿日:2019-07-01T15:10:21+09:00
GoのユニットテストでAWS SDKのモックをする
Goのユニットテストでどうしてもaws-sdkを叩くレイヤーのtestがしたくなったとき、localstackなど実際のawsを模した機能を用意できればそれが一番だが、たいてい大掛かりになってしまう。
goのaws-sdkには大抵interfaceが用意されているので、これをmockでうまく使うとなかなか良かった。そもそもDIの基本になるが、なるべくs3.S3などのstructそのものでなく、このようなinterfaceへの依存を持っておくことで簡単にmockが可能になるので、設計の際に留意しておく。
例えば、s3であれば S3APIというinterfaceがある。
今回はこういうものを用意した。
package aws_sdk import ( "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/request" "github.com/aws/aws-sdk-go/service/s3" ) type S3SdkMockImpl struct { //テストごとに差し替え可能にする ListObjects_Mock func(*s3.ListObjectsInput) (*s3.ListObjectsOutput, error) HeadObject_Mock func(*s3.HeadObjectInput) (*s3.HeadObjectOutput, error) } // auto generated by jetbrains func (S3SdkMockImpl) AbortMultipartUpload(*s3.AbortMultipartUploadInput) (*s3.AbortMultipartUploadOutput, error) { panic("implement me") } func (S3SdkMockImpl) AbortMultipartUploadWithContext(aws.Context, *s3.AbortMultipartUploadInput, ...request.Option) (*s3.AbortMultipartUploadOutput, error) { panic("implement me") } func (S3SdkMockImpl) AbortMultipartUploadRequest(*s3.AbortMultipartUploadInput) (*request.Request, *s3.AbortMultipartUploadOutput) { panic("implement me") } func (S3SdkMockImpl) CompleteMultipartUpload(*s3.CompleteMultipartUploadInput) (*s3.CompleteMultipartUploadOutput, error) { panic("implement me") } func (S3SdkMockImpl) CompleteMultipartUploadWithContext(aws.Context, *s3.CompleteMultipartUploadInput, ...request.Option) (*s3.CompleteMultipartUploadOutput, error) { panic("implement me") } ... // ダミーが刺されていれば使う func (self *S3SdkMockImpl) HeadObject(in *s3.HeadObjectInput) (*s3.HeadObjectOutput, error) { if self.HeadObject_Mock != nil { return self.HeadObject_Mock(in) } panic("implement me") } .... func (self *S3SdkMockImpl) ListObjects(in *s3.ListObjectsInput) (*s3.ListObjectsOutput, error) { if self.ListObjects_Mock != nil { return self.ListObjects_Mock(in) } panic("implement me") }interfaceを埋めるメソッド自体はGolang等のIDEですぐにgenerateできるが、テストケースごとに生成するのも見通しが悪いため、必要なメソッドごとに差し替え可能にし、使いまわせるようにした。
使用側はこうなる。s3SdkMockTestCase01 := aws_sdk.S3SdkMockImpl{ ListObjects_Mock: func(input *s3.ListObjectsInput) (output *s3.ListObjectsOutput, e error) { return &s3.ListObjectsOutput{ ... //自由に返す } , nil }, } s3SdkMockTestCase02 := aws_sdk.S3SdkMockImpl{ ListObjects_Mock: func(input *s3.ListObjectsInput) (output *s3.ListObjectsOutput, e error) { return &s3.ListObjectsOutput{ ... //自由に返す } , nil }, } s3DataRepoisitoryForTest01 := NewS3DataRepository(s3SdkMockTestCase01) s3DataRepoisitoryForTest02 := NewS3DataRepository(s3SdkMockTestCase02)場合に応じて差し替えが簡単になり、使いまわせるようにもなった。
- 投稿日:2019-07-01T14:49:20+09:00
(メモ)su させない
/etc/sudoers.dディレクトリ配下を編集
rootユーザで/etc/sudoers.d配下に ban_commandファイル(このファイル名はなんでもいい)を作成。
# cd /etc/sudoers.d # touch ban_command # vi /etc/sudoers.d/ban_command Cmnd_Alias BAN_COMMAND = /bin/su <ユーザ名> ALL=NOPASSWD: ALL, !BAN_COMMANDvisudoで内容を確認し、「:q」でvisudoから抜ける
# visudosuできないか確認
「Sorry〜」のメッセージが出力されればOK
$ su - <ユーザー名> $ sudo su Sorry, user <ユーザ名> is not allowed to execute '/bin/su' as root on ip-xx-xxx-xx-xx.ap-northeast-1.compute.internal.参考
- 投稿日:2019-07-01T14:35:35+09:00
Javaでlambda layerを使用する
はじめに
javaでlambda layerを使用する方法が探したけどなかったのでメモりました。
参考:使用するJavaソース
lambda layer側(layer_print.jarでエクスポートする)
Print.javapackage layer_print; public class Print { public static void print() { System.out.println("print from layer!!"); } }layerを使用するHandlerクラス
MyLambda.javapackage lambda_layer_java; import com.amazonaws.services.lambda.runtime.Context; import com.amazonaws.services.lambda.runtime.RequestHandler; import layer_print.Print; public class MyLambda implements RequestHandler<Integer, String> { @Override public String handleRequest(Integer in, Context context) { // lambda layer呼び出し Print.print(); return "success"; } }手順
1.ローカルでjava/libフォルダ作成
2.libにlayerにするjarファイルを置く
3.javaフォルダをzip変換
4.AWSコンソールのlambdaのLayers選択。レイヤーの作成押下
5.名前、説明を入力。互換性のあるランタイムでjava 8を選択。作成したzipファイルをアップロードしてlayer作成
6.layerを使用するlambda関数に移動して、Layersを選択して、レイヤーの追加を押下
7.layer、バージョンを選択して追加
8.保存して完了
以上です。








- 投稿日:2019-07-01T14:35:35+09:00
JavaでLambda Layersを使用する
はじめに
JavaでLambda Layersを使用する際の手順を探したけど、わかりやすいのがなかったのでメモりました。
事前準備:使用するJava
lambda layer側
layer_print.jarでエクスポートする
Print.javapackage layer_print; public class Print { public static void print() { System.out.println("print from layer!!"); } }layerを使用するLambdaのHandlerクラス
layer_print.jarを含まずにjar作成 → lambda関数にアップロードする
MyLambda.javapackage lambda_layer_java; import com.amazonaws.services.lambda.runtime.Context; import com.amazonaws.services.lambda.runtime.RequestHandler; import layer_print.Print; public class MyLambda implements RequestHandler<Integer, String> { @Override public String handleRequest(Integer in, Context context) { // lambda layer呼び出し Print.print(); return "success"; } }手順
ローカルでjava/libフォルダ作成
libにlayerにするjarファイルを置く
javaフォルダをzipに変換
AWSコンソールのlambdaのLayers選択。レイヤーの作成押下
名前、説明を入力。互換性のあるランタイムでjava 8を選択。作成したzipファイルをアップロードしてlayer作成
layerを使用するlambda関数に移動して、Layersを選択して、レイヤーの追加を押下
layer、バージョンを選択して追加
保存して完了
以上です。
- 投稿日:2019-07-01T14:27:06+09:00
Linux(主にAWS)でのユーザー追加方法
ユーザーの追加とSSHの認証用の鍵を生成する。
# useradd ユーザー名 # su - ユーザー名 $ ssh-keygen -t rsasudoをパスワード無しで利用するためvisudoで下記のコメントアウトを外す。
%wheel ALL=(ALL) NOPASSWD: ALL対象ユーザーをwheelグループに追加する。
usermod -aG wheel ユーザー名所属グループを確認する。
groups下記は単体ユーザーを設定するやり方。
sudoを使用する場合はvisudoでユーザーを追加する。# Allow root to run any commands anywhere ユーザー名 ALL=(ALL) NOPASSWD:ALL
- 投稿日:2019-07-01T13:32:13+09:00
【Rails 備忘録】デプロイする時に定番で使うコマンド
はじめに
備忘録です。
デプロイで使うコマンド
前提条件として、
AWS EC2環境/var/www/app/配下でgit cloneさせます。git clone
言わずもがなgit cloneです。
git pull
言わずもがなgit pullです。
bundle install
bundle install --path=vendor/bundle --without development testassets precompile
bundle exec rails assets:precompile RAILS_ENV=stagingmigrate
bundle exec rails db:migrate RAILS_ENV=stagingrails server起動
bundle exec rails s -e staging -drails server停止
ps aux | grep rails (rails s -e staging -d のプロセスidを見つける) kill プロセスidrails コンソール
bundle exec rails c -e stagingちなみに
上記はstaging環境でのコマンドとなります。
production環境の場合、stagingをproductionに変更すればOK。
- 投稿日:2019-07-01T11:42:44+09:00
【AWS】git clone ssh...をするために必要なこと
AWS の CodeCommit に ssh接続するために
ssh接続に必要なキーペアを生成する
ターミナルで以下のコマンドを実行する
$ ssh-keygenこれにより 秘密鍵(secret_key) と 公開鍵(public_key) のキーペアが生成される
秘密鍵は
~/.ssh/id_rsa
公開鍵は~/.ssh/id_rsa.pub
にそれぞれ記載されているIAMユーザーに公開鍵情報を登録する
サービス > IAM > ユーザー > 認証情報 の「SSHパブリックキーのアップロード」をクリック
公開鍵~/.ssh/id_rsa.pubの中身をコピーし、フィールドに貼り付けアップロードする
するとSSHキーIDが生成されるのでコピーしておく設定ファイルにSSHキーIDと秘密鍵ファイルパスを記述する
ターミナルで以下のコマンドを実行する
$ vim ~/.ssh/configconfigには以下のように記述する
Host git-codecommit.*.amazonaws.com User SSHキーID IdentityFile ~/.ssh/id_rsaconfig のアクセス権限を変更する
ターミナルで以下のコマンドを実行する
$ chmod 600 ~/.ssh/id_rsaSSH設定をテストする
ターミナルで以下のコマンドを実行する
$ ssh git-codecommit.us-east-2.amazonaws.com初めて接続する場合は接続の確認メッセージが表示される
(yes? or no? ) と聞かれるので yes と書いて enter するここまで出来れば事前準備完了!
これからは SSH で git clone し放題なのでぜひ試してみて欲しい
- 投稿日:2019-07-01T11:42:44+09:00
【AWS】git clone ssh...をする前に
AWS の CodeCommit に ssh接続するために必要なこと
ssh接続に必要なキーペアを生成する
ターミナルで以下のコマンドを実行する
$ ssh-keygenこれにより 秘密鍵(secret_key) と 公開鍵(public_key) のキーペアが生成される
秘密鍵は
~/.ssh/id_rsa
公開鍵は~/.ssh/id_rsa.pub
にそれぞれ記載されているIAMユーザーに公開鍵情報を登録する
サービス > IAM > ユーザー > 認証情報 の「SSHパブリックキーのアップロード」をクリック
公開鍵~/.ssh/id_rsa.pubの中身をコピーし、フィールドに貼り付けアップロードする
するとSSHキーIDが生成されるのでコピーしておく設定ファイルにSSHキーIDと秘密鍵ファイルパスを記述する
ターミナルで以下のコマンドを実行する
$ vim ~/.ssh/configconfigには以下のように記述する
Host git-codecommit.*.amazonaws.com User SSHキーID IdentityFile ~/.ssh/id_rsaconfig のアクセス権限を変更する
ターミナルで以下のコマンドを実行する
$ chmod 600 ~/.ssh/id_rsaSSH設定をテストする
ターミナルで以下のコマンドを実行する
$ ssh git-codecommit.us-east-2.amazonaws.com初めて接続する場合は接続の確認メッセージが表示される
(yes? or no? ) と聞かれるので yes と書いて enter するここまで出来れば事前準備完了!
これからは SSH で git clone し放題なのでぜひ試してみて欲しい
- 投稿日:2019-07-01T11:42:44+09:00
【AWS】git clone ssh...をする前に行う簡単な設定
AWS の CodeCommit に ssh接続するために必要なこと
ssh接続に必要なキーペアを生成する
ターミナルで以下のコマンドを実行する
$ ssh-keygenこれにより 秘密鍵(secret_key) と 公開鍵(public_key) のキーペアが生成される
秘密鍵は
~/.ssh/id_rsa
公開鍵は~/.ssh/id_rsa.pub
にそれぞれ記載されているIAMユーザーに公開鍵情報を登録する
サービス > IAM > ユーザー > 認証情報 の「SSHパブリックキーのアップロード」をクリック
公開鍵~/.ssh/id_rsa.pubの中身をコピーし、フィールドに貼り付けアップロードする
するとSSHキーIDが生成されるのでコピーしておく設定ファイルにSSHキーIDと秘密鍵ファイルパスを記述する
ターミナルで以下のコマンドを実行する
$ vim ~/.ssh/configconfigには以下のように記述する
Host git-codecommit.*.amazonaws.com User 先ほどコピーしたSSHキーID IdentityFile ~/.ssh/id_rsaconfig のアクセス権限を変更する
ターミナルで以下のコマンドを実行する
$ chmod 600 ~/.ssh/id_rsaSSH設定をテストする
ターミナルで以下のコマンドを実行する
$ ssh git-codecommit.us-east-2.amazonaws.com初めて接続する場合は接続の確認メッセージが表示される
(yes? or no? ) と聞かれるので yes と書いて enter するここまで出来れば事前準備完了!
これで SSH で git clone し放題なのでぜひ試してみて欲しい
- 投稿日:2019-07-01T11:40:01+09:00
RDS for Oracle DataPump(エクスポート)をやってみた
事前準備
テストユーザ/データ作成
まずはテストデータ(SCOTT)を作成する。
テストデータなので unlimited tablespaxe と DBAロールでも付与しといた。SQL> sho user USER is "TEST" ★マスターユーザ SQL> SQL> create user scott identified by tiger; SQL> grant unlimited tablespace to scott; SQL> grant dba to scott;SCOTTでログイン
SQL> conn scott/tiger@orcl1 Connected. SQL> SQL> sho user USER is "SCOTT"テストデータとして、100万行のデータ作成
SQL> CREATE TABLE tbl1 ( id number(8), txt varchar2(250) ); SQL> set timing on SQL> declare vID char(8); vText varchar2(250); begin dbms_random.seed(uid); for i in 1..1000000 loop vID := to_char(i, 'FM00000000'); vText := dbms_random.string('x', 16); insert into tbl1 (id, txt) values (vID, vText); if (mod(i, 1000) = 0) then commit; end if; end loop; commit; end; / SQL> select count(*) from tbl1; COUNT(*) ---------- 1000000ディレクトリオブジェクトの確認
ディレクトリオブジェクトを確認。今回は検証なので、DATA_PUMP_DIR を使用する。
SQL> set pages 100 line 200 SQL> col owner for a10 SQL> col directory_name for a20 SQL> col directory_path for a30 SQL> select * from dba_directories; OWNER DIRECTORY_NAME DIRECTORY_PATH ORIGIN_CON_ID ---------- -------------------- ------------------------------ ------------- SYS BDUMP /rdsdbdata/log/trace 0 SYS ADUMP /rdsdbdata/log/audit 0 SYS OPATCH_LOG_DIR /rdsdbbin/oracle/QOpatch 0 SYS OPATCH_SCRIPT_DIR /rdsdbbin/oracle/QOpatch 0 SYS OPATCH_INST_DIR /rdsdbbin/oracle/OPatch 0 SYS DATA_PUMP_DIR /rdsdbdata/datapump 0エクスポート
expdpコマンドは使えないのでDBMS_DATAPUMPパッケージを使用しエクスポートを行う。
SQL> conn TEST/Passw0rd@orcl1 Connected. SQL> SQL> sho user USER is "TEST"スキーマ単位(SCOTTユーザ)でエクスポート
SQL> DECLARE hdnl NUMBER; BEGIN hdnl := DBMS_DATAPUMP.open( operation => 'EXPORT', job_mode => 'SCHEMA', job_name => null, version => 'COMPATIBLE'); DBMS_DATAPUMP.ADD_FILE( handle => hdnl, filename => 'scott.dmp', directory => 'DATA_PUMP_DIR', filetype => dbms_datapump.ku$_file_type_dump_file); DBMS_DATAPUMP.add_file( handle => hdnl, filename => 'exp_scott.log', directory => 'DATA_PUMP_DIR', filetype => dbms_datapump.ku$_file_type_log_file); DBMS_DATAPUMP.METADATA_FILTER(hdnl,'SCHEMA_EXPR','IN (''SCOTT'')'); DBMS_DATAPUMP.start_job(hdnl); END; /
DBMS_DATAPUMP.OPEN
- データ・ポンプAPIを使用して新規ジョブを設定するために使用
- operation:実行する操作のタイプ
- EXPORT:データおよびメタデータをダンプ・ファイル・セットに保存します。または操作に必要なデータの見積りサイズを取得
- IMPORT:データおよびメタデータをダンプ・ファイル・セットあるいはデータベース・リンクからリストア
- SQL_FILE:ダンプ・ファイル・セット内あるいはネットワーク・リンクからのメタデータをSQLスクリプトとして表示。SQLスクリプトの場所は、ADD_FILEプロシージャで指定
- job_mode:実行する操作の有効範囲
- FULL:Oracle Databaseの内部スキーマを除く、全データベースまたは全ダンプ・ファイル・セットで動作
- SCHEMA:選択された一連のスキーマで動作
- TABLE:選択された一連の表で動作
- TABLESPACE:選択された一連の表領域で動作
- TRANSPORTABLE:選択された一連の表領域内の表(およびその表が依存するオブジェクト)に関するメタデータで動作し、トランスポータブル表領域のエクスポートおよびインポートを実行
- version:抽出されるデータベース・オブジェクトのバージョン
- COMPATIBLE:(デフォルト)データベース互換性レベルおよび機能の互換性リリース・レベルに対応するメタデータのバージョン
- LATEST:データベース・バージョンに対応するメタデータのバージョン
- 11.0.0'など特定のデータベース・バージョン
DBMS_DATAPUMP.ADD_FILE
- エクスポート、インポートまたはSQL_FILEの各操作に使用されるダンプ・ファイル・セットにファイルを追加します。あるいは、SQL_FILE操作に使用されるログ・ファイルまたは出力ファイルを指定
- handle:ジョブのハンドル。 現行のセッションは、OPENファンクションまたはATTACHファンクションへのコールを使用して、あらかじめこのハンドルに連結しておく必要があります。
- filename:追加されるファイルの名前
- directory:filenameを探すために使用するデータベース内のディレクトリ・オブジェクトの名前
- filetype:追加されるファイルのタイプ。有効な値は次のとおりで、DBMS_DATAPUMP.を前に付ける必要があります
- KU$_FILE_TYPE_DUMP_FILE(ジョブのダンプ・ファイル)
- KU$_FILE_TYPE_LOG_FILE(ジョブのログ・ファイル)
- KU$_FILE_TYPE_SQL_FILE(SQL_FILEジョブの出力)
DBMS_DATAPUMP.METADATA_FILTER
- ジョブに含まれる項目を制限するためのフィルタを提供
- handle:OPENファンクションから戻されたハンドル
- name:フィルタ名
- SCHEMA_LIST:スキーマ・モードでは、処理対象のユーザーを指定
DBMS_DATAPUMP.START_JOB
- ジョブの実行を開始または再開
- handle:ジョブのハンドル。現行のセッションは、OPENファンクションまたはATTACHファンクションへのコールを使用して、あらかじめこのハンドルに連結しておく必要があります
DBMS_DATAPUMP.WAIT_FOR_JOB
- 正常に完了するか、またはなんらかの理由で停止するまでジョブを実行
- handle:ジョブのハンドル。現行のセッションは、OPENファンクションまたはATTACHファンクションへのコールを使用して、あらかじめこのハンドルに連結しておく必要があります。このプロシージャが終了すると、ユーザーはハンドルから連結を解除されます。
- job_state:実行を停止したときのジョブの状態(STOPPEDまたはCOMPLETEDのどちらか)。
出力されたダンプを確認
SQL> set pages 100 line 200 SQL> col filename for a20 SQL> select * from TABLE(RDSADMIN.RDS_FILE_UTIL.LISTDIR('DATA_PUMP_DIR')) ORDER BY MTIME; FILENAME TYPE FILESIZE MTIME -------------------- ---------- ---------- --------- expdb_tables.dmp file 4096 28-JUN-19 expdb_tables.log file 89 28-JUN-19 exp_scott.log file 88 28-JUN-19 ★出力されたログ datapump/ directory 4096 28-JUN-19 scott.dmp file 24576 28-JUN-19 ★出力されたダンプ出力されたログを確認
SQL> col text for a100 SQL> SELECT TEXT FROM TABLE(RDSADMIN.RDS_FILE_UTIL.READ_TEXT_FILE('DATA_PUMP_DIR','exp_scott.log')); TEXT ---------------------------------------------------------------------------------------------------- Starting "TEST"."SYS_EXPORT_SCHEMA_04": Estimate in progress using BLOCKS method... Processing object type SCHEMA_EXPORT/TABLE/TABLE_DATA Total estimation using BLOCKS method: 30 MB Processing object type SCHEMA_EXPORT/USER Processing object type SCHEMA_EXPORT/SYSTEM_GRANT Processing object type SCHEMA_EXPORT/ROLE_GRANT Processing object type SCHEMA_EXPORT/DEFAULT_ROLE Processing object type SCHEMA_EXPORT/PRE_SCHEMA/PROCACT_SCHEMA Processing object type SCHEMA_EXPORT/TABLE/TABLE Processing object type SCHEMA_EXPORT/TABLE/STATISTICS/TABLE_STATISTICS Processing object type SCHEMA_EXPORT/STATISTICS/MARKER . . exported "SCOTT"."TBL1" 24.78 MB 1000000 rows Master table "TEST"."SYS_EXPORT_SCHEMA_04" successfully loaded/unloaded ****************************************************************************** Dump file set for TEST.SYS_EXPORT_SCHEMA_04 is: /rdsdbdata/datapump/scott.dmp Job "TEST"."SYS_EXPORT_SCHEMA_04" successfully completed at Fri Jun 28 03:56:29 2019 elapsed 0 00: 03:35 18 rows selected.インポートはこちら
参考
- 投稿日:2019-07-01T11:15:54+09:00
RDS for Oracle 接続後の確認
管理ユーザ(マスターユーザ)でログイン後、DBの中を確認してみました。
※RDSへの接続方法はこちら
SQL> sho user USER is "TEST" SQL>TESTユーザのシステム権限をUSER_SYS_PRIVSビューで確認
SQL> set pages 100 line 200 SQL> col username for a10 SQL> col privilege for a30 SQL> select * from user_sys_privs; USERNAME PRIVILEGE ADM COM ---------- ------------------------------ --- --- TEST DROP ANY DIRECTORY YES NO TEST EXEMPT REDACTION POLICY YES NO TEST FLASHBACK ANY TABLE YES NO TEST EXEMPT ACCESS POLICY YES NO TEST SELECT ANY TABLE YES NO TEST CHANGE NOTIFICATION YES NO TEST GRANT ANY OBJECT PRIVILEGE YES NO TEST ALTER PUBLIC DATABASE LINK YES NO TEST EXEMPT IDENTITY POLICY YES NO TEST ALTER DATABASE LINK YES NO TEST UNLIMITED TABLESPACE YES NO TEST RESTRICTED SESSION YES NO 12 rows selected.TESTユーザに付与されたロールをUSER_ROLE_PRIVSビューで確認
SQL> col granted_role for a30 SQL> select granted_role from user_role_privs; GRANTED_ROLE ------------------------------ AQ_ADMINISTRATOR_ROLE AQ_USER_ROLE CAPTURE_ADMIN CONNECT CTXAPP DATAPUMP_EXP_FULL_DATABASE ★DataPumpつかえる DATAPUMP_IMP_FULL_DATABASE ★DataPumpつかえる DBA ★ DELETE_CATALOG_ROLE EM_EXPRESS_ALL EM_EXPRESS_BASIC EXECUTE_CATALOG_ROLE EXP_FULL_DATABASE GATHER_SYSTEM_STATISTICS HS_ADMIN_EXECUTE_ROLE HS_ADMIN_SELECT_ROLE IMP_FULL_DATABASE OEM_ADVISOR OEM_MONITOR OPTIMIZER_PROCESSING_RATE RDS_MASTER_ROLE RECOVERY_CATALOG_OWNER RECOVERY_CATALOG_USER RESOURCE ★ SCHEDULER_ADMIN SELECT_CATALOG_ROLE SODA_APP XDBADMIN XDB_SET_INVOKER 29 rows selected.DBAロールの中身をROLE_SYS_PRIVSビューで確認
SQL> set pages 300 line 200 SQL> col role for a20 SQL> col privilege for a50 SQL> select * from role_sys_privs where role='DBA' order by 2; ROLE PRIVILEGE ADM COM -------------------- -------------------------------------------------- --- --- DBA ADMINISTER ANY SQL TUNING SET YES YES DBA ADMINISTER DATABASE TRIGGER YES YES DBA ADMINISTER RESOURCE MANAGER YES YES DBA ADMINISTER SQL MANAGEMENT OBJECT YES YES DBA ADMINISTER SQL TUNING SET YES YES DBA ADVISOR YES YES DBA ALTER ANY ASSEMBLY YES YES DBA ALTER ANY CLUSTER YES YES DBA ALTER ANY CUBE YES YES DBA ALTER ANY CUBE BUILD PROCESS YES YES DBA ALTER ANY CUBE DIMENSION YES YES DBA ALTER ANY DIMENSION YES YES DBA ALTER ANY EDITION YES YES DBA ALTER ANY EVALUATION CONTEXT YES YES DBA ALTER ANY INDEX YES YES DBA ALTER ANY INDEXTYPE YES YES DBA ALTER ANY LIBRARY YES YES DBA ALTER ANY MATERIALIZED VIEW YES YES DBA ALTER ANY MEASURE FOLDER YES YES DBA ALTER ANY MINING MODEL YES YES DBA ALTER ANY OPERATOR YES YES DBA ALTER ANY OUTLINE YES YES DBA ALTER ANY PROCEDURE YES YES DBA ALTER ANY ROLE YES YES DBA ALTER ANY RULE YES YES DBA ALTER ANY RULE SET YES YES DBA ALTER ANY SEQUENCE YES YES DBA ALTER ANY SQL PROFILE YES YES DBA ALTER ANY SQL TRANSLATION PROFILE YES YES DBA ALTER ANY TABLE YES YES DBA ALTER ANY TRIGGER YES YES DBA ALTER ANY TYPE YES YES DBA ALTER PROFILE YES YES DBA ALTER RESOURCE COST YES YES DBA ALTER ROLLBACK SEGMENT YES YES DBA ALTER SESSION YES YES DBA ALTER TABLESPACE YES YES DBA ALTER USER YES YES DBA ANALYZE ANY YES YES DBA ANALYZE ANY DICTIONARY YES YES DBA AUDIT ANY YES YES DBA AUDIT SYSTEM YES YES DBA BACKUP ANY TABLE YES YES DBA BECOME USER YES YES DBA CHANGE NOTIFICATION YES YES DBA COMMENT ANY MINING MODEL YES YES DBA COMMENT ANY TABLE YES YES DBA CREATE ANY ASSEMBLY YES YES DBA CREATE ANY CLUSTER YES YES DBA CREATE ANY CONTEXT YES YES DBA CREATE ANY CREDENTIAL YES YES DBA CREATE ANY CUBE YES YES DBA CREATE ANY CUBE BUILD PROCESS YES YES DBA CREATE ANY CUBE DIMENSION YES YES DBA CREATE ANY DIMENSION YES YES DBA CREATE ANY EDITION YES YES DBA CREATE ANY EVALUATION CONTEXT YES YES DBA CREATE ANY INDEX YES YES DBA CREATE ANY INDEXTYPE YES YES DBA CREATE ANY JOB YES YES DBA CREATE ANY LIBRARY YES YES DBA CREATE ANY MATERIALIZED VIEW YES YES DBA CREATE ANY MEASURE FOLDER YES YES DBA CREATE ANY MINING MODEL YES YES DBA CREATE ANY OPERATOR YES YES DBA CREATE ANY OUTLINE YES YES DBA CREATE ANY PROCEDURE YES YES DBA CREATE ANY RULE YES YES DBA CREATE ANY RULE SET YES YES DBA CREATE ANY SEQUENCE YES YES DBA CREATE ANY SQL PROFILE YES YES DBA CREATE ANY SQL TRANSLATION PROFILE YES YES DBA CREATE ANY SYNONYM YES YES DBA CREATE ANY TABLE YES YES DBA CREATE ANY TRIGGER YES YES DBA CREATE ANY TYPE YES YES DBA CREATE ANY VIEW YES YES DBA CREATE ASSEMBLY YES YES DBA CREATE CLUSTER YES YES DBA CREATE CREDENTIAL YES YES DBA CREATE CUBE YES YES DBA CREATE CUBE BUILD PROCESS YES YES DBA CREATE CUBE DIMENSION YES YES DBA CREATE DATABASE LINK YES YES DBA CREATE DIMENSION YES YES DBA CREATE EVALUATION CONTEXT YES YES DBA CREATE INDEXTYPE YES YES DBA CREATE JOB YES YES DBA CREATE LIBRARY YES YES DBA CREATE MATERIALIZED VIEW YES YES DBA CREATE MEASURE FOLDER YES YES DBA CREATE MINING MODEL YES YES DBA CREATE OPERATOR YES YES DBA CREATE PLUGGABLE DATABASE YES YES DBA CREATE PROCEDURE YES YES DBA CREATE PROFILE YES YES DBA CREATE PUBLIC DATABASE LINK YES YES DBA CREATE PUBLIC SYNONYM YES YES DBA CREATE ROLE YES YES DBA CREATE ROLLBACK SEGMENT YES YES DBA CREATE RULE YES YES DBA CREATE RULE SET YES YES DBA CREATE SEQUENCE YES YES DBA CREATE SESSION YES YES DBA CREATE SQL TRANSLATION PROFILE YES YES DBA CREATE SYNONYM YES YES DBA CREATE TABLE YES YES DBA CREATE TABLESPACE YES YES DBA CREATE TRIGGER YES YES DBA CREATE TYPE YES YES DBA CREATE USER YES YES DBA CREATE VIEW YES YES DBA DEBUG ANY PROCEDURE YES YES DBA DEBUG CONNECT SESSION YES YES DBA DELETE ANY CUBE DIMENSION YES YES DBA DELETE ANY MEASURE FOLDER YES YES DBA DELETE ANY TABLE YES YES DBA DEQUEUE ANY QUEUE YES YES DBA DROP ANY ASSEMBLY YES YES DBA DROP ANY CLUSTER YES YES DBA DROP ANY CONTEXT YES YES DBA DROP ANY CUBE YES YES DBA DROP ANY CUBE BUILD PROCESS YES YES DBA DROP ANY CUBE DIMENSION YES YES DBA DROP ANY DIMENSION YES YES DBA DROP ANY EDITION YES YES DBA DROP ANY EVALUATION CONTEXT YES YES DBA DROP ANY INDEX YES YES DBA DROP ANY INDEXTYPE YES YES DBA DROP ANY LIBRARY YES YES DBA DROP ANY MATERIALIZED VIEW YES YES DBA DROP ANY MEASURE FOLDER YES YES DBA DROP ANY MINING MODEL YES YES DBA DROP ANY OPERATOR YES YES DBA DROP ANY OUTLINE YES YES DBA DROP ANY PROCEDURE YES YES DBA DROP ANY ROLE YES YES DBA DROP ANY RULE YES YES DBA DROP ANY RULE SET YES YES DBA DROP ANY SEQUENCE YES YES DBA DROP ANY SQL PROFILE YES YES DBA DROP ANY SQL TRANSLATION PROFILE YES YES DBA DROP ANY SYNONYM YES YES DBA DROP ANY TABLE YES YES DBA DROP ANY TRIGGER YES YES DBA DROP ANY TYPE YES YES DBA DROP ANY VIEW YES YES DBA DROP PROFILE YES YES DBA DROP PUBLIC DATABASE LINK YES YES DBA DROP PUBLIC SYNONYM YES YES DBA DROP ROLLBACK SEGMENT YES YES DBA DROP TABLESPACE YES YES DBA DROP USER YES YES DBA EM EXPRESS CONNECT YES YES DBA ENQUEUE ANY QUEUE YES YES DBA EXECUTE ANY ASSEMBLY YES YES DBA EXECUTE ANY CLASS YES YES DBA EXECUTE ANY EVALUATION CONTEXT YES YES DBA EXECUTE ANY INDEXTYPE YES YES DBA EXECUTE ANY LIBRARY YES YES DBA EXECUTE ANY OPERATOR YES YES DBA EXECUTE ANY PROCEDURE YES YES DBA EXECUTE ANY PROGRAM YES YES DBA EXECUTE ANY RULE YES YES DBA EXECUTE ANY RULE SET YES YES DBA EXECUTE ANY TYPE YES YES DBA EXECUTE ASSEMBLY YES YES DBA EXEMPT DDL REDACTION POLICY YES YES DBA EXEMPT DML REDACTION POLICY YES YES DBA EXPORT FULL DATABASE YES YES DBA FLASHBACK ANY TABLE YES YES DBA FLASHBACK ARCHIVE ADMINISTER YES YES DBA FORCE ANY TRANSACTION YES YES DBA FORCE TRANSACTION YES YES DBA GLOBAL QUERY REWRITE YES YES DBA GRANT ANY OBJECT PRIVILEGE YES YES DBA IMPORT FULL DATABASE YES YES DBA INSERT ANY CUBE DIMENSION YES YES DBA INSERT ANY MEASURE FOLDER YES YES DBA INSERT ANY TABLE YES YES DBA LOCK ANY TABLE YES YES DBA LOGMINING YES YES DBA MANAGE ANY FILE GROUP YES YES DBA MANAGE ANY QUEUE YES YES DBA MANAGE FILE GROUP YES YES DBA MANAGE SCHEDULER YES YES DBA MANAGE TABLESPACE YES YES DBA MERGE ANY VIEW YES YES DBA ON COMMIT REFRESH YES YES DBA QUERY REWRITE YES YES DBA READ ANY TABLE YES YES DBA REDEFINE ANY TABLE YES YES DBA RESTRICTED SESSION YES YES DBA RESUMABLE YES YES DBA SELECT ANY CUBE YES YES DBA SELECT ANY CUBE BUILD PROCESS YES YES DBA SELECT ANY CUBE DIMENSION YES YES DBA SELECT ANY DICTIONARY YES YES DBA SELECT ANY MEASURE FOLDER YES YES DBA SELECT ANY MINING MODEL YES YES DBA SELECT ANY SEQUENCE YES YES DBA SELECT ANY TABLE YES YES DBA SELECT ANY TRANSACTION YES YES DBA SET CONTAINER YES YES DBA UNDER ANY TABLE YES YES DBA UNDER ANY TYPE YES YES DBA UNDER ANY VIEW YES YES DBA UPDATE ANY CUBE YES YES DBA UPDATE ANY CUBE BUILD PROCESS YES YES DBA UPDATE ANY CUBE DIMENSION YES YES DBA UPDATE ANY TABLE YES YES DBA USE ANY SQL TRANSLATION PROFILE YES YES 212 rows selected.RESOURCEロールの中身を確認
select * from role_sys_privs where role='RESOURCE' order by 2; ROLE PRIVILEGE ADM COM -------------------- -------------------------------------------------- --- --- RESOURCE CREATE CLUSTER NO YES RESOURCE CREATE INDEXTYPE NO YES RESOURCE CREATE OPERATOR NO YES RESOURCE CREATE PROCEDURE NO YES RESOURCE CREATE SEQUENCE NO YES RESOURCE CREATE TABLE NO YES RESOURCE CREATE TRIGGER NO YES RESOURCE CREATE TYPE NO YES 8 rows selected.デフォルトユーザ確認
QL> col username for a20 SQL> select username from dba_users; USERNAME -------------------- SYS SYSTEM GSMADMIN_INTERNAL TEST ★RDS作成時に指定したマスターユーザ AUDSYS GSMUSER XS$NULL SYSKM APPQOSSYS XDB RDSADMIN DBSNMP SYSDG DIP OUTLN ANONYMOUS CTXSYS SYSBACKUP GSMCATUSER 19 rows selected.V$DATABASEビューでアーカイブログモードの確認
SQL> select name,log_mode from v$database; NAME LOG_MODE --------- ------------ ORCL1 ARCHIVELOG ★デフォルトでアーカイブログモードになっているちなみに、archive log listでアーカイブログモードを確認しようとすると「権限が不足してると」怒られる
SQL> archive log list; ORA-01031: insufficient privilegesその他にも shutdownコマンド も使えない
SQL> shu immediate ORA-01031: insufficient privileges(ノーアーカイブログモードにするにはどうすれば。。。)
制御ファイルはデフォルト1つ
SQL> sho parameter control_fi NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ control_file_record_keep_time integer 7 control_files string /rdsdbdata/db/ORCL1_A/controlf ile/control-01.ctlオンラインREDOログ・ファイルは1グループ1メンバ
SQL> col member for a60 SQL> select group#,status,type,member from v$logfile order by 1,4;SQL> GROUP# STATUS TYPE MEMBER ---------- ------- ------- ------------------------------------------------------------ 1 ONLINE /rdsdbdata/db/ORCL1_A/onlinelog/o1_mf_1_gk942xc0_.log 2 ONLINE /rdsdbdata/db/ORCL1_A/onlinelog/o1_mf_2_gk942yh1_.log 3 ONLINE /rdsdbdata/db/ORCL1_A/onlinelog/o1_mf_3_gk9430l1_.log 4 ONLINE /rdsdbdata/db/ORCL1_A/onlinelog/o1_mf_4_gk9432od_.log表領域とデータファイル確認。RDSADMIN表領域ってのがある。
SQL> col file_name for a60 SQL>select tablespace_name,file_name,status,bytes/1024/1024 mbytes,increment_by,autoextensible,online_status from dba_data_files; TABLESPACE_NAME FILE_NAME STATUS MBYTES INCREMENT_BY AUT ONLINE_ ------------------------------ ------------------------------------------------------------ --------- ---------- ------------ --- ------- SYSTEM /rdsdbdata/db/ORCL1_A/datafile/o1_mf_system_gf76cbh1_.dbf AVAILABLE 400 12800 YES SYSTEM SYSAUX /rdsdbdata/db/ORCL1_A/datafile/o1_mf_sysaux_gf76d1l1_.dbf AVAILABLE 328.9375 12800 YES ONLINE UNDO_T1 /rdsdbdata/db/ORCL1_A/datafile/o1_mf_undo_t1_gf76df41_.dbf AVAILABLE 300 1280 YES ONLINE USERS /rdsdbdata/db/ORCL1_A/datafile/o1_mf_users_gf76dh0r_.dbf AVAILABLE 100 12800 YES ONLINE RDSADMIN /rdsdbdata/db/ORCL1_A/datafile/o1_mf_rdsadmin_gf77glhp_.dbf AVAILABLE 7 128 YES ONLINE一時表領域を確認。
SQL> col TABLESPACE_NAME for a10 SQL> select TABLESPACE_NAME,FILE_NAME,BYTES/1024/1024 as MB from dba_temp_files;SQL> TABLESPACE FILE_NAME MB ---------- ------------------------------------------------------------ ---------- TEMP /rdsdbdata/db/ORCL1_A/datafile/o1_mf_temp_gk94bo9j_.tmp 100alter system文 での初期化パラメータの変更はできなさそう(権限が不十分と言われる)。
初期化パラメータの変更はマネージメントコンソールからおこなうみたい。SQL> sho parameter strea NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ streams_pool_size big integer 0 SQL> SQL> SQL> alter system set streams_pool_size=150m scope=both; alter system set streams_pool_size=150m scope=both * ERROR at line 1: ORA-01031: insufficient privilegesPFILEもくつれない(そもそもOSにアクセスできない)
SQL> create pfile from spfile; create pfile from spfile * ERROR at line 1: ORA-01031: insufficient privilegesDATABASE_PROPERTIESビューでDBのプロパティを確認。
デフォルト表領域は 「USERS」、デフォルト一時表領域は「TEMP」SQL> col property_name for a30 SQL> col property_value for a40 SQL> select property_name,property_value from database_properties; PROPERTY_NAME PROPERTY_VALUE ------------------------------ ---------------------------------------- DICT.BASE 2 DEFAULT_TEMP_TABLESPACE TEMP DEFAULT_PERMANENT_TABLESPACE USERS DEFAULT_EDITION ORA$BASE Flashback Timestamp TimeZone GMT TDE_MASTER_KEY_ID EXPORT_VIEWS_VERSION 8 DEFAULT_TBS_TYPE BIGFILE GLOBAL_DB_NAME ORCL1 NLS_RDBMS_VERSION 12.1.0.2.0 NLS_NCHAR_CHARACTERSET AL16UTF16 NLS_NCHAR_CONV_EXCP FALSE NLS_LENGTH_SEMANTICS BYTE NLS_COMP BINARY NLS_DUAL_CURRENCY $ NLS_TIMESTAMP_TZ_FORMAT DD-MON-RR HH.MI.SSXFF AM TZR NLS_TIME_TZ_FORMAT HH.MI.SSXFF AM TZR NLS_TIMESTAMP_FORMAT DD-MON-RR HH.MI.SSXFF AM NLS_TIME_FORMAT HH.MI.SSXFF AM NLS_SORT BINARY NLS_DATE_LANGUAGE AMERICAN NLS_DATE_FORMAT DD-MON-RR NLS_CALENDAR GREGORIAN NLS_CHARACTERSET AL32UTF8 NLS_NUMERIC_CHARACTERS ., NLS_ISO_CURRENCY AMERICA NLS_CURRENCY $ NLS_TERRITORY AMERICA NLS_LANGUAGE AMERICAN DST_SECONDARY_TT_VERSION 0 DST_PRIMARY_TT_VERSION 33 DST_UPGRADE_STATE NONE MAX_STRING_SIZE STANDARD DBTIMEZONE +00:00 WORKLOAD_CAPTURE_MODE WORKLOAD_REPLAY_MODE NO_USERID_VERIFIER_SALT 9FBAD6D3759B5204F101F9E263E81045 37 rows selected.
- 投稿日:2019-07-01T11:15:54+09:00
RDS for Oracle デフォルトの設定もろもろ確認
管理ユーザ(マスターユーザ)でログイン後、DBの中を確認してみました。
※RDSへの接続方法はこちら
SQL> sho user USER is "TEST" SQL>TESTユーザのシステム権限をUSER_SYS_PRIVSビューで確認
SQL> set pages 100 line 200 SQL> col username for a10 SQL> col privilege for a30 SQL> select * from user_sys_privs; USERNAME PRIVILEGE ADM COM ---------- ------------------------------ --- --- TEST DROP ANY DIRECTORY YES NO TEST EXEMPT REDACTION POLICY YES NO TEST FLASHBACK ANY TABLE YES NO TEST EXEMPT ACCESS POLICY YES NO TEST SELECT ANY TABLE YES NO TEST CHANGE NOTIFICATION YES NO TEST GRANT ANY OBJECT PRIVILEGE YES NO TEST ALTER PUBLIC DATABASE LINK YES NO TEST EXEMPT IDENTITY POLICY YES NO TEST ALTER DATABASE LINK YES NO TEST UNLIMITED TABLESPACE YES NO TEST RESTRICTED SESSION YES NO 12 rows selected.TESTユーザに付与されたロールをUSER_ROLE_PRIVSビューで確認
SQL> col granted_role for a30 SQL> select granted_role from user_role_privs; GRANTED_ROLE ------------------------------ AQ_ADMINISTRATOR_ROLE AQ_USER_ROLE CAPTURE_ADMIN CONNECT CTXAPP DATAPUMP_EXP_FULL_DATABASE ★DataPumpつかえる DATAPUMP_IMP_FULL_DATABASE ★DataPumpつかえる DBA ★ DELETE_CATALOG_ROLE EM_EXPRESS_ALL EM_EXPRESS_BASIC EXECUTE_CATALOG_ROLE EXP_FULL_DATABASE GATHER_SYSTEM_STATISTICS HS_ADMIN_EXECUTE_ROLE HS_ADMIN_SELECT_ROLE IMP_FULL_DATABASE OEM_ADVISOR OEM_MONITOR OPTIMIZER_PROCESSING_RATE RDS_MASTER_ROLE RECOVERY_CATALOG_OWNER RECOVERY_CATALOG_USER RESOURCE ★ SCHEDULER_ADMIN SELECT_CATALOG_ROLE SODA_APP XDBADMIN XDB_SET_INVOKER 29 rows selected.DBAロールの中身をROLE_SYS_PRIVSビューで確認
SQL> set pages 300 line 200 SQL> col role for a20 SQL> col privilege for a50 SQL> select * from role_sys_privs where role='DBA' order by 2; ROLE PRIVILEGE ADM COM -------------------- -------------------------------------------------- --- --- DBA ADMINISTER ANY SQL TUNING SET YES YES DBA ADMINISTER DATABASE TRIGGER YES YES DBA ADMINISTER RESOURCE MANAGER YES YES DBA ADMINISTER SQL MANAGEMENT OBJECT YES YES DBA ADMINISTER SQL TUNING SET YES YES DBA ADVISOR YES YES DBA ALTER ANY ASSEMBLY YES YES DBA ALTER ANY CLUSTER YES YES DBA ALTER ANY CUBE YES YES DBA ALTER ANY CUBE BUILD PROCESS YES YES DBA ALTER ANY CUBE DIMENSION YES YES DBA ALTER ANY DIMENSION YES YES DBA ALTER ANY EDITION YES YES DBA ALTER ANY EVALUATION CONTEXT YES YES DBA ALTER ANY INDEX YES YES DBA ALTER ANY INDEXTYPE YES YES DBA ALTER ANY LIBRARY YES YES DBA ALTER ANY MATERIALIZED VIEW YES YES DBA ALTER ANY MEASURE FOLDER YES YES DBA ALTER ANY MINING MODEL YES YES DBA ALTER ANY OPERATOR YES YES DBA ALTER ANY OUTLINE YES YES DBA ALTER ANY PROCEDURE YES YES DBA ALTER ANY ROLE YES YES DBA ALTER ANY RULE YES YES DBA ALTER ANY RULE SET YES YES DBA ALTER ANY SEQUENCE YES YES DBA ALTER ANY SQL PROFILE YES YES DBA ALTER ANY SQL TRANSLATION PROFILE YES YES DBA ALTER ANY TABLE YES YES DBA ALTER ANY TRIGGER YES YES DBA ALTER ANY TYPE YES YES DBA ALTER PROFILE YES YES DBA ALTER RESOURCE COST YES YES DBA ALTER ROLLBACK SEGMENT YES YES DBA ALTER SESSION YES YES DBA ALTER TABLESPACE YES YES DBA ALTER USER YES YES DBA ANALYZE ANY YES YES DBA ANALYZE ANY DICTIONARY YES YES DBA AUDIT ANY YES YES DBA AUDIT SYSTEM YES YES DBA BACKUP ANY TABLE YES YES DBA BECOME USER YES YES DBA CHANGE NOTIFICATION YES YES DBA COMMENT ANY MINING MODEL YES YES DBA COMMENT ANY TABLE YES YES DBA CREATE ANY ASSEMBLY YES YES DBA CREATE ANY CLUSTER YES YES DBA CREATE ANY CONTEXT YES YES DBA CREATE ANY CREDENTIAL YES YES DBA CREATE ANY CUBE YES YES DBA CREATE ANY CUBE BUILD PROCESS YES YES DBA CREATE ANY CUBE DIMENSION YES YES DBA CREATE ANY DIMENSION YES YES DBA CREATE ANY EDITION YES YES DBA CREATE ANY EVALUATION CONTEXT YES YES DBA CREATE ANY INDEX YES YES DBA CREATE ANY INDEXTYPE YES YES DBA CREATE ANY JOB YES YES DBA CREATE ANY LIBRARY YES YES DBA CREATE ANY MATERIALIZED VIEW YES YES DBA CREATE ANY MEASURE FOLDER YES YES DBA CREATE ANY MINING MODEL YES YES DBA CREATE ANY OPERATOR YES YES DBA CREATE ANY OUTLINE YES YES DBA CREATE ANY PROCEDURE YES YES DBA CREATE ANY RULE YES YES DBA CREATE ANY RULE SET YES YES DBA CREATE ANY SEQUENCE YES YES DBA CREATE ANY SQL PROFILE YES YES DBA CREATE ANY SQL TRANSLATION PROFILE YES YES DBA CREATE ANY SYNONYM YES YES DBA CREATE ANY TABLE YES YES DBA CREATE ANY TRIGGER YES YES DBA CREATE ANY TYPE YES YES DBA CREATE ANY VIEW YES YES DBA CREATE ASSEMBLY YES YES DBA CREATE CLUSTER YES YES DBA CREATE CREDENTIAL YES YES DBA CREATE CUBE YES YES DBA CREATE CUBE BUILD PROCESS YES YES DBA CREATE CUBE DIMENSION YES YES DBA CREATE DATABASE LINK YES YES DBA CREATE DIMENSION YES YES DBA CREATE EVALUATION CONTEXT YES YES DBA CREATE INDEXTYPE YES YES DBA CREATE JOB YES YES DBA CREATE LIBRARY YES YES DBA CREATE MATERIALIZED VIEW YES YES DBA CREATE MEASURE FOLDER YES YES DBA CREATE MINING MODEL YES YES DBA CREATE OPERATOR YES YES DBA CREATE PLUGGABLE DATABASE YES YES DBA CREATE PROCEDURE YES YES DBA CREATE PROFILE YES YES DBA CREATE PUBLIC DATABASE LINK YES YES DBA CREATE PUBLIC SYNONYM YES YES DBA CREATE ROLE YES YES DBA CREATE ROLLBACK SEGMENT YES YES DBA CREATE RULE YES YES DBA CREATE RULE SET YES YES DBA CREATE SEQUENCE YES YES DBA CREATE SESSION YES YES DBA CREATE SQL TRANSLATION PROFILE YES YES DBA CREATE SYNONYM YES YES DBA CREATE TABLE YES YES DBA CREATE TABLESPACE YES YES DBA CREATE TRIGGER YES YES DBA CREATE TYPE YES YES DBA CREATE USER YES YES DBA CREATE VIEW YES YES DBA DEBUG ANY PROCEDURE YES YES DBA DEBUG CONNECT SESSION YES YES DBA DELETE ANY CUBE DIMENSION YES YES DBA DELETE ANY MEASURE FOLDER YES YES DBA DELETE ANY TABLE YES YES DBA DEQUEUE ANY QUEUE YES YES DBA DROP ANY ASSEMBLY YES YES DBA DROP ANY CLUSTER YES YES DBA DROP ANY CONTEXT YES YES DBA DROP ANY CUBE YES YES DBA DROP ANY CUBE BUILD PROCESS YES YES DBA DROP ANY CUBE DIMENSION YES YES DBA DROP ANY DIMENSION YES YES DBA DROP ANY EDITION YES YES DBA DROP ANY EVALUATION CONTEXT YES YES DBA DROP ANY INDEX YES YES DBA DROP ANY INDEXTYPE YES YES DBA DROP ANY LIBRARY YES YES DBA DROP ANY MATERIALIZED VIEW YES YES DBA DROP ANY MEASURE FOLDER YES YES DBA DROP ANY MINING MODEL YES YES DBA DROP ANY OPERATOR YES YES DBA DROP ANY OUTLINE YES YES DBA DROP ANY PROCEDURE YES YES DBA DROP ANY ROLE YES YES DBA DROP ANY RULE YES YES DBA DROP ANY RULE SET YES YES DBA DROP ANY SEQUENCE YES YES DBA DROP ANY SQL PROFILE YES YES DBA DROP ANY SQL TRANSLATION PROFILE YES YES DBA DROP ANY SYNONYM YES YES DBA DROP ANY TABLE YES YES DBA DROP ANY TRIGGER YES YES DBA DROP ANY TYPE YES YES DBA DROP ANY VIEW YES YES DBA DROP PROFILE YES YES DBA DROP PUBLIC DATABASE LINK YES YES DBA DROP PUBLIC SYNONYM YES YES DBA DROP ROLLBACK SEGMENT YES YES DBA DROP TABLESPACE YES YES DBA DROP USER YES YES DBA EM EXPRESS CONNECT YES YES DBA ENQUEUE ANY QUEUE YES YES DBA EXECUTE ANY ASSEMBLY YES YES DBA EXECUTE ANY CLASS YES YES DBA EXECUTE ANY EVALUATION CONTEXT YES YES DBA EXECUTE ANY INDEXTYPE YES YES DBA EXECUTE ANY LIBRARY YES YES DBA EXECUTE ANY OPERATOR YES YES DBA EXECUTE ANY PROCEDURE YES YES DBA EXECUTE ANY PROGRAM YES YES DBA EXECUTE ANY RULE YES YES DBA EXECUTE ANY RULE SET YES YES DBA EXECUTE ANY TYPE YES YES DBA EXECUTE ASSEMBLY YES YES DBA EXEMPT DDL REDACTION POLICY YES YES DBA EXEMPT DML REDACTION POLICY YES YES DBA EXPORT FULL DATABASE YES YES DBA FLASHBACK ANY TABLE YES YES DBA FLASHBACK ARCHIVE ADMINISTER YES YES DBA FORCE ANY TRANSACTION YES YES DBA FORCE TRANSACTION YES YES DBA GLOBAL QUERY REWRITE YES YES DBA GRANT ANY OBJECT PRIVILEGE YES YES DBA IMPORT FULL DATABASE YES YES DBA INSERT ANY CUBE DIMENSION YES YES DBA INSERT ANY MEASURE FOLDER YES YES DBA INSERT ANY TABLE YES YES DBA LOCK ANY TABLE YES YES DBA LOGMINING YES YES DBA MANAGE ANY FILE GROUP YES YES DBA MANAGE ANY QUEUE YES YES DBA MANAGE FILE GROUP YES YES DBA MANAGE SCHEDULER YES YES DBA MANAGE TABLESPACE YES YES DBA MERGE ANY VIEW YES YES DBA ON COMMIT REFRESH YES YES DBA QUERY REWRITE YES YES DBA READ ANY TABLE YES YES DBA REDEFINE ANY TABLE YES YES DBA RESTRICTED SESSION YES YES DBA RESUMABLE YES YES DBA SELECT ANY CUBE YES YES DBA SELECT ANY CUBE BUILD PROCESS YES YES DBA SELECT ANY CUBE DIMENSION YES YES DBA SELECT ANY DICTIONARY YES YES DBA SELECT ANY MEASURE FOLDER YES YES DBA SELECT ANY MINING MODEL YES YES DBA SELECT ANY SEQUENCE YES YES DBA SELECT ANY TABLE YES YES DBA SELECT ANY TRANSACTION YES YES DBA SET CONTAINER YES YES DBA UNDER ANY TABLE YES YES DBA UNDER ANY TYPE YES YES DBA UNDER ANY VIEW YES YES DBA UPDATE ANY CUBE YES YES DBA UPDATE ANY CUBE BUILD PROCESS YES YES DBA UPDATE ANY CUBE DIMENSION YES YES DBA UPDATE ANY TABLE YES YES DBA USE ANY SQL TRANSLATION PROFILE YES YES 212 rows selected.RESOURCEロールの中身を確認
select * from role_sys_privs where role='RESOURCE' order by 2; ROLE PRIVILEGE ADM COM -------------------- -------------------------------------------------- --- --- RESOURCE CREATE CLUSTER NO YES RESOURCE CREATE INDEXTYPE NO YES RESOURCE CREATE OPERATOR NO YES RESOURCE CREATE PROCEDURE NO YES RESOURCE CREATE SEQUENCE NO YES RESOURCE CREATE TABLE NO YES RESOURCE CREATE TRIGGER NO YES RESOURCE CREATE TYPE NO YES 8 rows selected.デフォルトユーザ確認
SQL> col username for a20 SQL> select username from dba_users; USERNAME -------------------- SYS SYSTEM GSMADMIN_INTERNAL TEST ★RDS作成時に指定したマスターユーザ AUDSYS GSMUSER XS$NULL SYSKM APPQOSSYS XDB RDSADMIN DBSNMP SYSDG DIP OUTLN ANONYMOUS CTXSYS SYSBACKUP GSMCATUSER 19 rows selected.V$DATABASEビューでアーカイブログモードの確認
SQL> select name,log_mode from v$database; NAME LOG_MODE --------- ------------ ORCL1 ARCHIVELOG ★デフォルトでアーカイブログモードになっているちなみに、archive log listでアーカイブログモードを確認しようとすると「権限が不足してると」怒られる
SQL> archive log list; ORA-01031: insufficient privilegesその他にも shutdownコマンド も使えない
SQL> shu immediate ORA-01031: insufficient privileges(ノーアーカイブログモードにするにはどうすれば。。。)
制御ファイルはデフォルト1つ
SQL> sho parameter control_fi NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ control_file_record_keep_time integer 7 control_files string /rdsdbdata/db/ORCL1_A/controlf ile/control-01.ctlオンラインREDOログ・ファイルは1グループ1メンバ
SQL> col member for a60 SQL> select group#,status,type,member from v$logfile order by 1,4;SQL> GROUP# STATUS TYPE MEMBER ---------- ------- ------- ------------------------------------------------------------ 1 ONLINE /rdsdbdata/db/ORCL1_A/onlinelog/o1_mf_1_gk942xc0_.log 2 ONLINE /rdsdbdata/db/ORCL1_A/onlinelog/o1_mf_2_gk942yh1_.log 3 ONLINE /rdsdbdata/db/ORCL1_A/onlinelog/o1_mf_3_gk9430l1_.log 4 ONLINE /rdsdbdata/db/ORCL1_A/onlinelog/o1_mf_4_gk9432od_.log表領域とデータファイル確認。RDSADMIN表領域ってのがある。
SQL> col file_name for a60 SQL>select tablespace_name,file_name,status,bytes/1024/1024 mbytes,increment_by,autoextensible,online_status from dba_data_files; TABLESPACE_NAME FILE_NAME STATUS MBYTES INCREMENT_BY AUT ONLINE_ ------------------------------ ------------------------------------------------------------ --------- ---------- ------------ --- ------- SYSTEM /rdsdbdata/db/ORCL1_A/datafile/o1_mf_system_gf76cbh1_.dbf AVAILABLE 400 12800 YES SYSTEM SYSAUX /rdsdbdata/db/ORCL1_A/datafile/o1_mf_sysaux_gf76d1l1_.dbf AVAILABLE 328.9375 12800 YES ONLINE UNDO_T1 /rdsdbdata/db/ORCL1_A/datafile/o1_mf_undo_t1_gf76df41_.dbf AVAILABLE 300 1280 YES ONLINE USERS /rdsdbdata/db/ORCL1_A/datafile/o1_mf_users_gf76dh0r_.dbf AVAILABLE 100 12800 YES ONLINE RDSADMIN /rdsdbdata/db/ORCL1_A/datafile/o1_mf_rdsadmin_gf77glhp_.dbf AVAILABLE 7 128 YES ONLINE一時表領域を確認。
SQL> col TABLESPACE_NAME for a10 SQL> select TABLESPACE_NAME,FILE_NAME,BYTES/1024/1024 as MB from dba_temp_files;SQL> TABLESPACE FILE_NAME MB ---------- ------------------------------------------------------------ ---------- TEMP /rdsdbdata/db/ORCL1_A/datafile/o1_mf_temp_gk94bo9j_.tmp 100alter system文 での初期化パラメータの変更はできなさそう(権限が不十分と言われる)。
初期化パラメータの変更はマネージメントコンソールからおこなうみたい。SQL> sho parameter strea NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ streams_pool_size big integer 0 SQL> SQL> SQL> alter system set streams_pool_size=150m scope=both; alter system set streams_pool_size=150m scope=both * ERROR at line 1: ORA-01031: insufficient privilegesPFILEもくつれない(そもそもOSにアクセスできない)
SQL> create pfile from spfile; create pfile from spfile * ERROR at line 1: ORA-01031: insufficient privilegesDATABASE_PROPERTIESビューでDBのプロパティを確認。
デフォルト表領域は 「USERS」、デフォルト一時表領域は「TEMP」SQL> col property_name for a30 SQL> col property_value for a40 SQL> select property_name,property_value from database_properties; PROPERTY_NAME PROPERTY_VALUE ------------------------------ ---------------------------------------- DICT.BASE 2 DEFAULT_TEMP_TABLESPACE TEMP DEFAULT_PERMANENT_TABLESPACE USERS DEFAULT_EDITION ORA$BASE Flashback Timestamp TimeZone GMT TDE_MASTER_KEY_ID EXPORT_VIEWS_VERSION 8 DEFAULT_TBS_TYPE BIGFILE GLOBAL_DB_NAME ORCL1 NLS_RDBMS_VERSION 12.1.0.2.0 NLS_NCHAR_CHARACTERSET AL16UTF16 NLS_NCHAR_CONV_EXCP FALSE NLS_LENGTH_SEMANTICS BYTE NLS_COMP BINARY NLS_DUAL_CURRENCY $ NLS_TIMESTAMP_TZ_FORMAT DD-MON-RR HH.MI.SSXFF AM TZR NLS_TIME_TZ_FORMAT HH.MI.SSXFF AM TZR NLS_TIMESTAMP_FORMAT DD-MON-RR HH.MI.SSXFF AM NLS_TIME_FORMAT HH.MI.SSXFF AM NLS_SORT BINARY NLS_DATE_LANGUAGE AMERICAN NLS_DATE_FORMAT DD-MON-RR NLS_CALENDAR GREGORIAN NLS_CHARACTERSET AL32UTF8 NLS_NUMERIC_CHARACTERS ., NLS_ISO_CURRENCY AMERICA NLS_CURRENCY $ NLS_TERRITORY AMERICA NLS_LANGUAGE AMERICAN DST_SECONDARY_TT_VERSION 0 DST_PRIMARY_TT_VERSION 33 DST_UPGRADE_STATE NONE MAX_STRING_SIZE STANDARD DBTIMEZONE +00:00 WORKLOAD_CAPTURE_MODE WORKLOAD_REPLAY_MODE NO_USERID_VERIFIER_SALT 9FBAD6D3759B5204F101F9E263E81045 37 rows selected.FORCE LOGGINGモードの確認。デフォルトはOFF
SQL> select force_logging from v$database; FORCE_LOGGING --------------------------------------- NOサプリメンタルロギングの確認。デフォルトはOFF。
SQL> SELECT supplemental_log_data_min FROM v$database; SUPPLEME -------- NO
- 投稿日:2019-07-01T09:00:14+09:00
AWS CloudFormationのAWS Lambda-backedカスタムリソースで最新のAWS SDKを利用する
AWS Lambda-backed カスタムリソースを利用するとAWS CloudFormationが対応していないリソースを管理することができて便利なのですが、AWS Lambdaで利用できるAWS SDK(ここではPythonのboto3)のバージョンが最新じゃない場合に困ることがあります。
AWS Lambda-backed カスタムリソース - AWS CloudFormation
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/template-custom-resources-lambda.htmlそんなときにどうしたら良いものか悩んでいたのですが、AWS Lambda Layersが利用できるみたいだったので試してみました。
前提
- AWSアカウントがある
- AWS CLIが利用できる
- AWS Lambda、Lambda Layers、CloudFormationの作成権限がある
AWS Lambda Layersに最新のAWS SDKのLayerを作成する
AWS Lambda Layersで最新のAWS SDKを利用する方法は下記を参考にさせてもらいました。(感謝
Lambda Layers で最新の AWS SDK を使用する - Qiita
https://qiita.com/hayao_k/items/b9750cc8fa69d0ce91b0> mkdir 任意のディレクトリ > cd 任意のディレクトリ > mkdir python > pip install -t ./python boto3 > zip -r python.zip ./python > aws lambda publish-layer-version \ --layer-name boto3 \ --zip-file fileb://python.zip \ --compatible-runtimes python3.7 { "Content": { "Location": "https://prod-04-2014-layers.s3.amazonaws.com/snapshots/(略)", "CodeSha256": "JZM5sEEyGBPgips+y+F0/X5rHXJIPkcLYeazyXiLkTk=", "CodeSize": 8572137 }, "LayerArn": "arn:aws:lambda:us-east-1:xxxxxxxxxxxx:layer:boto3", "LayerVersionArn": "arn:aws:lambda:us-east-1:xxxxxxxxxxxx:layer:boto3:1", "Description": "", "CreatedDate": "2019-06-21T08:57:29.995+0000", "Version": 1, "CompatibleRuntimes": [ "python3.7" ] }AWS CloudFormationのテンプレートを作成する
AWS Lambda-backedカスタムリソースで
boto3のバージョンを確認するテンプレートを作成します。
比較のためにLayer利用する/しないのリソースを準備します。> touch cfn-template.yamlcfn-template.yamlResources: NonUseLambdaLayer: Type: Custom::CustomResource Properties: ServiceToken: !GetAtt NonUseLambdaLayerFunction.Arn UseLambdaLayer: Type: Custom::CustomResource Properties: ServiceToken: !GetAtt UseLambdaLayerFunction.Arn # 標準のboto3を利用 NonUseLambdaLayerFunction: Type: AWS::Lambda::Function Properties: Handler: index.handler Role: !GetAtt FunctionExecutionRole.Arn Code: ZipFile: !Sub | import cfnresponse import boto3 def handler(event, context): print(boto3.__version__) cfnresponse.send(event, context, cfnresponse.SUCCESS, {}) Runtime: python3.7 # Lambda Layerのboto3を利用 UseLambdaLayerFunction: Type: AWS::Lambda::Function Properties: Handler: index.handler Role: !GetAtt FunctionExecutionRole.Arn Code: ZipFile: !Sub | import cfnresponse import boto3 def handler(event, context): print(boto3.__version__) cfnresponse.send(event, context, cfnresponse.SUCCESS, {}) Runtime: python3.7 Layers: - arn:aws:lambda:us-east-1:xxxxxxxxxxxx:layer:boto3:1 FunctionExecutionRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Principal: Service: - lambda.amazonaws.com Action: - sts:AssumeRole Path: "/" Policies: - PolicyName: root PolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Action: - logs:CreateLogGroup - logs:CreateLogStream - logs:PutLogEvents Resource: "arn:aws:logs:*:*:*"AWS CLIからCloudFormationのスタックを作成します。Lambda関数実行用のロールを作成するので、
--capabilities CAPABILITY_IAMオプションを指定します。> aws cloudformation create-stack \ --stack-name cfn-lambda-backed-test \ --template-body file://cfn-template.yaml \ --capabilities CAPABILITY_IAM { "StackId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-lambda-backed-test/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" }スタック作成できたらリソース一覧からAWS Lambdaの関数名を取得します。
> aws cloudformation list-stack-resources \ --stack-name cfn-lambda-backed-test { "StackResourceSummaries": [ { "LogicalResourceId": "FunctionExecutionRole", "PhysicalResourceId": "cfn-lambda-backed-test-FunctionExecutionRole-XXXXXXXXXXXX", "ResourceType": "AWS::IAM::Role", "LastUpdatedTimestamp": "2019-06-24T07:25:29.253Z", "ResourceStatus": "CREATE_COMPLETE", "DriftInformation": { "StackResourceDriftStatus": "NOT_CHECKED" } }, { "LogicalResourceId": "NonUseLambdaLayer", "PhysicalResourceId": "2019/06/24/[$LATEST]8e94b0b2ffc54b00acf35a004e68c522", "ResourceType": "Custom::CustomResource", "LastUpdatedTimestamp": "2019-06-24T07:25:37.368Z", "ResourceStatus": "CREATE_COMPLETE", "DriftInformation": { "StackResourceDriftStatus": "NOT_CHECKED" } }, { "LogicalResourceId": "NonUseLambdaLayerFunction", "PhysicalResourceId": "cfn-lambda-backed-te-NonUseLambdaLayerFunctio-XXXXXXXXXXXXX", "ResourceType": "AWS::Lambda::Function", "LastUpdatedTimestamp": "2019-06-24T07:25:32.817Z", "ResourceStatus": "CREATE_COMPLETE", "DriftInformation": { "StackResourceDriftStatus": "NOT_CHECKED" } }, { "LogicalResourceId": "UseLambdaLayer", "PhysicalResourceId": "2019/06/24/[$LATEST]200facdec8cb4d77ac3dd5f333ceb848", "ResourceType": "Custom::CustomResource", "LastUpdatedTimestamp": "2019-06-24T07:25:41.716Z", "ResourceStatus": "CREATE_COMPLETE", "DriftInformation": { "StackResourceDriftStatus": "NOT_CHECKED" } }, { "LogicalResourceId": "UseLambdaLayerFunction", "PhysicalResourceId": "cfn-lambda-backed-test-UseLambdaLayerFunction-XXXXXXXXXXXXX", "ResourceType": "AWS::Lambda::Function", "LastUpdatedTimestamp": "2019-06-24T07:25:36.240Z", "ResourceStatus": "CREATE_COMPLETE", "DriftInformation": { "StackResourceDriftStatus": "NOT_CHECKED" } } ] }リソースが取得できたらLambda関数のログから
boto3のバージョンを確認します。
上記リソースリストにあるResourceTypeがAWS::Lambda::FunctionのPhysicalResourceIdが関数名になります。
スタック作成時のログを確認しても良いのですが、ここでは簡単にしたかったので関数を実行して確認します。# 標準のboto3 > aws lambda invoke \ --function-name cfn-lambda-backed-te-NonUseLambdaLayerFunctio-XXXXXXXXXXXX \ --log-type Tail \ outputfile.txt \ --query 'LogResult' | tr -d '"' | base64 -D START RequestId: 859e7e0b-4041-4fa6-bf61-84a31bd72cc9 Version: $LATEST 1.9.42 responseUrl = event['ResponseURL']e 15, in sendCCESS, {}) END RequestId: 859e7e0b-4041-4fa6-bf61-84a31bd72cc9 REPORT RequestId: 859e7e0b-4041-4fa6-bf61-84a31bd72cc9 Duration: 54.69 ms Billed Duration: 100 ms Memory Size: 128 MB Max Memory Used: 56 MB # Lambda Layerのboto3 > aws lambda invoke \ --function-name cfn-lambda-backed-test-UseLambdaLayerFunction-XXXXXXXXXXXXX \ --log-type Tail \ outputfile.txt \ --query 'LogResult' | tr -d '"' | base64 -D START RequestId: 2e422fb4-95ae-4274-b9a5-4ced212a78ec Version: $LATEST 1.9.173 responseUrl = event['ResponseURL']e 15, in sendCCESS, {}) END RequestId: 2e422fb4-95ae-4274-b9a5-4ced212a78ec REPORT RequestId: 2e422fb4-95ae-4274-b9a5-4ced212a78ec Duration: 28.95 ms Billed Duration: 100 ms Memory Size: 128 MB Max Memory Used: 35 MBLayerを利用している関数で最新のAWS SDKを利用できることが確認できました。
まとめ
AWS Lambda LayersへのLayer作成部分もスタックに含めることができればよいのですが、Zipファイルを事前にS3へ上げるなりの準備が必要で、そうなるとS3のリソースを事前に作成しなきゃ。。。
など、、、
どうしても1アクションで完結しなさそうだったので、Layer作成は手動ですることにしました。もう少し考えればうまくまとまりそうな気がしてますが、今のところはこれで満足です。
参考
AWS Lambda-backed カスタムリソース - AWS CloudFormation
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/template-custom-resources-lambda.htmlLambda Layers で最新の AWS SDK を使用する - Qiita
https://qiita.com/hayao_k/items/b9750cc8fa69d0ce91b0
- 投稿日:2019-07-01T04:02:06+09:00
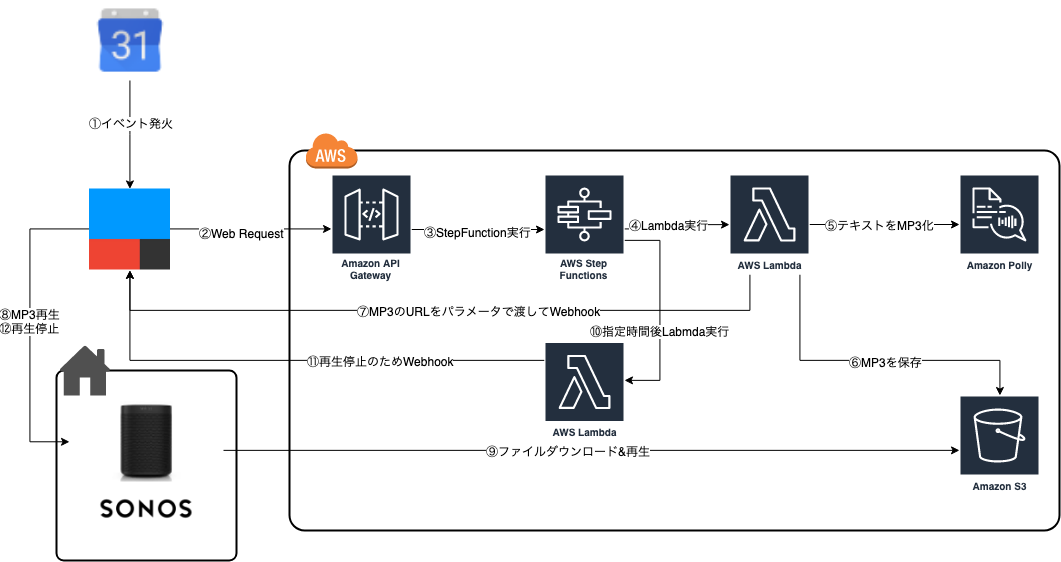
スマートスピーカーに自発的に喋らせよう (IFTTT + Sonos + AWS)
目的
Amazon Echo や Google Home などのスマートスピーカーは基本的にこちらから話しかけないと喋ってくれない。個人的に何か起きたらスマートスピーカー側から話して欲しかったのでそのための仕組みを作る。
必要なもの
- IFTTT
- Sonos スピーカー (Sonos One)
- AWS
Sonos スピーカーは IFTTT に対応してて API 経由で音声ファイルを再生できるスマートスピーカーで、一番安いのでも2.5万円ぐらいするけど便利だし楽しいしみんな買うといい(販促
構成
今回作ったのはGoogle カレンダーの予定を時間になったら喋らせる仕組み。ただし、パラメータ渡して API を叩いてるだけなので IFTTT 上のトリガーだったら Twitter だろうが Slack だろうがなんでも使える。
作ったもの
IFTTT
作るアプレットは3種類
- Google Calendar の発火をトリガーに Web Request を飛ばす
- Webhook を受け取り Sonos に指定ファイルを再生させる
- Webhook を受け取り Sonos を停止させるGoogle Calendar の発火をトリガーに Web Request を飛ばす
Any events starts をトリガーにして Webhooks の Make a web request をアクションに設定。リクエストの設定は以下の通り。
- Method: Post
- Content Type: application/json
- Body:{ "text": "{{Title}}の時間だああああああ", "voiceId": "Takumi", "during": 30 }Body 内の各パラメータの意味
- text: 再生する音声
- voiceId: Polly の音声の種類 (日本語なら Takumi か Mizuki)
- during: 音声を再生する秒数Webhook を受け取り Sonos に指定ファイルを再生させる
トリガーを Webhooks の Receive a web request にし、Sonos の Play stream をアクションに設定。
Event Name は適当なものを設定し、What do you want to play のところに {{Value1}} を設定する。Webhook を受け取り Sonos を停止させる
トリガーを Webhooks の Receive a web request にし、Sonos の Pause をアクションに設定。
AWS
API Gateway
IFTTT から Webhook を受けるための入り口。
統合リクエストの設定は以下のように設定(参考:https://docs.aws.amazon.com/ja_jp/step-functions/latest/dg/tutorial-api-gateway.html)
マッピングテンプレートは以下のように設定する。stateMachineArn には StepFunction のステートマシンの ARN を指定する。{ "input": "$util.escapeJavaScript($input.json('$'))", "stateMachineArn": "arn:aws:states:us-east-1:123456789012:stateMachine:HelloWorld" }Step Functions
音声を再生するだけなら Lambda だけでいいのだが、IFTTT の API だと Sonos が無限リピートで再生を始める。どこかで再生を止めるために、音声再生 → 指定時間後に音声を止める Lambda を実行するステートマシンを作成する。マシン定義は以下の通り。IFTTT から渡ってくる during パラメータの秒数分待機し、その後再生を停止する Lambda を実行する。
{ "StartAt": "PlayVoiceState", "States": { "PlayVoiceState": { "Type": "Task", "Resource": "arn:aws:lambda:ap-northeast-1:1:123456789012:playVoiceOnSonos", "ResultPath":"$", "Next": "WaitSeconds" }, "WaitSeconds": { "Type": "Wait", "SecondsPath": "$.during", "Next": "PauseVoice" }, "PauseVoice": { "Type": "Task", "Resource": "arn:aws:lambda:ap-northeast-1:123456789012:function:pauseSonos", "End": true } } }Lambda
作ったものは以下の通り。
1. テキストから音声ファイルを作り、再生の Webhook を飛ばす Lambda
2. 再生停止の Webhook を飛ばす Lambda実装はいずれも Node.js 10.x で実行ロールに Polly と S3 の権限がそれぞれ必要。
テキストから音声ファイルを作り、再生のWebhookを飛ばすLambdaconst crypto = require('crypto'); const https = require('https'); const AWS = require('aws-sdk'); const IFTTT_EVENT_NAME = process.env.IFTTT_EVENT_NAME; const IFTTT_KEY = process.env.IFTTT_KEY; const polly = new AWS.Polly(); const s3 = new AWS.S3(); const err_response = { statusCode: 500 }; exports.handler = async (event, context, callback) => { console.log(event); const pollyParams = { OutputFormat: 'mp3', VoiceId: event.voiceId, Text: event.text, TextType: 'text' }; const pollyRes = await polly.synthesizeSpeech(pollyParams).promise(); const s3Params = { Body: pollyRes.AudioStream, Bucket: process.env.S3_BUCKET, Key: crypto.randomBytes(32).toString('hex') + '.mp3' }; const s3Res = await s3.upload(s3Params, async (err, data) => { if (err) { console.log(err.message); err_response['body'] = err.message; callback(JSON.stringify(err_response)); } }).promise(); const body = JSON.stringify({ value1: s3Res.Location }); const httpsOptions = { hostname: 'maker.ifttt.com', path: `/trigger/${IFTTT_EVENT_NAME}/with/key/${IFTTT_KEY}`, method: 'POST', headers: { 'Content-Type': 'application/json' } }; const res = await new Promise((resolve, reject) => { const iftttHttpReq = https.request(httpsOptions, (res) => { resolve(res); }); iftttHttpReq.write(body); iftttHttpReq.end(); }); const response = event; response.statusCode = res.statusCode; context.succeed(response); };再生停止のWebhookを飛ばすLambdaconst https = require('https'); const IFTTT_EVENT_NAME = process.env.IFTTT_EVENT_NAME; const IFTTT_KEY = process.env.IFTTT_KEY; exports.handler = async (event, context) => { const httpsOptions = { hostname: 'maker.ifttt.com', path: `/trigger/${IFTTT_EVENT_NAME}/with/key/${IFTTT_KEY}`, method: 'POST', headers: { 'Content-Type': 'application/json' } }; const response = await new Promise((resolve, reject) => { const iftttHttpReq = https.request(httpsOptions, (res) => { resolve(res); }); iftttHttpReq.end(); }); context.succeed(response.statusCode); };S3
バケットを用意するだけなのだが、時間が経つと余計な音声ファイルが残り続けるので、ライフサイクルルールで一定期間後に削除するよう設定するのがよい。
課題
- 再生中に他のイベントが発生すると次の再生が強制的に始まってしまう
- 今回は実装を楽にするために IFTTT 経由で Sonos を操作しているけど、直接 API を叩けばキューに追加できるので暇があればその対応をするかも
- リピートしないで一回しか再生しないようにできない
- 音声ファイルの再生時間を見るようにするか、直接 API で操作すればなんとかなりそう
おわりに
他にもスマートロックをトリガーにおかえりメッセージ流すとか、暇そうにしてるときにツイッターのタイムライン流すとか、それ以外にも応用しがいがある気がするので、こういうアイデアあるぜ!みたいなのを教えてくれると嬉しい。

- 投稿日:2019-07-01T01:18:42+09:00
Qiitaの記事をランダムに読めるAPI / サービス に機能追加してみた
数日前に公開された上記のサービスがとても素晴らしく、
このサービスを通じて普段はなかなか出会うことのない類の記事とたくさん出会うことができました!きっかけ
しかし個人的に一点問題が。元記事の筆者の方も指摘なさっているとおり、スパム記事の割合がなかなか高い。
ざっくりとした体感、10分の1くらいの確率でスパムをツモってしまう印象です。ちょっと残念。そこで元のサービスに一部機能を追加し、引き当てる記事をある程度スクリーニングできるようにしました。
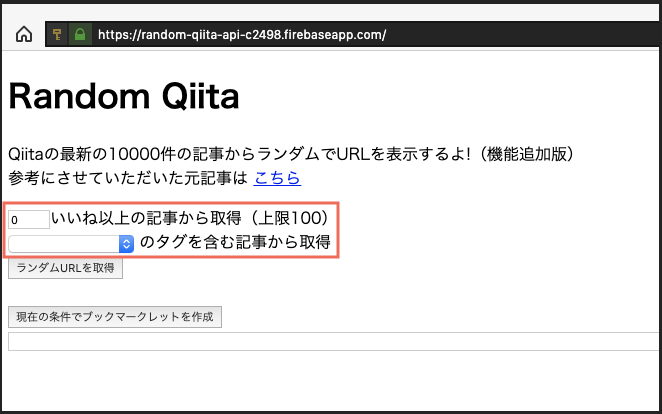
(元々のバイアスなしに謎の知識(?)を仕入れることができます。という意図から少し逸れてしまいますが…)モノ
赤枠の箇所が追加部分になります。
https://random-qiita-api-c2498.firebaseapp.com/
Webサービス版のリンクは↑こちら。追加した機能は大きくふたつです。1. 特定数以上のいいねを獲得している記事のみを取得対象にする
そのままですね。獲得いいね数を1以上にするだけでもスパム記事との遭遇率はだいぶ下がります。
いっぽうでいいね数を上げすぎると既知の記事との遭遇率が上がるので、上限値は100としています。2. 指定したタグを含む記事のみを取得対象にする
全取得対象の10000記事のうち100以上の記事に付されているタグを対象に、タグ指定で取得します。
1. のいいね数での絞り込みと組み合わせて使用することももちろん可能です。エンドポイント例
いいね数が5以上、タグに
Pythonを含む記事のみを取得する場合の例です。
ご覧の通り、いずれもクエリストリングに入力値を渡してスクリーニングに使用しています。
リクエストからクエリストリングを抜き出している箇所は以下。exports.get = functions.https.onRequest((request, response) => { cors(request, response, () => { const likes_min = request.query.likes_min; const tag = request.query.target_tag;またそれぞれの条件を指定した状態のブックマークレットをワンクリックで作成できるようにしました。
元記事と同じ引用となってしまいますが、ブックマークレットの登録方法を参照のこと。使ってみて
個人的にはだいぶストレスが減りました。
いいね数を適度に高く設定するとやはり良記事との遭遇率も上がり、良い感じです。
まだ動かしはじめたばかりなので、不具合などありましたらご指摘いただけるとありがたいです。ところでアーキテクチャなどは元々のものをまるっきり流用しているのですが、
この機能追加だけで数時間かかってしまいました。。。
元記事の方の4時間で実装というのは脱帽です。すごい。
- 投稿日:2019-07-01T01:03:07+09:00
ローカル上にLocalStackをDockerで実行
はじめに
開発用にAWSのサービスをローカル環境に構築できる、LocalStackというプロジェクトがあります。
https://github.com/localstack/localstack今回はDockerを使ったLocalStackの実行方法をまとめます。
環境
OS: macOS Mojave 10.14.5
Docker: 18.09.0
Docker Compose: 1.23.2プロジェクトをプル
git clone https://github.com/localstack/localstack.git cd localstack/サービスの指定
環境変数
SERVICESにカンマ区切りでサービス名を指定することで起動させたいサービスを選ぶことができます。
指定がない場合、全て指定と同意です。指定できるサービスは以下の通り
サービス サービス名 エンドポイント API Gateway apigateway http://localhost:4567 Kinesis kinesis http://localhost:4568 DynamoDB dynamodb http://localhost:4569 DynamoDB Streams dynamodbstreams http://localhost:4570 Elasticsearch elasticsearch http://localhost:4571 S3 s3 http://localhost:4572 Firehose firehose http://localhost:4573 Lambda lambda http://localhost:4574 SNS sns http://localhost:4575 SQS sqs http://localhost:4576 Redshift redshift http://localhost:4577 ES (Elasticsearch Service) es http://localhost:4578 SES ses http://localhost:4579 Route53 route53 http://localhost:4580 CloudFormation cloudformation http://localhost:4581 CloudWatch cloudwatch http://localhost:4582 SSM ssm http://localhost:4583 SecretsManager secretsmanager http://localhost:4584 StepFunctions stepfunctions http://localhost:4585 CloudWatch Logs logs http://localhost:4586 STS sts http://localhost:4592 IAM iam http://localhost:4593 EC2 ec2 http://localhost:4597 ※ サービス名はaws cliのリファレンスから
http://docs.aws.amazon.com/cli/latest/reference/#available-services注意点: Dockerに割り当てるメモリが少ないと正しく起動しない
Dockerへのメモリ割り当てが少ないと、指定した全てのサービスが正しく実行されないことがあります。
例えば、以下のような elasticsearch の起動で実行エラーが発生します。... WARNING:infra.py: Service "elasticsearch" not yet available, retrying... ERROR:infra.py: Error checking state of local environment (after some retries): Traceback (most recent call last): ...だいたいメモリを 4 GB にすれば全てのサービスが実行できました。
多くのサービスを実行させたいときは、割り当ての量を増やすか、増やせないときは最小のサービスを指定して実行が必要です。
Dockerで実行
Docker Composeを実行
TMPDIR=/private$TMPDIR \ DATA_DIR=/tmp/localstack/data \ SERVICES=apigateway,kinesis,dynamodb,dynamodbstreams,elasticsearch,s3,\ lambda,sns,sqs,redshift,es,ses,route53,cloudformation,cloudwatch,\ ssm,secretsmanager,stepfunctions,logs,sts,iam,ec2 \ docker-compose up -d
TMPDIR: Macの場合は指定が必須
DATA_DIR: データの永続化のために指定
SERVICES: 実行するサービスを指定 (全てのサービスを実行する際は指定はいらない。上ではサンプルとして全てを列挙)バックグランドで実行のために
-dオプションをつけています。ログの最後に
Readyと出れば、起動完了です。
すると、デフォルトではDocker上にlocalstack_localstack_1という名前でプロセスが実行されていると思います。ホストOS起動時に自動で実行するように設定
ホストOSが再起動した際も自動で実行されるよう設定値を変更します。
docker update --restart=always localstack_localstack_1まとめ
これでAWSサービスをローカルで利用できる環境が整いました。
あとは、CLIやSDKで、各サービスのエンドポイントをLocalStackへ向けることで利用可能となります。