- 投稿日:2019-07-01T23:18:27+09:00
Oracle認定Java Silver SE 8 合格体験記
2019年6月に、Oracle認定のJava Silver SE 8に合格したので、その時の勉強法などをまとめてみました。
Java Silverとは
- Oracle社が認定するJava技術者の資格の1つで、「開発初心者向け資格」という位置づけになっています。
- Java Gold:中上級者向け資格
- Java Silver:開発初心者向け資格
- Java Bronze:言語未経験者向けの入門資格
- 最上位のGoldを取得するためには、事前にSilverに合格している必要があります。
- なお、ITSSキャリアフレームワークと認定試験・資格の関係を見ると、Java Silver(OCJP Silver)はITパスポートと同じレベル1に位置付けられています。
- ですが、実際の試験のレベルはITパスポートよりは難しいと思います。
- 受験料は為替によって変化するかもしれませんが、私が受験した時は26,600円(税抜)でした。
- これまでに受験した資格試験の中で最も高い受験料だったので、受験申込をするのに少し躊躇しましたが...
受験までの大まかな流れ
実施したこと 実施日 受験を思い立った時期 2018/02頃 試験に関する情報収集の開始 2018/02頃 問題集(白本)の購入 2019/02/11 問題集(黒本)の購入 2019/05末頃 受験申込日 2018/06/06 本格的な学習の開始 2018/06/09 試験日 2018/06/29
- 問題集を2月に買った後、引っ越しや身内の不幸などが相次いだ結果、ずっと勉強せずに4ヶ月ほど経ってしまいました。
- そこで、これではダメだと思い立ち、「先に受験申し込みをして引っ込みがつかない状態にする」という荒業を使いました。
- そうでもしないと勉強に身が入らない"うつけ者"なのです...
- Javaを使った開発の経験はのべ5年以上あったため、参考書は買わずに問題集だけを買いました。
- 最初はKindle版の白本を買いましたが、しばらくは「たまに電車の中で読む程度」でした。
- 5月末頃に書籍版の黒本を買いましたが、巻末の演習問題以外はほとんど見なかったです。
- 私の勉強スタイルは、通勤時間でJava Silverを取得しよう!の@Keitaro-G-21さんと同じく、通勤電車内で勉強するのがメインで、休日は演習問題を1回分解いたらお終い...というあっさりした感じでした。
- 通勤電車内での勉強時間が長いとは言っても、単に白本をパラパラと読むだけだったので、そこまで頭に入っていなかったと思います。
- ですが、これまでにJavaの経験がそれなりにあったので、これで平気だったのだと思います。
- 結局、黒本と白本の演習問題を2周やっただけですが、正解率90%で無事に一発で合格することができました。
- Javaの経験が5年以上ある人の中では、正解率が低い方だと思います...
白本と黒本
- 以下の記事にも書かれていますが、Java Silverの受験者の方から絶大な支持を受けているのが「黒本」です。
- 皆さんが指摘されているように、黒本と同じ問題、あるいはほぼ同じ問題が幾つも出題されていたので、黒本は必ず読んでおいた方が良いと思います。
- 白本の問題とほぼ同じ問題も出題されていましたが、白本の問題の方が全体的にレベルが低めなので、黒本の問題を解いて自信と実力を養っておいた方が良いと思います。
- 白本にも目を通しておけば、様々な問題に対応できるようになると思いますが、費用対効果を考えると微妙かもしれません。
最大の難所:受験申し込み
- こちらの記事にも書かれていますが、受験申し込みがとても厄介でした。
- 上記の記事は非常に分かりやすく書かれているので、受験申し込みに迷う前にぜひご覧下さい。
- 受験申し込みの入口が分かりづらいだけでなく、「ピアソンVUEのアカウント」と「Oracleアカウント」を別々に作成するところがとてもややこしいです。
その他
- 受験後30分程度で、合否を通知するメールが届きますが、私は合否をすぐに確認できませんでした。
- なぜかと言うと、ピアソンVUEのアカウントのパスワードを3回連続で間違えてしまい、それが原因でアカウントがロックされてしまったからです(涙)
- アカウントがロックされてしまった場合は、エラー画面に表示されている連絡先(メールアドレス)へ以下の3点を伝えれば、早ければ翌営業日にロックを解除してもらえます。
- 名前
- Oracle Testing ID
- Oracle.comアカウントのユーザー名(メールアドレス)
参考URL
- 投稿日:2019-07-01T22:28:07+09:00
【解決法】Eclipseの警告:クラスパス・エントリー /XXXXXXXXXXX.jarはエクスポートまたは公開されません。ランタイムClassNotFoundExceptionsが発生する可能性があります
どうも新米エンジニアのnoyです。
Servletとajaxを使って非同期通信できるwebアプリを作っているのですが、
エラー解決に少々時間がかかったので記録を残します。開発環境
エディター:Eclipse 2019-03 (4.11.0)
Webサーバー:Apache Tomcat v9.0
言語:Java
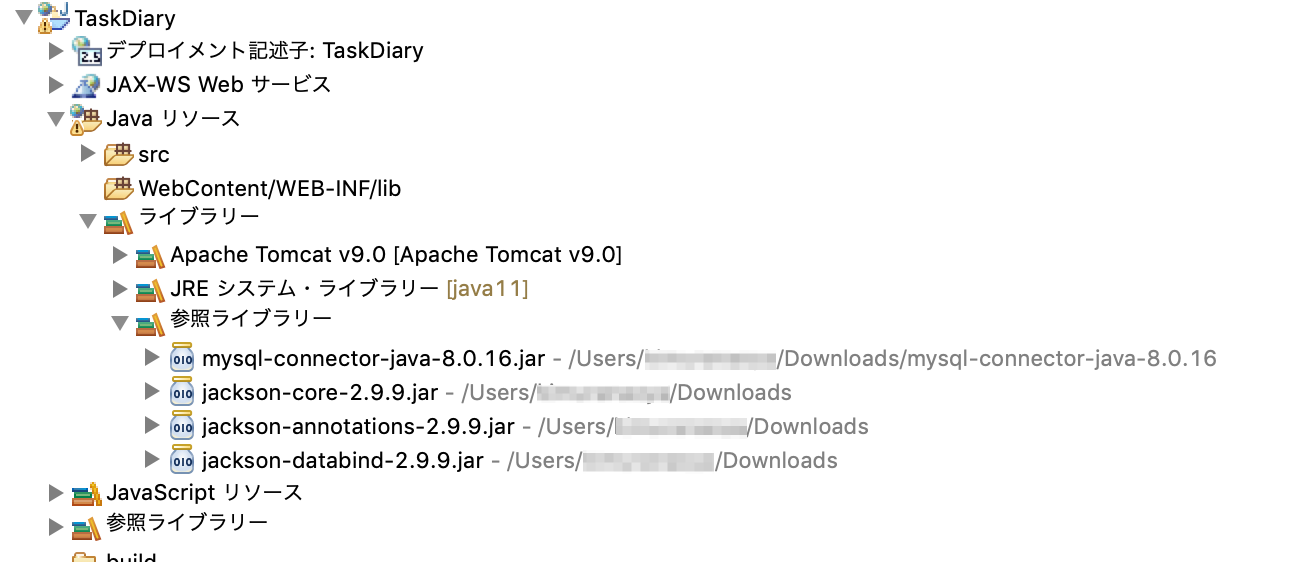
ライブラリ:
・jquery-3.4.1.min.js
・jackson-annotations-2.9.9.jar
・jackson-core-2.9.9.jar
・jackson-databind-2.9.9.jarエラー内容
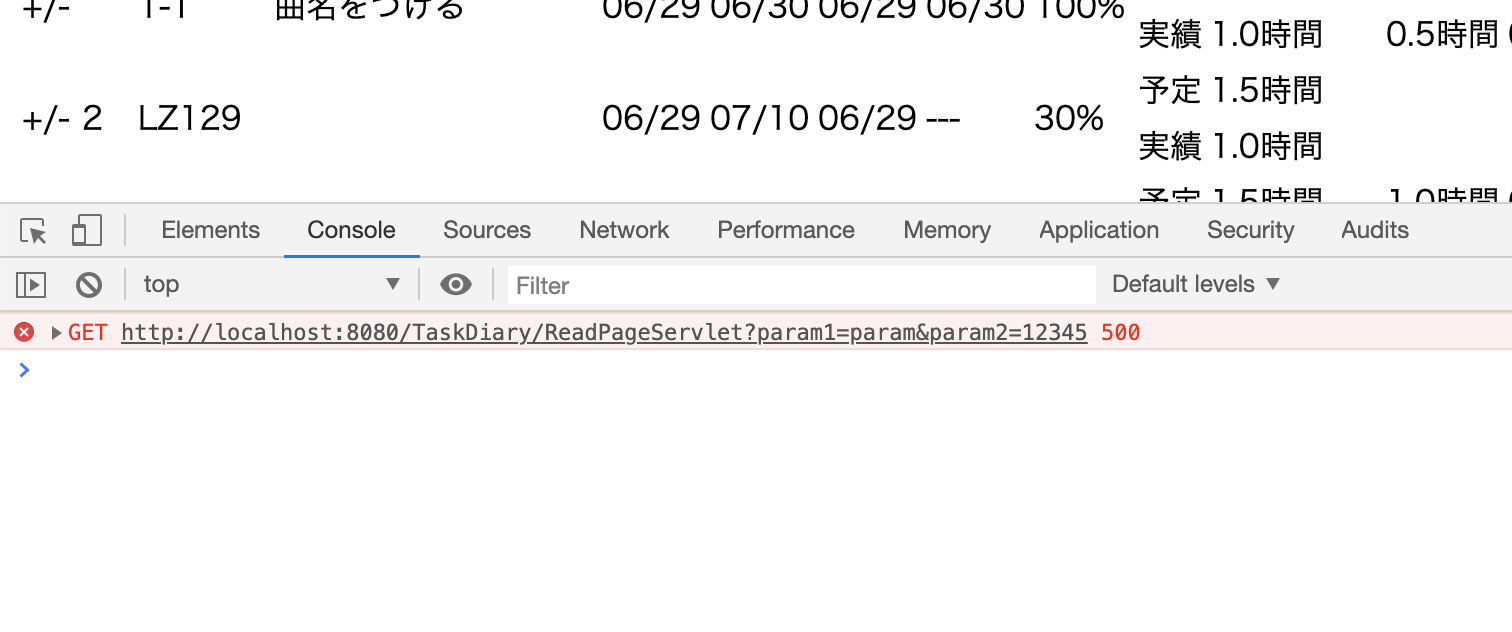
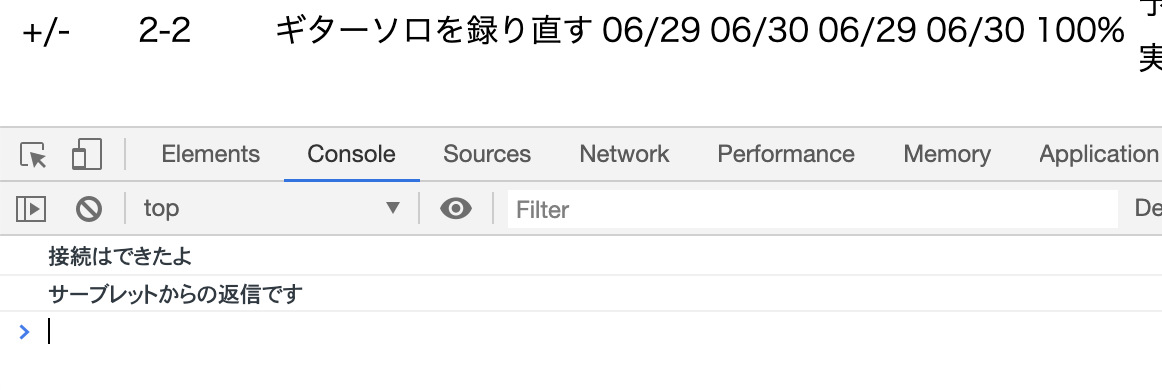
Servletからajaxにレスポンスを返そうとしたところ、HTTPステータス 500 – Internal Server Errorが発生
Chromeのディベロッパーツール「console」タブ「500エラーってなに?!」となり、わんやわんやと少々時間を潰してしまいましたが、
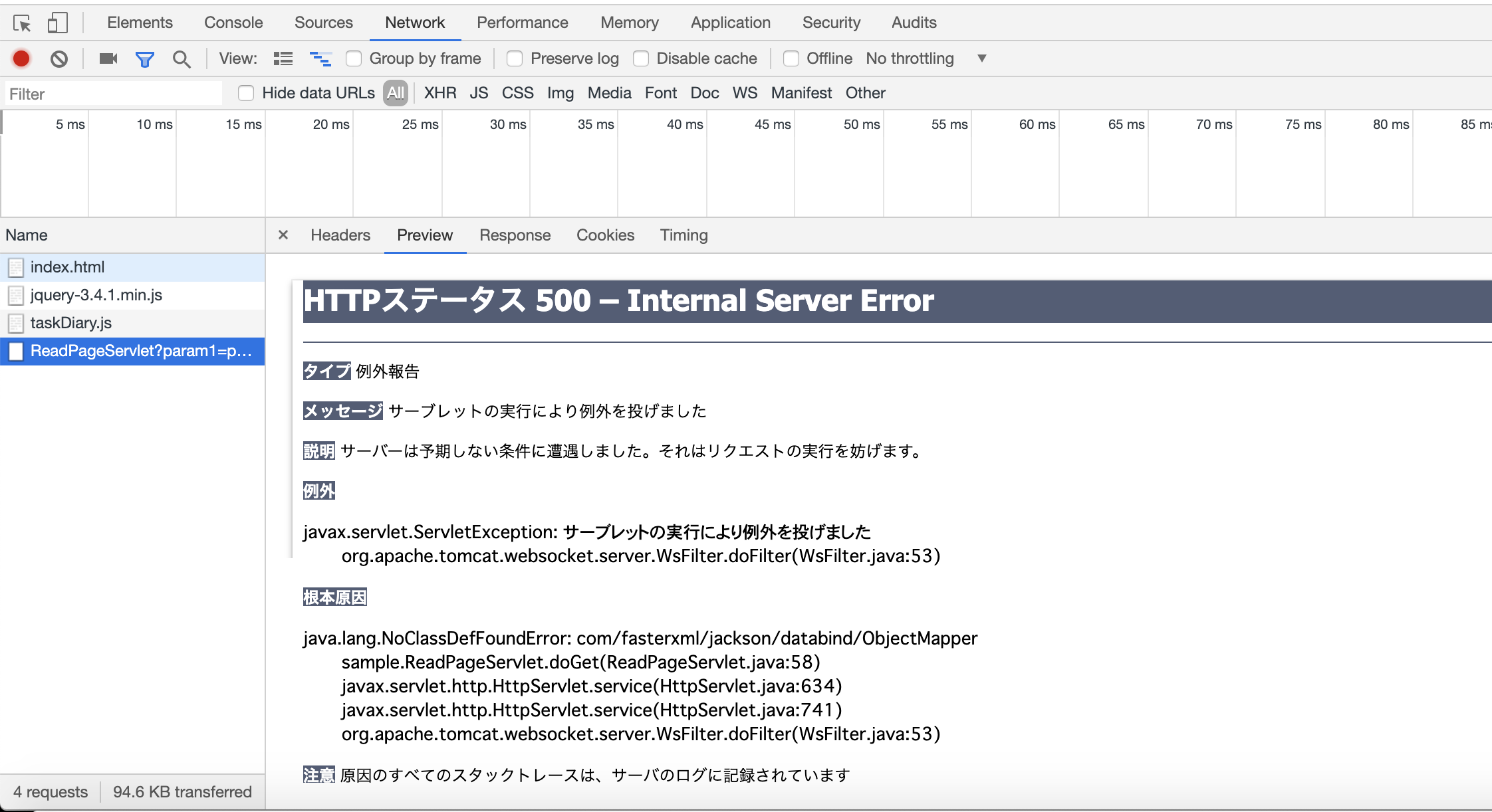
エラーをクリックしていくと例外報告を発見。
「根本原因
java.lang.NoClassDefFoundError: com/fasterxml/jackson/databind/ObjectMapper」あれ?ObjectMapperを定義しているファイルはimportしてるはずなんだけど....
そう思いながらEclipseを色々見直してると「問題」タブで以下の警告を発見。
あれ、クラスパスに追加してるはずのjackson-XXXXXX-2.9.9.jarファイルが参照されてないのかも...?
原因
ObjectMapper(Jacksonのクラス)が定義されているファイル(jackson-XXXXXX-2.9.9.jar)を参照することができず、java.lang.NoClassDefFoundErrorとなっているため。
※ Jacksonとは…Java用のJSONパーサーライブラリの1つ。JavaオブジェクトとJSONの相互変換ができる。
ということで「eclipse クラスパス・エントリー は、エクスポートまたは公開されません。」でググってみたところ、以下のページを見て解決できました。
https://codeday.me/jp/qa/20190201/208565.html
「spring-mvc – Eclipseの警告:XXXXXXXXXXX.jarはエクスポートまたは公開されません。ランタイムClassNotFoundExceptionsが発生する可能性があります」解決策
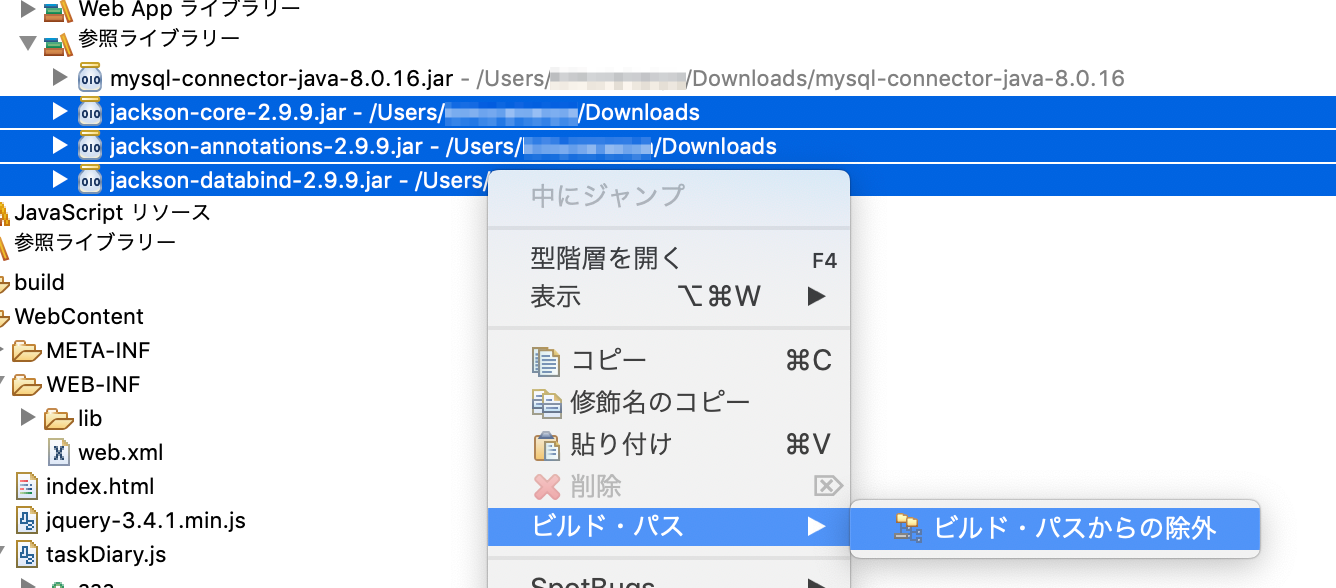
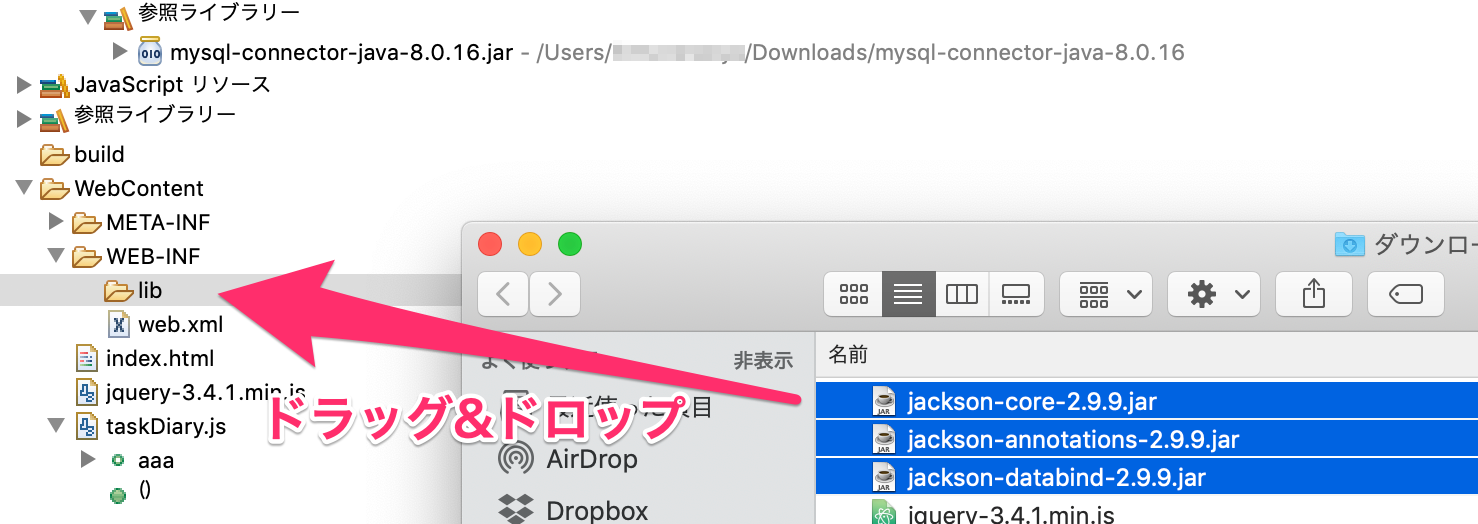
jackson-XXXXXX-2.9.9.jarファイルを参照ライブラリーから削除し、WEB-INF / libフォルダに直接格納する。
参照ライブラリーにある、3つのjackson-XXXXXX-2.9.9.jarファイルを「ビルド・パスから除外」で削除。
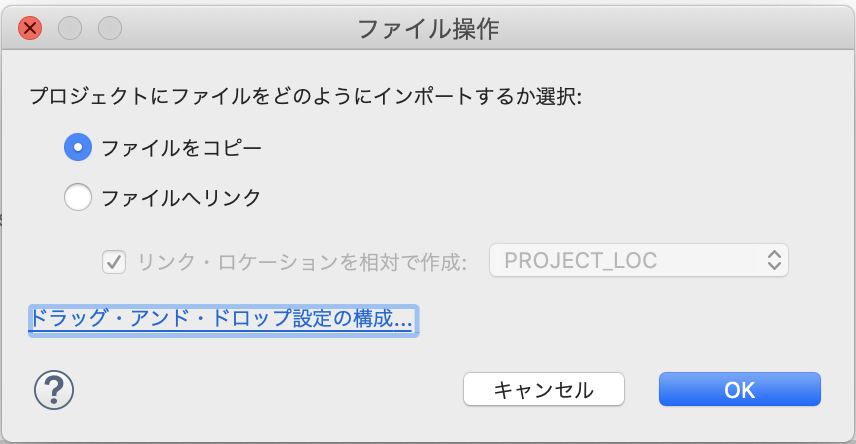
WebContent/WEB-INF/libフォルダに3つのjackson-XXXXXX-2.9.9.jarファイルを直接ドラッグ&ドロップ。
「ファイルをコピー」を選択して「OK」
ファイルが格納されました。
3つのjackson-XXXXXX-2.9.9.jarファイルに関する警告が消えています。(今は残り2項目については無視)
500エラーも消えてServletが実行できました。



- 投稿日:2019-07-01T22:28:07+09:00
[Servlet/Ajax]NoClassDefFoundErrorの解決方法[Eclipse]
どうも新米エンジニアのnoyです。
ServletとAjaxを使って非同期通信できるwebアプリを作っているのですが、
エラー解決に少々時間がかかったので記録を残します。開発環境
エディター:Eclipse 2019-03 (4.11.0)
Webサーバー:Apache Tomcat v9.0
言語:Java
ライブラリ:
・jquery-3.4.1.min.js
・jackson-annotations-2.9.9.jar
・jackson-core-2.9.9.jar
・jackson-databind-2.9.9.jarエラー内容
Servletからajaxにレスポンスを返そうとしたところ、HTTPステータス 500 – Internal Server Errorが発生
Chromeのディベロッパーツール「console」タブ「500エラーってなに?!」となり、わんやわんやと少々時間を潰してしまいましたが、
エラーをクリックしていくと例外報告を発見。
「根本原因
java.lang.NoClassDefFoundError: com/fasterxml/jackson/databind/ObjectMapper」あれ?ObjectMapperを定義しているファイルはimportしてるはずなんだけど....
そう思いながらEclipseを色々見直してると「問題」タブで以下の警告を発見。
あれ、クラスパスに追加してるはずのjackson-XXXXXX-2.9.9.jarファイルが参照されてないのかも...?
原因
ObjectMapper(Jacksonのクラス)が定義されているファイル(jackson-XXXXXX-2.9.9.jar)を参照することができず、java.lang.NoClassDefFoundErrorとなっているため。
※ Jacksonとは…Java用のJSONパーサーライブラリの1つ。JavaオブジェクトとJSONの相互変換ができる。
ということで「eclipse クラスパス・エントリー は、エクスポートまたは公開されません。」でググってみたところ、以下のページを見て解決できました。
https://codeday.me/jp/qa/20190201/208565.html
「spring-mvc – Eclipseの警告:XXXXXXXXXXX.jarはエクスポートまたは公開されません。ランタイムClassNotFoundExceptionsが発生する可能性があります」解決策
jackson-XXXXXX-2.9.9.jarファイルを参照ライブラリーから削除し、WEB-INF / libフォルダに直接格納する。
参照ライブラリーにある、3つのjackson-XXXXXX-2.9.9.jarファイルを「ビルド・パスから除外」で削除。
WebContent/WEB-INF/libフォルダに3つのjackson-XXXXXX-2.9.9.jarファイルを直接ドラッグ&ドロップ。
「ファイルをコピー」を選択して「OK」
ファイルが格納されました。
3つのjackson-XXXXXX-2.9.9.jarファイルに関する警告が消えています。(今は残り2項目については無視)
500エラーも消えてServletが実行できました。
- 投稿日:2019-07-01T22:11:01+09:00
Javaの配列におけるCloneメソッドとは[Clone method for Java arrays]を訳してみた。
Javaの配列における
clone()についての分かりやすい説明を見つけたので訳してみました。[引用]stackoverflow
Clone method for Java arrays
cloneメソッドが配列に呼び出される時、同じ配列要素の新しいインスタンスを返却します。
例えば、次のコードではint[]aとint[]bでは違うインスタンスを生成します。int[] a = {1,2,3}; int[] b = a.clone(); * 「a == b ?」 は、aとbが同じインスタンスか?という判定 System.out.println(a == b ? "同じインスタンスです":"違うインスタンスです"); //出力: 違うインスタンスです2つは異なるインスタンスなので、int[]bに対する変更は、int[]aには影響しないということになります。
b[0] = 5; System.out.println(a[0]); System.out.println(b[0]); //出力 : 1 // : 5これがオブジェクトの配列操作となると少しややこしい話になります。(配列の場合)クローンメソッドにより新しい配列の参照先を返却します。これはコピー元の配列オブジェクトと同じ参照先になります。
例えば
Dogクラスがあったとします。class Dog{ private String name; public Dog(String name) { super(); this.name = name; } public String getName() { return name; } public void setName(String name) { this.name = name; } }そして私は
Dogクラスの配列を追加します。Dog[] myDogs = new Dog[4]; myDogs[0] = new Dog("Wolf"); myDogs[1] = new Dog("Pepper"); myDogs[2] = new Dog("Bullet"); myDogs[3] = new Dog("Sadie");そして
dogをクローンすると・・・Dog[] myDogsClone = myDogs.clone();2つは同じ要素を参照します。
System.out.println(myDogs[0] == myDogsClone[0] ? "同じ":"違う"); System.out.println(myDogs[1] == myDogsClone[1] ? "同じ":"違う"); System.out.println(myDogs[2] == myDogsClone[2] ? "同じ":"違う"); System.out.println(myDogs[3] == myDogsClone[3] ? "同じ":"違う"); //出力: 同じ (4回)これはどうゆうことかというと、2つは同じ参照先なのでクローンした配列に対して変更を加えた場合、その変更がもともとの配列にも反映されるということです。
// myDogsCloneに変更を加えると、myDogsの要素の値にも反映される。 myDogsClone[0].setName("Ruff"); System.out.println(myDogs[0].getName()); //出力: Ruffしかし、配列に対して新しくインスタンスを作成するとその変更は元のインスタンスに影響しません。
myDogsClone[1] = new Dog("Spot"); System.out.println(myDogsClone[1].getName()); System.out.println(myDogs[1].getName()); //出力: Spot // Pepperとても勉強になりました!
- 投稿日:2019-07-01T21:07:59+09:00
grpc の binary log
grpc-java でログ取るのにどういった項目やどういったフローで取ることになるんだろうなーと調べていたら、
BinaryLogというクラスがあって良さそうなのにググっても全く英語でも概要や使い方が殆ど出てこず、気になったので調べてみた。つまり、バイナリ形式でログを取り、RPC の再現や問題の発見のためのログということらしい。けれど、提案中の機能で、まだ本番で使えるようなものではない様子。
使い方はサーバや、channel に仕込めばいいだけ。
- https://grpc.github.io/grpc-java/javadoc/io/grpc/ServerBuilder.html#setBinaryLog-io.grpc.BinaryLog-
- https://github.com/grpc/grpc-java/blob/master/api/src/main/java/io/grpc/ManagedChannelBuilder.java#L490
このインスタンスは、 BinaryLogs というヘルパークラスを使って作ることができる。ファイルの出力先やログのフィルタ設定などはここから実装をたどれば良い。
実装を見ると、ログに残す対象のサービス・メソッドやログに残す項目を設定できる環境変数の名前が、提案と実装で違っているので本当にまだ試験段階なんだと思う。
BinaryLogSink で、受け取ったログを出力する実装を書けるみたいだが、受け取るメッセージの型のが
MessageLiteで扱いづらい。Slf4j に json 化して出力とかできるかな?JSON にするはこれ使う:
- 投稿日:2019-07-01T18:11:55+09:00
余計なクラスを作り、他のクラスに依存させてばかりいるな!!!
ここは?
私のこれまでの不必要なユーティリティクラスの乱生成による不都合の連発とそれに因る教訓を、個人的戒めの意味合いを込めて綴っています。
留意事項
詳しくはこちらをお読みいただけると幸いです。
他でまとめている私の記事と比べて、この記事は個人的戒めの要素が特に強いです。
冒頭タイトルから語気が強めで、人によっては不快感を生じさせてしまうかもしれませんが、あくまでも「過去の自分」への呼びかけですのでお気になさらず。また、ここで一部扱っている「継承」は、抽象クラスと具象クラスにあるべき関係を指す言葉(extendsの方)に限定しています。
インターフェースを用いた継承についてではありませんので、誤解なさらないようお願いいたします。なおおそらくいないとは思いますが、ここで扱っているような例を万が一実践されたことにより生じた如何なる損害につきましては、その責を負いかねますのでご了承願います。
経緯
Javaによるプログラミングの勉強が進んで半年くらいたった頃からです。
クラスの作り方やオブジェクトへの作用の施し方などの知識が身についてきたことをひしひしと感じてきた頃、次のような想いが湧き始めるようになりました。
- なるべくワンライナーにしたい!
- よく使う文字は定数化してクラスに持たせたい!
- 正規表現めんどくさすぎ!専用のユーティリティクラス作ってその中で全部やらせたい!
今思えば、これだけでも危険な香り満載だったのですが、失敗を学ぶ前の私にはその後に味わう恐怖を知る由もありませんでした。
悲劇の幕開け
Letterクラス
よーし!まずは文字クラスからじゃぁ!
毎回リテラル使うのめんどいし、誤字があってもいけないから予め定数にもたせてしまえ!!!
ついでに括弧クラスも定義じゃあ!!!public final class Letter { public static final Bracket ROUND = new Bracket('(', ')'); public static final Bracket CURLY = new Bracket('{', '}'); public static final Bracket SQUARE = new Bracket('[', ']'); public static final char ASTERISK_CHAR = '*'; public static final char COMMA_CHAR = ','; public static final char DOT_CHAR = '.'; public static final String ASTERISK = String.valueOf(ASTERISK_CHAR); public static final String AT = "@"; public static final String BACKSLASH = "\\"; public static final String CARET = "^"; public static final String COLON = ":"; public static final String COMMA = String.valueOf(COMMA_CHAR); public static final String DOT = String.valueOf(DOT_CHAR); public static final String DOLLER = "$"; public static final String EQUAL = "="; public static final String EM = " "; public static final String HALF_SPACE = " "; public static final String MINUS = "-"; public static final String PLUS = "+"; public static final String SHARP = "#"; public static final String SLASH = "/"; public static final String TAB = "\t"; public static final String UNDERSCORE = "_"; public static final String VERTICAL_BAR = "|"; public static final String QUESTION = "?"; public static final String LINE_SEPARATOR = System.lineSeparator(); private Letter() {} }MyStringクラス
次に文字列ユーティリティじゃぁ!
文字列連結でもストリーム生成でも文字列に関することならなんでもやらせてしまえ!public final class MyString { private String str; private Stream<String> stream; public MyString(Object obj) { str = obj.toString(); } ... // 省略 public String get() { return str; } public IntStream intStream() { return mapToInt(); } public Iterator<Integer> intIterator() { return mapToInt().iterator(); } public Iterator<String> iterator() { return stream.iterator(); } public static String join(Object left, Object right) { return left.toString() + right.toString(); } @SafeVarargs public static <T> String join(T... values) { StringBuilder sb = new StringBuilder(); stream(values).forEach(sb::append); return sb.toString(); } @SafeVarargs public static <T> String joinWith(Object delimiter, T... values) { Iterator<String> iterator = stream(values).iterator(); if (!iterator.hasNext()) return ""; StringBuilder sb = new StringBuilder(iterator.next()); while (iterator.hasNext()) { sb.append(delimiter) .append(iterator.next()); } return sb.toString(); } @SafeVarargs public static <T> String joinWithAffix(Bracket bracket, T... values) { return joinWithAffix( String.valueOf(bracket.getStarting()), String.valueOf(bracket.getClosing()), values); } @SafeVarargs public static <T> String joinWithAffix(CharSequence prefix, CharSequence suffix, T... values) { Iterator<String> iterator = stream(values).iterator(); if (!iterator.hasNext()) return join(prefix, suffix); StringJoiner sj = new StringJoiner("", prefix, suffix); while (iterator.hasNext()) sj.add(iterator.next()); return sj.toString(); } @SafeVarargs public static <T> String joinWithColon(T... values) { return joinWith(COLON, values); } @SafeVarargs public static <T> String joinWithComma(T... values) { return joinWith(COMMA, values); } @SafeVarargs public static <T> String joinWithLineSeparator(T... values) { return joinWith(LINE_SEPARATOR, values); } @SafeVarargs public static <T> String joinWithSpace(T... values) { return joinWith(HALF_SPACE, values); } public static String reverse(Object x) { return new StringBuffer(x.toString()).reverse().toString(); } public static String separateThousands(Object... args) { return String.format("%,d", args); } public MyString split() { stream = createStream(Regex.of("")); return this; } public MyString splitBy(Object regex) { stream = createStream(Regex.of(regex)); return this; } public MyString splitByComma() { stream = createStream(Regex.escape(COMMA_CHAR)); return this; } public MyString splitByCommaWhieKeepingEmpty() { stream = createStream(Regex.escape(COMMA_CHAR), -1); return this; } public MyString splitByDot() { stream = createStream(Regex.escape(DOT_CHAR)); return this; } public MyString splitBySpace() { stream = createStream(Regex.of(HALF_SPACE)); return this; } public Stream<String> stream() { return stream; } public String[] toArray() { return stream.toArray(String[]::new); } public double[] toDoubleArray() { return mapToDouble().toArray(); } public int[] toIntArray() { return mapToInt().toArray(); } public List<String> toList() { return stream.collect(Collectors.toList()); } ... // 省略 }よしよし、これでワンライナーじゃぁ!!!
Regexクラス
手打ちで
{\d}なんて[A-C]なんてもうええねん!
エスケープ処理もやってくれるええやつやでぇ!!!public final class Regex { public static final Regex ANY = of(DOT); public static final Regex ANY_DIGIT = asEscapeSequence('d'); // [0-9]と同じ public static final Regex BOL = of(CARET); public static final Regex EOL = of(DOLLER); public static final Regex NON_DIGIT = asEscapeSequence('D'); // [^0-9]と同じ public static final Regex NON_SPACE = asEscapeSequence('S'); // [^\t\n\x0b\r\f]と同じ public static final Regex ONE_MORE = of(PLUS); public static final Regex OR = of(VERTICAL_BAR); public static final Regex SPACE = asEscapeSequence('s'); // [\t\n\x0b\r\f]と同じ public static final Regex ZERO_MORE = of(ASTERISK); public static final Regex ZERO_ONE = of(QUESTION); private final String regex; private Regex(Object obj) { this.regex = obj.toString(); } private Regex(Object... objects) { this.regex = toString(objects); } public static Regex capture(int index) { if (index < 1) throw new MyIllegalArgumentException(index); return new Regex(BACKSLASH + index); } public static Regex escape(char c) { return of(MyString.join(BACKSLASH, c)); } public static Regex group(Object... objects) { String regex = toString(objects); regex = ROUND.getStarting() + regex + ROUND.getClosing(); return new Regex(regex); } public boolean isMatchedTo(String input) { return input.matches(regex); } public static Regex nor(Object... objects) { String regex = toString(objects); regex = SQUARE.getStarting() + CARET + regex + SQUARE.getClosing(); return new Regex(regex); } public static Regex of(Object... objects) { return new Regex(objects); } public static Regex or(char... chars) { String regex = toString(chars); regex = SQUARE.getStarting() + regex + SQUARE.getClosing(); return new Regex(regex); } public static Regex or(Object... objects) { String regex = Stream.of(objects) .map(o -> o.toString()) .collect(MyCollectors.joiningWithVerticalBar()); regex = SQUARE.getStarting() + regex + SQUARE.getClosing(); return new Regex(regex); } public static Regex range(char startInclusive, char endInclusive) { if (startInclusive > endInclusive) throw new MyIllegalArgumentException(startInclusive, endInclusive); return new Regex( MyString.join(SQUARE.getStarting(), startInclusive, MINUS, endInclusive, SQUARE.getClosing())); } public String replace(String target, String replacement) { return target.replaceAll(regex, replacement); } public static Regex times(int times) { if (times < 0) throw new MyIllegalArgumentException(times); return new Regex(MyString.join(CURLY.getStarting(), times, CURLY.getClosing())); } public static Regex times(int startInclusive, int endInclusive) { if (startInclusive < 0 || startInclusive > endInclusive) throw new MyIllegalArgumentException(startInclusive, endInclusive); return new Regex( MyString.join(CURLY.getStarting(), startInclusive, COMMA, endInclusive, CURLY.getClosing())); } public static Regex timesOrMore(int timesOrMore) { if (timesOrMore < 0) throw new MyIllegalArgumentException(timesOrMore); return new Regex(MyString.join(CURLY.getStarting(), timesOrMore, COMMA, CURLY.getClosing())); } @Override public String toString() { return regex; } private static Regex asEscapeSequence(char c) { return of(MyString.join(BACKSLASH, c)); } private static String toString(Object... objects) { return Stream.of(objects) .map(o -> o.toString()) .collect(Collectors.joining()); } }MyMatcherクラス
マッチャはどんな時でも予めパターンをコンパイルさせて持たせたほうがええな!!!
(パフォーマンスに逆らいかねない発想なので、決してマネしないで下さい。)public final class MyMatcher { private final Matcher m; private final String input; private final String regex; private MyMatcher(Regex regex, CharSequence input) { this.regex = regex.toString(); this.input = input.toString(); m = Pattern.compile(this.regex).matcher(input); } public String getInput() { return input; } public String group() { return m.group(); } public String group(int group) { return m.group(group); } public int groupAsInt(int group) { return Integer.parseInt(m.group(group)); } public void ifFind(Runnable runnable) { if (m.find()) runnable.run(); } public <T> T ifFind(Supplier<T> supplier) { if (m.find()) return supplier.get(); return null; } public void ifMatch(Runnable runnable) { if (m.matches()) runnable.run(); } public boolean matches() { return m.matches(); } public static MyMatcher of(Regex regex, CharSequence input) { return new MyMatcher(regex, input); } public String pattern() { return regex; } public void runWhileFind(Runnable runnable) { while (m.find()) runnable.run(); } }一年後の感想
- 逆に見づれぇ・・・。
- サクッと考えたようなコードを他の人に見せたくても、クラスに依存させてしまえば乱立したライブラリを説明しないといけなくなるし、仮に他の人がコードを参考にしたくても、無駄なライブラリ依存のせいで使えない。
- 今となってはこんな恥ずかしいライブラリを自信満々に説明できる勇気はない。
- そもそもそんなライブラリが含まれているコードをはなから参考にしようと思えるわけがない。
- 正規表現を理解してしまった今では、かえってRegexクラス使って組むと見づらい。
- 正規表現コピペしてやりゃあええだけじゃん。
- 既存メソッドの丸写しばっか(MyMatcherクラスに至ってはほぼそれ)。
- パターンの再コンパイルすらできないMyMatcherクラスの存在価値って一体。
- 引数を関数型インターフェースに制限させる意味って一体。
- もともとあるライブラリ素直に使えばいいじゃんという話に戻ってきてしまった自分が情けない。
- and so on...
つまらぬものを作ってしまったという虚無感が残り、せっかくライブラリ用に修正したソースコードを結局手作業で元に戻すという要らない災害を招く結果となりました。
完全に過去の遺異物です。元々は、情報収集していて「ワンライナー」とか「スマート」とかいう悪魔のささやきにホイホイ釣られてしまった自分が甘かったんです。
言葉に囚われてしまった哀れな結末が、これです。
その他
これまで挙げてきたものにとどまらず、他にも色々と自作API(と言えるかどうかすらも怪しい悲劇)を作ってきました。どれぐらい酷い有り様かというと、そこにはっきりとした継承させるべき理由がないにも関わらず、殆どのswingにまつわるクラスのサブクラスを作ってるくらいです。
クラスの責務を親子間で共有するためではなく、ただ既存のクラスの機能を一部利用し、一部拡張させるためだけという安易な考えで。
どうです?見事なまで「My」丸出しの羅列でしょ?
どうにかせんとな・・・はぁ。教訓
既存のライブラリを知れ
これに尽きます。
例えばPatternやMatcherは、慣れない挙動を必死に理解し今でこそ何とか使えるようになりましたが、この頃はそうではありませんでした。
既存のライブラリの機能を知る前に、そのライブラリがもたらす恩恵以上の恩恵を求めようと思うことは冒険であると認識しなければならないということが、よくわかりました。
先人たちが「とにかくAPIドキュメントを見ろ」と口酸っぱく言っていた理由がよくわかりました。「記号」を「言葉」化するな
例えば
Regex#timesOrMoreにあるCURLY.getStarting(), timesOrMore, COMMA, CURLY.getClosing()の記述とか。
間違いなく多くの人は「『CURLY』ってなんだよ!」と突っ込むはずでしょう。
最初から"{2,}"と書かれていれば、正規表現を知っている人なら「ああ2文字以上にしたいのか」となるはずです。
「情報の伝達を補助すること」を意義にもつ記号を言語化し、よりその情報の伝達を阻害してしまうほど無意味なことはないことがよくわかりました。クラスを依存させる必要性を考えろ
クラスに依存関係をもたせるときは、得られる恩恵と考えうる不都合の有無を十分考慮しなければなりません。
クラスが親子関係にあるならば、親の仕様が変われば、子が影響を受けます。
親子関係になくとも、その依存関係が後々必要なものでなかったと気づいた時の代償は、依存関係が多くなればなるほど以前の状態に戻す操作が複雑となり、高く付きます1。
仮にも仕様を新規に考えたり、大幅に修正したものを既存のコードに広範囲にわたり適用させる前には、必ずバックアップが鉄則でしょう。目先の利便性を追い求める前に、せめてそれで犠牲となる要素や悪影響の度合いを追い求めておけということですね。
継承は「is-a」の関係を成り立たせる時だけにしろ
あえて「成り立つ」ではなく「成り立たせる」としている理由はちゃんとあります。
実現したいシステムやプログラムによって継承を取り入れるべき概念は変わってくるはずだからです。
- 継承させたいクラス(オブジェクト)は何なのか
- 何を抽象化させるべきなのか
- それが単なる機能の一部利用や拡張のためではないことが言い切れるか
最低限、これらを明確にしておく必要はあるかと思います。
しかしこれだけではないはずです。論理包含「p→q」という考え方があります。
「pを満たすものは全てqも満たす」が言えるとき、「pはqである為の十分条件」又は「qはpである為の必要条件」という表現ができる(嫌いな人にとっては嫌いな)やつです2。
個人的なイメージとして、私はこのpを具象クラスと、qを抽象クラスと置き換えて考えるようにしています。
- 具象クラスのすべての機能を抽象クラスに十分に実装させるべき目的・意義は何なのか
- 抽象クラスのすべての機能が、具象クラスにもすべて必要といえるのか
この両者が明確にできない(「p→q」にふさわしくない可能性がある)ものについては、インタフェースやコンポジションを利用したほうが良さそうです。
強がり
失敗が失敗であるとわかり、その負担の大きさを肌身で知れただけでも収穫です。
「わからないことすらわからなかった」かつては、当然「何が失敗なのか」もわからなかったので。もくじに戻る

- 投稿日:2019-07-01T17:34:02+09:00
初心者がJavaでエンコードした画像をデコードするよー
画像をデコードするよっていう話
JavaでBASE64エンコードされた画像をデコードするというのを初めてやったので、その中のエッセンスの部分を抽出したものをまとめていきます。
環境など
Java8
BASE64を取り扱う
まずはBASE64形式でデータをいただいているかチェックします。
そのチェックのために、Matcherを使っていきます。
Matcherというのは簡単に言うと、自分の設定したパターンと特定の入力がマッチするか判断できると言うとてもありがたいものです。
使い方は以下の通り。sample.javaString str = "YuruFuwaGang"; String regex = "Yuru" Pattern p = Pattern.compile(regex); Matcher m = p.matcher(str);説明としては、
一行目でチェックしたい文字列を作成。
二行目でパターンを設定。
三行目でJavaがプログラム内で使えるパターンオブジェクトというものに設定したパターンを変換。
四行目でMatcherを使って一行目の文字列がパターンとマッチしているか確認。
という流れです。
で、ここのパターンに画像としての正規表現を入れてあげることで、今回は形式のチェックをしてあげます。
今回は正規表現の書き方については省略しますが、以下のサイトを参考にして作成しました。
正規表現の基本
基本的な正規表現の使い方
忘れっぽい人のための正規表現チートシート
ちなみにBASE64ですと、画像は
"data:image/jpeg;base64,xxx......"
という形で送られてきます(多分)。デコードする
デコードはシンプルで、java.util.Base64を使います。
byte[] bytes = Base64.getDecoder.decode("デコードするデータ");おまけ:画像を書き込む
今回ファイルはbyte形式のものを書き込むために、FileOutputStreamを使います。
byte b = 74; FileOutputStream file = new FileOutputStream("パス/ファイル名"); file.write(b);以下、解説です。
二行目で書き込むファイルを指定。
そして三行目で書き込みをおこなっています。まとめ
画像のデコードが初めてで、とにかく難しかったです。
また、まだFileOutputStreamなんかも掴みきれてないので、精進しなきゃなぁという感じでした。頑張ります。その他参考
正規表現のグループに名前をつける(Java)
→パターン内の部分部分をとるのにとても便利でした(画像の形式やエンコード部分など)。
クラスPattern
→Patternクラスについて。また、正規表現の方法についてもまとめっています。
java – Base64エンコードイメージをファイルに書き込む
→日本語が変だけれども、わかりやすいです。
- 投稿日:2019-07-01T16:25:03+09:00
Azure CosmosDB でJavaSDKから全削除
概要
文書を取得してから、文書のIDとPartitionKeyを指定して削除する。
コード
// Azure Cosmos DB Libraries for Java // https://docs.microsoft.com/ja-jp/java/api/overview/azure/cosmosdb?view=azure-java-stable FeedOptions queryOptions = new FeedOptions(); queryOptions.setEnableCrossPartitionQuery(true); String host = "yourhost"; // Get key from Azure Web Console // read write key String key = "yourkey"; DocumentClient client = new DocumentClient("https://" // + host // + ".documents.azure.com:443", key, // new ConnectionPolicy(), ConsistencyLevel.Session); String collectionLink = String.format("/dbs/%s/colls/%s", DATABASE_ID, COLLECTION_ID); // 適当に指定する String q = "SELECT * FROM container1"; // 全文書 List<Document> results = client // .queryDocuments(collectionLink, q, queryOptions).getQueryIterable().toList(); for (Document doc : results) { System.err.println(doc); String documentLink = doc.getSelfLink(); RequestOptions options = new RequestOptions(); // check your configuration of cosmos db container String partitionKey = ((org.json.JSONObject) doc.get("item")).getString("xxx"); options.setPartitionKey(new PartitionKey(partitionKey)); client.deleteDocument(documentLink, options); System.err.println("deleted: " + documentLink); } client.close();所感
「SELECT * FROM c」ができるのだから「DELETE * FROM c」ができてもよさそうなのだが、できないらしいです。
どなたかご存知でしたら教えてください。
- 投稿日:2019-07-01T16:25:03+09:00
Azure CosmosDB でJavaSDKから Delete All (全削除)
概要
文書を取得してから、文書のIDとPartitionKeyを指定して削除する。
コード
// Azure Cosmos DB Libraries for Java // https://docs.microsoft.com/ja-jp/java/api/overview/azure/cosmosdb?view=azure-java-stable FeedOptions queryOptions = new FeedOptions(); queryOptions.setEnableCrossPartitionQuery(true); String host = "yourhost"; // Get key from Azure Web Console // read write key String key = "yourkey"; DocumentClient client = new DocumentClient("https://" // + host // + ".documents.azure.com:443", key, // new ConnectionPolicy(), ConsistencyLevel.Session); String collectionLink = String.format("/dbs/%s/colls/%s", DATABASE_ID, COLLECTION_ID); // 適当に指定する String q = "SELECT * FROM container1"; // 全文書 List<Document> results = client // .queryDocuments(collectionLink, q, queryOptions).getQueryIterable().toList(); for (Document doc : results) { System.err.println(doc); String documentLink = doc.getSelfLink(); RequestOptions options = new RequestOptions(); // check your configuration of cosmos db container String partitionKey = ((org.json.JSONObject) doc.get("item")).getString("xxx"); options.setPartitionKey(new PartitionKey(partitionKey)); client.deleteDocument(documentLink, options); System.err.println("deleted: " + documentLink); } client.close();所感
Patitionのキーを指定するのではなく、値を指定する必要があります。
「SELECT * FROM c」ができるのだから「DELETE * FROM c」ができてもよさそうなのだが、できないらしい。
- 投稿日:2019-07-01T14:35:35+09:00
Javaでlambda layerを使用する
はじめに
javaでlambda layerを使用する方法が探したけどなかったのでメモりました。
参考:使用するJavaソース
lambda layer側(layer_print.jarでエクスポートする)
Print.javapackage layer_print; public class Print { public static void print() { System.out.println("print from layer!!"); } }layerを使用するHandlerクラス
MyLambda.javapackage lambda_layer_java; import com.amazonaws.services.lambda.runtime.Context; import com.amazonaws.services.lambda.runtime.RequestHandler; import layer_print.Print; public class MyLambda implements RequestHandler<Integer, String> { @Override public String handleRequest(Integer in, Context context) { // lambda layer呼び出し Print.print(); return "success"; } }手順
1.ローカルでjava/libフォルダ作成
2.libにlayerにするjarファイルを置く
3.javaフォルダをzip変換
4.AWSコンソールのlambdaのLayers選択。レイヤーの作成押下
5.名前、説明を入力。互換性のあるランタイムでjava 8を選択。作成したzipファイルをアップロードしてlayer作成
6.layerを使用するlambda関数に移動して、Layersを選択して、レイヤーの追加を押下
7.layer、バージョンを選択して追加
8.保存して完了
以上です。








- 投稿日:2019-07-01T14:35:35+09:00
JavaでLambda Layersを使用する
はじめに
JavaでLambda Layersを使用する際の手順を探したけど、わかりやすいのがなかったのでメモりました。
事前準備:使用するJava
lambda layer側
layer_print.jarでエクスポートする
Print.javapackage layer_print; public class Print { public static void print() { System.out.println("print from layer!!"); } }layerを使用するLambdaのHandlerクラス
layer_print.jarを含まずにjar作成 → lambda関数にアップロードする
MyLambda.javapackage lambda_layer_java; import com.amazonaws.services.lambda.runtime.Context; import com.amazonaws.services.lambda.runtime.RequestHandler; import layer_print.Print; public class MyLambda implements RequestHandler<Integer, String> { @Override public String handleRequest(Integer in, Context context) { // lambda layer呼び出し Print.print(); return "success"; } }手順
ローカルでjava/libフォルダ作成
libにlayerにするjarファイルを置く
javaフォルダをzipに変換
AWSコンソールのlambdaのLayers選択。レイヤーの作成押下
名前、説明を入力。互換性のあるランタイムでjava 8を選択。作成したzipファイルをアップロードしてlayer作成
layerを使用するlambda関数に移動して、Layersを選択して、レイヤーの追加を押下
layer、バージョンを選択して追加
保存して完了
以上です。
- 投稿日:2019-07-01T14:14:50+09:00
dockerコンテナ内のビルド済みファイルを更新する方法
はじめに
dockerコンテナ内でエントリーポイントとして指定された実行ファイルを更新する方法について調べた内容になります。
背景・問題点
JavaやkotlinでWebアプリケーション開発を行う上でdockerコンテナを立てて開発することはよくあるかと思います。
下に示すのはアプリケーション層用コンテナのDockerfileの一部です。FROM openjdk:8-jdk-alpine COPY build/libs/application.jar application.jar ENTRYPOINT ["java", "-jar", "application.jar"]ファイル内で行っているのは以下です。
1行目:ベースイメージの指定
2行目:ビルド済みjarファイル(実行ファイル)をホスト側(左)からコンテナ側(右)にコピー
3行目:コンテナの起動プロセスを設定(上記では渡したjarファイルを実行している)最後のエントリーポイントで指定したコマンドの実行プロセスが起動することでアプリケーションが動作します。
開発中は変更のたびにプログラムの再ビルドを行いますが、実際のアプリケーション上で変更を確認するためには再ビルドした結果をコンテナに反映させなければなりません。単純な方法としては作成したコンテナを一旦停止し、削除した後でコンテナの再ビルド・起動を行うことが考えられますが、それなりの時間がかかってしまいます(特にコンテナの再ビルド)。解決方法
上の問題の解決策の一つとして以下の方法があります。
解決策
1 . 起動中のコンテナに対してコンテナ内の古いjarファイルを新しいファイル(application-new.jar)で上書きする。docker cp build/libs/application-new.jar application.jar2 . コンテナ(コンテナ名:app)を再起動する。
docker restart appこの方法だとコンテナの再ビルドが必要ないため、より短時間でコンテナの更新ができます。
参考
- docker公式ドキュメント http://docs.docker.jp/engine/reference/builder.html#from
- 投稿日:2019-07-01T07:53:28+09:00
[Java]DateTimeFormatterのFormatStyle別出力
ロケールを日本
Locale locale = Locale.JAPAN; LocalDateTime now = LocalDateTime.now();出力プログラム
ofLocalizedDateTimeでフォーマットを行う。
System.out.println( now.format(DateTimeFormatter.ofLocalizedDateTime(FormatStyle.FULL).withLocale(locale)) ); System.out.println( now.format(DateTimeFormatter.ofLocalizedDateTime(FormatStyle.LONG).withLocale(locale)) ); System.out.println( now.format(DateTimeFormatter.ofLocalizedDateTime(FormatStyle.MEDIUM).withLocale(locale)) ); System.out.println( now.format(DateTimeFormatter.ofLocalizedDateTime(FormatStyle.SHORT).withLocale(locale)) );実行結果(上から、FULL, LONG, MEDIUM, SHORT)
java.time.DateTimeException: Unable to extract ZoneId from temporal 2019-07-01T07:58:21.538531 java.time.DateTimeException: Unable to extract ZoneId from temporal 2019-07-01T07:58:21.538531 2019/07/01 7:59:30 2019/07/01 7:59ロケールをアメリカ
実行結果(上から、FULL, LONG, MEDIUM, SHORT)
java.time.DateTimeException: Unable to extract ZoneId from temporal 2019-07-01T07:58:21.538531 java.time.DateTimeException: Unable to extract ZoneId from temporal 2019-07-01T07:58:21.538531 Jul 1, 2019, 7:57:26 AM 7/1/19, 7:57 AM
- 投稿日:2019-07-01T07:38:34+09:00
Effective Java を Kotlin で読む(7):第8章 プログラミング一般
章目次
Effective Java を Kotlin で読む(1):第2章 オブジェクトの生成と消滅
Effective Java を Kotlin で読む(2):第3章 すべてのオブジェクトに共通のメソッド
Effective Java を Kotlin で読む(3):第4章 クラスとインタフェース
Effective Java を Kotlin で読む(4):第5章 ジェネリックス
Effective Java を Kotlin で読む(5):第6章 enum とアノテーション
Effective Java を Kotlin で読む(6):第7章 メソッド
Effective Java を Kotlin で読む(7):第8章 プログラミング一般 ?この記事
Effective Java を Kotlin で読む(8):第9章 例外
Effective Java を Kotlin で読む(9):第10章 並行性
Effective Java を Kotlin で読む(10):第11章 シリアライズ第8章 プログラミング一般
項目45 ローカル変数のスコープを最小限にする
概要
コードの可読性と保守性を上げるために、ローカル変数のスコープは最小限にすべきである。
関連: 項目13 クラスとメンバーへのアクセス可能性を最小限にするスコープを最小限にするため、以下の点に気をつける
- ローカル変数が初めて使用される時に宣言を行う
- ローカル変数宣言は、初期化子を含ませる
- while ループより for ループを選ぶ
- メソッドを小さくして焦点をはっきりさせる
Kotlin で読む
Java の try-catch 文にて例外を投げるメソッドでローカル変数を初期化し、tryブロックの外でも変数を利用する場合、以下のように宣言と初期化を同時に行えなかった。
javaHoge hoge = null; try { hoge = newInstance(); } catch (FugaException e) { System.exit(1); } doSomething(hoge);Kotlin では try-catch も式になったので、以下のように書くことができる。
kotlinval hoge = try { newInstance() } catch (e: Exception) { exitProcess(1) } doSomething(hoge)また Kotlin ではスコープ関数を利用する事ができる。
let, with, run, apply, also などがあるが、これがスコープを狭めるのに特に便利。
- 例: メソッドの戻り値が null でない場合のみ、戻り値のオブジェクトが持つメソッドを実行したい場合
javaHoge hoge = getNullOrHoge(); if (hoge != null) { hoge.fuga(); }kotlingetNullOrHoge()?.let { // hoge のスコープを let のブロックスコープ内に収められる it.fuga() } getNullOrHoge()?.fuga() // ※1行のみならこれも可
- 例: Bean を初期化してメソッドの引数として使う場合
javaHoge hoge = new Hoge(); hoge.a = "a"; hoge.b = "b"; doSomething(hoge);kotlindoSomething(Hoge().apply { a = "a" b = "b" })項目46 従来の for ループより for-each ループを選ぶ
概要
リリース1.5より以前は、配列やコレクションをイテレートする好ましいイディオムは以下のようなものだった。
// コレクション for (Iterator i = c.iterator(); i.hasNext(); ) { doSomething((Element) i.next()); } // 配列 for (int i = 0; i < a.length; i++) { doSomething(a[i]); }リリース1.5より for-each ループが導入され、これらは以下のように書けるようになった。
for (Element e : elements) { doSomething(e); }さらに for-each ループは Iterable インタフェースを実装したいかなるオブジェクトに対してもイテレートが可能である。
従来の for ループより優れており、利用できる場所ではどこでも使用すべきである。
ただし、for-each ループが使用できない場合もいくつか存在する。
- フィルタリング
- 選択された要素だけを削除する場合
- 変換
- 要素のいくつか、あるいは全部を置換する必要がある場合
- 並列イテレーション
- 複数のコレクションを並列にイテレートする場合
※ また Java 8 からは Iterable#forEach が追加されたため、コレクションに関しては以下のようにさらに簡潔に書くこともできるようになった。
elements.forEach(e -> doSomething(e));Kotlin で読む
Kotlin ではそもそも Java の従来型の for ループ(初期化、継続条件、増分処理の3つ組)のような構文は存在せず、for-each 型しか利用できない。
val array = arrayOf(1, 2, 3, 4, 5) for (e in array) { println(e) }ただし Kotlin では Iterable が大幅に強化されているので、大抵の場合 Iterable<T>.forEach を使えば問題なさそう。(Kotlin でも Array は相互互換性の為 Iterable を実装していないが、同名のメソッドを持っている為実用上問題ない)
val array = arrayOf(1, 2, 3, 4, 5) array.forEach { println(it) }for-each ループで出来なかったフィルタリングや変換も Iterable のメソッドで可能。
val array = arrayOf(1, 2, 3, 4, 5) array.filter { it%2 == 1 }.map { it*10 }.forEach { println(it) } // output: 10, 30, 50項目47 ライブラリーを知り、ライブラリーを使う
概要
ライブラリーを使用することで、それを書いた専門家の知識と、それをあなたよりも前に使用した人々の経験を利用することになる。無駄な努力はするべきでなく、共通な事をするように思われるときは、ライブラリが存在するか調べ、利用するようにすべきである。
また Java の主要リリース毎には数多くの機能が標準ライブラリに追加されるため、それらを知っておくことは重要である。
特に、すべての Java プログラマは java.lang、java.util と、ある程度の java.io の内容については知っておくべきである。Kotlin で読む
標準ライブラリについて
Kotlin の標準ライブラリのドキュメント の内容は、ざっと目を通しておくと良いと思う。
特に kotlin.collections 、中でも Iterable についてはしっかり読んでおくととても捗る。
参考: (Qiita)Kotlin のコレクション使い方メモリリース情報について
Kotlin のリリース毎の変更点については公式リファレンスでもまとめられるが(例: What's New in Kotlin 1.3)、JetBrains の Kotlin Blog や、公式 Twitter (@kotlin) なんかをフォローしておくと最新の情報を追えて良さそう。項目48 正確な答えが必要ならば、float と double を避ける
概要
金銭計算等、正確な数値が必要な場合は float と double は避けるべきである。それらは2進浮動小数点数であり、近似を行うために設計されている。
正確な数値計算を行うためには BigDecimal や、int あるいは long を使うべきである。
Kotlin で読む
Kotlin でも Java 同様、正確な値が欲しい場合は int や BigDecimal 等を使う。
Kotlin の場合は演算子オーバーロードによって BigDecimal でも通常の演算子を利用でき、可読性が良いのが嬉しい。val pointOneDouble: Double = 0.1 val pointOneBigDecimal: BigDecimal = pointOneDouble.toBigDecimal() println(pointOneDouble + pointOneDouble + pointOneDouble) // output: 0.30000000000000004 println(pointOneBigDecimal + pointOneBigDecimal + pointOneBigDecimal) // output: 0.3項目49 ボクシングされた基本データより基本データ型を選ぶ
概要
Java は int などの基本データ型 (primitive type)と、String や List などの参照型 (reference type) から構成される2部型システムを持っており、全ての基本データ型はボクシングされた基本データ (boxed primitive) と呼ばれる対応する参照型を持っている。
またリリース1.5では自動ボクシング (autoboxing) と自動アンボクシング (auto-unboxing) が言語に追加された。
これは項目5で意図しないオートボクシングについて記述したように、基本データ型とボクシングされた型の2つの違いを不明瞭にしたが、違いを消し去ったわけではない。どちらの型を使っているのかを意識し、注意深くどちらかを選択する事が重要である。
基本的には安全面やパフォーマンス面から基本型を利用するべきである。型パラメータとして利用する場合(例: コレクションの要素)や、リフレクションを使ってメソッドを呼び出す場合など基本型が利用できない場合、ボクシングされた型を利用する。
Kotlin で読む
項目5でも触れたが、Kotlin の数値型は通常基本データ型、必要な場合のみ参照型として扱われるため、特に自分で基本データ型を選ぶという事はない。
使い分けを意識しなくても良くなったが、内部的には Nullable 型やジェネリクスの型引数の場合にオートボクシングが行われているため、この事を頭には入れておいた方が良さそうに思う。
項目50 他の型が適切な場所では、文字列を避ける
概要
文字列はテキストを表現するために設計されており、それ以外の目的で使うことは不適切である。
- 他の値型の代替としては貧弱
- 外部からの入力は大抵文字列なのでやりがち
- int、 boolean 等適切な型にすぐ変換すべき
- 列挙型の代替としては貧弱
- enum を使おう
- 集合型の代替としては貧弱
- 適切なクラスを作成すべき
- 一意の偽造できないキー(capability)の代替としては貧弱
- 偽造できない事をコード上で示せない
Kotlin で読む
特に Kotlin 特有の何かはないので、Java 同様に意識して文字列ではなく適切な型を使う。
項目51 文字列結合のパフォーマンスに用心する
概要
Java の String は不変である。そのため
+や+=を使って結合を行う場合、無駄なインスタンスが生成される。String result = ""; for (int i = 0; i < N; i++) { result += HOGE_STRING; // String 結合 }頻繁に結合を行う場合は、 StringBuilder を利用すべきである。
StringBuilder b = new StringBuilder(); for (int i = 0; i < N; i++) { b.append(HOGE_STRING); } String result = b.toString();また、 StringBuffer は同期化処理を含む分パフォーマンスが低く、もはや使うべきでない。
Kotlin で読む
標準ライブラリに StringBuilder の拡張がある(StringBuilder.kt)ので、さらに簡潔に書けて良い。
val ONE = "one" val TWO = "two" val result = buildString { // StringBuilder をレシーバとしたラムダを引数とするトップレベル関数 append(ONE) appendln(TWO) // 文字列+改行を追加 append(ONE, TWO) // 複数の文字列を追加 } println(result) // output: onetwo\nonetwoまた String Template を使って可読性を上げるという選択肢も取れる。
val result = "$ONE$TWO\n$ONE$TWO"※ 余談だが、
+演算子を使っても大抵コンパイル時の最適化で StringBuilder を使ったものに変換される。ループ内で append したりでなければそこまで気にしなくて良いのかもしれない。項目52 インタフェースでオブジェクトを参照する
概要
適切なインタフェース型が存在するならば、パラメータ、戻り値、変数、およびフィールドはすべてインタフェース型を使用して宣言されるべきである。オブジェクトのクラスを参照する必要がある唯一の場合は、オブジェクトを生成するときのみである。
型としてインタフェースを使用する事で、オブジェクト生成を別のクラスにするだけで簡単に実装を切り替える事ができるようになる。
オブジェクト生成の変更で他の実装に修正可能List<Hoge> hoges = new Vector<Hoge>(); // 修正 ↓ List<Hoge> hoges = new ArrayList<Hoge>();オブジェクト生成の変更では他の実装に修正不可能Vector<Hoge> hoges = new Vector<Hoge>(); // 修正 ↓ Vector<Hoge> hoges = new ArrayList<Hoge>(); // コンパイルエラーまた、もしインタフェースを持っていなければ、必要な機能を提供する最も上位のクラスを利用すること。
Kotlin で読む
この項目の本質は、プログラムの意図をコードに適切に反映することの重要性であろう。
インタフェースを利用することで実装を気にしていない事を表現できるし、最も上位のクラスを利用することで下位クラスの持つ不必要な機能を使わない事を表現できる。書籍では、 インタフェース型でフィールドを宣言することで「あなたを誠実にしてくれます」 と述べられている。
概要の例が readonly の用途であれば、Kotlin であればさらに MutableList でなく List を使用することで追加で意図を表現できる。
項目53 リフレクションよりインタフェースを選ぶ
概要
リフレクション機構である java.lang.reflect を利用すると、ロードされたクラスに関する情報へプログラムからアクセスができる。コンパイルされた時点で存在さえしないクラスでも使用できる強力な機能であるが、これには代価が伴う。
- コンパイル時の型検査の恩恵をすべて失う
- リフレクションを使うコードは冗長
- パフォーマンスが悪くなる
一般に、実行時に普通のアプリケーション内で、オブジェクトはリフレクションによりアクセスされるべきではない。コンパイル時に知られていないクラスと一緒に動作しなければならないプログラムを書くのであれば、可能な限りオブジェクトのインスタンス化のためだけにリフレクションを利用し、コンパイル時に分かっているインタフェースやスーパークラスを使用してオブジェクトへアクセスすべきである。
Kotlin で読む
Kotlin においてリフレクション機能は kotlin.reflect で提供される。
このパッケージを利用するには、別途 kotlin-reflect.jar をプロジェクトに追加する必要がある。(サイズがでかいため。v1.3.20 では 2.5MB になる。)java.lang.Class に相当するものとして KClass があり、これは以下のように取得できる。
1.コンパイル時に取得class Person(val name: String, val age: Int) // Java でいう クラス名.class val kClass1 = Person::class2.実行時に取得val person = Person("Tom", 20) // Java でいう オブジェクト.getClass() val kClass2 = person.javaClass.kotlin3.実行時に取得v1.1~val person = Person("Tom", 20) // v1.1 以降なら Bound Class References が使える val kClass3 = person::classReflection#Bound Class References (since 1.1)
簡単な利用例
kClass1.memberProperties.forEach { print(it.name) } // output: agenameその他色々便利な機能が用意されている。詳細はドキュメントを参照。
ただし Java 同様にリフレクションを使うには代価が伴う。可能な限り利用せず、インタフェースを使うようにする。
項目54 ネイティブメソッドを注意して使用する
概要
Java Native Interface (JNI) を利用する事で、 C や C++ などのネイティブのプログラミング言語で書かれたメソッドを呼び出すことができる。
これには歴史的に3つの主な用途があった。
- レジストリやファイルロックなどのプラットフォーム固有の機構へのアクセス
- 古いコードのライブラリへのアクセス
- パフォーマンスの改善
しかし、これらはJavaプラットフォームの成熟に伴い機会は減ってきている。
例えば 1.4 の java.util.prefs でレジストリに、1.6 の java.awt.SystemTray でシステムトレイにアクセス可能になった。
パフォーマンスに関しても JVM はバージョンを重ねる毎に高速になってきたため、ネイティブメソッドを使用するメリットは薄くなっている。結論としては、ネイティブメソッドを使う前にはもう一度考え直し、本当に必要な場合のみに限り、徹底的にテストした上で使うべきである。
Kotlin で読む
Kotlin/Native の進化次第ではどうなるかわからないが…
JVM 上で動かすならば Kotlin から ネイティブコードを呼ぶ場合 Java 同様 JNI を利用することになる。
Using JNI with KotlinJava の
native修飾子の代わりに、Kotlin の場合external修飾子を利用する。
それ以外は Java 同様になる。項目55 注意して最適化する
概要
最適化に関しては様々な格言が知られている。
(例:ドナルド・クヌースの「早すぎる最適化は諸悪の根源である」等)速いプログラムよりも良いプログラムを書く努力をすべきである。
パフォーマンスを制限するような設計上の決定を避けるように努めるべきである。
(例:public クラスを可変とすると防御的コピーが必要になる、インタフェース型でなく実装型を利用すると後からより速い実装に差し替えられなくなる、等)実装した結果、パフォーマンスに満足できない場合に初めて最適化を検討すべきであり、その際には前後に必ず計測を行うべきである。
何故なら Java ではコードと実際に CPU で実行されるものには「意味的ギャップ(semantic gap)」が従来のコンパイル言語よりも大きく、最適化によるパフォーマンスの向上を事前に見積もる事は非常に困難だからである。
また、プログラムの時間の80%はコードの20%で費やされている事が一般的に知られており、効果的な箇所のみ最適化を行うためでもある。Kotlin で読む
意味的ギャップについて言えば、Kotlin は Java への変換を1段階挟んでいるようなものであるため、Java 単体よりもギャップが大きいと言えるのかもしれない。
パフォーマンス計測については Java 同様 JVisualVM 等のプロファイラを用いたり、そもそもパフォーマンスが計測可能な設計としておく事が望まれるだろう。
項目56 一般的に受け入れられている命名規約を守る
概要
Java プラットフォームには確立された命名規則があり、これは Java 言語仕様(Java Language Specification Chapter 6. Names)に含まれている。大雑把に言えば、命名規約は活字的(typographical)と文法的(grammatical)の2つに分離される。
それぞれの例をいくつか簡単に示す。
活字的命名規約
- パッケージ名はピリオドで区切られた要素を持ち、階層的であるべき
- クラス名・インタフェース名は1つかそれ以上の単語から構成されるべきで、単語の最初の文字は大文字であるべき
- メソッド名・フィールド名は、クラス等と同じ規則だが最初の単語は小文字にすべき
- 型パラメータは通常1文字で、T(任意の型)・E(コレクションの要素の型)・K(Mapのkey)・V(MapのValue)・X(例外)のどれかになる。
活字的命名規約はめったに破るべきでない。
文法的命名規約
- クラス名は、単数名詞あるいは名詞句
- 何らかの処理を行うメソッドは、一般に動詞あるいは動詞句
- boolean 値を返すメソッドは、大抵 is まれに has ではじまり、その後に名詞・名詞句等が続く
- boolean でない機能や属性を返すメソッドは、大抵は名詞・名詞句・getで始まる動詞句で命名される
- オブジェクトの型を、別の型のオブジェクトに変換するメソッドは、大抵 toType とされる(例: toString、toArray)
文法的命名規約は柔軟で議論の的とされる。
Kotlin で読む
Kotlin では基本的に Java の命名規約に従えばよい。
Kotlin では、クラスのプロパティを宣言すると自動的にアクセサが生成されるので、命名規約的にも気にする事が減る。
ただし、クラスのプロパティが Boolean の場合、以下の例外的な動作をするので少し気をつける。getter と setter の命名規則には例外があり、プロパティ名が is で始まっている場合は getter には接頭辞は追加されず、 setter では is が set に置き換わることになっています。
(Kotlinイン・アクション 2.2.1 プロパティ, p.31)class Person( val name: String, var isMarried: Boolean // Boolean プロパティは is〇〇 と命名すれば良い ) // こう使う val person = Person("hoge", false) person.isMarried = true println(person.isMarried) // trueJavaから呼ぶPerson person = new Person("hoge", false); person.setMarried(true); System.out.println(person.isMarried()); // trueおわり
- 前: Effective Java を Kotlin で読む(6):第7章 メソッド
- 次: Effective Java を Kotlin で読む(8):第9章 例外
参考資料等
- Kotlin Reference
- Kotlin Language Documentation
- Effective Java 第2版
- Kotlin イン・アクション
- (Qiita)[Java] Stringの結合について
- (Blog)文字列連結と+演算子について整理しておく
- (Blog)【Kotlin】BooleanフィールドはisXXXという命名が推奨されている

- 投稿日:2019-07-01T00:12:24+09:00
スキルアップ意識を無くした3年目が一応使えるレベルになるまでにしたこと
本記事について
本記事は、1年間スキルアップする意識を無くしてしまった私が、
同じように悩んでいる方に対して、「こうしたらどうでしょう」という
提案をするものです。
実際に後半にコードも出てくるので、Qitta利用規約には触れていないつもりです
もしこの手の内容がよくない場合はお手数ですがコメントをお願い致します。
応援も待ってます対象読者
・SEの仕事楽勝だろ、遊びまくろうと思っている新人の方
・実績を出しつつスキルアップしなくてはならない中堅の方
・スキルアップの方法がわからない方筆者がスキルアップ意識を捨ててどうなったか
私は今年で3年目になるJavaをメインとした業務系Webアプリケーションを
作ることを一応生業としているエンジニアです。
私は1年目は、そこそこできる方でしたが、
それに胡坐をかいた結果現在は以下の状態です。
・Javaの基本(特にラムダやストリーム)が理解できない
・他の言語が理解できない
・機械学習、ビッグデータ等世間での流行をまるで知らなかった。
・新人の方が速く正確なコードを書ける。スキルアップするための3ステップ
・実務以外の時間を使い、基本から始める。
実際に自宅でコーディングの勉強をしてみるとわかると思いますが、
私のような状態に1度なると、予想以上にITの知識は忘れています。
私はいつも実務で使っているEclipseの環境構築すらできませんでした。
最初は、「一番簡単な○○言語」といった本を購入し、その内容を写経しましょう
このステップで理解できていれば自信になりますし、
理解できていなければ今後一生使える(かもしれない)知識を
もう一度身に着けなおすことができます。・実務で全く使わなくても最新技術を学ぶ
個人の経験ではありますが、
JavaScriptを学ぶことでJavaの型のありがたみを理解できたり、
AWSを使うことでインフラ側の苦悩や技術に触れたりします。
実務で全く使わなくても、プログラムに関連することであれば無駄にはならないので、
毎日15分記事を読むことぐらいから、最新技術のキャッチアップをしましょう。・実務におけるプライドを捨てる
実務でいままで実績があると、少し天狗になる気持ちは大いに理解できます。
実際に3年目あたりになると、現場で最もできないということは少なくなると思います。
しかし、心持ちだけは新人のつもりで業務にあたりましょう。
これにより、
・人に質問する障壁が減る。
・アドバイスを素直に聞き入れられる
ようになるはず。とはいえ、実務で成果を出さなきゃ切られる!
切実な悩みですが、ある程度経験年数がたつと、1人で現場に放り込まれて
結構な難題を投げられます。
能力が足りないのであれば見せ方を工夫しましょう。最低限品質を守れば、
キレられることは大幅に少なくなるはずです。
以下の2点だけは、必ず意識するようにしましょう。
1.「確認漏れ」を無くす。
試験仕様書に不備が…!画面の項目名の大文字小文字が違う…!
こういったものが頻発すると、
使えない人から使えないがさつな人に進化します。
具体的な対策としては、
・仕様書(あれば)や完成イメージと、
実際に完成したものを見比べながら作業する。
・80パーセント完了時点で一度軽くテストを行う。
等があります。
私は画面の作成が多いのですが、まずモックアップを作成し、
項目に不備がなければ1つ1つサーバ側の
処理を肉付けしていく方式をとってから
実務における単純ミスは減りましたのでお試し下さい。2.コーディング規約を守りつつ、基本に徹する。
コーディング規約は必ず遵守しましょう。
これは自分のソースで人に質問する時や、コードレビューで無駄な指摘を減らせます。
また、コーディング規約にならないレベルのもの(インデント等)は、
自力ないし静的解析ツールを用いて対策をとりましょう。例として、以下のコード(Java)を見てください。
JavaHelloWorld.javaclass JavaHelloWorld { public static void main(String args[]) { a(); } // クラス名である「JavaHelloWorld」を出力する。 public static void a(){ System.out.println("HelloWorldRuby"); } }極端な例ですが上記のソースコードは、以下の問題点があります。
・aメソッドは名称から何を実行するのか不明
・インデントの位置がおかしなことになっている
・コメントと実装が乖離しているこういったことをしてしまうと、ダメな奴とレッテルを張られ、
復活が難しくなるので、注意を払ってコーディングしましょう。【修正例】
JavaHelloWorld.javaclass JavaHelloWorld { public static void main(String args[]) { hello(); } // インデントはブロックの先頭に合わせる // 「HelloWorldRuby」を出力する。 public static void hello(){ System.out.println("HelloWorldRuby"); } }焦りや辛さが勝ってしまい、やる気が出ない場合でも
「インデントの位置は合わせる」ことを意識しましょう。
私がJavaやJavaScriptを書くときは、処理ブロック1つにつき1段下げ、処理ブロックを抜けたら1段上げることを意識しています。まとめ
・毎日家で自分のできることの基礎の勉強をしよう
・最新技術をキャッチアップしよう
・能力がつくまでは見せ方を工夫しよう
・インデントだけでも綺麗なコードを意識しよう上記を守ると、私は多少ですが実務において復権できました。
同じように苦しんでいる方が一人でも苦しまなくなれば幸いです。