- 投稿日:2019-07-01T19:02:39+09:00
Deep Learning推論用デバイスその3 Google Edge TPU
はじめに
この記事はDeepLearning推論用デバイスまとめ記事の第三弾です。第三弾ではGoogleが提供しているEdge TPUについて紹介します。他のデバイスに関しては下記にまとめています。
- Deep Learning推論用デバイスその1 Intel NCS2
- Deep Learning推論用デバイスその2 Nvidia Jetson Nano
- Deep Learning推論用デバイスその3 Google Edge TPU
Google Edge TPU
TPUとは
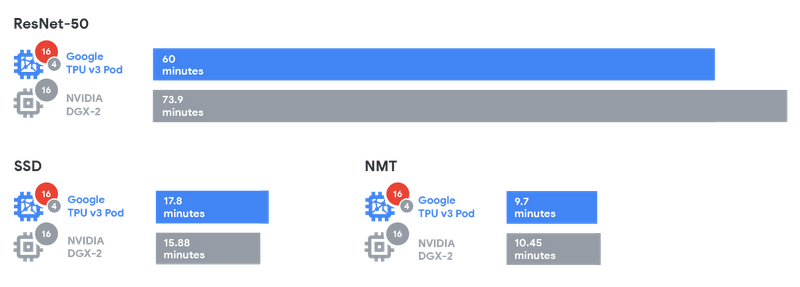
Tensor Processing Unit(TPU)はGoogleが開発したプロセッサです。TPUは機械学習の計算を高速化するために設計されたASICで、Google翻訳やGoogle検索などのクラウドサービスでもCloud TPUとして利用されておりました。他社のアクセラレータ(NVIDIAなど)とTPUのパフォーマンス検証についてはGoogleの技術ブログにて公開されています。
(引用:https://storage.googleapis.com/gweb-cloudblog-publish/images/Graphic2_2x.max-800x800.png)
上記の表を見るとSSD以外の2つのモデルに対しては学習時間が短くなっています。Edge TPU
Cloud TPUはGoogleのクラウドサービスやGCPでのモデル学習などに利用されています。それに対してTPUを推論に利用するために開発されたのがEdge TPUです。Edge TPUは開発ボードとUSB型アクセラレータの2つが提供されています。
Dev Board
CPU NXP i.MX 8M SoC (quad Cortex-A53, Cortex-M4F) GPU Integrated GC7000 Lite Graphics ML accelerator Google Edge TPU coprocessor RAM 1 GB LPDDR4 Flash memory 8 GB eMMC Wireless Wi-Fi 2x2 MIMO (802.11b/g/n/ac 2.4/5GHz) and Bluetooth 4.2 Dimensions 48mm x 40mm x 5mm (引用:https://coral.withgoogle.com/products/dev-board)
USB Accelerator
USB AcceleratorはDev BoardからAcceleratorを分離してUSBとして提供したものです。これにより、Accelerator以外のマシンをカスタマイズできるようになっています。ホストマシンはLinux OSである必要があります。
推論速度
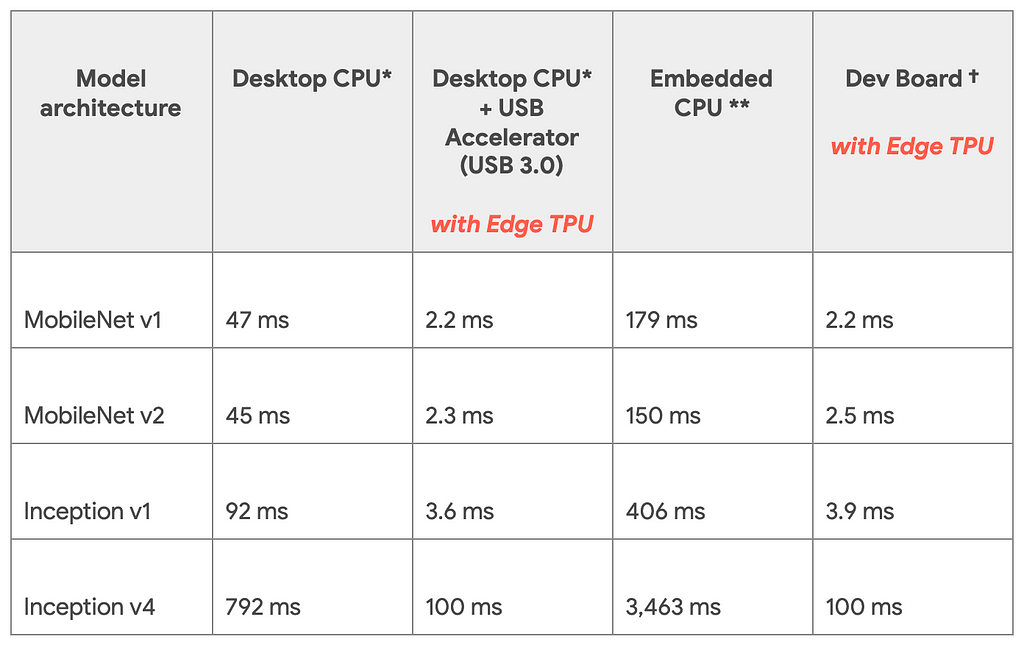
Googleの技術ブログより公開されている推論速度の比較です。TPU Edgeを利用したときと利用していない時で比較を行っています。モデルはImagenetを学習させたモデルです。
(引用:https://cdn-images-1.medium.com/max/1024/1*pCYQHA_PmF2_awq2coMJvg.png)Dev BoardとUSB Acceleratorで推論速度が変わっていないことからCPU自体のスペックにはほとんど影響しないということがこの表からわかります。
また同じハードでモデル同士を比較するとDesktop CPUにおけるInception v4からMobile Net V1は16倍速くなっているといえますが、Dev Boardの場合だと45倍速くなっていると計算できます。ここを見るとモデルアーキテクチャの違いも速度に影響すると考えられます。対応環境
前回のNVIDIA Jetson Nanoの記事でも紹介した通り、Edge TPUを利用して実行するためにはいくつか条件がありますので紹介します。
量子化
モデルの重みは32bitで利用されますが、Edge TPUでは8bit integerに量子化をする必要があります。こちらは学習後の重みを量子化するのではなく学習の段階からQuantization Aware Trainingという手法を利用して学習する必要があります。
テンソルのサイズが定数
Edge TPUで推論する時にはモデル内で利用するテンソルのサイズは定数である必要があります。なので入力サイズの変わるRNN系統のモデルは利用できないです。
こちらにサポートされている演算が載っています。モデルパラメータがコンパイル時に定数
重み・バイアスは定数である必要があります。なので学習などは想定しておりません。また、VAEで利用されるReparametrization Trickのような乱数を利用した演算はこちらの条件にあってないので推論させることはできなさそうですが、今後検証する必要があります。
参考文献

- 投稿日:2019-07-01T17:27:38+09:00
[訓練・データ不要]ディープラーニングフレームワークを使ったアニメの線画の自動生成
ディープラーニングのフレームワークを使って、アニメ本編から線画を生成します。ただし、一切訓練や訓練データを与えていません。アニメ1話分全4.3万フレームの線画化を1時間程度で終わらせることができました。
あらまし
このようにアニメ本編から自動的に線画が生成できます。ディープラーニングのフレームワークを使うとできます。ただし、一切訓練をしていません。
OP https://t.co/52t0dFZNZL pic.twitter.com/7aCEJ9SkTc
— しこあん@『モザイク除去本』(技術書典6)好評通販中 (@koshian2) 2019年7月1日本編1 https://t.co/52t0dFZNZL pic.twitter.com/oicU8UPopS
— しこあん@『モザイク除去本』(技術書典6)好評通販中 (@koshian2) 2019年7月1日本編2 https://t.co/52t0dFZNZL pic.twitter.com/K7Y6scHiqK
— しこあん@『モザイク除去本』(技術書典6)好評通販中 (@koshian2) 2019年7月1日元ネタ
そこそこな線画を目指す OpenCV
https://qiita.com/khsk/items/6cf4bae0166e4b12b942こちらの記事のアルゴリズムを使います。もともとはOpenCVの実装ですが、ディープラーニングの関数に変換することができます。
OpenCV→ディープラーニングへの置き換え
OpenCVを使った線画化のアルゴリズムは以下の処理の構成です。
- カラー画像のグレースケール化
- 1の画像を8近傍で膨張処理を1回
- 膨張処理した画像と1の画像の差分の絶対値を取る
- 3の画像の白黒反転させる
膨張処理をどうにかすれば、あとは四則演算や行列積でできそうな気がしますよね。OpenCVのモルフォロジー変換のドキュメントを見ると次の式が書かれていました。
$$dst(x,y)=\max_{(x',y'):\rm{element} (x',y')\neq0}src(x+x',y+y') $$
この式をよく見ると、MaxPoolingっぽくないですか? ただし、普通のMaxPoolingは解像度が下がってしまうので、入力と出力の解像度が変わらないように「pool_size=(3,3), stride=1, padding="same"」という特殊なプーリングを行います(GoogLe NetのInceptionブロックでこういう使い方しています)。
つまり、ディープラーニングの処理でOpenCVの線画化の処理を置き換えると次のようになります。
- カラー画像のグレースケール化 → 行列積 or 1x1畳み込み
- 1の画像を8近傍で膨張処理を1回 → stride=1, padding="same"の3x3 MaxPooling
- 膨張処理した画像と1の画像の差分の絶対値を取る → ただの絶対値+引き算
- 3の画像の白黒反転させる → 1.0-画像
OpenCVの処理を無事にディープラーニングの文脈に置き換えることができました。あとは実装するだけです。
何が美味しいの?
ディープラーニングフレームワークに置き換えてなにが美味しいの?という疑問があるかもしれません。理由はいくつかあります。
- GPUブーストが簡単に使える
OpenCVの処理をGPU上で簡単に行うことができます。KerasならCPUと同じコードでできます。- ディープラーニング上で「線画」の概念が扱える
もともと自分が欲しかったのはこっちで、損失関数内で線画の損失関数を定義したかったのです。この方法なら、カラー画像→線画への変換をディープラーニングのモデル内で行えます。ディープラーニングフレームワークによる実装
元画像
元の記事と同じように「響け!ユーフォニアム」の画像を使います。これを「eupho.jpg」とします。
Keras
Kerasの場合は以下のような処理になります。ディープラーニングのフレームワークでは、画像は4階テンソルとして扱うため前後にテンソル変換を挟んでいます(load_tensor, show_tensor)。
import numpy as np from PIL import Image import keras.backend as K import matplotlib.pyplot as plt def load_tensor(): with Image.open("eupho.jpg") as img: array = np.asarray(img, np.float32) / 255.0 # [0, 1] array = np.expand_dims(array, axis=0) # KerasはNHWC return K.variable(array) def show_tensor(input_image_tensor): img = K.eval(input_image_tensor * 255.0) img = img.astype(np.uint8)[0,:,:,0] plt.imshow(img, cmap="gray") plt.show() def linedraw(): # データの読み込み x = load_tensor() # Y = 0.299R + 0.587G + 0.114B でグレースケール化 gray_kernel = K.variable( np.array([0.299, 0.587, 0.114], np.float32).reshape(3, 1)) x = K.dot(x, gray_kernel) # dot積でOK # 3x3カーネルで膨張1回(膨張はMaxPoolと同じ) dilated = K.pool2d(x, pool_size=(3, 3), strides=(1, 1), padding="same") # 膨張の前後でL1の差分を取る diff = K.abs(x-dilated) # ネガポジ反転 x = 1.0 - diff # 結果表示 show_tensor(x) if __name__ == "__main__": linedraw()
うまくいきました。
PyTorch
PyTorchの場合は以下のようになります。グレースケール化で1x1畳み込みを使っているのが違うところです。
import numpy as np from PIL import Image import torch import torch.nn.functional as F import matplotlib.pyplot as plt def load_tensor(): with Image.open("eupho.jpg") as img: array = np.asarray(img, np.float32) / 255.0 # [0, 1] array = np.expand_dims(array, axis=0) array = np.transpose(array, [0, 3, 1, 2]) # PyTorchはNCHW return torch.as_tensor(array) def show_tensor(input_image_tensor): img = input_image_tensor.numpy() * 255.0 img = img.astype(np.uint8)[0,0,:,:] plt.imshow(img, cmap="gray") plt.show() def linedraw(): # データの読み込み x = load_tensor() # Y = 0.299R + 0.587G + 0.114B でグレースケール化 gray_kernel = torch.as_tensor( np.array([0.299, 0.587, 0.114], np.float32).reshape(1, 3, 1, 1)) x = F.conv2d(x, gray_kernel) # 行列積は畳み込み関数でOK # 3x3カーネルで膨張1回(膨張はMaxPoolと同じ) dilated = F.max_pool2d(x, kernel_size=3, stride=1, padding=1) # 膨張の前後でL1の差分を取る diff = torch.abs(x-dilated) # ネガポジ反転 x = 1.0 - diff # 結果表示 show_tensor(x) if __name__ == "__main__": linedraw()
ディープラーニングなのに訓練/データ不要
このアルゴリズムの面白いところなのですが、ディープラーニングなのに学習する係数が1個もありません。したがって、モデルを定義をした段階で訓練フェーズをすっ飛ばしてすぐ使うことができます。
アニメ1話分を全て線画に変換してみよう
応用例として、YouTubeにあるアニメ1話分を丸々線画に変換して、Before-Afterで動画として保存します。以下の流れで行います。
- YouTubeからPyTubeで動画をダウンロード
- フレーム単位で静止画(カラー画像)で切り出し
- Kerasでカラー画像を全て線画に変換
- もとのカラー画像と線画を組み合わせて動画として再エンコード
今回はKerasを使っていますが、PyTorchや他のフレームワークでもできます。暇な方はやってみてはいかがでしょうか。
ちなみにColabでやる場合はYouTubeの再生地域制限に引っかかるケースがあります。日本から動画が見れてもColabのサーバーがアメリカにあるので、アメリカからの接続と認識されてDLできないケースがあります(その場合は日本のHTTPSプロキシ経由で接続しますが説明は省略します)。ローカルにDLする場合は特に心配しなくてOKです。
必要ライブラリ
ffmpeg
ffmpegはPythonのライブラリの他に、本体のバイナリが必要なので本家から必要なバイナリをダウンロードしておきます。Windowsならffmpegのexeファイルを実行ディレクトリにおきます。
OpenH264
H264でエンコードする際に必要。以下のリポジトリから、H264の1.8.0かつ64ビットのライブラリをOSに応じてダウンロード。同じく実行ディレクトリにおいておきます。
https://github.com/cisco/openh264/releases
その他ライブラリ
pip install ffmpeg-python pip install pytube他にインストールされていないライブラリがあったら適宜pip installでインストールします。
コード
動画はYouTubeの公式配信の侵略!イカ娘の第1話を使っています。
import ffmpeg from pytube import YouTube import os import glob import cv2 import numpy as np from tqdm import tqdm import keras from keras import layers import keras.backend as K from PIL import Image def download_youtube(): if not os.path.exists("video"): os.mkdir("video") yt = YouTube("https://www.youtube.com/watch?v=JUIk6a1nzFw") query = yt.streams.filter(fps=30, subtype="mp4", res="360p").all() query[0].download("video") def extract_images(): if not os.path.exists("images"): os.mkdir("images") stream = ffmpeg.input(glob.glob("video/*")[0]) stream = ffmpeg.output(stream, f"images/frame_%05d.png", f="image2", q=4) ffmpeg.run(stream) def linedraw_func(input_tensor): gray_kernel = K.variable( np.array([0.299, 0.587, 0.114], np.float32).reshape(3, 1)) x = K.dot(input_tensor, gray_kernel) # dot積でOK # 1枚単位でmin-maxスケーリングしてコントラスト補正する mins = K.min(x, axis=(1,2,3), keepdims=True) maxs = K.max(x, axis=(1,2,3), keepdims=True) x = (x-mins) / (maxs-mins+K.epsilon()) dilated = K.pool2d(x, pool_size=(3, 3), strides=(1, 1), padding="same") diff = K.abs(x-dilated) x = 1.0 - diff return x IMG_WIDTH, IMG_HEIGHT = 640, 360 def linedraw_model(): input = layers.Input((IMG_HEIGHT, IMG_WIDTH, 3)) x = layers.Lambda(linedraw_func)(input) return keras.models.Model(input, x) def convert_all(): # KerasのImageDataGeneratorはroot/classes/img という構造なので、 # ルートディレクトリをカレントディレクトリにし、サブディレクトリとして画像のあるディレクトリを1クラスとして指定 # batch_size分の画像を一度に読み込む、シャッフルはしないようにする(連番で読まれる) gen = keras.preprocessing.image.ImageDataGenerator(rescale=1.0/255).flow_from_directory( "./", class_mode=None, classes=["images"], batch_size=256, shuffle=False, target_size=(IMG_HEIGHT, IMG_WIDTH) ) # 出力ディレクトリ if not os.path.exists("images_line"): os.mkdir("images_line") # ファイル数 n_files = len(glob.glob("images/*.png")) # 線画化の操作をモデルとして読み込む model = linedraw_model() cnt = 1 for X in tqdm(gen): out = model.predict_on_batch(X) # 線画化 # ファイルの保存 for i in range(out.shape[0]): img = (out[i,:,:,0]*255.0).astype(np.uint8) with Image.fromarray(img) as img: img.save(f"images_line/frame_{cnt:05}.png") cnt += 1 if cnt > n_files: return def encode(): fourcc = cv2.VideoWriter_fourcc("h", "2", "6", "4") video = cv2.VideoWriter("output.mp4", fourcc, 29.97, (IMG_WIDTH, IMG_HEIGHT*2)) n = len(glob.glob("images/*")) for i in tqdm(range(1, n + 1)): img_original = cv2.imread(f"images/frame_{i:05}.png") img_original = cv2.resize(img_original, (IMG_WIDTH, IMG_HEIGHT), cv2.INTER_LANCZOS4) img_convert = cv2.imread(f"images_line/frame_{i:05}.png") #img_convert = cv2.resize(img_convert, (IMG_WIDTH, IMG_HEIGHT), cv2.INTER_LANCZOS4) x = np.concatenate([img_original, img_convert], axis=0) video.write(x) if __name__ == "__main__": encode()これで生成したのが冒頭の動画。ただし、Twitterの埋め込み動画の画質が悪いので実際はもう少し綺麗に出てたりします1。
生成結果比較
実際の静止画としての出力はこちらになります。カラー画像との比較です。
なかなか良いのではないでしょうか?
速度
ダウンロードからエンコードまでおおよそ1時間程度でした。ffmpegによるフレームの切り出しとストレージがボトルネックになるので、CPU性能とストレージ速度(HDDよりSSD)を上げると高速に出力できます。GPUはほとんど使っていませんでした(使用率でせいぜい5%程度)。もちろんこのあとDeepの訓練につなげる場合は、GPU等のデバイスがあればより高速化できます。
しかし、アニメ1話分の線画が1時間でできてしまうというのはびっくりでした。1話で4.3万フレームあったので(29.97fps × 累計秒)、アニメ本編と既存の画像処理を組み合わせればかなり簡単かつ大量にデータが作れるのかもしれません。
応用 / まとめ
これを使うと、(線画, カラー画)のペアデータが簡単に作れるので2、生成モデルとの相性が良くなります。具体的には、pix2pixなどを使えばアニメの原画~動画の工程をかなり自動化できるのではないでしょうか。
この記事のポイントは、OpenCVで書けるような従来の画像処理も、畳み込みやプーリングといったディープラーニングの操作にある程度置き換えることができるということです。これに気づくとディープラーニングの幅がぐっと広がると思われます。







- 投稿日:2019-07-01T11:17:47+09:00
【脱MNIST!】機械学習のデータセットの管理と Chainer の Dataset クラスを自作するときのTips
はじめに
この記事では、機械学習プロジェクトのデータセットの管理と Chainer のDataset クラスを自作する際のTipsを紹介します。データセットの管理については、 Chainer に限らず使える Tips だと思います。あくまで自分が良いと思った開発フローや設計におけるTipsなので、より良い方法がございましたら、コメントしていただけると幸いです。
今回は、以下のブログ記事で紹介されている、CNNとLSTMを用いたファッションコーディネートモデルのプロジェクトを題材にハンズオン形式で、データセットまわりの開発フローや設計のTipsを紹介していきます。
https://techblog.zozo.com/entry/outfit_generator
対象者・前提知識
学部4年生など、Chainer を用いて、研究などの機械学習プロジェクトを始められる方が対象です。MNISTのチュートリアルは動かせたけど、論文の再実装や自分の作りたいものを作るためには、どう着手すればよいかわからない、といった初級者から中級者を目指す方も対象です。記事の内容が少なくはないので、実際に自分のプロジェクトを進めていく中で、ぶつかった課題を解決したいときに、読み返すのも良いと思います。
上記の対象者以外でも、Chainerを用いる際に、このような設計があるのか、と参考にしていただけたら幸いです。初中級者向けということもあり、記述が冗長ですので、最後のまとめだけでも読んでいただけたら幸いです。
前提知識として、以下のチュートリアルは完了しているものとします。
Chainer v4 ビギナー向けチュートリアル - Qiita
実行環境
- chainer==5.0.0
- chainercv==0.12.0
プロジェクトのディレクトリ構成
この記事では、データセットまわりのみを紹介しますが、Chainer を用いたプロジェクトのディレクトリ構成は以下のようなものを想定しています。
. ├── configs │ └── {model}.yml # 学習条件の yml ファイル ├── notebooks # デバッグやモデル評価用の ipynb ファイル └── scripts ├── **datasets # 自作 Dataset 置き場** ├── functions # 重みを持たない関数の置き場 ├── links # モデル、重みを持つ関数の置き場 │ └── {model}.py ├── extensions # 自作 Extension 置き場 ├── utils │ ├── read_data.py # 画像などの読み込み │ ├── transforms.py # 前処理 │ └── visalization.py # 可視化 ├── train_{model}.py # 学習スクリプト └── eval_{model}.py # 評価スクリプト今回は特に
scripts/datasetsに焦点を当てます。データセットリポジトリの別途作成
この章では、機械学習プロジェクトにおけるデータセット管理の Tips を説明します。
プロジェクトのリポジトリについては前章で説明しましたが、それとは別にデータセット用のリポジトリを作成します。プロジェクトリポジトリの目的は「ある1つのプロジェクト(研究など)に必要なコードの管理」であるのに対しい、データセットリポジトリの目的は「ある1つのデータセットのセットアップや加工をするコードの管理」です。
プロジェクトとデータセットでリポジトリを分ける理由は、あるデータセットを他のプロジェクトでも再利用しやすくするためです。プロジェクトに依存しないセットアップや加工のコードはデータセットリポジトリで管理し、プロジェクトに依存するコードはプロジェクトリポジトリで管理します。
また、プロジェクトリポジトリ内のコードからデータセットリポジトリ内のファイルにアクセスする方法として、そのパスを環境変数に設定する方法があります。Pipenv の
.envファイルで設定すると楽です。具体的な実装は、 Chainer
の Dataset に関する Tips の章で説明します。データセットリポジトリのディレクトリ構成は以下です。
. ├── README.md # データセットのスキーマやセットアップ手順 ├── raw # 第三者による配布を、そのままの形式で置く場所 ├── main # raw を使いやすいように加工した本番データ │ ├── images # 画像 │ └── labels # json, csv, txt などのテキスト ├── tiny # main からサンプルしたデバッグ用の小さいデータ │ ├── images │ └── labels └── make_*.py # 前処理Polyvore データセットを使って、私が実際に作ったデータセットリポジトリはこちらになります。 こちらを見つつ読み進めていただけると、イメージしやすいと思います。
データセットのダウンロード
今回、用いるデータセットはPolyvoreというファッションコーディネートのデータセットです。 公式リポジトリから polyvore.tar.gz と polyvore-images.tar.gz を
rawにダウンロードします。rawには基本、第三者が配布したままの形式で置き、read only にします。今回のデータセットの場合、画像も配布されていますが、json ファイルなどに記載されているURLから画像をダウンロードしなければならない場合もあります。このような場合に使える、非同期処理で高速に大量のファイルをダウンロードする aiodl というCLIツールを作成しましたので、よろしければ使ってください。画像5万枚程度なら30分ほどで終わります。(作った後で気づきましたが、同名で別のPythonライブラリがありますので、ご注意ください。)
また、画像全てをダウンロードする前に、次の節を参考に小さいデータセットを先に用意します。理由は、小さいデータセットを先に用意をしておけば、残りをダウンロードしている間に小さいデータセットで開発を進められるからです。
小さいデータセットの用意
データセットリポジトリに小さいデータセットを用意する理由はデバッグを効率化するためです。
データセットリポジトリにおける具体的な作業は以下です。
rawにダウンロードしたものを、使いやすい形に加工してmainに置く。mainから、少量のデータをサンプルしてtinyに置く。
mainからtinyを作成する際の注意点は、main以下とtiny以下のディレクトリ構成は全く同じにすることです。理由は、プロジェクトのコード内で参照するパスをmainからtinyに変えるだけで、データセットの規模を切り替えられるようにするためです。また、json ファイルから少量のデータをサンプルする場合に使える ml_json_processor というCLIを作成したので、よろしければ使ってください。 json ファイルを train と test に分割する際にも使えます。
json ファイルに記載されたURLから画像をダウンロードする場合、小規模の json ファイルを作成したタイミングで
make_url_file.pyなどのスクリプトを書き、tiny→mainの順で画像をダウンロードします。また、
raw,main,tinyは、データの著作権や容量的な問題で、基本的には.gitignoreに記述して git 管理しないようにします。ところで、「デバッグを効率良く行う」ことが目的であれば、 以下の用にプロジェクトのコード側でデータの規模を小さくする方法も考えられます。
(プロジェクトリポジトリ内のあるコード).pydataset[:100] # 100 サンプルだけ使うこちらの方が簡単ですが、データセットが大きすぎる場合、データをメモリに読み込む際に長い時間がかかってしまいます。また、プロジェクトごとに、小さくする記述を書く必要があります。データセットリポジトリ側に責任を持たせることで、プロジェクトのコードに余計な記述をせずに済みますし、データセットの規模の切り替えをプロジェクト間で再利用しやすくなります。また、特殊なケースですが、 Amazon の SageMaker を使う場合も、今回紹介した方が適しています。SageMakerでは学習のたびにS3から学習インスタンスにデータセットをアップロードする必要があるため、小さいデータセットを用意した方がデバッグを効率的に行えます。
重い前処理は予め施しておく
軽い処理(画像の正規化、左右反転など)であれば、後に実装する Dataset クラス内に記述しても良いです。しかし、重い処理(画像特徴量の抽出、ピクセルの値の平均値の計算など)の場合、学習や推論のたびに時間を取られてしまいます。そのため、そのような重い処理は予め施しておき、結果を中間ファイルに保存しておきます。
前処理のスクリプトは、プロジェクトに依存する処理であればプロジェクトリポジトリ側で、汎用的なものであればデータセットプロジェクト側で管理します。
Chainer の Dataset に関する Tips
この章では、 Chainer の Dataset クラスの設計の開発フローの Tips について説明します。この章で使うスクリプトはプロジェクトリポジトリ側で管理します。
Dataset 間で共通の処理は別モジュールに切り分ける
画像の読み込みや、前処理など、 Dataset クラスに依存しない共通の処理は Dataset クラスを定義するモジュールとは分けて定義します。そうすることで、それらの処理を Dataset クラス間で共有でき、保守性が上がります。(Dataset クラスAでは前処理の方法を更新したのに、Dataset クラスBでは更新し忘れていて、学習結果がオジャン、、、といったことも回避できます。)
最初は Dataset クラス内に定義しても良いですが、 Dataset を複数作成する際に、共通部分を別モジュールに切り分けます。このとき、バグが混入しやすいので、学習結果がオジャンにならないよう、しっかりテストをしておきます(後述の可視化モジュールの節の jupyter notebook による視覚的なテストを参照)。
今回の例では、画像の読み込みと前処理のモジュールを定義しておきます。
一応、コードの解説も後述しますが、記事のメインテーマから外れるので、読み流して構いません。
scripts/utils/read_data.pyfrom PIL import Image from chainercv.transforms import resize from chainercv.transforms import resize_contain from chainercv.transforms import scale from chainercv.utils import read_image def read_square_img(img_file, keep_aspect=True): """ Args: img_file (str): An image file path. keep_aspect (bool, optional): Defaults to True. Returns: img (np.array: (C=3, H=299, W=299)): A Chainer format square image. """ img = read_image(img_file) img = resize_img(img, keep_aspect=keep_aspect) return img def resize_img(img, size=(299, 299), keep_aspect=False): """ Args: img (np.array: (C=3, H, W)): A Chainer format image. size (tuple<int>, optional): Defaults to (299, 299). keep_aspect (bool, optional): Defaults to False. Returns: img (np.array: (C=3, H=299, W=299)): A Chainer format square image. """ if keep_aspect: img = scale(img, size[0], fit_short=False) img = resize_contain(img, size, fill=255) else: img = resize(img, size, Image.BILINEAR) return img
read_square_imgは、画像ファイルのパスを受け取り、Chainer形式で画像を読み込み、(3, 299, 299)の正方形にリサイズして返します。
read_img内の.convert('RGB')は、白黒画像を読み込んだ場合にも(3, H, W)の形の配列として読み込むための記述です。
resize_imgは読み込んだ画像を(3, 299, 299)にリサイズします。keep_aspect=Trueであれば、アスペクト比を保ったままリサイズし、できた余白の部分は白(255)でパディングします。keep_aspect=Falseであれば、アスペクト比を無視してリサイズします。本来、 CNN はアスペクト比の変更にロバストではないため、
keep_aspect=Trueとするのが妥当ですが、先行研究ではアスペクト比が無視されていたため、追実験用に keep_aspect 引数を設けました。scripts/utils/transforms.pyfrom chainercv.transforms import random_flip def transform_img(img, train=False): """ Args: img (np.array: (c=3, h, w)): Chainer format image. Return: img (np.array: (c=3, h, w)): Transformed Chainer format image. """ # rescale pix value from [0, 255] to [-1, 1] img = 2 * (img / 255 - 0.5) if train: img = random_flip(img, x_random=True) return img前処理では、ピクセルの値の正規化と、ランダムな左右反転の data augumentation を行います。
train引数を設けて、 学習時だけ必要な前処理の切り替えを行います。**trainのデフォルトはFalse** にしておきます。理由は、大抵のプロジェクトの場合、学習より推論の記述をする方が多いからです。Dataset クラスの実装
chainer.dataset.DatasetMixinを継承して Dataset クラスを定義します。主にオーバーライドするメソッドは以下の3つです。
__init____len__:Dataset 内のデータ数を返します。 Iterator が Dataset を回すときに必要になります。get_example:データのインデックスを受け取り、そのインデックスのデータを返します。まず、
__init__メソッドをオーバーライドします。scripts/datasets/polyvore.pyimport os import pandas as pd class PolyvoreDataset(DatasetMixin): def __init__( self, max_num=8, keep_aspect=True, json_filename='train_no_dup.json', ): super().__init__() self.max_num = max_num self.keep_aspect = keep_aspect self.img_dir = os.environ['POLYVORE_IMAGE_DIR'] lbl_dir = os.environ['POLYVORE_LABEL_DIR'] json_file = os.path.join(lbl_dir, json_filename) self.df = pd.read_json(json_file)
__init__では、主にデータの読み込みや準備を行います。json や csv ファイルはpandasのDataFrameに読み込み、 attribute として持たせておくと、後の処理が楽です。DataFrame の1行が、get_exampleで指定するデータの1サンプルに対応するようにしておきます。今回、データの1サンプルは、1つのコーディネートとしたいです。 Polyvore の json ファイルは以下のようになっているので、 DataFrame に読み込むと、すでに1行が1つのコーディネートを表しているので、今回は特に加工の必要はありません。(データセットリポジトリ)/main/labels/train_no_dup.json[ { "name": "コーデ名", "views": 8743, "items": [ { "index": 1, "name": "アイテム名 A", "price": 24.0, "likes": 10, "image": "http://example/image01.jpg", "categoryid": 4495 }, { "index": 2, "name": "アイテム名 B", "price": 150.0, "likes": 2250, "image": "http://example/image02.jpg", "categoryid": 25 }, ... ], "image": "http://example/tiled/image.jpg", "likes": 394, "date": "One month", "set_url": "http://example/set/", "set_id": "01234567", "desc": "コーデの説明" }, ... ]画像データはメモリにすべて乗らないことがほとんどなので、
get_example内で逐次、読み込みます。ただ、画像が置いてあるディレクトリのパスは、__init__内で attribute (self.img_dir) として持たせておくと楽です。また、参照するデータがあるディレクトリのパスを環境変数で指定することで、コードのポータビリティが上がります。コードのポータビリティは実験の再現性には欠かせません。 Pipenv を用いている場合、これらの環境変数を、以下のように
.envファイルに設定しておくのが楽です。env.shexport SIZE="tiny" export POLYVORE="${HOME}/datasets/Polyvore/${SIZE}" export POLYVORE_IMAGE_DIR="${POLYVORE}/images" export POLYVORE_LABEL_DIR="${POLYVORE}/labels"次に、
__len__を定義します。DataFrame の長さをとるだけです。scripts/datasets/polyvore.py... class PolyvoreDataset(DatasetMixin): ... def __len__(self): return len(self.df)次に、
get_exampleを定義します。データのインデックスを受け取り、そのインデックスのデータを返すメソッドです。get_exampleの返り値であるデータの1サンプルの型は、モデル(の__call__メソッド)の入力に対応するように設計します。(この場合、モデルの__call__内で損失関数を呼び出すことを前提としていますが、損失関数をモデルとは別で定義する場合は、損失関数の入力の型に合わせます。)今回の例では、モデルの学習時の入力は、あるコーディネートを成すアイテム画像の系列ですので、
get_exampleの返り値の型も画像の系列とします。具体的に、以下のように実装します。scripts/datasets/polyvore.py... import numpy as np class PolyvoreDataset(DatasetMixin): ... def get_example(self, i): """ Args: i (int): An index of a data sample. Returns: imgs (np.array: (N, C=3, H, W)): A set of item images. N: the number of items in the outfit """ outfit = self.df.iloc[i] items = outfit['items'][:self.max_num] imgs = np.array([ self.read_img(outfit['set_id'], item['index']) for item in items ]) # imgs: (N, C=3, H, W) return imgs def read_img(self, set_id, index): img_file = os.path.join( self.img_dir, str(set_id), '{}.jpg'.format(index) ) return read_square_img(img_file, keep_aspect=self.keep_aspect)
self.df.iloc[i]で DataFrame の1行をoutfit(コーディネート)として取り出します。itemsはリストで、要素は、そのコーデを成すアイテムの情報を持つ辞書です。この items を内包表記で画像の系列に変換しています。その内包表記内で、画像を読み込むときに、read_imgというread_square_imgをラップしたメソッドを呼んでいます。ラッパーを用意した理由はget_example内の可読性を良くするためと、モデルの定性評価時などにPolyvoreの画像の読み込みを簡単にするためです。また、 Dataset クラスに限った話ではありませんが、 テンソル(ndarray)の形をコメントとして明記しておくと可読性があがり、開発しやすいです。
Dataset クラスの実装をまとめると、以下のようになります。
scripts/datasets/polyvore.pyimport os import pandas as pd import numpy as np class PolyvoreDataset(DatasetMixin): def __init__( self, max_num=8, keep_aspect=True, json_filename='train_no_dup.json', ): super().__init__() self.max_num = max_num self.keep_aspect = keep_aspect self.img_dir = os.environ['POLYVORE_IMAGE_DIR'] lbl_dir = os.environ['POLYVORE_LABEL_DIR'] json_file = os.path.join(lbl_dir, json_filename) self.df = pd.read_json(json_file) def __len__(self): return len(self.df) def get_example(self, i): """ Args: i (int): An index of a data sample. Returns: imgs (np.array: (N, C=3, H, W)): A set of item images. N: the number of items in the outfit """ outfit = self.df.iloc[i] items = outfit['items'][:self.max_num] imgs = np.array([ self.read_img(outfit['set_id'], item['index']) for item in items ]) # imgs: (N, C=3, H, W) return imgs def read_img(self, set_id, index): img_file = os.path.join( self.img_dir, str(set_id), '{}.jpg'.format(index) ) return read_square_img(img_file, keep_aspect=self.keep_aspect)可視化モジュールの実装
Dataset クラスの実装が一通り終わったら、データのサンプルを可視化するためのモジュールを実装します。可視化モジュールを作る目的は以下の2つです。
- Dataset クラスの視覚的なテスト
- モデルの定性的評価
Dataset クラスにバグがあった場合、学習する際にエラーが出れば、それに気づけます。しかし、 Dataset クラスにいくつもバグがあった場合、学習スクリプトを通してのデバッグだと、原因の切り分けが難しかったり、起動のオーバーヘッドに時間を取られ、非効率です。そのため、Dataset クラス単体でテストをしておきます。特に画像系のデータを扱う場合、可視化しないと気づかないバグ(バウンディングボックスのアノテーションがズレていた、など)もあります。視覚的なテストは jupyter notebook 上で行います。
また、モデルの定性的評価にデータや予測結果の可視化は欠かせません。その際にも、可視化モジュールを作っておくと、効率的な定性的評価が行え、実験サイクルを素早く回せます。
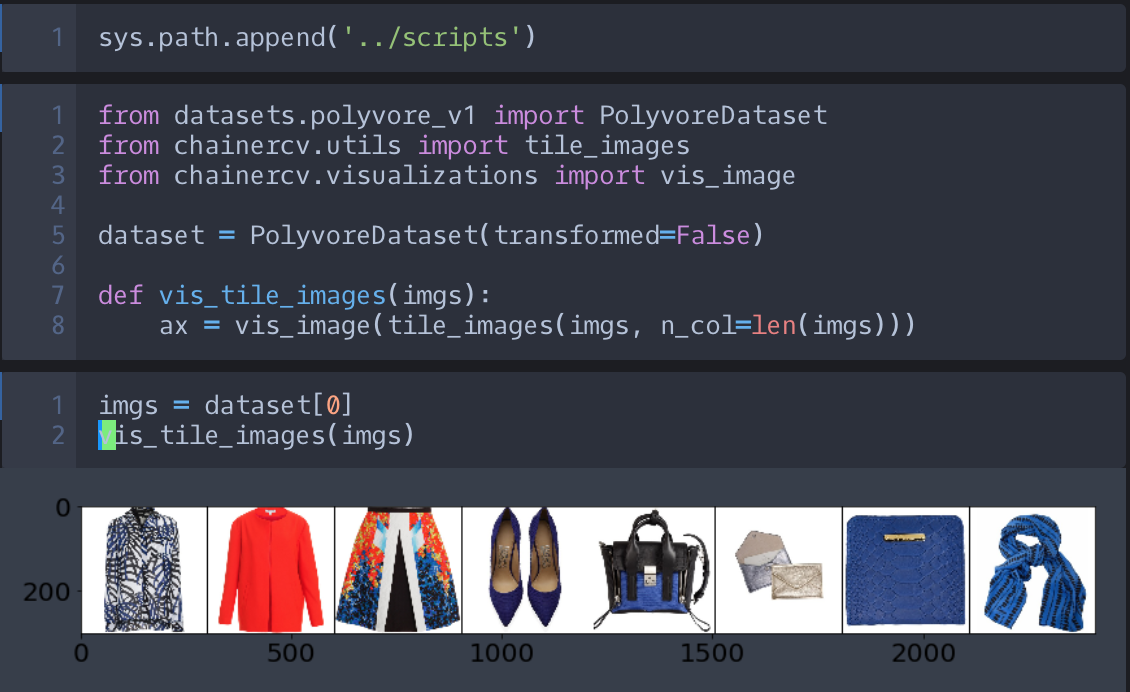
今回、この段階では、アイテム画像1枚、もしくは、画像の系列、を可視化できれば良いので、特に自作はせず、chainercv.visualizations.vis_image と chainercv.utils.tile_images を使います。ただ、今回のプロジェクトでは系列の可視化を良くするので vis_image と tile_images のラッパーを書いておいてもいいかもしれません。
jupyter notebook 上で実行した様子は、以下の図のようになります。
transform の実装
データの1サンプル(
Dataset.get_exampleの返り値)に対し、前処理を施す transform 関数を実装します。transform は基本、get_exampleが呼ばれる度に実行するので、軽い前処理(画像の正規化、左右反転など)を記述します。重い処理(画像特徴量の抽出、ピクセルの値の平均値の計算など)の場合は別スクリプトにして、学習・推論前に施しておき、結果を中間ファイルに保存しておきます。transform を関数で定義し、
chainer.datasets.TransformDatasetを用いる方法がありますが、そうではなく、 transform を Dataset クラスのメソッドとして定義し、get_example内で呼び出します。get_example内で trasnform を施す理由は以下のメリットがあるためです。
- Dataset クラスを呼び出す度に transform を施す処理を書かなくて良い。
- ゆえに、transform を施し忘れない。
- 学習・推論スクリプトの記述量が減り、可読性が上がる。
特に、「trasnformを施し忘れる」は、(少なからず私は)初心者のときにしがちなミスです。モデルの性能に致命的なダメージを与えるにも関わらず、エラーを吐かないことも多い悪質なバグです。
get_example内で施すことにより、忘れる可能性を低くできます。関数ではなく、 Dataset クラスのメソッドとして持たせる理由は、 transform の命名の手間が省け、名前空間も節約できる点です。また、 Dataset クラスの attribute に依存した処理の記述もしやすいです。 大抵のプロジェクトでは1つの Dataset クラスに対する前処理は同じであり、transform の引数は
get_exampleの返り値であるため、 1つの Dataset クラスに対し、 1つの transform を定義することになります。ですので、 Dataset クラスのメソッドとして持たせてしまいます。ただ、異なる Dataset クラス間で、画像に対しては同じ前処理を施したい、など、一部の処理を共有させたい場合は、その処理を[transforms.py](http://transforms.py)などに切り出して、各 Dataset クラスの transform メソッド内で、その処理を呼びます。今回の例では以下のように実装します。
scripts/datasets/polyvore.py#v---------------変更点-----------------v import sys from os.path import dirname #^---------------変更点-----------------^ ... #v---------------変更点-----------------v scripts_dir = dirname(dirname(__file__)) sys.path.append(scritps_dir) from utils.transforms import transform_img #^---------------変更点-----------------^ class PolyvoreDataset(DatasetMixin): def __init__( self, max_num=8, keep_aspect=True, json_filename='train_no_dup.json', #v---------------変更点-----------------v transformed=True, train=False, #^---------------変更点-----------------^ ): super().__init__() self.max_num = max_num self.keep_aspect = keep_aspect #v---------------変更点-----------------v self.train = train self.transformed = transformed #^---------------変更点-----------------^ self.img_dir = os.environ['POLYVORE_IMAGE_DIR'] lbl_dir = os.environ['POLYVORE_LABEL_DIR'] json_file = os.path.join(lbl_dir, json_filename) self.df = pd.read_json(json_file) ... def get_example(self, i): ... #v---------------変更点-----------------v if self.transformed: imgs = self.transform(imgs) #^---------------変更点-----------------^ return imgs ... #v---------------変更点-----------------v def transform(self, example): imgs = example imgs = np.array([ transform_img(img, train=self.train) for img in imgs ]) return imgs #^---------------変更点-----------------^transform を施すか施さないかを決める
transfomed引数のデフォルトはTrueにしておきます。 transform の施し忘れを防ぐためです。また、前処理を学習時と推論時で切り替えるtrain引数も追加しました。また、画像に対する処理は、他の Dataset クラスでも共有させたいため、
transforms.pyに切り出しておき、 transform メソッド内で呼んでいます。正直、 Dataset クラス内に定義するのでれば、trasnform を定義せず、すべて
get_example内に記述すれば良いとも思います。一応、個人的には「その処理を施したらデータを可視化しづらいかどうか」で、transform かget_example、どちらに記述するかを分けています。しかし、そうなると、 左右反転やクロッピングなどの augumentation は可視化したいですし、正直、私も良い分け方を見つけられていません。また、応用時を考えて、モデル側に持たせるというのも1つの方法です。converter の実装
converter の実装はモデルによって必要な場合と、そうでない場合があります。大抵の場合は、
chainer.dataset.concat_examplesを使えば良いので、 自作する必要はありません。 どのような場合に converter を自作するかの説明の前に、 converter の役割について、おさらいしておきます。converter の役割を明確に理解しておくことで、 converter を自作する際の指針になると思います。converter の役割は主に以下の2点です。
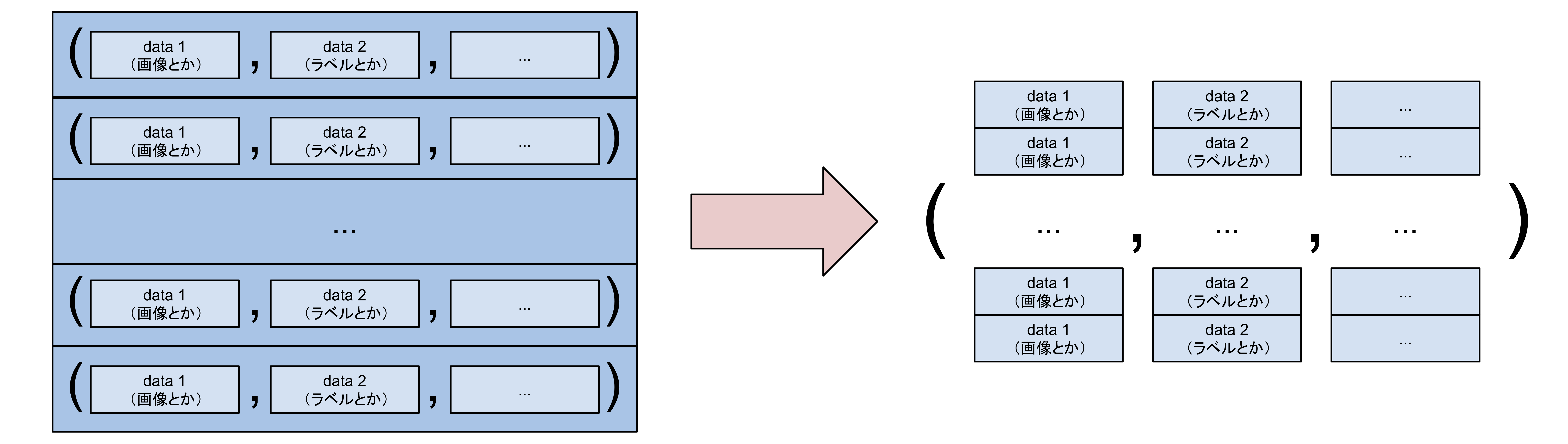
- タプルのバッチをバッチのタプルに変換する。
- GPU学習時に ndarray をGPUに転送する。
converter の1つ目の役割の例として、 concat_example では以下の図のような処理をします。
converter の入力は、
Iteratorから渡される、Dataset.get_exmapleの返り値(タプル)のlist(バッチ)です。それをバッチのタプルに変換し、それがモデルの入力となります。1つ目の役割が、
concat_exampleでは対応できない場合に converter を自作する必要があります。特に、今回の例のようにバッチ内の1サンプルが可変長の場合、バッチ方向に concat して、バッチを1つの ndarray にしてしまうconcat_exampleでは対応できません。ndarray でなくlistのままのバッチである必要があります。今回は以下のように実装しました。また、 converter の入力は
Dataset.get_exampleの出力に依存するため、 transform 同様、 Dataset 1つに対し1つの converter が必要になります。ですので、Dataset クラスのメソッドとして持たせます。scripts/datasets/polyvore.pyimport os import sys from os.path import dirname import numpy as np import pandas as pd from chainer.dataset import DatasetMixin #v---------------変更点-----------------v from chainer.dataset import to_device #^---------------変更点-----------------^ scripts_dir = dirname(dirname(__file__)) sys.path.append(scripts_dir) from utils.transforms import transform_img from utils.read_data import read_square_img class PolyvoreDataset(DatasetMixin): ... #v---------------変更点-----------------v def converter(self, batch, device=-1): """ Args: batch imgs_b (list<np.array>: B * (N, C, H, W)) A batch of image sequences. device (int, optional): >= 0 : GPU -1 : CPU """ imgs_b = batch imgs_b = [ to_device(device, imgs) for imgs in imgs_b ] return imgs_b #^---------------変更点-----------------^今回は入力が画像の系列のみなので、
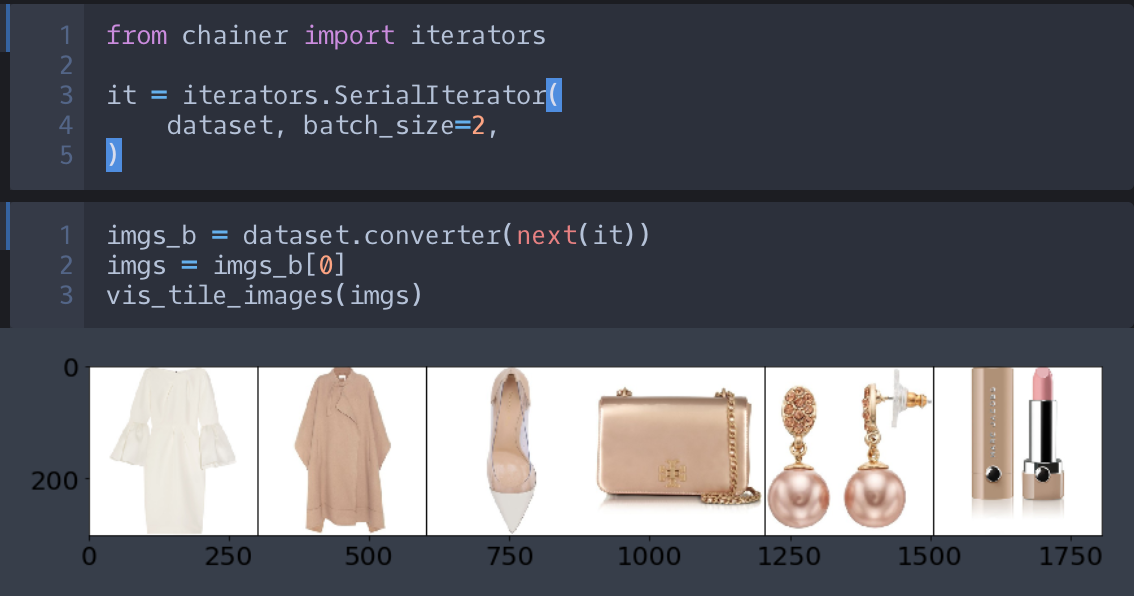
imgs_b = batchとしましたが、データが複数ある場合は、data1_b, data2_b, ... = list(zip(*batch))とすることで、タプルのバッチをバッチのタプルに変換できます。ところで、可変長のサンプルへの対応の処理などを、Iterator や Updater を自作することで対応する方法もあります。しかし、 Iterator の主な役割は「Dataset のサンプルを巡回すること」、 Updater はの主な役割「毎 iteration ごとに、 あるバッチを使ってモデルの重みを更新すること」です。ですので、可変長サンプルへの対応は、「タプルのバッチをバッチのタプルにする」役割を持つ converter に責任を持たせた方が適切だと考えられます。また、 Iterator や Updator より converter の方が処理や構造がシンプルですので、 converter を書き換えた方が簡単です。ですので、 Iterator や Updater をオーバーライドする前に、まず converter のオーバーライドで対応できないかを考えます。
converter も、以下の図の jupyter 上でテストします。
デバッグ時のバッチサイズは基本的に2が良いと考えています。理由は、大きいほど計算に時間がかかりますし、1だと複数のときにしか発生しないバグを見つけられないことがあるからです。
DatasetBase クラスの実装
以上で、1つの Dataset クラスを実装する開発フローは終了です。この節では、複数の Dataset クラスを実装するときの Tips について説明します。 共通部分を多く含んだ、複数の Dataset クラスを作る場合、DatasetBase という親クラスを作ります。例えば、同じデータセット(Polyvore など)でも、学習・評価、評価タスク、モデルによって
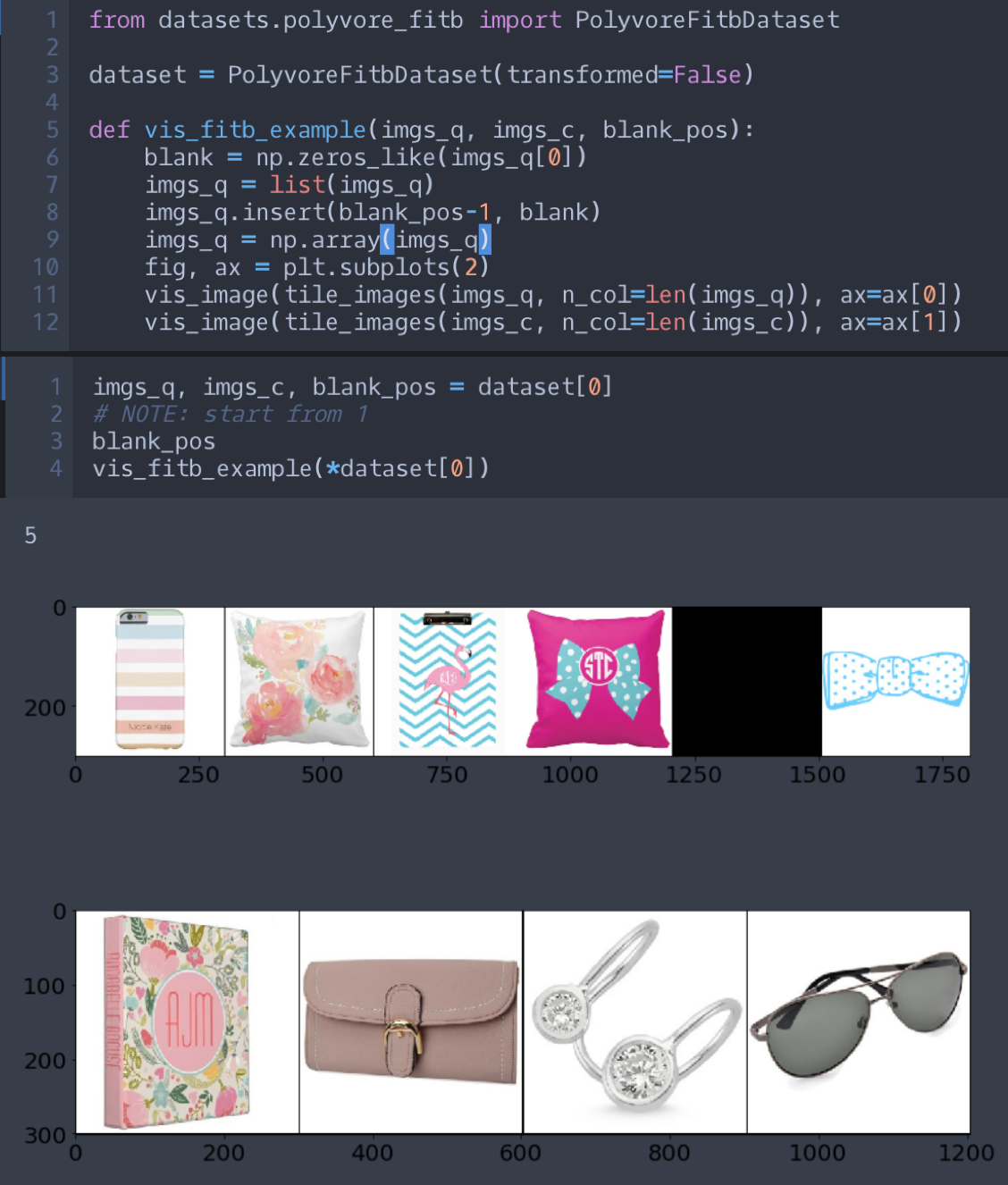
get_exampleの返り値の型を変えなければいけないことがあります。複数の Dataset クラスを作るとなると、jsonファイルの読み込みや、画像ディレクトリのパスの設定など、共通部分が多く保守性が落ちます。(Dataset クラスAの読み込み部分は変更したのに、 Dataset クラスBは変更し忘れていた、などのミスが起きやすくなります。)そこで、親クラスとなる DatasetBase クラスを1枚噛ませ、それに共通部分を持たせます。今回の例では、FITB(Fill in the Blank)という評価タスクの Dataset クラスを追加してみます。FITBとは以下の図のように、いくつかのアイテム(未完成のコーデ)に合うアイテムを、4つの選択肢から推薦するタスクです。
まず、先ほど定義した
PolyvoreDatasetから汎用的な処理を切り出してPolyvoreDatasetBaseクラスを実装します。そして、その DatasetBase クラスを継承してPolyvoreFitbDatasetを実装します。具体的な実装は以下になります。scripts/datasets/polyvore_base.pyimport os import sys from abc import ABCMeta, abstractmethod from os.path import dirname import pandas as pd from chainer.dataset import DatasetMixin scripts_dir = dirname(dirname(__file__)) sys.path.append(scripts_dir) from utils.read_data import read_square_img from utils.transforms import transform_img class PolyvoreDatasetBase(DatasetMixin): __metaclass__ = ABCMeta def __init__( self, keep_aspect=True, json_filename='train_no_dup.json', ): super().__init__() self.keep_aspect = keep_aspect self.img_dir = os.environ['POLYVORE_IMAGE_DIR'] lbl_dir = os.environ['POLYVORE_LABEL_DIR'] json_file = os.path.join(lbl_dir, json_filename) self.df = pd.read_json(json_file) def __len__(self): return len(self.df) @abstractmethod def get_example(self, i): raise NotImplementedError() def read_img(self, set_id, index): img_file = os.path.join( self.img_dir, str(set_id), '{}.jpg'.format(index) ) return read_square_img(img_file, keep_aspect=self.keep_aspect) def read_img_from_item_id(self, item_id): set_id, index = item_id.split('_') return self.read_img(set_id, index)
PolyvoreDatasetから json ファイルの読み込み、画像ディレクトリのパスの設定など、学習・評価、評価タスク、モデルに依存しない部分をPolyvoreDatasetBaseに切り出しました。get_exampleは各 Dataset に依存しますが、必ず必要なので、抽象メソッドにします。 画像の読み込みは学習・評価、評価タスク、モデルに依存せず、1つのデータセットでだいたい同じですので、read_imgメソッドを DatasetBase クラスに持たせておきます。続いて、上記の
PolyvoreDatasetBaseクラスを継承して作り直したPolyvoreDatasetが以下になります。scripts/datasets/polyvore.pyimport sys from os.path import dirname import numpy as np from chainer.dataset import to_device scripts_dir = dirname(dirname(__file__)) sys.path.append(scripts_dir) from utils.transforms import transform_img from datasets.polyvore_base import PolyvoreDatasetBase class PolyvoreDataset(PolyvoreDatasetBase): def __init__( self, max_num=8, transformed=True, train=False, *args, **kwargs, ): super().__init__(*args, **kwargs) self.max_num = max_num self.transformed = transformed self.train = train def get_example(self, i): """ Args: i (int): An index of a data sample. Returns: imgs (np.array: (N, C=3, H, W)): A set of item images. N: the number of items in the outfit """ outfit = self.df.iloc[i] items = outfit['items'][:self.max_num] imgs = np.array([ self.read_img(outfit['set_id'], item['index']) for item in items ]) # imgs: (N, C=3, H, W) example = imgs if self.transformed: example = self.transform(example) return example def transform(self, example): imgs = example imgs = np.array([ transform_img(img, train=self.train) for img in imgs ]) return imgs def converter(self, batch, device=-1): """ Args: batch imgs_b (list<np.array>: B * (N, C, H, W)) A batch of image sequences. device (int, optional): >= 0 : GPU -1 : CPU """ imgs_b = batch imgs_b = [to_device(device, imgs) for imgs in imgs_b] return imgs_b
get_exampleは学習時のモデルの__call__の型に依存するため、子クラスのPolyvoreDatasetに定義します。 また、transformもconverterもget_exampleの返り値の型に依存するため子クラスに定義します。最後に、
PolyvoreDatasetBaseを継承して新たに作った評価用データセットであるPolyvoreFitbDatasetが以下になります。scripts/datasets/polyvore_fitb.pyimport sys from os.path import dirname import numpy as np from chainer.dataset import to_device scripts_dir = dirname(dirname(__file__)) sys.path.append(scripts_dir) from utils.transform import transform_img from datasets.polyvore_base import PolyvoreDatasetBase class PolyvoreFitbDataset(PolyvoreDatasetBase): def __init__( self, transformed=True, json_filename='fill_in_blank_test.json', *args, **kwargs, ): self.transformed = transformed kwargs['json_filename'] = json_filename super().__init__(*args, **kwargs) self.df['set_id'] = self.df['question']\ .apply(lambda item_ids: item_ids[0].split('_')[0]) self.outfit_ids = self.df['set_id'].tolist() self.n_choices = len(self.df.iloc[0]['answers']) def get_example(self, i): """ Args: i (int): An index of a data sample. Returns imgs_q (np.array: (n-1, c, h, w)) question image sequence n: the original number of items in an outfit imgs_c (np.array: (k, c, h, w)) choice images k: the number of choices blank_pos (int) blank position starting from **1** """ row = self.df.iloc[i] question_ids = row['question'] choice_ids = row['answers'] blank_pos = row['blank_position'] imgs_q = np.array([ self.read_img_from_item_id(item_id) for item_id in question_ids ]) imgs_c = np.array([ self.read_img_from_item_id(item_id) for item_id in choice_ids ]) return imgs_q, imgs_c, blank_pos def transform(self, example): """ Args: example (tuple<imgs_q, imgs_c, blank_pos>) imgs_q (np.array: (N-1, C, H, W)) A question image sequence. N: the original number of items in an outfit. imgs_c (np.array: (K, C, H, W)) A choice images. K: the number of choices. blank_pos (int) The blank position starting from **1**. Returns: example (tuple<imgs_q, imgs_c, blank_pos>) imgs_q (np.array: (N-1, C, H, W)) The transformed question image sequence. N: the original number of items in an outfit. imgs_c (np.array: (K, C, H, W)) The transformed choice images. K: the number of choices. blank_pos (int) The blank position starting from **1**. """ imgs_q, imgs_c, blank_pos = example imgs_q = np.array([transform_img(img) for img in imgs_q]) imgs_c = np.array([transform_img(img) for img in imgs_c]) example = imgs_q, imgs_c, blank_pos if self.transformed: example = self.transform(example) return example def converter(self, batch, device=-1): """ Convert batch of tuples into tuple of batches and send them to GPU Args: batch (list<tuple<imgs_q, imgs_c, blank_pos>>) imgs_q (np.array: (N-1, C, H, W)) A question image sequence. N: the original number of items in an outfit. imgs_c (np.array: (K, C, H, W)) A choice images. K: the number of choices. blank_pos (int) The blank position starting from **1**. device (int, optional): >= 0 : GPU -1 : CPU Returns: imgs_q_b (list<np.array>: B * (N-1, C, H, W)) A batch of question image sequences. N: the original number of items in an outfit. imgs_c_b (list<np.array>: B * (K, C, H, W)) A batch of choice image sets. K: the number of choices. blank_pos_b (list<int>) A batch of blank positions starting from **1**. """ imgs_q_b, imgs_c_b, blank_pos_b = list(zip(*batch)) imgs_q_b = [to_device(device, imgs) for imgs in imgs_q_b] imgs_c_b = [to_device(device, imgs) for imgs in imgs_c_b] return imgs_q_b, imgs_c_b, blank_pos_b
PolyvoreDataset同様に、get_example,transform,converterを定義します。json_filenameを変えているので、ご注意ください。また、こちらも、jupyter notebook でテストします。
上段が質問となるコーデで、下段が選択肢です。選択肢の一番左が正解のアイテムです。
ところで、1つのデータセットに対し、学習・評価、評価タスク、モデルによって get_example の返り値を変えたければ、 Dataset を1つだけ定義し、
__init__の引数でget_exampleの出力を切り替える方法も考えられます。しかし、この方法だと、get_exmapleの可読性が落ちますし、モデルを追加する度に Dataset を編集しなければならず、思わぬバグを引き起こす可能性があります。まとめ
この記事では、ファッションコーディネートモデルのプロジェクトを題材に、データセットの管理と Chainer の Datasetクラスを自作する際のTipsを紹介しました。以下に大事な点をまとめておきます。
- データセットのセットアップや加工にまつわるコードはデータセットリポジトリに切り分ける。
- 小さいデータセットを用意してデバッグを効率化する。
- 重い前処理はあらかじめ施しておく。
- Dataset クラスを自作するときは、
chainer.dataset.DatasetMixinを継承して、__init__,__len__,get_exampleの3つオーバーライドする。- データのパスは環境変数で指定することで、コードのポータビリティを上げる。
get_exampleの返り値の型は、モデルの入力に合わせて決める。- テンソルの形はコメントとして明記していおく。
- Dataset クラス、 converter などの単体テストを行う。画像系は特に jupyter notebook を用いて視覚的なテストを行う。
- transform と converter は Dataset のメソッドとして持たせ、transform は
get_example内で施す。- converter、 Iterator 、 Updater などの Chainer のオブジェクトの役割を明確に理解し、役割に適したオーバーライドを行う。
- converter の役割は、タプルのバッチをバッチのタプルに変換することと、テンソルをGPUに転送すること。
- DatasetBase クラスに汎用的な処理を切り分けることで、保守性を上げる。
今回は Dataset まわりについての内容でしたが、今後、モデルや学習・評価スクリプトまわりの Tips の記事も書く予定です。
参考URL
chainer: 独自datasetを定義する方法 - 午睡二時四十分

- 投稿日:2019-07-01T11:02:23+09:00
Distortion,UndistortionのChainer実装
レンズ歪みを扱う関数(distortion, undistortion)のChainer実装が欲しかったので探したが、見つけられなかったので自作した。なかなか大変だったのでメモを残す。
distortion
OpenCVに習って、歪み係数を $(k_1, k_2, p_1, p_2, k_3, k_4, k_5, k_6)$ としたときの歪み関数を以下の式で定める。
$$(x', y') = {\rm distort}(x, y)$$
$$ \begin{aligned}
r^2 &= x^2 + y^2 \\
x' &= x\frac{1+k_1r^2+k_2r^4+k_3r^6}{1+k_4r^2+k_5r^4+k_6r^6}+2p_1xy+p_2(r^2+2x^2)\\
y' &= y\frac{1+k_1r^2+k_2r^4+k_3r^6}{1+k_4r^2+k_5r^4+k_6r^6}+2p_2xy+p_1(r^2+2y^2)\\
\end{aligned}$$distortionはこれをそのまま実装すれば良い。
undistortion
逆関数 $(x, y) = {\rm undistort}(x', y')$ を陽に求める事は出来ないので、数値解法によって求める事が必要。
初期近似解の導出
まず最初に出来るだけ良い初期値を求める。以下の文献によればradial distortionの部分(第一項目)は厳密に解く事ができる。と言っても無限級数としてだが。
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4934233/まず、
$$P(x) = 1+k_1x+k_2x^2+k_3x^3$$
と置く。本関数は$x\geq 0$において単調増加かつ連続である。これを用いるとradial distortionは
$$
\begin{pmatrix} x'\\y'\end{pmatrix} = P(r^2)\begin{pmatrix} x\\y\end{pmatrix} \\
$$と表せる。同様に、逆方向のradial distortionを
$$\begin{aligned}
Q(x) &= 1+a_1x+a_2x^2+a_3x^3+\cdots\\
\begin{pmatrix} x\\y\end{pmatrix} &= Q(r'^2)\begin{pmatrix} x'\\y'\end{pmatrix}\\
\end{aligned}$$と表すと、これらは逆関数なので
$$P(r^2)Q(r'^2) = 1$$
が成立する。また $r'^2 = r^2P(r^2)^2$ であるので
$$P(r^2)Q(r^2P(r^2)^2) = 1$$
が任意の $r\geq 0$ について成立する。$x=r^2 \geq 0$ と置換して
$$P(x)Q(xP(x)^2) = 1$$
となる。これを展開して係数を求めればよいが、面倒なのでsympyで計算する。
from sympy import Symbol, Poly, solve DEGREE = 3 x = Symbol('x') Ks = [Symbol('k%d'%i) for i in range(1, 4)] As = [Symbol('a%d'%i) for i in range(1, DEGREE+1)] P = sum(k * x**d for d, k in enumerate([1] + Ks)) Q = sum(a * x**d for d, a in enumerate([1] + As)) print('P(x) =', P) print('Q(x) =', Q) coeffs = Poly(P * Q.subs(x, x*P**2) - 1, x).coeffs() answer = solve(coeffs[-len(As):], As) for a in As: print(a, '=', answer[a])実行結果は以下の通り(とりあえず3次で打ち切った)。
P(x) = k1*x + k2*x**2 + k3*x**3 + 1 Q(x) = a1*x + a2*x**2 + a3*x**3 + 1 a1 = -k1 a2 = 3*k1**2 - k2 a3 = -12*k1**3 + 8*k1*k2 - k3Newton-Raphson法での解改良
続いて、上で求めた初期解をNewton-Raphson法により改良する。
$$ f({\mathbf x}) = {\rm distort}({\mathbf x}) - {\mathbf x'}$$
と置く。これを微分すると
$$\nabla f({\mathbf x}) = \begin{pmatrix}
g(r^2) + 2x^2g'(r^2) + 2p_1y + 6p_2x & 2xyg'(r^2)+2p_1x+2p_2y\\
2xyg'(r^2) + 2p_1x + 2p_2y & g(r^2) + 2y^2g'(r^2) + 2p_2x + 6p_1y\\
\end{pmatrix}$$となる。但し
$$g(x) = \frac{1+k_1x+k_2x^2+k_3x^3}{1+k_4x+k_5x^2+k_6x^3}$$
これを使って、前節で求めた値を初期値として用いて更新式
$${\mathbf x_{i+1}} = {\mathbf x_i}-\nabla f({\mathbf x_i})^{-1}({\rm distort}({\mathbf x_i})-{\mathbf x'})$$
を数回まわして解を改善する。
実装
こちら。
https://github.com/Idein/chainer-graphics実験
下の画像の左がOpenCVの
cv2.undistortレナ画像を変換したもの。右がchainer_graphics.camera.undistort_imageで同じパラメータを用いて変換したもの。
正しく出来ていそう。
これを
chainer_graphics.camera.distort_imageで同じパラメータで逆変換すると元に戻る。こちらも正しく出来ていそう。



- 投稿日:2019-07-01T03:17:19+09:00
1万9000作品のHiphop歌詞から実在しない歌詞をAIで生成する
経緯
2018年、フェイクニュースを自動生成するAI、GPT-2がOpenAIから発表されました。
あまりにリアルなので、このすべての学習モデルの公開は延期されています(2019年7月現在は345M版まで公開されている)。学習用のコードとしてnshepperd氏がnshepperd/gpt-2を公開し、
これを応用してGwern氏が英語の詩の自動生成を行っていました。
それを参考にして、今回はKaggleで公開されていた歌詞データから、19,289作のHiphopの歌詞を抽出して、GPT-2に学習させてみることにします。参考
Gwern氏による英語詩の自動生成
GPT-2 Neural Network Poetry免責事項
今回GitHubの方で公開している歌詞データには(英語ですが)性的卑語、人種差別的と思われる言葉、性差別表現などが含まれる可能性があります。
文化研究の一環ということで修正などしておりません。
データを利用する際はこの点に注意してご使用ください。データ
ソースコード
devinoue/Notorious-GPTGoogle Colabでサンプルを実行できます。
Noutrious-GPT2 sample前処理
以下の条件で前処理をします。
- 英語のみ抽出(データにはフランス語、ドイツ語、スペイン語と思われる歌詞データが含まれており、これらに該当するだろう歌詞を排除する)
- Verse1といった言葉を削除
- カッコは消去 これで歌詞データのうちまとめて処理できるものは
# 歌詞データすべてを読み込む df = pd.read_csv("lyrics.csv") # Hiphopだけ抽出 df_hiphop = df.loc[df['genre'] == "Hip-Hop"] # 歌詞が欠損している場合は削除 df_hiphop = df_hiphop.dropna(subset=['lyrics']) # 不要な要素の置き換え df_hiphop['lyrics'] = df_hiphop['lyrics'].replace('\[[^]]+\]', '', regex=True) df_hiphop['lyrics'] = df_hiphop['lyrics'].replace('\([^)]+\)', '', regex=True) df_hiphop['lyrics'] = df_hiphop['lyrics'].replace('\{[^}]+\}', '', regex=True) df_hiphop['lyrics'] = df_hiphop['lyrics'].replace('[+]+', '', regex=True) df_hiphop['lyrics'] = df_hiphop['lyrics'].replace('[. ]{2,}', '', regex=True) df_hiphop['lyrics'] = df_hiphop['lyrics'].replace('(VERSE|Verse|verse)+[ ]*\d', '', regex=True) drop_germany = df_hiphop.index[df_hiphop['lyrics'].str.contains("ich") == True] df_hiphop = df_hiphop.drop(drop_germany) drop_french = df_hiphop.index[df_hiphop['lyrics'].str.contains("suis") == True] df_hiphop = df_hiphop.drop(drop_french) drop_spanish = df_hiphop.index[df_hiphop['lyrics'].str.contains(" que ") == True] df_hiphop = df_hiphop.drop(drop_spanish) drop_other = df_hiphop.index[df_hiphop['lyrics'].str.contains(" je ") == True] df_hiphop = df_hiphop.drop(drop_other) drop_other = df_hiphop.index[df_hiphop['lyrics'].str.contains(" ca ") == True] df_hiphop = df_hiphop.drop(drop_other)次に歌詞の行ごとに処理します。
一度データを一行にまとめて、不要な改行を削除します。import re arr=[] arr = df_hiphop['lyrics'].values.tolist() text = "\n".join(arr) text = re.sub("\\n","\n",text) text = re.sub("\n{2,}","",text) text = re.sub("\\'","'",text) text = re.sub(" \n","\n",text)次に行を配列にしてから短すぎる行などを削除します。
今回悩みましたが、重複する内容も削除しています(これは歌詞的にダメかもしれない……)# Delete too short or too long lines. lines = text.split("\n"); lines = [line for line in lines if line] lines = [line for line in lines if len(line) > 3 and len(line) < 369] lines = [line for line in lines if " " in line] # 重複を削除(できる限り順番を維持して) seen = set() seen_add = seen.add lines = [ x for x in lines if x not in seen and not seen_add(x)] text = "\n".join(lines)最後に、ファイルに保存します。
with open("lyrics.txt","w",encoding="utf-8") as f: f.write(text)学習開始
Google Colabで公開しています。
コード通りに実行すれば、自動的に学習が始まります。
!PYTHONPATH=src ./train.py --dataset lyrics.txt.npz --batch_size 2 --save_every 1040 --sample_every 100 --learning_rate 0.0001学習実行のためコマンドになっています。
lerning_rateオプションは文字通りに学習率ですが、デフォルトの「0.0001」を入力しています。学習が進まないと感じたら、この数字を小さくしていくといいでしょう。
batch_sizeに関しては、この数字より大きくすると自分の場合は止まってしまいました。適切な数字を入れるようにしてください。結果
卑語などが含まれます。
筆者は英語に通じていないので判断し辛いのに加えて、黒人英語なのか、それとも単に出力として失敗しているのかよく分からない点も多いです。Wrap up in plastic Tucked in some cotton Grown man I know I could hang The nigga just got out of jail He's gonna make a million this year I'll take a shot I'll just kill for ya Like a man I'll just kill for ya Nigga if I have to Fuck around and lose my life I wanna die for ya Nigga I wanna kill, nigga fuck around and lose my friend if you want me to nigga I can't stay on the streets I gott a get to that money And I got a brother that'll ride with me He a gangsta for life so I can't let him go And I know a girl I'm gonna take to my town tonight And she know I gotta be up in my way tonight 'Cause I'm the kind of nigga that'll kill for ya But I can't let 'em ride with you I wanna die for ya I wanna kill Whip it out ya I'm gonna show them nigga what you about I got a little brother too So I'm gonna give him a nigga way You gon' be in the cut wit a big nigga body I know I got to be up in this shit Might slip and slide But I'm a be on the down down No I ain't leavin'I wanna just help out like I said in my last song But I just got to do my own thing Please don't want to hurt me, I just got to do my own thing And I can't give you shit thoughI feel nothing Nothing for you nothing for us nothing that you want you just listen to me and listen to me I wanna just help out like I said in my last song But I just got to do my own thingPlease don't want to hurt me, I just got to do my own thing Please don't want to hurt me, I just got to do my own thing It's my right to do what I feel This is not a game baby please don't call it that There might not be no stars but still I'll always be your number one And I just wanna let you know that I will always love you so much more than words Yes, yes I'll always love you with all my heart The next time you see me I'll know that I really mean it Yeah, baby I know that there will never be another you But I will always love you with all my heart I've done a bunch of things I regret That I'll never, I've been on my own If I would have known that I'd be what I ammoney as a fuckin' dream P-p-passing laws, it's just what I'm on And I gots to go in and get a fuckin' mill Get the money, it's on, I'm coming back This that motherfucker shit that you need To get the bread, just to get up on a fuckin' table You want me, get a hundred and fifty Fuck that, that's right, that's two hundred and fifty I think You really want me, motherfucker get one If you really want me, nigga go get one You want me, motherfucker get one You really want me to go get one To all my people out the ghetto All the ghetto niggas out the ghetto In the ghetto, on the west, on the east It's real all around, and it's here to stay All around, and it's here to stay In the ghetto, in the ghetto It's real all around Now I was born in the ghetto This is where my mother came from The ghetto was the city From a ghetto bed to a ghetto house My father started off in the ghetto Now I come from a ghetto bed That's why I'm a ghetto star Now I'm from a house where the rent's by the door And I'm from a ghetto mind That's why I'm a ghetto nigga I'm from a ghetto man That's why I'm a ghetto nigga Now a ghetto nigga never had nothin'th to do But play the ghetto card and go and get my hustle on I'm on the block with my tool on I just had to get my hustle onちょっと意味不明で面白かった
I'm a man, I'm a man I'm a man, she's a woman I'm a man, I'm a manShe's a woman I'm a woman Man I get so hot in the summer She get so hot all the time Cause I got a thing for you I'm a man and a woman I'm a woman, man I got that thing for you Uh I'm a guy, I'm a girl I'm a guy, I'm a girl, I'm like A girl, a girl I'm like I wanna run up on you Tell you what I'm gonna do I'm gonna grab a pen Wanna write somethin', man? I'm gonna write somethin', uh I'm a writer, you gonna run up on 'em Shoot a few somethin', make something Wanna make somethin', I wanna spend somethin', uh I'm a man, I'm a girl A girl, a girlYo, I'm a man, I'm a girl, I'm like I got a thing for you A girl, a girlYo, I'm a man, I'm a girl, I'm likeShe's a girlYou know, uh, uh, I'm a man, I'm a girl, I'm a girl A girl, a girlIt's the way I write I'm a man You could never see me at the bar, no Cause I got this thing on, man My girls like they know you Girl you know they got youSo here's a little something to consider: I got this book that tells the story of the race between man and rock And the man who conquered was not a man at all He was the race of god and he lived in heaven But his race was not made just because his God lived in heaven He was a god who beat God Then God beat God And that was all the reason you had to believe the story But if that's the same story I don't wanna read the story to keep you away So tell me what you say Ain't no way we can leave the place we call home Even though you're gone, no matter how many we lost One more friend to bring home a home that I will remember A baby girl, and her mother was his wife Then she was killed in a car crash A boy with a dream, he tried to fly and now he dies A young girl, who didn't come from the city just to give him a ring A young man who always said that love was something he would never achieve And that his life is full of pain But he could see a way out, and he did in his life In our day and In our place Even though you're gone Even though you love your time In our place and we love our time If it was up to meなんか悲しい感じの歌詞
me at home I got no money, so it's time to eat And here I am again as a visitor On a Saturday night, no one notices me I wonder to myself, who cares I'm just a homeless man in a rain jacket With the sun shining like sunshine I'm not worried about getting left and right In the dark darkness of a dark room Waiting for that man called fate This might be a sad movie, but reality hits And it's not the bad guys, no way But I can't help but smile Sometimes I wonder what I am A homeless man in a cold and wet world If I could I'd be happy I could have a house, a car, a girlfriend, a wife A crib and a dog, I'm happy I'd be all that I'd be so happy, that's my goal I wonder what I am It seems to me, everybody in this world is sick And maybe in tomorrow people will know Just what their friends and family can bring Some will laugh while some will hate So I guess I live my life Until I go away, I won't know If I'm happy or if I'm sad And I wonder who it is inside me Sometimes I wonder how I know Why I had to live in a bad way終わりに
まぁまぁいい感じにできましたが、なかなか収束しないのがもどかしいです。